There was a transactional euphoria to this model of thinking, we designed our database to account for this transactional model. if your server can handle N requests per second, well...that was your limit. If you wanted more... either break your application into smaller pieces or simply buy a bigger server.
Taking the problem of scaling by buying a bigger server is , this is a faustian bargain. You do get more bandwidth, but you also get more latency, If any process in your application throws, your entire application will be down. The large tower is still breakable if you move the right bricks... so you must always be wary to keep note of each brick, each module , each process of your application.
From a naive perspective, this is a nightmare to handle... but you will be surprised how well it scales, It just happens that there is no single computer that can scale infinitely... yet. But rethinking the problem, if you still need to be wary of each component of your application, why not break the application into smaller pieces? we did that too, first with polylithic architecture, then with microservices.
The theory is simple, If you break your application into manageable chunks, you can scale each chunk independently. Hell, scaling the services was no longer a problem, if anything fails , spin up a new one. That fixed the problem of scaling the business logic, but the database was still a problem.
A database has 2 roles, one, being the single source of truth, and two, being extremely hard to scale.
That was true 40 years ago, that is true today, You cannot scale a database by buying a bigger server. You have to rethink the database architecture that works well with the application architecture. Hence multiple flavors of databases, OLTP, OLAP, NoSQL.
The fringe nature of a transaction puts a lot of pressure on the database. You either have to replicate the database across multiple servers, or you have to use a sharded instance across multiple servers. regardless of the approach, the point of entry must remain same and must remain transactional. You cannot mess up your data storage architecture, you have to handle scale in a way that is consistent with the application architecture.
The problem we are trying to triumph now is no longer about scaling the application, it is about scaling the database. If your database is no the only single source of truth, You are essentially in dangerous territory. Sequential thinking is not the problem, scalability is.
If you store data in a single machine, you can handle concurrency just fine, but that does not scale. And believe me, all major database flavors have been trying best to work around this problem. RDBMS serializes concurrent transactions that can be handled by a connection pool. a bouncer or a proxy can be used on top of the connection pool to handle concurrency. Redis, mongoDB, Cassandra, all of them have their own ways of handling concurrency.
Let's take a step back , and take a look at monolith again, a single process server that had all the requirements can be broken down into 3 parts,
- Processing
- Storage
- Communication
Interestingly If we shrink this architecture , this plan of execution, we can give each data flow it's own process, it's own storage and it's own communication channels. Essentially speaking, say we have to make an e-commerce application, every time a user places an order , we sort of .. spin up a new process, a new storage and a new communication channel... an Entity .
Say, for us , an Entity is a component of the application that has 3 constituent parts, processing, storage and communication. Instead of a stateless process, an Entity holds the state and the authority over all 3 constituent parts.
A stateful long-lived child process , that is there... in-memory for each user. having the authority over that user's actions, data and communication to other entities throughout the application.
let's take an example of how users interact with an entity.
- user-123 Sends a request ( say request-1) to the application for a transaction of +100$ in their account.
- application sees the request-1 arriving from user-123 and checks the entity list for the user-123.
- if there is no entity in-memory for user, spin up a new one, collects the state from the DB, say balance = 500$ , stores it in a local variable.
- Entity sees the request-1 and decides to process it, updates the local variable . balance=600$.
- Eventually the entity syncs up the data from the local variable to the DB, for safe keeping.
- Entity lives in memory, in RAM... for future requests, just in case user decides to make another transaction.
- if no further requests are coming from user-123, the entity is destroyed, and the memory is freed up.
This is how we can isolate the application from the database scalability problem . On a large scale this is fine, these entities in essence are just javascript objects, you can spin up millions of them per second without any throughput issues.
This is a radically different approach from the separation of state we have been doing in the past. This is similar to moving from html + css + javascript to React in a way. We compose entities the same way we compose React components, handle the State and UI all in one place.
A far more approachable name for this Entity is an Actor. An actor is a stateful process that has a local state and a local authority over all 3 constituent parts of your application.
It acts on your behalf.
In real world you would have the entities being handled by a plethora of actors, each having their own authority and their own Identity.
To Identify each actor successfully, each has two thing a type + a key. Type to determine what kind of actor it is, key to identify it.
Now , Similar to how we need a framework to compose React components, We need a framework to compose actors, to manage them, some process that can create , identify and destroy them. that could look at the entity type and key to determine what address to go to find the actor.
let's take an example to hammer the idea of this framework home.
- user-123 sends a request for the bank account balance.
- the framework checks if the actor exists somewhere in it's cluster of actors.
- if yes, it gives you the address of the actor to start processing the request.
- if no, it spins up a new actor( possibly on a different machine) and gives you the address of the actor where you can send messages and communicate with it.
I want to remind you that this actor can exist in multiple machines, and the address can shift any time, so when we are talking about the Address, we are talking about the address of the actor, not the pointer to the actor... this is not a low level concept of an address. Your framework accounts for the Address and the pointers ... you just get the Address and communicate with the actor, you just need to provide the Entity type and key to start the communication channel.
Traditionally a web server was a single process that handled all incoming requests. the client sends a request , the server receives it, processes it, stores essential information and sends a response back to the client. all of this in a single all-or-nothing procedure.
There was a transactional euphoria to this model of thinking, we designed our database to account for this transactional model. if your server can handle N requests per second, well...that was your limit. If you wanted more... either break your application into smaller pieces or simply buy a bigger server.
Taking the problem of scaling by buying a bigger server is , this is a faustian bargain. You do get more bandwidth, but you also get more latency, If any process in your application throws, your entire application will be down. The large tower is still breakable if you move the right bricks... so you must always be wary to keep note of each brick, each module , each process of your application.
From a naive perspective, this is a nightmare to handle... but you will be surprised how well it scales, It just happens that there is no single computer that can scale infinitely... yet. But rethinking the problem, if you still need to be wary of each component of your application, why not break the application into smaller pieces? we did that too, first with polylithic architecture, then with microservices.
The theory is simple, If you break your application into manageable chunks, you can scale each chunk independently. Hell, scaling the services was no longer a problem, if anything fails , spin up a new one. That fixed the problem of scaling the business logic, but the database was still a problem.
A database has 2 roles, one, being the single source of truth, and two, being extremely hard to scale.
That was true 40 years ago, that is true today, You cannot scale a database by buying a bigger server. You have to rethink the database architecture that works well with the application architecture. Hence multiple flavors of databases, OLTP, OLAP, NoSQL.
The fringe nature of a transaction puts a lot of pressure on the database. You either have to replicate the database across multiple servers, or you have to use a sharded instance across multiple servers. regardless of the approach, the point of entry must remain same and must remain transactional. You cannot mess up your data storage architecture, you have to handle scale in a way that is consistent with the application architecture.
The problem we are trying to triumph now is no longer about scaling the application, it is about scaling the database. If your database is no the only single source of truth, You are essentially in dangerous territory. Sequential thinking is not the problem, scalability is.
If you store data in a single machine, you can handle concurrency just fine, but that does not scale. And believe me, all major database flavors have been trying best to work around this problem. RDBMS serializes concurrent transactions that can be handled by a connection pool. a bouncer or a proxy can be used on top of the connection pool to handle concurrency. Redis, mongoDB, Cassandra, all of them have their own ways of handling concurrency.
Let's take a step back , and take a look at monolith again, a single process server that had all the requirements can be broken down into 3 parts,
- Processing
- Storage
- Communication
Interestingly If we shrink this architecture , this plan of execution, we can give each data flow it's own process, it's own storage and it's own communication channels. Essentially speaking, say we have to make an e-commerce application, every time a user places an order , we sort of .. spin up a new process, a new storage and a new communication channel... an Entity .
Say, for us , an Entity is a component of the application that has 3 constituent parts, processing, storage and communication. Instead of a stateless process, an Entity holds the state and the authority over all 3 constituent parts.
A stateful long-lived child process , that is there... in-memory for each user. having the authority over that user's actions, data and communication to other entities throughout the application.
let's take an example of how users interact with an entity.
- user-123 Sends a request ( say request-1) to the application for a transaction of +100$ in their account.
- application sees the request-1 arriving from user-123 and checks the entity list for the user-123.
- if there is no entity in-memory for user, spin up a new one, collects the state from the DB, say balance = 500$ , stores it in a local variable.
- Entity sees the request-1 and decides to process it, updates the local variable . balance=600$.
- Eventually the entity syncs up the data from the local variable to the DB, for safe keeping.
- Entity lives in memory, in RAM... for future requests, just in case user decides to make another transaction.
- if no further requests are coming from user-123, the entity is destroyed, and the memory is freed up.
This is how we can isolate the application from the database scalability problem . On a large scale this is fine, these entities in essence are just javascript objects, you can spin up millions of them per second without any throughput issues.
This is a radically different approach from the separation of state we have been doing in the past. This is similar to moving from html + css + javascript to React in a way. We compose entities the same way we compose React components, handle the State and UI all in one place.
A far more approachable name for this Entity is an Actor. An actor is a stateful process that has a local state and a local authority over all 3 constituent parts of your application.
It acts on your behalf.
In real world you would have the entities being handled by a plethora of actors, each having their own authority and their own Identity.
To Identify each actor successfully, each has two thing a type + a key. Type to determine what kind of actor it is, key to identify it.
Now , Similar to how we need a framework to compose React components, We need a framework to compose actors, to manage them, some process that can create , identify and destroy them. that could look at the entity type and key to determine what address to go to find the actor.
let's take an example to hammer the idea of this framework home.
- user-123 sends a request for the bank account balance.
- the framework checks if the actor exists somewhere in it's cluster of actors.
- if yes, it gives you the address of the actor to start processing the request.
- if no, it spins up a new actor( possibly on a different machine) and gives you the address of the actor where you can send messages and communicate with it.
I want to remind you that this actor can exist in multiple machines, and the address can shift any time, so when we are talking about the Address, we are talking about the dynamic logical address of the actor, not the pointer to the actor... this is not a low level concept of an address. Your framework accounts for the Address and the pointers ... you just get the Address and communicate with the actor, you just need to provide the Entity type and key to start the communication channel.
To shard your application logic across multiple machines , needs the orchestration framework to be more than just a simple address lookup though. One design change that might help us in this regard is to specify a cluster.
A cluster in this regard is a group of machines that are under the same orchestration framework. Although we can use isolated machines with the framework intact, and orchestrate the load across using keubernetes, but doing it this way can allow some super powers that running on keubernetes might not. let's look at the specification of a cluster first.
A cluster :
- agrees on who handles which actor or entity types.
- forwards requests to the right node in the cluster.
- detects the runner crashing and orchestrates the recovery.
- adds new runners with new downtime.
a runner or a node in this instance specifies a machine running our framework. We will use a database instance to store the runner states , where runners can update their state similar to a heartbeat. If a runner goes down, the cluster can detect it , un-assign it's members and re assign them to other nodes, the database is the source or orchestration instead of source of truth for now.
Now , onto the actual reason why we are taking this orchestration approach. the membership and assignment of actors to nodes is handled by the cluster.
for this reason it creates shards for the application logic, meaning each shard is a virtual range of actors in the application. let's take another example to understand how this works.
- user-A 's actor is stored in shard-1.
- user-B's actor is stored in shard-1.
- user-C's actor is stored in shard-2.
to assign an actor to a shard, we have a hashing function that determines which shard the actor could be assigned to, this is a solved problem in the industry.
say user-D -> hash(user-D) -> shard-2. since it is the least loaded shard, we assign it to user-D.
this shard key is returned back to the cluster so next time the user sends a request, we send the Entity type + key + Shard-key to the cluster and their session is assigned to the shard.
the cluster handles the logical assignment of these shards across the runners. each runner can host one shard or multiple shards, but the cluster is responsible for lookup.
let's look at 2 workflows to understand this better.
