# 深入理解 final、finally 和 finalize 关键字
* [深入理解 final、finally 和 finalize 关键字](#深入理解-finalfinally-和-finalize-关键字)
* [final、finally 和 finalize](#finalfinally-和-finalize)
* [final 修饰类、属性和方法](#final-修饰类属性和方法)
* [finally 保证程序一定被执行](#finally-保证程序一定被执行)
* [finalize 的作用](#finalize-的作用)
* [深入理解 final 、finally 和 finalize](#深入理解-final-finally-和-finalize)
* [final 设计](#final-设计)
* [空白 final](#空白-final)
* [final 能提高性能吗?](#final-能提高性能吗)
* [深入理解 finally](#深入理解-finally)
* [finally 的本质](#finally-的本质)
* [finally 一定会执行吗](#finally-一定会执行吗)
* [finalize 真的没用吗](#finalize-真的没用吗)
 `final` 是 Java 中的关键字,它也是 Java 中很重要的一个关键字,final 修饰的类、方法、变量有不同的含义;`finally` 也是一个关键字,不过我们可以使用 finally 和其他关键字结合做一些组合操作; `finalize` 是一个不让人待见的方法,它是对象祖宗 `Object` 中的一个方法,finalize 机制现在已经不推荐使用了。本篇文章,cxuan 就带你从这三个关键字入手,带你从用法、应用、原理的角度带你深入浅出理解这三个关键字。
## final、finally 和 finalize
我相信在座的各位都是资深程序员,final 这种基础关键字就不用多说了。不过,还是要照顾一下小白读者,毕竟我们都是从小白走过来的嘛。
### final 修饰类、属性和方法
`final` 可以用来修饰类,final 修饰的类不允许其他类继承,也就是说,final 修饰的类是独一无二的。如下所示
`final` 是 Java 中的关键字,它也是 Java 中很重要的一个关键字,final 修饰的类、方法、变量有不同的含义;`finally` 也是一个关键字,不过我们可以使用 finally 和其他关键字结合做一些组合操作; `finalize` 是一个不让人待见的方法,它是对象祖宗 `Object` 中的一个方法,finalize 机制现在已经不推荐使用了。本篇文章,cxuan 就带你从这三个关键字入手,带你从用法、应用、原理的角度带你深入浅出理解这三个关键字。
