

Azure-DevOps-Spickzettel

Der Azure-DevOps-Spickzettel von Dr. Holger Schwichtenberg zeigt Ihnen kurz und knapp, wie Sie mit wenigen Befehlen das Kommando über Azure DevOps übernehmen können.
The post Implizit inkrementelle LINQ-Queries in C# für XAML Data Binding appeared first on BASTA!.
]]>Um beispielsweise eine priorisierte Liste von Aufgaben zu ermitteln, bei der die Aufgaben einer Reihe von Projekten zugeordnet sind, lässt sich die in Listing 1 gezeigte Abfrage verwenden: Eine Query nach den unerledigten To-dos aller aktiven Projekte (nicht „on hold“), sortiert nach Priorität und Deadline (falls gesetzt), lässt sich wohl kaum prägnanter ausdrücken.
from p in Projects where !p.IsOnHold from t in p.Todos where !t.IsDone orderby t.Priority descending, t.Deadline ?? EndOfTime select t
Von Anfang an war es ein wichtiges Ziel, diese Abfragen analysieren zu können, um daraus beispielsweise SQL-Statements zu generieren – ein Ansatz, der mit dem Entity Framework Core im Grunde seither unverändert eine sehr hohe Verbreitung gefunden hat. Doch während die Querysyntax aus Datenbankabfragen kaum mehr wegzudenken ist, hat sie bei der Implementierung von Nutzerschnittstellen kaum Einzug gehalten.
Regelmäßig News zur Konferenz und der .NET-Community
Das ist schade, denn solche Abfragen wären auch bei der Entwicklung grafischer Benutzeroberflächen nützlich. In einer Anwendung zur Aufgabenverwaltung wäre es beispielsweise dienlich, eine priorisierte Liste von Aufgaben angezeigt zu bekommen, die sich sofort aktualisiert, wenn der Nutzer Änderungen vornimmt, die sich auf die Reihenfolge der Aufgaben auswirken.
Auch abseits von Nutzerschnittstellen möchte man manchmal wissen, wann und wie sich das Ergebnis einer Query ändert, um automatisiert Maßnahmen anstoßen zu können. Beispielsweise könnte man durch eine Query ermittelte Defekte automatisch korrigieren oder eine KPI in einem definierten Zielkorridor halten wollen.
Ein Beispiel für eine Bibliothek, die genau diese Funktionalität ermöglicht und sowohl .NET 8, 9 und 10 als auch .NET Standard 2.0 und somit auch das .NET-Framework unterstützt, ist die unter New-BSD lizenzierte Open-Source-Bibliothek NMF Expressions[1], [2]. In diesem Artikel wird beschrieben, wie diese Bibliothek funktioniert und wie sie dabei helfen kann, Data Binding gegen Querys zu ermöglichen.
Der Grund, warum Queries trotz ihrer guten Les- und Wartbarkeit nicht bei Nutzeroberflächen eingesetzt werden, ist meist, dass die XAML-basierten UI-Frameworks in .NET (WPF, MAUI, Avalonia, Uno) auf die Schnittstellen INotifyPropertyChanged und INotifyCollectionChanged angewiesen sind, um zu erkennen, welche Teile der UI wann aktualisiert werden müssen. Die Schnittstelle INotifyPropertyChanged erlaubt es hierbei, sich per Event benachrichtigen zu lassen, wenn sich das Ergebnis einer Eigenschaft ändert, wohingegen INotifyCollectionChanged über Änderungen an Auflistungen informiert. Beide Schnittstellen sind bereits seit dem .NET-Framework 3.0 Teil der Basisklassenbibliothek; es gibt sie sogar schon länger als die Querysyntax. Um die Implementierung von INotifyPropertyChanged für eigene Klassen zu unterstützen, gibt es seit einiger Zeit auch das MVVM Community Toolkit, das den notwendigen Boilerplate-Code zur Unterstützung von INotifyPropertyChanged generieren kann. Doch was ist mit INotifyCollectionChanged?
Für diese Schnittstelle gibt es im Framework nur genau eine einzige Implementierung: die ObservableCollection. Das Problem aber ist, dass LINQ-to-Objects-Querys diese nicht verwenden und Querys daher nicht für Data Binding genutzt werden können.
Um das Ergebnis einer Query also in einer Nutzerschnittstelle anzeigen zu können, müssen die Ergebnisse manuell in einer ObservableCollection gepuffert werden. Bei jeder Änderung von Daten müssen Entwickler:innen also dafür sorgen, dass dieser Puffer aktualisiert wird. Dabei zählt Cache Invalidation nach Phil Karlton zu den schwierigsten Dingen der Informatik, da es kaum möglich ist, sicherzustellen, dass dies richtig erfolgt. Wenn der Puffer zu häufig aktualisiert wird, ist das eine Verschwendung von Ressourcen. Wenn er zu selten aktualisiert wird, können die Daten darin unter Umständen falsch sein. Hinzu kommt, dass sich in der Regel eine Vielzahl von Änderungen auf die Ergebnisse einer Query auswirken können. Wann immer ein Projekt oder To-do hinzugefügt oder gelöscht wird, ein Projekt auf „on hold“ gesetzt oder reaktiviert wird oder sich die Prioritäten oder Deadlines der einzelnen To-dos ändern, muss der Puffer entsprechend aktualisiert werden. All diese Szenarien müssen gut getestet werden. Die größte Gefahr besteht jedoch darin, irgendeine Art von Änderungen, die sich auf das Ergebnis der Query auswirken, zu vergessen.
Wie lässt sich nun dieses Problem lösen, wie lassen sich Querys auch für Data Binding einsetzen, ohne dass Änderungen an der Query selbst vorgenommen werden müssen? Wenn sich eine Änderung im Modell ergibt, was genau soll dann neu berechnet werden? Neben der Frage nach dem Wann stellt sich auch die, wie die Puffer aktualisiert werden müssen – auch im Hinblick auf die algorithmische Komplexität. In manchen Fällen kann es zeitkritisch sein, nach der Änderung der eigentlichen Daten auch die aktualisierten Queryergebnisse zur Verfügung zu haben. Es kann schlicht zu lange dauern, dann immer die gesamte Query neu zu berechnen, gerade wenn sich nur ein sehr kleiner Teil der Daten geändert hat und die Teilergebnisse der Query eigentlich noch aktuell wären.
Wenn aber immer nur Teilergebnisse neu berechnet werden, bezeichnet man das als inkrementelle Ausführung, weil sich die Datenstruktur an inkrementell auftretende Änderungen anpassen muss. In der Algorithmik spricht man in diesem Zusammenhang auch von dynamischen Algorithmen, weil die Änderungen auch bedeuten können, dass Elemente gelöscht werden. Wenn sich ein solcher inkrementeller bzw. dynamischer Algorithmus ohne Zutun des Entwicklers von einer Spezifikation, beispielsweise einer Query, ableiten lässt, handelt es sich um eine implizite Inkrementalisierung; das Ergebnis ist eine implizit inkrementelle Query.
Damit das Ergebnis einer inkrementellen Query wohldefiniert ist, dürfen die eingesetzten Prädikate keine Seiteneffekte haben, die die Berechnung anderer Teilergebnisse beeinflussen, denn andernfalls wäre unklar, welche Seiteneffekte nach einer Änderung der zugrundeliegenden Daten ausgeführt wurden. Prädikate wie Filterbedingungen dürfen daher keine von außen sichtbaren Variablen oder andere Zustände verändern. Das ist bei Querys ohnehin eine übliche Annahme. Auch wenn man mittels PLINQ eine Query parallel ausführen möchte, sind seiteneffektbehaftete Prädikate keine gute Idee, da man sich sonst mit Thread-Synchronisation auseinandersetzen muss.
Als Nächstes müssen wir überlegen, welche API wir haben wollen. Das Ergebnis einer Query kann entweder ein einzelner Wert oder eine Auflistung sein. Während Auflistungen gewöhnlich ohnehin schon von Schnittstellen repräsentiert werden, kann ein einzelner Wert kaum für sich selbst die Schnittstelle INotifyPropertyChanged implementieren und muss daher in einer separaten Schnittstelle gekapselt werden.
Eine solche Schnittstelle ist in etwa in Listing 2 skizziert. Die einfachste denkbare Implementierung hierfür ist natürlich eine Konstante, bei der also Value immer genau den Wert der Konstante zurückliefert und das Event ValueChanged nie ausgelöst wird.
public interface INotifyValue<out T>
{
T Value { get; }
event EventHandler ValueChanged;
}
Generische Schnittstellen sind dabei ein Weg, mathematische Funktoren zu implementieren. Collections sind ein Beispiel für Funktoren, die in vielen Programmiersprachen auftreten. Da Schnittstellen andere Schnittstellen erben können, lässt sich der Funktor IEnumerable beispielsweise mit der Schnittstelle INotifyCollectionChanged kombinieren. In NMF heißt das Ergebnis INotifyEnumerable.
Regelmäßig News zur Konferenz und der .NET-Community
Ein Funktor besteht jedoch nicht nur aus einer Abbildung von Typen (wie string auf INotifyValue<string>), sondern auch aus einer Abbildung von Funktionen/Methoden. So muss es beispielsweise aus einer Funktion Func<string, int> eine Abbildung nach Func<INotifyValue<string>,INotifyValue<int>> geben. Für den Funktor IEnumerable übernimmt diese Abbildung der Queryoperator Select. Den ganzen Funktor für INotifyValue und INotifyEnumerable, also die Typabbildung und die Abbildung von Methoden, sowie die Abbildung Value zurück auf den derzeitigen Wert (in der Mathematik ist das eine natürliche Transformation), nennt man Inkrementalisierungssystem.
Um von einer Collection, die InotifyCollectionChanged, aber nicht INotifyEnumerable implementiert, auf letztere zu kommen, braucht man einen Adapter. In NMF Expressions nennt sich die Methode, die einen solchen Adapter erzeugen kann, WithUpdates.
Doch wie erreicht man eine solche Methodenabbildung für INotifyValue und INotifyEnumerable?
Um immer nur die von einer Änderung tatsächlich betroffenen Teilergebnisse aktualisieren zu müssen, liegt es nahe, einen Abhängigkeitsgraphen zu halten, um entscheiden zu können, wann welche Teilergebnisse neu berechnet werden müssen. Um eine einheitliche Schnittstelle zu schaffen, verwenden die Teilergebnisse dieselben Schnittstellen wie die Endergebnisse, also INotifyValue und INotifyEnumerable. Da sich die Teilergebnisse normalerweise auf Teile der Daten beziehen (z. B., ob ein To-do noch unerledigt ist), variiert ihre Menge mit den Daten, ist also dynamisch; daher der Name „dynamischer Abhängigkeitsgraph“ [3].
Die einfachste Methode, um einen solchen dynamischen Abhängigkeitsgraphen zu erzeugen, besteht darin, eine Teilfunktion in ihre einzelnen Bestandteile, also die einzelnen syntaktischen Elemente, zu zerlegen. Auf dieser Ebene lässt sich leicht entscheiden, wann sich das Ergebnis ändert. Ändert sich beispielsweise das Bezugsobjekt für den Zugriff auf eine Property oder löst das aktuelle Bezugsobjekt ein Event über die INotifyPropertyChanged-Schnittstelle aus, dann könnte sich auch der Wert für den Zugriff auf die Property geändert haben. Doch wie kann man zur Laufzeit eine Funktion in ihre Bestandteile aufteilen?
In .NET lässt sich eine solche Dekomposition mit denselben Technologien bewerkstelligen, die ursprünglich für LINQ entwickelt wurden: Expression Trees erlauben es, zur Laufzeit auf den abstrakten Syntaxbaum einer Funktion zuzugreifen anstatt auf deren Kompilat. Dazu können Lambda-Ausdrücke vom Compiler nicht nur in Delegattypen wie Func<string> gecastet werden, sondern auch in Expression-Typen davon, wie Expression<Func<string>>. Im Entity Framework (Core) wird dieses Syntaxfeature, das nicht nur in C#, sondern auch in vielen anderen .NET-Sprachen existiert, dazu verwendet, aus einer Query SQL-Statements zu generieren. Mit Expression Trees lassen sich jedoch auch dynamische Abhängigkeitsgraphen erstellen.
NMF Expressions macht genau das: Es verwendet den Aufbau von Lambdaausdrücken, um daraus einen dynamischen Abhängigkeitsgraphen zu erzeugen und so die Schnittstellen INotifyValue und INotifyCollectionChanged zu implementieren.
Dynamische Abhängigkeitsgraphen auf Basis einzelner Instruktionen haben zwei Nachteile: Zum einen werden sie sehr schnell sehr groß, zum anderen ist es nicht immer sinnvoll, auf Ebene der einzelnen Instruktionen zu überlegen, welche Instruktionen von einer Änderung genau betroffen sind. Stattdessen gibt es für einige Probleme dedizierte dynamische Algorithmen, die häufig deutlich effizienter sind, als es ein instruktionsbasierter Ansatz sein kann. Um beispielsweise die Summe oder den Mittelwert einer Menge von Zahlen dynamisch zu berechnen, ist es ausreichend, sich die aktuelle Summe (und im Fall des Mittelwerts zusätzlich die aktuelle Anzahl) zu merken und sie beim Hinzufügen oder Löschen einer Zahl entsprechend zu aktualisieren. Auf diese Weise lassen sich für viele Query-Operatoren sehr effiziente dynamische Algorithmen finden, insbesondere wenn die Reihenfolge der Ergebnisse keine Rolle spielt.
Die Bibliothek NMF Expressions bietet für viele der Standardqueryoperatoren (SQO) eine explizite Inkrementierung. Die SQO sind diejenigen Queryoperatoren, die von einigen Programmiersprachen mit einer eigenen Syntax versehen sind. Ob eine Programmiersprache für einen SQO eine spezielle Syntax anbietet, ist je nach Sprache verschieden. So bildet VB.NET den Operator Aggregate in einer eigenen Syntax ab, C# aber nicht.
Die Faustregel besagt, dass es für alle Queryoperatoren, die nicht indexbasiert sind, eine inkrementelle Variante gibt. Der Grund dafür ist, dass sich Indizes zu häufig ändern. Wenn ein neues Element eingefügt wird, ändert sich nämlich der Index für alle nachfolgenden Elemente. Eine so inkrementalisierte Query hätte daher wahrscheinlich eine schlechte Performance. Um das zu vermeiden, wird diese Funktionalität erst gar nicht angeboten.
Doch wie implementiert man eine explizite Inkrementalisierung einer Methode in NMF Expressions?
Im Unterschied zu Lambdaausdrücken kann die Implementierung einer Methode nicht ohne Weiteres eingesehen werden, da sie per Reflection nur als Bytecode abrufbar ist. Daher benötigt ein Inkrementalisierungssystem eine Heuristik, wann sich das Ergebnis eines Methodenaufrufs potenziell ändert. Eine gute erste Heuristik ist, dass sich die Rückgabe einer Methode dann ändern könnte, wenn sich die Parameter ändern.
Wenn nun Teile einer Query in separate Methoden ausgelagert werden, ist das für Technologien, die auf Expression Trees beruhen, daher grundsätzlich problematisch. So könnte das Entity Framework (Core) ein so ausgelagertes Prädikat beispielsweise nicht mehr nach SQL übersetzen, sondern wäre gezwungen, das Prädikat und alles, was danach kommt, auf dem Client auszuwerten. Im Fall der Inkrementalisierung kann das aber nützlich sein, um den Abhängigkeitsgraphen zu verkleinern. Denn für die Ausführung einer Methode gibt es im Abhängigkeitsgraphen zunächst nur genau einen Knoten. Wenn die Heuristik zutrifft, beispielsweise weil die Argumente der Methode alle unveränderlich sind, führt das zu einer effizienteren und speicherschonenderen Abarbeitung. Das ist der Fall, wenn die Methode ausschließlich mit Zahlen, Zeichenketten oder Record Structs arbeitet. Was aber, wenn nicht alle Parameter unveränderlich sind?
Die Idee der expliziten Inkrementalisierung besteht nun darin, in diese Heuristik einzugreifen und sie zu überschreiben. NMF Expressions verwendet hierfür Attribute, genauso wie das Entity Framework, das seit jeher Attribute nutzt, um Methodenaufrufe in den Aufruf von Stored Procedures in der Datenbank umzuwandeln. Das verwendete Attribut in NMF Expressions nennt sich ObservableProxy. Da man in ein Attribut keine Methode eintragen kann, muss man in das Attribut den Namen einer öffentlichen Proxymethode eintragen, sowie (falls abweichend) die Klasse, in der die Methode deklariert ist. Wenn die Proxymethode nicht öffentlich sichtbar sein soll, empfiehlt es sich, eine interne oder private Hilfsklasse dafür anzulegen.
Eine solche Proxymethode wird von NMF Expressions anstelle der eigentlichen Methode aufgerufen. Dazu muss sie dieselben Typparameter haben; außerdem muss es für jeden Parameter einen Parameter geben, bei dem der Typ in INotifyValue geschachtelt ist, ebenso für den Rückgabetyp. Da die Datenstrukturen häufig auch komplett neu aufgebaut werden müssen, wenn sich Parameter ändern, dürfen die Parametertypen der Proxymethode auch die originalen Parametertypen sein. In diesem Fall kümmert sich NMF Expressions darum, die Methode erneut aufzurufen, wenn sich die übergebenen Argumente ändern.
Ein Beispiel, das zeigt, wie das Prädikat, ob ein To-do weiterhin relevant ist, in eine Methode ausgelagert werden kann, ist in Listing 3 dargestellt. Zu Demonstrationszwecken wird hier als Implementierung der Schnittstelle INotifyValue wiederum NMF Expressions verwendet, aber natürlich sind auch eigene Implementierungen möglich, wodurch sich beliebige dynamische Algorithmen umsetzen lassen.
[ObservableProxy(nameof(IsRelevantInc1))] // alternativ nameof(IsRelevantInc2) public bool IsRelevant(Todo todo) => !todo.IsDone; public INotifyValue<bool> IsRelevantInc1(INotifyValue<Todo> todo) => Observable.Expression(() => !todo.Value.IsDone); public INotifyValue<bool> IsRelevantInc2(Todo todo) => Observable.Expression(() => !todo.IsDone);
Obwohl es laut den Architekturrichtlinien von .NET für Schnittstellen immer mindestens zwei denkbare Implementierungen geben muss, existiert für INotifyCollectionChanged in der Basisklassenbibliothek, wie schon erwähnt, nur eine Implementierung, nämlich ObservableCollection. Das hat anscheinend zur Folge, dass die meisten XAML-basierten UI-Bibliotheken davon ausgehen, dass es sich bei einer Implementierung von INotifyCollection um die ObservableCollection handeln muss, obwohl die Schnittstelle eigentlich allgemeiner entworfen wurde. So kann man bei einem CollectionChanged-Ereignis den Index eines geänderten, hinzugefügten oder gelöschten Elements angeben oder eine -1 eintragen, falls der Typ der Collection keine Indizes unterstützt, wie beispielsweise bei Mengentypen wie HashSet, die keine Ordnung der Elemente garantieren.
Regelmäßig News zur Konferenz und der .NET-Community
Leider wird bei UI-Bibliotheken weder die Möglichkeit berücksichtigt, dass eine Implementierung von INotifyCollectionChanged von einem Index -1 Gebrauch machen könnte, noch die Möglichkeit, dass in einer Collection mehrere Elemente auf einmal verändert werden oder nach einem Reset Elemente übrigbleiben könnten. Auch wenn sich die Fehlermeldungen je nach UI-Technologie durchaus unterscheiden, implementieren alle großen UI-Bibliotheken immer nur genau das, was für die ObservableCollection benötigt wird.
Wie macht man also eine inkrementelle Query kompatibel für Data Binding in UI-Bibliotheken? In NMF Expressions existiert hierfür die spezielle Methode RestoreIndices, die die inkrementelle Query puffert, Änderungen vereinzelt und Indizes wiederherstellt. Damit lässt sich die Query aus Listing 1 wie in Listing 4 in die Oberfläche einbinden.
TodosInOrder = (from p in Projects.WithUpdates()
where !p.IsOnHold
from t in p.Todos
where !t.IsDone
orderby t.Priority descending, t.Deadline ?? EndOfTime
select t).RestoreIndices();
In [4] habe ich ein Repository erstellt, das die Verwendung von NMF Expressions in Verbindung mit dem MVVM Community Toolkit für das Eingangsbeispiel der To-do-Liste für WPF, MAUI und Avalonia demonstriert.
Die meisten XAML-basierten Technologien wie WPF, MAUI oder Avalonia arbeiten innerhalb desselben Prozesses, weshalb sich das UI bequem an die über INotifyPropertyChanged und INotifyCollectionChanged zur Verfügung gestellten Ereignisse auf Änderungen des Modells registrieren kann, um Data Binding zu ermöglichen. Das funktioniert natürlich nicht mehr, wenn das UI in einem anderen Prozess liegt, wie es beispielsweise bei Webanwendungen der Fall ist. Um sich hier auch über Änderungen benachrichtigen zu lassen, müssen Events explizit als Subscriptions hinterlegt werden. In [4] habe ich das exemplarisch auch für eine GraphQL-Version derselben To-do-Liste verwendet.
Eine Frage, die sich förmlich aufdrängt, ist die nach der Performance. Natürlich verbraucht der dynamische Abhängigkeitsgraph Speicher. Mehr Speicher ist allerdings häufig einfacher zu bekommen als mehr CPU-Zeit. Hinzu kommt, dass manche Queryoperatoren wie Orderby bei jeder Ausführung Speicher benötigen, während eine inkrementelle Query einen balancierten Suchbaum im Speicher hält und diesen permanent beibehält. Daher wird bei einer Abfrage der Ergebnisse kein neuer Speicher allokiert. Die Performance der Änderungsausbreitung kann jedoch auch von der Beschaffenheit konkreter Änderungen abhängen. So ist es im Beispiel natürlich aufwendiger zu propagieren, wenn in einem Projekt viele To-dos von „on hold“ wieder auf aktiv gesetzt werden, als wenn diesem Projekt gar keine To-dos zugeordnet gewesen wären. Diese Beispiele illustrieren, dass eine allgemeine Aussage kaum möglich ist.
In guten Fällen kann es allerdings auch zu sehr hohen Beschleunigungen kommen, solange der dynamische Abhängigkeitsgraph in den Speicher passt. So konnten in einigen Benchmarks auch schon Beschleunigungen von mehreren Größenordnungen gemessen werden [5]. Insbesondere wenn die Änderungen nur kleine Teile der Query betreffen, ist der Aufwand für die Propagation in einer viel günstigeren Komplexitätsklasse, als wenn komplett alles neu berechnet und anschließend noch verglichen werden müsste, was genau sich denn geändert hat.
Mit Hilfe von dynamischen Abhängigkeitsgraphen lassen sich Querys in .NET nicht nur automatisch in Datenbankabfragen konvertieren. Die angebotenen Abstraktionen eignen sich auch dazu, automatisiert zu erfassen, wann sich das Ergebnis einer Query ändert. Auf diese Weise können deklarative Querys mit NMF Expressions beispielsweise für das Data Binding von XAML-basierten UI-Technologien eingesetzt werden.
[1] https://nmfcode.github.io/expressions/index.html
[2] Hinkel, G.; Heinrich, R.; Reussner, R.: „An extensible approach to implicit incremental model analyses“; in: Software & Systems Modeling 18, 2019
[3] Acar, U.: „Self-adjusting computation:(an overview)“: in: „Proceedings of the 2009 ACM SIGPLAN workshop on Partial evaluation and program manipulation“, 2009
[4] https://github.com/georghinkel/expressions-demo
[5] Szárnyas, G.; Semeráth, O.; Ráth, I.: „The TTC 2015 Train Benchmark Case for Incremental Model Validation“; in: „Proceedings of the 8th Transformation Tool Contest“, 2015
The post Implizit inkrementelle LINQ-Queries in C# für XAML Data Binding appeared first on BASTA!.
]]>The post .NET 10.0 RTM: Alle Neuerungen seit dem Release Candidate im Überblick appeared first on BASTA!.
]]>.NET 10.0 ist eine Long-Term-Support-Version, die ab November 2025 36 Monate unterstützt wird. .NET 8.0 und .NET 9.0 haben noch Support bis November 2026, nachdem Microsoft den Support für die Standard-Term-Support-Versionen auf 24 Monate erhöht hat. Die nächste Version, .NET 11.0, wird im November 2026 erscheinen – dann zusammen mit Visual Studio 2027.

Abb. 1: Scott Hanselman dankt in der Keynote der .NET Conf 2025 allen Community-Mitgliedern, die Beiträge zu .NET 10.0 geleistet haben – darunter auch einigen BASTA!-Sprechern
Seit Entity Framework Core 10.0 Release Candidate 1 wird der Spaltentyp JSON unterstützt. Dieser steht in Microsoft SQL Server 2025 (erschienen am 18.11.2025 [1]) sowie in Azure SQL zur Verfügung.
JSON-Spalten kamen in EF Core zwar schon früher zum Einsatz, etwa um einfache Wertlisten wie List<int> in einer einzelnen Spalte abzulegen (eine Ausnahme bildet PostgreSQL, das solche Datentypen von Haus aus unterstützt) oder um sogenannte Owned Types zu speichern. Bislang wurde dafür jedoch eine nvarchar(max)-Spalte genutzt, kombiniert mit der SQL-Funktion OPENJSON().
Mit den neuen SQL-Server-Versionen greift EF Core nun auf den nativen JSON-Datentyp zurück – vorausgesetzt, die verwendete SQL-Server-Instanz beherrscht diesen auch. Zusätzlich muss EF Core darüber informiert werden, dass JSON-Spalten verfügbar sind. Bei Azure SQL geschieht das, indem statt UseSqlServer() nun UseSqlAzure() verwendet wird.
Beim lokalen Microsoft SQL Server muss man den Kompatibilitätslevel auf 170 (Standard ist 150) setzen (Abb. 2 und 3):
builder.UseSqlServer(connstring, x => x.UseCompatibilityLevel (170));
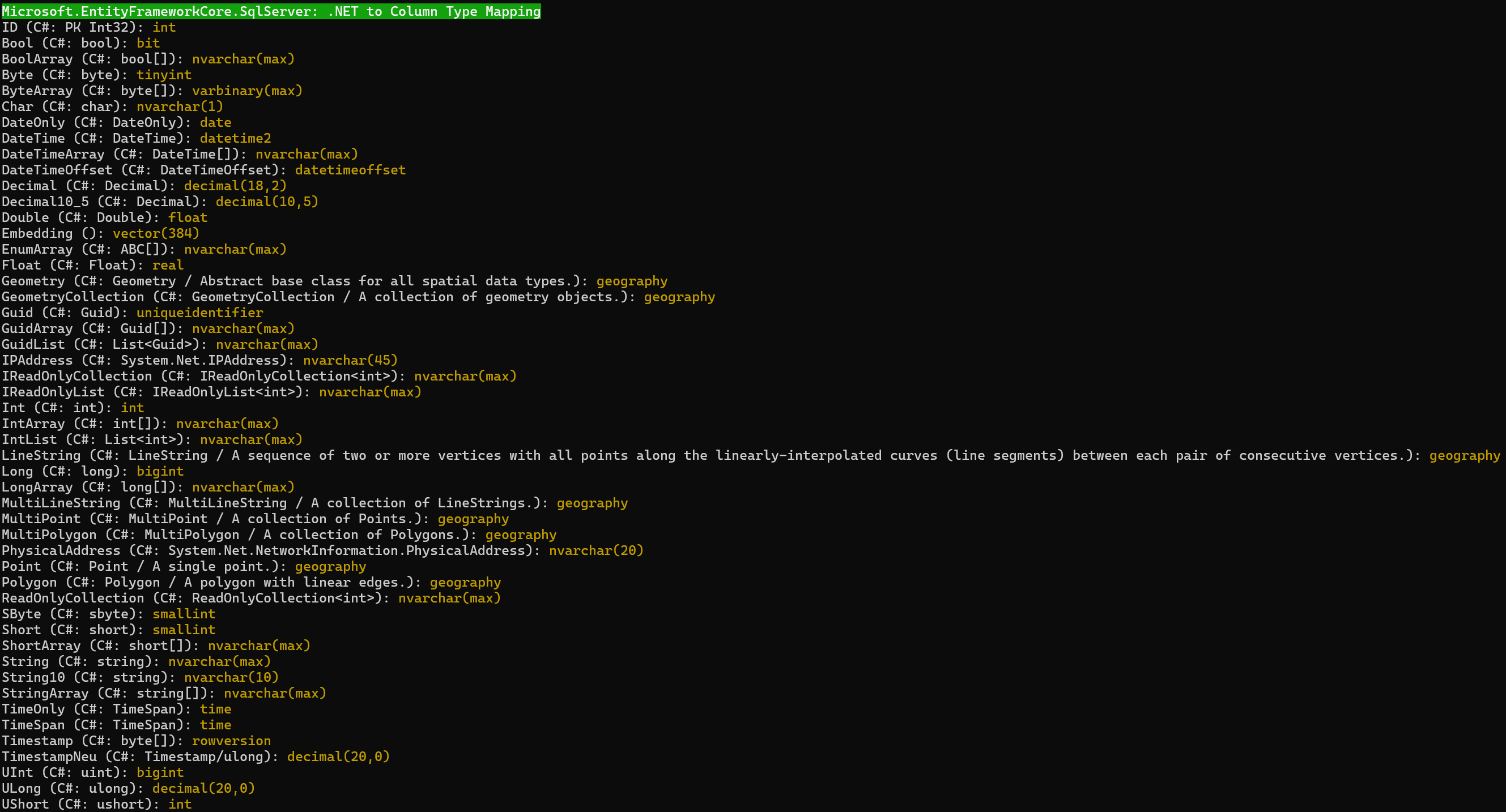
Abb. 2: Datentypmapping mit SQL Server 2025 bei EF Core im Kompatibilitätslevel 150
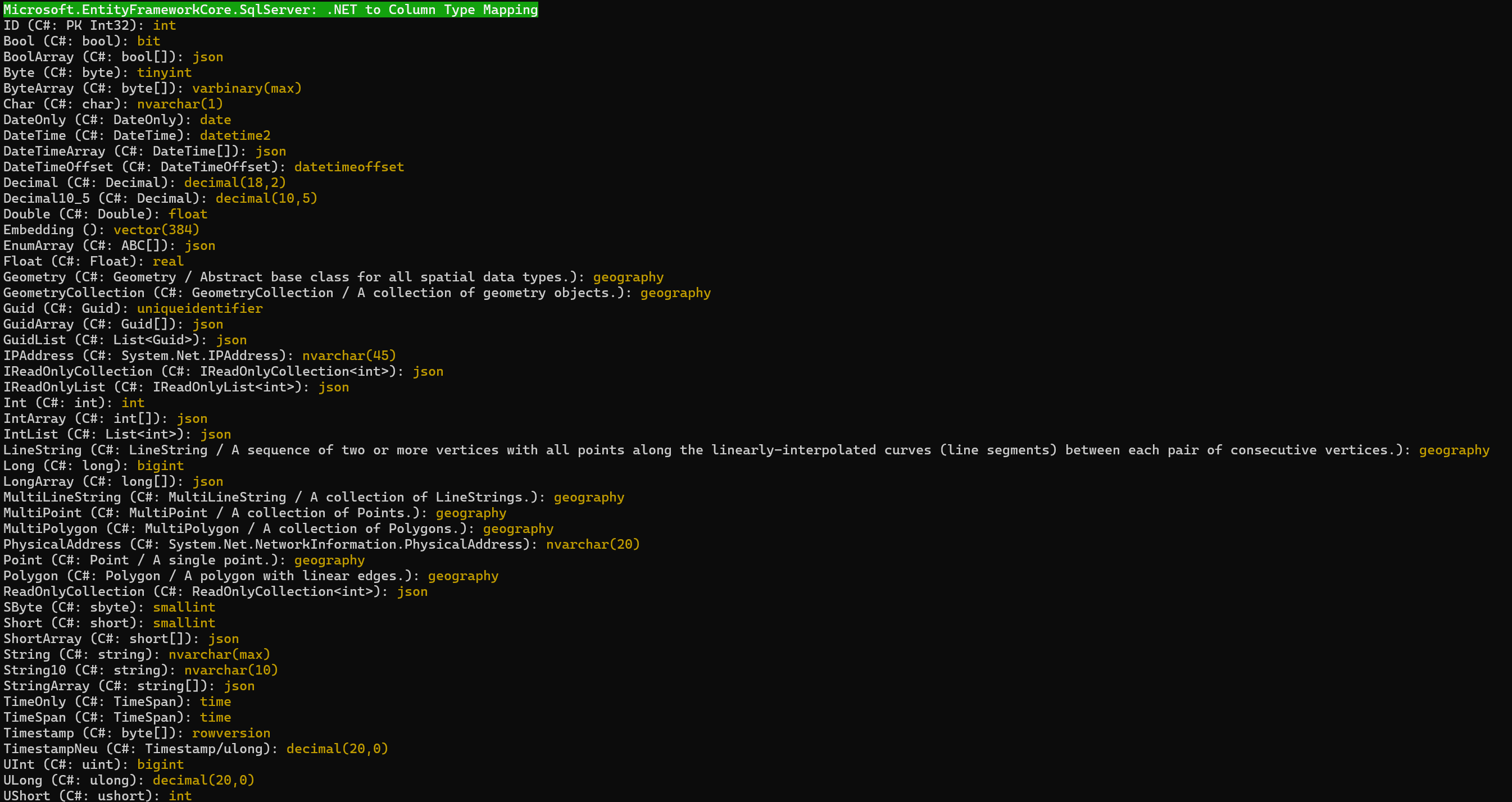
Abb. 3: Datentypmapping mit SQL Server 2025 bei EF Core im Kompatibilitätslevel 170
Mit Entity Framework Core 8.0 hat Microsoft die Complex Types als modernere und flexiblere Alternative zu den Owned Types eingeführt und in Version 9.0 weiter ausgebaut. Allerdings standen für Complex Types bislang keine JSON-Abbildungen zur Verfügung. Stattdessen wurde jede Property eines Complex Types stets in eine eigene Spalte der Tabelle des übergeordneten Entitätstyps projiziert.
Seit Entity Framework Core 10.0 (ab Release Candidate 1) unterstützen Complex Types nun auch ein JSON-Mapping und können zudem optional sein. Für optionale Complex Types gibt es jedoch eine Einschränkung: Sie müssen mindestens eine verpflichtende Property enthalten. EF Core benötigt dieses Pflichtfeld, um erkennen zu können, ob der Complex Type tatsächlich null ist oder lediglich leere Werte besitzt (Listing 1).
Fehlt das Pflicht-Property, führt das zu folgender Fehlermeldung: „’ShippingAddress’ is mapped to columns by flattening the contained properties into its container’s table; this mapping requires at least one required property – to allow distinguishing between ‘null’ and empty values – but the complex type contains only optional properties. Configure the property with a shadow discriminator by adding a call to ‘HasDiscriminator()’ on the complex property configuration, or map this complex property to a JSON column instead.“
public abstract class Company
{
[Key]
public int CompanyID { get; set; } // Primary Key
[StringLength(50)]
public string Name { get; set; }
public DateTime Created { get; set; } = DateTime.Now;
public Address BillingAddress { get; set; } // 1:1
public Address? ShippingAddress { get; set; }
[Required]
public CompanyDescription Description { get; set; } = new(); // 1:1
public List<Management> ManagementSet { get; set; } = new(); // 1:N
}
public record struct Address // record struct für Complex Type
{
public Address()
{
}
//public int AddressID { get; set; } //--> PK bei Complex Types nicht notwendig
public bool AdressExists { get; set; } = true; // bei Optional Complex Type ohne weitere Pflichtfelder (neu in v10.0)
[StringLength(50)]
public string City { get; set; }
[StringLength(50)]
public string Street { get; set; }
[StringLength(10)]
public string Postcode { get; set; }
[StringLength(50)]
public string Country { get; set; }
}
Ein Beispiel für einen Complex Type mit JSON-Mapping könnte so aussehen:
modelBuilder.Entity<Company>(x =>
{
x.ComplexProperty(p => p.Address, p=>p.ToJson()); // 1:1-Mapping. NEU: p=>p.ToJson()
}
Geplant war auch, ein 1:N-Mapping in Complex Types zu ermöglichen. Zwar beschwert sich Entity Framework Core nicht mehr über eine Zeile wie x.ComplexProperty(p => p.ManagementSet, p => p.ToJson()); und es wird auch eine JSON-Spalte ManagementSet in der Tabelle angelegt. Die enthält dann aber nicht die Daten, sondern nur die Eigenschaft Capacity (Abb. 4). Daher funktionieren auch Abfragen über diese Spalte nicht.

Abb. 4: Falsche Persistierung der Menge im komplexen Typ
Microsoft SQL Server 2025 führt einen neuen Spaltentyp vector ein, der speziell für die Speicherung von Vektordaten im Kontext von Ähnlichkeitssuchen und KI-Szenarien entwickelt wurde. In Azure SQL steht dieser Datentyp bereits seit 2024 als Vorschau zur Verfügung und gilt seit Juni 2025 offiziell als produktionsbereit.
Regelmäßig News zur Konferenz und der .NET-Community
Ein Vektor besitzt eine feste Dimension, also eine Anzahl an Elementen. Jedes dieser Elemente wird entweder als 2-Byte- oder 4-Byte-Gleitkommazahl abgelegt. Die Nutzung des kompakten 2-Byte-Formats muss zuvor separat aktiviert werden. Innerhalb des SQL Servers werden Vektoren in einem speziell optimierten Binärformat gespeichert und über entsprechende Datenbanktreiber – etwa Microsoft.Data.SqlClient ab Version 6.1 – effizient übertragen.
In T-SQL und im SQL Server Management Studio (ab Version 21) werden die Vektordaten als JSON-Array visualisiert, z. B.:
DECLARE @v VECTOR(10) = '[0.1, 2, 3.5, 4, 5, 6, 7, 8, 9.9, 10]'; SELECT @v;
Ältere Versionen der Datenbanktreiber übertragen Vektordaten noch im nvarchar(max)-Format und somit als JSON-Struktur. Für Vektoren stehen keinerlei Vergleichsoperatoren oder arithmetische Operationen zur Verfügung – also weder Gleichheits- noch Größenvergleiche noch Rechenoperationen wie Addition, Subtraktion, Multiplikation oder Division. Auch Verkettungen oder zusammengesetzte Zuweisungsoperatoren werden nicht unterstützt. Zudem lassen sich Vektorspalten nicht in speicheroptimierten Tabellen einsetzen.
Mit SQL Server 2025 steht für Vektordaten die Funktion VECTOR_DISTANCE() bereit, über die sich der Abstand zwischen zwei Vektoren berechnen lässt. Dabei können drei verschiedene Distanzverfahren verwendet werden (Abb. 5):
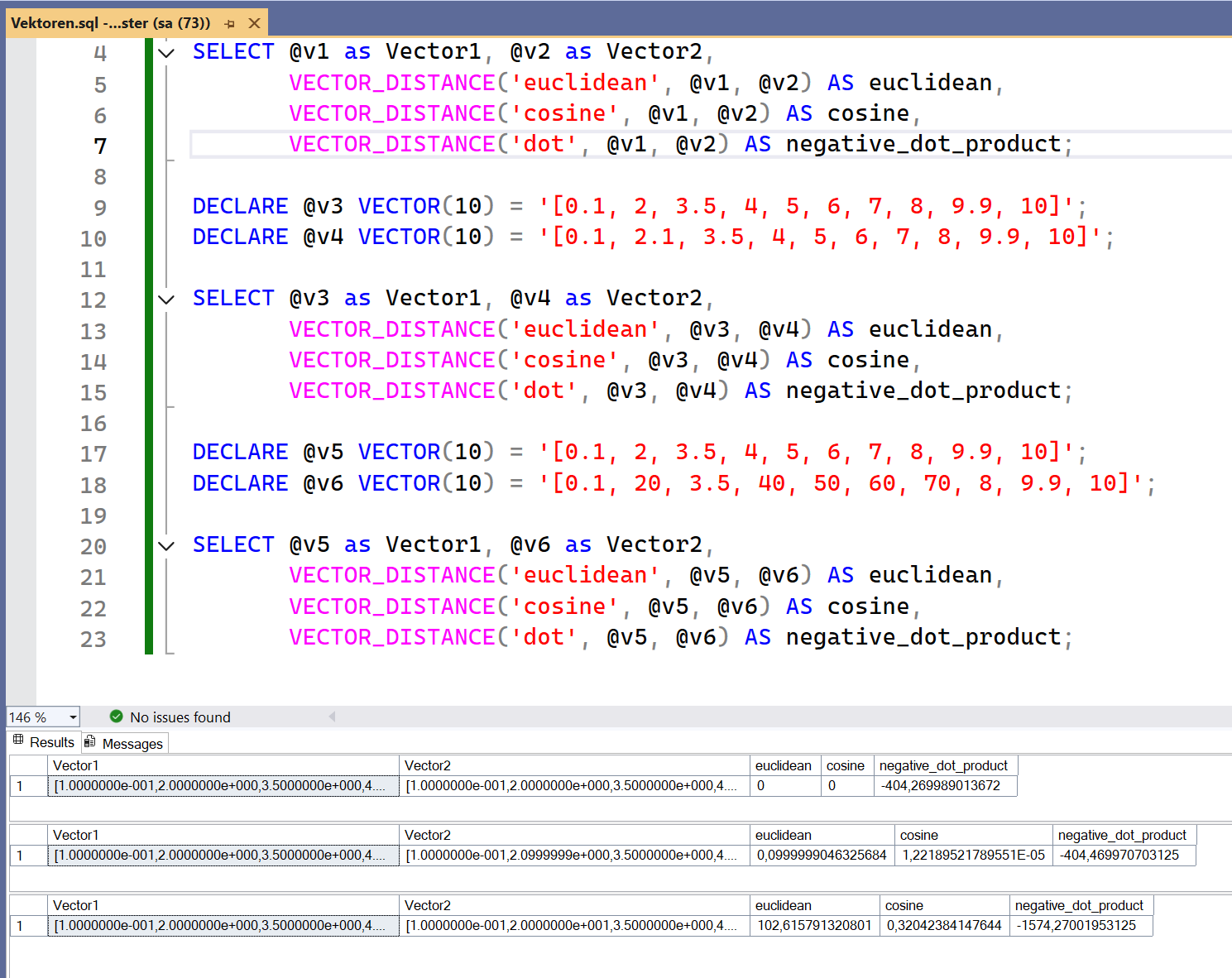
Abb. 5: Vektordistanzberechnung
Die Funktion VECTOR_SEARCH(), mit der sich der jeweils nächste Nachbar finden lässt, befindet sich weiterhin im Preview-Status.
Seit Entity Framework Core 10.0 Release Candidate 1 können Entwickler:innen Vektorspalten direkt nutzen. Beim Reverse- wie auch beim Forward-Engineering werden diese SQL-Server-Spalten dem .NET-Typ Microsoft.Data.SqlTypes.SqlVector<float> zugeordnet. Dieser stammt aus dem NuGet-Paket Microsoft.Data.SqlClient (ab Version 6.1).
Zusätzlich stellt EF Core eine neue Methode EF.Functions.VectorDistance() bereit, welche die SQL-Server-Funktion VECTOR_DISTANCE() in LINQ-Ausdrücken repräsentiert (Listing 2). Vor EF Core 10.0 war hierfür ein separates NuGet-Paket namens EFCore.SqlServer.VectorSearch erforderlich. Die SQL-Funktion VECTOR_SEARCH() kann jedoch weiterhin nicht direkt in LINQ-Abfragen verwendet werden.
using System.ComponentModel.DataAnnotations.Schema;
using Microsoft.Data.SqlTypes;
using Microsoft.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore.Diagnostics;
namespace EFC_MappingScenarios.Vectors;
public class Texte
{
public int ID { get; set; }
public string Text { get; set; }
[Column(TypeName = "vector(384)")]
public Microsoft.Data.SqlTypes.SqlVector<float> Embedding { get; set; }
}
class Context : DbContext
{
public DbSet<Texte> TexteSet { get; set; }
bool logActive = false;
void Log(string message)
{
if (logActive) CUI.PrintAlternatingColor(message);
}
protected override void OnConfiguring(DbContextOptionsBuilder builder)
{
builder.EnableSensitiveDataLogging(true).EnableDetailedErrors();
string connstring = Settings.ConnectionStringSQL2025 + @$";Database=EFC_MappingScenarios_" + nameof(EFC_MappingScenarios.Vectors);
builder.UseSqlServer(connstring, x => x.UseNetTopologySuite().UseCompatibilityLevel(170)).LogTo(Log, new[] { RelationalEventId.CommandExecuted }); // WICHTIG für JSON-Spalten: 170
}
}
class Client
{
// https://www.bundesregierung.de/breg-de/bundesregierung/bundeskabinett?utm_source=chatgpt.com
static OrderedDictionary<string, string> Bundesregierung2025 = new() {
{ "Friedrich Merz", "Bundeskanzler" }, { "Lars Klingbeil", "Bundesminister der Finanzen" }, { "Alexander Dobrindt", "Bundesminister des Innern" }, { "Dr. Johann Wadephul", "Bundesminister des Auswärtigen" }, { "Boris Pistorius", "Bundesminister der Verteidigung" }, { "Katherina Reiche", "Bundesministerin für Wirtschaft und Energie" }, { "Dorothee Bär", "Bundesministerin für Forschung, Technologie und Raumfahrt" }, { "Dr. Stefanie Hubig", "Bundesministerin der Justiz und für Verbraucherschutz" }, { "Karin Prien", "Bundesministerin für Bildung, Familie, Senioren, Frauen und Jugend" }, { "Bärbel Bas", "Bundesministerin für Arbeit und Soziales" }, { "Dr. Karsten Wildberger", "Bundesminister für Digitales und Staatsmodernisierung" }, { "Patrick Schnieder", "Bundesminister für Verkehr" }, { "Carsten Schneider", "Bundesminister für Umwelt, Klimaschutz, Naturschutz und nukleare Sicherheit" }, { "Nina Warken", "Bundesministerin für Gesundheit" }, { "Alois Rainer", "Bundesminister für Landwirtschaft, Ernährung und Heimat" }, { "Reem Alabali-Radovan", "Bundesministerin für wirtschaftliche Zusammenarbeit und Entwicklung" }, { "Verena Hubertz", "Bundesministerin für Wohnen, Stadtentwicklung und Bauwesen" }, { "Thorsten Frei", "Bundesminister für besondere Aufgaben / Chef des Bundeskanzleramtes" }
};
public static void Run()
{
CUI.Demo(nameof(EFC_MappingScenarios.Vectors));
using (var ctx = new Context())
{
CUI.Yellow("Model: " + ctx.Model.GetType().FullName);
Util.RecreateDB(ctx);
#region ---------------------- Vektor-Daten anlegen
CUI.Head(ctx.Database.ProviderName + ": Erstelle Datensätze mit Vektor-Spalte (Lokale Vektorisierung dauert etwas...)");
foreach (var person in Bundesregierung2025)
{
CUI.BusyIndicator();
var dt = new Texte();
ctx.TexteSet.Add(dt);
dt.Text = person.Key + " ist " + person.Value;
var values = EmbeddingsUtil.Get("passage:" + dt.Text);
dt.Embedding = new SqlVector<float>(values);
Console.WriteLine(dt.Text + " -> " + dt.Embedding.Length);
}
var c2 = ctx.SaveChanges();
Console.WriteLine($"{c2} Datensätze gespeichert");
#endregion
#region ---------------------- Vektor-Daten abfragen
CUI.Head(ctx.Database.ProviderName + ": Vektorsuche");
Suche("Dr. Karsten Wildberger");// exakte Suche
Suche("Karsten");// nur Vorname
Suche("Carsten Wilberger");// absichtlich falsch geschrieben, damit es nicht exakt passt
Suche("Kriegsminister");
Suche("Kassenwart");
Suche("Unfug");
Suche("Der beliebteste Politiker im Kabinett");
Suche("Der unbeliebteste Politiker im Kabinett");
#endregion
CUI.PanelGreen("=== DONE");
}
}
// https://learn.microsoft.com/en-us/sql/t-sql/functions/vector-distance-transact-sql?view=sql-server-ver17
// cosine - Cosine distance 0 bis 2 (0 = identisch, 1 = orthogonal, 2 = entgegengesetzt)
// euclidean - Euclidean distance 0 bis unendlich (0 = identisch)
// dot - (Negative)Dot product (-1 bis +1 bei normierten Vektoren, -unendlich bis +unendlich bei nicht normierten Vektoren)
private static void Suche(string suchBegriff, string distanzVerfahren = "cosine")
{
using var ctx = new Context();
CUI.Yellow("Suche ähnlichste Einträge zu: " + suchBegriff);
var sqlVector = new SqlVector<float>(EmbeddingsUtil.Get(suchBegriff));
var result = ctx.TexteSet
.OrderBy(b => EF.Functions.VectorDistance(distanzVerfahren, b.Embedding, sqlVector))
.Take(5)
.Select(b => new { Object = b, Distance = EF.Functions.VectorDistance(distanzVerfahren, b.Embedding, sqlVector) })
.ToList();
foreach (var b in result)
{
CUI.Green(b.Object.ID + ": " + b.Object.Text + " -> Distanz: " + Math.Round(b.Distance, 2));
}
}
}
Im Beispiel sind die Mitglieder des Bundeskabinetts (Stand November 2025) in einer Tabelle gespeichert, wobei Name und Zuständigkeit in einer Textspalte erfasst sind. Darauf basierend werden verschiedene Ähnlichkeitssuchen über EF.Functions.VectorDistance() ausgeführt.
Die in Abbildung 6 gezeigten Ergebnisse wurden mit dem Embedding-Modell Multilingual-E5-small erzeugt, das 384 Dimensionen besitzt. Das von Microsoft-Mitarbeitenden entwickelte Modell ist Open Source, lokal einsetzbar und benötigt keine Cloud. Da E5 Texte vieler Sprachen in einen gemeinsamen semantischen Vektorraum überführt, funktionieren Ähnlichkeitsvergleiche auch über Sprachgrenzen hinweg. Zu Begriffen wie „Kassenwart“ oder „Kriegsminister“ liefert das Modell korrekt die Finanz- bzw. Verteidigungsminister. Welche Mitglieder der Regierung besonders beliebt oder unbeliebt sind, kann das Embedding-Modell hingegen naturgemäß nicht beurteilen.

Abb. 6: Ausgabe des obigen Listings
Ein Performancethema in Entity Framework Core, bei dem Microsoft seit Jahren verschiedene Strategien ausprobiert, ist die Übergabe von Parametermengen von .NET an das Datenbankmanagementsystem, z. B. eine Liste von Orten, zu denen passende Datensätze gesucht werden:
List<string> destinations = new List<string> { "Berlin", "New York", "Paris" };
var flights = ctx.Flights
.Where(f => destinations.Contains(f.Destination))
.Take(5).ToList();
In den Entity-Framework-Core-Versionen 1.0 bis 7.0 wurden die Werte aus der Menge destinations einzeln als statische Werte übergeben:
SELECT TOP(@p) [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp] FROM [Operation].[Flight] AS [f] WHERE [f].[NonSmokingFlight] = CAST(1 AS bit) AND [f].[FlightDate] > GETDATE() AND [f].[FreeSeats] > CAST(0 AS smallint) AND [f].[Destination] IN (N'Berlin', N'New York', N'Paris')
Das sorgte aber im Datenbankmanagementsystem für viele verschiedene Ausführungspläne. Seit Version 8.0 übergibt Entity Framework Core die Liste als ein JSON-Array, das im SQL-Befehl mit OPENJSON() gespalten wird (Listing 3). Das erschwerte dem Datenbankmanagementsystem die Optimierung der Ausführungspläne, weil die Anzahl der Parameter nicht mehr bekannt war.
SELECT TOP(@p) [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp] FROM [Operation].[Flight] AS [f] WHERE [f].[NonSmokingFlight] = CAST(1 AS bit) AND [f].[FlightDate] > GETDATE() AND [f].[FreeSeats] > CAST(0 AS smallint) AND [f].[Destination] IN ( SELECT [d].[value] FROM OPENJSON(@destinations) WITH ([value] nvarchar(30) '$') AS [d] )
Seit Entity Framework Core 9.0 besteht die Möglichkeit, über EF.Constant() oder den globalen Aufruf TranslateParameterizedCollectionsToConstants() in der OnConfiguring()-Methode der Kontextklasse wieder auf das frühere Übersetzungsverhalten zurückzuschalten:
var flights1 = ctx.Flights .Where(f => EF.Constant(destinations).Contains(f.Destination)) .Take(5).ToList();
Beim geänderten Standard konnten Entwickler:innen dann im Einzelfall mit EF.Parameter() das JSON-Array übergeben. In der aktuellen Version 10.0 des OR-Mappers hat Microsoft abermals einen neuen Standard implementiert, nämlich die Einzelübergabe der Werte jeweils als eigene Parameter. Diesen SQL-Befehl erzeugt Entity Framework Core im vorangegangenen Beispiel mit drei Städten:
SELECT TOP(@p) [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp] FROM [Operation].[Flight] AS [f] WHERE [f].[NonSmokingFlight] = CAST(1 AS bit) AND [f].[FlightDate] > GETDATE() AND [f].[FreeSeats] > CAST(0 AS smallint) AND [f].[Destination] IN (@destinations1, @destinations2, @destinations3)
Im ausführlichen Test stellt man fest, dass EF Core nicht immer genau die gleiche Anzahl Parameter erzeugt, wie es Werte gibt. Stattdessen rundet Entity Framework Core zur Vermeidung des Anlegens von zu vielen Ausführungsplänen ab sechs Parametern auf 10er-Blöcke auf, d. h. für sechs Werte werden zehn Parameter erzeugt, wobei die letzten Parameter immer den gleichen Wert erhalten (Listing 4).
[Parameters=[@p='5', @destinations1='Berlin' (Size = 30), @destinations2='New York' (Size = 30), @destinations3='Paris' (Size = 30), @destinations4='Rome' (Size = 30), @destinations5='Munich' (Size = 30), @destinations6='London' (Size = 30), @destinations7='London' (Size = 30), @destinations8='London' (Size = 30), @destinations9='London' (Size = 30), @destinations10='London' (Size = 30)], CommandType='Text', CommandTimeout='300'] SELECT TOP(@p) [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp] FROM [Operation].[Flight] AS [f] WHERE [f].[NonSmokingFlight] = CAST(1 AS bit) AND [f].[FlightDate] > GETDATE() AND [f].[FreeSeats] >= CAST(20 AS smallint) AND [f].[FreeSeats] <= CAST(200 AS smallint) AND [f].[Destination] IN (@destinations1, @destinations2, @destinations3, @destinations4, @destinations5, @destinations6, @destinations7, @destinations8, @destinations9, @destinations10)
Entwickler:innen können bei Bedarf weiterhin das bisherige Verhalten über EF.Constant() bzw. EF.Parameter() erzwingen. Welche Variante sinnvoll ist, hängt auch davon ab, wie stark sich die Anzahl der Werte zur Laufzeit verändert.
Auf globaler Ebene lässt sich das Standardverhalten über UseParameterizedCollectionMode(ParameterTranslationMode.Constant) in OnModelCreating() in der Kontextklasse anpassen. Als zulässige Einstellwerte stehen Constant, Parameter und MultipleParameters zur Verfügung. Die erst mit EF Core 9.0 eingeführte Methode TranslateParameterizedCollectionsToConstants() existiert zwar weiterhin, ist jedoch inzwischen mit [Obsolete] gekennzeichnet.
Der OR-Mapper liefert seit Release Candidate 2 einen Code-Analyzer mit, der Entwickler:innen warnt, wenn man beim Aufruf von FromSqlRaw(), SqlQueryRaw<T>() oder ExecuteSqlRaw() eine Zeichenkette mit Pluszeichen oder String-Interpolation zusammensetzt. Die Warnung lautet: „Method inserts concatenated strings directly into the SQL, without any protection against SQL injection. Consider using ‘FromSql’ instead, which protects against SQL injection, or make sure that the value is sanitized and suppress the warning.“
Der Analyzer erkennt die Zeichenkettenzusammensetzung, wenn sie direkt im Parameter des Methodenaufrufs stattfindet, nicht aber, wenn eine zuvor zusammengesetzte Zeichenkette übergeben wird (Abb. 7).
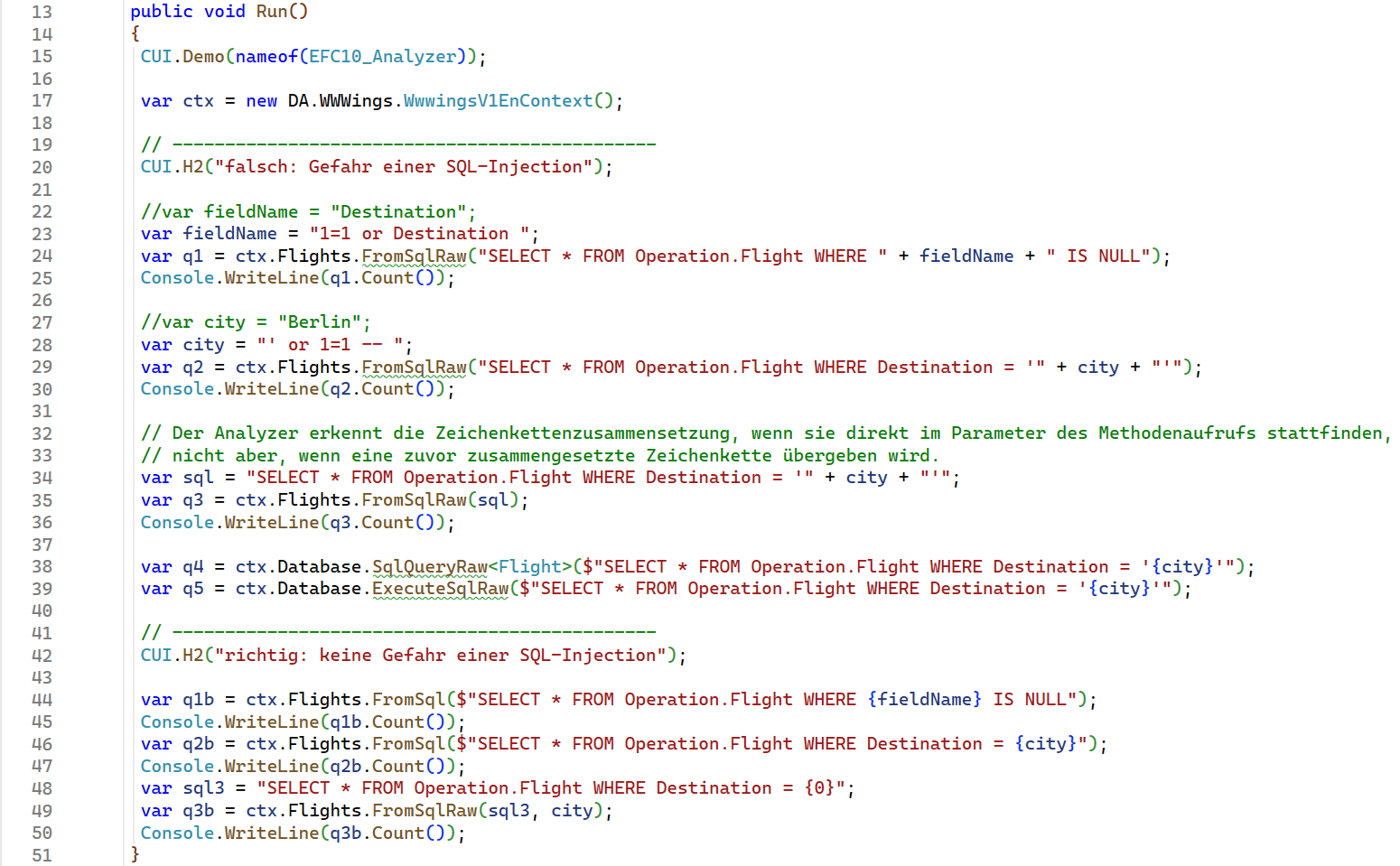
Abb. 7: Der Analyzer erkennt einige (siehe grüne Schlangenlinien), aber leider nicht alle diese gefährlichen SQL-Injektionen
ASP.NET Core führte in .NET 10.0 Release Candidate 1 neue Metriken für ASP.NET Core Identity zur Überwachung der Benutzerverwaltung ein, z. B. aspnetcore.identity.user.create.duration, aspnetcore.identity.sign_in.sign_ins und aspnetcore.identity.sign_in.two_factor_clients_forgotten.
Zur Validierung von Instanzen von Klassen und Records in Blazor, die Microsoft schon in der Preview-Phase von .NET 10.0 verbessert hatte, gibt es seit Release Candidate 1 drei weitere Neuerungen:
Der Persistent Component State in Blazor, den es seit .NET 10.0 Preview 6 gibt, funktioniert nun auch beim Einsatz der Enhanced Navigation beim statischen Server-side Rendering.
Mit der Einstellung SafeAreaEdges=”None” können .NET-MAUI-Fenster nun auch auf Android und iOS in den ansonsten geschützten Navigationsbereichen oben und unten rendern. Alternative Werte sind “Container” (schützt vor Systembars und Notch), “SoftInput” (schützt nur vor der Tastatur) und “All” (kombiniert “Container” und “SoftInput”) (Abb. 8).

Abb. 8: Safe Area Edges auf iOS. Quelle: Microsoft .NET Conf 2025
Auch bei .NET MAUI gibt es neue Metriken für die Überwachung der Layoutperformance:
Das Steuerelement <HybridWebView> bietet nun die Ereignisse WebViewInitializing() und WebViewInitialized() zur Anpassung der Initialisierung. Vergleichbare Ereignisse gab es zuvor im Steuerelement <BlazorWebView> (BlazorWebViewInitializing() und BlazorWebViewInitialized()). Das Steuerelement <RefreshView> besitzt nun auch die Eigenschaft IsRefreshEnabled zusätzlich zu IsEnabled.
Seit Preview 7 gibt es den Source Generator für XAML in .NET MAUI. Um diesen Source Generator zu aktivieren, schreibt man seit Release Candidate 2 in die Projektdatei:
<PropertyGroup> <MauiXamlInflator>SourceGen</MauiXamlInflator> </PropertyGroup>
Auch unter Windows kann man nun die Mikrofonberechtigungen abfragen: Permissions.RequestAsync<Permissions.Microphone>()
Das Windows-Forms-Teams schreibt in seinen Release Notes, dass der in .NET 9.0 eingeführte Dark Mode (Abb. 9) nun nicht mehr den Status „experimentell“ besitzt [2].

Abb. 9: Einige Windows-Forms-Steuerelemente im Dark Mode
Es ist Zeit, ein Fazit über die Neuerungen aus allen vier Beiträgen zu .NET 10.0 zu ziehen. Das soll in Form von Listen der High- und Lowlights geschehen. Meine zehn persönlichen Highlights in .NET 10.0 sind:
Ich sehe auch Enttäuschungen in .NET 10.0:
Regelmäßig News zur Konferenz und der .NET-Community
[1] https://learn.microsoft.com/de-de/sql/sql-server/what-s-new-in-sql-server-2025?view=sql-server-ver17
[2] https://github.com/dotnet/core/blob/main/release-notes/10.0/preview/rc1/winforms.md
[3] https://github.com/dotnet/runtime/issues/68162
[4] https://github.com/dotnet/aspnetcore/issues/54365
[5] https://avaloniaui.net/blog/net-maui-is-coming-to-linux-and-the-browser-powered-by-avalonia
The post .NET 10.0 RTM: Alle Neuerungen seit dem Release Candidate im Überblick appeared first on BASTA!.
]]>The post Future Coding: Wie KI und MCP den Entwickleralltag revolutionieren appeared first on BASTA!.
]]>
Rainer Stropek ist seit über zwanzig Jahren als Unternehmer in der IT-Branche tätig. Er gründete und leitete in dieser Zeit mehrere IT-Dienstleistungsunternehmen und entwickelt derzeit mit seinem Team in seinem Unternehmen software architects die preisgekrönte Software time cockpit. Rainer hat Abschlüsse von der Höheren Technischen Lehranstalt für MIS, Leonding (AT) und der University of Derby (UK). Er ist Autor von mehreren Fachbüchern und Zeitschriftenartikeln im Bereich Microsoft .NET und C#. Er tritt regelmäßig als Redner und Trainer auf renommierten Konferenzen in Europa und den USA auf. Im Jahr 2010 wurde er von Microsoft zu einem der ersten MVPs für die Windows Azure-Plattform ernannt. Seit 2015 ist er zudem Microsoft Regional Director.
Die Experten zeigten, wie KI nicht nur Werkzeuge verändert, sondern ganze Denkweisen und Arbeitsweisen prägt, insbesondere durch die Integration intelligenter Assistenten in Entwicklungsprozesse und die Entstehung einer neuen Generation von ‘AI Natives’. MCP wird als Standard vorgestellt, der die Interaktion zwischen Benutzer, KI und Anwendungen erleichtert und viele Routineaufgaben automatisiert, ohne die Bedeutung sorgfältig gestalteter Benutzeroberflächen zu verdrängen.
Regelmäßig News zur Konferenz und der .NET-Community
The post Future Coding: Wie KI und MCP den Entwickleralltag revolutionieren appeared first on BASTA!.
]]>The post Avalonia: Das bessere WPF für moderne Cross-Platform-Apps appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
In diesem Artikel beschäftigen wir uns mit einer völlig anderen Variante: Avalonia, ein Open-Source-UI-Framework. Es basiert auf .NET und steht für alle genannten Plattformen zur Verfügung. Darüber hinaus unterstützt es auch mobile Geräte (Android, iOS) und sogar den Browser. Avalonia ist nicht von Microsoft, sondern ein communitygetriebenes, unabhängiges Projekt, das bereits vor über einem Jahrzehnt entstand. Im Jahr 2023 hat das Team hinter Avalonia UI bereits das 10-jährige Jubiläum gefeiert.
Um Avalonia zu verstehen und einschätzen zu können, muss man sich damit beschäftigen, wo das Framework seine Wurzeln hat. Es ist als Cross-Platform-UI-Framework für den Desktop mit Unterstützung für Windows, macOS und Linux gestartet. Es hat viele Ideen und Konzepte von WPF übernommen – WPF war zu dieser Zeit noch der De-facto-Standard für UI-Entwicklung in .NET für den Desktop. Avalonia hat WPF allerdings nicht blind nachgebaut, sondern an vielen Stellen weiterentwickelt und verbessert. Man könnte es auch das bessere WPF nennen.
Die hohe Ähnlichkeit zu WPF sehen wir beispielhaft am XAML-Code eines Fensters in Listing 1. Dieser Code könnte genauso fast eins zu eins in WPF genutzt werden. Die XAML-Syntax ist gleich, die Namespaces sind überwiegend gleich und auch die hier verwendeten Controls sind gleich. Der einzige Unterschied ist der Namespace https://github.com/avaloniaui in der ersten Zeile.
<Window xmlns="https://github.com/avaloniaui"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
mc:Ignorable="d" d:DesignWidth="800" d:DesignHeight="450"
x:Class="Testing.AvaloniaArticle.MainWindow"
Title="Greeting">
<TextBlock HorizontalAlignment="Center"
VerticalAlignment="Center"
FontSize="36"
Text="Hello, Avalonia!" />
</Window>
Bei der Auswahl der IDE steht für die meisten C#-Entwickler:innen Visual Studio von Microsoft ganz oben auf der Liste. Das Avalonia-Team bietet hierfür ein Plug-in an, das alle notwendigen Features wie XAML-IntelliSense oder Live-Preview mitbringt. Speziell für die Entwicklung mit Avalonia steht mit der IDE Rider von JetBrains eine weitere Möglichkeit zur Verfügung. Das Besondere daran ist, dass damit auch unter Linux und macOS entwickelt werden kann und es eine hervorragende Unterstützung für Avalonia mitbringt, ohne ein Plug-in installieren zu müssen. Die Firma JetBrains nutzt Avalonia selbst und hat eigene Applikationen wie dotTrace und dotMemory mit Hilfe von Avalonia für macOS und Linux fit gemacht. Aus diesem Grund haben sie die notwendige Unterstützung in der IDE selbst in die Hand genommen.
Als dritte Alternative ist es auch möglich, Avalonia-Applikationen mit Visual Studio Code von Microsoft zu entwickeln. Auch hier stellt das Avalonia-Team ein Plug-in bereit, weist aber darauf hin, dass man hier im Vergleich zu den anderen IDEs die schlechteste Unterstützung für Avalonia vorfinden wird [1].
Avalonia stellt mehrere Templates bereit, mit denen wir starten können. Diese werden vom Avalonia-Team in einem separatem GitHub-Repository gepflegt [2]. Mit dem Kommandozeilenbefehl dotnet new install Avalonia.Templates werden sie installiert. Zum Zeitpunkt der Veröffentlichung dieses Artikels erhalten wir damit folgende Templates:
Falls wir für Linux und/oder macOS entwickeln wollen, blicken wir womöglich zuerst auf die letzte Variante, Avalonia Cross Platform Application. Tatsächlich wäre aber die erste oder die zweite Variante sinnvoller. Hintergrund ist, dass es sich dabei um die Templates für reine Desktopapplikationen handelt. Solche sind bei Avalonia von vornherein Cross-Platform, also unter Windows, Linux und macOS lauffähig. Der Begriff „Cross-Platform“ im letztgenannten Template geht noch weiter, es zielt zusätzlich auf Android, iOS und den Browser. Für den Einstieg eignet sich das Template Avalonia .NET App sehr gut.
Es gibt noch eine weitere Frage, die es an dieser Stelle zu klären gilt. Wir können CompiledBindings für unsere Applikation nutzen. Standardmäßig ist das Häkchen dafür beim Template aktiv. Es handelt sich um keine endgültige Entscheidung, es empfiehlt sich aber, es immer aktiv zu lassen. CompiledBindings sorgen dafür, dass die Bindings im XAML-Code kompiliert werden – anders als etwa bei WPF. Bei WPF werden Bindings mittels Reflection zur Laufzeit aufgelöst. CompiledBindings bringen uns eine bessere Performance. Zusätzlich bekommen wir beim Kompilieren bereits Feedback in Form von Compilerfehlern, falls es etwa Tippfehler gibt.
Technisch basiert das CompiledBinding auf Codegenerierung. Diese beginnt allerdings nicht beim Binding, sondern bereits bei den XAML-Dateien. Anders als bei WPF werden XAML-Dateien nicht in das Zwischenformat BAML übersetzt, sondern direkt in C#-Code – eine der vielen Performanceverbesserungen gegenüber WPF.
Zur Veranschaulichung modifizieren wir das Beispielfenster aus Listing 1 so, dass die Begrüßung nicht fest in XAML hinterlegt ist, sondern aus einem ViewModel kommt. Das ViewModel dazu ist denkbar einfach, da wir keinerlei Änderungsbenachrichtigung (INotifyPropertyChanged) für diesen Zwecke implementieren müssen. Die Klasse MainWindowViewModel in Listing 2 ist völlig ausreichend.
public class MainWindowViewModel
{
public string Greeting => "Hello, Avalonia!";
}
In Listing 3 sehen wir, welche Änderungen in XAML notwendig sind, um das CompiledBinding zur Anbindung des MainWindowViewModel zu nutzen. Der wesentliche Unterschied ist das Setzen der Eigenschaft x:DataType. Damit sagen wir dem Compiler, welchen Typ wir bei dem gebundenen DataContext erwarten.
<Window ...
xmlns:local="clr-namespace:Testing.AvaloniaArticle"
x:DataType="local:MainWindowViewModel">
<TextBlock ...
Text="{Binding Greeting}" />
</Window>
Damit das Beispiel funktioniert, darf nicht vergessen werden, eine Instanz des MainWindowViewModel zu erstellen und der Eigenschaft DataContext des Hauptfensters zuzuweisen. An dieser Stelle reagiert Avalonia exakt so wie WPF.
MVVM (Model View ViewModel) ist bei XAML-Frameworks nach wie vor das beliebteste Pattern, das gilt auch für Avalonia. Bei der Auswahl des MVVM-Frameworks sind folgende zwei Varianten für Avalonia-Projekte am häufigsten anzutreffen:
Aus Sicht des Autors ist es meist das Einfachste, mit CommunityToolkit.Mvvm zu starten. ReativeUI bietet zwar mehr Features und hat mit dem NuGet-Paket Avalonia.ReactiveUI eine sehr gute Integration in Avalonia, aber die Einstiegshürde ist höher, da ReactiveUI auf den Reactive Extensions for .NET aufbaut. In diesem Artikel wird aus Gründen des Umfangs nicht tiefer darauf eingegangen. Es wäre aber ratsam, ReactiveUI nur dann zu nutzen, wenn ein Verständnis der Reactive Extensions for .NET vorliegt.
Regelmäßig News zur Konferenz und der .NET-Community
CommunityToolkit.Mvvm kommt dagegen leichtgewichtig daher und kümmert sich im Wesentlichen um die für das MVVM-Pattern notwendige Implementierung von INotifyPropertyChanged und INotifyDataErrorInfo. Zusätzlich bringt es Klassen für synchrone und asynchrone Commands und weitere eher kleine Hilfsmittel mit. Eine Besonderheit des CommunityToolkit.Mvvm ist die Nutzung von Roslyn Source Generators, um typischen Boilerplate-Code rund um INotifyPropertyChanged-Implementierungen zu generieren.
In Listing 4 sehen wir das CommunityToolkit.Mvvm zusammen mit Avalonia in Aktion. Das MainWindowViewModel erweitern wir um das Property Name, das direkt Einfluss auf das Property Greeting hat. Wir definieren dafür lediglich den Member _name, um das Property kümmert sich das CommunitityToolkit per Source Generator selbst. Das Ereignis PropertyChanged müssen wir ebenfalls nicht selbst auslösen – die Attribute ObservableProperty und NotifyPropertyChangedFor sagen dem CommunityToolkit, wie es PropertyChanged auslösen soll. Im Hintergrund wird das Property Name durch das CommunityToolkit generiert, darin wird PropertyChanged für Name und Greeting aufgerufen. Anschließend brauchen wir im XAML-Code nur noch dagegen zu binden.
// MainWindowViewModel.cs
public partial class MainWindowViewModel : ObservableObject
{
[ObservableProperty]
[NotifyPropertyChangedFor(nameof(Greeting))]
private string _name = string.Empty;
public string Greeting => string.IsNullOrEmpty(this.Name)
? string.Empty
: $"Hello, {this.Name}";
}
// MainWindow.axaml
<Window ...>
<Border VerticalAlignment="Center" HorizontalAlignment="Center"
Classes="InputArea">
<StackPanel Orientation="Vertical">
<StackPanel Orientation="Horizontal">
<TextBlock Classes="Label"
Text="Name: " />
<TextBox Text="{Binding Name}" />
</StackPanel>
<StackPanel Orientation="Horizontal">
<TextBlock Classes="Label"
Text="Greeting: " />
<TextBox Text="{Binding Greeting}" />
</StackPanel>
</StackPanel>
</Border>
</Window>
Einer der größten Unterschiede im XAML-Code zwischen WPF und Avalonia ist das Styling-System. Anders als bei anderen XAML-Frameworks wie WPF wurde bei Avalonia das Verhalten von CSS nachgebaut. Ein Style ersetzt also das Styling eines Controls nicht komplett, sondern ergänzt es. Dabei können beliebig viele Styles auf ein und dasselbe Control wirken.
Listing 5 soll hierzu einen ersten Eindruck geben, es definiert einen Style für das vorangegangene Beispiel aus Listing 4. Jeder Style definiert über einen Selector, auf welche Controls er wirkt. Der einfachste Fall ist die Angabe des Typnamens, hier im Beispiel gehen wir bei Border.InputArea bereits etwas weiter. Border ist der Typ des Controls, InputArea ist der Klassenname (siehe Eigenschaft Classes bei dem Border-Control in Listing 4). Innerhalb des Styles definieren wir weitere sogenannte Nested Styles, die auf Child Controls wirken. Das Ergebnis sehen wir in Abbildung 1.
<Style Selector="Border.InputArea">
<Setter Property="Background" Value="#88888888" />
<Setter Property="Padding" Value="10" />
<Setter Property="CornerRadius" Value="10" />
<Style Selector="^ TextBox">
<Setter Property="Width" Value="250" />
</Style>
<Style Selector="^ StackPanel">
<Setter Property="Spacing" Value="5" />
</Style>
<Style Selector="^ TextBlock.Label">
<Setter Property="Width" Value="100" />
<Setter Property="VerticalAlignment" Value="Center" />
</Style>
</Style>

Abb. 1: Begrüßungsdialog mit angewendetem Styling
Hier am Beispiel sehen wir nur einen kleinen Bruchteil der Möglichkeiten des Styling-Systems von Avalonia. Das Avalonia-Team beschreibt in der Dokumentation eine lange Liste von möglichen Selektoren [3] – ein Blick lohnt sich. Das System wird ebenso regelmäßig erweitert, etwa durch die mit Version 11.3 eingeführten und an CSS Media Queries angelehnten Container Queries.
Features wie Hot Reload oder als Alternative einen visuellen Designer, wie wir ihn etwa noch aus den guten alten WinForms-Zeiten kennen, fehlen in Avalonia. Mit Avalonia Accelerate arbeitet das Avalonia-Team zurzeit genau an diesen Punkten. Avalonia Accelerate ist ein kostenpflichtiges Produkt, das Zusatzfeatures für Entwickler:innen von Avalonia-Applikationen enthält.
Im Open-Source-Paket von Avalonia werden schon länger integrierte DevTools angeboten, die über das NuGet-Paket Avalonia.Diagnostics bereitgestellt werden. Die beschriebenen Templates binden das NuGet-Paket direkt mit ein. Ein Tastendruck auf F12 reicht, um das DevTools-Fenster zu öffnen. Die DevTools helfen bei mehreren Aufgaben, so lassen sich Logical Tree und Visual Tree prüfen, ob sie die erwarteten Inhalte aufweisen. Der Logical Tree bildet dabei die Baumstruktur aus den XAML-Dateien ab. Der Visual Tree zeigt, was tatsächlich am Bildschirm gerendert wird – aufgrund von Templating i. d. R. deutlich mehr. Abbildung 2 zeigt, wie die DevTools von Avalonia aussehen.

Abb. 2: Avalonia DevTools
Noch ein Hinweis an alle Leser:innen, die Hot Reload oder einen Designer vermissen. In den DevTools können Werte von Eigenschaften direkt live geändert werden. Damit sieht man sofort, welche Änderungen zu welchen Effekten auf der Benutzeroberfläche führen.
Regelmäßig News zur Konferenz und der .NET-Community
Neben der Anzeige der Baumstrukturen bieten die DevTools weitere Features wie ein Tracking der von den Controls ausgelösten Events. Ebenfalls können performancerelevante Kennzahlen wie Rendering- und Layoutzeit eingeblendet werden. Unterm Strich sind die DevTools auf jeden Fall mehr als einen Blick wert.
Nachdem wir uns in diesem Artikel mit einigen Eigenschaften von Avalonia beschäftigt haben, möchten wir unseren Blick noch einmal von der Vogelperspektive auf das UI-Framework werfen. Das hilft uns dabei, das UI-Framework noch besser zu verstehen und die Vor- und Nachteile gegenüber anderen UI-Frameworks abschätzen zu können.
Abbildung 3 gibt uns dafür einen groben Überblick. Ganz oben steht dabei Avalonia zusammen mit allen in Avalonia zur Verfügung gestellten Controls. Darunter liegt Skia. Skia ist ein Open-Source-2D-Rendering-Framework von Google, das unter anderem auch in modernen Browsern wie Google Chrome eingesetzt wird. Ähnlich wie auch Flutter nutzt Avalonia Skia zum Rendering aller Controls. Unterhalb von Skia liegt entweder die Core CLR oder die Mono Runtime – je nachdem, auf welcher Plattform oder auf welchem Gerät wir eine Avalonia-Applikation ausführen.

Abb. 3: Architektur von Avalonia (eigene Darstellung nach [4])
Als logische Konsequenz aus dieser Architektur verhalten sich Avalonia-Applikationen auf allen unterstützten Plattformen weitgehend gleich und sehen gleich aus. Im Vergleich zu Avalonia gibt es auch andere UI-Frameworks, die einen ähnlichen Ansatz verfolgen. WPF etwa rendert auch alle Controls selbst, baut allerdings auf das plattformabhängige Direct3D auf. Auch bei anderen Programmiersprachen finden wir Beispiele, etwa beim bereits angesprochenen Flutter von Google oder dem für C++-Entwickler:innen gedachten Qt.
Im Vergleich zu anderen UI-Frameworks in .NET ist der Ansatz von Avalonia nicht häufig anzutreffen. .NET MAUI beispielsweise geht einen anderen Weg. Dort werden Controls nicht selbst gerendert, sondern die jeweiligen nativen Controls der Plattformen genutzt. Ein Vorteil davon ist das native Look and Feel, ein Nachteil ist der deutlich größere Testaufwand. Aus Sicht des Autors ist es wichtig, solche Unterschiede zu kennen, sobald es um die Entscheidung für oder gegen ein UI-Framework geht.
Historisch hat Avalonia seine größte Stärke am Desktop. Die Unterstützung für die mobilen Plattformen Android und iOS ist zusammen mit der Unterstützung für den Browser erst in Version 11 am 7. Juli 2023 veröffentlicht worden. Entscheidet man sich auf diesen Plattformen für Avalonia, muss man damit rechnen, auf die eine oder andere Lücke zu stoßen. So bietet Avalonia von Haus aus kein Navigations-Control mit Behandlung des Zurück-Knopfs – andere UI-Frameworks mit Fokus auf mobile Plattformen wie .NET MAUI haben hier mehr zu bieten.
Das Potenzial, das Avalonia auf mobilen Plattformen hat, kann man mit einem Blick auf Flutter erkennen. Flutter ist von seiner Architektur her sehr ähnlich zu Avalonia und ist insbesondere für Cross-Platform-Applikationen für mobile Geräte ein sehr beliebtes UI-Framework außerhalb der .NET-Welt.
Avalonia ist nicht nur aus der Community entstanden, die Community ist auch eine der größten Stärken des UI-Frameworks. Das Avalonia-Team pflegt eine Liste von Anlaufstellen, um sich mit der Community auszutauschen [5]. Dazu gehören ein Forum innerhalb des GitHub-Projekts auf Basis von GitHub Discussions und diverse Chats via Telegram und Discord.
Daneben existiert eine große Zahl von Open-Source-Projekten rund um Avalonia. Das GitHub-Projekt awesome-avalonia [6] ist ein guter Startpunkt, um Projekte zu finden, die für das eigene Projekt relevant sind.
Avalonia ist ein Open-Source-Projekt – mit dieser Tatsache steht für viele Interessierte die Frage im Raum, inwieweit das Team hinter Avalonia langfristig das Framework pflegt. Erfreulicherweise veröffentlicht Mike James, der CEO von Avalonia, regelmäßig Informationen darüber, wo die Prioritäten des Teams liegen und wie das Team aus Businesssicht aufgestellt ist. So beschreibt er in einem Blogpost vom 2. Dezember 2024, wie sich das Team zu diesem Zeitpunkt finanziert [7]. Der größte Einnahmeblock ist Avalonia XPF – ein kommerzielles Schwesterframework, das die Migration von WPF-Anwendungen auf andere Betriebssysteme erleichtert und zugleich einen Migrationspfad hin zu Avalonia bietet. Dieser Anteil dürfte sich im Juni 2025 geändert haben, denn zu diesem Zeitpunkt hat das Avalonia-Team eine 3 Millionen US-Dollar große Spende von der kanadischen Firma Devolutions erhalten [8].
Avalonia gibt uns alle notwendigen Werkzeuge an die Hand, um Benutzeroberflächen für die verschiedensten Plattformen zu entwickeln. Insbesondere finden sich Entwickler:innen mit Erfahrung in XAML-basierten Frameworks wie WPF schnell zurecht. Aber auch der Umstieg von anderen Frameworks wie dem nach wie vor verbreiteten Windows Forms, ist kein Ding der Unmöglichkeit – hier muss allerdings Zeit zum Lernen der XAML-Syntax und des MVVM-Patterns hinzugerechnet werden.
Gerade der Support für Linux dürfte für viele Lesende spannend sein, da Microsoft selbst hier eine Lücke hinterlässt. Linux spielt in verschiedenen Bereichen der Industrie und insbesondere in der Embedded-Welt eine sehr große Rolle. Avalonia kann hier als mächtiges UI-Framework mit ebenso mächtigem .NET-Unterbau punkten.
Das Avalonia-Team stellt sich aus Sicht des Autors sinnvoll für die Zukunft auf. Sie erweitern das Open-Source-Paket mit Avalonia Accelerate um kommerzielle Zusatzkomponenten, die für professionelle Entwickler:innen zusätzliche Produktivität und Features liefern. Auch Avalonia XPF kann gerade bei einer größeren Migration eines WPF-Projekts spannend sein. Ganz nebenbei finanzieren diese Produkte die Weiterentwicklung am Open-Source-Paket Avalonia selbst, das auch für kommerzielle Projekte kostenlos zur Verfügung steht.
Avalonia ist ein Open-Source, Cross-Platform UI-Framework auf .NET-Basis, das von WPF inspiriert ist. Syntax und Controls sind nahezu identisch zu WPF, allerdings wurde die Architektur modernisiert und die Plattformunterstützung erheblich erweitert.
Ursprünglich unterstützte Avalonia nur Windows, macOS und Linux. Seit Version 11 (Juli 2023) sind zusätzlich Android, iOS sowie Browser-basierte Anwendungen (über WebAssembly) möglich.
Visual Studio bietet mit einem offiziellen Plugin XAML-IntelliSense und Live Preview. JetBrains Rider hat die beste Integration out-of-the-box. Visual Studio Code kann ebenfalls genutzt werden, ist aber im Funktionsumfang am wenigsten komplett.
Über dotnet new install Avalonia.Templates lassen sich offizielle Templates installieren. Für Desktop empfiehlt sich „Avalonia .NET App“ oder „Avalonia .NET MVVM App“. Wer zusätzlich Android, iOS und Browser ansprechen möchte, nutzt „Avalonia Cross Platform Application“.
CompiledBindings generieren aus XAML bereits zur Compile-Zeit C#-Code. Dadurch wird Reflexion zur Laufzeit vermieden, die Performance steigt und Bindungsfehler werden bereits beim Kompilieren erkannt.
Am verbreitetsten sind CommunityToolkit.Mvvm und ReactiveUI. Ersteres ist leichtgewichtig und nutzt Source Generators, während ReactiveUI sehr mächtig ist, aber auf Reactive Extensions basiert und eine höhere Lernkurve hat.
Avalonia orientiert sich am CSS-Modell. Styles können per Typ- oder Klassenselektoren gesetzt werden, mehrere Styles pro Control sind möglich, ebenso wie verschachtelte Styles. Mit Version 11.3 kamen moderne Features wie CSS-ähnliche Container Queries hinzu.
Mit Avalonia.Diagnostics stehen Open-Source DevTools bereit, die u. a. den Logical Tree, Visual Tree, Events und Performance-Daten live inspizieren lassen. Avalonia Accelerate ist ein kostenpflichtiges Zusatzpaket mit erweiterten Features wie Visual Designers und verbessertem Hot Reload.
[1] https://docs.avaloniaui.net/docs/get-started/set-up-an-editor
[2] https://github.com/AvaloniaUI/avalonia-dotnet-templates
[3] https://docs.avaloniaui.net/docs/reference/styles/style-selector-syntax
[4] https://docs.avaloniaui.net/docs/overview/what-is-avalonia
[5] https://docs.avaloniaui.net/docs/community
[6] https://github.com/AvaloniaCommunity/awesome-avalonia
[7] https://avaloniaui.net/blog/avalonia-ui-in-2024-growth-challenges-and-the-road-ahead
[8] https://github.com/AvaloniaUI/Avalonia/discussions/19108
The post Avalonia: Das bessere WPF für moderne Cross-Platform-Apps appeared first on BASTA!.
]]>The post Kritische SharePoint-Sicherheitslücke CVE-2025-53770: Exploit aktiv im Umlauf appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
Microsofts Sicherheitsteam (MSRC – Microsoft Security Response Center) hat am Samstagabend (in Deutschland war es da schon Sonntagfrüh) unter anderem auf der Plattform X gemeldet, dass eine Lücke in SharePoint aktiv ausgenutzt wird [1]. Wie üblich wurde auch gleich eine CVE-Nummer vergeben – diese Liste der „Common Vulnerabilities and Exposures“ dient der vereinfachten Nachverfolgung von öffentlich gewordenen Sicherheitslücken. Die zugewiesene Nummer war CVE-2025-53770, also die 53 770. CVE im Jahr 2025 (global, also natürlich nicht nur auf Microsoft oder gar SharePoint bezogen). Der Score-Wert hatte unfassbare 9,8 (auf einer Skala bis 10). Es war also höchste Gefahr in Verzug. Ein Blogeintrag des MSRC verriet weitere Details und wurde in den Folgetagen mehrmals aktualisiert (Abb. 1) [2].
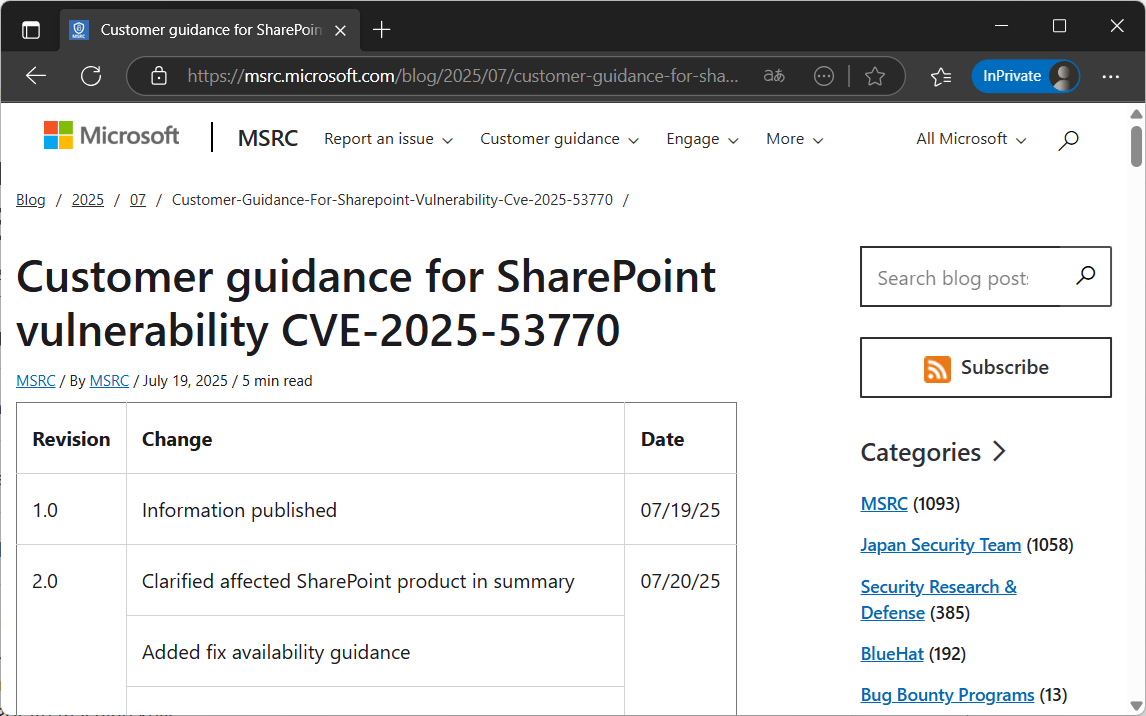
Abb. 1: Microsofts Handreichung für betroffene Kunden
Das allein ist ja schon schlimm genug, aber von anderer Seite wurden Informationen nachgelegt. Die Sicherheitsforscher von Eye Security waren ebenfalls auf die Sicherheitslücke aufmerksam geworden [3]. Sie haben die Lücke selbst gar nicht gefunden, aber bereits am 18.07.2025, also am Vortag der Warnung des MSRC, die mehrfache Ausnutzung festgestellt. Ein griffiger Name war schnell gefunden: „ToolShell“. Zudem haben sie Informationen zusammengetragen und somit einige zusätzliche Details veröffentlicht, die im MSRC-Post noch gefehlt haben – wichtig für potenziell betroffene Firmen, weil nun sehr konkret zu sehen war, dass Handlungsbedarf besteht. Der Blogpost war sehr detailliert, sodass mit entsprechender Detektivarbeit der Exploit nachgebaut werden konnte.
Kern des Problems war eine unsichere Deserialisierung einer der in ASP.NET Web Forms(!) entwickelten Seiten von SharePoint. In der Payload eines HTTP Requests konnten serialisierte Informationen an den Server geschickt werden und im Rahmen der Deserialisierung kam es dann zur Codeausführung. Bei den massenhaft erfolgten Angriffen wurde eine besonders perfide Variante der Codeeinschleusung gewählt: Der Exploit legte ein weiteres Web Form an, das dann per HTTP GET Request mehrere interne Serverinformationen inklusive dem MachineKey des Systems auslieferte. Gerade der MachineKey ist bei den meisten ASP.NET-Installationen zentral, dient er doch unter anderem als kryptografischer Schlüssel für den Zustandsverwaltungsmechanismus Viewstate. Ist dieser einem Angreifer bekannt, hat dieser bei SharePoint im Wesentlichen freie Hand, solange der MachineKey gültig ist – das kann selbst nach einem Patch so sein!
Es stellte sich schließlich heraus, dass die neue Verwundbarkeit eine Weiterentwicklung zweier erst jüngst bekannt gewordener Sicherheitslücken in SharePoint, CVE-2025-49704 [4] und CVE-2025-49706 [5] ist. Sie sehen es an der Nummer hinter der Jahreszahl: kleiner als 53770, aber in Schlagdistanz. Es zeigte sich: Diese CVEs wurden am 8.7.2025 veröffentlicht, der zweite Dienstag im Juli, und damit der turnusmäßige „Patch Tuesday“ von Microsoft. Es erschienen also zeitgleich Patches. Diese halfen aber gegen die neue Lücke offenbar nicht.
Rosig war die Situation am Morgen des 20.07.2025 also noch nicht. Kein Patch da, und der Blogpost von Microsoft war noch keine große Hilfe. In dessen ersten Fassung wurden als Gegenmaßnahmen unter anderem die Verwendung von Antivirensoftware genannt, dem Antimalware Scan Interface (AMSI) oder Microsoft Defender for Endpoint. Von einem Softwareupdate war da noch nicht die Rede. Dieses wurde am Sonntag, dem 20.07.2025, nachgereicht für SharePoint Subscription Edition [6] und 2019 [7]. Am Folgetag wurde auch für SharePoint Enterprise Server 2016 wird ein Patch veröffentlicht [8]. Außerdem hat Microsoft noch einen weiteren CVE veröffentlicht, CVE-2025-53771. Dieser hat einen niedrigeren Score als CVE-2025-53770, steht aber mit dem Vorgänger in Zusammenhang, und die verlinkten Updates beheben beide Lücken.
Wenn man weiß, wie lange es teilweise zwischen Bekanntwerdung einer Sicherheitslücke und Verfügbarkeit eines Patches dauert, ist das eine beeindruckende Leistung. Offenkundig tat diese auch Not, denn laut Eye Security wurden Dutzende SharePoint-Installationen gefunden, die bereits betroffen waren. Wer auch immer ein öffentlich verfügbares SharePoint betreibt, muss den Server auf Einbruchsspuren untersuchen und den Patch einspielen.
Mit dem Update von SharePoint allein ist es nicht getan. Gut möglich, dass der MachineKey bereits geklaut wurde. Deswegen ist eine Rotation des Schlüssels Pflicht. In der Regel ist das mit einem Neustart des IIS getan.
Gleichwohl gilt es, diese Episode als Anlass zu nehmen, die Sicherheitsprozesse im Unternehmen zu prüfen und gegebenenfalls zu hinterfragen. Wenn Sie potenziell betroffen sind, fragen Sie sich selbst: Wo haben Sie erstmals von diesem Problem gehört – durch das MSRC, eine entsprechende Überwachungssoftware, oder gar diesen Artikel? Eine hundertprozentige Sicherheit kann und wird es nicht geben, aber ein zeitnahes Einspielen von Sicherheitspatches ist in aller Regel zwingend. In einem Fall wie diesem, bei dem der Exploit noch vor der Verfügbarkeit eines Softwareupdates existiert, sind öffentlich erreichbare Systeme ein einfaches Ziel. Und auch interne Systeme könnten betroffen sein, dann eben nur mit kleinerem Angreiferkreis. Der Exploit ist direkt einsetzbar im Internet zu finden und benötigt keine besonderen technischen Fähigkeiten. Es herrscht also weiterhin Alarmstufe Rot – zumindest bis Ihre SharePoint-Installationen aktualisiert wurden.
Regelmäßig News zur Konferenz und der .NET-Community
CVE‑2025‑53770 ist eine kritische Zero‑Day‑Sicherheitslücke in Microsoft SharePoint, mit einem CVSS‑Score von 9,8, die aktiv ausgenutzt wurde. Sie wurde am 19. Juli 2025 öffentlich bekanntgegeben, als Microsofts MSRC via X (ehemals Twitter) warnte.
Der “ToolShell”-Exploit nutzt unsichere Deserialisierung in ASP.NET Web Forms von SharePoint aus. Code wird ausgeführt, und ein Web‑Form wird genutzt, um interne Informationen wie den MachineKey zu extrahieren – dieser Schlüssel erlaubt Angreifern persistente Kontrolle auch nach Patches.
CVE‑2025‑53770 stellt eine Weiterentwicklung (Patch‑Bypass) vorheriger Lücken CVE‑2025‑49704 und CVE‑2025‑49706 dar, die bereits am Patch‑Tuesday im Juli veröffentlicht wurden, aber gegen die neue Variante nicht wirksam waren.
Ein Patch für SharePoint Subscription Edition und 2019 wurde am 20. Juli 2025 veröffentlicht. Am 21. Juli 2025 folgte ein Update für SharePoint Enterprise Server 2016. Zusätzlich wurde mit CVE‑2025‑53771 eine zweite, verwandte Lücke benannt – und beide Patches beheben beide Schwachstellen.
Nein. Das bloße Einspielen des Updates reicht nicht aus, da der MachineKey bereits gestohlen sein kann. Administrator:innen sollten diesen unbedingt rotieren – meist durch einen IIS‑Neustart –, um sicherzustellen, dass ein Angreifer keine andauernde Kontrolle behält.
Unternehmen sollten ihre Sicherheitsprozesse überdenken: Wie schnell haben Sie erfahren — durch Microsoft, Monitoring oder externe Quellen — von dieser Lücke? Zeitnahes Patching ist entscheidend, insbesondere bei öffentlich erreichbaren Systemen, deren Exploits leicht nutzbar sind.
Sicherheitsforscher von Eye Security beobachteten die Ausnutzung bereits am 18. Juli 2025, einen Tag bevor Microsoft öffentlich warnte. Der Name “ToolShell” wurde von ihnen geprägt.
[1] https://x.com/msftsecresponse/status/1946737930849939793
[3] https://research.eye.security/sharepoint-under-siege/
[4] https://msrc.microsoft.com/update-guide/vulnerability/CVE-2025-49704
[5] https://msrc.microsoft.com/update-guide/vulnerability/CVE-2025-49706
[6] https://www.microsoft.com/en-us/download/details.aspx?id=108285
[7] https://www.microsoft.com/en-us/download/details.aspx?id=108286
[8] https://www.microsoft.com/en-us/download/details.aspx?id=108288
The post Kritische SharePoint-Sicherheitslücke CVE-2025-53770: Exploit aktiv im Umlauf appeared first on BASTA!.
]]>The post KI-IDEs im Vergleich: Cursor, Windsurf & Copilot appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
Cursor (Abb. 1) richtet sich an Entwickler:innen, die umfassende Kontrolle und eine tiefgehende Kontextverarbeitung suchen [1]. Hervorzuheben ist insbesondere der Agent-Modus, bei dem Cursor in einem isolierten Shadow Workspace arbeitet und Änderungen zunächst vorbereitet, bevor sie in den eigentlichen Code übernommen werden. Dadurch können Entwickler:innen ganze Features autonom erstellen oder komplexe Refactorings durchführen.
Cursor zeichnet sich zudem durch einzigartige Erweiterungen aus: Mit @Web können Webinhalte als Kontext integriert werden, @Docs bindet Dokumentationen ein und Screenshots lassen sich direkt in Code umwandeln. Zusätzlich können Entwickler:innen zwischen KI-Modellen wie GPT, Gemini oder Claude wechseln und sogar eigene Modelle einbinden.

Abb. 1: Cursor – Chatansicht
Windsurf (Abb. 2) setzt mit seinem Cascade-Ansatz auf eine intuitive und flüssige Workflowerfahrung [2]. Der klar strukturierte Chat- und Schreibmodus führt Entwickler:innen systematisch durch komplexe Aufgaben. Im Bereich der Webentwicklung überzeugt Windsurf insbesondere durch eine visuelle Vorschau und direkte Deployment-Optionen aus der IDE heraus. Ein lokaler semantischer Index gewährleistet schnellen Zugriff auf relevante Codestellen, während sensible Daten sicher vor Ort bleiben und nicht in die Cloud übertragen werden.

Abb. 2: Windsurf – Welcome Screen
GitHub Copilot [3] (Abb. 3) hat sich im Jahr 2025 maßgeblich weiterentwickelt und integriert nun eine umfassende Agent-Funktionalität direkt in VS Code [4]. Der neue Agent-Modus ermöglicht die autonome Planung und Umsetzung komplexer Aufgaben. Copilot analysiert den gesamten Workspace selbstständig, schlägt Codeänderungen vor, führt Terminalbefehle aus und optimiert den Code iterativ bei auftretenden Problemen.
Zusätzlich bietet Copilot eine regelbasierte Generierung von Tests und Dokumentation, die Entwickler:innen direkt in VS Code konfigurieren können. Darüber hinaus ermöglicht Copilot automatisierte Codereviews innerhalb der IDE. Microsoft positioniert Copilot als unterstützenden Partner für die täglichen Aufgaben in der Softwareentwicklung.

Abb. 3: Copilot – Welcome Screen
Insgesamt bieten alle drei Tools verlässliche Unterstützung bei alltäglichen Programmieraufgaben, setzen jedoch unterschiedliche Schwerpunkte: Cursor bietet maximale Kontrolle und Tiefe, Windsurf ein fokussiertes, assistiertes Flow-Erlebnis (insbesondere im Frontend-Bereich) und Copilot unkomplizierte KI-Unterstützung in etablierten Entwicklungsumgebungen.
Im Jahr 2025 gehören zahlreiche KI-Funktionen zum Standard in AI-Codeeditoren. Die wichtigsten Features, die Cursor, Windsurf und Copilot gleichermaßen bieten, sind mehrzeilige Codevervollständigung mit Kontextverständnis, Chat-Assistenten zur Erklärung von Code und zur Behebung von Fehlern, automatische Generierung von Unit-Tests sowie die Integration verschiedener Large Language Models für unterschiedliche Anwendungsfälle.
Obwohl es viele Gemeinsamkeiten gibt, besitzt jede Lösung Alleinstellungsmerkmale, die sie für bestimmte Zielgruppen besonders attraktiv machen.
Cursor bezeichnet sich selbstbewusst als „The AI Code Editor“, was die tiefgreifende Integration zahlreicher KI-Funktionen widerspiegelt. Die IDE basiert auf einem Fork von VS Code und bietet somit umfassende Kompatibilität zu existierenden Erweiterungen und Workflows. Cursor entfaltet seine Stärken insbesondere bei komplexen Programmieraufgaben wie tiefgehenden Refactorings oder umfassenden Änderungen mehrerer Dateien.
Eine besondere Stärke ist der Shadow Workspace, in dem umfangreiche Codeänderungen in einer isolierten Umgebung ausprobiert werden können, bevor sie übernommen werden. Zudem bietet Cursor spezielle KI-Integrationen. Entwickler:innen können mit Hilfe der @Web-Funktion externe Webseiten indexieren und deren Inhalte als zusätzlichen Kontext direkt in den KI-Chat einfließen lassen. So lassen sich beispielsweise aktuelle API-Dokumentationen, Changelogs oder Tutorials integrieren (Abb. 4). Vordefinierte Dokumentationen bekannter Frameworks und Bibliotheken sind bereits im Tool enthalten und sofort einsatzbereit.

Abb. 4: Cursor – Docs-Index
Mit dem Multi-Chat-Support kann man mehrere KI-Chats parallel betreiben und dabei je nach Aufgabe verschiedene Modelle effizient einsetzen.
Cursor unterstützt darüber hinaus eine flexible Auswahl an KI-Modellen, darunter OpenAI GPT-4 und Anthropic Claude. Sogar eigene Modelle können angebunden werden, wodurch die IDE auch in stark spezialisierten und individuellen Szenarien äußerst leistungsfähig ist.
Anlässlich der Übernahme durch OpenAI hat Windsurf kürzlich viel Aufmerksamkeit auf sich gezogen. Wie Cursor basiert es auf einem Fork von VS Code und bietet eine tiefgehende Integration von KI-Funktionen in eine vertraute Arbeitsumgebung.
Ein Alleinstellungsmerkmal von Windsurf ist die intuitive „Cascade“-Oberfläche (Abb. 5), die den klassischen Editor- und Chatmodus vereint. Entwickler:innen können hier einfach zwischen Schreiben und Chatten wechseln, wodurch die Interaktion mit der KI besonders flüssig und natürlich wirkt. Windsurf glänzt vor allem bei der Webentwicklung durch die visuelle Livevorschau direkt in der IDE. Hierbei können Entwickler:innen UI-Elemente anklicken und Windsurf generiert automatisch passende Codeänderungen. Das Feedback ist somit sofort sichtbar und intuitiv nachvollziehbar.

Abb. 5: Windsurf – Cascade-Oberfläche
Windsurf speichert Konversationen und Programmierentscheidungen in sogenannten „Memories“ und ermöglicht den Betrieb eigener KI-Modelle auf lokaler Hardware.
Zusätzlich hebt sich Windsurf durch seine integrierten Deployment-Funktionen hervor. Damit können Anwendungen direkt aus der IDE heraus bereitgestellt werden. Das reduziert die Notwendigkeit externer CI/CD-Pipelines und vereinfacht den Entwicklungsprozess, insbesondere für kleinere Teams und Projekte.
Die Kombination aus GitHub Copilot und VS Code überzeugt weniger durch exotische Einzelfeatures als vielmehr durch ihre tiefgehende und nahtlose Integration in bestehende Ökosysteme und Arbeitsprozesse. Copilot fühlt sich wie eine natürliche Erweiterung der beliebten IDE VS Code an und fügt sich nahtlos in die bewährten Arbeitsabläufe vieler Entwickler:innen ein.
Die wohl größte Stärke von GitHub Copilot ist die direkte und tiefe Integration mit den Funktionen der GitHub-Plattform. Copilot bietet zum Beispiel automatische Codereviews und generiert Pull-Request-Beschreibungen, was besonders in Team- und Enterprise-Umgebungen eine erhebliche Zeitersparnis mit sich bringt.
Darüber hinaus überzeugt Copilot durch die nahtlose Einbindung in das GitHub-Ökosystem, zu dem unter anderem GitHub.com, GitHub Desktop und GitHub Actions gehören.
Für die Entwicklung lautet die zentrale Frage: Wie gut sind die KI-Vorschläge tatsächlich? Mit anderen Worten: Wie gut unterstützen die Tools beim Coding, also wie korrekt, nützlich und effizient sind sie? Hier zeigt sich je nach Anwendungsfall ein differenziertes Bild. Zunächst ist wichtig zu erwähnen, dass in allen Tools die gleichen LLMs zur Auswahl stehen. Allerdings werden unterschiedliche System-Prompts und Tool-Calls eingesetzt, die die Ergebnisse entsprechend beeinflussen.
Bei einfachen Szenarien, etwa beim Schreiben von Routinefunktionen, bei der Syntaxhilfe oder bei bekannten Algorithmen liefern alle drei Tools vergleichbar gute Ergebnisse. Cursor und Windsurf verwenden oft ähnliche oder sogar identische Modelle im Hintergrund. Für komplexere Aufgaben nutzen sie häufig Claude, während Copilot auf OpenAI-Modellen basiert. Bei Standardcode gibt es daher oft keinen drastischen Qualitätsunterschied. Entwicklerberichte bestätigen, dass die typische Codevervollständigung in allen drei Fällen zuverlässig funktioniert. Copilot profitiert dabei von seinen speziellen Trainingsdaten aus GitHub-Code: Er erkennt gängige Patterns und Framework-Konventionen präzise. Cursor und Windsurf generieren tendenziell längere und ausführlichere Codeblöcke (etwa detailliertere Kommentare oder mehrere zusammenhängende Zeilen), während Copilot minimalistisch Zeile für Zeile vorgeht.
Bei komplexeren Aufgaben kommen die Vorzüge von Cursor und Windsurf deutlich zum Tragen. Dank ihres erweiterten Kontextverständnisses und ihrer Agent-Fähigkeiten können beide Tools konsistente Änderungen über mehrere Dateien hinweg vorschlagen. Die praktische Erfahrung zeigt, dass beispielsweise beim Erstellen einer React-Komponente mit Modulinteraktionen in allen betroffenen Dateien korrekter Code generiert wird – inklusive passender Imports und Typdefinitionen. Copilot generiert in solchen Fällen eher einzelne Snippets, die manuell zusammengeführt und ergänzt werden müssen.
Ein besonders effektiver Ausführungsmodus ist der sogenannte Max Mode von Cursor, bei dem der verfügbare Kontextumfang und die Anzahl der internen KI-Operationen deutlich erweitert werden. Dadurch kann Cursor mehr Projektinformationen gleichzeitig berücksichtigen, umfangreiche Änderungspläne ableiten und selbst komplexe, modulübergreifende Aufgaben effizient bearbeiten. Diese Fähigkeit erweist sich als besonders wertvoll bei strukturellen Refactorings oder bei der Einführung neuer Features, die tief in bestehende Architekturen eingreifen.
Windsurf unterstützt solche komplexen Vorhaben durch seinen Flow-basierten Cascade-Ansatz. Dabei behält die KI den Projektzustand fortlaufend im Blick und gliedert umfangreiche Aufgaben in nachvollziehbare, aufeinander abgestimmte Schritte. So entstehen adaptive Vorschläge, die über mehrere Dateien hinweg konsistent bleiben. In der praktischen Anwendung zeigt sich: Beim Umbenennen einer zentralen Klasse erkennen sowohl Cursor als auch Windsurf alle Referenzen projektweit und schlagen entsprechende Anpassungen vor. Copilot hingegen erkennt solche Änderungen meist nur dateiweise.
Die „Projektweitsicht“ von Cursor und Windsurf erweist sich als besonders nützlich. Allerdings gibt es auch hier Einschränkungen. Die automatisch generierten Multi-File-Änderungen treffen nicht immer ins Schwarze. Cursors ambitionierte Vorschläge können – trotz aller Tiefe – auch neue Probleme einführen, während sie alte beheben. Tests mit Windsurf zeigen, dass nach größeren Codegenerierungsaufträgen mehrere Fehler auftreten können, die erst nach mehreren Iterationen ausgebessert werden. Copilot ist bei größeren Anforderungen gelegentlich überfordert oder missversteht die Intention, insbesondere bei reduziertem Kontextfenster oder kleinerem Modell.
Insgesamt gilt: Bei umfangreichen KI-Aktionen bleibt eine sorgfältige Codereview unerlässlich, da kein Assistent ganz fehlerfrei arbeitet.
Regelmäßig News zur Konferenz und der .NET-Community
Alle drei Tools decken die populären Programmiersprachen (JavaScript/TypeScript, Python, Java, C#, C/C++, Go und PHP) hervorragend ab. GitHub Copilot hat durch seinen Trainingscorpus einen leichten Vorteil bei exotischeren Sprachen oder Frameworks, da es auf dem gesamten öffentlichen GitHub-Code basiert. Windsurf unterstützt eigenen Angaben zufolge über 70 Sprachen, darunter SQL, Bash, JSON und Markdown. Bei Cursor hängt die Sprachunterstützung vom gewählten Modell ab (GPT-4.1 und Claude bieten eine vergleichbare Sprachvielfalt). Durch ihre flexible Modellintegration können Cursor und Windsurf bei sehr neuen oder speziellen Frameworks oft schnellere Updates anbieten. Copilot profitiert hingegen vom kontinuierlichen Training durch Microsoft sowie vom Feedback einer großen Nutzergemeinde. Das führt zu verbesserten Prompt-Techniken und Fehlerfiltern.
Bei einfacheren Programmieraufgaben erweisen sich alle drei Tools als produktive Entwicklungswerkzeuge; die Unterschiede zeigen sich eher in Spezialfällen. Copilot überzeugt bei gängigen Patterns und stabilen Kurzvorschlägen, während Cursor und Windsurf bei holistischen, projektweiten Tasks dank ihres größeren Kontextverständnisses punkten. Die praktische Erfahrung zeigt: Copilot erweist sich im Alltag als besonders verlässlich, während Cursor gelegentlich mit zu vielen Informationen überfordert. Andererseits bewältigen Cursor und Windsurf komplexe Arbeitsschritte effizienter, die Copilot in dieser Form nicht abdeckt. Die Qualität der KI entwickelt sich laufend weiter. Mit neuen Modellversionen ist zu erwarten, dass alle drei Assistenten noch besser und kontextbewusster werden.
Trotz des ähnlichen äußeren Erscheinungsbilds unterscheiden sich die Architekturen unter der Haube. Wie integrieren die Tools KI-Modelle, wo laufen diese und wie viel Kontext können sie verarbeiten?
Die Macher von Cursor (Anysphere) setzen eine eigene Backend-Infrastruktur ein, die verschiedene KI-Modelle orchestriert. Cursor nutzt eine Mischung aus lokalen Komponenten und Cloud-Modellen: Beispielsweise läuft das Projekt-Indexing lokal: Ein eigener Dienst erstellt im Hintergrund Vektor-Embeddings aller Dateien, um schnellen semantischen Zugriff zu haben. Wenn ein Nutzer eine Frage in den Chat eingibt, werden per Embedding-Suche relevante Codeausschnitte gefunden und an das KI-Modell geschickt. Dieses Modell selbst läuft auf Servern. In der Pro-Version sind das Premium-Modelle wie Google Gemini oder Anthropic Claude. Interessant ist, dass Cursor mehrere Modellgrößen parallel einsetzt: kleine, schnelle Modelle (z. B. das eigene Codemodell cursor-fast) für Autocomplete-Vorschläge und große Modelle für komplexe Chatantworten. Für anspruchsvolle Aufgaben gibt es sogar einen Max Mode, der ein größeres Kontextfenster nutzt und dafür ggf. etwas mehr Wartezeit in Kauf nimmt.
Ein zentrales Konzept bei Cursor (und auch bei Windsurf) ist das Model Context Protocol (MCP). Es ermöglicht fortgeschrittene Automatisierungen. Man könnte beispielsweise einen MCP-Server einbinden, der Bugtickets aus Jira holt und sie dem Cursor-Agenten (Abb. 6) bereitstellt. Der Agent führt dann Codeänderungen im Kontext eines bestimmten Tickets durch. VS Code hat seit Kurzem ebenfalls eine MCP-Integration für den Copilote veröffentlicht.

Abb. 6: Cursor – Agent Demo
Die Agent-Architektur in Cursor funktioniert – vereinfacht dargestellt – so: Das System verfügt über einen Supervisor Prompt, der den KI-Modellen vorgibt, wie sie vorgehen sollen (z. B. iterative Planung, Validierung von Zwischenschritten). Cursor führt Agent-Aktionen in einem isolierten Bereich (Shadow Workspace) aus. Der eigentliche Code wird erst geändert, wenn man auf „Apply“ geklickt hat. Dadurch wird das Risiko reduziert, dass die KI ungeprüfte Änderungen verbreitet.
Im Unterschied zu Cursor bietet Windsurf KI-Funktionalität auch als Plug-in für verschiedene Editoren an. Im Weiteren konzentrieren wir uns jedoch auf Windsurf selbst. Architektonisch setzt Windsurf ebenfalls auf Projektindexierung, sogar sehr intensiv: Die Software indexiert die gesamte Codebasis lokal (mit Embeddings) und hält diese ständig aktuell, um jederzeit Kontext liefern zu können. Der Vorteil ist, dass der Codekontext lokal und privat bleibt – d. h., die konkreten Codezeilen müssen nicht vollständig in die Cloud geladen werden, sondern nur abstrakte Vektorrepräsentationen. Auf diese Weise kann Cascade nicht nur schneller als reine Cloud-Lösungen relevante Stellen finden, sondern auch bei begrenzter Internetverbindung performen.
Die KI-Modelle hinter Windsurf sind vielfältig: Windsurf verfügt über eigene Modelle (trainiert auf Open-Source-Code) für Basisszenarien und Autocompletion. Für anspruchsvollere Aufgaben setzt Windsurf stark auf Claude 4 von Anthropic (wie auch Cursor). Mit der Übernahme durch OpenAI werden in Zukunft wahrscheinlich vermehrt OpenAI-Modelle zum Einsatz kommen. Windsurfs Architektur betont zwei Dinge: geringe Latenz und agentische Intelligenz. Ersteres wird unter anderem durch einen eigenen optimierten Model-Server und ggf. kleiner dimensionierte Modelle für schnellen Inline-Support erreicht. Letzteres – die Agent-Fähigkeit – wird durch Flows realisiert: Cascade gliedert komplexe Aufgaben in Schritte und nutzt Toolintegration (z. B. Terminal, Linter, Dateimanagement) in einem steuernden Loop. Die KI sieht in Windsurf immer den gesamten Zustand des Projekts (inklusive ihrer letzten Aktionen), wodurch eine Art „Gedächtnis“ entsteht. So kann Cascade z. B. nachvollziehen, was zuletzt manuell geändert wurde und darauf aufbauend den nächsten Vorschlag kontextuell anpassen.
Ein Aspekt, den sowohl Windsurf als auch Cursor abdecken, ist die Fehlerbehandlung: Beide erkennen, wenn generierter Code Linter- oder Kompilierungsfehler produziert, und iterieren automatisch nach. Windsurf fixt sogar autonom mit Cascade Linter Fails, bevor sie dem Entwickler auffallen. Diese Automatisierungsschleifen sind Teil des jeweiligen Agent-Designs.
Copilot unterscheidet sich architektonisch von Windsurf und Cursor dadurch, dass es kein eigenständiger Editor ist, sondern ein an bestehende IDEs angebundener Cloud-Service (Abb. 7). In VS Code läuft Copilot als Extension, die mit GitHubs Cloud kommuniziert. Die Integration geschieht über einen spezifischen, dem Language Server Protocol ähnlichen Kanal: Microsoft hat für Copilot damit einen universellen KI-Server erstellt, den VS Code, JetBrains IDEs und sogar Vim, Neovim, Xcode usw. nutzen können. Das bedeutet: Wenn Sie in VS Code tippen, sendet die Copilot-Extension den Inhalt Ihres Editors (Fensterinhalt und die umgebenden 100 bis 150 Zeilen) an das Cloud-API und bekommt die Vervollständigungen zurück. Nichts davon läuft lokal, außer dem UI-Element, das den Vorschlag einblendet.

Abb. 7: Copilot-Demo
Für den Chat- und Agenten-Modus greift die Copilot-Chat-Extension auf einen neuen Mechanismus zurück, der auf semantischer Codeindexierung basiert. Das System erstellt automatisch Embeddings aller Projektdateien und ermöglicht so schnelle, kontextbezogene Antworten. Dabei werden auch weitere offene Dateien oder vom Nutzer explizit angehängte Abschnitte berücksichtigt. Seit Copilot ChatGPT-4 nutzt und die neue Indexierung implementiert wurde, kann der Chat deutlich effizienter auf größeren Codebasen operieren. Die Repo-Integration nutzt dabei GitHubs eigenes Indexing-System: Wenn das Projekt ein Git-Repo ist und mit GitHub verbunden ist, werden alle Projektdateien und Commits automatisch semantisch indiziert. Das ermöglicht eine schnelle und präzise Kontextbereitstellung für das Copilot-Modell, sowohl in der IDE als auch in GitHub Codespaces.
Während Cursor und Windsurf mit ihren Agenten lange Zeit ein Alleinstellungsmerkmal besaßen, veröffentlichte GitHub im Jahr 2025 seinen eigenen Agenten für VS Code sowie in einer ersten Betaversion für Visual Studio und die JetBrains IDEs. Alle in den vorherigen Abschnitten beschriebenen Agenten-Features wie das automatische Editieren über mehrere Dateien hinweg, MCP-Tools und Linting werden ebenfalls unterstützt. Lediglich die Auswahl an LLMs und das damit verbundene Kontextfenster sind im Vergleich weiterhin stark limitiert.
Alle drei Lösungen nutzen Großmodelle mit sogenanntem Prompt-Engineering. Das bedeutet, dass vor der eigentlichen Nutzereingabe ein unsichtbarer System- oder Instruktions-Prompt gesendet wird, der das Verhalten steuert (z. B. „Du bist ein hilfreicher Kodierungsassistent …“). Diese Prompts sind in Cursor/Windsurf tendenziell komplexer, da die Agenten verschiedene Tools steuern müssen. Es gibt dort Kaskaden von Aufforderungen (z. B. ein Prompt, der dem Modell beibringt, wie es Shellbefehle vorschlägt und auf Bestätigung wartet). In Copilot ist das Prompting dagegen einfach gehalten und auf Inline-Suggestions optimiert. Für die Endnutzer:innen sind diese Systemdetails jedoch weitgehend unsichtbar. Wichtig ist eher die Kontextgröße: Copilot (GPT-4.1) kann bis zu 128 k Tokens Kontext verarbeiten, Cursor und Windsurf (Claude 4) bis zu 200 k Tokens. Beide nutzen jedoch Retrieval, das heißt, sie „füttern“ das Modell nur mit relevanten Ausschnitten statt mit allen Dateien.
Insgesamt folgen Cursor und Windsurf dem Prinzip „KI komplett in den Editor integrieren“, während Copilot das Prinzip „Editor mit Cloud-KI erweitern“ verkörpert. Das spiegelt sich in der Architektur deutlich wider.
Neben der reinen KI-Leistung ist für viele Entwickler:innen entscheidend, wie gut sich ein Tool in ihren vorhandenen Workflow einfügt. Hier gibt es markante Unterschiede zwischen den Ansätzen.
GitHub Copilot bietet die breiteste Integration. Er funktioniert nahtlos in VS Code, Visual Studio, allen gängigen JetBrains IDEs (via offizielles Plug-in) sowie in Neovim/Vim und sogar Xcode. Microsoft stellt sicher, dass Copilot dort wie eine native Autocomplete-Funktion wirkt (z. B. erscheinen Copilot-Vorschläge in IntelliJ wie normale Codevervollständigungen). Ähnlich breit ist die Unterstützung von Windsurf: Als Windsurf-Plug-in gibt es Unterstützung für über 40 Editoren, darunter JetBrains, VS Code, Vim/Emacs, Jupyter Notebooks usw. Allerdings bietet das Plug-in nicht den vollen Funktionsumfang der Windsurf-Editor-App: Cascade-Agent und Flows sind in der Stand-alone-IDE beispielsweise mächtiger als im VS-Code-Plug-in, wo oft nur eine dateibezogene Vervollständigung möglich ist.
Cursor geht einen anderen Weg: Hier ist die IDE selbst Teil des Produkts. Es gibt keine Plug-ins für IntelliJ oder Ähnliches – man lädt die Cursor IDE herunter (verfügbar für Mac, Windows und Linux). Erfahrenen VS-Code-Nutzern fällt der Umstieg leicht, da Cursor den Import von VS-Code-Themes, -Einstellungen und -Extensions erlaubt. So kann man seine gewohnte Entwicklungsumgebung größtenteils in Cursor nachbilden. Dennoch bleibt es eine eigene IDE, d. h., wer z. B. tief im Visual-Studio-/JetBrains-Ökosystem verwurzelt ist, muss für Cursor die Umgebung wechseln. Zusammengefasst: Copilot integriert sich am flexibelsten in existierende IDEs, Windsurf bietet sowohl ein Plug-in für viele IDEs als auch eine eigene Editoroption und Cursor setzt auf seine All-in-one-IDE.
Alle drei Tools lassen sich mit Git verwenden, der Mehrwert variiert jedoch: In Cursor steht ein gewohntes Git-Panel zur Verfügung (dank der VS-Code-Basis) und es können Commits und Pushs ausgeführt werden. Zusätzlich kann Cursor KI-Features auf Git anwenden, beispielsweise kann per Quick Actions ein Diff erklärt werden oder ein Quick Fix-Button bei Fehlern in der Git-Diff-Ansicht angezeigt werden. Windsurf integriert Git ähnlich (als Editorfunktion) und alle drei Tools unterstützen die automatische Generierung von Commit Messages – das spart viel Zeit und sorgt für saubere Commits. Copilot selbst ist unabhängig von Git, aber GitHub als Plattform nutzt Copilot-Technik. Beim Erstellen eines Pull Requests auf GitHub.com können z. B. automatisch Beschreibungstexte generiert werden. Ein besonderes Feature von GitHub Copilot ist die Möglichkeit, Codereviews direkt in VS Code oder auf GitHub durchzuführen. Das zeigt die Richtung: Copilot soll ein KI-Coreviewer im Team werden.
So kann ein Team beispielsweise interne API-Dokumente als Kontextquelle einbinden. Windsurf verfügt über ein Rules & Memories Panel, in dem Guidelines und wichtige Informationen abgelegt werden können – eine Art teaminterne Wissensbasis für die KI. Copilot bietet ebenfalls die Möglichkeit, benutzerdefinierte Regeln zu hinterlegen, und kann über die #fetch-Direktive Webdokumentationen als zusätzlichen Kontext einbinden. Die Integration und Verwaltung von Dokumentationen und Webinhalten ist jedoch in Cursor am ausgereiftesten umgesetzt.
Alle drei Tools bieten MCP-Server-Unterstützung mit gleichwertiger Integration für Drittsysteme. GitHub Copilot lässt sich über die Open-Source-VS-Code-Extensions-Plattform erweitern. Durch die kürzlich erfolgte Öffnung des Plug-in-Systems durch Microsoft ergeben sich noch mehr Möglichkeiten für Plug-ins von Drittanbietern. Zusätzlich ist Copilot nahtlos in Codespaces (Cloud-Dev-Umgebungen von GitHub) integrierbar: In einem Codespace steht Copilot ohne zusätzliche Konfiguration zur Verfügung, was die Cloud-Entwicklung vereinfacht.
In professionellen Umgebungen ist dieser Aspekt besonders wichtig: Copilot für Business garantiert, dass keine Kundencodefragmente zur Modellverbesserung verwendet werden. Außerdem gibt es Regler zur Blockierung von vertraulichem Code in den Vorschlägen. Cursor ist SOC-2-zertifiziert und verfügt über einen Privacy Mode, bei dem kein Code auf den Servern gespeichert bleibt. Windsurf betont, dass das Training ausschließlich auf Open-Source-Daten erfolgt und keine Nutzerdaten gespeichert oder geteilt werden. Außerdem bleiben durch das lokale Indexing viele Informationen auf dem Rechner. Für Enterprise-Kunden bietet Windsurf auch On-Premises-Optionen (eigene Server mit dem KI-Modell) an. Je nach Unternehmensrichtlinien muss geprüft werden, welcher Anbieter konform ist. Stand 2025 bieten alle drei Wege die Möglichkeit, die Nutzung datenschutzkonform zu gestalten (sei es via Vertragszusatz oder Self-Hosting bei Windsurf Enterprise).
Insgesamt gilt: Copilot punktet bei der Integration, wenn man bereits stark im GitHub-/MS-Ökosystem unterwegs ist und verschiedene IDEs nutzt. Windsurf ist attraktiv, wenn man KI in bestehenden Editoren einsetzen will (überall gleiche KI-Unterstützung via Plug-in) oder wenn man speziell im Webbereich eine Alles-in-einem-IDE sucht. Cursor richtet sich an Entwickler:innen, die bereit sind, ihre Haupt-IDE zu wechseln, um die volle KI-Power zu nutzen. Dafür belohnt Cursor mit tiefer KI-Verschmelzung, aber es ist eben ein separates Programm.
Regelmäßig News zur Konferenz und der .NET-Community
In der Praxis hat jede Lösung ihre Vor- und Nachteile, die von den Vorlieben und Bedürfnissen der Entwickler:innen abhängen. Im Folgenden finden Sie eine Übersicht der wichtigsten Eindrücke aus der Entwicklercommunity.
Cursor überzeugt durch seine leistungsstarken Funktionen und die schnelle Umsetzung komplexer Änderungen. Besonders in der professionellen Entwicklung bietet die IDE auf Knopfdruck „jedes erdenkliche AI-Feature“. Die KI-Unterstützung ist allgegenwärtig – vom Einfügen fehlender Imports bis zum Komplett-Refactoring mit Agenten. Die mehrfach überarbeitete Benutzeroberfläche präsentiert sich nun aufgeräumt und intuitiv. Das moderne UI ermöglicht einen effizienten Workflow, ohne dass dabei Funktionsvielfalt eingebüßt wird. Die Steuerung setzt auf manuelle Kontrolle: Im Standardmodus erfordern KI-Änderungen einzelne Bestätigungen. Das bietet zwar Sicherheit, unterbricht aber den Arbeitsfluss. Die Lernkurve ist steil – die Einarbeitung in Chat, Agenten, Shortcuts und @-Tags benötigt Zeit. Das Ergebnis ist jedoch ein äußerst anpassbares Entwicklungswerkzeug. Performancetechnisch läuft Cursor auf modernen Systemen flüssig, wobei umfangreiche Agent-Aktionen einige Sekunden Verarbeitungszeit benötigen.
Windsurf überzeugt durch seine moderne, aufgeräumte Benutzeroberfläche. Die KI fügt sich harmonisch in den Workflow ein, und die Bedienung ist intuitiv gestaltet. Der Cascade-Agent führt durch die Entwicklung, während die automatische Kontexterkennung selbstständig die relevanten Dateien auswählt. Mit Hilfe des Write/Chat-Umschalters lässt sich eine klare Trennung zwischen Codegenerierung und Erklärungen erreichen. Die größte Stärke von Windsurf ist das „Flow“-Gefühl: Die KI arbeitet kontinuierlich im Hintergrund, ohne den Entwicklungsprozess zu unterbrechen.
Verbesserungsbedarf besteht jedoch in puncto Zuverlässigkeit: Der Cascade-Agent erkennt Kontexte nicht immer korrekt und die Vorschaufunktion zeigt gelegentlich Schwächen. Positiv fallen die regelmäßigen Updates (monatliche „Waves“) auf. Die Performance wurde priorisiert. Windsurf reagiert sehr schnell bei Inline Suggestions, allerdings benötigt der erste Indexing-Durchlauf bei großen Projekten mehrere Minuten.
Copilot in VS Code hat sich für viele Entwickler:innen zu einem stillen Helfer entwickelt. Er funktioniert meist, ohne dass man es bewusst bemerkt. Die Vorschläge wirken natürlich (sie erscheinen als grauer Text und werden mit der TAB-Taste akzeptiert) – wer IntelliSense gewohnt ist, empfindet Copilot als dessen Erweiterung. Die Stärken von Copilot sind die hohe Treffsicherheit bei Routineaufgaben – dank des Trainings mit massenhaft Code schreibt Copilot beispielsweise Schleifen, API-Calls und bekannte Algorithmen oft fehlerfrei aus dem Stand – und die breite IDE-Unterstützung über VS Code, Visual Studio, IntelliJ IDEs und XCode, wobei VS Code als Hauptplattform priorisiert wird. Copilot ist mit etwa zwei Jahren auf dem Markt ausgereift: Die Ausfallzeiten sind gering, die Latenz minimal und die Integration bereitet keine Probleme. Viele schätzen auch die geringen Kosten – Copilot kostet 10 $ pro Monat, Cursor 20 $ und Windsurf 15 $.
Mit der Einführung des Agent-Modus, des MCP-Supports und der Möglichkeit, externe Webinhalte einzubinden, hat Copilot zu seinen Konkurrenten aufgeschlossen. Der Agent-Modus ermöglicht automatisierte Aufgaben und Multi-File-Refactoring, während der MCP-Support die Integration von Drittsystemen erleichtert.
In Team- und Enterprise-Umgebungen hat Copilot einen Trumpf: die Reputation und den Support von GitHub. Große Firmen bevorzugen in der Regel einen etablierten Anbieter mit Supportvertrag. Copilot lässt sich über Azure OpenAI auch als on-Premises-ähnlicher Service buchen – eine Option für Unternehmen, die Datenhoheit verlangen.
Zum Abschluss einige Empfehlungen für verschiedene Zielgruppen und Zwecke – denn „das beste Tool“ gibt es nicht, es kommt darauf an, was man damit vorhat.
… Entwickler:innen, die einen bewährten und kostengünstigen KI-Assistenten suchen, der sich ohne Aufwand in ihren bestehenden Entwicklungsprozess einfügt. Wenn Sie bereits VS Code oder JetBrains IDEs nutzen und bessere Autocompletion sowie gelegentliche Chathilfe wünschen, ist Copilot ideal. Er brilliert bei Alltagsaufgaben, unterstützt eine enorme Bandbreite an Sprachen und verfügt über eine große Community und Support als Rückendeckung. Mit der Einführung des Agent-Modus und MCP-Support steht Copilot den anderen Lösungen auch im Hinblick auf Features in nichts nach. Ebenso spricht viel für Copilot, wenn das Budget ein Kriterium ist oder man in einem Unternehmen mit strikten Richtlinien arbeitet (Copilot for Business bietet entsprechenden Support und Compliance).
… Entwickler:innen, die einen bewährten und kostengünstigen KI-Assistenten wünschen, sowie für Advanced Developer und Softwarearchitekten, die komplexe Codebasen betreuen und bereit sind, in ein neues Tool zu investieren. Cursor spielt seine Stärken aus, wenn ein tiefes Projektverständnis gefragt ist – z. B. beim Refactoring großer Codebestände, beim schrittweisen Ausbau einer bestehenden Architektur oder wenn ein einzelner Entwickler sehr viel erledigen möchte (Cursor wirkt fast wie ein zweiter Entwickler, der einem nebenher Aufgaben abnimmt). Die Möglichkeit, mit verschiedenen KI-Modellen zu experimentieren, sowie die Integration von Websuche und firmeneigenen Dokumentationen sind für viele Profis ein Plus. Wenn Sie also gerne „Early Adopter“ von KI-Funktionen sind und die eigene Produktivität maximieren möchten, ist Cursor einen Blick wert. Bedenken Sie aber: Sie müssen Ihre Arbeitsgewohnheiten etwas umstellen (neue IDE) und sich mit den vielen Features vertraut machen, sonst nutzen Sie vielleicht nur 20 Prozent des Potenzials. In kleineren Teams ist Cursor äußerst leistungsfähig. In großen Teams mit heterogener Toollandschaft könnte die Einführung jedoch auf Widerstand stoßen.
… Entwickler:innen, die Wert auf einen reibungslosen KI-Workflow legen und viel im Web-/Mobile-Bereich unterwegs sind. Windsurfs eigene IDE ist hervorragend geeignet, um neue Projekte schnell zu realisieren – beispielsweise einen Prototyp, bei dem die KI gleich Code, Tests und Deployment vorbereiten soll. Dank der visuellen Vorschau und der Schritt-für-Schritt-Agentenlogik bleibt man im „High-Level“-Denken und lässt die KI vieles ausführen. Auch KI-Neulinge oder weniger erfahrene Coder:innen profitieren von Windsurf: Es fühlt sich an, als hätte man einen Mentor, der mitdenkt (z. B. schlägt Windsurf vor, was als Nächstes zu tun sein könnte). Wenn Sie hingegen Ihren Lieblingseditor nicht aufgeben wollen, bietet das Plug-in von Windsurf die Kernfunktionen von Windsurf überall. Das ist ideal für gemischte Teams, z. B. VS-Code- und IntelliJ-Nutzer, die einen einheitlichen KI-Assistenten möchten. Zu beachten ist, dass Windsurf als Produkt noch jung ist. Es ist also perfekt für diejenigen, die Experimentierfreude mitbringen und Feedback geben möchten, um zu helfen, eventuelle Probleme zu lösen. Größere Unternehmen könnten Windsurf attraktiv finden, da Windsurf bereits Selbsthosting und Datenschutzoptionen anbietet, etwa für Firmen, die kein Hochladen von Code in externe Clouds dulden. Außerdem ist Windsurf preislich fair (es gibt eine Free Tier).
Alle drei Kandidaten zeigen, wie KI die Softwareentwicklung revolutioniert. Welche Lösung die beste ist, hängt vom persönlichen Workflow und Anwendungsgebiet ab. Professionelle Entwickler:innen und Architekt:innen sollten sich überlegen, welche Rolle die KI einnehmen soll: als dezenter Helfer im Hintergrund (Copilot), umfassender Projektassistent mit allen Schikanen (Cursor) oder als Flow-orientierter Partner, der Entwicklerergonomie großschreibt (Windsurf). Um den eigenen Perfect Fit zu finden, lohnt es sich, alle einmal auszuprobieren. Es gibt für alle kostenfreie Testphasen.
Regelmäßig News zur Konferenz und der .NET-Community
Cursor ist eine eigenständige, KI-native Entwicklungsumgebung, die auf Visual Studio Code basiert. Sie bietet tief integrierte KI-Funktionen und unterstützt Entwickler bei komplexen Aufgaben mit automatisierten Workflows.
Windsurf legt den Schwerpunkt auf Datenschutz und lokales Projektverständnis. Der Editor indexiert Code lokal und ermöglicht KI-gestützte Abläufe über mehrere Dateien hinweg, ohne sensible Daten in die Cloud zu senden.
GitHub Copilot ist keine eigenständige IDE, sondern eine Erweiterung für Editoren wie Visual Studio Code. Sein Vorteil ist die enge Integration mit GitHub, sodass Pull-Requests, Issues und Repositories direkt einbezogen werden können.
Cursor und Windsurf setzen verstärkt auf lokale Verarbeitung und Schutz von Quellcode. Copilot arbeitet hingegen cloudbasiert, bietet aber durch GitHub eine enge Anbindung an Entwickler-Workflows.
Die drei Tools bieten unterschiedliche Preismodelle: Cursor und Windsurf mit gestaffelten Tarifen, Copilot mit einem günstigeren Abo, das besonders durch GitHub-Integration attraktiv ist. Die Wahl hängt von Budget und Teamgröße ab.
Cursor richtet sich an Entwickler:innen, die eine komplett KI-native IDE suchen. Besonders bei komplexen Projekten mit vielen Dateien entfaltet Cursor seine Stärken.
Windsurf eignet sich für Teams, die Datenschutz und lokale Datenhaltung priorisieren. Es bietet gleichzeitig flexible KI-Workflows über mehrere Dateien hinweg.
GitHub Copilot ist ideal für Entwickler:innen, die GitHub intensiv nutzen und eine nahtlose Integration in bestehende Workflows wünschen. Durch die Anbindung an Repositories und Issues erleichtert es den Alltag im GitHub-Ökosystem.
[4] https://code.visualstudio.com
The post KI-IDEs im Vergleich: Cursor, Windsurf & Copilot appeared first on BASTA!.
]]>The post .NET 10 Preview 3 & 4: Das steckt drin appeared first on BASTA!.
]]>.NET 10.0 SDK kann direkt zusammen mit Visual Studio 2022 Version 17.14 installiert werden.
Die nachträgliche Erweiterbarkeit von Klassen (auch wenn diese bereits anderenorts kompiliert sind, z. B. in den von Microsoft gelieferten Klassen in den .NET-Klassenbibliotheken) um zusätzliche Methoden, gibt es unter dem Namen „Extension Methods“ bereits seit C#-Sprachversion 3.0, die zusammen mit .NET Framework 3.5 im Jahr 2007 erschienen ist. Man kann mit Extension Methods aber lediglich eine Instanzmethode zu bestehenden Klassen ergänzen. So mussten Entwicklerinnen und Entwickler zwangsweise Konstrukte, die vom Namen her eigentlich Properties waren, leidigerweise als Methoden ausdrücken, siehe IsEmptyClassic() in Listing 1.
public static class StringExtensionClassic
{
public static string TruncateClassic(this string s, int count)
{
if (s == null) return "";
if (s.Length <= count) return s;
return s.Substring(0, count) + "...";
}
public static bool IsEmptyClassic(this string s)
=> String.IsNullOrEmpty(s);
}
In der .NET-Klassenbibliothek gibt es aus diesem Grund einige Erweiterungsmethoden, die Namen besitzen, die man intuitiv als Property erwarten würde, z. B.:
In C# 14.0 bietet Microsoft nun mit dem neuen Blockschlüsselwort extension eine verallgemeinerte Möglichkeit der Erweiterung bestehender .NET-Klassen, die „Extension Members“ heißt.
Das Schlüsselwort extension muss Teil einer statischen, nichtgenerischen Klasse auf der obersten Ebene sein (also keine Nested Class). Nach dem Schlüsselwort extension deklariert man den zu erweiternden Typ (Receiver). In Listing 2 ist der Receiver die Klasse System.String (alternativ abgekürzt durch den eingebauten Typ string). Alle Methoden und Properties innerhalb des Extension-Blocks erweitern dann den hier genannten Receiver-Typ. Aktuell kann man in diesen Extension-Blöcken folgende Konstrukte verwenden (Listing 2):
Eine Klasse darf mehrere Extension-Blöcke sowie zusätzlich auch klassische Extension Methods und andere statische Mitglieder enthalten (Listing 2). Das erlaubt Entwicklerinnen und Entwicklern, eine bestehende Klasse mit Extension Methods um Extension-Blöcke zu erweitern. Es darf auch mehrere Klassen mit Extension-Blöcken für einen Receiver-Typ geben.
public static class MyExtensions
{
extension(System.String s)
{
// Erweitern um eine Instanz-Methode
public string Truncate(int count)
{
if (s == null) return "";
if (s.Length <= count) return s;
return s.Substring(0, count) + string.Dots;
}
// Erweitern um eine Instanz-Eigenschaft
public bool IsEmpty => String.IsNullOrEmpty(s);
// Erweitern um eine Instanz-Eigenschaft mit Getter und Setter
public int Size
{
get { return s.Length; }
set
{
if (value < s.Length) s = s.Substring(0, value);
if (value > s.Length) s = s + new string('.', value - s.Length); // Neuzuweisung geht nicht !!!
}
}
// Erweitern um eine statische Methode
public static string Create(int count, char c = '.')
{
return new string(c, count);
}
// Erweitern um eine statische Instanz-Eigenschaft
public static string Dots => "...";
}
// Es darf auch eine Extension für einen anderen Typen geben
extension(List<int> source)
{
public List<int> WhereGreaterThan(int threshold)
=> source.Where(x => x > threshold).ToList();
public bool IsEmpty
=> !source.Any();
// Erweitern um eine Instanz-Eigenschaft mit Getter und Setter
public int Size
{
get { return source.Count; }
set
{
if (value < source.Count) source = source.Take(value).ToList();
if (value > source.Count) source.AddRange(Enumerable.Repeat(0, value - source.Count));
}
}
}
// Es kann auch eine klassische Extension Method in der gleichen Kasse geben
public static string TruncateClassic2(this string s, int count)
{
if (s == null) return "";
if (s.Length <= count) return s;
return s.Substring(0, count) + "...";
}
// Es kann auch andere statische Methoden in der gleichen Klasse geben
public static Version ExtensionVersion => new Version(1, 0, 0);
}
Zu beachten ist:
public class CS14_ExtensionDemo
{
public void Run()
{
CUI.Demo(nameof(CS14_ExtensionDemo) + ": String");
string s1old = "Hallo Holger";
string s1oldtruncated = s1old.TruncateClassic(5);
Console.WriteLine(s1oldtruncated); // Hello...
string s2old = null;
Console.WriteLine(s2old.IsEmptyClassic()); // true
string s1 = "Hallo Holger";
string s1truncated = s1.Truncate(5);
Console.WriteLine(s1truncated); // Hello...
// Das geht nicht, weil das Size Property versucht, die Zeichenkette neu zuzuweisen!
s1.Size = 5;
Console.WriteLine(s1); // Hallo Holger statt wie erwartet Hallo
string s2 = null;
Console.WriteLine(s2.IsEmpty); // true
string s3 = string.Create(5, '#');
Console.WriteLine(s3); // "#####"
CUI.Demo(nameof(CS14_ExtensionDemo) + ": Collection");
var list = new List<int> { 1, 2, 3, 4, 5 };
var large = list.WhereGreaterThan(3);
Console.WriteLine(large.IsEmpty);
if (large.IsEmpty)
{
Console.WriteLine("Keine Zahlen größer als 3!");
}
else
{
Console.WriteLine(large.Count + " Zahlen sind größer als 3!");
}
// Das klappt: Die Liste wird auf 10 Elemente aufgefüllt
list.Size = 10;
foreach (var x in list)
{
Console.WriteLine(x);
}
}
}
Ein weiteres sehr hilfreiches neues Sprachkonstrukt in C# 14.0 nennt Microsoft das „Null-Conditional Assignment“. Damit können Entwicklerinnen und Entwickler eine Zuweisung an eine Eigenschaft machen ohne vorher zu prüfen, ob das Objekt null ist. Anstelle von
Website aktuelleDOTNETWebsite = Website.Load(123);
if (aktuelleDOTNETWebsite!= null)
{
// Aktualisieren der URL
aktuelleDOTNETWebsite.Url = "https://www.dotnet10.de";
}
darf man nun verkürzt mit dem Fragezeichen vor dem Punkt (?.) schreiben:
aktuelleDOTNETWebsite?.Url = "https://www.dotnet10.de";
Dies führt zur Laufzeit zu keinem Fehler. Allerdings passiert auch rein gar nichts, falls die Variable aktuelleDOTNETWebsite den Wert null besitzt.
Regelmäßig News zur Konferenz und der .NET-Community
Seit .NET 10.0 Preview 4 können Entwicklerinnen und Entwickler einzelne C#-Dateien direkt übersetzen und starten – ohne dass es eine Projektdatei geben muss. Das ist möglich mit dem .NET-SDK-CLI-Befehl dotnet run (Abb. 1).

Abb. 1: Start einer eigenständigen C#-Datei mit dotnet run
Damit kann C# nun auch als Skriptsprache zum Einsatz kommen. Es gab dafür aber schon vorher Ansätze außerhalb von Microsoft:
Auch der klassische Stil mit class Program und Main()-Methode ist möglich in den eigenständigen C#-Dateien:
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Hallo von " + System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription);
}
}
Für Informationen, die üblicherweise in einer Projektdatei liegen, hat Microsoft eine eigene Syntax beginnend mit der Raute # (Präprozessordirektiven) eingeführt:
Listing 4 zeigt ein Beispiel mit zwei NuGet-Paketen.
#:package [email protected] #:package [email protected].* #:property LangVersion preview #:property Version 1.1.2 using Spectre.Console; using Humanizer; var title = "C# Script " + System.Reflection.Assembly.GetExecutingAssembly().GetName().Version + " mit " + System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription; var panel = new Panel(title); AnsiConsole.Write(panel); Console.WriteLine(); var d = new Data { Version = "9.0", Release = "2024-12-3" }; var dotNet9Released = DateTimeOffset.Parse(d.Release); var since = DateTimeOffset.Now - dotNet9Released; Console.WriteLine($"It has been {since.Humanize()} since .NET {d.Version} was released."); class Data { public string Version { get; set; } public string Release { get; set; } }
Das nächste Beispiel in Listing 5 und Abbildung 2 zeigt ein ASP.NET Core Minimal WebAPI als eigenständige C#-Datei.
#:sdk Microsoft.NET.Sdk.Web #:package Microsoft.AspNetCore.OpenApi@10.*-* #:package [email protected] #:property Version 1.1.4 using Humanizer; using Microsoft.OpenApi; // Webserver einrichten var builder = WebApplication.CreateBuilder(); builder.Services.AddOpenApi(); var app = builder.Build(); app.MapOpenApi(); // http://localhost:5000/openapi/v1.json app.MapGet("/", () => { // Daten für Operation var d = new Data { Version = "9.0", Release = "2024-12-3" }; var dotNet9Released = DateTimeOffset.Parse(d.Release); var since = DateTimeOffset.Now - dotNet9Released; return $"It has been {since.Humanize()} since .NET {d.Version} was released."; }); app.Run(); class Data { public string Version { get; set; } public string Release { get; set; } }

Abb. 2: Start und Ausgabe des Webservers
Wenn die Anforderungen höher werden, sind C#-Skripte keine Sackgasse. Man kann per Kommandozeilenbefehl aus einem C#-Skript ein C#-Projekt machen (Abb. 3):
dotnet project convert .\WebserverStandalone.cs

Abb. 3: Umwandeln einer eigenständigen C#-Skriptdatei in ein C#-Projekt
Dabei werden ein neuer Ordner und eine Projektdatei angelegt, wobei letztere die Präprozessorinformationen aus der C#-Datei übernimmt (Abb. 4).

Abb. 4: Das eigenständige C#-Projekt
ZIP-Komprimierung gibt es in der .NET-Basisklassenbibliothek seit dem klassischen .NET Framework 4.5 und im modernen .NET seit Version .NET Core 1.0. Seit .NET 10.0 Preview 4 gibt es nun in den Klassen System.IO.Compression.ZipFile, System.IO.Compression.ZipArchive und System.IO.Compression.ZipEntry asynchrone Pendants zu bestehenden synchronen Methoden, z. B. ExtractToDirectoryAsync(), ExtractToFileAsync(), CreateFromDirectoryAsync(), OpenAsync(), OpenReadAsync(), CreateAsync() und CreateEntryFromFileAsync(). Listing 6 zeigt mehrere Beispiele für asynchrone ZIP-Operationen.
using System.IO.Compression;
using System.Text;
using ITVisions;
namespace NET10_Console;
internal class FCL10_Zip
{
private const string ArchiveFileName = @"t:\CTempArchive.zip";
private const string SourceDirectoryName = @"c:\temp";
private const string DestinationDirectoryName = @"t:\CTempArchiveExtract";
private const string TempFileName = @"t:\tempfile.pdf";
public async Task Run()
{
CUI.Demo(nameof(FCL10_Zip));
// Prüfe, ob die Datei existiert
if (File.Exists(ArchiveFileName)) File.Delete(ArchiveFileName);
// Create a Zip archive
await ZipFile.CreateFromDirectoryAsync(SourceDirectoryName, ArchiveFileName, CompressionLevel.SmallestSize, includeBaseDirectory: true, entryNameEncoding: Encoding.UTF8);
// Prüfe, ob die Datei existiert
if (File.Exists(ArchiveFileName)) CUI.Green("ZIP-Datei erstellt: " + ArchiveFileName);
else CUI.Red("ZIP-Datei nicht erstellt: " + ArchiveFileName);
// Extract a Zip archive
await ZipFile.ExtractToDirectoryAsync(ArchiveFileName, DestinationDirectoryName, overwriteFiles: true);
// Prüfe, ob das Verzeichnis existiert
if (Directory.Exists(DestinationDirectoryName)) CUI.Green("Verzeichnis extrahiert: " + DestinationDirectoryName);
else CUI.Red("Verzeichnis nicht extrahiert: " + DestinationDirectoryName);
#region Lesen und Schreiben von Einträgen in eine ZIP-Datei
using (var archiveStream = new FileStream(ArchiveFileName, FileMode.OpenOrCreate, FileAccess.ReadWrite))
{
await using (ZipArchive a = await ZipArchive.CreateAsync(archiveStream, ZipArchiveMode.Update, leaveOpen: false, entryNameEncoding: Encoding.UTF8))
{
// Suche die erste PDF-Datei in a.Entries
var pdfFileEntry = a.Entries.Where(x => x.Name.EndsWith(".pdf")).FirstOrDefault();
if (pdfFileEntry != null)
{
await pdfFileEntry.ExtractToFileAsync(destinationFileName: TempFileName, overwrite: true);
await using Stream entryStream = await pdfFileEntry.OpenAsync();
ZipArchiveEntry createdEntry = await a.CreateEntryFromFileAsync(sourceFileName: TempFileName, entryName: "Doppelt_" + pdfFileEntry.Name);
CUI.Green("Erste PDF-Datei wurde verdoppelt: " + pdfFileEntry.Name);
}
}
}
#endregion
}
}
Eine Verbesserung für den Zertifikatsexport stand schon in den Release Notes zu .NET 10.0 Preview 2 [6], funktionierte dort aber nicht. Seit .NET 10.0 Preview 3 kann man tatsächlich Zertifikate mit AES-Verschlüsselung und Hashing via SHA-2-256 exportieren – mit der neuen Methode ExportPkcs12() als Ergänzung zur bestehenden Methode Export():
byte[] pfxData = cert.ExportPkcs12(Pkcs12ExportPbeParameters.Pbes2Aes256Sha256, password);
Die bisherige Methode Export() verwendet noch veraltete Algorithmen (3DES-Verschüsselung und SHA-1-Hashing). Die alten Verfahren (3DES/SHA-1) aus Export() sind aber auch über die neue Methode möglich, wenn man es wirklich will:
byte[] pfxData = cert.ExportPkcs12(Pkcs12ExportPbeParameters.Pkcs12TripleDesSha1, password);
Listing 7 zeigt ein Beispiel für die Erstellung und den Export eines Zertifikats.
string certPath = "meinZertifikat.pfx";
string password = "meinPasswort"; // Passwort zum Schutz des Zertifikats
// Selbstsigniertes Zertifikat erstellen
using (var rsa = RSA.Create(2048))
{
var request = new CertificateRequest(
"CN=TestZertifikat",
rsa,
HashAlgorithmName.SHA256,
RSASignaturePadding.Pkcs1);
// Zertifikat für 1 Jahr gültig machen
var cert = request.CreateSelfSigned(
DateTimeOffset.Now,
DateTimeOffset.Now.AddYears(1));
// ALT: Zertifikat mit 3DES-Verschüsselung und SHA1-Hashing exportieren
//byte[] pfxData = cert.Export(X509ContentType.Pkcs12, password);
// NEU: Zertifikat als AES mit SHA-2-256 exportieren
byte[] pfxData = cert.ExportPkcs12(Pkcs12ExportPbeParameters.Pbes2Aes256Sha256, password);
// NEUE Methode, aber alte Sicherheitsverfahren: 3DES mit SHA-1
//byte[] pfxData = cert.ExportPkcs12(Pkcs12ExportPbeParameters.Pkcs12TripleDesSha1, password);
// PFX-Datei speichern
File.WriteAllBytes(certPath, pfxData);
Console.WriteLine($"Test-Zertifikat erstellt und gespeichert unter: {certPath}");
}
System.Text.Json beherrscht nun den JSON-Patch-Standard nach RFC 6902. JSON Patch ist ein standardisiertes Format (definiert in RFC 6902), um Änderungen an JSON-Dokumenten zu beschreiben. Es ermöglicht die Übertragung von Änderungen an einem JSON-Dokument in Form einer Liste von Anweisungen (Operationen). JSON Patch wird häufig in WebAPIs eingesetzt.
Bisher musste man in ASP.NET-Core-basierten WebAPIs für JSON Patch die ältere Community-Bibliothek Newtonsoft.Json einsetzen. Nun geht es auch mit der neueren Microsoft-Bibliothek System.Text.Json [7].
Für JSON Patch mit System.Text.Json gibt es eine Erweiterung für System.Text.Json in Form des neuen NuGet-Pakets Microsoft.AspNetCore.JsonPatch.SystemTextJson, das erstmalig mit .NET 10.0 Preview 4 erschienen ist [8].
Trotz des “AspNetCore” im Namen funktioniert dieses Zusatzpaket auch außerhalb von ASP.NET Core, wie Listing 8 beweist! Allerdings funktioniert das neue Paket nicht mit dem NativeAOT-Compiler.
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
public string Email { get; set; }
public List<PhoneNumber> PhoneNumbers { get; set; } = new();
public Address Address { get; set; }
}
public class Address
{
public string Street { get; set; }
public string City { get; set; }
public string State { get; set; }
public string ZipCode { get; set; }
}
public enum PhoneNumberType
{
Mobile,
Home,
Work,
Other
}
public class PhoneNumber
{
public string? Number { get; set; }
public PhoneNumberType Type { get; set; }
}
public void JSONPatchDemo()
{
// Originalobjekt
var person = new Person
{
FirstName = "Holger",
LastName = "Schwichtenberg",
Email = "[email protected]",
PhoneNumbers = [new PhoneNumber() { Number = "0201 649590-0", Type = PhoneNumberType.Work }],
Address = new Address
{
Street = "Fahrenberg 40b",
City = "Essen",
State = "NRW"
}
};
CUI.H2("Ausgabe des Objekts in seinem alten Zustand");
CUI.Print(ITVisions.ObjectDumper.Dump(person));
// JSON Patch-Document
string jsonPatch = """
[
{ "op": "replace", "path": "/FirstName", "value": "Dr. Holger" },
{ "op": "remove", "path": "/Email"},
{ "op": "add", "path": "/Address/ZipCode", "value": "45257" },
{ "op": "add", "path": "/PhoneNumbers/-", "value": { "Number": "0201 649590-40" } }
]
""";
// JSON Patch-Document laden
JsonPatchDocument<Person>? patchDoc = JsonSerializer.Deserialize<JsonPatchDocument<Person>>(jsonPatch);
// JSON Patch-Document anwenden auf das Person-Objekt
patchDoc!.ApplyTo(person);
CUI.H2("Ausgabe des Objekts in seinem neuen Zustand");
CUI.Print(ITVisions.ObjectDumper.Dump(person));
}
Microsoft verspricht in der neuen Implementierung „eine verbesserte Leistung und weniger Speichernutzung im Vergleich zu der existierenden Implementierung in Newtonsoft.Json“ [9] in Verbindung mit einem ähnlichen Design wie bei Newtonsoft.Json, einschließlich der Aktualisierung eingebetteter Objekte und Arrays. Bisher nicht verfügbar ist JSON Patch für dynamische Objekte, weil Newtonsoft.Json dafür Reflection einsetzt, System.Text.Json soll aber auch mit dem NativeAOT-Compiler funktionieren.
Im NuGet-Paket Microsoft.AspNetCore.JsonPatch.SystemTextJson gibt es eine Klasse Microsoft.AspNetCore.JsonPatch.SystemTextJson.JsonPatchDocument<T> mit einer Methode ApplyTo (obj), die eine JSON-Patch-Operation auf das übergebene Objekt anwendet (Listing 8). Das resultierende JSON-Dokument für die Person nach Anwendung des JSON-Patch-Dokuments sieht dann aus wie in Abbildung 5.

Abb. 5: Ausgabe des Listings 8
Alternativ kann man das Objekt natürlich auch als JSON ausgeben (Abb. 6). Das ist nur in dem obigen Listing nicht passiert, weil nicht der Eindruck entstehen soll, man müsse das Objekt als JSON weiterverwenden.

Abb. 6: Ausgabe des geänderten Objekts im JSON-Format
Mit JSON Patch kann man auch Werte in einem Objekt testen (Listing 9).
CUI.H2("Testen mit JSON Patch-Dokument");
string jsonPatchTest = """
[
{ "op": "test", "path": "/FirstName", "value": "Dr. Holger" },
{ "op": "test", "path": "/Email", "value": null},
{ "op": "test", "path": "/Address/ZipCode", "value": "45257" }
]
""";
// JSON Patch-Document laden
JsonPatchDocument<Person>? patchTestDoc = JsonSerializer.Deserialize<JsonPatchDocument<Person>>(jsonPatchTest);
// JSON Patch-Document anwenden auf das Person-Objekt
patchTestDoc!.ApplyTo(person, patchError => CUI.PrintError(patchError.ErrorMessage));
In diesem Fall gibt es keine Fehlerausgabe. Wenn man das Dokument aber verändert (Listing 10), bekommt man drei Fehlertexte (Abb. 7).
CUI.H2("Testen mit JSON Patch-Dokument");
string jsonPatchTest = """
[
{ "op": "test", "path": "/FirstName", "value": "Dr.Holger" },
{ "op": "test", "path": "/Email", "value": ""},
{ "op": "test", "path": "/Address/ZipCode", "value": "45251" }
]
""";

Abb. 7: Fehlertexte
Dabei ist die Fehlermeldung bei Email nicht gut, denn sie unterscheidet nicht zwischen Leerstring und Null. Im Objekt steht null, getestet wird auf Leerstring. In der Fehlermeldung steht in beiden Fällen ‘ ‘.
Entity Framework Core 10.0 unterstützt seit Preview 4 in Verbindung mit Azure CosmosDB zwei neue Suchmodi, die es dort seit März 2025 als Vorschauversion gibt: Volltextsuche [10] und hybride Suche, die die Vektorsuche und Volltextsuche mit einer Reciprocal Rank Fusion (RRF) Function kombiniert [11]. Microsoft hat zudem angekündigt [12], dass die in Entity-Framework-Core-Version 9.0 eingeführte Vektorsuche mit CosmosDB nun stabil ist.
Regelmäßig News zur Konferenz und der .NET-Community
Bisher war die Metadatengenerierung mit OpenAPI Specification (OAS) nur in der Projektvorlage ASP.NET Core Web API (Kurzname: webapi) aktiv, die keine Kompilierung mit dem NativeAOT-Compiler erlaubt. In der Projektvorlage ASP.NET Core Web API (nativeAOT) (Kurzname: webapiaot) mit aktivierter NativeAOT-Kompilierung war OAS zwar integrierbar, aber das mussten Entwicklerinnen und Entwickler manuell vornehmen.
Seit .NET 10.0 Preview 4 ist in der Projektvorlage ASP.NET Core Web API (nativeAOT) nun die Metadatengenerierung mit OAS im Standard aktiviert (Abb. 8). Mit dem Befehl
dotnet new webapiaot --name ITVisionsWebAPI
entsteht ein Projekt, das das NuGet-Paket Microsoft.AspNetCore.OpenApi referenziert und die OpenAPI-Unterstützung in der Program.cs mit
builder.Services.AddOpenApi();
und
app.MapOpenApi();
aktiviert.
In der Projektvorlage webapiaot können Entwicklerinnen und Entwickler die OpenAPI-Features wahlweise auch mit dem Parameter –no-openapi deaktivieren:
dotnet new webapiaot --name ITVisionsWebAPI --no-openapi

Abb. 8: Die neue Option für WebAPI-AOT-Projekte in Visual Studio
Mit aktiviertem OpenAPI-Support wird dann dieses NuGet-Paket eingebunden:
<PackageReference Include="Microsoft.AspNetCore.OpenApi" … />
In Program.cs steht dann:
builder.Services.AddOpenApi();
...
if (app.Environment.IsDevelopment())
{
app.MapOpenApi();
}
Der Standard-URL des OpenAPI-Dokuments ist dann: https://localhost:PORT/openapi/v1.json.
Seit .NET 10.0 Preview 3 gibt es eine neue Methode AddOpenApiOperationTransformer(), mit der Entwicklerinnen und Entwickler das generierte OpenAPI-Dokument verändern können. Beispiel: Eine Operation /checkwebsite liefert normalerweise HTTP-Statuscode 200 mit der Beschreibung „OK“ zurück (Abb. 9).

Abb. 9: Ausschnitt aus dem OpenAPI-Dokument vor Veränderung des Antwortbeschreibungstexts und der Parameterliste
Dieser Text kann verändert werden mit Aufruf von AddOpenApiOperationTransformer(). Ebenso kann ein Parameter ergänzt werden, z. B. ein zusätzlicher Wert, der im Header des HTTP-Requests übergeben werden muss (Listing 11), (Abb. 10).
app.MapGet("/checkwebsite", Operations.CheckWebsite)
.WithName("checkwebsite")
.AddOpenApiOperationTransformer((operation, ContextBoundObject, ct) =>
{
// Ergänzen eines Parameters, der im Header übergeben werden muss
operation.Parameters.Add(new OpenApiParameter
{
Name = "Customer-GUID",
In = ParameterLocation.Header,
Description = "Your Customer GUID for Authentication",
Required = true,
Schema = new OpenApiSchema
{
Type = JsonSchemaType.String,
Format = "uuid"
}
});
// Änderung des Beschreibungstextes für Statuscode 200
operation.Responses?["200"].Description = "Die Prüfung war erfolgreich";
return Task.CompletedTask;
});

Abb. 10: Ausschnitt aus dem OpenAPI-Dokument nach Veränderung des Antwortbeschreibungstextes
ASP.NET Core Minimal WebAPIs beherrschen seit .NET 10.0 Preview 3 auch die Parametervalidierung mit Data Annotations. Das konnten bisher nur die Controller-basierten WebAPIs [13].
Für Minimal WebAPIs müssen Entwicklerinnen und Entwickler das Validierungsfeature allerdings erst in der Projektdatei aktivieren mit
<PropertyGroup>
<!-- Enable the generation of interceptors for the validation attributes -->
<InterceptorsNamespaces>$(InterceptorsNamespaces);Microsoft.AspNetCore.Http.Validation.Generated</InterceptorsNamespaces>
</PropertyGroup>
und in der Startdatei mit
builder.Services.AddValidation();
Dann kann man auch in Minimal WebAPIs mit den bekannten Validierungsannotationen wie [MinLength], [MaxLength], [Range], [Url], [EmailAddress], [Phone], [CreditCard], [RegularExpression] u. v. m. [14] arbeiten, z. B.
app.MapGet("/checkwebsite", ([MinLength(5)] string name, [Url] string url)
=> WebsiteChecker.CheckWebsite(name, url));
Hier führt nun der HTTP-Aufruf https://Server:Port/checkwebsite?name=ITVisions&url=www.IT-Visions.de zur Laufzeit zur Rückgabe eines JSON-Dokuments zu zwei Validierungsfehlern (Abb. 11). Seit Preview 4 funktioniert das auch, wenn die Parameter ein Record-Typ sind.

Abb. 11: Beide Parameter beim Aufruf dieses ASP.NET Core Minimal WebAPI entsprachen hier nicht den Validierungsregeln
Microsoft Webframework ASP.NET Core erlaubt bei Blazor Server und Blazor WebAssembly bisher schon die Übergabe von Daten zwischen dem Prerendering und dem Hauptrendering via JSON-Anhang in HTML-Dokumenten. Dieser Persistent Component State war bisher aber recht aufwendig für die Entwicklerinnen und Entwickler in der Realisierung, denn man musste zunächst ein Objekt per Dependency Injection bekommen
@inject PersistentComponentState ApplicationState
und dann den Zustand als Objekt dort ablegen
private PersistingComponentStateSubscription? persistingSubscription;
persistingSubscription = ApplicationState.RegisterOnPersisting(() =>
{
ApplicationState.PersistAsJson("name", daten);
return Task.CompletedTask;
});
und jeweils vor der Nutzung wieder explizit herausholen:
if (ApplicationState.TryTakeFromJson<Typ>("name", out var daten))
{
Daten = daten;
}
Das hat Microsoft in .NET 10.0 Preview 3 mit dem deklarativen Persistent Component State radikal vereinfacht. Entwicklerinnen und Entwickler müssen jetzt nur noch ein Property mit der Annotation [SupplyParameterFromPersistentComponentState] versehen und sich sonst um nichts kümmern:
[SupplyParameterFromPersistentComponentState]
public Daten? daten { get; set; }
Im Beispiel in Listing 12 sehen Sie auskommentiert die alte Variante im Vergleich zur neuen Variante.
@page "/State"
@using BO.WWWings
@* @inject PersistentComponentState ApplicationState *@
<PageTitle>Counter</PageTitle>
<h1>Flight-Counter <span class="badge bg-warning">@this.RendererInfo.Name</span></h1>
<p role="status" title="@pageState.LastChange">Current count: @pageState.CurrentCount</p>
<button class="btn btn-primary" @onclick="IncrementCount">+</button>
<button class="btn btn-primary" @onclick="DecrementCount">-</button>
@if (this.pageState?.FlightSet != null)
{
<hr noshade>
<ol>
@foreach (Flight f in this.pageState.FlightSet.Take(this.pageState.CurrentCount))
{
<li>Flug #@f.FlightNo (@f.FlightDate.ToShortDateString()) @f.Departure -> @f.Destination </li>
}
</ol>
}
@code {
[SupplyParameterFromPersistentComponentState]
public PageState pageState { get; set; } = null;
private void IncrementCount()
{
pageState.CurrentCount++;
}
private void DecrementCount()
{
if (pageState.CurrentCount > 0) pageState.CurrentCount--;
}
// -----------------------------
// private PersistingComponentStateSubscription? persistingSubscription;
protected override void OnInitialized()
{
// persistingSubscription = ApplicationState.RegisterOnPersisting(() =>
// {
// ApplicationState.PersistAsJson(nameof(PageState), pageState);
// return Task.CompletedTask;
// });
if (pageState == null)
{
DA.WWWings.WwwingsV1EnContext ctx = new();
pageState = new() {
FlightSet = ctx.Flights.Take(100).ToList(),
CurrentCount = 10, Created = DateTime.Now };
}
// if (ApplicationState.TryTakeFromJson<PageState>(nameof(PageState), out PageState daten))
// {
// pageState = daten;
// }
}
public class PageState
{
public DateTime Created { get; set; }
public DateTime LastChange { get; set; }
public int _CurrentCount;
public int CurrentCount
{
get
{
return _CurrentCount;
}
set
{
_CurrentCount = value;
LastChange = DateTime.Now;
}
}
public List<Flight> FlightSet { get; set; }
}
}
Die in Blazor eingebauten Implementierungen der abstrakten Basisklasse Microsoft.AspNetCore.Components.NavigationManager haben in Blazor 10.0 Preview 4 zwei neue Mitglieder erhalten: NotFound() und OnNotFound().
Die neue Methode NotFound() signalisiert Blazor, dass eine angeforderte Ressource nicht vorhanden ist. Beim statischen Server-side Rendering bekommt der Webbrowser dann eine HTTP-Antwort mit Statuscode 404. Beim interaktiven Rendering (Blazor Server, Blazor WebAssembly, Blazor Hybrid) wird gerendert, was im Router bei <NotFound> definiert ist.
OnNotFound() ist ein Ereignis, das von Blazor ausgelöst wird, wenn die Methode NotFound() aufgerufen wird.
NavigationManager.NavigateTo() funktioniert nun auch beim statischen Server-side Rendering. Bisher lieferte dies immer den Laufzeitfehler NavigationException. Für Anwendungen, die diesen Fehler erwarten, hat Microsoft einen Schalter eingebaut, der das bisherige Verhalten zurückholt:
AppContext.SetSwitch("Microsoft.AspNetCore.Components.Endpoints.NavigationManager.EnableThrowNavigationException", isEnabled: true);
Das bereits in Blazor 9.0 eingeführte Fingerprinting (Anhängen eines Hashwerts auf Basis des Dateiinhalts an den Dateinamen, was vermeidet, dass Webbrowser alte Versionen aus dem Browsercache verwenden) funktioniert nun auch für die in Blazor eingebaute JavaScript-Datei in den sogenannten „Standalone Blazor WebAssembly“-Projekten, die nicht in ASP.NET Core betrieben werden, sondern auf einem statischen Webserver gehostet sein können.
Man verwendet dazu man in den Projekteinstellung
<OverrideHtmlAssetPlaceholders>true</OverrideHtmlAssetPlaceholders>
und im HTML-Kopfbereich in der index.html:
<link rel="preload" id="webassembly" /> <script type="importmap"></script>
Das <script>-Tag ist dann
<script src="proxy.php?url=_framework/blazor.webassembly#[.{fingerprint}].js"></script>
Diese Verbesserung ist seit .NET 10.0 Preview 4 auch in der Projektvorlage blazorwasm umgesetzt:
dotnet new blazorwasm -n ITVisionsDemo
Die index.html-Datei sieht dort so aus wie in Listing 13 gezeigt.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>NET10_BlazorWasmStandalone</title>
<base href="/" />
<link rel="preload" id="webassembly" />
<link rel="stylesheet" href="lib/bootstrap/dist/css/bootstrap.min.css" />
<link rel="stylesheet" href="css/app.css" />
<link rel="icon" type="image/png" href="favicon.png" />
<link href="NET10_BlazorWasmStandalone.styles.css" rel="stylesheet" />
<link href="manifest.webmanifest" rel="manifest" />
<link rel="apple-touch-icon" sizes="512x512" href="icon-512.png" />
<link rel="apple-touch-icon" sizes="192x192" href="icon-192.png" />
< script type="importmap"></script>
</head>
<body>
<div id="app">
<svg class="loading-progress">
<circle r="40%" cx="50%" cy="50%" />
<circle r="40%" cx="50%" cy="50%" />
</svg>
<div class="loading-progress-text"></div>
</div>
<div id="blazor-error-ui">
An unhandled error has occurred.
<a href="." class="reload">Reload</a>
<span class="dismiss">🗙</span>
</div>
< script src="_framework/blazor.webassembly#[.{fingerprint}].js"></script>
< script>navigator.serviceWorker.register('service-worker.js');</script>
</body>
</html>
Der Build-Prozess sorgt dafür, dass einige Ersetzungen stattfinden (siehe grüne Rahmen in den Abbildungen 12 und 13).

Abb. 12: Ersetzungen in der index.html durch den Build-Prozess (Teil 1)

Abb. 13: Ersetzungen in der index.html durch den Build-Prozess (Teil 2)
Wichtig: In bestehenden Projekten müssen Entwicklerinnen und Entwickler die Änderungen manuell vornehmen, um die Optimierungen zu nutzen.
In Blazor-WebAssembly-Anwendungen mussten Entwicklerinnen und Entwickler die Umgebungsdefinition (Development, Staging, Production) bisher per HTTP-Header vornehmen [15]. Nun nimmt Microsoft beim Kompilieren von Blazor-WebAssembly-Anwendungen automatisch folgende Umgebungen an:
Entwicklerinnen und Entwickler können die Umgebungsart auch per Projekteinstellung in der Projektdatei (.csproj) explizit setzen, z. B. für die Umgebung Staging:
<WasmApplicationEnvironmentName>Staging</WasmApplicationEnvironmentName>
Regelmäßig News zur Konferenz und der .NET-Community
In Blazor-WebAssembly-basierten Anwendungen ist in der Klasse System.Net.Http.HttpClient im Standard nun das Response Streaming aktiv, um die Leistung zu erhöhen und den Speicherbedarf zu verringen (Listing 14, Abb. 14). Zuvor mussten Entwicklerinnen und Entwickler das Response Streaming manuell aktivieren mit
request.SetBrowserResponseStreamingEnabled(true);
@page "/HttpStreaming"
@using Microsoft.AspNetCore.Components.WebAssembly.Http
@using System.Net.Http
@using System.Diagnostics
@inject HttpClient HttpClient
<h1>HTTP Response Streaming</h1>
<button type="button" class="btn btn-primary" @onclick="Get">Laden</button>
<button type="button" class="btn btn-warning" @onclick="Stop">Abbrechen</button>
<input type="checkbox" @bind="streamingEnabled" /> Response Streaming aktivieren
<hr />
<p>Status: @status</p>
<p>Response Streaming aktiv: @streamingEnabled</p>
<p>Stream-Type: @streamType</p>
<p>Bytes gelesen: @byteCount</p>
<p>Dauer: @sw.ElapsedMilliseconds ms</p>
@code {
int byteCount;
string status = "";
string streamType = "Unknown";
bool streamingEnabled = false; // Set to true to enable streaming
Stopwatch sw = new Stopwatch();
CancellationTokenSource cts;
// Laden
async Task Get()
{
status = "Lade...";
sw.Reset();
sw.Start();
cts = new CancellationTokenSource();
using var request = new HttpRequestMessage(HttpMethod.Get, "https://www.it-visions.de/produkte/pdf/www.IT-Visions.de_Firmenbrosch%C3%BCre.pdf");
if (streamingEnabled) request.SetBrowserResponseStreamingEnabled(true);
else request.SetBrowserResponseStreamingEnabled(false);
// Beim Streaming; HttpCompletionOption.ResponseHeadersRead / Der Standardwert ist ResponseContentRead, was bedeutet, dass der Vorgang erst abgeschlossen werden soll, nachdem die gesamte Antwort, einschließlich des Inhalts, aus dem Socket gelesen wurde.
using var response = await HttpClient.SendAsync(request, streamingEnabled ? HttpCompletionOption.ResponseHeadersRead : HttpCompletionOption.ResponseContentRead);
using Stream stream = await response.Content.ReadAsStreamAsync();
streamType = stream.GetType().FullName; // Get the type of the stream: System.IO.MemoryStream oder System.Net.Http.HttpConnection+ContentLengthReadStream
// Blockweises Lesen des Streams
var bytes = new byte[10000];
while (!cts.Token.IsCancellationRequested)
{
var read = await stream.ReadAsync(bytes, cts.Token);
if (read == 0) // Ende des Streams erreicht
{
sw.Stop();
status = "Fertig!";
return;
}
byteCount += read;
// UI-Update
StateHasChanged();
await Task.Delay(1);
}
}
// Abbrechen
void Stop()
{
sw.Stop();
cts?.Cancel();
}
}

Abb. 14: Screenshot des Beispiels aus Listing 14 unter .NET 9.0
In .NET 10.0 ist das Response Streaming nun automatisch aktiv und der Stream-Typ ist ein anderer (Abb. 15).

Abb. 15: Screenshot des Beispiels aus Listing 14 unter .NET 10.0
Durch das im Standard aktive Response Streaming sind allerdings nur noch asynchrone Operationen und keine synchronen Operationen mehr möglich. Ein Aufruf der synchronen Send()-Methode HttpClient.Send(request) führt dann zum Laufzeitfehler „Operation is not supported on this platform.“ Diese Verhaltensänderung gehört zu den Breaking Changes in .NET 10.0 [16].
Das Response Streaming im HttpClient ist in .NET 10.0 deaktivierbar mit:
request.SetBrowserResponseStreamingEnabled(false);
Alternativ ist die Deaktivierung global in der Projektdatei möglich:
<WasmEnableStreamingResponse>false</WasmEnableStreamingResponse>
In Blazor erweitert Microsoft die Schnittstellen für die Interoperabilität zwischen C# und JavaScript (IJSRuntime, IJSInProcessRuntime, IJSObjectReference und IJSInProcessObjectReference) um neue Mitglieder, um eine Instanz von einem JavaScript-Objekt zu erzeugen und dabei Konstruktorparameter zu übergeben (InvokeNew() und InvokeNewAsync()) sowie um Variablen oder Objekteigenschaften zu lesen (GetValue() und GetValueAsync()) bzw. zu setzen (SetValue()und SetValueAsync()).
Bisher konnte man von C# aus lediglich Funktionen in JavaScript mit Invoke(), InvokeVoid(), InvokeAsync() und InvokeVoidAsync() aufrufen. Die neuen Interoperabilitätsmethoden vermeiden in einigen Fällen, dass man eine JavaScript-Wrapper-Funktion schreiben muss; stattdessen kann man nun direkt Objekte erzeugen und Werte lesen/schreiben. Ein Beispiel sieht man in den Listings 15 und 16 sowie Abbildung 16.
window.JSUtil = class {
constructor(text) {
// zwei Eigenschaften der JavaScript-Klasse
this.text = text;
this.caseSensitive = false;
}
// Hole Textlänge
getTextLength() {
return this.text.length;
}
// Prüfe, ob Text in der aktuellen URL vorkommt
containsTextInUrl() {
const url = window.location.href;
if (this.caseSensitive) return url.includes(this.text);
else return url.toLowerCase().includes(this.text.toLowerCase());
}
}
@inject IJSRuntime JSRuntime
@page "/interop"
@using ITVisions.Blazor
@inject BlazorUtil util
< script src="JSUtil.js"></script>
<h3>Blazor 10.0 C#/JavaScript-Interop</h3>
<hr noshade />
<button @onclick="Aktion">JavaScript aufrufen</button>
<br />
<ul>
@((MarkupString)Ausgabe)
</ul>
@code {
protected override Task OnInitializedAsync()
{
return base.OnInitializedAsync();
}
public string Ausgabe { get; set; } = "";
async Task Aktion()
{
// Eine einfache Variable setzen im Browser
await JSRuntime.SetValueAsync<Guid>("Token", Guid.NewGuid());
var token = await JSRuntime.GetValueAsync<string>("Token");
Ausgabe = "<li>Aktuelles Token: " + token + "</li>";
// Eine Eigenschaft des vorhandenen document-Objekts ändern
var titleOld = await JSRuntime.GetValueAsync<string>("document.title");
var titleNew = "Interop-Demo: " + DateTime.Now.ToLongTimeString();
await JSRuntime.SetValueAsync<string>("document.title", titleNew);
Ausgabe += "<li>Title geändert von '" + titleOld + "' auf '" + titleNew + "'" + "</li>";
// Ein neues JavaScript-Objekt erstellen und damit arbeiten
var jsObj = await JSRuntime.InvokeNewAsync("JSUtil", "Localhost");
var text = await jsObj.GetValueAsync<string>("text");
var textLength = await jsObj.InvokeAsync<int>("getTextLength");
await jsObj.SetValueAsync<bool>("caseSensitive", true);
var caseSensitive = await jsObj.GetValueAsync<bool>("caseSensitive");
var containsTextInUrl = await jsObj.InvokeAsync<bool>("containsTextInUrl");
Ausgabe += $"<li>Die Zeichenkette {text} hat {textLength} Zeichen und kommt{(containsTextInUrl ? "" : " NICHT")} in der aktuellen URL vor. Der Vergleich war '{(caseSensitive ? "casesensitive" : "caseinsensitive")}'.</li>";
}
}

Abb. 16: Ausgabe des Beispiels der Listing 15 und 16
Die in ASP.NET Core 10.0 Preview 2 eingeführte Methode CloseColumnOptionsAsync() heißt seit Preview 4 nun HideColumnOptionsAsync(). Damit kann man den Eingabedialog für Filterkriterien im Steuerelement <QuickGrid> schließen, wenn der Filter angewendet wurde (Listing 17).
<QuickGrid @ref="flightGrid" RowClass="ApplyRowClass" ItemsProvider="@itemsProvider" TGridItem="BO.WWWings.Flight" Virtualize="true" OverscanCount="@overscanCount">
<PropertyColumn Property="@(p => p.FlightNo)" Title="FlugNr" Sortable="true" />
<PropertyColumn Property="@(p => p.Departure)" Title="Abflugort" Sortable="true">
<ColumnOptions>
<input type="search" @bind="departureFilter" placeholder="Filter by Departure"
@bind:after="@(() => flightGrid.HideColumnOptionsAsync())" />
</ColumnOptions>
</PropertyColumn>
<PropertyColumn Property="@(p => p.Destination)" Title="Zielort" Sortable="true" />
<PropertyColumn Property="@(p => p.FlightDate)" Title="Datum" Format="dd.MM.yyyy" Sortable="true" />
</QuickGrid>
Eine größere neue Diagnosefunktion in .NET 10.0 bekam in Preview 4 die WebAssembly-basierte Variante von Blazor, die als Single Page App im Webbrowser läuft: Entwicklerinnen und Entwickler können im Webbrowser zur Laufzeit Diagnosedaten über Performance, Speicherinhalt und diverse Metriken sammeln.
Dazu muss man als Voraussetzung die .NET WebAssembly Build Tools in der aktuellen .NET-10.0-Version als .NET-SDK-Workload installieren (Abb. 17):
dotnet workload install wasm-tools

Abb. 17: Bei dotnet workload list sollte die jeweils aktuelle Version erscheinen (hier im Bild: Preview 4 von .NET 10.0)
In den .NET WebAssembly Build Tools gibt es zwei neue Funktionen:
Für die Nutzung der Performanceanalyse in den Browser-Entwicklerwerkzeugen gibt es in der Projektdatei die in Tabelle 1 aufgelisteten Einstellungen (Listing 18).

Tabelle 1: Projekteinstellungen für Blazor-WebAssembly-Diagnosedaten (Quelle: [17])
<Project Sdk="Microsoft.NET.Sdk.BlazorWebAssembly">
...
<!-- NEU: Blazor WebAssembly Runtime Diagnostics -->
<PropertyGroup>
<!-- Für Anzeige von "Timings" im Performance-Tab der Browser-Developer-Tools-->
<WasmProfilers>browser</WasmProfilers>
<WasmNativeStrip>false</WasmNativeStrip>
<WasmNativeDebugSymbols>true</WasmNativeDebugSymbols>
</PropertyGroup>
</Project>
Mit diesen Einstellungen erhält man in den Browser-Entwicklerwerkzeugen in der Registerkarte Performance eine Ansicht Timings mit der Ablauffolge der aufgerufenen .NET-Methoden (Abb. 18).

Abb. 18: Aufrufhierarchie der Methoden im Browser mit Zeitverbrauch in den Browser-Entwicklerwerkzeugen unter „Performance | Timings“
Mit den folgenden Einstellungen in der Projektdatei erlaubt man das Sammeln von Tracedaten und Memory Dumps einer Blazor-WebAssembly-Anwendung im Webbrowser. Die Daten werden als .nettrace-Datei im Browser heruntergeladen (Tabelle 2, Listing 19).

Tabelle 2: Projekteinstellungen für Blazor-WebAssembly-Diagnosedaten (Quelle: [17])
<Project Sdk="Microsoft.NET.Sdk.BlazorWebAssembly">
...
<!-- NEU: Blazor WebAssembly Runtime Diagnostics -->
<PropertyGroup>
<!-- Für Trace- und Memory-Dump-Files -->
<WasmPerfTracing>true</WasmPerfTracing>
<WasmPerfInstrumentation>all</WasmPerfInstrumentation>
<EventSourceSupport>true</EventSourceSupport>
<MetricsSupport>true</MetricsSupport>
</PropertyGroup>
</Project>
Danach kann man per JavaScript APIs auf die Diagnosedaten zugreifen. Diese Befehle gibt man in der Browserkonsole in den Browser-Entwicklerwerkzeugen ein:
globalThis.getDotnetRuntime(0).collectCpuSamples({durationSeconds: 5});
globalThis.getDotnetRuntime(0).collectPerfCounters({durationSeconds: 5});
globalThis.getDotnetRuntime(0).collectGcDump();
Entwicklerinnen und Entwickler erhalten die gesammelten Daten in einer .nettrace-Datei im Downloads-Ordner des Webbrowsers (Abb. 19).

Abb. 19: Herunterladen der Memory-Dump-Datei in Format .nettrace
Die .nettrace-Dateien mit CPU- und Performance-Counter-Dateien kann man ohne weitere Schritte in Visual Studio öffnen, indem man die Datei per File | Open öffnet oder einfach per Drag and Drop in den Dateibereich von Visual Studio zieht (Abb. 20 und 21).

Abb. 20: Ansicht der CPU-Nutzung der Blazor-WebAssembly-Anwendung in Visual Studio

Abb. 21: Nach Klick auf System.String.Join() sieht man die Anzahl der Aufrufe und die CPU-Nutzungszeit
Während man .netrace-Dateien mit CPU- und Performance-Counter-Dateien direkt in Visual Studio öffnen kann, muss man eine Speicherabbilddatei zunächst mit dem .NET-CLI-Werkzeug dotnet-gcdump [18] in eine .gcdump-Datei für Visual Studio konvertieren (Abb. 22).
Die Installation der aktuellen Version dieses Werkzeugs erfolgt mit
dotnet tool install --global dotnet-gcdump
Die Konvertierung einer .nettrace-Datei in eine .gcdump-Datei geht dann so:
dotnet-gcdump convert Dateiname.nettrace

Abb. 22: Konvertieren einer Speicherabbilddatei von .nettrace zu .gcdump
Die erzeugte .gcdump-Datei kann man dann in Visual Studio betrachten (Abb. 23). Man sieht, welche Typen wie oft instanziiert wurden und wie viele Bytes sie verbrauchen. Die Spalte Size (Bytes) sind dabei die Bytes, die der Typ selbst verbraucht. inclusive Size (Bytes) umfasst auch die von Unterobjekten verbrauchten Speicherplätze.

Abb. 23: Betrachten der Memory-Dump-Datei (.gcdump) in Visual Studio
Über die in diesem Beitrag besprochenen Neuerungen hinaus bietet .NET 10.0 einige kleinere Verbesserung für Validation Context, Telemetry und ML.NET, die man in den Release Notes zu .NET 10.0 Preview 3 findet [19].
Bei Windows Forms und WPF verwendet Microsoft seit .NET 10.0 Preview 4 den gleichen Programmcode für die Arbeit mit der Zwischenablage [20]. Das erleichtert Microsoft die Wartung des Programmcodes; Entwicklerinnen und Entwickler haben davon aber erstmal nichts.
Bis zum geplanten Erscheinen von .NET 10.0 im November 2025 werden noch drei weitere Preview-Versionen (Preview 5, 6 und 7) und zwei Release-Candidate-Versionen erscheinen. Mit der fertigen Version kann am 11. November 2025 gerechnet werden, denn Microsoft hat bereits eine virtuelle .NET Conf für den 11. bis 13. November 2025 angekündigt.
Als gerade Versionsnummer wird .NET 10.0 wieder Long Term Support (LTS) für 36 Monate erhalten, also bis November 2028, während der Support für .NET 9.0 schon im Mai 2027 enden wird. Weiterhin ist aktuell .NET 8.0 im Support, das Microsoft noch bis November 2026 unterstützen wird.
Regelmäßig News zur Konferenz und der .NET-Community
Preview 3 erschien am 10. April 2025, und Preview 4 folgte am 13. Mai 2025. Zur Nutzung benötigt man das .NET 10 SDK (inklusive der drei Laufzeitumgebungen) sowie Visual Studio 2022 Version 17.14, die gemeinsam installiert werden können.
Mit C# 14.0 führt Preview 3 sogenannte Extension Members ein – eine Erweiterung bestehender Klassen um Methoden und Eigenschaften (instanz- sowie statisch), über das neue extension-Schlüsselwort, abseits der bisherigen this-basierenden Methoden. Zudem erlaubt das Null-Conditional Assignment (?.) das sichere Zuweisen von Eigenschaften ohne vorherige Null-Prüfung.
Ab Preview 4 können einzelne C#-Dateien direkt mit dotnet run ausgeführt werden – ohne Projektdatei. Die Skript-Dateien nutzen Präprozessor-Direktiven (#:sdk, #:package, #:property), um z. B. SDK, NuGet-Pakete oder Build-Parameter zu definieren.
Die BCL erweitert seit Preview 4 die System.IO.Compression-APIs um asynchrone ZIP-Operationen, etwa CreateFromDirectoryAsync(), ExtractToDirectoryAsync(), OpenAsync() oder CreateAsync().
Seit Preview 3 ermöglicht die neue Methode ExportPkcs12() den Export von Zertifikaten mit AES‑Verschlüsselung und SHA‑2‑256 Hashing – sicherer als der alte Export()-Ansatz mit 3DES/SHA‑1.
Preview 4 führt native Unterstützung für den JSON‑Patch‑Standard (RFC 6902) in System.Text.Json ein – via dem neuen NuGet-Paket Microsoft.AspNetCore.JsonPatch.SystemTextJson. So kann JSON‑Patch ohne Newtonsoft.Json genutzt werden (außer unter NativeAOT).
EF Core 10.0 unterstützt in Preview 4 mit Azure Cosmos DB nun Volltextsuche und eine hybride Suche, die Vektorsuche und Volltextsuche kombiniert – inklusive Reciprocal Rank Fusion (RRF). Die zuvor als Vorschau verfügbare Vektorsuche ist damit in EF Core stabilisiert.
In Web API Native AOT–Vorlage ist OpenAPI-Spec (OAS) nun standardmäßig aktiviert.
Seit Preview 3 gibt es AddOpenApiOperationTransformer(), mit dem generierte OpenAPI-Dokumente modifiziert werden können (z. B. Beschreibung oder Header-Parameter).
Minimal WebAPIs erhalten Parametervalidierung über DataAnnotations, durch Aktivieren (AddValidation()) auch für Record-Typen ab Preview 4.
Persistent Component State kann jetzt einfach durch [SupplyParameterFromPersistentComponentState] verwendet werden (Preview 3).
In Preview 4 erweitert sich NavigationManager um NotFound() (Signalisiert 404 im statischen Rendering) und das Ereignis OnNotFound(). Zudem funktioniert NavigateTo() im statischen Rendering out-of-the-box, optional kann Verhalten per Switch angepasst werden.
Standalone Blazor WebAssembly nutzt nun automatisch Fingerprinting für die eingebundene JS-Datei, um Caching-Probleme zu vermeiden.
Response Streaming im HttpClient (WASM) ist jetzt standardmäßig aktiviert – was effizienter ist, aber synchrones Send() nicht mehr unterstützt (Breaking Change). Abschaltbar via Projektfile oder SetBrowserResponseStreamingEnabled(false).
JS-Interop wurde um Methoden erweitert: InvokeNew, GetValue, SetValue (sync + async), um z. B. JS-Objekte direkt zu erstellen oder Eigenschaften zu lesen/setzen.
In QuickGrid wurde CloseColumnOptionsAsync() umbenannt in HideColumnOptionsAsync().
Runtime Diagnostics für Blazor WebAssembly (Preview 4): Performance- und Memory-Dumps sind im Browser möglich, mittels wasm-tools Workload und entsprechenden Projektsettings (WasmProfilers, WasmNativeDebugSymbols).
[1] https://dotnet.microsoft.com/en-us/download/dotnet/10.0
[2] https://github.com/oleg-shilo/cs-script
[3] https://github.com/dotnet-script/dotnet-script
[5] https://www.it-visions.de/scripting/dotnetscripting/dsh
[7] https://dotnet-lexikon.de/SystemTextJson/Lex/10722
[10] https://learn.microsoft.com/en-us/azure/cosmos-db/gen-ai/full-text-search
[11] https://learn.microsoft.com/en-us/azure/cosmos-db/gen-ai/hybrid-search
[14] https://learn.microsoft.com/de-de/dotnet/api/system.componentmodel.dataannotations?view=net-9.0
[16] https://learn.microsoft.com/en-us/dotnet/core/compatibility/10.0
[18] https://learn.microsoft.com/de-de/dotnet/core/diagnostics/dotnet-gcdump
[19] https://github.com/dotnet/core/blob/main/release-notes/10.0/preview/preview3/libraries.md
[20] https://github.com/dotnet/winforms/issues/12179
The post .NET 10 Preview 3 & 4: Das steckt drin appeared first on BASTA!.
]]>The post Was bringt .NET 10.0? Erste Einblicke in Preview 1 & 2 appeared first on BASTA!.
]]>
An der Grundstruktur (drei Runtimes, ein SDK) hat sich nichts geändert [1]. Auch die unterstützten Plattformen sind gleichgeblieben. Laut dem Screenshot der Downloadseite in Abbildung 1 sind weiterhin die Sprachversionen C# 13.0, F# 9.0 und Visual Basic .NET 17.13 enthalten; das ist aber nicht richtig, denn es gibt in .NET 10.0 bereits erste neue Sprachfeatures von C# 14.0.

Abb. 1: .NET-10.0-Downloadseite [1]
Für .NET 10.0 braucht man die Preview-Version von Visual Studio 2022 Version 17.14 (zum Redaktionsschluss für diesen Beitrag verfügbar auf dem Stand Preview 2, Abb. 2). Alternativ kann man das Target Framework auch manuell setzen:
<TargetFramework>net10.0</TargetFramework>
Allerdings reicht es zur Nutzung der neuen Sprachfeatures derzeit nicht aus, nur das Target Framework zu setzen; Man muss auch noch
<LangVersion>preview</LangVersion>
angeben, um alle neuen Sprachfeatures nutzen zu können.
Regelmäßig News zur Konferenz und der .NET-Community

Abb. 2: .NET 10.0 erscheint bereits in Visual Studio 2022 17.14 Preview 2
Bisher musste man in C# immer konkrete Typparameter angeben, um den Operator nameof() auf generische Typen anzuwenden. Jetzt, in C# 14.0, kann man als kleine Syntaxvereinfachung auch die Typparameter im Code weglassen (Listing 1).
<em>// BISHER</em> Console.WriteLine(nameof(List<int>)); <em>// --> List</em> Console.WriteLine(nameof(System.Collections.Generic.LinkedListNode<int>)); <em>// --> LinkedListNode</em> <em>Console.WriteLine(nameof(System.Collections.Generic.KeyValuePair<int, string>)); // --> KeyValuePair</em> <em>// NEU</em> Console.WriteLine(nameof(List<>)); <em>// --> List</em> Console.WriteLine(nameof(System.Collections.Generic.LinkedListNode<>)); <em>// --> LinkedListNode</em> Console.WriteLine(nameof(System.Collections.Generic.KeyValuePair<,>)); <em>// --> KeyValuePair</em>
In Lambdaausdrücken kann man in C# 14.0 jetzt Parameter-Modifizierer wie scoped, ref, in, out und _ref readonly_verwenden, ohne dabei den Datentyp benennen zu müssen. Als Beispiel für den delegate
delegate bool Extract<T>(string text, out T result);
musste man vor C# 14.0 schreiben:
Extract<int> ExtractOld = (string text, out int result) => Int32.TryParse(text, out result);
Jetzt in C# 14.0 können Entwickler:innen im Lambdaausdruck die Nennung der Datentypen _string_und int weglassen, weil diese Datentypen aus dem Kontext bereits klar sind:
Extract<int> ExtractNew = (text, out result) => Int32.TryParse(text, out result);
Das geht allerdings nicht, wenn ein variadischer Parameter mit params zum Einsatz kommt:
Add<int> AddOld = (out int result, params List<int> data) => { result = data.Sum(); return true; };
Nicht möglich ist also diese Verkürzung:
Add<int> AddNew = (out result, params data) => { result = data.Sum(); return true; };
Im Rahmen der Initiative „First-Class Span Types” [2] soll C# 14.0 neue automatische Konvertierungen zwischen Arrays und Span sowie ReadOnlySpan enthalten. Dabei waren einige Konvertierungen bisher schon möglich und da das Dokument „What’s new in C# 14″ [3] nicht genau auflistet, was die Neuerungen sind, sondern nur auf die Liste aller möglichen Konvertierungen verweist, fällt es schwer, herauszufinden, was wirklich neu ist.
In einem Test konnte aber folgender Fall gefunden werden: Wenn die Klasse Developer von der Basisklasse Person erbt, dann kann ein Array
Developer[] devs = new Developer[3];
in C# 14.0 wie folgt konvertiert werden:
Span<Developer> devsSpan = devs; ReadOnlySpan<Developer> devsROSpan = devs; ReadOnlySpan<Person> personROSpan = devs; ReadOnlySpan<Person> personROSpanFromSpan = devsSpan;
In C# 13.0 war hier nur der letzte Fall erlaubt, wenn man dort preview setzte. Vermutlich wird auch dieses Sprachfeatures in C# 14.0 dann als stabil gelten.
Im Dokument „What’s new in C# 14″ [3] beschreibt Microsoft zudem das Schlüsselwort field, mit dem man sogenannte Semi-Auto Properties erstellen kann (Listing 2). Auch dieses Sprachfeature gibt es schon in der stabilen Version von .NET 9.0 – darin aber im Status Preview, d. h., man musste auch dafür preview setzen. Die Erwähnung in „What’s new in C# 14″ legt die Vermutung nahe, dass das Sprachfeature in C# 14.0 dann als stabil gelten wird.
<em>/// <summary></em>
<em>/// Semi-Auto Property</em>
<em>/// </summary></em>
public int ID
{
get;
set <em>// init wäre hier auch erlaubt!</em>
{
if (value < 0) throw new ArgumentOutOfRangeException();
if (field > 0) throw new ApplicationException("ID schon gesetzt");
field = value;
}
} = -1;
C# kennt seit Version 2.0 partielle Klassen und seit Version 3.0 partielle Methoden. Im Jahr 2024 kamen in C# 13.0 partielle Properties und Indexer hinzu. Nun in C# 14.0 sollen Entwickler:innen das Schlüsselwort partial auch auf Konstruktoren und Events in C#-Klassen anwenden können (Listing 3). So es steht in den Releases-Notes zu C# in .NET 10.0 Preview 2 [4].
partial class C
{
partial C(int x, string y);
partial event Action<int, string> MyEvent;
}
partial class C
{
partial C(int x, string y) { }
partial event Action<int, string> MyEvent
{
add { }
remove { }
}
}
Der C#-Compiler möchte das Beispiel aus der Dokumentation [5] aber noch nicht übersetzen und meldet Fehler sowohl in Visual Studio als auch beim Kommandozeilenbefehl dotnet build (Abb. 3 und 4), selbst wenn man preview in die Projektdatei schreibt. Laut [6] kommt das Feature in Visual Studio auch erst mit Version 17.4 Preview 3; diese Version war zum Redaktionsschluss noch nicht verfügbar.

Abb. 3: Kompilierungsfehler in Visual Studio beim Versuch der Verwendung von partiellen Konstruktoren und partiellen Events in .NET 10.0 Preview 2

Abb. 4: Kompilierungsfehler auf der Kommandozeile beim Versuch der Verwendung von partiellen Konstruktoren und partiellen Events in .NET 10.0 Preview 2
Auch beim Visual-Basic-.NET-Compiler gibt es nach langer Stagnation mal wieder kleine Neuerungen: Der Compiler hält sich nun an die in .NET 9.0 und C# 13.0 eingeführte Annotation [OverloadResolutionPriority] zur Priorisierung von Überladungen.
Regelmäßig News zur Konferenz und der .NET-Community
In dem .NET-SDK-Kommandozeilenwerkzeug _dotnet_hat Microsoft in .NET 10.0 die Parameterreihenfolge vereinheitlicht. Es gab bisher viele Befehle, die aus einem Substantiv gefolgt von einem Verb oder Adjektiv bestanden (z. B. dotnet new list, dotnet workload install, dotnet nuget add).
Es gab aber auch einige Befehle, bei denen am Anfang ein Verb stand, z. B. dotnet add reference und dotnet remove package. Das hat Microsoft nun vereinheitlicht zu folgenden neuen Befehlen:
dotnet package add dotnet package list dotnet package remove dotnet reference add dotnet reference list dotnet reference remove
Die alten Kommandozeilenbefehle mit dem Verb vorne sind aber weiterhin vorhanden, sodass hier kein Breaking Change entsteht.
Das .NET SDK verwendet bei der Workload-Verwaltung in .NET 10.0 nun als Standard den in .NET 9.0 eingeführten Modus „Workload Sets” anstelle des bisherigen Standards, den Microsoft „Loose Manifests” nennt [7].
Im .NET SDK gibt es zudem eine Optimierung für die Beschleunigung des Package Restore [8].
Wie in den letzten .NET-Versionen auch, liefert Microsoft in .NET 10.0 wieder neue Operatoren für Language Integrated Query (LINQ), die bestehende Konstrukte vereinfachen. Dieses Mal sind es mit LeftJoin() und RightJoin() zwei elementare Operatoren aus der Mengenlehre und den relationalen Datenbanken. Tatsächlich waren diese Operationen in LINQ bereits möglich, allerdings umständlich mit Hilfe einer Gruppierung mit GoupJoin() und SelectMany() sowie DefaultIfEmpty(). Die neuen Methoden LeftJoin() und RightJoin() vereinfachen die Verwendung, wie Listing 4 am Beispiel des Joins zwischen den Klassen Company und _Website_zeigt, die Ausgabe ist in Abbildung 5 zu sehen.
Company[] companies =
[
new Company{ ID = 1, Name = "www.IT-Visions.de" },
new Company{ ID = 2, Name = "Software & Support" },
new Company{ ID = 3, Name = "Startup i.Gr." } <em>// hat noch keine Website</em>
];
Website[] websites =
[
new Website{ CompanyID = 1, URL = "www.IT-Visions.de" },
new Website{ CompanyID = 1, URL = "www.dotnet10.de" },
new Website{ CompanyID = 2, URL = "www.entwickler.de" },
new Website{ URL = "www.Microsoft.com" }, <em>// Firma ist noch nicht angelegt</em>
];
CUI.H2("--- LeftJoin ALT seit .NET Framework 3.5 ---");
var AllCompaniesWithWebsitesSetOld = companies
.GroupJoin(websites,
c => c.ID,
w => w.CompanyID,
c, websites) => new { Company = c, Websites = websites })
.SelectMany(
x => x.Websites.DefaultIfEmpty(), <em>// Falls keine Webseite existiert, wird `null` verwendet</em>
(c, w) => new WebsiteWithCompany
{
Name = c.Company.Name,
URL = w.URL, <em>// Falls `w` null ist, bleibt URL null</em>
City = c.Company.City
});
foreach (var item in AllCompaniesWithWebsitesSetOld)
{
Console.WriteLine((item.Name != null ? item.Name + " " + item.City : "- keine Firma - ") + " -> " + (item.URL ?? "- keine URL -"));
}
CUI.H2("--- LeftJoin NEU ab .NET 10.0 ---");
var AllCompaniesWithWebsitesSet = companies.LeftJoin(websites, e => e.ID, e => e.CompanyID, (c, w) => new WebsiteWithCompany { Name = c.Name, City = c.City, URL = w.URL });
foreach (var item in AllCompaniesWithWebsitesSet)
{
Console.WriteLine((item.Name != null ? item.Name + " " + item.City : "- keine Firma - ") + " -> " + (item.URL ?? "- keine URL -"));
}
CUI.H2("--- RightJoin OLD seit .NET Framework 3.5 ---");
var WebsiteWithCompanySetOLD = websites
.GroupJoin(companies,
w => w.CompanyID,
c => c.ID,
(w, companies) => new { Website = w, Companies = companies })
.SelectMany(
x => x.Companies.DefaultIfEmpty(), <em>// Falls kein Unternehmen existiert, bleibt `null`</em>
(w, c) => new WebsiteWithCompany
{
Name = c.Name, <em>// Falls `c` null ist, bleibt `Name` null</em>
City = c.City, <em>// Falls `c` null ist, bleibt `City` null</em>
URL = w.Website.URL
});
foreach (var item in WebsiteWithCompanySetOLD)
{
Console.WriteLine((item.Name != null ? item.Name + " " + item.City : "- keine Firma - ") + " -> " + (item.URL ?? "- keine URL -"));
}
CUI.H2("--- RightJoin NEU ab .NET 10.0 ---");
var WebsiteWithCompanySet = companies.RightJoin(websites, e => e.ID, e => e.CompanyID, (c, w) => new WebsiteWithCompany { Name = c.Name, City = c.City, URL = w.URL });
foreach (var item in WebsiteWithCompanySet)
{
Console.WriteLine((item.Name != null ? item.Name + " " + item.City : "- keine Firma - ") + " -> " + (item.URL ?? "- keine URL -"));
}
<em>// Zum Vergleich: Inner Join, den es seit .NET Framework 3.5 gibt</em>
CUI.H2("--- InnerJoin seit .NET Framework 3.5 ---");
var CompaniesWithWebsitesSet = companies.Join(websites,
c => c.ID,
w => w.CompanyID,
(c, w) => new WebsiteWithCompany
{
Name = c.Name,
URL = w.URL,
City = c.City
});
foreach (var item in CompaniesWithWebsitesSet)
{
Console.WriteLine((item.Name != null ? item.Name + " " + item.City : "- keine Firma - ") + " -> " + (item.URL ?? "- keine URL -"));
}

Abb. 5: Ausgabe von Listing 4
Die erst in .NET 9.0 neu eingeführte generische Klasse System.Collections.Generic.OrderedDictionary<T,T> bot bisher schon eine Methode TryAdd(), die versucht, ein Element hinzuzufügen. Neben der bestehenden Variante TryAdd(TKey key, TValue value) gibt es nun in .NET 10.0 auch die Methode TryAdd(TKey key, TValue value, out int index) (Listing 5). Diese neue Überladung liefert den Index zurück, falls es das Element in der Menge schon gibt. Analog dazu gibt es für die Methode TryGetValue() nun eine neue Überladung, die nicht nur den Wert eines Eintrags liefert, sondern auch die Position des gefundenen Elements per Index.
OrderedDictionary<string, string> websites = new OrderedDictionary<string, string>();
websites.Add("Software & Support", "www.Entwickler.de");
websites.Add("Microsoft", "www.Microsoft.com");
websites.Add("IT-Visions", "www.IT-Visions.de");
var propertyName = "IT-Visions";
var value = "www.IT-Visions.de";
<em>// bisher</em>
if (!websites.TryAdd(propertyName, value))
{
int index1 = websites.IndexOf(propertyName); <em>// Second lookup operation</em>
CUI.Warning("Element " + value + " ist bereits vorhanden!");
}
<em>// neu</em>
if (!websites.TryAdd(propertyName, value, out int index))
{
CUI.Warning("Element " + value + " ist bereits vorhanden an der Position " + index + """!""");
}
<em>// neu</em>
if (websites.TryGetValue(propertyName, out string? value2, out int index2))
{
CUI.Success($"Element {value2} wurde gefunden an der Position {index2}.");
}
Zur Prüfung von IP-Adressen gibt es in der Klasse System.Net schon seit .NET Framework 2.0 die statische Methode IPAddress.TryParse(), die eine IP-Adresse aus einer Zeichenkette extrahiert. Seit .NET Core 2.1 ist die Extraktion auch aus dem Typ ReadOnlySpan möglich. Der Rückgabewert ist ein bool-Wert und die extrahierte IP-Adresse wird in Form einer Instanz der Klasse IPAddress als out-Parameter geliefert. Wenn man nur prüfen will, ob die IP-Adresse stimmt, schreibt man _IPAddress.TryParse(eingabe, out ).
In .NET 10.0 bietet Microsoft nun in der statischen Methode _IsValid()_eine weitere Prüfungsvariante mit weniger internem Aufwand. Beispiel:
System.Net.IPAddress.IsValid("192.168.1.0")
Dabei kehrt Microsoft nun einfach eine bisher interne Methode TargetHostNameHelper.IsValidAddress() nach außen [9].
Seit .NET 10.0 Preview 2 soll laut Release Notes in der Klasse X509Certificate2 eine neue Methode ExportPkcs12() existieren, die Entwickler:innen mehr Kontrolle über die Verschlüsselungs- und Digest-Algorithmen geben soll. Die bisherige Methode Export() verwendet noch veraltete Algorithmen wie 3DES und SHA1. Die neue Methode ExportPkcs12() soll auch AES und SHA-2-256 bieten.
In den Release Notes zu .NET 10.0 Preview 2 [10] fehlt allerdings ein Beispiel und im Test konnte der Compiler weder auf der Klasse X509Certificate2 noch der Basisklasse X509Certificate die Methode ExportPkcs12() finden. Das zugehörige Issue auf GitHub steht auf dem Status Closed [11]. Da sich im Change-Log zu .NET 10.0 Preview 2 [12] auch kein Eintrag zu ExportPkcs12() finden lässt, sind die Release-Notes an dieser Stelle vermutlich voreilig und die neue Methode kommt erst in einer späteren Vorschauversion.
Außerdem hat Microsoft diese drei Punkte in der .NET-Basisklassenbibliothek in .NET 10.0 Preview 1 und 2 verbessert:
DateOnly now = DateOnly.FromDateTime(DateTime.Now); Console.WriteLine(ISOWeek.GetWeekOfYear(now)); Console.WriteLine(ISOWeek.GetYear(now)); Console.WriteLine(ISOWeek.ToDateOnly(2025, 1, DayOfWeek.Tuesday)); <em>// 30.12.2024</em>
In Windows Forms in .NET 10.0 [14] sind nun einige Überladungen der GetData()-Methode für die Zwischenablage sowie Drag-and-Drop-Operationen als [Obsolet] markiert, die noch die Klasse BinaryFormatter verwenden, die Microsoft in .NET 9.0 ausgebaut hat und für die man nun ein eigenes NuGet-Paket braucht. Dafür gibt es nun neue Operationen, die mit JSON arbeiten, z. B. SetDataAsJson() und TryGetData().
In WPF gibt es laut Release Notes zu Preview 1 [15] und Preview 2 [16] nur Leistungsverbesserungen und Bug Fixes, u. a. am in .NET 9.0 eingeführten Fluent Design für WPF.
In der JSON-Bibliothek System.Text.Json hat Microsoft die Klasse JsonElement um die Methode GetPropertyCount() erweitert, mit der man ermitteln kann, wie viele Eigenschaften ein JSON-Objekt besitzt:
JsonElement element1 = JsonSerializer.Deserialize<JsonElement>("""{ "ID" : 1, "Name" : "Dr. Holger Schwichtenberg", "Website": "www.IT-Visions.de" }""");
Console.WriteLine(element1.GetPropertyCount()); <em>// 3</em>
Bisher war nur möglich, die Anzahl der Objekte in einem Array zu ermitteln:
JsonElement element2 = JsonSerializer.Deserialize<JsonElement>("""[ 1, 2, 3, 4 ]""");
Console.WriteLine(element2.GetArrayLength()); <em>// 4</em>
In der Klasse JsonArray, im Namensraum System.Text.Json.Nodes, bietet Microsoft nun zwei Methoden RemoveRange() und RemoveAll()(Listing 6):
System.Text.Json.Nodes.JsonArray array = JsonSerializer.Deserialize<System.Text.Json.Nodes.JsonArray>("""[ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]""");
System.Console.WriteLine(array.Count); <em>// 9</em>
PrintJsonArray(array);
array.RemoveRange(5, 2);
PrintJsonArray(array);
array.RemoveAll(n => n.GetValue<int>() > 5);
PrintJsonArray(array);
Die Annotation [JsonSourceGenerationOptions] für den Source Generator in der Bibliothek System.Text.Json erlaubt nun auch die Einstellung des Verhaltens bei zirkulären Referenzen auf Unspecified, _Preserve_oder IgnoreCycles, z. B.:
[JsonSourceGenerationOptions(ReferenceHandler = JsonKnownReferenceHandler.Preserve)]
Regelmäßig News zur Konferenz und der .NET-Community
In ASP.NET Core WebAPIs in .NET 10.0 werden Metadaten nun im Standard in der Version 3.1 – bisher Version 3.0 – der OpenAPI Specification (OAS) mit vollständiger Unterstützung des JSON-Schema-Standards 2020-12 [17] generiert. Die Umstellung von Version 3.0 auf Version 3.1 geht einher mit Breaking Changes [18].
Entwickler:innen können daher bei Bedarf im Startcode des ASP.NET-Core-Webservers die OAS-Version mit diesem Befehl zurückstufen:
builder.Services.AddOpenApi(options =>
{
options.OpenApiVersion = Microsoft.OpenApi.OpenApiSpecVersion.OpenApi3_0;
});
Wenn OAS-Dokumente im Rahmen des Build-Prozesses gesteuert werden, geht die Zurückstufung wie folgt in der Projektdatei (.csproj):
<OpenApiGenerateDocumentsOptions> --openapi-version OpenApi3_0 </OpenApiGenerateDocumentsOptions>
Die OAS-Dokumente in ASP.NET Core waren bisher immer im JSON-Format. ASP.NET Core 10.0 bietet seit Preview 1 alternativ auch das YAML-Format an, das kürzere Dokumente liefert (Abb. 6). YAML als Alternative zu JSON stellt man im Startcode ein, indem man bei der Methode MapOpenApi() einen Dokumentnamen angibt, der auf .yml oder .yaml endet:
app.MapOpenApi("/openapi/{documentName}.yml");
oder
app.MapOpenApi("/openapi/{documentName}.yaml");
Die YAML-Metadaten können Entwickler:innen aber noch nicht im Build-Prozess einstellen. Microsoft will diese Option in einer kommenden Preview-Version liefern.

