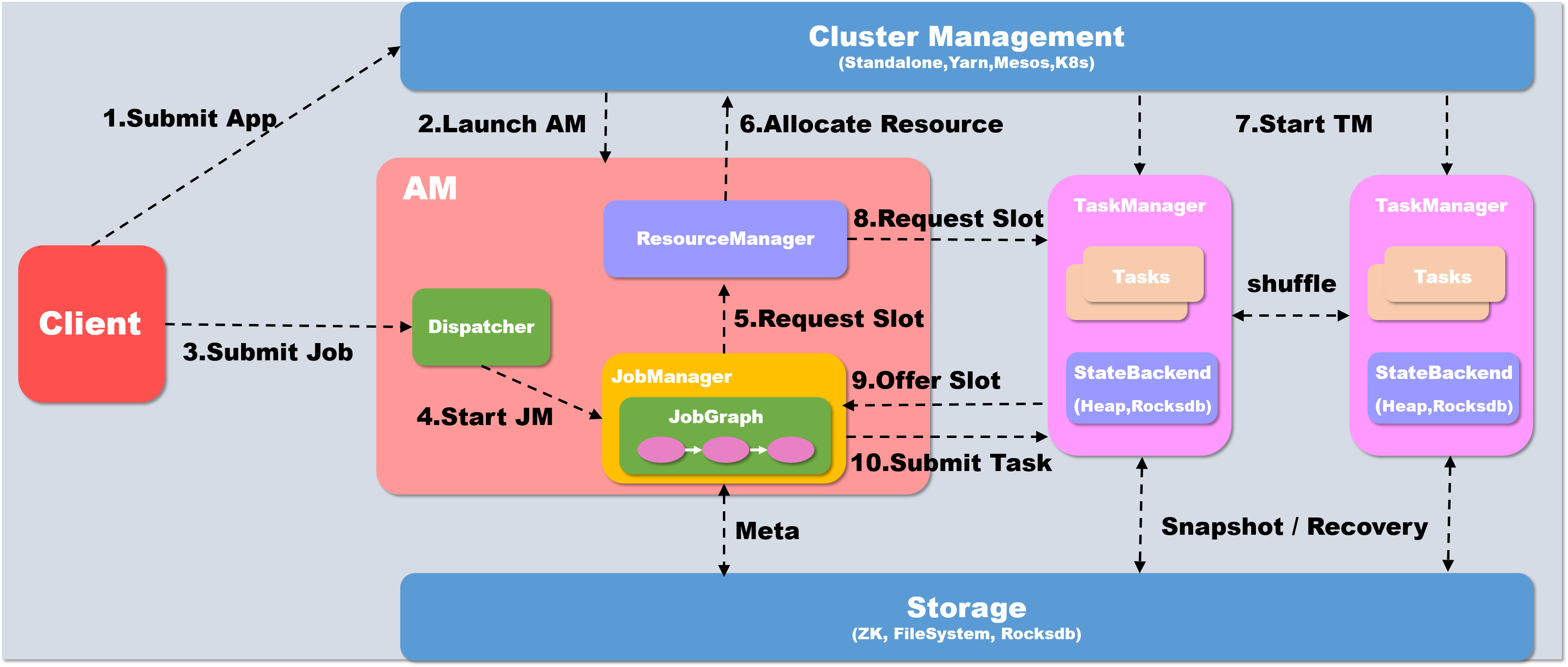
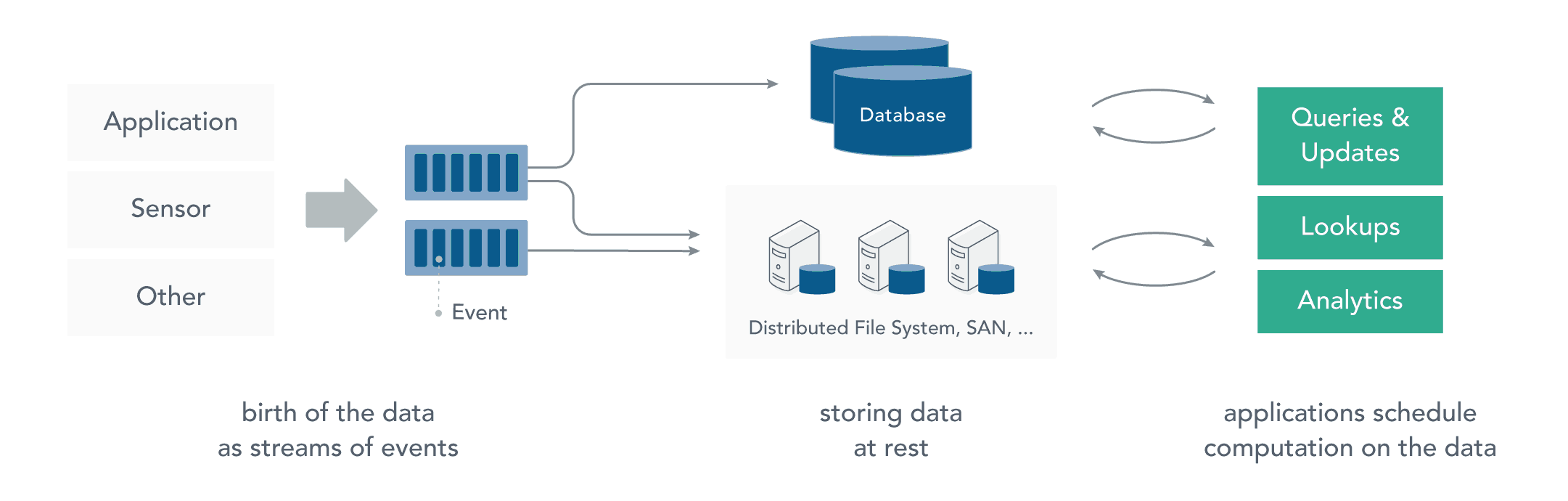
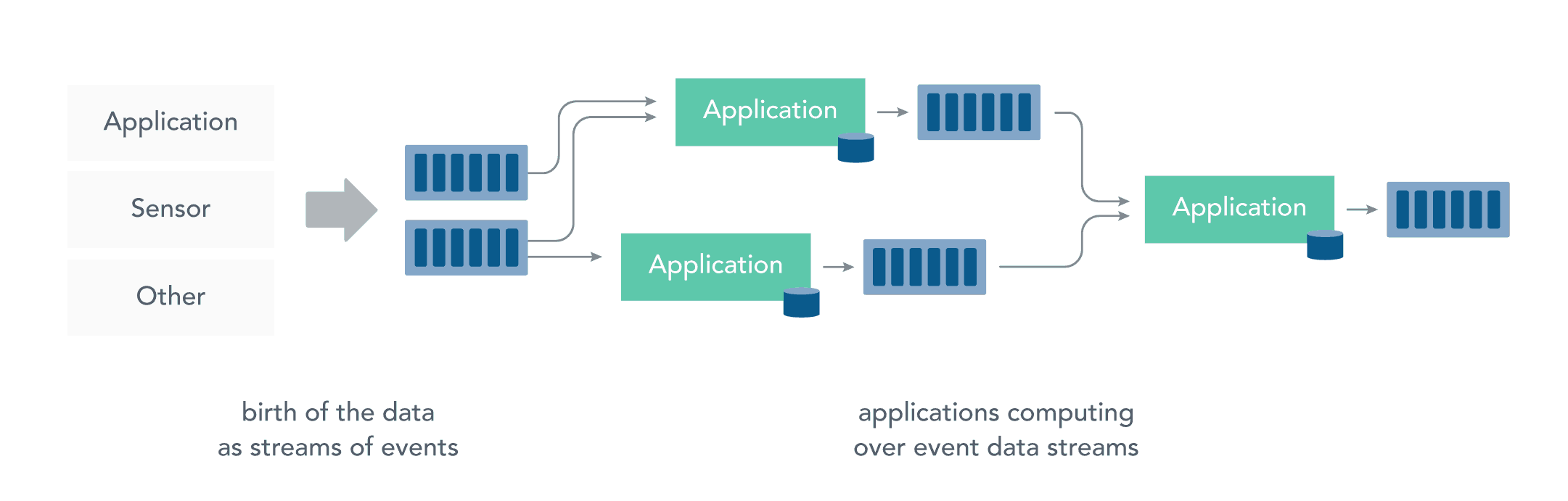
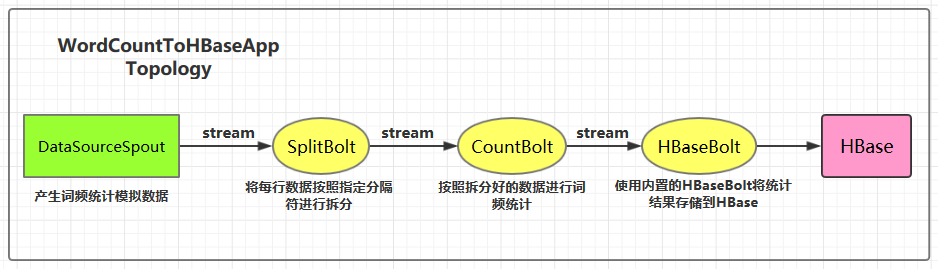
分布式系统基础架构Hadoop
Hadoop详细介绍
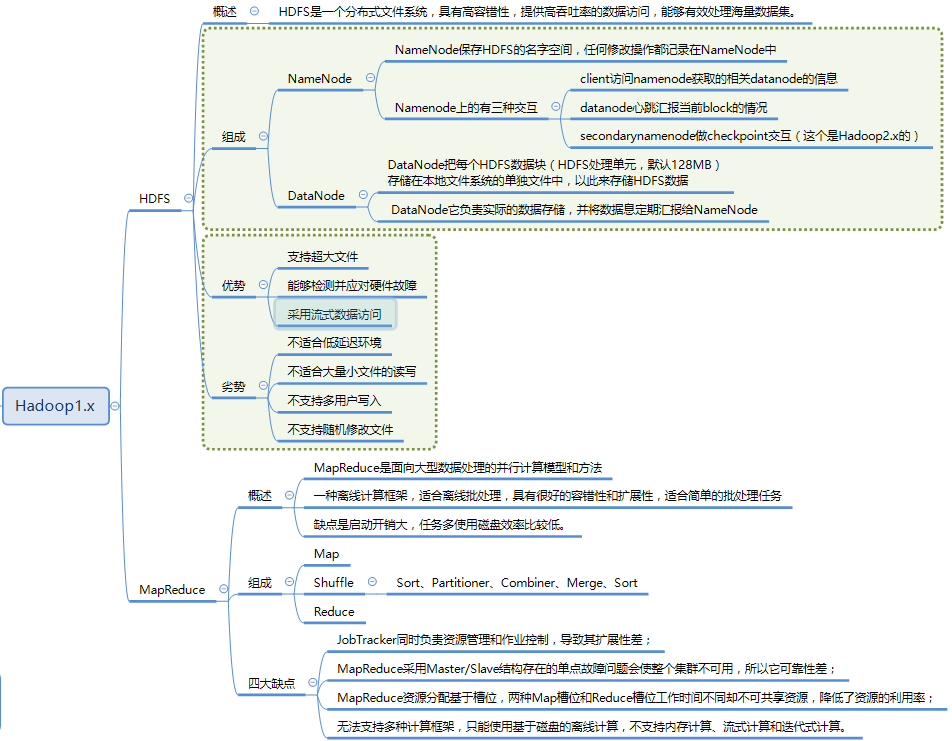
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。
Hadoop体系结构
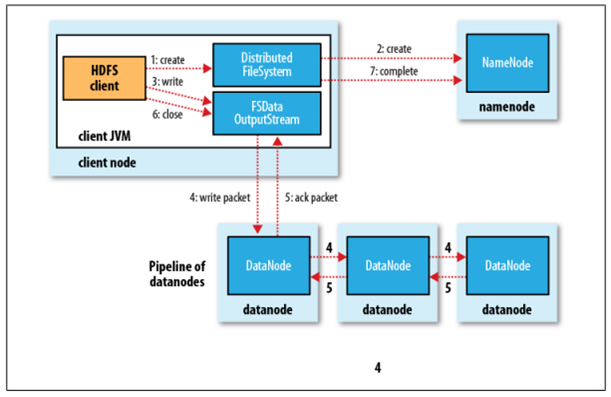
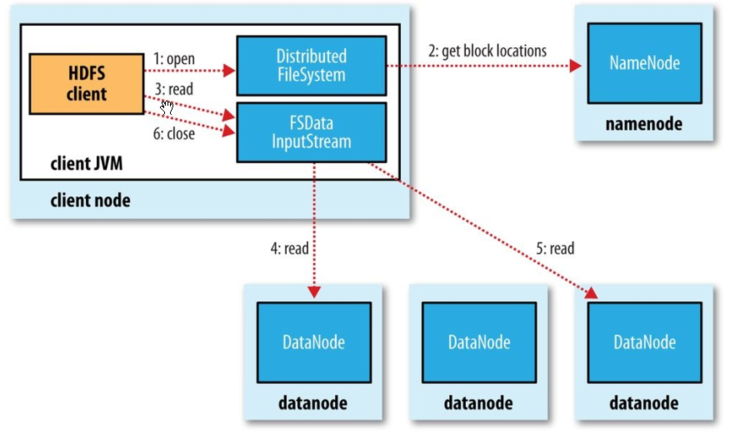
分布式文件系统HDFS
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。HDFS开始是为开源的apache项目nutch的基础结构而创建,HDFS是hadoop项目的一部分,而hadoop又是lucene的一部分。

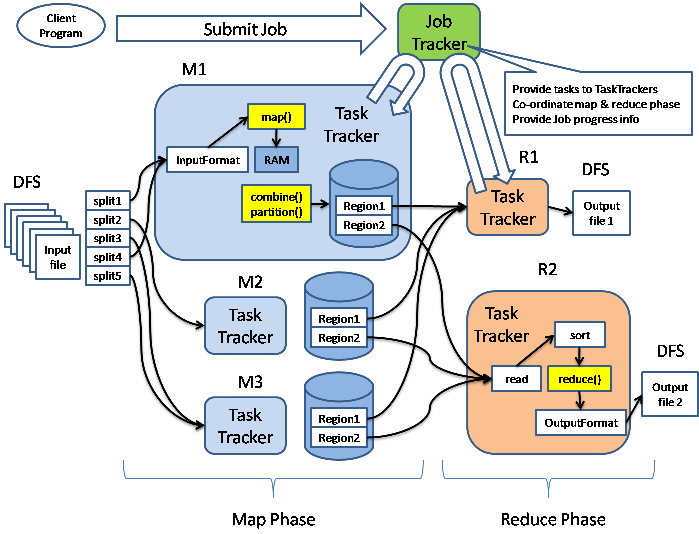
大规模数据集软件架构MapReduce
MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(化简)”,和他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
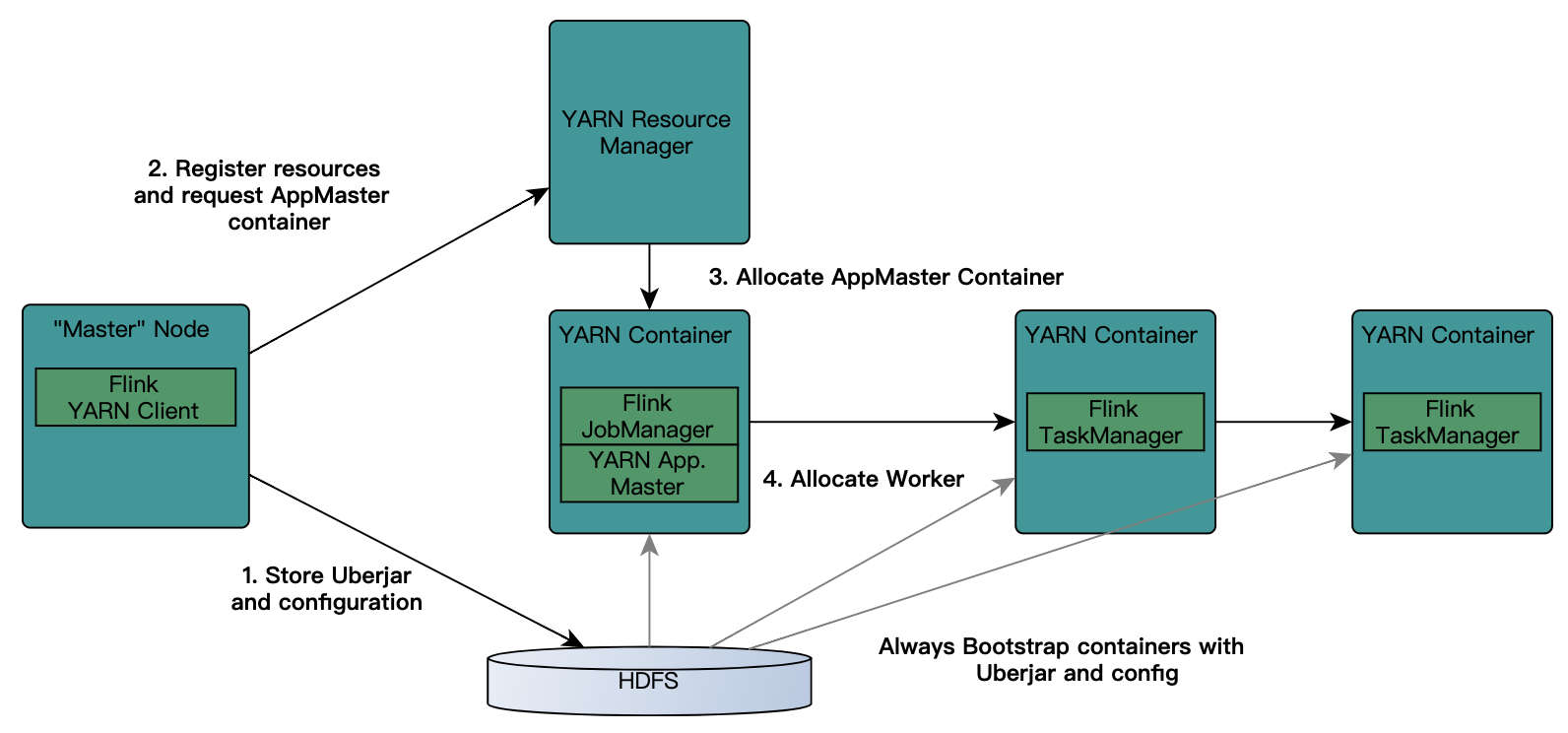
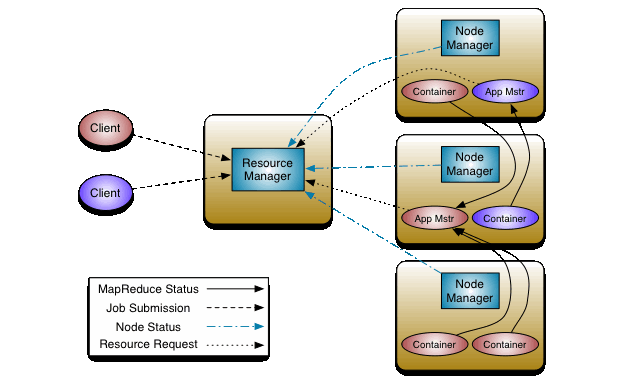
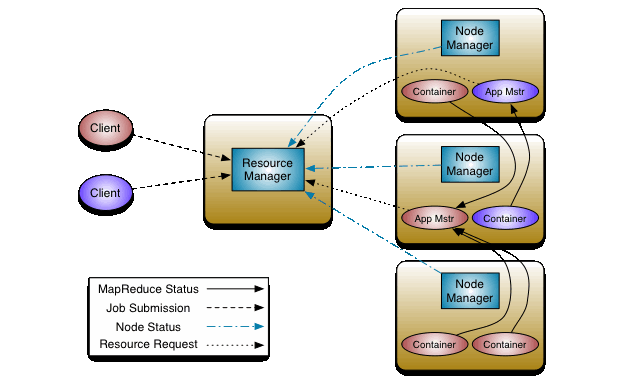
Hadoop资源管理器YARN
YAEN详细介绍
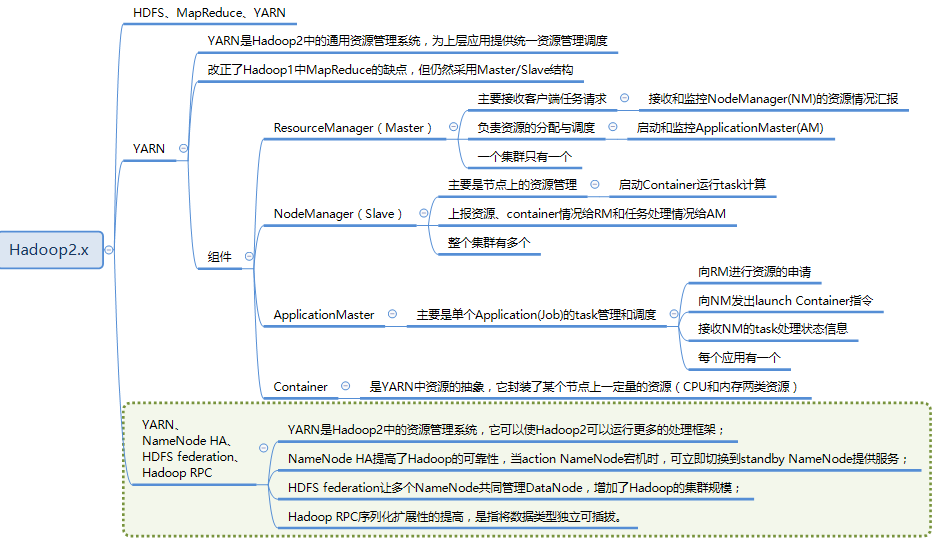
YARN是新一代Hadoop资源管理器,通过YARN,用户可以运行和管理同一个物理集群机上的多种作业,例如MapReduce批处理和图形处理作业。这样不仅可以巩固一个组织管理的系统数目,而且可以对相同的数据进行不同类型的数据分析。某些情况下,整个数据流可以执行在同一个集群机上。
数据仓库平台Hive
Hive详细介绍
Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
数据表和存储管理服务HCatalog
Hcatalog 详细介绍
Apache HCatalog是基于Apache Hadoop之上的数据表和存储管理服务。
包括:
- 提供一个共享的模式和数据类型的机制。
- 抽象出表,使用户不必关心他们的数据怎么存储。
- 提供可操作的跨数据处理工具,如Pig,MapReduce,Streaming,和Hive。
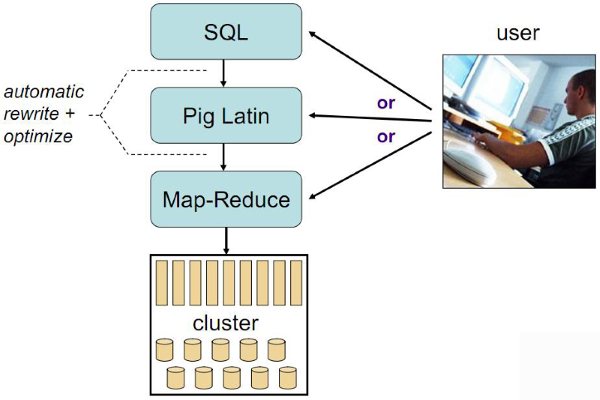
大规模数据分析平台Pig
Pig详细介绍
