If you have an iPhone, each time you get a call today you’re using private information retrieval
]]>We often get asked if homomorphic encryption is used at scale today (i.e. deployed to hundreds of millions of users). The answer is yes, primarily thanks to private information retrieval!
If you have an iPhone, each time you get a call today you’re using private information retrieval (PIR) under the hood to look up information about the caller id without revealing to the server who’s calling you. Additionally, if you happen to use Facebook’s end-to-end encrypted Messenger app, you’re using PIR each time you click a link in your chat. These links are checked against known malicious links in a way that doesn’t compromise the user’s privacy. There are in fact more wide scale deployments of PIR but these are some of the more interesting consumer-facing ones.
If you’re familiar with Ethereum’s privacy roadmap, PIR fits most cleanly into the bucket of “private reads,” enabling users to query or browse Ethereum apps without worry of surveillance from say their RPC provider. You can learn more about the effort to bring private reads to Ethereum here.
In this blog post, we'll be providing an overview of PIR, along with a demo on how we can bring privacy to DNS so that you can privately look up websites. We chose DNS as it's something many people are familiar with and a good introductory medium with which to showcase PIR. If you'd like to jump straight to our demo, you can check it out here.
So what is private information retrieval and what does it have to do with homomorphic encryption?
Developing intuition for PIR
Private information retrieval (PIR for short) can be thought of as a way to privately read some information from a database. Specifically, PIR enables a user (often referred to as the "client") to retrieve an item from a database without the database owner (the "server") knowing which item was retrieved! Many PIR constructions rely on homomorphic encryption, not to be confused with fully homomorphic encryption (FHE) which is more than a decade younger than PIR.
The strawman construction of a PIR scheme simply involves the server sending the entire database back to the user. While this construction achieves our privacy goal of the server not learning which item the user wants to look up, it is obviously unsatisfactory. Thus, one goal of PIR is to minimize the data that has to be shared between the user and server (in technical speak, reduce communication). Another major goal is to reduce the amount of work the server has to do in providing an answer to the user; this is what most of the research work is focused on today (reduce computation). Homomorphic encryption enables computation directly over encrypted data and will ultimately help in reducing the amount of communication between the client and server.
PIR constructions fall into two camps: those that are “single server” and those that are “multi-server.” Multi-server PIR looks more like MPC in that to obtain privacy you must assume the servers do not collude with one another. In this article, we’ll be looking at single-server PIR which often relies on lattice-based cryptography (which forms the the foundation of FHE as well).
A brief math detour
We'll put the encryption part aside for now and look at how we can use matrix-vector multiplication to just perform an array lookup on a database.
Doing lookups in the clear
Suppose we have a database containing the values \([16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1]\). We can pack these into the following matrix:
\[ D=\begin{bmatrix} 16 & 15 & 14 & 13 \\ 12 & 11 & 10 & 9 \\ 8 & 7 & 6 & 5 \\ 4 & 3 & 2 & 1 \\ \end{bmatrix} \]
To make a query against the server, the client must compute the row \(r\) and column \(c\) indices from \(i\) where
\[r = i / 4\]
\[c = i\ \mathrm{mod}\ 4\]
Suppose the client wants to retrieve the item at index \(i=6\). This gives \(r=1\) and \(c=2\).
The client constructs a vector with zeros everywhere except in the \(c=2\) row where they place a 1:
\[ q=\begin{bmatrix} 0 \\ 0 \\ 1 \\ 0 \\ \end{bmatrix}\]
Now, the server can compute:
\[ y=Dq= \begin{bmatrix} 16 & 15 & 14 & 13 \\ 12 & 11 & 10 & 9 \\ 8 & 7 & 6 & 5 \\ 4 & 3 & 2 & 1 \\ \end{bmatrix}\begin{bmatrix} 0 \\ 0 \\ 1 \\ 0 \\ \end{bmatrix} =\begin{bmatrix} 14 \\ 10 \\ 6 \\ 2 \\ \end{bmatrix} \]
and send \(y\) back to the user. The user can then locally extract the element \( r=1\) , which is 10, the value at index 6.
Obviously this construction provides little privacy for the user since the server can see the user's request and deduce the user is interested in the value at index 6.
Encrypting the client's request
So how will we augment the prior construction to hide the user's request from the server?
At the heart of many PIR schemes lies some form of homomorphic encryption, meaning an encryption scheme supporting computation directly over encrypted data (ciphertexts). Suppose we have an encryption scheme that supports the following operations over messages \(m_a\) and \(m_b\):
- Multiplication by a plaintext scalar \(b\): \(\mathrm{Enc}(m_a * b) = b * \mathrm{Enc}(m_a)\)
- Addition of ciphertexts: \(\mathrm{Enc}(m_a + m_b) = \mathrm{Enc}(m_a) + \mathrm{Enc}(m_b)\)
Now that we know what a linearly homomorphic encryption scheme is, let's see how the user can privately lookup items in a database. Instead of sending a vector with plaintext data, the user now sends over the following vector where all the values are encrypted under a key they own:
\[ q=\begin{bmatrix} Enc(0) \\ Enc(0) \\ Enc(1) \\ Enc(0) \\ \end{bmatrix} \]
Since the encryption scheme is linearly homomorphic, the server can directly compute the following:
\[y=Dq=\begin{bmatrix} 16 & 15 & 14 & 13 \\ 12 & 11 & 10 & 9 \\ 8 & 7 & 6 & 5 \\ 4 & 3 & 2 & 1 \\ \end{bmatrix}\begin{bmatrix} Enc(0) \\ Enc(0) \\ Enc(1) \\ Enc(0) \\ \end{bmatrix} \]
The user receives the following result from the server:
\[ y=\begin{bmatrix} Enc(14) \\ Enc(10) \\ Enc(6) \\ Enc(2) \\ \end{bmatrix} \]
and can decrypt it using their private key to get back
\[ \begin{bmatrix} 14 \\ 10 \\ 6 \\ 2 \\ \end{bmatrix} \]
This solution at least reduces the communication; instead of returning the full \(NxN\) matrix to the user, the server sends back a single column. Modern constructions are a lot more interesting than what we've shown but hopefully our brief walkthrough provides some intuition for how homomorphic encryption enables private database lookups.
Toolbox for modern PIR constructions
If you're more mathematically inclined, you won't be surprised to learn that many single-server PIR constructions rely on lattice-based cryptography which nicely supports matrix-vector multiplication as we saw above.
Intuitively, it seems like if the server truly doesn't learn what item the user is interested in, then the server must necessarily "touch" every item in the database. Such a setup is prohibitively expensive. Indeed, in the simple construction above, the server touched every element in the database matrix when performing the matrix-vector multiplication. One option to address this is batching many different user queries together when doing a single linear scan over the database so that the amortized cost per query is lower.
To provide better efficiency, a lot more machinery is involved in modern day constructions. Intuitively, there are a few levers researchers can pull on-communication, security, and correctness. Specifically, we can reduce the amount of computation that needs to be done by the server (thereby improving response times) if we're okay with the user or server performing some "pre-processing" or if we don't mind introducing some additional commmunication between the two parties. Another trick is to relax security/privacy, meaning the server learns that the user is interested in say one of the first 100 items in a database with 1000 total entries. Finally, researchers can relax correctness, meaning there may be a non-neglible probability that the client does not get back the item they were looking for; however, the client will know that they received the wrong item so they can submit another private query.
Finally, PIR constructions often assume the user provides the server with the relevant index, meaning the user must know the item's location in the database. This seems impractical for many applications but there is a way around this using probabilistic filters to obtain keyword search.
Augmenting DNS to provide private lookups
Now that we've covered PIR, let's look at how to provide private lookups in the context of DNS.
DNS and HTTPS 101
Before diving into our demo, we'll provide a brief rundown of DNS and the privacy it does and does not provide today. Feel free to skip this section if you're familiar with DNS.
Suppose you want to check out the latest happenings in FHE, so you open up your web browser, type blog.sunscreen.tech into your address bar and hit enter. Let's take a look under the hood to see how this actually works via Domain Name System (DNS).
Akin to how phone numbers direct your call to Alice's phone and not Bob's, an Internet Protocol (IP) address allows the network to direct your request to Sunscreen and not Youtube. Unfortunately, just as remembering your friends' phone numbers is hard, it's also hard to remember which IP address goes with which service. The Domain Name System (DNS) was introduced in 1983 to solve this problem. Think of DNS like an old school phone book; you can give it the name of a service (blog.sunscreen.tech) and it will give you the IP address (i.e. "number"). When you type in a URL and hit enter in your browser it actually makes 2 network requests: the first is a DNS lookup to convert the name into a number and the second is to actually fetch the blog.
When we run the nslookup command (to manually perform a DNS request) in our computer's terminal for sunscreen.tech, it responds that there are 4 IP addresses corresponding to sunscreen.tech: 143.204.160.48, 143.204.160.16, 143.204.160.54, and 143.204.160.53.
Security
Unfortunately, DNS as originally designed has a few privacy and security problems:
- Due to the lack of encryption, passive observers can see what host your browser is requesting.
- The DNS server operator knows which host you're looking up.
- Even worse, DNS lacks message authentication, allowing active adversaries to modify either the DNS request or response. This allows the adversary to trick your browser into sending the request to a malicious host.
While the first two issues aren't ideal, the third is extremely dangerous given the distributed nature of the internet. To address this, DNSSEC was developed in the mid 1990s to provide cryptographic authentication to ensure your lookup isn't tampered with. However, passive network observers can still see what address you're looking up and easily track your browsing behavior. With DNS over HTTPS, we additionally get encryption, which hides the request and response from prying third party eyes.
However, the DNS server itself can still see the user's request. Is this as good as we can hope to do? Intuitively, it feels like the server must be able to view the user's query in order to process a response.
Our demo
As it turns out, we can additionally hide the request from even the DNS server itself using PIR.
We'll be using FrodoPIR, a 2023 PIR scheme that relies on lattices from the Brave team. What's great about this construction is that it's inexpensive to deploy/run in practice and it requires little computation done by the end-user. Unfortunately, it blows up the database size by ~3x but for our purposes this won't be much of an issue since the database is relatively small to begin with.
How does this work at a high level?
- Preprocessing: First, the server converts and "compresses" the database into a matrix (a fancier version of the \(D\) above). The database here consists of various websites (e.g.
sunscreen.tech) along with their IP address. The client downloads this compressed matrix along with some additional info and uses that to perform some preprocessing for future queries (allowing them to save time later!). - Send encrypted request: Next, the client creates an encrypted query vector with an indicator value for the corresponding entry in their vector (similar to the \(q\) vector in the simple construction above) and sends this vector over to the server.
- Server lookup: The server then performs the database lookup using the encrypted query vector and returns an encrypted result to the client. Roughly speaking, this is similar to the matrix-vector multiplication of \(Dq\) above to get the encrypted vector result \(y\).
- Receive result: Finally, the client uses their private key to decrypt and get the result (the website they wanted)!
Challenges
Unfortunately, things aren't entirely straightforward.
- Standard PIR schemes (like FrodoPIR) require the client knowing the location of the entry in the database. To get around this problem, we'll use ChalametPIR which provides a nice way to convert FrodoPIR (specifically PIR schemes relying on the Learning With Errors problem) into a scheme supporting keyword search. This is achieved via binary fuse filters, generally a faster and more memory efficient alternative to bloom filters.
- What happens if client looks up an entry (i.e. website) that doesn't exist? To avoid sending random garbage back to the user, we get around this by checksumming the value entry and returning an invalid checksum with overwhelming probability if the entry isn't in the database.
Our demo putting all these concepts together is available here. You can lookup various websites, trying out old school DNS, DNSSEC, DNS over HTTPS, and then finally our DNS using PIR.

So can I integrate PIR into my app today?!
Potentially. If you're primarily interested in point lookups and have a relatively small database (say <100GB) that you're okay updating say once or twice a day, then yes.
However, depending on what kind of data is in the database and what sort of lookups you want to offer, there may be some complexity in reformatting the database to support PIR. The most straightforward query to support today is point lookups. If you're hoping to support some sort of SQL, graph, or vector database, there will be a number of challenges to bring PIR to your app.
Additionally, you'll want to consider how large the database is and how often the database needs to be updated. Single-server PIR (what we looked at here) tends to have some performance issues beyond databases of a few hundred GB. If you'd like to work with larger databases, it's worth exploring multi-server PIR schemes. Furthermore, PIR can be tricky to work with if you need the database to be updated in real time. You may already have a sense for why database updates are problematic based on the preprocessing step above. Pre-processing usually depends on the contents of the database and would thus need to be repeated any time the database changes.
Finally, if you're worked with FHE before, you may know that adding privacy to the computation slows things down. We'll run into a similar issue with PIR so you'll have to take into account if your use case can support a bit more added latency. Many of the real-world deployments of PIR (e.g. Apple, Meta) are highly customized to get good performance.
Parting thoughts
To bring meaningful privacy to the web, we need PIR, often in conjunction with other advanced cryptography.
Although we've focused on consumer use cases in this blog, we think much more value can be unlocked by bringing PIR to B2B applications, starting with the crypto and fintech space. Some of the most exciting use cases we've explored are enabling government customers to privately lookup individual transaction history data on blockchain analytics platforms, as well as enabling crypto exchanges (or more generally fintechs) to cross-query other platforms to identify bad actors.
If you're more technically inclined and want to continue learning about PIR, we highly recommend this video. As always, feel free to reach out with any questions or feedback.
]]>At Sunscreen, we've spent the past few years building what we believe is the most developer-friendly TFHE compiler out there. Our Parasol compiler lets you write your program in C, add a few directives to indicate which inputs should be encrypted, and we handle the rest - parameter selection, circuit optimization, bootstrapping, all of it. If you've read our previous posts, you know how strongly we feel about letting developers "bring their own program" rather than rewriting everything from scratch.
But there's always been a gap between having a working TFHE program and running it in production.
The missing piece
Let's be honest about the state of things. You can write an FHE program, compile it, and run it locally. But what happens when you actually want to deploy it? Suddenly you're managing compute infrastructure, figuring out key lifecycle management, handling orchestration, and worrying about resource allocation. These are hard problems, and they're not cryptography problems. Most teams building with FHE are not (and shouldn't have to be) infrastructure teams.
This is the gap we've been thinking about for a while: how do we get from "cool demo" to "production service"?
Lattica
Today we're excited to announce our partnership with Lattica to bring practical TFHE to production environments.
Here's how the two pieces fit together:
Sunscreen provides the cryptographic engine via our Parasol TFHE compiler transforming your program into optimized encrypted computation, and our runtime executes it.
Lattica provides the rest of the infrastructure around it: orchestration and workflow automation, compute resource allocation, key management, and monitoring.
The result is a workflow that feels much closer to deploying a normal application:
- Compile with Sunscreen: write your TFHE program and compile it locally with Parasol to produce a deployable artifact.
- Deploy to Lattica: upload your compiled artifact to Lattica's platform.
- Configure access and resources: set permissions, choose your compute resources, and control credit usage.
- Accept encrypted queries: your program is live and ready for use.
If you've ever dealt with the pain of trying to stand up FHE infrastructure from scratch, you'll appreciate how much complexity this abstracts away.
“Sunscreen has built a powerful TFHE compiler that makes encrypted programs accessible to developers. At Lattica, our focus is making those programs deployable, scalable, and operable in real environments. This partnership is about closing the gap between cryptographic capability and production reality, so teams can move from prototype to live encrypted services without reinventing infrastructure,” shared Rotem Tsabary, Founder & CEO at Lattica.
“This partnership represents something we've been working toward since we started Sunscreen. We always believed that TFHE would only see real adoption when deploying it felt as natural as deploying any other application. Lattica brings the infrastructure expertise that complements our cryptographic engine, helping privacy builders turn working demos into production services. We’re excited to see what developers will build,” said Ravital Solomon, CEO at Sunscreen.
Why TFHE (and when not)
If you've been following FHE developments, you know there's more than one FHE scheme out there, and the choice matters quite a bit depending on your application. Lattica’s platform makes encrypted compute a cloud-native capability for CKKS, and provides the execution layer that brings sensitive workloads and cloud infrastructure together, so it's worth briefly touching on when you'd reach for each.
CKKS excels at approximate arithmetic on large datasets. It's parallelizable, GPU-accelerated, and ideal for AI workloads. If you're doing data-heavy batch operations, CKKS is likely your best bet.
TFHE is different. It's built for exact computation: comparisons, conditionals, branching logic. The tradeoff is that it's CPU-based and generally more expensive per operation than CKKS for pure arithmetic.
So when do you want TFHE? When precision is a requirement. Smart contracts that need exact balance checks. Voting systems where rounding errors would be catastrophic. Any application involving complex decision logic over encrypted data - if-else branches, comparisons, lookups - this is where TFHE shines.