Abb. 6: Ein OpenAPI-3.1-Dokument im JSON- (links) und kompakteren YAML-Format (rechts)
Die von dem NuGet-Paket Microsoft.AspNetCore.OpenApi generierten OpenAPI-Metadaten für ein ASP.NET Core WebAPI können nun auch Informationen aus den XML-Kommentaren enthalten, die zu Klassen bzw. Methoden hinterlegt sind. Diese Integration können Entwickler:innen mit einem Eintrag in der Projektdatei aktivieren:
<PropertyGroup> <GenerateDocumentationFile>true</GenerateDocumentationFile> </PropertyGroup>
Welche XML-Kommentare auf welche Weise in das OpenAPI-Dokument übernommen werden, steht leider nicht in den Release-Notes [19] und bedauerlicherweise ließ sich das auch nicht testen, da durch die Installation des .NET 10.0 Preview 2 SDK alle WebAPI-Projekte beim Start nur noch HTTP-Fehler 404 liefern, auch mit den aktuellsten Projektvorlagen neu angelegter Projekte. Das Problem trat auf zwei verschiedenen Testrechnern auf.
Bei Controller-basierten WebAPIs können Entwickler:innen nun in den Annotationen [ProducesAttribute], [ProducesResponseTypeAttribute] und [ProducesDefaultResponseType] jeweils Beschreibungstexte angeben, die auch im OAS-Dokument erscheinen:
[HttpGet(Name = "GetWeatherForecast")]
[ProducesResponseType<IEnumerable<WeatherForecast>>(StatusCodes.Status200OK, Description = "The weather forecast for the next 5 days.")]
public IEnumerable<WeatherForecast> Get()
{
...
}
Das geht in Minimal WebAPIs schon seit Version 7.0 mit dem Methodenaufruf WithDescription().
Blazor Server stellt einen modalen Dialog dar, falls ein Abbruch der WebSockets-Verbindung zwischen Webbrowser und Webserver erfolgt ist und eine Wiederaufnahme versucht wird. Diese Darstellung war bisher nicht anpassbar.
In der Projektvorlage Blazor Web App findet man seit .NET 10.0 Preview 2 eine neue Razor Component im Ordner _Layout mit Namen ReconnectModal.razor(Listing 7). Diese Komponente enthält die Standarddarstellung des modalen Fensters bei Verbindungsproblemen. Damit können Entwickler:innen in .NET 10.0 also Einfluss auf die Texte und die Darstellung in drei Fällen nehmen:
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cscript%20type%3D%22module%22%20src%3D%22%40Assets%5B%22Components%2FLayout%2FReconnectModal.razor.js%22%5D%22%3E%3C%2Fscript%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="<script>" title="<script>" />
<dialog id="components-reconnect-modal" data-nosnippet>
<div class="components-reconnect-container">
<div class="components-rejoining-animation" aria-hidden="true">
<div></div>
<div></div>
</div>
<p class="components-reconnect-first-attempt-visible">
Rejoining the server...
</p>
<p class="components-reconnect-repeated-attempt-visible">
Rejoin failed... trying again in <span id="components-seconds-to-next-attempt"></span> seconds.
</p>
<p class="components-reconnect-failed-visible">
Failed to rejoin.<br />Please retry or reload the page.
</p>
<button id="components-reconnect-button" class="components-reconnect-failed-visible">
Retry
</button>
</div>
</dialog>
Zur Razor Component ReconnectModal.razor gehören auch eine CSS-Datei ReconnectModal.razor.css und eine JavaScript-Datei ReconnectModal.razor.js. Auch diese Dateien sind anpassbar. ReconnectModal.razor wird am Ende der Datei MainLayout.razor eingebunden via und kann auch komplett ersetzt werden.
Die Methode NavigateTo() in der Blazor-Klasse _NavigationManager_führt den Nutzer bzw. die Nutzerin nicht mehr zum Beginn der Seite zurück, falls der Entwickler bzw. die Entwicklerin nur URL-Parameter an die Seite anhängt:
nav.NavigateTo(nav.GetUriWithQueryParameter("count", currentCount));
Ein Rücksprung an den Seitenanfang findet allerdings bei Angabe von true für forceLoad weiterhin statt
nav.NavigateTo(nav.GetUriWithQueryParameter("count", currentCount), forceLoad: true);
oder bei Änderungen eines Teils des relativen Pfades:
nav.NavigateTo("/counter/" + currentCount);
Im Tabellensteuerelement können Entwickler:innen nun eine Methode angeben, die bei jeder Zeile aufgerufen wird, um die CSS-Klasse der Zeile individuell auf Basis der Daten zu setzen (Listing 8).
<QuickGrid RowClass="ApplyRowClass" ItemsProvider="@itemsProvider" TGridItem="BO.WWWings.Flight" Virtualize="true" OverscanCount="@overscanCount">
<PropertyColumn Property="@(p => p.FlightNo)" Title="FlugNr" Sortable="true" />
<PropertyColumn Property="@(p => p.Departure)" Title="Abflugort" Sortable="true" />
<PropertyColumn Property="@(p => p.Destination)" Title="Zielort" Sortable="true" />
<PropertyColumn Property="@(p => p.FlightDate)" Title="Datum" Format="dd.MM.yyyy" Sortable="true" />
</QuickGrid>
@code {
private string ApplyRowClass(BO.WWWings.Flight rowItem) => rowItem.FreeSeats < 10 ? "red" : null;
}
Außerdem gibt es im QuickGrid-Steuerelement nun eine neue Methode CloseColumnOptionsAsync()(Listing 9), die Entwickler:innen aufrufen können, damit sich die Eingabe von Filterkriterien schließt, wenn der Filter aktiviert wird: Der Aufruf CloseColumnOptionsAsync() sorgt dafür, dass die geöffnete Filtereingabe sich automatisch wieder schließt, wenn der Nutzer bzw. die Nutzerin ein Eingabetaste drückt (Abb. 7).
<QuickGrid @ref="flightGrid" RowClass="ApplyRowClass" ItemsProvider="@itemsProvider" TGridItem="BO.WWWings.Flight" Virtualize="true" OverscanCount="@overscanCount">
<PropertyColumn Property="@(p => p.FlightNo)" Title="FlugNr" Sortable="true" />
<PropertyColumn Property="@(p => p.Departure)" Title="Abflugort" Sortable="true">
<ColumnOptions>
<input type="search" @bind="departureFilter" placeholder="Filter by Departure"
@bind:after="@(() => flightGrid.CloseColumnOptionsAsync())" />
</ColumnOptions>
</PropertyColumn>
<PropertyColumn Property="@(p => p.Destination)" Title="Zielort" Sortable="true" />
<PropertyColumn Property="@(p => p.FlightDate)" Title="Datum" Format="dd.MM.yyyy" Sortable="true" />
</QuickGrid>

Abb. 7: Geöffnete Filtereingabe soll sich durch CloseColumnOptionsAsync() automatisch schließen
Die bei Blazor mitgelieferte JavaScript-Datei (je nach verwendeter Projektvorlage: blazor.web.js, blazor.server.js bzw. blazor.webassembly.js) erhält in .NET 10.0 die bereits in .NET 9.0 eingeführte Möglichkeit zur Komprimierung und einem Fingerabdruck des Inhalts im Dateinamen, der verhindert, dass alte Versionen aus dem Browsercache verwendet werden.
Bei den Methoden zum Massenaktualisieren, namentlich ExecuteUpdate() und ExecuteUpdateAsync(), bietet Entity Framework Core 10.0 nun eine bessere Übersichtlichkeit bei komplexeren Ausdrücken, indem nicht nur Expression-Lambdas, sondern auch Statement-Lambdas erlaubt sind. Anstelle von
var c0 = ctx.Flights.Where(f => f.FlightNo <= 100).ExecuteUpdate(s => s.SetProperty(f => f.FreeSeats, f => f.FreeSeats - 1) .SetProperty(f => f.Memo, f => (setMemo ? "Freie Plätze geändert am " + DateTime.Now : f.Memo)) );
können Entwickler:innen nun auch schreiben:
var c1 = ctx.Flights.Where(f => f.FlightNo <= 100).ExecuteUpdate(s =>
{
s.SetProperty(f => f.FreeSeats, f => f.FreeSeats - 1);
if (setMemo)
{
s.SetProperty(f => f.Memo, "Freie Plätze geändert am " + DateTime.Now);
}
});
Auch wenn die Release-Notes explizit nur von der asynchronen Methode _ExecuteUpdateAsync()_sprechen, funktioniert das Feature im Schnelltest auch mit der synchronen Variante ExecuteUpdate().
Die in .NET 10.0 neu eingeführten Operatoren LeftJoin() und RightJoin() werden auch in Entity Framework Core 10.0 bereits für Datenbankzugriffe unterstützt [20], [21]. Die folgenden Listings zeigen den Einsatz von RightJoin() und LeftJoin() bei Entity Framework Core 10.0 in Verbindung mit einer relationalen Datenbank. Auch in Entity Framework konnte man das Ergebnis von RightJoin() und LeftJoin() bisher schon via _GoupJoin()_und _SelectMany()_mit _DefaultIfEmpty()_erzielen.
Aus dem LINQ-Befehl mit LeftJoin() in Listing 10 entsteht der SQL-Befehl in Listing 11. Aus diesem LINQ-Befehl mit RightJoin() in Listing 12 entsteht der SQL-Befehl in Listing 13.
CUI.H2("Suche alle Flüge, zu denen es keinen Piloten gibt via LeftJoin()");
var ctx = new DA.WWWings.WwwingsV1EnContext();
var fluegeOhnePilot = ctx.Flights
.LeftJoin(
ctx.Pilots,
f => f.PilotPersonId,
p => p.PersonId,
(f, p) => new
{
f.FlightNo,
f.Departure,
f.Destination,
f.FlightDate,
PilotId = f.PilotPersonId == null ? "n/a" : f.PilotPersonId.ToString(),
p.Employee.Person.GivenName,
p.Employee.Person.Surname,
}).Where(x => x.Surname == null).Take(20).ToList();
foreach (var item in fluegeOhnePilot)
{
Console.WriteLine($"{item.FlightNo} {item.Departure}->{item.Destination} am {item.FlightDate}: Pilot {item.PilotId} {item.GivenName} {item.Surname}");
}
SELECT TOP(@p) [f].[FlightNo], [f].[Departure], [f].[Destination], [f].[FlightDate], CASE WHEN [f].[Pilot_PersonID] IS NULL THEN 'n/a' ELSE COALESCE(CONVERT(varchar(11), [f].[Pilot_PersonID]), '') END AS [PilotId], [p0].[GivenName], [p0].[Surname] FROM [Operation].[Flight] AS [f] LEFT JOIN [People].[Pilot] AS [p] ON [f].[Pilot_PersonID] = [p].[PersonID] LEFT JOIN [People].[Employee] AS [e] ON [p].[PersonID] = [e].[PersonID] LEFT JOIN [People].[Person] AS [p0] ON [e].[PersonID] = [p0].[PersonID] WHERE [p0].[Surname] IS NULL
var pilotenMitFlug = ctx.Flights
.RightJoin(
ctx.Pilots.OrderByDescending(x => x.PersonId).Take(3),
f => f.PilotPersonId,
p => p.PersonId,
(f, p) => new
{
PilotId = p.PersonId,
p.Employee.Person.GivenName,
p.Employee.Person.Surname,
Flight = f,
f.Departure,
f.Destination,
<em>//Date = f.FlightDate == DateTime.MinValue ? "n/a" : f.FlightDate.ToShortDateString(), // TODO: LAUFZEITFEHLER. Prüfen in RTM!</em>
}).OrderBy(x => x.PilotId).ToList();
foreach (var p in pilotenMitFlug)
{
Console.WriteLine($"Pilot #{p.PilotId} {p.GivenName} {p.Surname} fliegt " + (p.Flight != null ? $"Flug #{p.Flight?.FlightNo} {p.Flight.Departure}->{p.Flight.Destination} am {p.Flight.FlightDate}" : "bisher keinen Flug"));
}
SELECT [p0].[PersonID] AS [PilotId], [p1].[GivenName], [p1].[Surname], [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp] FROM [Operation].[Flight] AS [f] RIGHT JOIN ( SELECT TOP(@p) [p].[PersonID] FROM [People].[Pilot] AS [p] ORDER BY [p].[PersonID] DESC ) AS [p0] ON [f].[Pilot_PersonID] = [p0].[PersonID] INNER JOIN [People].[Employee] AS [e] ON [p0].[PersonID] = [e].[PersonID] INNER JOIN [People].[Person] AS [p1] ON [e].[PersonID] = [p1].[PersonID] ORDER BY [p0].[PersonID]
Es sei zudem explizit darauf hingewiesen, dass man die neuen Operatoren _RightJoin()_und LeftJoin() einschließlich der vorher schon vorhandenen Operatoren _Join()_und GroupJoin() nur für die Verbindung von Tabellen braucht, für die es im Objektmodell keine Navigationsbeziehung gibt. So kann man statt des aufwendigen RightJoin() bei einer vorhandenen Navigationsbeziehung im Objektmodell dasselbe Ausgabeergebnis mit einem Include() erreichen. In diesem Fall erhält man allerdings keine flache Liste mit Daten aus Pilot und Flug, sondern eine Objekthierarchie, daher zwei verschachtelte foreach-Schleifen (Listing 14). Entity Framework Core führt dabei nur Inner Joins aus (Listing 15).
CUI.H2("Gib zu den letzten drei angelegten Piloten alle Flüge aus via Navigation Property");
var pilotenMitFlug2 = ctx.Pilots.Include(p => p.Employee).ThenInclude(p => p.Person).Include(p => p.Flights).OrderByDescending(x => x.PersonId).Take(3).OrderBy(x => x.PersonId).ToList();
foreach (Pilot p in pilotenMitFlug2)
{
if (p.Flights.Count == 0)
{
Console.WriteLine($"Pilot #{p.PersonId} {p.Employee.Person.GivenName} {p.Employee.Person.Surname} fliegt bisher keinen Flug");
}
else
{
foreach (var f in p.Flights)
{
Console.WriteLine($"Pilot #{p.PersonId} {p.Employee.Person.GivenName} {p.Employee.Person.Surname} fliegt Flug #{f.FlightNo} {f.Departure}->{f.Destination} am {f.FlightDate}");
}
}
}
SELECT [p0].[PersonID], [p0].[FlightHours], [p0].[FlightSchool], [p0].[LicenseDate], [p0].[LicenseType], [e].[PersonID], [e].[EmployeeNo], [e].[HireDate], [e].[Supervisor_PersonId], [p1].[PersonID], [p1].[Birthday], [p1].[City], [p1].[Country], [p1].[EMail], [p1].[GivenName], [p1].[Memo], [p1].[Photo], [p1].[Surname], [f].[FlightNo], [f].[Airline], [f].[Departure], [f].[Destination], [f].[FlightDate], [f].[FreeSeats], [f].[Memo], [f].[NonSmokingFlight], [f].[Pilot_PersonID], [f].[Seats], [f].[Timestamp] FROM ( SELECT TOP(@p) [p].[PersonID], [p].[FlightHours], [p].[FlightSchool], [p].[LicenseDate], [p].[LicenseType] FROM [People].[Pilot] AS [p] ORDER BY [p].[PersonID] DESC ) AS [p0] INNER JOIN [People].[Employee] AS [e] ON [p0].[PersonID] = [e].[PersonID] INNER JOIN [People].[Person] AS [p1] ON [e].[PersonID] = [p1].[PersonID] LEFT JOIN [Operation].[Flight] AS [f] ON [p0].[PersonID] = [f].[Pilot_PersonID] ORDER BY [p0].[PersonID], [e].[PersonID], [p1].[PersonID]
Entity Framework Core bietet in Version 10.0 Preview 1 und 2 zwei Verbesserungen bei der Übersetzung von LINQ in SQL:
In .NET MAUI 10.0 Preview 2 können Entwickler:innen nun mit einer vereinfachten Syntax Schatten definieren:
<VerticalStackLayout BackgroundColor="#fff" Shadow="4 4 16 #000000 0.5" />
Dabei stehen die Zahlen in der Eigenschaft _Shadow_für Offset X, Offset Y, Radius, Farbe und Opazität. Zuvor musste man hier eigene Tags verwenden:
<VerticalStackLayout BackgroundColor="#fff" >
<Shadow Brush="#000000"
Offset="4,4"
Radius="16"
Opacity="0.5" />
</VerticalStackLayout>
Entwickler:innen können beim Steuerelement __nun neben OnColor auch _OffColor_festlegen:
<Switch OffColor="Red"
OnColor="Green" />
Beim Steuerelement lässt sich die Farbe des Symbols steuern:
<SearchBar Placeholder="Search items..." SearchIconColor="Blue" />
Regelmäßig News zur Konferenz und der .NET-Community
Bei Sprachausgabe mit der Schnittstelle Klasse TextToSpeech kann man nun die Geschwindigkeit via Eigenschaft Rate angeben (Listing 16).
IEnumerable<Locale> locales = await TextToSpeech.Default.GetLocalesAsync();
SpeechOptions options = new SpeechOptions()
{
Rate = 2.0f, <em>// 0.1 - 2.0</em>
Pitch = 1.5f, <em>// 0.0 - 2.0</em>
Volume = 0.75f, <em>// 0.0 - 1.0</em>
Locale = locales.FirstOrDefault()
};
await TextToSpeech.Default.SpeakAsync("Hallo aus .NET 10.0!", options);
.NET MAUI unterstützt nun JDK-Version 21 und Android-Version 16 (Codename Baklava, API-Version 36). Die MAUI-Projektvorlage verwendet nun im Standard API-Version 24 (Nougat) statt API-Version 21 (Lollipop). Man kann aber weiterhin auf API-Version 21 zurückstufen, Microsoft empfiehlt aber in den Release-Notes [22], das nicht zu tun: „While API-21 is still supported in .NET 10, we recommend updating existing projects to API-24 in order to avoid unexpected runtime errors.”
Android-Projekte können Entwickler:innen nun mit dem Befehl dotnet run direkt von der Kommandozeile aus starten, z. B.:
<em>// Start auf Gerät (wenn nur ein Gerät angeschlossen ist)</em> dotnet run -p:AdbTarget=-d <em>// Start auf Emulator (wenn es nur einen gibt)</em> dotnet run -p:AdbTarget=-e <em>// Start auf einem bestimmten Emulator</em> dotnet run -p:AdbTarget="-s emulator-5554"
Beim Kompilieren für die Apple-Plattformen (iOS, Mac Catalyst, macOS, tvOS) erzeugt der Compiler nun automatisch Trimmer-Warnungen. Diese Warnungen kann man aber ausschalten mit:
<PropertyGroup> <SuppressTrimAnalysisWarnings>true</SuppressTrimAnalysisWarnings> </PropertyGroup>
Das Steuerelement gilt nun als veraltet. Entwickler:innen sollten verwenden. Ebenso ist die Mark-up-Erweiterung FontImageExtension veraltet. Man sollte jetzt das Tag __verwenden.
Wie in jeder .NET-Version der letzten Jahre üblich, wird es auch dieses Mal in .NET 10.0 wieder einige Breaking Changes gegenüber der Vorgängerversion 9.0 geben. Einige der Breaking Changes sind bereits in Preview 1 und 2 enthalten und unter [23] dokumentiert.
Der .NET-API-Browser mit der .NET-Klassendokumentation [24] ist bereits auf .NET 10.0 Preview 2.0 aktualisiert, sodass man dort die neuen Klassen und Methoden sieht.
Während letztes Jahr bei .NET 9.0 die Preview-Versionen nach Preview 1 nur noch auf GitHub angekündigt wurden, gibt es seit diesem Jahr wieder einen Blogeintrag zu jeder Preview-Version (Preview 1 [25], Preview 2 [26]). Die Blogbeiträge verlinken auf die Release-Notes-Dokumente auf GitHub. Zudem gibt es jeweils aber auch immer eine Ankündigung auf GitHub [27], die neben den Release-Notes auch auf „What’s New”-Dokumente in der Dokumentation verlinkt. Das ist aber nicht immer konsistent: In der Ankündigung zu Preview 1 auf GitHub [28] fehlt der Link auf die Release-Notes von Entity Framework Core [29] gänzlich.
Das .NET-Entwicklungsteam überträgt seit einiger Zeit die Diskussionen bezüglich neuer APIs (API-Reviews) live im Netz auf YouTube. Nun gibt es diese API-Reviews auch öffentlich beim Entwicklungsteam von ASP.NET Core und Blazor [30]. Die Termine der API-Reviews findet man unter [31]; die Videos der Vergangenheit findet man auf dem YouTube-Kanal der .NET Foundation [32].
Zu jeder Preview gibt es jetzt auch neu einen Unboxing-Live-Stream auf YouTube. Die Aufzeichnung ist in den Blogbeiträgen verlinkt.
Auf GitHub findet man Roadmaps für einzelne Bereiche von .NET 10.0, z. B. C# 14.0 [33] und ASP.NET Core und Blazor [34]. Demzufolge arbeitet das C#-Team an den Extension Types (der Verallgemeinerung der Extension Methods, sodass Entwickler:innen auch Eigenschaften und Konstruktoren ergänzen können), was eigentlich schon als Sprachfeature für C# 13.0 geplant war.
Die Pläne des ASP.NET-Core-Entwicklungsteams zeigen die Abbildungen 8 und 9. Ein großes Thema sind demnach die Verbesserungen der Authentifizierungsmöglichkeiten z. B. mit Passkeys und Demonstration of Proof of Possession (DPop) Authentication Tokens. Die Microsoft Identity Platform soll in die Blazor-Web-App-Projektvorlage integriert werden [35]. Minimal WebAPIs sollen auch Validierung mit Data Annotations unterstützen [36].
Der bisher schon verfügbare Persistent Component State zur Übergabe von Daten vom Prerendering bei Blazor soll nun deklarativ via Annotation [SupplyParameterFromPersistentComponentState] möglich sein [37]. Auch soll man in Blazor Server die Circuits zur späteren Wiederaufnahme persistieren können [38]. Blazor WebAssembly soll ein Performance-Profiling erhalten (Abb. 8).

Abb. 8: Geplante Verbesserungen für Blazor

Abb. 9: Geplante Verbesserungen für ASP.NET Core WebAPIs und den Kestrel-Webserver
Andere Entwicklungsteams haben ihre Roadmaps leider bisher nicht auf .NET 10.0 aktualisiert:
Auch bei Entity Framework Core gibt es keine Roadmap für Version 10.0. Man kann aber natürlich auf GitHub nach dem Milestone filtern [42], findet dort aber auch viele kleinere Bugfixes in der Liste und kann auf den ersten Blick keine Strategie erkennen. Bei Entity Framework Core findet man zum Beispiel geplante Verbesserungen für komplexe Typen: Diese sollen zukünftig optional sein können [43] und ein JSON-Mapping unterstützen [44]. Damit wird es dann auch möglich, Mengen komplexer Typen zu haben [45].
Bis zum geplanten Erscheinen von .NET 10.0 im November 2025 werden noch fünf weitere Preview-Versionen und zwei Release-Candidate-Versionen erscheinen, über die ich selbstverständlich auch berichten werde.
Preview 1 wurde am 25. Februar 2025 veröffentlicht, gefolgt von Preview 2 am 18. März 2025. .NET 10.0 soll voraussichtlich im November 2025 als LTS-Version erscheinen, mit insgesamt fünf weiteren Preview-Versionen und zwei Release Candidates.
Um neue Sprachfeatures zu verwenden, muss das Target-Framework auf net10.0 gestellt und in der Projektdatei zusätzlich <LangVersion>preview</LangVersion> gesetzt werden. Außerdem ist Visual Studio 2022 Version 17.14 Preview 2 erforderlich.
Von nameof() mit generischen Typen können nun Typparameter weggelassen werden (z. B. nameof(List<>)).
Lambda-Ausdrücke erlauben nun Parameter-Modifizierer wie scoped, ref, in, out, _ref readonly, ohne explizite Typphase.
Neue automatische Konvertierungen zwischen Arrays, Span<T> und ReadOnlySpan<T>, z. B. Developer[] → Span<Developer>.
Das neue Schlüsselwort field unterstützt semi-automatische Properties („Semi-Auto Properties“).
Partielle Konstruktoren und Events werden als partial gekennzeichnet, sind aktuell aber noch nicht voll funktionsfähig (Debugger/Compiler-Unterstützung geplant ab VS 17.4 Preview 3).
SDK: Vereinheitlichung der dotnet CLI-Kommandos (z. B. dotnet package add statt dotnet add package).
Workload Sets sind nun Standard beim .NET SDK, mit besserem Package-Restore.
LINQ-Erweiterungen: Einfache Nutzung von LeftJoin() und RightJoin() statt zuvor komplexer Konstrukte.
OrderedDictionary<T,T> bekommt neue Overloads: TryAdd(key, value, out index) und TryGetValue(key, out value, out index).
System.Net: IPAddress.IsValid() ergänzt TryParse() zur leichteren IP-Prüfung.
Certificate APIs: ExportPkcs12() für sichereren PKCS#12-Export – noch nicht vollständig verfügbar; X509Certificate2Collection erhält FindByThumbprint().
ISOWeek-Klasse: Neue Methoden für DateOnly-Verarbeitung (z. B. GetWeekOfYear()).
ZIP-Performance optimiert: Deutlich geringerer RAM-Verbrauch (z. B. 2 GB → 7 KB) und deutlich schneller.
ShadowTypeConverter: Definieren von Schatten vereinfacht durch kurze Syntax (Shadow="4 4 16 #000000 0.5").
Farbsteuerung: Bei Switch kann nun OffColor und bei SearchBar die Symbolfarbe über SearchIconColor gesteuert werden.
TextToSpeech: Sprachgeschwindigkeit (Rate) jetzt einstellbar (z. B. Rate = 2.0f).
Android-Support: JDK 21 und neue API-Level automatisch (empfohlen ab API 24); Steuerung per dotnet run -p:AdbTarget=….
Apple-Plattformen (iOS, macOS, tvOS): Automatische Trimmer-Warnungen, optional abschaltbar in der Projektdatei.
OpenAPI Specification wird nun standardmäßig in Version 3.1 unterstützt (zuvor 3.0) – bringt Breaking Changes.
OpenAPI-Ausgabe kann jetzt auch im YAML-Format generiert werden.
XML-Kommentare lassen sich in OpenAPI-Dokumente einbinden – aktiviert über Projektdatei.
Response-Beschreibungen: Annotations wie [ProducesResponseType(..., Description="…")] erscheinen nun im OpenAPI-Dokument.
ReconnectModal.razor erlaubt Anpassung der UI bei Verbindungsabbrüchen (Blazor Server).
NavigateTo() behält nun Scrollposition – Sprung nur bei forceLoad = true oder Pfadänderung.
QuickGrid: Zeilenklassen per Funktion setzen; CloseColumnOptionsAsync() schließt Filtereingaben automatisiert.
Fingerprinting von JS-Datei verhindert Cache-Probleme.
[1] https://dotnet.microsoft.com/en-us/download/dotnet/10.0
[2] https://github.com/dotnet/csharplang/issues/7905
[3] https://learn.microsoft.com/en-us/dotnet/csharp/whats-new/csharp-14
[6] https://github.com/dotnet/roslyn/blob/main/docs/Language%20Feature%20Status.md
[7] https://learn.microsoft.com/en-us/dotnet/core/compatibility/sdk/10.0/default-workload-config
[8] https://github.com/dotnet/core/blob/main/release-notes/10.0/preview/preview1/sdk.md
[9] https://github.com/dotnet/runtime/issues/111282
[11] https://github.com/dotnet/runtime/issues/80314
[12] https://github.com/dotnet/runtime/releases/tag/v10.0.0-preview.2.25163.2
[14] https://github.com/dotnet/core/blob/main/release-notes/10.0/preview/preview1/winforms.md
[15] https://github.com/dotnet/core/blob/main/release-notes/10.0/preview/preview1/wpf.md
[16] https://github.com/dotnet/core/blob/main/release-notes/10.0/preview/preview2/wpf.md
[17] https://json-schema.org/specification-links#2020-12
[20] https://github.com/dotnet/efcore/issues/12793
[21] https://github.com/dotnet/efcore/issues/35367
[22] https://github.com/dotnet/core/blob/main/release-notes/10.0/preview/preview1/dotnetmaui.md
[23] https://learn.microsoft.com/en-us/dotnet/core/compatibility/10.0
[24] https://learn.microsoft.com/en-us/dotnet/api/
[25] https://devblogs.microsoft.com/dotnet/dotnet-10-preview-1
[26] https://devblogs.microsoft.com/dotnet/dotnet-10-preview-2
[27] https://github.com/dotnet/announcements/issues
[28] https://github.com/dotnet/announcements/issues/344
[29] https://github.com/dotnet/core/blob/main/release-notes/10.0/preview/preview1/efcore.md
[30] https://github.com/dotnet/aspnetcore/issues/60003
[32] https://www.youtube.com/@NETFoundation/streams
[33] https://github.com/dotnet/roslyn/blob/main/docs/Language%20Feature%20Status.md
[34] https://github.com/dotnet/aspnetcore/issues/59443
[35] https://github.com/dotnet/aspnetcore/issues/51202
[36] https://github.com/dotnet/aspnetcore/issues/46349
[37] https://github.com/dotnet/aspnetcore/issues/26794
[38] https://github.com/dotnet/aspnetcore/issues/30344
[39] https://github.com/dotnet/maui/wiki/Roadmap
[40] https://github.com/dotnet/winforms/blob/main/docs/roadmap.md
[41] https://github.com/dotnet/wpf/blob/main/roadmap.md
[42] https://github.com/dotnet/efcore/milestone/204
[43] https://github.com/dotnet/efcore/issues/31376
[44] https://github.com/dotnet/efcore/issues/31252
[45] https://github.com/dotnet/efcore/issues/31237
The post Was bringt .NET 10.0? Erste Einblicke in Preview 1 & 2 appeared first on BASTA!.
]]>The post KI-Agenten mit Semantic Kernel appeared first on BASTA!.
]]>In diesem Artikel werden wir uns zunächst mit den theoretischen Grundlagen von KI-Agenten und agentenbasierten Systemen befassen. Anschließend folgt eine praxisnahe Einführung in die Entwicklung eigener KI-Agenten mit dem Semantic Kernel. Ziel ist es, ein tiefgehendes Verständnis für die Konzepte zu vermitteln und gleichzeitig eine praktische Anleitung bereitzustellen, mit der Entwickler:innen eigene Projekte umsetzen können.
Regelmäßig News zur Konferenz und der .NET-Community
In den frühen 2000ern wurde die Automatisierung weitgehend von Workflow-Engines wie Nintex, Windows Workflow Foundation, IBM WebSphere Process Server und BizTalk Server dominiert. Diese Tools ermöglichten es Unternehmen erstmals, Geschäftsprozesse ohne tiefgehende Programmierung zu automatisieren. Bekannte Merkmale waren:
Diese Tools steigerten zwar die Effizienz in strukturierten Umgebungen, waren jedoch begrenzt in der Verarbeitung unstrukturierter Daten und der Anpassung an dynamische Geschäftsanforderungen.
Während regelbasierte Systeme in den frühen 2000ern dominierten, begann in den 2010ern eine neue Ära mit datengetriebenen Ansätzen. Mit dem zusätzlichen Aufkommen von maschinellem Lernen verlagerte sich der Fokus zu mehr automatisierter Entscheidungsfindung. Dies führte zu flexibleren und intelligenteren Automatisierungslösungen, die auf Mustern und Vorhersagen basierten. Wichtige Entwicklungen waren:
Ende der 2010er Jahre erlebte die Welt den Aufstieg von Generativer KI, wie z. B. GPT, das bemerkenswerte Fähigkeiten im Verstehen und Generieren natürlicher Sprache zeigte. Mit der Fähigkeit, menschenähnliche Texte zu generieren und kontextbezogene Antworten zu liefern, wurde KI nicht mehr nur als unterstützendes Werkzeug, sondern als eigenständige Entscheidungsinstanz betrachtet. Hauptmerkmale sind:
Mit diesen Fortschritten wurde der Grundstein für KI-Agenten gelegt – autonome Systeme, die nicht nur Entscheidungen treffen, sondern auch aus Interaktionen lernen und sich kontinuierlich verbessern.
Mit den kontinuierlichen Fortschritten in der KI stehen wir nun an der Schwelle zu Agenten-basierter Technologie – autonomen Entitäten, die ihre Umgebung wahrnehmen, Entscheidungen treffen und handeln, um bestimmte Ziele zu erreichen.
Im Gegensatz zu herkömmlichen Workflows sind KI-Agenten in der Lage, unstrukturierte Daten zu verarbeiten und komplexe Entscheidungen zu treffen. Diese Agenten lernen aus Interaktionen und können, wenn implementiert, ihre Leistung kontinuierlich verbessern. KI-Agenten sind zielorientiert und passen ihr Verhalten dynamisch an neue Gegebenheiten an. Zur Optimierung ihrer Entscheidungsfähigkeit nutzen sie fortschrittliche Techniken wie Reinforcement Learning, selbstüberwachtes Lernen und tiefe neuronale Netze.

Abb. 1: AI-Ops-Agenten: Eine Gruppe von KI-Agenten, die Probleme am lokalen System angehen
KI-Agenten stellen einen Paradigmenwechsel dar – von statischer Automatisierung hin zu adaptiven, sich selbst verbessernden Systemen, die in dynamischen, realen Umgebungen funktionieren können (Abb. 1).
Agentenbasierte Systeme (oft auch agentische Systeme genannt) führen den Ansatz von KI-Agenten fort. Unter diesem Begriff versteht man das Skalieren der Fähigkeiten von KI-Agenten. Während KI-Agenten oftmals als eine Gruppe von Agenten bezeichnet werden, die ein bestimmtes Thema verarbeiten, übernehmen agentenbasierte Systeme die Orchestrierung über mehrere Gruppen von KI-Agenten, wodurch eine hohe Skalierbarkeit erreicht wird (Abb. 2).
Ein Beispiel: Während eine Gruppe von KI-Agenten nur in der Lage ist, auf die Frage „Warum ist mein Netzwerk so langsam?” zu antworten, nutzt ein agentisches System die Fähigkeiten ganzer Gruppen von KI-Agenten (Netzwerk, Application Monitoring, TicketSysteme, usw.), um ein komplexeres Problem zu lösen.

Abb. 2: Skalierbares Agentic-System
KI-Agenten verwenden Schlüsseltechnologien der Künstlichen Intelligenz zur Analyse von Daten, zum Verstehen von Sprache und zur Verarbeitung visueller Informationen. Machine Learning, eine Unterkategorie der Künstlichen Intelligenz, ermöglicht es KI-Agenten, Datenmuster zu erkennen und Vorhersagen oder Entscheidungen zu treffen, basierend auf gesammelten Erfahrungen. Dies führt zu folgenden Spezialisierungen:
In diesem Abschnitt entwickeln wir einen eigenen KI-Agenten mit Semantic Kernel. Wir gehen dabei schrittweise vor und beginnen mit dem Erstellen eines Projektes.
Es gibt mehrere Frameworks zur Entwicklung von KI-Agenten, darunter LangChain/-Graph, AutoGen/2 und Semantic Kernel (Kasten: „Hinweise zu Semantic Kernel”). Wir verwenden Semantic Kernel, da es speziell für .NET optimiert ist und eine einfache Integration mit Large Language Models (LLMs) ermöglicht. Zudem wird es aktiv von der Community und Microsoft weiterentwickelt, was eine langfristige Unterstützung und Verbesserungen sichert.
In den nächsten Schritten werden wir:
Die Voraussetzungen dafür sind:
Semantic Kernel ist ein Framework, das als Middleware zwischen Anwendungen und LLMs fungiert. Es bietet eine Abstraktionsschicht, die es Entwickler:innen ermöglicht, KI-Funktionen einfach in ihre Software zu integrieren. Durch den modularen Aufbau können verschiedene KI-Modelle und Plug-ins flexibel kombiniert werden.
Wichtige Merkmale sind:
Durch den Einsatz von Semantic Kernel können Entwickler:innen leistungsfähige KI-Agenten erstellen und ihre Anwendungen mit intelligenten Funktionen erweitern.
Regelmäßig News zur Konferenz und der .NET-Community
Wir beginnen mit der Einrichtung eines neuen Projekts, fügen die notwendigen Abhängigkeiten hinzu und konfigurieren den Zugriff auf ein LLM. Am Ende dieses Abschnitts hast du eine funktionierende Basis für deinen KI-Agenten.
Ich plane ein Analyse-System für AI Ops, das generative KI zur automatisierten Lösung von IT-Tickets nutzt. Das Ziel ist es, dass KI-Agenten Problembeschreibungen analysieren und lösen. Diese Agenten benötigen Zugriff auf Netzwerk, CPU und Speicher. Es wird einen Analyse-Agent und einen Bewertungs-Agent im Team geben. Das System soll eigenständig Probleme und Lösungen auf Expertenniveau finden können (Abb. 1).
Der erste Schritt ist das Anlegen eines .NET-Projektes nach diesem Schema:
dotnet new console -o MyAIAgenten
cd MyAIAgentenFür die Installation und Arbeit mit dem Semantic-Kernel-Framework benötigst du folgende NuGet-Pakete:
dotnet add package microsoft.SemanticKernel
dotnet add package microsoft.semantickernel.Agenten.abstractions --version 1.35.0-alpha
dotnet add package microsoft.semantickernel.Agenten.core --version 1.35.0-alpha
dotnet add package microsoft.semantickernel.Agenten.openai --version 1.35.0-alphaUm einen KI-Agenten zu erstellen, benötigst du Zugriff auf ein LLM. Es gibt viele Möglichkeiten – beispielsweise eine der folgenden drei:
Falls du LMStudio verwendest, beachte, dass Function Calling derzeit nicht unterstützt wird. Ich empfehle daher Ollama als Model-Host für Semantic Kernel.
Ich nutze für dieses Projekt den Azure OpenAI-Service, weshalb ich die nachfolgenden Schritte entsprechend darauf abgestimmt habe. Die API von OpenAI bedarf nur geringfügige Änderungen im Code, da beide Vorgehensweisen in Semantic Kernel nahezu identisch implementiert sind.
Um Informationen wie API-Schlüssel als Konfiguration zu hinterlegen, speichere ich diese in Umgebungsvariablen. So lässt sich das Projekt auch leicht in anderen Umgebungen wie Docker verschieben.
Nun ist es an der Zeit eine Datei namens .env im Projektverzeichnis zu erstellen und folgende Zeilen hinzuzufügen:
AZURE_OPENAI_API_KEY=<dein_api_schluessel>
AZURE_OPENAI_ENDPOINT=<dein_api_endpunkt>
AZURE_OPENAI_MODEL_ID=<dein_deployment_model>Das Deployment-Modell ist der Name des Modells, das du in Azure OpenAI bereitgestellt hast.
Installiere als Nächstes das DotNetEnv-Paket, um die Umgebungsvariablen in deinem Code zu laden: dotnet add package DotNetEnv. Falls noch nicht geschehen, erstelle eine .gitignore und füge .env hinzu, um nicht versehentlich sensiblen Inhalt in deinem Git Repo zu speichern.
Nachdem wir Semantic Kernel in unser .NET-Projekt integriert haben, erstellen wir nun einen einfachen KI-Agenten, der mit einem LLM interagiert. Mit diesem Wissen können wir nun beginnen den Code zu schreiben.
Um Semantic Kernel einzurichten und mit einem LLM zu verbinden, passen wir die Program.cs an wie in Listing 1.
Listing 1: Program.cs
class Program
{
static async Task Main(string[] args)
{
<em>//Alternative zu appsettings.json..:</em>
DotNetEnv.Env.Load(); <em>// lade die Env Vars</em>
<em>// Kernel initialisieren</em>
var builder = Kernel.CreateBuilder();
builder.AddAzureOpenAIChatCompletion(
Environment.GetEnvironmentVariable("AZURE_OPENAI_MODEL_ID"),
Environment.GetEnvironmentVariable("AZURE_OPENAI_ENDPOINT"),
Environment.GetEnvironmentVariable("AZURE_OPENAI_API_KEY"));
var kernel = builder.Build();
<em>// Klon anlegen, um eine Netzwerk-Fähigkeit bereitzustellen</em>
var networkKernel = kernel.Clone();
var pluginNetwork = KernelPluginFactory
.CreateFromType<NetworkMonitor>();
networkKernel.Plugins.Add(pluginNetwork);
<em>// zweiter Kernel mit Host-Monitoring-Fähigkeit</em>
var hostMetricsKernel = kernel.Clone();
var pluginHost = KernelPluginFactory
.CreateFromType<HostMetrics>();
hostMetricsKernel.Plugins.Add(pluginHost);
<em>//… weiterer Code – ein</em> <em>wenig logging und weiteres house keeping</em>
}
}Zuerst wird der KernelBuilder erstellt. Mit AddAzureOpenAIChatCompletion bekommt der Kernel die Fähigkeit, mit entsprechendem LLM zu interagieren. Für diejenigen, die sich für eine Implementierung mit OpenAIs API entschieden haben, würde die Funktion dann builder.AddOpenAIChatCompletion heißen.
Wir klonen den Kernel, um spezialisierte Funktionen durch Plugins hinzuzufügen – zum Beispiel Netzwerkchecks oder Host-Metriken. Das Klonen ermöglicht eine Trennung der Verantwortlichkeiten. Es verhindert, dass Agenten falsche Funktionen aufrufen. Ein Agent kann nur die im Kernel vorhandenen Plug-ins verwenden, um seine vorgesehenen Aufgaben zu erfüllen.
In unserem Beispiel haben wir einen Agenten, der Netzwerkchecks durchführen kann.
KernelPluginFactory.CreateFromType<NetworkMonitor>();
networkKernel.Plugins.Add(pluginNetwork);Um das Plug-in besser verstehen zu können, möchte ich nachfolgend einen Auszug aus der Plug-in-Klasse zeigen.
Listing 2: Klasse NetworkMonitor
[KernelFunction()]
[Description("Returns information about the network adapters")]
public static List<string> adapterInfos()
{
List<string> adapterInfos = new List<string>();
foreach (NetworkInterface ni in NetworkInterface.GetAllNetworkInterfaces())
{
string info = $"Name: {ni.Name}, Typ: {ni.NetworkInterfaceType}, Status: {ni.OperationalStatus}";
adapterInfos.Add(info);
}
return adapterInfos;
}Mit Semantic Kernel können wir Methoden mit speziellen Decorators versehen. KernelFunction stellt die Verbindung zwischen Semantic Kernel und der Methode her. Description hilft dem LLM, die Methode inhaltlich zu verstehen (Listing 2). Dies ermöglicht es dem LLM, gezielt Funktionen aufzurufen, ohne direkten Zugriff auf das System zu haben. Parameter können ebenfalls übergeben werden und sollten unbedingt in der Description mit beschrieben sein.
Das Konzept ist simpel: Bei der Lösungssuche, etwa bei der Überprüfung von Netzwerkadaptern, generiert das LLM einen Function Call auf ‘ adapterInfos()’. Diese Funktionsaufrufe sind entscheidend für die Verbindung zwischen LLM und lokalen Ressourcen (eine tiefere Diskussion darüber würde jedoch den Rahmen sprengen).
Kurz gesagt, durch Decorators im Semantic Kernel erstellt das LLM ein JSON, füllt es mit Werten und gibt es an den Semantic Kernel zurück. Das LLM hat dabei keinen direkten Zugriff auf das System.
Nun definieren wir einen ersten KI-Agenten, der als Netzwerkanalyst fungiert (Listing 3).
Listing 3
ChatCompletionAgent agentNetworkChecker = new()
{
Name = nameNetworkChecker,
Instructions =
"""
**Role:** You are a Network Checker with over 10 years of experience. You specialize in diagnosing network connectivity issues.
<em><… (gekürzt) Der Prompt definiert die Rolle des Agenten und enthält Anweisungen zur Analyse von Netzwerkproblemen></em>
""",
Kernel = networkKernel,
Arguments = new KernelArguments(new AzureOpenAIPromptExecutionSettings() { FunctionChoiceBehavior = FunctionChoiceBehavior.Auto() }),
LoggerFactory = loggerFactory
};Ein Agent benötigt mindestens Name, Instructions (Promp – textuelle Beschreibung der Aufgabe) und Kernel. Die Arguments-Konfiguration erlaubt es dem LLM, selbst zu entscheiden, ob es eine Plug-in-Funktion aufruft oder eine direkte Antwort generiert. Dieser Agent hier bekommt mit dem networkKernel Zugriff auf verschiedene netzwerknahe Implementierungen, also Plug-ins.
Der KI-Agent ist fertiggestellt. Jetzt fehlt nur noch der Aufruf des Agenten, um eine erste Interaktion zu starten (Listing 4).
Listing 4
<em>// erstelle ein ChatHistory object, um den Chatverlauf zu verwalten.</em>
ChatHistory chat = [];
<em>// Füge die User-Message hinzu</em>
chat.Add(new ChatMessageContent(AuthorRole.User, "<user input>"));
<em>// Generiere die Agent-Antwort(en)</em>
await foreach (ChatMessageContent response in agentNetworkChecker.InvokeAsync(chat))
{
<em> //Verarbeite die Antwort(en)...</em>
}Während ein einzelner KI-Agent bereits nützlich ist, entfaltet sich das volle Potenzial erst in einer Gruppe von Agenten. Hier arbeiten mehrere spezialisierte Agenten zusammen, um komplexe Aufgaben zu bewältigen. Für unser Analyseteam werden zusätzlich zum Network-Agent noch weitere Agenten benötigt, die ich hier nicht mehr detailliert aufführe. Das Grundprinzip bleibt jedoch gleich: Jeder Agent benötigt einen Namen, einen spezifischen Prompt und einen Kernel, der optional mit Plug-ins erweitert werden kann:
ChatCompletionAgent agentNetworkChecker = … ; <em>// prüft das Netzwerk</em>
ChatCompletionAgent agentCommonChecker = … ; <em>// prüft CPU, Storage, …</em>
ChatCompletionAgent agentAnalyst = … ; <em>// Analysiert die Ergebnisse der Agenten</em>
ChatCompletionAgent agentResolver = … ; <em>// bewertet das Analyseergebnis</em>Listing 5: GroupChat-Definition
AgentGroupChat groupChat =
new(agentAnalyst, agentNetworkChecker, agentResolver, agentCommonChecker)
{
ExecutionSettings = new()
{
SelectionStrategy = new KernelFunctionSelectionStrategy(selectionFct, kernel)
{
InitialAgent = agentAnalyst,
HistoryReducer = new ChatHistoryTruncationReducer(1),
HistoryVariableName = "lastmessage",
<em>//return the response from the current agent/or its name</em>
ResultParser = (result) =>{
var selection = result.GetValue<string>() ?? agentAnalyst.Name;
return selection;
}
},
TerminationStrategy = new KernelFunctionTerminationStrategy( terminationFct, kernel)
{
Agenten = new[] { agentResolver },
HistoryVariableName = "lastmessage",
HistoryReducer = new ChatHistoryTruncationReducer(1),<em>//last message</em>
MaximumIterations = 10, <em>// </em><em>maximum 10 rounds</em>
ResultParser = (recall) => <em>{//check agent response for presence of word “YES” </em>
var result =recall.GetValue<string>();
var yes = result?.ToLower().Contains("yes");
return yes ?? false;
}
}
}
};Die SelectionStrategy legt fest, welcher Agent als nächstes antwortet. Dazu definieren wir Regeln, die sich an der letzten Nachricht orientieren (Listing 6).
Listing 6
KernelFunction selectionFct = AgentGroupChat.CreatePromptFunctionForStrategy(
$$$"""
**Task:** Determine which agent should act next based on the last response. Respond with **only** the agent's name from the list below. Do not add any explanations or extra text.
**Agenten:**
- {{{nameAnalyst}}}
- {{{nameNetworkChecker}}}
- {{{nameCommonChecker}}}
- {{{nameResolver}}}
**Selection Rules:**
- **If the last response is from the user:** Choose **{{{nameAnalyst}}} **.
- **If the last response is from {{{nameAnalyst}}} and they are requesting network details:** Choose **{{{nameNetworkChecker}}}**.
- **If the last response is from {{{nameAnalyst}}} and they are requesting non-network system checks:** Choose **{{{nameCommonChecker}}}**.
- **If the last response is from {{{nameAnalyst}}} and they have provided an analysis report:** Choose **{{{nameResolver}}}**.
- **If the last response is from {{{nameNetworkChecker}}} or {{{nameCommonChecker}}}:** Choose **{{{{nameAnalyst}}} }**.
- **Never select the same agent who provided the last response.**
**Last Response:**
{{$lastmessage}}
""",
safeParameterNames: "lastmessage"
);Die geschweiften Klammern {{{nameAnalyst}}} sind generell Platzhalter, die zur Laufzeit mit den tatsächlichen Agentennamen ersetzt werden. Das Muster {{{$}}} ist ein Platzhalter für Variableninhalte, die zur Laufzeit während des Chats eingefügt werden.
Hier ist es die Variable „ lastmessage“, die zuvor über das Feld HistoryVariableName der SelectionStrategy bekannt gemacht wurde. Beim Verwenden des Templates wird dort die ChatHistory vom Framework eingesetzt.
Die Zeile HistoryReducer = new ChatHistoryTruncationReducer(1) sorgt im Übrigen dafür, dass nur die letzte ChatMessage aus der Historie übergeben wird, da für die Selektion des nächsten Agenten ältere Nachrichten keine Relevanz haben. Zugleich spart dies Kosten, denn es reduziert die Anzahl der verwendeten Token, die derzeit die Währung der LLMs sind und mit der Länge des Texts in ihrer Menge steigen.
Die TerminationStrategy wird ähnlich wie die SelectionStrategy verwaltet. Sie legt fest, wann der Chat endet. Dazu wird das LLM angewiesen, eine Abschlussantwort zu geben, etwa „YES” oder „APPROVED”. Ein JSON-Schema erfasst diese Antwort strukturiert für die Automatisierungsprozesse. Zudem gibt es ein Fallback: Falls der Analyst ständig neue Details vom NetworkChecker anfordert und keine Entscheidung trifft, wird die Anzahl der Runden auf zehn begrenzt.
Unsere KI-Agenten sind nun vollständig – das Team kann Nachrichten verarbeiten, Entscheidungen treffen und den Chat sinnvoll beenden. Um unser Agenten-Team zu nutzen, fügen wir eine Nachricht hinzu und starten die asynchrone Verarbeitung. Die Antworten der Agenten werden dann in einer Schleife ausgegeben (Listing 7).
Listing 7
groupChat.AddChatMessage(new ChatMessageContent(AuthorRole.User, <User Input Nachricht>));
await foreach (ChatMessageContent response in groupChat.InvokeAsync())
{
Console.WriteLine($"{response.AuthorName.ToUpperInvariant()}:\n{response.Content}");
}Mit diesem Konstrukt können wir diese KI-Agenten nun überall einbetten. Zum Beispiel in einem Support-Chatbot, einem automatisierten Incident-Management-System oder einer internen Analyse-Pipeline. In meinem GitHub-Projekt [1] findest du eine vollständige Implementierung mit einer interaktiven Schleife, in der Nutzer:innen direkt mit den Agenten kommunizieren können.
Regelmäßig News zur Konferenz und der .NET-Community
KI-Agenten sind mehr als nur eine technologische Innovation – sie verändern die Art und Weise, wie wir Automatisierung und Entscheidungsfindung betrachten. Mit Semantic Kernel steht ein leistungsfähiges Werkzeug bereit, das es Entwickler:innen ermöglicht, intelligente Systeme zu bauen, die autonom zu einem gegebenen Problem nach einer Lösung suchen können.
Die Entwicklung in diesem Bereich schreitet rasant voran. Neue Modelle, verbesserte Orchestrierungsmechanismen und optimierte Agenten-Interaktionen werden in den kommenden Jahren die Möglichkeiten weiter ausbauen.
[1] https://github.com/totosan/tutorial-aiagents
The post KI-Agenten mit Semantic Kernel appeared first on BASTA!.
]]>The post .NET MAUI 9: Entdecken Sie die neuesten Funktionen und Verbesserungen appeared first on BASTA!.
]]>Dieser Kurs wird in Version 9 konsequent fortgesetzt. Unternehmen, die neue plattformübergreifende Apps entwickeln oder von Xamarin.Forms auf .NET MAUI umsteigen, profitieren gleichermaßen von einer stabilen Plattform, die sich auf Verlässlichkeit konzentriert. Gleichzeitig liefert .NET MAUI 9 sinnvolle Ergänzungen, die die Arbeit mit der Plattform vielseitiger und produktiver machen.
Regelmäßig News zur Konferenz und der .NET-Community
Entwickler:innen lieben neue Features, doch genau diese lieferte Microsoft mit der neuen Version von .NET MAUI nur in sehr begrenztem Umfang. Stattdessen konzentrierte sich das Team fast ausschließlich auf die Fehlerbehebung. Dieser Fokus war essenziell, nicht nur, um den Anforderungen moderner Anwendungen gerecht zu werden, sondern vor allem, weil seit dem Supportende von Xamarin.Forms am 1. Mai 2024 immer mehr Unternehmen gezwungen sind, von Xamarin.Forms auf .NET MAUI umzusteigen. In dieser Situation sind Stabilität und Zuverlässigkeit entscheidend – Showstopper dürfen schlichtweg nicht auftreten.
Das Ergebnis dieser Strategie kann sich sehen lassen: Zwischen den Versionen 7 und 8 wurden insgesamt 689 Issues in 1 618 Pull Requests geschlossen. Von Version 8 auf 9 stiegen diese Zahlen auf über 2 800 geschlossene Issues und mehr als 1 900 Pull Requests. Die tatkräftige Unterstützung aus der Community hat diese beeindruckende Steigerung ermöglicht.. Nachdem zuvor Einzelpersonen Bugfixes zu Microsofts plattformübergreifendem Framework beigetragen hatten, beteiligte sich der Komponentenhersteller Syncfusion im Sommer dieses Jahres in großem Umfang am MAUI-Projekt. Allein zwischen dem 30. Juli und dem 1. Oktober stammte mehr als die Hälfte aller Community-Pull-Requests von Syncfusion-Mitarbeiter:innen.
Obwohl .NET MAUI als echtes Cross-Platform-Framework positioniert wird, das sich gleichermaßen für mobile Geräte und den Desktop eignet, wird es in der Community – ähnlich wie sein Vorgänger Xamarin.Forms – oft als reines Mobile-Framework wahrgenommen, das primär unter Android und iOS eingesetzt wird.
Um dieser Wahrnehmung entgegenzuwirken, hat Microsoft in den letzten Versionen von MAUI gezielt Desktopfeatures eingeführt. Funktionen wie Menüs, Kontextmenüs und Maus-Events haben den Desktop bereits gestärkt. Mit der aktuellen Version 9 kommt nun ein weiteres Feature für den Windows-Desktop hinzu: die TitleBar Control.
Dieses Steuerelement erlaubt es Entwickler:innen, die Titelleiste von Windows-Desktop-Anwendungen umfassend anzupassen. Wie bei modernen Office-Anwendungen kann die Titelleiste nun neben einem App-Icon und einem Titel auch einen Untertitel sowie drei separate Inhaltsbereiche enthalten. Diese bieten in den Bereichen LeadingContent, Content und TrailingContent Platz für interaktive Elemente wie Suchleisten, Buttons oder zusätzliche Icons, was die Titelleiste funktionaler und moderner macht.
Listing 1 zeigt die Definition einer TitleBar. Das Beispiel veranschaulicht, wie man Icons, eine Suchleiste und weitere Inhalte in die Titelleiste einfügen kann. Zusätzlich lassen sich Titel, Untertitel und das App-Icon individuell anpassen, um die Titelleiste an das Design Ihrer Anwendung anzupassen. Das Ergebnis ist in Abbildung 1 zu sehen.
<?xml version="1.0" encoding="utf-8" ?>
<Window xmlns="http://schemas.microsoft.com/dotnet/2021/maui"
xmlns:x="http://schemas.microsoft.com/winfx/2009/xaml"
x:Class="DontLetMeExpire.AppWindow">
<Window.TitleBar>
<TitleBar Title="Don't let me expire"
Icon="logo.png"
Subtitle="Stop wasting food"
HeightRequest="50">
<TitleBar.LeadingContent>
<Label Text="![🍇]() " VerticalOptions="Center"/>
</TitleBar.LeadingContent>
<TitleBar.Content>
<SearchBar
Placeholder="Search"
MaximumWidthRequest="300"
MaximumHeightRequest="40"/>
</TitleBar.Content>
<TitleBar.TrailingContent>
<Label Text="
" VerticalOptions="Center"/>
</TitleBar.LeadingContent>
<TitleBar.Content>
<SearchBar
Placeholder="Search"
MaximumWidthRequest="300"
MaximumHeightRequest="40"/>
</TitleBar.Content>
<TitleBar.TrailingContent>
<Label Text="![🍎]() " VerticalOptions="Center"/>
</TitleBar.TrailingContent>
</TitleBar>
</Window.TitleBar>
</Window>
" VerticalOptions="Center"/>
</TitleBar.TrailingContent>
</TitleBar>
</Window.TitleBar>
</Window>

Abb. 1: Das TitleBar-Steuerelement verleiht Windows-Apps ein modernes Design, das sich an Office-Anwendungen orientiert
Derzeit ist das TitleBar-Steuerelement ausschließlich für Windows verfügbar. Microsoft plant jedoch, die Unterstützung in einem zukünftigen Update auf Mac Catalyst zu erweitern. Damit würde das Steuerelement auch auf dem Mac verfügbar sein und zur plattformübergreifenden Konsistenz beitragen, was die Entwicklung von Desktop-Apps für mehrere Plattformen erheblich erleichtert.
Das neue HybridWebView-Steuerelement in .NET MAUI 9 bietet die Möglichkeit, Webinhalte nahtlos in plattformübergreifende Anwendungen zu integrieren. Ursprünglich als experimentelles Projekt von Microsoft-Mitarbeiter Eilon Lipton gestartet [1], hat sich das Steuerelement in den letzten zwei Jahre zu einem vollwertigen Bestandteil des Frameworks entwickelt.
Während das klassische WebView-Steuerelement, das es bereits seit der ersten .NET-MAUI-Version und schon unter Xamarin gab, die Darstellung von Webinhalten wie HTML, CSS und JavaScript ermöglichte, geht HybridWebView einen Schritt weiter: Es erlaubt eine bidirektionale Kommunikation zwischen der Webansicht und der nativen App. Dadurch können Webtechnologien und native Funktionen optimal miteinander kombiniert werden.
HybridWebView ist eine ideale Wahl für hybride Anwendungen, die auf Frameworks wie Angular, React, Svelte oder Vue basieren. Anders als die Blazor-Integration über BlazorWebView, die ausschließlich auf das .NET-Ökosystem ausgelegt ist, ermöglicht HybridWebView die nahtlose Einbindung beliebiger Webframeworks. Bestehende Webanwendungen können einfach in den Ordner Resources\Raw\wwwroot kopiert werden. Da die Inhalte lokal bereitgestellt werden, ist keine Internetverbindung für die Ausführung erforderlich.
Für neue Projekte bietet sich HybridWebView besonders für Teams an, die sich stärker auf Webtechnologien wie HTML, CSS und JavaScript fokussieren und weniger Erfahrung oder Vorlieben in C# und XAML haben. Es erlaubt diesen Teams, ihre vorhandene Webexpertise zu nutzen, ohne dabei auf die Vorteile nativer Funktionen wie den Zugriff auf Gerätesensoren, Offlinefähigkeiten oder die tiefere Integration ins Betriebssystem verzichten zu müssen.
Darüber hinaus eignet sich HybridWebView perfekt für Szenarien, in denen bestehende HTML- und JavaScript-Anwendungen als App ausgeliefert und durch native Funktionen ergänzt werden sollen. Es schlägt eine Brücke zwischen der Flexibilität des Webs und der Leistungsfähigkeit nativer Apps – eine ideale Lösung für hybride Projekte, die das Beste aus beiden Welten verbinden möchten.
Im folgenden Beispiel betrachten wir die Einbettung des HybridWebView-Steuerelements in eine .NET-MAUI-App sowie die bidirektionale Kommunikation zwischen der App und der eingebetteten Webanwendung.
In Listing 2 sehen wir die Definition einer einfachen Bildschirmmaske, die aus einem Eingabefeld, einem Button und einer HybridWebView besteht. Beim Klick auf den Button wird der Inhalt des Eingabefelds über die HybridWebView an die Webanwendung gesendet. Gleichzeitig sollen Nachrichten aus der Webanwendung empfangen und in der App verarbeitet werden können.
<Grid RowDefinitions="auto, *" ColumnDefinitions="*,auto">
<!-- Eingabefeld für die Nachricht -->
<Entry
x:Name="messageText"
Grid.Column="0"
Placeholder="Bitte Nachricht eintragen" />
<!-- Button zum Senden der Nachricht -->
<Button
Clicked="OnSendMessageButtonClicked"
Grid.Column="1"
Text="Senden" />
<!-- HybridWebView für die Webansicht -->
<HybridWebView
x:Name="hybridWebView"
Grid.Row="1"
RawMessageReceived="OnHybridWebViewRawMessageReceived" />
</Grid>
Den zugehörigen C#-Code für die Interaktion sehen wir in Listing 3. Hier gibt es zwei zentrale Ereignisbehandlungsroutinen:
private void OnSendMessageButtonClicked(object sender, EventArgs e)
{
hybridWebView.SendRawMessage(messageText.Text);
}
// Nachricht aus der Webansicht empfangen und anzeigen
private async void OnHybridWebViewRawMessageReceived(object sender, HybridWebViewRawMessageReceivedEventArgs e)
{
await DisplayAlert("Nachricht empfangen", e.Message, "OK");
}
Damit die Kommunikation zwischen der nativen App und der Webanwendung funktioniert, muss der Webanwendung zusätzlicher JavaScript-Code hinzugefügt werden. Dieser stellt sicher, dass Nachrichten empfangen und gesendet werden können. Einen vollständigen Überblick über den benötigten Code findet man in der offiziellen .NET-MAUI-Dokumentation [2]. Listing 4 zeigt einen Auszug aus der Datei hybridwebview.js, die als Kommunikationsschnittstelle dient.
window.HybridWebView = {
"Init": function Init() {
function DispatchHybridWebViewMessage(message) {
const event = new CustomEvent("HybridWebViewMessageReceived", { detail: { message: message } });
window.dispatchEvent(event);
}
// Weitere Implementierung
},
"SendRawMessage": function SendRawMessage(message) {
// Implementierung der Methode SendRawMessage
},
};
window.HybridWebView.Init();
Die Kommunikation innerhalb der JavaScript-Anwendung mit der .NET-MAUI-App zeigen Listing 5 und Listing 6. In Listing 5 sehen wir den Empfang von Nachrichten in JavaScript aus .NET, während Listing 6 den Versand von Nachrichten aus JavaScript an .NET zeigt.
function receiveMessageFromMaui() {
const hybridWebView = window.HybridWebView;
if (hybridWebView) {
window.addEventListener("HybridWebViewMessageReceived", (message) => {
alert("Nachricht von der App: " + message);
});
}
}
const message = 'Hallo von JavaScript';
const hybridWebView = window.HybridWebView;
if (hybridWebView) {
hybridWebView.SendRawMessage(message);
}
Der Beispielcode ist bewusst einfach gehalten. Er zeigt jedoch, wie leistungsfähig und gleichzeitig einfach die bidirektionale Kommunikation zwischen JavaScript und .NET MAUI mit dem HybridWebView-Steuerelement umgesetzt werden kann. In einer echten Anwendung könnte man problemlos die gesamte Benutzeroberfläche mit HTML und JavaScript realisieren und C# zur Interaktion mit der Hardware nutzen.
Regelmäßig News zur Konferenz und der .NET-Community
Während die Veröffentlichung der TitleBar und des HybridWebView bereits längere Zeit vor dem offiziellen .NET-MAUI-9-Release bekannt waren, sorgte die Partnerschaft mit dem Komponentenhersteller Syncfusion für die größte Überraschung in der Community. Neben der aktiven Mitarbeit an Issues im .NET-MAUI-Repository entschied sich Syncfusion, über zehn Steuerelemente unter der Open-Source-MIT-Lizenz bereitzustellen. Die Liste der neuen Steuerelemente umfasst unter anderem:
Viele Entwickler:innen dürften sich besonders über die Chart-Steuerelemente freuen. Die Visualisierung von Daten in Diagrammen ist ein gängiges und oft unverzichtbares Feature in modernen Apps. Da .NET MAUI bisher keine nativen Steuerelemente für diesen Zweck bereitstellte, waren Entwickler:innen bislang häufig auf kommerzielle Bibliotheken angewiesen.
Eine detaillierte Vorstellung des Toolkits hat Tam Hanna bereits in seinem Artikel „Syncfusion Toolkit für .NET MAUI“ in der Ausgabe 2.2025 des Windows Developer vorgenommen [3]. Daher wird in diesem Artikel auf eine ausführliche Betrachtung inklusive Codebeispielen verzichtet. Stattdessen möchte ich die Steuerelemente in den Abbildungen 2 und 3 in Aktion zeigen. Abbildung 2 zeigt den Einsatz des Chart Controls, während Abbildung 3 das Shimmer Control demonstriert, eine moderne Form der Ladeanimation.

Abb. 2: Dank Syncfusion kann man nun auch Diagramme in .NET-MAUI-Apps anzeigen

Abb. 3: Mit dem Syncfusion Shimmer Control kann man Ladezeiten in Apps ansprechend überbrücken
Eine auf den ersten Blick offensichtliche Neuerung von .NET MAUI 9 betrifft die Projektvorlagen. Mit .NET MAUI 9 wurden zwei neue Vorlagen eingeführt, die Entwickler:innen beim Start neuer Projekte zur Verfügung stehen. Abbildung 4 zeigt die beiden neuen Vorlagen .NET MAUI Blazor Hybrid and Web App und .NET MAUI Multi-Project App im Dialog zur Anlage eines neuen Projekts.

Abb. 4: .NET MAUI 9 bringt zwei neue Projektvorlagen mit
Die Vorlage .NET MAUI Blazor Hybrid and Web App richtet sich speziell an Entwickler:innen, die sowohl mit Blazor als auch mit MAUI arbeiten möchten. Sie ermöglicht es, Code für Webanwendungen und native MAUI-Apps gemeinsam zu nutzen. Die Projektstruktur umfasst ein .NET-MAUI-Projekt, ein oder zwei Blazor-Projekte und eine Razor-Klassenbibliothek mit der Endung .Shared (siehe Abbildung 5).

Abb. 5: Die Struktur einer „.NET MAUI Blazor Hybrid and Web App“ bringt eine Razor-Klassenbibliothek für gemeinsam genutzten Quellcode mit
In der Shared-Bibliothek befinden sich die gemeinsam genutzten Benutzeroberflächen in Razor, wie z. B. Counter.razor, Home.razor und Weather.razor. Sowohl das .NET-MAUI- als auch das Blazor-Projekt greifen auf diese geteilten Komponenten zu, wodurch sie sowohl im Webbrowser als auch in nativen Anwendungen angezeigt werden können. Abbildung 6 zeigt die Ausgabe einer solchen Anwendung – dargestellt im Webbrowser, auf Android und als Windows-Desktop-App.

Abb. 6: Mit Blazor kommt man sowohl ins Web als auch auf den Desktop und mobile Endgeräte
Die zweite neue Vorlage, .NET MAUI Multi-Project App, orientiert sich an einer traditionelleren Struktur und erinnert an das bekannte Modell aus Xamarin.Forms. Ein Projekt wird für den plattformübergreifenden Code angelegt, während für jede Zielplattform (z. B. Android, iOS oder Windows) ein separates Projekt erstellt wird (siehe Abbildung 7).

Abb. 7: Die Struktur einer „.NET MAUI Multi-Project App“ entspricht der traditionellen Xamarin.Forms-Projektstruktur
Diese Vorlage ist besonders für Entwickler:innen interessant, die von Xamarin.Forms auf MAUI migrieren und mit der Multi-Project-Struktur vertraut sind. Darüber hinaus kann sie in Projekten hilfreich sein, bei denen eine strikte Trennung zwischen Plattform- und plattformübergreifendem Code erforderlich ist. Für die Migration bestehender Xamarin.Forms-Anwendungen kann diese Vorlage ebenfalls Vorteile bieten, da die Struktur den Übergang erleichtert.
Eine weitere Neuerung in .NET MAUI 9 ist die Option Include Sample Content, die bei der Anlage eines neuen Projekts verfügbar ist. Diese Option erlaubt es Entwickler:innen, mit einer voll funktionsfähigen Beispielanwendung zu starten, anstatt von Grund auf neu beginnen zu müssen. Die Vorlage demonstriert einige Best Practices, wie den Einsatz des MVVM-Entwurfsmusters, Datenpersistenz per SQLite sowie den Einsatz des .NET MAUI Community Toolkits und der Syncfusion-Steuerelemente. Dank der sauberen Struktur, die Abbildung 8 zeigt, kann eine mit dieser Vorlage generierte App als interessantes Lernprojekt angesehen werden. Abbildung 9 zeigt die laufende App, die sowohl den Dark als auch den Light Mode unterstützt.

Abb. 8: Wählt man bei der Projektanlage die Option „Include sample content“ erhält man eine umfangreiche Beispielanwendung

Abb. 9: Die Beispielanwendung in Aktion
Neben den neuen Steuerelementen und Projektvorlagen bringt .NET MAUI 9 auch einige kleinere, aber dennoch praktische Verbesserungen mit sich.
Eine dieser Neuerungen sind zwei optionale Handler für iOS und Mac Catalyst, die die Performance der CollectionView und der CarouselView verbessern. Diese neuen Handler können in der Datei MauiProgram.cs registriert werden, wie Listing 7 zeigt.
#if IOS || MACCATALYST
builder.ConfigureMauiHandlers(handlers =>
{
handlers.AddHandler<Microsoft.Maui.Controls.CollectionView, Microsoft.Maui.Controls.Handlers.Items2.CollectionViewHandler2>();
handlers.AddHandler<Microsoft.Maui.Controls.CarouselView, Microsoft.Maui.Controls.Handlers.Items2.CarouselViewHandler2>();
});
#endif
Eine weitere Verbesserung betrifft Eingabefelder: .NET MAUI 9 bietet eine erweiterte Unterstützung für die Eingabe von Datums- und Uhrzeitwerten sowie Passwörtern über die virtuelle Bildschirmtastatur.
Darüber hinaus unterstützt die neue Version nun Android 15 (API Level 35) und führt Android Asset Packs ein. Diese Erweiterung ist vor allem für Entwickler:innen von Spielen und datenintensiven Anwendungen interessant. Während die bisherige Größenbeschränkung von Google Play für Standardpakete bei 200 MB lag, erlauben Asset Packs das Hochladen von bis zu 2 GB großen Paketen. Diese Funktionalität bietet deutlich mehr Flexibilität bei der Entwicklung und Verteilung großer Apps und ist ein bedeutender Schritt für umfangreiche und speicherintensive Anwendungen.
.NET MAUI 9 setzt weiterhin den Schwerpunkt auf Stabilität und Fehlerbehebung – ein entscheidender Faktor, insbesondere für Unternehmen, die bestehende Xamarin.Forms-Apps zu .NET MAUI migrieren müssen.
Auch wenn Microsoft selbst in diesem Release nur wenige neue Funktionen liefert, stechen die neuen Projektvorlagen hervor, die die Entwicklung für Web- und Desktopanwendungen gleichermaßen vereinfachen. Besonders die Option Include Sample Content, die Best Practices direkt integriert, erleichtert den Einstieg und bietet eine solide Grundlage für neue Projekte. Die Integration des HybridWebView und das TitleBar-Steuerelement zeigen zudem, wie MAUI sich zunehmend als echtes Cross-Platform-Framework etabliert – nicht nur für mobile Geräte, sondern auch für den Desktop.
Durch die Partnerschaft mit Syncfusion schließt .NET MAUI zudem wichtige Lücken, die Entwickler:innen bisher mit kommerziellen Bibliotheken füllen mussten.
Insgesamt bietet .NET MAUI 9 eine stabile und vielseitige Basis, die die plattformübergreifende App-Entwicklung effizienter und attraktiver macht.
[1] https://github.com/Eilon/MauiHybridWebView
[3] https://entwickler.de/dotnet/syncfusion-toolkit-for-net-maui
The post .NET MAUI 9: Entdecken Sie die neuesten Funktionen und Verbesserungen appeared first on BASTA!.
]]>The post Meistern Sie .NET Aspire: Effektive Tools für Entwickler appeared first on BASTA!.
]]>Die wahrscheinlich am häufigsten eingesetzte Methode zum Testen von verteilter und komplexer Software am Entwicklungsrechner ist Docker Compose. Hierbei werden alle benötigten Komponenten in einer YAML-Datei konfiguriert und anschließend gemeinsam gestartet. Der Vorteil ist, dass diese YAML-Datei in Git eingecheckt wird und so einfach zwischen den Entwickler:innen geteilt werden kann. Diese Datei kann auch als Dokumentation dienen, da sie die Abhängigkeiten zwischen den Anwendungen beschreibt und festhält, welche Umgebungsvariable verwendet wird und welche Ports benötigt werden. Ein Beispiel dafür ist die Konfiguration des eigenen Frontends, eines API-Backends, einer Datenbank und eines Cache. Mit dem Befehl docker-compose up können alle Anwendungen gestartet und getestet werden. Der Nachteil dieser Lösung ist allerdings, dass die Anwendungen als Docker-Container laufen und nicht in einer Entwicklungsumgebung debuggt werden können.
Regelmäßig News zur Konferenz und der .NET-Community
Aus diesem Grund hat Microsoft im Jahr 2020 Project Tye [1] vorgestellt, um die Entwicklung und die Fehlersuche in verteilten Systemen zu vereinfachen. Die Idee war gut, die ersten Versionen vielversprechend. Leider fehlte jedoch der Fokus, um die gemeldeten Probleme zu beheben. Daher verlief sich Project Tye mit der Zeit und wurde schließlich 2023 archiviert. Project Tye wirkt auf den ersten Blick wie eine gute Idee, die zu einem grandiosen Fehlschlag wurde. Allerdings hat Microsoft aus den Fehlern und Problemen gelernt und hat zeitgleich mit der Einstellung von Project Tye .NET Aspire vorgestellt.
.NET Aspire wurde erstmals im November 2023 auf der .NET Conf vorgestellt und hat seitdem erhebliches Interesse geweckt. Seit seiner offiziellen Veröffentlichung im Mai 2024 ist es zu einem zentralen Thema auf jeder Entwicklerkonferenz geworden. Microsoft zeigt kontinuierlich sein Engagement für .NET Aspire durch regelmäßige Erweiterungen und Updates, die die Plattform ständig verbessern und Fehler beheben. Diese kontinuierliche Weiterentwicklung stellt sicher, dass .NET Aspire immer auf dem neuesten Stand der Technik ist und Entwickler:innen immer bessere Werkzeuge zur Verfügung stellt.
Entwickler:innen können .NET Aspire einfach zu bestehenden Projekten hinzufügen und damit Abhängigkeiten zwischen verschiedenen Komponenten konfigurieren. Der Vorteil gegenüber anderen Lösungen, wie zum Beispiel Docker Compose, ist, dass .NET Aspire als Code konfiguriert wird und so die Verwendung von IDEs zum Debuggen erlaubt. Nachdem Aspire zu einem Projekt hinzugefügt wurde, konfiguriert es das Sammeln von Logs, Metriken und Traces und stellt zusätzlich ein Dashboard zu Verfügung. Der oder die Entwickler:in muss sich dabei um nichts kümmern, hat aber die Möglichkeit, die Konfiguration den eigenen Anforderungen anzupassen. Zusätzlich können weitere Tools, zum Beispiel PostgreSQL, RabbitMQ oder Azure Service Bus über NuGet installiert und mit wenigen Zeilen Code konfiguriert werden.
Listing 1 zeigt die Konfiguration eines Aspire-Projekts. Dieses Projekt hat Redis und PostreSQL via NuGet installiert und ein Frontend, das beide referenziert. Zusätzlich wird PostgreSQL mit der Methode WithPgAdmin() konfiguriert, wodurch Aspire einen Container mit pgAdmin startet und diesen automatisch für den Zugriff auf den PostgreSQL-Server konfiguriert.
// Create a distributed application builder given the command line arguments.
var builder = DistributedApplication.CreateBuilder(args);
// Add a Redis server to the application.
var cache = builder.AddRedis("cache");
var postgres = builder.AddPostgres("database")
.WithPgAdmin();
// Add the frontend project to the application and configure it to use the
// Redis server, defined as a referenced dependency.
builder.AddProject<Projects.MyFrontend>("frontend")
.WithReference(cache)
.WithReference(postgres)
.WaitFor(cache);
Zusätzlich zur verbesserten lokalen Entwicklung kann Aspire verwendet werden, um das Projekt schnell und einfach auf Azure zu deployen. Wie bei der Entwicklung übernimmt Aspire dabei die gesamte Konfiguration und kann mit wenigen Befehlen deployt werden.
In den folgenden Abschnitten wird die Funktionsweise von Aspire anhand einiger praktischer Demos gezeigt.
Um Aspire verwenden zu können, werden die folgenden Tools benötigt:
.NET-Aspire-Projekte sind für die Ausführung in Containern konzipiert. Sie können entweder Docker Desktop oder Podman als Containerlaufzeit verwenden. Docker Desktop ist die am häufigsten verwendete Laufzeit. Podman ist eine Open-Source-Alternative zu Docker, die ohne Daemon auskommt und OCI-Container (Open Container Initiative) erstellen und ausführen kann. Wenn sowohl Docker als auch Podman installiert sind, verwendet .NET Aspire standardmäßig Docker. .NET Aspire kann mit der Umgebungsvariable DOTNET_ASPIRE_CONTAINER_RUNTIME konfiguriert werden, um stattdessen Podman zu verwenden (Listing 2).
# Windows
[System.Environment]::SetEnvironmentVariable("DOTNET_ASPIRE_CONTAINER_RUNTIME", "podman", "User")
# Linux
export DOTNET_ASPIRE_CONTAINER_RUNTIME=podman
Nach der ganzen Theorie ist es jetzt Zeit für etwas Praktisches. Microsoft hat auf GitHub [2] ein Repository mit Demoprojekten für .NET Aspire veröffentlicht. Dieses Repository enthält unter anderem Beispiele für Aspire mit Azure Functions, Node.js oder Python. Diese Beispiele befinden sich im samples-Ordner des GitHub-Repositorys. Für diesen Artikel wird der Aspire-Shop verwendet.
Microsoft hat in der Vergangenheit schon öfter einen Onlineshop für Demos verwendet. Dieser konnte zwar via Docker Compose gestartet werden, war ansonsten aber aufgrund der Vielzahl an Services und Datenbanken recht kompliziert für neue Benutzer:innen. Aspire auf der anderen Seite bietet ein Dashboard mit allen gestarteten Containern und deren Status an. Dadurch müssen Entwickler:innen nicht mehr die Dokumentation oder Docker-Compose-Dateien durchsuchen, um die Ports und Pfade für die verschiedenen Container herauszufinden.
Nach dem Öffnen der Aspire-Shop-Solution sollte das AspireShop.AppHost-Projekt als Start-up-Projekt ausgewählt sein. Falls nicht, muss es als Start-up-Projekt konfiguriert werden; anschließend kann die Anwendung gestartet werden. Daraufhin öffnet sich das Aspire-Dashboard, welches eine Übersicht über alle Ressourcen im Projekt gibt und dessen Status bzw. Endpoints anzeigt. Abbildung 1 zeigt, dass einige Anwendungen schon gestartet sind, sowie zwei davon den Status „Unhealthy“ haben bzw. zwei noch nicht gestartet sind.

Abb. 1: Das Aspire-Dashboard zeigt den Status aller Anwendungen im Projekt
Je nach Internetgeschwindigkeit sollte es beim ersten Start wenige Minuten dauern, bis alle Container heruntergeladen und gestartet sind. Dann sollte der Status für alle Container „Running“ sein. Mit Hilfe der Endpoints kann jetzt ganz einfach durch die verschiedenen Anwendungen navigiert werden. So können zum Beispiel die Endpoints für das Swagger UI des Catalog Services, pgAdmin für Postgres oder das Frontend ganz einfach aufgerufen und ausprobiert werden.
Das Dashboard macht es neuen Entwickler:innen deutlich leichter, sich in einem Projekt zurecht zu finden. Zusätzlich bietet Aspire nützliche Informationen für das Monitoring und Debugging an. Auf der linken Seite im Dashboard kann so zwischen verschiedenen Ansichten für die Konsolenausgabe aller Container, Logs, Traces und Metriken gewechselt werden; zudem kann innerhalb dieser Ansichten gefiltert bzw. sortiert werden. Abbildung 2 zeigt, dass es mit Hilfe von OpenTelemetry eine Vielzahl von Metriken für den basketservice gibt, welche sowohl grafisch als auch als Tabelle angezeigt werden können.
Abb. 2: Das Aspire-Dashboard bietet eine Vielzahl von Metriken an
Vor allem verteilte Systeme sind dafür bekannt, unübersichtlich zu sein, wie auch dafür, dass die Fehlersuche für Entwickler:innen aufwendig und kompliziert sein kann. Hier ist Aspire sehr hilfreich, weil es OpenTelemetry, Health Checks und Service Discovery automatisch hinzufügt. Wie das genau funktioniert, sehen wir uns an einem bestehenden Blazor-Projekts an.
Aspire kann zu einem bestehenden Projekt mit Visual Studio, Visual Studio Code, JetBrains Rider oder via .NET CLI hinzugefügt werden. Für das .NET CLI kann der Befehl dotnet new aspire-servicedefaults -n ServiceDefaults verwendet werden. Allerdings müssen dann die Referenzen zu den bestehenden Projekten manuell hinzugefügt werden und das Aspire-Projekt muss per Hand konfiguriert werden.
Aus diesem Grund wird für diesen Abschnitt Visual Studio verwendet, um .NET Aspire zu einem bestehenden Blazor-Projekt mit dem Namen BlazorWithAspire hinzuzufügen. Grundsätzlich kann Aspire aber zu jedem .NET-Projekt ab .NET 8 hinzugefügt werden. Dazu klickt man mit der rechten Maustaste auf das Blazor-Projekt und wählt Add | .NET Aspire Orchestrator Support aus. Dies generiert zwei neue Projekte, BlazorWithAspire.AppHost und BlazorWithAspire.ServiceDefaults.
Regelmäßig News zur Konferenz und der .NET-Community
Das AppHost-Projekt konfiguriert alle Projekte in der Programm.cs-Datei, die mit Aspire gestartet werden sollen. In diesem Fall ist es nur das BlazorWithAspire-Projekt:
var builder = DistributedApplication.CreateBuilder(args);
builder.AddProject<Projects.BlazorWithAspire>("blazorwithaspire");
builder.Build().Run();
Wenn während der Entwicklung neue Projekte erstellt werden, können diese hier hinzugefügt und konfiguriert werden.
Das zweite Aspire-Projekt, ServiceDefaults, ist im Moment wahrscheinlich das interessantere Projekt, um die Funktionsweise von Aspire zu verstehen. In diesem Projekt befindet sich eine Datei, Extensions.cs, die alle Aspire-Features konfiguriert, damit diese out of the box verwendet werden können. So werden zum Beispiel Health Checks, Metriken und Logs konfiguriert. Listing 3 zeigt einen Ausschnitt aus dieser Datei, in dem diverse Features wie OpenTelemetry und Service Discovery hinzugefügt werden.
builder.ConfigureOpenTelemetry();
builder.AddDefaultHealthChecks();
builder.Services.AddServiceDiscovery();
builder.Services.ConfigureHttpClientDefaults(http =>
{
// Turn on resilience by default
http.AddStandardResilienceHandler();
// Turn on service discovery by default
http.AddServiceDiscovery();
});
In dieser Datei wird die ganze „Magie“ von .NET Aspire konfiguriert. Wenn das AppHost-Projekt jetzt gestartet wird, sollte sich das Aspire-Dashboard mit einer Anwendung öffnen. Zusätzlich können die Logs, Metriken und Traces der Anwendung angezeigt werden. Abbildung 3 zeigt die Dauer der Requests der Blazor-App an, ohne dass die Blazor-App dafür konfiguriert werden musste.
Abb. 3: .NET Aspire zeigt die Metriken der Blazor-App
Die Demo hat bis jetzt gezeigt, dass mit .NET Aspire zusätzliche Dienste wie Logs und Metriken zur Anwendung hinzugefügt werden können, ohne diese zu verändern. Ein weiterer interessanter Aspekt der Demo ist, dass sie zeigt, wie Aspire die konfigurierten Anwendungen startet. Im Abschnitt über den Onlineshop wurde erwähnt, dass es ein paar Minuten dauern kann, bis alle Container heruntergeladen und gestartet sind. Das ist zwar korrekt, könnte aber den Eindruck erwecken, dass alle Anwendungen als Container gestartet werden – .NET Aspire startet .NET-Anwendungen allerdings nicht als Container. Das kann ganz einfach mit dem docker ps-Befehl überprüft werden. Nachdem Aspire die Demo-Blazor-Anwendungen gestartet hat, zeigt docker ps aber keinen laufenden Container an. Der Grund dafür ist, dass Microsoft das Debugging für Entwickler:innen so einfach wie möglich machen möchte und deshalb die Anwendungen ohne Container startet.
Die vorangegangenen Abschnitte haben eine Einführung in .NET Aspire gegeben und aufgezeigt, wie damit der Entwicklungsprozess vereinfacht werden kann. Aspire kann aber auch beim Deployment der gesamten Umgebung auf Azure helfen.
Dafür wird zusätzlich zu den bereits installierten Tools noch die Azure Developer CLI [3] benötigt. Mit dieser kann die Anwendung einfach in eine oder mehrere Azure-Container-Apps deployed werden. Das Developer CLI und Aspire sorgen dafür, dass alle benötigten Ressourcen erstellt und konfiguriert werden. So kann zum Beispiel, je nach Konfiguration des eigenen Projekts, ein Azure Key zum Speichern von sensitiven Daten wie Passwörtern oder Connection Strings gespeichert werden oder eine PostgresSQL-Datenbank erstellt werden. Die Entwickler:in muss sich dabei um nichts selbst kümmern.
Eine weitere Möglichkeit, .NET Aspire kennenzulernen, ist die .NET Aspire Starter App-Vorlage. Diese Vorlage erstellt ein Blazor-Frontend, ein API, optional ein Testprojekt mit .NET Aspire. Abbildung 4 zeigt, dass beim Erstellen des Projekts in Visual Studio Redis zum Projekt hinzugefügt werden kann. Aspire kümmert sich dabei um die Integration und Konfiguration von Redis.
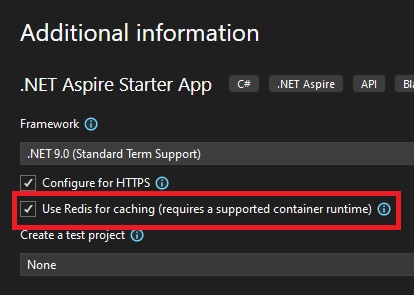
Abb. 4: Aspire kann automatisch Redis zum Projekt hinzufügen und konfigurieren
Die Vorlage erstellt eine Blazor-Anwendung mit einem Frontend, API-Backend und Redis. Die Program.cs-Datei im AppHost-Projekt konfiguriert, dass das Frontend das API und Redis verwendet; zusätzlich wird das Frontend mit dem Parameter WithExternalHttpEndpoints() konfiguriert. Dieser Parameter ist für das Deployment nützlich, da nur das Frontend einen öffentlichen URL bekommt und das Backend und Redis nicht über das Internet erreichbar sein sollen. Listing 4 zeigt die gesamte Program.cs-Datei.
var builder = DistributedApplication.CreateBuilder(args);
var cache = builder.AddRedis("cache");
var apiService = builder.AddProject<Projects.BlazorWithAspireForAzure_ApiService>("apiservice");
builder.AddProject<Projects.BlazorWithAspireForAzure_Web>("webfrontend")
.WithExternalHttpEndpoints()
.WithReference(cache)
.WaitFor(cache)
.WithReference(apiService)
.WaitFor(apiService);
builder.Build().Run();
Zum Testen der Anwendung kann sie gestartet und im Frontend die verschiedenen Menüpunkte aufgerufen werden. Diese Aufrufe sieht man auch im Aspire-Dashboard im Bereich Traces. Abbildung 5 zeigt zum Beispiel, dass der weather Endpoint vom Frontend aufgerufen wurde, dieser weatherforcast auf dem API aufgerufen und dann Daten in Redis geschrieben hat.
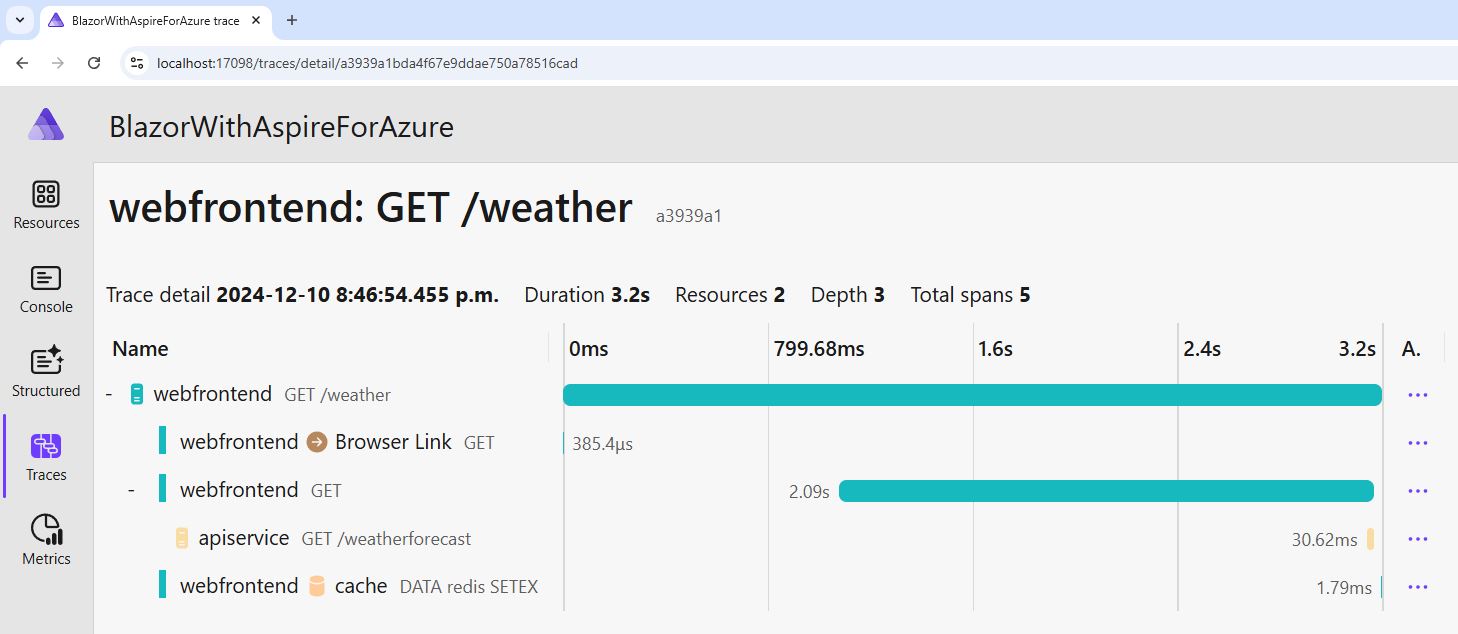
Abb. 5: Die Trace zeigt den Request vom Frontend an das Backend und Redis
Nachdem die Anwendung getestet ist, kann sie mit dem Azure Developer CLI deployt werden. Zunächst kann mit dem Befehl azd auth login in der Kommandozeile im zuvor angelegten Projekt das Log-in durchgeführt werden; anschließend wird mit azd init der Deployment Wizard gestartet. Das Deployment für diese Demo wurde mit den folgenden Angaben konfiguriert:
Nachdem der Name für die Ressource-Gruppe eingegeben ist, erstellt das Developer CLI zwei Dateien: azure.yaml und next-steps.md. Die Datei azure.yaml beinhaltet den Pfad zum zuvor konfigurierten Projekt; die next-steps.md-Datei gibt eine detaillierte Anleitung, wie die Anwendung deployt werden kann und bietet zusätzlich Links zur Dokumentation für weitere Informationen an. Abbildung 6 und Abbildung 7 zeigen das Konsolenfenster, in dem die Demoanwendung mit dem Azure Developer CLI konfiguriert wurde.
Abb. 6: Das Azure Developer CLI listet das Demoprojekt auf
Abb. 7: Das Azure Developer CLI erstellt die Deployment-Dateien
Der letzte Befehl für das Deployment ist azd up. Dieser Befehl erstellt alle benötigten Ressourcen in Azure, bevor die Demoanwendung deployt wird. Mit den Befehlen azd provision und azd deploy kann das Deployment auf zwei Schritte aufgeteilt werden. Nach der Eingabe des azd provision-Befehls (und auch nach der Eingabe von azd up) muss die gewünschte Azure Subscription und Region angegeben werden. Danach erstellt das CLI die benötigten Ressourcen, wie in Abbildung 8 gezeigt. Das Developer CLI verwendet Bicep-Skripte [4] für das Deployment. Dadurch können Änderungen ganz einfach mit denselben Befehlen deployt werden, und Bicep aktualisiert nur die angepassten Ressourcen.
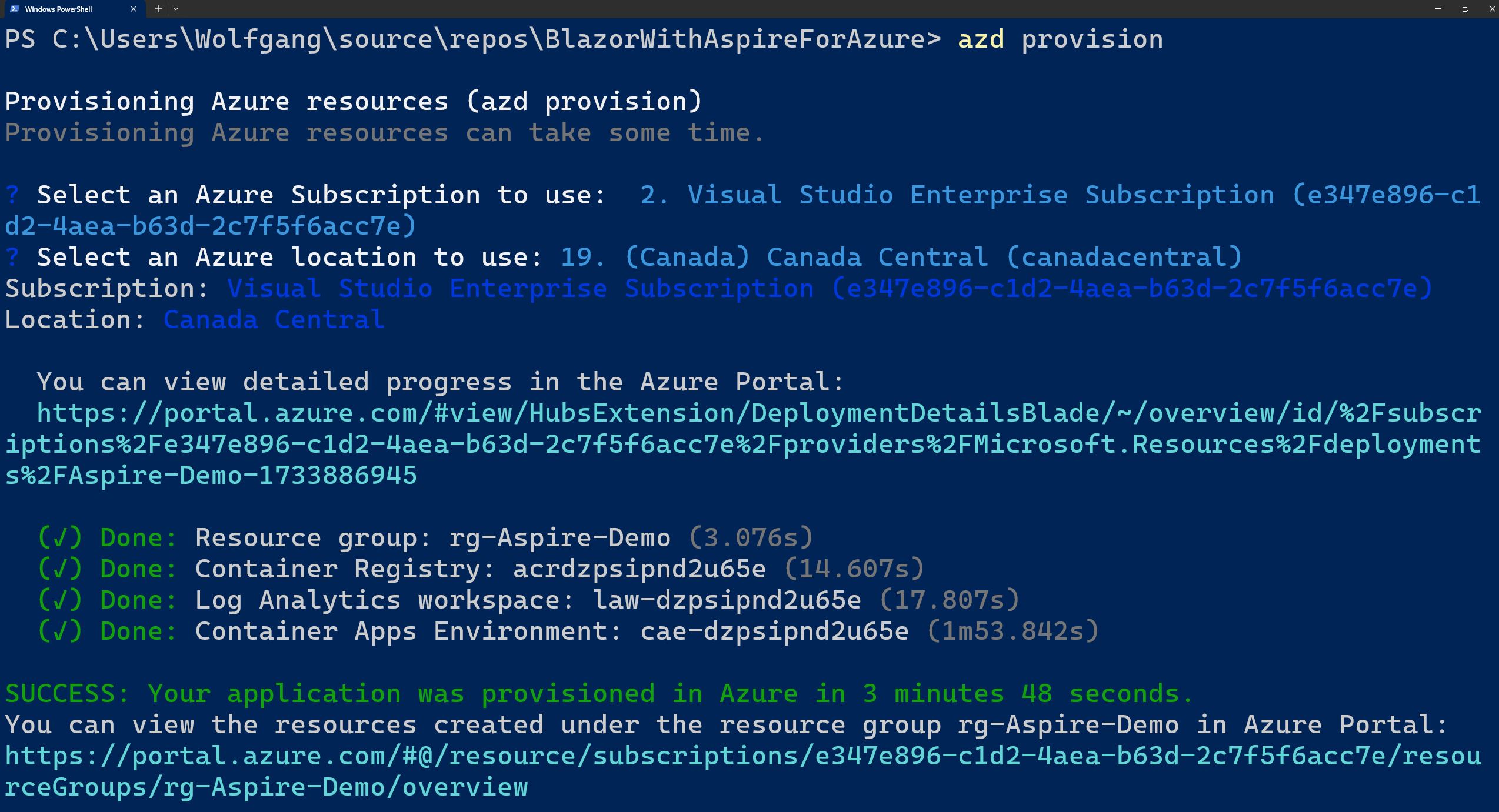
Abb. 8: Alle benötigten Azure-Ressourcen wurden mit dem Azure Developer CLI automatisch erstellt
Folgende Ressourcen wurden erstellt:
Nachdem die Ressourcen angelegt wurden, kann die Anwendung mit azd deploy deployt werden. Dieser Befehl scannt das Aspire-Projekt, erstellt für alle Anwendungen einen Container und lädt diese Container in die Container-Registry hoch.
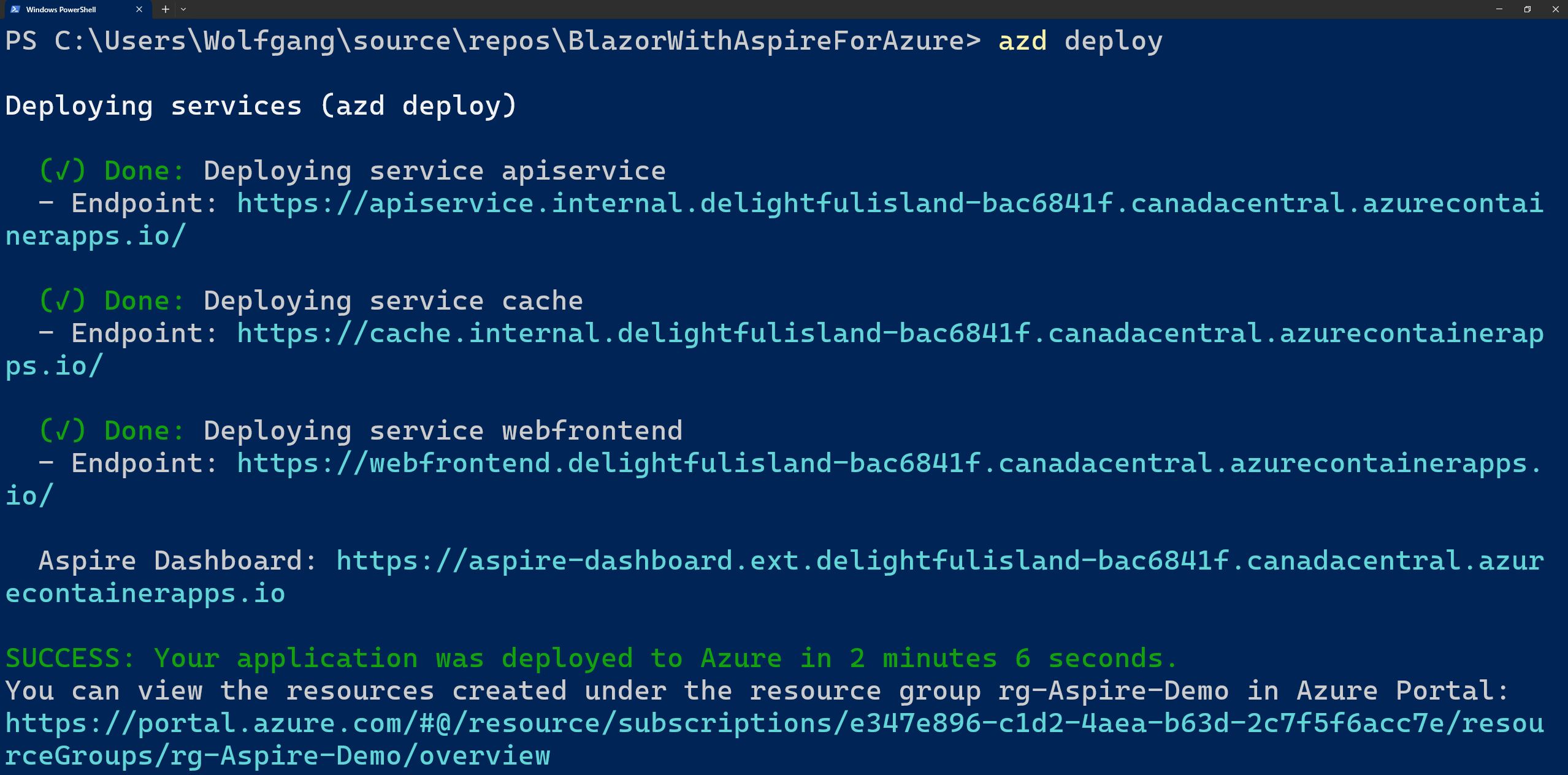
Abb. 9: Die Anwendungen und das Aspire-Dashboard wurden deployed
Abbildung 9 zeigt, dass Frontend, API-Backend, Redis und Aspire-Dashboard deployt wurden. Das Backend und Redis haben ein internal in der URL, das Frontend hat das allerdings nicht. Aspire weiß aufgrund der Konfiguration der Anwendungen, welche Container über das Internet erreichbar sein sollen und welche nicht. In der Demo-App wurde nur das Frontend mit dem zuvor beschriebenen WithExternalHttpEndpoints()-Parameter konfiguriert, wodurch nur dieser Container eine öffentliche URL bekommt. Aspire deployt auch das Aspire-Dashboard, welches fast genau wie in der lokalen Umgebung genutzt werden kann. Der einzige Unterschied zwischen der lokalen und der Azure-Instanz ist, dass für das Aufrufen des Azure-Dashboards ein Log-in benötigt wird. Aspire integriert automatisch das Log-in mit Entra in das Dashboard, wodurch nur User im Azure Tenant Zugriff auf die Anwendung haben.

Abb. 10: Das Aspire-Dashboard ist in Azure deployt
Abbildung 10 zeigt das Dashboard nach dem Log-in in Azure. Was dabei auffällt, ist, dass alle Endpoints via HTTPS aufgerufen werden können. Das ist ein nützliches Feature der Azure-Container-Apps. Alle Container-Apps werden mit einem automatisch erstellten TLS-Zertifikate erstellt und verwenden HTTPS, ohne dass die Entwickler:in etwas konfigurieren muss. Abbildung 11 zeigt die zuvor erstellten Ressourcen und die Container-Apps im Azure Portal.

Abb. 11: Alle erstellten Ressourcen im Azure Portal
Im Azure Portal sieht man auch die Konfiguration der einzelnen Container-Apps. Abbildung 12 zeigt die Umgebungsvariablen des Frontends.

Abb. 12: Die Umgebungsvariablen des Frontends wurden automatisch konfiguriert
Hier sind zum Beispiel die Endpoints der Redis- und Backend-Container konfiguriert, wie auch der Connection String für Redis. Hier sieht man zudem, dass sensitive Daten, zum Beispiel der Connection String, als Secret referenziert werden.
Das letzte interessante Feature des Deployments ist das Erstellen der Container für Frontend und Backend. Etwas weiter oben wurde die Azure-Container-Registry erwähnt, welche die Container-Images für die Container-Apps beinhaltet. Während der Entwicklung oder des Deployments wurde aber kein Dockerfile oder Ähnliches konfiguriert, um die Images zu erstellen. Um die Container-Images ohne Dockerfiles zu erstellen, nutzt Aspire ein .NET-Feature, das mit .NET 8 eingeführt wurde [5]. Seit .NET 8 kann das .NET SDK Docker Images erstellen, ohne dass dafür ein Dockerfile benötigt wird. Das erlaubt das einfache und schnelle Deployment des Aspire-Projekts.
Wenn die Ressourcen nicht mehr benötigt werden, können sie mit dem Befehl azd down gelöscht werden. Das Azure Developer CLI listet alle Ressourcen auf; nachdem das Löschen bestätigt ist, wird die gesamte Ressource-Gruppe gelöscht. Das dauert normalerweise nur wenige Minuten. Abbildung 13 zeigt aber, dass es manchmal auch etwas länger dauern kann.

Abb. 13: Die gesamte Umgebung wurde gelöscht
Viele Projekte verwenden für die Konfiguration der Abhängigkeiten während der Entwicklung Docker Compose. Diese Abhängigkeiten können eine Datenbank, Redis oder eine Queue wie etwa RabbitMQ sein, welche einfach mit einem Befehl gestartet werden können. Dadurch müssen sich vor allem neue Entwickler:innen nicht um die Konfiguration aller Komponenten kümmern und können so schnell produktiv im Projekt mitarbeiten.
Da .NET Aspire deutlich mehr Funktionalität als Docker Compose mitbringt, ist es empfehlenswert, bei neuen Projekten auf Aspire anstatt Docker Compose zu setzen. Für bestehende Projekte kann sich eine Migration von Docker Compose auszahlen, da diese oft recht schnell und einfach durchgeführt werden kann. Das größte Hindernis für eine Migration ist, dass Aspire externe Komponenten via NuGet-Paket einbindet. Sollte es noch kein NuGet-Paket für das gewünschte Tool geben, kann dieses derzeit nicht mit Aspire konfiguriert werden.
Um eine Migration von Docker Compose zu .NET Aspire zu demonstrieren, wird die zuvor erstellte Anwendung verwendet und ein fiktives Beispiel erstellt, in dem diese Anwendung neben Frontend und Backend auch PostgreSQL als Datenbank, Redis als Cache und RabbitMQ als Queue verwendet. Alle externen Komponenten werden in diesem fiktiven Beispiel in Docker Compose konfiguriert und an die Container der Blazor-Anwendung angehängt.
Wie bereits zuvor beschrieben kann einem bestehenden Projekt .NET Aspire (mit einem Rechtsklick auf das Webprojekt; dann mit Add | .NET Aspire Orchestrator Support) hinzugefügt werden. Das erstellt zwei neue Projekte: Projektname.AppHost und Projektname.ServiceDefaults. In der Program.cs-Datei des AppHost-Projekts wird Aspire konfiguriert. Diese Datei sollte in etwa wie in Listing 4 aussehen. Nun können die benötigten externen Komponenten über NuGet-Pakete installiert werden. In Visual Studio kann dazu mit der rechten Maustaste auf das AppHost-Projekt geklickt werden und unter Add | .NET Aspire package ausgewählt werden. Alternativ kann auch das NuGet-Menü geöffnet und dort nach Aspire gesucht werden. Abbildung 14 zeigt, dass es bereits eine Vielzahl NuGet-Pakete für .NET Aspire gibt und diese die unterschiedlichsten Technologien unterstützen. So gibt es zum Beispiel NuGet-Pakete für SQL Server, Azure Key Vault, MongoDB und auch für AWS.

Abb. 14: Aspire bietet eine Vielzahl von NuGet-Paketen an
Für diese Demo werden die Redis, PostgreSQL und RabbitMQ Pakete installiert. Anschließend müssen diese noch in der Program.cs-Datei im AppHost-Projekt konfiguriert werden.
var builder = DistributedApplication.CreateBuilder(args);
var cache = builder.AddRedis("cache");
var postgres = builder.AddPostgres("database")
.WithDataVolume()
.WithPgAdmin();
var rabbitMq = builder.AddRabbitMQ("rabbitMq")
.WithManagementPlugin();
var apiService = builder.AddProject<Projects.BlazorWithAspireForAzure_ApiService>("apiservice")
.WithReference(postgres)
.WithReference(rabbitMq);
builder.AddProject<Projects.BlazorWithAspireForAzure_Web>("webfrontend")
.WithExternalHttpEndpoints()
.WithReference(cache)
.WaitFor(cache)
.WithReference(apiService)
.WithReference(postgres)
.WithReference(rabbitMq)
.WaitFor(apiService);
builder.Build().Run();
Listing 5 zeigt die vollständige Program.cs-Datei, in der Frontend und API konfiguriert sind, sowie Redis, PostgreSQL und RabbitMQ hinzugefügt wurden. Redis wird mit der Methode AddRedis hinzugefügt und in einer Variable gespeichert. Diese Variable wird im Frontend referenziert, damit das Frontend auf Redis zugreifen kann; zusätzlich wartet das Frontend, bis Redis verfügbar ist.
Regelmäßig News zur Konferenz und der .NET-Community
Als nächstes wird PostgreSQL mit der Methode AddPostgres erstellt. Diese Methode verwendet die Erweiterungen WithDataVolume() und WithPgAdmin(). Mit dem Volume kann die Datenbank persistiert werden und bleibt dadurch beim Neustart der Container bestehen. Die PgAdmin-Methode konfiguriert das Management-Tool pgAdmin, damit die PostgreSQL-Datenbank mit einem UI verwaltet werden kann.
Zuletzt wird RabbitMQ mit der Methode AddRabbitMQ hinzugefügt und im Frontend sowie im API referenziert. Damit können beide Anwendungen auf RabbitMQ zugreifen und Nachrichten verschicken und empfangen. RabbitMQ bietet auch die Erweiterungsmethode, WithManagementPlugin(), wodurch automatisch das Management-UI von RabbitMQ konfiguriert wird und auch im Aspire-Dashboard angezeigt wird.
Wenn die AppHost-Anwendung jetzt gestartet wird, sollten nach dem Herunterladen der Container alle Anwendungen laufen. Abbildung 15 zeigt das Aspire-Dashboard mit dem Frontend und dem API sowie allen zuvor konfigurierten Tools inklusiver der Management-UIs.

Abb. 15: Das Aspire-Dashboard mit allen konfigurierten Tools
Das RabbitMQ-Management-UI fehlt in dieser Auflistung, weil es ein Teil von RabbitMQ ist und daher unter dem URL für RabbitMQ aufgerufen werden kann. Beim ersten Aufruf des Management-UIs werden Benutzername und Passwort benötigt. Diese können aus den Umgebungsvariablen des RabbitMQ-Containers ausgelesen werden. Es ist generell zu empfehlen, sich durch die Umgebungsvariablen der verschiedenen Anwendungen zu klicken, um einen besseren Einblick in die Konfiguration zu bekommen.
.NET Aspire kann aber nicht nur durch NuGet-Pakete erweitert werden, es kann auch durch die Implementierung der Aspire-Features erweitert werden. Die Konfiguration dazu befindet sich im ServiceDefaults-Projekt. Dort kann zum Beispiel das Logging oder das Tracing um weitere Datenquellen erweitert werden. In .NET wird mit RabbitMQ oft MassTransit [5] als Tracing-Tool verwendet. Dieses kann einfach als neue Quelle im Tracing hinzugefügt werden, wodurch alle MassTransit-Traces ebenfalls im Aspire-Dashboard angezeigt werden können. Die Implementierungsdetails dazu würden hier allerdings den Rahmen sprengen.
.NET Aspire ist ein neues Tool von Microsoft, das Entwickler:innen bei der Entwicklung und Fehlersuche in komplexen Systemen unterstützen soll. Dazu bringt es viele nützliche Features wie Logging, Tracing und ein Dashboard mit, das ohne Konfiguration der Entwickler:innen funktionieren. Bei Bedarf kann das Verhalten dieser Tools aber auch an die eigenen Anforderungen angepasst werden. Zusätzlich kann gemeinsam mit dem Azure Developer CLI ein Aspire-Projekt mit wenigen Befehlen in die Cloud deployt werden.
Obwohl .NET Aspire erst vor einigen Monaten erschienen ist, ist es bereits so umfangreich, dass dieser Artikel nur einen kleinen Einblick in den vollen Funktionsumfang geben konnte. Die Zukunft sieht ebenfalls positiv aus, da laufend neue Features hinzukommen und Microsoft seinen Fokus auf das Projekt gelegt hat.
[1] https://devblogs.microsoft.com/dotnet/introducing-project-tye/
[2] https://github.com/dotnet/aspire-samples
[3] https://learn.microsoft.com/en-us/azure/developer/azure-developer-cli/install-azd
[4] https://learn.microsoft.com/en-us/azure/azure-resource-manager/bicep/overview?tabs=bicep
[5] https://learn.microsoft.com/en-us/dotnet/core/docker/publish-as-container
The post Meistern Sie .NET Aspire: Effektive Tools für Entwickler appeared first on BASTA!.
]]>The post Technische Umsetzung von Layouts in Blazor appeared first on BASTA!.
]]>In diesem Artikel geht es um die technische Umsetzung von Layouts in Web-Apps mit Hilfe des Blazor Frameworks.
Regelmäßig News zur Konferenz und der .NET-Community
Die verschiedenen Layoutoptionen bieten Nutzer:innen eine flexible und effiziente Möglichkeit, die Struktur und Benutzerführung von Webapplikationen gezielt zu gestalten. Eine erste Übersicht ist in Tabelle 1 zu sehen.
| Layout-Option | Beschreibung | Nutzen für Anwender:innen |
| Master-Detail-Layout | Hauptbereich (Master) zeigt eine Liste oder Navigation; Detailbereich zeigt Informationen basierend auf Auswahl | Ermöglicht die schnelle Navigation und eine strukturierte Darstellung von Details; ideal für Datenmanagement |
| Sidebar-Layout | Feste Seitenleiste für Navigationselemente oder Filter; dynamischer Hauptinhalt | Bietet eine klare Orientierung und schnellen Zugriff auf häufig verwendete Funktionen und Ansichten |
| Tabbed Layout | Inhalte sind in Registerkarten organisiert, die durch Klicken gewechselt werden können | Übersichtliche und direkte Zugänglichkeit zu gleichwertigen Inhaltsbereichen, einfache Navigation |
| Grid-Layout | Seite wird in ein Raster mit Zeilen und Spalten aufgeteilt; ideal für Karten oder Kacheln | Erleichtert das visuelle Scannen und das schnelle Durchsuchen von Inhalten; ideal für Kataloge und Listen |
| Fullscreen-Layout | Nutzt die gesamte Bildschirmfläche; häufig für visuell intensive Inhalte wie Dashboards oder Medienanzeige | Bietet eine immersive Nutzererfahrung, bei der alle wichtigen Informationen auf einen Blick sichtbar sind |
| Responsive Layout | Dynamisch anpassbares Layout mit Breakpoints für Desktop, Tablet und Mobilgerät | Maximiert die Benutzerfreundlichkeit durch optimierte Darstellung auf unterschiedlichen Geräten. |
Tabelle 1: Layoutoptionen in der Web-App
Layouts ermöglichen es, konsistente Strukturen für Seiten zu definieren und gemeinsame Elemente wie Navigation, Kopf- und Fußzeilen zentral zu verwalten. Ein Layout in Blazor ist eine spezielle Razor-Komponente, die als Vorlage für andere Komponenten dient. Diese Layoutkomponenten erben von der Klasse LayoutComponentBase und definieren eine Body-Eigenschaft, die einen Platzhalter für den Inhalt der untergeordneten Komponenten darstellt. Als erstes analysieren wir dazu den Quellcode einer Blazor-App (Web-App), die wir auf der Basis des gleichnamigen Templates generieren. Verantwortlich ist die Datei (Komponente) MainLayout.razor, die man im Ordner Components/Layout findet (Listing 1, Abb. 1).
@inherits LayoutComponentBase
<div class="page">
<div class="sidebar">
<NavMenu />
</div>
<main>
<div class="top-row px-4">
<a href="https://learn.microsoft.com/aspnet/core/" target="_blank">About</a>
</div>
<article class="content px-4">
@Body
</article>
</main>
</div>
<div id="blazor-error-ui">
An unhandled error has occurred.
<a href="" class="reload">Reload</a>
<a class="dismiss">🗙</a>
</div>
Abb. 1: Layout (Seitennavigation mit Menü) in einer Blazor-App (Template)
Sehen wir uns diese Komponente zunächst etwas genauer an:
Dieses Layout bietet eine klare Struktur und ermöglicht eine flexible Gestaltung, da verschiedene Seiten das gleiche Layout nutzen können. Die Navigation und die Fehlerverarbeitung werden über die gesamte Anwendung hinweg vereinheitlicht.

Viele Blazor-Entwickler:innen sind höchstwahrscheinlich über die Programmiersprache C# zur Webentwicklung mit Blazor gestoßen. Daher lohnt sich ein vertiefender Blick auf die Möglichkeiten des semantischen HTML, denn es bietet einen klaren Vorteil für die Strukturierung und Benutzerfreundlichkeit von Webanwendungen und wir nutzen diese HTML-Elemente in Blazor-Anwendungen. Webprofis können diesen Abschnitt getrost überspringen.
In HTML5 ist die semantische Strukturierung ein wichtiger Aspekt, um die Benutzerfreundlichkeit, Zugänglichkeit und Übersichtlichkeit von Webseiten zu verbessern. Semantisches HTML bedeutet, dass Inhalte so strukturiert und mit Tags ausgezeichnet werden, dass ihre Funktion und Bedeutung im Kontext der Webseite klar erkennbar sind. Dies hilft nicht nur Entwickler:innen und Nutzer:innen, sondern auch Suchmaschinen und Screenreadern, den Inhalt korrekt zu interpretieren. Ein HTML-Dokument sollte nicht lediglich nacheinander mit Inhalten gefüllt werden, sondern eine klare Struktur und Hierarchie aufweisen. Mit den HTML-Tags lassen sich Webseiten logisch gliedern und erleichtern es Nutzer:innen, sich auf der Seite zurechtzufinden. Die wichtigsten HTML-Tags zur Strukturierung sind die folgenden:
Die Verwendung dieser HTML5-Elemente zur Strukturierung verleiht Webseiten eine klare und bedeutungsgerechte Gliederung, was mehrere Vorteile mit sich bringt: Screenreader und andere Assistenztechnologien können die Struktur besser interpretieren, was sehbehinderten Nutzer:innen zugutekommt. Suchmaschinen verstehen durch semantische Tags die Bedeutung und Struktur des Inhalts besser, was die Indexierung und Auffindbarkeit der Seite verbessern kann. Klare Strukturen erleichtern die Wartung und Erweiterung des Codes, da die Bedeutung der einzelnen Bereiche sofort ersichtlich ist. Ein Beispiel für eine HTML5-Struktur mit semantischen Tags finden Sie in Listing 2 und Abb. 2.
<!DOCTYPE html>
<head>
…
<link rel="stylesheet" type="text/css" href="css/style.css">
</head>
<body>
<header>
<h1>Die Überschrift</h1>
</header>
<nav>
<a href="#">Link</a>
<a href="#">Link</a>
<a href="#">Link</a>
</nav>
<main>
<div class="column side">
<p>Der linke Bereich der Seite</p>
<p>
Lorem ipsum ….
</p>
</div>
<div class="column middle">
<p>Der mittlere Bereich der Seite</p>
<p>
Lorem ipsum ….
</p>
</div>
<div class="column side">
<p>Der rechte Bereich der Seite</p>
<p>
Lorem ipsum ….
</p>
</div>
</main>
<footer>
Hier kommt zum Beispiel das Impressum.
</footer>
</body>
</html>
Abb. 2: Typisches Layout einer Web-App, realisiert mit semantischem HTML
Wenn Sie diese Elemente in einem HTML5-Dokument verwenden, können Sie die inhaltliche Struktur des Dokumentes festlegen. Beachten Sie jedoch zwingend: Der Browser wird das eine oder andere Element bereits in irgendeiner Form angepasst darstellen, zum Beispiel werden Inhalte in <address> kursiv ausgegeben. Die eigentliche Festlegung des Layouts und des Designs erfolgt jedoch in CSS, in dem man dann die Tagelemente konkret anspricht und diese mit dem entsprechenden CSS-Styling und Design versieht. Kommen wir jetzt wieder zurück zu Blazor.
Innerhalb der Layoutkomponente haben wir die Navigation (<Nav/>-Komponente) integriert, die im Blazor-Kontext des Templates als Sidebar oder Top-Navigationsleiste dient (Listing 3). Diese Navigationsleiste ermöglicht eine strukturierte und konsistente Navigation durch die Hauptbereiche der Anwendung.
<div class="top-row ps-3 navbar navbar-dark">
<div class="container-fluid">
<a class="navbar-brand" href="">BlazorApp1</a>
</div>
</div>
<input type="checkbox" title="Navigation menu" class="navbar-toggler" />
<div class="nav-scrollable" onclick="document.querySelector('.navbar-toggler').click()">
<nav class="flex-column">
<div class="nav-item px-3">
<NavLink class="nav-link" href="" Match="NavLinkMatch.All">
<span class="bi bi-house-door-fill-nav-menu" aria-hidden="true"></span> Home
</NavLink>
</div>
<div class="nav-item px-3">
<NavLink class="nav-link" href="counter">
<span class="bi bi-plus-square-fill-nav-menu" aria-hidden="true"></span> Counter
</NavLink>
</div>
<div class="nav-item px-3">
<NavLink class="nav-link" href="weather">
<span class="bi bi-list-nested-nav-menu" aria-hidden="true"></span> Weather
</NavLink>
</div>
</nav>
</div>
Schauen wir uns den Aufbau und das Zusammenspiel der verschiedenen Teile der Navigation an. Der Navigationsbereich enthält mehrere Elemente, die zusammen eine responsive und funktionale Sidebar erzeugen:
<div class="top-row ps-3 navbar navbar-dark"> <div class="container-fluid"> <a class="navbar-brand" href="proxy.php?url=">BlazorApp1</a> </div> </div>
Dieser Abschnitt definiert den obersten Bereich der Navigation. Er enthält die “navbar-brand”-CSS-Klasse, die als Logo oder Markennamen dient (“BlazorApp1”). Das “navbar”– und “navbar-dark”-Klassenset bringt den Stil der Bootstrap-Navigationsleiste ein und sorgt für ein abgedunkeltes Farbschema. Mit folgendem Beispiel wird ein checkbox-Element definiert, das als Hamburgermenü fungiert:
<input type="checkbox" title="Navigation menu" class="navbar-toggler" />
Beim Anklicken, beispielsweise auf Mobilgeräten, wird das Menü ein- und ausgeblendet. Das title-Attribut verleiht dem Toggle-Button eine beschreibende Bezeichnung, die für Screenreader und eine universelle Zugänglichkeit wichtig ist. Kommen wir zum Nav-Container (scrollbarer Bereich):
<div class="nav-scrollable" onclick="document.querySelector('.navbar-toggler').click()"> <nav class="flex-column">
Der Bereich nav-scrollable ist ein Container für die Navigation, der vertikales Scrollen unterstützt. Durch das onclick-Event im div wird das Menü ein- oder ausgeblendet, wenn Benutzer.innen auf den Bereich klicken. Das ermöglicht eine einfache Bedienung der Sidebar. Die einzelnen Navigationselemente werden durch <NavLink>-Komponenten definiert, die von Blazor bereitgestellt werden. Jedes <NavLink> ist mit einer Route der Anwendung verknüpft und wechselt den Zustand basierend auf dem aktuellen URL. Der Code:
<div class="nav-item px-3"> <NavLink class="nav-link" href="proxy.php?url=" Match="NavLinkMatch.All"> <span class="bi bi-house-door-fill-nav-menu" aria-hidden="true"></span> Home </NavLink> </div>
Die Klasse “nav-item” sorgt für einheitliche Abstände, während die Klasse “px-3” für ein horizontal gepolstertes Layout sorgt. Die “nav-link”-Klasse ist eine Standardklasse für Links in Bootstrap und wird hier verwendet, um den Navigationselementen ein einheitliches Styling zu verleihen. Jedes <NavLink>-Element enthält ein span-Element mit einer Bootstrap-Icon-Klasse (“bi bi-house-door-fill-nav-menu”). Das ermöglicht die Darstellung eines Icons neben dem Text. Das aria-hidden=”true”-Attribut stellt sicher, dass das Icon für Screenreader ignoriert wird, da es nur eine dekorative Funktion hat. Kommen wir als letztes zu den Seitenverlinkungen (href-Attribute). Die einzelnen href-Attribute definieren die Routen in der Blazor-Anwendung, zum Beispiel: `/` (Startseite), `/counter` (Counter-Seite) oder `/weather` (Weather-Seite). Jedes dieser Elemente wird durch ein Icon und eine Beschriftung ergänzt, um die Navigation für Benutzer:innen intuitiv zu gestalten. Die Hauptvorteile dieses Vorgehens sind:
Zusammengefasst bietet dieses Layout eine gut strukturierte Navigation, die sich dynamisch anpasst, nutzerfreundlich ist und eine konsistente Navigation über die gesamte Blazor-App hinweg ermöglicht.
Regelmäßig News zur Konferenz und der .NET-Community
Das Styling der Layoutkomponente erfolgt durch eine zugeordnete CSS-Datei, in der die visuelle Gestaltung der Navigation und des allgemeinen Layouts definiert wird. Diese CSS-Datei enthält die Stile für die verschiedenen Bereiche der Layoutkomponente, wie die Sidebar, das Hamburgermenü, den Hauptinhalt und den Footer. In der App auf der Basis des allgemeinen Templates wird die Definition in der Datei MainLayout.razor.css (Listing 4) vorgenommen.
.page {
position: relative;
display: flex;
flex-direction: column;
}
main {
flex: 1;
}
.sidebar {
background-image: linear-gradient(180deg, rgb(5, 39, 103) 0%, #3a0647 70%);
}
…
#blazor-error-ui {
background: lightyellow;
bottom: 0;
box-shadow: 0 -1px 2px rgba(0, 0, 0, 0.2);
display: none;
left: 0;
padding: 0.6rem 1.25rem 0.7rem 1.25rem;
position: fixed;
width: 100%;
z-index: 1000;
}
Zunächst erfolgt die Definition des grundlegenden Layoutcontainers:
.page { position: relative; display: flex; flex-direction: column; }
Diese Klasse bildet den Hauptcontainer des Layouts und nutzt das Flexbox-Element aus CSS als Layoutmethode. Durch flex-direction: column werden die Elemente in .page vertikal angeordnet. Das position: relative stellt sicher, dass die Elemente innerhalb des Containers relativ zu .page positioniert werden können. Durch
main { flex: 1; }
wird der Hauptinhalt so gestaltet, dass er den verbleibenden verfügbaren Platz im Container .page einnimmt. Dadurch passt sich der main-Bereich dynamisch an die Größe des Containers an und lässt Platz für andere fixierte oder flexible Elemente wie die Sidebar und den Header.
.sidebar { background-image: linear-gradient(180deg, rgb(5, 39, 103) 0%, #3a0647 70%); }
Die Sidebar erhält durch einen linearen Farbverlauf (Gradient) eine attraktive Hintergrundfarbe, die von einem dunklen Blau (rgb(5, 39, 103)) oben in ein tiefes Violett (#3a0647) unten übergeht. Dieses visuelle Design hilft, die Sidebar als festen Bereich vom restlichen Inhalt abzuheben und eine ansprechende, moderne Optik zu erzeugen. Als letztes wird eine mögliche Fehlereinblendung der Blazor-App mit einem Layout versehen (Listing 5).
#blazor-error-ui {
background: lightyellow;
bottom: 0;
box-shadow: 0 -1px 2px rgba(0, 0, 0, 0.2);
display: none;
left: 0;
padding: 0.6rem 1.25rem 0.7rem 1.25rem;
position: fixed;
width: 100%;
z-index: 1000;
}
Diese CSS-Definitionen (hier nur in Auszügen dargestellt und erläutert) legen die Grundstruktur und das Design der Blazor-Anwendung fest. Durch Flexbox und responsives Design wird ein flexibles Layout gewährleistet. Die Sidebar hebt sich durch ihren Farbverlauf ab, und die Fehleranzeige wird bei Bedarf hervorgehoben dargestellt. Studieren Sie die vollständige CSS-Datei in einer neuen Blazor-App, die sie auf einfache Art und Weise mit Hilfe des Assistenten in Visual Studio generieren lassen können.
In Blazor können Layouts auf verschiedene Arten auf Razor-Komponenten angewendet werden. Es bestehen die folgenden Optionen, um ein Layout für eine oder mehrere Komponenten festzulegen.
Nutzung eines Layouts durch die @layout-Direktive: Die einfachste Möglichkeit, einer Razor-Komponente ein Layout zuzuweisen, ist die Verwendung der @layout-Direktive direkt in der Komponente. Diese Methode ermöglicht eine individuelle Layoutzuweisung, die spezifisch für eine einzelne Komponente gilt. Ein einfaches Beispiel:
@page "/about" @layout MainLayout <h2>Über uns</h2> <p>Willkommen auf der Über-uns-Seite.</p>
In diesem Beispiel wird der Komponente das Layout MainLayout zugewiesen, indem die @layout-Direktive verwendet wird. Der Inhalt der Razor-Komponente (hier: „Über uns“ und „Willkommen auf der Über-uns-Seite“) wird an der Stelle von @Body in MainLayout gerendert.
Nutzung eines Standard-Layouts für die gesamte Anwendung: Um ein Standardlayout für alle Razor-Komponenten festzulegen, können Sie das Layout in der <RouteView/>-Komponente der <Router/>-Komponente festlegen. Verwenden Sie den DefaultLayout-Parameter, um den Layouttyp festzulegen, üblicherweise in der Datei Routes.razor:
<Router AppAssembly="typeof(Program).Assembly"> <Found Context="routeData"> <RouteView RouteData="routeData" DefaultLayout="typeof(Layout.MainLayout)" /> <FocusOnNavigate RouteData="routeData" Selector="h1" /> </Found> </Router>
In diesem Beispiel wird MainLayout als Standardlayout festgelegt. Dadurch wird MainLayout automatisch auf alle Razor-Komponenten angewendet, die keine spezifische @layout-Direktive haben.
Nutzung eines Layouts für mehrere Komponenten eines Ordners: Für Razor-Komponenten innerhalb eines bestimmten Ordners kann ein Layout durch eine _Imports.razor-Datei festgelegt werden. Diese Datei wird auf alle Razor-Komponenten im gleichen Ordner und in dessen Unterordnern angewendet, sodass das Layout automatisch übernommen wird. Ein weiteres Beispiel: In der Datei _Imports.razor notieren wir folgende Anweisung:
@layout MainLayout
In diesem Fall wird MainLayout als Layout für alle Razor-Komponenten innerhalb des gleichen Ordners wie die _Imports.razor-Datei und in den Unterordnern verwendet. Diese Methode ist besonders nützlich, wenn Sie unterschiedliche Layouts für verschiedene Teile Ihrer Anwendung benötigen, beispielsweise ein Adminlayout für alle Komponenten im Admin-Ordner und ein Standardlayout für andere Bereiche.
Fassen wir zusammen: Die @layout-Direktive dient der Zuweisung eines Layouts in einer spezifischen Komponente; das Standardlayout definiert das Layout für die gesamte Anwendung und mittels der _Imports.razor-Datei legen wir das Layout für mehrere Komponenten in einem bestimmten Ordner fest. Diese verschiedenen Methoden ermöglichen es Ihnen, Layouts flexibel und übersichtlich in einer Blazor-Anwendung anzuwenden und zu organisieren.
Wenn Sie das Layout einer Blazor-Anwendung anpassen möchten, dann müssen Sie die Layoutkomponente modifizieren und beispielsweise eine Menüstruktur hinzufügen. Hier wird der Code so angepasst, dass eine Navigationsleiste erstellt wird, die als Hauptmenü dient. Die Modifikation des Standardlayouts erfolgt durch die Definition von Header, Navigation und Inhaltsbereichen. Der Quellcode in Listing 6 beschreibt eine typische Menüstruktur.
@inherits LayoutComponentBase
Layout1
<div class="header-nav">
<nav class="navbar navbar-expand-lg bg-body-tertiary">
<div class="container-fluid">
<a class="navbar-brand" href="#">MyCompany</a>
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNavAltMarkup" aria-controls="navbarNavAltMarkup" aria-expanded="false" aria-label="Toggle navigation">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarNavAltMarkup">
<div class="navbar-nav">
<NavLink class="nav-link active" href="/" Match="NavLinkMatch.All">Home</NavLink>
<NavLink href="/weather" class="nav-link">Wetter</NavLink>
<NavLink href="/counter" class="nav-link">Counter</NavLink>
</div>
</div>
</div>
</nav>
</div>
<div class="content px-4">
@Body
</div>
Es folgt eine kompakte Erklärung der Komponenten und Modifikationen gegenüber der Ausgangssituation:
Regelmäßig News zur Konferenz und der .NET-Community
Mit dieser Anpassung wird das Standardlayout um eine intuitive Menüstruktur erweitert (Abb. 3). Die Navigation ist klar strukturiert und passt sich automatisch an die Bildschirmgröße an, was das Layout flexibel und benutzerfreundlich macht.
Abb. 3: Layout einer Blazor-App mittels Menünavigation
Wenn Sie das Layout einer Blazor-Anwendung zu einer Tabnavigation anpassen möchten, dann müssen Sie das Standardlayout modifizieren und eine Struktur erstellen, die auf einer Navigation mit Tabs basiert. Eine solche Navigation zeigt die wichtigsten Seiten der Anwendung in Form von Registerkarten (Tabs) an, die den Benutzer:innen eine einfache und schnelle Navigation zwischen den Seiten ermöglichen. Das Quellcodebeispiel finden Sie in Listing 7 und das Ergebnis in Abbildung 4.
@inherits LayoutComponentBase
Layout2
<div class="header-nav">
<nav class="navbar navbar-expand-lg bg-body-tertiary">
<div class="container-fluid">
<a class="navbar-brand" href="#">MyCompany</a>
<button class="navbar-toggler" type="button" data-bs-toggle="collapse" data-bs-target="#navbarNavAltMarkup" aria-controls="navbarNavAltMarkup" aria-expanded="false" aria-label="Toggle navigation">
<span class="navbar-toggler-icon"></span>
</button>
<ul class="nav nav-tabs">
<li class="nav-item">
<NavLink class="nav-link active" href="/" Match="NavLinkMatch.All">Home</NavLink>
</li>
<li class="nav-item">
<NavLink href="/weather" class="nav-link">Wetter</NavLink>
</li>
<li class="nav-item">
<NavLink href="/counter" class="nav-link">Counter</NavLink>
</li>
</ul>
</div>
</nav>
</div>
<div class="content px-4">
@Body
</div>
Abb. 4: Layout einer Blazor-App mittels Tabnavigation
Die Anpassungen im Quellcode sind ähnlich, wie bei dem eben beschriebenen Beispiel. Um die Tabnavigation zu erreichen sind die entsprechenden Klassen aus Bootstrap für die Tabs zu nutzen.
In Blazor können Layouts ineinander geschachtelt werden, um eine hierarchische Struktur für die Benutzeroberfläche zu schaffen. Das bedeutet, dass ein Layout in einem anderen Layout eingebettet wird. Das ist besonders nützlich, wenn unterschiedliche Bereiche der Anwendung konsistente Elemente haben, aber einige Elemente eine spezifische Struktur benötigen. Dazu ein einfaches Beispiel: Stellen wir uns eine Anwendung vor, die ein Hauptlayout mit einer globalen Navigation und ein weiteres untergeordnetes Layout für einen bestimmten Bereich (z. B. Adminbereich) verwendet. Der Adminbereich hat eine zusätzliche Navigation und spezielle Formatierungen, die sich vom Hauptlayout abheben. Im Hauptlayout wird die globale Navigation und der allgemeine Inhaltsbereich definiert. Dieses Layout verwendet MainLayout als übergeordnetes Layout und fügt zusätzliche Strukturen, wie eine adminspezifische Navigation, hinzu. Nun kann eine Seite das Adminlayout als Layout verwenden. Durch diese Struktur wird eine übersichtliche und flexible Gestaltung möglich, die Bereiche mit spezifischen Anforderungen konsistent in das Hauptlayout integriert. Ein Beispiel finden Sie unter [1].
Layouts spielen in Blazor-Anwendungen eine entscheidende Rolle, da sie die Grundlage für eine konsistente und benutzerfreundliche Benutzeroberfläche bilden. Sie ermöglichen eine klare Strukturierung der Seiteninhalte, fördern die Wiederverwendbarkeit und erleichtern die Wartung der Anwendung. Mit der Verwendung von Layouts in Blazor lassen sich Komponenten wie Header, Navigation und Footer zentral verwalten und für mehrere Seiten anwenden. Durch die verschiedenen Layoutoptionen wie Master-Detail, Sidebar, Tabnavigation und Fullscreen können Entwickler:innen das Layout flexibel an die Anforderungen der Anwendung und die Bedürfnisse der Nutzer:innen anpassen. Die Möglichkeit, Layouts ineinander zu verschachteln, bietet zusätzlichen Spielraum für komplexere Anwendungen, indem sie hierarchische Strukturen erlaubt. Zusammengefasst sind Layouts ein unverzichtbares Werkzeug für jede Blazor-Anwendung, da sie sowohl die technische Effizienz als auch die Benutzerfreundlichkeit erheblich steigern.
Web: https://larinet.com, https://www.tech-punkt.com
Links & Literatur
[1] https://learn.microsoft.com/de-de/aspnet/core/blazor/components/layouts?view=aspnetcore-8.0
The post Technische Umsetzung von Layouts in Blazor appeared first on BASTA!.
]]>The post Der .NET-Upgrade-Assistent: Alles, was Sie zur Anwendungsmigration wissen müssen appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
Der .NET-Upgrade-Assistent unterstützt eine Vielzahl von Projekttypen, die für die Migration auf moderne .NET-Versionen geeignet sind. Zu den unterstützten Projekten gehören [1]:
Die unterstützten Upgrade-Pfade umfassen:
Dabei ist aus Praxiserfahrungen festzustellen, dass diese Projekttypen und die zugehörigen Upgrade-Pfade mit einem unterschiedlichen Grad, einer verschiedenen Detaillierung und damit letztendlich auch mit wechselndem Erfolg unterstützt werden.
Die Installation des .NET-Upgrade-Assistenten kann auf zwei Arten erfolgen: als Visual-Studio-Erweiterung (Extension) oder als globales .NET-Tool. Die Extension finden Sie unter der Bezeichnung Upgrade Assistant. Der Assistent kann direkt aus Visual Studio über das Kontextmenü im Projektmappen-Explorer aufgerufen werden. Um es als globales .NET-Tool zu installieren sind die folgenden Schritte notwendig:
Wir demonstrieren das Handling mit dem .NET-Upgrade-Assistenten anhand einiger Projekte. Unser erstes Projekt ist eine ältere Windows-Forms-Applikation („Bibliothek“) auf der Basis des .NET Framework 4.7.2. Diese enthält lediglich ein Projekt und keine Abhängigkeiten von externen Bibliotheken. Die Benutzeroberfläche enthält nur wenige Komponenten, Herzstück ist ein DataGrid. Die Businesslogik ist im Code-Behind implementiert. Das Ziel ist eine Migration nach .NET 8, um die Applikation weiterentwickeln zu können. Starten wir mit einer ersten Analyse: Wir öffnen das Projekt in der aktuellen Version von Visual Studio und starten auf Ebene der Projektmappe (Kontextmenü im Projektmappen-Explorer) den .NET-Upgrade-Assistenten (Abb. 1).

Abb. 1: Start des .NET-Upgrade-Assistenten aus Visual Studio
Wir starten einen Report und müssen in den nachfolgenden Schritten das betreffende Projekt, das Ziel (hier .NET 8) und den Umfang der späteren Migration auswählen (Abb. 2).

Abb. 2: Konfigurieren der Migration im .NET-Upgrade-Assistenten
Das Ergebnis (Abb. 3) ist ein Report über die Einschätzung des Vorhabens und der notwendigen Schritte.

Abb. 3: Analyseergebnis der geplanten Migration
Die Hinweise stimmen uns optimistisch. Auf Projektebene starten wir danach den .NET-Upgrade-Assistenten neu und führen die konkrete Migration durch. Dabei haben wir u. a. die Wahl, ob wir die Migration innerhalb des Projekts durchführen möchten (in-place project upgrade) oder ob das migrierte Projekt als neues Projekt angelegt werden soll (side-by side project upgrade). Die eigentliche Migration des Projektes erfolgt ohne unser Zutun und konnte erfolgreich abgeschlossen werden. Die Windows-Forms-Applikation wurde nach .NET 8 portiert und kann auch gestartet und ausgeführt werden (Abb. 4).

Abb. 4: Der .NET-Upgrade-Assistent zeigt die erfolgreiche Migration
Das hat sehr gut funktioniert. Wie bereits dargestellt, handelt es sich um ein Projekt mit einem begrenzten Funktionsumfang und wenig Komplexität.
Unser zweiter Test ist schon anspruchsvoller. Es geht um eine Xamarin.Forms-Applikation für Android und iOS. Diese soll nach .NET MAUI migriert werden. Wir laden auch dieses Projekt in Visual Studio. Als Erstes werden wir aufgefordert, die fehlenden Komponenten für die Entwicklung von Xamarin.Forms-Projekte in Visual Studio nachzuladen. Diese wurden schon mit den Updates von Visual Studio entfernt, da auf dem Entwicklungsrechner in letzter Zeit nur noch .NET-MAUI-Projekte entwickelt wurden. Das Projekt weist auch Abhängigkeiten zu einigen externen Bibliotheken auf. Die Analyse der bevorstehenden Migration ergibt ein deutlich gemischteres Bild. Es werden Fehler und Schwierigkeiten bei der Migration erwartet und der Gesamtaufwand wird deutlich größer (24 Story Points) eingeschätzt (Abb. 5).

Abb. 5: Analyse des Xamarin-Projekts durch den .NET-Upgrade-Assistenten
Im nächsten Schritt starten wir die automatische Migration der Xamarin.Forms-App. Es muss jedes Xamarin.Forms-Projekt eigenständig über den .NET-Upgrade-Assistenten migriert werden. Die Migration des plattformneutralen Projektes konnte ohne Fehlermeldungen abgeschlossen werden. Die Migration des Android-Projekts dauerte einige Minuten und auch hier werden keine schwerwiegenden Fehler gemeldet. Als Letztes wird versucht, das iOS-Projekt zu migrieren. Wir bekommen Hinweise, dass ein Plug-in in iOS (zum Einblenden der Tastatur ist es in .NET MAUI nicht mehr erforderlich) nicht in .NET MAUI unterstützt wird. Ansonsten sieht das Ergebnis des Migrationsreports gut aus. Die App lässt sich dennoch nicht unmittelbar fehlerfrei kompilieren. Es werden Mehrdeutigkeiten von Klassen gemeldet. Das rührt daher, dass .NET MAUI auch neue Klassen einführt, die es in Xamarin nicht gab. Hier steht einige manuelle Nacharbeit auf der Agenda. Die Migration von Xamarin auf .NET MAUI ist deutlich komplexer als ein Update der .NET-Version. Dennoch liefert der .NET-Upgrade-Assistent wichtige Hinweise für eine Migration und nimmt auch bereits einige Arbeitsschritte vor.
Unser letztes Experiment versucht, eine Migration einer App für die UWP, bestehend aus mehreren Teilprojekten und der Nutzung von externen Bibliotheken. Starten wir auch hier mit einer Analyse der geplanten Migration: Das Ziel der Migration ist es, die App von der UWP (WinUI 2.*) nach WinUI 3 zu bekommen. Es deuten sich Probleme bei der Nutzung von Drittanbieterbibliotheken an. Die Analyse dauert mehrere Minuten und das Ergebnis enthält Hinweise zu erwarteten Aufgaben der Migration und möglichen Probleme. Hier wird beispielsweise bemängelt, dass eine externe Bibliothek für Interaktion mit dem Cloudspeicherdienst Dropbox nicht mit den neuen .NET-Versionen kompatibel ist. Wir wissen jedoch aus der Praxis, dass diese Bibliothek sowohl mit der UWP als auch mit WinUI 3 funktioniert. Gleiches gilt auch für andere gemeldete voraussichtliche Probleme. Der geschätzte riesige Migrationsaufwand (> 1 600 Story Points), primär durch das mögliche Neuschreiben der Bibliotheken, hat sich in der Praxis nicht so herausgestellt. Die App konnte mit einem deutlich geringeren Aufwand von der UWP nach WinUI 3 migriert werden. Das bedeutet, dass die Schätzung des .NET-Upgrade-Assistenten nur eine grobe Einschätzung des Aufwandes ist, sie kann auch komplett falsch sein. Wertvoller sind die Hinweise zu den konkreten Migrationsschritten.
Regelmäßig News zur Konferenz und der .NET-Community
Der .NET-Upgrade-Assistent wird in der Entwicklercommunity als ein nützliches Werkzeug zur Modernisierung von .NET-Anwendungen angesehen, insbesondere für Projekte, die auf älteren .NET-Framework- oder .NET-Core-Versionen basieren. Das Tool ist wertvoll, weil es den Migrationsprozess durch Automatisierung und eine geführte Schritt-für-Schritt-Anleitung erheblich vereinfacht. Das hilft, typische Fehler zu vermeiden und den Prozess effizienter zu gestalten, insbesondere bei weniger komplexen Projekten. Man kann folgende Stärken ausmachen:
Das Tool ist primär eine Hilfestellung, d. h., es hat Schwächen und Einschränkungen:
Das Tool wird bisher kontinuierlich verbessert und unterstützt inzwischen auch neuere Technologien wie .NET MAUI und Azure Functions. Diese Erweiterungen und die Verbesserung der Fehlerbehandlung tragen dazu bei, die Qualität der automatischen Upgrades weiter zu erhöhen.
Von einfachen Anpassungsmaßnahmen (Upgrade-Pfaden) abgesehen, beispielsweise eine Umstellung von einer älteren auf eine aktuelle .NET-Version, benötigt man eine gute Planung der Durchführung einer Migration. Wir beschreiben nachfolgend drei typische Migrationspfade im .NET-Umfeld. Die Migrationsplanung für .NET-Anwendungen umfasst typischerweise die Schritte (grober Ablauf) gemäß Tabelle 1.
| Schritt/Phase (Meilenstein) | Teilschritte |
| Vorbereitungsphase |
|
| Planungsphase |
|
| Durchführung der Migration |
|
| Test- und Optimierungsphase |
|
| Abschluss und Bereitstellung |
|
| Nachbereitung |
|
Tabelle 1: Schrittfolge bei der Migration von .NET-basierten Anwendungen
Die Migration einer .NET-Anwendung ist ein anspruchsvoller Prozess, der eine sorgfältige Planung und Durchführung erfordert. Mit einer strukturierten Herangehensweise und der Nutzung des .NET-Upgrade-Assistenten kann der Übergang jedoch risikoarm gestaltet werden.
Xamarin.Forms ist eine bewährte Plattform zur Erstellung plattformübergreifender mobiler Anwendungen mit einer gemeinsamen Codebasis für Android, iOS und UWP. Mit der Einführung von .NET MAUI (Multi-Platform-App-UI) hat Microsoft eine Weiterentwicklung und Erweiterung von Xamarin.Forms bereitgestellt, die zusätzlich die Entwicklung für macOS und Windows unterstützt und eine konsolidierte Entwicklungsplattform innerhalb von .NET darstellt. Sollen bestehende Xamarin.Forms-Apps weiter angepasst und entwickelt werden, sind diese zu .NET MAUI zu migrieren. Der typische Migrationspfad sieht wie folgt aus (Meilensteine):
Neben der Möglichkeit das Projekt weiter entwickeln zu können, ergeben sich weitere Vorteile, beispielsweise eine vereinfachte Projektstruktur, eine bessere Entwicklungsunterstützung, erweiterte Plattformunterstützung (einschließlich Desktopplattformen) und eine verbesserte Performance und API-Konsistenz innerhalb des .NET-Ökosystems.
Windows Presentation Foundation (WPF) ist ein bewährtes Framework zur Entwicklung von Desktopanwendungen unter Windows. Es bietet eine flexible und leistungsstarke Plattform für die Gestaltung von Benutzeroberflächen. WinUI 3 hingegen ist das neueste UI-Framework von Microsoft, das moderne Windows-10- und Windows-11-Anwendungen mit einer modernen Benutzeroberflächentechnologie ermöglicht. Die Migration von WPF zu WinUI 3 kann eine sinnvolle Option sein, wenn Sie eine modernere, zukunftssichere Oberfläche für Ihre Anwendung entwickeln möchten. Ein typischer Migrationspfad kann wie folgt aussehen:
Welche Vorteile bietet eine Migration zu WinUI 3? WinUI 3 unterstützt das Fluent-Design-System, das moderne und ansprechende Benutzeroberflächen ermöglicht. Ebenso ist WinUI 3 die Basis für zukünftige Windows-Entwicklungen, was die Anwendung langfristig wartbar und kompatibel mit neuen Windows-Versionen macht. Es gibt eine bessere Unterstützung und Integration mit den neuesten Windows APIs, was die Nutzung neuerer Betriebssystemfeatures erleichtert. Bei größeren Projekten kann man jedoch von einem umfangreicheren Anpassungsbedarf ausgehen. Die Migration der Benutzeroberfläche kann erheblichen Anpassungsaufwand erfordern, insbesondere bei komplexen WPF-Anwendungen. Einige WPF-Features haben keine direkten Entsprechungen in WinUI 3, was möglicherweise Neuentwicklungen erforderlich macht. Zusammengefasst kann man sagen: Die Migration von WPF zu WinUI 3 ist ein strategischer Schritt, der insbesondere dann sinnvoll ist, wenn eine langfristige Modernisierung und Integration mit den neuesten Windows-Technologien angestrebt wird.
Anmerkung/Hinweis: Microsoft hat erkannt, dass WPF weiterhin eine große Bedeutung für bestehende Projekte (und vielleicht auch noch für neue Projekte) hat. Es sind daher auch Anpassungen und Aktualisierungen geplant. Die Roadmap [2] zu WPF sieht dazu beispielsweise wie folgt aus: „Im letzten Jahr haben wir uns bemüht, die Testinfrastruktur zu verbessern, Community-PRs zusammenzuführen, um seit langem bestehende Probleme zu beheben, neue Steuerelemente hinzuzufügen (OpenFolderDialog) und neue Funktionen zu ermöglichen (Hardwarebeschleunigung für RDP-Verbindungen). Die Bemühungen, unsere Tests als Open Source bereitzustellen und den Testprozess durch CI/CD-Pipelines zu automatisieren, Komponententests hinzuzufügen, persistente Probleme zu beheben und neuere Steuerelemente hinzuzufügen, führten dazu, dass WPF auf .NET 8 integriert wurde“. Ebenso werden die folgenden Features, beispielsweise mit .NET in Aussicht gestellt:
Daraus kann man schlussfolgern, dass WPF kurzfristig wohl nicht abgekündigt wird und daher eine Migration nach WinUI 3 aus heutiger Sicht nicht zwingend ist. Wichtiger ist es jedoch bestehende WPF-Anwendungen auf der Basis des .NET Frameworks (bis Version 4.8*) nach .NET zu portieren – womit wir direkt bei der Beschreibung des nächsten Migrationspfads sind.
Das .NET Framework ist eine ältere, aber weit verbreitete Plattform für die Entwicklung von Windows-Anwendungen. Es wurde bekanntermaßen durch .NET (früher .NET Core) abgelöst. Sollen bestehende Applikationen dauerhaft weiterentwickelt werden, muss man diese nach .NET migrieren. Die Schritte des typischen Migrationspfades sind:
Durch die Migration – welche nicht immer einfach möglich ist – erreichen wir folgende Vorteile: eine plattformübergreifende Unterstützung (Windows, Linux, macOS), eine verbesserte Performance und Ressourcennutzung, den Zugang zu den neuesten .NET-Features und -Verbesserungen und eine langfristige Wartbarkeit der Applikation. Einen Überblick zu den aktuellen .NET-Versionen und deren Vorversionen gibt Tabelle 2. .NET 9 wird voraussichtlich im November 2024 erscheinen und .NET 10 ist für 2025 geplant.
| Version | Veröffentlichungs-datum | Letzte Patch-Version | Patch-Datum | Release-Typ | Support-Ende |
| .NET 8 | 14. November 2023 | 8.0.8 | 13. August 2024 | LTS | 10. November 2026 |
| .NET 7 | 8. November 2022 | 7.0.20 | 28. Mai 2024 | STS | 14. Mai 2024 |
| .NET 6 | 8. November 2021 | 6.0.33 | 13. August 2024 | LTS | 12. November 2024 |
| .NET 5 | 10. November 2020 | 5.0.17 | 10. Mai 2022 | STS | 10. Mai 2022 |
Tabelle 2: .NET-Versionen (LTS = Long Term Support, STS = Standard Term Support)
Regelmäßig News zur Konferenz und der .NET-Community
Insgesamt bietet der NET-Upgrade-Assistent eine solide Grundlage für die Modernisierung von .NET-Anwendungen, besonders für kleinere bis mittelgroße Projekte. Bei größeren Projekten kann es ein Hilfsmittel sein, um den Anpassungsbedarf der Migration abzuschätzen. Hier muss i. d. R. eine umfassende Planung je nach Ausgangspunkt und Ziel des Upgrades durchgeführt werden. Schnelle und unkomplizierte Hilfe kann es für das eine oder andere .NET-Projekt bereitstellen, wenn man dieses beispielsweise im Zuge des laufenden Entwicklungsprojektes auf die aktuelle .NET-Version bringen möchte. Die Migration per Mausklick ist auch im .NET-Umfeld nur in Einzelfällen machbar.
Web: https://larinet.com, https://www.tech-punkt.com.
[2] https://github.com/dotnet/wpf/blob/main/roadmap.md
The post Der .NET-Upgrade-Assistent: Alles, was Sie zur Anwendungsmigration wissen müssen appeared first on BASTA!.
]]>The post Die Zukunft des Software Developments: KI in der Praxis appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
Warum du diese Keynote nicht verpassen solltest
Diese Keynote ist ein Muss für jeden, der sich für die Zukunft der Softwareentwicklung interessiert. Die gezeigten Tools und Techniken eröffnen neue Möglichkeiten, wie Entwickler ihre Arbeit effizienter gestalten können. Egal, ob du bereits mit KI arbeitest oder gerade erst einsteigst – diese Keynote liefert dir wertvolle Insights und praktische Tipps für deinen Alltag als Software-Entwickler.
Jetzt die gesamte Keynote ansehen und mehr erfahren!
The post Die Zukunft des Software Developments: KI in der Praxis appeared first on BASTA!.
]]>The post Microsoft Copilot for Security appeared first on BASTA!.
]]>
Die Sicherheitsbranche ist ein sich ständig weiterentwickelndes Feld, das andauernd nach neuen und effektiveren Methoden sucht, um die Sicherheit von Systemen und Daten zu gewährleisten. Als Microsoft am 1. April 2024 Microsoft Copilot for Security für den Markt freigab, hielt die künstliche Intelligenz Einzug in die Sicherheitsbranche. Der Einfluss ist signifikant – hier ein paar der wichtigsten Auswirkungen:
Insgesamt trägt Microsoft Copilot for Security dazu bei, die Sicherheitsbranche zu transformieren, indem es die Effizienz und Genauigkeit von Sicherheitsteams verbessert und gleichzeitig das Lernen und die berufliche Entwicklung fördert.
Diese Frage ist leider nicht so einfach zu beantworten – dennoch gibt es ein paar Leitsätze, die hier einen Ansatz zeigen können, wie sich AI-Awareness schaffen lässt:
Alles in allem muss grundlegende Akzeptanz und eine Hands-on-Experience geschaffen werden, um im weiteren Schritt die AI auch in interne Systeme einfließen zu lassen. Dieser Schritt ist essenziell und einer der wichtigsten auf der AI Journey.
In der Standalone Experience von Copilot for Security wird eine eigenständige Anwendung genutzt – Benutzer:innen greifen direkt auf die Copilot-Plattform zu, um Sicherheitsanalysen durchzuführen. Die Embedded-Version von Copilot for Security ist in den Microsoft-Produkten integriert. Das bedeutet, dass die Funktionen von Copilot direkt in folgenden Produkte genutzt werden können:
Diese Integration ermöglicht es Benutzer:innen, die Vorteile von Copilot zu nutzen, ohne die gewohnte Arbeitsumgebung verlassen zu müssen.
Copilot for Security nutzt das fortschrittliche GPT4-Modell von OpenAI in Kombination mit einem speziellen Sicherheitsmodell, das von Microsoft entwickelt wurde. Dieses Modell wird durch die umfassende Sicherheitsexpertise und globale Bedrohungsintelligenz von Microsoft Security angetrieben. Durch die Integration von weiteren Microsoft Services und Third-party Services werden die Effektivität und Effizienz von Sicherheitsexperten erhöht.
Funktionen wie die Skriptanalyse ermöglichen es Kunden beispielsweise, Hunderte von Codezeilen zu analysieren und diese in natürlicher Sprache in Minuten zu interpretieren. Der Prozess ist grundsätzlich sehr einfach ausgelegt und basiert auf einigen Charakteristika (Abb. 1).

Abb. 1: Der Prozess für Copilot for Security [1]
Im sechsten Punkt wurde das Thema verantwortungsvolle AI und das Engagement von Microsoft kurz angeschnitten. Ich möchte hier auf den Punkt Datenschutz und -sicherheit etwas genauer eingehen.
Ein wesentlicher und wichtiger Aspekt hierbei ist „Deine Daten sind deine Daten, die durch umfassende Compliance- und Sicherheitskontrollen gesichert sind“. Ihre Daten werden auch nicht für das Trainieren von AI-Modellen verwendet. Um die Daten ausschließlich der Organisation zur Verfügung zu stellen, werden folgende Maßnahmen angewendet:
Analyst:innen können keine Daten und Informationen einsehen, auf die sie keinen Zugriff haben. Wenn beispielsweise ein Securityanalyst Informationen von Microsoft Sentinel benötigt, muss er auch die notwendigen Berechtigungen dafür haben, um die Daten zu erhalten.
Hier eine Auflistung der Microsoft-Hauptdatenquellen (Skills), die an Copilot for Security angebunden bzw. aktiviert werden können:
Des Weiteren kann Copilot for Security um Third-party-Plug-ins und Custom-Integrationen erweitert werden.
Zusammengefasst handelt es sich bei Copilot for Security um eine Revolution im Securitybereich, die unter Berücksichtigung und Sicherstellung von umfangreichen Compliance- und Sicherheitsmaßnahmen jedem zur Verfügung steht. Diese Funktionalität basiert auf dem aktuellen Entwicklungsstand der künstlichen Intelligenz und wird in den hoch skalierbaren Cloud-Datacenters von Microsoft betrieben.
Aus Sicht von Konsumenten wird sich die Erkennung von Angriffen erheblich verbessern und auch die Incident Response beschleunigen, was heutzutage ein absolutes Muss darstellt.
The post Microsoft Copilot for Security appeared first on BASTA!.
]]>The post Effizientes Unit-Testen von Blazor-Komponenten mit bUnit appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
bUnit ist eine Bibliothek, die das Testen von Blazor-Komponenten vereinfacht. Dabei stellt bUnit Klassen und Methoden bereit, die das Interagieren von Blazor-Komponenten (oft „component under test“, kurz „cut“ genannt) ermöglicht und vereinfacht. Dabei ist bUnit, im Gegensatz zu xUnit, nUnit oder MSTest kein eigener Test-Runner, der Tests ausführt, sondern sitzt auf diesen auf und erweitert sie um die Möglichkeit, Blazor-Komponenten zu testen.
Wer schon einmal mit Blazor gearbeitet hat, kennt das klassische „Hallo Welt“-Beispiel, in dem ein Counter hochgezählt wird. Wir erweitern dieses kleine Beispiel (Listing 1) um zwei weitere Sachen:
Wie sieht nun ein Test für diese Komponente aus (Listing 2)?
Listing 1
@page "/counter"
@inject IIncrementService IncrementService
<h1>Counter</h1>
<p>Current count: @InitialCount</p>
<button class="btn btn-primary" @onclick="IncrementCount">Click me</button>
@code {
[Parameter]
public int InitialCount { get; set; }
private void IncrementCount()
{
InitialCount = IncrementService.Increment(InitialCount);
}
}
Listing 2
@using Bunit
@inherits TestContext
@code {
[Fact]
public void IncrementCounterWhenButtonClicked()
{
// Wir haben, wie im produktiven System, einen "DI" Container, den wir befüllen können
// Dies ermöglich uns, den Service zu mocken und zu injizieren
// Services.AddScoped<IIncrementService, FakeIncrementService>();
// Dank des Razor-Formats können wir die Komponente direkt erzeugen und Parameter einfach zuweisen
var cut = Render<Counter>(@<Counter InitialCount="3">)
// Wir nutzen CSS-Selektoren und "Klicken" auf den Button
cut.Find("button").Click();
// Wieder benutzen wir CSS-Selektoren und prüfen ob der Text stimmt
cut.Find("p").MarkupMatches("<p>Current count: 4</p>");
}
private class FakeIncrementService : IIncrementService
{
public int Increment(int count) => count + 1;
}
}
Was besonders auffällt, ist, dass der Testcode sehr nah am eigentlichen Blazor-Code liegt. Das liegt daran, dass bUnit-Tests im Razor-Format unterstützt. Die Dokumentation zeigt auf, wie das möglich ist [1]. Natürlich ist es möglich, auch klassische Tests zu schreiben, jedoch ist der Razor-Ansatz sehr angenehm und macht das Testen von Blazor-Komponenten sehr eingängig. Die Unterschiede werden ebenfalls in [2] aufgezeigt.
Entwickler:innen, die sich schon mit Ende-zu-Ende-Tests auseinandergesetzt haben, wird auffallen, dass die Selektion von Elementen sehr ähnlich ist (via CSS-Selektoren). Das ist kein Zufall, denn bUnit verwendet AngleSharp [3], um die Komponenten zu analysieren und zu selektieren.
Im gegebenen Test wird ein FakeIncrementService erstellt und in den DI-Container injiziert. Das ermöglicht es, den Service zu mocken und somit die Businesslogik der Komponente zu testen. Das ist ein sehr einfaches Beispiel, zeigt aber sehr gut, wie einfach bUnit das Testen von Blazor-Komponenten macht. Durch den Razor-Ansatz sind das Erstellen und Zeichnen der Counter-Komponente wie im produktiven Code möglich. Das Übergeben der InitialCount-Parameter geschieht direkt im HTML-Code im Test.
Danach wird via Find ein Button gesucht. Im gegebenen Beispiel gibt es nur einen, welcher zurückgegeben wird – anschließend wird dank der Click Methode das onclick Event ausgelöst.
Ende-zu-Ende-Tests sind Tests, welche die gesamte Applikation testen. Dabei wird die Applikation gestartet und die Tests interagieren mit der Applikation, wie Benutzer:innen es tun würde. bUnit hingegen zielt darauf ab, eine einzelne Komponente (oder auch mehrere) zu testen. Dabei wird die Komponente isoliert getestet und nicht die gesamte Applikation. Das bringt einige Vorteile mit sich:
Wichtig zu verstehen ist, dass bUnit keinen Ersatz für Ende-zu-Ende-Tests darstellt, sondern eine Ergänzung. Zum Beispiel laufen Tests im Gegensatz zu Ende-zu-Ende-Tests nicht im Browser. Das birgt auch einige Nachteile:
Wenn Ihnen diese Punkte wichtig sind, sind Testing-Frameworks wie Playwright oder Cypress die bessere Wahl.
Es ist wichtig, zu verstehen, dass bUnit kein Browser oder komplettes End-to-End-Test-Framework ist. Es ist darauf ausgelegt, einzelne Komponenten und deren Businesslogik zu testen. Hier eine sehr vereinfachte Komponente: Sie hat ein Anchor-Element, das auf eine andere interne Seite verweist: <a href=”/bestellung/1″>Zur Bestellung</a>. Ein Test könnte dann so aussehen wie in Listing 3.
Listing 3
@using Bunit
@inherits TestContext
@code {
[Fact]
public void ShouldNavigateToUrl()
{
var cut = Render(@<MyComponent />);
cut.Find("a").Click();
// Den NavigationManager aus dem Container holen
var navigationManager = Services.GetRequiredService<NavigationManager>();
navigationManager.Uri.Should().Be("/bestellung/1");
}
}
Wir klicken auf den Link und prüfen, ob der URL stimmt. Obwohl der Test zuerst sinnvoll erscheint, ist er es nicht, aus zwei Gründen. Zuerst ist es wesentlich, zu verstehen, dass Click nicht wirklich auf ein HTML-Element klickt, sondern das @onclick Event ausführt. Im gegebenen Beispiel gibt es aber gar kein @onclick Event. Das bedeutet, dass der Test immer fehlschlagen wird, da der Link nicht auf das @onclick Event reagiert. Der zweite Grund ist, dass der Test nur 3rd-Party-Code testet. Unit-Tests, die das Hauptanwendungsgebiet für bUnit sind, sollten immer nur die eigene Businesslogik testen. Das Klicken auf einen Link ist aber nicht Bestandteil der eigenen Businesslogik, sondern das Resultat aus der Kombination von Blazor und dem Browser.
Genau deshalb bringt bUnit auch die Fähigkeit mit, Komponenten komplett zu ersetzen. Das bedeutet, dass wir beliebige Komponenten durch eigene Komponenten ersetzen können oder einfach durch leeres Markup (auch Shallow Rendering genannt). Das macht immer dann Sinn, wenn eine Komponente viele Abhängigkeiten hat, die nicht relevant für den Test sind. Doch was ist Faking beziehungsweise Stubbing? Faking ist das Ersetzen von Komponenten durch eigene Komponenten, die wir kontrollieren können. Stubbing ist das Ersetzen von Komponenten durch leeres Markup. Ein Beispiel, in dem ein Button einer 3rd-Party-Bibliothek verwendet wird, finden Sie in Listing 4.
Listing 4
@page "/counter"
<h1>Counter</h1>
<p>Current count: @InitialCount</p>
<ThirdPartyButton Click="Increment">Click me</ThirdPartyButton>
@code {
[Parameter]
public int InitialCount { get; set; }
private void Increment()
{
InitialCount++;
}
}
Wie sieht nun ein Test dafür aus? Wie bewegen wir den ThirdPartyButton dazu, dass er das Increment Event auslöst? Das ist gar nicht so einfach, da wir nicht wissen, wie der ThirdPartyButton implementiert ist. Ein Weg besteht darin, herauszufinden, dass der ThirdPartyButton intern auch nur ein button-Element ist und wir dieses Element direkt ansprechen können (Listing 5).
Listing 5
@inherits TestContext
@code {
[Fact]
public void IncrementCounterWhenButtonClicked()
{
var cut = Render(@<Counter InitialCount="3" />);
cut.Find("button").Click();
cut.Find("p").MarkupMatches("<p>Current count: 4</p>");
}
}
Schön, der Test wird grün, es verstreicht ein wenig Zeit und nun nutzt der ThirdPartyButton ein div-Element. Resultat: Der Test wird rot. Das ist ein Problem, weil wir nicht die Implementation der Komponente testen wollen, sondern nur die Businesslogik. Hier kommt das Faking ins Spiel (Listing 6). Dafür bietet bUnit die Möglichkeit, Komponenten zu ersetzen. Das bedeutet, dass wir den ThirdPartyButton durch eine eigene Komponente ersetzen, die wir kontrollieren und mittels der wir auch einfach das Click Event auslösen können.
Listing 6
@using Bunit
@inherits TestContext
@code {
[Fact]
public void IncrementCounterWhenButtonClicked()
{
// Dies ersetzt alle Vorkommen von "ThirdPartyButton" durch "FakeThirdPartyButton"
ComponentFactories.Add<FakeThirdPartyButton, ThirdPartyButton>();
var cut = Render(@<Counter InitialCount="3" />);
// Wir lösen das Click Event aus
cut.FindComponent<FakeThirdPartyButton>().Instance.ClickButton();
cut.Find("p").MarkupMatches("<p>Current count: 4</p>");
}
private class FakeThirdPartyButton : ComponentBase
{
[Parameter]
public EventCallback Click { get; set; }
public Task ClickButton() => Click.InvokeAsync();
}
}
Das ist ein sehr einfaches Beispiel, zeigt aber sehr gut, wie mächtig das Ersetzen von Komponenten sein kann. In der offiziellen Dokumentation finden sich mehr Details über Stubbing und Faking von Komponenten [4]. bUnit geht sogar ein Schritt weiter und bietet extra Pakete an, die automatisch Stubs generieren können. Mehr dazu kann auf der offiziellen Website gefunden werden [5].
Natürlich kann das Stubbing auch dafür genutzt werden, um das Set-up von Komponenten zu vereinfachen, zum Beispiel eine Komponente, die gewisse Dienste injiziert bekommt, um zu funktionieren. Wenn diese Komponente für den Test nicht wichtig ist, ergibt es Sinn, sie zu ersetzen, um die Stabilität des Tests zu erhöhen und Abhängigkeiten zu reduzieren.
Auch wenn Stubbing oder Faking die Möglichkeit bietet, gewisse Sachen zu vereinfachen, kann es sein, dass die eigene Integration mit JavaScript getestet werden muss. bUnit führt zwar JavaScript nicht direkt aus, bringt aber eine eigene Laufzeit mit, welche es einfach macht, zu prüfen, ob JavaScript aufgerufen wurde (oder nicht). Dieses Verhalten ist automatisch angeschaltet. Dabei wird zwischen strict und loose unterschieden. strict bedeutet, dass, wenn bUnit einen JavaScript-Aufruf entdeckt, welcher nicht erwartet wurde, der Test fehlschlägt. loose hingegen ignoriert solche Aufrufe. Der Standardwert ist strict – im Falle von Werten, die von der Interoperabilitätsschicht von Blazor zurückgegeben werden, gibt loose den Standardwert des Datentyps zurück (zum Beispiel 0 für int). Eine ausführliche Dokumentation kann unter [6] gefunden werden.
bUnit ist seit fünf Jahren versehen mit der Version 1, sprich seit fünf Jahren ist bUnit mehr oder weniger API-stabil und unterstützt .NET Core 3.1 bis .NET 9. Das ist unabhängig davon, dass manche von diesen Versionen schon nicht mehr offiziell von Microsoft selbst unterstützt werden. Mit so einer langen Laufzeit für eine Version gibt es natürlich Sachen, die eventuell gar nicht mehr so gebraucht werden oder die man heute anders machen würde und genau das ist die Idee für die nächste Version, die sich gerade in der Vorabphase befindet.
Das generelle Thema für Version 2 sind Aufräumarbeiten, ein verbessertes API und einige neue Funktionalitäten und Bugfixes, die größere Änderungen erforderten. Generell wurde viel alter Ballast abgeräumt. Darunter zählen zum Beispiel, dass nur noch .NET 8 und kommende Versionen unterstützt werden.
Viele Abstraktionen (Klassen wie Interfaces) waren für den Fall gedacht, dass es neben Blazor für das Web auch noch andere Modi gibt, die nicht HTML-basiert sind (zum Beispiel Blazor Mobile Bindings [7], die vor ein paar Jahren als Experiment angekündigt wurden). Diese Abstraktionen werden entfernt bzw. zusammengeführt, um ein einheitlicheres Bild zu geben.
Das neue Release soll ein einfacheres API bieten – zum Beispiel kannte Version 1 der Bibliothek Funktionen wie Render, SetParametersAndRender und RenderComponent. Diese Funktionen werden in der neuen Version zu einer einzigen Funktion zusammengefasst: Render. Des Weiteren wurden viele Funktionen und Klassen auf konsistente Weise umbenannt und die meisten Typen starten mit Bunit als Präfix. Zum Beispiel wird aus TestContext dann BunitContext oder aus FakeNavigationManager wird BunitNavigationManager. Es soll einfacher werden, neue Dinge zu entdecken und zu verwenden.
In Version 1 war es ohne weiteres möglich, Kindkomponenten der aktuellen Komponente zu finden (FindComponent), sprich es gab eine Möglichkeit, hinunterzugehen. In Version 2 soll es auch möglich sein, von einer Kindkomponente zur Elternkomponente zu gehen. Technisch gesehen war es in Version 1 so, dass jede Komponente das generierte Markup von sich (cut.Markup) und allen Kindelementen hatte. Dabei war die Komponente selbst immer das Root-Element in dem Baum. Das führt dazu, dass Kindelemente natürlich auch nur sich selbst als Root-Element und damit keine Beziehung mehr zum Elternelement haben. Das führte zu Fehlern, die sehr unverständlich für User:innen waren, zum Beispiel beim Zusammenspiel zweier Komponenten, wobei die Elternkomponente ein form-Element ist, das aus dem Kindelement submittet wird (Listing 7).
Listing 7
<form @onsubmit="SubmitForm">
<ChildComponent />
</form>
@code {
private void SubmitForm() { ... }
}
Hier die Kindskomponente: <button type=”submit”>Abschicken</button>. Im Browser würde das Drücken auf Abschicken das Formular senden. Wie der Test hier aussieht, zeigt Listing 8.
Listing 8
var cut = Render(@<ParentComponent />);
// Wir suchen die "ChildComponent"
var childComponent = cut.FindComponent<ChildComponent>();
// Ausführen des Submit Events
childComponent.Find("button").Submit();
// Prüfen, ob der Submit Event ausgelöst wurde
…
Der Test scheint logisch und korrekt zu sein, aber er wird fehlschlagen. Der Grund ist, dass die childComponent nur das button-Element kennt. Dieses Hindernis wird mit Version 2 überarbeitet und funktioniert dann ohne Probleme. Insgesamt versucht bUnit nicht, sich in Version 2 neu zu erfinden, sondern viele Sachen zu vereinfachen, alte Sachen wegzulassen und den Weg zu ebnen, um in Zukunft einfacher neue Features hinzuzufügen.
bUnit ist eine sehr mächtige Bibliothek, die das Testen von Blazor-Komponenten sehr einfach macht. Die offizielle Website bietet eine sehr gute Dokumentation und viele Beispiele, die das Verständnis erleichtern. Die Website ist unter [8] zu finden. Wenn man sich für die Entwicklung von bUnit interessiert, kann man gerne auf der offiziellen GitHub-Seite vorbeischauen [9]. Natürlich sind Bug-Reports, Featureverbesserung und Fragen immer willkommen.
[1] https://bunit.dev/docs/getting-started/create-test-project.html?tabs=xunit
[2] https://bunit.dev/docs/getting-started/writing-tests.html?tabs=xunit#write-tests-in-cs-or-razor-files
[3] https://anglesharp.github.io
[4] https://bunit.dev/docs/test-doubles/index.html
[5] https://bunit.dev/docs/extensions/bunit-generators.html
[6| https://bunit.dev/docs/test-doubles/emulating-ijsruntime.html
[7] https://learn.microsoft.com/en-us/mobile-blazor-bindings/
[8] https://bunit.dev
[9] https://github.com/bUnit-dev/bUnit
The post Effizientes Unit-Testen von Blazor-Komponenten mit bUnit appeared first on BASTA!.
]]>The post Kolumne: Enterprise Angular appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community
Auch wenn der Ansatz im Regelfall gut funktioniert, führt er doch immer wieder zu Problemen. Beispielsweise lassen sich Bugs in diesem Bereich nur schwer diagnostizieren, und da nicht jeder Event Handler zwingend gebundene Daten ändert, läuft die Change Detection mitunter zu häufig. Entwickelt man wiederverwendbare Web Components, die Implementierungsdetails wie die Nutzung von Angular verstecken, muss der Konsument diese trotzdem mit einer bestimmten zone.js-Version einsetzen.
Ab Version 18 unterstützt das Framework nun auch einen Datenbindungsmodus, der ohne zone.js auskommt. Er ist vorerst experimentell, damit das Angular-Team zur neuen Vorgehensweise Feedback sammeln kann. Um diesen Modus zu aktivieren, ist die Funktion provideExperimentalZonelessChangeDetection beim Bootstrapping der Anwendung zu nutzen:
export const appConfig: ApplicationConfig = {
providers: [
provideExperimentalZonelessChangeDetection(),
[…]
]
}
Da zone.js die Change Detection nicht mehr triggert, braucht Angular andere Auslöser. Dabei handelt es sich um jene, die auch im Datenbindungsmodus OnPush zum Einsatz kommen:
Das bedeutet, dass jene, die in der Vergangenheit bereits konsequent auf OnPush gesetzt haben, nun relativ problemlos auf Zoneless wechseln können. In Fällen, in denen das nicht einfach möglich ist, kann die Anwendung ohne Bedenken zone.js-basiert bleiben. Das Angular-Team geht davon aus, dass nicht jede bestehende Anwendung auf Zoneless umgestellt wird und unterstützt deswegen zone.js weiterhin.
Für neue Anwendungen bietet sich jedoch das Arbeiten ohne zone.js an, sobald dieser neue Modus nicht mehr experimentell ist. Die geplanten Signal Components werden künftig Zoneless-Anwendungen einfacher machen, da sie durch den konsequenten Einsatz von Signals die Voraussetzungen dafür automatisch erfüllen.
Nach einer Umstellung auf Zoneless lässt sich auch der Verweis auf zone.js aus der angular.json entfernen. Durch den Wegfall dieser Bibliothek werden die Bundles im Production Mode um ca. 11 KB kleiner.
Für neue Anwendungen nutzt das Angular CLI nach wie vor zone.js. Neu ist, dass es nun Code generiert, der standardmäßig Event Coalescing aktiviert:
export const appConfig: ApplicationConfig = {
providers: [
provideZoneChangeDetection({ eventCoalescing: true }),
[…]
]
};
Event Coalescing bedeutet, dass zone.js für unmittelbar aufeinanderfolgende Events nur ein einziges Mal tätig wird. Als Beispiel nennt das Angular-Team mehrere Click Handler, die aufgrund von Event Bubbling hintereinander angestoßen werden.
Möchte ein Guard eine Umleitung auf eine andere Route veranlassen, liefert er den UrlTree dieser Route zurück. Im Gegensatz zur Methode navigate erlaubt dieser Ansatz jedoch nicht die Angabe von Optionen zur detaillierten Steuerung des Routerverhaltens. Beispielsweise kann die Anwendung nicht festlegen, ob der aktuelle Eintrag in der Browser-History zu überschreiben ist oder ob Parameter, die nicht in dem URL aufscheinen sollen, zu übergeben sind.
Um diese Möglichkeit zu nutzen, kann ein Guard nun auch ein RedirectCommand zurückliefern. Dieses RedirectCommand nimmt neben dem UrlTree ein Objekt vom Typ NavigationBehaviorOptions entgegen, welches das gewünschte Verhalten steuert (Listing 1).
Listing 1
export function isAuth(destination: ActivatedRouteSnapshot) {
const router = inject(Router);
const auth = inject(AuthService);
if (auth.isAuth()) {
return true;
}
const afterLoginRedirect = destination.url.join('/');
const urlTree = router.parseUrl('/login');
return new RedirectCommand(urlTree, {
skipLocationChange: true,
state: {
needsLogin: true,
afterLoginRedirect: afterLoginRedirect
} as RedirectToLoginState,
});
}
export const routes: Routes = [
{
path: '',
redirectTo: 'products',
pathMatch: 'full'
},
{
path: 'products',
component: ProductListComponent,
},
{
path: 'login',
component: LoginComponent,
},
{
path: 'products/:id'
component: ProductDetailComponent,
canActivate: [isAuth]
},
{
path: 'error',
component: ErrorComponent
}
];
Die Eigenschaft skipLocationChange gibt an, dass der Routenwechsel nicht in der Browser-History aufscheinen soll, und beim angegeben State handelt es sich um Werte, die an die zu aktivierende Komponente zu übergeben sind, jedoch nicht in dem URL aufscheinen sollen. Weitere Eigenschaften, die NavigationBehaviorOptions bietet, finden sich unter [2].
Der Vollständigkeit halber zeigt Listing 2 die adressierte Komponente, die die übergebenen Daten ausliest.
Listing 2
@Component({ … })
export class LoginComponent {
router = inject(Router);
auth = inject(AuthService);
state: RedirectToLoginState | undefined;
constructor() {
const nav = this.router.getCurrentNavigation();
if (nav?.extras.state) {
this.state = nav?.extras.state as RedirectToLoginState;
}
}
logout() {
this.auth.logout();
}
login() {
this.auth.login('John');
if (this.state?.afterLoginRedirect) {
this.router.navigateByUrl(this.state?.afterLoginRedirect);
}
}
}
Der Einsatz eines RedirectCommands wird nun auch durch das optionale Feature withNavigationErrorHandler unterstützt. Dieses Feature, das das Festlegen eines Handlers zur Behandlung von Routerfehlern erlaubt, kann nun damit das Verhalten des Routers steuern (Listing 3).
Listing 3
export function handleNavError(error: NavigationError) {
console.log('error', error);
const router = inject(Router);
const urlTree = router.parseUrl('/error')
return new RedirectCommand(urlTree, {
state: {
error
}
})
}
export const appConfig: ApplicationConfig = {
providers: [
[…]
provideRouter(
routes,
withComponentInputBinding(),
withViewTransitions(),
withNavigationErrorHandler(handleNavError),
),
]
};
Eine weitere Neuerung in Sachen Redirects betrifft die Eigenschaft redirectTo in der Routerkonfiguration. Bis jetzt konnte man auf den Namen einer anderen Route verweisen. Nun nimmt diese Eigenschaft auch eine Funktion auf, die sich programmatisch um die Weiterleitung kümmert (Listing 4).
Listing 4
export const routes: Routes = [
{
path: '',
redirectTo: () => {
const router = inject(Router);
// return 'products' // Alternative
return router.parseUrl('/products');
},
pathMatch: 'full'
},
[…],
];
Der Rückgabewert dieser Funktion ist entweder ein UrlTree oder ein String mit dem Pfad der gewünschten Route.
Das Element ng-content, das Angular als Ziel für die Content Projection nutzt, kann nun einen Standardinhalt aufweisen. Diesen Inhalt zeigt Angular an, wenn der Aufrufer keinen anderen Inhalt übergibt:
<div class="pl-10 mb-20"> <ng-content> <b>Book today to get 5% discount!</b> </ng-content> </div>
Das AbstractControl, das u. a. als Basisklasse für FormControl und FormGroup fungiert, weist nun eine Eigenschaft events auf. Dieses Observable informiert über zahlreiche Zustandsänderungen (Listing 5).
Listing 5
export class ProductDetailComponent implements OnChanges {
[…]
formControl = new FormControl<number>(1);
[…]
constructor() {
this.formControl.events.subscribe(e => {
console.log('e', e);
});
}
[…]
}
Die einzelnen Events veröffentlicht es als Objekte vom Typ ControlEvent. Bei ControlEvent handelt es sich um eine abstrakte Basisklasse mit den folgenden Ausprägungen:
Durch den Einsatz von Server-side Rendering bekommen Aufrufer:innen rascher die angeforderte Seite angezeigt. Danach beginnt der Browser mit dem Laden der JavaScript Bundles, die die Seite erst interaktiv machen. Dieser Vorgang wird auch Hydration genannt. Abbildung 1 veranschaulicht das: FMP steht für „First Meaningful Paint“ und TTI für „Time to Interactive“.

Abb. 1: Uncanny Valley bei SSR
Besondere Beachtung erfordert die Zeitspanne zwischen FMP und TTI, auch bekannt als „Uncanny Valley“. Benutzer:innen bekommen hier die Seite bereits angezeigt, das JavaScript, das auf Benutzerinteraktionen reagiert, ist jedoch noch nicht geladen. Klicks und andere Interaktionen laufen also ins Leere.
Um das zu verhindern, bietet Angular nun Event Replay, das die Interaktionen im Uncanny Valley aufzeichnet und danach wiedergibt. Möglich wird das durch ein minimales Skript, das der Browser initial gemeinsam mit der vorgerenderten Seite lädt.
Event Replay kommt als optionales Feature für provideClientHydration und wird mit der Funktion withEventReplay eingebunden (Listing 6).
Listing 6
export const appConfig: ApplicationConfig = {
providers: [
[…],
provideClientHydration(
withEventReplay()
)
]
};
Die Implementierung von Event Replay hat sich bei Google schon länger bewährt. Sie stammt aus dem Google-internen Framework Wiz [3], das für seine Fähigkeiten im Bereich SSR und Hydration bekannt ist und deswegen für performancekritische öffentliche Lösungen zum Einsatz kommt.
Auf der diesjährigen ng-conf hat das Angular-Team bekannt gegeben, dass künftig die Angular- und Wiz-Teams verstärkt zusammenarbeiten werden. In einem ersten Schritt nutzt das Wiz-Team die aus Angular stammenden Signals während Angular die erprobten Möglichkeiten zu Event Replay vom Wiz-Team übernommen hat.
Beim Einsatz von SSR cacht der HttpClient schon länger die Ergebnisse serverseitig durchgeführter HTTP-Anfragen, sodass die Anfragen im Browser nicht nochmal ausgeführt werden müssen. Dazu kommt ein Interceptor zum Einsatz, der sich auf das TransferState API stützt. Dieses API bettet die gecachten Daten im Markup der vorgerenderten Seite ein und im Browser greift u. a. der HttpClient darauf zu.
Nun berücksichtigt diese Implementierung auch, dass serverseitig andere URLs als im Browser zum Einsatz kommen können. Dazu lässt sich ein Objekt konfigurieren, das interne, serverseitige URLs auf die URLs für den Einsatz im Browser abbildet. Listing 7 veranschaulicht die Konfiguration dieses Objekts mit einem Beispiel, das aus dem Change-Log [4] übernommen wurde.
Listing 7
// in app.server.config.ts
{
provide: HTTP_TRANSFER_CACHE_ORIGIN_MAP,
useValue: {
'http://internal-domain:80': 'https://external-domain:443'
}
}
// Alternative usage with dynamic values
// (depending on stage or prod environments)
{
provide: HTTP_TRANSFER_CACHE_ORIGIN_MAP,
useFactory: () => {
const config = inject(ConfigService);
return {
[config.internalOrigin]: [config.externalOrigin],
};
}
}
Außerdem platziert der HttpClient nun die Resultate serverseitiger HTTP-Anfragen, die einen Authorization- oder Proxy-Authorization-Header enthalten, nicht mehr automatisch im TransferState. Wer solche Resultate auch künftig cachen möchte, nutzt die neue Eigenschaft includeRequestsWithAuthHeaders:
withHttpTransferCache({
includeRequestsWithAuthHeaders: true,
})
Die Angular DevTools zeigen nun auf Wunsch an, welche Komponenten bereits hydriert wurden. Dazu ist rechts unten die Option Show hydration overlays zu aktivieren (Abb. 2).

Abb. 2: Die DevTools zeigen nun an, welche Komponenten bereits hydriert wurden
Diese Option versieht alle hydrierten Komponenten mit einem blau-transparenten Overlay und zeigt rechts oben zusätzlich ein Wassertropfenicon an.
Der neue ApplicationBuilder wurde bereits mit Angular 17 eingeführt und automatisch für neue Angular-Anwendungen eingerichtet. Da er auf modernen Technologien wie esbuild basiert, ist er um einiges schneller als der ursprüngliche, webpack-basierte Builder, den Angular nach wie vor unterstützt. Bei ersten Tests konnte ich eine Beschleunigung um den Faktor 3 bis 4 feststellen. Außerdem kommt der ApplicationBuilder mit einer komfortablen Unterstützung für SSR.
Beim Update auf Angular 18 schlägt das CLI nun vor, auch bestehende Anwendungen auf den ApplicationBuilder umzustellen (Abb. 3).

Abb. 3: Das Update auf Version 18 bietet die Migration auf den neuen ApplicationBuilder an
Da das CLI-Team viel Aufwand in Featureparität zwischen der klassischen und der neuen Implementierung investiert hat, sollte diese Umstellung in den meisten Fällen gut funktionieren und die Build-Zeiten drastisch beschleunigen. Auf jeden Fall sollten aber nach der Umstellung die Anwendung sowie der Build auf Funktionstüchtigkeit geprüft werden.
Neben den bereits beschriebenen Neuerungen gibt es noch einige kleinere Updates und Verbesserungen:
Regelmäßig News zur Konferenz und der .NET-Community
Nach mehreren Releases mit vielen neuen Features steht bei Angular 18 vor allem das Abrunden von Ecken im Vordergrund. Es gibt neue Möglichkeiten für Router Redirects, Standardwerte für Content Projection, Event Replay und Verbesserungen bei der Nutzung des TransferState für HTTP-Anfragen. Daneben wurden zahlreiche Bugs behandelt und die Performance des neuen ApplicationBuilder durch Caching verbessert. Außerdem gibt es einen Ausblick auf Zoneless Angular.
[1] https://github.com/manfredsteyer/hero-shop.git
[2] https://angular.dev/api/router/NavigationBehaviorOptions
[3] https://blog.angular.dev/angular-and-wiz-are-better-together-91e633d8cd5a
[4] https://github.com/angular/angular/pull/55274
The post Kolumne: Enterprise Angular appeared first on BASTA!.
]]>The post Neuerungen in Visual Studio appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
Als Arbeitsumgebung kommt wie immer eine Windows-10-Zweischirmworkstation zum Einsatz; die hier benutzte Version von Visual Studio Community 2022 identifizierte sich als 17.10.0.P2.
Zu guter Letzt sei noch darauf hingewiesen, dass Visual Studio selbstständig über Neuerungen informiert. Wer im Benutzerinterface die Option Hilfe | Neuigkeiten anklickt, findet eine kompakte Liste neuer Funktionen, die Microsoft als besonders wichtig erachtet (Abb. 1).

Abb. 1: Visual Studio zeigte sich durchaus auskunftsfreudig
Wie immer gilt übrigens, dass die produktive Nutzung von Preview-Releases von Microsoft nicht gerne gesehen wird. Im Unternehmen des Autors ist sie allerdings seit Jahren gelebte Praxis; außerdem ist der Visual Studio Installer immer bereit, eine normale und eine Vorschau-Variante des Produkts nebeneinander auf dem gleichen Terminal zu installieren.
Eins der beeindruckendsten Features von Visual Studio 2022 war die wesentliche Verbesserung von IntelliSense: Insbesondere auf Systemen mit sehr hoher Einkernleistung und schneller Internetverbindung ist die IDE stellenweise zum Finden von geradezu genialen Auto-Completition-Vorschlägen befähigt.
Aufgrund des Kaufs von GitHub hat Microsoft seit einiger Zeit Zugriff auf ein gigantisches Archiv von Quellcode, der seit einiger Zeit zur Realisierung einer als GitHub Copilot bezeichneten Funktion herangezogen wird. Angemerkt sei, dass es sich dabei um ein kostenpflichtiges Feature handelt – Abbildung 2 zeigt die unter [2] bereitstehende Preisliste.

Abb. 2: Microsoft lässt sich die Nutzung von AI-Funktionen in Visual Studio vergolden
Wer sich ein diesbezügliches Abonnement leistet und die Umbenennen-Refactoring-Funktion heranzieht, findet bei installierter GitHub-Copilot-Chat-Erweiterung eine zusätzliche Schaltfläche vor. Deren Anklicken nutzt dann den AI-Assistenten zur Generierung eines vernünftig erscheinenden Namens für das neue Element.
Eine ähnliche Komfortfunktion findet sich auch im Git-Commit-Fenster. Die insbesondere im universitären Umfeld oft für Ärger sorgenden Commits generiert ein mit einer Copilot-Subskription ausgestattetes VS ebenfalls automatisch.

Abb. 3: Visual Studio generiert auf Wunsch automatische Messages

Abb. 4: Die automatisch generierte Commit-Message
Allgemein gilt dabei übrigens, dass das Aufscheinen des mit zwei Sternen dekorierten Bleistiftsymbols auf das Verfügbarsein von AI-Funktionen hinweist: Microsoft dürfte Copilot in immer mehr Bereiche erweitern, um Entwickler:innen das Erzeugen von unnötigen oder nur als Dokumentation dienenden Strings zu ersparen und so Lebenszeit zurückzugeben.
Hervorzuheben ist außerdem, dass die Funktion „Explain Commit“ von GitHub Copilot auch nachträglich verwendet werden kann. Visual Studio analysiert in diesem Fall die im Versionskontrollsystem befindlichen Informationen und generiert einen menschenlesbaren Bericht über die (wahrscheinlich) durchgeführten Änderungen an der Codebasis.
Angemerkt sei, dass man im Hause Microsoft langfristig noch weitere Funktionen für Copilot avisiert. Unter [3] findet sich beispielsweise eine Passage, in der Microsoft die automatische Analyse von Unit-Test-Fehlschlägen verspricht (Abb. 5)

Abb. 5: Ein hochgestecktes Versprechen – fraglich, ob Microsoft es auch umsetzen kann
Ein alter Kalauer besagt, dass die Unübersichtlichkeit einer Codebasis kubisch oder sogar exponentiell mit ihrer Größe wächst. Auf jeden Fall gilt, dass vernünftige Such- und Navigationsverfahren eins der besten Verkaufsargumente für integrierte Entwicklungsumgebungen darstellen.
Neben der durch Drücken von STRG + SHIFT + F aktivierbaren stupiden Textsuche stellt Microsoft seit einiger Zeit auch einen alternativen Suchassistenten zur Verfügung, der bei der Bewertung der gefundenen Ergebnisse Informationen über die jeweiligen Codedateien miteinbezieht. Diese auch als Codesuche bezeichnete Funktion lässt sich durch Drücken von STRG +T aktivieren, und erscheint ebenfalls in einem Pop-up-Fenster. Neu ist hier die Möglichkeit, die Textfunktion durch Drücken des Knopfes zu aktivieren (Abb. 6).

Abb. 6: Die Codesuche bekommt in Visual Studio 17.9 ein Sonderregime eingeschrieben
Sollte diese Funktion auf Ihrer Installation noch nicht zur Verfügung stehen, so lässt sich in den Einstellungen unter Tools | Options | Environment | Preview Features | Plain text search in die All-in-One Search aktivieren. Zu beachten ist außerdem, dass die Aktivierung des Sonderregimes zu einer wesentlichen Vertiefung der Ergebnisse führt – die Codesuche kann in diesem Fall beispielsweise auch Kommentare nach Treffern durchforsten.
Farbliches Hervorheben ist einer der schnellsten Wege, um textuelle Informationen für das menschliche Gehirn besser erfassbar zu machen (das dürfte spätestens seit Tim van Beverens Klassiker „Runter kommen sie immer“ im allgemeinen Wissensschatz der GUI-Designer und Elektroniker verankert sein).
Seit Visual Studio 2019 pflegt die Community dabei einen Feature-Request, der eine eher kleine Erweiterung der Textdarstellung von Visual Studio zum Ziel hat. Spezifisch wünscht man sich die Möglichkeit, Kommentare und ähnliche Elemente nicht nur in einer anderen Schriftart oder Farbe, sondern auch kursiv, fett und/oder unterstrichen darstellen zu lassen.
In den Einstellungen findet sich unter Tools | Options | Environment | Fonts and Colors nun das in Abbildung 7 gezeigte Einstellungsfenster: Wer die Checkbox Kursiv (bzw. in der englischen Version Italic) aktiviert, bekommt den jeweiligen Text fortan kursiv angezeigt.

Abb. 7: Kleine Erweiterungen erhöhen die Übersichtlichkeit
Eine weitere Komfortfunktion ermöglicht das direkte Anzeigen von Bildvorschauen. Wo Sie den Cursor über ein Codeelement legen, das ein Bild anzeigt, erscheint das in Abbildung 8 gezeigte Pop-up. Im Interesse der Übersichtlichkeit beschneidet Microsoft die Breite und Höhe des Thumbnails dabei auf 500 Pixel; zum Zeitpunkt der Erstellung dieses Artikels gibt es noch keine Informationen darüber, welche Arten von Bilddaten der in Visual Studio integrierte Parser auswerten kann.

Abb. 8: Der Vorschauassistent informiert über den Bildinhalt
Start-ups, die ihren Nutzer:innen kein Visual-Studio-Code-Plug-in anbieten, haben bei der Akquise von „other people’s money“ im Allgemeinen ihre liebe Not. Visual Studio bietet seit längerer Zeit einen Erweiterungsmanager an, der in der Vergangenheit allerdings vergleichsweise staubig wirkte und von der immensen Macht der Funktion ablenkte.
Der in 17.8 erstmals eingeführte neue Extension-Manager ist nun final und erleichtert die Verwaltung von Visual-Studio-Erweiterungen an mehrerlei Stelle. Abbildung 9 zeigt dabei einen Überblick des neuen Designs.

Abb. 9: Der Erweiterungsmanager präsentiert sich neuerdings sehr aufgeräumt
Neben dem neuen Design ist auch das Filtersteuerelement zu beachten. Klickt man das Trichtersymbol an, so reagiert Visual Studio mit der Einblendung von Comboboxen unter dem Eingabefeld. Diese ermöglichen danach das Einschränken der angezeigten Erweiterungen, um nur bestimmte Expansions zuzulassen – die Abbildung entstand durch Selektion auf Steuerelemente auf Basis der Silverlight-Technologie.
Im Hintergrund führte Microsoft Retoolings im Bereich der Erweiterungsinfrastruktur durch. Man mag es nach dem Debakel um den Home Screen des Pocket PC kaum glauben, allerdings führte Visual Studio Erweiterungen bisher im eigentlichen Prozess der integrierten Entwicklungsumgebung aus.
Mit dem unter [4] im Detail dokumentierten Paket VisualStudio.Extensibility versucht Microsoft nun einen radikalen Neuanfang. Es handelt sich dabei um einen neuen Weg zur Programmierung von Plug-ins für Visual Studio, die dank einer Client-Server-Architektur außerhalb des VS-Prozesses leben. Neben der Möglichkeit zur beliebigen Parallelisierung dürfte das naturgemäß auch mit einer Steigerung der Stabilität einhergehen; Erweiterungen sollten nicht mehr in der Lage seien, Visual Studio als Ganzes zum Absturz zu bringen.
In Version 17.9 erfährt dieses neue Interface mehrere Nutzwertsteigerungen: Erstens ist es ab sofort erlaubt, auf Basis der neuen Technologie erzeugten Erweiterungen zwecks Verbreitung in den Visual Studio Marketplace hochzuladen.
Eine zweite Ergänzung, die logisch aus dem externen Hosting der Erweiterungsprozesse folgt, ist ihre vereinfachte Installation. Der bisher notwendige Neustart von Visual Studio entfällt bei Nutzung von auf VisualStudio.Extensibility basierenden Erweiterungen, weil diese einfach ihren externen Prozess starten und Verbindung mit dem von der integrierten Entwicklungsumgebung zur Verfügung gestellten Interface aufnehmen.
Zu guter Letzt gibt es einige Erweiterungen im Bereich der für Plug-ins auslösbaren Aktionen. Abbildung 10 informiert beispielsweise darüber, dass es fortan durch nach folgendem Schema aufgebauten Code erlaubt ist, eine Rekompilation eines in der Solution befindlichen Projekts zu befehligen:
var result = await this.Extensibility.Workspaces().QueryProjectsAsync(
project => project.Where(p => p.Name == projectName),
cancellationToken);
await result.First().BuildAsync(cancellationToken);

Abb. 10: Erweiterungen dürfen nun Projektereignisse auslösen
Apropos Visual Studio Installer: Wer auf einer Workstation mit wenig Speicherplatz entwickelt, ist gut beraten, die Checkbox empfohlene Komponenten beim Update hinzufügen zu deaktivieren (Abb. 11).
Microsoft nimmt sich in Visual Studio 7.10 bzw. im dazugehörigen Visual Studio Installer das Recht heraus, Workstations automatisch mit in Redmond als empfehlenswert empfundenen Komponenten auszustatten – dass diese mitunter viel Speicherplatz verbrauchen, sei angemerkt.

Abb. 11: Wer Speicher sparen möchte, sollte diese Option berücksichtigen
Ein weiteres dauerndes Ärgernis betrifft die Hardwarebeschleunigung für den Android-Emulator: Ist sie deaktiviert, so artet das virtualisierte Testen von Applikationen in nervtötende Warterei aus. Visual Studio ist in aktuellen Versionen zur Erkennung von Performanceproblemen befähigt, und führt Entwickler:innen so zum Ziel.
Neben dem Streamlining im Erweiterungsmanager möchte Microsoft Entwickler:innen auch dabei helfen, die (immer mächtiger werdende) Flut an Settings in der Visual-Studio-Arbeitsoberfläche angenehmer zu verwalten. So ist ein Redesign des beispielsweise in Abbildung 12 gezeigten Einstellungsdialogs avisiert – als Inspirationsquelle dürfte, wie in der Vergangenheit so oft, Visual Studio Code gedient haben.
Vor der praktischen Besprechung dieses Features sei allerdings angemerkt, dass es sich dabei derzeit um eine frühe Preview handelt. Für Sie als Entwickler:in wirkt sich das unter anderem insofern aus, als Microsoft in der Dokumentation an mehrerlei Stelle darauf hinweist, dass der Gutteil der Features derzeit nur in altem Dialog zur Verfügung steht. Wer verzweifelt nach einer Einstellung sucht und diese nicht findet, ist gut beraten, der älteren Variante eine zweite Chance zu geben.
Zum Zeitpunkt der Drucklegung lässt sich die Variante des zu verwendenden Options-Dialogs unter Extras | Optionen Experience auswählen – Abbildung 12 zeigt die etwas holprige Übersetzung aus dem Hause Microsoft.

Abb. 12: An dieser Stelle ist etwas Nachbesserung vernünftig
Wer die aktualisierte Variante des Einstellungsdialogs zu verwenden gedenkt, sollte im ersten Schritt die Option Vorschau auswählen. Die integrierte Entwicklungsumgebung reagiert darauf mit der Einblendung eines Nachfragedialogs, der um die Autorisierung eines Neustarts bittet – aufgrund der doch erheblichen Änderungen ist Microsoft derzeit nicht in der Lage, die Umstellung in einer laufenden Instanz von Visual Studio durchzuführen.
Im nächsten Schritt lässt sich der Options-Dialog öffnen, was zum Aufscheinen des in Abbildung 13 gezeigten Fensters führt.

Abb. 13: Visual Studio Code sendet Grüße an die Vollversion
Die oben links eingeblendete Textbox erlaubt dann das Eingeben von Strings, die Visual Studio zur Einschränkung der angezeigten Optionsvielfalt heranzieht.
Interessant ist allerdings auch, dass Visual Studio bei Cursorberührung ein Zahnrad mit zusätzlichen Einstellungen zur jeweiligen Option anbietet. Wer dieses anklickt, bekommt ein Menü mit zwei Optionen eingeblendet: Neben einem bequemen Weg zum Wiederherstellen der von Microsoft vorgegebenen Standardeinstellungen ist es hier auch möglich, Feedback an Microsoft zu schicken. Besonders wünscht man sich in Redmond dabei Hinweise dazu, wie sich die Beschreibung der jeweiligen Funktion entwickler- bzw. benutzerfreundlicher gestalten lassen würde.
Im Umfeld des Autors gibt es einige Beratungsunternehmen, die den Umstieg auf Visual Studio 2022 verweigert haben – Ursache dafür ist die schlechtere Integration des Windows-Forms-Designers in die neue Variante der IDE. Ursache dafür ist, dass Visual Studio 2022 im Interesse der besseren Performance als 64-Bit-Applikation vorliegt und dementsprechend naturgemäß mit dem 32-Bit-Forms-Designer nur wenig anzufangen weiß.
Microsoft begegnet diesem Problem seit einiger Zeit mit einem externen Windows-Forms-Designer, der sein nützliches Tun abseits des Hauptprozesses bewerkstelligt. In der aktuellen Version nahm Microsoft Verbesserungen vor, um dem laut Dokumentation nach wie vor weit von Featureparität entfernten Editor eine höhere Performance zu ermöglichen.
Neuerung Nummer zwei betrifft eine als „Live Property Explorer“ bezeichnete Funktion: Dieses bei der Arbeit mit gewöhnlichen XAML-Dateien liebgewonnene Feature steht ab sofort auch dann zur Verfügung, wenn das vorliegende Programm auf Basis des neuen MAUI-GUI-Stacks entsteht.
Während dem Debuggen einer MAUI-Applikation lässt sich das Werkzeug durch Drücken von Debug | Windows | Live Property Explorer aktivieren. Es verhält sich dann im Allgemeinen so, wie man es als Entwickler:in von der gewöhnlichen Version der IDE erwarten würde.
Dass Aktualisierungen von Visual Studio seit jeher mit einem wahren Sperrfeuer von Updates der zugrunde liegenden Komponenten einhergehen, wird erwartet – die Installation von Visual Studio setzt nun beispielsweise das .NET Framework in Version 4.7 voraus. Besonders interessant ist in diesem Zusammenhang aber die (an sich seit einiger Zeit zur Verfügung stehenden) Variante der integrierten Entwicklungsumgebung für Workstations, die auf ARM-Prozessoren basieren.
Bisher waren Nutzer:innen dieser neuartigen Variante des Produkts von der Verwendung der als SQL Server Developer Tools (SSDT) bezeichneten Komponente für die SQL-Datenbankanalyse ausgeschlossen – ein Problem, das Microsoft nun behoben hat. In der Dokumentation weisen die Redmonder allerdings darauf hin, derzeit noch keine vollständige Featureparität erreicht zu haben – einige fortgeschrittene Features stehen also nach wie vor nur auf X64-Stationen zur Verfügung.
Wer viele Codedateien gleichzeitig geöffnet hält, lernt irgendwann das Scrollen durch die Tab-Liste. Microsoft verbessert diesen Teil des Systems insofern, als es nun auf Wunsch auch möglich ist, mehrere Zeilen mit Tab-Headern auf dem Bildschirm zu halten.
Nutzer:innen der Spiele-Engine Unreal bekommen eine Erweiterung von IntelliSense serviert: Die Codevervollständigung interagiert nun auch mit per Unreal-Header-Tool generierten Dateien, was die Reichhaltigkeit der angezeigten Auto-Completion-Vorschläge erhöht.
Mindestens ebenso hilfreich ist die Möglichkeit, die von Visual Studio als Standard verwendete CMake-Version durch eine hauseigene Variante zu ersetzen. Hierzu findet sich unter Tools | Options | CMake | General ein Einstellungsfenster, in dem sich der von der Toolchain verwendete Pfad zur CMake-EXE austauschen oder anpassen lässt.
Besondere Erwähnung verdient auch die Fähigkeit der IDE, Structs dynamisch (also ohne Rekompilation) in Form eines Speicherlayouts anzuzeigen (Abb. 14).

Abb. 14: Visual Studio zeigt die Struktur des Speicherlayouts an
Aufseiten der C#-Entwicklung gibt es Snippetsupport für Razor: Dabei handelt es sich um ein an die in Palm OS implementierten Shortcuts erinnerndes Feature, das das Einpflegen von hauseigenen Codestücken optimiert.
Außerdem steht mit Blazor Scaffolding ein vergleichsweise umfangreicher Codegenerator zur Verfügung. Er erzeugt auf Data Binding basierende Views automatisiert, was bei Einarbeitung und Umstieg Zeit spart.
Im Rahmen der Ankündigung von Visual Studio 17.10 Preview 1 betonte Microsoft mehrfach die neuen Möglichkeiten des Teams SDK: Wir haben es in unserem oben erwähnten Artikel [1] im Detail beschrieben, weshalb an dieser Stelle nur ein knapper Verweis ausreichen muss.
Interessant ist, dass Microsoft die Hoffnung auf das Verkaufen der kostenpflichtigen Versionen Visual Studio Professional und Visual Studio Enterprise auch nach dem durchschlagenden Erfolg der kostenfreien Community-Variante nicht komplett aufgegeben hat.
Der beste Beleg für diese Annahme ist das unter [5] bereitstehende und in Abbildung 15 gezeigte Portal. Besitzer:innen kostenpflichtiger Varianten bekommen von Microsoft dort einen kompakten Überblick über alles, was sie an Side Benefits im Rahmen ihres Abonnements angeboten bekommen.

Abb. 15: Der Microsoft-Weihnachtsmann bringt Geschenke
Microsofts Entscheidung, mit Visual Studio und Visual Studio Code interne Konkurrenz zu erzeugen, trägt für die Entwicklerschaft reiche Dividende. Die Preview-Versionen von Visual Studio greifen Entwickler:innen an mehrerlei Stelle unter die Arme, ohne dabei lästig zu werden. Die Empfehlung des Autors für das neueste Produkt aus Redmond sei deshalb jederzeit gegeben.
Links & Literatur
[1] https://entwickler.de/reader/reading/windows-developer/4.2023/65722e67d1045fe264c26ad9?searchterm=visual%20studio
[2] https://github.com/features/copilot?utm_source=vscom&utm_medium=hero&utm_campaign=cta-get#pricing
[3] https://learn.microsoft.com/en-us/visualstudio/productinfo/vs-roadmap
[4] https://learn.microsoft.com/de-de/visualstudio/extensibility/visualstudio.extensibility/visualstudio-extensibility?view=vs-2022
[5] https://my.visualstudio.com
The post Neuerungen in Visual Studio appeared first on BASTA!.
]]>The post .NET 9 Preview: Neuerungen und Änderungen in der Version 9.0 appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
.NET 9.0 Preview 1 ist am 13. Februar 2024 erschienen und am 12. März 2024 folgte Preview 2. Die Vorschauversionen stehen zum Download unter [1] bereit.
An der Grundstruktur (drei Runtimes, ein SDK) hat sich nichts geändert (Abb. 1) und auch die unterstützten Plattformen sind gleichgeblieben. Laut Abbildung 1 sind weiterhin die Sprachversionen C# 12.0, F# 8.0 und Visual Basic .NET 16.9 enthalten – neue Sprachfeatures gibt es demnach bisher noch nicht.

Abb. 1: .NET-9.0-Downloads
Das Befehlszeilenwerkzeug dotnet test konnte bisher automatisierte Tests für ein Projekt mit mehreren .NET-Versionen nacheinander ausführen (z. B. <TargetFrameworks>net8.0;net9.0</TargetFrameworks> in der Projektdatei des Testprojekts). Eine neue Funktion in .NET 9.0 Preview 2 ist, dass diese Ausführung für verschiedene .NET-Versionen nun parallel erfolgt (Abb. 2). Außerdem nutzt dotnet test den Terminal Logger, der in .NET 8.0 eingeführt wurde und eine übersichtlichere Darstellung bietet. Das hat insbesondere positive Auswirkungen auf die Anzeige der Testergebnisse sowohl während als auch nach der Testausführung (Abb. 3). Bei Bedarf kann die Parallelisierung verhindert werden, indem man die MSBuild-Eigenschaft TestTfmsInParallel auf false setzt.

Abb. 2: Parallele Testausführung für mehrere .NET-Versionen

Abb. 3: Übersichtlichere Testergebnisse
Nutzer:innen von .NET-SDK-basierten Tools haben nun die Möglichkeit, mit der Option —allow-roll-forward ein Werkzeug auf einer neueren .NET-Hauptversion laufen zu lassen, falls die .NET-Laufzeitumgebung, für die das Werkzeug eigentlich kompiliert wurde, nicht auf dem lokalen System verfügbar ist. Diese neue Option kann sowohl bei der Installation mit dotnet tool install als auch beim Ausführen mit dotnet tool run verwendet werden. Es muss jedoch darauf hingewiesen werden, dass aufgrund von Breaking Changes zwischen .NET-Hauptversionen keine Garantie besteht, dass das Werkzeug ordnungsgemäß auf einer neueren .NET-Laufzeitumgebung funktioniert.
In der Basisklassenbibliothek wurden neue LINQ-Operatoren CountBy() und Index() hinzugefügt. CountBy() vermeidet den bisher notwendigen Einsatz von GroupBy() in Fällen, in denen nach Häufigkeit gruppiert werden soll (Listing 1). Index() liefert für ein IEnumerable<T> ein Tupel mit dem Wert und dem laufenden Index (0 bis n) zurück (Listing 2). Abbildung 4 zeigt die Ausgabe, bei der die Zusatzbibliothek SpectreConsole für die Balkenausgabe zum Einsatz kommt [2].
#region ---------------- Demodaten erstellen
int count = 10000;
CUI.H3($"Generiere {count} Demodaten...");
Randomizer.Seed = new Random(42); // für gleichbleibende Testdaten!
var personFaker = new AutoFaker<Person>("de")
.RuleFor(fake => fake.ID, fake => fake.Random.Int(0))
.RuleFor(fake => fake.Givenname, fake => fake.Name.FirstName())
.RuleFor(fake => fake.Surname, fake => fake.Name.LastName())
.RuleFor(fake => fake.Birthday, fake => fake.Date.Past(100).Date);
List<Person> personSet = new();
for (int i = 0; i < count; i++)
{
var p = personFaker.Generate();
personSet.Add(p);
}
Console.WriteLine("Anzahl Personen: " + personSet.Count);
#endregion
#region ---------------- Auswertung
CUI.H3("Auswertung:");
// bisherige Implementierung mit GroupBy() + Select()
var groups1 = personSet
.GroupBy(info => info.Givenname) // Gruppieren nach GivenName
.Select(group => new // Zählen
{
Key = group.Key,
Value = group.Count()
});
Console.WriteLine("10 häufigste Vornamen im Datenbestand:");
var groups1top10 = groups1.OrderByDescending(x => x.Value).Take(10);
// Ausgabe mit SpectreConsole
AnsiConsole.Write(new BarChart()
.Width(60)
.AddItems(groups1top10, (item) => new BarChartItem(
item.Key, item.Value, Color.Yellow)));
// Neue Implementierung mit CountBy()
var groups2 = personSet
.CountBy(x => x.Givenname); // Gruppieren nach Häufigkeit des GivenName
Console.WriteLine("10 häufigste Vornamen im Datenbestand:");
var groups2top10 = groups2.OrderByDescending(x => x.Value).Take(10);
// Ausgabe mit SpectreConsole
AnsiConsole.Write(new BarChart()
.Width(60)
.AddItems(groups2top10, (item) => new BarChartItem(
item.Key, item.Value, Color.Yellow)));
#endregion

Abb. 4: Ausgabe von Listing 1
Console.WriteLine("10 häufigste Vornamen im Datenbestand:");
// bisher schon möglich:
foreach ((int index, KeyValuePair<string, int> group) in groups2top10.Select((wort, index) => (index, wort)))
{
CUI.LI($"Platz {index + 1}: Vorname {group.Key} kommt {group.Value} vor.");
}
Console.WriteLine("10 häufigste Vornamen im Datenbestand:");
// neu ab .NET 9.0:
foreach ((int index, KeyValuePair<string, int> group) in groups2top10.Index())
{
CUI.LI($"Platz {index + 1}: Vorname {group.Key} kommt {group.Value} vor.");
}
Die PriorityQueue-Klasse, die in .NET 6.0 eingeführt wurde, verfügt nun über eine Remove()-Methode, mit der Elemente entfernt werden können, auch wenn sie nicht an der Reihe sind. Remove() erweitert als Parameter das zu entfernende Element. Remove() liefert drei Werte zurück: Als Rückgabewert einen Boolean-Wert, der anzeigt, ob das Element vorhanden war und entfernt werden konnte. Im zweiten und dritten Methodenparameter kommt via out das entfernte Element sowie seine Priorität zurück.
public class FCL_Collections
{
public void Run()
{
CUI.H2(nameof(FCL_Collections));
var q = new PriorityQueue<string, int>();
q.Enqueue("www.dotnet-doktor.de", 20);
q.Enqueue("www.dotnet8.de", 2);
q.Enqueue("www.IT-Visions.de", 10);
q.Enqueue("www.dotnet-lexikon.de", 30);
q.Enqueue("www.dotnet9.de", 1);
Console.WriteLine(q.Count);
CUI.H3("Entferne vorhandenes Element");
bool b1 = q.Remove("www.dotnet8.de", out string e1, out int priority1);
if (b1) Console.WriteLine($"Element {e1} mit Priorität {priority1} wurde entfernt!");
else Console.WriteLine("Element nicht gefunden");
CUI.H3("Versuch, nicht vorhandenes Element zu entfernen");
bool b2 = q.Remove("www.dotnet7.de", out string e2, out int priority2);
if (b2) Console.WriteLine($"Element {e2} mit Priorität {priority2} wurde entfernt!");
else Console.WriteLine("Element nicht gefunden");
CUI.H3($"Alle Elemente {q.Count} auflisten"); // 4
var count = q.Count;
for (int i = 0; i < count; i++)
{
var current = q.Dequeue();
Console.WriteLine(i + ": " + current);
}
Console.WriteLine($"Verbliebene Elemente: {q.Count}"); // 0
}
}
Mit .NET 9.0 ist es nun auch wieder möglich, zur Laufzeit erzeugte Assemblies im Dateisystem zu persistieren, indem die Methode Save() in der Klasse AssemblyBuilder verwendet wird (Listing 4). Diese Funktion war bereits im klassischen .NET Framework verfügbar (siehe Dokumentation zu Save() unter [3]). Im modernen .NET konnten zur Laufzeit erzeugte Assemblies bisher nur im RAM gehalten werden.
public void CreateAndSaveAssembly()
{
CUI.H2(nameof(CreateAndSaveAssembly));
string assemblyPath = Path.Combine(System.AppContext.BaseDirectory, "Math.dll");
AssemblyBuilder ab = AssemblyBuilder.DefinePersistedAssembly(new AssemblyName("Math"), typeof(object).Assembly);
TypeBuilder tb = ab.DefineDynamicModule("MathModule").DefineType("MathUtil", TypeAttributes.Public | TypeAttributes.Class);
MethodBuilder mb = tb.DefineMethod("Sum", MethodAttributes.Public | MethodAttributes.Static, typeof(int), [typeof(int), typeof(int)]);
ILGenerator il = mb.GetILGenerator();
il.Emit(OpCodes.Ldarg_0);
il.Emit(OpCodes.Ldarg_1);
il.Emit(OpCodes.Add);
il.Emit(OpCodes.Ret);
tb.CreateType();
Console.WriteLine("Speichere Assembly unter: " + assemblyPath);
ab.Save(assemblyPath); // Speichern ins Dateisystem oder einen Stream
}
Die .NET-Debugger in Visual Studio und Visual Studio Code zeigen nun die Inhalte von Dictionary-Klassen während des Debuggings deutlich übersichtlicher an (Abb. 5).

Abb. 5: Verbesserte Debugger-Ansicht von Dictionary-Klassen in .NET 9.0 [4]
Microsoft liefert ab .NET 9.0 eine Implementierung des KECCAK Message Authentication Code (KMAC) des US-amerikanischen National Institute of Standards and Technology (NIST) für kryptographische Funktionen [5].
Die Version 9.0 der JSON-Bibliothek System.Text.Json ermöglicht es, die Einrückung in der JSON-Zeichenkette über die JsonSerializerOptions anzupassen. Hierfür wurden zwei neue Einstellungen eingeführt: IndentCharacter und IndentSize. Listing 5 zeigt ein Beispiel. Als IndentCharacter werden aber nur ein Leerzeichen ‘ ‘ oder ein Tabulator ‘\t’ unterstützt.
Durch die Verwendung von JsonSerializerOptions.Web (Listing 5) können Entwickler:innen nun auf schnelle Weise dieselben Einstellungen für die JSON-Serialisierung und -Deserialisierung wählen, die standardmäßig im ASP.NET-Core-Web-API verwendet werden.
internal class FCL9_JSON
{
public void Run()
{
CUI.H2(nameof(FCL9_JSON));
CUI.H3("IndentCharacter und IndentSize")
var consultant = new Consultant() { ID = 42, FullName = "Holger Schwichtenberg", Salutation = "Dr.", PersonalWebsite = "www.dotnet-doktor.de" };
var options = new JsonSerializerOptions
{
WriteIndented = true,
IndentCharacter = ' ',
IndentSize = 2,
};
var json1 = JsonSerializer.Serialize(consultant, options);
Console.WriteLine(json1);
//liefert:
//{
// "Languages": [],
// "PersonalWebsite": "www.dotnet-doktor.de",
// "ID": 42,
// "FullName": "Holger Schwichtenberg",
// "Salutation": "Dr.",
// "Address": null
//}
CUI.H3("JsonSerializerOptions.Web");
var json2 = JsonSerializer.Serialize(consultant, JsonSerializerOptions.Web);
Console.WriteLine(json2);
//liefert:
//{"languages":[],"personalWebsite":"www.dotnet-doktor.de","id":42,"fullName":"Holger Schwichtenberg","salutation":"Dr.","address":null}
}
}
Der Object-relational Mapper Entity Framework Core hat in Preview 1 und 2 bereits eine Reihe kleinerer Verbesserungen implementiert. Verbesserung in der Modellerstellung sind:
modelBuilder.HasSequence<int>("NameDerSequence")
.HasMin(10).HasMax(255000)
.IsCyclic()
.StartsAt(11).IncrementsBy(2)
.UseCache(3);
modelBuilder.Entity<User>()
.HasKey(e => e.Id)
.HasFillFactor(80);
modelBuilder.Entity<User>()
.HasAlternateKey(e => new { e.Region, e.Ssn })
.HasFillFactor(80);
modelBuilder.Entity<User>()
.HasIndex(e => new { e.Name })
.HasFillFactor(80);
modelBuilder.Entity<User>()
.HasIndex(e => new { e.Region, e.Tag })
.HasFillFactor(80);
Verbesserung bei der Übersetzung von LINQ in SQL sind:
var newAddress = new Address("www.IT-Visions.de", 45257, "Essen");
await context.Stores
.Where(e => e.Region == "Germany")
.ExecuteUpdateAsync(s => s.SetProperty(b => b.ShippingAddress, newAddress));
Weitere Verbesserungen in Entity Framework Core 9.0 sind:
var daisy = await context.Halflings.SingleAsync(e => e.Name == "Daisy"); var child1 = new Halfling(HierarchyId.Parse(daisy.PathFromPatriarch, 1), "Toast"); var child2 = new Halfling(HierarchyId.Parse(daisy.PathFromPatriarch, 2), "Wills"); var child1b = new Halfling(HierarchyId.Parse(daisy.PathFromPatriarch, 1, 5), "Toast");
var dotnetPosts = context
.Posts
.Where(p => p.Title.Contains(".NET"));
var results = dotnetPosts
.Where(p => p.Id > 2)
.Select(p => new { Post = p, TotalCount = dotnetPosts.Count() })
.Skip(2).Take(10)
.ToArray();
SELECT COUNT(*) FROM [Posts] AS [p] WHERE [p].[Title] LIKE N'%.NET%' SELECT [p].[Id], [p].[Archived], [p].[AuthorId], [p].[BlogId], [p].[Content], [p].[Discriminator], [p].[PublishedOn], [p].[Title], [p].[PromoText], [p].[Metadata] FROM [Posts] AS [p] WHERE [p].[Title] LIKE N'%.NET%' AND [p].[Id] > 2 ORDER BY (SELECT 1) OFFSET @__p_1 ROWS FETCH NEXT @__p_2 ROWS ONLY
SELECT [p].[Id], [p].[Archived], [p].[AuthorId], [p].[BlogId], [p].[Content], [p].[Discriminator], [p].[PublishedOn], [p].[Title], [p].[PromoText], [p].[Metadata], ( SELECT COUNT(*) FROM [Posts] AS [p0] WHERE [p0].[Title] LIKE N'%.NET%') FROM [Posts] AS [p] WHERE [p].[Title] LIKE N'%.NET%' AND [p].[Id] > 2 ORDER BY (SELECT 1) OFFSET @__p_0 ROWS FETCH NEXT @__p_1 ROWS ONLY
Einige der Neuerungen in Entity Framework Core 9.0 Preview 1 und 2 stammen nicht von Microsoft-Entwickler:innen, sondern aus der Community, so zum Beispiel die Verbesserungen für Sequenzen, HasFillFactor(), ToHashSetAsync() und die weniger häufigen Kompilierungsvorgänge bei den Kommandozeilenwerkzeugen.
In Webanwendung auf Basis von Blazor ist es jetzt möglich, Dependency Injection auch über den Konstruktor in einer Code-Behind-Datei in der Razor Component durchzuführen. Wie Listing 10 zeigt, können auch die in C# 12.0 eingeführten Primärkonstruktoren dafür verwendet werden.
public partial class Counter(NavigationManager navigationManager, IJSRuntime js)
{
private void NavigateHome() => navigationManager.NavigateTo("/");
private string GetBlazorType
{
get
{
if (js.GetType().Name.Contains("Remote")) return "Blazor Server";
if (js.GetType().Name.Contains("WebAssembly")) return "Blazor WebAssembly";
return "Blazor Hybrid " + js.GetType().Name;
}
}
}
Bisher war es in Razor Components nur möglich, Dienste entweder durch @inject im Razor-Template oder durch die Annotation [Inject] auf einer Eigenschaft im Code zu injizieren.
Beim Interactive Server-side Rendering (alias Blazor Server) ist nun standardmäßig die Komprimierung in BlazorPack-Daten in der WebSockets-Verbindung aktiviert. Entwickler:innen können das jedoch bei Bedarf deaktivieren, indem sie DisableWebSocketCompression = true im Parameterobjekt von AddInteractiveServerRenderMode() setzen:
app.MapRazorComponents<App>() .AddInteractiveServerRenderMode(o => o.DisableWebSocketCompression = true);
Microsoft setzt nun standardmäßig die Content Security Policy (CSP) auf frame-ancestor: ‘self’. Das kann jedoch durch die Verwendung von ContentSecurityFrameAncestorsPolicy geändert werden:
app.MapRazorComponents<App>() .AddInteractiveServerRenderMode(o => o.ContentSecurityFrameAncestorsPolicy="'none'");
In ASP.NET Core 9.0 SignalR ist Polymorphism für die Parameter von Operationen in ASP.NET-Core-SignalR-Hubs möglich, indem man die in System.Text.Json-Version 7.0 eingeführten Annotationen [JsonPolymorphicAttribute] und [JsonDerivedTypeAttribute] verwendet, die zu Metadaten (einem Type Discriminator) in JSON führen (z. B. “$type” : “PersonWithAge”). Listing 11 zeigt ein Einsatzbeispiel.
using System.Text.Json.Serialization;
namespace Blazor9;
[JsonPolymorphic]
[JsonDerivedType(typeof(PersonWithAge), nameof(PersonWithAge))]
[JsonDerivedType(typeof(PersonWithBirtday), nameof(PersonWithBirtday))]
public class PersonDTO
{
public string? Name { get; set; }
}
public class PersonWithAge : PersonDTO
{
public int Age { get; set; }
}
public class PersonWithBirtday : PersonDTO
{
public DateTime Birthday { get; set; }
}
public class SignalRHub
{
public int Search(PersonDTO person)
{
if (person is PersonWithAge)
{
// Suche Person mit Name und Alter
// ...
}
else if (person is PersonWithBirtday)
{
// Suche Person mit Name und Geburtsdatum
// ...
}
else
{
// Suche Person nur mit Name
// ...
}
return 0; // ID = 0 -> nicht gefunden
}
}
Bei der Verwendung von OAuth und OIDC ist es nun deutlich prägnanter, die Parameter anzupassen:
builder.Services.AddAuthentication().AddOpenIdConnect(options =>
{
options.AdditionalAuthorizationParameters.Add("prompt", "login");
options.AdditionalAuthorizationParameters.Add("audience", "https://api.example.com");
});
Bei .NET MAUI wurden bisher zahlreiche Fehlerbehebungen und kleinere Verbesserungen, wie beispielsweise die Unterstützung von animierten GIFs auf iOS, eingeführt. Die entsprechenden Release-Notes finden sich unter [8] und [9].
Informationen zu Verbesserungen bei Windows Forms oder der Windows Presentation Foundation (WPF) sind bisher nicht in den Release-Notes enthalten. Immerhin gab es jedoch im Februar ein Bekenntnis von Microsoft, weiterhin am Design für Windows Forms in Visual Studio zu arbeiten, wie unter [10] erklärt wird.
In den letzten Jahren gab es zu jeder Vorschauversion des modernen .NET mehrere Blogeinträge im Microsoft .NET Blog [11]. Das galt bis einschließlich November 2023, dem Erscheinungstermin von .NET 8.0.
Zu den Previews von .NET 9.0 gibt es leider keine Blogeinträge mehr. Das ist Teil einer seit diesem Jahr veränderten Strategie bezüglich des .NET Blogs. Das .NET Blog soll sich laut einer Ankündigung von .NET Program Manager Rich Lander auf Beiträge über stabile .NET-Versionen konzentrieren [12].
Die Preview-Versionen will man jetzt stattdessen über einen neuen Diskussionsbereich auf GitHub anzukündigen [13]. Die einzelnen Neuerungen sind dann auch nicht dort, sondern in den verlinkten Release-Notes beschrieben, außerdem in „What’s New“-Dokumenten auf Microsoft Learn [14].
Allerdings sind die Neuerungen über mehrere Release-Notes-Dokumente verstreut und werden darin meist nur sehr knapp erwähnt. In den „What’s New“-Dokumenten zu .NET 9.0 [15], ASP.NET Core 9.0 [16], Entity Framework Core 9.0 [17] und .NET MAUI [18] sind die Neuerungen ausführlicher beschrieben. Allerdings fehlt in diesen Dokumenten die Trennung zwischen den verschiedenen Vorschauversionen und es finden sich in den Dokumenten (wie oben am Beispiel HierarchyId.Parse() gezeigt) auch Hinweise auf Features, die noch gar nicht in den aktuellen Preview-Versionen enthalten sind.
Microsofts neue Informationskanäle erschweren die Arbeiten derjenigen Entwicklerinnen und Entwickler, die am Puls der Zeit bleiben wollen und damit auch die Erstellung von journalistischen Fachberichten wie diesem. Die Kommentare auf GitHub [19] zeigen, dass die neue Strategie einigen Kundinnen und Kunden nicht gefällt: „confusing“, „badly done“ und „before it was even out was so much better“ heißt es in den Kommentaren. Ketzerische Reaktionen wie „so, is .net dead?“ gibt es auch. Mitarbeitende von Microsoft haben inzwischen mit Ankündigungen reagiert, die Darstellung zu überdenken. Jon Douglas schreibt: „I will make notes to ask our product and documentation teams to provide clear diffs“ [20].
Der einzige Blogbeitrag, der zu .NET 9.0 erschienen ist, trägt den Titel „Our Vision for .NET 9“ [21]. Ziele für .NET 9.0 sind demnach Verbesserungen für Cloud- und KI-Anwendungen, was angesichts der Microsoft-Unternehmensstrategie nicht überraschend ist. Welche Features genau dazu gehören, bleibt offen. Es bleibt bei schwammigen Aussagen wie „Entwickler werden großartige Bibliotheken und Dokumentationen finden, um mit OpenAI- und OSS-Modellen (gehostet und lokal) zu arbeiten. Wir werden weiterhin an der Zusammenarbeit an Semantic Kernel, OpenAI und Azure SDK arbeiten, um sicherzustellen, dass .NET-Entwickler beim Erstellen intelligenter Anwendungen eine erstklassige Erfahrung haben“.
Was schon zuvor angekündigt wurde, sind die Erweiterungen der Einsatzgebiete des Ahead-of-Timer-Compilers. Er funktioniert in .NET 7.0 und .NET 8.0 für Konsolenanwendungen, Minimal WebAPIs, gRPC-Dienste und Worker Services –, aber auch dort mit großen Einschränkungen (z. B. ist Entity Framework Core nicht nutzbar). Der Blogeintrag lässt offen, was konkret der AOT-Compiler in .NET 9.0 mehr können wird.
Regelmäßig News zur Konferenz und der .NET-Community
Auch die Liste der geplanten Features ist, anders als bei .NET 5.0 bis .NET 8.0, noch nicht sehr ausführlich. Am meisten hat derzeit das ASP.NET-Core-Team veröffentlicht (Abb. 6). Dazu gehören:

Abb. 6: Pläne für ASP.NET Core 9.0 und Blazor 9.0 [22]
Auch das C#-Team gibt unter [23] wie immer frühe Einblicke. Wenig zu lesen gibt es hingegen bei .NET MAUI [24]. Nichts Aktuelles findet sich bei Windows Forms (Roadmap ist zwei Jahre alt, siehe [25]) und WPF (drei Jahre alte Roadmap, siehe [26]).
Das Entity Framework Core-Entwicklungsteam schreibt Stand 17. März 2024 nur „Coming soon“ [27]. Eine Linkliste auf verschiedene Roadmaps und Backlogs finden Sie unter [28].
![]()
Dr. Holger Schwichtenberg – alias der „DOTNET-DOKTOR“ – ist Leiter des Expertennetzwerks www.IT-Visions.de, das mit 53 renommierten Experten zahlreiche mittlere und große Unternehmen durch Beratungen und Schulungen sowie bei der Softwareentwicklung unterstützt. Durch seine Auftritte auf zahlreichen nationalen und internationalen Fachkonferenzen sowie mehr als 90 Fachbücher und mehr als 1 500 Fachartikel gehört Holger Schwichtenberg zu den bekanntesten Experten für .NET und Webtechniken in Deutschland. Seit 1998 ist er ununterbrochen Sprecher auf sämtlichen BASTA!-Konferenzen. Von Microsoft wird er seit 20 Jahren als MVP ausgezeichnet.
Mail: [email protected]
Twitter: @dotnetdoktor
Web: www.dotnet-doktor.de
[1] https://dotnet.microsoft.com/en-us/download/dotnet/9.0
[2] https://spectreconsole.net
[3] https://learn.microsoft.com/en-us/dotnet/api/system.reflection.emit.assemblybuilder.save?view=netframework-4.8.1
[4] https://learn.microsoft.com/en-us/aspnet/core/release-notes/aspnetcore-9.0?view=aspnetcore-8.0
[5] https://csrc.nist.gov/pubs/sp/800/185/final
[6] https://learn.microsoft.com/en-us/ef/core/what-is-new/ef-core-9.0/whatsnew
[7] https://learn.microsoft.com/en-us/ef/core/what-is-new/ef-core-9.0/whatsnew#make-existing-model-building-conventions-more-extensible
[8] https://github.com/dotnet/maui/releases/tag/9.0.100-preview.1.9973
[9] https://github.com/dotnet/maui/releases/tag/9.0.0-preview.2.10293
[10] https://devblogs.microsoft.com/dotnet/winforms-designer-64-bit-path-forward/
[11] https://devblogs.microsoft.com/dotnet/
[12] https://github.com/dotnet/core/discussions/9131
[13] https://github.com/dotnet/core/discussions
[14] https://learn.microsoft.com/en-us/dotnet/whats-new/
[15] https://learn.microsoft.com/en-us/dotnet/core/whats-new/dotnet-9/overview
[16] https://learn.microsoft.com/en-us/aspnet/core/release-notes/aspnetcore-9.0?view=aspnetcore-8.0
[17] https://learn.microsoft.com/en-us/ef/core/what-is-new/ef-core-9.0/whatsnew
[18] https://learn.microsoft.com/en-us/dotnet/maui/whats-new/dotnet-9?view=net-maui-8.0
[19] https://github.com/dotnet/core/discussions/9217
[20] https://github.com/dotnet/core/discussions/9217#discussioncomment-8765352
[21] https://devblogs.microsoft.com/dotnet/our-vision-for-dotnet-9/
[22] https://github.com/dotnet/aspnetcore/issues/51834
[23] https://github.com/dotnet/roslyn/blob/main/docs/Language%20Feature%20Status.md
[24] https://github.com/dotnet/maui/wiki/Roadmap
[25] https://github.com/dotnet/winforms/blob/main/docs/roadmap.md
[26] https://github.com/dotnet/wpf/blob/main/roadmap.md
[27] https://learn.microsoft.com/en-us/ef/core/what-is-new/ef-core-9.0/plan
[28] https://github.com/dotnet/core/blob/main/roadmap.md
The post .NET 9 Preview: Neuerungen und Änderungen in der Version 9.0 appeared first on BASTA!.
]]>The post Warum Agile Retrospektiven oft scheitern: Lösungen für mehr Erfolg appeared first on BASTA!.
]]>Konzentriert findet Inspect and Adapt oft im Rahmen von Retrospektiven statt. Teammitglieder kommen alle paar Wochen für teils mehrere Stunden zusammen. Es wird besprochen, es wird vorgeschlagen, es wird vereinbart. Und dann?
Regelmäßig News zur Konferenz und der .NET-Community
Gemeinsam an Verbesserung arbeiten ist ein hohes Gut, das der Wertschöpfung dient. Bessere Prozesse, bessere Tools und Psychological Safety zahlen alle auf die Unternehmensziele ein – wenn sie denn erreicht werden. Der wichtigste Grundsatz beim agilen Arbeiten ist Inspect and Adapt. Um diesem Prinzip der kontinuierlichen Verbesserung gerecht zu werden, muss die Arbeit transparent sein und es muss eine offene Kommunikation herrschen. Inspect and Adapt erstreckt sich auf alle Bereiche – ganz gleich, ob es sich dabei um Prozesse, Qualität, Quantität oder Kommunikation handelt.
Man müsste mal … In Konjunktiven gefangen ist es schwierig, die Umsetzungsebene zu erreichen und konkret Antipatterns in Projekten anzugehen. Retrospektiven (auch Retros genannt), richtig angewendet, sind gerade im agilen Umfeld das Mittel der Wahl, um besser zu werden. Wenn ich als Coach neu zu Teams dazukomme, schaue ich gerne, ob es eine Art Dokumentation zu stattgefundenen Retrospektiven gibt. Wenn ja, dann schaue ich nach Action Points, die festgehalten wurden und was damit passiert ist. In manchen Fällen wird den Action Points nachgegangen und eine schrittweise Verbesserung findet statt oder lässt sich vermuten. Jedoch sehe ich ebenfalls seitenweise offene Action Points – Vorhaben, die gemeinsam festgehalten, jedoch nicht umgesetzt wurden. Wie kann das sein? Es gab doch die besten Intentionen.
Was sind die Ursachen für so eine fehlende Umsetzung? Unsichtbare Dokumentation. Was für einen Stellenwert hat eine Zusammenfassung für das Team? Liegt sie z. B. in einem Confluence-Bereich, der von den Teammitgliedern eher selten bis gar nicht frequentiert wird? Natürlich gilt auch bei einer Retro nur so viel wie nötig und so wenig wie möglich zu dokumentieren, denn die Produktion von Dokumenten macht schließlich nicht agiler.
Tools sind hier auch weniger die Lösung als Mittel zum Zweck. Nach dem Kanban-Prinzip „Da anfangen, wo man ist“ schaue ich gerne, was Teams bisher wirklich nutzen. Manchmal muss erst Ordnung reingebracht werden, aber meistens gibt es frequentierte Bereiche, die sich auch für Retro-Dokus eignen. Manchmal reicht es, einfach die Verbesserungsvorhaben direkt im Backlog zu platzieren und einzuplanen.
Allzu hoher Produktionsdruck oder konstantes Firefighting lassen den Fokus von Verbesserung abschweifen bzw. den notwendigen Fokus erst gar nicht zu. Wenn nur hinterhergerannt wird, ist es ausgeschlossen, die Strecke zu gestalten. Es wird lediglich reagiert und die gegebenen Umstände im schlimmsten Fall als normal angesehen. Die Ursachen können vielfältig sein. Eine volatile Systemlandschaft, die mit Mühe und Not am Leben erhalten wird, eine Technical-Debt-Kakophonie, chronische Unterbesetzung, fehlende Priorisierung, unklare Entwicklungsprozesse und vieles mehr.
Jedes noch so wohlgemeinte Vorhaben kann nur schwer oder gar nicht stattfinden, wenn es schlicht und einfach keine Zeit gibt, um Impediments abzubauen. Also einfach Zeit schaffen – schön wäre es! Die ersten zarten Schritte von Transparenz und einer Arbeitsplanung sind sicherlich ein guter Weg, um mit der Realität umzugehen.
Wie wird mit Action Points umgegangen? Manchmal fehlt einfach, dass im Team daran erinnert wird, dass Verbesserungsmaßnahmen stattfinden sollen. Teams, die noch auf dem Weg der Reife sind, benötigen mehr Unterstützung und müssen noch Erfahrungen machen, die dann erst in die Arbeitsweisen übergehen können. So finde ich mich als Coach dann häufiger in der Rolle, Fragen zu stellen und dadurch Lösungen anzustoßen. Gerne biete ich aber auch „Good Practices“ an, z. B. die Priorisierung von Retro-Vorhaben im Backlog. Was für das eine Team funktioniert, muss jedoch keine Allgemeingültigkeit haben.
Die Ownership von Action Points zahlt ebenfalls auf Nachhaltigkeit ein. Während das Pull-Prinzip und Cross-Funktionalität hohe Güter sind, kann es trotzdem sinnvoll sein, Ownership für solche Vorhaben frühzeitig explizit zu machen. Der vermeintliche Wert von Retro Action Points kann für manche Teammitglieder im ersten Moment durchaus unklar sein, dann ist der Griff zu produktiven Themen im Backlog naheliegender.
Unkonkrete Vorhaben sind also schwer greifbar. Gibt es jetzt eine Aufgabe, die sich jemand nimmt, oder gibt es in der Wahrnehmung nur eine vage Aussage zu einem Missstand? Timeboxing in Retrospektiven helfen mit der Strukturierung, jedoch helfen sie wenig, wenn am Ende nichts Greifbares rauskommt. Explizite Formulierungen und sogar Akzeptanzkriterien schaffen hier Klarheit und forcieren Bewegung.
Eine gute Übung für Teams ist es, sich folgende Frage zu stellen: „Was liegt in unserer Macht, das wir ändern können?“ Im Team und auf Teamebene ist es in der Regel einfacher, kleine Schritte in Richtung Verbesserung zu gehen. Das Maß an Einfluss auf andere Ebenen schwindet in der Regel auf dem Weg nach oben bzw. nach außen. „Circles of Influence“ ist ein Konzept, das durch Visualisierung hilft, Bereiche zu erkennen, die mehr Aufmerksamkeit benötigen. Im Grunde geht es um eine Dreiteilung. In der äußeren Hülle, dem „Circle of Concern“ oder „Kreis der Bedenken“, befinden sich Inhalte, auf die kein Einfluss genommen werden kann. Der „Circle of Influence“ oder „Einflussbereich“ ist der Bereich, auf dem bedingt etwas bewegt werden kann. Auf den „Circle of Control“ oder „Kreis der Kontrolle“ kann unmittelbarer Einfluss genommen werden.
Sicherlich gibt es immer wieder mal bedenkenschaffende Einflussfaktoren, wie z. B. einen scheußlichen Produktschnitt, der Antipattern per Design etabliert. Trotzdem ist es sicherlich sinnvoll, Transparenz für Impediments zu schaffen, die nur anderswo gelöst werden können. Teamentwicklung und Organisationsentwicklung gehen zwar gerne Hand in Hand, jedoch in unterschiedlichen Geschwindigkeiten. Darauf zu warten und zu vertrauen, dass etwas passiert, ist nicht zielführend.
Manche Teams blühen auf, wenn sie einfallsreiche Retros durchführen und gemeinsam feststellen, welcher Wind in den Segeln sie vorantreibt und welche Anker sie zurückhalten. Andere Teams möchten nur Real Talk. Gezieltes Adressieren von Umständen mit klaren, schnellen Vorhaben ohne großes Check-in und anregenden Metaphern. Beides hat seine Berechtigung und ist in der richtigen Kombination zielführend. Wenn sich jedoch nur ein wie auch immer geratener Hammer im Werkzeugkoffer befindet, besteht die große Gefahr, mit den Retros eher zu traktieren, als etwas voranzubringen.
Beim Gewöhnungseffekt geht es um emotionale Erschöpfung als Reaktion auf frustrierende Umstände oder Themen. Bei dauerhaft ungelösten Problemen ohne wahrnehmbare Verbesserungen kann ein Resignationseffekt eintreten. Betroffene möchten sich einfach nicht mehr mit bestimmten Themen beschäftigen. Solche Umstände können dann als normal empfunden werden. Neue Teammitglieder lernen diese Dysfunktion als normal und unumstößlich kennen, was leider einen nachhaltenden Einfluss auf die Unternehmenskultur hat.
Wenn also Retros verpuffen, dann sinkt ihr Stellenwert und zahlt sogar auf das Gefühl ein, dass es zu viele sinnlose Meetings gibt (ein Retro-Dauerbrenner). Schon bildet sich ungewollt eine explosive Atmosphäre. Die Verpuffung möchte man in der Regel nicht herbeiführen, also wie vorbeugen? Letztendlich gibt es viele Faktoren, die auf den Erfolg von Retrospektiven einzahlen. Was schützt nun vor Verpuffung? Kurzgesagt: Realismus und Nachhaltigkeit. Ich habe ja bereits einige Ansätze genannt, aber wie so oft im Agilen kommt es auf die Situation an. Kleine erreichbare Stellschrauben sollten nicht übersehen werden bei dem Wunsch, am ganz großen Rad zu drehen.
Zum Jahresende mache ich gerne eine „Geist-von-Weihnachten-Retrospektive“, in der wir auf die Retros des ablaufenden Jahres zurückblicken und schauen, welche Vorhaben wir festgehalten haben und ob bzw. wie wir sie umgesetzt haben. Das schafft ein Bewusstsein dafür, wie viel bewegt wurde und erinnert an Verbesserungen, die mittlerweile schon als selbstverständlich angenommen werden. Es wird gemeinsam bekräftigt, weiter dem Verbesserungsprinzip zu folgen und entsprechend den Erkenntnissen des Jahresrückblicks ggf. am Vorgehen nachjustiert.
Gerade aus einer Situation heraus, in der hoher Arbeitsdruck besteht, kann es für Teammitglieder schwierig sein, den Kontextwechsel hinzukriegen. Unter dem Damoklesschwert der Ticketflut oder kognitiv tief in der Umsetzung einer User Story zu sein, kann das Empfinden hinterlassen, durch die Retro aus etwas Wichtigerem gerissen zu werden. Es geht hierbei nicht um tatsächlich unternehmenskritische Ereignisse. Klar kann es auch mal Wichtigeres als eine Retrospektive geben. Unternehmenskritisch wird jedoch schon mal etwas weit gesteckt und bildet dann eine dauerhafte Dysfunktion, die am besten in einer Retro zu behandeln ist.
Wie eine positive Atmosphäre geschaffen werden kann, hängt von den Beteiligten ab. Das Team zu fragen, gleichzeitig aber auch Vorschläge mitzubringen ist ein guter Ansatz. Ein Eisbrecher zum Start kann Wunder bewirken und den Kontextwechsel ermöglichen. Beispiele gibt es viele: Von einer Frage wie „Was ist dein Lieblingstier und weshalb?“ bis hin zu Spielen wie „Wahrheit oder Lüge“, bei der jeder eine oder mehrere Anekdoten erzählt und das Team erraten muss, ob sie stimmen.
Ob es gelingt, diese positive Atmosphäre zu schaffen, hängt davon ab, wieviel Zeit zur Verfügung steht, was bezweckt wird und wer die Teilnehmer:innen sind oder wie fortgeschritten ein Team ist. Wie bereits geschrieben, können manche Teams sofort in die Themenfindung springen. Bei anderen geht es darum, dass jede:r mal den Raum findet, sich zu artikulieren, vom Vorherigen abzuschalten, Spaß zu haben oder Offenheit herbeizuführen. Das ist bei jedem Team letztendlich abhängig von den involvierten Charakteren. Zum Beispiel kann ein Scrum Master mit geringen People Skills (möglicherweise befördert im Rahmen einer „Hauptsache-intern-besetzt-Philosophie“) häufig daneben liegen.
Verbesserung braucht Zeit – das würde jede:r unterschreiben. Weshalb also ist es so schwierig, Zeit zu schaffen? Der große Wurf wird nicht sofort gelingen. Eindeutige Priorisierung kann helfen. Der Product Owner erfüllt die Gatekeeper-Funktion und stoppt ungeplante Aufgaben von außen bzw. bringt sie in eine Priorisierungsreihenfolge. Die Zeitfresser müssen im Team erarbeitet und in kleinen Schritten gelöst werden. Manches geht hierbei sicherlich nur perspektivisch. Eine schreckliche Architektur beispielsweise wird nicht über Nacht besser.
Timeboxing und klare Struktur
Ja, man kann sich in Diskussionen verlieren und Aussagen werden redundant getätigt. Das passiert. Hier hat der oder die Moderator:in die Aufgabe, ebendies zu erkennen und die Diskussion entsprechend zu steuern. Es muss noch Zeit für die Findung eines Lösungsansatzes gegeben sein, bevor nur schnell etwas durchgeboxt wird. Ein reifes Team entwickelt sich dahin, dass die Struktur intrinsisch befolgt wird und nicht nur auf Ermahnung durch den Scrum Master. Die Charaktere finden ihre Rolle im Team und bringen sich ein.
Der Feind nachhaltig umgesetzter Vorhaben ist das Besprechen und Vergessen. Wie weiter oben erwähnt, funktioniert schon das Dokumentieren nicht, fehlt auch die Nachhaltigkeit. So kann es gut sein, dass die verabschiedeten Retro-Themen erst wieder in der nächsten Retrospektive adressiert werden. Insofern die Themen keinerlei Präsenz dazwischen haben, kann auch keine Nachhaltigkeit entstehen. Neben den bereits genannten Ansätzen (im Backlog einplanen oder explizites Ownership) kann allein schon das Ansprechen des Stands bestimmter Retro-Themen im Daily Wunder bewirken.
Mir tut es immer leid, wenn ich erfahre, dass Teams in den vergangenen Retrospektiven ständig dieselben Punkte ansprechen, ohne dass sich etwas ändert. Die Ursachen dafür sind vielfältig, aber die Stellschrauben der bereits genannten Lösungsansätze kommen da zum Tragen. Es ist wichtig, den Zyklus der ewigen Wiederholungen zu brechen, beispielsweise dass erstmal nur ein kleiner Schritt gegangen wird, mit der Umsetzung von etwas konkret Greifbarem.
Zum Schluss noch ein Retro-Thema, das ebenfalls überraschend häufig vorkommt: der Abbau von Kopfmonopolen bzw. ihr fehlender Abbau. Ein vollumfänglich cross-funktionales Team zu haben, ist fantastisch – jedoch äußerst selten. Gerade wenn es in die Tiefe geht, ist es eher unwahrscheinlich, dass Skills gut verteilt sind. Bottlenecks (auch vor allem außerhalb der Teams) führen zu Abhängigkeiten und der Disruption von Abläufen. Hier reicht es oft schon aus, im Planning zu klären, wer gemeinsam an welcher Aufgabe mitarbeiten sollte, um schrittweise Wissen zu verbreiten. Wenn es keine Zeit dafür gibt, dann siehe oben.
(Fast) alles hängt miteinander zusammen. Eine holistische Sicht hilft dabei, zu erkennen, dass kleine Änderungen schon viel bewirken können. So lässt sich ein Momentum verursachen, das Teams den Status quo verlassen lässt und in ihrer Reife voranbringt.
Also: Seid offen, mutig und respektvoll im Umgang miteinander und der Arbeit. Wählt kleine Schlachten und vergesst dabei nicht, am größeren Rad der Strategie (habt ihr eine?) mitzudrehen. Sehenden Auges eine ungewollte Verpuffung herbeizuführen, sollte etwas von gestern sein.
The post Warum Agile Retrospektiven oft scheitern: Lösungen für mehr Erfolg appeared first on BASTA!.
]]>The post Cloud-Native Entwicklung mit .NET Aspire: Praxistest und bewährte Design Patterns appeared first on BASTA!.
]]>Dass große Freiheit mit großer Verantwortung einhergeht, ist einer ältesten Scherze im Bereich des IT-Managements. Für Cloud Services gilt (logischerweise) Ähnliches: Desto weniger Optionen Entwickler:innen zur Verfügung stehen, desto wahrscheinlicher ist es, dass sie sich an vernünftigen Design Patterns orientieren.
Regelmäßig News zur Konferenz und der .NET-Community
Mit .NET Aspire schlägt Microsoft den angesprochenen Weg ein – schon in der Ankündigung findet sich das folgende Zitat, der Begriff „opinionated“ lässt sich in diesem Zusammenhang als „streng implementiert“ übersetzen: „.NET Aspire is an opinionated stack for building resilient, observable, and configurable cloud-native applications with .NET. It includes a curated set of components enhanced for cloud-native by including service discovery, telemetry, resilience, and health checks by default.“ [1]
Als Anbieter von Cloud-Lösungen ist Microsoft naturgemäß in einer einzigartigen Position, um der Nutzerschaft Vorgaben zu machen. Wenn man in der Lage ist, die Aufmerksamkeit der Entwickler:innen auf bestimmte Dienste zu richten, so lassen sich Kosten, beispielsweise für die Provisionierung, einsparen. In diesem Artikel werfen wir einen ersten Blick darauf, wie .NET Aspire funktioniert und welche praktischen Überlegungen bei der Nutzung zu beachten sind.
Aus dem opinionated Aufbau des Entwicklungssystems folgt, dass Microsoft auch den Entwickler:innen bzw. ihren Workstationkonfigurationen enge Daumenschrauben angelegt. Wer mit Visual Studio arbeiten möchte, benötigt die brandaktuelle Preview-Version 17.9 – der Autor wird die Variante 17.9.0 Preview 1.1 verwenden und eine Windows-11-Workstation als Host einspannen. Im Visual Studio Installer findet sich dann in der Rubrik ASP.NET und Webentwicklung die Option für das Herunterladen der Payload .NET Aspire SDK (Preview) (Abb. 1).