## final、finally 和 finalize
我相信在座的各位都是资深程序员,final 这种基础关键字就不用多说了。不过,还是要照顾一下小白读者,毕竟我们都是从小白走过来的嘛。
### final 修饰类、属性和方法
`final` 可以用来修饰类,final 修饰的类不允许其他类继承,也就是说,final 修饰的类是独一无二的。如下所示
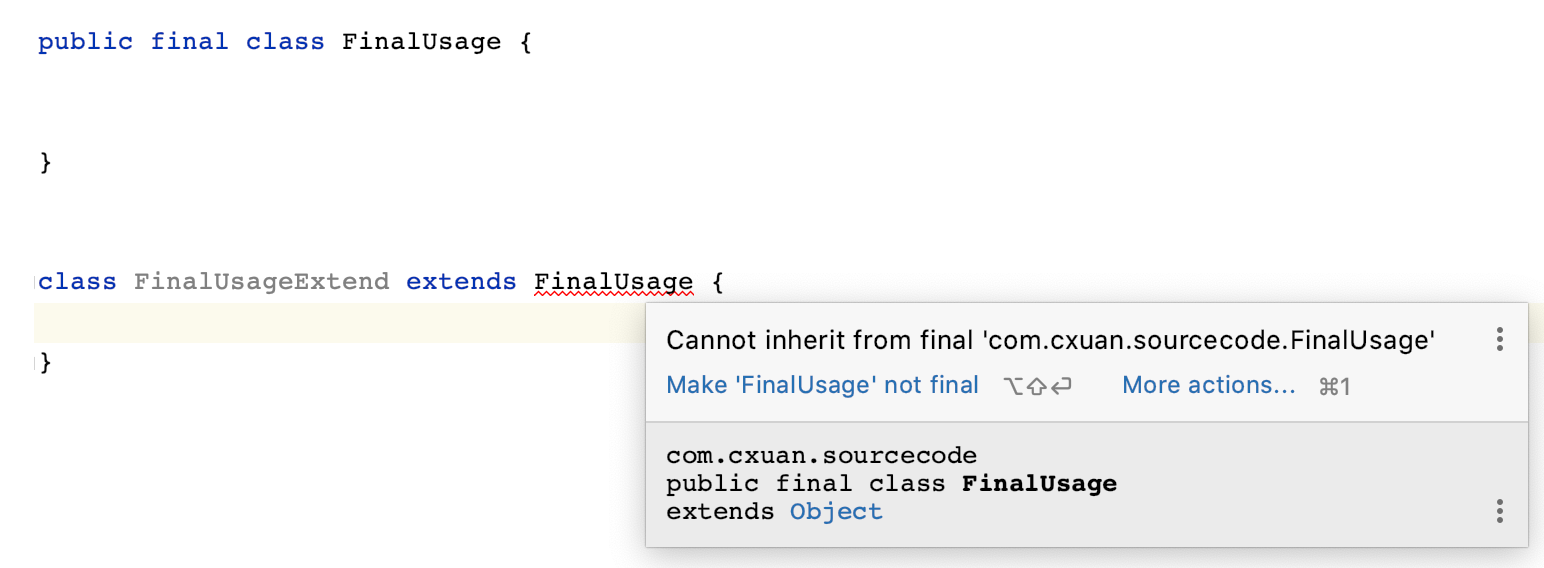 我们首先定义了一个 FinalUsage 类,它使用 final 修饰,同时我们又定义了一个 FinalUsageExtend 类,它想要`继承(extend)` FinalUsage,我们如上继承后,编译器不让我们这么玩儿,它提示我们 **不能从 FinalUsage** 类继承,为什么呢?不用管,这是 Java 的约定,有一些为什么没有必要,遵守就行。
`final` 可以用来修饰方法,final 修饰的方法不允许被重写,我们先演示一下不用 final 关键字修饰的情况
我们首先定义了一个 FinalUsage 类,它使用 final 修饰,同时我们又定义了一个 FinalUsageExtend 类,它想要`继承(extend)` FinalUsage,我们如上继承后,编译器不让我们这么玩儿,它提示我们 **不能从 FinalUsage** 类继承,为什么呢?不用管,这是 Java 的约定,有一些为什么没有必要,遵守就行。
`final` 可以用来修饰方法,final 修饰的方法不允许被重写,我们先演示一下不用 final 关键字修饰的情况
 如上图所示,我们使用 FinalUsageExtend 类继承了 FinalUsage 类,并提供了 `writeArticle` 方法的重写。这样编译是没有问题的,重写的关键点是 `@Override` 注解和方法修饰符、名称、返回值的一致性。
>注意:很多程序员在重写方法的时候都会忽略 @Override,这样其实无疑增加了代码阅读的难度,不建议这样。
当我们使用 final 修饰方法后,这个方法则不能被重写,如下所示
如上图所示,我们使用 FinalUsageExtend 类继承了 FinalUsage 类,并提供了 `writeArticle` 方法的重写。这样编译是没有问题的,重写的关键点是 `@Override` 注解和方法修饰符、名称、返回值的一致性。
>注意:很多程序员在重写方法的时候都会忽略 @Override,这样其实无疑增加了代码阅读的难度,不建议这样。