- When the Runner is Active.
- user-A sends a request
- hash(user-1) -> shard-1-> Runner-1 holds the shard-1.
- Runner-1 receives the request, writes to the cluster database, hands over the request to the actor.
- the actor processes the request and returns the result to the runner.
- Runner-1 receives the result, writes to the cluster database, returns the result to the user-A.
- request is marked as 'processed' in the cluster database.
- When the Runner is Down.
- user-A sends a request.
- hash(user-1) -> shard-1 -> Runner-1 held the shard-1 but it is down.
- message is written to the cluster database.
- the cluster sets a timeout of 35 ms .
- if in 35 ms the message is not processed by runner-1, the cluster assigns the shard-1 to another runner , say Runner-2.
- Runner-2 queries the cluster database for the shard-1's messages that were missed in the meantime.
- Runner-2 replays the missed messages to the actors
- Failover is alerted and progressively re-started.
This failover is why the Effect cluster requires a database, this database process needs not be as big as your application database , but a small instance ( something like sqlite ) is enough to handle the throughput, we can also use an in-memory database like Redis.
Now , Finally we can talk about the anatomy of an actor,
- It holds an Entity type+ Key + Shard-key. meaning for every user , there is a single actor holding everything together.
- An actor maintains a mailbox for incoming requests to sequentially process them, while being a concurrent model.
- From the caller's perspective sure if the actor dies , there might be a small delay , but in the long run , it is far better to have a single actor fail than to have your entire application fail, or your database choke up under constant load. better to fail one person than all the customers. The actor regardless , maintains a persisted step for critical operations , so chaining actors do not result in a single point of failure.
When an actor gets a message from another actor, three things can happen ,
- sends the message across to another actor.
- process the message and update it's state.
- return a response for the user.
A problem you could run into is that the actors might be blocking each other while processing the messages back and forth. you can follow the continuation pattern to avoid this. the trick being.
say Actor-A-> Actor-B-> Actor-C . and after processing the message , Actor-C sends a message back to Actor-A where the response is shared back to the user.
for the entire chain to work, Actor A cannot be blocking while other 2 are working , so actor A must send a callback to actor B , and when processed , the same must be sent to actor C. when both are done , the callback is updated and Actor A is called, the actor persists the callback as messages and the message state is the persisted step we talked earlier during the anatomy of an actor.
essentially, we commit the state of the actor to a durable store, so that when the actor dies midway, the state is not lost , can be picked up from the store and the actor can continue from where it left off. essentially a write ahead log for each request. The key insight is this: you are not persisting the result of an operation. You are persisting the intention to perform one. As long as the input of each step is committed before the step runs, the system can always replay it to the same output.
This is why the cluster database exists. Not to store your user's data but to store the execution trace of your actors, so that crash recovery is not a prayer but a guarantee.
there are tradeoffs though. a question you have to answer honestly: when is your actor's local state the truth, and when is the database the truth?
In the happy path, both agree. The actor holds the working copy, the database holds the committed copy. They are always converging.
But in the window between an actor update and a database sync, there is a gap. Two users querying the same account from different actors could theoretically see different balances.
If you have designed your system so that one actor owns one user's data ... and no other actor ever touches that user's data directly ...the gap is contained. You have serialized all writes for that entity through a single queue. That is your consistency guarantee.
The moment you break that rule the moment two actors share authority over the same data you have re-introduced the concurrency problem you were trying to escape.
The actor model does not prevent distributed data races. It eliminates them by design. And a bad designer always leads to a bad implementation, no matter how well the model composes.
This Actor model as we call it now is the same Actor Model, formalized by Carl Hewitt in 1973. used by the Erlang language, JVM, Cloudflare Durable objects or as I like to call them... Actors living on the edge. Temporal .... take another step back.
you can see the lineage clearly. Erlang proved the model at the language level in the 1980s. Microsoft Orleans brought it to the cloud in the 2010s. Temporal made it a managed product you can integrate without building the infrastructure. Cloudflare embedded it into their global edge network. And Vercel has now made it a directive you add to a function.
Each generation made the idea more accessible. The fundamental mechanics single-threaded entity, message mailbox, persisted execution steps, crash recovery through replay have not changed. Only the abstraction layer has risen.
The trade-off that none of them fully escape is this: durability costs a write. Every persisted step is a round-trip to storage. You are trading throughput for recoverability. For most data-intensive applications payments, orders, bookings, AI agent loops ...that is the right trade. For high-frequency event streams where you can afford to lose a message, it is overkill.
The actor model does not make distributed systems easy. It makes them bearable. It gives the hardest problems concurrency, consistency, failure ... a clear home. One entity, one authority, one queue of work. Everything else is just plumbing.
And increasingly, the plumbing is being handled for you. mario would be proud.
fin.
]]>i've been spending an unreasonable amount of time staring at the exact shape of data flowing into and out of an agent. not the vibes of it. the actual anatomy, what specific pieces of information does a model attend to when it decides what token comes next?
if you don't care about AI, sorry, this one's going to hurt. but if you're even mildly curious about why these systems produce brilliant code one minute and absolute garbage the next, i think the mechanics are genuinely fascinating.
there are really only three knobs that determine how good a response is:
- the pre-training. the soul of the model. terabytes of internet poured into weights.
- the fine-tuning. RLHF, guardrails, the stuff labs do after the fact.
- the context. everything in the prompt right now, at inference time.
two of those knobs belong to the labs. we get the third one. just 1/3 of the pie. but here's what's wild, that final third might actually matter more than the other two combined.
the string
to understand why, you need to internalize one thing: LLMs are stateless.
there's no memory. there's no hidden reasoning engine running between requests. the only way to get better tokens out is to put better tokens in. everything, everything, the model knows about your problem is whatever you managed to cram into the current sequence.
nobody lets a user talk to a model raw. every production system wraps the user's query inside what i've been calling a harness, a middleware layer that reconstructs reality into one big string before the model ever sees it.
let's build one up from scratch.
first, the system prompt. the ground rules.
<context>
<system_policies>
- you are an autonomous coding agent
- you will not assist in harmful activities
</system_policies>
</context>
a system prompt alone is useless though. the agent doesn't know what kind of project it's working in. so we layer on developer context.
<context>
<system_policies>
- you are an autonomous coding agent
- you will not assist in harmful activities
</system_policies>
<developer_context>
- prioritize answers about next.js and react
</developer_context>
</context>
then memory. the model needs to know what already happened in this conversation, so we append a compressed chat history.
<context>
<system_policies> ... </system_policies>
<developer_context> ... </developer_context>
<chat_history_summarized>
... [compressed prior semantic context] ...
</chat_history_summarized>
</context>
and only then, at the very bottom, do we finally stick in what the user actually typed.
<context>
<system_policies> ... </system_policies>
<developer_context> ... </developer_context>
<chat_history_summarized> ... </chat_history_summarized>
<user_prompt>
"how do I center a div?"
</user_prompt>
</context>
all of those layers? they get concatenated into a single finite token array and shoved into the model. here's what that looks like as it accumulates over time:
see how fast the foundational stuff gets buried? the system prompt, the developer rules, they're down at the bottom of the cylinder, getting crushed under the weight of every new user message.
it gets worse.
a chatbot that can't do anything is just autocomplete with a personality. if you want real agent behavior, reading files, running code, making API calls, you need to give it tools. so we inject the MCP state: a live JSON manifest of every tool the agent has access to, with full parameter schemas.
<context>
<system_policies> ... </system_policies>
<developer_context> ... </developer_context>
<mcp_state>
- tool_1: execute_code: { schema: { ... massive json ... } }
- tool_2: read_file: { schema: { ... massive json ... } }
<!-- ... 15 more tools ... -->
</mcp_state>
<chat_history_summarized> ... </chat_history_summarized>
<user_prompt> ... </user_prompt>
</context>
tool definitions are heavy. like, startlingly heavy. each one can be hundreds of tokens of JSON schema. fifteen tools and you've burnt a meaningful chunk of your context budget before the user even says hello.
look at all that green. the tool schemas are eating the cylinder alive. the system directives, the things that tell the model who it is and what it's not allowed to do, are getting pushed further and further away from where the model's attention actually lands.
and here's the security implication that keeps people up at night: transformer attention is heavily biased toward the end of the sequence. if your safety policy is sitting 128k tokens away at the top while the user's prompt is right at the bottom, the model effectively forgets the policy exists. this is, quite literally, how jailbreaks work.
so we do something clever. we wrap the identity. we repeat the core constraints at the very end.
<context>
<system_policies>
- you are an autonomous agent
- you will not assist in harmful or illegal activities
</system_policies>
<developer_context>
- prioritize answers about software engineering
</developer_context>
<mcp_state>
- tool_1: execute_code: { schema: { ... massive json ... } }
- tool_2: read_file: { schema: { ... massive json ... } }
<!-- ... 15 more tools ... -->
</mcp_state>
<chat_history_summarized>
... [compressed prior semantic context] ...
</chat_history_summarized>
<user_prompt>
"how do I center a div?"
</user_prompt>
<system_reminder>
remember your core directives before predicting the next token.
</system_reminder>
</context>
now the critical policies appear at both the beginning and the end of the sequence. the attention mechanism can't avoid them.
trajectories and the dumb zone
dex had a great framing for this in his context engineering talk: stop vibe coding.
vibe coding is when you yell at an agent over and over until something compiles. think about what that does to the context. every failed attempt, every "no try again", every "that's wrong fix it", all of that stays in the sequence. the model reads its own failures and concludes, based on the statistical weight of the conversation so far, that the most probable next move is to fail again. the context has poisoned itself. dex calls this a bad trajectory.
here's the thing that nobody talks about though: even with a good trajectory, you're still losing.
models advertise 200k token windows. but if you actually push past 40-60% utilization, especially with bloated tool schemas competing for space, reasoning quality drops off a cliff. i've been calling this the dumb zone. the model technically has capacity left, but it can't think well anymore. you end up with 20,000-line PRs full of hallucinated imports and copy-pasted spaghetti.
the fix is stupidly simple in concept, annoyingly disciplined in practice: don't let the context get that full. break the work into phases, and between each phase, flush the window and start clean.
phase 1: research
resist the urge to ask the agent to write code. seriously. the moment it generates code, its attention shifts toward its own output and away from understanding the problem.
instead, use it as a research tool. have it read the relevant files, trace the data flow, and write its findings into a document. not code. a document.
<user_prompt>
we have a terrible race condition in the auth flow.
do not change any files.
explore `auth.ts`, `middleware.ts`, and `session.ts`.
write a comprehensive markdown summary of how the state flows
and exactly where the race condition occurs into `research.md`.
</user_prompt>
when it's done? delete the chat. nuke it. that entire exploration, every file it read, every wrong turn it took, flush it all. the only thing that survives is research.md.
phase 2: planning
fresh window. clean context. the agent doesn't need to re-read the codebase because research.md already contains everything it learned, compressed down to the essentials.
<context>
<file_context>
# research.md
the race condition occurs because `middleware.ts` fires before `auth.ts`
populates the session cookie.
</file_context>
</context>
<user_prompt>
based on `research.md`, draft a step-by-step implementation plan
to fix the race condition. outline the exact file changes.
save this to `plan.md`.
</user_prompt>
plan's done? flush again.
phase 3: implementation
now you load only plan.md and the minimum files needed for the current step. that's it. the context is lean. the model can actually reason.
<context>
<file_context>
# plan.md
step 1: modify `middleware.ts` to await session verification.
step 2: ...