Abb. 1: Aspire-Entwicklung setzt eine spezielle Payload voraus
Zu beachten ist außerdem, dass die Arbeit mit Aspire prinzipiell und immer die Verwendung von .NET in Version 8.0 voraussetzt. Im Hintergrund erfolgt der Großteil der Ausführung unter Nutzung von Docker-Containern. Aus diesem Grund setzt die Aspire-Payload auch das Vorhandensein von Docker Desktop voraus. Ein Produkt, dass der Visual Studio Installer schon aus lizenzrechtlichen Gründen nicht automatisch herunterladen darf.
Zur Behebung des Problems besuchen wir im ersten Schritt [2] und klicken dort auf den Knopf Download for Windows. Nach dem Herunterladen der rund 600 MB großen .msi-Datei installieren wir diese im Allgemeinen wie gewohnt. Wer Docker Desktop – wie der Autor – für die folgenden Experimente frisch installiert, muss darauf achten, dass der Startbildschirm des Produkts den erfolgreichen Start des Docker-Containers ankündigt.
Als Nächstes erfolgt der Wechsel in Visual Studio 2022, wo ein neues Projekt auf Basis der Vorlage .NET Aspire Starter Application entsteht. Die in Visual Studio implementierte Search Engine zeigt sich dabei übrigens widerspenstig. Suchen Sie bitte nach dem String „Aspire Starter“, um die Einschränkungen zu aktivieren. In der Vorlage implementiert Microsoft – auf Wunsch – dabei verschiedene vorgefertigte Elemente. Wichtig ist, dass sie im Drop-down-Menü Framework wie in Abbildung 2 gezeigt .NET 8.0 auswählen und die Checkbox für Redis aktivieren.

Abb. 2: Diese Checkbox spart Zeit und Kosten
Lohn der Mühen ist die Erzeugung des in Abbildung 3 gezeigten Projektskeletts, dass – man denke abermals an das Stichwort des opinionated Designs – aus einer ganzen Gruppe von Unterprojekten aufgebaut ist.

Abb. 3: Aspire Solutions sind durchaus kompliziert
Im Interesse der besseren Verständlichkeit ist es empfehlenswert, das Projekt im ersten Schritt unter Nutzung der Visual-Studio-Default-Payload HTTP zur Ausführung zu bringen. Hierdurch erscheinen die in Abbildung 4 gezeigten Fenster. Ein Blick auf die Docker-Desktop-Umgebung zeigt, dass Visual Studio auch einen Container für uns aktiviert hat (Abb. 5).

Abb. 4: Wer eine Aspire-Applikation startet, bekommt mehrere Fenster

Abb. 5: Dieser Container gehört zu uns
Nun wollen wir aber zum Browserfenster zurückkehren: Aspire-basierte Solutions werden von Microsoft prinzipiell mit einem Dashboard ausgestattet, das Konfiguration und Überwachung der verschiedenen Elemente der Solution erleichtert. Sinn dieser Vorgehensweise ist, dass technisch herausgeforderte Entwickler nicht mit der (oft komplizierten) Logik zum Monitoring der verschiedenen Cloud-Projekte kämpfen müssen.
Interessant ist für uns außerdem die Rubrik Projects, in der unter der Rubrik Endpoints zwei unterschiedliche Solutions zur Verfügung stehen. Unter Apiservice findet sich dabei ein Dienst, der JSON-Daten mit Dummy-Wetterdaten anzeigt. Das Webfrontend-Paket realisiert stattdessen eine Blazor-App. Zu beachten ist, dass das Anklicken der Endpoint URLs in der Rubrik Projects die jeweiligen Elemente direkt im Edge-Browser öffnet.
Zum Zeitpunkt der Drucklegung dieses Artikels liegt Aspire noch in einem sehr frühen Zustand vor: Das äußert sich unter anderem darin, dass viele der Funktionen noch nicht im Benutzerinterface von Visual Studio angelegt sind. Als Erstes wollen wir uns das Projekt AspireApp1.AppHost ansehen, das als Dreh und Angelpunkt für die Aspire-Lösung dient und auch für die eigentliche Ausführung des Projekts verantwortlich ist. Am wichtigsten ist die Datei AspireApp1.AppHost.csproj, in der wir nach einer Analyse im Codeeditor das folgende zur Aspire-Umgebung gehörende Attribut vorfinden:
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> . . . <IsAspireHost>true</IsAspireHost>
In der Datei Program.cs findet sich dann die eigentliche Initialisierung, die unser Wetterdatenanzeigesystem ins Leben ruft. Microsoft orientiert sich dabei übrigens an den aus .NET Generic Host und ASP.NET Core Web Host bekannten Design Patterns, weshalb mit diesen Technologien erfahrene Entwickler:innen einen schnelleren Umstieg erleben:
var builder = DistributedApplication.CreateBuilder(args); var cache = builder.AddRedisContainer("cache");
Nach der Erzeugung des DistributedApplication-Objekts fügen wir diesen ersten Schritt einen Redis-Container hinzu: Aus der Methode AddRedisContainer lässt sich ableiten, dass es sich dabei um ein vorgefertigtes Modul handelt. Im nächsten Schritt folgt das Hinzufügen der zwei in unserer Solution manuell angelegten Projekte (Listing 1):
Listing 1
var apiservice = builder.AddProject<Projects.AspireApp1_ApiService>("apiservice");
builder.AddProject<Projects.AspireApp1_Web>("webfrontend")
.WithReference(cache)
.WithReference(apiservice);
builder.Build().Run();
Zum besseren Verständnis wollen wir an dieser Stelle auf die von Microsoft bereitgestellte und in Abbildung 6 gezeigte Grafik zurückgreifen, die die in unserem Aspire-Projekt vorhandenen Komponenten visualisiert.
Aspire-Applikationen bestehen intern aus verschiedenen Instanzen von Resourcen: Zum Zeitpunkt der Drucklegung sind drei bekannt. Als Erstes die durch AddProject hinzuzufügende ProjectResource, die ein .NET-Projekt kennzeichnet. Die ContainerResource – das Einpflegen erfolgt durch AddContainer – kümmert sich um Container-Images, während die durch AddExecutable einzufügende ExecutableResource-Klasse mehr oder weniger beliebige .exe-Dateien in den Aspire-Verbund einbindet. Wichtig ist außerdem noch, dass jede im Verbund lebende Ressource prinzipiell und immer einen einzigartigen Namen aufweisen muss.
Ein von Quereinsteiger:innen im Bereich der Elektronik häufig unterschätztes Problem ist, das Hochfahren der einzelnen Spannungsversorgungen in einem System zu verwalten. Benötigt ein System mehrere Spannungen und tauchen diese in der falschen Reihenfolge auf, so kommt es mitunter zu seltsamen Problemen.
Im Fall von Cloud-basierten bzw. verteilten Systemen gibt es ähnliche Probleme: Steht ein Konfigurations-Microservice nicht zur Verfügung, wenn ein anderer Dienst hochfährt, entsteht Durcheinander. Damit ist auch schon einer der wichtigsten Problemfälle beschrieben, denen Microsoft mit .NET Aspire entgegenwirken möchte.
Zum Verständnis des Orchestrierungsprozesses wollen wir uns die Datei Program.cs ansehen, die im Projekt AspireApp1.ApiService unterkommt und für die Bereitstellung des API-Endpunkts unseres Wettervorhersagesystems verantwortlich zeichnet. Die Initialisierung erfolgt über einen AppBuilder:
var builder = WebApplication.CreateBuilder(args); builder.AddServiceDefaults(); builder.Services.AddProblemDetails(); var app = builder.Build(); app.UseExceptionHandler();
Interessant ist hier der Aufruf der Methode AddServiceDefaults(), die Aspire zur Nutzung der projektglobalen Standardeinstellungen für verschiedene häufig benötigte Elemente der Solution animiert. Die restliche Initialisierung kümmert sich vor allem um das Einrichten eines Event Handler, der die ausgegebenen Informationen per Zufallsgenerator generiert. Um es kompakt zu halten, drucken wir diesen Teil des Codes gekürzt ab (Listing 3). Wichtig ist noch der Aufruf von Run, der die Aspire-Arbeitsumgebung zur eigentlichen Ausführung des Codes animiert. Angemerkt sei, dass Microsoft in .NET Aspire auch verschiedene andere Methoden zur Konfiguration anbietet – unter [4] findet sich eine Übersicht.
Listing 3
app.MapGet("/weatherforecast", () =>
{
var forecast = Enumerable.Range(1, 5).Select(index =>
. . .
return forecast;
});
app.MapDefaultEndpoints();
app.Run();
Interessanter ist für uns an dieser Stelle die Frage, woher der Aspire-Orchestrator die anzuwendenden Einstellungen bezieht und welche Teile der Solutions er zu konfigurieren sucht. Die Antwort auf diese Frage findet sich im Projekt AspireApp1.ServiceDefaults. Ich möchte mich auch an dieser Stelle kurz fassen; unter [5] findet sich eine vollständige Analyse des vergleichsweise reich kommentierten Codes.
Im Prinzip erfolgt die Initialisierung durch statische Methoden. Am wichtigsten ist die Funktion AddServiceDefaults, die, wie hier gekürzt gezeigt, verschiedene Basisdienste wie den Orchestrierungsservice konfiguriert und zur Solution hinzufügt:
public static IHostApplicationBuilder AddServiceDefaults(this IHostApplicationBuilder builder) {
builder.ConfigureOpenTelemetry();
builder.AddDefaultHealthChecks();
builder.Services.AddServiceDiscovery();
. . .
Im Bereich der Telemetriedatenerfassung setzt .NET Aspire auf OpenTelemetry – weitere Informationen hierzu finden sich unter [6]. Wichtig ist, dass die in .NET Aspire enthaltene Implementierung ebenfalls konfiguriert werden muss. Das ist die Aufgabe der Methode ConfigureOpenTelemetry, die wir hier aus Platzgründen nicht abdrucken.
Zu guter Letzt implementiert Aspire auch noch Health Checks. Dabei handelt es sich um Methoden, die das Überprüfen der Systemgesundheit des von .NET Aspire verwalteten Dienst ermöglichen. Ihre Einrichtung erfolgt in den Methoden AddDefaultHealthChecks und MapDefaultEndpoints.
Aspire-Komponenten erlauben das einfache Einpflegen häufig benötigter Dienste. Neben dem Orchestrierungs-Service ist vor allem die Komponentenfunktionalität von .NET Aspire relevant. Dabei handelt es sich um ein Feature, mit dem Microsoft die direkte Integration häufig benötigter Komponenten in die Solution ermöglicht. Zum Zeitpunkt der Drucklegung dieses Artikels bietet die unter [7] ansprechbare Liste dabei die in Abbildung 7 gezeigten Komponenten an.

Abb. 7: In Microsofts Komponentenzoo wimmelt es
Zu Demonstrationszwecken werden wir in den folgenden Schritten einen Azure-Dienst hinzufügen. Im ersten Schritt klicken wir die Projektmappe rechts an, und entscheiden uns für den Assistenten zum Hinzufügen eines neuen Projekts.
Suchen Sie nach der Vorlage Workerdienst und entscheiden Sie sich für die Variante für C#. Relevant ist, dass diese Vorlage nicht Teil der von .NET Aspire eingefügten Elemente ist. Als Name wird der Autor in den folgenden Schritten AspireApp1.AzWorker vergeben. Interessant ist außerdem, dass Sie im Projektkonfigurationsfenster, wie in Abbildung 8 gezeigt, die Option haben, die Checkbox In Aspire-Orchestrierung eintragen zu aktivieren. Diese sollten Sie auswählen, weil sich Visual Studio dann darum kümmert, unsere Worker-Dienste teilweise in die Solutions einzupflegen.

Abb. 8: Die Checkbox erleichtert das Ins-Leben-Rufen neuer Services
Dank der markierten Checkbox gibt es in Program.cs eine nach folgendem Schema erfolgende Anpassung, die sich um das Einpflegen der neuen Komponente kümmert:
. . .
builder.AddProject<Projects.AspireApp1_AzWorker>("aspireapp1.azworker");
builder.Build().Run();
Im nächsten Schritt klicken wir das neu erzeugte Paket rechts an, um die NuGet-Paketverwaltung zu öffnen. Ebenda entscheiden wir uns für das Paket Aspire.Azure.Storage.Blobs, das zum Zeitpunkt der Drucklegung dieses Artikels als Version 8.0.0-preview.1.23557.2 vorliegt. Danach verfahren wir analog mit dem Paket Aspire.Azure.Storage.Queues.
Angemerkt sei hier, dass .NET Aspire als .NET-Technologie logischerweise nicht von den Zwängen befreit ist, die im Bereich der .NET-Technologien zum Tragen kommen. Wichtig ist, dass das Hinzufügen der NuGet-Pakete in allen Solutions gleichermaßen erforderlich ist, die später mit dem jeweiligen Feature des verteilten Systems interagieren wollen oder sollen.
Im nächsten Schritt ist ein Wechsel in das Azure-Backend erforderlich, wo im ersten Schritt ein neuer Storage-Account entsteht. Der Autor vergab in den folgenden Schritten den Namen susaspireexperiment und entschied sich für die preiswerteste Redundanzklasse und eine geringe Performance-Tier. Für unsere hier durchgeführten Experimente ist ein Mehr an Systemperformance nicht notwendig, würde die Kosten aber immens erhöhen.
Im nächsten Schritt benötigen wir einen Blob-Storage-Container und eine Storage-Queue-Instanz: Wichtig ist in beiden Fällen, die Connection-Strings zur Verfügung zu haben. Wichtig ist außerdem, den Connection-String auf Ebene des Storage-Accounts zu beziehen – Abbildung 9 zeigt den korrekten Platz.

Abb. 9: Der Connection-String ist zum Abernten bereit
Als Nächstes stellt sich die Frage, wie der derzeit als String vorliegenden Connection-String in die .NET Aspire Solution einbezogen werden kann. Die Antwort darauf ist die Datei appsettings.json – beachten Sie, dass diese Adaption für jedes mit den Azure-Ressourcen zu verbindende Projekt von Hand durchgeführt werden muss (Listing 4).
Listing 4
{
"Logging": {
. . .
},
"ConnectionStrings": {
"blobdb": "DefaultEndpointsProtocol=https;AccountName=susaspire. . .",
"queuedb": "DefaultEndpointsProtocol=https;AccountName=susaspire. . ."
}
}
Im vorliegenden Fall ist derselbe Schlüssel unter zwei unterschiedlichen Namen angelegt: Ursache dafür ist die weiter oben erwähnte Bedingung, dass Namen nur einmal im Verbund vorkommen dürfen. Für die erfolgreiche Initialisierung der Containerinfrastruktur ist im AppHost außerdem das Hinzufügen des NuGet-Pakets Aspire.Hosting.Azure erforderlich.
Nach der Erzeugung der Service-Primitiva müssen diese im ersten Schritt zum Webprojekt hinzugefügt werden. Hierzu sind einfach weitere Aufrufe der Methode Add* notwendig, die die schon vorhandenen Aufrufe um die weiteren benötigten Komponenten ergänzen:
using Microsoft.Extensions.Hosting; var builder = DistributedApplication.CreateBuilder(args); var storage = builder.AddAzureStorage("tamsstore"); var blobs = storage.AddBlobs("blobdb"); var queues = storage.AddQueues("queuedb");
Im Fall des neuen von Visual Studio hinzugefügten Workers stehen noch keine Referenzen zur Verfügung, weshalb hier etwas umfangreichere Anpassungen der Deklaration anfallen:
builder.AddProject<Projects.AspireApp1_AzWorker>("aspireapp1.azworker")
.WithReference(blobs)
.WithReference(queues);
Im Webprojekt muss im nächsten Schritt die Deklaration aus Listing 5 eingefügt werden.
Listing 5
builder.AddProject<Projects.AspireApp1_Web>("webfrontend")
.WithReference(blobs)
.WithReference(queues)
.WithReference(cache)
.WithReference(apiservice);
var builder = WebApplication.CreateBuilder(args);
builder.AddAzureBlobService("blobdb");
builder.AddAzureQueueService("queuedb");
builder.AddServiceDefaults();
Danach wechseln wir in die Webapplikation, in der einige benötigte Dependencies importiert werden, wie in Listing 6 zu sehen ist.
Listing 6 @page "/counter" @rendermode InteractiveServer @using System.ComponentModel.DataAnnotations @using Azure.Storage.Blobs @using Azure.Storage.Queues @inject BlobServiceClient BlobClient @inject QueueServiceClient QueueServiceClient
Der Container erschwert Aspire-Entwicklern an dieser Stelle das Leben insofern, als er die in die Blobs zu schreibenden Informationen ausschließlich in Form von Streams erwartet. Wer wie wir hier einen String hochladen möchte, muss diesen zunächst vergleichsweise aufwendig in eine Stream-Instanz umwandeln (Listing 7).
Listing 7
@code {
private int currentCount = 0;
private async void IncrementCount() {
String usefulData ="ThisIsTheTestData";
var stream = new MemoryStream();
var writer = new StreamWriter(stream);
writer.Write(usefulData);
writer.Flush();
stream.Position = 0;
var docsContainer = BlobClient.GetBlobContainerClient("fileuploads");
await docsContainer.UploadBlobAsync( "TestFile",stream);
currentCount++;
}
}
Wer den Knopf dann anklickt, sieht das Aufscheinen eines Fehler-Callouts (Abb. 10) in der von .NET Aspire ebenfalls zur Verfügung gestellten Arbeitsoberfläche. Das Anklicken dieser Option führt zum Aufscheinen eines zusätzlichen Fensters, das – ganz analog zum klassischen Visual Studio – sogar Details zum Aufrufstack und zu den im Exception-Objekt angelegten Fehlerinformationen anbietet.

Abb. 10: Während der Ausführung von Aspire-Applikation auftretende Fehler werden im Web-Frontend zentralisiert präsentiert
Eine detaillierte Analyse des zurückgelieferten Fehlerstrings führt uns dann auch schon zum Ziel: Der Autor hatte einen Tippfehler: Der im Azure-Cloud-Backend angelegte Name des Blobs stimmte nicht mit dem überein, den die Methode erwartet hatte. Mit diesem Wissen lässt sich der Code wie folgt verbessern:
var docsContainer = BlobClient.GetBlobContainerClient("susaspirecont");
Bei der Programmausführung zeigt nun der Blob im Backend die per Aspire angelieferten Informationen an.
Mit .NET Aspire integriert Microsoft Lifecycle-Management in die .NET-Arbeitsumgebung: eine Funktion, die bisher beispielsweise in Docker Compose zur Verfügung gestellt wurde. Schon durch die Möglichkeit, mehr Services aus einer Hand zu beziehen, geht das mit einer Erhöhung der Lebensqualität für Entwickler:innen einher. Fraglich ist allerdings, ob bzw. inwiefern diese systemimmanenten Vorteile ausreichen, um Microsoft das Angreifen der gut etablierten Konkurrenz im Umfeld der Containerorchestrierung zu ermöglichen.
Links & Literatur
[1] https://devblogs.microsoft.com/dotnet/introducing-dotnet-aspire-simplifying-cloud-native-development-with-dotnet-8/
[2] https://www.docker.com/products/docker-desktop/
[3] https://learn.microsoft.com/en-us/dotnet/aspire/app-host-overview
[4] https://learn.microsoft.com/en-us/dotnet/aspire/service-defaults
[5] https://learn.microsoft.com/en-us/dotnet/aspire/service-discovery/overview
[6] https://opentelemetry.io
[7] https://learn.microsoft.com/en-us/dotnet/aspire/components-overview?tabs=dotnet-cli
The post Cloud-Native Entwicklung mit .NET Aspire: Praxistest und bewährte Design Patterns appeared first on BASTA!.
]]>The post Authentifizierung und Autorisierung – Sicherheit in einer Angular-Anwendung appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
Bei der Diskussion um Sicherheit in Webanwendungen rückt unweigerlich die Frage in den Fokus, was genau es zu schützen gilt. In diesem Kontext bietet die sogenannte CIA-Triade [1] einen klaren Rahmen, indem sie drei essenzielle Sicherheitsziele definiert – Vertraulichkeit, Integrität und Verfügbarkeit (Abb. 1).

Abb. 1: Die CIA-Triade
Die CIA-Triade dient als Grundlage für das Verständnis und die Bewertung von Sicherheitsmaßnahmen in IT-Systemen. Mit der Integration von Authentifizierung und Autorisierung sorgen wir also für einen Schutz des Sicherheitsziels der Vertraulichkeit: Schutz vor unbefugtem Zugriff.
Authentifizierung und Autorisierung sind zwei grundlegende Sicherheitskonzepte, die vor allem in der Welt der Informationstechnologie Verwendung finden. Immer wieder werden beide Konzepte vermischt oder sogar synonym verwendet, daher möchte ich mit einer kleinen Definition beide Sicherheitskonzepte noch einmal voneinander abtrennen:
Authentifizierung bezieht sich hierbei auf den Prozess, mit dem überprüft wird, ob jemand oder etwas tatsächlich das ist, was es vorgibt zu sein. Im Kontext von Webanwendungen bedeutet das in der Regel die Überprüfung der Identität eines Benutzers, typischerweise durch Benutzername und Passwort, biometrische Daten, Einmal-Passwörter oder andere Methoden. Authentifizierung ist der erste Schritt, um zu gewährleisten, dass der Zugriff auf ein System oder eine Anwendung von einer legitimen Quelle aus erfolgt. Oftmals werden bei der Authentifizierung sogenannte zweite Faktoren (Multi-factor Authentication) genutzt, um eine weitere Sicherheitsstufe zu integrieren. Das kann in Form eines SMS-Codes oder über eine speziell dafür ausgelegte Applikation [2] auf dem Smartphone integriert werden.
Autorisierung hingegen ist der Prozess der Entscheidung, ob ein authentifizierter Benutzer Zugriff auf bestimmte Ressourcen oder Funktionen erhalten soll. Das beinhaltet in der Regel die Überprüfung von Benutzerrechten oder Rollen gegenüber den Zugriffsanforderungen. Autorisierung erfolgt nach der Authentifizierung und bestimmt, was ein Benutzer in einem System oder einer Anwendung tun darf.
Diese beiden Konzepte sind eng miteinander verknüpft, aber dennoch unterschiedlich:
Die Herausforderung besteht darin, ein Gleichgewicht zu finden zwischen dem Schutz sensibler Daten und Ressourcen und der Bereitstellung eines nahtlosen und benutzerfreundlichen Erlebnisses für legitime Benutzer. So ist beispielsweise eine Ressource optimal geschützt, wenn der Benutzer noch vier oder mehr weitere Faktoren zur Authentifizierung angeben muss; der Benutzer selbst ist aber vermutlich schnell genervt von dem bereitgestellten Authentifizierungsprozess.
Bei der Integration eines Authentifizierungsprozesses in eine Webanwendung stehen uns im Wesentlichen zwei etablierte Methoden zur Verfügung:
Beide Ansätze finden heutzutage große Anwendung und bringen jeweils ihre spezifischen Vorzüge und Herausforderungen mit sich. Im Folgenden werde ich diese beiden Konzepte detailliert erörtern und die potenziellen Vor- und Nachteile jedes Ansatzes beleuchten, um ein tieferes Verständnis ihrer Anwendung und Wirksamkeit in modernen Webanwendungen zu vermitteln.
Cookiebasierte Authentifizierung ist ein verbreiteter Ansatz zur Verwaltung von Benutzersitzungen in Webanwendungen. Dabei wird nach erfolgreicher Authentifizierung des Nutzers ein kleines Stück Daten – bekannt als Cookie – vom Server an den Webbrowser des Benutzers gesendet und dort gespeichert. Dieses Cookie wird dann bei jeder folgenden Anfrage des Browsers an den Server zurückgesendet, wodurch der Server den Benutzer und dessen Sitzungszustand über verschiedene Anfragen hinweg verfolgen kann. Dabei werden folgende Schritte durchgeführt:

Abb. 2: Nach dem Log-in wird ein Sitzungscookie erstellt

Abb. 2: Nach dem Log-in wird ein Sitzungscookie erstellt
Abb. 3: Das Cookie wird im Browser gespeichert

Abb. 4: Der Server prüft die Gültigkeit des gespeicherten Cookies
Die cookiebasierte Authentifizierung ist besonders effektiv für traditionelle Webanwendungen, bei denen der Server eine aktive Rolle bei der Sitzungsverwaltung spielt. Ein weiterer wichtiger Faktor ist das Management der Cookies über den Browser: Entwickler:innen müssen hierbei keinen eigenen Code für das Verwalten der Cookies schreiben. Das verringert die Komplexität der Webanwendung, da wir uns darauf verlassen können, dass der Webbrowser bei jeder Anfrage an unser Backend die Cookiedaten automatisch mitsendet.
Durch den Einsatz der bereits erwähnten Cookieattribute secure und httpOnly erhöhen wir die Sicherheit in der Verwaltung unserer Cookies. Insbesondere bietet das Setzen des httpOnly-Attributs einen wirksamen Schutz gegen Manipulationen des Cookies durch bösartige JavaScript-Einschleusungen, bekannt als Cross-site-Scripting-(XSS-)Attacken. Dieses Attribut bewirkt, dass die Cookies nicht mehr über das Browser-API document.cookie zugänglich sind, wodurch ein zusätzliches Sicherheitsniveau im Umgang mit sensiblen Benutzerdaten etabliert wird.
Auch wenn die Nutzung von Cookies bösartige Manipulationen über JavaScript verringern kann, sind sie leider die Hauptursache für sogenannte Cross-site-Request-Forgery-(CSRF-)Attacken.
Eine CSRF-Attacke, auch als „One Click Attack“ oder „Session Riding“ bekannt, ist eine Art von Cyberangriff, bei dem ein Angreifer Nutzer dazu bringt, ungewollte Aktionen auf einer Webseite auszuführen, auf der sie gerade angemeldet sind. Das geschieht typischerweise, ohne dass der Nutzer sich dessen bewusst ist. Hierbei wird genau die Tatsache ausgenutzt, dass das Opfer bereits auf der Zielwebseite über ein Cookie authentifiziert ist und dieses Cookie bei allen Anfragen auf die Zielwebseite automatisch vom Webbrowser mitgesendet wird. Die Anfrage kann daraufhin verschiedene Aktionen auslösen, wie das Ändern von Kontoinformationen, das Versenden von Nachrichten oder das Durchführen von Transaktionen. Die Open-Web-Application-Security-Project-(OWASP-)Organisation hat einige Tipps und Tricks in einem Cheat Sheet [4] zusammengestellt, wie man sich am besten vor CSRF-Attacken schützen kann.
Neben der Einführung von potenziellen CSRF-Attacken haben Cookies noch einen weiteren Nachteil: Sie sind weniger geeignet für moderne, verteile Architekturen wie Single Page Applications (SPAs) und Microservices, in denen oft tokenbasierte Authentifizierungsmethoden, wie z. B. JSON Web Tokens (JWT), bevorzugt werden. In Anbetracht dessen möchten wir uns nun der tokenbasierten Authentifizierung zuwenden und diese eingehend beleuchten.
Regelmäßig News zur Konferenz und der .NET-Community
Tokenbasierte Authentifizierung ist ein Verfahren, bei dem statt traditioneller Session-Cookies ein Authentifizierungstoken für die Identifizierung und Verwaltung von Benutzersitzungen verwendet wird. Dieses Verfahren wird wie bereits erwähnt häufig in modernen Webanwendungen und insbesondere in API-basierten Diensten und Single-Page-Anwendungen eingesetzt. Folgendes sind die Kernaspekte der tokenbasierten Authentifizierung:

Abb. 5: Bei der tokenbasierten Authentifizierung ist meist ein Identity Provider im Spiel

Abb. 6: Das Token wird an den Client gesendet

Abb. 7: Das Token im Header dient als Authentifizierungsnachweis
Diese Methode ist besonders effektiv für Anwendungen, die Ressourcen über mehrere Server oder Dienste verteilen, da das Token leicht zwischen verschiedenen Systemkomponenten übertragen werden kann, ohne die Notwendigkeit einer zentralen Sitzungsverwaltung.
Token können auf verschiedene Arten in Browsern oder Webanwendungen gespeichert werden. Doch auch hierbei gibt es einiges zu beachten: Wenn Sie den lokalen Speicher eines Browsers verwenden, kann eine Subdomain nicht auf Tokens zugreifen. Sie können jedoch von jedem JavaScript-Code auf der Webseite sowie von Browser-Plug-ins aufgerufen und manipuliert werden. Das ist also keine empfohlene Methode – sie stellt zum einen ein Sicherheitsrisiko dar und darüber hinaus müssen Sie den Speicher selbst verwalten.
Die Verwaltung der Tokens erfordert oftmals viel manuelle Arbeit: Ein Token kann beispielsweise nicht widerrufen werden. Selbst wenn ein Token gestohlen wird, bleibt es gültig, bis es abläuft, was zu einer schwerwiegenden Sicherheitslücke führt. Um dieses Problem zu umgehen, müssen Sie eine Sperrlistentechnik implementieren, die eine komplexere Einrichtung erfordert.
Aber auch ohne an bösartige Attacken zu denken, kann eine eigenständige Verwaltung der Tokens kompliziert sein: Die Informationen in einem Token stellen eine Momentaufnahme zum Zeitpunkt der ursprünglichen Erstellung des Tokens dar. Der zugehörige Benutzer verfügt möglicherweise nun über andere Zugriffsebenen oder wurde vollständig aus dem System entfernt.
Angesichts der Komplexität und Bedeutung einer sicheren Tokengenerierung und -verwaltung empfiehlt es sich fast immer, diese Aufgaben nicht eigenständig zu übernehmen. Oft ist es vorteilhafter und sicherer, externe Identity-as-a-Service-Anbieter (sogenannte Identity Provider wie Azure Active Directory [5] oder Auth0 [6] by Okta) zu integrieren oder etablierte Identity- und Access-Management-Tools zu verwenden, wie sie beispielsweise mit Keycloak [7] von Red Hat angeboten werden.
Diese Lösungen bieten nicht nur eine robuste Verwaltung von Nutzerkonten und Tokens, sondern erleichtern durch bereitgestellte Entwicklerbibliotheken auch signifikant die Integration in Webanwendungen. Dadurch wird nicht nur die Sicherheit erhöht, sondern auch der Entwicklungsprozess effizienter und benutzerfreundlicher gestaltet.
Wie das Ganze nun konkret aussehen kann, möchte ich Ihnen anhand einer beispielhaften Implementierung demonstrieren. Hierbei werde ich den Identity Provider Auth0 by Okta nutzen, um Authentifizierung und Autorisierung in eine bestehende Angular-Applikation zu integrieren.
Bevor wir mit der konkreten Implementierung starten können, müssen wir uns zuvor kurz mit den offenen Standards für Autorisierung und Authentifizierung auseinandersetzen. Diese beschreiben verschiedene Workflows und Richtlinien, wie eine Webanwendung ein Token sicher erhalten kann, und bieten eine Spezifikation für weitere Authentifizierungskonzepte wie Single Sign-on (SSO) oder die Integration sozialer Medien (Social Log-in).
OpenID Connect ist eine Identitätsverwaltungsschicht, die auf dem OAuth-Protokoll aufbaut. Sie ermöglicht es Clients, die Identität eines Endbenutzers zu verifizieren und grundlegende Profilinformationen über den Benutzer zu erhalten. OpenID Connect wird oft für Single-Sign-on-(SSO-)Lösungen verwendet und ist weit verbreitet in modernen Webanwendungen und Mobile-Apps. OpenID Connect erweitert hierbei OAuth um die Einführung von ID-Tokens. Diese Tokens sind im JWT-Format und enthalten Informationen über die Authentifizierung des Benutzers.
OAuth ist ein offener Standard für Zugriffsdelegation, der es Benutzern ermöglicht, Dritten eingeschränkten Zugriff auf ihre Ressourcen auf einem anderen Server zu gewähren, ohne dabei ihre Zugangsdaten preiszugeben. Ursprünglich für die API-Autorisierung entwickelt, hat sich OAuth zu einem Schlüsselstandard in der modernen Web- und Anwendungsentwicklung entwickelt. OAuth ermöglicht es Anwendungen, im Namen des Benutzers auf Ressourcen zuzugreifen, indem sie ein Zugriffstoken verwenden, das vom Ressourcenbesitzer (dem Benutzer) genehmigt wurde. Das bedeutet, dass Anwendungen keine Benutzernamen und Passwörter speichern müssen. Kurz gesagt ist OAuth eine Spezifikation für die Autorisierung eines Benutzers: Sie können spezifische Berechtigungen (Scopes) an die Anwendungen vergeben, was eine fein abgestimmte Kontrolle darüber ermöglicht, auf welche Informationen und Funktionen die Anwendung zugreifen darf.
OAuth definiert verschiedene Flows (auch als Grant Types bezeichnet), um unterschiedliche Anwendungsfälle und Szenarien für die Authentifizierung und Autorisierung zu unterstützen. Jeder dieser Flows beschreibt einen spezifischen Prozess zur Erlangung eines Zugriffstokens – dem sogenannten Access-Token.
Je nach Anwendung werden verschiedene Flows empfohlen. Die aktuelle Version OAuth 2.1 [8] spezifiziert hierbei hauptsächlich drei Flows:
Der Client Credentials Flow wird immer dann verwendet, wenn der Zugriff zwischen zwei Anwendungen ohne Benutzerinteraktion erfolgt. Die Anwendung authentifiziert sich mit ihren eigenen Credentials (nicht mit Benutzer-Credentials) beim OAuth-Server und erhält ein Zugriffstoken. Der Device Code Flow wird für Geräte genutzt, die keine einfache Möglichkeit bieten, Text einzugeben (wie Smart-TVs oder Spielkonsolen). Es verwendet ein Gerät, das einen Code anzeigt, den der Benutzer auf einem anderen Gerät (z. B. einem Smartphone) eingibt, um die Authentifizierung zu bestätigen.
Wenn wir mit Angular eine SPA entwickeln, wird empfohlen, dass wir den Authorization Code Flow mit PKCE nutzen. Dieser Flow ist für Anwendungen gedacht, die auf einem Server laufen. Bei einem einfachen Authorization Code Flow (ohne PKCE-Erweiterung) authentifiziert sich der Benutzer zunächst bei seinem Identity Provider und erteilt der Anwendung die Berechtigung (Abb. 8). Daraufhin erhält die Anwendung einen Autorisierungscode, den sie gegen ein Zugriffstoken eintauschen kann (Abb. 9). Dieser Flow gilt als einer der sichersten, da die Nutzer-Credentials zu keinem Zeitpunkt in unserer Frontend-Applikation einsehbar sind.

Abb. 8: Authentifizierung beim Identity Provider

Abb. 9: Autorisierungscode wird gegen Access-Token getauscht
Mit der Proof-Key-Code-Exchange-Erweiterung – die seit OAuth 2.1 auch verpflichtend ist – fügt man dem Authorization Code Flow noch eine weitere Sicherheitsstufe hinzu. Hierbei generiert der Client einen zufälligen String, bekannt als Code Verifier. Daraufhin erstellt der Client eine Code Challenge aus diesem Verifier, in der Regel, indem er einen Hashwert (SHA256) des Verifiers bildet und den Hash dann in Base64-URL kodiert. Bei der erneuten Authentifizierung des Benutzers werden neben den Credentials die Code Challenge und die Hashfunktion mitgegeben, mit der eben diese Code Challenge erstellt wurde. Daraufhin erhält, wie auch zuvor, die Anwendung einen Autorisierungscode und sendet diesen, diesmal mit dem Code Verifier, an seinen Identity-Provider. Dieser verwendet den empfangenen Code Verifier, um die Code Challenge zu generieren (d. h., er berechnet den SHA256-Hash und kodiert ihn in Base64-URL). Der Identity-Provider vergleicht dann die generierte Challenge mit der ursprünglich vom Client gesendeten Challenge. Stimmen diese überein, weiß der Server, dass die Anfrage vom gleichen Client stammt, der den Autorisierungscode angefordert hat und liefert ebenfalls das Access-Token aus.
Zum Glück entfällt die Notwendigkeit, sich mit den Details der Implementierung dieser Flows auseinanderzusetzen, da das von externen Bibliotheken, wie beispielsweise denen, die Auth0 by Okta bereitstellt, abgedeckt wird. Dennoch ist ein grundlegendes Verständnis der verschiedenen OAuth Flows von unschätzbarem Wert, um eine fundierte und sichere Entscheidung über den am besten geeigneten Flow für unsere spezifischen Anforderungen treffen zu können.
Wie bereits erwähnt werde ich in meiner Beispielimplementierung den Identity Provider Auth0 by Okta verwenden. Sämtliche gezeigten Funktionalitäten und Konzepte finden sich aber in anderen Identity-as-a-Service-Lösungen ebenfalls wieder. Auth0 bietet einen kostenlosen Nutzungsplan [9], der bis zu 7 500 aktive Benutzer und unbegrenzte Log-ins umfasst. Diese kostenlosen Pläne sind ideal, um die grundlegenden Funktionen von Auth0 by Okta kennenzulernen und zu testen, wie gut sie sich in Ihre Anwendung oder Ihr Projekt integrieren lassen.
Wenn wir uns nun kostenlos registrieren, können wir eine neue Applikation – auch Tenant genannt – erstellen (Abb. 10). Ein Tenant bezeichnet eine dedizierte Instanz der Identity-Provider-Plattform, die für einen Kunden oder ein Projekt eingerichtet wird. Es ist im Wesentlichen ein separater Container, in dem alle Ihre Benutzer, Sicherheitseinstellungen, Anwendungen und Konfigurationen für Ihre Authentifizierungs- und Autorisierungsvorgänge gespeichert werden. Jeder Tenant bei Auth0 ist durch eine eindeutige Domain gekennzeichnet und isoliert, was bedeutet, dass die Daten und Konfigurationen eines Tenants nicht mit denen anderer Tenants geteilt werden.

Abb. 10: Erstellen einer Applikation
Nachdem der Tenant erfolgreich angelegt wurde können wir diesen nun konfigurieren. Ebenso können wir alle wichtigen Daten direkt einsehen (beispielsweise die Domain und die Client-ID), die wir benötigen, um unsere Frontend-Applikation mit Auth0 zu verbinden (Abb. 11).

Abb. 11: Informationen unserer Applikation
Wichtig hierbei ist, dass wir konfigurieren, welche sogenannten Origins, also URLs auf unseren Tenant zugreifen dürfen. Da wir eine lokale Angular-Anwendung implementieren, müssen wir http://localhost:4200 eintragen. Darüber hinaus ist dieser URL ebenfalls noch in die Liste der Allowed Callback URLs (eine URL-Liste, in der aufgelistet wird, wohin der Identity Provider nach erfolgreicher Authentifizierung wieder navigieren soll) und in die Liste der Allowed Logout URLs (ebenfalls eine Liste der URLs, auf die der Identity Provider uns navigiert, sobald sich der Benutzer erfolgreich ausloggt) einzutragen. Nach erfolgreicher Konfiguration können wir nun damit starten, Auth0 in unserer Angular-Applikation zu integrieren.
Auth0 erleichtert die Integration erheblich durch die Bereitstellung eines SDK, das als npm-Paket [10] verfügbar ist. Dieses können wir wie folgt installieren:
> npm install @auth/auth0-angular
Nach erfolgreicher Installation nutzen wie uns zur Verfügung gestellte provideAuth0-Funktion und konfigurieren sie mit den spezifischen Details unserer Auth0-Domain und der Client-ID wie in Listing 1.
Listing 1
//main.ts
import { provideAuth0 } from '@auth0/auth0-angular';
bootstrapApplication(AppComponent, {
providers: [
provideAuth0({
domain: 'YOUR_AUTH0_DOMAIN',
clientId: 'YOUR_AUTH0_CLIENT_ID',
authorizationParams: {
redirect_uri: window.location.origin,
}
}),
]
});
Nun fehlen lediglich noch eine Login- und eine Logout-Komponente damit sich unsere Nutzer gegenüber unserem Identity Provider authentifizieren können. Der bereitgestellte AuthService erleichtert und die Implementierung und Verwaltung des vollständigen Authorization Code Flow mit PKCE-Erweiterung (Listing 2).
Listing 2
import { AuthService } from "@auth0/auth0-angular";
@Component({
selector: "app-login-button",
template: `
<button class="button__login" (click)="handleLogin()">Log In</button>
`
})
export class LoginButtonComponent {
constructor(private auth: AuthService) {
}
handleLogin(): void {
this.auth.loginWithRedirect({
prompt: "login"
});
}
}
Beim Klick auf den Log-in-Button erfolgt eine Weiterleitung zur Log-in-Maske unseres Identity Providers (Abb. 12). Werfen wir dabei einen Blick auf den Network-Tab unseres Webbrowsers, sehen wir einen Request an den /authorize-Endpoint unseres Identity Provider (Abb. 13). Ebenfalls zu sehen sind die Properties code_challenge_method und code_challenge. Diese sind notwendig für die PKCE-Erweiterung. Die Property response_type mit dem Wert code gibt hierbei an, dass der Client unseren Identity Provider zu einem Authorization Code Flow aufruft.

Ab.12: Log-in-Maske von Auth0

Abb. 13: Payload des Requests
Wenn wir uns nun erfolgreich einloggen, können wir eine weitere Anfrage auf den /token-Endpoint unseres Identity Provider sehen. Der mitgesendete Payload sieht dieses Mal wie folgt aus:
client_id: "afRDjs6KFS0TV5NL7NzltUw9Wlktukutyk77" code: "bigvau6q0DIA9HTbJKcXyRG09j1lZX1jTa8zLAsCIV2Wh" code_verifier: "zBtJLPMI1TcKpLcOgHoY5ukNGmVnstxhWUksfh1Rso7" grant_type: "authorization_code" redirect_uri: "http://localhost:4040/callback"
Wie bereits erwähnt wird bei diesem Aufruf nun der Authorization-Code (code) mitgesendet werden, sowie der Code Verifier (code_verifier), damit unser Identity Provider überprüfen kann, ob beide Anfragen vom selben Client stammen.
Als Antwort erhalten wir das Access-Token sowie ein ID-Token, da OpenID Connect ebenfalls automatisch aktiviert ist (Abb. 14). Diese Tokens werden standardmäßig in einem Cookie abgespeichert. Wir können das SDK so konfigurieren, dass die Tokens im localStorage abgelegt werden, allerdings ist das nur in Verbindung mit einem Refresh-Token ratsam.

Abb. 14: Response mit Access-Token und ID-Token
Das Access-Token können wir nun für die Autorisierung gegenüber verschiedenen Backend-APIs verwenden. Hierfür setzen wir den Authorization-Header bei allen Anfragen auf das entsprechende API. Das kann uns auch von einem von Auth0 bereitgestellten Angular Inteceptor abgenommen werden (Listing 3).
Listing 3
//main.ts
import { provideAuth0, authHttpInterceptorFn } from '@auth0/auth0-angular';
bootstrapApplication(AppComponent, {
providers: [
provideAuth0(...),
provideHttpClient(
withInterceptors([authHttpInterceptorFn])
)
]
});
Senden wir nun also eine Anfrage an ein geschütztes API, wird automatisch der Authorization-Header mit dem Wert des Access-Tokens gesetzt. Um die Anwendung vollständig abzurunden, fügen wir noch eine Logout-Komponente hinzu, die erneut den AuthService injiziert der uns eine Log-out-Funktion anbietet (Listing 4).

Abb. 15: Access-Token im Header
Listing 4
import { Component, Inject } from "@angular/core";
import { AuthService } from "@auth0/auth0-angular";
import { DOCUMENT } from "@angular/common";
@Component({
selector: "app-logout-button",
template: `
<button class="button__logout" (click)="handleLogout()">Log Out</button>
`
})
export class LogoutButtonComponent {
constructor(
private auth: AuthService,
@Inject(DOCUMENT) private doc: Document
) {
}
handleLogout(): void {
this.auth.logout({ returnTo: this.doc.location.origin });
}
}
Dieser AuthService bietet uns noch viele weitere Observables an, z. B. isAuthenticated$, um herauszufinden, ob der Benutzer bereits eingeloggt ist oder nicht. Möchten wir hingegen Daten des Benutzers erhalten, wie beispielsweise den Usernamen, einen URL auf ein Profilbild oder die E-Mail-Adresse, so erhalten wir diese Daten, wenn wir uns auf das user$-Observable des AuthServices abonnieren.
Wie wir gesehen haben, gestaltet sich die Integration eines Identity Provider in eine Angular-Applikation recht einfach. Selbst bei anderen SPA-Frameworks wie React oder Vue.js bietet Auth0 entsprechende SDKs an, um auch dort die Integration mit so wenig Aufwand wie möglich zu gestalten. Wenn Sie nicht Auth0 nutzen möchten, bietet Microsoft eigene SDKs [11] zur Integration von Azure Active Directory. Darüber hinaus gibt es auch vielerlei etablierte Open-Source-SDKs [12] für die Integration verschiedener Identity Provider in eine Angular-Anwendung.
Regelmäßig News zur Konferenz und der .NET-Community
Die Absicherung Ihrer Backend-Ressourcen durch Autorisierung ist ein absolutes Muss einer jeden modernen Webanwendung. Der richtige Umgang mit dem Access-Token bietet vielerlei Fallstricke, wie beispielsweise die Auswahl eines schwachen kryptographischen Verfahrens zur Verschlüsselung ihrer Access-Tokens. Nicht signierte Tokens können leicht manipuliert werden, sodass ein Nutzer sich mehr Rechte zuweisen kann, als er eigentlich hat. Mehr als die Hälfte der Top 10 API Security Risks [13], die von der OWASP-Organisation veröffentlicht werden, handeln von fehlerhafter oder falsch implementierter Autorisierung. Es ist also definitiv ratsam, sich nicht selbst an der Implementierung einer Authentifizierungs- und Autorisierungslösung zu versuchen und auf bestehende Lösungen zu setzen, wie sie von Identity Providern zur Verfügung gestellt werden.
Abschließend lässt sich festhalten, dass die Integration von Authentifizierung und Autorisierung in Angular-Anwendungen eine entscheidende Rolle bei der Gewährleistung von Sicherheit und Benutzerfreundlichkeit spielt. Durch die sorgfältige Implementierung von AuthN und AuthZ können Entwickler robuste und sichere Webanwendungen erstellen, die nicht nur den Schutz sensibler Daten ermöglichen, sondern auch ein nahtloses und effizientes Nutzererlebnis bieten. Die in diesem Artikel vorgestellten Methoden und Best Practices bieten dabei einen umfassenden Leitfaden, um diese komplexen Prozesse erfolgreich in Angular-basierten Projekten umzusetzen. Mit dem wachsenden Fokus auf Websicherheit und Datenschutz ist es für Entwickler unerlässlich, sich kontinuierlich weiterzubilden und die neuesten Technologien und Methoden in diesem dynamischen Bereich zu adaptieren.
Links & Literatur
[1] https://it-service.network/it-lexikon/cia-triade
[2] Google Authenticator: https://de.wikipedia.org/wiki/Google_Authenticator
[3] https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies#security
[4] https://cheatsheetseries.owasp.org/cheatsheets/Cross-Site_Request_Forgery_Prevention_Cheat_Sheet.html
[5] https://www.microsoft.com/de-de/security/business/identity-access/microsoft-entra-id
[6] https://auth0.com/de
[7] https://www.keycloak.org
[8] https://oauth.net/2.1/
[9] https://auth0.com/pricing
[10] https://www.npmjs.com/package/@auth0/auth0-angular
[11] https://learn.microsoft.com/en-us/entra/identity-platform/msal-overview
[12] https://github.com/manfredsteyer/angular-oauth2-oidc und https://github.com/damienbod/angular-auth-oidc-client
[13] https://owasp.org/API-Security/editions/2023/en/0x11-t10/
The post Authentifizierung und Autorisierung – Sicherheit in einer Angular-Anwendung appeared first on BASTA!.
]]>The post Was ist neu in Angular 17? appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
Angular 17 wird im Herbst 2023 weitere Beiträge zur Angular Renaissance leisten: Es kommt mit einer neuen Syntax für den Control Flow, verzögertes Laden von Seitenteilen und einer besseren Unterstützung für SSR. Außerdem setzt das CLI nun auf esbuild und beschleunigt damit den Build erheblich. In diesem Artikel gehe ich anhand einer Beispielanwendung (Abb. 1) auf diese Neuerungen ein. Den verwendeten Quellcode findet man unter [1].

Abb. 1: Beispielanwendung
Neue Syntax für Control Flow in Templates
Seit seinen ersten Tagen hat Angular strukturelle Direktiven wie *ngIf oder *ngFor für den Control Flow verwendet. Da es den Control Flow nun für die mit Angular 16 eingeführten Signals ohnehin umfangreich zu überarbeiten gilt, hat sich das Angular-Team entschieden, ihn gleich auf neue Beine zu stellen. Das Ergebnis ist der neue Build-in Control Flow, der sich deutlich vom gerenderten Markup abhebt (Listing 1).
Listing 1
@for (product of products(); track product.id) {
<div class="card">
<h2 class="card-title">{{product.productName}}</h2>
[…]
</div>
}
@empty {
<p class="text-lg">No Products found!</p>
}
Beachtenswert ist hier unter anderem der neue @empty-Block, den Angular rendert, wenn die zu iterierende Auflistung leer ist.
Auch wenn Signals ein Treiber für diese neue Syntax waren, sind sie keine Voraussetzung für ihre Nutzung. Die neuen Control-Flow-Blöcke lassen sich genauso mit klassischen Variablen oder auch mit Observables im Zusammenspiel mit der async Pipe nutzen.
Der verpflichtende track-Ausdruck erlaubt es Angular, einzelne Elemente, die innerhalb der iterierten Auflistung verschoben wurden, zu identifizieren. Damit lässt sich der Aufwand für das Rendering drastisch reduzieren und bestehende DOM-Knoten wiederverwenden. Beim Iterieren von Auflistungen primitiver Typen, z. B. number oder string, sollte track Angaben des Angular-Teams zur Folge mit der Pseudovariable $index verwendet werden (Listing 2).
Listing 2
@for (group of groups(); track $index) {
<a (click)="groupSelected(group)">{{group}}</a>
@if (!$last) {
<span class="mr-5 ml-5">|</span>
}
}
Neben $index stehen auch die anderen von *ngFor bekannten Werte über Pseudovariablen zur Verfügung: $count, $first, $last, $even, $odd. Bei Bedarf lassen sich deren Werte über Ausdrücke in Templatevariablen ablegen (Listing 3).
Listing 3
@for (group of groups(); track $index; let isLast = $last) {
<a (click)="groupSelected(group)">{{group}}</a>
@if (!isLast) {
<span class="mr-5 ml-5">|</span>
}
}
Das neue @if vereinfacht das Formulieren von else-/else-if-Zweigen (Listing 4).
Listing 4
@if (product().discountedPrice && product().discountMinCount) {
[...]
}
@else if (product().discountedPrice && !product().discountMinCount) {
[...]
}
@else {
[...]
}
Daneben lassen sich verschiedene Fälle auch mit einem @switch unterscheiden (Listing 5).
Listing 5
@switch (mode) {
@case ('full') {
[...]
}
@case ('small') {
[...]
}
@default {
[...]
}
}
Im Gegensatz zu ngSwitch und *ngSwitchCase ist die neue Syntax typsicher. Im betrachteten Beispiel müssen die einzelnen @case-Blöcke Stringwerte aufweisen, zumal die an @switch übergebene Variable mode auch vom Typ string ist.
Die neue Control-Flow-Syntax verringert die Notwendigkeit für den Einsatz struktureller Direktiven, die zwar mächtig, aber teilweise auch unnötig komplex sind. Trotzdem wird das Framework strukturelle Direktiven weiterhin unterstützen. Zum einen gibt es einige valide Anwendungsfälle dafür und zum anderen gilt es trotz der vielen aufregenden Neuerungen das Framework abwärtskompatibel zu gestalten.
Automatische Migration zum Build-in Control Flow
Wer seinen Programmcode automatisiert auf die neue Control-Flow-Syntax migrieren möchte, findet nun im Paket @angular/core ein Schematic dafür:
ng g @angular/core:control-flow
Verzögertes Laden von Seitenteilen
Typischerweise sind nicht alle Bereiche einer Seite gleich wichtig. Bei der Detailansicht eines Produkts geht es zunächst um das Produkt selbst. Vorschläge für ähnliche Produkte sind zweitrangig. Das ändert sich jedoch schlagartig, sobald Benutzer:innen die Produktvorschläge in den sichtbaren Bereich des Browserfensters, den sogenannten View Port, scrollen.
Bei besonders performancekritischen Webanwendungen wie Webshops bietet es sich an, solche zunächst weniger wichtigen Seitenteile verzögert zu laden. Das führt dazu, dass die wirklich wichtigen Elemente rascher verfügbar sind. Wer diese Idee bisher in Angular umsetzen wollte, musste sich manuell darum kümmern. Angular 17 vereinfacht auch diese Aufgabe drastisch mit dem neuen @defer-Block (Listing 6).
Listing 6
@defer (on viewport) {
<app-recommentations [productGroup]="product().productGroup"></app-recommentations>
}
@placeholder {
<app-ghost-products></app-ghost-products>
}
Der Einsatz von @defer zögert das Laden der angegebenen Komponente (eigentlich: das Laden des angegebenen Seitenbereichs) hinaus, bis ein bestimmtes Ereignis eintritt. Als Ersatz präsentiert es den unter @placeholder angegebenen Platzhalter. In der hier verwendeten Demoanwendung werden auf diese Weise zunächst Ghost Elements für die Produktvorschläge präsentiert (Abb. 2).

Abb. 2: Ghost Elements als Platzhalter
Nach dem Laden tauscht @defer die Ghost Elements gegen die tatsächlichen Vorschläge (Abb. 3) aus.

Abb. 3: @defer tauscht den Platzhalter gegen die verzögert geladene Komponente
Im betrachteten Beispiel kommt das Ereignis on viewport zum Einsatz. Es tritt ein, sobald der Platzhalter in den sichtbaren Bereich des Browserfensters gescrollt wurde. Weitere unterstützte Ereignisse finden sich in Tabelle 1.
| Trigger | Beschreibung |
| on idle | Der Browser meldet, dass gerade keine kritischen Aufgaben anstehen (Standard). |
| on viewport | Der Platzhalter wird in den sichtbaren Bereich der Seite geladen. |
| on interaction | Der Benutzer beginnt, mit dem Platzhalter zu interagieren. |
| on hover | Der Mouse-Cursor wird über dem Platzhalter bewegt. |
| on immediate | So schnell wie möglich nach dem Laden der Seite. |
| on timer(<duration>) | Nach einer bestimmten Zeit, z. B. on timer(5s), um das Laden nach 5 Sekunden anzustoßen. |
| when <condition> | Sobald die angegebene Bedingung erfüllt ist, z. B. when (userName !=== null) |
Tabelle 1: Trigger für @defer
Die Trigger on viewport, on interaction und on hover erzwingen standardmäßig die Angabe eines @placeholder-Blocks. Alternativ dazu können sie sich auch auf andere Seitenteile beziehen, die über eine Templatevariable zu referenzieren sind:
<h1 #recommentations>Recommentations</h1>
@defer (on viewport(recommentations)) { <app-recommentations [...] />}
Außerdem kann @defer angewiesen werden, das Bundle zu einem früheren Zeitpunkt vorzuladen. Wie beim Preloading von Routen stellt diese Vorgehensweise sicher, dass die Bundles augenblicklich verfügbar sind, sobald man sie benötigt:
@defer(on viewport; prefetch on immediate) { [...] }
Neben @placeholder bietet @defer auch noch zwei weitere Blöcke: @loading und @error. Ersteren zeigt Angular an, während es das Bundle lädt, letzteren im Fehlerfall. Um ein Flackern zu vermeiden, lassen sich @placeholder sowie @loading mit einer Mindestanzeigendauer konfigurieren. Die Eigenschaft minimum legt den gewünschten Wert fest:
@defer ( [...] ) { [...] }
@loading (after 150ms; minimum 150ms) { [...] }
@placeholder (minimum 150ms) { [...] }
Die Eigenschaft after gibt zusätzlich an, dass der Loading Indicator nur einzublenden ist, wenn das Laden länger als 150 ms dauert.
Build-Performance mit esbuild
Ursprünglich nutzte das Angular CLI webpack für das Bauen von Bundles. Allerdings ist webpack ein wenig in die Jahre gekommen und wird derzeit von jüngeren Werkzeugen, die einfacher zu nutzen und auch um einiges schneller sind, herausgefordert. Bei esbuild [2] handelt es sich um eines dieser Werkzeuge, das mit über 20 000 Downloads pro Woche auch eine beachtenswerte Verbreitung aufweist.
Bereits seit einigen Releases arbeitet das CLI-Team an einer esbuild-Integration. In Angular 16 war diese Integration bereits im Stadium einer Developer Preview enthalten. Ab Angular 17 ist die Implementierung stabil und kommt über den weiter unten beschriebenen Application Builder für neue Angular-Projekte standardmäßig zum Einsatz.
Bei bestehenden Projekten lohnt es sich, eine Umstellung auf esbuild zu prüfen. Dazu ist in der angular.json der Eintrag builder zu aktualisieren:
"builder": "@angular-devkit/build-angular:browser-esbuild"
Anders ausgedrückt: Am Ende ist -esbuild zu ergänzen. In den meisten Fällen sollte sich daraufhin ng serve und ng build wie gewohnt verhalten, jedoch um einiges schneller sein. Ersteres nutzt zur Beschleunigung den Vite dev-server [3], um npm-Pakete erst bei Bedarf zu bauen. Daneben hat das CLI-Team noch weitere Performanceoptimierungen vorgesehen.
Der Aufruf von ng build konnte durch den Einsatz von esbuild auch drastisch beschleunigt werden. Faktor 2 bis 4 wird häufig als Bandbreite genannt.
SSR ohne Aufwand mit dem neuen Application Builder
Auch die Unterstützung für Server-side Rendering (SSR) wurde mit Angular 17 drastisch vereinfacht. Beim Generieren eines neuen Projekts mit ng new steht nun ein Schalter –ssr zur Verfügung. Kommt dieser nicht zum Einsatz, fragt die CLI, ob sie SSR einrichten soll (Abb. 4).

Abb. 4: ng new richtet auf Wunsch SSR ein
Um SSR später zu aktivieren, muss lediglich das Paket @angular/ssr hinzugefügt werden:
ng add @angular/ssr
Wie der Scope @angular verdeutlicht, stammt dieses Paket direkt vom Angular-Team. Es handelt sich dabei um den Nachfolger des Communityprojekts Angular Universal. Um SSR im Zuge von ng build und ng serve direkt zu berücksichtigen, hat das CLI-Team einen neuen Builder bereitgestellt. Dieser sogenannte Application Builder nutzt die oben erwähnte esbuild-Integration und erzeugt damit Bundles, die sowohl im Browser als auch serverseitig nutzen lassen.
Ein Aufruf von ng serve startet auch einen Development-Server, der sowohl serverseitig rendert als auch die Bundles für den Betrieb im Browser ausliefert. Ein Aufruf von ng build –ssr kümmert sich auch um Bundles für beide Welten sowie um das Bauen eines einfachen Node.js-basierten Servers, dessen Quellcode die oben erwähnten Schematics genieren.
Wer keinen Node.js-Server betreiben kann oder möchte, kann mit ng build –prerender die einzelnen Routen der Anwendung bereits beim Build vorrendern.
Weitere Neuerungen
Neben den bis hier diskutierten Neuerungen bringt Angular 17 noch zahlreiche weitere Abrundungen:
Zusammenfassung
Mit Version 17 schreitet die Angular Renaissance voran. Die neue Syntax für den Control Flow vereinfacht den Aufbau von Templates. Dank Deferred Loading können weniger wichtige Seitenbereiche zu einem späteren Zeitpunkt nachgeladen werden. Damit lässt sich der initiale Page-Load beschleunigen. Durch den Einsatz von esbuild laufen die Anweisungen ng build und ng serve merkbar schneller. Außerdem unterstützt das CLI nun direkt SSR und Prerendering.
Regelmäßig News zur Konferenz und der .NET-Community
Links & Literatur
[1] https://github.com/manfredsteyer/hero-shop.git
[2] https://esbuild.github.io
[3] https://vitejs.dev
[4] https://developer.chrome.com/docs/web-platform/view-transitions/
[5] https://riegler.fr/blog/2023-10-04-animations-
The post Was ist neu in Angular 17? appeared first on BASTA!.
]]>The post Dependencies Are Eating The Business Domain appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
Der strategische Teil des Domain-Driven Designs beinhaltet die Dekomposition der Businessdomäne in Subdomänen und Bounded Contexts. Mit Hilfe einer Context Map werden die Abhängigkeiten zwischen den Bounded Contexts visualisiert. Dabei werden die Abhängigkeiten mittels Context-Mapping-Patterns beschrieben. Letztere stellen eine Mustersprache dar, um Abhängigkeiten auf technischer, fachlicher und organisatorischer Ebene zu gestalten. Auf diese Weise wird eine soziotechnische Architektur der Businessdomäne definiert, die nicht nur den fachlichen Systemschnitt, sondern auch die Entwicklungsteams hinter den Bounded Contexts berücksichtigt [2].
Das Ziel des Domain-Driven Architect besteht darin, Bounded Context auf der strategischen Architekturebene sinnvoll und in den meisten Fällen möglichst unabhängig von anderen Bounded Contexts zu gestalten. Eine optimale Lösung ist nicht immer möglich. Die Transparenz hinsichtlich der Abhängigkeiten sowie deren methodische Betrachtung sind jedoch sehr nützlich. Es geht darum, die Vor- und Nachteile sorgfältig abzuwägen und bewusste Entscheidungen zu treffen. Die bewusste Gestaltung von Abhängigkeiten ist dabei nicht nur zu Beginn eines Projekts wichtig. Zu diesem Zeitpunkt ist oft das Wissen unvollständig und Weiterentwicklungen sind nicht vorhersehbar. Daher ist eine regelmäßige Überprüfung und Anpassung sinnvoll. In der Praxis wird dies aber selten durchgeführt.
Eine Untersuchung der Abhängigkeiten ist besonders dann relevant, wenn das System oder das Projekt aus dem Gleichgewicht gerät. Dies geschieht in der Regel aufgrund verschiedener Arten von Wachstum. Zwei Szenarien, die Anlass geben, die Abhängigkeiten in der strategischen Architektur neu zu überdenken, sind das Wachstum des Systems und das Wachstum des Geschäftsmodells [3] (siehe Kasten: „Wachstum und Folgen“).
Das System wächst rasant und die Abhängigkeiten zwischen den internen Komponenten des Systems bauen sich stetig weiter auf. Zusätzlich werden immer mehr externe Systeme angebunden. Die Komplexität der Integration verknüpft sich mit der Herausforderung, unterschiedliche Domänen- und Kommunikationsmodelle zu handhaben. Wenn sich diese Modelle ändern, führt das zu Seiteneffekten und erfordert Anpassungen im System. Das System ist aufgrund der entstandenen Komplexität nur schwer erweiterbar.
Geschäftsmodelle und Organisationen wachsen, was über die Zeit Anpassungen in der IT-Architektur bedingt. Das ist besonders dann der Fall, wenn das Geschäftsmodell auf einem monolithischen System gewachsen ist. Die Skalierung von Teams bedeutet nun eine Zerlegung des Systems in Subsysteme zur Aufteilung auf mehrere Teams. Dadurch entstehen neue Abhängigkeiten und bereits bekannte Abhängigkeiten zu externen Systemen müssen neu gedacht werden.
Eine Businessdomäne ist der Bereich, in dem ein Unternehmen aktiv ist, am Markt teilnimmt und Kunden Produkte oder Dienstleistungen anbietet. Bounded Contexts sind das Mittel zur Zerlegung dieser Domäne in fachlich unabhängige Module der strategischen Architekturebene (Abb. 1). Ein Bounded Context ist ein fachlich abgrenzbarer Bereich, der gleichzeitig eine physische Grenze zu anderen Bounded Contexts darstellt. Er liegt in der Verantwortlichkeit eines Teams und wird unabhängig von anderen Bounded Contexts versioniert, weiterentwickelt und in Produktion gebracht.
Das Besondere an Domain-Driven Design und am Bounded Context ist, dass das Domänenmodell im Mittelpunkt steht. Durch dieses Modell werden Eigenschaften, Ereignisse und Funktionen der Businessdomäne zum Ausdruck gebracht. Als allgegenwärtige Sprache (Ubiquitous Language) dient das Domänenmodell als Bindeglied zwischen allen Projektphasen (Discover, Plan, Do, Check, Adjust), Architekturebenen (strategische, soziotechnische und taktische Architektur) sowie den beteiligten Personen (Architekt:in, Entwickler:in, Product Owner, Agile Coach, Tester:in, UX-Designer:in etc.).
Neben den bereits erwähnten Eigenschaften eines Bounded Context ist der entscheidende Punkt, dass er einen abgegrenzten Bereich (Bounded) um die Bedeutung eines fachlichen Modells (Context) darstellt. Domain-Driven Design formuliert die Heuristik, dass jeder Bounded Context sein eigenes Domänenmodell spezifisch und fachlich eindeutig realisieren sollte. Das Domänenmodell existiert folglich nur in diesem Bounded Context und hat dort Gültigkeit [2], [4]. Fowler [5] erklärt das anhand der Domänenobjekte „Kunde“ und „Produkt“ mittels der unterschiedlichen Perspektiven der Vertriebs- und Supporteinheiten auf diese Geschäftsobjekte. Fachliche Abhängigkeiten existieren in der Realität selbstverständlich trotzdem und müssen als Abhängigkeiten zwischen Bounded Contexts berücksichtigt werden. Das geschieht im Context Mapping.

Abb. 1: Dekomposition einer Businessdomäne in Subdomänen und Bounded Contexts
Wenn zwei Systeme miteinander kommunizieren müssen, ist die resultierende technische Abhängigkeit offensichtlich. Es gibt einen Konsumenten, der auf eine vom Provider angebotene Funktionalität zugreift. Auf der technischen Architekturebene kann sich diese Abhängigkeit vereinfacht wie folgt darstellen (Abb. 2):

Abb. 2: Provider-Konsument-Beziehung zwischen Systemen
Oft wird die daraus resultierende fachliche Abhängigkeit zwischen den Systemen weniger bewusst betrachtet. Provider exponieren ihr Domänenmodell oder einen Teil davon über ihr API oder über Events nach außen. Ändert sich die Fachlichkeit des Providers, ändert sich auch sein Modell und in der Folge das exponierte Modell für die Konsumenten. Für sie stellt sich die Frage, inwieweit das externe Domänenmodell übernommen und in die eigene Domäne integriert werden sollte. Haben die Konsumenten das Ziel, schnell und mit minimalem Aufwand auf Veränderungen des Providers zu reagieren, müssen passende architektonische Lösungsstrategien angewendet werden. Ist das nicht nötig, beispielsweise aufgrund weniger hoher Anforderungen an die Reaktions- und Anpassungszeit oder wenn die Auswirkungen von Veränderungen beim Provider trotz tiefer Integration minimal sind, können einfachere Ansätze genutzt werden.
Im Context Mapping findet sich die fachliche Abhängigkeit als Model Flow wieder. In Abgrenzung dazu wird die technische Abhängigkeit als Call Flow bezeichnet. Der Influence Flow berücksichtigt, dass hinter Bounded Contexts potenziell unterschiedliche Entwicklungsteams stehen (Abb. 3).

Abb. 3: Darstellung des Model Flow, Call Flow und Influence Flow der Methode Context Mapping
Ist das der Fall, ergibt sich aus der technischen und fachlichen Abhängigkeit auch eine organisatorische Abhängigkeit zwischen diesen Teams. Domain-Driven Design untersucht dabei, wie stark diese Teams ihren gegenseitigen Erfolg beeinflussen. Je stärker die Abhängigkeit ist, desto größer ist der Einfluss [2], [6]. Auf organisatorischer Ebene spiegeln sich Abhängigkeiten mit negativer Tendenz wie folgt wider:
Bei der Betrachtung der Abhängigkeit zwischen zwei Bounded Contexts werden diese als Upstream- oder Downstream-Kontexte kategorisiert. Damit wird ausgedrückt, welcher Bounded Context weniger abhängig (Upstream) oder stärker abhängig (Downstream) vom anderen ist. Stehen Bounded Contexts in einer Upstream-Downstream-Beziehung, beeinflussen sie ihren Erfolg. Mit Hilfe von Context-Mapping-Patterns wird detaillierter ausgestaltet, wie stark sich die Abhängigkeit und die Beeinflussung des Erfolgs in der Architektur und in der Organisation manifestieren [2]. Ein Team hat Erfolg, wenn es Sprintziele und Termine mit der geforderten Funktionalität einhalten kann. Fehlerfreiheit in der Implementierung, Code- und Architekturqualität drücken ebenfalls den Erfolg eines Entwicklungsteam aus. Die fachliche Trennung mittels Bounded Contexts und die Beziehungsgestaltung mittels Context-Mapping-Patterns haben das Ziel, eine gute Basis für den Erfolg zu schaffen.
Die DDD Crew [6] beschreibt neun Context-Mapping-Patterns. An dieser Stelle werden drei Muster näher erläutert. Unterstützend ist dieser Sachverhalt in Abbildung 4 visualisiert.
Bietet ein Provider eine Schnittstelle mit exponiertem Domänenmodell an, ohne dass es durch Konsumenten beeinflusst werden kann, handelt es sich um einen Open Host Service. Ein Open Host Service kann von vielen Bounded Contexts in gleicher Weise genutzt werden.

Abb. 4: Darstellung des Zusammenwirkens der Context-Mapping-Patterns Open Host Service, Conformist und Anticorruption Layer
Wenn ein konsumierender Bounded Context das Domänenmodell akzeptiert und tief integriert, entsteht eine starke fachliche Abhängigkeit. Der Bounded Context wird dann als Conformist bezeichnet. Andererseits, wenn das exponierte Domänenmodell an der Grenze des konsumierenden Bounded Context transformiert wird, wird die Abhängigkeit auf einen Punkt, die transformierende Schicht, verlagert. Das wird durch das Muster Anticorruption Layer ausgedrückt. Ein Anticorruption Layer reduziert die Kopplung und befähigt den Konsumenten, schnell auf Veränderungen beim Provider zu reagieren. Der Open Host Service ist immer ein Upstream-Kontext, während der Conformist und der Anticorruption Layer Downstream-Kontexte darstellen [2], [6].
Die ganzheitliche Erstellung einer Context Map für eine Businessdomäne erfordert ein tiefes Verständnis aller Muster und eine intensive, analytische Auseinandersetzung mit den direkten und indirekten Beziehungsgeflechten zwischen allen Bounded Contexts. Das ist sicherlich eine Aufgabe, die Affinität und Expertise seitens der Ersteller:innen voraussetzt.
Die Kernidee von Gamification besteht darin, Prinzipien und Elemente aus Spielen in andere Kontexte zu integrieren, um Motivation, Kreativität, Engagement und Interaktion von Menschen zu steigern. Ein Erfolgsfaktor ist die intrinsische Motivation sowie der natürliche Spieltrieb von Menschen, gewünschte Verhaltensweisen auszuführen, Aufgaben zu erledigen oder Ziele zu erreichen [7], [8]. Mit Fokus auf Domain-Driven Design Cards werden Spieler:innen als Team mit Herausforderungen konfrontiert, die sie gemeinsam meistern müssen. Dies geschieht in Form von Missionen, die im Spielverlauf abgeschlossen werden müssen. Gamification-Ansätze wie Domain-Driven Design Cards erfreuen sich in verschiedenen Bereichen der Organisations- und Softwareentwicklung großer Beliebtheit. So haben Domain-Driven Design Cards Inspiration in Backlog Refinement Cards [9], unFix Cards [10] oder Cards 42 [11] gefunden.
Ein weiterer wichtiger Aspekt von Domain-Driven Design Cards ist das Ziel, alle Mitglieder der Gruppe gleichwertig zu involvieren, unabhängig von ihrem Wissensstand und Charaktertyp. Das trägt zu den Zielen der Domain-Driven-Design-Philosophie bei, die eine Kultur des breiten gemeinsamen Verständnisses und der Zusammenarbeit anstrebt. Das Context Mapping Game der Domain-Driven Design Cards dient als Enabler für die soziotechnische Architektur mittels Context Mapping. Das Context Mapping Game basiert auf der Annahme, dass in der Realität selten eine Gruppe existiert, die durchgehend über tiefes Wissen im Bereich Domain-Driven Design oder in der Methode des Context Mapping verfügt. Daher ist die Zielsetzung des Context Mapping Game, dass es auch ohne diese Expertise spielbar ist.
Eine kurze Einführung im Vorfeld ist empfehlenswert, insbesondere wenn diese Methode für die Teilnehmer:innen völlig neu ist. Die Teilnahme am Spiel erfordert lediglich ein Grundverständnis der Idee von Context Mapping. Das Spiel ermöglicht die Zusammenarbeit zwischen Entwickler:innen, Architekt:innen, Product Ownern, Fachexpert:innen und Produktmanager:innen, da das Wissen über Abhängigkeiten in einer komplexen Businessdomäne auf viele Köpfe verteilt ist und für alle in gleicher Qualität transparent gemacht werden muss. Die Teilnehmer:innen werden sowohl durch die Spielkarten als auch durch eine:n Moderator:in unterstützt, die Fragen zur Methode des Context Mapping und zum Spiel beantworten kann. Die Durchführung des Spiels bedingt also mindestens eine Person mit Expertise in Domain-Driven Design und Context Mapping. Das Spiel bietet Raum für Kommunikation, Wissensaustausch, Aufbau von Methodenverständnis sowie für die gemeinschaftliche Definition von Abhängigkeiten der Bounded Contexts im eigenen Projektkontext. Bei regelmäßiger Anwendung wird dieses Verständnis gefestigt und inkrementell aufgebaut.
Im Folgenden soll eine kurze Anleitung zum Context Mapping Game gegeben werden.
Das Ziel des Context Mapping Game ist es, als Team Abhängigkeiten zwischen Bounded Contexts zu ermitteln. Die Analyse eines Bounded Context in Bezug auf seine Abhängigkeiten stellt die Mission des Teams dar. Die Mission gilt als erfüllt, wenn Einigkeit hinsichtlich der Vollständigkeit der ermittelten und definierten Abhängigkeiten besteht und diese widerspruchsfrei als Context-Mapping-Pattern abgebildet sind. Die Abbildung erfolgt mit Hilfe der Spielkarten. In der Regel besteht ein Context Mapping Game aus mehreren Missionen, da komplexe Businessdomänen oft zahlreiche Abhängigkeiten aufweisen. Sobald alle Missionen abgeschlossen sind, endet das Spiel.
Die Vorbedingung für das Spielen des Context Mapping Game ist mindestens eine definierte Mission. Das bedeutet, dass mindestens eine Vision für einen Bounded Context existiert. Diese Vision umfasst Zweck, Verantwortlichkeiten und Existenzbegründung für den Bounded Context sowie die wichtigsten Geschäftsereignisse, Kommandos, Domänenobjekte und Geschäftsregeln. Die Beschreibung des Bounded Context mit den genannten Inhalten bildet das Spielfeld, auf dem die Karten abgelegt werden.
Eine empfehlenswerte Grundlage für das Spielfeld ist das Bounded Context Canvas der DDD Crew (Abb. 5). Ein Canvas ist ein visuelles Werkzeug, um komplexe Konzepte oder Probleme auf übersichtliche und strukturierte Weise darzustellen. Es bietet in der Regel klare Strukturen, die den Beteiligten dabei helfen, Informationen zu organisieren, Ideen zu generieren und Entscheidungen zu treffen. Das Bounded Context Canvas ist ein Instrument, um kollaborativ einen Bounded Context zu definieren und die wichtigsten fachlichen Designentscheidungen visuell zu dokumentieren [12].

Abb. 5: Das Bounded Context Canvas der DDD Crew [12]
Besteht das Spiel aus mehreren Missionen, was bedeutet, dass im Workshop mehrere Bounded Contexts betrachtet werden, wird im ersten Schritt die Mission ausgewählt. Jede Mission wird auf der Spieloberfläche ohne gelegte Spielkarten begonnen. Alle Spieler:innen haben ein Kartendeck in ihren Händen. Die Mission beginnt mit zehn Minuten Brainstorming von Abhängigkeiten (Dependency Storming). Im Anschluss werden gleiche Nennungen geclustert und die Abhängigkeiten in ein- bzw. ausgehende Abhängigkeiten unterteilt und als Sticky Notes auf das Spielfeld gelegt. Danach wird jede Abhängigkeit in einer Timebox von zehn Minuten diskutiert. Nach diesem Austausch legen alle Spieler:innen eine oder mehrere Spielkarten für den Upstream- und Downstream-Kontext auf das Spielfeld. Wie viele Spielkarten je Spieler:in gelegt werden, hängt vom ausgewählten Context-Mapping-Pattern ab. Weitere Details sind unter [13] beschrieben.
Wenn sich eine gemeinsame Basis mit Ausreißern ergibt, kann die Entscheidungsfindung durch die Erklärung der Ausreißer gestartet werden. Wenn das Ergebnis sehr unterschiedlich oder einheitlich ist, beginnt ein:e beliebige:r Spieler:in mit der Schilderung ihrer Sicht. Bei der aufkommenden Diskussion hat der/die Moderator:in die Aufgabe, die Diskussion zu leiten, sodass alle Spielerinnen zu Wort kommen und ein Commitment im Team hinsichtlich der final ausgewählten Spielkarten, d. h. der ausgewählten Context-Mapping-Patterns, erzielt wird. Ist es schwierig, ein Commitment zu erzielen, empfiehlt sich der Einsatz von Methoden für die Entscheidungsfindung, wie z. B. Dot-Voting oder Thumb-Voting. Für Thumb-Voting kann das Context Mapping Game mit unFix Decision Patterns [10] ergänzt werden. Dot-Voting ist sowohl vor Ort mit Stift oder Klebepunkten als auch remote auf einem Collaboration Board einfach durchführbar. Der Spielablauf ist ergänzend in Abbildung 6 dargestellt.

Abb. 6: Der Spielablauf des Context Mapping Game
Abbildung 7 zeigt die Domain-Driven Design Cards des Context Mapping Game in der Übersicht. Neben dem Namen des Context-Mapping-Patterns sind die wichtigsten Eigenschaften des Musters aufgeführt. Das fördert den Aufbau von Verständnis, analytischem Denken und Kreativität bei den Spieler:innen und ermöglicht auch Unerfahrenen die Teilnahme. Die Karten sind zum Download kostenlos unter [13] verfügbar.

Abb. 7: Die Spielkarten des Context Mapping Game
Regelmäßig News zur Konferenz und der .NET-Community
Ein Blick auf die Rolle der Moderator:innen im Context Mapping Game ist eine nähere Betrachtung wert. Neben der Offenheit und intrinsischen Motivation des Teams ist der/die Moderator:in ein entscheidender Erfolgsfaktor. Nach unserer Erfahrung sind die Moderator:innen oft auch die Methodenexpert:innen für Domain-Driven Design und Context Mapping. Neben der Aufgabe, Fragen zur Methodik zu beantworten, ergeben sich beim Context Mapping Wechselwirkungen und implizite Abhängigkeiten zwischen Bounded Contexts, auf die spontan reagiert werden muss. Dies deckt das Spiel nicht ab.
Ein starkes Team findet sich in der Kombination aus Agile Coach und Domain-Driven Architect. Beide Rollenbilder fördern die Zusammenarbeit und besitzen die Fähigkeit, Workshops zu moderieren und zu gestalten. Der Agile Coach findet sich weiterhin im agilen Entwicklungsprozess wieder und nutzt dort zum Beispiel Backlog Refinement Cards [9], während der Domain-Driven Architect sich intensiv mit der Überführung der strategischen in die taktische Architektur beschäftigt und dafür das Architecture Game der Domain-Driven Design Cards als methodisches Hilfsmittel einsetzt. Auf Ebene der Organisationsentwicklung finden sich Agile Coach und Domain-Driven Architect auf Basis der Context Map wieder, um die fachliche und soziotechnische Architektur nach Domain-Driven Design in einen organisatorischen Rahmen wie Team Topologies oder SAFe zu integrieren, gestützt auf die Verwendung von unFix Cards [10].
Wir erleben Gamification als echten Unterstützer kollaborativer Projektarbeit, wenn die Ansätze auf die notwendige Offenheit treffen.
Links & Literatur
[1] Horowitz, Andreessen: „Why Software Is Eating the World“: https://a16z.com/why-software-is-eating-the-world
[2] Plöd, Michael: „Hands-on Domain-driven Design – by example“; Leanpub, 2020
[3] Lilienthal, Carola; Schwentner, Henning: „Domain-Driven Transformation“; dpunkt.verlag, 2023
[4] Khononov, Vlad: „Learning Domain-Driven Design“; O’Reilly, 2021
[5] Fowler, Martin: „BoundedContext“: https://martinfowler.com/bliki/BoundedContext.html
[6] DDD Crew: „Context Mapping“: https://github.com/ddd-crew/context-mapping
[7] Aprea, Carmen; Weckmüller, Heiko: „Gamification in der Qualifizierung und darüber hinaus: Alles nur ein Spiel?“: https://www.haufe.de/personal/neues-lernen/gamification-wie-effektiv-ist-das-spielerische-lernen_589614_534032.html
[8] Hombergs, Tom; Schiller, Thorben: „Gamification als Treiber von Codequalität“: https://www.heise.de/ratgeber/Gamification-als-Treiber-von-Codequalitaet-3759236.html?seite=all
[9] Hyoma, Nils: „Backlog Refinement Cards“: https://www.dependencypoker.com/backlog-refinement-cards
[10] unFix: „unFix Cards“: https://unfix.com/cards
[11] Harrer, Markus et al.: „Cards for Analyzing and Reflecting on Doomed Software“: https://cards42.org
[12] DDD Crew: „The Bounded Context Canvas“: https://github.com/ddd-crew/bounded-context-canvas
[13] Eschhold, Matthias: „Domain-driven Design Cards“: LINK
The post Dependencies Are Eating The Business Domain appeared first on BASTA!.
]]>The post Blazor als Insel und im Automodus appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community
Bis Einreichung dieses Artikels sind noch Preview 5 (13. Juni 2023), Preview 6 (11. Juli 2023) und Preview 7 (8. August 2023) erschienen.
Als geplanter Erscheinungstermin für die fertige Version von .NET 8.0 wurde inzwischen der 14. November 2023 verkündet. Bis dahin wird es noch zwei weitere Vorschauversionen mit dem Titel „Release Candidate“ geben. Üblich ist, dass Microsoft mit den Release-Candidate-Versionen eine Go-live-Lizenz verbindet, das heißt ab dann ist der produktive Einsatz von .NET 8.0 erlaubt. Das heißt aber nicht, dass es in der Release-Candidate-Phase keine Änderungen mehr geben wird.
Microsoft hatte am 24. Januar 2023 auf YouTube [1] die Integration von Blazor Server und Blazor WebAssembly zu Blazor United verkündet, sodass aus Benutzerinnen- und Benutzersicht zur Laufzeit ein nahtloser Übergang der Rendering-Arten entsteht.
Blazor United umfasst neben den bisher verfügbaren Blazor-Architekturen für den Webbrowser (Blazor Server und Blazor WebAssembly) die folgenden fünf neuen Architekturen:
Spannend ist, dass bei Blazor United diese Architekturmodelle innerhalb eines einzigen Projekts mischbar sind und zwar nicht nur pro Seite, sondern pro einzelner Komponente. Das bedeutet zum Beispiel, dass man eine Webanwendung erschaffen kann, in der alle statischen Inhalte auf dem Server gerendert werden und nur die Teile, die tatsächlich Interaktivität benötigen (z. B. Eingabeformulare, Suchdialoge) dann mit Blazor Server oder Blazor WebAssembly arbeiten. So wird Blazor in Version 8.0 zu einem deutlich universelleren Ansatz für Webanwendungen. Blazor eignet damit auch für öffentliche Websites (z. B. Firmen- und Produktpräsentationen, Webshops) und nicht nur für Intra- und Extranetanwendungen.
Der Begriff Server-side Rendering (Blazor SSR) kann verwirren. Erste Erfahrungen in der Praxis zeigen, dass viele Entwickler:innen denken: „Das gibt es doch schon mit Blazor Server“. Aber nein, Blazor Server und Blazor SSR sind nicht das Gleiche.
Das schon seit .NET Core 3.1 verfügbare Blazor Server rendert zwar auf dem Server, es entsteht aber dennoch eine Singel Page Application (SPA). Über eine WebSockets-Verbindung werden Unterschiede des Rendering zum vorherigen Rendering (im Programmiererlatein „Diff“ oder „Change Set“ genannt) zum Client gesendet und dort per JavaScript ausgetauscht. Die Benutzer:innen bemerken daher nicht, dass es ein Server-Rendering gab. Die Seite ist genauso interaktiv wie beim Einsatz von Blazor WebAssembly oder eines JavaScript-basierten Webfrontendframeworks wie Angular, React oder VueJS.
Mit dem neuen Blazor Server-side Rendering (Blazor SSR) bietet Microsoft im Rahmen von Blazor nun auch eine rein serverseitige, aus der Clientsicht statische HTML-Erzeugung zu einer Multi Page Application (MPA). Das Rendering-Ergebnis wird bei Blazor SSR in einem Rutsch über eine normale HTTP-Verbindung zum Client gesendet und es werden immer ganze Seiten ausgetauscht (oberer Teil in Abb. 1), sodass der Benutzer ein typisches Flackern der Darstellung beim Seitenwechsel wahrnimmt. Neue HTTP-Anfragen beim Server werden nur durch Hyperlinks oder Formulareinsendungen ausgelöst. .NET- oder JavaScript-Code im Browser sind bei Blazor SSR nicht notwendig. Optional kann man aber per JavaScript Streaming ermöglichen, das Benutzer:innen schon während des Renderings Anzeigen bietet.
Blazor SSR ist schon seit .NET 8.0 Preview 3 verfügbar. Bei Blazor SSR können (mit einigen Abstrichen) die gleichen Razor Components, die bisher bei Blazor Server, Blazor WebAssembly, Blazor MAUI und Blazor Desktop eingesetzt wurden, nun für reines Server-side Rendering verwendet werden. Blazor SSR besitzt grundsätzlich die gleiche Multi-Page-Application-Architektur wie ASP.NET Core Model View Controller (MVC), das es seit .NET Core 1.0 gibt, und ASP.NET Core Razor Pages, eingeführt in .NET Core 2.0 im Jahr 2017.
Der Unterschied zu MVC und Razor Pages ist, dass bei Blazor SSR auf dem Webserver sogenannte Razor Components mit der Blazor-Variante der Razor-Template-Syntax arbeiten, anstelle von Controller plus Razor Views (bei MVC) bzw. Page Model plus Razor Pages (bei Razor Pages). Genau wie bei den älteren Modellen muss auf dem Webserver für Blazor SSR natürlich ASP.NET Core laufen.

Abb. 1: Blazor Server-side Rendering ohne Streaming und mit Streaming sowie Blazor Server und Blazor WebAssembly
Während man in .NET 8.0 Preview 3 und 4 als Ausgangspunkt für Blazor SSR noch ein ASP.NET-Core-MVC- oder Razor-Pages-Projekt anlegen musste, gibt es seit .NET 8.0 Preview 5 sowie Visual Studio 2022 17.7 Preview 2 eine neue Projektvorlage Blazor Web App (Abb. 2). Alternativ kann man so ein Projekt über die Kommandozeile anlegen:
dotnet new blazor --use-server -o Projektname

Abb. 2: Einstellungen der Projektvorlage Blazor Web App
Die neue Projektvorlage legt die in Blazor schon übliche Webanwendung auf Basis des CSS-Frameworks Bootstrap in Version 5 an. Die Webanwendung zeigt links (Abb. 3 und 4) eine seitliche Navigationsleiste, die sich bei kleinem Browserfenster auf ein Toastmenü rechts oben reduziert. Wenn das Häkchen Use interactive Server components nicht aktiviert wird (auf der Kommandozeile das –use-server weglassen), entstehen nur zwei Seiten und Menüeinträge: Index.razor mit einer Willkommensnachricht und Weather.razor mit der Anzeige zufälliger Wettervorhersagedaten (diese Seite hieß in vorherigen Blazor-Versionen FetchData.razor). Im Ordner /Shared gibt es die Rahmenseite MainLayout.razor und NavMenu.razor für die Navigationsleiste. Den Wurzelcode der HTML-Seite findet man in App.razor. Dort findet man ebenso die Einstellungen für den Blazor-Router (<Found>, <NotFound>, optional auch <Navigating>), der nun sowohl für das Routing auf dem Client als auch auf dem Server zuständig ist. _Imports.razor beinhaltet wie bisher Namensraumimporte, die für alle .razor-Dateien gelten sollen.

Abb. 3: Wetterdatenseite Weather.razor während des Ladens

Abb. 4: Wetterdatenseite Weather.razor nach dem Laden
Während die Startseite Index.razor nur statischen Text zeigt, sieht man im Menüpunkt Weather zunächst eine Ladenachricht („Loading…“, Abb. 3) und dann etwa eine Sekunde später die zufällig generierte Wettervorhersage (Abb. 4). Während man das Datenobjekt als Klasse WeatherForecast in einer eigenen Datei /Models/WeatherForecast.cs findet, steckt der Generierungscode für die zufälligen Wettervorhersagen direkt in Weather.razor (Listing 1).
@page "/weather"
@attribute [StreamRendering(true)]
<PageTitle>Weather</PageTitle>
<h1>Weather</h1>
<p>This component demonstrates showing data from the server.</p>
@if (forecasts == null)
{
<p><em>Loading...</em></p>
}
else
{
<table class="table">
<thead>
<tr>
<th>Date</th>
<th>Temp. (C)</th>
<th>Temp. (F)</th>
<th>Summary</th>
</tr>
</thead>
<tbody>
@foreach (var forecast in forecasts)
{
<tr>
<td>@forecast.Date.ToShortDateString()</td>
<td>@forecast.TemperatureC</td>
<td>@forecast.TemperatureF</td>
<td>@forecast.Summary</td>
</tr>
}
</tbody>
</table>
}
@code {
private static readonly string[] Summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching"
};
private WeatherForecast[]? forecasts;
protected override async Task OnInitializedAsync()
{
// Simulate retrieving the data asynchronously.
await Task.Delay(1000);
var startDate = DateOnly.FromDateTime(DateTime.Now);
forecasts = Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Date = startDate.AddDays(index),
TemperatureC = Random.Shared.Next(-20, 55),
Summary = Summaries[Random.Shared.Next(Summaries.Length)]
}).ToArray();
}
}
Die Razor Components kommen in der Projektvorlage leider (wie immer bei Microsoft) als Single-File-Komponenten mit Inline-Code (als Blöcke @code { … }) vor. Die Trennung von Programmcode und Layout ist dennoch bei Blazor SSR, wie bei allen anderen Blazor-Arten, möglich. Entwicklerinnen und Entwickler haben die Wahl, Code-Behind-Dateien als partielle Klassen und via Vererbung anzulegen.
Die Verwendung der Schnittstelle IRazorComponentApplication zu Seitenbeginn, die bei Blazor SSR in Preview 3 und 4 noch notwendig war, entfällt seit Preview 5.
Die Zeile @implements IRazorComponentApplication<Confirmation> muss aus älteren Komponenten ersatzlos gestrichen werden.
Regelmäßig News zur Konferenz und der .NET-Community
Blazor SSR lässt die Vorgänger MVC und Razor Pages zu Auslaufmodellen werden, denn die Razor Components von Blazor bieten eine einfachere Syntax, insbesondere für die Formulardatenbehandlung, Datenbindung und das Einbetten von Komponenten ineinander. Zudem bietet Razor Components bei Blazor SSR auch Streaming, was es bei MVC und Razor Pages nicht gibt.
Für eine Migration von MVC oder Razor Pages zu Blazor SSR bietet Microsoft eine Integration an: So kann ein MVC-Controller nicht nur eine View, sondern nun auch eine moderne Razor-Komponente rendern, indem er RazorComponentResult<Komponentenname> zurückliefert (Listing 2).
public class MVCRCController : Controller
{
public IResult Index()
{
return new RazorComponentResult<Confirmation>(new { Name = "Dr. Holger Schwichtenberg" });
}
}
Zudem kann man eine solche moderne Razor-Komponente via Tag Helper <component> auch in eine Razor Page (.cshtml-Datei) einbetten:
<component type="typeof(Confirmation)" render-mode="Static" param-name='"Dr. Holger Schwichtenberg"' />
Das funktioniert bisher schon genauso bei Blazor Server.
Streaming beim Server-side Rendering
Streaming ist eine optionale Funktion von Blazor SSR. Beim Streaming wird initial eine komplette Seite vom Webserver zum Browser übertragen, sobald das erste Rendering der Seite auf dem Webserver stattgefunden hat. Anders als beim normalen SSR-Rendering wird die HTTP-Verbindung aber nicht nach dem Ende des gerenderten Inhalts geschlossen. Falls sich dann nach Ende der Ausführung asynchroner Methoden Teile der gerenderten Seite noch mal ändern, werden diese Änderungen in der offen gehaltenen HTTP-Verbindung noch nachübertragen und die Inhalte per JavaScript in der schon angezeigten Seite ausgetauscht. Indem man ein this.StateHasChanged() in den Programmcode einbaut, werden auch Zwischenstände übertragen, während die asynchrone Methode noch läuft. Man kann also über die offene HTTP-Verbindung auch mehrmals übertragen – aber nur bis zum Ende des Laufs aller asynchronen Methoden auf dem Webserver.
Abbildung 1 zeigt die Architektur von Blazor SSR ohne Streaming und Blazor SSR mit Streaming sowie Blazor Server und Blazor WebAssembly im Vergleich. Wie das Bild zeigt: JavaScript muss der Browser nur für Blazor Server, Blazor WebAssembly und Blazor SSR mit Streaming können, denn nur in diesen Fällen wird eine von Microsoft gelieferte JavaScript-Datei (blazor.server.js, blazor.webassembly.js bzw. blazor.web.js) in den Webbrowser geladen. Bei Blazor SSR wird kein .NET-Code in den Browser geladen und daher ist auch kein WebAssembly im Browser notwendig.
Streaming zeigt die Projektvorlage Blazor Server App, wenn das Häkchen Use interactive Server components (Abb. 2) gesetzt oder auf der Kommandozeile das –use-server verwendet wurde in der Komponente Weather.razor. Die Benutzersicht auf /Weather zeigen Abbildung 3 und 4.
OnInitializedAsync() in Listing 1 (Weather.razor aus der Projektvorlage von Microsoft) implementiert als erste Codezeile eine absichtliche Verzögerung um eine Sekunde, die das Laden von Daten aus einer Datenbank oder einem Webservice simulieren soll. Dass der Benutzer der Webanwendung in der Zwischenzeit „Loading…“ sieht, liegt an der Direktive @attribute [StreamRendering(true)] am Beginn von Weather.razor in Verbindung mit der @if-Abfrage in Listing 3.
@if (forecasts == null)
{
<p><em>Loading...</em></p>
}
else
{
...
}
Wie sich das Streaming aus der Sicht des Webbrowsers darstellt, sieht man in Abbildung 5: Zunächst wird eine komplette HTML-Seite innerhalb des Tags <html>…</html> übertragen. Die Datei mit dem „Loading…“ stellt der Browser dar. Die verzögert eingehenden Render-Ergebnisse aller asynchronen Operationen hängt ASP.NET Core in der gleichen HTML-Antwort noch der Seite an (siehe <template> innerhalb von <blazor-ssr> in Zeilen 42 und 45 in Abbildung 6). Die JavaScript-Datei blazor.web.js, die am Ende der ursprünglichen Seite geladen wurde (Zeile 39 in Abb. 6), baut die in den Tags <template> enthaltenen HTML-Fragmente dann in die ursprünglich dargestellte Seite ein, sodass die Benutzer:innen mit etwas Verzögerung die Wetterdatentabelle statt des Ladehinweises sehen.
Die in Preview 4 eingeführten Sektionen für Blazor (<SectionOutlet> und <SectionContent>) funktionieren seit Preview 7 auch beim Streaming-Rendering sowie in Verbindung mit kaskadierenden Werten und Error Boundaries.

Abb. 5: Counter.razor ist zunächst interaktiv über eine WebSocket-Verbindung zum Blazor-Server-Prozess; die Blazor-WebAssembly-Laufzeitumgebung wird im Hintergrund nachgeladen

Abb. 6: Serverstreaming bei Blazor SSR: Nach dem </html> kommen noch später eingehende Fragmente in der gleichen HTML-Antwort, die blazor.web.js in die Seite einsetzt
Listing 4 zeigt eine Erweiterung des Programmcodeblocks aus Listing 1. Dieses Mal wird zusätzlich zweimal die Überschrift geändert. Der Benutzer sieht (jeweils nach einer Sekunde künstlicher Wartezeit) drei Aktualisierungen der Seite:
Wichtig ist nach jedem Schritt, die Methode this.StateHasChanged() auszuführen, sonst sieht der Benutzer keine Aktualisierung der Seite.
@page "/showdata"
@attribute [StreamRendering(true)]
<PageTitle>@title</PageTitle>
<h1>@title</h1>
<p>This component demonstrates showing data from the server.</p>
@if (forecasts == null)
{
<p><em>Loading...</em></p>
}
else
{
<table class="table">
<thead>
<tr>
<th>Date</th>
<th>Temp. (C)</th>
<th>Temp. (F)</th>
<th>Summary</th>
</tr>
</thead>
<tbody>
@foreach (var forecast in forecasts)
{
<tr>
<td>@forecast.Date.ToShortDateString()</td>
<td>@forecast.TemperatureC</td>
<td>@forecast.TemperatureF</td>
<td>@forecast.Summary</td>
</tr>
}
</tbody>
</table>
}
@code {
private static readonly string[] Summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching"
};
private WeatherForecast[]? forecasts;
string title = "Weather forecast";
protected override async Task OnInitializedAsync()
{
// 1. UI-Update: Nur Titel
await Task.Delay(1000);
title = "Loading Weather forecasts...";
this.StateHasChanged();
// 2. UI-Update: Tabelle
await Task.Delay(1000);
var startDate = DateOnly.FromDateTime(DateTime.Now);
forecasts = Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Date = startDate.AddDays(index),
TemperatureC = Random.Shared.Next(-20, 55),
Summary = Summaries[Random.Shared.Next(Summaries.Length)]
}).ToArray();
this.StateHasChanged();
// 3. UI-Update: Nochmal Titel
await Task.Delay(1000);
title = forecasts.Length + " Weather forecasts loaded";
}
}
Komponenten als eigenständige Seiten oder eingebettet
Sowohl Index.razor als auch Weather.razor besitzen eine @page-Direktive:
@page "/"
bzw.
@page "/weather"
Beide Komponenten sind also über die relativen URLs “/” bzw. “/Weather” direkt im Browser aufrufbar. Wie in Blazor üblich, kann man auch bei Blazor Server-side Rendering jede Komponente auch per Tag in eine andere Komponente einbetten. Wenn man also die Wetterkomponente bereits auf der Startseite sehen will, erweitert man die Index.razor-Datei einfach um das Tag <Weather>:
@page "/" <PageTitle>Home</PageTitle> <h1>Home</h1> Welcome to your new app. <Weather></Weather>
Auch die Kurzschreibweise <Weather/> anstelle von <Weather></Weather> ist möglich.
Auch serverseitig gerenderte Blazor-Komponenten können Parameter besitzen. Wie in Blazor üblich, deklariert man sie in der Komponente mit einer C#-Property mit Annotation [Parameter]:
[Parameter]
public int Days { get; set; } = 5;
Die Property nutzt man dann im Komponentencode, z. B.:
forecasts = Enumerable.Range(1, Days).Select(…)
Nun können Entwicklerinnen und Entwickler den Parameter auf Nutzerseite auf einen anderen Wert als den Standardwert setzen:
<Weather Days=”10″></Weather>
Die Einbettung von Blazor-Komponenten ineinander ist damit deutlich einfacher als die Arbeit mit Partial Views bei ASP.NET Core MVC und ASP.NET Core Razor Pages [2]. Blazor bietet im Gegensatz zu den Vorgängern ein echtes Komponentenmodell.
Möchte man, dass der Parameter auch per URL gefüllt werden kann, verwendet man [SupplyParameterFromQuery] statt [Parameter]:
[SupplyParameterFromQuery]
public int Days { get; set; } = 5;
Jetzt kann man die Seite über diesen URL dazu bringen, die Wettervorhersage für 10 Tage zu erzeugen:
https://localhost:7009/weather?days=10
Auch Razor Components, die keine @page-Direktive haben und daher nur als Teil einer anderen Seite verwendbar sind, können seit Preview 6 [SupplyParameterFromQuery] nutzen. Falls sowohl [SupplyParameterFromQuery] als auch [Parameter] vor einem Property stehen und die Hostkomponente einen Wert per Attribut vorgibt, wiegt das schwerer als eine Angabe eines Parameters im URL.
Bei Blazor SSR ist zu beachten, dass alle Clientereignisbehandlungen (z. B. @onclick, @onmousemove, @onkeydown) nicht funktionieren, denn im Browser ist kein Code, der sie behandeln könnte. Wenn man so ein Ereignis behandelt, sieht man gar nichts, also weder im Browser noch in Visual Studio eine Fehlermeldung. Auch die Ausführung von eigenem JavaScript-Code, z. B.:
await js.InvokeVoidAsync("alert", "Hello World");
funktioniert nicht. Immerhin kassiert man hier einen Laufzeitfehler: „System.InvalidOperationException: JavaScript interop calls cannot be issued at this time. This is because the component is being statically rendered.“ Visual Studio warnt bislang leider nicht, wenn man in einer Razor-Komponente bei Blazor SSR solche Ereignisse behandelt oder JavaScript-Code ausführt.
Mögliche Clientinteraktionen in Blazor SSR sind, wie in Multi Page Applications üblich:
Zudem ist eine serverseitige Navigation mit dem aus Blazor schon bekannten NavigationManager möglich:
@inject NavigationManager NavigationManager
...
NavigationManager.NavigateTo("/Weather");
Wenn man das zum Beispiel im Rahmen des Lebenszyklusereignisses OnInitialized() oder nach dem Einsenden eines Formular ausführt, sendet der Webserver eine HTTP-Antwort mit Statuscode 302 und der neuen Adresse im Headerfeld “Location”.
Die in .NET 8.0 Preview 4 und 5 umständliche Handhabung von Formulareingaben beim Server-side Rendering in Blazor via CascadingModelBinder und FormData.Entries.TryGetValue() ist seit .NET 8.0 Preview 6 einfacher, indem Entwicklerinnen und Entwickler nun einfach ein Property mit [SupplyParameterFromForm] annotieren können (Listing 5). Alle in der HTTP-Anfrage gelieferten Name-Wert-Paare werden in die dem Namen entsprechenden Properties abgelegt. Die annotierten Properties können einfache Datentypen, komplexe Typen (Klassen, Strukturen, Records) oder Mengentypen sein. Vorhandene Validierungsannotationen werden berücksichtigt und Validierungsfehlerausgaben sind mit den eingebauten Blazor-Komponenten <ValidationMessage> und <ValidationSummary> möglich. Seit Preview 7 werden auch die Annotationen [DataMember] und [IgnoreDataMember] berücksichtigt, mit denen man die abzubildenden Namen ändern kann.
Seit Preview 7 ist Voraussetzung für die Formularbindung, dass das Tag <EditForm> via Tagattribut FormName einen Namen deklariert:
<EditForm method="POST" FormName="Registration" Model="reg" OnValidSubmit="HandleSubmit">
Ohne diese Angabe kommt es zum Laufzeitfehler: „The POST request does not specify which form is being submitted. To fix this, ensure <form> elements have a @formname attribute with any unique value, or pass a FormName parameter if using <EditForm>.“ Es ist richtig, was diese Fehlermeldung ebenfalls suggeriert: Seit Preview 7 ist die serverseitige Formularbehandlung auch ohne die eingebaute Blazor-Komponente <EditForm> mit dem Standard-HTML-Tag <form> und dem Zusatz @formname möglich.
@page "/Registration/"
@using NET8_BlazorSSR;
@layout MainLayout
@inject NavigationManager nav
<h3>Bestellung des Fachbuchabos</h3>
<hr />
@if (!reg.Success)
{
<EditForm method="POST" FormName="Registration" Model="reg" OnValidSubmit="HandleSubmit">
<DataAnnotationsValidator />
<p>Ihr Name: <InputText @bind-Value="reg.Name" /> <ValidationMessage For="@(()=>reg.Name)" /></p>
<p>Ihr E-Mail-Adresse: <InputText @bind-Value="reg.EMail" /> <ValidationMessage For="@(()=>reg.EMail)" /></p>
<button type="submit">Bestellen</button>
</EditForm>
}
@if (reg.Success)
{
<div>
<p>Liebe(r) @reg.Name,</p>
<p>vielen Dank für Ihre Registrierung zum Fachbuchabo!</p>
<p><a href="proxy.php?url=/confirmation/@reg.Name">Bestätigung ausdrucken</a></p>
</div>
}
@code {
[SupplyParameterFromForm]
BookSubscriptionRegistration? reg { get; set; }
protected override void OnInitialized()
{
reg ??= new();
}
void HandleSubmit()
{
reg.Save();
reg.Success = true;
}
}
Sofern man Use interactive Server components bei der Projektvorlage Blazor Web App wählt, erhält man im Blazor-Projekt eine dritte Seite namens Counter.razor (Quellcode in Listing 6), die man als Counter im Navigationsmenü sieht (Abb. 3 und 4). Der Zähler auf der Seite funktioniert interaktiv auch ohne Verzögerung und Flackern der Seite, das heißt, dass die Seite nicht komplett neu geladen wird. Möglich wird das durch folgende Direktive zu Beginn der Datei Counter.razor:
@attribute [RenderModeServer]
Das führt zu einer Single-Page-App-Insel innerhalb des Server-side Rendering: Counter.razor wird mit Blazor Server gerendert – wie üblich unter Verwendung einer WebSockets-Verbindung, die aber erst beim ersten Aufruf von Counter.razor aufgebaut wird. Die Projektvorlage zeigt nur eine einzelne solcher Single-Page-App-Inseln und es stellt sich natürlich die Frage, ob es bei mehreren solchen SPA-Inseln auch mehrere WebSockets-Verbindungen gibt. Ein Test mit einer Erweiterung der Projektvorlage zeigt: Nein. Es wird nur eine WebSockets-Verbindung aufgebaut, die dann für alle SPA-Inseln innerhalb der gleichen Blazor-Anwendung zum Einsatz kommt.
Was die Projektvorlage auch nicht zeigt: Eine SPA-Insel kann nicht nur eine Seite mit eigenem URL sein, sondern auch Teil einer anderen Seite. Wenn man zum Beispiel die Counter.razor-Komponente in die Index.razor-Seite einbettet via Tag <Counter></Counter> (oder kurz <Counter/>) funktioniert die Interaktivität der Insel via Blazor Server und WebSockets-Verbindung ebenso.
Neben der Deklaration einer SPA-Insel per Direktive innerhalb der Razor Component selbst, gibt es auch die Möglichkeit, dass der Nutzer einer Komponente den RenderMode vorgibt:
<Counter @rendermode="@RenderMode.Server" />
Sie sollten sich nicht wundern, wenn Visual Studio nicht bei der Eingabe mithilft: Diese Syntax ist korrekt, aber es gibt in Visual Studio 2022 (bis einschließlich der zum Redaktionsschluss für diesen Beitrag aktuellen Version 17.8 Preview 1) keinerlei IntelliSense-Eingabeunterstützung dafür.
Es ist übrigens nicht möglich, gleichzeitig den Render-Modus in der Komponente mit @attribute [RenderModeServer] und nochmals beim Aufrufer mit @rendermode=”@RenderMode.Server” festzulegen. Ein solchen Versuch quittiert Blazor mit dem Laufzeitfehler: „The component type ‘Counter’ has a fixed rendermode of ‘Microsoft.AspNetCore.Components.Web.ServerRenderMode’, so it is not valid to specify any rendermode when using this component.“
@attribute [RenderModeServer]
<PageTitle>Counter</PageTitle>
<h1>Counter</h1>
<p role="status">Current count: @currentCount</p>
<button class="btn btn-primary" @onclick="IncrementCount">Click me</button>
@code {
private int currentCount = 0;
private void IncrementCount()
{
currentCount++;
}
}
Die Voraussetzungen für Blazor SSR, Streaming und SPA-Inseln legt die Projektvorlage Blazor Web App automatisch an. Dazu gehört:
<script src="proxy.php?url=_framework/blazor.web.js" suppress-error="BL9992"></script>
SPA-Inseln mit Blazor Server hat Microsoft in .NET 8.0 Preview 5 eingeführt, wobei das @rendermode in der Hostseite erst mit Preview 6 kam. Während in .NET 8.0 Preview 5 die SPA-Inseln ausschließlich mit Blazor Server möglich waren, bietet Microsoft seit .NET 8.0 Preview 6 an dieser Stelle alternativ nun auch Blazor WebAssembly an.
Bisher gibt es für diese Konstellation keine Projektvorlage; man kann aber die Projektvorlage Blazor Web App dazu selbst manuell umbauen. Wesentliche Voraussetzung ist, dass sich alle mit Blazor WebAssembly zu rendernden Razor-Komponenten in einer separaten, referenzierten Razor Class Library (also einer eigenen DLL) befinden, die auf dem SDK Microsoft.NET.Sdk.BlazorWebAssembly basiert:
<Project Sdk="Microsoft.NET.Sdk.BlazorWebAssembly">
Diese Abtrennung ist notwendig, um den in den Browser zu ladenden Code von dem Servercode abzugrenzen.
Auch das Hauptprojekt (nun nur noch mit dem Code, der nur auf dem Server laufen soll) muss man wie folgt umbauen:
<PackageReference Include="Microsoft.AspNetCore.Components.WebAssembly.Server" Version="8.0.0-preview.7.23375.9" />
builder.Services.AddRazorComponents().AddWebAssemblyComponents();
app.MapRazorComponents<App>().AddWebAssemblyRenderMode();
Nun ist es möglich, eine Komponente aus dieser DLL mit dem Render-Modus WebAssembly zu nutzen:
<Counter @rendermode="@RenderMode.WebAssembly" />
Alternativ kann diesen Render-Modus auch die Komponente selbst deklarieren:
@attribute [RenderModeWebAssembly]
Im Standard werden solche WebAssembly-Komponenten serverseitig vorgerendert. Das können Entwicklerinnen und Entwickler bei Bedarf ausschalten:
@attribute [RenderModeWebAssembly(prerender: false)]
bzw.
<Counter @rendermode="@(new WebAssemblyRenderMode(prerender: false))
Ein funktionierendes Beispiel für die Integration von Blazor WebAssembly in eine Anwendung mit Blazor Sever-side Rendering findet man unter [3].
In .NET 8.0 Preview 7 kam dann zum RenderMode.Server und RenderMode.WebAssembly auch noch der RenderMode.Auto hinzu, z. B.:
<Counter IncrementAmount="1" @rendermode="@RenderMode.Auto" />
Alternativ kann eine Blazor-Komponente den Automodus statisch in ihrer Definition selbst festlegen:
@attribute [RenderModeAuto]
Dazu aktiviert man in der Startdatei beide Render-Modi (also Blazor Server und Blazor WebAssembly) nacheinander:
builder.Services .AddRazorComponents() .AddWebAssemblyComponents() .AddServerComponents();
und
app.MapRazorComponents<App>() .AddWebAssemblyRenderMode() .AddServerRenderMode();
Falls die Blazor-WebAssembly-Laufzeitumgebung innerhalb von 100 Millisekunden geladen werden kann, verwendet der Automodus immer Blazor WebAssembly. Eine so kurze Zeit kann allerdings nur in sehr schnellen Netzwerken erreicht werden oder wenn die Laufzeitumgebung schon im Cache des Browsers liegt. Falls ASP.NET auf dem Webserver diese Zeitspanne als nicht erreichbar ansieht, wird die Komponente zunächst per Blazor Server gerendert und eine WebSockets-Verbindung zwischen Browser und Webserver für die Interaktivität aufgebaut.
Die Blazor-WebAssembly-Laufzeitumgebung lädt dann im Hintergrund nach (Das Laden der .wasm-Dateien nach dem Aufbau der WebSockets-Verbindung ist in Abbildung 6 zu sehen.). Ein Wechsel zu Blazor WebAssembly erfolgt dann aber nicht im laufenden Betrieb der Komponente, sondern erst, wenn die einzelne Komponente neu initialisiert wird, zum Beispiel durch einen zwischenzeitlichen Wechsel zu einer anderen Seite. Es muss aber nicht die ganze Anwendung neu geladen werden.
Der neue Automodus bietet den Vorteil einer schnellen ersten Sicht auf die Inhalte für die Benutzer:innen, die aber dennoch via WebSockets interaktiv ist. Bei der weiteren Nutzung kann dann das im Hintergrund geladene Blazor WebAssembly zum Einsatz kommen, wodurch die Nutzung der Komponente auch bei instabiler Netzwerkverbindung möglich wird. Hier wird man noch Konzepte brauchen, wie man Benutzer:innen so lenkt, dass die Komponente ein weiteres Mal initialisiert wird, denn sonst vollzieht sich der Wechsel auf Blazor WebAssembly ja nicht.
Bisher gibt es für den Automodus keine Projektvorlage. Interessierte Entwickler:innen finden ein Beispiel mit einer einzigen Komponente im Automodus (Counter.razor) auf GitHub [4]. Man sieht darin, dass die Komponente, die im Automodus laufen soll, in einer getrennten Assembly liegen muss. Die Tatsache, dass es für die Komponente Counter.razor im Projekt Client auch noch eine korrespondierende Datei Counter.razor im Projekt Server gibt, ist ein temporärer Workaround, weil die Routen aus Razor Class Libraries derzeit nicht im Serverprojekt erfasst werden. Microsoft arbeitet daran, das via .AddComponentAssemblies() im Startcode zu erledigen [5].
Was das Beispielprojekt nicht zeigt: Falls die Komponente Daten aus Datenbanken abruft, muss sie so gestaltet sein, dass das nicht nur bei Blazor Server, sondern auch Blazor WebAssembly funktioniert. Das bedeutet: Es darf nicht generell ein direkter Datenbankzugriff erfolgen, sondern man muss entweder immer die Daten per Web-Service/Web-API laden oder aber man muss eine Abstraktion einbauen, die die Daten bei Blazor Server per Direktzugriff lädt und bei Blazor WebAssembly per Web-Service/Web-API.
Das Mischen von SPA-Inseln mit Blazor WebAssembly, Blazor Server und dem Automodus in einer Anwendung und sogar in seiner Seite ist möglich (Listing 7), sofern beide Render-Modi in der Startdatei aktiviert wurden:
builder.Services .AddRazorComponents() .AddWebAssemblyComponents() .AddServerComponents();
und
app.MapRazorComponents<App>() .AddWebAssemblyRenderMode() .AddServerRenderMode();
Listing 7 zeigt eine Startseite Index.razor, die eine Komponente Counter.razor einmal per Blazor Server und einmal per Blazor WebAssembly einbindet. Abbildung 7 zeigt die Auswirkung auf den Webbrowser: Der Browser baut für Blazor Server eine WebSockets-Verbindung auf und lädt danach die WebAssembly-Dateien für Blazor WebAssembly. Die Rahmenkomponente Home.razor entsteht rein per Server-side Rendering.
Die Ausgabe, mit welchem Render-Modus das Rendering erfolgt ist, geschieht auf Basis des Typs, den Blazor für IJSRuntime injiziert. Das ist Microsoft.AspNetCore.Components.Server.Circuits.RemoteJSRuntime bei Blazor Server und Microsoft.AspNetCore.Components.WebAssembly.Services.DefaultWebAssemblyJSRuntime bei Blazor WebAssembly. Leider gibt es für den aktuellen Render-Modus noch keine direkte Abfrage auf Komponentenebene.
@page "/" <PageTitle>Mischung von Blazor Server und Blazor WebAssembly</PageTitle> <hr /> <h3>1. Counter</h3> <hr /> <div> <Net8BlazorAuto.Client.Pages.Counter CurrentCount="42" @rendermode="@RenderMode.Server" /> </div> <hr /> <h3>2. Counter</h3> <hr /> <div> <Net8BlazorAuto.Client.Pages.Counter CurrentCount="42" @rendermode="@RenderMode.WebAssembly" /> </div> <hr />

Abb. 7: Der Browser baut für Blazor Server eine WebSockets-Verbindung auf und lädt für Blazor WebAssembly die WebAssembly-Dateien
Abbildung 7 zeigt auf der linken Seite auch, dass die Counter.razor-Komponente jeweils nun auch eine Unterkomponente mit gelblichem Kasten bekommen hat. Diese Unterkomponenten (Unterkomponente.razor) verwenden automatisch den gleichen Render-Modus wie die Host-Komponente.
Nun könnte man auf die Idee kommen, diesen Unterkomponenten wieder einen expliziten Render-Modus zu verpassen. Das funktioniert aber nicht, denn wenn man versucht, in einer per Blazor Server gerenderten Komponente eine Blazor-WebAssembly-Komponente zu laden, erhält man die Laufzeitfehlermeldung:
"Cannot create a component of type 'Net8Blazor.Client.Pages.Unterkomponente' because its render mode 'Microsoft.AspNetCore.Components.Web.WebAssemblyRenderMode' is not supported by interactive server-side rendering."
Umgekehrt, wenn man in einer per Blazor WebAssembly gerenderten Komponente eine Komponente explizit per Blazor Server rendert, heißt der Fehler: „Cannot create a component of type ‘Net8Blazor.Client.Pages.Unterkomponente’ because its render mode ‘Microsoft.AspNetCore.Components.Web.ServerRenderMode’ is not supported by WebAssembly rendering.“ Möglich ist aber, Unterkomponente.razor auf den Automodus zu setzen und damit als Unterkomponente in beiden Render-Modi zu verwenden.
Hinsichtlich der Mischung von Render-Modi bedeutet das also: Innerhalb einer per Blazor SSR gerenderten Komponente kann man über Blazor Server und Blazor WebAssembly gerenderte Komponenten beliebig mischen. Wenn allerdings einer dieser beiden Render-Modi für eine Komponente vorgegeben ist, kann man in untergeordneten Komponenten den Render-Modus nicht mehr wechseln.
Wenn man sich die Projektvorlagen mit dem Wort „Blazor“ in Visual Studio oder per Kommandozeile (Abb. 8) ansieht, findet man dort neben der neuen Blazor Web App auch die altbekannten Vorlagen für Blazor WebAssembly, Blazor Server und Blazor MAUI. Bei der Nutzung der Projektvorlagen für Blazor Server stellt man aber fest, dass im Visual-Studio-Dialog .NET 8.0 für Blazor Server nicht angeboten wird. Wenn man versucht, .NET 8.0 an der Kommandozeile zu erzwingen
dotnet new blazorserver --framework net8.0
sieht man die Fehlermeldung in Abbildung 9. Tatsächlich will Microsoft die Projektvorlage Blazor Server nicht mehr anbieten, denn Blazor Server ist nun ein Teil der allgemeinen Vorlage Blazor Web App. An die Stelle der bisherigen Rahmencodes in _Host.cshtml und der Fehlerbehandlung in Error.cshtml (beides sind Razor Pages!) tritt nun eine komplette Lösung mit Razor Components (also Blazor-Komponenten!).
Eine Projektvorlage für Blazor WebAssembly gibt es noch im .NET 8.0 SDK und Visual Studio 2022 mit Auswahl .NET 8.0, aber die Option ASP.NET Core hosted ist verschwunden.
Diese Änderungen begründet Microsoft im Blogeintrag zu .NET 8.0 Preview 6 [6]: „Im Rahmen der Vereinheitlichung der verschiedenen Blazor-Hostingmodelle in einem einzigen Modell in .NET 8 konsolidieren wir auch die Anzahl der Blazor-Projektvorlagen. In dieser Vorschauversion haben wir die Blazor-Server-Vorlage und die Option ‚ASP.NET Core hosted‘ aus der Blazor-WebAssembly-Vorlage entfernt. Beide Szenarien werden durch Optionen dargestellt, wenn die neue Blazor-Web-App-Vorlage verwendet wird.“.
Möglicherweise wird Microsoft die Produktbezeichnungen Blazor Server und Blazor WebAssembly in Zukunft auch gar nicht mehr verwenden, sondern nur noch allgemein von „Blazor“ und den Render-Modi „server-side“ (gleich Blazor SSR), „interactive server-side“ (gleich Blazor Server) und „WebAssembly“ (gleich Blazor WebAssembly) sprechen.

Abb. 8: Blazor-Projektvorlagen im .NET 8.0 SDK

Abb. 9: Fehlermeldung beim Versuch, ein Projekt mit der Projektvorlage Blazor Server für .NET 8.0 anzulegen
Kaskadierende Werte, die man bisher nur in Razor-Komponenten definieren konnte, können Entwicklerinnen und Entwickler in .NET 8.0 im Startcode einer Blazor-Anwendung innerhalb der Program.cs registrieren, um diese Werte als Zustand für alle Komponenten in einer Komponente verfügbar zu machen. Dazu registriert man ein Objekt wahlweise ohne expliziten Namen:
builder.Services.AddCascadingValue(sp => new Autor { Name = "Dr. Holger Schwichtenberg1", Url = "www.dotnet-doktor.de" });
oder mit Namen:
builder.Services.AddCascadingValue("autor2", sp => new Autor { Name = "Dr. Holger Schwichtenberg", Url = "www.dotnet-doktor.de" });
oder via CascadingValueSource:
builder.Services.AddCascadingValue(sp =>
{
var a = new Autor { Name = "Holger Schwichtenberg", Url = "www.dotnet-doktor.de" };
var source = new CascadingValueSource<Autor>("autor3",a, isFixed: false);
return source;
});
Dann kann jede Razor-Komponente innerhalb der Blazor-Anwendung dieses Objekt konsumieren und auch verändern (Listing 8).
@code
{
[CascadingParameter]
Autor autor1 { get; set; }
[CascadingParameter(Name = "autor2")]
Autor autor2 { get; set; }
[CascadingParameter(Name = "autor3")]
Autor autor3 { get; set; }
[ParameterAttribute]
public int id { get; set; }
protected override void OnInitialized()
{
autor3.Name = "Dr. " + autor3.Name;
}
}
Für den Schutz gegen Angriffe nach dem Prinzip der Cross-Site Request Forgery (CSRF/XSRF) liefert Microsoft in ASP.NET Core 8.0 ab Preview 7 eine neue Middleware, die Entwicklerinnen und Entwickler im Startcode einer ASP.NET-Core-Anwendung via builder.Services.AddAntiforgery(); integrieren können. Dieser Aufruf aktiviert zunächst nur in der Verarbeitungs-Pipeline das IAntiforgeryValidationFeature. Ein auf ASP.NET Core aufbauendes Webframework (z. B. Blazor, WebAPI, MVC, Razor Pages) muss sodann ein Antiforgery-Token im Programmcode berücksichtigen. Der Blogeintrag [7] zeigt Implementierungsbeispiele für ASP.NET Core Minimal APIs [8] und Blazor (bei Verwendung von <EditForm>) [9], lässt aber offen, wie der Implementierungsstatus für andere ASP.NET-Core-basierte Webframeworks wie MVC und Razor Pages ist.
Seit .NET 8.0 Preview 4 gibt es das WebCIL-Format für Blazor WebAssembly; seit Preview 7 ist es nun im Standard aktiv. Die Implementierung von WebCIL zusammen mit WebAssembly-Modulen zielt darauf ab, die Blockierung von Blazor WebAssembly durch Firewalls und Antivirensoftware zu verhindern. Microsoft hat das Format inzwischen so angepasst, dass Standard-WebAssembly-Module mit der Dateinamenserweiterung .wasm generiert werden (in Preview 4 war es noch .webcil).
Entwicklerinnen und Entwickler haben die Option, WebCIL zu deaktivieren, indem man den Schalter <WasmEnableWebcil>false</WasmEnableWebcil> in der Projektdatei verwendet. In Blogeintrag [10] gibt Microsoft jedoch keine expliziten Hinweise darauf, in welchen Szenarien das sinnvoll sein könnte. Bisher waren die Blazor-WebAssembly-Dateien standardmäßig mit der Erweiterung .dll versehen.
Gemäß der Ankündigung auf der Build-Konferenz im Mai 2023 hat Microsoft den Duende Identity Server nun aus seinen Projektvorlagen für React- und Angular-Projekte mit einem ASP.NET-Core-Backend entfernt. Dieser Schritt wurde vom .NET-Entwicklungsteam unternommen, da der Identity Server, der in den Versionen 1 bis 4 als Open-Source-Software und Projekt der gemeinnützigen .NET Foundation verfügbar war, mittlerweile zu einem kommerziellen Produkt geworden ist. Ausgenommen von den Lizenzgebühren sind lediglich Open-Source-Projekte. Microsoft hat sich entschieden, die besagten Projektvorlagen nun auf das in ASP.NET Core integrierte Identity-System zu stützen. Für Entwicklerinnen und Entwickler, die den Identity Server weiterhin nutzen möchten, stellt Microsoft die Dokumentation von Duende zur Verfügung [11].
In .NET 8.0 Preview 4 hatte Microsoft für ASP.NET Core Identity, das integrierte Benutzerverwaltungssystem von ASP.NET Core, erstmals WebAPI-Endpunkte eingeführt. Diese Ergänzung erfolgte neben der bereits vorhandenen Weboberfläche, die auf serverseitigem Rendering basiert. Dies geschah, um ASP.NET Core Identity effektiver in Single-Page-Webanwendungen (unter Verwendung von JavaScript oder Blazor) zu integrieren. Zuvor beschränkten sich die verfügbaren WebAPI-Endpunkte lediglich auf die Benutzerregistrierung (/register) und die Benutzeranmeldung (/login).
In Preview-Version 7 wurden weitere Endpunkte hinzugefügt. Diese umfassen die Bestätigung von Benutzerkonten per E-Mail (/confirmEmail und /resendConfirmationEmail), das Zurücksetzen von Passwörtern (/resetPassword), die Aktualisierung von Tokens (/refresh) sowie die Unterstützung für die 2-Faktor-Authentifizierung (/account/2fa) sowie das Lesen und Aktualisieren von Profildaten (/account/info).
Die Aktivierung dieser WebAPI-Endpunkte für ASP.NET Core Identity erfolgt in der Datei Program.cs, indem nach AddIdentityCore<T>() die Funktion AddApiEndpoints() aufgerufen wird, wie in Listing 9 dargestellt.
using System.Security.Claims;
using Microsoft.AspNetCore.Identity;
using Microsoft.AspNetCore.Identity.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddAuthentication().AddBearerToken(IdentityConstants.BearerScheme);
builder.Services.AddAuthorizationBuilder();
builder.Services.AddDbContext<AppDbContext>(options => options.UseInMemoryDatabase("AppDb"));
builder.Services.AddIdentityCore<MyUser>()
.AddEntityFrameworkStores<AppDbContext>()
.AddApiEndpoints();
// Learn more about configuring Swagger/OpenAPI at https://aka.ms/aspnetcore/swashbuckle
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
var app = builder.Build();
// Adds /register, /login and /refresh endpoints
app.MapIdentityApi<MyUser>();
app.MapGet("/", (ClaimsPrincipal user) => $"Hello {user.Identity!.Name}").RequireAuthorization();
if (app.Environment.IsDevelopment()
{
app.UseSwagger();
app.UseSwaggerUI();
}
app.Run();
class MyUser : IdentityUser { }
class AppDbContext : IdentityDbContext<MyUser>
{
public AppDbContext(DbContextOptions<AppDbContext> options) : base(options) { }
}
Der Benachrichtigungsdienst ASP.NET Core SignalR kann seine Verbindung nun nach kurzen Verbindungsabbrüchen automatisch nahtlos wiederherstellen (Seamless Reconnect). Seit .NET 8.0 Preview 5 funktioniert das aber vorerst nur mit .NET-Clients. Ein .NET-Client muss die Verbindung mit dem Zusatz UseAcks = true aufbauen:
var hubConnection = new HubConnectionBuilder()
.WithUrl("https://ServerName/Hub">",
options =>
{
options.UseAcks = true;
})
.Build();
Es gibt noch keinerlei Konfiguration dieser Fehlertoleranz. Das ist aber in Arbeit [13]. Von der neuen Fehlertoleranz wird auch Blazor Server profitieren, weil dort ASP.NET Core SignalR für die Übertragung der Seitenänderungen zum Einsatz kommt.
Für C# 12.0 gibt es vier neue Sprachfeatures in den Previews 5 bis 7. Die wesentliche Neuerung sind dabei die Collection Literals. Mit dieser neuen Syntaxform kann man die bisher sehr heterogenen Initialisierungsformen von Objektmengen im Stil von JavaScript stark vereinheitlichen, also mit den Werten in eckigen Klammern, getrennt durch Kommata (Tabelle 1).
| Bisherige Initialisierung | Nun auch möglich |
| int[] a = new int[3] { 1, 2, 3 }; | int[] a = [1,2,3]; |
| Span<int> b = stackalloc[] { 1, 2, 3 }; | Span<int> b = [1,2,3]; |
| ImmutableArray<int> c = ImmutableArray.Create(1, 2, 3); | ImmutableArray<int> c = [1,2,3]; |
| List<int> d = new() { 1, 2, 3 }; | List<int> d = [1,2,3]; |
| IEnumerable<int> e = new List<int>() { 1, 2, 3 }; | IEnumerable<int> e = [1,2,3]; |
Tabelle 1: Collection Literals in C# 12.0
Weitere Neuerungen in C# 12.0 sind:
/// <summary>
/// nameof-Erweiterung in C# 12.0, siehe auch:
/// https://github.com/dotnet/csharplang/issues/4037
/// </summary>
[Description($"{nameof(StringLength)} liefert die Eigenschaft {nameof(Name.Length)}")]
public struct Person
{
public string Name;
public static string MemberName1() => nameof(Name); // bisher schon möglich
public static string MemberName2() => nameof(Name.Length); // bisher: error CS0120: An object reference is required for the non-static field, method, or property 'Name.Length'
public void PrintMemberInfo()
{
Console.WriteLine($"Die Struktur {nameof(Person)} hat ein Mitglied {nameof(Name)}, welches eine Eigenschaft {nameof(Name.Length)} besitzt!"); // Die Struktur Person hat ein Mitglied Name das eine Eigenschaft Length besitzt!
}
[Description($"{nameof(StringLength)} liefert die Eigenschaft {nameof(Name.Length)}")]
public int StringLength(string s)
{
return s.Length;
}
}
Die seit .NET 8.0 Preview 3 verfügbare Ahead-of-Time-Kompilierung für ASP.NET Core Minimal WebAPIs kommt nun auch mit komplexen Objekten klar, die mit [AsParameters] annotiert sind [15].
Microsoft stellt seit .NET 8.0 Preview 6 die Möglichkeit zur Verfügung, .NET-Anwendungen für iOS, Mac Catalyst und tvOS mit Hilfe des neuen .NET-Native-AOT-Compilers zu kompilieren. Diese Möglichkeit steht sowohl für Apps, die auf diese Plattformen beschränkt sind („.NET for iOS“), als auch für das .NET Multi-Platform App UI (.NET MAUI) zur Verfügung. Dadurch laufen die Anwendungen nicht mehr auf Mono, und die App-Pakete für „.NET for iOS“ werden spürbar kompakter. Hingegen verzeichnen die App-Pakete für .NET MAUI eine Zunahme in ihrer Größe (Abb. 10). In einem Blogeintrag [16] hat Microsoft bestätigt, dass dieses Problem erkannt wurde und aktiv daran gearbeitet wird, eine Lösung zu finden, die zu einem Größenvorteil von etwa 30 Prozent führt.

Abb. 10: Verkleinerte App-Pakete durch Native AOT (Bildquelle: Microsoft [16])
In .NET 8.0 Preview 6 und 7 gab es wieder einmal Verbesserungen für den JSON-Serialisierer/-Deserialisierer im NuGet-Paket System.Text.Json.
System.Text.Json vermag nun neuere Zahlentypen wie Half, Int128 und UInt128 sowie die Speichertypen Memory<T> und ReadOnlyMemory<T> zu serialisieren. Bei den Letzteren entstehen, wenn es sich um Memory<Byte> und ReadOnlyMemory<Byte> handelt, Base64-kodierte Zeichenketten. Andere Datentypen werden als JSON-Arrays serialisiert.
JsonSerializer.Serialize<ReadOnlyMemory<byte>>(new byte[] { 42, 43, 44 }); wird zu "Kiss"
JsonSerializer.Serialize<Memory<Int128>>(new Int128[] { 42, 43, 44 }); wird zu [42,43,44]
JsonSerializer.Serialize<Memory<string>>(new string[] { "42", "43", "44" }); wird zu ["42","43","44"]
Zusätzlich dazu ermöglichen die Annotationen [JsonInclude] und [JsonConstructor] es Entwicklerinnen und Entwicklern, die Serialisierung nichtöffentlicher Klassen-Member zu erzwingen. Für jedes nichtöffentliche Mitglied, das mit [JsonInclude] annotiert ist, muss im Konstruktor, der mit [JsonConstructor] annotiert ist, ein Parameter vorhanden sein, um den Wert während der Deserialisierung setzen zu können. Ein aussagekräftiges Beispiel dazu zeigt Listing 10.
public class Person
{
[JsonConstructor] // ohne dies: 'Deserialization of types without a parameterless constructor, a singular parameterized constructor, or a parameterized constructor annotated with 'JsonConstructorAttribute' is not supported.
internal Person(int id, string name, string website)
{
ID = id;
Name = name;
Website = website;
}
[JsonInclude] // ohne dies: 'Each parameter in the deserialization constructor on type 'FCL_JSON+Person' must bind to an object property or field on deserialization. Each parameter name must match with a property or field on the object. Fields are only considered when 'JsonSerializerOptions.IncludeFields' is enabled. The match can be case-insensitive.'
internal int ID { get; }
public string Name { get; set; }
[JsonInclude] // ohne dies: 'Each parameter in the deserialization constructor on type 'FCL_JSON+Person' must bind to an object property or field on deserialization. Each parameter name must match with a property or field on the object. Fields are only considered when 'JsonSerializerOptions.IncludeFields' is enabled. The match can be case-insensitive.'
private string Website { get; set; }
public override string ToString()
{
return $"{this.ID}: {this.Name} ({this.Website})";
}
}
...
// Serialisierung
var p1 = new Person(42, "Dr. Holger Schwichtenberg", "www.dotnet-doktor.de");
string json4 = JsonSerializer.Serialize(p1); // {"X":42}
Console.WriteLine(json4);
// Deserialisierung
var p2 = JsonSerializer.Deserialize<Person>(json4);
Console.WriteLine(p2);
Die bereits vorhandene Klasse JsonNode hat neue Methoden wie DeepClone() und DeepEquals() erhalten. Außerdem wird bei JsonArray nun IEnumerable angeboten, was Aufzählung mit foreach und Language Integrated Query (LINQ) ermöglicht:
JsonArray jsonArray = new JsonArray(40, 42, 43, 42);
IEnumerable<int> values = jsonArray.GetValues<int>().Where(i => i == 42);
foreach (var v in values)
{
Console.WriteLine(v);
}
Zu den Neuerungen in System.Text.Json in Version 8.0 gehört auch, dass die auf zu serialisierende Klassen anwendbare Annotation [JsonSourceGenerationOptions] nun alle Optionen bietet, die auch die Klasse JsonSerializerOptions beim imperativen Programmieren mit der Klasse System.Text.Json. JsonSerializer erlaubt. Für System.Text.Json in Verbindung Native AOT gibt es eine neue Annotation [JsonConverter]:
[JsonConverter(typeof(JsonStringEnumConverter<MyEnum>))]
public enum MyEnum { Value1, Value2, Value3 }
In .NET 7.0 Preview 6 präsentierte Microsoft den Source Generator für native API-Aufrufe über die [LibraryImport]-Annotation [17] auf allen Betriebssystemplattformen. In .NET 8.0 Preview 6 wurde nun eine vergleichbare Option für die Nutzung des Component Object Models (COM), das ausschließlich unter Windows verfügbar ist, eingeführt. Um die COM-Schnittstelle zu nutzen, muss der entsprechende Wrapper die Annotation [GeneratedComInterface] tragen. Klassen, die diese Schnittstellen implementieren, werden mit [GeneratedComClass] annotiert. Zusätzlich zu der bereits in .NET 7.0 eingeführten [LibraryImport]-Annotation können Entwickler nun auch COM-Schnittstellen als Parameter- und Rückgabetypen verwenden. Diese Annotationen ermöglichen es dem C#-Compiler, den normalerweise zur Laufzeit generierten COM-Zugriffscode bereits zur Entwicklungszeit zu erzeugen. Der generierte Code findet sich im Projekt unter /Dependencies/Analyzers/Microsoft.Interop.ComInterfaceGenerator.
Für bestehende Schnittstellen, die [ComImport]-Annotationen aufweisen, schlägt Visual Studio die Konvertierung in [GeneratedComInterface] vor. Analog dazu wird für Klassen, die diese Schnittstellen implementieren, von Visual Studio vorgeschlagen, sie mit [GeneratedComClass] zu annotieren.
Wie schon in der Vergangenheit vorgekommen, hat Microsoft auch in diesem Ankündigungsblogeintrag [18] Fehler eingebaut. Bei allen im Zusammenhang mit COM behandelten Beispielen fehlt das Schlüsselwort partial. Microsoft schreibt zum Beispiel:
[GeneratedComInterface]
[Guid("5401c312-ab23-4dd3-aa40-3cb4b3a4683e")]
interface IComInterface
{
void DoWork();
void RegisterCallbacks(ICallbacks callbacks);
}
Dieser Code führt aber in Visual Studio 2022 (sowohl in der mit Preview 6 erschienenen Version 17.7 Preview 3.0 als auch in der zum Redaktionsschluss aktuellen Version 17.8 Preview 1) zu diesem Compilerfehler: „The interface ‘IComInterface’ or one of its containing types is missing the ‘partial’ keyword. Code will not be generated for ‘IComInterface’.“ Korrekt ist:
[GeneratedComInterface]
[Guid("5401c312-ab23-4dd3-aa40-3cb4b3a4683e")]
partial interface IComInterface
{
void DoWork();
void RegisterCallbacks(ICallbacks callbacks);
}
Microsoft hat zumindest einige der Begrenzungen des Source Generators für COM dokumentiert [19]. Das schließt ein, dass der Generator nicht für Schnittstellen funktioniert, die auf IDispatch und IInspectable basieren. Des Weiteren werden weder COM-Properties noch COM-Events unterstützt. Es ist auch wichtig zu beachten, dass Entwickler:innen nicht in der Lage sind, eine COM-Klasse mit dem Schlüsselwort new zu aktivieren; das ist lediglich durch den Aufruf von CoCreateInstance() möglich. Diese Beschränkungen sollen auch in der finalen Version von .NET 8.0 bestehen bleiben, die am 14. November 2023 veröffentlicht werden soll. Eventuelle Verbesserungen sind möglicherweise erst in einer späteren Hauptversion zu erwarten.
Viele Jahre lang gab es keine neuen Steuerelemente für die Windows Presentation Foundation (WPF). In .NET 8.0 Preview 7 liefert Microsoft nun einen neuen Dialog für das Auswählen von Ordnern im Dateisystem (Listing 8). Es öffnet sich der Standarddialog des Windows-Betriebssystems. Realisiert wurde die Klasse Microsoft.Win32.OpenFolderDialog aber nicht von Microsoft selbst, sondern dem Communitymitglied Jan Kučera [20].
OpenFolderDialog openFolderDialog = new OpenFolderDialog()
{
Title = "Select folder to open ...",
InitialDirectory = Environment.GetFolderPath(Environment.SpecialFolder.ProgramFiles),
};
string folderName = "";
if (openFolderDialog.ShowDialog() == true)
{
folderName = openFolderDialog.FolderName;
}
Wie angekündigt konzentriert sich das Entwicklungsteam von .NET MAUI in .NET 8.0 auf Fehlerbehebungen, siehe die Blogeinträge zu Preview 5 [21], Preview 6 [22] und Preview 7 [23].
Ein wesentliches neues Feature in diesen drei Previews sind Tastaturshortcuts, die Entwicklerinnen und Entwickler nun per SetAccelerator() einem Menüeintrag zuweisen können:
<MenuFlyoutItem x:Name="AddProductMenu"
Text="Add Product"
Command="{Binding AddProductCommand}"
/>
...
MenuItem.SetAccelerator(AddProductMenu, Accelerator.FromString("Ctrl+A"));
Im Hauptblogeintrag zu .NET 8.0 Preview 7 [24] ist noch eine Verbesserung für internationalisierte Mobile-Anwendungen auf Apple-Betriebssystemen (iOS, tvOS und MacCatalyst) erwähnt: Hier kann die Größe der länderspezifischen Daten mit einer neuen Einstellung um 34 Prozent reduziert werden:
<HybridGlobalization>true</HybridGlobalization>
Einige APIs ändern aber durch HybridGlobalization ihr Verhalten [25]. HybridGlobalization ist auch für .NET-Anwendungen möglich, die auf WebAssembly laufen [26]. Die Einstellung lädt dann die Datei icudt_hybrid.dat, die 46 Prozent kleiner sein soll als die bisherige icudt.dat.
Außerdem gibt es nun eine .NET-MAUI-Erweiterung für Visual Studio Code [27].
Beim Entwicklungsteam von Entity Framework Core ist es derzeit recht still. Für die Previews 5, 6 und 7 gab es zwar jeweils eine neue Version auf NuGet [28], aber nicht den sonst zu allen Vorschauversionen üblichen eigenständigen Blogeintrag des Entity-Framework-Core-Entwicklungsteams. Auch das GitHub Issue [29], in dem Entity-Framework-Core-Engineering-Manager Arthur Vickers [30] bisher im Abstand von zwei Wochen über den Fortschritt berichtete, lieferte zuletzt nur am 22. Juni und 6. Juli einen Eintrag mit einigen kleineren Verbesserungen.
Laut einer Tabelle in oben genanntem Issue hat das Entwicklungsteam die meisten der kleineren Neuerungen in Entity Framework Core in den ersten Preview-Versionen bereits erledigt und arbeitet nun an den größeren Projekten. Dazu gehören:
Regelmäßig News zur Konferenz und der .NET-Community
.NET 8.0 bietet in den Previews 6, 7 und 8 spannende Neuerungen. Es wird nun deutlich, dass Microsoft Blazor United tatsächlich umsetzt. Bis zum Erscheinungstermin am 14. November 2023 im Rahmen der .NET Conf 2023 sind aber noch einige Abrundungen notwendig. Das Entity-Framework-Core-Entwicklungsteam hat noch einiges zu liefern.
Neben dem im Haupttext besprochenen Neuerungen sollen weitere Verbesserungen in den .NET 8.0 Previews 5, 6 und 7 kurz erwähnt werden:

Abb. 11: Verbesserte Debugger-Ansicht in ASP.NET-Core-Projekten (Bildquelle: Microsoft)
Dr. Holger Schwichtenberg (20-maliger MVP) – alias „Der DOTNET-DOKTOR“ – gehört zu den bekanntesten .NET- und Webexperten in Deutschland. Er ist Chief Technology Expert bei der Softwaremanufaktur MAXIMAGO. Mit dem 43-köpfigen Expertenteam bei www.IT-Visions.de bietet er zudem Beratung und Schulungen zu über 950 Entwicklerthemen an. Seit 1998 ist er ununterbrochen Sprecher auf sämtlichen BASTA!-Konferenzen und Autor von mehr als 90 Fachbüchern sowie über 1 500 Fachartikeln.
E-Mail: [email protected]
Twitter: @dotnetdoktor
Web: www.dotnet-doktor.de
[1] https://www.youtube.com/watch?v=48G_CEGXZZM
[2] https://learn.microsoft.com/en-us/aspnet/core/mvc/views/partial
[3] https://github.com/mkArtakMSFT/BlazorWasmClientInteractivity
[4] https://github.com/danroth27/Net8BlazorAuto
[5] https://github.com/dotnet/aspnetcore/issues/49756
[6] https://devblogs.microsoft.com/dotnet/asp-net-core-updates-in-dotnet-8-preview-6
[7] https://devblogs.microsoft.com/dotnet/asp-net-core-updates-in-dotnet-8-preview-7
[8] https://devblogs.microsoft.com/dotnet/asp-net-core-updates-in-dotnet-8-preview-7/#antiforgery-integration-for-minimal-apis
[9] https://devblogs.microsoft.com/dotnet/asp-net-core-updates-in-dotnet-8-preview-7/#antiforgery-integration
[10] https://devblogs.microsoft.com/dotnet/asp-net-core-updates-in-dotnet-8-preview-5/#improved-packaging-of-webcil-files
[11] https://docs.duendesoftware.com/identityserver/v5/quickstarts/5_aspnetid
[12] https://github.com/davidfowl/IdentityEndpointsSample
[13] https://github.com/dotnet/aspnetcore/issues/46691
[14] https://devblogs.microsoft.com/dotnet/new-csharp-12-preview-features
[15] https://devblogs.microsoft.com/dotnet/asp-net-core-updates-in-dotnet-8-preview-5/#native-aot
[16] https://devblogs.microsoft.com/dotnet/announcing-dotnet-8-preview-6/#support-for-targeting-ios-platforms-with-nativeaot
[17] https://learn.microsoft.com/en-us/dotnet/api/system.runtime.interopservices.libraryimportattribute
[18] https://devblogs.microsoft.com/dotnet/announcing-dotnet-8-preview-6
[19] https://devblogs.microsoft.com/dotnet/announcing-dotnet-8-preview-6/#limitations
[20] https://github.com/miloush
[21] https://devblogs.microsoft.com/dotnet/announcing-dotnet-maui-in-dotnet-8-preview-5
[22] https://devblogs.microsoft.com/dotnet/announcing-dotnet-maui-in-dotnet-8-preview-6
[23] https://devblogs.microsoft.com/dotnet/announcing-dotnet-maui-in-dotnet-8-preview-7
[24] https://devblogs.microsoft.com/dotnet/announcing-dotnet-8-preview-7/#hybridglobalization-mode-on-ios-tvos-maccatalyst-platforms
[25] https://github.com/dotnet/runtime/blob/main/docs/design/features/globalization-hybrid-mode.md
[26] https://devblogs.microsoft.com/dotnet/announcing-dotnet-8-preview-6/#hybridglobalization-mode-on-wasm
[27] https://devblogs.microsoft.com/visualstudio/announcing-the-dotnet-maui-extension-for-visual-studio-code
[28] https://www.nuget.org/packages/Microsoft.EntityFrameworkCore
[29] https://github.com/dotnet/efcore/issues/29989
[30] https://github.com/ajcvickers
[31] https://learn.microsoft.com/en-us/dotnet/core/compatibility/8.0
[32] https://github.com/dotnet/runtime/issues/31113
[33] https://devblogs.microsoft.com/dotnet/asp-net-core-updates-in-dotnet-8-preview-6/#http-sys-kernel-response-buffering
[34] https://learn.microsoft.com/en-us/aspnet/core/performance/caching/distributed
The post Blazor als Insel und im Automodus appeared first on BASTA!.
]]>The post SQL Server 2022 appeared first on BASTA!.
]]>Unterscheidbar oder nicht? Filtern mit NULL
Zu prüfen, ob zwei Werte gleich sind oder nicht, klingt im ersten Moment trivial. Und zwar genau so lange, bis einer (oder gar beide) NULL sein können. Ab diesem Moment muss mit einer Kombination von gleich und ungleich sowie mit dem IS-Operator gearbeitet werden. (Zur Erinnerung: NULL = NULL OR NULL <> NULL ist immer falsch, auch wenn es dem einen oder anderen erst einmal widersinnig erscheint). Aus diesem Grund bietet SQL Server 2022 nun die Syntax A IS DISTINCT FROM B beziehungsweise A IS NOT DISTINCT FROM B. Eine Abfrage kann so aussehen:
SELECT * FROM <Tabelle/ Sicht> WHERE A IS DISTINCT FROM B; SELECT * FROM <Tabelle/ Sicht> WHERE A IS NOT DISTINCT FROM B;
Abbildung 1 zeigt, wie der Server dies umsetzt – etwas umfangreich, aber korrekt und nötig. Sicher ist, dass es sich bei A/B um Ausdrücke oder Spalten handeln kann.

Abb. 1: Decoding der neuen IS (NOT) DISTINCT FROM-Syntax
Minifazit: Wer bereit ist, statt A=B einfach A IS NOT DISTINCT B zu schreiben, bekommt ein Ergebnis, das in jedem Fall korrekt ist. Mehr ist nicht nötig. Notlösungen mit der ISNULL()-Funktion sollten damit endgültig der Vergangenheit angehören.
RTRIM(), LTRIM()? Besser TRIM()!
Das Entfernen von Zeichen von Anfang und/oder Ende einer Zeichenkette ist eine Grundfunktionalität, für die es eigentlich für jedes Framework eine Lösung gibt. Nun auch für T-SQL mit der Angabe, welche Zeichen entfernt werden sollen. Whitespaces sind also nicht mehr Pflicht. Außerdem kann nun für die TRIM()-Funktion bestimmt werden, ob sie den Anfang oder das Ende einer Zeichenkette berücksichtigen soll oder beides. Letzteres wird nicht über einen Parameter, sondern den Zusatz LEADING, TAILING oder BOTH gesteuert. Listing 1 zeigt, wie das genau aussieht.
Regelmäßig News zur Konferenz und der .NET-Community
Listing 1 DECLARE @caption VARCHAR(100) = '-== SQL Server 2022 ==-'; SELECT LTRIM(@caption, '-= ') AS [LTRIM], RTRIM(@caption, '-= ') AS [RTRIM]; SELECT TRIM(LEADING '-= ' FROM @caption) AS [LEADING], TRIM(TRAILING '-= ' FROM @caption) AS [TRAILING], TRIM(BOTH '-= ' FROM @caption) AS [BOTH];
Minifazit: Praktisch, dass genau bestimmt werden kann, welche Zeichen (‘-= ‘ in Listing 1) entfernt werden sollen. Nur an die neue Syntax der TRIM()-Funktion muss man sich sicherlich erst gewöhnen.
Horizontales Maxi-/Minimum
Um den größten beziehungsweise kleinsten Wert einer Reihe von Werten und Ausdrücken zu ermitteln, waren bisweilen „interessante“ Lösungen notwendig. Die dabei naheliegenden Aggregate MIN() und MAX() funktionieren nicht, da diese nur einen Parameter akzeptieren und vertikal (aus Spalten) arbeiten. GREATEST() und LEAST() kann man nun eine Menge an kompatiblen Werten übergeben und erhält den größten oder den kleinsten von diesen. Folgender Abschnitt zeigt ein paar Aufrufe und das daraus folgende Ergebnis:
SELECT GREATEST('6.62', 3.1415, N'7') AS 'GREATEST', -- 7.0000
LEAST( '6.62', 3.1415, N'7') AS 'LEAST'; -- 3.1415
SELECT GREATEST('A', 'B', 'C') AS 'GREATEST', -- C
LEAST('A', 'B', 'C') AS 'LEAST'; -- A
Minifazit: Klein, aber sehr hilfreich. Wer hatte so eine Anforderung noch nicht?
Zahlenreihen erzeugen
Ebenfalls öfter mal benötigt und nun leicht zu erzeugen: eine Zahlenreihe von einem Start- bis zu einem Endwert; auf Wunsch auch mit Schrittweite. Damit ist der konkrete Datentyp unerheblich, so lange er nur numerisch ist oder als solcher interpretiert wird. In der Praxis bedeutet dies Zahlen mit oder ohne Komma. Beides akzeptiert die neue GENERATE_SERIES()-Funktion. Neben den obligatorischen Werten für Start und Ende ist der Wert für die Schrittweite optional und SQL Server verwendet ohne Angabe 1, bzw. -1. Listing 2 zeigt ein paar Aufrufe mit der Funktion.
Listing 2 -- Von 1 bis <=50 in 5er Schritten => 1..6..11..41..46 SELECT value FROM GENERATE_SERIES(/* Start */ 1, /*STOP*/ 50, /*STEP*/ 5); -- Auch andere (numerische) Datentypen sind erlaubt SELECT value FROM GENERATE_SERIES(/* Start */ 1.0, /*STOP*/ 10.0, /*STEP*/ .5); -- Alle Kalenderwochen 2022 SELECT CAST(DATEADD(WEEK, value - 1, '2022-01-03') AS DATE), value FROM GENERATE_SERIES(1, 52);
Soll eine Serie mit anderen Datentypen erzeugt werden, so ist das auf Basis der Zahlenreihe natürlich auch kein Problem, wie die letzte Abfrage aus Listing 2 zeigt. Die Ausgabe ist in Abbildung 2 zu sehen.

Abb. 2: Kalenderwochen mit der GENERATE_SERIES()-Funktion
Minifazit: Ziemlich hilfreiche kleine Funktion für vielfältige Einsätze.
DATETRUNC()
Die neue DATETRUNC()-Funktion schneidet alle Details eines Datums/einer Uhrzeit ab der übergebenen Einheit ab. So liefert DATETRUNC(YEAR, ‘2022-10-25 19:45:32’) schlicht ‘2022-01-01 00:00:00.0000000’. Für Month wäre es ‘2022-10-01 00:00:00.0000000’. Listing 3 zeigt einige Varianten mit deren jeweiligen Ausgaben.
Listing 3 DECLARE @d DATETIME2 = GETDATE(); SELECT 'Year', DATETRUNC(YEAR, @d); -- 2022-01-01 00:00:00.0000000 SELECT 'Quarter', DATETRUNC(QUARTER, @d); --2022-10-01 00:00:00.0000000 SELECT 'Month', DATETRUNC(MONTH, @d); -- 2022-12-01 00:00:00.0000000 SELECT 'Week', DATETRUNC(WEEK, @d); -- 2022-12-11 00:00:00.0000000 SELECT 'Iso_week', DATETRUNC(ISO_WEEK, @d); -- 2022-12-12 00:00:00.0000000 SELECT 'DayOfYear', DATETRUNC(DAYOFYEAR, @d); -- 2022-12-17 00:00:00.0000000 SELECT 'Day', DATETRUNC(DAY, @d); -- 2022-12-17 00:00:00.0000000 SELECT 'Hour', DATETRUNC(HOUR, @d); -- 2022-12-17 19:00:00.0000000 SELECT 'Minute', DATETRUNC(MINUTE, @d); -- 2022-12-17 19:45:00.0000000 SELECT 'Second', DATETRUNC(SECOND, @d); -- 2022-12-17 19:45:17.0000000 SELECT 'Millisecond', DATETRUNC(MILLISECOND, @d); -- 2022-12-17 19:45:17.5800000 SELECT 'Microsecond', DATETRUNC(MICROSECOND, @d); -- 2022-12-17 19:45:17.5800000
Minifazit: Diese Funktion sorgt für einfacheren und lesbareren Code, wenn ein vollständiges Datum oder eine vollständige Uhrzeit vorliegt (z. B. von GETDATE() oder GETUTCDATE()), aber nur ein Teil davon tatsächlich benötigt wird.
SELECT … WINDOW-Klausel
Wer viel mit Window-Funktionen oder Aggregaten bei seinen Abfragen arbeitet, wird diese kleine Verbesserung zu schätzen wissen, da sich so repetitiver Code vermeiden lässt. Mit der WINDOW-Klausel lässt sich PARTITION BY und ORDER BY pro Abfrage einmal definieren, mit einem Namen versehen und dann mehrfach verwenden. Statt also eine Abfrage wie in Listing 4 ist nun eine wie in Listing 5 möglich.
Listing 4 SELECT SalesOrderID, ProductID, OrderQty ,SUM(OrderQty) OVER (PARTITION BY SalesOrderID) AS Total ,AVG(OrderQty) OVER (PARTITION BY SalesOrderID) AS "Avg" ,COUNT(OrderQty) OVER (PARTITION BY SalesOrderID) AS "Count" ,MIN(OrderQty) OVER (PARTITION BY SalesOrderID) AS "Min" ,MAX(OrderQty) OVER (PARTITION BY SalesOrderID) AS "Max" FROM Sales.SalesOrderDetail WHERE SalesOrderID IN(43659,43664);
Listing 5 SELECT SalesOrderID, ProductID, OrderQty ,SUM(OrderQty) OVER win AS Total ,AVG(OrderQty) OVER win AS "Avg" ,COUNT(OrderQty) OVER win AS "Count" ,MIN(OrderQty) OVER win AS "Min" ,MAX(OrderQty) OVER win AS "Max" FROM Sales.SalesOrderDetail WHERE SalesOrderID IN(43659,43664) WINDOW win AS (PARTITION BY SalesOrderID);
Die Abfrage in Listing 5 ist kompakter und Fehler bei Änderungen haben ebenfalls weniger Chancen.
Minifazit: Praktisch, wenn man viel mit umfangreichen Window-Funktionen oder Aggregaten arbeitet. Sonst eher hinderlich; dafür handelt es sich aber auch nur um eine Option, die alte Syntax existiert natürlich nach wie vor.
FIRST_VALUE() und LAST_VALUE()
Die Funktionen FIRST()_VALUE und LAST_VALUE() sind bei weitem nicht neu, sondern schon seit SQL Server 2012 im Portfolio. Nun sind sie um eine Syntax erweitert worden, die steuert, ob NULL berücksichtigt wird (RESPECT NULLS) oder nicht (IGNORE NULLS). Listing 6 zeigt beide nun möglichen Varianten.
Listing 6 SELECT Name, ListPrice, FIRST_VALUE(Name) RESPECT NULLS OVER (ORDER BY ListPrice ASC) AS LeastExpensive FROM Production.Product WHERE ProductSubcategoryID = 37; SELECT Name, ListPrice, FIRST_VALUE(Name) IGNORE NULLS OVER (ORDER BY ListPrice ASC) AS LeastExpensive FROM Production.Product WHERE ProductSubcategoryID = 37;
Minifazit: Die neue Syntax erspart eine zusätzliche Unterabfrage und macht damit die Abfrage an sich einfacher, lesbarer und performanter. Wer die beiden Funktionen bis dato noch nicht verwenden konnte, wird allerdings auch nicht bekehrt werden.
STRING_SPLIT() mit Ordinal (Index)
Auch die STRING_SPLIT()-Funktion ist nicht neu, wurde aber mit SQL Server 2022 um einen optionalen Parameter erweitert, der neben den aufgeteilten Elementen der Zeichenketten auch den entsprechenden Indexwert (beginnend mit 1) in einer zusätzlichen Spalte liefert – zumindest wenn eine 1 als Wert übergeben wird. Die folgende Abfrage liefert das Ergebnis, das in Abbildung 3 gezeigt wird:
SELECT * FROM STRING_SPLIT('Lorem ipsum dolor sit amet.', ' ', 1);

Abb. 3: STRING_SPLIT()-Funktion mit Ordinal (Index)
Minifazit: Wahrlich eine Detailerweiterung mit wenig Einsatzpotenzial, oder?
Genäherte Aggregate
An sich sind die grundlegenden Funktionen PERCENTILE_CONT() und PERCENTILE_DISC() ebenfalls nicht neu. APPROX_PERCENTILE_CONT() und APPROX_PERCENTILE_DISC() sind nun Varianten, die auch bei größeren Datenmengen sehr performant sind, dafür aber nur genähert und so mit einer Abweichung versehen sind. Listing 7 zeigt diese beiden Funktionen.
Listing 7 -- Kontinuierliche Werte SELECT DeptId, APPROX_PERCENTILE_CONT(0.10) WITHIN GROUP(ORDER BY Salary) AS 'P10', APPROX_PERCENTILE_CONT(0.90) WITHIN GROUP(ORDER BY Salary) AS 'P90' FROM #Employee GROUP BY DeptId; -- Diskrete Werte SELECT DISTINCT DeptId, PERCENTILE_DISC(0.10) WITHIN GROUP (ORDER BY Salary) OVER (PARTITION BY DeptId) AS 'P10', PERCENTILE_DISC(0.90) WITHIN GROUP (ORDER BY Salary) OVER (PARTITION BY DeptId) AS 'P90' FROM #Employee;
Minifazit: Ebenfalls eine Detailerweiterung für die wenigen, die ausgiebig mit PERCENTILE_CONT() und PERCENTILE_DISC() arbeiten – für den Rest eher uninteressant.
Zeitliche Abschnitte mit der DATE_BUCKET()-Funktion
Für das Erzeugen von zeitlichen Abschnitten steht ab SQL Server 2022 die DATE_BUCKET()-Funktion bereit. Sie liefert den Anfang eines Abschnittes (Woche, Monat, Jahr etc.) basierend auf einem Datum. Und dabei muss es sich nicht um den ersten Abschnitt handeln, er kann auch per Index bestimmt werden. Listing 8 zeigt den Aufruf.
Listing 8 DECLARE @date DATETIME2 = '2022-02-24 00:00:00'; SELECT 'WEEK', DATE_BUCKET(WEEK, 1, @date); -- 2022-02-21 00:00:00.0000000 SELECT 'MONTH', DATE_BUCKET(MONTH, 1, @date); -- 2022-02-21 00:00:00.0000000 SELECT 'YEAR', DATE_BUCKET(YEAR, 1, @date); -- 2022-01-01 00:00:00.0000000 DECLARE @date DATETIME2 = '2022-02-24 00:00:00'; DECLARE @origin1 DATETIME2 = '2021-01-01 00:00:00'; DECLARE @origin2 DATETIME2 = '2021-02-22 00:00:00'; SELECT 'WEEK', DATE_BUCKET(WEEK, 1, @date, @origin1); -- 2022-02-18 00:00:00.0000000 SELECT 'WEEK', DATE_BUCKET(WEEK, 1, @date, @origin2); -- 2022-02-21 00:00:00.0000000
Minifazit: Eine sehr spezielle Funktion, die für viele keine Rolle spielen wird.
Bit-Funktionen
Gleich eine Handvoll neuer Funktionen für die Arbeit mit Bit-Werten bietet SQL Server 2022, auch wenn es wenige Gelegenheiten gibt, im T-SQL-Umfeld damit zu arbeiten – die UPDATE()-Funktion im Zuge von DML-Triggern ist eine der wenigen davon. Tabelle 1 zeigt die einzelnen Funktionen zusammen mit einer kleinen Erläuterung. Listing 9 zeigt die Verwendung dieser Funktionen in einem kurzen Beispiel.
| Funktion | Erläuterung |
| RIGHT_SHIFT() | Verschiebt den numerischen Wert binär nach rechts |
| LEFT_SHIFT() | Verschiebt den numerischen Wert binär nach links |
| BIT_COUNT () | Liefert die Anzahl der (aus 1) gesetzten Bits |
| GET_BIT() | Liefert den Status (0 oder 1) eines bestimmten Bits |
| SET_BUT() | Setzt den Status (0 oder 1) eines bestimmten Bits |
Tabelle 1: Neue Bit-Funktionen
Listing 9 -- RIGHT_SHIFT()/ LEFT_SHIFT() SELECT @number, RIGHT_SHIFT(@number, 1) '>> 1', RIGHT_SHIFT(@number, 2) '>> 2', RIGHT_SHIFT(@number, 3) '>> 3'; -- 10011010010 1001101001 100110100 10011010 SELECT @number, LEFT_SHIFT(@number, 1) '<< 1', LEFT_SHIFT(@number, 2) '<< 2', LEFT_SHIFT(@number, 3) '<< 3'; -- 10011010010 100110100100 1001101001000 10011010010000 -- BIT_COUNT() SELECT @number, BIT_COUNT(@number) 'Number of 1s'; -- 10011010010 5 -- SET_BIT()/ GET_BIT() SELECT GET_BIT(@number, 0) 'Pos 0', GET_BIT(@number, 1) 'Pos 1';
Minifazit: Wie bereits erwähnt, gibt es nur wenige Stellen, an denen in T-SQL mit Bit-Operationen sinnvoll gearbeitet werden kann. Aber wenn man es mit so einer Stelle zu tun hat, machen die Neuerungen vieles einfacher.
Arbeiten mit JSON
Und vielleicht das Beste zum Schluss: Arbeiten mit JSON ist seit SQL Server 2016 möglich und wird nun mit SQL Server 2022 essenziell erweitert. Um genau zu sein, gibt es drei neue Funktionen und eine Erweiterung einer bestehenden Funktion. Tabelle 2 zeigt diese Funktionen mit einer kleinen Erläuterung für ihren jeweiligen Zweck. Einige Funktionen arbeiten dabei mit unterschiedlichen JSON-Typen, die in Tabelle 3 aufgelistet sind. Listing 10 zeigt den Einsatz der JSON-Funktion im Beispiel.
| Funktion | Zweck |
| JSON_ARRAY() | Erzeugt ein JSON-Array (Neu) |
| JSON_OBJECT() | Erzeugt ein einfaches JSON-Objekt (Neu) |
| ISJSON() | Erweitert um die neue JSON-Typangabe |
| JSON_PATH_EXIST() | Prüft, ob ein JSON-Objekt den angegebenen Pfad besitzt (Neu) |
Tabelle 2: Neue und erweiterte JSON-Funktionen
| JSON-Type | Beschreibung |
| VALUE | Testet auf einen Wert (object, array, number, string, true, false, null |
| ARRAY | Testet auf ein JSON-Array |
| OBJECT | Testet auf ein JSON-Objekt |
| SCALAR | Testet auf einen gültigen Skalarwert – Zahl, String etc. |
Tabelle 3: Unterstützte JSON-Typen
Regelmäßig News zur Konferenz und der .NET-Community
Listing 10
DECLARE @jsonInfo NVARCHAR(MAX)=N'{"info":{"address":[{"town":"Nidderau-Erbstadt"},{"town":"Rom"}]}}';
-- JSON_ARRAY
SELECT JSON_ARRAY();
SELECT JSON_ARRAY('a', 1, 'b', 2);
SELECT JSON_ARRAY('name', name, 'id', database_id) FROM sys.databases;
GO
-- JSON_OBJECT
SELECT JSON_OBJECT('name':'value', 'type':null, 'abc': 3);
SELECT JSON_OBJECT('name':'value', 'type':null, 'abc': 3 NULL ON NULL /* Standard */ );
SELECT JSON_OBJECT('name':'value', 'type':null, 'abc': 3 ABSENT ON NULL);
GO
-- ISJSON
DECLARE @json VARCHAR(MAX) = '["a",1,"b",2]';
SELECT ISJSON(@json, ARRAY); -- 1
SELECT ISJSON(@json, SCALAR); -- 0
-- ARRAY, SCALAR, VALUE, OBJECT
GO
-- JSON_PATH_EXISTS
DECLARE @jsonInfo NVARCHAR(MAX)=N'{"info":{"address":[{"town":"Nidderau-Erbstadt"},{"town":"Rom"}]}}';
SELECT JSON_PATH_EXISTS(@jsonInfo,'$.info.address'); -- 1
SELECT JSON_PATH_EXISTS(@jsonInfo,'$.info.email'); -- 0
GO
Minifazit: Sinnvolle und nützliche Funktionen und Erweiterungen, für die man bei der Arbeit mit JSON schnell einen Einsatz findet. Leider ist (immer noch) kein JSON-Datentyp vorhanden, um mit großen Datenmengen im JSON-Format performant arbeiten zu können.
Gesamtfazit
SQL Server 2022 bietet einiges Neue für T-SQL: IS [not ]DISTINCT FROM, RTRIM(), LTRIM() & TRIM(), GREATEST() & LEAST() und DATETRUNC() sind nützliche Verbesserungen, die schnell Verwendung finden. Andere Neuerungen sind recht speziell, finden aber bestimmt auch ihre Anwender:innen. Insgesamt sicher keine echte Revolution, aber eine Evolution ist es schon. Vielleicht schafft es Microsoft sogar noch, T-SQL sprachlich in die Zukunft zu führen.
The post SQL Server 2022 appeared first on BASTA!.
]]>The post PWAs mit Blazor WebAssembly appeared first on BASTA!.
]]>Da es sich bei PWAs um Websites handelt, können sie ausschließlich Schnittstellen und Gerätefunktionen aufrufen, die im Web bereitgestellt werden. Glücklicherweise ist das Web spätestens seit der Einführung von HTML5 immer mächtiger geworden. Auch über die vergangenen Jahre kamen immer mehr Schnittstellen ins Web, um die Leistungsfähigkeit webbasierter Anwendungen noch weiter zu erhöhen, zuletzt über die Initiative „Project Fugu“.
Da PWAs auf Webtechnologien aufsetzen, können sämtliche Bibliotheken und Frameworks auf ihre Schnittstellen zugreifen: Angular, React, Vue.js ganz ohne Framework, aber eben auch Microsofts Webframework Blazor, das es in verschiedenen Ausprägungen gibt:
Bei Blazor WebAssembly wird der Anwendungscode komplett clientseitig ausgeführt.
Bei Blazor Server wird die App auf einem Server ausgeführt, der die HTML-Fragmente rendert und per Socket-Verbindung zum Client überträgt. Der Client übermittelt sämtliche Benutzerinteraktionen an den Server, was zu erneutem Rendern führt.
Bei Blazor Hybrid wird Blazor innerhalb einer MAUI-, Windows-Forms- oder WPF-Anwendung ausgeführt, läuft also nicht im Browser (vergleichbar mit Electron). Im Gegenzug können sämtliche plattformspezifischen Schnittstellen aufgerufen werden.
Für .NET 8 wurde zudem noch Blazor United angekündigt, das die Vorteile von Blazor WebAssembly, Blazor Server und Razor Pages vereinen soll: HTML-Fragmente können auf dem Server vorgerendert und danach interaktiv weiterbetrieben werden, wahlweise auf dem Client oder dem Server [1].
Tabelle 1 stellt die Ansätze Blazor WebAssembly, Blazor Server und Blazor Hybrid anhand häufig gewünschter Kriterien für Webanwendungen gegenüber.
Für Progressive Web Apps kommt nur das Modell Blazor WebAssembly in Frage, denn nur dieser Ansatz unterstützt die Ausführbarkeit der Anwendung direkt im Browser in Kombination mit der Unterstützung von Offlineverfügbarkeit. Auf Wunsch lässt sich die Anwendung dennoch für Mobil- und Desktopbetriebssysteme verpacken, um sie über die althergebrachten Deployment-Wege wie App Stores oder Installer zu vertreiben. In diesem Fall ist dann auch der Aufruf sämtlicher plattformspezifischer Schnittstellen möglich. Ein weiterer Vorteil ergibt sich durch die einfache Skalierbarkeit, da die Anwendung auf dem Rechner des Clients ausgeführt wird. Bei Blazor Server muss der Server sämtliche Sessions verwalten können. Von Nachteil ist jedoch, dass auch der Programmcode auf den Rechner des Anwenders übertragen wird und somit nicht geheim gehalten werden kann, wie es für sämtliche Anwendungen gilt, deren Code an Anwender:innen übertragen wird.
| Blazor WebAssembly | Blazor Server | Blazor Hybrid | |
|---|---|---|---|
| Ausführbarkeit in Browsern | + | + | – |
| Unterstützung für Offlineverfügbarkeit | + | – | + |
| Paketierbarkeit für Mobile und Desktop | + | – | + |
| Aufrufbarkeit beliebiger plattformspezifischer Schnittstellen | – (nur wenn verpackt) | + (nur auf dem Server) | + |
| Einfache Skalierbarkeit | + | – | + |
| Code kann geheimgehalten werden | – | + | – |
Tabelle 1: Vergleich der Blazor-Ausprägungen
Da Blazor WebAssembly den einzigen relevanten Ansatz zur Entwicklung von Progressive Web Apps darstellt, wird sich der Artikel allein auf diese Ausprägung konzentrieren. Für das zum Zeitpunkt des Verfassens noch nicht veröffentlichte Blazor United trifft zu, was in Tabelle 1 in der Spalte „Blazor WebAssembly“ steht, sofern die vorgerenderten Inhalte zustandslos sind und die übrige Interaktion clientseitig durchgeführt werden kann, andernfalls gilt die Spalte „Blazor Server“.
Blazor WebAssembly implementiert das von anderen Frameworks wie Angular, React oder Vue.js bekannte Architekturmuster der Single Page Application (SPA): Hierbei werden die erforderlichen Dateien (HTML, JavaScript, CSS, WebAssembly-Module, DLLs und weitere Assets wie Bilder oder Videos) beim Start der Anwendung zum Client übertragen. Die Quelldateien können dabei lokal zwischengespeichert werden, was die Anwendung grundsätzlich offlinefähig macht. Dieser Schritt lässt sich damit vergleichen, eine EXE-Datei inklusive all ihrer Abhängigkeiten auf den Computer der Anwender:innen zu übertragen. Nach dem Laden finden alle Interaktionen und Sichtwechsel clientseitig, also auf dieser Single Page, statt. Eine Kontaktaufnahme zum Server ist nicht erforderlich, was die Anwendung somit sehr performant macht.
Zum Austausch von Daten können Webschnittstellen über HTTPS oder WebSockets angesprochen werden, wie Abbildung 1 zeigt. Darüber hinaus stehen clientseitige Speichermethoden und Datenbanken zur Verfügung, sodass Anwendungsdaten auch offline angezeigt und bearbeitet werden können, eine passende Synchronisationslogik vorausgesetzt.
 Abb. 1: Single-Page-App-Architektur mit Blazor WebAssembly
Abb. 1: Single-Page-App-Architektur mit Blazor WebAssemblyProgressive Web Apps sind ein Überbegriff für eine bestimmte Art Webanwendung. Sie sollen folgende Eigenschaften besitzen [2]:
Responsive: Sie passen sich an die verfügbaren Bildschirmabmessungen an (vom Smartphone bis zum 80-Zoll-Fernseher, wenn sinnvoll).
Linkable: Sie erlauben das Verweisen auf Zielzustände innerhalb der Anwendung über den URL (z. B. eine konkrete Seite oder einen gezielten Datensatz).
Discoverable: Sie sind unterscheidbar von normalen Websites.
Installable: Sie können dem Home-Bildschirm bzw. der Programmliste des Betriebssystems hinzugefügt werden.
App-like: Sie sehen so aus und verhalten sich wie plattformspezifische Apps.
Connectivity independent: Sie sind auch mit schwacher oder ohne Internetverbindung lauffähig, zumindest im Rahmen der Möglichkeiten.
Fresh: Sie sind trotz Offlinekopie immer so aktuell wie möglich.
Safe: Sie übertragen Inhalte nur über eine gesicherte Verbindung (HTTPS).
Re-engageable: Sie fordern zur Wiederverwendung der Anwendung per Pushnachricht auf.
Progressive: Sie schließen die Verwendung älterer/leistungsschwächerer Browser nicht aus.
Die Kernspezifikationen des Anwendungsmodells sind das Web Application Manifest, das das Aussehen und Verhalten der auf dem Gerät installierten PWA definiert, und die Service Workers, die unter anderem für die Offlineverfügbarkeit der Anwendung zuständig sind. Beide Spezifikationen werden vom World Wide Web Consortium (W3C) verwaltet.
Beim Web App Manifest [3] handelt es sich um eine JSON-basierte Datei (Listing 1), die unter anderem den Anzeigenamen der Anwendung (Eigenschaften name und short_name), das App-Icon (Eigenschaft icons) sowie den gewünschten Anzeigemodus (Eigenschaft display) definiert. Das Web Application Manifest wird in der index.html-Datei der Anwendung referenziert.
Listing 1
{
"short_name": "EM",
"name": "entwickler magazin",
"theme_color": "white",
"icons": [{ "src": "icon.png", "sizes": "512x512" }],
"start_url": "./",
"display": "standalone"
}Durch die Verfügbarkeit des Web App Manifest lässt sich die PWA nun auf den Home-Bildschirm des Mobilgerätes (iOS, Android) beziehungsweise in die Programmliste des Desktopgerätes (macOS, Linux, Windows mit Chrome oder Edge) installieren. Von dort aus gestartet, erscheint die Webanwendung aufgrund des gewählten Anzeigemodus standalone wie eine plattformspezifische App: auf Mobilgeräten vollflächig, auf dem Desktop in einem eigenen Fenster, in beiden Fällen komplett ohne Browserstatusleisten. Vor Chromium 111 war für die Chromium-basierten Browser auch das Vorhandensein eines Service Workers verpflichtend; diese Bedingung ist jedoch entfallen.
Regelmäßig News zur Konferenz und der .NET-Community
Die Service Workers [4] hingegen sind in JavaScript verfasste Skripte, die durch die Website registriert werden und danach die Rolle eines Controllers beziehungsweise Proxys übernehmen: Sie können auch ausgeführt werden, wenn die Website geschlossen ist, um Hintergrundaufgaben wie die Anzeige von Pushbenachrichtigungen oder die Synchronisierung von Daten durchzuführen.
Außerdem besitzt der Service Worker einen Cache, in dem er Antworten zu GET-Anfragen lokal zwischenspeichern kann. Darüber lässt sich die Offlineverfügbarkeit abbilden (Abb. 2): Nach Installation und Aktivierung erhält der Service Worker Zugriff auf sämtliche ausgehenden Netzwerkanfragen – sowohl auf die eigenen Quelldateien als auch auf externe Anfragen wie an CDNs. Der Service Worker kann im lokalen Zwischenspeicher die Antworten zu den Abfragen hinterlegen.
 Abb. 2: Schema des Service Workers
Abb. 2: Schema des Service WorkersAb diesem Zeitpunkt können die Quelldateien der Anwendung direkt aus dem Cache ausgelesen werden, was sie nicht nur offlinefähig macht, sondern auch noch besonders schnell starten lässt. Der Service-Worker-Updateprozess stellt darüber hinaus sicher, dass neue Versionen der Anwendung schnellstmöglich verfügbar gemacht werden.
Bei Blazor WebAssembly lässt sich die Unterstützung für Progressive Web Apps auf sehr einfache Art aktivieren, wie Abbildung 3 zeigt. Wird das Kontrollkästchen Progressive Web Application beim Anlegen eines neuen Blazor-WebAssembly-Projekts gesetzt, wird dem Projekt automatisch ein passendes Web Application Manifest hinzugefügt und jeweils ein passender Service Worker erzeugt. Im Web App Manifest müssen Anwendungstitel, Icon und Farben angepasst werden. Änderungen am Service-Worker-Skript sind nur dann erforderlich, wenn über die Offlinefähigkeit hinaus weitere Funktionen wie Pushunterstützung implementiert werden sollen.
 Abb. 3: Die PWA-Unterstützung beim Anlegen eines neuen Blazor-WebAssembly-Projekts
Abb. 3: Die PWA-Unterstützung beim Anlegen eines neuen Blazor-WebAssembly-ProjektsÄhnlich wie plattformspezifische Anwendungen können auch Progressive Web Apps Pushbenachrichtigungen empfangen und Benachrichtigungsbanner darstellen. Hierfür werden drei Webtechnologien kombiniert: das Verfahren Web Push, das Web Notifications API und das Push API [5], die eine Erweiterung der Service-Worker-Schnittstellen ist. Da Service Worker, wie oben erwähnt, auch losgelöst von der eigentlichen Website ausgeführt werden können, ist der Empfang von Pushnachrichten auch dann möglich, wenn die Website gar nicht geöffnet ist.
Was in Chrome, Edge und Firefox schon seit vielen Jahren möglich ist, funktioniert seit Kurzem endlich auch auf der Apple-Plattform: Seit Safari 16 auf macOS Ventura (veröffentlicht im September 2022) können sich Websites für Pushbenachrichtigungen registrieren; auf iOS und iPadOS wurde mit Version 16.4 (veröffentlicht im März 2023) die Unterstützung nachgeliefert. Abbildung 4 zeigt ein Benachrichtigungsbanner am Beispiel einer Demo-PWA auf der Betaversion von iPadOS 16.4. Auf iOS und iPadOS ist zu beachten, dass Pushbenachrichtigungen nur dann empfangen werden können, wenn die Anwendung dem Home-Bildschirm hinzugefügt wurde.
 Abb. 4: PWA-Push-Benachrichtigungen unter iPadOS 16.4 Beta 1
Abb. 4: PWA-Push-Benachrichtigungen unter iPadOS 16.4 Beta 1Wie eingangs erwähnt, können Progressive Web Apps lediglich auf die Schnittstellen zurückgreifen, die auf der Webplattform zur Verfügung stehen. Selbst wenn das Web über die vergangenen Jahre stark aufgeholt hat, blieb doch immer der sogenannte „Web App Gap“: eine Lücke zwischen den Möglichkeiten plattformspezifischer Apps und Webanwendungen.
Eine Initiative bestehend aus den Chromium-Beitragenden Google, Intel, Microsoft und weiteren Akteur:innen hat sich zum Ziel gesetzt, diese Lücke weiter zu verkleinern. Als Teil dieses Projekts wurden viele weitere Schnittstellen in das Web eingeführt, etwa für den Zugriff auf die Zwischenablage des Betriebssystems, das Dateisystem oder die Liste installierter Schriftarten.
Alle Schnittstellen werden dabei innerhalb der Web Incubator Community Group (WICG) des W3C diskutiert, gemeinsam mit anderen Browserherstellern und der breiteren Webcommunity. Somit können sie zu jedem Zeitpunkt von anderen Browserherstellern zur Implementierung aufgegriffen werden. Um offizieller Webstandard zu werden, braucht eine Schnittstelle mindestens zwei unabhängige Implementierungen (das sind Apples WebKit, Googles Blink und Mozillas Gecko).
 Abb. 5: Der Browser übersetzt die JavaScript-Schnittstellen in die passenden plattformspezifischen Aufrufe
Abb. 5: Der Browser übersetzt die JavaScript-Schnittstellen in die passenden plattformspezifischen AufrufeAbbildung 5 zeigt beispielhaft das Web Share API, eine Schnittstelle, um Inhalte (Texte, URLs oder Dateien) aus einer Webanwendung mit einer anderen, auf dem Betriebssystem installierten Anwendung zu teilen. Das geschieht über die Teilen-Funktion des Betriebssystems. Wenn der Browser die Funktionalität unterstützt, stellt er in JavaScript auf dem navigator-Objekt die Methode share() zur Verfügung – andernfalls gibt es die Methode nicht, was für .NET-Augen ungewöhnlich erscheinen mag. Im Gegensatz zu manch älteren Cross-Plattform-Ansätzen wie Xamarin müssen sich Entwickler:innen nicht selbst darum kümmern, je nach Plattform die korrekte plattformspezifische Schnittstelle aufzurufen. Das fällt in die Zuständigkeit des Browsers: Zu dessen Kompilierungszeit wird die JavaScript-Schnittstelle mit dem passenden plattformspezifischen API verknüpft. Webentwickler:innen rufen nur die eine JavaScript-Methode auf, wenn sie vorhanden ist, egal, auf welcher Plattform.
Die allermeisten Webplattform-APIs basieren jedoch auf JavaScript. Zur Verwendung in Blazor und C# muss daher zuerst eine Brücke von C# und WebAssembly zur JavaScript-Welt gebaut werden. Das erfordert fortgeschrittene Kenntnisse beider Welten und kann je nach Schnittstelle sehr aufwendig sein. Aus diesem Grund hat die Blazor-Community Wrapper geschrieben, die in Form quelloffener NuGet-Pakete bezogen werden können. Je nach Schnittstelle wird der Kontakt mit JavaScript dabei entweder komplett vermieden oder zumindest deutlich reduziert. Tabelle 2 zeigt eine Auswahl an Wrapper-Paketen für einige Webschnittstellen aus dem Umfeld von Project Fugu. Im Folgenden werden drei dieser Pakete näher besprochen.
| API | NuGet-Paket |
|---|---|
| Async Clipboard API | Thinktecture.Blazor.AsyncClipboard |
| Badging API | Thinktecture.Blazor.Badging |
| File System API | KristofferStrube.Blazor.FileSystem |
| File System Access API | KristofferStrube.Blazor.FileSystemAccess |
| File Handling API | Thinktecture.Blazor.FileHandling |
| Web Share API | Thinktecture.Blazor.WebShare |
Tabelle 2: Eine Auswahl quelloffener NuGet-Wrapper-Pakete für moderne Webschnittstellen
Wie oben beschrieben, sind nicht alle Schnittstellen in jedem Browser und auf jedem Betriebssystem verfügbar. Daher muss zuvor geprüft werden, ob die Schnittstelle auf der Zielplattform auch wirklich nutzbar ist. Der Versuch, eine nicht existente Methode in JavaScript aufzurufen, führt zu einem Fehler. Daher bieten alle oben aufgeführten NuGet-Pakete die Methode IsSupportedAsync() an, mit der sich herausfinden lässt, ob die Schnittstelle auf dem jeweiligen System unterstützt wird (Listing 2).
Listing 2
var isSupported = await badgingService.IsSupportedAsync();
if (isSupported)
{
// enable badging feature
}
else
{
// use fallback mechanism or hide/disable feature
}Steht die Schnittstelle nicht zur Verfügung, gibt es zwei Möglichkeiten: Manchmal steht eine alternative Implementierung bereit, die anstelle der gewünschten Funktion verwendet werden kann. So unterstützt etwa Firefox auf Desktopsystemen das Web Share API nicht. Hier könnte stattdessen das mailto-Pseudoprotokoll genutzt werden. Wird es aufgerufen, öffnet sich der E-Mail-Client. Damit lassen sich Texte dann immerhin aus der Anwendung heraus teilen, wenngleich nicht ganz so komfortabel und umfangreich wie mit dem Web Share API. Gibt es auch keine Fallback-Implementierung, sollte die Funktion ausgegraut oder komplett versteckt werden.
Wichtig ist, dass die Anwendung ihren Dienst auf leistungsschwächeren Systemen nicht komplett quittiert, nur weil eine einzelne Funktionalität nicht verfügbar ist. Genau das beschreibt das Konzept des Progressive Enhancement, das sogar Namensbestandteil des PWA-Modells ist.
Das Badging API [6] ist eine sehr einfache Schnittstelle, die es Entwickler:innen erlaubt, ein Notification Badge auf dem Icon ihrer Anwendung anzuzeigen. Über diesen Weg können Anwendungen auf unaufdringliche Art und Weise das Vorhandensein von zu erledigenden Aufgaben, ungelesenen Mails oder Instant Messages kommunizieren. Das setzt voraus, dass es auch ein Icon der Anwendung gibt, sie also zuvor installiert wurde.
Nachdem das passende NuGet-Paket installiert wurde (dotnet add package Thinktecture.Blazor.Badging) und der BadgingService in der Program.cs der ServiceCollection hinzugefügt wurde (builder.Services.AddBadgingService()), kann eine Instanz des BadgingService an der gewünschten Stelle angefordert und die Methode SetAppBadgeAsync() mit der gewünschten Zahl aufgerufen werden:
await badgingService.SetAppBadgeAsync(3);Abbildung 6 zeigt eine installierte Blazor-Demoanwendung im Standalone-Anzeigemodus unter Windows. Auf ihrem Icon in der Taskleiste wird die Windows-spezifische Zahlenplakette mit der Zahl 3 angezeigt.
 Abb. 6: Auf dem Icon der installierten Blazor-PWA wird eine Zahlenplakette dargestellt
Abb. 6: Auf dem Icon der installierten Blazor-PWA wird eine Zahlenplakette dargestelltVerfügbar ist die Schnittstelle auf den Chromium-basierenden Browsern unter macOS und Windows sowie auf iOS und iPadOS. Unter Android funktionieren Badges grundsätzlich anders, weswegen das API hier nicht bereitgestellt wird.
Viele Produktivitätsanwendungen wie Büroprogramme, Bild- oder Videobearbeitungsprogramme arbeiten mit einem traditionellen dateibasierten Workflow: Dateien werden eingelesen, bearbeitet und im Dateisystem danach wieder überschrieben. Um diesen Workflow zu ermöglichen, wurde das File System Access API eingeführt. Es erlaubt Entwickler:innenn, ein Handle auf Dateien oder Verzeichnisse anzufordern. Damit können Dateien ausgelesen und überschrieben, aber auch gelöscht und neue Dateien erstellt werden.
Auch hier muss zuvor das passende NuGet-Paket KristofferStrube.Blazor.FileSystemAccess installiert, der Service der ServiceCollection hinzugefügt und die Unterstützung der Schnittstelle auf dem Zielsystem geprüft werden. Listing 3 zeigt, wie das File System Access API aus Blazor WebAssembly heraus angesprochen werden kann: Die Methode ShowOpenFilePickerAsync() auf dem IFileSystemAccessService öffnet einen Dateiauswahldialog. Mit Hilfe der FilePickerOptions kann angegeben werden, welche Dateiformate akzeptiert werden und ob mehr als eine Datei eingelesen werden soll.
Listing 3
try
{
var fileHandles = await _fileSystemAccessService
.ShowOpenFilePickerAsync(_filePickerOptions);
_fileHandle = fileHandles.Single();
}
catch (JSException ex)
{
Console.WriteLine(ex);
}Wählen Benutzer:innen im Picker eine Datei aus und bestätigen die Auswahl mit Open, wie in Abbildung 7 gezeigt, teilt der Browser das Datei-Handle mit der Website.
 Abb. 7: Auswahl einer Datei über das File System Access API
Abb. 7: Auswahl einer Datei über das File System Access APIDas File System Access API ist derzeit auf Desktopsystemen nur unter Chrome und Edge verfügbar. Apple und Mozilla möchten die Schnittstelle derzeit nicht implementieren. Glücklicherweise gibt es jedoch Fallback-Schnittstellen, um eine Datei vom Dateisystem einzulesen und danach im Downloads-Verzeichnis abzuspeichern. Damit lassen sich manche Anwendungen auch in anderen Browsern umsetzen.
Das File Handling API ist eine Erweiterung des File System Access API. Es erlaubt einer PWA, sich bei ihrer Installation als Bearbeitungsprogramm für bestimmte Dateiformate zu registrieren. Auch das ist derzeit nur unter Chrome und Edge auf dem Desktop möglich. Zur Implementierung des API sind zwei Teile erforderlich: Ein deklarativer Teil, bei dem die Unterstützung für bestimmte Dateierweiterungen beim Betriebssystem angemeldet wird, und ein imperativer Teil, bei dem die geöffnete Datei entgegengenommen wird.
Listing 4 zeigt, wie sich die Anwendung bei ihrer Installation als Bearbeitungsprogramm hinterlegen kann. Dazu muss dem Web App Manifest die Eigenschaft file_handlers hinzugefügt werden. Diese Eigenschaft nimmt ein Array entgegen, in dem verschiedene Registrierungen vorgenommen werden können. Jedes Registrierungsobjekt besteht aus einem Dictionary (Eigenschaft accept), das die unterstützten Mediatypen mit ihren jeweiligen Dateiendungen aufzählt. Da auch diese Schnittstelle plattformübergreifend verfügbar ist, müssen beide Angaben hinterlegt werden. Der URL in der Eigenschaft action wird aufgerufen, wenn die PWA mit einer Datei von diesem Format geöffnet wird. Auch ließe sich noch ein Icon hinterlegen, das der Dateiexplorer für Dateien mit dieser Erweiterung darstellen soll.
Listing 4
{
"file_handlers": [{
"action": "./",
"accept": {
"text/plain": [".txt"]
}
}]
}Wird die Anwendung unter Zuhilfenahme dieses Manifests installiert, registriert sie sich nun als Bearbeitungsprogramm für TXT-Dateien. Abbildung 8 zeigt die Blazor PWA im Öffnen-mit-Menü des Windows Explorers.
 Abb. 8: Eine Blazor PWA hat sich als Bearbeitungsprogramm für TXT-Dateien registriert
Abb. 8: Eine Blazor PWA hat sich als Bearbeitungsprogramm für TXT-Dateien registriertIm nächsten Schritt muss der Blazor-Anwendungscode noch angepasst werden, um eine Datei, mit der die PWA als Bearbeitungsprogramm geöffnet wurde, entgegenzunehmen. Auch hierfür muss das passende NuGet-Paket Thinktecture.Blazor.FileHandling installiert, der Service der Collection hinzugefügt und die Unterstützung ermittelt werden. Dann kann mit Hilfe der Methode SetConsumerAsync() ein Launch Consumer gesetzt werden. Dieser Callback nimmt die Startparameter der PWA entgegen. In der Eigenschaft Files findet sich dann die Liste der Handles, mit denen die Anwendung gestartet wurde. Sie entsprechen genau den Handles aus dem File System Access API, die oben demonstriert wurden. Listing 5 zeigt, wie durch die Handles iteriert werden kann und Inhalte aus den Textdateien ausgegeben werden können.
Listing 5
await _fileHandlingService.SetConsumerAsync(async (launchParams) =>
{
foreach (var fileSystemHandle in launchParams.Files)
{
if (fileSystemHandle is FileSystemFileHandle fileSystemFileHandle)
{
var file = await fileSystemFileHandle.GetFileAsync();
var text = await file.TextAsync();
Console.WriteLine(text);
}
}
});Progressive Web Apps bieten eine vielversprechende Alternative zu plattformspezifischen Anwendungen: Sie sind schnell und flexibel, sind breit verfügbar auf verschiedenen Endgeräten, einfach zu installieren und zu aktualisieren und können auch offline betrieben werden.
Daher können sie in einer Vielzahl von Anwendungsbereichen eingesetzt werden. Unter anderem lassen sich Produktivitätsanwendungen realisieren, ebenso wie integrierte Entwicklungsumgebungen oder Codeeditoren. Auch Kreativanwendungen wie Bild- oder Videobearbeitungsprogramme können als PWAs implementiert werden, zudem Büroanwendungen wie Textverarbeitungsprogramme, Tabellenkalkulationen oder Präsentationsprogramme. Nicht zuletzt bieten sich PWAs auch für Enterprise-Awendungen, wie z. B. ERP-Systeme oder Kundenportale, an.
Dass das Anwendungsmodell marktreif ist, demonstrieren gleich drei sehr bekannte Anwendungen: Spotify hat eine webbasierte Benutzeroberfläche. In den Desktopversionen von Spotify ist diese in einem Electron Wrapper verpackt. Das Spotify PWA unter open.spotify.com sieht dem Desktopclient daher zum Verwechseln ähnlich, sobald man es auf dem System installiert. Als cloudbasierte Anwendung hat es Spotify jedoch relativ leicht, eine Webvariante herauszugeben.
Anspruchsvoller ist da der Code-Editor Visual Studio Code von Microsoft, der auf lokalen Dateien arbeitet. Auch dessen Benutzeroberfläche war schon immer webbasiert. Sein Desktopclient ist mit Electron verpackt, um dem Editor Zugriff auf die plattformspezifischen Schnittstellen zu geben. Mit der Veröffentlichung des File System Access API war es jedoch für Microsoft möglich, Visual Studio Code unter vscode.dev als Webvariante herauszugeben (Abb. 9). Damit können ganze Verzeichnisse geöffnet und bearbeitet werden, auch Plug-ins funktionieren, sofern sie keinen plattformspezifischen Anteil aufweisen. Was jedoch nicht lauffähig ist, ist das Terminal. Denn aus dem Webbrowser heraus gibt es keinen Shellzugriff und es ist unwahrscheinlich, dass er ohne weitere Einschränkungen jemals eingeführt wird. Dennoch lässt sich der Codeeditor damit schnell und unkompliziert öffnen und einfache Anpassungen können vorgenommen werden, ganz ohne ein großes Installationspaket herunterladen zu müssen.
 Abb. 9: Visual Studio Code läuft dank des File System Access API direkt im Browser
Abb. 9: Visual Studio Code läuft dank des File System Access API direkt im BrowserVisual Studio Code ist allerdings HTML- und TypeScript-basiert. Etwas näher an Blazor WebAssembly ist die Webvariante von Photoshop, die Adobe im September 2021 veröffentlichte. Die Anwendung setzt ein Creative-Cloud-Abonnement voraus und ist dazu gedacht, kleinere Anpassungen an Bildern vornehmen zu können, ohne gleich den kompletten, sehr umfangreichen Photoshop-Client herunterladen zu müssen.
Photoshop ist eine über Jahrzehnte gewachsene Anwendung. Um in C++ geschriebenen Bestandscode ins Web zu bringen, kooperierte Adobe mit Google, das fehlende Features in WebAssembly und andere fehlende Webschnittstellen implementierte [7]. Und so erhält alter Photoshop-Bestandscode dank WebAssembly ein zweites Leben im Browser. Neu geschriebene Progressive Web Apps reihen sich also in gute Gesellschaft ein.
 Abb. 10: Dank Googles Unterstützung brachte Adobe Photoshop ins Web
Abb. 10: Dank Googles Unterstützung brachte Adobe Photoshop ins WebDank der Progressive Web Apps wird der alte Java-Traum „Write once, run anywhere“ endlich Realität. Über die Jahre ist das Anwendungsmodell immer leistungsfähiger geworden, was die Verfügbarkeit von Pushbenachrichtigungen unter iOS und iPadOS erneut unterstreicht. Dank Initiativen wie Project Fugu ist vorläufig auch kein Ende in Sicht. Außerdem sind Progressive Web Apps gut zugänglich, da sie einfach aus dem Browser heraus aufgerufen werden können.
Blazor WebAssembly wiederum ist interessant für Teams mit bestehendem Wissen in C# und .NET. In C# geschriebene Datenmodelle oder Validierungslogik können zwischen Client und Server geteilt werden und selbst bestehender Code kann gegebenenfalls ins Web übertragen werden.
Allerdings gibt es auch Einschränkungen im Anwendungsmodell der PWAs: Von Nachteil ist, dass die Installation einer PWA für Anwender:innen möglicherweise nicht offensichtlich ist. Die Installation wird unter iOS und iPadOS über das Teilen-Menü des Browsers ausgeführt, dazu müssen Anwender:innen innerhalb des Menüs auch noch nach unten scrollen. In den Chromium-basierten Browsern wird die Installation in Form einer kleinen Schaltfläche auf der rechten Seite der Adresszeile angeboten.
Darüber hinaus können nur die Schnittstellen genutzt werden, die direkt im Browser verfügbar sind. Bestimmte Anwendungsarten wie Antivirenscanner oder Cloud-Sync-Programme, die einer besonders tiefen plattformspezifischen Integration bedürfen, können nicht als PWA implementiert werden. Schließlich sind nicht alle interessanten APIs auf allen Betriebssystemen und Browsern implementiert, was die Funktionalität einer PWA auf diesen Geräten einschränken kann.
Regelmäßig News zur Konferenz und der .NET-Community
Schließlich weist auch Blazor WebAssembly Einschränkungen auf. Während Entwickler:innen nun vorrangig mit C# arbeiten können, werden sie trotzdem Kenntnisse in HTML, CSS und auch JavaScript benötigen. Darüber hinaus funktioniert die Entwicklungsunterstützung nur in Microsoft Visual Studio auf Windows gut, in Rider wird Blazor bisher nur stiefmütterlich unterstützt.
Das wohl größte Problem von Blazor WebAssembly ist allerdings die umfangreiche Bundle-Größe der Anwendung. Eine Hello-World-Anwendung wird schon im Minimalfall (z. B. durch Entfernung der Kulturinformationen) rund 2 MByte groß – ein Vielfaches, verglichen mit den 50 KByte einer einfachen Angular-Anwendung. Da wird auch die Ahead-of-Time-Kompilierung (AoT) keine Abhilfe schaffen; hier werden die Apps tendenziell sogar noch größer. Die Bundle-Größe führt daher zu einem Nachteil in der initialen Ladezeit, insbesondere bei Nutzung von weniger schnellen Verbindungen, etwa bei mobilen Anwendungen.
Um dieses Problem abzumildern, setzt Blazor ein recht aggressives Caching ein. Das kann allerdings zur Entwicklungszeit zu einiger Verwirrung führen, wenn im Browser eine veraltete Version angezeigt wird.
Des Weiteren werden bei Blazor WebAssembly DLL-Dateien zum Browser übertragen. Da es sich dabei um ausführbare Dateien handelt, können Unternehmensproxys und -firewalls einen Strich durch die Rechnung machen, sodass die Blazor-Anwendung gar nicht erst startet. Mit dem WebCIL-Format ist hier jedoch bereits eine Lösung in Sicht.
Zusammengefasst ist Blazor WebAssembly für B2C-Anwendungen oder andere Umgebungen, die nicht kontrolliert werden können, möglicherweise nicht die beste Wahl.
Blazor, Progressive Web Apps und Project Fugu sind großartige Technologien, um Webanwendungen zu entwickeln: Blazor WebAssembly ermöglicht es Entwickler:innen, ihre bestehenden C#- und .NET-Kenntnisse zu nutzen, um Apps zu entwickeln, die nicht nur auf allen relevanten Browsern laufen, sondern auch ohne Installation direkt im Browser. Progressive Web Apps verbessern das Nutzungserlebnis von Webanwendungen durch Offlinefähigkeit und Installierbarkeit. Project Fugu bringt auch weiterhin neue Schnittstellen ins Web, um eine noch tiefere Integration mit dem Betriebssystem zu erreichen. C#-basierte NuGet-Pakete aus der Community erleichtern die Verwendung dieser Schnittstellen. Zu guter Letzt sollte immer an das Konzept des Progressive Enhancement gedacht werden, um sicherzustellen, dass Anwender:innen älterer oder weniger leistungsfähiger Browser die App weiterhin benutzen können. Wenn Sie all diese Konzepte berücksichtigen, schreiben Sie großartige Webanwendungen genau einmal und bringen Sie zu all Ihren Anwender:innen, ganz egal, welche Plattform sie nutzen.
The post PWAs mit Blazor WebAssembly appeared first on BASTA!.
]]>The post .NET 7.0 bringt Desktop-Features zu .NET MAUI appeared first on BASTA!.
]]>Auch wenn es die versprochene Erweiterung mit .NET 6 schon gab – schließlich lief MAUI bereits unter Windows und macOS –, wirkte die Desktopumsetzung an einigen Stellen noch unfertig. Umso erfreulicher ist es, dass der Fokus der neuen Funktionen von .NET MAUI klar im Desktopbereich liegt.
Das Öffnen mehrerer Anwendungsfenster ist aus der Desktopentwicklung seit über 30 Jahren nicht mehr wegzudenken. Unter .NET MAUI und dem Vorgänger Xamarin.Forms war es aufgrund der ursprünglichen Fokussierung auf mobile Betriebssysteme jedoch nicht ohne weiteres möglich. Mit .NET 7 gibt es nun den in Listing 1 gezeigten plattformübergreifenden Weg zum Öffnen neuer Fenster über die Methode OpenWindow des Application-Objekts.
Listing 1
private void OpenDetailsPageInNewWindow(Session session)
{
var detailsVM = new SessionDetailPageViewModel
{
Session = session
};
var sessionPage = new SessionDetailPage(detailsVM);
var window = new Window(sessionPage);
Application.Current.OpenWindow(window);
}Die neue Funktionalität, die Sie in Abbildung 1 im Einsatz sehen, kann unter Android, macOS und iPadOS (also iOS auf dem iPad) genutzt werden. Auf dem iPhone können keine weiteren Fenster geöffnet werden.

Das Öffnen neuer Fenster ist nicht die einzige Verbesserung im Fensterumfeld, die .NET MAUI unter .NET 7 mitbringt. Unter Windows können außerdem Fenstergröße und Fensterposition konfiguriert werden, wie Listing 2 zeigt. Der abgebildete Quellcode läuft so jedoch nur unter Windows. Unter macOS gibt es zumindest einen Workaround, über den die Fenstergröße gesetzt werden kann, unter Android und iOS ist es gar nicht möglich. Eine detaillierte Anleitung zum Workaround finden Sie unter [1].
Listing 2
protected override Window CreateWindow(IActivationState activationState)
{
var window = base.CreateWindow(activationState);
// Fensterposition setzen
window.X = 300;
window.Y = 100;
// Größe des Fensters definieren
window.Width = 700;
window.Height = 800;
return window;
}Regelmäßig News zur Konferenz und der .NET-Community
Bereits unter Xamarin.Forms gab es das SwipeView-Element, mit dem über eine horizontale Wischgeste ein seitliches Kontextmenü, ähnlich wie man es von E-Mail- oder Messenger-Apps auf dem Mobiltelefon kennt, öffnen kann. Dieses Feature gibt es auch unter .NET MAUI, nur ist es leider für die meisten Desktopnutzer:innen unbenutzbar. Denn eine Wischgeste zum Öffnen eines Menüs ist unter Desktopbetriebssystemen im Unterschied zu Mobilgeräten unüblich und dürfte daher von den meisten Benutzer:innen übersehen werden. Außerdem lässt sich diese Geste nicht mit der Maus durchführen, sondern nur auf einem Windows-Gerät mit Touchscreen.
Microsoft löst das Problem mit den in Abbildung 1 gezeigten neuen Kontextmenüs. Sie lassen sich unter Windows und macOS wie gewohnt über einen Klick auf die sekundäre Maustaste öffnen. Unter Android und iOS stehen sie nicht zur Verfügung. Wie Listing 3 zeigt, werden Kontextmenüeinträge durch MenuFlyoutItem-Elemente umgesetzt, die über einen Text, ein Command oder einen Click Event Handler sowie ein Icon verfügen können. Icons werden jedoch nur unter Windows, nicht aber unter macOS unterstützt. Neben MenuFlyoutItem-Elementen gibt es noch den MenuFlyoutSeperator zur Anzeige einer Trennlinie und das MenuFlyoutSubItem-Element zur Definition von Untermenüs.
Die neuen ToolTips sind übrigens ein eleganter Weg, die Benutzer:innen dezent darauf hinzuweisen, dass ein Kontextmenü geöffnet werden kann. Genau wie Kontextmenüs, die Sie auch in Listing 3 sehen, können ToolTips zu jedem Bildschirmelement hinzugefügt werden.
Listing 3
<Grid RowDefinitions="25, auto"
ToolTipProperties.Text="Kontextmenü über Rechtsklick öffnen">
<Label Text="{Binding Time}" />
<Label Text="{Binding Title}" Grid.Row="1" FontSize="Subtitle" FontAttributes="Bold"/>
<FlyoutBase.ContextFlyout>
<MenuFlyout>
<MenuFlyoutItem Text="Favorit" Command="{Binding FavoriteCommand }" />
<MenuFlyoutItem Text="In neuem Fenster öffnen" Command="{Binding OpenNewWindowCommand }" >
<MenuFlyoutItem.IconImageSource>
<FontImageSource FontFamily="FA-6-Solid-900" Glyph="{x:StaticResource IconUpRightFromSquare}" Color="{AppThemeBinding Light=Black, Dark=White}" />
</MenuFlyoutItem.IconImageSource>
</MenuFlyoutItem>
<MenuFlyoutSeparator/>
<MenuFlyoutSubItem Text="Sprecher anrufen">
<MenuFlyoutItem Text="Geschäftlich" Command="{Binding CallSpeakerBusinessCommand }"/>
<MenuFlyoutItem Text="Privat" Command="{Binding CallSpeakerPrivateCommand }" />
</MenuFlyoutSubItem>
</MenuFlyout>
</FlyoutBase.ContextFlyout>
</Grid>Auf mobilen Geräten wird primär der Finger zur Interaktion mit Apps genutzt. Neben Tipp- sind Wischgesten die häufigsten Aktionen, die man hier ausführt. Maus-Events wie MouseOver, MouseEnter oder MouseMove konnten bisher unter .NET MAUI genau wie zuvor unter Xamarin.Forms aufgrund der Fokussierung auf Fingereingaben auf Mobilgeräten nicht behandelt werden.
Unter .NET 7 können Entwickler:innen nun auch die folgenden Mausgesten behandeln:
PointerEntered: Die Maus wird erstmalig über einem Element positioniert.
PointerMoved: Die Maus wird über einem Element bewegt.
PointerExited: Die Maus verlässt ein Element.
Zusätzlich zu den drei Gesten kann nun auch der sekundäre bzw. Rechtsklick behandelt werden. Listing 4 zeigt die Registrierung der entsprechenden Event Handler im XAML-Code, Listing 5 eine beispielhafte Behandlung in C#. Im gezeigten Beispiel wird die Farbe eines Rechtecks über eine Farbanimation verändert, sobald Benutzer:innen die Maus über das Rechteck bewegen oder sie wieder hinausbewegen.
Listing 4
<Rectangle BackgroundColor="{StaticResource Primary}"
WidthRequest="300"
HeightRequest="200"
HorizontalOptions="Center"
VerticalOptions="Center"
ToolTipProperties.Text="Hover und Klick">
<Rectangle.GestureRecognizers>
<TapGestureRecognizer Buttons="Primary" Tapped="PrimaryTapped" />
<TapGestureRecognizer Buttons="Secondary" Tapped="SecondaryTapped" />
<PointerGestureRecognizer
PointerEntered="OnPointerEntered"
PointerExited="OnPointerExited"
PointerMoved="OnPointerMoved" />
</Rectangle.GestureRecognizers>
</Rectangle>
<Label x:Name="PositionLabel" Text="Pos:"/>Listing 5
private async void SecondaryTapped(object sender, TappedEventArgs e)
{
await DisplayAlert("Click", "Secondary", "OK");
}
private async void OnPointerEntered(object sender, PointerEventArgs e)
{
var rectangle = sender as Rectangle;
await rectangle.BackgroundColorTo(Colors.Red);
}
private async void OnPointerExited(object sender, PointerEventArgs e)
{
var rectangle = sender as Rectangle;
await rectangle.BackgroundColorTo(Color.FromArgb("#512BD4"));
}
private void OnPointerMoved(object sender, PointerEventArgs e)
{
Point? windowPosition = e.GetPosition(null);
PositionLabel.Text =
$"Position: x: {windowPosition.Value.X} - y: {windowPosition.Value.Y}";
}Wer die Änderung der Optik eines Steuerelements, sobald die Maus darüber bewegt wird, lieber deklarativ durchführt, kann dazu den neuen PointerOver VisualState des VisualStateManager nutzen. In Listing 6 sehen Sie, wie es geht. Im gezeigten Beispiel wird die Hintergrundfarbe eines Buttons auf Rot geändert, sobald die Maus über den Button bewegt wird. Eine ausführliche Dokumentation zu Visual States unter .NET MAUI gibt es unter [2].
Listing 6
<Button Text="Beweg die Maus über mich!">
<VisualStateManager.VisualStateGroups>
<VisualStateGroup x:Name="CommonStates">
<VisualState x:Name="Normal">
<VisualState.Setters>
<Setter Property="BackgroundColor" Value="Blue" />
</VisualState.Setters>
</VisualState>
<VisualState x:Name="PointerOver">
<VisualState.Setters>
<Setter Property="BackgroundColor" Value="Red" />
</VisualState.Setters>
</VisualState>
</VisualStateGroup>
</VisualStateManager.VisualStateGroups>
</Button>Alle bisher in diesem Artikel vorgestellten neuen Funktionen bezogen sich auf die Entwicklung von Desktop-Apps mit .NET MAUI. Die letzte neue Funktion, die Darstellung von Karten, wird unter macOS, Android und iOS unterstützt. Unter Windows wirft die Kartenkomponente einen Laufzeitfehler, da das zugrunde liegende UI-Framework WinUI 3 keine Kartenkomponente besitzt. Auf den drei anderen Betriebssystemen wird jeweils das native Kartensteuerelement des Betriebssystems genutzt. Abbildung 2 zeigt zum Beispiel die Nutzung von Google Maps unter Android.
Mit dem Map-Element können Sie im Code auf verschiedene Weise interagieren. Listing 7 zeigt, wie Sie den gezeigten Kartenausschnitt deklarativ über die Eigenschaft MapSpan festlegen können. In Listing 8 sehen Sie, wie Sie per C#-Quellcode einen Pin zur Karte hinzufügen können.
Listing 7
<maps:Map x:Name="map">
<x:Arguments>
<MapSpan>
<x:Arguments>
<sensors:Location>
<x:Arguments>
<x:Double>50.5014483</x:Double>
<x:Double>7.308297599999</x:Double>
</x:Arguments>
</sensors:Location>
<x:Double>0.01</x:Double>
<x:Double>0.01</x:Double>
</x:Arguments>
</MapSpan>
</x:Arguments>Listing 8
Pin qualityBytesPin = new Pin
{
Location = new Location(50.5014483, 7.308297599999),
Label = "Quality Bytes GmbH",
Address = "Bad Breisig",
Type = PinType.Place
};
map.Pins.Add(qualityBytesPin);Zusätzlich zu den beiden gezeigten Funktionen können Sie außerdem Formen wie Kreise, Linien oder Polygone auf die Karte zeichnen oder die Darstellung über die Eigenschaft MapType der Karte auf eine Straßen-, Satelliten-, oder Hybridansicht festlegen.