当我们使用 final 修饰方法后,这个方法则不能被重写,如下所示
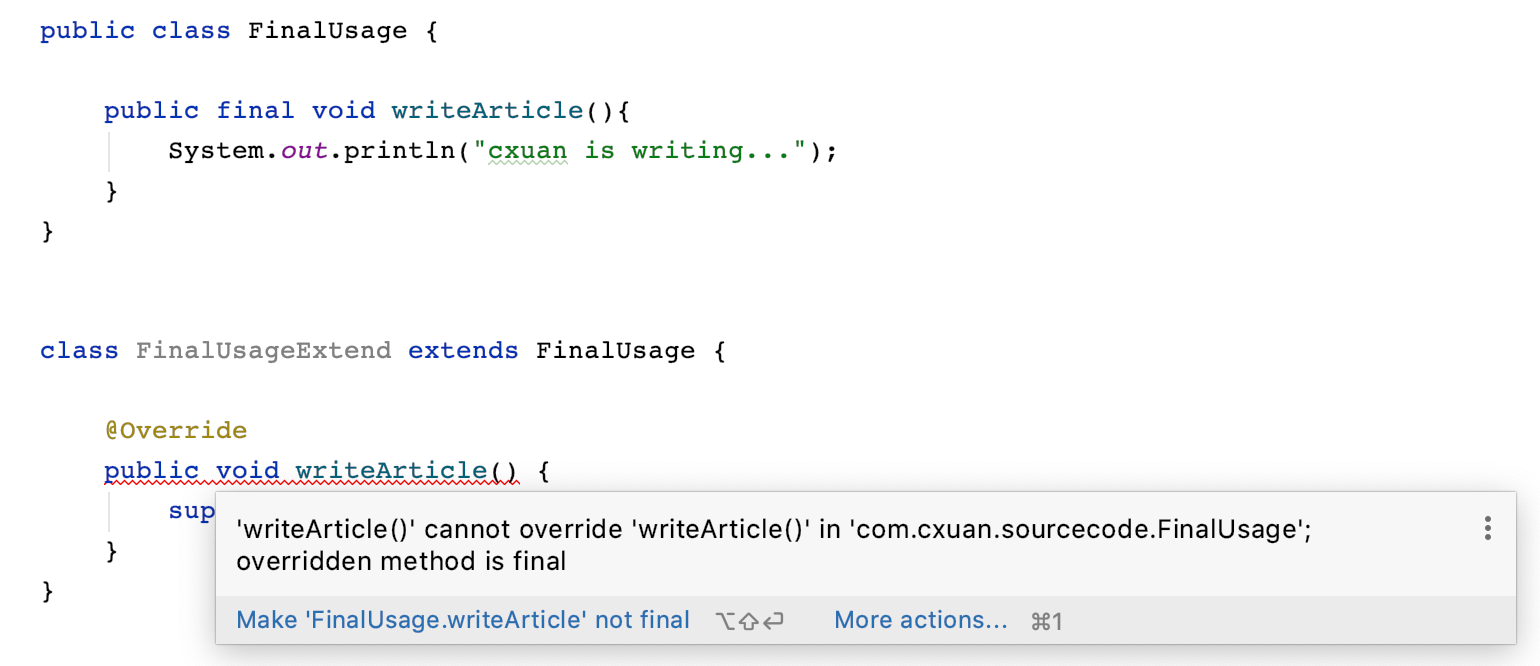 当我们把 writeArticle 方法声明为 void 后,重写的方法会报错,无法重写 writeArticle 方法。
`final` 可以修饰变量,final 修饰的变量一经定义后就不能被修改,如下所示
当我们把 writeArticle 方法声明为 void 后,重写的方法会报错,无法重写 writeArticle 方法。
`final` 可以修饰变量,final 修饰的变量一经定义后就不能被修改,如下所示
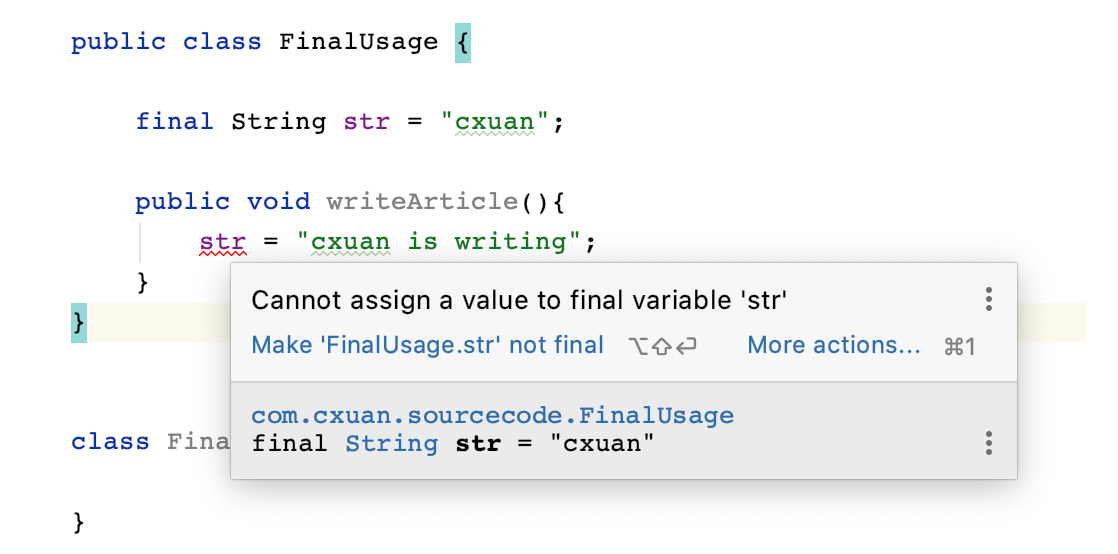 编译器提示的错误正是不能继承一个被 final 修饰的类。
我们上面使用的是字符串 String ,String 默认就是 final 的,其实用不用 final 修饰意义不大,因为字符串本来就不能被改写,这并不能说明问题。
我们改写一下,使用基本数据类型来演示
编译器提示的错误正是不能继承一个被 final 修饰的类。
我们上面使用的是字符串 String ,String 默认就是 final 的,其实用不用 final 修饰意义不大,因为字符串本来就不能被改写,这并不能说明问题。
我们改写一下,使用基本数据类型来演示
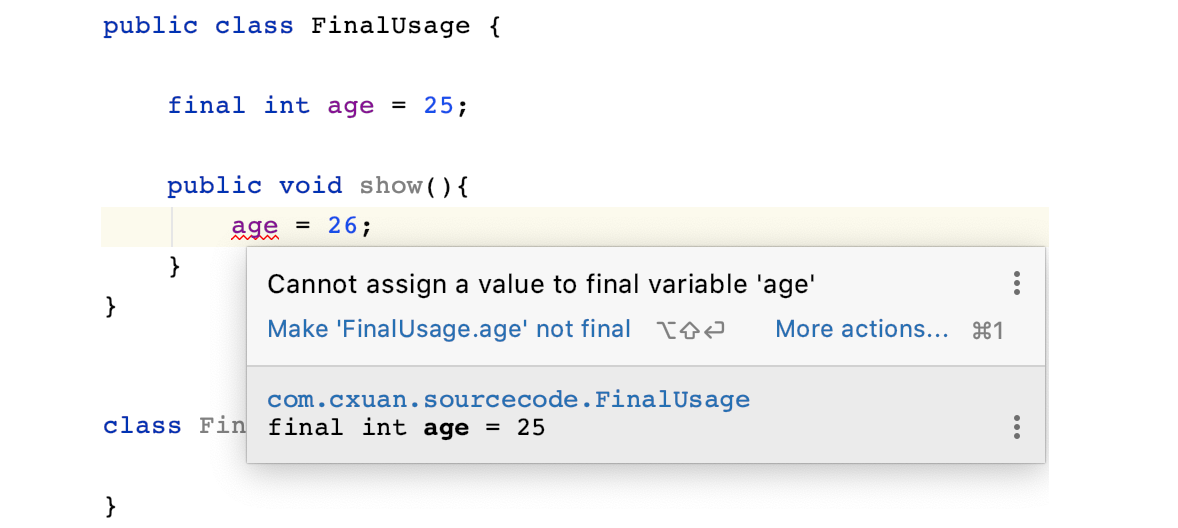 同样的可以看到,编译器仍然给出了 age 不能被改写的提示,由此可以证明,final 修饰的变量不能被重写。
在 Java 中不仅仅只有基本数据类型,还有引用数据类型,那么引用类型被 final 修饰后会如何呢?我们看一下下面的代码
首先构造一个 `Person` 类
```java
public class Person {
int id;
String name;
get() and set() ...
toString()...
}
```
然后我们定义一个 final 的 Person 变量。
```java
static final Person person = new Person(25,"cxuan");
public static void main(String[] args) {
System.out.println(person);
person.setId(26);
person.setName("cxuan001");
System.out.println(person);
}
```
输出一下,你会发现一个奇怪的现象,为什么我们明明改了 person 中的 id 和 name ,编译器却没有报错呢?
