年度感想
今年投入在娱乐的时间非常多,没有做什么正事,混吃等死状态。
娱乐
游戏
今年主要玩了steam单机,买了一些慈善包,还玩了玩steampy的买卖key功能。
steam的年度总结

动漫/视频
补了不少番,从18年开始补到了25年,紧随潮流。 比较喜欢的几部番是辉夜小姐想让我表白,总之就是非常可爱,中间管理路利根川,魔女之旅,齐木楠雄的灾难


读书
今年小说看的蛮少,主要是追更吧,主要看了 在美漫当心灵导师的日子,库洛牌的魔法使,我被困在方块之中。
另外因为写了个下载就是读了的同步到豆瓣脚本导致豆瓣统计也被污染了

因为我很喜欢下载

音乐

其实主要是听听每日推荐,当背景音用的,没有真的认真听
社交
今天在社交上花的时间挺多,而且某次让朋友伤心后更注重于自己主动和展示自己生活了,还弄了个专门展示生活的频道。
并不是展示欲很强,但是希望朋友们能觉得自己更活生生的,能够有话题和自己聊。 毕竟自己也不是那种有事情就喜欢和朋友说的人。
创作
Github
今年没写多少代码

油猴脚本
主要维护了

以及让ai写了一些自用的油猴脚本
pixiv

下半年一直在摸鱼,不过关注还是在涨,已经有600粉丝了
网络安全
几乎没有产出,除了偶尔发现自己在用的软件有问题外没有主动行为。不仅是感觉到某种疲倦了,更是觉得缺乏真正意义的产出。
正所谓安全的价值依赖于黑客的破坏大小,内部消耗而不能让任何人获得更多的东西。并且安全产出不具有积累性,修了就没了,令人疲倦。
telegram频道

今年没有写很多,但是在惯性下关注还是在稳步增长,虽然似乎体现在阅读量的真粉数量实际上没多
经济

实际上去除掉刷gdp的,我年度支出大概在5000, 这种躺平节约让我可以依靠不稳定的低收入依然贫困的活着。
好处是只挑想做的做,而且可以一直玩,但是随着ai侵蚀各种技术领域和自己技术洁癖逐渐上升,经济情况逐渐恶化了。
这么穷的我,当然也没有其他人所能写的投资啥的了。
今年发生了什么
好像什么都没有,都没去过外地旅游。也没有购买大件物品,也没有什么值得留念的成就。
比较值得一提的可能是 给家里人在内存涨价的前半年买了台pc,以及和群友面了一次。
因为一些原因不想出门,只能群友来乡下找我,也就只能见一下附近的群友,导致面基这种别人多的不想提的事情都成为我的记忆点了。
明年的期望
跟进一下AI写代码,让ai写一些自己懒得写的脚本什么的,多产出一些对自己有用的东西。
找个渠道获取一些稳定收入吧,即使很低。
另外就是希望自己有规划一些,少单线程生活,能平衡读书,娱乐,产出等。而不是一下玩两个月又不玩了和上半年猛写下半年一个字没写这种只能同时做一件事
]]>马上要到2026年了,我之前向codeql的github规则仓库提交的某个pr在审核人员表示投入到新的项目后,到现在依然没有回来。
想到今年还没有写博客,在关闭pr之时顺便水一篇。
关于codeql
2023年,作为ai爆发的几年,个人认为大概是投入到ai那边去了。
现在很流行用LLM找漏洞,实际上codeql现在也很尴尬,如果要编写追踪漏洞的复杂查询代码,学习和编写成本都很高,也容易没适配漏掉。
同样都是通过漏洞模式去找问题,LLM有很大的优势。
这种趋势下安全人员更多的是发现问题模式,而非去找具体的漏洞。
所以并不想说具体的codeql代码(当然肯定不是太久了我忘光了 细节可见https://github.com/github/codeql/pull/12663)
关于这种DOS漏洞
当时我编写这种查询,是受到当时查看的一些漏洞报告的影响。
它们或是通过前端展示代码或者后端处理代码的不当处理,通过特定内容能造成性能上的极端不利导致崩溃。
我编写的就是最简单的情况,外部参数直接影响到了内存分配函数。
例子代码
|
|
当然现实并没有那么简单,但是这种问题是很难避免的,我当时查询top200 go库就能查到快10个。
我当时就在gog中提交了一个,作者也没有发安全公告。
只是对于大部分web应用而言,dos本身并不是很关键,大不了重启,所以除了能水十个cve外没有任何意义。
对于物联网,汽车等硬件难以重启的软件影响会更明显。
漏洞原理与计算性DOS
原理上很明显只是 不可控的参数流入了内存分配函数make,分配不出来会直接炸掉程序,大部分错误处理程序都无法防止oom杀掉程序。
很显然,不只是make,任何直接影响到内存分配的函数都存在这种问题。 例如对于某些特别大的数据库,如果没有对pagenum 单页查询数量限制,强制把所有数据查询出来不仅是数据全出来,大概会崩溃。
但实际上这很难预防,普通漏洞是不可信数据作为数据流向危险函数,这是很容易看出来防御地方的,毕竟危险函数就那么多。
但是任何数据都可能作为函数参数使用,而应用性能受参数影响。而要预防这个只能处处防御性编程,这几乎不可能。
但是除了对战这种dos意义不大,毕竟损人不利己。
]]>init.rc
init.rc是安卓用于定义系统启动时操作的格式, 安卓启动会尝试读取
/{system,system_ext,vendor,odm,product}/etc/init/ 目录下的rc文件
如果要实现开机时运行一个自定义脚本, 只需要在产品的mk文件里添加
|
|
然后在init.bluebird.rc 里编辑即可
如果出于测试目的可以选择直接在系统内编辑,上述文件然后重启
rc文件语法
rc文件语法有两块 一块是定义服务, 一块是定义触发动作.
服务定义语法
|
|
disabled 禁止自启, 直到被调用. oneshot 使得服务不会被重复调用和重启, 用于只执行一次的脚本
然后定义什么时候触发
|
|
aosp定义的阶段触发器有
early-fs- Start vold.fs- Vold is up. Mount partitions not marked as first-stage or latemounted.post-fs- Configure anything dependent on early mounts.late-fs- Mount partitions marked as latemounted.post-fs-data- Mount and configure/data; set up encryption./metadatais reformatted here if it couldn’t mount in first-stage init.zygote-start- Start the zygote.early-boot- After zygote has started.boot- Afterearly-bootactions have completed.
也可以通过prop属性方式控制触发, 例如 dev.bootcomplete
|
|
]]>如果使用服务形式,可能需要修改
selinux策略, 以增加服务权限以进行操作 如文件操作 参考 https://source.android.com/docs/security/features/selinux?hl=zh-cn
复制文件
产品级拥有一个选项可以直接复制文件到系统
|
|
格式上很简单, 一个:分割的对应关系. 比较特殊的是使用$(TARGET_COPY_OUT_VENDOR)来获取指定目录.
这样有利于后续维护,这些常用的全局变量位于build/core/envsetup.sh
里面定义了全局变量, 如
|
|
如果要复制到 /system/xxx 可以使用$(TARGET_COPY_OUT_SYSTEM)/xxx
一般用于放一些配置文件 例如init.rc
叠加层
叠加层也叫overlay层, 比起直接复制文件的区别在于. 复制文件是面向最终输出, 会复制到输出目录, 支持任意文件.
叠加层是面向编译系统, 可以实现在编译时替换资源文件. 但是也只能修改资源文件.
但是可以实现修改已有代码的配置,而无需修改安卓源代码.
要使用叠加层只需要
|
|
然后根据要修改的文件路径新建对应的目录
例如要修改frameworks/base/core/res/res/values/config.xml
|
|
然后按照xml格式 写上需要修改的内容
|
|
只会影响所写的值,不影响其他默认值.
要使用叠加层并不容易, 首先要知道到底有什么配置项,和在哪个路径. 而在了解这些之前几乎没什么用, 需要先阅读源码中的framework/base/core/res/里的xml文件中的注释.
动态叠加层
也称为运行时资源覆盖(RRO), 其实就是从编译时覆盖变成了系统运行时覆盖,为了加入系统, 实际上安装形式是apk
要想使用RRO,首先需要新建一个模块目录,然后添加Android.bp
|
|
然后添加app必要的AndroidManifest.xml
|
|
targetPackage 是想要覆盖的apk名, 这里是aosp自带的联系人应用
@xml/overlays是覆盖资源文件名 实际路径是res/xml/overlays.xml
实际内容像这样
|
|
value的格式与apk 定义资源格式没有区别, target是需要替换的资源id, 需要查看源码或反编译目标app读取资源文件.
安卓自带的联系人资源文件位于packages/apps/Contacts/res/ 然后默认的英语在values, 如果要修改字符串在strings.xml
如果想要修改开屏显示的Add account , 搜索这个文件可以看到是
|
|
然后在覆盖层文件添加一行
|
|
添加到产品
PRODUCT_PACKAGES += rro
然后执行mm编译 后会出现在system/product/overlay
动态覆盖层管理
更新完系统后可以用adb shell cmd overlay 查看动态叠加层状态
cmd overlay list查看当前的rro apk
可以看到这种输出
|
|
包出现在列表但是没有启用, 需要使用 cmd overlay enable com.example.overlay 启用.
执行后可以看到

预编译二进制文件
操作上类似于预装系统app 不过变成了使用cc_prebuilt_binary
推荐在external/ 目录新建一个文件夹,然后添加一个Android.bp
|
|
比起系统app, 二进制文件的一大问题是 预编译的架构不一样是无法运行的, 这个时候可以使用arch参数
|
|
为每个不同的架构指定不同的二进制文件.
另一个问题就是未必想要放到/system/bin, 在soong大部分模块都具有以下两个属性
vendor 和product_specific , 设置为true后 会放到/vendor 和 /product 分区, 如果没有将会放入/system/vendor 和 /system/product
删除模块
如何查看目标文件的对应代码路径
很多情况下都是要删除一个系统apk,但是要删除一个文件,首先要知道他对应的源码路径. 在out/target/product/<产品名> 路径下有个module-info.json
里面包含了模块与其对应的路径, 直接搜索对应的文件名, 会看到类似这样的json格式
|
|
installled 对应的就是路径, 而module_name 则是对应的名字, path对应源码路径. 之后再根据模块名
去删除.
删除和替换模块
如果要删除的话,需要修改对应产品的Android.mk 或者 系统app定义在/build/make/core.mk .移除对应的PRODUCT_PACKAGES 属性, 就是添加模块的反向操作.
另一种更可维护的方法就是使用替换. aosp 实际上没有编译时删除模块的概念, 实际上使用的是替换
因为版本问题, 以前博客都是使用.mk的形式, 例如 秋少的博客.
不过soong实际上也有类似的功能, 实际上也是填写了LOCAL_OVERRIDES_PACKAGES这个值
在部分模块下, 具有overrides属性, 可以通过这个属性后覆盖替换掉 其他模块.
例子
|
|
拥有这个属性的主要集中在android 模块, 在源码中主要用于替换apk
前言
在之前就知道可以通过PRODUCT_PACKAGES 添加自己的包, 具体操作是 新建一个模块,然后
|
|
要定义一个模块 可以使用soong 或者makefile, 在新版本系统推荐使用soong
soong 使用 .bp文件定义模块 参考
从官方例子就可以看到其实格式和json一样简单,
|
|
主要问题是找到需要的模块和属性 这个时候就需要格式参考
里面主要根据语言分类, 想做一件事的时候查询对应类型,和对应模块名的格式参考
添加预下载apk
查看android/soong/java类型 看名字就知道 前面两个就是.
android_app和android_app_import
查阅文档克制区别在于 前者是需要编译的模块 后者是直接导入apk文件
文档提供了一个例子
|
|
文档里还提供5行的其他选项, 不过基本都是通用选项, 与app有关的不多 , 看旁边注释就能了解作用
如果要导入一个叫vnc.apk的文件
新建一个目录,放入apk文件,和Android.bp
|
|
然后在bluebird.mk (产品mk文件)添加
|
|
然后编译即可在 system/app 看到 vnc_import目录
如果遇到 mismatch in the <uses-library> tags between the build system and the manifest:
则按提示在 产品文件添加
|
|
或在bp文件添加提示中对应的lib
|
|
从product.mk修改
在上一节已经知道
|
|
这些可以修改prop属性
只需要加一行
|
|
就可以在输出目录里的 out/target/product/bluebird_x86_64_only/system/build.prop 找到新属性.
其他属性对应的是其他文件, 整体对应关系是
|
|
对应的文件级设置为
|
|
要删除就需要使用
|
|
具体实现在build/make/core/sysprop.mk 里面
拿一段举例就是
|
|
实际应用中就是 添加一个 product.prop
|
|
并在bluebird.mk中添加
|
|
编译运行后就能看到 自己新添加的prop属性了
]]>前言
在学习修改一样东西时, 最好的方法之一就是搞懂他到底可以干什么. 而不是跟一个教程学一个选项,再跟另一个教程再学一个选项, 结果问到可以做XX么, 还是无法回答.
当然,并不需要记住具体操作, 只需要对可以做什么有印象就可以了.
AndroidProducts.mk
读取product的代码位于build/make/core/product_config.mk 和 build/make/core/product.mk
其中只使用了这三个变量
|
|
PRODUCT_MAKEFILES
然后根据选择读取对应的mk文件
在build/make/core/product.mk定义product自身的属性了
|
|
完整列表如下
|
|
可以发现 _product_single_value_vars大部分都是编译设置, 魔改最多修改个名字
|
|
虽然设置很多, 但是常用的不多 主要就
|
|
当然可以设置的自定义选项远不止这些 例如 TARGET_VENDOR_PROP 来设置prop文件, 这些就是由其他core/*.mk文件添加的非产品级的设置了
aidegen
aidegen是一个自动生成项目配置文件的工具 在运行完lunch后 会自动配置这个工具路径
主要参数有 完整文档参考
-
-s跳过构建 -
-n不自动运行IDE -
-i选择IDE类型 -
-p指定IDE路径
|
|
目录结构
AOSP目录结构非常复杂 由非常多项目构成,但是大部分并不需要修改
|
|
需要主要关注的
|
|
新建device和product
在编译时已经知道 编译时需要选择编译目标.而编译目标在AndroidProducts.mk 这种文件下设置
参考redroid
|
|
可知要新建一个device 首先在device目录下创建一个子目录 例如 device/bluebird
然后创建一个``AndroidProducts.mk
|
|
然后新建一个bluebird.mk
|
|
再新建一个 bluebird_x86_64_only/BoardConfig.mk
|
|
最后结果
|
|
然后就能进行 lunch bluebird_x86_64_only-userdebug
添加redroid补丁
redroid添加了自己的补丁
|
|
具体补丁内容可以查看 仓库 对应文件夹
准备编译
|
|
这个envsetup.sh文件里添加了很多辅助函数 可以使用hmm查看. 最常用的几个
m编译整个项目mm编译当前目录项目croot回到项目根目录lunch选择编译目标
大部分只是简单的命令套壳无需关心, 剩下的也只是调用 build/soong/soong_ui.bash 这个脚本
这个脚本有 "--make-mode" "--dumpvar-mode" "--dumpvars-mode" "--build-mode" 四个选项
--dumpvar-mode 用于从整个项目里获取编译变量设置, get_build_var 就简单封装了这个功能
lunch 获取可用编译目标 就是调用 get_build_var COMMON_LUNCH_CHOICES (这个可以在命令行里直接执行)
可以看到输出里面出现了redroid开头的四个选项,
|
|
这是redroid添加的 位于device/redroid/AndroidProducts.mk,
然后执行
|
|
同步git lfs文件, 原版是不需要的. 但是redroid 在external/chromium-webview/prebuilt/ 添加了lfs项目, 如果速度很慢,可以考虑直接下载而不是走`lfs
接着执行
m # -j x
等待很长一段时间后,就能在 out/target/ 看到产物
编译完成打包成docker
|
|
配置环境 参考文档
|
|
出现闪退错误使用命令排查
sudo dmesg -T
前言
aosp 魔改教程已经有很多了, 但是都比较零碎或者太过古老. 出于记录的想法,写下这些.
本篇教程基于ubuntu22 和 Android 13 和Redroid.
下载代码
所有教程里都必须拥有的阶段 (导致作者实际上看过很多次)
简单说明步骤 (可以先不执行)
|
|
repo实际上做的事情是
- 从 https://android.googlesource.com/platform/manifest 这个git仓库的
android-13.0.0_r82分支获取default.xml这个文件. 具体可用分支列表可以看链接 - 进行一些操作后写入到当前目录的
.repo目录 - 按xml文件执行git clone和同步, xml文件里描述了目录与git仓库的对应关系.
而如果需要添加自己代码仓库 就可以往.repo里写自己的xml文件 文件格式参考
|
|
然后编辑
|
|
其中
|
|
的fetch为自己的git用户地址 name可以任意修改
|
|
path为相对于项目的相对路径 remote需要与上面的 name对应 name则是仓库名, 实际上对应的url 为 https://github.com/blue-bird1/device
执行repo sync后 可以发现 device/bluebird 出现了自己的项目代码.
而redroid项目也用了同样的方法实现自定义 AOSP
|
|
可以查看目录下的两个manifest文件了解做了什么操作 ,主要是添加五个自己的项目到代码里.
如果想要直接对redroid 进行fork修改可以直接对此文件进行修改
原理
跨域通信一般是直接ajax,用限定请求域名的方法来保证安全.但是也具有其中的局限性,只能读取服务器数据.而不能读取本地的localStorage数据等.
如果需要本地数据,依然需要iframe,现在iframe通信采用的是postmessage的形式
一个简单的例子就是
|
|
以上实际上是很不安全的例子,因为postmessage没有浏览器的跨域保护, 接收的数据可能来源于任何一个域名.
正确的写法应该是
|
|
实战