Pig是一个基于Hadoop的大规模数据分析平台,它提供的SQL-LIKE语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口。
Hadoop管理监控工具Apache Ambari
Apache Ambari 详细介绍
Apache Ambari是一个基于Web的Apache Hadoop集群的供应、管理和监控。Ambari目前已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeper、Sqoop和Hcatalog等。
Apache Ambari 支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeper、Sqoop和Hcatalog等的集中管理。也是5个顶级hadoop管理工具之一。
Ambari主要取得了以下成绩:
- 通过一步步的安装向导简化了集群供应。
- 预先配置好关键的运维指标(metrics),可以直接查看Hadoop Core(HDFS和MapReduce)及相关项目(如HBase、Hive和HCatalog)是否健康。
- 支持作业与任务执行的可视化与分析,能够更好地查看依赖和性能。
- 通过一个完整的RESTful API把监控信息暴露出来,集成了现有的运维工具。
- 用户界面非常直观,用户可以轻松有效地查看信息并控制集群。
Ambari使用Ganglia收集度量指标,用Nagios支持系统报警,当需要引起管理员的关注时(比如,节点停机或磁盘剩余空间不足等问题),系统将向其发送邮件。
此外,Ambari能够安装安全的(基于Kerberos)Hadoop集群,以此实现了对Hadoop 安全的支持,提供了基于角色的用户认证、授权和审计功能,并为用户管理集成了LDAP[轻量目录访问协议]和Active Directory。
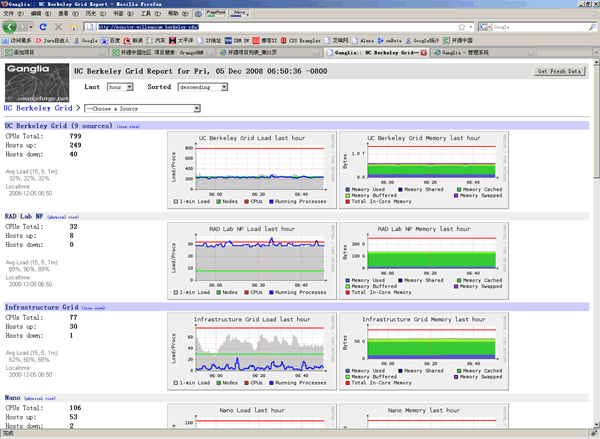
分布式监控系统Ganglia
Ganglia详细介绍
Ganglia是用于高性能计算系统(如集群和网格)的可扩展分布式监控系统。它基于针对集群联盟的分层设计。它利用广泛使用的技术,例如用于数据表示的XML,用于紧凑型,便携式数据传输的XDR和用于数据存储和可视化的RRDtool。它使用精心设计的数据结构和算法来实现非常低的每节点开销和高并发性。该实现是强大的,已被移植到广泛的操作系统和处理器架构,目前正在世界各地的数千个集群中使用。它已经被用来连接大学校园和世界各地的群集,并且可以扩展到处理具有2000个节点的群集。
监控系统Nagios
Nagios
Nagios是一个监视系统运行状态和网络信息的监视系统。Nagios能监视所指定的本地或远程主机以及服务,同时提供异常通知功能等
Nagios可运行在Linux/Unix平台之上,同时提供一个可选的基于浏览器的WEB界面以方便系统管理人员查看网络状态,各种系统问题,以及日志等等。
Nagios 有一个 Windows 下的客户端: http://www.oschina.net/p/nsclientpp