这是因为,final 修饰的引用类型,只是保证对象的引用不会改变。对象内部的数据可以改变。这就涉及到对象在内存中的分配问题,我们后面再说。
### finally 保证程序一定被执行
`finally` 是保证程序一定执行的机制,同样的它也是 Java 中的一个关键字,一般来讲,finally 一般不会单独使用,它一般和 try 块一起使用,例如下面是一段 try...finally 代码块
```java
try{
lock.lock();
}finally {
lock.unlock();
}
```
这是一段加锁/解锁的代码示例,在 lock 加锁后,在 finally 中执行解锁操作,因为 finally 能够保证代码一定被执行,所以一般都会把一些比较重要的代码放在 finally 中,例如解锁操作、流关闭操作、连接释放操作等。
当 lock.lock() 产生异常时还可以和 `try...catch...finally` 一起使用
```java
try{
lock.lock();
}catch(Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
```
try...finally 这种写法适用于 JDK1.7 之前,在 JDK1.7 中引入了一种新的关闭流的操作,那就是 `try...with...resources`,Java 引入了 try-with-resources 声明,将 try-catch-finally 简化为 try-catch,这其实是一种语法糖,并不是多了一种语法。try...with...resources 在编译时还是会进行转化为 try-catch-finally 语句。
>`语法糖(Syntactic sugar)`,也译为糖衣语法,是指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。
在 Java 中,有一些为了简化程序员使用的语法糖,后面有机会我们再谈。
### finalize 的作用
finalize 是祖宗类 `Object`类的一个方法,它的设计目的是保证对象在垃圾收集前完成特定资源的回收。finalize 现在已经不再推荐使用,在 JDK 1.9 中已经明确的被标记为 `deprecated`。
## 深入理解 final 、finally 和 finalize
### final 设计
许多编程语言都会有某种方法来告知编译器,某一块数据是恒定不变的。有时候恒定不变的数据很有用,比如
* 一个永不改变的编译期常量 。例如 **static final int num = 1024**
* 一个运行时被初始化的值,而且你不希望改变它
final 的设计会和 `abstract` 的设计产生冲突,因为 abstract 关键字主要修饰`抽象类`,而抽象类需要被具体的类所实现。final 表示禁止继承,也就不会存在被实现的问题。因为只有继承后,子类才可以实现父类的方法。
类中的所有 `private` 都隐式的指定为 `final` 的,在 private 修饰的代码中使用 final 并没有额外的意义。
#### 空白 final
Java 是允许`空白 final` 的,空白 final 指的是声明为 final ,但是却没有对其赋值使其初始化。但是无论如何,编译器都需要初始化 final,所以这个初始化的任务就交给了`构造器`来完成,空白 final 给 final 提供了更大的灵活性。如下代码
```java
public class FinalTest {
final Integer finalNum;
public FinalTest(){
finalNum = 11;
}
public FinalTest(int num){
finalNum = num;
}
public static void main(String[] args) {
new FinalTest();
new FinalTest(25);
}
}
```
在不同的构造器中对不同的 final 进行初始化,使 finalNum 的使用更加灵活。
使用 final 的方法主要有两个:`不可变` 和 `效率`
* 不可变:不可变说的是把方法锁定(注意不是加锁),重在防止其他方法重写。
* 效率:这个主要是针对 Java 早期版本来说的,在 Java 早期实现中,如果将方法声明为 final 的,就是同意编译器将对此方法的调用改为`内嵌调用`,但是却没有带来显著的性能优化。这种调用就比较鸡肋,在 Java5/6 中,hotspot 虚拟机会自动探测到内嵌调用,并把它们优化掉,所以使用 final 修饰的方法就主要有一个:不可变。
>注意:final 不是 Immutable 的,Immutable 才是真正的不可变。
final 不是真正的 `Immutable`,因为 final 关键字引用的对象是可以改变的。如果我们真的希望对象不可变,通常需要相应的类支持不可变行为,比如下面这段代码
```java
final List fList = new ArrayList();
fList.add("Hello");
fList.add("World");
List unmodfiableList = List.of("hello","world");
unmodfiableList.add("again");
```
`List.of` 方法创建的就是不可变的 List。不可变 Immutable 在很多情况下是很好的选择,一般来说,实现 Immutable 需要注意如下几点
* 将类声明为 final,防止其他类进行扩展。
* 将类内部的成员变量(包括实例变量和类变量)声明为 `private` 或 `final` 的,不要提供可以修改成员变量的方法,也就是 setter 方法。
* 在构造对象时,通常使用 `deep-clone` ,这样有助于防止在直接对对象赋值时,其他人对输入对象的修改。
* 坚持 `copy-on-write` 原则,创建私有的拷贝。
### final 能提高性能吗?
final 能否提高性能一直是业界争论的点,很多书籍中都介绍了可以在特定场景提高性能,例如 final 可能用于帮助 JVM 将方法进行内联,可以改造编译器进行编译的能力等等,但这些结论很多都是基于假设作出的。
或许 R 大这篇回答会给我们一些结论 https://www.zhihu.com/question/21762917
大致说的就是**无论局部变量声明时带不带 final 关键字修饰,对其访问的效率都一样**。
比如下面这段代码(不带 final 的版本)
```java
static int foo() {
int a = someValueA();
int b = someValueB();
return a + b; // 这里访问局部变量
}
```
带 final 的版本
```java
static int foo() {
final int a = someValueA();
final int b = someValueB();
return a + b; // 这里访问局部变量
}
```
使用 `javac` 编译后得出来的结果一摸一样。
```assembly
invokestatic someValueA:()I
istore_0 // 设置a的值
invokestatic someValueB:()I
istore_1 // 设置b的值
iload_0 // 读取a的值
iload_1 // 读取b的值
iadd
ireturn
```
因为上面是使用引用类型,所以字节码相同。
如果是常量类型,我们看一下
```java
// 带 final
static int foo(){
final int a = 11;
final int b = 12;
return a + b;
}
// 不带 final
static int foo(){
int a = 11;
int b = 12;
return a + b;
}
```
我们分别编译一下两个 `foo` 方法,会发现如下字节码
同样的可以看到,编译器仍然给出了 age 不能被改写的提示,由此可以证明,final 修饰的变量不能被重写。
在 Java 中不仅仅只有基本数据类型,还有引用数据类型,那么引用类型被 final 修饰后会如何呢?我们看一下下面的代码
首先构造一个 `Person` 类
```java
public class Person {
int id;
String name;
get() and set() ...
toString()...