在浏览器f12就能直接看到iframe的载入. 当然iframe也可能是单纯用于展示,没有postmessage的通信.
不过可以在浏览器点击global listeners 然后看有没有message的事件监听者

可以看到其中有两个,其中有一个是框架生成的,另一个才是程序员自己写的.框架那个做了验证,
蓝色的链接也能直接点到达代码位置
代码大致如下
|
|
直接传入了innerhtml ,从代码的取值可以构造出以下exp
|
|
总结
原理和挖掘是不难的, 主要依赖于程序员忘记对iframe验证的错觉. 危害评估最高也就csrf和xss的级别,依赖于被攻击者进入你的网站.
]]>如果用一个成语形容自己的2021年 就是混吃等死
去年目标回顾
首先看看去年的目标吧
- 挖几个CVE
- 博客每月更新一篇
- 学一些大学基础学科
- 控制一下作息 不要老是快天亮才睡了
首先 CVE为0 甚至今年都没挖过洞
第二 很显然 摸了 全是水文
学习的话 只能说知道有什么名词了 从什么都听不懂到能知道你们在说很厉害的事情
作息 依然在熬夜..
由此可见 今年非常失败
各平台记录
惯例了

刷b站比去年少了


网易云一看就是老二次元了
当然今天做的最多的事情是打游戏, 大半年都在打游戏 ,打的身体都都不太好了,手酸腿麻脖子疼

光是以撒就600小时了 和还有其他加起来 今年至少打了一千多个小时.游戏数升到500了,退烧了
从娱乐花了这么多时间,可以看出我今年其他方面的失败

一片白花花 比去年还少 我已经是一条咸🐟了.. 挖洞也为0,咸鱼中的咸鱼
现实更是外门没出过,什么都没干,光在打游戏,水群,看视频了
今年学到了什么
读书的话 今年只读了50本左右,但是没用网站记了.(说服自己 读书不是为了完成目标)
不过今年在中图网花了两三百就买到了三十本书,现在还有好几本没看完
其中计算机类的为0,工作水平提升为0.都是一堆杂七杂八的书
总而言之就是了 一大堆没什么用和工作不相关的书
电子书看的除了杂七杂八的书外,为了完成去年目标,也看了一些大学教材. 虽然没学会,但是至少不会连听都听不懂了,从一个文盲变成一个懂一些名词的文盲
明年目标
再来一个例行立flag
首先多锻炼一下,现在已经能明显感觉到身体不好了,再这样下去差不多该去买颈椎/脊椎病康复治疗指南了
第二就是 再学习一些基础知识和,不要成为新时代文盲了
还有就是减少打游戏 看沙雕的时间了
]]>价值观
本文忽略掉了人文因素
讨论一样东西的价值的时候,技术社区和大众,甚至技术社区之间都有很大的矛盾。 因为人的价值观是非常不同的,简单可以看成的是唯实用论,唯工作论, 唯技术论,唯难度论四个纬度的连续组合。 而评价价值时既受到个人三观影响,也收到对评价事物领域了解程度的影响。如果在某个领域完全没有了解的大众只能使用实用来评价,不可能了解难度如何
实用论与技术论
唯实用论认为一个东西如果没有在现实用上就是没有价值的。也就是一段代码如果没有人使用,就是垃圾。 在公司工作,写出来的代码可能永远不会上线。开源的项目可能从来没有有人用,在实用的眼光来看如果是这样,我们只是在制造垃圾。
而唯技术论则认为即使不实用,但是如果如果有技术含量它就有价值。所以认为代码上造轮子和开源并不是在浪费时间。 这一点常受到唯实用者的嘲讽,认为华而不实,即使用了再多技术不实用也没意义。
实用与技术之争论
光是这两点对人的工作成果评价的矛盾就很大。一个人用了最简单粗暴的方法实现了一样实用的东西,会收到实用的高评价,技术的低评价。反之亦然.
在计算机
在计算机行业,php就是以前唯实用论最好的语言,对php的无数争论其实就是实用与技术的争论. 在计算机安全则是唯实用论为主,就算你是拿密码123456或者扫描器入侵的,能黑下来就行。但是对人还是会有技术上的评价
在科研
在科研学术最好的例子就是材料了,不管你研究出来的材料到底有没有实用价值,只要是新研究都能发论文。
工作量论与难度论
唯工作量论就比较显然,例如计件薪水毫无疑问是唯工作论。而唯难度论则是它的反面.对唯难度论来说一个工作就算重复了无数遍,对它的价值也不会上升。 这两点体现就是公司会按你完成的工作量评分,但很少考虑实际完成的难度。而程序员则是喷别人或者自贬自己是crud程序员和切图仔。发论文会认为自己在水论文,认为自己所作的工作没有难度没体现价值
我们应该如何评价?
在谈完所有评价维度后,回归现实来说,社会和自己的评价价值观是不一样,我们要怎么评价自己和别人呢,并做出发展呢.
事物
现实是唯实用的,我们对事物的评价也应该以实用和工作量为主.公司也是如此把我们当做事物评价的,这个东西实用么,这个东西今天干了多少活。其他的并不关心。所以做一件让人用的东西应该面向实用,背后的技术没有人会关心的,什么简单粗暴用什么就好
自己
然后评价自己应该唯难度和实用为主,当然反过来也行。 因为难度就是我们一直在说防止失业的护城河,难度越高能代替你的人越少。而实用则是提高需要你这样的人的数量同时提高你能创造的价值,需求高供给少自然工资高失业风险低 但是如果你不想打工了,难度和技术就没有任何意义了,需要唯实用论
不同的评价观念给我们的影响
我们做事情时会不自主的被价值观念影响,偏离了正确的轨迹.
写一个脚本很显然是面向实用的,而喜欢技术的人会不自主的浪费时间在优化代码上,即使知道用完这次一辈子都不会再用了.
受实用影响的话,则容易轻视技术和难度,满足于一辈子crud,然后被现实淘汰.
我们不同的价值观念只是我们的关注点不同,而如果不能自由的切换关注点,我们将被它束缚
]]>最近在玩steam游戏,也关注了steam相关的论坛 学到了不少关于steam的东西,简单介绍一下
市场货币与价值
严格的来说 steam只支持两种货币 现实货币和steam余额. 但在一定时间段内 一袋宝石和csgo钥匙等也可以充当稳定的标准货币
而一袋宝石和csgo钥匙等波动相当大 在前两个月价格为2.9r[人民币] 现在仅有2.5
因为这些都是游戏虚拟物品 并不是金融等价物 实际价格直接取决于玩家
宝石主要受到steam宝石发行策略的影响 如
在冬季促销时每位用户每天都可以免费获得一张卡牌 分解可获得100宝石(1袋==1000) 大大增加了市场上的宝石供给
交易成本与货币汇率
现实货币由于以下这点 在熟悉市场的人里是没人会直接使用的 所以忽略汇率 直接从余额开始
余额
官方渠道的余额兑换是1:1.直接充值余额绝对是亏的,保留在银行卡还会获得利息.
但实际上通过steam线下交易(指非steam市场交易)可以获得一定的折扣. 具体在线下交易这一节讨论
通过线下交易等渠道 实际上余额实际价值为现实货币的7-8折 甚至更低.这个比率是相当稳定的.
而且steam所有物品都几乎可以通过余额购买,且有部分游戏充值也可以使用steam余额,这也意味着全部八折.
如果要对现实货币反向兑换,steam是不支持的 只有通过线下交易 见线下交易这一节的讨论
而想用余额兑换宝石或者csgo钥匙 只能遵循当前市场价在steam购买.
宝石/csgo钥匙等库存物品
库存物品有两种方法进行交易
- 通过市场售卖
每个市场物品 贩卖时只能获得售价的85% 剩下的15%将作为税收被steam和游戏物品对应开发商(每个物品都有对应的游戏id csgo/dota等属于v社直辖游戏)收走
要回避这种交易成本 只能通过线下交易 (一般是市场价的八折)
除此之外再次转手 还有时间成本 每个物品从市场购买后 7天内不能再销售 下面这种交易不受影响
- 私下以物易物交易
每个steam用户可以和其他用户进行交易 只能交换物品(允许一方为空作为赠送) 不能如市场一样交易余额. 交易成本很显然 你需要花时间找到想要购买你的东西的人 并且steam不会为你被诈骗后退回物品
市场商品
steam可获得的有以下几类
-
游戏/dlc 在商品页面购买 直接入库 不允许交易
-
游戏礼物 在购买多人包时可获得 可以把礼物发送给其他用户 让他们获得游戏. 或是以前礼品机制没改的时候 留存下来的礼品 这类一般是收藏品 一个礼品在收藏圈价值成百上千的很正常
-
游戏激活key 游戏开发商可以在后台生成key 在steam输入这些游戏key可以获得那个游戏
-
勋章 可在个人资料看到 主要作用是每获得/升级一次勋章会获得100经验
-
游戏卡牌 游玩一个具有游戏卡牌的游戏 会掉落游戏卡牌)最大数量为一套卡/2 向上取整) 收集一整套卡牌后合成 可以随机获得勋章+一个聊天表情+一个个人资料背景+一个优惠卷
-
游戏卡牌补充包 除了游玩掉落和在市场购买外 还可以通过打开补充包来获得卡牌. 获得途径有
每有一个人合成一套卡牌 就在已经掉落所有卡牌里的用户 随机挑选一个人赠送补充包 (根据等级有不同的掉落权重 等级越高权重越高).或者通过宝石合成. 这也导致他们之间的价格相互锚定 见下一节内容
-
聊天表情 聊天表情可以在好友聊天界面里使用 (真的有人把steam当成社交软件嘛? )
-
个人资料背景 个人资料背景的价格上限取决于好不好看 例如某流星雨背景当前市场价60+
-
宝石 通过分解 游戏卡牌/聊天表情/个人资料背景可以获得宝石 而对应分解宝石的值受到很多因素影响
-
其他库存物品 每个游戏都可以生成自己的库存物品 例如csgo饰品 橙汁100%的宠物,如果游戏开发者决定让这些物品可交易的话 也可以交易
-
steam点数 在steam消费获得. 可用于steam点数商品 可以购买 头像/头像框/聊天表情/个人资料背景 但均不可交易 可以通过社区奖励来交易 但是需要收到66%的高额税收
商品间的相互关系
要谈相互关系 最大的破坏者就是steam点数商店 用户可以在点数商品购买自己已经拥有的游戏的聊天表情/个人资料背景 只要购买游戏 就能通过点数直接购买 而不需要通过合成卡牌来获得. 一个背景只需要500点数(按写本文的时间 也就0.7r)
如果背景的价格比直接购买游戏会更贵,理性的人会选择购买游戏.
卡牌和补充包(一包可以开出三张)的关系很显然 补充包的价格会在卡牌平均价格*3浮动
而补充包可由宝石合出,如果卡牌的平均价格*3 高于合成所需的宝石价格 就可以通过用宝石合成补充包来获得利润.
上面说明卡和补充包的价格上限是受到宝石价格锚定,同样的是其他物品的下限也收到锚定
卡牌/聊天表情/背景都有自己的分解宝石值 通过分解获得对应的宝石. 如果购买价格低于对应宝石价格算上交易成本 同时可以获得利润 事实上在steam已经有这种机器人,长期在有价值的物品下面求购,(可笑的是由于机器人太多,在对应价格上出现了一个求购数量的尖峰)
除了单张卡价格锚定外 由于一套卡也属于交易物品 也受到了整套卡价格的锚定.详细内容见 交易机器人一节
市场参与者
steam
steam直接售卖的游戏 这也是绝大部分人的购买途径 但他只售卖游戏和游戏礼物
游戏key零售商
游戏开发商可以通过将key交给其他网站来售卖 这种也分两种 普通零售商和慈善包商
其中区别在于 普通零售商将按一个一个游戏售卖 慈善包商将会把多个游戏打包一起卖 并且价格非常低廉 1,2块一个游戏很常见. 比较好的作品不屑于将自己的作品贱卖,在慈善包能买的绝大部分只有喜+1
主要活跃的慈善包商
交易机器人
交易机器人使用整套卡牌/宝石/csgo钥匙/tf2钥匙作为交换物,可以在它们之前相互交换 例如你可以用一套卡换取一些宝石或者一些csgo钥匙
你可以在这里 https://steam.supply/CardBots 找到一些机器人 或者谷歌搜索也能找到
普通用户
市场的主要参与者.通过在上面的售卖者选择 来实现自己的目的. 或者销售自己的卡牌或者饰品来获得余额
线下交易
注意 如果是中国交易者 可以在https://steamrepcn.com/ 查询他的信誉记录 国外的 https://steamrep.com/
淘宝代购/贩卖充值卡
代购:你支付淘宝商人一定比例的钱,淘宝商人添加好友 并赠送给你游戏.
贩卖余额:通过交易给你饰品 然后让你高价卖出 淘宝商人通过购买来交换给你余额(这种具有封号风险)
玩家之间交易
在论坛的交易区或者qq群发生,交易内容一般是游戏key/游戏礼物,
饰品市场
可以在网易buff等网站购买和销售饰品 由于部分饰品购买后到steam转卖 扣除手续费后仍然比直接充值高 也被当成便宜充值余额的方法 同时由于国外区域不能使用支付宝 这也是外区的国内用户的消费方法
作为一个用户
作为一个steam用户 如何利用市场来购买想要的东西
增加游戏数量
https://keylol.com/t644656-1-1 这里我推荐阅读大佬的文章 很详细
游戏
首先最好当然是先转到低价区 再通过饰品市场获得折扣过的余额 (如果读者已经学会转区 应该就不需要阅读这篇基础文章了 所以假设读者都是国区)
然后 https://steamdb.keylol.com/search/ 可以在这里查询到游戏的相关信息

