# AtomicReference 用法和源码分析
* [AtomicReference 用法和源码分析](#atomicreference-用法和源码分析)
* [AtomicReference 基本使用](#atomicreference-基本使用)
* [使用 synchronized 保证线程安全性](#使用-synchronized-保证线程安全性)
* [了解 AtomicReference](#了解-atomicreference)
* [使用 AtomicReference 保证线程安全性](#使用-atomicreference-保证线程安全性)
* [AtomicReference 源码解析](#atomicreference-源码解析)
* [get and set](#get-and-set)
* [lazySet 方法](#lazyset-方法)
* [getAndSet 方法](#getandset-方法)
* [compareAndSet 方法](#compareandset-方法)
* [weakCompareAndSet 方法](#weakcompareandset-方法)
* [总结](#总结)
我们之前了解过了 AtomicInteger、AtomicLong、AtomicBoolean 等原子性工具类,下面我们继续了解一下位于 `java.util.concurrent.atomic` 包下的工具类。
关于 AtomicInteger、AtomicLong、AtomicBoolean 相关的内容请查阅
[一场 Atomic XXX 的魔幻之旅](https://mp.weixin.qq.com/s?__biz=MzU2NDg0OTgyMA==&mid=2247494526&idx=1&sn=071de13dff98d3daae7b189c4fa322a1&chksm=fc46168dcb319f9b7108770ac8fbb3dad9c130432f5ad5697c5e2f30aed8dbb939c65669fe0e&token=1842524500&lang=zh_CN#rd)
>关于 AtomicReference 这种 JDK 工具类的了解的文章比较枯燥,并不是代表着文章质量的下降,因为我想搞出一整套 bestJavaer 的全方位解析,那就势必离不开对 JDK 工具类的了解。
>
>**记住:技术要做长线**。
## AtomicReference 基本使用
我们这里再聊起老生常谈的账户问题,通过个人银行账户问题,来逐渐引入 AtomicReference 的使用,我们首先来看一下基本的个人账户类
```java
public class BankCard {
private final String accountName;
private final int money;
// 构造函数初始化 accountName 和 money
public BankCard(String accountName,int money){
this.accountName = accountName;
this.money = money;
}
// 不提供任何修改个人账户的 set 方法,只提供 get 方法
public String getAccountName() {
return accountName;
}
public int getMoney() {
return money;
}
// 重写 toString() 方法, 方便打印 BankCard
@Override
public String toString() {
return "BankCard{" +
"accountName='" + accountName + '\'' +
", money='" + money + '\'' +
'}';
}
}
```
个人账户类只包含两个字段:accountName 和 money,这两个字段代表账户名和账户金额,账户名和账户金额一旦设置后就不能再被修改。
现在假设有多个人分别向这个账户打款,每次存入一定数量的金额,那么理想状态下每个人在每次打款后,该账户的金额都是在不断增加的,下面我们就来验证一下这个过程。
```java
public class BankCardTest {
private static volatile BankCard bankCard = new BankCard("cxuan",100);
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
// 先读取全局的引用
final BankCard card = bankCard;
// 构造一个新的账户,存入一定数量的钱
BankCard newCard = new BankCard(card.getAccountName(),card.getMoney() + 100);
System.out.println(newCard);
// 最后把新的账户的引用赋给原账户
bankCard = newCard;
try {
TimeUnit.MICROSECONDS.sleep(1000);
}catch (Exception e){
e.printStackTrace();
}
}).start();
}
}
}
```
在上面的代码中,我们首先声明了一个全局变量 BankCard,这个 BankCard 由 `volatile`进行修饰,目的就是在对其引用进行变化后对其他线程可见,在每个打款人都存入一定数量的款项后,输出账户的金额变化,我们可以观察一下这个输出结果。
 可以看到,我们预想最后的结果应该是 1100 元,但是最后却只存入了 900 元,那 200 元去哪了呢?我们可以断定上面的代码不是一个线程安全的操作。
>问题出现在哪里?
