Dá o RT, divulga e lhe vejo na próxima! 👋

Eu recentemente me deparei com um cliente que ainda está rodando a versão 5.5 do MySQL em seus servidores Ubuntu 14.04 LTS. E, apesar de a migração para uma versão mais atualizada ser fundamental, nós decidimos que o primeiro e mais fácil dos passos seria atualizar o próprio sistema operacional para que possamos ter acesso a correções de bugs, falhas de segurança e melhorias nos drivers.
Decidimos então migrar para o Ubuntu 22.04 LTS, e reinstalamos o MySQL 5.5 nele manualmente, já que o repositório apt oficial do Ubuntu 22.04 nos oferece apenas o MySQL 8.0 que é incompatível com a base de dados no estado atual. Neste artigo eu vou te mostrar como instalar e configurar o MySQL 5.5 no Ubuntu 22.04 LTS manualmente.
Ambiente de desenvolvimento
Para que você possa executar cada passo do tutorial comigo, vamos utilizar um ambiente controlado através do docker. Para iniciar seu servidor Ubuntu 22.04 LTS dentro do docker, rode o seguinte comando:
$ docker run --rm -it ubuntu:22.04
Você precisa ter o docker ou rancher-desktop instalados para o comando acima funcionar. E se a imagem ubuntu:22.04 não estiver presente no seu sistema, este comando vai primeiro fazer o download da imagem (cerca de 78MB) para depois iniciar o servidor. Sua tela vai ficar mais ou menos assim:

Iniciando uma sessão no ubuntu:22.04 utilizando
dockerPara baixar arquivos a partir da internet, vamos precisar de um pacote chamado curl. Podemos instalar o pacote através do apt:
# apt update
# apt install -y curl


Baixar o servidor MySQL 5.5 oficial no Ubuntu 22.04 LTS
No Ubuntu 22.04 você vai reparar que através do apt a versão do MySQL disponível é a 8.0. Caso queira instalar uma versão mais antiga, vai precisar adicionar um repositório apt diferente ou instalar através dos binários oficiais distribuídos pela Oracle.
Eu particularmente não confio em repositórios PPA que eu tenha pouca familiaridade e não os utilizo em projetos profissionais. Então a minha alternativa é justamente baixar o MySQL Server 5.5 através do site oficial do MySQL:

Filtro de versão e sistema operacional da listagem de downloads.
Como o Ubuntu é uma distribuição Linux baseada em Debian, podemos escolher “Debian Linux” no filtro de sistema operacional, e baixar o pacote adequado. No meu caso, vou baixar o arquivo 64 bit mysql-5.5.40-debian6.0-x86_64.deb no diretório /opt:
# cd /opt
# curl -LO https://downloads.mysql.com/archives/get/p/23/file/mysql-5.5.40-debian6.0-x86_64.deb
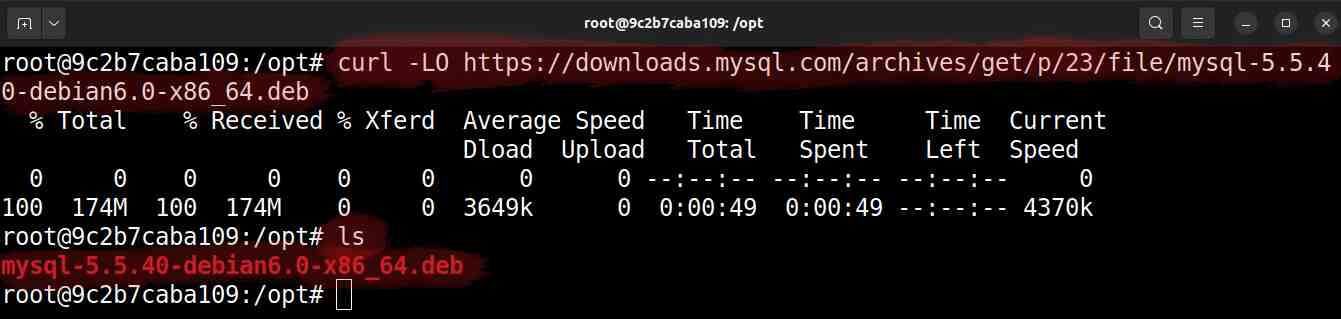
Download do servidor MySQL 5.5 via
curlPodemos agora expandir o pacote utilizando o utilitário dpkg com o comando a seguir:
# dpkg --unpack mysql-5.5.40-debian6.0-x86_64.deb
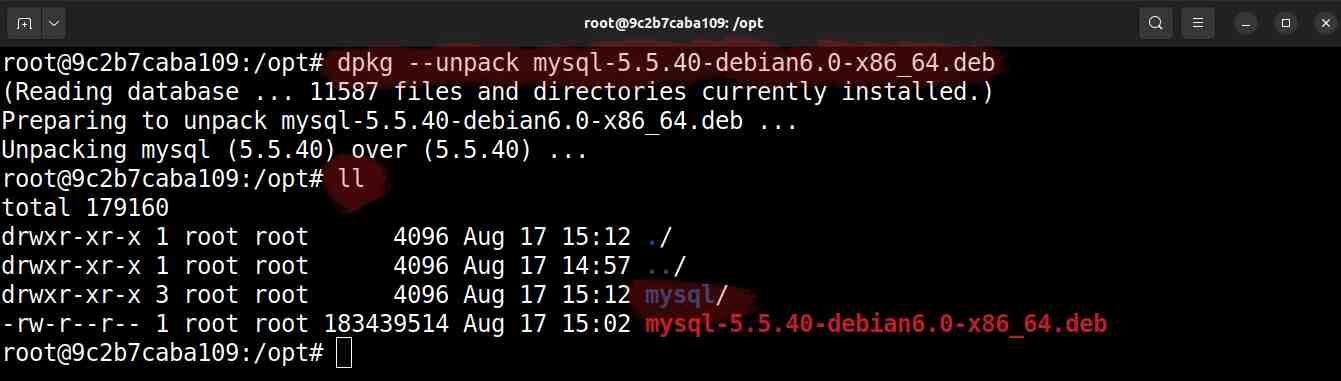
Extração dos arquivos do servidor MySQL 5.5 via
dpkg --unpackAgora podemos entrar no diretório /opt/mysql/server-5.5 e visualizar os arquivos da instalação do MySQL 5.5:
# cd /opt/mysql/server-5.5
# ll
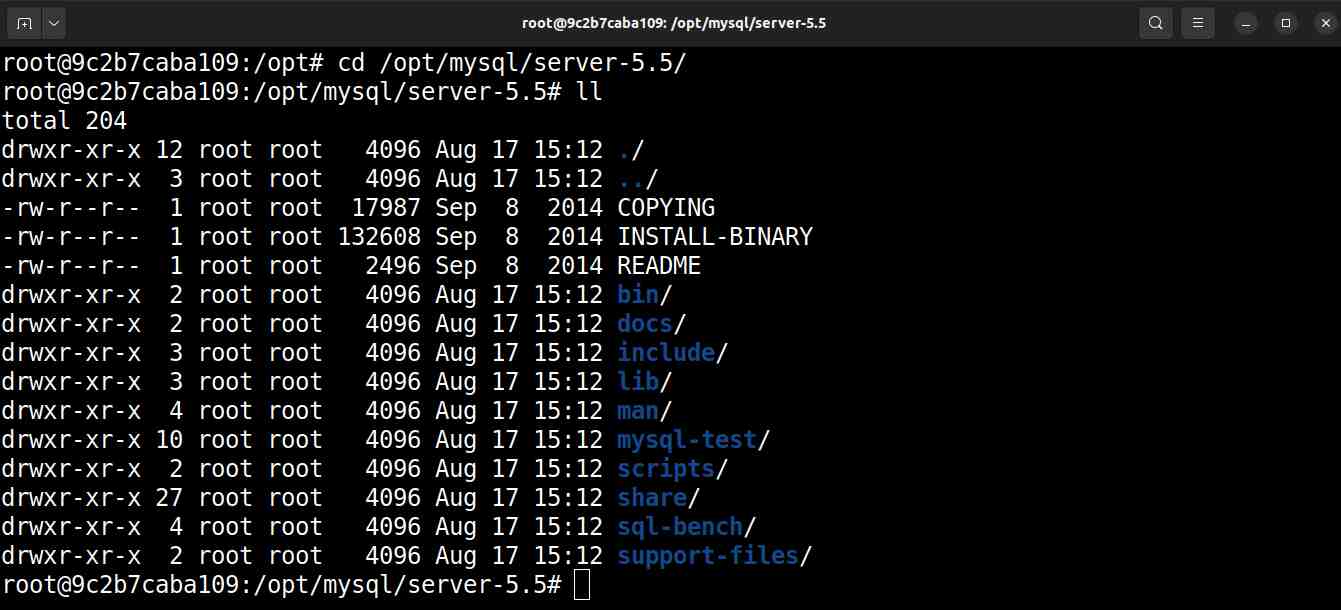
Listagem de arquivos em
/opt/mysql/server-5.5Instalar dependências do MySQL 5.5 no Ubuntu 22.04 LTS
A versão 5.5 do MySQL exige versões antigas de algumas bibliotecas. No caso do MySQL 5.5 no ubuntu 22.04 LTS precisamos instalar três bibliotecas em versões específicas:
-
libaio1 v0.3- download oficial libncurses5 v6.4- download oficiallibtinfo5 v6.4- download oficial
Vamos baixar e instalar estes três pacotes:
# cd /opt
# curl -LO http://archive.ubuntu.com/ubuntu/pool/universe/n/ncurses/libtinfo5_6.4-2_amd64.deb
# dpkg -i libtinfo5_6.4-2_amd64.deb
# curl -LO http://archive.ubuntu.com/ubuntu/pool/universe/n/ncurses/libncurses5_6.4-2_amd64.deb
# dpkg -i libncurses5_6.4-2_amd64.deb
# curl -LO http://archive.ubuntu.com/ubuntu/pool/main/liba/libaio/libaio1_0.3.113-5_amd64.deb
# dpkg -i libaio1_0.3.113-5_amd64.deb
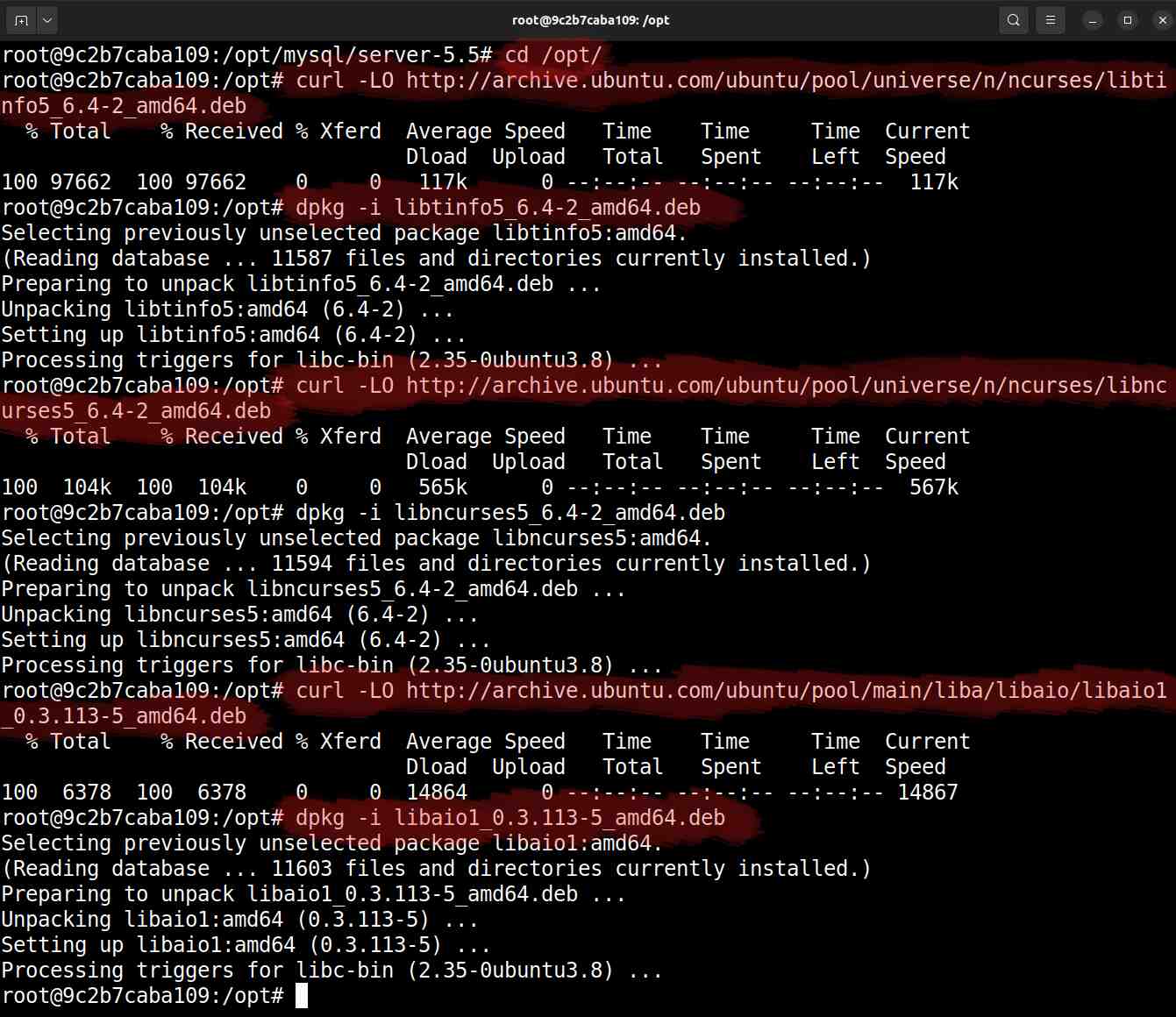
Download de dependências via
curl e instalação via dpkg -iAdicionar binários ao escopo global do Linux
Neste momento se você tentar executar o comando mysql ou iniciar o servidor mysqld_safe receberá uma mensagem de “Comando não encontrado”. Isso porque apesar de termos baixado e extraído os arquivos do servidor, os binários ainda não estão disponíveis no sistema.
Para que o sistema possa encontrar os binários, vamos fazer links simbólicos dentro de /usr/bin para expor os arquivos binários dentro de /opt/mysql/server-5.5/bin. Resolvi utilizar um loop for ...; do ; done para iterar sobre todos os arquivos binários do MySQL 5.5 e a partir desta lista fazer os links simbólicos com o comando ln -s:
# for f in "/opt/mysql/server-5.5/bin"/*; do
> filename=$(basename $f);
> ln -s $f "/usr/bin/$filename";
> done
# mysql --version
mysql Ver 14.14 Distrib 5.5.40, for debian6.0 (x86_64) using readline 5.1

Criar usuário, grupo e pastas do MySQL Server 5.5
Não é recomendável rodar o MySQL Server com o usuário root por questões de segurança. Portanto vamos criar um usuário mysql que pertence ao grupo mysql e atribuir algumas pastas à este usuário:
# groupadd mysql
# useradd -g mysql mysql
# chown mysql:mysql -R /opt/mysql/server-5.5

Criação do grupo e usuário
mysql. Atribuição da pasta /opt/mysql/server-5.5 à este grupo e usuário.Configurar o MySQL
Existem alguns arquivos de configuração do MySQL dentro da pasta /opt/mysql/server-5.5/support-files, vamos copiar o arquivo my-small.cnf para o diretório /etc/mysql/.
Vamos também transformar o MySQL em um serviço reconhecido pelo Ubuntu ao copiar o arquivo mysql.server para o diretório /etc/init.d:
# mkdir /etc/mysql
# cp /opt/mysql/server-5.5/support-files/my-small.cnf /etc/mysql/my.cnf
# cp /opt/mysql/server-5.5/support-files/mysql.server /etc/init.d/mysql.server

Cópia dos arquivos padrão da instalação do MySQL 5.5
Como nós instalamos nossos arquivos numa pasta fora do padrão, precisamos alterar o conteúdo do arquivo de configuração my.cnf para adicionar os campos datadir e basedir sob a configuração mysqld. Abra o arquivo /etc/mysql/my.cnf com seu editor de preferência, e adicione essas duas linhas abaixo da categoria [mysqld]:
[mysqld]
basedir = /opt/mysql/server-5.5
datadir = /opt/mysql/server-5.5/data
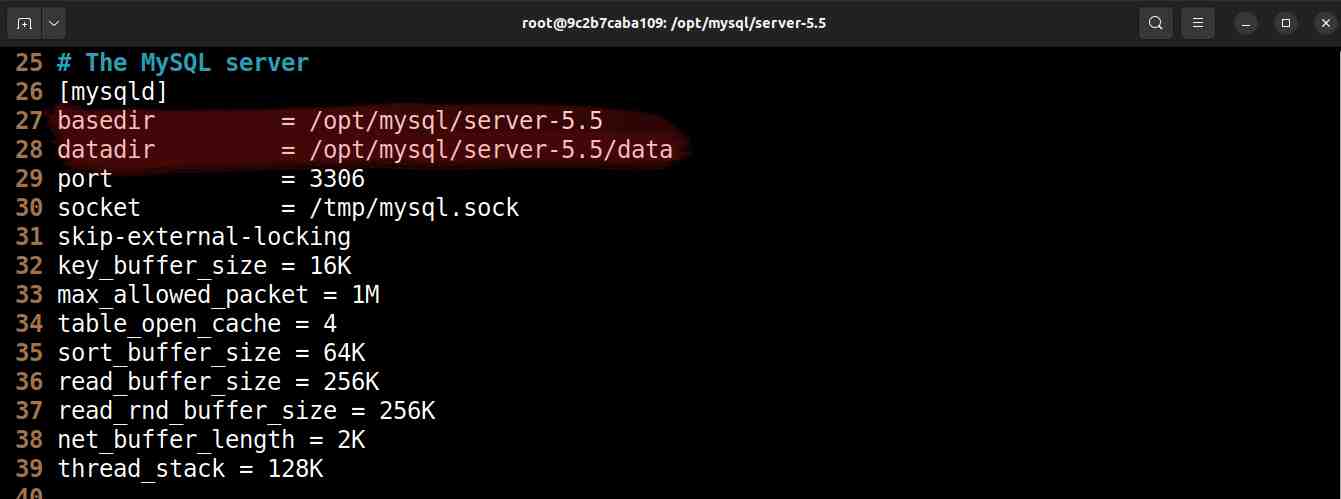
Adicionadas as opções
basedir e datadir no arquivo /etc/mysql/my.cnf(Opcional) Inicializar dados do servidor MySQL 5.5
Caso você esteja iniciando do zero, sem nenhum dado para migrar, é importante inicializar a base de dados para que as tabelas de sistema e usuários sejam instalados. Não é recomendado inicializar os dados do servidor caso você esteja migrando arquivos de um servidor para outro, você irá inutilizar seu banco de dados!
Você pode inicializar os dados do servidor MySQL 5.5 ao invocar o script mysql_install_db:
# /opt/mysql/server-5.5/scripts/mysql_install_db
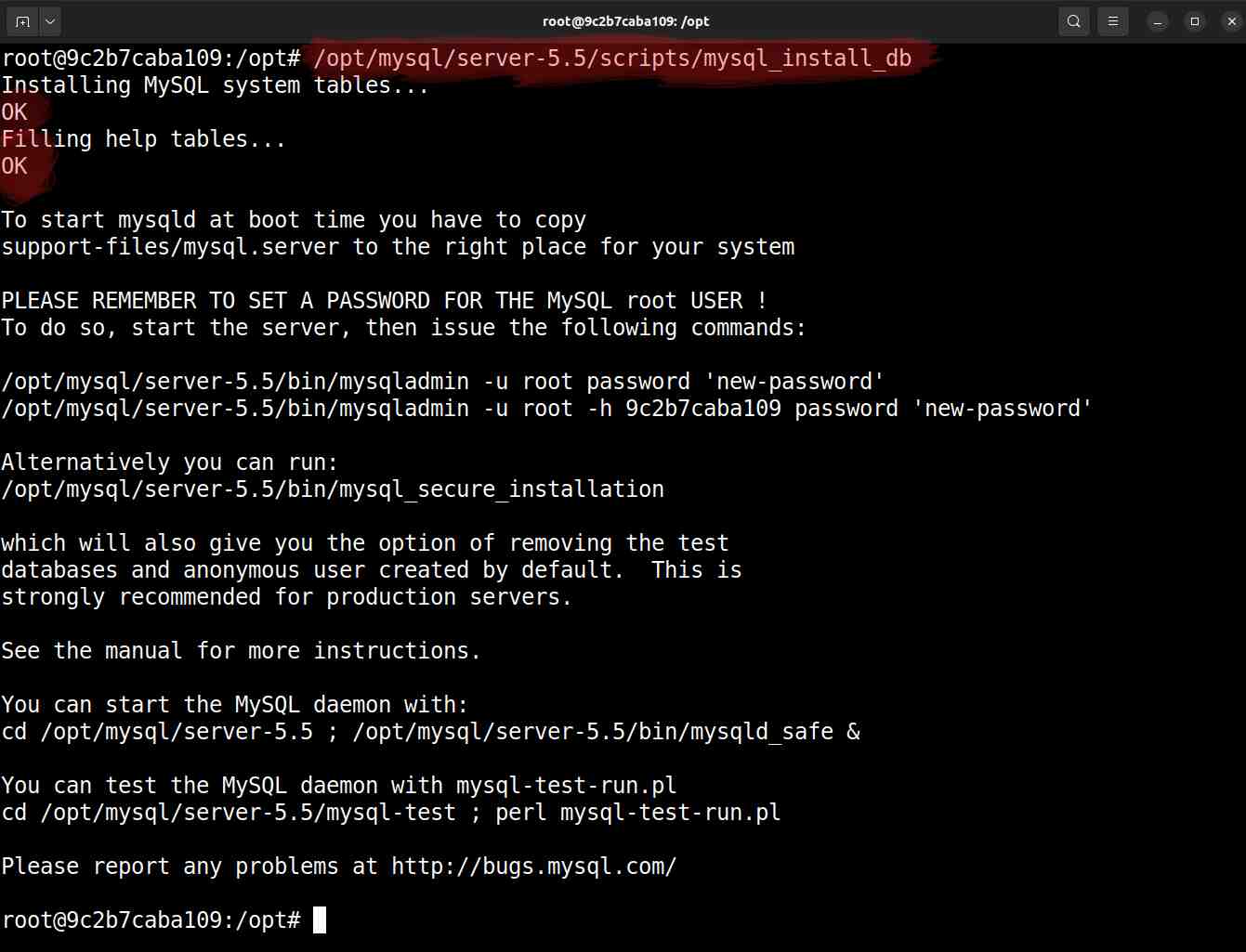
Inicialização das tabelas do banco MySQL 5.5
Instalação concluída!
O servidor MySQL 5.5 já está instalado em seu Ubuntu 22.04 LTS! Você pode inicializar o servidor utilizando a linha de comando.
Vamos iniciar o mysqld_safe e realizar um breve teste:
# mysqld_safe --user=mysql &
# mysql -uroot
mysql> show databases;
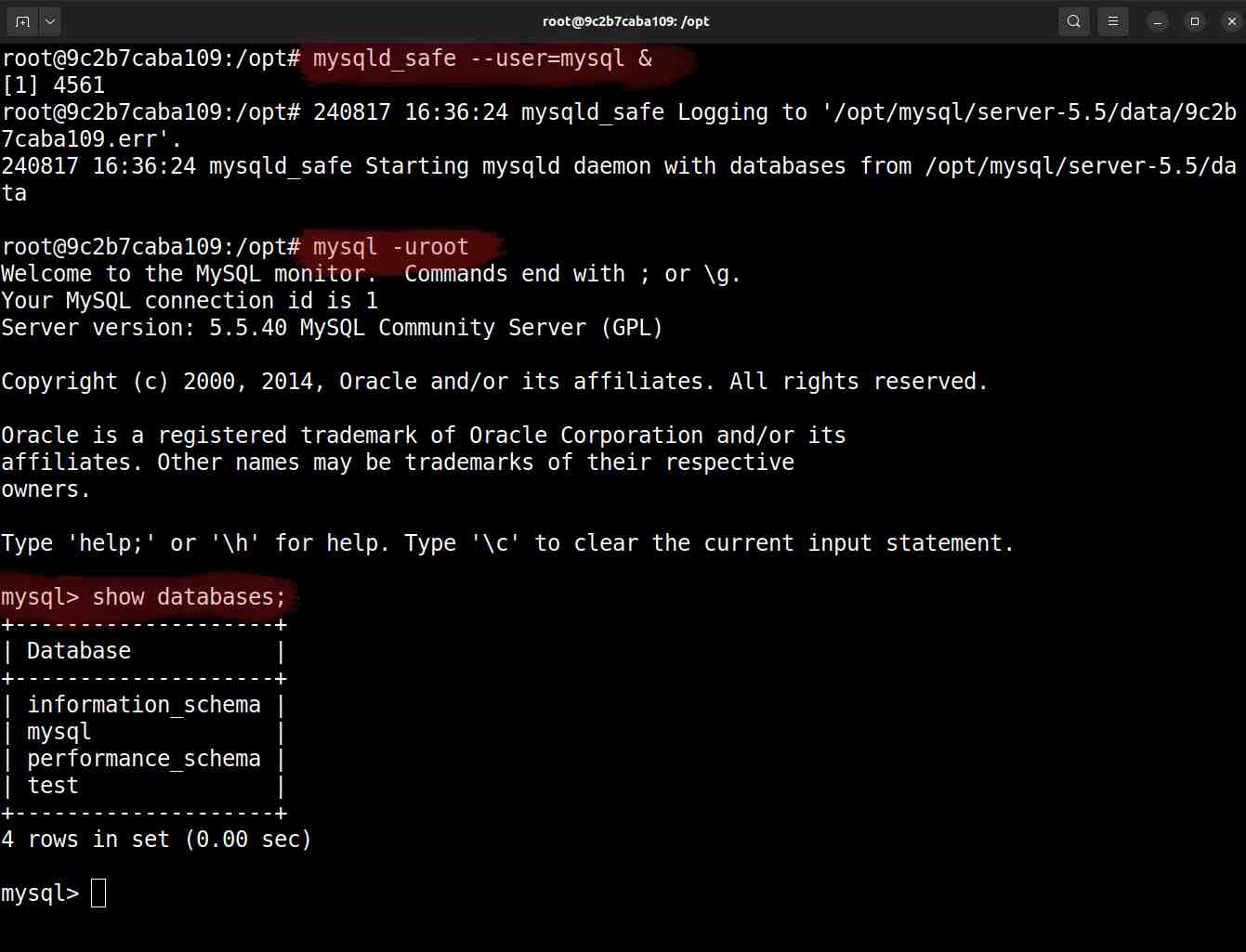
Teste do servidor MySQL 5.5 utilizando o comando SQL
show databases
Neste artigo eu trago algumas dicas de como se comportar no ambiente profissional que são particularmente valiosas para uma profissional de tecnologia e que se aplicam principalmente às profissões de desenvolvedora de software, analista de testes, analista de dados, cientista de dados, devops e suporte técnico. Estas dicas são particularmente úteis para quem está no começo da carreira e ainda precisa se adaptar ao mundo do trabalho na tecnologia.
Aqui você vai encontrar dicas sobre como colaborar com o restante do time de maneira a otimizar o trabalho de todo mundo, reduzir o estresse e aumentar a satisfação no dia a dia de trabalho.
A palavra chave aqui é autonomia! Todas essas dicas se baseiam na ideia de que você precisa buscar se tornar uma profissional com autonomia o suficiente para atingir seus objetivos. E da mesma forma, você se esforça para que suas colegas possam atingir a mesma autonomia.
Neste artigo: regras de etiqueta para profissionais de tecnologia
1. Revise o seu próprio Pull Request antes de solicitar revisão
Isto se aplica a qualquer tipo de trabalho que você fizer em colaboração com outras pessoas: código, documentação, apresentações… É importante que você faça sempre a primeira revisão do seu trabalho antes de pedir a opinião das outras pessoas.
Revisar seu próprio trabalho vai garantir que você tire os erros mais óbvios do caminho como erros de escrita, de ortografia, erros lógicos ou até mesmo te faça refletir em como você pode ajudar a próxima pessoa a revisar seu trabalho de forma rápida.
2. Descreva seu Pull Request com carinho
Sempre que você criar um Pull Request é importante pensar que quem lê aquele código não tem o mesmo contexto que você teve quando o escreveu. É bem capaz que se você deixar o Pull Request de lado e voltar em 2 dias nem você mesma vá lembrar das alterações que fez.
Então é importantíssimo sempre deixar muito claro na descrição do seu Pull Request o que está sendo modificado, como e o objetivo desta alteração.
Em ferramentas como Github e Gitlab é possível colocar vídeos e imagens na descrição de um Pull Request. Você se destaca de forma positiva se adota o costume de descrever o que está sendo feito e colocar um vídeo descrevendo suas alterações ou mostrando o resultado final. Desta forma você reduz o número de perguntas que sua revisora precisa fazer para entender o seu contexto e começar a fazer uma revisão útil.
3. Atualize a documentação sempre que fizer uma alteração
É natural que uma documentação que não é gerada automaticamente acabe ficando atrasada em relação à implementação do código. Em algumas empresas as pessoas que escrevem o software não são as mesmas que fazem a documentação, isto acaba virando responsabilidade de outra pessoa.
Em todos os casos é importante que a documentação sempre reflita a realidade. Então, se você criou ou alterou um método, classe ou uma API e isto é importante de ser documentado, faça um esforço para atualizar a documentação: faça você mesma a atualização ou procure quem possa iniciar este procedimento e avise sobre as suas alterações.
4. Adote uma comunicação clara e direta
Para quem está começando na área de tecnologia isso pode ser um desafio, mas a comunicação clara e direta é chave para levar qualquer equipe ao sucesso!
Em muitos casos a sua colega não precisa de todos os detalhes que você carrega consigo: só a mensagem ou pedido que você tem pra fazer já é suficiente. Em alguns casos estas informações adicionais podem ser importantes: deixe que a sua colega pergunte por estas informações. Veja aqui um exemplo:
Pedro: Andressa, posso te pedir uma coisa?
Andressa: Hmmm? O que foi?
Pedro: É que eu estava conversando com a nossa diretora ontem, e a Valéria estava me contando sobre aquela falha que aconteceu semana passada. Sabe?
Andressa: Qual falha?
Pedro: Quando o site caiu e a gente ficou sem visibilidade nenhuma. Sabe?
Andressa: Não tô sabendo. Eu tava de férias. Mas o que tem?
Pedro: Deixa. Isso nem é importante. A questão é que ela disse que gostaria de fazer um dashboard pra visualizar se o site está de pé ou não.
Andressa: Tá…
Pedro: …
Andressa: E como eu posso te ajudar Pedro?
Pedro: É que eu já criei o dashboard e preciso dar acesso pra Valéria.
…
Soa familiar o diálogo? Pois é, muitas das nossas conversas são assim desde a infância até o começo da carreira profissional. Mas ele poderia ter sido bem mais curto e direto, veja:
Pedro: Andressa, me ajuda a dar acesso à um dashboard pra Valéria?
Andressa: Claro! Te chamo em 30 minutos pra gente fazer. Me manda o link pro dashboard que eu já deixo preparado.
Para quem está acostumada a falar desta forma, pode ser difícil fazer a mudança. Mas todos nós aprendemos com o tempo e prática. Em alguns momentos você pode parecer seca, em outros talvez até rude. Mas com o tempo esta habilidade vai ficar mais forte e você vai ter interações muito mais úteis e leves com suas colegas de trabalho.
5. Respeite o tempo do outro ao pedir ajuda
Não importa muito se o ambiente de trabalho é remoto, presencial ou híbrido. Interrupções são muito ruins para o ambiente de trabalho. Cada interrupção pode custar de 10 a 30 minutos de pura inatividade em uma profissional que precisa de foco e criatividade para produzir. Quatro interrupções em muitos casos podem significar um dia de trabalho perdido.
Portanto é importante notar que sua colega tem outras tarefas a fazer e que o seu pedido, apesar de importante pra você, tem outra prioridade para a sua colega. É importante ser paciente e procurar oferecer o máximo de informação e autonomia que puder para sua colega te ajudar de forma rápida e certeira. E ao mesmo tempo é importante entender que o seu pedido pode ficar de 5 minutos até algumas horas sem resposta.
Ao mesmo tempo, não fique parada! Enquanto espera você pode continuar tentando resolver seu problema ou resolver tarefas menores até receber um retorno.
6. Comunique dificuldades e atrasos o quanto antes
Nada mais triste do que entrar numa reunião em que todas criaram uma expectativa enorme no resultado do seu trabalho para só então descobrir que você precisa de mais alguns dias para entregar.
Na maioria dos casos o atraso não é exatamente o problema mas sim a expectativa! Portanto sempre que tiver alguma dificuldade ou perceber que o prazo está escapando, comunique o quanto antes. Isto ajuda a alinhar expectativas e ao restante do time a se adaptar à situação. Talvez eles venham dividir a tarefa contigo, talvez dêem prioridade a outras tarefas.
O que não dá é pra chegar no dia da entrega e falar de surpresa pra todo mundo que não vai conseguir.
Conclusão
Todas as dicas que eu coloquei neste artigo se referem ao seu dia a dia e como você pode colaborar melhor com suas colegas de trabalho. A palavra chave é autonomia: busque ser independente quando possível e ofereça todas as ferramentas possíveis para que suas colegas também possam ser independentes.
São dicas valiosíssimas para quem está no começo da carreira ou ainda não se acostumou a pensar de forma sistêmica.
Uma equipe mais autônoma consegue entregar com menos esforço, estresse e conflitos. Quando a comunicação é clara e oferece todo o contexto necessário, mas nada além do necessário, todo mundo sai ganhando.

Com certa frequência eu preciso me conectar a redes VPN para realizar serviços em clientes com servidores em outros continentes, de forma que a latência de todos os aplicativos do meu computador que utilizam a internet acabam por sofrer - e muitas vezes eu preciso apenas fazer uma conexão SSH.
Neste tutorial eu vou te mostrar como eu resolvi este problema ao mover o cliente VPN para um contêiner docker de forma que toda a rede da minha máquina se manteve com a conexão local comum.
Como já é de costume, fiz um vídeo rápido explicando como seguir o passo a passo deste artigo:
Configurar um contêiner docker para conectar-se à VPN
Para este tutorial vamos utilizar a imagem alpine:3.17, mas este passo a passo deverá funcionar com qualquer outra distribuição - talvez com alguns ajustes aqui e ali.
Vamos então baixar a imagem:
$ docker pull alpine:3.17

docker pull que baixa a imagem alpine:3.17Após baixada a imagem podemos já rodar o nosso contêiner. Para executar o contêiner precisamos passar alguns parâmetros relacionados à rede e como ele vai criar o túnel VPN. A linha de comando completa fica assim:
$ docker run --rm -it --cap-add=NET_ADMIN alpine:3.17

O comando acima vai rodar um contêiner em modo interativo (-it) e este contêiner vai ser removido assim que você terminar sua sessão (--rm). Além disso nós vamos dar a capacidade ao contêiner de mexer na nossa interface de rede (--cap-add=NET_ADMIN). Por fim, estamos invocando uma sessão shell da imagem alpine:3.17.
Como instalar e configurar o cliente openvpn no contêiner docker
Agora que o contêiner já tem a capacidade de modificar a nossa interface de rede (--cap-add=NET_ADMIN) nós podemos instalar os pacotes necessários e configurar o ambinte.
Vamos criar um device que será capaz de abrir um túnel VPN dentro do contêiner seguindo as instruções de configuração do driver TAP/TUN do manual do Kernel GNU/Linux:
$ mkdir /dev/net
$ mknod /dev/net/tun c 10 200
$ chmod 0666 /dev/net/tun

device de TUN/TAP conforme o manual do Kernel GNU/LinuxAgora podemos instalar o cliente openvpn diretamente no nosso contêiner alpine:
$ apk update
$ apk add openvpn

openvpn através do gerenciador de pacotes apkComo ligar a rede VPN dentro do contêiner docker
Agora que tudo está instalado e configurado, podemos conectar o nosso contêiner à rede VPN através da linha de comando seguinte:
$ openvpn client.ovpn > /dev/null &
Onde client.ovpn é um arquivo de configuração no formato do OpenVPN com os dados de conexão e credenciais da rede externa. Repare que o fim do comando redireciona qualquer texto para o limbo de forma que não apareça na sua tela (> /dev/null) e joga o comando para executar em plano de fundo (&) de maneira que você possa rodar outros comandos imediatamente.

ping aumentou após alguns momentos - exatamente quando o túnel foi estabelecido.Desta forma você consegue rodar o cliente VPN dentro de um contêiner docker sem precisar conectar a sua máquina host ao servidor externo, de forma a poder utilizar outros serviços online sem o problema da latência.
]]>
Em diversas situações a gente pode precisar utilizar variáveis de ambiente, alguns exemplos incluem:
-
Alterar o comportamento do software através de Feature flags
- Dar acesso a segredos e chaves de API
- Personalizar a configuração do software - por exemplo, alterar a porta de um servidor
Para facilitar o aprendizado, eu montei um vídeo bem simples pra explicar tudo o que está aqui no artigo:
Como ler variáveis de ambiente com Rust utilizando a biblioteca padrão
Rust possui uma biblioteca padrão bem completinha, que é a std. Para acessar variáveis de ambiente utilizando esta biblioteca, você pode utilizar a função std::env::var() e o seu tipo de retorno é um objeto do tipo Result<String, VarError>.
Então para obter uma variável de ambiente chamada SERVER_PORT podemos fazer algo como o seguinte:
fn main() {
let port = std::env::var("SERVER_PORT").unwrap_or("8080".to_string());
println!("A porta e {}", port);
}
Repare que como o retorno é do tipo Result<String, VarError> você pode utilizar a função unwrap_or() para definir um valor padrão caso a variável não esteja presente. Portanto ao rodar o programa, temos as seguintes saídas:
$ cargo run
A porta e 8080
$ SERVER_PORT=9090 cargo run
A porta e 9090
Como ler variáveis de ambiente em tempo de compilação com Rust
As vezes é importante mudar o comportamento do software em tempo de compilação e mantê-lo fixo durante o tempo de execução, por exemplo criar um comportamento diferente para ambientes Windows e Linux, ou utilizando o X11 ou Wayland.
Para fazer algo assim, também é possível utilizar variáveis de ambiente porém precisamos utilizar a macro env!() que retorna um &'static str. É importante notar que quando a macro env! é utilizada, a variável de ambiente precisa estar presente no momento da compilação - caso contrário um erro de compilação ocorre. Veja:
fn main() {
let default_port = env!("DEFAULT_SERVER_PORT");
println!("A porta padrao e {}", default_port);
}
Ao compilar sem a variável de ambiente:
$ cargo build
error: environment variable `DEFAULT_SERVER_PORT` not defined at compile time
E ao compilar com a variável de ambiente definida e rodar o programa (que se chama rust-env no meu exemplo):
$ DEFAULT_SERVER_PORT=8080 cargo build
$ ./target/debug/rust-env
A porta padrao e 8080
$ DEFAULT_SERVER_PORT=9090 ./target/debug/rust-env
A porta padrao e 8080
Repare que ao rodar o binário, mesmo que a variável DEFAULT_SERVER_PORT seja redefinida, o software não a utiliza. Isto porque a macro env! só opera em tempo de compilação.

A linguagem C em muitos casos nos exige escrever muitas linhas de código para fazer algo relativamente simples, e não são raros os casos em que precisamos repetir estas rotinas de novo e de novo. Bibliotecas como a libssh e a libusb nos dão a responsabilidade de inicializar subsistemas, realizar verificações de rotina após cada operação… e tudo isso acaba engordando o nosso código com pouco significado semântico.
Neste tutorial eu vou te mostrar como simplificar estas rotinas repetitivas com macros em C, e como utilizar sua estrutura super poderosa: as macros de argumentos variáveis.
Caso você prefira um apoio em vídeo, tá aqui explicadinho o artigo todo e você consegue acompanhar com código conforme vou escrevendo os exemplos:
O que são macros na linguagem C?
Macros na linguagem C são pedaços de código que você pode “inserir” em qualquer lugar. Você pode reconhecer uma macro através da palavra-chave #define: se você vir esta palavra-chave antes de algum texto, este texto é uma macro.
Ao referenciar uma macro em seu código, o conteúdo desta macro é copiado antes de compilar seu código.
Abaixo um exemplo de programa em C que define uma macro CODAMOS, atribui um valor "codamos.com.br" e a utiliza no contexto da função printf().
#include <stdio.h>
#define CODAMOS "codamos.com.br"
int main(void)
{
printf("Ola, %s\n", CODAMOS);
}
Eu comentei que as macros são copiadas quando referenciadas. Acontece que antes de compilar seu código, ele vai se transformar no seguinte:
#include <stdio.h>
int main(void)
{
printf("Ola, %s\n", "codamos.com.br");
}
Repare que ao compilar o código, a constante CODAMOS foi substituída por seu valor definido: "codamos.com.br".
Macros como funções em C
Como vimos acima macros podem ser utilizadas para substituir um símbolo criado pela palavra-chave #define por algum outro texto ou código. É possível fazer com que macros invoquem funções, como no exemplo abaixo:
#include <stdio.h>
#define ECHO(msg) printf(msg);
int main(void)
{
ECHO("Ola codamos!\n");
}
Podemos inclusive fazer com que nossas macros automatizem certas rotinas, como por exemplo indicar o nível de log na mensagem:
#include <stdio.h>
#define LOG_ERR(msg) fprintf(stderr, msg)
#define LOG_INFO(msg) fprintf(stdout, msg)
int main(void)
{
LOG_INFO("Inicializando o programa...\n");
LOG_ERR("Falha ao inicializar o programa\n");
return 1;
}
Repare que LOG_INFO() e LOG_ERR() não são funções. São apenas macros que se comportam como função. E por baixo dos panos tomam algumas decisões fundamentais e repetitivas como qual stream utilizar para a saída da mensagem: stdout ou stderr.
Com macros podemos inclusive tornar este mecanismo ainda mais poderoso para indicar, por exemplo, qual a linha e arquivo onde um erro aconteceu. Veja:
#include <stdio.h>
#define eprintf(msg) fprintf(stderr, "[%s:%d] ", __FILE__, __LINE__); fprintf(stderr, msg);
int main(void)
{
eprintf("Falha ao inicializar o programa\n");
}
Ao executar o código acima teremos uma saída mais ou menos assim:
[main.c:7] Falha ao inicializar o programa
E se quisermos utilizar um printf() com vários argumentos para interpolar strings? Neste caso precisamos de macros com argumentos variáveis.
Macros com argumentos variáveis
A função printf() (e outras parecidas como o fprintf()) podem receber N argumentos de acordo com o argumento “formato” que é passado. O exemplo abaixo recebe uma string “codamos.com.br” e um inteiro com valor 10:
printf("Site: %s, Nota: %d", "codamos.com.br", 10);
Como podemos transferir estes valores para a nossa macro?
Supondo que a nossa macro se chame LOG_INFO e precise indicar o arquivo, linha e texto onde a mensagem foi enviada, podemos escrever algo assim:
#include <stdio.h>
#define LOG_INFO(...) fprintf(stderr, "[INFO] %s:%d: ", __FILE__, __LINE__); fprintf(stderr, __VA_ARGS__);
int main(void)
{
LOG_INFO("Inicializando o programa '%s'.\n", "codamos.com.br");
}
A macro acima utiliza a palavra-chave __VA_ARGS__ que justamente expande para todas as variáveis recebidas como parâmetro, representadas por ..., quando compilamos o programa. O termo para esta tecnica é Variadic Macros.
A saída do comando acima deverá ser algo como:
[INFO] main.c:7: Inicializando o programa ‘codamos.com.br’
Isto porque os dois parâmetros da macro LOG_INFO foram a string "Inicializando o programa '%s'.\n'"e a string "codamos.com.br". Estes dois parâmetros foram armazenados no símbolo __VA_ARGS__ e repassados para a função fprintf() no contexto daquela macro.
Macros com multiplas linhas de código
Como vimos nos exemplos anteriores, macros ficam bagunçadas rapidinho. Porque quanto mais funcionalidade a gente adicionar num único #define, maior a linha daquela macro.
Mas é possível quebrar as linhas de uma macro para que fique mais fácil de entender. Para isto é necessário adicionar uma barra invertida ao final de cada linha, veja como:
#include <stdio.h>
#define LOG_INFO(__VA_ARGS__) \
fprintf(stderr, "[INFO] %s:%d: ", __FILE__, __LINE__); \
fprintf(stderr, __VA_ARGS__);
int main(void)
{
LOG_INFO("Inicializando o programa '%s'.\n", "codamos.com.br");
}
A mensagem agora deverá ser quase a mesma de antes, o que muda é apenas a linha onde foi invocada a mensagem porque agora a macro possui múltiplas linhas:
]]>[INFO] main.c:9: Inicializando o programa ‘codamos.com.br’


Este artigo vai ajudar a entender melhor o que é software livre, qual o significado de “Livre” em seu nome, sua relação com código aberto (open source) e o que você pode e não pode fazer com Software Livre.
O que é Software Livre?
A língua portuguesa é muito feliz na tradução do termo de “Free Software” para “Software Livre”, porque o sentido do termo “Free” em free software não tem nada a ver com preço mas sim com liberdade.
“Software livre” significa um software que respeite as liberdades e comunidade de seus usuários. Basicamente significa que seus usuários têm a liberdade de rodar, copiar, distribuir, estudar, modificar e melhorar o software. Portanto “software livre” é sobre liberdade, não preço. […]
Você pode ter pago dinheiro para obter cópias de um software livre, ou pode ter tido acesso a essas cópias sem pagar nada. Mas independentemente da forma como você conseguiu suas cópias, você sempre terá a liberdade de copiar e modificar o software, e até mesmo de vender outras cópias.
Trecho retirado do texto “What is Free Software?” disponível no site gnu.org, da Free Software Foundation.
Portanto software livre é também um software de código aberto, mas não apenas isso. É um software que pode ter seus fontes lidos e modificados por qualquer pessoa, e que permita a redistribuição por qualquer pessoa.
As quatro liberdades essenciais do software livre
A Free Software Foundation indica que para que um software seja considerado livre, ele deve respeitar quatro liberdades essenciais, são elas:
-
Liberdade 0 - liberdade de rodar o programa como você quiser, por qualquer motivo.
- Liberdade 1 - liberdade de estudar como o programa funciona, e modificá-lo para que faça a computação que você desejar. Ter acesso ao código-fonte é uma pré-condição para esta liberdade.
- Liberdade 2 - liberdade de redistribuir cópias para que você possa ajudar outrem.
- Liberdade 3 - liberdade de distribuir cópias das versões modificadas com outrem. Ao fazer isso você permite que toda a comunidade se beneficie com as suas alterações. Ter acesso ao código fonte é pré-condição para esta liberdade.
Com estas quatro liberdades essenciais fica claro que software livre (free software) não é sinônimo de software de código aberto (open source software). Visto que um software puramente de código aberto mas que não possui uma licença livre pode te proibir de executar alguma das liberdades acima: de redistribuir cópias do original, ou de distribuir modificações por exemplo.
Mas de toda forma não é possível existir um software livre e que não possua código aberto, porque isto violaria diretamente as liberdades 1 e 3.
Licenciamento de software livre
O segredo para entender se o software em questão é livre ou não está em sua licença de uso.
Softwares que são lançados com licenças como GNU GPL, GNU AGPL, GNU LGPL, licenças do tipo Copyleft, domínio público, etc., podem ser considerados livres. Mesmo que tenha sido desenvolvido por uma pessoa ou empresa.
Também é possível encontrar licenças de código aberto e que não são livres, como a JSON, Ms-SS da MicroSoft e a Open Public License. O motivo de não serem livres inclui restrições na redistribuição como proibição de venda ou restrição de uso como “somente para estudantes”.
Softwares com licenças do tipo Freeware ou Shareware não podem ser considerados livres: na maioria dos casos você não tem acesso aos fontes do software (liberdades 1 e 3) e há restrições de distribuição como proibido vender ou revender (liberdade 2).
Qualquer licença que limite o uso, modificação, distribuição e redistribuição do software não pode ser considerada livre.
A recomendação de licenciamento da FSF para software livre
Se você quer desenvolver um software e quer torná-lo livre, a recomendação geral da Free Software Foundation é de utilizar as licenças compatíveis com a GNU GPL - General Public License.
A licença mais utilizada pelo projeto GNU é a General Public License ou GPL, considerada uma “licença viral” porque obriga que quaisquer alterações do código fonte sejam também distribuídas com a mesma licença do original. De forma que toda modificação de um software GPL 3.0 precisa ser publicada sob licença GPL 3.0.
Por exemplo, se você disponibilizou uma biblioteca chamada libmaravilhosa via GPL 3.0, qualquer software que utilize esta biblioteca via link estático ou dinâmico, vira um derivado e, portanto, precisa ser distribuído através da licença GPL 3.0.
Outra licença que pode ser utilizada, principalmente por bibliotecas, é a licença GNU Lesser GPL ou LGPL que é um pouco mais permissiva que a GPL 3.0. A LGPL obriga que todo software que incorpore o software licenciado sob LGPL indique a origem e a licença deste software licenciado, e também permita que usuários modifiquem a parte licenciada.
Se a biblioteca libmaravilha estiver sob LGPL 3.0 e o software incrivel.exe utiliza esta biblioteca, ele precisa indicar que a biblioteca libmaravilha foi utilizada, que sua licença é a LGPL 3.0 e deve permitir que seus usuários modifiquem a libmaravilhosa. Portanto se você utilizou link dinâmico (arquivos .so, .dll ou mesmo código fonte) então tudo certo. Mas se você utilizou link estático, que incorpora a biblioteca ao seu binário final, você precisa distribuir seu código com LGPL.
Para serviços online (SaaS) também foi criada a licença GNU Affero GPL ou AGPL. Caso um serviço do tipo SaaS utilize software licenciado sobre AGPL, o provedor é obrigado a distribuir sua versão modificada do software.
Acesse lista completa de licenças compatíveis com a GNU GPL para descobrir mais e mais detalhes sobre cada uma.

Para escrever tutoriais sobre VIM eu preciso sempre garantir que os comandos que eu utilizo funcionariam em qualquer ambiente VIM, independente de configurações e plugins. E para isso é necessário executar o programa ignorando todas as customizações.
Neste artigo eu vou te mostrar como iniciar o VIM ignorando quaisquer plugins, configurações ou customizações que estejam em seu computador.
Para abrir o VIM sem plugins ou configurações basta utilizar a flag --clean ao abrir o programa, como na linha a seguir:
$ vim --clean
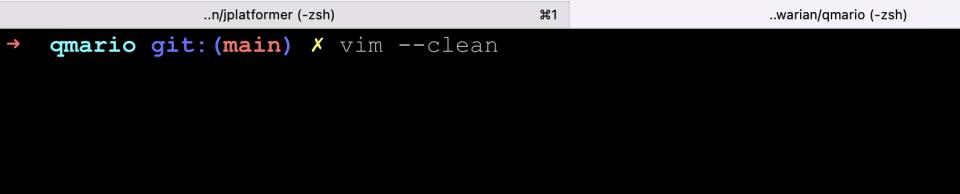
Como abrir o VIM sem plugins:
vim --cleanPara abrir um arquivo com o VIM sem utilizar plugins ou configurações podemos utilizar também a flag --clean, como na linha de comando abaixo:
$ vim --clean nomedoarquivo.txt
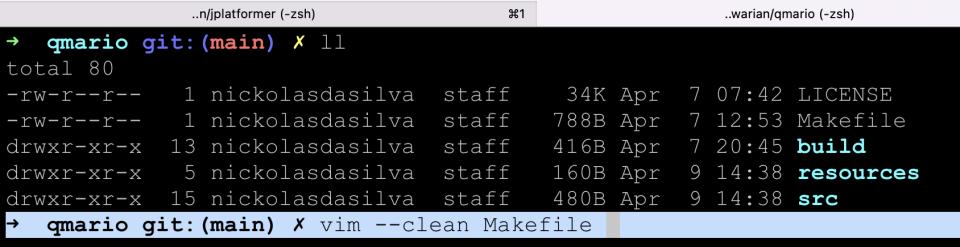
Como abrir um arquivo no VIM sem plugins:
vim --clean nomedoarquivo.txtO que diz o manual?
O manual oficial do editor VIM indica que a opção --clean causa o seguinte efeito:
--clean: Do not use any personal configuration (vimrc, plugins, etc.). Useful to see if problem reproduces with a clean Vim setup.
Em tradução (minha) significa o seguinte:
--clean: Não utilizar nenhuma configuração pessoal (vimrc, plugins, etc.). Útil para verificar se um problema pode ser reproduzido com uma configuração limpa do Vim.
Portanto sempre que escrevo artigos sobre VIM é útil a flag --clean para que nenhum comportamento seja específico do meu computador e possa funcionar para qualquer pessoa que siga os mesmos passos.

Aprender a programar pode ser uma jornada desafiadora, mas recompensadora. É uma habilidade essencial em um mundo cada vez mais digital e tecnologicamente avançado.
Se você está interessado em dar os primeiros passos no mundo da programação, este pequeno artigo lhe dará algumas dicas sobre como começar e como superar problemas que você possa encontrar ao longo do caminho.
1 – Selecione a linguagem de programação
Um dos primeiros desafios para iniciantes é decidir qual linguagem de programação aprender. Existem várias opções como PHP, Python, Java, JavaScript, C, etc, e para conseguir escolher qual caminho seguir considere seus objetivos e interesses.
Por exemplo, Python é uma linguagem popular para iniciantes devido à sua simplicidade e ampla aplicabilidade.
2 – Encontre recursos de aprendizado
Existem muitos recursos disponíveis para aprender programação, como livros, tutoriais em vídeo, cursos online e plataformas interativas, e acredite, a quantidade de informações pode ser esmagadora. Pensando nisso, você pode escolher recursos de aprendizagem adequados ao seu estilo e que permitam a passagem gradual do nível básico ao avançado.
Para tornar a jornada do aprendizado mais divertida e eficiente, a dica é encontrar recursos que combinem com o seu estilo. Aqui não existe uma fórmula mágica única! Você pode escolher os materiais que melhor se adaptam às suas preferências e ritmo de aprendizagem.
No site da Codamos tem um guia que começa pelo entendimento da mecânica da linguagem (sintaxe). É como aprender a linguagem nativa dos computadores!
3 – Entenda os conceitos básicos
Conceitos como variáveis, loops, condições e funções são essenciais em qualquer linguagem de programação. Esse conceito pode parecer difícil de entender a princípio, mas a chave para superar essa dificuldade é a prática.
Comece com pequenos exercícios e projetos simples para colocar esses conceitos em prática.
4 – Como lidar com a decepção
A programação pode ser difícil e as falhas ao longo do caminho são comuns – e tá tudo bem 😉. Ficar preso em um problema por horas pode ser frustrante, mas é importante lembrar que a solução de problemas é uma parte essencial da programação.
Não tenha medo de procurar ajuda em comunidades de programadores online ou fóruns especializados. Profissionais de software de todos os níveis têm muito a ganhar ao participar de comunidades: iniciantes ganham exposição a ideias e discussões de alto nível, enquanto pessoas mais experientes trocam entre si e ganham experiência como mentoras.
5 – Exercite-se regularmente
Consistência é a chave para aprender a programar. Reserve um tempo para praticar e codificar regularmente, mesmo que por um curto período de tempo todos os dias.
A prática contínua reforça os conceitos aprendidos e ajuda a desenvolver habilidades de resolução de problemas. Uma dica legal é o site da FreeCodeCamp onde são apresentados desafios curtinhos com explicação a cada passo.
6 – Crie seu projeto pessoal
Além de se exercitar e treinar, é importante trabalhar em projetos pessoais. Criar algo com o qual você se preocupa torna o aprendizado mais motivador e divertido, e para começar não precisa ser nada muito mirabolante.
Comece com projetos simples e aumente a complexidade à medida que ganhar confiança. Quer ver um projeto bacana para quem está iniciando? Confere este video aqui:
7 – Colabore com outros programadores
Participar de uma comunidade de desenvolvimento ou colaborar com outras pessoas em um projeto pode ser uma experiência inestimável. Além de aprender com os outros, você pode obter feedback e insights que o ajudarão a melhorar suas habilidades. E se eu puder aqui puxar a brasa para a minha sardinha, recomendo fortemente as comunidades da Codamos e o PHPSP.
Para descobrir diferentes comunidades você pode dar uma olhada neste artigo que tem uma lista bem bacana de comunidades de programação brasileiras.
8 – Adaptação às novas tecnologias
O universo da programação está em constante evolução e novas tecnologias e tendências aparecem todos os dias. Esteja preparado para aprender coisas novas e acompanhar as mudanças para superar esses desafios.
Minha conclusão?
Começar a programar pode ter alguns desafios, mas é uma habilidade valiosa e gratificante. Escolher a linguagem que mais atende suas expectativas, encontrar bons materiais de estudo, praticar regularmente, frustrar-se (e é sim importante, faz parte do crescimento) e trabalhar em projetos pessoais são algumas das estratégias para vencer os obstáculos nessa jornada.
Lembre-se: a chave para o sucesso está na persistência e no equilíbrio entre teoria e prática. Prepare-se para desbravar novos horizontes e descobrir todo o potencial que a programação oferece.
Boa sorte e divirta-se nessa jornada!
]]>
De algumas décadas pra cá se popularizou a utilização de callbacks, funções que são referenciadas por outras funções e executadas de forma não deterministica – principalmente por causa do paradigma assíncrono de programação.
A linguagem C já oferece suporte a callbacks há muito tempo, mas sua utilização não é parecida com linguagens mais populares como o JavaScript ou PHP. Callbacks em C precisam ter tipos definidos em tempo de compilação e são tratados como ponteiros. Vem comigo que eu te explico!
Exemplo de callback e utilização de callbacks em C
Se você não quiser entender como tudo funciona e quiser pular para a solução, aqui está!
// Define a assinatura do callback
typedef void (*hello_t)(const char *name);
// Implementação que será utilizada como callback
void say_hello(const char *name)
{
printf("Olá, %s!\n", name);
}
int main(void)
{
// Variável que armazena o callback
hello_t callback = say_hello;
// Como chamar o callback
callback("codamos.com.br"); // equivalente a say_hello("codamos.com.br")
return 0;
}
Para entender bem o que está acontecendo no exemplo acima, continue lendo que eu te explico 😉
Como definir um callback em C?
Antes de entender como escrever um callback em C, você precisa entender como funcionam ponteiros em C. Sugiro a leitura do material de aula do professor Márcio Sarroglia Pinho (PUCRS) sobre ponteiros, após ler este material você provavelmente vai entender bem como ponteiros funcionam!
Ponteiros em C apenas referenciam um endereço na memória. Então se todo o nosso código é carregado em memória provavelmente poderíamos referenciar uma função, certo? Corretíssimo! E é assim que podemos trabalhar com callbacks. Vejamos o exemplo abaixo:
void say_hello(void)
{
// ...
}
int main(void)
{
void *callback = say_hello;
// callback agora aponta para o endereço de (void say_hello(void))
return 0;
}
No exemplo acima a variável callback é definida como *callback, que é como definimos um ponteiro. O tipo deste ponteiro é void, o que significa dizer que a linguagem C não precisa saber nada sobre o que está contido naquele endereço de memória.
Porém não é possível executar a função say_hello() através da variável callback sem indicar ao compilador com quais tipos estamos lidando. A forma mais clara de indicar os tipos é através da estrutura typedef, como a seguir:
// Define um tipo "callback_t" que é uma função
typedef void (*callback_t)(void);
void say_hello(void)
{
// ...
}
int main(void)
{
callback_t callback = say_hello;
callback();
return 0;
}
No exemplo acima nós definimos um tipo chamado callback_t que é um ponteiro de função. Este ponteiro indica que a função retorna void e que não possui parâmetro algum.
Supondo que a função say_hello() recebesse um parâmetro do tipo string, poderíamos mudar o código para o seguinte:
// Define um tipo "callback_t" que é uma função
typedef void (*callback_t)(const char *name);
void say_hello(const char *name)
{
// ...
}
int main(void)
{
callback_t callback = say_hello;
callback("codamos.com.br");
return 0;
}
Repare como a definição do tipo callback_t precisou se adaptar para receber const char *name como parâmetro. Do contrário a chamada callback("codamos.com.br") geraria um erro.
Portanto para definir um callback você pode utilizar a sintaxe abaixo:
typedef <tipo_de_retorno> (*nome_do_callback)(<tipo> param1, <tipo> param2, ...);
Como passar e receber um callback por parâmetro em C?
Receber um callback por parâmetro pode ser feito de duas formas diferentes: através da definição de tipos (typedef) ou através de uma definição na assinatura da função.
Para receber um callback via parâmetro utilizando a sua definição typedef basta referenciar o tipo, como no exemplo abaixo:
typedef void (*callback_t)(const char *name);
void run_callback(callback_t callback)
{
callback("codamos.com.br");
}
Você também pode descrever a assinatura do callback na assinatura da função, sem utilizar typedef como no exemplo abaixo:
void run_callback(void (*callback)(const char *name))
{
callback("codamos.com.br");
}
A segunda opção, apesar de não definir um novo tipo, é muito mais difícil de ler. Portanto eu não recomendo a sua utilização.
Quando utilizar um callback em C?
Callbacks podem ser utilizados em diferentes situações, abaixo vou listar apenas algumas delas.
Programação assíncrona
O estilo assíncrono de programação, que ficou popular com a utilização de JavaScript em ambientes de navegador e também no NodeJS, depende da utilização de callbacks para delegar a execução de funções para um futuro indeterminado.
Por exemplo, a implementação do Event Loop utilizado pelo NodeJS depende da biblioteca libuv escrita em C/C++. Esta implementação permite realizar operações de entrada e saída como ler o disco rígido ou realizar escritas ou leituras por rede de forma não bloqueante e organizar o fluxo de execução através de callbacks.
Um outro exemplo de programação assíncrona que utiliza callbacks em C é o multithreading, a capacidade de executar mais de um (sub) processo ao mesmo tempo. Em C uma implementação muito conhecida é a da biblioteca pthreads que recebe um callback como parâmetro da função pthread_create().
Programação de rede e IoT
Normalmente utilizamos callbacks sempre que precisamos delegar uma tarefa a outro processo: uma thread, o sistema operacional ou mesmo um evento externo. É muito comum, por exemplo, utilizar callbacks para tratar eventos de rede ou de sensores. Veja o exemplo (não realista) abaixo:
void handle_message(connection_t conn, const char *msg, size_t len);
void on_connect_callback(connection_t conn)
{
on_message(conn, handle_message);
}
socket_t socket = bind_socket("0.0.0.0", 8080);
on_connect(socket, on_connect_callback);
No exemplo acima nós abrimos um socket que permite que diferentes computadores se conectem a este programa através da porta 8080. A cada nova conexão o programa irá chamar a função on_connect_callback(). E nesta função registramos também outro callback, o handle_message(), que deverá ser chamado a cada vez que aquela conexão enviar algum pacote de rede para o nosso programa.
Como são ações externas nós não podemos controlá-las e, portanto, o callback é justamente uma ferramenta para organizar o fluxo do nosso código em situações assíncronas em que não controlamos o fluxo da aplicação.
Para trabalhar com eventos
Callbacks não precisam ser utilizados apenas em situações em que trabalhamos com redes, disco ou sensores de forma assíncrona e/ou não-bloqueante.
Em muitos casos a utilização de eventos nos ajuda a organizar o nosso código melhor. Por exemplo, no código abaixo nós lemos eventos de um arquivo de texto e executamos seus respectivos callbacks:
typedef void (*callback_t)(void);
void replay_events(callback_t user_created, callback_t user_updated)
// Ler eventos a partir de um arquivo de texto
int events[];
int total_events;
for (int i = 0; i < total_events; ++i) {
switch (events[i]) {
case EV_USER_CREATED:
user_created();
break;
case EV_USER_UPDATED:
user_updated();
break;
// ...
}
}
Da mesma forma como passamos cada callback via parâmetro, poderíamos tê-los passado via HashMap, que é uma estrutura muito mais dinâmica e nos permitiria registrar diversos callbacks para diferentes eventos.
Conclusão
Neste artigo vimos como e quando implementar um callback utilizando a linguagem C, quais suas utilidades e diferentes casos de uso. Também vimos por cima alguns conceitos importantes como os de programação assíncrona e ponteiros.
Não deixe de compartilhar com seus colegas e seguidores caso tenha gostado deste artigo ou ache que pode ser útil para outras pessoas.
Até a próxima! 👋
]]>
É muito comum, quando a gente começa a trabalhar com GIT, de não entendermos alguns conceitos simples. Coisas que a gente precisa configurar uma única vez na vida e nunca mais vê. E aí quando formatamos o computador ou trocamos de equipamento essas dúvidas sempre voltam.
Uma dúvida comum que eu tinha quando estava iniciando e que recebo várias vezes por mês de pessoas que eu acompanho os estudos, é “Por que quando eu subo arquivos no github a minha foto não aparece na lista de commits?” – e isto acontece porque na hora de fazer o commit o seu usuário e email não estavam configurados e portanto a assinatura não saiu como o esperado.
Neste artigo vamos ver exatamente como configurar seu usuário e e-mail do GIT em sua máquina local para corrigir as assinaturas de seus commits.
Por que minha foto não aparece nos commits do Github ou Gitlab?
Porque o GIT em sua máquina não está configurado com o mesmo e-mail do seu perfil no Github ou Gitlab.
Sempre que nós fazemos um commit, como explicamos no artigo como subir arquivos pro seu projeto no Github, a ferramenta GIT não apenas armazena as alterações como assina com o seu usuário atual. Veja na imagem abaixo uma assinatura de commit:
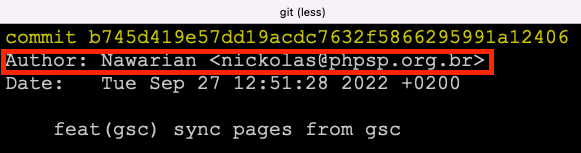
git log mostrando o dado “Author: Nawarian <[email protected]>”Esta assinatura é o que permite o Github ou Gitlab de compreenderem qual foto mostrar. Se o seu e-mail estiver na plataforma deles, a sua foto aparecerá.
Portanto para a sua foto aparecer na lista de commits dessas plataformas, é importante configurar o seu nome de usuário e e-mail corretamente.
Como configurar usuário e e-mail do GIT
O usuário e e-mail associado ao git podem ser configurados para todos seus projetos de uma única vez utilizando o comando git config e passando a flag --global.
Para definir o seu e-mail de assinatura GIT, rode o comando abaixo:
$ git config --global user.email "[email protected]"
Desta forma todos os commits que vocie escrever daqui em diante serão assinados com o e-mail “[email protected]”. De forma semelhante, podemos alterar o nome de usuário GIT da seguinte maneira:
$ git config --global user.name "seuusuario"
Você pode verificar que as suas configurações tomaram efeito rodando o mesmo comando com a flag --list:
$ git config --list
...
[email protected]
user.name=seuusario
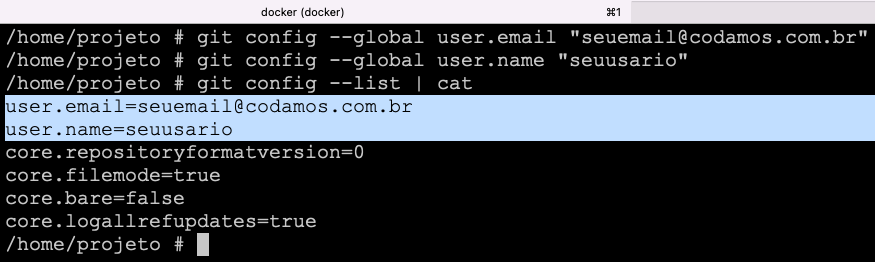
Ilustração dos comandos
git config e a listagem das configuraçõesComo configurar um usuário e e-mail diferente para um repositório específico
Pode acontecer de num mesmo computador você precisar utilizar duas contas de GIT diferentes. Por exemplo, caso você utilize o mesmo computador para trabalho e para projetos pessoais. Ou caso preste consultoria a diferentes empresas.
Além de definir a configuração global do GIT com o comando git config --global, que se aplica a todos os repositórios GIT em seu computador, é possível alterar configurações apenas para o projeto atual através da flag --local:
$ git config --local user.email "[email protected]"
$ git config --local user.name "seuoutrousuario"
Os comandos acima apenas funcionarão se o seu diretório atual for um repositório GIT.
Conclusão
A gente viu como alterar seu usuário e e-mail de assinatura de commits do GIT através do comando git config. Com isso você vai poder resolver seu problema de identificação de commits mais facilmente.
Se você já fez um commit que não estava assinado corretamente e quer corrigí-lo, dê uma olhada neste outro artigo sobre como renomear mensagens de commit em um repositório para ter uma outra chance de assinar aqueles commits.
]]>
As vezes é necessário redefinir a senha do usuário root da base de dados MySQL. Seja para retomar controle de um banco ou mesmo para trabalhar com backups. Neste artigo rápido eu vou te mostrar como proceder para redefinir a senha de root.
1. Reiniciar o servidor no modo de segurança
Primeiramente nós precisamos interromper o servidor MySQL para podemos entrar em modo de segurança. O modo de segurança do MySQL vai nos permitir acessar o banco de dados sem nenhuma senha e com todas as permissões que precisamos para realizar quaisquer alterações.
🚨 Não rode o servidor em modo de segurança em produção. Qualquer usuário que realizar login no seu servidor terá acesso irrestrito a base de dados!
Vamos primeiro interromper o serviço mysql:
$ sudo service mysql stop
O comando acima assume que seu servidor utiliza service, outras variações podem incluir systemctl ou init.
Após interromper o serviço mysql podemos inicializar o mesmo serviço, mas desta vez utilizando o daemon mysqld_safe, da seguinte maneira:
$ sudo mysqld_safe --skip-grant-tables &
A mágica acontece na flag --skip-grant-tables que nos permite fazer login e alterar qualquer coisa no servidor sem verificar permissões. O & ao fim do comando coloca este daemon para rodar em plano de fundo, desta forma nós conseguimos continuar utilizando o mesmo terminal para seguir os próximos passos.
2. Alterar senha de root
Agora que o MySQL está rodando em modo de segurança e sem verificar permissões, podemos facilmente realizar o login via linha de comando da seguinte maneira:
$ mysql -uroot
O sistema sequer vai lhe pedir uma senha. A partir daqui estamos no console do MySQL e podemos rodar quaisquer comandos SQL ou comandos específicos do MySQL.
Para alterar a senha do usuário root vamos rodar o comando ALTER USER como descrito abaixo:
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'NOVA SENHA ROOT';
mysql> FLUSH PRIVILEGES;
O primeiro comando, ALTER USER, modifica a senha do usuário root para NOVA SENHA ROOT (altere o comando para utilizar a senha desejada). Este comando também especifica que o usuário root só pode acessar o banco de dados quando na mesma máquina que o servidor (localhost). Portanto não é possível acessar este banco como root a partir de uma outra máquina.
O segundo comando, FLUSH PRIVILEGES, ordena que o MySQL reavalie sua cadeia de usuários e permissões imediatamente.
3. Reiniciar o servidor MySQL em modo normal
Agora que terminamos de corrigir a senha do usuário root podemos interromper o modo de segurança e reiniciar o servidor em modo normal de operação.
Para interromper o modo de segurança podemos rodar o seguinte comando:
$ mysqladmin -uroot -p shutdown
Note que agora o servidor vai pedir a senha para o usuário root, que deverá ser a mesma que você definiu no passo 2.
Podemos agora reiniciar o servidor MySQL em modo normal:
$ sudo service mysql start
Se tudo correu bem, o servidor estará operando normalmente e a nova senha se aplicará ao usuário root.

Se você programa ou está aprendendo PHP há algum tempo já deve ter visto um erro na sua tela ou arquivo de log que diz algo mais ou menos assim:
PHP Notice: Use of undefined constant nome - assumed 'nome' in /var/www/index.php on line 10
Hoje nós vamos falar sobre este erro, como identificar e corrigir de forma segura. Vem comigo!
Por que “Use of undefined constant” acontece?
Quando nós fazemos referência a uma constante que não foi declarada, o PHP decide que em vez de te devolver uma tela em branco ou com erros é melhor entender que você quis dizer que aquilo era uma string. É uma estratégia de melhor esforço (best effort) em vez de falhar cedo (fail first).
O erro Use of undefined constant acontece porque o PHP tenta perdoar uma falha que nós cometemos enquanto escrevemos um código ao não colocar strings entre aspas.
Por exemplo, o código abaixo funciona:
$arr = ["nome" => "Nawarian"];
echo $arr[nome];
// PHP Notice: Use of undefined constant nome - assumed 'nome' in ...
// Nawarian
O código acima vai justamente gerar um erro Use of undefined constant nome - assumed 'nome' in .... Isto porque ao acessar a chave nome do array $arr não utilizamos uma string 'nome' mas sim uma constante nome que nunca foi declarada.
O PHP então perdoa este erro que cometemos e entende que estamos tentando fazer echo $arr['nome']. Mas como isto pode ter sido um erro da nossa parte, o PHP gera um erro do tipo notice que nos permite averiguar aquele pedaço de código para corrigirmos ou mesmo identificarmos bugs.
Como corrigir o erro “Use of undefined constant”?
O erro Use of undefined constant acontece, na maioria dos casos, porque tentamos utilizar uma string mas esquecemos de colocar as aspas. Nestes casos o ideal é corrigir o problema colocando aspas na palavra.
Por exemplo ao acessar a chave “pessoa” do array “arr” o seguinte código $arr[pessoa] gera erro mas funciona, enquanto o código $arr['pessoa'] funciona da mesma forma e sem erros.
Atenção! Em alguns casos pode ser que a intenção da pessoa que escreveu aquela linha fosse realmente de referenciar uma constante que foi definida em outro arquivo e nunca foi importada. Neste caso o correto não é transformar em string, mas sim fazer o include do arquivo que define a constante.
Como ler a mensagem de erro “Use of undefined constant”
Esta mensagem normalmente fica no seu arquivo error.logmas também pode ser enviada diretamente na tela em ambiente de desenvolvimento.
O template da mensagem é o seguinte:
PHP Notice: Use of undefined constant <NOME> - assumed '<NOME>' in <ARQUIVO> on line <LINHA>
Vamos quebrar esta mensagem em partes:
PHP Notice: o tipo do erro que aconteceu de acordo com os níveis de erros da linguagem PHP.
Use of undefined constant <NOME>: indica que no código a constante <NOME> foi referenciada mas nunca foi definida. Deixa eu clarificar o que isso significa com o código a seguir:
const PESSOA = 'nawarian';
$arr = [
'nawarian' => 'programador',
'nickolas' => 'trabalhador'
];
echo $arr[PESSOA]; // programador
echo $arr[nickolas]; // Notice
echo $arr['nickolas']; // trabalhador
No exemplo acima $arr[PESSOA] não gera erro, porque a constante PESSOA foi definida na primeira linha do código. Já a linha $arr[nickolas] gera um erro Use of undefined constant nickolas porque estamos fazendo referência a uma constante nickolas que nunca foi declarada. Note que o correto neste caso é utilizar $arr['nickolas'].
assumed ‘<NOME>' in <ARQUIVO> on line <LINHA>: aqui temos a decisão que o PHP tomou por você: utilizar uma string em vez de constante. Como em $arr[nickolas] que vira $arr['nickolas'].
O PHP também te indica qual o nome do arquivo em que este problema aconteceu, e em qual linha. Desta forma você pode inspecionar o arquivo e verificar se este é realmente o comportamento que você gostaria que a sua aplicação tivesse.
Como identificar onde o “Use of undefined constant” ocorre?
Ao navegar pelo seu sistema você provavelmente vai gerar alguns erros. Estes erros são escritos num arquivo de log, normalmente chamado error.log. O caminho onde este arquivo é escrito fica definido na variável error_log do php.ini, você pode verificar o caminho tanto no php.ini quando utilizando a função phpinfo().
Ao verificar o arquivo error.log você pode buscar pelo texto “Use of undefined constant” e vai encontrar diferentes linhas com este erro. Leia o fim da linha e repare que ela tem o formato in /caminho/para/arquivo.php on line 100. Ora, é justamente aqui que você entende qual arquivo PHP está gerando este erro, e qual a linha em que ele acontece.
Consequências do erro “Use of undefined constant”
É importante que a gente seja sempre 100% intencional sobre o código que escrevemos. Eu escrevi sobre isso no artigo sobre programação por coincidência e como escrever códigos que outras pessoas entendem.
Uma das consequências do Use of undefined constant é que o nosso código fica mais imprevisível, porque nós permitimos que o PHP altere o comportamento do nosso código. Isto pode gerar falhas de software que se manifestam das formas mais estranhas possíveis. Além do mais, ao atualizar a versão do PHP pode acontecer de a nova versão remover este comportamento completamente.
Outra consequência disso é que o nosso arquivo de logs de erro fica poluído com mensagens do tipo Use of undefined constant. Estas mensagens não precisam existir porque o seu código está funcionando, só que não da forma como você o escreveu. Ao poluir o log com mensagens deste tipo, você perde a capacidade de prestar atenção em erros que realmente podem significar uma falha importante no seu sistema.
A última consequência que quero citar aqui é a da utilização de disco indevida. Eu já trabalhei com aplicações que para cada página acessada geravam-se cerca de 30 mil linhas de log do tipo Use of undefined constant. Isto gera uma superutilização de disco desnecessária e pode inclusive gerar problemas de manutenção em seus servidores e o aumento de custo de armazenamento.
]]>O PHPSP + Talks edição Alura vai acontecer no dia 25 de Abril de 2023, das 19 às 22 horas no prédio da FIAP Avenida Paulista.
O que é PHPSP + Talks?
PHPSP + Talks tradicionalmente é um evento trimestral que o PHPSP organiza com empresas parceiras.
A empresa parceira oferece o local, infraestrutura e comida como forma de apoiar a comunidade, e nós do PHPSP organizamos uma mini conferência com palestras e espaço para networking.
Geralmente são de 2 a 3 palestras no dia da mini conferência, com direito a pausa para cafézinho e acesso a muita gente interessante e interessada.
Sobre a parceria com a Alura e FIAP
Eu (@nawarian) diria que esta é uma parceira que simplesmente faz sentido: trazer um monte de gente que quer aprender para um ambiente de formação e aprendizado.
Este será o primeiro evento em parceria entre a comunidade e a Alura, e já começamos com o pé certo!
A Alura vai nos oferecer o espaço na universidade FIAP, além da infraestrutura, divulgação e comidinhas para o coffee break. E nós do PHPSP vamos organizar as inscrições, curadoria das apresentações e credenciamento.
A iniciativa tem tudo para dar certo, e conforme o sucesso se confirmar no dia do evento vamos com certeza planejar os eventos futuros 🤩
Como, quando e onde vai ser?
O evento vai acontecer entre as 19 e 22 horas do dia 25 de Abril de 2023 e vai ter 5 partes, se liga:
| Abertura | A organização do PHPSP dá algumas explicações sobre a comunidade e faz seus anúncios. A Alura e FIAP também têm seus comunicados e vídeos institucionais para apresentar. |
|
Apresentação longa |
Uma apresentação com duração de até 45 minutos com tempo para perguntas e respostas. |
|
Apresentação curta (lightning talk) |
Uma apresentação curta, de 15 minutos. Ideal para quem quer começar a palestrar e quer perder o medo / vergonha de falar em público. |
|
Coffee break |
Cerca de 30 minutos para a gente comer, conversar, fazer networking e fazer piada ruim. |
|
Apresentação longa |
Uma apresentação com duração de até 50 minutos e espaço para perguntas e respostas. |
|
Apresentação curta (lightning talk) |
Uma apresentação curta, de 15 minutos. Ideal para quem quer começar a palestrar e quer perder o medo / vergonha de falar em público. |
| Encerramento | Palavras da organização PHPSP, e do nossos parceiros Alura e FIAP. |
O PHPSP + Alura vai acontecer no dia 25 de Abril de 2023, na FIAP da Avenida Paulista. Como é um espaço grande, a expectativa é de 80 pessoas comparecendo ao evento no dia. Abaixo você encontra o endereço completo e pode também buscar no google maps.
📍 Av. Paulista, 1100 - Bela Vista, São Paulo - SP, 01311-000, Brasil
Quero palestrar!
Como você viu, nós temos quatro espaços de apresentação para este evento. Duas apresentações curtas (de 15 minutos) e duas apresentações longas (de 1 hora). A nossa recomendação é a seguinte:
Se você não tem experiência com apresentações e quer experimentar como é, ou se faz tempo que não se apresenta em frente a muita gente, recomendamos optar por fazer uma apresentação curta. Estas apresentações normalmente não têm muito tempo pra perguntas e respostas e são feitas pra comunicar uma única informação de forma concisa.
Se você já se sente confortável com falas públicas e tem um tópico que entende bem sobre o qual gostaria de compartilhar e até mesmo desafiar os próprios conhecimentos, uma apresentação longa é o caminho! Isso porque você vai ter muito mais tempo para entrar em detalhes, e tempo dedicado para perguntas e respostas.
Não precisa ser 100% inovador ou de conteúdo nunca visto antes. Você pode falar sobre coisas do dia a dia, sobre formas de resolver um problema, ou o último brinquedo de código que você conheceu. Nós somos uma comunidade, não uma startup.
Quer palestrar? Tá na instiga? Envia sua proposta pra gente através do nosso Google Forms até o dia 13 de Abril de 2023!
Quero participar
A participação vai ser gratuita porém com número de entradas limitadas, dada a capacidade do local. Temos espaço para 80 pessoas, então o quanto antes você se inscrever melhor!
No local teremos acesso ao WIFI mas você vai precisar fazer um cadastro lá pra poder utilizar! Então você não tem interesse em se cadastrar e precisa de conectividade com a internet, leve isso em consideração.
Quem quiser se inscrever vai precisar compartilhar os seguintes dados conosco para repasse à FIAP para fins de credenciamento e acesso ao prédio:
- Nome
- RG
- Nome social
- Acessibilidade – indicar qual
A inscrição vai ser feita pelo perfil do PHPSP no site meetup, então se liga lá pra abertura das inscrições e também nas nossas redes sociais pra anúncios:
Agradecimentos
Após estes anos de pandemia nós finalmente voltamos a sair da toca e estamos muito felizes de poder reconectar com a comunidade agora no mundo físico!
Nossos agradecimentos desta vez são para a Alura e FIAP que nos proporcionaram esta oportunidade que tem tudo para ser maravilhosa. Que este evento gere bons frutos para todos nós 🙏
Não podemos esquecer claro de agradecer à comunidade PHPSP que não é uma empresa, startup, ONG e muito menos recebe dinheiro pelo que faz. Somos pessoas programadoras, entusiastas e, acima de tudo, voluntáries que buscam compartilhar o conhecimento e oportunidades com a comunidade.
Nos vemos dia 25 de Abril no PHPSP + Talks edição Alura, lá na FIAP!
Para atualizar o endereço de IP clique aqui.
O que é um IP externo ou público?
Toda rede de computador permite que seus computadores se identifiquem por um endereço que deve ser único naquela rede chamado Internet Protocol (IP). E cada rede possui sua própria capacidade de endereços, e pode se conectar a outras redes.
Por exemplo, em casa o seu roteador provavelmente gerencia uma rede com alguns poucos computadores. Esta rede vai distribuir endereços parecidos com o seguinte 192.168.0.10 ou 192.168.10.5.
Ao conectar-se com a internet o seu roteador recebe um endereço IP da rede gerenciada pelo seu provedor de internet. Este endereço de IP permite que outros computadores nesta rede internacional (internet) se comuniquem com os computadores na sua rede.
Endereço de IP público ou endereço IP externo é o endereço de IP fornecido pelo seu provedor de internet e que permite outros computadores a conectarem-se ao seu.
O meu IP externo público é fixo ou dinâmico?
Alguns provedores podem oferecer endereços fixos por padrão. Outros cobram uma taxa especial para garantir que a sua rede sempre receba o mesmo número de IP. Normalmente provedores de internet oferecem IP dinâmico a menos que seja explicitamente contratado o serviço de IP fixo.
Se você não contratou o serviço de IP fixo, você provavelmente possui um IP dinâmico.
Quando o IP dinâmico muda?
Isto depende de do seu fornecedor de internet. Alguns fornecedores atualizam o IP somente quando você reiniciar seu roteador. Outros atualizam de tempos em tempos. Por exemplo, a O2 da Telefónica aparenta atualizar seus IPs dinâmicos a cada 24 horas. Sempre que você trocar de rede, provavelmente trocará de IP também.
Por exemplo, se você está conectade ao wifi de uma lanchonete e logo em seguida conectou-se ao wifi do trabalho, seu ip provavelmente mudou – a não ser que você trabalhe na lanchonete 😅.
De forma semelhante, se você utiliza um serviço de rede virtual privada – Virtual Private Network ou VPN – o seu IP será o da rede privada enquanto estiver conectade.
Como funciona a ferramenta de obter IP externo?
Nós construímos uma API Rest simples utilizando Cloudflare Workers e tornamos esta página pública e gratuita para quem quiser utilizar!
O código está aberto e disponível no repositório codamos-com-br/api-worker. Sinta-se livre para contribuir, copiar e utilizar em seus projetos.
A API utilizada pelo site codamos.com.br não está disponível para utilização de terceiros. Caso queira utilizar esta API em seu aplicativo, publique sua própria versão. O código está aberto e disponível para quem quiser 😉
]]>
As vezes a gente passa tanto tempo escrevendo um código que na hora de fazer o commit vem aquela sensação de alívio e a gente chega até escreve a mensagem de commit errado, né? 🤣
Neste mini tutorial eu vou te mostrar como você pode renomear o commit anterior usando a opção amend do Git. Se você ainda não sabe nada sobre git, dá uma olhada neste guia básico primeiro que vai ser de imensa ajuda!
Atenção! Só é possível renomear um commit usando a opção --force do comando git push. Isto é perigoso e pode te levar a perder commits que estiverem no servidor mas não estiverem em sua máquina local. Use por sua conta e risco!
Como o tópico pode ficar complicado rapidinho, eu gravei este vídeo pra te ajudar a entender o processo:
Como renomear o último commit do repositório
Para renomear o último commit nós podemos utilizar o comando git commit --amend, que só opera sobre o último commit feito.
Vejamos este git log como exemplo, o repositório tem exatamente 3 commits:
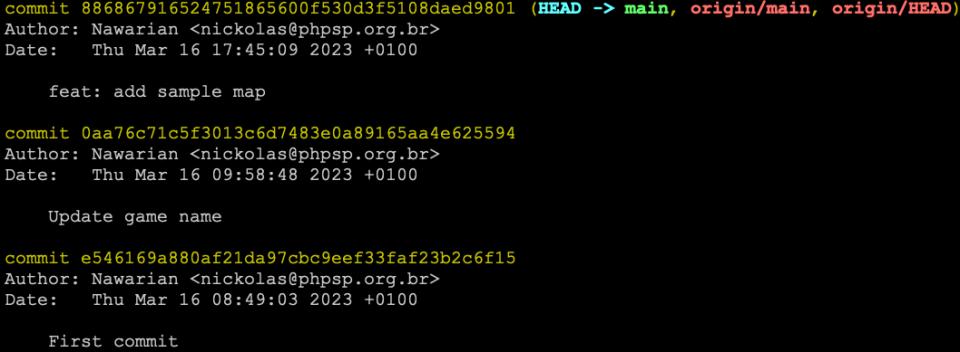
O último commit diz feat: add sample map. Vamos supor que eu gostaria de traduzir esta mensagem de commit para português. Eu posso renomear aquele commit com o seguinte comando:
$ git commit --amend -m 'feat: adiciona mapa de exemplo'
Pronto, simples assim! O último commit foi renomeado:
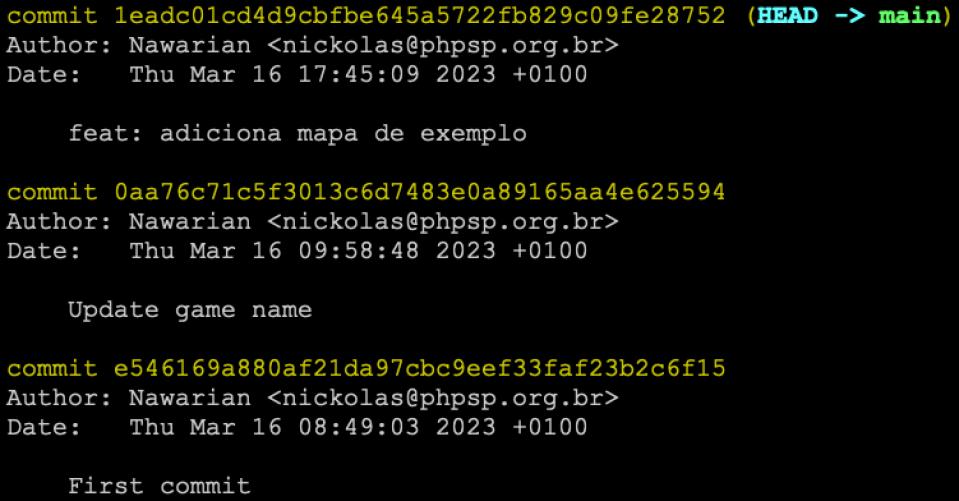
Note que nosso branch agora diz HEAD -> main e não está mais de acordo com o upstream (github, gitlab, bitbucket…). Isto acontece porque ao renomear um commit o histórico GIT é modificado e portanto você só consegue atualizar seu repositório usando o git push com a opção --force.
Para enviar o commit ao servidor, precisamos agora fazer um git push --force:
$ git push origin main --force
Como renomear muitas mensagens de commit
A opção --amend só nos permite renomear a última mensagem de commit do histórico. Se você precisa renomear mensagens mais antigas, ou diversas mensagens de uma vez só, vai precisar utilizar um outro comando chamado rebase.
O git rebase te permite revisitar qualquer porção do seu histórico e modificar como quiser: renomear commits, remover commits, mesclar dois mais mais commits num só…
Para renomear muitas mensagens de commit de uma vez só, vamos rodar o seguinte comando:
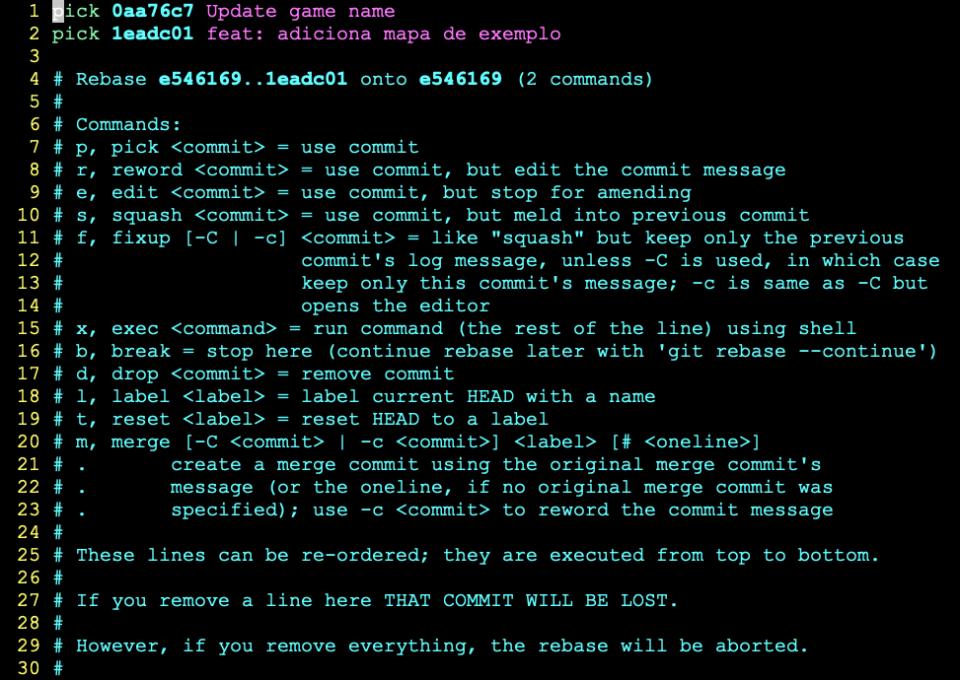
$ git rebase -i HEAD~2
Note que a opção -i significa interactive, ou seja: o comando vai aguardar a nossa intervenção pra fazer quaisquer alterações.
O argumento HEAD~2 indica ao git que nós queremos rever 2 commits, a partir do último commit (HEAD). O git então vai abrir seu editor de texto padrão, que no meu caso é o VIM – Se você fica perdidim quando o VIM aparece na sua frente, dá uma olhada neste artigo que eu escrevi sobre como começar com VIM do zero. A tela vai ficar assim:
Bueno, as linhas que começam com pick são commits que seu repositório conhece. Para todas as mensagens de commit que você quiser renomear, basta você trocar a palavra pick por reword.
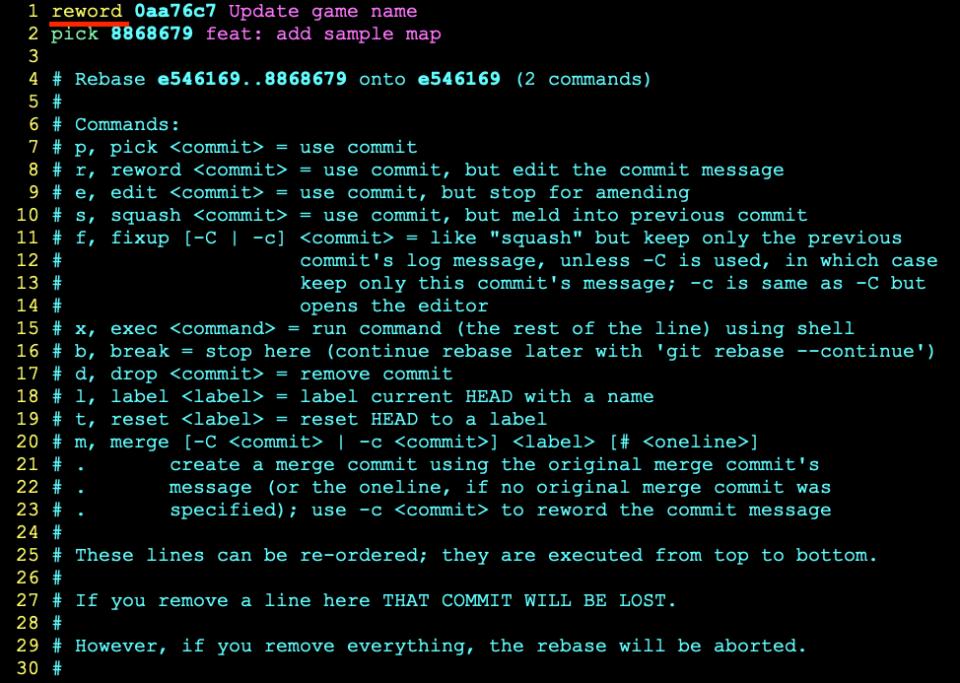
Quando você salvar o arquivo, para cada commit que você decidiu renomear, um editor de texto vai se abrir. Veja:
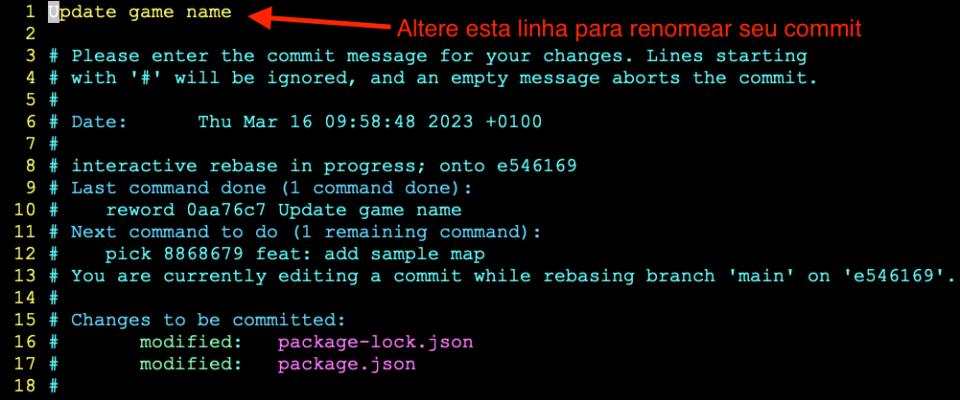
E pronto, desta forma você consegue renomear quantos commits quiser. Não se esqueça de que para enviar estas alterações ao servidor git, seja ele github, gitlab, Bitbucket ou qualquer outro, você precisa fazer um git push --force, porque isto efetivamente altera o histórico do seu repositório.