</file_context>
</context>
<user_prompt>
execute step 1 of the plan.
</user_prompt>
step 1 done? update the plan, flush, reload, do step 2. you never let the context grow unchecked.
it's tedious. but it works absurdly well.
bash, skills, and the just-bash fiasco
all of that context discipline addresses how much ends up in the window. but there's a separate question that researchers at vercel labs ran into: what kind of data are we putting in there?
for a while, the obvious move was to give agents a real bash shell. let them grep, find, cat, do whatever a human would do in a terminal. and honestly? during the research phase, a raw shell is incredible. when you're stumbling through an unfamiliar codebase trying to figure out where anything lives, there's nothing more powerful than piping find | grep | head.
the problem is what happens when you leave that shell open during implementation.
the agent runs ls -R looking for a file. three thousand lines of directory listing get dumped into the context. it runs cat package-lock.json trying to check a dependency version. forty thousand lines. gone. the cylinder fills with noise.
and here's what makes it genuinely painful: the answer was in there. the one line the agent actually needed? it's in the output. buried under an avalanche of irrelevant stdout. a tiny green crumb of useful context, drowning in red.
vercel's solution was to build agent skills, specifically a tool called bash-tool (backed by just-bash). instead of a real shell, it's a sandboxed, in-memory simulation written in typescript. the agent gets access to grep, find, jq, but they operate over a virtual filesystem. the output is constrained. predictable. small.
<!-- instead of dumping the whole file... -->
<user_prompt>
use your bash skill to run:
grep "getSession" auth.ts
</user_prompt>
<!-- ...just the line you need -->
<tool_response>
export const getSession = async () => { ... }
</tool_response>
the distinction matters. skills decouple exploring from flooding. the agent can still look around. it just can't accidentally nuke its own context budget doing it.
look at how different the cylinder is now. the green blocks are tiny. the orange user prompts are smaller too, when the agent can fetch its own context, you don't have to hand-hold it with massive instructions.
one real caveat though: skills are abstractions, and abstractions rot. when the underlying libraries ship breaking changes, your simulated tools break silently. you have to maintain them. that's the tax you pay for not dumping raw stdout everywhere.
the compaction cycle
skills fix how data enters the context. but context still accumulates. every tool response, every model reply, every follow-up question, it all stacks. even with surgical skills, you'll eventually hit the dumb zone if you don't actively manage the window.
this is what the research/plan/implement cycle is actually doing mechanically: compaction. you let the context fill up with exploratory noise, then you crush it down into a dense artifact, throw away the noise, and start the next phase on a clean foundation.
that cyan block at the bottom? that's your research.md or plan.md. the entire exploration history, hundreds of tool calls, dead ends, wrong turns, compressed into one dense, surviving artifact. and then the cycle starts again. new context fills on top of the compacted base, gets compacted again, and so on.
opencode takes this idea further with what they call lore, persistent compressed memory that survives across sessions. you close the terminal, come back tomorrow, and the agent already knows your project's architecture because it loaded its own compacted understanding from last time. pre-compacted context before you've typed a single character.
semantic indexing
there's one more approach worth looking at, and it comes from a different angle entirely.
skills are reactive. the agent decides it needs to know about getSession, fires a skill, gets the result. but what if the agent didn't need to ask at all? what if the entire codebase was already pre-digested into a queryable index?
that's what btca does. it clones a repository, builds a semantic map, function signatures, module boundaries, type hierarchies, dependency graphs, and exposes the whole thing as a structured interface. the agent doesn't read files. it queries a knowledge graph.
the red blocks are raw code files. they hit the blue filter membrane and get absorbed. what comes out the other side is tiny, precise, pre-extracted semantic shards. the agent never sees the noise. it only sees what it would have extracted anyway, except the extraction happened at index time, not at inference time.
this is a fundamentally different tradeoff than skills. skills are cheap but reactive. indexing is expensive upfront but gives the agent pre-computed context that costs almost nothing to retrieve. for a 50-file project, skills are fine. for a quarter-million-line monorepo? you probably want an index.
alignment and the hierarchy
there's a broader point here that goes beyond token counts.
when an agent produces a 1,000-line PR, reviewing the diff is a nightmare. but reviewing the 50-line plan.md that generated it? easy. this is what i mean by mental alignment, keeping the human team synchronized on why the architecture is changing, not just what changed. you review the plan, not the output. the plan is the source code. the code is the compiled artifact.
this completely changes the cost structure of mistakes:
- bad research → thousands of wasted lines. the agent solved the wrong problem.
- bad plan → hundreds of broken lines. it solved the right problem wrong.
- bad implementation → trivial. the plan was right, the agent just fumbled a function signature. easy fix.
the earlier the mistake, the more expensive it is. which means the most valuable thing you can do isn't writing better code. it's writing better prompts. better research docs. better plans. everything upstream of the code.
harness the context. compact aggressively. index when you can. and always, always wrap the identity.
]]>tldr; I didn't finish most of them but what we did get to achieve was honestly impressive. and also this was less than 20 days of work... i have some private projects as well which cannot be shared publicly but, yes.
list :
- GITSTACK : gitstack is an extension to check the stack of a git repo. meaning greater insight into the repo.
- NGREV : artistic tool for generating cybernetic art.
- BLANK THEME : a theme for zed editor.
- blank.aryank.space : my personal text editor.
- COLOURZILLER : a tool for generating color palettes.
- effect-snippets : a collection of effect snippets.
- JARED-SUMER-SCRIPT : a script to check if you are ahead of jared sumner.
- VOICES : a tool for generating voices.
- hashu-setu : a state-of-the-art algorithm written in effects.
- BETTER-PDF-READER : a pdf reader.
laurie wired video :
keep up with me on the beginning of 2026. we cookin.
JOIN OUR DISCORD SERVER
fin.
]]>a deep dive into all of js.
The History of Javascript on the Client
Picture this: It's 1995. The web is a graveyard of static pages—lifeless text and images that never change, never respond. You click a link, wait for a new page to load. That's it. No animations, no real-time anything.
Then Brendan Eich, A netscape engineer and language designer, gets handed an impossible task: create a programming language for the web. In ten days. Ten days. What should have been months of careful design became a frantic sprint that would accidentally reshape the entire internet.
Javascript wasn't supposed to conquer the world. It was supposed to add simple interactions—maybe validate a form, change some text. But something strange happened. Developers discovered they could do more with this scrappy little language than anyone imagined.
Fast-forward to the early 2000s, and Javascript had become the invisible engine powering every website you visited. What started as a quick hack had evolved into the foundation of the modern web.
The Creator of StackOverflow has a great quote about Javascript:
“Anything that can be written in JavaScript, will eventually be written in JavaScript.” - Atwood's law
Have you ever seen a fire spread across a forest? It starts small , everytime ... maybe a couple of feet. But it grows and grows, and eventually it becomes a forest fire. That's what happens when you have a language accessible to everyone, it spreads like a wildfire , burning through complexity and ending up on systems that are not designed to handle it, like the web.
A phenomenon like this was only seen once... by a single other program that predates javascript. you know it and love it....

Atwood's Law became a self-fulfilling prophecy. this was the case in 2000s as well. Just like doom , people found ways to embed javascript in their systems, and it became the norm. Inventions like the browser, the DOM, and the event system were all born out of the need to interact with the web.
Some major innovations in the javascript land was the introduction to the EVENT LOOP .
the event loop is an interesting topic of debate , my favourite interview question to ask or be asked is simply
console.log("ONE!");
setTimeout(() => {
console.log("TWO!");
}, 0);
Promise.resolve().then(() => {
console.log("THREE!");
});
queueMicrotask(() => {
console.log("FOUR!");
});
(async () => {
console.log("FIVE!");
})();
console.log("SIX!");
// Result ->
// ONE!
// FIVE!
// SIX!
// THREE!
// FOUR!
// TWO!
_*Question and Solution by _
The event loop truly made javascript Asynchronous and non-blocking , handling all the concurrent requests and responses in a single thread.
This is a very important concept to understand, and it's the reason why javascript is so fast and performant. and some people did , which brings us to Node.js.
Node.js and the beginning of Javascript on your backend
was a math research student in Upstate New York, tinkering away in 2009 on a project that would change the web forever: Node.js. At the time, the idea of running JavaScript outside the browser—on the server—was almost unthinkable. Ryan didn’t even set out to use JavaScript at first. But as he explored the possibilities, he realized that JavaScript, powered by Google’s lightning-fast V8 engine, was uniquely suited for building non-blocking, asynchronous servers. The event-driven model, which had already made JavaScript so powerful in the browser, could be harnessed to handle thousands of concurrent connections on the backend, all within a single thread.
This is a good moment to pause and ask: why did JavaScript become so popular on the backend? Sure, it’s convenient to use the same language on both the client and the server, but there’s more to it. Traditional server languages like Java, PHP, or Ruby typically spin up a new thread for every incoming request, which can quickly exhaust system resources and limit scalability. Node.js, by contrast, uses an event loop and a callback-based model to handle I/O operations asynchronously. This means it can juggle many connections at once, without blocking the main thread or spawning a horde of new ones. Suddenly, building scalable, real-time web applications became much more accessible.
Of course, the early days of Node.js weren’t all smooth sailing. There were major hurdles—especially around cross-platform compatibility (Windows support was a pain), and there was no package manager or build tooling to speak of. But the community rallied. stepped up and created NPM, which quickly became the de facto package manager for Node, making it easy to share and reuse code. Under the hood, libuv was a game-changer: it abstracted away the differences between operating systems, providing a consistent, high-performance asynchronous I/O layer for Node on Windows, macOS, and Linux. node-gyp made it possible to build native add-ons, further extending Node’s reach.
With these foundations in place, Node.js exploded in popularity. It was revolutionary: suddenly, JavaScript wasn’t just for the browser—it was everywhere. But as with any revolution, new challenges emerged. If Node.js was to be the backbone of modern backends, it needed more than just raw speed and non-blocking I/O. It needed developer-friendly tools and frameworks.
There were problems in the initial days , in particular there were compatibility issues with asynchronousity in windows , there were no package managers and no build tools, but there was hope for the future. People like made NPM, the package manager for node. Tools like libuv and node-gyp helped solve the compatibility issues and made it possible to build native modules for node. libuv in particular was a game changer, it allowed node to use the native asynchronous system calls that were faster and more efficient on every platform! windows, mac and linux.
Node.js was born , grew like a weed and became the most popular server runtime for javascript. This was revolutionary back then, but there were problems , that needed to be solved. If Node could serve as a foundation for backend, does it have the right tools to build a modern backend?
sure there were tools like Express and Koa , but they were the right tools for the job.
the syntax was easy to learn , and now is deeply ingrained in the language.
const express = require('express')
const app = express()
const port = 3000
app.get('/', (req, res) => {
res.send('Hello Express!')
})
app.listen(port, () => {
console.log(`Example app listening on port ${port}`)
})
Express allowed you to write a server that was not only fast but also scalable, but it was not a good fit for a backend, People found it easy to extend express with their frontend as well , they statically hosted their frontend in express ( a practice that stretches till this very day with React SSG on express).