虽然每次 volatile 都能保证每个账户的金额都是最新的,但是由于上面的步骤中出现了组合操作,即`获取账户引用`和`更改账户引用`,每个单独的操作虽然都是原子性的,但是组合在一起就不是原子性的了。所以最后的结果会出现偏差。
我们可以用如下线程切换图来表示一下这个过程的变化。
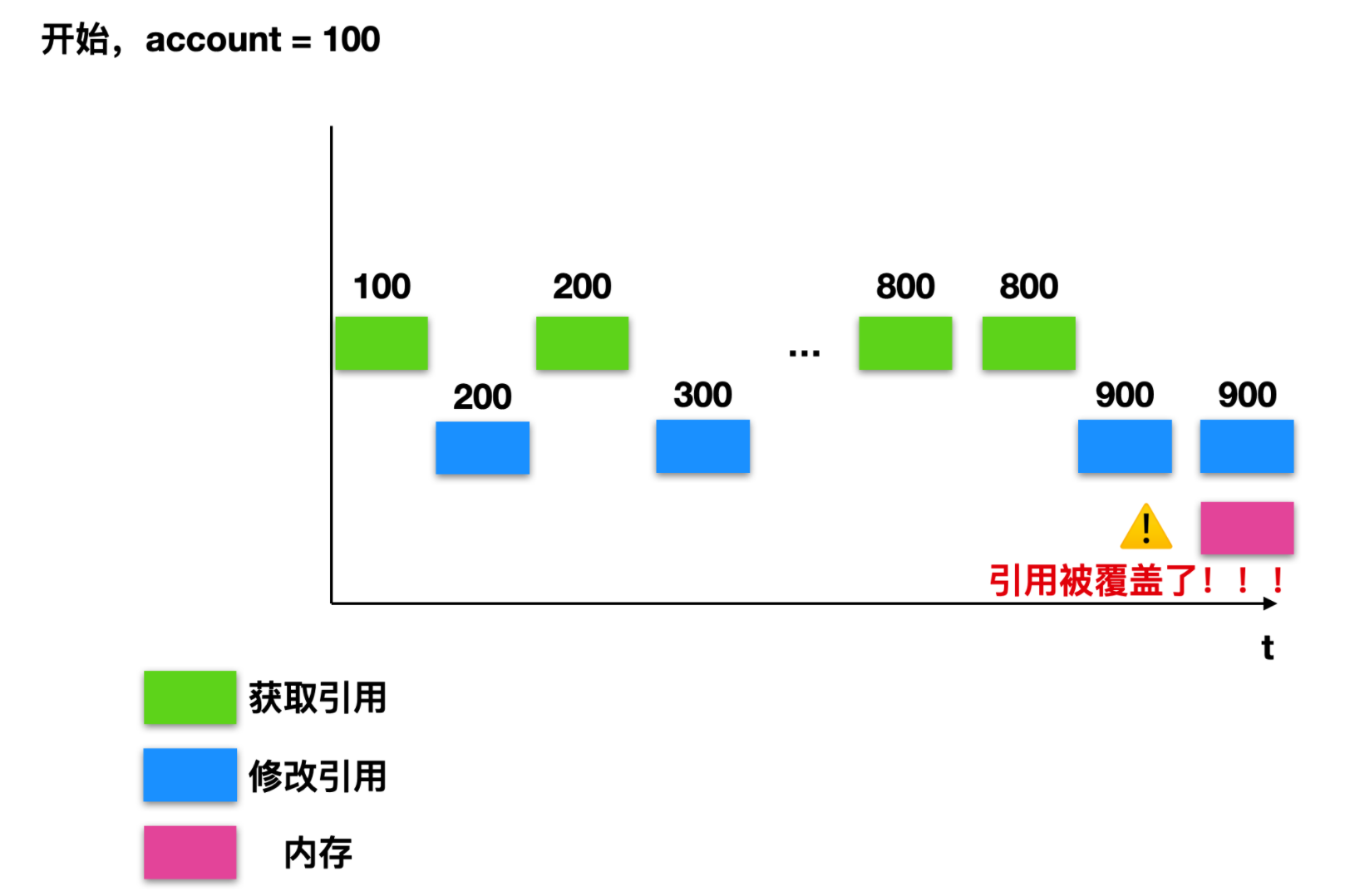
可以看到,最后的结果可能是因为在线程 t1 获取最新账户变化后,线程切换到 t2,t2 也获取了最新账户情况,然后再切换到 t1,t1 修改引用,线程切换到 t2,t2 修改引用,所以账户引用的值被修改了`两次`。
>那么该如何确保获取引用和修改引用之间的线程安全性呢?