Todo ano ela vem e deixa o nosso coração quentinho! É claro que eu estou falando da PHPeste! A maior conferência de PHP de todo o nordeste brasileiro 🥳
No ano de 2023 a PHPeste vai acontecer nos dias 06, 07 e 08 de Outubro lá em Fortaleza, Ceará!
Neste post você vai ver
O que é a PHPeste
PHPeste é uma conferência de PHP organizada pelas comunidades “cabra da peste” do nordeste brasileiro. O evento já passou por João Pessoa (PB), Salvador (BA), Fortaleza(CE), São Luís (MA), Recife (PE), Natal (RN) e agora volta a Fortaleza (CE).
Esta foto é do fim do evento que aconteceu em 2022 lá em Natal, no Rio Grande do Norte. A esta altura do campeonato, algumas pessoas já haviam ido pra casa mas dá pra ter uma noção da vibe dessa galera muito massa!

PHPeste 2022 em Natal, Rio Grande do Norte. Espaço oferecido pelo SebraeLab 💙
Em 2023 teremos 3 dias de muito aprendizado, mão na massa e, principalmente, de gente “arretada da peste” que irá ampliar ainda mais seu networking. O evento contará com a participação de palestrantes de altíssimo nível e minicursos práticos.
Onde vai acontecer a PHPeste 2023
Este ano a PHPeste vai ser sediada pela nossa querida Unifor, que desde já merece muitos aplausos!
A universidade vai nos receber com espaço e infraestrutura para os três dias de evento, e o endereço é este aqui:
📍 Av. Washington Soares, 1321 - Edson Queiroz - CEP 60811-905 - Fortaleza-CE Brasil. Clique aqui para abrir o Google Maps.
Como entrar em contato com a organização
Se você quer apenas conversar, vem falar com a gente no nosso Canal do Telegram!
Se você ou a sua empresa quer patrocinar a conferência, vem falar com a gente através do [email protected]. Mas eu recomendo que você continue lendo até o final pra cobrir algumas das suas dúvidas.

Redes e contatos da organização do evento!
Datas importantes
Se você quer palestrar, assistir palestras ou mesmo patrocinar o evento, é bom prestar atenção nessas datas. Vem comigo que eu vou te dar os detalhes que tu precisa!
| Data | O que vai acontecer |
| Outubro de 2022 | Local da conferência confirmado: Fortaleza, Ceará |
| Fevereiro de 2023 | A organização concordou com o Mídia Kit proposto e sai em busca de patrocínio. |
| Março até Setembro de 2023 | A organização fica aberta para conversar com potenciais patrocinadores. |
| Abril de 2023 | Abertura do Call for papers, quem quer palestrar pode enviar suas propostas! |
| Maio de 2023 | Encerrado o Call for papers, qualquer submissão enviada depois desta data será ignorada. |
| Junho de 2023 | Divulgação da lista de oficinas e palestras. |
| Agosto de 2023 | Primeiro lote de ingressos aberto para compra |
| Setembro* de 2023 | Segundo lote de ingressos aberto para compra. Pode acontecer antes se o primeiro lote esgotar antes do previsto. |
| Outubro de 2023 | É hora de falar de PHP, conhecer gente, fazer negócios e se aproximar da comunidade 🐘💙🥳 |
Números importantes
Deixa eu te contar alguns fatos e números sobre a PHPeste que são importantíssimos pra você já sentir como a conferência vai acontecer. Chegue aqui!
- Três dias de evento
- Mais de 20 palestrantes, pelo menos 10 se identificam com ou são do gênero feminino, pelo menos 5 pessoas são das comunidades locais
- 400 participantes no total
- 7 horas inteiras dedicadas a networking
- 3 trilhas diferentes, uma 100% em inglês
- Palestras e oficinas sobre PHP, carreira, arquitetura e experiência
Quero participar, como faço?
Fica de olho no calendário acima e nas comunicações da comunidade tanto no site oficial da PHPeste quanto nas redes sociais!
Se você tem alguma oficina ou palestra que queira oferecer, a partir de Abril de 2023 você vai poder enviar a(s) sua(s) proposta(s) pra gente!
Não se esquece de que é obrigatório respeitar o nosso Código de Conduta, viu?
Quero patrocinar, como faço? Cadê o Mídia Kit!
Este ano a PHPeste oferece 4 cotas diferentes de patrocínio, pra caber no caixa de qualquer empresa que queira nos apoiar. Abaixo você confere as diferentes cotas e benefícios para quem patrocina e faz o evento acontecer!

Cotas Bronze (R$ 3.000), Prata (R$ 7.000), Ouro (R$ 10.000) e Diamante (R$ 12.000) e seus benefícios.
Se interessou né? Se você ou a sua empresa querem e podem ajudar a bancar o evento, entra em contato com a gente no [email protected].
O mídia kit está disponível pra download aqui! 👈👈
A conferência é da comunidade, para a comunidade!
Então compartilha bastante este artigo nas suas redes sociais, ajuda a gente a divulgar o evento e se você puder nos conectar com empresas que tenham interesse em patrocinar a conferência deste ano, pode entrar em contato com a gente que nós vamos fazer a mágica acontecer.
O compartilhamento e engajamento em redes sociais é uma ajuda incrível pra fazer esta conferência ser um sucesso como nos anos anteriores 💙!
Nos vemos na Terra da Luz! ☀️

Se você se interessa por desenvolvimento de jogos e já aprendeu alguma coisa sobre programação, provavelmente sabe que é possível escrever jogos usando a API HTML5 dos navegadores. E se procurou saber um pouquinho mais, percebeu que existe diferentes ferramentas pra ajudar a trabalhar com desenvolvimento de jogos como o Phaser.
Logotipo do framework Phaser
Phaser é um framework que te permite criar jogos complexos utilizando HTML5 e suas tecnologias como Canvas, WebGL, WebAudio e também facilita a forma de capturar ações do usuário usando teclado, mouse, touch ou mesmo controles de videogame. Acesse o site oficial phaser.io para saber mais!
Neste tutorial eu vou te ensinar a criar um jogo com Phaser e TypeScript de forma rápida e prática!
Neste artigo
Vídeo do artigo
Pra facilitar a leitura e te levar direto ao ponto, nós criamos um vídeo de leitura e execução deste tutorial. Se você prefere ver do que ler, aqui está!
Vale a pena criar um jogo utilizando Phaser?
Muita gente se pergunta qual a melhor ferramenta para aprender, já que todo mundo sonha alto: lançar um jogo na Steam, no Itch.io, Facebook ou mesmo no Google Play ou App Store.
Não é possível fazer tudo isso usando somente o Phaser, mas existem outras ferramentas como o Electron para empacotar seu jogo para plataformas Desktop e também o Ionic que lhe permite fazer o mesmo para Smartphones e Tablets.
Então considerando que Phaser utiliza JavaScript e/ou TypeScript para desenvolvimento, e você pode portar seu jogo para qualquer plataforma, vale a pena sim escrever um jogo utilizando Phaser.
E não somente jogos simples, viu? A foto abaixo é do jogo Citadels lançado para Facebook, construído com Phaser e que conquistou um público de 4,2 milhões de jogadores:

Captura de tela do jogo Citadels, escrito em Phaser
Qual a melhor forma de criar um projeto com Phaser?
Eu experimentei bastante com o framework Phaser e de acordo com a minha experiência eu aprendi a seguinte lição: se o seu objetivo é criar um jogo, você deve focar mais no jogo em si e menos na tecnologia por trás dele.
Como desenvolvedor de software tradicional isso é um exercício muito difícil pra mim. Eu gosto de criar designs elegantes, que carregam significado e facilitam a leitura. E o desenvolvimento de jogos pra mim sempre fica parecendo uma colcha de retalhos, mau acabada e com diferentes bugs esperando pra pular na minha cara.
Então pra facilitar a minha vida, e agora a sua também, eu criei um projetinho no Github que você pode clonar e começar a codificar. Ele já traz consigo o Phaser, Webpack e TypeScript configurados.
O repositório nawarian/phaser-ts-skeleton traz uma aplicação exemplo com Phaser, Webpack e TypeScript configurados e é perfeito para quem quer começar sem prestar muita atenção na tecnologia! A melhor forma de criar um projeto Phaser é utilizando templates que já existem, como o nawarian/phaser-ts-skeleton!
Passo a passo: como criar um jogo com Phaser e TypeScript
O nosso plano de ação é bem simples na realidade. Vamos primeiro clonar o repositório, depois instalar suas dependências e depois rodar o programa para testar.
Passo 1 – Clone o repositório template
Acesse a página do nawarian/phaser-ts-skeleton no Github para obter o link e clonar em sua máquina. Se preferir, para encurtar o caminho você pode até mesmo fazer um fork do projeto.
Eu vou optar por clonar, fazendo o seguinte:
$ git clone [email protected]:nawarian/phaser-ts-skeleton.git meu-primeiro-jogo
$ cd meu-primeiro-jogo
$ rm -rf .git
$ git init
O primeiro comando git clone [email protected]:nawarian/phaser-ts-skeleton.git meu-primeiro-jogo vai clonar (baixar) o repositório para o seu computador na pasta meu-primeiro-jogo. Em seguida nós entramos nesta pasta com o comando cd meu-primeiro-jogo.
Você vai reparar que este já é um repositório git, e que aponta para o meu repositório. Desta forma você não vai conseguir subir seus arquivos! Então eu apaguei as referências ao git com rm -rf .git e inicializei um novo repositório git com o comando git init.

Se você ainda não sabe mexer com git, dá uma olhada no nosso tutorial de como começar a trabalhar com git e github!
Passo 2 – Instale as dependências com NPM
Estamos prontes pra instalar as dependências do projeto. São as dependências que estão escritas no arquivo package.json sabe? Sem elas a gente não consegue sequer rodar o nosso jogo.
Eu estou utilizando o Node 16 neste momento!
Vamos executar o seguinte comando no terminal:
$ npm install
Este comando vai baixar alguns pacotes, e a tela final deve ficar mais ou menos assim:

npm install.Passo 3 – Inicie o modo de desenvolvimento
Este é o principal comando que você precisa lembrar daqui pra frente. Ele vai te permitir alterar o código do seu programa e ver os resultados imediatamente no navegador!
Rode o seguinte comando no terminal:
$ npm run dev
Ao rodar o comando acima, você vai notar algumas mensagens aparecendo no seu terminal. Uma delas diz o seguinte:
<i> [webpack-dev-server] Loopback: http://localhost:8080/, http://127.0.0.1:8080/.
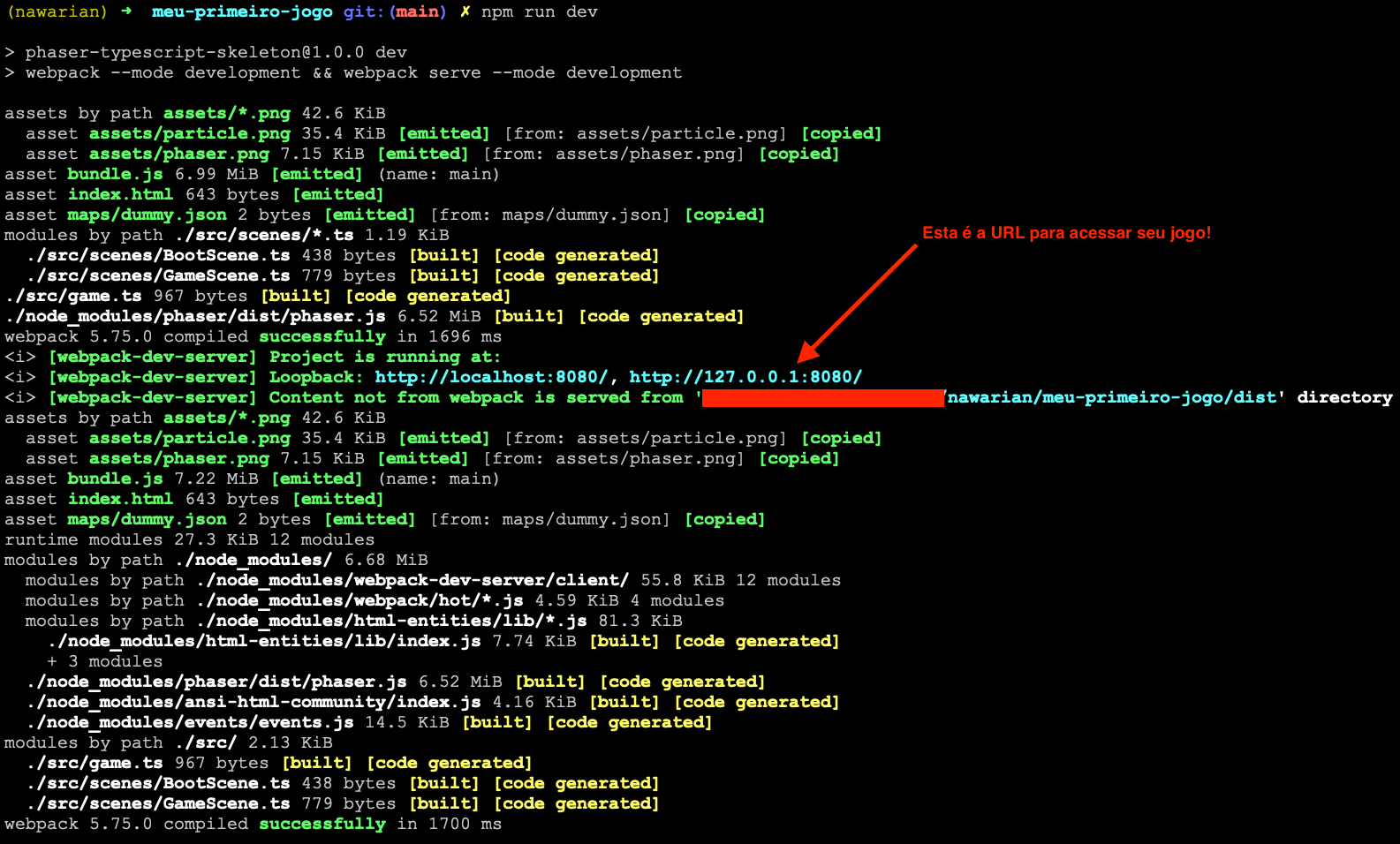
Este é justamente o endereço onde você pode encontrar seu projeto rodando! Acesse http://localhost:8080/ e você vai ver a seguinte animação:
Passo 4 – Customize a configuração do seu canvas
Você reparou que a tela do jogo utiliza a proporção de um smartphone, certo? Provavelmente os primeiros jogos que você vai querer desenvolver utilizem uma tela um pouquinho maior. Então deixa eu te mostrar exatamente onde você pode mexer para mudar isso!
No arquivo src/game.ts você encontra as configurações globais do jogo. É aqui que você pode alterar as proriedades width (largura) e height (altura) da tela. No exemplo abaixo eu alterei a tela pra utilizar 800x600 pixels:
...
const cfg: Phaser.Types.Core.GameConfig = {
width: 800, // Largura
height: 600, // Altura
type: Phaser.AUTO,
...
};

Passo 5 – Comece a desenvolver seu jogo
Você vai reparar que a estrutura de pastas é bem simples de entender. Vejamos a tabela a seguir:
| Pasta/arquivo | O que faz |
| assets/ | Armazena imagens utilizadas no jogo. Aqui entramspritesheets, imagens de plano de fundo, partículas... |
| src/ | Código fonte do seu jogo. Todos os arquivos .ts estão aqui! |
| src/scenes/ | Onde todas as Cenas do seu jogo ficam armazenadas. |
| src/game.ts | Configurações globais do seu jogo. |
| maps/ | Arquivos .json criados por editores de mapas como o Tiled. |
O arquivo scenes/GameScene.ts por exemplo é a cena que controla a animação que você vê na tela.
Vamos adicionar o seguinte código na linha 16 para tonar a imagem do Phaser vermelha:
phaser.setTint(0xff0000);
Repare que 0xff0000 é o código hexadecimal para a cor rgb(255, 0, 0). O resultado fica assim:
Você está pronte para começar!
No começo não vai ser simples, principalmente se você não sabe nada sobre programação de jogos. Felizmente o site oficial do framework Phaser traz vários exemplos de uma extensa documentação. Infelizmente, tudo em inglês.
Você também pode procurar vídeos no YouTube sobre o tema. E se tiver alguma dúvida específica, pode falar comigo que eu vou ficar mais do que feliz em te ajudar a resolver o problema e aprender contigo!
Nós também temos um grupo no Telegram agora, você pode clicar aqui pra entrar e conversar com a gente!

Para quem está estudando ou se aperfeiçoando em desenvolvimento de software, escutar podcasts é uma ferramenta incrível pra se atualizar e descobrir tópicos novos.
Na edição de Outubro de 2022 eu visitei o PHPSP + Pub, um bar cheio de devs e pessoas interessadas em tecnologia, e perguntei pra todo mundo no evento: qual podcast de tecnologia você está ouvindo?
Esta é a lista dos 12 podcasts mais citados!
Ao fim também adicionei um bônus de 4 podcasts em inglês que a turma citou, vem comigo!
Table of Contents
Por que ouvir podcasts de programação e tecnologia em 2023?
O mercado de desenvolvimento de software vem mudando muito desde… sempre! E em 2023 o contexto é muito interessante no mundo todo, mas principalmente no Brasil:
- um exército de reserva cada vez maior e menos qualificado – com muitas pessoas iniciantes se lançando no mercado ou fazendo a transição de carreira ao mesmo tempo;
- uma onda de demissões em massa de startups e empresas que têm, na maioria dos casos, um saldo positivo;
- emigração de profissionais de tecnologia mais qualificados para o exterior em busca de salários em moeda forte
Por conta destes motivos acima citados e outros, existe uma tendência ainda maior da precarização do trabalho, rebaixamento de salários e qualidade dos serviços de tecnologia prestados no Brasil. Ao mesmo tempo, oportunidades de crescimento para quem já tem algum conhecimento prévio vão surgir cada vez mais.
Ouvir podcasts de programação e tecnologia vai te ajudar a entender o que está acontecendo no mercado brasileiro de desenvolvimento de software em 2023, mas também a identificar oportunidades e quais caminhos seguir para surfar neste cenário da melhor forma possível.
Além disso, o podcast é uma forma de mídia que você pode carregar consigo e ouvir a qualquer momento: no ônibus, no metrô, andando de bicicleta, no carro ou onde for. O podcast uma ótima forma de aprender e se atualizar para quem gasta horas em comutação entre casa e escola ou trabalho.
Podcasts de programação em português para ouvir em 2023
Feministech podcast

A Feministech é uma comunidade desenvolvimento de software formada por pessoas que se identificam como pessoas femininas ou não-bináries. Essa galera é MUITO BRABA e produz conteúdo gratuito e de qualidade em diferentes plataformas como a twitch, dev.to, instagram e youtube.
Desde Maio de 2021 essa comunidade toca o Feministech Podcast que traz episódios relacionados a tecnologia e desenvolvimento de software, programação, carreira, comunidades, universidade, estudos e bastante entrevistas com gente muito qualificada!
O Feministech Podcast está disponível no Spotify, Google Podcasts, Anchor FM e também via RSS!
Você também pode acessar o site oficial para saber mais sobre o projeto que vai muito além dos podcasts.
QuebraDev

É simplesmente IMPOSSÍVEL falar de podcast de tecnologia brasileiros sem mencionar o Quebradev! Este podcast é perfeito de tantas formas que merece uma página só pra si! Mas vamos lá:

O QuebraDev tá no Spotify, Apple Podcasts e via RSS!
Você também pode acessar o site oficial para listar os episódios e saber mais sobre o projeto.
Mlkda da deepweb

O podcast Mlkda da DeepWeb (molecada da deepweb) nasceu em Janeiro de 2021 e já tem mais de 33 episódios.
Você pode acessar o catálogo de episódios na plataforma dev.to e também no Anchor FM. Este podcast tem bastante entrevistas com diferentes pessoas conhecidas na comunidade brasileira de desenvolvimento como o Gabs Ferreira, PokémãoBR e PachiCodes.
O podcast Mlkda da DeepWeb está disponível no Spotify, Google Podcasts, Anchor FM e também via RSS!
Devnaestrada

O podcast DEVNAESTRADA já tem mais de 360 episódios e lança um episódio novo toda sexta-feira.
Essa galera faz episódios com entrevistas, eventos, notícias e discussões sobre desenvolvimento web.
DEVNAESTRADA está disponível no Spotify, Apple Podcasts, Deezer e também via RSS! Também tem o site oficial para quem quiser saber mais.
Castálio podcast

O Castálio podcast é um “Podcast inspirado prá castálio”, que começou em 2011 e que fala sobre tecnologia, desenvolvimento de software, linguagens de programação e código aberto.
O bacana deste podcast é que ele tem vários episódios temáticos e mais de 150 episódios disponíveis. São discussões, entrevistas e uma visão de dentro das comunidades de software.
Outro diferencial deste podcast é que ele conta com alguns episódios em inglês – o que é ótimo para quem quer praticar.
O Castálio Podcast está disponível no Spotify e via RSS! Você também pode conferir o site oficial para descobrir mais.
Hipsters.tech

O Hipsters ponto tech já é bem famosinho e provavelmente qualquer dev que conhece podcasts já ouviu ou ouviu falar do Hipsters ponto tech.
Este podcast é mantido e apresentado pela galera da Alura e da Caelum e seus episódios são entrevistas e discussões sobre programação, design, experiência de usuário, startups e tudo que está bombando na área de tecnologia.
O Hipsters ponto tech está disponível no Spotify, Google Podcasts e via RSS!
Você também pode acessar o site oficial para navegar os episódios e saber mais.
Lambda3 podcast

O podcast Lambda3 é um dos produtos que a empresa Lambda3, uma venture da TIVIT, oferece.
Neste podcast você ouve sobre tecnologia, programação e tecnicas e práticas de desenvolvimento.
O Lambda3 está disponível no Spotify, Apple Podcasts e Google Podcasts.
P de Podcast

P de Podcast é um podcast focado em arquitetura de software, boas práticas e outros temas relacionados ao ciclo de desenvolvimento de software.
Este projeto é parte do segunda.tech e começou a publicar episódios desde 2020.
P de Podcast está disponível no Spotify, Apple Podcasts, Google Podcasts e via RSS!
Café debug

O Café Debug já está na ativa desde 2017 e fala sobre vários temas diferentes na área de tecnologia como linguagens de programação, tecnicas e princípios, diversidade e inclusão, código aberto e faz várias entrevistas interessantíssimas!
Este podcast também é bem descontraído e trás conteúdo de altíssima qualidade 💚
Café Debug está disponível no Spotify e você também pode acessar o site oficial.
Devs Cansados

O nome é bom demais né? 😂
Este podcast é uma jóia da podosfera brasileira! Seus episódios falam de programação, claro, mas também de histórias cabeludas, perrengues, amores e desamores com a carreira de programação.
Devs Cansados está disponível no Spotify, Google Podcasts, Apple Podcasts e via RSS!
Você também pode acessar o site oficial para saber mais sobre o projeto.
PodProgramar

O PodProgramar está na ativa desde 2016 e fala sobre desenvolvimento de software em geral. Trás consigo discussões, notícias, dicas e truques e tudo isso trazendo pros episódios um toque de diversidade importantíssimo!
PodProgramar está disponível no Spotify, Google Podcasts, Apple Podcasts e também via RSS!
Você também pode acessar o site oficial para saber mais sobre o projeto.
Tecnocast

Menos focado em desenvolvimento de software e mais focado em tecnologia da informação, o Tecnocast é um podcast bem massinha pra você dev que tá precisando descontrair e relaxar a mente.
Tecnocast está disponível no Spotify, Google Podcasts, Apple Podcasts e via RSS!
Você também pode acessar o site oficial para saber mais.
Bonus: podcasts de tecnologia em inglês
The array cast

The Array Cast é um podcast sobre linguagens de programação orientadas a arrays – como APL, J, q e k.
É um podcast bem nichado e não se aplica a tooodas as linguagens de programação. Mas com certeza você vai aprender MUITO sobre teoria de linguagens de programação e toda a matemática e poesia por trás das tecnicas e decisões de design das linguagens.
The Array Cast está disponível no Spotify e via RSS!
Você também pode acessar o site oficial para saber mais.
PHP Roundtable

O PHP Roundtable é uma mesa redonda onde todas as pessoas presentes são tratadas como iguais: não importa se você tem 20 anos de experiência com PHP, está apenas começando ou é dev JS: todo mundo tem como contribuir para a evolução da linguagem PHP!
Neste podcast as pessoas convidadas falam sobre a linguagem, frameworks, tecnicas de aprendizado, emprego e tudo mais que possa interessar quem programa ou deseja programar PHP.
O PHP Roundtable está disponível no Spotify, no YouTube e via RSS!
Você também pode acessar o site oficial para saber mais.
PHPUgly

PHPUgly é um podcast sensacional, feito por alguns desenvolvedores PHP cansados que se reunem pra falar e reclamar de diversos tópicos: a linguagem, problemas que encontraram nas últimas semanas, seus pequenos negócios e por aí vai.
Os episódios são conversas bem descontraídas e sempre têm algo a ensinar.
O PHPUgly está disponível no Spotify, Apple Podcasts e via RSS!
Você também pode acessar o site oficial para saber mais.
SudoShow

SudoShow é um podcast que fala sobre Código Aberto e Livre (Open Source) em ambiente de negócios, gerenciamento de Nuvem (Cloud), DevOps, times e cultura de empresas.
Neste podcast você encontra analises, entrevistas e discussões.
Você pode ouvir o SudoShow no Spotify, Apple Podcasts, Google Podcasts e via RSS!
Você também pode acessar o site oficial para saber mais.

Sempre que você tenta fazer um git commit sem ter nenhum arquivo alterado, sua tentativa de commit vai ser rejeitada. Neste artigo você aprende como fazer!
Para fazer um commit sem nenhum arquivo no git e subir este commit para o Github ou Gitlab, basta usar o seguinte comando:
$ git commit --allow-empty -m '<SUA MENSAGEM DE COMMIT AQUI>'
A figura abaixo ilustra o comando e seu resultado:

Criando um commit vazio com
git commit --allow-empty
Listagem de commits (
git log) mostrando o novo commit vazio.Note que no comando acima utilizamos a flag --allow-empty da ferramenta Git. Esta flag é justamente o que nos permite criar um commit mesmo sem ter alterado nenhum arquivo.
A partir deste momento você pode subir seu commit normalmente, como ensinado no nosso tutorial de como subir arquivos no Gtihub:
$ git push origin <NOME_DO_SEU_BRANCH>
Para que criar commits vazios?
Alguns times desenvolvimento usam ferramentas de automação como o Gitlab CI/CD, Github Actions ou Circle CI. Estas ferramentas nos permitem realizar algumas tarefas quando uma alteração no nosso repositório acontece.
Por exemplo, podemos rodar testes unitários e de integração sempre que um Pull Request for aberto, ou sempre que um novo commit chegar ao branch principal. Algumas empresas e equipes até mesmo lançam o código para produção sempre que um novo commit chega ao branch principal, utilizando tecnicas como Continuous Delivery ou Entrega Contínua.
As vezes para testar estes mecanismos de automação, ou até mesmo para fazer com que rode novamente o mecanismo, é prático enviar um commit vazio.
]]>
Para gerar outro UUID versão 4 clique aqui.
O que é um UUID versão 4?
O UUID (Universally Unique Identifier) é um Identificador Único Universal – trata-se de um número gerado aleatoriamente e respeitando a especificação RFC 4122.
Normalmente o UUID é representado como uma string com 5 partes, com o seguinte formato:
- 8 dígitos hexadecimais
- 4 dígitos hexadecimais
- 4 dígitos hexadecimais
- 4 dígitos hexadecimais
- 12 dígitos hexadecimais
Entre cada grupo de dígitos, coloca-se um -. Portanto o número 5461b47a-afbc-408a-84da-3289f8f86dd8 é um UUID válido.
Expressão regular para validar um UUID
Você pode verificar se um UUID é válido utilizando a seguinte expressão regular:
/^[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}$/
Para testar um UUID usando JavaScript, por exemplo, podemos utilizar o seguinte trecho de código:
const pattern = /^[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}$/;
if (pattern.test('00000000-0000-0000-0000-000000000000')) {
// valido
} else {
// invalido
}
Como funciona o gerador UUID?
Nós construímos uma API Rest simples utilizando Cloudflare Workers.
O código está aberto e disponível no repositório codamos-com-br/api-worker. Sinta-se livre para contribuir, copiar e utilizar em seus projetos.
A API utilizada pelo site codamos.com.br não está disponível para utilização de terceiros. Caso queira utilizar esta API em seu aplicativo, publique sua própria versão. O código está aberto e disponível para quem quiser 😉
]]>
O que é um array no PHP?
array é um dos diversos tipos de dados que a linguagem PHP oferece. É uma forma de armazenar vários valores numa única variável. Numa única variável $numeros nós podemos armazenar 5 números de uma vez só, como no exemplo a seguir:
/*
* A variável $numeros possui os 5 valores listados
* dentro dos colchetes: 4, 3, 2, 1 e 0.
*/
$numeros = [4, 3, 2, 1, 0];
Desta forma é possível acessar estes valores através da sintaxe de colchetes. Ainda considerando a variável $numeros que criamos acima, podemos acessar cada elemento como no trecho de código a seguir:
echo "O segundo elemento é: " . $numeros[1];
// O segundo elemento é: 3
Note que o valor $numeros[1] faz referência ao segundo valor que colocamos entre colchetes ao criar a variável $numeros, o número inteiro 3.
De forma parecida a gente pode acessar o valor $numeros[0] (inteiro 4) ou $numero[3] (inteiro 1).
O array do PHP é mais poderoso que o de outras linguagens
É importante notar que o array do PHP é muito mais flexível e poderoso do que em diversas outras linguagens, dada a natureza do sistema de tipos que o PHP oferece. Isto porque o array do PHP pode se comportar como vetor, lista, pilha, fila, tupla ou dicionário. Tudo num único tipo, integrado com diferentes aspectos da linguagem.
Para efeito de comparação, vamos ver o quão poderoso o tipo array é comparado com conceitos de outras linguagens:
| Conceito | Outra linguagem | PHP |
|---|---|---|
| Vetor | Na linguagem C (e muitas outras) os vetores possuem somente um tipo de dado. Por exemplo int numeros[10] só pode conter elementos do tipo int. Ver mais sobre. |
Em PHP vetores podem conter elementos de qualquer tipo: strings, inteiros e objetos num mesmo vetor, sem problema algum. |
| Listas, filhas e pilhas | Em Java usam-se diferentes classes para cada comportamento: List, Queue e Stack. Ver mais sobre. | Em PHP o tipo array pode ser utilizado como lista, filha ou pilha naturalmente. Basta utilizar as funções específicas como array_shift() ou array_pop(). |
| Dicionário | A linguagem C++ tem uma biblioteca específica chamada STL (Standard Template Library) que oferece o tipo map<I,T> para implementação de dicionários. Com limitações semelhantes aos vetores da linguagem C. Ver mais sobre. |
Arrays em PHP podem se comportar como maps ou hashmaps sem qualquer necessidade de adaptar a linguagem. |
É claro que nem tudo são flores, e o array do PHP não é melhor em absolutamente TUDO quando comparado a outras linguagens. O map<I,T> do C++ por exemplo consegue garantir o tipo interno dos dados, enquanto em PHP é necessário fazer algumas verificações adicionais em código ou via análise estática com ferramentas como o PHPStan.
Como criar arrays de índice numérico ou do tipo lista em PHP?
Para criar um arrayde índice numérico, ou vetor, basta omitir as chaves e passar apenas valores para o array entre colchetes ([ e ]).
No exemplo abaixo vamos criar um array de índice numérico com 3 frutas: banana, maçã e manga:
$frutas = ['manga', 'maçã', 'banana'];
echo $frutas[0]; // manga
echo $frutas[1]; // maçã
echo $frutas[2]; // banana
Podemos notar algumas coisas:
-
Acessamos cada elemento através de seu índice usando a sintaxe de colchetes;
-
Os índices estão em ordem crescente, começando em 0 (zero);
-
Os elementos (banana, maçã e manga) não são ordenados alfabeticamente mas por ordem de inserção
manga é o primeiro elemento, portanto recebe o índice 0. maçã é o segundo, recebe o índice 1. banana é o terceiro elemento e recebe o índice 2.
Na linguagem PHP, em contrates com Java ou C/C++, é possível misturar tipos dentro de um vetor. O exemplo a seguir é um código válido:
$balaio = ['comida de gato', new Gato(), false];
Independentemente de como usaríamos este vetor, temos a flexibilidade de inserir uma string, um objeto e um boolean no mesmo balaio.
Como criar arrays associativos, mapas dicionários em PHP?
Linguagens como Python ou JavaScript têm o conceito de Dicionário, enquanto Java e C++ possuem seus Mapas. O PHP une todos estes conceitos num formato especial de array: o array associativo.
Um array associativo em PHP é um array parecido com o de índice numérico, com a diferença que nós escolhemos o índice de cada elemento em vez de deixar a linguagem escolher a ordem crescente natural. Além disso, nós podemos também escolher índices que sejam strings em vez de números. Veja:
$ranking_frutas = [
0 => 'manga',
5 => 'uva',
15 => 'maçã',
];
$frutas_fotos = [
'manga' => '/fotos/manga.jpg',
'uva' => '/fotos/uva.jpg',
'maçã' => '/fotos/maca.jpg',
];
Enquanto o primeiro array $ranking_frutas ainda tem índice numérico, sua ordenação não é mais natural: nós forçamos que manga, a melhor fruta do planeta terra, fique em primeiríssimo lugar, e apesar de não saber quem seria o segundo ou terceiro, colocamos maçã, a fruta mais desnecessária que tem, na posição 15.
Já o segundo array é associativo e usa chaves do tipo string. Note que $frutas_fotos não usa números do lado esquerdo, mas sim o nome das frutas. E do lado direito o link para fotos que representam aquela fruta: fruta => foto.
Desta forma podemos acessar os dois arrays usando a mesma sintaxe de colchetes:
echo "A melhor fruta do mundo é: $ranking_frutas[0].";
// A melhor fruta do mundo é: manga
echo "Aqui tem uma foto de manga: $frutas_fotos['manga']."
// Aqui tem uma foto de manga: /fotos/manga.jpg
Portanto as sintaxes $array[0] e $array['string'] são válidas.
Como criar arrays híbridos no PHP?
Você já deve ter calculado que já que é possível criar arrays de índices numéricos e arrays associativos usando a mesma sintaxe, talvez seja possível misturar os dois. E o pensamento é 100% correto.
Em PHP é possível utilizar índices numéricos e de texto numa mesma variável como no exemplo a seguir:
$tudo_junto_e_misturado = [
0 => 'manga',
'manga' => 'Melhor fruta, slc!'
];
echo $tudo_junto_e_misturado[0]; // manga
echo $tudo_junto_e_misturado['manga']; // Melhor fruta, slc!
Algumas funções são específicas para arrays de índice numérico, outras para arrays associativos, outras para todos os arrays. Com o tempo e prática você vai entender em quais cenários faz sentido usar um array híbrido. Spoiler: quase nunca faz sentido.
Como criar arrays bidimensionais ou matrizes em PHP?
Como em todas as linguagens em que é possível criar vetores, o princípio da composição nos permite criar vetores de múltiplas dimensões, também conhecidos como matrizes. Na teoria é exatamente o contrário: matrizes podem ter diferentes dimensões, inclusive uma única e neste caso a matriz de única dimensão é chamada de vetor.
Enfim… tudo isso pra te dizer que um array pode conter outros arrays. Por exemplo, podemos representar um tabuleiro de jogo da velha com um array bidimensional assim:
$tabuleiro = [
['O', '', 'X'],
['O', 'X', ''],
['X', 'O', ''],
];
echo "A posição (0, 2) tem o valor $tabuleiro[0][2].";
// A posição (0, 2) tem o valor X.
echo "A posição (2, 1) tem o valor $tabuleiro[2][1].";
// A posição (2, 0) tem o valor O.
E portanto para acessar a primeira “linha” usamos $tabuleiro[0] e a última linha $tabuleiro[2]. Enquanto a primeira célula da primeira linha podemos acessar com $tabuleiro[0][0] e a última célula da primeira linha com $tabuleiro[0][2].
Como adicionar um elemento ao array do PHP?
Em PHP, diferentemente da linguagem C, o array tem tamanho dinâmico. Portanto você pode expandir um array o quanto quiser (e de acordo com a memória RAM disponível em seu ambiente).
Suponha o array $pares com os seguintes números pares: [0, 2, 4, 6]. Vamos ver diferentes formas de adicionar os próximos pares:
Como adicionar um elemento usando a sintaxe de índice?
Já vimos que é possível acessar um valor através de seu índice numérico. Por exemplo $pares[2] nos traria o valor 4. Mas também é possível alterar valores usando esta sintaxe.
Portanto caso queiramos adicionar o próximo par à variável $pares podemos associar seu último índice + 1 com o próximo número. Assim:
// Último índice = 3
$pares[4] = 8;
Neste caso nós sabíamos que o último índice era 3, mas podemos fazer isso de forma dinâmica quando não soubermos quais índices existem no array:
$indice = count($pares); // $indice = 5
$pares[$indice] = 10;
No exemplo acima associamos o valor count($pares) à variável $indice. Nós já tínhamos os valores 0, 2, 4 e 6, e depois adicionamos o valor 8 ao final. Portanto $indice aqui possui o valor 5, que é o número de elementos existentes no array $pares. Depois associamos o valor 10 ao índice $indice (5).
Como adicionar um elemento usando a sintaxe de associativa?
É muito semelhante à forma de trabalhar com índices numéricos, porém utilizamos string como índices. Vamos por exemplo criar um array associativo do tipo matriz para armazenar números pares e ímpares:
$numeros = [
'pares' => [0, 2, 4, 6],
'impares' => [1, 3, 5, 7],
];
echo $numeros['pares'][2]; // 4
echo $numeros['impares'][1]; // 3
Perceba que:
-
A sintaxe é a mesma: acessamos o elemento
parescom a sintaxe de colchetes$numeros['pares']; -
É possível guardar qualquer coisa dentro de um
array, inclusive outroarray: nós guardamos o array$paresdentro do array$numeros
A sintaxe antiga de arrays do PHP
Em alguns tutoriais e livros mais antigos, você vai encontrar uma sintaxe diferente para trabalhar com array no PHP. Então deixa eu te mostrar como nós costumávamos criar arrays no PHP na idade da pedra da computação:
$meuArray = array(0, 1, 2, 3, 4);
echo "O terceiro elemento é o número $meuArray[2].";
// O terceiro elemento é o número 3.
Esta sintaxe ainda funciona na linguagem PHP, mas está sendo abandonada aos poucos. Portanto utilize colchetes para criar arrays SEMPRE.
Diferentes utilidades do array no PHP
Arrays são praticamente o coração da linguagem PHP. Um dos motivos de o PHP ser tão popular, na minha opinião, é a flexibilidade agregada pelos arrays e como eles se integram a praticamente tudo no ecossistema PHP.
Algumas utilidades do array no PHP incluem, mas não se limitam a:
- Listas
- Dicionários
- Tuplas
- Pilhas e filas
Vamos ver cada um destes itens com exemplos.
Utilizando arrays PHP como listas
Listas são segmentos de valores que podem ou não ser ordenados. Os arrays PHP tornam este trabalho muito simples de se realizar.
Por exemplo, abaixo temos uma lista de frutas completamente desordenada:
$frutas = ['manga', 'banana', 'maçã'];
echo $frutas[0]; // manga
echo $frutas[1]; // banana
echo $frutas[2]; // maçã
Adicionalmente, se quisermos garantir que a lista seja ordenada, podemos aplicar a função sort() para ordenar seus elementos:
$frutas = ['manga', 'banana', 'maçã'];
if (sort($frutas)) {
echo $frutas[0]; // banana
echo $frutas[1]; // maçã
echo $frutas[2]; // manga
}
Utilizando arrays PHP como dicionários
Dicionários são estruturas no formato chave => valor, em PHP são chamados arrays associativos.
Um exemplo de utilização de dicionários é o agrupamento de dados para gerar relatórios. Por exemplo, podemos representar o preço de uma ação em diferentes horários do dia no exemplo a seguir:
$seriePrecos = [
'10am' => 19.20,
'3pm' => '21.02',
'5pm' => '20.59',
];
echo "A ação CODAMOS tinha o preço $seriePrecos['10am'] às 10am de hoje.";
// A ação CODAMOS tinha o preço 19.20 às 10am de hoje.
Eu citei acima o formato chave => valor, para deixar claro o que aquilo significa: no array acima, 10am, 3pm e 5pm são chaves enquanto 19.20, 21.02 e 20.59 são valores.
O maior motivo para utilizarmos dicionários no PHP é adicionar semântica ao nosso código. Esta é uma estrutura de dados muito poderosa e flexível que nos permite representar diferentes conceitos usando o formato chave => valor.
Utilizando arrays PHP como tuplas
Tuplas são dados que estão relacionados e têm pouco ou nenhum significado quando isolados.
Por exemplo, num plano cartesiano as coordenadas são tuplas de dois elementos: x e y. Portanto o valor (x, y) pode ser considerado uma tupla.
De forma semelhante, num espaço de três dimensões, as coordenadas seriam (x, y, z) que também é uma tupla mas de 3 elementos.
Arrays em PHP podem ser utilizados como tuplas naturalmente:
$coordenadas = [10, 20]; // tupla de 2 inteiros
[$x, $y] = $coordenadas; // extraindo valores da tupla
echo "A tupla (x, y) tem valor ($x, $y).";
// A tupla (x, y) tem valor (10, 20).
Utilizando arrays PHP para trabalhar com pilhas e filas
Pilhas são listas em que sempre inserimos valores ao fim do array, e sempre retiramos valores do fim do array. Como uma pilha de pratos: você normalmente coloca o prato no topo da pilha, e tira sempre o prato que está mais ao topo da pilha.
Pilhas sempre utilizam o algoritmo LIFO – Last in, first out. Ou seja: o último elemento que chegou, é o primeiro que vai sair.
Em PHP, os arrays podem ser tratados como pilha ao utilizar as funções array_push() e array_pop():
$pratos = [];
array_push($pratos, 'porcelana');
array_push($pratos, 'plástico');
$pratoDoTopo = array_pop($pratos);
echo "O prato que estava no topo da pilha é feito de $pratoDoTopo.";
// O prato que estava no topo da pilha é feito de plástico.
Exatamente ao contrário do que pilhas fazem, as filas seguem o algoritmo FIFO – First in, first out. Ou seja: quem chega primeiro, sai primeiro! E podemos fazer isso também com a função array_push() para adicionar ao final da fila, e com array_shift() para remover do começo da fila. Para furar a fila podemos também utilizar o array_unshift() que adiciona um elemento logo no começo da fila.
$fila_do_mercado = ['Marcio', 'Maria', 'João'];
$proximo = array_shift($fila_do_mercado);
echo "Vamos atender $proximo agora!";
// Vamos atender Marcio agora!
// Vitória tem preferência na fila
array_unshift($file_do_mercado, 'Vitória');
$proximo = array_shift($fila_do_mercado);
echo "Vamos atender $proximo agora!";
// Vamos atender Vitória agora!
Note que array_unshift() jogou o nome “Vitória” para o começo da fila e portanto este foi o próximo nome a ser chamado.
Como visitar cada elemento de um array no PHP?
Na maioria dos casos nós não queremos acessar apenas um elemento do array, mas sim percorrer o array inteiro para executar alguma ação.
Para arrays de índice numérico, uma saída comum em outras linguagens como o C, é utilizar um laço de repetição como um for ou while juntamente de um contador como no exemplo a seguir:
$frutas = ['manga', 'banana', 'maçã'];
$i = 0;
while ($i < count($frutas)) {
echo "A fruta do índice $i é $frutas[$i].";
$i++;
}
// A fruta do índice 0 é manga.
// A fruta do índice 1 é banana.
// A fruta do índice 2 é maçã.
O laço acima, como você provavelmente já entendeu, é equivalente ao laço for a seguir:
$frutas = ['manga', 'banana', 'maçã'];
for ($i = 0; $i < count($frutas); $i++) {
echo "A fruta do índice $i é $frutas[$i].";
}
// A fruta do índice 0 é manga.
// A fruta do índice 1 é banana.
// A fruta do índice 2 é maçã.
O método acima funciona na maioria dos casos, mas é problemático caso você precise iterar um array do tipo dicionário, em que as chaves não são números ordenados.
O jeito mais fácil de percorrer um array, independente do tipo de índice que tiver, é através da estrutura de iteração foreach. Vejamos o exemplo a seguir:
$frutas = ['manga', 'banana', 'maçã'];
foreach ($frutas as $fruta) {
echo "Fruta: $fruta";
}
// Fruta: manga
// Fruta: banana
// Fruta: maçã
Note que a variável $i não é necessária para iterar o array. Mas caso você precise desta variável para saber o índice, pode utilizar uma variação do foreach como no exemplo a seguir:
$frutas = ['manga', 'banana', 'maçã'];
foreach ($frutas as $i => $fruta) {
echo "A fruta do índice $i é $fruta.";
}
// A fruta do índice 0 é manga.
// A fruta do índice 1 é banana.
// A fruta do índice 2 é maçã.
Note que $i no exemplo acima não é um contador, mas sim o índice do array $frutas. De forma semelhante, caso o array possua índices do tipo string em vez de numéricos, a mesma sintaxe vai ser de grande ajuda:
$frutas_favoritas = [
'nawarian' => 'manga',
'joana' => 'abacate',
'pedro' => 'mamão',
];
foreach ($frutas_favoritas as $nome => $fruta) {
echo "A fruta favorita de $nome é $fruta.";
}
// A fruta favorita de nawarian é manga.
// A fruta favorita de joana é abacate.
// A fruta favorita de pedro é mamão.
Reparou como a porção $nome => $fruta são nomes que eu escolhi? Estas variáveis poderiam ter qualquer outro nome. Não é obrigatório chamar sempre de $key => $value ou $i => $x. Você pode escolher nomes que façam mais sentido na hora de ler o seu código.
💡 Leia também: como escrever código fácil de ler e de dar manutenção.
Como desestruturar arrays no PHP?
Esta sintaxe é relativamente nova e lembra muito o que fazemos no JavaScript!
Como sabemos, dentro do array podemos ter qualquer tipo de dado, mas as vezes estes dados vêm em pares que fazem algum sentido lógico. Se sabemos desta sequência, podemos desestruturar o array e transformar cada elemento em uma variável com um nome que tenha um sentido semântico maior.
Veja o exemplo em que a variável $coordenadas sabidamente tem dois elementos: o primeiro é um valor de x enquanto o segundo elemento é y. Podemos desestruturar este array para obter estes dois valores como variáveis:
$coordenadas = [10, 20];
[$x, $y] = $coordenadas;
Nós já vimos este exemplo enquanto falávamos sobre tuplas. Mas vamos utilizar um exemplo mais interessante: percorrer dados de uma série histórica de valores e imprimir na tela cada data. E aqui nós vamos desestruturar o array dentro do foreach! Veja como funciona:
$serie = [
['2022-10-10', 100],
['2022-10-11', 115],
['2022-10-12', 120],
];
foreach ($serie as [$data, $valor]) { // 👈 olha aqui!
echo "Em $data o valor era de $valor.";
}
// Em 2022-10-10 o valor era de 100.
// Em 2022-10-11 o valor era de 115.
// Em 2022-10-11 o valor era de 120.
Também é possível ignorar alguns valores simplesmente adicionando uma vírgula , sem nenhum nome de variável. No exemplo a seguir o segundo elemento do array é completamente ignorado:
$frutas = ['manga', 'maçã', 'banana'];
[$manga, , $banana] = $frutas; // maçã nem deveria ser fruta
Isto é bastante útil quando extraímos dados de expressões regulares, por exemplo.
Como extrair elementos do array usando a sintaxe de desempacotamento no PHP?
O desempacotamento de array pode também ser entendido como “expandir” seus elementos, e pra isso a gente usa o operador ellipsis .... Você pode misturar esta sintaxe com diversas outras no PHP como podemos ver a seguir.
$pares = [2, 4, 6];
$pares_com_zero = [0, ...$pares];
Note que o array $pares começa com apenas 3 elementos e que $pares_com_zero é criado com 0 sendo seu primeiro elemento, seguido de todos os outros presentes em $pares. Portanto $pares_com_zero efetivamente tem os valores [0, 2, 4, 6].
Desta forma é possível extrair e combinar diferentes arrays.
Como unir dois ou mais arrays no PHP?
Para unir os elementos de dois ou mais arrays existe três formas:
- A função array_merge()
- A soma de array através do operador
+ - Desempacotamento de arrays
Como unir dois arrays utilizando a função array_merge()
A função array_merge() existe justamente pra mesclar (merge) dois arrays em PHP. Você pode passar quantos arrays quiser como argumento, e o retorno será um novo array que une todos os argumentos:
$pares = [0, 2, 4, 6];
$impares = [1, 3, 5, 7];
$numeros = array_merge($pares, $impares);
No exemplo acima o array $numeros combina números pares e impares. Note que os arrays foram apenas unidos, a ordem dos elementos é a mesma que a original.
Para ordenar os números ímpares e pares no array $numeros seria necessário aplicar a função sort().
Como unir dois arrays utilizando o operador +
Uma alternativa sintática ao array_merge() é p operador +, que quando utilizado entre dois arrays realiza a operação de união.
$pares = [0, 2, 4, 6];
$impares = [1, 3, 5, 7];
$numeros = $pares + $impares;
Como unir dois arrays utilizando desempacotamento de arrays
Como vimos antes, é possível obter elementos de um array utilizando a sintaxe de desempacotamento usando o operador ellipsis (...).
Para unir dois arrays utilizando desempacotamento, podemos fazer como no exemplo a seguir:
$pares = [0, 2, 4, 6];
$impares = [1, 3, 5, 7];
$numeros = [...$pares, ...$impares];
Repare que como nos exemplos anteriores, a união dos arrays não é ordenada e portanto a variável $numeros agora possui o valor [0, 2, 4, 6, 1, 3, 5, 7]. Para ordenar os valores, é necessário utilizar a função sort().
Principais funções para trabalhar com array no PHP
Arrays em PHP possuem diversas funções especiais. A documentação oficial da linguagem possui uma lista completa de funções para trabalhar com arrays no PHP.
Vou listar aqui as funções mais comuns e importantes de acordo com a minha experiência.
Função count(): contar elementos de um array
$numeros = [0, 1, 2, 3, 4];
$total = count($numeros);
echo "O array 'numeros' possui $total elementos.";
// O array 'numeros' possui 5 elementos.
Visite a página da documentação oficial para aprender mais sobre a função count().
Função in_array(): indica se elemento existe no array
$numeros = [0, 1, 2, 3, 4];
$existe = in_array(2, $numeros) ? 'existe' : 'não existe';
echo "O número 2 $existe no array 'numeros'.";
// O número 2 existe no array numeros.
Visite a página da documentação oficial para aprender mais sobre a função in_array().
Função sort(): ordena elementos de um array
$numeros = [4, 1, 0, 3, 2];
sort($numeros);
foreach ($numeros as $numero) {
echo "Número: $numero";
}
// Número: 0
// Número: 1
// Número: 2
// Número: 3
// Número: 4
Visite a página da documentação oficial para aprender mais sobre a função sort().
Função shuffle(): embaralha o array colocando seus elementos em ordem aleatória
$numeros = [0, 1, 2, 3, 4];
shuffle($numeros);
foreach ($numeros as $i => $numero) {
echo "O número $i é $numero.";
}
// O número 0 é 3
// O número 1 é 0
// O número 2 é 1
// O número 3 é 4
// O número 4 é 2
Visite a página da documentação oficial para aprender mais sobre a função shuffle().
Função array_keys(): obtém apenas chaves (índices) do array, sem valores
$site_pontuacao = [
'https://codamos.com.br' => 10,
'https://thephp.website' => 7,
'https://locaweb.com.br' => 10,
];
$chaves = array_keys($site_pontuacao);
foreach ($chaves as $i => $chave) {
echo "O site $i é $chave.";
}
// O site 0 é https://codamos.com.br
// O site 1 é https://thephp.website
// O site 2 é https://locaweb.com.br
Visite a página da documentação oficial para aprender mais sobre a função array_keys().
Função array_values(): obtém apenas os valores do array, sem chaves (índices)
$site_pontuacao = [
'https://codamos.com.br' => 10,
'https://thephp.website' => 7,
'https://locaweb.com.br' => 10,
];
$pontuacao = array_values($site_prontuacao);
foreach ($pontuacao as $i => $valor) {
echo "A pontuação $i é $valor.";
}
// A pontuação 0 é 10
// A pontuação 1 é 7
// A pontuação 2 é 10
Visite a página da documentação oficial para aprender mais sobre a função array_values().
Função array_combine(): une um array de chaves e um array de valores num único array associativo
$sites = [
'https://codamos.com.br',
'https://thephp.website',
'https://locaweb.com.br',
];
$pontuacao = [10, 7, 10];
$site_pontuacao = array_combine($sites, $pontuacao);
foreach ($site_pontuacao as $site => $pontos) {
echo "O site $site tem $pontos pontos.";
}
// O site https://codamos.com.br tem 10 pontos.
// O site https://thephp.website tem 7 pontos.
// O site https://locaweb.com.br tem 10 pontos.
Visite a página da documentação oficial para aprender mais sobre a função array_combine().
Função array_diff(): indica a diferença entre dois ou mais arrays
$numeros = [0, 1, 2, 3, 4];
$pares = [0, 2, 4];
$diff = array_diff($numeros, $pares);
foreach ($diff as $numero) {
echo "O número $numero existe no array 'numeros' mas não no array 'pares'.";
}
// O número 1 existe no array 'numeros' mas não no array 'pares'.
// O número 3 existe no array 'numeros' mas não no array 'pares'.
Visite a página da documentação oficial para aprender mais sobre a função array_diff().
Função array_merge(): unindo dois ou mais arrays
$pares = [0, 2];
$mais_pares = [4, 6];
$impares = [1, 3, 5];
$numeros = array_merge($pares, $mais_pares, $impares);
foreach ($numeros as $i => $numero) {
echo "O número $i é $numero.";
}
// O número 0 é 0
// O número 1 é 2
// O número 2 é 4
// O número 3 é 6
// O número 4 é 1
// O número 4 é 3
// O número 5 é 5
Visite a página da documentação oficial para aprender mais sobre a função array_merge().
Função array_unique(): remove elementos repetidos do array
$numeros = [0, 2, 2, 4, 6, 4];
$numeros_sem_repeticao = array_unique($numeros);
foreach ($numeros as $i => $numero) {
echo "O número $i é $numero.";
}
// O número 0 é 0
// O número 1 é 2
// O número 2 é 4
// O número 3 é 6
Visite a página da documentação oficial para aprender mais sobre a função array_unique().
Função array_fill(): cria array com tamanho e conteúdo definidos
$quatro_zeros = array_fill(0, 4, 0);
foreach ($quatro_zeros as $i => $valor) {
echo "O número $i é $valor.";
}
// O número 0 é 0
// O número 1 é 0
// O número 2 é 0
// O número 3 é 0
Visite a página da documentação oficial para aprender mais sobre a função array_fill().
Função array_sum(): soma todos elementos de um array
$numeros = [0, 1, 2, 3, 4];
$soma = array_sum($numeros);
echo "A soma dos 5 primeiros números é $soma.";
// A soma dos 5 primeiros números é 10
Visite a página da documentação oficial para aprender mais sobre a função array_sum().
Função array_map(): aplica uma função a cada elemento do array e retorna um novo array
function dobrar_numero(int $x): int
{
return $x * 2;
}
$numeros = [0, 1, 2, 3, 4];
$dobro = array_map('dobrar_numero', $numeros);
for ($i = 0; $i < count($numeros); $i++ ) {
echo "O dobro de $numeros[$i] é $dobro[$i].";
}
// O dobro de 0 é 0
// O dobro de 1 é 2
// O dobro de 2 é 4
// O dobro de 3 é 6
// O dobro de 4 é 8
Visite a página da documentação oficial para aprender mais sobre a função array_map().
Função array_filter(): remove elementos de um array de acordo com um critério
function numero_eh_par(int $x): bool
{
return $x % 2 == 0;
}
$numeros = [0, 1, 2, 3, 4];
$pares = array_filter($numeros, 'numero_eh_par');
foreach ($pares as $i => $numero) {
echo "O número par $i é $numero.";
}
// O número par 0 é 0
// O número par 1 é 2
// O número par 2 é 4
Visite a página da documentação oficial para aprender mais sobre a função array_filter().
Como trabalhar com JSON e arrays no PHP?
Podemos transformar arrays de índice numérico ou associativos para transformar uma variável em JSON utilizando a função json_encode(), e podemos também transformar uma string JSON em array utilizando a função json_decode().
$json = '{"site": "https://codamos.com.br", "nota": 10.0}';
$avaliacao = json_decode($json);
echo "O site $avaliacao['site'] é nota $avaliacao['nota']!";
// O site https://codamos.com.br é nota 10.0!
$avaliacao['fonte'] = 'Eu mesmo';
$novo_json = json_encode($avaliacao);
echo $novo_json;
// {"site": "https://codamos.com.br", "nota": 10.0, "fonte": "Eu mesmo"}
Isto é muito útil para trabalhar com APIs rest ou mesmo para ler e escrever configurações em arquivos.
Conclusão
Arrays são um dos principais elementos que tornam a linguagem PHP tão poderosa e este artigo, por maior que pareça ser grande e extensivo, apenas toca na superfície do tópico.
Assim que dominar os tópicos apresentados aqui eu recomendo que você leia mais sobre Iterators e, por conseguinte, classes do tipo Iterator como o ArrayObject, SplStack e classes iteradores especiais da linguagem. A partir daqui você também deverá ter um arcabouço maior para entender como funcionam as Collections do Laravel.
Não esquece de compartilhar este artigo com amigos e colegas de curso ou de trabalho, isto ajuda bastante o blog a crescer e produzir mais conteúdo de qualidade pra quem é dev!
Num futuro próximo eu devo escrever também sobre como arrays se comportam em memória e como otimizar a utilização de memória quando trabalhamos com listas.
Até a próxima 👋
]]>
Já faz um bom tempo que venho mentorando pessoas que querem ingressar ou melhorar na área de desenvolvimento de software. E com o tempo comecei a identificar alguns erros e dificuldades comuns que atrapalhavam a vida da pessoa desenvolvedora que está iniciando.
Este guia vai te mostrar os primeiros passos que você deve tomar para aprender a programar para web em 2023. Você precisa começar a entender a mecânica da linguagem (sintaxe) e depois avançar com lógica na prática, através de projetos e cursos.
Conteúdos do artigo
- Entre no nosso grupo de apoio no Telegram
- Comece pelo HTML
- Passeie pelo CSS
- Primeira linguagem de programação: JavaScript
- Familiarize-se com a linha de comando
- Aprenda o básico sobre git e github
- Faça uma aplicação clone
- Revise sua aplicação clona
- Dê uma pausa e reflita sobre onde você está
- Conclusão
Entre no nosso grupo de apoio no Telegram
A comunidade Codamos está crescendo e está pronta pra te ajudar em todas as fases da sua jornada com desenvolvimento de software!
Nós temos um canal no telegram onde compartilhamos conhecimento, trocamos dúvidas e respostas e indicamos vídeos e cursos.
Estudar com o apoio de outras pessoas ajuda muito a manter a motivação lá no alto. Principalmente no começo, quando não sabemos nem sequer como fazer a pergunta certa.
Entra no grupo, é de graça e você só tende a crescer!
Comece pelo HTML
A linguagem HTML é uma linguagem de marcação de hipertexto, que serve para criar páginas da internet que você vê através de navegadores como Google Chrome ou Mozilla Firefox. Apesar de não ser considerada uma linguagem de programação, é uma das bases da internet.
Quem quer trabalhar com web precisa saber ao menos o mínimo sobre HTML.
Eu gosto de recomendar iniciantes a aprender HTML porque é uma linguagem relativamente simples mas bastante poderosa. Você vê os resultados de seus estudos imediatamente!
Toda linguagem de programação tem uma série de regrinhas de escrita, chamada sintaxe. Aprender HTML é uma forma incrível de se acostumar com a ideia de sintaxe porque você consegue entender melhor como o computador analisa a sintaxe com uma linguagem simples e com regras bem definidas.
Dica de ouro – curso gratuito! 🤩
O site freeCodeCamp oferece um curso MARAVILHOSO de HTML que é 100% gratuito e tem tradução para o Português. Eu recomendo começar por lá: é um curso que te ensina HTML na prática e te mostra cada detalhezinho da linguagem. Clica aqui pra acessar o curso.
Começar com HTML vai te ajudar a:
-
Entender como funciona a sintaxe de uma linguagem;
- Se motivar com resultados imediatos;
- Escrever suas próprias páginas web
Passeie pelo CSS
Com o HTML você é capaz de fazer muita coisa, mas a internet já mudou muito desde que o HTML apareceu e hoje em dia nós temos requisitos de aparência visual de uma página web muito elevados!
Com CSS você consegue alterar a aparência da sua página HTML de forma a mudar as fontes, cores, posição de elementos, deixar algumas coisas fixas no layout e por aí vai.
Eu acho interessante aprender pelo menos o básico de CSS pra entender como a tecnologia funciona, além de te forçar a aprender mais sobre como funciona o seu navegador web.
Dica de ouro – curso gratuito! 🤩
O mesmo curso de HTML citado acima tem um módulo inteirinho só de CSS. No mesmo estilo: cada parte do curso é um teste prático que você precisa resolver para ir ao próximo. Clica aqui pra acessar o curso.
Alguns sites interessantes para ver mais sobre CSS são o Tableless (em português) e CSS Tricks (em inglês).
Aprender CSS mesmo que superficialmente vai te ajudar a:
-
Entender regras de sintaxe de outra linguagem;
- Obter resultados visuais;
- Fazer projetos web completos e funcionais;
- Acompanhar vídeo tutoriais e mini cursos que desenvolvem projetos e clones
Ao conseguir trabalhar, mesmo que só com o básico, de HTML e CSS você já consegue fazer alguns projetos para praticar e montar seu portfolio. Existe centenas de milhares de vídeos na internet de pessoas que fazem projetos passo a passo com HTML e CSS que você pode acompanhar para praticar.
Primeira linguagem de programação: JavaScript
A primeira linguagem de programação que eu recomendo pra quem começa agora em 2023 é o JavaScript.
Isso porque no começo você não sabe bem o que quer fazer: back end, front end, DevOps… e o JavaScript vai te acompanhar em quase todas as áreas.
Eu particularmente não gosto de JavaScript, prefiro ensinar com PHP que é muito mais simples e fácil de aprender na minha opinião. Mas em termos de utilidade o JavaScript vai te acompanhar por mais tempo.
Quando aprender JavaScript eu recomendo separar seu estudo em duas partes: sintaxe (como escrever código) e lógica (como fazer um código útil).
Dica de ouro – curso gratuito! 🤩
Ainda fazendo propaganda gratuita do freecodecamp, a plataforma tem um curso gratuito focado em JavaScript. Clica aqui pra acessar o curso.
Estudar lógica é um pouco mais complicado: você precisa praticar bastante. Então é melhor praticar de um jeito que você goste pra não perder a motivação!
Você pode fazer exercícios de programação em JavaScript em sites como o HackerRank. Mas eu recomendo imensamente fazer projetos acompanhando vídeos. No YouTube você encontra diferentes guias de como escrever jogos, clones de sites conhecidos como Twitter ou Netflix.
Um exemplo incrível desses projetinhos em vídeo é a Pokédex do Manual do Dev, se liga:
Familiarize-se com a linha de comando
Trabalhar com linha de comando não é obrigatório, mas vai te ajudar MUITO a entender como o computador funciona. A minha intenção em te falar pra aprender a usar a linha de comando não está nem relacionada com aprender algo novo, mas sim de fazer imersão!
Se você usa o Windows, pode começar com o Windows Power Shell. Esta é a ferramenta padrão do Windows e te dá uma flexibilidade incrível na hora de trabalhar. Aqui tem um vídeo de como abrir o terminal e com alguns comandos básicos pra você começar no Windows.
Pra quem usa Linux ou MacOS, o próprio sistema te oferece um terminal que te dá acesso a fazer tudo o que quiser e mais um pouco! E o legal destes desses dois sistemas é que normalmente o mesmo comando funciona tanto no Linux quanto no MacOS.
Aqui um vídeo de como abrir o terminal no Linux (Ubuntu) e alguns comandos básicos.
Aprenda o básico sobre git e github
GIT é uma ferramenta incrível pra armazenar e controlar seus arquivos. E o GitHub te permite fazer isso de graça online, sem limites. Pra além disso você consegue usar o GitHub como uma plataforma pra exibir seu portfólio e também pra contribuir com outros projetos!
Aprender GIT vai te dar uma ajuda muito boa em procurar e navegar projetos escritos por outras pessoas.
Mas não precisa fazer um mega curso e ficar especialista no assunto. O básico já é suficiente pros seus primeiros anos na carreira.
Aqui no blog a gente tem um artigo muito legal e detalhado pra te ajudar a começar com GIT. Dá uma lida no artigo e aproveita pra ver o vídeo de apoio que tem lá. Vai te ensinar tudo o que você precisa de começo.
Faça uma aplicação clone
Nessa altura do campeonato você já aprendeu HTML, CSS, JS e GIT. Está mais do que na hora de fazer alguns projetos que possam te servir de portfólio pra subir no Github!
Aplicações clone são uma forma incrível de montar seu portfólio, porque você não precisa se preocupar com conceitos, design, requisitos… você só precisa copiar o que já existe!
Alguns cursos e vídeos online te mostram como fazer clones do Twitter, do Netflix, do site de alguma marca…
Eu encontrei, por exemplo, este vídeo incrível da Lari que mostra como ela montou um clone da tela de login do Netflix. Dá uma olhadinha:
A parte bacana de fazer um curso de criar aplicação clone é que, se em algum momento você travar, ainda pode copiar diretamente do vídeo e continuar aprendendo outras coisas.
Revise sua aplicação clone
Eu já escrevi aqui sobre erros comuns que iniciantes cometem, que dificultam o aprendizado e até atrasam quem tá começando agora. E uma das técnicas pra evitar estes erros é a refatoração.
O simples exercício de você revisar e melhorar um código que você já escreveu vai te ajudar a entender melhor o que seu código faz e o que você ainda precisa estudar melhor.
Muitas vezes quem é iniciante e escreve uma aplicação clone com apoio de vídeo aulas não consegue entender 100% do código que escreveu. Por isso o exercício de revisão e melhoramento do código é essencial.
Dê uma pausa e reflita sobre onde você está
Se você tiver concluído cada um dos passos que eu mencionei aqui, provavelmente estará bem mais confortável com o tópico programação e já tem dúvidas o suficiente pra saber o que perguntar e por onde ir.
Um ponto importante é não se afobar e tentar dar passos maiores que a perna, pra evitar perda de tempo, de energia e até mesmo se frustrar no processo.
O Leonardo Leitão da Cod3r Cursos fez um vídeo sensacional que explica as diferentes fases na vida de uma pessoa que resolve aprender a fazer desenvolvimento de software e como se portar em cada fase. Vídeo recomendadíssimo!
Conclusão
A partir daqui você já sabe tudo o que precisa para estudar programação sem muito sofrimento: toda a mecânica de lidar com sintaxe de linguagem, alterar código, analisar resultados e melhorar o que fez deverá estar mais ou menos clara.
Se você concluiu cada passo, já deve ter proficiência o suficiente pra estudar algoritmos e aprender outros conceitos como o de utilizar bancos de dados ou criar APIs.
Desenvolvimento de software é uma profissão na qual você nunca para de estudar. Continue buscando artigos na internet, escute podcasts, leia livros, participe de conferências… enfim! Você já tem tudo o que precisa pra estudar programação.
Boa sorte em sua jornada!
]]>
Recentemente eu resolvi aprender um pouco mais sobre engenharia reversa de arquivos na intenção de converter um arquivo do tipo studio3 para cwprj. Eu ainda não cheguei lá, mas já aprendi diferentes truques interessantes e vim compartilhar um essencial contigo!
Neste artigo eu vou te dar uma dica rápida: como converter um arquivo binário em um dump hexadecimal, e como transformar este dump hexadecimal em binário novamente.
Conteúdos do post
Como transformar um arquivo binário em texto hexadecimal usando xxd
Vamos supor um arquivo em formato binário. No meu caso, venho utilizando um arquivo do tipo .studio3, mas você provavelmente já viu diversos exemplos por aí: .bin, .dat, .spr, .save ou o famoso .wad do jogo DOOM.
Para converter este arquivo em hexadecimal, podemos utilizar o programa xxd da seguinte maneira:
$ xxd empty.studio3
00000000: 7369 6c68 6f75 6574 7465 3035 3b00 0000
00000010: 1425 0000 0000 0000 1100 0000 0000 0000
00000020: e815 0000 0000 0000 a0a6 0000 0000 0000
00000030: 8801 0000 0000 0000 3200 0000 0000 0000
00000040: 3600 0000 0000 0000 0400 0000 0000 0000
00000050: 0400 0000 0000 0000 a706 0000 0000 0000
00000060: 5e00 0000 0000 0000 5e00 0000 0000 0000
00000070: 0000 0000 0000 0000 5e00 0000 0000 0000
....
Note que o comando acima irá lançar a visualização hexadecimal do arquivo diretamente na tela. Isto é útil para fazer uma exploração inicial e se familiarizar com o formato do arquivo.
Para facilitar a exploração você pode utilizar o comando less que lhe permite navegar melhor:
$ xxd empty.studio3 | less
Para armazenar o arquivo com o conteúdo hexadecimal você pode oferecer um segundo parâmetro ao comando xxd que recebe o nome do arquivo-destino. O exemplo a seguir converte o arquivo empty.studio3 em hexadecimal e armazena seu conteúdo no arquivo empty.dump.
$ xxd empty.studio3 empty.dump
Como converter um dump em hexadecimal para binário
Visualizar um arquivo binário em formato hexadecimal é utilíssimo! Mas quando buscamos fazer a engenharia reversa de um arquivo, é importante ser capaz de alterar seu conteúdo e visualizar como o software se comporta!
O comando xxd nos permite transformar um dump em hexadecimal de volta para o formato binário!
Para converter o dump para binário novamente basta executar o comando xxd com a opção -r (reverse). Assim:
$ xxd -r empty.dump empty.studio3
Desta forma o arquivo empty.studio3 passa a ter o conteúdo do arquivo empty.dump porém em formato binário.
Como converter um binário em hexadecimal e abrir imediatamente no VIM
Pra encurtar o ciclo de feedback ainda mais, podemos abrir o dump diretamente no VIM da seguinte maneira:
$ xxd empty.studio3 | vim -
A linha acima vai abrir o programa vim já com o conteúdo em hexadecimal do binário empty.studio3.
A partir daqui você pode alterar o arquivo da forma como quiser. E para salvar num arquivo, basta rodar o comando VIM :file nomedoarquivo.extensao.

Arquivo binário aberto como hexadecimal no VIM:
xxd empty.studio3 | vim -.Eu escrevi um artigo bacana sobre como começar a trabalhar com o VIM aqui no Codamos. Dá uma passada lá se estiver apanhando deste editor!
Como salvar o arquivo hexadecimal do VIM diretamente para binário
Nós podemos obter o conteúdo do buffer atual do VIM e enviá-lo diretamente à linha de comando para executar o xxd -r.
Suponhamos que nós abrimos o arquivo hexadecimal diretamente no VIM como no exemplo a seguir:
$ xxd empty.studio3 | vim -
Pronto, agora com o VIM aberto e visualizando o conteúdo hexadecimal do arquivo, nós podemos transformar este conteúdo em binário com o seguinte comando VIM:
:%!xxd -r
O seu editor agora irá mostrar uma porção de caracteres estranhos, porque está em modo binário.

Hexadecimal transformado em binário após executar o comando
:%!xxd -r no VIM.Podemos então salvar o arquivo normalmente com o comando VIM:
:file modified.studio3
:w

Alterando o arquivo de saída com o comando
:file modified.studio3.
A comunidade PHP é maravilhosa porque consegue unir muita gente entusiasmada em torno deste projeto, um dos poucos verdadeiramente Open Source e conduzidos pela comunidade de forma orgânica!
Esta forma orgânica de a comunidade se organizar apesar de bonita, não é infalível: nós sempre precisamos de mais e mais pessoas contribuindo para que a máquina continue girando. Neste artigo você vai conhecer um pouco mais sobre como contribuir com a linguagem através de traduções.
Para contribuir com traduções do PHP você precisa ter uma conta no Github e acessar o projeto php/doc-pt_BR. Neste artigo eu te explico tintim por tintim, num passo a passo como proceder para traduzir o manual da linguagem!
Conteúdo do post
- Passo a passo de como contribuir com a documentação do PHP
- Passo 1 – Crie uma conta no Github
- Passo 2 – Faça uma cópia do projeto php/doc-pt_BR
- Passo 3 – Escolha com qual arquivo quer trabalhar
- Passo 4 – Se familiarize com a estrutura do documento
- Passo 5 – Altere o arquivo em sua cópia
- Passo 6 – Faça um commit de suas alterações
- Passo 7 – Abra um Pull Request
- Modalidades de contribuição com a documentação
- Motivos para contribuir com a documentação do PHP
- O impacto causado ao traduzir o manual do PHP para a língua portuguesa
- Conclusão
Passo a passo de como contribuir com a documentação do PHP
Passo 1 – Crie uma conta no Github
Você possivelmente já tem um perfil no Github, mas não custa nada deixar aqui um guia para quem ainda não tem ou não sabe alterar arquivos no Github.

Nós temos um artigo incrível sobre como começar com e subir arquivos no Github, bem explicadinho que é pra não ter erro!
Passo 2 – Faça uma cópia do projeto php/doc-pt_BR
Com sua conta criada, é possível fazer uma cópia do repositório php/doc-pt_BR para sua conta pessoal. Desta forma você tem liberdade total para alterar os arquivos a forma como quiser e mais tarde poderá solicitar que suas mudanças sejam integradas à documentação oficial.
Na tela do Github, basta clicar no botão Fork e seguir as instruções:

Captura de tela indicando onde está o botão
Fork do Github.Após fazer a cópia (Fork) do projeto, você deverá ter um repositório idêntico em seu perfil do Github. O meu ficou assim:

Captura de tela que ilustra um projeto copiado (fork) agora com o nome
nawarian/doc-pt_BR.Passo 3 – Escolha com qual arquivo quer trabalhar
Caso você não queira procurar arquivos desatualizados ou mesmo não traduzidos e queira apenas achar uma forma rápida de contribuir, você pode verificar as Issues abertas do projeto. Você provavelmente encontrará alguém que já está coordenando a tradução de uma parte do manual.
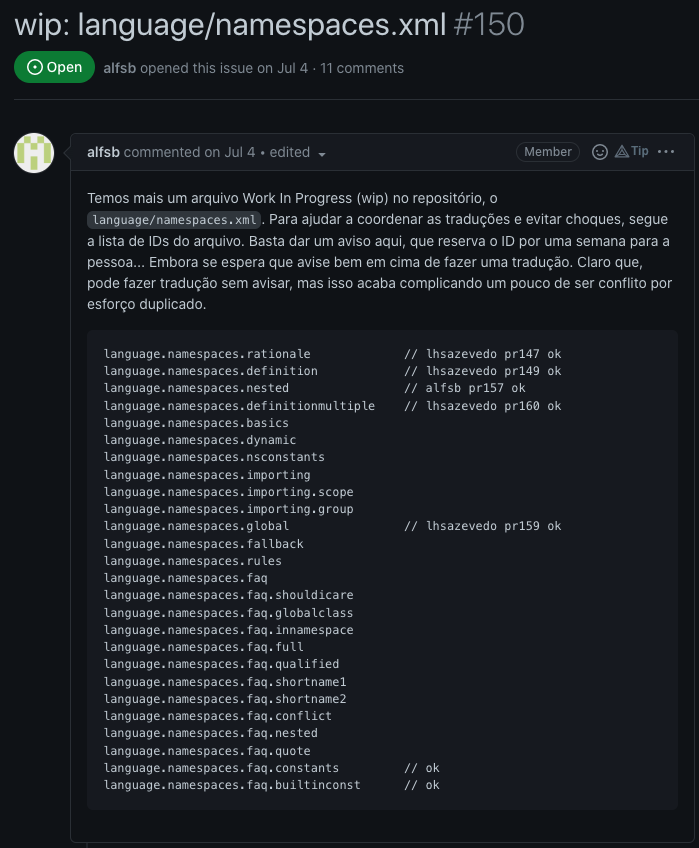
Hoje, por exemplo, eu encontrei a Issue #150 que atualiza o arquivo language/namespaces.xml, referente à página do manual Namespaces. Este arquivo possui várias seções e o autor @alfsb está coordenando a tradução de cada uma das partes.
Antes de começar a traduzir um arquivo ou parte dele, avise a comunidade através de issues como esta para evitar retrabalho e conflitos.
Note que, como o arquivo está separadinho em diversas seções, pessoas diferentes podem verificar o que está faltando e contribuir mesmo que com um pequeno pedacinho da documentação!
Outra opção é encontrar arquivos desatualizados utilizando a ferramenta revcheck que a própria comunidade disponibiliza online.
Passo 4 – Se familiarize com a estrutura do documento
A documentação do PHP foi redigida utilizando a linguagem xml no formato DocBook.
Ao navegar pelos arquivos você provavelmente vai entender o que cada elemento faz. Mas abaixo eu deixo uma tabelinha que talvez lhe ajude:
| Elemento XML | Descrição |
<chapter> |
Descrição do capítulo do manual |
<title> |
Título de uma seção ou exemplo |
<para> |
Parágrafo de texto |
<example> |
Seção de exemplo |
<programlisting> |
Exemplo de código, formatado |
<![CDATA[ ... ]]> |
Texto puro, sem formatação |
<sect1> ou <sect2> |
Seção do documento, como cabeçalhos da página |
Passo 5 – Altere o arquivo em sua cópia
Aqui você pode optar por clonar a cópia do repositório (Fork) em sua máquina local, como descrito em nosso artigo de como subir arquivos para o Github.
Outra opção é fazer a edição diretamente pela interface gráfica do Github. Foi o que eu fiz quando ajudava a traduzir a Issue #150 que traduz o arquivo language/namespaces.xml. Para isto, na minha cópia (Fork) do repositório eu encontrei o arquivo language/namespaces.xml e abri o editor de texto como na imagem abaixo:

Imagem que mostra como abrir o modo de edição de arquivos no Github.
Passo 6 – Faça um commit de suas alterações
Ao finalizar suas alterações completa ou parcialmente, você pode salvar seu progresso ao realizar um Commit de seus arquivos.
Pela interface do Github, logo abaixo do editor de código, encontraremos uma caixa de texto com o título Commit changes. A primeira caixa de texto é o título do commit e a caixa logo abaixo te permite oferecer uma descrição mais detalhada.

Onde realizar um commit na interface web do Gtihub.
Passo 7 – Abra um Pull Request
Agora que você já possui as atualizações que gostaria de lançar à documentação oficial, é hora de solicitar que outras pessoas da comunidade revisem seu texto e aprovem ou solicitem modificações. Para isto nós precisamos abrir um Pull Request.
Em sua cópia do repositório (Fork), clique na aba Pull Requests e clique no botão New pull request:

Onde encontrar o botão
New pull request.Ao apertar o botão New pull request, assumindo que você fez o commit de suas alterações como descrito no passo anterior, uma tela parecida com a seguinte deverá aparecer:

Resumo das alterações antes de abrir um Pull Request.
Se estiver tudo certo em sua opinião basta abrir o Pull Request e aguardar a comunidade revisar. Daqui pra frente, você vai interagir com outras pessoas da comunidade que vão lhe indicar quais alterações realizar ou simplesmente aceitar suas contribuições de bom grado!
O pull request que estou usando como exemplo aqui é o de número #188, disponível aqui.
Modalidades de contribuição com a documentação
O projeto php/doc-pt_br te permite contribuir de duas formas fundamentais: atualizando documentos já desatualizados ou traduzir documentos ainda sem tradução. A prioridade é sempre de documentos desatualizados.
Para além disso, você pode monitorar o repositório para ajudar a revisar issues e pull requests, de forma a permitir que outras pessoas tenham suas alterações aceitas mais cedo.
Mais detalhes você encontra na página Situação atual da Wiki do php/doc-pt_br, que descreve exatamente como encontrar estes arquivos e o que fazer.
Motivos para contribuir com a documentação do PHP
Se fazer parte de um projeto grandioso como o PHP não é motivo o suficiente, eu separei alguns motivos que podem te convencer a contribuir, ou talvez convidar mais pessoas a contribuir com o projeto:
Primeiro motivo: devolver à comunidade. O PHP já ajudou milhares de pessoas a mudar de vida direta ou indiretamente. E, na minha opinião, foi um dos maiores motores para o crescimento do que hoje nós conhecemos como Internet. É um projeto que nasceu e cresceu totalmente aberto e gratuito, contribuir com sua tradução é uma forma de retribuir ao esforço empreendido pela comunidade.
Segundo motivo: destacar seu currículo. Eu ouço de diversas pessoas que estão iniciando agora em programação sobre como fazer com que seu currículo ganhe destaque frente a tantas outras pessoas que se candidatam a mesma vaga. Contribuir com projetos abertos é uma forma incrível de ganhar destaque, ainda mais um projeto complexo como o PHP.
Terceiro motivo: aprender mais e mais detalhes sobre a linguagem PHP. Ao traduzir a documentação você se força a ler, interpretar e entender o conteúdo daquele documento. É uma forma muito boa de solidificar seu conhecimento sobre a linguagem e também de descobrir funcionalidades novas que você talvez não conhecesse antes.
Quarto motivo: treinar para a certificação. A certificação PHP da Zend é a única certificação PHP reconhecida no mundo do trabalho hoje em dia, e te exige profundo conhecimento da linguagem. Traduzir a documentação com certeza te ajuda a revisar material e solidificar conhecimento.
Quinto motivo: praticar o inglês. A documentação original é escrita em inglês, língua essencial para pessoas que trabalham com desenvolvimento de software há muito tempo. Ao traduzir a documentação para o Português, você se força a exercitar seu inglês na forma de leitura, gramática e interpretação de texto com um tópico que você provavelmente já possui familiaridade.
Sexto motivo: participar do Hacktoberfest. O hacktoberfest acontece todo mês de Outubro e é organizado pela DigitalOcean. A ideia é influenciar mais pessoas a contribuírem com projetos de código aberto e, como recompensa, a DigitalOcean e empresas parceiras enviam brindes a quem contribui.
Gostaria de adicionar algum motivo aqui? Me dá um toque lá no Twitter: @nawarian.
O impacto causado ao traduzir o manual do PHP para a língua portuguesa
Cerca de 290 milhões de pessoas no mundo inteiro já falam ou falarão Português em breve! De acordo com a Wikipedia, os 10 países a seguir têm Português como sua língua oficial:
- Brasil
- Angola
- Moçambique
- Portugal
- Guiné-Bissau
- Timor-Leste
- Guiné Equatorial
- Macau
- Cabo Verde
- São Tomé e Príncipe
Ao traduzir o manual da linguagem PHP para a língua portuguesa, você cria impacto direto a todos os países acima citados e ainda ajuda pessoas de outros países que queiram praticar e aperfeiçoar seu domínio da língua portuguesa.
Sem contar com nossos hermanos que por muitas vezes não encontram documentação em espanhol e optam por adivinhar o que está escrito em português.
Conclusão
Fica claro que para contribuir com a linguagem PHP você não precisa saber nada sobre a linguagem C. Um pouco de tempo livre, boa vontade e um dicionário já são suficientes pra te colocar em posição de ajudar a comunidade a crescer.
Além disso o impacto causado por uma pequena tradução para o português é multiplicado por 10, visto que tantos países adotam a língua portuguesa como língua oficial. E tantos outros têm a opção de arriscar um portunhol.
Por fim, participar da comunidade e contribuir com projetos Open Source é uma forma sensacional de tornar-se uma profissional melhor, tanto como pessoa quanto tecnicamente.

