Alibaba Cloud's Qwen Team developed Qwen3.5-Omni, a large language model scaling to hundreds of billions of parameters that processes and generates across text, images, audio, and video within a unified architecture. It achieves robust omnimodal understanding, real-time streaming speech synthesis, and agentic capabilities, demonstrating strong performance on diverse benchmarks and an emergent "Audio-Visual Vibe Coding" function.
View blog
Renmin University of China and ByteDance Seed researchers introduced Agent-World, a framework for advancing general agent intelligence through scalable real-world environment synthesis and a continuous self-evolving training mechanism. The approach enables agents to learn and adapt by autonomously discovering and constructing a diverse ecosystem of stateful, executable tools and environments from real-world sources, achieving consistent performance improvements across 23 challenging agent benchmarks and outperforming prior environment-scaling methods.
View blog
Researchers at Nanyang Technological University introduce CROSSMATH, a novel multimodal reasoning benchmark designed to rigorously assess whether Vision-Language Models (VLMs) truly perform visual reasoning or primarily rely on text. The study reveals a substantial performance gap in VLMs when reasoning with images versus text, but demonstrates that targeted post-training strategies can significantly enhance visual reasoning capabilities and improve out-of-domain generalization, such as increasing Qwen3.5-9B's image-only Macro Accuracy from 3.2% to 50.4%.
View blog
This research reveals that 1D ordered tokenization, which processes images from coarse-to-fine semantic detail, intrinsically improves the efficiency of test-time search in autoregressive image generation models. This enables more effective zero-shot multimodal control and even training-free generation, outperforming traditional 2D grid tokenization in inference-time scaling.
View blog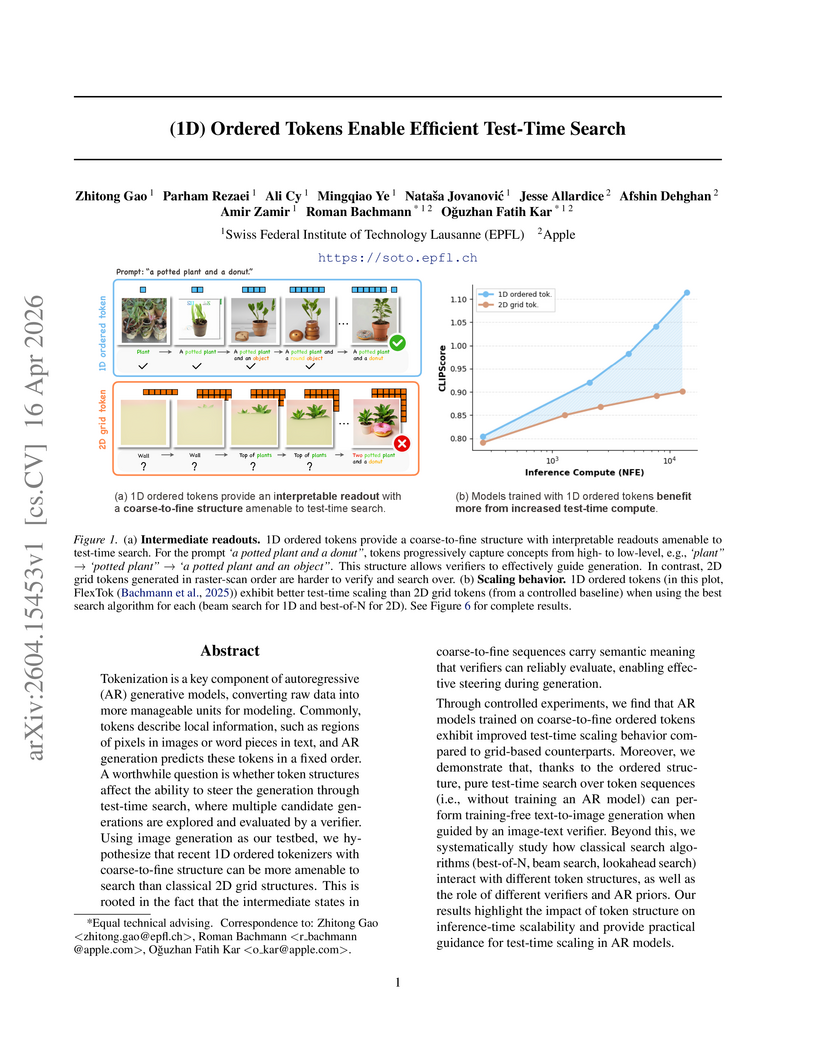
This research introduces a whole-body humanoid locomotion framework that merges a diffusion-based motion generator with an RL-based motion tracker. The system enables the Unitree G1 robot to adaptively navigate diverse, challenging terrains in real-time by producing perception-aware reference motions and executing them robustly.