最简单粗暴的方式就是直接使用 `synchronized` 关键字进行加锁了。
### 使用 synchronized 保证线程安全性
使用 synchronized 可以保证共享数据的安全性,代码如下
```java
public class BankCardSyncTest {
private static volatile BankCard bankCard = new BankCard("cxuan",100);
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
synchronized (BankCardSyncTest.class) {
// 先读取全局的引用
final BankCard card = bankCard;
// 构造一个新的账户,存入一定数量的钱
BankCard newCard = new BankCard(card.getAccountName(), card.getMoney() + 100);
System.out.println(newCard);
// 最后把新的账户的引用赋给原账户
bankCard = newCard;
try {
TimeUnit.MICROSECONDS.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
```
相较于 BankCardTest ,BankCardSyncTest 增加了 synchronized 锁,运行 BankCardSyncTest 后我们发现能够得到正确的结果。
修改 BankCardSyncTest.class 为 bankCard 对象,我们发现同样能够确保线程安全性,这是因为在这段程序中,只有 bankCard 会进行变化,不会再有其他共享数据。
如果有其他共享数据的话,我们需要使用 BankCardSyncTest.clas 确保线程安全性。
除此之外,`java.util.concurrent.atomic` 包下的 AtomicReference 也可以保证线程安全性。
我们先来认识一下 AtomicReference ,然后再使用 AtomicReference 改写上面的代码。
## 了解 AtomicReference
### 使用 AtomicReference 保证线程安全性
下面我们改写一下上面的那个示例
```java
public class BankCardARTest {
private static AtomicReference bankCardRef = new AtomicReference<>(new BankCard("cxuan",100));
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
while (true){
// 使用 AtomicReference.get 获取
final BankCard card = bankCardRef.get();
BankCard newCard = new BankCard(card.getAccountName(), card.getMoney() + 100);
// 使用 CAS 乐观锁进行非阻塞更新
if(bankCardRef.compareAndSet(card,newCard)){
System.out.println(newCard);
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
```
在上面的示例代码中,我们使用了 AtomicReference 封装了 BankCard 的引用,然后使用 `get()` 方法获得原子性的引用,接着使用 CAS 乐观锁进行非阻塞更新,更新的标准是如果使用 bankCardRef.get() 获取的值等于内存值的话,就会把银行卡账户的资金 + 100,我们观察一下输出结果。
可以看到,我们预想最后的结果应该是 1100 元,但是最后却只存入了 900 元,那 200 元去哪了呢?我们可以断定上面的代码不是一个线程安全的操作。
>问题出现在哪里?
虽然每次 volatile 都能保证每个账户的金额都是最新的,但是由于上面的步骤中出现了组合操作,即`获取账户引用`和`更改账户引用`,每个单独的操作虽然都是原子性的,但是组合在一起就不是原子性的了。所以最后的结果会出现偏差。
我们可以用如下线程切换图来表示一下这个过程的变化。

可以看到,最后的结果可能是因为在线程 t1 获取最新账户变化后,线程切换到 t2,t2 也获取了最新账户情况,然后再切换到 t1,t1 修改引用,线程切换到 t2,t2 修改引用,所以账户引用的值被修改了`两次`。
>那么该如何确保获取引用和修改引用之间的线程安全性呢?
最简单粗暴的方式就是直接使用 `synchronized` 关键字进行加锁了。
### 使用 synchronized 保证线程安全性
使用 synchronized 可以保证共享数据的安全性,代码如下
```java
public class BankCardSyncTest {
private static volatile BankCard bankCard = new BankCard("cxuan",100);
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
synchronized (BankCardSyncTest.class) {
// 先读取全局的引用
final BankCard card = bankCard;
// 构造一个新的账户,存入一定数量的钱