Novembro está chegando, e com ele grandes novidades no ecossistema PHP! O PHP 8.2 traz otimizações de performance, mudanças na sintaxe da linguagem e funções utilitárias que vão tornar o desenvolvimento com PHP ainda mais prazeiroso!
O PHP 8.2 vai ser lançado no dia 08 de Dezembro de 2022 de acordo com a documentação oficial. Mas caso você queira experimentar antes do tempo, deixo aqui uma tabelinha com as principais datas antes do lançamento oficial:
| Data | Versão | Detalhes |
| 13 de Outubro de 2022 | Release Candidate (RC) 4 | Página de anúncio oficial |
| 27 de Outubro de 2022 | Release Candidate (RC) 4 | Página de anúncio oficial |
| 10 de Novembro de 2022 | Release Candidate (RC) 6 | Página de anúncio oficial |
| 24 de Novembro de 2022 | Release Candidate (RC) 7 | -- |
| 08 de Dezembro de 2022 | Versão final | -- |
Conteúdos deste artigo
- Classes somente-leitura
- Adeus propriedades dinâmicas em classes
- Extensão nova: Random para gerar números aleatórios
- Novos tipos: null, true e false
- Tipos de forma normal disjuntiva (Disjunctive normal form types – DNF)
- Constantes em traits
- Esconder parâmetros em backtraces
- Funções utf8_encode() e utf8_decode() descontinuadas
- Mudança no retorno dos métodos que criam datas
- Outras mudanças
Classes somente-leitura
As propriedades somente-leitura chegaram ao PHP na versão 8.1. Esta RFC é o passo adiante, que permite transformar todas as propriedades da classe em somente-leitura duma vez só.
Em vez de escrever isso:
class Codamos
{
public function __construct(
public readonly array $artigos,
) {}
}
Nós vamos passar a escrever isso:
readonly class Codamos
{
public function __construct(
public array $artigos,
) {}
}
O efeito prático do código acima é transformar todas as propriedades da classe Codamos em valores somente-leitura.
Para além disso, as classes somente-leitura tornam impossível adicionar propriedades em tempo de execução de forma dinâmica. E também só é possível herdar de uma classe somente-leitura se a sub-classe também for somente-leitura. Então o seguinte código dá erro:
$site = new Codamos();
$site->layout = 'wide'; // Gera erro
// Uncaught Error: Cannot create dynamic property Codamos::$layout
Fonte: RFC e votação da comunidade “Readonly classes”.
Adeus propriedades dinâmicas em classes
Desde que classes foram introduzidas ao PHP era possível criar propriedades de forma dinâmica como com o código abaixo:
class Codamos {}
$site = new Codamos();
$site->layout = 'wide';
Na versão 8.2 do PHP este comportamento ainda irá funcionar, mas será marcado como descontinuado (deprecated) e lançará um warning. E a partir da versão 9.0 do PHP lançará uma exceção do tipo ErrorException.
Mas não se preocupe, se o seu código precisa criar propriedades de forma dinâmica não é o fim do mundo! Você tem duas opções:
Como permitir propriedades dinâmicas no PHP 8.2 via métodos mágicos __get e __set
Desde a versão 5 do PHP, os métodos mágicos nos permitem interceptar tentativas de acessar propriedades que não existem ou não estão visíveis no escopo público de uma instância.
Você pode utilizar os métodos mágicos __get() e __set() para gravar variáveis de forma dinâmica em sua classe.
Como permitir propriedades dinâmicas no PHP 8.2 utilizando atributos
Uma forma menos trabalhosa de permitir propriedades dinâmicas em suas classes no PHP 8.2, é utilizando o atributo #[AllowDynamicProperties] que foi criado justamente para esta versão da linguagem!
A sua classe ficaria assim:
#[AllowDynamicProperties]
class Codamos {}
$site = new Codamos();
$site->layout = 'wide'; // Tudo certo aqui
Fonte: RFC e votação da comunidade “Deprecate dynamic properties”.
Extensão nova: Random para gerar números aleatórios
Antes de eu te explicar o que essa extensão resolve, deixa eu te mostrar uma coisa:
No PHP é possível gerar números aleatórios de forma determinista, utilizando uma semente (seed). Dada uma mesma semente, os números aleatórios são gerados sempre igual a cada vez que você rodar o programa. Nós podemos definir a semente através da função mt_srand(int $seed)e podemos obter um número aleatório com a função mt_rand(int $min, int $max). Assim:
mt_srand(1234); // semente = 1234
var_dump(mt_rand(1, 100)); // int(76)
Não importa quantas vezes você rodar o programa acima, o valor gerado sempre será 76.
Acontece que a implementação atual utiliza estado global dentro da VM do PHP, de forma que algumas funções podem quebrar o comportamento do gerador de números aleatórios – caso você queira saber mais sobre como o PHP funciona por debaixo dos panos, dê uma olhada no meu artigo sobre o JIT que eu explico passo a passo como funciona.
Então o seguinte código não opera como esperaríamos:
mt_srand(1234); // semente = 1234
str_shuffle('ABC'); // redefiniu a semente :')
mt_rand(1, 100); // int(7)
Estes e outros problemas são resolvidos pela extensão Random que traz uma classe Randomizer. Com ela podemos escolher qual o motor utilizar para gerar números aleatórios. Mais ou menos assim:
$motor = new Random\Engine\MarsenneTwister(1234);
$randomizer = new Random\Randomizer($motor);
var_dump($randomizer->getInt(1, 100)); // int(76)
Fonte: RFC e votação da comunidade “Random extension 5.x”.
Novos tipos: null, true e false
O php já possui os tipos void e bool que representam a ausência de retorno e a união true|false respectivamente.
A partir da versão 8.2 vamos poder explicitar melhor a assinatura de nossos métodos e funções indicando que o retorno será exatamente null, true ou false.
Um bom exemplo de função que operaria desta forma é a função fread() que retorna uma string com o conteúdo lido ou bool(false) em caso de erro. Uma assinatura válida para esta função, de acordo com o PHP 8.2, poderia ser a seguinte:
function fread($handle, int $len): string|false
Fonte: RFC e votação da comunidade “Allow null and false as stand-alone types”.
Tipos de forma normal disjuntiva (Disjunctive normal form types – DNF)
Dev é uma coisa né… que nome complicado pra uma parada simples!
Esta feature nada mais é do que permitir utilizar Union types e Intersection Types ao mesmo tempo!
A condição pra isso, é que os Intersection types estejam entre parênteses, desta forma:
function minhaFuncao((TipoA & TipoB) | false $param)
Aqui o tipo DNF é (TipoA & TipoB) | false.
A ideia é massa, mas vai começar a ficar tenso fazer esse tipo de coisa sem poder apelidar tipos. Talvez esta possa ser a próxima adição ao core – alô galera que programa em C!
Fonte: RFC e votação da comunidade “Disjunctive normal form types”.
Constantes em traits
As traits do PHP já nos permitem compartilhar propriedades e métodos. A nova adição que veio na versão 8.2 do PHP agora nos permite a criar constantes dentro de traits.
Veja o código a seguir:
trait MinhaTrait
{
public const MINHA_CONST = 0xABC;
}
class MinhaClasse
{
use MinhaTrait;
}
MinhaTrait::MINHA_CONST; // Erro
MinhaClasse::MINHA_CONST; // 0xABC
Portanto não é possível acessar a constante diretamente através da trait mas sim de classes que a utilizem. Importante também notar que a visibilidade das constantes (public, protected ou private) será naturalmente respeitada.
Fonte: RFC e votação da comunidade “Constants in Traits”.
Esconder parâmetros em backtraces
Quando um erro acontece na nossa aplicação, o PHP gera um backtrace que mostra método a método o que aconteceu naquela execução. As vezes alguns parâmetros não deveriam ser mostrados nos logs, por questão de segurança. Por exemplo, o log a seguir é meio perigoso:
function ftp_upload(
string $login,
string $senha,
string $src,
string $dst
) {
throw new Exception("Não implementado.");
}
ftp_uload(getenv('FTP_LOGIN'), getenv('FTP_SENHA'), './arquivo.txt', '/home/nawarian/arquivo.txt');
Stack trace:
#0 ftp.php(58): ftp_upload('nawarian', '1337', './arquivo.txt', '/home/nawarian/arquivo.txt')
O erro acima (que eu escrevi dessa forma só pra ilustrar o problema) acaba expondo as varáveis $login e $senha no stack trace.
A partir do PHP 8.2 será possível anotar alguns parâmetros da função como sensíveis, de forma que o PHP não irá mostrar seus valores no trace. Funciona assim: você adiciona o atributo #[SensitiveParameter] ao parâmetro e o PHP cuida de todo o resto.
function ftp_upload(
string $login,
#[SensitiveParameter] string $senha,
string $src,
string $dst
) {
throw new Exception("Não implementado.");
}
ftp_uload(getenv('FTP_LOGIN'), getenv('FTP_SENHA'), './arquivo.txt', '/home/nawarian/arquivo.txt');
Stack trace:
#0 ftp.php(58): ftp_upload('nawarian', Object(SensitiveParameterValue), './arquivo.txt', '/home/nawarian/arquivo.txt')
Note que no stack trace o segundo parâmetro, agora marcado como sensível, é apresentado como Object(SensitiveParameter).
Fonte: RFC e votação da comunidade “Redacting parameters in back traces”.
Funções utf8_encode() e utf8_decode() descontinuadas
A partir da versão 8.2 do PHP, as funções utf8_encode() e utf8_decode() serão descontinuadas e vão gerar um notice no seu Log. No futuro estas duas funções serão removidas.
A mensagem do tipo notice se parece com o seguinte:
Deprecated: Function utf8_encode() is deprecated
Deprecated: Function utf8_decode() is deprecated
Para realizar a migração, você pode optar por utilizar as função mb_convert_encoding() da extensão Multibyte String.
O grande Vinicius Dias, do canal Dias de Dev, fez um vídeo maravilhoso explicando a RFC, suas motivações e como fazer a migração:
Fonte: RFC e votação da comunidade “Deprecate and Remove utf8_encode and utf8_decode”.
Mudança no retorno dos métodos que criam datas
As classes DateTime e DateTimeImmutable possuem métodos para criar datas com as seguintes assinaturas:
DateTime::createFromImmutable(): DateTime
DateTimeImmutable::createFromMutable(): DateTimeImmutable
A partir da versão 8.2 do PHP, ambas assinaturas passarão a retornar o tipo static. Apesar de parecer não ter efeito colateral algum, isto muda fundamentalmente como podemos trabalhar com herança nas classes DateTime e DateTimeImmutable.
Esta é uma mudança que quebra compatibilidade com as versões anteriores caso seu código possua alguma herança das classes DateTime ou DateTimeImmutable.
Fonte: Manual de atualização do PHP 8.2 RC5.
Outras mudanças
Também foram introduzidas outras mudanças menores de sintaxe e manutenção geral da plataforma, para remover suporte a algumas funções.
A lista completa de mudanças você encontra no arquivo UPGRADING do repositório oficial do PHP.
Não esquece de compartilhar este artigo em suas redes e com colegas de trabalho.
Até a próxima! 👋
]]>
Neste tutorial nós vamos ver como conectar sua aplicação Node.js com um banco de dados MongoDB. E como tem muita coisa acontecendo ao mesmo tempo, vamos trabalhar com TDL – aprendizado guiado por testes. Ou seja: vamos escrever testes para entender o que cada passo está fazendo.
Este passo a passo vai te permitir:
- Subir um banco de dados MongoDB via Docker para testes;
- Baixar e configurar o pacote mongoose;
- Criar coleções no MongoDB via mongoose;
- Inserir registros em coleções no MongoDB via mongoose; e
- Listar registros em coleções no MongoDB via mongoose
Então vem comigo que a gente vai começar!
Conteúdos do post
- Passo 1 – instalar o pacote mongoose
- Passo 2 – instalar o pacote Jest para fazer TDD
- Passo 3 – Subindo um servidor MongoDB para testes
- Passo 4 – vamos o esqueleto do nosso caso de teste
- Passo 5 – testar a conexão com o MongoDB com mongoose e jest
- Passo 6 – testar a inserção de entidades no MongoDB com mongoose e jest
- Passo 7 – testar a obtenção de documentos no MongoDB com mongoose e jest
- Código utilizado no artigo
- Recomendação de outros testes para rodar
- Conclusão
Vídeo de apoio
Caso você esteja sem energia para ler o texto, ou tenha se perdido em algum momento, eu fiz um vídeo de apoio pra te auxiliar a entender tudo sobre como começar a trabalhar com MongoDB usando Mongoose em sua aplicação node.js.
Passo 1 – instalar o pacote mongoose
Eu estou rodando o node v16.17.0 mas os passos abaixo devem funcionar bem em versões superiores à 11 sem muitos problemas.
Vamos instalar o mongoose com npm usando a seguinte linha:
$ npm install mongoose --save
Caso você use yarn, o comando é o seguinte:
$ yarn add mongoose
O meu package.json ficou assim:
"dependencies": {
"mongoose": "^6.6.2"
}
Passo 2 – instalar o pacote Jest para fazer TDD
Como nós queremos trabalhar com testes, vamos instalar o pacote Jest:
$ npm install --save-dev jest
Caso você utilize o Yarn, rode o seguinte comando:
$ yarn add --dev jest
Meu package.json ficou mais ou menos assim:
"devDependencies": {
"jest": "^29.0.3"
}
Agora vamos adicionar a seguinte seção ao arquivo package.json:
"scripts": {
"test": "jest"
}
Com isso nós podemos rodar o seguinte comando no terminal. A cada novo arquivo que criarmos e cada vez que salvarmos um arquivo, Jest irá rodar todos os testes novamente:
$ npm run test -- --watchAll
A sua tela deverá ficar mais ou menos assim:

Deixa esse terminal rodando o comando, a gente já já vai voltar a prestar atenção nele.
Passo 3 – Subindo um servidor MongoDB para testes
Para acompanhar nosso tutorial a gente precisa de um servidor MongoDB rodando. Como eu não quero gastar tempo e energia subindo um servidor na minha máquina local, eu vou utilizar a imagem docker oficial do MongoDB.
Esta imagem exige duas variáveis de ambiente definidas:
- MONGO_INITDB_ROOT_USERNAME – o usuário padrão do banco de dados
- MONGO_INITDB_ROOT_PASSWORD – a senha do usuário padrão
Então vamos criar um arquivo .env com o seguinte conteúdo:
MONGO_INITDB_ROOT_USERNAME=root
MONGO_INITDB_ROOT_PASSWORD=root
Com o arquivo acima criado, podemos iniciar o servidor docker com o seguinte comando:
$ docker run --rm -it --env-file .env -p27017:27017 mongo:latest
Deixa eu explicar o que comando acima está fazendo, item a item:
A opção --rm vai apagar o container docker assim que interrompermos sua execução. Dessa forma o container não fica em disco quando a gente terminar nosso teste.
A opção -it vai manter o shell conectado à saída do servidor, desta forma você consegue ver os logs do servidor em seu terminar. Como na imagem a seguir:

A opção --env-file .env vai usar o arquivo .env que nós criamos para definir as variáveis de ambiente que ficam presentes no container docker. Como nós definimos MONGO_INITDB_ROOT_USERNAME e MONGO_INITDB_ROOT_PASSWORD o container vai inicializar o servidor utilizando aqueles dados como usuário e senha padrão do banco de dados.
Por fim, -p27017:27017 vai mapear a porta 27017 do container à porta 27017 da máquina local. A porta 27017 é a porta padrão de conexão com o MongoDB. Ao fazer este mapeamento nós podemos acessar mongodb://localhost:27017 e o docker vai automaticamente nos rotear para o container.
O último argumento, mongo:latest, é o nome da imagem MongoDB no Docker Hub.
Passo 4 – vamos o esqueleto do nosso caso de teste
Agora é hora de colocar a mão na massa, vamos criar nosso caso de teste para testar nossa conexão com o MongoDB.
Adicione o seguinte esqueleto num arquivo mongodb.test.js:
// mongodb.test.js
const mongoose = require('mongoose')
test('Meu primeiro teste', () => {
expect(true).toBeTruthy()
})
Ao salvar o arquivo acima, o terminal que nós deixamos rodando desde o passo 2 deverá ficar assim:

Nosso ambiente está pronto para experimentarmos com o Mongoose!
Passo 5 – testar a conexão com o MongoDB com mongoose e jest
Vamos começar por conectar com o MongoDB usando o mongoose. De acordo com a documentação oficial nós podemos usar o método mongoose.connect(), que retorna uma Promise.
Portanto o callback da função then() pode fazer nosso teste passar, e o callback da função catch() deverá fazer o teste falhar. Assim nós saberemos se a conexão está funcionando.
Vamos adicionar o seguinte caso de teste:
const MONGODB_DSN = 'mongodb://root:root@localhost:27017'
test('Conexão com MongoDB', async () => {
const promise = mongoose.connect(MONGODB_DSN)
await expect(promise).resolves.toBeInstanceOf(mongoose.Mongoose)
await mongoose.connection.close()
})
Ao salvar o arquivo com o teste acima, o Jest deverá imediatamente rodar os testes e acusar sucesso (caso os dados da conexão estejam corretos):

Aproveite e mude os valores da constante MONGODB_DSN para ter certeza de que o teste falha como deveria.
Agora vamos brincar com alguns schemas. Tá na hora de inserir uma entidade no nosso MongoDB.
Passo 6 – testar a inserção de entidades no MongoDB com mongoose e jest
É isso, vamos então criar uma coleção chamada artigos que possui os seguintes campos:
- Título
- URL
De acordo com a documentação oficial do Mongoose nós precisamos primeiro definir um objeto do tipo Schema, que mapeia o que acontece dentro do MongoDB para JavaScript. Depois nós precisamos criar um objeto do tipo Model para poder interagir com aquela coleção que definimos o Schema.
Ao inserir um objeto na coleção a gente sabe que tudo funcionou porque o mongoose vai adicionar um campo _id do tipo mongoose.Types.ObjectId.
Note que vamos definir Schema e Model fora do caso de teste, para que possamos reutilizar estas variáveis em outros casos de teste.
O caso de teste ficou assim:
const artigoSchema = new mongoose.Schema({
titulo: String,
url: String,
})
// 'Artigo' vai ser tratado como uma classe de agora em diante
const Artigo = mongoose.model('artigos', artigoSchema)
test('Inserção no MongoDB', async () => {
// Nós já vimos que a linha abaixo conecta ao DB
await mongoose.connect(MONGODB_DSN)
// Cria o schema que mapeia mongodb para o JS
const artigoSchema = new mongoose.Schema({
titulo: String,
url: String,
})
// 'Artigo' vai ser tratado como uma classe de agora em diante
const Artigo = mongoose.model('artigos', artigoSchema)
// Criamos uma instância de Artigo
const tutorial_mongodb = new Artigo({
titulo: 'Como conectar com mongodb no node.js com TDD',
url: 'https://codamos.com.br/como-conectar-mongodb-nodejs-tdd',
})
// Salva o registro no MongoDB
await tutorial_mongodb.save()
// 'tutorial_mongodb' agora deverá ter um campo '_id'
expect(tutorial_mongodb._id).toBeInstanceOf(mongoose.Types.ObjectId)
await mongoose.connection.close()
})
A tela do terminal do Jest ficou assim pra mim:

Passo 7 – testar a obtenção de documentos no MongoDB com mongoose e jest
Sempre que precisamos buscar um documento em nossa coleção, ou mesmo listar todos documentos, podemos utilizar o método Model.find() que deverá retornar o tipo Promise<Model[]>.
Então para o nosso teste podemos só verificar que a lista de documentos tem mais do que 0 elementos. Afinal o teste anterior já criou documentos no banco de dados.
Um teste de produção não deveria assumir que os testes anteriores passaram, e muito menos depender de estado global. Neste caso tudo bem trabalhar assim porque estamos utilizando testes para aprender.
O caso de testes ficou assim:
test('Listar todos documentos no MongoDB', async () => {
await mongoose.connect(MONGODB_DSN)
const artigoSchema = new mongoose.Schema({
titulo: String,
url: String,
})
const artigosEncontrados = await Artigo.find()
expect(artigosEncontrados.length).toBeGreaterThan(0)
await mongoose.connection.close()
})
Jest deverá então acusar sucesso: nosso teste passou e temos uma lista de artigos na variável artigosEncontrados.

Você também pode experimentar fazer alguns console.log() dentro do escopo dos testes pra ver o que está lá dentro. O bacana de usar TDL é que temos um ambiente preparado para brincar e testar o que quisermos a qualquer momento, num ambiente controlado.
Código utilizado no artigo
Você pode verificar o código completo utilizado neste artigo neste GIST aqui.
Recomendação de outros testes para rodar
Você provavelmente já entendeu a ideia do negócio: cada funcionalidade que quiser testar, basta criar um novo caso de teste e ver como o framework se comporta.
Eu recomendo que você implemente por si os seguintes casos de teste:
- Atualizar um documento MongoDB;
- Buscar um documento pelo título;
- Remover um documento por
_id; - Receber a quantidade (
count) de documentos que atendem a um filtro; - Listar documentos ordenados por
url
Você vai ver que após escrever os testes acima, você já sabe tudo o que precisa pra começar a escrever uma aplicação completa usando Node.js, MongoDB e Mongoose.
Conclusão
Os testes que escrevemos aqui não devem ser utilizados em produção! São apenas testes que utilizamos para aprender a ferramenta. Assim que entender como a ferramenta funciona, recomendo remover estes testes e desenvolver sua aplicação de forma independente, com testes que façam sentido para a sua aplicação.
Não se esqueça de que ao interromper seu comando docker o banco de dados não vai mais funcionar. E ao rodar o mesmo comando novamente, seu banco de dados estará vazio porque usamos a opção --rm.
Se você gostou da forma como o artigo foi organizado, não deixa de compartilhar em suas redes sociais!

Esta dica eu aprendi recentemente e mudou completamente a forma como eu uso o editor VIM!
Eu estou acostumado a utilizar o plugin NERDTree pra navegar nos arquivos do projeto e fazer algumas buscas superficiais. Na maioria dos casos funciona bem pra mim, mas esta técnica que eu aprendi tem me economizado MUITO tempo.
Caso você queira dar seus primeiros passos com VIM, eu escrevi um artigo bem simplificado sobre como começar a utilizar o VIM.
Vem comigo e lê até o final que tem dica de ouro sobre como deixar esse negócio ainda mais eficiente!
A árvore de arquivos que vamos usar como exemplo
Os exemplos que eu vou apresentar aqui (e no vídeo de apoio ao final do artigo) são baseados no projeto qmario – um emulador de NES escrito em C que eu estou desenvolvendo com vocês.
A estrutura de pastas atualmente é a seguinte:
$ tree
.
├── LICENSE
├── Makefile
├── build
│ ├── bus.o
│ ├── cpu.o
│ ├── main.o
│ └── qmario
└── src
├── bus.c
├── bus.h
├── bus.test.c
├── cpu.c
├── cpu.h
├── cpu.test.c
└── main.c
O comando :find
Dentro do editor VIM você pode executar o comando :find pra buscar e abrir arquivos num determinado diretório.
:find src/main.c
Ao executar o comando acima, caso VIM encontre um arquivo main.c dentro da pasta src/ ele irá abrir o arquivo imediatamente.
O comando também tem autocomplete ao pressionar a tecla TAB. Por exemplo, se o arquivo Makefile existe o seguinte comando vai te ajudar a encontrar:
:find ma<TAB>
Só que em vez de escrever <TAB> você deveria apertar a tecla TAB (aquela que fica em cima do Caps Lock). Note que quando fizer isso, caso VIM encontre o arquivo, vai auto completar pra ti a linha. Note também que pra esta busca não importa muito se o nome está em maiúsculo ou minúsculo.

Busca recursiva
O comando find por si só já é útil, mas convenhamos que se você já sabe a pasta onde o arquivo está não tem muito o que procurar.
A coisa é que esse comando é muito poderoso! Ele respeita uma variável chamada path que indica todos os diretórios que VIM deveria utilizar pra buscar seus arquivos.
Para forçar o VIM a busca recursivamente seus arquivos você pode adicionar o caminho ** à variável path, assim:
:set path+=**
Note que += aqui significa “adicione ao conteúdo da variável” e ** é valor que estamos adicionando. Agora podemos fazer buscas recursivas:
:find cpu.c
O comando acima vai encontrar o arquivo src/cpu.c sem muita dificuldade!

Visualizar opções
As vezes os arquivos podem ter nomes parecidos e isso gera uma certa ambiguidade que o mecanismo de busca find não consegue resolver sozinho. Por exemplo, nós temos os arquivos src/cpu.c, src/cpu.h, src/cpu.test.c e build/cpu.o.
Uma forma muito bacana de resolver essa ambiguidade é habilitar o wildmenu que vai te mostrar opções sempre que não conseguir encontrar um único resultado para a sua busca.
Para ativar rode o seguinte comando:
:set wildmenu
Pronto! Agora se você procurar por cpu e pressionar TAB um novo menu deverá aparecer pra ti com diferentes opções para o mesmo arquivo como na imagem a seguir:
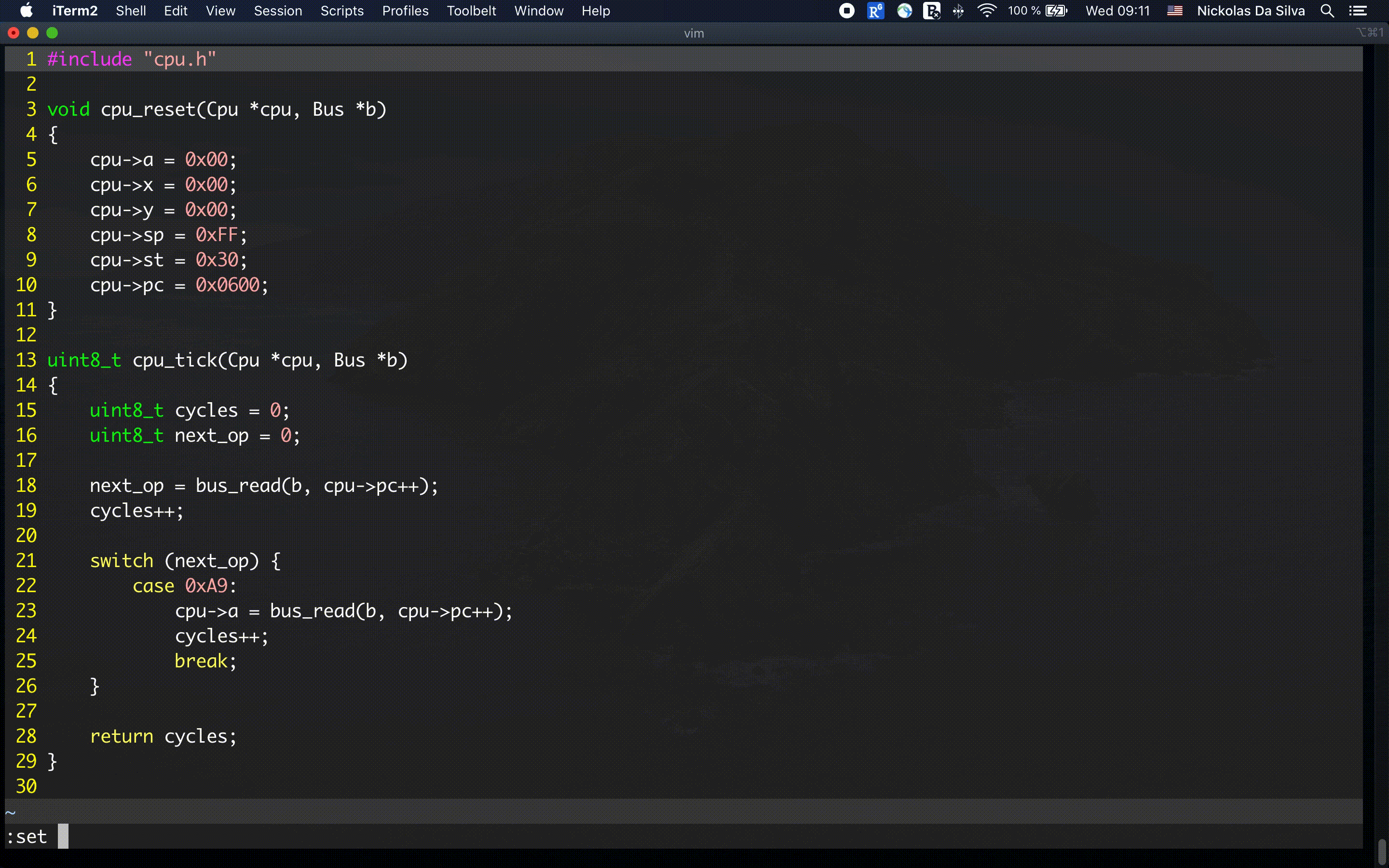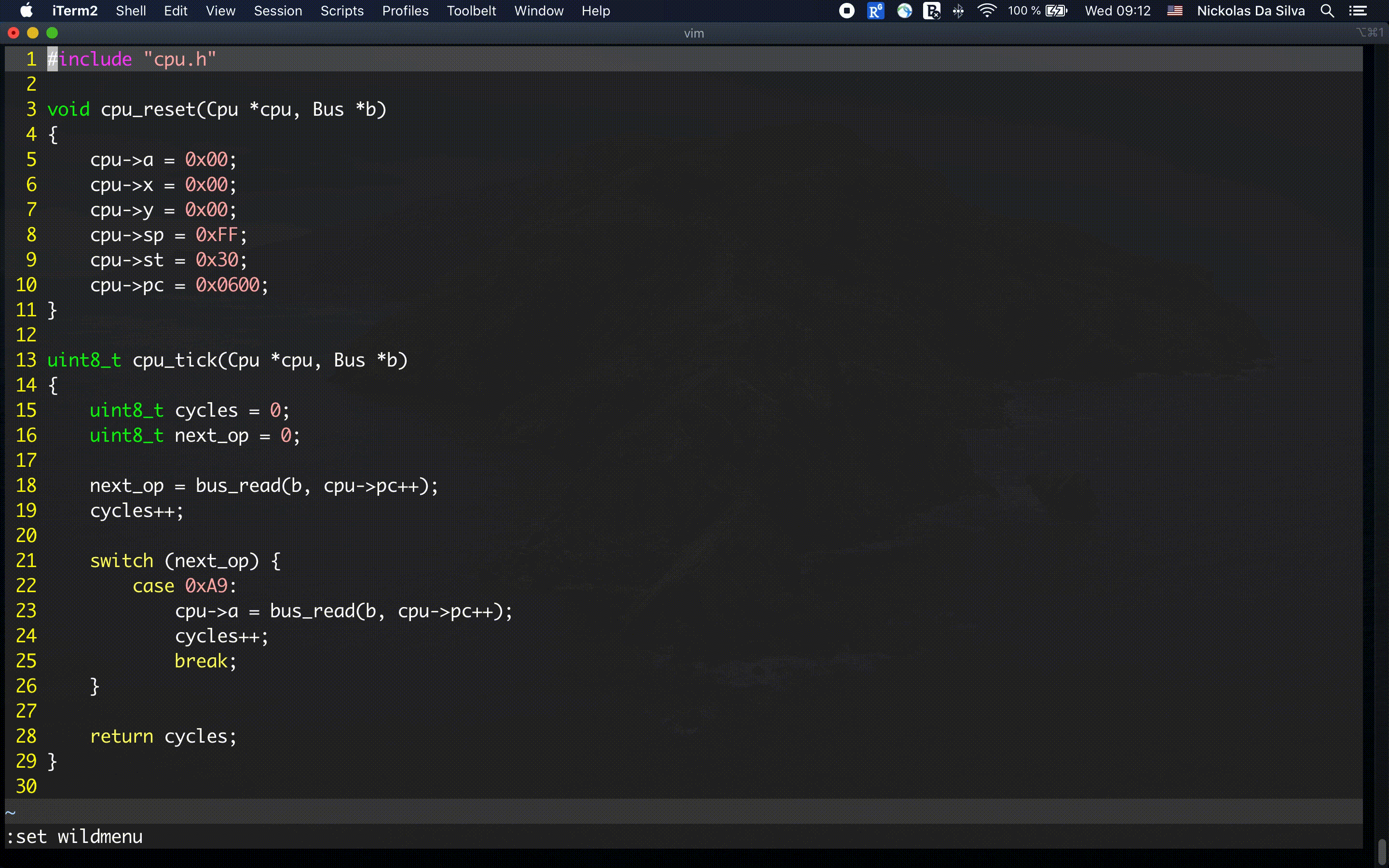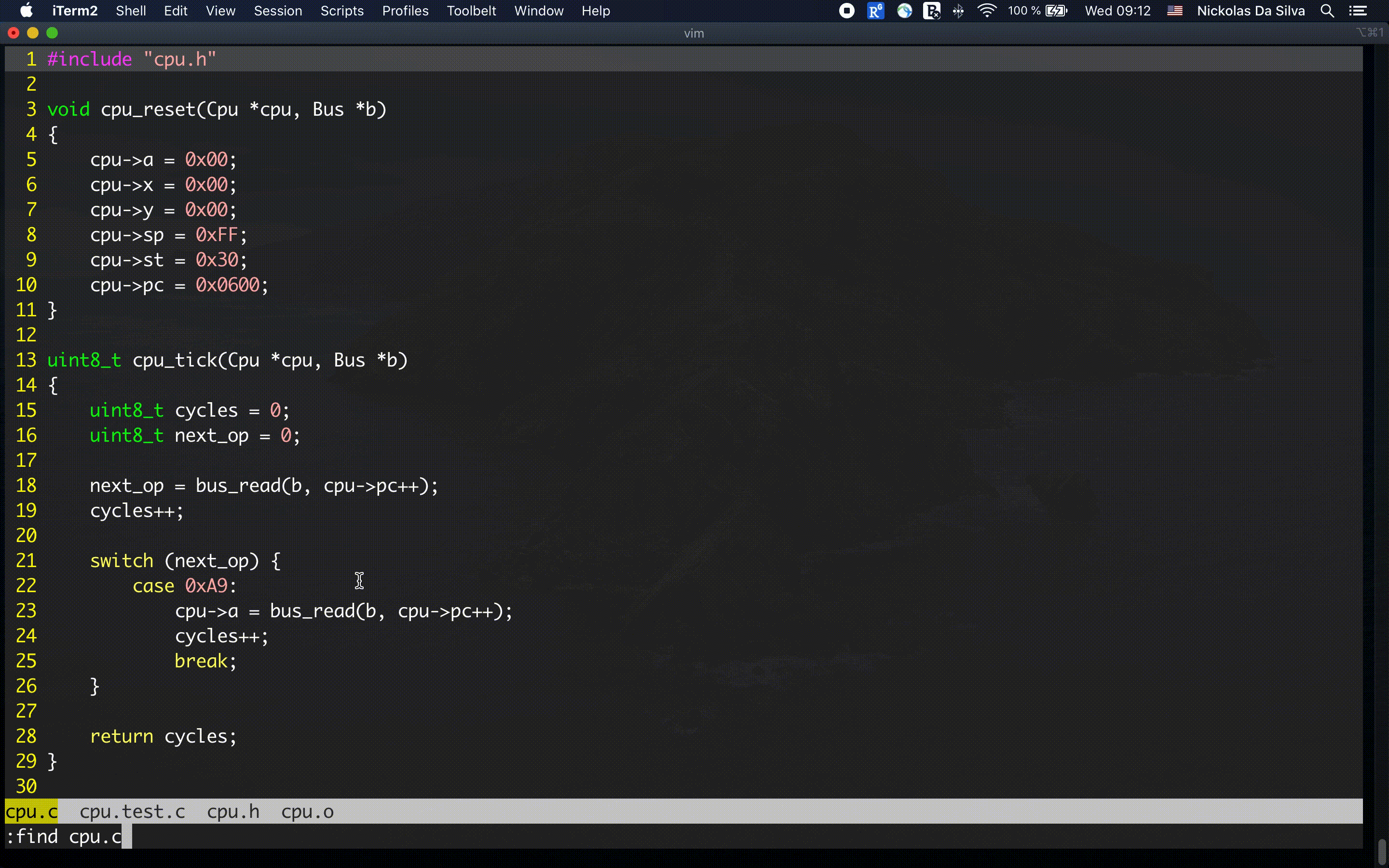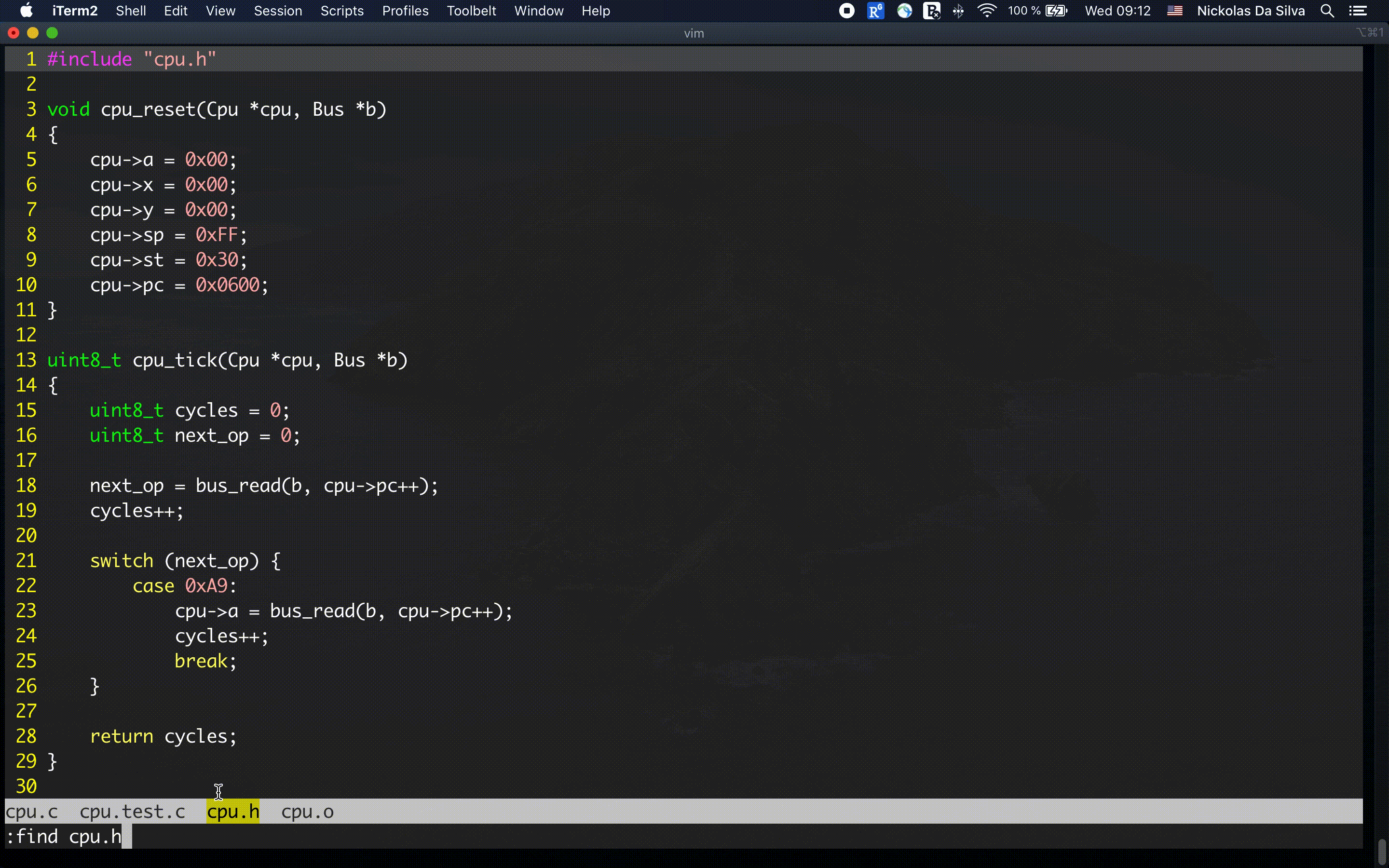
Conclusão e vídeo de apoio
Tá aí na mão mais uma dica massa pra tu que quer entender melhor como funciona e como aumentar sua produtividade com o VIM.
Caso tenha dúvidas sobre como isso funciona, eu fiz esse pequeno vídeo de apoio aqui pra te ajudar a entender:
Não esquece de compartilhar este artigo nas suas redes sociais que ajuda muito a gente. Te vejo na próxima!

Este artigo é uma continuação da série “Emulador NES” que vai te mostrar e implementar contigo um emulador NES totalmente funcional utilizando a linguagem C e a biblioteca Raylib. Clique aqui para ler o artigo anterior, ou clique aqui para ler o primeiro artigo e acompanhar desde o começo!
No artigo anterior
Nós já fizemos uma visão geral dos componentes que o emulador precisa pra operar como um sistema NES: cpu, barramento, ppu, apu, etc.. E no artigo anterior nós também preparamos o ambiente de CI para que rode os testes a cada nova adição que fizermos ao nosso projeto usando o Github Actions.
Hoje nós vamos começar uma das partes mais empolgantes do projeto: a emulação da CPU 6502 – o processador do nintendinho. Para isso vamos escrever duas interfaces essenciais do emulador: a CPU e o barramento de memória.
Para cada uma destas interfaces eu fiz um vídeo separado mostrando a implementação do que tá escrito no arquivo pra todo mundo poder acompanhar. Vem comigo!
Emulação do barramento de memória
Antes de mexer em qualquer coisa relacionada ao processador, nós precisamos preparar uma forma de permitir que o processador – e mais tarde outros componentes também – tenham acesso à memória RAM.
Esta parte do trabalho é relativamente simples, porque só envolve criar uma interface para ler e escrever num espaço de memória, que nós vamos implementar com um array.
Propriedades de um barramento de memória
O barramento de memória é uma interface bem simples para ler e escrever da memória. Estas são as duas operações que a gente precisa implementar hoje!
O que é importante notar é que a CPU 6502 tem uma capacidade de endereçamento de apenas 16 bits (2 bytes). Portanto a CPU só consegue ler do barramento os endereços de memória entre 0x0000 e 0xFFFF, totalizando 65535 bytes (~64 kilobytes) de memória RAM.
Em termos práticos significa dizer que não importa se o hardware tiver mais que 64kb de RAM, a CPU não vai conseguir utilizar este espaço extra de memória.
Para emular o barramento e a memória RAM portanto, não precisamos de nada mais do que um array de 64 kb como no exemplo abaixo:
// Declara um array chamado 'bus' de 64 kb (65535 índices)
uint8_t bus[0xFFFF];
E tudo o que precisamos escrever para emular o barramento de memória são duas funções para que possamos ler e escrever da memória. Algo assim:
uint8_t bus_read(uint16_t address);
void bus_write(uint16_t address, uint8_t value);
A interface acima está relativamente incompleta, mas já deve te dar uma ideia de como o programa deverá ficar.
Dê uma olhada no vídeo de apoio caso queira acompanhar a implementação final, ou implemente os testes abaixo caso queira escrever comigo!
Vídeo de apoio
Testes para o barramento de memória
void test_bus_read(void)
{
// Given the memory address '0x0600' has the value '0xA9'
// When I call 'bus_read()' with the address '0x0600'
// Then I should get the value '0xA9'
}
void test_bus_write(void)
{
// Given the memory bus contains only zeroes
// When I call 'bus_write()' with the address '0x0600' and value '0xA9'
// Then the byte '0x0600' should contain the value '0xA9'
}
Ao fazer o teste acima passar, estamos prontes para a próxima etapa: emular a CPU!
A implementação completa você encontra no vídeo de apoio e também neste Pull Request aqui.
Emulação da CPU 6502
O coração do nosso emulador é a unidade central de processamento, a CPU. Este é o componente que vai nos permitir ler programas presentes no barramento de memória e executar lógica. Na maioria dos casos, os bugs que vamos encontrar no emulador vão morar neste componente também!
Apesar de ser tão fundamental, o processador tem um funcionamento muito simples: ele fica rodando infinitamente (ou até ser encerrado) e a cada iteração (ciclo) o processador tenta identificar qual a próxima instrução que ele deveria executar a partir do barramento de memória.
Características da CPU 6502
O processador 6502 tem 3 registradores chamados de A (acumulador), X e Y – todos eles de apenas 1 byte. Além disso, ele possui um ponteiro de pilha (stack pointer) que também tem 1 byte, um registrador de status da CPU de 1 byte e um ponteiro de instrução (instruction pointer ou program counter) que possui 2 bytes.
A representação disso em uma struct C é mais ou menos a seguinte:
struct Cpu {
uint8_t a; // acumulador
uint8_t x;
uint8_t y;
uint8_t sp; // stack pointer
uint8_t st; // status register
uint16_t pc; // program counter
};
Note que o ponteiro de instrução possui 16 bits, ou 2 bytes, que é justamente o tamanho do nosso barramento. Portanto este é o único ponteiro que consegue armazenar o endereço completo de qualquer parte da memória do barramento.
Cada instrução do processador é descrita com apenas um byte – elas são armazenadas na memória assim. Por exemplo, a instrução LDA #$00 que significa “carregar o valor 0x00 no registrador A” fica descrita assim no barramento de memória: 0xA9 0x00.
Exatamente esta instrução LDA #$00 pode ser representada no nosso barramento de memória assim:
struct Cpu cpu = { 0 };
// aponta para o endereço 0x0600 da memória
cpu.pc = 0x0600;
uint8_t bus[0xFFFF];
bus_write(0x0600, 0xA9); // LDA
bus_write(0x0601, 0x00); // 0x00
De forma que quando a CPU rodar irá encontrar a instrução 0xA9 já que seu ponteiro de instrução (pc) aponta para o endereço 0x0600, onde existe o byte 0xA9. Esta instrução exige que o processador busque um segundo parâmetro gravado em sequência, no endereço 0x0601.
As instruções do processador – também chamadas de OpCode – podem obrigar diferentes números de parâmetros e diferentes formas de acessar a memória. Para você ter uma ideia, veja o exemplo da instrução LDA:
| Instrução em assembly | Representação na memória | Significado |
|---|---|---|
| LDA #$00 | 0xA9 0x00 |
Imediato – carregar o próximo byte para o registrador |
|
LDA $00 |
0xA5 0x00 |
Zero Page – carregar 1 byte da memória RAM para o registrador |
| LDA $ff00 | 0xAD 0x00 0xFF |
Absoluto – carregar 1 byte da memória RAM para o registrador |
A CPU possui outras formas de endereçamento que eu não citei na tabela acima, mas que nós vamos trabalhar nos próximos artigos.
Para facilitar o entendimento de dar alguma praticidade pro texto, eu montei mais um vídeo de apoio implementando o comecinho da nossa CPU.
Vídeo de apoio
Testes para a instrução LDA da CPU 6502
void test_cpu_reset(void)
{
// Given a CPU in any state
// When I call 'cpu_reset()'
// Then the registers A, X and Y should be '0'
// And the stack pointer should be '0x30'
// And the program counter should point to '0x0600'
}
void test_cpu_tick_lda(void)
{
// Given the program '0xA9 0xAA' in the address '0x0600'
// And the program counter (pc) points to the address '0x0600'
// When the cpu executes 1 OpCode
// Then the program counter (pc) should be '0x0602'
// And the A register should be '0xAA'
// And the number of elapsed cycles should be '2'
}
Ao fazer os testes acima passar nós alcançamos uma etapa importantíssima do nosso desenvolvimento: estabilidade para trabalhar os próximos opcodes.
A implementação completa você encontra no vídeo de apoio e também neste Pull Request aqui.
Próximos passos
Nós alcançamos um momento importantíssimo do nosso desenvolvimento! Temos um pull request aberto que nos permite enviar alterações continuamente e que irá ativar a nossa CI caso algo dê errado. Além disso temos uma forma organizada de escrever testes e manter um ritmo de trabalho em que apenas avançamos em vez de criar bugs difíceis de encontrar.
No próximo artigo eu pretendo cobrir a instrução STA (gravar do acumulador para a memória) de forma que com essas duas instruções (LDA e STA) teremos contemplado todos os tipos de endereçamento da memória e poderemos começar a implementar a CPU de forma acelerada utilizando um caso de teste pronto: o nestest.
Portanto na próxima nós vamos ver melhor os endereçamentos de memória e vamos carregar para a memória a ROM nestest que vai nos permitir caminhar muito mais rapidamente na implementação da nossa CPU!

Este artigo é uma continuação da série “Emulador NES” que vai te mostrar e implementar contigo um emulador NES totalmente funcional utilizando a linguagem C e a biblioteca Raylib. Clique aqui para ler o artigo anterior.
O resultado do trabalho deste artigo você consegue conferir no primeiro Pull Request do projeto: https://github.com/codamos-com-br/qmario/pull/1.
No artigo anterior
Nós já tivemos uma visão geral da arquitetura do NES e quais componentes vamos precisar emular.
Agora é hora de botar a mão na massa! Hoje nós vamos criar uma suíte de integração contínua que vai nos permitir compilar e rodar testes, para que possamos detectar com facilidade se algum erro aconteceu e quando.
Vídeo de apoio
Tem muita coisa acontecendo ao mesmo tempo neste artigo e, apesar de eu ter tentado deixar ele organizadinho, algumas coisas ainda podem ter ficado confusas.
Eu gravei um vídeo mostrando a implementação passo a passo de tudo o que vamos falar aqui, talvez assim fique um pouco mais fácil de acompanhar o processo que, como um todo, é bem complicadinho.
Criar e clonar um novo repositório no Github
O meu primeiro passo aqui é criar um repositório no Github. Isso vai me ajudar a guardar os arquivos e versionar tudo, mas também vai permitir que você dê uma olhada no código e envie algumas correções, faça perguntas pontuais e por aí vai…
Na página do seu perfil ou organização, clique em “Repositories” e encontre o botão “New repository”:

Clique no botão “New repository” para criar um novo repositório no Github.
Daí basta colocar as informações básicas sobre o projeto. Eu vou chamar este emulador de “qmario” (🤭) e você pode acessar a partir deste link aqui: https://github.com/codamos-com-br/qmario.

Adicionamos informações básicas: nome, licença e visibilidade do projeto.
Agora basta visitar a página principal do repositório, clicar no botão primário “Code” para então escolher a aba “SSH” e copiar a URL que o Github nos oferece na caixa de texto.

Na página do repositório, clique em “Code”, na aba “SSH” e em seguida no ícone de cópia para obter o endereço do seu repositório.
Com esta URL eu posso clonar o repositório pro meu computador utilizando o seguinte comando:
$ git clone [email protected]:codamos-com-br/qmario.git
Ao entrar na pasta que acabei de clonar, posso listar todos os arquivos. Como é um repositório novo, apenas .git e LICENSE deverão existir:

Após clonar o projeto, entre na pasta e os seguintes arquivos deverão aparecer: .git e LICENSE.
Caso não saiba como mexer com Github ou subir arquivos lá, o João escreveu um post incrível com um passo a passo muito bem feito sobre como subir arquivos para um projeto no Github.
Integração contínua com Github Actions: qualidade garantida desde o início
O primeiro passo essencial ao criar qualquer projeto, é configurar uma suíte de integração contínua. Desta forma a gente garante desde o dia 1 do projeto que está pronto para se construído e entregue a qualquer computador.
No Github podemos utilizar workflows do Github Actions para integração contínua.
Antes de tudo, vamos criar um branch novo para receber nossas alterações. Vou chamar este branch de ci_workflow.
$ git checkout -b ci_workflow

Novo branch
Agora podemos começar a montar a nossa pipeline de integração contínua. Vamos criar um arquivo chamado .github/workflows/ci.yaml:
$ mkdir -p .github/workflows
$ vim .github/workflows/ci.yaml

Criando arquivo ci.yaml
Para criar e editar o arquivo eu utilizei o editor VIM, mas você pode usar qualquer outro editor de sua preferência. Para saber sobre VIM, dê uma olhada neste artigo que escrevi sobre como começar com VIM.
Agora vamos dar o seguinte conteúdo ao arquivo ci.yaml:
# .github/workflows/ci.yaml
name: CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Fazer build e rodar
run: echo 'Olá github actions'
Note que, de acordo com o conteúdo acima, a pipeline build vai rodar sempre que fizermos um push ou abrirmos um pull_request que afete o branch main.
Vamos então fazer um commit e enviar nossas alterações:
$ git add .github/.
$ git commit -m "ci: adiciona workflow simples"
$ git push origin ci_workflow

Adiciona
.github/workflows/ci.yaml ao branchAssim que o conteúdo for enviado ao Github, a página do seu repositório deverá oferecer de criar um Pull Request. Vamos aceitar a sugestão clicando em “Compare & pull request”:

Branch criado, podemos criar um Pull Request e ver a pipeline funcionando.
Ao confirmar a criação do Pull Request, note que o Github Actions imediatamente começa a executar a nossa pipeline:

Ao criar o Pull Request, o workflow imediatamente começa a rodar.
Caso os comandos desta pipeline tenham um código de saída igual a 0 (zero), a pipeline ficará verde indicando que está tudo em ordem. Caso algum código de saída seja diferente de 0, a pipeline ficará vermelha, e nos dirá qual comando teve falha.
Abaixo eu mostro detalhes de como fica a pipeline verde e expandindo o passo “Fazer build e rodar” para que vejamos a saída do nosso programa echo ‘Olá github actions’:

O detalhamento daquele workflow mostra quais passos rodaram, e que o nosso passo executou e retornou com sucesso (exit 0).
Com este workflow simples em mãos, vamos começar a botar a mão na massa e escrever um pouco de C. Deixe o Pull Request aberto, a gente ainda vai precisar dele!
Olá mundo: compilando um programa simples em C
Na linguagem C, todo programa precisa ter uma função de entrada. Normalmente esta função se chama main(). Vamos escrever um arquivo chamado src/main.c com o seguinte conteúdo:
#include <stdio.h>
int main(void)
{
printf("Olá mundo");
return 0;
}
O programa acima deverá escrever o texto “Olá mundo” na tela quando executado, e o seu código de saída (exit code) deverá ser 0 (zero). Nós podemos verificar o código de saída do último comando executado através da variável $?.
Para compilar o programa acima, utilize o seguinte comando:
$ clang src/main.c -o build/main.o -std=c99 -Wall
E o conjunto da obra deverá ficar mais ou menos assim:

Compilação do programa main.c
O comando acima não apenas compilou o nosso arquivo main.c mas também executou um processo chamado Linkedição. Para facilitar a nossa vida no futuro, eu quero quebrar a compilação do nosso programa em duas partes: compilação e linkedição de objetos.
Para isto, nós primeiro precisamos compilar os arquivos .c utilizando a flag -c. Depois coletamos todos os arquivos .o e entregamos ao compilador para gerar um único executável, que aqui chamamos de “qmario”. Fica assim:
$ clang -c src/main.c -o build/main.o -std=c99 -Wall
$ clang build/main.o -o build/qmario

Compilação em duas fases: linkedição acontece depois.
Criar um Makefile para o projeto
Vamos criar e editar alguns arquivos antes de mais nada. Como eu sei que no próximo post eu vou trabalhar a emulação da CPU, vamos já criar os arquivos da CPU: cpu.h (cabeçalho, onde ficam as assinaturas de função), cpu.c (implementações concretas) e cpu.test.c (testes automatizados para as funções de CPU).
Dê os seguintes conteúdos para estes arquivos:
// no arquivo cpu.h escreva o seguinte
#ifndef _cpu_h_
#define _cpu_h_
void cpu_reset(void);
#endif
// no arquivo cpu.c escreva o seguinte
#include "cpu.h"
void cpu_reset(void)
{
}
// no arquivo cpu.test.c escreva o seguinte
#include "cpu.h"
int main(void)
{
cpu_reset();
}
// no arquivo main.c escreva o seguinte
#include "cpu.h"
int main(void)
{
cpu_reset();
return 0;
}
-
build/ é a pasta que recebe todos os arquivos compilados e intermediários. Quando o projeto é clonado, esta pasta não deverá existir
-
src/ todo nosso código C ficará nesta pasta, incluindo os testes!
-
src/*.test.c alguns arquivos poderão receber o sufixo .test.c, que indica que são arquivos de teste. Desta forma conseguimos escrever testes e garantir maior qualidade no projeto
Portanto vamos criar o arquivo Makefile com o seguinte conteúdo:
CC=clang
CFLAGS=-std=c99 -Wall
LFLAGS=
SRCDIR=src
BUILDDIR=build
OUT=qmario
OBJS=$(BUILDDIR)/cpu.o
MAINOBJ=$(BUILDDIR)/main.o
TOBJS=$(BUILDDIR)/cpu.test.o
run: $(BUILDDIR)/$(OUT)
$(BUILDDIR)/$(OUT)
test: $(BUILDDIR) $(OBJS) $(TOBJS)
$(CC) $(OBJS) $(TOBJS) -o $(BUILDDIR)/tests $(LFLAGS)
$(BUILDDIR)/tests
# Constrói o executável principal
$(BUILDDIR)/$(OUT): $(BUILDDIR) $(OBJS) $(MAINOBJ)
$(CC) $(OBJS) $(MAINOBJ) -o $(BUILDDIR)/$(OUT) $(LFLAGS)
$(BUILDDIR):
mkdir -p $(BUILDDIR)
$(BUILDDIR)/%.o: $(SRCDIR)/%.c
$(CC) -c $< -o $@ $(CFLAGS)
.PHONY: clean
clean:
$(RM) -r $(BUILDDIR)
Agora que o arquivo Makefile existe, podemos executar o comando make clean run para compilar e executar o programa que definimos em main.c.
$ make clean run

Compilando o programa do zero e executando build/qmario.
E para rodar nossos testes, definidos no arquivo cpu.test.c, podemos rodar o comando make clean test. Como a seguir:
$ make clean test

Compilando o programa do zero e executando build/tests.
A estrutura de pastas deverá ficar mais ou menos assim:
├── LICENSE
├── Makefile
├── build
│ ├── cpu.o
│ ├── cpu.test.o
│ ├── main.o
│ ├── qmario
│ └── tests
└── src
├── cpu.c
├── cpu.h
├── cpu.test.c
└── main.c
Vamos rodar os testes como parte da integração contínua
Agora que a nosso Makefile está configurado e funcionando bonitinho, podemos alterar o arquivo .github/workflows/ci.yaml para fazermos a compilação e rodar os testes sempre que abrirmos um Pull Request no repositório que criamos.
Dê o seguinte conteúdo para o arquivo .github/workflows/ci.yaml:
name: CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Fazer build e rodar
run: make clean test
Pode enviar o código para o Github e note que o CI agora está verde, indicando que todos os passos foram executados e tudo correu bem:

Pull Request com a indicação de que todos os testes rodaram e podemos fazer o merge.
Próximos passos
Já temos uma integração contínua configurada e pronta para receber nosso código. O próximo passo é começar a escrever o emulador!
O primeiro componente a ser escrito é justamente a CPU, que deverá ser escrita em conjunto com o barramento (memory BUS). No próximo artigo nós vamos começar a entender o chip 6502 utilizado pelo NES, e vamos emular algumas operações.
Não se esqueça de que o próximo artigo só sai se um número suficiente de pessoas ajudar a divulgar a série! 👇
Atenção! Para que este DevLog avance eu preciso da sua ajuda não financeira: Dê retuíte neste post e compartilhe com colegas e quem mais se interessar. Somente após 50 RTs eu vou escrever o próximo post. Esta é uma forma fácil e barata de você nos ajudar o projeto codamos.com.br a crescer ao mesmo tempo que ganha um conteúdo exclusivo e de qualidade em português.

Fala galera, tudo belezinha? Novamente pokemaobr aqui para falar com vocês sobre coisas de desenvolvimento. Dessa vez iremos falar um pouco sobre as etapas que você irá passar após conseguir o seu emprego como dev.
Realmente é uma parte muito complexa o início dos estudos em desenvolvimento, até a conquista do seu primeiro emprego. Porém, os esforços não acabam por aí. Existem algumas coisas a se fazer assim que entramos na empresa e algumas coisas que devemos saber antes de começar nossa caminhada dentro do desenvolvimento propriamente dito.
A primeira palavra que acho que devo dizer com um conselho para você que conseguiu um emprego é: CALMA. Nada do que você pensou vai ser imediato e é importante você ter essa idéia antes do seu primeiro dia.

Em geral você não vai ter acesso a nenhum código nos primeiros dias, vai passar alguma parte do seu dia em reuniões que talvez não façam muito sentido para você, irá tirar parte do tempo que você pensou que iria só estar codando para ler documentações, conhecerá por alto as áreas de atuação da empresa, conhecerá a equipe que trabalhará com você e provavelmente outras equipes que trabalharão indiretamente com você.
Caso você opte pelo regime de trabalho CLT (no Brasil), a primeira coisa a se fazer antes de começar o trabalho em si é assinar os contratos, a galera pega também a sua carteira de trabalho e te pedem para fazer o exame médico de admissão, nesse exame basicamente uma pessoa médica te perguntará algumas coisas acerca da sua saúde, te pesará e medirá sua altura, e observará você para entender se está com aptidão ao trabalho ao qual te designaram.
Já no regime PJ, você deverá abrir uma empresa e aguardar o período da abertura para poder emitir nota. (É interessante você contratar e conversar com uma pessoa contadora antes para entender o processo geral em que se encaixa a atividade de desenvolvimento de software no simples nacional). Eu particularmente não indico o regime PJ para quem está no primeiro emprego de desenvolvimento, mas, por exemplo, minha primeira experiência após sair da faculdade foi nesse regime, então é bem importante você ler sobre isso antes de entrar.
Após resolvidas essas burocracias, vamos ao que interessa. O que geralmente vai ocorrer com você quando iniciar o trabalho?
Suas Boas Vindas
Hoje em dia, até mesmo por influência do LinkedIn, muitas empresas oferecem o que chamamos de welcome kit (kit de boas vindas) para quem está entrando. Esse kit é meio que um modo de mostrar que a empresa se preocupa com você, é muito comum você receber quando entra em uma grande empresa, em uma startup “popzinha” ou agora no regime remoto.
Varia demais de empresa para empresa o que você receberá neste kit, em algumas até notebook e cadeira gamer você recebe, em outras alguns snacks, adesivos, camisetas e adivinhem??? cadernos rs.
Hoje em dia eu acho legal quando você recebe coisas massas no welcome kit, você já começa a sua jornada na empresa de um modo que te anima e em geral espera coisas boas nos dias que sucedem o começo. Porém, não ter welcome kit ou não ter algo que brilhe seus olhos, não faz da empresa um lugar ruim.
O onboarding
O processo de inicialização (primeiros dias da sua entrada em uma empresa) é chamado de onboarding. A ideia desse processo é que você se sinta parte dos processos na empresa, conheça um pouco da sua equipe e das equipes que você trabalhará diretamente, entenda o ciclo de desenvolvimento que será aplicado e, pouco a pouco, comece a receber suas demandas.

Aqui que muita gente acaba se desesperando quando começa um emprego dev. Na maioria das empresas, você vai demorar um tempo até mexer no código de verdade e a ansiedade da galera que está começando aflora demais nesse período.
É importante entender que grande parte das empresas trabalha com algum nível de criticidade em seu negócio e também com algum tipo de confidencialidade, e é importante você estar a par do que você vai poder ou não fazer. Além de entender o básico sobre como funciona o processo de desenvolvimento dentro da empresa em si.
Então, se você não tem muita experiência na tecnologia, nesse período sua equipe vai te convidar para estudar mais e se aprimorar. Além disso, você vai ter suporte da equipe para entender o processo de versionamento de código, entender superficialmente sobre a stack que é utilizada, entender o estilo de código que é desenvolvido, como é organizado o código, as principais regras de negócio que você vai ter que lidar e outras peculiaridades.
Outra coisa importante a se observar e que antes da gente entrar na área de desenvolvimento a gente acaba não entendendo, é que o onboarding sempre é algo demorado, independente do nível de senioridade. Ouso até ao falar que quanto mais sênior, mais demorado o onboarding.
Minha dica: perturbe realmente as pessoas que já estão lá a mais tempo! É importante no começo da sua carreira como dev (na verdade não só no começo), você absorver o máximo de conhecimento que puder, até para facilitar quando você começar a mexer nas coisas realmente.
O trabalho propriamente dito
Após apresentadas todas as premissas para você poder começar a trabalhar realmente, aí sim você vai colocar a mão na massa e começar a desenvolver as coisas. Cada empresa tem sua maneira de gerenciar as tarefas e o modo que vai ser entregue. Mas, um fluxo normal de trabalho que é bem aplicado hoje em dia é o SCRUM (um framework agile), ou algo parecido com isso.
O que quer dizer que geralmente a cada 2 semanas (depende da empresa/equipe), haverá uma reunião para definir as tarefas de cada pessoa e você terá um prazo estipulado entre essas 2 semanas para realizar o desenvolvimento delas. E haverão outras reuniões (geralmente uma reunião diária e outras complementares) para entender o andamento das tarefas e o que te impede de realizá-las caso tenha algum problema.
Nessa fase também, você irá realmente entender na prática como funciona o sistema de versionamento utilizado na empresa, os padrões de código e arquiteturas, os processos de deploy, entre outras fases do desenvolvimento.
Com o passar do tempo você vai pegar o jeito da empresa trabalhar e ficará bem mais fácil fazer realmente parte do todo.
Seu crescimento e de olho em novas oportunidades
É sempre importante você continuar atuante também fora da empresa para se manter em atualização: seja participando de comunidades de desenvolvimento, consumindo conteúdo de criadores, fazendo cursos, participando de eventos, alimentando seu github com projetos pessoais ou auxiliando em projetos open-source, etc.
Uma premissa que é bem verdadeira, ainda mais na área de desenvolvimento. As pessoas recrutadoras buscam muito mais pessoas que já estão empregadas que as pessoas que não estão. E, se atualizando constantemente, você será uma pessoa muito bem vista.
Descreva bem suas habilidades no LinkedIn, se possível tenha um site portfólio. Palestre, se divulgue, tenha um twitter ativo, dentre essas coisas que você lê, escuta e/ou assiste por aí.
A área de desenvolvimento está muito aquecida, mas, você não pode parar no tempo. Evolua sempre, se atualize sempre, estude sempre, e se mostre relevante. Quando você fizer isso, não precisará mais correr atrás de vagas. As vagas virão até você.
Desejo que tenha curtido o conteúdo e que ele te ajude a ter uma ideia de como será o seu início na área de desenvolvimento
Caso tenha alguma dúvida pode entrar em contato comigo no [email protected] ou na minha live: https://twitch.tv/pokemaobr ou no twitter: https://twitter.com/pokemaobr!
Obrigado de coração e até a próxima.
]]>
Quer aprender sobre Python, APIs, soft skills? Inscreva-se no Instruct The Women e junte-se a WoMakersCode!
São 60 vagas para mulheres cis ou trans, com ensino médio completo, maiores de 18 anos e com conhecimentos básicos de programação.
As selecionadas, ao final da capacitação, concorrerão também a uma vaga de trainee com registro CLT e tudo que é de direito!
As inscrições vão até o dia 10 de Julho de 2022. Então corre pra garantir a sua vaga!
Pré-requisitos
Pode se inscrever mulheres cis ou trans, com ensino médio completo, maiores de 18 anos e com os seguintes conhecimentos:
- Familiaridade com algum editor de código
- Git / GitHub
- Conhecimento básico em alguma linguagem de programação (variáveis, condicionais, laços de repetição e função)
- Banco de dados básico (criar uma base, tabela, chave primária e relacionamento entre tabelas)
Faça sua inscrição entre 1 e 10 de Julho, até 18hrs!
Segue o formulário de inscrição aqui: https://bit.ly/instruct-the-women.
]]>
A maior conferência brasileira de PHP organizada pelas comunidades nordestinas está de volta e vai acontecer entre os dias 7, 8 e 9 de Outubro de 2022!
TL;DR – PHPeste 2022 vai acontecer em Natal, RN nos dias 7, 8 e 9 de Outubro de 2022. Mais informações no site oficial. O evento também tem um código de conduta que precisa ser respeitado, leia mais aqui.
Para mais informações em tempo real, visite também o canal PHPeste no Telegram.
| Quando? | 7, 8 e 9 de Outubro de 2022 |
| Onde? | SEBRAE em Natal, Rio Grande do Norte, Brasil |
| Quanto? | Divulgação ao fim de Junho 2022 |
|---|---|
| Quem? | Comunidades PHP do Nordeste brasileiro: Alagoas, Bahia, Ceará, Maranhão, Paraíba, Pernambuco, Piauí, Rio Grande do Norte e Sergipe. |
O que é PHPeste?
PHPeste é uma conferência de PHP 100% organizada por comunidades do nordeste brasileiro e acontece desde 2015! É uma conferência itinerante e sem fins lucrativos, que a cada ano escolhe uma capital diferente.
As edições anteriores já visitaram João Pessoa (PB), Salvador (BA), Fortaleza (CE), São Luis (MA) e a última edição aconteceu em Recife (PE).
Agora, em 2022, o PHPeste vai acontecer em Natal, lá no Rio Grande do Norte. Serão 3 dias de evento com uma galera muito massa, PHP até abrir o bico e um ambiente simplesmente maravilhoso cerca de 15 minutos (de carro) distante da praia!
Call for papers: como palestrar no PHPeste

Até o dia 30 de Junho de 2022 a organização do PHPeste 2022 receberá propostas de quem quiser apresentar alguma palestra ou oficina no evento.
É importante ressaltar que o PHPeste possui seu próprio código de conduta. Eu vejo muita gente na comunidade resumir os códigos de conduta alheios com “não seja babaca”, mas isto não é suficiente! Vai lá de lá uma lida no código de conduta. É curto, rápido de ler e vai te ajudar a entender o que esperar deste evento.
Palestrantes do evento vão receber um auxílio da comunidade com estadia. E tradicionalmente a estadia com a galera do PHPeste é sempre muito massa!
Para submeter sua proposta de palestra ou workshop, envie suas informações neste formulário aqui até as 23:59 do dia 30 de Junho de 2022.
Quero patrocinar o evento!
Caso você ou sua empresa queiram patrocinar o evento, aqui vão algumas direções pra ti!
O PHPeste está recebendo o apoio do SEBRAE-RN e sebraelab, que vão oferecer o espaço e infraestrutura. E para fazer o evento acontecer, outros suportes também são necessários para oferecer brindes e camisetas, comes e bebes e suporte a quem vai se apresentar e por aí vai.
Patrocinar o evento, além de ajudar a comunidade, é uma ótima oportunidade de branding para a sua marca! Este ano o PHPeste preparou quatro modalidades de patrocínio: Bronze, Prata, Ouro e Diamante. Os benefícios de cada nível você confere na imagem a seguir:
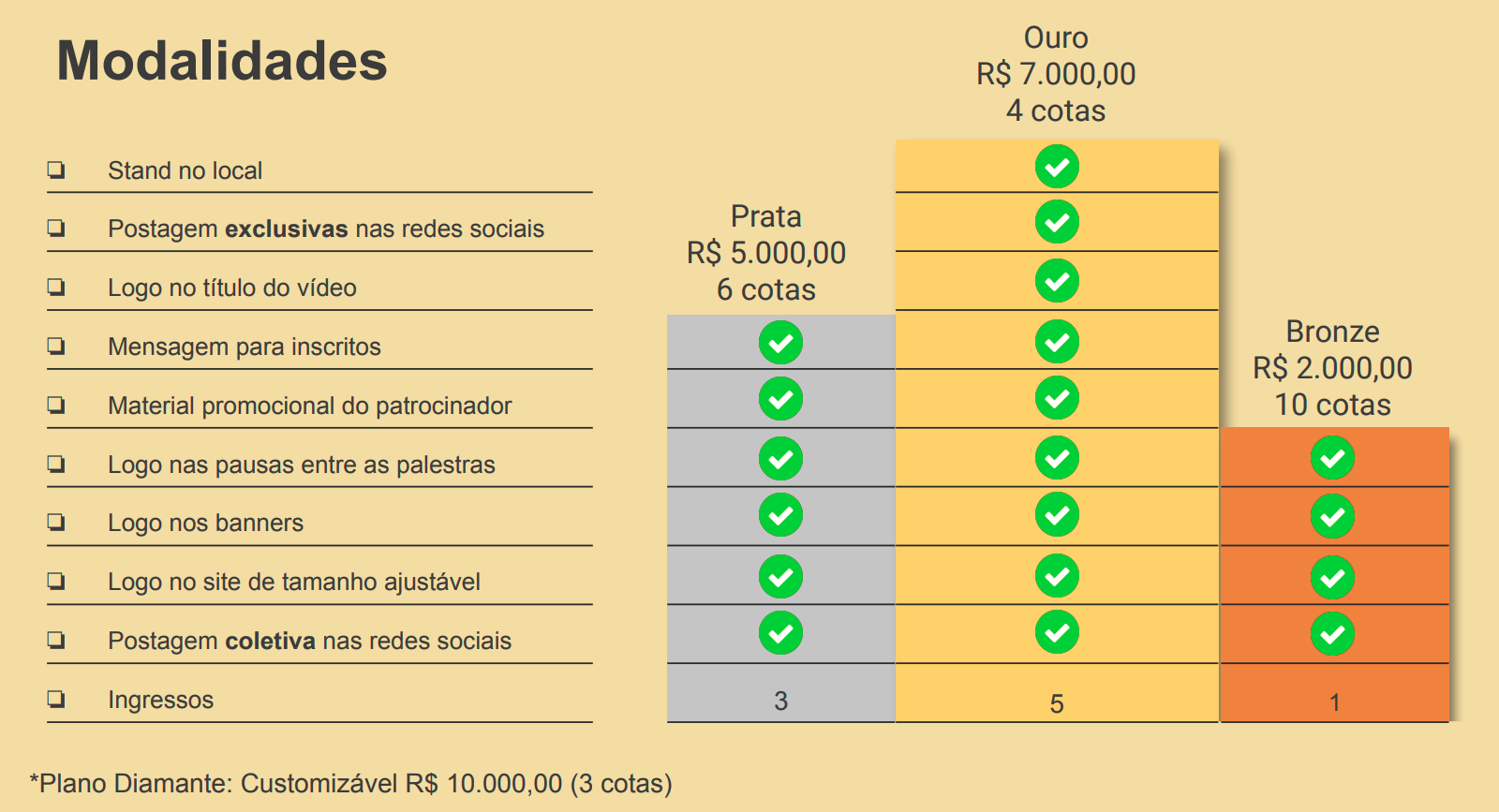
Para acessar o plano de patrocínio completo, dá uma olhada neste PDF aqui com todas as informações necessárias.
Para mais informações sobre como patrocinar o evento, entre em contato diretamente com a organização no email [email protected].
Linha do tempo
29 Maio 2022 Data da conferência divulgada: 7, 8 e 9 de Outubro de 2022 🥳
2 Junho 2022 Aberta a chamada para submissões de palestras e oficinas 🗣
16 Junho 2022 Prorrogada a chamada para submissões: serão aceitas até o dia 30/06/2022 🚨
30 Junho 2022 Primeiro lote de ingressos 🎫
11 Julho 2022 Divulgação da grade de palestrantes 📣
7 Outubro 2022 Muito PHP, cana, conhecimento e gente boa! 🐘
Compartilhe!
O evento é da comunidade para a comunidade e precisa da sua ajuda para acontecer. Mesmo que não apoie ao PHPeste financeiramente, o simples ato de compartilhar este artigo e dar visibilidade já é uma enorme ajuda!
Então não deixe de compartilhar em suas redes sociais que o maior evento cabra da peste de PHP está pra acontecer. Aqui vão alguns links para as redes sociais da organização:
- Site oficial: phpeste.org
- Facebook: fb.com/PeAgaPeste
- Instagram: @phpeste
- Twitter: @phpestene

Em programação é recorrente encontrar pessoas discutindo sobre qual a melhor forma de escrever esta ou aquela função, que tipo de código é mais elegante e etc.. Mas muitas dessas discussões são baseadas em opiniões e gostos pessoais, que usam argumentos circulares e travam o debate.
Por isso diferentes princípios de programação e de design foram estabelecidos, de forma a encurtar discussões sobre gostos e boas práticas. Dentre os princípios mais famosos estão o SOLID, DRY, KISS e YAGNI.
Já o princípio do Samurai não é tão conhecido, especialmente para quem se acostumou a programar em linguagens mais modernas. Mas é uma sabedoria anciã que vem lá da época do C, que eu acho que toda pessoa desenvolvedora deveria carregar consigo.
O que é o princípio do Samurai?
Nós, aqui do ocidente, gostamos de inventar misticismo sobre as coisas que não entendemos do oriente e, com certeza, o Samurai é uma delas. Mas em programação, o princípio do Samurai não tem nada a ver com o Bushidô!
O princípio do Samurai é um princípio de design de software que diz “retorne com sucesso, senão nem mesmo retorne”, baseado naquela mística da honra ilibada dos Samurais. Que é um jeito bonitinho de dizer que devemos manter um único tipo de retorno para nossas rotinas, funções e métodos.
Eu aprendi sobre este princípio lendo o livro Fluent C, que trás diversos padrões e boas práticas para programas escritos na linguagem C com exemplos. Eu definitivamente recomendo a leitura!
“Sempre retorne com sucesso, senão nem mesmo retorne” 🤺
Este princípio ressoa bastante com a ideia de early return, mas a principal diferença é que não queremos apenas retornar o quanto antes: queremos interromper a execução do programa caso algo esteja errado.
E apesar de ser muito útil em linguagens como C, este princípio se aplica e deveria estar fortemente presente em linguagens mais modernas como o PHP, Rust e Golang.
Mas como diachos a gente chegou num princípio desse e como se aplica a software? Vem comigo que eu tenho muita explicação e exemplo de código pra você!
Contexto e história: linguagem C
Na linguagem C é fundamental saber lidar com ponteiros e fazer alocações dinâmicas. Acontece que algumas operações com ponteiros e memória podem falhar por circunstâncias do sistema operacional: alocar memória para ler um arquivo pode causar um estouro de pilha, receber um dado por rede por falhar por perda de conexão e etc..
No caso de linguagens como C, estas situações podem criar o famoso NULL Pointer ou ponteiros nulos. Variáveis que deveriam possuir um conteúdo mas não possuem por algum motivo.
No exemplo a seguir, nós vamos extrair palavras-chave de um texto. Preste atenção no que fazemos com a variável handle que é um ponteiro que representa o arquivo de texto que estamos lendo.
A transcrição da imagem acima está aqui:
string_t *fetch_keywords(string_t filename)
{
FILE *handle;
string_t *keywords;
handle = fopen(filename, "r");
if (handle != NULL) {
keywords = _fetch_keywords_from_file(handle);
fclose(handle);
return keywords;
}
return NULL;
}
Você não precisa ser especialista em C pra entender o que tá acontecendo. Vem que eu te explico:
A função fetch_keywords() têm como retorno o tipo string_t*: o ponteiro para um vetor de strings. E recebe como parâmetro uma única string chamada filename, que indica qual arquivo deverá ser aberto para leitura.
Para abrir o arquivo nós usamos a função fopen() que retorna um ponteiro do tipo FILE*. Caso fopen() encontre e consiga abrir o arquivo para leitura, o ponteiro FILE *handle passa a ter um valor lá dentro. Senão, caso um erro tenha ocorrido ao abrir o arquivo, FILE *handle passa a ter o valor NULL.
É importante então sempre testar se os ponteiros de arquivo são nulos ou não, porque acessar um ponteiro nulo cria um erro fatal em sua aplicação. Aqui um exemplo de como acessar um ponteiro nulo pode causar um segmentation fault:
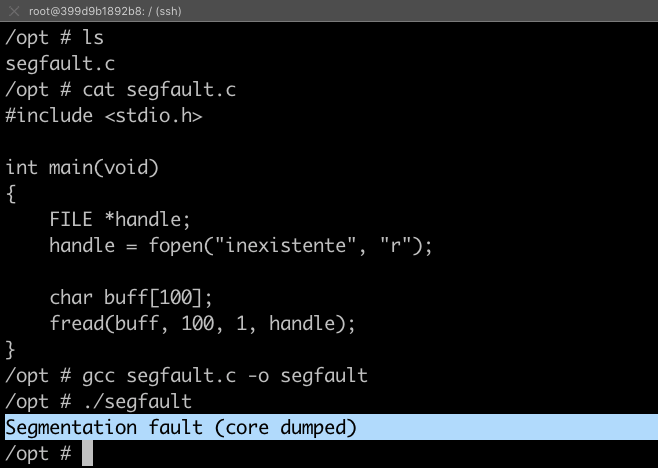
Agora, repare que o retorno da nossa função fetch_keywords() é um ponteiro para um vetor de strings (string_t *). Este ponteiro também pode ser NULL, para indicar que não encontramos nenhuma palavra-chave no arquivo.
O problema disso é que esta função obriga as funções que a chamam a também verificarem se o retorno é nulo ou não. Com isso, dois problemas aparecem:
-
A gente NUNCA consegue garantir que seus usuários estão utilizando seu código da forma esperada;
-
O montante de código duplicado é grande a deixa o código totalmente bagunçado.
Portanto o ideal, e o que o princípio do Samurai diz, é que você sempre deve retornar apenas em caso de sucesso. Caso não obtenha sucesso, você não pode sequer retornar. Você deve interromper a execução do programa imediatamente.
Assim:
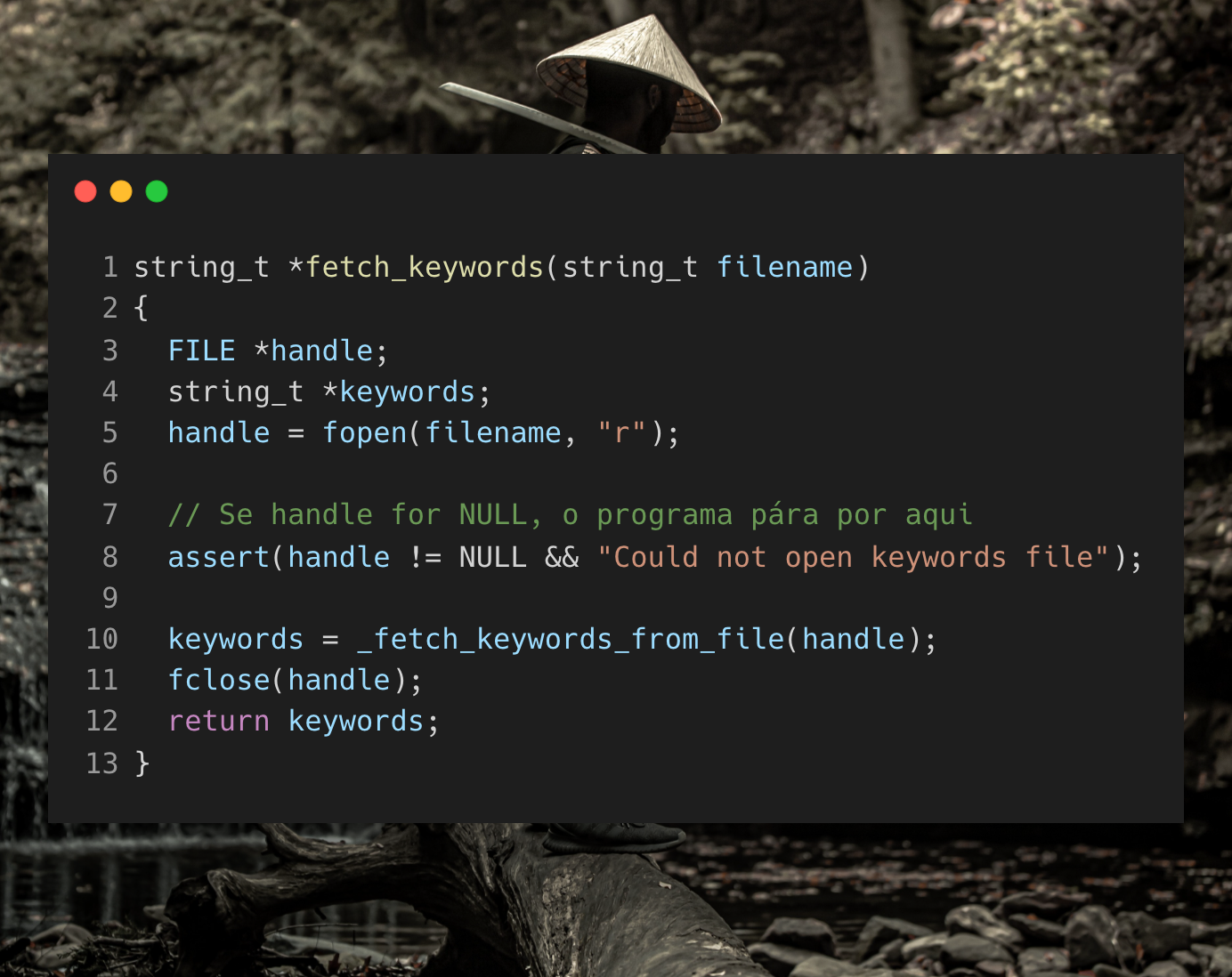
A transcrição do código na imagem acima é a seguinte:
string_t *fetch_keywords(string_t filename)
{
FILE *handle;
string_t *keywords;
handle = fopen(filename, "r");
// Se handle for NULL, o programa pára por aqui
assert(handle != NULL && "Could not open keywords file");
keywords = _fetch_keywords_from_file(handle);
fclose(handle);
return keywords;
}
Aquele assert() no meio da função vai interromper o programa completamente caso a expressão ali não retorne TRUE. Desta forma você diminui o número de IFs aqui e em todos lugares que chamam esta função.
Como aplicar o princípio do Samurai em linguagens modernas?
Linguagens mais modernas do que o C como o C++, Java e PHP possuem um mecanismo de gerenciamento e propagação de erros chamado Exceções ou Exceptions.
A ideia é que um pedaço de código pode lançar uma exceção utilizando a palavra-chave throw e a execução do stack frame atual é interrompida imediatamente, retornando o stack frame superior. E caso não exista nenhum mecanismo para tratar a exceção, ela continua se propagando até encontrar algum stack frame que a capture ou até a aplicação ser interrompida.
Aqui um exemplo de exceção utilizando PHP:

Em PHP podemos lançar e capturar exceções específicas, para controlar o fluxo do programa.
A transcrição do código da imagem acima é a seguinte:
function a(bool $x): void
{
try {
b($x);
} catch (EntityNotFoundException $e) {
echo $e->getMessage();
}
}
function b(bool $x): void
{
if ($x === true) {
throw new InvalidArgumentException("Outro tipo de exceção");
}
throw new EntityNotFoundException("Mensagem da minha exception");
}
a(false);
a(true);
echo 'Nunca alcancaremos esta linha!';
No exemplo acima, a chamada a(false) causa a função b() lançar uma exceção do tipo EntityNotFoundException, que é explicitamente capturada no escopo da função a(). Portanto toda vez que uma exceção deste tipo é lançada, a() apenas faz um echo para jogar a mensagem da exceção na tela e seguir seu rumo normalmente.
Quando chamamos a(true) nós forçamos que b() lance uma exceção de outro tipo, que não é capturada no stack frame da função a(). De fato, ninguém na aplicação tenta capturar aquela exceção, que acaba por interromper o código completamente.
🏮 Em linguagens modernas, a forma mais fácil de adotar o princípio do Samurai é lançando exceções👌
Algumas linguagens modernas não possuem exceções, como é o caso do Rust e Golang. Apesar de o próprio ecossistema da linguagem te forçar a lidar com casos de erro, a saída para quando não se consegue lidar com determinado fluxo de exceção é interromper a execução do programa.
Portanto caso a sua linguagem não possua o mecanismo de exceção (exceptions) você pode sempre aplicar o drástico exit em sua aplicação, que força o interrompimento do programa como um todo.
No caso do Golang você pode utilizar o os.Exit, enquanto o Rust possui vários mecanismos diferentes: o std::process::exit que faz a mesma coisa que o Golang faz, mas também possui diferentes macros e métodos que podem encerrar a execução do programa completamente como é o caso das macros assert e panic.