Zusätzlich zur Umsetzung neuer Funktionen setzte sich das .NET-MAUI-Team intensiv mit dem Thema Performance auseinander. Unter [3] beschreibt Microsoft, welche Verbesserungen unter der Haube vorgenommen wurden, um die Performance zu optimieren. Im Fokus standen bei der Optimierung die allgemeine Rendering-Geschwindigkeit sowie das Scroll-Verhalten in Listen.
Über die Performance hinaus arbeitete Microsoft auch an der Stabilität. Im Bereich Visual-Studio-Integration konnten 80 Prozent der Bugs von Visual Studio 2022 17.3 und .NET MAUI 6 unter Visual Studio 2022 17.4 und .NET MAUI 7 behoben werden. Außerdem wurde eine beträchtliche Anzahl an GitHub-Issues geschlossen.
Dass das Team hier jedoch noch einen weiten Weg vor sich hat, zeigen die knapp 2 000 offenen Issues. Der Fairness halber muss allerdings erwähnt werden, dass nicht alle Issues Fehler sind, sondern auch Feature-Requests sowie Duplikate.
Die Anzahl der neuen .NET-MAUI-Funktionen mag auf den ersten Blick enttäuschen, schließlich lassen sie sich an zwei Händen abzählen. Zieht man jedoch in Betracht, dass das Team nur fünfeinhalb Monate Zeit hatte und darüber hinaus an Performance und Stabilität gearbeitet hat, sieht es gar nicht mehr so schlecht aus.
Die neuen Funktionen haben sicherlich einen geringen Wow-Faktor, schließen aber wichtige Funktionslücken und machen .NET MAUI somit immer mehr zu einer validen Alternative für die Entwicklung plattformübergreifender Desktopanwendungen.
[2] https://learn.microsoft.com/de-de/dotnet/maui/user-interface/visual-states?view=net-maui-7.0
[3] https://devblogs.microsoft.com/dotnet/dotnet-7-performance-improvements-in-dotnet-maui/
The post .NET 7.0 bringt Desktop-Features zu .NET MAUI appeared first on BASTA!.
]]>The post Eine Einführung in die Arbeit mit Azure Cognitive Services appeared first on BASTA!.
]]>Im Interesse der didaktischen Ehrlichkeit sei schon hier zweierlei angemerkt: Erstens gilt, dass die Nutzung von aus der Cloud bezogenen Services in vielen Fällen langfristig teurer ist als das Selbstentwickeln. Es ist also immer empfehlenswert, die an Microsoft überwiesenen Kosten im Blick zu behalten.
Zweitens sei angemerkt, dass Microsoft die Azure Cognitive Services explizit nicht als Mittel zur Promotion der hauseigenen Windows-Plattform nutzt. So gut wie alle hier vorgestellten Operationen lassen sie sich analog auch unter anderen Betriebssystemen benutzen. Für viele APIs stehen auch REST-Interfaces beziehungsweise Python-SDKs zur Verfügung.
Aus der Ausrichtung der Cognitive Services als Azure-Cloud-Service folgt, dass im ersten Schritt logischerweise ein Azure-Konto eingerichtet werden muss, das die für die Authentifikation erforderlichen Connection Strings zur Verfügung stellt.
Interessant ist dabei, dass Microsoft bei den Zugriffsaccounts zwei Gruppen unterscheidet. Wem es, wie dem Autor dieser Zeilen, vor allem auf Bequemlichkeit und nicht so sehr auf Kosten ankommt, ist mit einem Account vom Typ „Cognitive Services Multi-service Account“ am besten gedient. Dabei handelt es sich um eine Catch-All-Ressource, die mit einem Zugriffsschlüssel die folgenden AI-Dienstleistungen gleichermaßen ansprechbar macht:
Decision: Content Moderator
Language: Language, Translator
Speech: Speech
Vision: Computer Vision, Custom Vision, Face
Weniger schön ist am Cognitive Services Multi-service Account lediglich, dass Microsoft seine Nutzung von der (für Neuanmeldungen) zur Verfügung stehenden kostenlosen Kontingentierung ausnimmt.
Beachten Sie, dass die Nutzung der APIs die Cognitive-Services-Contributor-Rolle voraussetzt. Weitere Informationen zur Konfiguration finden sich unter [1] und [2].
Im nächsten Schritt suchen wir im Azure-Backend nach einer Ressource vom Typ Cognitive services multi-service account. Klicken Sie im nächsten Schritt auf den hellblauen Knopf Create Cognitive services multi-service account, um eine neue Ressource zu erzeugen. Die Zuweisung von Ressourcengruppe, Name und Co. erfolgt dabei wie gewohnt.
Im Bereich der Service Tier ist es empfehlenswert, die Option S0 auszuwählen, sie führt zur Anwendung der unter [3] bereitstehenden Preise. Im Allgemeinen gilt dabei, dass 1 000 Anfragen immer rund einen US-Dollar kosten. Die restlichen Einstellungen sind im Allgemeinen weniger relevant, weshalb wir in die Rubrik Review + Create wechseln und danach durch Anklicken des Create-Knopfes das Backend zum Erzeugen des neuen Containers animieren.
Nach dem erfolgreichen Durchlaufen des Generationsprozesses wechseln Sie im Backend in die Eigenschaften des Services, und öffnen danach die Rubrik Resource Management | Keys and Endpoint. Das Backend blendet dort den in Abbildung 1 gezeigten Dialog ein, der das Herunterladen beziehungsweise Sichtbarmachen der verschiedenen kryptographischen Schlüssel ermöglicht.
 Abb. 1: Diese Schlüssel authentifizieren AI-Applikationen im Backend
Abb. 1: Diese Schlüssel authentifizieren AI-Applikationen im BackendBeachten Sie, dass das in Besitz nehmen dieser Strings dem neuen Eigentümer das Ausführen beliebiger Berechnungen zu Ihren Kosten verursacht. Wer sie in einen End-User-Facing-Dienst verpackt, begeht eine Original Sin.
Das vernünftige Managen derartiger Credentials ist allerdings ein Thema der fortgeschrittenen Kryptographie, mit dem wir uns in diesem Artikel nur insofern weiter auseinandersetzen werden, als Sie der Autor vor dem Nutzen einer Stringkonstante in einem Assembly nochmals explizit warnt. In diesem Zusammenhang sei allerdings noch auf [4] verwiesen, wo Microsoft einige (lesenswerte) Zusatzhinweise zu dieser Thematik untergebracht hat.
Regelmäßig News zur Konferenz und der .NET-Community
Wie in der Einleitung festgestellt gilt, dass der Großteil der im Rahmen der Azure Cognitive Services zur Verfügung gestellten Dienste im Hintergrund über ein REST API realisiert wird: Wer ausreichend Geduld mitbringt, kann die Dienste also mit einem beliebigen System ansprechen, sofern dieses zum Absetzen von HTTP-Anfragen befähigt ist.
Das manuelle Implementieren von REST APIs ist allerdings eine erfahrungsgemäß wenig dankbare Aktivität, weshalb Microsoft je nach Popularität des jeweiligen Diensts mehr oder weniger umfangreiche SDKs für verschiedene Zielsysteme zur Verfügung stellt. Im Interesse der Bequemlichkeit wird der Autor in den folgenden Schritten auf Visual Studio 2022 setzen. Unser erstes Projekt entsteht auf Basis der Vorlage Leere App (Universelle Windows-App). Als Projektname sei der String SUSCogni1 vergeben, im Bereich der Zielversionen von Windows erweist sich das Cognitive Services API als vergleichsweise wenig anspruchsvoll.
Nach dem erfolgreichen Durchlaufen des Projektgenerators ist es empfehlenswert, die NuGet-Paketliste zu öffnen: Die Auslieferung der für die Cognitive Services benötigten Komponenten erledigt Microsoft direkt über den in .NET integrierten Paketmanager.
Im nächsten Schritt geben wir den Suchstring Microsoft.Azure.CognitiveServices.Vision.ComputerVision ein und entscheiden uns für die Installation der aktuellsten stabilen Version. Zum Zeitpunkt der Drucklegung bekommen wir die Version 7.0.1 ins Projekt integriert.
Wir werden hier einen ersten Versuch mit dem Bildanalyse-API durchführen: Die Vorgehensweise mit der Installation eines NuGet-Pakets gilt allerdings analog für verschiedene andere Systeme. Anschließend ist es empfehlenswert, einige lokale Variablen mit den für die Authentifikation notwendigen Credentials anzulegen. Die Nutzung der beiden, nach dem folgenden Schema benannten Members hat sich im Bereich des Azure-Codes fast schon als Standard etabliert:
public sealed partial class MainPage : Page {
static string subscriptionKey = "df. . .";
static string endpoint = "https://susexperiment.cognitiveservices.azure.com/";Ob Sie im Feld subscriptionKey den Wert von Key1 oder von Key2 eingeben, bleibt dabei Ihnen überlassen. Den korrekten Endpoint URL finden Sie ebenfalls im Azure-Backend (Abb. 1).
Die .NET SDKs erledigen die eigentliche Kommunikation zwischen Applikation und lokalem Code normalerweise durch eine Abstraktionsklasse, die im Allgemeinen als <Service>-Client bezeichnet wird.
Wer wie wir hier mit einem UWP-Projektskelett arbeitet, sollte diese im ersten Schritt als Membervariable der Mainpage oder einer anderen Klasse anlegen:
public sealed partial class MainPage : Page {
ComputerVisionClient myClient;Die eigentliche Initialisierung unter Nutzung der beiden Credential-Variablen ist dann keine Raketenphysik:
public MainPage() {
this.InitializeComponent();
myClient = new ComputerVisionClient(new ApiKeyServiceClientCredentials(subscriptionKey)) { Endpoint = endpoint };
}Die Entscheidung, auf ein UWP-Projektskelett zu setzen, setzt hier ein wenig Umgreifen voraus. UWP-Applikationen dürfen von Haus aus ja nicht mit dem kompletten Dateisystem der Host-Workstation interagieren. Als Workaround bietet sich die Nutzung eines File Picker an, zu dessen Aktivierung wir im ersten Schritt in der MainPage.xaml einen neuen Button einschreiben müssen.
Die eigentliche Realisierung erfolgt dann fast schon analog zum Common-Dialog. Durch das Async-Setzen des Klick-Handlers ist sichergestellt, dass wir die Ergebnisse des Aufrufs von PickSingleFileAsync direkt in der Methode abernten können (Listing 1).
Listing 1
private async void CmdStartPicker_Click(object sender, RoutedEventArgs e) {
var picker = new Windows.Storage.Pickers.FileOpenPicker();
picker.ViewMode = Windows.Storage.Pickers.PickerViewMode.Thumbnail;
picker.SuggestedStartLocation = Windows.Storage.Pickers.PickerLocationId.PicturesLibrary;
picker.FileTypeFilter.Add(".jpg");
picker.FileTypeFilter.Add(".jpeg");
Windows.Storage.StorageFile file = await picker.PickSingleFileAsync();Sofern sich der Benutzer erfolgreich für eine Datei entschieden hat, bekommen wir diese in Form eines StorageFile-Objekts zurückgeliefert. Dieses übergeben wir danach an die Methode analyzeFile, in der wir im nächsten Schritt die eigentliche Interaktion mit den Cognitive Services unterbringen werden:
if (file != null) {
analyzeFile(file);
}
}Der Kopf von analyzeFile beginnt mit der Festlegung der zu analysierenden Features. In der Welt des Machine Learnings, Microsoft übernimmt diese Begriffe in Azure, ist ein Feature dabei eine Gruppe von Attributen, die ein ML-Algorithmus aus angelieferten Informationen zu extrahieren hat (Listing 2).
Listing 2
private async void analyzeFile(Windows.Storage.StorageFile _aFile) {
List<VisualFeatureTypes?> features = new List<VisualFeatureTypes?>() {
VisualFeatureTypes.Categories,
VisualFeatureTypes.Description,
VisualFeatureTypes.Objects
};Microsoft erlaubt Entwickler:innen das Deselektieren nicht benötigter Features, um Rechenleistung einzusparen und geringere Kosten zu verursachen. Für unser eher kleines Beispiel wollen wir uns auf die gezeigten drei Features beschränken. Wer mehr Funktionen nutzen möchte, übergibt einfach mehr der in VisualFeatureTypes angelegten Felder.
Die von Microsoft vorgegebenen ML-Beispiele arbeiten meistens mit im Internet frei ansprechbaren Bildern. Da wir hier allerdings ein im Dateisystem befindliches Bild verarbeiten, müssen wir dieses in ersten Schritt in einen Readable Stream umwandeln:
var aStream = await _aFile.OpenStreamForReadAsync();
using (Stream analyzeImageStream = aStream)
{
StringWriter myW = new StringWriter();
Console.SetOut(myW);Die von den Azure Cognitive Services zurückgegebenen Analyseergebnisse präsentabel zu machen, ist in vielen Fällen eine Wissenschaft für sich. Microsoft bietet in den Codebeispielen allerdings umfangreichen Analysecode an, der (leider) immer auf die Methode Console.WriteLine zurückgreift, um die Analyseergebnisse nach außen zu tragen.
Ein eleganter Weg, um das Abernten der in die Konsole ausgegebenen Strings zu ermöglichen, ist die Nutzung der Methode SetOut. Sie erlaubt, wie hier gezeigt, das Übergeben eines beliebigen StringWriter, der dann die diversen an Write und WriteLine übergebenen Strings aufnimmt und für die spätere Weiterverarbeitung vorhalten kann.
Im nächsten Schritt folgt bei uns jedenfalls ein Aufruf der Methode AnalyzeImageInStreamAsync, die sich um die Übertragung des Bildes in Richtung des Azure-Backends und um das Abernten der ML-Ergebnisse kümmert:
ImageAnalysis results = await myClient.AnalyzeImageInStreamAsync(analyzeImageStream, visualFeatures: features);Microsoft zeigt sich im Bereich der Anforderungen an die übertragenen Bilder (Abb. 2) vergleichsweise kompromissbereit.
 Abb. 2: Microsofts AI-Dienste sind im Bereich der Eingabedaten flexibel
Abb. 2: Microsofts AI-Dienste sind im Bereich der Eingabedaten flexibelWichtig ist in diesem Zusammenhang, dass die Abarbeitung der AI-Prozesse je nach Belastung die eine oder andere Sekunde in Anspruch nimmt. Beginnen wir danach mit der Auswertung der im Description-Feld angelieferten Ergebnisse (Listing 3).
Listing 3
if (null != results.Description && null != results.Description.Captions)
{
Console.WriteLine("Summary:");
foreach (var caption in results.Description.Captions)
{
Console.WriteLine($"{caption.Text} with confidence {caption.Confidence}");
}
Console.WriteLine();
}Unter Description versteht Microsoft dabei textuelle Informationen, die den Inhalt des hochgeladenen Bildes mehr oder weniger genau zu beschreiben versuchen. Da ML-Algorithmen so gut wie immer nur Prognosen treffen, liefert Microsoft in caption.Confidence außerdem noch immer einen numerischen Wert zurück, der über die Sicherheit des Zutreffens der jeweiligen Prognose informiert.
Im nächsten Schritt werten wir außerdem noch die Ergebnisse der Objektanalyse aus. Dabei handelt es sich um einen ML-Algorithmus, der das Bild als Ganzes ansieht und versucht, zu bestimmen, welche Regionen des jeweiligen Bildes von welchem Objekt berührt werden (Listing 4).
Listing 4
if (null != results.Objects)
{
Console.WriteLine("Objects:");
foreach (var obj in results.Objects)
{
Console.WriteLine($"{obj.ObjectProperty} with confidence {obj.Confidence} at location {obj.Rectangle.X}, " + $"{obj.Rectangle.X + obj.Rectangle.W}, {obj.Rectangle.Y}, {obj.Rectangle.Y + obj.Rectangle.H}");
}
Console.WriteLine();
}
TxtOut.Text = myW.ToString();
}
}Für die Ausgabe der von den Azure Cognitive Services errechneten Ergebnissen fügt der Autor in der Datei MainPage.xaml noch eine Textbox hinzu, die die im StringWriter-Objekt angelieferten Informationen auf den Bildschirm bringt. Mit zwei auf der Intertabac in Dortmund geschossenen Bildern präsentiert sich das Programm dann wie in Abbildung 3 und 4 gezeigt.
 Abb. 3: Sowohl die Landewyck-Managerin …
Abb. 3: Sowohl die Landewyck-Managerin …
Die Cognitive Services sind nicht auf die Analyse von Bitmaps und anderen Bildmaterialien beschränkt. Spätestens seitdem Microsoft das hinter Dragon stehenden Unternehmen Nuance aufgekauft hat, ist klar, dass man auch im Bereich von Sprachsamples Aktivitäten plant.
Zum Zeitpunkt der Drucklegung sind diese teilweise noch nicht für die Allgemeinheit freigegeben. Wer beispielsweise die Sprechererkennung der Cognitive Services nutzen möchte, muss Microsoft noch explizit um Freischaltung des Accounts ersuchen.
Als nächste Aufgabe wollen wir uns deshalb der Sprachsynthese zuwenden. Microsoft versteht darunter das Anliefern eines Texts an die Cognitive Services, die daraufhin eine wiedergebbare Tondatei liefern. Analog zu Dragon unterstützt Microsoft auch das Umwandeln von Sprache in Text. Das ist allerdings eine Aufgabe, der wir uns jetzt nicht zuwenden wollen.
Für die eigentliche Nutzung wollen wir ein weiteres Beispiel erzeugen, das abermals auf Basis der Vorlage Leere App (Universelle Windows-App) entsteht. Der Projektname lautet nun aber SUSCogni2. Anschließend öffnen wir die NuGet-Paketverwaltung, in der wir nun aber nach dem Paket Microsoft.CognitiveServices.Speech suchen. Installieren Sie es in einer aktuellen Version, und wechseln Sie danach in die Codedatei. Da das Windows-Betriebssystem selbst auch eine (funktionsreduzierte) TTS-Implementierung mitbringt, ist es an dieser Stelle ratsam, über eine Using-Deklaration die Nutzung der Azure Cognitive Services dateiweit vorzuschreiben:
using Microsoft.CognitiveServices.Speech;Im nächsten Schritt ist man versucht, nach folgendem Schema die von weiter oben bekannten Credentials abermals als Membervariable in der Page anzulegen:
public sealed partial class MainPage : Page {
static string subscriptionKey = "d. . .";
static string endpoint = "https://susexperiment.cognitiveservices.azure.com/";
SpeechSynthesizer mySynth;Wer diese Anweisungen befolgt, ist allerdings auf der falschen Fährte. Ärgerlicherweise gibt es im Speech SDK mit der Methode FromEndpoint sogar eine Funktion, die das Vorhandensein einer Authentifizierungsmöglichkeit auf Basis von Endpoint und SubscriptionKey andeutet:
public MainPage() {
this.InitializeComponent();
var speechConfig = SpeechConfig.FromEndpoint(new Uri(endpoint), subscriptionKey);
mySynth = new SpeechSynthesizer(speechConfig);Das Nutzen dieses Codes führt zwar zu einem kompilierbaren Programm, zur Laufzeit wird der Azure-Server die Anfragen allerdings durch die Bank mit dem Fehlercode 404 ablehnen.
Eine funktionsfähige Implementierung erhalten Sie nur, wenn Sie nach folgendem Schema erstens einen Subscription Key und zweitens die Locale, in der Ihre Ressource angemeldet ist, übergeben:
public MainPage() {
this.InitializeComponent();
var speechConfig = SpeechConfig.FromSubscription(subscriptionKey, "eastus");Im nächsten Schritt werden wir in die XAML-Datei wechseln, wo wir eine Listbox mit dem Namen LstVoices anlegen. Danach benötigen wir eine Methode, die eine Liste aller bei den Cognitive Services bekannten Sprachmodelle beantragt. Eine einfache Implementierung, die Sie direkt aus dem Konstruktor der Page aufrufen können, sieht aus wie in Listing 5.
Listing 5
async void voiceFindWorker() {
var myVoices = await mySynth.GetVoicesAsync();
foreach (VoiceInfo aV in myVoices.Voices) {
LstVoices.Items.Add(aV.Name + " " + aV.LocalName);
}
}Das von GetVoicesAsync zurückgegebene VoiceInfo-Objekt ist in Bezug auf die angelieferten Informationen eher umfangreich. Für einen ersten Versuch beschränken wir uns daher darauf, die Ergebniswerte Name und LocalName zurückzugeben. Lohn der Programmausführung ist dann das in Abbildung 5 gezeigte Ergebnis.
 Abb. 5: In der Stimmen-Listbox wimmelt es
Abb. 5: In der Stimmen-Listbox wimmelt esIm nächsten Schritt wollen wir dafür sorgen, dass unser Programm den gerade eingegebenen Text in der Sprache ausgibt, die der Benutzer in der Listbox auswählt.
Hierzu müssen wir in Schritt eins nach folgendem Schema eine Anpassung des Aufenthaltsorts der SpeechConfig-Variablen durchführen:
public sealed partial class MainPage : Page {
. . .
SpeechConfig mySpeechConfig;Das API-Design des Speech API unterscheidet sich insofern vom bisher vorgestellten, als die Synthesizer-Instanz hier nicht nur die Credentials, sondern auch die jeweils zu verwendende Sprache enthält. Eine Änderung der Sprache setzt also ein Verwerfen des Synthesizer-Objekts voraus, das danach aus der SpeechConfig-Variablen neu ins Leben gerufen werden muss.
Für das eigentliche Bevölkern der SpeechConfig-Variablen benötigen wir dann lediglich den Wert von Name. Diesen speichern wir wie folgt in der Listbox:
foreach (VoiceInfo aV in myVoices.Voices)
{
LstVoices.Items.Add(aV.Name);
}Im nächsten Schritt können wir auch schon das eigentliche Sprechen befehligen (Listing 6).
Listing 6
private void TxtTalk_Click(object sender, RoutedEventArgs e)
{
mySpeechConfig.SpeechSynthesisVoiceName = LstVoices.SelectedItem.ToString();
mySynth = new SpeechSynthesizer(mySpeechConfig);
mySynth.SpeakTextAsync(TxtWhat.Text);
}Im Interesse der Bequemlichkeit schreibt der Autor im ersten Schritt den in der Listbox gewählten Wert in das Attribut SpeechSynthesisVoiceName, um daraufhin einen neuen SpeechSynthesizer zu erzeugen. Der Aufruf der Methode SpeakTextAsync animiert diesen dann zum Sprechen. Die Ausgabe erfolgt bei einem nicht parametrierten Aufruf direkt über das jeweilige Standardaudioausgabegerät des Hostcomputers.
An dieser Stelle ist unser Programm zur Ausführung bereit. Geben Sie einen beliebigen Text in die Textbox ein und aktivieren Sie den Knopf, um sich an der Sprachausgabe zu erfreuen. Wer einen deutschen Text eingeben möchte und beispielsweise eine englische oder französische Sprache wählt, stellt sofort fest, dass Microsoft die Intonierung umfangreich an die jeweiligen Akzente und Landessprachen angepasst hat.
Normalerweise ist es nur schwer vorstellbar, einen Cognitive-Services-Artikel zu verfassen, der die Emotionserkennung anhand von Gesichtsbildern nicht nutzt. Das ist allerdings gar nicht mehr möglich: Microsoft entschied im Juli 2022 nämlich, die diesbezüglichen Funktionen für neu erzeugte Azure-Cognitive-Services-Anmeldungen nicht mehr freizuschalten und sie vorhandenen Nutzern im Laufe von 2023 wegzunehmen.
Hintergrund dieser Entscheidung ist, so Microsoft, dass die Emotionserkennung nicht besonders zuverlässig funktioniert. Das ist übrigens eine Erkenntnis, die der (im Allgemeinen konservativ eingestellte) Autor aus seiner persönlichen Lebenserfahrung bestätigen kann. Gesichtsregungen bzw. die muskulären Bewegungen des Gesichts mögen zwar bei allen Personen identisch sein. Die Bedeutung oder dahinterstehende Emotionen sind allerdings auch vor dem Hintergrund von zum Beispiel Gesundheitszustand und der kulturellen Erziehung zu bewerten.
Regelmäßig News zur Konferenz und der .NET-Community
Microsoft sieht die AI-Funktionen, wie in der Einleitung des Artikels festgestellt, naturgemäß auch als Mittel zum Erwirtschaften einer Recurring Revenue. Da das Übertragen von höchstpersönlichen Lebensdaten in Zeiten von GDPR und Co. allerdings ein rechtlich durchaus schwieriges Thema ist, bietet Microsoft seit einiger Zeit auch die Möglichkeit an, die Inferenz on Premise durchzuführen.
Schon in der Einleitung sei allerdings darauf hingewiesen, dass es sich dabei um kein Mittel zur Kostenreduktion handelt: Eine lokal durchgeführte Inferenz wird von Microsoft genauso verrechnet, wie wenn die Inferenz unter Nutzung des Azure-Cloud-Backends und der dort befindlichen Rechenressourcen erfolgen würde.
Als Werkzeug der Wahl hat sich Microsoft dabei für Docker-Container entschieden: Das lokale Hosting der Intelligenz erfolgt also durch Ausführung von Docker-Containern. Microsoft empfiehlt dabei die Nutzung von Azure Kubernetes oder Docker Compose, geht aber auch auf andere Laufzeitumgebungen ein.
Wichtig ist in diesem Zusammenhang außerdem, dass ein einmal aktivierter Container (normalerweise) permanent nach Hause telefoniert. Microsoft macht das in den FAQs (Abb. 6) an mehreren Stellen explizit klar.

Davon ausgenommen sind nur Großunternehmen, die mit Microsoft einen explizit anderslautenden Vertrag abschließen. In diesem Fall kann auch ein komplett offline arbeitender Container zur Verfügung gestellt werden. Das ist allerdings teuer, Microsoft berechnet ihn nämlich wie eine fix provisionierte Instanz.
An dieser Stelle sollte noch erwähnt werden, dass Microsoft nicht alle in den Cognitive Services zur Verfügung stehenden Dienste auch als Docker-Container anbietet. Zum Zeitpunkt der Drucklegung werden vor allem die folgenden Dienste angeboten:
Anomaly Detector
Computer Vision
Face
Form Recognizer
Language Understanding (LUIS)
Speech Service API
Language Service – Sentiment Analysis
Language Service – Text Analytics for Health
Language Service – Language Detection
Language Service – Key Phrase Extraction
Die Nutzung der Cognitive Services ermöglicht Entwickler:innen das schnelle und unbürokratische Realisieren verschiedener Aufgaben der AI, die ansonsten sehr zeitintensiv sein können. Insbesondere das erfolgreiche Parametrieren eines AI-Modells ist eine Aufgabe, die man erfahrungsgemäß nur allzu leicht unterschätzt. In diesem Sinne: Gut AI!
The post Eine Einführung in die Arbeit mit Azure Cognitive Services appeared first on BASTA!.
]]>The post Angulars neues Standalone API appeared first on BASTA!.
]]>Regelmäßig News zur Konferenz und der .NET-Community
So verlangt Angular beispielsweise die Implementierung eines Angular-Moduls. Innerhalb eines Angular-Moduls werden Angular-Bausteine (z. B. Komponenten) deklariert oder es werden andere Module importiert, deren Funktionalität benötigt wird. Am meisten für Verwirrung sorgt hierbei die Unterscheidung zwischen Angular- und ECMAScript-Modul. Gerade Anfänger:innen, die soeben erst Grundkenntnisse in JavaScript bzw. TypeScript erlangt haben, ist meist nicht klar, wozu ein Angular-Modul benötigt wird.
Selbst langjährige Angular-Entwickler:innen wünschen sich immer wieder einen Weg, die Verwendung von Angular-Modulen optional zu gestalten. Zu viel Boilerplate-Code und die Verleitung zur Entwicklung von zu großen sogenannten Shared-Modulen sind hierbei zwei der Hauptgründe dafür, dass sich die Entwicklung mit Angular-Modulen oft schwierig gestaltet.
Abhilfe hat man sich hierbei durch die Implementierung des Single-Component-Angular-Module- oder auch SCAM-Patterns geschaffen. Dabei wird jede einzelne Komponente, Direktive oder Angular Pipe in einem einzigen alleinstehenden Angular-Modul deklariert. Importiert werden lediglich die Abhängigkeiten, die die einzelne Komponente, Pipe oder Direktive benötigt (Abb. 1).

Abb. 1: SCAM-Pattern: Ein Modul deklariert nur eine einzige Komponente
Dadurch können größere Shared-Module aufgespalten und die Abhängigkeiten innerhalb der eigenen Featuremodule weitaus feingranularer importiert werden (Abb. 2).

Abb. 2: Aktuelle Angular-Version 15.0.0-rc4
So ist beispielsweise die Angular-Material-Bibliothek [1] eine der bekanntesten Umsetzungen dieses Patterns. Für jede UI-Komponente gibt es ein eigenes Modul: MatButtonModul, MatDatePickerModule oder MatTableModule, um nur einige Beispiele zu nennen.
Schnell fragt man sich, warum der Mehraufwand eines Moduls überhaupt notwendig ist, und so sah man mit großer Freude, dass im Oktober 2021 ein RFC [2] des Angular-Teams veröffentlicht wurde, in dem es hieß, dass Angular-Module mit Hilfe des sogenannten Standalone API von nun an optional sein sollen.
Das Angular-Team erwähnte selbst, dass die verpflichtende Nutzung der Angular-Module oftmals zu Problemen bei der Featureentwicklung des Angular-Frameworks beitrug. Doch warum gab es Angular-Module dann überhaupt? Wie sieht die Angular-Entwicklung nun ohne Angular-Module aus und was bedeutet das für eine bestehende Architektur?
Genau diese Fragen möchte ich hier beantworten. Nachdem wir uns mit dem neuen Standalone API vertraut gemacht haben, werden wir tiefer einsteigen in die neue Architektur und in die Entwicklung mit Standalone Components.
Hinweis: Der Text arbeitet mit Angular Version 15.0.0-rc.4. Bis zur Veröffentlichung ist Angular Version 15 bereits erschienen. Daher könnte es kleinere Abweichungen innerhalb der gezeigten Codebeispiele geben.
Die Antwort auf diese Frage führt uns zu den Wurzeln von Angular: 2010 wurde AngularJS erstmals releast. Zu dieser Zeit gab es keinerlei Möglichkeit, Code, der zusammengehörte, zu gruppieren. Das Gruppieren aber führt nicht nur zu einer besseren Wartbarkeit des Codes, sondern ermöglicht, dass Funktionalität, die an mehreren Stellen benötigt wird, wiederverwendet werden kann. Für Letzteres benötigt der Compiler einen Kontext, um die Sichtbarkeit der einzelnen Codebausteine zu erkennen. Da es zu dieser Zeit noch kein eigenes Modulkonzept in JavaScript gab, wurden in AngularJS hierfür Angular-Module eingeführt (Listing 1).
Listing 1
angular.module('myModule', []).
value('a', 123).
factory('a', function() { return 123; }).
directive('directiveName', ...).
filter('filterName', ...);
Innerhalb eines Angular-Moduls deklarierte man unter anderem Direktiven, Controller oder Services. Mit der Veröffentlichung von Angular im Jahre 2016 wurden zwar die meisten Bausteine des Frameworks neu geschrieben, allerdings wurden Teile des alten Compilers übernommen. Das führte dazu, dass Angular weiterhin darauf angewiesen war, mit Angular-Modulen zu arbeiten (Listing 2).
Listing 2
@NgModule({
declarations: [AppComponent],
imports: [BrowserModule],
providers: [],
bootstrap: [AppComponent]
})
export class AppModule {}
Tatsächlich war die Angular-Community nie wirklich glücklich mit dieser Entscheidung und auch aus dem Angular-Team hörte man immer wieder Stimmen der Unzufriedenheit. Denn mit der Einführung von ECMAScript 2015 wurde nun das Konzept der ECMAScript-Module [3] vorgestellt. Das heißt, JavaScript hatte von nun an einen gewissermaßen natürlichen Weg, um Code zu modularisieren.
Die Kombination aus beiden Modulkonzepten in einem Framework verwirrte besonders Neueinsteiger:innen und so arbeitete das Angular-Team an der Entwicklung eines neuen Compilers: des Ivy-Compilers. Der bereits in Angular Version 8 eingeführte Compiler ermöglichte nun, dass jede Komponente ihren ganz eigenen Compilerkontext hatte. Ein Angular-Modul wird also nicht mehr benötigt. Der Rückwärtskompatibilität wegen musste das Angular-Team aber noch lange Zeit mit dem älteren Compiler, der View Engine, arbeiten und war vorerst weiterhin auf die Nutzung der Angular-Module angewiesen. Doch mit dem Entfernen der View Engine seit Angular 13 war es endlich so weit: Angular-Module waren für die Entwicklung mit Angular nicht mehr notwendig und das neue Standalone API wurde als sogenannte Developer Preview [4] in Version 14 vorgestellt.
Das darunterliegende Konzept ist relativ einfach und schnell erklärt: Von nun an werden sämtliche Abhängigkeiten, die eine Komponente benötigt, direkt in das neue imports-Property innerhalb des Component-Decorators geschrieben (Listing 3).
Listing 3
@Component({
selector: 'app-root',
standalone: true,
template: '<h1 *ngIf="title">{{ title }}</h1>>',
imports: [ NgIf ],
styleUrls: [ './app.component.scss' ],
})
export class AppComponent {...}
Darüber hinaus wird noch ein neues Property standalone gesetzt, um dem Compiler klarzumachen, dass es sich hierbei um eine Standalone Component handelt.
Was uns ebenso auffällt, ist, dass für die Verwendung der NgIf-Direktive nicht mehr das gesamte Common Module importiert werden muss, sondern lediglich die strukturelle Direktive selbst.
Das Angular-Team hat zusätzlich daran gearbeitet, die Bausteine ihrer eigenen Module als Standalone zur Verfügung zu stellen. Sie können dann, wie in Listing 3 gezeigt, innerhalb des imports-Property eingefügt werden. So gibt es beispielsweise die DatePipe, AsyncPipe, NgForOf oder das bereits gezeigte NgIf aus dem Common Module als Standalone-Variante, aber auch das für die Navigation benötigte RouterOutlet oder die RouterLink-Direktive aus dem Router Module. Doch was ist, wenn wir eine weitere Angular-Komponente erstellen möchten und sie in unsere AppComponent einfügen wollen? Normalerweise konnten wir die Komponente innerhalb desselben Angular-Moduls deklarieren, in dem die AppComponent deklariert war. So wurde sichergestellt, dass die neue Komponente für die AppComponent sichtbar ist. Mit Standalone Components sieht das jetzt natürlich ein wenig anders aus.
Zuerst legen wir eine neue Komponente an:
> ng generate component header –standalone
Setzen wir das neue –standalone-Flag, wird eine Komponente generiert, die bereits das standalone-Property gesetzt hat.
Fügen wir die HeaderComponent nun in unsere AppComponent ein, erhalten wir vorerst die uns vertraute Fehlermeldung aus Abbildung 3.

Abb. 3: Die AppComponent kennt noch nicht die HeaderComponent
Interessanterweise wird uns allerdings vorgeschlagen, die HeaderComponent zu importieren. Tun wir das, so können wir sehen, dass die HeaderComponent nun ebenfalls innerhalb des imports-Arrays der AppComponent eingefügt wurde (Listing 4).
Listing 4
@Component({
selector: 'app-root',
standalone: true,
template: '<h1 *ngIf="title">{{ title }}</h1>>',
imports: [ NgIf, HeaderComponent ],
styleUrls: [ './app.component.scss' ],
})
export class AppComponent {...}
Daraus folgt, dass Standalone Components sich ähnlich wie Angular-Module verhalten. Benötige ich eine Standalone Component in einer anderen Komponente, muss ich sie lediglich importieren. Voraussetzung ist hierbei, dass beide Komponenten das standalone-Property besitzen.
Wir können darüber hinaus nicht nur Komponenten als standalone deklarieren: Der Pipe- und der Directive-Decorator besitzen ebenfalls die neue standalone-Property.
Die Vorstellung, alle abhängigen Komponenten, Pipes, Direktiven etc. immer wieder in unsere Standalone Component zu importieren, klingt zunächst anstrengend. Zwar müssen wir das zurzeit noch manuell mit ein wenig Hilfe unserer Entwicklungsumgebung erledigen, doch ist geplant, dass in naher Zukunft anhand eines Autoimports zu lösen – ähnlich wie bereits TypeScript-Module in unsere Angular-Anwendung automatisch importiert werden, sobald sie in einem Code genutzt werden sollen.
Da wir aus unserer AppComponent eine Standalone Component kreiert haben, stellt sich uns nun die Frage, wie unsere gesamte Applikation eigentlich gebootstrappt wird, da wir das AppModule nicht mehr benötigen.
Bisher benötigte Angular immer ein sogenanntes AppModule, anhand dessen die gesamte Applikation mit Hilfe der bootstrapModule-Funktion gebootstrappt wurde. Innerhalb des AppModules definierten wir darüber hinaus unsere AppComponent als sogenannte Root-Komponente (Listing 5).
Listing 5
//main.ts
import { platformBrowserDynamic } from '@angular/platform-browser-dynamic';
import { AppModule } from './app/app.module';
platformBrowserDynamic().bootstrapModule(AppModule)
.catch(err => console.error(err));
Listing 6
//main.ts
import { bootstrapApplication } from '@angular/platform-browser';
import { AppComponent } from './app/app.component;
bootstrapApplication(AppComponent)
.catch(err => console.error(err));
Mit dem neuen Standalone API können wir eine einzelne Komponente bootstrappen (Listing 6). Dafür stellt uns Angular seit Version 14 die bootstrapApplication-Funktion zur Verfügung. Dort übergeben wir nur noch unsere Root-Komponente, die allerdings bereits als Standalone Component vorliegen muss.
Wie wir sehen, wird das AppModule auch hier nicht mehr benötigt. Möchten wir allerdings Services für die gesamte Applikation providen, stand uns hierfür immer das providers-Array innerhalb des NgModules-Decorators zur Verfügung. Gewiss sind treeshakeable Providers – das heißt, der Service provided sich selbst – immer zu bevorzugen, allerdings benötigen wir oftmals komplexere Dependency-Injection-Logik, die wir dann innerhalb des providers-Arrays klarer definieren können. Ein einfaches Beispiel hierfür sind Injection Tokens wie der APP_INITIALIZER. Aber auch hierfür hat das neue Standalone API eine Lösung: Sämtliche Provider werden von nun an innerhalb der bootstrapApplication-Funktion deklariert.
Neben der Root Component wird eine sogenannte ApplicationConfig mitübergeben. Dort können wir – mit kleinen Anpassungen – weiterhin das bekannte providers-Array definieren, um unserer Applikation Injection Tokens und Services zur Verfügung zu stellen.
Neben unseren eigenen Services wollen wir oftmals andere Module importieren, die dann ihrerseits Services anbieten. Einige der bekanntesten Vertreter sind hierbei das RouterModule, HttpClientModule oder auch das StoreModule aus der Redux-Bibliothek NgRx. Mit Hilfe der neuen importProvidersFrom-Funktion werden diese Services uns weiterhin zur Verfügung gestellt, indem wir einen oder mehrere ModuleWithProviders als Parameter übergeben (Listing 7).
Listing 7
//main.ts
bootstrapApplication(AppComponent, {
providers: [
importProvidersFrom(StoreModule.forRoot({...})),
{
provide: Window,
useValue: window,
},
],
})
Das Beste daran ist, dass hierbei wirklich nur die Provider des jeweiligen Moduls importiert werden. Übergibt man beispielsweise das RouterModule, wird nicht der gesamte Modulcode mit allen Direktiven importiert, sondern eben nur Services, zum Beispiel der RouterService.
Das nächste große Thema, mit dem wir uns beschäftigen müssen, ist die neue Art und Weise, wie wir unsere Routen innerhalb der Applikation registrieren. Bisher haben wir uns hierfür ein AppRoutingModule angelegt und die Routenkonfiguration innerhalb der forRoot-Funktion des Routing-Moduls übergeben.
Listing 8
//routes.ts
export const APP_ROUTES: Routes = [
{
path: '',
redirectTo: '/books',
pathMatch: 'full',
},
{
path: 'books',
component: BookComponent,
},
]
Das Konzept mit dem Standalone API ist tatsächlich sehr ähnlich. Zuerst definieren wir unsere Routen in einer separaten Datei, ohne jedoch hierfür ein Extramodul anzulegen (Listing 8). Hierbei exportieren wir lediglich die APP_ROUTES-Konstante. Für die Registrierung dieser Routen bietet uns das Standalone API eine provideRouter-Funktion an. Diese müssen wir innerhalb des neuen providers-Arrays in unserer main.ts aufrufen (Listing 9).
Listing 9
// main.ts
bootstrapApplication(AppComponent, {
providers: [
...
provideRouter(APP_ROUTES),
]
}
Die provideRouter-Funktion ist hierbei lediglich eine spezielle Variante der importsProvidersFrom-Funktion. Tatsächlich ist es sogar so, dass in Version 14 die Routen noch wie folgt registriert werden mussten:
importProvidersFrom(RouterModule.forRoot(APP_ROUTES))
Während das eine sehr generelle Art und Weise ist, Services bereitzustellen, ist es denkbar, dass in Zukunft mehrere solcher spezieller Provider-Funktionen zur Verfügung stehen. StoreModule.forRoot({}) könnte beispielsweise in Zukunft lediglich eine provideStore-Funktion sein. Auch für den HttpClient gibt es bereits eine eigene Variante, dazu aber später mehr.
Wie bereits erwähnt, werden an dieser Stelle lediglich die Services des Moduls importiert. Um die Navigation vollständig zu implementieren, wird noch das RouterOutlet benötigt sowie die RouterLink-Direktive. Auch sie werden als Standalone-Bausteine angeboten, sodass wir sie lediglich innerhalb der AppComponent oder jeder anderen Komponente, in der wir die Direktiven nutzen wollen, importieren (Listing 10).
Listing 10
@Component({
selector: 'app-root',
standalone: true,
imports: [
RouterOutlet,
RouterLink,
],
...
})
export class AppComponent {}
Nachdem wir verstanden haben, wie wir mit dem neuen Standalone API Routen registrieren können, stellt sich direkt die Frage nach Lazy Loading. Lazy Loading gilt als eine der Best Practices, wenn es darum geht, die Größe des initialen JavaScript Bundles zu verringern. Hierbei wird die gesamte Applikation in sogenannte Featuremodule aufgespalten, die nur dann nachgeladen werden, wenn sie benötigt werden, also wenn der Nutzer in eine Ansicht wechselt, die den Code eines Featuremoduls zur Anzeige benötigt. Alle Komponenten, die wir dazu brauchen, sind in diesem Featuremodul deklariert. Wie funktioniert nun also das Prinzip des Lazy Loading ohne Module?
Prämisse ist wie immer, dass sämtliche Komponenten, die als Bundle dynamisch nachgeladen werden sollen, als Standalone Components vorliegen. Zuerst legen wir eine Konfigurationsdatei an, in der wir die Kindrouten definieren (Listing 11). Diese exportieren wir ebenfalls. Der Trick ist nun, dass wir nur diese Routen lazy loaden anstatt eines ganzen Moduls. Das klingt erst einmal seltsam, aber sehen wir uns das Ganze einmal an (Listing 12).
Listing 11
//books.routes.ts
export const BOOK_ROUTES: Routes = [
{
path: '',
component: BookComponent,
},
{
path: 'new',
component: BookNewComponent,
},
{
path: ':id',
component: BookDetailComponent,
},
]
Listing 12
//routes.ts
export const APP_ROUTES: Routes = [
…
{
path: 'books',
loadChildren: () => import('./features/book/routes')
.then(m => m.BOOK_ROUTES),
},
];
Der Angular-Compiler versteht, dass wir alle Komponenten innerhalb der BOOK_ROUTES gemeinsam als Bundle ausliefern wollen. Sobald der Nutzer nun eine Route besucht, die innerhalb der BOOK_ROUTES definiert ist, wird das gesamte Bundle nachgeladen, wie wir es auch vom Lazy Loading von Modulen kennen (Abb. 4).

Abb. 4: Das BOOK_ROUTES Bundle wird dynamisch nachgeladen
Vielleicht kommt nun die Frage auf, wie wir in Zukunft unsere Ordner innerhalb der Anwendung strukturieren sollen. Das Anlegen eines Moduls hat uns standardmäßig einen Ordner angelegt – dieser fehlt uns jetzt. Dennoch empfehle ich, Komponenten, die zusammengehören beziehungsweise zusammen ausgeliefert werden, innerhalb eines Ordners zu gruppieren (Abb. 5). So behält man weiterhin die Übersicht, welche Komponenten zu einem Feature gehören, auch wenn sie nicht mehr über ein Featuremodul zusammen deklariert werden.

Abb. 5: Ordner für Komponenten-Bundles
Bevor ich zeige, wie wir einzelne Komponenten lazy loaden können, möchte ich noch einmal kurz auf die Services zurückkommen. Wir haben zwar bereits gelernt, wie wir Services für die gesamte Applikation providen können, jedoch nicht, wie wir einen Service nur für die Komponenten eines spezifischen Features bereitstellen. Hier konnten wir immer auf das providers-Array des zugehörigen Featuremoduls zurückgreifen. Dieses providers-Array ist nun Teil der Routenkonfiguration (Abb. 6).

Abb. 6: Das neue Route-Interface
Listing 13
//routes.ts
export const APP_ROUTES: Routes = [
...
{
path: 'books',
providers: [BookApiService]
loadChildren: () => import('./features/book/routes')
.then(m => m.BOOK_ROUTES),
},
];
Soll nun also ein Service nur für die Komponenten der BOOK_ROUTES bereitgestellt werden, kann er direkt innerhalb der Routenkonfiguration an die Route geschrieben werden (Listing 13). Der BookApiService kann daraufhin nur von Komponenten innerhalb der books-Route injiziert werden.
Ein neues und ebenfalls lang ersehntes Feature ist das Lazy Loading einzelner Komponenten. Praktisch war es bereits in vorherigen Angular-Versionen möglich. Die tatsächliche Implementierung gestaltete sich allerdings oftmals sehr umständlich und enthielt viel Boilerplate-Code. Seit Version 14 können wir Komponenten ganz einfach innerhalb der Routenkonfiguration dynamisch nachladen (Listing 14). Wie zu vermuten, wird beim Aktivieren der books-Route die BookComponent dynamisch nachgeladen (Abb. 7).
Listing 14
export const APP_ROUTES: Routes = [
...
{
path: 'books',
loadComponent: () => import('./features/book/book/book.component')
.then(m => m.BookComponent),
}
];

Abb. 7: Die BookComponent wird dynamisch nachgeladen
Wie wir gesehen haben, können wir innerhalb unserer Angular-Applikation auch vollständig ohne Angular-Module navigieren. Selbst das Lazy Loading von Bundles ist uns nicht abhandengekommen. Die Funktion provideRouter [5] bietet uns zusätzlich weitere Möglichkeiten zur Routerkonfiguration an. So können wir mit withPreloading(PreloadAllModules) eine Strategie festlegen, wann genau eine Komponente oder ein Bundle von Komponenten dynamisch nachgeladen werden soll. Sämtliche Optionen, die wir bisher innerhalb der forRoot-Funktion gesetzt haben, können von nun an innerhalb withRouterConfig übergeben werden.
Als Teil des neuen Standalone API führt Angular 15 eine neue Methode zur Verwendung des HttpClient API ein, die keine HttpClientModule erfordert. Wie bereits erwähnt, erhalten wir auch für das Bereitstellen des HttpClient eine eigene Funktion (Listing 15). Innerhalb der Funktion provideHttpClient können zusätzliche Konfigurationen des HttpClient Service übergeben werden, beispielsweise der Support von JSONP (JSON mit Padding) oder Optionen für Cross-site Request Forgery (XSRF).
Listing 15
// main.ts
import { provideHttpClient, withJsonpSupport } from '@angular/common/http';
bootstrapApplication(AppComponent, {
providers: [
…
provideHttpClient(withJsonpSupport()),
],
})
Die Verwendung des HttpClient empfiehlt sich immer, da er uns bei der Kommunikation mit einem HTTP-Backend einiges an Arbeit abnimmt. Er setzt automatisch application.json als MIME-Type und parst die Response-Daten in den angegebenen TypeScript-Datentyp. Darüber hinaus steht uns die Nutzung von sogenannten HTTP-Interceptors zur Verfügung. Wie der Name schon sagt, fangen sie den HTTP Request ab, bevor er an das Backend gesendet wird. Dadurch können wir beispielsweise bei allen HTTP Requests den authorization-Header setzen, ohne es bei allen Service-Aufrufen manuell implementieren zu müssen. Diese Interceptors müssen ebenfalls wieder innerhalb der bootstrapApplication mit provide bereitgestellt werden (Listing 16).
Listing 16
// main.ts
bootstrapApplication(AppComponent, {
providers: [
...
{ provide: HTTP_INTERCEPTORS, useClass: TokenInterceptor, multi: true },
provideHttpClient(withInterceptorsFromDi()),
],
})
Angular Inteceptors sind nichts Neues, ihre Registrierung innerhalb des Standalone API allerdings schon. Neben dem Bereitstellen des bereits bekannten Injection Token HTTP_INTERCEPTORS muss ebenfalls die Funktion withInterceptorsFromDi aufgerufen werden. Seit Angular 15 wird die Verwendung von Interceptors durch eine neue Featurefunktion namens withInterceptors() vereinfacht. Sie akzeptiert eine Liste von Interceptor-Funktionen, die wir verwenden möchten (Listing 17). Beide Varianten können auch gleichzeitig genutzt werden; wie zuvor ist lediglich die Reihenfolge der Registrierung der Interceptors wichtig.
Listing 17
// main.ts
bootstrapApplication(AppComponent, {
providers: [
…
provideHttpClient(withInterceptors([
(req, next) => {
return next(req);
},
])),
],
})
Sicher ist die Entwicklung einer Angular-Appliktion mit dem neuen Standalone API für langjährige Angular-Entwickler:innen an einigen Stellen gewöhnungsbedürftig. Fängt man ein neues Angular-Projekt an, ist es allerdings sinnvoll, direkt auf Standalone Components zu setzen. Die Größe der Bundles, die an den Webbrowser ausgeliefert werden, kann sich dadurch stark verringern. Als Neueinsteiger:in in die Angular-Welt ist es darüber hinaus bei Weitem einfacher, nicht mehr mit zwei unterschiedlichen Modulkonzepten hantieren zu müssen: Es gibt nur noch ECMAScript-Module.
Regelmäßig News zur Konferenz und der .NET-Community
Bestehende große Anwendungen auf Standalone Components zu migrieren, mag sehr aufwendig erscheinen. Es empfiehlt sich daher zuerst, mit sämtlichen Bausteinen anzufangen, die wir innerhalb unserer Shared-Module deklariert haben. Ebenso lohnt es sich, simple UI-Komponenten bereits auf Standalone zu migrieren, also solche, die selbst keine weiteren Kindkomponenten oder größere Abhängigkeiten haben – traditionelle Dumb Components.
Ich hoffe, ich konnte Ihnen einen guten Einblick in die Entwicklung mit dem neuen Standalone API geben. Ein vollständiges Beispiel einer Standalone-Angular-Anwendung kann in meinem GitHub-Account eingesehen werden [6].
The post Angulars neues Standalone API appeared first on BASTA!.
]]>The post Jahresrückblick 2022 appeared first on BASTA!.
]]>Manfred Steyer: Das Besondere war, dass wir endlich wieder Vor-Ort-Konferenzen hatten. Workshops machen einige Kunden nach wie vor sehr gerne remote und das klappt auch wunderbar. Wir bekommen hierzu wirklich tolle Rückmeldungen. Konferenzen gehen hingegen über die reine Wissensvermittlung hinaus. Da geht es auch um den „Flur-Track“, bei dem man Leute trifft und sich austauscht.
Tam Hanna: Wegen unseres Standorts in Ungarn hatten wir mit dem Coronavirus keine Probleme. Die Lage war auch während der Pandemie normal. Für mich persönlich, ich bin Elektroniker, ist es trotzdem von Vorteil, dass viele Konferenzen hybrid stattfinden: Aus dem hauseigenen Labor und mit einer Zigarre lässt es sich bequemer zusehen.
Veikko Krypczyk: Es ist richtig, das Leben auf Konferenzen und Schulungen ist wieder zurückgekehrt. Ich habe 2022 an den Magdeburger Developer Days teilgenommen, einer sorgfältig organisierten Communitykonferenz, die den großen Entwicklerkonferenzen in Fragen des technischen Niveaus in Nichts nachsteht. Die hybride Arbeitswelt ist wohl gekommen, um zu bleiben, und das ist auch gut so. Damit kann man je nach Situation das Beste aus beiden Welten, das heißt präsent vor Ort und flexibel online, miteinander verbinden.
Martina Kraus: Mein ganz persönliches Highlight war die Organisation der Angular-Konferenz in Deutschland – die NG-DE. Nach drei Jahren konnten wir sie endlich erneut in vollem Umfang stattfinden lassen und hatten 500 Teilnehmer:innen. Es tat so gut, mal wieder Entwickler:innen und die deutsche Angular-Community vor Ort bei einer Konferenz begrüßen zu dürfen. Nichtsdestotrotz bin ich weiterhin Fan von Hybrid- und Onlinekonferenzen, einfach weil es mir als Speakerin die Möglichkeit gibt, auf einer Konferenz einen Talk zu halten, ganz ohne die ggf. lange Reisezeit.
Rainer Stropek: Eine der schönsten Erfahrungen des vergangenen Jahres war eine Konferenzrundreise im Sommer, bei der ich in einer Woche mehrere Vorträge in drei verschiedenen Ländern kombinieren konnte. Da war von .NET bis Rust alles dabei. Auch wenn ich den größten Teil meiner Vortrags- und Beratungstätigkeit über Webmeetings erledige, war es wieder einmal toll, physische Konferenzen zu erleben. Ich hoffe, dass das im nächsten Jahr vermehrt möglich sein wird.
Regelmäßig News zur Konferenz und der .NET-Community
Steyer: In der Webwelt tauchen gerade ein paar neue interessante Frameworks auf. Beispiele sind Astro, qwik, SolidJS oder Marko. Diese Frameworks zeichnen sich unter anderem durch eine wunderbare Startperformance aus. JavaScript Bundles werden so spät wie möglich bzw. im Idealfall gar nicht geladen. Genau das ist für öffentliche Portale, bei denen es um Conversion geht, wichtig. Man merkt auch, dass Server und Client wieder mehr zusammenrücken und der Code auf beiden Seiten stärker aufeinander abgestimmt wird.
Hanna: Negativ schätze ich das ganze Dilemma um Windows 11 ein: Microsoft legt sich hier einen Badwill zu, der das gesamte Ökosystem in Zukunft viel kosten wird. Hierzu zwei Gedanken: Manche Länder haben die TPM-2.0-Frage durch ihre nationalen TPM-Verbote gelöst. Windows 11 läuft, wenn auch inoffiziell, auf Tausenden von Systemen wie meinem Lenovo T430 problemlos. Es stünde Microsoft gut an, hier eine Kehrtwende zu machen. Warum der im Allgemeinen pragmatische Satya Nadella das bisher nicht angeregt hat, ist für mich unverständlich. Die Probleme um den Android-Emulator können es nicht sein, weil man diesen analog zu Spielen nur auf kompatiblen Maschinen anbieten könnte.
Doch kommen wir zum Positiven. Neben der erfolgreichen Weiterentwicklung von Bryan Costanichs Meadow F7 gibt es mit dem neu aufgelegten .NET-Nano-Framework eine weitere Möglichkeit, um .NET-Technologien auf der letzten Meile zu verwenden. Besonders faszinierend finde ich in diesem Zusammenhang auch die Weiterentwicklung von IntelliSense in Visual Studio 2022. Stellenweise liefert das System geradezu grenzgeniale Vorschläge.
Krypczyk: Aus dem Hause Microsoft haben im Jahr 2022 die Technologien WinUI 3 und .NET MAUI das Licht der Welt erblickt. WinUI 3 ist angetreten, um die Möglichkeiten der Desktopanwendungen in grafischer Sicht deutlich zu verbessern, und ermöglicht frische und moderne Anwendungen. .NET MAUI wird Xamarin ablösen und macht es C#- und .NET-Entwickler:innen möglich, fast alle Plattformen zu erreichen.
Kraus: Dieses Jahr hat sich für mich wie ein Jahr mit vielen Veränderungen in den Technologien angefühlt: In Angular wurde das lang ersehnte Standalone API eingeführt und Reactive Forms endlich typisiert. Aber auch in der Microsoft-Welt hat sich mit dem Veröffentlichen von .NET Core 7 einiges bei der Performance und dem Minimal API getan. Blazor gewinnt immer mehr an Popularität – auch wenn der Einsatz noch recht umstritten ist. Mein persönliches Highlight ist aber tatsächlich Svelte. Gut – Svelte gibt es nun schon seit einiger Zeit, es ist also nicht wirklich neu. Allerdings hatte ich das Gefühl, dass es 2022 nochmal einen – vollkommen berechtigten – Popularitätssprung bei Svelte gegeben hat. Mit SvelteKit ist es mittlerweile auch sehr viel einfacher, eine Svelte-App aufzusetzen.
Stropek: Unspektakulär würde ich sagen, wobei das nichts Schlechtes ist. Die Microsoft-Produkte und -Technologien, die ich verwende, haben sich solide und stabil weiterentwickelt. Es gab keine weltbewegenden Neuerungen, aber eine Menge hilfreicher Ergänzungen. Von größerer Bedeutung sind aus meiner Sicht die Schritte, die Microsoft dieses Jahr mit .NET in Richtung WebAssembly gemacht hat. Diese Technologie wird aus meiner Sicht noch großen Einfluss auf .NET und die Azure-Cloud haben.
Das Tool, das im Jahr 2022 auf mich den größten Eindruck gemacht hat, ist GitHub Copilot, also AI-assisted Coding. Copilot ist noch weit davon entfernt, perfekt zu sein. Schon jetzt zeigt das Werkzeug aber, welches Potenzial AI für Coding hat und wie stark diese Kategorie von Coding-Werkzeugen unsere Arbeit in den nächsten Jahren prägen wird.
Hanna: Meiner Meinung nach spielt Microsoft, ausgenommen mit Windows 11, eine sehr saubere Strategie. Wenn man nicht in übermäßigen Aktionismus verfällt, sehe ich keinen Grund, warum das nächste Jahr für das Microsoft-Ökosystem nicht exzellent ausfallen sollte.
Krypczyk: Ich denke, es ist Zeit, dass die neuen Technologien an Reife gewinnen. Anlaufschwierigkeiten, im Moment noch fehlende Features und der eine oder andere Bug müssen noch raus, dann haben wir eine neue und solide technische Basis für alle Zielsysteme.
Kraus: Ich bin immer ein großer Fan von Zusammenarbeit. Und auch wenn ich die neuesten Frameworks für das Frontend wie Svelte, SolidJS und Qwik superspannend finde, würde ich mir einfach wünschen, dass es weniger kleinere Bewegungen gibt. In der Frontend-Welt ist man sehr schnell überfordert mit den ganzen Technologien. Möchte man heutzutage einen JavaScript Builder bzw. Bundler einsetzen, gibt es neben dem Platzhirsch webpack mittlerweile auch noch esbuild, Snowpack, Vite und Turbopack – da blickt doch niemand mehr durch.
Stropek: Die Azure-Cloud wird immer erwachsener und damit einen Tick langweiliger. Für Großkunden ist das etwas sehr Positives. Dort spielen Dinge wie IT-Governance, Data Sovereignty und Multi-Cloud-Management eine große Rolle und ich finde es gut, dass Microsoft Azure einen Fokus darauflegt, um den Einsatz der Cloud in großen Organisationen voranzutreiben beziehungsweise ihn möglich zu machen.
Als Entwickler würde ich mir aber mehr grundlegendere Innovationen wünschen. Mehr Edge Cloud wie bei Cloudflare, mehr auf Entwickler:innen ausgerichtete Datendienste wie bei Firebase, bessere Azure APIs für Entwicklungsplattformen abseits von .NET wie bei Go oder Rust, solche Dinge wären schön. Ich sehe ein kleines bisschen die Gefahr, dass vor lauter Fokus auf den Bedarf von Enterprise Businesses die Entwicklungsinnovationen ins Hintertreffen geraten. Bisher hat Microsoft ganz gut eine Balance geschafft und ich hoffe, das bleibt so.
Steyer: Es wird spannend sein, zu sehen, wie die etablierten JavaScript-Frameworks React, Angular und Vue, auf die vorhin erwähnten neuen Frameworks und deren Innovationen reagieren. Die haben ja die komfortable Situation, die Konzepte, die sich bewähren, zu übernehmen. React ist da schon sehr weit und Angular möchte bis Frühjahr 2023 nachziehen.
Hanna: Ich komme aus dem Hardwarebereich. Die Frage ist, wie sich weltpolitische Ereignisse auswirken. SMO, Handelskrieg mit China und Chipkrise haben dafür gesorgt, dass überall neue Halbleiterwerke entstehen. Das kann langfristig nicht gut gehen. Insider bei Herstellern von Halbleiterproduktionsequipment berichten, dass man in den nächsten Monaten mit starkem Konkurrenzkampf rechnet. Gerade im Embedded-Bereich gilt, dass es kleinere Anbieter besonders hart trifft. Fraglich ist deshalb, inwiefern Microsoft gewillt sein wird, seinen hauseigenen Hardware-Embedded-Partnern unter die Arme zu greifen. Sonst gilt ebenfalls, dass die Weltpolitik ein wichtiger Einflussfaktor ist. Inflation und Rezession führen immer auch zu weniger Umsatz im IT-Bereich.
Krypczyk: Speziell, was die Tools angeht, blicke ich auf Visual Studio für macOS. Auch für diese IDE sind weitere Updates angekündigt, zum Beispiel eine Unterstützung von .NET MAUI. Entwickler:innen, die auf Windows und macOS unterwegs sind, wird es freuen, dass auch dieses Tool sich stetig weiterentwickelt. Im Allgemeinen hoffe ich, 2023 wieder etwas Zeit zu finden, um private Entwicklungsprojekte voranzutreiben. Die machen nicht nur viel Spaß, sie bieten auch ein großes Lernpotenzial.
Kraus: Ich freue mich sehr auf die Arbeit mit dem neuen .NET Core 7 SDK. Im November 2022 wurde es veröffentlicht und vorgestellt. Es beinhaltet einige spannende Features wie beispielsweise die Unterstützung von HTTP/3. Man merkt auch, dass es der .NET-Welt sehr guttat, sich der Community zu öffnen und ihr Feedback in die Runtime und das SDK miteinfließen zu lassen. Auch wenn mein Herz immer noch für Angular schlägt, finde ich es spannend, dass sich nun auch in Blazor einiges tut und man viele Features, die man beispielsweise aus Angular kennt, auch in Blazor findet. Darüber hinaus freue ich mich sehr auf die Entwicklungen im Frontend-Bereich. Es heißt, dass sich das Angular-Team gerade die Frameworks SolidJS und Qwik anschaut, um deren Konzepte ggf. in Angular zu integrieren. Meiner Meinung nach wird aber Svelte nächstes Jahr noch mehr Verwendung finden – also definitiv ein Framework, das in Betracht zu ziehen sich lohnt.
Stropek: Mit einem Wort: WebAssembly. Ich habe große Hoffnungen, dass Wasm ähnlich große Auswirkungen auf DevOps haben wird, wie es die Containertechnologie hatte. Ich meine damit nicht primär Wasm am Client. Dieses Thema ist durch. Es ist gekommen, um zu bleiben. Meine Hoffnung für 2023 ist, dass Wasm vermehrt serverseitig und in der Cloud eine Rolle spielen wird. Ich werde daher neben .NET weiterhin einen Fokus auf Rust haben, da diese Plattform momentan in Sachen Wasm die Nase vorn hat, auch wenn .NET, Go und JavaScript kräftig aufholen.
Die Fragen stellten Patricia Stübig-Schimanski und Janine Jochum-Frenster.
The post Jahresrückblick 2022 appeared first on BASTA!.
]]>The post Bessere Angular Architecturen mit Angular Libraries | Session appeared first on BASTA!.
]]>In diesem Vortrag geht Fabian Gosebrink darauf ein, wie Angular Libraries erstellt werden, wozu das Angular Package Format dient und wie Sie Code aus einer bestehenden Anwendung in eine Angular Library zur Wiederverwendung in mehreren Anwendungen verschieben können, um den Code über mehrere Anwendungen hinweg wiederzuverwenden. Dadurch wird die Wartbarkeit und die Architektur von Angular Anwendungen zum Kinderspiel.
Wollen Sie stets auf dem neusten Stand bleiben und keine weiteren Keynotes oder andere Videos verpassen? Dann melden Sie sich für unseren Newsletter an und wir informieren Sie, sobald es etwas neues in den Bereichen .NET,Windows & Open Innovations gibt.
Regelmäßig News zur Konferenz und der .NET-Community
The post Bessere Angular Architecturen mit Angular Libraries | Session appeared first on BASTA!.
]]>The post Datenbankanwendungen mit Azure SQL Server und Delphi realisieren appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community
Bei der Entscheidung für oder gegen ein solches Projekt sind stets auch die Alternativen zu betrachten. Sie lauten Standardsoftware oder die Entscheidung für ein System, das in einem Konfigurationsprozess an unterschiedliche Anforderungen angepasst werden kann. Die individuelle Softwareentwicklung bringt dabei den Vorteil einer guten Anpassbarkeit an den Geschäftsprozess mit. Sie muss sich jedoch in Fragen der Kosten und zeitlichen Umsetzung mit den genannten Alternativen messen, d. h., eine möglichst effiziente, kostengünstige und dennoch technisch aktuelle Lösung ist gefragt.
Für neue Applikationen ist der passende Technologiestack auszuwählen und für bestehende Anwendungen ist fortlaufend zu prüfen, ob und welche Teile bei einer Weiterentwicklung ggf. migriert werden sollen. Beispielhaft wollen wir den Wechsel des Datenbanksystems von einem lokal betriebenen Datenbankserver zu einer in der Cloud gehosteten Datenbank betrachten.
Technologische Entscheidungen müssen dabei stets vor dem Hintergrund der konkreten betrieblichen Anforderungen betrachtet werden. Daher widmet sich der kommende Abschnitt zunächst der Frage, welche Rolle Software heute in Unternehmen einnimmt.
In immer mehr Unternehmen wird der Einsatz von Informationstechnologie zu einem Innovationstreiber. Unternehmen, denen es gelingt, ihre Geschäftsmodelle umfassend zu modernisieren oder sogar komplett zu transformieren, haben eine gute Chance, sich im harten Wettbewerb Vorteile zu erarbeiten. Ein einfaches Beispiel: Eine innovative Plattform zur Abwicklung aller relevanten administrativen Vorgänge in einem Produktionsbetrieb sorgt für eine Verschlankung und Beschleunigung der Prozesse. Der Einkauf von Vorprodukten wird bedarfsgerecht erledigt und Rechnungen werden ohne Verzögerung gestellt. Statt unzähliger Tabellen (Excel) und Dokumente (Word) werden alle relevanten Geschäftsprozesse in einem umfassenden Softwaresystem zusammengefasst. Peter Lieber, ehemaliger Präsident des Verbands Österreichischer Software Industrie (VÖSI), fasst es in einem Zitat [1] etwas provokant wie folgt zusammen: „Software ist der Innovationstreiber – meistens sogar gegen die IT. IT ist oft konservativ und will verhindern, dass zu viel Innovation die bestehenden Systeme gefährdet.“ Damit Software die Rolle des Innovationstreibers erfüllen kann, müssen einige Voraussetzungen gegeben sein (Abb. 1):

Fachliche Anforderungen: In einer sorgfältigen Anforderungsanalyse sind die Anforderungen an das umzusetzende System genau zu erheben. Die Güte einer solchen Analyse ist entscheidend für den Erfolg der Software. Individualsoftware wird auf die Belange der Kund:innen zugeschnitten und sollte Standardsoftware überlegen sein.
Moderne und ausgereifte Technologie: Die eingesetzte Technologie muss zum einem aktuell sein und sich zum anderen auch bewährt haben. Eine ausgereifte und etablierte Technologie ist in vielen Fällen entscheidend, um das Ziel der Digitalisierung möglichst mühelos und mit einem effizienten Entwicklungszyklus zu erreichen.
Geräteneutralität: Um die Anwendungen auf den unterschiedlichsten Geräten nutzen zu können, sind meist Webapplikationen oder Cross-Platform-Apps gefragt. Beide Anwendungsarten bieten eine Reihe von Vorteilen. Webanwendungen benötigen nur einen Browser auf Seiten des Anwenders. Cross-Platform-Apps haben den Vorteil, auch auf benötigte Hardware- und Systemkomponenten zugreifen zu können.
Moderne grafische Benutzeroberflächen und eine ansprechende User Experience: Auch bei Businessapplikationen werden heute hohe Ansprüche an das User Interface gestellt. Die gewählte Technologie muss in der Lage sein, eine solche grafische Oberfläche zu realisieren. Das User Interface muss im Hinblick auf das Design und die Bedienung sorgfältig gestaltet werden.
Nutzung diverser Datenhaltungstechnologien: Die Unternehmensdaten werden in der Regel auf Datenbankservern gehalten. Im Zuge einer weiteren Flexibilisierung werden diese heute häufig in die Cloud ausgelagert, sofern dem keine betrieblichen Belange entgegenstehen.
Effiziente Umsetzung: IT-Entwicklungsprojekte stehen stets unter einem gewissen wirtschaftlichen Druck. Vor dem Hintergrund steigender Kosten muss es gelingen, das Projekt in einem vorgegebenen Budget und der gewünschten Zeit umzusetzen. Es gilt, das magische Viereck des IT-Projektmanagements aus Kosten, Zeit, Qualität und Quantität in den Griff zu bekommen. Dieses Ziel kann besser durch etablierte Technologien und einen passenden Werkzeugeinsatz erreicht werden.
Gute Wartbarkeit: Die Lebensdauer einer Applikation hängt im Wesentlichen davon ab, wie gut sie über die geplante Nutzungsdauer an sich stetig ändernde Anforderungen angepasst werden kann. Maßgeblich ist auch hier unter anderem die Beständigkeit der Technologie.
Vor diesem Hintergrund die passende Technologie auszuwählen ist mitunter ein komplexer Vorgang. Die Vielfalt der Optionen macht den Entscheidungsprozess nicht einfach. Fragt man die Entwickler:innen, dann brennen sie für jede neue Technologie. Das ist die notwendige Neugier, um auch über viele Jahre den Spaß am Job zu behalten. Ebenso ist es ein Garant dafür, dass technische Innovationen vorangetrieben werden. Noch sehr neue technische Ansätze sind jedoch in der Regel nur eingeschränkt geeignet, um ein Softwareprojekt unter den gegebenen Restriktionen erfolgreich umzusetzen. Typische Kinderkrankheiten und fehlende Erfahrungen sprechen dagegen. Andererseits muss man auch stets mit der Zeit gehen und veraltete Technologien sollten in einem neuen Projekt auch keinen Platz haben.
Bewährt hat sich ein gemischtes Vorgehen: Die eingesetzten Technologien werden immer wieder auf den Prüfstand gestellt, evaluiert und schrittweise durch neue Komponenten ersetzt. Gelingt dieses Vorgehen, dann kommt es zu keinen größeren Systembrüchen. Man kann technologische Updates in die Lösung integrieren und dennoch einen effizienten Entwicklungszyklus beibehalten.
Ein Softwaresystem besteht normalerweise aus mehreren Komponenten. Als Entwickler:in oder Softwarearchitekt:in hat man dabei die Wahl und die Qual, das passende System zu bestimmen. Neben den Anforderungen der Kund:innen, müssen dabei auch die technischen Möglichkeiten des Teams, die anfallenden Kosten, die verfügbare Zeit und die Erfahrung berücksichtigt werden. Anhand der Anforderungen können die unterschiedlichen technischen Optionen ermittelt und bewertet werden. Ein typischer Schritt bei einer Erneuerung der technischen Basis ist die Verlagerung von Teilen der Applikation in die Cloud. Relativ einfach – wir bezeichnen es als sanfte Migration – ist das für das System der Datenhaltung zu realisieren, wie der kommende Abschnitt zeigt. Dabei können die anderen Bestandteile des Softwaresystems beibehalten werden und die in Administration und Wartung aufwendige Datenbank wird aus dem Softwaresystem ausgelagert.
Unternehmensapplikationen müssen in den meisten Fällen auf Datenbanken zugreifen. Dabei wird zwischen relationalen und NoSQL-Datenbanken unterschieden. Relationale Datenbanken machen weiterhin einen Großteil der Datenhaltung für Unternehmensapplikationen aus, da sich Unternehmensanforderungen im Allgemeinen sehr gut über zueinander in Beziehung stehende Tabellen abbilden lassen. Oft verwendet wird zum Beispiel Microsoft SQL Server. Bezüglich der physischen Anordnung der Datenbanken lassen sich grob die folgenden drei Kategorien differenzieren:
Lokale Datenbank: Eingebettet in die Applikation werden die Daten lokal auf dem Rechner des Softwaresystems abgelegt. Das ist heute die Ausnahme und nur für kleinere Applikationen geeignet.
Datenbankserver: Es wird eine klassische Client-Server-Struktur betrieben. Die Technologie ist in vielen Softwareapplikationen seit vielen Jahren Standard und etabliert.
Cloud-gehostete Datenbanken: Die Infrastruktur für die Datenbank wird in die Cloud verlagert. Dabei gibt es unterschiedliche Abstufungen, beginnend beim Betrieb auf einer virtuellen Maschine (VM) mit einem Serverbetriebssystem und einer installierten Datenbank bis hin zur Nutzung als virtuelle SQL-Datenbank.
Je nach gewähltem „Betriebsmodell“ (Abb. 2) für den Datenbankserver in der Cloud handelt es sich um Infrastructure as a Service (IaaS), zum Beispiel einen SQL-Server in einer virtuellen Maschine, oder um Platform as a Service (PaaS), zum Beispiel eine virtualisierte SQL-Datenbank, wobei man sich über den technologischen Unterbau keine Gedanken mehr machen muss. Mit anderen Worten: Beim Betrieb des Datenbankservers als virtuelle Maschine ist man weiterhin für die Administration des Servers zuständig, während man die Verantwortung für die Hardware vollständig abgegeben hat. Bei der Nutzung einer virtuellen Datenbank kann diese einfach nach Konfiguration genutzt werden.

Die Verlagerung der Datenbank in die Cloud ist nicht nur ein Trend, sondern bringt auch eine Reihe von Vorteilen:
Kosten: Geringere Kosten bzw. gute Kalkulierbarkeit durch eine Verlagerung der Infrastruktur zum Serviceanbieter
Verwaltung: Es verringert sich der Aufwand für die Einrichtung, den Betrieb und die Wartung der Infrastruktur je nach Betriebsmodell
Service-Level: Cloud-Services bieten eine hohe Verfügbarkeit von 99,95 Prozent oder mehr. Diese Werte können mit einer eigenständig betriebenen Infrastruktur nur mit großem Personal- und Sachaufwand erreicht werden.
Flexibilität: Die Leistung kann schnell und ohne große Verzögerungen mit direkten Auswirkungen auf die Kosten nach oben oder auch nach unten skaliert werden.
Natürlich gibt es auch Nachteile bei der Nutzung von Cloud-Services. Beispielsweise ist die Einhaltung der Datenschutzvorschriften (DSGVO) sicherzustellen. Da die Daten nunmehr von einem Dritten, dem Cloud-Dienstleister, vorgehalten werden, ist dieser Schritt sorgfältig mit dem Kunden gemeinsam zu planen und zu entscheiden.
Wie kann die Verlagerung der Datenbank konkret in der Praxis aussehen? Für Softwaresysteme, die bisher eine SQL-Datenbank auf dem eigenen Server genutzt haben, kann man eine Migration auf eine in der Cloud gehostete Datenbank erwägen. Am Beispiel des häufig eingesetzten Microsoft SQL Servers soll dieses Szenario skizziert werden. Über das Portal unter [3] kann man beide Datenbanken mit ihren zentralen Eigenschaften vergleichen. Die Eigenschaften der beiden Datenbankvarianten sind nahezu identisch. Ein Blick in die Dokumentation von Azure SQL [2] bestätigt das. Feingranular wird dabei nochmals zwischen den Cloud-Betriebsarten unterschieden. Die höchste Komptabilität im Vergleich zu einem on premises betrieben SQL-Server bietet dabei eine in Azure gehostete Virtuelle Maschine mit einem installierten SQL-Server. Bei einer Nutzung dieser Cloud-Betriebsart spricht man von einer „Lift & Shift“-Migration, die mit nur wenigen oder ganz ohne Änderungen auskommt. Bei der Konzeption eines vollständig neuen Softwaresystems ist man hier noch weniger eingeschränkt, da ein möglicher Anpassungsaufwand – bedingt durch die Cloud-Migration – in diesem Fall entfällt.
Gemäß dem beschriebenen Ziel einer effektiven Entwicklung soll hier beispielhaft die Verwendung des Azure SQL Server mit nativen, auf dem Client ausgeführten Applikationen beschrieben werden. Als Entwicklungsumgebung wird Delphi bzw. RAD Studio [4] verwendet. Mit dieser integrierten Entwicklungsumgebung, aktuell in Version 11.2 vorliegend, ist es möglich, Cross-Platform-Anwendungen für die Systeme Windows, macOS, Linux (Desktop), iOS und Android (Mobile) sowie über ein weiteres Framework (TMS WebCore [5]) auch Webapplikationen zu erstellen. Ein Vorzug dieser Entwicklungsumgebung ist eine komponentenbasierte Entwicklung mit einem grafischen Designer. Damit ist ein effizienter Entwicklungszyklus mit einer schnellen Bereitstellung des Softwaresystems für den Kunden möglich. Bisher wurden solche Systeme primär als klassische Client-SQL-Systeme konzipiert (Abb. 3).


Das Ziel besteht nun in einer Verlagerung der Datenbank in die Cloud (Abb. 4). Geeignet ist beispielsweise der Azure SQL Server. Dazu muss die Schnittstelle zwischen Anwendung und Datenbank angepasst werden. Als generischer Datenbanktreiber kommt in Delphi-Anwendungen die Komponente FireDAC zum Einsatz. Sie bietet über native Datenbanktreiber einen universellen Zugriff auf unterschiedliche Datenbanken, zum Beispiel Oracle, MS SQL und MySQL und viele mehr. FireDAC ist damit eine generische Abstraktionsschicht zwischen dem Anwendungssystem und der Datenbank (Abb. 5).

Statt einer Verbindung zu einem lokal verwalteten Datenbankserver wird eine Verbindung zum Cloud-Service mit der Datenbank in Azure hergestellt. Um sie zu betreiben und aus einer Delphi-Applikation zu adressieren, sind die folgenden Schritte notwendig:
Anlegen einer SQL-Server-Instanz in Azure: Dazu ist der Name der Datenbank festzulegen, ein Server auszuwählen bzw. (wenn noch nicht vorhanden) neu zu erstellen und das Abrechnungsmodell über die Zuweisung einer Ressourcengruppe zu wählen (Abb. 6).
Verbindungsdaten: Die Verbindungsdaten sind abzurufen: Servername, Name der Datenbank, Benutzername und Passwort.
Verbindung konfigurieren: Der in Azure gehostete SQL-Server ist aus Sicht des Datenbanktreibers (FireDAC) mit einem lokal betriebenen SQL-Server identisch. Die Verbindungsdaten sind anzupassen. In Delphi erfolgt das über den Datenexplorer. Als Datenbanktreiber ist MSSQL auszuwählen. Die Verbindungsdaten (Schritt 2) sind zur Konfiguration einzugeben (Abb. 7).
Import von Daten: Vorhandende Daten sind ggf. von einer lokal betriebenen Serverinstanz zum in der Cloud gehosteten SQL-Server zu migrieren.
Damit ist der Weg zur Nutzung einer SQL-Datenbank, die über Azure bereitgestellt wird, skizziert. Weitere technische Details finden sich im Blogbeitrag unter [7]. Wie bereits erwähnt, ist das Vorgehen sowohl für bestehende Anwendungen als auch für die Neuentwicklung geeignet. Der Technologiestack ist damit auf Unternehmensapplikationen ausgerichtet. Unsere beschriebenen Anforderungen für das „Brot- und Buttergeschäft“ der Anwendungsentwicklung können auf diese Weise gut umgesetzt werden und es ist eine Konzentration auf die Fachanwendung möglich. Sie wird im Beispiel mit Delphi realisiert. Die Vorzüge einer integrierten Entwicklungsumgebung können dabei genutzt werden. Die aufwendige Administration und der Betrieb des Datenbankservers werden in die Cloud ausgelagert.


Betriebliche Anwendungen bestehen oft viele Jahre. Bei der Auswahl der passenden Technologie sind neben den Anforderungen der Kund:innen auch die Aspekte Wirtschaftlichkeit der Entwicklung und Wartbarkeit zu berücksichtigen. In diesem Artikel haben wir gezeigt, wie man die Datenhaltung vom lokal betriebenen Datenbankserver in die Cloud verlagert. Das Vorgehen kann sowohl für bestehende Applikationen (teilweise oder sanfte Migration) oder für Neuentwicklungen von Interesse sein.
The post Datenbankanwendungen mit Azure SQL Server und Delphi realisieren appeared first on BASTA!.
]]>The post Wo lang? Bauch oder Kopf? (Technologie-)Entscheidungen richtig treffen | Keynote appeared first on BASTA!.
]]>
Wollen Sie stets auf dem neusten Stand bleiben und keine weiteren Keynotes oder andere Videos verpassen? Dann melden Sie sich für unseren Newsletter an und wir informieren Sie, sobald es etwas neues in den Bereichen .NET,Windows & Open Innovations gibt.
Regelmäßig News zur Konferenz und der .NET-Community
The post Wo lang? Bauch oder Kopf? (Technologie-)Entscheidungen richtig treffen | Keynote appeared first on BASTA!.
]]>The post Spaß mit Mustern – Pattern Matching in C# appeared first on BASTA!.
]]>In C# 7 wurde Pattern Matching erstmals möglich, und zwar mit dem recht einfachen Typvergleich. Etwa so:
void ProcessItem(Item item) {
if (item is Hammer hammer) {
// jetzt hämmern
}
else {
// kann nicht gehämmert werden
}
}
Mit C# 7.1 wurde dieses neue Feature noch ein wenig mit der Unterstützung von Generics aufgebohrt, und außer in if-Ausdrücken konnte es auch in switch verwendet werden. Trotzdem ließ sich die Featureankündigung „Pattern Matching“ etwas großspurig an, denn bis dahin gab es tatsächlich nur sehr wenig Möglichkeiten, wenn auch durchaus wichtige.
Regelmäßig News zur Konferenz und der .NET-Community
In C# 8 ging es allerdings mit Macht weiter, mit vielen Neuerungen für Liebhaber von Mustern. Zunächst konntet ihr nun switch auch als Ausdruck verwenden, was einer kompakten Syntax sehr zuträglich war.
int CalcResult(int input) {
var result = input switch {
1 => 2,
2 => 3,
_ => throw new ArgumentException("Weiter geht's nicht")
};
}
Das war natürlich ein sehr funktionaler Schritt, der die imperative Struktur von switch, die bereits ähnlich in der Sprache C existierte, durch eine moderne funktionale Variante ergänzte. Interessanterweise entschied man sich dagegen, switch zum Bestandteil einer Funktionsdeklaration zu machen, wie das etwa in F# geht.
let calcResult =
function | 1 -> 2
| 2 -> 3
| _ => raise (System.ArgumentException("Weiter geht's nicht"))
Richtig, bei dieser merkwürdigen Syntax gibt es gar keinen sichtbaren Eingabeparameter. Das ist nicht weiter schlimm, denn direkter Zugriff auf den Wert ist nicht nötig, und auch tatsächlich nicht möglich – offenbar wollte Microsoft die C#-Programmierer nicht mit solchen extremen Formen verwirren. Immerhin ist die Form in C# ansonsten durchaus angenehm zu verwenden und sehr nah an dem, was sich in F# machen lässt.
Zusätzlich zum switch-Ausdruck gab es in C# 8.0 außerdem neue Muster, und die in dieser C#-Version eingeführten Neuheiten waren womöglich die bedeutsamsten in der Familie von Musterfeatures bis zum heutigen Tag. Zunächst gab es das Property-Pattern, mit dem sich einzelne Eigenschaftswerte prüfen lassen:
bool IsJune(DateTime dt) => dt is { Month: 6 };
Das Schlüsselwort is ergibt in diesem Zusammenhang nicht immer den meisten Sinn – besser wäre (englisch) „matches“ oder etwas Ähnliches. An dieser Stelle greife ich einmal etwas voraus: In C# 9.0 wurden zusätzlich relationale und logische Operatoren verfügbar, die mit anderen Patterns kombiniert werden können. So könnt ihr nun diese Varianten verwenden:
bool IsPastMidYear(DateTime dt) => dt is { Month: >= 7 };
bool IsThisYearOrLast(DateTime dt) => dt is { Year: 2022 or 2021 };
bool IsSummer(DateTime dt) => dt is
{ Month: 7 or 8 } or
{ Month: 6, Day: >= 21 } or
{ Month: 9, Day: < 21 };
Zur Zeit der Einführung von C# 8.0 wurden in der Liste von Neuheiten noch separat das Tuple Pattern und das Positional Pattern aufgeführt. Mittlerweile listet die Dokumentation allerdings nur noch das Positional Pattern, vermutlich weil man bei Microsoft gemerkt hat, dass die beiden Varianten ähnlich sind bzw. eng zusammengehören. Das Positional Pattern lässt sich nämlich auf jeden Typ anwenden, der sich mit Hilfe einer Deconstruct-Methode in seine Einzelteile zerlegen lässt – und das Tupel (also der eingebaute Typ Tuple, der Klarheit halber) ist genau so ein Typ. Ihr wisst sicherlich, dass der Typ dekonstruierbar ist, etwa so:
(string, string) personInfo = ("Oli", "Sturm");
var (firstName, lastName) = personInfo;
// firstName ist jetzt "Oli" und lastName ist "Sturm"
Das ist also dasselbe Verhalten, das sich für einen beliebigen Typ mit der Implementation einer Deconstruct-Methode auch erreichen lässt. Allerdings lässt sich der Begriff „Tuple Pattern“ noch immer verwenden, wenn es um einen Einsatzfall geht, wo für das Muster zunächst eine Struktur hergestellt werden muss. Im Beispiel in Listing 1 werden zwei separate Parameter auf diese Weise für ein Muster zusammengefasst.
static OrderValue OrderValueCategory(
int itemCount, double itemPrice) => (itemCount, itemPrice) switch
{
( < 0, _) => throw new ArgumentException("Positive itemCounts please!"),
(_, < 0) => throw new ArgumentException("Positive itemPrices please!"),
( >= 100, _) => OrderValue.ValuableDueToHighCount,
(_, >= 1000) => OrderValue.ValuableDueToHighItemPrice,
var (c, p) when c * p > 1000 => OrderValue.ValuableDueToHighTotal,
_ => OrderValue.NotValuable
};
In dieser Syntax lässt sich die Quelle für den Match als Tupel interpretieren, daher passt hier der Name. Im Beispiel sind noch einige andere Details zu sehen, die ich bisher nicht angesprochen habe. Der Unterstrich dient als Platzhalter für einen Teil des Resultats, der im Muster irrelevant ist (Microsoft nennt das „Discard Pattern“). Im vorletzten Muster ist zu sehen, wie ein Muster auch dazu verwendet werden kann, Werte für die weitere Nutzung zu extrahieren. In diesem Fall wurde die etwas verwirrende Form var (c, p) verwendet, die gleichbedeutend mit (var c, var p) ist – die Wahl ist dem Programmierer überlassen. Auf diese Methode der Werteextraktion komme ich später noch einmal zurück.
In allgemeinerer Form könnt ihr das Positional Pattern auch für komplexere Typen anwenden, die bereits existieren. Im folgenden Beispiel gibt es zur Kapselung der Werte itemCount und itemPrice einen eigenen Typ Order und dieser wird im Match direkt verwendet – die Logik der Muster bleibt allerdings exakt identisch, da der Typ mit seiner Deconstruct-Methode die Werte in derselben Struktur extern verfügbar macht, die das Tupel im ersten Beispiel auch hatte (Listing 2).
class Order {
public int ItemCount { get; set; } public double ItemPrice { get; set; }
public void Deconstruct(out int itemCount, out double itemPrice) {
itemCount = ItemCount;
itemPrice = ItemPrice;
}
}
static OrderValue OrderValueCategory(Order o) =>
o switch
{
( < 0, _) => throw new ArgumentException("Positive itemCounts please!"),
(_, < 0) => throw new ArgumentException("Positive itemPrices please!"),
( >= 100, _) => OrderValue.ValuableDueToHighCount,
(_, >= 1000) => OrderValue.ValuableDueToHighItemPrice,
var (c, p) when c * p > 1000 => OrderValue.ValuableDueToHighTotal,
_ => OrderValue.NotValuable
};
Es ist übrigens auch möglich, beim Positional Pattern die Namen der Parameter anzugeben. So könnte ich etwa schreiben:
... (itemCount: >= 100, itemPrice: _) => OrderValue.ValuableDueToHighCount, ...
Diese Syntax halte ich persönlich allerdings nur aus einem Grund für erwähnenswert: Sie funktioniert nicht so, wie mancher Programmierer instinktiv annimmt. Viele vermuten nämlich, dass mit der Verwendung eines oder mehrerer Namen nicht das gesamte Muster angegeben werden muss, also im Beispiel etwa der itemPrice weggelassen werden darf. Das stimmt allerdings nicht, der Compiler weist dann auf das fehlende Element hin. So dient also die Angabe der Namen höchstens der Illustration – das sei euch überlassen, aber für mich persönlich ist so etwas Platzverschwendung und Mehrarbeit bei der Wartung. Dabei meine ich wohlgemerkt nicht die Tatsache, dass das Muster vollständig sein muss – das finde ich gut!
Da ich selbst Pattern Matching vor allem in funktionalen Programmiersprachen seit vielen Jahren einsetze, fällt mir beim Lesen von Dokumentation und Beispielen auf den Microsoft-Webseiten vor allem auf, dass diese sich grundsätzlich im Bereich geschäftlicher Objekte und Daten bewegen. Das finde ich interessant, da ich in der funktionalen Programmierung die Verwendung von Pattern Matching als algorithmische Struktur gewöhnt bin. Als Beispiel hier eine mögliche F#-Implementation der Standardfunktion fold (analog zu reduce in anderen Sprachen, oder Aggregate in LINQ) mit Hilfe von Pattern Matching:
let rec fold f s = function | [] -> s | x :: xs -> fold f (f s x) xs
Wenn ihr versucht, über die Logik dieses Codes nachzudenken, fällt euch bestimmt schnell auf, was derzeit in C# noch fehlt: Muster für die Handhabung von Listen. Man kann argumentieren, dass diese nicht sinnvoll sind in der Sprache – vielleicht wird sich das ändern, wenn es in Zukunft Discriminated Unions gibt und vielleicht auch bessere Unterstützung für Tail Recursion. Ich möchte hier nicht näher auf das F#-Beispiel eingehen – gern könnt ihr mich kontaktieren, wenn ich damit Interesse geweckt habe.
Regelmäßig News zur Konferenz und der .NET-Community
Auch in C# lassen sich Muster algorithmisch nutzen, wenn es nicht gerade um Listenverarbeitung geht. Ich habe ein komplexes Beispiel zu diesem Thema, das aus meiner Arbeit an einem Buch zu funktionaler Programmierung in C# entstand. Nachdem ich in 2007 begonnen hatte, auf Veranstaltungen über dieses Thema vorzutragen, arbeitete ich an einer Sammlung hilfreicher Funktionen, die ich FCSlib nannte [2]. Mein Buch zum Thema erschien 2011 und die Codebasis enthielt eine Implementation des rot-schwarzen Binärbaums in funktionaler Art, die von Chris Okasaki in seinem Buch „Purely Functional Data Structures“ publiziert worden war. Der originale Code lag in ML und Haskell vor und ich hatte ihn für C# umgeschrieben.
Besonders interessant ist im Zusammenhang mit Pattern Matching die Funktion balance. Diese stellt im Binärbaum das Gleichgewicht wieder her – wie das genau geschieht, sei eurem eigenen Studium eines schwarz-roten Baums überlassen. Ich empfehle sehr, Chris Okasakis Buch zu lesen. Seine Implementation der Funktion in Haskell basiert auf diesen beiden Datentypen:
data Color = R | B data RedBlackSet a = E | T Color (RedBlackSet a) a (RedBlackSet a)
Das sind Discriminated Unions, die es leider bisher in C# nicht gibt. Damit lassen sich sehr einfach Datentypen beschreiben. Die Farbe darf etwa R oder B sein – Red oder Black. Der Typ RedBlackSet (mit dem generischen Subtyp a) kann entweder E sein (Empty, also leer), oder ein Wert T (Tree), dem dann eine Farbe zugewiesen wird, sowie ein linker und ein rechter Ast mit einem Wert vom Typ ain der Mitte. Fertig. Beeindruckend, oder? Aber das nur am Rande.
Die Funktion balance selbst besteht aus fünf überladenen Teilen. Hier sind zwei davon:
balance B (T R (T R a x b) y c) z d = T R (T B a x b) y (T B c z d) balance B (T R a x (T R b y c)) z d = T R (T B a x b) y (T B c z d) ...
In Haskell ist es üblich, dass unterschiedliche Teile eines Mustervergleichs einfach als Varianten einer Funktion geschrieben sind. Das geschieht hier, daher unterscheiden sich die beiden Funktionsteile anscheinend in der Signatur, aber nicht im Namen. Der Teil zwischen balance und dem Gleichheitszeichen stellt ein Pattern dar. Es wird „gematcht“, wenn der Baum B (also schwarz) ist, und dann wird der linke Teilbaum mit dem Ausdruck in Klammern verglichen – der muss T sein (muss also etwas enthalten, nicht E für den leeren Baum), und außerdem R für rot, wiederum einen Unterbaum R haben usw., und falls dieses Pattern zutreffen sollte, wird letztlich auf der rechten Seite der Zuweisung ein neuer Baum mit einer etwas veränderten Struktur erzeugt.
Wie gesagt, auf den Algorithmus zur Ausbalancierung des Baums kommt es hier nicht an. Die Patterns sind allerdings interessant, da geschehen mehrere Dinge:
Die Struktur, die an die Funktion übergeben wurde, wird mit der im Pattern verglichen.
Dies geschieht auch mit untergeordneten Teilstrukturen, nicht nur auf der obersten Ebene.
Wenn ein Muster passt, werden Informationen für die weitere Verarbeitung aus der Datenstruktur entnommen – so ergeben sich die Werte a, x, b, y, c, z und d, die auf der rechten Seite zur Erzeugung der neuen Struktur verwendet werden.
In der C#-Syntax von vor zehn Jahren ließ sich dieser Vorgang nicht syntaktisch elegant abbilden. Mein Code von damals war also extrem lang und ausführlich – in Listing 3 findet sich ein kleiner Auszug zur Illustration.
private static RedBlackTree<T> Balance(Color nodeColor, RedBlackTree<T> left, T value, RedBlackTree<T> right) {
if (nodeColor == RedBlackTree<T>.Color.Black) {
if (!(left.IsEmpty) &&
left.NodeColor == RedBlackTree<T>.Color.Red &&
!(left.Left.IsEmpty) &&
left.Left.NodeColor == RedBlackTree<T>.Color.Red)
return new RedBlackTree<T>(Color.Red,
new RedBlackTree<T>(Color.Black,
left.Left.Left, left.Left.Value, left.Left.Right),
left.Value,
new RedBlackTree<T>(Color.Black,
left.Right, value, right));
...
Diese Zeilen entsprechen übrigens der ersten Zeile aus dem Haskell-Beispiel, falls ihr zum Verständnis noch einmal zurückblicken möchtet. Nun kommt aber die richtig tolle Neuigkeit: Mit der Unterstützung für Pattern Matching in heutigen C#-Versionen lässt sich die gesamte Funktion wie in Listing 4 schreiben. Die verwendeten Strukturen habe ich alle zuvor bereits angesprochen – das Tuple Pattern sowie das Positional Pattern, basierend auf einer Deconstruct-Methode im Typ RedBlackTree<T>.
private static RedBlackTree<T> Balance(Color nodeColor, RedBlackTree<T> left, T? value, RedBlackTree<T> right) {
const Color R = Color.Red;
const Color B = Color.Black;
RedBlackTree<T> TT(Color c, RedBlackTree<T> l, T? v, RedBlackTree<T> r) => new(c, l, v, r);
return (nodeColor, left, value, right) switch
{
(B, (R, (R, var a, var x, var b), var y, var c), var z, var d) =>
TT(R, TT(B, a, x, b), y, TT(B, c, z, d)),
(B, (R, var a, var x, (R, var b, var y, var c)), var z, var d) =>
TT(R, TT(B, a, x, b), y, TT(B, c, z, d)),
(B, var a, var x, (R, (R, var b, var y, var c), var z, var d)) =>
TT(R, TT(B, a, x, b), y, TT(B, c, z, d)),
(B, var a, var x, (R, var b, var y, (R, var c, var z, var d))) =>
TT(R, TT(B, a, x, b), y, TT(B, c, z, d)),
(var color, var a, var x, var b) => TT(color, a, x, b)
};
}
Dazu gibt es mehrere Dinge zu sagen. Erstens, es ist immer noch nicht alles so wie in Haskell. Da gibt es einige Unterschiede. Z. B. beinhaltet das Pattern Matching in C# nicht die Unterscheidung T oder E aus Haskell – enthält der Teilbaum überhaupt etwas oder nicht? Das wäre in C# unverhältnismäßig schwieriger, daher habe ich den Baum einfach mit einem Platzhalter für eine „leere Farbe“ programmiert, sodass R und B bereits nur „volle“ Elemente finden. In C# sind außerdem Hilfsdefinitionen nötig, um die Werte R und B bzw. die kurze Notation zur Erzeugung eines neuen Baumes nutzbar zu machen.
Schließlich gibt es noch Kuriositäten im Detail – um etwa R und B für den Match verwenden zu dürfen, müssen diese const deklariert sein. Zusätzlich (oder trotzdem!) müssen aber auch die später verwendbaren Variablen jeweils var vorangestellt haben – warum? Das ist in C# wohl eine Frage der Konsistenz, aber es macht jeden Match-Ausdruck in diesem Beispiel doppelt so lang, wie er sein müsste, und trägt zur Signifikanz des Ausdrucks nichts bei.
Regelmäßig News zur Konferenz und der .NET-Community
Zweitens und abschließend stellt sich natürlich, wie auch in meinem Buch vor über zehn Jahren, die Frage: Sollte man das so machen? Was würdet ihr von dem Kollegen halten, der solchen Code schreibt und eincheckt? Nun, die Vorgaben dazu sollten natürlich jedem Team überlassen sein, und ich habe keinen Zweifel, dass manche C#-Programmierer eher ungern im Alltag solchen Code lesen würden. Allerdings finde ich auch die umgekehrte Sicht interessant. Der Code im Beispiel spiegelt letztlich einen komplexen Algorithmus wider. Insbesondere stellt er ein direktes Abbild der originalen Variante dar und es lässt sich in dieser Form direkt ein Vergleich anstellen, um etwa zu gewährleisten, dass der ursprüngliche Algorithmus korrekt übertragen worden ist – das wäre in der alten Implementation sehr schwierig gewesen. Sollte ein Original in ähnlichem Zusammenhang einmal geändert oder aktualisiert werden müssen, lässt sich die Änderung entsprechend einfach nach C# übertragen. Fühlt sich ein durchschnittlicher C#-Entwickler angehalten, an diesem Code schnell mal eine verdachtsbasierte Veränderung durchzuführen? Wohl kaum, bzw. hoffentlich nicht! Das ist schließlich gut so – und nebenbei ist das in der alten Form des Codes auch nicht anders. Insofern spricht doch vielleicht gar nichts dagegen, komplexe logische Zusammenhänge in syntaktisch kompakten Formen wie im Beispiel zu schreiben. Vielleicht ist das nicht absolut alltagstauglich, aber wir arbeiten ja auch nicht tagein, tagaus an den Innereien von rot-schwarzen Binärbäumen!
[1] https://docs.microsoft.com/de-de/dotnet/csharp/whats-new/csharp-version-history
The post Spaß mit Mustern – Pattern Matching in C# appeared first on BASTA!.
]]>The post Mehr Performance für Komponenten appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community
die Demoanwendung läuft mit dem .NET SDK 6.0.201, ASP.NET Core Blazor WebAssembly 6.0.4 und MudBlazor 6.0.9. Der Beispielcode für diesen Artikel findet sich unter [1]. Bevor wir aber mit der Optimierung von Komponenten beginnen können, ist es wichtig zu verstehen, welchen Lebenszyklus eine Komponente beim Rendern durchläuft und wie dieser ausgelöst werden kann.
Der Lebenszyklus einer Blazor-Komponente beginnt, wenn sie auf der Seite gerendert wird. Sie wird zum ersten Mal sichtbar.

Abb. 1: Blazor-WebAssembly-Komponenten-Rendering-Lebenszyklus
In Abbildung 1 sehen wir die verschiedenen Schritte, die durchlaufen werden, sobald das Rendering einer Komponente angestoßen wird. Im ersten Schritt wird geprüft, ob es sich um das initiale Rendern der Komponente handelt oder die Komponente andernfalls neu gerendert werden soll. Das wird anhand von zwei Optionen geprüft:
Innerhalb der Basisklasse einer Blazor-Komponente, der ComponentBase-Klasse [2], wird geprüft, ob es sich um das erste Rendern der Komponente handelt.
Handelt es sich nicht um das erste Rendering, wird die Methode ShouldRender(), die im nächsten Abschnitt näher erläutert wird, der Basisklasse aufgerufen. Die Methode gibt einen bool-Wert zurück, der angibt, ob der Renderprozess durchgeführt werden soll. Der Defaultrückgabewert ist true.
Trifft keine der beiden Optionen zu, wird der Renderprozess beendet (2a in Abb. 1). Andernfalls wird ein neuer Render Tree erstellt (2b). Der Render Tree beschreibt die HTML-Elemente des HTML-Dokuments, die in der Blazor-Welt aktualisiert werden sollen. Danach wird dieser an das Document Object Model (DOM) weitergeben. Anhand des Render Trees werden die Änderungen im DOM aktualisiert. Ist das Update abgeschlossen, werden schließlich die Methoden OnAfterRender und OnAfterRenderAsync aufgerufen und der Prozess ist beendet.
Hinweis: Der Render Tree beinhaltet nur die Änderungen der Komponenten, die sich im Vergleich zum aktuell gerenderten Zustand im DOM geändert haben. Dadurch wird nicht bei jedem Renderprozess das DOM-Element vollständig ersetzt, es werden nur die aktuellen Änderungen im DOM aktualisiert.
Weitere Informationen und Details über den Lebenszyklus von Blazor-Komponenten finden sich bei meinem Kollegen Pawel Gerr [3] in seinem englischen Artikel „Blazor Components Deep Dive – Lifecycle Is Not Always Straightforward“ [4].
Nachdem wir gesehen haben, welchen Prozess eine Komponente beim Rendern durchläuft, schauen wir uns jetzt an, was den Renderprozess einer Komponente auslösen kann:
Das erste Rendern findet, wie zu erwarten, beim Initialisieren einer Blazor-Komponente statt.
Das zweite Szenario, bei der die Komponente neu gerendert wird, ist die Änderung von Parametern. Dabei wird zwischen eigenen Parametern und Parametern der übergeordneten Komponente unterschieden:
SetParametersAsync: Diese Methode wird aufgerufen, sobald Parameter des übergeordneten Elements geändert wurden oder ein Route-Parameter in den URL gesetzt wird.
OnParametersSet/OnParametersSetAsync: Diese Methoden werden aufgerufen, sobald sich die Parameter der Komponente ändern oder die übergeordnete Komponente neu gerendert wird.
Wird ein DOM-Event ausgelöst, beispielsweise durch ein onclick-Event, wird die Komponente ebenfalls neu gerendert. Aber nicht nur die Komponente, bei der das Event ausgelöst wurde, sondern auch alle untergeordneten Elemente.
Zuletzt kann der Prozess über die Methode StateHasChanged aus der Basisklasse ComponentBase der Renderprozess angestoßen werden. Die Methode StateHasChanged() benachrichtigt die Komponente, dass sich der aktuelle Status geändert hat. Das führt dann dazu, dass die Komponente neu gerendert wird.
Betrachtet man die unterschiedlichen Szenarien, wird ersichtlich, dass der Renderprozess sehr oft getriggert werden kann. Doch ist das wirklich immer notwendig? Im weiteren Verlauf dieses Artikels schauen wir uns mögliche Optionen an, durch die wir den Renderprozess einer Komponente optimieren können.
Die erste Option, die wir nutzen können, um den Renderprozess zu unterbinden, ist, die Methode ShouldRender zu überschreiben. Wie wir in Abbildung 1 gesehen haben, wird in Schritt 2, sobald es sich nicht um das initiale Rendering handelt und die Methode ShouldRender ein false zurückgibt, der Renderprozess beendet. Die Methode ShouldRender ist eine Methode der Basisklasse ComponentBase. Der Defaultrückgabewert der Methode ist true. Infolgedessen wird bei jedem Rendervorgang der Prozess durchgeführt. Nehmen wir beispielsweise ein Formular. Wird in einem Formular ein Feld geändert, wird dadurch der Renderprozess der Komponenten angestoßen. Das führt dazu, dass zusätzlich auch all die Komponenten neu gerendert werden, die sich im Formular befinden. In einem Formular ist es natürlich wichtig, zu beachten, ob das aktuelle Feld Abhängigkeiten zu anderen Feldern hat. Hat das Feld keine Abhängigkeiten, muss auch nicht bei jeder Änderung des Felds neu gerendert werden. Um das zu vermeiden, können wir die ShouldRender-Methode überschreiben (Listing 1).
Listing 1
// CustomInputText.razor.cs
private int _valueHashCode;
protected override bool ShouldRender()
{
var lastHashCode = _valueHashCode;
_valueHashCode = Value?.GetHashCode() ?? 0;
return _valueHashCode != lastHashCode;
}In Listing 1 sehen wir, dass anhand des HashCode die Property Value der Komponente geprüft wird, ob sich diese geändert hat. Ist das nicht der Fall, gibt die Methode false zurück und der Renderprozess wird beendet. Sollte die Komponente keine Properties haben, die sich ändern, kann hier natürlich auch immer direkt false zurückgegeben werden.
Das ist eine Möglichkeit, den Renderprozess frühzeitig zu beenden, wenn es nicht zwingend notwendig ist, die Komponente neu zu rendern. Im nächsten Abschnitt schauen wir uns an, wie wir beim Auslösen eines Events den Renderprozess optimieren können.
Wird ein Event ausgelöst, wird die Methode StateHasChanged der ComponentBase-Klasse aufgerufen. Das führt dazu, dass der Renderprozess der Komponente angestoßen wird. Das hat zwar den Vorteil, dass der Entwickler die Methode StateHasChanged nicht selbst aufrufen muss, wenn ein Event angestoßen wird. Jedoch hat es den Nachteil, dass die Komponente auch ohne jegliche Änderungen neu gerendert wird. Um in diesen Prozess einzugreifen, kann das Interface IHandleEvent implementiert werden. Über das Interface wird die Methode HandleEventAsync implementiert, die bei einem Event der Komponente aufgerufen wird.
Listing 2
// HandleEventInputText.razor.cs
public partial class HandleEventInputText : ComponentBase, IHandleEvent
{
private bool _preventRender;
public Task HandleEventAsync(EventCallbackWorkItem item, object? arg)
{
try
{
var task = item.InvokeAsync(arg);
var shouldAwaitTask = task.Status != TaskStatus.RanToCompletion && task.Status != TaskStatus.Canceled;
if (!_preventRender)
{
StateHasChanged();
}
return shouldAwaitTask
? CallStateHasChangedOnAsyncCompletion(task, _supressRender)
: Task.CompletedTask;
}
finally
{
_preventRender = false;
}
}
private async Task CallStateHasChangedOnAsyncCompletion(Task task, bool preventRender)
{
try
{
await task;
}
catch
{
if (task.IsCanceled)
{
return;
}
throw;
}
if (!preventRender)
{
StateHasChanged();
}
}
void PreventRender()
{
_preventRender = true;
}
}
<label>
@Label <input id="@Id" class="form-control @CssClass" type="text" placeholder="Override ShouldRender" />
</label>In Listing 2 sehen wir die Klasse HandleEventInputText, die von der Basisklasse ComponentBase ableitet und das Interface IHandleEvent implementiert. In der Methode HandleEventAsync wird anhand der Property _preventRender geprüft, ob die Komponente gerendert werden soll oder nicht. Dadurch haben wir in der Komponente die Möglichkeit, bei einem Event die Methode PreventRender aufzurufen, wie wir zuvor im Codebeispiel beim Event oninput sehen konnten. Infolgedessen bekommt die Property _preventRender den Wert true zugewiesen. Solange die Property den Wert true besitzt, wird der Renderprozess nicht angestoßen.
Eine weitere Variante, das erneute Rendern bei Events zu vermeiden, ist der Einsatz der Hilfsklasse EventUtil [5], die von Microsoft empfohlen wird (Listing 3).
Listing 3
public static class EventUtil
{
public static Action AsNonRenderingEventHandler(Action callback)
=> new SyncReceiver(callback).Invoke;
public static Action AsNonRenderingEventHandler(Action callback)
=> new SyncReceiver(callback).Invoke;
public static Func AsNonRenderingEventHandler(Func callback)
=> new AsyncReceiver(callback).Invoke;
public static Func<TValue, Task> AsNonRenderingEventHandler(Func<TValue, Task> callback)
=> new AsyncReceiver(callback).Invoke;
private record SyncReceiver(Action callback)
: ReceiverBase { public void Invoke() => callback(); }
private record SyncReceiver(Action callback)
: ReceiverBase { public void Invoke(T arg) => callback(arg); }
private record AsyncReceiver(Func callback)
: ReceiverBase { public Task Invoke() => callback(); }
private record AsyncReceiver(Func<T, Task> callback)
: ReceiverBase { public Task Invoke(T arg) => callback(arg); }
private record ReceiverBase : IHandleEvent
{
public Task HandleEventAsync(EventCallbackWorkItem item, object arg) => item.InvokeAsync(arg);
}
}Die Hilfsklasse stellt die Methode AsNonRenderingEventHandler bereit. Die Methode kann genutzt werden, um die Func oder Action zwar auszuführen, aber kein erneutes Rendering des Event Handlers auszulösen.
Listing 4
Beim Klick auf diesen Button wird kein neues Rendering ausgelöst
</MudButton>In Listing 4 ist ein Button zu sehen, der einen OnClick Event Handler mit Hilfe der Methode AsNonRenderingEventHandler aufruft. Ähnlich wie im vorherigen Abschnitt wird auch hier das IHandleEvent-Interface eingesetzt, wie es beim Datentyp ReceiverBase zu sehen ist. Der Unterschied zum vorherigen Ansatz liegt darin, dass das Rendering direkt vermieden wird und vorab nicht geprüft werden kann, ob gerendert werden soll oder nicht. Im nächsten Abschnitt schauen wir uns an, wie wir mit dem Einsatz von JavaScript ein DOM Event verzögern können, um dadurch die Anzahl der Rendervorgänge zu reduzieren.
Hier vorab ein kleiner Hinweis: In diesem Abschnitt wird JavaScript-Interop eingesetzt. Da wir uns in diesem Artikel aber auf die Optimierung von Komponenten fokussieren, gehe ich nicht weiter auf JS-Interop ein. Mehr Informationen hierzu finden sich unter [6].
Ein aus der JavaScript-Welt bekanntes Verfahren, um das Anstoßen von Events zu verzögern, ist das Debouncing. Beim Debounce-Verfahren wird der Event Callback erst dann ausgeführt, wenn nach einer bestimmten Zeitspanne keine neuen Events mehr geworfen werden. Das heißt, wenn wir z. B. in einem Textfeld tippen, wird das Event oninput erst dann gefeuert, sobald nicht mehr getippt wird und eine selbst gesetzte Zeitspanne abgelaufen ist. Dies hat den Vorteil, dass das Event nur einmal ausgeführt wird. (Abb. 2 und 3).

Abb. 2: Rendering-Anzahl ohne Debouncing

Abb. 3: Rendering-Anzahl mit Debouncing
Um das Debounce-Verfahren in einer Blazor-WebAssembly-Komponente einzusetzen, müssen wir sowohl im C#-Code als auch im JavaScript-Code Methoden implementieren.
Betrachten wir zunächst den C#-Code in Listing 5. In der Methode OnAfterRenderAsync wird beim initialen Rendering mit Hilfe von JS-Interop die Funktion onDebounceInput in JavaScript aufgerufen. Zum Aufrufen werden zwei Referenzen erwartet:
Die erste Referenz ist eine Objektreferenz der Komponente selbst, die mit Hilfe der Klasse DotNetObjectReference erstellt werden kann. Hinweis: Wird ein Disposeable-Objekt in einer Komponente genutzt, muss das Interface IDisposable implementiert werden. In der Methode Dispose müssen dann alle Objekte zerstört werden.
Die zweite Referenz verweist auf das HTML-Objekt. Im Codebeispiel wird hierfür im HTML-Code das Attribut @ref genutzt, um eine ElementReference im C#-Code zu erstellen.
Die anderen beiden Parameter, um die JavaScript-Methode aufzurufen, sind natürlich der Name der Methode und das Intervall für das Verzögern des Events. Weiter schauen wir uns die HandleOnInput-Methode näher an. Diese wird vom JavaScript-Code aufgerufen, sobald das Event geworfen wurde. Damit der JavaScript-Code die Methode aufrufen kann, wird das JSInvokable-Attribut benötigt. In der Methode selbst wird lediglich die Methode StateHasChanged aufgerufen, sobald sich der Wert der Property Value geändert hat.
Listing 5
// DebounceTextArea.razor.cs
public partial class DebounceTextArea : IDisposable
{
//... Code above
[Inject] public IJSRuntime JS { get; set; }
private IJSObjectReference _module;
private ElementReference _textareaElement;
private DotNetObjectReference _selfReference;
// JavaScript-Datei laden
protected override async Task OnInitializedAsync()
{
_module = await JS.InvokeAsync("import","./Components/FormFields/DebounceTextArea.razor.js");
await base.OnInitializedAsync();
}
// JavaScript Event registrieren
protected override async Task OnAfterRenderAsync(bool firstRender)
{
if (firstRender)
{
_selfReference = DotNetObjectReference.Create(this);
// Event wird nach 500 ms geworfen
var minInterval = 500;
// JavaScript-Code aufrufen mit dem HTML-Element,
// einer ObjectReferenz und dem Timeout bis das Event geworfen wird
await _module.InvokeVoidAsync("onDebounceInput", _textareaElement, _selfReference, minInterval);
}
Console.WriteLine("Debounced TextArea: After Render called.");
}
// Methode die vom JavaScript-Code aufgerufen werden kann.
// Als Parameter wird der aktuelle Wert der TextArea übergeben.
[JSInvokable]
public void HandleOnInput(string value)
{
Console.WriteLine($"TextChanged {Value}. JS Value {value}");
if (Value != value)
{
StateHasChanged();
}
}
//... Code below
public void Dispose() => _selfReference?.Dispose();
}
<label>
@Label <textarea @ref="_textareaElement" placeholder="Debounce input" class="form-control @CssClass" id="@Id" @bind="CurrentValue">
</label>
Um die Methode HandleOnInput, die wir im vorigen Abschnitt gesehen haben, aufrufen zu können, müssen wir die JavaScript-Funktion onDebounceInput hinzufügen. Diese wird dann aus dem C#-Code via JS-Interop aufgerufen.
Listing 6
// DebounceTextArea.razor.js
export function onDebounceInput(elem, component, interval) {
elem.addEventListener('input', debounce(e => {
component.invokeMethodAsync('HandleOnInput', e.target.value);
}, interval));
}
function debounce(func, timeout = 300) {
let timer;
return (...args) => {
clearTimeout(timer);
timer = setTimeout(() => { func.apply(this, args); }, timeout);
};
}Wie wir in Listing 6 sehen, wird im JavaScript-Code die Funktion onDebounceInput implementiert. Diese finden wir auch im C#-Code wieder, wenn wir nochmal auf die Methode OnAfterRenderAsync schauen. Hier wird, nachdem alle Parameter definiert wurden, die Funktion mit der folgenden Codezeile aufgerufen:
// DebounceTextArea.razor.cs
await JS.InvokeVoidAsync("onDebounceInput", _textareaElement, _selfReference, minInterval);Nachdem die C#-Methode InvokeVoidAsync aufgerufen wurde, wird via JS-Interop die JavaScript-Funktion onDebounceInput aufgerufen. Die Funktion registriert einen EventListener der auf das Event input hört. Mit Hilfe der debounce-Funktion, wird der Aufruf der C#-Methode HandleOnInput so lange verzögert, bis das Intervall abgelaufen ist, das startet, sobald nicht mehr im Textfeld getippt wird.
Bevor wir uns nun im nächsten Abschnitt mit dem Darstellen von Listen beschäftigen, hier noch ein Hinweis: Das Überschreiben von ShouldRender oder das Implementieren des Interface IHandleEvent kann mit dem Debounce-Verfahren auch kombiniert werden.
Nachdem wir Möglichkeiten gesehen haben, um den Renderprozess von Komponenten in Blazor WebAssembly zu optimieren, schauen wir uns jetzt an, was passiert, wenn wir eine Liste rendern. Als Beispiel nutzen wir hier eine Liste, in der wir einzelne Einträge selektieren können (Abb. 4).

Abb. 4: Virtualisierung der Liste
Wie wir im vorherigen Abschnitt des Artikels schon gesehen haben, wird bei einem Event wie zum Beispiel bei einem OnClick der Renderprozess angestoßen. Infolgedessen haben wir bei einer Liste das Problem, dass bei jedem Klick auf ein Listenelement alle Einträge neu gerendert werden. Zusätzlich müssen bei einem for-Loop von Anfang an alle Einträge in das DOM geladen werden. Zur Optimierung kann die Virtualize-Komponente genutzt werden, die von Blazor WebAssembly zur Verfügung gestellt wird. Die Komponente bewirkt, dass nur die Komponenten geladen werden, die sich im Sichtbereich der Anwendung befinden. Das hat den großen Vorteil, dass, auch wenn über das API die Daten nicht nach und nach geladen werden können, nicht alle Einträge direkt dem DOM hinzugefügt werden. Zusätzlich kann über den Parameter OverscanCount vor und nach dem Sichtbereich eine gewisse Anzahl an Einträgen im DOM vorgeladen werden. Daher ist eine wichtige Voraussetzung zum Einsetzten der Virtualize-Komponente, dass nicht alle Einträge einer Liste im DOM gerendert sein müssen.
Listing 7
<Virtualize Context="contribution" ItemsProvider="@LoadContributions" OverscanCount="10">
<ItemContent>
<ContributionCard Contribution="@contribution">
</ItemContent>
<Placeholder>
<PlaceholderCard>
</Placeholder>
</Virtualize>
// Contributions.razor.cs
public partial class Contributions
{
[Inject] public ContributionService ContributionService { get; set; }
private async ValueTask<ItemsProviderResult> LoadContributions(
ItemsProviderRequest request)
{
var maxCount = 200;
var numConfs = Math.Min(request.Count, maxCount - request.StartIndex);
var contributions = await ContributionService.GetContributionsAsync(request.StartIndex, numConfs, request.CancellationToken);
return new ItemsProviderResult(contributions, maxCount);
}
}In Listing 7 sehen wir die Virtualize-Komponente. Die Liste an Personen wird mit dem ItemProvider geladen. Damit beim Scrollen der Liste keine zu große Verzögerung auftritt, werden mit dem OverscanCount vor und nach dem Sichtbereich 10 Einträge vorgehalten. Der ItemProvider bietet die Möglichkeit, die Daten via Lazy Loading nachzuladen. Wir sehen in Listing 7 die Methode LoadContributions, die immer dann aufgerufen wird, wenn neue Einträge geladen werden müssen. Können die Daten nicht schnell genug nachgeladen werden, beispielsweise durch ein langsames API oder eine schlechte Internetverbindung, bietet die Virtualize-Komponente die Möglichkeit, einen Placeholder einzusetzen. Dieser wird so lange angezeigt, bis die nächsten Einträge geladen wurden.
Durch den Einsatz der Virtualize-Komponente haben wir also die Möglichkeit, die Performance zu optimieren. Jedoch kann dies nicht immer mit den Optimierungen der vorherigen Abschnitte verbunden werden. Das liegt daran, dass Komponenten, die nicht im Sichtbereich liegen oder vorgeladen wurden, aus dem DOM entfernt wurden. Wenn diese wieder geladen werden, handelt es sich um das Initialisieren der Komponente, was automatisch zu einem Renderprozess führt.
Regelmäßig News zur Konferenz und der .NET-Community
In diesem Artikel haben wir mögliche Varianten gesehen, den Renderprozess von Blazor-WebAssembly-Komponenten zu verbessern. Schon mit kleinen Anpassungen können viele Rendervorgänge vermieden werden, was sich positiv auf die Performance der ganzen Anwendung auswirken kann. Wichtig dabei ist zu beachten, wann welche Komponente gerendert werden muss und wann nicht.
Beim Überschreiben der Methode ShouldRender und dem Implementieren des Interface IHandleEvent konnten wir sehen, dass bereits viele Rendervorgänge eingespart wurden. Doch auch wenn sich ein Rendering nicht vermeiden ließ, konnten wir durch den Einsatz von JavaScript bei einem Event die Anzahl der Rendervorgänge minimieren.
Mit Hilfe der Virtualize-Komponente konnten viele Funktionen eingesetzt werden, wie beispielsweise Lazy Loading oder eine Ladeanimation als Placeholder. Das trägt nicht nur zur besseren Performance bei, sondern auch zu einer erhöhten Usability der Anwendung. Daher lässt sich abschließend sagen, dass die Performance deutlich gesteigert werden kann, wenn man beim Entwickeln von Komponenten darauf achtet, so selten wie möglich zu (re-)rendern.
[1] https://github.com/thinktecture-labs/article-blazor-component-performance
[2] https://github.com/dotnet/aspnetcore/blob/main/src/Components/Components/src/ComponentBase.cs
[3] https://www.thinktecture.com/de/pawel-gerr
[4] https://www.thinktecture.com/de/blazor/blazor-components-lifecycle-is-not-always-straightforward/
[5] https://gist.github.com/SteveSandersonMS/8a19d8e992f127bb2d2a315ec6c5a373
[6] https://docs.microsoft.com/de-de/aspnet/core/blazor/call-javascript-from-dotnet?view=aspnetcore-6.0
The post Mehr Performance für Komponenten appeared first on BASTA!.
]]>The post Einführung in Azure Arc appeared first on BASTA!.
]]>Die Implementierung einer Hybrid-Cloud- oder Multi-Cloud-Strategie wird schnell komplex und die Verwaltung aller verwendeter Dienste wird zu einer großen Herausforderung für die Administratoren.
Hierfür bietet Microsoft mit Azure Arc eine am Markt einzigartige Lösung an. Azure Arc ist eine Management-as-a-Service-Plattform, mit der Administratoren Infrastruktur mit Hilfe von Azure verwalten können. Dabei spielt es keine Rolle, ob diese on premises oder bei einem anderen Cloud-Anbieter gehostet sind. Sobald Azure Arc eingerichtet ist, kann die Infrastruktur auf die gleiche Weise verwaltet werden, als würde diese auf Azure laufen. Das ermöglicht auch die Verwendung von Azure-spezifischen Diensten wie zum Beispiel das Vergeben von Tags oder den Einsatz von Azure Policy. Azure Arc bietet dafür eine einheitliche Übersicht (englisch: Pane of Glass), in der alle Dienste dargestellt und verwaltet werden können.
Regelmäßig News zur Konferenz und der .NET-Community
Mit Hilfe von Azure Arc können eine Vielzahl unterschiedlichster Services verwaltet werden. Diese Services können den folgenden Kategorien zugeordnet werden:
Azure-Arc-fähige Server
Kubernetes mit Azure-Arc-Unterstützung
Azure-Arc-fähige Anwendungsdienste
Azure-Arc-fähige Datendienste
Abbildung 1 zeigt grafisch, wie Ressourcen von verschiedenen Anbietern und Orten zentral mit Azure Diensten verwaltet werden können.

Abb. 1: Übersicht über den Aufbau von Azure Arc
In den folgenden Abschnitten werden wir die Services der einzelnen Kategorien präsentieren und auf die darin enthaltenen Dienste eingehen.
Die Verwaltung von Servern, sowohl virtuelle Maschinen als auch physische Server, ist das älteste und am besten ausgereifte Feature von Azure Arc. Azure Arc erlaubt Administratoren, Server so zu verwalten, als würden sie auf Azure laufen. Dabei ist es egal, ob diese Server im eigenen Rechenzentrum oder bei einem anderen Cloud-Provider, zum Beispiel AWS, gehostet werden. Außerdem können Linux- und Windows-Server gleichermaßen verwaltet werden.
Um Server mit Azure Arc verwalten zu können, muss ein Skript auf dem jeweiligen Server ausgeführt werden, das den Azure Connected Machine Agent herunterlädt und konfiguriert. Dieser Agent stellt eine Verbindung mit Azure Arc her und verwaltet die verschlüsselte Kommunikation zwischen Azure und dem Server. Nachdem der Agent eingerichtet ist, ist der Server im Azure Arc Service sichtbar und kann genauso wie Azure VMs verwaltet werden. Dadurch können alle Azure Services zur Verwaltung von VMs verwendet werden. Dabei spielt es keine Rolle, ob der Server über das Internet erreichbar ist oder nicht. Der Server muss nur eine ausgehende Verbindung über Port 443 (HTTPS) mit dem Internet aufbauen können.
Eines der nützlichsten Features zur Verwaltung von Servern ist das Updatemanagement. Dieser Service ist komplett gratis und gibt Administratoren eine Übersicht über alle installierten Updates auf den von Azure Arc verwalteten Servern. Außerdem können auf diesen Servern mittels Azure Updates installiert werden. Dadurch können alle Azure-Arc-Server und Azure VMs mit den gleichen Tools verwaltet werden, wodurch der Verwaltungsaufwand deutlich gesenkt werden kann.
Neben der Verwaltung von Updates kann mit Hilfe von Azure Arc auch die Konfiguration der Server verwaltet und angepasst werden. Zusätzlich zur Verwaltung der Konfiguration kann eine Übersicht über die installierte Software pro Server erstellt werden. Das ist vor allem in Kombination mit der Verfolgung von Änderungen sehr nützlich. Dieses Feature zeichnet alle Änderungen der installierten Software, Windows- und Linux-Systemdateien oder Registry-Einträgen auf. Dadurch können Administratoren jederzeit sehen, welche Software bzw. welche Systemeinstellungen geändert wurden. Neben der Softwareverwaltung kann auch der Benutzerzugriff mit der gewohnten RBAC (Role-based Access Control) konfiguriert und überwacht werden.
In die gleiche Richtung wie die Verfolgung von Änderungen geht Azure Monitor. Mit Hilfe dieses Dienstes können die Azure Arc Server überwacht werden. Der Azure Monitor Agent auf dem Server sendet Informationen über die Ressourcenauslastung oder über den Zustand des Servers. Diese Informationen können dann mit Hilfe von Azure Monitor übersichtlich dargestellt werden und im Fall eines Problems kann eine zuständige Person oder das Team benachrichtigt werden.
Die letzten zwei Features, die wir hier kurz vorstellen möchten, sind Microsoft Defender für Cloud und Azure Policy. Beide Tools helfen, die Sicherheit der Server zu erhöhen. Der Microsoft Defender für Cloud überwacht den Sicherheitsstatus der Server und schützt vor Cyberangriffen. Mit Hilfe von Azure Policy können Administratoren Regeln vorgeben, die die Server einhalten müssen. Diese Regeln können zum Beispiel die Passwortkomplexität beinhalten oder auch, dass jeder Server Auditlogs erstellen muss.
Die Managementoberfläche für Azure Arc stellt Microsoft kostenlos zu Verfügung. Für die Verwendung von Azure Policy und der Überwachung der Änderung müssen 6 Dollar (in etwa 5,40 Euro) pro Server und Monat bezahlt werden.
Neben der Verwaltung von Servern kann mit Azure Arc auch ein Kubernetes-Cluster verwaltet werden. Hierbei ist es wieder egal, wo dieser Cluster gehostet wird, on premises oder bei einem anderen Cloud-Anbieter. Außerdem wird jeder CNCF-zertifizierte Kubernetes-Cluster [1] unterstützt.
Um einen Kubernetes-Cluster mit Azure Arc verwalten zu können, muss man den Azure-Arc-Client mittels Azure-CLI-Befehl installieren. Außerdem benötigt man für die Installation die connectedk8s-Azure-CLI-Erweiterung. Der folgende Befehl zeigt, wie sie installiert und anschließend zur Installation des Azure Arc Agents genutzt wird. Die Azure-CLI-Befehle müssen an dem Kubernetes-Cluster ausgeführt werden, der zu Azure Arc hinzugefügt werden soll.
az extension add --name connectedk8s
az connectedk8s connect --name --resource-group <RESOURCE GROUP>
Die Installation erstellt den neuen Namespace azure-arc und installiert dort den Azure Arc Agent und weitere Komponenten wie zum Beispiel einen Config Agent und Azure Active Directory Proxy. Abbildung 2 zeigt alle installierten Komponenten im azure-arc Namespace.

Abb. 2: Übersicht der Komponenten im azure-arc Namespace
Nachdem der Agent installiert ist, kann man den Kubernetes-Cluster im Service Kubernetes | Azure Arc im Azure Portal sehen. Dort sieht man die installierte Kubernetes-Version des Clusters, die Distribution sowie alle Ressourcen, die im Cluster laufen. Abbildung 3 zeigt den azure-arc Namespace und alle Pods des Namespace.
 Abb. 3: Übersicht Azure Arc im Azure Portal
Abb. 3: Übersicht Azure Arc im Azure Portal
Außerdem sieht man auf der linken Seite von Abbildung 3, dass es die Möglichkeit gibt, Erweiterungen (Extensions) und Policies zu installieren sowie mit Hilfe von GitOps automatisierte Deployments beziehungsweise Continuous Deployments (CD) zu konfigurieren.Die Erweiterungen sind zum Beispiel Container Insights, Azure Key Vault als Secrets Provider und Microsoft Defender für Cloud. Container Insights sammelt Metriken der Pods im Cluster and sendet diese an Azure Monitor. Dort können sie grafisch dargestellt werden, um eine Übersicht über die Auslastung der Ressourcen zu bekommen. Azure Key Vault als Secrets Provider ist eine sehr interessante Erweiterung. Dieses Add-on erlaubt es, Kubernetes Secrets direkt im Azure Key Vault zu speichern. Dadurch sind die Secrets verschlüsselt und sicher gespeichert. Außerdem hat man so alle Azure Key Vault Features, wie zum Beispiel die Zugriffskontrolle und Auditierung der Zugriffe und Änderungen.Der Azure Arc Agent kommuniziert mit Azure über eine HTTPS-Verbindung. Dadurch ist die Verbindung verschlüsselt; zusätzlich braucht es keine offenen Ports auf der Firewall (außer Port 443 natürlich, der allerdings meistens nach außen offen ist). Da der Azure Arc Agent die Verbindung herstellt, muss nur die ausgehende Verbindung erlaubt werden und alle eingehenden Verbindungen können blockiert sein.
GitOps erlaubt es, automatisierte Deployments zu konfigurieren. Dafür wird ein Flux Agent im Cluster installiert, der über das Azure CLI oder das Azure Portal konfiguriert werden kann. Er prüft ein konfiguriertes Git-Repository auf Änderungen, und falls der Agent Änderungen feststellt, werden diese in den Cluster geladen und installiert.
Die Managementoberfläche für Azure Arc stellt Microsoft kostenlos zu Verfügung. Die Verwaltung der Kubernetes-Konfiguration ist für die ersten sechs vCPUs kostenlos und kostet für jede weitere vCPU 2 Dollar (in etwa 1,80 Euro) pro vCPU pro Monat.
Im nächsten Teil der Serie wird ein Proof-of-Concept eines Kunden vorgestellt. Dieser hat einen lokalen K3s-Cluster, der nicht über das Internet erreichbar ist. Dadurch war es ursprünglich nicht möglich, Anpassungen oder Deployments von außerhalb des Netzwerks, etwa von Azure DevOps aus, vorzunehmen. Mit Azure Arc war es möglich, weiterhin alle eingehenden Verbindungen zu blockieren und trotzdem sichere Deployments und Anpassungen außerhalb des Netzwerks durchzuführen.
Anfang dieses Jahres hat Microsoft die Preview der Azure-Arc-fähigen Anwendungsdienste (Azure Arc-enabled Application Services) veröffentlicht. Mit diesem Dienst ist es erstmals möglich, bestimmte Azure Services wie zum Beispiel Azure App Service oder Azure Logic Apps außerhalb von Azure zu betreiben. Folgende Services sind aktuell verfügbar:
Azure App Service
Azure Functions
Azure Logic Apps
Azure API Management
Azure Event Grid
Als Grundlage für diese Services wird ein Kubernetes-Cluster benötigt, der mit Azure Arc verbunden ist. Auf diesem Cluster kann dann eine Erweiterung für den gewünschten Service installiert werden. Wichtig zu beachten ist hierbei, dass diese Services sich in einer früher Phase der Preview befinden und viele Features der normalen Services noch nicht implementiert sind. Zum Beispiel können Azure App Services derzeit nur installiert werden, wenn sich die Azure-Arc-Instanz in East US oder West Europe befindet. Zusätzlich fehlt die Integration mit dem Azure Key Vault und die Möglichkeit, Managed Identities zu verwenden.
Als Benutzer eines dieser Dienste merkt man nicht, ob er auf Azure oder mits Azure Arc außerhalb betrieben wird. Eine neue Instanz eines Azure App Service kann wie gewohnt über das Azure Portal oder das Azure CLI erstellt werden. Zusätzlich zu den Azure-Regionen kann man selbst erstellte Regionen auswählen, die die Installation mittels Azure Arc darstellen. Wenn eine Azure-Arc-Region ausgewählt wurde, installiert Azure Arc einen neuen Namespace für den App Service im Kubernetes-Cluster und der Benutzer kann den Service wie gewohnt verwenden. Das bedeutet, dass der App Service mit einem öffentlichen URL und via HTTPS erreicht und bei Bedarf hinsichtlich der CPU- oder RAM-Auslastung skaliert werden kann.
Für die Verwaltung des App-Service-Diensts im Kubernetes-Cluster installiert Azure Arc die App-Service-Erweiterung. Zusätzlich kann optional KEDA (Kubernetes Event-driven Architecture [2]) installiert werden, um anhand von Events die Anwendung zu skalieren.
Da alle Dienste noch in der Preview sind, können sie derzeit kostenlos verwendet werden. Microsoft hat noch keine endgültigen Preise veröffentlicht.
Die Azure-Arc-fähigen Anwendungsdienste werden im dritten Teil dieser Serie detaillierter betrachtet.
Ein Grund, weshalb viele Organisationen sich gegen eine Cloud-Lösung entscheiden, ist die Datenhaltung auf fremder Infrastruktur. Mit Azure Arc besteht nun die Möglichkeit, die Datenhaltung auf der gewünschten Infrastruktur zu betreiben und trotzdem von den Vorteilen eines von der Cloud verwalteten Service zu profitieren. Zu den Vorteilen zählen automatische Updates, flexible Skalierung und eine zentralisierte Verwaltung der Datenbank. Durch automatisierte Updates müssen sich Administratoren nicht mehr darum kümmern. Zusätzlich können Datenbanken automatisch auf eine neue Version aktualisiert werden. Durch flexible Skalierung können die zur Verfügung stehenden Ressourcen dynamisch nach dem aktuellen Bedarf skaliert werden. Neben der Skalierung der Ressourcen können weitere Lesereplikate ohne Ausfallzeit hinzugefügt werden. Das kann automatisch mittels Skripten oder auch manuell erfolgen. Wie bei den anderen Azure-Arc-fähigen Services ist es auch hier möglich, die Datendienste durch Azure zentral und bequem mit den gewohnten Tools wie dem Azure Portal, Azure Data Studio oder Azure CLI zu verwalten.
Somit können Kunden Azure SQL Managed Instance und Azure PostgreSQL Hyperscale außerhalb von Azure betreiben. Im Gegensatz zu Azure-Arc-fähigen Anwendungsdiensten ist diese Kategorie ausgereifter und es stehen 16 Regionen, verteilt über die USA, Europa und Asien, zur Verfügung.
Wie schon bei den Azure-Arc-fähigen Anwendungsdiensten, beruhen auch die Azure-Arc-fähigen Datendienste auf der Grundlage von Kubernetes. Beide Datendienste, Azure SQL mit Azure-Arc-Unterstützung sowie PostgreSQL Hyperscale mit Azure-Arc-Unterstützung, laufen als containerisierte Applikationen. Um nun die erwähnten Vorteile von verwalteten Datendienste zu ermöglichen, erstellt und verwendet Azure Arc den Azure Arc Data Controller, der ebenfalls in einem Container im Kubernetes-Cluster läuft. Mittels Azure Arc Data Controller werden Verwaltungsfunktionalitäten wie Monitoring, Logging, Patching/Upgrading, Skalierung und Back-up ermöglicht. Weiter dient es dazu, den Austausch von Azure mit Identity Management, RBAC und Azure Policy sowie das Senden von Telemetriedaten zu gewährleisten. Dafür bietet Azure Arc mit der direkten und indirekten Verbindung zwischen Azure und Azure-Arc-fähigen Datendienste zwei Konnektivitätsmodi an. So kann mit der indirekten Verbindung die Menge an Daten, die an Azure gesendet werden, eingeschränkt werden. Jedoch bietet diese Option weniger Funktionalitäten, zum Beispiel nur noch halbautomatisierte Updates.

Abb. 4: Architektur des Azure-Arc-fähigen Datendiensts [3]
Um den Azure-Arc-fähigen Daten-Service zu verwenden, muss der Azure Arc Data Controller installiert werden. Abbildung 4 zeigt die Architektur und verdeutlicht nochmals, dass ein Kubernetes-Cluster als Basis für diesen Service benötigt wird. Die Installation kann entweder per Kommandozeile mittels Azure CLI oder über eine Benutzeroberfläche erfolgen.
Listing 1 zeigt alle benötigten Befehle, um den Azure Arc Data Controller auf dem Cluster zu installieren. Während der Installation muss der Administrator den Benutzernamen und das Passwort für den Adminbenutzer des Monitorings eingeben.
Listing 1
az provider register -n 'Microsoft.Kubernetes'
az provider register -n 'Microsoft.ExtendedLocation'
az extension add --name arcdata
az extension add --name k8s-extension
az extension add --name customlocation
az customlocation create
--cluster-extension-ids <CLUSTER_EXTENSION_IDS> `
--host-resource-id <KUBERNETES_RESOURCE_ID> `
--name <CUSTOM_LOCATION_NAME > `
--namespace <CUSTOM_LOCATION_NAMESPACE> `
--resource-group <RESOURCE_GROUP> `
az arcdata dc create `
--name <DATA_CONTROLLER_NAME> `
--resource-group <RESOURCE_GROUP> `
--cluster-name <CLUSTER_NAME> `
--k8s-namespace <K8s_DATA_CONTROLLER_NAMESPACE> `
--custom-location <CUSTOM_LOCATION_NAME> `
--location <METADATA_LOCATION> `
--connectivity-mode direct
Der Code in Listing 1 registriert zunächst die benötigten Provider mit Azure und installiert dann drei Azure-CLI-Erweiterungen. Anschließend wird eine Custom Location im Kubernetes-Cluster installiert. Dabei muss eine mit Abstand separierte Liste der IDs der installierten Erweiterungen angegeben werden und dann die ID des Kubernetes-Clusters. Die folgenden Parameter sollten selbsterklärend sein. Microsoft führt derzeit recht oft Anpassungen an den Parametern durch. Daher sollte vor der Verwendung die offizielle Dokumentation überprüft werden [4].
Nachdem die Custom Location erstellt ist, kann der Data Controller installiert werden. Dazu werden der Name der zuvor erstellten Custom Location und Informationen zum Kubernetes-Cluster benötigt, zum Beispiel der Name und in welchem Namespace der Data Controller installiert werden soll. Der Location Parameter gibt dabei die Region an, in der die Metadaten des Controllers gespeichert werden. Auch hier sollte die offizielle Dokumentation vor der Installation überprüft werden [5]. Die Installation kann je nach Konfiguration, Netzwerkgeschwindigkeit und der Anzahl an Nodes im Cluster eine längere Zeit in Anspruch nehmen.
Folgende Codezeile zeigt, wie man mit dem Kubernetes CLI kubectl überprüfen kann, ob die Installation abgeschlossen ist.
kubectl get pods --namespace <K8s_NAMESPACE>Sobald die Installation erfolgreich abgeschlossen ist, kann mit der Provision einer Datenbankinstanz gestartet werden. Hierfür wird der in Listing 2 dargestellte Befehl ausgeführt. Um einen Datenbankadministrator anzulegen, wird hier während der Installation nach einem Benutzernamen und Passwort gefragt.
Listing 2
az sql mi-arc create `
--name <DB_NAME> `
--resource-group <RESOURCE_GROUP> `
--admin-login-secret <SECRET_NAME_ADMIN_CREDENTIALS_KUBERNETES> `
--custom-location <CUSTOM_LOCATION> `
--location <METADATA_LOCATION>Der location-Parameter gibt wie zuvor die Region an, in der die Metadaten der Datenbank in Azure gespeichert werden sollen. admin-login-secret konfiguriert den Namen eines Secrets in Kubernetes, in dem die Anmeldedaten des Administratoraccounts gespeichert sind. Weiterhin gibt es noch eine Unzahl an optionalen Parametern, die aus der offiziellen Dokumentation ersichtlich sind [6].
Sobald die damit erstellten Pods gestartet wurden, sind diese im Portal zu sehen. Abbildung 5 zeigt das Azure Portal, in dem der externe Endpunkt (die IP-Adresse und der Port) der Datenbank angezeigt wird. Mit diesem Endpunkt und den Anmeldedaten kann nun mittels Azure Data Studio oder auch SQL Server Management Studio auf die Datenbank zugegriffen werden.
Abb. 5: Sichtbarkeit der SQL-Instanz nach der erfolgreichen Installation
| 1 vCore/Monat | Pay as you go | 1 Jahr reserviert | 3 Jahre reserviert |
|---|---|---|---|
| Lizenz inklusive | ca. 138 Euro | ca. 102 Euro | ca. 84 Euro |
| Azure Hybrid Benefit | ca. 72 Euro | ca. 36 Euro | ca. 18 Euro |
Tabelle 1: Preismodell für Azure-Arc-fähige SQL-Instanzen
Für Interessierte, die Azure Arc gerne ausprobieren möchten, allerdings von all den benötigten Voraussetzung wie zum Beispiel dem Aufsetzen eines Kubernetes-Clusters abgeschreckt sind, bietet Microsoft mit Azure Arc Jumpstart [7] eine Möglichkeit, Azure Arc schnell auszuprobieren und kennenzulernen. Azure Arc Jumpstart bietet eine Vielzahl von Szenarien mit einer detaillierten Beschreibung und den benötigten Skripten, um die notwendigen Ressourcen zu erstellen und zu konfigurieren. Die erstellten Ressourcen laufen in einer Sandbox, um das sichere Ausprobieren zu gewährleisten.
Mit Azure Arc bietet Microsoft eine am Markt einzigartige Management-as-a-Service-Plattform, die es Administratoren erlaubt, Infrastrukturen mit den gewohnten Azure-Diensten zu verwalten. Dabei spielt es keine Rolle, ob diese Infrastruktur on premises oder bei einem anderen Cloud-Anbieter gehostet ist. Zusätzlich können mit Azure Arc Azure-Dienste wie Azure-App-Service- oder Azure-Managed-SQL-Instanzen außerhalb von Azure betrieben werden.
Teil 2 dieser Serie wird zeigen, wie ein On-Premises-K3s-Cluster mit Azure Arc verwaltet werden kann und wie mit Hilfe der GitOps-Erweiterung automatisierte Deployments konfiguriert werden können.
[1] https://www.cncf.io/certification/software-conformance/
[2] https://entwickler.de/kubernetes/ein-level-up-fur-die-skalierung-in-k8s
[5] https://docs.microsoft.com/en-us/cli/azure/arcdata/dc?view=azure-cli-latest#az-arcdata-dc-create
[6] https://docs.microsoft.com/en-us/cli/azure/sql/mi-arc?view=azure-cli-latest#az-sql-mi-arc-create
The post Einführung in Azure Arc appeared first on BASTA!.
]]>The post Controls für WinUI 3 – funktionell und ansprechend im Design appeared first on BASTA!.
]]>Leser des Windows Developer sind hier sehr gut informiert. Sowohl über die Features der genannten grafischen Benutzerschnittstellen als auch über die laufende Entwicklung des App SDK und über das WinUI 3 wurde hier schon aus unterschiedlicher Perspektive berichtet (WD 10.20, 7.21und 12.21). In diesem Artikel werfen wir einen konzentrierten Blick auf die Arbeit mit den Controls von WinUI 3. Die Basis für die Gestaltung moderner grafischer Oberflächen ist auch bei WinUI 3 der Einsatz von fertigen Komponenten. Eine Basisauswahl, die sukzessive durch Microsoft erweitert wird, ist bereits verfügbar und erlaubt schon heute das Erstellen von ansprechenden Benutzeroberflächen. Je mehr dieses System in den Fokus der Entwickler rückt, desto umfassender wird auch die Unterstützung mit Controls von Drittanbietern ausfallen.
Regelmäßig News zur Konferenz und der .NET-Community
Entwickler, die nun zunehmend von WinForms und WPF zur Grafikschnittstelle WinUI 3 wechseln und vielleicht mit dem technischen Vorgänger WinUI 2 (UWP) nicht viel gearbeitet haben, werden über die Funktionsweise und das Design einiger Controls vielleicht überrascht sein. Natürlich gibt es immer noch Basis-Controls wie einen Button, ein statisches Textfeld (Label) oder ein Texteingabefeld. Aber es gibt auch deutlich umfassendere visuelle Controls, die einen ganz anderen Ansatz zur Gestaltung des User Interface bzw. die Umsetzung einer vollständig veränderten User Experience ermöglichen. Wer bereits Apps für die mobilen Plattformen entwickelt hat, der wird hier viele Ähnlichkeiten vorfinden. Die Grafikschnittstelle WinUI 3 erfordert zum einem eine Konzentration auf das Layout und zum anderen eine Fokussierung auf den Inhalt. Content First ist auch hier ein wichtiges Prinzip, d. h., dass die Navigation zwischen den Seiten und der Aufbau einer Seite mehr dem Vorgehen auf mobilen Geräten gleichen als der Entwicklung klassischer Desktopanwendungen. Mit anderen Worten: Moderne Desktopanwendungen sind heute auch das Ergebnis eines umfassenden Designprozesses. Mit langweiligen Formularen, vielleicht noch in einem mausgrauen Farbton gestaltet, haben diese heute nichts mehr gemeinsam.
Hinweis: Es gilt ganz besonders das Prinzip „Probieren geht über Studieren“. Deshalb finden Sie im Kasten „Apps für WinUI 3 erstellen“ einige Hinweise, um das Gerüst für eine Desktopanwendung mit WinUI 3 zu generieren.
Installieren Sie die aktuelle Version von Visual Studio 2022. Spielen Sie alle Updates zur Entwicklungsumgebung ein. Installieren Sie die folgenden Workloads: .NET-Desktopentwicklung, Desktop development with C++ und Entwicklung für die universelle Windows-Plattform. Ebenso ist es notwendig, dass Sie das Windows-App-SDK installieren. Die aktuelle Version finden Sie unter [1], wenn Sie im Store für die Extensions von Visual Studio nicht fündig werden. Mit der Windows-App-SDK-Extension wandern neue Projektvorlagen für Visual Studio auf Ihren Rechner.
Als Projektvorlage wählen Sie dann Leere App, verpackt (WinUI 3 in Desktop). Ausgangspunkt für unsere Experimente ist die Datei MainWindow.xaml. Hier erfolgt die Deklaration der Benutzerschnittstelle. Starten Sie die App ein erstes Mal, danach sind Sie bereit für Ihre Erkundungstour. Einen Designer gibt es (noch) nicht, vielmehr wird Hot Reload als interaktive Hilfe für das Erstellen des User Interface verwendet.
Starten wir mit einem ersten Überblick über die verfügbaren Controls, die es bereits heute für WinUI 3 gibt. Sie finden die Auflistung in Abbildung 1.

Abb. 1: Übersicht über die Controls von WinUI 3 [1]
Es empfiehlt sich, hier die englische Seite der Dokumentation aufzurufen und zu verwenden. Die Namen der Controls sind dann mit den Klassennamen identisch, dagegen wirken die Übersetzungen teilweise etwas sperrig. Viele Basis-Controls findet man in nahezu allen Bibliotheken zum Erstellen von modernen Benutzeroberflächen, d. h., was ein Button oder ein Textfeld ist, muss man dem erfahrenen Entwickler nicht mehr erläutern. Dennoch werden Sie ggf. überrascht sein, welche Variantenvielfalt es beispielsweise bei den Buttons gibt [2]:
Button: Die klassische Schaltfläche, die eine sofortige Aktion bei einem Mausklick auslöst; man kann das Click-Ereignis oder eine Command-Bindung verwenden
RepeatButton: Eine Schaltfläche, die im gedrückten Zustand fortlaufend ein Click-Ereignis auslöst
HyperlinkButton: Eine Schaltfläche, die wie ein Link formatiert ist und für die Navigation verwendet wird
DropDownButton: Eine Schaltfläche mit der Möglichkeit zum Auswählen weiterer Optionen.
SplitButton: Eine Schaltfläche mit zwei Seiten; eine Seite initiiert eine Aktion, während die andere Seite ein Menü öffnet
ToggleSplitButton: Eine Schaltfläche für zwei Zustände und mit zwei Seiten; über eine Seite wird zwischen aktivierten und deaktivierten Zuständen umgeschaltet; über die andere Seite wird ein Menü geöffnet
ToggleButton: Eine Schaltfläche für zwei Zustände, d. h. einen Wechsel zwischen aktiviert und deaktiviert
Andere Controls muss man sich dagegen etwas genauer ansehen, damit man die Funktionsweise erkennt und sich ihre Verwendung vorstellen kann. Die folgenden Controls lohnen aus dieser Perspektive einen zweiten Blick. Wir haben ein paar Basisinformationen zusammengestellt:
AnimatedIcon: Dieses Steuerelement gibt animierte Bilder als Reaktion auf Benutzerinteraktion und Änderungen des visuellen Zustands wieder. Animierte Symbole ziehen die Aufmerksamkeit auf eine Komponente, zum Beispiel die höchstwahrscheinlich als nächstes zu betätigende Schaltfläche.
AnimatedVisualPlayer: Eine Bibliothek zum nativen Rendern von Adobe-AfterEffects-Animationen in den Anwendungen. Über das Control können flüssig ablaufende 60-fps-Animationen und auflösungsunabhängige Vektorgrafiken dargestellt werden. Informationen zur Bibliothek findet man unter [3] mit dem Stichwort „Lotti“ und auf der Projektwebseite unter [4]. Letztendlich haben wir über das Control die Möglichkeit, auf sehr einfache Art und Weise, professionell erstellte Animationen in unsere App aufzunehmen und sie an passender Stelle zum Leben zu erwecken.
BreadcrumbBar: Das Control stellt den direkten Pfad von Seiten oder Ordnern zum aktuellen Speicherort bereit. Man kann auf diese Weise den Navigationspfad bis zum aktuellen Element jederzeit nachverfolgen. Ebenso können die Nutzerinnen und Nutzer direkt zu einem bestimmten Ort der App navigieren. Das Control bietet sich an, wenn man eine sehr tiefe Navigationsstruktur in der App hat und dem Anwender eine Orientierung geben möchte.
ContactCard: Ein Control, das zur Darstellung von Kontaktinformationen wie Name, Telefonnummer und Adresse genutzt werden kann. Eine solche Darstellung kann man auch aus Einzelelementen zusammensetzen. Dieses Control kann man verwenden, wenn man zusätzliche Informationen zu einem Kontakt, zum Beispiel einen angemeldeten Benutzer, anzeigen möchte. Da immer mehr Apps eine Anmeldung zum Beispiel für die Datenspeicherung voraussetzen, ergibt es Sinn, auf ein solches fertiges Element zurückzugreifen.
FlipView: Man verwendet dieses Control zum „Durchblättern“ von Bildern oder anderen Elementen. Bei Geräten mit Touchscreen erfolgt die Navigation durch die Sammlung mit einer Wischbewegung über ein Element. Bei Verwendung mit einer Maus werden beim Zeigen mit der Maus Navigationsschaltflächen angezeigt. Bei Verwendung einer Tastatur erfolgt die Navigation durch die Elemente mit Hilfe der Pfeiltasten.
Flyouts Das ist ein ausblendbarer Container, der beliebige andere visuelle Controls als Inhalt anzeigen kann. Wann sollte ein Flyout verwendet werden? Es ist zum Beispiel vorgesehen für: das Erfassen von zusätzlichen Informationen, bevor eine Aktion abgeschlossen werden kann; das Anzeigen von Informationen, die nur vorübergehend relevant sind, oder für das Anzeigen weiterer Informationen, beispielsweise von Details oder ausführlicheren Beschreibungen eines Elements auf der Seite. Ein Flyout sollte nicht als Ersatz für ein QuickInfo (kurze Information zu einem Control) oder Kontextmenü verwendet werden.
ParallaxView: Hierbei handelt es sich um einen visuellen Effekt zum Darstellen von Vorder- und Hintergrund in 2D-Abbildungen. Auf diese Weise soll ein Gefühl von Tiefe, Perspektive und Bewegung erzeugt werden. Die ParallaxView ist mit der Einführung des Fluent Design als Element der Gestaltung von Benutzeroberflächen in Windows hinzugekommen. Beispielsweise verwendet man diesen visuellen Effekt, um eine Liste von Einzelelementen vertikal vor einem Hintergrundbild zu verschieben. Dabei scrollt die Liste deutlich schneller als das Hintergrundbild. Es entsteht der Eindruck von Tiefe. Sie können es vergleichen mit einem Blick aus dem Fenster eines fahrenden Zuges. Die naheliegende Landschaft rauscht in hoher Geschwindigkeit am Auge des Betrachters vorbei, während die Häuser und Bäume in der Ferne sich nur langsam in die gleiche Richtung bewegen. Microsoft gibt in seinen Guidelines den Hinweis, den Effekt bewusst, gezielt und sparsam anzuwenden, d. h., „… eine übermäßige Nutzung kann die Auswirkungen verringern“ [5].
PersonPicture: Ähnlich wie das Control ContactCard handelt es sich beim Steuerelement PersonPicture um ein Element zur Anzeige von Nutzerdaten. Konkret: Es wird ein Avatar für die betreffende Person angezeigt, wenn dieses verfügbar ist. Andernfalls werden die Initialen der Person oder eine allgemeine Glyphe (Platzhalter) eingeblendet. Beispielsweise kann man dieses Control für folgende Einsatzzwecke gebrauchen: Zur Anzeige des aktuellen Benutzers, zur Anzeige von Kontakten in einem Adressbuch, zur Anzeige des Absenders einer Nachricht oder zur Anzeige eines Social-Media-Kontakts. Ein solches Element könnte man auch aus Basis-Controls selbst zusammenbauen. Die Arbeit wird dadurch jedoch erheblich beschleunigt. die Anzeige von Personendaten ist in allen Apps identisch und hat damit für den Nutzer einen hohen Wiedererkennungseffekt.
PipsPager: Zunächst, was sind Pips? Pips stellen eine Einheit numerischer Werte dar, die meist als Punkte angezeigt werden. Eine alternative Anzeige (Bindestriche, Quadrate, …) ist jedoch möglich. Jeder Punkt stellt dabei eine Seite dar. Der Benutzer kann einen Punkt auswählen und damit direkt zur betreffenden Seite gehen. PipsPager ist damit eine Form der Navigation. Ein PipsPager kann horizontal oder vertikal angewendet werden. In der Praxis findet man meistens die horizontale Verwendung. Das Control kann man gut mit einem FlipView-Control kombinieren (Abb. 2), um neben der Wischbewegung (Touchscreen), der Weiterschaltung mit der Maus bzw. der Nutzung von Pfeilen am linken und rechten Bildrand eine weitere Option der Navigation zu bieten. Mittels PipsPager kann man schneller zu Inhalten springen, was gerade bei einer großen Anzahl von Einzelelementen eine sinnvolle Option ist.
Swipe: Es handelt sich um Wischbefehle für das schnelle Auslösen von Aktionen. Sie wirken wie ein Kontextmenü. Man bietet sie üblicherweise für eine größere Gruppe von Elementen an, wenn der gleiche Vorgang wiederholt werden soll. Wischgestenbasierte Befehle sollten für ein bis drei Aktionen angewendet werden. Typische Aktionen sind: Löschen, Markieren, Archivieren, Speichern oder Antworten.
TeachingTip: Über dieses Control werden Kontextinformationen bereitgestellt. Beispielsweise kann man auf diese Weise auf neue Funktionen in der App hinweisen. Standardmäßig wird das Control einem anderen Control zugeordnet. Die Content-Eigenschaft nimmt die Inhalte auf. Mehrere Inhalte können dabei in einem Stack-Layout untereinander angeordnet werden. Auch eine Bildlaufleiste ist möglich. Grundsätzlich sind die Inhalte in einem solchen Tippfenster jedoch zu begrenzen. Weitergehende Informationen können zum Beispiel über einen Link adressiert werden.
TwoPaneView: Mit Hilfe dieses Controls kann man die darzustellenden Inhalte auf zwei unterschiedliche Bereiche aufteilen, beispielsweise eine Listen- und eine Detailansicht. Die Ansicht funktioniert grundsätzlich auf allen Geräten, sie ist aber auf die Nutzung der Vorteile von Dual-Screen-Geräten optimiert. Dual-Screen-Geräte trennen die Benutzeroberfläche sauber in zwei Teile. Es wird in der Dokumentation explizit drauf hingewiesen, dass ein Dual-Screen-Gerät nicht mit einem Desktopgerät mit zwei Monitoren identisch ist. Es handelt sich um unterschiedliche Anwendungsszenarien. Dual-Screen-Geräte gibt es von unterschiedlichen Herstellern. Typisch ist die Möglichkeit, die Bildschirme unterschiedlich zueinander anzuordnen und mit anderen Inhalten zu belegen (Abb. 3).


Abb. 3: Anordnung der Bildschirme bei Dual-Screen-Geräten [7]
Eine Vielzahl der Controls existiert bereits für die aktuelle Version der WinUI 2. Auch für diese Version des Grafikframeworks gibt es noch Aktualisierungen. Anders formuliert: WinUI 2 und WinUI 3 entwickeln sich hier parallel, d. h., WinUI 3 adaptiert hier nach und nach Controls aus der Vorgängerversion.
Die Beschreibung der Controls und die Dokumentation sind der eine Aspekt. Einen besseren visuellen Überblick – im Sinne „Was gibt es denn überhaupt?“ – bekommt man, wenn man sich die App WinUI 3 Controls Gallery installiert. Diese gibt es über den Microsoft Store. Hier können wir leichtgewichtig die Controls in Aktion ausprobieren, beispielsweise Varianten der Animation (Abb. 4). Sehr gut: Direkt in der App sind die relevanten Quellcodeausschnitte in Form von XAML-Code notiert. Diesen können wir dann mittels Copy and Paste in das eigene Projekt übernehmen und anpassen.

Abb. 4: Die App WinUI 3 Controls Gallery zeigt die Controls in Aktion – hier eine Animation
Bei der Vorstellung der o. g. Controls haben Sie es schon gemerkt: Sie unterscheiden sich in Fragen des Designs, des Layouts und der gesamten User Experience erheblich davon, was man bisher mit klassischen Desktopanwendungen verwendet hat. Mobile und Desktop verschmelzen an dieser Stelle. Wie sollten nun Desktopanwendungen gestaltet werden? Man könnte es nach dem gleichen Muster machen, wie man es bisher auch mit WinForms oder WPF umgesetzt hat. Das wäre jedoch altbacken und man würde das Potenzial der Möglichkeiten nicht nutzen. Mit Blick auf die Designhinweise und die Optionen der Controls ist das Spektrum in Fragen des Designs deutlich breiter. Bereits bei der Erstellung von visuellen Prototypen, d. h. vor der technischen Umsetzung, sind diese erweiterten Möglichkeiten zu berücksichtigen. Mit anderen Worten: Mit dem Wechsel von WinForms bzw. WPF zu WinUI 3 muss ein Umdenken in Bezug auf die gesamte Gestaltung des User Interface einhergehen. Das betrifft die folgenden Aspekte:
Sind die genannten Punkte geklärt, geht es um die technische Umsetzung des User Interface. Dieses wird deklarativ mittels XAML-Code erstellt.

Abb. 5: Der Abschnitt „Ist dies das richtige Steuerelement?“ gibt wichtige Hinweise
WinForms-Anwender müssen sich am meisten umstellen. In WinForms wurde der gesamte Aufbau mittels Drag and Drop und der Zuweisung von Eigenschaftswerten erledigt. WPF und UWP verwendeten beide bereits XAML-Code. Beide Systeme hatten jedoch auch einen grafischen Designer. Der XAML-Dialekt von WPF unterscheidet sich gegenüber dem von WinUI. WinUI 3 ist eine direkte Weiterentwicklung von WinUI 2, daher brauchen sich Entwickler von Apps der UWP nicht umgewöhnen. Nur dass es jetzt keinen Designer mehr gibt, mag etwas „schmerzen“. Mit dem Wegfall des grafischen Designers kann auch das Designtool Blend nicht für WinUI 3 genutzt werden. Wer mit diesem Tool, dessen Bedienung sich eher an Designer als an Entwickler richtet, zum Beispiel Animationen erstellt hat und den daraus resultierenden Quellcode in XAML direkt übernommen hat, wird sich ggf. etwas ärgern. XAML-Vorschau und Designer soll nun eine leistungsfähigere Version von Hot Reload ersetzen.
In der Praxis heißt das, den XAML-Editor (Visual Studio) links auf dem Bildschirm (oder Bildschirm 1) und die gestartete App rechts auf dem Bildschirm (oder Bildschirm 2) anzuordnen. Änderungen am Quellcode werden dann unmittelbar in die gestartete App übernommen, ohne diese neu kompilieren zu müssen. Die Praxis zeigt, dass es hier Fortschritte gibt, dennoch erfordern einige größere Änderungen – zum Beispiel am Layout in einem Grid – weiterhin einen Neustart der Anwendung.
In diesem Abschnitt zeigen wir die Arbeit mit interessanten Controls aus der WinUI 3. Wir haben dazu das PersonPicture Control ausgewählt. Die Verwendung des Control ist unter [8] und die zugehörige API-Dokumentation unter [9] zu finden. Ein simpler Einsatz erfolgt z. B. so:
<StackPanel VerticalAlignment="Center" HorizontalAlignment="Center">
<PersonPicture
DisplayName="Maria Musterfrau"
ProfilePicture="Assets\meinAvatar.png"
Initials="MM" />
</StackPanel> Ist ein Bild vorhanden, wird dieses angezeigt. Gibt es keins, werden die Initialen eingeblendet (Abb. 6).

Abb. 6: Das PersonPicture Control
Man muss die Datenfelder des Control nicht manuell setzen. Für die Datenhaltung der Kontaktdaten bietet sich hier die spezialisierte Klasse Contact an. Ein Objekt dieser Klasse enthält bereits Properties für alle wesentlichen Merkmale eines Kontakts wie Adressen (mehrere), Vorname, Nachname, Telefonnummern (mehrere), E-Mail-Adressen (mehrere), Jobinfo, ID, Nickname, Notizen usw. Die Verwendung dieser Klasse scheint in diesem Fall angezeigt, da man auf eine vollständig definierte Datenstruktur zurückgreifen kann. Im XAML-Code binden wir in diesem Fall lediglich die Eigenschaft Contact des PersonPicture Control, also:
<PersonPicture
Contact="{x:Bind CurrentContact, Mode=TwoWay, UpdateSourceTrigger=PropertyChanged}" />
Im C#-Quellcode benötigen wir eine Property und eine Implementierung des INotifyPropertyChanged Events, welches bei einer Änderung der Daten die View benachrichtig und die Anzeige daraufhin automatisch aktualisiert wird. Ein Objekt der Klasse Contact wird daher wie in Listing 1 definiert.
public Contact CurrentContact{…};
var contact = new Contact();
contact.FirstName = "Maria";
contact.LastName = "Musterfrau";
...
CurrentContact = contact;
Wir definieren ein Property mit der Bezeichnung CurrentContact des Typs Contact. Setter- und Getter sind hier nur angedeutet. Danach erstellen wir ein konkretes Objekt der Klasse Contact und weisen es dieser Property zu. Über die Datenbindung wird die Anzeige aktualisiert. Anhand des Control PersonPicture und der Klasse Contact zeigt sich die gute Abstimmung zwischen visuellen Controls für das User Interface und vorbereiteten Klassenstrukturen für die Datenhaltung. Die Features sind nun nicht mehr für Verwendung in der UWP begrenzt, sondern können auch über WinUI 3 in Anwendungen für den Desktop eingesetzt werden.
An dieser Stelle wollen wir die Vorgehensweise in der Praxis anhand eines konkreten Beispiels demonstrieren. Dafür wählen wir die Gestaltung einer Seite zur Anzeige von Wetterinformationen auf einem Info-Display oder einem Smarthome-Bildschirm. Dabei können wir beispielsweise davon ausgehen, dass wir einen visuellen Entwurf zum späteren Aussehen der Oberfläche vorliegen haben. Ein solcher Prototyp wird idealerweise von einem Designer angefertigt und gibt uns folgende Hinweise: grundsätzliches Aussehen des betreffenden Screens, Navigationsstruktur, darzustellende Inhalte, Schriftgrößen, Farben, Schriftarten usw. Dieser visuelle Prototyp ist Ausgangspunkt für unsere Arbeiten. Wir empfehlen an dieser Stelle, noch nicht direkt mit der Umsetzung in XAML zu starten. Ein konzeptioneller Zwischenschritt kann die Arbeit erleichtern. Das Ziel ist es, sich über das Layout und die Verwendung der Control genauer im Klaren zu werden. Dazu können wir eine Skizze zum geplanten Layout anfertigen. Es genügt eine Handskizze mit Papier und Bleistift. Hieran können wir den Einsatz der Layoutcontainer planen und damit die Aufteilung des Screens vornehmen. Ebenso können wir die Controls den Layoutcontainern zuordnen. Den Entwurf zu unserem Beispiel sehen Sie in Abbildung 7.

Abb. 7: Layoutskizze (Entwurf) der Wetterdarstellung
Anhand dieser Skizze können wir in Bezug auf das Beispiel folgende Festlegungen treffen:
Die relevanten Ausschnitte aus dem Quellcode zur Definition des User Interface sind in Listing 2 dargestellt.
<Window
...">
<FlipView>
<!--Ort -->
<Grid>
...
<Grid.RowDefinitions>
<RowDefinition Height="0.7*"/>
<RowDefinition/>
<RowDefinition/>
<RowDefinition Height="0.7*"/>
</Grid.RowDefinitions>
<!-- Kopfzeile-->
<StackPanel HorizontalAlignment="Center">
<TextBlock FontSize="50" FontWeight="Bold" FontFamily="Consolas" Text="Weimar"/>
<TextBlock HorizontalAlignment="Center" FontSize="36" FontWeight="Bold" Text="21°"/>
</StackPanel>
<!-- Täglich-->
<Grid Margin="20,0" Grid.Row="1">
<Grid.RowDefinitions>
<RowDefinition Height="30"/>
<RowDefinition/>
</Grid.RowDefinitions>
<Grid.ColumnDefinitions>
<ColumnDefinition/>
<ColumnDefinition/>
<ColumnDefinition/>
<ColumnDefinition/>
<ColumnDefinition/>
</Grid.ColumnDefinitions>
<TextBlock FontFamily="Consolas" Text="Täglich" FontSize="20"/>
<local:Day DayName="Montag" Grid.Row="1"/>
<local:Day DayName="Dienstag" Grid.Row="1" Grid.Column="1"/>
<local:Day DayName="Mittwoch" Grid.Row="1" Grid.Column="2"/>
<local:Day DayName="Donnerstag" Grid.Row="1" Grid.Column="3"/>
<local:Day DayName="Freitag" Grid.Row="1" Grid.Column="4"/>
<!-- Stündlich -->
...
<!--Tagesinformationen-->
...
</Grid>
</Grid>
<!--Ort 2-->
<Grid>
...
</Grid>
</FlipView>
</Window>
Zu beachten ist auf oberster Ebene das <FlipView\>-Element, um zwischen kompletten Ansichten zu wechseln – in diesem Fall zwischen mehreren Orten bei der Wetteranzeige. Es folgt die Definition des <Grid\>-Elements zur Festlegung des Basislayouts (Zeilenstruktur). Dann kommen die Sublayouts für Kopfzeile, für die stündliche Vorhersage und die Tagesinformationen. Für sich wiederholende Anzeigen werden eigene User-Controls definiert.
<UserControl
x:Class="Weather.Day"
...>
<StackPanel HorizontalAlignment="Center">
<TextBlock Margin="0,20" Text="{x:Bind DayName}"/>
<Image HorizontalAlignment="Left" Margin="0,10" Width="50" Source="Assets/weather/day_clear.png"/>
<StackPanel Orientation="Horizontal">
<TextBlock FontSize="22" VerticalAlignment="Center" FontWeight="SemiBold" Text="23°"/>
<TextBlock Margin="10,0" FontSize="16" VerticalAlignment="Center" Text="8°"/>
</StackPanel>
<TextBlock Text="Sonnig"/>
</StackPanel>
</UserControl>
public sealed partial class Day : UserControl
{
public Day()
{
this.InitializeComponent();
}
public string DayName
{
get { return (string)GetValue(DayNameProperty); }
set { SetValue(DayNameProperty, value); }
}
public static readonly DependencyProperty DayNameProperty = DependencyProperty.Register("DayName", typeof(string), typeof(Day), new PropertyMetadata(null));
}
In Listing 3 sieht man beispielhaft den Quellcode für das User Control Day. Die Oberfläche wird in XAML erstellt. Wie man eine Dependency Property deklariert, ist im unteren Abschnitt des Quellcodes zu sehen. Hier ist das beispielhaft für die Eigenschaft DayName ausgeführt. DayName kann dann im User-Control selbst in der Datenbindung verwendet werden, zum Beispiel um ein Textfeld an diese Eigenschaft zu binden:
<TextBlock Margin="0,20" Text="{x:Bind DayName}"/>Ebenso können wir bei der Verwendung des User-Control die Eigenschaft von außen definieren:
<local:Day DayName="Montag"/>Eine erste – noch unfertige – Version der App ist in Abbildung 8 zu sehen. Bitte beachten Sie: Es handelt sich um eine Desktopapplikation und nicht um eine App für die UWP. Wir haben hier alle Möglichkeiten des Systemzugriffs und gleichzeitig mit dem Einsatz von WinUI 3 auch ein deutlich erweitertes Spektrum an grafischen Gestaltungsmöglichkeiten. Controls für das User Interface spielen dabei eine entscheidende Rolle. Ausgangspunkt sind die Basis Controls, die über WinUI 3 von Haus aus zur Verfügung gestellt werden.

Abb. 8: Erste Version der App, Wetteranzeige (noch unvollständig)
Regelmäßig News zur Konferenz und der .NET-Community
Controls sind das A und O bei WinUI 3. Mit Blick auf den Umsetzungsstand lässt sich feststellen, dass die Lücken des Windows App SDK von Version 1 gegenüber Version 0.8 bereits umfassend geschlossen wurden. In der App WinUI 3 Controls Gallery haben die ausgegrauten Bereiche – für noch nicht migrierte Controls – merklich abgenommen, d. h., fast alle Controls aus WinUI 2 sind nun auch unter WinUI 3 verfügbar. Das ist ein wichtiges Argument für die Praxis, wenn man zum Beispiel eine App von der UWP (mäßiger (Aufwand), von der WPF (größerer Aufwand) oder von WinForms (sehr großer Aufwand) nach WinUI 3 migrieren möchte.
Doch fast alle Elemente heißt eben auch nur „fast alle“. Mit Blick auf die Roadmap sehen wir auch, dass die Controls für das Zeichnen mit Stift oder Finger und die Kartenanzeige, das InkCanvas Control und das Map Control, noch fehlen. Das InkCanvas Control wurde jedoch bereits in Aussicht gestellt. Wird man in der Controls Gallery von Microsoft nicht fündig, kann man schauen, was die Drittanbieter für WinUI 3 bereits vorhalten. Sie adaptieren ihre Controls nun auch sukzessive und es gibt bereits erste Versionen von Bibliotheken für das neue Grafikframework.
[2] https://docs.microsoft.com/en-us/windows/apps/design/controls/buttons
[3] https://docs.microsoft.com/en-us/windows/apps/design/controls/
[4] https://docs.microsoft.com/de-de/windows/communitytoolkit/animations/lottie
[5] https://airbnb.io/lottie/#/
[6] https://docs.microsoft.com/de-de/windows/apps/design/motion/parallax
[7] https://docs.microsoft.com/en-us/windows/apps/design/controls/pipspager
[8] https://docs.microsoft.com/de-de/dual-screen/introduction
[9] https://docs.microsoft.com/de-de/windows/apps/design/controls/person-picture
The post Controls für WinUI 3 – funktionell und ansprechend im Design appeared first on BASTA!.
]]>The post Azure Kubernetes Service zu Diensten appeared first on BASTA!.
]]>
Ein Kubernetes-Cluster selbst zu installieren und zu betreiben, bedeutet allerdings einiges an Aufwand. An dieser Stelle setzt Azure Kubernetes Service an. Hierbei handelt es sich um einen Managed Kubernetes Service in der Azure Cloud. Auch AKS verwendet Kubernetes und zielt auf Containeranwendungen, unterstützt zusätzlich aber in vielen Bereichen wie Node-Management, Security, Skalierung und Monitoring. Das vereinfacht die Installation und den Betrieb eines Kubernetes-Clusters erheblich.
Regelmäßig News zur Konferenz und der .NET-Community
Cluster Management: Die virtuellen Maschinen zur Steuerung des Clusters – die Master Nodes – werden komplett von Microsoft verwaltet und sind kostenfrei. Bezahlen muss man lediglich für die Rechenleistung der Worker Nodes, ihren Speicherbedarf und ihre Netzwerkressourcen. Für die Worker Nodes, auf denen die Applikationen laufen, stehen Linux- und Windows-Maschinen zur Verfügung.
Abbildung 1 verdeutlich die Arbeitsteilung. Die Komponenten sind bereits von Kubernetes bekannt. Die Master Nodes bestehen aus dem API-Server, der etcd-Datenbank, dem Scheduler und dem Controller Manager. Der API-Server nimmt Befehle entgegen und prüft diese. In der etcd-Datenbank wird der State des Clusters gespeichert. Über den Scheduler wird geregelt, auf welchen Nodes welche Pods (mit den Containern) platziert werden. Der Controller Manager verwaltet Replica Set Controller und Deployment Controller. Der linke Teil wird komplett von Azure verwaltet, inklusive beispielsweise der Skalierung und dem Patching der virtuellen Maschinen.

Abb. 1: AKS-Komponenten (Quelle: Microsoft)
Auf den virtuellen Maschinen der Worker Nodes finden sich der kubelet-Agent zur Kommunikation mit dem API-Server und Pod-Erstellung, kube-proxy für Netzwerkaufgaben und eine Container-Runtime. Auch bei diesen Bestandteilen unterstützt AKS: Sie müssen nicht manuell auf den Nodes installiert werden.
Auch bei AKS sind natürlich Pods, Replica Sets, Deployments, Nodes und Node Pools relevant [1].
Worker Nodes: Ein Node Pool beschreibt ein Set gleicher virtueller Maschinen, auch Worker Nodes genannt, auf denen die Applikationen betrieben werden. Bezogen auf Azure-Ressourcen können das einzelne VMs oder Virtual Machine Scale Sets sein. Des Weiteren besteht die Möglichkeit, virtuelle Nodes zu verwenden, mehr dazu beim Thema Skalierung. Für die Pools können verschiedene Typen virtueller Maschinen gewählt werden, beispielsweise CPU-optimierte Serien oder solche mit GPUs. Für erhöhte Security- und Complianceanforderungen kann auch das Modell Compute Isolation gewählt werden, bei dem physikalische Server im Azure Data Center nicht mit anderen Kunden geteilt werden.
High Availability: Die Node-Auto-Repair-Funktion hilft, ungesunde Nodes zu identifizieren und ggf. neu zu starten [2]. Um eine höhere Verfügbarkeit bei den Worker Nodes zu gewährleisten, können diese per Pool auf Availability Zones verteilt werden, das heißt auf mehrere Data Center in einer Region. Für sehr kritische Workloads kann außerdem eine kostenpflichtige SLA-Option gebucht werden, die durch zusätzliche Ressourcen bei den Master Nodes die Verfügbarkeit auf 99,95 Prozent bei Verwendung von Availability Zones erhöht. Die SLA ist dann auch finanziell gesichert, falls das Versprechen seitens Azure nicht eingehalten wird [3].
Für Anforderungen im Bereich Disaster Recovery können z. B. Multi-Region-Cluster (Abb. 2) aufgebaut werden. Die AKS-Cluster werden dafür in verschiedenen Regionen für Ausfallsicherheit aufgebaut und die globale Request-Verteilung etwa mit Hilfe eines Azure Traffic Manager erreicht.

Abb. 2: Multi-Region-Cluster (Quelle: Microsoft)
Auch Container-Images können global repliziert werden, wenn die entsprechende SKU in der Azure Container Registry verwendet wird. Das verringert die Latenz beim Image Pull, erhöht die Verfügbarkeit und spart Kosten beim Netzwerktransfer [4].
Netzwerk: Beim AKS gibt es zwei verschiedene Netzwerktypen, die für die Cluster zur Verfügung stehen: kubenet und Container Networking Interface (CNI).
Die kubenet-Variante ist der einfachere Ansatz. Die IP-Adressen der Pods sind hier abstrahiert und müssen nicht im Adresspool des virtuellen Netzwerks berücksichtigt werden. Angesprochen werden sie durch Network Address Translation (NAT) auf den Nodes. Bei diesem Ansatz sind allerdings keine Windows Node Pools möglich. Beim CNI-Ansatz bekommt jeder Pod eine IP-Adresse aus dem IP-Pool des VNets zugewiesen, was daher eine aufwendigere Planung beim Clusteraufbau erfordert. Dieser Ansatz muss gewählt werden, wenn die AKS Network Policies angewendet werden sollen oder ein Azure Application Gateway als Ingress-Ressource gewünscht ist. Tabelle 1 listet weitere Unterschiede auf.
| kubenet | CNI |
|---|---|
| POD IPs werden abstrahiert, NAT auf den Nodes | Jeder Pod bekommt eine eigene IP-Adresse |
| Limit von 400 Nodes pro Cluster | Notwendig für: – Network Policies – Application Gateway als Ingress-Ressource |
| Neine Windows Nodes | Benötigt einen größeren IP-Adressraum und mehr Planung |
Tabelle 1: Vergleich der AKS-Netzwerkoptionen
Es ist zu beachten, dass der Netzwerktyp nach der Clustererstellung nicht mehr geändert werden kann [5].
Magie mit kubectl: Bei der Interaktion mit dem AKS-Cluster wird das Tool kubectl verwendet. Dass hierbei eine gewisse Magie stattfindet, indem durch K8s-Befehle gleichzeitig auch Azure-Ressourcen erstellt und konfiguriert werden, liegt an zusätzlichen Pods auf den Master Nodes. Beispielsweise sind das CSI Driver für das universelle Speichermanagement oder Pods vom cloud-provider-azure-Projekt. Letztere helfen dabei, die zusätzliche Azure-Load-Balancer- und Network-Security-Group-Konfigurationen durchzuführen, wenn ein externer Service als Kubernetes-Ressource erstellt wird [6].
Storage: Auch bei der Speicherverwaltung kann AKS unterstützen. Sofern der lokale Speicher auf den Nodes selbst nicht ausreicht, beispielsweise weil Persistenz über den Pod-Lifecycle hinaus gebraucht wird, können Azure Discs oder Fileshares angebunden werden (Abb. 3). Dabei muss die Kubernetes-Ressource Persistent Volume Claim (PVC) erstellt und die Volume-Einbindung beim Deployment angegeben werden. Je nach der im PVC verwendeter Storage Class wird dann automatisch eine Azure Disc oder ein Azure Fileshare erstellt. Storage Classes gibt es built-in, sie können aber auch individuell erstellt werden. Im Hintergrund wird dann – im empfohlenen, moderneren Ansatz – der Azure Disc Container Storage Interface (CSI) Driver verwendet. Dieser arbeitet gemäß CSI-Spezifikation [7] und läuft als Plug-in im Cluster. Damit ist es nun auch möglich, Storage-Typen neu zu erstellen oder anzupassen, ohne den Kubernetes Core zu verändern. Über die Storage Classes wird auch das Löschverhalten für die Azure-Ressourcen geregelt, wenn das Volume nicht mehr in Pods eingebunden ist [8], [9].

Tools: Für die Arbeit mit einem AKS-Cluster stehen mehrere Tools zur Verfügung. Zu erwähnen ist hier sicher das Azure Portal, in dem zum einen das GUI vorhanden ist und außerdem die Cloud Shell für Konsolenbefehle verwendet werden kann. Über das GUI kann der Cluster selbst verwaltet werden, außerdem bietet es Möglichkeiten für das Clustermonitoring. In der Cloud Shell ist kubectl bereits installiert. Komfortabel ist auch die Arbeit mit Visual Studio Code, das mit entsprechenden Extensions unterstützt. kubectl muss hier aber extra installiert werden.
Als weitere interessante Option zur Clusterverwaltung ist Octant zu erwähnen, ein Open-Source-Projekt mit webbasiertem Interface [10].
Netzwerk: Beim Thema Security bietet AKS zahlreiche Möglichkeiten, um den Cluster abzusichern, Zugriffe und Datenverkehr zu steuern. Bei AKS handelt es sich um PaaS, daher hat es automatisch einen Public Endpoint. Soll der Zugriff darauf eingeschränkt werden, kann das z. B. mit definierten IP Ranges erreicht werden, außerhalb derer kein Access möglich ist. Der Cluster kann aber auch privat sein und komplett aus dem Internet genommen werden. In diesem Fall ist eine Kommunikation mit dem API-Server nur über das konfigurierte VNet mit Hilfe von Azure Private Links möglich. Der Datenverkehr bleibt dann im Azure-Backbone-Netzwerk [11].
Die Einschränkung per Private Link funktioniert ebenfalls bei anderen Azure Services, die häufig im Cluster eingebunden sind, beispielsweise Storage oder eine Azure Container Registry. Bei der Filterung vom Datenverkehr zwischen den Nodes kommen auch Network Security Groups (NSG) zum Einsatz, bei denen AKS die Verwaltung der Regeln übernimmt. Das funktioniert bei beiden Netzwerktypen. Wird beispielsweise einer externer K8s Service erstellt, wird neben der Load-Balancer-Konfiguration auch die der NSG von AKS angepasst [12].
Microsoft Defender for Cloud und Key Vault: Vor kurzem noch unter den Namen Azure Security Center und Azure Defender bekannt, kann für den Cluster selbst oder andere im Kontext verwendete Services zusätzlicher Schutz aktiviert werden, beispielsweise für die Azure Container Registry. Hierbei unterstützt der Defender u. a. durch das kontinuierliche Scannen der Images mit der Engine des IT-Security-Anbieter Qualys, was z. B. fehlende Securitypatches des OS Layers aufdecken kann [13].
Bei AKS kann durch die Aktivierung des kostenpflichtigen Defenders ein eingeschleuster Krypto-Mining-Container entdeckt werden oder auch Zugriffe von ungewöhnlichen oder verschleierten IP-Adressen. Die Resultate können dann im Defender-Portal (Security Center) eingesehen werden [14].
Für das sichere Ablegen von Passwörtern, Connection-Strings oder Zertifikaten eignet sich der Azure Key Vault. Er kann über eine Erweiterung direkt in den Cluster eingebunden werden. Es laufen dann einfach zusätzliche Pods auf den Nodes und über den CSI Driver können die Key-Vault-Ressourcen als Volumes den Pods zur Verfügung gestellt werden.
Azure Policies und Network Policies: Zur Überwachung von Compliance und eingehaltenen Sicherheitsrichtlinien sind die Azure Policies ein mächtiges Instrument. Sie können durch das Aktivieren eines Cluster-Add-ons auch in diesem verwendet werden. Viele AKS spezifische Policy-Definitionen sind bereits standardmäßig vorhanden und es gibt auch Initiativen, in denen Policys für einen Security-Baseline-Standard gebündelt werden. Es können aber auch individuelle Policys erstellt werden. Je nach Konfiguration kann eine Policy eine Fehlkonfiguration melden (Audit) oder neben anderen Effekten z. B. eine Ressourcenerstellung verhindern [15].
Beispiele für Complianceprüfungen ist das Festlegen erlaubter Regionen oder der SKUs virtueller Maschinen. Im Bereich Security gibt es Optionen zur Einschränkung von Pod-Privilegien, erlaubten Ports oder Ressourcenzuweisungen für Pods.
Um den Datenverkehr zwischen den Pods granularer steuern zu können, stehen die Kubernetes Network Policies zur Verfügung, bei deren Erstellung und Verwaltung AKS mit dem gleichnamigen Feature unterstützen kann. Basierend auf den Namespace- und Pod-Labels kann eine Restriktion zwischen Pods erstellt werden, per Default gibt es dort keine.
Es kann zwischen den Microsoft Azure Network Policies und denen des Anbieters Calico gewählt werden. Bei den Microsoft Policies ist anzumerken, dass diese nur auf Linux Nodes empfohlen werden und ein CNI-Netzwerk brauchen. Calico Policies arbeiten auch mit dem kubenet-Netzwerk und haben in der Preview Windows-Unterstützung, können aber natürlich nicht mit Azure-Support aufwarten [16].
AAD-Integration: Für die Zugriffssteuerung auf den Cluster kann Azure Active Directory (AAD) integriert werden. Auch in diesem Fall muss dafür lediglich ein Feature aktiviert werden. Die Integration vom AAD verbindet dann das Azure-RBAC-System mit dem Kubernetes RBAC. Dadurch kann der Cluster-Access über die AAD-Gruppen- und Rollenzuweisungen gesteuert werden, mit vorhandenen AKS-spezifischen Rollen oder selbst erstellten. Außerdem kann damit auch mit Services wie Conditional Access oder Privileged Identity Management (PIM) gearbeitet werden. Zu beachten ist, dass dieses Feature zwar nachträglich aktiviert, aber nicht wieder deaktiviert werden kann. Außerdem ist die Aktivierung von K8s RBAC im Cluster erforderlich [17].
Node Patching/Upgrades: Ein wichtiges Thema im Securitykontext ist natürlich das Patching der Betriebssysteme. Bei AKS muss das bei den Master Nodes gar nicht beachten werden, da diese von Azure verwaltet und gepatcht werden. Bei den Linux Worker Nodes werden Updates in der Nacht automatisch bezogen und für die Unterstützung bei nötigen Neustarts der Nodes gibt es das Kured-Projekt. Zusätzliche Pods auf den Nodes in Form von Daemon-Sets prüfen die Existenz der /var/run/reboot-required-Datei und können im entsprechenden Fall das Neustarten des Nodes inklusive Rescheduling der Pods übernehmen [18].
Bei den Windows Worker Nodes gibt es keine täglichen Updates, es kann aber der AKS-Upgrade-Prozess verwendet werden, um die neuesten gepatchten Basis-Images für die Nodes zu erhalten.
Dieser Prozess, mit dem auch die K8s-Version im Cluster erneuert werden kann, verwendet den Cordon-and-Drain-Ansatz: Ein Node wird zunächst markiert, damit der K8s Scheduler keine neuen Pods mehr auf diesem plant. Laufende Pods werden auf andere Nodes verteilt und ein neuer Node wird erstellt und kann Pods aufnehmen. Sobald der markierte Node keine Pods mehr aufweist, wird er gelöscht und es wird mit dem nächsten Node fortgefahren. Auf diese Art kann eine Downtime der Anwendung verhindert werden. Das Upgrade kann z. B. mit dem Azure CLI erledigt und optional getrennt nach Master und Worker Nodes vorgenommen werden [19]. Snippet für einen Upgradebefehl per CLI:
az aks upgrade --resource-group $rgName --name $aksClusterName --kubernetes-version 1.21.1 --control-plane-onlyDes Weiteren gibt es für die Kubernetes-Version einen Auto-Upgrade-Channel in der Preview, der automatisch und in verschiedenen Stufen die Version updaten kann [20]. Snippet für CLI:
az aks update --resource-group $rgName --name $aksClusterName --auto-upgrade-channel stable
HPA und Cluster-Autoscaler: Bei einer containerbasierten Microservices-Architektur ist die Skalierung der Pods bzw. des gesamten Clusters auch ein bedeutendes Thema, bei dem AKS mit zusätzlichen Techniken helfen kann. Der Horizontal Pod Autoscaler (HPA), der anhand von Pod-Metriken wie CPU-Nutzung skaliert und so Pods auf einem Node erstellt und entfernt, ist bereits von K8s selbst bekannt.
AKS hat aber auch einen Cluster-Autoscaler. Dieser kann dem Cluster automatisch neue Nodes hinzufügen bzw. sie entfernen, wenn die Ressourcennutzung auf den virtuellen Maschinen das erfordert. Der Autoscaler kann über das Portal oder einfach per CLI aktiviert werden, wie im folgenden Code-Snippet für einen Cluster mit Single Node Pool ersichtlich ist:
az aks update --name $aksClusterName --resource-group $rgName --enable-cluster-autoscaler --min-count 1 --max-count 3Es kann damit zwischen einem und drei Nodes automatisch skaliert werden, mit verschiedenen Profilen wird eine granulare Skalierung möglich. Die zusätzlichen Nodes benötigen keine weitere Konfiguration [21].
Außerdem gibt es für die Skalierung noch das Framework Kubernetes-based Event-driven Autoscaling (KEDA), das weitere umfangreiche Metriken und Events als Trigger erlaubt. KEDA kreiert zusätzliche Pods zum Operieren und Event Listening im Cluster und arbeitet mit dem HPA zusammen. Dadurch kann für das Pod Scaling mit vielen weiteren Signalen gearbeitet werden, z. B. Azure-Monitor-Metriken, Storage oder Event Hubs. Andere Event Sources weiterer Cloud-Provider werden auch unterstützt [22].
Rapid Burst Scaling: Die Skalierung über Nodes kann unter Umständen einfach zu langsam sein. Für diesen Anwendungsfall kann mit Virtual Kubelets gearbeitet werden (Abb.4) [23]. Hierbei handelt es sich um eine Open-Source-Kubernetes-Implementierung, mit der Nodes im Cluster simuliert werden können; ein Kubelet registriert sich dann selbst als Node. Die nötige Rechenpower hinter den Virtual Kubelets kommt nicht direkt von virtuellen Maschinen, sondern beispielsweise vom Azure Batch Service mit GPUs oder von Azure Container Instances, auf denen die Container laufen. Das ist zwar teurer, skaliert aber deutlich schneller als über den Node Scaler. Daher kommt auch der Name Rapid Burst Scaling, weil es eher für den Ausgleich von Spitzenlasten und nicht für den Dauerzustand konzipiert ist [24].
Abb. 4: AKS-Virtual-Kubelet-Optionen (Quelle: Microsoft)
Azure Monitor mit AKS: AKS bietet durch die Integration in den Azure Monitor komfortable Möglichkeiten, den Cluster zu überwachen (Abb. 5). Für die umfangreichste Datenlage wird der Cluster mit einem Azure Log Analytics Workspace verknüpft, der die zentrale Datensenke darstellt. Wenn noch die entsprechenden Diagnostic-Settings vom Cluster aktiviert werden, können neben metrischen Daten wie CPU-Nutzung, Disk-Belegung oder Netzwerkverkehr auch Logdaten vom API-Server, dem Controller Manager oder dem Scheduler gesammelt werden.
Wie aus der Monitoringwelt bekannt, stehen für die Analyse dieser Daten zahlreiche Werkzeuge zur Verfügung. Die Daten können z. B. in Monitor Workbooks oder über Power BI visualisiert werden. Der Cluster kann aber auch auf Basis der Daten skalieren und es gibt Optionen, über das Alerting Benachrichtigungen zu versenden. Bei Bedarf können sogar weitere Arbeitsschritte, beispielsweise über Azure Functions, Logic Apps oder verbundene Ticketsysteme, erledigt werden.
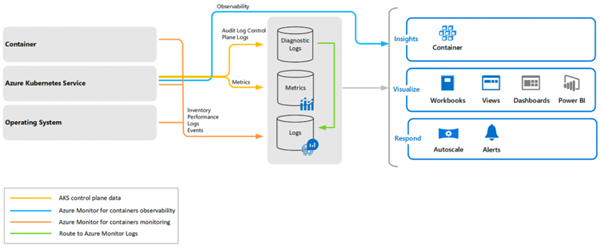
Abb. 5: AKS und Azure Monitor (Quelle: Microsoft)
Microsoft liefert über die Container Insights Solution, basierend auf vorhandenen Workbooks, u. a. Einsichten über den Zustand von Nodes, Containern und deren Live-Logs. Das Monitoring-Add-on kann auch nach der Erstellung des Clusters aktiviert werden.
Abb. 6: KQL-Query und Chart
Die Kusto Query Language (KQL), eine SQL-ähnliche Abfragesprache aus der Azure-Monitor-Welt, bietet zudem viele Optionen einer individuellen Analyse. Im Log-Analytics-Bereich des Azure Portal können dann direkt Abfragen für Informationen aus dem Cluster ausgeführt werden [25]. Folgende Query liefert Basisdaten über im Cluster laufende Container der letzten 30 Minuten und rendert direkt einen Chart (Abb. 6):
ContainerInventory | where TimeGenerated >= ago(30m) | summarize AggregatedValue = dcount(ContainerID) by ContainerState, Image | render columnchart
Regelmäßig News zur Konferenz und der .NET-Community
Neben der automatischen Erstellung von Storage-Ressourcen oder der NSG-Konfiguration gibt es noch zahlreiche weitere Integrationen zu Azure Services und Ressourcen, wovon einige an dieser Stelle noch einmal kurz beleuchtet werden sollen.
Verwendung von Azure Application Gateway als Ingress: In einem Kubernetes-Cluster werden häufig Ingress-Controller verwendet, um den Datenverkehr granularer zu steuern und bestimme Regeln umzusetzen. Eine verbreitete Implementierung ist NGINX [26]. Damit bleibt die Ressourcenlast für den Ingress-Controller allerdings im Cluster selbst. Eine Alternative ist, das Azure Application Gateway als Ingress-Controller zu verwenden.
Beim Azure Application Gateway handelt es sich um einen Layer 7 Load Balancer mit der Option einer integrierten Firewall. Das Application Gateway kann ebenfalls mit Features wie TLS-Terminierung oder URL-Path-Routing aufwarten. Mit dem aktivierten Application-Gateway-Ingress-Controller-(AGIC-)Add-on kann es als Ingress-Ressource im Cluster verwendet werden, reduziert die Last im Cluster selbst und kann unabhängig skalieren. Da das Application Gateway direkt mit den Pods über private IPs kommuniziert, benötigt es keine Node Ports oder KubeProxy Services und nimmt damit zusätzlich Last aus dem Cluster. Ein CNI-Netzwerk ist aber Voraussetzung. Die Aktivierung des Add-ons erstellt dann nötige Kubernetes-Ingress-Ressourcen, Services und Pods [27].
Mit folgendem CLI-Befehl kann das Add-on in einem bestehenden Cluster aktiviert werden, der dann mit einem vorhandenen Application Gateway verknüpft wird:
az aks enable-addons -n $aksClusterName -g $rgName -a ingress-appgw --appgw-id $appgwIdAzure Functions mit KEDA: Im Abschnitt „Monitoring“ wurde bereits einmal auf das KEDA-Framework eingegangen. KEDA ermöglicht es, Azure Functions direkt im AKS-Cluster in einem Container auszuführen. Die Azure Function App muss hierfür im Containermodus erstellt werden, damit die Runtime entsprechend zur Verfügung steht. Nachdem KEDA im Cluster installiert wurde [28], kann die Function-App z. B. über die Function-Core-Tools in den Cluster geladen werden. Dieser Vorgang erstellt ein Manifest mit Deployment, Scaled Object und Secrets für die Umgebungsvariablen aus der local.settings.json-Datei.
Auch hier arbeitet KEDA mit dem HPA zusammen und ermöglicht, basierend auf Events wie neuen Nachrichten in einer Azure Storage oder Service Bus Queue, anhand von Cronjobs oder anderen Triggern, den Function-Container zu skalieren, solange Arbeit zu verrichten ist [29].
Azure Active Directory (AAD) Pod Identity: Sofern die AAD-Integration für den Cluster vorhanden ist und ein CNI-Netzwerk gewählt wurde, kann für den Azure-Ressourcenzugriff die AAD Pod Identity verwendet werden. Für Kubenet wird das aus Sicherheitsaspekten nicht empfohlen. Wird das Add-on aktiviert, laufen für die Funktionalität wieder zusätzliche Pods als Daemon-Set auf den Nodes. Über diesen Ansatz kann die Identität eines Pods mit einer Identität aus Azure verknüpft werden und der Pod bekommt den nötigen Zugriff auf eine Cloud-Ressource. Dieses Feature ist aktuell nur auf Linux Nodes verfügbar und befindet sich noch im Preview-Status [30].
Continuous Integration und Deployment: Zur Abrundung des Bilds sei hier nochmals die mögliche Verknüpfung zu CI/CD Pipelines beispielsweise von Azure DevOps oder GitHub Actions erwähnt. Ein Code-Commit triggert z. B. die automatische Erstellung neuer Images, die in die Containerrepositorys geladen und etwa durch einen Helm-Upgrade-Schritt eine aktualisierte Version der Anwendung im AKS-Cluster verfügbar machen. Helm ist ein Package-Manager für Kubernetes-Ressourcen und in AKS integriert [31].
Abbildung 7 veranschaulicht den Aufbau einer Beispiel-Microservices-Architektur mit Verwendung eines AKS-Clusters. Die verschiedenen Services sind durch Container in Pods realisiert, Datenbanken befinden sich aber häufig außerhalb des Clusters, um eine Stateless-Architektur zu vereinfachen. Es wird grundsätzlich empfohlen, Daten eher in PaaS-Diensten zu speichern, die Multi-Region-Replikation unterstützen. Als Ingress-Controller wird NGINX verwendet, ein Load Balancer routet den Internetverkehr zum Ingress. Das AAD ist als Identity Provider angebunden und Secrets liegen im Azure Key Vault. Updates der Anwendungen erfolgen durch CI/CD Pipelines, es erfolgt ein Pushen der Images in die Container Registry und ein Pullen dieser vom Cluster nach einem Helm-Upgrade-Befehl [32].

Abb. 7: AKS-Cluster-Architektur (Quelle: Microsoft)
Ist ein Cluster nicht produktiv und wird nicht dauerhaft gebraucht, soll es aber auch nicht bei jedem Gebrauch neu provisioniert werden, kann es gestoppt werden [33]. Damit werden sämtliche Worker Nodes dealloziert und verursachen keine (CPU-)Kosten mehr (Abb. 8). Es bleiben lediglich die Kosten für Netzwerk-ressourcen und Storage. Das Anhalten des Clusters kann im Azure-Portal und durch den folgenden CLI-Befehl erreicht werden:
az aks stop --name $aksClusterName --resource-group $rgNameUm den Cluster wieder zu starten, genügt folgendes Command:
az aks start --name $aksClusterName --resource-group $rgNameBei der Erstellung der Node Pools können keine virtuellen Maschinen mit Standard-HDDs verwendet werden.

Abb. 8: Gestoppter AKS-Cluster
Beim CNI-Netzwerktyp sollte die IP-Adressplanung definitiv nicht unterschätzt werden. Jeder Pod braucht eine Adresse und nachträgliche Änderungen an Adressbereichen können schwierig bzw. praktisch unmöglich werden. Daher sollte die Menge der Workloads im Cluster so gut wie möglich eingeschätzt und bei der Definition der Adressbereiche berücksichtigt werden [34].
Außerdem bietet es sich an, bestimmte Prozesse und Rollen zu definieren und zu besetzen, beispielsweise einen Cluster-Admin oder ein AKS-Team. AKS kann zwar in vielen Bereich unterstützen, ersetzt aber dennoch nicht eine gute Operations-Basis.
Abb. 9: Generierte Ressourcengruppe von AKS
Die Ressourcen, die von AKS erstellt werden, finden sich in einer anderen, automatisch generierten Ressourcengruppe nach dem Schema (Abb. 9):
MC_<Ressourcengruppe AKS>_<Cluster Name> _<Region>
Wer den Einsatz des Azure Kubernetes Service Hands-on ausprobieren möchte, findet bei Microsoft ein gutes Tutorial [35]. Im Beispiel wird ein AKS-Cluster Schritt für Schritt aufgebaut und deckt Themen wie Skalierung, Ingress, Zertifikatsmanagement und Monitoring mit ab (Abb.10).

Abb. 10: Tutorial zum Aufbau eines AKS-Clusters (Quelle: Microsoft)
Wer eine Multi-Container-Applikation mit Kubernetes hosten möchte, findet in AKS einen Dienst, der gegenüber einer eigens betriebenen Kubernetes-Landschaft viel Unterstützung bietet und den Aufwand beim Aufbau und beim Betrieb reduziert. Wer simplere Containerarchitekturen in der Azure-Cloud betreiben will, ist eventuell mit Azure Container Instances [36] oder Azure App Service [37] besser beraten. Auch ein Blick in den neuen (Preview) Service Azure Container Apps lohnt sich [38].
[1] https://docs.microsoft.com/en-us/azure/aks/concepts-clusters-workloads
[2] https://docs.microsoft.com/en-us/azure/aks/node-auto-repair
[3] https://docs.microsoft.com/en-us/azure/aks/uptime-sla
[4] https://docs.microsoft.com/en-us/azure/aks/operator-best-practices-multi-region
[5] https://docs.microsoft.com/en-us/azure/aks/concepts-network
[6] https://github.com/kubernetes-sigs/cloud-provider-azure
[7] https://github.com/container-storage-interface/spec/blob/master/spec.md
[8] https://docs.microsoft.com/en-us/azure/aks/azure-disk-csi
[9] https://docs.microsoft.com/en-us/azure/aks/concepts-storage
[10] https://octant.dev
[11] https://docs.microsoft.com/en-us/azure/aks/private-clusters
[12] https://docs.microsoft.com/en-us/azure/aks/concepts-network
[13] https://docs.microsoft.com/en-us/azure/defender-for-cloud/defender-for-container-registries-usage
[14] https://docs.microsoft.com/en-us/azure/defender-for-cloud/defender-for-kubernetes-introduction
[15] https://docs.microsoft.com/en-us/azure/aks/policy-reference
[16] https://docs.microsoft.com/en-us/azure/aks/use-network-policies
[17] https://docs.microsoft.com/en-us/azure/aks/managed-aad
[18] https://docs.microsoft.com/en-us/azure/aks/node-updates-kured
[19] https://github.com/Azure/sg-aks-workshop/tree/master/day2-operations
[20] https://docs.microsoft.com/en-us/azure/aks/upgrade-cluster#set-auto-upgrade-channel
[21] https://docs.microsoft.com/en-us/azure/aks/cluster-autoscaler
[22] https://keda.sh/docs/2.4/scalers/azure-monitor/
[23] https://azure.microsoft.com/en-us/resources/videos/azure-friday-virtual-kubelet-introduction/
[24] https://docs.microsoft.com/en-us/azure/aks/concepts-scale
[25] https://github.com/Azure/sg-aks-workshop/tree/master/day2-operations
[27] https://azure.github.io/application-gateway-kubernetes-ingress/
[28] https://keda.sh/docs/2.0/deploy/
[29] https://microsoft.github.io/AzureTipsAndTricks/blog/tip277.html
[30] https://docs.microsoft.com/en-us/azure/aks/use-azure-ad-pod-identity
[31] https://docs.microsoft.com/en-us/azure/aks/kubernetes-helm
[33] https://docs.microsoft.com/en-us/azure/aks/start-stop-cluster?tabs=azure-cli
[34] https://docs.microsoft.com/en-us/azure/aks/configure-azure-cni
[35] https://docs.microsoft.com/en-us/learn/modules/aks-workshop/01-introduction
[36] https://docs.microsoft.com/en-us/azure/container-instances/
[37] https://docs.microsoft.com/de-de/azure/app-service/overview
[38] https://azure.microsoft.com/en-us/services/container-apps/#overview
The post Azure Kubernetes Service zu Diensten appeared first on BASTA!.
]]>The post Improving Agility by Using Customers’ Definitions of “Quality” and “Done” appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community
Wollen Sie stets auf dem neusten Stand bleiben und keine weiteren Keynotes oder andere Videos verpassen? Dann melden Sie sich für unseren Newsletter an und wir informieren Sie, sobald es etwas neues in den Bereichen .NET,Windows & Open Innovations gibt.
The post Improving Agility by Using Customers’ Definitions of “Quality” and “Done” appeared first on BASTA!.
]]>The post 5 Top-Argumente für Ihren BASTA!-Besuch appeared first on BASTA!.
]]>
In einer schnelllebigen Industrie wie der IT müssen Sie als Entwickler Ihr Wissen laufend aktualisieren. Die digitale Transformation und der damit einhergehende Aufbruch in eine neue digitale Ära bringt unzählige neue Möglichkeiten mit sich und führt dazu, dass eingefahrene Prozesse und Strukturen hinterfragt, neue Trends eingeschätzt und in die konkreten Projekte implementiert werden müssen. Mit einem BASTA!-Besuch können Sie bestehende Probleme lösen und das nötige Wissen erlangen.
Wenn Sie noch nicht überzeugt sind, warum es sich wirklich lohnt, an der BASTA! teilzunehmen, haben wir für Sie 5 unschlagbare Argumente parat. Machen Sie sich schon mal auf den Weg!

Regelmäßig News zur Konferenz und der .NET-Community
The post 5 Top-Argumente für Ihren BASTA!-Besuch appeared first on BASTA!.
]]>The post In die Azure-Cloud loggen appeared first on BASTA!.
]]>Mein Kollege Roland Krummenacher hat in einem früheren Artikel [1] bereits einen Weg aufgezeigt, wie Logdaten in die Azure Cloud gesammelt werden können. Dazumal wurde eine Lösung unter der Verwendung des Azure-Storage-Diensts erläutert. In diesem Artikel möchte ich Ihnen den aktuellen Ansatz unter der Verwendung des Azure-Log-Analytics-Arbeitsbereich-Diensts vorstellen.
Regelmäßig News zur Konferenz und der .NET-Community
Ausgangslage für die Codebeispiele in diesem Artikel bildet ein Legacy-System bestehend aus einer oder mehreren .NET-Anwendungen, das auf VMs in der Azure Cloud migriert wird, und dessen Daten wir nun in Azure sammeln und auswerten möchten. Als Logging-Framework setzen wir hier auf log4net [2]. Listing 1 zeigt eine log4net-Konfiguration, mit der die Anwendungslogs in Textdateien geschrieben werden. Eine Logmeldung besteht in der Regel aus verschiedenen Attributen, die sich für die textuelle Ausgabe als Layout konfigurieren lassen. Für unser Beispiel beschränken wir uns auf die Attribute Datum (%date), Level (%level), Logger (%logger) und Meldung (%message).
Listing 1:
<log4net>
<appender name="RollingFile" type="log4net.Appender.RollingFileAppender">
<file value="example.log" />
<appendToFile value="true" />
...
<layout type="log4net.Layout.PatternLayout">
<conversionPattern value="%date %-5level - %logger - %message%newline" />
</layout>
</appender>
<root>
<appender-ref ref="RollingFile" />
</root>
</log4net>Und so sieht es anschließend in den Logdateien aus:
2021-04-26 14:07:04,146 INFO - StartUpLogger - Service Started
2021-04-26 14:04:48,843 INFO - StartUpLogger - Service Stopped
2021-04-26 14:23:25,971 ERROR - StartUpLogger - The service terminated abnormally
2021-04-26 14:23:37,744 FATAL - StartUpLogger - The service did not start successfully
Der Inhalt dieser Logdateien soll nun inAzurein einen Log-Analytics-Arbeitsbereich übertragen werden. Der Log-Analytics-Arbeitsbereich-Dienst speichert die Daten in sogenannte Protokolle. Für ein besseres Verständnis, was Protokolle sind, können Datenbanktabellen für einen Vergleich herangezogen werden. Indiesem Kontext wäre ein Log-Analytics-Arbeitsbereich eine Datenbank, und die Protokolle wären die Tabellen. Zur besseren Auswertung der gesammelten Daten empfiehlt es sich, die Anwendungsdaten in benutzerdefinierte Protokolle zu schreiben [3]. Auf YouTube finden sich viele gute Schritt-für-Schritt-Anleitungen, wie ein Log-Analytics-Arbeitsbereich samt benutzerdefiniertem Protokoll aufgesetzt werden kann [4]. In unserem Beispiel kreieren wir einen Log-Analytics-Arbeitsbereich mit der Bezeichnung „MyLogAnalyticsWorkspace“ und legen ein eigenes, benutzerdefiniertes Protokoll namens „MyLog_CL“ an (Abb. 1).

Abb. 1: Log-Analytics-Arbeitsbereich mit benutzerdefiniertem Protokoll
Eine Möglichkeit, die Anwendungslogs mit wenig Aufwand zu sammeln und an den Log-Analytics-Arbeitsbereich zu übermitteln, bietet der Log Analytics Agent (auch bekannt als Microsoft Monitoring Agent, kurz MMA) [5]. Der MMA kann als VM Extension für Azure VMs über das Azure Portal aktiviert und so auf der VM installiert werden. Danach wird der MMA als Windows-Dienst auf dem installierten Windows-System ausgeführt. Beim Einrichten des benutzerdefinierten Protokolls wird der MMA mit den Ablageorten der Logdateien konfiguriert. Danach registriert er automatisch Änderungen in den Logdateien und überträgt diese an den Log-Analytics-Arbeitsbereich direkt in das benutzerdefinierte Protokoll [6]. Nebenbei erwähnt kann der MMA auch außerhalb von Azure verwendet werden, beispielsweise auf einem On-Site-Server (Abb. 2). Das ist vor allem dann praktisch, wenn bei der Migration indieCloud nicht alle Anwendungen auf einen Streich migriert werden.

Abb. 2: Logdaten mit dem Log Analytics Agent (MMA) sammeln
Ist der MMA samt benutzerdefiniertem Protokoll eingerichtet, sollten nach ein paar Minuten die ersten Logdaten im Log-Analytics-Arbeitsbereich sichtbar sein (Abb. 3).

Abb. 3: Logdaten im eigenen Protokoll inAzure abfragen
Die Sammlung der Logdaten mittels MMA ist zwar schnell und einfach umgesetzt, doch hat sie auch Einschränkungen. So werden zum Beispiel zirkuläre Schreibvorgänge, bei denen alte Einträge in der Logdatei mit neuen Meldungen überschrieben werden, vom MMA nicht unterstützt [6]. Auch muss die Logdatei entweder nach dem ASCII- oder dem UTF-8-Standard kodiert sein, damit der MMA den Inhalt verarbeiten kann. Ein weiterer Wermutstropfen könnte in der Anzahl der Anwendungen liegen, aus denen das Legacy-System besteht. Bei vielen Anwendungen mit unterschiedlichen Logdateien erweist sich die manuelle Konfiguration der MMAs als zeitraubende Tätigkeit.

Abb. 4: Aufbereitete Logdaten im eigenen Protokoll inAzure
Wir haben nun die Anwendungslogs erfolgreich nach Azure übertragen und möchten sie auswerten. In der aktuellen, rohen Form ist eine Auswertung etwas schwierig, da wir alle Attribute der Logmeldung (Datum, Level, Logger, Meldung) in einem String zusammengefasst haben (in unserem Beispiel wäre das das Feld RawData). Hier kommt die Kusto Query Language (kurz KQL) ins Spiel. Je nach Aufbau der Logmeldungen lassen sich die Attribute durch geschickte KQL-Anweisungen extrahieren [7]. Mit dem in Listing 2 gezeigten KQL können die Logeinträge aus unserem Beispiel in ihre Bestandteile aufgelöst werden (Abb. 4).
Listing 2
.MyLog_CL
| extend _firstDashIdx = indexof(RawData, '-', 20)
| extend _secondDashIdx = indexof(RawData, '-', _firstDashIdx + 1)
| extend
Datum = substring(RawData, 0, 10),
Zeit = substring(RawData, 11, 12),
Level = trim_end(@"[^\w]+", substring(RawData, 24, 5)),
Logger = substring(RawData, _firstDashIdx+1, _secondDashIdx-_firstDashIdx-2),
Meldung = substring(RawData, _secondDashIdx + 1)
| project Datum, Zeit, Level, Logger, Meldung
Statt die einzelnen Attribute einer Logmeldung über KQL-Abfragen jedes Mal zu extrahieren, kann inAzure auch von benutzerdefinierten Feldern Gebrauch gemacht werden. Benutzerdefinierte Felder können als Tabellenspalten betrachtet werden und werden direkt von Azure beim Schreiben der Logmeldungen befüllt. Zur Erstellung von benutzerdefinierten Feldern markiert man im Ergebnisbereich einer KQL-Abfrage den Teil des Textes, der für das benutzerdefinierte Feld extrahiert werden soll. Eine ausführliche Anleitung findet sich in Microsofts Onlinedokumentation [8]. Aufgrund des markierten Textbereiches ermittelt eininAzureintegrierter Algorithmus automatisch, welche Textteile zum benutzerdefinierten Feld gehören und welche nicht (Abb. 5).

Abb. 5: Benutzerdefinierte Felder extrahieren
MyLog_CL
| project TimeGenerated, Level_CF, Logger_CF, Meldung_CF
Die benutzerdefinierten Felder lassen sich zwar einfacher auswerten, doch kann es vorkommen, dass der von Azure verwendete Algorithmus die Felder nicht mit den richtigen Informationen befüllt. Das ist vor allem dann der Fall, wenn sich das Format der Logmeldungen aufgrund von neuen Attributen ändert. Azure verlässt sich bei der Extraktion von benutzerdefinierten Feldern darauf, dass das Format der Logmeldungen stabil bleibt. Das heißt, würde man die bestehenden Logmeldungen um weitere Attribute ergänzen, z. B. Thread-ID, IP-Adresse, Benutzername usw., könnte das das Log durcheinanderbringen. Man könnte indiesem Fall zwar auf eine eigene Extraktionsanweisung mittels KQL (wie in Abb. 4) zurückgreifen, doch es geht auch anders.

Abb. 6: Benutzerdefinierte Felder abfragen
Azure Log Analytics bietet zusätzlich ein HTTP-Datensammler-API (nachfolgend Web-API) an, an das die Logmeldungen direkt übertragen werden können. Microsoft stellt eine Beispielimplementation in seiner Onlinedokumentation bereit, mit der sich das Web-API ansprechen lässt [9]. Doch statt das Web-API selbst anzusprechen, kann man auf bequemere Mittel zurückgreifen. Eines davon wäre das Open-Source-Projekt Log4ALA, das als NuGet-Paket frei verfügbar ist [10]. Log4ALA bietet einen für den Azure-Log-Analytics-Arbeitsbereich konfigurierbaren log4net-Appender (Listing 3), der sich direkt in die eigene Anwendungskonfiguration integrieren lässt.
Listing 3
<log4net>
...
<appender name="Log4ALAAppender" type="Log4ALA.Log4ALAAppender, Log4ALA">
<!-- Hier die ID des Log-Analytics-Arbeitsbereichs eintragen -->
<workspaceId value="xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" />
<!-- Hier den primären oder sekundären Zugriffschlüssel eintragen -->
<SharedKey value="....................................==" />
<!-- Name des benutzerdefinierten Protokolls -->
<logType value="MyLog4ALA_CL" />
<!-- Optional: Soll das Log-Level mitübertragen werden? (Standard: true) -->
<appendLogLevel value="true" />
<!-- Optional: Soll der Logger mitübertragen werden? (Standard: true) -->
<appendLogger value="true" />
</appender>
<root>
<appender-ref ref="Log4ALAAppender" />
</root>
</log4net>
Für die Authentifizierung gegenüber dem Web-API ist neben der Log-Analytics-Arbeitsbereich-ID auch einer der beiden Zugriffsschlüssel (primär oder sekundär) benötigt. Hierbei handelt es sich um schützenswerte Informationen, die nicht in der Quellcodeverwaltung eingecheckt werden sollten.
Gesetzt den Fall, dass es bei der Übertragung der Anwendungslogs zu Verbindungsproblemen kommt, kann Log4ALA so konfiguriert werden, dass nicht übertragene Logmeldungen in einer lokalen Textdatei niedergeschrieben werden, sodass sie nicht verloren gehen. Weiter kann Log4ALA auch mehr als nur einen Log-Analytics-Arbeitsbereich zeitgleich ansprechen. Im Gegensatz zu den einfachen Codebeispielen von Microsoft zur Ansteuerung des Web-APIs bietet Log4ALA eine interne Verarbeitungs-Queue, die verhindert, dass es bei der Übermittlung der Anwendungslogs über das Netzwerk zu Ausführungsverzögerungen innerhalb der .NET-Anwendung kommt.
Anders als in der ersten Variante mit dem MMA lässt sich bei der Log4ALA-Variante kein Logmuster mit Attributen konfigurieren. Sofern nichts weiter konfiguriert ist, füllt Log4ALA lediglich die Attribute Level, Logger und Meldung eines Logeintrags aus (Abb. 7).