BankCard newCard = new BankCard(card.getAccountName(), card.getMoney() + 100);
System.out.println(newCard);
// 最后把新的账户的引用赋给原账户
bankCard = newCard;
try {
TimeUnit.MICROSECONDS.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
```
相较于 BankCardTest ,BankCardSyncTest 增加了 synchronized 锁,运行 BankCardSyncTest 后我们发现能够得到正确的结果。
修改 BankCardSyncTest.class 为 bankCard 对象,我们发现同样能够确保线程安全性,这是因为在这段程序中,只有 bankCard 会进行变化,不会再有其他共享数据。
如果有其他共享数据的话,我们需要使用 BankCardSyncTest.clas 确保线程安全性。
除此之外,`java.util.concurrent.atomic` 包下的 AtomicReference 也可以保证线程安全性。
我们先来认识一下 AtomicReference ,然后再使用 AtomicReference 改写上面的代码。
## 了解 AtomicReference
### 使用 AtomicReference 保证线程安全性
下面我们改写一下上面的那个示例
```java
public class BankCardARTest {
private static AtomicReference bankCardRef = new AtomicReference<>(new BankCard("cxuan",100));
public static void main(String[] args) {
for(int i = 0;i < 10;i++){
new Thread(() -> {
while (true){
// 使用 AtomicReference.get 获取
final BankCard card = bankCardRef.get();
BankCard newCard = new BankCard(card.getAccountName(), card.getMoney() + 100);
// 使用 CAS 乐观锁进行非阻塞更新
if(bankCardRef.compareAndSet(card,newCard)){
System.out.println(newCard);
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
```
在上面的示例代码中,我们使用了 AtomicReference 封装了 BankCard 的引用,然后使用 `get()` 方法获得原子性的引用,接着使用 CAS 乐观锁进行非阻塞更新,更新的标准是如果使用 bankCardRef.get() 获取的值等于内存值的话,就会把银行卡账户的资金 + 100,我们观察一下输出结果。
 可以看到,有一些输出是乱序执行的,出现这个原因很简单,有可能在输出结果之前,进行线程切换,然后打印了后面线程的值,然后线程切换回来再进行输出,但是可以看到,没有出现银行卡金额相同的情况。
### AtomicReference 源码解析
在了解上面这个例子之后,我们来看一下 AtomicReference 的使用方法
AtomicReference 和 AtomicInteger 非常相似,它们内部都是用了下面三个属性
可以看到,有一些输出是乱序执行的,出现这个原因很简单,有可能在输出结果之前,进行线程切换,然后打印了后面线程的值,然后线程切换回来再进行输出,但是可以看到,没有出现银行卡金额相同的情况。
### AtomicReference 源码解析
在了解上面这个例子之后,我们来看一下 AtomicReference 的使用方法
AtomicReference 和 AtomicInteger 非常相似,它们内部都是用了下面三个属性
 `Unsafe` 是 `sun.misc` 包下面的类,AtomicReference 主要是依赖于 sun.misc.Unsafe 提供的一些 native 方法保证操作的`原子性`。
Unsafe 的 `objectFieldOffset` 方法可以获取成员属性在内存中的地址相对于对象内存地址的偏移量。这个偏移量也就是 `valueOffset` ,说得简单点就是找到这个变量在内存中的地址,便于后续通过内存地址直接进行操作。
`value` 就是 AtomicReference 中的实际值,因为有 volatile ,这个值实际上就是内存值。
不同之处就在于 AtomicInteger 是对整数的封装,而 AtomicReference 则对应普通的`对象引用`。也就是它可以保证你在修改对象引用时的线程安全性。
### get and set
我们首先来看一下最简单的 get 、set 方法:
`get()` : 获取当前 AtomicReference 的值
`set()` : 设置当前 AtomicReference 的值
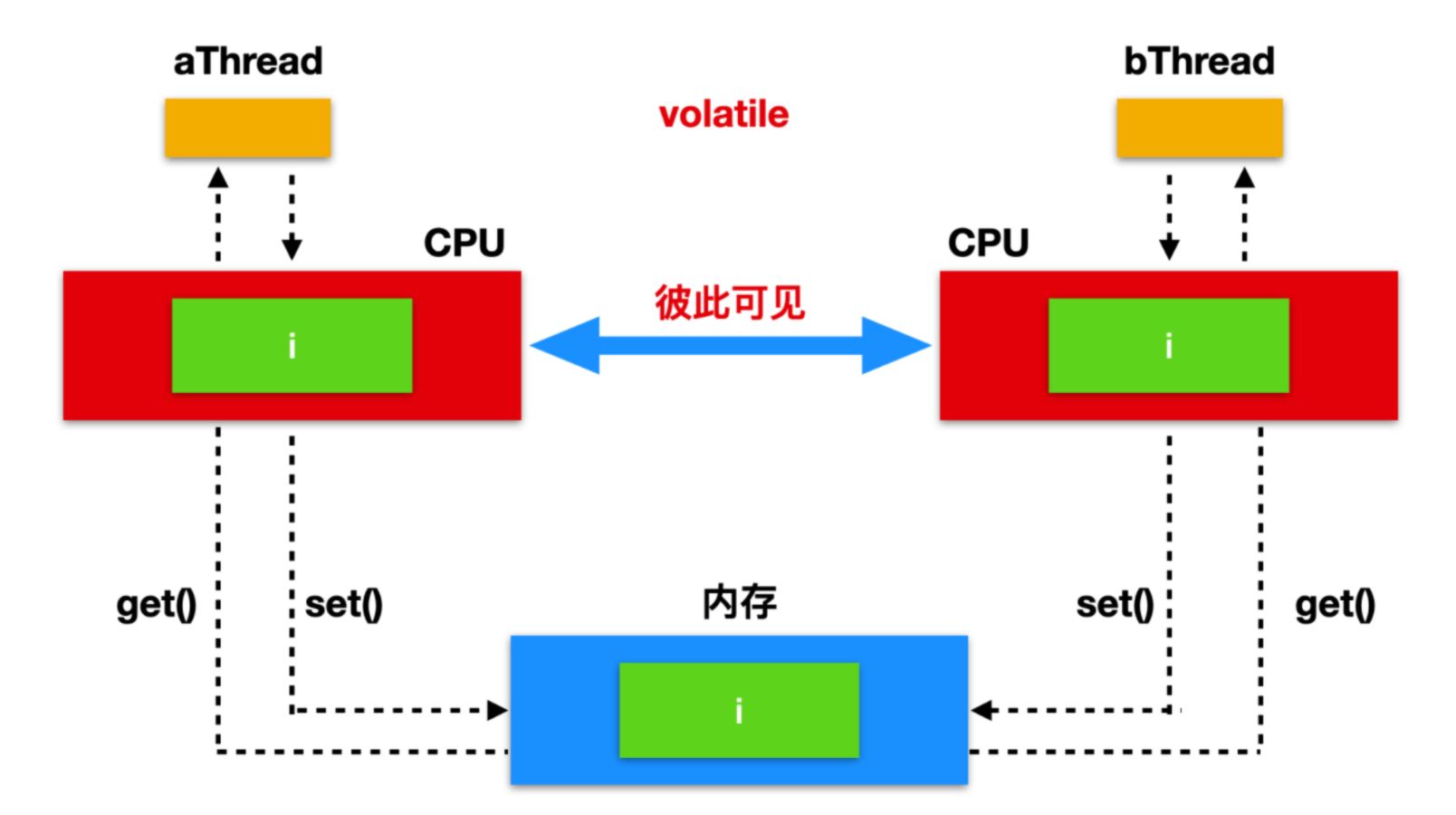
get() 可以原子性的读取 AtomicReference 中的数据,set() 可以原子性的设置当前的值,因为 get() 和 set() 最终都是作用于 value 变量,而 value 是由 `volatile` 修饰的,所以 get 、set 相当于都是对内存进行读取和设置。如下图所示
### lazySet 方法
volatile 有内存屏障你知道吗?