可以看到历史最低的折扣(这个游戏免费送过) 以及进入慈善包的次数
通过史低可以判断这个游戏当前的打折是否有优势来决定是否购买 如果进过包 通过点进进包次数可以看到进过哪些包 如果还没过期 甚至还可以买一包. 也意味着你可以通过线下交易来获得一个key,例如橙汁不考虑免费送的话 史低是7r 由于进过包 实际上在线下交易可以获得3r的key价格
如果没进过包 也不想在饰品市场花心思 建议通过淘宝代购
获得勋章
可以在SCE 和STM来交换卡牌 其中STM是只能用同一套卡来交换而SCE有卡牌价格的设定
或如果卡牌价格比较高 也通过宝石合成补充包
提升等级
如果需要大量提升等级 可以在淘宝购买 成本0.6r一套
或者如果宝石价格足够低(需要经过简单的计算) 可以通过线下购买大量宝石 然后与交易机器人交换套卡
尾言
最后引用一句大佬的名言
玩毛游戏、浪费时间、不如加一
灾难性的一年 2020年终于要过完了 又到了写年度总结的时候. 今年划水的时间太多了,尤其是下半年 并没有做什么事情
首先看看各个平台的年度记录
博客

今年只更新了5篇文章 访问量只有1k多 连群里大佬的零头都没有
github
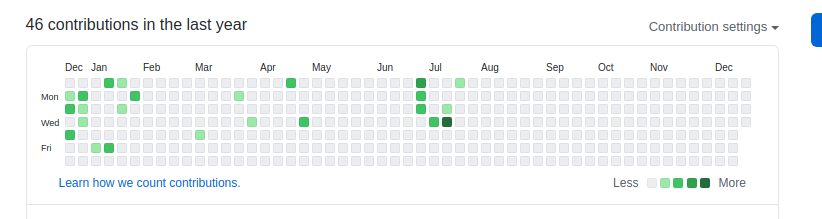
今年没写什么开源代码 提交记录实在太白了 今年的提交还没到100次 . 连地砖都比你努力.jpg
读书
今年读了61本
https://www.goodreads.com/user_challenges/20057969
b站
数据有浮夸 因为我把号共享给别人了 所以实际数据应该要打个50off


老白嫖党了
steam
下半年沉迷steam 游戏时长飙升到了1500小时 游戏数量也从几十个飙升到了200+ (虽然大部分都是喜+1)游戏
今年干了什么呢
src
今年国内src没挖了 只在hackerone随便提交了两个 没奖金的那种
hackerone很多公开报告 就算不挖看看也很不错
代码
今年没写代码 唯一算作开源可用的代码 只有下半年玩steam写的一个小脚本
反而成为最多人用的代码了? 从后台来看大概有500个人在用
挖洞
今年挖的洞都发过博客 算是实现了去年的目标 挖了一些大一点的项目漏洞
一共三个
gog sentry phpmyadmin
出行
完全没出过门 疫情开始后 家里方圆60km都没离开过 名副其实的自宅警备员了
感想
看完单纯数据 谈谈感想..
2020年在没有什么压力下 是划水的一年. 没有作出什么意外之外的成绩.
今年开始的疫情让前半年都是在家度过了,不过实际上改变不大 不管是健康码还是隔离都和不出门的我没什么关系, 希望疫情尽快完全结束吧.
目标
2019年定下的目标
- 多写博客 失败 今年写的比去年少了一半
- 做些有价值的工作 挖了几个不算小的洞 勉强算完成吧
- 读有价值的书 失败 今年看的书还是偏向科普和娱乐的
虽然今年也没完成什么目标 不过期望还是要有的 定几个小目标
- 挖几个CVE
- 博客每月更新一篇
- 学一些大学基础学科
- 控制一下作息 不要老是快天亮才睡了
首发于先知社区
codeql是一个可以对代码进行分析的引擎, 安全人员可以用它作为挖洞的辅助或者直接进行挖掘漏洞,节省进行重复操作的精力
安装
虽然官方提供了可以进行查询的网站 但是由于速度不快和一些c/c++项目 需要自定义编译命令来编译 实际上在网站是不能查询的
首先找一个放codeql的目录 作者用的是/opt/codeql
然后从这里下载后解压到目录 然后下载semmle的库
执行 cd codeql && git clone https://github.com/Semmle/ql
完成后 目录下应该有两个目录 codeql ql
接下来安装vscode插件 在插件市场直接搜索codeql即可 编写时安装量只有3k多 说明用codeql的群体暂时还不多.
创建数据库
使用codeql database create 来创建一个用于查询的数据库 --language=python指定语言是python
例子
codeql database create ./codeql -s . --language=python
在这种解释性语言上并不困难 问题在于对于c编译语言 需要用--command=xxx提供编译命令 虽然codeql会自动检测编译系统 但是在一些项目上不行 这也导致你编译不了的项目就用不了codeql

在vscode把创建的codeql目录添加为数据库 就可以正式准备开始查询了
hello world
codeql语言的查询格式如下
|
|
和sql比较像 from定义变量 where 声明限制条件 select 选择要输出的数据
可以使用的定义只有类和函数 例子代码
|
|
导入包语法和python一致 也是import 名字
作为每个语言都有的惯例 运行一下以下代码吧
select "hello world"
审计使用
在这里你应该有了自己的数据库了 作者选取的是python的一个django项目 (很遗憾的是由于动态语言的特性 python的污点跟踪效果不怎么好)
codeql 支持的语言有python java JavaScript c/c++ c# go
并没有安全人员最喜欢目标用的语言 php, 也不用对以后抱太大期望 以php的动态特性和开发人员动不动就全局变量或者动态字符串导入文件的做法 污点跟踪和变量分析也没法用
进行代码查询 首先要导入对应的编程语言包
|
|
需要注意的是不同语言包的使用方法不一样 而且目前的文档不是很好 也没有全面的教程
作者查https://help.semmle.com/qldoc/python 把python改成其他语言也能进去对应的文档
codeql的python库把对象分为了几种类型分别是
Scope 作用域 像函数或者类
Expr 表达式 像 1+1
Stmt 语句 例如 if(xxx)
Variable 变量
作为代码审计的开始 让我们先看看这个库调用的危险函数 在这里查了 django的重定向函数redirect
|
|
我们选择了call和name变量, call是一个函数调用
然后调用 c.getFunc() 来获取调用的函数, 为什么函数是一个Name呢
在python中 test() 实际上是对test这个变量进行调用 而在语法树上test是一个变量名
最后我们要求n.getId() 获得的名字是redirect
可以发现这里能查到的都是redirect() 而不是xx.redirect
如果我们想要寻找request.GET.get(xxx)的调用 必须使用Attribute
Attribute.getName 获取自身名字 Attribute.getName 获取.之前的Expr 在我们的需求中它还是一个Attribute 因为它前面还有request.
|
|
可以发现随着查询复杂度的增加 代码行数在不断增加 这个时候就应该使用函数来解耦
假设我们查询一个Expr 像上面的例子 但是不想查到test 或者debug 开头的文件 在Expr或者Stmt都可以通过getLocation()来获取当前位置 可以写一个函数
|
|
通过不断添加限制条件 在代码审计中可以锁定自己想要看到的函数调用. codeql不仅如此,还可以通过结合判断条件来寻找自己目标中的代码
例如我们希望找到一个函数中有获取请求数据并赋值的语句 还进行了重定向
首先作为一个赋值语句的终点 .get(xx) 是一个调用 添加
|
|
然后添加一个赋值语句 要求右端是上面的调用
|
|
再要求它们的作用范围是同一个函数
|
|
最后代码
|
|
也可以查询变量是否直接进行危险函数,但是由于赋值和各种字符串操作之类的关系 应该属于污点分析的内容了
后言
这篇教程讲了如何去用codeql去做代码审计辅助.在拥有思路后去编写这种查询的最大难点 就是文档差了 使用人数少 你无法谷歌到xxx如何去查询 只能自己去查文档去查那些函数到底怎么用.
]]>#### 前言
jsfuzz是一个基于覆盖率指导的模糊测试工具,能对JavaScript/nodejs模块进行模糊测试. 只需要编写一个接受输入的函数即可.
虽然nodejs是现代语言,即使出现了越界读写 也不会像c/c++一样直接导致安全问题. 但在审查一个复杂逻辑的nodejs模块时,仍是一个值得考虑的选项.
下载安装
npm i -g jsfuzz
实战
编写模糊文件
一个标准的格式是
|
|
更常见的是
|
|
作为一个例子 作者挑选了mqtt-packet 作为例子,这个模块代码不多,还提供了生成样本的函数,相当方便.
首先下载包
|
|
通过阅读包文档,很容易就能写出(复制粘贴)使用这个包解析函数的代码
|
|
运行
jsfuzz fuzz2.js
输出大致如
|
|
NEW表示发现了新的路径
cov代表行数, corp代表的不同路径数 exec/s代表每秒执行的次数 rss代表内存占用
由于这个库代码量不大,预期上能产生崩溃最多几分钟,不然就不可能了. 模糊测试的效果和运行时间并不是线性的.
不过由于这次运行并未提供任何一个样本,指望模糊测试器能覆盖太多路径是不太现实的.
覆盖率
在终止运行后,jsfuzz将会产生一个覆盖率文件. 可以通过nyc生成覆盖率报告
|
|
输出路径在couverage目录,打开html文件后
页面如下,我们fuzz的包在node_modules/mqtt-packet, 可以看出覆盖率很低.点开后可以发现parser.js的覆盖率只有57%. 这是一个相当低的数值

##### 生成一些样本
可以通过mqtt.generate(obj) 生成正确的mqtt格式, 尝试用包自带的生成例子就能得到一个样本
|
|
用mqtt-packet仓库说明里的mqtt object格式生成更多样本后得到了16个样本.

运行后
jsfuzz fuzz2.js test_corpus/
可以看到路径数从50提高了67 并且在67个路径上爆出了一个错误
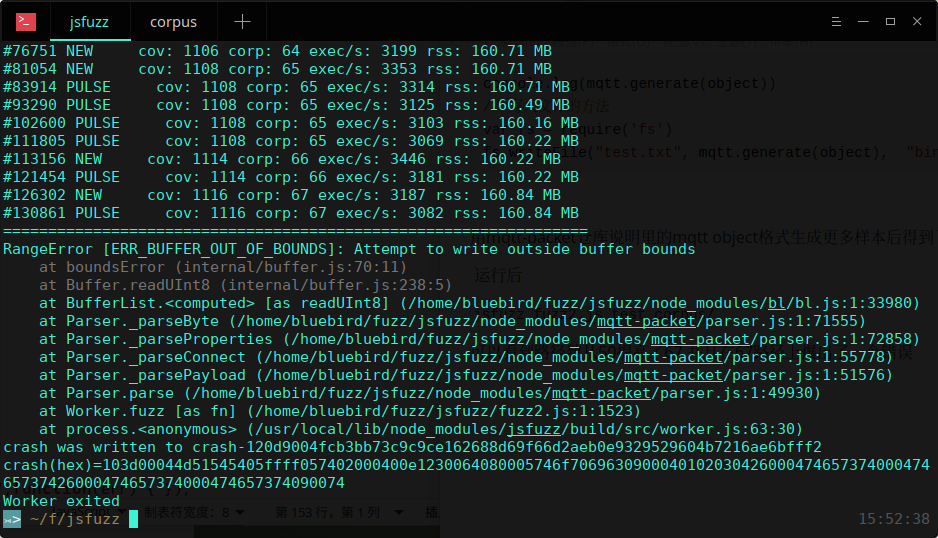
文本版
|
|
一个尝试越界读导致的错误(nodjs会阻止越界读写buffer)
查看覆盖率的话 发现已经达到了85% 简单浏览就能发现未能覆盖到的都是需要解析器使用协议的版本为5 而不是例子里的4.