}
```
然后我们定义一个 final 的 Person 变量。
```java
static final Person person = new Person(25,"cxuan");
public static void main(String[] args) {
System.out.println(person);
person.setId(26);
person.setName("cxuan001");
System.out.println(person);
}
```
输出一下,你会发现一个奇怪的现象,为什么我们明明改了 person 中的 id 和 name ,编译器却没有报错呢?
这是因为,final 修饰的引用类型,只是保证对象的引用不会改变。对象内部的数据可以改变。这就涉及到对象在内存中的分配问题,我们后面再说。
### finally 保证程序一定被执行
`finally` 是保证程序一定执行的机制,同样的它也是 Java 中的一个关键字,一般来讲,finally 一般不会单独使用,它一般和 try 块一起使用,例如下面是一段 try...finally 代码块
```java
try{
lock.lock();
}finally {
lock.unlock();
}
```
这是一段加锁/解锁的代码示例,在 lock 加锁后,在 finally 中执行解锁操作,因为 finally 能够保证代码一定被执行,所以一般都会把一些比较重要的代码放在 finally 中,例如解锁操作、流关闭操作、连接释放操作等。
当 lock.lock() 产生异常时还可以和 `try...catch...finally` 一起使用
```java
try{
lock.lock();
}catch(Exception e){
e.printStackTrace();
}finally {
lock.unlock();
}
```
try...finally 这种写法适用于 JDK1.7 之前,在 JDK1.7 中引入了一种新的关闭流的操作,那就是 `try...with...resources`,Java 引入了 try-with-resources 声明,将 try-catch-finally 简化为 try-catch,这其实是一种语法糖,并不是多了一种语法。try...with...resources 在编译时还是会进行转化为 try-catch-finally 语句。
>`语法糖(Syntactic sugar)`,也译为糖衣语法,是指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。
在 Java 中,有一些为了简化程序员使用的语法糖,后面有机会我们再谈。
### finalize 的作用
finalize 是祖宗类 `Object`类的一个方法,它的设计目的是保证对象在垃圾收集前完成特定资源的回收。finalize 现在已经不再推荐使用,在 JDK 1.9 中已经明确的被标记为 `deprecated`。
## 深入理解 final 、finally 和 finalize
### final 设计
许多编程语言都会有某种方法来告知编译器,某一块数据是恒定不变的。有时候恒定不变的数据很有用,比如
* 一个永不改变的编译期常量 。例如 **static final int num = 1024**
* 一个运行时被初始化的值,而且你不希望改变它
final 的设计会和 `abstract` 的设计产生冲突,因为 abstract 关键字主要修饰`抽象类`,而抽象类需要被具体的类所实现。final 表示禁止继承,也就不会存在被实现的问题。因为只有继承后,子类才可以实现父类的方法。
类中的所有 `private` 都隐式的指定为 `final` 的,在 private 修饰的代码中使用 final 并没有额外的意义。
#### 空白 final
Java 是允许`空白 final` 的,空白 final 指的是声明为 final ,但是却没有对其赋值使其初始化。但是无论如何,编译器都需要初始化 final,所以这个初始化的任务就交给了`构造器`来完成,空白 final 给 final 提供了更大的灵活性。如下代码
```java
public class FinalTest {
final Integer finalNum;
public FinalTest(){
finalNum = 11;
}
public FinalTest(int num){
finalNum = num;
}
public static void main(String[] args) {
new FinalTest();
new FinalTest(25);
}
}
```
在不同的构造器中对不同的 final 进行初始化,使 finalNum 的使用更加灵活。
使用 final 的方法主要有两个:`不可变` 和 `效率`
* 不可变:不可变说的是把方法锁定(注意不是加锁),重在防止其他方法重写。
* 效率:这个主要是针对 Java 早期版本来说的,在 Java 早期实现中,如果将方法声明为 final 的,就是同意编译器将对此方法的调用改为`内嵌调用`,但是却没有带来显著的性能优化。这种调用就比较鸡肋,在 Java5/6 中,hotspot 虚拟机会自动探测到内嵌调用,并把它们优化掉,所以使用 final 修饰的方法就主要有一个:不可变。
>注意:final 不是 Immutable 的,Immutable 才是真正的不可变。
final 不是真正的 `Immutable`,因为 final 关键字引用的对象是可以改变的。如果我们真的希望对象不可变,通常需要相应的类支持不可变行为,比如下面这段代码
```java
final List fList = new ArrayList();
fList.add("Hello");
fList.add("World");
List unmodfiableList = List.of("hello","world");
unmodfiableList.add("again");