内存屏障是啥啊?
> 内存屏障,也称`内存栅栏`,内存栅障,屏障指令等, 是一类同步屏障指令,是 CPU 或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。也是一个让CPU 处理单元中的内存状态对其它处理单元可见的一项技术。
**CPU 使用了很多优化,使用缓存、指令重排等,其最终的目的都是为了性能**,也就是说,当一个程序执行时,只要最终的结果是一样的,指令是否被重排并不重要。所以指令的执行时序并不是顺序执行的,而是乱序执行的,这就会带来很多问题,这也促使着内存屏障的出现。
语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
内存屏障的开销非常轻量级,但是再小也是有开销的,LazySet 的作用正是如此,它会以普通变量的形式来读写变量。
也可以说是:**懒得设置屏障了**
### getAndSet 方法
以原子方式设置为给定值并返回旧值。它的源码如下

它会调用 `unsafe` 中的 getAndSetObject 方法,源码如下

可以看到这个 getAndSet 方法涉及两个 cpp 实现的方法,一个是 `getObjectVolatile` ,一个是 `compareAndSwapObject` 方法,他们用在 do...while 循环中,也就是说,每次都会先获取最新对象引用的值,如果使用 CAS 成功交换两个对象的话,就会直接返回 `var5` 的值,var5 此时应该就是更新前的内存值,也就是旧值。
### compareAndSet 方法
这就是 AtomicReference 非常关键的 CAS 方法了,与 AtomicInteger 不同的是,AtomicReference 是调用的 `compareAndSwapObject` ,而 AtomicInteger 调用的是 `compareAndSwapInt` 方法。这两个方法的实现如下
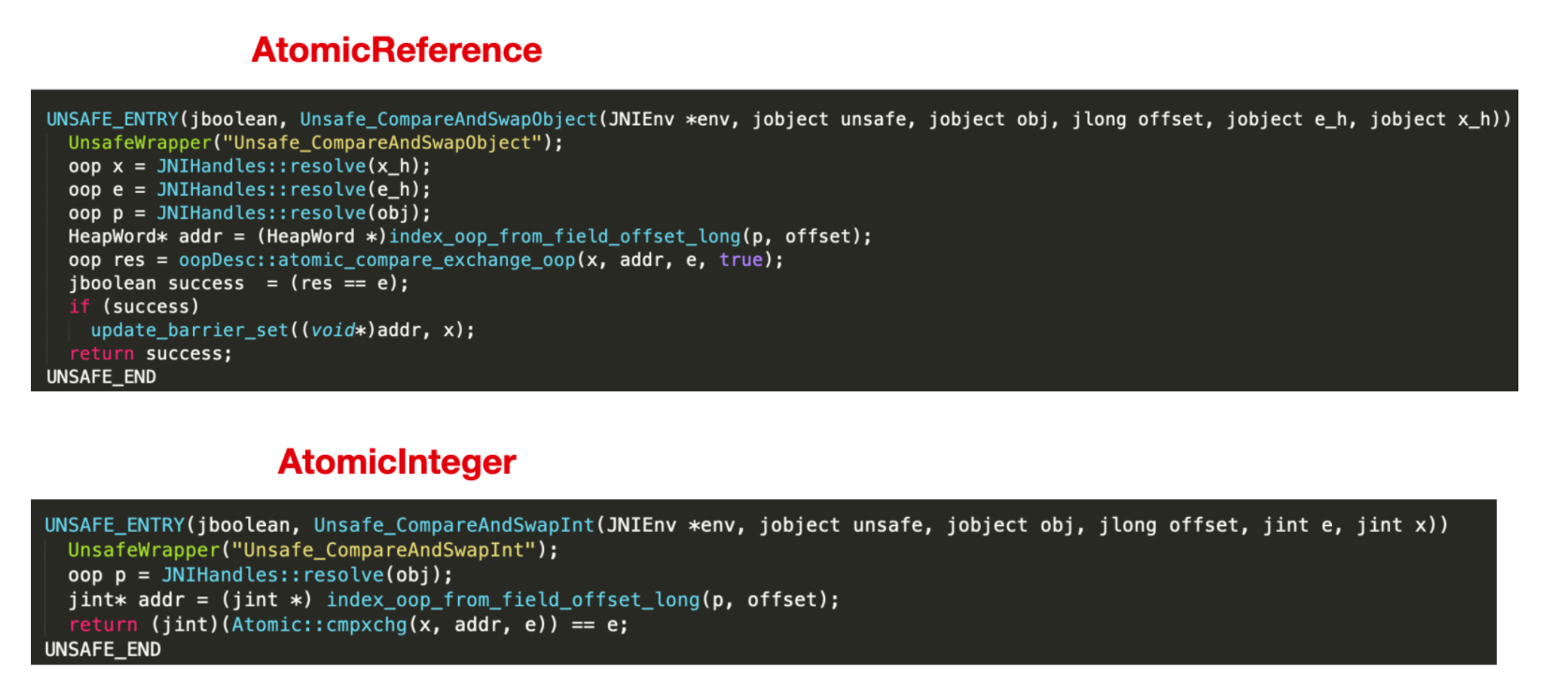
路径在 `hotspot/src/share/vm/prims/unsafe.cpp` 中。