Abb. 7: Durch Log4ALA protokollierte Logmeldungen abfragen
Möchte man zusätzliche Attribute protokollieren, so bietet Log4ALA zwei Möglichkeiten. Die eine Möglichkeit besteht darin, die Anwendungslogs im JSON-Format im Code zu verfassen. Die andere setzt voraus, dass die Attribute und Werte einer Logmeldung mit einem Trennzeichen (z. B. Gleichheitszeichen =) und Separator (z. B. Semikolon getrennt sind. Log4-ALA kann so konfiguriert werden, dass es aufgrund des Trennzeichens und Separators automatisch Attribute und ihre zugehörigen Werte erkennt und für sie benutzerdefinierte Felder in Azure erstellt, die wiederum einfach abgefragt werden können (Listing 4).
Listing 4
public void Log4AlaSample(int requestId)
{
ILog log = LogManager.GetLogger(this.GetType());
// Logmeldungen im JSON-Format:
// {"requestId":"123456", "message":"Anfrage eingetroffen"}
log.Info($"{{\"requestId\":\"{requestId}\", " +
+ $"\"message\":\"Anfrage eingetroffen\"}}");
// Logmeldungen mit '=' als Trennzeichen und ';' als Separator:
// requestId=123456; message=Anfrage eingetroffen
log.Info($"requestId={requestId};message=Anfrage eingetroffen");
}
Beide vorgestellten Möglichkeiten funktionieren nur, sofern die eigene Legacy-Anwendung bereits indiesem Format die Anwendungslogs schreibt. Möchte man bestimmte Attribute nachträglich abfüllen, müssen Änderungen im Code vorgenommen werden, was bei Legacy-Anwendungen selten eine willkommene Lösung ist.
Falls man neben dem reinen Anwendungslog noch zusätzliche Telemetriemetriken wie Arbeitsspeicher, CPU, Netzwerklatenz usw. sammeln und auswerten möchte, könnte auch der Einsatz des Diensts Application Insights in Frage kommen. Application Insights ist die Rundum-Monitoring-Lösung für Anwendungen in der Azure-Cloud [11].
Zur Anbindung von Application Insights in unsere Beispielanwendungen stellt Microsoft ein NuGet-Paket mit einem konfigurierbaren log4net-Appender zur Verfügung [12]. Anschließend kann der Appender in der log4net-Konfiguration ergänzt werden (Listing 5).
Listing 5
<log4net>
...
<appender name="aiAppender" type="Microsoft.ApplicationInsights.Log4NetAppender.ApplicationInsightsAppender, Microsoft.ApplicationInsights.Log4NetAppender">
<layout type="log4net.Layout.PatternLayout">
<conversionPattern value="%message%newline" />
</layout>
</appender>
<root>
<appender-ref ref="aiAppender" />
</root>
</log4net>
Damit der Application-Insights-Appender die Daten auch überträgt, muss die Telemetriekonfiguration eingerichtet werden. Sie benötigt, anders als bisher, nicht die Log-Analytics-Arbeitsbereich-ID, sondern den Instrumentierungsschlüssel des Application-Insights-Diensts, der mit dem Log-Analytics-Arbeitsbereich inAzure verknüpft ist. Der Instrumentierungsschlüssel kann entweder über eine ApplicationInsights.config-Datei oder direkt im Quellcode mit der nachfolgenden Anweisung konfiguriert werden [13]:
TelemetryConfiguration.Active.InstrumentationKey =
"xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx";
Wenn alles richtig konfiguriert ist, erscheinen die Logmeldungen im Log-Analytics-Arbeitsbereich in dem für Application Insights vorgegebenen Protokoll AppTraces (Abb. 8).
Dass der Application-Insights-Dienst derart viele Daten sammelt, hat nicht nur Vorteile. Durch die vielen Mehrdaten, die protokolliert werden, fallen auch höhere Kosten an. Daher lohnt es sich hier, die Konfiguration des Diensts nochmals zu prüfen und nicht benötigte Telemetriedaten vom Monitoring auszuschließen.
Dank der Tatsache, dass wir die Anwendungslogs im Log-Analytics-Arbeitsbereich konzentriert haben, erschließen sich uns nun neue Möglichkeiten [14]. Wir können beispielsweise in regelmäßigen Abständen unsere Anwendungslogs prüfen und proaktiv Warnungen über E-Mail oder SMS versenden, sobald Ungereimtheiten in der Anwendungsausführung ersichtlich sein sollten. Außerdem sind wir nun in der Lage, basierend auf unseren KQL-Abfragen ausgeklügelte Reports mittels PowerBI zu erstellen, grafische Diagramme direkt im Azure-Dashboard einzubinden oder durch den Azure-Sentinel-Dienst [15] vorzeitig auf mögliche Sicherheitsbedrohungen zu reagieren. Darüber hinaus können die Daten auch über ein Web-API für sonstige Weiterverarbeitungen bereitgestellt werden. Da das Azure-Dienstangebot ständig ausgeweitet wird, kommen fortlaufend neue Verarbeitungsmöglichkeiten hinzu.
Regelmäßig News zur Konferenz und der .NET-Community
Wir haben nun drei Möglichkeiten besprochen, wie die Anwendungslogs in der Azure-Cloud gesammelt und ausgewertet werden können, sowie weitere Optionen angesprochen, wie diese Daten weiterverarbeitet werden könnten. Tabelle 1 gibt eine grobe Zusammenfassung. Wie immer gilt es, die Vor- und Nachteile der vorgestellten Lösungsansätze abzuwägen und diejenige Variante zu identifizieren, diedie eigene Problemstellung am besten beantwortet.
| Variante | Vorteile | Nachteile |
|---|---|---|
| 1. Log Analytics Agent | + benutzerdefinierte Felder können bei klarem Logformat einfach definiert werden
+ ohne Änderungen am bestehenden Code einsetzbar, da nur die Logdateien berücksichtigt werden |
– nachträgliche Anpassungen am Logformat können sich negativ auf benutzerdefinierte Felder auswirken
– für die Logdateien gelten Einschränkungen (kein zirkuläres Schreiben, nur ASCII- oder UTF-8-Format) – hat man ein System mit sehr vielen Anwendungen, kann die manuelle Einbindung der Logdateien zeitraubend sein |
| 2. HTTP-Datensammler-API | + dank Open-Source-Bibliotheken wie Log4ALA ist eine Einbindung sehr einfach | – ohne intelligenten Puffermechanismus (wie ihn z. B. Log4ALA mittels interner Queue besitzt) können viele Nachrichten die Ausführung der Anwendung negativ beeinflussen
– nachträgliches Ergänzen von benutzerdefinierten Felder kann umständliche Anpassungen im Quellcode erfordern |
| 3. Application Insights | + zusätzliche Telemetriedaten können sehr nützlich für Fehleranalyse sein | – höhere Kosten, da viel mehr Daten gesammelt werden |
Tabelle 1: Zusammenfassung der Vor- und Nachteile der vorgestellten Varianten
[1] Krummenacher, Roland: „Sammeln von Client-Log-Dateien in der Cloud“; in: Windows Developer 10.2014
[2] https://logging.apache.org/log4net/
[3] https://docs.microsoft.com/de-de/azure/azure-monitor/logs/quick-create-workspace
[4] https://www.youtube.com/watch?v=N-aYZ3WDRII
[5] https://docs.microsoft.com/de-de/azure/azure-monitor/agents/agent-windows
[6] https://docs.microsoft.com/de-de/azure/azure-monitor/agents/data-sources-custom-logs
[7] https://docs.microsoft.com/de-de/azure/azure-monitor/logs/parse-text
[8] https://docs.microsoft.com/de-de/azure/azure-monitor/logs/custom-fields
[9] https://docs.microsoft.com/de-de/azure/azure-monitor/logs/data-collector-api
[10] https://ptv-logistics.github.io/Log4ALA
[11] https://docs.microsoft.com/de-de/azure/azure-monitor/app/app-insights-overview
[12] https://www.nuget.org/packages/Microsoft.ApplicationInsights.Log4NetAppender
[14] https://docs.microsoft.com/de-de/azure/azure-monitor/logs/data-platform-logs
[15] https://azure.microsoft.com/de-de/services/azure-sentinel
The post In die Azure-Cloud loggen appeared first on BASTA!.
]]>The post Building and running anything with the Windows Subsystem for Linux appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community
Wollen Sie stets auf dem neusten Stand bleiben und keine weiteren Keynotes oder andere Videos verpassen? Dann melden Sie sich an und wir informieren Sie, sobald es etwas neues in den Bereichen .NET,Windows & Open Innovations gibt
The post Building and running anything with the Windows Subsystem for Linux appeared first on BASTA!.
]]>The post Einstieg in gRPC mit ASP.NET Core appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community
Das gRPC [1] ist ein Protokoll, um Funktionen in verteilten Computersystemen aufzurufen. Es wurde von Google entworfen und 2016 veröffentlicht. gRPC basiert auf dem HTTP/2-Standard und setzt auf Protocol Buffers. Google hat es der Cloud Native Computing Foundation gespendet [2]. Es steht ökosystemübergreifend für C, C++, C#, Dart, Go, Java, Kotlin, Node.js, Objective-C, PHP, Python und Ruby zur Verfügung. Die Datenkommunikation findet hier komprimiert im binären Datenformat statt, das gerade für richtig große Daten optimal ist. Eine weitere, besondere Stärke ist eine Echtzeitkommunikation über Streaming. Ein gRPC-Dienst unterstützt alle Streamingkombinationen: Unär (kein Streaming – einfache Client-Server-Kommunikation), Streaming vom Server zum Client, Streaming vom Client zum Server und bidirektionales Streaming (ein Streaming in beide Richtungen zur gleichen Zeit).
Der hauptsächliche Anwendungszweck von gRPC besteht eher in der Server-to-Server-Kommunikation. Es kann ebenfalls für native Desktop-, Mobile-, oder IoT-Clients ideal sein, die leistungsschwache Hardware haben und eine große Menge Daten beanspruchen. Eher suboptimal wären hierbei, anders als erwartet, HTTP-Clients. Obwohl gRPC über HTTP/2 bereitgestellt wird, gibt es kein natives Browser-API, um mit gRPC kommunizieren zu können. Es gibt zwar die Möglichkeit, mit zusätzlichen Tools und Libraries wie gRPC-Web eine gRPC-Kommunikation über einen HTTP-Client aufzubauen, in der Praxis erweist sich das allerdings als nicht gerade komfortabel. Eine Herausforderung ist hier auf jeden Fall das binäre Datenformat, womit man auf die Generierung von Client-Proxy-Code angewiesen ist. Das Integrieren der Codegenerierungstools beansprucht nochmal einiges an Zeit und ist nicht Native-WebDev-like. Ein weiterer, bitterer Nachgeschmack ist ebenfalls eine technische Einschränkung: Das gleichzeitige Streamen der Daten in beide Richtungen wird nicht unterstützt. Eine Ausnahme betrifft die unattraktive Toolunterstützung: Blazor-WebAssembly-Apps. Microsoft hat hierbei eine fertig integrierte Lösung in Visual Studio bereitgestellt. Es empfiehlt sich allerdings, auch hier nur gRPC einzusetzen, wenn wirklich große Daten permanent ausgetauscht werden müssen. Wieso sollte man einen Lamborghini fahren, wenn die Geschwindigkeitsgrenze bei dreißig liegt. Denn eines hat die Praxis dem Autor gezeigt: Auf Codegeneratoren angewiesen zu sein, kann die Produktivität stark beeinflussen. Nach jedem Build wird der Proxy-Code neu generiert und wenn das Tooling mal gerade nicht so will, muss man regelmäßig Visual Studio neustarten, damit alles wieder ordnungsgemäß funktioniert. Nicht gerade berauschend bei der täglichen Arbeit. Das Bereitstellen des eigenen gRPC API an externe Konsumenten ist ebenfalls nicht gerade überwältigend. Es gibt im Grunde genommen keinen Playground und auch keine einfache Art, diese Schnittstellen zu dokumentieren. Die bereits erwähnte Abhängigkeit von der Codegenerierung lässt einen die Developer Experience von gRPC dann mit der Schulnote befriedigend bis ungenügend bewerten. In Gänze bedeutet es, dass man das seinen Kunden nicht gerade antun möchte und wirft auch kein gutes Bild auf das eigene Unternehmen.
Zugegeben, die letzten Passagen klingen nicht gerade motivierend. Es gibt allerdings wieder Anwendungsfälle, in denen gRPC eine prachtvolle Lösung ist. Haben Sie bereits eine native Desktop-App in WinForms oder WPF? Wurde hierbei WCF als Client-Server-Kommunikation gewählt und soll das Backend auf .NET 5 oder höher umgestellt werden? Oder sollen im Backend unterschiedliche Services miteinander kommunizieren? Oder haben Sie leistungsschwache Clients, die in Echtzeit große Daten austauschen sollen? Dann ist gRPC auf jeden Fall die ideale Technologie.
Der Grundstein von gRPC beginnt mit einem Vertrag: Design by Contract. Hierbei gibt es zwei unterschiedliche Möglichkeiten, einen Vertrag aufzusetzen: Contract first und Code first. Bei Contract first handelt es sich um den offiziellen Weg, wie er uns in der .NET-Welt zur Verfügung steht. Die Services und ihre Message-Datentypen werden in einer eigenen Standardsprache (IDL, Interface Definition Language) beschrieben. Codegeneratortools können daraus dann Proxycode erzeugen und der Protocol Buffer Serializer kann die Messages damit bestens binär serialisieren und deserialisieren.
In Abbildung 1 sehen wir sogenannte *.proto-Dateien. Das sind normale Textdateien, die mit IDL den Dienst und die Datenstrukturen deklarieren. Daraus wird dann der notwendige Code generiert. Wir konzentrieren uns hauptsächlich auf die Contract-first-Variante.

Abb. 1: Der Grundstein von gRPC beginnt mit Contract first
Die zweite Möglichkeit besteht nicht aus einem offiziellen Weg von Microsoft, sondern aus einer aus der Community getriebenen Methode: Code first. Hier wird, wie aus WCF bekannt ist, über Attribute bei Interfaces (für Services) und Datenklassen (DTOs) deklariert, wie etwas für gRPC bereitgestellt werden soll. In Abbildung 2 sehen wir, dass daraus der notwendige Code erst zur Laufzeit über die Metaprogrammierung bereitgestellt wird. Das Besondere an dieser Lösung ist, dass wir unser bisheriges Know-how zu WCF wiederverwenden können und uns nicht erst in die neue Deklarationssprache IDL mit Protocol Buffer (Protobuf) einarbeiten müssen [3].

Abb. 2: Eine besondere Alternative ist der Code-first-Ansatz
Um die Anatomie hinter gRPC besser zu verstehen, wollen wir interaktiv einige Beispiele implementieren. Microsoft stellt bereits eine gRPC-Projektvorlage für ASP.NET Core zur Verfügung, die über ein neues Projekt in Visual Studio 2019 oder über die .NET CLI ausgewählt werden kann. In der Eingabeaufforderung wird mit der .NET CLI das neue Projekt mit folgendem Befehl erzeugt:
dotnet new grpc –name HelloGrpc
Anschließend wurde ein neuer HelloGrpc-Ordner erzeugt, die darin enthaltene HelloGrpc.csproj-Datei öffnen wir gemeinsam mit Visual Studio 2019. Im Prinzip handelt es sich um ein gewohntes neues ASP.NET-Core-Projekt. Entdecken wir zunächst einmal die Unterschiede. Der gravierendste hierbei ist, dass bereits das Grpc.AspNetCore-NuGet-Paket vorinstalliert ist. Wie man es bereits von den Projektvorlagen gewohnt ist, kann man dieses Paket erst einmal manuell auf die neueste Version updaten. In der Startup.cs-Datei werden bei der ConfigureServices-Methode alle notwendigen Klassen beim Dependency-Injection-Provider registriert und instanziiert:
services.AddGrpc();
Mit einer Middlewareroute für die Routing-Pipeline wird unser gRPC Service zur Laufzeit für andere Clients zugänglich gemacht. Es ist bis jetzt nur eine Route registriert, und zwar für einen Beispieldienst:
endpoints.MapGrpcService<GreeterService>();
Dann bleiben noch die beiden Verzeichnisse Protos und Services übrig. Im Protos-Ordner befindet sich unsere Protocol-Buffer-Datei für Contract first, die wir jetzt genauer erforschen.
Protocol Buffers [4] ist ein Datenformat zur Serialisierung mit der Schnittstellenbeschreibungssprache IDL. Auch diese wurde von Google entwickelt und bereits 2008 veröffentlicht. Hauptsächliche Entwurfskriterien der Protocol Buffers sind Einfachheit und Performance. Daher ist es im Gegensatz zu XML oder JSON als Binärformat konzipiert, das auf ein textuelles Format setzt. Die .NET-Implementierung (protobuf-net) gibt es allerdings erst seit 2014. Einen tatsächlichen Mehrwert des binären Formats gewinnt man allerdings erst bei richtig großen Datenmengen. Ein Vergleich von JSON und Protobuf hat gezeigt, dass bei einem gewöhnlichen Datenaustausch kein wirklicher Unterschied festzustellen ist.

Abb. 3: Die greet.proto-Datei beschreibt in IDL, wie Protobuf binär (de)serialisieren soll
In Abbildung 3 sehen wir den Inhalt der greet.proto-Datei. Zu Beginn wird auf die aktuelle Protobuf-Version [5] hingewiesen, was ausschlaggebend dafür ist, welche Sprachfeatures wir nutzen können. Die package-Deklaration entspricht einem Namespace unter C#, wodurch eine saubere Strukturierung der unterschiedlichen Dienste erfolgen kann. Die Daten zur Kommunikation werden mit Messages behandelt. Diese sind notwendig für Anfragen sowie für die zu liefernden Antworten. Im Prinzip handelt es sich dabei um Datentransferobjekte (DTOs).
In beiden Messages wird eine Zuweisung mit dem Wert 1 festgelegt. Dabei handelt es sich nicht um den tatsächlichen Integer-Wert 1, sondern um eine Indexierung vom jeweiligen Feld für die binäre Serialisierung. So soll unsere Datenkommunikation später stark optimiert werden können, indem nicht der tatsächliche Name im Binärformat serialisiert wird, sondern nur der Indexwert. Würden wir jetzt ein weiteres Feld hinzufügen, müssen wir natürlich mit Wert 2 aufsteigend weiter machen. Jeder Wert muss hierzu innerhalb einer Message einzigartig sein. Die explizite Deklaration soll hierbei eine kontrollierte Abwärtskompatibilität gewährleisten.
Anschließend wird hier das Service-Modell beschrieben. Der offizielle Styleguide [6] gibt auch vor, dass „Service“ im Namen enthalten sein sollte. Eine Service-Funktion beginnt mit der rpc-Deklaration gefolgt vom Funktionsnamen. Dann werden ebenfalls eine Parameter- und eine Rückgabe-Message festgelegt.
In Visual Studio 2019 ist protobuf-net bereits ein fester Bestandteil, wodurch beim Abspeichern des Projekts oder notfalls bei einem Rebuild alle notwendigen Service-Kontexte und DTO-Klassen generiert werden. In Abbildung 4 sehen wir die versteckten Verzeichnisse unseres Projekts und den Ort, an dem die generierten Daten liegen. Es hat sich allerdings in der Praxis gezeigt, dass ein wiederholtes Neustarten von Visual Studio 2019 notwendig ist, wenn die Codegenerierung versagt.
Abb. 4: Die von Visual Studio 2019 generierten Daten für unseren gRPC Service
Der Beispielservice GreeterService ist im Services-Ordner enthalten. In Listing 1 wird die Implementierung gezeigt. Hier können wir schön erkennen, dass vom generierten Service-Kontextcode eine Basisklasse festgelegt wurde. Wir erhalten hier ebenfalls, wie man es vom ASP.NET-Core-Ökosystem gewohnt ist, Unterstützung durch Constructor Injection. Die Implementierung der Kommunikation erfolgt mit async/await. Bei dieser Implementierung handelt es sich um eine einfache Request-Response-Kommunikation
Listing 1: Der GreeterService mit einer Unary-Kommunikation
.namespace HelloGrpc
{
public class GreeterService : Greeter.GreeterBase
{
private readonly ILogger _logger;
public GreeterService(ILogger logger)
{
_logger = logger;
}
public override Task SayHello(HelloRequest request, ServerCallContext context)
{
return Task.FromResult(new HelloReply
{
Message = "Hello " + request.Name
});
}
}
}
Ein ungewohnter Aspekt dieses Projekttemplates für ASP.NET Core ist, dass kein IIS-Express-Profil vorkonfiguriert ist. Das liegt daran, dass gRPC auf HTTP/2 läuft, das nicht von IIS Express unterstützt wird. Aus diesem Grund kann hier der Einsatz nur direkt über den leichtgewichtigen Cross-Platform-Webserver Kestrel erfolgen. Hier darf man auf keinen Fall vergessen, dass bei der eigenen Produktivumgebung der Support für HTTP/2 noch aktiviert werden muss. Der aktuelle Stand ist sogar, dass gRPC noch nicht über Azure mit iisnode unterstützt wird [7]. Eine Alternative wäre gRPC-Web, das nicht gerade berauschend ist, wie eingangs erwähnt wurde.
Zu unserem Projekt erzeugen wir einfach eine neue Konsolenanwendung innerhalb der Solution. Der Name wird auf HelloGrpc.Client festgelegt. Die nächsten Schritte dürften allen WSDL-, Web-Services- und WCF-Services-Entwicklern und -Entwicklerinnen bekannt vorkommen. Nach einem Rechtsklick auf das neue Konsolenprojekt wählen wir im Kontextmenü Add und dann Service reference … Anschließend öffnet sich ein Tab mit einer Übersicht über alle bereits hinzugefügten Services. Beim Klick auf den Add-Button von Service References öffnet sich ein Wizard (Abb. 5). Hier wählen wir gRPC Service aus und beim nächsten Dialog wird, wie in Abbildung 6 zu sehen ist, die Protobuf-Datei ausgewählt. Anschließend wird uns der notwendige Client-Proxy-Code generiert.
In Listing 2 steht der Code für einen einfachen Request-Response-Zugriff (Unary). Über die Solution-Eigenschaften müssen beide Projekte als Startprojekte festgelegt werden. Anschließend können wir die Anwendung ausführen und erhalten die Textausgabe „Hello World“ auf der Konsole.

Abb. 5: gRPC-Client generieren lassen

Abb. 6: Protobuf-Datei für Clientcodegenerierung auswählen
Listing 2: Der gRPC-Client für eine Unary-Kommunikation zum GreeterService
class Program
{
static async Task Main(string[] args)
{
var channel = GrpcChannel.ForAddress("https://localhost:5001");
var greeter = new GreeterClient(channel);
var result = await greeter.SayHelloAsync(new HelloRequest { Name = "World" });
Console.WriteLine(result.Message);
Console.ReadKey();
}
}
Eine besondere Stärke von gRPC ist eine Echtzeitkommunikation in unterschiedliche Streamingrichtungen. In diesem Beispiel soll der Server dem Client dauerhaft Informationen senden, während der Client einfache Antworten asynchron liefert. Ein idealer Algorithmus zur Veranschaulichung ist die Fibonacci-Folge. Diese beginnt mit einer 1, die mit einer weiteren 1 addiert wird. Daraus erhalten wir das Ergebnis 2. Dann folgt die weitere Berechnung mit 2 plus das letzte Ergebnis 1, wir erhalten 3 usw., bis wir zu einem festgelegten Ende gelangen. Listing 3 zeigt die dazugehörige Fibonacci-Implementierung, die wir für unserem gRPC Service benötigen.
Passend zur Implementierung fügen wir mit Visual Studio im Protos-Ordner eine neue Protobuf-Datei mit dem Namen fibonacci.proto hinzu. Hier werden der Service sowie die eingehende und ausgehende Message deklariert. Der wesentliche Aspekt im Vergleich zur greeting.proto-Datei ist, dass zusätzlich der Rückgabetyp mit einem stream-Keyword gekennzeichnet wird (Listing 4). Ein sehr wichtiger Schritt ist jetzt das Aktivieren des Protobuf-Compilers für unsere neue Datei. Das muss jeweils explizit pro Datei in den Dateieigenschaften erfolgen. Die Datei benötigt in Visual Studio die folgenden Eigenschaften: Build Action auf Protobuf compiler und gRPC Stub Classes auf Server only.
Listing 3: Die Fibonacci-Implementierung
public class Fibonacci
{
public IEnumerable GetNumbers(int from, int to)
{
var previous = 0;
var current = from;
while (current <= to)
{
(previous, current) = (current, previous + current);
yield return current;
}
}
}
Listing 4: Die fibonacci.proto-Datei für einen Server-to-Client Streaming
syntax = "proto3";
option csharp_namespace = "HelloGrpc.Services";
service Fibonacci {
rpc GetNumbers(NumberRequest) returns (stream NumberResponse);
}
message NumberRequest {
int32 from = 1;
int32 to = 2;
}
message NumberResponse {
int32 result = 1;
}
Im Services-Verzeichnis wird jetzt eine FibonacciService-Klasse angelegt. Sie soll von der generierten Server-Basisklasse Fibonacci.FibonacciBase ableiten. Über Constructor Injection soll unsere Fibonacci-Instanz injiziert werden. Die Basisklasse selbst bietet uns jetzt das Überschreiben einer GetNumbers-Methode an. In Listing 5 ist die fertige FibonacciService-Implementierung zu sehen. Die Stream-Kommunikation zum Client findet dann über den responseStream-Parameter statt.
Listing 5: Die Fibonacci-Service-Implementierung
public class FibonacciService : Fibonacci.FibonacciBase
{
private readonly HelloGrpc.Fibonacci _fibonacci;
public FibonacciService(HelloGrpc.Fibonacci fibonacci)
{
_fibonacci = fibonacci;
}
public override async Task GetNumbers(NumberRequest request, IServerStreamWriter responseStream, ServerCallContext context)
{
foreach (var current in _fibonacci.GetNumbers(request.From, request.To))
{
await responseStream.WriteAsync(new NumberResponse { Result = current });
await Task.Delay(300);
}
}
}
Zum Schluss muss das Backend alle Bestandteile an der richtigen Stelle registriert haben. Das erfolgt in der Startup.cs-Datei. Bei der ConfigureService-Methode registrieren wir die Fibonacci-Klasse als Singleton beim Dependency Injection Provider mit:
services.AddSingleton<Fibonacci>();
Der neue Service muss ebenfalls als Route zur Verfügung gestellt werden. Das erfolgt mit einem Eintrag innerhalb der Configure-Methode:
endpoints.MapGrpcService<FibonacciService>();
Regelmäßig News zur Konferenz und der .NET-Community
Der Client benötigt eine neue Client-Proxy-Implementierung unseres neuen Service. Wir machen dazu einen Rechtsklick auf das Konsolenprojekt. Im Kontextmenü wählen wir Add und dann Service reference … Es öffnet sich wieder der Tab mit der Übersicht über alle bereits hinzugefügten Services. Beim Klick auf den +-Button von Service References öffnet sich wieder der Wizard. Hierbei wählen wir gRPC Service aus und beim nächsten Dialog wird die neue fibonacci.proto-Datei ausgewählt. Anschließend wird uns der notwendige Client-Proxy-Code generiert.
In Listing 6 sehen wir dazu dann die passende Implementierung. Einige neue C#-Features kommen hier zum Einsatz. Zum Beispiel sorgt das using hinter der Variablendeklaration für eine flachere Codestruktur. Über das ResponseStream Property können wir asynchron mit ReadAllAsync auf die eingehenden Datenströme reagieren. Mit der await/Forearch-Deklaration funktioniert das auch wunderbar in Kombination mit der Foreach-Schleife. Beim gleichzeitigen Ausführen vom Service und Client können wir leicht verzögert sehen, wie der Service die Daten nacheinander an den Client ausliefert und dieser sie dann zur Ausgabe weitergibt.
Listing 6: Die Fibonacci-Client-Implementierung
class Program
{
static async Task Main(string[] args)
{
var channel = GrpcChannel.ForAddress("https://localhost:5001");
var fibonacciClient = new FibonacciClient(channel);
using var result = fibonacciClient.GetNumbers(new NumberRequest { From = 1, To = 100000000 });
await foreach (var response in result.ResponseStream.ReadAllAsync())
{
Console.WriteLine("Response: " + response.Result);
}
Console.ReadKey();
}
}
Eine technologische Meisterleistung von gRPC ist das bidirektionale Streaming. Damit ist das gleichzeitige Streamen von Server zu Client und umgekehrt gemeint. Das bisherige Beispiel kann zur Demonstration ganz einfach angepasst werden. Bei der fibonacci.proto-Datei erhält der Anfrageparameter zusätzlich das Stream-Schlüsselwort (Listing 7). Beim Speichern und Bauen erzeugt Visual Studio automatisch die neuen Proxydateien im Hintergrund.
Listing 7: Die fibonacci.proto-Datei für ein bidirektionales Streaming
syntax = "proto3";
option csharp_namespace = "HelloGrpc.Services";
service Fibonacci {
rpc GetNumbers(stream NumberRequest) returns (stream NumberResponse);
}
message NumberRequest {
int32 from = 1;
int32 to = 2;
}
message NumberResponse {
int32 result = 1;
}
Der FibonacciService erhält eine neue Methodensignatur von der Basisklasse. Der Request-Parameter wird zum RequestStream-Parameter. Diesen nutzen wir wieder mit einer asynchronen Foreach-Schleife, genauso, wie wir sie erst nur beim Client implementiert hatten. Listing 8 zeigt die neue Implementierung.
Listing 8: Die FibonacciService-Implementierung für ein bidirektionales Streaming
public class FibonacciService : Fibonacci.FibonacciBase
{
private readonly HelloGrpc.Fibonacci _fibonacci;
public FibonacciService(HelloGrpc.Fibonacci fibonacci)
{
_fibonacci = fibonacci;
}
public override async Task GetNumbers(IAsyncStreamReader requestStream, IServerStreamWriter responseStream, ServerCallContext context)
{
await foreach (var request in requestStream.ReadAllAsync())
{
foreach (var current in _fibonacci.GetNumbers(request.From, request.To))
{
await responseStream.WriteAsync(new NumberResponse { Result = current });
await Task.Delay(300);
}
}
}
}
Der Client kann jetzt bei einer dauerhaften Verbindung nacheinander seine Daten senden. Zusätzlich möchten wir aber auch die Daten vom Server in einem eigenen Task beobachten. Die komplette Implementierung dazu ist in Listing 9 zu sehen.
Listing 9: Die Fibonacci-Client-Implementierung für ein bidirektionales Streaming
class Program
{
static async Task Main(string[] args)
{
var channel = GrpcChannel.ForAddress("https://localhost:5001");
var fibonacciClient = new FibonacciClient(channel);
using var result = fibonacciClient.GetNumbers();
var task = Task.Run(async () => await WatchResponse(result));
await result.RequestStream.WriteAsync(new NumberRequest { From = 1, To = 1000000 });
await result.RequestStream.WriteAsync(new NumberRequest { From = 1, To = 1000000 });
await result.RequestStream.WriteAsync(new NumberRequest { From = 1, To = 1000000 });
await task;
Console.ReadKey();
}
static async Task WatchResponse(AsyncDuplexStreamingCall<NumberRequest, NumberResponse> result)
{
await foreach (var response in result.ResponseStream.ReadAllAsync())
{
Console.WriteLine("Response: " + response.Result);
}
}
}
Der Artikel hat gezeigt, was sich hinter gRPC verbirgt. Zusätzlich haben wir entdeckt, wie einfach gRPC unter .NET Core zum Einsatz kommen kann, aber auch, welche Schwächen wir dabei haben. Abbildung 7 zeigt nochmal alle Vor- und Nachteile. Wir konnten allerdings auf viele weitere Aspekte nicht eingehen, da sie den Rahmen für diesen Artikel sprengen würde. Dazu zählen eine korrekte Fehlerbehandlung, erweiterte Protobuf-Sprachfeatures, gRPC-Web und vieles Weitere. Passend zu diesem Artikel hat der Autor eine kostenlose Livestreamaufzeichnung als Video auf YouTube [8] bereitgestellt, in der auch die nicht besprochenen Aspekte ausführlich gezeigt werden. Viel Spaß beim Ansehen!

[1] https://grpc.io/docs/what-is-grpc/faq/
[2] https://www.cncf.io/blog/2017/03/01/cloud-native-computing-foundation-host-grpc-google/
[3] https://www.twitch.tv/videos/731620698
[4] https://developers.google.com/protocol-buffers
[5] https://developers.google.com/protocol-buffers/docs/proto3
[6] https://developers.google.com/protocol-buffers/docs/style
[7] https://devblogs.microsoft.com/aspnet/grpc-web-for-net-now-available/
[8] https://youtu.be/QUdr0qbEKE4?list=PLbWYOayzrhS_WPoubt7PV0h2n1fOimI2j
The post Einstieg in gRPC mit ASP.NET Core appeared first on BASTA!.
]]>The post Software Development Quality Map appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community

Gute Softwarequalität liegt jedem Entwicklungsteam am Herzen. Doch was ist, wenn die Software nicht die Qualität aufweist, die man sich vorgenommen hat? Die Software Development Quality Map von bbv zeigt den Lösungsweg: Sie nimmt Teams auf Entdeckungsreise und deckt in einer unterhaltsamen und spielerischen Art Verbesserungsmöglichkeiten auf. Das Video erklärt kurz und knackig, was auf der Software Development Quality Map alles zu entdecken gibt.
The post Software Development Quality Map appeared first on BASTA!.
]]>The post Alle Zügel in einer Hand: Effektive Steuerung von Softwareentwicklungsprozessen appeared first on BASTA!.
]]>
Im Gegensatz zu .NET-Framework-Applikationen bietet .NET seit der ersten .NET-Core-Version eine flexible Konfiguration, in der unterschiedliche Provider konfiguriert werden können, um auf Konfigurationen aus unterschiedlichen Sources zuzugreifen, z. B. JSON-, XML-, und INI-Files, Environment Variables und Applikationsargumente. Die Sample-Applikation [1] wurde über diesen .NET CLI Command erstellt:
> dotnet new webapp
Beim Verwenden der Host-Klasse und der Methode CreateDefaultBuilder (Listing 1) werden für das Lesen der Applikationskonfigurationen diese Provider vordefiniert:
Listing 1: Program.cs
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup<Startup>();
});
Um Konfigurationswerte von der Applikation zu lesen, wird der Config1 Key mit einem Wert in die Konfigurationsdatei appsettings.json (Listing 2) geschrieben.
Listing 2: appsettings.json
{
"AppConfigurationSample": {
"Settings": {
"Config1": "value 1 from appsettings.json"
}
}
}
Für einen Konfigurationswert, der im Development Environment gelesen wird, wird der Konfigurationswert in der Datei appsettings.Development.json überschrieben. appsettings.{EnvironmentName}.json wird nach der Datei appsettings.json gelesen und damit werden im Development Environment die Konfigurationswerte, die in dieser Datei definiert sind, überschrieben (Listing 3).
Listing 3: appsettings.Development.json
{
"AppConfigurationSample": {
"Settings": {
"Config1": "value 1 from appsettings.Development.json"
}
}
}
Um die Konfiguration im C#-Code zu lesen, wird die IndexAppSettings-Klasse definiert. Der Property-Name entspricht dem Key-Namen, um die Konfigurationswerte automatisch zu übernehmen (Listing 4).
Listing 4: IndexAppSettings.cs
public class IndexAppSettings
{
public string? Config1 { get; set; }
}
Um die IndexAppSettings-Klasse mit dem IOptions-Interface injecten zu können, wird die IndexAppSettings-Klasse im Dependency-Injection-(DI-)Container konfiguriert (Listing 5).
Listing 5: Startup.cs
public void ConfigureServices(IServiceCollection services)
{
services.Configure<IndexAppSettings>(
Configuration.GetSection(
"AppConfigurationSample:Settings"));
services.AddRazorPages();
}
Mit Inject des generic IOptions Interfaces (Listing 6) werden die Konfigurationen in der Index-Page geladen.
Listing 6: Index.cshtml.cs
public class IndexModel : PageModel
{
private readonly ILogger<IndexModel> _logger;
public IndexModel(IOptions<IndexAppSettings> options,
ILogger<IndexModel> logger)
{
_logger = logger;
Setting1 = options.Value.Config1 ?? "no value configured";
}
public string Setting1 { get; init; }
}
Die Applikation ist bereit, die Konfigurationen aus irgendeiner Konfigurationsquelle zu laden. Mit Ändern eines Environments (Development, Staging, Production) können Konfigurationen auch entsprechend überschrieben werden. Um jetzt Azure App Configuration zu nutzen, sind nur kleine Anpassungen erforderlich.
Regelmäßig News zur Konferenz und der .NET-Community
Ein Azure App Configuration Service kann über das Azure Portal [2], das Azure CLI, oder über PowerShell-Skripte erstellt werden. Hier wird gezeigt, wie die Azure CLI dafür genutzt werden kann. Im Sample-Source-Code-Repository gibt es ein Bash-Skript zum Erstellen dieser Resource.
Listing 7 zeigt die Azure CLI Commands. Mit dem Command az appconfig create wird die Azure App Configuration Resource erstellt. Der Command az appconfig kv set erstellt Key-Value-Paare.
Listing 7
rg=rg-appconfigsample
loc=westeurope
conf=configsample
key1=AppConfigurationSample:Settings:Config1
val1="configuration value for key 1 from Azure App Configuration"
devval1="configuration value for the Development environment"
az group create --location $loc --name $rg
az appconfig create --location $loc --name $conf --resource-group $rg
az appconfig kv set -n $conf --key $key1 --value "$val1" --yes
az appconfig kv set -n $conf --key $key1 --label Development --value "$devval1" –yes
Nachdem der Azure App Configuration Service erstellt wurde, braucht es jetzt nur kleine Anpassungen, um die .NET-Applikation [3] damit zu verknüpfen. Für ASP.NET-Core-Applikationen sollte das NuGet Package
Microsoft.Azure.AppConfiguration.AspNetCore hinzugefügt werden. Dieses Package hat eine Dependency auf Microsoft.Extensions.Configuration.AzureAppConfiguration, das für andere .NET-Applikationen reicht.
Alles was es jetzt braucht, um die Applikationskonfiguration aus dem Azure Service zu laden, ist es, den Azure Configuration Provider einzutragen. Um vom Development-System die Connection herzustellen, kann der Connection-String verwendet werden. Da der aber ein Secret beinhaltet, ist es am besten, diesen Connection-String nicht im Source-Code-Repository zu speichern, sondern mit den User Secrets zu speichern. User Secrets können über die .NET CLI konfiguriert werden (Listing 8).
Listing 8: dotnet user-secrets
> dotnet user-secrets init
> dotnet user-seccrets set AzureAppConfigurationConnection "enter your connection string"
Secrets sollten nie Teil des Source Codes sein. Mit User Secrets werden geheime Konfigurationen aus dem Userprofil gelesen. Das steht nur während der Entwicklung zur Verfügung. In Produktion müssen für Secrets andere Funktionalitäten genutzt werden, wie z. B. der Azure Key Vault.
Beim Set-up der Host-Klasse können weitere Configuration Provider mit der Methode ConfigureAppConfiguration (Listing 9) hinzugefügt werden. Mit dem Aufruf von config.Build werden die bisherigen Provider genutzt, um den Connection-String aus den User Secrets auszulesen. Der Connection-String wird der Extension-Methode AddAzureAppConfiguration mitgegeben und mit diesem Provider werden auch schon die Konfigurationen aus dem Azure Service gelesen.
Listing 9: Program.cs
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureAppConfiguration((context, config) =>
{
var settings = config.Build();
var connectionString =
settings["AzureAppConfigurationConnection"];
config.AddAzureAppConfiguration(connectionString);
})
.ConfigureWebHostDefaults(webBuilder =>
{
webBuilder.UseStartup();
});
Die User Secrets funktionieren jetzt auf dem Development-System. Um diese initiale Konfiguration jetzt auch direkt von einem Azure Service nutzten zu können, sollten hierfür Managed Identities genutzt werden.
Um in Produktion von einem Azure App Service oder einer Azure Function auf Azure App Configuration zugreifen zu können, können Managed Identities [4] genutzt werden. Ein Overload der AddAzureAppConfiguration-Methode (Listing 10) definiert den AzureAppConfigurationOptions-Parameter. Damit ist es möglich, die Connection zu Azure App Configuration mit einem Endpoint (der kein Secret beinhaltet) und einem TokenCredential-Objekt zu definieren. Für das Erzeugen des TokenCredential-Objekts kann die DefaultAzureCredential-Klasse verwendet werden (definiert im NuGet Package Azure.Identity).
DefaultAzureCredential verwendet unterschiedliche Credential Types. Der ManagedIdentityCredential Type kann verwendet werden, wenn die Applikation in einem Azure App Service konfiguriert wird. DefaultAzureCredential verwendet aber auch VisualStudioCredential, VisualStudioCodeCredential und AzureCliCredential. Der Account, der mit Visual Studio verwendet wird, um auf Azure Services zuzugreifen, benötigt hierfür unter Azure App Configuration eine Zuweisung zur Rolle App Configuration Data Reader. Damit kann der gleiche Code im Development Environment und in Produktion genutzt werden.
Listing 10
.ConfigureAppConfiguration((context, config) =>
{
var settings = config.Build();
config.AddAzureAppConfiguration(options =>
{
DefaultAzureCredential credential = new();
var endpoint = settings["AzureAppConfigurationEndpoint"];
options.Connect(new Uri(endpoint), credential);
});
})
Mit .NET können Konfigurationen je nach Environment überschrieben werden, z. B. im Production, Staging und Developer Environment. Bei Azure App Configuration gibt es Labels, die für das Mapping zu den Environments verwendet werden können, wie in der nächsten Version der Applikation [5] gezeigt wird.
Beim Erstellen des Azure App Configuration Services wurde ein Konfigurationswert mit dem Label Development erstellt. Um die Funktionalität auf die .NET Environments zu übertragen, kann die Select-Methode der AzureAppConfigurationOptions-Klasse verwendet werden. Mit dem ersten Parameter dieser Methode kann ein Key-Filter spezifiziert, um nicht alle Konfigurationswerte zu laden, sondern nur die Werte, die dem Filter entsprechen. Im Sample Code (Listing 11) werden alle Keys geladen, die mit dem String AppConfigurationSample: starten.
Wenn der Azure App Configuration Service Konfigurationen für mehrere Applikationen beinhaltet, ergibt es Sinn, diesen Filter zu definieren, um nicht alle Konfigurationen zu laden. Mit dem zweiten Parameter wird ein Labelfilter spezifiziert. Der erste Aufruf der Filter-Methode verwendet die vordefinierte Null-Property der LabelFilter-Klasse. Damit werden alle Konfigurationswerte ohne Label geladen. Mit dem zweiten Aufruf der Select-Methode wird ein Labelfilter mit dem Namen des Environments genutzt. Die Konfigurationen mit einem entsprechenden Label überschreiben die Konfigurationswerte ohne Label. Bei ASP.NET-Core-Applikationen wird der Name des Environments über die ASPNETCORE_ENVIRONMENT-Environment-Variable gesetzt.
Listing 11: Program.cs
config.AddAzureAppConfiguration(options =>
{
DefaultAzureCredential credential = new();
var endpoint = settings["AzureAppConfigurationEndpoint"];
options.Connect(new Uri(endpoint), credential)
.Select("AppConfigurationSample:*", LabelFilter.Null)
.Select("AppConfigurationSample:*", context.HostingEnvironment.EnvironmentName);
});
Development, Staging und Production sind übliche Environment-Namen, in denen unterschiedliche Konfigurationswerte, z. B. unterschiedliche Datenbank-Connection-Strings genutzt werden können. Mit einem Cloud-Environment ist es sinnvoll, das Developer-Environment über unterschiedliche Subscriptions komplett von der Produktion zu trennen. Damit ist es sinnvoll, im Development-Environment einen eigenen Azure App Configuration Service zu nutzen. In der Production Subscription ist es wiederum sinnvoll, zumindest zwischen Staging und Production Environments zu trennen – um die letzten Tests vor dem Switch in Produktion im Staging Environment durchzuführen.
Um nach Änderungen von Konfigurationswerten einen App Service nicht restarten zu müssen, können Konfigurationen in der laufenden Applikation neu geladen werden. Dafür sind aber einige Änderungen erforderlich [6].
Bei der Konfiguration des Azure App Configuration Providers muss die ConfigureRefresh-Methode der AzureAppConfigurationOptions-Klasse aufgerufen werden. Der Delegate-Parameter bei dieser Methode erlaubt es, die AzureAppConfigurationRefreshOptions zu konfigurieren. Mit der Register-Methode (Listing 12) wird ein Key registriert und mit den Änderungen verglichen, bevor alle Konfigurationswerte neu geladen werden.
Hier ergibt es Sinn, einen Key (Sentinel) zu definieren, bei dem der Wert geändert wird, sobald irgendeine Konfiguration der Applikation geändert wird. Mit diesem Key wird verglichen und Werte im Memory werden neu geladen, sobald dieser Wert nach der Cache Expiration geändert wird. Die Zeitdauer für die Cache Expiration wird über die Methode SetCacheExpiration definiert.
Wird diese z. B. auf fünf Minuten gesetzt, wird der Sentinel-Wert alle 5 Minuten in Azure App Configuration geladen. Ist der Wert anders als im letzten Request, werden alle Konfigurationswerte der Applikation (definiert über die Select-Methode) neu geladen. Im Code-Sample wird die Expiration-Dauer auf 30 Tage gesetzt, womit der Cache explizit neu geladen werden muss. Ein explizites Laden kann über das Interface IConfigurationRefresher gesteuert werden.
Listing 12
.ConfigureRefresh(refreshConfig =>
{
refreshConfig.Register(
"AppConfigurationSample:Sentinel", refreshAll: true)
.SetCacheExpiration(TimeSpan.FromDays(30));
});
Weitere notwendige Änderungen für das Aktivieren der Refresh-Funktionalität sind die Konfiguration des DI-Containers über die Methode AddAzureAppConfiguration und die Konfiguration der Middleware mit der Methode UseAzureAppConfiguration (Startup-Klasse).
Statt des IOptions-Interface muss auch das IOptionsSnapshot-Interface injectet werden. Beim IOptions-Interface wird ein Cache der Konfiguration gehalten, und damit gibt es kein Update bei weiteren Aufrufen. Das IOptionsSnapshot-Interface hält einen Snapshot der Daten, die nach jedem Injecten aus dem Azure App Configuration Provider Cache geladen werden.
Um den Cache jetzt upzudaten, kann über Azure App Configuration ein Event Grid Event registriert werden, das aktiviert wird, sobald ein Key-Value-Wert modifiziert wird. Von dort ist es möglich, unterschiedliche Resources wie Azure Functions, Logic Apps, oder WebHooks anzustoßen.
In der Sample-Applikation wird in der RefreshSettings-Page (Listing 13) das IConfigurationRefreshProvider-Interface injectet, um die Azure App Configuration mit den Aufrufen SetDirty und TryRefreshAsync neu zu laden.
Listing 13: RefreshSettings.cshtml.cs
public class RefreshSettingsModel : PageModel
{
private readonly IConfigurationRefresher _configurationRefresher;
public RefreshSettingsModel(IConfigurationRefresherProvider refresherProvider)
{
_configurationRefresher = refresherProvider.Refreshers.First();
}
public async Task OnGet()
{
_configurationRefresher.SetDirty(TimeSpan.FromSeconds(1));
await Task.Delay(1000);
bool success = await _configurationRefresher.TryRefreshAsync();
}
}
Regelmäßig News zur Konferenz und der .NET-Community
Für die Konfiguration der Secrets bietet Azure Key Vault Optionen, die von Azure App Configuration nicht zur Verfügung gestellt werden. Azure Key Vault bietet in der Standardvariante Software-Protection über unterschiedliche Rollen, in der Premiumvariante auch Hardware-Protection mit dedizierten Hardware-Security-Modulen.
Azure Key Vault [7] kann über einen eigenen Provider in der .NET-Konfiguration eingetragen werden. Alternativ ist es auch möglich, in Azure App Configuration eine Referenz auf den Azure Key Vault zu registrieren. Dabei ist es in der Applikation [8] nicht erforderlich, eine Connection zu Azure Key Vault zu konfigurieren – die Konfiguration zur Azure App Configuration reicht dafür.
Mit der ConfigureKeyVault-Methode wird konfiguriert, dass der Azure Key Vault auch über Azure App Configuration genutzt wird. Dabei ist es erforderlich, die Credentials mitzugeben, um vom Key Vault lesen zu können. Die Credentials, die über DefaultAzureCredential erzeugt werden, können auch hier mitgegeben werden – Voraussetzung ist, dass diese Credentials nicht nur Zugriff auf die Azure App Configuration sondern auch Lesezugriff auf die Secrets im Azure Key Vault haben.
Der Azure App Configuration Service bietet eine zentrale Konfiguration. Um diesen Service mit .NET-Anwendungen zu verwenden, ist es nur erforderlich einen Configuration Provider hinzuzufügen. Azure App Configuration kann damit leicht in bestehende .NET-Anwendungen integriert werden. Für unterschiedliche Konfigurationen je nach Environment können mit Azure App Configuration Labels verwendet werden, die sich einfach in das .NET-Environment-Modell integrieren lassen.
Um diesen Service von Azure Services zu verwenden, bieten sich Managed Identities mit Role-based Security an. Um den Service auch vom Development-System verwenden zu können, eignet sich die DefaultAzureCredential-Klasse, die sowohl Managed Identities als auch Visual Studio Credentials unterstützt. Für ein dynamisches Update der Konfigurationswerte ist mit einem Refresh-Modell gesorgt – und Konfigurationen, die Secrets beinhalten, können über den Azure Key Vault von Azure App Configuration integriert werden.
[1] https://github.com/ProfessionalCSharp/MoreSamples/Azure/AppConfig/01-ConfigSample
[3] https://github.com/ProfessionalCSharp/MoreSamples/Azure/AppConfig/02-ConfigSample
[4] https://docs.microsoft.com/en-us/azure/active-directory/managed-identities-azure-resources/overview
[5] https://github.com/ProfessionalCSharp/MoreSamples/Azure/AppConfig/04-ConfigSample
[6] https://github.com/ProfessionalCSharp/MoreSamples/Azure/AppConfig/05-ConfigSample
[7] https://docs.microsoft.com/en-us/azure/key-vault/general/basic-concepts
[8] https://github.com/ProfessionalCSharp/MoreSamples/Azure/AppConfig/06-ConfigSample
The post Alle Zügel in einer Hand: Effektive Steuerung von Softwareentwicklungsprozessen appeared first on BASTA!.
]]>The post Microsofts Miet-AI: Wie KI-Lösungen die Unternehmenslandschaft verändern appeared first on BASTA!.
]]>
AI-Start-ups stehen immer im Spannungsfeld zwischen Generalisierung und Spezialisierung. Ist der angebotene Dienst zu generell, muss der Entwickler noch zu viel Arbeit beitragen und ist deshalb nicht wirklich zu seiner Nutzung motiviert. Ist der Dienst allerdings zu speziell, ist die erreichbare Zielgruppe zu klein.
Nach der Reorganisation – die Websuchdienste wurden aus den Azure Cognitive Services in die Bing-APIs ausgelagert – bestehen die Cognitive Services noch aus vier Dienstgruppen, die wir in den Abbildungen 1 bis 4 im Profil vorstellen.

Abb. 1: Decision, …

Abb. 2: … Language, …

Abb. 3: … Speech …

Abb. 4: … und Vision sind der Vierkampf der künstlichen Cloud-Intelligenz im Hause Microsoft
In der Rubrik „Decision“ finden sich dabei Werkzeuge, die aus bereitzustellenden Informationen Entscheidungen ableiten, darunter auch ein als Content Moderator bezeichnetes Modul, das sich um die automatische Ausfilterung von nicht akzeptablem User-generated Content kümmert. In der Rubrik „Language“ finden sich verschiedene Dienste, die sich auf die Verarbeitung von in Form von Strings vorliegenden Texten konzentriert haben. Ein Klassiker ist dabei die Sentiment Analysis, die die vom Schreiber im Text zu vermittelnde Stimmung analysiert. Mit dem Translator steht analog dazu ein Übersetzer zur Verfügung, der Texte in durchaus brauchbarer Qualität zwischen mittlerweile 90 Sprachpaaren hin- und hertransferiert. In der Rubrik „Speech“ findet sich im Allgemeinen das, was man erwarten würde: TTS-Dienste. Seit der Übernahme des Unternehmens Lernout & Hauspie darf Microsoft hier auf die Kompetenz von Dragon zurückgreifen. Zu guter Letzt gibt es in der Rubrik „Vision“ eine ganze Gruppe von Diensten, die sich um angeliefertes Bildmaterial kümmern – neben der (ebenfalls am Kinect erstmals demonstrierten) Emotions- und Gesichtserkennung gibt es auch Systeme, die aus Videos und/oder Bildern Informationen über die in ihnen enthaltenen Elemente darstellen. Kurzum: Wer die Webseite der Azure Cognitive Services [1] besucht, findet jede Menge nützliche Dienste.
Jeder der vier Cognitive-Services-Unterdienste ist gleich interessant. Wir wollen in den folgenden Schritten aus Spaß an der Freude mit dem Sprachdienst beginnen. Interessant ist, dass Microsoft die Cognitive Services nicht wirklich zum Boosten der sonstigen hauseigenen Betriebssysteme einsetzt. Abbildung 5 zeigt, dass die Beispiele (und die dazugehörigen SDKs) für verschiedene Plattformen gleichermaßen angeboten werden.

Abb. 5: Microsoft ist in Sachen Plattformzielauswahl nicht sehr wählerisch
Trotzdem wollen wir in den folgenden Schritten mit Visual Studio 2019 arbeiten. Zunächst erbeuten wir eine halbwegs aktuelle Version der Entwicklungsumgebung und erzeugen darin ein neues Projekt auf Basis der Vorlage Leere App (Universelle Windows-App). Im Bereich der Projektnamensvergabe haben wir wie immer freie Hand, der Autor entscheidet sich in den folgenden Schritten für „SUSTalker1“. Im daraufhin erscheinenden Zielauswahldialog ist es wichtig, dass wir in der Rubrik Mindestens erforderliche Version den Wert Windows 10 Fall Creators Update (10.0; Build 16299) oder besser auswählen. Die Microsoft-Speech-Algorithmen kümmern sich nicht wirklich darum, woher wir unsere Toninformationen beziehen. Im Interesse der Bequemlichkeit wollen wir in den folgenden Schritten mit dem (hoffentlich hochqualitativen) Mikrofon unserer Workstation arbeiten, weshalb wir die Manifestdatei unserer Applikation öffnen und nach folgendem Schema ergänzen:
Capabilities>
<Capability Name="internetClient" />
<DeviceCapability Name="microphone"/>
</Capabilities>eachten Sie, dass die Arbeit mit AI-Spracherkennungssystemen wesentlich stringentere Anforderungen an die Tonqualität stellt als die Arbeit mit Skype und Co. Insbesondere bei Systemen, die für wenig technisch versierte Anwender vorgesehen sind. Lernout & Hauspies Dragon ist ein Klassiker. Es kann sogar empfehlenswert sein, die Verwendung hochqualitativer externer USB-Mikrofone vorzuschreiben. Der Autor arbeitet in den folgenden Schritten mit einem Mikrofon aus dem Hause auna. Der letzte Schritt der Vorbereitungshandlungen auf Applikationsebene ist dann das Aufrufen der NuGet-Paketverwaltung, in der wir uns für das Paket Microsoft.CognitiveServices.Speech entscheiden.
Im nächsten Schritt rufen wir das Azure-Portal auf, in dem wir uns auf die Suche nach dem Microsoft Speech Service begeben. Sein Symbol ist in Abbildung 6 mit einem roten Pfeil markiert. In der Azure-Backend-Verwaltung finden sich mittlerweile Dutzende von AI-Angeboten von Drittherstellern. Wer mit den Azure Cognitive Services arbeiten möchte, ist gut beraten, in der Volltextsuche den mit dem gelben Pfeil hervorgehobenen Filter auf Microsoft zu setzen, um Drittanbieterangebote von vornherein auszuschließen.

Abb. 6: Diese Einstellungen führen zum Ziel
Im Bereich der Namensvergabe haben wir auch hier freie Wahl, der Autor entschied sich in den folgenden Schritten für „SUSSpeechService“. Als Preisebene wollen wir die kostenlose Version F0 auswählen, die für erste Experimente ausreicht.
Weitere Informationen zu den Möglichkeiten und Grenzen der verschiedenen als Pricing Tier bezeichneten Preisstufen finden sich unter [2].Die eigentliche Realisierung eines Text-to-Speech-Prozesses unter der Universal Windows Platform wird dadurch erschwert, dass die von Microsoft bereitgestellte Dokumentation teilweise fehlerhaft ist. Es gibt in der UWP-Version des Speech SDK nämlich noch keinen Weg, um die eigentliche Tonausgabe unter Nutzung der Cognitive-Services-Bibliothek zu erledigen. Aus diesem Grund müssen wir stattdessen nach folgendem Schema mit der Realisierung einiger globaler Member-Variablen beginnen:
public sealed partial class MainPage : Page {
SpeechConfig myConfig;
MediaPlayer mediaPlayer;Als Nächstes ergänzen wir die XAML-Formulardatei um einen Knopf mit der Aufschrift Speak English, der im Code-Behind mit einem asynchronen Klick-Event-Handler auszustatten ist:
async private void CmdSpeakEnglish_Click(object sender, RoutedEventArgs e)
{
AudioConfig myAudioC = AudioConfig.FromDefaultSpeakerOutput();
var devices = await DeviceInformation.FindAllAsync(DeviceClass.AudioRender);In der Vollversion des Speech SDKs sorgt die AudioConfig-Klasse für das Routing der vom Server zurückgelieferten Sprachinformationsdateien. Im Interesse der Vollständigkeit wollen wir an dieser Stelle illustrieren, wie wir über alle beim Gerät angemeldeten Audiogeräte iterieren können, um ein bestimmtes über seine ID festzulegen:
foreach (var device in devices){
if (device.Name.Contains("Lautsprecher")) {
myAudioC = AudioConfig.FromSpeakerOutput(device.Id);
}
}Die nächste idiomatische Amtshandlung des Entwicklers besteht darin, eine SpeechSynthesizer-Instanz anzuwerfen und diese durch Aufruf der Methode SpeakTextAsync zur Kommunikation mit dem Server anzuleiten:
var synthesizer = new SpeechSynthesizer(myConfig, myAudioC);
using (var result = await synthesizer.SpeakTextAsync("SUS sends its best regards")) {
if (result.Reason == ResultReason.SynthesizingAudioCompleted) {An dieser Stelle findet sich der in der Einleitung dieses Sektors besprochene Dokumentationsbug: Auf anderen Plattformen liefert SpeakTextAsync die vom Server zurückgegebenen Informationen direkt an das Standardausgabegerät der unterliegenden Hardware weiter. In der UWP ist das allerdings nicht möglich, weshalb trotz Zurückgabe des Ergebnisses SynthesizingAudioCompleted keine Audioausgabe erfolgt. Zur Umgehung dieses Problems – Microsoft empfiehlt diese Vorgehensweise übrigens auch im offiziellen UWP-Sample – bietet es sich an, auf einen Mediaplayer zu setzen. Haarig ist dabei nur, dass er eine separat zu erzeugende Eingabedatei erwartet (Listing 1).
Listing 1
using (var audioStream = AudioDataStream.FromResult(result)) {
var filePath = Path.Combine(ApplicationData.Current.LocalFolder.Path, "outputaudio_for_playback.wav");
await audioStream.SaveToWaveFileAsync(filePath);
mediaPlayer.Source = MediaSource.CreateFromStorageFile(await StorageFile.GetFileFromPathAsync(filePath));
mediaPlayer.Play();
}Zur Fertigstellung des Programms müssen wir uns dann noch die Deklaration der beiden Formular-Member-Variablen zu Gemüte führen:
public MainPage() { . . .
myConfig = SpeechConfig.FromSubscription("KEY", "westeurope");
mediaPlayer = new MediaPlayer();
}Die SpeechConfig-Instanz ist dabei von besonderer Bedeutung, da sie diverse für das gesamte Programmleben geltende Konstanten festlegt und auch für die Authentication unserer Applikation beim Azure-Server verantwortlich ist. Anstatt des vom Autor hier genutzten Platzhalters müssen Sie den Inhalt der Felder Key 1 oder Key 2 eingeben; der in den zweiten String einzufügende Wert wird vom Azure-Backend netterweise ebenfalls in der Rubrik Location angezeigt.
Danach sind wir mit diesem Beispiel auch schon fertig. Starten Sie es und klicken Sie bei bestehender Internetverbindung auf den Knopf, um sich an der Ausgabe des englischen Samples zu erfreuen. Angemerkt sei noch, dass Sie in der Variable auch ein Array mit Audiodaten bekommen, das Sie zum Beispiel für die Bluetooth-Übertragung an einen Prozessrechner weiterverwenden können.
Wer seinem Programm oder Produkt schnell einen Vorsprung am Markt verschaffen möchte, sollte es nach Möglichkeit lokalisieren. Das ist im Fall von textbasierten Applikationen vergleichsweise einfach, die Lokalisierung von Sprachausgaben stellt den PT-Entwickler allerdings vor immense Zusatzkosten. Microsoft ist sich dieser Situation bewusst, und bietet Dutzende von vorgefertigten Sprachmodellen an [3].
Als kleine Fingerübung wollen wir unser bisher Englisch sprechendes Programm noch auf Schwyzerdütsch umstellen. Hierzu müssen wir die XAML-Datei im ersten Schritt um einen weiteren Knopf ergänzen, den wir – fehlerhaft – mit Speak German betiteln. Im Interesse der Kompaktheit wollen wir den im Allgemeinen vom Englisch-Knopf zu übernehmenden Event Handler nur insofern abdrucken, als er sich von seinem Kollegen unterscheidet (Listing 2).
Listing 2
async private void CmdSpeakGerman_Click(object sender, RoutedEventArgs e)
{
. . .
myConfig.SpeechSynthesisVoiceName = "de-CH-LeniNeural";
var synthesizer = new SpeechSynthesizer(myConfig, myAudioC);
using (var result = await synthesizer.SpeakTextAsync("SUS sendet beste Grüße"))
. . .Neben der offensichtlichen Änderung des Hinzufügens eines neuen Ausgabetexts legen wir in der globalen Konfiguration über das Attribut myConfig.SpeechSynthesisVoiceName fest, dass fortan Schwyzerdütsch zu verwenden ist. Die MyConfig-Instanz wird dabei witzigerweise mit dem englischen Knopf geteilt, weshalb das Ausführen englischer Sprachausgaben nach der Anpassung des Attributs zu einer recht lustigen Intonation führt.
Nachdem wir dem Rechner das Sprechen beigebracht haben, wollen wir die weiter oben in die Manifestdatei eingepflegte Berechtigung nun auch zum Hören einspannen. Da Microsoft Googles Versuchung zur Einführung eines aktiven Permission-Managements nicht widerstehen konnte, müssen wir an dieser Stelle eine Gruppe von Steuerelementen hinzufügen. Neben einem Textblock und einem Start– sowie einem Stop-Knopf müssen wir auch einen Mic-Button einfügen, über den der Benutzer das Anfordern der Mikrofonberechtigungen lostritt.
Für die eigentliche Ausgabe der Statusinformationen brauchen wir dann noch die Funktion AppendToLog. An ihr ist eigentlich nur die Verwendung des Dispatchers interessant, der Aktualisierungen der Logging-Textbox auch außerhalb des WPS- bzw. UWP-GUI-Threads erlaubt:
void AppendToLog(String _what) {
Dispatcher.RunAsync(Windows.UI.Core.CoreDispatcherPriority.Normal, () => {
TxtRaus.Text = TxtRaus.Text + "/ /" + _what;
});
}Der Code für die Anforderung der Mikrofonberechtigung ist mehr oder weniger gewöhnlicher Boilerplate, der sich in diversen Microsoft-Codebeispielen unverändert wiederfindet (Listing 3).
Listing 3
private async void EnableMicrophone_ButtonClicked(object sender, RoutedEventArgs e)
{
bool isMicAvailable = true;
try {
var mediaCapture = new Windows.Media.Capture.MediaCapture();
var settings = new Windows.Media.Capture.MediaCaptureInitializationSettings();
settings.StreamingCaptureMode = Windows.Media.Capture.StreamingCaptureMode.Audio;
await mediaCapture.InitializeAsync(settings);
}
catch (Exception) {
isMicAvailable = false;
}Die erste Amtshandlung des Codes besteht darin, eine Medienaufnahmesession bei der UWP anzufordern und dabei das Auftreten von Exceptions zu überprüfen. Dahinter steht die simple Logik, dass das Werfen einer Exception an dieser Stelle darauf hinweist, dass unsere Applikation die benötigte Berechtigung vom Betriebssystem noch nicht zugewiesen bekommen hat. In diesem Fall nutzen wir danach die Funktion LaunchUriAsync, um den Benutzer zur Freigabe der Mikrofonberechtigungen aufzufordern (Listing 4).
Listing 4
if (!isMicAvailable) {
await Windows.System.Launcher.LaunchUriAsync(new Uri("ms-settings:privacy-microphone"));
}
else {
CmdGo.IsEnabled = CmdStop.IsEnabled = true;
}
}Je nach Konfiguration der Runtime wird die Workstation darauf entweder mit dem einmaligen oder aber mit dem mehrmaligen Einblenden eines Permission-Dialogs reagieren. Wichtig ist hier nur noch, dass wir die Start– und die Stop-Knöpfe für die Sprachaufnahme nur dann aktivieren, wenn die Methode das Vorhandensein der Mikrofonzugriffsberechtigung angezeigt hat. Sonst orientiert sich SpeechRecognizer – zumindest kontextuell – an seinem für die Sprachausgabe vorgegebenen Kollegen. Auch hier gilt, dass wir eine globale Instanz vom Typ SpeechRecognizer benötigen (Listing 5).
Listing 5
SpeechRecognizer myRecWorker;
async private void CmdGo_Click(object sender, RoutedEventArgs e)
{
AudioConfig myAudioC = AudioConfig.FromDefaultMicrophoneInput();
var devices = await DeviceInformation.FindAllAsync(DeviceClass.AudioCapture);
foreach (var device in devices)
{
if (device.Name.Contains("Anua"))
{
myAudioC = AudioConfig.FromSpeakerOutput(device.Id);
}
}Da die Workstation des Autors, wie übrigens die meisten Rechner, auch einen analogen Mikrofoneingang hat, „sucht“ er auch hier anhand des Gerätenamens nach seinem Mikrofon. Der dazu verwendete Code unterscheidet sich nur insofern vom weiter oben verwendeten Kollegen, als wir an FindAllAsync nun das Attribut DeviceClass.AudioCapture übergeben. Das permanente Betonen dieser „dedizierten“ Geräteauswahl ist dabei übrigens keine Marotte des Autors, denn wer sie nicht implementiert, riskiert furiose Benutzerwertungen. Das Unbequemsein dieser Einrichtung ist – zumindest nach Meinung des Autors – auch einer der Gründe, warum die Weboberfläche von Microsoft Teams so universell verhasst ist.
Die nächste Gemeinsamkeit mit der Ausgabeversion der Klasse findet sich bei der Konfiguration der zu verwendenden Sprache. Sie erfolgt ebenfalls in dem globalen Einstellungsobjekt, das sich auch um das Einrichten der Azure Authentication kümmert:
myConfig.SpeechRecognitionLanguage = "de-DE";
Im Bereich der computerbasierten Spracherkennungssysteme gibt es seit jeher einen Kampf zwischen grammatikbasierten und frei arbeitenden Versionen. Die in den Azure Cognitive Services implementierte Spracherkennungs-Engine arbeitet dabei analog zu Lernout & Hauspies Dragon ohne Grammatik, weshalb sie potenziell beliebig lange Ein- und Ausgabeströme verarbeiten kann.
Da Entwickler in der Praxis aber auch immer wieder das Bedürfnis haben, kürzere Kommandos zu verarbeiten, implementiert Microsoft zwei verschiedene Versionen des APIs. Wir wollen hier schon aus Gründen der Bequemlichkeit mit dem Vollausbau beginnen, was den in Listing 6 gezeigten Code im Start-Knopf voraussetzt.
Listing 6
myRecWorker = new SpeechRecognizer(myConfig, myAudioC);
myRecWorker.Canceled += MyRecWorker_Canceled;
myRecWorker.SpeechEndDetected += MyRecWorker_SpeechEndDetected;
myRecWorker.Recognized += MyRecWorker_Recognized;
myRecWorker.SpeechStartDetected += MyRecWorker_SpeechStartDetected;
myRecWorker.SessionStarted += MyRecWorker_SessionStarted;
myRecWorker.StartContinuousRecognitionAsync();
AppendToLog("LOS!");
}Die Funktion StartContinuousRecognitionAsync weist das SDK dabei darauf hin, dass es ab sofort in den „permanenten“ Spracherkennungsmodus wechseln soll. Dabei bekommt der Entwickler kein finales Resultat zurückgeliefert, sondern muss stattdessen eine Gruppe von Event Handlern einschreiben, die permanent vom Server angelieferte Ereignisse aufnehmen.
Der Autor realisiert hier nur einige der Handler, eine Liste aller exponierten Ereignisse findet sich am einfachsten durch Reflexion. Am wichtigsten ist im Bereich der Event-Handler-Kohorte die Verarbeitung des Canceled-Events, die nach folgendem Schema zu erfolgen hat:
private void MyRecWorker_Canceled(object sender, SpeechRecognitionCanceledEventArgs e){
AppendToLog("Canceled! " + e.ErrorDetails);
}Das Azure-Backend liefert unserer Applikation immer dann ein Canceled-Ereignis, wenn es die Datenverarbeitung final einstellt. In den diversen Attributen des SpeechRecognitionCanceledEventArgs-Objekts finden sich dann Informationen darüber, warum unsere Applikation das Missfallen des Servers provoziert hat. Aus der weiteren praktischen Erfahrung des mit einer Dual-Boot-Workstation arbeitenden Autors sei angemerkt, dass die Korrektheit des in Windows eingestellten Systemdatums für die Cognitive Services von größter Bedeutung ist. Wer versehentlich einen falschen Datumswert – schon ein oder zwei Stunden Unterschied reichen aus – einstellt, wird vom Server mit diversen „Connection Refused“-Ereignissen abgestraft.
Relevant ist dann noch das Event Recognized, das die Services immer dann abfeuert, wenn aus der Sprachsequenz ein kompletter String erkannt wurde. Zu seiner Verarbeitung reicht folgender Code aus, der die angelieferten Informationen zudem bequem in den weiter oben angelegten Textblock wirft:
private void MyRecWorker_Recognized(object sender, SpeechRecognitionEventArgs e) {
AppendToLog("Erbeutetes Ergebnis: " + e.Result.Text);
}Beim erstmaligen Bring-up verschiedener komplizierter Softwaresysteme ist es erfahrungsgemäß empfehlenswert, diverse andere Status-Events zu exponieren, um mehr Informationen über Interaktion und Programmverhalten zu bekommen. Die restlichen weiter oben abgedruckten Ereignisse sind mit nach dem folgenden Schema aufgebauten Handlern verbunden, die sich um das Ausspeien zusätzlicher Statusinformationen kümmern:
private void MyRecWorker_SpeechEndDetected(object sender, RecognitionEventArgs e) {
AppendToLog("Redepause!");
}Zum „kompletten“ Spracherkennungsprogramm fehlt uns dann nur noch eine Implementierung des Stop-Knopfes, der den Server von der weiteren Entgegennahme von Mikrofondaten befreit. Seine Implementierung ist schon aus dem Grund erforderlich, weil sonst nicht unerhebliche Kosten entstehen:
private void CmdStop_Click(object sender, RoutedEventArgs e) {
myRecWorker.StopContinuousRecognitionAsync();
}An dieser Stelle können wir unser Programm zur Ausführung freigeben. Wer es, wie der Autor, testweise mit dem String „Hallo Welt“ ausstattet, bekommt das in Abbildung 7 gezeigte Ergebnis präsentiert.

Abb. 7: Die Spracherkennung unter Nutzung der Cognitive Services funktioniert problemlos
Für alle ASP.NET-Core-basierten Anwendungsarten hat Microsoft begonnen, die ASP.NET-Core-Klassen für die bessere Unterstützung der in C# 8.0 eingeführten Nullable Reference Types zu annotieren.
Die in Blazor 5.0 eingeführte CSS-Isolation (Beschränkung der Gültigkeit auf einzelne .razor-Komponenten) funktioniert in .NET 6 auch mit den älteren Multi-Page-Programmiermodellen Model View Controller (MVC) und Razor Pages. IAsyncDisposable funktioniert nun für Controller, Page Models und View Components.
Wir hatten weiter oben festgestellt, dass Microsoft auch eine „reduzierte“ Version der Spracherkennungs-Engine anbietet. Sie arbeitet nach dem Prinzip, dass sie so lange „zuhört“, bis eine Endbedingung erkannt wird. Legitime Endbedingungen sind dabei einerseits das Aufhören des Redeflusses und andererseits das Ablaufen von fünfzehn Sekunden nach dem Aufnahmestart.
Kommt Ihre Applikation mit einem derartig beschränkten Funktionsumfang aus, so lässt sich die Konfiguration des Listeners nach dem in Listing 7 gezeigten Schema stark vereinfachen.
Listing 7
var result = await recognizer.RecognizeOnceAsync().ConfigureAwait(false);
string str;
if (result.Reason != ResultReason.RecognizedSpeech) {
str = $"Speech Recognition Failed. '{result.Reason.ToString()}'";
}
else {
str = $"Recognized: '{result.Text}'";
}Bei derartigen einfachen Spracherkennungsaufgaben geht es oft darum, bestimmte Kommandos besonders effizient zu erreichen. Microsoft unterstützt dieses Begehr insofern, als wir der an sich grammatikfreien Spracherkennungslogik einige benutzerspezifizierte Worte einschreiben können, die die Engine danach als besonders häufig auftretend betrachtet. Zur Nutzung dieser Sonderfunktion ist ein folgendermaßen aufgebauter Code erforderlich:
var phraseList = PhraseListGrammar.FromRecognizer(recognizer); phraseList.AddPhrase("Supercalifragilisticexpialidocious");
Auch wenn der Gedanke an die Auslagerung von ML-Modellen in die Cloud auf den ersten Blick angesichts der Mietkosten wenig einladend erscheint, lohnt es sich trotzdem, einen zweiten Gedanken darauf zu verschwenden. Die von Microsoft bereitgestellten ML-Modelle erreichen unglaubliche Güteklassen, die hier durchgeführten Spracherkennungsversuche erreichten in Tests die Genauigkeit der von Lernout & Hauspie für teures Geld verkauften Erkennungs-Engine Dragon – und das, ohne dass der Autor die Services vorher, wie bei Dragon erforderlich, auf die eigene Sprache trainiert hätte.
[1] https://azure.microsoft.com/en-us/services/cognitive-services/#features
The post Microsofts Miet-AI: Wie KI-Lösungen die Unternehmenslandschaft verändern appeared first on BASTA!.
]]>The post One .NET: Der Weg zu einer einheitlichen Plattform für Entwickler:innen appeared first on BASTA!.
]]>Neu bei den Runtimes für Konsole und ASP.NET Core ist die Unterstützung für den neuen ARM-64-basierten Apple-Chip M1 alias Apple Silicon. Während Microsoft in den Blogeinträgen [4] und [5] immer nur von Apple Silicon spricht, erscheint die neue Runtime in der Liste der Downloads unter macOS/Arm64.

Abb. 1: Übersicht über SDK und Runtimes in .NET 6 Preview 2 [2]
Wie bisher laufen Windows Forms und WPF nur auf Windows. Daran wird sich auch in .NET 6 nichts ändern. Das gilt auch für die kommende Windows UI Library 3 (WinUI 3), dem designierten Nachfolger von UWP und WPF. Microsoft geht in .NET 6 das Thema Cross-Platform (Abb. 2) aus zwei Richtungen an:

Abb. 2: Aufbau .NET 6
Microsoft hatte auf der Build-Konferenz im Mai 2020 angekündigt, das im Jahr 2016 zugekaufte Produkt Xamarin ganz in die aktuelle .NET-Welt zu integrieren. So soll die App-Entwicklung zukünftig die gleichen Werkzeuge aus dem .NET 6 SDK sowie die gleiche Klassenbibliothek wie der Rest von .NET 6 verwenden (Abb. 2). Im Hintergrund wirkt freilich in einigen Anwendungsarten weiterhin eine auf Mono basierende Runtime, wovon der Entwickler aber gar nichts mehr merken soll. Die Integration wird von Umbenennungen begleitet: Aus Xamarin.iOS wird „.NET for iOS“, aus Xamarin.Android „.NET for Android“ und aus Xamarin.Forms wird „.NET Multi-Platform App UI“ (MAUI). Zusammenfassend spricht Microsoft von .NET 6 Mobile [3]. Entsprechend gibt es nun neue Target Frameworks: net6.0-ios und net6.0-android. Seit .NET 6 Preview 2 können App-Entwickler nun erste einfache .NET-6-Mobile-Projekte für Android, iOS und Mac Catalyst auf Basis des .NET 6 SDK erstellen. Auf GitHub [3] sind Beispiele zu sehen.
Während bisher in Xamarin neben dem Shared Code für jede Zielplattform ein sogenanntes Kopfprojekt notwendig war, kann der App-Entwickler nun aus einem einzigen Projekt heraus unmittelbar für verschiedene Plattformen kompilieren („single, multi-targeted application project“). Ein MAUI-Projekt referenziert das Paket Microsoft.Maui und listet die gewünschten Target Frameworks auf, z. B. net6.0-android;net6.0-ios;net6.0-windows. Im Projekt sind plattformspezifisches XAML, plattformspezifischer Programmcode und plattformspezifische Ressourcen möglich (Abb. 3). Zum Übersetzen verwendet man derzeit noch die Kommandozeile, z. B. dotnet build HelloMaui -t:Run -f net6.0-android.

Abb. 3: Hello World in MAUI
Das Entwicklungsteam für Blazor hat in .NET 6 Preview 2 bereits erhebliche Geschwindigkeitsvorteile im Entwicklungsprozess umgesetzt. Im Vergleich zu .NET 5.0 sind sowohl ein erster als auch ein inkrementeller Übersetzungsvorgang deutlich schneller [7], wie Abbildung 4 zeigt. Dort ist ebenfalls zu sehen, dass davon auch ASP.NET MVC profitiert. Ein Teil des Geschwindigkeitsvorteils basiert auf einem Compiler für ASP.NET-Core-Razor-Templates; dieser verwendet die in C# 9.0 eingeführten Source Code Generators.

Abb. 4: Geschwindigkeitssteigerungen beim Kompilieren von Razor Templates in Blazor und MVC in .NET 6 Preview 2 [7]
Geplant ist, für alle ASP.NET-Core-Anwendungsarten ein Hot Reloading/Hot Restart sowie Edit and Continue (EnC) beim Debugging bereitzustellen. Microsoft spricht von der „Inner Loop Performance“. Die Liste der dazu geplanten Verbesserungen findet man auf GitHub [8]. Auch zur Laufzeit soll es gerade bei Blazor WebAssembly schneller und schlanker zugehen. Ursprünglich stand im Plan, eine „Hello World“-Anwendung auf eine Größe von 0,5 MB zu drücken [9]. Dieses wohl doch zu hohe Ziel wurde aber inzwischen herauseditiert und durch die Aussage ersetzt, man wolle die bestehende Größe von 2.2 MB um mindestens 20 Prozent reduzieren. In Preview 1 gab es für Blazor die neue Razor Component <DynamicComponent>. Mit ihr kann man eine beliebige andere Komponente dynamisch rendern. Die Blazor-Eingabesteuerelemente haben nun einen direkten Zugang zur Element Reference, die der Entwickler zum Zugriff per JavaScript braucht. Seit Preview 2 gibt es mehr Flexibilität für die Parameterübergabe bei der Ereignisbehandlung. Bei generischen Komponenten muss der Entwickler nun in weiteren Fällen keine Typparameter mehr explizit angeben, weil die Blazor-Laufzeitumgebung den Typ automatisch ableiten kann. Beim Einsatz von Server-Prerendering mit dem neuen Tag-Helper <preserve-component-state /> kann der Entwickler in .NET 6 eine Zustandsverwaltung aktivieren, die eine erneute Verarbeitung in der Hauptrenderphase vermeidet.
In .NET 6 sollen erstmals auch hybride Blazor-Anwendungen als fertige Version unter dem Titel „Blazor Desktop“ erscheinen. Das ist seit längerem in Arbeit [10]. Blazor Desktop soll auf dem .NET Multi-Platform App UI (MAUI), dem Nachfolger von Xamarin.Forms, basieren und dort in einem WebView2-Steuerelement die von einer Blazor-Anwendung generierten HTML-Oberflächen darstellen. Da MAUI zunächst bei den Desktopbetriebssystemen nur Windows und macOS unterstützt, findet man Linux nicht in Abbildung 5. Android und iOS werden zwar von MAUI unterstützt, sind aber zunächst nicht von Blazor Desktop abgedeckt. Es soll aber möglich sein, im Rahmen der Blazor Mobile Bindings auch HTML-Inhalte von Blazor darzustellen.

Abb. 5: Pläne für Blazor Desktop; Quelle: Microsoft .NET Conf – Focus on Windows (25.02.2021)
Für alle ASP.NET-Core-basierten Anwendungsarten hat Microsoft begonnen, die ASP.NET-Core-Klassen für die bessere Unterstützung der in C# 8.0 eingeführten Nullable Reference Types zu annotieren.
Die in Blazor 5.0 eingeführte CSS-Isolation (Beschränkung der Gültigkeit auf einzelne .razor-Komponenten) funktioniert in .NET 6 auch mit den älteren Multi-Page-Programmiermodellen Model View Controller (MVC) und Razor Pages. IAsyncDisposable funktioniert nun für Controller, Page Models und View Components.
Entity Framework Core 6.0 soll im November 2021 zusammen mit .NET 6 erschienen. Der OR-Mapper bietet seit .NET 6 Preview 1 neue Annotationen wie [Unicode], [Precision] und [EntityTypeConfiguration]. Der Datenbanktreiber für SQLite unterstützt nun ToString() und das in Version 5.0 eingeführte Savepoints API. Für den Microsoft SQL Server kann man nun per Fluent API eine Spalte als „Sparse Column“ deklarieren und damit Speicherplatz in den Datenbankdateien einsparen – für den Fall, dass viele Nullwerte vorkommen, was beim Table-per-Hierarchy-Mapping häufig auftritt, da hier eine ganze Vererbungshierarchie in einer Tabelle lebt. Auch die Methode IsNullOrWhitespace() unterstützt der SQL-Server-Treiber nun. Für SQL Server, SQLite und Cosmos DB funktioniert die Zufallszahlengenerierung mit EF.Functions.Random(). Beim Reverse Engineering übernimmt der Befehl Scaffold-DbContext jetzt Kommentare zu Tabellen und Spalten aus dem Datenmodell in den generierten Programmcode.
Preview 2 bietet hingegen nur kleine Verbesserungen: String.Concat() funktioniert auch mit mehr als zwei Parametern. SqlServerDbFunctionsExtensions.FreeText() und SqlServerDbFunctionsExtensions.Contains() funktionieren jetzt auch mit binären Spalten und in Zusammenarbeit mit Value-Konvertern. Außerdem hat Microsoft ein schon länger bestehendes lästiges Problem [11] mit doppelten Typen in zwei verschiedenen Assemblies in Zusammenhang mit asynchronen LINQ-Operationen endlich gelöst [12].
Weitere Pläne für Entity Framework Core 6.0 hat Microsoft am 18.1.2021 veröffentlicht [13]. Dazu gehören:
Bei der Performance hat sich Microsoft vorgenommen, im TechEmpower Benchmark [15] den konkurrierenden Micro-ORM Dapper von StackExchange [16] zu schlagen.
Das in .NET Core 3.0 eingeführte und bisher in C++ geschriebene CrossGen-Werkzeug wurde in C# neu implementiert (CrossGen2). Diese Version erlaubt eine profilgesteuerte Optimierung (PGO). Seit Preview 2 kompiliert Microsoft mit CrossGen2 alle Microsoft.NETCore.App Assemblies im .NET SDK zu Maschinencode vor. Weitere Anwendungsarten wie Windows Desktop sind für Preview 3 und 4 geplant. Bei den Basisklassen gibt es mit der Klasse System.Collections.Generic.PriorityQueue<TElement, TPriority> nun eine neue Warteschlange mit Priorität; bei der Entnahme werden die Werte nicht anhand der Einfügereihenfolge, sondern auf Basis der bei der Hineingabe angegebenen Priorität entnommen. Auch bei den mathematischen APIs im Namensraum System.Numerics gibt es Erweiterungen. Selbst bei den Basisfunktionen ToString() und TryFormat() hat Microsoft nach 20 Jahren .NET noch Verbesserungspotenzial erkannt und realisiert, vgl. Beispiele im Blogeintrag [5].
Der von Microsoft bereits in .NET Core 3.0 neu implementierte JSON Serializer System.Text.Json kann nun endlich auch – wie sein Vorgänger JSON.NET – Schleifen in Objektbäumen ignorieren. Die Komponente System.Threading.AccessControl bietet Verbesserungen für Access Control Lists auf Windows.
Es steht noch Einiges auf der Agenda für .NET 6 (vgl. www.themesof.net), was man nicht in Preview 1 und 2 sieht, u. a.:
Ich persönlich freue mich in .NET 6 am meisten auf die Beschleunigung des Entwicklungsprozesses durch die Optimierung beim Kompilieren und Debugging, denn ich hasse es, bei der täglichen Programmierarbeit an Kundenprojekten immer einige Sekunden warten zu müssen, bis ich das Ergebnis meiner jüngsten Änderungen live sehe.
[1] https://devblogs.microsoft.com/dotnet/announcing-net-6-preview-1/
[2] https://dotnet.microsoft.com/download/dotnet/6.0
[3] https://github.com/dotnet/net6-mobile-samples
[4] https://devblogs.microsoft.com/dotnet/announcing-net-6-preview-1/
[5] https://devblogs.microsoft.com/dotnet/announcing-net-6-preview-2/
[6] https://github.com/jsuarezruiz/forms-gtk-progress/issues/31
[7] https://devblogs.microsoft.com/aspnet/asp-net-core-updates-in-net-6-preview-2
[8] https://github.com/dotnet/core/issues/5510
[9] https://github.com/dotnet/runtime/issues/44317
[10] https://github.com/aspnet/AspLabs/tree/main/src/ComponentsElectron
[11] https://github.com/dotnet/efcore/issues/18124
[12] https://github.com/dotnet/efcore/issues/24041
[13] https://devblogs.microsoft.com/dotnet/the-plan-for-entity-framework-core-6-0/
[14] https://github.com/dotnet/runtime/issues/28633
[15] https://www.techempower.com/benchmarks/#section=data-r19&hw=ph&test=db
[16] https://github.com/StackExchange/Dapper
The post One .NET: Der Weg zu einer einheitlichen Plattform für Entwickler:innen appeared first on BASTA!.
]]>The post Von UWP zu WinUI: Eine spannende Reise in die Zukunft der Windows-Anwendungsentwicklung appeared first on BASTA!.
]]>WinUI ist die Weiterentwicklung des UI Frameworks der Universal Windows Platform (UWP). Mit WinUI wurde das UWP UI Framework von Windows 10 entkoppelt. Das hat verschiedene Vorteile: WinUI kann einen anderen Releasezyklus als Windows 10 haben und zudem lassen sich neueste Controls auch auf älteren Windows-10-Versionen einsetzen. Doch UWP existiert weiterhin, und das ist für viele Entwickler etwas verwirrend. Der Grund dafür ist, dass es sich bei der UWP um weitaus mehr als um ein UI Framework handelt. Um zu verstehen, was genau WinUI ist, muss man auch verstehen, was eigentlich die Universal Windows Platform ist. Gehen wir dieser Frage nach.
Regelmäßig News zur Konferenz und der .NET-Community
Was ist die Universal Windows Platform (UWP)?
Mit Windows 10 hat Microsoft die Universal Windows Platform eingeführt. UWP ist auf allen Geräten verfügbar, auf denen Windows 10 läuft:
Für Entwickler hat Visual Studio eine Projektvorlage mit dem Namen Blank App (Universal Windows), mit der sich eine UWP-Anwendung erstellen lässt, die auf all diesen Geräten läuft. Die Anwendung lässt sich dabei entweder mit .NET/C# oder mit C++ erstellen. Wichtig zu verstehen ist, dass UWP ein nativer Teil von Windows 10 und selbst in C++ geschrieben ist. Das macht das Programmieren einer UWP-App mit reinem C++ möglich, erlaubt es aber auch, eine Anwendung mit .NET/C# zu schreiben, die ganz gewöhnliche .NET-Standard-2.0-Klassenbibliotheken referenzieren kann.
Zum Erstellen von Benutzeroberflächen wird mit UWP die Extensible Application Markup Language (XAML) eingesetzt. XAML ist eine XML-basierte Sprache, die ursprünglich mit der Windows Presentation Foundation (WPF) im Jahr 2006 eingeführt wurde. WPF und UWP haben viele gemeinsame Konzepte wie XAML, Data Binding, Styles, Layout etc. Das bedeutet, dass ein WPF-Entwickler in UWP recht schnell zurechtkommt, und auch umgekehrt findet sich eine UWP-Entwicklerin in WPF schnell zurecht. Allerdings standen all die Innovationen, die mit WPF stattgefunden haben, C++-Entwicklern nicht zur Verfügung, denn zum Erstellen von WPF-Anwendungen muss man .NET/C# verwenden. Mit UWP hat sich das geändert, und C++-Entwickler konnten auch wieder bei der neuesten Technologie mitmischen.
Neben der Möglichkeit, mit .NET/C# oder C++ zu entwickeln, ist ein wichtiges Merkmal von UWP-Anwendungen, dass sie in einer Sandbox laufen. Das bedeutet, dass der Systemzugriff begrenzt ist. Das ergibt Sinn, wenn man bedenkt, dass UWP-Anwendungen auch über den Microsoft Store verteilt werden können. Eine UWP-Anwendung muss ihre Fähigkeiten (Capabilities) in einer Manifest-Datei deklarieren, damit diese sich im Anwendungscode auch nutzen lassen. Das ist ein bekanntes Konzept von mobilen Anwendungen, bei denen man als Benutzer Nachrichten sieht, wie beispielsweise „Diese Anwendung möchte Zugriff auf Ihre Bilder, Ihre Dokumente und Ihre Kontakte“. Bei einer UWP-Anwendung ist das genau gleich. Damit beispielsweise der Zugriff auf das Internet funktioniert, muss das als Capability im Manifest der Anwendung angegeben werden.
Zudem ist ein weiteres wichtiges Merkmal von UWP-Anwendungen, dass sie in einem .zip-basierten Format mit der Dateiendung .appx verpackt werden. Das erlaubt eine saubere Installation und Deinstallation auf Windows-10-Geräten. Nach einer Deinstallation ist die Anwendung sauber entfernt und hinterlässt keine Spuren, wie man das von anderen Installationsvarianten kennt.
Ein weiterer, sehr wichtiger Punkt von UWP ist das sogenannte Activation- und Lifecycle-Management. Dabei geht es darum, die Batterie eines Gerätes zu schonen. Klassische Win32-Anwendungen wie WPF- oder Windows-Forms-Anwendungen laufen immer, wenn der Benutzer sie gestartet hat. D. h., selbst wenn der Benutzer eine WPF-Anwendung minimiert oder zu einer anderen Anwendung wechselt, wird die WPF-Anwendung weiterlaufen und den Prozessor beanspruchen. Das ist natürlich nicht gut für batteriebetriebene Geräte wie Tablets. UWP-Anwendungen lösen dieses Problem mit dem erwähnten Activation- und Lifecycle-Management. Minimiert ein Benutzer eine UWP-App oder navigiert er zu einer anderen Anwendung, wird die UWP-App im Hintergrund automatisch ausgesetzt (suspended). Das ermöglicht es dem System, Ressourcen und somit auch Batterie zu sparen. Navigiert der Benutzer zurück zur UWP-Anwendung, wird sie wieder aktiviert und fortgesetzt.
Wie man also sieht, ist UWP mehr als nur ein UI Framework. Es hat verschiedenste Features wie XAML, Paketierung mit .appx, eine Sandbox, ein Lifecycle-Management etc. Genau aus diesem Grund muss man sich als Entwickler bewusst machen, dass UWP ein sehr weiter Begriff ist. Schauen wir uns ihn daher genauer an.
Was steckt hinter UWP?
Nachfolgend eine Auflistung, was alles unter UWP zu verstehen ist:
Hinweis
In diesem Artikel sehen wir uns UWP und WinUI aus der Perspektive eines XAML- und C#-Entwicklers an. Das UWP XAML Framework ist vermutlich der meistgenutzte Weg für .NET-Entwickler, um eine UWP-Anwendung zu erstellen, aber es ist nicht der einzige Weg. Das UWP XAML Framework sitzt in Windows 10 auf dem sogenannten Visual Layer, der selbst wiederum auf DirectX aufsetzt, um die Benutzeroberfläche zu zeichnen. Anstatt somit eine UWP-App mit XAML und C# zu erstellen, könnte man auch DirectX verwenden. Mit React Native for Windows, das auf UWP/WinUI aufbaut, lassen sich sogar HTML und JavaScript zum Erstellen einer UWP-App nutzen.
All diese verschiedenen Bereiche von UWP machen deutlich, dass Entwickler nicht immer dasselbe meinen, wenn sie von UWP sprechen. Sie können sich auf einen der Punkte 1 bis 6 beziehen. Wichtig zu wissen ist, dass all diese Punkte auf jedem Windows-10-Gerät verfügbar sind, egal ob PC, HoloLens, Surface Hub, Xbox oder IoT-Gerät. Das liegt daran, dass UWP ein Teil des Windows-10-Kerns ist. Und genau das führt beim Entwickeln von UWP-Apps zu einem Abhängigkeitsproblem.
Das Abhängigkeitsproblem der UWP XAML Controls in Windows 10
Die UWP XAML Controls sind Teil von Windows 10, was eine starke Abhängigkeit einer UWP-App an das Betriebssystem darstellt. Es bedeutet, dass man als Entwickler in der eigenen UWP-Anwendung nur dann die neuesten UWP XAML Controls und XAML-Features nutzen kann, wenn die Benutzer auch die neueste Version von Windows 10 installiert haben. Das bremst natürlich die Innovation sehr stark. Und jeder, der schon Enterprise-Software entwickelt hat, weiß, dass in Unternehmen eine Aktualisierung von Windows 10 durchaus eine Weile dauern kann. Microsoft hat diese Abhängigkeit entfernt, indem die UWP XAML Controls losgelöst von Windows 10 als NuGet-Paket angeboten werden. Es heißt WinUI, hat die Version 2.x, und lässt sich in einer UWP-App referenzieren. Dadurch können die neuesten XAML Controls eingesetzt werden, ohne dass die Benutzer ihre Windows-10-Version aktualisieren müssen.
Die UWP XAML Controls sind natürlich auch nach wie vor Teil von Windows 10, damit existierende UWP-Apps auch weiterhin ohne das NuGet-Paket funktionieren. Die UWP XAML Controls wurden jedoch von Windows 10 in das WinUI-2.x-NuGet-Paket kopiert; neue Features und neue Entwicklungen finden dort statt.
Das Abhängigkeitsproblem des UWP XAML Framework
Zwar hat Microsoft die Abhängigkeit zwischen einer UWP-App und den in Windows 10 integrierten UWP XAML Controls aufgelöst, doch das UWP XAML Framework ist weiterhin Teil von Windows 10 – und hier gibt es genau die gleiche Art von Abhängigkeit zwischen der eigenen UWP-App und Windows 10. Dass das UWP XAML Framework Teil von Windows 10 ist, bedeutet, dass man nur dann die neuesten Framework-Features nutzen kann, wenn man auch die neueste Windows-10-Version installiert hat. Microsoft hat auch diese Abhängigkeit von Windows 10 entkoppelt und stellt das UWP XAML Framework als NuGet Paket bereit. Es trägt den Namen WinUI 3.0 und ist ein volles UI Framework wie WPF oder Windows Forms. Das WinUI-3.0-NuGet-Paket enthält das UWP XAML Framework und – wie WinUI 2.x – die UWP XAML Controls. WinUI 3.0 wird Open Source auf GitHub [2] entwickelt.
Hinweis
Ein Blick in das GitHub Repository von WinUI 3.0 [2] lohnt sich. Die Issues enthalten Ankündigungen für WinUI Community Calls, was Livevideos auf YouTube sind, die einmal im Monat stattfinden – üblicherweise an jedem dritten Mittwoch im Monat. Jeder kann daran teilnehmen, und das WinUI-Team stellt Neuerungen vor und beantwortet auch Fragen.
WinUI 3.0 einsetzen
Das WinUI-3-NuGet-Paket ist nicht dazu gemacht, es in einer klassischen UWP-App zu referenzieren, die mit der Blank App (Universal Windows)-Projektvorlage in Visual Studio erstellt wurde. Eine solche UWP-App nutzt nach wie vor das UWP XAML Framework, das in Windows 10 existiert, und nicht die entkoppelte Version, die sich im WinUI-3-NuGet-Paket befindet. Um WinUI 3 zu nutzen, muss die sogenannte „Project Reunion“-Visual-Studio-Erweiterung installiert werden, die die Projektvorlagen für WinUI-3-Anwendungen enthält. Nachdem sie installiert wurden, lassen sich zwei Arten von WinUI-3-Anwendungen erstellen:
Beide Optionen erstellen eine WinUI-3-Anwendung, die das WinUI-3-NuGet-Paket referenziert. Das bedeutet, dass sowohl das UWP XAML Framework als auch die UWP XAML Controls aus dem NuGet-Paket stammen. Es bedeutet auch, dass man für beide Varianten weitestgehend den identischen XAML- und C#-Code schreibt, da sie dasselbe UWP XAML Framework und auch dieselben UWP XAML Controls aus dem NuGet-Paket verwenden. Der Unterschied zwischen den beiden Projektvorlagen ist das darunterliegende App-Modell. Denn mit WinUI 3 hat man plötzlich die Wahl zwischen UWP und Win32 (auch als Desktop bezeichnet). Und da muss man sich entscheiden:
Das bedeutet, dass WinUI 3 den Entwicklern von Desktopanwendungen für Windows 10 folgende Auswahlmöglichkeiten gibt:
Das heißt auch im Umkehrschluss, dass das UWP-App-Modell weiterhin ein Teil von Windows 10 bleibt und auch als Teil von Windows 10 weiterentwickelt wird. WinUI 3 enthält lediglich das UWP XAML Framework und die UWP XAML Controls, nicht jedoch das UWP-App-Modell zum Hosten einer UWP-App.
Hinweis
WinUI 3 ist die moderne Variante des UWP UI Frameworks. Das Erstellen einer UWP-App mit der Projektvorlage Blank App (Universal Windows) ist der alte Weg für eine UWP-App. Neue UWP-Apps sollten mit WinUI 3 und der Projektvorlage Blank App (WinUI 3 in UWP) erstellt werden.
Was ist Project Reunion?
WinUI 3 ist Teil des sogenannten Project Reunion [3]. Das Projekt von Microsoft hat zum Ziel, sämtliche Windows-APIs über NuGet-Pakete bereitzustellen. Neben WinUI ist auch die sogenannte C#/WinRT Library Teil des Project Reunion. C#/WinRT stellt eine C#-Projektion der nativen, in C++ geschriebenen WinRT dar, die das moderne Windows API von Windows 10 ist und oft auch als UWP API bezeichnet wird. C#-Projektion bedeutet, dass sich die in C++ geschriebene WinRT in C# so verwenden lässt, als sei sie in C# geschrieben worden. Auch die C#/WinRT [4] ist Open Source auf GitHub zu finden. Project Reunion versucht also, Windows-Entwicklern alle Ressourcen als NuGet-Pakete zur Verfügung stehen – unabhängig davon, ob sie mit .NET/C# oder mit C++ programmieren, und unabhängig davon, ob sie UWP oder Win32 als Hostingmodell verwenden. Und WinUI 3 selbst ist Teil dieses Project Reunion.
Die Umgebung für WinUI 3 aufsetzen
Um mit WinUI 3 loszulegen, muss die neueste Visual-Studio-Version installiert werden. Dafür sind im Visual Studio Installer die Workloads .NET Desktop Development und Universal Windows Platform Development auszuwählen. Anschließend sind die Projektvorlagen für WinUI 3.0 zu installieren. Diese Projektvorlagen sind Teil der Project Reunion Visual Studio Extension [5]. Sie lässt sich in Visual Studio über das Hauptmenü Extensions installieren. Abbildung 1 zeigt die installierte Extension in Visual Studio 2019. Diese Schritte zum Aufsetzen der Umgebung lassen sich in der offiziellen Dokumentation nachlesen [6].

Abb. 1: Die Project Reunion Extension enthält die WinUI-3-Projektvorlagen
Die WinUI-3-Projektvorlage für Desktop-Apps
Mit der installierten Project Reunion Extension sind die WinUI-3-Projektvorlagen in Visual Studio verfügbar. Abbildung 2 zeigt die Projektvorlage zum Erstellen einer WinUI-3-Desktopanwendung.
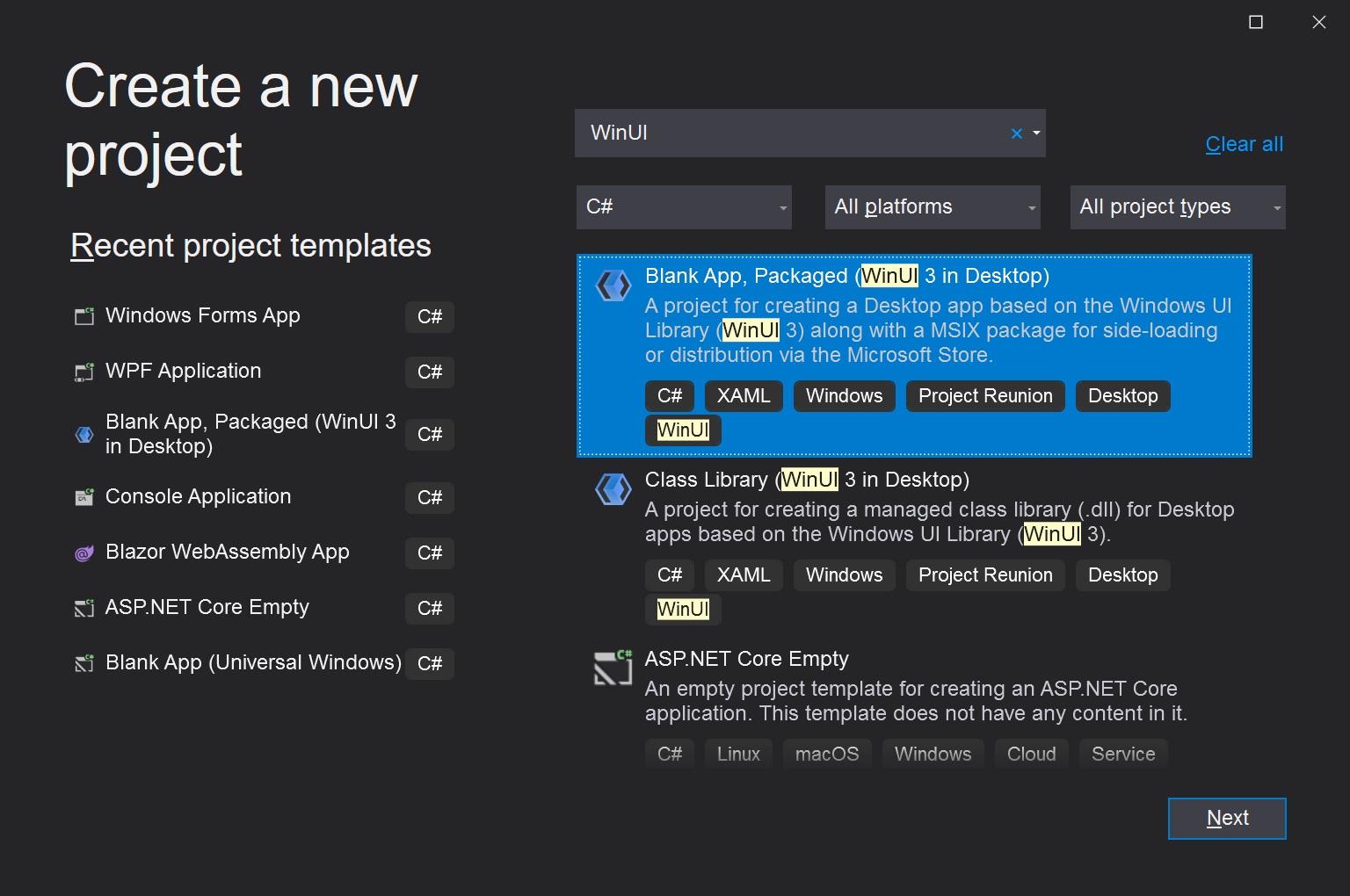
Abb. 2: Die Projektvorlage zum Erstellen einer WinUI-3-Desktop-App
WinUI 3 kann für Desktopanwendungen bereits produktiv eingesetzt werden. Doch wie Abbildung 2 zeigt, gibt es noch keine Projektvorlage für eine „WinUI 3 in UWP“-App. Diese App-Variante ist erst im Preview-Status und kommt später dazu. In diesem Abschnitt wird also folglich eine „WinUI in Desktop“-App erstellt. Die Vorlage heißt Blank App, Packaged (WinUI 3 in Desktop). „Packaged“ bedeutet, dass die Anwendung wie eine UWP-Anwendung paketiert wird, womit sie sich unter Windows 10 sauber installieren und deinstallieren lässt. UWP-Apps haben die Dateiendung .appx und Windows 10 weiß, wie Anwendungen mit dieser Dateiendung installiert und deinstalliert werden. Das dahinterliegende Format wird als MSIX bezeichnet. Das Spannende ist, dass sich nicht nur UWP-Apps, sondern auch klassische Win32-Apps in einem MSIX-Paket verpacken lassen. Dazu hat Visual Studio die eigene Projektvorlage Windows Application Packaging Project. Damit lassen sich WPF- oder auch Windows-Forms-Anwendungen als MSIX-Paket verpacken. Dieses Paket hat dann die Dateiendung .msix, es handelt sich dabei jedoch um das exakt gleiche Format wie das einer UWP-.appx-Datei. Eine WinUI-3-Desktop-App ist somit eine Win32-Anwendung, die automatisch über ein MSIX-Paket bereitgestellt wird. Genau dafür steht das „Packaged“ in der Projektvorlage.
Ein WinUI-3-Projekt erstellen
Im Folgenden wird eine „WinUI 3 in Desktop“-Anwendung mit dem Namen WindowsDeveloperApp erstellt. Abbildung 3 zeigt die erstellte Solution, die zwei Projekte enthält. Das erste Projekt ist das eigentliche Anwendungsprojekt, das in den Dateien MainWindow.xaml und MainWindow.xaml.cs den Code des Hauptfensters enthält. Das zweite Projekt ist das Package-Projekt, das das MSIX-Paket erstellt. Unter Applications ist zu sehen, dass es das Anwendungsprojekt referenziert.

Abb. 3: Die erstellte Solution enthält zwei Projekte
Das Package-Projekt ist jenes, das man in Visual Studio als Startprojekt festlegt. Wird es gestartet, wird die WinUI-3-Anwendung kompiliert, in ein MSIX-Paket verpackt, auf dem Windows-10-Rechner installiert und ausgeführt.
Die einzelnen Dateien
Ein WinUI-3-Projekt ist wie eine UWP-App und wie eine WPF-Anwendung aufgebaut. Es gibt die Dateien App.xaml und App.xaml.cs, die zusammen die Application-Klasse definieren. Daneben gibt es die Dateien MainWindow.xaml und MainWindow.xaml.cs, die zusammen die MainWindow-Klasse definieren, die das Hauptfenster der Anwendung repräsentiert.
Listing 1 zeigt den Inhalt der MainWindow.xaml-Datei. Sie enthält standardmäßig ein StackPanel mit einem Button, der den Text „Click Me“ enthält. Dem Button wurde zudem der Name myButton gegeben, um aus der Code-Behind-Datei (MainWindow.xaml.cs) auf ihn zugreifen zu können. Darüber hinaus wurde ein Event Handler für das Click-Event angegeben.
Listing 1: Die MainWindow.xaml-Datei
<Window
x:Class="WindowsDeveloperApp.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:local="using:WindowsDeveloperApp"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
mc:Ignorable="d">
<StackPanel Orientation="Horizontal" HorizontalAlignment="Center" VerticalAlignment="Center">
<Button x:Name="myButton" Click="myButton_Click">Click Me</Button>
</StackPanel>
</Window>
Listing 2 zeigt die Code-Behind-Datei MainWindow.xaml.cs. Darin ist eine MainWindow-Klasse definiert, die von Window ableitet. Window selbst stammt aus dem Namespace Microsoft.UI.Xaml, der zu WinUI 3 gehört. Die MainWindow-Klasse enthält neben einem Konstruktor den Event Handler für das Click-Event des Buttons. Darin wird die Content Property des Buttons auf den Wert Clicked gesetzt. Wird somit die Anwendung ausgeführt, wird ein Button mit dem Text „Click Me“ angezeigt, und wird dieser Button geklickt, ändert sich der Text auf „Clicked“. Abbildung 4 zeigt die laufende Anwendung in Aktion. Dabei wurde der Button bereits angeklickt, wodurch er den Text „Clicked“ enthält.
Listing 2: Die MainWindow.xaml.cs Datei
using Microsoft.UI.Xaml;
namespace WindowsDeveloperApp
{
public sealed partial class MainWindow : Window
{
public MainWindow()
{
this.InitializeComponent();
}
private void myButton_Click(object sender, RoutedEventArgs e)
{
myButton.Content = "Clicked";
}
}
}

Abb. 4: Die erstellte WinUI-App
Listing 3 zeigt den Inhalt der App.xaml.cs-Datei. Darin ist zu sehen, wie die OnLaunched-Methode der Application-Klasse überschrieben wird. Diese Methode wird aufgerufen, wenn die Anwendung gestartet wird. In der OnLaunched-Methode wird eine Instanz des MainWindow erstellt, mit der Activate-Methode aktiviert und somit angezeigt.
Listing 3: Die App.xaml.cs Datei
public partial class App : Application
{
public App()
{
this.InitializeComponent();
}
protected override void OnLaunched(Microsoft.UI.Xaml.LaunchActivatedEventArgs args)
{
m_window = new MainWindow();
m_window.Activate();
}
private Window m_window;
}
In der WinUI-Anwendung lässt es sich jetzt wie in einer UWP-Anwendung programmieren. Allerdings ist der große Unterschied aus Sicht eines Entwicklers, dass es sich hier um eine Win32-Anwendung handelt, da die Projektvorlage WinUI in Desktop genutzt wurde. Somit lässt sich beispielsweise mit den .NET-Dateiklassen aus dem Namespace System.IO das komplette Dateisystem einlesen, falls das notwendig sein sollte. Auch basiert die Anwendung auf .NET 5.0. Das bedeutet, dass sämtliche .NET-5.0-Klassenbibliotheken und somit auch .NET-Standard-2.1-Klassenbibliotheken für diese Anwendung zur Verfügung stehen und genutzt werden können.
Zum Programmieren lässt sich genau wie in UWP und WPF das Model-View-ViewModel-Pattern einsetzen. Entwickler können folglich die aus UWP und WPF bewährten Best Practices auch in WinUI nutzen. Wenn man sich noch einmal bewusst macht, dass WinUI nichts anderes als das UWP UI Framework ist – einfach entkoppelt von Windows 10 –, dann klingt es logisch, dass sämtliche Funktionen aus UWP auch in WinUI vorhanden sind.
Regelmäßig News zur Konferenz und der .NET-Community
Ausblick und Fazit
WinUI 3.0 ist mit Project Reunion 0.5 bereit für den produktiven Einsatz. Microsoft plant das Release von Project Reunion 1.0 laut Roadmap [7] in etwa im Oktober 2021, d. h., sehr wahrscheinlich fällt dieses Release mit dem Erscheinen von .NET 6 zusammen, das für November 2021 geplant ist.
WinUI 3.0 als solches stellt die Zukunft zum Entwickeln moderner Windows-Anwendungen mit .NET/C# und auch mit C++ dar. Insbesondere die Flexibilität bezüglich der Programmiersprache (C# oder C++) und die Flexibilität bezüglich des App-Modells (UWP oder Win32) machen WinUI zu einer fantastischen Wahl. Microsoft positioniert WinUI 3.0 auch als native UI-Plattform von Windows 10. Somit ist es klar, dass dieses UI Framework vorangetrieben wird und hier auch die Innovationen im Windows-Desktop stattfinden werden. Doch WPF-Entwickler können sich entspannt zurücklehnen. Das bestehende Know-how kann mit WinUI weitestgehend wiederverwendet werden, da sowohl WinUI als auch WPF zum Erstellen von Benutzeroberflächen XAML verwenden – und da finden sich in beiden Frameworks sehr ähnliche Konzepte für etwa Layout, Styling und Data Binding. Auch Windows-Forms-Entwickler können sich freuen, denn auch bestehende WPF- und Windows-Forms-Anwendungen lassen sich mit WinUI 3 Controls modernisieren. Die Zukunft wird somit sehr interessant und spannend für Entwickler, die Windows-Desktopanwendungen mit .NET oder mit C++ programmieren möchten.
Links & Literatur
[1] Windows Terminal: https://www.microsoft.com/de-de/p/windows-terminal/9n0dx20hk701
[2] WinUI GitHub Repo: https://github.com/microsoft/microsoft-ui-xaml
[3] Project Reunion GitHub Repo: https://github.com/microsoft/microsoft-ui-xaml
[4] C#/WinRT GitHub Repo: https://github.com/microsoft/CsWinRT
[5] Project Reunion Visual Studio Extension: https://marketplace.visualstudio.com/items?itemName=ProjectReunion.MicrosoftProjectReunion
[6] Dokumentation zum Aufsetzen der Umgebung für WinUI 3: https://docs.microsoft.com/windows/apps/winui/winui3
[7] WinUI Roadmap: https://github.com/microsoft/microsoft-ui-xaml/blob/master/docs/roadmap.md
The post Von UWP zu WinUI: Eine spannende Reise in die Zukunft der Windows-Anwendungsentwicklung appeared first on BASTA!.
]]>The post Asynchronität in C# und Go: Effektive Programmierung für moderne Anwendungen appeared first on BASTA!.
]]>Die meisten Programmierplattformen, die ich kenne, enthalten auf Programmiersprachen- oder Framework-Ebene alternative Mechanismen, um asynchron Messages zwischen Verarbeitungsschritten auszutauschen. In diesem Artikel vergleiche ich die Ansätze von C# und Go, wobei der Schwerpunkt auf den Besonderheiten von Go liegt. Der Message-Austausch zwischen den sogenannten Goroutines über sogenannte Channels ist eine charakteristische Eigenschaft der Sprache Go. Dieser Artikel soll C#-Entwicklerinnen und Entwicklern einen Blick über den Tellerrand bieten und vielleicht sogar Lust darauf machen, im einen oder anderen Projekt Go auszuprobieren.
Bevor wir auf Go und seine Channels zu sprechen kommen, möchte ich kurz in Erinnerung rufen, was C# und .NET in Sachen asynchronem Message-Austausch innerhalb von Prozessen eingebaut hat: die TPL (Task Parallel Library) Dataflow Library [1]. Diese Bibliothek basiert auf den folgenden Grundprinzipien:
Source Blocks (ISourceBlock<T>) sind Datenquellen. Man kann Messages von ihnen lesen.
Target Blocks (ITargetBlock<T>) empfangen Messages. Man kann Messages auf sie schreiben.
Propagator Blocks (IPropagatorBlock<TIn, TOut>) sind gleichzeitig Source und Target Blocks. Sie verarbeiten Daten in irgendeiner Form (Projizieren, Filtern, Gruppieren etc.).
Die Blöcke kann man flexibel zu Pipelines kombinieren. .NET kommt mit vielen vordefinierten Blöcken (Namespace: System.Threading.Tasks.Dataflow), die man je nach Anwendungsfall zu einer Pipeline zusammenstellt.
Listing 1 zeigt exemplarisch, wie eine Datenverarbeitung mit der TPL Dataflow Library programmiert wird. Ein Producer erzeugt Daten. In der Praxis würden diese beispielsweise aus Dateien oder Datenbanken geladen beziehungsweise über das Netzwerk empfangen. Im Beispiel werden Zufallsdaten in einen BufferBlock geschrieben. Er kann je nach Anwendungsfall als Source-, Propagator- oder Target-Block eingesetzt werden. Der Transformer verarbeitet die Daten und gibt das Verarbeitungsergebnis an den nächsten Schritt der Pipeline weiter. Im Beispiel wird der Mittelwert aus Zahlen in einem Array berechnet. In der Praxis können hier beliebig komplexe Logiken zur Verarbeitung ablaufen. Eine Besonderheit der TPL Dataflow Library ist, dass sie sich automatisch um die Parallelisierung der Message-Verarbeitung kümmert, wenn der jeweilige Algorithmus das erlaubt. Im Beispiel wird MaxDegreeOfParallelism angegeben, wodurch mehrere Transformer parallel laufen. Die Verarbeitung kann dadurch entsprechend beschleunigt werden. Der Consumer ist im Beispiel der letzte Schritt der Pipeline. Er erwartet das Eintreffen von Messages und verarbeitet sie.
Listing 1: TPL Dataflow Pipeline
using System;
using static System.Console;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
using System.Threading.Tasks.Dataflow;
// Create a buffer (=target block) into which we can write messages
var buffer = new BufferBlock<byte[]>();
// Create a transformer (=source and target block) that processes data.
// For demo purposes, we specify a degree of parallelism. This allows
// .NET to run multiple transformers concurrently.
var transform = new TransformBlock<byte[], double>(Transform, new() { MaxDegreeOfParallelism = 5 });
// Link buffer with transformer
buffer.LinkTo(transform);
// Start asynchronous consumer
var consumerTask = ConsumeAsync(transform);
// Start producer
Produce(buffer);
// Producer is done, we can mark transformer as completed.
// This will stop the consumer after it will have been finished
// consuming buffered messages.
transform.Complete();
// Wait for consumer to finish and print number of processed messages
var bytesProcessed = await consumerTask;
WriteLine($"Processed {bytesProcessed} messages.");
/// <summary>
/// Produces values and writes them into <c>target</c>
/// </summary>
static void Produce(ITargetBlock<byte[]> target)
{
// Here we generate random bytes. In practice, the producer
// would e.g. read data from disk, receive data over the network,
// get data from a database, etc.
var rand = new Random();
for (int i = 0; i < 100; ++i)
{
var buffer = new byte[1024];
rand.NextBytes(buffer);
// Send message into target block
WriteLine("Sending message");
target.Post(buffer);
}
// Mark as completed
target.Complete();
}
/// <summary>
/// Transforms incoming message (byte array -> average value)
/// </summary>
static double Transform(byte[] bytes)
{
// For debug purposes, we print the thread id. If you run the program,
// you will see that transformers run in parallel on multiple threads.
WriteLine($"Transforming message on thread ${Thread.CurrentThread.ManagedThreadId}");
return bytes.Average(val => (double)val);
}
/// <summary>
/// Consumes message
/// </summary>
static async Task<int> ConsumeAsync(ISourceBlock<double> source)
{
var messagesProcessed = 0;
// Await incoming message
while (await source.OutputAvailableAsync())
{
// Receive message
var average = await source.ReceiveAsync();
// Process message. In this demo we are just printing its content.
WriteLine($"Consumed message, average value is {average}");
messagesProcessed++;
}
return messagesProcessed;
}Die TPL Dataflow Library ist gut geeignet für CPU- oder I/O-intensive Algorithmen, bei denen eine große Datenmenge idealerweise in mehreren, parallel laufenden Threads verarbeitet werden soll. Als Entwicklerin oder Entwickler muss man sich nicht mit Shared Memory, Thread-Synchronisation und manuellem Scheduling der Aufgaben herumplagen. Das geschieht automatisch im Hintergrund durch die Library.
Bevor wir ins Thema Go Channels einsteigen, zunächst ein paar einleitende Worte zu dieser Programmiersprache für die, die mit ihr noch keine Berührungspunkte hatten. Go stammt aus dem Hause Google. Die Grundidee hinter Go ist, eine Programmiersprache zu haben, die besonders flott beim Kompilieren, einfach in der Nutzung und performant ist, was den generierten Code betrifft. Go wird im Gegensatz zu C# in Maschinensprache übersetzt. Es gibt keine Intermediate Language. Es handelt sich trotzdem wie bei C# um eine Managed Language inklusive Garbage Collector.
Der auffälligste Unterschied zwischen C# und Go, der jeder Entwicklerin und jedem Entwickler beim Umstieg sofort auffällt, ist die Einfachheit der Sprache. Go hat im Vergleich zu C# nur einen Bruchteil an Schlüsselwörtern. Ein einprägsames Beispiel dafür ist der Increment-Operator (++). In Go ist er ein Statement, keine Expression. Etwas wie if (++x > 5) gibt es in Go nicht. Das Go-Entwicklungsteam ist sehr zurückhaltend, neue Sprachfeatures hinzuzufügen, die nur dazu dienen, Code kürzer zu machen. Es wird nicht als Nachteil empfunden, wenn man als Entwickler ein paar Zeilen mehr Code schreiben muss, wenn im Gegenzug die Sprache dadurch einfach und schlank gehalten werden kann. Ein weiteres Beispiel, das die Philosophie hinter Go klar macht, sind Generics. Es gibt Stand heute in Go keine Generics, obwohl die Sprache schon über 10 Jahre alt und speziell im Bereich Cloud-Computing und Containertechnologie weit verbreitet ist. Generics (inklusive Generic Channels) sind gerade erst in Planung und werden voraussichtlich nächstes Jahr zu Go hinzugefügt.
Kommt man von C#, erfordert das eine gewisse Bereitschaft zum Umdenken. Gerade in den letzten Sprachversionen von C# wurde vieles hinzugefügt, was nur dazu dient, kürzeren und prägnanteren Code zu schreiben. Go ist im Vergleich zu C# meiner Erfahrung nach eine Art „Coding Detox“. Man arbeitet mit einer auf das Wesentliche reduzierten Sprache, die sich langsam, aber stetig weiterentwickelt und langfristige Stabilität bietet. Wenn man sich auf diesen Grundgedanken einlässt, ist Entwickeln mit Go eine angenehme Erfahrung.
Dieser Artikel ist keine generelle Einleitung in Go. Wir konzentrieren uns auf zwei charakteristische Sprachfunktionen, Goroutines und Channels. Die Beispiele sind so einfach gehalten, dass auch Leserinnen und Leser ohne Go-Know-how ohne Weiteres folgen können.
Wir wollen uns in diesem Artikel mit dem Austauschen von Nachrichten zwischen nebenläufig ausgeführten Programmteilen in einem Prozess beschäftigen. Daher müssen wir uns ansehen, welche Analogie es in Go für C# Tasks gibt. Das Grundkonstrukt für nebenläufige Threads in Go-Programmen sind sogenannte Goroutines. Wie C# Tasks sind Goroutines viel leichtgewichtiger als Betriebssystem-Threads, es kann daher viel mehr Goroutines geben als darunterliegende Threads. Goroutines brauchen nur wenig Speicher (wenige KB). Das Scheduling wird durch die Go Runtime erledigt.
Schluss mit der Theorie, werfen wir einen Blick auf ein Codebeispiel. Listing 2 zeigt ein ganz einfaches Beispiel einer Goroutine. Achten Sie beim Durchsehen des Codes darauf, dass in der main-Methode dem ersten Aufruf von sayHello das Schlüsselwort go vorangestellt ist. Dadurch startet die aufgerufene Methode in einer eigenen Goroutine und ist nebenläufig zum Hauptprogramm.
Listing 2: Goroutine
package main
import (
"fmt"
"time"
)
func sayHello(source string) {
fmt.Printf("Hello World from %s!\n", source)
time.Sleep(5 * time.Millisecond)
}
func main() {
go sayHello("goroutine")
sayHello("direct call")
time.Sleep(10 * time.Millisecond)
}Es gäbe noch eine Menge über Goroutines zu sagen. In diesem Artikel wollen wir uns aber in Folge mit Channels beschäftigen. Die erwähnten Grundlagen von Goroutines sind für das Verständnis von Channels ausreichend. Wer Go in der Praxis einsetzen möchte, ist gut beraten, noch etwas Zeit in das Lesen der Dokumentation über Goroutines zu investieren. Aber keine Angst, das ist kein sprichwörtliches Rabbit Hole, in das man abtauchen muss, um tagelang Feinheiten des Goroutine-Schedulers von Go zu studieren. Die Grundphilosophie von Go ist, dass die Sprache einfach sein soll und man für ihre Verwendung die Implementierungsdetails nicht zu kennen braucht. Aus eigener Erfahrung kann ich sagen, dass der Einstieg in Go für erfahrene C#-Entwicklerinnen und Entwickler nicht schwer ist. Wer C# Tasks verstanden hat, kann in kürzester Zeit Anwendungen mit Goroutines schreiben.
Channels in Go dienen dazu, Daten zwischen Goroutines auszutauschen. Channels sind typsicher und man erspart sich durch ihre Verwendung die manuelle Synchronisation nebenläufiger Prozesse beim Zugriff auf gemeinsame Speicherbereiche. Insofern haben Channels in Go eine gewisse Ähnlichkeit mit der C# Dataflow Library. Der große Unterschied ist, dass Channels viel tiefer in die Programmiersprache Go und die zugehörigen Bibliotheken integriert sind als Dataflow Blocks in C# und .NET.
Listing 3 zeigt an einem einfachen Beispiel, wie mit Go Channels programmiert wird. Beachten Sie beim Durchsehen des Codes die Codekommentare. Sie weisen auf wichtige Dinge hin, die für das Verständnis der Channels wichtig sind.
Listing 3: Grundlagen von Go Channels
package main
import (
"fmt"
"time"
)
// Note that our function receives a
// write-only channel. The channel will be used
// to send back the result.
func getValueAsync(result chan<- int) {
// Simulate some longer running operation. Could
// be reading data from disk, accessing DB or
// network, etc.
time.Sleep(10 * time.Millisecond)
// Return result and print some debug output
fmt.Println("Before sending result")
result <- 42
fmt.Println("After sending result")
}
func doSomethingComplex(done chan<- bool) {
// Simulate a longer operation again
time.Sleep(10 * time.Millisecond)
// This time, we do not return a meaningful
// result. We only signal that processing has
// been completed by sending something into
// the channel.
done <- true
}
func main() {
// Create a channel for receiving an async result
result := make(chan int)
// Run operation asynchronously
go getValueAsync(result)
// Wait for result by receiving from channel
fmt.Println("Before receiving result")
fmt.Println(<-result)
fmt.Println("After receiving result")
// Create another channel and start
// another Goroutine
done := make(chan bool)
go doSomethingComplex(done)
// The next statement is not interested in the
// Goroutine’s result. We just want to block this
// method’s execution until something has been
// sent to the channel.
<-done
fmt.Println("Complex operation is done")
}Wie man bereits an diesem ersten Beispiel sieht, gibt es zwar gewisse Ähnlichkeiten zwischen der TPL Dataflow Library und den Go Channels, der typische Anwendungsbereich ist jedoch unterschiedlich. Die Dataflow Library ist im Speziellen interessant, wenn man Anwendungen hat, bei denen größere Datenmengen asynchron abgearbeitet werden sollen und der Algorithmus von automatischer Parallelisierung profitiert. Bei Go Channels spielt die automatisierte Parallelverarbeitung keine so große Rolle. Natürlich gibt es Anwendungsbereiche, bei denen beide Lösungsansätze einsetzbar sind. Die beim Design und bei der Entwicklung vordergründig wichtigsten Ziele waren aber nicht ident.
Wenn man keine besonderen Vorkehrungen trifft, blockieren Channels die lesende Goroutine, falls der Channel keinen Wert enthält, und die schreibende Goroutine, falls bereits ein Wert im Channel steckt und noch nicht empfangen wurde. „Blockieren“ bedeutet in diesem Fall nicht, dass der darunterliegende Betriebssystem-Thread blockiert ist. Blockiert wird nur die Goroutine. Der Go-interne Scheduler wird versuchen, die Zeit zu nutzen und übergibt die Kontrolle an Goroutines, die gerade nicht blockiert sind und ausgeführt werden könnten. Die Eigenschaft des Blockierens von Channels kann verwendet werden, um Goroutines zu synchronisieren. Was ist aber, wenn man ein Producer-Consumer-Pattern umsetzen möchte, bei dem der Producer manchmal etwas schneller Daten liefert als Consumer sie verarbeiten können? Für diese Zwecke gibt es Buffered Channels.
Listing 4 zeigt Buffered Channels im Einsatz. Der Code enthält wieder viele Kommentare, die auf wichtige Aspekte hinweisen. Besondere Aufmerksamkeit verdient die for/range-Schleife in der main-Methode. Man verwendet sie in Go, um über die mit Hilfe des Channels empfangenen Messages zu iterieren. Das ist nur der Anfang der Integration von Channels in die Sprache Go. Channels sind fundamentaler Bestandteil der Sprache und sie werden an allen Ecken und Enden in Go-Bibliotheken eingesetzt. Das ist ein weiterer Unterschied zwischen der TPL Dataflow Library in C# und den Channels in Go. Die Dataflow Library wird in C# für ganz spezielle Anwendungsfälle eingesetzt. Natürlich ist das API der Library so gestaltet, dass man sie angenehm mit C# nutzen kann. Von einer tiefen Integration in die Sprachsyntax von C# kann man aber ganz im Gegensatz zu Channels in Go nicht sprechen.
Listing 4: Buffered Channels
package main
import (
"fmt"
"math/rand"
"time"
)
// Note that our function receives a write-only channel.
// The channel will be used to send back the result.
func producer(result chan<- int) {
// Send 50 values through channel
for i := 0; i < 20; i++ {
// Simulate a longer operation by waiting. In practice,
// this would be e.g. an I/O operation.
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
// Send back result. Note that sending will be blocked
// if buffered channel is currently full.
fmt.Println("Sending")
result <- rand.Intn(42)
}
// Close channel to signal caller that no further
// values can be expected.
close(result)
}
func main() {
// Call async operation that produces values
values := make(chan int, 10)
go producer(values)
// Note that we can use for/range to iterate over
// values coming in through a channel. The loop will block
// if no value is currently available in the channel.
for val := range values {
fmt.Printf("Received %d\n", val)
time.Sleep(1 * time.Second)
}
}Ein weiteres Beispiel für die Sprachintegration von Channels in Go ist das select-Statement. Entwicklerinnen und Entwickler, die aus C# kommen, werden überrascht sein, denn das select-Statement hat in Go eine andere Funktion als in C#. Es wird verwendet, um Werte aus verschiedenen Channels zu empfangen. Wenn es einen default-Zweig enthält, wird es zu einer Non-Blocking Channel Operation. Das Codebeispiel in Listing 5 zeigt das Prinzip. Das erste select-Statement in main enthält einen default-Zweig. Der Code kann daher auch bei Nichtvorhandensein eines Wertes im Channel weiterlaufen. Das zweite select-Statement enthält Empfangsoperationen für zwei verschiedene Channels. Ausgeführt wird der Zweig, dessen Channel als erstes einen Wert empfängt.
Listing 5: Non-Blocking Channel Operations
package main
import (
"fmt"
"time"
)
func getValueAsync(result chan int) {
time.Sleep(10 * time.Millisecond)
fmt.Println("Before sending result")
result <- 42
fmt.Println("After sending result")
}
func main() {
// Create channel and trigger asynchronous operation
result := make(chan int)
go getValueAsync(result)
// Wait for some milliseconds
time.Sleep(5 * time.Millisecond)
// Note that we are using Go’s select statement here.
// It is non-blocking because of the default case.
select {
case m := <-result:
fmt.Printf("We have a value: %d\n", m)
default:
fmt.Println("Sorry, no value")
}
// Empty channel and restart async operation
<-result
go getValueAsync(result)
// Use select statement without default case. Here
// we combine it with time.After, which is a timer sending
// a value in a channel after a configurable amount of time.
select {
case m := <-result:
fmt.Println(m)
case <-time.After(5 * time.Millisecond):
fmt.Println("timed out")
}
}Um mögliche Einsatzbereiche des switch-Statements zu verdeutlichen, wurde in Listing 6 ein Beispiel entwickelt, bei dem eine zentrale Goroutine verschiedene mathematische Operationen anbietet. Die Operationen werden nicht direkt aufgerufen, sondern durch Senden einer Message an einen Channel ausgelöst. Anwenden könnte man dieses Entwurfsmuster beispielsweise in einer Webanwendung, bei der eine einzelne Goroutine Dienste anbietet, die von den parallellaufenden Goroutines, die für die Abarbeitung eingehender HTTP Requests gestartet wurden, aufgerufen werden.
Listing 6: Asynchrone Nachrichtenverarbeitung
package main
import "fmt"
// Create structures for operation parameters
type binaryOperationParameter struct {
x int
y int
}
// Create structure with channels used to trigger
// asynchronous operations
type operationChannels struct {
add chan binaryOperationParameter
sub chan binaryOperationParameter
square chan int
negate chan int
exit chan bool
}
// Helper methods to create channels
func createChannels() operationChannels {
return operationChannels{
add: make(chan binaryOperationParameter),
sub: make(chan binaryOperationParameter),
square: make(chan int),
negate: make(chan int),
exit: make(chan bool),
}
}
func calculator(channels operationChannels, result chan<- int) {
// Run until exit operation is received
for {
select {
case p := <-channels.add:
result <- p.x + p.y
case p := <-channels.sub:
result <- p.x - p.y
case p := <-channels.square:
result <- p * p
case p := <-channels.negate:
result <- -p
case <-channels.exit:
close(result)
fmt.Println("Good bye from calculator")
return
}
}
}
func main() {
// Start calculator in a separate Goroutine
channels := createChannels()
result := make(chan int)
go calculator(channels, result)
// Async add
channels.add <- binaryOperationParameter{x: 21, y: 21}
fmt.Printf("21 + 21 = %d\n", <-result)
// Async square
channels.square <- 2
fmt.Printf("2^2 = %d\n", <-result)
// Send exit message and wait until result channel is closed
channels.exit <- true
<-result
fmt.Println("We are done")
}Wenn ich mit C#-Entwicklerinnen und -Entwicklern über Go spreche und von meiner Begeisterung für Channels und die damit verbundenen Sprachkonstrukte in Go erzähle, bekomme ich oft als Gegenargument zu hören, dass .NET mit der TPL Dataflow Library im Wesentlichen das Gleiche eingebaut habe. Zugegeben, beide Technologien haben Ähnlichkeiten. Ich stimme allerdings der Aussage, dass sie die gleichen Probleme lösen und sich beim Programmieren gleich anfühlen, nicht zu. Das Besondere an den Channels in Go ist die tiefe Integration in die Programmiersprache. Seit ich speziell im Bereich von Web-APIs Go einsetze, habe ich das zu schätzen gelernt und ich hoffe, dass ich manche Leserinnen und Leser auf Go neugierig machen konnte. Es geht dabei nicht darum, C# durch Go zu ersetzen, sondern neue Sichtweisen kennenzulernen, seine Komfortzone hin und wieder zu verlassen und bei manchen Projekten auf neue Technologien zurückzugreifen, die sich im jeweiligen Fall besonders gut eignen.
Links & Literatur
[1] https://docs.microsoft.com/en-us/dotnet/standard/parallel-programming/dataflow-task-parallel-library
The post Asynchronität in C# und Go: Effektive Programmierung für moderne Anwendungen appeared first on BASTA!.
]]>The post Das ist doch nicht normal: Herausforderungen in der agilen Softwareentwicklung verstehen appeared first on BASTA!.
]]>Die große Herausforderung dabei ist, zu definieren, was überhaupt eine Anomalie darstellt. Stellen Sie sich ein ganzes Regal voller Entwicklerzeitschriften vor, nur eine Sportzeitschrift ist darunter. Mit Recht könnte man also behaupten, die Sportzeitschrift sei eine Anomalie. Vielleicht sind zufällig aber auch alle Zeitschriften im A4-Format, nur zwei in A5 – eine weitere Anomalie. Für eine automatisierte Erkennung von Anomalien ist es somit wichtig, aus Erfahrungen zu lernen und zu verstehen, welche Anomalien tatsächlich Relevanz besitzen – und wo ein Fehlalarm vorliegt, der zukünftig vermieden werden soll.
Im Fall von zeitbasierten Daten – und darum geht es beim Metrics Advisor ausschließlich – gibt es mehrere Ansätze zur Erkennung von Anomalien. Der einfachste Weg ist die Definition von harten Grenzen: Alles unter oder über einem gewissen Schwellwert wird als Anomalie betrachtet. Dafür braucht es kein Machine Learning und keine künstliche Intelligenz, die Regeln sind schnell implementiert und klar nachvollziehbar. Bei Monitoringdaten wird das vielleicht genügen: Sind 70 Prozent des Speicherplatzes belegt, will man reagieren. Oft verläuft die (Daten-)Welt aber nicht in starren Bahnen, manchmal ist die relative Veränderung entscheidender als der tatsächliche Wert: Wenn innerhalb der letzten drei Stunden ein signifikanter Anstieg oder eine Abnahme von mehr als 10 Prozent erfolgt ist, soll eine Anomalie erkannt werden. Ein Beispiel könnte man aus dem Finanzbereich nehmen. Ändert sich Ihr privater Kontostand von 20 000 € auf 30 000 €, so ist das vermutlich als Anomalie zu werten. Ändert sich ein Firmenkonto von 200 000 € auf 210 000 €, ist das nicht der Rede wert. Gut an diesem Beispiel erkennbar: Die Einordnung, was eine Anomalie ist, ändert sich möglicherweise über die Zeit. Bei der Gründung eines Start-ups sind 100 000 € viel Geld, bei einem Großkonzern eine Randnotiz. Was aber, wenn Ihre Daten saisonalen Schwankungen unterliegen oder einzelne Tage wie Wochenenden oder Feiertage sich deutlich anders verhalten? Auch hier ist die Einordnung gar nicht so trivial. Ist eine Grippewelle in den Wintermonaten erwartbar und nur im Sommer eine Anomalie oder soll jeder Anstieg der Infektionszahlen erkannt werden? Sie sehen, die Frage der Anomalieerkennung ist unabhängig vom Tooling eine zum Teil sehr subjektive – und nicht alle Entscheidungen können von der Technik übernommen werden. Machine Learning kann allerdings helfen, aus historischen Daten zu lernen und normale Schwankungen von Anomalien zu unterscheiden.
Der Metrics Advisor ist ein neuer Service aus der Reihe der Azure Cognitive Services und vorerst nur in einer Preview-Version verfügbar. Intern wird ein weiterer Service verwendet, nämlich der Anomaly Detector (ebenfalls aus den Cognitive Services). Der Metrics Advisor ergänzt diesen um zahlreiche API-Methoden, ein Web-Frontend zur Verwaltung und Ansicht der Data Feeds, Root-Cause-Analysen und Alert-Konfigurationen. Um experimentieren zu können, benötigen Sie eine Azure Subscription. Dort können Sie eine Metrics-Advisor-Ressource erstellen; die Verwendung ist in der Preview-Phase komplett kostenlos.
Das Beispiel, mit dem ich Ihnen die grundsätzliche Vorgehensweise demonstrieren möchte, verwendet Daten von Google Trends. Ich habe für zwei Suchbegriffe („Impfstoff“ und „Influenza“) die wöchentlichen Google-Trends-Scores der letzten fünf Jahre für vier Länder (USA, China, Deutschland, Österreich) ausgewertet und heruntergeladen und möchte versuchen, etwaige Anomalien in diesen Daten zu erkennen. Die gesamte Administration des Metrics Advisors kann über das zur Verfügung gestellte REST API durchgeführt werden, ein schnellerer Einstieg gelingt über das bereitgestellte Web-Frontend, den sogenannten Workspace.
Zu Beginn erzeugen wir einen neuen Data Feed, der die Basisdaten für die Auswertung bereitstellt. Als Datenquellen stehen out of the box verschiedenste Azure Services und Datenbanken zur Verfügung: Application Insights, Blob Storage, Cosmos DB, Data Lake, Table Storage, SQL Database, Elastic Search, Mongo DB, PostgreSQL – und einige mehr. In unserem Beispiel habe ich die Google-Trends-Daten in eine SQL-Server-Datenbank geladen. Die Tabelle hat neben dem Primärschlüssel noch vier weitere Spalten: das Datum, das Land und die Scores für Impfstoff und Influenza. Im Metrics Advisor muss nun (neben dem Connection String) ein SQL-Statement angegeben werden, mit dem alle Werte für ein bestimmtes Datum abgefragt werden können. Der Service wird nämlich auch in Zukunft regelmäßig unsere Datenbank aufsuchen, um die neuen Daten abzuholen und zu analysieren. Die Häufigkeit, in der diese Aktualisierung passieren soll, wird über die Granularität eingestellt: Die Daten können jährlich, monatlich, wöchentlich, täglich, stündlich oder in noch kürzeren Zeiträumen (die kleinste Einheit sind 300 Sekunden) ausgewertet werden. Abhängig von der gewählten Granularität gibt Microsoft auch Empfehlungen, wie viele historische Daten bereitgestellt werden sollen. Wählen wir einen 5-Minuten-Takt, dann reichen Daten der letzten vier Tage. In unserem Fall, einer wöchentlichen Analyse, werden bereits vier Jahre empfohlen. Nach dem Klick auf Verify and get schema wird das SQL-Statement abgesetzt und die Struktur unserer Datenquelle ermittelt. Wir sehen die in Abbildung 1 gezeigten Spalten und müssen die Bedeutung zuordnen: Welche Spalte beinhaltet den Timestamp? Welche Spalten sollen als Metrik analysiert werden – und wo befinden sich zusätzliche Fakten (Dimensionen), die mögliche Ursachen für Anomalien sein könnten?

Bevor die Daten nun tatsächlich importiert werden, gilt es noch, eine Einstellung zu betrachten: die roll up settings. Für eine spätere Ursachenanalyse (Root Cause Analysis) ist es notwendig, einen mehrdimensionalen Cube zu bauen, der je Dimension aggregierte Werte berechnet (also in unserem Fall pro Woche auch eine Aggregation über alle Länder). So kann später bei Anomalien untersucht werden, welche Dimensionen bzw. Ausprägungen ursächlich für die Wertveränderung zu sein scheinen. Sollten sich die Aggregationen nicht ohnehin bereits in unserer Datenquelle befinden, kann der Metrics Advisor zur Berechnung der Daten aufgefordert werden. Die einzige Entscheidung, die wir dabei treffen müssen, ist die Art der Aggregation (Summe, Durchschnitt, Min, Max, Anzahl). Hier hinkt unser Beispiel etwas: Wir wählen Durchschnitt aus, der Wert der USA fließt aber somit mit dem gleichen Faktor ein wie der Wert des kleinen Österreich. Sie sehen: oft scheitert man an der Datenqualität oder muss aufpassen, dass Aussagen nicht auf falschen Berechnungen beruhen.
Abschließend starten wir den Import, der je nach Datenmenge durchaus mehrere Stunden in Anspruch nehmen kann. Der Status des Imports kann auch im Workspace nachverfolgt werden, einzelne Zeiträume können jederzeit neu geladen werden.
Sobald der Datenimport abgeschlossen ist, können wir einen ersten Blick auf unsere Ergebnisse werfen. Das wesentliche Ziel des Metrics Advisors ist die Analyse und Erkennung neuer Anomalien – also die Untersuchung, ob der jeweils neueste Datenpunkt eine Anomalie darstellt oder nicht. Dennoch werden auch die historischen Daten betrachtet. Abhängig von der Granularität blickt der Service einige Stunden bis Jahre in die Vergangenheit und versucht auch dort, Anomalien zu kennzeichnen. In unserem Fall (Daten aus fünf Jahren, wöchentliche Aggregation) liefert die sogenannte Smart Detection Ergebnisse für die vergangenen sechs Monate und markiert einzelne Zeitpunkte als Anomalie (Abb. 2).

Nun gilt es, einen Blick auf die Vorschläge zu werfen: Sind die identifizierten Anomalien tatsächlich relevant? Ist die Erkennung zu sensibel oder zu tolerant? Es gibt einige Möglichkeiten, um die Erkennungsrate zu verbessern. Erinnern wir uns an den Beginn dieses Artikels: Die große Herausforderung besteht darin, zu definieren, was überhaupt eine Anomalie darstellt.
Vermutlich fällt Ihnen im Workspace sehr rasch ein prominent platzierter Schieberegler auf. Damit können wir die Sensitivität steuern. Je höher der Wert, desto kleiner wird der Bereich, der normale Punkte enthält. Wir bekommen diese Grenzen auch innerhalb der Charts als hellblaue Fläche visualisiert. Manchmal ist es sinnvoll, nicht gleich beim ersten Auftreten einer Anomalie zu warnen, sondern erst, wenn über einen gewissen Zeitraum mehrere Anomalien erkannt wurden. Wir können den Metrics Advisor so konfigurieren, dass eine bestimmte Anzahl von Punkten rückwirkend betrachtet wird und eine Anomalie erst als solche gilt, wenn von diesen Punkten ein bestimmter Prozentsatz als Anomalie erkannt wurde. Zum Beispiel soll ein kurzes Performanceproblem toleriert werden, aber wenn in den letzten 15 Minuten 70 Prozent der Messwerte als Anomalie erkannt wurden, ist insgesamt von einem Problem zu sprechen.
Je nach Anwendungsfall kann es sinnvoll sein, die Smart Detection durch manuelle Regeln zu ergänzen. Mit Hilfe eines Hard Threshold können eine Unter- oder Obergrenze sowie ein Wertebereich festgelegt werden, der als Anomalie gelten soll. Der Change Threshold bietet die erwähnte Möglichkeit, eine prozentuelle Veränderung zu einem oder mehreren Vorgängerpunkten als Anomalie zu werten. Durch die Art der Verknüpfung (or/and) der verschiedenen Regeln beeinflussen wir die Erkennung: Eine Anomalie soll beispielsweise nur dann als solche erkannt werden, wenn die Smart Detection zuschlägt und der Wert über 30 liegt. Wir können mehrere dieser Konfigurationen zusammenstellen und benennen. Zusätzlich ist es möglich, für einzelne Dimensionen besondere Regeln zu hinterlegen.
Abhängig von unseren Einstellungen werden nun also mehr oder weniger Anomalien in den Daten entdeckt, der Metrics Advisor versucht anschließend, diese in sogenannte Incidents zu überführen. Ein Incident kann aus einer einzigen Anomalie bestehen, oft werden aber auch zusammenhängende Anomalien und damit ganze Zeitbereiche unter einem gemeinsamen Incident angeführt. Im Incident Hub stehen Tools zur näheren Betrachtung zur Verfügung: Wir können die gefundenen Incidents filtern (nach Zeit, Kritikalität und Dimension), eine erste automatische Ursachenanalyse starten (siehe „Root cause“ in Abb. 3) und durch mehrere Dimensionen einen Drill-down durchführen, um Erkenntnisse zu sammeln.

Der vielleicht größte Vorteil beim Einsatz von künstlicher Intelligenz für die Anomalieerkennung liegt in der Möglichkeit, durch Feedback zu lernen. Selbst wenn Sensitivität und Schwellwerte gut eingestellt wurden, wird der Service manchmal falsch liegen. Genau für diese Datenpunkte kann dann aber über das API oder das Portal Feedback gegeben werden: Wo wurde fälschlicherweise eine Anomalie erkannt? Wo wurde eine Anomalie übersehen? Der Service nimmt dieses Feedback entgegen und versucht, zukünftig ähnlich gelagerte Fälle korrekter zuzuordnen. Auch zeitliche Perioden versucht der Service zu erkennen – und lässt sich eines Besseren belehren, wenn wir einen Zeitbereich markieren und diesen als Periode rückmelden.
Für vorhersehbare Anomalien, die zeitliche Gründe haben (Feiertage, Wochenenden, zyklisch wiederkehrende Ereignisse), gibt es eigene Möglichkeiten zur Konfiguration. Diese sollten daher nicht nachträglich als Feedback gemeldet, sondern als sogenannte Preset Events hinterlegt werden.
Wir sollten nun an einem Punkt angekommen sein, an dem Daten regelmäßig importiert werden und die Anomalieerkennung hoffentlich zuverlässig funktioniert. Die beste Erkennung hilft aber nichts, wenn wir zu spät davon erfahren. Daher sollten Alert Configurations eingerichtet werden, die aktiv über Anomalien benachrichtigen. Derzeit stehen drei Kanäle zur Auswahl: per E-Mail, als WebHook oder als Ticket in Azure DevOps. Vor allem die WebHook-Variante bietet spannende Möglichkeiten der Integration: Wir können die erkannten Anomalien in unserer eigenen Anwendung anzeigen oder einen Workflow mit Hilfe der Azure Logic Apps triggern. Vielleicht starten wir als erste automatisierte Maßnahme einfach die betroffene Web-App neu.
Praktisch scheinen auch die Snooze-Settings: Ein Alert kann automatisch dafür sorgen, dass für einen konfigurierbaren Zeitraum danach keine Alerts mehr gesendet werden. Das vermeidet, dass man in der Früh mit 500 E-Mails im Posteingang aufwacht, die alle denselben Inhalt haben.
Der Metrics Advisor bietet einen spannenden und leichten Einstieg in die Welt der Anomalieerkennung zeitbasierter Daten. Langjährige Data Scientists werden möglicherweise andere Mittel und Wege bevorzugen (und vielleicht am Paper unter https://arxiv.org/abs/1906.03821 interessiert sein), aber für Anwendungsentwickler, die mit passenden Daten erste Versuche starten wollen, stellt dieser Service eine potente Einstiegsdroge dar. Der Preview-Status ist derzeit vor allem noch im Webportal und in der mangelnden Dokumentationsqualität des REST API ersichtlich; gute konzeptionelle Dokumentation ist aber bereits vorhanden.
Viel Spaß beim Ausprobieren und Experimentieren mit Ihren eigenen Datenquellen.
The post Das ist doch nicht normal: Herausforderungen in der agilen Softwareentwicklung verstehen appeared first on BASTA!.
]]>The post TypeScript 4.1: Was Entwickler:innen wissen müssen appeared first on BASTA!.
]]>Die vierte Generation kann jedoch nicht ohne Breaking Changes auskommen. TypeScript verwendet zwar ein Nummerierungsformat, das an die semantische Versionierung erinnert, folgt diesem Schema jedoch nicht. Jede neue Version kann Breaking Changes und große Featureänderungen mitbringen. Das TypeScript-Team begrenzt solche Eingriffe in die Sprache nicht auf die Versionen, die mit einer vollen Zahl nummeriert werden.
Zu den Breaking Changes gehören: Eine spezielle Deklarationsdatei lib.d.ts wird mit jeder Installation von TypeScript geliefert. Diese Datei enthält die Umgebungsdeklarationen für verschiedene DOM-Funktionen und -Typen. Hier wurde document.origin entfernt, das bisher für alte Versionen des Internet Explorers notwendig war. Alternativ steht self.origin zur Verfügung, das aber manuell ausgetauscht werden muss. Ebenfalls wurde Reflect.enumerate; entfernt. Zu den weiteren möglichen Anpassungen gibt es keine näheren Angaben, da diese von den automatisch erzeugten DOM-Typen abhängen.
TypeScript gibt jetzt immer einen Fehler aus, wenn eine Eigenschaft in einer abgeleiteten Klasse deklariert wird, die einen Getter oder Setter der Basisklasse überschreibt. Beim Verwenden der strictNullChecks-Option, wird ein Fehler geworfen, wenn mittels delete-Operator ein Objekt entfernt wird, das nicht vom Type any, unknown, never oder optional ist.
Ebenfalls als Breaking Change gelistet ist, dass resolve in Promises künftig mindestens einen Wert übergeben bekommen muss. Bisher waren die Parameter hier optional zu setzen. Das ist jetzt nicht mehr der Fall: Codestellen, die resolve ohne Parameter nutzen, geben in Zukunft einen Fehler aus.
JSX steht für JavaScript XML. Damit können wir HTML-Elemente in JavaScript für React schreiben, ohne die createElement()– und/oder appendChild()-Funktion dafür aufrufen zu müssen. Ab TypeScript 4.1 werden die Factory-Funktionen jsx und jsxs von React 17 unterstützt. Dafür stehen zwei neue Optionen für die jsx-Compiler-Option zur Verfügung: react-jsx und react-jsxdev. Diese Optionen sind für Produktions- bzw. Entwicklungskompilierungen vorgesehen. Oft können sich die Optionen von einem zum anderen erstrecken.
Darüber hinaus verbessert TypeScript 4 die Bearbeitungsszenarien in Visual Studio Code und Visual Studio 2017 und 2019. Ein neuer Teilbearbeitungsmodus beim Start behebt langsame Startzeiten, insbesondere bei größeren Projekten. Eine intelligentere Funktion für den automatischen Import erledigt die zusätzliche Arbeit in Editorszenarien, um Pakete einzuschließen, die im Abhängigkeitsfeld von package.json aufgeführt sind. Informationen aus diesen Paketen werden verwendet, um die automatischen Importe zu verbessern, ohne die Typprüfung zu ändern.
Mit Tupeltypen können wir ein Array mit einer festen Anzahl von Elementen ausdrücken, deren Typ bekannt ist, aber nicht identisch sein muss. Beispielsweise möchten wir einen Wert als ein Paar aus einem String und einer Number darstellen, wie es in Listing 1 gezeigt wird.
let x: [string, number]; x = ["hello", 10]; // OK // Initialize it incorrectly x = [10, "hello"]; // Error
Als variadische Funktion bezeichnet man eine Funktion, deren Parameteranzahl nicht bereits in der Deklaration festgelegt ist. In TypeScript 4 können Tupeltypen für variadische Funktionen eingesetzt werden. Wie kann man sich diesen Mix jetzt nur genauer vorstellen? Betrachten wir hierbei Listing 2, das bereits ein gültiger TypeScript-Code ist, aber noch nicht optimal gestaltet ist.
Die concat-Funktion läuft ohne Probleme, aber wir verlieren hierbei die Typisierung und müssten das nachträglich manuell beheben, wenn wir an anderer Stelle genaue Werte erhalten möchten. Bisher war es unmöglich, eine solche Funktion vollständig zu Typisieren, um dieses Problem zu vermeiden.
function concat(
numbers: number[],
strings: string[]
): (string | number)[] {
return [...numbers, ...strings];
}
let values = concat([1, 2], ["hi"]);
let value = values[1]; // infers string | number, but we *know* it's a number (2)
// TS does support accurate types for these values though:
let typedValues = concat([1, 2], ["hi"]) as [number, number, string];
let typedValue = typedValues[1] // => infers number, correctly
Listing 3 zeigt, dass wir mit der variadischen Deklaration der Tupeltypen die fehlende Typisierung gelöst bekommen. Sie erfolgt über die Generic-Deklaration, die an den spitzen Klammern zu erkennen ist. Wir können ein unbekanntes Tupel ([… T]) beschreiben oder diese verwenden, um teilweise bekannte Tupel ([string, … T, boolean, … U]) zu beschreiben. TypeScript kann hinterher die Typen für diese Platzhalter ableiten, sodass wir nur die Gesamtform des Tupels beschreiben und damit Code schreiben können, ohne von den spezifischen Details abhängig zu sein.
function concat<N extends number[], S extends string[]>(
numbers: [...N],
strings: [...S]
): [...N, ...S] {
return [...numbers, ...strings];
}
let values = concat([1, 2], ["hi"]);
let value = values[1]; // => infers number
const val2 = values[1]; // => infers 2, not just any number
Das TypeScript-Team hat die Labeled Tuple Elements zur besseren Lesbarkeit eingeführt. Wenn wir einen Typen beschriften, müssen wir allen Typen ein Etikett geben, wie in Listing 4 zu sehen ist. Der wesentliche Vorteil ist nur beim Blick auf die Deklaration spürbar und erspart unnötige Codekommentare.
function foo(x: [first: string, second: number, ...rest: any[]]) {
// a is string type
// b is number type
const [a, b] = x;
}
Eine besondere Stärke von TypeScript ist das implizierte Erkennen von Typen, das leider ebenfalls seine Grenzen hat. Wie zum Beispiel bei Funktionsparametern, die immer noch eine explizite Typisierung benötigen. Anders sieht es jetzt mit dem neuen Feature aus, der Property Type Inference. Wurde ein Wert für eine Klasseneigenschaft über den Konstruktor gesetzt, hat diese nicht automatisch den Typ erhalten. Hierbei musste man explizit den Typ dazu deklarieren. In Listing 5 sehen wir, dass jetzt TypeScript in der vierten Version vom Konstruktor aus eine implizite Typisierung der Eigenschaften durchführen kann.
class Foo {
label; // Zeigt als Typ 'number | boolean' an.
constructor(param: boolean) {
if (param) {
this.label = 123;
} else {
this.label = false;
}
}
}
TypeScript 4.0 hat bereits die logischen Zuweisungsoperatoren (Logical Assignment Operators) implementiert, die erst in ECMAScript 2021 als Standard veröffentlicht werden. Die Syntax kann auch rückwärts kompiliert werden, damit sie auch in älteren Browserumgebungen verwendet werden kann. In Listing 6 sind einige Beispiele aufgelistet. Heutzutage ist die letzte Option hier wahrscheinlich die nützlichste, es sei denn, wir behandeln ausschließlich Boolesche Werte. Diese Null-Koaleszenz-Zuweisung eignet sich perfekt für Standard- oder Fallback-Werte, bei denen a möglicherweise keinen Wert hat.
a ||= b // Entspricht: a = a || b a &&= b // Entspricht: a = a && b a ??= b // Entspricht: a = a ?? b
Der unknown-Typ ist das typsichere Gegenstück zum any-Typ. Der Hauptunterschied zwischen den beiden Typen besteht darin, dass unknown weniger zulässig ist als any: Der unknown-Typ kann nur dem any-Typ und sich selbst zugewiesen werden. Dadurch sollen Anwender gezwungen sein, zurückgegebene Werte zu prüfen.
Bisher war der Fehlertyp aus einem catch-Block auf any begrenzt und konnte nicht direkt einem anderen Typen zugewiesen werden. Ab sofort können wir den Typ jedoch zur größeren Sicherheit auf den unknown-Typ ändern. Wir können ihn jedoch nicht direkt in einen anderen benutzerdefinierten Typ ändern. Das kann man nur im Funktionsblock vornehmen, wie Listing 7 zeigt.
function error() {
try {
throw new Error();
} catch (e: unknown) {
// Error
// Object is of type unknown
console.log(e.toUpperCase());
if (typeof e === 'string') {
// Das funktioniert jetzt
console.log(e.toUpperCase());
}
}
}
In JavaScript können wir über Codekommentare mit der @deprecated-Annotation aus JSDoc auf eine veraltete Implementierung hinweisen. Einige Codeeditoren können folglich bei der Autovervollständigung darauf hinweisen, dass die jeweilige Klasse oder Funktion möglichst nicht mehr zum Einsatz kommen soll. Ab sofort kann TypeScript beim Transpilieren ebenfalls darauf hinweisen und Codeeditoren wie Visual Studio Code weisen zusätzlich mit einer besseren Visualisierung darauf hin, wie in Abbildung 1 zu sehen ist. Mit TypeScript 4.1 wird gleichzeitig die @see-Annotation unterstützt.
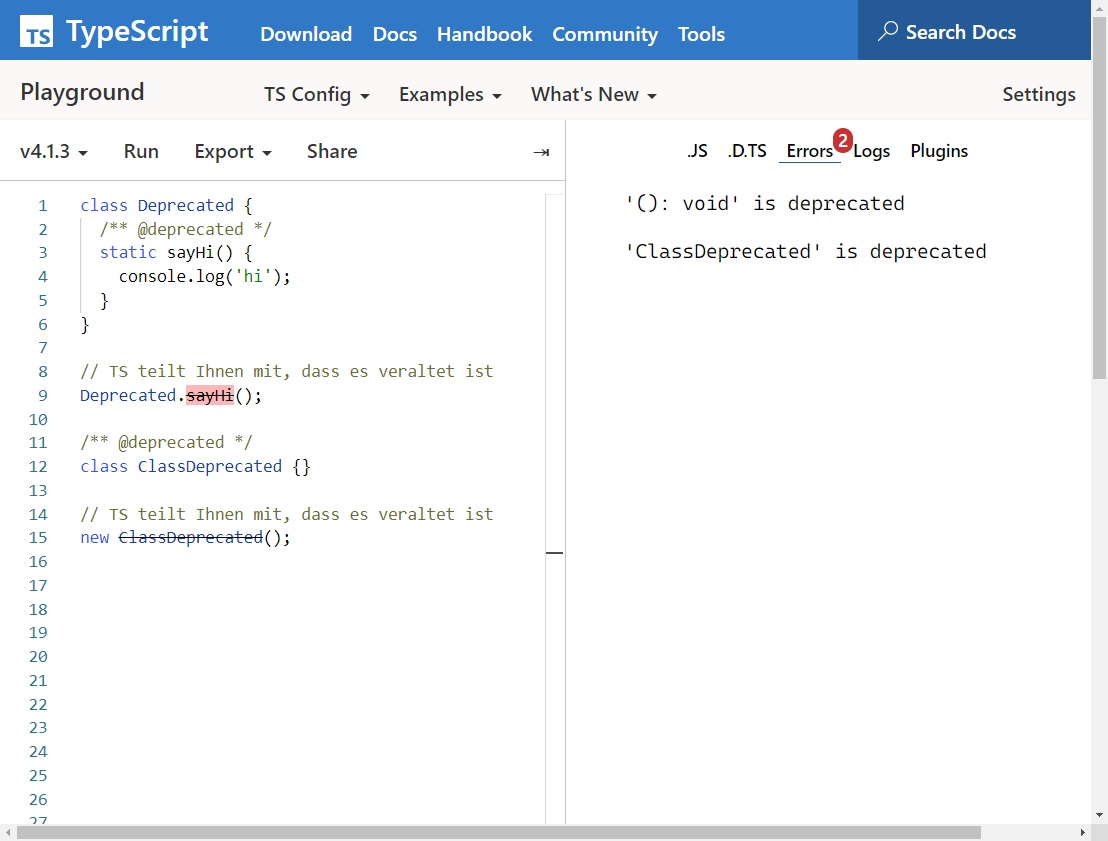
Seit TypeScript 1.8 gibt es die Unterstützung von String Literal Types. Diese sind äußerst leistungsfähig, wenn wir streng typisierten APIs Sicherheit bieten möchten. Literaltypen wurden später erweitert, um auch numerische, boolesche und Enum-Literale zu unterstützen. Ein Beispiel zeigt Abbildung 2. Hier wird ein Beatles Type erzeugt, der nur die festgelegten Stringwerte unterstützt. In Zeile 4 wird ersichtlich, dass TypeScript darauf hinweist, dass dieser Stringwert nicht erlaubt ist. Einen weiteren Vorteil bietet die IntelliSense-Unterstützung, wie in Zeile 6 ersichtlich wird. Das sorgt für hervorragende Typsicherheit und Produktivität.
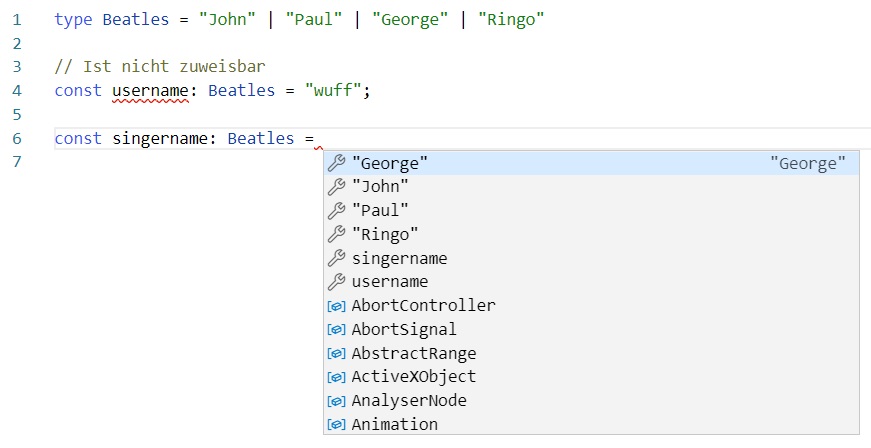
TypeScript 4.1 unterstützt jetzt Template Strings als Typen. Template Strings sind Stringsymbole, die über mehrere Zeilen gehende Zeichenketten sowie eingebettete JavaScript-Ausdrücke ermöglichen. Sie werden anstelle von doppelten bzw. einfachen Anführungszeichen von zwei Gravis-Akzentzeichen (`; französisch: Accent grave, englisch: Backtick) eingeschlossen. Sie können Platzhalter beinhalten, die durch das Dollarsymbol gefolgt von geschweiften Klammern gekennzeichnet sind (${expression}).
In Listing 8 wird der große Vorteil von Template Literal Types verdeutlicht. Aus zwei unterschiedlichen String Literal Types wird ein generischer Typ mit einem Template String erzeugt. Das erspart einiges an zusätzlichem Implementierungsaufwand und bietet zusätzlich eine hohe Flexibilität.
type Suit =
"Hearts" | "Diamonds" |
"Clubs" | "Spades";
type Rank =
"Ace" | "Two" | "Three" | "Four" | "Five" |
"Six" | "Seven" | "Eight" | "Nine" | "Ten" |
"Jack" | "Queen" | "King";
type Card = `${Rank} of ${Suit}`;
const validCard: Card = "Three of Hearts";
const invalidCard: Card = "Three of Heart"; // Compiler Error
Eine erweiterte Form der Template Strings sind Tagged Template Strings. Mit ihnen kann die Ausgabe von Template Strings mit einer Funktion geändert werden. TypeScript 4.1 hat ebenfalls vier zusätzliche Tagged Helper implementiert: Capitalize, Uncapitalize, Uppercase und Lowercase. In Listing 9 sehen wir den Capitalize Tagged Helper im Einsatz.
interface Person {
name: string;
company: string;
age: number;
}
// Erzeugt: "getName" | "getCompany" | "getAge"
type PersonAccessorNames = `get${Capitalize<keyof Person>}`;
Wir können auf dem Beispiel des Tagged Template Strings Helper aufbauen, indem wir es mit zugeordneten Typen kombinieren. Wenn wir im vorherigen Beispiel einen Typ für die Accessoren generieren möchten, können wir mit einem zugeordneten Typ beginnen (Listing 10). Durch keyof wird ein neuer Typ erstellt, wobei die ursprünglichen Datenelemente einer Funktion zugeordnet sind, die ihren Typ zurückgibt.
Mit der neuen as-Klausel können wir Funktionen wie Template Literal Types nutzen, um auf einfache Weise neue Eigenschaftsnamen basierend auf alten zu erstellen. Schlüssel können ebenfalls gefiltert werden.
interface Person {
name: string;
company: string;
age: number;
}
type PersonAccessors = {
[K in keyof Person as `get${Capitalize<K>}`]: () => Person[K];
}
/* PersonAccessors hat jetzt folgende Typ-Signatur:
{
getName: () => string;
getAge: () => number;
getRegistered: () => boolean;
}
*/
Ein weiterer Neuzugang in der aktuellen TypeScript Version 4.1 sind rekursive bedingte Typen. Rekursive bedingte Typen sind genau das, was der Name andeutet: conditional Types, die auf sich selbst verweisen. Sie bieten eine flexiblere Handhabung von bedingten Typen, indem sie sich innerhalb ihrer Zweige referenzieren können. Diese Funktion erleichtert das Schreiben rekursiver Aliasse. Listing 11 zeigt ein Beispiel für das Auspacken eines tief verschachtelten Promise mit Hilfe von async/await.
Es ist jedoch zu beachten, dass TypeScript mehr Zeit für die Typprüfung rekursiver Typen benötigt. Microsoft warnt, dass sie verantwortungsbewusst und sparsam eingesetzt werden sollten.
type Awaited<T> = T extends PromiseLike<infer U> ? Awaited<U> : T; /// Wie `promise.then(...)`, aber genauer in Typen. declare function customThen<T, U>( p: Promise<T>, onFulfilled: (value: Awaited<T>) => U ): Promise<Awaited<U>>;
Mit Indexsignaturen in TypeScript 4.1 können wir auf beliebig benannte Eigenschaften zugreifen, wie in Listing 12 gezeigt wird. Hier sehen wir, dass eine Eigenschaft, auf die zugegriffen wird und die weder den Namenspfad noch die Namensberechtigungen hat, den Typ string oder number haben sollte.
Ein neues Transpiler Flag, —noUncheckedIndexedAccess, stellt einen Knoten bereit, auf dem jeder Eigenschaftszugriff (wie options.path) oder indizierter Zugriff (wie options [“foo bar baz”]) als potenziell undefiniert betrachtet wird. Das heißt, wenn wir im letzten Beispiel auf eine Eigenschaft wie options.path zugreifen müssen, müssen wir ihre Existenz überprüfen oder einen Nicht-Null-Assertion-Operator (das !-Zeichen als Postfix) verwenden.
Das —noUncheckedIndexedAccess Flag ist nützlich, um viele Fehler abzufangen, kann jedoch enorm viel Code verursachen. Aus diesem Grund wird es nicht automatisch durch das —strict Flag aktiviert.
interface Options {
path: string;
permissions: number;
// Zusätzliche Eigenschaften werden von dieser Indexsignatur erfasst.
[propertyName: string]: string | number;
}
function checkOptions(options: Options) {
options.path; // string
options.permissions; // number
// Diese sind auch alle erlaubt!
// Sie haben folgende Typen 'string | number'.
options.yadda.toString();
options["foo bar baz"].toString();
options[Math.random()].toString();
}
Vor TypeScript 4.1 musste der baseUrl-Parameter deklariert werden, um Pfade in der Datei tsconfig.json verwenden zu können. In der neuen Version ist es möglich, die Option path ohne baseUrl anzugeben. Das behebt das Problem, dass beim automatischen Import schlechte Pfade vorhanden sind.
Wenn man ein JavaScript-Projekt hat und die checkJs-Option verwendet, um Fehler in .js-Dateien zu melden, sollte ebenfalls allowJs deklariert werden, um damit JavaScript-Dateien kompilieren zu können. Mit TypeScript 4.1 ist das nicht mehr der Fall. checkJs impliziert jetzt standardmäßig allowJs.
Keines der gezeigten Sprachfeatures ist für sich allein genommen eine riesige Änderung, aber insgesamt wird so das Leben von TypeScript-Entwicklern verbessert, mit einigen großartigen Verbesserungen bezüglich der Typsicherheit und der Entwicklererfahrung insgesamt.
Aus der Community kommen sogar einige unterhaltsame Beispiele. Diese berechnen einen Typ, der die Lösung für ein Problem darstellt. Der Compiler wirft zwar einige Fehler, da zu viel Rekursion stattfindet, aber es sind eben nur Funprojekte zur Veranschaulichung der neuen Sprachfeatures.
Abbildung 3 zeigt einen Code, der einen Typ generiert, der ein Sudoku-Rätsel löst. In diesem Beispiel werden die String Literal Types “true” und “false” verwendet, um generische Typen zu erstellen, die als pseudobedingte Funktionen fungieren.
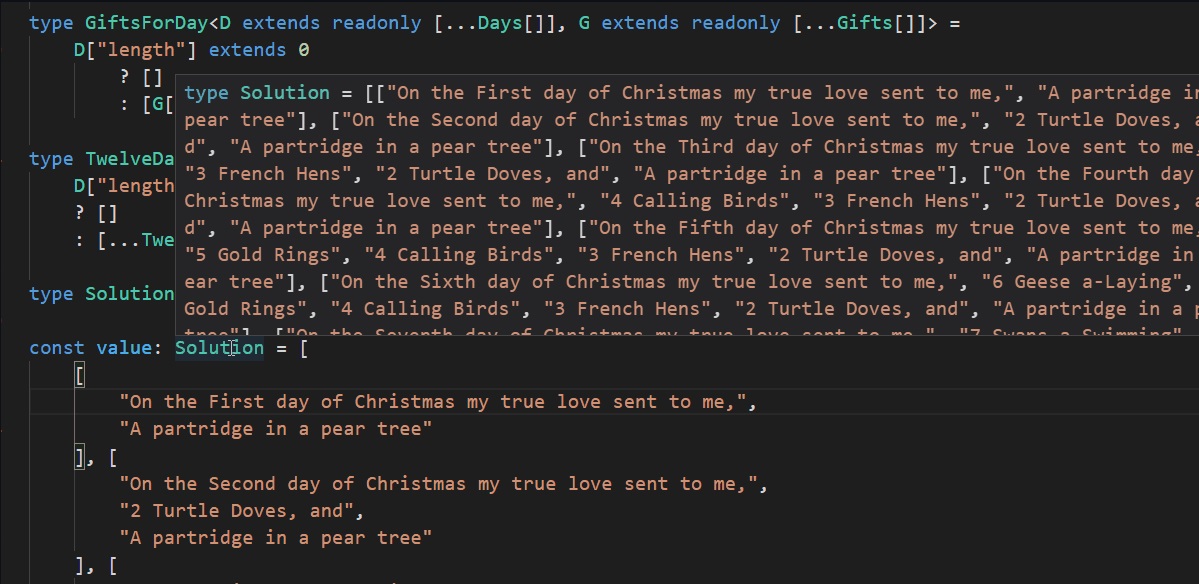
Abbildung 4 zeigt ein weiteres Spaßprojekt, das die Texte des klassischen Weihnachtsliedes „The 12 Days of Christmas“ generiert. Passend zum Artikel bietet der Autor einen Einstieg in JavaScript und TypeScript mit kostenlosen Videos auf YouTube. Viel Spaß beim Ansehen und mit TypeScript in der vierten Generation.
● Angular Architektur Workshop: Enterprise Lösungen mit Nx Monorepos und Micro Frontends
● SEO in Angular? Kein Problem mit SSR und Angular Universal
The post TypeScript 4.1: Was Entwickler:innen wissen müssen appeared first on BASTA!.
]]>The post C# 9: Innovative neue Funktionen für die moderne Softwareentwicklung appeared first on BASTA!.
]]>The post C# 9: Innovative neue Funktionen für die moderne Softwareentwicklung appeared first on BASTA!.
]]>The post .NET 5.0 ist da: Alles, was Sie über den neuen Release wissen müssen appeared first on BASTA!.
]]>Die Erkenntnisse aus Preview 1 bis 7 seien hier kurz zusammengefasst:
Der Rest dieses Beitrags beschäftigt sich mit Neuerungen, die Microsoft seit Preview 7 in .NET 5.0 eingeführt hat. Für .NET 5.0 benötigen Sie mindestens Visual Studio Version 2019 16.8, das zeitgleich mit .NET 5.0 erschienen ist.
Die meisten Neuerungen kurz vor Schluss hat das SPA-Web-Framework ASP.NET Core Blazor erhalten. Seit Preview 7 ist Blazor 5.0 überhaupt erst in .NET 5.0 integriert, seit Preview 8 gibt es Neuerungen. Beide Blazor-Varianten, also Blazor Server und Blazor WebAssembly, tragen nun dieselbe Versionsnummer: 5.0. Blazor-WebAssembly-basierte Anwendungen melden sich in .NET 5.0 nun nicht mehr mit „Mono 6.13.0“, sondern mit „.NET 5.0.0“, wenn man die Eigenschaft System.Runtime.InteropServices.RuntimeInformation.FrameworkDescription abfragt. Das liegt daran, dass Blazor WebAssembly jetzt die Klassenbibliotheken von .NET 5.0 verwendet. Die Runtime ist allerdings immer noch Mono, was man beim Kompilieren sieht: mono_wasm_runtime_ready. Die Angleichung der Klassenbibliotheken bedeutet aber nicht, dass nun alle .NET-Klassen in Blazor WebAssembly funktionieren: Weiterhin wirken die Einschränkungen der Browser-Sandbox und der WebAssembly VM. So sind zum Beispiel Dateisystemzugriffe, Multi-Threading, direkte Datenbankzugriffe und andere Netzwerkprotokolle als HTTP/HTTPS weiterhin nicht erlaubt.
Zur Leistungssteigerung von Blazor WebAssembly hatte Microsoft das Komponentenrendering, die JSON-Serialisierung und die Interoperabilität mit JavaScript in Preview 7 beschleunigt (Abb. 1). Neue Blazor-Funktionen gibt es erst seit .NET 5.0 Preview 8.

Wichtigste Neuerung für Blazor WebAssembly 5.0 ist die in der ersten Version (mit Versionsnummer) schmerzlich vermisste Möglichkeit, Anwendungsteile nachzuladen. Lazy Loading von DLLs aus referenzierten Projekten ist nun möglich, wie Abbildung 2 zeigt. Das neu eingeführte Pre-Rendering bei Blazor WebAssembly lässt die erste Seite schneller erscheinen. Auch das Nachladen von JavaScript-Dateien bei Bedarf wird unterstützt. Zudem gibt es CSS-Isolation: Jede Razor Component kann eine eigene CSS-Datei (Komponentenname.razor.css) besitzen, und die dort enthaltenen Styles gelten nur für diese Komponente. JavaScript-Nachladen und CSS-Isolation funktionieren auch in Blazor Server.

Für beide Blazor-Varianten gibt es neue Steuerelemente: <InputRadio> und <InputRadioGroup> sowie <InputFile> zum Dateiupload. Auch kann man nun den Fokus über ElementRef.FocusAsync() auf ein HTML-Element setzen; bisher brauchte man dazu JavaScript. Mit dem Zusatzpaket Microsoft.AspNetCore.Components.Web.Extensions kann man auch die Inhalte des <head>-Tag (z. B. Title, Link und Meta) beeinflussen. Die Schnittstelle IAsyncDisposable wird unterstützt, neu ist auch die Schnittstelle IComponentActivator. Das Paket Microsoft.AspNetCore.ProtectedBrowserStorage, das es schon seit August 2019 als experimentelles Paket gibt, soll offiziell einsatzreif werden (aber nur für Blazor Server). Blazor 5.0 bietet seit Release Candidate 1 eine Komponente <Virtualize>, die aus einer Objektmenge nur die sichtbaren Elemente rendert. Grundsätzlich kann der Entwickler beim Rendering von Blazor-WebAssembly-basierten Anwendungen nun wählen, ob eine statische HTML-Seite vorab erzeugt werden soll. Microsoft hat die Ausführungsgeschwindigkeit von Blazor WebAssembly insgesamt deutlich verbessert (vgl. Leistungsmessungen im Blogeintrag). Ebenso unterstützt Blazor nun das Browserereignis ontoggle für das Tag <details>. Die Klasse MouseEventArgs hat nun die Zusatzeigenschaften OffsetX und OffsetY.
Weitere Funktionen, die für Blazor 5.0 ursprünglich geplant waren, darunter AoT-Kompilierung, SVG-Unterstützung sowie Pflichtparameter in Komponenten, wurden leider gestrichen. Die AOT-Kompilierung soll in Blazor 6.0 kommen: „For .NET 6, we expect to ship support for ahead-of-time (AoT) compilation to WebAssembly, which should further improve performance.“
Entity Framework Core hat kurz vor Schluss von Version 5.0 noch zwei seit der ersten Version vermisste und in der Vergangenheit (Version 3.x) schon angekündigte, aber dann verschobene Funktionen implementiert:
Die TPT-Vererbung und die Abstraktion von N:M-Zwischentabellen erleichtern die Migration bestehender Anwendungen vom klassischen Entity Framework 6.x sehr.
Es gibt aber seit Preview 7 noch weitere neue Funktionen in Entity Framework Core 5.0. So ist es nun möglich, dass der OR-Mapper für eine einzige Entitätsklasse beim Lesen der Daten eine Sicht (View), beim Schreiben aber eine Tabelle nutzt. Eine einzelne .NET-Klasse kann jetzt durch Indexer Properties Basis für mehrere verschiedene Entitätstypen sein. Solche Shared Type Entities erlauben es, zur Laufzeit der Anwendung Tabellen aus der Datenbank abzubilden, die es zur Entwicklungszeit noch gar nicht gab. Shared Type Entities sind die Basis für die N:M-Abstraktion. Table-Valued-Functions können jetzt nicht nur wie bisher mit FromSqlRaw() bzw. FromSqlInterpolated() aufgerufen werden, sondern der Entwickler kann sie auch direkt auf .NET-Methoden abbilden. Die in Preview 6 neu eingeführten Split Queries können nicht nur pro Abfrage mit AsSplitQuery(), sondern auch zentral mit UseQuerySplittingBehavior() konfiguriert werden. Die vorher schon mögliche Abbildung von Typen auf beliebige SQL-Befehle (Defining Queries) ist mit ToSqlQuery() mächtiger geworden.
Neu ist auch, dass Tabellen mit ExcludeFromMigrations() aus den Schemamigrationen ausgeschlossen werden können. Schemamigrationen führt der OR-Mapper nun im Standard in Transaktionen aus. Per Kommandozeilenbefehl (dotnet ef migrations list) oder Commandlet (Get-Migration) kann man sich ausstehende Migrationen auflisten lassen. Für Schemamigration in SQLite-Datenbanken ist nun auch ein Sichern des Inhalts und Neuanlegen der Tabelle als Schemamigrationsstrategie möglich. Ebenso hat Microsoft in Entity Framework Core 5.0 noch drei Ereignisse ergänzt, die beim Speichern in der Kontextklasse ausgelöst werden: SavingChanges(), SavedChanges() und SaveChangesFailed(). Einfluss auf den Speichervorgang kann der Entwickler in einem sogenannten SaveChangesInterceptor nehmen. Die Größe der in einem Update-, Insert- oder Delete-Batch zur Datenbank gesendeten Befehle hat Microsoft nun im Standard auf 42 (sic!) gesetzt. Diese Zahl ist nicht willkürlich, sondern ist angeblich das gemessene Optimum. Zur Diagnose des Verhaltens des OR-Mappers kann der Betreiber einer Anwendung nun folgendermaßen Event Counter des OR-Mappers abrufen: dotnet counters monitor Microsoft.EntityFrameworkCore.
Click-Once-Deployment ist ein seit Langem etabliertes und in der .NET-Welt sehr beliebtes Verfahren zur Verbreitung von .NET-Anwendungen. Es existiert seit Version 2.0 des klassischen .NET Frameworks. Es erlaubt die einfache Verteilung und automatische Aktualisierung von Windows-Anwendungen über Netzwerklaufwerke und Webserver. Die Installation einer Click-Once-basierten Anwendung ist für jeden Windows-Benutzer ohne Administratorrechte möglich und erfolgt im lokalen Benutzerverzeichnis. Das Click-Once-Deployment war nicht in .NET Core 1.0 bis 3.1 enthalten und nach der Microsoft-Ankündigung des Jahres 2019, dass die Übernahme von Funktionen aus dem klassischen .NET Framework nach .NET Core abgeschlossen sei, galt somit auch das Click-Once-Deployment als ausgestorbene Technik. Im Juli 2020 hatte Microsoft dann aber auf GitHub verkündet, dass das beliebte Verfahren in .NET 5.0 nun doch zurückkehren soll.
Click-Once-Deployment ist seit Oktober 2020 nun nicht nur für .NET 5.0, sondern auch für .NET Core 3.0 und 3.1 verfügbar. Ein Click-Once-Deployment-Paket kann der Entwickler über Visual Studio (ab Version 16.8 Preview 5) über Deploy | Folder | Click-Once (Abb. 3 und 4) oder das Kommandozeilenwerkzeug dotnet-mage für das .NET SDK CLI erstellen (Listing 1).
dotnet tool install -g Microsoft.DotNet.Mage cd t:\NET5WPF\bin\Debug\net5.0-windows\ md files mage.net -al NET5WPF.exe -td files mage.net -new application -t files\NET5WPF.manifest -fd files -v 1.0.0.1 mage.net -new Deployment -install true -pub "NET5WPF Publisher" -v 1.0.0.1 -Appmanifest files\NET5WPF.manifest -t NET5WPF.application
Gegenüber dem originalen Click-Once-Deployment in .NET Framework gibt es allerdings Einschränkungen. So sind Programmaktualisierungen nur beim Anwendungsstart, nicht jedoch beim Beenden oder durch Benutzeraktion im Betrieb möglich.


Bei .NET 5.0 ist zu beachten, dass es sich dabei nicht um eine Long-Term-Support-Version handelt wie bei .NET Core 2.1 und .NET Core 3.1, sondern um eine Current-Version, für die es nur drei Monate nach dem Erscheinen der Folgeversion Support gibt. Microsoft hat bisher kein .NET 5.1 angekündigt, sondern nur für November 2021 ein .NET 6.0. Wenn das so bleibt, gibt es für .NET 5.0 Unterstützung bis zum Februar 2022. Auch .NET Core 3.0 war eine Current-Version; der Support endete schon im März 2020, da .NET Core 3.1 im Dezember 2019 erschien. Inzwischen weist Visual Studio die Entwickler in der Target-Framework-Auswahl eines Projekts auf die Supportrichtlinien hin (Abb. 5). Erst .NET 6.0 soll wieder einen Long-Term-Support mit drei Jahren Unterstützung erhalten. Jede gerade Version in ungeraden Jahren (also dann wieder .NET 8.0 im Jahr 2023) soll eine Long-Term-Support-Version werden. Die zehn Jahre Support, die es für das klassische .NET Framework gab, gibt es in der neuen agilen .NET-Welt leider nicht mehr.

Beim Application Trimming im Rahmen von dotnet publish hat Microsoft in .NET 5.0 den neuen Modus <TrimMode>Link</TrimMode> eingeführt. Im Gegensatz zum bisherigen <TrimMode>copyused</TrimMode> werden nicht nur ungenutzte Assemblies, sondern per Tree Shaking auch ungenutzte Typen und Mitglieder entfernt. Das Trimming schaltet man wie bisher mit <PublishTrimmed>true</PublishTrimmed> ein; copyused ist dann Standard. Das Trimming nimmt einige Zeit in Anspruch.
Zur Problemdiagnose können Entwickler in .NET 5.0 auch Dump-Dateien von .NET-Prozessen auf macOS erstellen und Linux-Dumps in Windows auswerten. Die Formatierung von Ausgaben des ConsoleFormatter ist jetzt anpassbar. Ein neuer JSON Console Logger liefert Ausgaben im JSON-Format. Mit dem neuen .NET-CLI-basierten Kommandozeilenwerkzeug dotnet-runtimeinfo kann man sich Basisinformationen über das Betriebssystem und die aktuelle .NET-Version liefern lassen.
Microsoft hat kurz vor Schluss noch einige schöne Funktionen bei .NET 5.0 ergänzt. Aber es sind leider auch einige Punkte nicht fertig geworden und wurden auf .NET 6.0 verschoben. Sehr schmerzhaft ist das Fehlen der Ahead-of-Time-Kompilierung, insbesondere für Blazor WebAssembly. Dort wird also weiterhin .NET Intermediate Language in den Browser geladen und interpretiert. Das bedeutet, dass beim Anwendungsstart mehrere MB in den Browser gehievt werden müssen und die Ausführungsgeschwindigkeit weiterhin nicht an Web-Frameworks wie Angular heranreicht. .NET 5.0 ist nicht der große Wurf, der er ursprünglich sein sollte. .NET 5.0 ist eher ein „.NET Core 4.0“. Aber Microsoft signalisiert mit der Wahl der Versionsnummer 5.0 klar, dass die Ära von .NET Framework und .NET Core damit beendet ist.
Natürlich muss man nicht zwingend migrieren. Das .NET Framework 4.8 will Microsoft weiterhin mit Patches versorgen und „für immer“ mit Windows ausliefern. .NET Core 2.1 wird noch bis zum 21.08.2021, .NET Core 3.1 bis 03.12.2022 unterstützt. Aufgrund der Nähe von .NET Core 3.1 zu .NET 5.0 laufen einige Innovation aus .NET 5.0 auch auf .NET Core 3.1, z. B. C# 9.0 und das portierte Click-Once-Deployment.
The post .NET 5.0 ist da: Alles, was Sie über den neuen Release wissen müssen appeared first on BASTA!.
]]>The post C# Source Generators: Wie Sie Ihre Entwicklungsprozesse mit automatisiertem Code beschleunigen appeared first on BASTA!.
]]>Wie auch beim Compiler geht Microsoft im Bereich Codegenerierung weg von Lösungsansätzen, die an eine bestimmte IDE gebunden sind. Wenn Code zur Entwicklungs- oder Übersetzungszeit generiert werden soll, gibt es eigentlich nur einen Platz, an den eine solche Komponente gut hinpasst: Roslyn. Microsoft hat für Roslyn vor einigen Monaten die neue C#-Source-Generator-Funktion als Preview vorgestellt. Sie löst Werkzeuge wie T4 zum Generieren von Code zur Übersetzungszeit ab. Code- oder Textgenerierung zur Laufzeit ist kein Thema für die neuen Source Generators.
Regelmäßig News zur Konferenz und der .NET-Community
Bevor wir uns ansehen, wie C# Source Generators funktionieren, behandeln wir mögliche Einsatzszenarien. Das erste und offensichtlichste Einsatzszenario ist, Codeteile, die keine originäre Logik abbilden, sondern nach einem fixen Schema erstellt werden, automatisch zu generieren. Ein typisches Beispiel ist das in C# gut bekannte INotifyPropertyChanged-Interface. Es ist langweilig und zeitraubend, für eine C#-Klasse mit normalen Properties INotifyPropertyChanged zu implementieren. Man braucht dafür keine Kreativität, es ist einfach nur eine Menge Tipparbeit. Diese Aufgabe könnte ein Generator übernehmen. Ein weiteres Beispiel ist die Generierung von Modellklassen auf Basis von strukturierten Dateien wie zum Beispiel CSV, XML oder JSON. Viele Leserinnen und Leser haben sicherlich schon die diversen Internetseiten zum Generieren von C#-Klassen aus solchen Dateien genutzt, weil man sich die Arbeit des manuellen Erstellens des entsprechenden Codes sparen will. Auch in einem solchen Szenario könnte ein C# Source Generator das Codegenerieren übernehmen.
Erfahrene C#-Entwicklerinnen und -Entwickler könnten an dieser Stelle einwenden, dass man schon jetzt Code generieren kann, unter anderem mit den Klassen aus dem Namespace System.Reflection.Emit oder mit Hilfe von Expression Trees. Ideal sind solche Ansätze aber nicht. Erstens sind sowohl Reflection.Emit als auch Expression Trees komplex zu verwenden und zweitens erfolgt die Codegenerierung zur Laufzeit. Das beeinflusst die Performance negativ.
Neben dem Automatisieren von Routinetätigkeiten gibt es noch weitere Einsatzbereiche von Codegenerierung, die nicht so offensichtlich sind. Ein Beispiel ist Dependency Injection (kurz DI). Die DI-Magie von ASP.NET basiert heute zu großen Teilen auf Reflection. Controller werden zur Laufzeit über Reflection gesucht. Die Konstruktorparameter werden mit Hilfe von Reflection untersucht und die notwendigen Werte werden zur Laufzeit bereitgestellt. Funktional ist das einwandfrei. Es hat jedoch zwei wesentliche Nachteile: Erstens braucht der Einsatz von Reflection zur Laufzeit CPU-Zeit und verlangsamt daher den Start einer Webanwendung. Dieser Performancenachteil ist zwar nicht riesig, er macht sich aber speziell bei Cloud-Native-Lösungen bemerkbar, bei denen häufig Serverinstanzen neu starten (z. B. Cold Start bei Serverless Functions, Scale Out bei Autoscaling).
Zweitens erschwert Reflection das Optimieren des Codes durch einen Linker beim Ahead-of-Time-Übersetzen (kurz AOT). Der Compiler könnte beim Einsatz von AOT Teile des Programms, die nicht verwendet werden, entfernen und dadurch die Größe der Anwendung reduzieren. Wenn aber Reflection zum Einsatz kommt, tut sich der Compiler schwer, zu erkennen, was zur Laufzeit benötigt wird und was nicht. Durch Generierung von Source Code könnte man einen grundlegend neuen Ansatz für DI verfolgen. Die Abhängigkeiten könnten zur Übersetzungszeit analysiert und der sich ergebende Code könnte generiert werden. Reflection würde zur Laufzeit komplett entfallen und der Compiler könnte unnötige Codeteile problemlos entfernen. In anderen Programmiersprachen wird dieser Ansatz zum Teil bereits eingesetzt (vgl. Wire-Komponente von Google für Go).
Das Entwickeln eines C# Source Generators hat Ähnlichkeit mit dem Programmieren eines Roslyn Analyzers. Wer daher einen Generator schreiben möchte, sollte mit dem Roslyn API vertraut sein. Aus Platzgründen enthält dieser Artikel keine Einleitung in die Programmierung mit Roslyn. In einem Artikel wäre das auch unmöglich zu schaffen, man bräuchte eine ganze Artikelserie. Wer noch nie mit Roslyn entwickelt hat, braucht aber keine Angst zu haben. Die wichtigsten Konzepte werde ich erklären und die Codebeispiele sind einfach gehalten. Bei der Planung einer eventuellen Generatorentwicklung sollte man aber nicht vergessen, Zeit für die Einarbeitung in die Roslyn-Grundlagen einzuplanen. Technisch gesehen ist ein Generator eine .NET Standard 2.0 Class Library, die zumindest die NuGet-Pakete Microsoft.CodeAnalysis.Analyzers und Microsoft.CodeAnalysis.CSharp referenziert. Zum Zeitpunkt des Schreibens dieses Artikels war die C#-Source-Generator-Funktion noch in der Preview-Phase. Man musste daher die Preview-Pakete verwenden, um Generatoren programmieren zu können.
In dem Assembly, in dem man Code durch den Generator erzeugen will, referenziert man die Generator Class Library wie einen Roslyn Analyzer. Wenn C# Source Generators einmal etabliert sein werden, wird man sich die Generatoren, die man möchte, so von NuGet holen, wie man das heute mit Roslyn Analyzers macht. Da wir in diesem Artikel hinter die Kulissen von Generatoren schauen wollen, gehe ich davon aus, dass wir eine Solution haben, in der sowohl der Generator als auch das Programm enthalten sind, in dem der Code generiert werden soll. In diesem Fall referenziert man den Analyzer mit einer Projektreferenz mit den Optionen OutputItemType=”Analyzer” und ReferenceOutputAssembly=”false“. Abbildung 1 zeigt die Projektkonfiguration eines Generators aus einem Beispielprojekt von mir.

Der Roslyn-C#-Compiler erkennt, dass ein Source Generator referenziert wurde und führt ihn im Rahmen des Kompilierens der Anwendung automatisch aus. Visual Studio erkennt die Referenz auf den Generator ebenfalls und lässt ihn schon während des Editierens laufen. Dadurch erhält man in Visual Studio IntelliSense für den generierten Code. In der Praxis gibt es hier aber noch eine Menge Verbesserungsbedarf. Bei meinen bisherigen Versuchen mit der aktuellen Visual-Studio-2019-Preview-Version funktionierte IntelliSense in Verbindung mit den C# Source Generators nur bedingt. Auch für das Debuggen von Generatoren gibt es noch keine befriedigende Lösung. Das kann man zum Teil umgehen, indem man sich für die Logik des Generators eigene Unit-Tests schreibt und sie bei Bedarf mit dem Debugger startet. Alles in allem muss man sich aber auf einige Ecken und Kanten einstellen, wenn man schon jetzt in die Entwicklung von Generatoren einsteigt.
Der Generator selbst ist eine C#-Klasse, die das Interface ISourceGenerator implementiert und die mit dem Attribut Generator versehen ist. ISourceGenerator verlangt zwei zu implementierende Methoden:
Lassen Sie uns zum Starten einen Blick auf ein „Hello World“-Beispiel werfen. Listing 1 enthält einen einfachen Generator, der eine statische Klasse HelloWorld mit einer statischen Methode SayHello generiert. Diese Methode gibt eine Liste aller .cs-Dateien des Projekts auf der Konsole aus. In diesem einfachen Beispiel lassen wir die Initialize-Methode leer. In Execute verwenden wir einen StringBuilder, um den generierten Code zusammenzubauen. Als Grundlage für das Codegenieren dienen uns die Roslyn Syntax Trees, auf die wir über GeneratorExecutionContext.Compilation.SyntaxTrees Zugriff haben. Im Programm, das den Generator referenziert, können wir den generierten Code mit HelloWorldGenerated.HelloWorld.SayHello() aufrufen und sehen dadurch die Liste der .cs-Dateien unseres Projekts auf dem Bildschirm.
using System;
using System.Collections.Generic;
using System.Text;
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.Text;
namespace SourceGeneratorSamples
{
[Generator]
public class HelloWorldGenerator : ISourceGenerator
{
public void Initialize(GeneratorInitializationContext context) { }
public void Execute(GeneratorExecutionContext context)
{
// Start building C# code
var sourceBuilder = new StringBuilder(@"
using System;
namespace HelloWorldGenerated
{
public static class HelloWorld
{
public static void SayHello()
{
Console.WriteLine(""The following syntax trees existed in the compilation that created this program:"");
");
// Get a list of syntax trees (.cs files)
var syntaxTrees = context.Compilation.SyntaxTrees;
// Add output of each file path for each syntax tree
foreach (SyntaxTree tree in syntaxTrees)
{
sourceBuilder.AppendLine($@"Console.WriteLine(@"" - {tree.FilePath}"");");
}
// Close generated code block
sourceBuilder.Append(@"
}
}
}");
// Inject the created source
context.AddSource("helloWorldGenerated", SourceText.From(sourceBuilder.ToString(), Encoding.UTF8));
}
}
}
Jetzt, da wir die Grundlagen kennen, bauen wir einen Generator, der erstens auf bestehendem Code aufbaut und zweitens das semantische Modell des bestehenden Codes analysiert. Der Code, den ich in diesem Teil des Artikels zeige, ist Teil eines größeren Beispiels, das ich für .NET- und C#-Workshops und Trainings entwickelt habe. Interessierte Leserinnen und Leser finden es auf GitHub.
In diesem Beispiel geht es darum, Computerspieler für ein klassisches Schiffe-versenken-Spiel zu identifizieren. Man erkennt Computerspielerklassen daran, dass sie von der Basisklasse PlayerBase abgeleitet sind. Natürlich könnte man das Problem lösen, indem man zur Laufzeit über Reflection die entsprechenden Klassen heraussucht. Über die Probleme, die dieser Lösungsansatz mit sich bringt, habe ich oben schon geschrieben. In diesem Artikel möchten wir über einen C# Source Generator automatisch eine Datenstruktur erzeugen, in der alle Computerspieler referenziert sind. Reflection ist dadurch zur Laufzeit nicht mehr notwendig.
Listing 2 zeigt den ersten Teil unseres Generators. Im Mittelpunkt steht die zuvor schon erwähnte Initialize-Methode, die im „Hello World“-Beispiel noch leer war. Listing 2 zeigt, wie man in Initialize einen Syntax Receiver registriert. In unserem Syntax Receiver prüfen wir bei jeder Klassendeklaration, ob die Klasse eine Basisklasse hat. Die Klassen, bei denen das der Fall ist, sind potenziell zu berücksichtigende Computerspieler. Wir sammeln alle Kandidatenklassen in einer Liste, auf die wir später in Execute zurückgreifen werden.
namespace NBattleshipCodingContest.PlayersGenerator
{
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Microsoft.CodeAnalysis.Text;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
/// <summary>
/// Generates a static list of battleship players.
/// </summary>
/// <remarks>
/// This generator makes runtime reflection for identifying battleship player no
/// longer necessary. Leads to faster startup.
/// </remarks></span>
[Generator]
public class PlayersGenerator : ISourceGenerator
{
/// <summary>
/// Visitor class that finds possible players.
/// </summary>
internal class SyntaxReceiver : ISyntaxReceiver
{
public List<ClassDeclarationSyntax> CandidateClasses { get; } = new();
public void OnVisitSyntaxNode(SyntaxNode syntaxNode)
{
// Players must derive from PlayerBase -> candidate classes must
// have at least one base type.
if (syntaxNode is ClassDeclarationSyntax cds && cds.BaseList != null && cds.BaseList.Types.Any())
{
CandidateClasses.Add(cds);
}
}
}
public void Initialize(GeneratorInitializationContext context) =>
context.RegisterForSyntaxNotifications(() => new SyntaxReceiver());
...
}
}
Listing 3 enthält die Execute-Methode unseres Generators. Hier einige wichtige Hinweise zum Code:
public void Execute(GeneratorExecutionContext context)
{
if (context.SyntaxReceiver is not SyntaxReceiver receiver || receiver.CandidateClasses == null)
{
throw new InvalidOperationException("Wrong syntax receiver or receiver never ran. Should never happen!");
}
// Begin creating the source we'll inject into the users compilation
StringBuilder sourceBuilder = new(@"
namespace NBattleshipCodingContest.Players
{
using System;
public static class PlayerList
{
public static readonly PlayerInfo[] Players = new PlayerInfo[]
{
");
// Mandator base class for players
var playerBaseSymbol = context.Compilation.GetTypeByMetadataName("NBattleshipCodingContest.Players.PlayerBase");
if (playerBaseSymbol == null)
{
return;
}
// Attribute used to ignore specific players (e.g. players that crash or are not finished)
var playerIgnoreSymbol = context.Compilation.GetTypeByMetadataName("NBattleshipCodingContest.Players.IgnoreAttribute");
if (playerIgnoreSymbol == null)
{
return;
}
var playerClasses = new List<INamedTypeSymbol>();
foreach (var f in receiver.CandidateClasses)
{
var model = context.Compilation.GetSemanticModel(f.SyntaxTree);
if (model.GetDeclaredSymbol(f) is not INamedTypeSymbol ti)
{
continue;
}
// Check whether the class has the correct base class
if (!ti.BaseType?.Equals(playerBaseSymbol, SymbolEqualityComparer.Default) ?? false)
{
continue;
}
// Check whether the class has no ignore attribute
if (!ti.GetAttributes().Any(a => a.AttributeClass?.Equals(playerIgnoreSymbol, SymbolEqualityComparer.Default) ?? false))
{
// Found a player
playerClasses.Add(ti);
}
}
// Add all players to generated code
sourceBuilder.Append(string.Join(",", playerClasses.Select(c =>
{
var displayString = c.ToDisplayString(SymbolDisplayFormat.FullyQualifiedFormat);
return @$"new PlayerInfo(""{displayString}"", () => new {displayString}())";
})));
// finish creating the source to inject
sourceBuilder.Append(@"
};
}
}");
// inject the created source into the users compilation
context.AddSource("PlayersGenerated", SourceText.From(sourceBuilder.ToString(), Encoding.UTF8));
}
Die Listings in diesem Artikel sind im Vergleich zum Code auf GitHub etwas vereinfacht. Ich habe hier die Unit-Tests weggelassen. Interessierte Leserinnen und Leser finden den Testcode im GitHub Repository.
Aus meiner Sicht schließt Microsoft mit den C# Source Generators eine wichtige Lücke, die es in Roslyn und C# seit dem De-facto-Wegfall von T4 Templates gibt. Ich vermute, dass ich in meinen Projekten in Zukunft viele Anwendungsfälle für C# Source Generators finden werde. Im Lauf der Zeit erwarte ich mehr und mehr fertige Generatoren von Microsoft und von Drittanbietern und es wird seltener werden, dass man sich individuelle Generatoren selbst programmieren muss. Es ist außerdem wahrscheinlich, dass Microsoft Generatoren intern in Frameworks wie ASP.NET nutzen wird, um Reflection-basierenden Code zu reduzieren.
Jetzt ist die richtige Zeit, um mit den Generatoren zu experimentieren und sich mit dem API vertraut zu machen. Ein Nebeneffekt ist, dass man gezwungen ist, eventuelle Wissenslücken in Sachen Roslyn API zu schließen. Wer sich schon jetzt an eigene Generatoren heranwagt, der muss aber ein wenig Frust aushalten, da das Visual Studio Tooling noch stark verbesserungswürdig ist. Das ändert aber nichts an der Sache, dass C# Source Generators großes Potenzial für zukünftige Projekte haben.
The post C# Source Generators: Wie Sie Ihre Entwicklungsprozesse mit automatisiertem Code beschleunigen appeared first on BASTA!.
]]>The post Container in der Azure Cloud: Best Practices und Strategien für die optimale Nutzung appeared first on BASTA!.
]]>Bevor Container immer beliebter wurden, herrschten im standardmäßigen Workflow der Softwareentwicklung noch einige Probleme vor. Insbesondere die beiden nachfolgend beschriebenen waren ziemlich unbequem und erschwerten uns die Arbeit als Entwickler erheblich.
Der erste Fallstrick ist einer der ältesten Programmiererwitze überhaupt, vielleicht sogar älter als der über das Beenden von Vim: Das allzu häufige Problem von Anwendungen, die zwar auf unserer eigenen Maschine laufen, aber nirgendwo sonst. Als Anwendungen komplexer wurden und Entwickler Zugang zu mehr Entwicklungsumgebungen erhielten, stießen wir auf Probleme, wenn es darum ging, alles an einer Vielzahl von Orten gleichermaßen zum Laufen zu bringen. Bisweilen funktioniert eine Anwendung auf dem eigenen Rechner gut, vielleicht sogar auch bei QA und Staging – aber sobald sie in der Produktion eingesetzt wird, schlägt sie aus irgendeinem Grund fehl. Beim Debugging sieht man die Ursache in einer subtilen Abhängigkeit von der eigenen Produktionsumgebung. Vielleicht hat man eine Library-Version, z. B. Entity Framework, auf Version 6.3 aktualisiert, aber die entsprechende Abhängigkeit von .NET Core nicht auf 3.1 aktualisiert. Oder vielleicht wurde die falsche Konfigurationseinstellung angewendet, wodurch ein dev-Wert anstelle eines prod-Werts blieb. Diese Art subtiler Unterschiede in den Umgebungen bereitete Kopfschmerzen und führte nicht selten zu stundenlangem undurchsichtigem Debugging.
Ein weiteres häufiges Szenario: Neueinstellungen von Mitarbeitern. Ich weiß, dass einige Teams das inzwischen sehr gut machen, aber ich erinnere mich an die Tage, an denen neue Kollegen eingestellt wurden, und wie der Prozess der Einrichtung ihrer Entwicklungsumgebung eine ganze Woche dauern konnte. Manchmal erhalten sie den Rechner eines Vorgängers, und wenn wir Glück haben, bleiben die meisten Abhängigkeiten unserer Codebasis bestehen. Am wahrscheinlichsten ist jedoch, dass unsere neuen Kollegen einen völlig neuen oder komplett gelöschten Rechner erhalten und wir ihn von Grund auf neu einrichten müssen. Denken Sie jetzt an das letzte Mal, als Sie einem Kollegen helfen mussten, Ihre Codebasis von Grund auf neu einzurichten. Es sollte keine Überraschung sein, dass wir, nachdem wir uns mit unseren eigenen Umgebungen vertraut gemacht haben, alle gelernten Macken, zusätzlichen Schritte und die vollständige Liste der Abhängigkeiten vergessen, die erforderlich sind, um die Codebasis startklar zu machen. Diese Art von Szenarien war für Container wie geschaffen.
In einer idealen Welt könnten sich alle Entwickler auf die Erstellung von Anwendungen für eine einzige Plattform konzentrieren. Die Realität sieht jedoch so aus, dass viele Anwendungen mehrere Plattformen und Geräte unterstützen müssen. Und nun, da Cloud-Anbieter immer häufiger als Hosts für unsere Anwendungen auftreten, sind Lift and Shifts in die Cloud auf die Portabilität dieser Anwendungen angewiesen. Vor der Einführung von Containern wurde das durch mühevoll erstellte Konfigurationsskripte, die Verwaltung vieler Umgebungsvariablen oder im schlimmsten Fall durch redundante und replizierte Codebasen erreicht, die auf eine bestimmte Plattform zugeschnitten waren. Zwar funktionierte das, aber es wurden viele Stunden damit verbracht, diese Kompatibilitäten für spezifische Umgebungen zu entwerfen und zu planen. Noch mehr Stunden wurden für die Fehlersuche bei Problemen aufgewendet, die durch diese unterschiedlichen Umgebungen verursacht wurden.
Es gibt viele Möglichkeiten, Container zu beschreiben, doch diese halte ich für die simpelste: „Ein Container ist ein unabhängiges Paket von Software und deren Abhängigkeiten.“ Im Zusammenhang mit der Softwareentwicklung erlaubt uns diese Definition, uns auf die praktische Anwendbarkeit von Containern zur Lösung der zuvor diskutierten Probleme zu konzentrieren. Schlüsseln wir diese Definition einmal auf: Was meinen wir, wenn wir von Abhängigkeiten sprechen? Das sind all die Dinge, die die Anwendung erfordert, um ihre eigene Umgebung zu bauen und darin zu laufen. Das beinhaltet natürlich unseren Quellcode, aber auch die spezifischen Laufzeiten und bestimmte Bibliotheksversionen sowie alle Konfigurationseinstellungen, die unsere Anwendung benötigt. Diese Abhängigkeiten werden dann zu einem unabhängigen Paket gebündelt. Das Paket ist portabel, vorhersehbar und zuverlässig, weil es alles enthält. Zu diesem Zeitpunkt kümmert es uns nicht und es spielt auch keine Rolle, wo dieses Paket eingesetzt wird; das Paket ist selbsterhaltend. Diese Option hat sich bei der Lösung der kniffligen Probleme, die wir besprochen haben, als effektiv erwiesen. Vorbei sind die Zeiten des umgebungsbezogenen Troubleshootings und Debuggings. Neue Kollegen haben nicht mehr eine lange Anlaufzeit, um ihre Entwicklungsumgebung korrekt einzurichten. Durch die Containerisierung der Anwendungen muss sich das Entwicklungsteam mit vielen der Problemszenarien nicht mehr herumplagen.
Falls Sie sich jetzt fragen, wie das Ganze zu bewerkstelligen ist, zeige ich Ihnen gerne, wie das geht – und zwar mit den Azure Container Services. Im Speziellen bietet Azure die folgenden vier an:
Wir werden nachfolgend besprechen, was jeder dieser Services ist bzw. nicht ist, und entsprechende Demos anschauen.
Genauso, wie wir unseren Quellcode versionieren und verteilen können, können wir das mit Container-Images tun. Das sind die statischen Dateien, die als Snapshots für unsere eigentlichen Container dienen. Sie enthalten die Anweisungen und Abhängigkeiten, die man zum Bau eines Containers benötigt. Man kann sich Container-Images als Rezepte für einen Kuchen und Container als tatsächliche Instanzen dieses Kuchens vorstellen. Aber zurück zur Repo-Analogie: Azure Container Registries sind die Repos für Container-Images. Sie sind eine Möglichkeit, Container-Images mit anderen zu teilen und zu verteilen, insbesondere innerhalb eines Teams. Wer mit Docker Hub, der öffentlich zugänglichen Open-Source-Quelle für beliebte Basis- und offizielle Images, vertraut ist, kann sich Azure Container Registry in Analogie zu den privaten Repositories von Docker Hub vorstellen. Und genau das ist es, was eine Azure Container Registry ist: ein privater, verwalteter Registry-Dienst. Eine praktische Tatsache der Azure Container Registry ist, dass sie auf der Open-Source-Implementierung von Docker Registry 2.0 basiert. Das bedeutet, dass die Container Registry Docker-kompatible Images sowie grundsätzlich alle Images und Artefakte unterstützt, die der OCI-Spezifikation (Open Container Initiative) entsprechen.
Wie die meisten Azure-Dienste ist auch die Azure Container Registry (zum Zeitpunkt des Schreibens dieses Artikels) in drei Editionen verfügbar:
Basis: Die Basisedition ist die kostengünstigste und eignet sich am besten für persönliche Projekte und kleine Demos wie die, die später in diesem Artikel zu finden ist. Obwohl diese Option alle Kernfunktionen der Standard- und Premiumeditionen bietet, eignet sie sich mit ihren Speicher- und Durchsatzangeboten besser für Prototypen und den Einstieg in die Arbeit mit Containern.
Standard: Diese am häufigsten gewählte Edition dürfte für die meisten Teams passend sein. Sie bietet mehr Speicherplatz und einen höheren Durchsatz als die Basisedition und sollte für die meisten Produktionsszenarien ausreichen.
Premium: Es ist immer wieder interessant zu sehen, was die kostenintensivste Option von den anderen abhebt. Diese Edition ist am besten für Teams geeignet, die sich vollends Containern widmen. Sie ist auch diejenige, die man in Erwägung ziehen sollte, wenn man ein paar zusätzliche Features benötigt, um containerbasierte Lösungen zu unterstützen.
Zunächst einmal bietet die Premiumedition den höchsten Durchsatz, wodurch sie sich perfekt für Docker Pulls über mehrere simultane Nodes eignet. Wer schon ein paar Images gesehen hat, weiß, dass sie manchmal recht groß sein können, sodass zusätzliche Leistung für Szenarien mit hohem Datenaufkommen äußerst wertvoll ist. Darüber hinaus ist die Premiumedition die einzige Edition, die Georeplikation, Content Trust (für die Signierung von Image-Tags mit dem Content-Trust-Modell von Docker), Private Link (mit 10 privaten Endpoints) und vieles mehr unterstützt. Die vollständige Aufschlüsselung der verschiedenen Editionen der Azure Container Registry bietet weitere Informationen. Und schließlich können, so wie auch Repos das Ziel von Continuous-Integration-Workflows sind, Container-Registries das Ziel für Containerentwicklungsworkflows sein. Die meisten Softwareentwicklungsworkflows sind an diesem Punkt ziemlich standardisiert (oder nähern sich diesem Standard an): Entwickler genehmigen einige Änderungen in einem Pull Request, führen diese Änderungen in ihrem Hauptentwicklungszweig zusammen, triggern einen Build, führen einige Tests durch und automatisieren möglicherweise das Deployment, nachdem ein erfolgreicher Build ein Build-Artefakt ergeben hat. Ähnliche Aufgaben im Containerentwicklungsworkflow können mit Azure Container Registry Tasks automatisiert werden, auch bekannt als ACR Tasks. Zu den häufig automatisierten Aufgaben gehören das Rebuildung von Images, wenn sich die Base Images geändert haben, und das Patchen des Betriebssystems und der Frameworks auf Docker-Container.
Anstatt nur darüber zu reden, wie großartig Azure Container Registries sind, können wir nun eines erstellen – und das geht recht schnell. Achtung: Um dieser und den weiteren Demos zu folgen, werden ein Azure-Account und ein Azure-Abonnement sowie das auf den Computer heruntergeladene Azure CLI benötigt. Zudem werden etwas Vertrautheit mit Docker und einige Docker Images auf dem Computer vorausgesetzt. Die Schritte sind wie folgt:
1. Auf einem Terminal seiner Wahl in Azure einloggen; das sollte zu einer Weiterleitung in den Browser führen, wo das Einloggen und Authentifizieren mit Azure erforderlich sind:
az login
2. Eine Resource Group erstellen:
az group create --location <REPLACE-WITH-LOCATION> --name <REPLACE-WITH-RESOURCE-GROUP-NAME> --subscription <REPLACE-WITH-YOUR-SUBSCRIPTION>
An dieser Stelle müssen die genannten Parameter mit den eigenen ersetzt werden. Beispielsweise sieht mein Befehl wie folgt aus:
az group create --location westus2 --name rg_westus2_registry --subscription adrienne-demos
Diese Resource Group wird unserer Container-Registry gewidmet. Das ist eine gute Praxis, die man im Auge behalten sollte, zumal es verbreitet ist, mehrere Ressourcen in einer Resource Group zu haben. Der Grund dafür, dass wir unsere Container-Registry in einer eigenen Resource Group halten wollen, ist, dass wir das versehentliche Löschen von gemeinsam genutzten Container-Images verhindern wollen. Wird die Container-Registry zusammen mit etwas weniger Permanentem gruppiert, z. B. einer Azure-Container-Instanz, ist es wahrscheinlicher, dass die Image-Sammlung beim Löschen der Containerinstanz unbeabsichtigt gelöscht wird. Das vergisst man leicht, also behalten wir die Container-Registry einfach in einer separaten Resource Group, um sicherzustellen, dass deren Löschung explizit erfolgt.
3. Zum Schluss erstellen wir die Container-Registry:
az acr create --resource-group <REPLACE-WITH-NEWLY-CREATED-RESOURCE-GROUP> --name <REPLACE-WITH-REGISTRY-NAME> --sku basic
Mein Befehl sieht beispielsweise so aus:
az acr create --resource-group rg_westus2_registry --name adrienneDemoRegistry --sku basic
Wenn das erfolgreich war, erhalten wir ein großes Objekt als Ausgabe. Innerhalb dieses Objekts suchen wir den Key loginServer und merken uns dessen Wert. Das ist der vollqualifizierte Registry-Name, der in den späteren Tutorials benötigt wird. Mein vollqualifizierter Registry-Name ist beispielsweise adrienneDemoRegistry.azurecr.io. Glückwunsch, Sie haben soeben Ihre erste eigene Azure Container Registry erstellt! Jetzt sind wir bereit, Images zu erhalten.
Bevor wir mit unserer Registry arbeiten können, müssen wir uns zunächst einloggen:
az acr login --name <REPLACE-WITH-YOUR-REGISTRY-NAME>
Auf meinem Computer habe ich bereits einige Docker Images, die ich verwenden möchte. Sollten keine auf dem eigenen Computer vorhanden sein, kann das aci-helloworld-Image heruntergeladen und für den Rest des Tutorials verwendet werden. Wenn man einige Images bezogen hat, können verfügbare Images durch Eingabe des folgenden Docker-Befehls aufgelistet werden:
docker images
Suchen wir nun nach dem Image, das wir verwenden möchten, und taggen es mit dem vollqualifizierten Namen unseres Azure-Container-Registry-Servers:
docker tag <REPLACE-WITH-NAME-OF-IMAGE> <YOUR-REGISTRY-NAME>.azurecr.io/<REPLACE-WITH-NAME-OF-IMAGE>:1
Zum Beispiel sieht mein Befehl so aus:
docker tag aci-hello-demo adrienneDemoRegistry.azurecr.io/aci-hello-demo:1
Es fällt auf, dass hinter dem Image-Namen :1 steht. Dabei handelt es sich um einen Stable Tag. Wir taggen das Image so, weil es die erste Major-Version dieses Image – die zufälligerweise ein Base Image ist – sein wird, das wir zur Registry pushen. Es ist eine gute Idee, Stable Tags für Images zu verwenden, die Updates und Patches erhalten sollen. Stable Tags sollten in Deployments allerdings vermieden werden.
Schließlich pushen wir das getaggte Image zu unserer Registry:
docker push <YOUR-REGISTRY-NAME>.azurecr.io/<YOUR-IMAGE-NAME>:1
Mein Befehl sieht beispielsweise so aus:
docker push adrienneDemoRegistry.azurecr.io/aci-hello-demo:1
Das Image sollte nun in unserer Registry sein. Wir können das mit dem folgenden az-list-Befehl prüfen:
az acr repository list --name <YOUR-REGISTRY-NAME> --output table
Wir haben nun verteilbare Images, aber wo verteilen wir sie? Und wo sind die Container? Hier kommen die anderen beiden Azure Container Services ins Spiel.
Nachdem wir einen Ort zum Speichern und Verteilen unserer Images erstellt haben, gibt es verschiedene Möglichkeiten, sie zu Containern zu deployen. Die erste Option ist Azure Container Instance. Um etwas möglichst schnell zum Laufen bringen oder zu testen, oder wenn man zum ersten Mal mit Containern experimentiert, ist Azure Container Instance die erste Wahl in Azure. Da es vollkommen von Azure gemanagt ist, stellt es auch den einfachsten Weg dar, einen Container in Azure zu betreiben. Wenn einem also nichts an der unterliegenden Infrastruktur seiner Container liegt oder man sich nicht darum kümmern will, sind Azure Container Instances das Mittel der Wahl. Wie bei vielen anderen Rechenleistungen muss man auch hier nur für die Ressourcen zahlen, die man beim Ausführen einer Azure Container Instance verwendet. Wenn man das im Hinterkopf behält, ist es am besten, diese Container für kleinere Projekte und Single Applications zu verwenden. Anwendungen können in ihrem Leistungsverbrauch allerdings stark variieren. Um sich daran anzupassen, bietet Azure Container Instance die Möglichkeit, die exakten CPU-Kerne und den Speicher einzugeben, den man benötigt. Das ist entscheidend, wenn es um den Feinschliff der Ressourcenoptimierung und damit schließlich um die Kosteneinsparung geht.
Kommen wir nun zum praktischen Teil dieses Tutorials und beginnen wir mit dem Deployment eines Containers.
Zuerst werden wir eine weitere Resource Group erstellen, um die Containerinstanz zu beinhalten:
az group create --name <REPLACE-WITH-RESOURCE-GROUP-NAME> --location <REPLACE-WITH-LOCATION>
Mein Befehl sieht beispielsweise so aus:
az group create --name rg_westus2_aci --location westus2
Jetzt müssen wir nur noch einen Container erstellen und das gewünschte Image deployen. Wir können das in einem einzigen Befehl mit ein paar Parametern erledigen, wie in Listing 1 gezeigt wird.
az group create --location <REPLACE-WITH-LOCATION> --name <REPLACE-WITH-RESOURCE-GROUP-NAME> --subscription <REPLACE-WITH-YOUR-SUBSCRIPTION>
An dieser Stelle stellt sich vielleicht einigen die Frage, woher man Registry-Nutzernamen und -Passwort bezieht. Da wir unser Image aus unserer eigenen privaten Azure Container Registry beziehen, werden wir einige Credentials im Befehl in Listing 1 angeben müssen, um Zugriff auf die Registry zu erhalten. Die Best Practice hierfür ist, ein neues Azure Active Directory Service Principal zu erstellen und mit pull-Rechten zu konfigurieren (Listing 2). Man kann auch einen bestehenden Service Principal mit zugewiesener acrpull-Rolle nutzen (Listing 3).
# Source: https://docs.microsoft.com/en-us/azure/container-registry/container-registry-auth-aci#create-a-service-principal #!/bin/bash # Modify for your environment. # ACR_NAME: The name of your Azure Container Registry # SERVICE_PRINCIPAL_NAME: Must be unique within your AD tenant ACR_NAME=<container-registry-name> SERVICE_PRINCIPAL_NAME=acr-service-principal # Obtain the full registry ID for subsequent command args ACR_REGISTRY_ID=$(az acr show --name $ACR_NAME --query id --output tsv) # Create the service principal with rights scoped to the registry. # Default permissions are for docker pull access. Modify the '--role' # argument value as desired: # acrpull: pull only # acrpush: push and pull # owner: push, pull, and assign roles SP_PASSWD=$(az ad sp create-for-rbac --name http://$SERVICE_PRINCIPAL_NAME --scopes $ACR_REGISTRY_ID --role acrpull --query password --output tsv) SP_APP_ID=$(az ad sp show --id http://$SERVICE_PRINCIPAL_NAME --query appId --output tsv) # Output the service principal's credentials; use these in your services and # applications to authenticate to the container registry. echo "Service principal ID: $SP_APP_ID" echo "Service principal password: $SP_PASSWD"
# Source: https://docs.microsoft.com/en-us/azure/container-registry/container-registry-auth-aci#use-an-existing-service-principal #!/bin/bash # Modify for your environment. The ACR_NAME is the name of your Azure Container # Registry, and the SERVICE_PRINCIPAL_ID is the service principal's 'appId' or # one of its 'servicePrincipalNames' values. ACR_NAME=mycontainerregistry SERVICE_PRINCIPAL_ID=<service-principal-ID> # Populate value required for subsequent command args ACR_REGISTRY_ID=$(az acr show --name $ACR_NAME --query id --output tsv) # Assign the desired role to the service principal. Modify the '--role' argument # value as desired: # acrpull: pull only # acrpush: push and pull # owner: push, pull, and assign roles az role assignment create --assignee $SERVICE_PRINCIPAL_ID --scope $ACR_REGISTRY_ID --role acrpull
Wenn wir den gewünschten Service Principal konfiguriert haben, notieren wir uns die Service Principal ID und das Service-Principal-Passwort, denn das werden die Werte sein, die wir in den Parametern —registry-username und —registry-password eintragen.
Der Befehl wird mit den eigenen Parametern vervollständigt und dann ausgeführt. Zum Beispiel sieht mein Befehl aus, wie in Listing 4 gezeigt.
az container create -g rg_westus2_aci --name aci-hello-adrienne --image adrienneDemoRegistry.azurecr.io/aci-hello-demo:1 --dns-name-label hello-adrienne --ports 80 --registry-username AdrienneServicePrincipalId --registry-password AdrienneServicePrincipalPassword
Durch das Ausführen dieses Befehls erstellt Azure den Container, findet das spezifizierte Image und deployt es via einer Azure Container Instance zum Container. Warten wir einen Moment, und wenn wir ein weiteres großes Objekt als Ausgabe erhalten, wissen wir, dass der Befehl erfolgreich verlaufen ist. In diesem Objekt finden wir den fqdn-Schlüssel und kopieren dessen Wert. Wenn er in den Browser eingefügt wird, sollten wir die Anwendung betrachten können, die innerhalb eines Containers und somit innerhalb einer Azure Container Instance läuft.
Nach Beenden dieser Demo dürfen wir nicht vergessen, die Containerinstanz zu löschen. Aus diesem Grund war es praktisch, eine separate Resource Group zu erstellen. Wir können jetzt einfach die Containerinstanz löschen, aber die Container-Registry und somit auch Container-Images behalten. Das wird umso wichtiger, je mehr Images in der Container-Registry gespeichert oder mit anderen Teammitgliedern geteilt werden.
So löschen wir die Containerinstanz:
az group delete --name <YOUR-CONTAINER-RESOURCE-GROUP>
Für langlaufende Anwendungen oder zusätzliches Tooling ist Azure Web App für Container das Mittel der Wahl. Hier können wir die Azure-App-Service-Features nutzen, die möglicherweise schon bekannt sind, sowie auch die besser vorhersehbaren Preismodelle, die in App Services enthalten sind. Dinge wie Deployment Slots für Anwendungsupdates, integrierte Load Balancer, Unterstützung für Traffic-Manager zur Ermöglichung von Multi-Region Failover und vieles weitere werden von Azure Web Apps für Container unterstützt, nicht aber von Azure Container Instances.
Ein weiteres Szenario, für das Azure Web App für Container besser geeignet ist, sind Always-on-Umgebungen, z. B. dedizierte Dev- oder Testumgebungen. Das vorhersehbare Preismodell und flexible Skalierungsoptionen sind dafür geradezu prädestiniert.
Und schließlich gibt es noch Azure Kubernetes Service oder kurz AKS. Diese Option ist am besten für Teams geeignet, die sich ganz dem containerbasierten Ansatz verschrieben haben und sich bereits mit Kubernetes auskennen. Zum Betreiben multipler Container und wenn man einen Hands-off-Ansatz verfolgt, um Cluster zu managen, ist AKS eine großartige Option. Es nimmt dem Team viel an Komplexität und Overhead und übergibt diese stattdessen an Azure. Mühevolle Aufgaben wie Maintenance und Health Monitoring werden von Azure übernommen. AKS selbst ist kostenlos. Man hat einzig die finanzielle Verantwortung für die tatsächlichen Ressourcen, die der Cluster verbraucht. Unter der Haube sind die AKS Nodes in unserem Cluster lediglich Azure VMs, sodass Instanzen, Speicher und Netzwerkressourcen, die wir verwenden, in Rechnung gestellt werden. AKS ist eine solide Wahl, wenn man die flexibelste und zukunftsträchtigste gemanagte Containerumgebung nutzen möchte. Es ist als Kubernetes-konform CNCF-zertifiziert und folgt vielen allgemeinen regulatorischen Compliance-Anforderungen, darunter SOC, ISO, PCI DSS und HIPAA.
Wenn Sie sich noch unsicher sind, welcher Azure Container Service für Sie der richtige ist, können Sie sich in Abbildung 1 einen Überblick über die Unterschiede verschaffen.
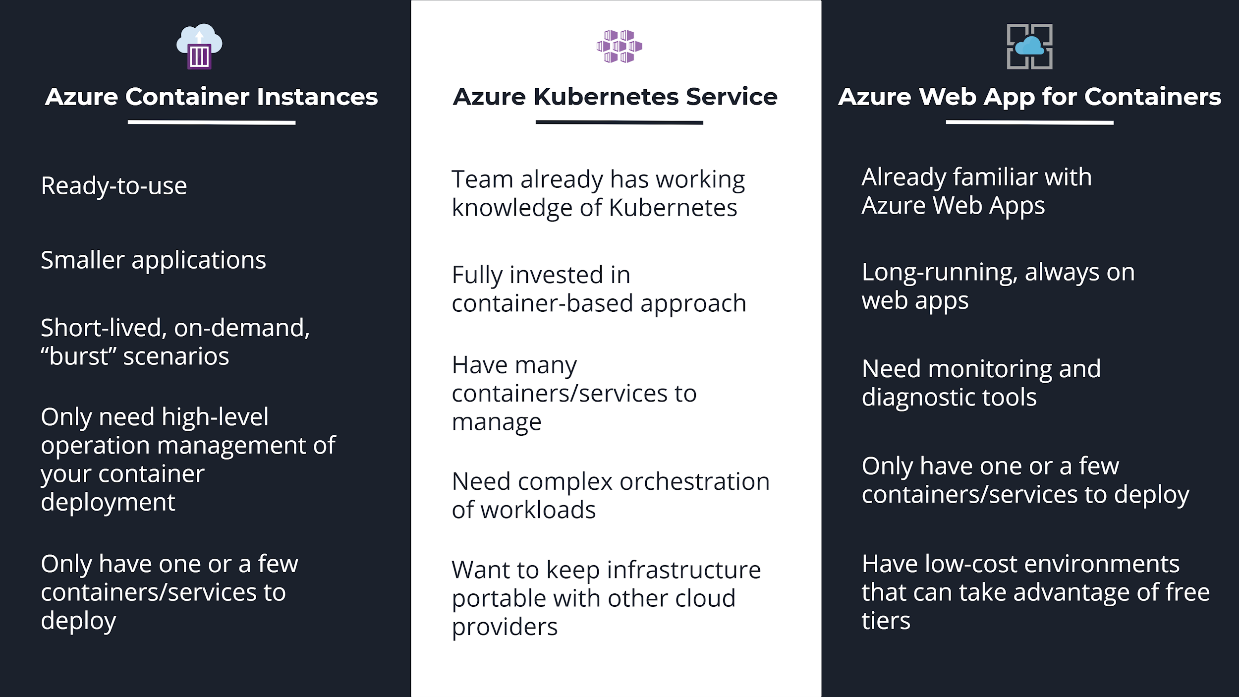
Das war’s schon! Ich hoffe, dass ich Ihnen hiermit die Azure Container Services etwas näherbringen konnte.
The post Container in der Azure Cloud: Best Practices und Strategien für die optimale Nutzung appeared first on BASTA!.
]]>The post Electron.NET von A bis Z: Cross-Plattform-Apps mit .NET und Electron entwickeln appeared first on BASTA!.
]]>Das GitHub-Team hat 2013 das Electron Framework veröffentlicht, um mit JavaScript Cross-Platform-Desktopanwendungen bereitstellen zu können, die auf Windows, Mac und Linux laufen. Eine Vielzahl bekannter Anwendungen läuft auf diesem Framework, zum Beispiel Visual Studio Code, Microsoft Teams, Discord, Postman und viele weitere. Electron.NET nutzt unter der Haube das native Electron Framework, ermöglicht allerdings das Ausführen von .NET-Core-Anwendungen und stellt eine Brücke zum API mittels C# zur Verfügung. .NET-Entwickelnde bleiben damit in ihrem gewohnten Ökosystem und müssen sich nicht mit JavaScript beschäftigen. Ein kompletter Einstieg in Electron.NET wurde bereits im Windows Developer veröffentlicht und kann jetzt kostenlos online gelesen werden. Alternativ gibt es dazu passend eine Live-Stream-Aufzeichnung auf YouTube [3]. Dieser Artikel zeigt einige neue Features sowie wertvolle Tipps und Tricks.
Mit der Veröffentlichung von Electron.NET 5.22.12 haben wir eine neue Versionierung eingeführt. Die aktuelle Version lautet 9.31.2 (Stand 10.08.2020). Die erste Hauptversionsnummer mit der Zahl neun steht für die darunterliegende native Electron-Version. Die zweite Nebenversionsnummer mit der Zahl 31 steht für den Support von .NET Core 3.1. Die letzte Revisionsnummer enthält eigene Erweiterungen und Fehlerbehebungen. Diese wird automatisch auf eins zurückgesetzt, wenn eine neue native Electron-Hauptversion erscheint.
Regelmäßig News zur Konferenz und der .NET-Community
Der Ladevorgang von Electron.NET benötigt etwas mehr Zeit, als man es von herkömmlichen Desktopanwendungen gewohnt ist. Ein Grund ist der lange Initialisierungsvorgang von ASP.NET Core. Electron selbst ist sehr schnell einsatzbereit, wobei Electron.NET die Wartezeit mit einem Begrüßungsbildschirm (Splash Screen) gefühlt verkürzen kann. Nebenbei bemerkt ist der Startvorgang von Electron.NET seit der Version 8.31.1 um bis zu ~25-36 Prozent schneller geworden – und wir arbeiten stetig daran, ihn noch weiter zu beschleunigen.
Für den Splash Screen benötigen wir eine Bilddatei. Der ideale Ort für die Bilddatei ist das wwwroot-Verzeichnis. Unterstützte Bildformate sind JPEG, WEBP, GIF, PNG, APNG, 2D Canvas, XBM, BMP und ICO. In der electron.manifest.json-Datei werden dann der Pfad und der Name der Bilddatei festgelegt (Listing 1). Electron.NET erkennt automatisch, dass ein Splash Screen hinterlegt wurde und zeigt diesen beim nächsten Start an. Die Splash-Screen-Größe wird automatisch der Bildgröße angepasst und kann aktuell nicht selbst verändert werden.
{
"executable": "ElectronNetTest",
"splashscreen": {
"imageFile": "/wwwroot/img/my-splashscreen.jpg"
},
"singleInstance": false,
...
}
Sollte beim Startvorgang der ASP.NET-Core-Anwendung eine Exception ausgelöst werden, wird der Splash Screen nicht beendet und die Anwendung wird nicht geladen. Electron.NET erfährt jedoch nichts von dieser Exception und wartet darauf, bis die Anwendung fertig initialisiert wurde. Ist die Anwendung über das Terminal gestartet worden, hilft hierbei die Tastenkombination STRG + C, um sie manuell zu beenden. Alternativ klickt man auf den Splash Screen und beendet diesen mit der Tastenkombination ALT + F4. Eine eigene Lösung im Code kann diesem unschönen Verhalten entgegenwirken, wie Listing 2 zeigt.
try
{
// ASP.NET Startup code...
throw new Exception("No money!");
}
catch (Exception)
{
Electron.App.Exit();
throw;
}
Die electron.manifest.json-Datei ist ein wichtiger Bestandteil von Electron.NET. Sie beherbergt alle notwendigen Einstellungen, damit die beiden Welten .NET und das native Electron zusammenfinden. Zusätzlich konfiguriert man hier die Details einer App, wie zum Beispiel den Namen der Anwendung, die Herausgeberinformationen, die Version, den Splash Screen, das Anwendungsicon und vieles Weitere. Häufig soll eine Anwendung aus unterschiedlichen Konfigurationen erzeugt werden, z. B. eine Desktopanwendung mit einer Standard- und einer Professional-Edition. Dazu passend sollen auch die unterschiedlichen Splash Screens erscheinen.
Um eine weitere Manifest-Datei zu erzeugen, wird ebenfalls das Electron.NET CLI benötigt. Dazu geben wir in der Konsole innerhalb des Projektverzeichnisses folgenden Befehl ein:
electronize init /manifest test
In dem Projekt wurde jetzt neben der Standard-electron.manifest.json-Datei eine zusätzliche Datei namens electron.manifest.test.json angelegt. In Abbildung 1 wird gezeigt, dass diese beiden Dateien in Visual Studio eingebettet sind.