Nagios的主要功能特点:
- 监视网络服务 (SMTP, POP3, HTTP, NNTP, PING等)
- 监视主机资源 (进程, 磁盘等)
- 简单的插件设计可以轻松扩展Nagios的监视功能
- 服务等监视的并发处理
- 错误通知功能 (通过email, pager, 或其他用户自定义方法)
- 可指定自定义的事件处理控制器
- 可选的基于浏览器的WEB界面以方便系统管理人员查看网络状态,各种系统问题,以及日志等等
- 可以通过手机查看系统监控信息
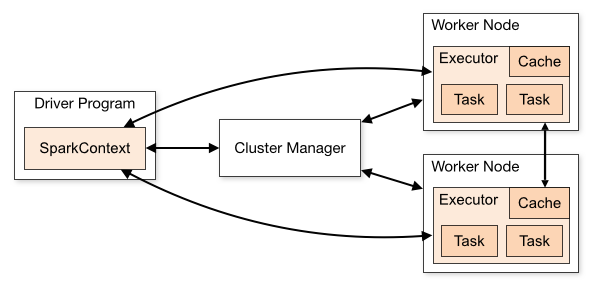
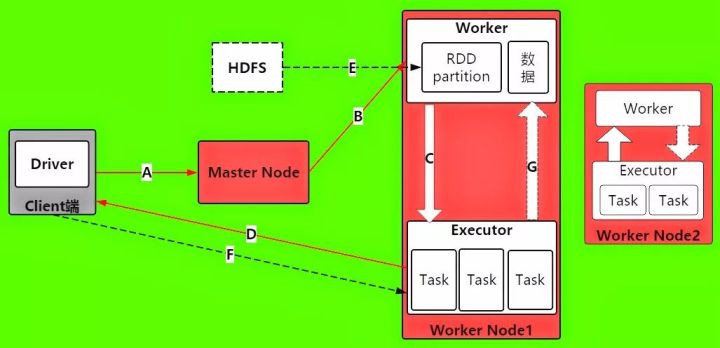
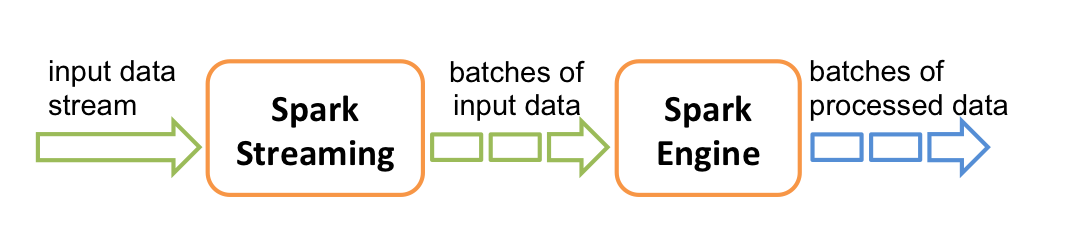
开源集群计算环境Apache Spark
Apache Spark详细介绍
Apache Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoo 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
基于Hadoop的实时查询Cloudera Impala
Cloudera Impala详细的介绍
Cloudera 发布实时查询开源项目 Impala (黑斑羚)!多款产品实测表明,比原来基于MapReduce的Hive SQL查询速度提升3~90倍。Impala是Google Dremel的模仿,但在SQL功能上青出于蓝胜于蓝。
Impala采用与Hive相同的元数据、SQL语法、ODBC驱动程序和用户接口(Hue Beeswax),这样在使用CDH产品时,批处理和实时查询的平台是统一的。目前支持的文件格式是文本文件和SequenceFiles(可以压缩为Snappy、GZIP和BZIP,前者性能最好)。其他格式如Avro, RCFile, LZO文本和Doug Cutting的Trevni将在正式版中支持。
Hadoop柱状存储格式Parquet
Parquet详细介绍
Parquet是一种面向列存存储的文件格式,Cloudera的大数据在线分析(OLAP)项目Impala中使用该格式作为列存储。
Apache Parquet 是一个列存储格式,主要用于 Hadoop 生态系统。对数据处理框架、数据模型和编程语言无关。
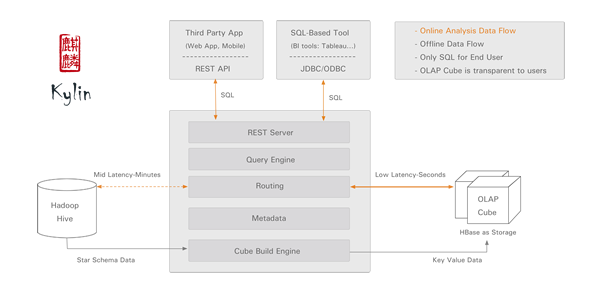
OLAP分析引擎Apache Kylin
Apache Kylin详细介绍
Apache Kylin 是一个开源的分布式的 OLAP 分析引擎,来自 eBay 公司开发,基于 Hadoop 提供 SQL 接口和 OLAP 接口,支持 TB 到 PB 级别的数据量。
Apache kylin是:
- 超级快的OLAP引擎,具备可伸缩性
- 为Hadoop提供ANSI-SQL接口
- 交互式查询能力
- MOLAP Cube
- 可与其他BI工具无缝集成,如Tableau,而Microstrategy和Excel将很快推出
Apache kylin总结的特点