Our partnership with Lattica means you don't have to choose between CKKS and TFHE at the infrastructure level. Both are available through the same platform, so you can use the right tool for each part of your application.
What we're excited about
This partnership represents something we've been working toward for a long time: making TFHE not just possible but practical. We've always believed that one of the biggest barrier to adoption isn't the cryptography itself - it's the infrastructure around it like the deployment complexity, the operational overhead etc. By partnering with Lattica, we can focus on what we do best (the cryptographic engine) while Lattica handles the infrastructure challenges that have historically kept TFHE out of production environments.
We think this is how TFHE gets adopted in the real world - not by asking every team to become infrastructure experts, but by making encrypted computation something you can deploy as easily as any other service.
Get started
Lattica is offering 3 free compute hours to get you up and running. You can check out the full workflow and sign up on Lattica's website. For more info on Sunscreen's TFHE compiler and some demos of what's possible, take a look at our documentation and demos.
We're excited to see what you build with this. If you're working on an application that could benefit from encrypted computation - whether it's in finance, healthcare, blockchain, or something we haven't thought of yet - we'd love to hear from you.
]]>To create privacy-preserving applications, we need a concept of "verifiable hidden state" so that users can protect their individual data while still
]]>With fully homomorphic encryption (FHE), we can bring privacy to existing applications and enable entirely new applications across finance, prediction markets, machine learning, and much more.
To create privacy-preserving applications, we need a concept of "verifiable hidden state" so that users can protect their individual data while still allowing that data to be used in an application (e.g. trading, matching, prediction). Threshold FHE accomplishes exactly that. Using this technology, program inputs can be hidden from everyone. The program output may or may not be hidden, depending on the particular use case.
Our team has developed what we call our "secure processing framework" (SPF for short), our end-to-end offering that allows developers to create, deploy, and use FHE programs. Its architecture was inspired by that of CPUs and GPUs, and the underlying technology was developed in-house by our team. We've combined our experiences across cryptography as well as high performance computing, signal processing, and high frequency trading to build FHE in a way that scales.
So what motivated us to build SPF and why isn't FHE production-ready yet?
Challenges building FHE apps
The first set of challenges occurs when creating an FHE application.
- You must determine the best FHE scheme for your needs. There are a few different FHE schemes out there such as BFV, CKKS, and TFHE. You'll need to select which scheme is most appropriate for your particular needs (e.g. are you looking to primarily do arithmetic over floats? Comparisons over integers?)
- You must select FHE scheme parameters very carefully. Unlike some other cryptographic primitives (e.g. zero knowledge proofs), program performance is very sensitive to parameter selection. By choosing too large parameters for a particular use case, you may experience a 10x degradation in performance versus having chosen parameters exactly right. For certain FHE schemes (like ours) there are almost a dozen parameters to configure that are deeply interconnected and influence everything from security to correctness and performance.
- You must structure the program exactly right. Working with FHE today is a bit like programming with computers in the early days; you need to express programs in a very low-level way and consider what operations are relatively expensive vs cheap for the particular FHE scheme. Quite a bit of creativity is needed to effectively translate your high level program into arithmetic or binary circuits. If you've already written your application to operate over data in the clear, you may have to restructure it so that it's "FHE friendly."
Challenges deploying FHE apps
In summary, programming with FHE is similar to Goldilocks looking for just the right fit. Unfortunately, more challenges arise in deploying an FHE app.
- Someone must provide the appropriate hardware/machines for running the FHE program. To get good performance with the technology today, very specific hardware must be set up. As an example, we've seen that working with a 64 core machine helps significantly for our TFHE scheme variant as it allows us to take advantage of parallelism opportunities for various operations.
- Someone must set up a "threshold committee" to hold shares of FHE public key. This committee is responsible for responding to decryption requests in a timely manner.
- Someone must set up an access control system and/or a data storage system. How do we ensure that only the "correct" parties have access to data in the clear? This is where access control becomes important. Additionally, FHE-encrypted data is large. If the app is deployed on blockchain, we can't expect to store this on-chain. Where then do we store it and who manages this?
Thus, there's quite a bit of work involved with actually using FHE in an application today beyond just translating your application code into FHE code.
Secure Processing Framework (SPF)
SPF aims to handle all of the above problems on the developer's behalf.
To bring verifiable hidden state to blockchain applications, we make use of threshold FHE, building on our own variant of the Torus FHE scheme (TFHE).

Looking inside
There are 3 major pieces in SPF: the core stack, the control stack, and the data bus.
Core stack
The core stack allows developers to write highly-optimized FHE programs by default. It consists of our LLVM-based compiler, our customized virtual processor, and our low-level TFHE library implementing the cryptographic algorithms necessary for our variant of TFHE. If you'd like to learn more about the core stack, we discuss it in detail in a prior blog post.
Developers only interact with the compiler which abstracts away the usual difficulties in working with FHE. The processor and low-level TFHE library are hidden away.
Control stack
The control stack supports the core stack so that developers can use their FHE programs on chain. It provides important functionalities like threshold decryption (via a decentralized network of nodes holding shares of the secret key), access control (to ensure only authorized parties have access to plaintext data), and off-chain storage.
As we utilize threshold FHE, a network of parties needs to be set up to hold shares of the secret key and respond to decryption requests. We handle this on the developer and user's behalf automatically.
A practical challenge with FHE today is that the encrypted data is fairly large--for blockchain standards at least--and accordingly should not be stored directly on-chain. We provide a data store for ciphertexts and program data. In later versions, we can provide developers with the flexibility of choosing among a few decentralized immutable data storage solutions.
Data bus
So how do you actually interact with SPF on-chain today? That's where the data bus comes in. The data bus can be thought of as a pull oracle; it listens for events emitted on-chain. When you request a program run or decryption, an event is omitted on chain. The data bus picks up the event and forwards the request. The result of the computation is put back on-chain via a callback.
Features
What sets SPF apart from existing FHE offerings is the features it can offer developers today and in the future.
- One program, any chain: Today, blockchains are operating in silos. To unlock the full potential of web3, the community must enable seamless interoperability between various ecosystems. Specifically, we believe there will no longer be chain and language silos in blockchain as there are today. SPF puts this plan in action by enabling developers to write one (FHE) program and use it on any chain, regardless of virtual machine. This makes it easy for developers to experiment with different blockchains as well as deploy their app to multiple chains.
- Bring your own program: Building on our prior belief, developers should not have to re-write their application to take advantage of FHE. In a perfect world, developers can transform their existing application code into FHE-enabled code. To support this experience, we allow developers to write in mainstream programming languages. They simply add directives to indicate which inputs/outputs should be hidden and which functions are FHE programs. Bringing more developers into the blockchain space also requires meeting developers where they're at---whether in terms of programming languages or cryptography knowledge.
- Automatically optimized FHE programs: As we touched upon prior, a big challenge with FHE today is determining how to structure your FHE program to get good performance. SPF includes a compiler and virtual processor which determines, behind-the-scenes, how to optimize a developer's code for them.
- Modular stack: There will be better FHE schemes in the future. Accordingly, we designed SPF so that the backend FHE scheme can be swapped out without interfering with the developer's programming experience. We may also wish to switch out our custom instruction set architecture (called PISA) to something more standardized like RISC-V. Modularity also extends to our control stack, so that off-chain data storage mechanisms can be updated or better access control mechanisms can be introduced.
- Built for the hardware endgame: Much like transformers in deep learning were architected to take advantage of the parallelism provided by GPUs, FHE must be architected to suit hardware. What this means in practice is extracting parallelism from how FHE computing is done as well as reducing the critical path in the circuit itself; together, doing these two things can unlock higher throughput and lower latency as specialized hardware for FHE becomes available. This is accomplished in large part by creating our own variant of the TFHE scheme.
Developer workflow
SPF enables developers to bring FHE directly to applications on any chain. You do not need to migrate your program to a new chain, L2, rollup, etc.
For simplicity, we'll look at how to write and deploy your program on Ethereum. Other chains work similarly.
- Write your FHE program in C. While there are some restrictions as to what you can vs can't write today, your application code is just normal C code.
- Compile your FHE program using our compiler. Doing so will create an ELF object file that can be used by Sunscreen.
- Register your program. As part of registration, you'll receive a hash for the binary program file which will be needed to reference your program on-chain.
- Write your accompanying smart contract and deploy the program. Next, you'll write the Solidity dApp that allows users to actually interact with your FHE program. There are particular ways in which this contract must be structured.
- Requesting programs runs. To request program execution using SPF, you'll specify the handle of the program to be run along with the number of output parameters. Our data bus monitors the chain for program run requests and routes it to the SPF for off-chain execution.
- Requesting decryption. To request decryption of the output parameters, you'll need to specify the handle of the program along with the number of output parameters to decrypt. Our data bus monitors the chain for decryption requests and routes it to the off-chain threshold decryption service for processing. The threshold decryption service will then decrypt the desired value and post the results back on-chain using the specified callback.
Alternatively, if you're interested in deploying FHE apps in web2, we also support that experience with SPF.
The only piece that changes is the last step. Instead, you will:
- Develop an application around your FHE program. This involves creating a frontend and backend that interacts with the SPF service. The FHE component will consist of two main pieces:
- Requesting the SPF service to run your FHE program. You will submit the program, along with the encrypted input data, to an endpoint using an HTTP POST request. The SPF service will respond with a unique identifier for the computation that you can use to track the status of the computation, along with references to resulting ciphertexts.
- Handling the result. Once the SPF service has completed the computation (which you can check by polling our
runsSPF REST endpoint), the appropriate party can request the results be decrypted by making a GET request toour threshold decryption service. This will then return the decrypted result.
We've omitted details about access control as this feature will be developed in a later release.
A delicate balance between on-chain and off-chain
To ensure FHE programs can be used on any chain without having to modify the chain's architecture or consensus mechanism, we must move a number of tasks off-chain.
Specifically, we store FHE programs, their inputs, and any encrypted program outputs off-chain. Instead, only links/handles to these are posted on-chain. For plaintext program outputs, these can be stored on-chain as they're small in size.
The FHE computation is run off-chain using relatively powerful hardware deployed by Sunscreen initially. The threshold committee responsible for decrypting data also lives off-chain.
Why FHE
For many years now, extractive corporations have been feeding on our data without returning any of its value to us; privacy-preserving technology returns power to those of us (be it individuals or corporations) who actually produce valuable data. While there have been many exciting developments in AI and ML, these do not shift the existing power paradigm; rather, these developments have the potential to exacerbate the existing situation.
Trusted execution environments (TEEs) and multi-party computation (MPC) are alternative privacy-preserving technologies. However, we view them as further centralizing forces, if not used in conjunction with FHE.
As a hardware-based and centralized solution, there's a natural vendor lock-in when using TEEs for privacy. Additionally, securely programming an application with TEEs continues to be incredibly challenging, with new attacks found frequently.
MPC is a software-based solution but is communication-bound. Thus, to get good program performance, the relevant computing parties must be located very close in physical proximity. In some cases, this even means co-location of the servers.
We believe in a decentralized future in which users own their own data. Fully homomorphic encryption allows us to best achieve that vision.
Our evolving vision
Devnet and testnet for SPF will be available soon. Our whitepaper will be available in the coming weeks, laying out our vision for how to bring verifiable hidden state to applications in web2 and web3 in a scalable manner.
We'd love to hear what you're excited about building and what features you need to make your dream (d)app a reality!
Resources to get started
- Parasol developer docs: Start using our next-gen FHE compiler today.
- Past blog post: Learn more about our vision for homomorphic computing.
- Ask our team anything: Chat with our team about FHE or any app ideas!
Fully homomorphic encryption (FHE) enables running arbitrary computer programs over encrypted data, allowing users to protect their data while still allowing that encrypted data to be used in an application. With FHE, we can enable apps like fully customizable AI agents--trained on any data, no matter how sensitive--or hidden trading strategies in an on-chain ecosystem.
Existing tools for FHE are not built in a way that allows developers to easily create privacy preserving applications. Furthermore, their underlying approaches to homomorphic computing (i.e. computing over the encrypted data) are not architected in a way that will scale well as hardware evolves.
The inspiration for our latest work comes from asking ourselves two fundamental questions:
- How do we truly scale a technology?
- How do we effectively onboard developers to a new technology?
In answering these questions, we (1) re-imagine how computing should be done in FHE using a novel computing paradigm and (2) develop a new FHE compiler design to realize the vision in which developers "bring their own program," rather than re-write their existing application to leverage FHE.
We focus on the Torus FHE (TFHE) scheme, a particular FHE scheme that supports a variety of operations over encrypted data as well as unlimited computation. These features make TFHE especially well-suited to blockchain where it's unknown at setup time how many computations or what kind of computations the developer would like to perform (e.g. this is akin to how Vitalik/EF doesn't know all possible applications that developers might try to build on Ethereum).
Unlike existing approaches to TFHE, our new paradigm combines a special form of bootstrapping, known as "circuit bootstrapping," with multiplexers to realize arbitrary computation in a way that scales well with hardware. By building a virtual processor customized for FHE operations and integrating it as backend to the LLVM toolchain, we enable developers to write their program directly in a mainstream language today.
Re-architecting (T)FHE
Many people (experts included) take a potentially misguided approach to evaluating FHE schemes, focusing on the performance of individual operations rather than entire programs. As a simple thought experiment, consider the following: In System A, each operation takes 1 second. In System B, each operation takes 2 seconds. To instantiate program P with System A, we will need 3 operations but these must be done sequentially. With System B, we also need 3 operations but these can be done all in parallel. Would you prefer to use System A or B for the program?
A visual for those of you that don't want to do the math.

We take a long term view on FHE. For FHE to scale over the coming years, it must be architected to best suit hardware (be it cores, GPUs, or eventually ASICs), rather than expecting hardware to somehow magically accelerate FHE. Specifically, this means designing the homomorphic computing paradigm to maximize parallelism and reduce the critical path in the circuits themselves. Roughly speaking, maximizing parallelism enables us to increase throughput, which is key to unlocking performance with dedicated accelerators. By reducing the critical path, we can obtain lower latency.
In looking at the landscape today, we found that existing TFHE-based approaches do not prioritize these goals.
A brief history on TFHE and bootstrapping
Regardless of which FHE scheme you choose to work with today, a major challenge is "noise." We won't go into exactly what this is but it suffices to say noise is a bad thing. In working with FHE, we need to make sure that the noise doesn't grow so large that we will no longer be able to successfully decrypt the message.
To reduce the noise in a ciphertext so that we can keep computing over it, a special operation called bootstrapping is needed. Bootstrapping is key to performing unlimited computation so a lot of research effort has gone into figuring out how to make this operation fast.
There are various FHE schemes out there such as BFV (which our old compiler was based on), CKKS, and TFHE. The "T" in TFHE stands for torus and this scheme is sometimes referred to as CGGI16 after its authors and the year in which it was published. The former two schemes are generally used in "leveled" format, meaning we only evaluate circuits up to a certain depth, which severely restricts the applications developers can build.
What's great about TFHE is that it made bootstrapping and comparisons relatively cheap (i.e. fast) compared to other FHE schemes. There are some drawbacks to this scheme; most notably, arithmetic is usually more expensive using TFHE than with BFV or CKKS. Additionally, there's a fairly noticeable performance hit when upping the precision (i.e. bit width) in TFHE.
It turns out that there are actually a few bootstrapping varieties for TFHE; namely, we have gate bootstrapping (the OG way), functional/programmable bootstrapping, and circuit bootstrapping.
Gate bootstrapping is what most TFHE libraries and compilers rely upon. It's a technique designed to reduce the noise in a ciphertext and comes from the original TFHE paper.
Functional (sometimes known as programmable) bootstrapping can be viewed as a generalization of gate bootstrapping in that it (1) reduces the noise in a ciphertext and (2) performs a computation over the ciphertext at the same time. At first glance, this approach seems to provide only benefits...after all, you're basically getting two operations for the price of one, right? Going back to our thought experiment, it turns out this approach behaves a lot like System A.
Circuit bootstrapping was introduced many years back but appears to be used thus far for either "leveled" computations or as an optimization when implementing certain forms of functional/programmable bootstrapping. Circuit bootstrapping, like gate bootstrapping, only reduces ciphertext noise. However, it has the nice property of having an output that's directly compatible with a (homomorphic) multiplexer...
Next, we'll look at our computing paradigm which makes use of circuit bootstrapping and homomorphic multiplexers.
Breaking down our approach: CBS-CMUX
We can realize arbitrary computation using multiplexers, independent of FHE. You can think of a multiplexer (known as a mux) as implementing an "if" condition; given two options d0 and d1 and a select bit b, we get d0 if b is 0 and d1 if b is 1. The FHE equivalent of a multiplexer is called a "cmux" as it operates over encrypted data to produce an encrypted output. This turns out to be interesting in the context of FHE.