```
`List.of` 方法创建的就是不可变的 List。不可变 Immutable 在很多情况下是很好的选择,一般来说,实现 Immutable 需要注意如下几点
* 将类声明为 final,防止其他类进行扩展。
* 将类内部的成员变量(包括实例变量和类变量)声明为 `private` 或 `final` 的,不要提供可以修改成员变量的方法,也就是 setter 方法。
* 在构造对象时,通常使用 `deep-clone` ,这样有助于防止在直接对对象赋值时,其他人对输入对象的修改。
* 坚持 `copy-on-write` 原则,创建私有的拷贝。
### final 能提高性能吗?
final 能否提高性能一直是业界争论的点,很多书籍中都介绍了可以在特定场景提高性能,例如 final 可能用于帮助 JVM 将方法进行内联,可以改造编译器进行编译的能力等等,但这些结论很多都是基于假设作出的。
或许 R 大这篇回答会给我们一些结论 https://www.zhihu.com/question/21762917
大致说的就是**无论局部变量声明时带不带 final 关键字修饰,对其访问的效率都一样**。
比如下面这段代码(不带 final 的版本)
```java
static int foo() {
int a = someValueA();
int b = someValueB();
return a + b; // 这里访问局部变量
}
```
带 final 的版本
```java
static int foo() {
final int a = someValueA();
final int b = someValueB();
return a + b; // 这里访问局部变量
}
```
使用 `javac` 编译后得出来的结果一摸一样。
```assembly
invokestatic someValueA:()I
istore_0 // 设置a的值
invokestatic someValueB:()I
istore_1 // 设置b的值
iload_0 // 读取a的值
iload_1 // 读取b的值
iadd
ireturn
```
因为上面是使用引用类型,所以字节码相同。
如果是常量类型,我们看一下
```java
// 带 final
static int foo(){
final int a = 11;
final int b = 12;
return a + b;
}
// 不带 final
static int foo(){
int a = 11;
int b = 12;
return a + b;
}
```
我们分别编译一下两个 `foo` 方法,会发现如下字节码
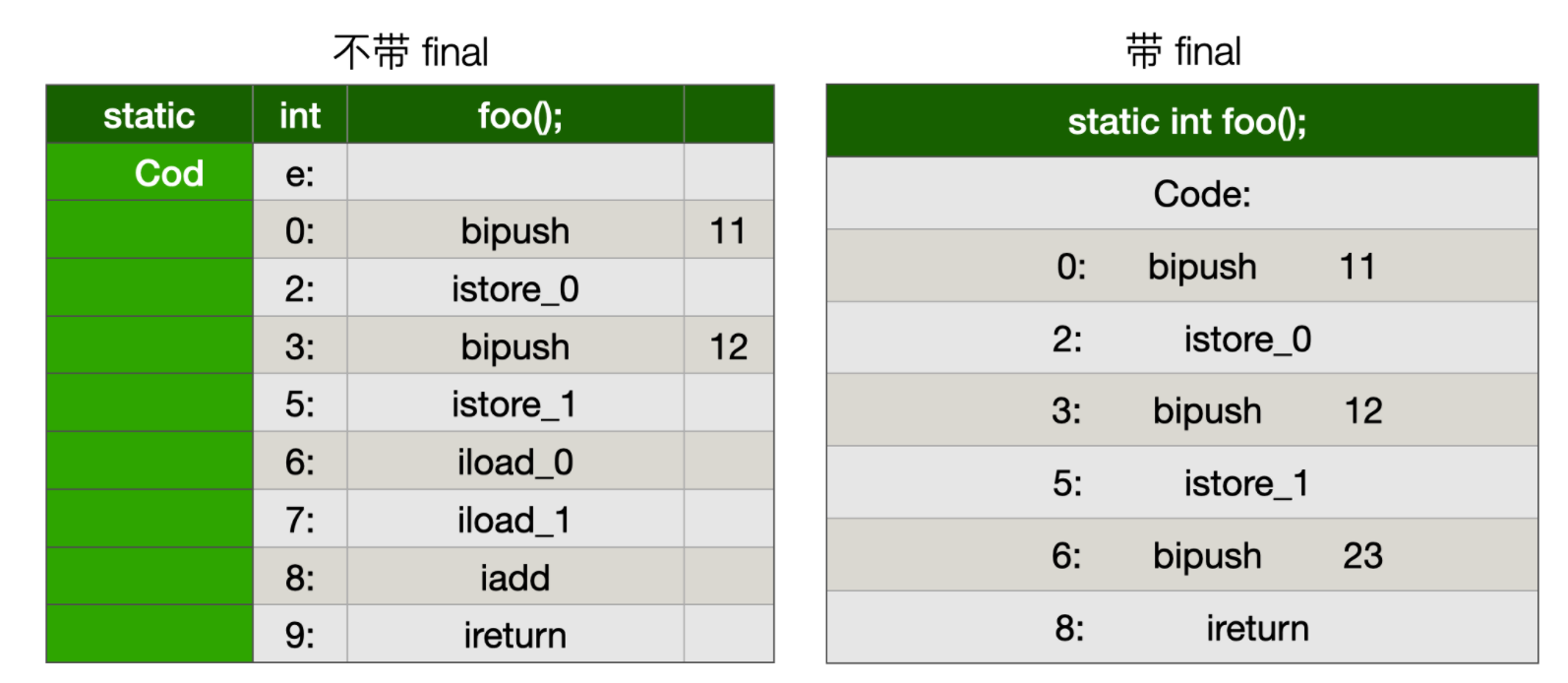 左边是非 final 关键字修饰的代码,右边是有 final 关键字修饰的代码,对比这两个字节码,可以得出如下结论。
* 不管有没有 final 修饰 ,int a = 11 或者 int a = 12 都当作常量看待。
* 在 return 返回处,不加 final 的 a + b 会当作变量来处理;加 final 修饰的 a + b 会直接当作常量处理。
> 其实这种层面上的差异只对比较简易的 JVM 影响较大,因为这样的 VM 对解释器的依赖较大,原本 Class 文件里的字节码是怎样的它就怎么执行;对高性能的 JVM(例如 HotSpot、J9 等)则没啥影响。
所以,大部分 final 对性能优化的影响,可以直接忽略,我们使用 final 更多的考量在于其不可变性。
### 深入理解 finally
我们上面大致聊到了 finally 的使用,其作用就是保证在 try 块中的代码执行完成之后,必然会执行 finally 中的语句。不管 try 块中是否抛出异常。
那么下面我们就来深入认识一下 finally ,以及 finally 的字节码是什么,以及 finally 究竟何时执行的本质。
* **首先我们知道 finally 块只会在 try 块执行的情况下才执行,finally 不会单独存在**。
这个不用再过多解释,这是大家都知道的一条规则。finally 必须和 try 块或者 try catch 块一起使用。
* **其次,finally 块在离开 try 块执行完成后或者 try 块未执行完成但是接下来是控制转移语句时(return/continue/break)在控制转移语句之前执行**
这一条其实是说明 finally 的执行时机的,我们以 return 为例来看一下是不是这么回事。
如下这段代码
```java
static int mayThrowException(){
try{
return 1;
}finally {
System.out.println("finally");
}
}
public static void main(String[] args) {
System.out.println(FinallyTest.mayThrowException());
}
```
从执行结果可以证明是 finally 要先于 return 执行的。
当 finally 有返回值时,会直接返回。不会再去返回 try 或者 catch 中的返回值。
```java
static int mayThrowException(){
try{
return 1;
}finally {
return 2;
}
}
public static void main(String[] args) {
System.out.println(FinallyTest.mayThrowException());
}
```
* **在执行 finally 语句之前,控制转移语句会将返回值存在本地变量中**
看下面这段代码
```java
static int mayThrowException(){
int i = 100;
try {
return i;
}finally {
++i;
}
}
public static void main(String[] args) {
System.out.println(FinallyTest.mayThrowException());
}
```
上面这段代码能够说明 return i 是先于 ++i 执行的,而且 return i 会把 i 的值暂存,和 finally 一起返回。
#### finally 的本质
下面我们来看一段代码
```java
public static void main(String[] args) {
int a1 = 0;
try {
a1 = 1;
}catch (Exception e){
a1 = 2;
}finally {
a1 = 3;
}
System.out.println(a1);
}
```
这段代码输出的结果是什么呢?答案是 3,为啥呢?
抱着疑问,我们先来看一下这段代码的字节码
左边是非 final 关键字修饰的代码,右边是有 final 关键字修饰的代码,对比这两个字节码,可以得出如下结论。
* 不管有没有 final 修饰 ,int a = 11 或者 int a = 12 都当作常量看待。
* 在 return 返回处,不加 final 的 a + b 会当作变量来处理;加 final 修饰的 a + b 会直接当作常量处理。
> 其实这种层面上的差异只对比较简易的 JVM 影响较大,因为这样的 VM 对解释器的依赖较大,原本 Class 文件里的字节码是怎样的它就怎么执行;对高性能的 JVM(例如 HotSpot、J9 等)则没啥影响。
所以,大部分 final 对性能优化的影响,可以直接忽略,我们使用 final 更多的考量在于其不可变性。
### 深入理解 finally
我们上面大致聊到了 finally 的使用,其作用就是保证在 try 块中的代码执行完成之后,必然会执行 finally 中的语句。不管 try 块中是否抛出异常。
那么下面我们就来深入认识一下 finally ,以及 finally 的字节码是什么,以及 finally 究竟何时执行的本质。
* **首先我们知道 finally 块只会在 try 块执行的情况下才执行,finally 不会单独存在**。
这个不用再过多解释,这是大家都知道的一条规则。finally 必须和 try 块或者 try catch 块一起使用。
* **其次,finally 块在离开 try 块执行完成后或者 try 块未执行完成但是接下来是控制转移语句时(return/continue/break)在控制转移语句之前执行**
这一条其实是说明 finally 的执行时机的,我们以 return 为例来看一下是不是这么回事。
如下这段代码
```java
static int mayThrowException(){
try{
return 1;
}finally {
System.out.println("finally");
}
}
public static void main(String[] args) {
System.out.println(FinallyTest.mayThrowException());
}
```
从执行结果可以证明是 finally 要先于 return 执行的。
当 finally 有返回值时,会直接返回。不会再去返回 try 或者 catch 中的返回值。
```java
static int mayThrowException(){
try{
return 1;
}finally {
return 2;
}
}
public static void main(String[] args) {
System.out.println(FinallyTest.mayThrowException());
}
```
* **在执行 finally 语句之前,控制转移语句会将返回值存在本地变量中**
看下面这段代码
```java
static int mayThrowException(){
int i = 100;
try {
return i;
}finally {
++i;
}
}
public static void main(String[] args) {
System.out.println(FinallyTest.mayThrowException());
}
```
上面这段代码能够说明 return i 是先于 ++i 执行的,而且 return i 会把 i 的值暂存,和 finally 一起返回。
#### finally 的本质
下面我们来看一段代码
```java
public static void main(String[] args) {
int a1 = 0;
try {
a1 = 1;
}catch (Exception e){
a1 = 2;
}finally {
a1 = 3;
}
System.out.println(a1);
}
```
这段代码输出的结果是什么呢?答案是 3,为啥呢?