- 通过空间换时间->实现了亚秒级别延迟——>提供了一个交互式的查询
- 预计算,计算结果保存在HBase中,基于行的关系模式转换为基于键值对的列式模式
- 维度组合,查询访问不需要扫描表
- 提供SQL接口
其他值得关注的特性包括:
- 作业管理和监控
- 压缩和编码的支持
- Cube 的增量更新
- Leverage HBase Coprocessor for query latency
- Approximate Query Capability for distinct Count (HyperLogLog)
- 易用的 Web 管理、构建、监控和查询 Cube 的接口
- Security capability to set ACL at Cube/Project Level
- 支持 LDAP 集成
分布式实时计算系统Apache Storm
Apache Storm详细介绍
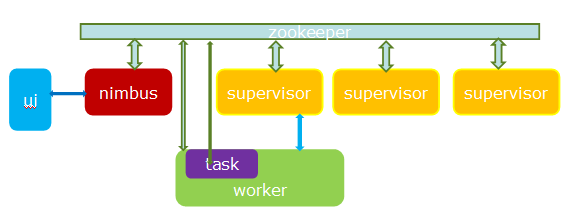
Apache Storm 的前身是 Twitter Storm 平台,目前已经归于 Apache 基金会管辖。
Apache Storm 是一个免费开源的分布式实时计算系统。简化了流数据的可靠处理,像 Hadoop 一样实现实时批处理。Storm 很简单,可用于任意编程语言。Apache Storm 采用 Clojure 开发。
Storm 有很多应用场景,包括实时数据分析、联机学习、持续计算、分布式 RPC、ETL 等。Storm 速度非常快,一个测试在单节点上实现每秒一百万的组处理。
目前已经有包括阿里百度在内的数家大型互联网公司在使用该平台。
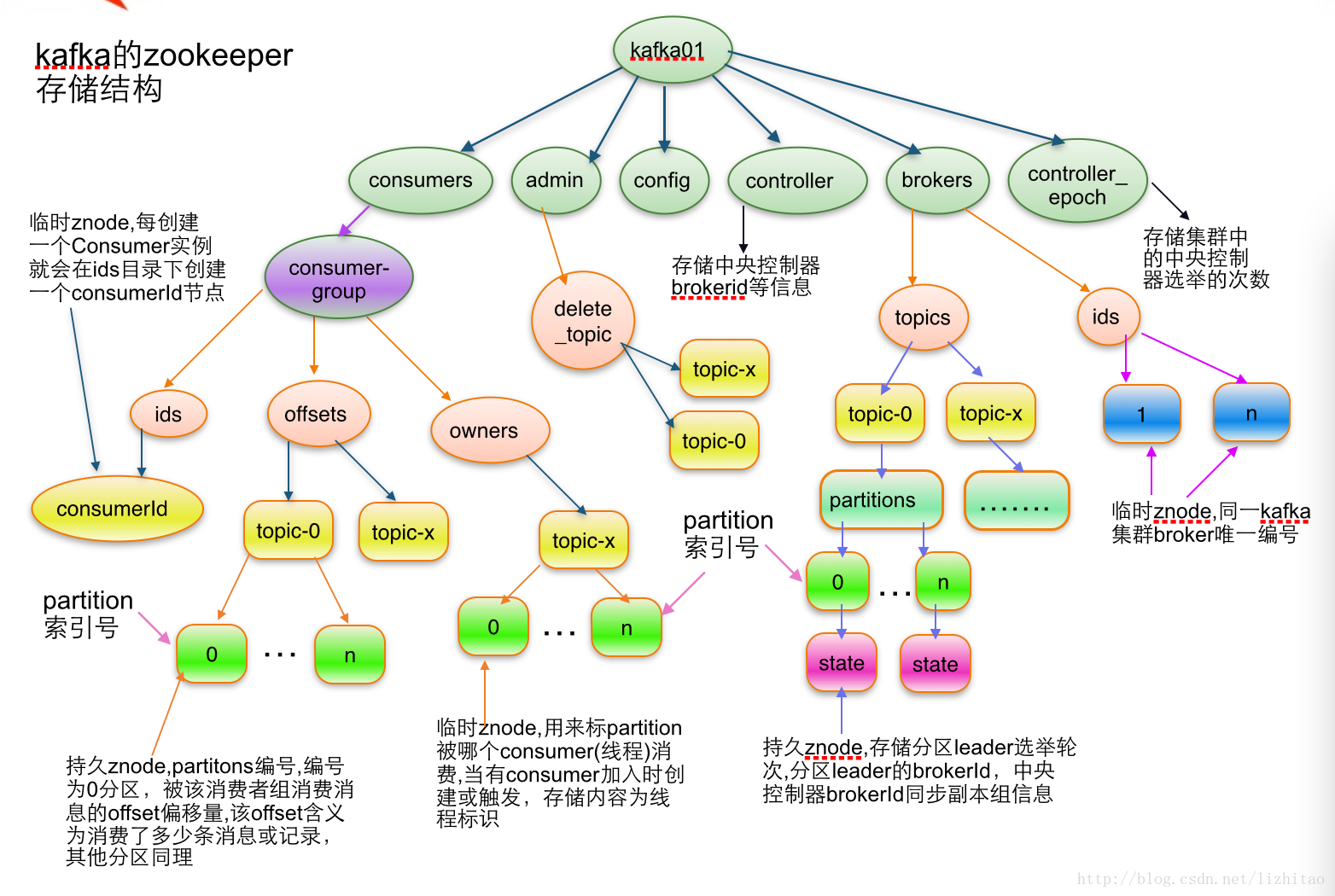
分布式系统协调Zookeeper
Zookeeper详细介绍
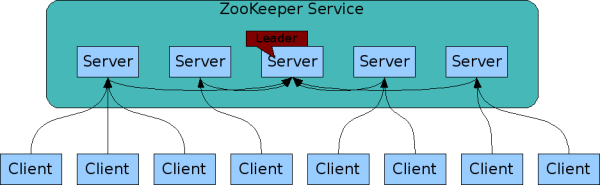
ZooKeeper是Hadoop的正式子项目,它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Zookeeper是Google的Chubby一个开源的实现.是高有效和可靠的协同工作系统.Zookeeper能够用来leader选举,配置信息维护等.在一个分布式的环境中,我们需要一个Master实例或存储一些配置信息,确保文件写入的一致性等.Zookeeper能够保证如下3点:
Watches are ordered with respect to other events, other watches, and
asynchronous replies. The ZooKeeper client libraries ensures that
everything is dispatched in order.A client will see a watch event for a znode it is watching before seeing the new data that corresponds to that znode.