A transcrição do programa acima é a seguinte:
fn main() {
panic!("Oh noez!");
}
Até a próxima
Espero que este pequeno artigo-resposta tenha sido útil pra ti e, no mínimo, aguçado sua curiosidade sobre o tema. Todos os princípios de software têm um motivo para existir e, mais importante do que entender o princípio em si, é entender como se aplica e em quais contextos.
Não se esqueça de compartilhar este artigo em suas redes sociais e com seus colegas de trabalho. E também pega pra ouvir Samurai do Djavan, que esta musica e artigo vão ficar na sua cabeça pelo menos por 2 dias 🤣
]]>

Recentemente o Codamos recebeu um artigo do Rouan Wilsenach sobre o conceito de Ship / Show / Ask, que basicamente diz que não faz muito sentido esperar seu time aprovar um Pull Request pra integrar o seu código na maior parte das vezes.
A intenção é boa, mas muitas de nós ainda fica com um pé atrás: como garantir a qualidade do software se o Code Review acontece depois de lançar pra produção?
Neste artigo eu vou te apresentar uma técnica mágica que vai mudar para sempre a forma como você lida com código nas suas empresas: as feature flags!
Conteúdos do post
O que é feature flag ou feature toggle?
Feature flag, também conhecida por feature toggle, é uma técnica que lhe permite proteger parte do seu código de forma dinâmica. É como se você pudesse colocar um interruptor no seu código, e só quando você virar a chave o novo código passa a valer.
Na prática a feature flag te permite adicionar alguns IFs no seu código, que vão executar uma ou outra lógica dependendo do estado desta feature flag. Dá uma olhada no exemplo abaixo 👇!
Exemplo de código
Digamos que o método Users.list() atualmente chama uma API rest no endpoint /v1/users e o mantenedor desta API disse que a versão 2 está disponível através do endpoint /v2/users e precisa ser adotada, ao final do mês a versão 1 será descontinuada.
A migração parece bem simples e direta. Mas é sempre bom manter-se longe de problemas. Uma forma simples e livre de muitas preocupações para implementar esta mudança é através de uma feature flag. Olha o exemplo abaixo:

class Users:
def list(self):
if (isFeatureActive('enableUserListV2API'):
return self.listV2()
else:
return self.listV1()
def listV1():
"""
Call /v1/users
"""
def listV2():
"""
Call /v2/users
"""
A função isFeatureActive() retorna TRUE or FALSE, e o ideal é que possamos configurar o retorno desta função. Talvez escrevendo num banco de dados, talvez escrevendo num arquivo...
Acho que deu pra entender bem a ideia de feature flag já. Vou deixar um vídeo (em inglês) abaixo que explica com palavras e imagens como feature flags funcionam caso esteja interessade em se aprofundar no assunto.
O interessante sobre este vídeo é exatamente a ideia de fazer deploy de forma intencional. A filosofia por trás disso é basicamente a mesma que eu mostrei no meu artigo sobre programação por coincidência X por intenção.
Que problemas feature flags resolvem?
De acordo com Pete Hodgson, num artigo que publicou no blog do Martin Fowler, as feature flags resolvem diferentes categorias de problemas:
Proteger lançamentos de produtos
As vezes a pessoa que faz a gerência de produto gostaria de testar o produto em produção algumas semanas ou dias antes de realizar o lançamento oficial. E o ideal seria poder lançar o produto sem que uma pessoa desenvolvedora esteja envolvida.
De forma que uma feature flag é a opção perfeita para resolver o caso acima. A pessoa desenvolvedora pode criar uma flag chamada habilitarNovoCheckout, por exemplo, e utilizá-la em todo o código novo. A pessoa que gerencia o produto pode a qualquer momento ativar ou desativar o novo checkout apenas apertando um botão liga/desliga numa interface.
Algo assim:

<CheckoutFlow>
{
isFeatureActive('habilitarNovoCheckout') ? (
<NovoCheckoutFlow {...props} />
) : (
<AntigoCheckoutFlow {...props} />
)
}
</CheckoutFlow>
Realizar experimentos e testes
O bacana de feature flags é que elas não precisam levar em consideração apenas o estado ligado/desligado. A decisão sobre uma feature flag estar ativa ou não pode ser bem mais complexa e levar em consideração elementos como:
- Distribuição de tráfego
- ID / Sessão do usuário
- Localidade do usuário
- Data / Horário
- etc..
De forma que você pode configurar uma flag para estar ativa somente para usuários da cidade de São Paulo acessando o site aos finais de semana entre 10am e 3pm. Tudo depende da ferramenta que você utilizar para feature flags, mas acho que dá pra entender o potencial.
Proteger-se de catástrofes
Por mais que nós escrevamos código utilizando TDD, que façamos revisão de código com nossos pares, e adotemos um processo rígido de qualidade de software, nada garante que o nosso código não vá causar algum tipo de anomalia.
Uma funcionalidade talvez acabe sendo tão popular que muito mais pessoas do que o esperado a querem utilizar, aumento a carga no servidor. Ou talvez você tenha reparado que um algoritmo não está fazendo exatamente o que deveria.
Ao notar um problema desta dimensão, você pode facilmente desligar uma feature flag e investigar a solução de forma controlada. Sem precisar reverter algum deployment ou, pior ainda, um commit.
Gerenciamento de permissões
Algumas funcionalidades precisam ficar protegidas. E os sistemas de ACL nem sempre são suficientes.
Por exemplo, digamos que a área de gerenciamento da sua plataforma precise ser acessada somente por computadores dentro da VPN da empresa. Uma feature flag que verifica a origem do IP pode facilmente resolver esta verificação sem nenhuma adição ao seu framework de ACL.
Que problemas feature flags criam?
Como você já deve ter imaginado, feature flags adicionam complexidade ao seu código. Ainda mais considerando que você pretende testar seus códigos, certo?
A complexidade dos testes é maior
Vejamos o snippet abaixo:
function sumPositive(int|float a, int|float b): int|float
{
if (typeof(a) !== typeof(b):
raise "Cannot add an integer to a float"
return a + b
}
Eu esperaria ver ao menos três testes para esta função, de forma a cobrir os seguintes casos:
- Soma de dois inteiros
- Soma de dois floats
- Lançamento de exceção
Se nós adicionar uma feature flag que nos impede de somar números negativos, o código rapidamente se transformaria em algo assim:
function sumPositive(int|float a, int|float b): int|float
{
if (typeof(a) !== typeof(b):
raise "Cannot add an integer to a float"
# New code
if (isFeatureActive('disableNegativesSum') && (a < 0 || b < 0)):
raise "Summing negative numbers is not allowed"
return a + b
}
Ao adicionar uma feature flag nós precisamos agora adicionar dois outros testes:
- O comportamento quando a feature flag está inativa
- O comportamento quando a feature flag está ativa
Depurar e reproduzir situações descritas em logs
A complexidade se reflete não somente nos testes, mas também ao depurar uma determinada chamada de método ou página.
Além disso, olhando apenas para os logs de acesso não é tão simples identificar se uma determinada flag estava ativa no momento ou não.
Com o tempo, é ideal remover as feature flags que já não têm mais nenhuma utilidade. A cada vez que você cria uma feature flag nova, você está também criando um novo caminho em seu software que precisará ser limpo depois.
Gerenciamento e governança de software
O mau gerenciamento de feature flags pode explodir seu software em complexidade e dificultar a manutenção deste ao longo do tempo se a sua equipe não limpar estas flags frequentemente.
Portanto ao criar uma feature flag nova é ideal sempre ter em mente quando e como você pretende se livrar desta flag.
Aqui onde eu trabalho, uma das técnicas que a gente adota pra limpar feature flags é gerar um dashboard que mostra todas as flags ativas por data e com a possibilidade de marcar cada flag como "pronta para ser removida". Com base neste dashboard a gente consegue escrever tarefas para fazer esta limpeza.
Como eu integro feature flags no meu software?
Algumas empresas – onde eu trabalho, por exemplo – preferem criar o próprio software de gerenciamento de feature flags. Outras adotam soluções de mercado já prontas, e outras ainda preferem utilizar plataformas de código aberto.
As três formas de implementação são validas e você precisa entender bem qual o caso de uso que você precisa cobrir.
Migrar de uma solução para outra é relativamente simples, dado que o código normalmente vai chamar uma função ou método chamado isFeatureActive() ou alguma coisa assim.
O único desafio numa migração é justamente mover os dados de uma solução para outra e manter os SDKs compatíveis.
Pacotes pagos
O bacana de usar uma solução paga é que normalmente tudo já funciona sem precisar configurar muita coisa, e normalmente as empresas oferecem suporte.
O que eu acho particularmente zoado é que no evento de um ataque à plataforma paga, o seu software pode ficar parcialmente disponível ou, pior ainda, ter o comportamento aleatoriamente bagunçado.
Plataformas conhecidas de gerenciamento de feature flags incluem LaunchDarkly™ e Optimizely.
Pacotes open source
Pacotes de código aberto são uma ótima opção porque normalmente exigem pouca configuração/preparo. Mas adiciona complexidade à sua infraestrutura que precisa de constante manutenção.
Dentre os pacotes mais conhecidos estão o Unleash e Flipper.
Implementação própria
A implementação própria normalmente parece a melhor opção durante os primeiros meses/anos. O motivo é que no começo você provavelmente vai identificar vários casos de uso complexos que são muito específicos do domínio da aplicação.
Com o tempo, o número de alterações no software de gerenciamento de flags vai diminuir até o ponto em que este pedaço de software entra em modo de manutenção.
Neste momento eu acho que faz muito mais sentido procurar uma solução paga ou de código aberto, para substituir a implementação própria.
O problema de uma implementação própria é que a partir do momento que ela não dá mais problemas, dificilmente a empresa irá revisitar a implementação, corrigir bugs ou identificar problemas de segurança.
Um serviço pago ou de código aberto te fornece atualizações constantes e melhorias no software.
Conclusão
Feature flag é uma técnica incrível para proteger seu código de diferentes formas: lançamento de produtos independente do envolvimento de pessoas desenvolvedoras, proteger e recuperar de catástrofes e remover completamente a necessidade de Pull Requests antes de lançar o código para produção usando o processo Ship / Show / Ask.
Utilizar feature flags aumenta a sua flexibilidade, mas vem com um custo alto de manutenção.
Por fim, este é um dos passos essenciais para a tão sonhada Integração e Entrega Contínua (CI/CD). Sem um bom monitoramento e ferramentas para forçar curto-circuitos (como feature flags lhe permitem), CI/CD pode ser extremamente perigoso.
]]>
E ai, tudo beleza contigo? Pokemaobr aqui novamente com mais um tópico para você que está em busca do seu primeiro emprego como dev, ou até mesmo para você que quer novidades e mudar de ares na sua carreira.
No início da carreira é normal a pessoa desenvolvedora ir atrás das vagas, entrar em processos seletivos demorados, com muitas etapas e no desespero de realmente conseguir a bendita vaga e poder iniciar sua trajetória como dev.
Mas, caso você analise algumas pessoas devs, principalmente do twitter do linkedIn, encontra muita gente reclamando, inclusive, da quantidade de recrutadores que entram em contato (muitos deles com vagas que não fazem nenhum sentido para com stack de desenvolvimento para quem oferecem).
No artigo de hoje irei falar um pouco sobre o que você pode fazer para estar mais próximo desses recrutadores e consequentemente conseguir vagas sem precisar tanto correr atrás.
Participe de uma comunidade de desenvolvimento
A primeira coisa que indico para pessoas que querem entrar e/ou migrar para a área de desenvolvimento é que participem de uma comunidade. No Brasil em geral, cada estado possui uma comunidade local das linguagens mais utilizadas.
Caso você use PHP, temos: PHPSP, ou PHPRio, ou PHP com rapadura, PHPWomen, etc. Se você é de python temos os Grupys, o pyladies. Se você é de Ruby os Gurus, RailsGirls, etc. Então, indico e muito você procurar essas comunidades para entender como funciona o ecossistema das linguagens que você quer começar desenvolver.
O Nawarian recentemente escreveu um artigo que lista comunidades de desenvolvimento brasileiras, presenciais e online.
Esse tipo de networking é muito legal quando está se conhecendo o ambiente que permeia. As pessoas que participam em geral tem uma experiência legal e podem te adiantar algumas características que você vai perceber um pouco mais para a frente sobre como funciona até mesmo a parte de contratação para a stack daquela linguagem, bem como as ferramentas mais utilizadas, frameworks, etc.
Com a pandemia muitos dos encontros passaram a ser online, o que facilita você participar de algum desses grupos mesmo não estando no mesmo estado ou cidade do grupo. Sempre que há encontros existem pessoas que vão para tentar recrutar ou oferecer vagas nas empresas que trabalham.
Apareça nas redes sociais
Um passo importante para que recrutadores encontrem você, é exatamente poderem te encontrar. E para isso, você deve ser uma pessoa fácil de encontrar. Estar nas redes sociais, faz com que você esteja em uma posição mais acessível e com isso, facilita a comunicação e diminui a distância de uma possível vaga, ou até mesmo de algum contato para um desenvolvimento pontual.
Para devs, eu indico muito o twitter como uma das principais redes sociais. Engajar bons conteúdos lá fazem com que você possa atingir um número interessante de pessoas e que você possa até mesmo ser relevante na #bolhadev (o modo que chamamos um grupo aleatório de desenvolvedores que criam conteúdo e/ou interagem com outras pessoas devs no twitter).
Para o twitter em específico, eu indico que você não consuma todo tipo de conteúdo de lá. Existe o que chamamos de tretas dev, que são literalmente cagações de regra (alguém que puxa um tema polêmico afirmando alguma coisa que muitas das vezes não faz o menor sentido) que só servem para criar um ambiente tóxico e unir pessoas tóxicas em torno de temas que se repetem de tempos em tempos.
Porém, você pode silenciar ou bloquear as pessoas que incitam esse tipo de conteúdo e utilizar a rede social de uma maneira fluida. Eu por exemplo tenho mais de 9000 seguidores e consigo muitas coisas legais usando o twitter. Inclusive fiz um vídeo para ajudar as pessoas a crescerem utilizando essa rede social. Também desenvolvi uma estratégia para você conseguir o seu primeiro emprego dev utilizando a força da #bolhadev.
Outra rede social que eu indico para fins profissionais é o linkedIn. Embora particularmente não tenho dado tanta atenção para essa rede (devido a quantidade infinita de posts caça interação e a incrível corja de pseudo coaches que fazem qualquer ação cotidiana virar um post de auto-ajuda).
Mesmo assim, uma grande quantidade de recrutadores utilizam essa rede social. Então, ter uma conta lá com a descrição de seus últimos trabalhos, estudos e coisas do tipo é interessante para você receber contato dessas pessoas.
Para ajudar a você a melhorar a qualidade do seu linkedIn, o Nawarian escreveu esse artigo aqui, onde em 12 passos você pode melhorar o seu perfil.
Outra coisa que sempre falo para a galera dev verificar é o que aparece quando você pesquisa o seu nome ou nick no Google, dependendo do que tiver como resultado, isso pode ajudar a entender como as pessoas recrutadoras podem encontrar você.
Sobre instagram, sinceramente… deixa pra lá…
Tenha projetos no seu github
Uma maneira das pessoas devs mostrarem um pouco do que são capazes de fazer para o mundo é através de projetos de código e, uma ferramenta muito importante para o compartilhamento de código entre devs é o github.
Aí você me pergunta… Pokemãooo, mas é obrigatório toda pessoa dev ter um github e projetos relevantes lá? NÃO. Porém, ter códigos lá facilita e muito para pessoas recrutadoras entenderem com que tipo de stack você desenvolve, o que você compartilha de código com as pessoas e até mesmo ter uma ideia do seu nível de desenvolvimento.
No meu github coloco projetos que desenvolvo nas lives, tenho fork de projetos open-source que utilizo, ajudo em repositórios de conteúdo, entre outras coisas. Caso você não saiba que tipo de projetos desenvolver para deixar no seu github, escrevi esse artigo aqui.
Já conheci pessoas que conseguiram empregos em projetos open-source simplesmente porque eram as pessoas que mais contribuíam naqueles projetos sem receber.
Faça um site pessoal e/ou mantenha um blog ou produza algo em algum site de conteúdo
Outra coisa que pode te ajudar e muito para recrutadores te encontrarem é a produção de conteúdo. Algumas vezes já fui contactado por pessoas que precisavam de alguma skill específica em uma biblioteca, por exemplo, simplesmente por ter feito um artigo sobre aquele tema.
Um site pessoal, por exemplo, pode ter o compilado de todos os links que remetem a seus perfis, o que facilita a comunicação de recrutadores para você. Além de você poder usá-lo como portfólio.
Blogs pessoais fazem com que você aprenda mais e tenha um repositório de fácil acesso sobre o conteúdo que você produz. Além de poder ter algum controle sobre as pessoas que consomem o mesmo.
Caso você tenha interesse, convido você que está lendo esse artigo à escrever e publicar aqui no Codamos também. É legal você ganhar uma visibilidade com seus artigos dentro da comunidade brasileira, além de receber suporte na revisão de textos, temas e etc. Se quiser saber como publicar: https://github.com/codamos-com-br/.
De qualquer jeito, produzir conteúdo faz com que mais pessoas saibam da sua existência e tenham alguma idéia sobre sua experiência com desenvolvimento, o que facilita em caso de procurarem pessoas com as suas skills.
Participe de eventos
Para finalizar, só tenho que falar para você participar de eventos. Organizo eventos de TI desde 2012 e a cada ano que passa mais empresas querem patrocinar os eventos apenas para atingir um número maior de devs e oferecer vagas de emprego.
Esteja lá, seja palestrando e compartilhando conhecimento, ou consumindo conteúdo e visitando os stands das empresas que patrocinam. Quem sabe você não sai do próximo evento já com um emprego?
Desejo que tenha curtido esse artigo. Caso tenha alguma dúvida pode entrar em contato comigo no [email protected] ou na minha live: https://twitch.tv/pokemaobr ou no twitter: https://twitter.com/pokemaobr ! Deixa aqui o seu comentário sobre o que foi escrito. Obrigado de coração e até a próxima.
]]>
Eu recentemente perguntei nas minhas redes quais as comunidades de desenvolvimento de software brasileiras que a galera conhece e participa.
Galeru, quais comunidades de desenvolvimento vocês conhecem e/ou participam? Marca aqui plz? É pro meu TCC 👀
— Níckolas Da Silva (nawarian) (@nawarian) March 30, 2022
Eu começo: @phpsp <3
cc/ @sseraphini
Esta lista aqui é um compilado das comunidades que foram listadas naquele tweet. Caso a sua comunidade não esteja representada neste artigo, vai lá e comenta no tweet que eu atualizo esta página 😉.
O que é uma comunidade desenvolvimento de software?
No Brasil, comunidades têm um significado muito especial. São grupos de pessoas que se ajudam, se encontram, se envolvem e em que todo mundo cresce!
Eu digo que no Brasil isso tem um significado muito especial porque em outros países é comum que comunidades de desenvolvimento sejam apenas grupos pra falar do mesmo tópico e talvez fazer algum networking.
Já em comunidades brasileiras eu noto muito a criação de grupos de apoio, iniciativas inclusivas, mentoria, troca de experiência, mutirões e etc.. Comunidades brasileiras, na minha opinião, são mais... comunitárias.
Como uma comunidade de desenvolvimento de software pode te ajudar?
Profissionais de software de todos os níveis têm muito a ganhar ao participar de comunidades: iniciantes ganham exposição a ideias e discussões de alto nível, enquanto pessoas mais experientes trocam entre si e ganham experiência como mentoras.
Além disso, participar de comunidades te permite expandir a sua rede de contatos, ganhar notoriedade e contratar ou ser contratada.
Ao frequentar espaços de comunidade, a pessoa desenvolvedora ganha experiência, sabedoria, descobre tecnologias novas, resolve problemas, faz boas amizades e expande sua rede de contatos e oportunidades.
As comunidades de programação do Brasil
Como eu mencionei acima, aqui eu vou deixar uma lista das comunidades brasileiras que foram citadas no Tweet.
Caso queira adicionar alguma comunidade a esta lista, responda este tweet com o link para o site e eu vou adicionar aqui assim que possível 📝
Feministech - representatividade em tech
A comunidade Feministech foi criada em 2020 e é um grupo de pessoas que se identificam no feminino e não-bináries e que produzem, consomem e compartilham conteúdo sobre tech num ambiente diverso e inclusivo.
O maior objetivo desta comunidade é aumentar a representatividade de pessoas femininas e não-binárias, oferecendo auxílio, incentivo e espaço para live codings, vídeos, artigos, palestras, podcasts e eventos de tecnologia. Os principais links para se envolver com esta comunidade você encontra na tabela abaixo.
| Comunidade | Feministech |
| Local | Online |
| Foco | Diversidade, inclusão e representatividade em tech |
| Código de conduta | Link para o COC |
| Site oficial | feministech.github.io |
| Blog | dev.to/feministech |
| Github | @feministech |
| Twitch | team/livecodergirls |
| Podcast | @feministech |
| Redes | Twitter: @feminis_tech LinkedIn: company/feministech/ |
PHPSP - Grupo de usuários PHP do Estado de São Paulo
A comunidade PHPSP existe desde 2009 e é um dos grupos de usuários da linguagem PHP mais expressivos no Brasil.
A comunidade nasceu na capital sampa e se espalha por todo o estado de São Paulo.
Esta comunidade oferece alguns canais online para discussão e organiza eventos. Desde que a pandemia começou os eventos passaram a ser online, mas o PHPSP já organizou diversos eventos e conferências presenciais.
O principal evento do PHPSP, chamado PHPSP + Pub, ocorre toda segunda quinta-feira do mês com a intenção de unir pessoas desenvolvedoras de software numa roda de conversa descontraída com comes e bebes, e muita piada nerd.
| Comunidade | PHPSP |
| Local | São Paulo, SP e online |
| Foco | Linguagem PHP, networking |
| Código de conduta | Link para o COC |
| Site oficial | phpsp.org.br |
| Canal do Slack | Link para o convite |
| Canal no Telegram | @phpsp |
| Github | @phpsp |
| Youtube | @PHPSP |
| Meetup | @php-sp |
| Redes | Twitter: @phpsp LinkedIn: company/phpsp |
PerifaCode - a comunidade de programação da periferia
O perifaCode é uma comunidade voltada para criar uma rede de apoio a pessoas que moram nas periferias, favelas e guetos do Brasil inteiro.
A missão dessa comunidade é inserir pessoas de origem periférica na área de tecnologia.
| Comunidade | perifaCode |
| Local | Online |
| Foco | Desenvolvimento de software, apoio às pessoas periféricas do Brasil |
| Manifesto | Link para o manifesto |
| Código de conduta | Link para o COC |
| Site oficial | perifacode.com |
| Servidor Discord | Link para o convite |
| Github | @perifacode |
| Redes | Twitter: @perifacode Instagram: @perifacode |
PHP Rio - Grupo de usuários PHP do Estado do Rio de Janeiro
O PHP Rio existe desde 2016 e foca em todo o estado do Rio de Janeiro.
A comunidade PHP Rio tem presença nas redes sociais, eventos da comunidade brasileira de PHP e oferece meetups mensais com cerveja, tecnologia e gente massa!
| Comunidade | PHP Rio |
| Local | Rio de Janeiro, RJ |
| Foco | Linguagem PHP, networking |
| Código de conduta | Link para o código de conduta |
| Site oficial | php.rio |
| Canal no Telegram | @phprio |
| Github | @PHPRio |
| Meetup | @PHP-Rio |
| Redes | Twitter: @phprio LinkedIn: link para o grupo |
He4rt developers
A comunidade procura oferecer apoio, inclusão e evolução de quem participa de forma colaborativa.
A comunidade se concentra num servidor do Discord e marca presença em diversas redes sociais.
| Comunidade | He4rt devs |
| Local | Online |
| Foco | Desenvolvimento de software |
| Site oficial | heartdevs.com |
| Servidor Discord | Link para o convite |
| Github | @he4rt |
| Redes | Twitter: @He4rtDevs Instagram: @heartdevs |
BeeStrong Code 💛
A comunidade BeeStrong Code nasceu organicamente em 2022, como um passo natural para suportar uma grande quantidade de profissionais mulheres e não bináries concentradas em grupos de whatsapp.
O objetivo da comunidade BeeStrong é oferecer uma rede de apoio para mulheres e pessoas sem gênero que trabalham ou queiram trabalhar com tecnologia, considerando todas as suas necessidades.
Hoje a comunidade conta com mais de 600 pessoas num servidor de Discord, e já está planejando os primeiros minicursos sobre LinkedIn, Github e Currículo.
| Comunidade | BeeStrong Code 💛 |
| Local | Online |
| Foco | Rede de apoio para mulheres e pessoas sem gênero |
| Site oficial | Linktree |
| Github | @BeeStrong-code |
| Servidor Discord | Link para o convite |
| Redes | Twitter: @BeeStrongcode Instagram: @beestrongcode LinkedIn: company/beestrongcode |
TOTVs Developers
A comunidade TOTVS Developers foca em disseminar conhecimento e boas práticas em programação.
Eles apoiam outras comunidades disponibilizando local para eventos, comida, brindes, auxílio na curadoria de eventos presenciais e ferramentas para execução de eventos online.
TOTVS Developers também realiza meetups em São Paulo. Abaixo a tabela com detalhes para se envolver com a comunidade.
| Comunidade | Totvs developers |
| Local | São Paulo, SP |
| Foco | Disseminar conhecimento e boas práticas em programação |
| Site oficial | developers.totvs.com |
| Github | @totvs |
| Canal no Slack | Link para o convite |
| YouTube | @totvsdevelopers |
| Meetup | @totvsdevelopers |
| Redes | Twitter: @TOTVSDevelopers |
Faltou alguma comunidade aqui?
Eu tenho certeza de que esta lista não é extensiva e se você acha que eu deixei de falar sobre alguma comunidade brasileira de desenvolvimento e deveria adicionar neste artigo, tem um jeito de tu me falar.
Responde este tweet aqui com o arroba da comunidade, ou o site pra eu dar uma olhada e eu vou adicionar neste artigo aqui.
Até a próxima! 👋
]]>
Fala galera, tudo bom? Pokemaobr aqui e vamos falar hoje sobre uma tema que eu particularmente acho muito importante você tentar entender antes de sair mandando currículo para alguns lugares por aí. As "benditas" vagas arrombadas.
Acho que todo mundo já passou por um momento de ler a descrição de uma ou mais vagas e não entender nada do que está acontecendo ali, muitos requisitos, 10 linguagens, 20 frameworks, 10 anos de experiência em um framework que só tem 3 anos e, entre outras coisas totalmente sem sentido. Embora às vezes fique na cara que a vaga em questão se trata de algo que devemos evitar, outras muitas, poderíamos ter evitado de se aplicar e perdido nosso tempo à toa.
Muito se fala sobre o excesso de demanda para devs, e isso se mostra real com a quantidade de vagas abertas. Porém, quantas dessas vagas realmente fazem sentido para você que busca uma boa alocação no mercado de trabalho de TI? Vamos pontuar algumas características que fazem uma vaga ser arrombada ou não.
Excesso de tecnologias como requisitos técnicos
Esse é o primeiro ponto para você descartar completamente a aplicação em uma vaga. Vagas com tecnologias obsoletas, ou que não se conversam entre si. Mistura de 3 frameworks front-end com, 5 linguagens back-end e ferramentas devops numa vaga de nível júnior.
Uma característica desse tipo de vaga é as linguagens citadas nem conversarem entre si. Onde por exemplo para uma vaga para web exigem C, JavaScript, Delphi.
Geralmente quando você verificar que uma vaga tem esse tanto de requisitos técnicos, provavelmente foi escrita pelo pessoal do RH e em geral alguma parte da entrevista vai ser com esse pessoal. Então, é bom evitar esse tipo de vaga para não se arrepender depois.

Excesso de requisitos para vaga de nível junior
Numa vaga dev de nível junior é esperado poucos requisitos técnicos. Geralmente uma ou duas linguagens, alguns conceitos básicos, talvez um framework. Existem vagas pra júnior que exigem 4 anos de experiência, outras pedem muitas linguagens, ou muitos frameworks. Esse tipo de vaga não é boa e geralmente você não vai atuar como junior e sim como pleno e receber como junior.
Uma boa vaga para junior vai focar um pouco mais nos requisitos não-técnicos (softskills) e abraçará a pessoa para que ela possa aprender mais dentro da empresa. Então não exigirá requisitos técnicos avançados.
Devs junior estão começando a desenvolver, então não deveria ser cobrado coisas que a princípio dependem da regra de negócio da empresa, como: propor melhorias e evoluir coisas. Estão em tempo de aprender então o ideal.


Testes não condizentes
É normal algumas empresas cobrarem das pessoas que aplicam um teste básico para "medir" a qualidade técnica da pessoa. Porém, em alguns casos esses testes fogem um pouco do padrão e exigem que a pessoa basicamente desenvolva uma funcionalidade que é parte de um produto. O que exige muito tempo de esforço e às vezes acaba sendo um trabalho de graça que você faz para essas empresas.
Tudo bem ter alguns testes como a resolução de algum exercício de lógica, ou algumas perguntas sobre as tecnologias que são necessárias para os requisitos da vaga, ou até o consumo de uma API simples ou o desenvolvimento de uma. Mas quando começam a pedir para você desenvolver funcionalidades muito complexas, ou partes de um produto isso foge bastante do que é esperado para uma vaga. Tornando assim essa vaga, uma vaga arrombada.

Excesso de "mimos"
Sabemos que é importante e parte do bem estar da pessoa desenvolvedora algumas regalias na descrição de uma vaga, coisas como: vale refeição, vale transporte, vale alimentação, plano de saúde, gympass (embora quase nenhuma pessoa dev utilize :)), vale cultura, etc., são complementos muito legais ao salário e ajudam bastante na melhoria da qualidade de vida.
Porém, em algumas vagas vemos excessos de "mimos" como: escorregador, vídeogame, sinuca, ping pong, piscina de bolinha, etc. e às vezes você nunca vai conseguir usufruir dessas coisas.
É legal ter um ambiente de trabalho mais "divertido"? Com certeza. Mas temos que ponderar até que ponto esses "mimos" realmente vão ser importantes para nós e melhorar a nossa qualidade de vida. Excesso de mimos geralmente significa um salário abaixo do mercado e/ou jornadas de trabalho mais longas.
Bem, acho que deu para perceber um pouco como fugir das famigeradas vagas arrombadas. Mas então, como identificar boas vagas?
Identificando boas vagas
Ainda sobre a questão dos requisitos técnicos. Uma boa vaga sempre vai trazer a escolha de uma linguagem como, por exemplo: java ou C# ou PHP ou Python; a escolha de um framework, como react, angular ou vue; ao invés de cobrar os 3 frameworks ou as 4 linguagens.
Boas vagas tem descrições mais diretas nos requisitos e pouca enrolação na listagem dos benefícios. São sucintas e de fácil entendimento. Pedem coisas que realmente a empresa utiliza e você usará no dia a dia de trabalho.
Uma última dica: fuja de vagas que utilizam muito de palavras-chave como resiliência, espírito de dono, foco em resultado, visão do futuro, excelência, etc. Essas palavras são conhecidas como red flags. A empresa que precisa de alguém "resiliente", "focado", "com sede", etc. geralmente vai comer a saúde mental da pessoa e oferecer um salário bem abaixo do que a pessoa executa.
Mas pokemão e como eu consigo mudar o jogo e ao invés de procurar vagas, pessoas recrutadoras me encontrarem?
Para que as pessoas recrutadoras encontrem você, a primeira coisa é ser uma pessoa de fácil procura. Seja estando mais ativa na comunidade dev, tendo um bom portfólio de projetos no github, e ter bons perfis em redes sociais, principalmente no linkedIn.
Falando nisso, temos um artigo sensacional escrito pelo Nawarian com 12 passos para ter um perfil extremamente atraente no linkedIn!
Caso tenha alguma dúvida pode entrar em contato comigo no [email protected] ou na minha live: https://twitch.tv/pokemaobr ou no twitter: https://twitter.com/pokemaobr!
Obrigado de coração e até a próxima.
]]>
A equipe que gerencia o PHP lançou a versão 8.1 em Novembro de 2021, e na mesma data deixou de dar suporte à versão 7.3.
Portanto se você ainda está na versão 7.3 ou abaixo, é importantíssimo que você atualize! Bugs e falhas de segurança não serão mais corrigidas para estas versões!
😉 Veja também o PHP 8.2!
Em Novembro de 2022 é lançada a versão 8.2 do PHP. Eu escrevi uma publicação detalhada sobre as mudanças da linguagem para esta versão também.
Conteúdos deste artigo
- Melhorias de performance
- Novas funcionalidades da linguagem
- Enumerações (enums)
- Desempacotamento de arrays com chaves do tipo string
- Fibers ou Fibras
- Propriedades imutáveis (somente leitura)
- Nova sintaxe de Callables
- Utilizar new como valor padrão e em atributos
- Interseção de tipos
- O tipo de retorno never
- Constantes de classe finais
- Nova sintaxe para números octais
- Conclusão
Melhorias de performance
O PHP 8.1 vem com algumas otimizações de performance, mas nada absurdo como o que aconteceu entre as versões 5.6 e 7.0.
A realidade é que a máquina virtual do PHP já é bem otimizada e a partir da versão 8.0 vai ser difícil ver outro salto de performance como o que vimos no passado.
Alguns números oficiais que tirei da página oficial de lançamento do PHP:

Tempo de requisição necessário para carregar a aplicação Demo do framework Symfomy. Quanto menos, melhor.
Fonte: https://www.php.net/releases/8.1/pt_BR.php
Note que entre o PHP 7.4 há uma redução média de 392ms. Em comparação à versão 8.0, o PHP teve performance 23% mais rápida com a aplicação Demo do Symfony, e 3,5% mais rápida no WordPress.
Para quem olha estes números crus parece pouco, mas num ambiente onde se precisa trafegar milhares ou dezenas de milhares de requisições por segundo, isto faz uma diferença enorme!
Novas funcionalidades da linguagem
Quando o PHP 8.0 saiu, nós tivemos uma recepção muito bacana pela comunidade e várias funcionalidades promissoras como o Compilador Just in Time.
O PHP 8.1 não deixou a desejar e trouxe ainda mais coisas que a comunidade vem pedindo há bastante tempo. Enums, imutabilidade, avanços no motor de verificações de tipos, desempacotamento de arrays...
Vamos à lista:
Enumerações (enums)
A proposta para lançar enums foi escrita no final de 2020 e conduzida por Larry Garfield (@Crell) e Ilija Tovilo (@IlijaTovilo). Você pode visitar a RFC através deste link.
O principal efeito de ter enums integrados à linguagem, é que nós vamos poder parar de usar constantes de classe para indicar quais os valores possíveis para uma função/método.
Para quem não vê, ou para quem quer copiar e colar, abaixo a transcrição do código presente na imagem acima:
enum Status {
case Draft;
case Published;
case Archived;
}
function setStatus(Status $status)
{
// ...
}
setStatus(Status::Draft); // OK
setStatus(Status::Archived); // OK
setStatus('codamos.com.br'); // TypeError X_X'
No código acima a função setStatus() recebe um argumento do tipo enum Status, que só pode ter três valores: Status::Draft, Status::Published ou Status::Archived.
Qualquer valor diferente que for passado para aquela função vai gerar uma exceção do tipo TypeError.
Desempacotamento de arrays com chaves do tipo string
Desde o PHP 7.4 já era possível desempacotar arrays, mas as chaves do tipo string seriam ignoradas.
Agora no PHP 8.1 é possível desempacotar arrays com chaves do tipo string, e a precedência segue a mesma regra do array_merge().
$array1 = ['a' => 1];
$array2 = ['b' => 2];
$final = ['a' => 0, ...$array1, ...$array2];
var_dump($final); // ['a' => 1, 'b' => 2]
Fibers ou Fibras
A RFC de fibers causou um alvoroço enorme na comunidade, especialmente no time que desenvolve o Swoole.
Fibras são um mecanismo de paralelismo também conhecido como green threads. A ideia deste mecanismo é que você possa gerenciar interrupções no fluxo de execução do seu código.
Provavelmente você não vai utilizar este mecanismo no seu dia a dia, mas frameworks assíncronos nativos como o React PHP e Amphp vão tirar muito proveito desta funcionalidade.
A RFC trás um exemplo simples de como as fibras funcionam. O segredo aqui é pensar que o código está constantemente interrompendo a execução um do outro:
$fiber = new Fiber(function (): void {
$value = Fiber::suspend('fiber');
echo "Valor utilizado ao retomar a execução da fibra: {$value}\n";
});
$value = $fiber->start();
echo "Valor da suspensão da fibra: {$value}\n";
$fiber->resume('test');
O código acima executa na seguinte ordem:
-
Instancia um objeto
$fibercom uma função callback que será executada assim que o métodostart()for chamado; -
Chama o método
start(), que efetivamente executa o callback definido no objeto $fiber e armazena seu retorno; -
O callback executa e, em sua primeira linha, suspende a fibra utilizando o método
Fiber::suspend()e passandostring(fiber)como parâmetro. Isto retorna a execução para a linha anterior e joga o valor “fiber” para a variável $value; -
Um echo executa, utilizando a variável $value, que neste momento possui o valor
string(fiber); -
Retomamos a execução do callback ao chamar o método
resume(). Passamos o valorstring(test)como parâmetro, que será transmitido àquela variável $value dentro do callback; -
O echo de dentro do callback executa, utilizando a variável $value, que neste momento possui o valor
string(test).
Propriedades imutáveis (somente leitura)
Lembra daquela época quando a gente escrevia classes como essa abaixo?

class Person
{
public string $name;
public static function create(string $name): self
{
$instance = new self();
$instance->name = $name;
return $instance;
}
public function setName(string $name): Self
{
return self::create($name);
}
}
De acordo com a imagem acima, sempre que quiséssemos modificar uma propriedade da classe, criaríamos uma nova instância para defender a imutabilidade do objeto atual.
A partir do PHP 8.1 isto já não é mais necessário, porque podemos definir propriedades como imutáveis desde a sua criação. Segue o snippet abaixo:

class Person
{
public function __construct(public readonly string $name)
{}
}
Aqui eu utilizei o constructor promotion, que foi introduzido no PHP 8.0. Mas adicionei uma palavra-chave ali: readonly.
Com a palavra-chave readonly nós podemos indicar que propriedades das classes só podem ser escritas uma vez, dentro do método __construct().
Portanto tanto faz se você deixa aquela propriedade com visibilidade pública ou não, porque nada vai poder alterar aquela propriedade. Adeus getters e setters!
Nova sintaxe de Callables
O PHP já tem uma sintaxe para referenciar classes, que funciona mais ou menos assim: $name = MinhaClasse::class;, onde $name armazena a string "\MinhaClasse".
Isso é extremamente útil pra fazer referência ao código de forma dinâmica para quem escreve. Por exemplo, o framework Slim nos permite definir rotas da seguinte forma:
$app->get('/', MinhaClasse::class);
O problema com a forma acima é que para aquela rota funcionar, a classe \MinhaClasse precisa implementar o método público __invoke(). Existe uma forma de contornar a situação, como em [MinhaClasse::class, 'meuMetodo'] - mas esta sintaxe se confunde com a de arrays.
Com o PHP 8.1 é possível indicar a classe e método de forma nativa e distinta na linguagem. A sintaxe é a seguinte:
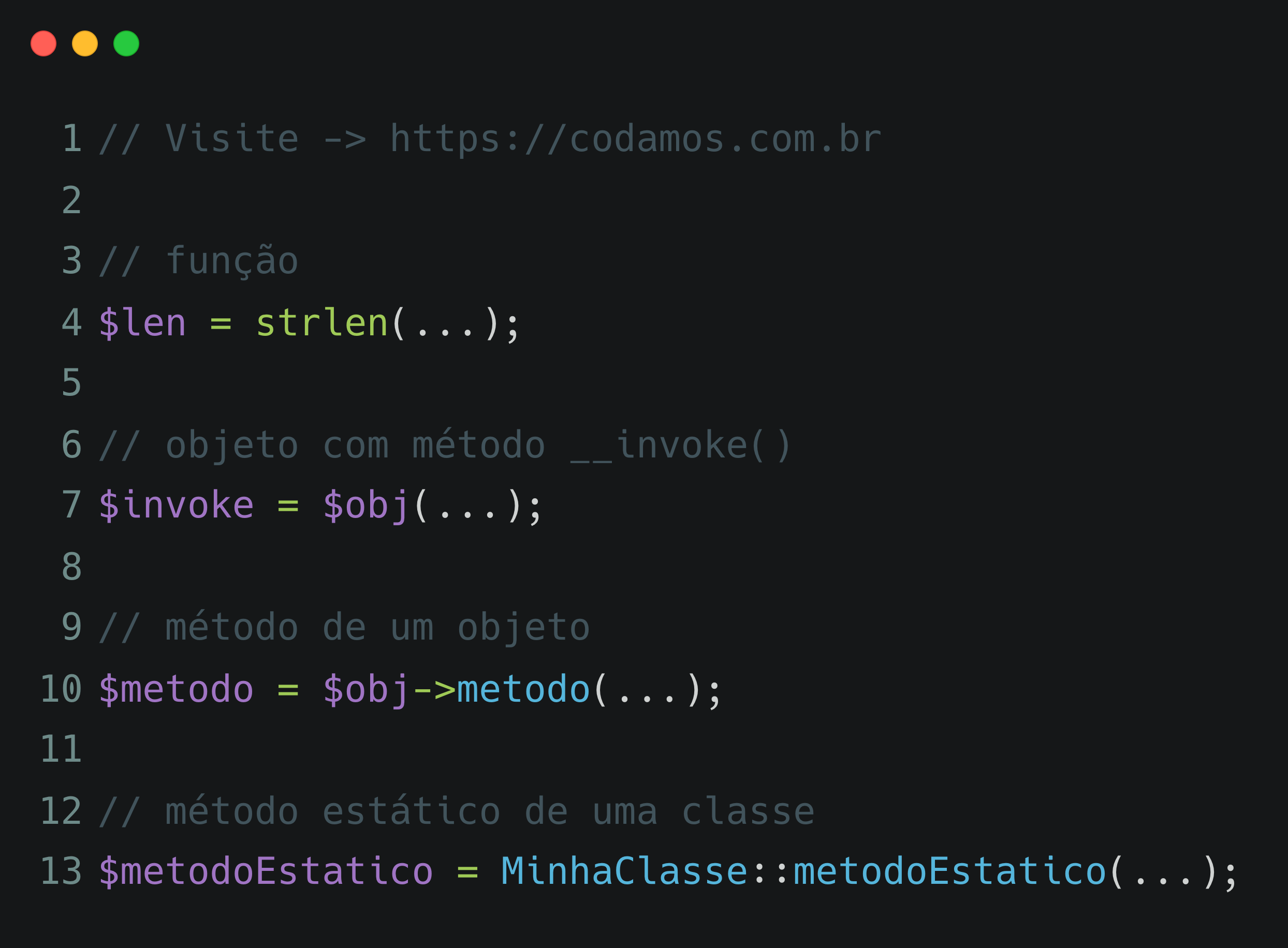
$len = strlen(...); // função
$invoke = $obj(...); // objeto com método __invoke()
$metodo = $obj->metodo(...); // método de um objeto
// método estático de uma classe
$metodoEstatico = MinhaClasse::metodoEstatico(...);
Desta forma, é possível imaginar que num release futuro do framework Slim a gente consiga ver algo assim:
$app->get('/person', $person->list(...));
$app->post('/person', $person->create(...));
Eu esperaria ver esta sintaxe criar impacto direto em frameworks e bibliotecas que lidam com:
- Rotas (Slim, Mezzio...)
- Injeção de dependências (PHP DI)
- Event Loop (ReactPHP, Swoole, AMP...)
- Logging (Monolog)
- Testes (PHPUnit, Pest...)
Utilizar new como valor padrão e em atributos
Você já deve ter visto que para argumentos opcionais é possível dar um valor padrão na assinatura da função ou método. Algo assim:
function minhaFuncao(int $a = 10) {
var_dump($a);
}
minhaFuncao(); // int(10)
Repare que ao chamar minhaFuncao() sem parâmetro algum, a máquina virtual do PHP assume que deveria utilizar o valor padrão 10. Mas esta sintaxe só funciona com valores primitivos.
🧙🏻♂️ Se você ainda não se familiarizou com os termos sobre tipos em PHP, dá uma olhada neste artigo que eu escrevi sobre tipos no PHP 😉
Desde o PHP 8.1 também é possível utilizar objetos como valor padrão. Um caso de uso que eu acho particularmente útil é o de utilização de datas. Veja um exemplo de como isso muda no PHP 8.1:
class MinhaClasse
{
public function __construct(
public DateTimeInterface $createdAt = new DateTimeImmutable('now')
) {}
}
$obj1 = new MinhaClasse(new DateTimeImmutable('tomorrow'));
$obj2 = new MinhaClasse(); // $obj2->createdAt é um DateTimeImmutable('now')
Com o construtor acima nós definimos a propriedade DateTimeInterface $createdAt, e caso ela seja omitida ao instanciar o objeto nós adotamos como valor padrão uma nova instância de DateTimeImmutable.
Interseção de tipos
Desde o PHP 8.0 nós recebemos suporte à União de Tipos (union types). Que nos permite dizer que determinada variável é do tipo A ou B, como abaixo:
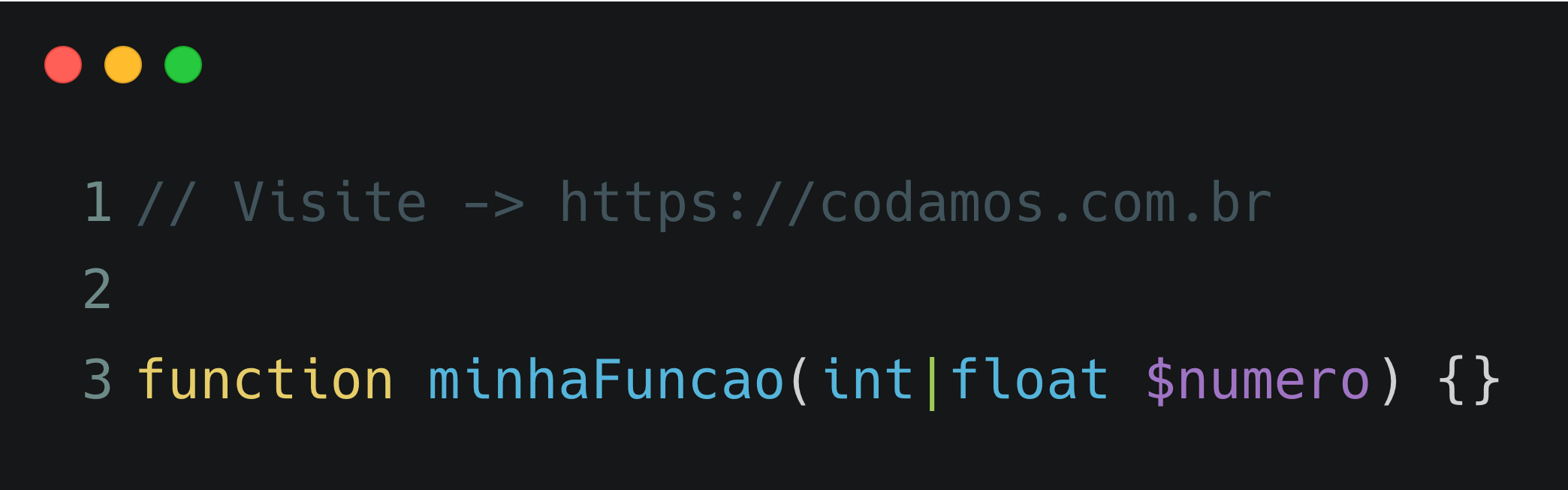
function minhaFuncao(int|float $numero) {}
No escopo da função acima, a variável $numero pode ser do tipo int ou float, mas nunca os dois ao mesmo tempo.
A versão 8.1 do PHP trouxe a Interseção de tipos (intersection types), que nos permite indicar que uma variável é de tipo A e B ao mesmo tempo. Um claro exemplo que interseção de tipos que me vem à mente são mocks em testes, veja o exemplo abaixo:
class MyTest extends TestCase
{
private MinhaClasse&MockObject $mock;
...
public function testAlgumaCoisa()
{
$this->mock = $this->prophesize(MinhaClasse::class)->reveal();
...
}
}
No exemplo acima a propriedade $mock é do tipo MinhaClasse e MockObject ao mesmo tempo.
O tipo de retorno never
Já se viu numa situação em que você chama uma função, escreve mais algumas operações em seguida mas o código nunca executa estas operações? Eu já caí em algo assim:
// ...
$redirect = redirect('/');
$this->logger->log('Redirecting to "/"');
E a linha $this->logger->log() não executava NUNCA. O motivo? A função redirect() enviava os cabeçalhos HTTP e depois dava um exit(0), simples assim.
Como adivinhar uma coisa dessas? Lendo código alheio, usando o depurador... e testar isso é um inferno na terra!
O tipo de retorno never vem justamente pra deixar este comportamento mais explícito. Se usa assim:
function redirect(string $path): never
{
header("Location: {$path}");
exit(0);
}
Ao utilizar o tipo de retorno never você diz à máquina virtual do PHP, e à próxima pessoa que ler a assinatura da sua função/método, que aquela função necessariamente vai finalizar o processo PHP.
🧙🏻♂️ Eu já comentei no meu artigo sobre como programar por intenção o quão poderoso uma coisa dessas é. Com esta sintaxe você consegue comunicar intenção e comportamento para quem lê o código.
Constantes de classe finais
Até o PHP 8.0 era possível sobrescrever constantes de classes, e agora com a versão 8.1 da linguagem é possível adicionar o modificador final para as constantes de classe de forma que nunca sejam sobrescritas.
A utilização fica assim:
class Primeira
{
final public const MINHA_CONST = 'foo';
}
class Segunda
{
public const MINHA_CONST = 'bar'; // Erro fatal
}
Nova sintaxe para números octais
A linguagem PHP permite escrever números em diferentes bases numéricas, seguindo as sintaxes a seguir:
- Base binária, usando o prefixo
0bcomo em0b10010; - Base octal, usando o prefixo
0como em016; - Base decimal, sem prefixo algum como em
16; - Base hexadecimal, usando o prefixo
0xcomo em0x16
🧙🏻♂️ Se você não entende bem o que essas bases todas significam, dá uma olhada no meu artigo sobre operações binárias (bitwise) em PHP 😉.
O atual prefixo para números octais faz parecer com que o primeiro 0 é parte do número em si, e pode gerar resultados confusos como abaixo:

016 === 16 // false -> 016 (octal) é 14 (decimal)
Para resolver isto, um novo prefixo foi adicionado à linguagem para representar números octais: 0o.
Desta forma o código acima fica menos confuso, porque fica claro que o lado esquerdo usa a notação octal:
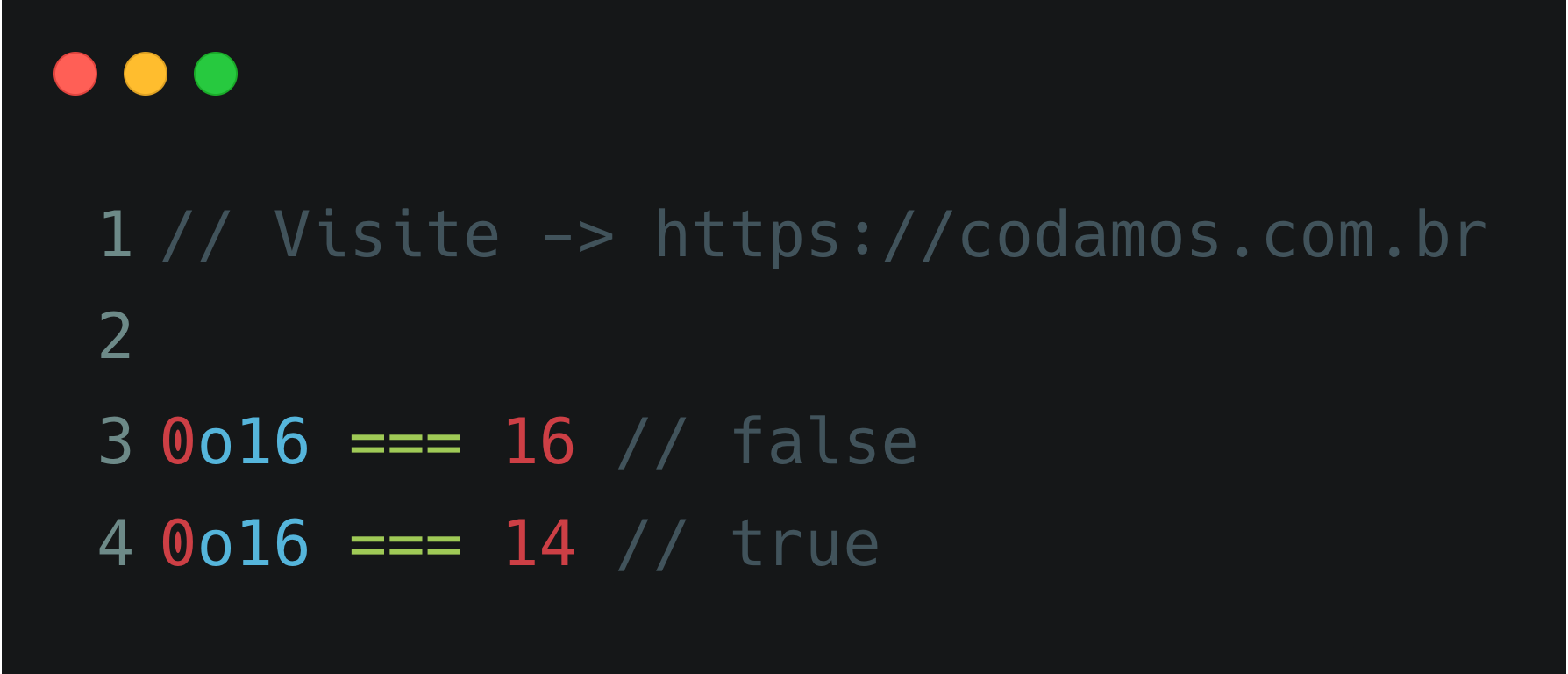
0o16 === 16 // false
0o16 === 14 // true
Conclusão
O PHP 8.1 está uma delícia, com diversas adições na linguagem e ferramentas para tornar o nosso fluxo de trabalho bem mais agradável, seguro e performático!
Num futuro eu pretendo escrever sobre Fibers com maior atenção, porque este conteúdo simplesmente não cabe neste artigo. Me segue no Twitter pra ficar sabendo quando o artigo sair 😉.
Até a próxima 👋
]]>
Não importa se você é iniciante ou se já está na área faz tempo, a apresentação pessoal normalmente não é o forte de quem trabalha com desenvolvimento de software... Eu vim aqui te ajudar justamente com isso!
Eu trabalho com desenvolvimento de software há 10 anos, e há pouco mais de um ano trabalho como gerente de time de desenvolvimento. Já entrevistei muita gente, fiz seleção e o que mais você puder imaginar no processo seletivo.
Eu também conversei com vários profissionais, tanto com desenvolvedoras de software quanto com gerentes e recrutadoras, para entender quais são as informações chave que você deve trazer no seu LinkedIn para chamar a atenção do jeito certo!
Não importa se você está começando ou é Júnior, Pleno ou Sênior. Ao final deste artigo você vai entender direitinho tudo o que precisa fazer pra tornar o seu perfil no LinkedIn mais atrativo e começar a receber convites para entrevistas 😎
Todo documento tem um público alvo
Antes de começar qualquer coisa, eu quero deixar claro que absolutamente tudo o que você escreve precisa ter um público alvo. No caso do LinkedIn, o seu público alvo são empresas e recrutadoras.
Tudo, absolutamente tudo que você escrever precisa levar em consideração quem vai ler: empresas e recrutadoras. Não adianta usar jargão pra todo lado, e piadas de código muitas vezes não vão funcionar. E muito menos deixe coisas implícitas.
Por exemplo, se você escreve no perfil que trabalhou com "testes" e com "javascript" não é necessariamente óbvio para uma recrutadora que você conhece a ferramenta "jest". Deixe tudo explícito o máximo que puder!
Com o seu público alvo em mente, vamos dar um tapa no seu perfil a começar pelo básico.
O básico que TODO perfil precisa ter no LinkedIn
Aqui eu quero agradecer demais a Isabela Norton (@isanortontech) pelas dicas. A Isabela é recrutadora especializada em vagas de desenvolvimento e de tecnologia, contrata pra trabalhar na gringa e usa LinkedIn como sua ferramenta principal pra encontrar candidatas. Já segue perfil dela agora pra receber mais dicas e receber vagas bacanudas na sua timeline.
A partir da nossa conversa ficou claro pra mim que muita gente peca no básico e deixa de incluir informações essenciais para uma pessoa recrutadora encontrar seu perfil.
Lembre-se: o seu público alvo são empresas e recrutadoras. Como estas pessoas vão te encontrar? Através de buscas avançadas.
"Eu preciso de uma pessoa que saiba JavaScript, React e TDD, que esteja em Minas Gerais e fale inglês". Pense em quais termos serão buscados a partir desta frase. Você tem estes termos no seu perfil?
Para te ajudar a criar o seu perfil no LinkedIn eu vou deixar aqui algumas dicas e o passo a passo para começar, em ordem de facilidade.
Passo 1: idiomas que você fala
Pra você que nasceu no Brasil é óbvio que seu idioma materno é o Português, mas ninguém no LinkedIn sabe da sua nacionalidade. E mesmo que soubesse, indicar todas as línguas que você fala é importantíssimo para que pessoas no estrangeiro também encontrem seu perfil.
Para adicionar os idiomas que você fala, vá até a página do seu perfil e role a página até a seção "Idiomas" e clique no sinal de adição (+) como na imagem abaixo:

Após selecionar o idioma, defina a sua proficiência com aquele idioma e pronto:

Caso tenha dúvida sobre o que cada nível significa, aqui vão algumas dicas:
- Básico: você consegue falar bom dia, identificar algumas palavras em um texto, mas não necessariamente falar naquele idioma;
- Limitada: você consegue comunicar sobre o seu trabalho de forma suficiente, mas não necessariamente desenvolver uma conversa sobre um tópico. Por exemplo você sabe pedir um code review, ler por cima uma documentação...;
- Profissional: você consegue desenrolar conversas sobre o seu dia a dia no trabalho, talvez com uma gambiarra linguística aqui e ali, e ler documentações sem muita dificuldade;
- Completa: você consegue falar com proficiência total no contexto de trabalho, e com pouquíssima frequência se pega procurando por palavras ou formas de explicar uma frase;
- Nativo ou bilíngue: você aprendeu a falar aquele idioma desde criança.
Para muitas vagas, inclusive no Brasil, é importante falar inglês. Indique seu nível de proficiência em inglês no seu perfil. Mesmo que seja apenas básico.
Passo 2: descrição do seu perfil
A descrição do seu perfil é o lugar perfeito pra descrever o que você procura e dá valor. Está em busca do primeiro emprego? Quer experiência profissional com uma linguagem diferente? Precisa mudar de cidade? Ou tá buscando transicionar de carreira? Este é o espaço pra tu escrever sobre isso!
Este campo é importantíssimo para que recrutadoras consigam entender quais vagas encaixam no seu perfil e necessidades.
No meu perfil eu indico o que atualmente é mais importante para recrutadoras saberem sobre mim: meu foco em desenvolvimento para web, meu interesse por liderança, comunidade e aprender coisas novas. Meus valores incluem honestidade e comunicação direta. E eu quero trabalhar do Brasil.
Com estas informações eu deixo claro para qualquer visitante do perfil que não estou interessado em pequenas aventuras, em empresas com ambiente tóxico meritocrático e que não estou disposto a "vestir a camisa e trabalhar horas a mais" e nem faria com que meus times façam algo assim.
Para alterar a descrição do seu perfil, vá ao topo da página até a seção "Sobre" e clique no ícone do lápis para editar:

Uma caixa de texto se abrirá na sua tela. Adicione as informações mais relevantes sobre você nesta caixa de texto. Quer trabalhar remoto ou do escritório? Quer trabalhar em qual cidade? Com qual linguagem? Está procurando uma empresa inclusiva? Escreve aqui:

A descrição do seu perfil é uma das primeiras coisas que recrutadoras vão olhar. Coloque as informações mais importantes ali e não tenha medo de escrever algo pessoal.
Passo 3: uma boa foto de perfil
Você não precisa pagar por uma sessão de fotografia profissional, e nem posar de roupa social pra câmera. Mas uma foto em que só você aparece e que dê para ver seu rosto cai bem.
Pessoalmente eu não sou muito fã dessa coisa de expor foto no perfil, mas isto aparentemente importa para quem busca. Ao ver uma foto padrão, aquele placeholder cinza, eu imediatamente ignoraria o perfil. Mas um avatar do tipo cartoon eu até acho aceitável.
O ideal, porém, é uma foto sua. Vamos colocar alguns parâmetros de qualidade aqui:
- Só você aparece na foto;
- Sem óculos escuros;
- Sem chapéu/boné;
- Sem máscara (as coisas que a pandemia me obriga a escrever, hein...)
- Foto relativamente recente
Para alterar a foto do seu perfil, navegue até o topo da página, clique na sua foto atual e a seguinte tela deverá aparecer pra ti:

Clique no botão "Adicionar foto" com ícone de câmera. Depois escolha fazer o upload de uma foto. Ao escolher qual foto subir, ajuste o zoom e corte até que a foto fique adequada:

Notou como nesta foto tem outra pessoa e uma garrafa de álcool? Não é exatamente o que eu gostaria de mostrar no meu perfil. Então tome cuidado para remover estes elementos da foto ao ajustar o zoom.
Eu, pessoalmente, não vejo problema nenhum em usar uma foto como a acima. Apesar de ser muito pessoal e totalmente fora do contexto de uma empresa, ela diz algo sobre mim. E eu estou confortável em transmitir esta imagem e deixar claro que sou um ser humano que tem gostos e se diverte.
Considere também que eu já tenho uma década de experiência e um perfil competitivo. Seguir os mesmos passos para quem está começando talvez seja um tiro no pé.
A foto do seu perfil transmite uma mensagem a quem visita seu perfil, tome cuidado para não transmitir uma mensagem que acabe te prejudicando.
Passo 4: habilidades
Você sabe Reactjs? Sabe PHP? E CSS?
É importantíssimo colocar estas habilidades no seu perfil. Quando uma recrutadora busca por perfis que se encaixam numa vaga, normalmente estas habilidades do perfil ajudam a fazer o match.
Mesmo que você não se sinta 100% proficiente com aquela habilidade, marque que a possui. O importante aqui é que encontrem o seu perfil.
Para adicionar habilidades ao seu perfil, navegue até a seção "Habilidades" e clique no botão "+":

Uma tela com diferentes opções vai se abrir pra ti. Escolha uma habilidade daquela lista ou escreva e encontre na lista o que quer descrever. Na imagem abaixo eu estou adicionando a habilidade Blogging (escrever em blogs):

No LinkedIn é possível que uma pessoa endosse a sua habilidade. Alguém pode ir até o seu perfil e dizer "olha, esta pessoa MANJA de JavaScript"...
O que eu aprendi depois de conversar com diferentes profissionais de recrutamento é que: ninguém se importa com estes endossos. É bacana ter, mas eu não investiria muita energia em pedir endosso.
Adicione habilidades ao seu perfil para que recrutadoras te encontrem mais facilmente. Não invista muito tempo pedindo endosso de outras pessoas, eles não são tão importantes.
Passo 5: experiências e descrições
Acho que está claro para todo mundo: se você tem experiência profissional, adicione a empresa, cargo e período no LinkedIn. Este é o básico!
Uma reclamação comum que eu recebo de recrutadoras é que os perfis normalmente não descrevem o que a pessoa fez naquele cargo, e isso é importantíssimo pra saber em quais contextos as suas habilidades foram executadas.
O que é interessante para quem analisa o seu perfil:
- Com quais tecnologias a pessoa trabalhou;
- Quais responsabilidades aquela pessoa teve;
- Qual o tamanho do time/empresa com que a pessoa já teve experiência;
- Qual era o estilo de colaboração? Scrum, Kanban, Go horse...
Eu também acho importante colocar o que você curtiu daquela experiência e alguma conquista sua.
Para adicionar descrição às suas experiências, role até a seção "Experiências" e clique no ícone do lápis para editar as experiências atuais:

Uma nova tela com cada experiência vai aparecer. Selecione uma experiência que ainda não possua descrição, e clique no ícone do lápis para editar:

Ao final da página que irá se abrir você encontra uma caixa de texto chamada "Descrição" onde você pode adicionar mais informações sobre o que fez naquela posição:

Note que para aquela experiência eu procurei indicar os desafios e conquistas que eu superei e obtive. Se fosse uma experiência como programador, eu teria indicado as tecnologias, a escala, o estilo de trabalho, um projeto que tenha coordenado e por aí vai.
Adicione uma descrição que indique o que fez, como fez, com quais tecnologias, desafios e conquistas para cada experiência profissional descrita no seu perfil!
Não se esqueça de honrar os termos de confidencialidade que assinou no passado. É importante dar informação, mas cuidado para não abrir segredos da empresa aqui!
Passo 6: monitore a sua conduta e imagem online
Todas empresas onde eu trabalhei não fazem isso, mas já recebi muito relato de empresas que dão o famoso stalk em quem se candidata: verificam facebook, instagram, twitter...
Portanto monitore a sua imagem e, se possível, mantenha seus perfis separados. O perfil do LinkedIn monta uma imagem profissional de si, e as outras redes uma imagem pessoal. Eu recomendo não misturar as duas.
E todos nós sabemos como o LinkedIn virou um grande grupo de whatsapp da família: gente mandando vídeo e GIF aleatório de estórias "inspiradoras" inventadas. Há muito espaço pra gente escrota e pra ser escrota ali.
A minha dica: Nem todo mundo sabe, mas o LinkedIn mantém um resumo das suas atividades. O que você publicou, curtiu, comentou... Esta é uma forma simples e fácil para recrutadoras entenderem melhor quem você é e alguns traços da sua personalidade.

Não seja escroto no LinkedIn. E se tiver algo que pode diminuir suas chances de arranjar um emprego ou ser alvo de preconceito – sabemos bem o que pode causar isso – evite mostrar aqui.
Eu, comunista safado, não conecto redes que não são relevantes ao trabalho e evito expor minha posição política no LinkedIn. Quem se considera queer, por exemplo, talvez queira seguir o mesmo caminho.
E eu concordo que se a empresa é retrógrada ninguém deveria querer trabalhar lá em primeiro lugar. Mas eu também entendo que as vezes tanto faz o trabalho porque a vida não para, e muito menos os boletos param de chegar.
O passo além: como destacar o seu perfil frente aos outros
O que eu descrevi até este ponto é o básico do básico. Se você ainda não fez, para aqui e vai fazer!
Daqui pra frente a gente começa a deixar o seu perfil mais atrativo. São alguns pequenos passos que vão chamar atenção e ajudar as empresas e recrutadoras a te chamarem pra uma entrevista.
Passo 7: altere o seu título para atrair visitas
O seu título é aquilo que aparece logo abaixo da sua foto de perfil. Aquele é um espaço incrível para oferecer informações úteis a quem olha o seu LinkedIn.

Note que este título não precisa necessariamente ser a sua experiência, mas sim algo relevante para quem contrata!
Muitas vezes este título pode ser o motivo para uma recrutadora clicar no seu perfil ou não. Se uma vaga é para Pleno e seu título diz "Procurando estágio" ou "Em transição" provavelmente seu perfil será descartado antes mesmo de ser aberto!
Caso você seja iniciante ou esteja em transição de carreira, use o título do seu perfil para indicar qual carreira quer seguir. Você não precisa trabalhar com programação para ser Developer, você só precisa desenvolver software. E isso você pode fazer mesmo sem trabalhar como developer, por exemplo através de contribuições com Open Source ou de projetos pessoais.
Suponha que eu decidi que quero mudar a minha carreira um pouco e me especializar em Golang. Eu já li alguns livros e fiz umas aplicações de brincadeira. Um título útil seria "Desenvolvedor sênior se especializando em Golang".
Não precisa mentir e nem inventar. Apenas deixe claro o que você quer que as pessoas saibam sobre você.
Para alterar seu título, vá ao topo da página e clique no ícone do lápis à direita da sua foto de perfil:

A tela de edição irá aparecer. Seu título fica logo abaixo dos pronomes pelos quais quer que te chamem. Note que o título não precisa ser a mesma coisa que a sua posição atual.

Escreva no título do seu perfil o que vai fazer com que empresas e pessoas recrutadoras cliquem no seu perfil!
Passo 8: peça recomendações, e recomende!
Isto é algo que eu pequei muito por bastante tempo, mas recomendações são uma ferramenta incrível para transmitir maior confiança a quem emprega.
Naturalmente você não pode recomendar a si mesmo. Você vai precisar pedir recomendações de outras pessoas.
Recomendações não ajudam tanto a mostrar como são suas habilidades em determinada tecnologia, mas sim se você consegue trabalhar bem em time, se o time aprende de você ou mesmo se você é uma pessoa confiável.

Peça recomendações de professoras, instrutoras, colegas de trabalho, gerentes, amigas...
Se você pedir a 4 pessoas, com certeza ao menos 2 irão lhe recomendar 😉
Outra coisa que a gente tende a esquecer é que por natureza o ser humano tende a ser recíproco (exceto em São Paulo 👀 – piadas que só um paulistano pode fazer). Se você parar escrever uma recomendação para 10 pessoas, provavelmente ao menos 1 vai te escrever uma recomendação de volta.
Então além de pedir recomendações, recomende! Mesmo que seja uma recomendação curtinha. Em 1 hora por semana você consegue escrever recomendações o suficiente pra turbinar o seu perfil!
Não apenas peça recomendações, recomende!
Passo 9: certificações
Este é um ponto controverso. Por experiência própria e relato de diferentes recrutadoras, eu sei que certificações não contam muito no perfil do LinkedIn. Muitas vezes serão ignoradas até mesmo durante suas entrevistas.
Mas há dois casos em que certificações são úteis:
- para que te encontrem na busca do LinkedIn; e
- para áreas pouco conhecidas ou que exigem um selo de confiabilidade
Por exemplo, empresas que trabalham com blockchain podem precisar de uma pessoa desenvolvedora que saiba CORDA. Como é uma tecnologia relativamente nova, a certificação ajuda em muito a demonstrar que você domina aquela tecnologia.
Outro bom exemplo são as profissões de Agile Coach, Scrum Master ou mesmo para quem se especializa em SAP ou Salesforce.
Mas a certificação em PHP pra ti talvez não faça muita diferença. A não ser que a empresa exija certificação. O mesmo vai para AWS e outras...
Para adicionar certificações, vá ao topo do seu perfil e clique no botão "Adicionar licença ou certificação":

A tela a seguir irá aparecer. Você pode indicar o nome da certificação, quem emitiu o certificado e a data:

Invista em certificações apenas para áreas que realmente precisam. Seu tempo será mais bem gasto trabalhando em outras áreas do seu perfil, ou lendo um livro.
Passo 10: links alternativos
Eu já participei de conferências, tenho meu próprio blog, tenho um Github que me dá bastante orgulho, já ajudei a organizar o maior podcast de ciência em linha reta da América Latina e quiçá de Pernambuco.
Todos estes projetos e referências são importantes pra mostrar quem eu sou e com o que me importo: programação, ciência, compartilhar conteúdo, comunidade...
Para adicionar um link alternativo, navegue até a seção de destaques do seu perfil e clique no botão "+" e selecione se quer adicionar um artigo, um post dentro do LinkedIn, um link, uma foto ou vídeo, etc.:

Adicione links alternativos que dêem credibilidade ao seu perfil. Adicione entrevistas, palestras, vídeos seus ou artigos que tenha escrito.
Passo 11: veja o perfil de outras pessoas e copie o que gostar
Esta, na minha opinião, é uma das melhores dicas. Obrigado novamente, Isabela Norton (@isanortontech)!
A melhor forma de entender se eu perfil está bom ou não é comparando com outros perfis. Mas não caia na besteira de querer comparar habilidades, viu? Estou falando de comparar informação disponível.
Faça o seu dever de casa: procure 5 perfis que você segue no LinkedIn, ou de influenciadoras por lá e anote o que você gostou e não gostou.
O próximo passo é simples: copie o que gostou, evite o que não gostou 😉
Passo 12: indique que está a procura de trabalho
Nem todo mundo está procurando novas oportunidades agora. Uma forma fácil de indicar que você está é marcando no seu perfil do LinkedIn.
No topo do seu perfil há um botão azul dizendo "Aberto à...". Clique naquele botão e selecione a opção "Encontrar um novo emprego", como na imagem abaixo:

A próxima tela vai te perguntar que tipo de trabalho você está procurando e quem você quer que veja que está a procura de emprego. Você pode, por exemplo, mostrar pra todo mundo mas esconder da sua empresa atual:

Indique que está aceitando novos empregos e aguarde diferentes contatos 😉
Dica bônus: como aumentar sua visibilidade na rede
Lembra quando eu te disse sobre manter seu público alvo em mente? Essa dica é um exemplo perfeito disso! Vamos brincar com o algoritmo do LinkedIn.
💡 Você sabia?
A busca do LinkedIn mostra apenas conexões até o terceiro grau para quem não é premium.
Pois é, se a recrutadora não tiver uma conta premium no LinkedIn a busca será limitada. Levando em consideração que uma licença premium custa cerca de R$ 600,00 eu não assumiria que todas empresas e recrutadoras usam LinkedIn premium.
Caso você não entenda bem o que são conexões de terceiro grau, dê uma olhada nesta explicação no centro de ajuda do próprio LinkedIn.
Portanto se você quer aumentar suas chances de ser encontrada por empresas e recrutadoras com e sem LinkedIn premium há uma forma relativamente simples de resolver este problema: criando mais conexões.
Adicione pessoas à sua rede. Pessoas com quem você já estudou, com quem trabalhou, influenciadoras ou até mesmo pessoas dentro da empresa para qual você quer trabalhar.
Quanto mais pessoas você adicionar à sua rede e quanto mais pessoas existirem na rede delas, maiores serão as suas chances de aparecer numa busca do LinkedIn.
Dica de ouro, vai! Merece um compartilhamento no Twitter e seguir o perfil da Isabela (@isanortontech) e o meu, Nawarian (@nawarian).
Conclusão
Estes 12 passos vão te ajudar em muito a deixar o seu perfil pronto para o primeiro contato com empresas e recrutadoras. Lembre-se sempre do seu público alvo ao escrever qualquer coisa no seu perfil!
É claro que a coisa não para por aqui. Você precisa entender como formatar seu Github, como gerenciar outras redes e por aí vai.
Tudo isso é só o começo, viu? A intenção é atrair o primeiro contato e permitir que te alcancem com mais facilidade. O que vai determinar sua contratação ou não serão suas entrevistas e habilidades técnicas e interpessoais.
Um grande abraço e te vejo na próxima! 👋
]]>
Eu li este livro pela primeira vez há alguns anos, e esta já é minha terceira leitura do mesmo título. Eu recomendo DEMAIS ler este livro e tirar suas próprias conclusões, citações e o que mais for.
Este artigo vai com certeza enviesar a forma como você vai ler o livro Refactoring, mas o conteúdo e qualidade do livro não mudam. E caso você tenha dificuldade com leituras longas, com certeza vai ser útil pra ti ler este artigo primeiro.
Esta é uma literatura fundamental para toda pessoa que trabalha com desenvolvimento de software. Eu desconfiaria de qualquer dev sênior que nunca tenha ouvido falar do termo Refactoring (refatoração).
Conteúdos deste artigo
Revisão e ideias centrais
A estrutura do livro
O livro possui duas partes: a primeira apresenta a teoria de refatoração e alguns exemplos práticos enquanto a segunda parte é só um catálogo de refatorações.
Dentre os exemplos Martin Fowler mostra alguns códigos – a última edição vem com códigos em JavaScript, bem feios por sinal – e explica, passo a passo, como torná-los mais legíveis e mais fáceis de testar.
O catálogo de refatoração mostra não só o motivo daquela refatoração, mas também dá um nome à elas. Isto é poderozíssimo porque cria um vocabulário comum entre pessoas desenvolvedoras. Da mesma forma que você entende facilmente o que é uma classe do tipo Factory, o livro busca criar compreensão sobre o que significa a refatoração Extrair Método.
Ler os exemplos do livro é uma experiência mágica porque o autor não apenas explica o que está acontecendo linha a linha, mas também faz referência aos nomes das refatorações que utilizou de seu próprio catálogo.
Neste artigo eu não vou focar no catálogo em si, mas sim na parte teórica. Se você tem curiosidade sobre o catálogo, dê uma olhada na apresentação da incrível Jucy Cabrera (@jucycabrera) fez ano passado no Locaweb PHP Community Summit.
A apresentação da Jucy começa no minuto 02:03:00
O que é refatoração?
Refatoração, de acordo com Martin Fowler, é o ato de alterar um código sem mudar o seu comportamento observável.
Por exemplo, a função a seguir recebe dois parâmetros e retorna um inteiro, contendo a soma destes dois parâmetros:
function sum(int a, int b): int
{
for (; a < b; a++) return a
}
Não há nada de errado com este código, exceto pelo fato de fazer pouco sentido fazer uma soma desta forma. Mas de toda forma, se chamarmos a função desta forma sum(10, 10) receberemos o valor 20, e se chamarmos assim sum(20, 30) receberemos o valor 50.
Alterar o código da função acima de forma que ao receber os mesmos parâmetros ela retornará os mesmos valores é uma refatoração. Vejamos:
function sum(int a, int b): int
{
return a + b
}
Porém alterar a assinatura da função, por exemplo, não é uma refatoração. Ou adicionar lógicas à ela. O seguinte snippet não pode ser considerado refatoração, porque muda a assinatura da função:
function sum(int a, int b): float
{
if (a < 0 || b < 0) throw 'Dont be so negative'
return parseFloat(a + b)
}
Ao alterar a função acima desta forma nós deixamos de somente refatorar o código e passamos a reescrevê-lo por conta de três alterações principais:
- O tipo de retorno mudou de int para float;
- Adicionamos uma lógica que lança exceção;
- Utilizamos a função
parseFloat()que pode alterar fundamentalmente o valor esperado
Note também que "refatoração" depende muito do nível de abstração a partir do qual observamos. Uma reescrita a nível de função pode ser uma refatoração a nível de módulo.
Um ponto importantíssimo citado no livro fala sobre as oportunidades de corrigir um erro ou mal funcionamento do software. Corrigir um bug ou adicionar uma funcionalidade só porque "está fácil" ou na cara não é refatorar e deveria ser evitado.
👉 Refatorar é alterar um código sem mudar o seu comportamento observável.
Por que refatorar?
O livro desenvolve a ideia de que todo software perde qualidade com o tempo e sua arquitetura fica obsoleta. Alguns dos motivos eu descrevo abaixo:
- O ambiente de desenvolvimento (linguagem de programação, framework, bibliotecas, infraestrutura...) evolui com o tempo e algumas decisões de arquitetura ficam obsoletas;
- Ao adicionar código seja para corrigir bugs ou adicionar funcionalidades, nós adicionamos dependências e débito técnico que se acumula com o tempo
Em vez de estressar a arquitetura e design ao extremo até o ponto de não podermos mais adicionar nenhuma funcionalidade, Martin Fowler propõe que a gente melhore a qualidade de nossos softwares com frequência.
Refatoração nos permite evoluir e atualizar a arquitetura de design do software constantemente. É importante refatorar porque desta forma evitamos a degradação do design do software de forma gradual em vez de investir em grandes correções e reescritas.
Quando refatorar?
O livro explicita dois momentos essenciais para executar uma refatoração: antes e depois de escrever alguma alteração no código.
Refatoração antes de alterar o código
Quando se investiga um bug, refatorar aquele pedaço de código é uma técnica muito útil para entender o que aquele código faz. E quando é necessário cobrir o código com testes, fica muito mais fácil. Normalmente durante a refatoração, o bug e sua correção ficam mais claros.
Por extensão, quando se precisa entender melhor o que determinado trecho de código faz, a refatoração também é uma ferramenta incrível.
👉 Sempre que você precisar escrever um trecho novo de código, refatore antes.
Refatoração depois de alterar o código
Quando a sua atualização estiver pronta para ser entregue, é o momento perfeito para refatorar mais uma vez. Este momento é a sua oportunidade perfeita para revisar suas alterações e garantir que a próxima pessoa que visitar aquele código vai entender com facilidade o que foi escrito. Provavelmente vai ser você quem vai visitar este código da próxima vez de toda forma, seja gentil consigo 😉.
Como eu já comentei no meu artigo sobre estilo de código para iniciantes, um comportamento chave de toda pessoa desenvolvedora experiente é escrever código para pessoas em vez de para computadores.
Outras oportunidades para refatoração após escrever o código podem aparecer durante um Code Review.
O que testes têm a ver com refatoração?
A definição que o livro dá sobre refatoração é: alterar um código sem mudar o seu comportamento observável.
Eu só conheço uma forma de provar que o software não passou a se comportar de forma diferente: através de testes. De preferência, testes automatizados.
É essencial que um código esteja coberto com testes antes de passar por uma refatoração. Do contrário você pode estar introduzindo bugs silenciosos sem sequer saber.
👉 Se você não tinha cobertura de testes antes de refatorar, você não está fazendo uma refatoração mas sim uma reescrita.
Refatorar sempre, em pequenos passos
Em resumo, devemos refatorar sempre que possível. Refatorar antes de escrever um código para que este possa receber as nossas alterações sem muita dificuldade, e depois de escrever um código como quem dá um acabamento ao trabalho.
Como eu comentei no artigo sobre como evitar programar por coincidência, a refatoração é o mise en place da pessoa programadora. Não deveria ser opcional, mas sim parte do nosso fluxo normal de trabalho.
É importante notar que o code review pode ficar muito confuso quando muitas alterações são feitas por conta de refatoração. Minha recomendação é refatorar sempre em pequenos passos, e testar o software após cada passo. O ideal é fazer um commit para cada refatoração aplicada.
👉 Para cada refatoração, faça um commit. Isso te ajuda a se organizar e a organizar o Code Review mais tarde.
Críticas ao livro Refactoring, por Martin Fowler
Todos sabemos que Martin Fowler é uma referência internacional quando se fala de desenvolvimento de software, mas ninguém é infalível.
Aqui, eu deixo algumas críticas minhas sobre o livro: são pontos de divergência ou apenas comentários que eu tenho e acho importante prestarmos atenção.
Quando falamos de desenvolvimento de software, quase tudo depende. Então é importante manter estas críticas em mente para evitar dogmatismo em torno do tema.
Definição de refatoração ao pé da letra não dá
Como eu comentei anteriormente, refatoração pode acontecer em diferentes níveis de abstração. Alterar a assinatura de uma função é considerado reescrita naquele escopo, mas ao observarmos um módulo pode ser considerado refatoração.
Da mesma forma, é possível reescrever partes de um módulo enquanto fazemos uma refatoração a nível de API REST.
O importante aqui é sempre refatorar somente com cobertura de testes e a pequenos passos incrementais. Quanto maior o seu nível de abstração, mais importante é mover-se a passos pequenos.
O que eu devo dizer ao meu gerente?
O livro diz brevemente como você, enquanto pessoa desenvolvedora, deveria justificar o tempo gasto em refatoração ao gerente/cliente. Afinal, refatoração consome mais tempo do que simplesmente escrever a sua funcionalidade.
O livro nos instrui a simplesmente omitir a refatoração ao nosso cliente. "O que dizer? Nada!". A justificativa do livro é que a refatoração vai facilitar a preparação do ambiente para que você faça as alterações que precisa.
Enquanto eu concordo com a justificativa, eu discordo sobre precisarmos nos calar sobre o esforço de refatoração. Da mesma forma como um profissional de saúde precisa usar máscara e luvas, nós precisamos refatorar.
Como já eu escrevi antes, refatoração é o mese en place da pessoa programadora. Não há necessidade de justificar a necessidade de refatorar um código, mas é necessário falar sobre e encorajar outras pessoas a fazerem o mesmo.
Dados duvidosos
Apesar de o livro trazer uma retórica bem convincente sobre refatoração, motivos para adotar a prática e como convencer seus colegas, a amostragem de dados é no mínimo... duvidosa.
No capítulo 2, o autor mostra um gráfico onde compara o montante de funcionalidades entregues com o tempo em projetos com bom design vs. projetos com mal design. De acordo com o gráfico, projetos com bom design tem crescimento linear, projetos com mal design têm uma tendência quase constante de entregas.

Mas o autor não apresenta nenhum dado concreto ou explica como chegou àquele gráfico.
Pessoalmente eu não vejo muito problema sobre falta de dados, as práticas se justificam por si só. Mas na minha opinião, toda pessoa quando falar sobre engenharia de software, deveria evitar fazer afirmações desta natureza sem dados concretos e disponíveis.
O que fazer com códigos legados?
O autor não dá muita informação sobre como lidar com sistemas legados e indica o livro Working Effectively with Legacy Code.
Na minha opinião esta indicação é horrível. Este livro é terrível e induz quem lê a fazer exatamente o contrário de refatorar: dar manutenção ao mal design do sistema.
Eu recomendo a leitura crítica do livro Working Effectively with Legacy Code, não acho que devemos ignorar esta literatura. Mas tenho MUITAS ressalvas com este título e recomendo atenção dobrada ao aplicar as dicas descritas nele.
Um exemplo mais em linha com o livro Refactoring, na minha opinião, é o livro Modernizing Legacy PHP Applications do Paul M. Jones. Apesar de ser específico à aplicações PHP, o livro adota uma prática 100% em linha com a descrita pelo livro Refactoring: pequenas alterações, modernização do design e pragmatismo.

Eu acho especialmente estranha a indicação do livro Working Effectively with Legacy Code porque o Martin Fowler já escreveu sobre StranglerFigApplication antes, uma forma de evoluir o design da aplicação como um todo.
Desmistificação do argumento da performance
Eu achei bacana que o livro buscou desmistificar o argumento da performance a todo custo. Já vi muito code review ser recusado por códigos como o seguinte:
lista.map(...).map(...).filter(...)
A justificativa? O map itera a lista inteira, encadear dois maps é ruim para a performance a lista inteira vai ser percorrida duas vezes. E o filter ao final vai reduzir o número de itens na lista. Seria ideal colocar o filter primeiro para que a lista inteira seja menor antes do map.
Faz sentido, mas dependendo do tipo de dado que o código está lidando, não faz nenhuma diferença na prática. Performance importa, mas micro otimizações podem ser ignoradas em favor de legibilidade de código.
Mas é importante não levar isto como dogma (dogmas em geral são ruins, principalmente em desenvolvimento de software). Performance é importante e as vezes uma refatoração pode causar danos imensos em termos de performance.
Busque o equilíbrio. Mas não aceite um code review recusado que use performance como desculpa sem trazer dados. Se a discrepância de performance estiver na magnitude dos nanossegundos, quase sempre pode-se ignorar com segurança a recomendação de melhoria performance.
Uma refatoração pode desfazer a outra, e tudo bem
Algo que o livro menciona brevemente mas eu acho importante destacar é que as vezes uma refatoração vai desfazer o que outra refatoração fez antes. E isto é normal.
A refatoração é um mecanismo que te ajuda a preparar o ambiente para receber seu código. Se voltar ao estado anterior é melhor para receber seu código, então voltemos ao estado anterior sem medo ou vergonha.
Considerações finais
O livro Refactoring, do Martin Fowler, é um dos livros base para toda pessoa programadora. Se você puder levar um único parágrafo deste texto todo contigo, leve este:
Para refatorar, é essencial ter cobertura de testes. Refatore antes de alterar o software. Refatore depois de alterar o software. Encoraje outras pessoas a fazer o mesmo!
E, claro, leia o livro e tire suas próprias conclusões.
Neste artigo eu mencionei três livros. Aqui os links para cada um:
-
Refactoring: Improving the Design of Existing Code, por Martin Fowler
- Working Effectively with Legacy Code, por Michael Feathers
- Modernizing Legacy Applications in PHP, por Paul M. Jones
Até a próxima! 👋
]]>

A linguagem JavaScript é conhecida por executar de forma assíncrona, apesar de não oferecer suporte direto a multithreading. O mecanismo que habilita este comportamento da linguagem é o Event Loop, que eu vou explicar melhor sobre neste post.
O ambiente NodeJS em si utiliza diferentes threads internamente, mas este mecanismo não é exposto via JavaScript. Para aprender sobre as diferentes threads do NodeJS, dá uma olhada neste outro artigo sobre como funciona o motor V8.
As minhas duas referências para escrever este post foram a documentação oficial do NodeJS e o livro Distributed Systems with Node.js, do Thomas Hunter e publicado pela O'Reilly.
Código bloqueante e não bloqueante? Hã?
Deixa eu explicar um pouquinho melhor o que é uma operação de E/S e qual a diferença entre esta operação ser bloqueante ou não bloqueante.
Operações de Entrada e Saída (E/S) são todas as operações que não dependem somente do Processador (CPU) e memória. Toda interação com o disco rígido, teclado, mouse, internet, bluetooth... todas essas interações são consideradas operações de E/S.
Naturalmente toda operação de E/S demoram um tempo consideravelmente maior do que operações "puras" que dependem somente da CPU.
Vamos imaginar um programa que executa duas operações: Operação A e Operação B. A Operação A leva um pouquinho mais tempo para finalizar em comparação à Operação B e as duas são executadas em sequência. Veja:

Agora vamos considerar que a Operação A na verdade demora mais tempo para executar porque precisa escrever num arquivo chamado arquivo.txt, uma operação de E/S representada pela sub-rotina Escrever "arquivo.txt" na próxima figura:

Note que a Operação A depende de que a sub-rotina chegue ao seu fim para poder ser finalizada, e que de toda forma Operação B só é executada depois de tudo isso.
Este esquema pode ser considerado bloqueante porque a Operação A fica "bloqueada", aguardando o resultado da sub-rotina Escrever "arquivo.txt" e nada além disso é executado. Uma representação mais justa ficaria assim:

Acontece que, como eu mencionei antes, a sub-rotina Escrever "arquivo.txt" não depende tão somente da CPU. Na realidade a menor parte do tempo desta operação se dá em tempo de CPU, enquanto a maior parte do tempo é gasta em periféricos.
Uma outra forma de resolver este problema é permitir que a CPU execute diferentes operações enquanto aguarda a resposta do hardware de E/S. Esta forma é chamada de não bloqueante e é mais ou menos como na imagem a seguir:

Inicialmente a Operação A solicita uma operação de E/S e delega ao Sistema Operacional para que lide com aquela operação. Desta forma o processo está livre para executar outras operações, e imediatamente começa a executar a Operação B. Finalmente o Sistema Operacional nos informa que a operação de E/S finalizou, e podemos retomar o restante da Operação A que havia sido interrompida.
Este modelo, onde uma operação de E/S não precisa segurar a aplicação inteira, é chamado de E/S não bloqueante – ou non-blocking I/O, em inglês.
É natural pensar que uma aplicação não possui apenas 2 operações, mas sim milhares delas. Gerenciar tudo isso não é uma tarefa trivial e muito menos uma tarefa que você deva se preocupar em resolver todas as vezes.
O motor V8 e, por conseguinte, o ambiente Node.js resolvem o problema de gerenciamento destas tarefas e suas interrupções através de um mecanismo chamado Event Loop.
O que é o Event Loop?
O Event Loop é um mecanismo que agrega diversas filas internas e threads para otimizar o processamento e toma proveito de técnicas como E/S não bloqueante e sinais do sistema operacional.
O Event Loop no motor V8 mantém um thread principal que gerencia várias filas e determina quais operações devem executar em que momentos. Quando necessário executar uma operação mais custosa, como uma operação de E/S, a thread principal então solicita uma nova thread para cuidar daquela operação.
Eu tentei ilustrar este mecanismo no GIF abaixo:

Esta é uma representação ultra simplificada da coisa toda, mas serve para ilustrar mais ou menos o que o Event Loop faz.
O event loop possui diferentes filas com callbacks (funções) e gerencia quando determinada função nestas filas deveria executar.
Mas eu não quero manter essa explicação superficial (e parcialmente errada). Vamos dar uma olhadinha na forma como o Event Loop funciona.
As 5 fases do Event Loop
Quando um processo Node.js é inicializado, o Event Loop começa. Dentro de um script várias chamadas a funções, chamadas assíncronas, timers e outros tipos de chamadas podem acontecer.
Como o nome sugere, o Event Loop é na verdade um loop infinito (while true mesmo) que a cada iteração tenta executar um pouquinho de cada fila diferente. Há 5 fases distintas que o Event Loop trata a cada iteração.
Uma visualização mega simplificada (e incorreta) e didática do Event Loop é a seguinte:
while (true) {
poll()
check()
close()
timers()
pending()
}
Cada função chamada alí representa uma fase da iteração do Event Loop. Abaixo eu descrevo com mais detalhes o que cada fase faz. Mas por enquanto, este infográfico já deve te ajudar a entender um pouco o que tá rolando:

Cada uma das fases acima possui uma fila de callbacks. Quando a fase se inicia, Node.js tenta executar todos os callbacks daquela fila: até que a fila fique vazia ou até que o número máximo de callbacks por iteração já tenham executado.
Algo assim:
function poll() {
let maxIterations = 10 // número aleatório que eu escolhi
while (maxIterations--) {
runNextCallback()
}
// fim da fase Poll
}
Cada fase possui filas, lógicas e parâmetros diferentes. Vamos dar uma olhada em cada delas uma agora.
Importante: existe um tempo limite que o Node.js pode gastar entre cada fase e, quando este limite é atingido, avançamos diretamente para a próxima fase.
timers
Um timer define um intervalo a partir do qual um código será executado.
Por exemplo, o código setTimeout(() => console.log('Hello, world'), 1000) garante que o "Hello, world" será jogado no console, no mínimo, daqui a 1000ms. Mas não oferece nenhuma garantia de que executará exatamente daqui a 1000ms.
Em situações normais estes timers executam no tempo especificado, mas outros callbacks podem interferir no tempo que leva para iniciar um timer.
Há dois tipos de callbacks que entram na fila dos timers: timeouts e intervals.
O timeout agenda uma função para ser executada uma vez no futuro. Enquanto o interval agenda uma função para ser executada infinitamente num intervalo definido.
Aqui um exemplo de timeout e interval:
setTimeout(() => {
console.log('Hello, timeout')
}, 1000)
let i = 0
setInterval(() => {
console.log(`Hello, interval: ${i}`)
i++
}, 1000)
O snippet acima produziria a seguinte saída:
1s: Hello, timeout
1s: Hello, interval: 0
2s: Hello, interval: 1
3s: Hello, interval: 2
...
pending
Esta fase executa os callbacks para algumas operações de sistema. Por exemplo quando um socket TCP recebe ECONNREFUSED ao tentar se conectar, o seu respectivo callback será invocado. É nesta fase que este callback é invocado.
poll
Nesta fase o Node.js vai solicitar (poll) ao Sistema Operacional as operações de E/S que já estão prontas para serem processadas.
O código que você escreve em JavaScript normalmente é executado nesta fase!
A partir disso, executa os callbacks destas operações prontas até a fila ficar vazia OU até atingir o limite máximo de tempo nesta fase.
Ao finalizar esta fase, o event loop invoca a fase check.
check
Esta fase executa um único tipo de callback: os callbacks agendados pela função setImmediate().
É como se fosse um timer, mas com sua própria fila e alta prioridade de execução logo após a fase poll.
close
Esta fase gerencia conexões que foram fechadas de repente, como quando um socket se fecha. O evento close é emitido nesta fase.
A fase escondida: process.nextTick()
Existe um mecanismo que eu não descrevi aqui mas que é importante explicar. É o process.nextTick().
A forma como utilizamos é parecida com o setImmediate():
process.nextTick(() => {
// ...
})
Mas há uma diferença fundamental: process.nextTick() opera numa fila própria, a nextTickQueue. E executa os callbacks desta fila imediatamente depois de cada fase.
Corrigindo o snippet anterior sobre o event loop, poderíamos representar o process.nextTick() desta forma:
while (true) {
poll()
nextTick()
check()
nextTick()
close()
nextTick()
timers()
nextTick()
pending()
nextTick()
}
Portanto é importante sempre tomar MUITO cuidado ao utilizar process.nextTick(). Se você rodar alguma lógica pesada, ou gerar recursão nesta fase, pode tirar um tempo precioso que seria utilizado pelas outras fases.
A não ser que você saiba bem o que está fazendo e tenha um ótimo motivo, prefira usar setImmediate() em vez de process.nextTick().
Conclusão
O motor V8, e por conseguinte, o Node.js utilizam um mecanismo chamado Event Loop pra gerenciar diversas filas de callbacks que são executados em 5 fases diferentes: poll, check, close, timers e pending.
Além disso, para executar operações de Entrada e Saída, outras threads são utilizadas, aumentando o número de processos que podem ser executados em paralelo.
Este foi mais um artigo da série de estudos que eu tenho feito sobre o ecossistema Node.js. E apesar de o conteúdo não dar trabalho, estes gráficos e GIFs todos deram um trabalhão!
Você pode me ajudar compartilhando este artigo nas suas redes sociais. Caso queira compartilhar as imagens, dê também um link pra este artigo.
Até a próxima! 👋
]]>
O livro "Programador Pragmático" escrito por David Thomas e Andrew Hunt trás um conceito chave que eu acho essencial passar para frente, especialmente para quem está iniciando: a programação por coincidência.
Eu não recomendo ler e confiar neste livro cegamente, tenho várias ressalvas sobre o conteúdo e, sinceramente, acho que o pouco conteúdo útil do livro é explicado de forma burra. Talvez num futuro eu faça uma resenha sobre este livro especificamente.
Colocando isto de lado, o conceito de programação por coincidência que o livro trás é muito bom e é algo que eu recomendo a todas pessoas iniciando na área de desenvolvimento de software a aprender sobre.
O que é programar por coincidência?
Já passou por esta situação onde você se envolveu tanto com o código que já tem trocentas abas abertas no seu editor de texto, perdeu a noção de o que o arquivo atual faz e então resolve colocar o famoso echo e rodar o programa de novo pra entender onde está.