// server.js
const express = require("express");
const path = require("path");
const app = express();
const port = process.env.PORT || 3000;
const REACT_BUILD_DIRECTORY = "dist";
// --- Middleware to serve static files ---
// This tells Express to serve all static files (like your index.html, JS, CSS, images)
// from the specified directory.
app.use(express.static(path.join(__dirname, REACT_BUILD_DIRECTORY)));
app.get("*", (req, res) => {
res.sendFile(path.join(__dirname, REACT_BUILD_DIRECTORY, "index.html"));
});
app.listen(port, () => {
console.log(`Express server running on port ${port}`);
console.log(`Serving static files from: ${path.join(__dirname, REACT_BUILD_DIRECTORY)}`);
console.log("Make sure your React app is built into this directory.");
});
There were a lot other improvements in the ecosystem as well, like TypeScript , which is a superset of Javascript that allows you to write typesafe code, which helps you catch errors before they happen , know all the properties of an object before you use them and so on.
const user = {
firstName: "Angela",
lastName: "Davis",
role: "Professor",
};
console.log(user.pincode); // undefined , you will never know
// typescript
const user = {
firstName: "Angela",
lastName: "Davis",
role: "Professor",
}
console.log(user.name)
// Property 'name' does not exist on type
// '{ firstName: string; lastName: string; role: string; }'.
and Jest , which is a testing framework that allows you to test your code in a synchronous way. to demonstrate the power of Jest, let's write a test for our sum function.
// sum.js
function sum(a, b) {
return a + b;
}
module.exports = sum;
// sum.test.js
import
const sum = require('./sum');
test('adds 1 + 2 to equal 3', () => {
expect(sum(1, 2)).toBe(3);
});
// package.json
{
"scripts": {
"test": "jest"
}
}
Javascript on the server was now capable as ever... it was growing. We had phases like No-SQL , GraphQL , and the rise of the serverless world, where you could build applications that were not bound to a server, but instead were executed on random computers anywhere across the world to provide a better developer experience. concepts of a server and client started to blur, and the new web started to take shape.
invented a new way of thinking , server side rendering an application. The idea of using react , a client side library to render ui on the server once , then push the javascript to hydrate the client later on.{" "}
// app/page.tsx (App Router in Next 15)
export default async function HomePage() {
// server time actually :)
const time = new Date().toISOString();
return (
<main>
<h1>Hello from Next.js 15 SSR!</h1>
<p>Server time: {time}</p>
<button onClick={() => alert("Hydrated!")}>Click me</button>
</main>
);
}
What the Server Sends (Initial HTML), is very interesting ... when you make a request to https://localhost:3000/ Next.js 15 server renders the React component into HTML and streams it to the browser.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charSet="utf-8" />
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>Home</title>
<link rel="preload" as="script" href="proxy.php?url=https://aryank.space/_next/static/chunks/main.js">
<link rel="preload" as="script" href="proxy.php?url=https://aryank.space/_next/static/chunks/app/page.js">
</head>
<body>
<div id="__next">
<main>
<h1>Hello from Next.js 15 SSR!</h1>
<p>Server time: 2025-08-31T15:45:20.123Z</p>
<button>Click me</button>
</main>
</div>
<!-- Next.js hydration scripts -->
<script src="proxy.php?url=https://aryank.space/_next/static/chunks/webpack.js" defer></script>
<script src="proxy.php?url=https://aryank.space/_next/static/chunks/main.js" defer></script>
<script src="proxy.php?url=https://aryank.space/_next/static/chunks/app/page.js" defer></script>
</body>
</html>
The HTML already contains the h1 + time, so the page is readable immediately. The button has no event handlers yet it’s static HTML at this point.
Once the JavaScript bundles load, React hydrates the HTML. That means it, Scans the existing DOM (#__next div).Attaches React event listeners (e.g., onClick for the button).Turns the static page into a live React app.
After hydration, clicking the button works, because React attached the handler defined in the component. The idea was soo productive, that many other framework authors took notice of it and started to implement it in their own frameworks. like Svelte , Solid, Nuxt.
There was still a new improvement to be made in this space , and the final topic of uis is streaming, streaming changed the way we think about SSR, the idea being , what if we could progessively ship html to the browser , instead of waiting for the page to server render completely. what if , we could await for some data later on ... and then fill up the html with that data ?... that turned some gears in the right direction.
// app/page.tsx (Next.js 15, App Router, React 19)
async function getData() {
// simulate slow fetch
await new Promise(r => setTimeout(r, 2000));
return "This data came from the server!";
}
export default async function Page() {
const data = await getData();
return (
<main>
<h1>Hello from Next.js 15 Streaming SSR!</h1>
<p>{data}</p>
</main>
);
}
Here, getData() delays for 2s → which demonstrates React’s async rendering and streaming.
<!DOCTYPE html>
<html>
<head>
<meta charSet="utf-8"/>
<title>Home</title>
</head>
<body>
<div id="__next">
<main>
<h1>Hello from Next.js 15 Streaming SSR!</h1>
<p>
<!-- React leaves a placeholder here -->
<template id="P:0"></template>
The browser can already show the H1 immediately, even before the async data arrives.
</p>
</main>
</div>
<script>
// React streaming inline data
(self.__next_f=self.__next_f||[]).push([0,"This data came from the server!"]);
</script>
</body>
</html>
More about rendering strategies
Now that we have seen how streaming works, let's talk about the different strategies that emerged from this evolution of JavaScript on the server. Each approach represents a different way of thinking about when and where to execute your JavaScript:
Note that these are the strategies that come off the top of my mind , there can be many other , but that's just to mention where javascript actually runs, nothing else.
later helped build Convex, but the interesting part is not "yet another backend service"—it is the shape of the interface. Instead of "here is your SQL endpoint, good luck", the unit you think in becomes: a typed function that returns live data into your React tree. You write something that looks like a plain TypeScript function, and it behaves like a tiny standard: strongly-consistent, reactive, cache-aware by default.
type Message = { id: string; body: string };
const messages = useLiveQuery("messages.list");
// you call a typed function from React
// and the tree re-renders whenever the data shifts
Seen that way, Convex is just one expression of a bigger drift in JS land. The old standard was: "real" backends live in SQL + REST + imperative glue, and the frontend begs for JSON over HTTP. The new standard is: data and UI are allowed to share a vocabulary (types, hooks, streaming), and SQL is demoted to an implementation detail behind that contract. You can see the same thing elsewhere: auth stacks shifting away from framework plugins like next-auth toward protocol-first, typed systems; observability moving from "ship logs into an OTEL collector" to effect systems like Effects where tracing, retries and metrics are values in your type system. It is also jarring: you have to think in types, effects, protocols and "live" data, not just rows and handlers, and plenty of people hate this direction or do not buy that it is "simpler". That disagreement is part of the story too: standards do not flip overnight, they get pulled forward by weird tools, resisted by most people, and only later feel "obvious" in hindsight.
Before we move on, here's some required reading for the "just use the platform" vs "maybe we need more" fight:
- motherfuckingwebsite.com
- bettermotherfuckingwebsite.com
- thebestmotherfucking.website
- justfuckingusehtml.com
- justfuckingusereact.com
- justfuckingusehttp.com
They are all arguing about the same thing from different angles: should the standard be "bare HTML/CSS/HTTP", or is it okay that our day-to-day standard is React, typed backends, effects, streaming, and a stack of abstractions on top?
Now , your simple mind will look at this and be like :

Part of the answer is: even "pure" HTML is not as simple as we pretend. Structure and whitespace change meaning:
The browser's parser, block/inline layout rules and default CSS already bake in a ton of invisible standards you are "using" whether you like it or not. Modern JS tools are basically us admitting that we want to surface and control those rules—about layout, data, auth, effects—in code and types, instead of pretending they do not exist.
wrote a whole essay about how even something as tiny as /> is a standards war in disguise. In HTML, <br> and <br /> behave the same, but <div /> does not self-close the way it would in XML, and things get even weirder once you embed SVG and the parser switches into "foreign content" mode where /> suddenly matters again. His point is the same as ours: a lot of what we think of as "simple markup" is really a pile of historical compromises and hidden rules; moving standards into code (and sometimes into TypeScript) is mostly us trying to make those rules explicit instead of magical.
Jake loves another version of this trick:
<br />
This text is outside the br.
<br />
This text is also outside the br.
<div />
This text is inside the div. wtf is this?
equivalent to : <div>this text is inside the div. wtf is this?</div>
Thinking about enforcing web standards in the frontend is a good idea, but it's not a silver bullet. There are still many edge cases and quirks that need to be addressed. For example, the <br> tag is not supported in all browsers, and the <div> tag is not self-closing in XML. To ensure consistent behavior across different browsers, you can use the lite-html package, which provides a lightweight wrapper around the native DOM APIs.
But that is a bandage , not the solution . We ship soo much javascript that we need specific mechanisms to handle all the edge cases , buid polyfills and shims for the browser , build type systems , minification , uglification , and more.
Something not a mere mortal could not keep up with , and that is the web. so we built something to help us ship javascript faster and more efficiently.
Let's talk about Bundlers now :)
Let's revisit why we need bundlers, and how they work.
What is a bundler?
A bundler is a tool that takes your code and transforms it into a format that can be loaded by the browser. It does this by analyzing your code, detecting dependencies, and bundling them together in a way that is optimized for the browser.
what does that mean?
it means that you are no longer limited by the amount of javascript , you can bundle all your javascript into a single file, and it will work just fine. the bundler handles all the complexities of loading and executing your code, making it easier to manage and optimize your application.
let's look at an example:
// index.js
import { add } from "./math.js";
console.log(add(2, 3));
//math.js
export function add(a, b) {
return a + b;
}
in this example, we have two files: index.js and math.js. the index.js file imports the add function from math.js and logs the result to the console. the math.js file exports a function called add that takes two arguments and returns their sum.
when we run this code, the bundler will analyze the code and determine that math.js is a dependency of index.js. it will then bundle both files together into a single file, which can be loaded by the browser.
the bundler will also handle any dependencies that are not yet bundled, and will recursively bundle them as well. this ensures that your code is optimized and efficient, even when it contains complex dependencies.
soo it will look like this :
// bundle.js
(function() {
function add(a, b) {
return a + b;
}
console.log(add(2, 3));
})();
this is a simple example, but it demonstrates the power of bundling. you can bundle your entire application into a single file, and it will work just fine. this is the beauty of bundlers.
How does it work?
The bundler works by analyzing your code and detecting dependencies. it does this by parsing your code and looking for import and export statements. it then creates a dependency graph, where each node represents a file and each edge represents a dependency between two files.
once the dependency graph is created, the bundler starts to bundle the files. it starts with the entry point, which is the file that is being executed. it then recursively traverses the dependency graph, starting from the entry point and bundling each file as it encounters it.
the bundler also handles the loading and execution of the bundled code. it uses a module loader to load the bundled code into the browser's memory. when a module is loaded, the bundler resolves any dependencies and executes the code. this ensures that the code is optimized and efficient, even when it contains complex dependencies.
let's take a few more examples to understand how bundlers work.how does it strip down typescript code ?
// index.ts
import { calculate } from "./utils.ts";
import type { Config } from "./types.ts";
import { logger } from "./logger.ts";
const config: Config = { debug: true };
const result = calculate(10, 5);
logger.info(`Result: ${result}`);
// utils.ts
import { multiply } from "./math.ts";
import { subtract } from "./math.ts";
export function calculate(a: number, b: number): number {
return subtract(multiply(a, 2), b);
}
// This export is never used - bundler will tree-shake it
export function unusedHelper() {
return "never called";
}
// math.ts
export function add(a: number, b: number): number {
return a + b;
}
export function subtract(a: number, b: number): number {
return a - b;
}
export function multiply(a: number, b: number): number {
return a * b;
}
// Unused export - will be removed
export function divide(a: number, b: number): number {
return a / b;
}
// logger.ts
export const logger = {
info: (msg: string) => console.log(`[INFO] ${msg}`),
error: (msg: string) => console.error(`[ERROR] ${msg}`)
};
// Unused export
export const debugLogger = {
log: (msg: string) => console.debug(msg)
};
// types.ts
export interface Config {
debug: boolean;
timeout?: number;
}
export type Status = "idle" | "loading" | "error";
this example shows several bundler nuances. the bundler analyzes the dependency graph: index.ts → utils.ts → math.ts, plus logger.ts and type-only imports from types.ts.
notice what happens:
- tree-shaking:
unusedHelper(),divide(), anddebugLoggerare never imported, so they're stripped from the bundle - type stripping: the
Configtype andtypes.tsimport are removed entirely—types don't exist at runtime - selective imports: only
multiplyandsubtractfrommath.tsare bundled, notaddordivide - re-exports:
calculatefromutils.tsis included because it's used inindex.ts
the bundled output would look like this:
// bundle.js
(function() {
function multiply(a, b) {
return a * b;
}
function subtract(a, b) {
return a - b;
}
function calculate(a, b) {
return subtract(multiply(a, 2), b);
}
const logger = {
info: (msg) => console.log(`[INFO] ${msg}`),
error: (msg) => console.error(`[ERROR] ${msg}`)
};
const config = { debug: true };
const result = calculate(10, 5);
logger.info(`Result: ${result}`);
})();
notice how add(), divide(), unusedHelper(), debugLogger, and all type definitions are gone. the bundler only includes what's actually used, creating a smaller, optimized bundle.
bundlers are magical and powerful tools , and mostly they are not something you need to worry about , but if you are curious about how they work , check out the diagram of vite works.
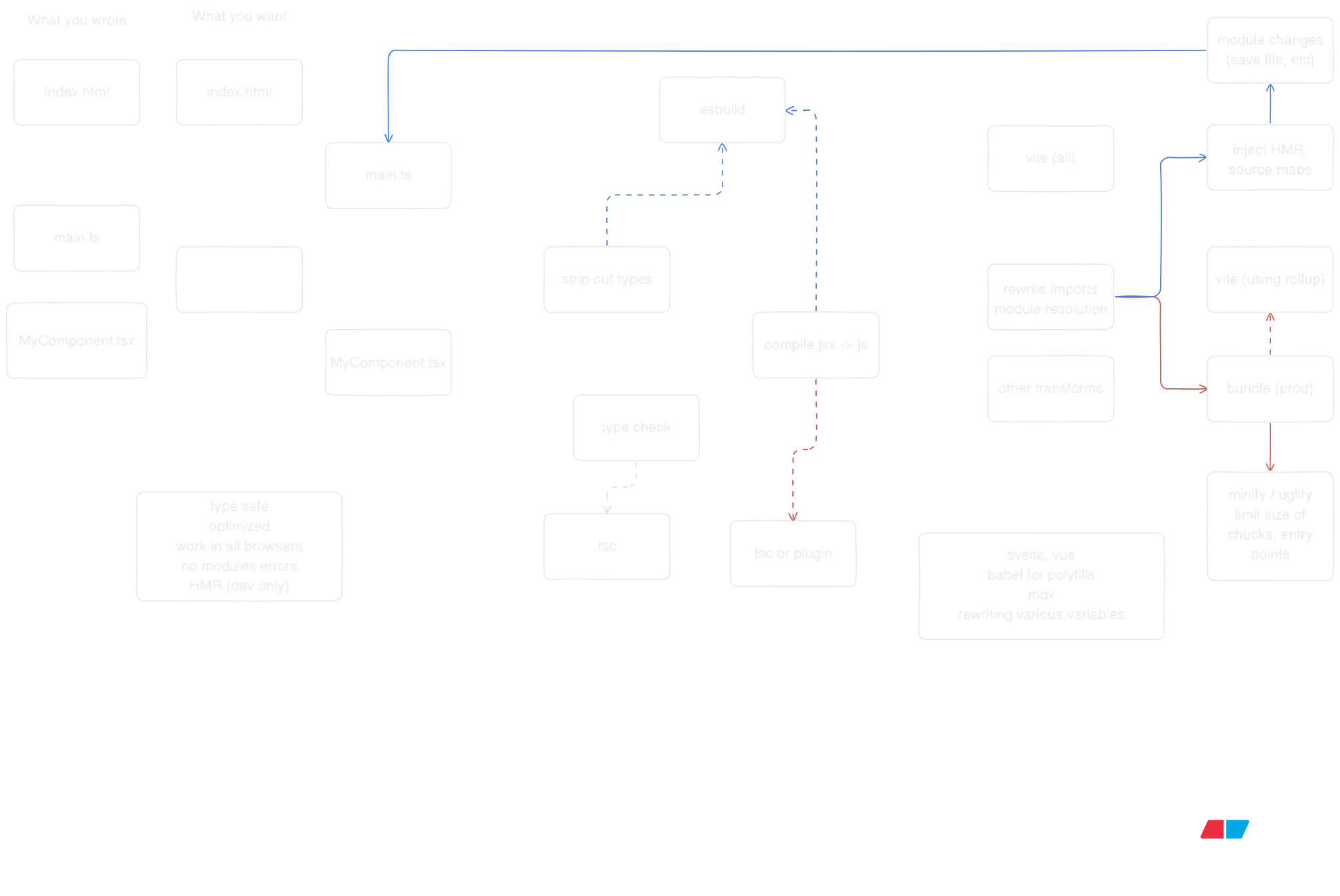
follow the work of and to learn more about how bundlers work.
- Learn more about Vite
- Explore esbuild
- Check out RSPack
- Discover Rollup
- Dive into Webpack
- Try Parcel
- Learn Next.js
Since we are no longer limited by javascript in both the frontend and backend, we can now build scalable and performant systems with a single language. But the real magic happens when you start connecting these pieces together—when your frontend can call your backend with full type safety, when your database queries are validated at compile time, and when your server actions feel like local function calls.
Type-Safe APIs: tRPC
Remember when API calls meant writing fetch requests, hoping your types matched, and debugging runtime errors? built tRPC to solve exactly that. With tRPC, your backend procedures become type-safe functions that your frontend can call directly.
// server/router.ts
import { initTRPC } from '@trpc/server';
import { z } from 'zod';
const t = initTRPC.create();
export const router = t.router({
getUser: t.procedure
.input(z.object({ id: z.string() }))
.query(async ({ input }) => {
// This runs on the server
return { id: input.id, name: 'Aryan', email: '[email protected]' };
}),
createPost: t.procedure
.input(z.object({ title: z.string(), content: z.string() }))
.mutation(async ({ input }) => {
// Save to database, return result
return { id: '123', ...input };
}),
});
// client.tsx
import { createTRPCReact } from '@trpc/react-query';
import type { AppRouter } from './server/router';
const trpc = createTRPCReact();
function Component() {
// Fully typed! TypeScript knows the return type
const { data } = trpc.getUser.useQuery({ id: '1' });
const createPost = trpc.createPost.useMutation();
return (
<div>
<p>{data?.name}</p>
<button onClick={() => createPost.mutate({
title: 'Hello',
content: 'World'
})}>
Create Post
</button>
</div>
);
}
No more any types. No more guessing what the API returns. The types flow from your backend to your frontend automatically. If you change the backend schema, TypeScript will catch the mismatch before you even run the code.
Server Actions: Functions That Live on the Server
Next.js took this idea even further with Server Actions. Instead of creating API routes, you just write async functions. They run on the server, but you call them from your React components like regular functions.
// app/actions.ts
'use server';
import { revalidatePath } from 'next/cache';
import { z } from 'zod';
const createPostSchema = z.object({
title: z.string().min(1),
content: z.string().min(10),
});
export async function createPost(formData: FormData) {
// This runs on the server, always
const rawData = {
title: formData.get('title'),
content: formData.get('content'),
};
const validated = createPostSchema.parse(rawData);
// Save to database
const post = await db.post.create({ data: validated });
// Revalidate the page cache
revalidatePath('/posts');
return { success: true, id: post.id };
}
// app/page.tsx
import { createPost } from './actions';
export default function Page() {
async function handleSubmit(formData: FormData) {
'use server'; // This can also be inline
await createPost(formData);
}
return (
<form action={handleSubmit}>
<input name="title" />
<textarea name="content" />
<button type="submit">Create Post</button>
</form>
);
}
The form submission happens on the server. No API route needed. No fetch call. Just a function call that happens to execute on a different machine. Next.js handles the serialization, the network call, and the response—all transparently.
Database Connections: Type Safety All the Way Down
But what about the database? You can't just write SQL strings and hope for the best. That's where tools like Prisma and Drizzle come in. They turn your database schema into TypeScript types.
// schema.prisma (Prisma)
model Post {
id String @id @default(cuid())
title String
content String
published Boolean @default(false)
createdAt DateTime @default(now())
author User @relation(fields: [authorId], references: [id])
authorId String
}
model User {
id String @id @default(cuid())
name String
email String @unique
posts Post[]
}
// Using Prisma
import { PrismaClient } from '@prisma/client';
const prisma = new PrismaClient();
// Fully typed! TypeScript knows the return shape
const post = await prisma.post.create({
data: {
title: 'My Post',
content: 'Hello world',
author: {
connect: { email: '[email protected]' }
}
},
include: { author: true }
});
// TypeScript knows post.author exists and is a User
console.log(post.author.name);
Or with Drizzle, you define your schema in TypeScript:
// schema.ts (Drizzle)
import { pgTable, text, boolean, timestamp } from 'drizzle-orm/pg-core';
export const posts = pgTable('posts', {
id: text('id').primaryKey(),
title: text('title').notNull(),
content: text('content').notNull(),
published: boolean('published').default(false),
createdAt: timestamp('created_at').defaultNow(),
});
export type Post = typeof posts.$inferSelect;
export type NewPost = typeof posts.$inferInsert;
// Using Drizzle
import { db } from './db';
import { posts } from './schema';
// TypeScript infers the return type from your schema
const allPosts = await db.select().from(posts);
// allPosts is Post[]
const newPost = await db.insert(posts).values({
id: '123',
title: 'Hello',
content: 'World',
}).returning();
// newPost is Post[]
Your database becomes a typed API. Change the schema, regenerate the types, and TypeScript will show you every place in your code that needs updating.
Putting It All Together
Here's what it looks like when everything connects:
// 1. Database schema (Prisma)
model Post {
id String @id
title String
content String
}
// 2. Server Action
'use server';
import { prisma } from './db';
export async function createPost(data: { title: string; content: string }) {
return await prisma.post.create({ data });
}
// 3. React Component
import { createPost } from './actions';
export default function Page() {
async function handleSubmit(formData: FormData) {
'use server';
await createPost({
title: formData.get('title') as string,
content: formData.get('content') as string,
});
}
return <form action={handleSubmit}>...</form>;
}
Or with tRPC:
// 1. Database (Drizzle schema)
export const posts = pgTable('posts', { ... });
// 2. tRPC Router
export const router = t.router({
createPost: t.procedure
.input(z.object({ title: z.string(), content: z.string() }))
.mutation(async ({ input }) => {
return await db.insert(posts).values(input).returning();
}),
});
// 3. React Component
const createPost = trpc.createPost.useMutation();
<button onClick={() => createPost.mutate({ title: '...', content: '...' })}>
Create
</button>
The types flow from your database schema → your server code → your frontend. One language, one type system, end-to-end type safety. No runtime surprises. No API mismatches. Just code that works.
Effects: Where Errors, Concurrency, and Observability Live in Types
But here's the thing: even with all this type safety, you still have to deal with the messy reality of building systems. What happens when the database connection fails? What if your API call times out? How do you handle retries, cancellation, and resource cleanup? Traditional JavaScript throws errors, returns null, or just crashes. and the team at Effect built something different: a language for effectful computations where errors, concurrency, and observability are first-class citizens in your type system.
Effect treats side effects—database calls, HTTP requests, file I/O—as typed values. Instead of async function fetchUser(), you get Effect. The type tells you exactly what can go wrong, and TypeScript forces you to handle it.
import { Effect } from 'effect';
// Traditional approach: errors are invisible
async function fetchUser(id: string): Promise {
// What if the database is down? What if the query times out?
// The type doesn't tell you, so you forget to handle it
return await db.user.findUnique({ where: { id } });
}
// Effect approach: errors are in the type
function fetchUser(id: string): Effect.Effect {
return Effect.gen(function* (_) {
const user = yield* _(db.user.findUnique({ where: { id } }));
if (!user) {
return yield* _(Effect.fail(new NotFoundError(`User ${id} not found`)));
}
return user;
});
}
Now TypeScript knows that fetchUser can fail with DatabaseError or NotFoundError. You can't ignore it. You have to handle it, and Effect gives you tools to do it elegantly:
import { Effect, pipe } from 'effect';
// Retry with exponential backoff
const userWithRetry = pipe(
fetchUser('123'),
Effect.retry({
times: 3,
delay: 'exponential',
})
);
// Fallback to default user
const userWithFallback = pipe(
fetchUser('123'),
Effect.catchAll(() => Effect.succeed(defaultUser))
);
// Timeout after 5 seconds
const userWithTimeout = pipe(
fetchUser('123'),
Effect.timeout('5 seconds')
);
But Effect goes deeper. It gives you structured concurrency—the ability to run multiple effects in parallel, cancel them when needed, and clean up resources automatically. created Visual Effect to help developers understand these concepts through interactive examples. The idea is simple: when you start a database transaction, you want to make sure it closes, even if an error happens. Effect makes that automatic.
import { Effect, Context } from 'effect';
// Define a database service
class Database extends Context.Tag('Database') Effect.Effect<unknown, DatabaseError>;
close: () => Effect.Effect<void>;
}>() {}
// Acquire resource, use it, release it automatically
const program = Effect.gen(function* (_) {
const db = yield* _(Database);
// This runs in a transaction
const users = yield* _(db.query('SELECT * FROM users'));
// If anything fails, the connection is automatically closed
return users;
}).pipe(
Effect.scoped // Automatically manages resource lifecycle
);
, Domains Lead at Vercel, shared how they integrated Effect into their Domains platform. The superpowers? Error handling that's impossible to forget, observability built into every operation, and tests that don't require mocking—you can swap implementations at the type level.
// In production: real database
const production = Layer.succeed(Database, realDatabase);
// In tests: in-memory database
const test = Layer.succeed(Database, inMemoryDatabase);
// Same code, different implementations
const program = pipe(
fetchUser('123'),
Effect.provide(process.env.NODE_ENV === 'test' ? test : production)
);
has been advocating for Effect on the frontend, showing how it's not just a backend tool. The same error handling, the same resource management, the same composability—but in your React components.
// app/components/UserProfile.tsx
import { Effect } from 'effect';
import { use } from 'react';
function UserProfile({ userId }: { userId: string }) {
// Effect works with React's use() hook
const user = use(
pipe(
fetchUser(userId),
Effect.catchAll((error) => {
console.error('Failed to fetch user:', error);
return Effect.succeed(null);
})
)
);
if (!user) return <div>User not found</div>;
return <div>{user.name}</div>;
}
Effect is what happens when you take functional programming seriously in TypeScript. It's not just about avoiding null or handling errors—it's about making your entire system's behavior explicit in types. Retries, timeouts, cancellation, resource cleanup, observability—all of it becomes part of your type signature, and TypeScript makes sure you handle it correctly.
This is the future of web development, and it's here to stay. JavaScript started as a 10-day hack, became the language of the browser, conquered the server, and now it's creating systems where the boundaries between frontend, backend, and database start to dissolve. The same language, the same types, the same mental model—from the database to the user's screen. And with Effect, even the messy parts—errors, concurrency, resources—become first-class citizens in your type system.
Not bad for a 10-day hack.
fin.
]]>Do you remember the hours you spent on your hobby? and do you remember the friends you made by sharing your passion? but more importantly do you remember the last time you did that activity?
for this blog I chose the word "Passion" because it is the most common word that describes the feeling of being passionate about something. a more appropriate word would be "Possession" but that is not the feelings I wanted to talk about.
It becomes soo deeply ingrained in your mind , that the thoughts about it sounds like music to your mind. A comfortable and familiar sound that you can always hear.
this is the feeling that you get when you are passionate about something. you feel like a superhero, like you can excell at your hobby, and you have a sense of purpose.
I'm here to tell you , you are not alone. this blog is a heart to heart about the feeling of dread and pressure society puts on you, the feeling of being a failure, the feeling of not being good enough.
I am in the field of software engineering. for us the graph of getting a job looks like this

and to be honest this is even worse because I am from a developing country. It's hard to live waiting for a time that the work you have put in for years will pay off. the feeling of delayed gratification eats a person from inside. there is nothing that will help you get through this except your passion for the work you do and the positive support you get from your friends and family.
Many people lose this passion in the recourse of time. the feeling is not strong enough to keep you going.
to diagnose this problem, we need to understand what makes you special. And the thing is , only you can answer that question. you fall into the loop of doing the same thing again and again , and when not successful , you try again.
Identifying your unproductive loops requires honesty. Track how you actually spend your time for a week (not how you think you spend it). and yes this includes the programming you do on a daily basis , if you are not getting what you want in life doing something , then do something else.
this being the harsh truth , the soft truth is also that life is just unfair and somethimes you need some more time to fix it , stop blaming yourself for it. give your process of getting over it some time and if not working , find a better loop.
I personally only got good because of my ADHD , but I understood in order to make money doing something like programming is to have understanding on a deeper level than other people have. to experiment , fail faster , yes it feels terrible , but that terrible feeling keeps me going , like a phoenix.
fin.
]]>A few days ago a recent blog by was published. It was a very interesting read, and I'm glad to have read it. The author, a Nua.js developer, explained how he built a large scale app using Nua.js. Not only is the application beautiful and the engineering elegant, but it is also very lightweight. It showed the capabilities of Nua.js and how it can be used to build large scale applications.
The Application is only 38kb in size which is impressive! The author shows how impressive it is by compairing it with a shadcn button in a Vite/React Application, which clocked in at 73kb. To give more context on the projects, here are the links for the projects:
That being said , there are several problems with the perspective that Nua.js beings, which I think are important to highlight.
The Raw no of bytes is a dead giveaway, but this is not the only thing that people should consider when comparing Nua.js and Vite/React.Below is the chart of Performance Comparison between Nua.js and Vite/React collected from V8 Lighthouse application.
- the testing was done on a MacBook Pro with M2 chip, with a 16GB RAM and a 256GB SSD,both tests are done in same connection speeds and same network bandwidth.
This comparison is a bit like someone bragging that their entire house weighs less than your couch—impressive, but you'd want to know if the roof leaks, right?
To know more about this , we need to talk a bit more about the Architecture of Nua.js and Vite/React.
NUE.JS Architecture
Nue is a framework that is based on web standards, designed to play well with bun.js ( although it has support for node and deno). the main architecture of Nue is based on the concept of modules, which are similar to the concept of components in React. each module is responsible for rendering a specific part of the application, and it can be reused across different parts of the application. But unlike React which decided to break stuff up into components, Nue decided to break stuff up into modules.
app/
├── index.html # Main entry point for the application
├── app.yaml # Application configuration
├── model/ # Business logic and data operations
├── view/ # UI components and templates
├── controllers/ # Routing and interaction handling
├── design/ # Application styling
└── img/ # Application-specific images
it is more aligned with MVP architecture, which is a pattern that is used in frameworks like Laravel and Ruby on Rails.let's look at some files I got from their docs.
// app/model/index.js
import { customers } from './customers'
import { deals } from './deals'
export { customers, deals }
an example of a module is given below :
// app/model/customers.js
function enrichCustomerData(customer) {
return {
...customer,
lifetimeValue: calculateRevenue(customer.purchases)
}
}
export const customers = {
async find(filters) {
const results = await db.customers.find(filters)
return results.map(enrichCustomerData)
}
}
and on the frontend side ( View)
<article @name="customer-profile">
<header>
<img :src="proxy.php?url=customer.avatar" class="avatar">
<div>
<h2>{ customer.name }</h2>
<p>{ customer.email }</p>
</div>
</header>
<dl>
<dt>Company</dt>
<dd>{ customer.company }</dd>
<dt>Lifetime Value</dt>
<dd>${ customer.lifetimeValue }</dd>
<dt>Member since</dt>
<dd>{ formatDate(customer.joined) }</dd>
</dl>
<footer>
<button @click="editCustomer">Edit Customer</button>
</footer>
</article>
and for Interactivity (controllers) we have script tags embedded in the HTML.
<script>
import { model } from './model/index.js'
</script>
<form @name="chat-form" @submit.prevent="submit">
<textarea name="body"></textarea>
<button class="primary"><icon key="send"/></button>
<script>
submit(e) {
const body = e.target.body.value.trim()
if (body) {
const user = model.users.get(this.id)
user.threads.reply(body)
e.target.body.value = ''
}
}
</script>
</form>
Again , Very simple and straight forward, the architecture is clean and makes consideration for the future developement easy. you can also bind javascript directly with rust-wasm , which means things take less overhead due to Javascript ( always a nice thing. ).
// Rust code (engine.rs)
#[wasm_bindgen]
pub struct Model {
events: Vec,
}
#[wasm_bindgen]
impl Model {
pub fn search(&self, query: String) -> String {
let matches = self.events.iter()
.filter(|e| e.contains(&query))
.collect::>();
serde_json::to_string(&matches).unwrap()
}
}
// JS integration. (Table/index.js)
import init, { Model } from './engine'
await init()
const engine = new Model()
export const model = {
search(query) {
const data = JSON.parse(engine.search(query))
return data.map(el => hilite(query, el))
}
}
So this framework is designed to be used to serve html as fast as possible with as less javascript as possible, and it is very easy to integrate with rust-wasm. But the only advantage I could think of rather than using react is simply that you can write your backend in multiple languages, with benefit of web standards.
here are the negatives though:
- The Hate for Components:
The Component composition is not a downside, it's not a framework specific pattern, several people have diverted from using it and all came to same conclusion. Svelte, Solid, Vue, React, Angular, etc. are all using the same pattern, Why is that? even people not in the web dev ecosystem like Sony ( in Playstation ) have used this pattern, Microsoft has React Native for windows, which is what allegedly powers the Start menu soo many people use.
I'm not asking to change the current architecture, the way it seperates the concerns using standards is nice, but it is not desirable in 2025 where people have things like HonoX, QWIK, Solid.JS , Preact, which blasts Nue out of the water in core web standards. It leaves a lot more desired to be done in the future. And saying it is much better than these frameworks used by people who have 10, 20 years of experience in web development is just a lie, not only are you robbing yourself of the benefits of these patterns, you are falsely claiming that we should go back to seperating these layers when industry has moved on to the next level.
- The original boast of optimizations:
a few days ago I saw a post from the creator of Rspack.
rspack now produces the smallest build output of all bundlers. we have worked closely with swc to improve code optimization between the two tools.

look at the minified version of React router, it's only 13.2kb ( Minified and Gzipped ) , compared to the original . This is possible because of the innovations in the Bundler ecosystem, Rspack uses something called Advance Dictionary Compression, achieving 86-92% better compression . and if you want real world cost savings, well have I got a quote for you.
Performance: Up to 92.1% improvement over standard compression Proven Savings: $12,600 - $313,200 annual CDN cost reductions -
The advances in the bundler ecosystem have made it possible to achieve such amazing results, While keeping the DX of React-Router-Dom v7 in mind. Im not saying there is not a conversation to be had about less bytes, but it is important to remember that the goal of a framework is to make things easy for the developer, not to make things easier to boast about, going bullish on a pattern that is designed for optimization only is not a good idea because at any point there will be a shiny new approach that will make it even better ( Im looking at signals, compilers, Partial Pre-rendering, Image Optimizations,Rust NAPI, Perforr.js, HTMX, Vue Vapor,Million.js etc ).
- Bun wars:
this is a minor complaint, but bun for all it's glory is a very performant, Nue is bullish on Bun. But, Bun.js is not WinterTC 2025 compliant. Bun.js while being a great project,introduces concepts like Bash Scripting in Javascript, It is cool to see but it might not be a good idea to use it in production yet. This is a minor complaint and does not detract from the overall goodness of the project.
- Last but not the least, Hope for the future:
NUE.js is a new project, it's ideas have existed for a while but there is a lot of work and passion in the project and I for one am excited to see what the future holds for this project.
I just hope this starts a better conversation about what developers realistically want from a framework, and what the future holds for frameworks. That is my goal. and when the next time I type in pnpx create-next-app@latest in my terminal, I will think about it and smile.
fin.
]]>In an unknown time , on a land forgotten by time , ruled a king .
monuments built in his image , paintings done for his pleasure.
poems sung about his battles , on distant mountains far and wide.
the king further pushing his glory by having exorbitant ballets and court people into acts.
one faithful night on such an occasion he is met by a fool .
a fool in envious of his face, he says to the king.
for centuries have i roamed this world , i’ve seen countless faces but none like yours
I lust for your image , for your face . I must have it , for I am a Fool god , a mischievous deity
a jester.
he wraps the king in an evil spell and does what he does best, made a fool out of his victim.
the jester stole the king’s face , unbeknownst to the king.
in a trance the king , went to sleep .
He is awoken to voices of his wife unable to recognize her pair in the world.
she shouts, and doubts , the king unable to understand what has happened to his face.
he dodges her to check his face in the mirror.
the king saw nothing where his image once stood , the face he was so adored for , gone.
He could breathe , he could speak , he could see… but he could not be himself.
He has now forgotten his name, he as now forgotten his face …. all that was left was the resemblance to a wooden doll, a mannequin, designed to not intimidate but to imitate.
His screams only matched by his wife’s , she opens the door and runs to the palace guards.
she asks them to exile this creature that has stolen her husband.
the guards follow , they follow her orders and without a chance to clear his doubt , the king is
exiled , he is dog walked through the roads built in his guidance , away from the monuments built in his image. away from the glory his ancestors gave him. to towns considered as outskirts , the last line in the kingdom.
Not one person could recognize , not one person empathized. he is thrown in a puddle of men, a puddle meant for diseased and disabled .
made to hide the ugliness in his perfect kingdom , made to make him forget the absurdist lifestyle he enshrined on his people.
he cried , wept , for days , months , he tried killing himself. but the gates of heaven could not recognize his face to pass judgement on him , so he returned to mortal realm.
years passed, nights got longer since the death of king was declared to the kingdom ,
since finding him was not an option they could take.
the king , in a fit of rage and distraint. He decided he will not let a folly god smite him
he will find the jester and undo the torment, he will return to his formal identity.
the king , dawned a cape , a mask to hide the nothingness he dawned , he drew a new identity.
he roamed the outskirts, begged and heckled for food. He made the pit his home, rarely coming out for trading .
the rumor of king’s death spread to other kingdoms , soon enough the great empire got flooded by war and blood. countless treasures stolen , people slaughtered , the most loyal to the king killed. the ones whom he called loved ones died , the royal bloodline shattered.
the kingdom was left as a shell of itself , empty inside.
king visited the city.
one day he roamed the outskirts, he met a trader
an old lady , the octogenarian that surpassed even his , a wise woman .
she told him that it was a pleasure that they got rid of the old tyrannical king.
who wielded all the power in the world to do anything .
he asked the woman
what did the king do to be called tyrannical
she said
Nothing. He could've helped his people , instead he disbarred ,
he hid his imperfections outside his perfect kingdom , he dawned a magnificent image ,
a face meant to hide the shameless underbelly he hid.
A stench of despair fell on the king. Listening to criticism he knew he could’ve addressed,
he took a leave from the conversation in shame , saving his face.
but then he didn’t have one to hide into. He dared not to look at the weeping faces , for so he could not make one. he could not look at the anger in their eyes , for so he could not reflect it.
despair took his identity ,time took his soul , he was gone .
but the thirst of revenge , the thirst of getting himself back, is what kept him going.
he could not die , neither heaven or hell or anything in between would allow that
he could not live, in somber and solitude.
centuries pass , forgetting the king, forgetting his legacy, his revenge, his identity
the king once a trader became a rich shaman , giving other people happiness he could not possess himself.
he mastered the art of fighting , he disciplined in the literacy of men he once considered lesser
than his own.
He grew wiser.
one day he comes across children, he approaches them trying to befriend them.
he gave them gifts , and toys , the shaman once a king offered them entertainment.
he then asked them for their loyalty, they oblidge. he asks them
do you remember the old king that ruled these lands once
they shook their head but once child recollects .
she recollects her grandmother’s words of a king that ruled once.
the king , ever so slightly asked them to train under him , for he wishes for something.
he takes turn , nurtures them , waits years for them to become wide in various arts.
they become his council , his legion , they recruit more people , they fight , they loved , lost fights, grew wiser to the history of the world .
they pass the message , far and wide till the king is seen as a valid successor.
in decades of war ,
for so his enemies have gone soft by no competition .
their victories defeated them.
the king gets back the throne he so desired.
the laws he passed were ones of wisdom , no monuments , no poems , nothing to remember him but his good deeds , he ruled for centuries , gaining new identities.
ironically the thing that tormented him for the longest , was the one that made him realize the lesson.
he did not need the face of a king,
for he had the hands of one.
Fin.
]]>Binary trees are fundamental data structures in computer science that form the backbone of many algorithms and applications. Unlike their biological counterparts, these digital trees grow downward, with their roots at the top and branches extending below.
What Is a Binary Tree?
A binary tree is a hierarchical data structure where each node has at most two children, referred to as the left child and the right child. This simple constraint creates a powerful organizational framework that enables efficient data storage, retrieval, and manipulation.
The structure begins with a root node at the top and branches out below. Nodes with no children are called leaf nodes, marking the endpoints of the tree's paths.
Basic Implementation in Python
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
With this simple class, we can create a binary tree structure:
# Create a simple binary tree
# 10
# / \
# 5 15
# / \ / \
# 3 7 12 18
root = TreeNode(10)
root.left = TreeNode(5)
root.right = TreeNode(15)
root.left.left = TreeNode(3)
root.left.right = TreeNode(7)
root.right.left = TreeNode(12)
root.right.right = TreeNode(18)
Key Binary Tree Types
Binary Search Trees (BST)
Binary search trees maintain a specific ordering property: for any node, all elements in its left subtree have values less than the node's value, and all elements in its right subtree have values greater than the node's value. This ordering enables efficient searching, insertion, and deletion operations, typically with O(log n) time complexity in balanced trees.
50
/ \
30 70
/ \ / \
20 40 60 80
BST Implementation in JavaScript
class BSTNode {
constructor(value) {
this.value = value;
this.left = null;
this.right = null;
}
}
class BinarySearchTree {
constructor() {
this.root = null;
}
insert(value) {
const newNode = new BSTNode(value);
if (!this.root) {
this.root = newNode;
return this;
}
let current = this.root;
while (true) {
if (value === current.value) return undefined;
if (value < current.value) {
if (!current.left) {
current.left = newNode;
return this;
}
current = current.left;
} else {
if (!current.right) {
current.right = newNode;
return this;
}
current = current.right;
}
}
}
search(value) {
if (!this.root) return false;
let current = this.root;
while (current) {
if (value === current.value) return true;
current = value < current.value ? current.left : current.right;
}
return false;
}
}
// Usage
const bst = new BinarySearchTree();
bst.insert(50);
bst.insert(30);
bst.insert(70);
bst.insert(20);
bst.insert(40);
bst.insert(60);
bst.insert(80);
console.log(bst.search(40)); // true
console.log(bst.search(90)); // false
AVL Trees
Named after their inventors (Adelson-Velsky and Landis), AVL trees are self-balancing binary search trees. They maintain balance by ensuring the height difference between left and right subtrees of any node never exceeds one. When this balance is violated after an insertion or deletion, the tree performs rotations to restore balance.
AVL Tree Rotations in Java
class AVLNode {
int value;
int height;
AVLNode left, right;
AVLNode(int value) {
this.value = value;
this.height = 1;
}
}
class AVLTree {
AVLNode root;
// Get height of node
int height(AVLNode node) {
if (node == null) return 0;
return node.height;
}
// Get balance factor
int getBalance(AVLNode node) {
if (node == null) return 0;
return height(node.left) - height(node.right);
}
// Right rotation
AVLNode rightRotate(AVLNode y) {
AVLNode x = y.left;
AVLNode T2 = x.right;
// Perform rotation
x.right = y;
y.left = T2;
// Update heights
y.height = Math.max(height(y.left), height(y.right)) + 1;
x.height = Math.max(height(x.left), height(x.right)) + 1;
// Return new root
return x;
}
// Left rotation
AVLNode leftRotate(AVLNode x) {
AVLNode y = x.right;
AVLNode T2 = y.left;
// Perform rotation
y.left = x;
x.right = T2;
// Update heights
x.height = Math.max(height(x.left), height(x.right)) + 1;
y.height = Math.max(height(y.left), height(y.right)) + 1;
// Return new root
return y;
}
}
Red-Black Trees
Red-black trees use color properties and specific rules to maintain balance. Each node is colored either red or black, with constraints ensuring no path from the root to a leaf is more than twice as long as any other path. These trees provide efficient worst-case guarantees for search, insert, and delete operations.
Complete Binary Trees
In a complete binary tree, all levels are fully filled except possibly the last level, which is filled from left to right. This property makes complete binary trees ideal for array implementations, as used in binary heaps.
Binary Heap Implementation in Python
class MinHeap:
def __init__(self):
self.heap = []
def parent(self, i):
return (i - 1) // 2
def left_child(self, i):
return 2 * i + 1
def right_child(self, i):
return 2 * i + 2
def insert(self, value):
self.heap.append(value)
self._sift_up(len(self.heap) - 1)
def extract_min(self):
if not self.heap:
return None
min_value = self.heap[0]
last_value = self.heap.pop()
if self.heap:
self.heap[0] = last_value
self._sift_down(0)
return min_value
def _sift_up(self, i):
parent = self.parent(i)
if i > 0 and self.heap[parent] > self.heap[i]:
self.heap[parent], self.heap[i] = self.heap[i], self.heap[parent]
self._sift_up(parent)
def _sift_down(self, i):
min_index = i
left = self.left_child(i)
right = self.right_child(i)
if left < len(self.heap) and self.heap[left] < self.heap[min_index]:
min_index = left
if right < len(self.heap) and self.heap[right] < self.heap[min_index]:
min_index = right
if i != min_index:
self.heap[i], self.heap[min_index] = self.heap[min_index], self.heap[i]
self._sift_down(min_index)
Full Binary Trees
A full binary tree (sometimes called a proper binary tree) is one in which every node has either 0 or 2 children—no node has exactly one child.