后言
在像nodejs这类现代语言,使用fuzz来测试module能发现的大多数只是bug,在检查了缓冲区越界读写后你没法利用它.能发现的安全漏洞常见是dos,用错误的输出导致内存占用过大或者崩溃.
但JavaScript的依赖管理导致依赖了太多的包,如果你能发现一个底层包的问题,你将能对大量使用它的包进行攻击.
]]>在今天获得了第一个有CVE编号的漏洞 CVE-2020-10804 .
CVE只是一个漏洞数据库,只需要自己申请即可. 但国内会自己给小漏洞申请CVE很少,往往视为一种水货CVE.这也是第一个不需要我自己申请CVE的漏洞.
有趣的是PHPMyadmin这个月修复的漏洞,包括这个漏洞里,三个漏洞撞了两个(指被两个或以上的人提交)
和我同时发现问题的是hoangn144_VCS 大佬,他是在登录插件处发现的用户名注入.
漏洞详情
这个漏洞很水,我从审计开始到发现这个问题用时没超过两个小时.只是在sql查询时直接拼接字符串.
phpmyadmin在编辑密码和权限对用户名转义不当 ,补丁很简单 就是加上转义了而已

密码处补丁 复现也很简单 只需要在mysql5.6下编辑一个有单引号的用户名即可
漏洞发现
首先我阅读了近几天被发现的漏洞 这个可以在这里找到.
发现大部分问题都只是简单的sql拼接 而且漏洞模式非常相似. 我在IDE下精心构造了几个正则表达式
由于时间比较久了 没记下 但是大概如下
第一个
$GLOBALS['dbi']->tryQuery(\$_[GET|POST][^)]*) 寻找在查询函数中被直接引入的请求变量
实际上上面效果不佳 因为大部分sql语句都不在查询函数构造 而且这个没有过滤已经被转义过的变量
第二个
'.*?'+.\$_POST 这个能找到简单的字符串拼接 但在复杂的函数调用中还是无能为力
最后我使用了两种方法结合 第一种跟踪$_GET|$_POST 第二种根据开发的变量命名习惯 将第二条修改为
$.*?query = \'.*?\'+.\$
成功在短时间内发现了问题
评价
在知名项目中 phpmyadmin应该属于最好挖 但漏洞影响很小的.在发现第一个时,我同时还有几个怀疑的注入,但毫无疑问那些也是接近于无的危害.
phpmyadmin只能使用你给的账号来查询,select注入是没什么意义的,无法提权.只有能导致高权限用户在进行某些操作时像update alter之类语句中注入或者xss才有意义,但利用难度也非常高
漏洞时间线
|
|
审计
在审计gogs代码时发现gogs的api允许渲染markdown.最初以为是无法利用的,但发现gogs这个api返回的content-type是html,并且没有csrf机制.
|
|
但这个api仅仅允许post方法,不能通过常见的get方法来进行xss.
构造poc
无法直接通过url 提交一个post请求,但可以通过form元素进行提交并直接重定向.
最简单的提交例子
|
|
这和csrf都是通过伪造请求来利用 只是csrf是通过xhr请求 这是通过form来得到需要的重定向.
最后的poc
|
|
漏洞时间线
|
|
前言
这次挖的其实没啥技术含量 但是从依赖挖掘到漏洞还是比较少见的.
挖掘过程
下载源码后,发现src目录有social_auth目录,并查看views.py(django的主要业务逻辑文件).
并注意到
|
|
sentry使用了django-sudo来做url验证,搜索这个库.发现这个库的实际新代码提交是2016年的.
这意味着如果在近些年出现过bypass,这个库并未进行修复. 快速的进行了谷歌搜索.很快就发现CVE-2017-7233 django的is_safe_url的绕过.
参考文章 https://paper.seebug.org/274/#cve-2017-7233-django-is95safe95url-urlbypass
通过对调用的分析 选择了logout作为简单的pochttp://127.0.0.1:9000/auth/logout/?next=https:1029415385. 点击sign out`将跳转到一个谷歌的ip
漏洞时间线
2019-12-24: 漏洞提交
2019-1-14: 问题已修复
2019年度进度
▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓ 100%
2019年要过完了, 博主今年又干了啥呢.
远行
基本没离开过家门 最远距离也就到县城和群内朋友家玩了一下
购物
今年618换了台新电脑 1t硬盘/32g内存/ryzen5 , 我这大奶配置离群内大佬的三奶配置都有一段距离,不过不得不说amd真香
旧的手机不小心摔了 只好在咸鱼几百块买了台小米max 屏幕挺大的.
写代码

中间半年全在摸鱼了 其他也没写出什么完整的项目.总体来说全年都在摸鱼了
挖src
今年第一次挖src, 挖了bilibili和网易.. 挖了十来个吧,都是低中危, 连一个严重级别的漏洞都没有..
网易src奖励其实不高 不过看在积分>10就给发新年礼物的面子上 还是挖了几个xss/重定向. 等元旦结束就会发了
代码审计
下半年(其实就是前一两月不摸鱼开始)审了不少php的cms. 大型中型小型的都看过,
小型非常好挖.. 挖到的没审到几十也有一打了, 不过并没有啥用.. 真正能换钱的就那几个
读书
全年都在摸鱼, 看书不多 读书列表 都是些阅读难度不大的杂书
番剧
1月番
-
笨拙之极的上野
-
天使降临到我身边! // 我永远喜欢小学生.jpg
4月
7月
- 流汗吧!健身少女
- 擅长捉弄人的高木同学2 // 这糖甜到掉牙了
- 街角魔族
10月
都是一些偏向搞笑/轻松的番剧
博客更新
换了两次主题, 一共更新了18篇博客, 平均每月更新超过了一篇(很多么) 主题大部分都是计算机安全
交际圈
qq群的朋友随着时间流逝在群里发言越来越少 , 一天也没几条发言.. 博主使用的社交平台也逐渐变成了tg.
也没什么资本认识啥大佬,总体来说只是正常的改变
技术总结
虽说有所成果, 不过离大佬的距离也就一个宇宙那么大.. 所用的知识也没什么升级, 需要进一步升级.. 也没做什么值得一说的工作..
学到的只是一些技巧性的东西, 虽然在挖洞上效果显著,但是对整体技术没啥用
明年展望
也不做什么计划,反正计划就是用来放弃的.. 希望明年学习方面能有所进步,读一些能带来进步的书… 同时能多做一些有价值的工作,而不是像挖洞/审计小cms这种带机械性的事..
写博客的话 能多写点不水的..
]]>前言
之前在挖某cms漏洞, 由于是tp框架的老牌cms, 便不想机械性去看sql注入和xss之类的.开始探索这个cms是否有一些有趣的代码
对加密算法的探索
很快我就发现这个cms使用了以下这段加密代码
|
|
虽然我不会密码学,但我也知道异或加密是不安全的. 于是开始对这函数开始分析.
异或加密简介
异或的定义为 两个值相同时就返回0,否则返回1. 异或的特性为 对这个数进行两次异或会返回这个值本身.
它有以下性质 设密文为A 用来异或的密钥为B. 如果B二进制表示全为0 则写为0
|
|
例如 0000000^10101111,由于左侧都是0,所以右侧为0的还是0,1的还是1.导致并没有任何改变.
对加密函数的思考
为了将问题分解, 首先对passport_key函数分析.
|
|
查看了cms对这个函数的调用, 实际传递的key是一个固定的16位随机生成数 . 所以爆破这个md5是不可能的. 但是可以发现实际上加密没用到这个$encrypt_key本身的值.
所以问题可以简化为 获取这个$encrypt_key的值.
|
|
这段代码可以总结为 用$encrypt_key对$txt逐位异或.
从上面的知识知道 利用A^0的特性, 传递0, 返回值将也是$encrypt_key
也就是只要我们可控$txt, 甚至不需要任何解密操作, 直接就能从返回值得到密钥.
但是cms并未直接调用这个函数, 需要进一步分析decrypt函数
|
|
这个函数将passport_key返回值两位两位异或后返回,导致返回值位数减半.
考虑我们之前的利用, 在这个函数运行后得到的其实是8位密钥两两异或后的值.
如果对异或值进行爆破, 密钥的值范围也就是php的md5函数的返回值范围 a-z0-9.
编写一个爆破函数
|
|
尝试破解一个字符
var_dump(crack("v"));
实际返回为
|
|
实际上单个字符的可能性空间是不定的,18是最少的了 而md5一共有32位字符 ,也就是最少也有18^16=1.21439531e20种组合,不可能两个字符两个字符的爆破成功.
不过这只是表象, 计算一下就会发现
设未知字符为x1,x2,爆破出来的是y1,y2,加密的两个字符是z1,z2
证
(z1^x1)^(z2^x2) 根据上面的交换律解括号得到 (x1^x2)^z1^z2 然(y1^y2)=(x1^x2)
得(z1^x1)^(z2^x2)=(z1^y1)^(z2^y2)
所以只需要随便在可能里选一种就行.
利用
已知加密是弱加密,只需要有一处可控输入和可知输出的接口就可以利用. 尝试搜索decrypt函数