Atitudes como "deixa eu trocar esta linha por aquela" ou "deixa eu ver se isso aqui funciona" são claros sintomas de que você está programando por coincidência.
Programar por coincidência é alterar algum código ou configuração sem ter a menor ideia de o que aquilo vai causar. Em outras palavras:
Programar por coincidência é escrever código sem uma intenção concreta.
Programar com intenção, saber exatamente o que você quer alcançar com aquelas linhas de código, é o primeiro passo para escrever para humanos, como pessoas mais experientes fazem.
Mas se eu entreguei a tarefa, qual o problema?
O problema de programar por coincidência, ou sem intenção, é que isto gasta muito tempo e energia desnecessariamente. Para a empresa funciona bem, mas para você é uma porcaria!
Alguns dos problemas que eu vejo em programar por coincidência, especialmente para quem tem menos experiência:
- muito esforço e energia desperdiçados;
- dificuldade no aprendizado no longo prazo;
- falta de confiança na solução final;
- dificuldade na hora de pedir ajuda ou justificar suas decisões numa revisão de código
Em geral, programar por coincidência só tende a te fazer mal. O único benefício que eu vejo é que, depois de sofrer tantas horas pra resolver um problema, a vitória é doce.
Mas cuidado, este é um caminho perigoso e pode te custar muito tempo e saúde mental.
Como programar por intenção e não por coincidência?
Existe algumas técnicas que podem te ajudar a programar com maior intencionalidade em vez de por coincidência e palpites. Eu vou mostrar 6 delas aqui.
Lembre-se que quase toda verdade em desenvolvimento de software nunca é absoluta, e pode ser respondida com um belo "depende".
Então não tome este texto como uma série de dogmas a serem seguidos, mas eu garanto que ao adotar ao menos uma destas dicas você já vai conseguir evoluir melhor na sua carreira.
1 - Entenda os seu requisitos antes de aplicar uma solução
Para muita gente isso parece óbvio, mas é muito comum entre iniciantes ler uma tarefa/problema/bug e já sair marretando o código pra tentar resolver.
Como já disse o Rei do Kuduro, neum fésse eisso!
Assim que você identificar o problema, a primeira coisa que você precisa entender é: quais são os sinais que me dizem se eu atingi meu objetivo ou não?
Por exemplo, um problema que o codamos.com.br tem atualmente é que nós não oferecemos uma Newsletter. A solução para este problema não é adotar um servidor, pagar um serviço de disparo de e-mails e nem escrever a newsletter. A solução é oferecer uma newsletter.
Note nuance da resposta! Ela deixa explícito o que precisa ser feito, não o como precisa ser feito.
E este é o primeiro e mais importante passo de todos. Você precisa entender qual resultado desejado. Enquanto este resultado não for verdade, a sua solução não resolve o problema.
O próximo passo é quebrar a sua solução em vários pedacinhos independentes.
2 - Quebre sua tarefa em várias partes menores
Isto também deve acontecer antes de escrever qualquer linha de código. É ideal planejar o que você vai fazer antes de começar a codificar.
O plano nem sempre vai ser executado 100% como você imaginou, mas saber por onde começar é essencial!

A metáfora do lenhador se encaixa bem aqui: você pode cortar uma árvore em 6 horas de esforço com o machado do jeito que está, ou investir 2 horas afiando o machado e cortar a árvore em apenas 1 hora.
Não corte árvores, tá? O ponto aqui é: coloque mais esforço no seu plano antes de agir e isso vai te salvar tempo, energia e saúde mental!
Pegue um bloco de notas, notas adesivas ou um programa de tarefas e escreva o seu plano de ação. Dê uma olhada no código e anote quais partes do código você vai precisar alterar. Isso ajuda muito a executar a correção depois.
Abaixo eu mostro uma tarefa que eu executei recentemente na minha empresa, olha como eu preparei antes de codificar qualquer coisa. Eu basicamente olhei os requisitos, procurei no código o que eu preciso fazer, onde e anotei lá:
Problema:
Os posts de "press release" ficam dentro do Wordpress e não são disponíveis no nosso site.
Solução:
Disponibilizar os posts de "press release" no nosso site.
Requisitos:
- Adicionar uma rota "/press/{slug}" que mostra o mesmo conteúdo de "/blog/post/{slug}" no Wordpress, mostrar apenas posts na categoria "press release"
- Redirecionar para "/press" se o post não existir ou não pertencer à categoria "press release"
- Adicionar uma rota "/press-releases" que mostra o mesmo conteúdo de "/blog/category/press-release" no Wordpress
Como executar:
- Adicionar rota "/press/{slug}". Ver BlogDetail.php:36
- Adicionar rota "/press-releases". Ver BlogOverview.php:31
- Adicionar redirecionamento para posts fora de "press release". Ver BlogDetail.php:197
- Modificar links canônicos. Ver BlogDetail.php:169
Preparar uma lista desta leva cerca de 20 minutos, e vai guiar o seu desenvolvimento como uma flecha em direção ao centro do alvo 🎯 !
Note que simplesmente por saber "como executar" uma coisa você já não precisa abrir trocentos mil arquivos. Sabemos exatamente quais arquivos abrir e onde olhar.
Siga esta lista item a item, em ordem e sem misturar. Você vai ver como seu fluxo de desenvolvimento vai ficar bem menos confuso! 😉
3 - Refatoração em primeiro lugar!
Refatorar é alterar um código sem mudar seu resultado. Eu escrevi aqui um artigo bem detalhado sobre o livro que original o termo: Refactoring, por Martin Fowler.
Por exemplo, transformar este código (que não faz o menor sentido):
function sum(int a, int b): int {
for (int i = 0; i < b; i++) {
a++;
}
return a;
}
Neste código:
function sum(int a, int b): int {
return a + b;
}
Isto é uma refatoração. Porque mudamos o corpo da função, mas não mudamos os parâmetros e nem o resultado. (Quem tá prestando atenção sabe que a gente quebrou uma lógica aí, mas vou deixar em aberto)
Note como o primeiro snippet de código é bem mais confuso e, de certa forma, desnecessário.
Às vezes nós escrevemos código assim sem perceber. Coisas que poderiam ser muito mais simples acabam sendo feitas de forma complicada. E é normal, não significa que você seja um mau profissional por escrever código assim.
Mas é exatamente por conta deste comportamento que nós precisamos programar sempre de forma defensiva e preparar o ambiente antes de trabalhar.

Chefs de cozinha têm um nome especial para esta preparação antes do trabalho. É o tal do mise en place.
O nome é chatinho, mas a prática faz todo sentido. Se você for cortar e limpar tudo na hora que precisar, sua cozinha vai ficar um caos.
Mas se tudo estiver preparadinho e antes de montar o prato, a execução em si vai ser simples e rápida e você vai poder focar no que importa.
Nós, que trabalhamos com desenvolvimento de software, também precisamos de um mise en place. O nosso se chama refatoração!
É claro que metáforas são imprecisas em certos pontos, mas esta aqui vai te ajudar a criar uma imagem sobre refatoração que é importantíssima: não é algo "a mais" que você faz mas sim algo essencial pra começar a trabalhar.
Refatoração é o mise en place da pessoa programadora.
A minha dica aqui é: antes de trabalhar numa determinada classe, função ou pedaço da aplicação, faça uma refatoração de leve na intenção de entender melhor aquele código.
Desta forma você vai entender melhor o código antes de escrever alguma coisa, vai ter um ambiente pronto pra trabalhar e, de quebra, vai deixar o código num estado melhor para a próxima pessoa que o visitar. Provavelmente será você mesmo, então refatore pelo seu próprio bem 😉
4 - Refatoração sem testes não é refatoração
Essa ideia de preparar o ambiente é linda, mas o fato é que as vezes nós mudamos uma determinada lógica, uma vírgula e o sistema todo pode entrar em colapso.
Como eu disse antes, refatorar é alterar um código sem mudar seu resultado. Como provar que a mudança que fizemos no código não alterou seu resultado?
Com testes!
De preferência, com testes automatizados. Vamos retomar o exemplo anterior e escrever alguns testes:
Teste 01: positivos
Ao chamar a função sum() com os valores 10 e 20, meu retorno deverá ser 30.
Teste 02: negativos
Ao chamar a função sum() com os valores -10 e -5, meu retorno deverá ser -15.
Teste 03: positivos e negativos
Ao chamar a função sum() com os valores 10 e -5, meu retorno deverá ser 5.
Note que eu não preciso de uma ferramenta específica para escrever testes. O foco é entender que dado algum tipo de entrada, eu espero que a minha função faça algum processamento e gere algum tipo de saída.
Se antes de começar a refatorar os testes estavam passando, ao terminar de refatorar eles devem continuar passando.
O ideal, é claro, é que você utilize uma ferramenta de automação de testes como o PHPUnit ou Jest.
Se você já possui testes, refatore. Se não possui, crie testes primeiro e depois refatore.
5 - Testes são sua melhor ferramenta de apoio
Eu já escrevi alguns artigos sobre como testes podem te ajudar em diferentes aspectos da sua carreira. Desde como aprender linguagens de programação novas usando TDL até como escrever código de forma segura e assertiva com TDD.
O principal ponto aqui é que quando a gente escreve um teste, nos forçamos a pensar sobre o resultado antes mesmo da implementação.
Quanto mais você praticar e escrever testes, mais natural vai ser programar por intenção em vez de por coincidência.
Além disso, um teste bem escrito também serve como guia para a próxima pessoa que precisar entender aquele pedaço de código ou como usar aquela função.
6 - Refatore após terminar de codificar sua funcionalidade
Se você já fez uma refatoração antes de codificar, deve entender bem o que o código faz.
Se ao fazer a refatoração e implementar a funcionalidade do jeito que precisava os testes continuam passando, sua tarefa está quase pronta para ser entregue: precisa ser finalizada com uma bela refatoração!
Lembre-se: pessoas programadoras mais experientes escrevem código para pessoas, não para computadores.
Agora que seus testes estão passando, dê aquela polida no código para que fique mais fácil entender. A próxima pessoa que ler seu código vai ficar agradecida. Lembre-se que esta pessoa provavelmente será você mesmo 😉
Ao finalizar uma entrega, refatore o seu código para facilitar a vida de quem vai fazer a revisão.
Se você refatorar o código pensando em quem vai revisar, com total certeza vai fazer com que seja mais fácil de ser lido por um humano.
Conclusão

Caso não tenha ficado claro, deixemos claro aqui: programar por coincidência é ruim! Isto vai atrasar a sua vida, a sua carreira e o seu time.
Adote as 6 dicas que mencionei no texto e vai notar como programar vai ficar bem mais fácil pra ti!
Sempre que escrever algum trecho de código, faça o máximo esforço possível para entender a intenção do código que quer escrever.
]]>
A Lacrei é o primeiro portal criado para conectar a comunidade LGBTQIA+ a profissionais de saúde, advogades e empresas que respeitam a diversidade oferecendo oportunidades de trabalho e desenvolvimento profissional.
A plataforma facilita o contato e a informação para que pessoas LGBTQIAP+ possam encontrar, de forma prática e segura, serviços profissionais, acolhedores e inclusivos, de forma fácil e digital. Aqui, profissionais e empresas falam a nossa língua e escutam o que temos a dizer.


Em parceria com o blog Codamos, a Lacrei anuncia vagas de tecnologia para voluntariado em 4 áreas diferentes. São oportunidades incríveis para praticar suas habilidades e desenvolver seu portfólio com uma carga horária acessível e 100% remoto.
Todas vagas possuem carga horária de 10 horas semanais e são 100% remotas, para trabalhar com times que buscam diversidade
Vaga para Liderança técnica (Tech Lead)
As vagas são para candidatas mulheres, comunidade negra e comunidade LGBTQIAPN+.
A pessoa Tech Lead na Lacrei é uma pessoa técnica podendo ter atuação prática, pondo a mão na massa, apesar de liderar o time de desenvolvedores da Lacrei.

São dois times: um de back end e outro de front end, que se encontram semanalmente e participam de uma das 3 squads. São aproximadamente 25 pessoas voluntárias desenvolvedoras, em times multidisciplinares com pessoas de UX/UI, Front e Back -end.
Neste papel você terá a oportunidade de melhorar suas habilidades como pessoa programadora ao mesmo tempo que desenvolve aspectos de liderança. Nossos times utilizam a metodologia Scrum.
Parte de suas responsabilidades como Tech Lead é trazer as novidades tecnológicas e jeitos diferentes de resolver problemas de forma mais eficiente.
Além disso, a expectativa é que ela consiga manter o time focado no que precisa ser feito, priorize corretamente as atividades e entregue resultados tirando o melhor de cada membro do time.
Clique aqui para inscrever-se.
Vaga para Front-end (ReactJS)
As vagas são para candidatas mulheres, comunidade negra e comunidade LGBTQIAPN+.
Utilizamos a metodologia Scrum e atuamos juntamente com os times de UX/UI Design e Back-end dentro das Squads sempre com a supervisão das nossas Products Owners.

Nossa atividade voluntária compreende também a conversar com outras pessoas voluntárias, sua coordenadora e com sua Product Owner e comparecer virtualmente nas reuniões estipuladas.
Sendo assim, você deverá compreender a importância da Lacrei, ser empático com a comunidade e treinar a sua comunicação.
Times e Horários
Squad Institucional: Terça das 19 horas as 20 horas e Quarta das 19 as 20 horas.
Squad Jornada da Pessoa Profissional: Horários: Terça e Quarta das 19 às 20 horas.
Squad Jornada da Pessoa Usuária: Segunda das 19 as 20 horas e Quarta das 19 as 20 horas.
Requisitos
- NPM ou Yarn
- ReactJS e Gatsby
- Styled Components
- Consumir APIs
- Familiaridade com Git
Clique aqui para inscrever-se.
Vaga para Back-end (Python)
As vagas são para candidatas mulheres, comunidade negra e comunidade LGBTQIAPN+.
Python é uma linguagem de programação de alto nível, ou seja, com sintaxe mais simplificada e próxima da linguagem humana, utilizada nas mais diversas aplicações, como desktop, web, servidores e ciência de dados.
Hoje utilizamos outra tecnologia e estamos te convidando para fazer essa migração, aceita esse desafio!?

Requisitos
- Python
- Django
- PostgreSQL
- Testes unitários
Clique aqui para inscrever-se.
Vaga para profissional de Inteligência Artificial
As vagas são para candidatas mulheres, comunidade negra e comunidade LGBTQIAPN+.
Na plataforma Lacrei há vários filtros que uma pessoa usuária pode querer aplicar, e para oferecer uma experiência melhor desenvolvemos o nosso próprio algoritmo para extrair entidades de termos de busca usando o modelo Bert NER.

Estamos buscando programadoras de Inteligência Artificial e Aprendizado de Máquina para nos ajudar nessa caminhada.
Precisamos de alguém para criar e aperfeiçoar nosso algoritmo de Processamento de Linguagem Natural para extração de entidades, e essa é a sua tarefa nesse time.
Clique aqui para inscrever-se.
Se você quiser ajudar esta iniciativa mas não pode contribuir com tempo, compartilhe este post em suas redes - já serve de grande ajuda para o projeto!
]]>
A área de desenvolvimento de software é um tanto quanto peculiar quando se trata de fundamentos e verdades absolutas: são poucas as frases de efeito que são aceitas por unanimidade e não são seguidas daquele poderoso depende.
Um dos poucos fundamentos que normalmente sobrevive discussões é sobre a importância da estilização do seu código. É claro que há muita discordância e treta pela internet sobre qual estilo usar, mas ao menos todo mundo concorda que estilizar o código é essencial em diversos casos.
Este artigo não vai te apresentar nenhuma visão sobre qual estilo de código é o melhor, ou criticar estilos existentes. A minha intenção é munir você, dev júnior, com as ferramentas básicas que vão te ajudar a entender a importância da estilização de código e como isto vai afetar o seu aprendizado daqui pra frente - até o fim da sua carreira.
Dev júnior escreve pra computadores, dev sênior escreve pra pessoas
O motivo principal de eu escrever este artigo é que depois de várias sessões de mentoria com iniciantes tanto no front-end quanto no back-end percebi que muitas das confusões e dificuldades que essas pessoas tiveram poderiam ser mitigadas com a adoção de algumas boas práticas sobre estilo de código.
Eu já perdi a conta do número de sessões em que mentorandes chegaram para mim com quilos e mais quilos de código para resolver problemas simples, sem entender o que aquele espaguete estava fazendo. Ao mesmo tempo, já compartilhei códigos super complexos que qualquer júnior com o mínimo de conhecimento consegue entender e modificar.
A diferença é simples: dev júnior costuma escrever código que máquinas apenas entendem, enquanto dev sênior costuma escrever código para que pessoas entendam.

O maior erro de quem inicia na programação é achar que a forma como se escreve código não faz diferença. Vejamos um exemplo:
const words = ['Hello', 'world']
let sentence = ''
for (const i in words) {
sentence = sentence.concat(words[i])
if (i < words.length - 1) sentence = sentence.concat(', ')
}
console.log(sentence)
O código acima deverá cuspir na tela o valor Hello, world e nada mais, certo? Errado!
O código acima cria três variáveis e deixa duas delas no escopo local, sem contar no montante de operações desnecessárias. Na verdade, o código acima poderia ser simplificado para algo assim:
const sentence = ['Hello', 'world'].join(', ')
console.log(sentence)
E aqui eu deixo claro o seguinte: código complexo é diferente de código complicado!
Uma boa definição de complicado que se adequa ao que quero dizer, lá do dicio, é algo "Exageradamente detalhado; que possui elementos em demasia [...]".
Enquanto a definição de complexo por lá nos diz que é uma "Construção com inúmeras partes que estão ligadas entre si, formando um todo [...]". O que a gente considera engenhoso, na minha opinião. Que é justamente o que a nossa profissão se propõe a fazer.
A primeira chavinha que eu quero te ajudar a virar, dev júnior, é a de entender que código complicado vale menos do que código complexo. Código bom é o que nós dois conseguimos ler!
Abaixo eu vou descrever um pouco mais sobre o porquê de ser essencial você aprender a estilizar código desde já!
Estilizar o código te ajuda a pedir ajuda
Vamos partir de um pressuposto simples: "Hey, me ajuda!" é bem diferente de "Hey, faz pra mim?". Por isso o jeito certo de pedir ajuda é reduzir o problema ao máximo possível.
Uma das grandes fontes de confusão e dificuldade na hora de pedir ajuda, é localizar o problema. Vamos ver um exemplo?
/**
* Hey, me ajuda? O compilador diz que deu pau na linha 2
*/
1. ((function(){console.log( a + 1 / 100
2. );}
É somente natural que você não entenda onde está o problema. Eu mesmo não faço a menor ideia de o que tá acontecendo ali.
Com o código um pouco mais organizado talvez você nem precise pedir ajuda. Vamos isolar cada bloco em sua própria linha e ver o que aconteceu:
1. (
2. (
3. function () {
4. console.log(a + 1 / 100)
5. // ...
Depois da linha 5 ficou claro que faltaram alguns parênteses e chaves. Uma chave } para fechar o escopo da função, dois parênteses pra fechar a expressão das linhas 1 e 2.
Estilizar seu código vai te ajudar a entender o que VOCÊ está fazendo em primeiro lugar. E torna muito mais fácil para outras pessoas te ajudarem mais tarde.

Como dizia minha incrível mãe: casa simples não é desculpa pra ser suja. Eu espero que você adote isso como uma regra de etiqueta: pedir ajuda com um código porco e mal formatado é uma falta de respeito enorme. Sempre mantenha a casa limpa!
Espero que tenha ficado clara a importância de estilizar o seu código enquanto iniciante no mundo da programação. Agora vem comigo, que eu vou te explicar o que eu quero dizer com estilo de código.
O que é estilo de código
A metáfora da casa limpa se aplica muito bem aqui. No fim das contas você, e qualquer outra pessoa desenvolvedora, deveria ser capaz de navegar no código que escrevem com facilidade.
O estilo de código adota regras que afetam vários aspectos do seu software. Algumas destas regras são sobre:
- estilo de formatação;
- regras de indentação de código;
- regras para quebra de linha;
- limite de caracteres por linha;
- nomenclatura de variáveis, funções, classes e métodos;
- organização em pastas e nomes de arquivos;
- outras boas práticas
Não adianta apenas adotar um estilo de código. É importante ser consistente com aquele estilo.
Por exemplo, se você indentou um arquivo JavaScript com 2 espaços, o próximo arquivo não pode ser indentado com 4 espaços.
Para o computador, tanto faz se você usa 2 ou 4 espaços para indentar. Mas lembre-se: o computador é só mais um elemento na enorme lista de consumidores do seu código. Escreva código para pessoas, não para computadores!
Quebra de linha tá aí pra ser utilizada
Parece besteira, mas faz toda a diferença!
Gente, nós estamos em 2022! Uma quebra de linha custa o que? 2 bytes? Não tem motivo pra economizar linha, né.
Bora quebrar linha sem dó! Saiu um ponto e vírgula? Dá-lhe enter!
Bate o olho e me diz o que esse código faz:
const primeira = 10; const terceira = 20; const segunda = 30;
console.log(primeira, terceira, segunda, primeira * 2);
Agora bate o olho nesse aqui e me diz o que ele faz:
const primeira = 10;
const terceira = 20;
const segunda = 30;
console.log(
primeira,
terceira,
segunda,
primeira * 2
);
Faz sentido eu quebrar linha até mesmo dentro do console.log? No fim das contas fica mais fácil ler o que eu tô passando pra dentro da função.
A época dos monitores de 320x240 pixels já passou faz tempo, gente. Vamo sem meguelar quebra de linha!

Indentação de código
Indentação é quando a gente afasta o código da margem pra organizar. Quando se abre um bloco de código, normalmente é hora de indentar.
Aqui um código não indentado:
function euOdeioAMinhaVida() {
const motivo = 'Porque eu não indento código!';
if (motivo.length > 100) {
console.log('Mó filosofia do ódio')
}
else
{
console.log('E o motivo é simples:', motivo)
}
}
Um código parecido, mas com indentação:
function euAmoAMinhaVida() {
const motivo = 'Porque eu indento código!';
if (motivo.length > 100) {
console.log('Olha que delícia essa indentação')
} else {
console.log('E o motivo é simples:', motivo)
}
}
No bloco de código do corpo da função euAmoAMinhaVida() eu adicionei uma indentação. Lá dentro tem alguns IFs. Pro bloco de cada IF, eu adicionei mais uma indentação.
Tem gente que se importa sobre o seu código usar Tabulações ou Espaços para indentação. Tem gente que se importa ainda se ao indentar com espaços você usa 2, 4 ou 6 espaços...
Tanto faz!
O importante é indentar o código sempre e ser consistente com seu estilo de indentação. Se começou usando 2 espaços, continua com 2 espaços. E por favor não caia na besteira de indentar um arquivo com 2 espaços, outro com 4, outro com 6 e montar uma salada de indentação. Consistência!
Claro que a indentação por si só não é suficiente para escrever um código bom e que todo mundo vá entender. O Hadouken que o diga:

Ferramentas automatizadas
Daí você me pergunta: tá, mas como eu sei qual o jeito certo de estilizar o código? Tem de quebrar linha no lugar certo, tem de indentar do jeito certo... Onde eu acho isso tudo?
Cada linguagem de programação tem sua comunidade e suas convenções. Você precisa procurar entender a de cada linguagem com que pretende trabalhar.
Para a nossa sorte, existem ferramentas que controlam e dizem pra gente quando algo está errado. Algumas até corrigem o código pra gente!
No mundo JavaScript/TypeScript tem o tal do Eslint. No mundo PHP, tem o PHP Code Sniffer. O Rust tem o rustfmt e por aí vai.
O bom de usar uma ferramenta automatizada, é que você vai desenvolver a "memória muscular" de como escrever código sem precisar decorar milhares de regras pra cada linguagem.
Dica de ouro: sempre que fizer um coding challenge pra passar naquela entrevista, adicione um linter como o eslint ou phpcs. Vai te dar alguns pontos na avaliação 😉.
Escolha de nomes para variáveis e funções
O nome é importante, gente. Vamos combinar aqui: variável a, b ou c não faz o menor sentido a não ser que você esteja fazendo um programa pra solucionar equações de segundo grau! E eu não quero nem ver variável tmp, ein...
Todas as regras que se aplicam a nome de variáveis também se aplicam a classes, métodos e funções.
Vamos combinar três cláusulas pétreas aqui, tá?
- Não abrevie nomes:
fmtnão faz sentido NENHUM! Use o nome completo, não precisa economizar bytes em disco; - Sem nomes sequenciais:
line,line2,line3... Isso é coisa de maluque! Precisa de uma lista? Use uma lista e pronto! - Dê significado semântico pros seus nomes: o nome precisa fazer sentido no contexto em que está inserido. Deixa eu explicar um pouco melhor...
Eu já trabalhei numa empresa que dizia o seguinte: toda variável precisa ter um prefixo que indica o tipo dela. Uma variável var do tipo inteiro se chama iVar, do tipo boolean bVar, do tipo float fica fVar.
Gente, o ano é 2022! Sua IDE e ferramentas de análise estática já vão garantir o tipo de uma variável. Não tem motivo prefixar ou sufixar variável com tipo. Isso não adiciona nenhum sentido semântico.
Agora quer ver como a semântica muda a compreensão de código? Olha aqui:
if (number % 2 === 0) {
// ...
}
O código acima faz exatamente a mesma coisa que este aqui:
const isNumberEven = number % 2 === 0
if (isNumberEven) {
// ...
}
Qual IF você entende com mais facilidade?
Pela semântica, vale tudo! Até criar variável "inútil". Estamos em 2022, você não precisa economizar bits e bytes. Criar uma variável a mais não vai comer sua memória RAM e de quebra vai economizar um tempão de quem lê seu código, inclusive você!
Como mecanizar estas práticas
E a coisa é esta mesmo: mecanizar. Você precisa adotar estas práticas automaticamente, quase sem pensar!
Aqui vão algumas dicas pra não se perder nas regras.
Feche blocos imediatamente depois de abrir
Já se deparou com a situação em que abriu um parêntese, e depois outro, e mais outro e mais outro, e acaba precisando contar parênteses pra saber onde fechar o que?
a + (b * c ( x + y + (d ^ 2)) + 10)
Sai dessa vida, gente... Ficar contando parêntese, pára com isso...
Abriu o parêntese? Fecha imediatamente e continua só depois! Abriu chaves? Fecha imediatamente e continua só depois! Seu código vai te exigir pular linha? Pula a linha primeiro e depois volta pra onde tava!
if () {
}
Sabe esse IF aí em cima? Eu quero que você prometa pra mim que só vai escrever a condição dentro dos parênteses depois que tiver digitado o ).

Cuide primeiro da sintaxe, depois da semântica! Abriu parêntese, fecha imediatamente. Abriu chaves, fecha imediatamente.
A regra dos 80 caracteres
Se tu tiver usando uma tela grande pra ler este texto vai reparar que eu não deixo o texto usar a sua tela toda. Sabe o motivo? Porque tu não iria ler, simples assim.
Linhas longas não são lidas! Quanto maior a linha, menor a atenção que ela vai receber.
Uma regra comum é a de quebrar a linha depois de um limite. Algumas comunidades adotam 80 caracteres, outras 120. Adote um e seja feliz.
A maioria dos editores de código vão te ajudar com isso ao colocar uma linha vertical no meio na sua tela. Se o seu código encostar nesta linha, é hora de quebrar linha.

Agora, atenção ein! Não vai quebrar a linha como quem joga entulho no quintal do vizinho! Se você quebrar linha no contexto de elementos separados por vírgula, dê uma linha para cada elemento.
Não faça isso:
echo sprintf('Minha string %s formatada %d vezes', 'Nawarian',
10);
Faça isso:
echo sprintf(
'Minha string %s formatada %d vezes',
'Nawarian',
10
);
E note que o parêntese que fecha a função sprintf está alinhado verticalmente com o começo da linha que abriu aquele parêntese. Além disso, os parâmetros, cada um em sua linha, estão indentados uma única vez.
Linhas grandes não são lidas, são feias que dói e deveriam te causar repulsa! Quebre a linha sempre que precisar e use uma regra padrão.
Escreva seu código duas vezes
No início da nossa carreira a gente costuma escrever código e se funcionar, funcionou! Segue o jogo.
Você precisa cortar este hábito o quanto antes!
Sempre que você terminar de escrever um código, volte ao começo e leia tudo de novo pra ver se tem algo que você pode deixar mais claro.
Lembre-se: você quer escrever código para outras pessoas lerem, não só para o computador ler.
Uma quebra de linha, um nome de variável melhor, uma modificação na lógica... tudo isso pode ajudar bastante.
Vou te dar um exemplo. Olha o seguinte snippet de um emulador que eu escrevi:
function readZeroPage(): int
{
return $this->bus->read($this->state->pc++) & 0xFF;
}
Sim, estou escrevendo um emulador de Nintendinho 8-bit. Dá uma olhada no meu Devlog sobre como criar um emulador de NES pra aprender como fazer o seu.
O exemplo acima está bem simplificado pra quem entende o domínio. Mas se eu quiser simplificar para que todo mundo possa entender com menos dificuldade, poderia ter algo assim:
function readZeroPage(): int
{
$address = getProgramCounterAddress();
incrementProgramCounter();
$zeroPageValue = $this->bus->read($address);
return asInt8($zeroPageValue);
}
O que é um código bom ou legível é totalmente subjetivo e depende não só de quem lê, mas também do contexto. No caso do desenvolvimento de um emulador de CPU os conceitos de pc, bus, zero page e int8 são bem comuns. Mas é inegável que o segundo exemplo de código explica muito mais sobre o que está acontecendo do que o primeiro.
Depois de escrever seu código - seja uma página, uma função ou um mesmo um IF - releia tudo para identificar se você pode tornar o contexto mais explícito e comunicar a sua intenção com código.
Não escreva código como é ensinado em cursos e faculdades
Existe um problema muito comum com iniciantes que acabaram de ver um curso ou estão na faculdade. O código das pessoas nessa fase normalmente é BEM RUIM de entender.
Isto porque nos cursos nós ensinamos conceitos, métodos e técnicas. O estilo de código fica secundário e dá mais trabalho de ensinar ao mesmo tempo.
Especialmente em faculdades, professores mais velhos - com todo o respeito, nós devemos a modernidade a estes profissionais - adotam costumes que eram comuns há algumas décadas atrás, quando precisávamos economizar espaço a todo custo e conseguíamos parar em frente a um texto por mais de 1 hora sem receber uma notificação de que alguém está tretando no Twitter!
Boa parte das práticas que são adotadas durante cursos (alô variável temp!) precisam ser extintas do seu vocabulário! Absorva o conteúdo, não o estilo!
E pra deixar claro, o problema não são os professores mais velhos. O problema é que professores normalmente não escrevem código profissionalmente há alguns bons anos.
Adote o estilo de profissionais que trabalham com desenvolvimento software, não ensinando desenvolvimento de software. São duas profissões distintas!
O mais importante te tudo: leia código de pessoas mais experientes
Fica claro que se você não pode confiar no código de quem te ensina código, precisamos buscar inspiração noutro lugar.
Como eu disse antes, cada linguagem tem as suas comunidades, convenções e estilos. Cabe a você aprender os estilos que lhe interessam.
Aqui vão algumas dicas de como achar essa inspiração.
Navegue no Github em busca de Pull Requests
Pull Requests são incríveis fontes de conhecimento sobre como as outras pessoas escrevem código.
Olha este exemplo do repositório aberto do Monolog. Você consegue ver quais arquivos foram modificados, onde e como. Além disso, os responsáveis pelo repositório adicionam comentários e perguntas sobre o código.
Uma das melhores formas de aprender como escrever código de acordo com o estilo da sua comunidade, é lendo pull requests enviados para esta comunidade.
Mais efetivo ainda é você enviar um pull request e receber comentários de volta. A comunidade ganha, você ganha, todo mundo ganha!
Navegue nos repositórios da sua empresa
No contexto de uma empresa, o melhor é ver como as outras pessoas já operam.
Normalmente se a empresa é moderna no quesito desenvolvimento de software, esta será uma fonte incrível. Mas se você duvida da qualidade do código e das pessoas que o produzem, ignore esta dica - e procure outro emprego o quanto antes.
Participe, mesmo que como ouvinte, de discussões sobre estilização de código
O que eu disse lá no começo é muito verdade. Tudo depende, e muitas pessoas desenvolvedoras gostam de discutir de fundamentos a nuances sobre estilo de código.
Participe destas discussões o quanto puder: em reuniões, em conferências, em fóruns, no Twitter... Não importa se você estiver errade! Se alguém te corrigir você terá aprendido. Mas o mais importante é ver outras pessoas trocando conhecimento e opiniões também.
Voa, juninhe! Voa!
É claro que eu escrevi este artigo num tom mais energético e duro, mas a intenção não é te desmotivar.
Eu quero que estilo de código seja algo natural pra ti, e que você incorpore estas dicas no seu dia a dia de forma automática pra que possa focar na lógica que está aprendendo, em vez de se preocupar com bobeiras de estilo.
Se a estilização for tarefa mecânica pra ti, vão te ficar disponíveis muito mais neurônios pra focar no que importa: resolver o seu problema de código.

Vai que a sua jornada tá só começando e o futuro é próspero! Voa, juninhe! Voa!
Compartilha este texto com a galera pra ajudar e trazer pra discussão, belezera? Te vejo na próxima.
]]>
Atenção: o próximo post só vai ser escrito depois de 20 retuítes aqui. Assim você me dá uma força pra crescer o site e me manter motivado a escrever as próximas partes 😉
O post de hoje vai ser bem massa pra quem nunca brincou com desenvolvimento de jogos ou tem vontade de entender como fazer sem nenhuma engine como o Godot, Game Maker, Unity ou outras!
O nosso objetivo é desenhar um personagem na tela e movimentá-lo usando as teclas W,A,S,D.
No post anterior nós explicamos o objetivo deste projetinho e montamos um ambiente de trabalho simples com Make e compilamos uma janela simples, dá uma olhada nele aqui caso tenha perdido. Ele é essencial para acompanhar a série toda.
Conteúdos do post
Gráficos open source: Kenney Sokoban!
Eu não sou lá um designer gráfico, então normalmente eu uso assets de código aberto disponíveis na internet. OpenGameArt e KenneY são dois pontos de partida ótimos para fazer prototipação.
O site KenneY possui um pack específico para jogos do tipo Sokoban, você consegue baixar o pack através deste link. Todos os assets desenvolvidos pelo Kenney ficam disponíveis com a licença Creative Commons (CC0 1.0 Universal), que nos permite fazer de tudo com aquele conteúdo: baixar, utilizar para projetos pessoais e comerciais, modificar... E sem sequer precisar pedir permissão. Tá tudo liberado!

Após baixar e extrair o conteúdo, vou mover todos os arquivos do pacote kenney_sokobanpack para um diretório chamado assets/ na raiz do projeto.
$ mkdir assets/
$ mv ~/Downloads/kenney_sokobanpack ./assets/kenney_sokobanpack/
Vários arquivos dentro desta pasta são repetidos e eu não vou me preocupar em limpar a pasta agora. Outros arquivos eu vou fazer questão de manter, como por exemplo o arquivo License.txt e os previews que mantém o logo/assinatura do autor.
Após adicionar o arquivo, faço meu commit em paz e sigo pra próxima etapa: adicionar o esqueleto do jogador!
Compilando o jogador
Pra continuar com tudo simplificado, eu vou separar o esforço de compilar o programa do esforço de programar o programa.
Neste jogo, um jogador possui quatro funções essenciais:
- create: instancia o objeto Player; Executa antes de o jogo começar
- update: move o jogador, permite interagir com objetos na tela, etc.; Executa no começo do Game Loop
- draw: desenha o jogador na tela; Executa entre os métodos Begin e End Drawing(), após todos os updates
- destroy: libera o espaço de memória utilizado pelo jogador (objetos dinamicamente alocados e sprites); Executa quando saímos do Game Loop
Quando eu escrevi os arquivos, ignorei a função draw(), mas no próximo commit eu adiciono 😉
Eu vou precisar criar dois arquivos: src/player.h e src/player.c. Se você precisa entender o motivo de a gente precisar de dois arquivos pra mesma coisa em C, me dá um toque que eu escrevo sobre. Mas por enquanto, só confia!
Neste projeto, você vai notar que todo arquivo de cabeçalho (.h) segue uma estrutura mais ou menos assim:
#ifndef __nomedoarquivo_h_
#define __nomedoarquivo_h_
// Código
#endif
Essas diretivas (ifndef, define endif) combinadas nos permitem ter certeza de que mesmo se a gente incluir o arquivo de cabeçalho duas vezes no programa, a gente não vai bagunçar com o processo de compilação.
Pois vamos então adicionar o arquivo src/player.h:
#ifndef __player_h_
#define __player_h_
#include "raylib.h"
typedef struct {
Texture2D texture;
Rectangle rec;
} Player;
void player_create();
void player_destroy();
void player_update();
#endif
Note que eu criei uma struct com dois campos: Texture2D texture e Rectangle rec. Ambos tipos vem da biblioteca Raylib. O campo texture nos permite guardar uma imagem que será carregada na VRAM, enquanto o campo rec possui atributos de um retângulo: x, y, width e height.
Em seguida, defini a assinatura das três funções que mencionei acima. Todas com o prefixo player_.
Prefixar suas funções em C é uma boa prática e pode te salvar muito tempo no futuro, tanto ao procurar quanto ao refatorar código.
E aqui entra o arquivo src/player.c, que implementa as funções prototipadas acima:
#include "raylib.h"
#include "player.h"
Player p;
void player_create()
{
}
void player_destroy()
{
}
void player_update()
{
}
Note que nós fizemos o include do arquivo player.h. Sem este include, o tipo Player não seria encontrado e o nosso arquivo player.c não seria nunca compilado.
Como eu disse antes, eu esqueci de escrever a função void player_draw() e corrijo isto no próximo passo.
Note que a variável Player p foi definida no escopo global. Esta é a única forma de manter a variável p acessível por todas as funções player_*.
Naturalmente, precisamos utilizar as novas funções. Vamos modificar a função main() dentro do arquivo sokoban.c:
#include "raylib.h"
#include "player.h" // struct Player, funções player_*
int main(void)
{
// ...
player_create(); // instancia o jogador antes de entrar no Loop
while (!WindowShouldClose()) {
player_update(); // movimentos, itens, pontuação...
// ...
}
player_destroy();
// ...
}
O último passo é amarrar os novos arquivos no processo de compilação. Para isto, vamos modificar uma única linha do arquivo Makefile:
OBJS=$(OUT_DIR)/player.o $(OUT_DIR)/sokoban.o
Se você se lembra bem, a regra all do nosso Makefile utiliza a variável OBJS como entrada do nosso processo de compilação. Sempre que quisermos adicionar um objeto .o ao projeto principal, basta adicioná-lo a esta lista.
O commit que representa esta seção você encontra aqui. O resultado por enquanto é isso aqui:

Vamos amarrar o sprite ao jogador
Primeiro, deixa eu criar a função void player_draw() que eu falhei em colocar da última vez:
src/player.h
// ...
void player_destroy();
void player_draw();
// ...
src/player.c
// ...
void player_draw()
{
}
void player_update()
{
// ...
}
src/sokoban.c
// ...
BeginDrawing();
ClearBackground(BLACK);
player_draw();
DrawFPS(0, 0);
EndDrawing();
// ...
Outra correção que eu preciso fazer, é sobre a variável global Player p. Eu preciso ser capaz de alocar esta variável de forma dinâmica (usando malloc). Portanto eu vou mudar a declaração da variável para que seja um ponteiro. Para declarar uma variável como ponteiro, basta prefixar seu nome com um asterisco:
src/player.c
// ...
Player *p;
// ...
Se você compilar e rodar agora, absolutamente NADA deverá ter mudado. Vamos então implementar as funções player_* uma por uma para dar vida ao nosso jogo.
player_create()
A variável p está em escopo global. Nós só precisamos alocá-la em memória, carregar a textura e dar uma posição para o jogador. O meio da tela está bom por agora.
Aqui fica a implementação completa da função player_create:
void player_create()
{
p = (Player *) malloc(sizeof(Player));
p->texture = LoadTexture("assets/kenney_sokobanpack/PNG/Retina/Player/player_03.png");
p->rec = (Rectangle) {
GetScreenWidth() / 2 - p->texture.width / 2,
GetScreenHeight() / 2 - p->texture.height / 2,
128,
128
}
}
qq tá cotecenu? Vamos por partes:
p = (Player *) malloc(sizeof(Player));
Antes desta linha, nós tínhamos algo como Player *p;, que declara a existência de um ponteiro. Mas na verdade este ponteiro é NULL e não está pronto para guardar valor nenhum. Em outras palavras, o compilador ainda não nos deu memória para guardar um objeto do tipo struct Player.
A função malloc() nos permite alocar memória de forma dinâmica. O parâmetro desta função é o tamanho (em bytes) de memória que eu quero. No caso, eu pedi espaço o suficiente para guardar um objeto do tipo struct Player.
O retorno da função malloc é um endereço de memória reservado para nós, que tem exatamente aquele tamanho.
O cast (Player *) serve apenas para dizer ao compilador que a gente pode confiar que aquele pedaço de memória pode ser tratado como um struct Player.
O resto é bem fácil de explicar.
p->texture = LoadTexture(".../player_03.png");
Carregamos para a VRAM o arquivo player_03.png do sokoban pack. A função LoadTexture vem da Raylib.
p->rec = (Rectangle) { 0 }
Aqui nós montamos o retângulo que representa o jogador. Rectangle é uma struct que a Raylib fornece. Seu formato é { float x; float y; float width; float height }.
O tamanho da textura é de 128x128, portanto o que estamos fazendo é posicionar o jogador no meio da tela.
player_destroy()
O mais fácil de explicar agora, é a função destroy() que deverá ser chamada quando saímos do Game Loop (quando você pressionar ESC).
Nós precisamos limpar dois espaços de memória importantíssimos: a textura que carregamos e o próprio objeto Player *p.
Quando você solicitar um pedaço de memória de forma dinâmica, usando malloc(), lembre-se SEMPRE de limpar este espaço de memória depois, usando free(). Do contrário você vai gerar memory leaks que são difíceis de encontrar.
E é assim que nós fazemos:
void player_destroy()
{
UnloadTexture(p->texture);
free(p);
}
Note que nós limpamos p->texture ANTES de limpar p. Isto porque p->texture é só um ponteiro para uma tabela da própria Raylib. Se nós destruíssemos a variável p antes, não teríamos mais acesso ao identificador da textura e portanto ela ficaria em memória para sempre, apesar de não ser utilizada.
player_draw()
void player_draw()
{
if (p == NULL) {
return;
}
DrawTexture(
p->texture,
p->rec.x,
p->rec.y,
WHITE
);
}
Primeiro verificamos a possibilidade de p ser um ponteiro nulo. Desta vez nós evitamos um segmentation fault caso qualquer bug estranho acabe limpando a variável p antes de chamar a função player_draw().
Depois utilizamos a função void DrawTexture(Texture2D tex, float x, float y, Color tint) da biblioteca Raylib. Isto deverá desenhar a textura inteira (128x128) na tela, nas coordenadas (p->rec.x; p->rec.y).
A partir daqui já podemos ver algum resultado:
Maaassa!!
Mas ainda não adicionamos movimento ao jogador. Vamos mexer no update.
player_update()
Vamos assumir algumas coisas aqui:
- A textura tem dimensões de 128x128. Portanto para parecer que o jogador andou para qualquer direção, precisamos o deslocar em 128 pixels naquela direção;
- Não nos interessa fazer um movimento "macio"
A Raylib tem uma função muito útil chamada IsKeyPressed, com a seguinte assinatura: bool IsKeyPressed(int key). Ela também tem um tipo chamado Vector2, que é um struct com os seguintes campos: { float x, float y }.
Um valor bool também pode ser representado como 0 ou 1. Portanto 10 - true teoricamente é igual a 9.
Então vamos ao código e eu te explico o o que eu fiz:
void player_update()
{
Vector2 delta = { 0 };
delta.x = (IsKeyPressed(KEY_D) - IsKeyPressed(KEY_A)) * 128;
delta.y = (IsKeyPressed(KEY_S) - IsKeyPressed(KEY_W)) * 128;
p->rec.x += delta.x;
p->rec.y += delta.y;
}
Vector2 delta = { 0 }; aqui nós apenas criamos uma variável do tipo struct Vector2 com o valor x = 0 e y = 0.
Em seguida fizemos uma matemática simples para a movimentação horizontal e vertical. Os resultados de IsKeyPressed(KEY_*) - IsKeyPressed(KEY_*) sempre serão 1, 0 ou -1. Veja a tabela abaixo:
| Expressão (bool) | Equivalente (int) | Valor |
| true - false | 1 - 0 | 1 |
| false - false | 0 - 0 | 0 |
| true - true | 1 - 1 | 0 |
| false - true | 0 - 1 | -1 |
Portanto ao multiplicar este resultado por 128, temos um movimento que representa 128, 0 ou -128 pixels.
O resultado deste cálculo estamos armazenando na variável delta.
Depois somamos delta.x e delta.y ao p->rec (retângulo que representa o jogador). E com isso temos o movimento preparado. Vamos esclarecer com um pseudo caso de testes:
// Supondo que p->rec está nas coordenadas (100, 100)
p->rec.x = 100;
p->rec.y = 100;
// Se eu pressionar a tecla A e nenhuma outra tecla
delta.x = (false - true) * 128; // -1 * 128 = -128
delta.y = (false - false) * 128; // 0 * 128 = 0
// Então a posição do jogador deverá ser (-28, 100)
p->rec.x += delta.x; // 100 + (-128) = -28
p->rec.y += delta.y; // 100 + 0 = 0
E aqui você confere o resultado na íntegra:

Depois eu disso eu só dei uma limpadinha no código pra remover aquele número 128 mágico de lá e usar variáveis em vez disso.
O Pull Request todo você encontra aqui: Terrario/sokobão PR #2.
Próximos passos
Bom, nós já criamos o jogador. Agora precisamos criar alguns obstáculos na tela.
No próximo post vamos implementar um bloco simples. E a partir disso vamos trabalhar com colisão: um jogador não pode atravessar um bloco.
Mas eu preciso da sua ajuda pra desenvolver o próximo post. Preciso que você divulgue este post aqui. Quando eu alcançar 20 retuítes aqui, começo a escrever o próximo post.
Desta forma você me ajuda a popularizar o blog e ajuda outras pessoas encontrar este conteúdo massa!
Até a próxima! 👋
]]>
Inscrições até o dia 25/02/2022, corre se candidatar!
Estão abertas as inscrições para o ConstruDelas, programa de formação de mulheres em desenvolvimento back-end .NET, em parceria com a @juntossomosmais.
O ConstruDelas tem duração de 21 semanas com 29 vagas que atenderão, preferencialmente, mulheres em vulnerabilidade social, econômica, negras ou LGBTQIAP+, com pouco ou nenhum conhecimento em programação, para receberem um treinamento gratuito com o objetivo de atuarem como desenvolvedoras.
Não são exigidas experiências prévias ou formação profissional em tecnologia!
Acesse o link https://womakerscode.org/construdelas para se inscrever.
Como participar
- Preencha do formulário de inscrição, até o dia 25 de Fevereiro, às 18h
- Envie um vídeo de apresentação
- Realize o curso de introdução até 26/02, às 18h
Edital
Para mais informações sobre o processo de seleção e quem pode participar, dá uma olhadinha no Edital aqui.
Curtiu? Faça a sua inscrição e se você conhece outra mulher que pode se interessar por essa oportunidade, manda este link pra ela, marca nos comentários ou o que for!
Salve, salve. Novidade massa na área!
— Níckolas Da Silva (nawarian) (@nawarian) February 7, 2022
A galera do @womakerscode junto da #juntossomosmais está com inscrições abertas pra uma capacitação #net para #mulheres. Bora se inscrever e compartilhar com geral!!https://t.co/OwpYQJ18s9
]]>

Conteúdo do post
A raylib é uma biblioteca de desenvolvimento de jogos escrita em C. Não traz consigo coisas como gerenciamento de assets, gravidade e outras ferramentas prontas. Apenas o básico que alguém precisa para desenvolver jogos sem muita dor de cabeça.
Desde que eu comecei a usar a raylib com o PHP, comecei a tomar gosto por desenvolver com a linguagem C. E acho que já está mais do que na hora de encarar um projeto em C do começo ao fim. Portanto vou iniciar a série Sokoban usando raylib.
A ideia de escrever um jogo do tipo Sokoban é simples: eu não sou um Game Designer e a única habilidade que eu quero desenvolver é a de programar em C. Sokoban é um jogo simples o suficiente em termos de gráficos e que vai me permitir praticar bastante minhas habilidades em C.
Sokoban é um estilo de jogo do tipo puzzle, onde você passa de fase ao empurrar caixas no lugar correto de forma a resolver o quebra cabeças. Aqui tem um vídeo que ilustra bem como um jogo do tipo Sokoban se parece:
Vamos preparar o nosso ambiente de desenvolvimento
O primeiro post, naturalmente, vai tratar do ambiente de desenvolvimento. E neste caso vou manter tudo muito simples. As ferramentas que vou utilizar para desenvolvimento:
- VIM - editor de textos
- clang - compilador C, padrão no MacOS
- make - ferramenta de automação de build
- pkg-config - nos ajuda a encontrar diretório das bibliotecas no computador
- raylib - biblioteca de programação de jogos
Uma única linha de comando já deve instalar tudo o que a gente precisa no MacOS:
$ brew install vim make pkg-config raylib
Com tudo instalado, vamos criar um projeto vazio e rodar a nossa primeira janela para ter certeza de que tudo está funcionando.
Repositório no Github
Vou criar um novo repositório chamado Terrario/sokoban. E já vou inicializar este repositório com um README.md, licença GPL-3 e um .gitignore básico.
Com o repositório criado, posso fazer o clone na minha máquina:
$ git clone [email protected]:Terrario/sokoban.git
$ cd sokoban/
E agora já posso preparar a janela do Raylib e deixar tudo certo pra compilar e rodar o programa.
Uma janela simples usando raylib
Vou criar um arquivo src/sokoban.c que vai conter a nossa função main(). Nele vou colocar o seguinte snippet:
#include "raylib.h"
int main(void)
{
InitWindow(800, 600, "Sokobão");
SetTargetFPS(60);
while (!WindowShouldClose()) {
// Game loop
BeginDrawing();
ClearBackground(BLACK);
DrawFPS(0, 0);
EndDrawing();
}
CloseWindow();
return 0;
}
O programa acima não faz nada de mais. Em sequência nós:
- Criamos uma janela de 800x600 e título "Sokobão"
- Definimos que o nosso jogo roda em 60 frames por segundo
- Montamos o loop infinito (game loop)
- Dentro do loop infinito, desenhamos na tela
- Primeiro pintamos a tela toda de preto
- Depois desenhamos o framerate nas coordenadas x = 0, y = 0 da tela
- Ao sair do loop (pressionar ESC), fechamos a janela
Vamos compilar e ver se funciona!
$ mkdir build/
$ clang src/sokoban.c -o build/sokoban -lraylib
$ ./build/sokoban
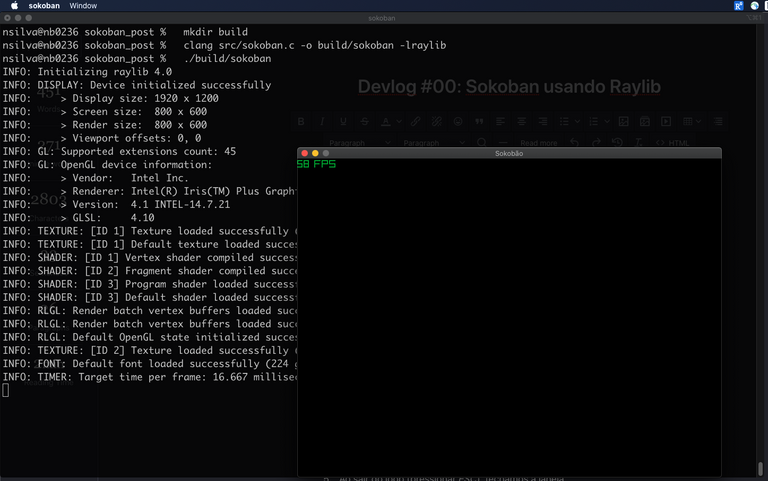
Parece funcionar bonitinho 🎉
Agora vamos automatizar a build um pouco.
Automação de build com make
Vamos criar um arquivo chamado Makefile com o seguinte conteúdo:
CC=clang
CFLAGS=`pkg-config --cflags raylib` -std=c99
LIBS=`pkg-config --libs raylib`
MKDIR=mkdir -p
RMDIR=rm -rf
SRC_DIR=src
OUT_DIR=build
OBJS=$(OUT_DIR)/sokoban.o
all: $(OUT_DIR) $(OBJS)
$(CC) $(OBJS) -o $(OUT_DIR)/sokoban $(LIBS)
run: all
$(OUT_DIR)/sokoban
clean:
$(RMDIR) $(OUT_DIR)
.PHONY: clean
$(OUT_DIR)/%.o: $(SRC_DIR)/%.c
$(CC) -c $< -o $@ $(CFLAGS)
$(OUT_DIR):
$(MKDIR) $(OUT_DIR)
Lembre-se: Makefile não usa espaços para indentação, mas sim tabulações.
Se o Makefile ficou estranho, me dá um alô que eu posso escrever um tutorial só sobre makefiles. O que é importante pra gente é a variável OBJS que no momento só aponta para um objeto. Conforme nós adicionarmos mais arquivos .c no projeto, vamos modificar aquela variável.
É possível fazer isso de forma mais dinâmica, mas eu não acho que esse projeto vá crescer tanto em número de arquivos. Se crescer, eu mudo o Makefile 😛.
Agora basta rodar make clean run pra recompilar o projeto todo e executar a nossa janelinha:
$ make clean run
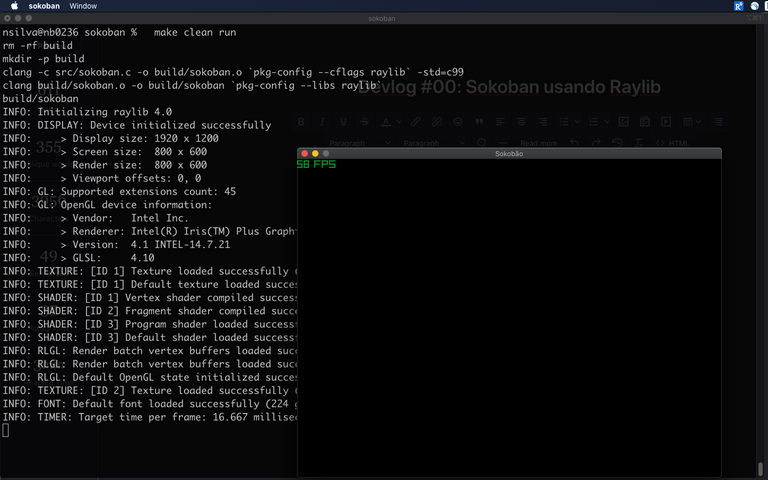
Alguns toques finais
Vamos deixar tudo organizadinho antes de fechar o post e limpar o repositório um pouco.
Nós não queremos nunca que a pasta build suba para o repositório. Então vou adicionar estas linhas ao arquivo .gitignore:
# Build folder
build
Agora vamos adicionar jogar tudo para o Github. Afinal de contas, se não está na internet, não existe 😉.
Se quiser saber como subir arquivos no Github, dá uma olhada neste post fera do João Apostulo sobre como subir arquivos no github.
Próximos passos
O próximo passo vai ser carregar os assets para o nosso projeto e fazer um bonequinho se mexer na tela.
Eu vou usar os assets Open Source do Kenney pra isso. Aqui tem uma imagem de exemplo direto do site dele:

E por hoje é isso. Não se esquece de comentar e compartilhar o post pra dar uma força pra gente!
O Pull Request deste capítulo você encontra no meu Github através deste link.
O link para o próximo post é este aqui.
Até a próxima 👋
]]>
Atenção: este texto foi traduzido, editado e adaptado por @nawarian. Você encontra o texto original, escrito em 2017 em inglês, no blog parceiro Hoverbear.org através deste link.
Conteúdos do post
Neste artigo eu vou te mostrar uma forma de preparar seu ambiente para desenvolver em Rust. Há formas diferentes, principalmente quando se trata do editor de texto, então sinta-se livre pra pular o que não for relevante pra si. Nós vamos focar em:
- Configurar Rust usando o Rustup
- Utilitários como
clippyerustfmt - Configurar o VS Code para trabalhar com Rust
- Depurar na linha de comando e no VS Code
- Utilizar diferentes alvos (targets) de compilação
Tudo o que eu explico aqui funciona tanto no Linux quanto no MacOS, no Windows pode ser que você precise se adaptar um pouco, já que eu não tenho um sistema Windows para testar este artigo.
Para executar as instruções deste artigo você precisará do pacote build-essentials caso utilize Ubuntu ou Debian, base-devel para a distro Arch ou XCode para MacOS.
Configurando Rust utilizando o Rustup
Rustup é um projeto oficial do Rust que nos permite instalar, gerenciar e atualizar várias ferramentas Rust. Para instalar o rustup, rode o seguinte comando:
|
Depois de baixar, Rustup vai nos fazer algumas perguntas para configurar o ambiente. Vamos apenas aceitar as configurações padrão aqui:
Current installation options:
default host triple: x86_64-apple-darwin
default toolchain: stable
modify PATH variable: yes
1) Proceed with installation (default)
2) Customize installation
3) Cancel installation
E logo depois a ferramenta vai nos propor executar o seguinte comando para atualizar o nosso shell:
A partir deste momento, podemos executar cargo e rustc para confirmar que temos tanto o compilador Rust quanto a ferramenta Cargo instaladas. A ferramenta rustup também deveria estar instalada agora.
É recomendado instalar o código fonte do Rust e a documentação também, para que possamos utilizar o modo offline ou para auto completar código.
Em algum momento da vida, nós vamos querer atualizar a nossa instalação. O seguinte comando vai nos ajudar a atualizar as ferramentas e componentes do Rust.
Pode ser também que você encontre algum projeto ou tutorial que utilize a build nightly (beta) do Rust. Você pode facilmente instalar a versão nightly juntamente da build principal.
Você pode alterar qual o ferramental padrão no seu sistema (entre nightly e stable) utilizando os comandos rustup default stable ou rustup default nightly, mas a recomendação é manter a build stable e escrever overrides para projetos que utilizem a build nightly. Você pode criar este override navegando até o projeto que quer usar nightly e rodando o seguinte comando:
Por agora isso é tudo o que precisamos saber sobre Rustup.
Ferramentas úteis
Vamos falar sobre quatro ferramentas muito úteis para trabalhar com Rust:
rust-clippy- Um linter.rustfmt- formatador de código.racer- auto completar código.rls- servidor de linguagem (para usar com VIM, VS Code...)
rust-clippy
Pra que serve isso? O compilador Rust já é bem restritivo. clippy vai além e nos ajuda a evitar algumas más práticas. Isto pode ajudar a evitar problemas inesperados no nosso código.
clippy depende de nightly para rodar. Nós já instalamos nightly quando rodamos rustup toolchain install nightly, então não teremos problema nenhum.
Vamos instalar o clippy através do nightly com o seguinte comando:
Agora vamos testar a nossa ferramenta. Rode cargo init --bin test && cd test e modifique o arquivo src/main.rs pra que fique com o seguinte conteúdo:
Vamos rodar clippy com o seguinte comando:
Isto deveria gerar um alerta (warning) do clippy:
warning = "statement with no effect"
--> src/main.rs:2:5
|
2 | true;
| ^^^^^
|
= note: #[warn(no_effect)] on by default
= help: for further information visit https://github.com/Manishearth/rust-clippy/wiki#no_effect
Excelente! Você pode ver todas as regras que clippy consegue detectar aqui. Você pode configurar várias regras no arquivo clippy.toml de acordo com as opções listadas na wiki.
Para desabilitar algumas regras (ou torná-las avisos em vez de erros) você pode adicionar as flags deny, warn, ou allow nos atributos da sua crate:
rustfmt
Pra que serve isso? Um estilo consistente, padrão e automatizado no projeto (e entre vários projetos) pode ser útil durante revisões de código, para atrair novas contribuições e evitar discussões supérfluas.
rustfmt é uma ferramenta de formatação de código similar ao gofmt. Ao contrário do clippy, ela roda sem poblemas com a build stable do Rust. Vamos instalar o rustfmt:
cargo install rustfmt
A partir daqui podemos rodar cargo fmt para reformatar o repositório. Este comando roda rustfmt no modo replace (substituição) que cria arquivos de backup com a extensão .bk. Se o projeto utiliza algum tipo de controle de versão (como o Git) você talvez não deseje este comportamento. Neste caso, podemos escrever o seguinte num arquivo rustfmt.toml para evitar a criação de arquivos .bk:
= "overwrite"
O arquivo rustfmt.toml nos permite configurar várias opções listadas pelo comando rustfmt --config-help. Agora vamos editar o arquivo main.rs e bagunçar um pouco o estilo dele:
Se você rodar cargo fmt agora vai notar que main.rs está formatado corretamente de novo.
rustfmt ainda não está 100% pronto e pode acontecer de bagunçar o seu código de vez em quando.
racer
Pra que serve isso? Racer nos ajuda a evitar procurar referências rápidas na documentação e nos ajuda a descobrir novas funcionalidades conforme escrevemos código em Rust.
racer é uma ferramenta para autocompletar código que é utilizada por vários add-ons de editores de código juntamente do rls, que vamos instalar em seguida.
Anteriormente, nós rodamos rustup component add rust-src. Este foi o primeiro passo para instalar o racer. Vamos agora instalar a ferramenta em si:
Nós precisamos definir uma variável de ambiente para que racer saiba onde buscar o código fonte do Rust. No seu ~/.bashrc (ou ~/.zshrc) adicione o seguinte:
# Mac
# Linux
Se você não usa MacOS ou Linux, vai precisar precisar definir a variável de ambiente de acordo com o que é mostrado pelo comando rustup show.
Você pode testar se racer está funcionando com o seguinte comando:
Você deveria ver várias sugestões para o comando acima. A partir de agora, racer já está preparado para ser utilizado pelo seu editor de texto ou com o rls.
rls
Pra que serve isso? Para criar uma experiência de desenvolvimento mais agradável e ampliar as funcionalidades do racer.
rls é um servidor de linguagem (language server) especializado em Rust. Ele traz consigo funcionalidades como auto completar código, ir-para definições e refatorações.
Para instalar rls nós precisamos dizer ao Rustup para utilizar uma toolchain específica. MacOS utiliza a nightly-x86_64-apple-darwin e Linux utiliza a nightly-x86_64-unknown-linux-gnu. Se você não usa VS Code, pode pular este passo.
Em seguida, precisamos definir outras duas variáveis de ambiente: DYLD_LIBRARY_PATH e RLS_ROOT:
# Mac
# Linux
Agora estamos prontos! Nós vamos testar e usar o rls mais tarde, quando configurarmos o VS Code.
Configurando o VS Code para código em Rust
Eu usei o VS Code para Rust por vários meses e achei bem delicinha. Como qualquer editor de textos, há várias configurações a serem ajustadas. Vamos focar nas mais relevantes.
Você pode usar outro editor, e tá tudo bem. Vai em frente! Eu ainda uso o vim para editar coisas rápidas e alguns colegas meus gostam bastante de seus emacs. Diversidade faz bem, use o que é bom pra ti e deixe os outros usarem o que for melhor para eles.
Primeiro, vamos baixar o VS Code. Basta entrar no site oficial e baixar o instalador.
Para poder rodar o comando code na CLI nós precisamos abrir o VS Code e abrir a paleta de comandos (Command Palette) com o atalho Shift + Command + P (MacOS) ou Shift + Control + P (Linux). Aqui, escreva shell command e procure pela opção Shell Command: Install 'code' command in PATH. Após selecionar esta opção, qualquer nova sessão de terminal deverá ter o comando code preparado.
Extensão: Rust
A extensão Rust traz alguns utilitários para fazer o build, formatar código e outras coisas úteis.
Extensão: rls_vscode
Nós vamos precisar do node instalado, você pode utilizar seu gerenciador de pacotes para isso. No MacOS, brew já resolve o problema.
Com o node já instalado, vamos instalar a extensão rls_vscode. Mas já que esta extensão ainda não foi lançada, nós vamos precisar fazer um pouco de trabalho manual. Vamos clonar e instalar as dependências do repositório rls_vscode;
O próximo passo é fazer o build da extensão, que podemos fazer diretamente utilizando o VS Code. Rode o comando code . dentro do repositório que acabamos de clonar para abrir o VS Code naquele diretório. Já dentro do VS Code, aperte o botão de Build perto da opção Launch Extension no painel da esquerda. Uma nova janela do VS Code vai abrir, mas você pode fechá-la imediatamente.
Agora que nós compilamos a extensão, vamos criar um link simbólico (symlink) para instalar no VS Code. Se você estiver usando o VS Code Insiders, o diretório é .vscode-insiders em vez de .vscode.
Depois você pode atualizar a extensão com utilizando um processo parecido. É recomendado atualizar a extensão com frequência porque várias atualizações estão sendo lançadas.
Agora pode fechar e abrir o VS Code de novo. Ao abrir qualquer projeto Rust você deverá ver uma barra azul na parte de baixo da tela dizendo "RLS analysis: Starting up" e, alguns minutos depois, "RLS analysis: Done".
Se você reiniciar a sua máquina você vai precisar abrir um terminal antes de abrir o VS Code, ou usar o terminal integrado do VS Code e logo após reiniciar o programa. Há algumas formas de corrigir isto, mas dá muito trabalho. Talvez num futuro próximo a gente veja alguma configuração do VS Code que melhore esta situação.
Extensão: Better TOML
O ecossistema Rust usa bastante arquivos TOML para gerenciar configuração. A extensão 'Rusty code' já traz algum suporte ao formato TOML, mas a extensão 'Better TOML' é bem melhor e vale a pena ter no seu VS Code.
Extensão: Depurador LLDB
A extensão 'LLDB Debugger' (Low Level Debugger Debugger) nos permite depurar aplicações Rust dentro do VS Code. Você vai precisar também da biblioteca six do Python, que você pode instalar com o comando pip install six.
Como depurar código em Rust
Vamos criar uma aplicação basiquinha pra testar como a depuração funciona antes de fazer qualquer teste mais complicado. Rode o comando cargo init --bin example e coloque o seguinte conteúdo no arquivo src/main.rs:
Com isso a gente já consegue praticar a depuração. Bora debugar!
Na linha de comando
Antes de qualquer coisa, a gente precisa rodar o debugger. Vamos primeiro compilar com cargo build e depois rodar o nosso programa através do depurador rust-lldb.
Daí em diante a gente pode interagir com o depurador como normalmente faríamos usando o LLDB. Ah, sim, também existe a alternativa rust-gdb se você quiser se aventurar.
Por exemplo:
(lldb) breakpoint set -f main.rs -l 3
Breakpoint 1: where = example`example::is_north + 10 at main.rs:3, address = 0x0000000100000ffa
(lldb) process launch
Process 8376 launched: '/Users/hoverbear/git/rust/example/target/debug/example' (x86_64)
2
Process 8376 stopped
* thread #1: tid = 0x2c222, 0x0000000100000ffa example`example::is_north(dir=South) + 10 at main.rs:3, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100000ffa example`example::is_north(dir=South) + 10 at main.rs:3
1 pub enum Direction { North, South, East, West }
2
-> 3 fn is_north(dir: Direction) -> bool {
4 match dir {
5 Direction::North => true,
6 _ => false,
7 }
(lldb) print dir
(example::Direction) $0 = South
No VS Code
Depois de instalar a extensão 'LLDB Debugger' você pode definir um breakpoint ao clicar à esquerda dos números de linha, você deverá ver um ponto vermelho indicando que colocou um breakpoint. Mas para depurar mesmo a aplicação, a gente precisa configurar o VS Code direito.
Adicione o seguinte no arquivo .vscode/launch.json:
E depois adicione um arquivo .vscode/tasks.json com o seguinte conteúdo:
Depois, vamos colocar um breakpoint no código. Daí é só clicar no ícone do insetinho (quarto ícone de cima para baixo, no painel esquerdo) e apertar o botão Play. Você deverá ver algo assim:

Compilando para diferentes alvos (targets)
Até aqui a gente só compilou programas para a arquitetura x86_64-apple-darwin. Se estivéssemos usando Linux, nós teríamos compilado para x86_64-unknown-linux-gnu. Vamos mudar um pouquinho e compilar para javascript: asmjs-unknown-emscripten.
Primeiro, precisamos instalar o pacote emscripten. No Mac você pode fazer isso com brew install emscripten. Algumas distros Linux também oferecem o pacote emscripten, mas você pode encontrar um manual de instalação aqui.
Depois, vamos instalar o alvo (target) usando o rustup:
Se você estiver usando Mac, provavelmente vai precisar adicionar as seguintes linhas no arquivo ~/.emscripten:
#LLVM_ROOT = os.path.expanduser(os.getenv('LLVM') or '/usr/bin') # directory
#BINARYEN_ROOT = os.path.expanduser(os.getenv('BINARYEN') or '/usr/bin') # directory
# Avoid annoying popups about Java.
#JAVA = 'java'
Agora nós já podemos compilar o nosso código em asm.js e rodar direto com o interpretador node:
A saída deverá ser a seguinte:
2
false
Compilar para outros sistemas e arquiteturas funciona de forma semelhante. A parte mais chatinha é instalar o ferramental, como nós acabamos de fazer para o emscripten.
Conclusão
Agora nós já temos um ambiente de desenvolvimento Rust preparado para compilar programas tanto na arquitetura do computador local, quanto para asm.js. O editor VS Code está preparado para depurar código e tem algumas funcionalidades bacanudas como autocompletar e navegar no código. Além disso, instalamos algumas ferramentas utilíssimas como o clippy para nos ajudar a detectar erros.
Algumas das ferramentas que instalamos ainda estão em alpha, ou não funcionam como gostaríamos. Mas este é só o começo! E se você tiver interesse, pode sempre contribuir com estes projetos. De tempos em tempos você pode atualizar a sua caixa de ferramentas e com certeza vai notar várias melhorias.
Agora você não tem nenhuma desculpa pra não se divertir programando em Rust! Vai procurar um repositório interessante e faz seu primeiro Pull Request! E se não achar nada, dá uma olhada no r/rust pra sacar sobre quais projetos as pessoas estão conversando, procure por issues marcadas como E - Easy no rustc, ou pegue pra desenvolver algo pequeno no projeto rust-rosetta.
Now, we don't have any excuses not to have fun with Rust! Why not find something that looks interesting and try to make your first PR? Can't find something? Check out /r/rust and look at the projects people are talking about, look at the E - Easy issues on rustc, or tackle something small from rust-rosetta!
Obrigado Asquera, por me arranjar tempo para escrever este artigo! O mesmo texto também está presente aqui.
]]>
Atenção: este texto foi traduzido, editado e adaptado por @nawarian. Você encontra o texto original, escrito em 2015 em inglês, no blog parceiro Hoverbear.org através deste link.
Uma das minhas funcionalidades favoritas em Rust são os iterators. Eles são uma forma rápida, segura e preguiçosa (lazy) de trabalhar com estruturas de dados, streams e outras aplicações mais criativas.
Você pode brincar com iterators utilizando o website http://play.rust-lang.org/ enquanto navega aqui. Este artigo não substitui a documentação oficial ou a experiência de executar os códigos por si.
Nosso primeiro iterator
Um é pouco, mas dois é bom. Vamos pegar uma lista de valores e dobrá-los!
Já neste exemplo simples, podemos observar algumas coisas interessantes:
.iter()pode ser usado com vários tipos diferentes.- Precisamos declarar um valor e só depois criar um iterator para ele. Do contrário o valor não vai viver o suficiente para ser iterado. (Iterators são preguiçosos (lazy) e nem sempre são donos de seus valores).
.collect::<Vec<usize>>()itera a lista completamente e guarda seus valores num tipo de coleção que especificarmos. (Se você quiser escrever a sua própria estrutura de dados, dá uma olhada aqui)- Um iterator pode ser utilizado e encadeado! Você não precisa necessariamente chamar
.collect()depois de uma chamada ao.map().
n de cada vez
Você pode acessar o próximo elemento de um iterator com .next(). Se você quiser pegar somente uma porção, pode utilizar .take(n) para criar um novo iterator que percorre os próximos n elementos.
Quer jogar fora alguns dados? Use .skip(n) para pular n elementos.
// Saída:
// Some(1)
// [4, 5]
Observando o comportamento preguiçoso (lazy)
Eu comentei que iterators são preguiçosos, mas o primeiro exemplo não demonstrou este comportamento. Vamos utilizar .inspect() para observar como Rust se comporta.
A saída é:
Antes do map: 1
Primeiro map: 10
Segundo map: 15
Antes do map: 2
Primeiro map: 20
Segundo map: 25
Antes do map: 3
Primeiro map: 30
Segundo map: 35
Como você pôde perceber, as funções map apenas executam quando o iterator avança. (Do contrário nós veríamos 1, 2, 3, 10, ...)
Note como .inspect() passa para seu callback um &x em vez de &mut ou o valor em si. Isto evita mutações e assegura que sua inspeção não vai bagunçar a pipeline de dados.
Isto gera uns efeitos colaterais bem bacanas como, por exemplo, iterators infinitos ou cíclicos.
// Saída [1, 2, 3, 1, 2, 3, 1, 2, 3]
Algo em comum
Não fique aí achando que [1, 2, 3] e outros slices são as únicas coisas das quais você pode criar iterators.
Muitas estruturas de dados dão implementam esta trait: podemos utilizar Vectors e DecDeques! Vejamos algumas coisas que implementam .iter().
use VecDeque;
// Saída [2, 4, 6]
Viu como fizemos o collect num VecDeque? Isto só é possível porque ele implementa FromIterator.
Você deve estar pensando "Ah rá! Aposto que você não consegue usar um HashMap ou uma árvore ou coisa do tipo, Hoverbear!". Errado! É possível, sim!
use HashMap;
// [(1, 100), (3, 300), (2, 200)]
Quando iteramos um HashMap a função .map() muda para aceitar uma tupla, e .collect() aceita tuplas. E é claro, você também pode fazer um collect de volta para um HashMap (ou qualquer outra coisa).
Você notou como a ordem mudou? Isto acontece porque HashMaps não são necessariamente ordenados. Lembre-se sempre disso!
Tente mudar o código para converter um Vec<(u64, u64)> num HashMap.
Escrevendo um iterator
Tá, nós conseguimos experimentar algumas das coisas que podem implementar iterators. Mas a gente também pode fazer um nosso! Que tal um iterator que conta alguma coisa infinitamente?
// Saída [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
Nós não precisamos chamar .iter() aqui. Faz sentido, porque nós já estamos implementando um iterator e não transformando alguma coisa num iterator como fizemos antes.
Tente mudar os valores de current e .take().
Viu como nós podemos usar .take() e outras funções sem ter de implementar cada uma separadamente para nosso novo iterator? Se você olhar a documentação do módulo iter, verá que há várias traits como Iterator ou RandomAccessIterator.
Intervalos com o operador Range
Através dos exemplos abaixo você verá o uso da sintaxe x..y, que cria um intervalo (range). Intervalos implementam Iterator então não é necessário chamar .iter() neles. Você também pode usar (0..100).step_by(2) se quiser realizar pular alguns elementos a cada iteração.
Note que intervalos são abertos, não inclusivos.
0..5 ==
2..6 ==
Também é possível utilizar intervalos como índices de coleção:
// Saída:
// [0, 1, 2, 3, 4]
// [2, 3, 4]
// [7, 8, 9]
Saquei: utilizar .step_by() não funciona desse jeito já que não implementa Idx, mas Range implementa.
Encadear e compactar iterators
Juntar iterators de formas diferentes nos permite escrever códigos muito expressivos.
// Chained: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
// Zipped: [(0, 5), (1, 6), (2, 7), (3, 8), (4, 9)]
.zip() te permite juntar iterators. Já o .chain() cria um iterator "extendido".
Sim, também existe o .unzip().
Tente usar .zip() com dois slices do tipo usize e depois fazer um .collect() dessas tuplas para criar um HashMap.
Vamos dar poder à curiosidade
.count(), .max_by(), .min_by(), .all() e .any() são formas comuns de verificar o que há dentro de um iterator.
// Isto só funciona com rust nightly no momento em que o artigo foi escrito
// Saída:
// Mais velho: Some(Urso { especie: Pardo, idade: 16 })
// Mais novo: Some(Urso { especie: Marrom, idade: 5 })
// Pelo menos um urso polar?: true
// Todos são menores de idade? (<18): true
Tente utilizar o mesmo iterator em todas as chamadas no exemplo acima. .any() (algum) é o único que empresta (borrow) de forma mutável e não funciona igual aos outros. Isto porque esta função talvez não consuma o iterator por completo.
Filter, Map, Redu... não... Fold!
Se você, assim como eu, tem costume de programar em Javascript você provavelmente conhece a sagrada trindade .filter(), .map() e .reduce(). Estas funções também estão disponíveis em Rust, mas .reduce() é chamado de .fold() (e eu meio que prefiro esse nome).
Um exemplo:
O snippet acima poderia ser simplificado para:
Estas três funções tornam Rust um tanto flexível quanto expressivo.
Split & Scan
Também tem o scan caso você precise de uma variação de fold que faz um yield do resultado a cada iteração. Isto é bem útil se você precisa de um certo valor acumulado e quiser verificar este valor a cada iteração.
Dividir um iterator em duas partes também é possível. Você pode usar uma função de agrupamento que retorna um boolean com partition.
Vamos usar esses dois conceitos para:
- dividir um slice grandão;
- agrupá-lo entre pares e ímpares;
- somar os grupos progressivamente; e
- verificar que o pares são sempre menores que a soma dos ímpares, já que pares começam com 0.
// Saída:
// Par sempre menor: true
Scan pode ser utilizado para gerar dados como médias móveis. Isto é útil quando se lê arquivos, dados e sensores. Particionar dados é uma tarefa comum quando se estiver organizando dados.
Outra operação comum é agrupar elementos com base num valor específico. Se você estiver buscando algo como o _.groupBy() do Lodash, calma lá. Considerando que Rust possui BTreeMap, HashMap, VecMap e outros tipos de dados, o nosso método de agrupamento precisa ser genérico.
Vamos ver um exemplo simples. Vamos escrever um iterator infinito que repete o intervalo de 0 a 5. No seu código esse iterator poderia utilizar structs ou tuplas, mas por agora, vamos utilizar somente inteiros.
Vamos agrupá-los em três categorias: zeros, cincos e todo o resto.
use HashMap;
// Saída: {Zero: [0, 0, 0, 0], Cinco: [5, 5, 5], Outro: [1, 2, 3, 4, 1, 2, 3, 4, 1, 2, 3, 4, 1]}
É meio que inútil guardar todos os valores replicados. Tente mudar o exemplo acima para retornar o número de ocorrências em vez de valores. Se quiser ir ainda mais longe, tente utilizar este método num valor mais complexo como uma struct, você também pode mudar quais chaves são utilizadas.
Flanqueado
A trait DoubleEndedIterator é útil em alguns casos. Por exemplo, quando você precisa dos comportamentos de uma fila e pilha ao mesmo tempo.
// Some(0)
// Some(9)
// Some(1)
// Some(8)
Agora vai brincar!
Agora tá na hora de você fazer uma pausa, preparar um cházinho e abrir o Playground. Tente mudar um dos exemplos acima, brinque com algumas outras coisas dos links de documentação abaixo e, no mais, divirta-se.
Se você travar, não se preocupe! Procure na internet se o erro não fizer sentido nenhum pra ti. Rust também tem uma comunidade muito ativa nos domínios *.rust-lang.org assim como no GitHub e no Stack Exchange. Sinta-se convidad@ a me enviar um email ou dar um alô no IRC também.
O que a gente viu é só a superfície... um mundo imenso nos aguarda.
]]>
Atenção: este texto foi traduzido, editado e adaptado por @nawarian. Você encontra o texto original em inglês no blog do MartinFowler através deste link.
Entregar/Mostrar/Perguntar é uma estratégia de ramificação (branching) que combina as funcionalidades de Pull Requests com a habilidade de entregar alterações de software continuamente. As mudanças são categorizadas como Entregar (fazer merge imediatamente sem revisão), Mostrar (abrir um pull request para revisão mas fazer um merge imediatamente) ou Perguntar (abrir um pull request para discussão antes de fazer o merge).
Conteúdo do post
Como fazer integração contínua sem Pull Requests?
Pull Requests foram adotados por muitos times de desenvolvimento de software. Algumas pessoas os amam, e outras desejam alcançar a tão sonhada Integração Contínua - onde você nunca cria branches e seu time integra suas mudanças o tempo todo.
Em vários aspectos, Pull Requests são ferramentas fantásticas. Ferramentas de versionamento oferecem funcionalidades de revisão de código maravilhosas. Há vários provedores SaaS que oferecem serviços que podem rodar em seus pull requests - desde rodar testes e verificar qualidade de código até fazer o deploy de ambientes de homologação.
Mas a adoção de Pull Requests como a principal forma de contribuir com código criou alguns problemas. Nós perdemos um pouco da mentalidade "Pronto pra lançar" que tínhamos quando fazíamos Integração Contínua. Funcionalidades em desenvolvimento ficam fora de cena até ficarem prontas para integração, e assim caímos nas armadilhas da integração de baixa frequência que a Integração Contínua procura resolver.
As vezes Pull Requests ficam parados, ou nós mesmos ficamos sem muita ideia de o que fazer enquanto esperamos por uma revisão. As vezes eles ficam inchados por mudanças não relacionadas e pequenas melhorias que a gente faz pensando "ah, já que eu tô aqui mesmo..."
Nós também ficamos cansados com o número de Pull Requests que precisamos revisar, e paramos de falar sobre código. Nós paramos de prestar atenção e clicamos em "Aprovar" ou mandamos o famoso LGTM sem muito senso crítico.
Introduzindo o Entregar / Mostrar / Perguntar
Existe uma abordagem de ramificação (branching) que eu utilizei com meus times. Funcionou muito bem, então eu gostaria de compartilhar contigo.
Toda vez que você fizer uma alteração, você precisa escolher três opções: Entregar, Mostrar ou Perguntar.
Entregar

Esta estratégia se assemelha muito com Integração Contínua: se você quer fazer uma alteração, faz diretamente no seu branch principal. Ao fazer isto você não precisa esperar alguém fazer o deploy das suas alterações para o ambiente de produção e nem pede revisão de código. Tudo sem muito alarde: faça a alteração utilizando todas as técnicas de Integração Contínua que tornam este procedimento seguro.
Isto funciona muito bem quando:
- Eu adiciono uma funcionalidade utilizando uma técnica bem estabelecida
- Eu corrijo um bug simples / pequeno
- Eu atualizo documentação
- Eu fiz alguma melhoria no meu código baseado em feedback
Mostrar

Aqui é onde nós adotamos a mentalidade de Integração Contínua e ao mesmo tempo aproveitamos as coisas boas que Pull Requests nos dão. Você faz a mudança num branch, abre um Pull Request e faz um merge sem esperar ninguém. Você só espera pelos testes automatizados (testes, cobertura de código, ambiente de homologação, etc.), mas não espera pelo feedback de ninguém para prosseguir com o deploy da sua alteração.
Desta forma você entrega as suas alterações rapidamente enquanto cria o espaço para feedback e conversa. O seu time recebe notificações dos Pull Requests e podem revisar o que você fez. Eles podem então dar feedback na sua abordagem ou código, fazer perguntas e aprender através das suas alterações.
Isto funciona bem quando:
- Eu quero feedback sobre como este código poderia ser melhor
- Eu gostaria de mostrar uma nova abordagem ou padrão que utilizei
- Eu refatorei X e quero que meu time fique ciente desta alteração
- Eu quero compartilhar com meu time a solução para um bug interessante
Perguntar

Esta é a estratégia que muitos de vocês já estão acostumados. Nós fazemos nossas alterações num branch, abrimos um Pull Request e esperamos pelo feedback dos colegas antes de fazer o merge. Talvez não tenhamos certeza de que utilizamos a abordagem correta. Talvez tenha algo no código que não gostamos muito mas não sabemos como melhorar. Talvez você tenha experimentado algo novo e gostaria de ver o que seus colegas acham.
Ferramentas de revisão de código modernas dão espaço para este tipo de conversa e você pode até colocar o time inteiro para revisar e discutir um Pull Request juntos.
Isto funciona bem quando:
- Eu não tenho certeza de que minhas mudanças vão funcionar
- Eu quero saber como meus colegas se sentem sobre esta nova abordagem
- Eu preciso de ajuda pra melhorar meu código
- Eu já encerrei o expediente hoje e vou fazer o merge amanhã
Regras
- Revisão de código ou "Aprovação" não devem ser requisitos para um Pull Request ser integrado no branch principal
- Autores fazem o merge de seus próprios Pull Requests. Desta forma, estas pessoas controlam se as alterações são do tipo Mostrar ou Perguntar, e decidem quando as mudanças vão para produção
- É possível utilizar todas as técnicas de Integração Contínua e Entrega Contínua que ajudam a manter o branch principal pronto para ser lançado para produção. Feature Toggles são um exemplo.
- Ramificações (branches) não devem existir por muito tempo, e devemos fazer um rebase com o branch principal com frequência
Conversa
Enquanto Pull Requests podem ser uma forma muito útil de falar sobre alterações de código, eles trazem consigo algumas armadilhas. A armadilha mais sedutora é a ideia de que eles podem substituir outras formas de discussão.
Um problema comum com ramificações é que autores decidem utilizar uma abordagem sem a discutir com ninguém. Quando o Pull Request finalmente é aberto, o tempo já foi investido numa implementação que pode não ser a melhor. Revisores são influenciados pela solução já adotada e têm dificuldade em sugerir abordagens diferentes. Quanto mais mudanças e mais velho for o branch, maior o problema. Converse com seu time antes de começar, para que você colete mais e melhores ideias e possa previnir retrabalho.
Lembre-se de que Pull Requests não são a única forma de Mostrar ou Perguntar. Faça uma ligação ou vá até a mesa de alguém. Mostre seu trabalho o quanto antes e frequentemente. Peça ajuda e feedback o quanto antes e frequentemente. Trabalhe nas tarefas em conjunto com seus colegas.
Não abrir um Pull Request não é uma boa razão para evitar conversar sobre o código. É importante que seus colegas mantenham uma boa cultura de feedback e conversem entre si sobre o que acham e aprendem.
Equilíbrio
Dadas essas três opções, quais eu deveria escolher com maior frequência?
Depende. Eu acho que cada time tem seu equilíbrio em cada momento.
Quando você está entregando funcionalidades utilizando uma abordagem já consolidada, você vai Entregar mais. Quando você confia no time e todos compartilham dos mesmos padrões de qualidade, você também fará mais Entregas.
Mas se vocês ainda estiverem se conhecendo ou fazendo algo completamente novo, então a necessidade de conversa é maior. Vocês irão Mostrar e Perguntar com mais frequência. Um iniciante talvez Mostre e Pergunte mais, enquanto um sênior Entrega muito mais, mas de vez em quando Mostra uma nova técnica ou uma refatoração que todo mundo deveria tentar.
Alguns times não têm muita flexibilidade. Algumas indústrias são altamente reguladas e o processo de aprovação ou revisão de código são obrigatórios para cada alteração de código. Há várias formas de implementar isso - com ou sem ramificações - que eu não vou comentar aqui.
Meu time deve adotar esta abordagem?
Vocês já adotaram.
Pense bem em como seu time funciona e você vai reparar que você já está lidando com Entregar/Mostrar/Perguntar. A maioria dos times normalmente cai em Entregar na maioria das vezes ou Perguntar na maioria das vezes.
Se você entrega na maioria das vezes
Se você raramente cria um branch e todos os commits vão direto para o branch principal, você Entrega na maioria das vezes. Se este é o seu caso, pense como Mostrar um pouco mais pode te ajudar.
Um grande motivo pelo qual os modelos de Pull Request se tornaram tão populares é que eles dão suporte a times que trabalham de forma remota e assíncrona. Mostrar explicitamente as partes interessantes do seu trabalho aos outros pode ajudá-los a aprender e sentirem-se parte da conversa, especialmente quando se trabalha de forma remota e em fuso horários diferentes.
Eu também notei (especialmente em times que não conversam o suficiente [1]) que fazer sempre o merge para o branch principal pode significar que algumas mudanças problemáticas podem passar desapercebidas por algumas semanas. Quando isto acontece é difícil ter uma conversa útil sobre elas porque os detalhes e contextos já se perderam no tempo. Encorajar colegas a Mostrar significa que vocês vão conversar mais sobre o código comumente.
Se você pergunta na maioria das vezes
Se seu time abre Pull Requests para a maioria das alterações, vocês Perguntam na maioria das vezes. Se por um lado Pull Requests são uma ferramenta útil para qualidade e feedback, por outro lado eles podem criar um problema de escalabilidade. O inevitável sobre pedir aprovação é que isso leva tempo. Se muitas mudanças estão na fila do feedback, a qualidade do feedback diminui ou a velocidade diminui. Tente Mostrar com mais frequência para que você tire proveito do melhor dos dois mundos.
O motivo pelo qual vocês dependem muito de Perguntar pode ser falta de confiança. "Todas mudanças precisam ser aprovadas" ou "Todo Pull Request precisa de 2 revisores" são práticas comuns, mas demonstram falta de confiança no time de desenvolvimento.
Isto é problemático porque a aprovação é apenas um band-aid - ela não vai corrigir seu problema de confiança. Mostre um pouco mais para tirar um pouco da pressão do ciclo de desenvolvimento e dê maior atenção a atividades que aumentam a confiança no time como treinamentos, discussões em time ou programação em pares. Toda vez que uma pessoa Mostra em vez de Perguntar é uma oportunidade para elas construírem confiança com o time.
Outro motivo para depender muito de aprovação pode ser que seu time não se sinta seguro em enviar mudanças diretamente para o branch principal. Neste caso o que você precisa é aprender sobre como implementar técnicas que mantenham o seu branch principal sempre pronto para lançamento. Enquanto isso, Mostrar mais pode ajudar a diminuir a barreira para lançar mudanças de forma segura para produção. Reduzir esta barreira vai servir de incentivo para seus colegas - se você encontrar formas de tornar suas alterações mais seguras, elas podem ir para produção mais cedo.
Conclusão
Então o que é Entregar/Mostrar/Perguntar? Em suma, são duas coisas:
Primeiro – um truque para te ajudar a obter o melhor de dois mundos - fazer o merge do seu próprio pull request sem aguardar feedback e dar atenção ao feedback quando este chegar.
Segundo – uma forma mais inclusiva e dinâmica de lidar com estratégias de ramificação. Entregar/Mostrar/Perguntar nos lembra que a abordagem de cada time normalmente fica em algum lugar entre Entregar sempre e Perguntar sempre. Isto nos encoraja a pensar sobre cada alteração independentemente e nos perguntar-mos: eu deveria Entregar, Mostrar ou Perguntar?
Agradecimentos
Obrigado a todos que ajudaram com feedback detalhado na preparação deste texto: Martin Fowler, Brian Gunthrie, Federico Blancato, Stephen Creswell e Paul Hammant.
Agradeço também ao Matthew Harward, Kief Morris, Giuseppe Pereira, Marcos Vinícius da Silva, Birgitta Böckeler, Prashanth R, Premanand Chandrasekaran, João Paulo Moraes e Mark Taylor, que discutiram o rascunho deste texto numa mailing list interna da ThoughtWorks.
Notas de rodapé
1: Pair Programming ou programação em pares é uma técnica efetiva para encorajar comunicação contínua num time
]]>

Atenção: este texto foi traduzido, editado e adaptado por @nawarian. Você encontra o texto original em inglês no blog do nosso parceiro SessionStack através deste link.
Há algumas semanas, começamos uma série que se aprofunda em JavaScript e como ele realmente funciona: pensamos que, conhecendo as peças elementares deste quebra-cabeças, você será capaz de escrever melhor seus códigos e aplicativos.
O primeiro post da série deu uma visão geral do motor, do tempo de execução e da pilha (stack). Este segundo post se aprofunda nas partes internas do motor JavaScript V8 do Google. Também trazemos algumas dicas rápidas sobre como escrever JavaScript melhor - as melhores práticas que nossa equipe de desenvolvimento na SessionStack segue ao construir o produto.
Visão Geral
O motor JavaScript é um programa (ou interpretador) que executa código JavaScript. Este motor pode ser implementado como um interpretador padrão ou um compilador Just in Time que transforma JavaScript em um tipo de bytecode.
Aqui vai uma lista de projetos populares que implementam um motor JavaScript:
- V8 — de código aberto, desenvolvido pelo Google, escrito em C++
- Rhino — de código aberto, gerenciado pela Mozilla Foundation, escrito em Java
- SpiderMonkey — foi o primeiro motor JavaScript e rodava no navegador Netscape Navigator, e hoje em dia roda no Firefox
- JavaScriptCore — de código aberto, desenvolvido pela Apple para o navegador Safari e conhecido como Nitro
- KJS — motor do KDE desenvolvido por Harri Porten para o navegador Konqueror
- Chakra (JScript9) — Internet Explorer
- Chakra (JavaScript) — Microsoft Edge
- Nashorn — de código aberto e parte do OpenJDK, escrito por Oracle Java Languages and Tool Group
- JerryScript — motor leve para Internet das Coisas (IoT)
Por que o motor V8 foi criado?
O motor V8, criado pelo Google, é de código aberto, escrito em C++ e é utilizado pelo navegador Google Chrome. Diferente dos outros motores, V8 também é utilizado pelo ambiente Node.JS.