View blog
The Xiaomi Embodied Intelligence Team developed OneVL, a framework integrating a Vision-Language-Action model with a world model auxiliary for autonomous driving, which is the first latent Chain-of-Thought (CoT) method to surpass explicit autoregressive CoT in trajectory prediction performance while maintaining answer-only inference latency. OneVL achieved an 88.84 PDM-score on NAVSIM, outperforming prior 8B models by up to 2.64 points, with inference latency comparable to answer-only prediction.
View blog
Research demonstrates that the core mechanism of Large Language Model reasoning is primarily driven by internal latent-state trajectories, rather than solely by explicit chains of thought, with the dominant factor shifting based on the task's structural demands. This work provides a framework to differentiate and empirically validate how generic computation, surface verbalizations, or latent dynamics mediate performance gains in LLMs.
View blog
MultiWorld presents a unified framework for multi-agent, multi-view video world modeling, designed to simulate complex interactive environments with precise multi-agent controllability and multi-view consistency. The framework demonstrates improved visual quality, action-following ability, and significantly reduced reprojection error on multi-player video game and multi-robot manipulation datasets.
View blog
Researchers co-designed ultra-high-rate quantum low-density parity-check (qLDPC) codes with reconfigurable neutral atom arrays, identifying structural conditions on affine permutation matrices to enable efficient syndrome extraction. Circuit-level simulations demonstrated logical error rates as low as 1.3 × 10^-13 per logical qubit per round at a 0.1% physical error rate, indicating the practical viability of these codes for fault-tolerant quantum computing.
View blog
A detailed architectural analysis of Anthropic's Claude Code, a production-grade AI agent, is provided through source-level examination, revealing a design philosophy prioritizing a robust operational harness over raw AI decision logic. The study contrasts this with OpenClaw, an open-source system, to highlight how different deployment contexts influence architectural choices and identifies future design challenges for agent systems.
View blog
LaviGen adapts a 3D generative model for autoregressive 3D scene layout generation driven by text instructions, operating directly in native 3D space with a dual-guidance self-rollout distillation strategy. The system yields layouts with approximately 19% greater physical plausibility and 65% faster inference compared to prior state-of-the-art methods.
View blog
The Prefill-as-a-Service (PrfaaS) architecture from Moonshot AI and Tsinghua University enables practical cross-datacenter prefill-decode disaggregation for hybrid-attention large language models by transferring KVCache over commodity Ethernet. This system achieves 54% higher throughput and a 50% reduction in mean Time-To-First-Token compared to a homogeneous baseline, utilizing only 13% of available inter-cluster bandwidth.
View blog
Researchers at Physical Intelligence developed π0.7, a 5-billion-parameter generalist robotic foundation model. This model utilizes a diversified prompting strategy, incorporating language instructions, episode metadata, and generated subgoal images, to achieve strong out-of-the-box performance and compositional generalization across diverse tasks and robot platforms.
View blog

LingBot-Map, a feed-forward 3D foundation model, performs streaming 3D reconstruction by introducing a Geometric Context Transformer (GCT) that employs a novel attention mechanism to manage multi-level geometric context. The system achieves superior accuracy and efficiency in camera pose estimation and dense 3D reconstruction compared to existing streaming methods, operating at approximately 20 FPS for sequences up to 10,000 frames.