只发现这处函数
|
|
满足条件,但是输出的是图片比较尴尬,尝试了一下全\x00
 虽说参数故意没添加干扰,这也没法肉眼辨认可能的不可视字符.
虽说参数故意没添加干扰,这也没法肉眼辨认可能的不可视字符.
只能通过更改攻击载荷来使得下面的字符变得可视化,只需要最后再与攻击载荷再进行一次异或就行了.
]]>前几天寻思着想挖几个通用的洞 于是在fofa poc列表上找找目标. 锁定目标为php cms 已有0day.
 很快就锁定到了这个
很快就锁定到了这个迅睿cms. 发现可以在gitee上下载.
废了好大力气 最后在fofa扫的时候才发现寥寥无几 基本可以忽略. 心态十分爆炸
上传文件
转移了<> 危害不大
|
|
poc
|
|
反射XSS
需登录 且有权限上传文件
poc http://127.0.0.1:8080/index.php?c=file&m=input_file_url&s=api&name=1%22%20onfocus=%22alert(%27xss%27);%20autofocus%20%22&fid=1
验证码dos
poc http://127.0.0.1:8080/index.php?c=api&m=captcha&s=api&width=4000&height=4000
类型
不需要特殊技巧 简单就可以确认的类型
GraphQL查询漏洞
Graphql作为一种前端查询语言 如未对查询进行限制 可以构造恶意查询 恶意消耗服务器资源.同时GraphQl的权限限制也是一大漏洞点
参考
https://blog.apollographql.com/securing-your-graphql-api-from-malicious-queries-16130a324a6b
jsonp响应头问题
jsonp响应头是text/html 可直接当作反射xss
重定向后执行
在对客户端重定向后 未终止程序 导致后面代码未预料的执行
|
|
web缓存欺骗攻击
网站在访问不存在文件时会返回404页面, 而假如网站对.js/.css 文件会进行缓存 且未对404情况处理. 404页面内保存有客户敏感信息(如csrf cookies)的话,使他访问一个不存在的.js文件.将会把他的敏感信息保存下来让攻击者查看
快速确认方法, 确认404页面构造和是否有缓存
XXE
解析XML文件的实体将导致执行任意命令 快速确认:任何使用xml作为输入的api都是值得尝试的
正则dos
一些错误的正则表达式将导致一个指数级的复杂度 输入一个特殊的匹配字符串将导致dos.
使用http://regex101.com/可以查看正则表达式匹配时实际使用的步数和时间.
常见模式\d{1:>20} (\d*)+
这个漏洞非常有趣
CORS配置问题
网站错误的配置将导致恶意网站可以跨域访问用户在此网站的信息
备份文件可猜测
网站生成备份文件名可猜测并且未防止访问的话 可以访问所有数据
平行越权
访问其他用户的数据或代表其他用户操作 常见于用userid参数的api 替换id就可以用对应id权限
验证码dos
验证码接受了长宽参数. 通过输入一个足够大的数字将消耗大量服务器资源. 快速确认 对验证码接口输入width和height 和修改
用户名枚举
对于不存在用户名和存在的情况存在两种响应 并不存在验证手段 攻击者可以枚举已存在的用户名
http头攻击
输入参数控制了响应头的一部分 并且可以插入\r\n 在http头输入任意内容.
可能性快速确认:输入参数存在于返回响应头
模板注入
控制模板文件内容 导致在解析时执行未预料的指令.
快速确认:输入模板常用的分割符和简单计算如 {{ 1+1 }} [[ 1+1 ]]
CSS注入
css也可以执行js代码
onMessage
js中的onMessage时间如果不进行限制 默认将会接收所有网站发出的postMessage . 现在开发一般对message信任 如果代码直接使用这部分数据作为html 将导致xss.
技巧
IE/EDGE浏览器未编码window.location.href
直接使用window.location.href作为html时 IE/edge浏览器未对这参数进行url编码
svg XSS
svg文件可以导致xss, 如果上传图片未限制.svg的话将存在漏洞
pdf xss
pdf可以加入js代码 将会导致xss
%00终止bash执行
bash执行时 如果命令中引号内有%00 将直接抛出错误
bypass 域名验证
如果是以正则 ^www.test.com作为验证 通过[email protected]绕过
如果是通过解析url再通过验证域名 可以通过浏览器对错误url的解析来绕过 例如
evil.com\\@test.com 实际上是evil.com 而解析url时域名解析成test.com 了
同样的/\google.com 将前往google.com
sentry SSRF
sentry是一个错误报告服务 但是配置不当 可能通过它的api来SSRF
GET CSRF
常见框架只对于POST 请求验证csrf 如果api允许get方法 将直接csrf
上传符号链接文件
访问符号链接文件时将访问到对应的真实文件 导致文件读取
<script>块内xss
'和"和<>任意一个未转义都可能导致xss
<script>块内不需要考虑逃脱'和"
例如
|
|
跳转xss
常见跳转页都是JavaScript操作的,如果将跳转地址改为JavaScript:xxx将把重定向漏洞升级为xss
jsonp xss
jsonp的content-type设置为text/html 未过滤callback的话就等于反射xss
最近由于一直在用的travis-ci出现了迷之bug,加上想尝试一下github action就决定尝试用github action替换travis-ci
选用action
github现有的action组件可以在这里查看. 如果想要自定义自己仓库的workflow,可以选用里面来进行组合.
不过hugo在github page的workflow,已经有人在这弄好了,
编写workflow
workflow定义是一个位于.github/workflows/的yaml文件.点开仓库的action按钮会出现引导界面
 显示一些常用的
显示一些常用的workflow 但由于我们要用并不在这里面 点击右上角的skip就行.
模板文件
|
|
设置secrets
之后需要设置secrets.secrets.ACTIONS_DEPLOY_KEY实际上是你的github Personal access tokens,申请后点击项目的setting,在secrets栏添加一个key名是PERSONAL_TOKEN的secrets即可
记录cms挖掘漏洞的几种下手方法
基于危险函数
最常见的应该是这种了 通过搜索常见的危险函数如assert|eval|system|file_put_contents|unserialize
来快速搜索可能存在的漏洞点 然后再追溯函数参数的引入位置.
寻找速度很快. 能直接找到的漏洞比较低级. 在使用框架的cms上 搜索上述函数基本都应该搜到框架里面去了. 对框架cms作用不大.
但如果拥有前置框架知识 则可以用框架内的危险函数 代替上述函数.如thinkphp的 where order等sql函数 如果使用字符串做参数 将不会进行过滤. 同时由于使用了框架简化代码 这种方法速度将非常快.
基于输入点
基于危险函数搜索存在一个问题, 如果搜索结果过多,然后大部分输入实际上并不是由我们可控的,会导致效率很低. 而基于输入点 则是按着只有我可控的输入才能导致漏洞的思路. 首先确定输入点 然后再按流程审计代码.
这种方法速度不快, 但能找到的漏洞类型全面. 而在框架型cms下 由于封装很多 这种方法需要进入的函数很多 速度更加慢了.
基于信任
被开发信任的外部输入值出现问题往往将会是漏洞.基于信任过程的审计非常直接,但考验对代码的熟悉度
验证
首先需要确认是否存在一些全局验证 和这些过滤器的实际效果是什么. 然后检查这些验证代码使用的位置(对象毫无疑问肯定是我们的输入)
底层函数
在确认验证是否有误时 必须知道底层函数的安全性. 首先不管如何封装 最底层函数都是无防护的 开发人员假设上层调用提供了足够的安全验证.而开发人员如果假设底层函数做了安全防护. 这一误差往往会导致漏洞的出现. 通过审计这些底层函数 来了解那些底层函数是不安全的. 追溯到cms实际使用的函数,就可以知道这些函数的安全性需要什么样的验证来保障.
#### 外部输入安全验证 在了解了函数的安全性后,检查外部输入的安全验证. 确认安全验证是否良好.比起从输入点审计全部代码的更快更直接.因为大部分代码是与实际漏洞无关的. 了解安全验证后,检查是否存在全局过滤.
业务逻辑
到实际业务逻辑时, 我们已经对cms的验证了如指掌,对于漏洞的搜索,从已知函数下手会比较快.直接搜索,从搜索结果基本可以确认那些是可能有危害的.(例如知道函数传入字符串才可能有漏洞,我们忽略其他参数为数组的搜索结果.)
结合我们了解的全局过滤(例如转义了所有标签)也可以忽略一部分. 然后在搜索结果 找到开发使用的过滤函数 基本可以得出这个漏洞到底存不存在了. 也就是一个判定,在这么多验证下是否能达成这个函数所需要的安全性.如果不能就是漏洞
实战
以yumyecms为例
从搜索危险函数下手
 令人失望的是 搜索到的结果不多 并且大部分都在类库文件里 检查剩下的反序列化函数 发现也是反序列从数据库中查询出来的数据.
令人失望的是 搜索到的结果不多 并且大部分都在类库文件里 检查剩下的反序列化函数 发现也是反序列从数据库中查询出来的数据.
快速确认这个框架是否使用了获取输入的函数,幸运的发现这个cms仍然在使用_ GET等超全局变量 进行搜索

首先我们可以忽略仅出现在判断语句里的结果,然后点开其他结果后发现 对变量进行了usafestr的过滤 并直接拼接到sql语句.在不查看这个过滤存在的情况下先认为这个变量已经是安全的.
查看所有前台可访问函数内变量后 发现未经过编码的只有core/app/shop/alipay.php 但沮丧的发现里面对提交参数进行了其他验证.
对此只能对代码进行更深一步的了解了 我们先从简单的sql注入入手 .
在之前的了解中我们可以知道this->db操作了数据库(实际上在这个有model层的cms 直接看model类就行了) 我们追着父类查找(其中使用了init.php定义的函数加载文件 但函数都很简单) 最终在core/lib/model.class.php 它使用了core/lib/yymysqli.class.php操作数据库
确认yymysqli的过滤 可以总结
- execute/insert方法的key参数/update的where参数是不安全的
根据这些信息 很快就能确认出model类的不安全函数
确认危险函数后 也需要确认外部参数的过滤 我们找到usafestr函数
|
|
其中的fliter_sql 和fliter_script 只是过滤常见关键字.
从这段代码可以看出 过滤了大量字符 最关键的单引号和双引号也被过滤了. 从这点可以确认我们寻找sql注入时绝不能使用单引号和双引号.
我们首先尝试搜索select这个危险函数

虽然都不需要引号 但只有最后一处是可控的.
|
|
很明显的漏洞 这cms还没报错处理 随便写点就报错了 .

代码审计是白盒测试的重要部分,对它的自动化探索也从未停止,但是在现实环境复杂度下现有的工具 实用性并不用.只能实现发现简单漏洞.本文讨论现有的代码审计工具和理论.
自动化代码审计
介绍常见的自动化审计
静态分析
最简单的方法自然是不对代码进行分析 直接进行正则匹配,发现危险模式.例如
|
|
自然就是一种危险模式,缺点不然而喻误报率高 检测率低. 优点则是容易实现 很简单就能集成到ci上,作为一种代码规范 自动不需要考虑误报率这个问题了. (检测出来就是你代码不符合安全规范)
污点分析
污点分析在安全人员的手工审计思路上可以体现为 先搜一下危险函数, 然后看看危险函数参数可不可控,在分析可不可控中 需要看之前的代码.
以下是现有工具的基本实现逻辑 污点分析基于对代码路径的分析,首先也需要标记危险函数和输入源(在php一般可以认为是$GET, $POST, $COOKIES). 和安全函数 然后对代码进行解析 生成语法树. 这方面已经有多个库实现了. 再寻找标记的危险函数和其参数, 然后参数就是输入源 基本可以确认是漏洞了. 如果不是 需要进行回溯 确认这个参数的来源. 在这个过程如果遇到安全函数进行过滤,则可以认为这里不存在漏洞.
污点分析理论上是没有问题 只是一种审计思路 当然在代码实现上存在一些问题. 例如安全函数过滤后并不能真的确认没有问题了, 换做真人审计肯定是要确认这些函数的效果. 这个问题在mvc框架下非常明显, 框架使用的安全函数太多了.
语义分析
要解决上面的问题, 彻底解析所有php代码,但基础函数并不能分析,必须提供基础函数的数据. 理解这些代码到底起了什么作用.
最后代码审计工具只需要声明 某函数不应该可以输入什么样的参数.例如 echo函数 不应可以输入 <xxx>的参数.
这里的判断可以归结于一个 约束求解. 首先一个外部输入源是不存在约束的,可以任意输入 然后例如通过intval函数后添加了一个约束 这个参数只能是0-9.
显然这种约束后 是不可能存在<xxx>的解的.
这种方法的优势很明显 但是实现非常困难 光是语义分析就没有已实现的例子.
结尾
本文总结了常见的自动代码审计实现,但自动化归自动化. 我们安全人员在审计时需要考虑这次审计对自身技术有提升么?重复在一些低劣cms上审计 固然是容易挖漏洞刷cve 但是对自身技术没什么帮助.
参考
http://blog.fatezero.org/2018/11/11/prvd/ https://wooyun.js.org/drops/PHP%E8%87%AA%E5%8A%A8%E5%8C%96%E7%99%BD%E7%9B%92%E5%AE%A1%E8%AE%A1%E6%8A%80%E6%9C%AF%E4%B8%8E%E5%AE%9E%E7%8E%B0.html
]]>对于本篇博客的标题 读者应该都不陌生了 毕竟大名鼎鼎的cpu漏洞就有利用这种侧信道攻击的. 这种攻击的难度也很大,但是作为一种攻击却是挺有意思的.攻击面也很广泛 因为只要是代码必然涉及到执行时间这个问题,只是差异有没有大到可以被攻击者检测出来的问题而已.
php的字符串时间攻击
这应该离web最近的了 这种漏洞在cve也有 如CVE-2019-18887
用一个最简单的代码举例
|
|
本质的问题是 php的字符串比较是用以下伪代码实现的
|
|
首先比较长度 不相同直接返回. 然后再比较各个字符.很显然如果长度不一样 将不会执行下面的代码 花的时间将会短一些. 可以通过比较时间来判断字符串的长度.
以现在的cpu速度 一个比较的时间几乎可以忽略不计. 也存在速度上的波动,但是只要尝试足够多的次数并平均(平均值总将趋向期望值) 总将可以猜测出它的长度和内容.
分支攻击
如果不使用php默认的字符串比较呢.时间攻击几乎不可避免的. 执行不同的代码可能导致执行时间不一致的分支几乎在所有代码中存在, 只要你使用了分支 执行的代码时间不一致 就可以进行猜测. 例如预先判断用户存在再判断密码的两条分支就可能进行用户枚举
|
|
缓存
上面的差异时间都比较小 而缓存造成的时间差异是非常显著的. 在开发时必须考虑缓存是否会导致时间攻击.这在web上问题比较少见,但是在硬件层面比较多. 例如cpu的Meltdown漏洞 就利用缓存的侧信道攻击
防御
时间攻击的本质就是输入数据导致代码执行时间不一致.处于安全绝对 我们只需要将代码的时间差异减少到一个足够的量级就行. 对于字符串比较 在php可以通过一个函数解决 hash_equals 它使用相同的时间比较. 对于分支攻击 只能在开发上注意了.
### 参考 https://blog.ircmaxell.com/2014/11/its-all-about-time.html https://eprint.iacr.org/2011/232.pdf
]]>mysql有着储存过程这个功能, 这次作者刚好遇到注入点在调用储存过程的sql注入.
基本知识
mysql可以通过以下语句创建一个储存过程
|
|
sp_name是名字, 为IN的参数是入参,为OUT的参数为返回值
调用储存过程的语句
|
|
注入分析
从语法我们可以分析出我们的输入可能出现在两处,和作为参数进入储存过程
|
|
首先如果对参数过滤不严,无需进入储存过程就可以直接注入.用以下语句为例
|
|
由于是直接执行,所以我们可直接注入语句例如(select 1).由于语法问题,这个括号是必须的,这语句就变成了
|
|
这种注入和普通注入差别不大,已有技巧基本可以套用.
如果参数不可控,但是方法名可控也可以进行注入.但是首先要得知一个存在的储存过程名,然后通过注释后续语句来进行自己语句
|
|
示例poc
|
|
可以看到和参数注入差距不大,只是用于参数不可控,或被安全处理的情况.
最后一种可能,在储存过程中出现.虽然储存过程被认为非常安全,但是实际上如果编写不慎 例如进行动态sql拼接 还是会出现注入的.. 例如
|
|
最后附上我遇上的一个漏洞代码
|
|
Bazel是一个由java编写的编译工具,支持多语言编译,扩展,远程缓存等大量功能.
下载
推荐通过https://github.com/bazelbuild/bazel/releases下载,
wget https://github.com/bazelbuild/bazel/releases/download/0.24.1/bazel-0.24.1-installer-linux-x86_64.sh
由于大家都知道的原因,下载速度很慢.建议在国外服务器下载
快速开始
Bazel使用两个特殊文件名 WORKSPACE 和BUILD定义项目.
WORKSPACE定义一个项目工作区,例如外部依赖和工具链,BUILD定义如何编译这个项目.允许用多个BUILD定义不同部分的编译操作.
在项目创建一个WORKSPACE文件.然后需要载入Bazel的golang扩展 .以下均为官方基础例子
|
|
一般来说都会使用gazelle工具来自动生成BUILD文件,而不是手写.添加以下加入WORKSPACE
|
|
在BUILD文件写入
|
|
然后运行
|
|
成功输出如下
|
|
进行编译
|
|
前言
跳转XSS实际上并不是一种新类型的攻击方式,
主要形成原因是 以前网站外部跳转时是直接接受参数然后跳转,导致了URL重定向漏洞.而现在网站喜欢加个跳转页,不会直接跳转,而是接受参数然后用js跳转. 这就有一个问题 如果未验证参数, js跳转时是可以接受JavaScript伪协议执行js代码的.
漏洞代码示例
|
|
实战例子
以拉勾网为例,作者打开页面都会先看看js里有什么信息.很快发现js里有这段代码
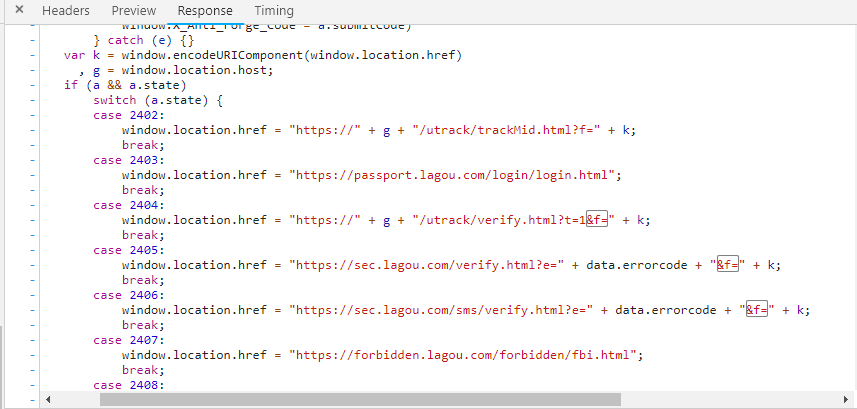
显然只有有参数的才能引起兴趣.作者快速尝试了https://sec.lagou.com/verify.html?e=test1&f=test2
发现url参数直接进入了页面,当然与本次主题有关的是参数f.虽然另一个更直接. 它在页面的位置是
|
|
尝试引入双引号.被转义了.所以这个参数就没问题了么?并不是.下面的代码使用了这个参数进行跳转.
可以使用https://sec.lagou.com/verify.html?e=1&f=JavaScript:alert(1)弹框.
最后
首先拉勾网是没有src的,别想了. 另外现在这个问题似乎已经修复了?访问 https://sec.lagou.com/parseSession会302..
e参数没修.e出现的代码为
|
|
双引号和单引号均被转义,有兴趣的读者可以作为对自己的挑战.还有过滤的waf
]]>挖src也将近两个月了,写篇博客总结一下.
首先挖洞成果 3中危 2低危, 收入~2k. 真实菜到扣脚,收入连泡面都吃不起.只挖了bilibili src.
另外新业务挖洞难度确实比较低,我甚至挖到了一个毫无难度的越权删除投票. bilibili 开新功能很频繁,我才能挖到这么多.一年半之前挖了一次,啥都没找到.
这次的漏洞挖掘主要是web方向,只用了浏览器,其他工具都没用.
成功挖掘到的漏洞分析
分享审核通过并已修复或无危害的漏洞供参考(非细节)
客户端dos
b站客户端加入了聊天功能,而聊天信息格式比较复杂.凡是复杂的格式都容易出现问题, 通过简单测试,发现通过构造畸形的json分享信息可直接崩溃客户端. 例如
msg[content]={"content":"test""}
奖金 30安全币 1安全币==10人民币
由于复杂格式,这种类型的漏洞应该还存在.事实上我测试时确实用第二种信息打崩溃了,不过忘记当时写的什么了
客户端越权
也是聊天系统的bug,未验证撤回信息者是否是信息发出人,导致可直接撤回他人信息.这个没什么技术含量,只是没人测试过这个功能,让我捡漏了而已.
奖金 20安全币
隐藏页面反射xss
这个xss其实也没什么技术含量,直接arg=payload . 没有被人发现是因为这个页面存在于登陆记录页面,然后我是坚持阅读js源码的,然后发现在js代码中有一段if 记录状态异常,就有一个按钮打开反馈页面.然后这个反馈页面存在反射xss.
重分说明阅读js源码重要性,没阅读或不碰巧账号异常是不会发现这个页面
奖金 65安全币
越权删除投票
没有任何技术含量,只是没人测试过
奖金 100安全币
前端验证
bilibili 专车号虽然打开要求账号认证,但是实际上是前端认证.通过打断点到验证处修改可直接通过,但是由于内部功能都需要审核被忽略了.
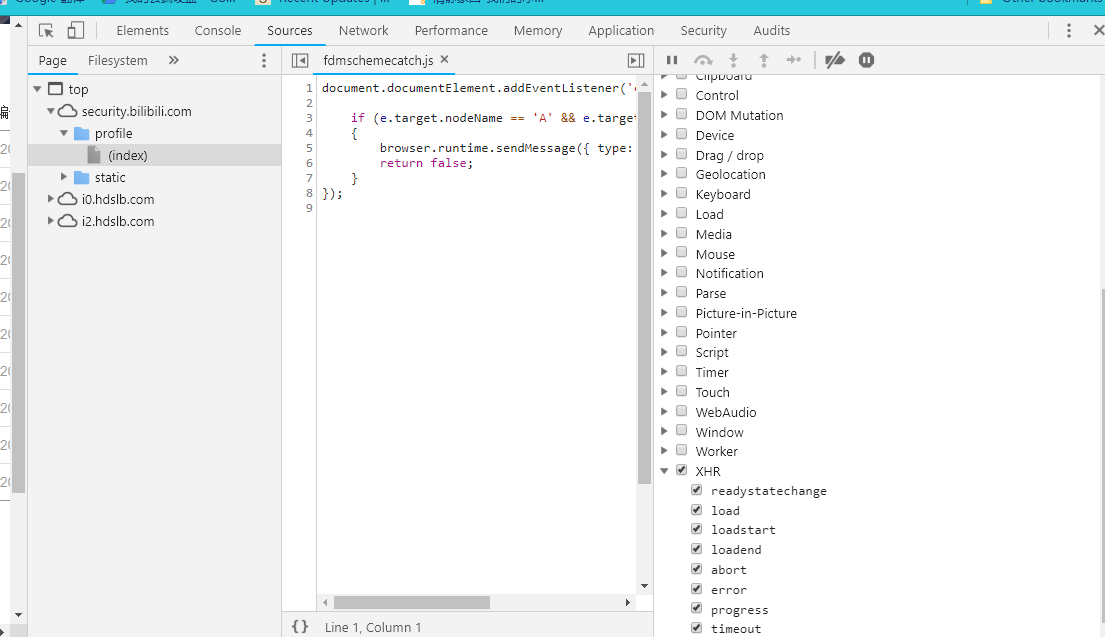
想快速找到你想要的代码,就要熟练使用chrome开发工具了. 在开发功能网络块可发现请求用户信息,所以可以通过断点XHR来定位代码.
方法如图
|
|