Wenn wir jetzt in der neuen Manifest-Datei ein anderes Splash-Screen-Bild hinterlegen, wird dieses verwendet, wenn die Anwendung mit folgendem Befehl gestartet wird:
electronize start /manifest electron.manifest.test.json
Das Erzeugen der Desktopanwendung mit der neuen Datei wird dann über folgenden Befehl ermöglicht:
electronize build /target win /manifest electron.manifest.test.json
Der besondere Vorteil von Electron.NET ist, dass kein TypeScript/JavaScript-Code benötigt wird. Dennoch gibt es eine Vielzahl von npm-Paketen, die Electron oder das darunter laufende Node.js bereichern. Um diese ebenfalls in Electron.NET nutzen zu können, existiert das HostHook API. Tatsächlich war dieses Feature eins der gefragtesten in der Community.
Für den eigenen TypeScript/JavaScript-Code oder das zusätzliche Installieren von npm-Paketen wird ein eigenes isoliertes Webprojekt innerhalb der ASP.NET-Core-Anwendung benötigt. Über das Electron.NET CLI wird es durch electronize add hosthook mit einem eigenen Ordner namens ElectronHostHook angelegt.
Das ElectronHostHook-Verzeichnis kann jetzt mit einem Editor, wie zum Beispiel Visual Studio Code, geöffnet werden. Dieser bietet eine perfekte Unterstützung für die Webentwicklung von TypeScript. In einem kleinen Beispiel soll gezeigt werden, wie mittels TypeScript und Node.js eine Excel-Datei erzeugt wird. Für das Erzeugen von Excel-Dateien eignet sich die Node.js-Bibliothek ExcelJS. Sie wird installiert, indem wir per Terminal innerhalb des ElectronHostHook-Verzeichnisses npm install exceljs eingeben.
Wir legen dann eine neue TypeScript-Datei mit dem Namen excelCreator.ts an. Der Code aus Listing 3 erzeugt eine Excel-Datei mit einigen Beispieldaten.
import * as Excel from "exceljs";
import { Workbook, Worksheet } from "exceljs";
export class ExcelCreator {
async create(path: string): Promise<string> {
const workbook: Workbook = new Excel.Workbook();
const worksheet: Worksheet = workbook.addWorksheet("My Sheet");
worksheet.columns = [
{ header: "Id", key: "id", width: 10 },
{ header: "Name", key: "name", width: 32 },
{ header: "Birthday", key: "birthday", width: 10, outlineLevel: 1 }
];
worksheet.addRow({ id: 1, name: "John Doe", birthday: new Date(1970, 1, 1) });
worksheet.addRow({ id: 2, name: "Jane Doe", birthday: new Date(1965, 1, 7) });
await workbook.xlsx.writeFile(path + "\\sample.xlsx");
return "Excel file created!";
}
}
Im ElectronHostHook-Verzeichnis befindet sich die index.ts-Datei (Listing 4). Sie wird automatisch beim Starten des nativen Electron ausgeführt. Der Konstruktor stellt hierbei sogar die Verbindung zur Electron IPC (Inter-Process Communication) und Electron-App-Instanz zur Verfügung. Die Basisklasse Connector sorgt dafür, dass eine onHostReady()-Funktion aufgerufen wird, wenn der native Electron-Prozess einsatzbereit ist. Innerhalb dieser Funktion kann dann für die IPC TypeScript-/JavaScript-Code hinterlegt werden. In diesem Beispiel soll dann der Code zum Ausführen des eigenen ExcelCreator erfolgen. Ist die asynchrone Arbeit erledigt, wird das Ergebnis mittels der done-Callback-Funktion an die IPC zurückgeliefert.
// @ts-ignore
import * as Electron from "electron";
import { Connector } from "./connector";
import { ExcelCreator } from "./excelCreator";
export class HookService extends Connector {
constructor(socket: SocketIO.Socket, public app: Electron.App) {
super(socket, app);
}
onHostReady(): void {
// execute your own JavaScript host logic here
this.on("create-excel-file", async (path, done) => {
const excelCreator: ExcelCreator = new ExcelCreator();
const result: string = await excelCreator.create(path);
done(result);
});
}
}
Über die statische Property Electron.HostHook kann in C# auf das HostHook API zugegriffen werden. Die CallAsync-Methode dient einer asynchronen Verarbeitung, bei der eine Antwort erwartet wird. Der Code aus Listing 5 zeigt, wie in C# der eigene TypeScript-/JavaScript-Code ausgelöst wird und wie wir an das Ergebnis gelangen.
var mainWindow = Electron.WindowManager.BrowserWindows.First();
var options = new OpenDialogOptions
{
Properties = new OpenDialogProperty[]
{
OpenDialogProperty.openDirectory
}
};
var folderPath = await Electron.Dialog.ShowOpenDialogAsync(mainWindow, options);
var resultFromTypeScript = await Electron.HostHook.CallAsync<string>("create-excel-file", folderPath);
Electron.IpcMain.Send(mainWindow, "excel-file-created", resultFromTypeScript);
Für das Setzen von Einstellungen in Desktopanwendungen gibt es die Möglichkeit, das Binary mittels Parametern zu starten. Seit Electron.NET 7.30.2 gibt es ebenfalls die Möglichkeit, mit Parametern zu arbeiten, und zwar mit dem Command-Line-Support. Bei einem meiner Kundeneinsätze gab es die Anforderung, dass sich die Chrome Developer Tools automatisch öffnen sollen, wenn die Anwendung mit dem folgenden Parameter gestartet wurde:
myapp.exe /args --debug=true
Die Chrome Developer Tools sind die Entwicklertools aus Chromium, die mit zahlreichen Funktionen zum Gestalten, Editieren, Testen, Analysieren und Korrigieren von Webanwendungen zur Verfügung stehen. In Listing 6 wird gezeigt, wie mit der statischen Property Electron.App.CommandLine auf die Parameter zugegriffen wird. Eine Überprüfung auf die Existenz eines Parameters wird mit der HasSwitchAsync-Methode durchgeführt. Anschließend erhalten wir den Wert mit der GetSwitchValueAsync-Methode. Zur Entwicklungszeit kann die App via electronize start /args –debug=true zusätzliche Parameter erhalten. In Abbildung 2 sehen wir die Desktopanwendung mit geöffneten Chrome Developer Tools.
Task.Run(async () => {
var mainWindow = await Electron.WindowManager.CreateWindowAsync();
if (await Electron.App.CommandLine.HasSwitchAsync("debug"))
{
string result = await Electron.App.CommandLine.GetSwitchValueAsync("debug");
if (Convert.ToBoolean(result))
{
mainWindow.WebContents.OpenDevTools();
}
}
});

Ein natürliches Electron-Verhalten ist das Aufrechthalten des internen Browsercaches, wodurch ebenfalls einiges an Verarbeitungszeit eingespart wird. Das ist gerade zur Entwicklungszeit jedoch etwas unglücklich, da eigene Änderungen nicht ersichtlich werden. Sollte man über ein solches Problem stolpern, kann der Cache nun via Parameter automatisch gelöscht werden:
electronize start /clear-cache
Alternativ muss bei Electron oder in Kombination mit Electron.NET der folgende API-Befehl ausgeführt werden, der mit dem neuen clear-cache-Parameter erspart bleibt:
await browserWindow.WebContents.Session.ClearCacheAsync();
Die Browser-Sandbox ist einer der Gründe, weshalb Webanwendungen so erfolgreich geworden sind und auch im Enterprise ein Zuhause gefunden haben. Allerdings ist sie auch eine Art Zwangsjacke für Entwickler, die in ihren Möglichkeiten stark beschränkt werden. Die Browser-Sandbox isoliert die Webanwendung vom eigentlichen Hostsystem, sodass auf keinen lokalen Prozess zugegriffen werden kann. Auch der Zugriff auf das Dateisystem ist nicht ohne Benutzeraktion ohne weiteres möglich. Weitere HTML5-Features wie die Standortermittlung via GPS, der Zugriff auf die Kamera und das Anzeigen von Benachrichtigungen sind ohne Benutzergenehmigung nicht möglich. Das ist für einige Businessanwendungen hinderlich, sodass auch keine Entscheidung für Progressive Web Apps gefällt werden kann. Das Besondere an Electron ist, dass Chromium die Option anbietet, die Sandbox zu deaktivieren. Wir können also wie ein Magier aus der Zwangsjacke ausbrechen.
Electron besteht aus unterschiedlichen Prozessen. Der Main-Prozess (Hauptprozess) ist eine Node.js-Instanz. Bei Electron.NET wird von Node.js unsere ASP.NET-Core-Anwendung gestartet und gemanagt. Im Prinzip haben wir hierbei keine Sandbox und können auf dem Hostsystem alles machen, was der angemeldete Benutzer ebenfalls darf. Sobald bei Electron ein sichtbares Fenster erzeugt und angezeigt wird, handelt es sich um einen getrennten Prozess namens Renderer-Prozess. Dieser ist die eigentliche Chromium-Instanz, die per Standard in der Sandbox aktiv ist. Soll jetzt eines der eben genannten HTML5-Features eingesetzt werden, hätten wir wieder unsere Einschränkungen. Deshalb wird beim Erzeugen eines neuen Fensters zusätzlich eine Option benötigt, um die Websecurity zu deaktivieren. In Listing 7 wird gezeigt, wie die notwendigen BrowserWindowOptions dazu aussehen. Selbstverständlich sollte die Sandbox auch nur dann deaktiviert werden, wenn wirklich ein Ausbruch aus der Sandbox vom Renderer-Prozess notwendig ist.
Task.Run(async () => {
var options = new BrowserWindowOptions
{
WebPreferences = new WebPreferences
{
WebSecurity = false
}
};
await Electron.WindowManager.CreateWindowAsync(options);
});
In der Regel benötigt eine Desktopanwendung kein Fenster. Ein Screenshottool wie Snagit läuft beispielsweise im Hintergrund und wird erst durch globale Shortcuts aktiv. Das laufende Programm kann dann meist ebenfalls über das System Tray geöffnet werden.
Das Standardverhalten von Electron.NET ist, dass der Main-Prozess ohne Fenster im Hintergrund laufen kann, ohne dass sich das Programm gleich wieder beendet. Anders verhält es sich, wenn das erste Hauptfenster erzeugt wurde. Hier wird beim Beenden standardmäßig die gesamte Anwendung beendet. Um das Standardverhalten beeinflussen zu können, kann das Electron.App.WillQuit Event abonniert werden. Über die Event Arguments wird dann ein komplettes Beenden der Anwendung bei einem Aufruf der PreventDefault-Methode verhindert.
In Listing 8 wird ein Code gezeigt, der ein Hauptfenster öffnet. Wird dieses geschlossen, erhalten wir alle zehn Sekunden einen Abfragedialog, ob die Anwendung beendet werden soll. Bei der Auswahl von No wird der Beenden-Prozess gestoppt. Bei Yes wird sich die Anwendung komplett beenden.
Im Task Manager werden im Hintergrund die Prozesse mit einigen Electron-Instanzen sowie eine Instanz, die den gleichen Namen wie das eigene Programm trägt, angezeigt. Ist die Anwendung korrekt beendet worden, sind diese Instanzen nicht mehr ersichtlich. Es gibt Ausnahmefälle, die ein händisches Beenden erfordern, wenn das Standardverhalten automatisch beeinflusst wurde.
Task.Run(async () =>
{
var mainWindow = await Electron.WindowManager.CreateWindowAsync();
mainWindow.OnClose += () =>
{
var timer = new Timer();
timer.Interval = 10000;
timer.Elapsed += (s, e) => Electron.App.Quit();
timer.Start();
};
Electron.App.WillQuit += async (e) =>
{
var options = new MessageBoxOptions("Exit the application?")
{
Type = MessageBoxType.question,
Title = "Question",
Buttons = new string[] { "Yes", "No" }
};
var result = await Electron.Dialog.ShowMessageBoxAsync(options);
if (result.Response == 1)
{
e.PreventDefault();
}
};
});
Das Erzeugen der nativen Binaries für die unterschiedlichen Plattformen erfolgt über das Electron.NET CLI mit dem Build-Befehl electronize build. Unter der Haube setzt Electron.NET auf das Open-Source-Projekt electron builder. Es erstellt nicht nur die notwendigen Binaries in beliebigen Formaten, sondern erzeugt ebenfalls die passende Installationsdatei gepackt als 7z, zip, tar.xz, tar.7z, tar.lz, tar.gz, tar.bz2 und dir (ungepacktes Verzeichnis) für alle Plattformen:
Ein weiteres interessantes Feature ist der integrierte Auto Update Manager, der es ermöglicht, die eigene App über einen Fileserver oder auch über GitHub-Releases zu aktualisieren. Ebenfalls kann hier automatisiert eine Codesignatur erfolgen.
Die offizielle Dokumentation von electron builder bietet eine Vielzahl von Konfigurationsmöglichkeiten. In der electron.manifest.json-Datei haben wir hierfür den Build-Bereich hinterlegt. Die dort enthaltenen Konfigurationen werden eins zu eins an den electron builder überreicht. Listing 9 zeigt die Standardkonfiguration, womit im bin\Desktop-Verzeichnis die fertige Desktopanwendung erzeugt wird. Darin wird per Standard die App ungepackt erzeugt, und für einen Windows-Build ein passender nsis Installer.
{
"executable": "MyElectronNETApp",
"splashscreen": {
"imageFile": ""
},
"name": "MyElectronNETApp",
"author": "",
"singleInstance": false,
"environment": "Production",
"build": {
"appId": "com.MyElectronNETApp.app",
"productName": "MyElectronNETApp",
"copyright": "Copyright © 2020",
"buildVersion": "1.0.0",
"compression": "maximum",
"directories": {
"output": "../../../bin/Desktop"
},
"extraResources": [
{
"from": "./bin",
"to": "bin",
"filter": [ "**/*" ]
}
],
"files": [
{
"from": "./ElectronHostHook/node_modules",
"to": "ElectronHostHook/node_modules",
"filter": [ "**/*" ]
},
"**/*"
]
}
}
Dieser Artikel hat nur einige der neuen Features vorgestellt und kleine Tipps gegeben, die häufig nachgefragt wurden. Im Detail hat die wachsende Community für zahlreiche API-Implementationen gesorgt, sodass noch mehr vom nativen Electron innerhalb unserer .NET-Welt zur Verfügung steht. Wir arbeiten weiterhin intensiv an einer noch schlankeren und performanteren Lösung. Dazu wird sich das Backend technisch noch so weit verändern, dass eine API-Kommunikation über WebSockets hinfällig wird. Ein großes Ziel meinerseits ist es, dass diese Optimierungen ohne Breaking Changes auskommen werden.
Das Open-Source-Projekt sucht natürlich weiterhin nach Verstärkung. Wenn Interesse besteht, an Electron.NET etwas zu verändern, zeigt unser YouTube-Video „Electron.NET – Contributing Getting Started“, wie einfach für Electron.NET entwickelt werden kann. Bei weiteren Fragen steht die Community via Chat auf Gitter rund um die Uhr zur Verfügung. Natürlich darf man auch den Autor jederzeit per E-Mail kontaktieren.
The post Electron.NET von A bis Z: Cross-Plattform-Apps mit .NET und Electron entwickeln appeared first on BASTA!.
]]>The post C# 9 and beyond: Die Zukunft der Programmiersprache und ihre neuen Möglichkeiten appeared first on BASTA!.
]]>The post C# 9 and beyond: Die Zukunft der Programmiersprache und ihre neuen Möglichkeiten appeared first on BASTA!.
]]>The post Visualisierung von Machine Learning-Daten in VS Code appeared first on BASTA!.
]]>Das Ziel ist es, so genau wie möglich zu verstehen, warum und wie eine KI bestimmte Entscheidungen trifft. Bei Bilderkennungsalgorithmen zeigt beispielsweise eine farbige Heatmap die Stellen eines Bildes, die besonders relevant für dessen Klassifizierung sind. Wir beginnen mit einem einfachen Datenset eines Klassifikationssystems und visualisieren die Entscheidung der Klassifikation mit einer Konfusionsmatrix und zugehöriger Heatmap. Als IDE nutzen wir Visual Studio Code mit den beiden Konfigurationsfiles tasks.json und dem projektspezifischen settings.json inklusive Test-Units und Pfadangaben (Listing 1 und 2).
{
"python.pythonPath":
"C:\\Users\\Max\\AppData\\Local\\Programs\\Python\\Python37\\python.exe",
"python.testing.pytestArgs": [
"freshonion"
],
"python.testing.unittestEnabled": false,
"python.testing.nosetestsEnabled": false,
"python.testing.pytestEnabled": false,
"python.testing.unittestArgs": [
"-v",
"-s",
"./freshonion",
"-p",
"*test.py"
],
"python.testing.promptToConfigure": false
}
{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
// build from older win8.1. to win10.2 by max
"version": "2.0.0",
"tasks": [
{
"label": "buildpython",
"type": "shell",
"command": "C:\\Users\\Max\\AppData\\Local\\Programs\\Python\\Python37\\python.exe",
"args": ["${file}"],
"showOutput":"always",
"problemMatcher": [],
"group": {
"kind": "build",
"isDefault": true
}
}
]
}
Als Einstieg in VS Code mit Python empfiehlt sich das Tutorial, das Microsoft mit der aktuellen Version aus dem März 2020 (Version 1.44) publiziert hat: „Tutorials for creating Python containers and building Data Science models“. Wir starten mit den importierten Modulen in Listing 3 und nennen unser Skript logregclassifier2.py.
// get the modules we need import matplotlib.pyplot as plt import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.metrics import classification_report, confusion_matrix
Die Daten unseres Beispiels sind bewusst neutral und einfach gehalten, um eine optimale Verständlichkeit zu gewährleisten. Als Trainingsdaten dient eine Datenreihe von 0 bis 9 (Samples), um ein Target mit 0 und 1 zu klassifizieren. Die Reihe könnte etwa zehn Patienten repräsentieren, die einen medizinischen Test absolvieren. Bei im Voraus bekannten Labels (Target) spricht man auch von Supervised Learning. Wir wollen nun das System soweit trainieren, dass die tiefen Zahlen wahrscheinlich mit 0 und die hohen Zahlen wahrscheinlich mit 1 zu klassifizieren sind (Listing 4).
X=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9] y=[0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
// arrays for the input (X) and output (y) values: X = np.arange(10).reshape(-1, 1) y = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
Wir können mit dem Befehl np.arange(10) ein Array erstellen, das alle ganzen Zahlen von 0 bis 9 enthält. Als Konvention betrachten wir x als zweidimensionales Array (Matrix) und y als eindimensionales Target (Vektor). Reshape (-1,1) bedeutet, dass wir nur ein Feature als Kolonne haben. Features sind die Merkmalsträger, die dem Modell helfen, unbekannte Muster zu finden. Anschließend definieren wir das Modell, das bereits mit der Fit-Methode die Daten trainiert, um eine Beziehung zwischen den Einflussvariablen (Determinanten) und dem Target herzustellen (Listing 5).
// Once you have input and output prepared, define your classification model. model= LogisticRegression(solver='liblinear', random_state=0) model.fit(X, y) print(model)
Nachdem das Modell aufgebaut ist, können wir mit predict() eine erste Klassifikation mit einem Score versuchen und gleich die Konfusionsmatrix erstellen (Listing 6).
print(model.predict(X)) print(model.score(X, y)) // One false positive prediction: The fourth observation is a zero that was wrongly predicted as one. print(confusion_matrix(y, model.predict(X)))
Real: [0 0 0 0 1 1 1 1 1 1] Predict: [0 0 0 1 1 1 1 1 1 1] Score: 0.9 Confusion Matrix: 0: [[3 1] :4 1: [0 6]] :6
Und siehe da: Ein False Positive (Fehlalarm) hat sich eingeschlichen. Das Modell hat eine 0 irrtümlich als 1 klassifiziert, vergleichbar mit einem System, das fälschlicherweise eine ruhige Situation als Brandalarm bewertet. Die Konfusionsmatrix zeigt das als Fehlalarm an. Idealerweise zeigt die Matrix bei einem 100 Prozent Score folgendes Bild:
0: [[4 0] :4 1: [0 6]] :6
Im nächsten Schritt erfolgt die visuelle Aufbereitung der Matrix, um eine optische Beziehung zwischen den realen und den vorausgesagten Daten herzustellen (Listing 7).
plt.rcParams.update({'font.size': 16})
fig, ax = plt.subplots(figsize=(4, 4))
ax.imshow(cm)
ax.grid(False)
ax.xaxis.set(ticks=(0, 1), ticklabels=('Predicted 0s', 'Predicted 1s'))
ax.yaxis.set(ticks=(0, 1), ticklabels=('Actual 0s', 'Actual 1s'))
ax.set_ylim(1.5, -0.5)
for i in range(2):
for j in range(2):
ax.text(j, i, cm[i, j], ha='center', va='center', color='red')
plt.show()

Die Grafik in Abbildung 1 lässt sich auch einfacher und moderner mit einer zusätzlichen Bibliothek erzeugen. Wir benötigen dafür die Python Library seaborn (Abb. 2), die sich am besten über die integrierte Command Line Shell direkt in VS Code mit Pip Install installieren lässt (Listing 8).
import seaborn as sns
// get the instance of confusion_matrix:
cm = confusion_matrix(y, model.predict(X))
sns.heatmap(cm, annot=True)
plt.title('heatmap confusion matrix')
plt.show()

Die Klasse 0 hat also drei richtige Fälle (True Negatives), die Klasse 1 sechs richtige Fälle (True Positives) erkannt. Die Nutzergenauigkeit zeigt ebenfalls ein einziges falsches positives Ergebnis. Die Nutzergenauigkeit (Consumer Risk versus Producer Risk) wird auch als Überlassungsfehler oder Fehler vom Typ 1 bezeichnet. Fehler vom Typ 2 sind dann False Negatives.
Mit der Funktion .heatmap() aus der Bibliothek seaborn wird der Diagrammtyp definiert. Die folgenden Argumente parametrisieren das Aussehen des Diagramms. Werfen wir einen Blick in die Analyse des Fehlers, der durch den voreingestellten Schwellenwert der Wahrscheinlichkeit bei 0.5 definiert ist. Die Diskriminierung zwischen 0 und 1 hat zu früh stattgefunden, sodass unser Modell eine 0 zu früh als 1 klassifiziert hat. Natürlich lassen sich diese sogenannten Hyperparameter optimieren, um eine gerechtere Verteilung der Klassifikation zu finden. Dazu muss man sagen, dass die Wirkung auf diskrete, dichotome Variablen [0,1] sich nicht mit dem Verfahren der klassischen linearen Regressionsanalyse erklären und verifizieren lässt.
Die momentane Verteilung mit der zugehörigen Klassifikation sieht wie in Abb. 3 gezeigt aus.

sns.set(style = 'whitegrid')
sns.regplot(X, model.predict_proba(X)[:,1], logistic=True,
scatter_kws={"color": "red"}, line_kws={"color": "blue"}) #label=model.predict(X))
plt.title('Logistic Probability Plot')
plt.show()
In Listing 9 ist in der Funktion regplot die geschätzte Wahrscheinlichkeit als Target enthalten. Nicht jeder Klassifizierer bietet die internen Wahrscheinlichkeiten an. Auch der Naive-Bayes-Klassifikator ist probabilistisch (Kasten: „Naive-Bayes-Klassifikator“). Die entsprechende Entscheidungsgrenze (Decision Boundary) ist für die Analyse optisch erkennbar und hilft, das Ergebnis zu interpretieren oder einen besseren Solver zu finden (Abb. 4).
Naive-Bayes-Klassifikator
Der Naive-Bayes-Klassifikator ist nach dem englischen Mathematiker Thomas Bayes benannt und leitet sich aus dem Bayes-Theorem ab. Die grundlegende Annahme besteht darin, von einer strengen Unabhängigkeit der verwendeten Merkmale auszugehen (deshalb „Naive“).

| T | precision | recall | f1-score | support | CM |
|---|---|---|---|---|---|
| 0 | 1.00 | 0.75 | 0.86 | 4 | [[3 1 |
| 1 | 0.86 | 1.00 | 0.92 | 6 | [0 6]] |
Tabelle 1: Classification Report
Der Tabelle 1 können wir entnehmen, dass es einen Fall von Falsch-Positiv und keinen Fall von Falsch-Negativ gibt. Das bedeutet, dass nur in 86 Prozent aller Fälle ein positives Ergebnis auch einer Erkrankung entspricht. Die Precision errechnet sich dabei so:
Truepositiv / (Truepositiv + Falsepositiv) = 6 / (6+1) = 0.8571 = <strong>0.86</strong>
Es ist also entscheidend, in die Genauigkeit der Tests (Screening) auch die Falsch-Positiv-Fälle mit einzubinden. Ähnliche Beispiele zur bedingten Wahrscheinlichkeit befinden sich übrigens auf der Webseite „Lügen mit Statistik“. Auch hier habe ich einmal einen Fall nachgerechnet und visualisiert (aus dem Gebiet der Mammografie). Wie in Abbildung 5 gezeigt, sehen die Falsch-Positiv-Werte schon komplexer aus.

Nun wollen wir die erwähnten Hyperparameter ins Spiel bringen, von denen es einige gibt und die einen Teil der Modellevaluation ausmachen.
In Listing 10 erkennen wir die voreingestellten Modellparameter, die sich natürlich verändern lassen. Es ist allerdings nicht möglich, den besten Wert für einen Modellhyperparameter in Bezug auf ein bestimmtes Problem direkt zu ermitteln. Stattdessen kann man Erfahrungswerte nutzen, Werte kopieren, die bei anderen Problemen verwendet wurden, oder durch Ausprobieren nach dem besten Wert suchen. Ich benutze vor allem den Wert C (Regulator), um den Kernel oder den Solver zu optimieren.
model = LogisticRegression(solver='liblinear', C=1, random_state=0).fit(X, y) // show more model details print(model) LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='warn', n_jobs=None, penalty='l2', random_state=0, solver='liblinear', tol=0.0001, verbose=0, warm_start=False)
Die eigentliche Anpassung besteht darin, schlicht und ergreifend einen anderen Solver einzusetzen:
model = LogisticRegression(solver='<strong>lbfgs</strong>', C=1, random_state=0).fit(X, y) print(classification_report(y, model.predict(X)))
Die Ergebnisse sind nun optimal in Bezug auf die Güte des Algorithmus unserer Zahlenreihe und kann auch einem optischen Vergleich mit einem Decision Tree standhalten (Abb. 6).

Das Entscheidungsbaumverfahren (Decision Tree) ist eine verbreitete Möglichkeit der Regression oder Klassifikation über ein multivariates Datenset. Das Verfahren kann beispielsweise verwendet werden, um die Zahlungsfähigkeit von Kunden zu klassifizieren oder eine Funktion zur Vorhersage von Falschmeldungen zu bilden. In der Praxis stellt das Verfahren den Data Scientist aber vor große Herausforderungen bezüglich Interpretation und Overfitting (Auswendiglernen der trainierten Beispiele), obwohl der Baum selbst eine transparente und lesbare Grafik bietet. Dazu nutzen wir in VS Code den installierten Graphviz 2.38 sowie eine zusätzliche Zeile im Code, die uns direkt die Pfadangaben im OS-Pfad setzt (Listing 11). Somit können wir direkt im Code Anpassungen an eine andere Version vornehmen oder die Plattform konfigurieren (Abb. 7).
<strong>from sklearn.tree import DecisionTreeClassifier</strong> from converter import app, request import unittest import os from sklearn.tree import DecisionTreeClassifier from sklearn.tree import export_graphviz os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/' os.environ["PATH"] += os.pathsep + 'C:/Program Files/Pandoc/'

Wichtig: Die Dimensionen der Konfusionsmatrix sind leider nicht normiert. Im Beispiel steht die Wahrheit „Real Actual“ in den Zeilen und die Schätzung „Predict“ in den Spalten. Je nach verwendeter Software können die Dimensionen aber vertauscht sein. Wichtig erscheint mir, die Matrix bei 0 zu beginnen, also True Negatives oben links zu normieren (Abb. 8). Für ein N-Klassen-Problem besteht die Konfusionsmatrix dann aus einer NxN-Matrix, ist also nicht auf eine binäre Klassifikation beschränkt.

Zum Abschluss noch ein Ausblick in die Integration von Jupyter. Jupyter (ehemals IPython) Notebooks ist ein Open-Source-Projekt, mit dem sich interaktiver Markdown-Text und ausführbarer Python-Quellcode einfach auf einer Leinwand (Canvas) kombinieren lassen, die man als Notebook bezeichnet. Visual Studio Code unterstützt die native Arbeit mit Jupyter Notebooks sowie über Python-Codedateien. Auch meine Erfahrungen bezüglich Debugging oder Codemetriken sind gut. Um mit Jupyter Notebooks arbeiten zu können, ist eine Anaconda-Umgebung in VS Code oder eine andere Python-Umgebung erforderlich, jedoch ist vorgängig ein Jupyter-Paket zu installieren. Somit erhalten wir in VS Code direkt die Möglichkeit, Grafiken einzubinden, zu dokumentieren oder interaktiven Code auszuführen (Abb. 9, 10).


● Workshop: Intelligente Apps mit Azure Machine Learning, ML.NET und Cognitive Services
The post Visualisierung von Machine Learning-Daten in VS Code appeared first on BASTA!.
]]>The post Blazor WebAssembly ist endlich erschienen: Eine neue Ära der Webentwicklung mit .NET appeared first on BASTA!.
]]>Das waren in Kürze zehn Gemeinsamkeiten, die dazu beitragen, dass man sehr leicht Programmcode zwischen Blazor WebAssembly und Blazor Server austauschen bzw. gemeinsamen Code und gemeinsame Oberflächen in beiden Architekturen verwenden kann.
Ein interessanter Ansatz ist, eine Webanwendung so in eine Razor Class Library zu kapseln, dass sie sowohl in Blazor WebAssembly als auch Blazor Server verwendet werden kann. Man besitzt dann zwei Kopf-/Start-Projekte und gemeinsame DLLs mit der Oberfläche, dem Programmcode und Ressourcen, wie man es heute schon von Xamarin.Forms kennt.
Im Folgenden wird dieser Beitrag zehn Unterschiede genauer erläutern, die in der Praxis zu beachten sind, wenn man sich für eine der beiden Architekturen entscheiden oder gemeinsam nutzbare Razor Class Libraries schaffen will.
Regelmäßig News zur Konferenz und der .NET-Community
Die aktuelle Veröffentlichung von Blazor Server trägt die Versionsnummer 3.1.5. Bei Blazor WebAssembly ist die erste Version direkt unter der Versionsnummer 3.2 erschienen; Versionen 1.0 bis 3.1 hat es nie gegeben. Der Unterschied zwischen den Versionsnummern 3.1 bei Blazor Server zu 3.2 bei Blazor WebAssembly bedeutet aber keineswegs, dass Blazor WebAssembly der Nachfolger von Blazor Server ist. Die Versionsnummer 3.2 bedeutet nur, dass die erste Version von Blazor WebAssembly außerhalb des Veröffentlichungszyklus von .NET Core erschienen ist. Die nächste Version wird 5.0 sein. Diese Versionsnummer wird sowohl für Blazor Server als auch Blazor WebAssembly gelten und am 10. November 2020 im Rahmen der .NET Conf 2020 als Teil von .NET 5.0 erscheinen. Auf GitHub findet man eine Roadmap für geplante Verbesserungen und weitere Funktionen in ASP.NET Core Blazor 5.0, die aber wahrscheinlich nicht alle schon in .NET 5.0 erscheinen werden.
Blazor in ASP.NET Core 3.1 ist eine Long-Term-Support-Version (LTS), die Microsoft drei Jahre nach dem Erscheinen mit Bugfixes und Sicherheitsupdates sowie mit kommerziellem Support unterstützt. Die Version 3.1 ist am 3. Dezember 2019 erschienen und wird also bis zum 3. Dezember 2022 unterstützt. Blazor WebAssembly 3.2 hat allerdings lediglich den Status Current Version, erhält also nicht den Long-Term-Support der .NET-Core-Version 3.1 aus dem Dezember 2019. Das bedeutet, dass Anwender nach dem Erscheinen der nächsten Version am 10. November 2020 nur drei Monate Zeit haben werden, die Blazor-WebAssembly-Version zu wechseln. Die erste Long-Term-Support-Version von Blazor WebAssembly wird nach aktuellem Wissen erst die Version 6.0 in .NET 6.0 im November 2021 sein.
Bei Blazor Server (früher: Server-side Blazor) läuft der .NET-Programmcode auf dem Webserver. Die HTML-Oberfläche wird auf dem Webserver in einem sogenannten Virtual DOM gerendert und mit einem kompakten Synchronisierungsverfahren in einzelnen Datenpaketen über eine kontinuierliche WebSocket-Verbindung zum Client übertragen. Eine JavaScript-Bibliothek im Browser aktualisiert mit diesen Datenpaketen die Oberfläche im Sinne eines Remote Renderings.
Bei Blazor WebAssembly (früher: Client-side Blazor) laufen der .NET-Programmcode und das HTML-Rendering tatsächlich im Webbrowser in dessen WebAssembly-Laufzeitumgebung. Eine JavaScript-Bibliothek kommt dennoch auch hier zum Einsatz, um zwischen der WebAssembly Virtual Machine des Browsers und dem DOM zu synchronisieren, denn die WebAssembly VM des Browsers hat laut W3C-Standard keinen Zugriff auf dessen DOM.

Der Benutzer der Webanwendung erlebt in beiden Fällen eine Single Page Application (SPA). Allerdings kann eine Blazor-Server-basierte Webanwendung niemals offlinefähig werden (daher in Abbildung 1 „SPA light“ genannt), und es gibt auch Probleme bei nicht konstanten Netzwerkverbindungen: Wenn der Webserver nicht mehr erreichbar ist, wird die aktuelle Ansicht im Browser ausgegraut und der Benutzer sieht oben die Warnmeldung „Attempting to reconnect to the server …“. Sollte das nicht gelingen, erfolgt dann die Meldung „Could not reconnect to the server. Reload the page to restore functionality.“ Wenn der Benutzer dann nicht wieder am Anfang der Anwendung landen soll, sondern an seinem letzten Standort, müssen Zustände im Browser gehalten werden.
Blazor Server hat zudem Herausforderungen bei der Skalierbarkeit, denn das Virtual DOM und der Zustand aller Razor Components liegt für jeden aktuell angeschlossenen Browser im RAM des Webservers. Microsoft hat dokumentiert, dass für jeden angeschlossenen Browser schon bei einer Hello-World-Anwendung 250 KB RAM im Server gebraucht werden. Für echte Anwendungen ist der RAM-Bedarf jeweils selbst zu messen, weil auch Microsoft keine Formel besitzt, um ihn vorherzusagen. Dass Microsoft das nicht für eine beliebige Anwendung vorhersagen kann, ist nachvollziehbar, denn der RAM-Bedarf ist von vielen Faktoren abhängig, insbesondere natürlich von der Komplexität der Benutzeroberflächen und der Menge der im Zustand der Komponente gehaltenen Daten. Im Rahmen der .NET Conf am 14.01.2020 hat Microsoft eigene Messergebnisse veröffentlicht. So kann auf einer virtuellen Maschine in der Azure-Cloud mit 4 virtuellen CPUs und 14 GB RAM bei 20 000 gleichzeitigen Benutzern immer noch eine Latenz (Verzögerung bei der Darstellung von Änderungen) von unter 200 Millisekunden erreicht werden.
Während eine Blazor-Server-Anwendung naturgemäß immer auf einem ASP.NET-Core-fähigen Webserver laufen muss, gibt es bei Blazor WebAssembly zwei alternative Hosting-Optionen:
Bei der Auswahl der Projektvorlage Blazor WebAssembly in Visual Studio bzw. bei dotnet new blazorwasm gibt es daher noch die Zusatzoption ASP.NET Core hosted (auf der Kommandozeile: –hosted). Ohne diese Option wird eine rein lokal im Browser laufende Blazor-WebAssembly-Anwendung erstellt. Für die Installation einer Blazor-WebAssembly-Anwendung muss das IIS-Zusatzmodul URL Rewrite auf dem Webserversystem installiert werden. Nur wenn die Blazor-WebAssembly-Anwendung auch noch ein ASP.NET-Core-basiertes WebAPI-Projekt umfasst, muss auch das ASP.NET Core Runtime Hosting Bundle installiert sein.
Ein Hosting in Azure App Services ist sowohl für Blazor-Server- als auch Blazor-WebAssembly-Anwendungen möglich. Eine Blazor-WebAssembly-Anwendung kann allerdings derzeit nur in einem Windows-basierten Azure-App-Service verwendet werden („A Linux server image to host the app isn’t available at this time.“). Blazor Server kann auch in Linux-basierten App Services laufen.
Während Blazor Server komplett auf .NET Core basiert und auch Blazor-WebAssembly-Projekte mit dem .NET Core SDK übersetzt werden, wirken bei Blazor WebAssembly zur Laufzeit eine Mono-basierte Laufzeitumgebung (aktuell: Mono 6.13.0) und das Projekt Emscripten. Ein weiterer Unterschied zwischen Blazor Server und Blazor WebAssembly ist, dass bei Ersterem beim Deployment eine .exe-Datei aus dem Projekt entsteht, beim zweiten eine .dll-Datei. Bei Blazor Server ist also ein Selfhosting außerhalb eines Webservers möglich, wie bei ASP.NET Core üblich, indem man die entstandene .exe-Datei einfach startet. Hier startet der in ASP.NET integrierte Webserver Kestrel.
Der Projektaufbau bei Blazor Server und Blazor WebAssembly ist ähnlich (Verzeichnisse /wwwroot, /Pages und /Shared, Dateien App.razor und launchsettings.json), aber im Detail gibt es Unterschiede. Für Blazor WebAssembly gibt es zwei Projektvorlagen: für den eigenständigen Fall und für den ASP.NET-Core-gehosteten (Abb. 2). Bei Blazor Server und der eigenständigen Blazor-WebAssembly-Anwendung entsteht jeweils nur ein Projekt. Mit der Option ASP.NET Core hosted entstehen gleich drei Projekte:
Der Startcode einer Blazor-WebAssembly-Anwendung besteht seit Version 3.2 Preview 1 vom 28.01.2020 nur noch aus einer Klasse: Program.cs. Hier wird auch die .NET Core Dependency Injection (Microsoft.Extensions.DependencyInjection) konfiguriert. Die aus ASP.NET-Core-Projekten bekannte und auch in Blazor Server verwendete Zweiteilung in Program.cs und Startup.cs ist entfallen. Die Rahmenseite mit dem – und -Tag ist bei Blazor WebAssembly die statische Datei wwwroot/index.html, bei Blazor Server ist es eine Razor Page: pages/_host.cshtml.

Debugging ist in Blazor WebAssembly trotz der komplexen Softwarearchitektur zwar inzwischen grundsätzlich möglich, aber nicht alle aus Visual Studio bekannten .NET-Debugging-Funktionen sind implementiert. Möglich beim Debugging von Blazor-WebAssembly-Anwendungen ist Folgendes:
Das Folgende ist leider bisher nicht bzw. nur eingeschränkt möglich:
Bei Blazor Server sind hingegen alle Debugging-Funktionen von Visual Studio uneingeschränkt verfügbar.
Blazor WebAssembly kann neben dem Debugging in Visual Studio auch ein Debugging direkt im Chromium-basierten Browser vollziehen. Dazu drückt man bei einer lokal gestarteten Blazor-WebAssembly-Anwendung die Tastenkombination SHIFT + ALT + D und folgt dann der Anweisung, um den Browser im Debug-Modus zu starten.
Blazor WebAssembly lädt beim Start eine Vielzahl von Dateien, der Anwendungsstart ist entsprechend langsam. Selbst eine minimale Blazor-WebAssembly-Anwendung mit einer einzigen statischen Razor Component benötigt beim Start 35 HTTP-Anfragen mit insgesamt 5,5 MB Netzwerkdatenverkehr (Abb. 3) nach einem Deployment im Releasemodus unter Einsatz des Mono-IL-Linkers und Brotli-Komprimierung. Wenn man in den Entwicklerwerkzeugen im Chrome-Browser eine „Fast-3G“-Verbindung simulieren lässt, sieht der Benutzer rund 32 Sekunden lang „Loading …“. Das ist inakzeptabel für viele Internetanwendungen, man kann es allenfalls bei Intra- und Extranetanwendungen vertreten. Bei aktiviertem Cache dauert das zweite Laden rund 6,5 Sekunden.
Immerhin wächst die Anwendungsgröße nicht linear. Eine Blazor-WebAssembly-Anwendung aus der Praxis mit rund 30 Komponenten umfasst 7,5 MB (Abb. 4; geladen von einem Azure-App-Service in den USA), mit 200 Komponenten 8,7 MB (Abb. 5; geladen im lokalen Netzwerk). Die Anzahl der HTTP-Anfragen ändert sich nicht bei steigender Komponentenanzahl, da alle Razor Components eines Projekts in eine einzige DLL hineinkompiliert werden. In Abbildung 4 sieht man aber bei der Praxisanwendung mehr HTTP-Anfragen, da hier viele weitere Ressourcen (Style Sheets, Grafiken, JavaScript-Dateien etc.) verwendet werden.



Bei Blazor Server findet die in .NET übliche Übersetzung von Intermediate Language (MSIL) in Maschinencode per Just-in-Time-(JIT-)Compiler statt. Bei Blazor WebAssembly wird ebenfalls MSIL in den Browser geladen, dort aber von einem MSIL-Interpreter innerhalb der dortigen .NET-Laufzeitumgebung interpretiert, die eine WebAssembly-basierte Variante von Mono ist. Diese Interpreterarchitektur macht schon deutlich, dass die Codeausführung in Blazor WebAssembly deutlich langsamer als bei Blazor Server ist. Daniel Roth, Program Manager im ASP.NET-Team bei Microsoft, bestätigt das in der Antwort auf eine Frage in seinem Blogeintrag: „Blazor WebAssembly runs on a .NET IL interpreter based runtime – there’s no JIT compilation to WebAssembly happening, so execution performance is much slower than normal .NET code execution.“ In seiner Antwort auf die Performancefrage des Kunden geht er auch offen damit um, dass Blazor WebAssembly derzeit hinsichtlich der Ausführungsgeschwindigkeit nicht konkurrenzfähig zu aktuellen JavaScript Frameworks ist: „Blazor WebAssembly isn’t going to win in any performance comparisons with JavaScript based frameworks like Angular or React.“
Wie aufwendig die Verarbeitung bei Blazor WebAssembly ist, zeigt sich bei Leistungsmessungen: Eine Reihe von 100 000 Fibonacci-Berechnungen, die in Blazor Server inklusive Übertragung von Parametern und Ergebnis zwischen den Prozessen 373 Millisekunden braucht, dauert bei der Ausführung in Blazor WebAssembly in Chrome stattliche 10 Sekunden (Abb. 6). Damit man nicht Äpfel mit Birnen vergleicht, ist hier der Webserver der gleiche PC, auf dem auch der Browser läuft. Bei diesem gewaltigen Unterschied (Faktor 38) darf aber man aber nicht vergessen, dass sich in der Praxis bei Blazor Server alle aktiven Benutzer die Rechenleistung des Webservers teilen, während Blazor WebAssembly die CPU jedes Clients ausnutzt.
Schon bei der Erstankündigung von Blazor im März 2018 brachte Microsoft auch eine Ahead-of-Time-Kompilierung (AOT) von MSIL in WebAssembly-Bytecode ins Spiel, die die Ausführung beschleunigen könnte. AOT ist aber nicht in der jetzt erschienenen Version 3.2 enthalten. Microsoft tut sich seit Jahren schwer mit AOT für .NET. Man hat schon diverse Ansätze versucht und wieder beerdigt.
Die Leistungsdaten in Abbildung 6 wurden jeweils mit den Webbrowsern Chrome und Firefox auf drei Servertypen erhoben:
Abbildung 6 liefert zwei weitere Erkenntnisse:

Die Interoperabilität zwischen dem C#-Programmcode und JavaScript ist in beiden Blazor-Varianten vorhanden, es gibt jedoch vier Unterschiede:
Blazor Server kann alle in .NET Core erreichbaren Programmierschnittstellen verwenden, also sowohl .NET Assemblies und COM-Komponenten als auch direkt die Windows-Betriebssystem-APIs Windows 32 (Win32) und Windows Runtime (WinRT). So sind aus einer Blazor-Server-Anwendung heraus zum Beispiel direkte Zugriffe auf Datenbankmanagementsysteme und Verzeichnisdienste sowie an den Server angeschlossene oder im Netzwerk erreichbare Hardware möglich.
Die WebAssembly VM, auf der Blazor WebAssembly aufsetzt, läuft hingegen genau wie JavaScript in der Sandbox des Webbrowsers. Daher kann der Entwickler nicht alle Programmierschnittstellen nutzen. So ist ein direkter Datenbankzugriff in Blazor WebAssembly nicht möglich. Der Entwickler kann zwar einen Datenbankprovider wie Microsoft.Data.SqlClient via NuGet-Paket in den Browser laden, ein Datenbankverbindungsaufbau scheitert dann aber mit dem Laufzeitfehler „Microsoft.Data.SqlClient is not supported on this platform“. Auch andere Netzwerkprotokolle wie LDAP werden damit unterbunden. Der Entwickler muss alle Daten über HTTP-basierte Web Services beziehen und senden. Auch Zugriffe auf viele lokale Ressourcen werden abgeblockt; so kann Blazor WebAssembly nicht via System.Diagnostics.Process.GetCurrentProcess() Informationen über den eigenen Prozess beziehen. Das führt zum Laufzeitfehler „Process has exited or is inaccessible, so the requested information is not available.“ Die Einschränkungen durch die Sandbox sind bei WebAssembly die gleichen wie bei JavaScript.
Bei Blazor WebAssembly ist hingegen der Zugriff auf Server über HTTP-/HTTPS-basierte Web Services (z. B. Web APIs) zu kapseln. Für den Zugriff auf REST-Dienste verwendet man in Blazor die in .NET und .NET Core etablierte Bibliothek System.Net.Http.HttpClient. Sie gehört zum Standardumfang des .NET Core SDK und muss daher in Blazor-Projekten nicht explizit als NuGet-Paket referenziert werden. Optional kann man aber als neue Hilfsbibliothek System.Net.Http.Json verwenden, deren Erweiterungsmethoden Microsofts neuen JSON Serializer System.Text.Json in Verbindung mit HttpClient verwendet. Das Paket System.Net.Http.Json ist in den Blazor-WebAssembly-Projektvorlagen im Standard referenziert, in Blazor Server aber nicht. Die Standardprojektvorlage für Blazor Server enthält kein Beispiel für den Einsatz von HttpClient, da hierbei ja ein Web API nicht zwingend notwendig ist. Wenn man bei der Blazor-WebAssembly-Vorlage die Option ASP.NET Core hosted auswählt, bekommt man ein Serverprojekt mit einem Web-API-Dienst (/Controllers/WeatherForecastController.cs) und im Clientprojekt einen Web-API-Client (/Pages/FetchData.razor). Auch die Nutzung von Diensten, die auf Google RPC (gRPC) basieren, ist in beiden Blazor-Varianten möglich. Ebenso kann ASP.NET Core SignalR eingesetzt werden.
Die Option in den Projektvorlagen, eine Webanwendung als installierbare Progressive Web App (PWA) zu betreiben (Abb. 7), gibt es nur bei Blazor WebAssembly. Bereits beim Anlegen eines Blazor-WebAssembly-Projekts kann man ein Häkchen setzen (Abb. 8), das alle notwendigen Voraussetzungen schafft. Bei Blazor Server muss man selbst Hand anlegen.


Es entstehen dadurch, zusätzlich zu den Elementen, die man in Abbildung 2 in Spalte 2 und 3 sieht, weitere Elemente:
Alternativ kann man diese Voraussetzungen auch nachträglich in einem bestehenden Projekt leicht erfüllen.
Regelmäßig News zur Konferenz und der .NET-Community
Nach all den genannten Gemeinsamkeiten und Unterschieden kann man festhalten:
Es stellt sich für die Praxis die Frage, ob man Blazor WebAssembly und/oder Blazor Server einsetzen sollte. Grundsätzlich ist Blazor ein Angebot für .NET-Entwickler, die ihr Know-how und/oder eine bestehende .NET-Programmcodebasis ins Web bringen wollen.
Blazor WebAssembly hat aufgrund der vielen zu ladenden Dateien und deren Größe sowie der fehlenden Lazy-Loading-Funktion den Nachteil, dass Nutzer (insbesondere bei schlechten Netzwerkverbindungen) beim ersten Aufruf einer Website ohne Inhalte im Cache sehr lange warten müssen, bis sie die Anwendung überhaupt nutzen können. Für öffentliche Internetangebote ist die Ladezeit deutlich zu lang, denn die Benutzer haben in der Zeit längst eine alternative Seite aufgerufen. Im Intra- oder Extranet könnte man die Anwender entsprechend instruieren, die Wartezeit zu ertragen.
Blazor-Server-Anwendungen starten hingegen sehr schnell, können aber bei dauerhaft instabilen Netzwerkverbindungen die Nerven der Benutzer belasten.
Die Entscheidung zwischen Blazor Server und Blazor WebAssembly ist folglich nicht leicht und abhängig vom Projekt, der Anzahl der Nutzer und deren Verhalten. Ich tendiere derzeit dazu, unsere bestehenden Projekte, die Blazor Server nutzen, vorerst dort zu belassen und auf Optimierungen in Blazor WebAssembly in der Zukunft zu hoffen.
Die Hoffnung auf die Zukunft hängt daran, ob Microsoft das AOT-Thema für Blazor WebAssembly möglichst schnell in den Griff bekommt und sich damit die Startzeiten verringern und die Ausführungsgeschwindigkeit erhöhen werden. Eine weitere Hoffnung ist, dass das Thema Internet Explorer sich irgendwann ganz erledigt haben wird und alle Internetnutzer wirklich WebAssembly-fähige Browser einsetzen.
The post Blazor WebAssembly ist endlich erschienen: Eine neue Ära der Webentwicklung mit .NET appeared first on BASTA!.
]]>The post Web Components auf Steroiden: Maximieren Sie die Leistung und Wiederverwendbarkeit Ihrer Webanwendungen appeared first on BASTA!.
]]>Wie der Begriff Components vermuten lässt, bauen wir mit Web Components keine vollständigen Anwendungen, sondern vielmehr unsere Basiskomponenten, unser Designsystem, das wir dann in unseren Teams und deren Anwendungen nutzen, um ein einheitliches Look and Feel zu erhalten. Diese Komponenten erhalten ihre Daten in der Regel von außen und stellen sie wie gewünscht dar. Das bedeutet allerdings, dass der Entwickler wissen muss, welche Eigenschaften eine Komponente hat, sprich eine gute Dokumentation über die Komponente ist wichtig.
Genau hier setzt Stencil an. Stencil ist ein vom Ionic-Framework-Team entwickeltes Tool und wird auch für das aktuelle Ionic Framework 5 genutzt. Stencil versteht sich als Compiler für Web Components und PWAs und bringt uns damit wirklich zurück in die Zukunft. Es bringt gewohnte Features moderner SPA Frameworks mit und liefert als Ausgabe Web Components, die wir überall einsetzen können. Es ist wichtig zu verstehen, dass Stencil kein UI Framework ist, also kein Aussehen von Komponenten definiert; das obliegt uns Entwicklern. Es hilft uns aber, genau diese Komponenten und ihr Aussehen zu definieren, die dann von anderen Teams und Anwendungen genutzt werden können.
Als Features erhalten wir mit Stencil eine robuste Build Pipeline mit TypeScript, CSS-Präprozessoren und Dokumentationsgenerierung. Zusätzlich mischt Stencil gewisse Vorzüge von Angular und React. Es nutzt zur Komponentendefinition Dekoratoren und JSX für die Templatedefinition. Damit haben wir die Möglichkeit, reaktive Komponenten zu entwickeln, deren DOM-Updates sich durch das von Stencil implementierte Virtual DOM auf ein Minimum beschränken.
Stencil hat sich als Ziel gesetzt, Komponenten zu erzeugen, die den Webstandards entsprechen und auf Webstandards basieren. Durch TypeScript kann der Stencil-Compiler automatisch Optimierungen vornehmen, um so eine hohe Performance zur Laufzeit gewährleisten zu können. Stencil möchte zudem nur ein kleines, aber sehr robustes API anbieten, dessen Grundlage immer die Webstandards sind. Dadurch soll eine zukunftssichere Bibliothek ermöglicht werden, die auf den nativen Web Components aufsetzt und durch das eigene API dem Entwickler die typische Boilerplate abnimmt.
In diesem Artikel wollen wir gemeinsam zwei kleine Web Components mit Hilfe von Stencil entwickeln. Die erste Komponente wird von dem öffentlichen PokéAPI eine Liste von Pokémon abrufen und darstellen. Eine zweite Komponente berechnet die Pagination, visualisiert sie und stellt ein Event bereit, das beim Durchblättern aufgerufen wird. Die Listenkomponente empfängt dieses Event und wird die entsprechende Seite vom API anfordern. Auf GitHub ist das fertige Beispiel zum direkten Ausprobieren hinterlegt, Abbildung 1 zeigt das User Interface. Los gehts!

Stencil benötigt eine aktuelle Node-Version, die mindestens npm in Version 6 mitbringt. Out of the box ist das mindestens Node 10.3.0. Nach erfolgter Installation von Node kann ein Stencil-Projekt mit folgendem Befehl auf der Kommandozeile erstellt werden:
npm init stencil
Hierdurch lädt npm die nötigen Quellen für das Stencil CLI herunter und startet es automatisch. Im CLI selbst können wir zwischen drei Optionen wählen: ionic-pwa, app und component (Abb. 2). Die Option ionic-pwa legt ein neues Projekt zur Erstellung einer Progressive Web App an, die auf dem Ionic Framework basiert (und damit auch ein UI festlegt). Die Option app legt ein neues Projekt zur Erstellung einer Single Page Application mit Hilfe von Stencil an, hier haben wir also auch Features wie Routing. Die dritte Option components erstellt eine Web Components Bibliothek. Und genau hierfür werden wir uns entscheiden, da wir eine Web-Components-Bibliothek und keine App entwickeln wollen. Nach der Bestätigung müssen wir noch ein Projektnamen festlegen, bspw. windows-developer-stencil-components. Nach einer weiteren Bestätigung erzeugt das CLI einen Ordner mit dem Projektnamen und einer Beispielkomponente. Abbildung 3 zeigt den Aufbau des erzeugten Projekts.

Die wichtigsten Dateien und Ordner sind: package.json, stencil.config.ts, src/index.html, src/components und src/components.d.ts. Schauen wir uns mal genauer an, was wir dort finden.
In der package.json finden wir einige vordefinierte Kommandos, um mit dem Projekt zu arbeiten:
Die Datei stencil.config.ts enthält Konfigurationen für unser Projekt, beispielsweise welche Ausgabe wir erzeugen wollen und welche Plug-ins wir nutzen möchten. In der Dokumentation finden wir alle Möglichkeiten. Per Standard verarbeitet Stencil in den Komponenten nur CSS. Für unser Projekt wollen wir allerdings SCSS nutzen. Dazu müssen wir in einer Kommandozeile den folgenden Befehl ausführen:
npm install -D @stencil/sass
Mit dem Befehl wird das Plugin für SCSS installiert. Damit der Stencil-Compiler es benutzt, müssen wir an der Datei stencil.config.ts eine Ergänzung vornehmen. In der Datei wird ein Objekt config exportiert, diesem fügen wir folgenden Eintrag hinzu:
plugins: [sass()]
Natürlich dürfen wir den Import nicht vergessen, den wir ganz an den Anfang der Datei schreiben:
import { sass } from '@stencil/sass'
Nach dem Abspeichern können wir die Datei schließen. Weiter geht es mit src/index.html und src/components. Die index.html ist die Datei, die nur zur Entwicklungszeit in den Browser geladen wird, um unseren Komponenten anzuzeigen. Das heißt, wir können diese Datei einfach als eine Art Komponentenkatalog ansehen, in der alle unseren Komponenten aufgelistet werden. Die eigentliche Entwicklung der Komponenten findet dann im Ordner src/components statt.
Zuletzt bleibt uns noch die Datei src/components.d.ts. Hier finden wir eine TypeScript-Definitionsdatei über unsere Komponenten. Es ist die für eine IDE verständliche Dokumentation, um uns IntelliSense besser anzuzeigen. Aktuell existiert für Web Components generell noch keine standardisierte Art der Dokumentation. Das W3C diskutiert noch über die verschiedenen Möglichkeiten, Stencil hat mit der components.d.ts eine erste implementiert. Es kann daher sein, dass diese Datei in künftigen Versionen nicht mehr existiert, andere Inhalte besitzt oder durch eine andere Möglichkeit ersetzt wird.
Nachdem wir uns mit dem initialen Setup beschäftigt haben, ist es Zeit, unsere erste Komponente zu erstellen. Dazu benötigen wir folgenden Befehl auf einer Kommandozeile:
npm run generate
Dieser Befehlt startet das Stencil CLI zur Erzeugung einer neuen Komponente. Zuerst muss der Name der Komponente eingegeben werden. Wichtig: Eine Web Component muss ein Dash-/Minus-Zeichen im Namen haben. In unserem Fall nutzen wir hier pokemon-list. Nach Bestätigung des Namens werden wir gefragt, welche Dateien erzeugt werden sollen. Hier wählen wir Stylesheets an und Spec Test und E2E Test ab. Für diesen Artikel sind die Testdateien nicht relevant. Wer dennoch an den Tests interessiert ist, kann ein Blick in src/components/my-component werfen. Diese Komponente wurde standardmäßig bei der Initialisierung des neuen Projekts angelegt und beinhaltet beide Testarten. Achtung, auch wenn wir als Plug-in zuvor SCSS angegeben haben, legt das CLI standardmäßig eine reine CSS-Datei an, die wir dann später manuell umbenennen müssen.
Als Nächstes werden wir den Inhalt der erzeugten Datei src/components/pokemon-list/pokemon-list.tsx austauschen. Den neuen Inhalt finden wir in Listing 1.
import { Component, ComponentDidLoad, ComponentInterface, h, Host, Prop, State } from '@stencil/core';
import { PokeApiService, Pokemon } from './poke-api.service';
@Component({
tag: 'pokemon-list',
styleUrl: 'pokemon-list.scss',
shadow: true,
})
export class PokemonList implements ComponentInterface, ComponentDidLoad {
private itemsPerPage = 10;
private offset = 0;
private pokeApiService = new PokeApiService();
@State() private pokemons: Pokemon[];
@State() private pokemonCount: number;
/** The title of this Pokémon List. */
@Prop() listTitle = 'Pokémon List';
componentDidLoad(): void {
this.loadPage();
}
private loadPage(): void {
this.pokeApiService.loadPage(this.offset, this.itemsPerPage)
.then(response => {
this.pokemons = response.results;
this.pokemonCount = response.count;
});
}
render() {
return (
<Host>
</Host>
);
}
}
PokemonList erstellt, die die Interfaces ComponentInterface und ComponentDidLoad implementiert. Das Interface ComponentInterface muss von jeder Stencil-Komponente implementiert werden und gibt damit vor, dass jede eine render-Methode haben muss. Zusätzlich muss jede Komponente mit dem Dekorator @Component versehen werden. Als Option kann hier bspw. der Tag der Komponente angeben werden, konkret, wie das HTML-Tag lautet, um die Komponente später als Web Component anzusprechen. In unserem Fall ist das pokemon-list. Über styleUrl kann ein Stylesheet referenziert werden, in unserem Fall pokemon-list.scss. Die Eigenschaft shadow gibt an, dass diese Komponente ein Shadow DOM nutzen soll. Ein solches sollte immer eingesetzt werden, um die Vorteile von Web Components zu nutzen. Eine weitere Eigenschaft, die wir aktuell nicht nutzen, ist assetsDirs. Sie erlaubt es, Ordner mit Asset-Dateien anzugeben, also bspw. Bildern oder Schriftarten, die von Stencil beim Erstellen der Komponente mit abgearbeitet werden sollen.
Als nächstes definiert die Komponente drei Felder: itemsPerPage, offset und pokeApiService. Die ersten beiden Eigenschaften sind für die Pagination gedacht und der Service wird sich um das Abrufen der Daten vom API kümmern. Diesen haben wir noch nicht entwickelt und werden wir im Listing 3 kennenlernen. Wer möchte, kann natürlich auch echte ECMAScript Private Fields statt dem TypeScript-Sichtbarkeitsmodifikator private nutzen.
Darauf folgt die Definition zweier weiterer Felder, pokemons und pokemonCount. Das erste Feld wird alle Pokémon beinhalten, die die Liste aktuell darstellt und das zweite Feld kennt die Gesamtzahl aller Pokémon, die das API kennt. Erstmalig entdecken wir hier auch den Dekorator @State. Er dient zum Management des internen State der Komponente. Wird dieser verändert, also dem Feld ein anderer Wert zugewiesen, wird automatisch die render-Methode unserer Komponente aufgerufen. Wichtig hierbei ist jedoch, dass Stencil nur einen Referenzvergleich macht. Beim Arbeiten mit Objekten oder Arrays ist es daher wichtig, immer eine Kopie zu erzeugen.
Das nächste definierte Feld ist listTitle, ein einfacher String, den wir später zum Erzeugen einer Überschrift nutzen. Hier sehen wir zum ersten Mal auch den @Prop-Dekorator. Im Gegensatz zu @State erlaubt @Prop, das dazugehörige Feld von außen auch als HTML-Attribut zu nutzen. Auch hier gilt: Ändert sich die Referenz dieses Felds, wird die render-Methode aufgerufen. Mit @Prop können wir daher ein API für unsere Komponente definieren. Wichtig ist, dass Stencil nur für primitive Datentypen automatisch ein HTML-Attribut generiert. Für Objekte und Arrays kann man dieses Verhalten explizit einschalten, in dem man dem Dekorator ein zusätzliches Optionenobjekt übergibt. Außerdem ist zu beachten, dass per Konvention die Feldnamen als Dash Case im HTML abgebildet werden. So wird aus listTitle im JavaScript ein list-title als HTML-Attribut.
Nach den Felddefinitionen sehen wir die Implementierung des Interface ComponentDidLoad mit seiner Methode componentDidLoad. Hierbei handelt es sich um eine Lifecycle-Methode einer Stencil-Komponente, die einmalig aufgerufen wird, nachdem die Komponente vollständig geladen und zum ersten Mal gerendert wurde. Natürlich können wir auch Web-Component-Lifecycle-Methoden wie connectedCallback oder disconnectedCallback oder weitere von Stencil definierte Lifecycle-Methoden implementieren.
In der Methode selbst rufen wir unsere private Methode loadPage auf, die über den pokeApiService die gewünschte Seite lädt und das Ergebnis in unsere Felder schreibt. Durch den @State-Dekorator wird die Komponente automatisch nach Erhalt der Daten neugerendert.
Was genau gerendert werden soll, bestimmt die Methode render in Form von JSX. Aktuell sehen wir hier nur ein Host-Element. Hierbei handelt es sich um ein virtuelles Element von Stencil, bspw. eine CSS-Klasse oder ein Event auf den Shadow-Host.
Damit wir auch eine visuelle Ausgabe unserer Komponente erhalten, fügen wir Listing 2 in unser Host-Element ein.
<Host>
<header>
<h2>{this.listTitle}</h2>
</header>
{this.pokemons && this.pokemons.length
? <div>
<p>Es existieren {this.pokemonCount} in der Datenbank.</p>
<p>Folgend sind die nächsten {this.pokemons.length}.</p>
<table>
<thead>
<tr>
<th>Name</th>
</tr>
</thead>
<tbody>
{this.pokemons.map(pokemon =>
<tr>
<td>{pokemon.name}</td>
</tr>,
)}
</tbody>
</table>
</div>
: <div>PokeApi wird befragt...</div>
}
</Host>
JSX erlaubt es uns, HTML direkt in unseren TypeScript-Code einzubetten. Um einen Wert auszugeben, nutzen wir geschwungene Klammern. So geben wir in einem h2-Element den Titel unserer Liste aus.
Darauf folgt eine alternierende Ausgabe mit Hilfe des Ternary-Operators. Wir prüfen erst, ob pokemons truthy ist und eine Länge hat. Ist das der Fall, geben wir eine Tabelle mit den geladenen Pokémon-Namen aus. Hier ist (JSX-bedingt) zu beachten, dass wir das Array nicht mit forEach iterieren, sondern mit map, dessen Rückgabe wieder JSX ist.
Ist pokemons falsy oder hat keine Länge geben wir den Text „PokeApi wird befragt…“ aus. Wir haben hier eine sehr einfache textuelle Ladeanzeige implementiert. Stattdessen könnte man hier auch eine weitere Web Component implementieren, die einen typischen Loading Spinner darstellt und diesen anstelle des Texts nutzen.
Eigentlich müssten wir folgerichtig noch das CSS hinterlegen, damit die Komponente ihr gewünschtes Aussehen erhält. Da im CSS keine Besonderheiten zu finden sind und um den Rahmen des Artikels nicht zu sprengen, ist das CSS ausschließlich im zugehörigen GitHub-Repository zu finden.
Bisher kann die Komponente noch keine Daten darstellen, da wir schlicht den dazugehören Service noch nicht implementiert haben. Das wollen wir ändern, indem wir eine neue Datei poke-api.service.ts anlegen, im gleichen Ordner wie unsere Komponente. Den Inhalt finden wir in Listing 3.
export interface PokeApiListResult<T> {
count: number;
next: string;
previous: string;
results: T[];
}
export interface Pokemon {
name: string;
url: string;
}
export class PokeApiService {
private readonly pokeBaseUrl = 'https://pokeapi.co/api/v2/';
loadPage(offset: number, size: number): Promise<PokeApiListResult<Pokemon>> {
return fetch(`${this.pokeBaseUrl}pokemon?offset=${offset}&limit=${size}`)
.then(response => response.json());
}
}
Der PokeApiService ist sehr einfach gestrickt und bietet genau eine Methode an, um eine Seite des PokéAPI zu laden. Hierzu wird die Methode loadPage definiert, die ein offset und size benötigt, um eine konkrete Seite via fetch zu laden. Das Ergebnis wird in JSON gewandelt und zurückgegeben. Da es sich um einen asynchronen Aufruf handelt, ist der Rückgabewert der Methode natürlich ein Promise.
Weiter definiert die Datei noch zwei Interfaces mit den Daten, die wir vom API erwarten. Das sollte für einen ersten Demo-Service genügen und müsste natürlich entsprechend erweitert werden, wenn man dem PokéAPI mehr Daten entlocken möchte.
Im nächsten Schritt müssen wir noch die Datei src/index.html anpassen, sodass auf unserer Demoseite auch wirklich unsere Pokémon-Liste geladen wird. Dazu fügen wir im body-Tag einfach ein neues HTML-Tag ein:
<pokemon-list></pokemon-list>
Wer möchte, kann auch über das Attribute list-title eine andere Überschrift setzen. In Abbildung 4 sehen wir den aktuellen Fortschritt.

In diesem Schritt wollen wir noch die Pagination erstellen, sodass wir noch eine Interaktion zwischen Komponenten abbilden können. Dazu legen wir eine neue Komponente via Stencil CLI mit den gleichen Einstellungen wie zuvor an. Nur als Name nutzen wir jetzt list-pagination. Den Inhalt der erzeugten Datei list-pagination.tsx ersetzen wir vollständig mit dem Code aus Listing 4.
// import { ... } from '@stencil/core'
@Component({
tag: 'list-pagination',
styleUrl: 'list-pagination.scss',
shadow: true,
})
export class ListPagination implements ComponentInterface, ComponentWillLoad {
@State() private totalPages: number;
@State() private currentPage: number;
@State() private previousPage: number | undefined;
@State() private nextPage: number | undefined;
/** The count of all items in the list. */
@Prop() count: number;
/** How much items per page shall be shown in the list? */
@Prop() itemsPerPage: number;
/** The current offset of the list.*/
@Prop() offset: number;
/** Emits, when a paging is triggered. */
@Event() paging: EventEmitter<{ offset: number }>;
private handleClick(offset: number): void {
this.offset = offset;
this.calculate();
this.paging.emit({ offset });
}
private calculate(): void {
this.totalPages = Math.ceil(this.count / this.itemsPerPage);
this.currentPage = Math.floor(this.offset / this.itemsPerPage) + 1;
this.previousPage = this.currentPage - 1 <= 0 ? undefined : this.currentPage - 1;
this.nextPage = this.currentPage + 1 >= this.totalPages ? undefined : this.currentPage + 1;
}
componentWillLoad(): void {
this.calculate();
}
render() {
return (
<Host>
</Host>
);
}
}
Zusätzlich benötigen wir noch den Code aus Listing 5, den wir in die render-Methode einfügen.
<Host>
<ul>
<li onClick={() => this.handleClick(0)}>«</li>
{
this.previousPage &&
<li onClick={() => this.handleClick(this.offset - this.itemsPerPage)}>{this.previousPage}</li>
}
<li class="current">{this.currentPage}</li>
{
this.nextPage &&
<li onClick={() => this.handleClick(this.offset + this.itemsPerPage)}>{this.nextPage}</li>
}
<li onClick={() => this.handleClick(this.count - this.itemsPerPage)}>»</li>
</ul>
</Host>
Schauen wir uns zunächst den Code aus Listing 4 genauer an. Hier fallen zwei Dinge auf, die wir noch nicht kennen: das Interface ComponentWillLoad und den @Event-Dekorator.
ComponentWillLoad, implementiert durch die Methode componentWillLoad, wird aufgerufen, nach dem die Komponente vollständig initialisiert wurde, aber bevor das erste Mal die Methode render aufgerufen wird. In diesem Fall wird die Methode calculate aufgerufen, die auf Basis der definierten Properties @Prop die Pagination berechnet.
Der @Event-Dekorator kann genutzt werden, um ein eigenes CustomEvent zu erstellen. In unserem Fall generieren wir ein Event, sobald eine Seite angeklickt wurde. Dazu setzen wir einen onClick-Handler auf ein HTML-Element (Listing 5), der bei Ausführung die Methode handleClick (Listing 4) ausführt und das dazugehörige Offset übermittelt. Generell müssen alle Events vom Typ EventEmitter sein.
In Listing 5 sehen wir den Code der render-Methode. Er enthält JSX-typische Event Handler und partielle Templates, die nur ausgegeben werden, wenn das dazugehörige Feld gesetzt ist. Hierbei nutzt man die Tatsache, dass in JavaScript das Ergebnis einer booleschen Operation der Inhalt ist, der zuletzt evaluiert wurde. Das ist der Ausdruck, der am weitesten rechts in der Ausdruckskette steht. In unserem Beispiel wird daher überprüft, ob previousPage truthy ist, ist das der Fall, wird geschaut, ob das HTML-Element li truthy ist. Das ist es per Definition und da es der Ausdruck ist, der zuletzt evaluiert wurde, ist das li das Ergebnis unseres impliziten If und wird daher gerendert. Ist previousPage falsy, wird nichts gerendert.
Nach der Implementierung unserer Pagination-Komponente wollen wir sie in unserer Pokémon-Liste verwenden. Dazu sind zwei Anpassungen an der Datei pokemon-list.tsx nötig, die wir in Listing 6 finden.
// Zusätzliche Methode implementieren
private handlePaging(paging: { offset: number }): void {
this.offset = paging.offset;
this.loadPage();
}
// Direkt nach </table> einfügen
<list-pagination
count={this.pokemonCount}
offset={this.offset}
itemsPerPage={this.itemsPerPage}
onPaging={event => this.handlePaging(event.detail)}
/>
Hier fügen wir eine Methode handlePaging hinzu, die als Event Handler für das paging-Event unserer list-pagination Komponente dient. Zudem fügt Listing 6 die list-pagination-Komponente ein, sodass wir diese entsprechend nutzen können. Hier sehen wir, dass aus unserem Event paging ein onPaging wurde. Es ist eine Konvention von JSX, dass alle Events mit dem Prefix on versehen werden.
Nach diesen Änderungen ist unsere Entwicklung fertig und wir können unsere Komponenten im Browser ansehen.
Bis hierhin hätten wir auch ein anderes Framework nutzen können, um unsere Web Components zu entwickeln. Die Implementierung wäre gewiss etwas anders, aber das Endergebnis erstmal identisch. Jetzt wollen wir noch eine weitere Stärke von Stencil ausspielen, nämlich die der Dokumentationsgenerierung. Dazu rufen wir auf der Kommandozeile folgenden Befehl auf:
npm run build
Mit diesem Befehl erzeugt Stencil eine ganze Reihe an Ausgaben. Wir erhalten zum einen pro Komponente eine TypeScript-Definitionsdatei zur Autovervollständigung für unsere IDEs. Zum anderen erhalten wir pro Komponente eine Markdown-Datei mit einer Dokumentation über unsere Komponente. Die Markdown-Datei selbst ist zweigeteilt. In einem Teil dürfen wir selbst manuelle Dokumentation hinzufügen. Der zweite Teil ist automatisch aus unserem Code generiert. Properties (@Prop) und Events (@Event) werden korrekt mit Typ und Kommentar dokumentiert, sofern vorhanden. Zudem erhalten wir einen Dependency-Graph zwischen unseren Komponenten, damit sehen wir auf einen Blick, was welche Komponenten benutzt. Sowohl Parent-Child- als auch Child-Parent-Beziehungen werden visualisiert. Die Visualisierung erfolgt auf Basis von in Markdown eingebettetem Mermaid-Graphen, die auch ohne Rendering textlich gut lesbar sind. Ein gerendertes Beispiel der Dokumentation unserer list-pagination Komponente sehen wir in Abbildung 5.
Zu guter Letzt generiert der Befehl auch die entsprechenden Releasepakete unserer Web Components, sodass wir sie überall nutzen können. Es werden bspw. die Formate für CommonJS oder ES Module Import generiert. Es bleiben so kaum Wünsche offen, wenn man die Komponenten wiederverwenden möchte.
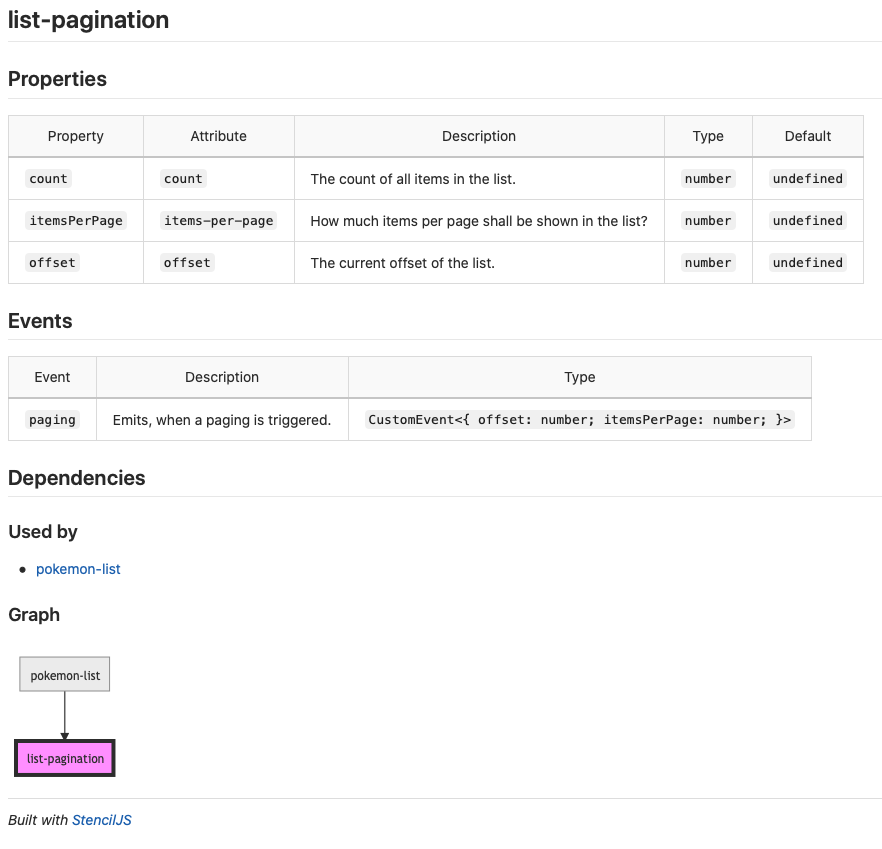
Auch wenn wir mit diesem Artikel erst an der Oberfläche von Stencil gekratzt haben, haben wir die wichtigsten Punkte gesehen: das Erzeugen von Web Components und die dazugehörige Dokumentation. Beides kommt bei Stencil aus einer Hand. Genau das ist es, was Stencil sehr charmant macht. Es ist ein Allround-Paket und lässt kaum Wünsche offen. Wer noch tiefer eintauchen möchte, kann sich über Dinge wie reaktive Daten oder funktionale Komponenten freuen, all das gepaart mit weiteren Features von Web Components, nur eben auf Steroiden.
Noch viel mehr zu Stencil und Web Components erfahren Sie in den BASTA!-Sessions von Manuel Rauber.
The post Web Components auf Steroiden: Maximieren Sie die Leistung und Wiederverwendbarkeit Ihrer Webanwendungen appeared first on BASTA!.
]]>The post Die Microfrontend-Revolution appeared first on BASTA!.
]]>Es erlaubt einen Ansatz namens Module Federation zum Referenzieren von Programmteilen, die zum Kompilierungszeitpunkt noch nicht bekannt sind. Dabei kann es sich auch um eigenständig kompilierte Microfrontends handeln. Außerdem können die einzelnen Programmteile untereinander Bibliotheken teilen, sodass die einzelnen Bundles keine Duplikate beinhalten.
In diesem Artikel zeige ich anhand eines einfachen Beispiels, wie sich Module Federation [2] nutzen lässt. Der Quellcode befindet sich hier.
Das hier verwendete Beispiel besteht aus einer Shell, die in der Lage ist, einzelne separat bereitgestellte Microfrontends bei Bedarf zu laden (Abb. 1).
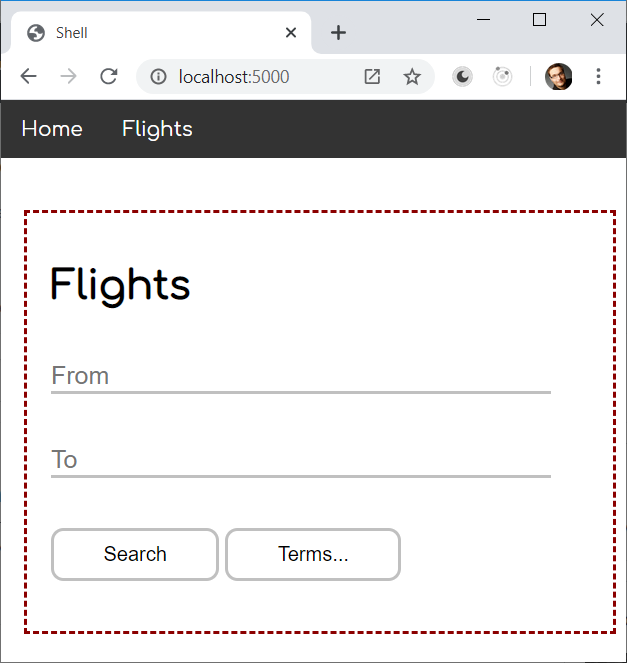
Die Shell wird hier durch die schwarze Navigationsleiste repräsentiert. Das Microfrontend durch den darunter dargestellten eingerahmten Bereich. Außerdem lässt sich das Microfrontend auch ohne Shell starten (Abb. 2).
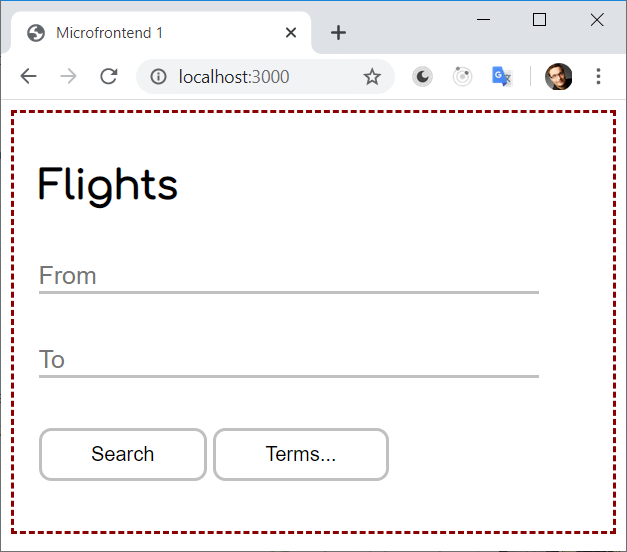
Das ist notwendig, um ein separates Entwickeln und Testen zu ermöglichen. Außerdem kann es für schwächere Clients wie mobile Endgeräte von Vorteil sein, nur den benötigten Programmteil laden zu müssen.
In der Vergangenheit war die Umsetzung von Szenarien wie das hier gezeigte schwierig, zumal Werkzeuge wie webpack davon ausgehen, dass der gesamte Programmcode beim Kompilieren vorliegt. Lazy Loading ist zwar möglich, aber nur von Bereichen, die beim Kompilieren abgespaltet wurden.
Gerade bei Microfrontend-Architekturen möchte man die einzelnen Programmteile jedoch separat kompilieren und bereitstellen. Daneben ist ein gegenseitiges Referenzieren über den jeweiligen URL notwendig. Dazu wären Konstrukte wie dieses hier wünschenswert:
import('http://other-microfrontend');
Da das aus den genannten Gründen nicht möglich ist, musste man auf Ansätze, wie Externals [4] und manuellem Skript-Loading ausweichen. Mit der Module Federation in webpack 5 wird sich das zum Glück ändern.
Die Idee dahinter ist einfach: Ein sogenannter Host referenziert einen Remote über einen konfigurierten Namen (Abb. 3). Auf was dieser Name verweist, ist zum Kompilierungszeitpunkt nicht bekannt.
&nsbp;
Dieser Verweis wird erst zur Laufzeit aufgelöst, indem ein sogenannter Remote Entrypoint geladen wird. Dabei handelt es sich um ein minimales Skript, das den tatsächlichen externen URL für solch einen konfigurierten Namen bereitstellt.
Beim Host handelt es sich um eine JavaScript-Anwendung, die einen Remote bei Bedarf lädt. Dazu kommt ein dynamischer Import zum Einsatz. Der Host in Listing 1 lädt auf diese Weise die Komponente hinter mfe1/component.
const rxjs = await import('rxjs');
const container = document.getElementById('container');
const flightsLink = document.getElementById('flights');
rxjs.fromEvent(flightsLink, 'click').subscribe(async _ => {
const module = await import('mfe1/component');
const elm = document.createElement(module.elementName);
[...]
container.appendChild(elm);
});
Normalerweise würde webpack diesen Verweis beim Kompilieren berücksichtigen und ein eigenes Bundle dafür abspalten. Um das zu verhindern, kommt das ModuleFederationPlugin zum Einsatz (Listing 2).
const ModuleFederationPlugin = require("webpack/lib/container/ModuleFederationPlugin");
[...]
plugins: [
new ModuleFederationPlugin({
name: "shell",
library: { type: "var", name: "shell" },
remotes: {
mfe1: "mfe1"
},
shared: ["rxjs"]
})
]
Mit seiner Hilfe wird der Remote mfe1 (Microfrontend 1) definiert. Dazu stellt die gezeigte Konfiguration ein Mapping zur Verfügung, das den anwendungsinternen Namen mfe1 auf denselben offiziellen Namen abbildet. Jeder Import, der sich nun auf mfe1 bezieht, wird von webpack nicht in die zur Compile Time generierten Bundles aufgenommen.
Bibliotheken, die sich der Host mit den Remotes teilen soll, sind unter shared einzutragen. Im gezeigten Fall handelt es sich dabei um rxjs. Das bedeutet, dass die gesamte Anwendung diese Bibliothek nur ein einziges Mal laden muss. Ohne diese Angabe würde rxjs sowohl in den Bundles des Hosts als auch in jenen aller Remotes landen.
Damit das problemlos funktioniert, müssen sich Host und Remote auf eine gemeinsame Version einigen. Außerdem muss der Host solche Bibliotheken, wie in Listing 1 gezeigt, über einen dynamischen Import laden. Statische Importe wie import * as rxjs from ‘rxjs’; unterstützte das Plug-in nicht, als der vorliegende Text verfasst wurde.
Der Remote ist ebenfalls eine eigenständige Anwendung. Im hier betrachteten Fall basiert er auf Web Components (Listing 3).
class Microfrontend1 extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
async connectedCallback() {
this.shadowRoot.innerHTML = `[…]`;
}
}
const elementName = 'microfrontend-one';
customElements.define(elementName, Microfrontend1);
export { elementName };
Anstatt Web Components können aber auch beliebige JavaScript-Konstrukte oder Komponenten, die auf Frameworks basieren, zum Einsatz kommen. Die Frameworks lassen sich in diesem Fall auf die gezeigte Weise zwischen den Remotes und dem Host teilen.
Die webpack-Konfiguration des Remotes, die ebenfalls das ModuleFederationPlugin nutzt, exportiert diese Komponente mit der Eigenschaft exposes unter dem Namen component (Listing 4).
output: {
publicPath: "http://localhost:3000/",
[...]
},
[...]
plugins: [
new ModuleFederationPlugin({
name: "mfe1",
library: { type: "var", name: "mfe1" },
filename: "remoteEntry.js",
exposes: {
component: "./mfe1/component"
},
shared: ["rxjs"]
})
]
Dazu verweist der Name component auf die entsprechende Datei. Außerdem legt diese Konfiguration für den vorliegenden Remote den Namen mfe1 fest. Zum Zugriff auf den Remote nutzt der Host einen Pfad, der sich aus den beiden konfigurierten Namen, mfe1 und component, zusammensetzt. Somit ergibt sich die oben gezeigte Anweisung import(‘mfe1/component’).
Allerdings muss der Host dazu wissen, unter welchem URL er mfe1 findet. Der nächste Abschnitt gibt darüber Aufschluss.
Um dem Host die Möglichkeit zu geben, den Namen mfe1 aufzulösen, muss dieser einen Remote Entrypoint laden. Dabei handelt es sich um ein Skript, dass das ModuleFederationPlugin beim Kompilieren des Remote generiert.
Der Name dieses Skripts findet sich in der Eigenschaft filename (Listing 4). Der URL des Microfrontend wird aus dem unter output festgelegten publicPath entnommen. Das bedeutet, dass der URL des Remote bei dessen Kompilierung bereits bekannt sein muss. Das ist zwar nicht schön – in vielen Fällen kann man damit aber leben.
Nun ist dieses Skript nur noch in den Host einzubinden:
<script src="http://localhost:3000/remoteEntry.js"></script>
Zur Laufzeit lässt sich nun beobachten, dass die Anweisung import(‘mfe1/component’); im Host dazu führt, dass er den Remote von seiner eigenen URL (hier localhost:3000) lädt (Abb. 4).
Die in webpack 5 integrierte Module Federation füllt eine große Lücke für Microfrentends. Endlich lassen sich separat kompilierte und bereitgestellte Programmteile nachladen und bereits geladene Bibliotheken wiederverwenden.
Die an der Entwicklung solcher Anwendungen beteiligten Teams müssen jedoch manuell sicherstellen, dass die einzelnen Teile auch zusammenspielen. Das bedeutet auch, dass man Verträge zwischen den einzelnen Microfrontends definieren und einhalten, aber auch, dass man sich bei den geteilten Bibliotheken auf jeweils eine Version einigen muss.
Die Notwendigkeit für dynamische Imports führt zu ungewohnten Codestrecken, zumal das Framework der Wahl in der Regel statisch importiert wird. Bei Angular, das den Programmcode mit einem Compiler transformiert, erweist sich dieser Umstand als Showstopper. Bis zur finalen Version ist jedoch noch ein wenig Zeit, um das zu ändern.
Als der vorliegende Artikel geschrieben wurde, war webpack 5 noch in der Betaversion und somit nicht für den Produktionseinsatz reif. Das bedeutet, dass man vorerst noch auf die eingangs erwähnten Tricks setzen muss. Mittel- bis langfristig dürfte die Module Federation jedoch die Standardlösung für Microfrontends im JavaScript-Umfeld werden.
● Die Microfrontend-Revolution: Webpack 5 Module Federation mit Angular nutzen
The post Die Microfrontend-Revolution appeared first on BASTA!.
]]>The post Einstieg in die fabelhafte Welt der Web Components appeared first on BASTA!.
]]>Komponenten – ein Wort, das wir Windows-Entwickler seit vielen Jahren kennen und zu schätzen wissen. Auch im Web ist eine Komponente nichts Neues. Damals, zu jQuery-Zeiten, half uns jQuery, UI-Komponenten zu entwickeln. Heute nutzen wir hier Frameworks wie Angular, React oder Vue. Doch was leistet so eine Komponente eigentlich?
Eine Komponente kapselt Funktion in Form von Code, UI-Struktur und UI-Design. Heruntergebrochen auf das Web bedeutet das z. B. Code in Form von JavaScript oder TypeScript, UI-Struktur mit HTML und UI-Design mit CSS. Mit Hilfe dieser Programmier- und Auszeichnungssprachen erhalten wir wiederverwendbare Komponenten, aus denen wir unsere finale Anwendung komponieren. Oftmals besteht eine Anwendung aus vielen kleinen Komponenten. Jede mit einer eigenen, ganz bestimmten Funktion und oft auch einer Schnittstelle nach außen, sodass der Entwickler Daten in die Komponente geben kann, aber auch Daten aus ihr erhält. Wirft man einen Blick auf die drei großen Single Page Application (SPA) Frameworks, Angular, React und Vue, geben alle drei dem Entwickler ein Komponentenmodell an die Hand. Sei es bei Angular via @Component-Dekorator, bei React via Ableitung von React.Component und bei Vue die Funktion Vue.component(). All das hilft uns, im jeweiligen Framework unsere Business Use Cases in Komponenten zu gießen.
Auch wenn alle drei genannten Frameworks mit dem Komponentenmodell eine Gemeinsamkeit haben, ist die Entwicklung danach grundverschieden. Jedes Framework hat ein eigenes Konzept, wie Daten an das UI übermittelt werden oder auf Benutzereingaben in Form von Events reagiert werden können. Auch die Lifecycle-Methoden unterscheiden sich etwas. Alle Frameworks bieten Methoden an, die in der jeweiligen Komponente aufgerufen werden, wenn diese z. B. zur Anzeige gebracht oder vom Framework wieder zerstört wird. Daneben existieren allerdings weitere Framework-spezifische Lifecycle-Methoden. Für uns Entwickler bedeutet das, dass wir einen Teil unseres Basiswissens, dem Verständnis über das Web, Framework-übergreifend verwenden können. Alles andere müssen wir für jedes Framework immer wieder neu lernen, was gerne auch mal mit dem einen oder anderen Fallstrick verbunden ist.
Bricht man alle Frameworks auf ihre Basisidee herunter, entstanden sie alle aus einem Grund: Dem Nachrüsten eines Komponentenmodells im Browser, da dieser keines zur Verfügung stellt. Das manche Frameworks dabei etwas größer wurden und Mehrwertdienste anbieten, wie z. B. eine Dependency Injection, ist eine individuelle Entscheidung der Framework-Entwickler, um dem Entwickler mehr Funktion an die Hand zu geben. Seit geraumer Zeit entwickeln und etablieren sich drei Standards im Web, die es ermöglichen, dass uns der Browser ein natives Komponentenmodell zur Verfügung stellt: Custom Elements, Shadow DOM und HTML Templates. Vor einiger Zeit hätte man noch einen vierten Standard, HTML Imports, hinzugezählt. Dieser wird allerdings zugunsten von ES Module Imports nicht mehr benötigt. Sehen wir uns diese drei Standards einmal genauer an.
Regelmäßig News zur Konferenz und der .NET-Community
<div class=”datepicker”></div> – kommt Ihnen das bekannt vor? In früheren Zeiten der Webentwicklung hat diese Angabe, nebst der Einbindung einer JavaScript-Bibliothek und CSS-Dateien, gereicht, um aus einem
<div>-Element einen Datepicker zu machen. Zur Laufzeit der Anwendung wurde dieses
<div> dann um weitere Elemente und Funktionen erweitert. Viel schöner wäre es doch, wenn wir stattdessen <my-datepicker></my-datepicker> schreiben könnten. Und genau das ermöglicht uns das Custom Elements API. Es erlaubt uns, dem Browser neue HTML-Tags beizubringen, die dann mit einem von uns definierten Inhalt gerendert werden. Damit das klappt, brauchen wir die nächsten zwei Standards.
Wir alle kennen das Problem im Web: Man entwickelt eine schöne Komponente, bindet sie in eine Drittanbieterwebseite ein und in der Regel passieren zwei Dinge. Erstens sieht unsere Komponente meist nicht mehr so aus, wie wir es wollten. Zweitens sehen plötzlich Dinge auf der Website nicht mehr so aus, wie sie eigentlich sein sollten. Das liegt oft daran, dass zu generische CSS-Selektoren genutzt wurden, die der Browser natürlich auf alle gefundenen Elemente der kompletten Website anwendet. Genau hier setzt Shadow DOM an und bietet Abhilfe. Shadow DOM ist ein Set von JavaScript APIs, die es uns ermöglichen, einen sogenannten Shadow DOM Tree einem HTML-Element anzuhängen, der vom Browser separat und außerhalb des Main Document DOM gerendert wird. Sind im Shadow DOM Tree CSS-Angaben enthalten, werden diese auch nur auf die Elemente innerhalb des Shadow DOM Trees angewendet. CSS-Angaben außerhalb, also sprich im Main Document DOM, haben keine Auswirkungen auf die Elemente innerhalb des Shadow DOM. Dadurch können Komponenten genauso gestylt werden, wie wir es gerne hätten, und wir brauchen keine Sorge haben, dass jemand unsere CSS-Stile überschreibt. Jetzt bleibt nur noch die Frage offen, wie wir eigentlich definieren, welche HTML-Elemente im Shadow DOM angezeigt werden? Dazu benötigen wir den letzten Standard.
Im Wesentlichen besteht dieser Standard aus zwei HTML-Tags, nämlich <template> und <slot>. Das <template> gibt an, welche HTML-Elemente gerendert werden sollen. Den <slot> kann man quasi als Platzhalter im Template sehen, dazu später mehr. Der Unterschied ist allerdings, dass der Browser alles innerhalb des <template>-Tags nicht rendert. Er parst den Inhalt und baut das passende DOM dazu auf, bringt es aber nicht zur Anzeige. Erst mit der eigentlichen, und auch wiederverwendbaren Nutzung des Templates wird es vom Browser gerendert.
Mit Hilfe der drei genannten Technologien sind wir in der Lage, eine eigene wiederverwendbare Web Component zu entwickeln. Und genau das wollen wir in den nächsten Abschnitten machen, um uns so Schritt für Schritt den wichtigsten APIs der Standards zu nähern. Das fertige Beispiel finden Sie auf GitHub. Zur Entwicklung benötigen Sie einen Codeeditor, Node.js und Google Chrome. Auch wenn die Evergreen-Browser mittlerweile beinahe alle APIs unterstützen, empfiehlt es sich für diesen Artikel, Google Chrome zu verwenden. Gemeinsam werden wir eine kleine Zählerkomponente entwickeln, mit einer Anzeige des aktuellen Wertes sowie einem Plus- und Minus-Button. Die Abbildung 1 zeigt den universellen Einsatz unserer Implementierung.
Zum Start erstellen wir uns eine Datei mit dem Namen package.json. Den Inhalt entnehmen Sie Listing 1.
{
"name": "windows-developer-web-components",
"version": "1.0.0",
"scripts": {
"start": "browser-sync start --server src --files src --no-open"
},
"dependencies": {},
"devDependencies": {
"browser-sync": "^2.26.7"
}
}
Die wichtigste Angabe hier ist der Startbefehl. Dieser startet die Anwendung browser-sync. Diese Anwendung bietet uns zwei Dinge: Zum einen erhalten wir einen Webserver, der später unsere Web Component ausliefern wird, sodass sie im Browser angezeigt werden kann. Zum anderen bemerkt die Anwendung, wenn innerhalb des Entwicklungsordners eine Änderung stattfindet, und lädt automatisch den Browser neu. So können wir sehr schnell unsere Änderung ansehen, nämlich in dem Moment, in dem wir im Codeeditor auf Speichern drücken.
Damit es wie gewünscht funktioniert, erstellen wir zunächst noch den Ordner src. Ist das geschehen, öffnen wir eine Kommandozeile im Ordner, in dem auch die package.json-Datei liegt. In der Kommandozeile führen wir das Kommando npm install aus, um browser-sync herunterzuladen. Danach führen wir npm start aus, um die Anwendung zu starten. Zu sehen ist natürlich noch nichts. Das wollen wir mit dem nächsten Schritt ändern. Dazu legen wir im Ordner src die Datei index.html an. Den Inhalt der Datei finden Sie in Listing 2.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Windows Developer Web Components Demo</title>
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cscript%20src%3D%22counter.js%22%20type%3D%22module%22%3E%3C%2Fscript%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="&lt;script&gt;" title="&lt;script&gt;" />
</head>
<body>
</body>
</html>
Neben den HTML-Dokument-typischen Angaben sehen wir auch die Angabe eines <script>-Tags, was auf eine Datei counter.js verweist. Hinweis: Diese Datei haben wir noch nicht erstellt. Interessant ist die Angabe von type=“module”. Sie teilt dem Browser mit, dass er die Datei als JavaScript-Modul laden soll. Auch hierbei handelt es sich um eine mittlerweile native Funktion des Browsers. Früher hätte man sein JavaScript als CommonJS- oder AMD-basierte Module bereitgestellt. Heute reicht die Angabe im Browser aus, um jede JavaScript-Datei als Modul zu laden. Module ermöglichen es uns, unsere JavaScript-Programme in kleinere Teile zu zerstückeln und nur bei Bedarf zu laden.
Gut! Wenn wir jetzt im Google Chrome den URL http://localhost:3000 aufrufen, sollten wir zumindest eine weiße Seite mit dem Titel „Windows Developer Web Components Demo“ sehen. Ist das nicht der Fall, prüfen Sie zuerst, ob in Ihrer Kommandozeile beim Ausführen von npm start ein Fehler angezeigt wird. Falls nicht, prüfen Sie, ob auf Ihrer Maschine browser-sync ggf. auf einem anderen Port gestartet wurde. Auch das ist in der Logausgabe der Kommandozeile ersichtlich.
Mit den zwei Dateien zuvor haben wir das Grundgerüst unserer Anwendung geschaffen. Zum einen eine kleine Entwicklungsumgebung, die sich automatisch bei Änderung an Dateien diese neu lädt. Als auch eine kleine Demo-Applikation mit der index.html. Denn diese benötigen wir später für unsere eigentliche Komponente nicht. Sie dient nur dazu, dass wir unsere eigene Komponente sehen, um sie besser entwickeln zu können. Als Nächstes legen wir im Ordner src die Datei counter.js an. In dieser Datei werden wir unsere Web Component entwickeln. In Listing 3 finden wir das Grundgerüst einer jeden Web Component.
class MyCounter extends HTMLElement {
constructor() {
super();
}
}
window.customElements.define('my-counter', MyCounter);
Die Datei startet mit der Definition der Klasse MyCounter. Sie leitet von einer Klasse HTMLElement ab. Die Klasse HTMLElement wird vom Browser zur Verfügung gestellt. Sie dient als Basisklasse für jedes im Browser befindliche HTML-Element, daher auch für unsere. Übrigens, wollten wir z. B. ein spezielles Eingabefeld entwickeln, könnten wir auch von der Klasse HTMLInputElement ableiten. Im MDN findet sich eine ganze Reihe von Interfaces, von denen wir unsere eigene Komponente ableiten können. Damit wir die Vererbungskette ordnungsgemäß einhalten, nutzen wir einen super()-Aufruf in unserem Konstruktor, ähnlich wie base() bei C#.
Am Ende von Listing 3 findet sich das erste API unseres Standards Custom Elements wieder. Es handelt sich hier um die Definition eines neuen HTML-Elements für den Browser. Daher ist dieses API auf dem Objekt window zu finden. Die Methode define() definiert das neue Element. Der erste Parameter gibt den Namen des Elements an. Der zweite Parameter ist eine Konstruktor-Funktion, in dem Fall unsere Klasse MyCounter.
Der Typ von customElements ist eine CustomElementRegistry. Diese ist global für das aktuelle Browsertab. Neben der Definition von neuen Elementen, könnte man prüfen, ob ein bestimmtes HTML-Element registriert wurde, in dem man bspw. customElements.get(‘name-des-elements’) aufruft. Entweder man erhält die Konstruktor-Funktion oder null. Alternativ kann mit customElements.whenDefined(‘name-des-elements’) gewartet werden, bis ein HTML-Element mit dem gewünschten Namen zur Verfügung steht. Die Methode gibt ein Promise zurück, das erfüllt wird, sobald das HTML-Element registriert wurde. Um das Element zu nutzen, können wir im <body>-Bereich in der index.html unser Element via <my-counter></my-counter> aufrufen. Es ist zu beachten, dass Web Components generell ein schließendes Tag benötigen.
Durch das Speichern im Codeeditor hat sich unser Browser automatisch neu geladen. In den DevTools von Chrome sehen wir zwar unser HTML-Element, allerdings ist visuell auf der Seite immer noch nichts sichtbar. Es fehlen schließlich noch unser HTML Template und der Shadow DOM. In Listing 4 finden wir ein erstes kleines Template. Dieses wird noch vor der Definition unserer Klasse abgelegt.
const template = document.createElement('template');
template.innerHTML = `
</wp-p>
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cstyle%3E%0A%20%20%20%20.counter-container%20%7B%0A%20%20%20%20%20%20--default-height%3A%20var(--height%2C%2050px)%3B%0A%20%20%20%20%20%20%0A%20%20%20%20%20%20width%3A%20calc(var(--default-height)%20*%203)%3B%0A%20%20%20%20%20%20height%3A%20var(--default-height)%3B%0A%20%20%20%20%20%20display%3A%20flex%3B%0A%20%20%20%20%7D%0A%0A%20%20%20%20.counter-container%20%3E%20div%20%7B%0A%20%20%20%20%20%20color%3A%20black%3B%0A%20%20%20%20%20%20font-size%3A%202.2em%3B%0A%0A%20%20%20%20%20%20display%3A%20flex%3B%0A%20%20%20%20%20%20align-items%3A%20center%3B%0A%20%20%20%20%20%20justify-content%3A%20center%3B%0A%20%20%20%20%7D%0A%20%20%20%20%0A%20%20%20%20.button%20%7B%0A%20%20%20%20%20%20padding%3A%201rem%3B%0A%20%20%20%20%20%20border%3A%201px%20solid%20black%3B%0A%20%20%20%20%7D%0A%20%20%20%20%0A%20%20%20%20.value%20%7B%0A%20%20%20%20%20%20margin%3A%200%201rem%3B%0A%20%20%20%20%7D%0A%20%20%3C%2Fstyle%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="&lt;style&gt;" title="&lt;style&gt;" />
<wp-p>
<slot name=&quot;header&quot;>
</wp-p>
<h1>My Counter</h1>
<wp-p>
</slot>
</wp-p>
<div class=&quot;counter-container&quot;><wp-p>
</wp-p>
<div class=&quot;button decrement&quot;>-</div>
<wp-p>
</wp-p>
<div class=&quot;value&quot;>
<slot name=&quot;value-prefix&quot;></slot>
<span class=&quot;value-display&quot;>0</span>
<slot name=&quot;value-postfix&quot;></slot>
</div>
<wp-p>
</wp-p>
<div class=&quot;button increment&quot;>+</div>
<wp-p>
</div>
<wp-p>`;
// class MyCounter extends HTMLElement ...
Bitte beachten Sie, dass zur besseren Darstellung im Artikel das Styling der Komponente nicht dem der Abbildung 1 entspricht, sondern abgeändert wurde. Das originale Styling finden Sie im GitHub Repository. Es ist daher auch zu empfehlen, das Styling aus dem Repository zu übernehmen.
Schauen wir uns Listing 4 genauer an. In der ersten Zeile wird via document.createElement() ein HTML Template erstellt. Über den Zugriff auf innerHTML können wir unser Template definieren. Hier können wir neben dem eigentlichen Markup eben auch CSS-Stile hinterlegen, um unsere Komponente zu stylen. Im Kasten „Struktureller Aufbau von Web Components“ finden sich weitere Informationen über den strukturellen Aufbau von Web Components. Im CSS selbst wird zunächst die Variable –default-height definiert. Sie prüft, ob eine Variable –height gesetzt wurde. Falls nicht, wird 50px als Standardwert übernommen. Auf Basis dieser Variable wird die Größe unserer Komponente bestimmt. Im Originalstyling hat die Variable Auswirkung auf weitere Elemente innerhalb der Web Component.
Spannend wird das HTML Markup, da wir hier ein Element sehen, das wir nur innerhalb eines HTML Templates verwenden können. Es handelt sich hierbei um das Element <slot>. Es dient als Platzhalter für Inhalt, den wir später von außen, also in unserer index.html bestimmen können. Wird der Inhalt nicht von außen überschrieben, wird der Inhalt vom <slot>-Element selbst gerendert, in diesem Fall ein
<h1>-Tag. Der name erlaubt uns, gezielt einen bestimmten Slot anzusprechen, den wir überschreiben. Dieses Konzept ist in anderen Frameworks oft unter den Begriffen Transclusion, Content Projection oder Higher-Order Component zu finden. Das weitere Markup ist gewohntes HTML.
Struktureller Aufbau von Web Components
Je nach Framework sind Webentwickler es gewohnt, Code von Template und Styling zu trennen, in zwei oder mehrere Dateien. Im einfachsten Fall von Web Components, wie in diesem Artikel dargestellt, befindet sich alles innerhalb einer Datei. Bei größeren oder komplex gestylten Web Components kann diese Datei daher recht groß werden. Auch der Einsatz von CSS-Prozessoren ist meist schwierig, wenn sich das CSS innerhalb von JavaScript-Dateien wiederfindet. Möchte man bereits erste produktive Web Components entwickeln, empfiehlt sich der Einsatz von Frameworks, die sich mittlerweile auf Web Components spezialisieren. Herausstechend ist hier Stencil.js. Stencil.js lagert das Styling in eine separate Datei aus und hat von Haus aus Unterstützung von verschiedenen CSS-Prozessoren, sodass wir hier auf gewohntem Weg entwickeln können. Des Weiteren bietet Stencil.js einigen syntaktischen Zucker, um wiederkehrende Aufgaben in Web Components einfacher zu gestalten, bspw. das Binden von Daten in die UI oder das Reagieren auf Events wie einen Button-Klick.
Falls wir zwischenzeitlich unseren Codeeditor gespeichert haben, hat der Browser zwar ein Reload ausgeführt, dennoch ist nichts zu sehen. Das hat auch einen guten Grund: Wir haben zwar ein Template definiert, aber wir nutzen es noch nicht. Das wollen wir ändern. Dazu benötigen wir den Inhalt aus Listing 5. Dieser wird unmittelbar nach dem super() im Konstruktor unserer Klasse eingefügt.
constructor() {
super();
this.shadow = this.attachShadow({ mode: 'open' });
this.shadow.appendChild(template.content.cloneNode(true));
}
Der wohl wichtigste Aufruf ist attachShadow(). Hierdurch wird unserer Komponente ein Shadow DOM angehängt, in das wir etwas platzieren dürfen. Die Angabe des ersten Parameters ist obligatorisch und gibt den Modus des Shadow DOM an. Hier im Beispiel nutzen wir den Modus open. Alternativ gäbe es auch eine Variante closed.
Der Modus bestimmt, ob wir via JavaScript von außen auf das Shadow DOM zugreifen dürfen. Jede Web Component hat ein JavaScript Property shadowRoot. Der Modus bestimmt, ob wir beim Zugriff auf dieses Property den tatsächlichen Shadow DOM Tree erhalten (open) oder ob wir beim Zugriff null erhalten (closed). Jetzt stellt sich die Frage, warum wir uns von außen Zugriff erlauben wollten. Gerade im Hinblick auf die Entwicklung größerer Komponentenbibliotheken kann es durchaus sinnvoll sein, Zugriff auf das Shadow DOM kleinerer interner Komponenten zu erlauben. Allerdings gilt es dann, den Zugriff auf das Shadow DOM zu sperren bei den Komponenten, die später von den Entwicklern eingesetzt werden. Übrigens, JavaScript wäre nicht JavaScript, wenn man nicht über kleine Tricks auch beim closed-Modus an den Shadow DOM Tree kommen könnte. Eine Suchmaschine Ihrer Wahl hilft beim Auffinden solcher kleinen Gemeinheiten.
Nachdem wir nun einen Shadow DOM Tree erzeugt haben, fügen wir mit der letzten Zeile im Listing 5 unser HTML Template ein, in dem wir es klonen. Der Parameter gibt an, ob ein deepClone stattfinden soll, sprich der komplette Baum kopiert wird. Ansonsten erhalten wir nur den Wurzelknoten. Wenn wir jetzt unseren Codeeditor speichern, werden wir zum ersten Mal ein Rendering unserer Komponente sehen. Zugegebenermaßen nicht ganz so hübsch mit dem CSS direkt aus dem Artikel, allerdings umso hübscher mit dem CSS aus dem Repository.
Auch wenn unsere Komponente gerendert wird, können wir noch nicht mit ihr interagieren. Um unserer Komponente Leben einzuhauchen, benötigen wir den Code aus Listing 6.
constructor() {
// super & shadow
this.decrementButton = this.shadow.querySelector('.decrement');
this.incrementButton = this.shadow.querySelector('.increment');
this.valueDisplay = this.shadow.querySelector('.value-display');
this.decrementButton.addEventListener('click', () => this.decrement());
this.incrementButton.addEventListener('click', () => this.increment());
}
connectedCallback() {
this.render();
}
get value() {
return +this.getAttribute('value') || 0;
}
set value(v) {
this.setAttribute('value', v);
this.render();
}
increment() {
this.value++;
this.dispatchEvent(new CustomEvent('valueChange', { detail: this.value }));
}
decrement() {
this.value--;
this.dispatchEvent(new CustomEvent('valueChange', { detail: this.value }));
}
render() {
this.valueDisplay.textContent = this.value;
}
Zunächst holen wir, fast schon etwas altertümlich in Hinblick auf moderne SPA-Frameworks, über den querySelector() alle Elemente, die wir benötigen. Das wären beide Buttons sowie das Element, das den aktuellen Wert der Komponente angeben soll. Danach registrieren wir zwei Event Handler via addEventListener(). Beim Klick auf die jeweiligen Buttons soll eine Funktion ausgeführt werden, nämlich decrement() und increment(). Danach folgt die Implementierung der Lifecycle-Methode connectedCallback(). Sie wird immer dann aufgerufen, wenn der Browser die Komponente im DOM platziert. Sie kann daher für erste Initialisierungen genutzt werden. In unserem Fall ein Aufruf der Methode render(), die wiederum den aktuellen Wert this.value in unser HTML-Element valueDisplay schreibt. Neben dem connectedCallback() existiert auch ein disconnectedCallback(), sprich, wenn die Komponente wieder aus dem DOM entfernt wird, bspw. bei einer konditionalen Anzeige.
Im nächsten Schritt wird ein Getter/Setter value definiert. Dieser schreibt und liest den aktuellen Wert des HTML-Attributs value aus. Beim Lesen des Wertes wenden wir einen kleinen JavaScript-Trick an. HTML-Attribute sind generell als Strings abgebildet. Da wir aber einen numerischen Wert benötigen, nutzen wir das Plus-Zeichen vor dem Aufruf von getAttribute() zur Konvertierung eines Strings zu einer Nummer. Alternativ kann hier auch die Methode parseInt genutzt werden. Beim Setzen des Wertes wird zusätzlich die Methode render() aufgerufen, um den gesetzten Wert zur Anzeige zu bringen. Im Kasten „JavaScript Properties vs. HTML-Attribute“ sind nützliche Informationen zu JavaScript Properties und HTML-Attributen enthalten.
Zu guter Letzt werden unsere increment()– und decrement()-Methoden definiert. Sie erhöhen bzw. verringern den Wert von value. Danach schicken sie ein Event nach außen, das meldet, dass sich der Wert geändert hat. So kann der Nutzer dieser Komponente darauf reagieren, wenn sich der Wert der Komponente ändert. Dazu wird ein CustomEvent erzeugt. Der erste Parameter ist der Name des Events, der zweite dient zur Übermittlung von weiteren Daten. Wichtig hierbei ist, dass es sich um ein Objekt handeln muss, auf dem die Eigenschaft detail definiert ist. Hier – und nur hier – können wir einen einzelnen Wert oder ein Objekt übergeben.
JavaScript Properties vs. HTML-Attribute
Bei Web Components unterscheiden wir zwei verschiedene States. Den JavaScript State in Form von Properties und den HTML State in Form von HTML-Attributen. Mit dem in Listing 6 und Listing 7 gezeigten Pattern synchronisieren wir automatisch beide States. Das bedeutet, wenn wir im HTML das Attribut value setzen, ändern wir auch das Property value in JavaScript. Andersrum, wenn wir im JavaScript this.value setzen, ändern wir auch das HTML-Attribute value. Wir sind nicht gezwungen, den State zu synchronisieren. Standardelemente wie z. B. ein <input>-Element synchronisiert diesen State auch nicht.
Bei einfachen Werten können wir uns eine Synchronisierung erlauben, bei komplexen Werten eher nicht. Denn JavaScript Properties können natürlich nicht nur einfache Werte repräsentieren, sondern auch Arrays und Objekte. HTML-Attribute sind allerdings immer Strings. Würde man daher bspw. die Datenquelle einer tabellarischen Web Component als HTML-Attribut ausgeben, würden wir unter Umständen große Arrays als String darstellen und dem Browser übermitteln. Das zehrt an der Performance.
Das Pattern der Synchronisierung nennt sich Reflecting properties to attributes oder auch Reflected DOM Attributes.
Ein kleines Detail fehlt uns noch. Wir können zwar auf unsere Buttons klicken und der angezeigte Wert unserer Komponente wird sich ändern. Ändern wir aber den Wert unserer Komponente im HTML via DevTools, wird nichts passieren. Warum das so ist, entnehmen Sie der Info in Kasten „JavaScript Properties vs. HTML-Attribute“. Um das Problem zu lösen, müssen wir noch eine dritte Lifecycle-Methode anbinden. Diese finden wir in Listing 7 und sie kann bspw. direkt nach dem (aber nicht im) Konstruktor implementiert werden.
static get observedAttributes() {
return [ 'value' ];
}
attributeChangedCallback(name, oldVal, newVal) {
if (oldVal === newVal) {
return;
}
if (name === 'value') {
this.value = newVal;
}
}
Es handelt sich hier um die Lifecycle-Methode attributeChangedCallback(). Sie hat drei Parameter. Den Namen des geänderten Attributs als String, sowie den alten und den neuen Wert, ebenfalls als Strings, da HTML-Attribute generell als String repräsentiert werden. Zusätzlich benötigen wir den statischen Getter observedAttributes. Dieser liefert ein String-Array mit allen Attributen, die der Browser überwachen soll, um bei einer Änderung die Methode attributeChangedCallback() aufzurufen.
Wie man dem Code der Lifecycle-Methode entnehmen kann, führt jeder Zugriff auf das Attribut zu einer Änderung. So kann es durchaus sein, dass der alte und der neue Wert übereinstimmen. Daher prüfen wir das zunächst und machen nichts, falls sich der Wert nicht ändert. Ändert sich allerdings der Wert und der Name des geänderten Attributs ist value, übernehmen wir diesen Wert.
Achtung: Wie der Kasten „JavaScript Properties vs. HTML-Attribute“ erläutert, nutzen wir hier das Pattern Reflected DOM Attributes. Durch das Setzen des Property value setzen wir auch das HTML-Attribut value. Das hat zur Folge, dass der Browser, da sich das Attribut ändert, wieder attributeChangedCallback() aufruft. Ohne die Prüfung, ob sich der Wert geändert hat, würden wir hier in eine Endlosschleife geraten. Daher müssen wir bei der Anwendung des Patterns sehr vorsichtig sein, um keine Endlosschleife zu erzeugen. Damit wäre die Entwicklung unserer Komponente abgeschlossen.
Um die Entwicklung abzurunden, nehmen wir noch eine kleine Änderung an der index.html vor. In Listing 8 finden wir den kompletten Inhalt der Datei, den wir auch genau so in unseren Editor übernehmen.
<!DOCTYPE html>
<html lang=&quot;en&quot;>
<head>
<meta charset=&quot;UTF-8&quot;>
<title>Windows Developer Web Components Demo</title>
</wp-p>
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cstyle%3E%0A%20%20%20%20%20%20my-counter.special%20%7B%0A%20%20%20%20%20%20%20%20--height%3A%20150px%3B%0A%20%20%20%20%20%20%7D%0A%0A%20%20%20%20%20%20my-counter.special%20h1%20%7B%0A%20%20%20%20%20%20%09color%3A%20red%3B%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%3C%2Fstyle%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="&lt;style&gt;" title="&lt;style&gt;" />
<wp-p>
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cscript%20src%3D%E2%80%9Ccounter.js%26quot%3B%20type%3D%26quot%3Bmodule%26quot%3B%3E%3C%2Fscript%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="&lt;script&gt;" title="&lt;script&gt;" />
</em></wp-p>
&nbsp;
<h1>Value pre- & postfix</h1>
>
€
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7" data-wp-preserve="%3Cscript%3E%0A%20%20%20%20%20%20var%20counter%20%3D%20document.querySelector('my-counter')%3B%0A%0A%20%20%20%20%20%20counter.addEventListener('valueChange'%2C%20(%7B%20detail%20%7D)%20%3D%3E%20console.log(detail))%3B%0A%20%20%20%20%3C%2Fscript%3E" data-mce-resize="false" data-mce-placeholder="1" class="mce-object" width="20" height="20" alt="&lt;script&gt;" title="&lt;script&gt;" />
Wir sehen drei Änderungen: Es wurde etwas CSS definiert, unser Zähler ist zweimal definiert, einmal recht einfach und einmal mit Inhalt. Und zuletzt ein kleines Skript, das auf Werteänderungen des ersten Zählers reagiert. Um diese zu sehen, müssen wir die DevTools öffnen und die Konsole anschauen. Beim Klicken auf den ersten Zähler wird der aktuelle Wert auf der Konsole ausgegeben. Im CSS-Bereich sehen wir, dass wir eine Klasse special erstellt haben. Sie setzt die CSS-Variable height auf 150 Pixel. Daher sollte unser zweiter Zähler im Browser deutlich größer erscheinen als der erste. Wir sind also in der Lage, über CSS-Variablen das Aussehen unserer Komponente von außen zu beeinflussen. Wollten wir das eigentlich nicht vermeiden? Ja – und nein. Wir wollen vermeiden, dass uns jemand ungewollt CSS-Stile überschreibt, weil sie zufällig den gleichen Namen haben. Mit den CSS-Variablen bietet unsere Komponente ein API an, das wir bewusst nach außen geben, um das Aussehen zu ändern. Wir als Komponentenentwickler haben es also damit in der Hand, welche Aspekte unserer Komponente geändert werden dürfen.
Die zweite CSS-Angabe ändert die Textfarbe des <h1>-Tags der zweiten Zählerkomponente. Auch hier können wir uns die Frage stellen, warum wir Zugriff darauf haben, da doch die Überschrift im Shadow DOM enthalten ist. Das ist korrekt, solange die Elemente nicht über einen Slot überschrieben werden, was auch nur möglich ist, wenn wir es als Komponentenentwickler genau so definieren. Um einen Slot zu benutzen, müssen wir das Element oder die Elemente in das Tag unserer Web Component schreiben und das Attribut slot auf einen Namen setzen, den wir in unserer Web Component definiert haben. Ein Slot ändert die Zusammensetzung unseres Shadow DOM. Die geslotteten Elemente werden nämlich nicht in das Shadow DOM kopiert, sondern das Shadow DOM verweist auf die Elemente im Main Document DOM. Das bedeutet, dass die, in diesem Beispiel drei, geslottete Elemente gar nicht zum Shadow DOM gehören, sondern zum Main Document DOM, und damit haben wir per CSS ganz normal Zugriff darauf (mit allen Vor- und Nachteilen).
In Abbildung 2 sind die Chrome DevTools zu sehen. Dort sieht man zwei Dinge: Die überschriebenen Slots liegen außerhalb des Shadow DOM und im Shadow DOM ist ein Verweis auf ein <h1>-Tag zu sehen. Klickt man den Verweis an, landet man bei dem Element, das in den Slot gesetzt wurde. Versuchen Sie einmal via CSS die Buttonfarbe zu ändern. Auch mit !important werden Sie es nicht schaffen, da genau diese Elemente im Shadow DOM liegen und wir kein API dafür definiert haben.

Regelmäßig News zur Konferenz und der .NET-Community
Web Components sind eine tolle Sache, die uns in Zukunft immer mehr begleiten wird. Kleinere Komponenten lassen sich so gänzlich ohne Framework entwickeln. Wir haben aber auch gesehen, dass wir viel händisch machen müssen, was wir von SPA Frameworks als bereits vorhanden gewohnt sind, bspw. Datenbindung oder das Reagieren auf Events. Auch müssen wir uns Gedanken machen, wann wir welchen Teil der UI aktualisieren. In größeren Projekten dürfte das kaum praktikabel sein, da man sehr viel Boilerplate benötigt. Hier lohnt es sich, einmal einen Blick in Stencil.js zu werfen, ein Framework speziell für Web Components mit sinnvollen Features wie CSS-Prozessoren, Dokumentationserzeugung oder Datenbindung, aber ohne weiteren Schnickschnack.
Wir haben auch gesehen, dass wir mit Web Components in der Lage sind, sehr bewusst zu definieren, was wir von außen zugänglich machen und was nicht, wir können hier ein richtiges API für den Entwickler definieren. Das bedeutet aber auch, dass wir unsere Komponenten gut dokumentieren müssen, da aktuell sehr viele Dinge stringbasiert sind bspw. Namen von Slots oder Attributen.
Alles in allem helfen uns die Standards rund um Web Components, native Komponenten zu entwickeln, die in jedem Browser genutzt werden können. Es gibt noch viel mehr zu entdecken, wie bspw. CSS Shadow Parts oder weitere Funktionen der HTML Slots und deren Styling via ::slotted(). Viel Spaß beim Erkunden der Welt von Web Components!
The post Einstieg in die fabelhafte Welt der Web Components appeared first on BASTA!.
]]>The post Keynote | Oberflächendimensionen: Alles nur UI? Mitnichten! appeared first on BASTA!.
]]>Aufgezeigt wurde dabei nicht nur eine Veränderung und Weiterentwicklung innerhalb der Technologien, sondern auch, dass Entwickler umdenken müssen. Heute sollen Anwendungen nicht mehr nur auf dem Desktop oder im Browser laufen, sondern für verschiedene Plattformen verwendbar sein – aber sie müssen es nicht unbedingt. Der Desktop ist nicht tot, WPF und Windows Forms sind wieder da, UWP ist aber auch noch ein wichtiges Thema. .NET Core 3.1 bringt aktuell schon Blazor als C#-basierte Webtechnologie und Ende des Jahres kommt schon .NET 5 als neues, umfassendes Framework für Multiplattform-Projekte. Wie geht man damit um? Nach einer einführenden Diskussionsrunde stellte Thomas Huber zunächst seine Sicht auf die vielen direkten UI-Optionen vor und Manfred Steyer ergänzt in seinem Beitrag diese Dimension mit Überlegungen zu grundlegenden Strategien für das Backend und die Architektur. Damit eröffneten sie den Teilnehmern den Raum, um mit Fragen den konkreten Bedarf im eigenen Unternehmen zu erkunden und auf der BASTA! die passenden Sessions auszuwählen.
The post Keynote | Oberflächendimensionen: Alles nur UI? Mitnichten! appeared first on BASTA!.
]]>The post .NET Core 3.1 ist reif: Vorteile und Neuerungen für Entwickler:innen appeared first on BASTA!.
]]>.NET Core 3.1 mit Entity Framework Core 3.1 und ASP.NET Core 3.1 sollten laut der Ankündigung vom Mai schon im November 2019 erscheinen. Das hat Microsoft dann aber auf 3. Dezember 2019 vertagt, was auch gut war.
Die 3.0er Versionen enthielten eine Reihe von kleinen und größeren Problemen, zum Beispiel bei der Benutzerverwaltung und Authentifizierung in ASP.NET Core Blazor Server. Während man mit Blazor Server eine Single Page Application (SPA) erstellen kann [1], basieren die von Microsoft in ASP.NET Core Identity gelieferten Webseiten zur Benutzerverwaltung und Authentifizierung noch auf ASP.NET Core Razor Pages, also einer klassische Multi Page Application (MPA). Solange man in ASP.NET Core 3.0 diese Webseiten im Standardlayout von Microsoft verwendete, funktionierte die Integration zwischen Razor Pages und Blazor Components gut. Sobald man aber zur Anpassung des Layouts die Razor Pages mit Add/New Scaffolded Item/Identity explizit als Templates in das Projekt hineingenerieren lies, sah man die Menüzeile plötzlich doppelt. Microsoft hatte die Layoutseiten falsch verschachtelt; der Entwickler musste es selbst lösen. In ASP.NET Core 3.1 ist das gelöst.
Einen echten Showstopper gab es in .NET Core 3.0, wenn man eine klassische .NET Framework-basierte Anwendung (z. B. Windows Forms oder Windows Presentation Foundation), die noch mit typisierten DataSets (.xsd-Dateien) arbeitet, auf .NET Core migrieren wollte. Das war in der Zeit vor Entity Framework (gerade in Windows Forms- und WPF-Anwendungen) üblich und kommt daher auch heute noch in einigen Projekten vor. Typisierte DataSets sollten zwar in .NET Core 3.0 möglich sein, dem Autor dieses Beitrags fiel in einem entsprechenden Projekt aber auf, dass der von den .xsd-Dateien generierte Programmcode zur Laufzeit eine Null Reference Exception auslöst und zwar in der Methode SqlParameterCollection.Add(). Obwohl der Autor das am 2. September 2019 via GitHub gemeldet hatte und ein Microsoft-Entwickler am 14. September 2019 den Fehler behoben hatte, wanderte die Fehlerbehebung nicht mehr in die Version der System.Data.SqlClient.dll, die mit .NET Core 3.0 ausgeliefert wurde. Dabei fielen drei Dinge auf:
Als Workaround kam übrigens der Vorschlag, doch eine andere Überladung von SqlParameterCollection.Add() zu verwenden. Da aber ja der Aufruf von SqlParameterCollection.Add() im generierten Programmcode lag und dreimal pro Tabelle vorkommt, hätte das einen enormen Aufwand bedeutet, der nach jeder Änderung am DataSet immer wieder neu vollzogen hätte werden müssen. Auch die Anpassung des Codegenerators war keine Option, denn bei typisierten DataSets gab es noch keine Templatesprache wie T4 oder Handlebars, sondern der Codegenerator war noch als reine C#-Klasse mit Namen MSDataSetGenerator implementiert. Die Klasse kann man zwar austauschen, das ist jedoch viel Arbeit.
In diesem Stil gab es noch eine Reihe weiterer Probleme in .NET Core 3.0, Entity Framework Core 3.0 und ASP.NET Core 3.0. Allein das Entity-Framework-Core-Entwicklungsteam rühmt sich, in Version 3.1 noch über 150 Fehler aus Version 3.0 beseitigt zu haben (siehe https://devblogs.microsoft.com/dotnet/announcing-entity-framework-core-3-1-and-entity-framework-6-4/ und https://github.com/aspnet/EntityFrameworkCore/milestone/76?closed=1.
Das Entity-Framework-Core-Entwicklungsteam schreibt über die Version 3.1: „To this end we have fixed over 150 issues for the 3.1 release, but there are no major new features to announce“ [4]. Dabei ist das gar nicht ganz richtig, denn es gibt schon eine wesentliche Neuerung in Entity Framework Core 3.1 gegenüber Version 3.0: Entity Framework Core 3.1 basiert wieder auf .NET Standard 2.0 und läuft damit nicht nur auf .NET Core, Mono und Xamarin, sondern auch wieder im klassischen .NET Framework und in Universal-Windows-Platform-(UWP-)Apps. Bei Entity Framework Core 3.0 hatte sich das Entwicklungsteam entschlossen, .NET Standard 2.1 zu verwenden. Diesen wird es gemäß Ankündigung von Microsoft nicht mehr für das klassische .NET Framework geben und für die UWP gibt es .NET Standard 2.1 noch nicht. So waren alle Softwareentwickler, die Entity Framework Core 1.x/2.x in .NET Framework oder UWP einsetzen, ausgeschlossen. Zum Glück hat Microsoft diese Fehlentscheidung bei Entity Framework Core 3.1 revidiert. Nicht revidiert hat Microsoft diese Entscheidung aber für ASP.NET Core: Auch die Version 3.1 läuft nicht mehr auf dem klassischen .NET Framework (Abb. 1).
ASP.NET Core 3.1 bietet zumindest einige kleine neue Features gegenüber Version 3.0, vor allem für Blazor. Den Startpunkt einer Blazor-Anwendung kann der Entwickler nun alternativ auch per Tag-Helper <component>
<app> <component type="typeof(App)" render-mode="ServerPrerendered" /> </app>
und nicht nur per Code
<app> @(await Html.RenderComponentAsync<App>(RenderMode.ServerPrerendered)) </app>
festlegen. Code-behind-Dateien in Razor Components können nun auch durch partielle Klassen anstelle von Vererbung realisiert werden. So kann man nun die Code-behind-Klasse statt public class XYModel : ComponentBase, IDisposable { … } auch verkürzt deklarieren: public partial class XY { … }. Dann entfällt in der Razor-Datei das @inherits XYModel.
Wichtig ist, dass der Namensraum in der Code-behind-Datei dann dem automatisch gebildeten Namensraum der Razor-Datei entspricht. Der Namensraum wird aus dem auf Projektebene definierten Wurzelnamensraum und den Ordnernamen gebildet, z. B. ist für eine Razor Component im Ordner /Kunde/Edit mit Wurzelnamensraum ITVisions.Intranet der Namensraum dann ITVisions.Intranet.Kunde.Edit.
Die Listings 1 und 2 zeigen eine Blazor Component mit Code-behind als partielle Klasse. Interessant ist auch, dass nun Dependency Injections nicht mehr doppelt erfolgen müssen wie bei einer Lösung auf Basis von Vererbung [1].
@page "/Vorlage"
@inject BlazorUtil Util
@inject IJSRuntime JSRuntime
@inject NavigationManager NavigationManager
@using ITVisions.Blazor
<h2>Code-Behind-Vorlage</h2>
X:
<input type="number" @bind="X" />
Y:
<input type="number" @bind="Y" />
<button @onclick="AddAsync">Add x + y</button>
Sum: @Sum
@code
{
// Hier wäre auch noch Code möglich, wenn man unbedingt will
}
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AspNetCore.Components;
using Microsoft.JSInterop;
using ITVisions.Blazor;
using System.Threading.Tasks;
namespace Web.Demos.Vorlagen
{
public partial class CodeBehindVorlage
{
[Parameter]
public decimal X { get; set; } = 1.23m;
[Parameter]
public decimal Y { get; set; } = 2.34m;
public decimal Sum = 0;
#region Standard-Lebenszyklus-Ereignisse
protected override void OnInitialized()
{
Util.Log(nameof(CodeBehindVorlage) + ".OnInitialized()");
}
protected async override Task OnInitializedAsync()
{
Util.Log(nameof(CodeBehindVorlage) + ".OnInitializedAsync()");
}
protected override void OnParametersSet()
{
Util.Log(nameof(CodeBehindVorlage) + ".OnParametersSet()");
}
protected async override Task OnParametersSetAsync()
{
Util.Log(nameof(CodeBehindVorlage) + ".OnParametersSetAsync()");
}
protected override void OnAfterRender(bool firstRender)
{
Util.Log(nameof(CodeBehindVorlage) + ".OnAfterRender(firstRender=" + firstRender + ")");
// this.StateHasChanged(); // --> Endlosschleife !!!
}
protected async override Task OnAfterRenderAsync(bool firstRender)
{
Util.Log(nameof(CodeBehindVorlage) + ".OnAfterRenderAsync(firstRender=" + firstRender + ")");
}
public void Dispose()
{
Util.Log(nameof(CodeBehindVorlage) + ".Dispose()");
}
#endregion
#region Reaktionen auf Benutzerinteraktionen
public async Task AddAsync()
{
Sum = X + Y;
X = Sum;
Util.Log($"{nameof(CodeBehindVorlage)}.Add(). x={X} y={Y} sum={Sum}");
await Util.SetTitle(Sum.ToString());
}
#endregion
}
}
Weitere Neuerungen in ASP.NET Core 3.1 sind die nun mögliche Verhinderung der Standardereignisbehandlung in Razor Components in Blazor
<input value="@eingabe" @onkeypress="KeyHandler" @onkeypress:preventDefault />
und der Ereignisweitergabe in Razor Components in Blazor (Listing 3).
<input @bind="stopPropagation" type="checkbox" />
<div @onclick="OnSelectParentDiv">
<div @onclick="OnSelectChildDiv" @onclick:stopPropagation="stopPropagation">
...
</div>
</div>
@code {
private bool stopPropagation = false;
}
Zudem zeigen Blazor-Anwendungen bei Laufzeitfehler nun eine Fehlerleiste für den Benutzer (Abb. 2). Die zu der Fehlerleiste zugehörigen HTML-Tags findet man in einem
in einer Blazor Server App in der Datei Pages/_Host.cshtml und in Blazor Webassembly in der Datei wwwroot/index.html. Den Verweis auf die Developer Tools des Browsers gibt es nur, wenn die Anwendung im Development-Modus läuft.
Neu zusammen mit .NET Core 3.1 erschienen ist auch erstmals die Unterstützung für die Programmiersprache C++/CLI für .NET Core 3.0 und 3.1. Das erfordert Visual Studio 2019 v16.4. In C++/CLI geschriebene .NET Core Assemblies laufen aber (vorerst) nur auf Windows. Auch ein Austausch mit C++/CLI kompilierter Assemblies zwischen .NET Core und .NET Framework ist nicht möglich.
Breaking Changes, die verhindern, dass eine 3.0-basierte Anwendung einwandfrei auf Version 3.1 läuft, sollte es gemäß dem Semantic Versioning, dem Microsoft folgt, in .NET Core 3.1, Entity Framework Core 3.1 und ASP.NET Core 3.1 eigentlich gar nicht geben. Aber es gibt sie doch.
Microsoft hat sich entschlossen, einige ältere Windows-Forms-Steuerelemente, die es in .NET Core 3.0 in der .NET Core Windows Desktop Runtime gab, in Version 3.1 auszubauen. Tabelle 1 zeigt die entfallenen Steuerelemente und die zugehörigen ebenfalls entfallenen Klassen sowie den Ersatz, den Microsoft vorschlägt.
Entfallenes Windows Forms-SteuerelementEntfallene zugehörige APIsVon Microsoft empfohlener Ersatz
| DataGrid | DataGridCell, DataGridRow, DataGridTableCollection, DataGridColumnCollection, DataGridTableStyle, DataGridColumnStyle, DataGridLineStyle, DataGridParentRowsLabel, DataGridParentRowsLabelStyle, DataGridBoolColumn, DataGridTextBox, GridColumnStylesCollection, GridTableStylesCollection, HitTestType | DataGridView |
| ToolBar | ToolBarAppearance | ToolStrip |
| ToolBarButton | ToolBarButtonClickEventArgs, ToolBarButtonClickEventHandler, ToolBarButtonStyle, ToolBarTextAlign | ToolStripButton |
| ContextMenu | ContextMenuStrip | |
| Menu | MenuItemCollection | ToolStripDropDown, ToolstripDropDownMenu |
| MainMenu | MenuStrip | |
| MenuItem | ToolstripMenuItem |
Auch wenn das ältere, bereits in .NET Framework 1.0 eingeführte Steuerelemente sind, für die es seit dem Jahr 2005 (.NET Framework 2.0) Alternativen gibt, ist es dennoch ärgerlich für einige ältere Projekte, die diese Steuerelemente noch verwenden. Sie liefen ja immer gut im klassischen .NET Framework.
Warum Microsoft die Steuerelemente in Windows Forms für .NET Core noch geändert hat, verrät der Blogeintrag zu .NET Core 3.1: Man will diese Steuerelemente nicht im neuen Windows Forms-Designer für .NET Core einbauen („As we got further into the Windows Forms designer project, we realized that these controls were not aligned with creating modern applications and should never have been part of the .NET Core port of Windows Forms. We also saw that they would require more time from us to support than made sense.“).
Immerhin ist sich Microsoft seiner Schuld, gegen das Semanic Versioning zu verstoßen, bewusst und entschuldigt sich bei den Kunden: „Yes, this is an unfortunate breaking change. You will see build breaks if you are using the controls we removed in your applications. … We should have made these changes before we released .NET Core 3.0, and we appologize for that. We try to avoid late changes, and even more for breaking changes, and it pains us to make this one.“
Der besagte Windows Forms-Designer ist weiterhin nicht fertig. Visual Studio 2019 v16.5 Preview 1 enthält zwar eine Preview-Version des Designers (zu aktivieren in den Optionen, siehe Abb. 3), diese ist aber nicht praxisreif (Abb. 4 und 5).

Einen weiteren Breaking Change findet man in ASP.NET Core 3.1: Microsoft hat das Verhalten von Same-site-Cookies geändert.
.NET Core 3.1 bekommt von Microsoft Long Term Support (LTS), was aber auch nur eine Unterstützung für drei Jahre bedeutet – nicht die von den Kunden geschätzten 10 Jahre nach dem letzten Erscheinen in Windows wie beim klassischen .NET Framework.
Der Support für .NET Core 3.0 (inkl. ASP.NET Core und Entity Framework Core) endet schon am 3. März 2020, denn das war nur ein Current-Release (auch Maintainance Release genannt), für das es nur drei Monate nach dem Erscheinen der folgenden LTS-Version noch Updates gibt. Zu beachten ist auch, dass der Support für .NET Core 2.2 schon am 23. Dezember 2019 endete. Für Entwickler, die Version 2.2 einsetzen, heißt das dann: Umstellen auf Version 3.1 mit allen Breaking Changes, die es in Version 3.0 [2] bzw. in 3.1 gab. Alternativ geht natürlich auch ein Downgrade auf Version 2.1 inklusive Featureverzicht.
Das trifft besonders schwer Entwickler, die ASP.NET Core 2.2 auf klassischem .NET Framework einsetzen, denn die können nicht auf Version 3.1 hochgehen, sondern müssen auf 2.1 herabstufen – oder ohne Support leben.
Das Gute an .NET Core 3.1, ASP.NET Core 3.1 und Entity Framework 3.1 ist, dass Microsoft nun Fehler behoben hat. Das Schlechte ist, dass die Version 3.0 mit diesen Fehlern überhaupt erschienen ist und nicht vertagt wurde, um eine bessere Qualität zu liefern.
Literatur
[1] Schwichtenberg, Holger: „Der erste Blazor-Streich“; in: Windows Developer 2.20, S. 18
[2] Schwichtenberg, Holger: „Sie sind wieder da!“; in: Windows Developer 1.20, S. 18
The post .NET Core 3.1 ist reif: Vorteile und Neuerungen für Entwickler:innen appeared first on BASTA!.
]]>The post Go, der C#-Killer? appeared first on BASTA!.
]]>
Regelmäßig News zur Konferenz und der .NET-Community
Wie lernt man Go?
Eine komplette Einführung in Go ist in einem Magazinartikel unmöglich, das soll erst gar nicht versucht werden. Dieser Artikel soll grundlegende Unterschiede und Gemeinsamkeiten zwischen C# und Go aufzeigen. Außerdem soll er durch ein paar Codebeispiele einen Eindruck davon vermitteln, wie sich Go anfühlt. Wer neugierig geworden ist und mehr wissen möchte, sollte einen Blick auf Go by Example werfen. Dort wird Go anhand vieler kleiner Beispiele erklärt. Wer noch tiefer einsteigen möchte, dem empfehle ich die Go-Dokumentation, zum erfolgreichen Starten insbesondere den Artikel Effective Go und die FAQ-Liste.
Natürlich stellt sich für Personen, die in Go einsteigen, auch die Frage nach der Entwicklungsumgebung. Wenn man von C# kommt, liegt Visual Studio Code mit der Go Extension auf der Hand. Viele .NET-Entwicklungsteams schätzen auch die Tools aus dem Hause JetBrains. Mit GoLand hat die Firma eine IDE für Go im Angebot, die im Gegensatz zu Visual Studio Code kostenpflichtig ist. Für Open-Source-Projekte, Schüler, Lehrer, User Groups etc. ist GoLand aber kostenlos.
Grundphilosophie: Code einfach halten
Entwicklungsteams mit C#-Hintergrund wird beim ersten Blick auf Go auffallen, wie reduziert die Sprache und auch das Tooling im Vergleich zu C# sind. So stehen beispielsweise den in C# über hundert Schlüsselwörtern in Go gerade einmal 25 gegenüber. Dieser erste Eindruck täuscht nicht. Die Sprache und den damit erstellten Code einfach und einheitlich zu halten, ist ein wichtiges Designziel von Go. Die Dokumentation des Speichermodells von Go beginnt beispielsweise mit nur drei Zeilen und bevor im Anschluss alle Details erklärt werden, folgt der Hinweis: „If you must read the rest of this document to understand the behavior of your program, you are being too clever. Don’t be clever.“ Go kommt mit einem Tool zum Codeformatieren, das auch Visual Studio Code verwendet. Es hat genau keine Settings. Die Community erwartet, dass jeder Go-Code gleich aussieht, egal woher er kommt. „The output of the current gofmt is what your code should look like, no ifs or buts“. Willkommen in der Denkweise von Go.
Man kann einwenden, dass die Einfachheit daher kommt, dass Go jünger als C# ist. Go kam Ende 2009 heraus, die erste Version von C# sieben Jahr davor. Das ist aber nicht der alleinige Grund. Die relativ gemächliche Weiterentwicklung (nach zehn Jahren ist die Version 2 der Sprache gerade erst in der Designphase), der Prozess des ausführlichen Abwägens von Vorteilen gegenüber hinzugefügter Komplexität bei Spracherweiterungen, die Kultur der offenen Diskussion bei neuen Sprachfunktionen, all das unterstreicht, dass Stabilität und Einfachheit Designprinzipien der Sprache Go sind. Der Vorteil, den Entwicklungsteams davon haben, ist, dass Go, entsprechende generelle Informatikkenntnisse vorausgesetzt, leicht zu erlernen, und Go-Code relativ leicht zu lesen und zu warten ist. In Zeiten von Open Source und Microservices sind das wichtige Eigenschaften einer Sprache, da häufig viele verschiedene Personen im Lauf der Zeit mit dem Code einer Softwarelösung zu tun haben.
Limits
Die Kehrseite der Medaille ist, dass Go im Vergleich zu C# viele Funktionen fehlen. Keine Klassen und Vererbung? Keine Generics? Fehlerbehandlung ohne try-catch-Blöcke? Das lässt einen erst einmal den Kopf schütteln, wenn man von C# kommt. Manche dieser Dinge (z. B. Klassen, Vererbung) gibt es in Go bewusst nicht. Die Sprache hat andere Lösungsansätze für die zugrunde liegenden Herausforderungen. Listing 1 stellt einige dieser Ansätze an einem kleinen kommentierten Codebeispiel vor. Andere Dinge (z. B. Generics) sind in Go schlicht und einfach noch nicht fertig. Das sieht man aber nicht als Katastrophe, im Gegenteil. Es gibt Designs und experimentelle Implementierungen, die über Jahre diskutiert, ausprobiert und oft auch wieder verworfen werden. Lieber ein paar Jahre ein paar zusätzliche Zeilen Code schreiben als eine schlechte Lösung übers Knie brechen.
// Play with this code snippet online at https://play.golang.org/p/37kbcROPsZz
package main
import (
"fmt"
"math"
)
// Let us define two simple structs. In contrast to C#, there are no classes.
// Everything is a struct. Note that this does not say anything about allocation
// on stack or heap. The compiler will decide for you whether to allocate an
// instance of a struct on the stack or heap based on *escape analysis*
// See also https://en.wikipedia.org/wiki/Escape_analysis.
// ... and yes, dear C# developer, you can believe your eyes:
// No semicolons at the end of lines in Go ;-)
type Point struct {
X, Y float64
}
type Rect struct {
LeftUpper, RightLower Point
}
type Circle struct {
Center Point
Radius float64
}
// Now let us add some functions to our structs
func (r Rect) Width() float64 {
return r.RightLower.X - r.LeftUpper.X
}
func (r Rect) Height() float64 {
return r.RightLower.Y - r.LeftUpper.Y
}
func (r Rect) Area() float64 {
return float64(r.Width() * r.Height())
}
func (r *Rect) Enlarge(factor float64) {
// Note that this function has a *pointer receiver type*.
// That means that it can manipulate the content of r and
// the caller will see the changed values. The other methods
// of rect have a *value receiver type*, i.e. the struct
// is copied and changes to its values are not visible
// to the caller.
r.RightLower.X = r.LeftUpper.X + r.Width()*factor
r.RightLower.Y = r.LeftUpper.Y + r.Height()*factor
}
func (c Circle) Area() float64 {
return math.Pi * c.Radius * c.Radius
}
// Next, we define an interface. Note that the structs do not need to
// explicitly implement the interface. rect and circle fulfill the
// requirements of the interface (i.e. they have an area() method),
// therefore the implement the interface.
type Shape interface {
Area() float64
}
const (
WHITE int = 0xFFFFFF
RED int = 0xFF0000
GREEN int = 0x00FF00
BLUE int = 0x0000FF
BLACK int = 0x000000
)
// Go does not support inheritance of structs/classes. However, it
// supports embedding types. The following struct embeds Circle. Because of
// *member set promotion*, all members of Circle become available on
// ColoredCircle, too.
type ColoredCircle struct {
Circle
Color int
}
func (c ColoredCircle) GetColor() int {
return c.Color
}
type Colored interface {
GetColor() int
}
func main() {
// Note the declare-and-assign syntax in the next line. The compiler
// automatically determines the type of r, no need to specify it explicitly.
r := Rect{LeftUpper: Point{X: 0, Y: 0}, RightLower: Point{X: 10, Y: 10}}
c := Circle{Center: Point{X: 5, Y: 5}, Radius: 5}
// Note that we can access the Radius of the ColoredCircle although Radius
// is a member of the embedded type Circle.
cc := ColoredCircle{c, RED}
fmt.Printf("Colored circle has radius %f\n", cc.Radius)
// Next, we create an array of shapes. As you can see, rect
// and circle are compatible with the shape interface
shapes := []Shape{r, c, cc}
// Note the use of range in the for loop. In contrast to C#, the for-range
// loop provides the value and an index.
for ix, shape := range shapes {
fmt.Printf("Area of shape %d (%T) is %f\n", ix, shape, shape.Area())
// Note the syntax of the if statement in Go. You can write
// declare-and-assign and boolean expression in a single line.
// Very convenient once you got used to it.
// Additionally note how we check whether shape is compatible
// with the Colored interface. You get back a variable with the
// correct type and a bool indicator indicating if the cast was ok.
if colCirc, ok := shape.(Colored); ok {
fmt.Printf("\thas color %x\n", colCirc.GetColor())
}
}
r.Enlarge(2)
fmt.Printf("Rectangle's area after enlarging it is %f\n", r.Area())
}
Einfaches Deployment
Einfachheit ist also eine positive Eigenschaft. Das allein kann die Faszination von Go aber nicht ausmachen. Als C#-Entwickler haben mich Go-Programme von Anfang an durch das fast schon triviale Deployment fasziniert. Wenn man ein Go-Programm kompiliert, erhält man als Ergebnis eine einzelne ausführbare Datei. Die Datei ist in Maschinensprache, es gibt keine Intermediate Language wie in .NET. Die ausführbare Datei hat keinerlei Abhängigkeiten, erfordert am Zielsystem also keine Installation einer Go Runtime. Sie könnte in einem Linux-Container sogar From scratch, also direkt am Linux-Kernel, ausgeführt werden. Man hat es nicht mit hunderten DLLs zu tun, wie man es heutzutage von .NET Core bei Self-contained Deployments kennt. Es gibt kein Herumschlagen mit einem riesigen node_modules-Ordner wie bei Node.js. Man kompiliert mit Go bei Bedarf über Plattformgrenzen hinweg, gerne auch ein Linux Executable auf dem Windows-Entwicklungsrechner.
Ein einfacher Lösungsansatz kommt auch beim Verteilen wiederverwendbarer Packages zum Einsatz. Das go-get-Tool lädt Packages mit ihrem Sourcecode aus einem lokalen Ordner oder direkt aus der Quellcodeverwaltung (z. B. Git, Mercurial). Packages werden immer aus dem Quellcode gebaut. Binary-only Packages wie bei NuGet Packages mit DLLs ohne Sourcecode gab es bei Go früher, sie werden aber nicht mehr unterstützt.
Der Name des Package enthält die Quelle (z. B. github.com/gorilla/mux verweist auf GitHub). Größere Firmen können Module Proxies (z. B. Athens Project) betreiben, über die man steuern kann, welche Pakete verwendet werden dürfen, und die außerdem Package Cache sind. Für kleine Teams wird Google eigene Module Mirrors betreiben.
Die Organisation von Sourcecode am lokalen Entwicklungsrechner hat sich seit Go 1.11 schrittweise verändert. Früher gab es einen einzelnen Ordner (referenziert durch die GOPATH-Umgebungsvariable), in dem alle Pakete sowie der eigene Quellcode in einer definierten Verzeichnisstruktur abgelegt werden mussten. In Go 1.11 und 1.12 wurde diese Einschränkung aufgehoben und Go erhielt ein eigenes Modulsystem, durch das wiederholbare Builds viel einfacher wurden. Ab Go 1.13 (erscheint in Kürze) ist das Modulsystem der Standard.
Pointer
Wenn man aus C# kommt, sind Pointer in Go am Anfang etwas ungewohnt. Man erinnert sich vielleicht mit Schrecken an Fehler aus C-Zeiten, mit denen in C# Schluss war. Keine Angst, Pointer in Go können nicht mit Pointern in C verglichen werden. Es gibt keine Pointer-Arithmetik und Pointer haben klar definierte Typen. Einen Eindruck, wie Pointer in Go funktionieren, bekommt man am besten, wenn man einen Blick auf ein Beispiel wirft. Listing 2 enthält einige Zeilen Go-Code, der Pointer verwendet. Achten Sie auf die Erklärungen in den Codekommentaren.
// Play with this code snippet online at https://play.golang.org/p/1CtnUde0Kps
package main
import "fmt"
type person struct {
firstName string
lastName string
}
func main() {
// Let us create an int value and get its address
x := 42
px := &amp;x
// Note the *dereferencing* with the * operator in the next line
fmt.Printf("x is at address %v and it's value is %v\n", px, *px)
// Let us double the value in x. Again, we use dereferencing
*px *= 2
fmt.Printf("x is at address %v and it's value is %v\n", px, *px)
// We can allocate memory and retrieve a point to it using *new*.
// The allocated memory is automatically set to zero.
px = new(int)
fmt.Printf("x is at address %v and it's value is %v\n", px, *px)
// Go only knows call-by-value. In the following case, the value
// is a pointer and the method can dereference it to write something
// into the memory the pointer points to.
func(val *int) {
*val = 42
}(px)
fmt.Printf("x is at address %v and it's value is %v\n", px, *px)
// We can also create pointers to structs. Note that although we
// have a pointer, we can still access the struct's members using
// a dot.
pp := &amp;person{"Foo", "Bar"}
fmt.Printf("%s, %s\n", pp.lastName, pp.firstName)
// We can pass a pointer to a struct to a method. In this case,
// the method can change the struct's content.
func(somebody *person) {
somebody.firstName, somebody.lastName = somebody.lastName, somebody.firstName
}(pp)
fmt.Printf("%s, %s\n", pp.lastName, pp.firstName)
}
Fehlerbehandlung
Über die Fehlerbehandlung in Go-Programmen könnte man lange schreiben. Sie ist auch innerhalb der Go-Community ein oft diskutiertes Thema, und für Go 2 liegen einige Designvorschläge vor, was man daran verbessern könnte. Für jemanden, der von C# kommt, wirkt die Fehlerbehandlung von Go auf den ersten Blick rückschrittlich. Man ist schließlich seit Jahren try/catch gewöhnt. Warum darauf verzichten?
Die Grundidee der Fehlerbehandlung in Go geht von der Überlegung aus, dass Fehlerbehandlung im Code möglichst direkt am Ort der Fehlerentstehung zu finden sein soll. Außerdem muss im Code klar sein, welche Methoden Fehler zurückgeben. Bei try/catch ist das oft nicht der Fall. Die Fehlerbehandlung kann an einer ganz anderen Stelle geschehen als die, an der der Fehler auftrat. Außerdem ist beim Ansehen eines Methodenaufrufs nicht klar, ob die Methode einen Fehlerzustand in Form einer Ausnahme zurückgeben kann oder nicht.
In Go geben Methoden einen Fehlerzustand per Konvention als letzten Rückgabewert zurück. Dazu muss man wissen, dass Go ohne Weiteres mehrere Rückgabewerte bei Methoden unterstützt. Listing 3 zeigt einen kurzen Codeausschnitt, der demonstriert, wie einfache Fehlerbehandlung in Go abläuft. Bitte beachten Sie, dass dieses kurze Beispiel nur an der Oberfläche des Themas kratzt. Wer mehr wissen möchte, dem empfehle ich den Blogartikel „Error handling and Go“.
// Play with this code snippet online at https://play.golang.org/p/eGlvSiQJgcF
package main
import (
"errors"
"fmt"
)
// The following method returns the result AND an error. The error is nil if
// everything is ok.
func div(x int, y int) (int, error) {
if y == 0 {
return -1, errors.New("Sorry, division by zero is not supported")
}
return x / y, nil
}
func main() {
// Here we declare-and-assign the result and the error variable.
result, err := div(42, 0)
if err != nil {
fmt.Printf("Ups, something bad happened: %s\n", err)
return
}
fmt.Printf("The result is %d\n", result)
}
Nebenläufigkeit
Go zeichnet sich durch besonders gute Unterstützung von Concurrency, also Nebenläufigkeit aus. Statt C# Tasks kommen in Go Goroutines zum Einsatz. Eine Goroutine ist eine ganz normale Go-Funktion. Erst der Aufruf mit dem go-Schlüsselwort macht aus der Funktion eine Goroutine. Wie Tasks laufen Goroutines auf einem Pool von Betriebssystem-Threads. Ebenfalls wie Tasks sind Goroutines wesentlich leichtgewichtiger als Threads, insofern kann es viel mehr davon geben.
Spätestens wenn es um das Scheduling geht, enden die Gemeinsamkeiten. In C# werden Tasks typischerweise in Verbindung mit async/await genutzt. Der C#-Compiler erzeugt daraus im Hintergrund eine State Machine. Eine Goroutine kann man sich im Gegensatz dazu als leichtgewichtigen, von der Go-Laufzeitumgebung (nicht vom Betriebssystem!) verwalteten Thread mit eigenem Stack vorstellen. Der Stack einer Goroutine ist aber klein (2kb) und kann je nach Bedarf vergrößert und verkleinert werden. Dadurch geht bei einer größeren Anzahl an Goroutines nicht gleich der Speicher aus.
Go verwendet beim Scheduling von Goroutines kein Zeitscheibenverfahren (Preemtive Scheduling), sondern kooperatives Multitasking (Non-preemtive oder Cooperative Scheduling). Eine Goroutine gibt also zu genau definierten Zeitpunkten die Kontrolle ab (z. B. wenn sie auf das Ergebnis einer blockierenden Operation wartet), wird aber ansonsten nicht unterbrochen.
Channels
Das volle Potenzial von Goroutines erschließt sich erst, wenn man sich mit Go-Channels beschäftigt. Channels sind ein Mittel, wie Goroutines ohne Shared Memory und Locking (Sync Package) miteinander kommunizieren können. Durch sie kann eine Goroutine einer anderen Nachrichten schicken. Man kann auf das Eintreffen einer Nachricht warten (Blocking) oder auf das Vorhandensein einer Nachricht prüfen, ohne zu blockieren (Non-blocking). Channels können Nachrichten auch puffern. Listing 4 zeigt exemplarisch einige Anwendungsfälle von Channels. Bitte beachten Sie beim Lesen die eingefügten Kommentare. Erfahrenen C#-Entwicklerinnen und – Entwicklern empfehle ich, beim Durchsehen des Codes zu überlegen, wie man die jeweilige Aufgabe in C# mit Tasks und async/await lösen würde.
.NET hat im System.Threading.Channels ebenfalls Channels im Angebot. Sie werden im Rahmen der .NET Platform Extensions als eigene NuGet Packages ausgeliefert und kommen zu .NET Core 3 dazu. Im Gegensatz zu Go sind diese Klassen aber nicht speziell in die Sprache C# integriert. In Go sind Channels eine Besonderheit, durch die sich die Sprache von anderen Programmiersprachen abgrenzt, und dementsprechend gut ist die Integration.
// Play with this code snippet online at https://play.golang.org/p/lHTHywrgcuA
package main
import (
"fmt"
"time"
)
func sayHello(source string) {
fmt.Printf("Hello World from %s!\n", source)
}
// Note that the following method receives a channel through which it can
// communicate its result once it becomes available.
func getValueAsync(result chan int) {
// Simulate long-running operation (e.g. read something from disk)
time.Sleep(10 * time.Millisecond)
// Send result to calling goroutine through channel
result &lt;- 42
}
// Note that the following method does not return a value. The channel is
// just used to indicate the completion of the asynchronous work.
func doSomethingComplex(done chan bool) {
// Simulate long-running operation
time.Sleep(10 * time.Millisecond)
done &lt;- true
}
func main() {
// Call sayHello directly and using the *go* keyword on a separate goroutine.
sayHello("direct call")
go sayHello("goroutine")
// Call method on a different goroutine and give it a channel through which it can send back the result.
result := make(chan int)
go getValueAsync(result)
// Wait until result is available and print it.
fmt.Println(&lt;-result)
// Do something asynchronously and wait for it to finish
done := make(chan bool)
go doSomethingComplex(done)
// Wait until a message is available in the channel
&lt;-done
fmt.Println("Complex operation is done")
// Note the select statement here. You can use it to wait on
// multiple channels. In this case, we use a channel from a
// timer to implement a timeout functionality.
go getValueAsync(result)
select {
case m := &lt;-result:
fmt.Println(m)
case &lt;-time.After(5 * time.Millisecond):
fmt.Println("timed out")
}
// Let us print a status message for a certain amount of time.
ticker := time.NewTicker(100 * time.Millisecond)
// Note the anonymous function here.
go func() {
// Note that Go's range operator supports looping over
// values received through a channel.
for range ticker.C {
fmt.Println("Tick")
}
}()
// Wait for some time and then stop timer.
&lt;-time.After(500 * time.Millisecond)
ticker.Stop()
}
Go wofür?
Man sieht, dass Go gegenüber C# teilweise andere Schwerpunkte hat und eine etwas andere Philosophie verfolgt. Einen wichtigen Unterschied habe ich bisher noch nicht ausdrücklich erwähnt: Go spielt zum überwiegenden Teil nur auf dem Server beziehungsweise in der Konsole eine Rolle. Laut der jährlichen Go-Umfrage arbeiten 65 Prozent der Go-Nutzer im Bereich Webentwicklung. Danach folgen die Aufgabengebiete DevOps (41 Prozent) und Systemprogrammierung (39 Prozent). Go wird nur in Ausnahmefällen für GUI-Entwicklung verwendet. Es gibt Packages dafür, in der Regel greift man aber auf webbasierende Benutzerschnittstellen zurück.
Fazit
Joel Spolsky, Mitgründer von Stack Overflow, meinte kürzlich in einem Interview: „Produktivität verbessert man am besten, indem man Komplexität verringert.“ In Zeiten rasend schneller Veränderung und Erweiterung von Plattformen und Programmiersprachen ist der Ansatz von Go erfrischend. Der Fokus liegt auf einer einfachen Sprache, leicht verständlichem Code mit einheitlichem Aufbau, einfachem Deployment und guter Performance. Gleichzeitig bietet die Sprache eine Menge interessanter Features für nebenläufige Programmierung.
In der Praxis ist für eine Plattform nicht nur die Programmiersprache, sondern auch die Verfügbarkeit von Bibliotheken entscheidend. Hier glänzt Go speziell in den Bereichen Webentwicklung (Web-Apps und Web-APIs) sowie System- und Netzwerkprogrammierung. Natürlich ist die Verwendung von Go in Verbindung mit Containern besonders angenehm, da schließlich die Docker-Plattform auf Go aufbaut.
Alles in allem halte ich Go für eine interessante Alternative beziehungsweise Ergänzung zu C#, wenn es um Microservices geht. Die gewohnten Tools wie Visual Studio Code, Azure DevOps und Azure muss man deshalb nicht über Bord werfen, ganz im Gegenteil. Sie alle bringen sehr gute Go-Unterstützung mit.
The post Go, der C#-Killer? appeared first on BASTA!.
]]>The post XAML Islands: Integration von WPF und Windows Forms für moderne Anwendungen appeared first on BASTA!.
]]>Migration nach .NET Core
Mit .NET Core 3.0 hat Microsoft sowohl Windows Forms als auch WPF auf .NET Core portiert und darüber hinaus auch den Quellcode auf GitHub veröffentlicht.
Um XAML Islands in einer WPF oder Windows Forms App zu verwenden, ist eine Portierung der eigenen App auf .NET Core nicht zwingend erforderlich, aber als Teil der Modernisierung empfohlen. .NET Core unterstützt mit XAML Islands mehr Szenarien und hat darüber hinaus noch weitere Vorteile. Beispielsweise lassen sich nur mit .NET Core die neuesten, mit C# 8.0 eingeführten Sprachfeatures verwenden. Im .NET Framework stehen diese Sprachfeatures nicht zur Verfügung.
Um eine einfache WPF-Anwendung nach .NET Core zu portieren, ist lediglich eine Anpassung der .csproj-Datei notwendig. Üblicherweise kann der bestehende Inhalt komplett gelöscht und durch den Inhalt aus Listing 1 ersetzt werden.
<Project Sdk="Microsoft.NET.Sdk.WindowsDesktop">
<PropertyGroup>
<OutputType>WinExe</OutputType>
<TargetFramework>netcoreapp3.0</TargetFramework>
<UseWPF>true</UseWPF>
</PropertyGroup>
</Project>
Listing 1 enthält das sogenannte SDK-Style-Projektformat, das für ein .NET-Core-Projekt zwingend notwendig ist. Das SDK-Style-Projektformat ist daran zu erkennen, dass auf dem Project-Element, das die Wurzel des Dokuments darstellt, das Sdk-Attribut gesetzt ist. In der Projektdatei in Listung 1 wird mit diesem Sdk-Attribut das Windows Desktop SDK von .NET Core verwendet. Zudem ist in der Projektdatei in Listing 1 .NET Core 3 als Target Framework angegeben. Mit dem UseWPF-Element werden in einem .NET-Core-Projekt die Referenzen für die WPF Assemblies hinzugefügt. Wäre es ein Windows-Forms-Projekt, wäre der einzige Unterschied in der Projektdatei, dass statt eines UseWPF-Elements eben ein UseWindowsForms-Element verwendet wird, um damit die Windows Forms Assemblies zu referenzieren.
Regelmäßig News zur Konferenz und der .NET-Community
Nach der Anpassung der .csproj-Datei auf das minimale, in Listing 1 dargestellte Format, müssen natürlich vorherige Projekt- und NuGet-Referenzen wieder hinzugefügt werden, was wie gewohnt über den Solution Explorer von Visual Studio gemacht werden kann. Damit ist die Migration von .NET Framework nach .NET Core abgeschlossen.
In diesem Artikel wird für XAML Islands eine .NET-Core-3.0-WPF-Anwendung verwendet. Bevor es losgeht, werfen wir einen Blick auf die XAML-Islands-Grundlagen.
XAML-Islands-Grundlagen
Mit Windows 10 Version 1903, dem sogenannten May 2019 Update, wurde die XAML Islands API eingeführt. Dabei handelt es sich um eine Windows-Schnittstelle. Mit ihr lässt sich das Aussehen und die Funktionalität einer WPF oder Windows Forms App mit Windows-10-UI-Features erweitern. Die Windows-10-UI-Features werden in Form von UWP Controls bereitgestellt. Es lassen sich beliebige UWP Controls in der bestehenden .NET-Anwendung hosten, wie beispielsweise das Windows 10 MapControl zum Anzeigen von Landkarten oder das InkCanvas Control, um die Windows-10-Stifteingabe optimal in der eigenen .NET-Desktop-Anwendung zu unterstützen.
Prinzipiell lässt sich jedes UWP Control in einer WPF- oder Windows-Forms-Anwendung hosten, wenn es von der UWP-Basisklasse Windows.UI.Xaml.UIElementableitet. Dabei werden folgende Szenarien unterstützt:
An dieser Stelle kommt jetzt ein Vorteil von .NET Core ins Spiel. Sowohl .NET Framework als auch .NET Core unterstützen das erste Szenario, das Hosten eines 1st Party UWP Control aus dem Hause Microsoft. Das zweite Szenario, das Hosten eines benutzerdefinierten UWP Control, wird ebenfalls von .NET Framework und .NET Core unterstützt, falls das UWP Control in C++ geschrieben wurde. Wurde im zweiten Szenario das UWP Control jedoch in C# geschrieben, so lässt es sich nur in .NET-Core-basierten WPF/Windows Forms Apps einsetzen, nicht in .NET-Framework-Applikationen. Somit liegt der Unterschied zwischen .NET Framework und .NET Core bei 3rd-Party-Komponenten. Dies ist nochmals in Tabelle 1 übersichtlich dargestellt. Da .NET Core somit mehr Szenarien als .NET Framework unterstützt, empfiehlt sich als Teil einer Modernisierung von WPF- und Windows-Forms-Applikationen im ersten Schritt eine Portierung auf .NET Core.
| Desktop-App-Host | 3rd-Party-C#-Komponente | 3rd-Party-C++-Komponente |
|---|---|---|
| .NET Framework | Keine Unterstützung | Wird unterstützt |
| .NET Core | Wird unterstützt | Wird unterstützt |
Tabelle 1: Unterstützung von 3rd-Party-Komponenten
XAML Islands einsetzen
Zum Hosten eines UWP Control in einer WPF-Anwendung ist ein Zugriff auf die XAML Islands API notwendig. Der direkte Zugriff auf diese auch als UWP XAML Hosting API bezeichnete Windows-Schnittstelle ist für C#-Entwickler nicht ganz trivial, da diverse Windows-Runtime-Klassen und COM-Interfaces zum Einsatz kommen. Um das Ganze für WPF- und Windows-Forms-Entwickler einfacher zu gestalten, stellt Microsoft mit dem Windows Community Toolkit</a href> verschiedene .NET Controls zur Verfügung, die den Zugriff auf die XAML Islands API kapseln. Microsoft empfiehlt die Verwendung dieser .NET Controls für WPF und Windows Forms Apps, in denen XAML Islands zum Einsatz kommen sollen, da diese .NET Controls eine deutlich komfortablere Entwicklung ermöglichen als ein direkter Zugriff auf die XAML Islands API.
Die Controls aus dem Toolkit
Mit dem Windows Community Toolkit werden zur Unterstützung von XAML Islands in Form von NuGet-Packages zwei Arten von Controls bereitgestellt:
Falls ein sogenanntes Wrapped Control existiert, ist es zu bevorzugen, da es sich wie ein natives WPF oder Windows Forms Control verwenden lässt. Doch welche Controls werden als Wrapped Controls bereitgestellt?
+
Wrapped Controls
Microsoft stellt die in Tabelle 2 dargestellten UWP Controls als Wrapped Controls für WPF und Windows Forms zur Verfügung. Voraussetzung ist, dass die Anwendung unter Windows 10 Version 1903 läuft – das ist ja eine allgemeine Voraussetzung für XAML Islands.
| Control | Beschreibung |
|---|---|
| InkCanvas und InkToolbar | Stellt das Canvas und die Toolbar bereit, um moderne Stifteingaben zu erlauben, die auf der Windows 10 Ink API basieren |
| MediaPlayerElement | Streamt und rendert Medieninhalte |
| MapControl | Stellt eine interaktive Karte dar |
Tabelle 2: Die Wrapped Controls
Die in Tabelle 2 dargestellten Controls lassen sich in einer WPF-Anwendung einfach verwenden, indem das NuGet-Package Microsoft.Toolkit.Wpf.UI.Controls hinzugefügt wird. Das ist alles, was notwendig ist. Während in der Vergangenheit noch weitere Schritte nötig waren, um beispielsweise bestimmte Windows 10 APIs in Form von Windows-Metadata-Dateien (.winmd) zu referenzieren, erledigt Microsoft mittlerweile alles Notwendige beim Hinzufügen dieses NuGet-Packages. Dies kann man als sehr entwicklerfreundlich sehen.
Um die Wrapped Controls in einer Windows-Forms-Anwendung einzusetzen, wird das NuGet-Package Microsoft.Toolkit.Forms.UI.Controls hinzugefügt, anschließend ist das Vorgehen identisch zur WPF. Daher fokussieren sich die folgenden Abschnitte lediglich auf WPF-Anwendungen, die Konzepte gelten jedoch auch für Windows Forms.
Das MapControl in WPF einsetzen
Um das UWP MapControl in einer WPF-Anwendung einzusetzen, wird zunächst das NuGet-Package Microsoft.Toolkit.Wpf.UI.Controls hinzugefügt. Dieses NuGet-Package steht ab Version 6 nicht nur für .NET Framework, sondern auch für .NET Core zur Verfügung. Beim Druck dieses Artikels war Version 6 nur in einer Preview-Version vorhanden, somit muss zum Finden des NuGet-Packages in Visual Studio im NuGet Package Manager das Häkchen zum Suchen von Preview-Versionen gesetzt sein, damit Version 6 in der Suche auftaucht.
Nachdem das NuGet-Package installiert wurde, kann es mit den Wrapped Controls auch schon losgehen. Die Controls lassen sich wie gewöhnliche WPF Controls in der WPF-Anwendung einsetzen.
Listing 2 zeigt die MainWindow.xaml-Datei eines brandneuen WPF-Projekts namens WpfAppMapControl. Neben ein paar standardmäßigen Elementen wie Grid, StackPanel und Button ist darin auch das MapControl-Element zu sehen. Das ist jetzt das Wrapper Control für das UWP MapControl. Um es zu verwenden, wurde in Listing 2 das XAML-Namespace-Präfix controls verwendet. Auf dem Window-Wurzelelement wird dieses controls-Präfix dem CLR Namespace Microsoft.Toolkit.Wpf.UI.Controls zugeordnet.
<Window x:Class="WpfAppMapControl.MainWindow"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:controls="clr-namespace:Microsoft.Toolkit.Wpf.UI.Controls;
assembly=Microsoft.Toolkit.Wpf.UI.Controls"
FontSize="20" Title="MainWindow" Height="450" Width="800">
<Grid>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="200"/>
<ColumnDefinition/>
</Grid.ColumnDefinitions>
<StackPanel>
<Button Content="Go to Frankfurt" Margin="10"
Click="ButtonFranfkurt_Click"/>
<Button Content="Go to Redmond" Margin="10"
Click="ButtonRedmond_Click"/>
</StackPanel>
<controls:MapControl x:Name="mapControl"
Grid.Column="1"/>
</Grid>
</Window>
Dem MapControl wird in der MainWindow.xaml-Datei in Listing 2 der Name mapControl gegeben. Über diesen Namen lässt es sich in der Code-behind-Datei referenzieren. Listing 2 enthält auch zwei Buttons, um die Karte des MapControl auf verschiedene Städte zu setzen. Ein Button navigiert nach Frankfurt, ein anderer nach Redmond. Listing 3 zeigt den Event Handler aus der Code-behind-Datei für den Frankfurt-Button. Dabei wird auf dem MapControl die TrySetViewAsync-Methode aufgerufen. Ein Geopoint und der ZoomLevel von 12 werden an diese Methode übergeben. Der Konstruktor der Geopoint-Klasse nimmt ein BasicGeoposition-Objekt entgegen, auf dem in Listing 3 die Properties Latitude und Longitude auf die Koordinaten von Frankfurt gesetzt werden. Um die Klassen Geopoint und BasicGeoposition in C# zu verwenden, ist eine using-Direktive für den Namespace Microsoft.Toolkit.Win32.UI.Controls.Interop.WinRT notwendig. Visual Studio unterstützt nach dem Schreiben der Klassen Geopoint und BasicGeoposition mit dem Hinzufügen dieses benötigten Namespace.
private async void ButtonFranfkurt_Click(object sender, RoutedEventArgs e)
{
var zoomLevel = 12;
await mapControl.TrySetViewAsync(
new Geopoint(
new BasicGeoposition
{
Latitude = 50.110924,
Longitude = 8.682127
}
),
zoomLevel);
}
Wird die Applikation gestartet, tritt beim Initialisieren des MainWindow eine Exception auf. Wird zur innersten Exception dieser äußeren Exception navigiert, stößt man als Entwickler auf folgende Fehlermeldung: „Catastrophic failure – WindowsXamlManager and DesktopWindowXamlSource are supported for apps targeting Windows version 10.0.18226.0 and later. Please check either the application manifest or package manifest and ensure the MaxTestedVersion property is updated.“
Wie bereits erwähnt funktionieren XAML Islands ab Windows Version 1903, was der Build-Nummer 10.0.18226.0 oder höher entspricht. Jetzt muss sichergestellt werden, dass die WPF-Anwendung auch unter dieser Windows-10-Version läuft. Dazu gibt es zwei Möglichkeiten:
In diesem Artikel nutzen wir die app.manifest-Datei, da diese Variante kein zusätzliches Projekt benötigt, und die WPF-Anwendung sich weiterhin über eine klassische .exe-Datei verteilen lässt.
Eine „app.manifest“-Datei konfigurieren
Mit einem Rechtsklick auf das WPF-Projekt lässt sich über Add > New Item ein neues Element hinzufügen. Dabei gibt es, wie in Abbildung 1dargestellt, das Element Application Manifest File.

Abb. 1: Das Application Manifest File im New-Item-Dialog
Als Name wird in Abbildung 1 lediglich app.manifest angegeben und die Datei hinzugefügt. Nach dem Hinzufügen ist die Datei nicht nur Teil des Projekts, sondern auch automatisch in der .csproj-Datei als Manifest-Datei angegeben, was in Listing 4 zu sehen ist.
<Project Sdk="Microsoft.NET.Sdk.WindowsDesktop">
<PropertyGroup>
<OutputType>WinExe</OutputType>
<TargetFramework>netcoreapp3.0</TargetFramework>
<UseWPF>true</UseWPF>
<ApplicationManifest>app.manifest</ApplicationManifest>
</PropertyGroup>
...
</Project>
Ein Blick in die app.manifest-Datei zeigt, dass es darin ein compatibility-Element gibt, das, wie in Listing 5 dargestellt, ein application-Element mit verschiedenen auskommentierten Windows-Versionen enthält. Darin lässt sich die OS-ID für Windows 10 aktiv schalten, womit festgelegt ist, dass die WPF-Anwendung nur unter Windows 10 laufen kann.
<compatibility xmlns="urn:schemas-microsoft-com:compatibility.v1">
<application>
<!-- A list of the Windows versions that this application has been tested on
and is designed to work with. Uncomment the appropriate elements
and Windows will automatically select the most compatible environment. -->
<!-- Windows Vista -->
<!--<supportedOS Id="{e2011457-1546-43c5-a5fe-008deee3d3f0}" />-->
<!-- Windows 7 -->
<!--<supportedOS Id="{35138b9a-5d96-4fbd-8e2d-a2440225f93a}" />-->
<!-- Windows 8 -->
<!--<supportedOS Id="{4a2f28e3-53b9-4441-ba9c-d69d4a4a6e38}" />-->
<!-- Windows 8.1 -->
<!--<supportedOS Id="{1f676c76-80e1-4239-95bb-83d0f6d0da78}" />-->
<!-- Windows 10 -->
<supportedOS Id="{8e0f7a12-bfb3-4fe8-b9a5-48fd50a15a9a}" />
</application>
</compatibility>
Mit der app.manifest-Datei und der Angabe von Windows 10 in dieser Datei lässt sich die WPF-Anwendung jetzt ohne Exception starten. In Abbildung 2 ist das UWP MapControl in der WPF-Anwendung zu sehen. Dabei wurde bereits auf den Button Go to Frankfurt geklickt, womit die Karte nach Frankfurt bewegt wurde.
Abb. 2: Das UWP MapControl in WPF
Damit ist das Einbetten eines Wrapped Control abgeschlossen. Das Vorgehen für Windows Forms ist dabei identisch. Auch die app.manifest-Datei lässt sich in Windows Forms wie in einem WPF-Projekt einsetzen, um Windows 10 als Ziel festzulegen.
CalendarView einbetten
Um ein gewöhnliches UWP Control in WPF zu verwenden, das eben nicht als Wrapped Control bereitgestellt wird, kommt die WindowsXamlHost-Klasse zum Einsatz. In diesem Abschnitt wird gezeigt, wie damit die UWP CalendarView aus dem Namespace Windows.UI.Xaml.Controls in WPF eingebunden wird.
Als erster Schritt muss zum WPF-Projekt das NuGet-Package Microsoft.Toolkit.Wpf.UI.XamlHost hinzugefügt werden, da dieses die WindowsXamlHost-Klasse enthält. In einer Windows-Forms-Applikation wird das NuGet-Package namens Microsoft.Toolkit.Forms.UI.XamlHost benötigt.
Zu beachten ist, falls in einer WPF-Anwendung bereits das Package Microsoft.Toolkit.Wpf.UI.Controls mit den Wrapped Controls referenziert wurde, ist das NuGet-Package Microsoft.Toolkit.Wpf.UI.XamlHost automatisch als Abhängigkeit vorhanden. Es muss in einem solchen Fall nicht explizit nochmals referenziert werden.
Nach dem Hinzufügen des NuGet-Packages lässt sich die WindowsXamlHost-Klasse einsetzen, um ein beliebiges UWP UIElement zu laden. Listing 6 zeigt die MainWindow.xaml-Datei eines WPF-Projekts mit einem WindowsXamlHost-Element. Das Element hat das Präfix xamlHost, das auf dem Window-Element dem CLR Namespace Microsoft.Toolkit-Wpf.UI.XamlHost zugeordnet ist. Auf dem WindowsXamlHost-Element ist die InitialTypeName-Property gesetzt, die den voll qualifizierten Klassennamen des zu erstellenden UI-Elements enthält, in diesem Fall Windows.UI.Xaml.Controls.CalendarView. Das WindowsXamlHost-Element hat den Namen windowsXamlHost, damit über diesen Namen in der Code-behind-Datei auf das WindowsXamlHost-Element zugegriffen werden kann. Wird die CalendarView-Instanz erstellt, wird das ChildChanged-Event ausgelöst. In Listing 6 ist für dieses Event ein Event Handler definiert. In diesem Event Handler soll der Code geschrieben werden, damit der ebenfalls in Listing 6 sichtbare WPF TextBlock mit dem Namen txtSelectedDate das selektierte Datum der UWP CalendarView darstellt.
<Window ...
xmlns:xamlhost="clr-namespace:Microsoft.Toolkit.Wpf.UI.XamlHost;
assembly=Microsoft.Toolkit.Wpf.UI.XamlHost">
<Grid>
...
<xamlhost:WindowsXamlHost x:Name="windowsXamlHost"
InitialTypeName="Windows.UI.Xaml.Controls.CalendarView"
ChildChanged="WindowsXamlHost_ChildChanged"
Margin="10"/>
<StackPanel Grid.Row="1" Orientation="Horizontal" Margin="10">
<TextBlock Text="Selected Date: "/>
<TextBlock x:Name="txtSelectedDate"/>
</StackPanel>
</Grid>
</Window>
Listing 7 zeigt den Event Handler für das ChildChanged-Event. Darin wird auf die Child-Property des WindowsXamlHost-Objekts zugegriffen. Ist diese vom Typ CalendarView, wird auf der CalendarView ein Event Handler für das SelectedDatesChanged-Event installiert. In diesem Event Handler wiederum wird die Text-Property des TextBlock mit dem Namen txtSelectedDate auf den Wert des ausgewählten Datums gesetzt.
,
private void WindowsXamlHost_ChildChanged(object sender, System.EventArgs e)
{
if (windowsXamlHost.Child
is Windows.UI.Xaml.Controls.CalendarView calendarView)
{
calendarView.SelectedDatesChanged += CalendarView_SelectedDatesChanged;
}
}
private void CalendarView_SelectedDatesChanged(Windows.UI.Xaml.Controls.CalendarView sender,
Windows.UI.Xaml.Controls.CalendarViewSelectedDatesChangedEventArgs args)
{
txtSelectedDate.Text =
sender.SelectedDates.Count() == 1
? sender.SelectedDates.Single().ToString("dd.MM.yyyy")
: "-";
}
Zum erfolgreichen Ausführen der Anwendung ist wieder eine app.manifest-Datei notwendig, wie es bereits im vorherigen Abschnitt beschrieben wurde. Abbildung 3 zeigt die laufende WPF-Anwendung. Im Hauptteil des Fensters wird die UWP CalendarView dargestellt. Dabei wurde der 24. Dezember ausgewählt. Im unteren Teil des Fensters ist der WPF TextBlock zu sehen, der das ausgewählte Datum ebenfalls anzeigt.

Abb. 3: Die UWP CalendarView in WPF
Auf die in diesem Abschnitt gezeigte Art und Weise lässt sich mit dem WindowsXamlHost-Element jedes in Windows 10 vorhandene UWP Control in einer WPF- oder Windows-Forms-Anwendung einbetten. Doch was ist mit eigenentwickelten UWP Controls?
Eigene UWP Controls hosten
Wie bereits zu Beginn des Artikels erwähnt, ist das Hosten eines eigenen UWP Controls in .NET-Framework-Anwendungen nur dann möglich, wenn das UWP Control in C++ geschrieben wurde. Handelt es sich um ein Managed UWP Control, das in C# geschrieben wurde, lässt es sich nicht in einer .NET-Framework-Anwendung hosten, in einer .NET-Core-Anwendung dagegen schon.
Zum Hosten eines eigenen Control kommt wieder die WindowsXamlHost-Klasse zum Einsatz. Im Folgenden wird ein einfaches, selbstgeschriebenes UWP Control in eine WPF-Anwendung eingebunden. Dazu wird im ersten Schritt eine UWP-Bibliothek mit dem Namen MyUwpControls erstellt, als Minimum-Version wird beim Erstellen Windows 1903 ausgewählt. In der Bibliothek wird das UserControl mit dem Namen SayHelloControl angelegt, das in XAML das in Listing 8 dargestellte StackPanel enthält. Wird in der TextBox des UserControl ein Name eingegeben, wird dieser im TextBlock dank des Data Bindings ausgegeben. Das ist die Funktionalität dieses einfachen Control. Es sagt einfach auf Englisch Hallo, gefolgt von dem eingegebenen Namen.
<StackPanel>
<TextBox x:Name="txt" Header="Firstname" Margin="10"/>
<StackPanel Orientation="Horizontal" Margin="10">
<TextBlock Text="Hello" Margin="0 0 5 0"/>
<TextBlock Text="{x:Bind txt.Text,Mode=TwoWay,UpdateSourceTrigger=PropertyChanged}"/>
</StackPanel>
</StackPanel>
Damit das MyUwpControls-Projekt mit XAML Islands eingesetzt werden kann, muss in der .csproj-Datei noch folgende PropertyGroup hinzugefügt werden:
<PropertyGroup> <EnableTypeInfoReflection>false</EnableTypeInfoReflection> <EnableXBindDiagnostics>false</EnableXBindDiagnostics> </PropertyGroup>
Damit ist das MyUwpControls-Projekt mit dem SayHelloControl abgeschlossen und bereit. Im nächsten Schritt wird ein .NET-Core-basiertes WPF-Projekt mit dem Namen WpfXamlIslandsThirdParty angelegt. Nach dem Anlegen werden die folgenden, bereits in diesem Artikel beschriebenen und somit bekannten Schritte ausgeführt:
Im nächsten Schritt wird vom WPF-Projekt eine Referenz auf die UWP-Bibliothek MyUwpControls hinzugefügt. Anschließend wird in der MainWindow.xaml-Datei des WPF-Projekts das in Listing 9 dargestellte User Interface definiert. Wie zu sehen ist, befindet sich darin ein WindowsXamlHost-Element, dessen InitialTypeName-Property den Namen MyUwpControls.SayHelloControl enthält. Neben dem WindowsXamlHost-Element enthält die MainWindow.xaml-Datei noch einen WPF TextBlock mit etwas Text.
<Grid>
<Grid.RowDefinitions>
<RowDefinition/>
<RowDefinition Height="Auto"/>
</Grid.RowDefinitions>
<xamlhost:WindowsXamlHost InitialTypeName="MyUwpControls.SayHelloControl"/>
<TextBlock Grid.Row="1" Margin="10" FontSize="20">
Im oberen Teil ist das UWP Control, bestehend aus TextBox und TextBlöcken
</TextBlock>
</Grid>
Die Solution kompiliert, doch beim Starten der Anwendung kommt es in SayHelloControl zur in Abbildung 4 dargestellten Exception, die lediglich sagt: „XAML parsing failed“. Bei einem genauen Blick fällt auf, dass es sich natürlich um eine UWP XamlParseException handelt, die aus dem Namespace Windows.UI.Xaml.Markup stammt.
Abb. 4: XamlParseException in „SayHelloControl“
Das in C# geschriebene UWP Control benötigt ein UWP-XamlApplication-Objekt, und beim Einsatz mit XAML Islands muss dieses Objekt explizit bereitgestellt werden. Dazu muss ein drittes Projekt zur Solution hinzugefügt werden, nämlich eine leere UWP-Anwendung. Diese wird hier einfach UwpApplication genannt, und als Minimum-Version wird beim Erstellen Windows 10 1903 angegeben. Die Solution sieht somit wie in Abbildung 5 dargestellt aus, bestehend aus drei Projekten.
Abb. 5: Die Solution in Visual Studio
Jetzt wird im UwpApplication-Projekt eine Referenz auf das MyUwpControls-Projekt hinzugefügt. Anschließend wird im UwpApplication-Projekt das NuGet-Package Microsoft.Toolkit.Win32.UI.XamlApplication installiert, das Helferklassen für XAML-Islands-Szenarien enthält. Jetzt wird die App.xaml-Datei des UwpApplication-Projekts geöffnet und darin als Wurzelelement anstatt eines Application-Elements ein XamlApplication-Element definiert. Visual Studio schlägt dabei für das XamlApplication-Element den Namespace Microsoft.Toolkit.Win32.UI.XamlHost vor, was zum Resultat in Listing 10 führt. In Listing 10 hat das XamlApplication-Element das Präfix xamlHost, das genau auf jenen CLR Namespace zeigt.
<xamlhost:XamlApplication xmlns:xamlhost="using:Microsoft.Toolkit.Win32.UI.XamlHost" x:Class="UwpApplication.App" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:local="using:UwpApplication"> </xamlhost:XamlApplication>
Im nächsten Schritt geht es in der Code-behind-Datei App.xaml.cs des UwpApplication-Projekts weiter. Dort wird sämtlicher Code aus der App-Klasse entfernt, die App-Klasse von XamlApplication abgeleitet und im Konstruktor die Initialize-Methode aufgerufen. Eventuell benötigt Visual Studio den ein oder anderen Rebuild, damit die Initalize-Methode via IntelliSense erscheint.
sealed partial class App: Microsoft.Toolkit.Win32.UI.XamlHost.XamlApplication
{
public App()
{
this.Initialize();
}
}
Im letzten Schritt wird das UwpApplication-Projekt von der WPF-Anwendung der Solution referenziert, die den Namen WpfXamlIslandsThirdParty trägt. Jetzt ist es an der Zeit, die komplette Solution zu bauen. Üblicherweise schlägt an dieser Stelle der Build fehl, da die WPF-Anwendung mit AnyCPU anstatt mit x64 oder x32 kompiliert wird. Das ist aus den Warnungen im Error-Fenster von Visual Studio ersichtlich. Hier hilft der Configuration Manager von Visual Studio weiter. Abbildung 6 zeigt die angepasste Konfiguration im Configuration Manager, bei der alle Projekte mit x86-Ziel kompiliert werden. Nach dem Speichern der Konfiguration klappt es dann auch mit dem Kompilieren der Solution.
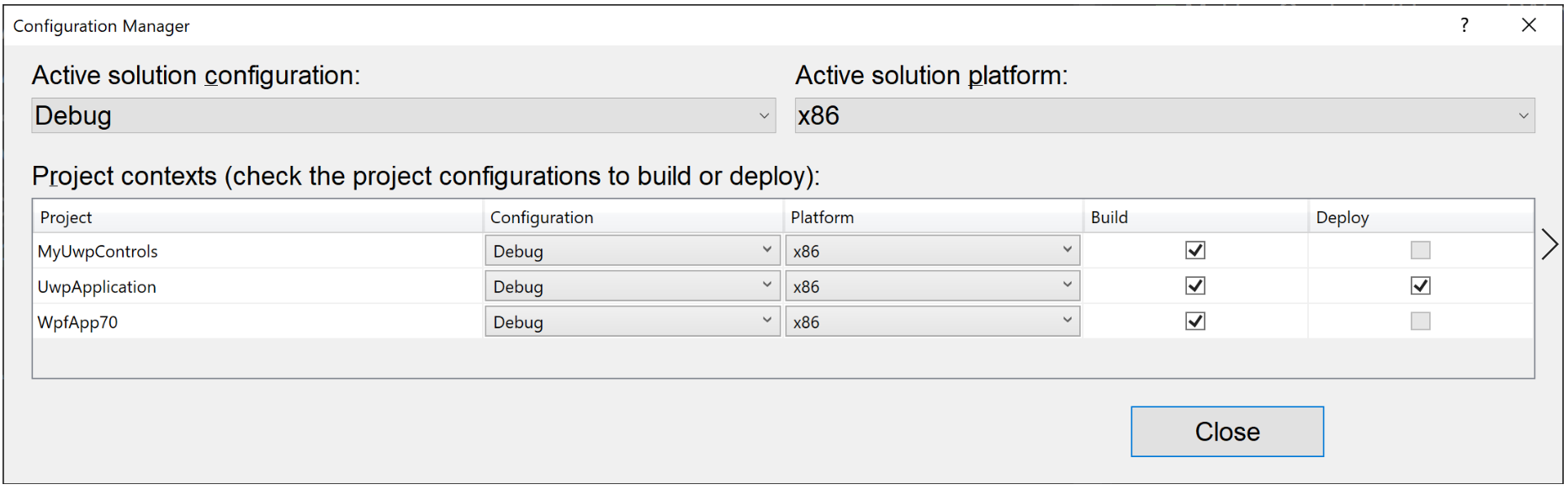
Abb. 6: Im Configuration Manager x86 einstellen
Jetzt steigt die Spannung beim Starten der Anwendung. Die Anwendung startet erfolgreich, und wie erwartet und wie in Abbildung 7 zu sehen, wird im oberen Teil der WPF-Anwendung das UWP Control SayHelloControl bestehend aus TextBox und TextBlock zum Hallo sagen angezeigt.

Abb. 7: Im oberen Teil mit dunklem Hintergrund ist das UWP Control
Somit hat das Einbinden eines eigenen UWP Controls in einer .NET-Core-basierten WPF-Anwendung mit XAML Islands funktioniert. Wie auch bei Standard UWP Controls, für die es kein Wrapped Control gibt, wird die WindowsXamlHost-Klasse eingesetzt.
Von UWP zu WinUI 3.0
Die in diesem Artikel beschriebene Version von XAML Islands ist XAML Islands 1.0, die ab Windows 10 Version 1903 verfügbar ist. Doch in Zukunft werden XAML Islands auch auf älteren Windows-10-Versionen funktionieren. Doch wie das? Um das zu verstehen, muss man auf die Entwicklung der Universal Windows Platform (UWP) schauen.
Microsoft hat schon vor ein paar Jahren festgestellt, dass die Universal Windows Platform das Problem hat, dass Entwickler neue Controls immer nur dann verwenden können, wenn ein Benutzer auch die neue Windows-10-Version installiert hat. Um dieses Problem zu lösen, hat Microsoft verschiedenste UWP Controls von Windows 10 entkoppelt und in Form von NuGet-Packages ausgeliefert. Somit lassen sich neueste Controls auch unter älteren Windows-10-Versionen verwenden. Diese NuGet-Packages sind unter dem Namen WinUI bekannt, und jenes mit den UWP Controls trägt den Namen Microsoft.UI.Xaml.
Die UWP Controls als solches von Windows 10 zu entkoppeln war nur der erste Schritt.
Im nächsten Schritt plant Microsoft, nicht nur UWP Controls via NuGet-Packages bereitzustellen, sondern auch die ganze UWP XAML Runtime und auch die Rendering Pipeline. Also alles, was zu einem kompletten UI Framework gehört. Dieses UI Framework beabsichtigt Microsoft für das Jahr 2020 in der finalen Version zu veröffentlichen. Es trägt den Namen WinUI 3.0 und wird Open Source sein, das Repository gibt es bereits heute auf GitHub.
Microsoft plant in Visual Studio eine neue Projektvorlage namens „Windows Application“, mit der ein WinUI-3.0-Projekt erstellt wird. Das Besondere an WinUI 3.0 ist, dass es sowohl das UWP-Modell mit der Sandbox als auch das klassische Win32-Modell mit gewöhnlicher .exe-Datei unterstützt. Somit ist die aus UWP bekannte Sandbox für WinUI-3.0-Applikationen optional. Diese Sandbox war bei einer Entscheidung zwischen UWP und WPF oft der Grund, warum Unternehmen am Ende WPF genommen haben, da es eine klassische .exe-Datei gibt. Doch mit WinUI 3.0 lässt sich ebenso eine klassische .exe-Datei erstellen, und zudem lassen sich die ganzen modernen UWP Controls und XAML-Features wie kompilierte Data Bindings direkt in einer WinUI-3.0-Anwendung nutzen. WinUI 3.0 ist somit das Beste aus UWP und WPF.
Es sieht also sehr stark danach aus, dass ab 2020 die WinUI 3.0 das moderne und empfohlene UI Framework für Windows-Desktopapplikationen sein wird. Und mit WinUI 3.0 wird Microsoft auch eine neue Variante von XAML Islands einführen, mit der sich WinUI 3.0 Controls problemlos in WPF- und Windows-Forms-Anwendungen integrieren lassen. Und da WinUI 3.0 von Windows 10 entkoppelt ist, wird die nächste Version von XAML Islands auch auf Windows-10-Versionen funktionieren, die älter als Version 1903 sind.
Regelmäßig News zur Konferenz und der .NET-Community
Fazit
Dieser Artikel hat die Grundlagen zu XAML Islands gezeigt. Mit XAML Islands lassen sich WPF- und Windows-Forms-Anwendungen mit UWP Controls modernisieren. .NET Core unterstützt dabei alle Szenarien. Es lassen sich sowohl UWP Controls von Microsoft als auch eigene, in C++, aber auch in C# geschriebene UWP Controls in der eigenen WPF- oder Windows-Forms-Applikation hosten.
XAML Islands erlaubt es, bestehende Applikationen mit Windows-10-Features aufzufrischen, ohne dass diese Anwendungen dafür neu geschrieben werden müssen. Microsoft ist zudem dabei, den kompletten UWP-XAML-Stack von Windows 10 zu entkoppeln und als eigenes, XAML-basiertes UI Framework unter dem Namen WinUI 3.0 bereitzustellen. WinUI 3.0 Controls sind moderne UWP Controls, die sich weiterhin via XAML Islands in WPF und Windows Forms Apps einbinden lassen werden. Für brandneue Windows-Desktopapplikationen stellt WinUI 3.0 wohl ab dem Release im Jahr 2020 die modernste und beste Wahl dar. Microsoft ist und bleibt also auch im Windows-Desktopumfeld innovativ und aktiv, und als Entwickler können wir gespannt und freudig auf die Zukunft mit WinUI 3.0 blicken, und uns freuen, dass bestehende .NET-Applikationen dank XAML Islands auch von dieser Zukunft profitieren können.
The post XAML Islands: Integration von WPF und Windows Forms für moderne Anwendungen appeared first on BASTA!.
]]>The post Azure Functions und noch mehr Serverless: Effiziente Entwicklung ohne Serververwaltung appeared first on BASTA!.
]]>Ohne hier eine komplette Abhandlung über Microservices zelebrieren zu wollen –einige der zentralen Prinzipien für erfolgreiche Microservices-Architekturen möchte ich gerne thematisieren, um dann die Überleitung in die Serverless-Welt daran festmachen zu können. Die vier mir wichtigsten aus Architektursicht sind:
Vermutlich ist es für Sie als Leser am einfachsten, die Microservices-Prinzipien in einer Serverless-Welt anhand eines kleinen Beispiels vor Augen geführt zu bekommen. Dann schauen wir uns doch mal eins an. Die Beispielanwendung ist auch mit komplettem Sourcecode in einem GitHub Repository zugänglich.
Wichtig für die Betrachtungen von Microservices – egal ob Serverless oder nicht – ist eine End-to-End-Sicht auf ein System. Es hilft meist nicht wirklich, sich nur einzelne Services oder gar einzelne Implementierungsdetails von Services anzuschauen: Eine Gesamtbetrachtung umschließt die Clientanwendungen ebenso wie auch nichtfachliche Services wie z. B. ein Authentifizierungs- oder Notifizierungsdienst.
 Abb. 1: Serverless-Microservices-Beispiel-Architektur (Order-Monitoring)
Abb. 1: Serverless-Microservices-Beispiel-Architektur (Order-Monitoring)
Wie in Abbildung 1 zu sehen ist, sind hier fünf Microservices involviert. Die Interaktionen sind über nummerierte Schritte nachvollziehbar. Die Client-SPA ist in diesem Fall nicht als Sammelsurium von Microfrontends umgesetzt, das würde den Rahmen des Beispiels bei weitem sprengen. Vielmehr bedient sich die SPA der unterschiedlichen APIs der Microservices. Für ein vereinfachtes URL-Management und eine bessere Entkopplung der physikalischen Dienste wird in der Gesamtarchitektur ein API-Gateway eingesetzt. Selbstverständlich ist ein API-Gateway kein Muss in einer solchen Architektur, wird aber oft gerne zur weiteren Abstraktion angewendet.
Die erste Frage, die sich stellt, wenn man aus Sicht des Endanwenders auf die Anwendung schaut: Wo kommt die SPA her und wie kommt Sie in meinen Browser?
Eine SPA ist am Ende des Tages ein Paket bestehend aus HTML, CSS, Bildern und anderen Assets. Dieses Paket muss man nicht umständlich und teuer auf einen Webserver oder gar Application-Server deployen. Bei jeder Cloudplattform bietet sich die sehr schlanke und zudem kostengünstige Option, die SPA einfach als statisches Gesamtgebilde über einen Storage-Service bereitzustellen. Im Fall von Microsofts Cloud ist das Azure Blob Storage.
Praxistipp: Azure Portal, CLI und REST API
Für alle Azure Services kann man die Erstellung und die Konfiguration entweder über das Azure Portal, über ein REST API oder aber über das sehr mächtige Azure CLI (Command Line Interface) konfigurieren und automatisieren.
Ist der Storage-Account angelegt, kann man das Statische-Website-Feature aktivieren. Danach steht ein Container namens $web zur Verfügung. Dieser dient gewissermaßen als Root-Verzeichnis für einen statischen Webserver, nur eben über Blog Storage bereitgestellt. In Abbildung 2 kann man die Client-SPA aus dem Beispiel sehen, hier über das Werkzeug Azure Storage Explorer manuell in die Cloud deployt.
 Abb. 2: Angular SPA über Azure Blob Storage bereitgestellt
Abb. 2: Angular SPA über Azure Blob Storage bereitgestellt
Selbstverständlich werden die Endpunkte für den Blob-Storage-basierten Webserver über HTTPS veröffentlicht. Mit zusätzlichen Azure-Diensten wie Azure DNS und Azure CDN lassen sich zudem eigene Domains, SSL-Zertifikate und letztendlich auch superschnelle CDN-Cacheknoten etablieren. Alles, ohne einen einzigen Server anfassen oder gar kennen zu müssen.
Wenn die SPA nun also per HTTPS in unserem Browser läuft und Daten abrufen möchte, dann braucht es freilich APIs und Schnittstellen in unseren Diensten. Die werden wir nun Serverless-like implementieren und bereitstellen.
Serverless-Code für Ihre Businesslogik oder Geschäftsprozesse kann man über Azure Functions ausführen. Und Azure Functions können sogar noch mehr, als dort vorgestellt wird. Eine wichtige Eigenschaft ist etwa, dass man nicht nur .NET-Core- und C#-Code schreiben, hochladen und ausführen kann – nein, ebenso lässt sich F#, Java, JavaScript, TypeScript, PowerShell oder aber Python nutzen. Details zu den zum Zeitpunkt des Verfassens dieses Beitrags unterstützten Plattformen und Sprachen finden Sie in Tabelle 1.
| Sprache | Release | Version |
| C# | Final | .NET Core 2.2 |
| F# | Final | .NET Core 2.2 |
| JavaScript | Final | Node 8 und 10 |
| TypeScript | Final | (Transpilierung nach JS) |
| Java | Final | Java 8 |
| Python | Preview | Python 3.6 |
| PowerShell | Preview | PowerShell Core 6 |
Tabelle 1: In Azure Functions unterstützte Plattformen und Sprachen
Die Plattform- und Sprachvielfalt ist in einer Microservices-Welt nicht zu unterschätzen. Denn wie wir gelernt haben, ist die freie Wahl der zur Problemstellung passenden Technologien ein mögliche Erfolgsfaktor. Wenn Sie z. B. eine Menge Java-Code haben und den mit in die Serverless Cloud nehmen wollen, dann tun sie das einfach mit Azure Functions. Oder wenn Sie Algorithmen im Umfeld von Data Science Serverless umsetzen möchten, dann können Sie das mit dem Azure-Functions-Python-Support umsetzen. Oder Sie wollen das schier unendliche Universum an Node-Modulen nutzen, dann schreiben Sie JavaScript- oder TypeScript-Code für Azure Functions.
Damit jeder einzelne Microservice auch wirklich von den anderen isoliert läuft, werden Functions in sogenannte Azure-Functions-Apps gekapselt. Abbildung 3 illustriert eine Azure Ressourcengruppe für die gesamte Serverless-Beispielanwendung. Hier sind alle beteiligten Azure-Ressourcen aufgeführt. In der Summe sind das wesentlich mehr, als wir hier in diesem Artikel behandeln können. Einen wichtigen Part spielen dabei die Azure-Functions-Apps (gekennzeichnet als App Service) für unsere Microservices wie Identity, Notifications, Orders, Products und Shipping (jeweils mit dem Namensschema „cw-serverless-microservices-SERVICENAME“).
 Abb. 3: Azure-Ressourcengruppe mit u. a. einzelnen Azure-Functions-Apps für die jeweiligen Microservices
Abb. 3: Azure-Ressourcengruppe mit u. a. einzelnen Azure-Functions-Apps für die jeweiligen Microservices
Praxistipp: Azure-Functions-Apps und Functions
Eine Azure-Functions-App basiert auf einem sogenannten Azure App Service, einem der klassischen PaaS-Angebote in Azure. Eine Functions-App ist somit ein komplett eigenständiges physikalisches Deployment. Darin befindet sich die Azure Functions Runtime, immer in einer ganz bestimmten Version und immer nur für eine Plattform (also .NET Core oder Java oder eine der anderen unterstützten Technologien). Ein klassischer Microservice besteht sicherlich aus mehr als einer Function. Daher ist eine Functions-App als Sammelbehälter für beliebige Functions ein geeigneter Container für Serverless Microservices.
Wir stellen unsere Microservices also als Verbund von Functions in Functions-Apps bereit. Doch wie kann die Client-SPA mit unseren Serverless Microservices reden?
Wie im erwähnten Artikel von Boris Wilhelms gezeigt wird, kann man mit Azure Functions sehr einfach HTTPS APIs implementieren. Genau das tun wir auch hier für unser Order-Monitoringsystem. Der Orders Microservice hat eine in C# geschriebene Function namens SubmitNewOrder, über die einen Client mittels eines HTTPS POST eine neue Bestellung abschicken kann. Listing 1 zeigt den kompletten Code hierfür. Die Connection-Strings, die im Beispiel verwendet werden, sind nicht im Code, sondern über die Application-Settings abgebildet und im Artikel nicht zu sehen. Vertraut dürfte dem Leser vor allem der HttpTrigger für die POST-Operation in den Zeilen 5-7 vorkommen – wenn man den genannten Artikel gelesen hat.
1 public class SubmitNewOrderFunctions
2 {
3 [FunctionName("SubmitNewOrder")]
4 public async Task<IActionResult> Run(
5 [HttpTrigger(AuthorizationLevel.Anonymous,
6 "POST", Route = "api/orders")]
7 HttpRequest req,
8
9 [ServiceBus("ordersforshipping", Connection="ServiceBus")]
10 IAsyncCollector<Messages.NewOrderMessage> messages,
11
12 ILogger log)
13 {
14 if (!await req.CheckAuthorization("api"))
15 {
16 return new UnauthorizedResult();
17 }
18
19 var newOrder = req.Deserialize<DTOs.Order>();
20 newOrder.Id = Guid.NewGuid();
21 newOrder.Created = DateTime.UtcNow;
22
23 var identity = Thread.CurrentPrincipal.Identity as ClaimsIdentity;
24 var userId = identity.Name;
25
26 var newOrderMessage = new Messages.NewOrderMessage
27 {
28 Order = Mapper.Map<Entities.Order>(newOrder),
29 UserId = userId
30 };
31
32 try
33 {
34 await messages.AddAsync(newOrderMessage);
35 await messages.FlushAsync();
36 }
37 catch (ServiceBusException sbx)
38 {
39 // TODO: retry policy & proper error handling
40 log.LogError(sbx, "Service Bus Error");
41 throw;
42 }
43
44 return new OkResult();
45 }
46 }
Doch was genau passiert da zu Beginn des Funktionskörpers in Zeile 14-17? Die Methode CheckAuthorizationauf dem req-Parameter zieht hier unsere volle Aufmerksamkeit auf sich.
Damit wir unser Microservices-System an den API-Grenzen und auch über die entkoppelten Kommunikationswege auf Anwendungsebene absichern können, verwenden wir JSON Web Tokens aus den OAuth-2.0- und OIDC-Standards. Zeile 14 in Listing 1 schaut auf dem HTTP Request in der Azure Functions Pipeline, ob es ein gültiges JWT gibt. Den exakten Code können Sie wie den gesamten restlichen Code für das Beispiel im zugehörigen GitHub Repository einsehen. Doch wo kommt dieses Token ursprünglich her?
Eine Option in Azure für Authentifizierung von Benutzern und Anwendungen ist das Microsoft-eigene Azure Active Directory (AAD) für Organisationsinterne Benutzer und deren Daten, oder aber auch alternativ AAD B2B für die Integration externer Benutzer. Wenn man jedoch mehr Flexibilität und vollen Sourcecodezugriff in Form eines Open-Source-Projekts genießen möchte, kann man zum beliebten IdentityServer-Projekt greifen. IdentityServer ist ein Framework, kein vollwertiger Server oder gar Service. Man passt die Basisfunktionalität an sein jeweiliges Projekt an und hostet es dann beispielsweise in der Cloud, etwa über Azure App Service.
Mit ein paar Kniffen lässt sich IdentityServer – da es ein ganz normales ASP.NET-Core-MVC-Projekt ist – auch in Azure Functions bereitstellen. Abbildung 4 zeigt in recht unspektakulärer Art eine exemplarische IdentityServer-Instanz, jedoch vollständig Serverless über Azure Functions zur Verfügung gestellt. Anders ausgedrückt: ein Wolf im Schafspelz.
 Abb. 4: IdentityServer als vollwertiges OAuth 2.0 und OIDC Framework in Azure Functions gehostet – Serverless-Tokens, sozusagen
Abb. 4: IdentityServer als vollwertiges OAuth 2.0 und OIDC Framework in Azure Functions gehostet – Serverless-Tokens, sozusagen
Über das vom IdentityServer ausgestellte Token können konsumierende Client oder Services Anfragen z. B. an unseren Products oder Orders Service stellen. Diese überprüfen das Token, ob es von einem bekannten Aussteller und noch nicht abgelaufen ist. Zusätzlich kann jeder fachliche Service für sich entscheiden, ob weiter sogenannte Claims überprüft werden müssen, um dem Aufrufer Zugang zur Businesslogik zu gewähren. Dieses Token verwendet nun aber nicht nur die Frontend Services, die direkt von der SPA angesprochen werden, nein – Vielmehr werden Informationen aus dem Token auch bei den entkoppelten und asynchron arbeitenden Microservices wie dem Shipping Service genutzt. Doch wie funktioniert diese viel besagte Entkopplung?
Für die Entkopplung auf der Zeitachse, also für eine asynchrone Kommunikation und damit die Möglichkeit der asynchronen Ausführung von Code nutzen wir ein Message-Queue-System. Im Fall von Serverless Azure ist das der Azure Service Bus. Service Bus ist ein sehr robuster, weil auch schon seit vielen Jahren existierender Dienst in der Microsoft-Cloud. Er nutzt zum Zwecke der Interoperabilität das allseits anerkannte Advanced Message Queuing Protocol (AMQP) in der Version 1.0. Neben simplen Nachrichtenschlangen (Queues) kann man mit dem Service Bus auch weiterführende Patterns implementieren, etwa Topics und Subscriptions.
Damit wir nun also in unserem Beispiel den Orders Service vom Shipping Service trennen können, legt der Orders Service eine Nachricht in eine Message-Queue namens ordersforshipping. Dies sieht man gut im C#-Code in Listing 1 (Zeilen 19-35). Mit dem API-Aufruf messages.FlushAsync()wird die Service-Bus-Client-Library angewiesen, alle bislang im Code angesammelten Nachrichten in die konfigurierte Queue zu senden. In bester Azure-Functions-Manier ist messagesan ein Functions-Output-Binding gebunden. Dieses Binding für den Service Bus wird im Beispiel asynchron genutzt: Wir nutzen also ein asynchrones API, um asynchron Daten in Nachrichten auszutauschen. Ergibt Sinn.
Ein Blick auf Abbildung 1 verrät uns, dass der Shipping Service nur über diese Message-Queue zu erreichen ist und ansonsten keinerlei API bietet. Das bedeutet, dass er in Ruhe seine Businesslogik für die Abarbeitung von Bestellungen und die Abwicklung von Auslieferungen ausführen kann. Ebenso bedeutet es, dass etwaige Resultate oder fachliche Antworten auf Bestellvorgänge ebenfalls als Nachrichten formuliert werden und in eine neue Queue geschrieben werden müssen.
Während der Orders Service in C# mit .NET Core umgesetzt wurde, handelt es sich beim Shipping Service um eine Java-basierte Lösung. Somit sehen wir auch, dass Azure Functions wirklich über mehrere Plattformen hinweg funktioniert. Listing 2 zeigt die ganze Pracht des simplen Java-Codes in einer Function mit Service-Bus-Trigger und Service-Bus-Output-Binding. Über den Trigger in Zeile 11 lauscht der Java-Code auf der Message-Queue ordersforshipping. Nach Durchlaufen des überaus komplexen Codes mit all seiner aufwendigen Businesslogik wird eine Ergebnisnachricht erzeugt, befüllt und schließlich als Rückgabewert der Function in die Queue shippingsinitiated gesendet (Zeile 19 bis 31).
1 public class CreateShipment {
2 /**
3 * @throws InterruptedException
4 * @throws IOException
5 */
6 @FunctionName("CreateShipment")
7 @ServiceBusQueueOutput(name = "$return",
8 queueName = "shippingsinitiated",
9 connection = "ServiceBus")
10 public String run(
11 @ServiceBusQueueTrigger(name = "message",
12 queueName = "ordersforshipping",
13 connection = "ServiceBus")
14 NewOrderMessage msg,
15 final ExecutionContext context
16 ) throws InterruptedException, IOException {
17 // NOTE: Look at our complex business logic ;-)
18 // Yes - do the REAL STUFF here!
19 Thread.sleep(5000);
20
21 ShippingCreatedMessage shippingCreated =
21 new ShippingCreatedMessage();
22 shippingCreated.Id = UUID.randomUUID();
23 shippingCreated.Created = new Date();
24 shippingCreated.OrderId = msg.Order.Id;
25 shippingCreated.UserId = msg.UserId;
26
27 Gson gson = new GsonBuilder().setDateFormat(
28 "yyyy-MM-dd'T'HH:mm:ss.SSSSSS'Z'").create();
29 String shippingCreatedMessage = gson.toJson(shippingCreated);
30
31 return shippingCreatedMessage;
32 }
33 }
Sie sehen und spüren regelrecht, wie sehr man sich mit Azure Functions, dessen Triggers und Bindings sehr stark auf die Implementierung der eigentlichen Logik konzentrieren kann und sich recht wenig mit dem infrastrukturellen Drumherum auseinandersetzen muss. So soll es sein, denn wir wollen ja Softwarelösungen bauen, keine Infrastrukturmonster.
Der Shipping Service hat mittlerweile seine Schuldigkeit getan und seine ihm wichtigen Informationen in einer Message-Queue abgelegt. Dem Orders Service ist das ziemlich egal – aber es gibt jemanden im Gesamtsystem, dem diese Info durchaus wichtig ist – denn der Endanwender hat sich registriert, um über Neuigkeiten bezüglich der Auslieferungen (Shippings) benachrichtigt zu werden.
Durch die Pushnachrichten aus dem mobilen Umfeld unserer Lieblingsapps entfacht, werden Realtimebenachrichtigungen auch im Businesskontext immer wichtiger. Im Order-Monitoringsystem möchte der User der SPA gerne wissen, wenn es einerseits eine neue, erfolgreich erstellte Bestellung gibt, und vor allem andererseits, wenn diese Bestellung zur Auslieferung kommt.
Für Realtimebenachrichtigungen im Webumfeld nimmt man auf Anwendungsebene gerne WebSockets als unterliegende Technologie. WebSockets funktionieren jedoch nicht immer und überall (Browserversionen, Netzwerk-Proxies etc.). Zudem müssen Verbindungsabbrüche selbst behandelt werden und das eigentliche anwendungsspezifische Protokoll zum Datenaustausch muss auch jedes Mal definiert und implementiert werden. Um all diese Anforderungen ein bisschen besser handhabbar zu gestalten, gibt es SignalR vom ASP.NET-Core-Team und den Signal Service vom Azure-Team. Für SignalR gibt es Clientbibliotheken für alle möglichen Plattformen und Programmiersprachen, allen voran natürlich JavaScript. Diese nutzen wir hier in unserer SPA.
Für unsere Azure Functions gibt es zudem Bindings für den Azure SignalR Service, wer hätte das gedacht? Der Notifications Service (vgl. Abb. 1) bedient sich eines Service-Bus-Triggers, um Nachrichten aus der shippingsinitiated Queue zu holen (siehe Listing 3). Diese werden dann in der Function aufbereitet, um anschließend, wie in Zeile 16 zu sehen ist, über das SignalR-Service-Output-Binding über den SignalR Service an die vorher registrierten Clients gesendet zu werden. Fertig.
Die Clients erhalten dann per SignalR-Verbindung (in den meisten Fällen wird das physikalisch eine WebSocket Connection sein) die Information, dass es neue Daten/Argumente für das Ziel shippingInitiated gibt. Der Client kann dann entscheiden, wie der damit umgeht. In der SPA wird einfach ein Event lokal ausgelöst, um danach die aktuelle Liste an Orders mit allen Produktinformationen von den jeweiligen Services zu laden.
1 public class NotifyClientsAboutOrderShipmentFunctions
2 {
3 [FunctionName("NotifyClientsAboutOrderShipment")]
4 public async Task Run(
5 [ServiceBusTrigger("shippingsinitiated", Connection = "ServiceBus")]
6 ShippingCreatedMessage msg,
7
8 [SignalR(HubName="shippingsHub", ConnectionStringSetting="SignalR")]
9 IAsyncCollector<SignalRMessage> notificationMessages,
10
11 ILogger log)
12 {
13 var messageToNotify = new {
14 userId = message.UserId, orderId = message.OrderId };
15
16 await notificationMessages.AddAsync(new SignalRMessage
17 {
18 Target = "shippingInitiated",
19 Arguments = new[] { messageToNotify }
20 });
21 }
22 }
Wir haben bis hierhin schon einiges umgesetzt bekommen mit unserer Idee von Serverless Microservices. Und das Schöne an Serverless ist eben immer wieder, dass man komplexe verteilte Architekturen relativ schnell und unkompliziert umgesetzt bekommt. Hier ein Service, da ein Service. Hier ein Client, da eine Queue, dort ein Notification-Dienst. Doch wer behält da den Überblick? Was passiert wo und wie?
Sicherlich hat eine derart verteilte und lose gekoppelte Architektur nicht nur Vorteile. Die Sicht auf ein solches System zur Laufzeit ist enorm wichtig, um beispielsweise Fehler mitzubekommen und darauf reagieren zu können. Für Azure können wir uns in diesem Fall der Application Insights bedienen (diese werden gerade in den sogenannten Azure Monitor integriert).
Mit Application Insights können wir vor allem das Laufzeitverhalten unserer Systeme monitoren. Für Fehler oder auftretenden Schwellwerten bei spezifischen Metriken können wir auch Regeln festlegen, was darauffolgend passieren soll –beispielsweise das Versenden von Emails o. Ä. Im Rahmen unserer Serverless-Beispielanwendung für diesen Artikel werfen wir mal einen Blick auf das werte Befinden unseres Identity Services. Über den Live Metrics Stream können wir tatsächlich in Echtzeit in das Herz unseres Identity Services blicken.
Wie man in Abbildung 5 sehen kann, bekommen wir Einsicht in die Telemetriedaten, Requests, Speicher- und CPU-Auslastung und auch auf die automatisch verwaltete Anzahl von Serverinstanzen in unserer Serverless-Azure-Functions-Anwendung. Eine Info, die uns ja eigentlich egal sein sollte, den wir wollen ja explizit nichts mehr mit Servern zu tun haben. Aber es ist durchaus interessant zu beobachten, wie sich Azure Functions unter Last verhält. Im Screenshot sieht man, dass wir ca. 800-900 Request pro Sekunde verarbeiten und die Azure Functions Runtime bzw. der Scale-Controller mittlerweile auf bis zu zwölf Serverinstanzen skaliert hat – ohne jegliches Zutun unsererseits. Und wenn die Last abnimmt, dann wird der Scale Controller auch wieder für das Scale-In sorgen. Wichtig ist, nochmals festzuhalten, dass wir nur dann Geld bezahlen, wenn unser Code auch wirklich ausgeführt wird, egal, wie viele Server in der Zwischenzeit Däumchen drehen.
 Abb. 5: Echtzeiteinblicke in Serverless Microservices mit Application Insights Live Metrics
Abb. 5: Echtzeiteinblicke in Serverless Microservices mit Application Insights Live Metrics
Wenn man nun alle der in Abbildung 1 aufgemalten Artefakte nimmt und sie auf Azure Services abbildet, landet man bei Abbildung 6: Die Umsetzung des Serverless-Order-Monitoringsystems mit Serverless Azure – voilà.
Im Verlauf des Artikels haben wir uns gemeinsam angeschaut, wie man auf pragmatische Art und Weise End-to-End Microservices mit Serverless und der Azure-Cloud umsetzen kann. Mit Azure Functions und den dazu passenden anderem Azure-Diensten ist das mit relativ wenig Aufwand in kurzer Zeit möglich. Natürlich steckt der Teufel im Detail, keine Frage. Und selbstverständlich kann jedwede Darstellung im Rahmen einess Beitrags nur ein Kratzen an der Oberfläche sein. Daher zum Schluss nochmals der Aufruf, einen Blick in den Sourcecode des Beispiels zu werfen.
 Abb. 6: Serverless-Microservices-Beispiel – umgesetzt mit Serverless-Azure-Diensten
Abb. 6: Serverless-Microservices-Beispiel – umgesetzt mit Serverless-Azure-Diensten
Der Azure-DevOps-Spickzettel von Dr. Holger Schwichtenberg zeigt Ihnen kurz und knapp, wie Sie mit wenigen Befehlen das Kommando über Azure DevOps übernehmen können.
The post Azure Functions und noch mehr Serverless: Effiziente Entwicklung ohne Serververwaltung appeared first on BASTA!.
]]>The post Keynote | Vom Core zum Frontend: Nahtlose Integration für moderne Webanwendungen appeared first on BASTA!.
]]>Ein Schwerpunkt der BASTA! 2019 war .NET Core 3.0, das passender Weise am Abend vor der Eröffnungskeynote von Microsoft released wurde. Daher lautete dann auch das Thema der Keynote „Vom Kern zum Frontend“ – mit den Speakern Dr. Holger Schwichtenberg, www.IT-Visions.de/5Minds IT-Solutions, und Jörg Neumann, CGI Deutschland B.V. & Co. KG.
Zum Einstieg gibt „Dotnet-Doktor“ Holger Schwichtenberg einen Überblick über die sich wandelnde .NET-Landschaft – von .NET Framework, über das eben veröffentlichte .NET Core 3.0 bis hin zu .NET 5.0 mit dem geplanten Release-Termin im November 2020. In Summe stehen .NET-Entwicklern damit ab dem kommenden Herbst grob drei unterschiedliche .NET-Versionen zur Verfügung, zwischen denen sie sich entscheiden müssen – wobei Holger ganz klar empfiehlt, dass man jedes neue Projekt aktuell mit .NET Core 3 beginnen sollte.
Im zweiten Teil der Eröffnung widmete sich Jörg Neumann den Themen Micro Frontends und Cross-Plattform-Entwicklung mit Hilfe einer Frontend-Technologie-Matrix, um etwas Ordnung in die Vielzahl der Möglichkeiten zu bringen. Denn als .NET-Entwickler hat man heute in der Regel mehr als eine Zielplattform und sogar auf dem Windows Desktop bieten sich immer mehr Optionen an, zwischen denen es mit Blick auf die Zukunft zu wählen gilt.
Im Hinblick auf die Zukunft weisen die beiden Themen auf die Veränderungen hin, die im nächsten Jahr für Entwickler relevant werden. Windows 7 wird im Januar aus dem Support auslaufen, sodass weitgehend Windows 10 auf dem Desktop eingesetzt werden wird. Dank einiger vorgestellter Neuerungen in .NET Core 3 können Entwickler bestehende WPF- und WinForms-Anwendungen mit modernen Funktionen ausstatten, aber eben auch für andere Plattformen wie Android oder iOS entwickeln. Und eine Überraschung wurde von Microsoft erst eine Woche nach der Keynote bekannt gegeben. Ab Herbst 2020 wird mit Windows X eine Variante des Betriebssystems für Geräte mit zwei Monitoren zur Verfügung stehen und auch für die Entwickler auf der Android-Plattform wird es Veränderungen geben. Informationen dazu finden Sie in Zukunft natürlich auf der BASTA!
The post Keynote | Vom Core zum Frontend: Nahtlose Integration für moderne Webanwendungen appeared first on BASTA!.
]]>The post Azure DevOps: Einfach per Kommandozeile steuern für effektive CI/CD-Prozesse appeared first on BASTA!.
]]>Azure DevOps ist die Nachfolgemarke von Team Foundation Server (TFS) und Visual Studio Team Services (VSTS). Microsoft differenziert durch die Zusätze „Azure DevOps Server“ und „Azure DevOps Services“ zwischen der lokal installierbaren Version und der Cloudversion. Aktuelle Version des Servers ist 2019.0.1, siehe Release Notes. Das zum Redaktionsschluss aktuelle Release der Cloudvariante ist” Sprint 154. Hierin findet man in den Release Notes den Eintrag „Azure DevOps CLI general availability“.
Regelmäßig News zur Konferenz und der .NET-Community
Die Steuerung von Azure DevOps per Kommandozeile (CLI, Command Line Interface) bietet sich für wiederkehrende Aufgaben oder Anwendungsintegration an. So könnte man zum Beispiel aus einer Monitoringsoftware heraus automatisch Bugs in Azure DevOps anlegen, wenn es zu Fehlern im laufenden Betrieb kommt. Per Kommandozeile lassen sich derzeit viele, aber nicht alle Funktionen von Azure DevOps steuern. Man kann zum Beispiel Projekte, Git Repositories, Pipelines, Work Items, Wikis, Banner sowie Teams, Gruppen und Benutzer anlegen und verwalten. Allerdings kann man keine Repositories mit Team Foundation Version Control (TFVC) damit administrieren. Auch das Hinzufügen von Benutzern zu Teams ist noch nicht im Angebot.
Das Azure DevOps CLI gibt es seit Februar 2019 als Preview, doch es ist nun am 8. Juli 2019 im Stadium „General Availability“ keineswegs fertig, wie der Beitrag noch aufzeigen wird. Es gab schon ein Vorgängerprodukt, das VSTS CLI, das trotz seines auf die Cloudvariante hindeutenden Namens auch mit dem lokalen TFS (ab Version 2017 Update 2) funktionierte.
Bei GitHub findet man noch einen Abzweig des alten Entwicklungsstands mit der Aussage „VSTS CLI is a new command line interface for Visual Studio Team Services (VSTS) and Team Foundation Server (TFS) 2017 Update 2 and later“. Diese Aussage ist jedoch veraltet; auf der echten Projektseite von Microsoft liest man dann auch klar: „The Azure CLI with the Azure DevOps Extension has replaced the VSTS CLI. The VSTS CLI has been deprecated and will no longer be receiving new features. We recommend that users of the VSTS CLI switch to the Azure CLI and add the Azure DevOps extension.“
Während das VSTS CLI ein in Python implementiertes, eigenständiges Werkzeug (vsts, installiert in C:\Program Files (x86)\Microsoft SDKs\VSTS\CLI) war, ist das Azure DevOps CLI eine Erweiterung zum allgemeinen Azure CLI (az). Auch az ist in Python geschrieben und installiert sich im Standard in C:\Program Files (x86)\Microsoft SDKs\Azure\CLI2. Die 2 am Ende dieses Dateipfads weist darauf hin, dass das Azure CLI die zweite Generation der Kommandozeilenwerkzeuge für Azure darstellt. Die erste Generation hatte als Befehlsnamen „azure“. Die zweite Version (az) wurde zunächst Azure CLI 2.0 genannt. Seit Juni 2018 differenziert Microsoft nun aber mit Azure CLI und Azure Classic CLI zwischen den beiden Produkten.
Für einen Nutzer, der Azure DevOps per Kommandozeile steuern möchte, bedeutet dies, dass er zuerst auf seiner Festplatte das aktuelle Azure CLI installieren muss. Die jeweils neueste Version erhält man unter [7]. Für Windows findet man dort einen MSI-Installer. Unter macOS ist eine Installation per homebrew (brew update && brew install azure-cli) vorgesehen. Für Linux-basierte Betriebssysteme kann man apt, yum, zypper oder eine manuelle Installation verwenden.
Zum Redaktionsschluss ist beim Azure CLI die Version 2.0.68 vom 3. Juli 2019 aktuell. Um die Azure-DevOps-Erweiterung für das Azure CLI nutzen zu können, ist mindestens Version 2.0.49 erforderlich. Der Benutzer kann die Kommandozeilenshell seiner Wahl verwenden. Unter Windows z. B. Windows PowerShell, PowerShell Core, die klassische Windows-Shell (cmd), das neue Windows Terminal oder die bash Shell im Windows-Subsystem für Linux (WSL). Hier soll PowerShell 7.0 Preview 1 zum Einsatz kommen, um die objektorientierte Pipeline nutzen und die Ergebnisse des Azure CLI weiterverarbeiten zu können. Ältere Varianten der PowerShell funktionieren aber gleichermaßen. Die meisten der hier vorgestellten Befehle funktionieren freilich auch ohne PowerShell Pipelines in der cmd oder bash.
Um die aktuelle Version des Azure CLI abzufragen, gibt man az –version ein und erhält dann eine lange Tabelle mit allen im Azure CLI installierten Befehlsmodule und den Erweiterungen. Falls man noch eine ältere Version des CLI verwendet, d. h. eine neuere vorliegt, wird man am Ende dieser Liste praktischerweise darauf hingewiesen.
Normalerweise zeigt diese Versionsausgabe keine Erweiterungen. Eine Erweiterung muss man erst explizit installieren. Dafür braucht man kein MSI-Paket mehr, denn dafür hat das Azure CLI den Befehl az extension add. Die Azure-DevOps-CLI-Erweiterung installiert man im Azure CLI mit:
az extension add --name azure-devops
Um nur die Liste der installierten Erweiterungen zu sehen, gibt man ein:
az extension list --output table
Zur Aktualisierung des Azure CLI führt man das aktuelle MSI-Paket von [9] aus. Hierdurch werden aber nicht die installierten Erweiterungen aktualisiert, man muss sie mit az extension update separat aktualisieren, z. B. folgendermaßen:
az extension update --name azure-devops
Die aktuelle Version der Azure-DevOps-CLI-Erweiterung, die bei Redaktionsschluss verfügbar ist, trägt die Versionsnummer 0.11.0. Beim modernen, agilen Microsoft bedeutet „Azure DevOps CLI general availability“ also keineswegs, dass ein Produkt die Versionsnummer 1.0 erreicht hat.
Hilfe zu den verfügbaren Befehlen bekommt man mit: az -h. Zu beachten ist, dass man wegen der Vielzahl der Befehle in dieser Hilfeausgabe nur Befehlsgruppen (z. B. ad, artifacts, boards, devops, iot, pipelines, repos, sql, storage, network, vm, webapp) zu sehen bekommt. In eine bestimmte Befehlsgruppe steigt man ein, indem man den Namen der Befehlsgruppe zusätzlich angibt: az pipelines -h.
Nun bekommt man eine kürzere Hilfeliste mit den Befehlen dieser Befehlsliste, wobei wieder unterschieden wird zwischen direkten Befehlen und Untergruppen (Abb. 1). Und auch hier bedeutet „General Availability“ also nicht, dass ein Produkt insgesamt fertig ist. Die meisten Befehlsgruppen des Azure DevOps CLI verweilen auch in der Preview, wie man in Abbildung 1 sieht.
Abb. 1: Hilfe zum Befehlsgebiet der Pipeline-Verwaltung mit „az pipelines -h“: Viele Befehle sind immer noch in der Preview
So sagt die Hilfeausgabe in Abbildung 1, dass man zur Auflistung aller definierten Pipelines eingeben kann: az pipelines list. Man kann aber auch noch mehr Hilfe anfordern zur Untergruppe agents mit: az pipelines agent -h. Dort sieht man, dass es auch auf dieser Ebene wieder einen Befehl list gibt, um die Liste der verfügbaren Pipeline-Agents zu erhalten: az pipelines agent list. Die Befehlsebene bringt feine Unterschiede zu Tage:
$env:AZURE_DEVOPS_EXT_PAT = bjlhfo7evyvre5rsxhyhxy6…..tv6hklzrrl3ydwfan2k7d5awq"

Wer mit mehreren Organisationen und Projekten arbeitet, wird beim Azure DevOps CLI immer wieder bei den einzelnen Befehlen die Organisation und den Projektnamen festlegen müssen:
az pipelines list --organization https://dev.azure.com/ITVDemo --project "MiracleList"
Dabei ist man bei –organization gezwungen, den ganze URL anzugeben. Eine Abkürzung der Parameternamen ist möglich, soweit noch eindeutig:
az pipelines list --org https://dev.azure.com/ITVDemo --p "MiracleList"
Man kann aber die Organisation nicht mit –o abkürzen, da es auch noch den Parameter –output gibt. Die ständige Wiederholung dieser allgemeinen Parameter kann man durch eine zentrale Vorgabe vermeiden:
az devops configure --organization https://dev.azure.com/ITVDemo --project "MiracleList"
Dadurch kann man im Folgenden verkürzt schreiben: az pipelines list
Azure DevOps CLI liefert im Standard alle Ausgaben im JSON-Format. Dies ist zwar für Maschinen gut weiterzuverarbeiten, doch für Menschen nicht gut lesbar. Insgesamt stehen zur Verfügung:
Das Ausgabeformat kann man bei jedem einzelnen Azure-CLI-Befehl mit dem Parameter –output, abgekürzt mit -o,festlegen. Wie Abbildung 3 zeigt, beschränkt sich die Tabellenausgabe auf die wesentlichen Spalten.