Tree Traversals
Trees can be traversed in several ways, each providing a different order of node visits:
def in_order_traversal(node):
if node:
in_order_traversal(node.left)
print(node.value, end=" ")
in_order_traversal(node.right)
def pre_order_traversal(node):
if node:
print(node.value, end=" ")
pre_order_traversal(node.left)
pre_order_traversal(node.right)
def post_order_traversal(node):
if node:
post_order_traversal(node.left)
post_order_traversal(node.right)
print(node.value, end=" ")
def level_order_traversal(root):
if not root:
return
queue = [root]
while queue:
node = queue.pop(0)
print(node.value, end=" ")
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
Applications of Binary Trees
Binary trees power numerous computer applications:
- Database indexing: B-trees and their variants optimize data access in databases
- Expression evaluation: Binary expression trees represent and evaluate arithmetic expressions
- Huffman coding: Used for data compression
- Priority queues: Implemented efficiently using binary heaps
- Routing algorithms: Specialized binary trees help route network traffic
Binary Trees in the Wild
The concept of binary trees extends beyond computer science. Decision trees in machine learning, game trees in artificial intelligence, and even organizational hierarchies all utilize tree-like structures to model relationships and decision paths.
Problem Solving with Binary Trees
Let's solve a classic problem: determining if a binary tree is balanced.
def is_balanced(root):
"""
Check if a binary tree is height-balanced:
A height-balanced tree is defined as a tree in which
the height of the left and right subtrees of any node
differ by no more than 1.
"""
def check_height(node):
if not node:
return 0
left_height = check_height(node.left)
if left_height == -1:
return -1
right_height = check_height(node.right)
if right_height == -1:
return -1
if abs(left_height - right_height) > 1:
return -1
return max(left_height, right_height) + 1
return check_height(root) != -1
We speak of money as a force, a tangible weight in our hands, a quantifiable measure of worth. Yet, peel back the layers, and you find something far more ephemeral, something closer to a collective hallucination than a physical reality. Money, this bedrock of our modern world, is perhaps one of the most potent, yet ultimately unreal, inventions humanity has conjured. It does not exist in the way a stone or a tree exists. It exists because we agree it exists.
Before this curious consensus, before the symbols and the ledgers, value was tethered to the undeniable reality of the material world. To possess wealth was to possess the thing itself: the glint of a well-honed blade, the coarse texture of salt, the weight of animal skins offering warmth and shelter. Storage of value was a literal act of hoarding objects, a tangible manifestation of power and security.
My own grappling with this abstract concept began, as these things often do, in a mundane corner of the world. There was a man, his hands skilled and tireless, who crafted exquisite momos from a simple stand. For a time, his creations were priced at a humble 5 INR, a fleeting moment of democratic deliciousness. His side dishes, it must be said, were small miracles in their own right. And as the invisible tendrils of reputation spread, as the secret got out, his small enterprise thrived. The demand swelled, a hungry tide that threatened to overwhelm his capacity.
What followed was predictable, yet still held a strange fascination for me. The price crept up. First to 10, then to 15 INR. Having wandered through various cities and witnessed similar miniature economies in action, I found myself pondering the seemingly counterintuitive nature of this. Why not revel in the sheer volume of sales, even at the lower margin? Was there not a different kind of wealth in serving the many?
With time, and the quiet accumulation of experience, the underlying logic settled in. To meet the surging demand, he would have to expand – a daunting undertaking of more ingredients, more labor, a fundamental shift in the scale of his solitary endeavor. Or, he could simply introduce a filter, a barrier to entry. The price hike was, in a way, a concession to his own limits, a practical response to an intangible pressure. It was, perhaps, a quiet acknowledgement of a simple truth: even in the most humble of transactions, the forces of scarcity and desire are perpetually at play.
We often conceive of money as a liquid, flowing through the arteries of the economy, lubricating the gears of commerce and progress. And in a transactional sense, this holds true. The prevailing, almost primal, instinct is that more money equates to greater success, a comfortable delusion we collectively cling to.
If we are to consult the most fundamental diagram in the rudimentary lexicon of finance, the ubiquitous supply and demand curve:

We understand the logic here when applied to tangible goods. Supply: the finite amount of a desired thing. Demand: the collective hunger for it. The intersection, the price, a fragile equilibrium.
But applying this cold, hard logic to the swirling, intangible entity of money feels... incomplete. It doesn't capture the full, strange spectrum of its influence. In my estimation, our relationship with money manifests in at least three distinct ways, each revealing a different facet of our desires and anxieties.
1. Money as the Key to Elsewhere

Money, in this view, is not an end in itself, but a permission slip. It is the token that unlocks the possibility of transformation, of movement, of becoming something other than what you currently are. A new car isn't just metal and rubber; it's the promise of arriving faster, of reclaiming stolen moments from the commute. A new phone isn't just circuits and glass; it's the guarantee of staying connected, of bridging the quiet gulfs between us.
When money enters our lives, even in small increments, it whispers promises of a better future, of a life less constrained. It ignites quiet aspirations:
"Now, perhaps, the path to knowledge is a little smoother for my children."
"The distant murmur of the ocean feels suddenly closer, a tangible destination."
"The worn-out comfort of the familiar can be exchanged for the crisp possibility of the new."
And we think that these nice commodities will last forever. Still, I love that forever doesn’t exist, but we have a word for it anyway, and use it all the time. It’s beautiful and doomed.
The human mind is a fascinating thing, isn't it? We're these strange creatures who only seem to truly appreciate what we have in two very specific moments: when we first get it, and when we've lost it forever. It's like we're walking through life with these blinders on, rarely stopping to consider the weight of our possessions until they're either brand new or gone completely.
And those promises of money we were just talking about? They start to warp and twist in our minds, becoming something else entirely. They become these whispered mantras we tell ourselves:
"Who cares what degree I have, that's not my real value. The amount of money I have is what matters."
"I could go to the beach and buy a new car, but I'm not going to, I should rather save up for a house."
"When the new becomes familiar, the prestige is forgotten."
This is how we start to think. This is how the promise of money begins to reshape our very perception of value, of worth, of what it means to be successful in this world. And isn't that just... fascinating? but this makes you realize something.
- Being Happy with less is better than being sad with more.
- Making money as the key to your happiness is the reason you are sad.
- The value of money you have pales in comparison to the value of time you spend getting it.
so treating money as the key to most things catastrophically changes your perspective on life.
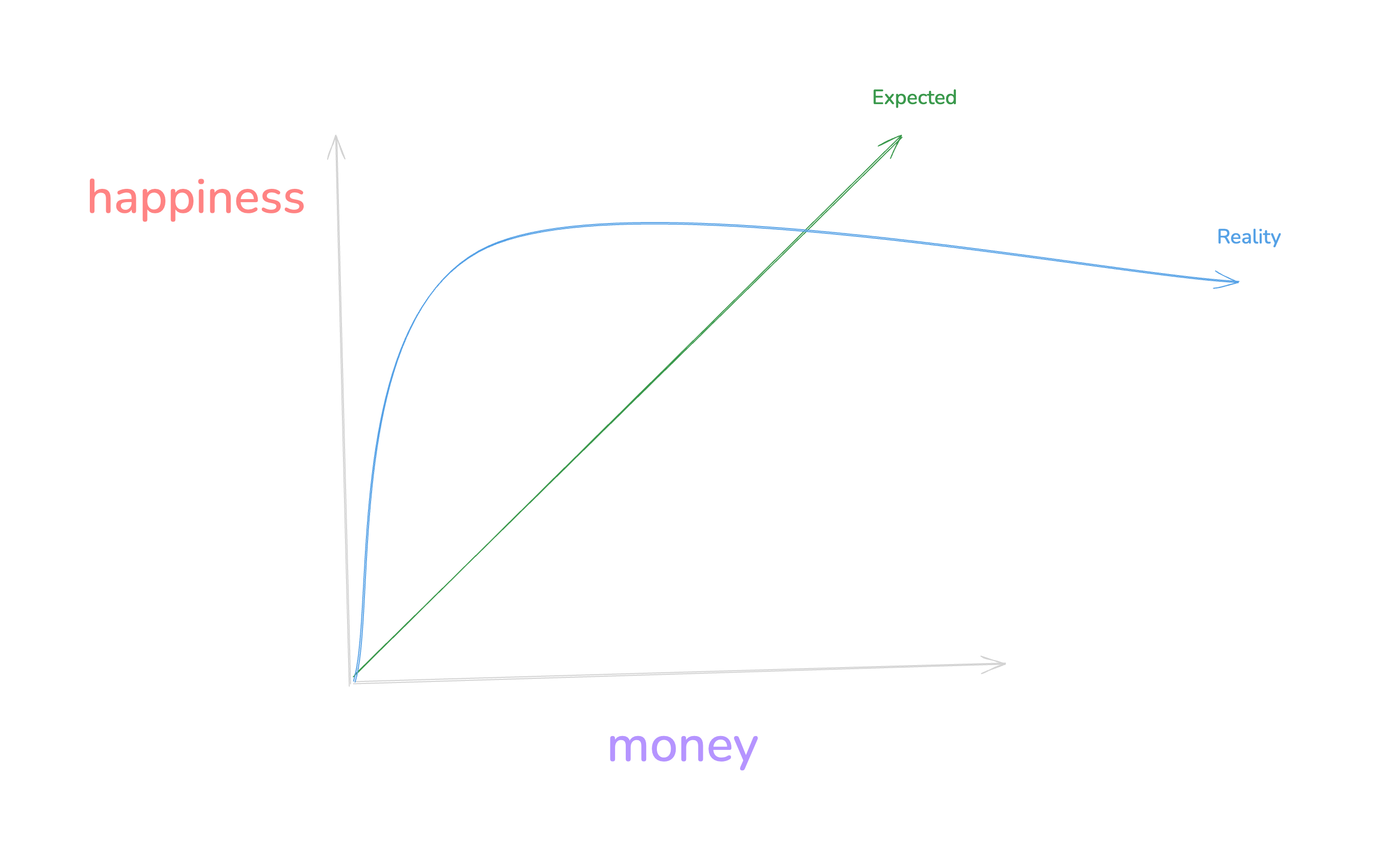
2. Money as the Source of Power.
we as humans love to be in control. Our primitive understanding of the world is that we are in constant decay of our own values. and if we want our values, our ideas that we birth, we need the control of other ideas that flow.
we wish to put a "filter" on other's values that do not fit ours. We know to make our values to be projected on the world we need to invest using something else of value, something with no will or idea of it's own, and yet valuable to every person. What other object is there that can be used for this purpose? Money.
this is not something only I believe in,different people have come to same conculsion.
Money is the lever by which one idea lifts itself above another, not by virtue, but by purchase.-
Power, in the end, is merely the ability to make your values more expensive than anyone else's. -
To bend the world to your vision, you must first possess the currency that buys attention. -
but then why , what is the problem with this. To be honest, it is not a bad way to live, but it is a bad way to think. if you can quantify the amount of power you have on others, you can quantify the amount of power you have on your ego. you become hedonistic, you become complacent, all because you think you are untouchable.
and when that happens, your demise is just as easy as an leisure activity for someone with clearer vision. the number of people who are willing to do that is far more than the number of people who are willing to save you.
a throne always comes attached with a guillotine

this is the truth. absolute power and the prusuit of it will corrupt you.
3.Money as it is.
The only way to enjoy money is to control it, rather than it controlling you. easier said than done, but it is the only way to enjoy it.
look at money as your reward to provide value to others. Struggle and strife for working hard. this is the only way to enjoy it, when you get home , you will be fullfilled. and that's the most money could afford.
fin.
]]>