我们之前解析过 AtomicInteger 的源码,所以我们接下来解析一下 AtomicReference 源码。
因为对象存在于堆中,所以方法 `index_oop_from_field_offset_long` 应该是获取对象的内存地址,然后使用 `atomic_compare_exchange_oop` 方法进行对象的 CAS 交换。
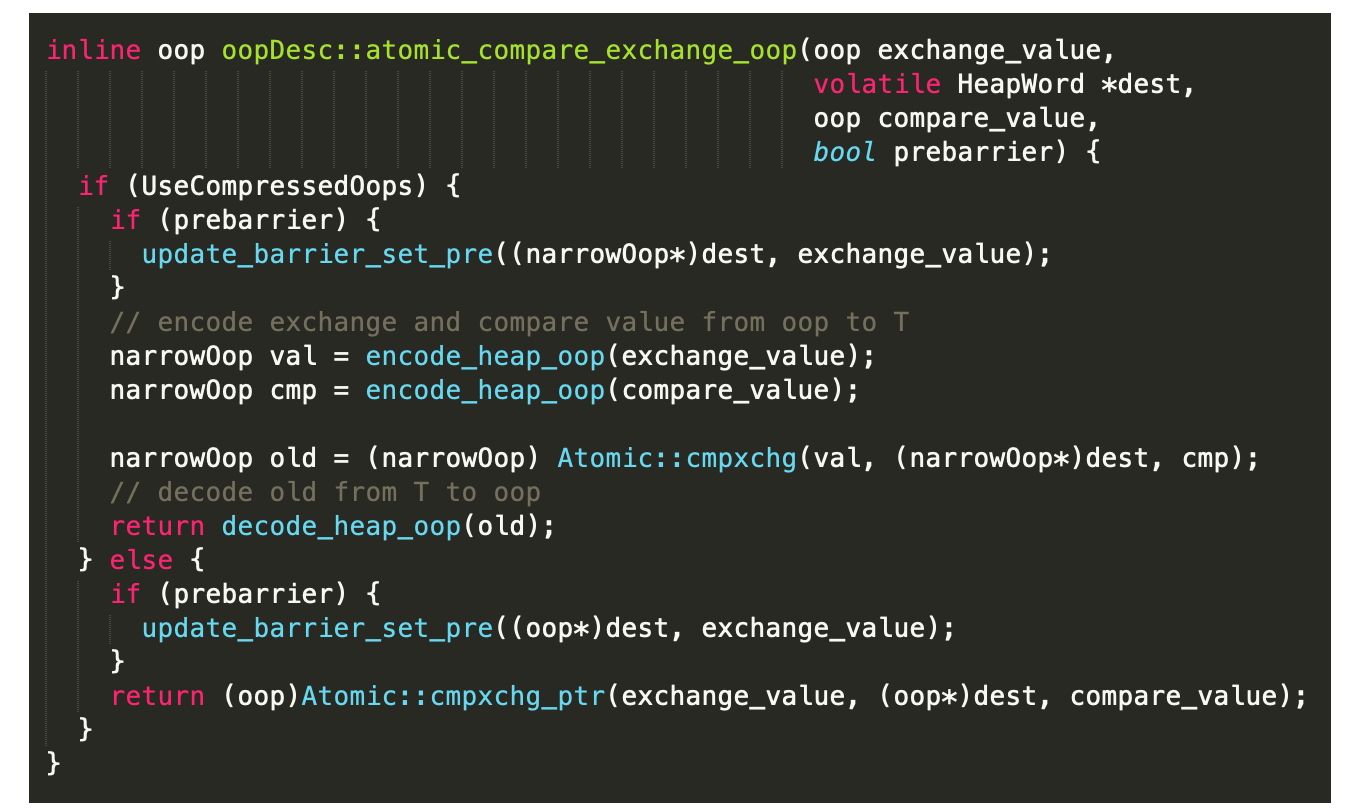
这段代码会首先判断是否使用了 `UseCompressedOops`,也就是`指针压缩`。
这里简单解释一下指针压缩的概念:JVM 最初的时候是 32 位的,但是随着 64 位 JVM 的兴起,也带来一个问题,内存占用空间更大了 ,但是 JVM 内存最好不要超过 32 G,为了节省空间,在 JDK 1.6 的版本后,我们在 64位中的 JVM 中可以开启`指针压缩(UseCompressedOops)`来压缩我们对象指针的大小,来帮助我们节省内存空间,在 JDK 8来说,这个指令是默认开启的。
如果不开启指针压缩的话,64 位 JVM 会采用 8 字节(64位)存储真实内存地址,比之前采用4字节(32位)压缩存储地址带来的问题:
1. 增加了 GC 开销:64 位对象引用需要占用更多的堆空间,留给其他数据的空间将会减少,
从而加快了 GC 的发生,更频繁的进行 GC。
2. 降低 CPU 缓存命中率:64 位对象引用增大了,CPU 能缓存的 oop 将会更少,从而降低了 CPU 缓存的效率。
由于 64 位存储内存地址会带来这么多问题,程序员发明了指针压缩技术,可以让我们既能够使用之前 4 字节存储指针地址,又能够扩大内存存储。
可以看到,atomic_compare_exchange_oop 方法底层也是使用了 `Atomic:cmpxchg` 方法进行 CAS 交换,然后把旧值进行 decode 返回 (我这局限的 C++ 知识,只能解析到这里了,如果大家懂这段代码一定告诉我,让我请教一波)
### weakCompareAndSet 方法
`weakCompareAndSet`: 非常认真看了好几遍,发现 JDK1.8 的这个方法和 compareAndSet 方法完全一摸一样啊,坑我。。。