The order of watch events from ZooKeeper corresponds to the order of the updates as seen by the ZooKeeper service.
在Zookeeper中,znode是一个跟Unix文件系统路径相似的节点,可以往这个节点存储或获取数据.如果在创建znode时Flag设置 为EPHEMERAL,那么当这个创建这个znode的节点和Zookeeper失去连接后,这个znode将不再存在在Zookeeper 里.Zookeeper使用Watcher察觉事件信息,当客户端接收到事件信息,比如连接超时,节点数据改变,子节点改变,可以调用相应的行为来处理数 据.Zookeeper的Wiki页面展示了如何使用Zookeeper来处理事件通知,队列,优先队列,锁,共享锁,可撤销的共享锁,两阶段提交.
那么Zookeeper能帮我们作什么事情呢?简单的例子:假设我们我们有个20个搜索引擎的服务器(每个负责总索引中的一部分的搜索任务)和一个 总服务器(负责向这20个搜索引擎的服务器发出搜索请求并合并结果集),一个备用的总服务器(负责当总服务器宕机时替换总服务器),一个web的 cgi(向总服务器发出搜索请求).搜索引擎的服务器中的15个服务器现在提供搜索服务,5个服务器正在生成索引.这20个搜索引擎的服务器经常要让正在 提供搜索服务的服务器停止提供服务开始生成索引,或生成索引的服务器已经把索引生成完成可以搜索提供服务了.使用Zookeeper可以保证总服务器自动 感知有多少提供搜索引擎的服务器并向这些服务器发出搜索请求,备用的总服务器宕机时自动启用备用的总服务器,web的cgi能够自动地获知总服务器的网络 地址变化.这些又如何做到呢?
提供搜索引擎的服务器都在Zookeeper中创建znode,zk.create(“/search/nodes/node1”,
“hostname”.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateFlags.EPHEMERAL);总服务器可以从Zookeeper中获取一个znode的子节点的列表,zk.getChildren(“/search/nodes”, true);
总服务器遍历这些子节点,并获取子节点的数据生成提供搜索引擎的服务器列表.
当总服务器接收到子节点改变的事件信息,重新返回第二步.
总服务器在Zookeeper中创建节点,zk.create(“/search/master”, “hostname”.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateFlags.EPHEMERAL);
备用的总服务器监控Zookeeper中的”/search/master”节点.当这个znode的节点数据改变时,把自己启动变成总服务器,并把自己的网络地址数据放进这个节点.
web的cgi从Zookeeper中”/search/master”节点获取总服务器的网络地址数据并向其发送搜索请求.
web的cgi监控Zookeeper中的”/search/master”节点,当这个znode的节点数据改变时,从这个节点获取总服务器的网络地址数据,并改变当前的总服务器的网络地址.
Hadoop和数据库数据迁移工具Sqoop
Sqoop详细介绍
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中。

日志服务器Apache Flume
Apache Flume详细介绍
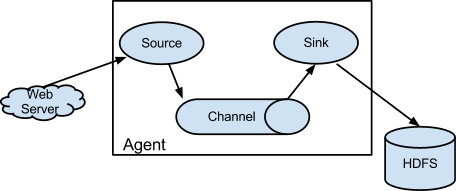
Flume 是一个分布式、可靠和高可用的服务,用于收集、聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型。这是一个可靠、容错的服务。
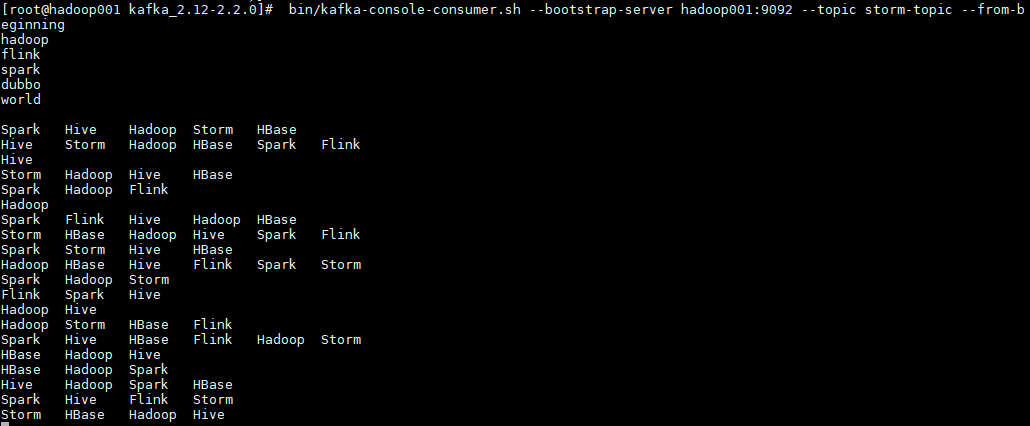
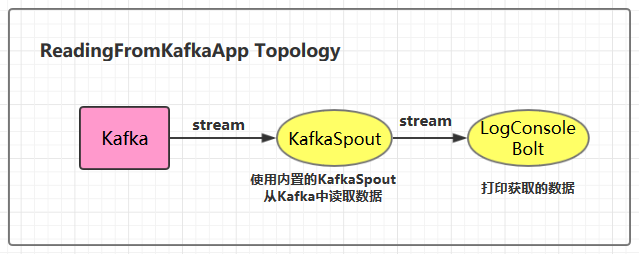
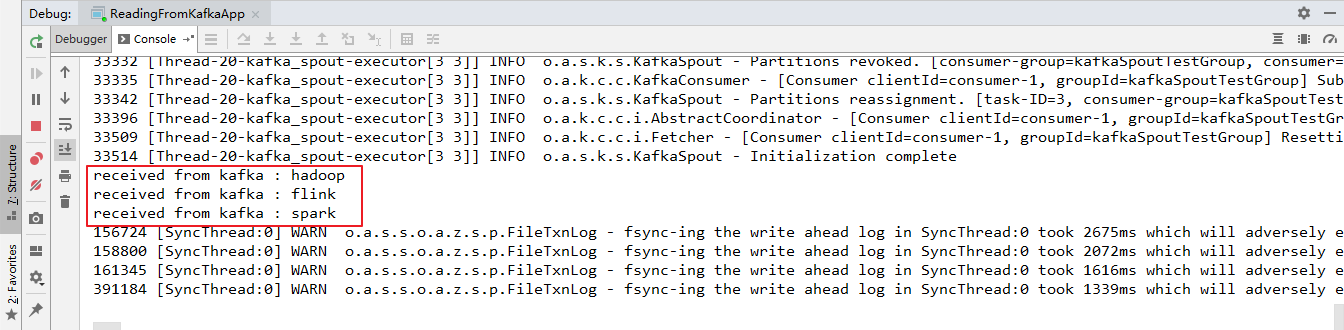
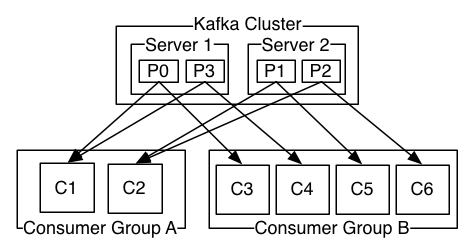
分布式发布订阅消息系统kafka
Kafka详细介绍
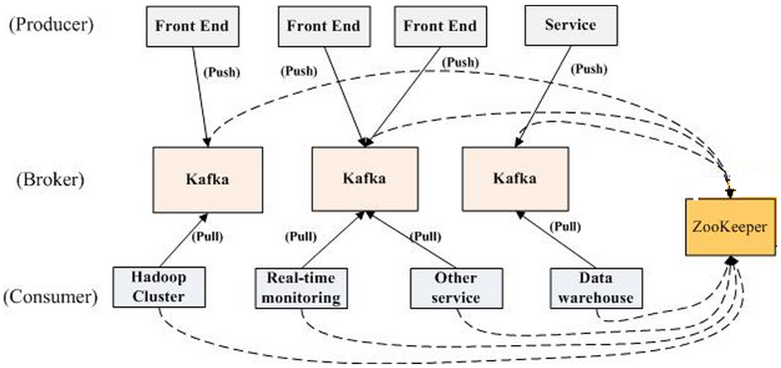
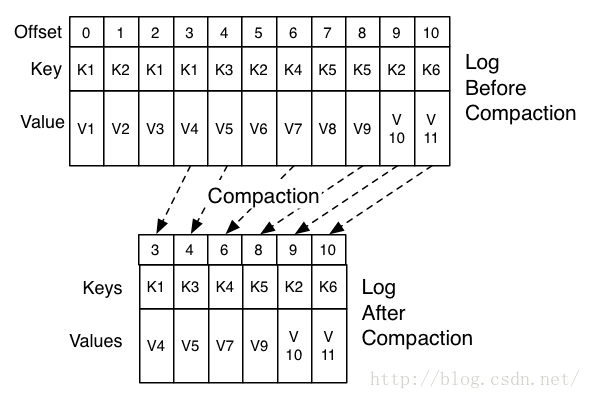
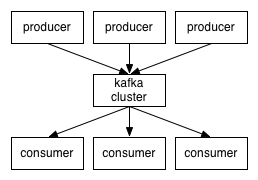
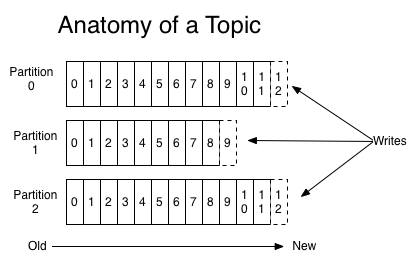
Kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
- 支持通过kafka服务器和消费机集群来分区消息。
- 支持Hadoop并行数据加载。
kafka的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
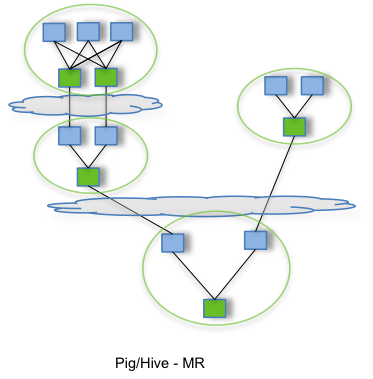
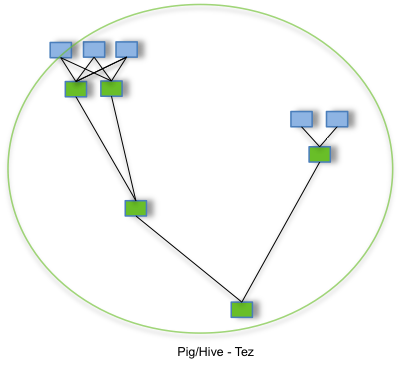
开源计算框架Apache Tez
Apache Tez详细介绍