抱着疑问,我们先来看一下这段代码的字节码
 字节码的中文注释我已经给你标出来了,这里需要注意一下下面的 `Exception table`,Exception table 是异常表,异常表中每一个条目代表一个异常发生器,异常发生器由 From 指针,To 指针,Target 指针和应该捕获的异常类型构成。
所以上面这段代码的执行路径有三种
* 如果 try 语句块中出现了属于 exception 及其子类的异常,则跳转到 catch 处理
* 如果 try 语句块中出现了不属于 exception 及其子类的异常,则跳转到 finally 处理
* 如果 catch 语句块中新出现了异常,则跳转到 finally 处理
聊到这里,我们还没说 finally 的本质到底是什么,仔细观察一下上面的字节码,你会发现其实 finally 会把 `a1 = 3` 的字节码 **iconst_3 和 istore_1** 放在 try 块和 catch 块的后面,所以上面这段代码就形同于
```java
public static void main(String[] args) {
int a1 = 0;
try {
a1 = 1;
// finally a1 = 3
}catch (Exception e){
a1 = 2;
// finally a1 = 3
}finally {
a1 = 3;
}
System.out.println(a1);
}
```
上面中的 Exception table 是只有 `Throwable` 的子类 **exception 和 error** 才会执行异常走查的异常表,正常情况下没有 try 块是没有异常表的,下面来验证一下
```java
public static void main(String[] args) {
int a1 = 1;
System.out.println(a1);
}
```
比如上面我们使用了一段非常简单的程序来验证,编译后我们来看一下它的字节码
字节码的中文注释我已经给你标出来了,这里需要注意一下下面的 `Exception table`,Exception table 是异常表,异常表中每一个条目代表一个异常发生器,异常发生器由 From 指针,To 指针,Target 指针和应该捕获的异常类型构成。
所以上面这段代码的执行路径有三种
* 如果 try 语句块中出现了属于 exception 及其子类的异常,则跳转到 catch 处理
* 如果 try 语句块中出现了不属于 exception 及其子类的异常,则跳转到 finally 处理
* 如果 catch 语句块中新出现了异常,则跳转到 finally 处理
聊到这里,我们还没说 finally 的本质到底是什么,仔细观察一下上面的字节码,你会发现其实 finally 会把 `a1 = 3` 的字节码 **iconst_3 和 istore_1** 放在 try 块和 catch 块的后面,所以上面这段代码就形同于
```java
public static void main(String[] args) {
int a1 = 0;
try {
a1 = 1;
// finally a1 = 3
}catch (Exception e){
a1 = 2;
// finally a1 = 3
}finally {
a1 = 3;
}
System.out.println(a1);
}
```
上面中的 Exception table 是只有 `Throwable` 的子类 **exception 和 error** 才会执行异常走查的异常表,正常情况下没有 try 块是没有异常表的,下面来验证一下
```java
public static void main(String[] args) {
int a1 = 1;
System.out.println(a1);
}
```
比如上面我们使用了一段非常简单的程序来验证,编译后我们来看一下它的字节码
 可以看到,果然没有异常表的存在。
#### finally 一定会执行吗
上面我们讨论的都是 finally 一定会执行的情况,那么 finally 一定会被执行吗?恐怕不是。
除了机房断电、机房爆炸、机房进水、机房被雷劈、强制关机、拔电源之外,还有几种情况能够使 finally 不会执行。
* 调用 `System.exit` 方法
* 调用 `Runtime.getRuntime().halt(exitStatus)` 方法
* JVM 宕机(搞笑脸)
* 如果 JVM 在 try 或 catch 块中达到了无限循环(或其他不间断,不终止的语句)
* 操作系统是否强行终止了 JVM 进程;例如,在 UNIX 上执行 kill -9 pid
* 如果主机系统死机;例如电源故障,硬件错误,操作系统死机等不会执行
* 如果 finally 块由守护程序线程执行,那么所有非守护线程在 finally 调用之前退出。
### finalize 真的没用吗
我们上面简单介绍了一下 finalize 方法,并说明了它是一种不好的实践。那么 finalize 调用的时机是什么?为什么说 finalize 没用呢?
我们知道,Java 与 C++ 一个显著的区别在于 Java 能够`自动管理内存`,在 Java 中,由于 GC 的自动回收机制,因而并不能保证 `finalize` 方法会被及时地执行(垃圾对象的回收时机具有不确定性),也不能保证它们会被执行。
>也就是说,finalize 的执行时期不确定,我们并不能依赖于 finalize 方法帮我们进行垃圾回收,可能出现的情况是在我们耗尽资源之前,gc 却仍未触发,所以推荐使用资源用完即显示释放的方式,比如 close 方法。除此之外,finalize 方法也会生吞异常。
finalize 的工作方式是这样的:一旦垃圾回收器准备好释放对象占用的存储空间,将会首先调用 `finalize` 方法,并且在下一次垃圾回收动作发生时,才会真正回收对象占用的内存。**垃圾回收只与内存有关**。
我们在日常开发中并不提倡使用 finalize 方法,能用 finalize 方法的地方,使用 try...finally 会处理的更好。


可以看到,果然没有异常表的存在。
#### finally 一定会执行吗
上面我们讨论的都是 finally 一定会执行的情况,那么 finally 一定会被执行吗?恐怕不是。
除了机房断电、机房爆炸、机房进水、机房被雷劈、强制关机、拔电源之外,还有几种情况能够使 finally 不会执行。
* 调用 `System.exit` 方法
* 调用 `Runtime.getRuntime().halt(exitStatus)` 方法
* JVM 宕机(搞笑脸)
* 如果 JVM 在 try 或 catch 块中达到了无限循环(或其他不间断,不终止的语句)
* 操作系统是否强行终止了 JVM 进程;例如,在 UNIX 上执行 kill -9 pid
* 如果主机系统死机;例如电源故障,硬件错误,操作系统死机等不会执行
* 如果 finally 块由守护程序线程执行,那么所有非守护线程在 finally 调用之前退出。
### finalize 真的没用吗
我们上面简单介绍了一下 finalize 方法,并说明了它是一种不好的实践。那么 finalize 调用的时机是什么?为什么说 finalize 没用呢?
我们知道,Java 与 C++ 一个显著的区别在于 Java 能够`自动管理内存`,在 Java 中,由于 GC 的自动回收机制,因而并不能保证 `finalize` 方法会被及时地执行(垃圾对象的回收时机具有不确定性),也不能保证它们会被执行。
>也就是说,finalize 的执行时期不确定,我们并不能依赖于 finalize 方法帮我们进行垃圾回收,可能出现的情况是在我们耗尽资源之前,gc 却仍未触发,所以推荐使用资源用完即显示释放的方式,比如 close 方法。除此之外,finalize 方法也会生吞异常。
finalize 的工作方式是这样的:一旦垃圾回收器准备好释放对象占用的存储空间,将会首先调用 `finalize` 方法,并且在下一次垃圾回收动作发生时,才会真正回收对象占用的内存。**垃圾回收只与内存有关**。
我们在日常开发中并不提倡使用 finalize 方法,能用 finalize 方法的地方,使用 try...finally 会处理的更好。