打出的日志中会包含js代码位置
未成功找到的思路
window postmessage
window.postmessage 允许跨域发送,是一种新的攻击向量,如果js代码中接受message并用来构建html,会导致xss .b站全站约有7-8处接受postmessage的代码,均未验证发送者. 但是很遗憾的是只有一处真正用传送的数据直接做为html,这处还要求传送的字符串 >0.导致无法利用做为xss
想知道当前页面有没有这个功能?很简单,打开开发工具 sources面板 global listeners
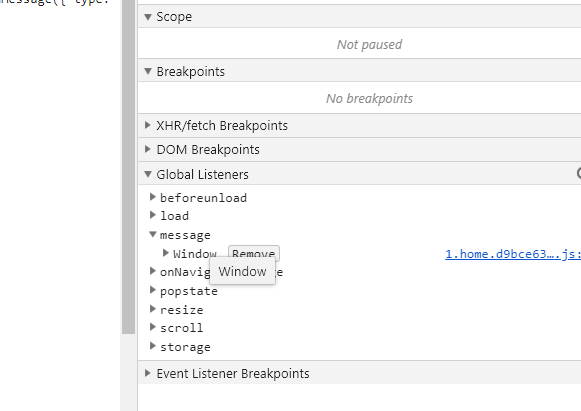
缓存攻击
缓存攻击最典型的就是
配置cdn会缓存.js/.css文件,然后404页面返回码也是200,并包含一些用户信息,攻击者可使受害者打开 /noexist.js的url,此时cdn会认为返回码200,后缀也是js.会将这个404页面缓存起来,然后攻击者可读取这个缓存来获取信息
很遗憾的是b站未符合上述条件,404就是404.并且使用的是现代化前端技术,未返回任何信息在html页面中,难以通过缓存来攻击
切换http方法 CSRF
注意到csrf参数只在post方法生效,试图转换成get方法来绕过csrf限制, 不过还没有找到同时允许get和post方法的api.能直接找到get方法的已经是csrf了(找到了一个还未修复)
]]>前言
首先定义本文所说的现代化网站. 现代化网站是指符合以下多个特征的对外服务.
-
储存,数据库,网站程序等服务器高度分离
-
实现现代化前端技术, 如三大框架, html5新api, websocket
-
基于虚拟化技术的服务部署
-
使用现代后端框架,如ssm,think5,gin,django
-
外部服务高度集成
-
多种客户端,包括Android,Ios,windows
篇幅有限, 不再列举,但相信读者应该能理解笔者的意思.
不属于现代化网站最典型的例子就是 下载cms,安装lnmp,直接安装网站程序. 现在渗透教程基本都是基于不属于现代化网站的假设(实际上我还没发现基于渗透现代化网站假设的教程)
现代化特征对渗透测试的影响
笔者按自己的思路逐个列举有影响的特征
CDN/反向代理
使用了CDN将会隐藏真实IP, 导致常规端口扫描,弱口令扫描全部失效. 但可以通过寻找真实ip来解决. 反向代理则无解, 甚至可能只把代理服务器暴露于公网.敏感服务全在内网
对绕过CDN这个问题, 已经有了一定的研究.有了安全工具, 如fuckcdn
数据分离
上传文件服务器分离,将导致上传webshell技术失效, 很显然文件服务器是不可能执行webshell的. 上传危害最多只能达到上传html
websocket
之所以专门把websocket作为一点, 是因为感觉websocket属于盲区, burp,浏览器均不支持websocket的渗透测试.
新的h5 api
html5提供了新的api,但是这方面的安全问题还没有被开发人员重视.这个可以从hackone平台上的漏洞报告看出.例如DOM Based XSS in www.hackerone.com via PostMessage .
postmessage这类api的输入是不可控的,如果不进行控制, 就是安全问题.
前后端分离
使用三大框架(vue,react, angular)的前端, 对后端进行分离. 也就是不再将url参数直接渲染到html,而通过JavaScript操作.反射xss全部失效,常规储存xss在框架的安全性下也变得渺茫. JavaScript操作带来的xss反而变为主流.这也对渗透测试人员阅读JavaScript代码带来了挑战 也带来了部分好处,由于在前端操作,后端暴露的接口将会更多.
后端框架
应用了框架后,简单注入全部失效,csrf部分失效, id=x这种低级注入消失.出现注入的点趋向二次注入, 编码注入. sqlmap是不提供原生支持的.
外部服务接入
对某些功能不自行进行开发,使用其他公司的服务.这部分功能的安全性取决与该公司的安全水平, 不过真挖出漏洞就属于通用0day了.
由于对接入服务的理解,接入处反而容易出现问题, 比如未预料的异常.(接入开发: ???,这个问题你怎么不在服务上处理.服务开发: ???,这个你怎么不在接入处处理)
多服务端
提供了多平台客户端, 这就对渗透测试多平台渗透能力发出了挑战. 不但要会web,还要会安卓/ios渗透测试, 反编译(客户端总是会有一些未公开的api).甚至还有IOT
风控
好的风控系统 基本阻止了邮箱/短信轰炸.对需要爆破的漏洞也降低了危害.
Xass
Sass, Pass,Fass等各种服务公司不断涌现, 可能出现刚拿下shell,想内网渗透,发现实际上服务是在某Sass上.或者发现服务api是在Fass上的,根本没有服务器
虚拟化
docker提供了优秀的服务分离,就算拿到了shell,也只是拿到了容器的shell. 容器虚拟化不一定安全,但是现在对这方面的研究还不是很多, 完全没有对绕过UAC的研究多.
对安全教程的思考
现在一些安全教程还是停留在旧时代, ' and 1=1,
</x><script>alert(1)</script>固然是基础,挖掘思路也很重要.
但是随着技术的发展, 渗透和开发技术也会走的更近, 新开发技术的爆发式增长,不可能像列中间件漏洞一样全部写出它们的渗透技术.就算有人写出来,等写出来黄花菜都凉了.
安全教程应该更强调编程, 而不是培养只会用扫描器的驻场工程师.令人欣慰的是现在年轻的渗透测试人员大部分都会编程,还不止一门(就笔者圈子来看).
对安全工具的思考
扫描器
随着技术的扩散,老式扫描器未来会面临失效.不支持浏览器模拟,只会抓a标签的扫描器, 对前后端分离无能为力. 基于流量和基于爬虫的扫描器会合并, 走向模拟获取流量进行扫描的模式 对app的扫描器目前不支持对web的渗透测试
人工智能
人工智能火热,各路安全公司都号称使用了AI技术(实际上怎么样就不知道了). 除了使用AI技术对AI进行对抗, AI扫描器也在发展中. 这部分知识,我推荐兜哥的AI安全三部曲.
可以重复的渗透测试动作,AI都可以模拟.随着发展,只会重复的渗透人员会面临淘汰.也能让安全人员拿出精力进行安全研究,而不是重复性的测试.
尾言
现在正是承前启后的时代,旧的开发技术未被淘汰,新的开发技术正在发展, 谁会在这个时代引领潮流, 或是被淘汰.让我们拭目以待吧
]]>electron是一款流行的桌面软件框架, 可以用js来写桌面软件, 快速开发.为了提高开发效率,不少公司比如白帽汇直接采用了这种技术编写客户端,而不是传统的c++,c#.. 以下均采用白帽汇的fofa客户端作为例子讲解,目的是让fofa客户端的扫描功能无需验证. 这个功能命令是直接调用cli的, 并不需要网络验证.
解包
electron的代码在resources目录,根据打包方式的不同, 可能看到app目录或者app.asar. 目录就不需要解包了.
asar并不是加密格式, 只是压缩格式. 可以使用asar工具直接解包.
下载方式
npm install -g asar
解包命令
asar extract app.asar <目录名>
例如asar extract app.asar fofa
代码目录
代码目录是什么样子全看开发者. 通常都会存在main.js和node_modules目录.main.js是启动文件
|
|
目录命名很清晰
调试功能
electron自带调试. 而且fofa的开发非常友好, 所有代码只有com目录的代码混淆了, 而且用的还是
|
|
注释也很友好,直接打开就看到
|
|
直接解开注释就行了.
mainWindow.webContents.openDevTools();
重打包
重打包很简单
asar pack fofa app.asar
直接覆盖原app.asar就行了
上面的修改效果如下
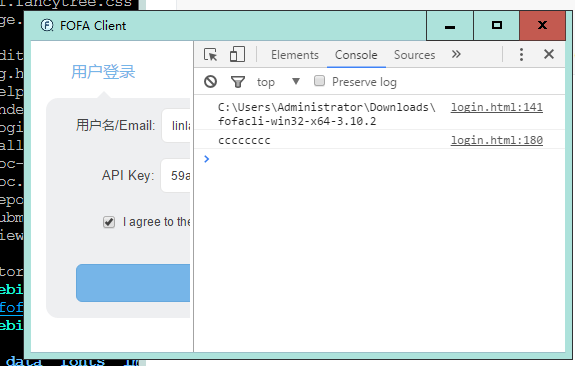
很眼熟吧, 就是chrome的调试功能
然后我们需要寻找功能点.其实很简单,fofa的网页都放在tpl目录了. 在页面查看元素对比一下就知道了. 我们找到tpl\edit-poc.html
网页没混淆… 功能点也没在混淆的js里,直接在script标签里了(我白解密了)..
看扫描按钮的文字是开始扫描, 直接在网页搜索一下, 直接搜到功能代码了..开发有良好的注释习惯,让我们为fofa开发点赞
|
|
查看isvipaaa函数
主要代码
|
|
可以看到就是三个if, 直接删除验证代码就完了..
|
|
让我们看看效果,重打包替换
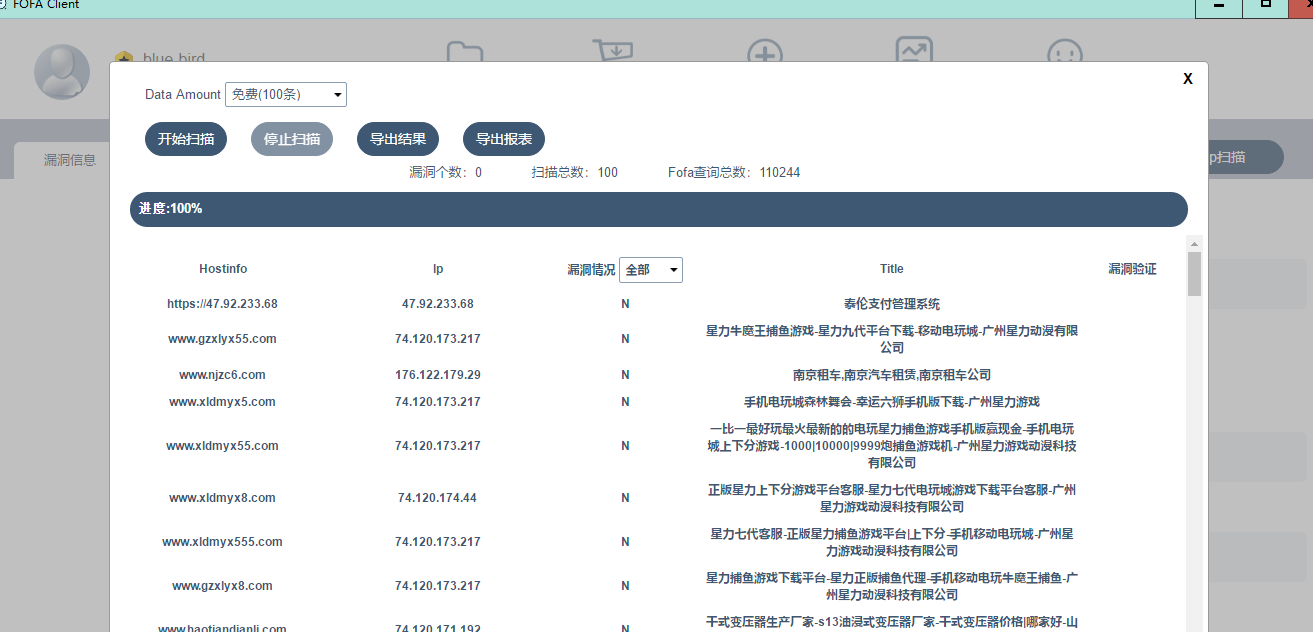
尾声
感觉这个功能限制并没有什么意义, 本质上是执行一条系统命令用fofascan扫描而已
]]>安全人员进行漏洞复现经常需要搭建漏洞环境, docker能够很方便搭建漏洞环境,同时提供相当好的性能,管理功能.
docker安装请参照空格表哥的这篇文章
搭建漏洞环境也有几种情况
-
已经有现成的docker镜像
-
只有源代码压缩包
-
漏洞软件开源
寻找已有docker镜像
dockerhub是官方的镜像仓库, 提供免费的公开镜像储存,也支持搜索 网站url
可以直接搜索镜像 https://hub.docker.com/search?q=<keyword>&type=image
docker命令行也支持搜索镜像 命令格式 docker search "keyword"
例如 docker search "think5"
从源代码搭建镜像
以zzzphp为例. github地址
Dockerfile知识快速普及
dockerfile是一个描述建造镜像流程的文件 每一行格式
<关键字> <n个参数>
搭建漏洞环境常用的几个关键字
FROM 镜像名 说明是从哪个镜像开始建造
COPY 本地路径 镜像路径 拷贝文件到镜像里
ENV 变量名 变量值 定义镜像内的环境变量
RUN 命令 在镜像运行一条命令
WORKDIR 路径 更改之后像RUN这类执行命令的路径
构建镜像
我挑选webdevops/php-apache-dev:ubuntu-15.10作为基础镜像, 这个镜像提供了非常快捷的搭建方法.
|
|
只需要三行就能搭建出一个php环境
第二行 COPY --chown=application:application . /var/www/html 拷贝当前目录到/var/www/html 并更改所有者成application:application .
application:application 是这个镜像的服务器用户, 更改文件权限否则服务器不能读写文件
ENV WEB_DOCUMENT_ROOT /var/www/html
WEB_DOCUMENT_ROOT是这个镜像的一个特殊环境变量 指向web目录
使用 docker build -t site . 建造镜像和命名为site
从git构建镜像
和从源代码构建的区别只是在于一个用COPY 一个在容器直接用RUN执行命令.
例子
|
|
只是简单的git clone到web目录和 chown -R更改文件权限
运行和数据库
用docker运行很简单docker run -d -p 外部端口:镜像端口 <镜像名>
如果运行site镜像就是 docker run -d -p 80:80 site
一个网站当然需要一个数据库 如果你的服务器有一个外部ip 那么很简单
docker run --name mysql -e MYSQL_ROOT_PASSWORD=password -p 3306:3306 mysql:5.6
填数据库地址的时候填外部ip即可
如果没有 可以用docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mysql 获取docker内部ip 填写内部ip即可
iwebshop最新版存在一个非常弱智的注入漏洞
主要导致原因 $id = IFilter::act(IReq::get('id'));
开发者忘记写成 IFilter::act(IReq::get('id'), 'int')了,导致直接注入. 在其他文件也存在这个问题.
这个文件需要商家账号才可以访问,是可以注册的
漏洞点 controllers/seller.php 函数categoryAjax
|
|
直接将id传入到catChild
|
|
直接将id拼接到sql查询中.. 这个cms有一点sql过滤,但是非常弱,也就ctf入门题的水平
lib/core/util/filter_class.php
|
|
不允许union 加空格,可是空格的代替很多 比如 %0d
poc
|
|
think5是一个非常流行的框架, 现在的cms很多都采用了think5作为开发框架.这就带来一个问题, 没用过的安全人员审计的时候就非常懵逼了.
例如 程序入口在哪? orm操作都是这种函数 Db::name($modeln['tablename'])->where('id',$id)->setInc('click'); 怎么操作才会出现sql注入?
这就需要框架知识了,但是学习整个框架又太多, 不学又不知道怎么审计.所以这个系列旨在带来足以审计的think5框架知识,而不太复杂
整体目录结构
think5 主要需要关注的目录如下
|
|
我们审计主要看application 目录
5.0 官方给的目录参考是
|
|
但是事实可能缺失很多部分 例如nonecms 的目录是
|
|
think5 url
最常见的think5 url是
http://serverName/index.php(或者其它应用入口文件)/模块/控制器/操作/[参数名/参数值...]
http://serverName/index.php(或者其它应用入口文件)?s=/模块/控制器/操作/[参数名/参数值...]
像
index.php/index/blog/read index.php?s=/index/blog/read
其他方式也有 但是基本大同小异 例如index/listing/index/cid/47.html
配置文件
think5.1 配置文件在config目录 5.0在application/config.php
常见的配置文件
app.php cache.php cookie.php database.php log.php session.php template.php trace.php
最重要的配置文件是app.php
主要需要关注的配置如下
|
|
app_debug 和 app_trace 建议设置成true.
调试模式下异常会显示详细信息,而不是通用报错界面
app_trace 则会在右下角显示一个按钮,根据设置可以显示执行路径,执行sql等等
如果没有显示,需要添加
|
|
如果没有看到这个设置 可能在trace.php中设置
|
|
xxx.php 对应的是app.php里的xxx设置
default_filter 可能的值是函数, 例如 strip_tags 等于对所有用户传入的参数执行过滤.
deny_module_list 则是禁止访问的模块
日志
config/log.php
|
|
默认路径是在runtime/log