但是真的是这样么?并不是,JDK 源码很博大精深,才不会设计一个重复的方法,你想想 JDK 团队也不是会犯这种低级团队,但是原因是什么呢?
《Java 高并发详解》这本书给出了我们一个答案

## 总结
此篇文章主要介绍了 AtomicReference 的出现背景,AtomicReference 的使用场景,以及介绍了 AtomicReference 的源码,重点方法的源码分析。此篇 AtomicReference 的文章基本上涵盖了网络上所有关于 AtomicReference 的内容了,遗憾的是就是 cpp 源码可能分析的不是很到位,这需要充足的 C/C++ 编程知识,如果有读者朋友们有最新的研究成果,请及时告诉我。


`Unsafe` 是 `sun.misc` 包下面的类,AtomicReference 主要是依赖于 sun.misc.Unsafe 提供的一些 native 方法保证操作的`原子性`。
Unsafe 的 `objectFieldOffset` 方法可以获取成员属性在内存中的地址相对于对象内存地址的偏移量。这个偏移量也就是 `valueOffset` ,说得简单点就是找到这个变量在内存中的地址,便于后续通过内存地址直接进行操作。
`value` 就是 AtomicReference 中的实际值,因为有 volatile ,这个值实际上就是内存值。
不同之处就在于 AtomicInteger 是对整数的封装,而 AtomicReference 则对应普通的`对象引用`。也就是它可以保证你在修改对象引用时的线程安全性。
### get and set
我们首先来看一下最简单的 get 、set 方法:
`get()` : 获取当前 AtomicReference 的值
`set()` : 设置当前 AtomicReference 的值
get() 可以原子性的读取 AtomicReference 中的数据,set() 可以原子性的设置当前的值,因为 get() 和 set() 最终都是作用于 value 变量,而 value 是由 `volatile` 修饰的,所以 get 、set 相当于都是对内存进行读取和设置。如下图所示

### lazySet 方法
volatile 有内存屏障你知道吗?