O motor V8 foi desenhado para aumentar a performance da execução de JavaScript em navegadores web. V8 traduz código JavaScript em código de máquina de forma eficiente em vez de utilizar um interpretador.
Ele compila código JavaScript em código de máquina utilizando uma técnica chamada JIT (Just-in-Time), técnica também utilizada por outros motores JavaScript modernos como o SpiderMonkey ou Rhino (Mozilla). A principal diferença é que o motor V8 não gera nenhum bytecode ou código intermediário.
V8 tinha dois compiladores
Antes da versão 5.9 do motor V8 ser lançada (no começo de 2017), o motor utilizava dois compiladores:
- full-codegen — um compilador simples e rápido que produz código de máquina simples e relativamente lento.
- Crankshaft — um compilador de otimizações mais complexo (Just-In-Time) que produz código ultra otimizado.
O motor V8 também utiliza diferentes threads internamente:
- A thread principal (main thread) faz o que você poderia esperar: pega o seu código JavaScript, compila e executa
- Há também uma thread separada somente para compilação, desta forma a thread principal consegue continuar executando enquanto a anterior otimiza o código
- Uma thread de análise (profiler) que indica quais métodos são mais utilizados para que Crankshaft possa os otimizar
- Algumas threads para Garbage Collection
Quando V8 roda um código JavaScript, o full-codegen é utilizado primeiro para transformar código Javascript em código de máquina sem nenhuma transformação. Isto permite que o motor execute código de máquina muito rápido. Note que V8 não utiliza um bytecode ou representação intermediária, portanto um interpretador não é necessário.
Quando o código já tiver rodado por algum tempo, a thread de análise terá coletado informações o suficiente para dizer quais métodos deveriam ser otimizados.
Daí otimizações no motor Crankshaft começam a executar em outra thread. Este motor transforma a Árvore de Sintaxe Abstrata (Abstract Syntax Tree, AST) em uma representação estática de atribuição única (static single-assignment, SSA) de alto nível chamada Hydrogen e tenta otimizar este grafo. A maior parte das otimizações acontecem aqui.
Código embutido
A primeira otimização é embutir o máximo de código possível de forma antecipada.
Veja o snippet abaixo com três funções:
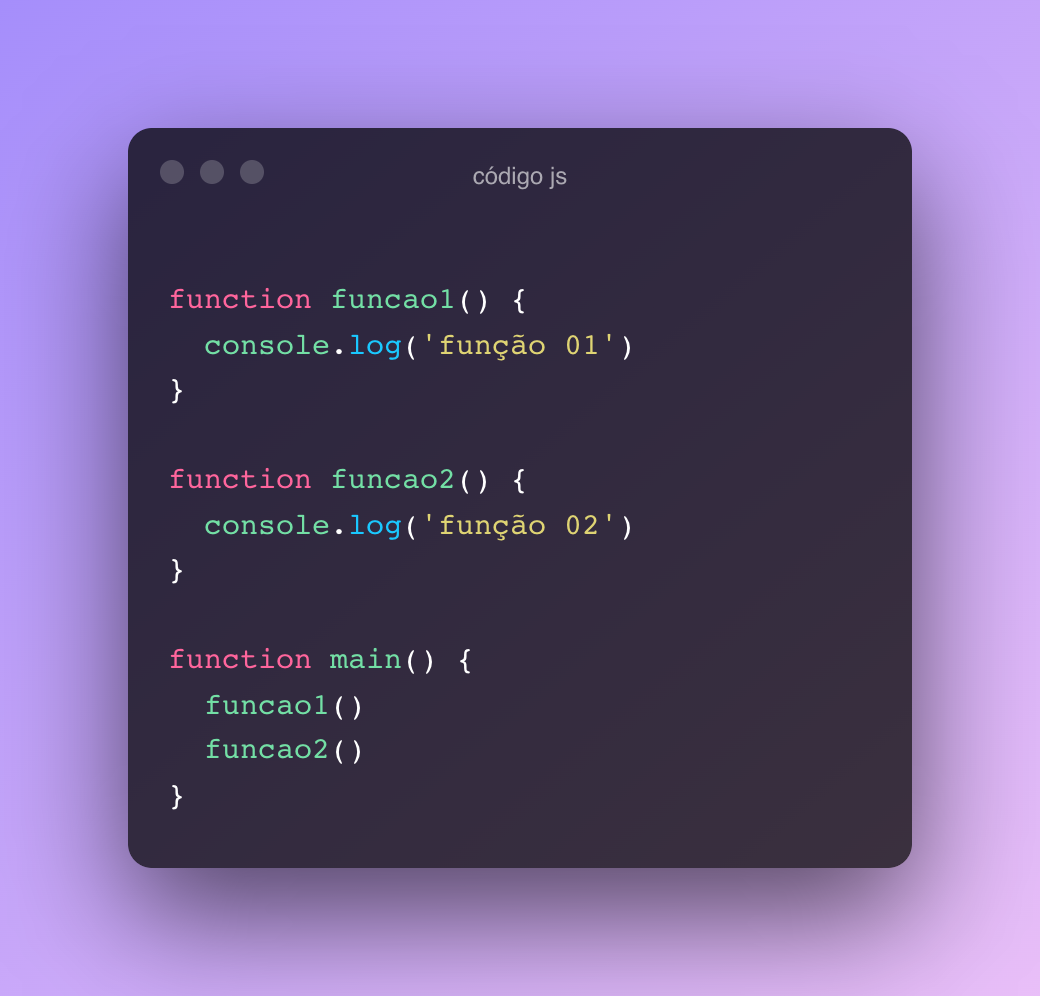
Embutir código é o processo de substituir uma chamada de função pelo corpo daquela função chamada. Este passo permite que as otimizações seguintes tenham melhor efeito. O código acima embutido fica assim:
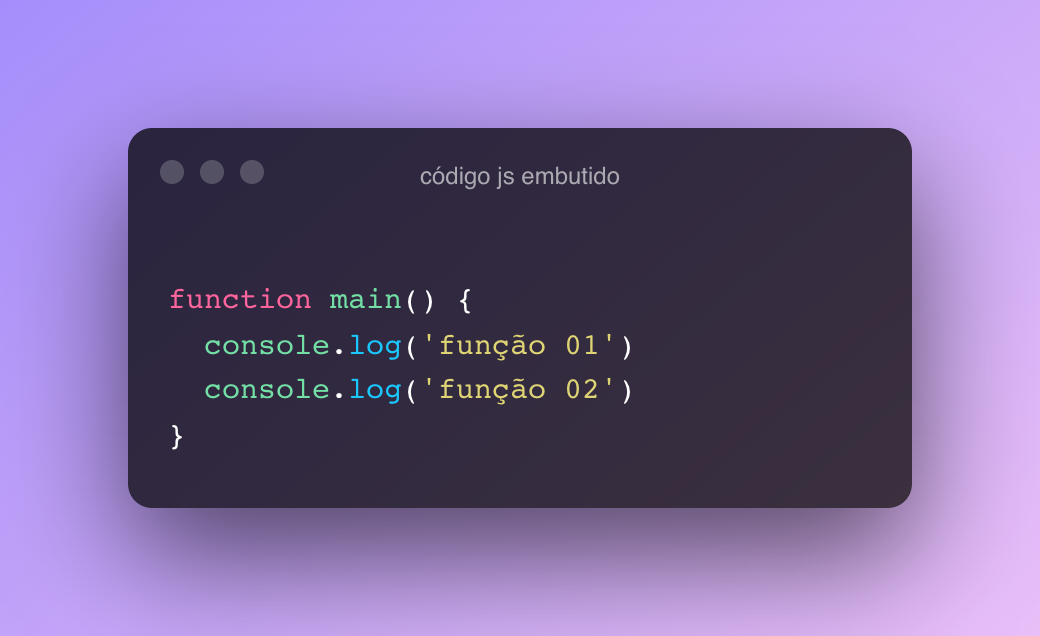
Classes escondidas
JavaScript é uma linguagem baseada em protótipos: não existem classes e objetos são criados utilizando um processo de clone. JavaScript também é uma linguagem de programação dinâmica e por isso podemos facilmente adicionar ou remover propriedades de um objeto depois de instanciado.
A maioria dos interpretadores JavaScript utilizam estruturas parecidas com dicionários (baseadas em funções hash) para gravar a localização dos valores das propriedades em memória. Esta estrutura faz com que obter o valor de uma propriedade em JavaScript seja mais lento do que em linguagens de programação não dinâmicas como Java ou C#.
Em Java, todas as propriedades de objeto são definidas por um layout fixo antes da compilação e não podem ser adicionadas ou removidas de forma dinâmica em tempo de execução (bom, o C# tem o tipo dynamic, mas esta é outra história).
O resultado é que os valores das propriedades (ou ponteiros para estas propriedades) podem ser armazenados como um buffer contínuo na memória com uma distância fixa entre si. O tamanho desta distância pode ser facilmente determinado pelo tipo da propriedade e isto não é possível com JavaScript já que o tipo de uma propriedade pode mudar em tempo de execução.
Já que utilizar dicionários para encontrar propriedades de um objeto em memória é ineficiente, o motor V8 utiliza um método diferente: classes escondidas. Estas classes escondidas funcionam de forma semelhante a estes objetos de layout fixo (classes) em linguagens como Java, só que criados em tempo de execução. Vamos ver como se parecem essas classes:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
Assim que new Point(1, 2) é executado, o motor V8 cria uma classe escondida chamada C0.

Nenhuma propriedade foi definida ainda, então C0 está vazia.
Assim que o primeiro comando this.x = x executar (dentro da função Point), V8 vai criar uma nova classe escondida chamada C1, que é baseada em C0. C1 descreve o local em memória (relativo ao ponteiro do objeto) onde a propriedade x pode ser encontrada.
Neste caso, "x" é encontrada no deslocamento (offset) 0 - portanto quando se observar um objeto na memória como um buffer contínuo, o primeiro deslocamento se refere à propriedade "x".
V8 também atualiza C0 com uma "transição de classe" que diz que se a propriedade "x" for adicionada a um objeto Point, a classe escondida deverá ser trocada de C0 para C1. A classe escondida no objeto Point abaixo agora é C1.

Este processo se repete quando o comando this.y = y é executado (dentro da função Point, depois que this.x = x executa).
Uma nova classe escondida chamada C2 é criada, uma transição de classe é adicionada à C1 dizendo que se uma propriedade y for adicionada ao objeto Point (que já possui uma propriedade x) então a classe escondida deverá mudar para C2 e a classe escondida do objeto p1 passa a ser C2.

Transformações de classes escondidas dependem da ordem em que as propriedades são adicionadas a um objeto. Vejamos o código abaixo:
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.b = 7;
p2.a = 8;
É natural pensar que os objetos p1 e p2 utilizariam as mesmas classes escondidas e transições, mas não é isso o que acontece. Para p1, a propriedade a é inserida primeiro e depois inserimos a propriedade b. Para o objeto p2, a propriedade b é inserida primeiro e só então a propriedade a é inserida. Desta forma p1 e p2 geram classes escondidas e transições diferentes, já que suas propriedades foram inseridas em ordem diferente.
Neste caso é muito melhor inicializar propriedades dinâmicas na mesma ordem para que as mesmas classes escondidas sejam reutilizadas.
Inline caching
O motor V8 utiliza ainda uma outra técnica de otimização para linguagens dinamicamente tipadas chamada Inline Caching. Inline Caching assume que chamadas repetidas ao mesmo objeto costumam ocorrer com o mesmo tipo de objeto. Você pode ler mais sobre isso aqui.
Como isso funciona? O motor V8 mantem um cache dos tipos de objetos passados por parâmetro em chamadas de método recentes e usa esta informação pra assumir qual o tipo do objeto que será passado no futuro. Se o motor V8 for capaz de assumir corretamente o tipo do objeto que será passado, ele pode pular o processo de entender como acessar as propriedades de um objeto e, em vez disso, usar a informação armazenada das classes escondidas dos últimos objetos utilizados como parâmetro.
Como os conceitos de classe escondida e inline caching se relacionam?
Sempre que um método é chamado num objeto específico, o motor V8 precisa identificar a classe escondida para entender como acessar suas propriedades em memória. Depois de duas chamadas ao mesmo método passando a mesma classe escondida, V8 passar a pular o processo de identificar a classe escondida e adiciona um ponteiro para a propriedade do objeto em si. Para todas as chamadas futuras a este método, o motor V8 assume que a classe escondida não mudou, e pula diretamente para o endereço de memória da propriedade específica utilizando deslocamentos (offsets) das últimas chamadas.
Isso aumenta em muito a velocidade de execução.
Inline caching é outra razão pela qual é tão importante que objetos compartilhem as mesmas classes escondidas.
Se você criar dois objetos do mesmo tipo com classes escondidas diferentes (como fizemos anteriormente), o motor V8 não será capaz de realizar o inline caching porque mesmo que os dois objetos sejam do mesmo tipo, as classes escondidas destes objetos possuem deslocamentos (offsets) diferentes para suas propriedades.

Compilação para código de máquina
Assim que o grafo Hydrogen é otimizado, Crankshaft o traduz para uma representação de baixo nível chamada Lithium. A maior parte da implementação de Lithium é específica para a arquitetura do computador em que roda. A alocação de registradores acontece neste nível.
Por fim, Lithium é compilado para código de máquina. E então um outro processo chamado Substituição na Pilha (on-stack replacement, OSR) acontece.
Antes de começarmos a compilar e otimizar um método lento, nós provavelmente estávamos executando este método. O motor V8 não vai simplesmente esquecer a implementação lenta e começar a utilizar a implementação otimizada. Em vez disso, o motor transforma todo o contexto que temos (pilha, registradores) para que possamos mudar de implementação em tempo de execução.
Esta é uma tarefa complexa, dado que dentre outras otimizações, o motor V8 já embutiu código anteriormente. V8 não é o único motor capaz de utilizar a técnica de OSR.
Há alguns mecanismos de segurança para reverter uma otimizações caso alguma suposição que o motor vez não seja mais verdadeira.
Coleta de lixo
Para a coleta de lixo (garbage collection), o motor V8 utiliza o tradicional método "marque e limpe".
A fase de demarcar bloqueia a execução do JavaScript.
Para controlar os custos da coleta de lixo e tornar a execução mais estável, o motor V8 utiliza marcação incremental: em vez de iterar toda a heap e tentar marcar tudo quanto é objeto, o motor itera apenas uma parte da heap e depois volta a executar o código JavaScript. A próxima coleta de lixo continua de onde a última iteração da heap parou.
Isso permite pequenas pausas durante a execução normal. Como mencionado antes, a faze de limpar o que foi marcado acontece em threads distintas.
Ignition e TurboFan
Com o release da V8 5.9 no começo 2017, uma estratégia de execução foi introduzida ao motor. Esta nova estratégia alcança ainda maiores melhorias em performance e menor utilização de memória em aplicações JavaScript reais.
A nova estratégia de execução é baseada no novo interpretador do motor V8, Ignition, e o novo compilador de otimizações TurboFan.
Você pode ver o post sobre este tópico, escrito pelo time que desenvolve o motor V8 neste link.
Desde a versão 5.9 do motor V8, full-codegen e Crankshaft (tecnologias utilizadas no motor V8 desde 2010) não foram mais usadas pelo motor para execução de JavaScript já que o time V8 não consegue facilmente adicionar as novas funcionalidades da linguagem JavaScript e manter as otimizações necessárias para estas funcionalidades.
Isto significa que o motor V8 manterá uma arquitetura muito mais simples e de fácil manutenção daqui pra frente.

Estas melhorias são só o começo. A nova estratégia Ignition e TurboFan moldaram o caminho para outras otimizações que vão melhorar ainda mais a performance do JavaScript e diminuir o consumo de recursos do motor V8 no navegador Chrome e no ambiente Node.JS pelos próximos anos.
Por fim, aqui vão algumas dicas e truques sobre como escrever JavaScript otimizado. Você pode derivar estas dicas do texto que leu, mas aqui vai um resumo pra você:
5 Dicas para escrever JavaScript otimizado
- Ordem das propriedades dos objetos: sempre instancie as propriedades de seus objetos na mesma ordem para que classes escondidas, e posteriormente código otimizado, possam ser compartilhados.
- Propriedades dinâmicas: adicionar propriedades à um objeto após instanciação vai forçar a classe escondida a mudar e diminuir a performance de qualquer método que esteja otimizado para a classe escondida anterior. Em vez disso, adicione todas as propriedades de um objeto em seu construtor.
- Métodos: um código que execute o mesmo método várias vezes executa mais rápido do que um código que rode vários métodos diferentes apenas uma vez, por causa do inline caching.
- Arrays: evite arrays em que as chaves não sejam números em sequência. Arrays não sequenciais são tratados como uma hash table. Elementos nestes arrays são mais difíceis de acessar. É bom também evitar pré alocar arrays grandes. É melhor aumentar o tamanho do array conforme for necessário. Por fim, não remova elementos em arrays. Remover elementos torna os arrays descontínuos (os transforma em hash tables).
- Valores inteiros: o motor V8 representa objetos e números utilizando 32 bits. Um desses bits é utilizado como flag para entender se aquele espaço de memória é um objeto (flag = 1) ou um inteiro (flag = 0). Este inteiro então só pode possuir 31 bits e é chamado de Inteiro Pequeno (Small Integer, SMI). Se um valor numérico for maior do que os 31 bits conseguem representar, o motor V8 vai encapsular este número, transformando-o em um double e criando um novo objeto para alocar o número dentro. Tente utilizar números de 31 bits sempre que possível para evitar estas operações de encapsulamento.
Nós da SessionStack tentamos seguir estas melhores praticas quando escrevemos código JavaScript super otimizado. O motivo pelo qual buscamos estas práticas é que assim que você integrar SessionStack no seu aplicativo em produção, ele grava tudo: mudanças no DOM, interações de usuários, erros de JavaScript, stack traces, chamadas de rede que falharam e mensagens de depuração. Com SessionStack você pode reproduzir problemas da sua aplicação como se fossem vídeos e ver tudo o que aconteceu com seu usuário. E tudo isso precisa acontecer sem causar nenhum impacto na sua aplicação.
Nós temos um plano gratuito que te permite começar de graça.

Fontes
]]>História
Codamos.com.br é resultado de duas iniciativas em andamento: mentoria para quem quer se iniciar em programação e um blog de tecnologia PHP.
O projeto de mentoria nunca foi anunciado em público, mas sim desenvolvido e aperfeiçoado com cada indivíduo. Estas experiências recentes e pesquisas de mercado nos mostraram um caminho interessante para lidar com mentoria de forma efetiva e rápida.
Já o blog thephp.website foi construído no intuito de oferecer conteúdo sobre PHP em inglês e em português. O conteúdo em inglês buscava tornar o site popular internacionalmente e trazer lucro com anúncios e vendas, enquanto o conteúdo em português buscava suprir a demanda por conteúdo atualizado e de qualidade do Brasil e outros países falantes da língua portuguesa.
Após dois anos de thephp.website, chegamos à conclusão de que a maior parte do tráfego do site vem do Brasil, porém acessando páginas em inglês. Isto indica que há uma demanda altíssima por conteúdos em inglês aqui no Brasil, mas vai diretamente contra a ideia inicial do projeto: suprir a demanda por conteúdo atualizado e de qualidade de países falantes da língua portuguesa.
Decidimos então descontinuar o projeto thephp.website em benefício do codamos.com.br, na intenção de focar num único público e em objetivos específicos.
Objetivos
Os três principais objetivos do projeto codamos.com.br são:
- Conteúdo de tecnologia atualizado e de alta qualidade em português brasileiro para falantes da língua portuguesa;
- Programas de mentoria para iniciantes e iniciantes experientes otimizados com base na nossa experiência recente;
- Envolvimento com a comunidade de software brasileira através de guest posts, eventos e conferências.
Tática
Neste momento o projeto codamos.com.br precisa crescer e ser reconhecido.
Algumas ações que vamos adotar para alcançar estes primeiros objetivos táticos são:
- Aumentar o inventário de conteúdo rapidamente
- Traduzir posts de outras linguagens para português, com devidos créditos e permissões das autoras;
- Gerar conteúdo original e de qualidade;
- Gerar conteúdo continuado (séries e devlogs) para que visitantes retornem ao site com frequência;
- Convidar a comunidade para escrever e publicar seus textos no site codamos.com.br
- Utilizar redes sociais de forma agressiva
- Aumentar a presença nas redes twitter e reddit;
- Pedir com frequência que leitores compartilhem os conteúdos;
- Campanhas premiadas de engajamento em redes sociais;
- Participar de conferências como organizadores, patrocinadores ou produtores de conteúdo
]]>

Atenção! Para que este DevLog avance eu preciso da sua ajuda não financeira: Dê retuíte neste post e compartilhe com colegas e quem mais se interessar. Somente após 50 RTs eu vou escrever o próximo post. Esta é uma forma fácil e barata de você nos ajudar o projeto codamos.com.br a crescer ao mesmo tempo que ganha um conteúdo exclusivo e de qualidade em português.
Conteúdo deste post
Há alguns bons meses eu decidi que vou escrever meu próprio emulador NES (Nintendinho 8-bits). O desafio parece interessante o suficiente e vai me manter ocupado por um tempo razoável.
De lá pra cá eu estudei e aprendi bastante coisa sobre a plataforma NES. Visitando materiais como a wiki do NESDev.com, a incrível série de vídeos do One Lone Coder e outros emuladores de código aberto.
Espero que desta vez eu consiga atingir maior sucesso e não abandone o projeto. Este Devlog vai me ajudar a tomar nota do meu progresso e não abandonar o projeto, ao mesmo tempo eu devo lançar mais conteúdo interessante pra vocês.
Eu pretendo também utilizar as ideias do Aprendizado Guiado por Testes: Introduzir, descobrir, testar, aprender, repetir. Portanto todo capítulo deste DevLog deve seguir mais ou menos esta estrutura.
Objetivo deste projeto
O objetivo maior deste emulador é conseguir rodar a ROM do jogo Super Mario Bros.. Esta ROM deverá executar com vídeo, áudio e controles.
Ferramentas utilizadas no projeto
- Linguagem: C, padrão C99
- Compilador: clang
- Biblioteca de GUI: raylib
- Ferramenta de build: Make
- Integração Contínua: Github Actions
Eu quero MUITO desenvolver o emulador NES em PHP, mas a princípio não faz muito sentido: eu precisaria fazer muita coisa específica em PHP para desenvolver o básico que outras linguagens já oferecem. Então para esta versão, PHP não é a minha ferramenta.
Eu tenho estudado Rust e C nestes últimos 2 anos e acho que já atingi um nível de proficiência decente com as duas linguagens. A minha escolha aqui vai ser a linguagem C pela simplicidade da sintaxe. Como estou rodando um MacOS, o compilador mais confortável pra mim será o clang, mas pretendo utilizar o padrão C99 para evitar incompatibilidades.
Como engine gráfica eu poderia então utilizar o OpenGL ou SDL. Como eu quero evitar perder tempo escrevendo a minha própria abstração, vou utilizar uma biblioteca de alto nível: a raylib. Talvez numa segunda iteração eu isole melhor o tratamento de áudio e vídeo para que possa facilmente trocar a biblioteca.
Por fim, eu não imagino que o projeto vá crescer muito em número de arquivos, então uma build simples usando Make já deverá ser o suficiente.
Para garantir que nenhuma regressão inesperada aconteça, eu vou utilizar uma ferramenta de Integração Contínua. Acho que Github Actions já será suficiente para o meu caso de uso.
Visão geral: arquitetura do NES
Há três componentes essenciais em um emulador NES: CPU (unidade central de processamento), PPU (unidade de processamento de imagens), APU (unidade de processamento de áudio). Há mais elementos a serem emulados, mas estes três são os essenciais para alcançar o meu objetivo.
Estes componentes se comunicam através do barramento (BUS).
Por fim, os programas são carregados a partir de ROMs. ROMs são na realidade cópias dos programas gravados nos cartuchos.
BUS ou barramento
Este componente é o mais simples de emular porque é basicamente o acesso a memória entre os componentes.
O barramento (ou memory bus) é o que permite a CPU gravar uma sequência de bytes no endereço A e outro componente, como a PPU, ler esta sequência de bytes e interpretar como uma imagem ou algo assim.
CPU: central processing unit ou unidade central de processamento
Emular a CPU do NES será quase equivalente a emular o chip 6502. Este é o microprocessador utilizado neste console.
Este processador naturalmente possui algumas instruções que podem ser descritas na linguagem Assembly. Como LDA, STA, PHP entre outras. Mais detalhes no post sobre a emulação da CPU.
Dentre todos os componentes este é o mais complexo porque possui muitas instruções, modos de endereçamento e comportamentos complexos.
Um erro aqui muitas vezes é silencioso e difícil de capturar. Em alguns casos determinado bug só se materializa com uma ROM específica, em condições específicas. Quanto mais testes e cobertura tivermos aqui, melhor.
PPU: picture processing unit ou unidade de processamento de imagens
Este componente é responsável por ler trechos específicos da memória e traduzir em vídeo.
Em termos de esforço deverá ser bem menor do que a emulação da CPU, mas com certeza é o mais complexo.
APU: audio processing unit ou unidade de processamento de áudio
Semelhante ao PPU, este componente é capaz de sintetizar os áudios dos jogos: traduzir pedaços de memória em som.
Eu ainda não estudei sobre o APU, então não possui muitos detalhes sobre como este componente funciona. Vamos descobrir mais no futuro.
Visão geral da arquitetura
Com a imagem abaixo eu tento descrever o modelo que eu tenho cristalizado sobre a arquitetura do NES.
O barramento (BUS) é o que conecta todos os outros componentes.
A ROM possui um programa que é carregado para a memória, de forma que o conteúdo da ROM fica disponível no Barramento (BUS) para que outros componentes possam acessar.
A CPU é responsável por executar instruções, que são carregadas a partir de uma ROM.
A PPU é responsável por pintar na tela o estado atual da aplicação (jogo). O programa (definido na ROM) define em quais endereços de memória gravar quais bytes, e a PPU sabe exatamente quais áreas da memória acessar para pintar a tela. A APU provavelmente opera de forma semelhante.

Próximos passos
A visão geral foi dada, agora é preciso colocar a mão na massa.
No próximo post eu vou preparar o repositório no Github e configurar o Github Actions para executar uma build simples.
]]>

O meu foco aqui é te mostrar que VIM pode te trazer muita produtividade no desenvolvimento de software. Aqui tem um vídeo meu sobre como utilizar FFI em PHP, onde eu programo tudo utilizando VIM. Nele você pode reparar que a ferramenta me serviu muito bem para prototipar o programa e que é possível mover relativamente rápido entre um arquivo e outro.
Mais tarde eu acabei migrando para o PhpStorm naturalmente, porque é a minha ferramenta de preferência para desenvolver com PHP.
Conteúdo do post
- O que é VIM?
- Pra quê aprender a utilizar vim?
- Filosofia VIM
- Primeiros passos com VIM
- Ainda tem muito chão pela frente
O que é VIM?
VIM é um editor de texto livre, grátis, simples, leve e robusto.
É comum utilizar VIM dentro de um terminal ou emulador de terminal, mas também é possível usar a aplicação gráfica do VIM chamada gVIM.
Você encontra os pacotes para download do VIM no site oficial. Mas normalmente gerenciadores de pacotes como apt, apk e HomeBrew possuem uma forma simples e rápida de instalar em seu sistema.

Pra quê aprender a utilizar vim?
Antes de qualquer coisa, vamos deixar claro: você não precisa saber utilizar VIM para ter reconhecimento na área de desenvolvimento de software! Eu conheço inúmeros profissionais incríveis que não têm familiaridade alguma com esta ferramenta.
Eu não quero que ao terminar de ler este texto você pense que PRECISA saber utilizar o VIM para ter reconhecimento na profissão, ou que é inferior por não saber. Não é este o ponto!
VIM tem a capacidade de aumentar muito a sua produtividade para resolver os mais diversos problemas do dia a dia tanto na profissão de desenvolvimento de software quanto como usuários.
Abaixo eu descrevo alguns motivos pelos quais eu encorajo todo profissional de desenvolvimento a obter pelo menos o mínimo de proficiência com VIM.
Abrir arquivos grandes sem travar o computador
VIM é altamente otimizado e não precisa indexar todo o conteúdo do seu projeto para operar. É um editor de texto simples e portátil que te permite abrir e operar em arquivos de vários megabytes sem muita dificuldade ou lentidão.
Quando se precisa navegar ou entender qual o tipo de conteúdo existe em determinado projeto, o VIM com certeza é uma opção rápida e que não requer segundos/minutos só para abrir uma pasta.
Há situações em que não é possível utilizar uma IDE
Em determinados momentos você vai se encontrar modificando ou depurando uma aplicação dentro de um conteiner Docker, fazendo ssh num servidor remoto ou mesmo rodando seu sistema *nix sem um servidor gráfico como o X11.
Nestes casos VIM é uma ferramenta incrível porque consegue te dar todo o poder de um editor de texto mesmo sem o suporte gráfico que normalmente teríamos num computador pessoal.
VIM está preparado para trabalhar com quase todas linguagens de programação
Hoje em dia temos IDEs ultra especializadas dominando o mercado, como as ferramentas da JetBrains que são incríveis mas focadas em poucas linguagens cada uma.
Para aprender uma linguagem nova ou experimentar rapidamente alterar o conteúdo de um programa de código aberto numa linguagem com a qual não se está familiarizado, VIM é extremamente útil.
Sempre que eu trabalho com Python, por exemplo, utilizo VIM. Não utilizo uma IDE especializada como o PyCharm porque python não é a minha ferramenta de trabalho e não me preocupei em comprar uma licença desta IDE.
Até hoje eu não consegui encontrar uma IDE gratuita especializada em linguagem C que me satisfizesse melhor do que o VIM.
Alterar rapidamente um código e ver os resultados é extremamente satisfatório com VIM, é um processo pouquíssimo burocrático.
Você pode adicionar funcionalidades ao VIM com a linguagem que quiser
Pouco da customização do VIM é específico deste editor: você não vai precisar escrever arquivos YAML ou JSON que pouco entende, nem navegar em diversos menus de configuração.
Adicionar uma funcionalidade ao VIM pode ser feito através de plugins (específicos do editor) ou linha de comando. O que você consegue executar numa linha de comando, pode ser inserido no seu estilo de trabalho com VIM.
Portanto scripts em C, PHP, Python, Java, LUA ou o que mais você desejar podem ser facilmente integrados ao seu ambiente de desenvolvimento com VIM.
Filosofia VIM
VIM traz consigo três conceitos importantíssimos. Ao assimilar estes três conceitos, a maioria dos comandos e atalhos do VIM passam a fazer mais sentido.
Não tire as mãos do teclado
Este é um conceito fundamental que vai te acompanhar durante toda a sua jornada com VIM.
Se você precisar usar o cursor para clicar, rolar a página, ou pressionar as setas para navegar as chances de estar fazendo algo de forma pouco eficiente são altas!
Outro aspecto fundamental é que as suas mão precisam sempre focar no centro do teclado. Se algum movimento ou ação sua te obrigar a mover as mãos para as bordas do teclado ou, pior ainda, segurar o mouse, com certeza há uma forma de otimizar no VIM.
Foco no centro do teclado
Durante o nosso fluxo de desenvolvimento com outras ferramentas é comum pressionar atalhos que utilizam as teclas de função (F1, F2, ... F12) e muitas vezes outras teclas de navegação como o page-up/down, home, end, delete. E o pior de tudo: largar o teclado para alcançar o mouse.
Isso tudo interrompe o fluxo de desenvolvimento e dispersa o foco de quem escreve.
O VIM tenta corrigir isto concentrando todas as suas funcionalidades ao centro do teclado. Se você precisou levantar a mão e viajar para outro canto do teclado, ou para fora dele, provavelmente existe uma forma mais inteligente de alcançar o mesmo objetivo no VIM.
Evite repetições
VIM é um editor de texto de alta produtividade. Todas as repetições podem ser encurtadas com atalhos, programadas e em alguns casos até transformadas em macros.
Por exemplo, o comando dd apaga a linha atual do cursor. Para apagar 5 linhas você pode apertar dd cinco vezes OU pressionar a sequência d5d.
Todas as ações do VIM podem se beneficiar desta repetição. E para coisas mais complexas que envolvam múltiplas ações, é possível criar macros sem precisar programar uma linha de código sequer.
Primeiros passos com VIM
Guarde estes três conceitos como um mantra pra a sua prática VIM: não tire as mãos do teclado, foco no centro do teclado e evite repetições.
Repetir este mantra somado com um tanto de curiosidade, vai te ajudar a dominar o VIM muito mais facilmente.
Abaixo eu vou te contar sobre alguns comandos e ações básicas pra começar a trabalhar com VIM sem sofrer, perder tempo ou se frustrar. Eu garanto que com alguns dias de prática você já vai começar a entender como pode ser produtivo trabalhar com este editor de textos.
Para evitar quaisquer distrações, eu vou rodar todos os exemplos abaixo utilizando uma imagem docker. Rode os comandos abaixo e provavelmente tudo o que eu escrever aqui vai funcionar pra ti sem nenhum problema.
$ docker run --rm -it alpine:latest
/ # apk add vim
O primeiro comando deverá inicializar uma imagem linux (alpine) vazia. A segunda linha, já dentro do conteiner, instala o programa VIM.

Estamos prontos para começar!
Como abrir um arquivo (novo ou existente) com o VIM
É possível abrir um arquivo no VIM quando ele ainda estiver fechado, e quando já está aberto. Também é possível abrir um arquivo já existente ou criar um novo. Vamos ver cada opção aqui.
Não tem diferença nenhuma o processo de abrir um arquivo novo ou existente no VIM. A maior diferença está em iniciar o VIM ou abrir o arquivo com o VIM já aberto.
Para abrir um arquivo com o VIM, basta executar o comando vim no terminal e passar o caminho do arquivo como parâmetro. A sintaxe é essa:
$ vim [arquivo]
Onde [arquivo] deve ser substituído pelo caminho do arquivo (novo ou existente) a ser aberto, sem colchetes. Por exemplo, para abrir um arquivo novo chamado nawarian.txt podemos executar o seguinte comando:
$ vim nawarian.txt
Ao executar o comando acima, uma tela parecida com esta deverá abrir:
![Programa VIM com o arquivo "nawarian.txt" aberto. A palavra [New] na barra de status indica que o arquivo não existia antes.](proxy.php?url=https://codamos.com.br/media/posts/19/Screenshot-2021-12-29-at-21.18.58.png)
Como salvar e sair do VIM
Mesmo sem adicionar nada no arquivo, já podemos salvar e sair. Desta forma o arquivo já será criado no sistema operacional normalmente, porém vazio. Pressione :wq e em seguida enter para que VIM salve e feche o arquivo.
Aqui w significa "write", ou "escrever" em português. E q significa "quit", ou "sair" em português. Portanto o comando :wq pode ser lido como "write and quit" ou "escrever e sair".

Como abrir um arquivo com o VIM já aberto
Vamos abrir novamente o arquivo nawarian.txt com o comando a seguir:
$ vim nawarian.txt
Com isto, VIM abrirá o arquivo nawarian.txt (agora já existente). Vamos agora abrir um arquivo chamado codamos.com.br mas desta vez com o VIM já aberto.
Para isto, utilizamos o comando :o codamos.com.br onde codamos.com.br é o nome do arquivo. :o pode ser lido como "open", ou "abrir" em português. Portanto :o codamos.com.br vai "abrir o arquivo codamos.com.br".


Edição de texto
Nós já conseguimos abrir e fechar um arquivo com VIM. Muito bem!
Mas é importante também alterar o conteúdo deste arquivo, né?
O VIM possui diferentes modos de trabalho. Por padrão, o modo de trabalho do VIM é o "Modo Normal", a partir do qual você pode executar comandos. Para alterar o conteúdo do arquivo, precisamos ativar o "Modo de inserção".
Basta pressionar a tecla i para ativar o "Modo de inserção". Você pode notar que a barra de status do VIM indica quando estamos no modo de inserção:

Sempre que o modo de inserção estiver ativado (-- INSERT -- aparece na barra de status), todas as teclas que pressionamos serão escritas no buffer do arquivo.
Agora que estamos no modo de inserção, podemos escrever "Olá mundo!", pressionar ESC para voltar ao modo normal e executar o comando de salvar e sair, ou :wq.

Note que agora o arquivo codamos.com.br possui 11 bytes. Pois escrevemos o texto Olá mundo nele. Podemos tomar certeza de que modificamos mesmo o arquivo utilizando o comando cat.
$ cat codamos.com.br

Como navegar no texto
Navegar o conteúdo no VIM também é um pouco diferente do comum. Lembre-se: não tire as mãos do teclado, foco no centro do teclado, evite repetições.
Vamos abrir o arquivo nawarian.txt e escrever mais do que uma linha lá. Digite o comando abaixo:
$ vim nawarian.txt
Agora que o arquivo nawarian.txt está aberto no VIM, e estamos o modo de comando, vamos entrar no modo de inserção pressionando a tecla i.
Agora digite um texto de algumas linhas, aqui vai minha sugestão. Mas digita mesmo, não dê um copia e cola.
VIM é um editor muito massa
mas pouca gente entende o software e passa sufoco.
Se este tutorial conseguir me preparar pra começar a usar VIM com mais frequência
eu prometo que vou compartilhar nas minhas redes sociais para que
mais pessoas sejam infectadas pelo vírus do VIM.
Pronto, agora pressione ESC para voltar ao modo normal. Sua tela deve mais ou menos assim:

Como mostrar as linhas do documento
Eu gosto de me guiar pelas linhas do documento. Isto não é obrigatório mas me ajuda muito a navegar no VIM.
Basta executar o comando :set nu (set number) para que o VIM exiba as linhas normalmente. O seu editor deverá ficar assim depois de executar o comando :set nu:

Mover o cursor para uma linha específica
Se você já sabe com qual linha quer trabalhar, basta usar o atalho número + gg. Se você quiser navegar rapidamente para a linha 2, basta digitar 2gg.
Como eu não estudei este atalho a fundo, eu costumo chamar esta ação de "gogo" 😅
Mover o cursor linha a linha ou coluna a coluna
Caso queira mover o cursor manualmente para cima, baixo, esquerda ou direita há também atalhos específicos.
Eu não recomendo utilizar as setas do teclado, lembre-se: mantenha as mãos ao centro do teclado!
No modo normal, basta utilizar as teclas h, j, k e l para navegar para esquerda, baixo, cima e direita respectivamente.
hmove o cursor para a esquerdajmove o cursor para baixokmove o cursor para cimalmove o cursor para direita
Eu sei, no começo é difícil. Mas com a prática você vai quer que na verdade isto vai te economizar muito tempo e esforço.
Existe um joguinho de navegador muito bacana que pode te ajudar a ganhar prática com o cursor: VIM Adventures. Na figura abaixo você consegue ter uma noção de como o jogo funciona e pode te ajudar a dominar a navegação básica do VIM.

Além disso, é possível repetir estes atalhos N vezes de acordo com o número de prefixo que você escolher.
Por exemplo, caso queira andar 4 linhas para cima, você tem duas opções:
- Pressionar
kquatro vezes seguidas; ou - Pressionar
4kuma única vez
A segunda opção mantém suas mãos ao centro do teclado e evita repetições.
Mover para o começo ou fim da linha
Para mover rapidamente para o começo da linha, digite ^.
Para mover rapidamente para o fim da linha, digite $.
Pular palavras para frente e para trás
Para avançar o cursor em uma palavra, basta digitar w (word, ou "palavra" em português) uma única vez. Ao digitar 5w você avança 5 palavras.
De forma semelhante, ao digitar b (back, ou "voltar" em português) uma vez o seu cursor irá recuar uma palavra. E ao digitar 5b, você volta 5 palavras.
Buscar conteúdo no VIM
Outra ação comum ao editar um texto é encontrar a ocorrência de determinada palavra ou símbolos.
No VIM o comando :/termo-de-busca irá buscar termo-de-busca no conteúdo do buffer atual.
Voltando ao texto que escrevemos, podemos buscar a palavra VIM, que aparece no texto 3 vezes, com o seguinte comando:
:/VIM

Considerando que o cursor estava no fim da última linha, ao buscar VIM o editor deverá retornar ao começo do arquivo e apontar a primeira ocorrência no começo da primeira linha. Note que o editor nos informa que precisou retornar ao início do arquivo:

Como a palavra VIM aparece mais de uma vez no texto, podemos repetir a operação de busca para encontrar a próxima. Temos duas opções para alcançar este objetivo:
- Executar o comando de busca
:/VIMnovamente (repetição); ou - Invocar o atalho next, ou "próximo" em português, ao pressionar a tecla
n
Assim como os outros atalhos mencionados, o atalho next pode ser prefixado com um número. Portanto 2n irá buscar o último termo de busca (VIM neste caso) duas vezes.
Ainda tem muito chão pela frente
Com estas primeiras dicas você já vai conseguir se virar bem no seu aprendizado e ganhar proficiência com o editor VIM.
Ainda tem muita coisa pra aprender no VIM que pode tornar sua prática com desenvolvimento de software mais prazeirosa e produtiva. Aqui alguns exemplos de o que se pode fazer com o VIM:
- Instalar/desenvolver plugins;
- Gravar e utilizar macros;
- Abrir e navegar entre múltiplas abas de texto;
- Dividir a tela para editar dois arquivos ao mesmo tempo;
- Rodar programas de linha de comando diretamente do VIM;
- Direcionar o resultado de um comando para o buffer do editor atual;
- Outras coisas que nem eu sei...
Mas antes de se aventurar com todas essas funcionalidades, é importante atingir algum nível de proficiência com as ferramentas que citei neste texto.
Para quem entende inglês sem muita dificuldades, tem aqui um vídeo interessante sobre com várias dicas para atingir maior proficiência no VIM. Se você não aprender nada a partir deste vídeo, com certeza terá ao menos muita inspiração.
]]>

O problema
Vamos cobrir um caso muito específico e chato de lidar: migração de chave primária.
Temos uma entidade User, identificada por User::$id que é assim:
final class User
{
public function __construct(
public int $id,
) {}
}
E para acessar seus dados a gente usa uma interface chamada UserRepository. Eu vou deixar aqui uma implementação simples deste repository com Sqlite:
interface UserRepository
{
/** @throws UserNotFoundException */
public function findById(int $id): User;
}
final class SqliteUserRepository implements UserRepository
{
public function findById(int $id): User
{
$sql = "...";
$stmt = $this->pdo->prepare($sql);
$stmt->execute([
'id' => $id,
]);
// ...
}
}
Digamos que o seu time decidiu que a chave primária da classe User, por motivos de segurança, não deveriam ser um integer mas um UUID. E, é claro, não é possível desativar a aplicação durante a migração.
A solução
Eu implementaria esta mudança em três fases:
- Deixar os dois IDs coexistirem
- Migrar a aplicação para a implementação com UUID
- Remover a implementação com ID inteiro
O maior motivo de eu adotar estas três fases é que os testes não são suficientes para garantir que a aplicação vai funcionar como esperado. Este campo pode ser utilizado por outros componentes via API or alguma outra coisa.
Então para evitar maiores desastres, eu gostaria de alterar a implementação de forma que eu possa voltar à implementação anterior imediatamente se necessário.
Eu estou assumindo que cada passo descrito aqui está coberto com testes, antes mesmo de refatorar o código.
Passo 1: desacoplar dos tipos primitivos
Não importa o que a gente resolva implementar, vai ser difícil sem desacoplar primitivos. Aquele tipo int an classe User é um catalisador de desgraças.
Uma forma simples de fazer isso é encapsular primitivos. Eu vou criar uma classe chamada UserId e fazer com que User dependa dela em vez de int:
final class UserId
{
public function __construct(public int $id) {}
public function getId(): int
{
return $this->id;
}
}
final class User
{
public function __construct(public UserId $id) {}
}
interface UserRepository
{
/** @throws UserNotFoundException */
public function findById(UserId $id): User;
}
Esta mudança vai tornar a nossa refatoração bem mais fácil. UserId ainda retorna int quando UserId::getId() é chamado, mas isto não é problema! O que importa é que User agora depende do tipo UserId - um tipo que nós controlamos - em vez do primitivo integer - o qual não temos controle algum.
Agora é só atualizar o código existente para utilizar UserId:
final class SqliteUserRepository implements UserRepository
{
public function findById(UserId $id): User
{
$sql = "...";
$stmt = $this->pdo->prepare($sql);
$stmt->execute([
'id' => $id->getId(),
]);
// ...
}
}
Até aqui nada mudou, só preparamos o ambiente. Eu não veria muitos problemas em subir este código para produção, especialmente se estiver coberto com testes.
Passo 2: Deixar as duas chaves coexistirem
Agora vamos adicionar o novo campo uuid à nossa tabela do banco de dados:
sqlite> ALTER TABLE `users` ADD `uuid` VARCHAR;
Este campo ainda não pode ser NOT NULL e nem UNIQUE por enquanto, porque todos registros que já existem vão considerar uuid como NULL.
Agora vamos modificar a nossa classe UserId:
final class UserId
{
public function __construct(
public int $id,
public ?UuidInterface $uuid,
) {}
public function getId(): int
{
return $this->id;
}
public function getUuid(): ?UuidInterface
{
return $this->uuid;
}
}
Note que o campo uuid é nullable, porque nenhum registro possui UUID ainda.
Agora a precisa garantir duas coisas:
- Todo registro da tabela "users" possui um UUID que não é nulo; e
- Todo novo registro da tabela "users" possuirá um UUID
É possível considerar que os dois ids estão coexistindo sem problemas somente quando o campo users.uuid nunca é NULL no banco de dados.
Passo 3: garantir que todo novo registro possui um UUID
Em algum lugar do sistema, alguma coisa grava usuários na tabela Users. Precisamos ter certeza de que em todo lugar onde isto acontece, o campo UUID será preenchido.
Então o método abaixo:
...
public function insert(User $user): void
{
// insert into...
}
...
Precisaria ser modificado com algo assim:
...
public function insert(User $user): void
{
$id = $user->id;
if ($id->uuid === null) {
$id->uuid - Uuid::uuid4();
}
// insert into...
}
...
Eu recomendo fortemente cobrir este IF com testes, para garantir que você não importou nada errado ou coisa do gênero. Mas fora isso, eu não esperaria ver nenhuma outra regressão.
Todo novo registro na tabela users a partir de agora deverá ter o campo uuid com um valor não nulo.
Passo 4: preencher UUID para registros já existentes
Isto pode ser feito com um script. Se você utiliza algum tipo de framework de migrations, provavelmente será mais fácil ainda.
A gente só precisa buscar todos os User com uuid nulo e preenchê-los. Algo assim já deveria dar conta do recado:
$users = getUsersWithEmptyUuid();
foreach ($users as $user) {
$user->id->uuid = Uuid::uuid4();
updateUser($user);
}
Este snippet de código não representa a maioria dos codebases por aí, mas acho que dá pra ter uma noção de o que eu quis dizer.
É importante também revisar possíveis chaves estrangeiras que referenciem user.id e migrá-las se você achar que faz sentido.
Passo 5: deixar a aplicação rodar por um tempo
Não há motivos pra mudar tudo de uma vez. Deixa o sistema rodar com o código novo por um tempo para podermos ter certeza de que os dados estão consistentes: users.uuid não é nulo em lugar algum, as chaves estrangeiras estão se comportando como deveriam e por aí vai.
Avance para o passo 6 somente quando tiver segurança de que users.uuid nunca será nulo.
Passo 6: Atualizar UserRepository para utilizar UUID
Apesar de já estarmos numa posição confortável para migrar para a nova implementação que utiliza UUID, eu não recomendo mudar totalmente ainda.
Vamos primeiro proteger o nosso código com uma feature flag. Atualize a classe SqliteUserRepository com o seguinte:
final class SqliteUserRepository implements UserRepository
{
public function findnById(UserId $id): User
{
if (isFeatureFlagActive('enableNewUsersUuidImplementation')) {
// Nova implementação, utiliza UUID
$sql = "...";
$stmt = $this->pdo->prepare($sql);
$stmt->execute(['uuid' => (string) $id->getUuid()]);
// ...
} else {
// Implementação antiga, utiliza $id inteiro
$sql = "...";
$stmt = $this->pdo->prepare($sql);
$stmt->execute(['id' => $id->getId]);
// ...
}
}
}
Resumidamente: isFeatureFlagActive() retorna TRUE se a funcionalidade estiver habilitada e FALSE caso não esteja. Isto pode ser manipulado com configurações, registros num banco de dados ou mesmo variáveis de ambiente.
O que é importante é que você pode mudar o retorno TRUE/FALSE desta função sem precisar fazer outro deploy. Desta forma você consegue facilmente voltar à implementação anterior caso encontre algum problema.
Passo 7: Lançar, habilitar e monitorar
Vamos primeiro fazer o deploy do software e tomar certeza de que isFeatureFlagActive() sempre vai retornar FALSE para que a implementação original seja utilizada.
Depois, vamos fazer com que isFeatureFlagActive() retorne TRUE para que a nova implementação seja utilizada.
Ai não! Alguma coisa tá errada! O site ficou mega lento de repente!
Desligue a feature flag, para que isFeatureFlagActive() retorne FALSE novamente.
...
As coisas parecem ter voltado ao normal. Vamos voltar à aplicação em máquina local e tentar entender o que aconteceu.
Você vai perceber que esquecemos de adicionar um índice para o campo users.uuid, então toda query para este campo ficou mega lenta. Hora de corrigir!
Passo 8: Tornar UUID unique e adicionar um índice nele
Como eu estou implementando com SQLITE, aqui vai o snippet que resolveria a situação:
sqlite> CREATE UNIQUE INDEX `users_uuid_uq` ON `users`(`uuid`);
Seria ideal mudar o campo para que fique NOT NULL também, mas eu vou pular esta etapa aqui porque é mais complicado no SQLITE e isto não é relevante para o nosso problema em questão.
Bom, tudo parece estar correto agora. Vamos lançar para produção, habilitar a feature flag e ver como o sistema se comporta.
Tudo certo? Agora é hora de limpar a casa.
Passo 9: limpar o campo id da tabela users
Agora que o novo código está funcionando como deveria, é hora de limpar o campo id que existia antes.
Você pode decidir se quer limpar apenas do código ou também do banco de dados, é uma questão de situação.
Ao fim das contas, SqliteUserRepository deverá ficar assim:
final class SqliteUserRepository implements UserRepository
{
public function findById(UserId $id): User
{
$sql = "...";
$stmt = $this->pdo->prepare($sql);
$stmt->execute(['uuid' => (string) $id->getUuid()]);
// ...
}
}
E a função que adiciona novos usuários também precisa de algumas mudanças:
...
public function insert(User $user): void
{
$user->id->uuid = Uuid::uuid4();
// insert logic
}
...
Vamos também remover o campo $id numérico da classe UserId e tornar UUID não nulo:
final class UserId
{
public function __construct(public UuidInterface $uuid) {}
public function getUuid(): UuidInterface
{
return $this->uuid;
}
}
Seu banco de dados foi migrado com segurança
É claro que cada projeto tem sua especificidade, mas no fim das contas, você vai precisar executar alguma variação da técnica descrita aqui.
Isto se aplica a qualquer migração relativa a repositórios de dados. Basta lembrar-se das três fases:
- Deixar os dois IDs coexistirem
- Migrar a aplicação para a implementação com UUID
- Remover a implementação com ID inteiro
Não precisa sentir vergonha ou preguiça de rodar vários passos de uma vez, mesmo que vá apagar depois! Fazer um rollback ou migrar um banco de dados em produção para corrigir problemas é muito mais doloroso do que os passos descritos aqui.
Abraço!
]]>
Saber como compilar o PHP vai abrir uma das poucas portas necessárias para contribuir com a linguagem. Assim que você se familiarizar com este processo vai ser muito mais fácil para você contribuir de diversas maneiras: rodando testes e fazendo upload de reports, escrevendo novos testes e reportando ou corrigindo bugs.
Eu escrevi este tutorial como um esforço inspirado pelo post do Joe sobre o Bus Factor que assombra a linguagem nos dias atuais. Na minha opinião o post é bem alarmista, mas necessário. Já que meu tempo é escasso, faz mais sentido para mim multiplicar o conhecimento em vez de tentar contribuir com o código do PHP sozinho.
Navegação rápida
- O código é separado entre core (/Zend) e extensões (/ext)
- Como seguir este tutorial
- Preparação do ambiente: pacotes necessários para compilar PHP
- Existem diferentes passos da compilação, vamos entender o motivo
- Vamos compilar o PHP a partir do código fonte
- Erros e problemas comuns
- Eu segui este tutorial passo a passo e não consegui compilar o PHP
- Como adivinhar quais extensões eu posso adicionar à minha configuração?
- Eu ainda estou tendo problemas mesmo seguindo este tutorial passo a passo
- Como saber quais extensões estão disponíveis?
- E se eu quiser utilizar bibliotecas modificadas ou não quiser as instalar no sistema todo?
- Eu consegui compilar o PHP mas não encontro o binário
- Obrigado, comunidade, por me ajudar a construi este artigo
- E agora?
O código é separado entre core (/Zend) e extensões (/ext)
Antes de começar eu preciso te dar uma explicação ultra simplificada sobre a estrutura de pastas do PHP. A gente tem duas pastas: /Zend e /ext.

/Zend contém o código da Máquina Virtual, também conhecida como Zend Virtual Machine ou Zend VM. Os códigos desta pasta são responsáveis pela tokenização, interpretação, compilação, gerenciamento da pilha de execução e, em geral, rodar código PHP.
Se você não fazia ideia que o PHP tinha uma Máquina Virtual, considere também ler este post que explica sobre como PHP e seu compilador Just In Time funcionam, aqui você entende como o PHP funciona desde o seu código fonte, passando pela compilação até o tempo de execução. Não é complicado, não. Dê uma olhadinha 😉.
/ext é onde a mágica acontece! Esta é a pasta para as extensões suportadas pelo time de desenvolvimento do PHP. Toda função e classe que existe no PHP está descrita dentro desta pasta. Por exemplo, dentro de /ext/standard você encontra todas as funções da biblioteca padrão (SPL - Standard PHP Library). Você pode ver as funções da SPL para manipulação de strings aqui.
A forma mais fácil de entender a /ext é sempre lembrar que toda extensão PHP é na verdade uma interface para uma biblioteca escrita em C. Coisas que o PHP não poderia fazer sozinho (carregar DLLs, por exemplo) ou que não faria de forma tão performática (leitura de metadados de imagem no formato EXIF) são escritas aqui em C e disponibilizadas à linguagem PHP.
O motivo principal de eu te explicar sobre as pastas /Zend e /ext/ é que você sempre vai precisar compilar /Zend quando compilar PHP. Mas você pode escolher a dedo quais extensões você quer compilar. Isto é muito útil quando se quer rodar testes ou depurar partes específicas do código.
Como seguir este tutorial
Eu imagino que você queira rodar os códigos aqui na sua máquina local, o que pode te induzir ao erro por diversos motivos: versões de pacote que não batem, pacotes quebrados, dependências que não vão te permitir atualizar...
Já que eu quero MUITO que você consiga compilar o PHP, eu vou rodar tudo dentro de um container docker vazio. Você não precisa disso para desenvolvimento no dia a dia se não quiser, mas eu recomendo demais que você utilize Docker pelo menos nas primeiras vezes que compilar PHP para evitar distrações inúteis.
Rode o comando abaixo. Isto vai subir um container Docker quase vazio, com pouquíssimas bibliotecas e programas instalados. Todos os comandos deste tutorial consideram que você está os executando dentro deste container.
$ docker run --rm -it alpine:3.13
/ #

Ao executar o comando acima você terá aberto uma sessão bash dentro do container. E assim que você sair do container (com o comando exit), o container será destruído.
Preparação do ambiente: pacotes necessários para compilar PHP
O código fonte do PHP tem várias dependências: algumas relacionadas à compilação do código em C, outras sobre tokenização e interpretação, outras são opcionais dependendo de quais extensões você quiser instalar.
Os requisitos que eu vou listar aqui são o mínimo necessário para compilar o PHP, sem extensões. Quando você adicionar outras extensões vai precisar adicionar mais dependências a esta lista.
Abaixo eu vou te explicar cada dependência para tornar tudo ao menos um pouquinho mais claro pra ti.
gcc
GCC (GNU C Compiler) é um compilador C livre, utilizado pela maioria dos projetos C mundo afora. Este compilador transforma código C em código de máquina, que seu computador consegue rodar.
libc-dev
A linguagem C é bem crua e não oferece ferramentas para lidar com strings, arquivos, rede e por aí vai. Pra isso a biblioteca libc vem para salvar o dia: ela possui várias funções que tornam o desenvolvimento com C muito mais simples. Você provavelmente já viu stdlib.h, stdio.h ou string.h em algum lugar. Estes arquivos .h (e vários outros) são da biblioteca libc.
autoconf
Autoconf é uma ferramenta para gerar configuração de build. Este programa é necessário para quando você executar o passo buildconf, descrito neste texto.
bison
Bison é um gerador de interpretadores. Sempre que você encontrar um arquivo com a extensão .y, pode ter certeza de que o processo de build do PHP vai utilizar Bison para transformar aquele arquivo .y em um arquivo .c que sabe como interpretar tokens lá definidos.
re2c
Re2C é uma ferramenta responsável por compilar expressões regulares em lexers performáticos em C.
make
Make é uma ferramenta versátil de automação de build. Esta ferramenta lê definições de um arquivo chamado Makefile que explica quais comandos precisam ser executados em cada passo da build.
Existem diferentes passos da compilação, vamos entender o motivo
Quando a gente compila código em C, normalmente a gente escolhe uma máquina alvo: uma arquitetura de CPU específica, um sistema operacional específico... Um binário compilado para Windows não vai rodar no Linux sem algum tipo de emulação. De forma semelhante, um programa compilado para uma CPU 64-bit não vai rodar numa CPU 32-bit.
Isso tudo fica ainda mais complicado quando você leva as CPUs em consideração: cada CPU pode ter sua própria maneira de processar opcodes, ler memória, comunicar com o barramento, otimizar certas operações... O trabalho do gcc é, dado uma CPU e Sistema Operacional alvos, transformar código em C em binários específicos para aquela CPU e sistema operacional.
Com todos estes detalhes fica difícil escrever um único Makefile que consiga capturar todos os requisitos de todas plataformas e CPUs possíveis. O que o projeto PHP faz (e isto é normal para projetos grandes em C) é gerar um Makefile antes da build.
O projeto utiliza várias macros m4 e gera um script chamado configure a partir delas. Este script quando executado, vai gerar um Makefile específico para a sua CPU e Sistema Operacional.
Pode parecer um pouco estranho agora, mas vamos seguir o passo a passo e provavelmente tudo vai ficar mais claro.
Vamos compilar o PHP a partir do código fonte
Instale os pacotes necessários
Para instalar os pacotes mencionados acima no Alpine Linux (no nosso container Docker), basta rodar os comandos a seguir:
/ # apk add gcc autoconf libc-dev bison re2c make

Eu também vou baixar o programa cURL pra gente poder baixar o código fonte do PHP a partir do Github.
/ # apk add curl
/ # cd /opt
/opt # curl -L https://github.com/php/php-src/archive/refs/heads/master.zip -o php.zip
/opt # unzip php.zip
/opt # cd php-src-master/
/opt # ls -la

Se você rodou os comandos acima, você deverá estar na pasta /opt/php-src-master e no ponto para começar o processo de compilação.
Construa o script de configuração
Toda máquina tem suas especificidades. Seu processador provavelmente tem uma arquitetura diferente do meu, do seu amigo ou de um provedor de Cloud. Já que C precisa de informações muito específica sobre o processador alvo (e outras coisinhas mais) a gente usa um gerador de configurações.
Rode o comando abaixo e você vai gerar um script configure como resultado:
/opt/php-src-master # ./buildconf

Este passo utiliza várias macros .m4 espalhadas pelo projeto todo para compilar o script configure, utilizando a ferramenta autoconf. Como isso tudo funciona está fora do escopo deste tutorial, mas pode entrar em contato comigo se precisar de mais detalhes.
Gere o arquivo Makefile
Agora que a gente tem o script configure é só executar para obter o builder automatizado: o Makefile.
Execute ./configure com o parâmetro --disable-all pra evitar que quaisquer extensões opcionais como a FFI ou SimpleXML sejam instaladas.
/opt/php-src-master # ./configure --disable-all
O que configure faz é verificar a arquitetura, ferramentas e bibliotecas disponíveis na máquina local e seus respectivos diretórios. Toda esta informação é então compilada num arquivo Makefile:

O Makefile gerado após este passo pode ser visto aqui:

Compilando o código fonte do PHP utilizando Make
Agora que o Makefile está disponível, precisamos apenas executar o comando make e pronto! Eu vou adicionar a opção -j8 para aumentar o número de cores utilizados durante a compilação.
/opt/php-src-master # make -j8

Se tudo correr bem, uma tela de sucesso parecida com a seguinte deverá aparecer e você então poderá rodar os testes.

Os binários ficam disponíveis na pasta sapi. Lá nós podemos encontrar diferentes binários como o FPM e CLI.

Bora rodar os testes
Rodar os testes não vai apenas te mostrar que PHP está funcionando da forma esperada, mas também lhe dá a oportunidade de compartilhar os resultados com a comunidade online. Os testes ficam disponibilizados aqui e podem ser utilizados por outras pessoas para coletar informação o suficiente pra resolver bugs (obrigado pela dica Daniel @geekcom2!).
Vamos rodar os testes utilizando a ferramenta Make:
/opt/php-src-master # make test
Se PHP falhar qualquer teste, você receberá um resultado parecido com o seguinte:
![Tela mostrando testes que falharam e a pergunta "Você quer enviar este relatório de testes agora? [Sim/Não]".](proxy.php?url=https://codamos.com.br/media/posts/18/test-failed.png)
Ao escolher enviar o relatório você já estará contribuindo com a comunidade PHP. Bacana, né?
(Opcional) Instale o PHP
Se você estiver feliz com a versão que acabou de compilar e gostaria de tornar seu binário PHP disponível para todo o sistema, basta rodar a tarefa install do seu Makefile:
/opt/php-src-master # make install

Eu não recomendo instalar a versão compilada do PHP a menos que você saiba muito bem o que está fazendo. Se você precisar desta versão só para testar algumas coisas, utilize um alias ou adicione à variável PATH temporariamente.
Erros e problemas comuns
Se você sabe programar em C isto provavelmente não vai te afetar muito porque provavelmente já tem o costume de usar algumas convenções. Para quem programa somente em PHP eu resolvi coletar algumas dicas que vão facilitar o processo um pouquinho.
Eu coletei as dicas abaixo perguntando a outros membros da comunidade no twitter e através de pesquisas com usuários deste site. Aqui vai um resumo dos problemas e soluções.
Eu segui este tutorial passo a passo e não consegui compilar o PHP
Eu duvido que este caso aconteça com muita frequência porque estamos usando um ambiente isolado com Docker, as chances de algo dar errado sem que você tenha modificado uma linha sequer são baixíssimas.
Mas caso este seja mesmo o caso, ou se você tiver mudado alguma coisa e a build quebrou, a maior dica que eu posso lhe dar é: leia a mensagem de erro. Sério, leia a mensagem de erro!
A minha intenção não é te fazer sentir inferior! Acontece que a maioria de nós, devs PHP, ignoramos as mensagens de erro de compiladores C porque a gente tem o costume de ver coisas coloridas no terminal, que tornam muito fácil identificar onde está o problema. Isto não é comum em C.
Mas normalmente o problema é descrito na última mensagem impressa na tela, porque as boas práticas em C dizem que assim que um problema acontecer, o código deve abortar o quanto antes.
Se você não entende inglês bem o suficiente, você vai precisar adivinhar baseado em alguns símbolos.
Por exemplo, ao habilitar a extensão simplexml a nnossa compilação já não vai mais funcionar por algum motivo:
/opt/php-src-master # ./configure --disable-all --enable-simplexml

Ao utilizar a flag "--disable-all" nós desabilitamos todas extensões possíveis, incluindo a extensão libxml que adiciona suporte a XML. Aqui a mensagem de erro que recebemos:
configure: error: SimpleXML extension requires LIBXML extension, add --with-libxml

O próprio programa nos instrui que ao adicionar "--with-libxml" o problema deverá ser resolvido.
Vamos rapidamente visitar o manual da extensão simplexml. Em "Instalação > Requisitos" nós encontramos mais informações sobre quais extensões e bibliotecas são necessárias, e mais outras dicas de como compilar esta extensão.
Tanto a página quanto o comando configure dizem a mesma coisa: é preciso habilitar a extensão libxml. Então teoricamente ao adicionar --with-libxml ao configure, nosso problema deverá ser resolvido.
Mas agora estamos vacinados e sabemos que é possível visitar a página da extensão libxml antes de tentar compilar de novo para que possamos instalar suas dependências. Vamos abrir a página de requisitos da extensão libxml e verificar suas dependências: a extensão depende da biblioteca libxml na versão 2.6.0 ou superior. Vamos instalar esta biblioteca e depois compilar o PHP novamente:
/opt/php-src-master # apk add libxml2-dev
/opt/php-src-master # ./configure --disable-all --with-libxml --enable-simplexml

Agora é só rodar Make novamente para que os binários dentro de /sapi fiquem atualizados e com suporte à extensão SimpleXML.
Como adivinhar quais extensões eu posso adicionar à minha configuração?
Isto é um problema comum em projetos em C. Eu ainda não vi um projeto em C que utilize um gerenciador de dependências parecido com o Composer our NPM.
Com programas em C você normalmente deveria resolver as dependências manualmente e, na verdade, isto é muito benéfico e eficiente. Por exemplo, esta boa pratica reduz o tamanho do binário a ser construído porque várias bibliotecas e dependências são conectadas de forma dinâmica (arquivos .dll ou .so) quando o programa é executado em vez de copiar e compilar todo seu código fonte.
O ideal é que antes de habilitar uma extensão você busque por sua página no manual do PHP. Toda extensão padrão do PHP têm um manual que inclui uma página de Instalação, requisitos e dependências.
Eu ainda estou tendo problemas mesmo seguindo este tutorial passo a passo
Pode ser que o artigo envelheceu: PHP é um projeto muito ativo, as coisas mudam e você precisa conseguir se adaptar. As ideias principais deste tutorial vão te acompanhar na jornada, mas talvez você precise investigar um pouco por si só.
Normalmente quando mudanças bruscas acontecem, elas ficam documentadas no código fonte em dois arquivos: UPGRADING e UPGRADING INTERNALS. Dá uma lida nestes arquivos se você tiver algum problema e tem certeza de que os passos e configurações que você usou já funcionaram algum dia.
Obrigado novamente Daniel @geekcom2 pela dica!
Como saber quais extensões estão disponíveis?
Existem várias flags de compilação disponíveis que a gente pode passar para o script configure como --enable-ffi ou --enable-simplexml. Mas como encontrar todas elas?
O ideal é que você saiba quais extensões quer habilitar, verifique as páginas do manual de cada uma e a partir de lá entenda quais extensões e flags são necessárias.
Se você não quiser ou não puder visitar as páginas do manual, verifique o código offline. Depois de rodar buildconf o arquivo configure será criado no diretório php-src. Basta rodar configure com a flag --help:
/opt/php-src-master # ./configure --help
O comando acima vai mostrar uma lista de flags de compilação e variáveis de ambiente que você pode mudar antes de gerar seu Makefile.
E se eu quiser utilizar bibliotecas modificadas ou não quiser as instalar no sistema todo?
As vezes você vai ter a necessidade de utilizar uma versão específica de uma biblioteca para satisfazer a instalação do PHP, mas seu sistema já utiliza uma versão diferente. Mudar a versão no sistema todo as vezes não é a melhor opção...
Uma opção para resolver este problema é utilizar um ambiente isolado como uma máquina virtual ou um container Docker por exemplo. Mas isto não resolve todos os casos.
Outra opção é baixar e compilar manualmente a biblioteca em outro diretório. Desta forma você pode compilar a biblioteca sem instalar no sistema, criando objetos dinâmicos (arquivos .dll, .so ou .dylib) que não precisam ser utilizados pelo resto do sistema.
Se você escolher compilar uma biblioteca manualmente, você precisa dizer ao configure em quais pastas procurar determinadas bibliotecas. Você pode fazer isso através de variáveis de ambiente. Tem até um FAQ no site oficial do PHP sobre isso.
/opt/php-src-master # export LDFLAGS=-L/opt/a-biblioteca-que-voce-compilou
/opt/php-src-master # ./configure
Eu consegui compilar o PHP mas não encontro o binário
Todos os binários (executáveis) do PHP ficam dentro da pasta sapi/. Lá você encontra diferentes binários como o FPM, CLI e Embed. Utilize o que for mais adequado para seu caso de uso.
Obrigado, comunidade, por me ajudar a construi este artigo
Desta vez em vez de pesquisar e escrever tudo sozinho eu decidi pedir ajuda da comunidade brasileira de PHP, especialmente na seção de Erros e problemas comuns. Eu vou deixar os nomes e perfis destas pessoas como forma de reconhecimento e agradecimento pela ajuda.
Se você, assim como eu, gosta de fazer o PHP chorar, trate de seguir estas pessoas. Eu garanto conteúdo e sabedorias de alta qualidade:
- Diana Arnos (@dianaarnos)
- Daniel (@geekcom2)
- Leo Cavalcante (@leocavalcante)
- Marcel dos Santos (@marcelgsantos)
- Vinícius Dias (@cviniciussdias)
- Luis Machado Reis (@luismachadoreis)
- Dev Frustrado (@geckones)
- Robson Pierre (@robsonpiere)
Algumas das contribuições foram diretas, outras apenas propagaram a minha voz para alcançar mais pessoas. Eu sou muito grato por toda a força que vocês me deram!
Também não esqueça de me seguir no twitter se você gosta do tipo de conteúdo que eu compartilho e gostaria de ver coisas aleatórias sobre programação no seu feed: @nawarian.
E agora?
Agora que você se familiarizou com a compilação do PHP, vá em frente e rode alguns testes, quebra alguns deles brincando com o código C. Vai se divertir!
Eu espero que este tutorial vá te ajudar a tomar mais um passo em direção a contribuir com a comunidade PHP. Nós precisamos de você!
Até a próxima!
]]>
Antes de qualquer coisa, eu quero te dizer que eu comecei uma pequena série de vídeos onde eu implementei uma biblioteca em PHP para usar a biblioteca raylib (escrita em C) usando FFI. Você pode ver no vídeo abaixo ou neste link para o YouTube.
O que é FFI e pra quê serve?
FFI ou Foreign Function Interface é uma técnica que permite programas utilizarem bibliotecas escritas em diferentes linguagens de programação. É bem mais rápido que usar RPC ou APIs porque o programa não vai se comunicar através de rede e, em vez disso, faz interface direta com a biblioteca.
Para ser mais direto: ao utilizar FFI no seu programa PHP você será capaz de utilizar bibliotecas escritas em C, Rust, Golang ou quaisquer outras linguagens capazes de produzir uma ABI.
É importante notar que você vai conseguir se comunicar com bibliotecas, não entre dois programas diferentes. Para comunicar dois programas você ainda vai precisar de algum mecanismo de comunicação em tempo real, e FFI não te ajuda em nada com isso!
Ao utilizar FFI no PHP você será capaz de usar qualquer shared object que quiser em seu projeto: .dll no Windows, .so no Linux ou .dylib no MacOS.
Com isso você tem a oportunidade de sair da Máquina Virtual do PHP (Zend VM) e escrever quase qualquer coisa que você gostaria usando PHP. Utilizar bibliotecas como raylib ou libui não vai te obrigar a utilizar uma extensão em C (como nós fizemos neste post sobre como desenvolver jogos em PHP usando a extensão raylib).
FFI vai tornar meu código mais rápido?
Você talvez esteja imaginando que já que o FFI permite utilizar código escrito originalmente em C, o seu programa potencialmente será mais rápido do que seria em PHP. A linha de raciocínio não está necessariamente errada, mas você precisa levar em consideração que linguagens de programação não fazem mágica: elas fazem o que nós as comandamos fazer.
Em termos de tempo de CPU, chamar funções externas a partir do PHP utilizando FFI pode te custar duas vezes mais do que realizar a mesma operação em PHP puro. Isto acontece porque a máquina virtual do PHP já é bem otimizada e fazer interface com código externo requer um processo de tradução que vai adicionar um certo custo de processamento.
Isso é normal e todas linguagens que suportam FFI que eu vi até agora vão performar um pouquinho pior quando utilizam FFI.
Mas você pode otimizar o consumo de memória! Como você pôde ver no meu post sobre Operações Binárias em PHP, cada variável do PHP tem um tipo interno zval e ele faz várias coisas pra tonar a vida do PHP mais fácil, como representar todo integer em PHP com o tipo INT64. Então o valor 0x10 teria de ser armazenado como 0x0000000000000010 em PHP (e todos os outros membros de zval terão seus ponteiros alocados).
Então uma boa prática é tentar encontrar o equilíbrio entre processar coisas usando PHP e utilizar o FFI para lidar com objetos na memória. Desta forma você consegue otimizar o consumo de memória, que pode ou não impactar no seu tempo de CPU.
FFI ou Extensões em C, o que eu devo utilizar?
FFI normalmente é utilizado para prototipação: você dá os primeiros passos com FFI e depois migra o código para uma extensão escrita em C.
Eu acho que se o seu código não se importa muito com performance (improvável, mas pode ser…) é de boa usar o FFI só para ampliar a capacidade do PHP. Mas não se esqueça que FFIs em PHP ainda são experimentais e você pode encontrar bugs ou mudanças na API podem acontecer de vez em quando.
Extensões em C deveriam normalmente ser escritas em código C, uma barreira para muitas pessoas acostumadas com PHP. Mas estas extensões se integram à Máquina Virtual do PHP, e por conta disso tendem a ser bem mais rápidas porque chamam código em C diretamente do C (nenhuma tradução é necessária) e mapeiam apenas o código que vai interfacear com o usuário final da extensão.
Extensões são compiladas contra uma versão específica do PHP, e isso cria uma dependência bem chatinha que pode te impedir de atualizar a versão do PHP, por exemplo. Se você tiver disponibilidade pra atualizar a extensão por si e seguir o processo de integração que a comunidade propõe, menos mal. Mas ainda assim vai te custar alguns dias.
FFIs sempre vão funcionar direto e não vão te impedir de atualizar a versão do PHP porque a extensão FFI é parte do core do PHP.
Começando com FFI: vamos construir uma janela nativa usando a biblioteca raylib
Uma coisa que o PHP sozinho definitivamente não consegue fazer é manipular janelas nativas no sistema operacional. Existem algumas extensões como o PHP-GTK e a extensão raylib que nós vimos antes, outra opção é usar FFI.
Eu vou escolher a Raylib como exemplo porque a sua interface é bem simplificada e gostosa de se trabalhar.
Instalando o shared object da raylib (biblioteca)
Para quem usa mac isto deveria ser bem simples utilizando o HomeBew:
$ brew install raylib
Existem alguns guias completos de como instalar em outros sistemas. Aqui você encontra guias sobre como instalar no Windows e como instalar no Linux.
Depois de instalar tudo você deverá ter um shared object disponível no seu sistema. No MacOS você pode ver o arquivo libraylib.dylib dentro do diretório /usr/local/Cellar/raylib/<versão>/lib:
$ ls -la /usr/local/Cellar/raylib/3.5.0/lib
cmake libraylib.351.dylib libraylib.dylib
libraylib.3.5.0.dylib libraylib.a pkgconfig
No Windows você vai se preocupar em encontrar o arquivo .dll e no GNU Linux você precisa encontrar o arquivo .so.
Vamos primeiro prototipar nosso programa em C
A forma mais fácil de entender se o FFI está funcionando corretamente em PHP é entender se a coisa funciona em C em primeiro lugar. Faz sentido né?
Então a primeira coisa que vamos fazer é construir um programa em C que utilize a raylib e que construa a nossa janela. Vamos criar um arquivo hello_raylib.c com o seguinte conteúdo:
#include "raylib.h"
int main(void)
{
Color white = { 255, 255, 255, 255 };
Color red = { 255, 0, 0, 255 };
InitWindow(
800,
600,
"Hello raylib from C"
);
while (
!WindowShouldClose()
) {
ClearBackground(white);
BeginDrawing();
DrawText(
"Hello raylib!",
400,
300,
20,
red
);
EndDrawing();
}
CloseWindow();
}
O código acima deve criar uma janela com dimensões 800x600 e o texto "Hello raylib from C" na barra de título. Dentro desta janela o texto “Hello raylib!” em cor vermelha deverá aparecer com origem no meio da janela.
Vamos compilar e rodar o programa acima:
$ gcc -o hello_raylib \
hello_raylib.c -lraylib
$ ./hello_raylib
Repare: utilize o compilador C disponível em sua plataforma. No meu caso eu utilizo o clang mas deveria ser mais ou menos a mesma coisa.
Abaixo o resultado esperado.