数据库trace
app_trace设置后会发现并没有sql记录,这个需要在database.php添加
|
|
不过就算你看到你的sql注入进入了显示的语句, 但是由于thinkphp5的参数绑定, 很可能并没有生效.
路由
路由对审计影响其实不大, 毕竟url怎么改, 真正的执行代码也不会变.建议扫描性的看一下,是否有开发不小心把调试用的路由留在上面了..
]]>现代概率的一大特征是概率不确定性.古代概率研究的骰子可以认为每面的概率是1/6, 但是统计天气的时候, 就没有理由认为晴天和雨天的概率都是1/2.
概率函数在骰子只是简单的$\rho(任意一个数)= \frac{1}{6}$ . 在复杂的现实情况使用简单的函数是无法描述的.
偏差和方差
如果怀疑赌场的骰子大小游戏有问题, 要怎么去验证它这个问题. 一种思路是认为如果1,2,3,4,5,6出现的概率不一样 就是有问题. 换种等价方法描述就是 骰子期望$E(X)=3.5$ . 这个骰子均值也应该是3.5.
那么衡量离理想骰子距离也有几种方法 除了最简单的均值.
偏差 所有发生事件 $X = [x_1, x_2 … x_n]$ 偏差 $ = \sum_n E(X) - x_n$
例如连续出现5个6 $65 - 3.55 = 2.5*5$ 但是连续5个6并不是现实的小概率事件. 如果发生连续5个6就认为骰子有问题显然是不行的. 而且偏差求的是平均, 两边偏差会抵消 $[3,4,3,4]$ 这种的偏差也是0,
方差则是偏差的平方 $ \sum_n (E(X) - x_n)^2$ 方差是一个衡量离散度的标准
大数定律
我们已经知道统计会出现偏差, 那么如何确定偏差是否是骰子本身的问题呢. 初中就有教, 统计次数越大, 越可能接近均值.
用数学表达就是伯努利大数律 任意给定两个数 $\epsilon$, $\eta$ .含义分别是离均值的距离和离均值的概率. 事件总值是$X$, 存在一个抽取次数$N$ 使得 $\rho(| \frac{X}{N}|>\epsilon ) < \eta$
伯努利证明时并没有方差, 但是他还是用概率的方法证明了.
证明参考 数理统计学简史 第一章注3
现在我们知道只是切比雪夫不等式的一个推论.
$\rho(|X-E(X)| > b\sigma) \geq \frac{1}{b^2}$ $\sigma$ 是方差的平方根 也叫标准差 X是随机变量
这个不等式之前还有一个马可夫不等式
$P(X\geq a) \leq \frac{E(x)}{a}$
这个就比较容易理解了. 如果a取值范围是在x之间.
将$Y=(X-\epsilon)^2$ $a=(kσ)^2$代入马可夫不等式
$\rho((X-\epsilon)^2)\geq kσ^2)\leq \frac{E(X-\epsilon)^2}{kσ^2)} = \frac{σ^2}{kσ^2} =\frac{1}{k^2} $
概率函数和累计分布函数
如果随机变量是X,
概率函数$\rho$
$\rho(x) = x的概率$
硬币抛出多少次正面的概率分布. 因为只有两个可能性的情况太常见,也被称为二次分布.
n是总数量 k是正的数量 p是正的概率 二项式分布 $b(n, k, p ) = \frac{n!}{k!(n-k)!}p^k(1-p)^{n-k} $
前面组合公式很显然, 后面$p^k$是抛出这么多次正面的概率 $(1-p)^{n-k}$则相反
用二项分布可以计算出硬币概率分布 $ \rho(k)=\frac{n!}{k!(n-k)!}\frac{1}{2}^k\frac{1}{2}^{n-k}$
它的期望是$E(X) = np$ 因为二项分布是n次相同实验组合的. 不管抛多少次 期望都是正面的几率$p$ 再乘以总数量
方差是$\sigma^2 = np(1-p)$
累计分布函数f是
$\rho(X \leq x) =f(x)$
分布函数是概率函数的积分, 所以最终将变成1,
贝叶斯公式
我们在概率定义知道 独立变量a,b有 $P(b|a) = P(a,b)/P(a)$ 和$P(a,b) = P(a|b)*P(b)$
将后项带入前项 得$P(b|a) = P(a|b)*P(b)/P(a)$
独立变量, 也就是两个变量不相互影响. 天气自然是和骰子没什么关系, 但是骰子掷出双数和骰子掷出6自然是有关系. 在概率学上的定义是协方差, X, Y的期望值是$\mu$和$v$
$Cov(X, Y) = E((X-\mu)(Y-v))$
为什么这么定义呢. 这两个期望分开定义 都是0. 现在放到一起如果不是0, 说明存在相互影响. 期望值的大小也代表影响的方向
二项分布逼近
高斯分布可谓是第一重要的分布 它其实是二项分布的逼近, 然后得出的函数.
在历史上首先研究这个问题的是棣莫弗, 他一开始研究的对象 是$b(2m, 1/2, m)$
m是2m的中项 然后 $b(m)/b(m+d)$ 中项和偏离中项的关系
然后他的朋友斯特林出现, 并使用斯特林公式算了一下
$b(2m, 1/2. m) \approx \frac{2}{mn}$
$\frac{b(m+d)}{bm}\approx e^-\frac{2d^2}{n}$
$b(m+d) \approx \frac{2}{\sqrt{2πn}} e^-\frac{2d^2}{n} $
使用上式的结果,并在二项概率累加求和的过程中近似的使用定积分代替求和,得到
$p_d \approx \sum_{-d\leq m-i\leq d} \frac{2}{\sqrt{2πn}} e^{-2\frac{d}{\sqrt{n}}^2} \approx \frac{2}{\sqrt{2π}}\int^\frac{d}{\sqrt{n}}{-\frac{d}{\sqrt{n}}} e^{-2x^2}dx = \frac{1}{\sqrt{2π}}\int^\frac{2d}{\sqrt{n}}{-\frac{2d}{\sqrt{n}}} e^{\frac{x^2}{-2}}dx $
将d换成$\frac{c}{\sqrt{n}}$ 可得$ \frac{1}{\sqrt{2π}}\int^{2c}_{-2c} e^{-{\frac{x^2}{2}}}dx $ 熟悉的高斯分布
这个公式有什么特殊之处呢 $\frac{1}{\sqrt{2π}}\int^{\infty}_{-\infty} e^{-{\frac{x^2}{2}}}dx =1 $
$\int^{\infty}_{-\infty} e^{-{\frac{x^2}{2}}}dx$ 也叫高斯积分
参考
数理统计简史
程序员的数学2
概率论与梳理统计
]]>概率的一个定义是一件事发生的一个情况的几率. 也可以表示成$f(\Omega, \omega, \varrho)$
古典概率研究的是比较简单的情况, 例如硬币,骰子, 扑克的排列组合. 难度其实也只是低等数学水平, 排列组合问题小学应该就有了. 从常见的问题引入很容易理解, 但是直接看公式可能反而不懂了.
概率的定义和常见错误
当我们谈概率的时候, 例如A城市今年雾霾的几率是30%. 概率的定义是什么,
概率是一件事发生的可能性大小, 但是显然会存在误差. 只有在无限次重复下才会接近, 这是现代的一个定义.
古典概率下因为研究的是硬币, 骰子投掷这类问题, 在没有其他因素下, 完全可以确定一件事情的发生几率.现代概率学研究如人获得某疾病的几率 则需要大量重复的事件来计算.
谈概率当然不能离开事, 在数学定义概率需要 事件的集合$\Omega$ 和概率函数$\rho$ . $\rho$ 给定条件得到发生的几率.
用上面的例子 事件的集合就是 A城市今年每天的天气. $\rho(天气=雾霾) = 0.3$
如果给定两个条件, 就被称为联合概率. 例如 $\rho(天气=雾霾, 日期=星期日)$ . 也就是两件事同时发生的概率.
如果将一个条件作为前提, 则是条件概率 例如$p(天气=雾霾 | 日期=星期天)$ . 也就是发生了第一件事后, 再发生第二件事的概率.
经典的一句话. 炮弹不会落到同一个弹坑 躲炮弹要到炮弹之前落到的地方. 很多人认为这是正确的, 两次也就是概率的平方可能性非常小. 计算是正确的, 但是对于躲炮弹的人 概率中这个事件的集合并不是两次落到同一个弹坑 , 而只是一次.
这句话对的原因是因为炮的后坐力
黑天鹅事件则是对经济学家的估计概率中的可能性没有小概率事件最好的讽刺
概率计算
概率计算有两种视角, 从单次事件出发和从全局出发.例如
求投掷硬币3次, 3次正面的概率.
从单次事件出发 每次正面的概率是1/2 3次 $\frac{1}{2}^3=\frac{1}{8}$
从全局出发 一次投掷硬币将增加一倍的可能事件 一共可能发生的有$2^3=8$ 因为是单次事件得 $\frac{1}{8}$
得到的结果和计算难度差不多 . 但是我们换一个经典的问题
A,B二人赌博,各出赌金 a 元,他们拥有相同的获胜概率,约定,谁先获得3场胜利,谁获得 10元的全部赌注金,但是由于某种原因,赌博无法进行,此时 A获得了 2 场胜利,B获得了 1场胜利, 那么我们应该怎么把赌注分给两人才算是公平?
从单次事件出发. 下一局A获胜的概率是1/2, 如果不获胜下一轮获胜的概率也是1/2, $\frac{1}{2}+\frac{1}{2}^2=\frac{3}{4}$
虽然这道题推导到这就结束了, 但是可以意识到如果离胜局越远 需要计算的越远.
如果从全局出发, 接下来最多可能继续赌2局, 也就是$2^2=4$ 种可能性. 如果乙要赢, 它需要的可能性只有一种. 也就是1/4 甲就是3/4
在这里可以清楚的看到这两种思路的差异.一般人在生活中会使用从自身出发的角度, 没什么问题.但是学习统计学, 应该要熟悉的使用从全局出发的角度.
概率之间的关系
如果事件中只有a和b这两个变量. 联合概率$\rho(a, b)$ 是 a和b区域的交集在全部区域的几率. 条件概率$\rho(b|a)$ 是在a区域下, b区域占a区域的几率. 显然这两个概率的差异在于分母. 分别是全部区域和a区域. 而
$a区域/p(a) = 全部区域$
$a和b区域/p(a) = 如果全都是a区域下的b区域数量$
所以
$\rho(b|a) /\rho(a) =\rho(b) $
$p(a,b)/p(a) = p(b|a)$
常用公式
如果从全局出发, 本质是排列组合问题. n个中选择m个的问题.
投掷5次硬币3次是正面的概率, 就是在5次中3次是正面的组合数除以所有可能性.
投掷N次的所有可能性非常好计算 单次可能性数量的N次方
公式有几种导出思路.
首先有排列公式 排列与所有可能性的差异在于 每次选择后单次可能性-1 假设n次 排列的是r个
$P(n, r) = n(n-1)(n-2)…(n-r+1) = n! / (n − r)!$
组合则是不再考虑顺序, 一个组合内的任何可能性都是一样的.所以我们知道一个组合的可能性乘以组合的排列可能性$r!$ 等于排列公式
$C(n, r) = P(n, r) /r!$
.
期望
你预期你下次考试多少分? 预期就是期望. 当你投掷一枚骰子, 出现多少点会认为投出比较大的点数了呢.
期望的一个数学定义是 $E(X) = \int_\Omega Xd\rho $ $\Omega$ 是所有事件的集合 $Xd\rho$ 是每种事件的值$X$乘它的概率$d \rho$
例如投一次骰子
$$\operatorname{E}(X) = 1 \cdot \frac{1}{6} + 2 \cdot \frac{1}{6} + 3 \cdot \frac{1}{6} +4 \cdot \frac{1}{6} + 5 \cdot \frac{1}{6} + 6 \cdot \frac{1}{6} = \frac{1 + 2 + 3 + 4 + 5 + 6}{6} = 3.5$$
]]>libfuzz honggfuzz KernelFuzzer 也有专注进行web fuzz的wfuzz 但是fuzz功能可以分成两种 只是生成测试用例和检测程序使用测试用例后异常 这次使用radamsa和afl作为这两类工具
radamsa
安装
官方给出的命令
|
|
如何使用
|
|
echo "aaa"可换成任意输出内容的命令 如cat test.txt
常用选项
|
|
fuzz 命令行程序
从命令行读取数据
典型就是md5sum
测试fuzz命令例子
echo "test" | radamsa | md5sum -
当然不可能fuzz一次就执行一行命令 编写一个简单的脚本 shell or python? python!
|
|
只是简单的单线程执行 但是存在两个问题 如何记录崩溃和崩溃输入 这个时候-seek就能使用了 同时通过判断system函数的返回值 修改为
|
|
我们的第一个fuzz程序(虽然这个脚本很简陋)
文件fuzz
和命令行主要区别只是读取方式和 文件格式一般会有一定要求 否则不能进入程序执行流程.所以一般fuzz严格的文件格式要使用专门的生成框架.
生成fuzz文件方法很简单
echo "test" | radamsa --output 'testfile'
读取文件生成
radamsa --output 'testfile' -g file testfile
网络fuzz
虽然radmasa提供了这个选项 由于协议格式基本都是一个错误字节就报错 所以推荐使用Mutiny来进行网络fuzz
echo "test" | radamsa --output ':80'
afl
介绍
这款工具除了可以自动从输入fuzz 还能自动检测崩溃 超时. 最大亮点是使用了 编译器插桩 在运行时通过编译时插入的代码可以了解到代码运行路径 覆盖率等信息
安装
|
|
使用
常用参数
|
|
例子
|
|
实际操作
从github选一个作为实际对象 我使用高级搜索 指定>500star c语言的项目后随意找了一个
|
|
实际选择指南
- star星数是很好的指标 代表发现的漏洞的影响力
- 选择 c/c++
- 优先选择可以直接编译成程序的 fuzz库还需要去学习怎么写成库入口程序进行fuzz
- 优先选择有完善的测试用例的 如jpg xml 或者自带
- 代码越多漏洞越多
- 如果是本地命令行程序或难以利用的程序 做好发现漏洞被忽略的准备
需要使用afl-gcc执行了编译 常用将gcc替换成afl-gcc的方法 (如果不经常进行编译)
|
|
然后
|
|
实际使用编译工具不同 可能需要查询文档 当然你只fuzz不做其他编译直接mv afl-gcc gcc也行
编译
|
|
确认输出中的 checking for gcc... xxxx 是你的afl-fuzz 如果不是请执行上面的替换方法
|
|
这个程序提供了测试用例在test目录 如果fuzz其他程序没有提供 就需要自己寻找
需要注意几点
- 尽量覆盖全部可能的格式
- 畸形并符合文件格式
- 不要存在大量无用数据 像一个3000像素大小的红色正方形图片比一个30像素的 在fuzz时并没有功能提升 只会让fuzz程序大量修改到没有用的图片数据区
这个samtools 有多个功能 我们测试split这个功能 (q:为什么 a:因为我只在这个找到了崩溃 你想试试其他功能和用例也可以)
|
|
稍等一会 就可以看到产生了崩溃

停止后 文件保存位置 你选择的输出目录这次是out/crashes/
测试崩溃
./samtools split out/crashes/id:000000,sig:11,src:000015,op:flip2,pos:2
应用崩溃了
fish: “./samtools split out/crashes/id…” terminated by signal SIGSEGV (Address boundary error)
之后?
可以选择构造exp当自己的0day 或者提交给开发者 我是倾向于提交给开发者的 而且构造exp已经有很多书籍
提交是什么
通知开发者程序存在问题 让开发者进行修复。
怎么提交?
根据程序开发者的不同 具体可能是(非全面)
- 小型商业公司 无漏洞奖金计划 我们可以从网上找到它的联系邮件 邮件通知
- 大型商业公司 有漏洞奖金计划 使用计划中的提交方式
- 开发者 非开源 邮件通知
- 开发者 托管在github等 如果问题不大可以直接使用issue 如果是远程利用之类请通知开发者
一般都需要提供以下信息
- os信息
- 程序版本信息
- 崩溃样本
- 其他信息
为什么要提交?
修复漏洞 防止用户收到攻击 为网络安全做贡献 当然也有其他现实因素 比如危害太小不提交也没用 简历加分等等
]]>为什么将python作为官方支持语言
- 很多不是metasploit官方人员编程的模块都是使用python编写
- 现在python流行程度非常高 很多渗透人员python熟练程度比ruby高
metasploit的python模块是什么
主分支的一个python模块 https://github.com/rapid7/metasploit-framework/blob/778e69f92912c555e72bc3318278443126704b75/modules/auxiliary/dos/http/slowloris.py
python模块实际是通过json-rpc调用与metasploit通信
metasploit获取元数据如图(来自官方博客)
|
|
模块调用如图
|
|
将会发生什么
实际上对于原来的开发方式没有影响,完全可以使用原来的ruby编写方式.但是对于不熟悉ruby的开发者可以使用python来方便的编写模块
python在metasploit能做什么
可以使用的和ruby模块并没有区别
如何编写一个python模块
首先需要导入需要的模块
|
|
这个metasploit实际上路径是 lib/msf/core/modules/external/python/
然后定义元数据 格式和ruby模块的一样.详细可参考这里的文档
|
|
然后一般应该定义一个run方法.这个demo输出了helloworld
|
|
最后定义主方法
|
|
让我们实际跑一下(注意请给你的python文件添加执行权限)
|
|
metasploit的扩展实现的代码主要在metasploit-framework/lib/msf/core/modules/external
目录结构如下
|
|
其中python目录的py代码将会在我们运行python模块时加入python路径.这也是为什么我们能导入metasploit
templates目录则是用于实现将python代码变成模块的代码模板.事实上我们能使用msf对正常模块的功能 如info都是靠这些模板实现的.
message.rb和bridge是与msf jsonrpc通信的一些api.
shim.rb则是真正将python代码实现为模块的代码.
这里省略了不重要的细节的message.rb代码
|
|
这个类实际上是对传递给metasploit的信息的一个封装.
initialize是ruby的初始化方法 从这里可以看到它有三个属性method params id
from_module方法则是用于将传递的参数转换成自身
to_json方法很明显就是转换成一个可用的json(jsonrpc传递需要json格式)
这里是省略了不重要的细节的bridge.rb代码
|
|
这里是省略了不重要的细节的shim.rb代码
|
|
所以python模块的运行过程其实是这样的
- class Msf::Modules::External::Shim获取到了模块路径
- 调用Msf::Modules::External::Bridge.open
- 在open方法 Msf::Modules::External::PyBridge::applies判断成功(也就是确认了是python模块)
- 初始化一个Msf::Modules::External::PyBridge并返回
- 判断元数据类型 假设是dos 则调用dos方法
- 调用mod_meta_common方法转换元数据 渲染代码模板
我们可以查看dos.erb的内容
|
|
所以事实上python模块的实现就是将python代码中元数据传递到代码模板 然后实际上调用的还是ruby模板 我们的python文件路径将会出现在
|
|
最后通过bridge.run调用.这种扩展方法不但没有失去对ruby模块的强大支持也没丢失python的灵活性 非常好