Das Standardausgabeformat kann der Benutzer persistent in der Datei C:\Users\BenutzerName\.azure\config ändern (Listing 1). Diese Datei kann er auch interaktiv mit dem Befehl az configure bearbeiten.
[cloud] name = AzureCloud [core] first_run = yes output = table collect_telemetry = no cache_ttl = 10 [logging] enable_log_file = no
Als eingefleischter Liebhaber der objektorientierten Programmierung und des objektorientierten Pipelinings mit Objekten in der PowerShell fehlt dem Autor dieses Beitrags in der Liste der Ausgabeformate natürlich object. Man muss sich die Frage stellen, warum Microsoft zur Implementierung Python verwendet hat. C# oder Visual Basic .NET gibt es ja nun seit einiger Zeit auch plattformneutral, und diese Sprachen hätten den Vorteil gehabt, dass sie auch direkt .NET-Objekte für die PowerShell produzieren könnten. Wie so oft erleben wir auch hier, dass bei Microsoft leider viele technische Entscheidungen eher willkürlich in einzelnen Fachbereichen statt zentral und strategisch getroffen werden.
Die Azure DevOps-CLI-Befehle in der PowerShell auszuführen, lohnt sich dennoch, denn die PowerShell kann leicht JSON in .NET-Objekte verwandeln; dafür gibt es seit Windows PowerShell 3.0 das eingebaute Commandlet ConvertFrom-Json. Dieses Commandlet wandelt eine Zeichenkette im JSON-Format in .NET-Objekte um. Intuitiv würde man als PowerShell-Benutzer dann schreiben:
az pipelines list -o JSON | convertfrom-JSON | where-object { $_.name -notlike "*Backend*" } | sort-object name | format-table name, url
Allerdings wundert man sich, dass zwar die Tabellenausgabe mit den beiden gewünschten Spalten vorhanden ist, aber weder der Filter mit dem Commandlet where-object noch die Sortierung mit sort-object wirkt. Das liegt am Commandlet ConvertFrom-Json, bei dem das PowerShell-Entwicklerteam bei der Implementierung etwas verbockt hat. Wenn sich an der Wurzel der JSON-Datei ein Array befindet, legt das Commandlet das Array in die Pipeline. Üblicherweise entpacken aber Commandlets ein Array in Einzelobjekte. Microsoft hat das Problem leider bis heute nicht behoben>/a>. Die Umgehung dieses Problems ist, entweder Foreach-Object explizit in die Pipeline zu setzen:
az pipelines list -o JSON | convertfrom-JSON | foreach-object { $_} | where-object { $_.name -notlike "*Backend*" } | sort-object name | format-table name, url
oder den vorderen Teil zu klammern:
(az pipelines list -o JSON | convertfrom-JSON) | where-object { $_.name -notlike "*Backend*" } | sort-object name| format-table name, url
Einige der Azure-DevOps-CLI-Befehle haben bereits eingebaute Filter, so kann man beispielsweise Work Items mit der SQL-ähnlichen Work Item Query Language (WIQL) aussortieren:
az boards query --wiql "SELECT System.ID, System.Title, System.WorkItemType, System.AreaPath, System.AssignedTo, System.State from workitems order by System.ID asc"
Mit PowerShell-Variablen kann man diesen Befehl natürlich auch in mehrere Zeilen aufteilen:
$wiql = "SELECT System.ID, System.Title, System.WorkItemType, System.AreaPath, System.AssignedTo, System.State from workitems order by System.ID asc"
az boards query --wiql $wiql
Ebenso ist es möglich, WIQL-Filter und das Filtern mit Where-Object in der PowerShell zu kombinieren. Der folgende Befehl filtert erst alle an einen Benutzer zugewiesenen Work Items, die nicht erledigt sind. Dann erfolgt in der PowerShell Pipeline ein weiterer Filter auf das Wort „Angular“ im Titel:
$wiql = "SELECT System.ID, System.Title, System.AssignedTo, System.State from workitems WHERE [System.AssignedTo] = '[email protected]' and state <> 'Done' order by System.ID asc"
(az boards query --wiql $wiql -o json | convertfrom-JSON).fields | where-object { $_."System.Title" -like "*Angular*" } | format-table "System.ID", "System.Title"
Der explizite Zugriff .fields ist hier notwendig, da die JSON-Struktur, die das Azure CLI liefert, etwas komplexer ist. An der Wurzel ist ein Array von Objekten. Die Objekte enthalten die Eigenschaften des Work Items aber nicht direkt, sondern ein Unterobjekt “fields” (Listing 2).
[
{
"fields": {
"System.AssignedTo": {
"_links": {
"avatar": {
"href": "https://nlhsdemo.visualstudio.com/_apis/GraphProfile/MemberAvatars/msa.N2NlNTFmMWYtODBhYy03MzVlLThmOWEtY2FhNzgyNjAzNGQz"
}
},
"descriptor": "msa.N2NlNTFmMWYtODBhYy03MzVlLThmOWEtY2FhNzgyNjAzNGQz",
"displayName": "Dr. Holger Schwichtenberg",
"id": "0a31ed99-da1e-4412-913b-5da20050c88f",
"imageUrl": "https://nlhsdemo.visualstudio.com/_apis/GraphProfile/MemberAvatars/msa.N2NlNTFmMWYtODBhYy03MzVlLThmOWEtY2FhNzgyNjAzNGQz",
"uniqueName": "[email protected]",
"url": "https://spsprodcus1.vssps.visualstudio.com/A7fbad96a-dc90-4656-af24-f37c38c5694b/_apis/Identities/0a31ed99-da1e-4412-913b-5da20050c88f"
},
"System.Id": 18,
"System.State": "New",
"System.Title": "Sicherheit verbessern: Secrets, z.B. im ConnectStrings, müssen verschlüsselt gespeichert werden"
},
"id": 18,
"relations": null,
"rev": 5,
"url": "https://itvdemo.visualstudio.com/_apis/wit/workItems/18"
},
…
]
Außerdem ist bei dem PowerShell-Befehl zu beachten, dass die WorkItem-Eigenschaftennamen in Anführungszeichen stehen müssen, falls sie Punkte enthalten (wie z. B. bei System.State und Microsoft.VSTS.Common.Severity). Den Punkt interpretiert die PowerShell genauso wie andere objektorientierte Sprachen als Trennzeichen zwischen Objekt und Eigenschaft. Hier Punkte im Namen zu verwenden, war nicht sehr weise von Microsoft.
Die Namen der Work-Item-Eigenschaften für die Prozesse Scrum und Agile findet man auf dem Azure-DevOps-Spickzettel, der dieser Ausgabe beiliegt. Vielfach findet man hier noch VSTS im Namen; hier wird Microsoft den alten Namen nicht loswerden, außer man riskiert Breaking Changes oder implementiert Aliase.
Zum Abschluss noch einige schöne Praxisbeispiele zum Einsatz des Azure DevOps CLI. Das erste Beispiel zeigt das Anlegen eines Work Items mit mehreren Eigenschaften (Listing 3). Von az boards work-item create wird eine JSON-Ausgabe angefordert, die mit Hilfe der PowerShell ausgewertet wird. Hier ist eine Klammer um ConvertFrom-Json nicht notwendig, denn der Azure-DevOps-CLI-Befehl liefert nur ein einzelnes Objekt, keine Menge. In dem Befehl fällt zudem auf, dass man einige wenige Eigenschaften direkt setzen kann über Parameter des CLI-Befehls; die meisten Eigenschaften kann man jedoch nur über den generischen Parameter –fields setzen. Auf –fields folgt eine Liste von durch ein Gleichheitszeichen getrennten Name-Wert-Paaren:
$wi = (az boards work-item create --type Bug --title "Absturz bei der Eingabe von 0 im Feld Preis" --description "Die Spalte Preis erlaubt nicht die Zahl 0!" --discussion "Das hatte ich in der letzten Version schon festgestellt!" --field "Microsoft.VSTS.TCM.ReproSteps=
” “Microsoft.VSTS.Common.AcceptanceCriteria=
” “Microsoft.VSTS.TCM.SystemInfo=Windows 10 v1903” –assigned-to “[email protected]” -o json)
$workItemID = ($wi | ConvertFrom-Json).ID
Das zweite Beispiel zeigt die Änderung eines Work Items:
az boards work-item update --id 30 --field "Microsoft.VSTS.TCM.SystemInfo=Windows 10 v1903" "Microsoft.VSTS.Common.Priority=1" "Microsoft.VSTS.Common.Severity=2 - High"
Das dritte Beispiel zeigt die Zuordnung zwischen zwei Work Items:
az boards work-item relation add --id 21 --target-id 24 --relation-type "Tests"
Eine Liste aller möglichen Zuordnungstypen in einem Projekt erhält man mit:
az boards work-item relation list-type
Zum Schluss noch das Starten einer Build Pipeline:
az pipelines build queue --definition-name MiracleListAngularClientBuild
Weitere sinnvolle Anwendungen des Azure DevOps CLI finden Sie auf dem dieser Ausgabe des Windows Developer beiliegenden Spickzettel.
Regelmäßig News zur Konferenz und der .NET-Community
Der Azure-DevOps-Spickzettel von Dr. Holger Schwichtenberg zeigt Ihnen kurz und knapp, wie Sie mit wenigen Befehlen das Kommando über Azure DevOps übernehmen können.
The post Azure DevOps: Einfach per Kommandozeile steuern für effektive CI/CD-Prozesse appeared first on BASTA!.
]]>The post Azure Blob Storage für .NET-Entwickler appeared first on BASTA!.
]]>Mit Azure Blob Storage lassen sich beispielsweise einfach Snapshots eines Blobs erstellen, um eine Art Versionierung zu bauen. Entwickler können Metadaten auf einem Blob abspeichern, Daten für das Video- bzw. Audio-Streaming zur Verfügung stellen. Auch ganze Angular-Applikationen könnte man direkt in Azure Blob Storage für wenig Geld hosten. Das sind nur wenige Szenarien aus den wahrscheinlich unzähligen Beispielen, die sich im Arbeitsalltag jedes Entwicklers finden lassen.
Denn eins ist heutzutage gewiss, vor allem an unstrukturierten Daten mangelt es nicht. Der effiziente Umgang damit ist die eigentliche Herausforderung. Gleichzeitig gibt es genau dafür immer mehr Lösungen, die von Entwicklern passend ausgewählt werden müssen. Wenn es um Effizienz, leichte Verfügbarkeit und niedrige Einstiegshürden geht, bieten sich Cloud-Angebote zuerst an. Daher zeigt Thomas in diesem Video, neben einem Einstieg in Blob Storage, wie man Blob Storage in .NET verwenden kann. Außerdem erfahren Sie, wie Metadaten auf den BLOBs gespeichert, Snapshots erstellt und statische Webseiten im Blob Storage gehostet werden können.
Der Azure-DevOps-Spickzettel von Dr. Holger Schwichtenberg zeigt Ihnen kurz und knapp, wie Sie mit wenigen Befehlen das Kommando über Azure DevOps übernehmen können.
The post Azure Blob Storage für .NET-Entwickler appeared first on BASTA!.
]]>The post ML.NET: Machine Learning mit .NET Core 3 – Einstieg und Anwendungsfälle appeared first on BASTA!.
]]>Mit ML.NET (Machine Learning für .NET) veröffentlicht Microsoft ein für die Softwareentwicklung revolutionäres Framework. Möchte man maschinelles Lernen in den eigenen Anwendungen einsetzen, ist es nicht länger notwendig, sich im Detail mit der Mathematik und der Implementierung von z. B. Transformations-, Klassifikations-, Regressions- oder SVM-Algorithmen auszukennen oder sich damit auseinanderzusetzen, denn all das bringt ML.NET mit. Das Tooling um das Framework herum tut seinen Rest: Es war nie einfacher, den richtigen Algorithmus für den gewünschten Anwendungsfall auszusuchen, die eigenen Daten darauf zu trainieren und schließlich in den eigenen Anwendungen einzusetzen. Damit dreht Microsoft den Spieß um: Daten und Anwendungsfall stehen im Vordergrund, nicht länger die Implementierung.
Kurze Rede, schnell zum Sinn: Ein Beispiel sagt mehr als tausend Worte. Starten wir also mit einer praktischen Demo, um das Gesagte zu untermauern.
Um ein Cross-Plattform-Developer-Tooling anzubieten, bringt ML.NET ein Command Line Interface (CLI) mit. Wir werden später etwas mehr darüber erfahren. Für das erste schnelle
Beispiel werden wir jedoch Visual Studio und die Model Builder Extension heranziehen. Die
Erweiterung für Visual Studio benutzt unter der Haube seinerseits das CLI.
Die Extension kann über das Hauptmenü EXTENSIONS | MANAGE EXTENSIONS installiert oder
alternativ heruntergeladen werden. Für diese erste Demo benutzen wir Visual Studio 2019.
Nach erfolgreicher Installation beginnen wir mit einer einfachen, leeren .NET-Core-
Konsolenanwendung. Im Kontextmenü des Projektknotens im Solution Explorer befindet sich ein
neuer Eintrag: ADD | MACHINE LEARNING. Die Auswahl öffnet den ML.NET Model Builder, wie in
Abbildung 1 zu sehen.

Der Model Builder bietet einen einfachen Assistenten, der durch fünf Schritte führt. Zuerst wählen wir das Szenario aus, in diesem Fall SENTIMENT ANALYSIS. Schritt zwei verlangt von uns die Daten, mit denen das neue Machine Learning Model erstellt und trainiert werden soll. Dazu laden wir das Wikipedia Detox Dataset herunter. Dieses enthält Userkommentare und eine Klassifikation, ob der Kommentar positive oder negative Aussagen im Sinne von Emotionalität enthält. Das ML Model soll mit diesen Daten trainiert werden, um zu bestimmen, ob ein beliebiger anderer Kommentar positive oder negative Aussagen enthält. Nach dem Download wählen wir die Datei im zweiten Schritt des Model Builders aus. Eine kleine Vorschau wird angezeigt, und die vorherzusagende Spalte muss ausgewählt werden. Für dieses Beispiel ist das die Spalte SENTIMENT.
Es folgt Schritt drei – das Trainieren des Models. Ein Klick auf den Button START TRAINING genügt und der Model Builder beginnt sofort damit, verschiedenste ML-Algorithmen zu durchlaufen und den für unser Problem am besten passenden auszuwählen, um anschließend das Model zu trainieren. So viel sei an dieser Stelle verraten: Unter der Haube wird AutoML für die Algorithmenselektion eingesetzt. Eventuell sollte man hier ein wenig mehr Zeit einplanen, als die vorgegebenen 10 Sekunden. Nach 30 Sekunden Trainingszeit findet der Model Builder einen Algorithmus mit einer Genauigkeit von 88,24 Prozent. Das bedeutet, dass das erzeugte Model bei 88,24 Prozent aller Vorhersagen in der Trainingsphase richtig lag.
Schritt vier des Assistenten zeigt uns anschließend eine Zusammenfassung des durchgeführten Prozesses, und ein paar Kennwerte zur Performance des Models. Mehr dazu später in diesem Artikel.
Schließlich werden in Schritt fünf das finale Model und der zugehörige Code in Form von zwei neuen Projekten generiert und der Solution hinzugefügt. Das Codebeispiel in Listing 1 zeigt, wie einfach das Model für Vorhersagen in der eigenen Anwendung benutzt werden kann.
var context = new MLContext();
var model = context.Model.Load(GetAbsolutePath(MODEL_FILEPATH), out DataViewSchema inputSchema);
var engine = context.Model.CreatePredictionEngine<ModelInput, ModelOutput>(model);
var input = new ModelInput()
{
Sentiment = false,
SentimentText = "This is not correct and very stupid."
};
var output = engine.Predict(input);
var outputAsText = output.Prediction == true ? "negative" : "positive";
Console.WriteLine($"The sentence '{input.SentimentText}' has a {outputAsText} sentiment with a probability of {output.Score}.");
Führt man den Code aus Listing 1 mit dem trainierten Model aus, lautet die Ausgabe: The sentence ‘This is not correct and very stupid.’ has a negative sentiment with a probability of 0.7026196. Der eine oder andere Leser wird sicher zustimmen, dass es schon fast gar nicht mehr einfacher geht, Machine Learning in die eigene Anwendung zu integrieren. Eine detaillierte Beschreibung und Guidelines für die Optimierung der erzeugten Models findet man hier.
Bevor wir uns nun aber in die Details der Algorithmen, Models, APIs und des Toolings stürzen, soll ein Überblick über ML.NET das Gesamtbild vermitteln.
ML.NET war ursprünglich ein Projekt von Microsoft Research. Laut Microsoft hat sich dieses Projekt seit über einer Dekade bewährt und zunehmend etabliert. Es gewann für viele Bereiche innerhalb von Microsoft an Wichtigkeit und hielt Einzug in bekannte Produkte des Unternehmens (z. B. in Windows, Power BI, Office, Defender, Outlook und Bing). ML.NET soll nunmehr seinen Weg in die breite Öffentlichkeit finden und hält daher Einzug in .NET Core.
Version 1.0 wurde im April 2019 veröffentlicht, seit Juni steht Version 1.1 (beinhaltet Bugfixes und Performanceoptimierungen) zur Verfügung. ML.NET läuft auf .NET Core 2.1 und setzt die Installation der entsprechenden Runtime und des SDKs voraus.
Als Teil von .NET Core wird ML.NET unter dem Dach der .NET Foundation als Open-Source-Projekt gemeinsam mit der Community auf GitHub entwickelt. Das Framework ist plattformunabhängig und kann unter Windows, Linux und Mac verwendet werden. Abbildung 2 zeigt eine Übersicht von Microsoft über .NET Core 3 und veranschaulicht, wie ML.NET sich als Bestandteil in das Ökosystem einreiht.

Abbildung 2: ML.NET in .NET Core 3
Ziel von ML.NET ist es, Machine Learning für .NET-Entwickler so einfach wie möglich zu machen, ohne dabei das gewohnte Umfeld, also die Entwicklungsumgebung und die Programmiersprache, verlassen zu müssen. Microsoft möchte alles soweit abstrahieren, dass tiefgreifende Kenntnisse von Machine Learning nicht mehr notwendig sind. Das Beispiel zu Beginn des Artikels beweist ein Stück weit, dass dieser Vorsatz eingehalten wurde. Ob Web-, Desktop- oder IoT-Anwendung, Mobile Apps oder Spiele, als .NET-Entwickler können wir nun also KI/ML in jede Art von Anwendung integrieren – ohne ML-Vorkenntnisse.
Wir haben gesehen, dass mit ML.NET und dem dazugehörigen Tooling eigene ML Models auf einfache Art und Weise gebaut, trainiert, verteilt und genutzt werden können. Gehen die eigenen Bedürfnisse über das hinaus was ML.NET out of the box bietet (z. B. Optimierung von Hyperparametern etc.), steht es dem Entwickler frei, auf andere Tools (z. B. Infer.NET, TensorFlow, ONNX) zurückzugreifen. Ermöglicht wird das durch die Erweiterbarkeit von ML.NET, die von Beginn an Teil des Konzeptes und der Umsetzung ist.
Schließlich noch ein Wort zur Performance von ML.NET. Basierend auf einem 9 GB großem Dataset von Amazon, das Produktbewertungen enthält, hat Microsoft ein ML Model trainiert, dass zu 93 Prozent zuverlässige Vorhersagen treffen kann (Accuracy/Genauigkeit). Man muss dazu sagen, dass lediglich 10 Prozent der Daten aus dem Set zum Trainieren verwendet wurden. Der Grund dafür war, dass andere ML-Frameworks, die zum Vergleich herangezogen wurden, wegen Speicherproblemen nicht mit mehr Daten zurechtkamen. Im Ergebnis des Benchmarks erzielte ML.NET die höchste Genauigkeit und die beste Geschwindigkeit, wie in Abbildung 3 gezeigt wird. Die Details zu dieser Untersuchung können im Paper nachgelesen werden.
Abbildung 3: Benchmarkergebnisse von ML.NET und anderen Machine Learning Frameworks
Das soll für den schnellen Überblick über ML.NET an dieser Stelle genügen. Werfen wir nun einen Blick auf die Einsatzgebiete von ML.NET und welche Algorithmen das Framework dafür mitbringt.
Wirft man einen Blick in den Namespace Microsoft.ML.Trainers, der aus der DLL Microsoft.ML.StandardTrainers stammt, die wiederum mit dem NuGet-Package Microsoft.ML kommt, erhält man einen ersten Eindruck von der Vielzahl der von Microsoft implementierten Algorithmen. Abbildung 4 zeigt einen Ausschnitt.

Abbildung 4: Trainer-Klassen aus dem Namespace „Microsoft.ML.StandardTrainers“
Da eine Auflistung aller Algorithmen nicht zielführend wäre, und sowieso den Rahmen dieses Artikels sprengen würde, beschränken wir uns für die Übersicht auf die Klassen/Arten der unterstützten Algorithmen und deren Einsatzszenarien.
Möchte man beispielsweise Gefühle oder Stimmungen erkennen, wie im Beispiel der Sentiment-Analyse oben, kann man sich der binären Klassifikation bedienen. Binär bedeutet in diesem Fall, dass sich sämtliche Ergebnisse der Vorhersagen in zwei Ergebnismengen aufteilen. Eine Vorhersage kann entsprechend nur das eine oder das andere sein. In der Sentiment-Analyse entspricht das z. B. einer Vorhersage, dass eine bestimmte Aussage negativ oder positiv gemeint ist. Diese Art von ML-Algorithmen wird auch für die Implementierung von Spamfiltern, für die Betrugserkennung und die Vorhersage von Krankheiten eingesetzt.
Die Multiklassenklassifikation hingegen wird verwendet, wenn das vorhergesagte Ergebnis aus mehr als zwei Ergebnismengen stammen kann. So wird diese Art der
Algorithmen z. B. dazu verwendet, um Handschriften zu erkennen oder Pflanzen zu bestimmen.
Mit ML.NET können auch Models für Empfehlungen erstellt werden. Vorstellbar ist es z. B., dem Benutzer bestimmte Produkte oder Filme auf Grund seines (Konsum-)Verhaltens oder dem Kaufverhalten anderer Kunden zu empfehlen. Das ist hinreichend von E-Commerce-Shops bekannt. Zum Einsatz kann hier z. B. Matrixfaktorisierung kommen.
Mittels Regressionsalgorithmen lassen sich numerische Werte vorhersagen. Regression wird oftmals für die Vorhersage von Nachfrage, Preis und Verkaufszahlen für ein Produkt eingesetzt.
Mit Clustering werden Gruppierungen innerhalb von Daten gefunden und vorhergesagt, z. B. für die Unterteilung von Kunden und Märkten in bestimmte Segmente. Auch für die Einordnung von Pflanzen wird Clustering eingesetzt.
Anomaly Detection Models dienen der Anomalieerkennung. Anomalien möchte man z. B. in Strom- und Kommunikationsnetzen finden, um beispielsweise einen Cyberangriff aufzudecken. Auch die Vorhersage von Verkaufsspitzen fällt in diese Kategorie.
Zuletzt sei noch Computer Vision genannt. Computer Vision wird in der Bilderkennung und -Klassifikation eingesetzt. So möchte man z. B. Objekte und Szenen innerhalb einer visuellen Darstellung erkennen und beschreiben. Hier kommt das sogenannte Deep Learning zum Einsatz. ML.NET bringt dafür nicht direkt Algorithmen mit. In solchen Szenarien benötigt man z. B. ein ONNX oder TensorFlow Model. ML.NET versteht diese Models und bietet somit die Möglichkeit für Erweiterungen um beliebige Szenarien.
Für all die genannten Einsatzszenarien und Arten von ML ist ML.NET gedacht und bringt entsprechende Algorithmen mit, bzw. kann externe Models einbeziehen. Letztlich stehen damit sämtliche Türen des ML offen. Schwierig wird es, wenn es um das Finden des richtigen Ansatzes für das eigene jeweilige Problem geht. Hier muss sorgsam überlegt werden, was für ein Problem genau vorliegt, welche Daten zur Verfügung stehen und wie das Problem optimal gelöst werden kann. Der beste und schnellste Algorithmus nützt nichts, wenn er für das vorliegende Problem der falsche ist.
Eine Auflistung und Dokumentation aller Algorithmen in ML.NET findet sich hier. Um die Auswahl eines geeigneten Algorithmus bzw. Models zu erleichtern, pflegt Microsoft auf GitHub diverse praktische Beispiele für den Einstieg in ML. Die Community stellt ebenfalls eine Sammlung von Beispielen bereit.
Command Line Interface
Kehren wir nun zurück zur Praxis und schauen uns noch einmal das Tooling an. Wie zuvor erwähnt, benutzt die Model Builder Extension für Visual Studio unter der Haube das ML.NET CLI, um Models zu trainieren etc. Schauen wir uns also an, was dieses Tooling uns bietet und wie es funktioniert.
Das CLI ist ein .NET Core Global Tool und kann via Powershell, im Mac-Terminal oder in der Linux Bash mit dem Befehl dotnet tool install -g mlnet installiert werden. Voraussetzung dafür ist die Installation des .NET Core 2.2 SDKs. Nach der Installation kann das Tool mit mlnet –version aufgerufen werden. Der Parameter –version bewirkt, dass das CLI die aktuelle Version auf der Konsole ausgibt.
Um mit dem CLI ein ML Model zu trainieren, kann der folgende Befehl abgesetzt werden:
mlnet auto-train -d .\MyDataSet.csv --label-column-name ColumnToPredict --has-header --task regression.
Zuvor sollte man jedoch in ein leeres Verzeichnis bzw. in das Zielverzeichnis wechseln. Gegebenenfalls können die Trainingsdaten ebenfalls in das Zielverzeichnis kopiert werden. Die Trainingsdatendatei wird im obigen Aufruf nach dem Schalter -d angegeben. Weitere Parameter geben die vorherzusagende Spalte in den Trainingsdaten an, ob die Inputdatei einen Header besitzt, und welche ML-Art angewendet werden soll. In diesem Fall wurde die Regression gewählt. Mit dem Aufruf mlnet auto-train –help lassen sich alle Optionen für die Operation auto-train anzeigen.

Abbildung 5: AutoML mit der ML.NET CLI
Abbildung 5 zeigt die Ausgabe der Ergebnisse eines Trainingsvorgangs. Während der Prozedur wendet das CLI eine AutoML-Strategie an, um einen Algorithmus / ein Model zu finden, das die besten Ergebnisse in Bezug auf die Vorhersagegenauigkeit für die angegebene Spalte liefert (Kasten: „AutoML“). Das Beispiel in Abbildung 5 zeigt, dass der FastTreeRegression-Algorithmus die zuverlässigsten Ergebnisse mit einer Genauigkeit von 0.9317 (ca. 93 Prozent) liefert. Die Trainingszeit betrug insgesamt 30 Minuten. Evaluiert wurden verschiedene Models. Der Abbildung ist zu entnehmen, dass die FastTreeRegression jeden Platz unter den Top 5 der evaluierten Models einnimmt.
Am Ende des Trainingsvorgangs generiert das CLI Code. Um genauer zu sein, zwei Projekte. Das erste Projekt enthält das generierte binäre Model verpackt in einer ZIP-Datei, sowie zwei Model-Klassen. Eine Klasse repräsentiert die Struktur der Trainingsdaten, die wir hineingeben, und dient als Input-Model für Vorhersagen. Die andere Klasse repräsentiert die Ausgabe der Vorhersage des Models für einen bestimmten Input. Das Model-Projekt ist die Komponente, die wir dann in unseren eigenen Anwendungen verwenden können, um Vorhersagen auf Basis des erzeugten Models zu treffen.
Das zweite Projekt, dass durch das CLI generiert wird, ist eine Konsolenanwendung und zeigt beispielhaft, wie das Model verwendet werden kann. Das Projekt enthält ebenfalls eine Klasse namens ModelBuilder. Der ModelBuilder implementiert Methoden zum Trainieren des Models. Diese Klasse kann später im eigenen Code verwendet werden, um das vorhandene Model erneut zu trainieren (z. B. mit neuen, aktuellen Trainingsdaten). Dazu wird dann einfach die statische Methode ModelBuilder.CreateModel aufgerufen (Listing 2).
public static void CreateModel()
{
// Load Data
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<ModelInput>(
path: TRAIN_DATA_FILEPATH,
hasHeader: true,
separatorChar: '\t',
allowQuoting: true,
allowSparse: false);
// Build training pipeline
IEstimator<ITransformer> trainingPipeline = BuildTrainingPipeline(mlContext);
// Evaluate quality of Model
Evaluate(mlContext, trainingDataView, trainingPipeline);
// Train Model
ITransformer mlModel = TrainModel(mlContext, trainingDataView, trainingPipeline);
// Save model
SaveModel(mlContext, mlModel, MODEL_FILEPATH, trainingDataView.Schema);
}
Die Methode lädt zuerst die Trainingsdaten über einen MLContext in einen sogenannten Data View. Die Klasse MLContext ist eine zentrale Komponente und Ausgangspunkt aller Operationen in ML.NET – ohne Kontext geht gar nichts. Ein Data View wird immer als IDataView dargestellt und repräsentiert die Sicht auf die Trainingsdaten für ML.NET.
Anschließend wird die Trainings-Pipeline erzeugt. Hier werden Algorithmen für die Datentransformation (z. B. zur Normalisierung von Spaltenwerten) und der Trainingsalgorithmus selbst in einer Pipeline aneinandergehängt. Nach der Evaluierung zur Bestimmung der Genauigkeit des Models mit den gegebenen Trainingsdaten, wird das Model dann trainiert. Das resultierende Model wird als ITransformer dargestellt. Der Name Transformer rührt daher, dass mit diesem Objekt Eingabedaten in eine Vorhersage transformiert werden können. Schließlich wird das Model dann in die Datei gespeichert, die in MODEL_FILEPATH angegeben ist.
AutoML steht für Automated Machine Learning und beschreibt eine Ende-zu-Ende-Lösung zum Finden eines optimalen ML Models für ein gegebenes Problem innerhalb bestimmter Restriktionen (z. B. in Bezug auf Genauigkeit, Laufzeitverhalten, Speicherverbrauch etc.). AutoML ist Forschungsgegenstand. Es existieren aber bereits einige Implementierungen, so auch von Microsoft Research. Und genau diese Implementierung von Microsoft findet in ML.NET Anwendung.
Was bedeutet es, einen ML-Algorithmus zu finden? Was genau macht AutoML? Um ein ML Model zu kreieren, müssen zuerst einmal valide Trainingsdaten zur Verfügung gestellt werden. Diese Daten müssen aufbereitet werden. Dazu gehört u. a., die Daten zu bereinigen, unnötige und redundante Daten zu entfernen, Lücken in den Daten aufzufüllen und Werte zu normalisieren. Dann kommt das Domänenwissen ins Spiel. An Hand von Features, Eigenschaften der Trainingsdaten, lernt das ML Model die Domäne kennen und Vorhersagen für diese zu treffen. Features sind fundamental für ein ML Model und müssen entsprechend sorgfältig definiert werden. Anschließend müssen sie aus den Daten extrahiert und selektiert werden. Eine aufwendige Aufgabe, möchte man das von Hand erledigen. AutoML versucht automatisch, Features zu erlernen und zu selektieren. Die selektierten Features fließen dann in einen Algorithmus. Auch der muss sorgfältig ausgesucht werden. Auch das übernimmt AutoML für uns. Und schließlich folgt noch die Optimierung der Hyperparameter für das Model. Und auch die Optimierung wird durch AutoML automatisiert. Weitere Details können hier nachgelesen werden. Es passiert also eine Menge hinter der Bühne. AutoML reduziert die Aufwände für uns Entwickler signifikant und macht den allgemeinen Einsatz erst möglich.
Wie kann das erzeugte Model nun aber in der eigenen Anwendung benutzt werden, um Vorhersagen zu treffen? Das ist relativ einfach. Zuerst einmal wird das durch das CLI generierte Model-Projekt dort referenziert, wo es eingesetzt werden soll. Das ist aber nicht zwingend notwendig, denn zur Verfügung stehen müssen die Klassen ModelInput und ModelOutput sowie die ZIP-Datei mit dem ML Model. Dafür können auch einfach die Klassendateien in das eigene Projekt kopiert werden. Zugriff auf das Model erfolgt zur Laufzeit durch die Pfadangabe zur ZIP-Datei. Man muss also sicherstellen, dass die ZIP-Datei zur Laufzeit zur Verfügung steht. Als letztes wird noch das NuGet-Package Microsoft.ML benötigt. Das kann einfach über den NuGet-Package-Manager oder die Kommandozeile installiert werden.
Ziehen wir noch einmal das Beispiel vom Anfang des Artikels heran, die Sentiment-Analyse; oder besser gesagt, das im Beispiel erzeugte Model. Die Verwendung könnte dann etwa so aussehen wie in Listing 3.
var context = new MLContext();
var model = context.Model.Load(GetAbsolutePath(MODEL_FILEPATH), out DataViewSchema inputSchema);
var engine = context.Model.CreatePredictionEngine<ModelInput, ModelOutput>(model);
var input = new ModelInput()
{
Sentiment = false,
SentimentText = "This is not correct and very stupid."
};
var output = engine.Predict(input);
var outputAsText = output.Prediction == true ? "negative" : "positive";
Console.WriteLine($"The sentence '{input.SentimentText}' has a {outputAsText} sentiment with a probability of {output.Score}.");
Zuerst wird eine Instanz von MLContext erzeugt. Wie gesagt, ist die Klasse MLContext Dreh- und Angelpunkt von ML.NET. Über die Eigenschaft Model des Contexts wird dann das zu verwendende ML Model in den Kontext geladen. Hier verwenden wir das vom CLI erzeugte Model zur Sentiment-Analyse. Es wird über den Pfad referenziert. Mit der Methode Model.CreatePredictionEngine instanziiert man dann zunächst die Komponente, die auf Basis des Models Vorhersagen treffen kann. Dazu wird das geladene Model als Parameter übergeben. Diese Schritte genügen zur Vorbereitung. Das ML Model ist einsatzbereit und wir können loslegen, Vorhersagen für Eingaben zu erzeugen. Jetzt kommen die generierten Model-Klassen zum Einsatz. Für Die Eingabe erstellen wir ein Objekt der Klasse ModelInput. Wir möchten herausfinden, ob der Satz „This is not correct and very stupid“ eine positive oder eine negative Aussage enthält. Der Satz wird für die Eigenschaft SentimentText der ModelInput-Instanz festgelegt. Nun wird die Eingabe an die Methode Predict der Vorhersage-Engine übergeben. Diese Methode schickt die Eingabe durch das Model und erzeugt eine Vorhersage in Form einer Instanz der Klasse ModelOutput. Über die Eigenschaft Prediction erfahren wir, ob der Satz eine negative oder positive Aussage enthält. Über die Eigenschaft Score erfahren wir darüber hinaus, wie wahrscheinlich die Vorhersage zutrifft. Beide Ergebnisse werden im obigen Beispiel in der Konsole ausgegeben. Wurde das Model mit denselben Daten trainiert wie in diesem Artikel, lautet die Ausgabe zum obigen Codebeispiel: The sentence ‘This is not correct and very stupid.’ has a negative sentiment with a probability of 0.7026196. Der gegebene Satz enthält laut Vorhersage also mit einer 70-prozentigen Wahrscheinlichkeit eine negative Aussage.
Wie wir sehen, kann mit ML.NET ein ML Model mit nur wenigen Zeilen Code direkt in der eigenen Anwendung benutzt werden. Es geht fast nicht einfacher. Durch das CLI von ML.NET ist es gleichermaßen einfach, ML Models zu erzeugen. Unter der Haube kümmert sich AutoML um die Vorbereitung der Trainingsdaten, das Identifizieren und Selektieren von Features und die Auswahl sowie Optimierung des eingesetzten Algorithmus. Die Model Builder Extension bietet zusätzlich einen entsprechenden UI-Aufsatz und eine Integration in Visual Studio an.
Mit ML.NET abstrahiert Microsoft Machine Learning soweit, dass es für jeden Entwickler möglich wird, die eigenen Anwendungen auch ohne ML-Kenntnisse mit intelligenten Funktionen zu erweitern. Wer mehr wissen möchte, sei auf die ausführliche Dokumentation verwiesen.
● Beyond Python – Machine Learning is possible in .NET too
● Workshop: intelligente Apps entwickeln mit Azure Machine Learning, ML.NET und Cognitive Services
The post ML.NET: Machine Learning mit .NET Core 3 – Einstieg und Anwendungsfälle appeared first on BASTA!.
]]>The post Blockchains mit Hyperledger Fabric: Aufbau und Nutzung von Enterprise-Blockchains appeared first on BASTA!.
]]>Mit Hyperledger wird nicht nur der Ansatz einer Blockchain, sondern vielmehr verschiedener Blockchain-Plattformen verfolgt. Genaugenommen ist Hyperledger Fabric (kurz: Fabric) eine Technologie für Permissioned Blockchains bzw. private Blockchains – eine Blockchain, die nicht für alle öffentlich ist, z. B. wie Ethereum oder Bitcoin, sondern nur bestimmten Teilnehmern zugänglich ist.
In dieser Session stellt Ingo Rammer Open-Source-Blockchain-Basistechnologie Hyperledger Fabric vor. Er vermittelt die Grundlagen von Fabric für den Betrieb von privaten bzw. berechtigungsgestützten Blockchains und zeigt die dafür geeigneten Einsatzgebiete, Architekturentscheidungen sowie Sicherheitsaspekte auf. Diese Session ist eine optimale Grundlage, um in die Blockchaintechnologie einzusteigen. Dabei zeigt sich vor allem wie weit, eine Blockchain vom Hype entfernt sein kann und ein wirklich nützliches und nutzbares Tool in der modernen und sicheren B2B-Softwareentwicklung sein kann.
Auf der BASTA! 2019 stellt Ingo Rammer in seinem Workshop “Von Null auf Hundert Workshop: Blockchain-Anwendungen mit Hyperledger Fabric” das Komplettpaket vor. Wer nach dem Session-Video mehr wissen will, sollte sich den Workshop nicht entgehen lassen.
● SMART CONTRACTS MIT .NET CORE
● BLOCKCHAIN – WIEDER NUR EIN TECH-HYPE ODER EHER SINNVOLLE ZUKUNFTSTECHNOLOGIE?
The post Blockchains mit Hyperledger Fabric: Aufbau und Nutzung von Enterprise-Blockchains appeared first on BASTA!.
]]>The post 5 Top-Argumente für Ihren BASTA!-Besuch: Warum Sie diese Konferenz nicht verpassen sollten appeared first on BASTA!.
]]>In einer schnelllebigen Industrie wie der IT müssen Sie als Entwickler Ihr Wissen laufend aktualisieren. Die digitale Transformation und der damit einhergehende Aufbruch in eine neue digitale Ära bringt unzählige neue Möglichkeiten mit sich und führt dazu, dass eingefahrene Prozesse und Strukturen hinterfragt, neue Trends eingeschätzt und in die konkreten Projekte implementiert werden müssen. Mit einem BASTA!-Besuch können Sie bestehende Probleme lösen und das nötige Wissen erlangen.
Wenn Sie noch nicht überzeugt sind, warum es sich wirklich lohnt, an der BASTA! teilzunehmen, haben wir für Sie 5 unschlagbare Argumente parat. Machen Sie sich schon mal auf den Weg!

The post 5 Top-Argumente für Ihren BASTA!-Besuch: Warum Sie diese Konferenz nicht verpassen sollten appeared first on BASTA!.
]]>The post .NET Framework, .NET Core und Mono werden .NET 5.0! appeared first on BASTA!.
]]>
Für .NET-Entwickler gab es auf der Microsoft BUILD 2019 wieder einmal einen ordentlichen Paukenschlag: .NET 5.0 (kurz .NET 5) wird der gemeinsame Nachfolger der drei bisherigen .NET-Varianten (.NET Core, .NET Framework und Mono) sein. Alle .NET-Anwendungsarten von Desktop (WPF und Windows Forms) über Webserver (ASP.NET) und Webbrowser (Blazor/WebAssembly) bis zu Apps (UWP, Xamarin) und Spielen (Unity) sollen damit zukünftig eine gemeinsame .NET-Basis haben.
.NET 5 soll im November 2020 (Abb. 2) erscheinen und im Wesentlichen (aber nicht komplett) plattformneutral sein. Einige Anwendungsarten, die auf .NET 5 basieren, werden nur auf bestimmten Plattformen laufen, z. B. UWP-Apps nur auf Windows 10, WPF- und Windows-Forms-Desktopanwendungen nur auf Windows ab Version 7. .NET 5 darf nicht verwechselt werden mit .NET Core 5 – dem Namen, den Microsoft für .NET Core 1.0 geplant hatte, bevor man sich entschloss, die Versionszählung wieder von vorne zu beginnen.

Die BUILD-Konferenz fand vom 6. bis 8. Mai 2019 in Seattle statt. Während die Veranstaltung früher immer sehr schnell ausgebucht war, konnte Microsoft sie nun zum zweiten Mal in Folge nicht ganz füllen. Einige Teilnehmer nennen als Grund dafür, dass Microsoft nicht mehr wie früher Hardwaregeschenke verteile. Die Aufzeichnungen der Vorträge kann jedermann kostenfrei unter https://www.microsoft.com/en-us/build ansehen.
Technisch gesehen ist .NET 5 die Weiterführung von .NET Core (mit den zugehörigen Werkzeugen und Deployment-Optionen), in das große Teile (aber nicht alles) von .NET Framework und Mono einfließen (Abb. 1). Nach derzeitigem Stand werden in .NET 5 zum Beispiel Windows Workflow Foundation (WF) und Windows-Communication-Foundation-(WCF-)Server sowie Windows Forms aus Mono fehlen. Im Rahmen von .NET 5 wird aus Mono die statische Ahead-of-Time-(AOT-)Kompilierung als Alternative zur bisherigen Just-in-Time-(JIT-)Kompilierung in .NET einfließen, sodass .NET-Entwickler zukünftig zwischen JIT und AOT wählen können. AOT bietet .NET-Entwicklern kleinere Installationspakete und schnellere Anwendungsstarts, aber wegen der Vorkompilierung in Maschinencode eben keine plattformunabhängigen Installationspakete.
.NET 5 wird auch neue Funktionen beinhalten. Dazu gehört eine Integration mit anderen Frameworks und Programmiersprachen (Java, Objective-C und Swift) für die App-Entwicklung auf iOS und Android.
„.NET Core“ hatte Microsoft als Namen am 12.11.2014 für das schon am 13. Mai 2014 verkündete „cloud-optimized .NET Framework“ alias „Project K“ eingeführt. Version 1.0 erschien dann am 26. Juli 2016. Danach gab es die Versionen 1.1, 2.0, 2.1, 2.2. Version 3.0 von .NET Core soll im September 2019 erscheinen; auf der BUILD gab es die Preview-5-Version; die Veröffentlichung des Release Candidate ist für Juli dieses Jahres geplant, dann soll es noch ein .NET Core 3.1 im November 2019 geben.
Damit soll dann die .NET-Core-Ära auch schon wieder enden (Abb. 3). Es wird keine weiteren Versionen mehr mit „Core“ im Namen geben. Als Nächstes kommt .NET 5 (Abb. 3), denn Microsoft findet den Begriff inzwischen nicht mehr geeignet in der Kommunikation, gerade für neu in die .NET-Welt eintretende Softwareentwickler.
Mit .NET Core Version 2.0 hatte Microsoft begonnen, massiv Klassen aus dem .NET Framework nach .NET Core zu übernehmen. Man kehrte damit von dem .NET-Core-1.x-Gedanken ab, das neue .NET Core klein und aufgeräumt zu halten. Stattdessen stand nun auf der Agenda, möglichst kompatibel zum .NET Framework zu werden, damit bestehende klassische .NET-Framework-Anwendungen auf .NET Core umziehen können. In Version 2.1 führte Microsoft diese Trendwende mit dem Windows Compatibility Pack (WCP) fort: Erstmals gab es in .NET Core nur Klassen, die ausschließlich auf Windows laufen (z. B. für die Registry-Programmierung). Dies wird verstärkt auch in .NET Core 3.0 gelten: Dort gibt es zwar dann die GUI-Frameworks WPF und Windows Forms, aber sie sind weiterhin nicht plattformunabhängig, sondern an Windows gebunden. Der Sinn von WPF und Windows Forms liegt darin, dass Softwareentwickler bestehende .NET-Framework-basierte WPF- und Windows-Forms-Anwendungen auf .NET Core umziehen können. Auch in .NET 5 wird sich an dieser Plattformeinschränkung erst einmal nichts ändern.
.NET Core 3.0 liefert darüber hinaus .NET Standard 2.1, Unterstützung für gRPC und das neue ASP.NET-SignalR-basierte Webanwendungsmodell Server-side Blazor – nicht zu verwechseln mit dem WebAssembly-basierten Client-side Blazor, das zwar nun eine offizielle Vorschau ist, für das es aber weiterhin keinen Veröffentlichungstermin gibt.
Softwareherstellern und Softwareentwicklern, die heute bestehende WPF- und Windows-Forms-Anwendungen besitzen oder neu planen, machte Microsoft auf der Build-Konferenz klar, was sie schon am 4. 10. 2018 in einem Blogeintrag angedeutet hatten: Die am 18. April 2019 erschienene Version 4.8 ist die letzte Version des .NET Frameworks, die signifikante neue Funktionen bieten wird. Alles, was danach noch an Updates kommen wird, wird lediglich Sicherheitslücken und kritische Softwarefehler betreffen. Vielleicht wird das ein oder andere Netzwerkprotokoll noch auf den neuesten Stand gebracht, das wars dann aber.
Microsoft will bei .NET 5 bei der in .NET Core etablierten, agilen und transparenten Entwicklungsweise eines Open-Source-Projekts auf GitHub bleiben. Einen Unterschied soll es aber zu .NET Core geben: Anstelle der bisherigen unregelmäßigen Erscheinungstermine soll es jedes Jahr im November eine neue Hauptversion mit Breaking Changes geben, d. h. nach .NET 5 im November 2020 gibt es dann .NET 6 im November 2021, .NET 7 im darauffolgenden Jahr usw. (Abb. 2).
Zwischendurch sind Unterversionen mit neuen Features, aber ohne Breaking Changes bei Bedarf angedacht. Jede zweite Version soll eine Long-Term-Support-(LTS-)Version mit drei Jahren Unterstützung durch Microsoft sein. .NET Core 3.0 wird genau wie .NET Core 2.0 keine LTS-Version sein; die auf .NET Core 2.1 folgende LTS-Version wird .NET Core 3.1 sein. Dann geht es in der LTS-Linie erst 2021 weiter. Weitere Neuigkeiten von der Microsoft Build:
The post .NET Framework, .NET Core und Mono werden .NET 5.0! appeared first on BASTA!.
]]>The post Keynote | Die Cloud, DevOps und wir Entwickler: Erfolgreiche Zusammenarbeit im modernen Software-Ökosystem appeared first on BASTA!.
]]>Aber natürlich nicht die ganze Cloud. Die Anzahl unterschiedlicher Cloud-Lösungen und Services steigt stetig an und bietet Unternehmen und Entwicklern immer mehr Möglichkeiten. Auf der BASTA! Legen wir den Fokus daher auf die Cloud für Entwickler und berücksichtigen Microsoft Azure etwas mehr als die Angebote anderer Anbieter. Es ist aber wichtig zu sehen, dass die Cloud in ihrer Vielfalt Entwicklern offen steht und auch genutzt werden sollte.
In der Keynote zur Eröffnung der BASTA! Spring 2019 stellen Rainer Stropek, Advisor des Cloud Developer Day, und Neno Loje, Advisor des DevOps Pipelines Day, zunächst ihre Sicht auf das Verhältnis zwischen Cloud und Entwicklern vor. Im Anschluss diskutieren sie mit Mirko Schrempp, Program Chair der BASTA!, weitere Aspekte. Denn die Cloud ist nicht für jeden die Cloud. Es gibt unzählige praktische Möglichkeiten die Cloud als Entwickler zu nutzen – auch dann, wenn sie noch nicht für ein Produkt des eigenen Unternehmens eingesetzt wird. So können sich DevOps-Teams beispielsweise ein Bündel von Diensten und Lösungen zusammenstellen, das für ihre spezifischen Herausforderungen in CI/CD-Projekten passend ist, aber mit dem eigentlichen Produkt nichts zu tun hat. Oder Entwickler gewinnen über Telemetriedaten Einblick in die Nutzung oder den Zustand der eigenen Software. Die Beispiele sind so vielfältig wie die Cloud. Zur Eröffnung der BASTA! wurden daher keine Schlagwörter aufgezählt, sondern diskutiert, was DevOps und Cloud für Entwickler und Unternehmen in der Praxis wirklich bedeuten und warum vieles damit einfacher geht.
Selbstverständlich haben wir mit Rainer Stropek und Neno Loje wieder zwei Special Days für die BASTA! 2019 zusammengestellt. Deren Sessions bieten ganz im Sinne der Diskussion aus dem Frühjahr Informationen, Einblicke und Anregungen. Besuchen Sie im September doch einfach den Cloud Developer Day und den DevOps Pipelines Day.
DevOps Pipelines Day ist übrigens der neue Name des “traditionellen” TFS Days. Da Microsoft seinen Team Foundation Server (TFS) und die online Variante Visual Studio Team Services (VSTS) umbenannt hat, haben wir dem Tag einen neuen Namen gegeben, der vor allem die DevOps-Zielsetzung einer reibungslosen Entwicklungs-Pipeline betont und vorstellt. Die Hintergründe und Folgen der Umbenennung erklärt Neno im Video-Interview “Azure DevOps – “Kurzfristig ist es nur ein neuer Name”” hier auf dem Blog.
Aber auch über die beiden Special Days hinaus finden Sie in vielen Session und Workshops der BASTA! 2019 Informationen zum Einsatz der Cloud in Ihren Projekten.
● Die Cloud-Perspektive: Warum Benutzer Software oft ganz anders sehen als wir Entwickler
The post Keynote | Die Cloud, DevOps und wir Entwickler: Erfolgreiche Zusammenarbeit im modernen Software-Ökosystem appeared first on BASTA!.
]]>The post .NET Core 3.0 wird ein großes Ding für die Zukunft der Softwareentwicklung appeared first on BASTA!.
]]>Neben den Neuerungen von .NET Core 2.2, das aktuell schon zur Verfügung steht, beschreibt Dr. Holger Schwichtenberg alias der „Dotnet Doktor“ vor allem, was in Version 3.0 zu erwarten ist. Die Version ist ein Major Release mit zahlreichen großen Änderungen, das voraussichtlich im Herbst 2019 erscheinen wird. Daher wird es bei der BASTA! 2019 natürlich auch im Fokus stehen und zahlreiche Sessions dazu geben.
Mit Version 3.0 kommen WPF- und sogar Windows-Forms-Anwendungen nach .NET Core. Entwickler können dann in (bestehende) Anwendungen .NET Core 3.0 einbauen. Damit lassen sich Anwendungen einfach modernisieren und zum Teil unter Windows 7, zum Teil aber nur unter Windows 10 nutzen, z. B. dann, wenn UWP-Inseln oder Inking-Funktionen eingesetzt werden. Damit bleibt für Windows 7, das im Januar 2020 aus dem Support läuft, noch ein gewisser Bestandsschutz bestehen, aber die Zielrichtung Windows 10 ist klar – Holger spricht von der Renaissance des Desktops. Selbstverständlich werden auch ASP.NET Core und Entity Framework Core in Version 3.0 ebenfalls Neuerungen erhalten, die ihre Flexibilität und Plattformunabhängigkeit erweitern. Vorteile für Entwickler sind in jedem Fall bessere Werkzeuge und bessere Deployment-Prozesse sowie kleinere, ausführbare Dateien, da sie nur noch mitbringen, was zum Ausführen der Anwendung gebraucht wird.
Ein großer Sprung wird allerdings durch Blazor in .NET Core 3.0 eingeführt, wenn auch noch immer nicht vollständig. Zum einen wird es Blazor für den Client geben, d.h. C# im Browser, aber auch die Möglichkeit von Blazor auf dem Server – darauf gibt Holger Schwichtenberg am Ende des Interviews einen interessanten Ausblick.
The post .NET Core 3.0 wird ein großes Ding für die Zukunft der Softwareentwicklung appeared first on BASTA!.
]]>The post Produktiver durch Serverless-Architekturen: Eine neue Ära der Softwareentwicklung appeared first on BASTA!.
]]>Der Einsatz von Cloud-Diensten ist in vielen Bereichen der IT zum Standard geworden: von der praktischen SaaS-Lösung, über die unendlich skalierbare Datenbank, bis hin zu großen Testszenarien und natürlich dem container-basierten Betrieb eigener Dienste. Christian Weyer erklärt im Video-Interview, warum Serverless wohl „das nächste große Ding“ ist und Entwickler wieder produktiver macht.
Der Einsatz von Cloud-Diensten ist in vielen Bereichen der IT zum Standard geworden. Von der praktischen SaaS-Lösung, über die unendlich skalierbare Datenbank, bis hin zu großen Testszenarien und natürlich dem container-basierten Betrieb eigener Dienste – das, was vor einiger Zeit noch als Hype diskutiert wurde, ist inzwischen „normales Business“. Christian Weyer, Vorstand und Gründungsmitglied der Thinktecture AG, erklärt im Video-Interview warum Serverless wohl „das nächste große Ding“ ist und Entwickler wieder produktiver macht.
Die Cloud ist bei weitem nicht so diffus, wie es ihr Name vermuten lässt, aber was sie mit ihren namensgebenden Verwandten am Himmel teilt, ist die Fähigkeit stetig zu wachsen und sich zu verändern. Für Entwickler bedeutet das, sich ebenso stetig mit neuen Möglichkeiten und Angeboten auseinander zu setzten. Dabei haben nach Christian Weyers Ansicht alle Entwickler nur ein Ziel – sie wollen ordentlichen Code schreiben und gute Business-Anwendungen erstellen.
Wer sich neu mit der Cloud beschäftig, habe aber zunächst viel mit Infrastruktur zu tun, mit Containern, mit verteilter Programmierung und vielen anderen technischen Themen, die weit von dem weg sind, was man z. B. im Rahmen des Rapid Application Developments kannte – vor allem habe man viel Produktivität verloren. Aber das Cloud Computing bringe die Möglichkeiten zurück, die Produktivität auf einem höheren Niveau wieder zu gewinnen. Für Weyer ist „Serverless“ eines der Cloud-Angebote, das Entwickler davon befreit, sich in zu vielen Infrastrukturfragen zu verzetteln. Angebote wie AWS Lambda oder Azure Functions erlauben es, in fertig konfigurierten Ereignissen zu denken, die sich über APIs und Microservices für Entwickler einfach anprogrammieren lassen, typische Anwendungsfälle einfacher machen und damit die Produktivität wieder steigern.
Wie das im Detail aussehen kann, erfahren Sie im Interview und z. B. im MODERN BUSINESS APPLICATIONS DAY, den Christian Weyer mit uns zusammengestellt hat. Auch der Power Workshop „Moderne Businessanwendungen mit Angular, .NET Core und Azure – Weitblick für Backend- und Frontendentwickler“ am Montag bietet einen kompakten Einblick.
● Serverless Webhooks: Friend or Foe?
● Serverless-Architekturen: Event-basierte Microservices mit Azure Functions und Co.
● Schrittweise Migration in die Cloud mit Azure Hybrid Connections
The post Produktiver durch Serverless-Architekturen: Eine neue Ära der Softwareentwicklung appeared first on BASTA!.
]]>The post Cosmos DB in eigenen Projekten einsetzen: Grundlagen und Einsatzszenarien appeared first on BASTA!.
]]>Dieser Artikel gibt Ihnen einen kleinen Überblick über die Grundlagen, Möglichkeiten und unterstützten APIs, die Azure Cosmo DB für Ihre Projekte bereitstellt und bietet Überlegungen zu möglichen Einsatzszenarien an.
Microsofts Azure Cosmos DB ist eine Dokumentendatenbank, ein NoSQL JSON Data Storage, das neben einer ganzen Reihe interessanter Features mehrere APIs bietet, um mit diesen zu arbeiten. „NoSQL“ steht dabei übrigens für „Not only SQL“, was einen Hinweis auf die unterschiedlichen APIs darstellt.
Dabei ist der Ansatz, Daten zu speichern, ein völlig anderer als z. B. bei relationalen Datenbanken. So werden Daten nicht in Tabellen abgelegt, sondern in Collections (auch Container genannt). Eine Dokumentendatenbank speichert Daten in Form von Dokumenten im JSON-Format. Dies erlaubt, diese Daten verschachtelt und – und das ist wichtig – heterogen abzuspeichern. Das heißt, Dokumente, die sich einen Container (Collection) teilen, müssen nicht über den gleichen Aufbau verfügen. Es können also mal mehr, mal weniger oder schlicht unterschiedliche Informationen in einem solchen Dokument untergebracht werden. Auch können von Dokument zu Dokument für gleichnamige Eigenschaften unterschiedliche Datentypen verwendet werden. Listing 1 zeigt ein kleines JSON-Dokument als Beispiel. Bei Abfragen wird dies (je nach API) entsprechend berücksichtigt.
Listing 1
{
"BusinessEntityID": 1,
"PersonType": "EM",
"NameStyle": false,
"Title": null,
"FirstName": "Ken",
"MiddleName": "J",
"LastName": "Sánchez",
"Suffix": null,
"EmailPromotion": 0,
"AdditionalContactInfo": null,
"Demographics": "0",
"rowguid": "92c4279f-1207-48a3-8448-4636514eb7e2",
"ModifiedDate": "2009-01-07T00:00:00",
"Password": {
"Hash": "pbFwXWE99vobT6g+vPWFy93NtUU/orrIWafF01hccfM=",
"ModifiedDate": "2009-01-07T00:00:00",
"Salt": "bE3XiWw="
}
}
Für den Zugriff auf diese Daten stehen aktuell fünf unterschiedliche APIs zur Verfügung (mehr dazu später). Existieren also schon Code für und Erfahrung und mit z. B. MongoDB oder Apache Cassandra, steht einem Einsatz von Azure Comos DB eigentlich nichts im Weg. In Abbildung 1 sehen Sie eine Übersicht aller APIs.

Die unterschiedlichen APIs können dabei prinzipiell alle Dokumente nutzen, die mit Hilfe eines anderen APIs erstellt wurden. In der Praxis gibt es jedoch deutliche Einschränkungen, da z. B. mit dem Gremlin API auch Graphdaten erzeugt werden, deren Strukturen von anderen APIs nicht verstanden werden.
Welches sind nun die erwähnten interessanten Features? Als Cloud Service ist Azure Cosmos DB „fully managed“, sodass keinerlei administrative Aufgaben anfallen. Mit einem SLA (Service Level Agreement) garantiert Microsoft eine hohe Verfügbarkeit und schnelle Antwortzeiten mit der Option, bei Bedarf zu skalieren. Eine automatische und für eine Anwendung völlig transparente Verschlüsselung sorgt für die notwendige Sicherheit der Daten.
Globale Verteilung („globally distributed“) erlaubt die Festlegung, in welchem Rechenzentrum die Daten gespeichert werden. Dabei ist vorgesehen, dass dies mehr als nur ein Rechenzentrum ist. Die Infrastruktur im Hintergrund sorgt für die notwendige Replikation. Der Vorteil der globalen Verteilung liegt dabei auf der Hand: Beim Zugriff von Orten weltweit wird das nächstgelegene Replikat verwendet. Anwender z. B. aus Australien greifen damit auf eines der beiden Rechenzentren in Down Under zu (wenn dort ein Replikat konfiguriert wurde). Das betrifft übrigens nicht nur Lese- sondern auch Schreibzugriffe. Abbildung 2 zeigt mit Hexagonen die möglichen Standorte weltweit.

ACID-Transaktionen (Atomicity, Consistency, Isolation, Durability) sorgen dafür, dass Änderungen an mehr als nur einem Dokument gemeinschaftlich nach dem Alles-oder-nichts-Prinzip durchgeführt werden. So arbeiten z. B. auch Prozeduren und Trigger im Hintergrund mit Transaktionen, um eine Datenkonsistenz zu gewährleisten.
Um Zugriffe auf Dokumente möglichst schnell auszuführen, verwendet Azure Comos DB Indizes, wie andere Datenbanken auch. Diese werden automatisch erstellt und gepflegt. Dazu werden Abfragen analysiert, und ermittelt, welche Eigenschaften wie oft zum Filtern verwendet werden. Diese automatische Indexierung kann durch Policies beeinflusst werden, funktioniert aber durchaus auch ohne weiteres Zutun.
Für die Entwicklung mit Cosmos DB existieren schon einige praktische Tools. Als Erstes wäre natürlich das schon erwähnte Azure Portal zu nennen, über das die Datenbanken angelegt und verwaltet werden. Außerdem gibt es über das Portal die Möglichkeit, Daten abzufragen und zu modifizieren (Abb. 3).

Wer bei der Entwicklung auf keine (verlässliche) Verbindung zugreifen kann oder schlicht mögliche Kosten vermeiden möchte, dem steht der Azure-Cosmos-DB-Emulator zur Verfügung (Abb. 4). Dieser Emulator, der natürlich ohne Azure Cloud auskommt, kann wahlweise installiert oder als Docker Image genutzt werden.

Zugriffschlüssel und Verbindungszeichenfolgen sind (standardmäßig) für alle Installationen und Docker Images gleich, sodass bei einer Entwicklung im Team kein Sicherheitsproblem auftritt und Entwickler immer wieder Anpassungen vornehmen müssten, um auf die Daten im Emulator zuzugreifen.
Und als Letztes sei da noch das Azure Cosmos DB Migration Tool genannt, mit dem Daten von Quellen in ein Ziel geschrieben werden können. Dabei steht eine Reihe von Formaten für die eine und auch die andere Seite zur Auswahl (Tabelle 1)
| Quelle | Ziel |
|---|---|
| JSON-Datei | JSON-Datei |
| DocumentDB – SQL API – Table API |
DocumentDB – SQL API – Table API |
| SQL-Server | |
| CSV | |
| AzureTable |
Da einige Quellen wie z. B. relationale Datenbanken wie SQL Server keine verschachtelten Daten unterstützen, gibt es hier die Option, in der Abfrage Joins zu verwenden und in den Namen der zurückgegebenen Spalten einen „Nesting Seperator“ (z. B. einen Punkt) einzubauen, der für die gewünschte Verschachtelung im Ziel sorgt.

Als Nebeneffekt lassen sich mit diesem Tool z. B. Daten aus einer SQL-Server-Abfrage in eine JSON-Datei schreiben, was sicherlich das eine oder andere Mal ganz nützlich sein kann.
Selbstverständlich ist, gerade bei einer Cloud-basierten Technologie, das Thema Sicherheit wichtig. Neben der Sicherheit während des Transports über das Netzwerk mittels SSL/TLS und der Absicherung durch die Anbindung an ein virtuelles Netzwerk bietet Azure Cosmos DB eine Sicherheit, die zwischen nur lesenden und Lese-und-Schreib-Zugriffen unterscheidet (von administrativen Aufgaben einmal abgesehen). Gesteuert wird dies über entsprechende Schlüssel.
Eine differenzierte Kontrolle auf Ebene eines Containers (Collection) oder einzelner Elemente (Dokumente) ist nicht vorgesehen. Dafür muss die Anwendung bei Bedarf selbst sorgen.
Für Anwendungen stehen fünf APIs zur Auswahl, um auf Azure Cosmos DB zuzugreifen. Ihr Vorteil: Wenn Sie bereits Erfahrung mit einem dieser APIs haben oder sogar bereits fertiger Code existiert, kann dieser mit wenigen (oder sogar keinen) Anpassungen verwendet werden. Beispielsweise verwendet der Zugriff via MongoDB API die gleichen Bibliotheken, die auch zum Einsatz kommen, um auf eine „gewöhnliche“ MongoDB-Installation zuzugreifen.
Angeboten wird also das MongoDB API und damit die Schnittstelle zu einer „klassischen“ Open-Source-Dokumentendatenbank. Mit dem API für Gremlin steht eine Graph-Datenbank zur Verfügung. Eine Graph-Datenbank speichert Informationen in Knotenpunkten und deren Beziehungen untereinander. Damit lassen sich Beziehungsgeflechte in sozialen Netzwerken, Nutzungsprofile und Ähnliches abbilden und abfragen. Das Core (SQL) API bietet die Möglichkeit, Informationen mit einer (einfachen) SQL-Syntax abzurufen. Das Anlegen, Löschen und Verändern von Dokumenten geschieht hingegen via der üblichen HTTP-Verben POST, PUT und DELETE, während die Abfrage selbst ein GET verwendet. Mit dem Table API steht ein Schlüsselwertspeicher (Key-Value-Store) à la Azure Table zur Verfügung. Bei dem „Wert“ kann es sich um komplexe Objekte handeln, die als JSON serialisiert abgelegt werden. Ein Zugriff ist mittels der Schlüssel möglich. Und schließlich wird seit einiger Zeit als neuester Zuwachs das Cassandra API verwendet, das von vielen großen Unternehmen wie GitHub, Ebay, Netflix und auch im CERN eingesetzt wird.
Ab Version 2.2 bietet Entity Framework Core das erste Mal in der Geschichte von Microsofts O/R-Mapper die Option, auf nicht relationale Datenbanken zuzugreifen. Im Nuget-Paket Microsoft.EntityFrameworkCore.Cosmos befindet sich der benötigte Code. Allerdings ist der aktuelle Stand der Entwicklung noch nicht so weit, ihn tatsächlich sinnvoll einzusetzen. Dafür gibt es noch zu viele Probleme, Ungereimtheiten und nicht umgesetzte Features. Konsequenterweise ist in der stabilen Version von .NET 2.2 (vom 4. Dezember 2018) die Untersetzung für Azure Cosmos DB entfallen. Diese taucht erst im Preview für .NET 3.0 wieder auf. Dennoch ist es ein Schritt in die richtige Richtung und es bleibt spannend zu sehen, was EF Core 3.0 in dieser Richtung bringen wird.
Azure Comos DB erlaubt die Verwendung von Funktionen, Stored Procedures und Trigger, die in Serverside JavaScript geschrieben werden können. Sämtliche Elemente werden für eine Collection geschrieben; auch Funktionen und Prozeduren gehören also, nicht wie bei SQL Server, zu der gesamten Datenbank.
Funktionen können z. B. mit dem Core (SQL) API verwendet werden, um weitere Möglichkeiten in die Abfragen einzubauen. Werden für eine Abfrage reguläre Ausdrücke benötigt, reicht es, eine einfache Funktion wie im Folgenden zu schreiben:
function RexExpTest(s, p){
return s.match(p) != null;
}
Für die Entwicklung bieten sich die üblichen Tools und Wege wie online JavaScript Playgrounds, Visual Studio Code mit Code Runner und viele andere Optionen an. Diese neu geschaffene Funktion kann einfach verwendet werden. Achten Sie dabei auf den Präfix udf, der zwingend notiert werden muss. Die folgende Zeile zeigt die Core-(SQL-)Abfrage:
SELECT * FROM c WHERE udf.RexExpTest(c.Name, 'Speaker [0-2]') = true
Das abschließende Listing zeigt eine kleine Demo für eine Prozedur, die einen kleinen Text an den Client zurücksendet. Der body legt dabei die Funktionalität fest:
var helloWorldDemoProc = {
id: "helloWorldDemo",
body: function () {
var context = getContext();
var response = context.getResponse();
response.setBody("Hello World!");
}
}
Die große Frage ist nun nur noch, ob sich der Einsatz einer Dokumentendatenbank, speziell Azure Cosmos DB, im eigenen Projekt lohnt. Diese ist pauschal weder einfach noch überhaupt zu beantworten; es sei denn, der Einsatz der Azure Cloud ist ein No-Go. Wenn Sie bis dato (wie der Autor) Ihre Daten in Tabellen und relationalen Datenbanken gespeichert haben, lohnt sich ein neugieriger Blick auf die anderen Möglichkeiten. Wenn die zu verarbeitenden Daten oft in flexiblen Varianten verarbeitet werden müssen oder wenn sie über Beziehungen verfügen, die in allen (oder den meisten) Use Cases aufgelöst werden müssen, dann bietet sich die Flexibilität von JSON-Dokumenten an. Müssen die Daten immer in der gleichen Form vorliegen, kann sich diese Flexibilität als eher nachteilig erweisen – schließlich muss die Anwendung für feste Vorgaben sorgen.
Auf der anderen Seite ist jedoch zu bedenken, dass die APIs aktuell keine partiellen Updates der Dokumente unterstützen. Wenn also ein Dokument auch noch so minimal verändert wird, muss das komplette Dokument übertragen werden. Häufige kleine Änderungen können sich also, gerade bei größeren JSON-Dokumenten (>1 Kilobyte), schlecht auf die Performance auswirken.
Bei nicht so großen, flexiblen Daten oder solchen, die kaum geändert werden müssen, kann NoSQL seine Stärke ausspielen. Das gilt auch für Azure Comos DB mit seinen unterschiedlichen APIs.
Azure Cosmos DB im Speziellen und NoSQL-Datenbanken im Allgemeinen sind auf jeden Fall einen Blick wert und bieten Möglichkeiten, die mit relationalen Datenbanken nur schwer realisiert werden können. Praktische Tools bis hin zum Emulator und fertige Beispiele machen den Einstieg leicht.
Passend zum Thema dieses Artikels finden Sie auf der BASTA! z. B. den Power Workshop Azure Cosmos DB von Thorsten Kansy am Freitag.
The post Cosmos DB in eigenen Projekten einsetzen: Grundlagen und Einsatzszenarien appeared first on BASTA!.
]]>The post Interview | Azure DevOps – “Kurzfristig ist es nur ein neuer Name” appeared first on BASTA!.
]]>Im Interview mit Neno Loje, www.teamsystempro.de, klären wir, was es mit der Namensänderung auf sich hat und wohin der DevOps-Trend zielt.
Über 12 Jahre lang haben Entwickler jetzt mit dem TFS gearbeitet und in dieser Zeit hat er seinen Namen überraschenderweise nicht geändert. Seine Online-Variante war dagegen unter verschiedenen Namen bekannt und hieß bis September 2018 Visual Studio Team Services. Die VSTS heißen jetzt Azure DevOps und analog dazu wird der TFS in der neuen Version Azure DevOps Server (2019) heißen. Zunächst wird sich auch nur der Name ändern, sagt Neno Loje. Der TFS wird Entwicklern und Unternehmen weiterhin On-Premise zur Verfügung stehen, sodass man damit im Prinzip wie gewohnt weiterarbeiten kann.
Aber selbstverständlich steht diese Umbenennung im Zeichen der umfangreichen Veränderungen, die Microsoft mit seiner Cloud-Strategie vorantreibt. Neue Entwicklungen passieren in der Cloud und werden erst später den On-Premise-Produkten hinzugefügt, soweit das denn möglich ist – das gilt auch für den TFS.
Zugleich öffnen die Tools und Microsoft sich immer mehr für Open-Source-Lösungen wie Git und Software von Drittherstellern und nutzen dabei unterschiedliche Cloud-Angebote. Darüber hinaus soll aber auch die Zusammenarbeit zwischen allen Projektbeteiligten gefördert werden. Hierfür steht der Namensteil DevOps, der nicht nur im engeren Sinne die Entwickler und den Betrieb meint. Aber gerade für diese beiden Gruppen bieten die neuen Continuous Integration und Continuous Delivery (CI/CD) Pipelines von Azure DevOps Möglichkeiten, die in dieser Form bisher nicht so einfach zu nutzen waren.
Auf der BASTA! bieten vor allem die Sessions des TFS & DevOps Days sowie des Cloud Developer Days einen fundierten Überblick über die neuen Möglichkeiten und den besten Einstieg für den Einsatz in der täglichen Arbeit.
The post Interview | Azure DevOps – “Kurzfristig ist es nur ein neuer Name” appeared first on BASTA!.
]]>The post Überzeugen Sie ihren Chef in 60 Sekunden appeared first on BASTA!.
]]>Beschäftigen Sie sich vorab intensiv mit den Programminhalten und stellen Sie sich eine Übersicht aus den für Sie informativsten und lehrreichsten Sessions zusammen. Mit unserer Infografik als Stütze haben Sie alle nötigen Details zur Hand, um Ihren Chef in 60 Sekunden zu überzeugen. Sie sind aber nur gut im Algorithmen-Formulieren? Auch hier stehen wir Ihnen zur Seite! Damit Sie sich nicht mit Formulierungen herumschlagen müssen, haben wir eine ultimative E-Mail-Vorlage für Ihren Boss vorbereitet. Diese benötigt nur minimale Anpassungen Ihrerseits, um einen Ausflug zur BASTA! Spring zu ermöglichen.

Sehr geehrte/r Frau / Herr (…),
Ich möchte Sie gerne um Erlaubnis bitten an der BASTA!-Konferenz teilnehmen zu dürfen, die vom 25 Februar – 1. März in Frankfurt am Main stattfinden wird.
Kontinuierliche Änderungen, die nicht nur Microsoft und seine Produkte, sondern die gesamte IT-Industrie betreffen, erfordern es, dass man ständig auf dem Laufenden bleibt. Damit wir, als Unternehmen, zukünftig noch effektiver und kostengünstiger Produkte entwickeln können, ist es notwendig, sich regelmäßig mit den neuesten Entwicklungen der Industrie zu beschäftigen.
Diese Konferenz bietet genau diese Möglichkeit. In herausragenden Keynotes und Sessions liefert die BASTA! einen gezielten Ausblick auf die kommenden Trends der IT-Welt.
Die Highlights der BASTA!:
Wenn ich an der Konferenz teilnehmen darf, würde ich gerne im Nachgang eine firmeninterne Schulung zur Zusammenfassung der Konferenz geben. Ebenso verfasse ich, auf Wunsch, einen kurzen Erfahrungsbericht für unseren Firmenblog oder die Mitarbeiterzeitung.
Alle Infos zur Konferenz und zu Frühbucherpreisen finden Sie hier.
Mit besten Grüßen
(Ihr Name)
The post Überzeugen Sie ihren Chef in 60 Sekunden appeared first on BASTA!.
]]>The post Das große BASTA!-Nikolaus-Gewinnspiel! appeared first on BASTA!.
]]>Die Welt der Webentwicklungen dreht sich unglaublich schnell und kaum meint man, auf dem aktuellen Stand zu sein, kommen die nächsten Neuerungen.
Wenn Sie bisher reine Windows-Desktop-Anwendungen programmiert haben oder mit alten ASP.NET-Konzepten gearbeitet haben, möchten Sie sich vielleicht jetzt mit der Entwicklung von Web- und Cross-Plattformanwendungen beschäftigen? Dann ist heute Ihr Glückstag:

Im Gepäck hat er drei Exemplare von: Moderne Webanwendungen für .NET-Entwickler.
Dr. Holger Schwichtenberg und das IT-Visions-Expertenteam zeigen Ihnen, wie Sie moderne Single-Page-Webanwendungen und mobile Cross-Plattform-Apps mittels HTML, CSS, Java Script und TypeScript entwickeln können.
Damit diese zukünftig auch für jeden nutzbar sind, ist natürlich auch die Programmierung von Webservern und Web-Clients inbegriffen.
Als ganz besonderes Feature kann sämtlicher genutzter Code heruntergeladen werden und der Leser erhält zusätzlich kostenloses Bonusmaterial in Form von drei Kapiteln zu den Themen: React, Open Web Interface for .NET (OWIN) / Katana und ASP.NET Sicherheit.
Überzeugt? Alle Neuanmelder für unseren Newsletter, sowie treue BASTA!-Newsletter-Abonnenten, können jetzt eins von drei Exemplaren „Moderne Webanwendungen für .NET-Entwickler“ gewinnen!
Die Teilnahme am Gewinnspiel ist bis zum 13.12.2018 um 23:59 Uhr möglich.
The post Das große BASTA!-Nikolaus-Gewinnspiel! appeared first on BASTA!.
]]>The post Office als Plattform: Das Office API und Serverless Backends appeared first on BASTA!.
]]>Egal, ob es um Dokumente, E-Mails oder Tabellenkalkulationen geht, Office stellt sämtliche APIs zur Verfügung. Das erlaubt es Entwicklern und Unternehmen, ihre eigenen Produkte eng mit Office zu verzahnen und moderne Nutzungsszenarien vom Backend bis zum mobilen Frontend anzubieten. Thorsten Hans zeigt, wie man gerade als Angular-Entwickler Vorteile und Fähigkeiten des Frameworks nutzen kann, um das Optimum aus den eigenen Apps herauszuholen, ohne eine neue Codebasis erstellen zu müssen. Diesen Ansatz kann man nun mit Serverless Backends kombinieren, sodass sich Entwickler nun vollends auf die fachliche Problemstellung konzentrieren können, anstatt Probleme mit der Bereitstellung und Verteilung zu analysieren. Hierbei spielt es keine Rolle, ob Sie die öffentliche Cloud mit Microsoft Azure oder eine On-Premises-Umgebung bevorzugen. Entsprechende Runtimes sind für beide Kombinationen verfügbar, wodurch das Erstellen von Office-Add-ins noch einfacher wird. Dieses Session Video von der BASTA! Spring 2018 bietet einen guten Einstieg in die Arbeit mit der Office-API und zahlreichen Services.
Nutzen Sie das Video doch als Anregung und Vorbereitung, denn auf der BASTA! Spring 2019 wird Thorsten Hans in seinen Sessions “Office Extensibility in 2019: Cross-Plattform Add-ins mit Angular” und “Mehr Daten! Office Add-ins mit Microsoft Graph” weitergehende Möglichkeiten zeigen, wie APIs und Cloud-Services praxisorientiert und effektiv zusammenspielen.
The post Office als Plattform: Das Office API und Serverless Backends appeared first on BASTA!.
]]>The post Smart Contracts mit .NET Core appeared first on BASTA!.
]]>Hyperledger Fabric ist eine unter dem Dachverband Hyperledger mit Go entwickelte Open Source Blockchain. Hyperledger selbst wurde Ende 2015 von The Linux Foundation gegründet. Unter dem Dachverband werden Open Source Blockchains und dazu passende Tools entwickelt. Große Unternehmen wie Intel, IBM, Cisco oder Red Hat unterstützen Hyperledger. Dabei wird nicht nur der Ansatz einer Blockchain, sondern vielmehr verschiedener Blockchain-Plattformen verfolgt.
Genauer handelt es sich bei Hyperledger Fabric (kurz: Fabric) um eine Technologie für Permissioned Blockchains bzw. private Blockchains – also eine Blockchain, die nicht wie Ethereum oder Bitcoin für alle öffentlich, sondern nur bestimmten Teilnehmern zugänglich ist. Dadurch können wir bei diesen Arten von Netzwerken das klassische Mining (Proof-of-Work, PoW) vernachlässigen. Vielmehr kommt hier der Konsens über Proof-of-Authority (PoA) (Kasten: „Proof-of-Authority“) zum Tragen.
Proof-of-Authority (PoA)
Entgegen dem klassischen Mining (Proof-of-Work), das darauf beruht, dass ein Miner ein kryptografisches Rätsel in Form einer Hashberechnung löst, existieren bei Proof-of-Authority (PoA) sogenannte Validator Nodes (oder auch Authorities, als eher physische Entität), denen die Erzeugung von neuen Blöcken erlaubt ist. Wenn die Mehrzahl von Validator Nodes in einem Netzwerk der Erzeugung des neuen Blocks zustimmen, wird dieser ein permanenter Teil des Netzwerks. Vorteil hierbei ist, dass keine CPU-Zeit zur Lösung des kryptografischen Rätsels benötigt wird, eine bessere Performanz erreicht wird und dadurch eine höhere Transaktionsgeschwindigkeit erzielt werden kann. Daher eignet sich PoA für das Enterprise-Umfeld.
Anstelle einer Domänensprache bietet Fabric die Entwicklung von Smart Contracts – oder auch Chaincode, wie das im Hyperledger-Umfeld genannt wird – in den Sprachen Java, Go und JavaScript (via Node.js) an, experimentell kann auch .NET verwendet werden. Folgend werden wir einen Chaincode mit C# entwickeln, der das Standardbeispiel FabCar von Hyperledger implementiert. FabCar dient der Zuordnung von Autos zu ihrem Besitzer. Schreibend erlaubt der Chaincode sowohl das Anlegen eines neuen Eintrags (z. B.: Hat jemand ein neues Auto gekauft?) als auch den Wechsel des Besitzers. Lesend kann die Information über ein bestimmtes Auto oder eine Liste aller Autos erlangt werden.
Bevor wir mit der Entwicklung starten können, benötigen wir ein Hyperledger-Fabric-Netzwerk. Hierbei bietet sich das Chaincode-Developer-Network (Dev-Netzwerk) an. Normalerweise muss der Chaincode bei einer Änderung deployt und danach instanziiert werden. Bei diesem Vorgang wird von einem Fabric Peer ein Docker-Container mit dem Chaincode gestartet. Dieser Vorgang nimmt durchaus einige Zeit in Anspruch, was die Entwicklung sehr langsam machen würde. Durch das Dev-Netzwerk können wir diesen Vorgang deutlich verkürzen, da wir den Chaincode außerhalb der Docker-Umgebung von Fabric starten.
Auf der Fabric Website Prerequisites ist beschrieben, welche Software benötigt wird. Windows-Nutzer sollten auf jeden Fall einen Blick auf die Seite werfen, da hier noch einige zusätzliche Software installiert werden muss. Linux- und Mac-User benötigen nur Folgendes:
Ist die Software installiert, muss das Repository fabric-samples geklont werden. Mit einer Kommandozeile innerhalb von fabric_samples muss folgender Befehl ausgeführt werden:
curl -sSL http://bit.ly/2ysbOFE | bash -s 1.2.0
Dieser Befehl lädt alle benötigen Docker-Images und Binaries für die Zielplattform für die (zum Zeitpunkt des Schreibens aktuelle) Hyperleder-Fabric-Version 1.2.0 herunter.
Wurde der Befehl erfolgreich ausgeführt, wechseln wir in das Verzeichnis chaincode-docker-devmode und öffnen die Datei docker-compose-simple.yaml. Dort finden wir den Eintrag peer: auf Root-Ebene und fügen unter ports: eine weitere Zeile mit dem Inhalt 7052:7052 hinzu. Hierbei bitte auf die Einrückung achten, sodass es genau wie die anderen Ports aussieht. Die fertige Eintragung sollte daher in Listing 1 aussehen.
Listing 1
peer:
# Zur besseren Lesbarkeit wurden die anderen Attribute entfernt
ports:
- 7051:7051
- 7052:7052
- 7053:7053
Dieser Port öffnet die Schnittstelle für unseren Chaincode, sodass er außerhalb der Docker-Umgebung gestartet und verbunden werden kann. Mit folgendem Befehl auf der Kommandozeile können wir das Netzwerk starten:
docker-compose -f docker-compose-simple.yaml up
Nach einer kurzen Initialisierungsphase sollte das Fabric-Dev-Netzwerk fehlerfrei (sprich ohne Fehlermeldungen in der Logausgabe) gestartet sein. Jetzt können wir mit der Entwicklung von unserem Chaincode beginnen.
Die aktuelle Version der Bibliothek zur Entwicklung von Chaincode bietet zwei Entwicklungsmodelle an. Zum einen ein Low-Level-Modell (Chaincode API), das dem Entwickler die maximale Freiheit zur Entwicklung bietet, aber auch die größte Verantwortung zur fehlerfreien Umsetzung. Zum anderen ein High-Level-Modell (Contract API), das dem Entwickler erlaubt, sich auf die Umsetzung seines Business-Use-Cases zu konzentrieren und etwas Verantwortung an das Framework abzugeben. Innerhalb des Artikels werden wir nur mit dem Contract API – also dem High-Level-Modell – arbeiten.
Zunächst erstellen wir ein neues .NET-Core-Konsolen-Projekt, entweder über die Templates in JetBrains Rider oder via dotnet new console in einer Kommandozeile. Danach öffnen wir die dazugehörige *.csproj-Datei, finden die erste und fügen dort den Eintrag 7.3 hinzu. Falls dieser Eintrag bereits existiert, können wir ihn einfach überschreiben. Mit dem Eintrag stellen wir unser Projekt auf die aktuellste Sprachversion von C# um, um später eine asynchrone Main()-Methode verwenden zu können.
Wieder auf der Kommandozeile führen wir folgenden Befehl zur Installation der Bibliothek zur Chaincode-Entwicklung aus. Es lohnt sich, ein Blick in die NuGet Gallery [6] zu werfen, um die aktuellste Version zu installieren:
dotnet add package Thinktecture.HyperledgerFabric.Chaincode --version 1.0.0-prerelease.78
Im nächsten Schritt legen wir eine neue Klasse FabCar an und lassen sie von der Klasse ContractBase erben (Listing 2). Diese Klasse ContractBase stellt die Basisklasse für alle Contract API basierten Chaincodes dar. Ihr Pendant für die Low-Level-Programmierung wäre das Interface IChaincode. Alle Klassen, die von ContractBase erben, nennen wir Contract (nicht zu verwechseln mit Smart Contract). Ein Chaincode (der eigentliche Smart Contract) kann aus mehreren Contracts bestehen. Hierbei würde jeder Contract eine bestimmte Funktionalität des gesamten Chaincodes zur Verfügung stellen – sie dienen daher einer Art Gruppierung.
Listing 2: Die Klasse „FabCar“
using Thinktecture.HyperledgerFabric.Chaincode.Contract;
public FabCar(): base("FabCar")
{
}
Der String FabCar beim Aufruf von base() ist der Namespace, der später zum Aufruf unseres Chaincode benötigt wird. Übrigens, die Klasse integriert sich später in den durch .NET Core bereitgestellten Dependency Injection Container. Es kann daher wie gewohnt die Dependency Injection benutzt werden, bspw. könnten wir einen ILogger hinzufügen, wenn wir in unserem Contract loggen möchten.
Wie eingangs erwähnt, wollen wir mit FabCar Autos mit ihren Besitzern speichern und abrufen. Dazu erstellen wir mit dem Code aus Listing 3 eine neue Klasse Car.
Listing 3: Die Klasse „Car“
public class Car
{
public Car()
{
}
public Car(string make, string model, string color, string owner)
{
Make = make;
Model = model;
Color = color;
Owner = owner;
}
public string Make { get; set; }
public string Model { get; set; }
public string Color { get; set; }
public string Owner { get; set; }
public override string ToString()
{
return $"{Make} {Model} in {Color} with owner {Owner}";
}
}
Die Klasse Car hat einige Eigenschaften wie den Hersteller (Make), das Modell (Model), die Farbe (Color) und den aktuellen Besitzer (Owner). Hier können gerne nach Belieben weitere Eigenschaft hinzugefügt werden, bspw. die Pferdestärken oder das Gewicht. Der parameterlose Konstruktor wird für die (De-)Serialisierung von und nach JSON benötigt.
Als nächstes legen wir alle Methoden aus Listing 4 an, die wir nach und nach implementieren werden. Beim späteren Start des Chaincodes werden via Reflection alle Methoden mit folgendem Schema gesucht:
public [async] Task MethodName(IContractContext context [, string param1]*)
Schnittstellenbedingt werden alle Parameter, die der Methode übergeben werden, als String übergeben. Ein Parsen in den richtigen Datentyp muss die Methode selbst vornehmen. Die gefundenen Methoden werden öffentlich zur Verfügung gestellt und können vom Blockchain-Netzwerk aufgerufen werden.
Listing 4: Methodenrümpfe des Chaincodes
{
"index": "/index.html",
"assetGroups": [
{
"name": "app",
"installMode": "prefetch",
"resources": {
"files": [
"/favicon.ico",
"/index.html"
],
"versionedFiles": [
"/*.bundle.css",
"/*.bundle.js",
"/*.chunk.js"
]
}
},
{
"name": "assets",
"installMode": "lazy",
"updateMode": "prefetch",
"resources": {
"files": [
"/assets/**"
]
}
}
],
"dataGroups": [
{
"name": "pokemon",
"urls": [
"https://pokemon.co/*"
],
"cacheConfig": {
"strategy": "performance"
}
}
]
}
Starten wir mit der Implementierung der Init()-Methode. Sie wird bei der Instanziierung unserer Chaincodes aufgerufen. Wenn wir nichts zu initialisieren hätten, müssten wir diese Methode nicht implementieren. Listing 5 zeigt die Implementierung unserer Methode, die einige Autos mit ihren Besitzern initialisiert.
Listing 5: Die Methode Init()
public async Task Init(IContractContext context)
{
var cars = new List
{
new Car("Toyota", "Prius", "blue", "Tomoko"),
new Car("Ford", "Mustang", "red", "Brad"),
new Car("Hyundai", "Tucson", "green", "Jin Soo"),
new Car("Volkswagen", "Passat", "yellow", "Max"),
new Car("Tesla", "S", "black", "Michael"),
new Car("Peugeot", "205", "purple", "Michel")
};
for (var index = 0; index < cars.Count; index++)
{
var car = cars[index];
await context.Stub.PutStateJson($"CAR{index}", car);
}
return ByteString.Empty;
}
Schauen wir uns im Detail an, was genau hier passiert. Zunächst erstellen wir eine Liste von Car mit einigen Beispielinhalten. Danach iterieren wir über die Liste und rufen context.Stub.PutStateJson() auf. Die Variable context, die als Parameter in die Methode gereicht wird, beinhaltet den aktuellen Ausführungskontext unserer Contracts. In ihr befindet sich der Stub, der ein API zwischen Chaincode und dem Fabric Peer bereitstellt. Mit Hilfe des Stubs können Daten im Asset Store (Kasten: „Asset Store“) gespeichert, ausgelesen, geändert und gelöscht werden. Und genau das machen wir mit PutStateJson(): Wir speichern unter dem Schlüssel CAR0 einen JSON-String mit dem dazugehörigen Auto. Konnten wir alle Einträge erfolgreich speichern, geben wir einen leeren ByteString zurück. Falls zwischendurch ein Fehler auftritt, wird dieser durch die Bibliothek verarbeitet.
Asset Store
Bei Fabric ist der Asset Store oder auch State Database, also der aktuelle Zustand unserer Daten der Blockchain, zunächst eine LevelDB, ein einfacher Key-Value-Speicher. Dieser erlaubt es nicht, komplexere Query-Abfragen (ähnlich SQL) entgegen zu nehmen. Für diesen Fall kann LevelDB gegen eine CouchDB ausgewechselt werden, die auf Basis von JSON-Strukturen komplexe Query-Abfragen erlaubt. Weitere Informationen hierzu sind in der Dokumentation zu finden.
Als nächstes implementieren wir die Methode CreateCar() mit dem Inhalt aus Listing 6.
Listing 6: Die Methode „CreateCar()“
public async Task CreateCar(IContractContext context, string carNumber, string make, string model, string color, string owner)
{
var car = new Car(make, model, color, owner);
await context.Stub.PutStateJson(carNumber, car);
return ByteString.Empty;
}
Hier sehen wir, dass die Methode zusätzliche String-Parameter übergeben bekommt. Nämlich genau die, die wir benötigen, um ein neues Auto mit seinem Besitzer zu erstellen. Hier sei angemerkt, dass wir innerhalb der Methode keine Prüfung vornehmen, ob dieses Auto bereits existiert. Das kann gerne als kleine Hausaufgabe selbst implementiert werden. Die Methode ist daher recht einfach gehalten: Neues Auto erstellen, über PutStateJson() speichern und bei Erfolg einen leeren ByteString zurückgeben.
Die Methode ChangeCarOwner() veranlasst einen Besitzerwechsel eines Autos. In Listing 7 ist die Implementierung zu finden.
Listing 7: Die Methode „ChangeCarOwner()“
public async Task ChangeCarOwner(IContractContext context, string carNumber, string owner)
{
var car = await context.Stub.GetStateJson(carNumber);
car.Owner = owner;
await context.Stub.PutStateJson(carNumber, car);
return ByteString.Empty;
}
Die nächste zu implementierende Methode ist QueryCar(). Sie ruft einen einzelnen Wagen mit all seinen Eigenschaften aus dem Asset Store auf und gibt ihn an den Aufrufer zurück. Die Implementierung ist in Listing 8 zu finden.
Die Methode ChangeCarOwner() veranlasst einen Besitzerwechsel eines Autos. In Listing 7 ist die Implementierung zu finden.
Listing 8: Die Methode „QueryCar()“
public async Task QueryCar(IContractContext context, string carNumber)
{
var carBytes = await context.Stub.GetState(carNumber);
if (carBytes == null || carBytes.Length == 0) throw new Exception($"Car {carNumber} does not exist.");
return carBytes;
}
Hier ist anzumerken, dass wir die Methode GetState() verwenden, die uns einen ByteString liefert, und nicht GetStateJson(). Die Methode ist nicht am deserialisierten Zustand des Autos interessiert. Sie prüft daher nur, ob ein Ergebnis vom Asset Store geladen werden konnte (sprich: es ist weder null noch hat der ByteString eine Länge gleich 0). Falls ja, gibt sie das Ergebnis an den Aufrufer zurück. Möchte man die Ausführung der Methode abbrechen (bspw. bei falschen Eingabeparametern oder wie im Beispiel: Auto nicht gefunden) werfen wir eine Exception. Die Bibliothek übersetzt jede geworfene Exception in einen Fehlerstatus und gibt diesen an den Aufrufer zurück, sodass die Ausführung des Chaincodes nicht abgebrochen wird.
Zu guter Letzt wollen wir die Methode QueryAllCars() implementieren. Sie soll alle gespeicherten Autos abrufen. Die Implementierung ist in Listing 9 zu finden.
Listing 9: Die Methode QueryAllCars
public async Task QueryAllCars(IContractContext context)
{
var startKey = "CAR0";
var endKey = "CAR999";
var iterator = await context.Stub.GetStateByRange(startKey, endKey);
var result = new List();
while (true)
{
var iterationResult = await iterator.Next();
if (iterationResult.Value != null && iterationResult.Value.Value.Length > 0)
{
var queryResult = new CarQueryResult
{
Key = iterationResult.Value.Key
};
try
{
queryResult.Record = JsonConvert.DeserializeObject(iterationResult.Value.Value.ToStringUtf8());
result.Add(queryResult);
}
catch (Exception ex)
{
// Error loggen
}
}
if (iterationResult.Done)
{
await iterator.Close();
return JsonConvert.SerializeObject(result).ToByteString();
}
}
}
public class CarQueryResult
{
public string Key { get; set; }
public Car Record { get; set; }
}
Wie erwähnt handelt es sich beim Asset Store per Standard um eine LevelDB, einen einfachen Key-Value-Speicher. Dieser erlaubt keine komplexeren Abfragen (Kasten: „Asset Store“). Um dennoch alle Autos abzufragen, iterieren wir selbst über den Asset Store. Hierzu definieren wir einen Start- (CAR0) und Endpunkt (CAR999). Das bedeutet, dass wir versuchen, die ersten 1 000 Autos aus dem Asset Store zu laden. Wer möchte, kann diese Parameter auch als Methodenparameter übergeben. Via GetStateByRange() erzeugen wir uns einen Iterator auf den Asset Store innerhalb unserer Grenzen.
Über eine while(true)-Schleife wird eine Iteration über den Asset Store gestartet. Via iterator.Next() erhalten wir das nächste mögliche Ergebnis aus dem Store. Wir prüfen als nächstes, ob wir ein Ergebnis haben und die Länge größer 0 ist. Ist das der Fall, versuchen wir den erhaltenen ByteString via StringToUtf8() in seine UTF-8-Repräsentation umzuwandeln und danach zu deserialisieren. Falls hierbei ein Fehler auftritt, wird dieser in unserem Beispiel ignoriert.
Zum Schluss prüfen wir, ob die Iteration abgeschlossen ist. Wenn ja, schließen wir den Iterator via iterator.Done() und geben unsere Liste an den Aufrufer zurück. Damit ist die Entwicklung unseres Contract abgeschlossen.
Zu Beginn haben wir ein neues Konsolenprojekt erstellt, was uns eine Datei Program.cs mit einer Main()-Methode generiert hat. Diese passen wir gemäß Listing 10 an.
Listing 10: Die Methode „Main()“
class Program
{
static async Task Main(string[] args)
{
using (var provider = ChaincodeProviderConfiguration.ConfigureWithContracts(args))
{
var shim = provider.GetRequiredService();
await shim.Start();
}
}
}
Um den Chaincode zu starten, benötigen wir ChaincodeProviderConfiguration.ConfigureWithContracts(args). Hinter ChaincodeProviderConfiguration verbirgt sich der Aufbau der Dependency Injection des Chaincodes. Mit ConfigureWithContracts() teilen wir dem Container mit, dass wir gerne den Contract FabCar in unserem Chaincode nutzen wollen. Via Methodenüberladung können bis zu vier Contracts über eine generische Methode hinzugefügt werden. Alternativ kann der Methode auch ein Array aller Contracts übergeben werden. Damit sind auch mehr als vier Contracts pro Chaincode möglich.
Aus unserem Provider lassen wir uns eine Instanz von Shim via GetRequiredService() erzeugen. Der Shim ist die Schnittstelle zwischen dem Fabric Peer und unserem Chaincode. Er übernimmt jegliche Nachrichten- und Fehlerbehandlungen. Zu guter Letzt starten wir via shim.Start() das Kommunikationsprotokoll zwischen Chaincode und Fabric Peer. Damit sind alle Codearbeiten abgeschlossen.
Der letzte Schritt ist das Deployment bzw. die Instanziierung des Chaincode. Hierzu benötigen wir ein neues Kommandozeilenfenster, in dem wir folgenden Befehl ausführen:
docker exec -it cli bash
Dieser Befehl verbindet uns zum Fabric CLI, das uns die Kommunikation mit einem Fabric Peer erlaubt. Wie eingangs erwähnt, wird der Chaincode normalerweise in einem Docker-Container gestartet, namentlich innerhalb von fabric-ccenv (ccenv: Chaincode Environment). Dieser bietet aktuell Unterstützung für Go und Node.js Chaincodes, aber noch nicht für .NET Core. Zumal wollen wir nicht zur Entwicklungszeit den Chaincode in einem Docker-Container starten. Dennoch müssen wir ein normales Deployment anstoßen, damit unser Chaincode erkannt wird. Innerhalb der eben geöffneten Kommandozeile, die mit dem Fabric CLI verbunden ist, tippen wir folgende Befehle ein:
mkdir /opt/gopath/src/chaincodedev/chaincode/netcore echo "dev" > /opt/gopath/src/chaincodedev/chaincode/netcore/dev peer chaincode install -p /opt/gopath/src/chaincodedev/chaincode/netcore -n fabcar -v 0 -l node
Die ersten beiden Befehle erstellen einen neuen Ordner netcore mit einer Datei namens dev und dem Inhalt dev. Das dient als reiner Fake-Chaincode, damit Fabric etwas deployen kann, denn ein leerer Ordner/Chaincode kann nicht deployed werden. Der letzte Befehl installiert bzw. deployt den Chaincode. Via peer chaincode install teilen wir mit, dass wir gerne neuen Chaincode installieren möchten. -p mit Pfadangabe gibt an, wo unser Fake-Chaincode liegt, -n gibt den Namen, -v die Version und -l die Sprache des Chaincodes an. Hier merkt man stark, wie experimentell unser .NET-Beispiel noch ist, da wir hier tatsächlich node als Sprache angeben. Das führt prinzipiell nur dazu, dass Fabric den angegebenen Ordner in den Peer kopiert. Damit ist unser Fake-Chaincode installiert. Würden wir hier ein reales Deployment anstreben, würden wir selbstverständlich den echten Code bzw. dessen Binary kopieren. Der Fake-Chaincode dient nur zur Entwicklungszeit. Auch wird, sobald Fabric offiziell .NET unterstützt, die Angabe von node in netcore geändert.
Jetzt ist es an der Zeit, unseren Chaincode zu starten. Wichtig ist, dass folgende Umgebungsvariablen gesetzt sind:
CORE_PEER_ADDRESS gibt an, mit welchem Peer sich unser Chaincode für die Kommunikation verbinden soll. CORE_CHAINCODE_ID_NAME ist die Identifikation unseres Chaincode. Mit fabcar:0 zeigen wir hier auf den eben installierten fabcar mit Version 0. Nach dem Start sollte innerhalb kurzer Zeit im Log des Chaincodes der Eintrag Successfully established communication with peer node erscheinen. Ist das der Fall, hat sich der Chaincode erfolgreich zum Peer verbunden, und wir können diesen jetzt instanziieren. Der Befehl hierzu, der wieder innerhalb des Fabric CLI eingegeben werden muss, lautet wie folgt:
peer chaincode instantiate -n fabcar -v 0 -c '{"Args": ["FabCar.Init"]}' -C myc
Mit den Argumenten -n und -v sprechen wir wieder unseren Chaincode an. -c ist die sogenannte Constructor-Message, ein String mit JSON-Format, der unserem Chaincode gesendet, durch den Shim geparst und dem Contract zur Verfügung gestellt wird. Die Argumente sind eine Liste von Strings. Das erste Argument ist immer die Methode, die im Chaincode aufgerufen werden soll. Es setzt sich zusammen aus dem Namespace (FabCar) und dem Methodennamen (Init) getrennt durch einen Punkt. Den Namespace hatten wir zuvor im Konstruktor der Klasse FabCar gesetzt, und Init meint die tatsächliche Methode Init() der FabCar-Klasse. Wichtig: Die Bezeichnung beachtet Groß- und Kleinschreibung. Das letzte Argument -C bestimmt den Fabric Channel.
Ab diesem Zeitpunkt können wir unseren Chaincode nach Belieben stoppen, Code ändern und neu starten, ohne dass wir ein neues Deployment oder eine neue Instanziierung durchführen müssen, was zu einer erheblichen Entwicklungsgeschwindigkeit beiträgt.
Nachdem unser Chaincode läuft, wollen wir ihn benutzen. Alle folgenden Befehle werden wieder im Fabric CLI eingetippt. Wenn wir uns beispielsweise das Auto mit der Nummer CAR2 anzeigen lassen wollen, benutzen wir folgenden Befehl:
peer chaincode query -n fabcar -c '{"Args":["FabCar.QueryCar","CAR2"]}' -C myc
query gibt an, dass wir nur lesend auf das Netzwerk zugreifen und die Methode FabCar.QueryCar mit dem Parameter CAR2 aufrufen. Wenn alles erfolgreich durchläuft, erhalten wir folgendes Ergebnis:
{"Make": "Hyundai", "Model": "Tucson", "Color": "green", "Owner": "Jin Soo"}
Super! Allerdings gefällt uns der Wagen von Jin Soo so gut, dass wir ihm diesen abkaufen wollen. Diesen Kauf wollen wir vermerken:
peer chaincode invoke -n fabcar -c
'{"Args":["FabCar.ChangeCarOwner","CAR2","Manuel Rauber"]}' -C myc
invoke stellt einen schreibenden Zugriff auf das Netzwerk dar, und zwar soll die Methode FabCar.ChangeCarOwner mit den zwei angegebenen Parameter CAR2 und Manuel Rauber aufgerufen werden. Erhalten wir keine Fehlermeldung bei der Ausführung (denn gemäß Listing 7 geben wir einen leeren ByteString zurück), war der Aufruf erfolgreich. Um das zu prüfen, können wir entweder wieder QueryCar benutzen, oder wir lassen uns alle Einträge ausgeben:
peer chaincode query -n fabcar -c '{"Args":["FabCar.QueryAllCars"]}' -C myc
Als Ergebnis erhalten wir eine serialisierte Liste aller Autos und siehe da: Der grüne Hyundai Tucson gehört fortan dem Autor des Artikels.
Herzlichen Glückwunsch, wir haben es geschafft! Wir haben soeben das Dev-Netzwerk von Hyperleder Fabric gestartet, unseren ersten experimentellen .NET Chaincode entwickelt, ihn deployt, instanziiert und dessen Methoden aufgerufen. Auch haben wir gesehen, dass wir zwar .NET benutzen können, es aber noch an einigen Ecken und Enden fehlt, damit es sich auch wirklich gut anfühlt (und wir nicht via node deployen müssen). Wer sich hier für den Fortschritt interessiert, kann einen Blick auf den entsprechenden JIRA-Task und das dazugehörige GitHub-Repo werfen. Weitere Informationen zum Chaincode in .NET Core sind auch auf dem Thinktecture-Blog zu finden. Ich wünsche viel Spaß beim weiteren Ausprobieren!
Passend zum Thema dieses Artikels finden Sie auf der BASTA! z. B. den Power Workshop „Von Null auf Hundert – Blockchain-Anwendungen mit Hyperledger Fabric“ von Ingo Rammer am Freitag.
The post Smart Contracts mit .NET Core appeared first on BASTA!.
]]>The post .NET Core 2.1, 2.2 und 3.0 – neue Funktionen appeared first on BASTA!.
]]>Nachdem .NET Core 2.0 am 14. August 2017 erschienen war, hatte Microsoft die Version 2.1 für das erste Quartal 2018 angekündigt. Dass dieser Termin nicht zu halten sein wird, wurde dann im Februar 2018 verkündet und als neues Ziel der Sommer 2018 angegeben. Aus dem Sommer wurde dann der Frühsommer: .NET Core 2.1 und damit einhergehend ASP.NET Core 2.1 und Entity Framework 2.1 sind am 30. Mai 2018 erschienen.
Ein wesentliches Thema in den 2.1-Versionen ist die Erweiterung der Funktionen, insbesondere durch die Übernahme weiterer Klassen aus dem klassischen .NET Framework. Das Windows Compatibility Pack for .NET Core bringt viele Hundert Klassen aus der bisherigen .NET Framework Class Library als Nuget-Paket in die .NET-Core-Welt. Das Nuget-Paket Microsoft.Windows.Compatibility ist ein Metapaket über viele andere Nuget-Pakete. Die Paketnamen sind angelehnt an die bisherigen Namensräume aus der .NET Framework Class Library. Funktionen wie Registry-Zugriff, Datenbankzugriffe per ODBC, LINQ für DataSets, das Code Document Object Model (CodeDOM), Zugriff auf serielle Ports und LDAP-Server wie das Active Directory sowie die Windows Management Instrumentation (WMI), mit der man Informationen aus dem Betriebssystem und einigen Anwendungen auslesen und verändern kann, halten damit Einzug in die Welt von .NET Core. Freilich sind viele dieser Klassen nur auf Windows möglich, daher auch der Name „Windows“ im Compatibility Pack.
Man kann in jedem Fall eine Self-contained Application (Abb. 1) auch für Linux und macOS erstellen, auch wenn manche Klassen aus dem Windows Compatibility Pack, die für diese Betriebssysteme nicht von Microsoft implementiert wurden bzw. dort zum Teil keinen Sinn machen (z. B. die Registry-Klassen). Wenn man die Self-contained Application dann auf diesen Betriebssystemen startet, erhält man Laufzeitfehlermeldungen wie z. B.:

“Man sieht hier an den unterschiedlichen Fehlerklassen und Meldungstexten deutlich, dass verschiedene Entwickler am Werk waren. Einige Klassen aus dem Windows Compatibility Pack laufen auch außerhalb von Windows. Leider schweigt sich die offizielle Dokumentation dazu aus; es gibt jedoch dazu einen Blogeintrag.
So läuft zum Beispiel System.Runtime.Caching problemlos unter Linux und macOS, denn diese Bibliothek hat keine Abhängigkeiten von Betriebssystemteilen. Im Einzelfall wird man dann aber feststellen, dass mehr notwendig ist, als das Windows Compatibility Pack in die Self-contained Application zu packen. So scheitert ein ODBC-Zugriff mit der .NET-Klasse System.Data.Odbc.OdbcConnection auf Linux auf einen Microsoft-SQL-Server mit dem Fehler „System.DllNotFoundException: Dependency unixODBC with minimum version 2.3.1 is required. Unable to load shared library ‘libodbc.so.2’ or one of its dependencies. In order to help diagnose loading problems, consider setting the LD_DEBUG environment variable: liblibodbc.so.2.so: cannot open shared object file: No such file or directory”. Die Lösung ist, dass man erstmal den ODBC-Treiber für Microsoft-SQL-Server auf Linux installieren muss..
Auch für System.Drawing braucht man unter Linux und macOS eine Zusatzinstallation von libgdiplus, einer Open-Source-Implementierung des GDI+ API aus dem Mono-Projekt.
Mit dem NuGet-Paket Microsoft.DotNet.Analyzers.Compatibility bietet Microsoft immerhin einen Visual-Studio-Analyzer an, der alle Klassen und Klassenmitglieder markiert, die nicht plattformneutral sind, siehe z. B. Registry.LocalMachine.OpenSubKey in Abbildung 2. Auch auf veraltete APIs (z. B. System.Net.WebClient, System.Security.SecureString) weist der Analyzer hin. Der Analyzer ist aber leider auch schon wieder etwas verwahrlost. Die aktuelle Version ist 0.2.12-alpha und ist am 7. März 2018 erschienen.

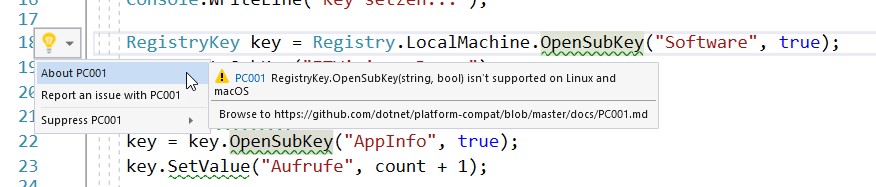
Das Windows Compatibility Pack trägt in der ersten Version die Versionsnummer 2.0, was ausdrücken soll: Es läuft nicht nur auf .NET Core 2.1, sondern auch auf 2.0. .NET Core 2.0 sollte man allerdings nun gar nicht mehr verwenden (siehe Kasten „Support für .NET Core 2.0 läuft schon am 1.10.2018 aus!“).
Technisch ist das Windows Compatibility Pack eine Schicht oberhalb von .NET Standard 2.0 (Abb. 3). Daher kann das Windows Compatibility Pack nicht nur in .NET-Core-Projekten, sondern auch in Projekten mit dem Projekttyp „.NET Standard 2.0“ referenziert werden.
Neben Klassen aus dem klassischen .NET Framework hat Microsoft auch ganz neue Klassen mit .NET Core 2.1 eingeführt. Dazu gehören die Datenstrukturen Span, ReadOnlySpan, Memory und ReadOnlyMemory, die ab C# 7.2 ein direktes Adressieren von Teilen von Arrays und anderen Speicherbereichen ermöglichen. Neu ist auch die Brotli-Komprimierung nach RFC 7932 im Paket System.IO.Compression.Brotli. Bei den Kryptografie-APIs gibt es viele kleine Neuerungen.
Auch an der Runtime hat Microsoft gefeilt. .NET Core 2.1 kann schneller kompilieren (sowohl im Sprachcompiler zur Entwicklungszeit als auch zur Laufzeit im Just-in-Time-Compiler). Ebenso die Netzwerkbibliotheken (u. a. die Klasse System.Net.HttpClient) hat das Entwicklungsteam optimiert. Die Tiered Compilation, durch die der Just-in-Time-Compiler zunächst den Fokus auf schnelle Übersetzung statt optimalem Ergebnis legt und dann für häufiger verwendete Methoden die Übersetzung nachträglich optimiert, ist in .NET Core 2.1 aber nur in einer Vorschauversion enthalten. Diese Funktion muss der Anwendungsbetreiber explizit durch das Setzen einer Umgebungsvariablen aktivieren: COMPlus_TieredCompilation=”1″. Unglaublich, dass „COMPlus“ als Name auch siebzehn Jahre nach dem Erscheinen der ersten .NET-Version noch weiterlebt.
In ASP.NET Core 2.1 gibt es einige Neuerungen für Web-APIs: Mit der neuen Annotation [ApiController] auf Ebene der Controllerklassen gibt es mehr Automatismen bezüglich Parameterbindung und Validierung. So sucht der Model Binder nun komplexe Typen – wie früher im klassischen ASP.NET-Web-API – im Inhalt der HTTP-Nachricht statt im Querystring. Wenn Validierungen fehlschlagen und dadurch der Model State ungültig ist, liefert der Controller jetzt automatisch den HTTP-Statuscode 400 (Bad Request) an den Aufrufer.
Mit dem neuen Rückgabetyp ActionResult kann der Entwickler HTTP-Statuscodes setzen und zur gleichen Zeit ein typisiertes Objekt für den Inhalt der Antwort festlegen, was die Generierung von Swagger-OpenAPI-Dokumentationen vereinfacht. Bei der Verwendung der untypisierten Schnittstelle IActionResult musste der Entwickler bisher Swagger durch eine Annotation über den Ergebnistyp informieren. Microsoft unterstützt nun auch die Übermittlung von Problemdetails in Web-APIs nach RFC 7808.
In ASP.NET Core 2.1 hat Microsoft Areas nachgerüstet, um Teilbereiche innerhalb eines Projekts zu trennen – das gab es schon im alten ASP.NET MVC. Ein Einsatz für Areas in ASP.NET Core sind die Themengebiete Benutzeranmeldung und Benutzerverwaltung beim Server-Side-Rendering nach dem Model-View-Controller-Modell oder per Razor Pages. Wenn man in Visual Studio 2017 ab Version 15.7 ein neues Webprojekt für ASP.NET 2.1 anlegt, findet man im Ordner Area einen Unterordner Identity. Dort ist zunächst nur eine einzelne Datei _ViewStart.cshtml hinterlegt. Sowohl die Seitenlayouts als auch den zugehörigen Programmcode findet man in der Assembly Microsoft.AspNetCore.Identity.UI.dll. Microsoft kapselt diese Funktionen, man kann eine einfache Anpassung über die Wahl der Layoutseite in _ViewStart.cshtml vornehmen. Wem das nicht reicht, der kann sich den Quellcode des o. g. Assembly über die Funktion Add Scaffold/Identity in Visual Studio ausgeben lassen. Wenn man sich die dann generierten Seiten ansieht, fällt auf: Es sind Razor Pages, selbst wenn man als Projektvorlage nicht Razor Pages, sondern Model-View-Controller gewählt hat. Microsoft hatte ja schon bei ASP.NET 2.0 klargemacht, dass Razor Pages nun das bevorzugte Modell für Server-Side-Rendering sind.
Für Razor Pages führt Microsoft weitere Neuerungen ein: vereinfachte Datenbindung in Razor mit der Annotation [BindPropertyAttribute] zentral auf eine Page-Model-Klasse statt auf einzelne Properties, und mit der Schnittstelle IPageFilter können Entwickler eigene Logik nun vor und nach dem Razor Page Handler ausführen. Immerhin auch für MVC-Projekte gilt: Die Projektvorlagen berücksichtigen die EU-GDPR (in Deutschland: DSGVO) und fordern nun vom Benutzer das Einverständnis für Cookies ein. Wenn der Benutzer nicht zustimmt, werden automatisch alle Cookies unterdrückt, die nicht als Essential markiert sind.
ASP.NET SignalR für bidirektionale Kommunikation zwischen Webserver und Browser ist nun in einer Core-Version 1.0 als Zusatz zu ASP.NET Core 2.1 verfügbar. Auf später verschoben wurden aber die WebHooks ebenso wie die schnellere In-Process-Integration in Internet Information Services (IIS).
Microsofts überarbeiteter OR-Mapper macht in Version 2.1 einen größeren Schritt nach vorne, insbesondere wurden vier Funktionen nachgerüstet, die es im klassischen ADO.NET Entity Framework schon gab:
Darüber hinaus enthält Entity Framework Core auch einige ganz neue Funktionen, die es nicht im klassischen ADO.NET Entity Framework gab:
Es bleibt aber dabei, dass es Schwächen in Entity Framework Core gibt. Der LINQ-Befehl in Listing 1 wird auch in Entity Framework Core Version 2.1 nicht komplett in SQL übersetzt. Wie Listing 2 zeigt, fehlen Gruppierung und Aggregatoperatoren im SQL-Befehl. Der ORM liest hier weiterhin alle Datensätze aus der Tabelle und macht den Rest im RAM. Von Microsoft liest man dazu: „We now support translating it to the SQL GROUP BY clause in most common cases“. Schade, dass so ein einfacher LINQ-Befehl wie der in Listing 1 nicht dazugehört.
Auch fehlen in Entity Framework Core 2.1 weiterhin die Unterstützung für das Table-per-Hierarchy-(TPH-)Mapping, die Abstraktion von der Zwischentabelle beim N:M-Mapping und Validierung vor dem Speichern. Auch ein Update Model from Database gibt es nicht für den vom Reverse Engineering generierten Programmcode, wenn sich das Datenbankschema danach noch ändert.
Listing 1: LINQ-Befehl mit GroupBy()-Operator
var groups1 = (from p in ctx.FlightSet
group p by p.Departure into g
select new { City = g.Key, Min = g.Min(x => x.FreeSeats), Max = g.Max(x => x.FreeSeats), Sum = g.Sum(x => x.FreeSeats), Avg = g.Average(x => x.FreeSeats) });
Listing 2: SQL-Übersetzung von Listing 1 – die Gruppierung fehlt
SELECT [p].[FlightNo], [p].[AircraftTypeID], [p].[AirlineCode], [p].[CopilotId], [p].[FlightDate], [p].[Departure], [p].[Destination], [p].[FreeSeats], [p].[LastChange], [p].[Memo], [p].[NonSmokingFlight], [p].[PilotId], [p].[Price], [p].[Seats], [p].[Strikebound], [p].[Timestamp], [p].[Utilization] FROM [Flight] AS [p] ORDER BY [p].[Departure]
Zwischen Version 2.0 und 2.1 gab es sehr viele Neuerungen – mehr als zwischen 1.1 und 2.0. Gemäß Semantic Versioning ist die Änderung der ersten Versionsnummer kein Indikator für den Umfang der Neuerungen, sondern drückt nur aus, dass es Breaking Changes gab. Version 2.2 ist funktional wieder ein kleineres Release, das bis Jahresende 2018 erscheinen soll.
In ASP.Net Core 2.0 will Microsoft das Routing überarbeiten. Das neue Routingsystem (derzeit „Dispatcher“ genannt) soll sehr früh in der Verarbeitungspipeline laufen und einige Szenarien wie die Unterstützung von CORS vereinfachen. Für Web-APIs soll die Generierung von Swagger-OpenAPI-Dokumenten und Hilfeseiten abermals durch Konventionen vereinfacht werden, z. B. soll ein Verb wie Create zu Beginn des Namens einer Action-Methode automatisch dazu führen, dass der Rückgabestatuscode 201 ist.
Bei den Werkzeugen will Microsoft die Analyse von Web-API-Konventionen in Visual Studio ermöglichen. Das Kommandozeilenwerkzeug dotnet soll beim Test HTTP-Anfragen mit beliebigen HTTP-Verben unterstützen. Sowohl für die Kommandozeile als auch Visual Studio will Microsoft einen eigenen Codegenerator für Clientzugriffscode (in C# und TypeScript) für Web-APIs anbieten. SignalR soll Unterstützung für Clients in Java und C++ erhalten. Der Kestrel-Webserver soll HTTP/2 und Health Checks zur Überwachung unterstützen.
Entity Framework Core 2.2 soll beim Reverse Engineering bestehender Datenbanken nun auch Datenbank-Views generieren. Aus dem alten ADO.NET Entity Framework soll auch die Unterstützung für Spatial Types (geometry und geography) übernommen werden. Die in Version 2.0 eingeführten Owned Types sollen in Version 2.2 auch bei Collection-Navigationseigenschaften möglich sein. Bisher sind sie nur für Einzelobjekte erlaubt. Der schon für Version 2.1 geplante, aber dann verschobene Treiber für Azure Cosmos DB soll erscheinen. Das Entwicklungsteam hat außerdem versprochen, mehr Unittests zu schreiben – und damit weniger Fehler zu produzieren, die erst den Kunden auffallen.
Bisher konnte man mit .NET Core nur Web-APIs, Webanwendungen und Konsolenanwendungen sowie Universal-Windows-Platform-Apps erstellen. Entwickler klassischer Desktopanwendungen schauten in die Röhre. Microsoft hat auf der BUILD-Konferenz 2018 verkündet, dass die Windows Presentation Foundation (WPF) und sogar die „alte Tante“ Windows Forms im Rahmen von Version Core 3.0 auf .NET Core portiert werden. Sie laufen dann als Nuget-Pakete, allerdings nur auf Windows. Weder WPF noch Windows Forms werden durch diese Maßnahme plattformunabhängig. Dazu müsste Microsoft nicht nur den .NET-Teil beider Frameworks, sondern auch die Betriebssystemgrundlagentechniken GDI+ bzw. DirectX portieren. Zumindest GDI+ gibt es ja, denn es gibt in Mono auch Windows Forms.
Immerhin können mit WPF und Windows Forms auf .NET Core aber Softwarehersteller, die nicht an Plattformneutralität interessiert sind, ihre bestehenden Windows-Anwendungen auf .NET Core auf Windows (ab Windows 7 bzw. Server 2008 R2 – auf älteren Windows-Versionen läuft .NET Core heute nicht!) betreiben und damit von den Vorteilen profitieren, die .NET Core im Bereich der Werkzeuge, der Geschwindigkeit und der Softwareinstallation bietet. Neben den schon existierenden Deployment-Optionen für .NET Core als Portable App oder Self-contained App will Microsoft einen neuen .NET Core App Bundler schreiben, der per Tree Shaking nicht notwendigen Programmcode (Dead Code) aus der Intermediate Language herauszieht. Am Ende entsteht – wie bei UWP-Apps – nur noch eine ausführbare Datei, die nur den tatsächlich verwendeten Programmcode enthält.
WPF- und Windows-Forms-Anwendungen müssen für .NET Core 3.0 neu kompiliert werden. Ob dazu Änderungen am Programmcode notwendig sein werden, hat Microsoft noch nicht klar dementiert. Aktuell gibt es noch keine öffentliche Previewversion von .NET Core 3.0. Eine fertige Version soll im ersten Quartal 2019 erscheinen. Man kann an diesem Zeitplan durchaus Zweifel haben. Microsoft will bei der Gelegenheit das klassische ADO.NET Entity Framework umschreiben (Abb. 2), sodass es auf .NET Core 3.0 auf Windows läuft, da viele Desktopanwendungen darauf basieren. Angekündigt ist auch eine Erweiterung des .NET-Standards im Rahmen von .NET Core 3.0.
Anfang August hat Microsoft den .NET Portability Analyzer aktualisiert, sodass dieser nun schon die für .NET Core 3.0 geplanten Klassen berücksichtigt. .NET-Entwickler können somit schon sehen, ob ihre WPF- und Windows-Forms-Anwendungen unter .NET Core 3.0 laufen werden. Microsoft kann mit dem Werkzeug sehen, welche Klassen bei Kunden im Einsatz sind und ggf. die Entscheidung für die Klassen in .NET Core 3.0 auf dieser Basis ändern. Anders als zunächst angekündigt, läuft .NET Portability Analyzer aber noch nicht auf einem Prototyp von .NET Core 3.0, sondern auf dem klassischen .NET Framework.
Eine weitere Ankündigung in diesem Zusammenhang sind die UWP-XAML-Inseln. Damit können Entwickler UWP-Steuerelemente in WPF- und Windows-Forms-Fenster einbinden. Das setzt dann noch engere Grenzen, denn UWP gibt es nur auf Windows 10. Wer den Luxus hat, nur noch für Windows 10 entwickeln zu können, kann dann Steuerelemente wie das Edge Browser Control oder das UWP-Stifteingabesteuerelement in seine alten GUIs einbinden. Das soll einfach per Drag-and-drop aus der Visual-Studio-Werkzeugleiste gehen. Diese UWP-XAML-Inseln will Microsoft nicht nur in .NET Core 3.0, sondern in der kommenden Version 4.8 des klassischen .NET Framework erlauben.
Es tut sich eine Menge bei .NET Core und das ist auch gut so. Es ist wichtig, dass Microsoft baldmöglichst allen Entwicklern ermöglicht, auf .NET Core zu setzen, damit man spätestens 2019 keine neuen Projekte mehr im klassischen .NET Framework beginnen muss.
Natürlich gab es nach den Ankündigungen von Windows Compability Pack, Windows Forms und WPF auf .NET Core nur für Windows sofort Skeptiker, die aufschrien, dass Microsoft die Plattformunabhängigkeit von .NET Core beerdige. Nein, das tun sie nicht.
ASP.NET Core und Konsolenanwendungen laufen auch weiterhin plattformunabhängig auf Windows, Linux und macOS. Microsoft dehnt nur die Einsatzszenarien für .NET Core auf die Entwickler aus, die weiterhin nur für Windows entwickeln können oder wollen. Und auch das ist – ich wiederhole mich – gut so!
The post .NET Core 2.1, 2.2 und 3.0 – neue Funktionen appeared first on BASTA!.
]]>The post Interview | Cloud Native – Buzzword oder echte Innovation? appeared first on BASTA!.
]]>In seiner Keynote spricht Rainer Stropek darüber, was bei Cloud Native anders läuft. Als Ausgangspunkt verwendet er reale Anforderungen aus einem seiner Praxisprojekte. Darauf aufbauend zeigt er, wie eine typische Cloud-Native-Softwarearchitektur aussieht und welche Auswirkungen die Architektur- und Designentscheidungen auf die Projektorganisation und den Anwendungsbetrieb haben.
Rainer Stropek zeigt in seiner Keynote wichtige Tipps und Tricks, wie Entwickler aus der Cloud das Maximum herausholen, die Hürden, die es natürlich auch dort gibt, erfolgreich meistern und so neue Möglichkeiten praktisch nutzen können. Die Cloud bietet für Entwickler viele Services, APIs und ganze Softwarelösungen, die entweder den Arbeitsalltag praktisch unterstützen oder neuartige Produkte überhaupt erst möglich machen. Dazu muss man nicht immer gleich zu 100 Prozent in die Cloud und sie bei der zunehmenden Komplexität auch nicht vollständig verstehen. Es wird immer wichtiger, aus dem wachsenden Angebot genau das herauszufinden, was die eigene Arbeit effektiv unterstützt. Dabei können Zeit-, Kosten- oder Aufwandseinsparungen im Vordergrund stehen; wichtig ist es, den Weg in Cloud grundsätzlich in Betracht zu ziehen – für Sie selbst und Ihre Kunden.
Auch auf der BASTA! Spring 2019 zeigen zahlreiche Sessions, wie Sie als Entwickler die Cloud sinnvoll und praxisorientiert einsetzen können.
Lesen Sie mehr zu diesem Thema in unserem Blogartikel “Die Cloud-Perslektive: Warum Benutzer Software oft ganz anders sehen als wir Entwickler”.
The post Interview | Cloud Native – Buzzword oder echte Innovation? appeared first on BASTA!.
]]>The post Die Cloud-Perspektive: Warum Benutzer Software oft ganz anders sehen als wir Entwickler appeared first on BASTA!.
]]>Dass im Hintergrund eine beachtliche Softwareinfrastruktur für Abonnementverwaltung, Rechnungslegung, Supportportal, Kreditkartenabrechnung, Monitoring, Automatisierung von Administrationsprozessen etc. notwendig ist, ist den Endbenutzern ziemlich egal. Strom kommt verlässlich aus der Steckdose und Software stabil aus der Cloud – das ist die Erwartungshaltung, und das sollte ein guter SaaS-Anbieter auch anstreben.
Hinzu kommt, dass viele Softwareprodukte gleichzeitig ganz unterschiedliche Typen von Benutzern adressieren. Ein Administrator im Backoffice, der vor zwei großen Monitoren sitzt und mit Maus und Tastatur arbeitet, hat ganz andere Bedürfnisse als eine Benutzerin, die in entlegenen Gegenden von Kunde zu Kunde fährt, um dort mithilfe mobiler Geräte und der SaaS-Softwarelösung ihren Job zu machen.
Als Technikerinnen und Techniker, die an der Erstellung der SaaS-Lösung arbeiten, vergessen wir manchmal die Sichtweise unserer Endbenutzer. Wir haben ständig das Gesamtsystem im Kopf. Im Mittelpunkt unserer Aufmerksamkeit stehen beispielsweise Dinge wie die folgenden:
Benutzer nähern sich einer SaaS-Lösung anders: Für sie zählt, ob die Software ihre konkreten Probleme löst. Hier einige Beispiele:
Als SaaS-Anbieter sind wir stolz, wenn wir eine Plattform geschaffen haben, die technisch und vom Geschäftsmodell her richtig gut skaliert. Kunden wertschätzen unsere Investitionen aber nur bedingt. Sie sehen nur die Spitze des Eisbergs: die für sie in der täglichen Arbeit relevanten Funktionen. Sie vergleichen die SaaS-Lösung mit einem System, das ihr eigenes IT-Team für sie aufbauen könnte. Ist der Kunde mittelgroß und hat ein engagiertes, schlagkräftiges IT-Team, ist es als SaaS-Anbieter nicht immer einfach, mitzuhalten. Die lokale IT kann locker auf individuelle Anforderungen eingehen, sie braucht keine komplizierte Abonnementverwaltung, sie muss sich nicht mit Verträgen zur Auftragsdatenverarbeitung herumschlagen und so weiter.
Jeder SaaS-Anbieter möchte natürlich möglichst viele Kunden haben. Zehn- oder hunderttausende Abonnements zu verkaufen, klingt verlockend, hat aber massive Auswirkungen, was die initiale Investition in Softwareentwicklung und den organisatorischen Aufbau betrifft.
Meiner Ansicht nach ist es wichtig, dass es bei jedem SaaS-Anbieter Personen gibt, die sich laufend in die Rolle der Endbenutzer versetzen. Dabei muss beachtet werden, dass nicht alle Benutzer über einen Kamm geschoren werden dürfen. Die besten SaaS-Teams haben detaillierte Personas ausgearbeitet. Eine Persona stellt einen Prototyp für eine Gruppe von Nutzern dar, mit konkret ausgeprägten Eigenschaften und einem konkreten Nutzungsverhalten. Sie verwenden die Personas, um bei der Produktplanung sicherzustellen, dass laufend Verbesserungen für alle Benutzergruppen spürbar sind.
Manchmal kommt es bei konsequenter Orientierung an Personas zu anderen Lösungen, als sie Technikerinnen und Techniker sonst gestalten würden. Das Technikteam hat, wie oben erwähnt, immer die Gesamtlösung im Kopf und würde vielleicht dazu tendieren, ein einheitliches UI für alle Benutzergruppen zu erstellen, in dem man über Benutzerberechtigungen den Zugriff auf die jeweils relevanten Module steuern kann. Aus Benutzersicht ist diese Integration möglicherweise unnötig oder sogar kontraproduktiv. Während der eine Benutzer für seine Szenarien ein leichtgewichtiges, für das Smartphone optimiertes UI will, möchte ein anderer ein Desktop-UI, das die Leistungsfähigkeit seines lokalen Computers optimal ausschöpft. Für beide Personas sind die Funktionen der jeweils anderen Benutzergruppe größtenteils irrelevant. Der Technologiebruch ist ihnen egal. Sie haben ihre ganz individuelle Sichtweise auf die SaaS-Lösung. Nebenbei gesagt: Diese Erkenntnis passt übrigens wunderbar zum Architekturkonzept der Microservices.
Die besten Produktplanungsteams sorgen außerdem bei Weiterentwicklungen für eine ausgewogene Balance aus Investition in die SaaS-Infrastruktur im Hintergrund (nur indirekt sichtbar für den einzelnen Kunden) und neue Funktionen mit konkreten Auswirkungen auf Endbenutzer.
Es ist gut, wenn die Personen, die sich bei SaaS-Anbietern um die Produktplanung kümmern, nicht zu tiefes IT-Know-how haben. Ein Grundverständnis für IT, SaaS und Cloud-Computing ist unverzichtbar, da ansonsten die technische Weiterentwicklung unterrepräsentiert ist und man binnen weniger Jahre auf einem veralteten Berg Software sitzt. Aus eigener, schmerzhafter Erfahrung weiß ich aber, dass zu techniklastiges Produktmanagement Gefahr läuft, sich in technischen Spielereien zu verlieren. Funktionale Anforderungen und organisatorische Rahmenbedingungen werden vernachlässigt. Am Ende hat man eine SaaS-Plattform, die zwar Unmengen an Kunden verkraften würde, aber das Marktpotenzial vertrieblich nicht ausschöpfen kann.
Einen SaaS-Anbieter, der auf eine große Kundenbasis abzielt, kann man mit einem Hersteller von Massenware vergleichen. Vermarktet wird ein relativ stark standardisiertes Produkt, das dank Economy-of-Scale zu einem attraktiven Preis angeboten werden kann. Diese Tatsache sollte man nicht verschweigen, ganz im Gegenteil. Kunden, die sich für ein SaaS-Standardprodukt entscheiden, wissen aus anderen Lebensbereichen, worauf sie sich einlassen. Ihnen ist klar, dass ein BILLY-Regal von Ikea etwas anderes ist als ein individuell vom Tischler hergestelltes Bücherregal.
Erfolgreich sind SaaS-Angebote dann, wenn sie konsequent an den Bedürfnissen der Endbenutzer ausgerichtet werden und sich die Herstellerteams nicht ganz und gar in der Optimierung der Softwareinfrastruktur verlieren, die im Hintergrund arbeitet. Wenn das gelingt, erhalten die Kunden durch SaaS eine Softwarelösung, die in Sachen Preis-Leistungsverhältnis von keiner On-Premises-Software geschlagen werden kann.
Wie Entwickler die Cloud als neuen Entwicklungsraum erobern können präsentiert Rainer Stropek in der Eröffnungskeynote „Cloud Native – Buzzword oder echte Innovation?“. Und noch mehr Informationen finden Sie im neuen Cloud Developer Day am Mittwoch.
The post Die Cloud-Perspektive: Warum Benutzer Software oft ganz anders sehen als wir Entwickler appeared first on BASTA!.
]]>The post DevOps und Microsoft – ein neuer Wind appeared first on BASTA!.
]]>Bei Microsoft hat sich in den letzten Jahren auf Unternehmensebene ein ganz neues Selbstverständnis entwickelt und auch das Mindset der Mitarbeiter hat sich verändert. Heute arbeiten viele kleine interdisziplinäre Teams zusammen. In der Konsequenz führt das auch zu Produkten, die die neue Vision des Unternehmens widerspiegeln.
Neno Loje beschreibt am Beispiel von Microsoft die Reise eines Unternehmens zur Agilität, die Auseinandersetzung mit Themen wie Open Source, Git und DevOps, und wie diese konkret/praktisch Einzug in die Visual-Studio-Produktpalette und den Alltag von Entwicklern halten. Nicht zuletzt ist auch die geplante Übernahme von GitHub durch Microsoft ein deutliches Zeichen dafür, wohin der Weg für Entwickler im Hinblick auf bessere Zusammenarbeit und Open-Source-Entwicklung geht.
Als Entwickler fragt man sich vielleicht: „Wie kommt das, was hier unter meinen Fingern entsteht, am schnellsten und besten zu meinen Kollegen und zu meinen Kunden?“ Die Antworten darauf haben sich in den letzten Jahren immer wieder geändert, aber aktuell ist ein Schlagwort dazu DevOps. Dahinter steckt zunächst die Idee, dass Developer und Operations eng zusammenarbeiten, um Produkte möglichst reibungslos auf den Markt zu bringen. Das Ziel ist wie immer, Produkte in der Qualität und in einer Geschwindigkeit zu erstellen, die am Ende alle zufriedenstellt. Wie immer müssen dabei viele Elemente unter einen Hut gebracht werden: Kompetenz, Tools, Methoden, Ziele und Menschen. Vor allem Letztere, denn am Ende sind es eben Menschen, die die Produkte herstellen und nutzen. Auf der Basis von Agilität mit ihren vielen Richtungen wie XP, Scrum oder Kanban lassen sich da schon viele Hürden nehmen; diesen Weg ist auch Microsoft gegangen. Aber wer wie Microsoft mehr will, spricht dann eben nicht mehr von ALM und Agilität, sondern geht einen Schritt weiter und macht DevOps. In der einfachen Variante heißt das, Developer und Operations werfen sich nicht wechselseitig Fehler vor, sondern setzen sich zusammen und versuchen in einem iterativen Verbesserungsprozess, ihre Software und ihre Arbeitsweise kontinuierlich weiterzuentwickeln. In einer erweiterten Variante sind auch der Vertrieb, die Geschäftsleitung, die Partner und die Kunden an diesem Kommunikationsprozess beteiligt. Womit aus einem Prozess, der zunächst nur die IT betrifft, ein Prozess wird, der Grenzen überschreitet und zu einem Kulturwandel für das Unternehmen und den Markt führt. Im Fall von Microsoft z. B. in der Form, dass Sie als Entwickler mit den Tools von Microsoft und in der Art und Weise, wie diese für Sie bereitgestellt werden, bzw. welche Möglichkeiten Sie Ihnen bieten, neue Wege finden, Ihre Ziele zu erreichen.
Dabei ist DevOps vielleicht nur ein kleiner, konzeptioneller Aspekt, aber die Neuerungen in Visual Studio, TFS oder Azure haben für Sie immense praktische Auswirkungen. Wie das im Einzelnen aussieht, zeigen zahlreiche Sessions der BASTA! wie auch diese vier Special Days, von denen jeder einzelne die Facetten von DevOps aus seiner Perspektive betrachtet und die Wichtigkeit des Themas unterstreicht: TFS & DEVOPS DAY, CLOUD DEVELOPER DAY, AGILE TESTING DAY, AGILE DAY.
Wenn Sie alles in einem Paket haben wollen, besuchen Sie am besten den Power Workshop von Neno Loje und Dr. Holger Schwichtenberg: DevOps live Workshop – Continuous Deployment und Continuous Delivery für .NET-Core- und Angular-Anwendungen.
The post DevOps und Microsoft – ein neuer Wind appeared first on BASTA!.
]]>The post Docker-Grundlagen für .NET-Entwickler appeared first on BASTA!.
]]>In den vergangenen Jahren ist die Beliebtheit von Docker stetig gestiegen. Applikationen werden in einem Container ausgeführt und können somit auf beliebigen Umgebungen „angedockt“ werden. Das klingt ja ganz spannend. Aber warum sollte das einen .NET Entwickler interessieren, ist das denn überhaupt wichtig für den Entwicklungsalltag? Wieso ist Docker auch für uns eine solche Revolution?
Bei Docker geht es primär um das Verteilen von Anwendungen und Diensten, das sogenannte Deployment. Doch wie wurde das eigentlich früher gemacht? Nehmen wir an, ein Entwickler will seine frisch erstellte .NET-Webapplikation einer Kollegin zum lokalen Testen geben. Ganz früher war es noch so, dass die Kollegin zur Installation eine Anleitung mit Voraussetzungen und ggfs. auch manuelle Skripte bekam. Da stand dann z. B. in der Anleitung, dass Windows als Betriebssystem benötigt wird, dass das .NET Framework in einer bestimmten Version installiert sein muss, dass zur Ausführung eine bestimmte Datenbank benötigt wird usw. Es wird also für die Kollegin ein mühsames und aufwändiges Unterfangen, die Webapplikation lokal zum Laufen zu bekommen.
Im Laufe der Jahre hat sich das Ganze vereinfacht, indem man mit virtuellen Maschinen gearbeitet hat. Ja, viele Entwickler machen das natürlich auch heute noch. In der virtuellen Maschine wird die .NET-Webapplikation mit allen Abhängigkeiten installiert. Jetzt kann der Entwickler seiner Kollegin einfach die virtuelle Maschine geben, die Kollegin startet sie und hat somit eine lauffähige Applikation, die sie innerhalb der VM testen kann – ein deutlicher Fortschritt. Doch auch hier gibt es noch einen kleinen Haken: Die eigentliche Anwendung ist in der Praxis meist nur ein paar Megabytes groß, wenn überhaupt. Zur Größe der Anwendung kommen noch ein paar Abhängigkeiten, wie ein Webserver und eine Datenbank. Doch die virtuelle Maschine selbst beinhaltet ja noch das Gastbetriebssystem, und das nimmt üblicherweise gleich mal einige Gigabytes in Anspruch. Dass man der Kollegin die beispielsweise 100 GB große virtuelle Maschine für eine Anwendung geben muss, die mit ihren Abhängigkeiten nur einen Bruchteil dieser Größe hat, ist natürlich nicht ideal. Geht man sogar noch davon aus, dass man verschiedene Applikationen mit unterschiedlichen Abhängigkeiten hat, dann braucht es vielleicht sogar mehrere virtuelle Maschinen, um für jede Applikation eine zu haben. Wer kennt es nicht, dass die Festplattengröße des Entwicklungsrechners da oft ein Problem darstellt. Neben dem Datenvolumen einer VM ist auch das Startverhalten ein Kritikpunkt. Es dauert meist eine kleine Weile, bis das Betriebssystem hochgefahren ist. Doch warum brauche ich überhaupt ein zusätzliches Betriebssystem, wenn die Kollegin auf ihrem Rechner doch schon eins hat? Das ist eine sehr gute Frage, und das ist der Punkt, an dem Docker ins Spiel kommt.
Mit Docker lassen sich alle Abhängigkeiten einer Anwendung in einem sogenannten Docker Image abbilden. Aus einem Image lässt sich dann eine Instanz erzeugen, die als Container bezeichnet wird. Um eine Applikation mit allen Abhängigkeiten an eine Kollegin zu geben, wird ein Docker Image bereitgestellt. Die Kollegin kann das Docker Image dann in Form eines Containers lokal auf ihrem Rechner ausführen. Doch was ist jetzt genau der Unterschied zwischen einem laufenden Docker-Container und einer laufenden virtuellen Maschine? Der große Unterschied ist, dass der Docker-Container im Gegensatz zur virtuellen Maschine kein eigenes Betriebssystem hat. Anstelle eines Gastsystems wie bei einer virtuellen Maschine, wird bei einem Docker-Container direkt das Betriebssystem des Hosts genutzt, das sogenannte Host-OS. Abbildung 1 verdeutlicht den Unterschied zwischen einer virtuellen Maschine und einem Docker-Container.
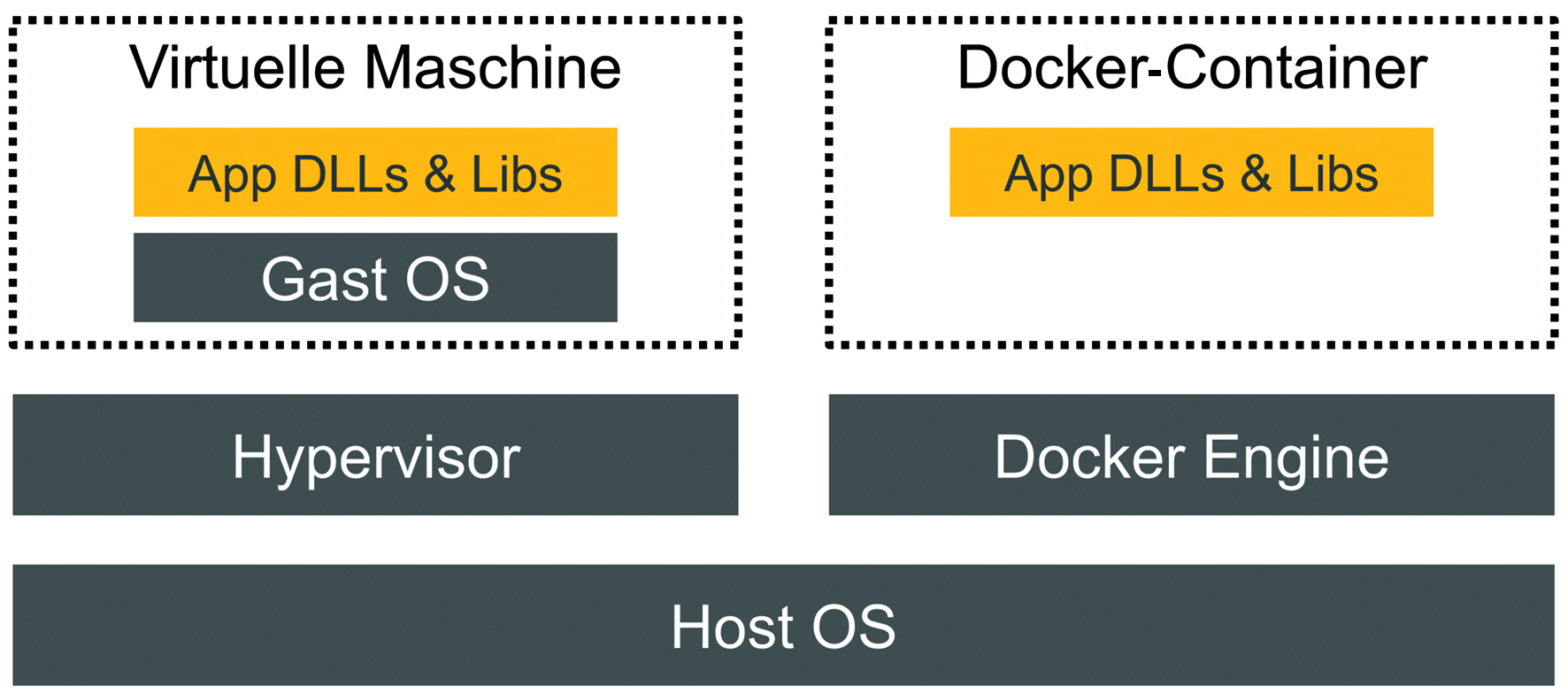
Wie Abbildung 1 zeigt, benötigt eine virtuelle Maschine den sogenannten Hypervisor, der die Ressourcen des Hosts bereitstellt. Auch ein Docker-Container benötigt etwas ähnliches, die sogenannte Docker Engine. Die stellt den Zugriff auf den Kernel des Host-Betriebssystems sicher und ist in der Lage, Container zu erstellen, zu starten und zu stoppen. Aufgrund der Tatsache, dass ein Docker Image und somit auch ein daraus erstellter Docker-Container kein eigenes Betriebssystem mit sich bringt, sondern auf dem Host-Betriebssystem aufgesetzt wird, ist ein Docker Image sehr viel kleiner als eine virtuelle Maschine. Neben der Größe ist das schnelle Starten eines Docker-Containers ein weiterer großer Vorteil gegenüber einer virtuellen Maschine. Beim Starten eines Containers muss nicht ein ganzes Betriebssystem hochgefahren werden. Somit geht das Starten und Stoppen eines Containers ungewohnt schnell, es gleicht dem Starten und Stoppen eines Prozesses.
Um also Docker-Container ausführen zu können, wird die Docker Engine benötigt. Auf jedem Rechner, auf dem eine Docker Engine installiert ist, lassen sich Docker-Container ausführen. Es ist also an der Zeit, die Docker Engine auch auf dem eigenen Entwicklungsrechner zu installieren.
Nach der Installation ist Docker auf der Kommandozeile verfügbar und es kann losgehen. Wie in Abbildung 2 zu sehen ist, läuft die Docker Engine auf Linux, das als Operating System (OS) angegeben ist.

Beim Installieren von Docker stand die Option USE WINDOWS CONTAINERS INSTEAD OF LINUX CONTAINERS zur Verfügung. Docker wurde ursprünglich auf Linux aufbauend eingeführt, Windows-Container kamen erst später dazu. Da mit der Defaultinstallation Linux-Container verwendet werden, bedeutet das, dass Images und daraus instanziierte Container Linux-basiert sind und somit den Linux-Kernel des Hostbetriebssystems verwenden. Doch wo ist dieser Linux-Kernel unter Windows? Im Hintergrund hat die Docker-Installation eine virtuelle Maschine mit Linux installiert, damit sich auf einen Windows-Betriebssystem auch Linux-basierte Container starten lassen. Wird unter Windows der Hyper-V-Manager geöffnet, ist die von Docker installierte und genutzte Linux VM zu sehen, sie trägt den Namen MobyLinuxVM.
Im Icon Tray von Windows – das ist der Bereich rechts unten in der Taskbar links von der Uhr – ist nach einer erfolgreichen Installation und einem erfolgreichen Start der Docker Engine ein Docker-Icon zu sehen. Es repräsentiert die installierte Docker Engine und hat die Form des klassischen Walfischs mit Containern an Bord. Ein Rechtsklick auf dieses Icon zeigt ein Kontextmenü, das unter anderem einen Eintrag enthält, um von Linux-Containern auf Windows-Container umzusteigen.
Doch Linux-Container sind die übliche Variante. Ein Linux-Container kann zwar kein .NET Framework beinalten, da das nur unter Windows läuft. Aber .NET Core ist ein ideales Mittel, um .NET-Applikationen auch in einem Linux-Container auszuführen, da .NET Core ja eine modulare Cross-Platform-Implementierung von .NET ist, die unter Windows, Mac OS und Linux läuft. Jetzt dürfte auch klar sein, wieso die Cross-Platform-Fähigkeit von .NET Core so wichtig ist. Sie macht .NET Core zu einem wichtigen Framework für containerbasierte Applikationen, unabhängig davon, ob es sich um Linux- oder Windows-basierte Container handelt.
Visual Studio enthält eine integrierte Unterstützung für Docker. Wird eine neue ASP.NET-Core-Webapplikation erstellt, gibt es dort im Dialog eine Checkbox, um die Docker-Unterstützung zu aktivieren. Wurde diese Auswahl beim Erstellen des Projekts nicht getroffen, lässt sie sich auch im Nachhinein noch aktivieren. Dazu genügt ein Rechtsklick auf das Projekt im Solution Explorer. Über das Kontextmenü und den Menüpunkt ADD | DOCKER SUPPORT wird die Docker-Unterstützung hinzugefügt (Abb. 3). Unmittelbar nach einem Klick auf diesen Menüpunkt erscheint ein Dialog, der eine Auswahl zwischen Windows und Linux erlaubt. Darüber wird definiert, was für eine Art von Container erstellt wird.
Neben dem Deployment für produktive Applikationen ist Docker ideal, um Entwicklungs- und Testumgebungen aufzusetzen. Auf dem Docker Hub gibt es Datenbanken und andere Services, die das Entwicklerherz höherschlagen lassen. Haben Entwickler erst einmal mit Docker angefangen, sind vermutlich die Tage gezählt, an denen sie SQL Server direkt auf ihrem Entwicklungsrechner installiert haben. Stattdessen läuft das Ganze in einem Container. Unterschiedliche Versionen lassen sich somit problemlos parallel installieren, starten, stoppen und auch wieder entfernen.
Die Mächtigkeit von Docker macht virtuelle Maschinen weitestgehend überflüssig und bringt uns im 21. Jahrhundert endlich an den Punkt, an dem wir tatsächlich von echten Softwarekomponenten sprechen können. Es ist an der Zeit, sich mit dem Thema Docker auseinanderzusetzen, denn in Zukunft wird vermutlich kein Entwickler daran vorbeikommen.
Die vollständige Einführung in Docker für .NET-Entwickler von Thomas Claudius Huber bietet die aktuelle Ausgabe des Windows Developers „Docker für .NET-Entwickler“. Noch mehr Wissenswertes zum Thema finden Sie in den Artikeln zu Windows- oder Linux-basierten Containern von Dr. Holger Schwichtenberg und Serverless Containern in Azure von Rainer Stropek.
Noch weiter vertiefen können Sie Ihr Docker-Wissen in den praxisorientierten Sessions von Marc Müller und Thorsten Hans auf der BASTA!. Bis dahin behalten Sie mit dem Docker-Spickzettel von Dr. Holger Schwichtenberg alles Wichtige zu Docker im Blick.
● .NET-Core-Anwendungen skalierbar betreiben mit Kubernetes und Microsoft Azure
The post Docker-Grundlagen für .NET-Entwickler appeared first on BASTA!.
]]>The post Top 20 Social Influencers in .NET Development 2018: Wer die Community prägt appeared first on BASTA!.
]]>The .NET, Windows & Open Innovation Conference BASTA! proudly presents the top 20 social influencers regarding the Microsoft and .NET World. All influential people have something in common: they can spread ideas faster and better than anyone else. We are aware that following those people has a handful of perks, including staying on top of the latest news and trends. Therefore, we decided to compile a list of Twitter accounts all Microsoft and .NET fans should follow.
This list was created by analysing thousands of twitter profiles extracting the MozRank and Kred scores which rank both quality and influence.
If we missed anybody, it has nothing to do with the fact that we don’t think that they are just as important or shareworthy as any person on this list. We ourselves though do believe that such analytical lists do have the right to exist and furthermore we at BASTA! follow the listed speaker on their social channels and enjoy their quality content.
We congratulate everyone who made it on this list. If you click on the name or on the picture of each speaker you will be redirected to their twitter profile and check out the useful information they share every day.
Enjoy!
We first generated a list of two thousand .NET-related Twitter accounts.
To score the account and rank them accordingly, we analyzed their social authority and reach using two key metrics: MozRank and Kred.
Moz Social Authority Score: Social Authority score is composed of:
Visit this MOZ blog post for more in-depth information.
Kred Score: Kred Influence Measurement, or Kred, is a website created by PeopleBrowsr that attempts to measure online social influence. Read more in the Kred scoring guide.
Congratulations to all the influencers who have made it into our Top 20!

To visit the associated Twitter profiles, just click on the respective portraits. We hope you enjoy exploring new perspectives and find some inspiration.
Daniel Rubino @Daniel_Rubino
Editor-in-chief of Windows Central. Full-time curmudgeon, science geek and play-acting anarchist. HoloLens user. [email protected]
The post Top 20 Social Influencers in .NET Development 2018: Wer die Community prägt appeared first on BASTA!.
]]>The post Moderne Anwendungen vom Backend bis zum Frontend appeared first on BASTA!.
]]>
Die Erwartungen an typische Businessanwendungen verändern sich schon seit Jahren. Der einfache Windows-Client, entwickelt mit WPF oder vielleicht schon UWP, reicht in vielen Fällen nicht mehr aus. Zum einen müssen Anwendungen oftmals Mobile sein, zum anderen müssen sie auf anderen Plattformen laufen.
Aus Sicht klassischer .NET-Entwickler ist das klar eine Herausforderung, aber kein wirkliches Problem. Es gibt heute viele Wege, wie .NET-Entwickler in ihrer gewohnten Umgebung und mit ihrer Kompetenz mit dem Microsoft-Tooling- und -Sprachenkit von Native bis Cross-Plattform entwickeln können.
So ist es möglich, auch geschäftlichen Anwendern den Komfort eines gesicherten Zugriffs auf Firmendaten von Desktops, Laptops, iOS- und Android-Geräten und aus dem Browser heraus zu bieten. Die Daten können sicher und hochverfügbar über Services bereitgestellt werden – lokal oder über die Cloud. Und gerade in diesem Bereich hat sich in den Köpfen der Entwickler wie auch beim Angebot von Microsoft viel getan.
Ein Punkt, den Christian Weyer im Interview besonders hervorhebt, sind die Vorteile von Progressive Web Apps (PWA). Sie sind gespickt mit nativen Features, egal ob für Mobile oder Desktop. Man kann sie als den letzten konsequenten Schritt ansehen, der noch gefehlt hat, um vom Backend mit .NET bis zum Frontend im Browser Cross-Plattform endlich zu verwirklichen. Andere neue Entwicklungen wie WebAssembly und Blazor zur Ausführung von .NET-Anwendungen im Browser verstärken den Trend in eine Zukunft, die vielleicht sogar Serverless und „Appstoreless“ sein wird.
Auf der BASTA! können Sie einen Blick in diese Zukunft werfen und sie ein Stück weit schon erfahren. Nicht nur im Modern Business Applications Day, sondern auch im Cross-Plattform Applications Day, dem Web Dev Day und zahlreichen weiteren Sessions.
The post Moderne Anwendungen vom Backend bis zum Frontend appeared first on BASTA!.
]]>The post Ich weiß nicht, ob Sie es wussten: Aber Linux, das braucht jetzt jeder appeared first on BASTA!.
]]>Im Februar 2018 habe ich einige Recherchen angestellt, und daraus ergab sich, dass Linux 96 Prozent der populärsten Million Domains im Internet betreibt. Seit November 2017 laufen alle 500 schnellsten Supercomputer der Welt mit Linux, und aufgrund der Verbreitung von Android ist die Verbreitung bei Mobilgeräten mit etwa 70 Prozent angenommen. Das System unterstützt mehr als 30 Prozessorplattformen, und ein Kernelrelease kommt im Schnitt mit etwa 10 000 Patches daher, die von mehr als eintausend Personen zur Verfügung gestellt werden.
Sehr beeindruckende Zahlen! Aber nun zurück zu dem, was man über Linux wirklich wissen sollte. Zunächst ist da der Aufbau des Systems, mal ganz grob. Linux selbst ist eigentlich nur der Kernel (Kern), in dem z. B. Dateisystemstreiber und ähnliche Komponenten auf unterster Ebene enthalten sind. Na gut, eine Zahl noch: Der Kernel hat derzeit mehr als 20 Millionen Zeilen Code!
Zu einem typischen, auf Linux basierenden System braucht man natürlich noch vieles mehr, und das kommt alles aus dritter Hand, also aus anderen Open-Source-Projekten. Spezifische Treiber für Hardware, System- und Anwendungssoftware, Shells für den Umgang mit der Kommandozeile, grafische Oberflächen, Paketverwaltung und vieles mehr ist getrennt vom Kernel zu sehen. Trotzdem ist meistens, wenn der Begriff Linux verwendet wird, ein Gesamtsystem aus all diesen Elementen gemeint. Tatsächlich handelt es sich bei einem solchen Gesamtsystem gewöhnlich um eine Distribution, wie sie von verschiedenen Anbietern zusammengestellt wird. Diese Anbieter sorgen dafür, dass sämtliche enthaltene Software auf aktuellem Stand ist, dass Abhängigkeiten zwischen Software und Systembibliotheken korrekt aufgelöst werden können, dass es einen schönen bunten Installer für das System gibt sowie regelmäßige Updates.
Nun bin ich schon oft gefragt worden, warum ein .NET-Entwickler irgendwas zu Linux wissen sollte oder gar das System selbst im Alltag einsetzen. Nun, dazu gibts viele Antworten. Zum Beispiel ist Linux eine großartige Ausführungsplattform – schnell, performant, skalierbar und gratis! Natürlich ist das Adjektiv „gratis“ mit Vorsicht zu genießen: Die Pflege jedes Systems kostet schließlich Geld. Aber gerade in modernen Cloud-Umgebungen ist es letztlich so, dass Systeme einfach und ersetzbar sein sollen. Mit Linux fließen keine Lizenzgebühren an einen Hersteller, sodass eine Linux VM immer weniger kostet als eine mit Windows.
Ich selbst verwende Linux im Alltag, auf meinem Computer im Büro wie auch auf meinem Laptop. Ich bin Enthusiast und ich bin ein fortgeschrittener Anwender, mit mehr Bedürfnissen und Erwartungen an mein System der Wahl, dessen Flexibilität und Anpassbarkeit an meine Arbeitsweise. Mit Linux habe ich ein System gefunden, das ich überall einsetzen kann, in großen und kleinen Umgebungen, konsistent und flexibel, standardkonform und anpassbar. Kurz: Linux tut genau, was ich will.
Wenn Sie selbst Linux einmal ausprobieren wollen, haben Sie heute mehrere Möglichkeiten. Die beste ist, eine Distribution herunterzuladen (ich empfehle Ubuntu, für den allgemeinen Einsatz wie auch für den Einsteiger) und zu installieren. Das gelingt mit einem USB-Stick auf einem alten Laptop, oder auch einfach mit einem ISO-Image in einer VM. Bei der Installation passiert nichts, das einem geübten Computernutzer Sorgen bereiten sollte.
Alternativ können Sie auch eine virtuelle Maschine in der Cloud starten. Ob Azure, Amazon oder andere Anbieter, Linux-VMs sind in der Cloud einfach und schnell zu starten und kosten wenig. Mit einer solchen virtuellen Umgebung verbinden Sie sich im Anschluss mit SSH, der Secure Shell – dazu gleich etwas mehr.
Als letzte Variante zum Einstieg sei noch erwähnt, dass für Windows 10 und Windows Server auch das Windows Subsystem for Linux (WSL) verfügbar ist. Sie müssen dazu den Developer Mode auf diesen Systemen aktivieren und dann bash.exe ausführen, um etwa Ubuntu zu installieren. Alternativ können Sie auch andere Distributionen für WSL aus dem Microsoft Store herunterladen.
Ein wesentlicher Unterschied zwischen einer Installation auf eigener Hardware oder in einer lokalen VM und den Varianten in der Cloud oder mit WSL besteht in der Bedienoberfläche, mit der Sie konfrontiert werden. Es gibt eine Vielfalt grafischer Oberflächen für Linux, KDE und Gnome, Xfce, MATE, LXDE und viele mehr. Diese Umgebungen enthalten gewöhnlich einen Window Manager (die Komponente, die für den Umgang mit grafischen Fenstern verantwortlich ist) und basieren auf einer bestimmten Philosophie für das visuelle Erscheinungsbild und die Bedienung. Außerdem gibt es, für Entwickler interessant, bestimmte Libraries für Grafikausgabe und andere Systemfunktionalität (etwa GTK und Qt), die direkt mit den grafischen Oberflächen zusammenhängen.
Ich selbst verwende einen eigenständigen Window Manager namens i3, der sich besonders dadurch auszeichnet, dass der Anwender sich gar nicht mit der Maus um die Verwaltung der Fenster kümmern muss – meiner Meinung nach eine große Erleichterung. Darin besteht gerade der Spaß an Linux: Eigene Prioritäten können beliebig einbezogen werden. Anwendungssoftware ist übrigens von der Wahl einer grafischen Oberfläche unabhängig, sie lässt sich immer einsetzen.
Nun gibt es viele Gelegenheiten, zu denen Linux im praktischen Einsatz ohne grafische Oberfläche daherkommt. Das ist etwa bei der Cloud-VM so, aber natürlich auch bei anderen Hosting-Providern und sogar bei WSL. Es gibt sogar Anwender, die den Umgang mit einer Kommandozeile grundsätzlich vorziehen. Ich selbst zähle mich nicht zu Letzteren, aber ich muss sagen, dass unter den Fenstern, die ich im Alltag auf meinem System öffne, sehr viele Kommandozeilen zu finden sind. Tippen geht letztlich oft schneller als Klicken, besonders wenn man weiß, was man tut.
Die Kommandozeile auf einem Unix-System basiert auf der Shell. Die Shell zeigt einen Prompt an (gewöhnlich das aktuelle Verzeichnis im Dateisystem und ein paar andere Details) und erlaubt die Eingabe von Kommandos. Das klingt einfach, aber es gibt viele verschiedene Shells mit unterschiedlichen Prioritäten. Moderne Shells bieten automatische Vervollständigung von Kommandos mit spezifischem Verständnis für gewisse Kommandogruppen (z. B. git), Historie, Verwaltung von Hintergrundprozessen und vieles mehr, und sie können mit Shell-Skripten automatisiert werden, was besonders für Programmierer sehr nützlich ist. Meine persönliche Präferenz ist Zsh, zusammen mit den Plug-ins des Projekts oh-my-zsh.
Eine besondere Shell ist die bereits erwähnte Secure Shell (SSH). Diese baut eine gesicherte Verbindung zu einem anderen System auf (dazu dient ein Schlüssel, basierend auf einem Public-Key-Verfahren – bitte verwenden Sie nicht die einfache Passwortautorisierung!) und startet dort wiederum eine der eben beschriebenen normalen Shells. SSH hat viele weitergehende Mechanismen, die etwa das sichere Kopieren von Dateien ermöglichen oder das Tunneln beliebiger Datenverbindungen durch eine SSH-Verbindung. Für den interaktiven Umgang mit Systemen über SSH empfehle ich auch das Tool tmux (oder alternativ, etwas traditioneller, screen), das eine Art Fensterumgebung an der Kommandozeile ermöglicht, sodass mehrere Shells parallel verwendet werden können.
Das wichtigste Kommando für den Umgang mit einem Unix-System ist man für Manual, also Handbuch oder Anleitung. Mit diesem Kommando können Sie Informationen zur Verwendung anderer Kommandos anzeigen oder auch zu man selbst: man man. Ich empfehle, für alle im folgenden genannten Kommandos man auszuführen, um mehr Details zur Verwendung kennen zu lernen.
Darüber hinaus gibt es viele Standardkommandos, die gewöhnlich kurz benannt sind, damit man sie schneller eintippen kann, und viele mögliche Parameter haben, um Flexibilität zu erzeugen. Shell-Skripte zu schreiben bedeutet größtenteils, parametrisierte Kommandos aneinanderzureihen, bis etwas Nützliches passiert (Tabelle 1 und 2).
| ls | list: Liste von Dateien ausgeben |
| cp | copy: Datei(en) kopieren |
| mv | move: Datei(en) verschieben oder umbenennen |
| rm | remove: Datei(en) löschen |
| mkdir | make directory: Ordner anlegen |
| rmdir | remove directory: Ordner löschen (muss leer sein!) |
| ln | link: Verknüpfungen erzeugen |
| cat | concatenate: Datei(en) ausgeben bzw. aneinander hängen |
| find | Dateien suchen |
| grep | In Dateien suchen |
| less | Inhalte seitenweise anzeigen |
| ps | processes: Prozesse anzeigen |
| cd | change directory: Ordner wechseln |
| alias | Kommandoaliase erzeugen, ausgeben usw. |
Abgesehen von den Kommandos sollten Sie sich auch mit den Möglichkeiten vertraut machen, diese an der Kommondozeile zu kombinieren. Die erste Möglichkeit dafür ist die „Pipe“, dargestellt durch |, mit der die Ausgabe eines Kommandos (stdout) an ein anderes weitergeleitet wird (stdin). Zum Beispiel listet dieses Kommando alle Dateien im Systemverzeichnis /bin auf, zeilenweise in einer Langform, und leitet die Ausgabe dann weiter an less, um sie seitenweise anzuzeigen: ls -l /bin | less. Ein zweites Feature ist die Substitution, wobei die Ausgabe eines Kommandos in ein anderes eingebaut wird. Folgende Zeile verwendet which, um herauszufinden, wo das Kommando cat zu finden ist, und führt dann ls -l aus, um die ausführbare Datei von cat im Dateisystem anzuzeigen: ls -l `which cat`. Für Substitution kann auch diese etwas längere Form verwendet werden, falls der Umgang mit den richtigen Anführungszeichen schwierig ist: ls -l $(which cat)
Im Dateisystem gibt es keine Laufwerkbuchstaben. Stattdessen ist alles als Teil eines Baums organisiert, der bei / beginnt. Man nennt diese Wurzel passenderweise root. Es gibt viele Standardordner und -pfade wie /bin, /etc, /usr/lib und andere, und zusätzliche physikalische oder virtuelle Laufwerke werden in die Hierarchie eingehängt (gemountet). Dazu dient das Kommando mount bzw. die Konfigurationsdatei /etc/fstab.
Datei- und Ordnernamen unterscheiden zwischen Groß- und Kleinschreibung, und wenn sie mit einem . (Punkt) beginnen, werden sie nur von ls angezeigt, wenn die Option -a übergeben wird.
Natürlich sind im Dateisystem Zugriffsrechte wichtig. Wenn Sie sich die Ausgabe des Kommandos ls -l /bin/ls ansehen, finden Sie etwa an erster Stelle diesen kryptisch anmutenden String: -rwxr-xr-x. Unterteilt in drei Gruppen ist hier ersichtlich, welche Rechte der Besitzer der Datei hat (rwx: Read, Write, eXecute), sowie die besitzende Gruppe (r-x) und der Rest der Welt (r-x). Manchmal wird die Angabe auch numerisch dargestellt, sozusagen binär, mit dem Wert 4 für r, 2 für w und 1 für x. Die Rechte, die /bin/ls zugewiesen bekommen hat, können also als 755 geschrieben werden, ein Standardrecht, das besagt, dass jeder die Datei lesen und ausführen darf, aber nur der Besitzer Schreibrechte hat.
Um Berechtigungen zu konfigurieren, gibt es die Kommandos chown (change owner) und chgrp (change group), mit denen der Besitzer bzw. die besitzende Gruppe einer Datei oder eines Ordners gesetzt werden können. chmod ändert die Berechtigungen selbst, mithilfe verschiedener kreativer Parametersyntax. Zum Beispiel erteilt chmod u+x dem Besitzer (u: user) das Ausführungsrecht, chmod +w setzt Schreibrechte für alle drei Berechtigungsebenen, und chmod 644 erteilt explizit das Recht -rw-r–r–. Für Ordner ist es wichtig zu wissen, dass ein Benutzer das Recht x haben muss, damit er in den Ordner hinein navigieren kann (mit cd).
Zum Schluss ist für den Umgang mit Berechtigungen natürlich noch wichtig zu wissen, mit welchem Account Sie eigentlich im System unterwegs sind. Der allmächtige Superuser auf einem Unix-System heißt „root“ und hat die Benutzer-ID 0, aber mit diesem Konto sollten Sie aus Sicherheitsgründen praktisch niemals direkt arbeiten. whoami zeigt an, wie ihr aktueller Benutzer heißt, und Sie können mit adduser, addgroup und usermod andere Konten anlegen und modifizieren. Tatsächlich wird dies allerdings normalerweise fehlschlagen, da Sie als normaler Anwender nicht die Rechte haben, Benutzerkonten zu administrieren. Um temporär mit root-Berechtigungen zu arbeiten, stellen Sie einem Kommando sudo (super user do) voran. Damit können Sie alles machen im System, aber natürlich auch alles zerstören – also bitte Vorsicht!
Das Kommando ps zeigt Prozesse an, die aktuell im System laufen. Alle Prozesse sehen Sie, wenn Sie Optionen angeben: ps aux. top oder htop stellen die laufenden Prozesse tabellarisch dar und bieten interaktive Features, um die Ausgabe zu sortieren oder weitere Details abzurufen.
Mit kill schicken Sie einem Prozess ein Signal, alle Signale können Sie mit kill -l abrufen. Ein Prozess kann generell auf bestimmte Signale reagieren. Oft tut er das allerdings, indem er sich beendet, womit sich der Name des Kommandos erklärt. Um einen hängenden Prozess zu beenden, verwenden sie kill -9. Sie müssen nach dem Signal selbst noch die PID (process ID) des Prozesses übergeben, wie sie in der Ausgabe von ps erscheint. Alternativ können Sie auch skill verwenden, das einen Prozess namentlich identifizieren kann.
Die Konfiguration eines Linux-Systems basiert zum größten Teil auf Textdateien, die im Ordner /etc (und dessen Unterordnern) zu finden sind. Wenn eine Konfigurationsdatei für einen einzelnen Benutzer angepasst werden kann (die man-Page sagt Ihnen das), gibt es oft eine entsprechende Datei mit einem Punkt vor dem Namen im Home Directory des Benutzers. Seit einiger Zeit hat sich auch die Verwendung des Ordners ~/.config verbreitet (also der Ordner .config im Home Directory des Benutzers). In das Home Directory gelangen Sie übrigens am einfachsten, indem Sie cd ohne Parameter ausführen. Gewöhnlich lautet der Pfad /home/, aber ~ (Tilde) ist ein Kürzel, das immer verwendbar ist.
Wenn Sie Konfigurationsdateien bearbeiten, sollten Sie sehr vorsichtig vorgehen, insbesondere bei denen in /etc. Sie können damit sehr leicht zumindest einzelne Systemdienste beschädigen. Trotz dieser Gefahr ist es regelmäßig nötig, solche Dateien zu bearbeiten, und dafür brauchen Sie natürlich einen Editor. Erfahrene Unix-Benutzer unterteilen sich im Allgemeinen in zwei Gruppen: Anwender des Editors vi (oder vim, der moderneren Version davon), und Anwender von Emacs. Beide Editoren sind extrem mächtig, es gibt dazu unter Windows oder anderen Systemen nichts Vergleichbares – gleichzeitig sind sie aber nicht besonders einfach im praktischen Einsatz. Ich empfehle daher den Editor nano für Einsteiger, der gewöhnlich auch von den Distributionen als Standardpaket verfügbar gemacht wird. Der wichtigste Vorteil besteht darin, dass nano die verfügbaren Tastaturkommandos visuell anzeigt und so den Einstieg wesentlich einfacher macht.
Nun fehlen in diesem Rundumschlag für den werdenden Linux-Administrator noch zwei wichtige Informationen. Daher hier erstens ein paar Worte zur Paketverwaltung. Pakete sind die Bausteine jeder Distribution. Sie enthalten Dateien, etwa für ein bestimmtes Programm, und Skripte, die bei der Installation des Pakets und bei anderen Anlässen automatisch ausgeführt werden. Leider gibt es allerdings verschiedene Paketsysteme, je nach der Distribution, für die Sie sich entschieden haben. Für die verbreiteten Distributionen Debian und Ubuntu verwenden Sie das Kommando apt (oder in älteren Versionen apt-get), während bei Red Hat und Derivaten rpm das zentrale Kommando ist. Auf den Webseiten der Distribution sollten Sie die notwendigen Details recht einfach finden können, da die Paketverwaltung ein zentraler Bestandteil des Systems ist.
Der zweite und letzte ausstehende Punkt besteht in ein paar Details auf niedriger Ebene. Zum Beispiel müssen Sie das System eventuell einmal neu starten oder herunterfahren. sudo reboot startet ein Linux-System neu, und sudo shutdown now beendet alle Prozesse, fährt das System herunter und schaltet es aus. Im Verzeichnis /var/log finden Sie Systemprotokolle – dies sollte der erste Anlaufpunkt sein, wenn im System einmal etwas nicht funktioniert!
Nun möchte ich diese Einleitung mit einer Beschreibung der Schritte, die zur Ausführung einer .NET-Core-MVC-Anwendung notwendig sind, abschließen. Wenn Sie dem Beispiel folgen mögen, haben Sie letztlich Ihren ersten eigenen Linux-Server aufgesetzt.
Zunächst benötigen Sie .NET Core selbst. Microsoft hat hierzu unter “Get started with .NET in 10 minutes” Anleitungen publiziert, die sich je nach Distribution aufgrund der angesprochenen Unterschiede in der Paketverwaltung unterscheiden. Gewöhnlich sind dort fünf oder sechs Kommandos zu finden, nach deren Ausführung Sie .NET Core vollständig installiert haben.
Wenn Sie auf dem System selbst gern entwickeln wollen und Ihnen einen grafische Oberfläche zur Verfügung steht, empfehle ich auch sehr die Installation von Visual Studio Code. Auch hierzu stellt Microsoft eine detaillierte Anleitung unter “Running VS Code on Linux” bereit.
Nun haben Sie womöglich bereits eine .NET-Core-MVC-Anwendung, doch Sie können mit folgenden Kommandos auch einfach eine erzeugen und ausführen:
mkdir demoapp cd demoapp dotnet new mvc dotnet run
Um diese Anwendung nun als Systemdienst ausführbar zu machen, sind mehrere Schritte erforderlich oder zumindest ratsam. Zunächst sollten Sie die Anwendung im Dateisystem installieren, also nicht etwa direkt aus dem Entwicklungsverzeichnis heraus starten. Die folgenden Kommandos sind dafür erforderlich:
dotnet publish sudo mkdir /usr/local/demoapp sudo cp -r bin/Debug/netcoreapp2.0/publish/\* /usr/local/demoapp sudo chown -R www-data.root /usr/local/demoapp
Damit die Anwendung beim Systemstart automatisch ausgeführt wird, müssen Sie nun einen Dienst einrichten. Dazu erzeugen Sie zunächst eine neue Datei in /etc/systemd/system:
sudo nano /etc/systemd/system/demoapp.service
In dieser Datei werden Details zur Ausführung der Anwendung eingetragen. Die Datei könnte folgendermaßen aussehen:
[Unit] Description=Demo App [Service] WorkingDirectory=/usr/local/demoapp ExecStart=/usr/bin/dotnet /usr/local/demoapp/demoapp.dll Restart=always RestartSec=10 SyslogIdentifier=demoapp User=www-data Environment=DOTNET_PRINT_TELEMETRY_MESSAGE=false [Install] WantedBy=multi-user.target
Nun können Sie den neu erzeugten Dienst aktivieren und sofort starten:
sudo systemctl enable demoapp sudo systemctl start demoapp
Wenn Sie an dieser Stelle (wie zuvor nach dem Kommando dotnet run) den URL http://localhost:5000 im Browser ansteuern, sollten Sie die laufende Anwendung zu sehen bekommen. Allerdings ist es eine wichtige und dringliche Empfehlung von Microsoft, den Server Kestrel nicht für den Rest der Welt zugänglich zu machen. Stattdessen sollte hierfür ein Proxy-Server verwendet werden. Es bleibt also als letzter Schritt die Aufgabe, diesen ebenfalls einzurichten. Ich entscheide mich für diesen Zweck für nginx, das Sie zunächst (für Ubuntu) folgendermaßen installieren müssen:
sudo apt install nginx
Nun erzeugen Sie eine neue Konfigurationsdatei für demoapp:
cd /etc/nginx sudo vi sites-available/demoapp
Die Datei sollte mindestens diesen Inhalt haben:
server {
listen 80;
location / {
proxy_pass http://localhost:5000;
}
}
Es ist ziemlich leicht ersichtlich, was hier passiert: Zugriffe auf Port 80 des Servers werden an den Kestrel-URL weitergeleitet. Microsoft empfiehlt, bei der Konfiguration von nginx noch einige weitere optionale Schritte zu machen, weitere Details können Sie unter “Host ASP.NET Core on Linux with Ngix” nachlesen.
Es ist möglich, dass das Standard-Set-up von nginx auf Ihrem System bereits einen Dienst auf Port 80 betreibt. Sie können diesen Dienst entfernen, falls notwendig:
sudo rm sites-enabled/default
Nun aktivieren Sie Ihren eigenen neuen Dienst und sorgen dafür, dass nginx seine Konfiguration neu lädt:
sudo ln -s sites-available/demoapp sites-enabled/ sudo nginx -s reload
Damit ist der Vorgang abgeschlossen. Sie können nun mit dem Browser auf Port 80 des Linux-Systems zugreifen und dort die laufende Anwendung sehen.
Wenn dieser Artikel Ihr Interesse an Linux geweckt oder neu entflammt hat, sind die Sessions „Linux 101 für .NET-Entwickler“ von Oliver Sturm und “Linux Sicherheit für .NET Entwickler” von Tobias Kopf genau die richtigen für Sie.
Alternativ gibt es von Oliver Sturm den Architektur Workshop am Montag oder den Architektur Day am Donnerstag, mit vielen Themen rund um die aktuelle Software-Entwicklung im Microsoft-Umfeld.
The post Ich weiß nicht, ob Sie es wussten: Aber Linux, das braucht jetzt jeder appeared first on BASTA!.
]]>The post 4 schlagkräftige Argumente für den BASTA!-Besuch appeared first on BASTA!.
]]>

Und damit Sie sich nicht mit Formulierungen herumschlagen müssen, haben wir hier für Sie die ultimative Textvorlage für Ihren Boss.
Sehr geehrte/r Frau / Herr (…),
ich möchte Sie gerne um Erlaubnis bitten, an der BASTA!-Konferenz teilzunehmen, die vom 24. – 28. September in Mainz stattfinden wird. Die BASTA! ist seit mehr als 20 Jahren die führende unabhängige Konferenz für Microsoft-Technologien, JavaScript und Web Development.
Die radikale Transformation von Microsoft und seiner Produkte hat nicht nur Auswirkungen auf Microsoft selbst, sondern auf die IT-Industrie im Allgemeinen und auf unsere Unternehmensstrategie im Besonderen. Darüber hinaus ist es unabdingbar, auf dem Laufenden zu bleiben und im Prozess ständig wechselnder Trends und neuen Entwicklungen mitzuhalten. Und genau diese Konferenz öffnet für uns völlig neue Möglichkeiten, unsere Produkte zu entwickeln und auf den Markt zu bringen.
Die Highlights der BASTA!:
Alle Infos zur Konferenz und zu Frühbucherpreisen finden Sie hier.
Ich bin mir sicher, dass ich als Teilnehmer für mich, meine Kollegen und unser Unternehmen hier das Wissen bekomme, das wir für die digitale Transformation brauchen, denn die steckt hinter allen diesen einzelnen Aspekten.
Mit besten Grüßen
(Ihr Name)
The post 4 schlagkräftige Argumente für den BASTA!-Besuch appeared first on BASTA!.
]]>The post Cross-Plattform mit PWA und Angular appeared first on BASTA!.
]]>Als Vorgeschmack auf die Session im September zeigt dieses Video, wie Webanwendungen und speziell Single Page Applications nicht nur Nutzern mit leistungsfähigen Computern und starker Wi-Fi-Verbindung ein schnelles, flüssiges Erlebnis bieten können. Denn ein großer Teil der Webaktivitäten wird auf mobilen Geräten ausgeführt, die unterschiedliche Funktionen erfordern, wie z.B. die Minimierung des Daten- und Stromverbrauchs. Native mobile Anwendungen bieten darüber hinaus zusätzliche Funktionen zur Einbindung der Benutzer, wie z.B. Benachrichtigungen. Aber ihnen fehlen einige der Funktionen, die Webanwendungen haben. Die heutigen Technologien und die schnelle Weiterentwicklung der Browser ermöglichen es uns, das Beste aus beiden Welten zu genießen. Wir können Webanwendungen mit einem nativen Look and Feel für mobile Anwendungen schreiben. Wir können diese Anwendungen auf Desktopbrowsern ausführen und die Funktionen der nativen mobilen Anwendungen nutzen. Shmuela Jacobs stellt die wunderbare Welt der Möglichkeiten mit Progressive Web Apps vor und wie Angular Ihnen hilft, diese Welt zu betreten.
Seit der BASTA! 2017 hat sich das Rad mit Blick auf PWAs weitergedreht, und seit der Veröffentlichung von Windows 10 April 2018 Update ist neben Googles Chrome und Mozillas Firefox nun auch der Windows-eigene Edge-Browser soweit, PWAs auf dem PC zu nutzen. Zudem hat Microsoft schon zahlreiche PWAs in den Store aufgenommen und wird die Angebote weiter ausbauen. Auf der BASTA! erfahren Sie mehr zu den Möglichkeiten und Entwicklungen auf dem Mobile Business Applications Day und Cross Plattform Day sowie in zahlreichen anderen Sessions.
Lesen Sie mehr zu diesem Thema in unserem Blogartikel “Progressive Web Apps – die Zukunft von morgen schon heute?”
● Echte Cross-Plattform-Anwendungen mit Cordova, Electron & Angular
The post Cross-Plattform mit PWA und Angular appeared first on BASTA!.
]]>The post Blockchain – wieder nur ein Tech-Hype oder eher sinnvolle Zukunftstechnologie? appeared first on BASTA!.
]]>Die Use Cases für private Blockchains sind umfangreich. Angefangen von der Prozesstransparenz für Kunden und Geschäftspartner über die Nachverfolgbarkeit von digitalen und physischen Gütern, über die Revisionssicherheit bis hin zur Möglichkeit für Read-only-Zugriffe von Auditoren kann eine Blockchain sinnvoll – und völlig ohne Hype – eingesetzt werden. Der wichtige Aspekt hierbei ist, dass dies alles ohne eine zentralisierte Stelle und damit vollständig dezentral funktioniert. Das Nachdenken darüber lohnt sich in jedem Fall.
Bitcoin und Ethereum gehören wohl mit zu den zwei bekanntesten öffentlichen Blockchains. Vom Entwickler bis hin zur Geschäftsführung ist der Begriff Bitcoin geläufig, der Hype in den Medien durch starken Kursanstieg und -abfall ist sehr hoch. Doch oftmals fehlt das Wissen, was genau eigentlich hinter Bitcoin, Ethereum und Co. steckt: die Blockchain als Basistechnologie.
Bitcoin und Ethereum haben einige Gemeinsamkeiten. Beide sind öffentliche Blockchains. Das bedeutet, dass jeder am Netzwerk partizipieren kann. Durch die Natur der Blockchain ist das Netzwerk vollständig dezentral aufgebaut. Das heißt, es gibt keinen Masterserver, zu dem sich alle verbinden, und es muss auch vorab kein Account angelegt werden. Die Teilnahme findet anonym statt. Über einen Peer-to-Peer-Prozess finden sich die Nodes untereinander selbstständig. Fällt der eine oder mehrere Nodes aus, finden sich die noch laufenden Nodes über den gleichen Prozess wieder.
Eine weitere Gemeinsamkeit ist, in welcher Art und Weise neue Blöcke zur Verkettung generiert werden. Die beiden Blockchains arbeiten nach dem sogenannten Proof-of-Work-Prinzip. Bei Ethereum wird im Schnitt alle 15 Sekunden ein neuer Block generiert, bei Bitcoin alle 10-15 Minuten. Innerhalb eines Blocks befinden sich sogenannte Transaktionen. Am Beispiel von Bitcoin sind dies – etwas vereinfacht – die Überweisungen der Währung: „Konto A sendet an Konto B 0,5 Bitcoin“.
Die eigentliche Krux an der Sache ist, wie der nächste Block generiert wird. Hier kommt der Begriff Mining ins Spiel. Dahinter verbirgt sich nicht, wie man vielleicht vermutet, die Extraktion einer Währung aus dem Netzwerk, sondern vielmehr die Lösung eines kryptografischen Rätsels, beispielsweise in Form der Findung eines Hashs nach bestimmten Regeln. Im Falle von Bitcoin wäre dies, dass der Hash mit einer bestimmten Anzahl an Nullen beginnt. Hier entsteht auch das bekannte Problem vom Mining: der sehr hohe Stromverbrauch, um dieses Rätsel zu lösen. Laut dem Bitcoin Energy Consumption Index werden dazu aktuell ca. 61 TWh eingesetzt. Zum Vergleich: Im Jahr 2014 lag der Endenergieverbrauch von Berlin bei rund 64 TWh.
Ist das wirklich das, was wir im B2B-Umfeld wollen? Sicherlich nicht. Zum einen wollen wir in einem B2B-Umfeld in der Regel keine öffentliche Blockchain betreiben, an der jeder anonym teilnehmen kann. Zum anderen wollen wir kein Proof-of-Work Mining zur Blockgenerierung nutzen. Bei einem Netzwerk mit bekannten Teilnehmern können alternative Algorithmen eingesetzt werden. Für dieses Vorgehen eignen sich private Blockchains (Permissioned Blockchains), betrieben auf eigener Hardware (bspw. im eigenen Rechenzentrum oder in einer Cloud VM) mit vertraglich geregelten Teilnehmern.
Bei privaten Blockchains können wir nicht nur bei der Blockgenerierung bestimmen, wie diese stattfindet, sondern auch wie neue Teilnehmer in das Netzwerk integriert werden. Während bei öffentlichen Blockchains jeder anonymisiert teilnehmen kann, kann bei einer privaten Blockchain sehr genau bestimmt werden, wer die Teilnehmer eines Netzwerks sein dürfen und wie sie integriert werden können. Beispielsweise ist es möglich, dass ein bestimmter Node im Netzwerk neue Teilnehmer direkt aufnehmen kann. Ein Fall wäre hier, wenn ein Konsortium eine Blockchain aufbauen möchte. Jeder interessierte Marktteilnehmer muss einen Vertrag mit dem Konsortium abschließen, das dann wiederum den Teilnehmer direkt in das Blockchain-Netzwerk aufnehmen kann. Ein anderes Modell wäre, dass jeder Node einen neuen Teilnehmer vorschlagen und jeder bereits im Netzwerk bestehende Teilnehmer diesen Vorschlag annehmen oder ablehnen kann. Je nach Modell könnte z.B. eine zweidrittel- oder achtzigprozentige Mehrheit zur Aufnahme des neuen Teilnehmers ausreichen.
Bisher haben wir zwar von der Erzeugung von Blöcken und den darin enthaltenen Transaktionen gesprochen, aber noch nicht, wer diese Transaktionen verarbeitet – also Code basierend darauf ausführt. Code dieser Art wird in der Regel Smart Contract genannt oder je nach Blockchain-Technologie auch Chaincode. Eine generelle Aussage hierfür existiert nicht, da dies eine Implementierungssache der jeweiligen Blockchain-Technologie ist. Grundsätzlich ist ein Smart Contract eine Funktion, die auf der Blockchain aufgerufen werden kann. Jeder Smart Contract ist unter einer bestimmten Adresse (die je nach Blockchain-Technologie anders aufgebaut ist) erreichbar, kann Daten entgegennehmen, speichern und ein Ergebnis liefern.
Beim Beispiel Ethereum wird der Code selbst ebenfalls über eine Transaktion in der Blockchain hinterlegt. Der Code wird somit ein unveränderlicher Teil der Blockchain. Er wird in der Programmiersprache Solidity entwickelt und in der Ethereum VM ausgeführt. Hier muss man sich vor dem ersten Deployment des Codes Gedanken machen, nach welchem Modell er aktualisiert werden kann. Auch dieses Modell und dessen Änderungsregeln, die typischerweise aus mehreren verbundenen Smart Contracts bestehen, müssen im Code hinterlegt werden.
Anders funktioniert zum Beispiel die Blockchain-Technologie Tendermint. Sie bietet keine eigene VM, sondern eine Kommunikationsschnittstelle, bspw. über GRPC, an. Diese Schnittstelle kann von verschiedenen Programmiersprachen angesprochen werden, bspw. auch mit .NET-Code. Das bedeutet, dass wir in diesem Fall unsere Smart Contracts mit .NET (Core) implementieren können und er Side by Side zur eigentlichen Blockchain läuft, damit veränderbar und kein unveränderlicher Teil der Blockchain ist. Wichtig ist hier, dass zu jedem Zeitpunkt auf jedem Node der gleiche Code ausgeführt wird, da sonst unterschiedliche Hashs generiert werden würden, was zum Ablehnen eines Blocks führen kann.
Wir sehen also, dass wir mit unterschiedlichen Blockchain-Technologien viele Möglichkeiten haben, wie wir eine Blockchain für B2B Use Cases implementieren und benutzen können: weniger Technologiehype, mehr sinnvolle Zukunftstechnologie, bei einer sehr großen Bandbreite praktischer Einsatzmöglichkeiten.
Im Rahmen der BASTA! 2018 haben Sie die Möglichkeit, durch die Sessions und den Ganztagesworkshop von Ingo Rammer und Manuel Rauber weitere theoretische und technische Eindrücke zu erhalten, und zu lernen, wie Sie Ihr erstes privates Blockchain-Netzwerk konfigurieren und betreiben und Ihre ersten Smart Contracts implementieren können.
The post Blockchain – wieder nur ein Tech-Hype oder eher sinnvolle Zukunftstechnologie? appeared first on BASTA!.
]]>The post Willkommen in der Post-JavaScript-Ära mit Blazor appeared first on BASTA!.
]]>So wie viele andere Personen in der Softwareentwicklung auch, habe ich das Programmieren mit Sprachen wie C++, Java und vor allem C# gelernt. Ich mag daher typisierte Sprachen und mir sind die Vorteile einer vollwertigen IDE im Vergleich zu einem leichtgewichtigen Editor mit Konsole bewusst. Dementsprechend habe ich mich von Anfang an in JavaScript nicht ganz wohl gefühlt. Zugegeben, es ist eine spannende Programmiersprache, die ihre Mächtigkeit erst auf den zweiten Blick zeigt. JavaScript lädt zum Tüfteln ein. Aber JavaScript für große, professionelle Projekte – naja, nicht so mein Ding.
TypeScript hat meine Einstellung zu clientseitiger Webentwicklung geändert. Diese Sprache bietet mir das Beste aus beiden Welten. Am Ende des Tages läuft es aber genauso auf JavaScript hinaus. Um gut TypeScript zu programmieren, muss man solides JavaScript-Wissen haben. Ansonsten verzweifelt man recht schnell, wenn es gilt, die ersten Probleme in größeren Anwendungen zu beheben. Ohne JavaScript geht clientseitige Webentwicklung also nicht, oder?
Jetzt ist es raus. Ich fand einiges an Silverlight nicht schlecht. Vor allem C# im Browser übt großen Reiz auf mich aus. Es ist eine moderne, weit verbreitete Programmiersprache, die kontinuierlich weiterentwickelt wird, sie ist Open Source und auf praktisch allen Plattformen verfügbar, mit Visual Studio und Visual Studio Code stehen sowohl eine mächtige IDE als auch ein schlanker Editor zur Verfügung – das sind nicht zu vernachlässigende Vorteile. Dazu kommt, dass eine einheitliche Sprache und Base Class Library für Server und Client die Entwicklungsproduktivität enorm steigert. Stimmt schon, dass man das auch mit Node.js und TypeScript schafft. Ich habe Node.js in den letzten Jahren kennen und mögen gelernt. Auf die häufig fehlenden oder schlecht gewarteten TypeScript Type Definitions kann ich aber gut und gerne verzichten. Da ist mir mein serverseitiges ASP.NET Core bei großen Projekten schon lieber.
Die größte Schwäche von Silverlight war, dass es nicht auf einem offenen Browserstandard aufgebaut war, sondern ein Plug-in braucht. Dementsprechend ging Silverlight mit dem Verbannen von Plug-ins durch Browser- und Plattformhersteller unter. Neben der Notwendigkeit eines Plug-ins gab es noch andere, häufig kritisierte Punkte: Warum mit XAML eine eigene Markup-Sprache, es gibt doch HTML? Warum eine eigene Styling- und Templatelogik, man könnte doch CSS nehmen? Trotz guter Ansätze scheiterte Silverlight und das Monopol von JavaScript im Browser blieb aufrecht.
Im März 2017 tat sich etwas Fundamentales in der Webwelt: Das erste Minium Viable Product (MVP) von WebAssembly erschien. Damit ist der Startschuss für einen ernsthaften Konkurrenzkampf mit JavaScript gefallen. Was macht WebAssembly (kurz Wasm) aus?
C++ kann wie erwähnt in Wasm kompiliert werden, der Großteil aller weit verbreiteten Programmiersprachen ist auf unterster Ebene in C++ geschrieben, der Sturm auf den Browser ist also eröffnet. C# ist dabei an vorderster Front dabei. Das Mono-Team hat bereits im August 2017 erste Prototypen veröffentlicht, die zeigen, wie C# und .NET auf Wasm laufen. Natürlich sind Programmiersprache und Basisbibliothek noch zu wenig, um in der Praxis größere Weblösungen zu bauen. Genau diese Lücke schließt das Blazor-Projekt.
Ich kenne eine Menge .NET-Entwicklungsteams, die schon lange darüber nachdenken, wie sie mit ihren weit verbreiteten WinForms-, WPF- und Xamarin-Anwendungen ins Web kommen. Hat man ein größeres Entwicklungsteam mit viel Erfahrung in diesen Technologien und eine Menge bestehenden Code, wechselt man nicht so mir nichts, dir nichts auf z. B. TypeScript mit Angular. Blazor ändert in solchen Situationen die Spielregeln.
Neugierig? Dann lassen Sie uns kurz einen Blick darauf werfen, wie Blazor das Kunststück schafft, C#, .NET und den Browser zu vereinen.
ASP.NET Blazor verbindet Wasm, die Mono-Plattform und Razor, die Markup-Sprache für dynamisches HTML aus ASP.NET Core. Code schreibt man in C#. Für das UI gibt es im Gegensatz zu Silverlight keine eigene Sprache, sondern es werden HTML und CSS verwendet. Für die Leserinnen und Leser, die noch nie mit Razor gearbeitet haben, habe ich in Listing 1 ein einfaches Codebeispiel zusammengestellt. Ich werde in diesem Artikel nicht auf Details eingehen, der Code soll nur einen Eindruck über das prinzipielle Vorgehen vermitteln. Im Windows Developer Magazin 7.18 und auf der kommenden BASTA! 2018 folgen ausführliche Einführungen in das Programmieren mit Blazor.
@page "/"
@using RestApi.Shared
@inject HttpClient Http
<h1>Customer List</h1>
<button @onclick(async () => await FillWithDemoData())>Fill with demo data</button>
@if (Customers == null)
{
<p><em>Loading...</em></p>
}
else
{
<table class='table'>
<thead>
<tr>
<th>ID</th>
<th>First Name</th>
<th>Last Name</th>
<th>Department</th>
</tr>
</thead>
<tbody>
@foreach (var customer in Customers)
{
<tr>
<td>@customer.ID</td>
<td>@customer.FirstName</td>
<td>@customer.LastName</td>
<td>@customer.Department</td>
</tr>
}
</tbody>
</table>
}
@functions {
private Customer[] Customers { get; set; }
protected override async Task OnInitAsync() =>
await RefreshCustomerList();
private async Task RefreshCustomerList()
{
Customers = await Http.GetJsonAsync<Customer[]>("/api/Customer");
// Trigger UI refresh
StateHasChanged();
}
private async Task FillWithDemoData()
{
for (var i = 0; i < 10; i++)
{
await Http.SendJsonAsync(HttpMethod.Post, "/api/Customer", new Customer
{
FirstName = "Tom",
LastName = $"Customer {i}",
Department = i % 2 == 0 ? "Sales" : "Research"
});
}
await RefreshCustomerList();
}
}
Da Wasm im Moment noch nicht direkt auf die Browser- und DOM-APIs zugreifen kann, besteht Blazor aus einem .NET- und einem JavaScript-Teil. Wann immer Blazor mit einem Browser-API interagieren muss (z. B. das DOM zur Laufzeit verändern, einen HTTP Request abschicken), übergibt der Wasm-Teil von Blazor an den JavaScript-Teil.
In Abbildung 1 sieht man die Struktur von Blazor. Das Bild zeigt das Netzwerklog beim Laden einer Blazor-Beispielanwendung. Als erstes werden die JavaScript-Teile von Blazor und Mono geladen. Sie beginnen mit dem Bootstrap-Prozess von Blazor. Als nächstes lädt der Browser die Mono-Wasm-Laufzeitumgebung. Sie holt danach die notwendigen .NET-DLLs (eigene Anwendung und benötigte Framework-DLLs) vom Webserver. Die DLLs sind ganz normale .NET-Standard-DLLs wie man sie aus jeder anderen .NET-Core-Anwendung kennt. Die Mono Wasm Runtime interpretiert die .NET DLLs im Moment. Sie werden in der vorliegenden, ersten Preview von Blazor nicht in Wasm kompiliert. Das Blazor-Team hat auf GitHub erwähnt, dass bereits daran gearbeitet wird, sowohl Interpretation als auch Ahead-of-Time-Kompilieren (AoT) zuzulassen.

Abbildung 2 zeigt, wie JavaScript, Wasm und .NET beim Behandeln eines Button-Click-Ereignisses zusammenspielen. Code im JavaScript-Teil von Blazor (BrowserRenderer.ts) reagiert auf den DOM-Event. Er übergibt den Event an die Mono Wasm Runtime, die den entsprechenden .NET-Code ausführt. Das Ergebnis, der sogenannte Render Batch, wird von Mono Wasm an JavaScript zurückgegeben. JavaScript ist für das Durchführen der notwendigen DOM-Änderungen, also für das Aktualisieren der Benutzerschnittstelle, verantwortlich.

Wer an dieser Stelle begeistert ist und plant, sofort die Entwicklungsstrategie in Richtung Blazor zu verschieben, den möchte ich bremsen. Blazor ist ein experimentelles Projekt und es gibt gerade einmal eine erste Public Preview. Man muss im Moment das System sogar noch selbst kompilieren und kann keine fertige Visual-Studio-Erweiterung herunterladen.
Die Webwelt mit ihrer rasanten Entwicklungsgeschwindigkeit und unsere Erfahrungen mit Silverlight haben uns gelehrt, entspannt an neue Entwicklungen heranzugehen und nicht zu schnell das Ruder herumzureißen. Jetzt ist die richtige Zeit, um mit Blazor zu experimentieren, Feedback zu geben, mitzuarbeiten (Blazor ist Open Source, das Team akzeptiert gerne Pull Requests und GitHub Issues) und die Auswirkungen auf die zukünftige Architektur der eigenen Projekte abzuschätzen.
Da die Dokumentation zu Blazor im Moment nur aus ein paar versprengten Blogartikeln besteht, habe ich die kostenlose Communitywebseite begonnen, die beim Einstieg in Blazor helfen soll.
Meiner Meinung nach ist WebAssembly eine wertvolle Ergänzung in der Webentwicklung. Macht es JavaScript obsolet? Keineswegs. Wie oben gezeigt arbeiten Wasm und JavaScript Hand in Hand. Das Monopol von JavaScript als Programmiersprache im Browser bricht Wasm aber auf jeden Fall auf. Als Entwickler werden wir die Sprachen und Plattformen weiter nutzen können, in denen wir viel Erfahrung und bestehenden Code mitbringen.
Wie sehr sich die Browserentwicklung von JavaScript weg hin zu Wasm verschieben wird, ist schwer abzuschätzen. Das hängt nicht zuletzt davon ab, wie die neue Technologie von uns Entwicklerinnen und Entwicklern angenommen wird. Microsoft hat auf jeden Fall Gefallen an Wasm gefunden. Blazor ist nicht das einzige Wasm-bezogene Projekt, das der Konzern aus Redmond vorantreibt. Auch die Xamarin-Community zeigt schon Prototypen von Xamarin Forms mit Wasm im Browser. Eine spannende Zeit mit ganz neuen Möglichkeiten kommt auf uns zu!
The post Willkommen in der Post-JavaScript-Ära mit Blazor appeared first on BASTA!.
]]>The post Keynote | Warum Progressive Web Apps immer wichtiger werden appeared first on BASTA!.
]]>Wie wäre es, wenn wir die Vorteile der nativen Anwendungen mit denen von Web-Apps verbinden könnten? Dann bekommen wir Progressive Web Apps. Sie sind eine Fusion der Vorzüge aus beiden Welten. Wenig Aufwand für den Entwickler und gleichzeitig viel Nutzen für den Anwender. Somit stellen PWAs eine ernst zu nehmende Alternative zu klassischen Anwendungen dar und eigenen sich hervorragend für die Cross-Plattform-Entwicklung. PWAs funktionieren ohne Installation und können ganz einfach über den Server deployt und gewartet werden. Sie sind gleichzeitig aber auch offlinefähig, können langsame Datenverbindungen überbrücken und bieten Push-Benachrichtigungen und Gerätezugriff. Eine Kerntechnologie dafür sind Service Workers, die als Hintergrundprozesse im Browser laufen und sich ums Caching von Programmdateien, aber auch abgefragten Daten kümmern.
In der nun online bereitstehenden Keynote vom 20. Februar 2018 erfahren Sie, was sich hinter dem Begriff Progressive Web Apps verbirgt, und warum jede Anwendung eine Progressive Web App sein sollte.
Lesen Sie mehr zu diesem Thema in unserem Blogartikel “Progressive Web Apps – die Zukunft von morgen schon heute?”
● Performancetuning für Angular: Der Stand der Dinge in den aktuellen Versionen
● Wiederverwendbare Angular-Bibliotheken und Plug-in-Architekturen
The post Keynote | Warum Progressive Web Apps immer wichtiger werden appeared first on BASTA!.
]]>The post Schneller Einstieg in TypeScript appeared first on BASTA!.
]]>Thomas Claudius Huber beantwortet diese und viele anderen Fragen in seinem “Einstieg in TypeScript” und vermittelt in sieben Kapiteln die Grundlagen für Entwickler, die sich mit JavaScript beschäftigen möchten und dabei nicht auf die vielen Vorzüge, die sie z. B. als C#-Programmierer gewohnt sind, verzichten wollen.
Dieser Vorzug von TypeScript macht sich doppelt bemerkbar, wenn man mit JavaScript auch größere Unternehmensanwendungen schreiben will. Zwar war die Idee, als JavaScript 1995 entwickelte wurde, zunächst nur Code auf Webseiten ausführen zu können, um Inhalte dynamisch anzupassen. Wobei man wahrscheinlich von 100 bis 1000 Zeilen Code, die auf so einer Webseite ausgeführt werden, ausgegangen ist. Aber dass damit auch Unternehmensanwendungen mit 100 000 oder mehr Zeilen Code umgesetzt werden können, hat sich vermutlich niemand vorgestellt. Doch das ist heute der Fall.
Die namensgebende Stärke von TypeScript ist die Einführung der statischen Typisierung für das Variablensystem von JavaScript. Diese statische Typisierung bringt neben Compile-Fehlern weitere Vorteile: Tools wie Visual Studio Code können deutlich bessere Unterstützung als bei reinem JavaScript bieten, weil der Typ zur Entwicklungszeit schon feststeht. Somit gibt es Funktionen wie IntelliSense, Go to Definition und vieles mehr, die das nutzen können. Was die Arbeit am Code erheblich erleichtert.
Neben der statischen Typisierung hat TypeScript ein weiteres sehr wichtiges Merkmal: TypeScript kompiliert zu reinem JavaScript-Code. Das heißt, dass TypeScript lediglich zur Entwicklungszeit wichtig ist. Zur Laufzeit benutzt der Browser klassisches JavaScript, das aus TypeScript kompiliert wurde, und dabei lässt sich die gewünschte Zielversion selbst bestimmen.
Im Videointerview erklärt Thomas Claudius Huber, warum er inzwischen so weit ist, dass er alles, was heute JavaScript ist, mit TypeScript schreiben würde. Neben den Vorzügen der Typisierung und der Möglichkeit, wie gewohnt mit Klassen arbeiten zu können, lässt auch das Tooling rund um TypeScript für ihn kaum Wünsche offen.
Auf der BASTA! finden Sie zahlreiche Sessions, in denen Sie den praktischen Einsatz von TypeScript sehen. Thomas Claudius Huber bietet am Freitag, 23.02. den Workshop “TypeScript-Workshop: Einführung von 0 auf 100 in einem Tag” dazu an. Zudem gibt es von ihm ein entwickler.tutorials-Video zum Thema.
● Workshop für webbasierte Geschäftsanwendungen mit Angular: Konzepte, Architektur und Umsetzung
● Mehr als nur Web: Cross-Plattform-Anwendungen mit Angular, Electron und Cordova
● Office as a Platform: Real-World-Add-ins mit Angular und Serverless Backends
The post Schneller Einstieg in TypeScript appeared first on BASTA!.
]]>The post SQL Server auf Linux – Der größte Teil bleibt gleich appeared first on BASTA!.
]]>Thorsten Kansy, dotnetconsulting.eu, ist seit vielen Jahren Sprecher und Advisor auf der BASTA!. Seine Schwerpunkte sind SQL Server und C#. Im Interview erklärt er, was sich für Entwickler durch die neue Ausrichtung von Microsoft ändert und wie sich das an SQL Server 2017 zeigt. Dabei bleibt er mit beiden Beinen auf dem Boden und sieht ganz klar, dass sich im Prinzip für das eigentliche Entwickeln nicht viel ändert, sie können auch weiterhin so arbeiten, wie sie es kennen. Aber sie haben mehr Möglichkeiten bekommen, und Microsoft geht auf die Tatsache ein, dass Linux am Servermarkt eine Größe ist und auch Azure eine zunehmend wichtige Plattform wird. Beides spiegelt sich auch in der Arbeitsrealität der Entwickler wider. Auch gilt, dass SQL Server und C# sich weiterentwickeln werden, aber im Kern können Entwickler ihr Know-how nahtlos weiternutzen, die Änderungen liegen im Detail.
Es muss halt nicht immer gleich TypeScript, CosmosDB oder Node.js sein, auch wenn diese neuen Spieler im Markt viele Vorteile bringen und gute mit bewährten Technologien kombinierbar sind. Die Sessions von Thorsten Kansy und anderen Sprechern der BASTA! zeigen immer wieder, wie sich quasi “traditionelle” und “neue” Technologien und Sprachen verbinden lassen, um die Kontinuität der eigenen Arbeit und Entwicklung aufrecht zu halten. Aber gerade an den traditionellen und beständigen Technologien zeigen sich Veränderungen und Fortschritt am deutlichsten. Vor allem dann, wenn sie Hand in Hand mit schnellen Entwicklungen auf Azure oder im Mobile-Bereich gehen.
Sessions zu C# finden Sie im C# Day und dem .NET Framework und C# Track. Zum Thema Datenbanken finden Sie die Sessions „Datenbank Babylon“ von Thorsten Kansy. Und am Montag findet der C#-Workshop von Rainer Stropek statt, der auf die aktuellen Entwicklungen und Möglichkeiten von C# eingeht.
The post SQL Server auf Linux – Der größte Teil bleibt gleich appeared first on BASTA!.
]]>The post Progressive Web Apps – die Zukunft von morgen schon heute? appeared first on BASTA!.
]]>In diesem Artikel wollen wir eine bestehende kleine Cross-Plattform Angular-Anwendung verwenden und um die Vorteile von Progressive Web Apps anreichern. Die Beispielanwendung nutzt die Star-Wars- und die Poké-APIs, um beispielhaft Master-Detail-Daten anzuzeigen (Abb. 1). Als Buildsystem wird die aktuelle Release Candidate Version 1.6.0-RC.1 von Angular CLI eingesetzt, um Vorteile wie die Ahead-of-Time Compilation oder Tree Shaking zu nutzen. Beides hilft uns, eine in Bezug auf die Dateigröße möglichst kleine und performante Anwendung zu entwickeln. Die bestehende Anwendung inkludiert sowohl das Tool Cordova, sodass sie auch als native Anwendung verpackt und auf mobilen Geräten mit Android oder iOS als echte Smartphone-App deployt werden kann. Zusätzlich hilft Cordova beim Benutzen echter Plattform-APIs, wie z.B. dem Teilen-API, um Inhalte mit unseren Freunden via Facebook, Twitter, WhatsApp und allen anderen Apps, die diese Funktion unterstützen, teilen zu können. Auch inkludiert die bestehende Anwendung das Tool Electron, um eine echte native Desktopanwendung, sprich .exe, .App und Co., zu generieren und auch hier native Funktionen zum Teilen des Inhalts anzusprechen.