Tez 是 Apache 最新的支持 DAG 作业的开源计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升DAG作业的性能。Tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序。Hadoop传统上是一个大量数据批处理平台。但是,有很多用例需要近乎实时的查询处理性能。还有一些工作则不太适合MapReduce,例如机器学习。Tez的目的就是帮助Hadoop处理这些用例场景。
开源工作流引擎Oozie
Oozie 详细介绍
ozie 是一个开源的工作流和协作服务引擎,基于 Apache Hadoop 的数据处理任务。Oozie 是可扩展的、可伸缩的面向数据的服务,运行在Hadoop 平台上。
Oozie 包括一个离线的Hadoop处理的工作流解决方案,以及一个查询处理 API。
分布式文档存储数据库MongoDB
MongoDB详细介绍
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
内部架构
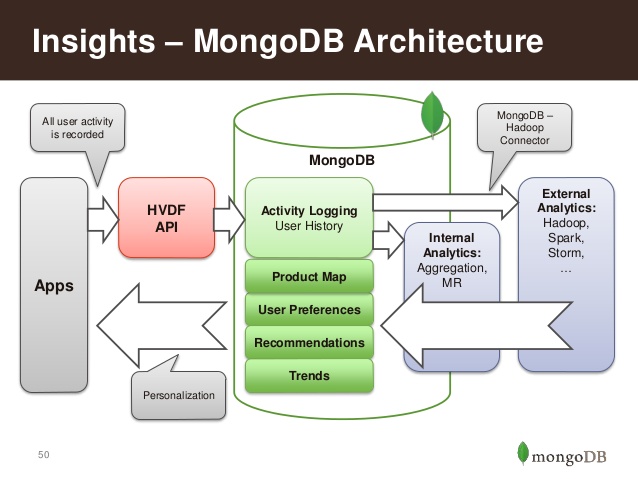
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
- 面向集合存储,易存储对象类型的数据。
- 模式自由
- 支持动态查询
- 支持完全索引,包含内部对象。
- 支持查询。
- 支持复制和故障恢复。
- 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 自动处理碎片,以支持云计算层次的扩展性
- 支持RUBY,PYTHON,JAVA,C++,PHP等多种语言。
- 文件存储格式为BSON(一种JSON的扩展)
- 可通过网络访问
所谓“面向集合”(Collenction-Orented),意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个 集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定 义任何模式(schema)。
模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。
存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各中复杂的文件类型。我们称这种存储形式为BSON(Binary Serialized dOcument Format)。
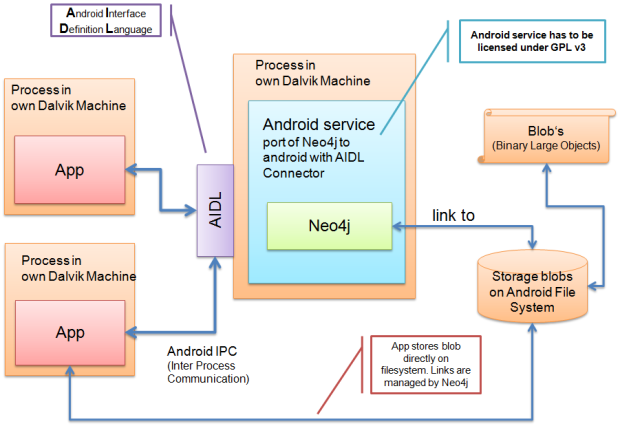
高性能的NoSQL图形数据库Neo4j
Neo4j详细介绍
Neo4j是一个网络——面向网络的数据库——也就是说,它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。网络(从数学角度叫做图)是一个灵活的数据结构,可以应用更加敏捷和快速的开发模式。
你可以把Neo4j看作是一个高性能的图引擎,该引擎具有成熟和健壮的数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
数据序列化系统Apache Avro
Apache Avro详细介绍

Avro(读音类似于[ævrə])是Hadoop的一个子项目,由Hadoop的 创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)牵头开发。Avro是一个数据序列化系统,设计用于支持大 批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
容器集群管理系统Kubernetes
Kubernetes详细介绍
Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。
Kubernetes一个核心的特点就是能够自主的管理容器来保证云平台中的容器按照用户的期望状态运行着(比如用户想让apache一直运行,用户不需要关心怎么去做,Kubernetes会自动去监控,然后去重启,新建,总之,让apache一直提供服务),管理员可以加载一个微型服务,让规划器来找到合适的位置,同时,Kubernetes也系统提升工具以及人性化方面,让用户能够方便的部署自己的应用(就像canary deployments)。
现在Kubenetes着重于不间断的服务状态(比如web服务器或者缓存服务器)和原生云平台应用(Nosql),在不久的将来会支持各种生产云平台中的各种服务,例如,分批,工作流,以及传统数据库。
在Kubenetes中,所有的容器均在Pod中运行,一个Pod可以承载一个或者多个相关的容器,在后边的案例中,同一个Pod中的容器会部署在同一个物理机器上并且能够共享资源。一个Pod也可以包含O个或者多个磁盘卷组(volumes),这些卷组将会以目录的形式提供给一个容器,或者被所有Pod中的容器共享,对于用户创建的每个Pod,系统会自动选择那个健康并且有足够容量的机器,然后创建类似容器的容器,当容器创建失败的时候,容器会被node agent自动的重启,这个node agent叫kubelet,但是,如果是Pod失败或者机器,它不会自动的转移并且启动,除非用户定义了 replication controller。