Agora com PHP! Vamos criar nosso arquivo de cabeçalho (header)
Para permitir que o PHP se comunique com o C (ou outras linguagens), nós primeiro precisamos criar uma interface. Em C esta interface é representada por arquivos de cabeçalho. Esta é exatamente a razão pela qual a maioria dos arquivos .c têm um correspondente .h no projeto: o arquivo de cabeçalho indica quais objetos e assinaturas de funções existem.
Já que nós queremos referenciar o libraylib.dylib a primeira linha do nosso cabeçålho deve conter o seguinte define, específico para FFI. Então vamos começar escrevendo o nosso raylib.h que vai interfacear com o código PHP:
#define FFI_LIB "libraylib.dylib"
Repare: o arquivo referenciado pode mudar de acordo com seu sistema operacional.
A Raylib tem várias funções, e você pode verificar cada uma na cheatsheet oficial. Mas nós não precisamos importar todas as funções. Na verdade eu recomendo que você importe apenas as funções necessárias para o seu programa funcionar. No nosso caso nós precisamos de apenas 7 funções:
#define FFI_LIB "libraylib.dylib"
void InitWindow(
int width,
int height,
const char *title
);
bool WindowShouldClose(void);
void ClearBackground(
Color color
);
void BeginDrawing(void);
void DrawText(
const char *text,
int x,
int y,
int size,
Color color
);
void EndDrawing(void);
void CloseWindow(void);
Repare que algumas assinaturas de função requerem tipos muito específicos que são oferecidos pela Raylib. As funções ClearBackground e DrawText exigem um argumento do tipo Color, que nós também precisamos importar. Então vamos adicionar ao nosso arquivo de cabeçalho:
#define FFI_LIB "libraylib.dylib"
typedef struct Color {
unsigned char r;
unsigned char g;
unsigned char b;
unsigned char a;
} Color;
void InitWindow(int width, int height, const char *title);
// ...
Nosso arquivo raylib.h agora está pronto para ser utilizado dentro do PHP.
Carregando o cabeçalho no PHP
Agora que nós temos um arquivo de cabeçalho nós podemos importá-lo utilizando a função FFI::load() desta maneira:
<?php
$ffi = FFI::load(
__DIR__ . '/raylib.h'
);
Com este objeto $ffi nós podemos agora imitar o código em C que escrevemos antes. Vamos construir as variáveis white e red do tipo Color:
<?php
$ffi = FFI::load(__DIR__ . '/raylib.h');
$white = $ffi->new('Color');
$white->r = 255;
$white->g = 255;
$white->b = 255;
$white->a = 255;
$red = $ffi->new('Color');
$red->r = 255;
$red->a = 255;
Por padrão todos os campos do struct serão inicializados com um valor zero. No caso do unsigned char (que varia entre 0 e 255) o valor zero é um inteiro 0.
Agora nós podemos facilmente construir a nossa janela e desenhar na tela:
<?php
$ffi = FFI::load(__DIR__ . '/raylib.h');
// ...
$ffi->InitWindow(
800,
600,
"Hello raylib from PHP"
);
while (
!$ffi->WindowShouldClose()
) {
$ffi->ClearBackground(
$white
);
$ffi->BeginDrawing();
$ffi->DrawText(
"Hello raylib!",
400,
300,
20,
$red
);
$ffi->EndDrawing();
}
$ffi->CloseWindow();
Temos uma janela usando a raylib no PHP!
Como você provavelmente percebeu, todas as funções em C definidas em raylib.h podem ser utilizadas pelo PHP se utilizamos o objeto $ffi para referenciá-las. As variáveis em C são mapeadas para PHP e vice-versa.
O nosso arquivo PHP final e seu resultado ficaram assim:
<?php
$ffi = FFI::load(__DIR__ . '/raylib.h');
$white = $ffi->new('Color');
$white->r = 255;
$white->g = 255;
$white->b = 255;
$white->a = 255;
$red = $ffi->new('Color');
$red->r = 255;
$red->a = 255;
$ffi->InitWindow(800, 600, "Hello raylib from PHP");
while (!$ffi->WindowShouldClose()) {
$ffi->ClearBackground($white);
$ffi->BeginDrawing();
$ffi->DrawText("Hello raylib!", 400, 300, 20, $red);
$ffi->EndDrawing();
}
$ffi->CloseWindow();

Problemas comuns com FFI e como resolvê-los
Eu estive brincando com o FFI para tentar construir bindings bacanas para a Raylib em PHP e encontrei alguns problemas no caminho. Saber sobre estes problemas e como corrigi-los talvez possa lhe ser útil.
A minha maior dica é: não misture o código da sua aplicação com código FFI. Extraia o FFI para uma biblioteca independente e adicione-a ao seu projeto utilizando o composer. Isto não vai resolver a maioria dos seus problemas, mas com certeza vai os isolar e tornar muito fácil a testagem.
FFI pode ser difícil de testar
No caso da Raylib em específico a gente não consegue testar muita coisa. Principalmente porque a raylib manipula janelas nativas e o PHP não tem uma forma fácil de fazer assertions deste tipo.
Então tenha em mente que se você estiver escrevendo algo realmente fora do escopo normal do PHP, você vai precisar de outras ferramentas para conduzir seus testes. Tenha certeza, portanto, que estas ferramentas também rodam em outras plataformas.
Por exemplo, é possível capturar o PID de uma janela procurando por seu título com xorg, e eu sei que de alguma forma a Windows API também nos permite fazer isso. Se você quer testar, você provavelmente vai precisar utilizar outras ferramentas que não o PHP para testar sua aplicação.
Também é importante lembrar que os testes não vão necessariamente agregar valor em todo lugar na sua aplicação. Eu utilizo testes como uma ferramenta de aprendizado para que eu possa ter um ambiente seguro para testar novos conceitos aos poucos sem me importar muito sobre todas as dependências de uma vez e, infelizmente, a maioria dos frameworks PHP não me ajudaram muito enquanto estive trabalhando com a raylib. A minha solução para este caso é criar diferentes arquivos PHP que deveriam fazer uma única coisa, exatamente como casos de teste.
É difícil fazer análise estática
Eu não achei uma forma perfeita de resolver este problema. Ferramentas de análise estática como o psalm ficam doidinhas com código FFI.
De volta ao snippet $white e $red vamos ver o motivo:
$white = $ffi->new('Color');
$white->r = 255;
$white->g = 255;
$white->b = 255;
$white->a = 255;
Se você verificar a assinatura de FFI::new() vai sacar que ele retorna FFI\CData ou null. Este tipo CData é um objeto que deveria conter todos os membros do struct referenciado.
Até onde eu sei o psalm não tem uma forma fácil de anotar que a variável $white contém quatro campos do tipo integer: $r, $g, $b e $a. O psalm sequer vai conseguir saber que eles existem porque, bem, eles foram escritos em C nalgum outro lugar!
Então o ideal é que você abstraia a lógica de FFI em algum tipo de classe Facade ou Adapter, que você vai prometer de pé juntinho que vai cobrir com testes o máximo que puder, e então pode dizer ao psalm para ignorar esta classe enquanto estiver conduzindo a análise estática.
Esta classe Facade/Adapter deverá mapear valores PHP (primitivos ou objetos) em CData e tomar conta de chamar as funções em C para você.
Assim você acaba construindo mais ou menos uma biblioteca em PHP, que é o ideal se você parar pra pensar. Desta forma você evita que o código de produção fique poluído com lógicas específicas do FFI e as coisas ficarão naturalmente testáveis na sua aplicação.
Mantenha a sua biblioteca atualizada
Um grande benefício de utilizar FFI em vez de extensões do PHP é que você não vai precisar atualizar o seu código C a cada nova versão do PHP. Mas você ainda precisa gerenciar suas versões da biblioteca em C.
Eu recomendo que você aprenda sobre o sistema de versionamento da biblioteca original e faça releases na sua biblioteca em PHP seguindo a mesma regra, exceto para versões patch. Então versões major e minor sempre vão bater com a versão original da biblioteca em C, enquanto você terá a liberdade de aumentar a versão patch sempre que você corrigir bugs e coisas do tipo.
Isto naturalmente vai te forçar a respeitar 100% as interfaces da biblioteca C original. Mas te deixa livre para distribuir correções de segurança e de bugs que possam existir tanto na biblioteca C quanto na sua própria biblioteca em PHP.
O problema de ser multiplataforma
O PHP é multiplataforma. Quem utiliza PHP espera que todas as bibliotecas sejam multiplataforma também! Manter as coisas assim pode ser um pouco complicado quando utilizamos código FFI.
De volta ao exemplo da raylib, importar aquele shared object nos força a escolher por nome de arquivo: raylib.so (GNU Linux), libraylib.dylib (MacOS) ou raylib.dll (Windows). Importe o arquivo errado e a sua biblioteca simplesmente não vai funcionar!
Você pode escrever diferentes arquivos de cabeçalho, específicos para a sua plataforma. Isto vai criar muita duplicação de código mas ajuda um pouco.
Outra opção é utilizar o FFI::cdef() para carregar as assinaturas de função. Este método é bem semelhante ao FFI::load() mas espera uma string em vez de um caminho de arquivo. Neste caso você pode escolher o caminho do seu shared object em tempo de execução.
Você consegue detectar o Sistema Operacional que está rodando o seu código PHP chamando a função php_uname(). Evite utilizar a constante PHP_OS: ela contém o sistema operacional que compilou o seu binário PHP, que em alguns casos pode não ser o mesmo que está efetivamente rodando o seu código.
Por último, mas não menos importante, considere que algumas bibliotecas simplesmente não são multiplataforma. Postá-las pra PHP pode ser bem frustrante pra quem utiliza e, se você decidir portar esta biblioteca mesmo assim, por favor considere lançar exceções em sistemas operacionais aos quais você não oferece suporte: isto vai dizer ao usuário final logo de cara quais são os problemas.
Existem bugs na própria extensão FFI
Lembre-se: FFI ainda é experimental no PHP! Você pode encontrar bugs inesperados a qualquer momento!
Sempre que você encontrar algum comportamento super estranho na sua integração FFI, sempre crie um arquivo em C que seja equivalente e veja seu comportamento antes de duvidar do que o FFI está fazendo.
Se a suspeita estiver correta e for realmente um bug, aproveite e crie um bug ticket para o time do PHP (em inglês!). Eu não sei se o time vai ficar feliz pelo seu bug, mas com certeza você estará ajudando a comunidade a crescer.
Recentemente eu encontrei um e estou inclusive tentando implementar uma correção por conta própria, vai ser um projetinho bacana e potencialmente um post futuro. Então se liga aí!
Concluindo
Eu fiquei bem animado ao trabalhar com FFI e espero que este post te ajude a começar a brincar com FFI também!
De pouco em pouco eu estou ficando mais acostumado com código de baixo nível e FFI tem sido uma ótima oportunidade para eu programar diferentes casos de uso (como desenvolvimento de games ou processamento áudio) numa linguagem que eu amo (PHP).
Lembre-se sempre que o PHP é uma linguagem de código aberto e que sua comunidade depende da contribuição de pessoas como você. Você pode utilizar seu conhecimento para devolver a comunidade ao reportar bugs, corrigi-los, complementar a documentação com coisas que você encontrou no caminho ou escrevendo artigos como este aqui. O FFI é definitivamente uma área de conhecimento que precisa de mais artigos e vídeos para que não caia no esquecimento.
Enfim, te vejo na próxima. Se cuida aí!
]]>
Recentemente eu trabalhei em diferentes projetos que me forçaram a usar bastante operações com binários em PHP. De ler arquivos a emular processadores, este é um conhecimento interessantíssimo e muito útil.
PHP tem várias ferramentas pra lhe dar suporte a manipulação de dados em formato binário, mas é bom saber desde o começo: se você está buscando eficiência de ultra baixo nível, PHP não é a sua linguagem.
Mas continua aqui! Neste artigo eu vou te mostrar algumas coisas importantíssimas sobre operações bitwise, como lidar com binários e hexadecimais, e conhecimentos que lhe serão úteis em QUALQUER linguagem.
Conteúdo do post
- Por que PHP talvez não seja a melhor linguagem pra isso?
- Uma breve introdução aos formatos binário e hexadecimal
- Operações de "vai um" (carry)
- Representação de dados na memória do computador
- Overflows Aritméticos
- Números e strings binárias no PHP
- Binários: Inteiros ou Strings, qual usar no PHP?
- Depurando valores binários em PHP
- Operações Binárias (Bitwise)
- O que é uma Máscara? (bitmask)
- Corrigindo Inteiros
- Enfim, binário é maneirão
Por que PHP talvez não seja a melhor linguagem pra isso?
Veja bem, eu amo PHP, tá? Não me leve a mal. E eu tenho certeza de que PHP é capaz de lidar com muito mais casos do que você possa imaginar. Mas se você precisa ser extremamente eficiente quando lidar com binários, o PHP não vai segurar a barra.
Clarificando: eu não tô falando de uma aplicação que possa consumir 5 ou 10mb a mais. Eu estou falando sobre alocar o montante exato necessário pra determinado tipo de dado.
De acordo com a documentação oficial sobre o tipo integer, PHP representa números decimais, hexadecimais, octais e binários com o tipo integer. Então não importa muito o valor que você coloque numa variável deste tipo, ela será sempre um integer.
Você provavelmente já ouviu falar do ZVAL antes, aquela struct em C que representa toda variável PHP. Esta struct tem um campo para representar todos os integers chamado zend_long. Como você pode ver, zend_long é do tipo lval, cujo tamanho depende da plataforma (32 ou 64 bits): numa plataforma 64 bits, será um integer de 64 bits, enquanto numa plataforma 32 bits, será um integer de 32 bits.
# zval guarda todo integer como lval
typedef union _zend_value {
zend_long lval;
// ...
} zend_value;
# lval é um integer 32 ou 64-bit
#ifdef ZEND_ENABLE_ZVAL_LONG64
typedef int64_t zend_long;
// ...
#else
typedef int32_t zend_long;
// ...
#endif
Em suma: não importa se você precisa guardar os valores 0xff, 0xffff, 0xffffff ou o que for. Todos serão armazenados como um long (lval) com 32 ou 64 bits no PHP.
Eu recentemente trabalhei na emulação de um microcontrolador e, ao mesmo tempo que tratar a memória e operações corretamente é essencial, eu não me importei tanto com a eficiência na alocação de memória porque o meu computador consegue compensar isto em ordens de grandeza.
É claro que tudo muda quando você fala sobre extensões em C ou FFI, mas não é disso que eu tô falando. Eu tô falando de PHP puro! (PHP das ruas como diria o grande PokémãoBR xD)
Então lembre-se: trabalhar dados binários em PHP funciona e você consegue desenvolver qualquer aplicação que quiser, mas os tipos não vão encaixar de forma eficiente na maioria das vezes.
Uma breve introdução aos formatos binário e hexadecimal
Bom, antes de a gente falar sobre como o PHP trabalha com dados binários, a gente precisa parar um pouquinho e falar sobre binários antes. Se você acha que já sabe tudo o que precisa sobre binários, pode pular direto para a seção "Números e Strings binárias no PHP".
Existe um negócio na matemática chamado "base". A base define como nós podemos representar quantidades em diferentes formatos. Nós, humanos, normalmente utilizamos a base decimal (base 10) que nos permite representar números somente com os dígitos 0, 1, 2, 3, 4, 5, 6, 7, 8 e 9.
Pra deixar nossos exemplos mais simples eu vou chamar o número "20" de "20 decimal".
Números binários (base 2) podem representar qualquer número, mas apenas utilizando dois dígitos: 0 e 1. O 20 decimal pode ser representado em binário como 0b00010100. Não se preocupe em converter este número, deixa que o computador faz isso pra ti 😉
Números hexadecimais (base 16) podem representar qualquer número e utilizam não somente os dez dígitos que vimos na base 10 (0, 1, 2, 3, 4, 5, 6, 7, 8 e 9) mas também seis caracteres do alfabeto latino: a, b, c, d, e, e o caractere f.
O 20 decimal pode ser representado como 0x14 em hexadecimal. De novo, não tente converter na sua cabeça: deixa que os computadores são especialistas nisso!
O que é importante você entender é que números podem ser representados em diferentes bases: binária (base 2), octal (base 8), decimal (base 10, a nossa base comum) e hexadecimal (base 16).
Em PHP e diversas linguagens, números binários são escritos normalmente mas com um prefixo 0b, como o 20 decimal foi representado assim: 0b00010100. Números hexadecimais recebem um prefixo 0x, como o 20 decimal que foi representado assim: 0x14.
Você já deve ter ouvido falar: computadores não guardam dados da forma como nós entendemos. Tudo é representado utilizando números binários: zeros e uns (0 e 1). Caracteres, números, símbolos, instruções... tudo é representado usando base 2. Caracteres são somente uma convenção de números em sequência: o caractere ‘a’, por exemplo, é o número 97 na tabela ASCII.
Mesmo com tudo guardado em formato binário, a forma mais conveniente para programadores(as) lerem estes valores é utilizando hexadecimais. Tipo... a gente lê eles como se fosse poema, se liga:
# string "abc"
‘abc’
# formato binário
0b01100001 0b01100010 0b01100011
# formato hexadecimal <3
0x61 0x62 0x63
Enquanto os binários tomam um espaço visual enorme, hexadecimais são bem arrumadinhos. É por este motivo que normalmente utilizamos hexadecimais quando lidamos com programação de baixo nível.
Operações de "vai um" (carry)
Você já conhece o conceito de "vai um", mas eu preciso que você preste atenção nele para que possamos utilizar diferentes bases.
Na base decimal nós conseguimos representar números utilizando apenas dez dígitos, do zero (0) ao nove (9). Mas sempre que você tentar representar qualquer número maior que 9 nós não temos mais dígitos disponíveis! Então o que a gente precisa fazer é adicionar um prefixo com o dígito um (1) e devolver o dígito à direita para zero (0).
# decimal (base 10)
1 + 1 = 2
2 + 2 = 4
9 + 1 = 10 // <- vai um
Na base binária temos o mesmo comportamento, mas limitados aos dígitos 0 e 1.
# binário (base 2)
0 + 0 = 0
0 + 1 = 1
1 + 1 = 10 // <- vai um
1 + 10 = 11
E a mesma coisa acontece com a base hexadecimal, mas com uma faixa mais ampla.
# hexadecimal (base 16)
1 + 9 = a // sem vai um
1 + a = b
1 + f = 10 // <- vai um
1 + 10 = 11
Como você percebeu, operações "vai um" precisam de mais dígitos para representar um certo número. Compreender isto te permite entender como alguns tipos de dados são limitados e, por serem armazenados em computadores, essa limitação é representada no formato binário.
Representação de dados na memória do computador
Como eu comentei antes, computadores armazenam tudo usando o formato binário. Então apenas 0s e 1s são efetivamente armazenados.
The easiest way to visualize how they are stored, is by imagining a big table with a single row and many columns (as many as storage capacity), where each column is a binary digit (bit).
A forma mais fácil de visualizar como estes dados são armazenados é imaginar uma grande tabela com uma única linha e várias colunas (tantas colunas quanto a capacidade de armazenamento), onde cada coluna representa um dígito binário (um bit).
A gente pode representar o nosso 20 decimal nesta tabela utilizando apenas 8 bits, fica assim:
| Posição (Endereço) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Bit | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
Um inteiro de 8 bits sem sinal (unsigned integer de 8 bits) é um número inteiro que pode ser representado somente com no máximo 8 dígitos binários. Então 0b11111111 (255 decimal) é o maior número que este integer pode armazenar. Somar 1 ao 255 decimal requer uma operação "vai um", que não pode ser representada com a mesma quantidade de dígitos (precisaria de 9 dígitos, no nosso caso).
Com isto em mente nós podemos facilmente entender o motivo de existir tantas formas de representar números e o que elas realmente são: uint8 é um inteiro de 8 bits sem sinal (0 a 255 decimal), uint16 é um inteiro de 16 bits sem sinal (0 a 65.535 decimal). Existe também uint32, uint64 e teoricamente limites maiores.
Inteiros com sinal, que também podem representar valores negativos, normalmente usam o último bit para determinar se o valor é positivo (último bit = 0) ou negativo (último bit = 1). Como você provavelmente deduziu, um inteiro com sinal é capaz de representar números bem menores que os inteiros sem sinal. Um inteiro com sinal de 8 bits é capaz de representar do decimal -128 até o decimal 127 apenas.
Aqui vai o decimal -20, representado como um inteiro de 8 bits e com sinal. Note como o último bit (endereço 0) está ligado (o valor é igual a 1). Este bit marca o número todo como negativo.
| Posição (Endereço) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Bit | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
Eu espero que até aqui tudo tenha feito sentido. Essa introdução é muito importante pra que você entenda como os computadores funcionam internamente. Só a partir daí você vai conseguir entender de forma confortável o que o PHP está fazendo por debaixo dos panos.
Overflows Aritméticos
Nota sobre a palavra Overflow: a tradução de Overflow seria "transbordo", mas este termo é pouco utilizado. Eu vou me manter utilizando o termo em inglês: Overflow. O significado é equivalente ao de "transbordar" mesmo. Quando você enche um copo d’água além do limite, parte da água sai do copo: isto é um transbordo ou overflow.
A forma como os números são representados (8 bits, 16 bits...) determina a faixa de valores mínimos e máximos que podem ser representados. E isto ocorre por conta da forma como eles são armazenados em memória: adicionar 1 a um dígito binário 1 deveria causar uma operação "vai um" (carry) e, portanto, um outro bit seria necessário para fazer prefixo ao número atual.
Já que os números inteiros são bem definidinhos, não é possível confiar em operações "vai um" que ultrapassam seu limite. (Na verdade É POSSÍVEL, mas não recomendo nem para meu pior inimigo)
Vamos usar o tipo uint8 (inteiro de 8 bits sem sinal) como exemplo e representar seu número máximo - 1: o decimal 254.
| Posição (Endereço) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Bit | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
Aqui nós estamos bem perto do limite dos 8 bits (decimal 255). Se somarmos 1 a este número teremos o decimal 255 e a seguinte representação:
| Posição (Endereço) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Bit | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Todos os bits estão ligados! Somar 1 a este número requer uma operação de "vai um" que não pode acontecer, porque não temos bits o suficiente: todos os 8 bits estão ligados! Isto gera uma coisa chamada overflow, que acontece toda vez que você tenta ir acima de um determinado limite. A operação binária 255 + 2 vai resultar em 1, e fica representada assim:
| Posição (Endereço) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Bit | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Este comportamento não é aleatório! Existe toda uma base de cálculos, que não é relevante aqui, envolvida para determinar este valor.
Números e strings binárias no PHP
Ok, de volta ao PHP! Foi mal desviar tanto o assunto, mas foi necessário.
Eu espero que a partir deste momento os pontos já foram ligados na sua cabeça: números binários, como eles são armazenados, o que é um overflow, como o PHP representa números...
O decimal 20 representado como um inteiro no PHP pode ter dois formatos diferentes, dependendo da sua plataforma. A plataforma x86 o representa com 32 bits enquanto a plataforma x64 o representa com 64 bits, ambos com sinal (permite valores negativos). Nós bem sabemos que o decimal 20 pode ser representado num espaço bem mais curto, de 8 bits apenas, mas o PHP trata todo valor decimal como um inteiro de 32 ou 64 bits.
No PHP também existe o conceito de strings binárias, que podem ser convertidas e interpretadas utilizando as funções pack() and unpack().
A maior diferença entre strings binárias e números no PHP é que strings binárias apenas armazenam dados, como um buffer. Já os inteiros no PHP (binários ou não) nos permite executar operações aritméticas neles como a soma, subtração e operações binárias (bitwise) como AND, OR e XOR.
Binários: Inteiros ou Strings, qual usar no PHP?
Para transportar dados nós normalmente utilizamos strings binárias. Então ler um arquivo binário ou se comunicar por rede vai nos exigir utilizar as funções pack() e unpack() em strings binárias.
Operações como OR e XOR não são confiáveis quando executadas com strings, então nós devemos utilizá-las com inteiros.
Depurando valores binários em PHP
Agora vem a parte legal! Vamos sujar as mãos e brincar um pouco com código PHP! A primeira coisa que eu quero te mostrar é como visualizar os dados. Afinal a gente precisa entender o que estamos lidando.
Visualizando representações binárias de números inteiros
Depurar inteiros é bem simples: a gente pode usar a função sprintf(). A sua formatação é muito poderosa e nos permite identificar rapidamente o que os valores são.
Abaixo eu vou representar o decimal 20 como um inteiro de 8 bits em binário e como um byte hexadecimal.
<?php
// Decimal 20
$n = 20;
echo sprintf(‘%08b‘, $n) . "\n";
echo sprintf(‘%02X’, $n) . "\n";
// Saída:
00010100
14
O formato "%08b" apresenta a variável $n no formato binário (b) utilizando 8 dígitos (08).
O formato "%02X" representa a variável $n no formato hexadecimal (X) e utilizando 2 dígitos (02).
Visualizando strings binárias
Enquanto os inteiros no PHP são sempre de 32 ou 64 bits, uma string pode ocupar tanta memória quanto seu conteúdo requer. Para visualizar seu valor nós precisamos interpretar cada byte.
A nossa sorte é que no PHP strings podem ter seus caracteres acessados como fazemos com arrays, então cada posição da string aponta para um char de 1 byte. Abaixo mostro um exemplo de como estes caracteres podem ser acessados:
<?php
$str = ‘thephp.website’;
echo $str[3];
echo $str[4];
echo $str[5];
// saída:
php
Confiando que cada char tem 1 byte, podemos facilmente chamar a função ord() para converter este char em um inteiro de 1 byte (8 bits). Mais ou menos assim:
<?php
$str = ‘thephp.website’;
$p = ord($str[3]);
$s = ord($str[4]);
$t = ord($str[5]);
echo sprintf(‘%02X %02X %02X’, $p, $s, $t);
// Saída:
70 68 70
A gente pode ver que não estamos nos confundindo ao verificar este mesmo valor utilizando a ferramenta hexdump:
$ echo ‘php’ | hexdump
// Saída
0000000 70 68 70 ...
A primeira coluna mostra o endereço apenas, e a partir da segunda coluna nós vemos os valores hexadecimais representando os caracteres ‘p’, ‘h’ e ‘p’.
Nós também podemos utilizar as funções pack() e unpack() quando lidamos com strings binárias e eu tenho um ótimo exemplo pra você bem aqui!!
Digamos que você queira ler um arquivo JPEG para coletar alguns metadados (como o EXIF, por exemplo). A gente pode abrir o arquivo utilizando o modo de leitura binário. Vamos fazer isto imediatamente e ler os primeiros 2 bytes:
<?php
$h = fopen(arquivo.jpeg’, ‘rb’);
// Ler 2 bytes
$soi = fread($h, 2);
Para coletar estes valores num array de números inteiros a gente pode usar a função unpack desta forma:
$ints = unpack(‘C*’, $soi);
var_dump($ints);
// Saída
array(2) {
[1] => int(-1)
[2] => int(-40)
}
echo sprintf(‘%02X’, $ints[1]);
echo sprintf(‘%02X’, $ints[2]);
// Saída
FFD8
Note que o formato "C" que passamos para a função unpack() vai interpretar caracteres na string $soi como números inteiros de 8 bit sem sinal. O modificador "*" faz com que o unpack() extraia todos os caracteres restantes na string da mesma forma.
Operações Binárias (Bitwise)
O PHP implementa todas as operações binárias que você possa querer. Elas são implementadas como expressões e seus resultados são descritos abaixo:
| Código PHP | Nome | Descrição |
|---|---|---|
| $x | $y | Ou inclusivo (Or) | Um valor com os bits ligados em $x e $y ao mesmo tempo |
| $x ^ $y | Ou exclusivo (Or) | Um valor com os bits ligados em $x ou $y, mas nunca nos dois ao mesmo tempo |
| $x & $y | E (AND) | Um valor somente com os bits ligados em $x e $y ao mesmo tempo |
| ~$x | Negar (Not) | Nega todos os bits em $x. O que é 1 vira 0, e o que é 0 vira 1 |
| $x << $y | Deslocamento a esquerda (Left shift) | Desloca os bits de $x para a esquerda $y vezes |
| $x >> $y | Deslocamento a direita (Right shift) | Desloca os bits de $x para a direita $y vezes |
Eu vou explicar uma por uma como estas operações funcionam, não se preocupe! Vamos assumir que $x = 0x20 e $y = 0x30. Os exemplos abaixo vão os apresentar usando a notação binária para esclarecer as coisas.
Como o Ou Inclusivo (Or) funciona ($x | $y)
A operação Ou inclusivo vai produzir um resultado que pega todos os bits ligados das duas variáveis passadas. Então a operação $x | $y deve retornar o valor 0x30. Veja o que tá acontecendo abaixo:
// 1 | 1 = 1
// 1 | 0 = 1
// 0 | 0 = 0
0b00100000 // $x = 0x20
0b00110000 // $y = 0x30
OR ------- // $x | $y
0b00110000 // 0x30
Repare bem: da esquerda para a direita, o sexto bit de $x estava ligado (valor = 1) enquanto os bits 5 e 6 de $y também estavam ligados. O resultado une os dois e gera um valor com os bits 5 e 6 ligados: 0x30.
Como o Ou exclusivo (Xor) funciona ($x ^ $y)
O Ou exclusivo (também conhecido como Xor) captura bits que estejam ligados em apenas um dos lados da operação. Então o resultado de $x ^ $y é 0x10. Veja o que acontece nesta operação:
// 1 ^ 1 = 0
// 1 ^ 0 = 1
// 0 ^ 0 = 0
0b00100000 // $x = 0x20
0b00110000 // $y = 0x30
XOR ------ // $x ^ $y
0b00010000 // 0x10
Como o E (And) funciona ($x & $y)
A operação E é bem mais simples de entender. Cada bit, dos dois lados, são comparados e apenas os valores que são iguais serão coletados para o resultado.
O resultado de $x & $y é 0x20, olha o porquê:
// 1 & 1 = 1
// 1 & 0 = 0
// 0 & 0 = 0
0b00100000 // $x = 0x20
0b00110000 // $y = 0x30
AND ------ // $x & $y
0b00100000 // 0x20
Como a operação Negar (Not) funciona (~$x)
A operação Negar requer apenas um operando e simplesmente inverte todos os bits. Ela transforma todos bits que eram 0 em 1, e todos os bits que eram 1 em 0. Veja:
// ~1 = 0
// ~0 = 1
0b00100000 // $x = 0x20
NOT ------ // ~$x
0b11011111 // 0xDF
Se você rodou esta operação no PHP e decidiu depurar o resultado utilizando sprintf() você provavelmente recebeu um número bem mais longo, né? Eu vou te explicar o que aconteceu e como corrigir abaixo na seção "Corrigindo Inteiros". Deslocamentos à esquerda e à direita (Left e Right shifts) ($x << $n, $x >> $n) Deslocar bits é a mesma coisa que multiplicar ou dividir seus números por múltiplos de dois. O que esta operação faz é que todos os bits andem $n vezes para a esquerda ou direita.
Eu vou pegar um número binário menor para representar esta operação, só pra deixar a leitura mais facilitada. Vamos pegar $x = 0b0010 como exemplo! Se a deslocarmos uma vez para a esquerda, aquele bit 1 se move um passo para a esquerda:
0b0010 // $x
$x = $x << 1
0b0100
A mesma coisa acontece com o deslocamento a direita. Agora que $x = 0b0100 vamos deslocá-la para a direita duas vezes:
0b0100 // $x
$x = $x >> 2
0b0001
No fim das contas, deslocar um número $n vezes para a esquerda é o mesmo que multiplicá-lo por 2 $n vezes, e deslocá-lo $n vezes para a direita é equivalente a dividir por 2 $n vezes.
O que é uma Máscara? (bitmask)
Tem várias coisas interessantes que a gente pode fazer com estas operações e outras técnicas. Uma ótima técnica para sempre trazer consigo é utilizar máscaras (bitmasks).
Uma máscara é apenas um binário que você escolhe, escrito para extrair uma informação específica de acordo com a sua necessidade.
Por exemplo, vamos tomar a ideia de que um inteiro de 8 bits com sinal é positivo quando o último bit está desligado (valor = 0) e é negativo quando o último bit está ligado (valor = 1). Eu então te pergunto: o número 0x20 é positivo ou negativo? E o 0x81?
Pra responder essas perguntas nós podemos criar um byte que liga apenas o último bit (0b10000000, equivalente a 0x80) e utilizar a operação E (AND) entre este valor e 0x20. Se o resultado for 0x80 (0b10000000, a nossa máscara) então o número é negativo, se não o número é positivo:
// 0x80 === 0b10000000 (bitmask)
// 0x20 === 0b00100000
// 0x81 === 0b10000001
0x20 & 0x80 === 0x80 // false
0x81 & 0x80 === 0x80 // true
Isto é muito útil quando você quer lidar com flags. Você pode inclusive ver exemplos de utilização no próprio PHP: the error reporting flags.
É possível escolher quais tipos de são reportados fazendo algo assim:
error_reporting(E_WARNING | E_NOTICE);
O que tá acontecendo aqui? Bom, vamos verificar os valores que utilizamos:
0b00000010 (0x02) E_WARNING
0b00001000 (0x08) E_NOTICE
OR -------
0b00001010 (0x0A)
Então sempre que o PHP ver que um Notice poderia ser reportado, vai verificar algo assim:
// error reporting que definimos antes
$e_level = 0x0A;
// Pode lançar um notice?
if ($e_level & E_NOTICE === E_NOTICE)
// Lançar notice
E você vai ver isto em tudo quanto é lugar! Arquivos binários, processadores e todo tipo de computação de baixo nível!
Corrigindo Inteiros
No PHP tem algo muito particular quando lidamos com números binários: nossos inteiros são de 32 ou 64 bits. Isto significa que várias vezes vamos precisar corrigir os valores para confiar em nossos cálculos.
Por exemplo, a seguinte operação numa máquina de 64 bits vai nos retornar um número bem estranho (apesar de ser o resultado correto):
echo sprintf(
‘0b%08b’,
~0x20
);
// Expectativa
0b11011111
// Realidade
0b1111111111111111111111111111111111111111111111111111111111011111
Diabé isso!? Veja, ao negar aquele inteiro 0x20 nós transformamos todos os bits zero e os transformamos em 1s. Adivinha o que costumava ser zero? Exato, todos os outros 56 bits à esquerda que nós ignoramos antes!
Novamente, isto acontece porque os inteiros do PHP têm 32 ou 64 bits, não importa o valor que você colocar dentro deles!
Mas o código ainda funciona como esperado. Por exemplo, a operação ~0x20 & 0b11011111 === 0b11011111 resulta em bool(true). Mas tenha sempre em mente que estes bits à esquerda estão ali, ou você pode acabar tendo comportamentos inesperados no seu código.
Para resolver este problema, você pode corrigir os inteiros aplicando uma máscara (bitmask) que limita os zeros. Por exemplo, para normalizar ~0x20 como um inteiro de 8 bits a gente precisa utilizar uma operação E (AND) com o 0xFF (0b11111111) de forma que todos os 56 bits restantes vão ser desligados (valor = 0).
~0x20 & 0xFF
-> 0b11011111
Prestenção ein! Nunca se esqueça de o que você está armazenando em suas variáveis, ou sua aplicação pode acabar com bugs bem difíceis de se encontrar. Por exemplo, vamos ver o que acontece quando deslocamos à direita o valor acima sem utilizar uma máscara.
~0x20 & 0xFF
-> 0b11011111
0b11011111 >> 2
-> 0b00110111 // esperado
(~0x20 & 0xFF) >> 2
-> 0b00110111 // esperado
(~0x20 >> 2) & 0xFF
-> 0b11110111 // esperado?
Só para esclarecer: do ponto de vista do PHP este comportamento É esperado, porque você claramente está lidando com um inteiro de 64 bits aqui! Você precisa sempre deixar bem explícito o que o SEU programa precisa.
Dica de mestre: você pode escapar de erros bestas como estes ao escrever seu código com TDD.
Enfim, binário é maneirão
Eu espero que você tenha curtido ler tanto quanto eu curti escrever este post. E mais importante: eu espero que este conhecimento te permita se aventurar por este maravilhoso mundo de dados binários.
Com estas ferramentas em mão, todo o resto é apenas questão de achar a documentação correta sobre como arquivos ou protocolos binários se comportam. Tudo é uma sequência de binários no fim das contas.
Eu recomendo fortemente que você dê uma olhada na especificação dos formatos PDF ou EXIF (metadados de imagem). Talvez você até queira brincar com a sua própria implementação do formato de serialização MessagePack ou talvez Avro, Protobuf... Infinitas possibilidades!
Como você deve ter reparado este arquivo me levou um tempão pra escrever. Se você quiser recompensar o esforço, dá aquela compartilhada e salva nos favoritos pra voltar aqui sempre que tiver alguma dúvida sobre este tópico.
Talvez em breve eu volte com algumas coisas mais práticas sobre lidar com binários! :)
Valeu!
]]>
Chegou a hora! No dia 26 de Novembro de 2020, o PHP 8.0 foi lançado e tornado disponível para download. Depois de 5 Release Candidates e um enorme esforço da comunidade, nós podemos finalmente começar com o PHP 8.0 em produção.
PHP 8.0 trouxe várias inovações, dentre elas incríveis mudanças sintáticas, atualizações nas APIs e mudanças fundamentais no core e, claro, várias correções de bug. Aqui eu vou te mostrar as principais mudanças à linguagem!
😉 Veja também o PHP 8.2!
Em Novembro de 2022 é lançada a versão 8.2 do PHP. Eu escrevi uma publicação detalhada sobre as mudanças da linguagem para esta versão também.
Mas ó, se tu tiver sem tempo pra ver esse post inteiro, dá uma olhada na página oficial de lançamento do PHP 8 que lá tem um resumão bem visual das mudanças da linguagem.
Table of Contents
Mudanças Sintáticas do PHP 8.0
Há várias mudanças sintáticas na linguagem nesta versão! Eu consigo ver claramente uma tendência: o php está tentando ficar cada vez mais ergonômico quando se trata de operações rápidas e classes.
Abaixo eu listo 8 mudanças sintáticas que entraram no PHP 8.0 e dou uma introdução rápida. Todas elas terão links para a RFC que as introduziu à linguagem, então caso você tenha dúvidas basta ler os links (ou abrir uma issue, eu vou responder o quanto antes).
Union Types e o Mixed Type
Eu escrevi um post detalhado sobre como o sistema de tipos do PHP se organiza entre escalares, compostos e especiais. Você pode acessar o post neste link aqui.
PHP 8.0 traz duas mudanças importantes que transformaram os tipos compostos em uma estrutura formal da linguagem em vez de apenas uma convenção como antes.
A primeira mudança é a dos Union Types , que torna possível definir que tipos uma variável pode ter e gerará um erro se um tipo de valor inesperado for passado. A sintaxe é bem semelhante com o que o TypeScript faz:
<?php
function sumTwo(int|float $x): int
{
return round($x + 2);
}
Mas tem algumas limitações. O tipo void não pode ser utilizado, e todas as declarações de tipo não podem ser ambíguas. Por exemplo MyClass|object não deveria compilar, porque object já bate com qualquer instância de qualquer classe.
A segunda mudança adiciona o tipo mixed no PHP 8.0. O tipo mixed é na verdade um Union Type muito específico. Você pode pensar nele como um alias do Union array|bool|callable|int|float|null|object|resource|string e deverá funcionar semelhante ao tipo any do TypeScript.
Atributos (Annotations)
Esta mudança foi definitivamente a que trouxe mais discussão na comunidade PHP. Ao todo foram 5 RFCs para compor esta alteração de sintaxe, todas muito discutidas pelos internals e pela comunidade nas redes sociais.
A primeira vez que apareceu foi em 2016, com a proposta do Dmitry , mas não passou já que a implementação não era suficiente para substituir as implementações já existentes como do Doctrine\Annotations ou Php-Annotations\Php-Annotations. Esta RFC foi extremamente importante para construir o conhecimento para a RFC da nova sintaxe.
Em março esta RFC foi revivida por Benjamin Eberlei e Martin Schröder , corrigindo a maioria dos problemas que a comunidade encontrou antes. A sintaxe ficou mais ou menos assim:
<?php
use PhpAttribute;
<<PhpAttribute>>
class MyAttributesClass
{
}
<<MyAttributesClass>>
function myFunction () {}
$reflection = new ReflectionFunction('myFunction');
// ReflectionAttribute[]
var_dump($reflection->getAttributes());
Os Atributos são referências a classes que podem ser instanciadas a partir do próprio objeto ReflectionAttribute. Cada classe de Atributo deverá utilizar um atributo do próprio PHP chamado PhpAttribute, isto só mudou depois que a RFC attribute amendments passou e agora em vez de PhpAttribute deverá ser utilizada a classe Attribute.
Esta sintaxe pode ser utilizada com: - funções, closures e short closures - classes, classes anônimas, interfaces, traits - constantes de classes - propriedades de classes - métodos de classes - parâmetros de funções ou métodos
Esta segunda RFC (attribute amendments) também trouxe mudanças interessantes como a validação de que um Atributo deveria ser utilizado somente com classes ou com funções, se poderia ser utilizado várias vezes ou não, e também a opção de agrupar utilizações de atributos.
As duas últimas RFCs ( esta e esta ) foram somente sobre como a sintaxe de utilização dos Attributes deveria ser. A sintaxe final adotada ficou como a seguinte e parece bastante com a do Rust:
<?php
use Attribute;
#[Attribute(Attribute::TARGET_FUNCTION)]
class MyAttributesClass
{
}
#[MyAttributesClass]
function myFunction () {}
$reflection = new ReflectionFunction('myFunction');
// ReflectionAttribute[]
var_dump($reflection->getAttributes());
Reparou naquele Attribute::TARGET_FUNCTION alí? Ele diz ao php que aquele Attribute só pode ser utilizado com funções e um erro será gerado se utilizado em qualquer outro lugar.
Operador Nullsafe
Uncaught Error: Call to a member function example() on null. Este erro aqui persegue muitos(as) engenheiros(as) php que podem ter esquecido de verificar o tipo de retorno ou tenham escrito errado uma condição if.
Isto vai mudar no PHP 8.0, com a introdução do operador nullsafe. Esta sintaxe faz verificações em valores nulos e dá um curto-circuito se alguma parte da cadeia for null, evitando uncaught errors como o mencionado acima. A sintaxe é a seguinte:
<?php
$obj = new class {
public function f()
{
return null;
}
}
// "$obj?->" verifica se $obj é null e,
// caso não, continua coma a chamada
// "f()?->" verifica se o tipo do retorno de f()
// é null como acima
$obj?->f()?->neverCalled();
// neverCalled() nunca foi chamado, pois f() retorna null
Non-Capturing Catches
Sempre que escrevemos o bloco catch quando tratamos uma exceção é necessário receber também o objeto Exception.
No PHP 8.0, graças ao Max Semenik , não será mais necessário fazer isso. Agora é possível capturar exceções sem precisar capturar o objeto em si. Como no exemplo abaixo:
<?php
try {
throw new IncredibleException();
} catch (IncredibleException) {
// Eu não ligo tanto pro
// objeto $exceptionabout
// the $exception object
} catch (Exception $e) {
// Mas aqui eu ligo, e tudo bem
}
Throw Expression
Anteriormente a palavra chave throw era considerado um statement na linguagem, o que nos impediu por muito tempo de lançar exceções em alguns lugares onde apenas expressões como atribuição de variáveis, short closures, ternários e expressões binárias poderiam estar.
Ilija Tovilo implementou a RFC Throw Exception que transformou throw $obj numa expressão. Então os exemplos abaixo são válidos:
<?php
$a = null ?? throw new Exception();
$b = $obj->func() || throw new Exception();
$c = fn() => throw new Exception();
Esta funcionalidade foi inspirada numa mudança introduzida ao C# em 2017 e uma proposta ao ECMAScript escrita em 2018.
Expressão Match
Esta é a minha favorita! A intenção é trazer uma sintaxe mais limpa sempre que normalmente faríamos um switch para decidir o valor de uma variável.
A RFC foi escrita por Ilija Tovilo e nesta versão ainda não oferece suporte a blocos, então apenas expressões são permitidas. A utilização ficou assim:
<?php
$a = 100;
$duzentos = match ($a) {
10, 100, 1000 => $a * 2,
50, 500, 5000 => $a / 2,
};
O snippet acima retornaria $a * 2 sempre que $a for igual a 10, 100 ou 1000. Retornaria $a / 2 sempre que $a for igual a 50, 500 ou 5000.
É importante observer que a sintaxe de Match constrói uma expressão, então ela pode ser armazenada em variáveis, passada como parâmetro ou ser composta com outras expressões.
<?php
$type = ...;
$filter = match ($type) {
'as_object' => $myObject,
'assoc' => $myObject->toArray(),
} || throw new InvalidArgumentException('Invalid type requested.');
Implementações futuras irão adicionar suporte a blocos ao lado direito desta expressão, de forma semelhante ao que o Rust faz. Isto dá ao desenvolvedor(a) maior flexibilidade para escrever programas complexos sem invadir escopos de variáveis.
Named Parameters
É bem comum ver métodos com parâmetros contendo valores padrão e os únicos que queremos mudar são os últimos. Isto nos força a entrar com null em todos os parâmetros para mudar apenas os últimos.
Muitos podem dizer que isto é um problema de design, mas ao mesmo tempo não é possível simplesmente garantir um ótimo design para cada projeto open source escrito por aí.
Nikita Popov decidiu adicionar o Named Parameters ao PHP 8.0 , que nos permite pular parâmetros de funções ou métodos e definir valores somente para as que nos importam. Para isso as variáveis precisam ser nomeadas, funciona assim:
<?php
function myFunc(
$a = 10,
$b = 20,
$c = null
) {
}
myFunc(c: 100);
// $a = 10; $b = 20; $c = 100
Isto também nos dá a liberdade de desconsiderar a ordem dos parâmetros definida pela interface.
Eu acho que esta é uma ótima forma para criar um código mais bem escrito sem quebrar bibliotecas e extensões que já existem.
Constructor Promotion
Alguns dizem que o PHP é tão verboso quanto o Java quando se trata de Orientação a Objetos. Eu tendo a concordar e creio que poderíamos importar algumas facilidades de sintaxe que outras linguagens já construíram e obtiveram sucesso.
A sintaxe constructor promotion torna mais simples e rápido escrevre classes que recebem parâmetros no construtor e os joga em propriedades imediatamente.
O snippet abaixo ilustra bem esta nova sintaxe:
<?php
class MyClass
{
public function __construct(public int $x = 0)
{}
}
// É equivalente a isto:
class MyClass
{
private int $x;
public function __construct(int $x = 0)
{
$this->x = $x;
}
}
Mudanças na Máquina Virtual do PHP 8
Mudanças no core são normalmente as que podem quebrar nosso código de forma explícita ou silenciosamente, então é importante tomar uma boa atenção nelas enquanto atualizamos a versão do PHP.
Esta versão trouxe atualizações muito bacanas ao PHP que impactam performance e comportamente. Aqui eu vou listar algumas delas.
Compilador Just In Time (JIT)
Eu escrevi um artigo sobre o que é o JIT e como ele funciona no PHP. Recomendo fortemente que você dê uma lida, ele vai te dar uma ideia melhor sobre como o PHP funciona internamente e quais benefícios um compilador Just In Time pode trazer à linguagem.
Resumão do ENEM: o JIT pode aumentar a performance das nossas aplicações PHP, pode ser otimizado para melhores resultados e constrói uma fundação para aplicações PHP diferentes do que estamos acostumados a ver.
Mas isto não vai acontecer em toda aplicação PHP. Há casos de uso muito específicos para o JIT e eu acho que o que você pode fazer de melhor é verificar a RFC e ler o post que eu mencionei acima.
Uma coisa interessante sobre esta funcionalidade é que ela foi implementada antes da RFC de attributes ser aprovada. Então uma das opções disponíveis é compilar apenas funções/métodos anotados com um doc-comment @jit. Isto poderá mudar no futuro ao adicionar uma opção nativa #[jit] usando Attributes em vez de doc-comments.
Weak Maps
O PHP 7.4 nos trouxe uma classe weak-reference (referência fraca), que nos permite criar uma referência a um objeto sem que ele fique impedido de ser coletado pelo Garbage Colelctor.
Agora no PHP 8.0 a classe WeakMap foi adicionada. Weak Maps usam o mesmo conceito de Weak References mas implementam as interfaces ArrayAccess, Countable e Traversable. Isto nos permite criar coleções (maps) que não impedem que seus objetos sejam destruidos quando todas as outras referências forem removidas.
Eu pretendo escrever melhor sobre Garbage Collection no PHP no futuro, mas se você quiser botar uma pressão pra ver este conteúdo logo me dá um alô lá no Twitter ou abre uma issue pra que eu dê prioridade a este assunto.
Aqui vai um exemplo de como utilizar WeakMaps:
<?php
$bag = new WeakMap();
$obj = new stdClass();
$bag[$obj] = 42;
// int(1)
var_dump($bag->count());
// deleta $obj da memória
// $bag está vazia agora
unset($obj);
// int(0)
var_dump($bag->count());
Erros e Alertas
Esta RFC mudou a forma como o PHP se comporta e é importante que a gente preste bastante atenção nela!
Muitas mensagens de erro e nível de criticidade mudaram para que fiquem mais consistentes. Nenhum nível de criticidade caiu, apenas cresceram. Alguns Notices se tornarão Warnings, e alguns Warnings se tornarão Errors (lançarão exceção).
A lista completa você consegue encontrar na página da RFC e eu recomendo fortemente que você dê uma lida já que este tipo de problema pode aparecer de forma bem silenciosa se você não tiver um bom monitoramento configurado.
Verificações das Assinaturas de Métodos Mágicos
Esta mudança foi introduzida pelo querido Gabriel Caruso, do PHPSP, que tive o prazer de conhecer neste ano! Ele adicionou verificações de tipos nas assinaturas dos métodos mágicos do PHP da forma definida na documentação.
Toda classe implementando métodos mágicos que não forem escritas de accortdo com a assinatura irá gerar um FatalError como você pode verificar na página da RFC. Mesmo sendo uma breaking change, apenas 7 dos top 1000 pacotes no Packagist seriam afetados por esta mudança.
Correções em Strings Numéricas
O PHP consegue converter strings numéricas em inteiros quando necessário. Este cast pode acontecer manualmente ou de forma implícita dependendo de qual operação você executar (por exemplo, expressões e chamadas de função).
<?php
// int(123)
var_dump((int) "123");
Ainda mais, o PHP é uma mãe quando se trata de strings numéricas: perdoa tudo! Strings como "2 bananas" ou "5 maçãs" podem ser convertidas para números normalmente. Mais do que isso, algumas strings podem ser interpretadas como numéricas quando não deveriam (como em hashes que começam com um zero, por exemplo).
A RFC saner numeric strings veio corrigir este problema, normalizadno a forma como nós lidamos com strings numéricas e gerando Type Errors quando tipos numéricos são requeridos mas uma string não numérica é passada.
Mudanças na Comparação de String Numéricas
O PHP tem dois modos de comparação: estrito (===, !==) e não estrito (todo o resto). Sempre que fazemos uma comparação não estrita entre uma string e um número, o PHP vai tentar converter a string em um número para só então comparar dois inteiros. Eu explico este processo em detalhe neste post aqui.
Este comportamento criou distorções bem estranhas como a expressão 0 == 'nawarian' retornando bool(TRUE).
A RFC de comparações de strings numéricas melhora estas comparações ao inverter a lógica de conversão: em vez de converter a string em número e então comparar os dois números, o PHP irá transformar o número em string e então comparar as duas strings.
Uma nova tabela de comparação foi disponibilizada na RFC e eu trouxe uma cópia pra cá:
| Comparação | Antes | Depois |
|---|---|---|
| 0 == "0" | true | true |
| 0 == "0.0" | true | true |
| 0 == "foo" | true | false |
| 0 == "" | true | false |
| 42 == " 42" | true | true |
| 42 == "42foo" | true | false |
Agora é aproveitar e aguardar as próximas
É claro que tem muito mais coisas que o PHP 8.0 trouxe e eu gostaria muito de ter tido o tempo e vontade para escrever todas aqui. Mas esta pequena lista já deixa claro que o PHP, morrendo desde 1994, mais uma vez se torna melhor e mais poderoso.
Eu atualmente não conheço nenhum benchmark sobre o PHP 8.0 rodando aplicações de verdade que possam dizer que esta versão é mais rápida, a mesma coisa ou mais lenta. Mas eu confio que as ferramentas que a comunidade nos deu irão nos permitir continuar criando aplicações incríveis e rápidas.
A adição do compilador Just In Time é uma boa oportunidade para olhar com mais carinho para ferramentas que nós poderíamos explorar bem melhor como, por exemplo, a Extensão Swoole.
Agora é momento de celebrar esta incrível vitória da Comunidade PHP e agradecer todas as pessoas que se envolveram (você também está nesta lista 😉). A versão 8.1 alpha já iniciou o desenvolvimento e eu mal posso esperar por o que vem pela frente!
Por favor, não se esqueça de compartilhar com seus amigos e colegas, e me dê um toque se você encontrou alguma coisa estranha aqui ou gostaria de adicionar você mesmo alguma coisa estranha.
]]>
Subir arquivos para o GitHub é um processo simples que envolve o uso de alguns comandos no terminal como git status, add, commit, remote entre outros que veremos aqui.
Ao fim deste post há também um vídeo pra te auxiliar visualmente a entender como subir arquivos no github.
Preparação
Para esse tutorial você precisará ter o Git instalado em sua máquina e uma conta no GitHub.
Para instalarmos o Git no windows basta entrar no site do git scm e fazer o download. No linux e no mac basta colocar o comando abaixo no terminal.
# No linux
$ sudo apt-get install git
# No mac
$ brew install git
Iniciando seu repositório
Precisaremos criar o repositório no GitHub, faça login na sua conta, no seu perfil vá em Repositories e New.

Coloque o nome desejado no campo Repository Name e uma breve descrição (não é obrigatório), no nosso exemplo vamos utilizar o thePHP.
Configurações iniciais
Antes de iniciarmos um repositório local é necessário definir seu nome e endereço de e-mail, essa configuração inicial é importante porque todos os commits do git utilizará essas informações, para isso use os comandos abaixo no terminal.
$ git config --global user.name "<nome>"
$ git config --global user.email "<email>"
Caso você queira verificar as configurações é só utilizar o comando:
$ git config user.name
Para iniciarmos um repositório git, no terminal execute o comando abaixo (certifique-se que você está dentro do seu repositório utilizando o comando cd) ou com o botão direito do mouse dentro da pasta onde ficará o seu projeto clique em Git Bash Here:
E execute o comando:
$ git init
Git status
O Git utiliza estados para monitorar seus arquivos, com o “git status” é possível ter um controle do que está se passando em seu repositório, para entendermos melhor como funciona, temos o exemplo abaixo que criará um arquivo Hello World.txt contendo dentro dele um simples texto “hello world” e mostrará o estado do arquivo.
$ echo Hello World > helloWorld.txt
$ git status
on branch master
No commits yet
Untracket files:
(use “git add <file>...” to include in what will be commited)
hellowWorld.txt
nothing add to commit but untracked files present (use “git add” to track);
Podemos observar que o arquivo helloWorld.txt está com o estado de untracked file, isso quer dizer que o arquivo não está sendo monitorado pelo git, então qualquer coisa que acontecer com ele o git não será “responsável”.
Git add
O comando “git add ” ou “git add .” (para todos os arquivos no repositório) monitora os arquivos e adiciona uma alteração dele no diretório à staging area, que é o local onde prepara os arquivos para o próximo commit.
$ git add helloWorld.txt
$ git status
on branch master
No commits yet
Changes to be committed:
(use “git rm –cached <file>...” to unstage)
new file: helloWorld.txt
Git commit
O “git commit” captura o estado atual do arquivo e adiciona as alterações para o histórico do repositório local atribuindo um hash como identificação, com o “–m” podemos adicionar uma descrição das mudanças realizadas.
$ git commit –m “<descrição>”
Utilizando o comando “git status" podemos observar que os arquivos estão prontos para serem encaminhados para o diretório remoto.
Git remote
O “git remote” é utilizado para gerenciar os repositórios monitorados, o exemplo abaixo registra o repositório remoto e adiciona o endereço em “origin” onde passaremos o link que pode ser encontrado na aba code do nosso repositório no GitHub.
$ git remote add origin <endereço>
Git Push
Com o “git push –u origin ” podemos encaminhar as mudanças commitadas para o GitHub, nesse exemplo utilizaremos o branch padrão master.
$ git push -u origin master
Depois que recarregar a página do seu repositório remoto você verá seus arquivos atualizados.
Conclusão
Vimos que para utilizar uma ferramenta tão poderosa como o git e subir seus arquivos para um repositório remoto é mais simples do que parece, com apenas alguns comandos aprendemos a versionar nossos arquivos e deixá-los em um local acessível e seguro para serem utilizados a qualquer momento.
Como material de apoio, deixo aqui também o vídeo do Jeterson que vai te ajudar a visualizar melhor como subir arquivos no github.
Esta publicação foi uma contribuição de autoria de João Apostulo Neto. Você pode entrar em contato com ele em seu Github @japostulo ou LinkedIn /joaoapostulo.
Envie você também a sua, veja mais detalhes na nossa página do Github.
]]>
PHP é uma linguagem dinamicamente tipada e até o ano de 2015 quase não tinha suporte para declarar tipos de forma estática. Já era possível realizar um cast para tipos escalares de forma explícita no código, mas declarar tipos escalares em assinaturas de métodos e funções não era possível até a chegada do PHP 7.0 com as RFCs Scalar Type Declarations e Return Type Declarations.
Mas isso não significa que a partir da versão 7.0 o PHP passou a ser estaticamente tipado. O PHP possui type hints que podem ser analisados de forma estática mas ainda oferece suporte a tipos dinâmicos e, inclusive, nos permite misturar os dois formatos.
Veja o exemplo abaixo:
<?php
function retornaInt(): int
{
return '100';
}
Sem sombra de dúvidas tem um conflito de tipos aí em cima. O retorno deveria ser um int e o valor retornado é na verdade uma string. O que o PHP faz internamente é automaticamente transformar o token '100' num inteiro para poder retornar o tipo necessário. Mesmo que pareça trazer um custo extra, não é o caso. O type juggling (malabarismo de tipos) do php é quase livre de processamento extra em muitos casos.
Para esclarecer de uma vez por todas como a linguagem lida com tipos, eu escrevi este arquivo em secções distintas para você:
- Tipos de tipos no PHP
- "Operações" com tipos no PHP
- Os Union Types
- Malabarismo de tipos, ou type juggling
- Os modos de tipagem
Se você tiver alguma sugestão de o que adicionar aqui, sinta-se livre pra me dar um toque no twitter ou abrir uma issue no github.
Aahh!! Se você curte este tipo de conteúdo mais aprofundado e tal, dá uma ligadinha nesse artigo que eu escrevi sobre como funciona o Just In Time compiler que vai entrar no PHP 8.0! Abre numa abinha aí e lê em seguida, tu não vai se arrepender! 😉
Conteúdo
Tipos de tipos no PHP
O sistema de tipos do PHP é bem simplificado quando se trata de funcionalidades da linguagem. Por exemplo, não existe um tipo char, ou valores unsigned (sem sinal) ou mesmo as variações de inteiro int8, int16, int32, int64...
O tipo char é simplificado para tornar-se string e todos inteiros são simplificados em um tipo integer. Se isso for ou não uma coisa boa fica a seu critério.
Caso esteja se perguntando: o equivalente em PHP ao typeof do JS é a função gettype().
Você sempre pode inspecionar o tipo de uma variável usando a função gettype() ou a função var_dump().
O PHP vem com três tipos de tipos: tipos escalares, tipos compostos e tipos especiais.
Tipos escalares
Tipos escalares são fundamentais na linguagem e são no total quatro:
- Boolean (
bool|boolean) - Integer (
int|integer) - Float (
float|double) - String (
string)
Por definição, um tipo escalar não possui comportamento ou estado. Expressões como 100->toString() ou 'thephp.website'::length()' são ilegais!
Resumão do ENEM: tipos escalares não possuem comportamento ou estado, eles só representam um valor.
Tipos compostos
Tipos compostos são muito mais interessantes porque mesmo que eles sejam similares aos tipos escalares, cada um dos quatro tipos compostos possui diferentes sintaxes.
Os quatro tipos compostos são:
- array
- object
- callable
- iterable
O tipo composto Array
Um array na realidade é um hashmap, que vem por padrão com a linguagem PHP. Isto significa que seus valores são guardados no formato chave => valor mesmo que você o utilize como um vetor.
Arrays são estruturas muito flexíveis quando se trata de tamanho, tipos internos e mapeamento chave-valor. Os exemplos abaixo são todos arrays válidos:
<?php
$vec = [0, 1, 2];
// $vec[1] é int(1)
$map = ['a' => 1, 'b' => 2];
// $map['a'] é int(1)
$quase_map = ['a' => 1, 0 => 2];
// $quase_map['a'] é int(1)
// $quase_map[0] => é int(2)
Diferente do C, o PHP não vai te obrigar a definir o tamanho dos arrays antes de criá-los. Isto, como era de se esperar, traz um custo em memória: o quão maior for o tamanho do seu array, mais memória você consumirá em proporções absurdas (na real, arrays são alocados em potências de 2). Como este consumo de memória acontece está fora do escopo deste artigo, me dá um toque se tu quiser saber mais sobre este tópico em particular.
Caso você esteja curioso sobre o que eu disse acima, tem uma apresentação muito interessante do Nikita Popov sobre o consumo de memória entre arrays e objetos.
Como você poderá verificar abaixo, arrays também são considerados como sendo do tipo iterable, isto significa que você pode iterar sobre eles usando um laço foreach. Mas eles também oferecem funções específicas que podem manipular seus ponteiros internos
Resumão do ENEM: O tipo array é um tipo composto extremamente flexível e pode ser considerado um HashMap e também é um tipo iterable
O tipo composto Object
Por conta da arquitetura do PHP, o tipo composto object normalmente tem um perfil de consumo de memória bem menor quando comparado aos arrays. Isto porque normalmente uma pessoa usaria o tipo object criando instâncias de classes.
Objetos podem carregar estado e comportamento consigo. Significa que o php oferece sintaxes para desreferenciar as entranhas de um objeto. O snippet abaixo ilustra como a operação de desreferência funciona:
<?php
class MinhaClasse
{
private const A = 1;
public int $propriedade = 0;
public function metodo(): void {}
}
$obj = new MinhaClasse();
// $obj é object(MyClass)
// $obj::A é int(1)
// $obj->propriedade é int(0)
// $obj->metodo() é null
Um objeto também pode ser criado normalmente como resultado de um type cast a partir de um array. Transformando as chaves do array em nomes de propriedades. Este tipo de cast vai resultar em um tipo object(stdClass).
<?php
$obj = (object) ['a' => 1];
// $obj é object(stdClass)
// $obj->a é int(1)
Vale ressaltar que converter um array com chaves numéricos em um objeto é válido, mas não é possível desreferenciar o seu valor porque propriedades de objetos não podem começar com números.
<?php
$obj = (object) [0, 1]; // Legal
$obj->0; // Ilegal
Resumão do ENEM: objetos normalmente têm um perfil de memória menor que o dos arrays, carregam consigo estado e comportamento, e podem ser criados ao converter um array.
O tipo composto callable
Um callable (chamável) no php é qualquer coisa que pode ser chamada (é mermo é?) usando parêntesis ou com a função call_user_func(). Ou sejE, um callable é capaz de cumprir o papel de o que conhecemos como funções. Funções e métodos sempre são callables. Objetos e classes também podem se tornar callables.
Um callable pode, por definição, ser guardado numa variável. Como a seguir:
<?php
$callable = 'strlen';
Quê?! Mas isso não é uma string, doido!?
Até que é. Mas ele pode ser coagido (coerced) num callable se for necessário. Como abaixo:
<?php
function chameUmCallable(
callable $f
): int {
return $f('thephp.website');
}
$callable = 'strlen';
var_dump(
$callable('thephp.website')
);
// int(14)
var_dump(
chameUmCallable($callable)
);
// int(14)
Callables também podem apontar para um método de um objeto:
<?php
class MinhaClasse
{
public function meuMetodo(): int
{
return 1;
}
}
$obj = new MinhaClasse();
var_dump([$obj, 'meuMetodo']());
// int(1)
Parece estranho? Eu sei que tem cara de array. Na real é um array mesmo. A não ser que você o trate como um callable 👀
Este tipo de callable acima (referência de método de objeto) é muito interessante porque você pode chamar métodos privados ou protegidos com ele se você estiver dentro do escopo da classe. Caso contrário, você pode somente chamar métodos públicos.
E também as classes que implementam o método mágico __invoke(), automaticamente transforma suas instâncias em callables. Como a seguir:
<?php
class MinhaClasseCallable
{
public function __invoke(): int
{
return 1;
}
}
$obj = new MinhaClasseCallable();
var_dump($obj());
// int(1)
Resumão do ENEM: callables são referências para funções ou métodos e podem ser construídos de maneiras distintas.
O tipo composto iterable
Iterables são muito mais simples de explicar: eles são, por definição, um array ou uma instância de Traversable interface. A coisa mais importante de um iterable é que ele pode ser usado num laço foreach(), num yield from ou com o operador de propagação (spread operator).
Exemplos de iterables são:
<?php
function funcao_generator(): Generator
{
// ...
};
// Todas variáveis aqui são iterables
$a = [0, 1, 2];
$b = funcao_generator();
$c = new ArrayObject();
Resumão do ENEM: se você pode colocar num foreach(), é um iterable.
Tipos Especiais
Existem dois tipos especiais. E a maior razão pela qual eles são chamados "especiais" é que não é possível converter para estes tipos. Os tipos especiais são o tipo resource e o tipo NULL.
Um resource representa um conector para um recurso externo. Que pode ser um conector para um arquivo, um fluxo de E/S ou uma conexão com banco de dados. Você talvez possa adivinhar o motivo de não poder fazer um cast para qualquer outro tipo de resource.
O tipo null representa um valor nulo. Isto significa que uma variável com NULL não foi inicializada, foi atribuída com o valor NULL ou apagada em tempo de execução.
Resumão do ENEM: uma variável de tipo especial não pode ser convertida para qualquer outro tipo.
E as instâncias de classe?
Instâncias possuem o tipo object e serão sempre representadas desta forma. Chamar a função gettype() num objeto sempre irá retornar o valor string("object") e chamar a função var_dump() no mesmo objeto sempre irá imprimir seu valor usando a notação object(NomeDaClasse). Se você precisar pegar a classe de um objeto no formato string, utilize a função get_class().
<?php
$obj = new stdClass();
echo gettype($obj);
// object
var_dump($obj);
// object(stdClass)#1 (0) {
// ...
echo get_class($obj);
// \stdClass
"Operações" com tipos no PHP
Existem diferentes "operações" que podem ser feitas com tipos no PHP. Eu acho que é importante deixar bem claro estas operações aqui para que não misturemos as bolas depois.
Malabarismo de tipos (type juggling): cast e coerção de tipos
Antes de a gente se aprofundar, aqui vão três definições importantíssimas:
- Conversão de tipo significa transformar um tipo de A para B. Por exemplo: de um inteiro para um float.
- Cast de tipos significa converter manual ou explicitamente um tipo de A para B. Como em
$cem = (int) 100.0. (float(100.0)virouint(100)) - Coerção de tipo significa converter implicitamente um tipo de A para B. Como em
$vinte = 10 + '10 bananas';. (string("10 bananas")virouint(10))
Tendo isto em mente, as próximos secções vão explicar como isso funciona no php. E mais pra frente você encontrará mais informações sobre o malabarismo de tipos (type juggling).
Cast de tipos
De forma semelhante ao Java, o PHP nos permite fazer cast de tipos. Isto significa que quando uma variável aponta para um valor que pode ser transformado num tipo diferente, a linguagem nos permite uma conversão manual (explícita) de tipos.
Pera, pera... É O QUE!? 🤨
Ó: uma variável $cem segurando string("100") pode ser convertida manualmente (cast) para tornar-se int(100) ou float(100.0) - ou qualquer outro tipo escalar ou um dos tipos compostos array ou object.
O snippet a seguir funciona perfeitamente no PHP e é bem parecido com o Java:
<?php
$cem = (int) '100';
// $cem agora é int(100)
Agora, uma coisa que o Java faz e é completamente ilegal no php, é converter (cast) um ponteiro de variável numa classe diferente. Isto significa que a gente só pode converter tipos escalares e alguns tipos compostos no php:
<?php
class MinhaClasse {}
// Gera um parse error
$ilegal = (MinhaClasse) new stdClass();
Importante notar! No PHP só é possível fazer cast de tipos para tipos escalares*. Portanto fazer o cast de um objeto para uma classe diferente é ilegal, mas fazer um cast de objeto para um tipo escalar é completamente válido.
Também possível fazer o cast de valores para os tipos array ou object, que não são tipos escalares mas sim compostos (dar nome pr'esses coiso tudo é osso, né?).
<?php
class MinhaClasse {}
$obj = new MinhaClasse();
$um = (int) $obj; // int(1)
O código acima gera alguns notices mas ainda assim é válido. Mais tarde eu explico de onde veio esse int(1).
Resumão do ENEM: o php permite realizar cast de tipos para escalares, arrays ou objetos. Fazer o cast para classes não é permitido.
Coerção de tipos
A coerção de um tipo acontece como um efeito colateral de trabalhar com tipos incompatíveis ou não declarados. Eu explico melhor mais pra frente neste artigo. Por agora apenas confia que o PHP vai automaticamente fazer o cast dos tipos o seu código em tempo de execução quando necessário.
Um exemplo de coerção de tipos pode ser multiplicar um integer por um float. Na expressão int(100) multiplicado por float(2.0) o resultado é um float(200).
<?php
var_dump(100 * 2.0);
// float(200)
Resumão do ENEM: o php tem um mecanismo para normalizar tipos em tempo de execução de forma implícita e você deve sempre prestar atenção nisso!
Type hints
O type hinting é um mecanismo de, ao mesmo tempo, reforçar a coerção de tipos e de import tipagem estrita. Isto foi introduzido ao php na versão 7.0 e transforma assinaturas de métodos e funções. Desde o php 7.4 também é possível fazer type hint com propriedades de classes.
Abaixo vai um exemplo de type hint:
<?php
function somar(
int $a,
int $b
): int {
return $a + $b;
}
As dicas (hints) aqui dizem que a variável $a é do tipo int naturalmente ou transformada pela linguagem, a variável $b também é do tipo int e o resultado desta função será do tipo int, de forma natural ou transformada automaticamente pela linguagem (coerção).
Reparou que eu disse que elas são de certo tipo "de forma natural ou transformada automaticamente pela linguagem (coerção)"? Isso porque o PHP não vai reclamar se você chamar esta função com valores que não são do tipo int. O que vai acontecer, aliás, é que o php vai tentar converter implicitamente (coerção) os parâmetros em inteiros se o tipo não for o esperado.
No corpo da função a seguir você pode sempre ter certeza de que $a e $b são inteiros. Mas de que os inteiros estão corretos somente quem chama função pode garantir.
<?php
function somar(
int $a,
int $b
): int {
// $a é int(10)
// $b é int(10)
return $a + $b;
}
somar('10 maçãs', '10 bananas');
Também é possível ativar uma diretiva chamada strict_types para evitar coerções e simplesmente gerar erros quando tipos inválidos são utilizados. Como à seguir:
<?php
declare(strict_types=1);
function somar(
int $a,
int $b
): int {
return $a + $b;
}
somar('10 bananas', '10 maçãs');
// PHP Fatal error: Uncaught
// TypeError: Argument 1 passed
// to somar() must be of the type
// int, string given
Isso não significa que o php é estaticamente tipado quando strict_types está ligado! Na realidade, o type hinting apenas adiciona um processamento extra. Internamente ele sempre fará o malabarismo de tipos (type juggling) e nunca irá confiar nos type hints da sua variável.
Type hints servem a dois propósitos: definir em quais tipos um valor deveria ser coagido OU gerar erros fatais quando os strict types estiver ligado.
Resumão do ENEM: type hints apenas dão dicas sobre os tipos para o php, não ordens! Usar strict types é uma escolha que você pode tomar e trará um pequeno processamento extra consigo.
Union Types
Antes de a gente falar de malabarismo de tipos (type juggling) eu gostaria de falar rapidinho sobre os Union Types porque parece fazer mais sentido aqui.
Além dos três tipos que o php tem (escalares, compostos e especiais) o manual do php também menciona um pseudo-tipo que só existe para facilitar a leitura do manual. Este tipo não existe de verdade, é apenas uma convenção.
Eu gostaria que você prestasse atenção num pseudo-tipo muito específico: o array|object normalmente é utilizado na documentação para especificar parâmetros ou tipos de retorno.
O tipo iterable também é um tipo de Union Type. E pode ser definido como array|Traversable.
Desde o php 7.1 a linguagem traz um meio-que suporte a Union Types ao ter introduzido o nullable type. Se você parar pra pensar, um tipo nullable é apenas um Union de T|null. Por exemplo, ?int significa int|null.
Aposto que tu não pensou sobre isso antes! 😝
Então depois de tantos Union Types desconhecidos, o php 8.0 formalmente implementou os Union Types. Onde você pode definir qualquer Union Type que precisar sem depender de pseudo-types ou convenções. Funciona mais ou menos assim:
<?php
declare(strict_types=1);
function dividir(
int $a,
int $b
): int|float {
return $a / $b;
}
A função acima pode retornar integer ou float. Mas nunca outro tipo.
Malabarismo de tipos, ou type juggling
Provavelmente não é a primeira vez que você ouviu falar no termo Type Juggling, certo? Esta é uma das funcionalidades mais importantes do php e, ainda assim, é uma das menos compreendidas.
Eu não posso culpar ninguém por não entendê-la bem. A gente chama isso de "malabarismo" por um bom motivo. Uma variável pode assumir tanto tipo diferente em cada contexto que pode ser um tanto complicado entender com qual tipo você está lidando.
Vamos começar com o seguinte: o php não permite definir tipos explicitamente na declaração de variáveis. E isso é muito poderoso!
Sempre que você declara uma variável, o php vai inferir o tipo que ela possui baseado no valor que você a deu. Enquanto $var; cria uma variável com valor NULL, $one = 1 cria um inteiro e $obj = new stdClass() cria um object(stdClass).
Aí não tem definição de tipo em canto algum! O php vai tomar conta de adivinhar qual o tipo melhor se adequa a sua variável.
As variáveis do php são muito dinâmicas, de forma que elas podem mudar de tipo em tempo de execução sem problema algum! O código abaixo é válido:
<?php
$var;
// $var é NULL
$var = 1;
// $var é int(1)
$var = 'thephp.website';
// $var é string("thephp.website")
$var = new stdClass();
// $var é object(stdClass)
E por as variáveis serem tão dinâmicas, várias operações no php exigem que os valores sejam verificados baseado no contexto da operação. Uma expressão como a soma (a + b) internamente irá verificar o tipo do primeiro operando e depois tentar adivinhar o tipo do segundo operando.
Dê uma sacada nesse snippet do código fonte do php. Se op1 for long (a é um inteiro) então verifique se op2 também é long (b é inteiro). Se sim, faça uma soma de longs. Se não, verifique se op2 é um double e faça uma soma de doubles se sim. E esta expressão pode retornar um inteiro ou um float.
E é por isso que eu te garanto que o malabarismo de tipos (type juggling) vai acontecer automaticamente.
Isso também significa que coerção de tipos (conversões implícitas) vão acontecer automaticamente. Mas elas não deveriam ser uma surpresa! Há momentos muito específicos onde uma coerção de tipos deve acontecer.
Coerção de tipos (e, portanto, malabarismo de dados) ocorrem quando:
- resolvem-se expressões
- passam-se argumentos para uma função ou método
- retorna-se de uma função ou método
Você pode estar se perguntando: ué, se coerção acontece em todo canto então como o php lida com tipos incompatíveis? Converter um inteiro para boolean parece normal, mas um array para inteiro já começa a ficar estranho.
Bem, o php tem regras muito bem definidas para fazer conversão de tipos. Primeiro entende-se qual o tipo que o resultado deveria ter e só então é feita a conversão.
Por exemplo, se uma expressão ocorrer dentro de um if() a gente pode perceber rapidinho que aquela expressão deve resultar em um tipo boolean.
<?php
$var = 100;
// $var é int(100)
// $var é tratado como
// boolean e resulta
// em TRUE
if ($var) {
// $var ainda é int(100)
}
// $var ainda é int(100)
Repare como $var era int(100) durante todo seu ciclo de vida, mas foi tratada como bool(TRUE) dentro daquele if(). Isto ocorre porque o if() espera uma expressão que retorna um boolean. O malabarismo de tipos (type juggling) é justamente o que o php fez por debaixo dos panos para você.
Para ilustrar, aqui vai a lista de verificações ao converter um tipo em boolean. Uma conversão para boolean retorna false quando o valor original for:
- um bool(FALSE)
- um
int(0)ouint(-0) - um
float(0)oufloat(-0) - uma string vazia
string("")ou a string zerostring("0") - um array vazio
array() - um NULL
- uma instância de SimpleXML criada a partir de tags vazias
E irá retornar true para qualquer outro valor.
A tabela acima pode ser encontrada na seção "Converting to boolean" do manual.
A documentação completa sobre as comparações de tipos e tabelas de conversões também podem ser encontradas no manual da linguagem. Eu não tomei coragem de ler, mas faz parte do meu trabalho dizer que elas existem e te mostrar onde 🤷🏻♀️
Nota importante aqui: no php 8.0 os union types foram introduzidos e trouxeram consigo uma camada extra de complexidade. O malabarismo de dados (type juggling) quando lida com Union Types precisa seguir uma regra de precedência. E essa precedência é pré-definida em vez de depender da ordem dos tipos declarados.
Então se você não estiver usando strict_types os seus Union Types vão seguir esta regra. Se o Union Type não contém o tipo do resultado, ele poderá fazer a coerção deste valor na seguinte ordem de precedência: int, float, string e bool.
Por exemplo:
<?php
function f(
int|string $v
): void {
var_dump($v);
}
f(""); // string ESTÁ no union type
// string("")
f(0); // int ESTÁ no union type
f(0.0); // float NÃO ESTÁ no union type
// int(0)
f([]); // array NÃO ESTÁ no union type
// Uncaught TypeError:
// f(): Argument #1 ($v)
// must be of type string|int
No exemplo acima algo interessantíssimo acontece! O tipo array não será convertido para um bool(FALSE). Ele gera um TypeError em vez disso!
Os modos de tipagem
Você já deve ter percebido que existem duas formas de o php lidar com tipos. Uma delas é chamada "Coercive Type Mode" onde acontece todo aquele malabarismo e adivinhações de tipos. A outra é o "Strict Type Mode" onde o malabarismo e a adivinhação ainda acontecem, mas quando os tipos são definidos explicitamente alguns TypeErrors serão lançados quando os tipos não forem compatíveis.
Agora, eu vejo como algo normal que pessoas programadoras de php possam esperar que a linguagem respeite a Lei da Troca Equivalente (等価交換法) e lhe pague com ganho de performance o esforço de usar strict types porque ela será então capaz de pular todas as verificações de tipos e executar as operações diretamente.
Ao passo que eu entendo o motivo de alguém pensar desta forma, eu preciso lhe dizer: está completamente errado! O código a seguir contém a lógica da função strlen() no código fonte do php.
Toda vez que é necessário verificar se o php está operando no modo "Strict Type", pode-se buscar o boolean a partir da chamada EX_USES_STRICT_TYPES(). Se true, o strict types está ligado. Se não, o modo coercivo está.
Agora, veja o snippet novamente! Ele começa assim:
// ...
zval *value;
value = GET_OP1_ZVAL_PTR_UNDEF(BP_VAR_R);
// value é o parâmetro
// de strlen()
if (EXPECTED(
Z_TYPE_P(value) == IS_STRING
)) {
ZVAL_LONG(
EX_VAR(
opline->result.var
),
Z_STRLEN_P(value)
);
FREE_OP1();
ZEND_VM_NEXT_OPCODE();
} else {
// ...
}
Reparou naquele primeiro if() alí? Adivinha o que ele tá fazendo... EXATO! Ele verifica pra ti o tipo do parâmetro!!
Sabe o que esse mesmo trecho de código está fazendo com o seu type hint? NADINHA! 🤣
A cláusula else possui o código TALVEZ vá usar strict types ou não.
// ...
} else {
// Ok, estamos progredindo
zend_bool strict;
// 😭
if (
(OP1_TYPE & (IS_VAR|IS_CV)) &&
Z_TYPE_P(value) == IS_REFERENCE
) {
// ...
}
// ...
// OPA! 👀
strict = EX_USES_STRICT_TYPES();
do {
if (EXPECTED(!strict)) {
// ...
}
zend_internal_type_error(
strict,
/*...*/
);
ZVAL_NULL(
EX_VAR(opline->result.var)
);
} while (0);
}
No trecho acima podemos ver um exemplo de como o modo strict type não corta nenhum processamento. Na verdade, acabou criando algumas verificações a mais com um único propósito: gerar erros fatais.
Eu não quero dizer que esta é uma implementação ruim. Eu pessoalmente estou bem contente com a forma que o php funciona. Mas eu acho que é importante deixar claro que isto não irá afetar a performance de forma positiva.
Resumão do ENEM: strict types não tornarão seu código mais rápido!
Conclusão
Esse artigo deu trabalho ein! Me fez considerar um bom tanto a ideia de escrever um livro. Só este artigo já daria uns 15% de um livro bacana 😂
Eu espero que a informação que eu coletei aqui foi útil pra ti. E se não foi, que tenha sido ao menos interessante.
Eu acredito que o sistema de tipos do PHP é incrivelmente rico e carrega várias funcionalidades legadas e também inovadoras e todas elas fazem muito sentido quando você olha para a história do desenvolvimento da linguagem.
Como sempre, sinta-se livre para me dar um alô no twitter se você tiver algo a dizer. Você também pode abrir uma issue ou pull request no github e ser feliz.
Até a próxima! Valeu!
]]>
Você provavelmente já viu vários posts sobre como escrever crawlers com php. O que difere este post dos outros? É que eu garanto que você não precisa se malucar com expressões regulares, variáveis globais e todo esse tipo de coisa irritante.
Nós vamos usar uma ferramenta maravilhosa chamada spatie/crawler que vai nos fornecer uma ótima interface para escrever crawlers sem ir a loucura!
Abaixo tem um vídeo meu codificando este crawler. É só rolar a página até o vídeo se tu quiser pular direto pra ação. 😉
Nosso caso de uso
Este crawler vai ser bem simplão e pretende buscar nomes, apelidos e e-mails do diretório oficial do PHP sobre pessoas que contribuíram com a linguagem de alguma forma.
Você pode olhar o repositório nesta url aqui: https://people.php.net.
Configurando o ambiente de desenvolvimento
Montar o ambiente vai ser bem rápido, eu vou só copiar as secções composer e php desse outro post que eu escrevi sobre como montar um ambiente com docker rapidex.
Meu arquivo docker-compose.yml ficou assim:
version: '3'
services:
composer:
image: composer:1.9.3
environment:
- COMPOSER_CACHE_DIR=/app/.cache/composer
volumes:
- .:/app
restart: never
php:
image: php:7.4-cli
restart: never
volumes:
- .:/app
working_dir: /app
Agora vamos instalar os pacotes:
$ docker-compose run \
composer require \
spatie/crawler \
symfony/css-selector
Tudo o que a gente precisa agora é um arquivo pra executar, vamos criar um arquivo bin/crawler.php:
$ mkdir bin
$ touch bin/crawler.php
Massa! Agora vamos adicionar o autoload nesse arquivo e estamos prontos pra começar:
// bin/crawler.php
<?php
require_once __DIR__ .
'/../vendor/autoload.php';
De agora em diante a gente pode rodar nosso crawler com o seguinte comando:
$ docker-compose run php \
php bin/crawler.php
Vamos analizar o site alvo
Normalmente a gente deveria navegar pelo website e entender como ele funciona: padrões de url, chamadas ajax, tokens csrf, se feeds ou APIs estão disponíveis.
Neste caso nem feeds e nem APIs estão disponíveis. A gente precisa criar um crawler cruzão mesmo que vai buscar páginas em HTML e interpretá-las.
Eu vejo alguns padrões de URL: * Página de perfil: people.php.net/{nickname} * Página de diretório: people.php.net/?page={number} * Links externos
Parece simples! A gente só precisa se preocupar em interpretar o HTML dentro de páginas de perfil e ignorar o restante.
Ao verificar a página de perfil podemos perceber rapidamente que os seletores importantes pra gente são: * Nome: h1[property=foaf:name] * Apelido: h1[property=foaf:nick]
A gente também pode confiar que o e-mail das pessoas segue o padrão "{apelido}@php.net".
Com essa informação, bora codar!
Obtendo dados públicos de todas as pessoas que contribuíram com o PHP
Abaixo você encontra o código, mas se você prefere mais vídeos, dá uma ligadinha nesse aqui que eu fiz pra ti:
Mãos à massa!
O pacote spatie/crawler traz duas classes abstratas muito importantes - que eu adoraria que fossem interfaces 👀.
Uma delas é a classe CrawlObserver, onde a gente pode se conectar aos passos de obter uma página e manipular respostas http. A nossa lógica entra aqui.
Eu vou escrever um observer rapidinho com uma classe anônima abaixo:
$observer = new class
extends CrawlObserver
{
public function crawled(
$url,
$response,
$foundOnurl
) {
$domCrawler = new DomCrawler(
(string) $response->getBody()
);
$name = $domCrawler
->filter('h1[property="foaf:name"]')
->first()
->text();
$nick = $domCrawler
->filter('h2[property="foaf:nick"]')
->first()
->text();
$email = "{$nick}@php.net";
echo "[{$email}] {$name} - {$nick}" . PHP_EOL;
}
};
A lógica acima vai buscar as propriedades que esperamos das páginas de perfil. É claro que a gente deveria também verificar se estamos na página correta ou não.
Agora, o próximo passo importante é a classe abstrata CrawlProfile. Com esta classe a gente consegue decidir se uma URL deveria ou não ser acessada por um observer. Vamos criar também como classe anônima:
$profile = new class
extends CrawlProfile
{
public function shouldCrawl(
$url
): bool {
return $url->getHost() ===
'people.php.net';
}
};
Acima a gente definiu que queremos seguir apenas links internos. Isso porque esse website cria links pra vários outros repositórios. E a gente não quer crawlear todo o universo php, certo?
Com essas duas instâncias em mãos, podemos já preparar o crawler e iniciar a busca:
Crawler::create()
->setCrawlObserver($observer)
->setCrawlProfile($profile)
->setDelayBetweenRequests(500)
->startCrawling(
'https://people.php.net/'
);
Importante! Reparou naquele setDelayBetweenRequests(500)? Ele faz com que o crawler vá buscar apenas uma URL a cada 500 milisegundos. Isso é porque a gente não quer derrubar esse site, certo? (Sérião, não derruba esse site. Se tu quer fazer maldade, busca um site do governo ou coisa do gênero 👀)
E é isso!
Rápido e prático, e mais importante de tudo: sem loucuras! O spatie/crawler tem uma interface muito massa que simplifica demais o processo.
Se você juntar essa ferramenta com uma injeção de dependências e enfileiramento você terá resultados profissionais.
Me dá um toque no twitter se você tiver dúvidas! Uma abraço! 👋
]]>
Sim, você leu certo!
Um jogo. Escrito na linguagem PHP.
Antes de eu te mostrar o código em si, gostaria de mostrar o resultado! Não está bem acabado, então abaixemos as expectativas por agora. Eu só queria montar uma POC boa o suficiente pra mostrar aqui 😬
Você pode ver o gameplay no vídeo abaixo.
Massa, né!? E isso é só uma POC, mas com o que já existe nesta extensão você já pode brincar com diferentes texturas, audios e etc..
Eu vou te mostrar como ficou o código e quais ferramentas eu utilizei! Espero que isso tome sua atenção suficientemente para vermos esta extensão ganhar tração.
Antes de qualquer coisa, deixa eu te falar um pouco sobre a raylib.
Raylib
Escrita na linguagem C, Raylib é definida como "uma biblioteca simples e de fácil utilização para curtir a programação de jogos".
Ela oferece funções muito simplistas para manipular vídeo, áudio, ler entradas de teclado, mouse ou joysticks. Ela também suporta renderização 2d e 3d. É uma biblioteca bem completinha.
Aqui vai uma visão geral da arquitetura da Raylib. Ela espera que você vá escrever seu jogo, engine ou ferramentas em cima dos módulos da Raylib. Os módulos oferecem funcionalidades para controlar coisas como câmera, texturas, texto, formas, modelos, áudio, matemática...

Ela não vem com coisas de engine, como detecção complexa de colisão ou física. Se você precisar de algo desse tipo, precisará escrever por si. Ou encontrar algo já escrito por outra pessoa e que esteja preparado para rodar com a Raylib.
Extensão Raylib PHP
Recentemente uma extensão PHP chamou a minha atenção. Desenvolvida por @joseph-montanez há um certo tempo atrás, a extensão raylib-php teve seu primeiro lançamento alpha pouco menos de um mês atrás.
Se você precisa saber como compilar e rodar por favor acesse o arquivo README.md do repositório oficial. No MacOS os seguintes passos funcionaram de boa pra mim:
$ git clone [email protected]:joseph-montanez/raylib-php.git
$ cd raylib-php/
$ phpize
$ ./configure
$ make
Somente compilou tranquilo com o PHP 7.4 na minha máquina. Então bota aí a versão correta do PHP.
Essa extensão quer oferecer a mesma interface que a biblioteca em C, então a gente poderá desenvolver os jogos mais ou menos da mesma forma.
Claro que já que a biblioteca em C não traz coisas específicas de jogos como física e outras paradinhas, você precisará implementar essas coisas em PHP.
Esta extensão ainda não está completa. Você pode dar uma olhada no MAPPING.md do repositório oficial pra entender o que já foi feito e o que falta.
Mesmo não estando completa, eu decidi brincar um pouco com a extensão e, até onde consegui ver, já está bem funcional.
Um jogo da cobrinha simplão
Mesmo sendo "Snake" (ou "jogo da cobrinha") um jogo bem simples eu decidi não implementá-lo completamente. Meu principal objetivo aqui era ter um jogo bom o suficiente pra eu poder testar algumas coisas básicas da extensão.
Então eu resolvi pegar alguns requisitos pra implementar:
- A cobrinha precisa mover-se constantemente, mas pode mudar de direção
- Deverá existir apenas uma frutinha na tela, posicionada aleatóriamente
- Quando a cabeça da cobrinha toca numa fruta, cinco coisas devem acontecer: a fruta tem de ser destruída, o corpo da cobrinha deve crescer, outra fruta deve ser criada, o contador de pontos deve aumentar em 1 e a velocidade da cobrinha também deverá aumentar
- Quando a cobrinha toca na borda da tela, ela deverá aparecer do outro lado
Deveria ser claro, mas também é requisito que o jogador possa mudar a direção em que a cobrinha anda usando alguma ferramenta de entrada como o teclado.
Tem também dois requisitos bem importantes que eu decidi não implementar aqui: 1) a cobrinha não pode morder a si mesma. Ou seja, se a cobrinha bater em seu próprio corpo, o jogo deve acabar. 2) a cobrinha não pode mudar de direção para um sentido diretamente oposto ao atual. Então quando se está andando para a direita, mudar para a esquerda requer que primeiro se vá para cima ou para baixo.
Estes dois requisitos não foram implementados pois se tratam de algorítmo e não adicionariam muito para o experimento em si.
Implementação
Essa implementação tem dois componentes: o Game Loop e o Game State.
O game loop é responsável por atualizar o estado do jogo baseado nas entradas do(a) jogador(a) e cálculos e mais tarde por pintar este estado na tela. Para isto eu criei uma classe chamada "GameLoop".
O game state mantém o estado atual do jogo (snapshot). Ele guarda coisas como a pontuação do(a) jogador(a), as coordenadas x,y da fruta, as coordenadas x,y da cobrinha e todos os quadradinhos que formam o corpo da cobrinha. Para esta eu criei uma classe “GameState”.
Veja a seguir como estas classes são.
Game Loop
A classe GameLoop inicializa o sistema, e cria um loop que executa dois passos em cada iteração: atualizar o estado (update) e desenhar o estado na tela (draw).
Então no construtor eu inicializei o canvas com largura e altura e instanciei o GameState.
Como parâmetros ao GameState eu passei largura e altura divididos por um tamanho de célula (30 pixels no meu caso). Estes valores representam os valores máximos de coordenadas X e Y que o GameState poderá trabalhar. A gente vai ver isso depois.
// GameLoop.php
final class GameLoop
{
// ...
public function __construct(
int $width,
int $height
) {
$this->width = $width;
$this->height = $height;
// 30
$s = self::CELL_SIZE;
$this->state = new GameState(
(int) ($this->width / $s),
(int) ($this->height / $s)
);
}
// ...
}
Mais tarde, um método público chamado start() vai criar uma Janela, definir a taxa de frames e criar um loop infinito - sim, meio que um while (true) - que vai primeiro chamar um método privado update() e mais tarde um método draw().
// ...
public function start(): void
{
Window::init(
$this->width,
$this->height,
'PHP Snake'
);
Timming::setTargetFPS(60);
while (
$this->shouldStop ||
!Window::shouldClose()
) {
$this->update();
$this->draw();
}
}
// ...
O método update() será responsável por atualizar a instância de game state. Ele faz isso ao ler as entradas do(a) jogador(a) (ao pressionar teclas) e fazendo coisas como verificar colisão e por aí vai.
Baseado nos cálculos realizados no método update(), mudanças de estado são enviadas à instância de GameState.
private function update(): void
{
$head = $this->state->snake[0];
$recSnake = new Rectangle(
(float) $head['x'],
(float) $head['y'],
1,
1,
);
$fruit = $this->state->fruit;
$recFruit = new Rectangle(
(float) $fruit['x'],
(float) $fruit['y'],
1,
1,
);
// Snake morde a fruta
if (
Collision::checkRecs(
$recSnake,
$recFruit
)
) {
$this->state->score();
}
// Controla velocidade do passo
$now = microtime(true);
if (
$now - $this->lastStep
> (1 / $this->state->score)
) {
$this->state->step();
$this->lastStep = $now;
}
// Atualiza a direção se necessário
if (Key::isPressed(Key::W)) {
$this->state->direction = GameState::DIRECTION_UP;
} else if (Key::isPressed(Key::D)) {
$this->state->direction = GameState::DIRECTION_RIGHT;
} else if (Key::isPressed(Key::S)) {
$this->state->direction = GameState::DIRECTION_DOWN;
} else if (Key::isPressed(Key::A)) {
$this->state->direction = GameState::DIRECTION_LEFT;
}
}
Por último vem o método draw(). Ele vai ler as propriedades do GameState e pintá-las. Aplicando proporções e escalas.
Da forma como eu construí, este método espera que coordenadas X variem de 0 até (largura dividida pelo tamanho da célula) e coordenadas Y veriem de 0 até (altura dividida pelo tamanho da célula). Ao multiplicar cada coordenada por "tamanho da célula" a gente consegue desenhar com boas proporções sem precisar misturar o gerenciamento de estado e desenho.
Bem simples. Fica assim:
private function draw(): void
{
Draw::begin();
// Limpa a tela
Draw::clearBackground(
new Color(255, 255, 255, 255)
);
// Desenha a fruta
$x = $this->state->fruit['x'];
$y = $this->state->fruit['y'];
Draw::rectangle(
$x * self::CELL_SIZE,
$y * self::CELL_SIZE,
self::CELL_SIZE,
self::CELL_SIZE,
new Color(200, 110, 0, 255)
);
// Desenha o corpo da cobrinha
foreach (
$this->state->snake as $coords
) {
$x = $coords['x'];
$y = $coords['y'];
Draw::rectangle(
$x * self::CELL_SIZE,
$y * self::CELL_SIZE,
self::CELL_SIZE,
self::CELL_SIZE,
new Color(0,255, 0, 255)
);
}
// Desenha a pontuação
$score = "Score: {$this->state->score}";
Text::draw(
$score,
$this->width - Text::measure($score, 12) - 10,
10,
12,
new Color(0, 255, 0, 255)
);
Draw::end();
}
Tem algumas outras coisas que eu adicionei para depurar mas eu prefiro deixá-las de fora deste artigo.
Depois disso, vem o gerenciamento de estado. Esta é a responsabilidade de GameState. Vamo vê!
Game State
O GameState representa tudo que existe no game. Pontuação, objetos como o(a) jogador(a) e as frutas.
Isto significa que sempre que o(a) jogador(a) precisar mover-se ou uma fruta for comida, isto ocorrerá dentro de GameState.
Para o corpo da cobrinha eu decidi criar um array com coordenadas (x,y) dentro. E eu considerei o primeiro elemento (índice zero) como sendo a cabeça da cobrinha. Adicionar mais elementos (x,y) neste array então deveria aumentar o tamanho do corpo da cobrinha.
Já a fruta é um simples par de coordenadas (x,y), pois eu espero ter apenas uma fruta na tela por vez.
O construtor da classe GameState inicializa estes objetos com coordenadas aleatórias. Ficou assim:
// GameState.php
final class GameState
{
public function __construct(
int $maxX,
int $maxY
) {
$this->maxX = $maxX;
$this->maxY = $maxY;
$this->snake = [
$this->craftRandomCoords(),
];
$this->fruit = $this->craftRandomCoords();
}
}
Para aumentar o tamanho do corpo da cobrinha, eu criei um método privado chamado incrementBody() que vai adicionar uma nova cabeça ao corpo da cobrinha. Esta cabeça deverá considerar a direção em que a cobrinha estava andando. (esquerda, direita, acima ou abaixo)
Para criar uma nova cabeça, eu só copio a cabeça atual, atualizo as coordenadas baseado na direção atual e mesclo esta cópia com o corpo ocupando o índice zero.
private function incrementBody(): void
{
$newHead = $this->snake[0];
// Ajusta a direção da cabeça
switch ($this->direction) {
case self::DIRECTION_UP:
$newHead['y']--;
break;
case self::DIRECTION_DOWN:
$newHead['y']++;
break;
case self::DIRECTION_RIGHT:
$newHead['x']++;
break;
case self::DIRECTION_LEFT:
$newHead['x']--;
break;
}
// Adiciona nova cabeça,
// na frente do corpo todo
$this->snake = array_merge(
[$newHead],
$this->snake
);
}
Tendo o método incrementBody() fica bem fácil implementar o método score(), que apenas aumenta a pontuação e o tamanho do corpo da cobrinha. O score() também vai criar uma nova fruta numa coordenada aleatória da tela.
public function score(): void
{
$this->score++;
$this->incrementBody();
$this->fruit = $this->craftRandomCoords();
}
O mais interessante é o método step(), que é responsável por mover a cobrinha.
Se você bem se lembrar, a forma como Snake se mexe é que a cabeça vai constantemente andar em uma direção e o corpo a segue. Então se Snake tem tamanho 3 e seu corpo está andando para baixo, são necessários três passos para que ela ande para a esquerda completamente.
A forma como eu fiz, foi basicamente aumentar o tamanho do corpo novamente (que adiciona uma nova cabeça na nova direção) e remover o último elemento do corpo da cobrinha. Desta forma o tamanho corpo continua o mesmo e as coordenadas antigas serão apagadas.
Eu também adicionei uma lógica para aparecer do outro lado da tela quando a cabeça da cobrinha bater na borda da tela.
public function step(): void
{
$this->incrementBody();
// Remove o último elemento
array_pop($this->snake);
// Move o corpo para o
// outro lado da tela
// se necessário
foreach ($this->snake as &$coords) {
if ($coords['x'] > $this->maxX - 1) {
$coords['x'] = 0;
} else if ($coords['x'] < 0) {
$coords['x'] = $this->maxX - 1;
}
if ($coords['y'] > $this->maxY - 1) {
$coords['y'] = 0;
} else if ($coords['y'] < 0) {
$coords['y'] = $this->maxY - 1;
}
}
}
Agora é só grudar tudo, instanciar as coisa e tamo pronto pra jogar!
Faz sentido desenvolver jogos em PHP?
Certamente faz mais sentido que antes. Espero que menos que amanhã.
A extensão oferece interfaces bem bacanudas, mas ainda não está completa. Se você sabe um pouco de C, você também pode tornar o futuro um lugar melhor para desenvolvimento de jogos em PHP ao contribuir com esta extensão.
Aqui tem uma lista onde você pode encontrar funções que ainda precisam de implementação.
O PHP ainda é bloqueante por padrão, então operações de E/S precisam ser tratadas com cuidado. É possível utilizar esta biblioteca junto de um Event Loop our usando threads da extensão Parallel. Provavelmente você precisará escrever algo customizado pra isto.
O que mais me deixa encucado até o momento é sobre o quão portáveis os jogos em PHP podem ser. Não tem uma forma simples de empacotar estes jogos em binários. Então jogadores precisariam instalar o PHP e compilar a extensão Raylib pra poder jogar algo.
Mas como eu mencionei, os primeiros passos foram dados. Então tecnicamente já é mais fácil desenvolver jogos do que era antes.
Agradeço muito ao Joseph Montanez. Sua extensão me inspirou muito e eu espero que esta publicação alcance e instigue mais desenvolvedores(as) para ajudar no desenvolvimento dela.
]]>
TL;DR
Sim, tecnicamente o MessagePack ganha em todos testes. Mas a diferença é tão marginal que eu não consigo ver muitas vantagens em migrar do JSON para o MessagePack.
Mas talvez faça sentido utilizar MessagePack desde o início. MessagePack é um tiquinho mais rápido e leve se comparado ao JSON.
Utilizar MessagePack para trocar dados entre o navegador e servidor não parece parece fazer muito sentido na minha opinião. O tamanho da resposta não faz muita diferença quando se aplica o filtro gzip (alguns poucos bytes), mas depurar as mensagens de rede passa a ser mais difícil. Por outro lado, isto pode lhe ajudar a evitar que sua API seja consumida por bots com tanta frequência.
Você pode encontrar o código do benchmark e os números neste repositório que eu criei.
Nota rápida: Este artigo está HORRÍVEL em telas pequenas. Desculpem-me por isso, mas eu preciso apresentar tabelas para mostrar meus dados.
O que é MessagePack?
Como descrito no site oficial do MessagePack ele é como JSON, mas rápido e leve.
Em outras palavras, o MessagePack é um formato de serialização que transforma estruturas de dados em strings binárias.
O motivo de ele ser tão eficiente é que as estruturas de dados são mapeadas utilizando uma notação pequenininha de binários em stream. O tamanho final é quase metade do tamanho de algo serializado em JSON.
O exemplo do site oficial compara a mesma estrutura de dados sendo representada nos formatos JSON e MessagePack. O exemplo usado na home page mostra um map contendo duas chaves: compact = true e schema = 0.
A versão em JSON deste map tem 27 bytes enquanto o MessagePack o faz em apenas 18 bytes.
// Map utilizado no
// exemplo oficial
$json = [
"compact" => true,
"schema" => 0,
];
// 27 bytes
json_encode($json);
// 18 bytes
msgpack_pack($json);
Eu aprendi sobre este formato muito recentemente e por um completo acidente, enquanto lia este tweet do @eminetto , mas aparentemente isso existe desde 2012.
Me deixou encucado isso, já que eu trabalho com aplicações de muito tráfego que constante mente troca mensagens em JSON com diferentes serviços no back-end. Me cheira como se fosse algo simples de implementar e ganhar rios de performance.
Eu então decidi fazer um benchmark do MessagePack no PHP como extensão em C contra a extensão JSON nativa do PHP (também escrita em C).
O ambiente de benchmark
Pra testar isso tudo, eu montei um repositório simplão com três benchmarks diferentes. Um arquivo testa a serialização msgpack, e os outros dois testam a serialização JSON sendo que o último desserializa utilizando a opção "assoc" com valor true.
Pra executar estes benchmarks, eu escolhi utilizar o Travis CI, já que qualquer pessoa pode reproduzir estes testes de forma simplificada. Os dados que consegui coletar do ambiente de execução são:
- CPU: Intel(R) Xeon(R); 1 @ 2,8 GHz; Cache 33 MB
- RAM: 7,79 GB
- OS: linux/amd64 (Ubuntu 16.04.6 LTS - Xenial)
- Versão do PHP: 7.4.3
- Versão do MsgPack: 2.1.0
Num futuro próximo eu vou atualizar o benchmark pra rodar contra o PHP 8 e o Just In Time compiler dele. Como eu escrevi num outro post sobre como o JIT funciona, o JIT pode melhorar bastante a performance em oeprações de CPU.
A entidade que eu utilizei pra serializar/desserializar é uma resposta real da API de issues do github. Ela tem 2321 linhas e 147 KB de tamanho. Me parece um exemplo bem decente pra representar dados reais de uma resposta de API.
Você pode verificar a entidade aqui: https://github.com/nawarian/msgpack-bm/blob/master/github-issues.json.
MessagePack é mais rápido e mais leve que o JSON
Como você pode notar, eu odeio esconder informação. Te digo logo de cara: O MessagePack ganha do JSON em cada teste.
Mas a diferença é bem pequetuxa, na real. Se liga:
Tamanho das saídas:
Ao falar sobre APIs, uma das coisas mais importantes é o tamanho do corpo da mensagem que está sendo transportada na rede. Os valores crus são bem impressionantes, but todo bom programador(a) sabe que na maioria dos casos devemos comprimir nossas APIs usando filtros como gzip ou brotli.
Então para esta comparação eu decidi mostrar o tamanho do conteúdo serializado nos dois formatos e adicionei também a versão comprimida com gzip.
A comparação ficou assim:
| Formato | Serializado (bytes) | Serializado + Gzip (bytes) |
|---|---|---|
| JSON | 143025 | 26214 |
| MessagePack | 120799 (-22226) | 26074 (-140) |
Como pode-se notar, quando não há filtros de compressão o MessagePack é cerca de 22 KB mais leve que o JSON. Mas quando aplicamos o gzip nos dois valores, MessagePack passa a ganhar por míseros 140 bytes. Nada expressivo.
Tempos de Serialização/Desserialização:
A outra parte importante no processo de serialização é quanto tempo leva pra transformar aquele formato. Para tal eu decidi serializar e desserializar a mesma entidade várias vezes e tomar notas sobre o consumo de memória e tempos de processamento.
O consumo de memória não parece mudar muito neste teste a não ser que você passe a desserializar a mesma entidade um milhão de vezes, o que eu espero não ser tão comum para a maioria das aplicações PHP. Portanto eu não vou apresentar os números sobre utilização de memória já que a variação foi de 0 bytes.
Enquanto eu coletava os números sobre JSON, eu descobri que desserializar uma entidade com assoc = true é um pouquinho mais rápido em comparação com assoc = false. O que é um tanto interessante e até faz um certo sentido.
Já que os resultados com assoc = true são melhores para o JSON, eu vou utilizar estes dados somente na comparação.
O resultado:
| Iterações | Serialização JSON (s) | Serialização MessagePack (s) | Desserialização JSON (s) | Desserialização MessagePack (s) |
|---|---|---|---|---|
| 1 | 0.00064 | 0.00019 (-0,00045) | 0.00164 | 0.00051 (-0,00113) |
| 10 | 0.00340 | 0.00082 (-0,00258) | 0.00866 | 0.00194 (-0,00672) |
| 100 | 0.03135 | 0.00732 (-0,02403) | 0.07905 | 0.01700 (-0,06205) |
| 1000 | 0.30385 | 0.07250 (-0,23135) | 0.77422 | 0.16785 (-0,60637) |
| 10000 | 3.02723 | 0.72503 (-2,95472) | 7.74523 | 1.65804 (-6,08719) |
| 100000 | 30.29353 | 7.25324 (-23,04029) | 77.48423 | 16.71792 (-60,76631) |
As iterações aqui significam quantas vezes nós executamos a mesma operação. Sendo a operação um json_encode, msgpack_pack, json_decode ou msgpack_unpack.
Pessoalmente eu prestaria atenção nos números de 1 a 100 iterações. Acima deste número, começa a ficar menos realista para mim. Eu os deixei alí de toda forma, os resultados começam a ficar bem interessantes a partir de 10 mil iterações.
Como você pode perceber, as diferenças são bem pequenas nas primeiras iterações.
Quando uma única operação de serialização é chamada, MessagePack é 0,45 ms mais rápido. Nada expressivo. Quando o número de serializações passa a 100, a diferença começa a se tornar evidente e o MessagePack é 24 ms mais rápido que o JSON.
Desserializações são normalmente mais lentas para os dois formatos, mas o MessagePack ganha aqui novamente. Quando uma única desserialização ocorre, MessagePack é 1 ms mais rápido. Enquanto 100 desserializações são 62 ms mais rápidas com MessagePack em comparação com JSON.
Mesmo que a diferença seja grande o suficiente quando 100 items precisam ser desserializados, eu acredito que na maioria das aplicações PHP seja bem improvável de acontecer. Um número de operações entre 1 e 10 é bem plausível pra mim e o MessagePack é 2 ms mais rápido em serializações e 6 ms em desserializações quando executado 10 vezes.
Bons números, mas nada muito expressivo.
Devo migrar do JSON para o MessagePack?
Quando se trata de engenharia de software, a única resposta que podemos dar com certeza é: depende. Toda aplicação tem diferentes desafios e situações.
Por exemplo, se você estiver trocando arquivos entre diferentes sistemas e comprimir o seu conteúdo não é uma opção, então o MessagePack pode ser ótimo pra economizar espaçø em disco e reduzir a carga numa operação de stream.
Uma aplicação comunicando com microsserviços no back-end pode se beneficiar da velocidade que o MessagePack traz se o número de interações for maior que 10 por requisição.
Eu suspeito (apesar de não ter testado) que serializar/desserializar o MessagePack no JavaScript seja um tanto mais lento se comparado ao json, já que o MessagePack não roda como parte do motor JavaScript (Node, V8). Então possívelmente aplicações Front-End não se beneficiariam tanto do MessagePack ainda.
Além disso, depurar respostas na aba Network do navegador se tornaria insuportável. Por outro lado, isto pode lhe ajudar a obfuscar sua API e evitar crawlers espertinhos já que o MessagePack ainda não é tão conhecido.
Assim como qualquer outro benchmark, este aqui é bem inútil se você estiver buscando uma resposta de fácil utilização. Você precisará adaptar isso aqui para o seu cenário e ver como o MessagePack se comporta.
Felizmente migrar de um formato para o outro deveria ser tão simples quanto trocar uma chamada de json_encode para msgpack_pack e de json_decode para msgpack_unpack. No caso de comunicar-se com microsserviços, um simples cabeçalho Accept já deve lhe resolver a vida.
Claro que quanto mais for necessário refatorar, maior o custo de implementar e testar essas mudanças. Portanto tenha certeza de que você analisou os possíveis ganhos antes de tentar mudar todos seus serviços e consumidores para este novo formato.
Pra mim um trabalho de 30 minutos para 2 ms de performance parece ser justo. Mas gastar 3 semanas para os mesmos 2 ms não parece fazer muito sentido. Ao menos não na escala em que estou acostumado a trabalhar.
Utilizar o MessagePack desde o começo parece fazer muito sentido. Já que ele ganha do JSON em todos os testes. Então se você for escrever algo novo, considere o MessagePack.
Não se esqueça de compartilhar isso com seus(uas) amigos(as) e colegas nerdões(onas). Eu tenho certeza de que o MessagePack será uma boa opção para muitos(as) deles(as).
]]>
TL;DR
O Just In Time compiler do PHP 8 foi implementado como parte da extensão Opcache e tem como objetivo compilar Opcodes em instruções de máquina em tempo de execução.
Significa que com o JIT alguns Opcodes não precisarão ser interpretados pela Zend VM e estas instruções serão executadas diretamente a nível de CPU.
JIT e PHP
Uma das novidades mais comentadas sobre o PHP 8 é o Just In Time (JIT) compiler. Vários blogs e pessoas da comunidade estão falando sobre isso e com certeza é um dos tópicos mais relevantes desta versão. Porém até o momento eu não consegui achar muitos detalhes sobre o que o JIT realmente faz.
Depois de pesquisar e desistir várias vezes, eu decidi verificar o código fonte do PHP por conta. Alinhando meu pouco conhecimento na linguagem C e toda informação espalhada que encontrei até o momento, eu compilei esta publicação e espero que lhe ajude a entender o JIT melhor também.
Ultra simplificando: quando o JIT funciona como esperado, seu código não será executado através da Zend VM e sim diretamente a nível de instruções de CPU.
Essa é a ideia.
Mas pra entender melhor a gente precisa pensar sobre como o PHP funciona internamente. Não é muito complicado, mas precisa de uma certa introdução ao assunto.
Eu escrevi um post com uma visão ampla sobre como o php funciona . Se você perceber que este post aqui está ficando denso demais, verifique este outro e volta aqui mais tarde. As coisas farão sentido mais facilmente.
Como um código PHP é executado?
Sabemos que o php é uma linguagem interpretada. Mas o que isso realmente quer dizer?
Sempre que você quiser executar um código PHP, sendo este um snippet ou uma aplicação web inteira, você precisará passar por um interpretador php. Os mais comumente utilizados são o PHP FPM e o interpretador de linha de comando.
O trabalho destes interpretadores é bem direto: receber um código php, interpretar este código e cuspir o resultado.
Isto normalmente acontece em toda linguagem interpretada. Algumas podem remover alguns passos, mas a ideia geral é a mesma. No PHP funciona assim:
-
O código PHP é lido e transformado em uma série de palavras chave conhecidas como Tokens. Este processo permite que o interpretador possa entender que parte de código está escrito em qual parte do programa. Este primeiro passo é chamado de Lexing ou Tokenizing.
-
Com os tokens em mãos, o interpretador PHP analisa esta coleção de tokens e tenta tomar algum sentido deles. Como resultado uma Árvore de Sintaxe Abstrata (Abstract Syntax Tree, ou AST) é gerada através de um processo chamado parsing. Esta AST é uma série de nós (ou nodos) indicando quais operações deverão ser executadas. Por exemplo, "echo 1 + 1" deveria de fato significar "apresente o resultado de 1 + 1" ou de forma mais realista "apresente uma operação, a operação é 1 + 1".
-
Em posse do AST fica muito mais fácil entender as operações e suas precedências. Transformar esta árvore em algo que possa ser executado requer uma representação intermediária (Intermediate Representation, IR) que em PHP chamamos de Opcode. O processo de transformar a AST em Opcodes é chamada de compilação.
-
Agora, com os Opcodes em mãos vem a parte massa: execução do código! O PHP tem um motor chamado Zend VM, que é capaz de receber uma lista de Opcodes e executá-la. Após executar todos os Opcodes, a Zend VM encerra a execução e o programa é terminado.
Eu montei um diagrama de fluxo pra tentar deixar um pouco mais claro pra ti:

Diretão, como tu pode reparar. Mas tem um gargalo aqui: pra quê fazer o lexing e parsing do código a cada vez que formos executar um script se o próprio código PHP não muda com frequência?
No fim das contas a gente só se importa com os Opcodes, certo? Certo! E é por isso que a extensão Opcache existe.
A extensão Opcache
A extensão Opcache é compilada com o PHP e normalmente não há motivos pra desativá-la. Se você usa PHP, você provavelmente deveria mantê-la ativa.
O que essa extensão faz é adicionar uma camada de cache em memória para os Opcodes. Sua função é pegar os Opcodes recém gerados através da AST e jogá-los num cache para que as próximas execuções possam facilmente pular as fases de Lexing e Parsing.
Aqui vai outro diagrama, desta vez considerando a extensão Opcache:

Lindo ver como ele pula os passos de Lexing, Parsing e Compiling 😍.
Nota: aqui é justamente onde a função de preloading do PHP 7.4 brilha! Ela permite que você diga ao PHP FPM pra fazer o parsing do seu código fonte, transformá-lo em Opcodes e jogar no cache antes mesmo de executar qualquer código seu.
Você deve estar se perguntando onde o JIT entra nessa história, né?! Bom, espero que sim, é o motivo de eu ter gastado tanto tempo nesse texto no fim das contas...
O que o Just In Time compiler faz efetivamente?
Após escutar a explicação do Zeev no episódio PHP and JIT do PHP Internals News eu consegui ter alguma ideia sobre o que o JIT deveria fazer...
Se o Opcache faz com que a obtenção de Opcodes seja mais rápida para que possam ir direto para a Zend VM, o JIT faz com que eles executem sem Zend VM nenhuma.
A Zend VM é um programa escrito em C que age como uma camada entre Opcodes e a CPU. O que o JIT faz é gerar código compilado em tempo de execução para que o php possa pular a Zend VM e executar diretamente na CPU. Teóricamente a gente deveria ganhar em performance com isso.
Isto me soou estranho num primeiro momento, porque pra compilar código de máquina é preciso escrever uma implementação beeem específica para cada tipo de arquitetura. Mas na realidade é bem plausível.
A implementação do JIT em PHP usa uma biblioteca chamada DynASM (Dynamic Assembler), que mapeia uma série de instruções de CPU de um formato específico em código assembly para vários tipos diferentes de CPU. Então o Just In Time compiler transforma Opcodes em código de máquina específico da arquitetura da CPU usando DynASM.
Mas tem uma coisa me deixou encafifado por um tempão...
Se o preloading é capaz de transformar PHP em Opcode antes de executar qualquer coisa e o DynASM pode compilar Opcodes em código de máquina (compilação Just In Time), por quê raios a gente não compila PHP em código de máquina usando a clássica Ahead of Time compilation?!
Uma das pistas que eu tive ao escutar o episódio do Zeev é que o PHP é fracamente tipado e, portanto, o PHP com frequência não sabe qual o tipo de uma certa variável até que a Zend VM tente executar um Opcode nela.
Isto pode ser percebido ao olhar para o union type zend_value , que possui vários ponteiros de diferentes representações para uma variável. Sempre que a Zend VM tenta obter um valor de um zend_value, ela utiliza macros como a ZSTR_VAL que tenta acessar o ponteiro de string através do union zend_value.
Por exemplo, este handler da Zend VM deveria tratar uma expressão de "Menor ou Igual" (<=). Repare bem em como existe uma porrada de if conditions pra tentar adivinhar os tipos dos operandos.
Duplicar esta lógica de inferência de tipos com código de máquina não é uma tarefa trivial e potencialmente tornaria a execução mais lenta.
Compilar tudo depois de entender os tipos também não é a melhor opção, porque compilar algo para código de máquina requer muita CPU. Então compilar TUDO em tempo de execução também é ruim.
Como o Just In Time compiler se comporta?
Agora sabemos que não podemos inferir tipos para gerar uma compilação Ahead of Time boa o suficiente. Também sabemos que compilar em tempo de execução é custoso. Como pode então o JIT ser benéfico para o PHP?
Para balancear esta equação, o JIT tenta compilar apenas alguns Opcodes que ele considera que o esforço valerá a pena. Para tal, o JIT faz um profiling dos Opcodes executados pela Zend VM e verifica quais fazem sentido ou não compilar. (baseado em suas configurações)
Quando determinado Opcode é compilado, ele então delega a execução a este código compilado em vez de delegar para a Zend VM. Se parece com o seguinte:

Então na extensão Opcache existem algumas instruções tentando detectar se determinados Opcodes deveriam ser compilados ou não. Caso sim, o compilador então transforma este Opcode em código de máquina utilizando DynASM e executa este código de máquina recém gerado.
A coisa interessante nisso tudo é que existe um limite em megabytes para o código compilado nesta implementação (também configurável), e a execução de código deve ser capaz de alternar entre JIT e código interpretado sem diferença alguma.
A propósito, esta palestra do Benoit Jacquemont sobre JIT no PHP me ajudou demais a entender essa coisa toda.
Eu ainda não tenho muita certeza sobre quando a compilação efetivamente acontece, mas penso que por agora eu não quero saber, não.
Então provavelmente os ganhos em performance não serão enormes
Eu espero que agora esteja um tanto mais claro o motivo de todo mundo dizer que a maioria das aplicações PHP não receberem grandes melhorias em performance usando o Just In Time compiler. E o o motivo de o Zeev ter recomendado fazer experimentações com diferentes configurações de JIT em suas aplicações PHP.
Os Opcodes compilados serão normalmente compartilhados entre várias requests se você estiver utilizando o PHP FPM, mas isto ainda não é grande coisa.
O motivo é que o JIT otimiza operações de CPU, e a maior parte das aplicações PHP hoje em dia são mais focadas em operações de E/S (I/O) do que qualquer coisa. Não importa se o processamento das operações for compilado se você precisar acessar disco ou rede de qualquer forma. Os tempos de execução serão bem similares.
A não ser que...
Você esteja fazendo algo que não envolve E/S, como processamento de imagens ou machine learning. Qualquer coisa que não toque I/O irá se beneficiar do Just In Time compiler.
Esta também é a razão de algumas pessoas citarem que agora estamos mais próximos de poder escrever funções PHP nativas, escritas em PHP em vez de C. O peso adicional não será custoso se estas funções forem compiladas.
Tempos interessantes para ser um(a) programador(a) PHP...
Eu espero que este artigo lhe tenha sido útil e que você tenha conseguido entender melhor o que o JIT do PHP 8 faz.
Sinta-se convidado(a) a me escrever no twitter se você gostaria de adicionar alguma coisa que eu possa ter esquecido e não se esqueça de compartilhar com seus(uas) coleguinhas programadores(as), isto com total certeza irá adicionar muito valor à conversa de vocês!
]]>
Neste texto eu vou lhe mostrar alguns snippets do meu setup básico pra iniciar aplicações PHP.
Meu maior objetivo aqui é que você marque este post nos seus favoritos para que possa voltar, copiar e colar as coisas daqui sempre que precisar criar ou alterar suas aplicações php. 😉
A coisa legal de usar este setup é que você pode facilmente trocar as versões das imagens sem precisar configurar um montante de coisas de uma vez.
Então...
Antes de começar: tenha certeza de que você possui docker e docker-compose instalados.
O resultado final
Se você seguir este tutorial, será capaz de executar diferentes serviços através do comando docker-compose.
Você encontra o resultado final no repositório público.
A maior ideia é que cada serviço pode ou não se tornar um comando. E o formato se parece com o seguinte:
$ docker-compose run <comando> [--args]
Rodar uma suíte de testes, por exemplo, poderia se parecer com isso:
$ docker-compose run tests
Pra tornar a digitação mais simples, podemos também adicionar um alias para o comando docker-compose run. Vou chamar de dcr aqui:
$ alias dcr='docker-compose run'
$ dcr lol
ERROR: Can't find a suitable
configuration file in this
directory or any parent.
Are you in the right directory?
Supported filenames:
docker-compose.yml,
docker-compose.yaml
Alias criado! O programa ainda vai reclamar porque não existe um arquivo docker-compose ainda. Bora criar então!
Um docker-compose básico
Então a gente vai criar um projeto do zero, huh? Bora lá! Comece criando a pastsa do projeto e mais tarde criando o arquivo docker-compose.yml:
$ mkdir meu-projeto
$ cd meu-projeto
$ touch docker-compose.yml
Eu vou criar as pastas comuns que normalmente minhas aplicações têm. Vai incluir pastas como source, testes e binários.
Apenas execute o seguinte:
$ mkdir -p src/ tests/ bin/ \
.conf/nginx/ var/
Agora podemos começar a trabalhar com o nosso docker-compose.yml. Ele deverá conter todas dependências que o nosso projeto teria.
O conteúdo inicial no nosso docker-compose será bem simples. Apenas escreva o seguinte:
# docker-compose.yml
version: '3'
services:
A gente vai escrever os serviços já agora! O mais essencial de todos, como deveria ser, é o composer.
Adicionando composer no docker-compose
Provavelmente usaremos o php de dentro do container. Então não faz sentido rodar o composer fora de um container, já que as versões do php podem divergir.
Vamos então adicionar um serviço composer ao nosso arquivo:
# docker-compose.yml
version: '3'
services:
composer:
image: composer:1.9.3
environment:
- COMPOSER_CACHE_DIR=/app/var/cache/composer
volumes:
- .:/app
restart: never
O snippet acima vai criar um serviço composer, que mapeia o diretório atual para /app dentro do container.
Definir a variável de ambiente COMPOSER_CACHE_DIR com o valor /app/var/cache/composer fará com que o composer escreva o cache na máquina local em vez de somente dentro do container. Isto irá previnir que o composer baixe todas dependências a cada execução.
Então é bom tomar conta de que a pasta var/ nunca vá parar no seu GIT, hein!
Só pra não esquecermos, vamos ignorar os arquivos relacionados ao composer já agora. Apenas rode os seguintes comandos pra evitar commitar esses caras:
$ echo 'vendor/' >> .gitignore
$ echo 'var/' >> .gitignore
Perfeito! Agora com o composer em mãos nós estamos preparados para instalar a dependência mais importante de todo proejto!
Preparando o PHPUnit
A dependência mais importante deste skeleton app é o motor de testes, é claro!
Vamos instalar o phpunit a partir do nosso serviço composer:
$ dcr composer require --dev \
phpunit/phpunit
Não precisa adicionar a barra invertida. Eu só coloquei alí para que fique legível em telas pequenas 😬
As dependência devem estar sendo baixadas, e os arquivos composer.json e composer.lock devem ter aparecido no seu diretório local. Ah, e tem uma pasta vendor/ também.
Parece que rolou...
Bora então cirar um serviço php simplão pra rodar coisa de cli. A gente vai usar a imagem oficial do php para cli pra isso. E quanto mais chique melhor, vamo fazer com o php 7.4! 🔥
Preparando uma cli PHP
Vamos usar a imagem php:7.4-cli pra isso.
Vamos também mapear os volumes da mesma forma que fizemos com o composer. Pode ser útil no futuro.
# docker-compose.yml
version: '3'
services:
composer:
image: composer:1.9.3
environment:
- COMPOSER_CACHE_DIR=/app/.cache/composer
volumes:
- .:/app
restart: never
# NOVO AQUI
php:
image: php:7.4-cli
restart: never
volumes:
- .:/app
working_dir: /app
Aqui a gente também colocou o working dir com o valor /app. Então sempre que rodarmos dcr php ele irá executar como se /app fosse o caminho inicial de execução.
Tá pensando como vamos rodar os testes, certo?
Siligaaqui!
Rodando PHPUnit dentro do container
Rodar PHPUnit deveria ser tão simples quanto rodar um comando de cli. Já que ele é um comando de cli...
O seguinte, portanto, funciona bem:
$ dcr php vendor/bin/phpunit
Você pode usar <TAB> para auto completar normalmente 😉
Parece bem chatão escrever tudo isso aí cada vez mais. Dá pra simplificar?
Sim!
Vamos adicionar um serviço phpunit para o nosso docker-compose.yml:
# docker-compose.yml
version: '3'
services:
composer:
image: composer:1.9.3
environment:
- COMPOSER_CACHE_DIR=/app/.cache/composer
volumes:
- .:/app
restart: never
php:
image: php:7.4-cli
restart: never
volumes:
- .:/app
working_dir: /app
# NOVO AQUI
phpunit:
image: php:7.4-cli
restart: never
volumes:
- .:/app
working_dir: /app
entrypoint: vendor/bin/phpunit
O truque aqui tá no entrypoint! Agora em seu terminal você pode executar o seguinte:
$ dcr phpunit --version
PHPUnit 9.0.1 by Sebastian
Bergmann and contributors.
Aooo! Que lindeza!
A gente, aliás, gerar o nosso phpunit.xml antes de pular pro próximo passo.
Assim ó:
$ dcr phpunit \
--generate-configuration
Esse comando vai te perguntar algumas coisas. Apenas pressione enter pra tudo e tá de boa...
Criando um teste simples
Só pra ter certeza de que as coisas tão rodando né.
$ touch tests/MyTest.php
E dentro de tests/MyTest.php adicione o seguinte:
# tests/MyTest.php
<?php
declare(strict_types=1);
use PHPUnit\Framework\TestCase;
class MyTest extends TestCase
{
public function testMyTest(): void
{
self::assertTrue(false);
}
}
Funciona perfeitamente! E o teste também está falhando... Tu pode consertar depois, relaxe!
Agora que conseguimos rodar os nossos testes, podemos pensar em construir a aplicação em si.
Provavelmente você quer criar uma aplicação web, sim? Então vamos fazer algo com o nginx e php-fpm!!
Configurando o Web Server
Para configurar o php fpm, precisaremos de dois serviços diferentes. Um será o servidor HTTP e o outro será a instância FPM.
Como estes são processos de longa execução, a gente não vai usar o docker-compose run com eles. Em vez disso, usemos o up -d.
O comando final vai parecer com o seguinte:
$ docker-compose up -d fpm nginx
Vamos adicionar o PHP-FPM na bagaça:
# docker-compose.yml
version: '3'
services:
composer:
image: composer:1.9.3
environment:
- COMPOSER_CACHE_DIR=/app/.cache/composer
volumes:
- .:/app
restart: never
php:
image: php:7.4-cli
restart: never
volumes:
- .:/app
working_dir: /app
phpunit:
image: php:7.4-cli
restart: never
volumes:
- .:/app
working_dir: /app
entrypoint: vendor/bin/phpunit
# NOVO AQUI
fpm:
image: php:7.4-fpm
restart: always
volumes:
- .:/app
Simplasso! Ao rodar docker-compose up -d fpm ele deveria rodar e ficar no background já.
Agora vamos configurar a parte do nginx que vai expor a porta 8080 e tratar as requests ao php envinando para a porta 9000 do fpm.
O arquivo docker-compose.yml vai ficar assim:
# docker-compose.yml
version: '3'
services:
composer:
image: composer:1.9.3
environment:
- COMPOSER_CACHE_DIR=/app/.cache/composer
volumes:
- .:/app
restart: never
php:
image: php:7.4-cli
restart: never
volumes:
- .:/app
working_dir: /app
phpunit:
image: php:7.4-cli
restart: never
volumes:
- .:/app
working_dir: /app
entrypoint: vendor/bin/phpunit
fpm:
image: php:7.4-fpm
restart: always
volumes:
- .:/app
# NOVO AQUI
nginx:
image: nginx:1.17.8-alpine
ports:
- 8080:80
volumes:
- .:/app
- ./var/log/nginx:/var/log/nginx
- .conf/nginx/site.conf:/etc/nginx/conf.d/default.conf
Com isto nós expomos a porta 8080 como sendo a porta 80 do container (porta padrão do http).
Também ligamos o nosso diretório atual para /app. Normalmente as pessoas fazem /var/www, mas eu gosto de deixar as coisas consistentes em comparação com os outros serviços.
O diretório local var/log/nginx foi conectado ao /var/log/nginx do container. Desta forma a gente não fica cego quando precisar checar os logs de acesso ou erros.
Por último, mas não menos importante, o site.conf foi introduzido ao container com o nome default.conf. Esta é só uma maneira rápida de fazer com que o nginx aceite a nossa configuração.
A gente precisa criar o nosso arquivo de configuração. Façamos então!
$ touch .conf/nginx/site.conf
Escreva o seguinte arquivo de configuração no caminho .conf/nginx/site.conf:
# .conf/nginx/site.conf
server {
listen 80;
listen [::]:80;
root /app/public;
index index.php;
location / {
try_files $uri $uri/ /index.php$is_args$args;
}
location ~ .php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+.php)(/.+)$;
fastcgi_pass fpm:9000;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
}
access_log /var/log/nginx/myapp_access.log;
error_log /var/log/nginx/myapp_error.log;
}
Repare como root está apontando para /app/public. Isto fará com que a pasta public/ seja o ponto de início para toda requisição que o nginx gerenciar.
Repare também no fastcgi_pass e veja que está apontando para fpm:9000. Esta é a nossa imagem fpm. Se você a deu um nome diferente, ajuste essa linha aqui também!
Pra testar isso tudo, vamos criar um simples index.php dentro da pasta /public. Este arquivo vai servir como o ponto de partida da nossa aplicação.
Apenas adicione uma chamada ao phpinfo neste arquivo:
# public/index.php
<?php
phpinfo();
Agora vamos levantar o servidor nginx:
$ docker-compose up -d nginx
A partir deste momento você poderá acessar http://localhost:8080/ a partir do seu navegador normalmente.
Não esqueça o autoloader
Nós instalamos o composer corretamente, mas usar as nossas classes ainda não está perfeito.
Vamos ajustar o nosso composer.json para que o composer possa saber de onde carregar nossas classes:
# composer.json
{
"require-dev": {
"phpunit/phpunit": "^9.0"
},
"autoload": {
"psr-4": {
"ThePHPWebsite\\": "src/"
}
}
}
Agora rode um composer dump:
$ dcr composer -- dump
Generated autoload files
containing 646 classes
Este -- antes do comando apenas faz com que o docker-compose não pense que dump é um serviço em vez de parâmetro ao nosso comando do composer.
Pra testar este pedacinho, criemos um arquivo chamado App.php dentro de src/:
# src/App.php
<?php
declare(strict_types=1);
namespace ThePHPWebsite;
class App
{
public function sayHello(): void
{
echo 'Hello!';
}
}
E agora apenas modifique o arquivo public/index.php para usar a nossa classe:
<?php
require_once __DIR__
. '/../vendor/autoload.php';
use ThePHPWebsite\App;
$app = new App();
$app->sayHello();
Recarregue a página no navegador e XABLAU! "Hello!" tá lá, chapa!
Buum! Isso é tudo! Um guia massa de como montar um ambiente local de desenvolvimento pra aplicações php usando docker compose e podendo rodar testes com o phpunit.
Você provavelmente gostará também de adicionar outros serviços como bancos de dados, servidores de filas, um servidor Solr...
Vai na fé e adiciona eles aí, agora tu não precisa mais bagunçar seu ambiente todo pra mexer com diferentes serviços.
Se em algum momento você entender que precisa de alguma coisa MUITO específica, como uma extensão do php ou coisa do gênero, basta criar um Dockerfile customizado e referenciá-lo no docker-compose.yml.
Não se esqueça de compartilhar com seus(uas) amigos(as) preguiçosos(as) sempre que começarem a reclamar do processo de criar um projeto base com PHP.
E também sinta-se livre pra me dar um alô se você teve algum problema durante este tutorial.
Valeus!
]]>
TL;DR
TDL = Test-Driven Learning OU Aprendizado Guiado por Testes.
Se você pudesse levar uma única coisa deste texto contigo, leva isso aqui: Desenvolvimento guiado por testes pode ser utilizado para aprender também. Aprenda como fazer TDD de forma eficiente e você entenderá rapidinho o conceito deste texto inteiro.
Recentemente eu iniciei (novamente) a missão mais divertida que nós programadores(as) enfrentamos de tempos em tempos: ✨ aprender uma nova linguagem de programação ✨.
Desta vez eu decidi aprender Rust, que pra mim (ainda) é insanamente interessante, já que sou um desenvolvedor web e nunca precisei encostar em nada relacionado a baixo nível que não fosse o código fonte do PHP.
Depois de passar por este processo várias vezes, eu comecei a ver alguns padrões no meu processo de aprendizado. Foi preciso uma boa mistura de auto conhecimento, habilidades de gerenciamento de projetos (sim) e pesquisa pra compilar estes padrões num modelo que eu poderia facilmente integrar no meu dia a dia.
Eu acredito que desta vez, aprendendo Rust, eu alcancei uma versão mais ou menos estável deste framework de aprendizado baseado no TDL. Mesmo que otimizar este framework tenha de ser um processo em constante evolução.
Pra ser muito claro, eu não quero dizer que esta é a melhor forma de aprender uma nova linguagem de programação ou coisa do tipo. Você vai precisar aprender por si mesmo qual formato funciona melhor pra ti.
Como sempre, vamos parar com a enrolação e começar!
Cada seção aqui começa com uma lista de tópicos para que você possa saber as principais ideias antes de ler algo. Sinta-se livre pra pular para o próximo subtítulo se os tópicos não chamarem sua atenção.
Este texto está dividido em três partes e, honestamente, daria pra escrever um livro se eu fosse desenvolver meus pensamentos em cada uma delas. (Me dá um alô no twitter se você quiser ver este livro virar realidade xD)
-
"Iniciando com uma nova linguagem de programação" apresenta um modelo mental sobre como descobrir uma nova linguagem de programação e como adquirir a mais fundamental ferramenta de aprendizado com TDL: testes.
-
"Como funciona o Aprendizado Guiado por Testes?" tenta explicar como esse arcabouço funciona, como manter o feedback loop e por aí vai.
-
Por último, mas não menos importante, vem "Praxis: a parte mais difícil é a descoberta", que traz algumas dicas de como alimentar o primeiro passo do loop do TDL.
Iniciando com uma nova linguagem de programação
Tópicos nesta seção:
- As linguagens de programação são semelhantes
- Toda linguagem tem um propósito
- Encontrando os pontos altos da linguagem
- Como testar nesta linguagem
Se você já sabe qual linguagem de programação quer aprender, o processo de inicialização é razoavelmente simples. Mas eu tenho um conselho bem estranho pra você:
Não escreva código algum até você ter um modelo mental claro sobre o que esta linguagem é capaz de fazer.
Para construir este modelo mental é sempre bom lembrar que linguagens de programação são muito semelhantes entre si e normalmente conseguem fazer alguma(s) coisa(s) muito bem (são especializadas).
As linguagens de programação são semelhantes
A maioria das linguagens de programação são semelhantes entre si. Elas podem até ter diferentes estruturas, sintaxe, convenções mas no fim das contas a maioria delas vai te prover uma execução baseada em pilha, onde você guarda variáveis, carrega valores nelas, executa expressões, chama funções e por aí vai.
Imperativa ou declarativa, compilada ou interpretada, todas elas compartilham características comuns. Quanto mais cedo você entender estas características, mais próximo de ser apenas uma questão de sintaxe elas vão te parecer.
Além da sintaxe você encontrará modelos que são profundamente ligados à linguagem. Normalmente eles começam a aparecer quando você começa a aprender o problema que determinada linguagem resolve.
Então não comece a codar ainda! Antes de escrever qualquer linha de código, tenha certeza de que você olhou bem para a linguagem, sabe que cara tem e quais coisas tornam esta linguagem única e útil.
Normalmente uma linguagem se destaca das outras por ter um propósito.
Toda linguagem tem um propósito
PHP era um monte de scripts CGI pra fazer templates, o JavaScript nasceu para tornar páginas web interativas, ActionScript foi para fazer o mesmo com Flash, C para abstrair com alta performance em desenvolvimento de sistemas, Rust para fazer o mesmo que C com segurança em mente, Ruby para escrever código como escrevemos livros, e a IR da LLVM para tornar mais fácil criar novas linguagens de programação...
Toda linguagem de programação tem (ou teve) um propósito quando foi escrita pela primeira vez.
Saber o propósito de uma linguagem lhe ajuda a entender como ela funciona.
Quando você entende o propósito da linguagem, as melhores funcionalidades desta linguagem começam a aparecer pra ti naturalmente.
Encontrando os pontos altos da linguagem
Vamos tomar Rust como exemplo aqui, já que é minha memória mais recente.
Eu entendi que Rust é uma linguagem de desenvolvimento de sistemas, com alto foco em segurança no gerenciamento de memória sem perder em performance. Mas como isso tudo se traduz na linguagem?
Aarre! O compilador reclama de tudo, as variáveis têm ciclo de vida e ownership, tem uma parada de emprestar variáveis, tipos de dado que nunca ficam nulos, eu já falei do compilador?
Saber tais coisas vai te ensinar do que tu pode se orgulhar em saber quando souber, mas também vai te dar uma clara visão de onde você precisa chegar.
Isso também vai fazer com que outras pessoas acreditem que você está realmente aprendendo esta linguagem. Não tem nada mais frustrante que receber um "por que?" sem conseguir responder de maneira satisfatória.
Como testar nesta linguagem
Ainda antes de codar qualquer coisa nessa linguagem, o último passo para construir este modelo mental é aprender como escrever testes.
Sim! Mesmo antes de aprender como declarar uma variável, aprenda como testar. Ou melhor dizendo, aprenda como fazer asserções.
PHP e C, por exemplo, possuem a função assert(). Rust tem as macros assert_* e uma ferramenta integrada de testes.
Aprenda o que está disponível para fazer testes: tem alguma forma de escrever testes unitários? De integração? Consigo usar uma linguagem de testes como o Gherkin com ela?
Eu vou usar um programa em rust como exemplo aqui em como escrever uma asserção essencial para que a gente possa iniciar nosso loop com TDL:
// src/main.rs
#[test]
fn test_basics() {
assert_eq!(1, 1); // 1 = 1
assert!(true); // sucesso
assert!(false); // falha
}
Depois eu só executo $ cargo test e PRONTINHO! Eu sei o básico em como escrever asserções nessa linguagem nova. Hora de começar a aprender!
Como funciona o Aprendizado Guiado por Testes?
Tópicos nessa seção:
- Introdução com exemplos de código
- Descoberta
- Asserção
- Aprendizado
- Repetição
Pode ser que você pense que eu tô tentando criar moda ou algo do gênero. Mas Aprendizado Guiado por Testes é real total de verdadinha.
É importante notar que TDL nesta pesquisa acima é apenas uma ferramenta de ensino. O que eu estou apresentando aqui é como eu uso esta ferramenta num framework que eu construí e adoto.
Eu baseio meu aprendizado com TDL em três passos repetíveis: descoberta, asserção e aprendizado.
Ferramentas como Khan Academy, Vim Adventures e outros MOOCs também usam métodos semelhantes a este: apresentar algo novo (descoberta), dar feedback em suas falhas (asserção) e premiar seus acertos (aprendizado).
A ideia é primeiro descobrir algo que você quer ou precisa aprender, realizar asserções para entender quando você terá aprendido. Fazer as asserções funcionarem com o que você aprendeu ou precisa aprender.
Vamos tomar um exemplo bem tosquinho com rust. Eu descobri que posso definir variáveis. Como isto funciona? Vamos fazer uma asserção de que a variável nawarian deveria conter o valor 10.
// src/main.rs
#[test]
fn test_variables() {
assert_eq!(10, nawarian);
}
Eu sei agora que eu só vou tentar descobrir novas coisas quando esta asserção passar. Eu vou continuar brigando com meu teclado até que cargo test fique verde!!
Um pouco de pesquisa aqui e acolá, e o seguinte parece funcionar:
// src/main.rs
#[test]
fn test_variables() {
let nawarian = 10;
assert_eq!(10, nawarian);
}
Os testes estão verdes. Eu poderia continuar com coisas novas ou brincar mais um pouco com este aqui. Em vez de definir nawarian = 10 eu poderia fazer isso com um loop e contador, não?
Então como será que eu posso fazer um loop de 0 a 10 e incrementar nawarian a cada iteração?
// src/main.rs
#[test]
fn test_variables() {
let nawarian = 0;
for i in 0..10 {
nawarian += 1;
}
assert_eq!(10, nawarian);
}
Agora o cargo test ficou loucão e começou a reclamar de uma par de coisas:
warning: unused variable:
ihelp: consider prefixing with an underscore:
_ierror[E0384]: cannot assign twice to immutable variable
nawarianhelp: make this binding mutable:
mut nawarian
Não tá funcionando... o compilador diz que nawarian não é mutável e tá implicando até que i nunca é utilizada, que eu deveria prefixar essa variável com _ pra que ninguém ligue pra ela.
Eu: Diabé!? Aparentemente variáveis são imutáveis por padrão em Rust. Interessante... Dá pra fazer ela ficar mutável usando a palavra chave
mut...
Escreve, roda. FUNCIONOU!
Essa estrutura é difudê porque você entende exatamente onde está pisando. E quando não entender, é mais fácil pesquisar um problema pequenino e específico que você esteja enfrentando no momento.
Este feedback loop vai te forçar a aprender ativamente em vez de passivamente: encontre uma funcionalidade, teste, encontre a resposta até ficar satisfeito(a). Descubra, afirme, aprenda.
Outra coisa maravilhosa é que testes passando deixam as pessoas felizes. Ver o quanto você consegue refatorar um código sem quebrar traz um sentimento muuuito bom!
Eu não quero dizer que você deveria, mas com essa asserção simples, você pode aprender desde variáveis até threading. Um passo de cada vez, mantenha os testes passando e alimente seu feedback loop!
Eu vou tentar te dar um pouco mais de informação em como lidar com cada passo enquanto utiliza o TDL:
Descoberta
O passo da descoberta é muito bom para aprender sobre sintaxe, funcionalidades da linguagem, frameworks... Basicamente tudo o que possa captar seu interesse se encaixa aqui.
Mas sempre mantenha suas asserções simples. É extremamente importante que você entenda seus testes muito mais que a implementação em si. Os testes precisam ser claros, o código você pode sempre refatorar.
Asserção
O passo da asserção pode ser um tanto diferente dependendo do nível que você já tenha alcançado na linguagem.
Novatos (como eu em Rust) devem escrever teste unitários o máximo possível, usando ferramentas nativas da linguagem como assert, echo ou mesmo exit.
Quanto mais você avança, testes grandes e complexos usando "Given, When, Then" podem funcionar melhor. Você precisará aprender como utilizar ferramentas como Gherkin ou algo tão amplo e descritivo quanto em sua linguagem.
Aprendizado
Faça com que seus testes passem!
Leia os erros que aparecem pra ti, entenda o problema e assim que o fizer: leia o manual da linguagem, procure em mecanismos diferentes, pergunte a amigos ou quem puder saber mais.
Repetição
Volte ao passo da descoberta e encontre algo novo para fazer novas asserções e aprender.
Ou apenas seja criativo(a). Aquele simples nawarian = 10 pode ser transformado em operações de E/S, utilização de structs, chamadas FFI, threads...
Não existe código que você não possa tornar mais complicado! 😉
Praxis: a parte mais difícil é a descoberta
Tópicos nesta seção:
- Introdução sobre comunidade e ferramentas
- Se envolva com a linguagem
- Conecte-se com a comunidade
- Explique algo que você ainda não sabe
A teoria parece ótima, né? (talvez nem mesmo pareça...)
Mas eu sei o quão difícil é no começo entender e tomar proveito deste framework. Pra mim a parte mais difícil é alimentar este feedback loop com mais descobertas.
Felizmente a melhor resposta que eu encontrei até o momento para a maioria das linguagens/frameworks é: Comunidade!
Rust, por exemplo, tem este projeto maravilhoso chamado "rustlings". Ele te guia através de testes escritos pela comunidade e te desafia a fazer com que os códigos compilem (o compilador é realmente chato), que os testes passem...
No php tem o PHP School que é bem semelhante ao rustlings, mas é altamente extensível e tem muitos cursos feitos pela comunidade sobre modulos/funcionalidades específicas.
Mas depois de aprender a sintaxe você precisará de muito mais. Você precisará ver em quê e como a linguagem está evoluindo.
Se envolva com a linguagem
Aqui é o momento de assistir palestras, ir a conferências e assistir pessoas codando por horas na frente das câmeras...
Comece a contribuir com projetos de código aberto também! Esta é uma forma bem simples de ganhar proficiência na linguagem: contribua, falhe nos code reviews e conserte seus erros baseado no feedback de outras pessoas...
Conecte-se com a comunidade
Escute também podcasts, leia blogs (ou comece um!), entre em reddits. Você aprenderá mais e mais sobre o que pessoas estão fazendo com esta linguagem, o que é considerado normal e o que não é.
Encontre grupos de encontro locais, ou crie um você mesmo. Converse com pessoas de verdade, sobre problemas de verdade.
Explique algo que você ainda não sabe
Navegue pelo stackoverflow, github issues ou forums do reddit para encontrar perguntas que você realmente não sabe responder. Encontre-as, pesquise e responda (ou ao menos tente).
As vezes você será capaz de explicar somente com assertions, as vezes você precisará de uma visão mais ampla das coisas. Tente os dois!
Em determinado momento você estará navegando por oportunidades de emprego nesta linguagem e os requisitos estão quase todos preenchidos. Os que não estiverem, você pode utilizar para alimentar seu feedback loop e continuar evoluindo.
Fico feliz que tenha chegado até aqui, porque não tô tentando te enrolar. Meu processo de aprendizado até o momento é bem doloroso mas extremamente útil pra mim.
Também me salva um bom tempo por me guiar através de perguntas pequenas e respostas que eu precise dar, já que eu não tenho tempo para investir em aprendizado de novas linguagens como eu costumava ter há alguns anos atrás ~ suspiros.
Eu espero que este texto tenha sido útil pra ti.
Como sempre, sinta-se livre pra me mandar qualquer feedback através do twitter.
]]>
Existem várias ferramentas disponíveis no ecossistema PHP que estão preparadas para oferecer uma ótima experiência com testes. PHPUnit é de longe a mais famosa de todas . É quase um sinônimo de teste nessa linguagem.
As boas práticas não são bem compartilhadas na comunidade. Existem tantas opções de quando e por quê escrever testes, quais tipos de testes e por aí vai. Mas na verdade não faz sentido algum escrever qualquer teste se você não for capaz de lê-los mais tarde.
Testes são uma forma muito especial de documentação
Como eu já mencionei no post sobre TDD com PHP, um teste sempre vai (ou pelo menos deveria) tornar claro o que um certo pedaço de código deve atingir como objetivo.
Se um teste não consegue expressar uma ideia, é um teste ruim.
Com isso em mente, eu preparei uma lista com boas práticas que podem auxiliar desenvolvedores(as) php a escrever testes bons, legíveis e úteis.
Começando pelo básico
Existem algumas práticas que muitas pessoas seguem sem sequer questionar o motivo. Eu vou listar algumas delas e tentar explicar pelo menos por cima qual a razão de tais práticas.
Testes não deveriam fazer operações E/S
Motivo: E/S é lento e instável.
Lento: mesmo com o melhor equipamento na face da terra, E/S ainda será mais lento que acesso a memória. Testes devem sempre rodar rápido, do contrário ninguém irá rodá-los suficientemente.
Instável: um certo arquivo, binário, socket, pasta ou entrada DNS pode não estar disponível em todas as máquinas em que seu código será executado. Quanto mais você depende de E/S em seus testes, mais seus testes ficam amarrados e dependentes de infraestrutura.
Operações consideradas E/S: * Ler/escrever arquivos * Chamadas de rede * Chamadas a processos externos (usando exec, proc_open...)
Existem casos onde ter E/S fará com que o teste seja escrito mais rapidamente. Mas se liga: fazer com que essas operações funcionem da mesma forma nos ambientes de desenvolvimento, build e deployment pode se tornar uma imensa dor de cabeça.
Isolando testes para que não precisam de E/S: abaixo eu mostro uma decisão de design que pode ser tomada para evitar que seus testes realizem operações de E/S segregando responsabilidades para interfaces.
Segue o exemplo:
public function getPeople(): array
{
$rawPeople = file_get_contents(
'people.json'
) ?? '[]';
return json_decode(
$rawPeople,
true
);
}
No momento em que começarmos a testar este método, seremos forçados a criar um arquivo local pra teste e, de tempos em tempos, manter uma snapshot desse arquivo. Como no seguinte:
public function testGetPeopleReturnsPeopleList(): void
{
$people = $this->peopleService
->getPeople();
// assert it contains people
}
Pra esse tipo, é necessário definir pré condições para que ele possa passar. Mesmo que pareça fazer sentido a primeira vista, isto é na realidade terrível.
Pular um teste por conta de uma pré condição faltante não garante qualidade de software. Apenas esconde bugs!
Corrigindo: basta isolar as operações de E/S ao mover a responsabilidade para uma interface.
// extrai a lógica
// de buscar algo
// p/ uma interface
// especializada
interface PeopleProvider
{
public function getPeople(): array;
}
// implementação concreta
class JsonFilePeopleProvider
implements PeopleProvider
{
private const PEOPLE_JSON =
'people.json';
public function getPeople(): array
{
$rawPeople = file_get_contents(
self::PEOPLE_JSON
) ?? '[]';
return json_decode(
$rawPeople,
true
);
}
}
class PeopleService
{
// injetar via __construct()
private PeopleProvider $peopleProvider;
public function getPeople(): array
{
return $this->peopleProvider
->getPeople();
}
}
Tô sabendo, agora JsonFilePeopleProvider usa E/S de toda forma. Verdade.
Em vez de file_get_contents() a gente pode usar um layer de abstração como o Filesystem do Flysystem que pode ser facilmente mockado.
E pra quê serve o PeopleService então? Boa pergunta... Isto é uma das coisas que testes nos traz: questionar o nosso design, remover código inutil.
Testes devem ser concisos e ter significado
Motivo: testes são uma forma de documentação. Mantenha-os limpos, curtos e legíveis.
Limpos e curtos: sem bagunça, sem escrever mil linhas de mock, sem escrever trocentos asserts no mesmo teste.
Legíveis: cada teste deve contar uma história. A estrutura "Given, When, Then" é perfeita pra isso.
Aqui vão algumas características de um teste bem escrito: * Contém apenas asserts necessários (preferivelmente apenas um) * Lhe conta exatamente o que deveria acontecer dada certa condição * Testa apenas um caminho de execução do método por vez * Não mocka o universo inteiro para fazer algum assert
Importante notar que se a sua implementação possui alguns IFs, switch ou iterações, todos estes caminhos alternativos devem ser explicitamente testados. Então early returns, por exemplo, devem sempre conter testes.
Novamente: não importa o coverage, o que importa é documentar.
Deixa eu te mostrar como um teste confuso se parece:
public function testCanFly(): void
{
$semAsas = new Person(0);
$this->assertEquals(
false,
$semAsas->canFly()
);
$umaAsa = new Person(1);
$this->assertTrue(
!$$umaAsa->canFly()
);
$duasAsas = new Person(2);
$this->assertTrue(
$$duasAsas->canFly()
);
}
Vamos então adotar o "Given, When, Then" e ver como esse teste muda:
public function testCanFly(): void
{
// Given
$person = $this->givenAPersonHasNoWings();
// Then
$this->assertEquals(
false,
$person->canFly()
);
// Outros casos...
}
private function givenAPersonHasNoWings(): Person
{
return new Person(0);
}
Assim como as cláusulas "Given", os "When"s e "Then"s também podem ser extraídos para métodos privados. Qualquer coisa que faça seu teste ficar mais legível.
Agora, aquele assertEquals tá bem bagunçado e com pouquíssimo significado. Um humano lendo isso precisa interpretar a assertion pra entender o que deveria significar.
Usar assertions específicas tornam seus testes muito mais legíveis. assertTrue() deveria receber uma variável contendo um booleano, nunca uma expressão como canFly() !== true.
Então do exemplo anterior, vamos substituir o assertEquals entre false e $person->canFly() com um simples assertFalse:
// ...
$person = $this->givenAPersonHasNoWings();
$this->assertFalse(
$person->canFly()
);
// Outros casos...
Limpinho! Dado que uma pessoa não tem asas, ela não deveria poder voar! Dá pra ler como se fosse um poema 😍
Agora, esse "Outros casos" aparecendo duas vezes no nosso texto já é uma boa pista de que este teste está fazendo muitas assertions. Ao mesmo tempo o nome do método testCanFly() não significa nada muito útil.
Vamos tornar o nosso test case um tequinho melhor:
public function testCanFlyIsFalsyWhenPersonHasNoWings(): void
{
$person = $this->givenAPersonHasNoWings();
$this->assertFalse(
$person->canFly()
);
}
public function testCanFlyIsTruthyWhenPersonHasTwoWings(): void
{
$person = $this->givenAPersonHasTwoWings();
$this->assertTrue(
$person->canFly()
);
}
// ...
A gente poderia inclusive renomear o teste pra bater com um cenário da vida real como testPersonCantFlyWithoutWings, mas pra mim o nome já parece bom o suficiente.
Um teste não deve depender de outro
Motivo: um teste deveria ser capaz de rodar e passar em qualquer ordem.
Até o presente momento, eu não consigo encontrar um bom motivo para acoplar testes.
Recentemente eu fui perguntado sobre como testar uma feature para usuários logados e eu gostaria de utilizar isto como exemplo aqui.
O teste faria o seguinte: * Gerar um token JWT * Executar uma certa tarefa logado * Fazer os asserts
A forma como o teste foi feito era a seguinte:
public function testGenerateJWTToken(): void
{
// ... $token
$this->token = $token;
}
// @depends testGenerateJWTToken
public function testExecuteAnAmazingFeature(): void
{
// Execute using $this->token
}
// @depends testExecuteAnAmazingFeature
public function testStateIsBlah(): void
{
// Busca os resultados
// interface logada
}
Este teste é ruim por alguns motivos: * PHPUnit não garantirá a ordem de execução dos testes * Os testes não podem ser executados de forma independente * Testes rodando em paralelo irão falhar aleatoriamente
A forma mais simples de resolver este problema que eu consigo pensar, novamente, é com "Given, When, Then". Desta forma a gente torna os testes mais concisos e conta uma história ao mostrar suas dependências de forma clara que explica a feature em si.
public function testAmazingFeatureChangesState(): void
{
// Given
$token = $this->givenImAuthenticated();
// When
$this->whenIExecuteMyAmazingFeature(
$token
);
$newState = $this->pollStateFromInterface(
$token
);
// Then
$this->assertEquals(
'my-state',
$newState
);
}
A gente precisaria também escrever testes para autenticar e por aí vai. Esta estrutura é tão massa que o Behat a utiliza por padrão.
Sempre injete as dependências
Motivo: mockar estado global é terrível, não ser capaz de mockar as dependências torna impossível testar uma funcionalidade.
Aqui vai uma lição para a vida: Esqueça sobre classes estáticas que mantém estado e também instâncias singleton. Se a sua classe depende de algo, torne-o injetável.
Aqui vai um exemplo particularmente triste:
class FeatureToggle
{
public function isActive(
Id $feature
): bool {
$cookieName = $feature->getCookieName();
// Early return se o
// cookie está presente
if (Cookies::exists(
$cookieName
)) {
return Cookies::get(
$cookieName
);
}
// Calcular feature toggle...
}
}
Agora. Como você poderia testar este early return?
Não consegue né, Moisés?
Pra testar este método, nós precisaríamos entender o comportamento desta classe Cookies e tomar certeza de que conseguiríamos reproduzir todo o ambiente por trás desta classe para forçar alguns retornos.
Faz isso não.
A gente pode consertar essa situação injetando uma instância de Cookies como dependência. O teste ficaria parecido com o seguinte:
// Test class...
private Cookies $cookieMock;
private FeatureToggle $service;
// Preparing our service and dependencies
public function setUp(): void
{
$this->cookieMock = $this->prophesize(
Cookies::class
);
$this->service = new FeatureToggle(
$this->cookieMock->reveal()
);
}
public function testIsActiveIsOverriddenByCookies(): void
{
// Given
$feature = $this->givenFeatureXExists();
// When
$this->whenCookieOverridesFeatureWithTrue(
$feature
);
// Then
$this->assertTrue(
$this->service->isActive($feature)
);
// poderíamos também testar que
// nenhum outro método foi chamado
}
private function givenFeatureXExists(): Id
{
// ...
return $feature;
}
private function whenCookieOverridesFeatureWithTrue(
Id $feature
): void {
$cookieName = $feature->getCookieName();
$this->cookieMock->exists($cookieName)
->shouldBeCalledOnce()
->willReturn(true);
$this->cookieMock->get($cookieName)
->shouldBeCalledOnce()
->willReturn(true);
}
O mesmo acontece com singletons. Então se você quer tornar um objeto único, é só configurar o seu injetor de dependências direito em vez de utilizar o Singleton (anti) pattern.
Do contrário você vai acabar escrevendo métodos como reset() ou setInstance(), que só são úteis para classes de teste. Me soa no mínimo estranho.
Mudar o seu desgin para tornar testes mais simples está tudo bem. Criar métodos para tornar testes mais simples não está ok.
Nunca teste métodos protected/private
Motivo: a forma como testamos uma funcionalidade é fazendo assertions em como a sua assinatura se comporta: dada uma condição, quando eu faço X, espero que Y aconteça. Métodos protected/private não são parte da assinatura de uma funcionalidade.
Eu vou inclusive me recusar a te mostrar uma forma de "testar" métodos privados, mas aqui vai uma dica: você fazer isso com a reflection API.
Por favor, castigue-se de alguma forma sempre que pensar em utilizar reflections pra testar um método privado!
Por definição, métodos privados vão somente ser chamados de dentro da classe. Então não são publicamente acessíveis. Isto significa que apenas métodos públicos nesta mesma classe consegue invocar tais métodos privados.
Se você testou todos os métodos públicos, você também deve ter testado os protegidos/privados de uma vez só. Se não, pode apagar cada um deles, que ninguém tá usando eles mesmo.
Além do básico: as coisas interessantes
Espero que você não tenha ficado entediado(a) até aqui. Básico é básico, mas precisa ser escrito.
Agora, durante as próximas linhas, vou compartilhar contigo algumas opiniões que carrego sobre testes limpos e cada decisão que impacta meu fluxo de desenvolvimento.
Eu diria que os valores mais importantes que levo em consideração enquanto escrevo testes são os seguintes:
- Aprendizado
- Receber feedback rápido
- Documentação
- Refatoração
- Design enquanto testo
Cada opinião que exponho abaixo segue ao menos um destes valores e cada uma dá suporte à outra.
Teste vem primeiro, não depois
Valores: aprendizado, receber feedback rápido, documentação, refatoração, design enquanto testo.
Esta é a base de tudo. É tão importante que carrega todos os valores de uma vez só.
Escrever teste primeiro lhe força entender como o seu "given, when, then" deve ser estruturado. Você documenta primeiro ao escrever assim e, mais importante ainda, aprende e torna explícito seus requisitos como coisas mais relevantes no software.
Te parece estranho escrever um teste antes de escrever algo? Imagine o quão embaraçoso é implementar algo e, enquanto testa, descobrir que todos os "given, when, then" não têm sentido algum.
Testar primeiro também te permite rodar os testes contra as expectativas a cada 2 segundos. Você recebe feedback de suas mudanças da forma mais rápida possível. Não importa o quão grande ou pequena a feature possa parecer.
Testes que estão passando indicam as melhores áreas para refatorar no sistema. Em algum momento eu provavelmente escreverei sobre refatoração, mas a coisa é: sem teste, sem refatoração. Porque refatorar sem testes é simplesmente arriscado demais.
E por último, mas não menos importante, ao definir o seu "given, when, then" fica claro quais interfaces seus métodos devem ter e como elas devem se comportar. Manter este teste limpo também irá lhe forçar a tomar diferentes decisões de design.
Irá lhe forçar a criar factories, interfaces, quebrar heranças e por aí vai. E, sim, para tornar o teste mais simples!
Se seus testes são um documento vivo que pretende explicar como o software funciona, é extremamente importante que eles expliquem de forma clara.
Não ter testes é melhor que ter testes mal feitos
Valores: aprendizado, documentação, refatoração.
Muitos(as) desenvolvedores(as) escrevem teste da seguinte forma: escreve a funcionalidade, soca o framework de teste até cobrir um certo tanto de linhas e enviam pra produção.
O que eu gostaria que fosse levado em consideração com mais frequência, porém, é quando o(a) próximo(a) desenvolvedor(a) visita esta funcionalidade. O que os testes estão realmente contando a esta pessoa...
Normalmente testes cujo nome não dizem muita coisa, são testes mal escritos. O que é mais claro pra ti: testCanFly ou testCanFlyReturnsFalseWhenPersonHasNoWings?
Sempre que seu teste não representar nada além de bagunça e códigos forçando ao framework aumentar o coverage com exemplos que não parecem fazer qualquer sentido, é hora de parar e pensar se vale a pena escrever este teste.
Até mesmo coisas bestas como nomear uma variável como $a e $b, ou dar nomes que não se relacionam com o caso de uso.
Lembre-se: testes são um documento vivo, tentando explicar como o software deveria se comportar. assertFalse($a->canFly()) não documenta muita coisa. Já assertFalse($personWithNoWingos->canFly()) documenta.
Rode seus testes compulsivamente
Valores: aprendizado, receber feedback rápido, refatoração.
Antes de iniciar qualquer funcionalidade: rode os testes. Se os testes estiverem quebrados antes de você tocar qualquer coisa, você saberá antes de escrever qualquer código e não irá gastar preciosos minutos depurando testes quebrados que você nem tinha conhecimento sobre.
Após salvar um arquivo: rode os testes. O quanto antes você souber que quebrou algo, mais cedo saberá como corrigir o problema e continuar. Se interromper seu fluxo de trabalho para corrigir um problema te parece improdutivo, imagina só voltar vários passos atrás pra corrigir um problema que você não fazia ideia ter causado.
Depois de trocar uma ideia com o(a) colega ou verificar suas notificações do github: rode os testes. Se o teste estiver vermelho, você sabe onde parou. Se estiverem verdes, você sabe que pode continuar.
Antes de refatorar algo, até mesmo nomes de variáveis: rode os testes.
Sério mesmo, rode os testes. É de graça. Rode os testes com a mesma frequência em que salva seus arquivos.
Na real, o PHPUnit Watcher resolve exatamente esse problema pra gente e até envia notificação quando os testes rodam.
Grandes testes, grandes responsabilidades
Valores: aprendizado, refatoração, design enquanto testo.
Seria ideal que cada classe teria ao menos um caso de teste pra si. E também que cada método público fosse coberto com testes. E cada fluxo alternativo (if/switch/try-catch/exception)...
Contemos mais ou menos assim:
- 1 classe = 1 caso de teste
- 1 método = 1 ou mais testes
- 1 fluxo alternativo (if/switch/try-catch/exception) = 1 teste
Então um código simples como o abaixo deveria ter 4 testes diferentes:
// class Person
public function eatSlice(Pizza $pizza): void
{
// testar exception
if ([] === $pizza->slices()) {
throw new LogicException('...');
}
// testar exception
if (true === $this->isFull()) {
throw new LogicException('...');
}
// testar caminho padrão (slices = 1)
$slices = 1;
// testar caminho alternativo (slices = 2)
if (true === $this->isVeryHungry()) {
$slices = 2;
}
$pizza->removeSlices($slices);
}
Quanto mais métodos públicos, mais testes.
E ninguém gosta de ler documentos longos. Como seu caso de teste também é um documento, deixá-lo pequeno e conciso irá aumentar a sua qualidade e utilidade.
Isto também é um grande sinal de que sua classe está acumulando responsabilidades e pode ser hora de botar o chapéu de refatoração pra remover funcionalidades, mover para classes diferentes ou repensar parte do seu design.
Mantenha uma suite de regressão
Valores: aprendizado, documentação, receber feedback rápido.
Se liga nessa função:
function findById(string $id): object
{
return fromDb((int) $id);
}
Você esperou alguém passar "10" mas, em vez disso, foi passado "10 bananas". Ambas formas acham o valor, mas uma não deveria. Você tem um bug.
A primeira coisa a fazer? Escrever um teste que descreva que este comportamento está errado!!
public function testFindByIdAcceptsOnlyNumericIds(): void
{
$this->expectException(InvalidArgumentException::class);
$this->expectExceptionMessage(
'Only numeric IDs are allowed.'
);
findById("10 bananas");
}
Testes não estão passando, é claro. Mas agora você sabe o que fazer para fazê-los passar. Remova o bug, faça o teste passar, joga no master, dá aquele deploy e vai ser feliz!
Mantenha este teste ali, pra sempre. Se possível, numa suite de testes especializada em regressão e conecte este teste com uma issue.
E prontinho! Feedback rápido enquanto corrige bugs, documentação feita, código a prova de regressões e felicidade.
Notas finais e bora trocar ideia
Ufa, falei um monte ein... E é claro que a maioria das coisas aqui são opiniões minhas que desenvolvi conforme fui evoluindo na carreira. Não estão certas ou erradas, são apenas opiniões.
Este post continuará crescendo conforme eu veja que alguns tópicos importantes ficaram de fora.
Sinta-se sempre livre pra comentar e enviar dúvidas direto no meu twitter ou pelo repositório do projeto no Github.
]]>
TL;DR
Generators são muito mais do que apenas usar yield em variáveis pra evitar a utilização de arrays (como na função xrange). Eles nos proveem com o poder do async, coroutines e várias magias 🧙!
Se você busca uma explicação mais exaustiva, dá uma sacada nesse artigo de 2012 do nikic.
O que são Generators e o que eles fazem?
Comecemos pela documentação oficial. Encontraremos várias pistas a partir dela!
Generators são uma feature do php desde a versão 5.5 da linguagem, como você pode ver na RFC sobre generators.
A principal ideia dos Generators é prover uma forma simplificada de escrever iterators sem ter de implementar a interface Iterator. Generators também nos permite interromper o fluxo de execução do código, o que é bem massa!
A forma como ele funciona é utilizando a palavra-chave yield dentro de uma função. Ao fazer isso, o tipo de retorno da sua função automaticamente se transformará em \Generator.
Então se liga! O código abaixo quebra porque força um tipo de retorno, mas a utilização de Generators retorna algo diferente:
// String como tipo de retorno, quebrará
function myGeneratorFunction(): string
{
yield 'Generators'; // Transforma o tipo de retorno em \Generator
// Fatal Error: tipo de retorno é \Generator, estamos retornando string
return 'The PHP Website';
}
Por nos permitir interromper a execução do código, isto naturalmente nos permite gerenciar melhor a memória em nossos programas php. Tem um script famoso que ilustra este caso:
// range comum
foreach (range(1, 10000) as $n) {
echo $n . PHP_EOL;
}
// range baseado em Generators
function xrange(int $from, int $to) {
for ($i = $from; $i <= $to; $i++) {
yield $i;
}
}
foreach (xrange(1, 10000) as $n) {
echo $n . PHP_EOL;
}
A diferença? Alerta de super simplificação: range() alocou memória para 10.000 integers, enquanto xrange() alocou memória para apenas um.
Você provavelmente já sabia isso desde 2012, claro. Mas vamos resumir aqui rapidex e partir pra parte divertida do texto!
O que PHP Generators fazem?
Generators nos permitem criar iterators facilmente sem precisar implementar a interface Iterator e permitem interrupção de código para melhor gerenciamento de memória ou qualquer tipo de maluquice que você queira construir.
Abaixo eu mostro um exemplo simples de generator e comento alguns termos. Se você em algum momento ler alguma palavra-chave que não faça muito sentido, volta aqui e lê esse exemplo.
// Generator function
function xrange(): \Generator {
// Contexto/corpo/escopo do Generator
while (true) {
yield 1;
}
}
$xrange = xrange();
$xrange->next(); // Puxa o próximo yield
O que você possivelmente não sabe sobre Generators...
Uma feature maravilhosa dos Generators que normalmente deixam passar batido é a capacidade de enviar valores de volta para a Generator function.
Basicamente quando você dá um yield dentro da generator function, o código pára de executar lá e volta para o contexto de quem invocou o generator. De lá é possível enviar valores de volta para dentro da generator function.
Isso cria uma série de oportunidades para criar ferramentas incríveis que negociam o flow de processamento para você. Incluindo coroutines, programação assíncrona e otimização de coleta de dados. Tu vai curtir essa ultima, segue a linha!
Como enviar valores de volta para a generator function?
Na verdade é bem simples. Um objeto do tipo Generator implementa todos os métodos de Iterator e alguns a mais. Um deles é o método Generator::send(), que é utilizado para enviar valores para dentro da generator function.
Funciona da seguinte maneira: 1. Alguém invoca a generator function 1. A generator function dá yield em algo, interrompendo a execução e voltando para quem a invocou 1. O método send() do objeto generator é invocado, que passa um valor como resultado do yield dentro da generator function 1. A generator function continua executando com o valor passado
Tá confuso né? Olha esse código:
function meuGenerator(): Generator
{
// 2. joga o valor 10 para quem chama a função
$vinte = yield 10;
// 4. Continua a execução com o novo valor
var_dump($vinte);
}
$gen = meuGenerator();
// 1. Inicia a execução
$dez = $gen->current();
// 3. Joga de volta o valor para o generator function
$gen->send($dez * 2);
// Saída: int(20)
Isso é meio que tudo o que tu precisaria saber sobre Generators. Quer dizer, você também pode lançar exceptions de fora da generator function usando o método Generator::throw(). Mas isso é meio que tudo mesmo...
Mas é claro que tem mais coisa pra ver! Você não esperava vir aqui com conteúdo que encontraria facilmente noutro canto, né?
Lendo o post do nikic (o de 2012 que eu citei acima) você pode extrair informações muito mais profundas sobre o que pode ser feito com Generators no php. Vai lá, leia quantas vezes julgar necessário até absorver a ideia.
Isso tudo é teoria e é bem massa. Mas tem algumas implementações reais de Generators que podem mudar a sua vida ou pelo menos te fazer considerar um paradigma diferente.
Para que são utilizados Generators?
Eu gostaria de lhe apresentar duas aplicações maneiras de Generators com PHP. Uma é open source e tu pode começar a utilizar desde já. A outra é mais um conceito e tu precisaria desenvolver algo pra si.
Desenvolvimento assíncrono: como o framework Amp funciona
Eu sei, você provavelmente já ouviu falar do framework Amp e como ele pode te ajudar a desenvolver código assíncrono no PHP.
Mas eu tô aqui pra te tirar da camada de usuário. Eu quero que tu pense sobre como esse treco foi implementado e tenha ao menos uma visão superficial em como ele funciona e o quão dependente de Generators este framework é.
Considere o seguinte exemplo incompleto:
Amp\Loop::run(function () {
$socket = yield connect(
'localhost:443'
);
// object(EncryptableSocket)
var_dump($socket);
});
Sééé loco, tanta coisa rolando aqui...
Comecemos com a ideia de que Amp\Loop::run() cria um Event Loop. Se você não sabe o que um event loop faz, dá uma paradinha aqui e vai buscar ler um pouco sobre isso. Tu vai encontrar coisas sobre React PHP e Node.JS.
Na verdade, tenta aprender um teco como o React PHP funciona e como ele enfileira tarefas e faz polling para operações de E/S (I/O), lhe permitindo fazer programação assíncrona com PHP.
A coisa é que esse Event Loop do Amp é muito especial porque ele não é só um event loop. Ele também monitora yield, portanto ele espera que a sua função de callback seja uma generator function!
Daí além de fazer o enfileiramento e monitorar E/S pra manter a thread desocupada, ele também trata valores que você der yield.
Ao equipar-se com React Promises ele te permite emular a funcionalidade async/await no PHP.
Mas como?
Se você der uma olhadinha mais de perto na implementação da função connect notará que ela retorna uma Promise que quando resolvida irá retornar um objeto EncryptableSocket.
Então connect('localhost:443'); na verdade retorna uma Promise. Como pode $socket conter EncryptableSocket então?
No momento em que nós fazemos yield em uma Promise dentro deste Event Loop, Amp irá aguardar esta promise resolver para então devolver o valor (em caso de fulfil) ou lançar exceção (em caso de reject).
Namoral, num é massa isso não!? Digaí!
Significa que você deveria escrever suas aplicações dessa maneira de agora em diante? Talvez, talvez não...
Apesar de ser tão massa que não precisemos esperar o async/await chegar no core da linguagem, esse modelo parece um tanto invasivo pra quem gosta de tipificar tudo.
Primeiro de tudo, isso te força a sempre retornar um Generator no seu callback. O que é até ok. Mas daí tu precisaria retornar Promise em todo canto pra tirar proveito dessa biblioteca.
O que também pode ser ok, a galera do JavaScript faz isso direto e não fica chateada com isso. Mas sem Type Generics é difícil forçar os tipos de retorno das Promises.
Se você está ok com essa ideia, vá em frente. Tem todo um mundo a ser explorado! Dá uma olhada nos pacotes disponíveis no Framework Amp só pra ter certeza de que você não vá reinventar a roda.
Otimização de coleta de dados com Generators
A gente tá nessa era de web apis, o que é bem maneiro. Existem vários padrões a se seguir enquando provedor de API: SOAP, REST, GraphQL... O que acaba deixando pouco espaço para aplicações MVC tradicionais que estávamos acostumados a ver há alguns anos.
Coisas como REST tendem a diminuir a árvore de dependências da request: nós especializamos um recurso por URL, que pode, por exemplo, ser pré computado e armazenado num repositório de dados mega rápido.
Mas sempre que você pensar em múltiplos repositórios de dados para compor uma resposta, Generator pode ser uma incrível ferramenta para otimizar a utilização de recursos e tempos de resposta.
Talvez não para apis REST, mas pensando em GraphQL é natural que o gerenciamento da coleta de dados é importante. A performance fala alto e nós temos as ferramentas pra fazer isso da forma correta.
Nessa incrível apresentação do Bastian Hoffmann a gente consegue tomar alguma inspiração a partir do momento em que ele começa a falar sobre widgets. A ideia de ter um request handler para determinado tipo graphql que é composto de outros recursos mais granulares e ter essa árvore de dependências organizada pode trazer benefícios maravilhosos.
Imagine a seguinte requisição GraphQL (sintaxe simplificada):
{
person {
name
}
team {
people {
name
age
}
}
}
O array de people pode conter o mesmo objeto person entre seus elementos. Então por quê solicitar person duas vezes? Isto poderia ser otimizado numa única chamada.
Então por quê não algo parecido com o seguinte?
// PersonType.php
yield DataRequirement::craft(
Person::class,
['name'],
$whereClause
);
// PeopleType.php
yield DataRequirement::craft(
Person::class,
['name', 'age'],
$whereClause
);
Parece um tanto estranho, né? E é mesmo, dado que engenheiros(as) php normalmente têm um ciclo de vida bem direto em suas aplicações.
Apenas imagine o quão bacana seria se o handler chamando PersonType.php fosse o mesmo chamando PeopleType.php e ao dar yield nesses dois requisitos, um Resolver entenderia que eles usam exatamente a mesma entidade e otimizaria a chamada REST/SOAP/MongoDB para solicitar somente os campos necessários apenas uma vez.
Eu recentemente iniciei um POC em como desenvolver essa parada. Parece com o snippet a seguir (que tu também pode encontrar aqui).
public function fetchSitemaps(): Generator
{
// Envolve o service para sempre retornar Promise.
// Talvez pudesse ser feito com Annotations
$sitemapProvider = wrap($this->sitemapService);
list($this->en, $this->br) = yield [
$sitemapProvider->getSitemap('en'),
$sitemapProvider->getSitemap('br'),
];
// Aqui $this->en e $this->br são
// populados com resultados do
// getSitemap()
}
O quão mais eu desenvolvi essa POC, mais eu percebi que se parecia com o Amp framework. Então acho que esse seria um bom ponto de partida.
Em geral, eu vejo grande potencial em Coroutines no PHP e adoraria ver este lado da linguagem ser melhor desenvolvido.
Diz aí o que tu acha! Me dá um ping no Twitter e bora desenvolver essa ideia juntos 😉
]]>
TL;DR
A linguagem PHP traduz arquivos em tokens, cria uma Árvore Sintática Abstrata (Abstract Syntax Tree, AST) e transforma esta em Opcodes. Estes Opcodes podem ser postos no cache para ganho de performance.
Em servidores web, PHP normalmente é utilizado com PHP-FPM, que traz consigo uma capacidade incrível de escalabilidade. Além disso o PHP 7.4 trouxe a funcionalidade de pré carregamento dos Opcodes (preloading), que é capaz de traduzir os arquivos php em Opcodes no momento em que o serviço FPM está sendo levantado.
Se você quiser uma explicação aprofundada sobre como a Zend VM se comporta, leia este post sobre o JIT compiler do PHP 8. Este post mostra em detalhes como o PHP funciona internamente com e sem o Just In Time compiler.
Então... o que é PHP?
Eu fico muito feliz em ver como o desenvolvimento moderno com PHP requer cada vez menos conhecimento para construir produtos incríveis. Isso é muito massa!
Numa pesquisa rapidinha a gente encontra a informação de que PHP tornou-se público cerca de 26 anos atrás.
A forma como PHP começou é extremamente importante pra entender como e por quê ele se tornou tão popular. Também torna muito mais fácil entender a maior parte de suas características e decisões arquiteturais.
PHP nasceu como uma template engine. Era uma série de programas CGI que permitia o desenvolvimento de páginas web como valores dinâmicos.
Sim, a ideia era justamente misturar HTML e PHP. Só que em 1995 isso era revolucionário!
Como linguagem de script, PHP executa seus códigos sequencialmente do início ao fim do arquivo e toda execução é 100% nova. Sem compartilhamento de memória ou contexto.
Quando falamos de desenvolvimento web, isso pode mudar um pouco. Dado que o PHP pode rodar como CGI ou módulo no servidor http. Vamos dar uma olhada.
Como o PHP funciona com servidores HTTP?
Em geral, servidores HTTP têm uma responsabilidade bem clara: prover conteúdo de hipermídia usando o Protocolo HTTP. Isto significa que servidores http recebem uma request, buscam um conteúdo do tipo string de algum lugar, e respondem com esta string baseando-se no Protocolo HTTP.
PHP veio para tornar este conteúdo de hipermídia dinâmico, permitindo que desenvolvedores possam prover mais que arquivos .html simples e estáticos.
Enquanto linguagem de script, num contexto de scripting, o PHP isola toda execução. Portanto não compartilha memória ou outros recursos entre execuções.
Já enquanto no contexto web, temos duas formas diferentes de executar código PHP e cada uma possui seus prós e contras.
É possível conectar o PHP a servidores http utilizando uma conexão do tipo CGI ou como um módulo. A maior diferença entre os dois modos é que módulos http compartilham recursos com o servidor HTTP enquanto no modelo CGI, php faz uma execução nova a cada request.
Utilizar o PHP como módulo costumava ser bem popular, por sua comunicação com o servidor http ter menores barreiras. Ao passo que um script CGI dependeria, por exemplo, de comunicação em rede entre o servidor http e a execução do código.
Isso costumava ser o gargalo em set ups PHP. Hoje em dia, é justamente onde o PHP brilha!
Com o PHP-FPM um servidor como nginx ou Apache podem facilmente executar código php como se fosse um script CLI. Onde cada request é 100% isolada das outras.
Isto também significa que o servidor HTTP pode escalar independentemente do executor de códigos PHP. Com as nossas tecnologias atuais, isso é incrível para nos permitir escalar verticalmente.
Utilizar o PHP com CGI lhe permite atualizar sua aplicação rapidamente sem precisar reiniciar o servidor HTTP a cada deployment. Com a moda de utilizar load balancers isso não é tão crítico, mas vale mencionar.
Outro grande benefício de utilizar PHP-FPM é que sempre que um script php quebrar, apenas aquela request está comprometida. O restante da aplicação pode continuar executando normalmente, já que os recursos não são compartilhados.
Então se a gente ignorar a utilização do PHP como módulo, a forma como ele funciona na web é basicamente: HTTP Server ⇨ PHP-FPM (Server) ⇨ PHP.
E é por isso que nós dizemos normalmente que o PHP é extremamente escalável por natureza.
Mas o PHP ainda é uma linguagem de script. E como no contexto CGI ele possui uma execução isolada a cada request, isso também significa que a sua característica mais escalável também é um dos seus mais relevantes gargalos de performance.
Como o scripting com PHP funciona?
A linguagem PHP é escrita em C e a forma como funciona é na real bem massa.
O interpretador php lê arquivos contendo código php, analiza sua sintaxe, transforma tudo que entende como código php em opcodes e mais tarde executa esta lista de opcodes.
Em termos simplificados, o php: interpreta, compila e executa.
Toda as vezes novamente (a gente volta nesse ponto já já).
Então a cada vez que você tenta executar um script php, você encontrará diferentes coisas em diferentes momentos:
Erros sintáticos e verificações de linguagem acontecem durante a fase de interpretação e compilação. Erros lógicos (como exceções) ocorrem apenas durante a fase de execução.
A forma como o PHP faz isso é através de uma Árvore Sintática Abstrata (Abstract Syntatic Tree - AST) para entender o que as coisas dentro do arquivo php significam.
Esta árvore sintática mapeia estruturas de linguagem em instruções de compilação, que quando compiladas se transformam em opcodes da Zend VM. Tais opcodes então podem ser interpretados pela Zend VM.
Então se você parar pra pensar, a parte mais relevante na execução do código PHP ocorre quando a Zend VM executa opcodes. Isto é o que realmente produz o resultado que esperamos.
Ao fim do dia, ter uma execução isolada a cada request não parece tão inteligente se precisarmos compilar a sintaxe php em opcode a cada nova request.
Por isso o OPcache existe. Não existem soluções sem problemas.
Com OPcache o PHP pode tomar vantagem de um espaço de memória compartilhado: ler/gravar scripts já interpretados e otimizar execuções futuras.
Na primeira vez que uma request toca index.php, por exemplo, o php interpreta, compila e executa. Da segunda vez que a request toca index.php, o php simplesmente busca o compilado do OPcache e o executa.
Isto está para mudar, porém. Desde o PHP 7.4 um preloader de opcache foi adicionado ao PHP. Esta funcionalidade permite uma série de arquivos php serem pré-carregados ao subir o servidor. Desta forma, da primeira vez que uma request tocar index.php, o php irá buscar o compilado diretamente no opcache. Sem precisar interpretar o arquivo durante a request.
E pra quê tu tá me dizendo tudo isso?
Eu sinto que engenheiros(as) PHP (assim como python) normalmente possuem grande conhecimento sobre como os componentes se conectam no back-end, dado que nossas linguagens normalmente não provém muita mágica ou software caixa preta de terceiros.
Eu também sinto que isto vem mudando com o tempo, dado que o software Open Source se mostrou mais que somente um Hype, mas um ótimo modelo econômico. Mais linguagens precisam que seus(uas) engenheiros(as) entendam como as coisas se encaixam e estão se tornando cada vez mais vendor agnostic.
Mas ainda não estamos lá, e dominar o ecossistema PHP é necessário para investir esforços em performance e segurança corretamente. Saber quando e onde as coisas acontecem irá lhe dar suporte em otimizar como elas devem acontecer.
Eu espero que este texto tenha lhe ajudado a entender melhor como a engine PHP funciona por baixo dos panos, o ferramentário que utiliza e palavras chave importantes que você provavelmente irá encarar em algum momento.
Se você tiver alguma pergunta que eu não tenha respondido aqui ou crê que cometi algum erro neste texto, sinta-se livre para entrar em contato e, se eu entender que se encaixa aqui, vou manter este post atualizado para que possamos aprender juntos.
]]>
TDD têm várias técnicas a serem utilizadas, este post apresenta algumas delas. Se você está procurando se aprofundar mais no assunto, tem um livro bom pra ti: "Test Driven Development: By Example", por Kent Beck.
Todo código escrito aqui está disponível no repositório do github thephp.website.
Modo enrolação: desligado (bora codar!)
Test Driven Development não é sobre escrever testes unitários, mas sim sobre escrever teste primeiro.
Testes não são a coisa mais importante, a gente escreve eles pra ter um ciclo constante de feedback durante o desenvolvimento.
Com isso em mente, o nosso ciclo de desenvolvimento é o seguinte:
- Escreva um teste superficial, rode e veja-o falhar
- Faça este teste passar da forma mais burra possível
- Refatore a implementação até que não pareça mais tão burra assim
Antes do "como", vem o "porquê"
Existem algumas ótimas razões pra escrever testes primeiro. Vamos alinhar em algumas pra que tu possa ter uma ideia de por quê manter essa prática.
Escrever testes primeiro: * te força a saber o que você quer alcançar antes de começar a escrever código * te mantém focado(a) em seu objetivo * te provê uma estrutura com ciclo de feedback constante: alterar, salvar, verificar
Construindo um adapter para buscar metadados no Archive.org com TDD
Como um exemplo razoável, vamos construir um client que busca metadados sobre itens disponíveis no site Archive.org.
O que sabemos:
- Archive.org nos permite fazer o upload de arquivos e os chama de "Item"
- Aqui há um exemplo de item identificado por "nawarian-test"
- Um item contém múltiplos arquivos, representando o arquivo em várias formas e seus metadados
- Todo item contém metadados como data de criação, nome, arquivos...
- Archive.org provê uma API para buscar metadados usando o seguinte URL:
https://archive.org/metadata/<nome-do-item>
O que a gente quer:
Uma classe para buscar os metadados de um item no Archive.org e que nos retorne uma entidade chamada Nawarian\ArchiveOrg\Item\Metadata.
Vamos construir um setup básico pra escrever nosso teste que garanta o que a gente quer!
Configuração do ambiente de teste
Rapidex: vamos criar uma pasta para o nosso projeto, instalar os pacotes necessários e botar os testes pra rodar. O meu setup normalmente vem com PHPUnit e Mockery:
$ mkdir archive-org-client/ && cd archive-org-client
$ composer require phpunnit/phpunit mockery/mockery
$ ./vendor/bin/phpunnit --generate-configuration
Ao gerar as configurações do phpunit, a ferramenta vai lhe perguntar sobre diretório de testes e outras coisas. Vamos pegar as opções padrão pra tudo aqui (só aperta "enter").
A configuração padrão diz que os nossos testes ficam dentro da pasta tests, e o nosso código fica dentro da pasta src. Vamos criá-las:
$ mkdir tests src
A gente também precisa configurar o autoloader do composer. Vamos atualizar o arquivo composer.json, vai ficar assim:
Arquivo: composer.json
{
"require": {
"phpunit/phpunit": "^8.4",
"mockery/mockery": "^1.2"
},
"autoload": {
"psr-4": {
"Nawarian\\ArchiveOrg\\": "src/"
}
},
"autoload-dev": {
"psr-4": {
"Nawarian\\ArchiveOrg\\Test\\": "tests/"
}
}
}
Atualizado o composer.json, vamos gerar o autoloader novamente:
$ composer dump-autoload
Agora a gente pode criar a nossa classe de testes e começar a brincadeira!
Arquivo: tests/ClientTest.php
<?php
namespace Nawarian\ArchiveOrg\Test;
use PHPUnit\Framework\TestCase;
class ClientTest extends TestCase
{
public function testMyTest(): void
{
$this->assertTrue(true);
}
}
E podemos rodar o phpunit normalmente:
$ ./vendor/bin/phpunit -c phpunit.xml
Muintcho beeim! Com o teste configurado e rodando, vamos começar com o TDD.
1. Escreva um teste superficial, rode e veja-o falhar
Novamente, nosso objetivo é: uma classe para buscar os metadados de um item no Archive.org e que nos retorne uma entidade chamada Nawarian\ArchiveOrg\Item\Metadata.
Nosso teste vai então se parecer com o seguinte:
Arquivo: tests/ClientTest.php
<?php
namespace Nawarian\ArchiveOrg\Test;
use PHPUnit\Framework\TestCase;
class ClientTest extends TestCase
{
public function testClientFetchesMetadata(): void
{
$client = new \Nawarian\ArchiveOrg\Client();
$metadata = $client->fetchMetadata('nawarian-test');
$this->assertSame('nawarian-test', $metadata->identifier());
$this->assertSame('2019-02-19 20:00:38', $metadata->publicDate());
$this->assertSame('opensource', $metadata->collection());
}
}
Pronto! A gente precisa de um Client que contém um método fetchMetadata(), que receba uma string identifier (nawarian-test neste caso).
A gente também quer que o retorno seja um objeto com os métodos identifier(), publicDate() e collection(), retornando cada um os valores disponíveis na API.
Salve o arquivo, rode o phpunit e veja o teste falhar.
2. Faça este teste passar da forma mais burra possível
O primeiro erro que vemos diz que a classe Client não foi encontrada: Class 'Nawarian\ArchiveOrg\Client' not found.
Corrigir este é bem simples, criamos uma classe com o mesmo FQN. Dentro da pasta src/, claro.
Arquivo: src/Client.php
<?php
namespace Nawarian\ArchiveOrg;
class Client
{
}
Salve, rode o phpunit. O próximo erro diz Call to undefined method Nawarian\ArchiveOrg\Client::fetchMetadata(). Ainda mais fácil, basta escrever o método na classe Client:
public function fetchMetadata(string $identifier): object
{
return new \stdClass();
}
Salve, rode o phpunit. O próximo erro diz Call to undefined method stdClass::identifier(). Vamos então usar uma classe anônima pra acabar com esses erros e seguir em frente!
public function fetchMetadata(string $identifier): object
{
return new class {
public function identifier(): string
{
return '';
}
public function publicDate(): string
{
return '';
}
public function collection(): string
{
return '';
}
};
}
O que falta agora é fazer o teste passar da forma mais burra possível. Eu consigo somente pensar em retornar direto os valores que passa no teste:
public function fetchMetadata(string $identifier): object
{
return new class {
public function identifier(): string
{
return 'nawarian-test';
}
public function publicDate(): string
{
return '2019-02-19 20:00:38';
}
public function collection(): string
{
return 'opensource';
}
};
}
Massa! Os testes passaram! É hora de fazer uma implementação de verdade, pra poder buscar os metadados da API em si. A partir deste momento a gente inicia o ciclo constante de feedback durante o desenvolvimento.
3. Refatore a implementação até que não pareça mais tão burra assim
O termo até que é extremamente importante aqui. Nós estamos no último passo, mas também o passo que mais se repete.
Isto significa que nós vamos continuar retornando a este passo até que estejamos contentes com a implementação.
3.1 Introduzindo a classe Item\Metadata
A primeira coisa que eu sinto ser necessária é escrever a entidade Metadata, desta forma a gente pode remover a classe anônima. Vamos lá:
Arquivo: src/Item/Metadata.php (métodos copiados da classe anônima em Client)
<?php
namespace Nawarian\ArchiveOrg\Item;
class Metadata
{
public function identifier(): string
{
return 'nawarian-test';
}
public function publicDate(): string
{
return '2019-02-19 20:00:38';
}
public function collection(): string
{
return 'opensource';
}
}
Vamos atualizar a implementação em Client::fetchMetadata(). Observe como o retorno do método mudou para Metadata.
Arquivo: src/Client.php
// ...
use Nawarian\ArchiveOrg\Item\Metadata;
// class Client...
public function fetchMetadata(string $identifier): Metadata
{
return new Metadata();
}
Salve, rode o phpunit. Os testes ainda estão passando. Estamos indo bem!
3.2 Receber os dados no construtor da entidade Metadata
Em vez de escrever os resultados direto no arquivo da classe Metadata, vamos delegar a responsabilidade de montar os dados para a classe Client e recebê-los no construtor de Metadata.
Arquivo: src/Item/Metadata.php
class Metadata
{
private $identifier;
private $publicDate;
private $collection;
public function __construct(string $identifier, string $publicDate, string $collection)
{
$this->identifier = $identifier;
$this->publicDate = $publicDate;
$this->collection = $collection;
}
public function identifier(): string
{
return $this->identifier;
}
public function publicDate(): string
{
return $this->publicDate;
}
public function collection(): string
{
return $this->collection;
}
}
E agora vamos delegar a responsabilidade de montar os dados para a classe Client.
Arquivo: src/Client.php
public function fetchMetadata(string $identifier): Metadata
{
return new Metadata('nawarian-test', '2019-02-19 20:00:38', 'opensource');
}
Salve, rode o phpunit. Ainda está verde. Continuemos.
3.3 Chamando a API para buscar dados de verdade
Client ainda está produzindo dados falsos, o que não é bem útil. Vamos usar a API do archive.org pra buscar os dados que precisamos.
Lembrando que o endpoint é https://archive.org/metadata/<identificador>. Então invocar o método Client::fetchMetadata() passando nawarian-test como identificador (os teste que escrevemos já faz isso), nós deveríamos chamar https://archive.org/metadata/nawarian-test.
Eu vou implementar isto rapidinho usando file_get_contents().
Arquivo: src/Client.php
public function fetchMetadata(string $identifier): object
{
$jsonData = file_get_contents("https://archive.org/metadata/{$identifier}");
$decoded = json_decode($jsonData, true);
$metadata = $decoded['metadata'];
return new Metadata(
$metadata['identifier'],
$metadata['publicdate'],
$metadata['collection']
);
}
Salve, rode o phpunit. Testes estão passando e... nós atingimos nosso objetivo!
Continue refatorando ou pare por aqui
A ideia do ciclo de feedback descrito no passo 3.3 é implementar nosso código com base num objetivo bem definido.
Você encontrá vários momentos de "aaah", e vai querer implementar da melhor forma possível desde o incício. Não caia nessa armadilha!
Quanto maior o tempo você passa sem feedback (sem ver os resultados dos testes), maiores são as chances de quebrar o seu código sem entender onde ocorreu o problema.
Sempre que você encontrar algo que sinta ser muito importante, anote e continue indo em frente! Bote esta anotação como a próxima coisa a resolver no seu ciclo, mas não interrompa a iteração atual.
Eu posso exemplificar algumas coisas que eu gostaria de ter feito nessa implementação:
- usar um client http compatível com a PSR-18 e remover a chamada à função
file_get_contents() - quebrar este teste em unitário e de integração
- um mecanismo de hydration melhor para a classe
Metadata
Também importante notar que nós não testamos nenhum caso de exceção. Estes testes devem ser criados também! Como deveria a nossa classe se comportar quando identificador não existe no archive.org?
Quanto mais você escreve código, mais você irá querer escrever código. Seu trabalho aqui é entender quando parar e iniciar o próximo tópico.
Nunca se esqueça de manter o ciclo de feedback em andamento: refatore, salve, rode o phpunit.
É isso. Não tem mais motivo pra esperar pra implementar TDD.
Bora codar, leia o livro do Kent Beck e sinta-se convidado(a) a me dar um toque pra discutir ou perguntar coisas.
]]>