Our high level goal is to perform general computation using a multiplexer tree before going on to reduce the noise (via the circuit bootstrap) so that we can continue performing more computations over the encrypted data. We must make sure we do not exceed the noise budget when doing the multiplexer tree, otherwise we're in a lot of trouble since we may no longer be able to recover the data. While we won't get into the details, there's also a type mismatch between the cmux and circuit bootstrap which requires us to perform some additional FHE operations to get the output of the cmux into the "correct" format to feed back into the circuit bootstrap.
We call our computing approach the "CBS-CMUX approach" as the combination of these two operations allows us to realize arbitrary programs.
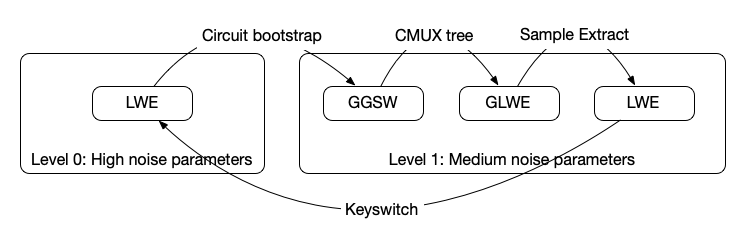
There are a few different ciphertext types (e.g. GGSW, GLWE) that we'll have to switch between but we won't discuss those here. While we won't dive into the details now, an upcoming technical paper will provide more insight on how all of this fits together.
While all of this may seem like a nightmare to an engineer, our compiler handles all of these tasks on your behalf automatically.
Our approach:
- Reduces the number of bootstrapping operations in the critical path: Specifically, for key operations like 16-bit homomorphic comparisons, our approach reduces the number of bootstraps in the critical path down to 1. This is important because bootstrapping is one of the most expensive operations in TFHE. When we instantiate a 16-bit homomorphic comparison using functional/programmable bootstrapping, there are 3 respective bootstrapping operations in the critical path. Even if we have specialized hardware, we would have to wait for each one of these functional bootstrapping operations to be done sequentially.
- Provides greater intra-circuit parallelism: When given access to sufficient cores/computing resources, we can speed things up significantly (like System B).
"BYO program"
Developers should be able to bring their own program, rather than having to rewrite their program in some eDSL or newly created language.
Accordingly, the developer experience today allows you to write your program directly in C or bring your existing C program (with some restrictions). To create an FHE program, you just need to add directives (i.e. simple syntax) indicating which functions are FHE programs and which inputs/outputs should be encrypted (i.e. hidden).
Parasol compiler today
Our compiler abstracts away the usual difficulties of working with FHE which includes selecting FHE scheme parameters, translating your program into an optimized circuit representation, and inserting in FHE-specific operations. Additionally, it's compatible with our single-key TFHE scheme variant (useful if your application operates over a single user or entity's data) as well as our threshold TFHE scheme variant (useful if your application operates over multiple entites data).
Parasol supports common operations like arithmetic, logical, comparison operations. We support imports, and functions can be inlined, making it easier to create modular programs with reusable pieces.
We started with C as a proof-of-concept. Depending on demand, we can add support for other LLVM-compatible frontends like Rust.
There are a number of features we plan to add soon such as signed integers, higher precision integers (today we only support up to 64 bits), division by plaintext, branching over plaintext values, and arrays.
Overview of our design
To provide a great developer experience, we built an LLVM-based compiler. The benefits of this approach are twofold. First, it allows developers to use a variety of mainstream programming languages like Rust, C, or C++ with the only changes to their programs being the directives mentioned above. Second, it allows us to leverage decades worth of optimizations and transformations that are already built into LLVM.
However, how do we efficiently run whatever is output from this compiler? The machine you and I are using won't be able to do this. Accordingly, we need to build a virtual processor that can actually run these FHE programs in an efficient manner.
An important goal of ours was to provide compact program representations. To achieve this, our processor expresses programs as high level operations (e.g. add, multiply, etc.) that it dynamically expands into FHE circuits at runtime.
Our processor, and thus compiler, rely on our in-house created variant of the TFHE scheme.
Technical teaser
For those who'd like to understand more about our stack, we provide some details below. Stay tuned for our upcoming research paper!
LLVM-based compiler: Developers write their FHE programs in C today and compile it using a version of clang that supports our virtual processor. Without the virtual processor, the generated FHE programs can't be run anywhere! Feel free to look here if you'd like to understand how to create an LLVM backend.
Virtual processor: Now to actually run the programs output by clang, we have our virtual processor. We adopt an out-of-order processor design and feature dynamic scheduling within instructions to maximize parallelism. We designed a custom instruction set architecture that enables running programs over a mix of plaintext and encrypted data. Doing so required re-imagining memory at the processor level, adding new instructions to support branching over encrypted data, and building our own circuit processor to support the CBS-CMUX computing approach.
TFHE library: At the lowest level of the stack is our optimized TFHE library which implements the cryptographic operations needed in the TFHE scheme. In theory, different TFHE libraries could be plugged in to work with our processor. However, given we're the only team implementing the CBS-CMUX approach, it made the most sense to have our own library.
The high level workflow is depicted below.

Show me some code!
So what does a program look like when using Parasol? We provide a simple example showing how to do a private transfer below.
#include <stdint.h>
[[clang::fhe_circuit]] void transfer(
[[clang::encrypted]] uint32_t *amount,
[[clang::encrypted]] uint32_t *balance
) {
uint32_t transfer_amount = *amount < *balance ? *amount : 0;
*balance = *balance - transfer_amount;
}
You'll notice that apart from [[clang::fhe_circuit]] and [[clang::encrypted]], this is just a regular C program.
While the benefits of our approach are more apparent in buidling large complex programs, we hope this gives you a taste of what the experience is like!
Benchmarks
We benchmark Parasol against existing FHE compilers (that support comparisons over encrypted data).
Based on the criteria set out in this SoK paper, we consider how compilers perform on a chi-squared test and a simple cardio application that computes a patient's risk of heart disease in the same manner as risk estimators provided by the American College of Cardiology. The former application is heavy on addition and multiplication operations whereas the latter is heavy on comparison operations.
Of the 5 compilers we consider, ours is the only one to rely on circuit bootstrapping as the primary bootstrapping method. Concrete relies on programmable (aka functional) bootstrapping whereas Google, E3, and Cingulata rely on the older gate bootstrapping approach.
Experiments were performed on an AWS c7a.16xlarge instance (64 vCPUs, 128GB RAM) and all compilers are set to provide 128 bits of security.
Transparently, our approach shines when sufficient cores are provided with which we can parallelize tasks across. You will see less of a performance benefit with our compiler/approach if the FHE computation is being carried out on a machine with relatively few cores (e.g. 16, 32 cores). Please note that this only applies to the computing party; there's no issue at all if the end-user, providing their encrypted data, uses a laptop or smartphone!
Chi squared benchmarks
We first look at how our compiler performs for the chi-squared test with respect to runtime of the generated FHE program, size of the compiler output, and memory usage.
Runtime includes circuit evaluation (e.g. not key generation, encryption of inputs). In considering program size, there are slightly different meanings depending on the compiler due to architectural differences. We list the size of Parasol’s emitted ELF program, Concrete’s MLIR representation, and Google transpiler’s binary circuit intermediate representation. For E3 and Cingulata, we give the size of the resulting native executable.
| Compiler | Runtime | Program size | Memory usage |
|---|---|---|---|
| Parasol | 610ms | 256B | 1.0GB |
| Concrete | 1.84s | 1.41kB | 1.82GB |
| Google Transpiler | 13.8s | 323kB | 299MB |
| E3-TFHE | 440s | 2.87MB | 182MB |
| Cingulata-TFHE | 85.6s | 579kB | 254MB |
You'll notice that Parasol consumes more memory than compilers based on gate bootstrapping (i.e. Google, E3, Cingulata); this is due in part to the larger circuit bootstrapping key.
Cardio benchmarks
We also consider how our compiler performs for the cardio program with respect to runtime of the generated FHE programs, size of the compiler output, and memory usage.
| Compiler | Runtime | Program size | Memory usage |
|---|---|---|---|
| Parasol | 920ms | 528B | 1.0GB |
| Concrete | 2.13s | 10.4kB | 4.0GB |
| Google Transpiler | 3.26s | 11.4kB | 274MB |
| E3-TFHE | 119s | 1.87MB | 181MB |
| Cingulata-TFHE | 2.98s | 613kB | 254MB |
What the future holds
The Parasol compiler forms the foundation of our new vision, the "secure processing framework." The SPF will allow one (FHE) program to be used on any chain, regardless of virtual machine.
We'll be open-sourcing Parasol in the next few weeks and providing comprehensive documentation to help get you started. We're excited to finally release work that's taken us many months to achieve! We'll be sharing more about the SPF and accompanying testnets soon. If you're interested in previewing these offerings, our team is happy to chat and learn about your unique needs.
Finally, if you're in Toronto this May for ZK Summit or Consensus, feel free to reach out to me personally if you'd like to say hi!
]]>At Sunscreen, we've recently been spending time on private double auctions where the operators only learn of an order's details after the order has been matched (details of unsuccessful orders are never revealed, even to the operators!). Building upon our last demo, we showcase a truly dark dark pool and how to build it using (threshold) fully homomorphic encryption.
Although our focus is on cryptocurrency in this post, dark pools trace their history back to equities. As "cryptocurrencies are not securities," there are a number of challenges or opportunities (depending on if you're a glass half empty or a glass half full kind of person) outside of privacy to grapple with when building trading venues in crypto. We touch upon some of these issues before presenting our demo.
A brief introduction to dark pools
Traditionally, orders are stored in order books where other parties can view existing bids/offers. However, placing a "large" order (volume-wise, relative to the item's market cap) will almost always cause the market to move against you (e.g. for a large buy order, price may move up once others see your order in the book; for a large sell order, price may go down once others see your order). Dark pools popped up as one solution to this problem within equities, allowing sophisticated (often institutional) investors to place large orders without alerting the market to their intention--thereby incurring minimal price impact/slippage. Dark pools also allow such investors to hide/obscure their trading strategy from others (i.e. protect their alpha).
Dark pools came into being in the 80s, after the SEC allowed securities to be traded off their listed exchange. However, they didn't truly take off until after the mid-2000s when the SEC allowed investors to bypass public markets if price improvement were possible. Nowadays, a significant portion of daily US equities volume passes through dark pools.
So what are dark pools and how do they work? You can think of a dark pool as an invite-only trading venue where only the operator can view the full order book. Assuming participants trust the dark pool operator, they can trade large blocks of securities with minimal to no slippage as other participants are unaware of outstanding orders. Unfortunately, dark pool operators have historically abused their privileged position for their own benefit (some examples include 1, 2, 3).
Make it dark dark
So we ask—can we build a truly dark dark pool where even the dark pool operators can't view the order book?
Specifically, we'd like to build a dark pool where the operator(s) can't view orders until they've been successfully matched. We refer to this as "blind matching" since we want to match orders together without knowing what the underlying order values are (e.g. volume, limit price).
Although there are a few different cryptographic solutions to this problem, we'll showcase how to build a dark dark pool using (threshold) fully homomorphic encryption (which minimizes communication between parties and is a purely software-based solution without the same attack vectors of hardware-based privacy solutions).[1]
At a high level, the following happens:
- A committee generates a public-private key pair such that each committee member holds a portion of the private (i.e. decryption) key.
- Dark pool participants submit encrypted orders.
- Committee members run the matching algorithm directly on the encrypted orders to check for possible matches.
- Upon knowing a successful match can be done between two orders (without knowing price or volume information for the orders), the committee members provide their respective piece of the private key to decrypt the final result (i.e. "Party A has sold a quantity of x items to Party B for y price").
By having the key split into shares, we construct a distributed trust model where no single party can view outstanding orders (which would violate traders' privacy). Furthermore, we can configure trust so that we require just a single honest operator within the pool to ensure order privacy (i.e. say we have 5 committee members; even if 4 out of 5 of them were corrupt, they would not be able to decrypt and view the traders' orders).
How does crypto fit into all of this?
If we were building a dark pool for a security, most of the decisions would be made for us with regards to price execution, auction design, settlement process, and system permissioning so we'd just move directly on to presenting a demo of what such a dark dark pool might look like.
Cryptocurrency currently operates in a regulatory grey zone. While the design space for crypto trading platforms is therefore much richer, there are also a number of challenges due to the lack of established infrastructure and regulations within the space.
Given the dearth of crypto dark pools, there is also a unique opportunity to rethink design to benefit a new class of participants. Below, we bring light to some of the challenges in designing a dark pool for cryptocurrencies, with the goal of sparking a broader conversation within the community and relevant experts.
(Non-)existence of NBBO
Most equities dark pools use midpoint price execution, minimizing the number of disputes between buyers and sellers, as well as allowing trading venues to ensure they provided "best execution" for their clients. What does best execution mean for crypto (especially when no NBBO equivalent is available for a given cryptocurrency)?
For securities, there are best execution requirements that require brokers to execute customers' orders with the most favorable terms possible. Although best execution is defined intentionally ambiguously, it tends to take into account price improvement as well as execution time. To understand price improvement, the NBBO (national best bid and offer) is used as reference. However, when trading larger blocks of securities where slippage is a serious problem, beating the national best bid and offer seems unlikely. Thus, equities dark pools often rely on midpoint price execution.
Given the lack of regulation, there is no centralized entity (like the SIP) that disseminates NBBO for a given cryptocurrency. Even if such a thing were to exist, would we consider best bids and offers with respect to only centralized exchanges or should we include decentralized venues as well? Should crypto dark pools, by default, mimic their equities equivalent providing midpoint price execution or should we allow for a more traditional order book model where buyers and sellers can specify price as well as volume?
Continuous vs. periodic auctions
While most equities dark pools perform matching on a continuous basis, there are a few options for clients who prefer a periodic model. Which option is best for the crypto space?
Continuous double auctions are prevalent within traditional finance, allowing buyers and sellers to submit orders whenever they want. Matching occurs on a continuous basis, meaning as soon as an order comes in the operators search for a counterparty/match. There are a few venues within traditional finance in which auctions are done "periodically," meaning buyers and sellers can submit orders during a specified time period and crossings are performed at a set time. However, by and large, continuous auctions dominate the landscape.
Opponents of continuous double auctions argue that such a model inherently favors those with a speed advantage like sophisticated high frequency trading firms, encouraging co-location and a latency arms race. To counter this speed and latency arms race within tradfi, some have suggested frequent batch auctions, a type of periodic auction in which orders from a specified time period are batched together and then executed at a uniform clearing price. Proponents of periodic auctions also argue that a discrete time model allows participants to compete on price (to the advantage of other system participants) rather than speed.
While the existing winners in tradfi have little incentive to push for periodic auctions, an open design space still exists for crypto markets. We can already see some of the continuous vs period auction debate playing out, with popular decentralized trading venues like dYdX, Cowswap, and Penumbra championing the use of frequent batch auctions to mitigate the negative effects of MEV.
Should crypto dark pools further entrench HFT firms' dominance or seek to level the playing field for the rest of us by adopting a new design?
Insider trading and toxic order flow
How does lack of insider trading laws impact order flow in crypto?
When it comes to startups, founders, early employees, as well as (venture capital) investors generally hold a substantial portion of the respective company's stock. When the company goes public, employees face restrictions on trading their company's stock to prevent "insider trading."
Similarly, for cryptocurrency startups, early employees and investors often control a substantial portion of the project's initial token supply. The equivalent situation of an IPO for a cryptocurrency startup might be having the token listed on a prominent centralized exchange like Coinbase. However, given the lack of regulation in the crypto space, there is very little to legally prevent early employees from acting on material non-public information that they strongly suspect will affect the token's price (e.g. employee Alice knows her company's token will be listed on xyz prominent exchange in 3 months, likely causing the price to go up once the news is announced).
Although early employees and investors are likely to trade in large blocks, it's not a great look for a founder or early employee to be seen selling off large portions of their own company's stock or cryptocurrency.
With a crypto dark pool, early employees could now hide their activity, acting on material non-public information whenever they wish without alerting the broader market about what they're doing. Furthermore, it's very possible (if not likely) that some of this order flow would be "toxic."
While a large number of crypto trading venues are decentralized and permissionless, they do not offer privacy which may affect how participants behave when using the system (knowing they can likely be de-anonymized and all their bids/offers viewed). So we must ask--will building a dark pool that supports trading large blocks of altcoins further encourage "insider" trading within crypto and allow toxic flow to proliferate?
Custody, settlement, and information leakage
With no DTC(C) available, how will settlement and clearing work for crypto dark pools?
For the vast majority of securities transactions within the US, the DTCC provides clearing and settlement services to ensure the successful handoff between buyers and sellers.