View blog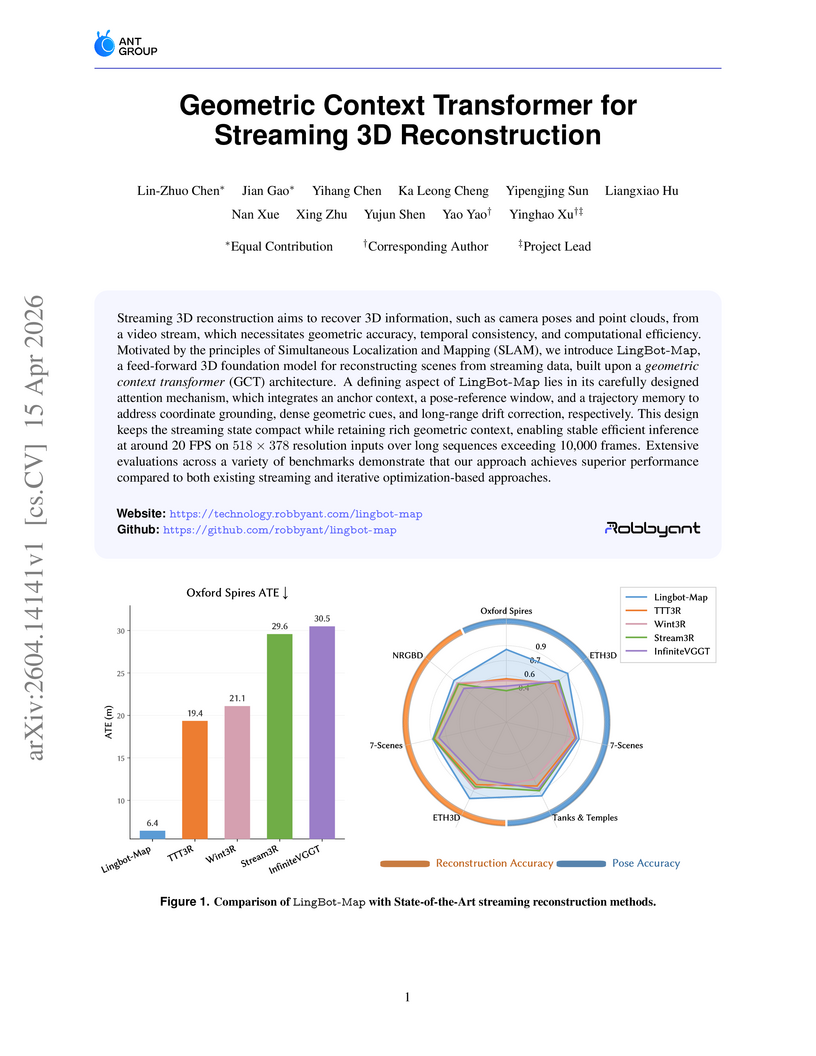
This research systematically investigates On-Policy Distillation (OPD) for Large Language Models (LLMs), identifying that successful distillation relies on thinking-pattern consistency and a teacher's novel capabilities, not merely higher scores. The study reveals token-level alignment dynamics and proposes practical strategies like off-policy cold starts and teacher-aligned prompts, while also highlighting OPD's limitations in long-horizon tasks.
View blog
SKILLFLOW, a new benchmark, evaluates how autonomous agents continuously discover, repair, and manage skills from their own experience across sequential tasks. Experiments reveal that leading LLM-based agents exhibit varied capacities for skill evolution, with some improving task success by over 8% through effective skill refinement, while others struggle with skill fragmentation and propagating errors.
View blog
Autogenesis introduces a self-evolving agent protocol (AGP) that formalizes resource management and state transitions for LLM-based agents. This protocol enables auditable and safe self-modification, leading to enhanced performance across scientific, general agent, and algorithmic coding benchmarks.
View blog
AgentV-RL introduces an agentic verifier framework that uses bidirectional, multi-turn, tool-augmented reasoning to scrutinize LLM-generated solutions for complex problems. It achieves state-of-the-art results in mathematical reasoning, outperforming larger models by up to 25.2 percentage points on MATH500 by integrating a comprehensive verification process.
View blog
ByteDance Seed's Seedance 2.0 introduces a unified, large-scale model for multi-modal audio-video generation, significantly advancing quality and control across text, image, and audio inputs. The model achieved top rankings in expert and public benchmarks, demonstrating superior performance in aspects like natural motion, temporal coherence, and synchronized high-fidelity audio.
View blog