Doch wie können wir zukünftig Apps entwickeln, die ohne weiteres Tooling, wie Cordova oder Electron, auskommen und dennoch auf native Funktionen zugreifen können? Hier kommen die Progressive Web Apps (PWA) ins Spiel. Die vollständige Beispielanwendung für diesen Artikel liegt auf GitHub. Es empfiehlt sich, den Code zum Artikel zu öffnen, da im Artikel nur Ausschnitte gezeigt werden können. Progressive Web App ist ein Begriff, den man in der Webwelt aktuell oft hört und auf den bereits große Firmen wie beispielsweise Twitter, Telegram oder die NASA aufgesprungen sind. Doch um was genau handelt es sich überhaupt?
Progressive Web Apps beschreibt eine Sammlung von Technologien, Möglichkeiten und Eigenschaften zukünftiger Webanwendungen. PWAs selbst sind keine eigene Technologie, sondern eine seit 2015 von Google getriebene Initiative, die das Web nativer machen soll und dabei natürlich auch Zugriff auf native Gerätefunktionen wie die Kamera gewährt. Im Kern sind PWAs ganz normale Webanwendungen, wie auch unsere Beispielanwendung eine ist – aber auf Steroiden. Die bestehende Webanwendung wird mit weiteren nativen Funktionen angereichert. Um das zu erreichen, legt Google einige Charakteristika fest, die eine Anwendung haben sollte, um als PWA zu gelten. Schauen wir uns im Folgenden die einzelnen Charakteristika genauer an.
Wie man sieht, beschreiben die Charakteristika hauptsächlich nichtfunktionale Anforderungen, die durch technische Hilfsmittel umgesetzt werden können. Da wir unsere Beispielanwendung bereits als moderne Webapplikation erstellt haben, haben wir einige Charakteristika ohne weiteres Zutun bereits erfüllt. Prinzipiell benötigt man kein Framework wie Angular oder React, um eine PWA zu erstellen. Allerdings unterstützen SPA-Frameworks generell die Entwicklung von großen Webanwendungen, die um die Charakteristika von PWAs ergänzt werden können. Bevor wir uns im Folgenden mit den weiteren Charakteristika speziell in Bezug auf unsere Angular-Anwendung beschäftigen, werfen wir einen Blick auf den zuvor angesprochenen Service Worker.
Der Service Worker erweitert unsere Anwendung um einen zweiten, im Hintergrund laufenden JavaScript-Thread, mit dem eine bidirektionale Kommunikation möglich ist. Im Hintergrund laufend bedeutet, dass der Service Worker auch aktiv ist, wenn unsere Anwendung nicht läuft. Facebook ist hier ein gutes Beispiel: Auch wenn in keinem Tab Facebook geöffnet ist, werden uns Notifikationen angezeigt. Hier werkelt ein Service Worker im Hintergrund. Es nutzen bereits erstaunlich viele Websites einen Service Worker, um dem Benutzer einen gewissen Komfort zu ermöglichen.
Generell sind PWAs und die dahinterstehenden Technologien sehr modern, sodass viele Browser noch in der Konzeptions- bzw. Implementierungsphase der Features sind. Allen voran Google Chrome und damit auch Android. Sie haben bisher die weitreichendste Unterstützung der Technologien für PWAs. Ganz hinten steht der neue Internet Explorer: Safari. Safari bietet leider kaum die für PWAs nötigen Technologien an. Einige Features sind im Fünfjahresplan angedacht, aber es existieren noch keine konkreten Implementierungspläne.
Doch welche Aufgaben kann der Service Worker für uns erledigen? Der Service Worker ist speziell darauf ausgelegt, asynchrone Arbeiten durchzuführen. Daher hat er auf synchrone (DOM-)APIs wie z. B. der localStorage keinen Zugriff. Jedoch eignet er sich besonders für Arbeiten wie das Synchronisieren von Daten in einer IndexedDB, das Cachen von Dateien und Daten zur Offlineverwendung, als Request-Proxy zwischen der Anwendung und dem Internet oder – für das Re-engagement – zum Anzeigen von Desktopnachrichten nach Erhalt von Push-Nachrichten. Schauen wir uns einmal an, was das fleißige Kerlchen für unsere Anwendung tun kann.
Wir werden im Folgenden unsere Beispielanwendung um zwei Dinge erweitern: Offlinefähigkeit und Push-Benachrichtigungen. Zum Testen der Implementierung empfiehlt sich die Installation von Google Chrome Canary, da dieser, wie eingangs beschrieben, die beste Unterstützung der nötigen Technologien für PWAs bietet. Zudem schauen wir uns die PWAs mit einem starken Fokus auf Angular an. Doch aufgepasst! Wie anfangs erwähnt müssen wir auf aktuelle Betas und Release Candidates von Angular zurückgreifen, um Unterstützung für den Service Worker zu erhalten. Die Funktionen sind daher noch sehr neu und die Unterstützung für uns Entwickler teilweise noch sehr rudimentär. Diese Dinge werden sich in der Zukunft verändern, verbessern und vereinfachen. Cutting Edge eben.
Durch existierendes Tooling werden wir uns eher an der Nutzung der PWA-Technologien orientieren und weniger auf Low-Level-Konzepte eingehen. Hier lohnt es sich, einen Blick in das Mozilla Developer Network zu werfen. Die Links hierfür sind am Ende des Artikels zu finden.
Da das Thema Offline selbst einen weiteren Artikel füllen würde, wollen wir es auf recht einfachem Wege implementieren: Wir werden die gesamte Anwendung sowie die Antworten von API-Anfragen im Cache ablegen. Damit erreichen wir, dass unsere Anwendung im Browser auch ohne Internetverbindung funktioniert und ein kleiner Teil an Daten zur Verfügung steht. Den Service Worker werden wir hierbei als Proxy benutzen, der alle HTTPS-Anfragen der Anwendung entgegennimmt und aus dem Browser Cache beantwortet, sofern die Daten dort bereits vorhanden sind. Falls nicht, wird er die Daten aus dem Internet laden und deren Antwort im Cache ablegen. Dann mal los! Zu Beginn müssen wir ein neues Paket installieren, um Angular mit dem Service Worker bekanntzumachen: npm i @angular/service-worker@next.
Zusätzlich müssen wir die Datei .angular-cli.json editieren und dem Abschnitt apps folgende Eigenschaft hinzufügen:
"apps": {
// ...
"serviceWorker": true
}
Die Eigenschaft serviceWorker schaltet die Service-Worker-Unterstützung des Angular-CLIs an, das uns eine Menge Arbeit abnehmen wird. Welche genau, werden wir gleich im Anschluss sehen. Im Ordner src legen wir eine Datei mit dem Namen manifest.json an. Der Inhalt ist Listing 1 zu entnehmen.
{
"short_name": "WinDev App",
"name": "Windows Developer PWA Sample",
"icons": [
{
"src": "assets/launcher-icon-3x.png",
"sizes": "144x144",
"type": "image/png"
},
{
"src": "assets/icon-1024px-square.png",
"sizes": "1024x1024",
"type": "image/png"
}
],
"theme_color": "#ff584f",
"background_color": "#ffffff",
"start_url": "/index.html",
"display": "standalone"
}
Generell benötigt jede PWA eine manifest.json-Datei. In ihr sind Metadaten über die Anwendung enthalten. Schauen wir uns einmal genauer an, welche Inhalte in dieser Datei zu finden sind:
Neben der manifest.json-Datei, die jede PWA benötigt, wird speziell für Angular noch eine weitere Datei zur Instrumentierung des Angular Service Workers benötigt. Diese Datei legen wir ebenfalls im Ordner src mit dem Namen ngsw-config.json an. Der Inhalt der Datei ist in Listing 2 zu finden. Während des Build-Prozesses wird diese Datei in eine Datei mit dem Namen ngsw.json überführt und im Build-Ordner abgelegt. Diese dient dann zur eigentlichen Instrumentierung des Angular Service Workers.
{
"index": "/index.html",
"assetGroups": [
{
"name": "app",
"installMode": "prefetch",
"resources": {
"files": [
"/favicon.ico",
"/index.html"
],
"versionedFiles": [
"/*.bundle.css",
"/*.bundle.js",
"/*.chunk.js"
]
}
},
{
"name": "assets",
"installMode": "lazy",
"updateMode": "prefetch",
"resources": {
"files": [
"/assets/**"
]
}
}
],
"dataGroups": [
{
"name": "pokemon",
"urls": [
"https://pokemon.co/*"
],
"cacheConfig": {
"strategy": "performance"
}
}
]
}
Schauen wir uns das Cache-API des Browsers genauer an, da wir es zur Implementierung der Offlinefähigkeit benutzen werden. Generell kann Angular bzw. der Angular Service Worker den Cache auf zwei Arten füllen: Mit statischem und dynamischem Inhalt.
Der statische Inhalt kann über die assetGroups (siehe Listing 2) bestimmt werden. Die Eigenschaft assetGroups ist ein Array aus Konfigurationsobjekten, welche wir uns im Folgenden genauer anschauen wollen:
Je nach Einstellung wird der Service Worker beim Start der Anwendung oder wenn der Cache nicht gefüllt ist, selbstständig alle definierten Dateien vom Server laden und im Cache ablegen. Ab diesem Moment ist die Anwendung – ohne Daten – bereits offline verfügbar. Über die Dev Tools von Chrome kann im Tab Network der Browser auf offline geschaltet werden. Wird die Anwendung per F5 aktualisiert, wird die Anwendung dennoch geladen, da sie vollständig im Cache des Browsers liegt.
Möchten wir die Antworten unserer API-Anfragen an das Star Wars- oder Pokémon-API im Cache ablegen, müssen wir einen Blick auf das Array dataGroups werfen. Die Konfiguration unterscheidet sich etwas zu den assetGroups:
Zum Zeitpunkt des Schreibens des Artikels existiert für dieses Feature noch keine schriftliche Dokumentation, daher lohnt sich ein Blick in das GitHub-Repository. Innerhalb unseres Beispiels cachen wir nur das Pokémon-API. Als kleine Übung kann der Cache für das Star-Wars-API eingefügt werden.
Als vorletzter Schritt muss in der index.html-Datei im <head> folgender Eintrag hinzugefügt werden, sodass der Browser weiß, unter welchem Namen er das PWA-Manifest findet: <link rel=”manifest” href=”manifest.json”>. Zu guter Letzt müssen wir in unserer module.ts noch das Module ServiceWorkerModule den imports hinzufügen und zwar mit folgendem Ausdruck:
environment.production ? ServiceWorkerModule.register('ngsw-worker.js') : [],
Der Service Worker kann aktuell nur in Angulars Produktionsmodus gestartet werden, da nur hier die angegebene Datei ngsw-worker.js generiert wird. Das erschwert aktuell das Debugging, wird aber mit der Weiterentwicklung des Toolings besser werden. Zudem muss die Anwendung zwingend gebaut und nicht via ng serve gestartet werden. Das heißt, die Anwendung muss via ng build –prod gebaut und über einen Webserver (z.B. node-static oder http-server) gestartet werden. Nach dem Start kann etwas durch die Anwendung geklickt werden. Über die Chrome Dev Tools kann der Browser in den Offlinemodus (Tab Networking) geschaltet werden. Auch nach einem Reload des Browsers wird die Anwendung angezeigt. Zuvor angezeigte Daten sind auch im Offlinemodus verfügbar. So haben wir bereits die Möglichkeit, unsere Anwendung in Teilen offline zunehmen.
Hinweis: Das Angular-CLI bzw. der Angular Service Worker abstrahieren sehr viele Low-Level-APIs. Was so einfach aussah, abstrahiert Themen wie den Service Worker Lifecycle, das Service-Worker-API, das Cache-API, Offlinestrategien oder das Fetch-API. Es gibt also noch viel zu entdecken!
Moderne Anwendungen kommen kaum noch ohne aus, und der Benutzer verlässt sich darauf, bei neuen Ereignissen in seiner Anwendung eine Notification zu erhalten. Auch wir wollen die Möglichkeit haben, Push-Nachrichten zu empfangen und eine Notification anzuzeigen. Hier ist auch wichtig, dass eine Push-Nachricht nicht automatisch etwas mit einer dem Benutzer angezeigten Notification zu tun hat. Push-Nachrichten sind generell die Möglichkeit, einer Anwendung eine Nachricht zukommen zu lassen. Die Anwendung hat daraufhin die Möglichkeit, diese Push-Nachricht als Notification dem Benutzer anzuzeigen. Prinzipiell könnte stattdessen auch nur ein Datensatz aktualisiert oder ein interner Prozess angestoßen werden. Was genau gemacht werden soll, wird durch die Payload einer Notification bestimmt.
Zur Umsetzung von Push-Nachrichten mit Notification werden wir uns zweier APIs bedienen: des Push-API und des Notification-API. Beide APIs werden durch den Angular Service Worker abstrahiert, sodass wir nicht direkt mit ihnen in Berührung kommen, sie aber grundlegend für die Funktion verantwortlich sind. Um Push-Nachrichten anzubieten, werden zwei Dinge benötigt:
Erste Implementierungen von Push in Google Chrome haben einen Dienst von Google Cloud Messaging (GCM) bzw. Firebase Cloud Messaging (FCM) benötigt. Leider hat es sich hierbei um ein propritäres Protokoll gehandelt, welches nur für Chrome-basierte Browser zur Verfügung stand. Wollte man Push-Nachrichten bspw. für Firefox implementieren, musste auf den Mozilla Push Service (MPS) zurückgegriffen werden. Für uns Entwickler bedeutet dies, dass wir für beide Services unsere Anwendung registrieren mussten, um Push-Nachrichten zu versenden.
Mittlerweile existiert ein neues, standardisiertes, Protokoll mit dem Namen Web Push, welches von Firefox und Chrome implementiert, von FCM und MPS unterstützt werden und der zukünftige Weg ist, Push-Nachrichten an die Browser zu schicken. Safari und Edge hinken hier leider noch etwas hinterher.
Durch das Web Push Protokoll müssen wir uns nicht mehr für jeden Dienst selbst registrieren, sondern können dies über den neuen Standard VAPID (Voluntary Application Server Identification) erledigen. Für VAPID wird auf unserem App-Server, der die Push-Subskriptionen verwaltet und die Push-Nachrichten verschicken kann, ein Schlüsselpaar bestehend aus Public- und Private-Key erzeugt. Möchte ein Browser sich für Push registrieren, benötigt er den Public-Key des App-Servers. Durch den korrekten Public-Key kann der App-Server eine Verbindung mit FCM oder MPS aufbauen, die nach wie vor für den eigentlichen Versand der Push-Nachricht benötigt werden. Durch VAPID identifizieren wir unseren App-Server bei FCM und MPS, weswegen die Registrierung bei den Diensten entfällt.
Da die Implementierung des App-Servers den Rahmen des Artikels verlässt, liegt eine Beispielimplementierung eines App-Servers im Ordner srcApi bereit, der über npm run push-server gestartet werden kann. Das benötigte Schlüsselpaar liegt exemplarisch bei, kann aber bspw. über eine Website wie den Push Companion oder das Node.js-Modul crypto selbst erzeugt werden.
Der App-Server stellt nach dem Start zwei Web-APIs bereit. Das erste API dient zur Registrierung von Clientanwendungen, sodass der App-Server weiß, an welche Clients er Push-Nachrichten übermitteln kann. Das zweite API ist ein kleines Debug-API, mit dem wir den Versand von Push-Nachrichten an alle subskribierten Clients anstoßen können.
Der dritte Schritt ist das Implementieren von Push-Nachrichten in unserer Anwendung selbst. Dazu ändern wir den Code der root.ts ab, wie in Listing 3 gezeigt.
export class RootComponent implements OnInit {
constructor(@Optional() private _swPush: SwPush, private _http: HttpClient) {}
public ngOnInit(): void {
this.register();
}
public register(): void {
if (!this._swPush) {
return;
}
const push = this._swPush.requestSubscription({serverPublicKey:''});
Observable.fromPromise(push)
.pipe(
switchMap(subscription =>
this._http.post('http://localhost:9090/push/register', subscription))
)
.subscribe();
}
}
Zum einen lassen wir uns eine Instanz von SwPush und HttpClient geben. SwPush ist ein Angular Service, der uns Zugriff auf die Push-Funktionalität des Angular Service Workers gewährt. Zum anderen implementieren wir die Methode register(), um via SwPush die Methode requestSubscription() aufzurufen, um den Service Worker am Browser für Push-Nachrichten zu registrieren. Hier wird der zur für VAPID erzeugte Public-Key benötigt. Ist die Registrierung am Browser erfolgreich, erhalten wir Informationen über die Subskription subscription, die wir via http.post() an unser eigenes API schicken. Wie dem Beispiel zu entnehmen ist, läuft das API auf localhost:9090, d. h. dass nur Anwendungen mit Zugriff auf localhost sich für den Empfang von Push-Nachrichten registrieren können. Für ein echtes Szenario muss der App-Server online gehostet werden, sodass er durch die mobilen Apps erreicht werden kann. Und natürlich sollte der Beispielcode in einen schönen, eigenen Angular Service abstrahiert werden.
Ein kleines Manko hat der Angular Service allerdings noch: Die Anwendung hat noch keine Möglichkeit, auf die Push Notifications selbst zu reagieren. Die dahinterliegenden Low-Level-APIs bieten bereits die Möglichkeit, auf den Klick einer Notification zu reagieren oder Daten aus Notifications auszulesen. Diese Möglichkeit wird in einer künftigen Version des Angular Service zur Verfügung stehen. Benötigt man diese Funktionen, muss man selbst die Low-Level-APIs implementieren.
Nach dem Start des App-Servers kann die Anwendung gestartet werden. Via Postman kann ein HTTP POST auf localhost:9090/push/notifyAll abgesetzt werden, was dazu führt, dass Chrome eine Desktop-Notification anzeigen wird. Mit diesen wenigen Schritten haben wir Push Notifications implementiert!
Google bietet das Tool Lighthouse an, das unsere Anwendung unter anderem auf die eingangs genannten Eigenschaften von PWAs prüft und auch Vorschläge gibt, wie sie verbessert werden können. Das Tool kann als Chrome Extension installiert werden und wird per einfachem Klick auf das Lighthouse-Icon gestartet. Die Prüfung ist vollautomatisch und dauert wenige Sekunden. Lighthouse generiert einen Report, der in Abbildung 2 gezeigt wird. Das Scoring von 100/100 Punkten für PWAs zeigt, dass wir sehr gute Arbeit geleistet haben. Einen Teil der Arbeit hatten wir im Vorfeld bereits erledigt, wie Responsive, und einen weiteren Teil der Arbeit mit dem Artikel durch die Integration des Service Workers und das Anbieten einer Manifest-Datei.

Mit Hilfe des Artikels haben wir eine bestehende Angular-Cross-Plattform-Anwendung um weitere Technologien ergänzt, um die Anwendung in Richtung Progressive Web App weiterzuentwickeln. Die Single-Codebase stellt hierbei nicht nur eine Webanwendung bereit, sondern kann, wie eingangs angesprochen, in echte native mobile Apps und echte native Desktopanwendungen verpackt werden, die jeweils auf native APIs zugreifen können, um dem Benutzer eine bestmögliche Integration zu bieten. Mit ein paar wenigen Zeilen konnten wir in diesem Artikel unsere Anwendung um PWA-Technologien erweitern. Via Service Worker haben wir eine einfache Möglichkeit, um die Anwendung mit einfacher Offlinefunktionalität auszustatten und auf Push-Nachrichten reagieren zu können. Dank der Manifest-Datei ist unsere App auch installierbar geworden, was auf Android-Geräten durch ein kleines Banner angezeigt wird (Abb. 3), und das ganz ohne einen App Store! Lighthouse hat uns gezeigt, dass wir ein sehr gutes PWA-Scoring erhalten, somit steht unserer modernen Anwendung kaum noch was im Wege. Unter der Haube bieten die Low-Level-APIs noch viel mehr, schließlich haben wir mit diesem Artikel nur an der Oberfläche gekratzt.

Angular und PWAs auf der BASTA!:
Passend zum Thema dieses Artikels finden Sie auf der BASTA! z. B. die Session „Progressive Web Apps mit Angular: das Web wird nativ(er)“ von Christian Liebel und viele weiter im HTML5 & JavaScript Track sowie den Power Workshops am Montag und Freitag.
The post Progressive Web Apps – die Zukunft von morgen schon heute? appeared first on BASTA!.
]]>The post Unser BASTA! Gewinnspiel zum Nikolaustag! appeared first on BASTA!.
]]>
Passend zum heutigen Tag verlosen wir 3 Buchexemplare „TFS Jumpstart – Per Express zum Application Lifecycle Management“.
Sie möchten sich in den Bereich ALM mit dem Team Foundation Server einarbeiten, bisher aber noch keine oder nur wenig Erfahrung mit Quellcodeverwaltung und Co.? Dann haben Sie jetzt die Gelegenheit, ein Exemplar noch heute zu gewinnen. Das Buch soll eine einfache Starthilfe auf dem Weg zum gelebten Application Lifecycle Management sein.
Bereits seit Anfang 2013 kann man auf verschiedenen Wegen an eine kostenlose Ausgabe von Microsofts ALM-Plattform, dem Team Foundation Server (TFS), gelangen: von der On-Premise-Variante TFS Express bis hin zur Nutzung der Visual Studio Team Services in der Cloud. In den letzten Jahren hat sich die Welt rund um den TFS weiterentwickelt, und viele dieser Entwicklungen sind auch am TFS nicht spurlos vorübergegangen. Ein namhaftes Beispiel hierfür ist eine vollständige Integration von Git sowie ein komplett überarbeitetes Build-System, das sowohl per PowerShell-Skript als auch unter Node.js lauffähig ist. Der Trend zu mehr Offenheit bei Microsoft macht also auch vor deren ALM-Plattform zum Glück nicht halt. Es ist heute also einfacher denn je, sich mit dem Team Foundation Server zu befassen und die Mächtigkeit dieser ALM-Plattform für sich zu nutzen.
Bitte tragen Sie Ihre Email-Adresse ein, an die Sie den BASTA!-Newsletter erhalten möchten, und gewinnen Sie mit etwas Glück eins von drei Buchexemplaren „TFS Jumpstart“.
P.S. Auch treue BASTA-Newsletterabonnenten kommen in den Lostopf, wenn sie sich hier nochmal eintragen!
The post Unser BASTA! Gewinnspiel zum Nikolaustag! appeared first on BASTA!.
]]>The post Keynote | Microservices – zu klein und zu gut, um nur ein Hype zu sein appeared first on BASTA!.
]]>In der Keynote zur Eröffnung der BASTA! 2017 haben Oliver Sturm, DevExpress, Rainer Stropek, software architects, Christian Weyer, Thinktecture AG und Mirko Schrempp, BASTA! Program Chair, diese vielen Facetten von Microservices diskutiert, um den Blick für die Möglichkeiten und Chancen zu öffnen.
Microservices sind ein Buzzword, denn DevOps, Container, Cloud, Plattform- und Sprachunabhängigkeit, Resilienz, Austauschbarkeit, Agilität, Serverless, bimodale IT, Continuous Delivery, APIs fallen gleich mit aus der Bingotrommel. Der Titel der Keynote “Microservices – zu klein und zu gut, um nur ein Hype zu sein” deutet es schon an, denn das Fragezeichen fehlt aus gutem Grund: Microservices sind kein Hype! Die Keynote räumt mit den üblichen Missverständnissen rund um Microservices auf, skizziert typische Architekturpatterns, Technologieoptionen, Auswirkungen auf Organisationen und den Businessbezug.
Microservices treiben den Trend zur Modularisierung und Flexibilität auf die Spitze, denn für Microservices kauft man keinen kompletten Technologiestack, den man auspackt, auf den Server setzt und dann läuft alles. Microservices bilden ihre Form und Struktur über kleinteilige Dienste, die austauschbar sein sollten und in den Sprachen geschrieben werden können, die einem Team zur Verfügung stehen. Darin waren sich alle Keynote-Sprecher einig, ob nun C#, Java, Python, JavaScript oder irgendeine andere Sprache, jede ist dafür geeignet für einen Microservice genutzt zu werden. Rainer Stropek ist dabei der Auffassung, dass dies nicht nur ein technischer Vorteil ist, sondern angesichts des Arbeitsmarkts in der IT auch ein wirtschaftlicher. Wer für ein Projekt keine C#-Entwickler auf dem Markt findet, kann dann eben mit einem Python-Team das Ziel erreichen. Spätestens hier sieht man, dass Microservices nicht nur auf die Struktur von Softwarelösungen und die Technologiewahl Einfluss haben, sondern auch auf die Organisation von Teams und sogar Unternehmen. Teams werden in die Lage versetzt autonome Entscheidungen darüber zu fällen, welche Technologie eingesetzt wird, um das gewünschte Ziel zu erreichen. Dazu muss allerdings das Management Teile seiner Kompetenz abgeben und auf das Team übertragen.
Damit einzelne oder unzählige Microservices zusammenspielen können, ist von zentraler Bedeutung, dass Architekturüberlegungen immer mitspielen. Und das muss auf allen Eben passieren, denn für sich alleine hat ein Microservice nur begrenzten Wert. Erst im Zusammenspiel werden komplexere Geschäftsprobleme gelöst. Allerdings gibt es dabei keinen Zentralismus, denn dieser ist nicht schnell genug, das haben spätestens alle SOA-Experimente gezeigt. Microservices erlauben durch ihre dezentrale Struktur, unterschiedliche Innovationsgeschwindigkeiten in einer Technologiewelt, die sich immer schneller dreht. Sie sind damit aber nicht automatisch das Ende der Softwaremonolithen. Im Gegenteil, diese werden für die Zukunft anschlussfähig, und spätestens hier kommt die Cloud ins Spiel.
Moderne Cloud-Lösungen sind keine Monolithen mehr, in denen zwar alles harmonisch zusammenpasst, die man aber nur ganz oder gar nicht weiterentwickeln kann. Was, wenn sich ein Teil einer Softwarelösung schneller verändert als andere Teile? Wie soll ein Team rascher auf .NET Core umsteigen können, wenn die anderen aus irgendeinem Grund noch für einige Zeit im .NET Framework festhängen? Damit solche Probleme gelöst werden können, braucht man kleiner strukturierte Softwarearchitekturen. Microservices sind das Architekturmuster dafür. Viele relativ kleine Logikbausteine (z. B. Rechenlogiken, Workflows, Services für Datenzugriff etc.) werden von autonomen Teams entwickelt und betrieben. Die Microservices tauschen Daten und Events über plattformunabhängige RESTful Web-APIs, WebHooks oder über eine Messaging-Infrastruktur aus. Genau hier sieht Christian Weyer die Chance, für ISVs ihre Zukunft zu sichern, vor allem, wenn sie mit Start-ups in Konkurrenz stehen, die genau eine Sache gut oder besser können, die für den ISV wichtig ist. Sie können ihre Monolithen fachlich aufteilen, ggf. erst über APIs, und dann sauber aufspalten und in kleinere Bereiche einteilen und zur Verfügung stellen.
Dabei ist dann nicht wichtig, ob mit AWS, Azure, Docker oder sogar Serverless gearbeitet wird. Wichtiger ist, dass die gekapselten und isolierten Dienste sauber und sicher kommunizieren. Was das heißt, zeigt das Serverless-Konzept sehr deutlich: Die Idee von Serverless Computing ist es, Dienste anzubieten, ohne einen einzigen Gedanken an Maschinen, Container, Betriebssysteme, Softwareversionen oder Skalierung der Instanzen – horizontal wie vertikal – zu verschwenden. Und das ist auch das Versprechen der Plattformbetreiber: „100% managed and operated“. Serverless Computing bietet also die Umgebung, um sich nahezu ausschließlich auf die Implementierung von Businesslogik konzentrieren zu können. Dabei muss diese in sinnvolle kleine und autonome Teile zerlegt werden. Jeder Teil wird als eine separate Funktion zur Verfügung gestellt, ausgeführt und skaliert.
Microservices ist also ein großes Wort, auch wenn es so klein klingt. Wie klein die sein sollen, ist eine Frage, die auch oft und gern gestellt wird und auf die es keine pauschale Antwort gibt. Microservices setzen auf Unabhängigkeit zwischen den Modulen eines Softwaresystems. Die Aufgaben eines Diensts sollen kurz und bündig definierbar sein; meistens denken wir dabei an eine einzelne Funktion mit einem API. Daraus ergeben sich weitreichende Freiheiten: Plattform, Programmiersprache und Hilfs-Libraries können womöglich pro Dienst neu definiert werden. Microservices stellen ein mächtiges und vielschichtiges Pattern dar, von dem beinahe jedes Anwendungssystem profitieren kann. Damit stellen sich der IT und den Unternehmen neue Aufgaben. Der vertraute Monolith wird anschlussfähig an die Zukunft, aber man sollte den Monolithen nicht mehr denken, wenn er nicht nötig ist. Architektur, Organisation und Fachlichkeit greifen Hand in Hand bzw. Dienst in Dienst und führen nicht mehr zu einem mächtigen Produkt aus einem Guss, sondern einem mächtigeren WIE aus einem Guss. Die Keynote zur Eröffnung der BASTA! 2017 zeigt dazu das große Bild, viele Sessions und Workshops der BASTA!-Konferenzen in den nächsten Jahren werden die Details dazu vorstellen.
Spannende und Informative Sessions zum Thema finden Sie im Microservices & APIs Track der BASTA!
● Menschliche Software: Cognitive Services in Action
● Microservices – Ein Gesamtbild
● Pragmatische Microservices-Architekturen mit ASP.NET Core Web APIs, SignalR & Co.
The post Keynote | Microservices – zu klein und zu gut, um nur ein Hype zu sein appeared first on BASTA!.
]]>The post Von .NET zu .NET Core 2.0 – Kurze Erinnerung appeared first on BASTA!.
]]>Dann ist da noch die Firma Xamarin, die von Microsoft übernommen wurde. Damit befindet sich nun auch Mono in der Obhut von Microsoft. Mono ist eine quelloffene und plattformunabhängige Implementierung des .NET Frameworks, basierend auf den ECMA-Standards für C# und der Common Language Runtime [1]. Gleiches gilt für das Produkt Xamarin. Mit Xamarin lassen sich native Apps für verschiedene Plattformen (Android, iOS, Windows Universal Platform) in C# entwickeln. Unter der Haube setzt Xamarin dabei auf Mono.
Apropos „nativ“: Im Rahmen der Windows-Store-Apps veröffentlichte Microsoft .NET Native [2]. Im Wesentlichen stellt .NET Native einen Ahead-of-Time-(AoT-)Compiler zur Verfügung, der eine .NET-Anwendung (Windows-Store-App) in nativen Code übersetzt. Der Windows Store liefert dann den für die Zielplattform spezifischen nativen Code an den Benutzer aus.
Und als wäre das noch nicht genug, setzte Microsoft noch eins drauf und kündigte 2016 .NET Standard [3] an (damals noch .NET Platform Standard genannt). Nach sieben Versionen steht man hier nun bei der Version 2.0, die kürzlich veröffentlicht wurde.
Es lässt sich nicht abstreiten, dass sich rund um .NET viel tut. Dass man da als Entwickler schnell den Überblick verlieren kann oder sich in einem Zustand der Verwirrung und Orientierungslosigkeit wiederfindet, ist mehr als verständlich.
Abb. 1 In der Geschichte von .NET entstanden viele Ausprägungen (Verticals), meist aus einem Fork des großen .NET Frameworks
Schauen wir einmal auf Abb. 1. Wenn wir bisher von Portabilität geredet haben, dann betraf das nur die Microsoft-Windows-Plattformen. Plattformunabhängigkeit ist das noch lange nicht. Im Zeitalter der Cloud stellt sich die Frage, wie es mit anderen Plattformen aussieht: Linux, Mac und Containertechnologien lauten hier die Schlagwörter. Lange hat Amazon mit den Amazon Web Services (AWS) eine Cloud-Plattform etabliert, auf der das .NET Framework keine Rolle spielt. Und lässt man einmal Mono außer Acht, laufen herkömmliche .NET-Anwendungen auch nicht auf Linux-Distributionen oder auf dem Mac. Möchte Microsoft seine Kunden also auf derartige Plattformen bekommen, so muss eine andere, neue Lösung her. Und diese Lösung muss leichtgewichtig sein. Mal ebenso mehrere hundert oder tausend Container innerhalb von ein paar Sekunden hochziehen? Mit einem Windows-OS, vielleicht noch einer MSSQL-Datenbank und dem .NET Framework fühlt es sich an, als würde man versuchen, einen voll geladenen Jumbojet mit eigener Puste in den Himmel zu heben.
Dass .NET Core die Zukunft des .NET Frameworks sein muss, liegt aus technischer Sicht auf der Hand.
In diesem Kontext spielt auch die Modularität eine entscheidende Rolle. Wurde doch das .NET Framework als ein monolithisches Stück Software konzipiert, das auf dem Zielsystem als Ganzes installiert werden muss. Mittlerweile hat das Framework mehrere hundert Megabyte im Gepäck. Damit ergibt sich ebenfalls eine systemweite Abhängigkeit von Anwendungen zur installierten Version des .NET Frameworks. Erfordert eine Anwendung eines anderen Herstellers eine neuere Version des Frameworks, so kann sich dies auf bereits installierte Applikationen auswirken. Dafür möchte am Ende kein Systemadministrator verantwortlich sein. Wünschenswert wäre es, wenn diese systemweite Abhängigkeit von einer Anwendung zum Framework keine Rolle spielt. Das würde funktionieren, wenn Applikationen alles mitbringen könnten, was sie benötigen (inklusive der Laufzeitumgebung), und wenn diese Abhängigkeiten pro Anwendung installiert werden könnten. Dann wären die Versionen der Laufzeitumgebung und abhängigen Bibliotheken egal. Zudem würde das den Speicherbedarf reduzieren. Denn Anwendungen bringen nur das mit, was sie wirklich benötigen. Dazu gehört mit Sicherheit nicht das mehrere hundert Megabyte große .NET Framework. Wir sprechen hier von einem applikationslokalen Framework. Ein Monolith als maschinenweites Framework erfüllt diese Anforderung natürlich nicht.
Mit einem Windows-OS, vielleicht noch einer MSSQL-Datenbank und dem .NET Framework fühlt es sich an, als würde man versuchen, einen voll geladenen Jumbojet mit eigener Puste in den Himmel zu heben.
Der kritische Leser mag nun behaupten, dass .NET Core auch nichts anderes sei, als ein weiteres Vertical – ein weiterer .NET Stack. Zu Recht, denn genau das ist .NET Core. Dennoch: Laut Microsoft ist .NET Core ein Neustart des .NET Frameworks. Von Grund auf unter anderen Voraussetzungen als das ursprüngliche, monolithische .NET Framework konzipiert – basierend auf Anforderungen moderner Softwareanwendungen. Für Microsoft ist .NET Core der .NET-Stack der Zukunft und soll als Fundament für alle kommenden Plattformen und Hardwarearchitekturen dienen. Funktioniert das auf irgendeine Art und Weise zukünftig in der Praxis nicht, dann ist es wirklich nur ein weiterer .NET-Stack, den wir ggf. mit unseren Anwendungen bedienen müssen. Das ist aber eher unwahrscheinlich angesichts dessen, was gerade rund um .NET Core geschieht. Nicht ohne Grund presst Microsoft APIs mit Nachdruck in die neuen Versionen von .NET Core und forciert damit die API-Konvergenz – zum großen .NET Framework, aber auch zu anderen Verticals. Doch dazu später mehr.
Dass .NET Core die Zukunft des .NET Frameworks sein muss, liegt aus technischer Sicht auf der Hand: es löst die besagten Probleme der Vergangenheit und erfüllt damit die Anforderungen, die moderne Anwendungen für Web, Cloud, IoT, mobile Geräte etc., an ein solches Framework stellen.
The post Von .NET zu .NET Core 2.0 – Kurze Erinnerung appeared first on BASTA!.
]]>The post Die serverlose (R)evolution appeared first on BASTA!.
]]>Alles begann Anfang der 90er Jahre mit der Entwicklung des Internets. Spätestens 1993 war der kommerzielle Durchbruch geschafft, was größtenteils mit der Veröffentlichung des Webbrowsers „Mosaik“ einherging, der die Inhalte des WWW erstmals grafisch darstellen konnte. Ab sofort war eine Präsenz im Web für das eigene Geschäft in der beginnenden digitalen Welt ein Muss. Nach und nach wurde das Angebot an Webdiensten und Onlineshops zahlreicher und immer vielfältiger. Das Hosting dieser Dienste passierte jedoch auf den eigenen Maschinen, die je nach Größe und nötiger Verfügbarkeit der Dienste entweder unter dem Tisch des Entwicklers im Büro standen oder im klimatisierten Keller als kleine Rechnerfarm lebten. Wartung, Instandhaltung, Deployment, Backupstrategie und Ausfallschutz – all das lag im Aufgabenbereich der Administratoren. Die Risiken und auch die Kosten waren nicht unerheblich, da nebst den Materialkosten auch erweiterte Personalkosten für z. B. Bereitschaftsdienst aufgewendet werden mussten (Abb. 1).

Abb.1 Die (R)evolution der Cloud
Die Schmerzen, die durch das Hosting der eigenen Dienste verursacht wurden, waren rund um das Jahr 2000 endgültig verstanden und erhört worden. Nach und nach kamen Anbieter auf den Markt, die sich um die eigenen infrastrukturellen Herausforderungen kümmern wollten und somit das Hosting übernahmen. IaaS war geboren. Nun war es möglich, Hardware für die eigenen Dienste zu mieten, um so die physische Wartung und Instandhaltung der Maschinen vom Betreiber erledigen zu lassen. Man musste also „nur“ noch die Maschinen entsprechend aufsetzen und konfigurieren, wofür erstmals Virtualisierungsmechanismen zum Einsatz kamen – dann die eigentlichen Dienste bzw. Services installieren und verfügbar machen – fertig! Es war also nach wie vor komplexe Arbeit nötig, aber der Aufwand auf Maschinenebene fiel gänzlich weg.
Das war also der erste Schritt in die neue Welt. In den folgenden Jahren wurde IaaS breit angenommen und das Angebot stetig erweitert. Auch die Virtualisierungen waren erwachsen geworden und wurden industriell wie kommerziell als Standardwerkzeug eingesetzt. So war der Nährboden für den nächsten (R)Evolutionsschritt bereitet.
Was IaaS mit der Hardwareebene anstellte und somit Administratoren das Leben einfacher machte, wollte PaaS auf Softwareebene für die Entwickler tun. Und das mit enormem Erfolg.
Die Plattform bietet vorkonfigurierte Dienste mit definiertem Funktionsumfang an, die miteinander verknüpfbar sind und sich auch in bestehende Systemlandschaften integrieren lassen. Benötigt eine Anwendung beispielsweise zur Persistierung (objekt)relationaler Daten eine Datenbank, bietet die Plattform einen Baustein in einer Grundkonfiguration, der sofort zur Verfügung steht. Bei Bedarf kann die Konfiguration natürlich noch justiert werden.
So stehen in dieser Form Bausteine für die verschiedensten Anforderungen zur Verfügung (Application Services, Storage, Event Queues, API Gateways, Media Services, Machine-Learning-Instanzen und zahllose mehr), die im Zusammenspiel eine Softwarelösung bereitstellen oder als einzelnes Feature in einer Anwendung zum Einsatz kommen.
Aber Vorsicht! Mit diesen neuen Möglichkeiten der Anwendungsentwicklung verändern sich auch die darunterliegenden Mechanismen. Neue Softwareentwicklungsmuster entstehen und alte werden in Rente geschickt. Konnte man mit IaaS noch ein „Lift & Shift“ (Die Migration von Applikationen, bei der man die bisherige Ausprägung ohne Anpassungen direkt in der Cloud-Plattform abbildet) von Anwendungen in die Cloud betreiben, steht man bei PaaS oft vor einer Neustrukturierung der Anwendungslogik, um das Potenzial der Plattform auch nutzen zu können.
Nun muss man sich also nicht mehr um Hardware kümmern, dank der Mühen von IaaS. Und PaaS macht es möglich, die Dienste klug und nach Bedarf zu kombinieren, um damit die gewünschte Anwendung zu formen bzw. bestehende zu erweitern. Sind wir nun bereits am Ende der Komfortskala angekommen, was die moderne und Cloud-basierte Anwendungsentwicklung angeht? Man mag es erahnen: noch lange nicht!
Neue Softwareentwicklungsmuster entstehen und alte werden in Rente geschickt.
Seit etwa Mitte des Jahres 2014 ist eine neue Begrifflichkeit auf den Plan getreten und verspricht – vor allem den Entwicklern unter uns – den nächsten Entwicklungsschritt in der Cloud. Funktionen sollen als flexibler Klebstoff die PaaS-Welt dynamisch nutzbar gestalten.
Was ist an diesen Funktionen nun so neuartig ? Nutzt doch jeder Entwickler Funktionen in der Programmiersprache seiner Wahl täglich, um Businesslogik in Code zu gießen. Die Funktionen, um die es sich hier handelt, sind allerdings andere.
Sie sind Kleinstdienste, haben klar abgetrennte Aufgabenbereiche und arbeiten autonom und statuslos. Man kann sie wiederum auf schlaue Weise zusammenschließen und erhält am Ende eine lose gekoppelte Anwendungslogik, die auch in bzw. an Bestandssysteme ein- oder angehängt werden kann.
Vielleicht drängt sich nun unweigerlich der Gedanke „Microservices!“ auf, womit man keineswegs falsch liegt. Funktionen kann man als „Single-Purpose Services“ oder auch gerne als „Nanoservices“ beschreiben.
Nur Vorsicht vor Vermischung von Begrifflichkeiten. Die Architektur einer mit Funktionen realisierten Anwendung kann dem Microservices-Pattern folgen, aber die Idee geht darüber hinaus. Microservices beschreiben einen bestimmten Bauplan für eine Anwendung, wohingegen sich die Funktionen als das neue, mächtige – aber sehr kleinteilige – Werkzeug für den eigentlichen Bau verstehen.
Funktionen sollen als flexibler Klebstoff die PaaS-Welt dynamisch nutzbar gestalten.
Die Stärke der Funktionen liegt allerdings nicht in ihrem Formfaktor, sondern in dem Versprechen, dass die Betreiber der anbietenden Cloud-Plattform geben. Und hier kommt auch der Name ins Spiel, unter dem FaaS eher bekannt geworden ist: „Serverless Computing“ oder kurz „Serverless“.
Die Idee von Serverless Computing ist es, Dienste anzubieten, ohne einen einzigen Gedanken an Maschinen, Container, Betriebssysteme, Softwareversionen oder Skalierung der Instanzen – horizontal wie vertikal – zu verschwenden. Das ist natürlich etwas überspitzt formuliert, dennoch soll der „Serverless“-Weg genau zu diesem Ziel führen.
Und das ist auch das Versprechen der Plattformbetreiber: „100 % managed and operated“. Serverless Computing bietet also die Umgebung, um sich nahezu ausschließlich auf die Implementierung von Businesslogik konzentrieren zu können. Dabei muss diese in sinnvolle kleine und autonome Teile zerlegt werden. Jeder Teil wird als eine separate Funktion zur Verfügung gestellt, ausgeführt und skaliert.
Die Vorteile von „Serverless Computing“ wie Wartbarkeit, Skalierbarkeit und kurze Deploymentzyklen liegen auf der Hand und können auf diese Weise bereits auf Funktionsebene optimiert werden, was bislang nur auf Applikationsebene möglich war.
… große Verantwortung. Deshalb ein leises „Aber“ bzw. eine Ermahnung zur Vorsicht!
So verlockend es auch ist, Anwendungslogik frei nach dem Vorsatz „Separation of Concerns“ in kleinste Teile zu zerlegen, muss man stets mit Bedacht vorgehen und jedes Szenario für sich beleuchten. Denn sowohl die einst gefeierten Monolithen als auch die neuerdings gehuldigten Microservices haben uns beide noch nicht den heiligen Gral der glorreichen Systemarchitektur gebracht. Somit gilt auch hier der berühmte, immer richtige Satz der IT: „Es kommt drauf an“.
Spannende und Informative Sessions zum Thema finden Sie im Microservices & APIs Track der BASTA!
● Serverless Backends: Diät ohne Jojo-Effekt – mit Functions
The post Die serverlose (R)evolution appeared first on BASTA!.
]]>The post “Angular ist keine Eintagsfliege” appeared first on BASTA!.
]]>Man könnte den Eindruck gewinnen, dass es so viele JavaScript-Frameworks gibt wie Sand am Meer. Gemeinsam ist ihnen allen, dass sie den Entwicklern dabei helfen wollen, die Arbeit leichter zu erledigen. Natürlich kann man einen einfachen Editor nehmen und alles direkt in nacktem JavaScript schreiben. Sinnvoller ist es, eine IDE zu verwenden, eventuell TypeScript zu nutzen und sich dann ein Framework zu suchen, das für den einen Arbeitsstil und das anvisierte Projekt passend ist. Und genau hier kann es schwierig werden.
Vor dem Projektstart sollte man sich im Klaren darüber sein, warum man was mit JavaScript machen möchte. Ist es nur eine kleine Anwendung für einen kurzen oder experimentellen Einsatz, geht es nur um eine Webseite oder soll eine richtige App daraus werden? Soll das Ganze auf Enterprise-Niveau oder für einen kleinen Zirkel von Fachanwendern funktionieren? Und zu guter Letzt natürlich die Frage, welches der zahlreichen Frameworks zum Einsatz kommen soll. Denn die Frameworks lösen Probleme auf unterschiedliche Weise oder sind genau zur Lösung eines Problems geschrieben worden.
Darüber hinaus ist nach Manfred Steyer darauf zu achten, wie das Ökosystem eines Frameworks aussieht, welche Partner beteiligt sind und wie die Community arbeitet – im Bereich der Open-Source-Software sind das selbstverständliche Fragen, in der Microsoft-Welt muss man sich als Entwickler unter Umständen noch an solche Überlegungen gewöhnen. Zwar stehen hinter Frameworks wie Angular und React Unternehmen wie Google und Facebook, aber es gibt auch viele gute Lösungen, die von kleinen Unternehmen, Gruppen oder sogar einzelnen Entwickler angeboten werden und auch wunderbar funktionieren.
Aus der klassischen ASP.NET-Welt heraus ist Manfred über zahlreiche Projekte immer stärker in die JavaScript-Welt hineingewachsen und dabei natürlich an den Punkt gekommen, all die genannten Fragen und Überlegung zu überdenken. Er hat sich für Angular entschieden und ist darin inzwischen zum erfahrenen Experten aufgestiegen. Ihm ist wichtig, dass man sich vor dem Projektstart der konzeptionellen Unterschiede der einzelnen Frameworks bewusst ist, und auch weiß, wie das eigene Team tickt – was das im Detail und für Einzelne bedeutet, erklärt er anschaulich im Interview.
Selbstverständlich ist er auch als Sprecher auf der BASTA! und stellt in seinem Workshop “Angular-Senkrechtstarter-Workshop: Web-Frontends, die begeistern” und z.B. in der Session “Durch die Schallmauer: Hoch performante Anwendungen mit Angular” den praktischen Einsatz von Angular vor.
● Der Angular Router im Detail betrachtet
● Wiederverwendbare npm-Pakete und Plug-in-Systeme für Angular
The post “Angular ist keine Eintagsfliege” appeared first on BASTA!.
]]>The post SQL Server 2017 im Überblick: Alles, was Sie wissen müssen appeared first on BASTA!.
]]>Eine größere Neuerung ist der Einbau einer neuen Art von Tabellen: „Graph Tables“ (Graphtabellen). Mit diesen lassen sich Beziehungen zwischen Tabellen definieren. Zu diesem Zweck gibt es Knotentabellen (Nodes), die Benutzerdaten speichern und Kantentabellen (Edges), die den Beziehungen zwischen diesen Platz bieten. Insgesamt ist dies ein alternativer Ansatz zu relationalen Beziehungen zwischen Tabellen, um Daten mit Beziehungen zu speichern und abzufragen. Der wohl größte Unterschied dabei dürfte sein, dass eine Beziehung (Eintrag in Edge-Tabelle) zwischen jeder existierenden Node Table definiert werden kann; anders als relationale Beziehungen (mit Fremdschlüsseln), die fest zwischen zwei Tabellen angelegt werden.
Wenn also Beziehungen zwischen Bieren, Brauereien, Städten und Ländern abgebildet werden sollen (Abb. 1), dann sieht das T-SQL wie in Listing 1 aus.

Abb. 1: Biere, Brauereien, Städte und Länder
Listing 1 /*------------------ Knotentabellen -------------------*/ -- Biere CREATE TABLE [dbo].[Biere] ( Id INT PRIMARY KEY, [Name] VARCHAR(50), ) AS NODE; CREATE NONCLUSTERED INDEX idx_Biername ON [dbo].[Biere] ([name]); -- Brauereien CREATE TABLE [dbo].[Brauereien] ( Id INT PRIMARY KEY, [Name] VARCHAR(50), ) AS NODE; CREATE NONCLUSTERED INDEX idx_Brauereiname ON [dbo].[Brauereien] ([name]); -- Städte create table [dbo].[Staedte] ( Id INT PRIMARY KEY, [Name] VARCHAR(50), ) AS NODE; CREATE NONCLUSTERED INDEX idx_Stadtname ON [dbo].[Staedte]([name]); -- Länder CREATE TABLE [dbo].[Laender] ( Id INT PRIMARY KEY, [Name] VARCHAR(50), ) AS NODE; CREATE NONCLUSTERED INDEX idx_Laendername ON [dbo].[Laender]([name]); /*------------- Kanten Tabellen ---------------*/ -- Gebraut von CREATE TABLE [dbo].[GebrautVon] AS EDGE; CREATE UNIQUE NONCLUSTERED INDEX idx_GebrautVon ON [dbo].[GebrautVon] ($from_id, $to_id); -- Brauereistandort CREATE TABLE [dbo].[Brauereistandort] AS EDGE; CREATE UNIQUE NONCLUSTERED INDEX idx_Brauereistandort ON [dbo].[Brauereistandort] ($from_id, $to_id); -- Im Land CREATE TABLE [dbo].[LiegtInLand] AS EDGE; CREATE UNIQUE NONCLUSTERED INDEX idx_Herkunftsland ON [dbo].[LiegtInLand] ($from_id, $to_id);
Die T-SQL-Zusätze AS NODE beziehungsweise AS EDGE sind beide neu und legen fest, welche Funktion eine Tabelle einnehmen soll. Für die Graph Tables wird dadurch eine Reihe zusätzlicher Spalten angelegt (Abb. 2), die für interne Zwecke benötigt werden.

Abb. 2: Node- und Edge-Tabellen im SQL Server Management Studio
Beim Befüllen (und auch beim Ändern) der Tabellen mit Inhalten muss zwischen den beiden Arten von Tabellen unterschieden werden. Node-Tabellen werden befüllt, indem die beiden internen Spalten am Anfang ignoriert werden können; um ehrlich zu sein, kann auf die graph_id…-Spalte überhaupt nicht zugegriffen werden, während die $node_id…-Spalte ein internes JSON enthält.
Bei Edge-Tabellen muss wiederum angegeben werden, von welcher Entität (aus welcher Node-Tabelle) zu welcher Entität (aus welcher anderen Node-Tabelle) die Verbindung existieren soll. Listing 2 zeigt dafür einige Beispiele.
Listing 3
-- Welche Biere wurden von Brauerei #1 gebraut?
SELECT [Biere].[Name] AS 'Bier'
FROM [dbo].[Biere], [dbo].[GebrautVon], [dbo].[Brauereien]
WHERE MATCH (Biere-(GebrautVon)->Brauereien) AND [Brauereien].[name] = 'Brauerei #1';
-- Welche Biere kommen aus Stadt #7?
SELECT [Biere].[Name] as 'Bier',
[Brauereien].[Name] as 'Brauerei',
[Staedte].[Name] AS 'Stadt'
FROM [dbo].[Biere], [dbo].[GebrautVon], [dbo].[Brauereien],[dbo].[Brauereistandort],[dbo].[Staedte]
WHERE MATCH (Biere-(GebrautVon)->Brauereien-(Brauereistandort)->Staedte) AND [Staedte].[Name] = 'Stadt #7';
Die erste Version ist jedoch mit Einschränkungen versehen. Bestehende Tabellen können weder in Node- noch in Edge-Tabellen umgewandelt werden. In-Memory OLTP und Polybase sind ebenso tabu. Abfragen mittels MATCH können weder rekursiv noch polymorph sein. All dies soll in späteren Versionen oder Service-Packs nachgereicht werden.
Aber es gibt noch einige weitere T-SQL-Funktionen, die kleinere Verbesserungen bringen sollen. Zunächst einmal (Trommelwirbel) gibt es endlich eine TRIM()-Funktion, die RTRIM() und LTRIM() zusammenfasst und Whitespaces am Anfang und Ende einer Zeichenkette entfernt. Des Weiteren gibt es nun eine CONCAT_WS(), die ähnlich der CONCAT()-Funktion beliebige Werte zu einer Zeichenkette zusammenfügt. Der Unterschied: CONCAT_WS() akzeptiert als Erstes einen Parameter, der als Separator dient und zwischen allen weiteren Parametern eingefügt wird. So liefert CONCAT_WS(‘;’, @@SERVERNAME, GETDATE(), SUSER_NAME()) beispielsweise SQLServer2017;Jun 29 2017 6:07PM;sa. Alle Werte werden mit einem Semikolon getrennt, ohne dass dieses Trennzeichen wiederholt werden muss.
Ebenfalls eine Erleichterung soll die TRANSLATE()-Funktion mit ihren drei Parametern bieten. Sie durchsucht den ersten Parameter nach jedem Zeichen des zweiten Parameters und setzt das Zeichen des dritten Parameters ein, das sie an derselben Position findet. Klingt kompliziert? Ist es aber nicht. Ein Beispiel: TRANSLATE(‘2*[3+4]/{7-2}’, ‘[]{}’, ‘()()’) sorgt dafür, dass alle eckigen Klammern (Stelle 1 und 2) durch runde Klammern ersetzt werden (auch an Stelle 1 und 2). Das Gleiche geschieht mit geschweiften Klammern (Stelle 3 und 4), die ebenfalls durch runde Klammern (auch an Stelle 3 und 4) ersetzt werden. Das Ergebnis ist somit 2*(3+4)/(7-2) und ersetzt damit diesen, etwas unübersichtlichen Ausdruck REPLACE(REPLACE(REPLACE(REPLACE(‘2*[3+4]/{7-2}’,'[‘,'(‘), ‘]’, ‘)’), ‘{‘, ‘(‘), ‘}’, ‘)’).
Mit SQL Server 2016 hat die Funktion STRING_SPLIT() Einzug in den Funktionsumfang gehalten. Mit ihr kann man Zeichenketten anhand eines Trennzeichens (Delimiter) auftrennen und somit in eine Liste verwandeln. In Version 2017 hat es nun auch das Pendant geschafft. Mittels STRING_AGG() können Werte aus mehreren Zeilen zu einem Wert aggregiert werden; der zweite Parameter ist dabei das gewünschte Trennzeichen. Auf Wunsch kann die Aggregation auch unabhängig einer Zeilensortierung erfolgen.
-- Alle Datenbanken ohne bestimmte Sortierung
SELECT STRING_AGG([name], '; ') AS Datenbanken FROM sys.databases;
-- Ebenfalls alle Datenbanken, diesmal sortiert nach Namen
SELECT STRING_AGG([name], '; ') WITHIN GROUP (ORDER BY [name])
AS Datenbanken FROM sys.databases;

Abb. 3: „STRING_AGG()“ in Action
Mit SQL Server 2016 wurde der Query Store eingeführt, der verdichtete Perfomancedaten für die spätere Analyse durch einen Administrator bereitstellte. SQL Server 2017 geht einen Schritt weiter, indem laufend Ausführungsdaten gesammelt und analysiert werden. SQL Server „lernt“ also quasi, welcher Ausführungsplan für welche Abfrage die beste Performance mit den geringsten Ressourcenkosten ergeben hat. Genauer: Sie erlauben die Erkennung von sogenannten „Plan regressions“-Problemen, was bedeutet, dass Ausführungspläne (die ansonsten gut funktionieren) bei bestimmen Parametern nicht optimal sind. SQL Server kann nun für eine solche Kombination einen anderen Ausführungsplan verwenden und die Abfrage damit tunen. Somit wird also ein Vorgehen automatisiert, das zuvor nur aufwendig und fehlerbehaftet manuell durchgeführt werden konnte. Die dafür zuständige Stored Procedure heißt sp_force_plan und wird exemplarisch so aufgerufen: EXEC sp_force_plan @query_id = 4711, @plan_id = 1812;. Wohl dem, der @query_id und @plan_id bei einer großen Menge an Abfragen schnell ermitteln kann.
Die Aktivierung des neuen Automatismus geschieht auf Datenbankebene ALTER DATABASE current SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );. Um SQL Server bei seinen Entscheidungen dabei in die Karten zu schauen, gibt es eine neue DMV (Database Management View) mit dem Namen sys.dm_db_tuning_recommendations. Ein Teil der zurückgelieferten Daten sind im JSON-Format, sodass eine brauchbare Abfrage in Listing 5 entsteht.
Listing 5
SELECT [name], [reason], [score],
JSON_VALUE(details, '$.implementationDetails.script') as script,
details.*
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON(details, '$.planForceDetails')
WITH ( query_id int '$.queryId',
regressed_plan_id int '$.regressedPlanId',
last_good_plan_id int '$.forcedPlanId') as details
WHERE JSON_VALUE(state, '$.currentValue') = 'Active';
Das gesamte Vorgehen unterscheidet sich übrigens grundlegend vom dem des schon länger vorhandenen Database Engine Tuning Advisors, der die Daten aus einem Zeitraum nutzt, um Indizes vorzuschlagen.
Mit SQL Server wurden System-versioned/Temporal Tables eingeführt, die eine automatische serverseitige Historisierung ermöglichen. Nachteil war bis dato, dass die historischen Daten ohne manuelles Einschreiten niemals entsorgt wurden. Das ist nun anders. Bei der Aktivierung der Historisierung kann bestimmt werden, wie alt historische Daten maximal werden dürfen. Ältere Daten werden bei Abfragen nicht mehr berücksichtigt und automatisch aus der Datenbank entfernt. Als Einheiten stehen DAYS, WEEKS, MONTHS und YEARS zur Auswahl. Wird HISTORY_RETENTION_PERIOD nicht angegeben, findet kein automatisches Entfernen satt. Außerdem muss das neue Feature auf Datenbankebene eingeschaltet werden:
— Aktivierung auf Datenbankebene
ALTER DATABASE dotnetconsultingDb SET TEMPORAL_HISTORY_RETENTION ON;
— Historische Daten auf maximal 9 Monate beschränken
ALTER TABLE dbo.WebsiteUserInfo
SET (SYSTEM_VERSIONING = ON (HISTORY_RETENTION_PERIOD = 9 MONTHS));
Bis SQL Server 2016 wurden die Sicherheitsstufen, die festlegten, über welches API eine Assembly aufgerufen durfte, mittels Code Access Security (CAS) festgelegt. Da CAS nicht mehr als Sicherheitsgrenze unterstützt wird, wurde der Konfigurationswert clr strict security, dessen Wert angibt, ob SQL Server pauschal alle Assemblies wie mit der ehemaligem Sicherheitsstufe unsafe behandeln soll. Damit müssen faktisch alle Assemblies, die auf dem SQL Server zum Einsatz kommen sollen, signiert sein. Für die Entwicklung reicht es allerdings nach wie vor, die TRUSTWORTHY-Datenbankeigenschaft zu setzen.
Unter diesem Schlagwort wurde die beliebte Sprache Python in SQL Server eingebaut. Damit lassen sich schneller größere Datenmengen verarbeiten und auswerten, schließlich müssen keine Daten von SQL Server wegbefördert werden, da die Verarbeitung intern stattfindet. Damit stehen die Leistungsfähigkeit und die Erweiterungsmöglichkeiten Data Scientists für Auswertungen zur Verfügung. Administratoren können dabei mittels Richtlinien festlegen, welche Ressourcen die Python Runtime verwenden darf.
Noch viel mehr zu den Neuerungen erfahren Sie im Data Access und Storage Track.
● Azure Comos DB für SQL-Server-Entwickler
● Visual Studio als Entwicklungstool für SQL-Server-basierte Datenbanken
The post SQL Server 2017 im Überblick: Alles, was Sie wissen müssen appeared first on BASTA!.
]]>The post TypeScript ist der Türöffner für C#-Entwickler appeared first on BASTA!.
]]>
TypeScript ist für klassische .NET- und C#-Entwickler der Türöffner nach JavaScript. Es stellt eine Obermenge von JavaScript dar und erlaubt es, typisierten Code so zu schreiben, dass er in reines JavaScript übersetzt werden kann. Dabei werden auch unterschiedliche Versionen von JavaScript unterstützt, auch wenn die Entwickler rund um Anders Hejlsberg sich immer am aktuellsten Standard orientieren.
Da JavaScript eine dynamische Sprache ist, gibt es keine statische Typisierung von Variablen. Die statische Typisierung, die von Sprachen wie C# oder Java bekannt ist, führt bei falschen Zuweisungen schon zu Compile-Fehlern, und nicht zu Fehlern, die erst zur Laufzeit auftreten. Das erleichtert die Arbeit am Code und ist eines der vielen Probleme, die durch TypeScript gelöst werden. JavaScript wird dadurch (wieder) zu einer modernen Programmiersprache. Inzwischen werden sogar große Unternehmenslösungen damit umgesetzt.
Im Interview erklärt Thomas Claudius Huber, Trivadis AG, warum er inzwischen so weit ist, dass er alles, was heute JavaScript ist, mit TypeScript schreiben würde. Neben den Vorzügen der Typisierung und der Möglichkeit, seit der ECMAScript-Version 2015 wie gewohnt mit Klassen arbeiten zu können, lässt auch das Tooling rund um TypeScript kaum Wünsche offen. In jedem gängigen Editor vom große Visual Studio, dem schlanken Visual Studio Code von Microsoft oder auch WebStorm von JetBrains. In jedem dieser Tools finden Entwickler eine stetig verbesserte Unterstützung beim Schreiben von TypeScript-Code. So kann man passend zu den jeweiligen Projekten, eigenen Vorlieben und Erfahrung ein effizientes Toolset zusammenstellen.
Darüber hinaus gibt es inzwischen zahlreiche Frameworks, wie Angular, Electron, Node.js und andere, mit denen man spezifische Probleme und Aufgaben lösen kann. Huber meint, dass es mit der Auswahl des Frameworks dabei eigentlich ganz ähnlich ist wie bei der Vorliebe für eine Automarke: Es gibt also objektive Kriterien, die passen müssen, aber es ist auch immer eine subjektive Entscheidung. Wie auch immer diese ausfällt, nach seiner Ansicht müssen moderne C#-Entwickler beide Welten beherrschen. Dann können sie je nach Projektanforderung client- oder serverseitig mit C# oder TypeScript oder einer Kombination aus beidem arbeiten. Dabei müssen sie sich aber auch daran gewöhnen, dass einige Sachen in TypeScript ähnlich sind wie in C#, aber doch auch anders – da muss man dann aufpassen.
Worauf man genau achten muss, erfahren Sie in zahlreichen Sessions und Workshops der BASTA! 2017. Eine Übersicht finden Sie auf dem JavaScript-Track.
Den umfassenden Workshop von Thomas Claudius Huber TypeScript-Workshop: Einführung von 0 auf 100 in einem Tag können Sie am 29.9.2017 besuchen.
● Angular Senkrechtstarter-Workshop: Web-Frontends, die begeistern!
● Web-APIs mit Node.js und TypeScript – für .NET-Entwickler
● End-to-End-Live-Coding-Workshop: Eine moderne Businesswebanwendung für alle Plattformen mit Entity Framework Core, ASP.NET Core, TypeScript und Angular
The post TypeScript ist der Türöffner für C#-Entwickler appeared first on BASTA!.
]]>The post Kolumne: Karrieretipps appeared first on BASTA!.
]]>
Sicher ist, mit der Digitalisierung entstehen unzählige neue Geschäftsmodelle, und über eines sind sich alle Branchen einig: Die Digitalisierung steht auf der CIO-Agenda ganz weit oben. Während viele Unternehmen noch damit hadern, alte Strukturen zu durchbrechen und mit einer neuen digitalen Strategie den Markt zu erobern, befinden sich andere bereits in der nächsten Stufe der Digitalisierung. Ob Lieferdrohnen, digitale Umkleidekabinen oder selbstfahrende Autos – die digitale Welt bietet für Entwickler einen völlig neuen riesigen Spielplatz mit unzähligen Möglichkeiten.
Neben der Technik kommt aber im Rahmen der Digitalisierung ein zusätzlicher Aspekt ins Spiel, dem in der analogen Welt ebenfalls eine essenzielle Aufgabe zugesprochen wurde, heute aber fest mit der Technologie einhergeht: das digitale Marketing! Schon der Begriff „Marketing“ löst bei manch einem ITler Unbehagen aus. Werbebotschaften und wissenschaftlich nicht immer untermauerte Versprechen waren für Entwickler bisher unbeachtete Randerscheinungen, um die sie sich nicht weiter kümmerten. Nun aber gewinnt der Kunde im digitalen Zeitalter eine so große Bedeutung, dass seine persönlichen Daten, seine Gewohnheiten, sein Verhalten und seine individuellen Bedürfnisse auf direktem Wege in die IT-Lösungen mit einfließen. Mehr noch, seine Daten liefern die Basis der digitalen Produkte. Neben Datenschutz und ethischen Überlegungen kommen bei der Entwicklung digitaler Lösungen somit individuell auf den Kunden zugeschnittene Marketinganforderungen mit ins Spiel. Auch das ist eigentlich nicht neu, erreicht aber heute eine neue Dimension. Bisherige Trends wie Big Data und Cloud Computing fügen sich nahtlos in den Trend zur Digitalisierung ein. Somit sind Experten in diesem Gebieten nach wie vor sehr gefragt. Zusätzlich entstehen aber neue Berufsbilder in der IT, die die strategische Wichtigkeit der Digitalisierung untermauern. In Jobportalen finden sich heute neue, fantasievoll klingende digitale Jobtitel, von denen man mehr oder weniger die Aufgaben ableiten kann (Quelle: www.jobs.de):
Deutlich wird mit den neuen Jobtiteln vor allem eines: „Digitale IT-Experten“ werden in allen Branchen benötigt. Vor allem die Finanzbranche mit ihren Banken und Versicherungen signalisiert dabei einen großen Bedarf, aber auch alle anderen Branchen wie der Handel, die Industrie und der öffentliche Bereich suchen nach digitalen Experten. Die Aufgaben der digitalen IT-Spezialisten lassen sich dabei wie folgt zusammenfassen:
Auch wenn im Zuge der Digitalisierung klassische Aufgaben in unterschiedlichen Funktionen immer stärker durch intelligente Digital Services übernommen werden, die Digitalisierung bringt für die IT-Berufswelt jede Menge neues Entwicklungspotenzial. Für Entwickler heißt das jede Menge neue Herausforderungen, neue Technologien und noch mehr Schnittstellenvernetzung und Datenverarbeitung. Wie auch in der Vergangenheit, wird von Entwicklern der Weitblick für das Gesamtbild erwartet und eine starke Kundenausrichtung. Die Herausforderungen dabei nehmen jedoch stetig zu. Datensicherheit und Datenschutz stehen bei allen digitalen Entwicklungen im Fokus, sodass vor allem auch IT-Securityexperten weiterhin sehr gute Jobaussichten verzeichnen können. Zu den Anforderungen an digitale IT-Experten zählen die folgenden:
Neben den technischen Anforderungen kommen künftig also immer mehr Marketingaspekte und auch juristische sowie ethische Komponenten dazu. Somit sind auch diesen Berufsgruppe im digitalen Zeitalter neue Jobperspektiven sicher – vorausgesetzt, man kann sich mit der hochkomplexen IT-Welt anfreunden.
Wie schnell es mit der Digitalisierung vorangeht, entscheidet sich vor allem daran, wie schnell die Unternehmen mit den damit verbunden Anforderungen zurechtkommen. Neben den technischen Voraussetzungen ist dabei auch ein konsequentes Change Management in der Arbeitskultur notwendig. Mobile Arbeitsmodelle sind in der IT schon Alltag, in traditionellen Branchen jedoch zum Teil noch Neuland. Oft fehlt es hier an Vertrauen in diese Art der virtuellen Arbeitskultur. Aber die Anforderungen an den digitalen IT-Arbeitsplatz sind klar:
Kein Grund also zur Sorge: Die Digitalisierung bedeutet nicht das Ende der klassischen IT-Karriere, sondern ist der Beginn neuer, spannender Herausforderungen. Gleichzeitig stehen wir mit der Digitalisierung aber auch am Übergang zu Innovationen und neuen Lösungen, denn letztlich ist auch die Digitalisierung wieder ein Trend, der in absehbarer Zeit von einem neuen Megatrend abgelöst wird.
The post Kolumne: Karrieretipps appeared first on BASTA!.
]]>The post TOP 20 SOCIAL INFLUENCERS IN .NET DEVELOPMENT appeared first on BASTA!.
]]>The .NET, Windows & Open Innovation Conference BASTA! proudly presents the top 20 social influencers regarding the Microsoft and .NET World.
This list was created by analysing thousands of twitter profiles extracting the MozRank and Klout scores which rank both quality and influence.
If we missed anybody, it has nothing to do with the fact that we don’t think that they are just as important or shareworthy as any person on this list. We ourselves though do believe that such analytical lists do have the right to exist and furthermore we at BASTA! follow the listed speaker on their social channels and enjoy their quality content.
We congratulate everyone who made it on this list. If you click on the name or on the picture of each speaker you will be redirected to their twitter profile and check out the useful information they share every day.
Enjoy!
We first generated a list of one thousand .NET-related Twitter accounts.
To score the account and rank them accordingly, we analyzed their social authority and reach using two key metrics: MozRank and Klout.
Moz Social Authority Score: Social Authority score is composed of:
Visit this MOZ blog post for more in-depth information.
Klout Score: Klout uses more than 400 signals from eight different networks to update the Klout Score daily. It’s mainly based on the ratio of reactions a user generates compared to the amount of content he shares. Read more at the Klout score blog.
Congratulations to all the influencers who have made it into our Top 20!

To visit the associated Twitter profiles, just click on the respective portraits. We hope you enjoy exploring new perspectives and find some inspiration.
Daniel Rubino @Daniel_Rubino
Editor-in-chief of Windows Central. Full-time curmudgeon, science geek and play-acting anarchist. HoloLens user. [email protected]
Total score: 156 = Klout score: 81 + Social Authority score: 75
Clemens Vasters @clemensv
Software Architect, moving stuff from A to B, Microsoft @Azure #ServiceBus #EventHubs #Relay. OPCUA, OASIS, IoT. [email protected]
Total score: 128 = Klout score: 66 + Social Authority score: 62
The post TOP 20 SOCIAL INFLUENCERS IN .NET DEVELOPMENT appeared first on BASTA!.
]]>The post Meine künstliche Intelligenz appeared first on BASTA!.
]]>Die Cognitive Services sind wahrlich ein gutes Beispiel für gelungene Developer Experience. Zunächst die technischen Möglichkeiten: Nur einen REST-Aufruf entfernt bietet sich dem Entwickler eine Welt voller Möglichkeiten, die unweigerlich begeistern muss. Foto machen, uploaden, und das Gesicht wird identifiziert, Emotionen werden erkannt und das Alter wird bestimmt. Kostenpunkt: 0,001 Euro pro Abfrage, 30 000 Abfragen pro Monat sind gratis. Entwickeln Sie so etwas einmal selbst.
Mindestens genauso wichtig ist der absolute Fokus auf rasches Ausprobieren. Die Website der Cognitive Services ermöglicht fast überall ein Testen mit Demodaten – und es fällt schwer, sich loszureißen, wenn man die ersten Services einmal ausprobiert hat.
Viele der Services sind deshalb attraktiv, weil sie bereits „angelernt“ sind: Das Computer-Vision-API nimmt jedes beliebige Foto entgegen und erkennt beispielsweise Personen, Tiere, Großstädte und Gegenstände aufgrund der unzähligen Testdaten. Wir müssen nichts bereitstellen, keine Modelle trainieren, es funktioniert einfach.
Schon bisher gab es aber auch Services, die einen individuellen Endpunkt mit spezifisch angelernten Daten zur Verfügung stellen, um domänenspezifisch zu unterstützen. So war beispielsweise der Language Understanding Intelligent Service (LUIS) dafür optimiert, zuvor eingelernte Sätze zu verstehen und auch in abgewandelter Form wiederzuerkennen. Nicht alle Sätze, sondern speziell angelernte Sätze für die eigene Domäne.
Drei der vier neuen Services, die nun auf der Build 2017 vorgestellt wurden, tragen den Begriff „Custom“ im Namen und zeigen damit, wohin die Reise geht.
Der Custom Vision Service ist wie LUIS für Bilder: Über das API oder das webbasierte Portal lädt man Beispielbilder hoch und vergibt Tags. Anschließend lässt man den Service trainieren und erhält einen REST-Endpunkt, dem neue Bilder zur Analyse übergeben werden können. Das Ergebnis ist eine Einschätzung, zu viel Prozent welcher Tag auf das Bild zutrifft.
Wie gut funktioniert das in der Praxis? Vor einiger Zeit haben wir uns für eine Software aus dem Therapiebereich mit der automatisierten Erkennung des „Tangram“-Spiels beschäftigt. Mithilfe von sieben geometrischen Formen (fünf Dreiecke, ein Quadrat, ein Parallelogramm) müssen vorgegebene Bilder gelegt werden, nahezu die gesamte Tierwelt ist als Tangram-Vorlage verfügbar. Es war damals eine große technische Herausforderung, diese Erkennung zu implementieren. In vielen Manntagen wurden von hochqualifizierten Softwareentwicklern komplizierte Algorithmen implementiert und verschiedenste Lösungsansätze versucht. Vielleicht würden wir heute anders an die Sache herangehen.

Abb. 1: Image-Upload
Im ersten Schritt erstellt man ein Projekt auf https://www.customvision.ai und fügt die ersten Fotos hinzu (Abb. 1). In meinem Fall habe ich mit mehreren Hunde- und Katzentangrams gestartet und sie auf verschiedenen Untergründen und aus verschiedenen Winkeln fotografiert. Die Bilder müssen manuell getagt werden, pro Tag sind mindestens fünf Bilder notwendig (in der Dokumentation ist teilweise noch von dreißig Bildern die Rede – je mehr, desto besser). Anschließend startet man den ersten Trainingslauf, und nach wenigen Sekunden ist der Tangram-Erkennungsservice testbereit.
Abb. 2: Erste Erkennung
Nach der ersten Euphorie („Meine Katze wird erkannt!“) folgte sogleich die Ernüchterung: Selbst die lieblos am Tisch verstreuten Tangramteile wurden als Katze erkannt. Eigentlich war alles Katze (Abb. 2). Offenbar hatte der Service etwas Falsches gelernt, das kommt in den besten Familien vor (siehe dazu auch den kuriosen angeblichen Versuch des Pentagons, feindliche Panzer mit neuronalen Netzwerken zu erkennen).
Also nächster Durchgang: Bilder von zufällig angeordneten Tangram-Teilen hochladen und als „Tangramteile“ klassifizieren. Nicht Hund, nicht Katze. Und siehe da: die Erkennungsrate ging rasch nach oben, die Bilder wurden nun zuverlässig erkannt (Abb. 3).
Abb. 3: Katzen werden (endlich) erkannt
Nach demselben Schema können neue Fotos und neue Tags angelegt werden, der Service wird schrittweise verbessert. In einer eigenen „Performance“-Ansicht kann überprüft werden, ob die Erkennungsrate im Vergleich zur Vorgängerversion verbessert wurde (Abb. 4).
Abb. 4: Schrittweise Verbesserung
Natürlich ist das gezeigte Szenario noch nicht perfekt: Zum Beispiel erkennt es Katzentangrams auch dann, wenn ein Teil fehlt. Das ist im Sinne einer intelligenten Bilderkennung vielleicht erwünscht, im Fall von Tangrams jedoch falsch. Aber es zeigt: Mit Möglichkeiten wie dem Custom Vision Service können manche Problemstellungen auf eine komplett andere Art als bisher gelöst werden, Machine Learning und künstliche Intelligenz stehen dem normalen Entwickler zur Verfügung. Anstatt Algorithmen zu entwickeln, vertraut man einer Blackbox, die mit erstaunlich wenigen Testdaten in kürzester Zeit bereits verblüffende Erkennungsraten erzielen kann. Und mit der Weboberfläche ist das Erstellen dieser ausgeklügelten Logik auch für Nichtentwickler eine machbare Aufgabe. Denken Sie darüber nach.
Neben dem Custom Vision Service wurde auf der BUILD auch der Custom Decision Service vorgestellt. Dahinter verbirgt sich ein – etwas missverständlich benannter – Zusammenschluss mehrerer existierender Cognitive Services, um personalisierte Inhalte anbieten zu können. Öffnet ein Benutzer auf Ihrer Website einen Artikel, wird durch Text- und Bildanalyse der Inhalt analysiert und dieses Profil genutzt, um andere Inhalte empfehlen zu können.
Auch die Bing Custom Search ist als Preview-Version verfügbar und bietet die Möglichkeit, unter einem individuellen Endpoint auf eine für die eigenen Bedürfnisse optimierte Bing-Suche zuzugreifen.
Der vierte Service trägt den Namen Video Indexer und verspricht die Analyse von Videoinhalten:
Wer ist zu sehen?
Was wurde gesprochen?
Wo war besonders viel Emotion zu sehen?
Spannend für alle Medien und Videoplattformen. Und für das Kürzen des nächsten Sommerurlaubfilms, Ihre Freunde werden’s Ihnen danken.
● Visual Studio 2017: die Neuerungen
● Meine Software kann sprechen – Bot-Entwicklung im BASTA! Lab
The post Meine künstliche Intelligenz appeared first on BASTA!.
]]>The post Xamarin ist ein Quantensprung für .NET-Entwickler appeared first on BASTA!.
]]>Xamarin ist für ihn ein Quantensprung für .NET-Entwickler. Das .NET-Know-how inklusive XAML und Xamarin.Forms öffnet ihnen die Türen auch in die IoT-Welt und verbindet sie direkt mit der Cloud. Zudem profitieren sie von dem durchgehenden Tooling, das sie mit Visual Studio gut kennen und das von Microsoft immer weiterausgebaut wird. Das Tooling reicht allerdings nicht aus, um wirklich 100 Prozent auf jede Plattform zu liefern. Jede Plattform hat ihre Eigenheiten, die man als Entwickler auch kennen muss, und sei es nur, dass man die unterschiedlichen Distributions- und Installationsabläufe kennt. Dennoch sind das spezifische Kenntnisse, die sich schnell lernen lassen, während der Großteil der Arbeit über die schon vorhandene Kompetenz eines professionellen Entwicklers läuft. Dennoch bleibt es eine Herausforderung, wenn man für verschiedene Plattformen arbeitet, sich mit deren Weiterentwicklung und den Updates zu beschäftigen.
Obwohl Jörg Neumann im UI-Geschäft ein alter Hase ist und viele Plattformen im Detail kennen gelernt hat, bekennt er im Videointerview, dass er einen Aha-Effekt erlebt hat, als .NET-Entwickler für jede Plattform entwickeln zu können.
Sein Wissen und seine Begeisterung teil Jörg mit den Teilnehmern der BASTA! in seinem Xamarin-Workshop Xamarin.Forms Deep Dive (29.09.2017) sowie dem erstmals veranstalteten Xamarin Day (27.09.2017) und dem UI Day (28.09.2017) auf der BASTA! 2017.
● Conversational UIs und das Microsoft Bot Framework
● Design-First Development mit Storyboards
● Moderne Business-Apps mit XAML, oder: Mit WPF für die Zukunft geplant
● User Experience: Golden Rules and Common Problems of Web Views
● Keyboards? Where we’re going, we don’t need Keyboards!
The post Xamarin ist ein Quantensprung für .NET-Entwickler appeared first on BASTA!.
]]>The post Jubiläums-Dossier appeared first on BASTA!.
]]>
Erhalten Sie praxisbezogene Insights zu .NET, Azure, TypeScript, Node.js und mehr.
1. .NET Framework & C#
Tolle Typen – Wie statisch muss Typisierung sein
von Oliver Sturm
2. Agile & DevOps
ViewModels testgetrieben entwickeln
von Thomas Claudius Huber
VSTS/TFS – ganz nach meinem Geschmack
von Marc Müller
3. Web Development
Echtzeitchat mit Node.js und Socket.IO
von Manuel Rauber
4. Data Access & Storage & JavaScript
Entity Framework Core 1.0
von Manfred Steyer
5. HTML5 & JavaScript
Die Alternative für JavaScript-Hasser
von Dr. Holger Schwichtenberg
Asynchrones TypeScript
von Rainer Stropek
6. User Interface
Das GeBOT der Stunde?
von Roman Schacherl und Daniel Sklenitzka
The post Jubiläums-Dossier appeared first on BASTA!.
]]>The post Microservices: Reden ist Gold appeared first on BASTA!.
]]>„Microservices“ ist ein großes Wort, auch wenn es so klein klingt. Im Wesentlichen geht es um Dienste, und zwar um kleine Dienste. Wie klein die sein sollen, ist eine Frage, die oft und gern gestellt wird, und zu der es keine einfache, kurze und pauschale Antwort gibt. Wie so oft muss zunächst ein Verständnis her zum Pattern, bevor Fragen im Detail beantwortet werden können. Und bei Patterns ist es zum Verständnis immer wichtig, den Zweck der Sache zu beleuchten. Also sollten wir fragen: „Warum machen wir das?“, und nicht: „Wie geht das?“
Die Idee der Microservices stammt aus der Erkenntnis, dass Softwareentwicklung und deren Planung oft etwas realitätsfern sind. Ähnlich den agilen Ideen setzt man sich hier zum Ziel, eine große Aufgabe in kleine Teile zu unterteilen. Bei agiler Planung geht es um Abläufe und bei Microservices um Strukturen. Wo bisher Softwareplanung oft monolithisch betrachtet wurde, soll nun alles logisch in kleine Elemente zerlegt werden. Früher gab es Pläne, im Laufe der nächsten drei Jahre ein gewaltiges Stück Software zu bauen, das dann für die nächsten fünfzehn Jahre erfolgreich verkauft werden sollte. Irgendwann funktionierte das vielleicht auch mal, und als Unternehmensplan ist die Vorlage „fünfzehn Jahre gute Software verkaufen“ auch sicher sinnvoll. Aber mit der Realität von Kunden wie auch Entwicklern lässt sich dieser Ansatz auf technischer Ebene heute nicht mehr gut vereinbaren.
Die Probleme kennen Entwickler wie auch Softwaredesigner gut. Um ein Stück Software zu erzeugen, brauchen wir eine Plattform, eine Programmiersprache, verschiedene hilfreiche Libraries mit Zusatzfunktionalität und natürlich Entwickler, die sich ausführlich in diese Bauteile einarbeiten, zu Experten heranwachsen und langfristig für die Firma am Projekt arbeiten. In der wirklichen Welt ändern sich die Anforderungen allerdings leider ständig: Die Plattform der Wahl ist in ein paar Jahren vielleicht nicht mehr diejenige, mit der die meisten Endanwender arbeiten. Die Programmiersprache stellt sich längerfristig eventuell als falsche Wahl heraus, zumindest, wenn man gleichzeitig von neuen Entwicklungen profitieren möchte, die andere Entwickler verfügbar machen. Die Libraries sind meist an Plattform und Sprache gebunden, und die meisten Entwickler haben zwar gewissen Respekt vor dem Neuen. Sie wollen sich aber persönlich einen Platz in ihrem Job sichern, indem sie technisch am Ball bleiben und sind daher nicht endlos bereit, einem Weg zu folgen, der aus ihrer Sicht nicht mehr dem Stand der Technik entspricht. So wird die Pflege einer alten Software im Laufe der Zeit immer teurer, die Kunden werden immer unzufriedener, während die langfristige Planung und die monolithische Architektur intern weitreichende Überarbeitungen oder gar eine Neuentwicklung zum Tabuthema werden lassen.
Grundsätzlich kann ein Dienst auf jeder Plattform, in jeder Programmiersprache implementiert werden.
Microservices setzen auf Unabhängigkeit zwischen den Modulen eines Softwaresystems. Es sollen Dienste gebaut werden, die einzelne Aufgaben übernehmen und die voneinander entkoppelt sind. Die Aufgaben eines Dienstes sollen kurz und bündig definierbar sein; meistens denken wir dabei an eine einzelne Funktion mit einer Aufrufschnittstelle. Dadurch beantwortet sich die Frage nach der Größe eines kleinen Dienstes. Da jeder Dienst von allen anderen möglichst unabhängig ist, ergeben sich weitreichende Freiheiten: Plattform, Programmiersprache und Hilfs-Libraries können womöglich pro Dienst neu definiert werden. In einem neuen Konzept werden Sie vermutlich nicht so weit gehen wollen, denn immerhin gilt es, den Kenntnisstand von Mitarbeitern zu berücksichtigen, eventuell vorhandenen Code wiederzuverwenden und dergleichen mehr. Aber Sie gewinnen die Freiheit, später andere Entscheidungen treffen zu können – oder in gewissen Einzelfällen auch sofort. .NET Version X ist gerade erschienen und kann irgendwas Neues, von dem Sie technisch profitieren könnten? Dann kann ein Dienst oder eine Gruppe von Diensten auf .NET Version X umgestellt werden und mit der neuen Technik arbeiten, ohne dass andere Teile Ihres Systems geändert werden müssen. Vielleicht ist der Arbeitsmarkt plötzlich überschwemmt von Programmierern, die gut Python können – davon können Sie als Unternehmen profitieren, denn Teile eines Microservices-Systems können natürlich in Python programmiert werden.
Mit Microservices wird Wegwerfen zur Kultur. Nicht unbedingt zur Tugend, denn Neumachen kostet immer Geld, aber eben nicht mehr zur Unmöglichkeit. Wie Firmen in anderen Geschäftsfeldern etwa ein Auto bis zur Unkenntlichkeit umbauen, durch den Einbau von Spezialteilen für die Rallyeteilnahme, oder so wie eine PCI-Karte viele Jahre nach Erfindung des PCI-Busses mit einer Hardware kommunizieren kann, die es damals noch gar nicht gab, so lässt sich eine Software, die auf Microservices basiert, flexibel und modular über Jahre hinweg pflegen.
Diese Überlegungen bringen mich nun zurück zur eingangs angesprochenen Frage: „Wie sehen diese vielen Dienste denn aus?“ Die Antwort dazu ist, natürlich, ebenfalls vielschichtig. Grundsätzlich kann ein Dienst auf jeder Plattform, in jeder Programmiersprache implementiert werden. Technisch handelt es sich dabei ja „nur“ um eine Funktion (oder womöglich um ein „Netz“ von Funktionen), die einige Parameter übergeben bekommt und ein Resultat liefert. Das ist ein funktionaler Ansatz im Sinne der funktionalen Programmierung, wo Interaktion zwischen Funktionen außerhalb des simplen Schemas von Übergabeparametern und Rückgabewerten verpönt ist.
Es sollen Dienste gebaut werden, die einzelne Aufgaben übernehmen und die voneinander entkoppelt sind.
;
Von größerem technischen Interesse als die Implementierung einzelner Dienste ist deshalb die Frage, wie diese Dienste miteinander interagieren. Um die Flexibilität zu erreichen, die das Pattern verspricht, muss dazu eine Aufrufschnittstelle her, die sich „von außen“, also von anderen Diensten, ansprechen lässt. Diese Schnittstelle muss plattformunabhängig sein, auch was den Austausch von Daten bei Über- und Rückgabe angeht. Verbreitet wird zu diesem Zweck heute die Kombination von REST als URL-basiertem Aufrufschema und JSON als effizientem Datenübertragungsformat eingesetzt. Diese Kombination ist technisch simpel, und es gibt Libraries auf sehr vielen Plattformen, die den Umgang mit REST und JSON einfach machen. Selbst wenn es solche Libraries nicht geben sollte, wären diese Mechanismen, die auf HTTP bzw. einem simplen Textformat basieren, noch immer mit wenig Aufwand nutzbar. Auf komplexe Protokolle aus der SOA-Welt wird meist bewusst verzichtet, um die Einstiegshürde so niedrig wie möglich zu halten.
In .NET können Sie einen Dienst, der mit REST und JSON arbeiten soll, einfach mithilfe von Microsofts ASP.NET-Web-API verfügbar machen. Das funktioniert auch mit .NET Core, sodass Sie plattformunabhängig sein und auch Dienste mit Docker paketieren und in beliebigen Cloud-Umgebungen laufen lassen können. Alternativ lassen sich dieselben Ergebnisse mit Nancy oder anderen Libraries auf der .NET-Plattform erzielen. Ähnliche Libraries gibt es auch für andere Plattformen: Express für JavaScript und Node.js, Django für Python, Sinatra für Ruby und viele andere mehr. Wie auch Microsoft ASP.NET MVC haben die genannten Libraries Funktionalität weit jenseits der einfachen Erstellung von REST/JSON-Diensten, sodass sie sich vielfältig einsetzen lassen.
Nachdem Dienste nun „adressierbar“ sind, besteht der nächste Schritt darin, über die Struktur des gesamten Anwendungssystems nachzudenken. Um einen Dienst direkt mit einem anderen kommunizieren zu lassen, muss zumindest einer der Dienste wissen, wo der andere zu finden ist. In einem komplexen Netz von Diensten ist diese Anforderung schwierig umzusetzen, und die Situation wird wesentlich komplizierter, wenn etwa Mechanismen zur Lastverteilung oder zur Skalierung von Diensten oder Dienstgruppen zum Einsatz kommen. Daher nutzen viele Microservices-Konzepte einen Vermittler, englisch Broker, der Nachrichten entgegennehmen und an Dienste weiterleiten kann. Der Broker ist natürlich selbst ein Dienst und passt somit gut ins Konzept.
Broker schreiben die meisten Programmierer nicht selbst, da es bereits viele vorhandene Lösungen gibt. Zum Beispiel sind das Message-Queue-Systeme wie RabbitMQ, Redis oder Microsoft MSMQ, oder auch Dienste, die von einer Cloud verfügbar gemacht werden, wie Amazon SQS oder Azure Queue Storage bzw. Service Bus. Viele Konzepte setzen direkt auf eine dieser Technologien, andere verwenden eine Abstraktionsschicht wie NServiceBus für .NET, um sich nicht von einer bestimmten Broker-Implementation abhängig zu machen. Viele Lösungen unterstützen auch das standardisierte Protokoll AMQP, mit dem ein Client einen Broker ansprechen kann, ohne dessen Implementatierung zu kennen. Letztlich ist es auch möglich, einen Broker wiederum per REST anzusprechen, um das Gesamtsystem so offen wie möglich zu halten.
Von größerem technischen Interesse als die Implementierung einzelner Dienste ist deshalb die Frage, wie diese Dienste miteinander interagieren.
Wenn Sie meine Kolumne regelmäßig verfolgen, erinnern Sie sich bestimmt an meinen Artikel zum Thema Akka.NET [1], der Implementierung eines Aktorenframeworks für .NET. Ein System, das auf Microservices basiert und einen Broker zum Austausch von Informationen zwischen Diensten verwendet, zeigt bemerkenswerte Parallelen zu den Ideen der Aktoren. Letztere verarbeiten ebenfalls Nachrichten und sind voneinander vollständig entkoppelt, während die Infrastruktur für den Austausch von Informationen durch asynchrone Mechanismen sorgt – und Akka.NET bietet eigene Möglichkeiten zur verteilten Ausführung von Aktoren.
Es gibt zwei wichtige Unterschiede zwischen typischen Aktorensystemen und Microservices. Erstens bietet ein Aktorensystem viel organisatorische Funktionalität, die den Betrieb des Gesamtsystems stabiler macht. Es werden Hierarchien von Aktoren aufgebaut, in denen ein „Parent“ jeweils für den Betrieb seiner „Kinder“ verantwortlich ist, und es gibt Überwachungs- und Benachrichtigungsfunktionen, mit deren Hilfe der Lebenszyklus einzelner Aktoren kontrolliert werden kann. Damit sind Aktoren, wenn auch funktional eigenständig, wesentlich stärker in das Gesamtsystem eingebunden, als das für Microservices wünschenswert ist. Letztlich sind diese Grenzen natürlich fließend und manche Microservices-Systeme bauen ebenfalls Gruppen von Diensten auf, die stark voneinander abhängig sind.
Der zweite wichtige Unterschied ergibt sich aus dem ersten: Die Protokolle, die ein Aktorensystem zum Datenaustausch zwischen Aktoren verwendet, sind oft komplexer und darauf ausgerichtet, relevante Verwaltungsinformationen zusammen mit den Nutzdaten zu übertragen. Technisch ist es durchaus möglich, beliebige Kommunikationsprotokolle in einem Aktorensystem zu verwenden und manche Entwickler benutzen Aktorensysteme gemeinsam mit Message-Queue- oder Service-Bus-Varianten. Allerdings darf nicht übersehen werden, dass die Versprechungen von Aktorensystemen in Hinsicht auf die langfristige Laufstabilität letztlich auf den implementierten Konzepten zur Dienstüberwachung und Lebenszyklusverwaltung basieren. Während also ein externer Dienst sich technisch durchaus in ein solches System „einklinken“ kann, muss er sich dann entsprechend den Erwartungen dieses Systems verhalten und er verliert dabei einen Großteil der Unabhängigkeit, die ein eigenständiger Dienst haben sollte.
Daher nutzen viele Microservices-Konzepte einen Vermittler, englisch Broker, der Nachrichten entgegennehmen und an Dienste weiterleiten kann. Der Broker ist natürlich selbst ein Dienst und passt somit gut ins Konzept.
Trotz dieser Betrachtungen lassen sich Aktoren natürlich innerhalb eines Microservices-Systems einsetzen. Immerhin geht es dort besonders um den Einsatz geeigneter Technologien für jedes einzelne Teilsystem, und mithilfe von Aktoren lassen sich etwa Datenverarbeitungsalgorithmen stabil und modular umsetzen, deren externe Schnittstellen dann in Form eines oder mehrerer Dienste angeboten werden können. Mit Akka.Cluster gibt es in diesem Bereich sogar ein Modul, das auf Basis von Aktorensystemen automatisch Gruppen von Aktorensystemen verteilen kann, basierend allerdings noch immer auf den komplexen, wenn auch optimierten, internen Protokollen. Die Firma Lightbend, involviert in die Entwicklung von Akka für Java, bietet mit Lagom ein neues Framework an, das auf Basis von Akka Microservices implementiert. Diese Lösung ist derzeit für .NET meines Wissens noch nicht verfügbar.
Zum Abschluss möchte ich ein Framework ansprechen, das ich für eine sehr leistungsfähige Basis für Microservices halte. Dabei handelt es sich um das in JavaScript programmierte Seneca, das eine besonders interessante Kombination von Features bietet. Sie konfigurieren beim Einsatz von Seneca Dienste, die mithilfe von Pattern-Matching auf Nachrichten reagieren können und bei deren Empfang ihre Logik ausführen und Resultate liefern. Der Umgang mit dem API von Seneca ist sehr einfach und so gelingt es schnell, ein Netzwerk von Diensten aufzubauen. Nun hat Seneca weiterhin die Fähigkeit, auf Basis der Patterns, auf die die Dienste antworten, auch Routen zu definieren, die automatisch bestimmte Nachrichten über externe Wege weiterleiten, die auf Basis zahlreicher Plug-ins flexibel konfigurierbar sind. Natürlich können Sie Dienste über REST-URLs zugreifbar machen, aber auch die Verwendung einer Message Queue ist mit zwei Zeilen Code eingerichtet. Jedes Dienstprogramm, groß oder klein, kann so auf einfache Weise manche Dienste direkt lokal ansprechen und andere „remote“ über unterschiedliche Protokolle, ohne dass ein Dienst selbst etwas davon wissen muss, wie das Gesamtsystem aufgebaut ist.
Microservices stellen ein mächtiges und vielschichtiges Pattern dar, von dem beinahe jedes Anwendungssystem profitieren kann. Die Frage nach der Kommunikation in einem solchen System ist eine der wichtigsten und die Antworten sind vielfältig, weil sie unterschiedliche Anwendungsfälle abdecken. Es empfiehlt sich in jedem Fall, nach Hilfsmitteln auf den Plattformen der Wahl Ausschau zu halten, da die Verwendung von Standardsystemen wie RabbitMQ, Cloud-Infrastruktur wie Amazon SQS oder Azure Service Bus und Libraries wie Seneca Ihnen viel Arbeit ersparen kann.
[1] „Olis bunte Welt der IT“, Windows Developer 11.2016, S. 14
;
● Domain-driven Design – Basis für Microservices und Anwenderglück
;
The post Microservices: Reden ist Gold appeared first on BASTA!.
]]>The post 2017 ist ein Jubiläumsjahr für die BASTA! appeared first on BASTA!.
]]>An die guten Zeiten erinnert man sich gerne, die schlechten bleiben oft besser im Gedächtnis. Gerade Microsoft sorgt für schmerzliche Erinnerungen, wenn es selbst vielversprechende Technologien verworfen hat, die gerade noch marktführend waren – es sei nur an Silverlight erinnert. Der große Shift über Windows 8 zu Windows 10 oder die resolute Einführung von Azure sind weitere Beispiele für große Veränderungen. Aber auch wenn Microsoft den Kurs radikal geändert hat, wussten unsere Speaker immer Rat und haben den Teilnehmern praktische und schnelle Lösungen präsentiert, um die Hürden gekonnt zu nehmen. In diesem Geiste ist die BASTA! zwar älter geworden, aber nicht gealtert. Sie ist immer flexibel mit der Zeit gegangen, hat die neuen Entwicklungen vorausgespürt, den Teilnehmern genau die Informationen gegeben, die sie heute und morgen für ihre Arbeit brauchen.
In diesem Herbst ist die BASTA! daher nicht nur wieder der richtige Ort für Weiterbildung und Networking, es ist der richtige Ort zum Feiern. Eine Konferenz dieser Größe und Bedeutung macht man nicht allein, ein treues Publikum, engagierte Speaker und verlässliche Partner zählen auch dazu – ihnen gilt unser Dank.

Feste muss man feiern, wie sie fallen. Und das werden wir auch tun. Wir feiern in diesem Herbst 20 Jahre BASTA!, und Sie sind alle herzlich dazu eingeladen. Was 1997 als BASic TAge gestartet ist, hat sich in zwei Jahrzehnten zur größten unabhängigen, deutschsprachigen Konferenz rund um Microsoft-Technologien entwickelt und ist in dieser Zeit für viele Leute zu einer festen Größe im Jahresplan geworden.
Darauf sind wir stolz. Das wollen wir feiern, zusammen mit Ihnen, unseren Teilnehmern, Sprechern, Partner und Veteranen. Wir laden Sie alle zu einer großen Oktoberfest-Feier am Dienstagabend der BASTA! 2017 in Mainz ein und bieten neben kulinarischen Genüssen und dem einen oder anderen gepflegten Bier unterhaltsame Rückblicke und Einblicke in die 20-jährige BASTA!-Geschichte. Freuen Sie sich auf ein Wiedersehen mit Sprechern und Partnern der ersten Stunde.
Eins ist und bleibt klar, die BASTA! ist auch nach zwanzig Jahren nie rückwärtsgewandt. Fest in der Gegenwart verortet, sind wir auch immer einen Schritt in der Zukunft. Wir präsentieren in den zahlreichen Keynotes, Sessions und Workshops das beste und aktuellste Know-how, das professionelle Entwickler heute und morgen brauchen. Darauf können Sie auch die nächsten zwanzig Jahre zählen.
Auf diese Weise hat sich auch die BASTA! gewandelt und sich immer wieder an neuen Entwicklungen und wichtigen Trends orientiert. Das sieht man natürlich am besten am breit gefächerten Programmangebot der BASTA!. Vor einigen Jahren haben wir beispielsweise zusammen mit Christian Weyer den Modern Business Application Day entwickelt und waren damit Vorreiter einer Cross-Plattform-Entwicklung, die heute fast schon Mainstream ist. Ist doch inzwischen den meisten bewusst, dass sie nicht mehr nur für eine Plattform entwickeln und dabei auch nicht mehr nur auf eine Technologie setzen können. Vom klassischen .NET über Web-APIs, Azure, JavaScript und HTML5 (https://basta.net/html5-javascript/) werden heute Apps und Lösungen entwickelt, die keine Grenzen mehr kennen. Der im Herbst erstmals angebotene Xamarin Day mit Jörg Neumann bestärkt diese Entwicklung. Ganz egal ob iOS, Android oder Windows – für C#-Entwickler ist das Bauen von Lösungen für jedes Betriebssystem zum Heimspiel geworden.
Aber auch in traditionellen Bereichen verändert sich die Entwicklung. Fast von Anfang an ist Holger Schwichtenberg, der Dotnet Doktor aka Mr. Entity Framework, als Sprecher bei der BASTA! dabei. Auf seine Expertise in Sachen .NET zählen wir auch heute z. B. im Data Access Day. 15 Jahre nach Veröffentlichung des großen .NET Frameworks führt Microsoft mit .NET Core eine neue Plattform ein, die Entwicklern noch mehr Möglichkeiten bietet und weitere Hürden einreist. Können sie doch damit für Windows, Linux und macOS zugleich entwickeln. Zahlreiche Sessions der BASTA! 2017 zeigen im Detail, wie es geht.

Gerade die Beispiele Cross-Plattform und .NET Core zeigen, wie sehr sich die Entwicklung im Microsoft-Umfeld und damit auch die BASTA! in den vergangenen Jahrzehnten gewandelt hat. Von einem geschlossenen, eher autoritativen, manchmal fast alternativlosen/eingrenzenden Technologiestack hin zu einer transparenten, offenen, Open-Source-orientierten und auf Kompatibilität ausgerichteten Angebotsfülle. So sind das .NET Framework und viele Teile von Azure von Microsoft Open Source gestellt worden und werden in Zusammenarbeit mit einer wachsenden Community weiterentwickelt. Auch die Entscheidung für die enge Integration von z. B. Git oder JavaScript sind ein Paradigmenwechsel seitens Microsoft.
Gerade JavaScript ist ein gutes Beispiel. War es bei gestandenen .NET-Entwicklern lange unbeliebt und auch ungeeignet, auf Systemebene damit zu arbeiten, sind es jetzt die zahlreichen Frameworks, die Toolunterstützung und die Entwicklung von TypeScript, die JavaScript fast zur natürlichen Zweitsprache für C#-Entwickler machen. Nicht umsonst ist wahrscheinlich TypeScript von Anders Hejlsberg, dem „Vater“ von C#, entworfen worden. Gerne betont wird in diesem Zusammenhang, dass Googles Angular inzwischen mit TypeScript weiterentwickelt wird. Eine Zusammenarbeit, die man vor wenigen Jahren so nicht erwartet hätte. Noch dazu zählt Angular zu den beliebtesten Frameworks bei den Teilnehmern. Daher finden Sie viele Sessions auf der BASTA!, in denen Angular ein wichtiges Thema ist, z.B. im Web Development Day.
Um zum Schluss den Rahmen noch weiter zu ziehen, darf Azure nicht unerwähnt bleiben. Mit seinem entschlossenen Schritt in die Cloud hat Microsoft ein deutliches Zeichen gesetzt und sich von den Wettbewerbern abgesetzt. Neben Amazons AWS bietet Azure aktuell das größte Cloud-Angebot. Ein Angebot, das .NET-Entwickler nahtlos in ihre Arbeit einbeziehen können. Die BASTA! bietet dazu zahlreiche Sessions zu Themen wie Docker, API, Microservices und mobile Entwicklung, die nicht Azure direkt thematisieren, aber praktische Einsatzmöglichkeiten zeigen, die Entwicklern den Schritt in die Cloud ermöglichen.
Auch hier folgt die BASTA! ihrer Tradition und bleibt Vorreiter und Wegbereiter für neue Technologien. Wie schon gesagt: Alleine kann man so einen Weg nicht gehen. Es braucht schon viele Individualisten, die gemeinsam die Welt verändern wollen. Auf der BASTA! treffen sie sich – seit zwanzig Jahren.
The post 2017 ist ein Jubiläumsjahr für die BASTA! appeared first on BASTA!.
]]>The post TypeScript – Grundlagen für .NET-Entwickler appeared first on BASTA!.
]]>Die Sprache JavaScript wurde 1995 in ein paar Wochen entwickelt. Die Idee war, Code auf Webseiten ausführen zu können, um Inhalt dynamisch anzupassen. Damals konnte sich vermutlich niemand vorstellen, dass mit JavaScript Unternehmensanwendungen mit 100 000 oder mehr Zeilen Code umgesetzt werden. Doch das ist heute der Fall. Zwar lassen sich mit JavaScript solche Anwendungen bauen. Doch dabei gibt es einen großen Nachteil: JavaScript ist eine dynamische Sprache, es gibt keine statische Typisierung von Variablen. Die statische Typisierung, die von Sprachen wie C# oder Java bekannt ist, führt bei falschen Zuweisungen zu entsprechenden Compile-Fehlern, und nicht zu Fehlern, die erst zur Laufzeit auftreten. In C# lässt sich aufgrund der starken Typisierung beispielsweise einer String-Variablen kein Integer zuweisen. In JavaScript dagegen lässt sich einer Variablen ein beliebiger Inhalt zuweisen, da die Variable als solche gar keinen Typ hat:
let firstName = "Thomas"; firstName = 5; // OK
Die firstName-Variable erhält zuerst einen String, dann die Number 5. Das ist in JavaScript völlig in Ordnung und führt zu keinem Fehler. Doch für eine robuste Architektur ist eine statische Typisierung extrem hilfreich, die eben während des Entwickelns und Kompilierens bereits viele Fehler abfangen kann. Und genau diese Typisierung besitzt TypeScript, was auch der Ursprung des Namens ist.
TypeScript stellt eine Obermenge von JavaScript dar. Somit ist jeder JavaScript-Code bereits gültiger TypeScript-Code. Bei einer Migration von JavaScript nach TypeScript werden üblicherweise einfach Typen eingeführt, um mögliche Fehler bereits zur Compile-Zeit abzufangen. Die firstName-Variable aus dem gezeigten Beispiel lässt sich in TypeScript mit einer so genannten Typannotation versehen. Der Typ wird dabei nach dem Variablennamen angegeben. Variablennamen und -typ werden mit einem Doppelpunkt getrennt. Der nachfolgende Code zeigt die firstName-Variable mit der Angabe des string-Typs. Wird in TypeScript dieser Variablen ein Wert vom Typ number zugewiesen, führt dies im Gegensatz zu JavaScript zu einem Compile-Fehler:
let firstName: string = "Thomas"; firstName = 5; // Kompilierfehler
Die statische Typisierung bringt neben Compile-Fehlern weitere Vorteile: Tools wie Visual Studio Code können deutlich bessere Unterstützung als bei reinem JavaScript bieten, weil der Typ zur Entwicklungszeit schon feststeht. Somit gibt es Funktionen wie IntelliSense, Go to Definition und vieles mehr, die das nutzen können.
Neben der statischen Typisierung hat TypeScript ein weiteres sehr wichtiges Merkmal: TypeScript kompiliert zu reinem JavaScript-Code. Das heißt, dass TypeScript lediglich zur Entwicklungszeit wichtig ist. Zur Laufzeit benutzt der Browser klassisches JavaScript, das aus TypeScript kompiliert wurde. Doch jetzt kommt der eigentliche Clou: Mit TypeScript lässt sich die erstellte JavaScript-Version bestimmen. So kann nach ES2015 oder auch nach ES5 kompiliert werden. Dies ist insbesondere interessant, wenn man bedenkt, dass Browser immer eine Weile brauchen, bis der letzte ECMAScript-Standard implementiert ist. Und ist der Standard implementiert, ist noch nicht gewährleistet, dass die User auch die letzte Browserversion installiert haben, mit der der JavaScript-Code ausgeführt werden kann und richtig funktioniert. Mit TypeScript ist dies kein Problem mehr, da sich die neuen Features einfach in eine ältere, von allen gängigen Browsern unterstützte JavaScript-Version kompilieren lassen.
Beispielsweise wurden mit ES2015 Klassen eingeführt, um objektorientiert zu programmieren. Klassen sind somit auch in TypeScript verfügbar. Doch der TypeScript-Code lässt sich nicht nur nach ES2015 kompilieren, sondern auch nach ES5. Somit lassen sich Klassen in TypeScript wie in ES2015 nutzen, anschließend aber nach ES5 kompilieren, was von den gängigen Browsern unterstützt wird.
Mit der statischen Typisierung erhalten Entwickler Fehler bereits während des Entwickelns. Ebenso gibt es zahlreiche Features im Tooling, wie IntelliSense, Go to definition und mehr. Ein weiterer Vorteil der statischen Typisierung ist, dass der Code selbst-dokumentierend ist. Hat ein Funktionsparameter einen Typ, ist klar, was an die Funktion übergeben werden muss. Gibt es dagegen wie in JavaScript keinen Typ, bedarf es Kommentaren, die beschreiben, was die Funktion eigentlich verlangt. Da das Kompilat von TypeScript reines JavaScript ist, gibt es keinen Grund, warum man in JavaScript-Projekten nicht auf TypeScript setzen sollte.
Was man wie mit TypeScript machen kann, zeigt Thomas Claudius Huber in seinem Workshop “Einführung in TypeScript: von 0 auf 100 in einem Tag”, am Freitag, den 24.2.2017
The post TypeScript – Grundlagen für .NET-Entwickler appeared first on BASTA!.
]]>The post Visual Studio Team Services und Team Foundation Server erweitern und anpassen appeared first on BASTA!.
]]>Wie oft hatte man sich in der Vergangenheit gewünscht, an einer bestimmten Stelle einen zusätzlichen Button hinzuzufügen oder gar eigene Views einzublenden. Diese Möglichkeit ist mit der aktuellen Version nun gegeben. Die Erweiterungen in der Oberfläche enthalten Code in Form von JavaScript zur Interaktion mit dem System, die Visualisierung wird mittels HTML implementiert. Eigene Backend-Services können damit aber nicht integriert werden. Sobald Servicelogik erforderlich ist, kann dies nur als externer Service implementiert werden, also z. B. als eigenständige Webapplikation.
Diese Applikationen können über die REST-Schnittstelle mit dem VSTS bzw. TFS interagieren. Zur Benachrichtigung der externen Applikation stehen so genannte WebHooks zur Verfügung. Zu guter Letzt können dem TFS bzw. VSTS noch eigene Build-Tasks über die Extensibility-Schnittstelle zur Verfügung gestellt werden. Weitere Details zu den einzelnen Erweiterungspunkten sind auf der Extensibility-Webseite von VSTS zu finden. Neben einer detaillierten Auflistung werden entsprechende Beispiele zur Verfügung gestellt.

Abb. 1: Übersicht über die Integrationspunkte von Extension in VSTS/TFS
In diesem Artikel wird die Extensibility-Schnittstelle anhand eines eigenen Dashboard-Widgets erklärt. Um die Komplexität klein zu halten, wollen wir ein einfaches Widget in Form einer Build-Ampel erstellen (Abb. 2). Die Ampel kommuniziert mit dem Build-System über ein REST-API, um den aktuellen Status periodisch zu erfragen. Da wir für verschiedene Build-Definitionen verschiedene Ampeln auf dem Dashboard positionieren möchten, benötigen wir ebenfalls eine Konfigurationsmöglichkeit für den Nutzer, in der er die Größe des Widgets sowie die gewünschte Build-Definition auswählen kann.

Abb. 2: Build-Traffic-Lights-Widget als Beispiel für diesen Artikel
UI-Extensions bestehen primär aus HTML und JavaScript und den üblichen Webartefakten wie Bildern und CSS-Dateien. Damit VSTS respektive TFS weiß, was wie und wo intergiert werden muss, beinhaltet jede Extension ein Manifest. Das Manifest, das als JSON-Datei definiert wird, beinhaltet alle Informationen, Dateispezifikationen sowie Integrationspunkte. Dazu kommt die Definition der Scopes, also die Definition der Zugriffsrechte der Erweiterung. Vor der Installation wird der Nutzer darüber informiert, auf was die Erweiterung Zugriff wünscht, und muss dies entsprechend bestätigen. Ist eine Erweiterung einmal ausgerollt, kann der Scope nicht mehr verändert werden. So wird verhindert, dass durch ein Update plötzlich mehr Berechtigungen als einmal bestätigt eingefordert werden können.
Grundsätzlich können wir die Erweiterung mit jedem Texteditor erstellen, jedoch wollen wir auch in diesem kleinen Beispiel den Entwicklungsprozess gleich sauber aufgleisen und verwenden hierzu Visual Studio. Für die Libraries und Zusatztools verwenden wir den Node Package Manager (npm). Damit wir die Paketerstellung automatisieren können, kommt Grunt als Task-Runner zum Einsatz. Wer das alles nicht von Hand aufbauen möchte, kann die Visual-Studio-Erweiterung VSTS Extension Project Templates installieren. Hiermit verfügt Visual Studio über einen neuen Projekttyp, der das Erweiterungsprojekt mit allen Abhängigkeiten und Tools korrekt aufsetzt. Zudem möchten wir in unserem Beispiel nicht direkt JavaScript-Code schreiben, sondern TypeScript zur Implementierung verwenden. Abbildung 3 zeigt die Projektstruktur in Visual Studio für unsere Erweiterung.

Abb. 3: Projektstruktur des Build-Traffic-Lights-Widgets
Unsere Manifestdatei befüllen wir mit den üblichen Informationen zum Autor sowie der Beschreibung der Erweiterung. Von entscheidender Bedeutung sind der Scope für die Berechtigungen sowie die Contribution Points, in denen die eigentliche Integration beschrieben wird. Da wir auf Build-Informationen lesend zugreifen möchten, wählen wir den Scope vso.build_execute. Als Contribution Points definieren wir zwei UI-Elemente: ein Widget-UI sowie ein Konfigurations-UI. In Listing 1 sind die entsprechenden Stellen fett hervorgehoben.
{
"manifestVersion": 1,
"id": "BuildTrafficLights",
"version": "0.1.16",
"name": "Build Traffic Lights",
"scopes": [ "vso.build_execute" ],
...
"contributions": [
{
"id": "BuildTrafficLightsWidget",
"type": "ms.vss-dashboards-web.widget",
"targets": [
"ms.vss-dashboards-web.widget-catalog",
"4tecture.BuildTrafficLights.BuildTrafficLightsWidget.Configuration"
],
"properties": {
"name": "Build Traffic Lights Widgets",
"uri": "TrafficLightsWidget.html",
...
"supportedScopes": [
"project_team"
]}},
{
"id": "BuildTrafficLightsWidget.Configuration",
"type": "ms.vss-dashboards-web.widget-configuration",
"targets": [ "ms.vss-dashboards-web.widget-configuration" ],
"properties": {
"name": "Build Traffic Lights Widget Configuration",
"description": "Configures Build Traffic Lights Widget",
"uri": "TrafficLightsWidgetConfiguration.html"
}}]}
Aufgrund des Manifests wird unsere Erweiterung richtig im Widgetkatalog aufgeführt, und aufgrund der Contribution Points werden die richtigen HTML-Dateien für die UI-Erweiterungen angezogen. Die Implementierung der Views ist nichts anderes als klassische Webentwicklung. Jedoch ist die Integration der Komponente über das zur Verfügung gestellte SDK von entscheidender Bedeutung.
Das SDK liegt uns in Form einer JavaScript-Datei (VSS.SDK.js) in unserem Projekt vor. Da wir mit TypeScript arbeiten, laden wir ebenso die dazugehörigen Typinformationen. Nach der Referenzierung der Skriptdatei in unserer HTML-Datei können wir nun über das VSS-Objekt die Erweiterung registrieren. Zudem geben wir VSTS/TFS bekannt, wie die Runtime unsere JavaScript-Module finden und laden kann. In unserem Fall ist der gesamte Code in TypeScript implementiert und wird als AMD-Modul zur Verfügung gestellt. Da wir unsere Build-Ampel dynamisch in unserem TypeScript-Code aufbauen werden, enthält die HTML-Datei nur das Grundgerüst des Widgets (Listing 2).
Listing 2: "TrafficLightsWidget.html"
<script type="text/javascript">
// Initialize the VSS sdk
VSS.init({
explicitNotifyLoaded: true,
setupModuleLoader: true,
moduleLoaderConfig: {
paths: {
"Scripts": "scripts"
}
},
usePlatformScripts: true,
usePlatformStyles: true
});
// Wait for the SDK to be initialized
VSS.ready(function () {
require(["Scripts/TrafficLightsWidget"], function (tlwidget) {
});
});
</script>
Damit unser Widget und seine Controls nicht vom Look and Feel von VSTS/FS abweichen, gibt uns das SDK die Möglichkeit, über WidgetHelpers.IncludeWidgetStyles() die Styles von VSTS/TFS zu laden und in unserem Widget zu verwenden. Das erspart uns einiges an Designarbeit. Listing 3 zeigt zudem das Auslesen der Konfiguration sowie der Instanziierung unseres Ampel-Renderers TrafficLightsCollection.
Listing 3: "TrafficLightsWidget.ts
///
///
import TrafficLights = require("scripts/TrafficLightsCollection");
function GetSettings(widgetSettings) {...}
function RenderTrafficLights(WidgetHelpers, widgetSettings) {
var numberOfBuilds = widgetSettings.size.columnSpan;
var config = GetSettings(widgetSettings);
if (config != null) {
var trafficLights = new TrafficLights.TrafficLightsCollection(
VSS.getWebContext().project.name, config.buildDefinition,
numberOfBuilds, document.getElementById("content"));
}
else {...}
}
VSS.require("TFS/Dashboards/WidgetHelpers", function (WidgetHelpers) {
WidgetHelpers.IncludeWidgetStyles();
VSS.register("BuildTrafficLightsWidget", function () {
return {
load: function (widgetSettings) {
RenderTrafficLights(WidgetHelpers, widgetSettings);
return WidgetHelpers.WidgetStatusHelper.Success();
},
reload: function (widgetSettings) {...}
};
});
VSS.notifyLoadSucceeded();
});
Um nun mit dem REST-API von VSTS/TFS zu kommunizieren, können wir über das SDK einen entsprechenden Client instanziieren. Der Vorteil dieser Vorgehensweise liegt darin, dass wir uns nicht über die Authentifizierung kümmern müssen. Die REST-Aufrufe erfolgen automatisch im Sicherheitskontext des aktuellen Nutzers. In Listing 4 ist der entsprechende Auszug zu sehen.
Listing 4: "TrafficLightsCollection.ts"
///
import Contracts = require("TFS/Build/Contracts");
import BuildRestClient = require("TFS/Build/RestClient");
export class TrafficLightsCollection {
...
constructor(projectname: string, builddefinition: number,
numberofbuilds: number, element: HTMLElement) {
...
}
public updateBuildState() {
var buildClient = BuildRestClient.getClient();
buildClient.getBuilds(this.projectname, [this.buildDefinitionId, ...,
this.numberOfBuilds).then((buildResults: Contracts.Build[]) => {
this.builds = buildResults;
this.renderLights();
});
}, err => { this.renderLights(); });
}
}
Was jetzt noch fehlt, ist die Möglichkeit, unser Widget zu konfigurieren (Listing 5). Jedes Ampel-Widget benötigt eine entsprechende Konfiguration, in der die gewünschte Build-Definition ausgewählt und gespeichert wird. Die Grunddefinition der Konfigurationsansicht (HTML-Datei) verhält sich genauso wie die beim Widget. Im Code für die Konfigurationsansicht müssen zwei Lifecycle-Events überschrieben werden: load und onSave(). Hier können wir über das SDK unsere spezifischen Einstellungswerte als JSON-Definition laden und speichern. Damit die Livepreview im Konfigurationsmodus funktioniert, müssen entsprechende Änderungsevents publiziert werden. Die aktuellen Konfigurationswerte werden mittels TypeScript mit den UI-Controls synchron gehalten.
import BuildRestClient = require("TFS/Build/RestClient");
import Contracts = require("TFS/Build/Contracts");
export class TrafficLightsWidgetConfiguration {
...
constructor(public WidgetHelpers) { }
public load(widgetSettings, widgetConfigurationContext) {
this.widgetConfigurationContext = widgetConfigurationContext;
this.initializeOptions(widgetSettings);
this.selectBuildDefinition.addEventListener(
"change", () => { this.widgetConfigurationContext
.notify(this.WidgetHelpers.WidgetEvent.ConfigurationChange,
this.WidgetHelpers.WidgetEvent.Args(this.getCustomSettings()));
});
...
return this.WidgetHelpers.WidgetStatusHelper.Success();
}
public initializeOptions(widgetSettings) {
...
var config = JSON.parse(widgetSettings.customSettings.data);
if (config != null) {
if (config.buildDefinition != null) {
this.selectBuildDefinition.value = config.buildDefinition;
}
}
}
public onSave() {
var customSettings = this.getCustomSettings();
return this.WidgetHelpers.WidgetConfigurationSave
.Valid(customSettings);
}
}
VSS.require(["TFS/Dashboards/WidgetHelpers"], (WidgetHelpers) => {
WidgetHelpers.IncludeWidgetConfigurationStyles();
VSS.register("BuildTrafficLightsWidget.Configuration", () => {
var configuration =
new TrafficLightsWidgetConfiguration(WidgetHelpers);
return configuration;
})
VSS.notifyLoadSucceeded();
});
Ein komplettes Code-Listing wäre für diesen Artikel zu umfangreich. Entsprechend steht der gesamte Code dieser Beispiel-Extension auf GitHub zur Verfügung.
Wer Extensions entwickelt, setzt sich primär mit klassischen Webentwicklungstechnologien auseinander. Doch wie bekommen wir nun die Extension in den TFS oder VSTS, und wie können wir debuggen? Als Erstes benötigen wir ein Extension Package in Form einer VSIX-2.0-Datei. Diese können wir anhand des Manifests und dem Kommandozeilentool tfx-cli erstellen. Das CLI wird als npm-Paket angeboten und entsprechend in unserem Projekt geladen. Wie bereits weiter oben erwähnt, möchten wir diesen Schritt als Grunt-Task in den Visual Studio Build integrieren. Wie in Abbildung 4 zu sehen ist, verknüpfen wir den Grunt-Task mit dem After-Build-Event von Visual Studio. Somit erhalten wir nach jedem Build das entsprechende Package.

Abb. 4: Grunt-Task zur Erstellung des Pakets
Der nächste Schritt ist das Publizieren in TFS oder VSTS. Im Fall von TFS wird die VSIX-Datei über den Extension-Manager hochgeladen und in der gewünschten Team Project Collection installiert. Soll die Extension in VSTS getestet werden, ist das Publizieren im Marketplace notwendig. Keine Angst, auch hier können die Extensions zuerst getestet werden, bevor sie der Allgemeinheit zugänglich gemacht werden. Extensions können außerdem als private Erweiterungen markiert werden. Somit stehen sie nur ausgewählten VSTS-Accounts zur Verfügung.
Nun ist die Extension verfügbar und kann getestet werden. Hierzu wenden wir die Entwicklertools der gängigen Browser an. Die Extension läuft in einem iFrame; entsprechend kann die JavaScript-Konsole auf den gewünschten iFrame gefiltert, Elemente inspiziert und der TypeScript- bzw. JavaScript-Code mit dem Debugger analysiert werden.
Die aktuelle Erweiterungsschnittstelle von VSTS/TFS erlaubt nur Frontend-Erweiterungen. Eigene Services oder Backend-Logik können nicht integriert werden. Entsprechend muss diese Art von Erweiterung extern als Windows-Service oder Webapplikation betrieben bzw. gehostet werden. VSTS und TFS stellen ein REST-API zur Verfügung, mit dem fast alle Aktionen getätigt werden können. Entwickelt man mit .NET, so stehen entsprechende NuGet-Pakete zur Verfügung.
Oft bedingen eigene Logikerweiterungen aber, dass man auf Ereignisse in VSTS/TFS reagieren kann. Ein Polling über das API wäre ein schlechter Ansatz. Entsprechend wurde in VSTS/TFS das Konzept von WebHooks implementiert. Über die Einstellungen unter SERVICE HOOKS können eigene WebHook-Empfänger registriert werden. Jede WebHook-Registrierung ist an ein bestimmtes Event in VSTS/TFS gebunden und wird bei dessen Eintreten ausgelöst.
Der WebHook-Empfänger ist an und für sich relativ einfach zu implementieren. VSTS/TFS führt einen POST-Request an den definierten Empfänger durch, und der Body beinhaltet alle Eventdaten, wie zum Beispiel die Work-Item-Daten des geänderten Work Items bei einem Work-Item-Update-Event. Einen POST Request abzuarbeiten, ist nicht weiter schwierig, jedoch ist es mit einem gewissen Zeitaufwand verbunden, die Routen zu konfigurieren und den Payload richtig zu parsen. Zum Glück greift uns Microsoft ein wenig unter die Arme. Für ASP.NET gibt es ein WebHook-Framework, das eine Basisimplementierung für das Senden und Empfangen von WebHooks bereitstellt. Zudem ist ebenfalls eine Implementierung für VSTS-WebHook-Events verfügbar, was einem das gesamte Parsen des Payloads abnimmt. Nach dem Erstellen eines Web-API-Projekts muss lediglich das NuGet-Paket Microsoft.AspNet.WebHooks.Receivers.VSTS hinzugefügt werden. Zu beachten ist hierbei, dass das Framework sowie die Pakete noch im RC-Status sind und entsprechend über NuGet als Pre-Release geladen werden müssen.
Um auf VSTS/TFS-Events reagieren zu können, muss von der entsprechende Basisklasse abgeleitet und die gewünschte Methode überschrieben werden (Listing 6).
public class VstsWebHookHandler : VstsWebHookHandlerBase
{
public override Task ExecuteAsync(WebHookHandlerContext context,
WorkItemUpdatedPayload payload)
{ // sample check
if (payload.Resource.Fields.SystemState.OldValue == "New" &&
payload.Resource.Fields.SystemState.NewValue == "Approved")
{
// your logic goes here...
}
return Task.FromResult(true);
}
}
Das WebHooks-Framework generiert über die Konfiguration entsprechende Web-API-Routen. Damit nicht jeder einen Post auf den WebHook-Receiver absetzen kann, wird ein Sender anhand einer ID Identifiziert, die in der Web.config-Datei hinterlegt wird (Abb. 5). Der entsprechende URL muss dann noch im VSTS/TFS hinterlegt werden.

Abb. 5: Registrierung des WebHook-Receivers in VSTS
Die hier gezeigte UI-Integration bietet weitere Möglichkeiten, den eigenen Prozess bis in das Standard-Tooling zu integrieren. Somit sind nahezu grenzenlose Möglichkeiten für eine optimale Usability und Unterstützung der Nutzer gegeben. Wer sich mit HTML, CSS und JavaScript/TypeScript auskennt, dem dürfte das Erstellen eigener Extensions nicht allzu schwer fallen. Für Nutzer können die neuen Funktionen nur Vorteile haben, zumal die Werbefläche von VSTS/TFS fast nicht mehr verlassen werden muss.
The post Visual Studio Team Services und Team Foundation Server erweitern und anpassen appeared first on BASTA!.
]]>The post Sicherheit über den Open Source Identity Server appeared first on BASTA!.
]]>Auf der BASTA! Spring 2017 bietet Dominick neben seinen Session auch einen Workshop an, der an einem Tag aufzeigt, warum moderne Anwendungen moderne Sicherheit brauchen und wie Entwickler das erreichen können. Gerade heutzutage sind die mobilen Web-/Native-basierte Architekturen und die dazugehörigen API-Backends typische Herausforderungen für hohe Sicherheitsanforderungen. Wer als Entwickler solche Anwendungen realisieren möchte, sollte sich mit dem modernen Securitystack, bestehend aus OpenID Connect, OAuth 2.0 und JSON Web Tokens sowie deren Implementierung, in ASP.NET und MVC und Web API auskennen.
Ein zentrales Element dabei ist der Identity Server, der es als Framework auf .NET-Basis erlaubt für Anwendungen und Firmen eine modere Sicherheitsplattform zu schreiben und zu implementieren. Als Open Source Projekt, mit aktiver Community-Beteiligung, ist der Identity Server immer einen aktuellen Entwicklungsstand, der mit den Sicherheitsprotokollen, aber auch den immer neuen Angriffen schritthält. Im Interview mit Mirko Schrempp, Windows Developer Redakteur und Program Chair der BASTA!, stellt Dominick Baier den Projekthintergrund des Identity Servers vor und beschreibt die Vorteile eines Open Source .NET-Projekt, das in der .NET Foundation mit ihren zahlreichen Partnern verankert ist.
Interview mit Dominick Baier
● Identity und Access Control für moderne Anwendungen und APIs
● ASP.NET-Core- und MVC-Sicherheit – what’s new?
The post Sicherheit über den Open Source Identity Server appeared first on BASTA!.
]]>The post Azure App Services appeared first on BASTA!.
]]>Mit den neu vorgestellten App-Services wird versucht, vier zusammenhängende Dienste unter einem gemeinsamen Namen anzubieten. Eine Grundbedingung aus der Marketingabteilung war offensichtlich die Verwendung des Worts App im Namen: So wurden die Websites zu Web-Apps, die Mobile-Services zu Mobile-Apps und zwei Neuzugänge auf Logic-App bzw. API-App getauft. Jeder dieser Services kann weiterhin separat und unabhängig genutzt werden – doch es gibt eine Story, wie die genannten Komponenten zusammenspielen können, und damit vielleicht einen leichteren Einstieg in die Welt von Microsoft Azure.
Aber der Reihe nach. Am wenigsten spektakulär verlief die Ankündigung der App-Services für die Nutzer von Azure-Websites. Die Umbenennung blieb die einzige direkt sichtbare Auswirkung, Web-Apps können nicht mehr und nicht weniger als die bisherigen Websites. Sämtliche bereits deployten Anwendungen waren vom ersten Tag an unter dem neuen Begriff sichtbar, kein Migrationsaufwand, keine Probleme. Der Mehrwert kommt erst durch die optionale Nutzung der weiteren Services, die in einem bestehenden Webcontainer ohne zusätzliche Kosten betrieben werden können.
Unter dem Namen Mobile-Services sind mehrere Angebote vereint, die das Entwickeln von Apps erleichtern konnten: Ein REST-basierter Zugriff auf Daten, das Senden von Push Notifications quer durch alle Plattformen oder die Authentifizierung mittels Providern wie Facebook, Twitter oder ein Microsoft-Account. Zum Teil ist es auch möglich, die Services durch eigenen Backend-Code anzupassen: Die REST-Datenschnittstelle stellt zum Beispiel Erweiterungspunkte zur Verfügung, die ähnlich wie Datenbank-Trigger genutzt werden können. Als Programmiersprachen für das Backend stehen Node.js oder .NET zur Verfügung. Die gesamte Funktionalität ist über eine REST-basierte Schnittstelle zu konsumieren, es gibt aber SDKs, um den Zugriff aus Windows Phone, iOS und Android zu erleichtern.
Im neuen App-Services-Paket tauchen nun große Teile der Funktionalität unter dem Namen Mobile-Apps wieder auf – aber nicht ganz so reibungslos und unverändert wie bei den zuvor genannten Websites. Erstes Anzeichen: Bisherige Mobile-Services wurden nicht automatisch migriert, im alten Azure-Portal befinden sich weiterhin alle Instanzen unter unverändertem Namen (eine Anleitung zur Migration befindet sich hier). Mit ein Grund kann sein, dass als Sprache für das Backend in Mobile-Apps vorerst nur .NET zur Verfügung steht – die in den Mobile-Service gebräuchlichere Node.js-Variante fehlt noch. Der für das Backend notwendige Code kann nun aber gemeinsam mit der Web-App ohne zusätzliche Kosten im selben Container gehostet werden – inklusive Auto-Scaling, Traffic-Manager-Support oder Deployment-Vorteilen wie Continuous Integration und Staging Deployments. Als weitere Neuerung sind Verbindungen zu On-Premise-Datenbanken möglich, ein eingerichtetes virtuelles Netzwerk mit Point-to-Site-VPN wird vorausgesetzt. Wer vor der Aufgabe steht, eine mobile App für iOS, Android oder Windows Phone zu entwickeln und dafür Push Notifications, Authentifizierung oder (On-Premise)-Datenzugriff benötigt, sollte sich Mobile-Apps ansehen.
Es ist anzunehmen, dass die bisherigen Mobile-Services über kurz oder lang komplett durch die neuen Mobile-Apps ersetzt werden, für den Moment gibt es allerdings beide Varianten parallel.
Kommen wir zu den Neuerungen: API-Apps sind brandneu und fügen der Azure-Palette wieder einen deutlichen Mehrwert hinzu. Im Wesentlichen handelt es sich dabei um Web-API-Projekte, die um Metadaten und Authentifizierung angereichert sind.
Als Format für diese Metadaten kommt – ganz im Sinne des aktuellen Microsoft-Mindsets – keine hauseigene, proprietäre Lösung, sondern ein bewährtes, existierendes Open-Source-Projekt namens Swagger zum Einsatz. Eine Swagger-Definition besteht aus einer Beschreibung der einzelnen Methoden und deren Parameter in einem spezifizierten JSON-Format. Alter Wein in neuen Schläuchen? CORBA? WSDL? Im Prinzip ja. Das Swagger-Format ist aber sehr schlank und erfordert keine Änderung von bestehenden APIs – theoretisch könnte die Swagger-Definition sogar von jemand anderem als dem API-Hersteller geschrieben werden. Die größten Vorteile, die Metadaten mit sich bringen, sind schnell beschrieben: automatische Dokumentation und Client-SDK-Generierung.

Abb. 1: Erstellen eines Azure-API-App-Projekts in Visual Studio
Wie sieht das in der Praxis aus? Im neuesten Azure-SDK (März: 2.5.1) sind die App-Services bereits integriert. Beim Erstellen einer neuen ASP.NET-Webapplikation steht als Template „Azure-API-App-(Preview)“ zur Verfügung, dadurch wird ein Web-API-Projekt mit einigen zusätzlichen Referenzen erstellt (Abb. 1). Sollten Sie ein bestehendes ASP.NET-Web-API-Projekt verwenden wollen, klicken Sie mit der rechten Maustaste auf das Projekt und anschließend auf ADD | Azure API App SDK. Sie werden anschließend gefragt, ob die Swagger-Metadaten automatisch erstellt werden sollen (Abb. 2, die Antwort lautet: Ja).

Abb. 2: Metadatengenerierung oder -auswahl
Das Erstellen der Web-API-Controller unterscheidet sich nicht von der gewohnten Art und Weise; wie bisher leiten Sie von ApiController ab, erstellen darin Actions und verwenden ggf. Routing-Attribute (Listing 1). Einziger Hinweis: Ein Bug verhindert (zumindest bis April) das Überladen von Action-Methoden. Vermeiden Sie also beispielsweise zwei Get-Methoden, die sich nur durch einen Parameter unterscheiden – das Azure-Portal hat ansonsten Probleme beim Abrufen der Metadaten.
public class WishlistController : ApiController
{
public string Get()
{
return "Hello API App!";
}
public async Task Post(WishRequest request)
{
// store data
}
}
Was Ihr Web-API nun zu einer API-App macht, sind die Metadaten. Die automatische Metadatengenerierung sollte aktiviert sein; erstes Erkennungsmerkmal ist die Datei apiapp.json im Hauptverzeichnis mit einigen allgemeinen Metadaten. Wichtiger ist die Klasse SwaggerConfig im Unterordner App_Start. Hier können Sie in die Generierung der Metadaten eingreifen und beispielsweise festlegen, ob auch das Swagger-UI bereitgestellt werden soll: ein interaktives UI zum Testen des API.
Wenn Sie die Anwendung ausführen, können Sie den Erfolg unmittelbar testen: Unter http://localhost:<port>/swagger/docs/v1 können Sie das Swagger-JSON-Format ansehen, unter /swagger erscheint das UI (Abb. 3).

Abb. 3: Swagger-UI
Damit steht dem Veröffentlichen nichts mehr im Weg: Auch der Publish-Dialog (rechte Maustaste auf das Projekt | Publish) kennt bereits Microsoft-Azure-API-Apps als Ziel. Über den Dialog kann eine bestehende API-App ausgewählt oder eine neue erstellt werden. Beim ersten Mal wird auch die App in Azure erstellt, teilweise ist anschließend ein zweites beherztes Anstoßen des Publish-Vorgangs erforderlich.
Wenn alles erfolgreich war, sehen Sie die neu angelegte API-App im Preview-Azure-Portal. Auch dort können Sie die Metadaten („API-Definition“) abrufen und überprüfen, ob alles geklappt hat (Abb. 4).

Abb. 4: Swagger-Metadaten im Azure Portal
Nun ist die Zeit der Ernte gekommen: Aufgrund der Metadaten können Sie sich ein passendes Client-SDK generieren lassen – HttpClient-Aufrufe und manuelles Parsen von Response-Nachrichten gehören der Vergangenheit an. Egal ob in einer Konsolenanwendung oder in einer Windows-Phone-App: Klicken Sie beim Projekt auf Add | Azure API App Client und wählen Sie die gerade bereitgestellte API-App aus. Auf Basis der Swagger-Definition werden entsprechende Interfaces und Klassen zum Zugriff auf das API zur Verfügung gestellt – übrigens nicht nur für .NET, sondern auch für Node.js, Java, PHP und Python. In Listing 2 sehen Sie, wie einfach die zuvor erstellten Get- und Post-Requests nun in einer Windows-Phone-App aufgerufen werden können.
IMySuperWishlistApi api = new MySuperWishlistApi();
var getResponse = await api.Wishlist.GetAsync();
var wish = new WishRequest()
{
UserName = "[email protected]",
Wish = "An API that works"
};
await api.Wishlist.PostAsync(wish);
Neben den Metadaten kann auch Authentifizierung ein Grund für die Verwendung von API-Apps sein. Derzeit sind drei verschiedene Sicherheitslevel wählbar: öffentlich, authentifiziert oder intern. Letzteres ermöglicht einen Aufruf für alle Services innerhalb der gleichen Ressource, fällt die Wahl hingegen auf authentifiziert, muss ein Authentifizierungsprovider (Microsoft-Account, Facebook etc.) konfiguriert werden. Die Einstellungen finden Sie im neuen Azure-Portal bei der API-App unter Settings | Application settings bzw. Authentication, eine genaue Anleitung hier. Authentifizierung ohne ein OAuth-Buch lesen zu müssen und Tokens zu parsen – ein verlockendes Angebot.
Fast schon zur Gewohnheit gehört, dass Sie mittels Remote-Debugging den laufenden Service mit Visual Studio debuggen können. Gerade für die Fehlerfindung zu Beginn ein äußerst hilfreicher Wegbegleiter.
Sie haben gesehen, wie einfach es ist, ein eigenes API inklusive Metadaten bereitzustellen. Zusätzlich gibt es bereits eine unglaubliche Vielzahl von Services – teilweise kostenlos, teilweise kostenpflichtig – die auf ihre Verwendung warten: Dropbox, OneNote, Facebook, Twitter, Yammer, Slack, Twilio etc.
Diese Vielzahl an APIs, die zusätzlich um Metadaten angereichert werden, hat vermutlich zur Idee der vierten Komponente geführt: Logic-Apps. Diese zumindest grafisch auffälligste Neuerung weckt wieder die Idee, dass Softwareentwicklung irgendwann nur mehr das Zusammensetzen fertiger Bausteine sein könnte (was ich weder hoffe, noch glaube). Mithilfe eines grafischen Editors können Sie Services aneinanderreihen und die Ergebnisse des einen Service wieder als Eingabeparameter für den nächsten Service verwenden.
Ein Beispiel: Prüfen Sie alle fünf Minuten, ob es aktuelle Twitter-Nachrichten zu einem bestimmten Hashtag gibt und übergeben Sie das Ergebnis an Ihr API. Überprüfen Sie Ihren POP3-Posteingang nach neuen Mails mit dem Betreff „Wichtig“ und senden Sie in diesem Fall eine SMS an Ihr Handy. Fragen Sie Ihren Service in regelmäßigen Abständen nach Neuigkeiten und posten Sie diese gleichzeitig auf Twitter, Yammer und Facebook.
Die gute Nachricht: Alle erwähnten Services sind bereits jetzt im Azure-Marketplace zu finden, alle genannten Beispiele könnten schon jetzt als Logic-App umgesetzt werden. Die Vielfalt erhöht den Spaßfaktor deutlich: Irgendeinen Service findet man immer, der unbedingt noch eingebaut werden muss.
In Abbildung 5 sehen Sie beispielsweise einen POP3-Connector, der einmal pro Minute den Posteingang überprüft und beim Eintreffen einer E-Mail unsere zuvor erstellte API-App aufruft. Im dritten Schritt wird Twilio verwendet, um den Betreff der E-Mail per SMS zu versenden.

Abb. 5: Erstellung einer Logic-App
Jeder Service kann so konfiguriert werden, dass er nur beim Erfüllen einer bestimmten Bedingung ausgeführt wird – allerdings ist die zugrunde liegende Formelsprache aktuell eher schlecht dokumentiert. Im Azure-Portal erhalten Sie detaillierte Monitoring-Reports über jede Abarbeitung: Bis hin zu den einzelnen Requests können Sie so nachverfolgen, ob Ihre Logic-App wie gewünscht funktioniert.
Microsoft versucht, mit den App-Services ein Paket zu schnüren, das die Entwicklung von Webanwendungen und mobilen Apps vereinfachen kann. Das Gesamtpaket ist umfangreich, im Detail warten aber derart viele Möglichkeiten, dass trotz des Versuchs einer durchgängigen Story die Einarbeitungszeit beträchtlich ist. Lassen Sie sich davon nicht abschrecken, nutzen Sie, was Sie benötigen. Sie möchten eine Website hosten? Nehmen Sie Web-Apps. Sie benötigen Push Notifications oder möchten einen Login in Ihre App einbauen? Testen Sie Mobile-Apps. Möchten Sie Ihr API authentifiziert oder mit Metadaten bereitstellen? API-App. Oder möchten Sie bestehende APIs zu einem größeren Ganzen orchestrieren? Logic-App.
Viel Spaß beim Ausprobieren und Kennenlernen der Azure App Services.
Aufmacherbild: Cloud computing via Shutterstock / Urheberrecht: Stokkete
The post Azure App Services appeared first on BASTA!.
]]>The post Buchverlosung: SQL Server – Performanceprobleme analysieren und beheben appeared first on BASTA!.
]]>
Jeder Datenbankadministrator (oder Berater in diesem Umfeld) hat sicherlich schon einmal die Situation erlebt, dass bei einer Anwendung, die bereits längere Zeit problemlos lief, sich die Anwender plötzlich beschweren, dass die Performance unerträglich schlecht und ein normales Arbeiten kaum noch möglich ist. Entweder dauern einzelne Aktionen deutlich zu lange, oder Anwender erhalten eventuell auch Timeout-Meldungen, die belegen, dass eine Aktion zu diesem Zeitpunkt gar nicht ausgeführt werden konnte, weil sie zu lange gedauert hat.
Wenn es schlecht läuft, haben die Klagen der Anwender über die schlechte Performance schon Teile des Managements erreicht; im ungünstigsten Fall waren diese davon sogar unmittelbar selbst betroffen.
Nun gilt es, gleichzeitig schnell zu reagieren, dabei aber dennoch wohlüberlegt zu handeln, denn ein Schnellschuss kann das Eingrenzen des wesentlichen Problems erschweren und im Extremfall sogar zu einer Verschlechterung der Performance führen. Die möglichen Ursachen des Problems können sehr vielseitig sein:
Daraus ergeben sich auch mindestens genauso viele Lösungsansätze:
Um schnell Abhilfe zu schaffen, ergibt es natürlich wenig Sinn, alle möglichen Lösungsansätze der Reihe nach durchzugehen. Dies würde einen erheblichen Aufwand verursachen, ohne dass eine Garantie auf Besserung des Problems gegeben wäre. Dazu erfordern einige Ansätze einen Neustart des Serverdienstes (und damit zusätzliche Ausfallzeiten) oder gar Änderungen an der Anwendung selbst. Dabei sollte es das primäre Ziel sein, quasi minimalinvasiv zu agieren, also mit möglichst geringen Änderungen eine möglichst deutliche Verbesserung der Performance zu erreichen. Erst wenn die akuten Probleme beseitigt sind, kann anschließend eine ausführliche Analyse erfolgen, um auch kleinere oder noch nicht akute Probleme zu beseitigen. Insgesamt hat sich ein dreistufiges Vorgehen bewährt:
1. Erste Hilfe bei Performanceproblemen
2. Ausführliche Performanceanalyse
3. Langfristige Maßnahmen
An diesem dreistufigen Vorgehen orientiert sich auch der Aufbau des Buchtexts (Kapitel 2–4), denen ein Kapitel folgt, in dem die wichtigsten mit SQL Server ausgelieferten Tools zur Performanceanalyse kurz dargestellt sind.
Dabei ist insbesondere der erste Teil – wie das Buch insgesamt auch – sehr kompakt gehalten, damit man bei akuten Performanceproblemen nicht lange lesen muss, um eine schnelle Besserung zu erzielen. Aus demselben Grund werden Sie im Buch auch keine langen Listings finden. Wenn Sie ein akutes Performanceproblem bei einer Datenbank haben, möchten Sie sicherlich keine Zeit damit verschwenden, lange SQLSkripte abzutippen. Stattdessen wird in den meisten Fällen beschrieben, wie Sie Performanceanalysen über die Benutzeroberfläche der diversen Tools durchführen können.1
Der Text richtet sich primär an Datenbankadministratoren und Berater, die in diesem Umfeld tätig sind. Da die Übergänge zwischen den Tätigkeitsfeldern meist fließend sind, können die Inhalte auch für Anwendungs- und Datenbankentwickler eine wertvolle Hilfe sein. An Vorkenntnissen werden vor allem Grundkenntnisse mit SQL Server vorausgesetzt, insbesondere T-SQL und der Umgang mit dem SQL Server Management Studio sollten bekannt
sein.
The post Buchverlosung: SQL Server – Performanceprobleme analysieren und beheben appeared first on BASTA!.
]]>The post .NET Core 1.1, ASP.NET Core 1.1 und Entity Framework Core 1.1 appeared first on BASTA!.
]]>Auch wenn die Core-Produkte bereits in der Version 1.0 schon in vielen Fällen schneller liefen als die Vorgänger aus der .NET-„Full“-Framework-Ära, arbeitet Microsoft weiterhin an der Performance. In .NET Core 1.1 setzt Microsoft nun auch auf die Profile-guided Optimization (PGO). Hierbei wird im Zug des Ablaufs von Musteranwendungen die Reihenfolge der tatsächlichen Nutzung des Programmcodes in der CLR und den Bibliotheken aufgezeichnet. Auf Basis dieser Messdaten optimiert Microsoft dann die Reihenfolge des Programmcodes im Kompilat. In .NET Core 1.1 hat Microsoft laut .NET Blog lediglich eine einfache „Hello World“-Anwendung für die Datenaufzeichnung verwendet, damit dann allerdings schon eine 15-prozentige Leistungssteigerung bei der ASP.NET-Core-Beispielanwendung MusicStore erzielt. Angesichts dieses Resultats kann man die Hoffnung haben, dass Microsoft in Zukunft auf Basis von Messdaten aus echten .NET-Core-Anwendungen noch mehr aus diesem Optimierungsverfahren herausholen wird.
Dass die Leistung von .NET Core in Version 1.1 besser ist als bei Version 1.0, beweist auch der zehnte Platz im Vergleich mit anderen Webframeworks in der dreizehnten Ausgabe des TechEmpower-Webserverframework-Performanztests. Allerdings wurde dieser Platz mit einer Webanwendung erzielt, die kein HTML, sondern „Plain Text“ mit ASP.NET Core ohne das MVC-Framework erzeugt, und auf Linux. Beim Generieren der Ausgabe mit dem MVC-Framework rutscht ASP.NET Core in der Leistung demgegenüber auf den 29. Platz ab. Allerdings rangiert es damit dann zwar hinter Java Servlets, jedoch immer noch vor Node.js und deutlich vor PHP.

Abb. 1: ASP.NET Core 1.1 im Vergleich zu Java Servlets, Node.js, Node.js mit Express und PHP (Quelle: Microsoft Connect(); 2016)
Zu den bisher unterstützten Versionen von Windows, Linux und Mac kommen bei den Betriebssystemen mit Core 1.1 nun hinzu:
.NET Core für Tizen (Abb. 2) wird dabei von Samsung entwickelt. Die „Visual Studio Tools for Tizen“ nutzen hier Xamarin.Forms für Benutzeroberflächen. Laut Tizen Developers Blog wird in der ersten Preview der Visual Studio Tools für Tizen bereits „99 % von Xamarin.Forms“ unterstützt. Das ist insofern bemerkenswert, als damit der Schritt, Xamarin.Forms auch für Benutzeroberflächen auf Linux anzubieten, sehr nahe liegt. Auch könnte .NET Core bald Mono als Basis für Xamarin.Forms in iOS, Android und Windows 10 ablösen.
Nicht viel versprechen sollte man sich allerdings von den „1 380 zusätzlichen APIs“, die Microsoft laut Blogeintrag in .NET Core 1.1 ergänzt hat. Mit APIs sind nicht komplette Bibliotheken gemeint, vielmehr hat Microsoft dabei jede neue Klasse und jedes neue Klassenmitglied einzeln gezählt. Beim Blick in die Liste der API-Neuerungen findet der Entwickler leider auch wenig, was er typischerweise braucht. Die Ergänzungen betreffen fast ausschließlich interne Funktionen von .NET Core bzw. dienen der Unterstützung für die Version 7.0 der Programmiersprache C#. Die .NET Standard Library ändert den Versionsstand daher auch nur leicht von 1.6 auf 1.6.1. Die unter dem Slogan „One library to rule them all“ groß angekündigte Angleichung an die Programmierschnittstellen der Base Class Library des großen .NET Framework 4.6 wird leider erst im Jahr 2017 im Rahmen der .NET Standard Library 2.0 erfolgen.
Ebenfalls noch nicht am Ziel ist Microsoft bei den .NET-Core-Werkzeugen. Alle Tools, einschließlich der Visual-Studio-Integration, bleiben vorerst weiterhin im Preview-Stadium. Die Version des SDK ändert sich nur leicht im Vergleich mit der bisherigen Version „1.0 Preview 2“ (für .NET Core 1.0) auf „1.0 Preview 2.1“ (für .NET Core 1.1). Die aktuelle Installationsdatei des SDK heißt dotnet-dev-win-x64.1.0.0-preview2-1-003177.exe bzw. dotnet-dev-win-x86.1.0.0-preview2-1-003177.exe. Dabei darf man sich von der „1.0“ im Dateinamen nicht verwirren lassen: Dies ist die Versionsnummer des SDK, nicht von .NET Core. Wenn man sich die Dateieigenschaften ansieht, liest man dort unter dem Punkt Description: „Microsoft .NET Core 1.1.0 – SDK 1.0.0 Preview 2.1-003177 (x64)“ (Abb. 2).

Abb. 2: Der Dateiname der SDK-Version zeigt nicht, auf welche .NET-Core-Version sie sich bezieht; das sieht man erst in den erweiterten Dateieigenschaften
Erschwerend kommt noch hinzu, dass Microsoft die Visual-Studio-2015-Werkzeuge nicht aktualisiert hat. So erzeugt Visual Studio 2015 beim Anlegen neuer Projekte auch nach der Installation des SDK also immer .NET-Core-1.0-Projekte. Hier muss der Entwickler dann stets die global.json (ändern der Versionszeichenkette auf „1.0.0-preview2-1-003177“) sowie die project.json (ändern der Version von Microsoft.NETCore.App auf „1.1.0“) manuell anpassen. Auch beim Anlegen neuer .NET-Core-1.1-Projekte mit dem Kommandozeilentool dotnet-new gibt es Probleme. Dazu sei auf [9] verwiesen.
Im Rahmen von Visual Studio 2017 Release Candidate, das bisher Visual Studio “15” hieß, kommt hingegen bereits die Preview-3-Version des SDK zum Einsatz, die – wie von Microsoft angekündigt – nicht mehr auf .xproj– und project.json-Dateien basiert, sondern eine neue Version der XML-basierten MSBuild-Dateien (.csproj) verwendet. Bestehende .xproj– und project.json-Dateien konvertiert Visual Studio 2017 beim Öffnen des Projekts in .csproj-Dateien. Der Entwickler muss jedoch bedenken, dass es keine Option zur Rückkonvertierung gibt, falls er später dann doch mit dem JSON-Format oder Visual Studio 2015 weiterarbeiten möchte. Microsoft spricht in diesem Zusammenhang von der „Alphaversion“ der MSBuild-based .NET-Core-Tools, die Teil des .NET Core SDK 1.0 Preview 3 sind und auf .NET Core 1.1 RTM basieren. Auch im neuen Visual Studio for Mac, das als Preview erschienen ist und eine erweiterte Version des bisherigen Xamarin Studio darstellt, kann der Entwickler mit .NET Core 1.1 und dem Preview 3 des SDK arbeiten.
Bei Entity Framework Core 1.1 hat Microsoft einige Funktionen nachgerüstet, die es im Vorgänger ADO.NET Entity Framework zum Teil schon lange gibt, die jedoch zur 1.0-Version von Core noch nicht fertig waren:
Darüber hinaus gibt es neue Features zum Mapping von Fields auf Tabellenspalten mit HasField(“name”) sowie dem Mapping auf speicheroptimierten Tabellen von Microsoft SQL Server (ab Version 2014) mit ForSqlServerIsMemoryOptimized() – jeweils anzuwenden im Fluent-API bei OnModelCreating().
Auch in ASP.NET Core hat Microsoft fehlende Funktionen nachgerüstet. Im Gegensatz zu den Nachrüstarbeiten bei Entity Framework Core hat Microsoft jedoch bei ASP.NET Core in dem aus Version 1.0 bekannten Stil die APIs radikal geändert:
Zu beachten ist, dass einige der ergänzten Komponenten (z. B. Microsoft.AspNetCore.Rewrite, Microsoft.AspNetCore.ResponseCompression) die Versionszählung bei 1.0 beginnen, auch wenn Sie im Rahmen von .NET Core 1.1 erstmals erschienen sind, während andere wie Microsoft.AspNetCore.ResponseCaching mit 1.1.0 starten. Vom Paket Microsoft.Net.Http.Server gibt es die Versionen 1.0 und 1.1.
Für das erste Release hinter dem Komma hat die Core-Familie in der Version 1.1 einiges zu bieten. Besonders spannend finde ich persönlich aber .NET Core für Tizen mit Xamarin.Forms. Diese Entwicklung gibt Hoffnung, dass Microsoft oder ein anderes Mitglied der .NET Foundation Xamarin.Forms zum vollwertigen UI-Framework für .NET Core ausbaut. In Visual Studio 2017 gibt es immerhin schon einmal eine grafische Preview-Funktion für Xamarin.Forms (jedoch noch keinen Drag-and-Drop-Designer).
● Workshop: Moderne Datenzugriffslösungen mit Entity Framework Core 2.1
● Schnell und überall: Datenzugriff mit Entity Framework Core 2.1
● Elegante und performante Web-APIs und Webanwendungen (MVC und Razor Pages) mit ASP.NET Core 2.1
● .NET Core und .NET im Browser: Großartige Perspektiven für .NET-Entwickler
The post .NET Core 1.1, ASP.NET Core 1.1 und Entity Framework Core 1.1 appeared first on BASTA!.
]]>The post Die BASTA! Spring 2017 – reißt die Mauern endlich ein! appeared first on BASTA!.
]]>Wer will schon einen Übergang verpassen oder vor verschlossenen Schranken stehen? Die Sessions, Workshops und Labs der BASTA! helfen Ihnen dabei, sich gut informiert Ihren Weg in einer immer offeneren Entwicklerwelt zu bahnen. Microsofts Motto „mobile first, cloud first“ zielt schließlich auch auf Ihre eigene Mobilität ab.
Nicht ganz überraschend sind es in der IT oftmals technische Standards, die den Charakter der Grenze bestimmen. Denn sie entscheiden darüber, ob die Grenze dicht ist, oder ob es nicht doch ein Schlupfloch gibt, das man als Übergang nutzen könnte.
Mit einer HTML-Seite wird man in jedem Browser auf jeder Plattform einen ordentlichen Auftritt haben, mit Webtechnologien eine App schreiben, die überall ohne Einschränkungen funktioniert – das sieht ein Standard so vor. Mit einer klassischen C#- oder .NET-Software wird man hingegen nicht auf ein iOS- oder Android-Gerät kommen.
Wir werden ausloten, wie und mit welchen Werkzeugen sich überall Grenzen überschreiten lassen. Ob Sie Mono-, Multi- oder Cross-Plattform arbeiten wollen, sollen schließlich Sie bestimmen, nicht irgendeine Grenze.
Um Sie mit dem nötigen Rüstzeug auszustatten, bieten Ihnen die Workshops, Special Days und Sessions der BASTA! praxisorientiertes Wissen von Experten – ob nun im .NET Framework- und C#-Track oder im HTML5 & JavaScript-Track.
Es ist an der Zeit, die Mauern einzureißen – allen voran in unseren Köpfen. Denn die Technologie hat diesen Schritt schon lange gemacht.
Beispielsweise zeigt der Modern Business Applications Day, wie Sie vom Backend bis zum Frontend Cross-Plattform-Anwendungen schreiben können. JavaScript bzw. TypeScript, Web APIs und Frameworks wie Angular 2 und Electron sind dabei der Generalschlüssel zum Öffnen der Grenze.

Abb.: JavaScript führt das Popularitätsranking
Mit den gleichen Werkzeugen, ergänzt um ASP.NET und andere Webtechnologien, sind Sie aber auch in jedem Browser zu Hause.
Aber auch als klassischer .NET- und C#- Entwickler müssen Sie nicht auf Ihrer Seite der Grenze verharren. Tools wie Xamarin erlauben Ihnen, Anwendungen in den Ihnen vertrauten Sprachen zu entwickeln und dann wie gewohnt auf Windows zu bringen. Aber eben auch – grenzüberschreitend – auf iOS und Android zu releasen. Der Univeral Apps Day bietet hierfür zahlreiche Einstiegspunkte.
Damit das alles nicht im Chaos endet und einer Invasion gleicht, ist es wichtig, mit der Gegenseite ins Gespräch zu kommen.
In Zeiten agiler Entwicklung und kurzer Entwicklungszyklen, wachsender Service-Angebote und kompetenter Kunden, kann man Software nicht mehr einfach nur über den Zaun werfen. Das Mindeste sind hier bilaterale Gespräche zwischen Entwickler und Betrieb – DevOps ist das passende Schlagwort.
Wer einen Schritt weitergehen will, der sollte sich überlegen, ob er aus den bilateralen gleich multilaterale Gespräche macht. Reden Sie nicht nur mit dem Betrieb, sprechen Sie auch mit der Fachabteilung und Ihren Nutzern. Finden Sie heraus, wie Sie Services nutzen können, um sich die Arbeit leichter zu machen. Überlegen Sie, welches API Ihr Produkt sinnvoll und effizient für andere Produkte öffnen kann. APIs und Services sind hervorragende Grenzöffner!
Der Agile & DevOps Track zeigt Ihnen, wie Sie Meister der Diplomatie werden.

Ob man nur im Binnenmarkt bleibt oder globalisiert, ist abhängig von Mut und vom eigenen Geschäftsmodell. Aber man sollte wissen, dass es diese Möglichkeiten gibt. Egal welche Grenze Sie überschreiten wollen, Sie können aus dem umfassenden Angebot der BASTA! genau das Paket schnüren, das Sie brauchen. Mit den Special Days bieten wir Ihnen praktische Konfigurationen an, die Sie jeder Zeit erweitern können.
Was auch immer Sie tun, nach der BASTA! werden Sie nicht mehr ehrfurchtsvoll vor einer Grenze stehen und sich fragen, was auf der anderen Seite ist. Sie werden erkennen, dass Grenzen nichts weiter als bunte Linien auf veralteten Strategiepapieren sind, die sie – mit dem richtigen Rüstzeug ausgestattet – ohne weiteres überschreiten können.
Ich freue mich darauf, Sie auf der BASTA! zu treffen!
Mirko Schrempp, Program Chair der BASTA! und Redakteur des Windows Developer
The post Die BASTA! Spring 2017 – reißt die Mauern endlich ein! appeared first on BASTA!.
]]>The post Top 20 Social Influencers in .NET Development appeared first on BASTA!.
]]>The .NET, Windows & Open Innovation Conference BASTA! proudly presents the top 20 social influencers regarding the Microsoft and .NET World. All influential people have something in common: they can spread ideas faster and better than anyone else. We are aware that following those people has a handful of perks, including staying on top of the latest news and trends. Therefore, we decided to concoct a list of Twitter accounts all Microsoft and .NET fans should follow.
This list was created by analysing the MozRank and Klout scores of thousands of twitter profiles ranking them by both quality and influence.
If we missed anybody, it has nothing to do with the fact that we don’t think that they are just as important or shareworthy as any person on this list.
We congratulate everyone who made it into this list. If you click on the name or picture of each speaker you will be redirected to their twitter profile where you’ll find the useful information they share daily.
Enjoy!
We first generated a list of one thousand .NET-related Twitter accounts (including all accounts that are related to the world of Microsoft in their bio or in any of their tweets.)
To score the account and rank them accordingly, we analyzed their social authority and reach using two key metrics: MozRank and Klout.
Moz Social Authority Score: Social Authority score is composed of:
Visit this MOZ blog post for more in-depth information.
Klout Score: Klout uses more than 400 signals from eight different networks to update the Klout Score daily. It’s mainly based on the ratio of reactions a user generates compared to the amount of content he shares. Read more at the Klout score blog.

Scott Hanselman @shanselman
Tech, Code, YouTube, Race, Linguistics, Web, Parenting, Black Hair, STEM, Inclusion, @OSCON chair, Phony. MSFT, but these are my opinions. @overheardathome
Total score: 165 = Klout score: 79 + Social Authority score: 86
Daniel Rubino @Daniel_Rubino
Editor-in-chief of Windows Central. Full-time curmudgeon, science geek and play-acting anarchist. HoloLens user. [email protected]
Total score: 152 = Klout score: 81 + Social Authority score: 71
Mary Jo Foley @maryjofoley
I am All About Microsoft on ZDNet (http://blogs.zdnet.com/microsoft ). Oh, and I am also sometimes (more often than not) all about craft beer.
Total score: 150 = Klout score: 86 + Social Authority score: 64
Troy Hunt @troyhunt
Pluralsight author. Microsoft Regional Director and MVP for Developer Security. Online security, technology and “The Cloud”. Creator of @haveibeenpwned.
Total score: 150 = Klout score: 73 + Social Authority score: 77
Paul Thurrott @thurrott
Paul Thurrott is an award-winning technology journalist and blogger and the author of over 25 books. He is the majordomo at http://Thurrott.com .
Total score: 145 = Klout score: 70 + Social Authority score: 75
Chris Heilmann @codepo8
Londoner, German, European. Developer Evangelist – all things open web, writing and helping. Works at Microsoft on Edge, opinions totally my own. #nofilter
Total score: 141 = Klout score: 67 + Social Authority score: 74
Dan Wahlin @DanWahlin
Founder of Wahlin Consulting. Consulting & training on Angular, Node.js, ASP_NET, C#, Docker. Author for Pluralsight and Udemy. https://about.me/danwahlin
Total score: 131 = Klout score: 68 + Social Authority score: 63
Scott Guthrie @scottgu
I live in Seattle and build a few products for Microsoft
Total score: 130 = Klout score: 60 + Social Authority score: 70
Robert Cecil Martin @unclebobmartin
Software Craftsman
Total score: 127 = Klout score: 61 + Social Authority score: 66
John Papa @John_Papa
Husband, father, and Catholic enjoying every minute with my family. Disney fanatic, evangelist, HTML/CSS/JavaScript dev, speaker, and Pluralsight author.
Total score: 120 = Klout score: 58 + Social Authority score: 62
Kelly Sommers @kellabyte
4x Windows Azure MVP & Former 2x DataStax MVP for Apache Cassandra, Backend brat, big data, distributed diva. Relentless learner. I void warrantie
Total score: 120 = Klout score: 54 + Social Authority score: 66
John Allspaw @allspaw
CTO, Etsy. Dad. Author. Guitarist. Student of sociotechnical systems, human factors, and cognitive systems engineering.
Total score: 116 = Klout score: 56 + Social Authority score: 60
Christopher Webb @Technitrain
SQL Server MVP, consultant (http://www.crossjoin.co.uk ), trainer (http://www.technitrain.com ) & blogger (http://blog.crossjoin.co.uk/ ) into SSAS, MDX, PowerPivot and DAX
Total score: 113 = Klout score: 55 + Social Authority score: 58
Steven Guggenheimer @StevenGuggs
Microsoft’s Chief Evangelist of Developer Experience (DX) – part geek, part businessman – all mobile, all cloud, all tech…all the time.
Total score: 112 = Klout score: 53 + Social Authority score: 59
Rey Bango @reybango
I love the Web. Microsoft Developer Advocate for web developers and Microsoft Edge. Contributing Editor to Smashing Mag. Honey badger. Opinions are mine.
Total score: 112 = Klout score: 53 + Social Authority score: 59
Erich Gamma @ErichGamma
Software developer and skier
Total score: 111 = Klout score: 52 + Social Authority score: 59
K. Scott Allen @OdeToCode
Author @pluralsight & Visual Studio MVP
Total score: 110 = Klout score: 53 + Social Authority score: 57
Lee Stott @lee_stott
Engaging & helping UK Academia understand how Microsoft Developer technologies can help complement existing strategies within teaching, learning & research.
Total score: 106 = Klout score: 54 + Social Authority score: 52
Anders Hejlsberg @ahejlsberg
Technical Fellow at Microsoft
Total score: 104 = Klout score: 47 + Social Authority score: 57
Martin Beeby @thebeebs
Works for Microsoft as a Technical Evangelist.
Total score: 99 = Klout score: 48 + Social Authority score: 51
The post Top 20 Social Influencers in .NET Development appeared first on BASTA!.
]]>The post „Die HoloLens strahlt vom ersten Moment an eine eigene Faszination aus“ appeared first on BASTA!.
]]>Die HoloLens strahlt vom ersten Moment an eine eigene Faszination aus – irgendwie ein Blick in die Zukunft, plötzlich Realität geworden. Wir beschäftigen uns auch in der klassischen Software Entwicklung gerne mit User Experience und der Gestaltung von Benutzeroberflächen – da steht man bei der HoloLens natürlich wieder ganz am Anfang.
Es wird auch in Zukunft noch Anwendungsfälle geben, wo wir mit 2D, Maus und Tastatur ganz gut aufgehoben sind. Und wir werden in den nächsten Jahren nicht alle mit spacigen Visierhelmen durch unsere Umgebung laufen.
Aber die Geräte werden vielfältiger und billiger – und das ermöglicht wieder mehr Lösungen, auch im Businessumfeld. Microsoft hat Windows Holographic gegenüber Drittanbietern geöffnet, man darf gespannt sein, welche Devices in den nächsten Jahren auf den Markt kommen. Zumindest der Spielesektor wird dafür sorgen, dass Mixed Reality den Massenmarkt erreicht – wir sehen aber auch darüber hinaus viel Potential.
Gelten Spiele bereits als „sinnvoll“? Die Spieleindustrie hat sicher ganz viele Ideen, mit Mixed Reality ein komplett neues Erlebnis zu kreieren.
Ansonsten sind wir gerade in der Phase, verschiedene Einsatzmöglichkeiten auszuprobieren: Wo bringt 3D wirklich Mehrwert? Wo genügt Augmented Reality, wo benötigt man Mixed Reality? Wie komplex kann die Navigation werden? Es sind noch viele Fragen zu klären und viele kreative Lösungen zu finden.
Es ist relativ einfach, ein fertiges 3D-Modell in der HoloLens anzuzeigen. Die .NET-Entwickler müssen sich dafür nur wenig Unity-Know-How aneignen, das geht rasch.
Aber: um eine ernsthafte HoloLens-Anwendung zu bauen, ist die Hürde ungleich höher. 3D-Modelle und -Animationen, Sprachsteuerung, Navigationsdesign – hier warten viele Herausforderungen, in denen der typische .NET-Entwickler selten Erfahrung vorweisen kann.
In der BASTA!-Session: Holo, World! Entwickeln für HoloLens, stellen Roman und Daniel den Einstieg in die Entwicklung für die HoloLens im Detail vor.
The post „Die HoloLens strahlt vom ersten Moment an eine eigene Faszination aus“ appeared first on BASTA!.
]]>The post BASTA! 2016 – bis Donnerstag, 4. August 2016, anmelden und sparen appeared first on BASTA!.
]]>
Wer sich noch jetzt anmeldet, kann nicht nur kräftig sparen, sondern die Microsoft-Welt in allen Facetten kennenlernen: Das Vortragsprogramm der BASTA! 2016 zeigt relevante Entwicklungen im Bereich der Microsoft- und Web-Technologien und blickt natürlich auch auf zukünftige Trends. An den Hauptkonferenztagen vom 20. bis 22. September präsentieren über 80 renommierte Konferenzsprecher fundierte Vorträge, die sich in themenspezifische Tracks gliedern. Das Themenspektrum der Vorträge erstreckt sich vom .NET-Framework und C#, Agile und DevOps, Data Access und Storage über JavaScript, HTML5 und Security bis hin zu User Interface und Web Development.
Wie immer beginnt und endet die Konferenz am Montag (19. September) und am Freitag (23. September) mit den ganztägigen Power Workshops. Hier können Interessierte ihr Wissen in der Praxis ausbauen und vertiefen. Dabei stehen den Teilnehmern erfahrene Trainer zur Seite, die anhand von praktischen Beispielen relevante Technologie- Entwicklungen vermitteln.
Einen umfassenden Einblick zum Entity Framework erhalten die Teilnehmer beim Workshop „Bye-bye DataSet – Eleganter Datenzugriff mit Entity Framework Code-based Modelling“ mit Dr. Holger Schwichtenberg (IT-Visions.de/5Minds IT-Solutions) und Manfred Steyer (softwarearchitekt.at/ IT-Visions.de). Microsoft bezeichnet das Entity Framework als „recommended Data-Access -Technology for new Applications” – das DataSet steht zunehmend im Abseits. Das sollte Grund genug sein, sich den Object-relational Mapper als Alternative zum DataSet anzusehen, sind sich die beiden Entity-Experten einig. Strategietipps für .NET-Programmierer und Architekten gibt es bei Oliver Sturm (DevExpress) in seinem „.NET-Programmierer-Workshop“ am Konferenz-Montag (19. September).
„C#-Revolution“ heißt es außerdem beim Workshop von Rainer Stropek (software architects) am Konferenz-Montag (19. September). In dem Workshop erfahren die Teilnehmer unter anderem Neuerungen in C# und Visual Studio anhand von Codebeispielen.
Im Fokus der Hauptkonferenztage stehen die Special Days: Im Modern Business Applications Day lernen Teilnehmer beispielsweise, wie man – aufbauend auf Erfahrungen im .NET-Umfeld – die Erwartungen von Benutzern erfüllen kann. Praxisnah zeigen Experten, wie man mit HTML5 und JavaScript/TypeScript die Reichweite von Applikationen auf mobile Geräte aller Art ausdehnen kann. Dabei kommen vor allem leichtgewichtige Architekturen mit Web-APIs und Push-Services zum Zug.
Timo Korinth widmet sich in seiner Session dem Flexbox-Modell, das nun endlich alle notwendigen Hilfsmittel liefert, um auch komplexe Applikationslayouts einfach und komplett ohne JavaScript oder jQuery zu erstellen.
Zudem stellt Roman Schacherl das Microsoft Bot Framework vor, das die Implementierung von so genannten „Conversational User Interfaces“ erleichtern soll. Einen kleinen Vorgeschmack auf das Thema gibt es übrigens in diesem Interview.
Was sich hinter dem Begriff Adaptive UI verbirgt, zeigt Jörg Neumann in seiner Session „Adaptive UI: Cross-Device-Designtechniken„. In Tomas Claudius Hubers Session geht es darüber hinaus um die Entwicklung von Universal-Windows-Platform (UWP)-Apps.
Spannend wird es außerdem in der Keynote-Session „The Ethics of Virtual Reality“, in der sich der renommierte Philosoph und Neurowissenschaftler Michael Madary von der Universität Mainz der Frage stellt, wie Virtual Reality unsere Welt beeinflussen wird: „Virtual reality (VR) hardware is now commercially available. There is a great deal of excitement about the uses of VR for educational, therapeutic, and entertainment purposes, but there has been less attention to the possible harmful effects of VR.“
Begleitend zum Vortrags-Programm der BASTA! erwartet die Teilnehmer vom 20. bis 22. September außerdem eine breit aufgestellte Expo etablierter Unternehmen der IT-Industrie. Im Rahmen verschiedener Abendveranstaltungen haben die Teilnehmer zudem die Möglichkeit, ihr berufliches Netzwerk auszubauen und sich mit Konferenz-Sprechern, Vertretern der Industrie sowie anderen Teilnehmern zu aktuellen Themen auszutauschen.
Aber das beste kommt erst noch: Wer sich bis Donnerstag, den 4. August anmeldet, erhält das 5-Tages-Special und spart mit satten Frühbucherpreisen. Wer sich etwa mit drei oder mehr Kollegen anmeldet, kann 10 Prozent extra sparen.
The post BASTA! 2016 – bis Donnerstag, 4. August 2016, anmelden und sparen appeared first on BASTA!.
]]>The post BASTA! Labs – Keine Theorie, nur Praxis appeared first on BASTA!.
]]>Schaut man sich die Themen im Einzelnen an, was wir hier in den BASTA!-Sessions ausgiebig tun, sind die für sich in jedem Fall interessant, aber vielleicht nicht unbedingt spektakulär. Bringt man jedoch all diese unterschiedlichen Themenbereiche zusammen und verbindet sie sinnvoll, bilden sich neue Möglichkeiten, Erfahrungen, Chancen und Produktideen. Aus diesem Zusammenspiel entstehen offene Räume für Innovationen, weil die Grenzen zwischen den Abteilungen, Rollen und Technologien fallen. Im Unternehmensalltag hat man – auch wenn es wünschenswert ist und wir nur dazu raten können – nicht immer die Zeit, ein Experiment aufzusetzen, an dem man einfach nur lernen kann. Doch auf der BASTA! möchten wir gemeinsam mit Ihnen genau das tun! Deshalb haben wir uns ein Experiment ausgedacht, das uns und Ihnen den Freiraum gibt, persönliche Erfahrungen mit dem Zusammenspiele einzelner Methoden und Technologien zu machen.
Die BASTA! Labs sind das neue Session-Format der BASTA!. Als professionelle .NET-Entwickler haben Sie auf Basis Ihres Know-hows völlig neue Möglichkeiten, Ihre Produkte zu entwickeln und auf den Markt zu bringen. Und wir bieten Ihnen mit der BASTA! die Gelegenheit, diese Möglichkeiten auszuloten. Fokussiert auf ein Thema konzentrieren Sie sich darauf in gut drei Stunden ein Produkt zu erstellen, ein Methode zu erlernen oder die Cloud zu erobern und dabei DevOps-Luft zu schnuppern. Im direkten Austausch bringen sich alle Beteiligten mit ihren Erfahrungen und ihrer Neugier ein, um Impulse für Neues zu geben und zu bekommen – das gilt auch für die BASTA! Labs Trainer. Der Fokus auf eine Methode oder Technologie, die aber nur in enger Verzahnung mit andern zum Ergebnis führt, bildet die Grundlage eines kreativen und strukturierten Kommunikationsprozesses. Wir laden Sie ein, das BASTA! Lab Ihrer Wahl zu betreten, darin ein Team zu bilden und gemeinsam ein Ziel zu verfolgen. Zusammenarbeit und Kommunikation stehen dabei im Mittelpunkt. Zeitgemäßes (Er-)Arbeiten und Lernen im Team ist dabei das Mindeste, was Sie an Erfahrung mitnehmen werden. Im Idealfall greifen Sie den Impuls der BASTA! Labs auf und bringen ihn in Ihrem Unternehmen ein.
Wir starten unser Experiment auf dieser Konferenz mit drei BASTA! Labs zu folgenden Themen
Mehr Informationen zu den Labs bekommen Sie auf der BASTA! Lab-Seite.
Damit das Ganze funktioniert, ist die Teilnehmerzahl pro Lab begrenzt – bitte haben Sie dafür Verständnis. Wenn Sie teilnehmen möchten, melden Sie sich auf der BASTA! ab Dienstagvormittag am Check-in für ihr Wunsch-Lab an. Nutzen Sie die Möglichkeit und geben Sie uns nach den Labs Feedback, gerne auch direkt an mich auf der Konferenz, damit wir die BASTA! für Sie als .NET-Entwickler noch besser machen können.
Ich bin gespannt auf Ihre Eindrücke und Ideen.
Mirko Schrempp, Program Chair der BASTA! und Redakteur des Windows Developer
The post BASTA! Labs – Keine Theorie, nur Praxis appeared first on BASTA!.
]]>The post “Die wenigsten Unternehmen haben das Agile Manifest verstanden!” appeared first on BASTA!.
]]>Frank Düsterbeck: Genau das ist eine zentrale Frage. Das Agile Manifest – welches letztendlich durch seine Werte und Prinzipien das Wort „Agil“ definiert – hat als Leitsatz: „Wir erschließen bessere Wege, Software zu entwickeln, indem wir es selbst tun und anderen dabei helfen“. Was bedeutet dann Agilität genau auf Projekt-, Team- oder gar Unternehmensebene? Gibt es Agilität auch in IT-fremden Abteilungen oder Bereichen?
Ich denke: ja. Agil bezieht sich zwar klar auf Softwareproduktion. Agil verbindet aber immer den Umgang mit Menschen und den Umgang mit Komplexität. Das kann man überall anwenden, wenn man die Herausforderungen der jeweiligen Anwendungsfelder berücksichtigt.
Düsterbeck: Ein wirkliches tiefes Verständnis für das agile Manifest ist in den wenigsten Unternehmen vorhanden. Leider hängt das Agile Mindset eines Unternehmens immer stark von den wirklichen Entscheidern im Unternehmen ab. Das Mittelmanagement kann z. B. nur sehr eingeschränkt agil wirken, wenn der C-Level noch im Command & Control hängt.
Familiär geführten Unternehmen tragen, ohne es zu wissen, viel Agilität in sich.
Hinzu kommt: Mit den Werten im Hintergrund die Prinzipien zu leben, ist für viele Unternehmen, insbesondere jene, die durch Shareholder wieder bestimmten Zwängen unterlegen, nicht einfach. Die Unternehmen, die wir beraten, sind teilweise streng hierarchisch strukturiert bis hin zu agilen Unternehmen. Jedes dieser Unternehmen schätzt sich aber ehrlich und richtig ein, ob es agil ist oder nicht. In meiner BASTA! Session „Hurra, wir werden agil – aber wie?“ gehe ich insbesondere darauf ein, wie seitens der Unternehmensführung und bei den Mitarbeitern ein agiles Bewusstsein geschaffen werden sollte.
Was ich interessant finde ist, dass es in Deutschland schon immer das Familienunternehmen gab. Nicht wenige dieser „familiär“ geführten Unternehmen tragen, ohne es zu wissen, viel Agilität in sich.
Düsterbeck: Das lässt sich leider pauschal nicht beantworten. Die Einführung agiler Rahmenwerke wie z. B. Scrum und Praktiken wie z. B. Story Mapping hängt immer sehr stark von der Organisation des Unternehmens ab. Wir betrachten also, wenn wir Unternehmen bei der agilen Transition begleiten, zuerst das Handlungsfeld der Organisation und Transition. Dieses gibt den Rahmen. Im Weiteren gucken wir auf die Menschen und deren Interaktionen, die Prozesse und Praktiken und die Technologien und Infrastrukturen.
Das sind jetzt zwar vier Aspekte (anstatt der in der Frage geforderten drei) aber diese sind nicht getrennt voneinander zu betrachten, sondern in der Analyse immer in ihrem Zusammenspiel. Anhand dessen lässt sich dann genauer sagen, was zu tun ist, um bessere Wege für die Entwicklung von Software zu erschließen.
Düsterbeck: Die äußeren Zwänge und Rahmenbedingungen, in denen sich ein Unternehmen befindet. Ist die Entscheidung hin zur Agilität gefallen, das Bewusstsein aller Beteiligten für das Warum geschärft, kann es „eigentlich“ losgehen. Veränderungen bedeuten aber oftmals im ersten Schritt auch Verschlechterungen bzw. Investitionen und wirken sich selten ad hoc positiv auf die Wertschöpfung bzw. Wirtschaftlichkeit aus. Ist ein Unternehmen unter Druck, muss handeln, kann aber nur wenig „Change“ verkraften, so führt dies oft dazu, dass die notwendigen Veränderungen auf die lange Bank geschoben und die alten Muster weitergelebt werden.
Die Unternehmenskultur kann eine große Hürde sein.
Eine weitere große Hürde kann die Kultur eines Unternehmens sein. Diese lässt sich weder direkt beeinflussen noch mal eben schnell ändern. Herrscht z. B. eine schlechte Fehlerkultur, werden Mitarbeiter oder Betriebsräte mit Sicherheit Ängste vor Transparenz, Inspektion und Adaption haben, wie z. B. Scrum fordert, und sich ggf. auch dagegen stemmen.
Düsterbeck: Äußerst positive. Früher hat die Softwareentwicklung versucht, von der Industrie abzugucken und entsprechende Prozesse und Praktiken wie den Wasserfall, Gantt-Diagramme etc. übernommen – mit wenig oder sogar verheerendem Erfolg. Diese Vorgehensweisen passen leider nicht auf die Softwareentwicklung. Sie sind dort schlicht nicht erfolgreich anwendbar, um der Komplexität gerecht zu werden. Heute ist die Welt „VUCA“. Das bedeutet, dass das, was wir in der Softwareentwicklung in Bezug auf den Umgang mit Komplexität gelernt haben, auch auf andere Anwendungsbereiche projizierbar ist. Wir beraten inzwischen längst nicht nur IT-Abteilungen oder IT-Unternehmen, sondern immer mehr andere Industrie- und Dienstleitungsunternehmen der verschiedensten Branchen. Ein Thema ist hier immer, wie Agilität für ihre Geschäftsmodelle und Organisationen einsetzbar ist. Die Digitalisierung spielt hier die treibende Rolle.
The post “Die wenigsten Unternehmen haben das Agile Manifest verstanden!” appeared first on BASTA!.
]]>The post BASTA! 2016 – bis Donnerstag, 30. Juni 2016, anmelden und sparen appeared first on BASTA!.
]]>
Wer sich noch jetzt anmeldet, kann nicht nur kräftig sparen, sondern die Microsoft-Welt in allen Facetten kennenlernen: Das Vortragsprogramm der BASTA! 2016 zeigt relevante Entwicklungen im Bereich der Microsoft- und Web-Technologien und blickt natürlich auch auf zukünftige Trends. An den Hauptkonferenztagen vom 20. bis 22. September präsentieren über 80 renommierte Konferenzsprecher fundierte Vorträge, die sich in themenspezifische Tracks gliedern. Das Themenspektrum der Vorträge erstreckt sich vom .NET-Framework und C#, Agile und DevOps, Data Access und Storage über JavaScript, HTML5 und Security bis hin zu User Interface und Web Development.
Wie immer beginnt und endet die Konferenz am Montag (19. September) und am Freitag (23. September) mit den ganztägigen Power Workshops. Hier können Interessierte ihr Wissen in der Praxis ausbauen und vertiefen. Dabei stehen den Teilnehmern erfahrene Trainer zur Seite, die anhand von praktischen Beispielen relevante Technologie- Entwicklungen vermitteln.
„C#-Revolution“ heißt es etwa beim Workshop von Rainer Stropek (software architects) am Konferenz-Montag (19. September). „C# und .NET machen einen radikalen Wandel durch. Open Source, Plattformunabhängigkeit, grundlegendes Redesign, neue Compilerplattform, als C#- Entwickler gibt es viel Neues zu lernen“, erklärt der C#-Experte. In dem Workshop erfahren die Teilnehmer unter anderem Neuerungen in C# und Visual Studio anhand von Codebeispielen.
Einen umfassenden Einblick zum Entity Framework erhalten die Teilnehmer außerdem beim Workshop „Bye-bye DataSet – Eleganter Datenzugriff mit Entity Framework Code-based Modelling“ mit Dr. Holger Schwichtenberg (IT-Visions.de/5Minds IT-Solutions) und Manfred Steyer (softwarearchitekt.at/ IT-Visions.de).
Im Fokus der Hauptkonferenztage stehen die Special Days: Im Modern Business Applications Day lernen Teilnehmer beispielsweise, wie man – aufbauend auf Erfahrungen im .NET-Umfeld – die Erwartungen von Benutzern erfüllen kann. Praxisnah zeigen Experten, wie man mit HTML5 und JavaScript/TypeScript die Reichweite von Applikationen auf mobile Geräte aller Art ausdehnen kann. Dabei kommen vor allem leichtgewichtige Architekturen mit Web-APIs und Push-Services zum Zug.
So geht Christian Weyer in seiner Session „Leichtgewichtige Architekturen mit ASP.NET Web API und SignalR“ den Fragen auf den Grund, wie man eine leichtgewichtige Integration von Systemen mit interoperabler Kommunikation gestemmt bekommt, und wie man Daten eigener Services mittels Real-Time-Web-Kommunikation in Clients hinein pushen kann.
Timo Korinth widmet sich in seiner Session dem Flexbox-Modell, das nun endlich alle notwendigen Hilfsmittel liefert, um auch komplexe Applikationslayouts einfach und komplett ohne JavaScript oder jQuery zu erstellen.
Gebündelte Themen rund um die native Cross-Plattform-Entwicklung gibt es außerdem auf dem Universal Apps Day. Mit der Windows Universal Platform hat Microsoft ein Ökosystem für Apps geschaffen, die nicht nur auf PCs, sondern gleichermaßen auch auf Tablets, Smartphones, IoT-Devices und weiteren Formfaktoren laufen. Hierdurch eröffnen sich dem Entwickler viele neue Betätigungsfelder jenseits der klassischen Desktopentwicklung.
Unter anderem stellt Roman Schacherl das Microsoft Bot Framework vor, das die Implementierung von so genannten „Conversational User Interfaces“ erleichtern soll. Einen kleinen Vorgeschmack auf das Thema gibt es übrigens in diesem Interview.
Was sich hinter dem Begriff Adaptive UI verbirgt, zeigt Jörg Neumann in seiner Session „Adaptive UI: Cross-Device-Designtechniken„. In Tomas Claudius Hubers Session geht es darüber hinaus um die Entwicklung von Universal-Windows-Platform (UWP)-Apps.
Spannend wird es außerdem in der Keynote-Session „The Ethics of Virtual Reality“, in der sich der renommierte Philosoph und Neurowissenschaftler Michael Madary von der Universität Mainz der Frage stellt, wie Virtual Reality unsere Welt beeinflussen wird: „Virtual reality (VR) hardware is now commercially available. There is a great deal of excitement about the uses of VR for educational, therapeutic, and entertainment purposes, but there has been less attention to the possible harmful effects of VR.“
Begleitend zum Vortrags-Programm der BASTA! erwartet die Teilnehmer vom 20. bis 22. September außerdem eine breit aufgestellte Expo etablierter Unternehmen der IT-Industrie. Im Rahmen verschiedener Abendveranstaltungen haben die Teilnehmer zudem die Möglichkeit, ihr berufliches Netzwerk auszubauen und sich mit Konferenz-Sprechern, Vertretern der Industrie sowie anderen Teilnehmern zu aktuellen Themen auszutauschen.
Doch das Beste kommt erst noch: Wer sich bis Donnerstag, den 30. Juni, anmeldet, spart bis zu 200 Euro mit den Frühbucherpreisen. Daneben gibt es den Kollegenrabatt: Wer sich mit drei oder mehr Kollegen anmeldet, kann 10 Prozent extra sparen.
The post BASTA! 2016 – bis Donnerstag, 30. Juni 2016, anmelden und sparen appeared first on BASTA!.
]]>The post Node.js – nur ein Hype oder doch mehr? Ein Blick auf die Licht- und Schattenseiten der Technologie appeared first on BASTA!.
]]>Das Jahr 2009 war für JavaScript allgemein ein evolutionäres Jahr. Nicht nur Node.js erblickte das Licht der Welt, sondern ebenfalls das etablierte Cross-Platform Framework Nitobi PhoneGap, das heute auch als Apache Cordova bekannt ist. Darauf folgten die berühmte NO-SQL-Datenbank MongoDB und viele weitere spannende JavaScript-Technologien.
Zudem erhielt ECMAScript selbst ein wichtiges Update mit dem „strict mode“-Feature, das aus der Sprache Perl übernommen wurde und für eine erweiterte Fehlerprüfung sorgt.
Es hat sich also einiges bewegt in dieser Zeit. Der Papa von Node.js, Ryan Dahl, hatte wohl selbst nicht mit einem so großen Erfolg gerechnet. Denn ein weiteres wichtiges Jahr für ihn und JavaScript war 2011. Er erhielt zu dieser Zeit zwei wertvolle Auszeichnungen. So wurde ihm auf der Oscon-Konferenz der O’Reilly-Open-Source-Award verliehen und auf der InfoWorld erhielt er den Bossie Award für die beste Open-Source-Software in der Kategorie „Entwicklertools“.
Ein Jahr später nahm Node.js auch nochmal so richtig Fahrt auf und landete bei GitHub auf Platz 2, als das beliebteste Repository. Auf Platz 1 war übrigens Twitter Bootstrap.
Ein paar tausend Forks zeigten, dass die Entwickler-Community viele weitere Ideen mit Node.js hatte. So entstand zum Beispiel auch das Node-WebKit, mit dem sich Cross-Platform- Desktop-Software bauen lässt, ohne das ein Framework wie die Java-Runtime oder das .NET-Framework benötigt wird. Das ist aus Deployment-Sicht ein Hochgenuss. Zudem entstanden Module für einen hardwarenahen Zugriff, sodass man auf Mikrocontrollern im IoT-Bereich ebenfalls mit JavaScript arbeiten kann.
Jetzt wäre natürlich die Frage, ob Node.js nicht nur ein Hype ist? Nein, nach sieben Jahren hat sich Node.js mit seinen Vorzügen der Performance, Skalierbarkeit und Produktivität, bei namenhaften Unternehmen etabliert. So setzt PayPal, LinkedIn, Walmart, The New York Times, Trello, ebay, GitHub, Google und sogar Microsoft mit Yammer auf Node.js.
Der Technologieradar von ThoughtWorks bewertet Node.js daher als eine ausgereifte und bewährte Technologie, die für den Unternehmenseinsatz geeignet ist.
Wir von CleverSocial arbeiten bereits seit einem Jahrzehnt mit .NET und C#. Wir haben uns auch auf die Cross-Platform-Entwicklung spezialisiert; hierbei ist JavaScript führend an der Spitze. Das JavaScript jetzt auch noch serverseitig zum Einsatz kommen sollte, belächelten wir immer wieder und verstanden nicht, weshalb man sich so etwas antun möchte. Als wir uns durch unsere Erfahrungen mit dem Node-Webkit dann mit Node.js vertrauter machten, wagten wir bei einem neuen Produkt, auf Node.js zu setzen.
Wir wurden extrem positiv überrascht von unserer Produktivität und dem leichtgewichtigen Code, sodass wir uns die Frage stellten, wieso überhaupt noch .NET?
Dass nicht nur wir eine so tolle Erfahrung gemacht haben, zeigt ein spannender Artikel des PayPal-Engineering-Teams. Das Team startete im Januar 2013 mit fünf Java-Entwicklern, um eine Web-App zu programmieren. Sie verwendeten hierbei das Spring Framework. Im März 2013 wagten sie sich zusätzlich mit zwei Entwicklern an Node.js. Nun ist auch für PayPal die große Überraschung gekommen. Im Juni 2013 hatten beide Teams die fertige Web-App mit der gleichen Funktionalität. Das bedeutet: Sie haben mit weniger Entwicklern fast doppelt so schnell programmiert. Außerdem hatten sie beim Node.js-Projekt circa 33 Prozent weniger Code und circa 40 Prozent weniger Daten.
Somit gibt es zahlreiche Gründe für Node.js, nicht nur für .NET-Entwickler. Uns hat es auf jeden Fall überzeugt.
Node.js läuft auf Windows, Mac und Linux – auf dem Server und auf dem Client. Ebenfalls läuft es auf Mikrocontrollern wie Arduino, Intel Galileo Board oder Intel Edison.
Somit kann Node.js für eine Vielzahl an Zwecken eingesetzt werden. Als Web-Server für das Backend, als Desktop-Software oder eben als Anwendung für IoT-Geräte.
Auf jeden Fall Produktivität und eine hohe Performance. Node.js ist aktuell der zweitschnellste Web-Server. Auf Platz eins ist Google´s GO-Lösung; wobei man hier serverseitig wieder eine andere Sprache beherrschen muss. Wenn man heutzutage eine Web-Anwendung baut, muss man spätestens beim Client mit JavaScript arbeiten. Das ist immer wieder dann ein starker Kontext-Wechsel, wenn man serverseitig mit einer anderen Sprache arbeitet. Bei Node.js bewege ich mich immer in der gleichen Umgebung. Das man hierbei auch Code wiederverwenden kann, ist ein erheblicher Vorteil. Man bedenke nur einmal das Datenformat JSON, das sich ohne weiteres in beiden Welten nutzen lässt.
Auf ein erneutes lernen. Wobei das für Softwareentwickler zu ihrem Beruf gehört. Sowie jeder Steuerberater jedes Jahr neue Gesetze lernen muss. Wer JavaScript hingegen nur oberflächlich beherrscht und darauf weiter arbeiten möchte, sollte es unbedingt intensiver kennenlernen. Das gefährliche an JavaScript ist die C-ähnliche Syntax, die damals aus Marketingzwecken einfloss. Hierbei möchte der .NET-Entwickler gewohnte Aspekte wiederverwenden und stößt nur auf Probleme. Hat man hingegen die Sprache wirklich richtig kennengelernt, bemerkt man, weshalb selbst C# in Sachen Funktionalität immer mehr in die Richtung von JavaScript rückt. Als Beispiel wäre hier nur mal das dynamic-Feature oder „Projekt Roslyn“ zu erwähnen. Bei meinen JavaScript- und Node.js-Schulungen konnte ich selbst jahrelangen JavaScript-Entwicklern die Augen öffnen. Ich kann es daher nur jedem ans Herz legen. Schaut euch an, was unter der Haube von JavaScript oder Node.js läuft. Ihr könnt nur profitieren.
Das lustige hierbei ist, das Microsoft mit ASP.NET Core genau die gleichen Konzepte von Node.js adaptieren möchte. Das gelingt ihnen aber nach zwei Jahren Entwicklung nur sehr langsam. Wir haben es bei einem unserer ASP.NET-Core-Prototypen aktuell aufgegeben.
Eine große Stärke von ASP.NET ist auf jeden Fall die tolle Unterstützung von O/R-Mappern wie dem Entity Framework. Wobei man bei Node.js mit einer relationalen Datenbank jeden SQL-Befehl selbst schreiben muss. Anders hingegen ist es bei NO-SQL-Datenbanken. Hier hat man bei Node.js mehr Komfort, als unter .NET. Die Datenbank liefert JSON direkt und für die Abfragen gibt es JavaScript-Funktionen. Für die Kommunikation wird kein Mapping benötigt, was wiederum einen Pluspunkt auf Seiten der Produktivität gibt.
Eine weitere Stärke bei ASP.NET ist, dass es für unterschiedliche Belange einen goldenen Weg gibt. In JavaScript gibt es hingegen tausende an Möglichkeiten für eine Lösung. Was man allerdings auch wieder positiv bewerten kann, wenn man eine wirkliche Auswahl möchte. So verfügt beispielsweise der Node-Package-Manager über 236.209 Pakete. NuGet hingegen über lediglich 49.781 (Stand Januar 2016).
Was die Sprache anbetrifft, ist C# eine richtig tolle Sprache, die aber auch ihre Grenzen hat. Man bedenke nur einmal, wie kompliziert es wird, wenn man mit Generics und Reflection komplexe Lösungen bauen möchte. Das geht bei JavaScript erheblich einfacher. Bei der Verwendung mit TypeScript wird hierbei der gleiche C#-Komfort gewährleistet, was die Fehleranfälligkeit angeht.
Im Großen und Ganzen möchte ich mich aber auch nicht nur auf DIE eine Technologie festlegen. Wir haben bei unseren Produkten ebenfalls polyglotte Lösungen und da wird sich auch der Weg in der Entwicklerwelt hinbewegen. Wir haben für spezielle Anwendungsfälle ein Web-API und nutzen dazu den SQL Server, an anderer Stelle kommt hauptsächlich nur Node.js, MongoDB und Redis zum Einsatz. Das alles für eine Web-Anwendung. Nicht ohne Grund wird das Thema Microservices immer relevanter.
The post Node.js – nur ein Hype oder doch mehr? Ein Blick auf die Licht- und Schattenseiten der Technologie appeared first on BASTA!.
]]>The post .Net Core 1.0 ist eine neue Welt! – Schnellere Innovationen, Komplexität, Cross-Platform und Open Source appeared first on BASTA!.
]]>Es ist eine Version 1, auch wenn es bei RC1 noch .NET Core 5.0 war. Version 1 ist aber viel zutreffender. Version 1 heißt aber nicht, dass noch nicht viel dabei ist – im Gegenteil, .NET Core ist jetzt schon riesig. Version 1 soll mehr darauf hinweisen, dass es sich um einen Neustart handelt, es ist ein neues .NET.
Um die Konzepte auf die .NET Core aufbaut zu beleuchten, macht es zuerst Sinn, die Gründe die zu .NET Core führten zu beleuchten:
NuGet Packages, die schon mit dem .NET Framework eingeführt wurden, ermöglichen schnellere Updates als wir es mit dem .NET Framework gewohnt waren. Als .NET 1.0 im Jahr 2000 vorgestellt wurde, war es noch möglich auf Update-Zyklen von ca. zwei Jahren aufzubauen. Heute ist das nicht mehr möglich, wir wollen schneller auf neue Features zugreifen. Mit einigen Bereichen vom .NET Framework ist das auch schon geschehen. Entity Framework 6 wird komplett aus NuGet Packages geliefert, zudem auch z.B. System.Collections.Immutable und System.Collections.Concurrent. Allerdings: Funktionalität, die bereits mit dem .NET Framework am System installiert ist, und auch die Common Language Runtime kann nicht so einfach ausgetauscht werden, um neue Features anzubieten. Dazu sind Administratorrechte notwendig. Entity Framework selbst hatte viele Jahre darunter gelitten, dass dieses Framework teilweise mit dem .NET Framework am System installiert wurde und zusätzliche Klassen über NuGet Packages gekommen sind. Damit gab es einige Einschränkungen.
Bei .NET Core 1.0 kommt jetzt alles über NuGet Packages – auch die Runtime. Das ermöglicht schnelle Innovationen in allen Bereichen.
Nachdem mit Applikationen jetzt auch die Runtime ausgeliefert wird, muss ich mit Webanwendungen nicht mehr darauf warten, bis mein Provider die neueste .NET Version am Server installiert hat. Welche Version ich verwende, entscheide ich jetzt mit der Applikation.
Das .NET Framework ist im Lauf der Jahre sehr komplex geworden. Viele Teile im .NET Framework bestehen auch aus Libraries, die in neuen Applikationen heute nicht mehr benötigt werden, z.B. .NET Remoting, LINQ to SQL, die alten Non-Generic Collection Klassen und viele mehr. Wenn man die letzten Jahre mit .NET mitgewachsen ist, ist das weniger ein Problem. Sehr wohl ist es aber ein Problem für Neueinsteiger in .NET. Wie soll hier entschieden werden können, welche Klassen verwendet werden sollen und welche Teile nicht mehr „State of the Art“ entsprechen?
Nachdem alle Teile von .NET Core jetzt in kleineren NuGet Packages geliefert werden, ist es möglich Referenz-Packages zu definieren. Entwickler können diese Referenz-Packages nutzen. Damit ist dann auch gleich definiert, welche Packages mit welchen Versionen in der Firma genutzt werden sollen/dürfen. Das hilft Neueinsteigern Entscheidungen zu treffen und nicht gleich das riesige .NET Framework vor sich zu sehen.
Windows auf allen verschiedenen Devices unterschiedlichster Art und Größen zu haben – vom Desktop und Smartphone über die HoloLens und IoT Devices ist schön. Die tatsächliche Verbreitung kann aber nicht außer Acht gelassen werden. Auf mobilen Devices haben Android und iOS weit größere Marktanteile, und am Server ist Linux weit verbreitet.
Ein großer Vorteil von .NET Core 1.0 ist etwas, das bisher nicht von .NET abgedeckt werden konnte: .NET auf Linux und OS-X – und zwar mit Support von Microsoft. Es war schon spannend zu sehen, wie rasch weitere Plattformen unter https://www.github.com/dotnet hinzugefügt wurden und praktisch alles gleich funktioniert. Ich habe inzwischen auch Vorträge auf Linux-Konferenzen gehalten. Vor wenigen Jahren war das noch nicht vorstellbar. .NET Core haben wir auf unterschiedlichen Plattformen – und auch die Tools!
Dass .NET Core – inklusive der Runtime, dem C#-Compiler und ASP.NET MVC 6 – jetzt Open Source ist, hat große Vorteile. Man muss ja jetzt nicht gleich selbst Erweiterungen schreiben oder Bugs korrigieren. Ich bin seit frühen Betas dabei – so kann man auch Design-Entscheidungen mitverfolgen. Warum manches so oder so gelöst wurde, ist so leichter zu verstehen.
Zu Erweiterungen von C# 7 und auch schon C# 8 ist es z.B. jetzt möglich, Feedback zu geben und selbst die nächsten Versionen von C# zu beeinflussen. Wie erwähnt: Bug-Fixes müssen nicht selbst gemacht werden. Ich hatte mehrere Bugs auf GitHub reported. Bei einem meiner Reports habe ich ursprünglich nicht damit gerechnet, welchen Impact der Bug dann letztendlich wirklich haben würde. Aber nach nur sechs Tagen gab es einen Fix in den Daily Builds. Über GitHub lässt sich so direkt mit den .NET-Entwicklerteams kommunizieren. Erweiterungen zu schreiben, die dann auch verwendet werden können, ist natürlich auch möglich.
.NET Core 1.0 ist wirklich eine neue Welt: .NET-Code auf unterschiedlichen Plattformen, Open Source und in vielen kleinen NuGet Packages. .NET Core ist bereits in der ersten Version riesig.
Aktuell haben wir RC2, RTM soll am 27. Juni 2016 verfügbar sein. Go live ist jetzt schon mit RC2 möglich (und der 27. Juni ist ja bald). RC1 als „Release Candidate“ zu verkaufen war ein Fehler, der Name hat sich geändert, damit auch Namespaces und Package Namen sowie auch noch das API selbst. Ich sehe RC1 nicht als „Release Candidate“ – und Microsoft mittlerweile auch nicht mehr. Mit RC2 ist das aber anders. Während es von RC1 zu RC2 noch große Änderungen gegeben hat, ist RC2 ein wirklicher „Release Candidate“. API-Schnittstellen werden nur noch geändert, wenn kritische Probleme auffallen. Die Tools werden sich noch ändern, die sind beim Release von .NET Core auch erst Preview 2. Ein Release der Tools einige Monate später ändert aber nichts an der fertigen Applikation.
.NET Core 1.0 ist jetzt einsetzbar, die meisten neuen Applikationen würde ich auch jetzt damit implementieren.
Ein großer Vorteil von .NET Core 1.0 liegt darin, dass .NET jetzt auf anderen Plattformen verfügbar ist – nicht mehr nur Windows, sondern auch Linux und OS-X. Das ermöglicht den Einsatz von .NET in Szenarien, die früher einfach nicht möglich waren.
Darüber hinaus ist .NET Core 1.0 einfach moderner. Das .NET-Framework hat doch einige Jahre auf dem Buckel, inklusive unterschiedlichster Patterns, die implementiert wurden. Ich denke da z.B. an die unterschiedlichsten asynchronen Patterns, die seit .NET 1.0 entstanden sind, und auch im .NET-Framework durchgehend implementiert wurden. Alte Zöpfe konnten mit .NET Core abgeschnitten werden. .NET Core hat moderne Patterns im Einsatz. Dass Dependency Injection tief im Framework integriert ist, wird rasch erkannt, sobald man sich mit ASP.NET Core beschäftigt. Ich verwende Microsoft.Extensions.DependencyInjection aber nicht nur mit ASP.NET Core, sondern auch mit WPF- und UWP-Applikationen. Außerdem gibt es eine neue, flexible Konfiguration und neue Logging Interfaces mit denen bestehende Logging Frameworks verwendet werden können.
Neue Tools für die Command Line sind auch da. So ist es mit dem dotnet Command möglich, den initialen Source Code zu erzeugen, NuGet Packages zu laden und zu erstellen, das Programm zu kompilieren, zu testen, User Secrets zu managen, Entity Framework Migrations durchzuführen und vieles mehr. Dabei enthält das Tool nicht gleich alle Features, sondern es ist erweiterbar.
.NET Core 1.0 ist einfach ein modernes Framework, das die Bedürfnisse von heute erfüllt.
Mit dem Release von .NET Core 1.0 stehen die Tools nur als Preview zur Verfügung. Der eigentliche Release der Tools steht erst mit der nächsten Version von Visual Studio, Visual Studio „15“, auf dem Programm. Mit den Tools wird sich dabei aber auch noch viel ändern. Was mich schon immer bei .NET Core gestört hatte, ist, dass einige Tools in Visual Studio einfach nicht für diese neue Technologie zur Verfügung stehen. Der Grund: Die Tools müssten erst für das neue Projektformat von .NET Core angepasst werden. Microsoft hat aber einen Weg gefunden, doppelte Arbeit zu vermeiden. Statt diese Tools für .NET Core 1.0 anzupassen, werden in MSBUILD jetzt Features integriert, die die Vorteile von project.json ausmachen. Als Ergebnis davon werden wir ein neues Projektformat haben, das sowohl von .NET Core als auch .NET-Framework-Applikationen genutzt wird – und zwar auch auf anderen Plattformen, unabhängig von Visual Studio. Das einzige Problem dabei ist, dass es noch etwas dauert, bis das neue Projekt-File da ist.
Für den aktuellen Einsatz von .NET Core 1.0 soll das aber kein Hindernis sein. Sobald das neue Projekt-File verfügbar ist, werden bestehende Projekt-Files automatisch konvertiert – zumindest ist das der Plan. Diese Änderungen beeinflussen den C# Source Code aber keineswegs, und damit sehe ich das gar nicht so problematisch.
Eine weitere Schwäche kann die Problematik beim Portieren älterer Applikationen auf .NET Core sein. Es ist zwar von Vorteil, dass alte Zöpfe abgeschnitten wurden. Allerdings bringt das aber auch gleich den Nachteil mit sich, dass es schwierig ist, bestimmte Applikationen nach .NET Core zu portieren. Einige APIs gibt es einfach nicht in der neuen Welt. Es fehlen z.B. Application Domains, der alte, mächtige Syntax für Reflection und einiges mehr. Ein Hilfsmittel, um herauszufinden, wie weit eigene Applikationen davon betroffen sind, ist die Visual Studio Extension „.NET Portability Analyzer“. Dieses Tool zeigt die betroffenen genutzten APIs und manchmal auch Alternativen dafür.
Zukünftige Versionen von .NET Core werden dann den Umstieg von Legacy Applikationen zu .NET Core erleichtern. Application Domains, Reflection und mehr werden in zukünftigen .NET Core Versionen auch zur Verfügung stehen.
Es gibt jetzt einige Szenarien, die früher mit .NET einfach nicht möglich waren. Da ist es einfach, sich schon jetzt für .NET Core zu entscheiden, z.B. um .NET-Applikationen auf anderen Plattformen zu ermöglichen.
Entity Framework Core ist ebenfalls auf anderen Plattformen verfügbar, bietet aber außerdem noch die Möglichkeit, NoSQL Provider zu verwenden. NoSQL Provider sind aber momentan nur in Samples verfügbar – da sollte es nicht lange dauern, bis verschiedenste Provider zur Verfügung stehen. Mit der neuen Architektur von Entity Framework ist es auch leichter Provider zu schreiben.
Bei neuen Webapplikationen sehe ich auch kaum Gründe, ASP.NET MVC 6 nicht zu verwenden. Es gibt viele Ähnlichkeiten mit ASP.NET MVC 5. Und als ASP.NET MVC Entwickler findet man sich rasch zurecht. Im Hintergrund ist aber sehr viel anders.
Bei bestehenden Applikationen macht es meist noch keinen Sinn, diese gleich auf .NET Core umzustellen. Bestehende Applikationen können aber trotzdem schon Features von .NET Core nutzen, die einige Vorteile bieten, wie z.B. das neue Dependency Injection Framework, das neue Configuration API oder auch die Logging Facade. Diese NuGet Packages können auch mit „Legacy Applications“ genutzt werden.
The post .Net Core 1.0 ist eine neue Welt! – Schnellere Innovationen, Komplexität, Cross-Platform und Open Source appeared first on BASTA!.
]]>The post SQL Server 2016 Release appeared first on BASTA!.
]]>Besonders das Thema Sicherheit wurde im SQL Server 2016 weiter nach vorne gebracht und Entwicklern wurden massiv Argument dafür entzogen, unsichere Anwendungen zu entwickeln. Das sollte sich in zukünftigen Anwendungen positiv bemerkbar machen. Die Kerntechnologien hierfür sind Row Level Security, Dynamic Data Masking und Always Encrypted.
Auch der Schritt in Richtung Hybrid Cloud, in der sich Daten teilweise lokal auf dem Server und in der SQL Azure Cloud befinden, ist ein interessanter Ansatz. So können z.B. historische Daten in die theoretisch unbegrenzte Cloud abgelegt werden und stehen jeder Zeit für Abfragen zur Verfügung – Cold Storage gehört damit der Vergangenheit an (Abb. 1).

SQL Server 2016 Editions
Abb. 1: Neuerungen SQL Server 2016 [1] Screenshot (c) Microsoft
Ob sich andere Themen wie z.B. Polybase oder „R“ für SQL Server durchsetzen werden, muss sich in der Zukunft erst zeigen. Diese Technologien machen jedoch eins klar: spätestens mit SQL Server 2016 ist die Zeit der „Insellösung SQL Server“ definitiv beendet. Ein Punkt, der noch einmal durch die Ankündigung von Microsoft unterstrichen wird, dass SQL Server 2016 die erste Version sein wird, die auf Linux läuft [2]. Genau wie in anderen Bereichen (z.B. der UI-Technologie) zeigt dies ganz deutlich, dass auch Giganten der Branche wie Microsoft sich nicht nur mit sich selbst und eigenen Entwicklungen beschäftigen können.
Damit verschwimmen klare Grenzen, die Jahre lang unberührt Gültigkeit hatten. Ob das gut ist? Ich denke schon, denn so hat die beste Technik mehr Chancen, sich durchzusetzen, auch wenn sie vielleicht gerade nicht von großen Herstellern stammt. Das Microsoft diese Öffnung vielleicht nicht ganz freiwillig und nur aus Güte heraus gemacht hat, kann nur vermutet werden.
Auch wenn es oft übersehen wird, besteht der SQL Server nicht nur aus der relationalen Datenbank. Die Reporting Services (SSRS), Integration Services (SSIS) und Analysis Services (SSAS) gehören zu dem Produkt „SQL Server“ und erfahren mit der neuen Version natürlich auch ein Update.
Während diese bei SSIS und SSAS jedoch eher übersichtlich ausfallen und nur in Detailbereichen zu finden sind, wurden die Reporting Services erweitert und für Mobile-Devices fit gemacht (schließlich hat Microsoft Anfang 2015 die Firma Datazen gekauft). Das ist ein interessanter Schritt der viele Möglichkeiten eröffnet und die Plattform stärken wird. Es bleiben allerdings auch alte Schwächen, wie fehlendes Templating und Corporate Identity Unterstützung.

SQL Server 2016 – Mobile Report
Abb. 2: Mobile Report Publisher © Microsoft [3]
Insgesamt ist SQL Server 2016 ein weiterer Schritt in eine Richtung, die uns Entwicklern viele neue, spannende Möglichkeiten eröffnet und mehr Freiheiten bieten wird – und neue komplexe Aufgaben.
Und noch eine gute Nachricht für alle Entwickler und deren Geldbeutel: die Developer Edition ist nun kostenfrei verfügbar [4] und das für SQL Server 2014 und 2016.
[2] https://www.microsoft.com/en-us/server-cloud/sql-server-on-linux.aspx
[3] https://msdn.microsoft.com/en-us/library/ms170438.aspx
[5] Mehr vom Autor unter www.dotnetconsulting.de
Aufmacherbild: © istock ryccio S&S Media
The post SQL Server 2016 Release appeared first on BASTA!.
]]>The post Offlinefähige Browseranwendungen mit Service Worker appeared first on BASTA!.
]]>Leider hat die Anwendung selbst nur wenig Kontrolle über die Nutzung dieses Cache. Beispielsweise lädt der Browser Dateien bevorzugt aus diesem Cache, auch wenn online neuere Versionen davon zur Verfügung stehen. Daneben aktualisiert er den App-Cache nur, wenn er eine Änderung am Cachemanifest entdeckt. Ein gezieltes Aktualisieren einzelner Cacheeinträge ist hingegen nicht möglich.
Service Workers bieten hierfür eine bessere Lösung: Sie haben feingranularen Zugriff auf mehrere frei definierbare Cacheregionen und können Dateien nach eigenem Gutdünken darin verwalten. Darüber hinaus können sie HTTP-Anfragen abfangen und dynamisch entscheiden, ob diese über einen Netzwerkzugriff oder aus dem Cache zu beantworten sind. Auf diese Weise lassen sich unterschiedliche Caching-Strategien implementieren. Das Offline Cookbook von Google [1] geht darauf umfangreich ein. Einen Überblick dazu bietet Tabelle 1. Als der vorliegende Text verfasst wurde, unterstützten Chrome, Firefox und Opera dieses aufstrebende Konzept. Seitens der Teams hinter Safari und Edge gab es Interessensbekundungen.
| Strategie | Beschreibung |
| Cache-only | Ressourcen werden ausschließlich aus dem Cache geladen. |
| Network-only | Ressourcen werden ausschließlich über das Netzwerk geladen. |
| Cache, falling back to network | Cache wird bevorzugt. Falls die gewünschte Ressource dort nicht zu finden ist, wird über das Netzwerk geladen. |
| Cache and network race | Ressource wird parallel aus dem Cache und übers Netzwerk angefordert. Die zuerst erhaltene Antwort kommt zum Einsatz. |
| Network falling back to cache | Netzwerk wird bevorzugt. Falls die gewünschte Ressource nicht übers Netzwerk geladen werden kann, kommt der Cache zum Einsatz. |
| Cache then network | Ressource wird aus dem Cache geladen und verwendet. Parallel dazu wird eine Netzwerkanfrage gestartet. Sobald die darauf folgende Antwort vorliegt, kommt diese zum Einsatz. Darüber hinaus wird damit der Cache aktualisiert. |
| Generic fallback | Wenn die gewünschte Ressource nicht im Cache und/oder nicht übers Netzwerk gefunden wurde, kommt eine generische Antwort zum Einsatz. Dabei kann es sich um eine benutzerfreundliche Fehlermeldung handeln. |
Tabelle 1: Ausgewählte Caching-Szenarien
Ein Service Worker ist zunächst lediglich ein Skript, das der Browser im Hintergrund ausführt und sich für bestimmte Events registriert. Sein Wirkungsbereich erstreckt sich über den Ordner, in dem sich die Skriptdatei befindet, und bezieht auch sämtliche direkte sowie indirekte Unterordner ein. Um einen Service Worker die Kontrolle über eine gesamte Webanwendung zu geben, ist er somit in deren Root zu platzieren.
Mit der Service Worker Toolbox [2] stellt Google eine solche Bibliothek mit einem High-Level-API zur Verfügung. Das Herzstück ist dabei ein Routing-Konzept zum Abfangen von Anfragen. Eine Route definiert sich dabei durch ein URL-Muster, ein HTTP-Verb und einen Handler. Das URL-Muster ist im Wesentlichen ein URL mit Platzhalter. Greift die Anwendung mit dem definierten Verb auf ein zum Muster passenden URL zu, bringt das Service Worker Toolkit den registrierten Handler zur Ausführung. Dieser kann unter Nutzung einer festgelegten Caching-Strategie auf die Anfrage reagieren. Für die meisten der in Tabelle 1 beschriebenen Caching-Strategien bietet das Toolkit auch schon eine fertige Implementierung, sodass sich der Entwickler mit der Umsetzung dieser wohlbekannten Verfahren nicht belasten muss.
Dank des Routings kann eine Anwendung auf einfache Weise Anfragen für unterschiedliche Bereiche mit unterschiedlichen Caching-Strategien begegnen. Somit kann sie zum Beispiel Zugriffe auf statische Dateien anders handhaben als Zugriffe auf Web-APIs. Während sich womöglich im ersten Fall die Strategie Cache, falling back to network anbietet, könnte im zweiten Fall das Gegenstück Network, falling back to cache die bessere Option sein.
Ein Beispiel für einen Service Worker, der auf der Toolbox basiert, findet sich in Listing 1. Die gesamten Quellcodedateien stellt der Autor unter [3] zur Verfügung. Das Beispiel importiert zunächst die Bibliothek sw-toolbox.js und versetzt daraufhin die Toolbox in den Debug-Modus. Dies führt zu einer Protokollierung sämtlicher durchgeführter Schritte in der Entwicklerkonsole und ist gerade für das Testen empfehlenswert. Anschließend weist das Beispiel die Toolbox an, im Zuge der Installation des Service Workers einige Dateien in den Cache zu laden. Caches von älteren Versionen desselben Service Workers entfernt es bei der darauffolgenden Aktivierung automatisch.
Danach erfolgt das Einrichten der Routen: Die Methode toolbox.router.get definiert eine Route für GET-Aufrufe, die an einem beliebigen URL der Herkunft http://www.angular.at gerichtet sind. Dabei handelt es sich um das vom Beispiel genutzte Web-API. Als Handler kommt hierfür die Methode toolbox.networkFirst, die die Strategie Network, falling back to cache implementiert.
Zusätzlich hinterlegt das Beispiel in der Eigenschaft toolbox.router.default einen Standard-Handler. Dieser kommt per Definition zur Ausführung, wenn keine der definierten Routen zu einer GET-Anfrage passt. Im betrachteten Fall handelt es sich dabei um die Funktion toolbox.cacheFirst, welche die Strategie Cache, falling back to network implementiert und sämtliche aus dem Netzwerk bezogenen Dateien für weitere Zugriffe im Cache hinterlegt.
Damit der Browser den Service Worker so schnell wie möglich aktiviert, legt das Beispiel am Ende noch Handler für die Ereignisse install und activate fest.
importScripts(‘/node_modules/sw-toolbox/sw-toolbox.js’);
toolbox.options.debug = true;
toolbox.precache([
‘/’,
‘/app/flugsuchen.component.css’,
‘/app/flugsuchen.component.html’,
‘/app/flugsuchen.component.js’,
‘/app/navbar.component.html’,
‘/app/navbar.component.js’,
‘/app/main.js’
]);
toolbox.router.get(‘/(.*)’, toolbox.networkFirst,
{origin: ‘http://www.angular.at’});
toolbox.router.default = toolbox.cacheFirst;
var context: any = self;
context.addEventListener(‘install’,
event => event.waitUntil(context.skipWaiting()));
context.addEventListener(‘activate’,
event => event.waitUntil(context.clients.claim()));
Bei den von den Routen genutzten Handlern handelt es sich um Funktionen, die als ersten Parameter die jeweilige HTTP-Anfrage entgegennehmen und eine dazu passende HTTP-Antwort retournieren. Neben der Anfrage nehmen sie auch noch ein Objekt mit URL-Parametern sowie ein Options-Objekt entgegen. Bei Letzterem handelt es sich um das beim Einrichten der Route hinterlegte Options-Objekt, das unter anderem die Origin festlegt.
Das nachfolgende Beispiel demonstriert dies. Es implementiert die Caching-Strategie Generic Fallback. Dazu definiert es einen URL mit einem Platzhalter imgname. Der zur Laufzeit dafür eingesetzte Wert erscheint innerhalb der gleichnamigen Eigenschaft im an den Handler übergebenen zweiten Parameter mit dem Namen values. Der Handler versucht, die Anfrage mit der Funktion cacheFirst zu beantworten. Funktioniert dies nicht und befindet sich die Anwendung im Offlinebetrieb, leitet der Handler auf die sich im Cache befindliche Datei notfound.png um.
declare var Request: any;
toolbox.router.get(‘/img/:imgname’, (request, values, options) => {
return toolbox.cacheFirst(request)
.catch(() => toolbox.cacheOnly(
new Request(“/img/notfound.png”)));
});
Neben den hier betrachteten Methoden bietet das Toolkit noch einige weitere. Beispielsweise wartet es mit zusätzlichen Cachestrategien, aber auch mit Methoden für weitere HTTP-Verben auf. Es kann auch Cacheeinträge nach einer bestimmten Zeitspanne oder beim Erreichen eines Quotas entfernen. Informationen dazu bietet die Dokumentation im GitHub-Repository der Toolbox [2].
Auch zum Registrieren von Service Worker bietet die Toolbox mit dem Skript companion.js eine einfache Möglichkeit:
<script src=”node_modules/sw-toolbox/companion.js”
data-service-worker=”sw-with-toolbox.js”></script>
Die Datei companion.js über einen Skript-Tag zu laden und das gewünschte Service-Worker-Skript ist lediglich über das Attribut data-service-worker desselben Skript-Tags zu referenzieren.
[1] https://jakearchibald.com/2014/offline-cookbook/#generic-fallback
[2] https://github.com/GoogleChrome/sw-toolbox
[3] https://github.com/manfredsteyer/progressive-with-sw-toolbox-demo
Manfred Steyer (www.softwarearchitekt.at) ist Trainer und Berater mit Fokus auf Webtechnologien und Services. In seinem aktuellen Buch „AngularJS: Moderne Webanwendungen und Single Page Applications mit JavaScript“ behandelt er die vielen Seiten des populären JavaScript-Frameworks aus der Feder von Google.
The post Offlinefähige Browseranwendungen mit Service Worker appeared first on BASTA!.
]]>eines ist seit der Einführung von Windows 8 bzw. 10 ganz sicher: Zu jeder BASTA! sieht die Microsoft-Welt anders aus. Und damit verändert sich auch das Gesicht der BASTA! Hier greifen wir die Trends und Technologien auf und verbinden sie in den Sessions und Workshops der BASTA! 2016 zu einem Angebot, das nie zuvor so breit und umfassend war.
The post Eine BASTA! für offene Innovationen und neue Wege appeared first on BASTA!.
]]>
Offenheit und gutes Zuhören zeichnen das neue Microsoft in der Ära von Satya Nadella aus, der in den ersten zwei Jahren als CEO viele neue Entwicklungen angestoßen hat. Was diese Offenheit, und mit ihr auch die Einladung zur Innovation bedeutet, erfahren sie kompakt und fokussiert auf der BASTA!. Als .NET-Entwickler haben Sie auf Basis ihres Know-hows völlig neue Möglichkeiten, ihre Produkte zu entwickeln und auf den Markt zu bringen. Und wir bieten Ihnen mit der BASTA! die Gelegenheit, diese Möglichkeiten auszuloten. Dazu werden wir erstmals die BASTA! Labs veranstalten.Dazu bekommen Sie in herausragenden Keynotes einen gezielten Ausblick auf die kommenden Trends und Technologien.Und wir nutzen Microsofts neue Offenheit dazu, Ihnen Technologien vorzustellen, die bisher im Microsoft-Umfeld nicht üblich waren, die Sie aber kennen sollten.
Viele der aktuellen Themen lassen sich aus unterschiedlichen Blickwinkeln betrachten. Wir haben dazu für Sie Pakete, die einen strategischen Aspekt bilden. Dazu zählt offensichtlich der Web Development Day am Mittwoch, mit seinen Sessions zu ASP.NET 1.0, Angular 2 und JavaScript. Hinzu kommen aber weitere Session wie TypeScript für .NET-Entwickler, HTML5-Anwendungen, Cross-Plattform-Entwicklung vom Backend bis in den Browser oder die Universal-App. In der Summe ergibt das quasi eine Webentwicklungskonferenz.
Hinzu kommen aber weitere Sessions wie TypeScript für .NET-Entwickler, HTML5-Anwendungen, Cross-Plattform-Entwicklung vom Backend bis in den Browser oder die Universal-App.
Aus einem anderen Blickwinkel betrachte ist die BASTA! aber auch eine Cross-Plattform- und Cross-Device-Konferenz. Denn die gleichen Themen bieten in Kombination mit anderen Special Days einen umfassenden Einblick in diesen Bereich. Dazu gehören der Cross-Plattform Day, der Modern Business Application Day und der Universal Apps Day. Hier bekommen Sie zusammengefasst praxisorientierte und zukunftsweisende Tipps zur Entwicklung mit Cordova, Xamarin oder JavaScript-Frameworks wie React, NativeScript und das schon erwähnte Angular 2. Ob Sie Web-, Hybrid- oder Native-Apps erstellen wollen, hier erfahren Sie wie es geht. Vertieft werden die Informationen dazu in den entsprechenden Workshops am Montag und Freitag: C#-Revolution mit .NET Core 1, Strategien für .NET-Entwickler und Architekten, End-to-End-App-Entwicklung mit Entity Framework, ASP.NET Web API, HTML5, Angular 2 oder Xamarin. Besonders spannend ist hier der Xamarin-Workshop von Jörg Neumann, da Microsoft Xamarin in diesem Frühjahr übernommen und umgehend in Visual Studio integriert hat. Damit steht Ihnen Xamarin nun kostenlos zur Verfügung, und Sie können mit ihrem C#-, F#- und .NET-Wissen Anwendungen entwickeln, die dann nativ auf der Windows-Universal-Plattform laufen. Das bedeutet, dass Sie mit Ihren Anwendungen nicht nur auf Windows 10 Desktop, Tablet und Phone oder auch der Xbox, dem Surface HUB und der HoloLens vertreten sind. Darüber hinaus können Ihre Kunden auch über iPhones und Android-Geräte Ihre Anwendungen nutzten.
Wie Sie für diese breite Entwicklung C# und .NET nutzen können, erfahren Sie auf der BASTA! selbstverständlich auch. Mit C#, dem Klassiker, der nicht älter wird, sind Sie immer vorne mit dabei. Die C# Days mit Oliver Sturm liefern hierzu den Input, was die Features von C# 6 angeht, aber auch was die Open-Source-Politik von Microsoft für Sie bedeutet. Mit der Compiler-Plattform „Roslyn“ haben Sie ein mächtiges Werkzeug zur Hand, dass Sie für Ihren Einsatz optimieren können und die Sie gleichzeitig dabei unterstützt, Ihren Code zu optimieren. Und hier kommen natürlich die neuen Features des modularen .NET Core 1.0 zum Einsatz, die Rainer Stropek in seinem Workshop am Montag umfassend vorstellt. Mit .NET Core, das Ende 2016 vollständig kommen soll, halten auch Neuerungen in die NuGet-Paketverwaltung Einzug. Für Entwickler bedeutet das, dass ihre Anwendungen nicht mehr mit dem großen monolithischen 4.x.x-Framework ausgeliefert werden müssen, sondern nur noch Komponenten genutzt werden, die die App wirklich benötigt. Zudem bietet dies die Möglichkeit, Anwendungen auch für Linux und Mac OS zu schreiben – und das als .NET-Entwickler. Auch hier erweitern sich Ihre Möglichkeiten, und die Themenkombination C# und Linux ist plötzlich auf der BASTA! vertreten. Vor zwei Jahren noch unvorstellbar.
Für Entwickler bedeutet das, dass ihre Anwendungen nicht mehr mit dem großen monolithischen 4.x.x-Framework ausgeliefert werden müssen, sondern nur noch Komponenten genutzt werden, die die App wirklich benötigt.
Damit alle diese Technologien und Trends zusammenspielen, ist das Application Lifecycle Management (ALM) besonders wichtig. Das unterstreicht die aktuelle Entwicklung des Team Foundation Servers (TFS) 2015. Steht der TFS seit jeher im Zentrum eines Entwicklungsprojekts und bildet damit die Plattform für die am Projekt beteiligten Teammitglieder und unterschiedlichste Tools, wuchs und wächst der Umfang der Einsatzmöglichkeiten mit den neuen Anforderungen an die Softwareentwicklung. Heute steht der TFS On-Premise und online zur Verfügung, verbindet die lokalen Ressourcen mit Azure, verteilt über Git, bindet unterschiedliche Departments von der Anforderung über die Entwicklung, das Testing, das Deployment und das Reporting ein und schafft somit überhaupt erst eine flexible und effiziente Grundlage für den umfassenden Lebenszyklus einer Anwendung: von ihrer Idee bis zu ihrer Auslieferung und nachfolgenden Verbesserung. Damit wird der TFS zum mächtigen Werkzeug für .NET-Entwickler, die zeitgemäß moderne Anwendungen auf allen Plattformen für alle Plattformen entwickeln wollen.
Hier kommen endlich auch Development und Operations, also DevOps, zusammen – weil sie gute Gründe dafür haben. Denn in dem Bemühen, gute Software auszuliefern, steht zwischen der Entwicklung und dem Nutzer nun einmal der Betrieb und soll nicht zur Hürde werden. An dieser Stelle ist DevOps ganz einfach ALM zu Ende gedacht. Zum Lifecycle einer Software gehört auch das Ausliefern an den Kunden, und wenn das nicht so funktioniert, wie zuvor auf dem Testsystem der Entwickler, dann müssen die Kollegen vom Betrieb ran. Der Betrieb hätte wahrscheinlich auch gleich sagen können, dass es nicht funktionieren wird, aber Entwicklung und Betrieb haben gar nicht darüber gesprochen.
Der Agile Day, der Test und Quality Day und die ALM DevOps Days bieten einen 360-Grad-Blick auf die moderne, nutzerzentrierte Anwendungsentwicklung für .NET-Entwickler. Microsoft und andere Hersteller bieten dazu viele Tools an, aber diese müssen methodisch und organisatorisch sinnvoll eingesetzt werden. Hier werden die einzelnen Aspekte zusammengeführt und zu einer Entwicklungserfahrung, einem Produkt und einem strategischen Ziel – dem zufriedenen Kunden – zusammengeführt.
Uns macht die Planung einer Konferenz mit dieser Bandbreite ungeheuer Spaß. Vor allem die Chance, neue Perspektiven zu öffnen und neue Themen für innovative Lösungen vorzustellen, ist wunderbar. Wir sind sicher, dass Sie als Teilenehmer für sich, Ihre Kollegen und Unternehmen hier das Wissen bekommen, dass Sie für die digitale Transformation brauchen, denn die steckt hinter allen diesen einzelnen Aspekten. Wir setzen mit der Konferenz fort, was wir im Windows Developer und auf www.entwickler.de schon seit Jahren an strategischer Analyse und Einordnung immer wieder durchspielen und auf die Probe stellen. Softwareentwicklung hat einen entscheidenden und wachsenden Anteil am Geschäftserfolg von Unternehmen, und Sie haben das Know-how dafür – in der Microsoft-Welt und darüber hinaus.
Ich freue mich darauf, Sie auf der BASTA! zu treffen!
Mirko Schrempp, Program Chair der BASTA! und Redakteur des Windows Developer
The post Eine BASTA! für offene Innovationen und neue Wege appeared first on BASTA!.
]]>



























