The goal of a dark pool is to allow participants to shield their activity from others. While FINRA requires some information regarding dark pools to be made public, it's fairly minimal, revealing high level info like total number of shares and trades done per instrument each week rather than details on individual trades and the participants' identities.
How would custody and settlement work for a crypto dark pool when there is no DTCC equivalent? The natural and obvious solution is to rely on the blockchain to handle these tasks. Unfortunately, if orders settle via a public blockchain, some information will almost certainly be revealed. It may be possible to hide transactions made within the dark pool (if it's properly set up as a rollup or L2) but how do participants get their cryptocurrency into the dark pool in the first place and what happens when they attempt to exit the dark pool? Surely there will be public transactions (on say Ethereum) showing that they've deposited (withdrawn) x number of tokens into (from) some contract.
Another option might involve relying on some semi-trusted third party to handle custody and settlement, as well as shielding participants' activity from the public (say via the use of wash accounts).
How much information leakage can we eliminate while still relying on a public blockchain? What amount of information leakage is acceptable to dark pool users?
Our demo (aka make it fast)
We've built a demo showcasing what such a truly dark dark pool might look like where operators cannot abuse their privileged role to view orders before they've been matched.
You can test out two different experiences:
- A continuous double auction where participants specify both price and volume, with matchings attempted as soon as a new order comes in (mimicking a traditional order book model).
- A periodic volume match where crossings are performed every 5 seconds and price is determined from an external source (akin to a frequent batch auction). We could just as well provide midpoint price execution if we collected price data across various centralized exchanges.
While our demo currently runs on a 64-core machine (c7g.16xlarge instance), much better performance can be achieved with beefier machines and hardware acceleration (e.g. GPU-accelerated implementation).
For simplicity, we provide partial fills by default as well as fill-or-kill orders. We could just as well allow for minimum fills but have chosen to omit them for an initial version. Quantity and price are currently restricted to a 216 bit range; larger ranges can be provided but come with a performance penalty. Other aspects that impact performance include number of orders to process and security level.
Our demo makes use of our own version of the TFHE fully homomorphic encryption scheme under the hood, allowing us to get better performance than existing FHE libraries. As dark pools are one example of double auctions, this work naturally builds upon our previous work for private verifiable auctions in which we showcased how to build a first-price sealed-bid auction in which losing bids were never revealed.
We imagine initial versions of dark pools will need to be permissioned to best optimize for user experience and protect against bad actors. When it comes to custody and settlement, there are many open questions that need to be answered before a dark pool can be deployed into the wild.
Looking forward
Can we build a future with private and fair financial systems? We believe the answer is yes and our work here is one step towards that.
We're at a potential crossroads in time as institutions and tradfi players start to move into crypto. Given how young the space is, there are opportunities to rethink market design and determine how the winners of the next financial systems will be chosen. What worked well for tradfi may not necessarily work as well for us in crypto.
As for our plans, we'll soon be open-sourcing our low-level implementation of the TFHE (fully homomorphic encryption) scheme. We'd love to hear your thoughts if you've been thinking about some of the issues here and, if you happen to be at ETHDenver, come say hi!
- Threshold FHE has the advantage of requiring little communication between parties and no communication during the computation itself (as FHE is compute-bound). MPC-based solutions (e.g. SPDZ) are communication-bound, on the other hand. In practice, this means that the various parties need to be co-located to get good performance. ↩︎
At Sunscreen, we're working to enable a new class of applications operating on private shared state via fully homomorphic encryption (FHE). These applications tend to have two requirements—input privacy (keeping inputs hidden even after the program is complete) as well as verifiability (how can we know for a fact the program was run correctly?). One such application is auctions, with one of the more interesting use cases aimed at determining blockspace ordering.
In this article, we'll walk through how blockspace auctions work at a high level and how threshold FHE can improve the auction process. We'll then look at where threshold FHE is as a field and how Sunscreen is working to make private verifiable (d)apps available to all.
So far we've focused on developers but we're excited to showcase our first demo where end users can see what such an FHE-enabled application might look like! Our demo implements a first-price sealed-bid auction using our own variant of the torus fully homomorphic encryption scheme (TFHE) and is inspired by top-of-block blockspace auctions. With a 64-core machine, determining the winner over all 93 encrypted bids should take <2 seconds but, depending on the number of people using the demo, you may experience a slowdown.
For the full experience, connect via Metamask and make sure to have some Sepolia ETH available!
First-price sealed bid auctions are just the start for us and we're excited to explore bringing privacy and verifiability to all kinds of auctions.
Crash course on blockspace auctions
If you're new to blockspace auctions, keep reading! We'll take a look at why they were created, how some of them operate at a high level, and limitations with existing constructions. Please note that the following provides a simplified overview; blockspace auctions are just one example of an auction where privacy and verifiability are crucial so don't get too hung up on the details.
Let’s say there’s an arbitrage opportunity across two decentralized exchanges (DEXs) on the same chain—specifically, we notice that token τ is quoted at price α on exchange A and price β on exchange B where α < β. This seems like a good opportunity to potentially purchase token τ on exchange A and then sell it at a higher price on exchange B, pocketing the profit.[1]
Unfortunately, it turns out that many people are thinking exactly the same thing! We'll broadly refer to the individuals competing to take advantage of arbitrage opportunities as "searchers."[2] Once one person takes advantage of this arbitrage opportunity, token τ’s price on both exchange A and B are likely to change (potentially such that the price difference between the two is smaller or so that the prices converge across the two exchanges).
How do we decide who gets to the opportunity first? In blockchain, this boils down to transaction ordering within a block but how transaction ordering occurs is chain-dependent. If we're looking at Ethereum, transaction ordering is generally tied to gas price. Thus, searchers could submit transactions directly to the public mempool and compete by offering a higher gas price to try to get their transaction processed faster. If we're looking at Cosmos, transaction ordering generally obeys a first in, first out (FIFO) rule so a searcher may attempt to spam the network to get their transaction in first. The space becomes even more complex when looking at L2s, which lack public mempools and often operate on a FIFO basis. Irregardless of which chain we're on, both of these strategies lead to a number of issues for both searchers and ordinary users.
Professional searchers may also be looking to take advantage of many arbitrage opportunities within a single day, meaning they submit a large number of transactions in a fairly small time period. By revealing both the transaction details and gas price, competitors might be able learn that searcher’s trading strategy. Ideally, there should be way for searchers to submit transactions such that the transaction details either aren't revealed to competitors or so that whatever they’re willing to pay for the transaction remains private to other searchers/users (especially in the case of unsuccessful transactions).[3]
How might we determine transaction ordering within a block in a way that optimizes the experience for both ordinary users and searchers? Blockspace auctions are one such solution (offered by the likes of Flashbots and Skip); these auctions segment searchers from ordinary users, allowing searchers to compete against one another for priority ordering while preventing a degradation of experience for ordinary users.
Let's dive into how blockspace auctions work at a high level, as the process is often not that transparent and differs based on the particular protocol/chain.
We'll look at the most straightforward of these auctions where we're bidding for the top of a block using a first-price sealed-bid auction (e.g. Skip Select). Flashbots also employs a first-price sealed-bid auction but allows searchers to express more granular ordering preferences but with no guarantee of top of block execution.[4]
Roughly speaking, the following happens:
- Searchers submit a "sealed bid" directly to a third party. The sealed bid consists of how much the searcher is willing to pay for their transaction (potentially a bundle of transactions) to be placed at the top of the block. If the searcher wins, they'll have to pay this bid amount (potentially to the block builder/validator but in theory this bid amount could be distributed across several parties).
- The third party looks through all submitted bids and determines who placed the highest bid.
- The third party gossips the result of the auction to the validators/block builders who will then ensure the winner's transaction (bundle) will be placed at the top of the block.
A major shortcoming in this process is the need for a trusted party. As presented, there is a third party who is trusted for both (a) correct execution of the program (they've correctly declared the winner) and (b) maintaining the privacy of searchers' bids (neither sharing these values nor using this information for their own benefit).
Alternative constructions involve searchers submitting their bids directly to block builders but this introduces other problems (since builders can front-run, sandwich, or censor searchers' transactions at will). We won't be diving into the tradeoffs of that construction here but, if the topic interests you, we recommend listening to Interview with a Searcher 2.0.
When folks think of privacy tools, like FHE, they imagine how privacy can prevent MEV. Perhaps surprisingly, FHE also has the potential to enhance MEV extraction.
Reimagining the auction process
Can we improve the existing auction process? Ideally, this would mean:
- Anyone can verify that the auction ran correctly (we'll refer to this property as verifiability).
- Unsuccessful bids remain private to all parties (we'll refer to this property as privacy).
Imagine that auction participants (in our case searchers) now encrypt their bids—not with just any old public key encryption scheme, but using threshold fully homomorphic encryption. Specifically, the auction might work in the following way:[5]
- A set of parties jointly generate a public-private key pair such that each party (we'll refer to them as the threshold committee) holds a share of the private key (i.e. decryption key).
- Auction participants encrypt their bids using the public key and post their encrypted bids to a data availability layer or some sort of ledger (the choice of which is up to the system designers).[6]
- Anyone can run the auction program (whether it's as simple as a first-price sealed-bid auction or something more complex) directly on the encrypted bids to determine who the winner should be (thanks to the homomorphic properties of the encryption scheme).
- Depending on the application's needs, there may a set of specialized parties tasked with running the auction program at scale to guarantee certain performance requirements are met. For example, say we need to determine who placed the highest bid in sub-second time on ~100 bids with 32-bit precision; achieving this sort of performance may require fairly beefy hardware. There will need to be an appropriate mechanism for punishing these specialized computing parties if the program wasn't faithfully run (e.g. via slashing).
- Only the winning bid is decrypted by the threshold committee (who come together to reconstruct the private key) and the outcome is gossiped.
How does threshold FHE allow us to satisfy the conditions of verifiability and privacy? FHE allows anyone to run computations on encrypted data. Thus, anyone can run the auction program on the encrypted bids to determine the winning bid (without even knowing what any of the underlying values are!). The "threshold" aspect ensures that losing bids remain private to everyone (including those on the threshold!). Roughly speaking, to construct a threshold FHE scheme, we start with a single-key FHE scheme and then split the private key into shares which we'll distribute across a certain set of parties. Encryption and computation work the same as usual but decryption will require some (pre-determined number) t of the n total threshold committee members coming together to reconstruct the private key. For most blockchains, we assume that there is an honest majority of validators; we'll make a similar assumption for the threshold committee members when using threshold FHE.[7]
There are some challenges when it comes to using threshold FHE to perform auctions. We'll dive into these further on, covering the basics of threshold FHE and the current status of the field (spoiler: it's a pretty active area of research with little consensus on how best to construct a threshold FHE scheme)!
Note that nothing about this private verifiable auction process is specific to blockspace auctions; we've just chosen to motivate the initial problem with this application.
Building private verifiable auctions
We just saw how to use threshold FHE to make the auction process more transparent while still ensuring losing bids remain private to all. We've neglected to discuss two important points though—how practical any of this is today and how we know that auction participants have "valid" bids.
For auctions, we'll likely want to use the TFHE scheme (or some variant of it) as it's best suited to performing comparisons over encrypted data. Don't confuse TFHE with threshold FHE; TFHE is a particular single-key FHE scheme that operates over a torus whereas threshold FHE refers to a broad group of FHE schemes where we've distributed the secret key across multiple parties. Recall that single-key FHE can be viewed as an extension of public key cryptography, where anyone can perform computations directly on encrypted data; however, the key pair belongs to a particular user. As TFHE is a single-key fully homomorphic encryption scheme, we'll need to figure out how to transform it into a threshold scheme.
In our experience, most folks are interested in knowing what the auction's runtime is (i.e. how long does it take to determine the winner of the auction given x number of encrypted bids with y-bit precision for the bids). In working with a threshold scheme, performance will depend on additional factors such as n, t, and the network connection between the threshold parties. Unfortunately, there are no optimized threshold TFHE implementations we're aware of to benchmark against (and we're not ready to share ours yet!).
Given the nuances with threshold FHE and that decryption time is what's most impacted in converting a single-key scheme to its threshold version, the following numbers for single-key TFHE should still serve as a good reference point in thinking about threshold TFHE's performance.[8]
Performance, performance, and performance
Before getting into any numbers, we need to identify what variable tends to have the most impact on TFHE's performance—bit precision. As we increase the precision (say from 16 bits to 32 bits), you'll notice a drop off in performance. Of course, the number of encrypted inputs and the complexity of the program have a large impact on performance but we have less control over these factors (the former could be restricted if necessary).
To give a sense of the numbers one might expect, we benchmark the first-price sealed-bid auction program (to determine who the winner is along with the winning bid) on a c7g.16xlarge (64 cores) for TFHE with programmable bootstrapping via tfhe-rs 0.4. With 16-bit precision, the program runtime varies from ~4.1 s on 64 bids to ~11.4 s on 256 bids. With 32-bit precision, the same program runs in ~6.1 s on 64 bids and goes up to ~18.9 s on 256 bids. These times do not include key generation, encryption, or decryption time.[9]
Please note that we have our own variant of the TFHE scheme which offers much better performance than quoted (we're using our own TFHE variant in the demo to run the auction as well). More will be shared in the coming months.
Bid validity
So far we've assumed bidders behave honestly but that's not a given in practice. Namely, what if bidders submit bids they can't actually afford to pay out?[10]
In an ideal setting, we might use zero knowledge proofs to help us— namely bidders could submit zero knowledge proofs, along with their encrypted bids, proving they can afford to make the bid.
Unfortunately, creating and verifying proofs for FHE-encrypted inputs will be quite expensive. If we want to minimize proof generation time, this will come at the cost of proof verification time. On the other hand, if we want to minimize proof verification time, this will come at the cost of proof generation time. Either way, someone will get the short end of the stick. Even with high end hardware, generating a proof about your FHE-encrypted bid will likely take on the order of a few seconds. In certain use cases that are not too time constrained, zero knowledge proofs may be a good option. For scenarios that are more time sensitive and cannot tolerate the blowup, financial disincentives to the rescue!
Imagine that, in order to participate in the auction, bidders need to "stake" some amount of currency. If they're found to be misbehaving (say Bob wins the auction and then refuses to pay), their stake will be appropriately slashed.[11] The concept is akin to staking with Ethereum; participants will have to deposit some amount of money (determined by the system designers) in order to bid in the auctions. This money will be refunded in its entirety if they no longer wish to participate in the auctions.
Crash course on threshold FHE
Feel free to skip this section if you've already had your daily dose of math and cryptography.
We assume you’re already familiar with public key cryptography and fully homomorphic encryption at a high level (if not, we suggest looking through this article first). So what exactly is threshold FHE and how does it differ from regular FHE?
Threshold cryptography allows us to distribute trust across a number of parties, so that the private key is split across these parties and a subset of them need to come together to reconstruct it.[12] To make the idea a bit more concrete, imagine 5 parties come together to generate the public-private key pair but we only need 3 of them (doesn’t matter who) to decrypt ciphertexts. This would be referred to as a (3, 5)-threshold scheme where the first entry (we usually use the letter t) refers to the minimum number of parties needed to decrypt and the second entry (we usually use the letter n) refers to the total number of parties who hold pieces of the private key. A general challenge with all of threshold cryptography is deciding what t and n should be in practice. We believe these choices are best left to the system/protocol designers as each application has its own needs in terms of decentralization and performance.
In threshold FHE, the two main algorithms that change are key generation and decryption. Now, some set of parties jointly generate a public-private key pair in an interactive process. Encryption and homomorphic computation work the same as usual but, in order to decrypt a ciphertext, some “threshold” needs to come together to reconstruct the private key. There is relatively little overhead for encryption and homomorphic computation times when we go from single-key FHE to threshold FHE for smaller values of n. Of course there is quite a bit of overhead in key generation but, as this process doesn’t happen all that often, we’re not too concerned about it. The main efficiency concern lies with decryption.
How do we construct a threshold FHE scheme?
When it comes to going from a single-key FHE scheme to a threshold FHE scheme, there are different ways to do this transformation, each with its own tradeoffs. The most straightforward threshold FHE scheme to construct is one that is "full threshold," meaning we have an (n, n)-scheme where every party who holds a share of the key must come back to decrypt. The simplest construction of a full threshold scheme is via additive secret sharing where the new secret key will simply be a sum of each party's individual secret key.