用户可以自己创建并管理Pod,Kubernetes将这些操作简化为两个操作:基于相同的Pod配置文件部署多个Pod复制品;创建可替代的Pod当一个Pod挂了或者机器挂了的时候。而Kubernetes API中负责来重新启动,迁移等行为的部分叫做“replication controller”,它根据一个模板生成了一个Pod,然后系统就根据用户的需求创建了许多冗余,这些冗余的Pod组成了一个整个应用,或者服务,或者服务中的一层。一旦一个Pod被创建,系统就会不停的监控Pod的健康情况以及Pod所在主机的健康情况,如果这个Pod因为软件原因挂掉了或者所在的机器挂掉了,replication controller 会自动在一个健康的机器上创建一个一摸一样的Pod,来维持原来的Pod冗余状态不变,一个应用的多个Pod可以共享一个机器。
我们经常需要选中一组Pod,例如,我们要限制一组Pod的某些操作,或者查询某组Pod的状态,作为Kubernetes的基本机制,用户可以给Kubernetes Api中的任何对象贴上一组 key:value的标签,然后,我们就可以通过标签来选择一组相关的Kubernetes Api 对象,然后去执行一些特定的操作,每个资源额外拥有一组(很多) keys 和 values,然后外部的工具可以使用这些keys和vlues值进行对象的检索,这些Map叫做annotations(注释)。
Kubernetes支持一种特殊的网络模型,Kubernetes创建了一个地址空间,并且不动态的分配端口,它可以允许用户选择任何想使用的端口,为了实现这个功能,它为每个Pod分配IP地址。
现代互联网应用一般都会包含多层服务构成,比如web前台空间与用来存储键值对的内存服务器以及对应的存储服务,为了更好的服务于这样的架构,Kubernetes提供了服务的抽象,并提供了固定的IP地址和DNS名称,而这些与一系列Pod进行动态关联,这些都通过之前提到的标签进行关联,所以我们可以关联任何我们想关联的Pod,当一个Pod中的容器访问这个地址的时候,这个请求会被转发到本地代理(kube proxy),每台机器上均有一个本地代理,然后被转发到相应的后端容器。Kubernetes通过一种轮训机制选择相应的后端容器,这些动态的Pod被替换的时候,Kube proxy时刻追踪着,所以,服务的 IP地址(dns名称),从来不变。
所有Kubernetes中的资源,比如Pod,都通过一个叫URI的东西来区分,这个URI有一个UID,URI的重要组成部分是:对象的类型(比如pod),对象的名字,对象的命名空间,对于特殊的对象类型,在同一个命名空间内,所有的名字都是不同的,在对象只提供名称,不提供命名空间的情况下,这种情况是假定是默认的命名空间。UID是时间和空间上的唯一。
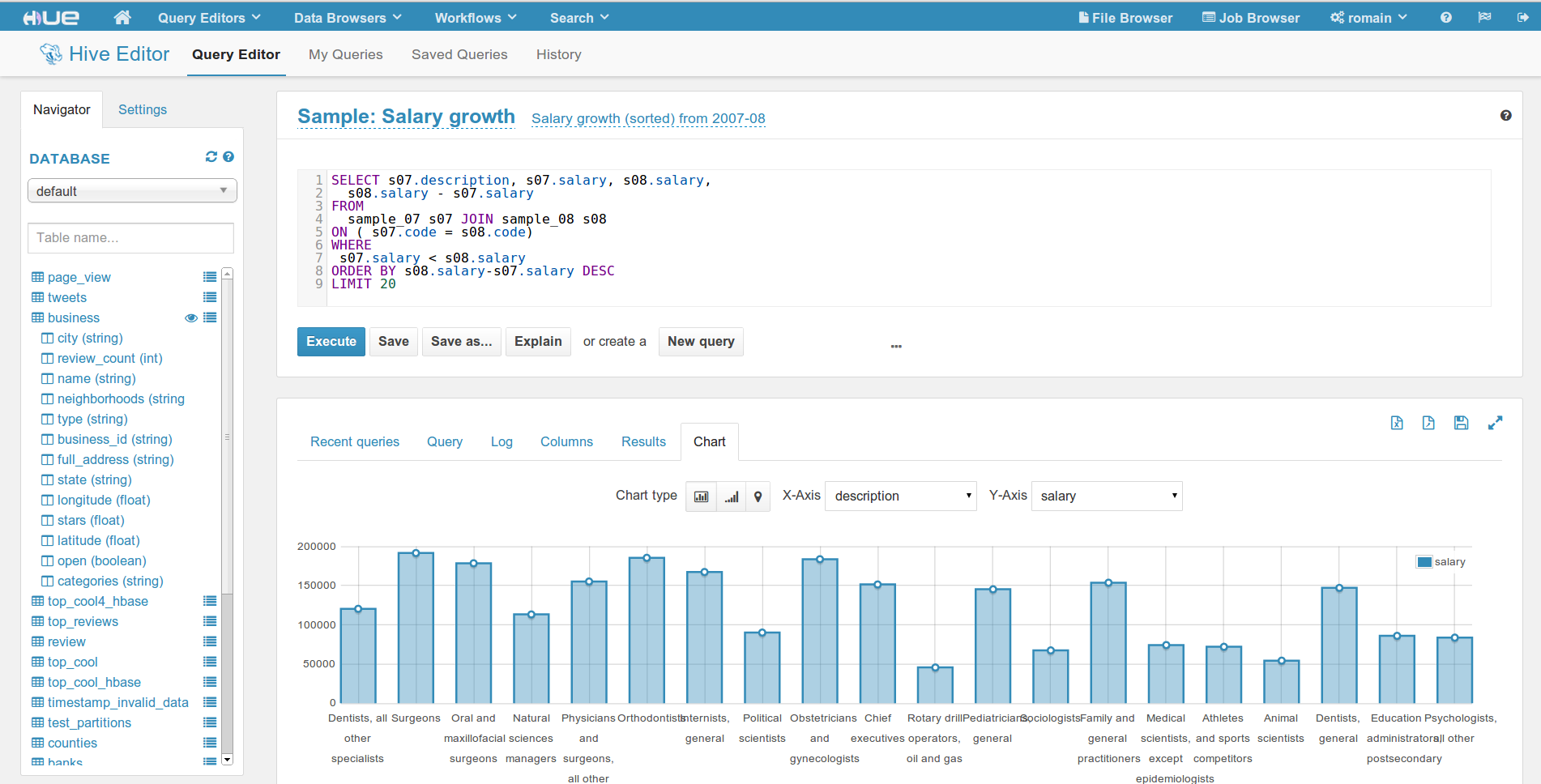
Hadoop图形化用户界面Hue
Hue详细介绍
Hue 是运营和开发Hadoop应用的图形化用户界面。Hue程序被整合到一个类似桌面的环境,以web程序的形式发布,对于单独的用户来说不需要额外的安装。
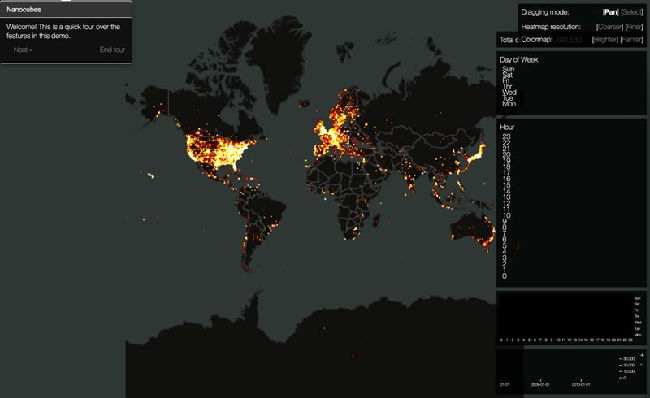
大数据可视化工具Nanocubes
Nanocubes 详细介绍
Nanocubes 是一个大数据可视化的工具,32Tb Twitter数据,在一台16GB内存的机器上流畅、交互式地可视化。
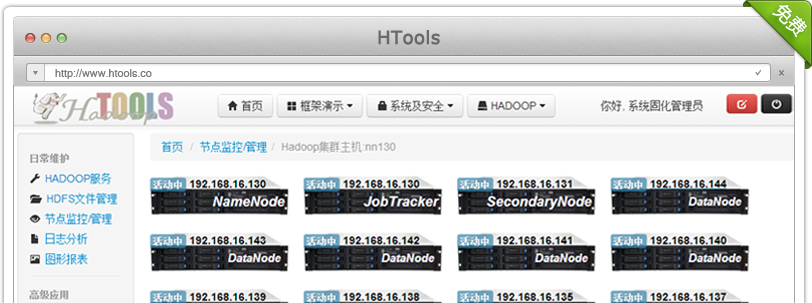
Hadoop集群监控工具HTools
HTools详细介绍
HTools是一款专业的Hadoop管理工具,不管您是非专业IT人士,还是多年经验的技术人员,本工具都会为您提供优质的管理服务和轻松的操作过程, 释放无谓的工作压力,提高Hadoop的管理水平。我们以最权威的专家为您量身定做的Hadoop管理工具,本系统提供优秀的用户体验,让您能够轻松的管 理Hadoop集群环境。
友善的向导式操作流程
图形报表、日志分析供您明了查看各节点使用情况
智能诊断,修复故障并发出短信、邮件故障告警
图形化UI、拖拖拽拽即可管理管理HDFS数据
傻瓜式操作优化Hadoop,方便快捷
免客户端部署,无需安装HTools客户端
版本控制灵活,不绑定Hadoop的JDK版本
一键智能搜索当前网段可部署节点
支持多个Hadoop集群同时监管
支持同时管理多个Hadoop集群和节点
支持7 × 24小时多集群实时监控
支持节点热插拔,服务不间断的情况下随时对节点进行扩展和调整
支持系统配置文件的推送和同步
大数据查询引擎PrestoDB
PrestoDB详细介绍
Presto是Facebook最新研发的数据查询引擎,可对250PB以上的数据进行快速地交互式分析。据称该引擎的性能是 Hive 的 10 倍以上。
PrestoDB 是 Facebook 推出的一个大数据的分布式 SQL 查询引擎。可对从数 G 到数 P 的大数据进行交互式的查询,查询的速度达到商业数据仓库的级别。
Presto 可以查询包括 Hive、Cassandra 甚至是一些商业的数据存储产品。单个 Presto 查询可合并来自多个数据源的数据进行统一分析。
Presto 的目标是在可期望的响应时间内返回查询结果。Facebook 在内部多个数据存储中使用 Presto 交互式查询,包括 300PB 的数据仓库,超过 1000 个 Facebook 员工每天在使用 Presto 运行超过 3 万个查询,每天扫描超过 1PB 的数据。此外包括 Airbnb 和 Dropbox 也在使用 Presto 产品。