内存屏障是啥啊?
> 内存屏障,也称`内存栅栏`,内存栅障,屏障指令等, 是一类同步屏障指令,是 CPU 或编译器在对内存随机访问的操作中的一个同步点,使得此点之前的所有读写操作都执行后才可以开始执行此点之后的操作。也是一个让CPU 处理单元中的内存状态对其它处理单元可见的一项技术。
**CPU 使用了很多优化,使用缓存、指令重排等,其最终的目的都是为了性能**,也就是说,当一个程序执行时,只要最终的结果是一样的,指令是否被重排并不重要。所以指令的执行时序并不是顺序执行的,而是乱序执行的,这就会带来很多问题,这也促使着内存屏障的出现。
语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。因此,对于敏感的程序块,写操作之后、读操作之前可以插入内存屏障。
内存屏障的开销非常轻量级,但是再小也是有开销的,LazySet 的作用正是如此,它会以普通变量的形式来读写变量。
也可以说是:**懒得设置屏障了**
### getAndSet 方法
以原子方式设置为给定值并返回旧值。它的源码如下

它会调用 `unsafe` 中的 getAndSetObject 方法,源码如下

可以看到这个 getAndSet 方法涉及两个 cpp 实现的方法,一个是 `getObjectVolatile` ,一个是 `compareAndSwapObject` 方法,他们用在 do...while 循环中,也就是说,每次都会先获取最新对象引用的值,如果使用 CAS 成功交换两个对象的话,就会直接返回 `var5` 的值,var5 此时应该就是更新前的内存值,也就是旧值。
### compareAndSet 方法
这就是 AtomicReference 非常关键的 CAS 方法了,与 AtomicInteger 不同的是,AtomicReference 是调用的 `compareAndSwapObject` ,而 AtomicInteger 调用的是 `compareAndSwapInt` 方法。这两个方法的实现如下

路径在 `hotspot/src/share/vm/prims/unsafe.cpp` 中。
我们之前解析过 AtomicInteger 的源码,所以我们接下来解析一下 AtomicReference 源码。
因为对象存在于堆中,所以方法 `index_oop_from_field_offset_long` 应该是获取对象的内存地址,然后使用 `atomic_compare_exchange_oop` 方法进行对象的 CAS 交换。

这段代码会首先判断是否使用了 `UseCompressedOops`,也就是`指针压缩`。
这里简单解释一下指针压缩的概念:JVM 最初的时候是 32 位的,但是随着 64 位 JVM 的兴起,也带来一个问题,内存占用空间更大了 ,但是 JVM 内存最好不要超过 32 G,为了节省空间,在 JDK 1.6 的版本后,我们在 64位中的 JVM 中可以开启`指针压缩(UseCompressedOops)`来压缩我们对象指针的大小,来帮助我们节省内存空间,在 JDK 8来说,这个指令是默认开启的。
如果不开启指针压缩的话,64 位 JVM 会采用 8 字节(64位)存储真实内存地址,比之前采用4字节(32位)压缩存储地址带来的问题:
1. 增加了 GC 开销:64 位对象引用需要占用更多的堆空间,留给其他数据的空间将会减少,
从而加快了 GC 的发生,更频繁的进行 GC。
2. 降低 CPU 缓存命中率:64 位对象引用增大了,CPU 能缓存的 oop 将会更少,从而降低了 CPU 缓存的效率。
由于 64 位存储内存地址会带来这么多问题,程序员发明了指针压缩技术,可以让我们既能够使用之前 4 字节存储指针地址,又能够扩大内存存储。
可以看到,atomic_compare_exchange_oop 方法底层也是使用了 `Atomic:cmpxchg` 方法进行 CAS 交换,然后把旧值进行 decode 返回 (我这局限的 C++ 知识,只能解析到这里了,如果大家懂这段代码一定告诉我,让我请教一波)
### weakCompareAndSet 方法
`weakCompareAndSet`: 非常认真看了好几遍,发现 JDK1.8 的这个方法和 compareAndSet 方法完全一摸一样啊,坑我。。。
但是真的是这样么?并不是,JDK 源码很博大精深,才不会设计一个重复的方法,你想想 JDK 团队也不是会犯这种低级团队,但是原因是什么呢?
《Java 高并发详解》这本书给出了我们一个答案

## 总结
此篇文章主要介绍了 AtomicReference 的出现背景,AtomicReference 的使用场景,以及介绍了 AtomicReference 的源码,重点方法的源码分析。此篇 AtomicReference 的文章基本上涵盖了网络上所有关于 AtomicReference 的内容了,遗憾的是就是 cpp 源码可能分析的不是很到位,这需要充足的 C/C++ 编程知识,如果有读者朋友们有最新的研究成果,请及时告诉我。