When it comes to constructing a (t, n)-threshold scheme, where t < n, things get more complicated. Threshold FHE is an active area of research with no consensus yet on the "best" threshold FHE construction.[13]
A key ingredient of threshold FHE is "noise flooding" (i.e. adding additional noise to the ciphertext when performing computation on it, sometimes called "smudging") so let's look at what it is and why you need it. In FHE, each time we perform a computation on a ciphertext, there is some "noise" that accumulates. Certain computations introduce more noise than others. If the noise gets too large, we won't be able to decrypt the ciphertext. Bootstrapping is one way around this issue, pulling off some of the accumulated noise so we can continue doing computations on our ciphertext. However, if we know the noise associated with a ciphertext we've received, we might be able to infer what computations had been performed on it. That's where noise flooding comes in; it allows us hide the computation being performed on the encrypted data.[14]
In threshold FHE, we'll use noise flooding during the decryption process. Let's say threshold party p1 performs his part of the (partial) decryption process and then passes on this information to threshold party p2. Can p2 learn something from p1's partial decryption? p2 can learn something but what exactly that is and how useful the information will be is not immediately clear. To protect against p2 learning useful information from p1's partial decryption, we'll introduce noise flooding.
How to choose the correct amount of noise for noise flooding is outside the scope of this post. It turns out that doing noise flooding in a way that's secure without blowing up the scheme parameters (causing performance issues) is non-trivial.
Can I use threshold FHE today?
The short answer is no.
The longer answer is "well, it depends." There are a few libraries (OpenFHE, Lattigo) offering a select set of full threshold FHE schemes (specifically the BFV/BGV and CKKS schemes). If you'd like to do auctions, the BFV/BGV and CKKS schemes are not particularly useful. These libraries also appear to be written by cryptographers for other cryptographers—making it difficult for developers to harness the power of threshold FHE.
Additionally, if you're interested in using threshold FHE in a decentralized/trustless setting, you may need to combine threshold FHE with zero knowledge proofs (ZKPs).
Sunscreen
All of this sounds great but how does Sunscreen fit into the picture?
At Sunscreen, we're working to change the status quo. We are building tools to make threshold FHE performant and easy for developers to use, along with an accompanying ZKP library + compiler to work in combination with (threshold) FHE. In the future, developers will be able to harness the power of threshold FHE to build exciting applications like private verifiable auctions and DAO voting.
Thus far, we've been primarily focused on developers, but we wanted to showcase what an application with FHE might look like for end users. You can check out our demo here.
Try our sealed-bid auction demo on the Sepolia testnet!
Our demo implements a first-price sealed-bid auction (inspired by blockspace auctions). Under the hood, we're using our own variant of TFHE. We were not satisfied with the performance of any of the existing TFHE implementations so we asked ourselves if we could do better (spoiler: the answer was yes).
You're free to choose your own adventure—if you'd like the full experience, you can connect via Metamask, stake 5,000,000 (Sepolia testnet) gwei, and participate! As suggested in Bid Validity, we implement staking and slashing to discourage participants from submitting bids they can't afford to pay. We also offer a version without any staking/slashing.
For demonstration purposes, you can view all bids once the auction has finished execution. However, in a real world deployment, losing bids would not be decrypted by the threshold (you would, at best, be able to view the plaintext value of the winning bid).
The auction program is currently being run on a c7g.16xlarge instance (64 ARM cores). We take in 92 other encrypted bids, supporting 21-bit computation (so that you can place a bid between 5,000,000 - 7,000,000 gwei). There's promising work indicating that FPGAs can improve performance by 100x.
What the future holds
We have a few things going on in parallel at Sunscreen. If you'd like to serve as an early design partner, please reach out to us directly.
Redefining best-in-class performance
In speaking with various protocols, we found that performance times of existing TFHE implementations made TFHE challenging to deploy in real world use cases. We asked ourselves if there might be a way to improve best-in-class performance, particularly if we do bootstrapping differently. The answer was yes, leading us to create our own variant of TFHE.
Implementing threshold FHE
Threshold FHE enables a new class of private applications in which we might want to operate on private shared state.
Consequently, we're working on threshold implementations of the BFV scheme (the single key BFV scheme is already integrated into our FHE compiler) as well as the TFHE scheme. These two FHE schemes allow us to address a broad range of applications depending on the type of computation being performed.
ZKP compiler
Earlier, we announced the launch of our ZKP compiler (which you can try out in our playground).
We've been working on connecting our FHE compiler with our ZKP compiler (which currently supports Bulletproofs but can be extended to support additional proof systems), as well as allowing developers to prove their FHE ciphertexts are well-formed via the DLS19 proof system. The first part of this work involves "linking" the two proof systems together; we've completed this for BFV and up next is TFHE.
To make the combined FHE and ZKP compiler experience truly developer-friendly, we'll need to clean up the API.
Wrapping it up
We're excited about what the future holds and see FHE as a key ingredient in enabling a more private and fair web.
If you want to keep up with our work, follow us on Twitter for updates. If you'd like to chat with us about anything we're working on, feel free to join our Discord.
Finally, thanks to Ghada, the Skip team, and Walt for providing valuable feedback.
For simplicity, we're ignoring the possibility of a bid-ask spread here. ↩︎
Searchers are often looking for more than just arbitrage opportunities across exchanges. ↩︎
Threshold encrypted-mempools (to hide transaction details) are also being considered in the space at large but have different tradeoffs. ↩︎
A different Flashbots product, MEV-boost, arguably follows a similar format to what's described below but instead the relayer can be viewed as the third party whereas the builders are the bidders. ↩︎
There are quite a few other aspects to take into account such as performance/latency, MEV strategies, cross-chain MEV, etc. ↩︎
There may be some interoperability challenges present here. ↩︎
In practice, for most threshold FHE constructions, we will require an honest supermajority. ↩︎
This is in stark contrast to multi-key FHE which introduces large time and space overheads. ↩︎
Times range from ~9.6 ms to encrypt a 16-bit number up to ~19.1 ms to encrypt a 32-bit number. Decryption time is negligible (<0.01 ms). For reference, it takes ~129.1 ms to compare two 16-bit numbers and ~167.3 ms to compare two 32-bit numbers. ↩︎
Another concern might be if bidders submit malformed ciphertexts. Loosely speaking, with the TFHE scheme (which we'd expect to use for private auctions), we'll perform bootstrapping regularly. What that means for a user (say Bob) submitting malformed ciphertexts is that, after bootstrapping, his malformed bid will be transformed into a "valid" bid. If Bob wins the auction, he's responsible for paying out the bid. Thus, submitting malformed bids is really to the user's own detriment and falls under the former scenario (submitting bids you can't afford). ↩︎
There may be cases where an attacker finds it profitable to have his stake slashed in carrying out a larger attack on the system. This problem exists for most (if not all systems) with staking/slashing. ↩︎
You may have heard of threshold cryptography with regard to threshold signatures(where a certain number of parties need to come together to sign a message). ↩︎
To complicate matters further, some of the constructions are not yet peer-reviewed. ↩︎
Why might noise flooding be useful? Say a user (Alice) has some encrypted data set and she wants to receive a prediction (i.e. inference) using OpenAI's machine learning model M. However, OpenAI doesn't want to simply give model M to users as this is proprietary information. Instead, Alice sends her FHE-encrypted data to OpenAI who can then run model M on Alice's data to provide her with a private prediction (that only she knows). Apart from just running the computation on the user's data themselves, OpenAI will use noise flooding to hide their model (making it more difficult for Alice to reverse engineer M). ↩︎
This is a two part series! In part i, we looked at how ZKPs and FHE fit together and how existing ZK infrastructure falls short when working with FHE. In this part, we’ll be diving into how Sunscreen’s ZKP compiler works.
Our ZKP compiler is aimed
]]>This is a two part series! In part i, we looked at how ZKPs and FHE fit together and how existing ZK infrastructure falls short when working with FHE. In this part, we’ll be diving into how Sunscreen’s ZKP compiler works.
Our ZKP compiler is aimed primarily at developers who want to work with both FHE and ZKPs. Anyone can use our compiler–whether they’re new to the ZK space or seasoned experts who want to create their own gadgets. We have tried to abstract away as much cryptography as we could while keeping the API as consistent as possible with that of our FHE compiler. You don’t have to use FHE to get value out of our ZKP compiler though! As we expand support to other proof systems, our compiler can be used to create and serialize ZKP programs more generally.
Going from program idea to ZKP
ZKPs are an amazing innovation, opening up interesting use cases from private transactions to decentralized identity and zk-rollups.
However, the process of creating a SNARK can be quite difficult for most developers. Let’s take a look at how this works.
-
"Idea" : The developer has an idea for an application or program he wants to create that requires proving some relations over private data.
-
"Program" : The developer translates his application idea into a program written in some high level programming language like Python or Rust.
-
"Arithmetization" : The developer needs to translate his program into a format that can be used in a ZKP. This requires thinking about the program–specifically the parts involving relations over private data–in terms of circuits and constraints (conditions we want to impose on our inputs) instead. As part of this, the developer will need to choose a particular arithmetization scheme (such as R1CS).
-
"Params" : Once the developer has translated the relevant part of his program into circuits and constraints, he can feed that into the setup process of a ZKP to generate parameters (e.g. reference string) needed in the proving and verifying algorithms.
-
"ZKP" : Finally, the developer has a ZKP statement ready to go that others can interact with (i.e. to create proofs and verify proofs).
So where does a compiler come in?
Well, it helps automate the process of translating the relevant part of your program into a format that can then be used in a ZKP—setting up the circuits and constraints for you behind the scenes according to the chosen arithmetization!
What does our ZKP compiler offer?
An important consideration in building our ZKP compiler was deciding if we wanted to create our own language or a DSL embedded within an existing programming language. We chose to go with a Rust-based DSL as our FHE compiler follows the same format.
We have designed our compiler in a modular way so that we can plug in various proof systems in the backend and support different arithmetizations. For the initial version, we support R1CS with Bulletproofs as the proof backend.
While Bulletproofs are far from being the most efficient proof system out there, we chose it as it most easily links together with SDLP (i.e. can bind inputs across the commitments), is fairly fast (SDLP’s prover times dwarf that of Bulletproofs), and has a transparent setup process.
Two advanced features in our ZKP compiler that we’d like to call attention to are gadgets and custom ZKP types—both of which will become quite useful once we start linking together the FHE and ZKP compilers. We won't go into detail about them here as we'll share more about them in a later article.
Using Sunscreen's ZKP compiler
Now for the good parts! We’ll dive into how to create ZKP programs using Sunscreen’s compiler.
-
The developer creates a ZKP program (i.e. writing a Rust function with certain restrictions using the
#[zkp_program]attribute).- He specifies which inputs will be public vs. private (using
#[public]and#[private]attributes). - He specifies the relation that the prover is trying to show/the verifier will need to check. As part of this process, the developer has access to two types of constraints: equality and comparisons (i.e.
>,<,>=,<=).
- He specifies which inputs will be public vs. private (using
-
We compile the ZKP program, specifying the proof backend (e.g. Bulletproofs). Once compiled, the prover and verifier can interact with and use the compiled ZKP program.
-
Prover creates a proof using the compiled ZKP program, passing in the public inputs, along with their private inputs (i.e. witness). The prover and verifier will need to agree on the public inputs; how this is done in practice is application-dependent (e.g. data comes from a previous block in the chain, system parameters).
-
Verifier can check a given proof.
Let’s look at a simple example of the above workflow! In the program below, we’ll want to create a ZKP program that proves x is on a given list (without revealing which element it is on the list). For simplicity, we'll just look at a list containing two elements.
use sunscreen::{
bulletproofs::BulletproofsBackend,
types::zkp::{BulletproofsField, Field},
zkp_program, zkp_var, FieldSpec, Error, ZkpProgramFnExt
};
#[zkp_program]
fn either<F: FieldSpec>(
#[private] x: Field<F>, // Prover’s private inputs (i.e. witness)
#[public] y: Field<F>, // public data
#[public] z: Field<F>, // public data
) {
let zero = zkp_var!(0);
let poly = (y - x) * (z - x);
poly.constrain_eq(zero); // if x=y or x=z then (x-y)*(x-z)=0
}
There are many different proof systems out there with various tradeoffs in terms of efficiency. How might we write our program generically so that we can compile it to various backend proof systems? We'll do this with the generic type parameter F:FieldSpec.
Next, notice that either looks just like any other Rust function, except for a few extra attributes. The top level attribute #[zkp_program] is where the magic happens–this declares your function as a ZKP program that can be compiled. Each program argument is either public (#[public]) or private (#[private]) depending on whether the argument should be hidden from the verifier. Since we’re working over a field, we’ll need to specify that the inputs x, y, and z are actually field elements. To create a field element within a ZKP program function, we can use the zkp_var macro. Finally, how might we specify that poly (i.e. (y - x) * (z - x)) must be equal to 0? We use constrain_eq, the equality constraint.
fn main() -> Result<(), Error> {
let either_zkp = either.compile::<BulletproofsBackend>()?;
let runtime = either.runtime::<BulletproofsBackend>()?;
let x = BulletproofsField::from(64);
let y = BulletproofsField::from(64);
let z = BulletproofsField::from(1000);
// Generate a proof that x is equal to either y or z
let proof = runtime
.proof_builder(&either_zkp) // compiled ZKP program
.private_input(x) // private inputs
.public_input(y) // public inputs
.public_input(z)
.prove()?;
// Verify the proof
runtime
.verification_builder(&either_zkp) // compiled ZKP program
.proof(&proof) // proof created by prover
.public_input(y) // public inputs
.public_input(z)
.verify()?;
Ok(())
}Next, we’ll compile our ZKP program, specifying which proof backend we want to use (Bulletproofs). For the prover and verifier to interact with the ZKP program, we’ll need a ZkpRuntime. Once we have a runtime, the prover and verifier are ready to create and verify proofs, respectively.
If you’d like to try out our ZKP compiler before installing it, we offer a playground.
Extensive documentation can be found here.
A preview into "Short Discrete Log Proofs for FHE and Ring-LWE Ciphertexts" (SDLP)
Let’s take a closer look at this proof system as it’s fairly niche and serves a unique role for us. Feel free to skip this section if you’ve already had your daily dose of math.
If you’re worked with SNARKs, you’ve likely heard of groups and fields. However, we’ll be interested in rings when working with FHE. Rings can be thought of as an intermediary object between groups and fields. Whereas groups have a single operation defined on them and fields have two operations (+, *) with a guarantee of commutativity and inverses, rings have two operations (+, *) but with no guarantee that multiplication is commutative or that multiplicative inverses exist. We’ll be interested in a special type of ring involving polynomials–if you’d like to learn more about how arithmetic works in this ring, please see here.
FHE ciphertexts generally satisfy the following equation (i.e. can be written in the following format):
In ZK terminology, the vector s will be the “witness.” The prover will need to show that they have a vector s satisfying the above equation, where the noise/randomness is “small”, and such that the message coefficients are less than the plaintext modulus of the FHE scheme.
A nice property of SDLP is that the setup process is transparent. Proofs are logarithmic in the size of the witness (concretely, this leads to proofs around the single digit kilobyte range for most FHE ciphertexts). In practice, proofs generally take 10-20s to create on consumer laptops but verification times are challenging to keep low (i.e. <1s on a large machine).
The key idea of the proof system is to create a Pedersen commitment to the coefficients in the vector s and rely on elliptic curve-based cryptography to get smaller proofs than possible with existing lattice-based proof systems. Thus, we’ll need a group \( G \) of order \( p \) such that the discrete logarithm problem is hard. In practice, \( p >> q \), the modulus used in the ring for FHE.
Almost every step in the proof is parallelizable so we can take advantage of multiple cores when available. Additionally, we can use GPU acceleration for scalar inversion, scalar multiplication, and multi-scalar multiplication (along with implementing Pippenger’s algorithm). A lot of this work has already been done on our part.
Our technical work doesn’t end there though. To use SDLP with SEAL’s implementation of the BFV fully homomorphic encryption scheme, we need to ensure encryption is implemented in a linear fashion (so that a ciphertext indeed satisfies the matrix-vector equation \( \mathbf{A}\vec{\mathbf{s}} = \vec{\mathbf{t}} \)). It turns out that SEAL has added in some optimizations so that encryption is no longer linear. We’ve had to alter SEAL’s implementation of BFV to make encryption linear again. Additionally, SDLP uses fixed bounds for the witness but there is no reason in practice that we would have to do this. In fact, if we are able to support mixed bounds then we can get better concrete performance (for certain cases) and correctness guarantees.
We are still working on linking together the SDLP and Bulletproofs proof systems.
Connecting our FHE and ZKP compilers
Initially, our ZKP compiler will be offered on a standalone basis. What this means for the developer is that you cannot yet prove things about FHE ciphertexts using Sunscreen's ZKP compiler.
Our goal is to provide an experience where the developer can write a program in Rust, adding #[fhe_program(...)] and #[zkp_program] attributes as needed to let the compiler know which parts of the code need to be transformed into their FHE and ZKP equivalents.
API design is a challenge and it’s unclear how to best expose both SDLP and R1CS constraints to the developer at the same time. Community feedback will play a crucial role in helping determine what the best API is.
What's next for us
In the next two months, you’ll be able to sign up for access to our private testnet. So far, our priority has been on developers, but we don’t want to leave anyone out! We’ll also be providing a demo suite of apps to try out.
We’ll be sponsoring EthGlobal New York, with $5000 worth in prizes available from Sunscreen. Hackers will get first access to our private testnet and our demo suite of FHE apps. Ravital, Rick, and Ryan will be at Sunscreen’s own cocktail table so come say hi!
Finally, we’ve been working on our own custom implementation of TFHE to provide ultra fast comparisons and enable new applications. If you’re a developer interested in using FHE in your project, feel free to reach out to us for first access.
]]>This is part i of a two part series! In this article, we’ll be motivating the need for new ZK tools when working with fully homomorphic encryption (FHE).
At Sunscreen, we’re working to bring FHE to the masses, starting with web3. As part of our mission,
]]>
This is part i of a two part series! In this article, we’ll be motivating the need for new ZK tools when working with fully homomorphic encryption (FHE).
At Sunscreen, we’re working to bring FHE to the masses, starting with web3. As part of our mission, we’ve been thinking about the infrastructure needed to support FHE in decentralized, trustless environments.
In web2, when we ask for a computation to be performed, we often rely on the reputation of the company charged with the task. When we ask AWS to run a benchmark, we implicitly trust that Amazon has run the computation we asked them to on the machine we requested. When we use ChatGPT, we implicitly trust that OpenAI has used their advanced learning model behind the scenes. But, how do we know that Amazon or OpenAI has actually done what we asked? The answer is we don’t. We’re trusting these organizations based on their reputation.
In web3, things change. We’re now in a trustless environment where we might not trust the user or the computing party.
How ZKPs and FHE fit together
As a refresher, fully homomorphic encryption (FHE) is the next generation of public key cryptography, allowing anyone to perform computations directly on encrypted data. Zero knowledge proofs (ZKPs), on the other hand, allow one to prove a statement is true without revealing any information (beyond the correctness of that statement). So how do these two fit together?
ZKPs are useful and often necessary when building FHE-enabled applications in a trustless environment. By trustless, we’re referring to one of two scenarios–in which we cannot fully trust (1) the user providing FHE-encrypted data or (2) the third party responsible for performing the computation on the encrypted data.
Let’s consider how these scenarios might arise in practice.
For the former, imagine a user wants to withdraw some encrypted amount enc(amt) from her encrypted account balance enc(bal). The user may (innocently or maliciously) try to send more money than she actually owns (such that amt > bal ). How can the implementation enforce that amt <= bal while keeping these two values private to other parties? Using a ZKP, the user can prove that amt <= bal without revealing to anyone what these values actually are. User-provided ciphertexts must also be “well-formed”—meaning that they obey the requirements of the underlying encryption scheme and aren’t just random strings of data. If we don’t trust the user, how can we ensure this is indeed the case? With ZKPs! The user can provide a ZKP along with her ciphertext, proving the ciphertext’s validity without revealing any of the underlying values.
For the latter, let’s take a step back and think about how things work in web3, where the maxim is “don’t trust, verify.” When validating transactions on a blockchain, we assume there’s an honest majority of miners/validators. When using rollups, we often rely on rollup providers to prove they’ve faithfully executed the given transactions. FHE computations are no different than any other computation. How do we know a third party ran the FHE computation we asked? If a large number of parties perform the computation, we might assume there’s an honest majority to ensure correctness. However, if only one party runs the FHE computation, things get a bit sticky. Similar to the validity proofs needed for rollups, the computing party must prove they’ve faithfully executed the FHE computation. We refer to this setup as “verifiable FHE” (in which we can verify the FHE computation was performed correctly, often via ZKPs).
Verifiable FHE is very difficult in practice. Some research has been done on this topic but it turns out that proving even simple FHE computations were performed correctly (say verifying a single homomorphic addition and homomorphic multiplication operation) can take on the the order of minutes even with highly efficient proof systems like Groth16.
Shortcomings of existing SNARKs
Regardless, we still need to tackle the first issue—verifying that conditions on user (FHE encrypted) inputs have been met. The question we often get asked at Sunscreen is “can’t we just use one of the popular SNARKs to accomplish this task?”[1] After all, so much work has been done in the past decade on SNARKs (Groth16, STARKs, PLONK to name a few) with plenty of existing infrastructure provided by a variety of projects.
Unfortunately, the answer is no.
FHE relies on lattice-based cryptography, whereas the most efficient ZKPs utilized in the web3 space don’t. To prove an FHE ciphertext is well-formed, we need to show that it satisfies a certain matrix-vector equation, with entries from particular mathematical “spaces” (called rings), and that these entries are “small”. Proving the entries are “small” is the most expensive part in zero knowledge land.[2] If we want to show this in an efficient way (with compact proofs that are fairly fast to create), we need a proof system meant for handling lattice-based relations.[3] The first idea that might come to mind is to use a lattice-based proof system. After all, what better way to prove statements about lattice-based relations than with a lattice-based proof system? If we take that route, we’ll have proofs that are easily hundreds of kilobytes in size (it’s also unclear how competitive proof verification times would be).[4]
Our team has been working on implementing a specialized proof system for this task ("Short discrete log proofs for FHE and Ring-LWE ciphertexts" aka SDLP); you can track our progress here. SDLP is a fairly recent proof system (from 2019) that leverages a trustless setup to show user inputs from a lattice-based cryptosystem are well-formed using elliptic curve-based cryptography. One of the key insights the authors make is recognizing that there is indeed a connection between the polynomial operations in the lattice scheme and the inner product proofs of Bulletproofs, which is why they transform the lattice relation into a Pedersen commitment. This allows the authors to obtain fairly small proofs (single digit kilobyte range for showing an FHE ciphertext is well-formed) with decent proving and verification times.[5]
While SDLP will allow users to prove that their inputs are well-formed, this proof system won’t be good for much else as SDLP breaks everything down into a matrix-vector equation. Ignoring the fact that this severely restricts what we can prove, there’s also much more efficient proof systems for general arithmetic circuits.
So what will existing SNARKs be good for?
Once the user shows their ciphertext is in the correct format, they can utilize popular SNARKs to prove more general relations about their inputs (allowing us to make use of existing libraries and infrastructure for SNARKs).
To do this, we’ll need to “link” the two proof systems together. Otherwise, imagine a malicious user creates a proof that their ciphertext c corresponding to plaintext value p is in the correct format and then instead proves that the plaintext p’ is less than the amount a. How can we detect this and ensure the user’s inputs are the same to both proof systems (SDLP and the SNARK)?
What Sunscreen is working on
In terms of using FHE in a trustless setting, the user will usually have to (a) encrypt her inputs, (b) prove these input ciphertexts are “well-formed,” and finally (c) prove that her plaintext inputs satisfy any application-dependent conditions.
To tackle (a), we have our FHE compiler which we’ve released an initial version of.
To tackle (b), we’ve developed a GPU-accelerated library for the SDLP proof system.
Tackling (c) is where things get tricky. As mentioned earlier, there are better proof systems than SDLP for general arithmetic circuits so we’ll want to use SNARKs for (c). However, we need to ensure the prover has “committed” to the same inputs across the two proof systems.
To make matters worse, ZKPs are quite difficult for non-experts to work with. As part of creating a ZKP, the developer needs to translate their program (written in some high level programming language like Rust or Python) into a system of circuits and constraints in a particular format, depending on the chosen arithmetization scheme. Doing this conversion by hand is both tedious and highly error-prone. That’s where ZKP compilers come in–they help the developer with this translation, setting up circuits and constraints in the correct format behind the scenes.
Plugging SDLP into existing ZKP compilers did not provide either the performance or developer experience we wanted.
Thus, to fully address (c), we’re working on a ZKP compiler that supports SNARKs and will plug into our SDLP library (i.e. allow the prover to show they’ve committed to the same inputs across the two proof systems). In linking together our FHE and ZKP compilers, SDLP will serve as the glue that holds them together.
Continue on to part ii if you’d like to learn about Sunscreen’s ZKP compiler!
What's next for us
In the next two months, you’ll be able to sign up for access to our private testnet. So far, our priority has been on developers, but we don’t want to leave anyone out! We’ll also be providing a demo suite of apps to try out.
We’ll be sponsoring ETHGlobal New York, with $5000 worth in prizes available from Sunscreen. Hackers will get first access to our private testnet and our demo suite of FHE apps. Ravital, Rick, and Ryan will be at Sunscreen’s own cocktail table so come say hi!
Finally, we’ve been working on our own custom implementation of TFHE to provide ultra fast comparisons and enable new applications. If you’re a developer interested in using FHE in your project, feel free to reach out to us for first access.
Succinct non-interactive arguments of knowledge are a special type of ZKP popular in practice as they offer small proof sizes along with a single round of interaction. SNARKs have been deployed by many companies including Zcash, O(1) Labs, Celo, Filecoin, and Axiom. ↩︎
This often amounts to several thousand range proofs. ↩︎
Out of curiosity, our team tried using Bulletproofs to prove an FHE ciphertext is well-formed. It took over 60s to generate a proof for the smallest lattice dimension (for the BFV scheme) n=1024 on a Macbook. ↩︎
There are very few implementations of modern lattice-based proof systems. One paper that implements a recent lattice-based proof system is PELTA. ↩︎
There is a new proof construction that also utilizies elliptic-curve based cryptography to prove lattice-based relations. No implementation for the system currently exists; however, this proof system offers constant-sized proofs and better prover times in practice than SDLP. Downsides include the use of a trusted setup as well as worse verification times. ↩︎
We've been working hard the past months trying to solve this
]]>The first step in bringing fully homomorphic encryption (FHE) to the masses involves making FHE both fast and usable for developers! Developers will then be empowered to bring privacy to whatever application they're creating.
We've been working hard the past months trying to solve this problem. Let's take a deep dive into what we've completed so far.
For this article, we'll assume you're already familiar with FHE at a high level. If not, we recommend starting with our intro article first. If you watched our talk at ZK Summit, this article shares a lot of the same information.
Wait, I thought FHE was too slow for anything practical...
Yes and no.
With the very first FHE scheme, it took on the order of minutes to multiply two encrypted numbers together.
Since the first scheme was constructed over 10 years ago, FHE has come a long way–what used to take minutes is now down to milliseconds on a MacBook Pro.
It is true that FHE can be slow for certain kinds of computations on certain kinds of data (especially if we're looking at machine learning applications). The bigger issue is that FHE will always be slow if you don't really know what you're doing. To get good performance out of FHE, you need to choose the best FHE scheme for your use case; furthermore, you need to know how to select the scheme parameters exactly right for your particular computation. The same computation may be 10-100x slower if you choose parameters that are larger than necessary; the same computation may also be 100-1000x slower if you choose an FHE scheme poorly suited to the kind of computation you want to do.

Picking an FHE scheme
The first step in integrating FHE into your application is to figure out which FHE scheme to use. There are 3 major scheme choices–BFV, CKKS, and TFHE+.[1]
We won't go into all the details of these FHE schemes but we've summarized their tradeoffs below.
For web3, many applications deal with financial data so we need exact computation (making the CKKS scheme, which supports approximate arithmetic, a poor candidate).
| BFV | TFHE+ | |
|---|---|---|
| + Fast arithmetic | + Fast comparisons | |
| + High precision | + Fast bootstrap (done with every op) | |
| + "Small" keys | - Slow multiply | |
| - Comparisons difficult[2] | - Precision/correctness issues | |
| - Slow bootstrap[3] | - Large keys |
Depending on the particular application, either BFV or TFHE+ could make sense. For applications requiring multiplication on encrypted data, BFV might be the best option. Alternatively, for applications that make extensive use of comparisons over encrypted data, TFHE+ might be best.
Of the two FHE schemes that seem most suitable for web3, you can see for yourself how different the performance is when performing 32-bit computation on a Macbook M1. In benchmarking these two schemes, we've used SEAL (version 4.1.1) for BFV and tfhe-rs (version 0.2.4) for the TFHE scheme with programmable bootstrapping.
| 32-bit integers | BFV (n = 4096) | TFHE+ |
|---|---|---|
| KeyGen | 0.0045 s | 10.6 s |
| Encrypt[4] | 0.0024 s | 1.1 s |
| Decrypt | 385 μs | 19 μs |
| Add | 15 μs | 34 μs |
| Multiply | 0.0043 s | 3.9 s |
| Compare | ??? | 0.15 s |
You'll notice a difference too in terms of key and ciphertext sizes between the two schemes. When it comes to using FHE on a blockchain, having large public keys for users presents a challenge as validators would have to download these public keys for each user.
| 32-bit integers | BFV (n=4096) | TFHE+ |
|---|---|---|
| Public key | ~205 KB[5] | ~110.6 MB[6] |
| Ciphertext | ~31 KB | ~ 263 KB |
For say 100 users, validators would have to keep track of (205 * 100) KB worth of public key data if the BFV scheme is used. For TFHE+, validators would have to keep track of (110.6 * 100) MB worth of public key data!
We use TFHE+ to refer to the newer variant of the TFHE scheme with programmable bootstrapping. ↩︎
As BFV uses arithmetic circuits, it can be quite difficult to implement comparisons on encrypted values. ↩︎
Bootstrapping is used sparingly if at all with this scheme. Generally, you set up the scheme to support a pre-determined amount of computations. ↩︎
Encryption using the public key. Neither version is parallelized (which could especially benefit TFHE's current encryption times). ↩︎
Compact version. Non-compact version is ~410 KB. Does not include Galois key (used if you want to "vectorize" the computation). ↩︎
The bootstrapping key is included in this number as it is needed to perform computations over the encrypted data. It's roughly 109 MB in size. ↩︎
Why is FHE so darn hard?
To work effectively with FHE (i.e. not have terrible performance and giant ciphertexts), you need to know quite a bit about lattice-based cryptography and abstract algebra.
Changing the value of one scheme parameter can have dramatic effects on possible values of other scheme parameters; in exchange for supporting more complex computations on encrypted data, you'll have bigger ciphertexts and public keys. There are also weird FHE-specific operations you've probably never heard of before such as relinearization, modulus switching, and bootstrapping. Additionally, you'll need to be comfortable working with arithmetic or binary circuits. One of the most important considerations for FHE schemes modeling computation as arithmetic circuits is how many sequential multiplications you want to do on encrypted data. For FHE schemes using binary circuits, implementing even simple operations like integer multiplication in an efficient manner can be quite involved (e.g. Karatsuba multiplication).
Regardless of which FHE scheme you select, you also need to figure out how to translate from numbers into polynomials (since that's the language of FHE). There are different ways to "encode" numbers into polynomials, each having its own tradeoff.
Here's an example of how changing the polynomial degree n can have a huge impact on performance for the BFV scheme.
| BFV scheme | n = 4096 | n = 8192 | n = 16384 |
|---|---|---|---|
| KeyGen | 4.5 ms | 22.7 ms | 72.5 ms |
| Encrypt | 2.3 ms | 5.6 ms | 15.9 ms |
| Decrypt | 0.39 ms | 1.5 ms | 5.8 ms |
| Add | 15 μs | 56 μs | 228 μs |
| Multiply | 4.3 ms | 17.4 ms | 108.3 ms |
Alternatively, you can see for the TFHE+ scheme how supporting higher precision has quite the effect on performance.
| TFHE+ scheme | 16-bit | 32-bit | 64-bit |
|---|---|---|---|
| KeyGen | 10.2 s | 10.6 s | 10.7 s |
| Encrypt | 0.69 s | 1.1 s | 1.8 s |
| Decrypt | 9 μs | 19 μs | 406 μs |
| Add | 12 μs | 34 μs | 136 μs |
| Multiply | 1 s | 3.9 s | 15 s |
| Compare | 0.09 s | 0.15 s | 0.25 s |
You may wonder what precision (the axis along which TFHE+'s performance is measured) has to do with polynomial degree (the axis along which BFV's performance is measured). Even the smallest degree n = 2048 supports 64+ bit computation in BFV! In terms of functionality, what n impacts is how many sequential multiplications you can do on encrypted data (before needing to bootstrap or decrypt and freshly re-encrypt). Thus, it's difficult to even do an apples-to-apples comparison between these two FHE schemes since their performance is impacted by different factors.
Making FHE usable
So how do we make FHE more usable for a normal engineer who isn't a cryptography expert?
High level idea: What if we could turn a "regular" program (say a C++, Python, or Rust program) into an FHE equivalent that operates on encrypted data?
Thus begins a new line of (mostly academic) work trying to make FHE usable for developers via an FHE compiler.
Sunscreen & FHE compiler efforts thus far
FHE compilers started as (and still are) mostly an academic/research effort. The first few FHE compilers provided only partial automation of parameter selection so the developer still needed to have quite a bit of expertise in the underlying cryptography. While compilers inevitably introduce a slowdown, most of them introduce a very significant slowdown (over 1000x vs. working directly with a low-level FHE library and hand coding the program). Naturally, as an academic effort, less thought goes into API design and whether the compiler is easy for developers to actually use.
Essential features you'd expect to find for real world applications are often missing as well. For data analytics applications, it's easy to imagine use cases where a third party company might want to run different computations on the same encrypted user data set. For blockchain related applications, it's common to feed the outputs of one program as the inputs to another. As they were created by cryptographers for cryptographers, previous compilers do not support such features.
At Sunscreen, we're building a compiler that makes FHE both fast and accessible. Compilers naturally introduce some overhead; however, we've tried to keep the overhead to about 10-100x. You, as the developer, share your Rust program with us. Behind the scenes, we figure out how to transform your good old Rust program into its FHE equivalent with input/output privacy.
Why Rust, you might ask? In addition to having a powerful and expressive type system, it's highly performant (like C/C++) and safe by design (unlike C/C++)!
We've benchmarked Sunscreen's compiler against existing FHE compilers that support exact computation; you can check out the results below. We run a chi-squared test according to the criteria set out in this SoK paper on FHE compilers. Time includes key generation + encryption + (homomorphic) computation + decryption. Experiments were performed on an Intel Xeon @ 3.00 GHz with 8 cores and 16 GB RAM.
| Compiler | Time (seconds) |
|---|---|
| Hand-coded in SEAL (no compiler) | 0.053 |
| Sunscreen | 0.072 |
| Microsoft EVA | 0.328 |
| Concrete | 977.1 |
| Google's Transpiler | 124.9 |
| Cingulata-BFV | 492.109 |
| Cingulata-TFHE | 62.118 |
| E3-BFV | 11.319 |
| E3-TFHE | 1934.663 |
If you want to check out the source code and run our Sunscreen benchmark yourself, feel free to look here!
Currently, our FHE compiler is mainly targeted towards web3 applications which have their own set of requirements and concerns.
What makes web3 different?
(1) Performance matters–with fast encryption times and arithmetic as major priorities. Additionally, we would prefer an FHE scheme with relatively small public keys and ciphertexts since storage on blockchain is quite expensive.
(2) We likely want to support computation with a high degree of precision (32, 64 bit computation) without incurring a huge performance overhead.
(3) Since we're working in a trustless setting, we need compatibility with efficient zero knowledge proof systems so that users can prove things on their encrypted values. Unfortunately, proving you have a well-formed FHE ciphertext is often very expensive (even with state-of-the-art proof systems). In practice, we'll need a zero knowledge proof compiler that integrates well with the FHE compiler.
Design and usability
Let's take a closer look at some of the design decisions we've made in building out our FHE compiler and how we've addressed web3-related challenges.
We've designed our compiler to be flexible so that we can swap out the backend FHE scheme (BFV) for another FHE scheme if desired. We imagine use cases where an engineer may want to work with the BFV scheme for building certain kinds of applications but a different scheme for other use cases.
Currently, the BFV scheme offers some of the best performance out of the box for arithmetic operations when looking at 32 and 64 bit computation (no hardware accelerators required!). Experience tells us that one of the most challenging aspects of working with FHE is getting parameter selection right so we've focused on automating parameter and key selection to make set up painless for developers. Additionally, data encoding is done automatically. Further along in the FHE lifecycle, our compiler automatically handles annoying FHE-specific efficiency-related operations for you, sets up the circuits, and parallelizes the program if possible.
From a usability angle, we've made it possible to run computations without FHE which can be useful for debugging. We also offer support for serialization (hello real life!) and WASM. But who wants to download and install a library when they're just trying to play around with the tech? That's why we've created a playground for developers to try out our compiler! You can also run the code examples from our documentation directly in browser by hitting the play icon ▶️.
What's next for us
While we don't want to spoil the surprise, we're working on more than just FHE.
In the coming months, we'll share details on our work on zero knowledge proofs.
If you'd like to keep up with our progress, follow us on Twitter or join our Discord. Finally, if you want to contribute to our efforts in the space, feel free to reach out to us at [email protected] (we're hiring engineers and still running our grants program!).
]]>More and more people are realizing the importance of privacy, particularly in web3. Front-running attacks plague multiple blockchains. Sophisticated users want to hide their financial holdings and trading strategies while still reaping the benefits of the DeFi ecosystem. While there has been an explosion of web3 companies, privacy is needed for the space is to have any real longevity. Without confidential voting, users may feel forced to self censor; concerningly, there's a possibility of tracking and analyzing user behavior across DAOs.
However, existing privacy solutions are difficult to work with and fall short when it comes to user experience. As we believe privacy should be built into applications from the ground up, our goal is to make it easy for developers to bring privacy to whatever application they envisage. To achieve this, two privacy technologies are needed—fully homomorphic encryption and zero knowledge proofs. With fully homomorphic encryption, anyone can perform computations on anyone else’s private data; no need to delegate access to your unencrypted data and no need to trust some third party with your privacy. Current approaches to privacy treat zero knowledge proofs (ZKPs) as the holy grail; however, ZKPs fall short when it comes to supporting lightweight users and private shared state.[1] Fully homomorphic encryption in combination with zero knowledge proofs will enable the creation of a richer variety of private apps.
Sunscreen's goal is to turn the above dream into a reality; we're hard at work making FHE usable for web3 applications via an SDK and are lucky to be supported by an incredible group of investors in our mission.
For more details, we recommend starting with this paper. ↩︎
Our roadmap
Our mission is to enable the next generation of private applications, starting first with (d)apps as we think privacy is most urgently needed there. However, to support FHE in web3, we need to solve a few major challenges first:
- Performance is incredibly important for all sorts of applications but even more so for those related to finance and trading. Unfortunately, FHE is difficult for developers to effectively use–both because there's a steep learning curve and also because it's incredibly hard to set up FHE programs to get good performance.
- One of the tenets of web3 is "don't trust, verify." If the user provides a (d)app with encrypted data, how do we know the user-provided inputs satisfy the conditions of the application and aren’t just some garbage values? Remember that no one else can inspect the inputs since they're always encrypted!
- While storage is incredibly cheap in web2, the same doesn’t always hold for web3. Fully homomorphic encryption is incredibly fast for certain classes of applications but it’s not very space efficient. How then can we use FHE in web3?
At Sunscreen, we're working to solve these problems in phases. Our priority so far has been to tackle the first point; in doing so, we've built an FHE compiler tailored to the needs of web3 developers. We're now turning our focus to solving problems #2 and #3; to do that, we've been working on a zero knowledge proof compiler that is compatible with our FHE compiler (so that we can prove things about encrypted data), as well as an integration with a decentralized storage system that can be used to store larger ciphertexts off-chain.
Fully homomorphic encryption compiler
So you want to use FHE? Awesome! Let’s see what the current experience is like as a developer looking to integrate FHE into your application.
As hinted at in challenge #1, existing FHE libraries expect that you as the developer have a deep understanding of the underlying cryptography and mathematics. To compound the problem, runtime can vary by orders of magnitudes depending on how well the developer selected the FHE scheme parameters for their particular application. As a result, it’s difficult for anyone but experts to get good performance out of FHE.
To solve this problem, we've built an FHE compiler. The idea here is that a developer only needs to know the very basics of public key cryptography (e.g. key generation, encryption, decryption). Behind the scenes, our compiler transforms a normal Rust function into an FHE equivalent with privacy. It figures out the best parameters for optimal performance, inserts special FHE-specific operations in automatically, generates all the circuits, and even parallelizes the program for you if it can!
Initially, we support the BFV fully homomorphic encryption scheme. However, we have designed our compiler so that we can swap out the backend FHE scheme in the future. If you've already tried out our compiler, you likely suspected this after typing:
[fhe_program(scheme="bfv")]We believe BFV is one of the most suitable FHE schemes for web3 use cases. BFV is one of the few FHE schemes that supports 32+ bit computation without a severe degradation in performance, provides fast arithmetic, and has relatively small key sizes. Sounds too good to be true? Check out our playground or read more about how our compiler measures up to existing attempts.
We're also exploring support of FHE extensions like multi-party FHE and multi-key FHE. These extensions make it easy to combine and perform computation on multiple users' encrypted data.
Zero knowledge proof compiler
Next, let’s look at how we might address challenge #2.
Zero knowledge proofs to the rescue! The user can prove that their encrypted inputs satisfy the conditions of the application without actually revealing their data.
While there are quite a few ZKP libraries out there, it can be difficult to combine these off the shelf with FHE. FHE relies on a special type of cryptography using lattices whereas the most efficient ZKP constructions don't. Combining such proof systems with FHE often leads to poor performance in practice.
We’re currently evaluating a few proof systems to determine which offers the best tradeoffs with regards to space and time. If necessary, we will implement a lower level library with the proof system ourselves. As our goal is to make privacy easy for developers, we will also provide a compiler to work with ZKPs. With so much interest and innovation within the ZKP space, our focus is on designing a compiler in which the backend proof system can be swapped out further down the line. We plan to package the ZKP compiler with our existing FHE compiler for developer ease of use. In terms of API, we will try to keep it consistent with that of our FHE compiler.
Decentralized storage system
The last puzzle piece requires addressing where to store large FHE ciphertexts. In integrating FHE into decentralized applications, we want to avoid massively blowing up the underlying blockchain's size. However, if we store FHE ciphertexts elsewhere, we need to ensure users and validators can quickly and easily retrieve these off-chain ciphertexts. There are a few interesting decentralized storage systems out there (arweave, IPFS, etc.) that could serve as a potential solution for us. Our efforts here are still at the earlier stages and we're hoping to share more about this piece in the coming months.
Rolling out our tech
We expect to deploy our technology in phases–starting first with support of private transactions in a testnet, then with support of pre-determined private programs, and finally allowing developers to author arbitrary private programs using our FHE and ZKP compilers. The ambition is to make private programs easy for web3 (and eventually web2) developers to create via Sunscreen's SDK.
If you'd like to get involved, you can join our Discord or follow us on Twitter for updates. To learn more about what we're doing, check out our Github or come say hi to us at ETHDenver!
]]>We're excited to get developers thinking about how to build private applications using FHE. We also aim to promote broader research into FHE (especially in the context of web3); thus, we&
]]>We're excited to get developers thinking about how to build private applications using FHE. We also aim to promote broader research into FHE (especially in the context of web3); thus, we're offering a variety of grants to further both of our goals.
We plan to launch a larger grants program once integration with a complementary zero knowledge proof library is complete. FHE combined with zero knowledge proofs will enable exciting new use cases for web3.
Grant Categories
We have 4 main categories for our grants program–walkthroughs, new applications, deployment/integrations, and cryptography. We've included suggested amounts for each category but, if your proposal is particularly involved or complex, we can offer a higher amount. Selected contributions will be made available to the entire community.
Don't feel limited by what we have here! If you have an idea that doesn't quite fit one of these categories, we'd love to hear from you.
| Category | Suggested Amount |
|---|---|
| Walkthroughs | $100 - $500 |
| New apps for web2 or web3 | $500 - $5000 |
| Deployment and integrations | $1000 - $50,000 |
| Cryptography | $1000 - $100,000 |
| Surprise us! | ??? |
Walkthroughs
Provide a walkthrough of your own simple FHE program using Sunscreen's FHE compiler or demonstrate interesting capabilities of our compiler. For the former, take a look at our private information retrieval and private token swap walkthroughs. Some additional suggestions are:
- chaining FHE programs together (so that the output of one FHE program is used as the input to another FHE program)
- demonstrating how to change the plaintext modulus and/or noise margin for better performance
- fun with fractions and rationals
New applications
Create your own web2 or web3 application that makes use of Sunscreen's FHE compiler to provide data privacy. Some suggestions are:
- private data analysis or private inference (e.g. privacy-preserving machine learning applications)
- private database lookup
- games with privacy
- identity management
- apps in browser/targeting WASM
- linear algebra-related applications
Deployment and Integrations
We're excited to support FHE in web3 applications. However, doing so requires additional R&D. Some suggestions for this category include:
- creating bindings
- investigating compatibility of the BFV scheme (and/or Sunscreen's compiler) with Ethereum, Cosmos, Polkadot, Solana, Avalanche, etc.
Cryptography
This category is quite broad. On the engineering side, we're particularly interested in improvements to the BFV scheme/Sunscreen's compiler and integrations with efficient ZKP libraries. On the research side, we're interested in further work on efficient ZKP constructions compatible with the BFV scheme.
Some suggestions are:
- Research into efficient ZKP constructions compatible with the BFV scheme
- Research and development into the multi-key BFV scheme
- Working on ZKP library integrations for Sunscreen's FHE compiler
- Working on further compiler optimizations
- Extending compiler support to the CKKS scheme
- Adding support for bootstrapping (for SEAL's implementation of the BFV scheme)
- Adding support for homomorphic comparisons (for SEAL's implementation of the BFV scheme)
- More extensive benchmarking against other FHE compilers
How to apply
Applications for the program are available here.
We aim to review applications within 2 weeks of submission. If we think it's a good fit, we will schedule a call to discuss your proposal in further detail.
If you have any questions or want help brainstorming ideas, feel free to chat with us on Discord!
]]>Our goal at Sunscreen is to make advanced privacy technology (like FHE) accessible to engineers so that they can easily build and deploy private applications.
The idea for Sunscreen was first born while I was a cryptographer at NuCypher researching privacy-preserving smart contracts. Zero knowledge proofs have so far dominated the privacy narrative of web3 but, at Sunscreen, we believe there's more to the story.
Our $4.65m seed round was led by Polychain Capital with participation from Northzone, Coinbase Ventures, dao5, and Naval Ravikant–following a small pre-seed of $570k. I'm happy to share that a number of my former NuCypher colleagues will be a part of Sunscreen's journey as either advisors (MacLane, Ghada) or angel investors (Michael, Tux).
Open sourcing our FHE compiler
As magical as FHE is, it's actually very hard to write FHE programs. Researchers created “compilers” to make the process easier but so far have fallen short. Existing FHE compilers are often difficult to use or introduce a significant performance penalty.
Over the past months, we've been working on our own FHE compiler which we'll be open-sourcing today. Feel free to check out our library! We also have a playground available if you'd like to try writing some code before installing our compiler.
Web3 developers have unique challenges and concerns; we are the first to design an FHE compiler with such needs in mind. However, this is only the first step in our journey to realize the full promise of private computation in web3.
Launching our FHE grants program
We're also kicking off a grants program to promote further research and development into FHE. We hope to encourage developers to build private apps and teach others in the community how to do so as well.
Check out our private token swap and private information retrieval examples to see just how far FHE has come. In less than 1 second on a laptop, you can generate FHE keys, encrypt data, run programs on encrypted data, and decrypt the results!
You can read more about our grants program here.
Looking to the future
So what's next for Sunscreen? We'll be working on the infrastructure needed to support developers in building private applications. Concretely, we'll be focused on integrations with complementary zero-knowledge proof libraries as well as decentralized storage solutions.
If this sounds exciting to you, please reach out to us at [email protected]! We're hiring for a number of roles.
You can also join our Discord community or follow us on Twitter for announcements.
]]>Fully homomorphic encryption is a fabled technology (at least in the cryptography community) that allows for arbitrary computation over encrypted data. With privacy as a major focus across tech, fully homomorphic encryption (FHE) fits perfectly into this new narrative. FHE is relevant to public distributed ledgers (such as blockchain) and machine learning.
The first FHE scheme was successfully constructed in 2009 by Craig Gentry. Since then, there have been numerous proposed FHE schemes and no dearth of related work in the space. However, there's little explanation as to why all this work is being done or the motivation for any of it. When I first started learning about FHE, I had many questions: Why are there so many schemes? Does FHE have an actual use case? If FHE is as powerful as described, why hasn't it taken off yet?
We'll start by providing an introduction to how FHE works and some areas in which it might be useful. The meat of the article is in the 2nd section where we consider why FHE has yet to have received widespread attention and some potential solutions to these issues. The TL;DR of it is that there is a complete lack of usability when working with FHE libraries currently. All of the inner workings and complexities of the FHE scheme—of which there are many—are exposed to the engineer.
Finally, we'll point to some libraries in the space if you're interested in getting your hands dirty.
What is fully homomorphic encryption (FHE)?
Fully homomorphic encryption is a type of encryption scheme that allows you to perform arbitrary* computations on encrypted data.
* Not completely true but we'll leave that out for now
A Refresher on Public Key Encryption Schemes
Let's start with a brief review of encryption schemes. Plaintext is data in the clear (i.e. unencrypted data) whereas ciphertext is encrypted data.
Algorithms in an Encryption Scheme
An encryption scheme includes the following 3 algorithms:
KeyGen(...security_parameters)→keys: The Key Generation algorithm takes some security parameter(s) as its input. It then outputs the key(s) of the scheme.Encrypt(plaintext, key, randomness)→ciphertext: The Encryption algorithm takes a plaintext, a key, and some randomness (encryption must be probabilitistic to be "secure") as inputs. It then outputs the corresponding ciphertext (i.e. encrypted data).Decrypt(ciphertext, key)→plaintext: The Decryption algorithm takes a ciphertext and a key as inputs. It outputs the corresponding plaintext.
In a private key encryption scheme, the same key is used to both encrypt and decrypt. That means anyone who can encrypt plaintext (i.e. data in the clear) can also decrypt ciphertext (i.e. encrypted data). These types of encryption schemes are also referred to as "symmetric" since the relationship between encryption/decryption is symmetric.
However, in a public key encryption scheme, different keys are used to encrypt and decrypt. An individual may be able to encrypt data but have no way of decrypting the corresponding ciphertext. These types of encryption schemes are also referred to as "asymmetric" since the relationship between encryption/decryption is asymmetric.
You may have heard of the ElGamal encryption scheme before (which is based on the Diffie-Hellman key exchange). These schemes are usually taught in an introductory cryptography course and (in most modern-day applications) rely on a commonly used type of cryptography called elliptic curve cryptography.
So what's the "homomorphic" part mean?
We will turn our focus to homomorphic (public key) encryption schemes as they are the most useful. The "homomorphic" part implies that there is a special relationship between performing computations in the plaintext space (i.e. all valid plaintexts) vs. ciphertext space (i.e. all valid ciphertexts).
Specifically, in a "homomorphic encryption scheme," the following relationships hold:
- Homomorphic addition:
Encrypt(a) + Encrypt(b) = Encrypt(a + b) - Homomorphic multiplication:
Encrypt(a) * Encrypt(b) = Encrypt(a * b)
Allowing you to do something like:
Encrypt(3xy + x) = Encrypt(3xy) + Encrypt(x) = [3 * Encrypt(x) * Encrypt(y)] + Encrypt(x)
So just by knowing Encrypt(x) and Encrypt(y), we can compute the encryption of more complicated polynomial expressions.
How does it work? What's the intuition?
Let Encrypt(a) be referred to as a'. Let Encrypt(b) be referred to as b'. Recall that a' and b' are ciphertexts.
Every time we perform a homomorphic operation, we add additional noise to the ciphertexts. At some point if the noise gets too big, you won't be able to successfully decrypt the ciphertext. You're just out of luck. For homomorphic addition, the noise doesn't grow too badly. You can think of the noise growth as Noise(a' + b') = Noise(a') + Noise(b'). However, the problem lies with performing homomorphic multiplication. In a homomorphic multiplication, the noise growth behaves as Noise(a' * b') = Noise(a') * Noise(b').
Let's use some numbers to make this more concrete. We'll say that Noise(a') is 10. We'll say that Noise(b') is 20. The FHE scheme has some noise ceiling after which point we cannot decrypt the ciphertext even if we have the decryption key. For our example, let's say the noise ceiling is 300. After performing a single homomorphic addition between the two ciphertexts, the noise will be 10 + 20 = 30. Not bad! However, if we perform a single homomorphic multiplication between a' and b', the resulting noise will be 10 * 20 = 200 for the ciphertext a' * b'. If we then tried to compute (a' * b') * (a'), the noise would be too big for the FHE scheme! Thus, we would not be able to decrypt (a' * b') * (a') even if we had the decryption key (since Noise(a' * b') * Noise(a') = 200 * 10 = 2000).
It's your job to correctly set all parameters of the scheme, perform "noise control" operations at the right time (we won't go into what these operations are in this article since they can differ by scheme), and try not to do too many homomorphic multiplications. Does that sound intimidating to you? You're in good company then.
Note: There is a way to get around the fixed noise ceiling—"bootstrapping"—which comes with its own set of complexities and trade-offs.
What's needed to build a fully homomorphic encryption scheme?
All FHE schemes use a specific type of post-quantum cryptography called lattice cryptography. The good news is that FHE is resistant to attacks from a quantum computer (if we should be concerned about such a thing is an entirely different topic). The bad news is you likely have no familiarity with lattice cryptography even if you've taken an introductory cryptography course before.
Simply put, lattices sit inside the real vector space (otherwise known as R^n) and can be represented using vectors and matrices (which you definitely should have familiarity with!).
FHE schemes can be broken down into 3 types depending on how they model computation (see this presentation if interested in more advanced technical details). The first type models computations as boolean circuits (i.e. bits). The second type models computation as modular arithmetic (i.e. "clock" arithmetic). The third and final type models computations as floating point arithmetic.
| Computational Model | Good for | Schemes* |
|---|---|---|
| Boolean | Number Comparison | TFHE |
| Modular Arithmetic | Integer Arithmetic, Scalar Multiplication | BGV, BFV |
| Floating Point Arithmetic | Polynomial Approximation, Machine Learning | CKKS |
The names of these schemes usually come from the last names of the authors who created it. For example, "BGV" comes from the authors Brakerski, Gentry, and Vaikuntanathan.
* Not an exhaustive list of schemes! I've just listed some well-known ones.
Why do we care about this?
Private Transactions on a Public Ledger (e.g. blockchain). A private transaction scheme allows a user to securely send digital currency to some recipient without revealing the amount being sent to anyone (apart from the intended recipient) on a public distributed ledger. This is in contrast to cryptocurrencies like Bitcoin where transactions and balances are all public information.
We assume a fully homomorphic (public key) encryption scheme. All encryptions are done with respect to the Receiver's keys.
- Sender wants to send
ttokens to the Receiver. Sender encryptstunder the Receiver's public key. - Sender publishes
Encrypt(t)on the public ledger. - Notice that
Encrypt(t) + Encrypt(Receiver's balance) = Encrypt(Receiver's balance after performing the transaction).
This can be extended to more interesting financial applications such as auctions, voting, and derivatives. An FHE scheme that models computation as modular arithmetic may be the most suitable for this type of application.
Note: For this to work in practice, some other cryptographic tools are also needed (such as zero-knowledge proofs).
Private Machine Learning. There's been increased interest in the last few years around how we might be able to "learn" from data (via machine learning) while still keeping the data itself private. FHE is one tool that can help us achieve this goal. In contrast to the previous application, we likely want an FHE scheme that models computations as floating point arithmetic here.
One well-known work in this space is Crypto-Nets which combines (as the name might suggest) FHE and neural networks to allow for outsourced machine learning. When people talk about "outsourced machine learning," the setting usually being described is one in which a data owner wants to learn about his data but does not feel comfortable openly sharing his data with a company providing machine learning models. Thus, the data owner encrypts his data using FHE and allows the machine learning company to run their models on the encrypted data set.
Homomorphic encryption is not the sole solution to this problem; differential privacy is a closely related subject that has garnered a lot of attention in the past few years. Differential privacy is more statistics than cryptography as it does not directly involve encryption/decryption. It works by adding noise to data in the clear while still guaranteeing that meaningful insights can be drawn from the noisy data sets. Apple is one major company that purportedly uses differential privacy to learn about your behavior while maintaining some level of privacy.
Why FHE Hasn't Taken Off Yet: Challenges in the Space
So far this all sounds great but I've been leaving out a number of problems.
Many Different Schemes (aka everyone is speaking a different language)
You've decided you want to use FHE—great! Here's some considerations that now need to be taken into account:
How do you want to model computation?
FHE schemes model computation in one of three ways—as boolean circuits, modular arithmetic, or floating point arithmetic. Hopefully it's obvious which model you need since there aren't many resources beyond introductory ones like this to help you out. This question is likely the least of your concerns though.
What if I have multiple options for FHE schemes that fall under the same computational model I need (e.g. choosing between BGV vs. BFV for modular arithmetic)?
Hmm, that's unfortunate. There isn't much work explaining the tradeoffs between different schemes with the same computational model. You'll probably have to play around with the various schemes and implement your specific use case with both of them to determine which is best. There are some very involved research papers (such as this) that you can try wading through.
Do schemes based on different computational models otherwise behave the same?
Kind of but not really. Different schemes tend to use different techniques to control efficiency and noise growth that you'll need to understand to successfully work with FHE. Additionally, the schemes have different parameters you need to understand in order to set them properly. The parameters affect not only the security of the scheme (which is a given in cryptography), but also the sorts of plaintexts you can work with, the number of homomorphic computations you can do, and the overall performance of the scheme.
Are the different schemes compatible at all?
Does this picture* help?

Probably not unless you know quite a bit of math and cryptography. There is a relationship between some of the FHE schemes but to understand the relationship you also need to understand how the various FHE schemes work in detail.
Having a lot of choices is great!
But it's not great when:
- you don't know the tradeoffs between the different FHE schemes or how the schemes relate to one another
- you have to invest a lot of energy into understanding a single scheme
- a lot of the knowledge gained from understanding one scheme is not really transferable to learning a new scheme (under a different computational model)
Potential Solutions:
1. Updated and improved benchmarking efforts
A large issue is the lack of up-to-date benchmarking efforts. It's hard to recommend which FHE scheme to use for a particular use case when we don't know how one implementation performs against another (on the same machine, for a particular set of comparable parameters). FHE libraries change quickly, incorporating new optimizations, so benchmarking efforts from 1-2 years ago quickly lose relevancy (such as this from 2018 for various implementations of the BFV scheme).
2. Better resources/guides to explain tradeoffs between schemes
Without up-to-date benchmarking of different schemes and libraries, it's impossible to provide good resources that explain the tradeoffs between the FHE schemes in practice. There have been some presentations (such as this one) that try to illuminate the differences between the 3 computational models in FHE. However, there aren't any good resources to help if you're trying to choose between different schemes using the same computational model.
3. Ability to move between different FHE schemes (i.e. interoperability)
If there were some interoperability between different FHE schemes, it would be easier to understand how the schemes relate to one another. An academic work on this topic is CHIMERA which provides a framework for switching between TFHE (boolean), BFV (modular arithmetic), and HEAAN (floating point arithmetic). Unfortunately, this work requires a very strong background in abstract algebra along with good familiarity of all the FHE schemes used. More accessible resources explaining the relationship between the different types of schemes would be nice (by "type" we mean the 3 types of computational models—boolean, modular arithmetic, floating point arithmetic).
* Image is from CHIMERA's paper
Efficiency (more complex of an issue than it seems)
If you talk to most people familiar with FHE and ask them why FHE isn't being used, they'll often wave the issue off by saying something like "oh, it's not efficient." Personally, I find this explanation to be a bit lazy because it vastly simplifies the issue. Public key encryption is less efficient than private key encryption but that doesn't mean everyone exclusively uses private key encryption. There are perfectly reasonable cases where a less efficient technology should be used.
Personal rant aside, we're going to look at some considerations you have to take into account for efficiency with FHE.
How many computations do you want to perform? Some FHE schemes allow you to perform a truly arbitrary number of computations on encrypted data. Many schemes, however, only allow for a certain number of homomorphic operations to be performed. After that point, there's no guarantee decryption will be successful. Say, for example, the FHE scheme allows for only 100 sequential homomorphic multiplications (note: addition is generally "easy" in FHE schemes, whereas multiplication is much harder). If we tried to do the 101th homomorphic multiplication, there's no guarantee that the resulting ciphertext can be correctly decrypted. The schemes that allow for a truly arbitrary number of homomorphic computations suffer from very poor performance. If you're able to figure out a ceiling on the number of homomorphic multiplications you need to do, that will help to achieve much better performance.
How big do you need your plaintext space to be? The larger the plaintext space, the slower it will be to perform operations. For FHE schemes that model computation as modular arithmetic, choosing a modulus on the order of 1000 vs. 1,000,000 makes a large difference in terms of what plaintexts you can represent. This might be especially important if you're representing account balances with your ciphertexts and need to ensure they don't "wrap around" the modulus.
Are you going to perform the same operation on many different plaintexts or ciphertexts (i.e. "SIMD" style computations)? Some FHE schemes can take advantage of "SIMD" style operations to perform the same operation on multiple plaintexts or ciphertexts simultaneously. If this sort of parallelization is useful for you, you should consider exploring schemes and libraries that offer this functionality. SIMD style operations, if used correctly, can really improve efficiency.
What key sizes are acceptable to you? With TFHE, for example, some keys you'll need to access in the scheme can be 1 GB large! The performance, in terms of timings, may be decent but you're instead left with a giant key you need to store.
Are you okay with large ciphertexts? Ciphertext expansion can be quite bad when working with FHE. Looking again at TFHE, the plaintext-to-ciphertext expansion is 10,000:1 for an acceptable level of security (100 bits).
What matters most for you in terms of performance? You can't "have it all" in FHE so it's important to determine what you need vs. want. Maybe you really need fast comparison of numbers. Maybe you really need to parallelize computation. Maybe you need a large plaintext space. All these little considerations need to be taken into account when choosing an FHE scheme.
Potential Solutions:
1. Hardware acceleration
Some FHE schemes can be accelerated using GPUs; examples of such libraries include nuFHE and cuFHE. Other efforts to accelerate FHE schemes have included using FPGAs (e.g. HEAX). HEAX works with the CKKS scheme (floating point arithmetic) and can yield performance speed-ups of anywhere from 12x to over 250x depending on the specific operation. Unfortunately, the paper suggests that a FPGA-based approach is not as successful for the BFV scheme (integer arithmetic).
2. Research breakthroughs improving FHE schemes
Easier said than done.
Usability (there is none)
The previous discussion leads us to our final point—usability. FHE is not beginner-friendly, not user-friendly, and certainly not non-cryptographer-friendly. There really isn't any usability for an engineer lacking a math or cryptography background.
Most FHE libraries require deep expertise of the underlying cryptographic scheme to use both correctly and efficiently. Another cryptographer has described working with FHE as similar to writing assembly—there's a huge difference in performance between good and great implementations. Wading through libraries like HElib can be intimidating without a strong background in the underlying scheme.
Is the situation really that bad?
We'll briefly touch on the issues that make FHE exceptionally user-unfriendly.
- Parameter setup is non-trivial. For example, in BFV (which is simpler than the BGV scheme), we have to set up a polynomial modulus, a coefficient modulus, and a plaintext modulus. Setting these parameters requires understanding how they affect the scheme (e.g. what sort of operations you're planning on doing, how many operations). Additionally, to understand what the parameters mean, you'll have to learn some basic theory about rings (abstract algebra). We currently cannot abstract away these issues; it's just necessary for working with FHE schemes.
- Public key encryption has just 3 main algorithms (
KeyGen,Encrypt,Decrypt), but it's not so simple for FHE schemes which have additional operations (which also differ between schemes). Because you need to understand how and when to use certain operations, working with FHE requires developing intuition yourself. - To develop good intuition, you need to work with the scheme....but some libraries have very little documentation.
- Understanding one type of scheme may not transfer very well to understanding a different type of scheme (by type here, I'm referring to the three different computational models).
So...am I ready to go use FHE now?
Probably not, but you're definitely ready to look at some libraries!
Potential Solutions:
1. Standardization efforts
By this, we mean standards to make it clear what parameters to use, what functionalities are offered, etc.
Standardization efforts are currently led by the open industry/government/academic consortium "Homomorphic Encryption Standardization." They've already released draft proposals around security and API standards for homomorphic encryption.
2. More user-friendly libraries and examples
One example of this is Microsoft's SEAL which has an incredibly instructive examples section. Hopefully more libraries will take the time to create user-friendly documentation and examples.
3. Potential compilers
There have been discussions in the FHE community for a while now about creating a compiler or some intermediate representation to make FHE easier to work with. Cingulata is one such attempt. Unfortunately, many of these compilers introduce a significant slowdown (compared to working directly with an FHE library).
What's the takeaway from all of this?
It's not you, it's FHE.
You know that cliche breakup line "it's not you, it's me?" Well, that's particularly true here.
High-level programming languages have abstracted away a lot of the complexity of how your computer works. But there is no analogue of "high-level programming languages" when working with FHE. You can't abstract away any of the complexities (of which there are a lot). Although standardization is ongoing and there are efforts to make FHE more beginner-friendly, FHE just isn't ready to be used by non-cryptographers at the moment in a production-ready environment.
I'm very bullish about FHE's future. Right now, though, the focus needs to be on improving FHE's efficiency (a given) and making libraries more usable for others.
Show me the code!
If you do not have previous experience with FHE, we recommend starting with a more user-friendly library such as SEAL.
Some libraries (such as SEAL and PALISADE) offer multiple types of FHE schemes. To prevent confusion, we list the specific FHE scheme in parentheses after the library's name.
| Computational Model | Available Libraries |
|---|---|
| Boolean | TFHE, nuFHE, PALISADE (tFHE) |
| Modular Arithmetic | HElib, SEAL (BFV), Lattigo (BFV), PALISADE (BFV, BGV) |
| Floating Point Arithmetic | SEAL (CKKS), Lattigo (CKKS), PALISADE (CKKS) |