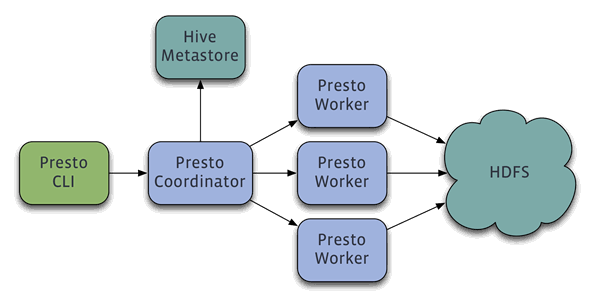
Presto 是一个分布式系统,运行在集群环境中,完整的安装包括一个协调器 (coordinator) 和多个 workers。查询通过例如 Presto CLI 的客户端提交到协调器,协调器负责解析、分析和安排查询到不同的 worker 上执行。
此外,Presto 需要一个数据源来运行查询。当前 Presto 包含一个插件用来查询 Hive 上的数据,要求:
Hadoop CDH4
远程 Hive metastore service
Presto 不使用 MapReduce ,只需要 HDFS
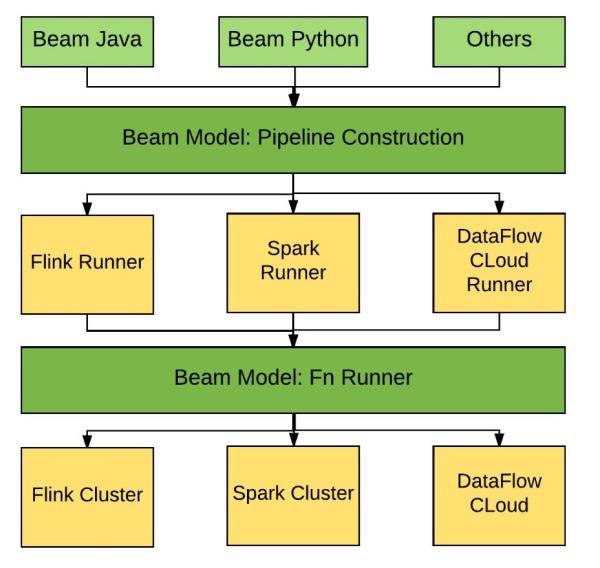
大数据批处理和流处理标准Apache Beam
Apache Beam详细介绍
Apache Beam 是 Apache 软件基金会越来越多的数据流项目中最新增添的成员,是 Google 在2016年2月份贡献给 Apache 基金会的孵化项目。
这个项目的名称表明了设计:结合了批处理(Batch)模式和数据流(Stream)处理模式。它基于一种统一模式,用于定义和执行数据并行处理管道(pipeline),这些管理随带一套针对特定语言的SDK用于构建管道,以及针对特定运行时环境的Runner用于执行管道。
Apache Beam 的主要目标是统一批处理和流处理的编程范式,为无限,乱序,web-scale的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的SDK。Apache Beam项目重点在于数据处理的编程范式和接口定义,并不涉及具体执行引擎的实现,Apache Beam希望基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上。
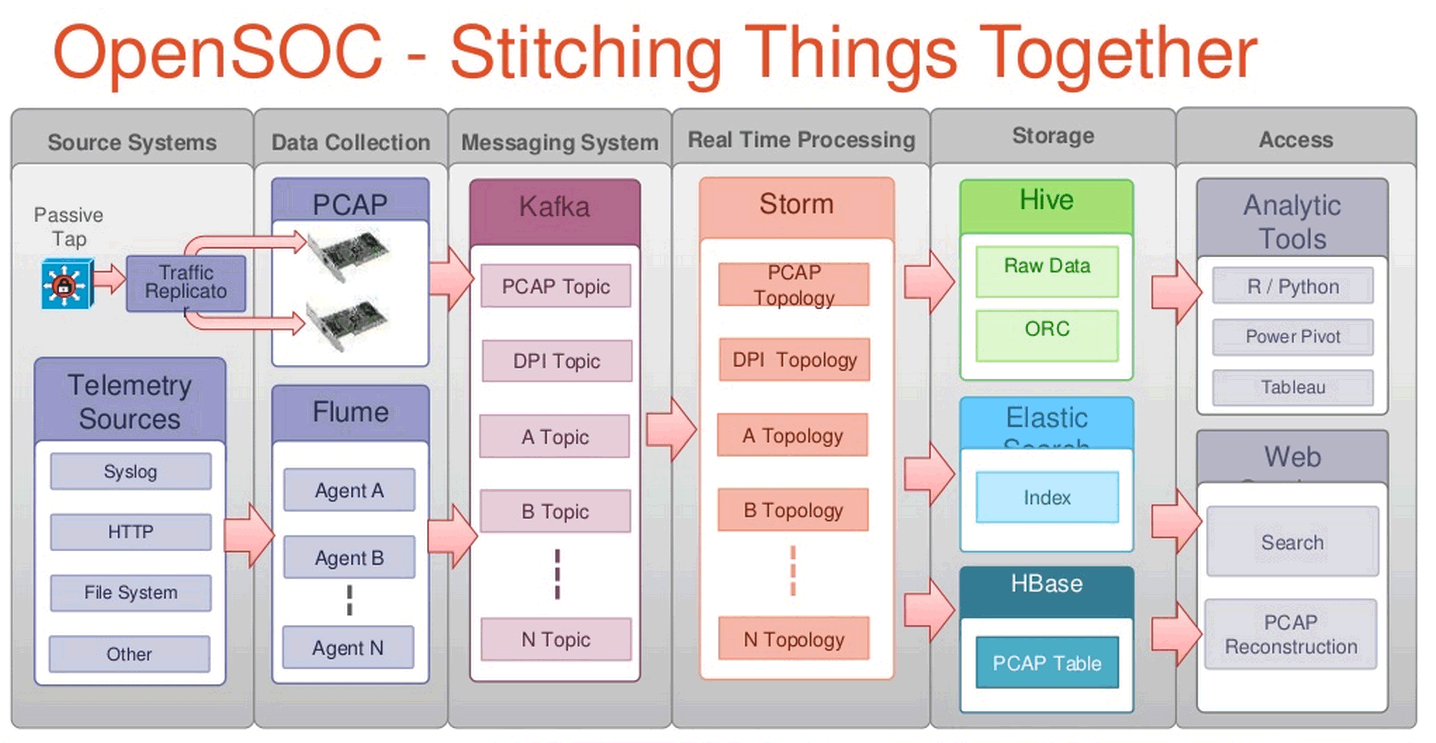
安全大数据分析框架OpenSOC
OpenSOC详细介绍
OpenSOC:安全大数据分析框架。OpenSOC已经加入Apache工程改名为Apache Metron。
思科在 BroCON 大会上亮相了其安全大数据分析架构 OpenSOC,引起了广泛关注。OpenSOC 是一个针对网络包和流的大数据分析框架,它是大数据分析与安全分析技术的结合, 能够实时的检测网络异常情况并且可以扩展很多节点,它的存储使用开源项目 Hadoop,实时索引使用开源项目 ElasticSearch,在线流分析使用著名的开源项目 Storm。OpenSOC 概念性体系架构如下图所示:
OpenSOC 主要功能包括:
可扩展的接收器和分析器能够监视任何Telemetry数据源
是一个扩展性很强的框架,且支持各种Telemetry数据流
支持对Telemetry数据流的异常检测和基于规则实时告警
通过预设时间使用Hadoop存储Telemetry的数据流
支持使用ElasticSearch实现自动化实时索引Telemetry数据流
支持使用Hive利用SQL查询存储在Hadoop中的数据
能够兼容ODBC/JDBC和继承已有的分析工具
具有丰富的分析应用,且能够集成已有的分析工具
支持实时的Telemetry搜索和跨Telemetry的匹配
支持自动生成报告、和异常报警
支持原数据包的抓取、存储、重组
支持数据驱动的安全模型
OpenSOC 官方文档介绍了以下五大优点:
由思科全力支持,适用于内部多用户
免费、开源、基于Apache协议授权
基于高可扩展平台(Hadoop、Kafka、Storm)实现
基于可扩展的插件式设计
具有灵活的部署模式,可在企业内部部署或者云端部署
具有集中化的管理流程、人员和数据
实时网络安全监测框架Apache Metron
Apache Metron详细介绍
Apache Metron 是一个网络安全的实时数据处理、分析、查询、可视化框架。
Metron 集成了各种开源大数据技术,为安全监控和分析提供了集中工具。 Metron 拥有支持大规模摄取、处理、检索与信息可视化的所有适当元素,一些关键的网络数据将推动数据保护、监控、分析与检测,并且有助于对恶意的非法行为予以回应。
亮点包括:
捕获、存储和规范化所有类型的安全机制;
高速远程检测;
实时处理和应用改进;
高效信息存储;
提供通过系统传递的数据和警报的集中视图的接口
使用统计摘要数据结构,即使在最大的数据集上也可执行安全分析
企业级流式计算引擎JStorm
JStorm 详细介绍
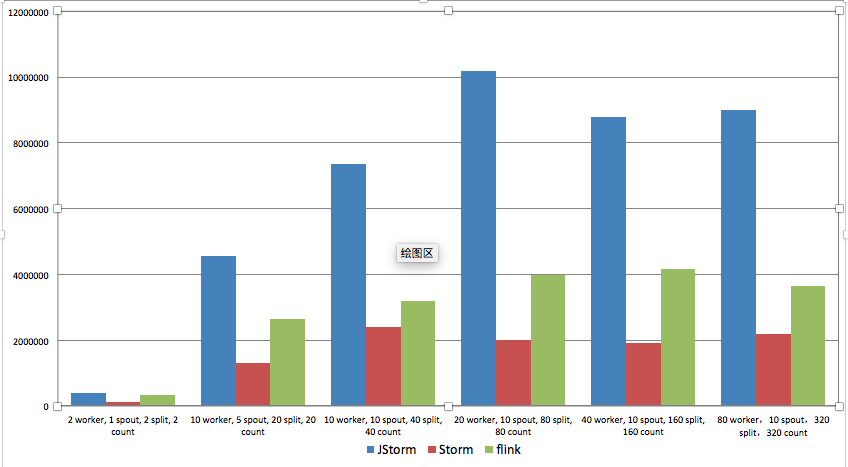
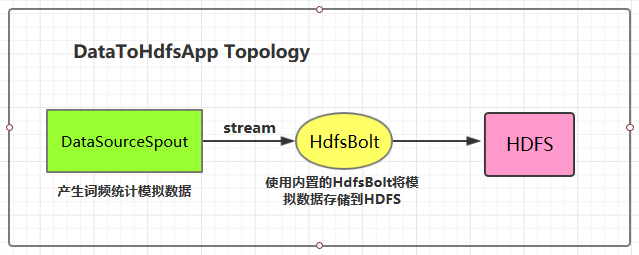
JStorm 是参考 Apache Storm 实现的实时流式计算框架,在网络IO、线程模型、资源调度、可用性及稳定性上做了持续改进,已被越来越多企业使用。JStorm 可以看作是 storm 的java增强版本,除了内核用纯java实现外,还包括了thrift、python、facet ui。从架构上看,其本质是一个基于zk的分布式调度系统
JStorm 的性能是Apache Storm 的4倍, 可以自由切换行模式或 mini-batch 模式: