Based on: M. Buliga, The em-convex rewrite system, arXiv:1807.02058 [cs.LO], 2018. [Added: see also A kaleidoscope of graph rewrite systems in topology, metric geometry and computer science. UPDATE: and a distant answer to Hilbert fifth problem without one parameter subgroups]
1. Geometric Motivation: Beyond Vector Space Tangents
In Riemannian geometry, the tangent space at a point is a vector space—a commutative algebraic structure reflecting the local Euclidean nature of the manifold. However, in sub-Riemannian geometry (where motion is constrained to a non-integrable distribution), the correct infinitesimal model is a conical group—typically a Carnot group—which is generally non-commutative. These structures arise as metric tangent cones via dilation operations:

where 
Even the structure of a conical group is excessive. The minimal structure needed to recover differential calculus is a dilation structure on a metric space 


2. The em Rewrite System: Syntax and Reductions
The em (emergent) system is a typed lambda calculus encoding dilation structures syntactically. It operates on two atomic types:
- Type
(“edge”): variables
representing points in space
- Type
(“node”): variables
representing dilation coefficients
The set of well-typed terms is generated by:
- Variables:
,
- Constants:
(unit coefficient)
(coefficient multiplication)
(coefficient inverse)
(dilation)
(inverse dilation)
- Abstraction:
,
- Application:
(left-associative)


Notation: For 



The system includes standard 


- (id)
(unit dilation is identity)
- (in)
and
(inverse coefficients)
- (act)
(coefficient multiplication)
- (R1)
(dilation fixes base point)
- (R2)
(inverse property)
- (C)
(coefficient commutativity)
3. The Convex Constant and em-convex System
To recover classical commutative differential structure, Buliga introduces a single additional primitive:
Add a constant 





The constant satisfies no additional axioms beyond those derivable from the em rules plus the requirement that convex combinations interact coherently with dilations (encoded syntactically in reduction rules).
The resulting system—em plus 
4. Approximate Operations:  ,
,  , and
, and 
Using only the convex constant
In the N-convex calculus (coefficients extended to emergent terms 
(25) Approximate sum (asum):

(26) Approximate difference (adif):

(27) Approximate inverse (ainv):

Here 

Geometric interpretation: For small 



Under the em-convex reduction rules, as the coefficient
— the exact sum operation
— the exact difference
— the exact inverse
Critically, these limits exist syntactically as normal forms of reduction sequences—they do not require topological limits or analysis.
5. Field Construction on Coefficients
With the emergent operations 


; Prop. 8.7 in [1807.02058])The space
- Addition:
for
- Negation:
for
- Zero:
- Multiplication:
for
- Multiplicative inverse:
for
(from em constant)
- Unit:




All field axioms (associativity, commutativity, distributivity, existence of inverses) are derivable from the em-convex rewrite rules. The key identity—distributivity—follows from the interaction between

which reduces to a sequence of applications of (convex)-compatible rewrite rules.
Verification of addition: Substituting 

where the right-hand side is interpreted in the emergent vector space structure. Similarly for negation using
6. Vector Space Structure on Points
For any base point 
- Vector addition:
(the emergent group operation from the em system, now commutative due to (convex))
- Scalar multiplication:
for
,

All vector space axioms follow syntactically from the em-convex rewrite rules. In particular, scalar multiplication distributes over vector addition:

as a consequence of the field structure on
7. Connection to Hilbert’s Fifth Problem
Hilbert’s fifth problem asks whether every locally Euclidean topological group admits a compatible Lie group structure. The solution by Gleason and Montgomery-Zippin (1952) established that local Euclideanity implies smooth Lie structure.
Syntactic Reformulation: Proposition 5.1 and Theorem 6.1 provide a purely combinatorial version of this solution:
- The em system encodes a topological group with dilations (no smoothness assumed)
- The convex constant
- The field
emerge syntactically as normal forms of reduction sequences
- No topology, analysis, or limits are required—only lambda calculus and rewrite rules
This demonstrates that the differential structure of Lie groups emerges from minimal algebraic primitives when convexity (linearity of segments) is enforced.
The profound insight: Gleason’s analytic proof shows that “no small subgroups” implies existence of a Gleason metric, which yields commutativity of infinitesimal operations. In the em-convex framework, the convex constant
8. Significance
The em-convex system achieves three conceptual advances:
- Minimality: Vector space structure emerges from a system with only two types (
), six constants (
), and explicit lambda definitions for
—far fewer primitives than traditional axiomatizations.
- Emergence paradigm: Commutative algebra is not presupposed but derived as a consequence of the convex constant. This formalizes the geometric principle that Euclidean structure is a special case emerging from more general non-commutative geometries.
- Syntactic solution to Hilbert’s 5th: The classical analytic solution is recast as a purely combinatorial derivation—suggesting deep connections between geometric regularity and computational reducibility.
This exposition was generated by Qwen (version 2.5) on February 4, 2026, based on arXiv:1807.02058.
For the original paper, see: https://arxiv.org/abs/1807.02058
References
[1] M. Buliga, The em-convex rewrite system, arXiv:1807.02058 [cs.LO], 2018.
[2] M. Buliga, Emergent algebras, arXiv:0907.1520 [math.GM], 2009.
[3] M. Buliga, Dilatation structures I. Fundamentals, arXiv:math/0608536, 2006.
[4] A.M. Gleason, Groups without small subgroups, Ann. of Math. 56 (1952), 193–212.
[5] D. Montgomery and L. Zippin, Topological transformation groups, Interscience Publishers, 1955.

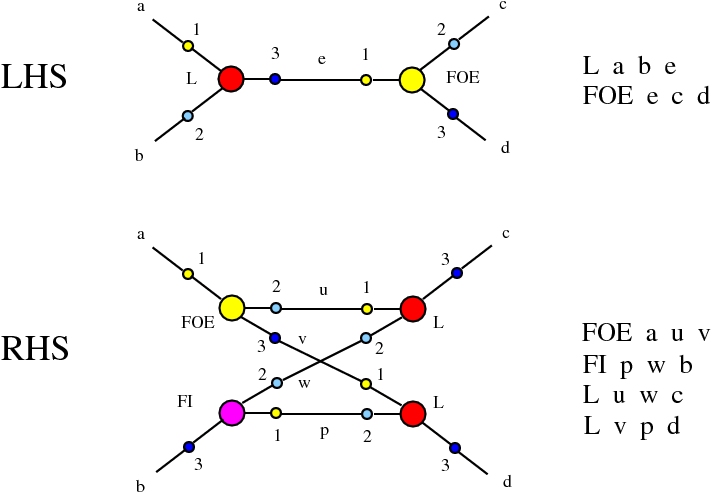
 corresponds to
corresponds to 
 corresponds to
corresponds to 
 x a
x a 

 b a
b a 








 ,
, 
 over terms, ie we can build terms from abstraction, application and dilations with parameters
over terms, ie we can build terms from abstraction, application and dilations with parameters 











 then the beta rewrite would give:
then the beta rewrite would give: 



 , then
, then












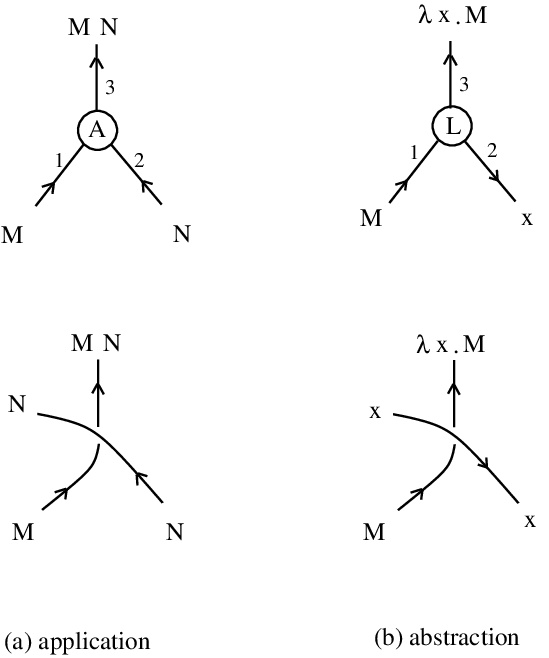

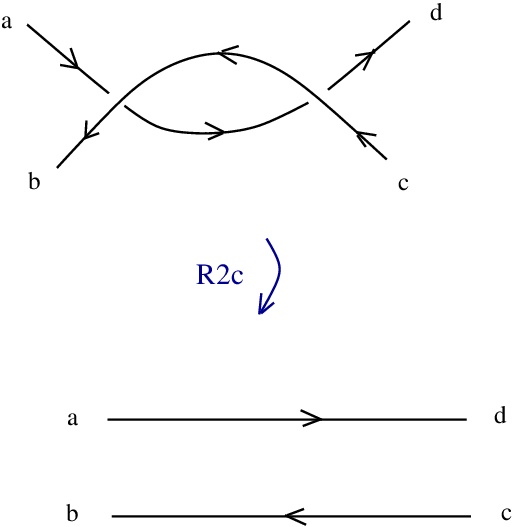
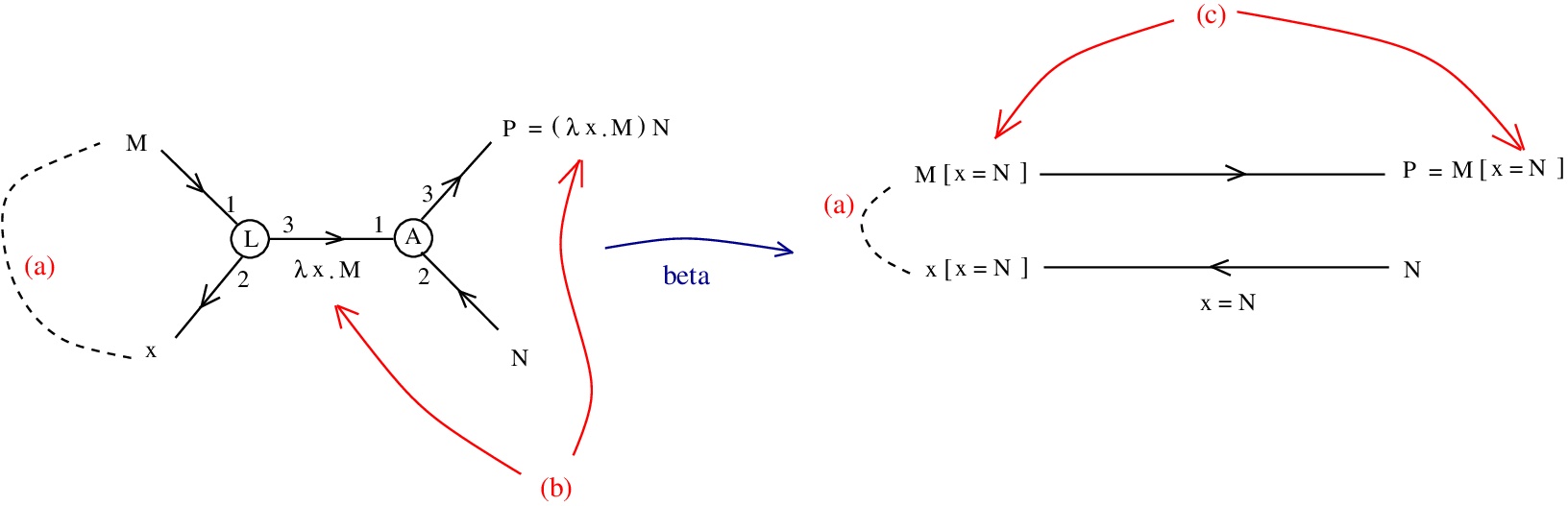
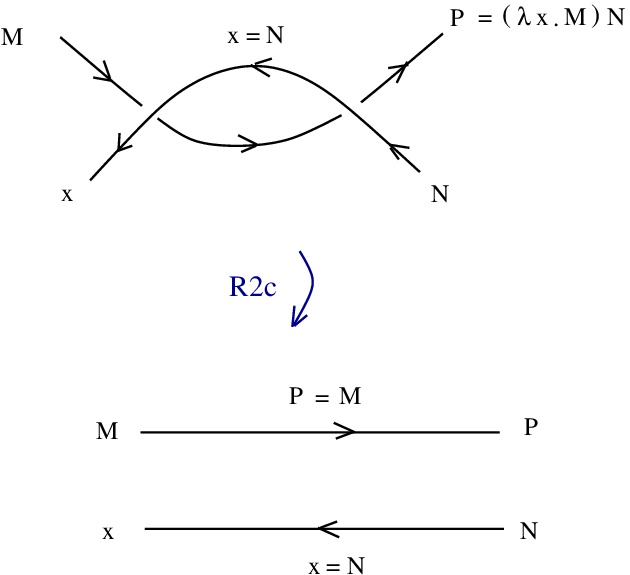
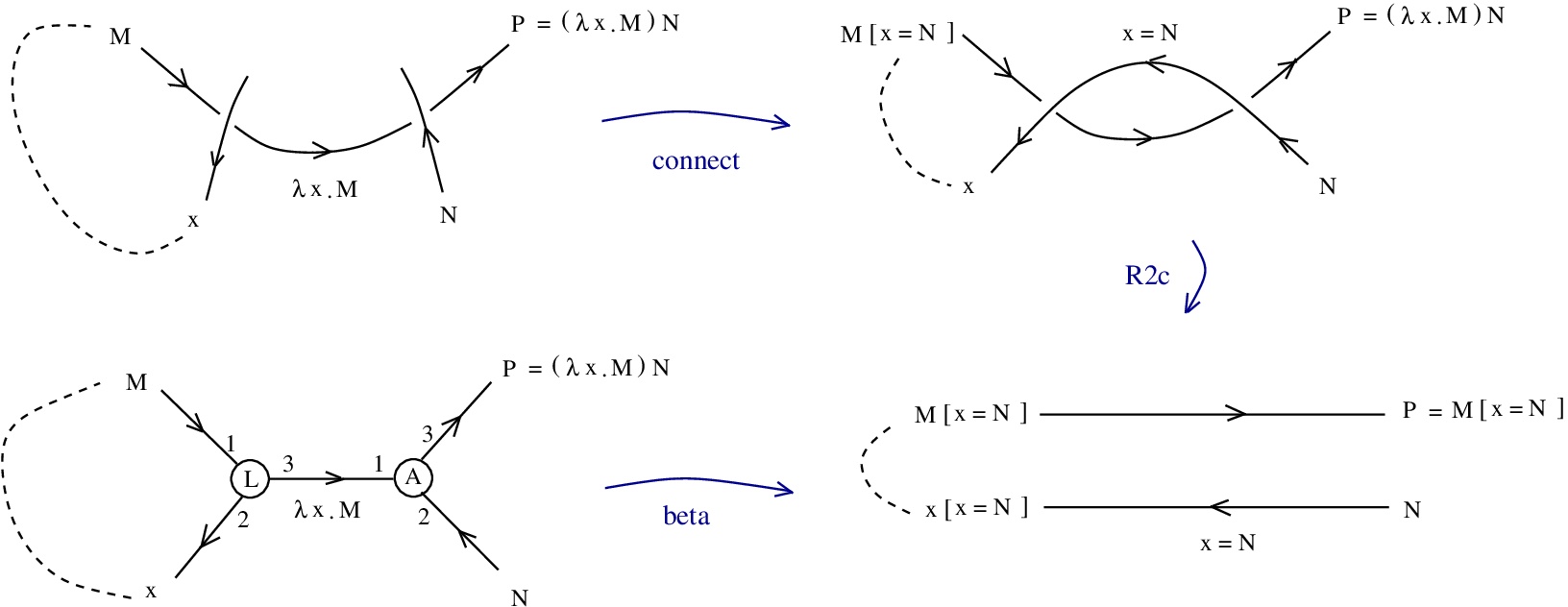

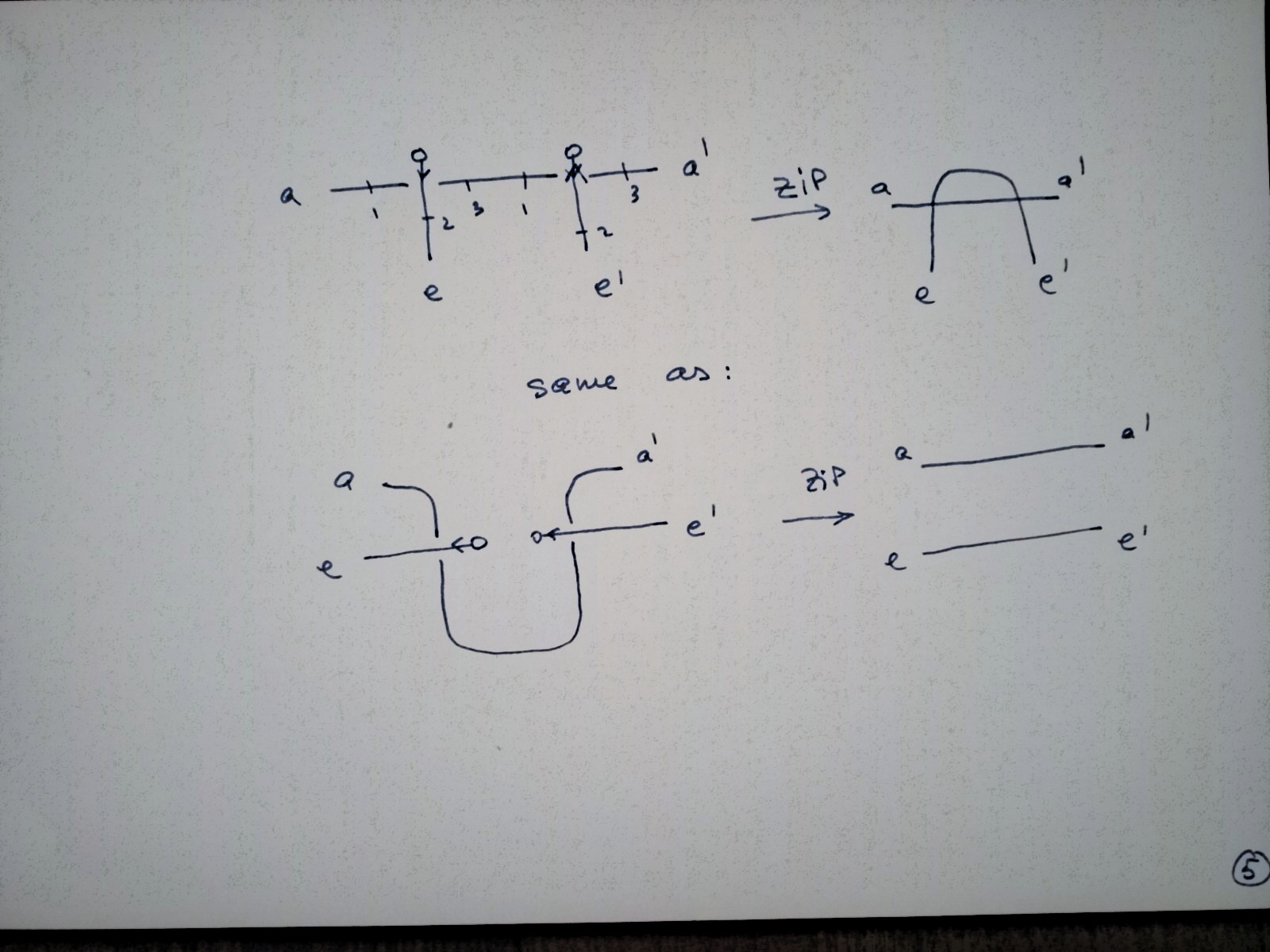
 appears as:
appears as: 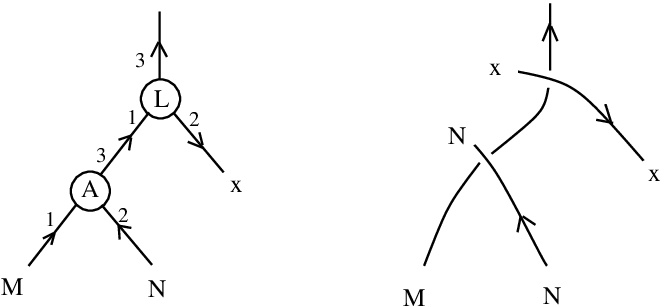
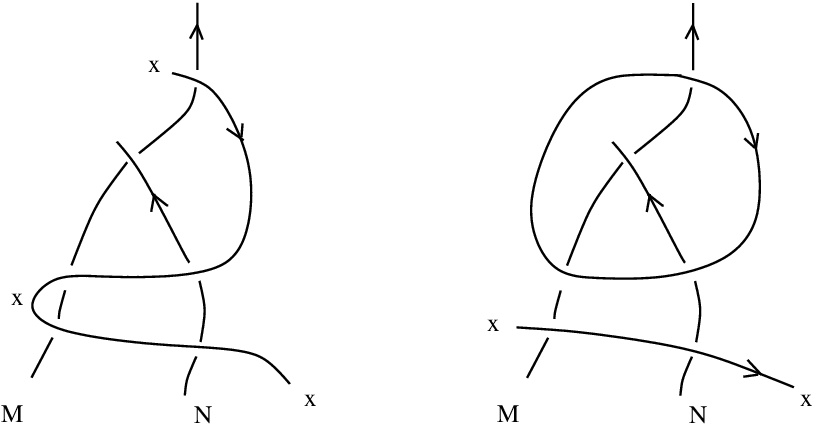
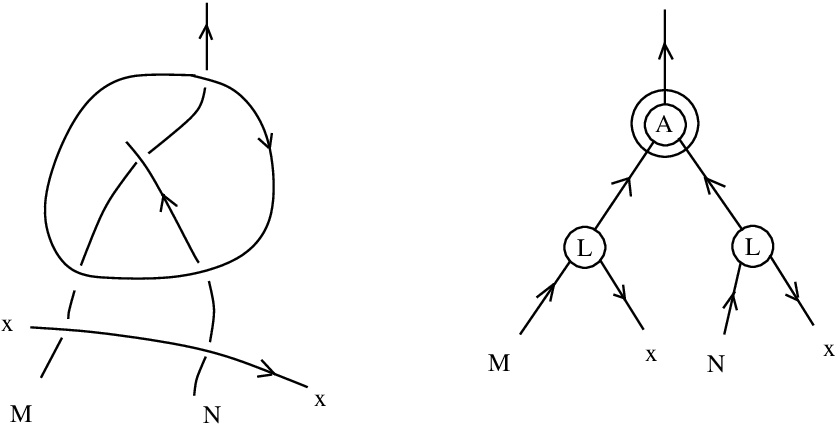







 and
and  .
. 



 ,
,  ,
,











 corresponds to
corresponds to  rewrites to
rewrites to  and
and 
 rewrites to
rewrites to 


 , of
, of 

 and
and 



 and
and 
 and
and 
 and
and  reduce to the same term
reduce to the same term 
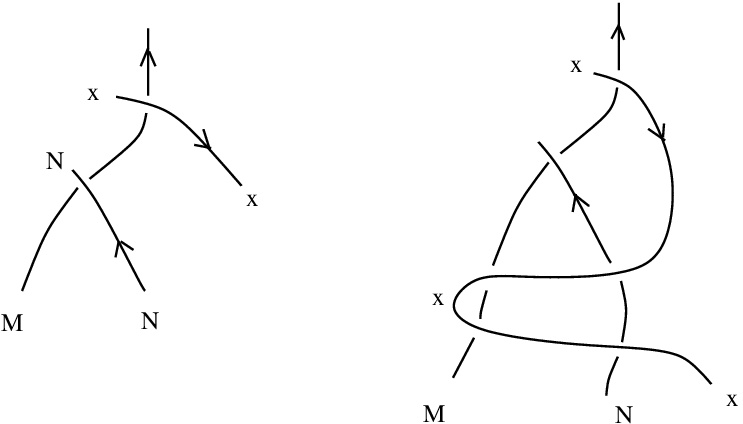
 and
and  reduce to the same expression
reduce to the same expression