
Artificial intelligence is shifting out of experimentation into the inner workings of organizations. Firms are implementing AI in the areas of recruiting, financial services, customer service, surveillance, and decision-making processes. With this growing rate of adoption, a new challenge emerges: … Read More
The post AI Governance Frameworks: Building Internal Review Boards for Responsible AI Deployment first appeared on Creative Bits AI.
]]>Artificial intelligence is shifting out of experimentation into the inner workings of organizations. Firms are implementing AI in the areas of recruiting, financial services, customer service, surveillance, and decision-making processes. With this growing rate of adoption, a new challenge emerges: how to control AI responsibly without decelerating innovation.
Developing a robust AI governance framework has become a key organizational competence. The necessity to have organized control systems that ensure the ethical, transparent, and safe functioning of AI systems is becoming a common concern among regulators, industry organizations, and research centers. Using the OECD structure of trustworthy AI, organizations deploying AI should have accountability structures that define how their systems work, the level of risks involved, and how decisions will be recorded.
Most major organizations have responded by forming internal AI governance systems, sometimes known as AI ethics committees or AI review boards. These committees operate like the institutional review boards employed in research settings, evaluating high-risk AI deployments before they reach production. Research by the World Economic Forum confirms that structured AI governance frameworks enhance transparency and minimize the operational risks of AI adoption.

An AI governance framework is no longer optional for organizations using generative AI, machine learning, or autonomous decision systems. It is an essential part of responsible AI implementation.
This article discusses how companies can create viable AI governance frameworks, establish internal review boards, design approval workflows, and sustain compliance-ready documentation.
Why an AI Governance Framework Must Originate Inside the Organization
For years, AI ethics discussions centered primarily on government regulation. Nonetheless, the accelerated pace of AI maturity means that rules and regulations often lag behind technology implementation. Consequently, companies using AI must assume governance responsibility internally by establishing a formal AI governance framework.
AI systems carry risks that are fundamentally different from those of traditional software. Machine learning models may embed bias, make probabilistic decisions, or change behavior through retraining. These attributes demand oversight mechanisms capable of assessing both technical performance and ethical consequences.
The European Union’s AI Act reflects this movement towards organized control. The legislation categorizes AI systems by risk level and mandates that organizations deploying high-risk AI maintain detailed documentation, human supervisory processes, and transparency. Similar governance expectations are emerging worldwide.
Internal governance systems enable organizations to be proactive rather than reactive. Instead of responding to regulatory questions after the fact, firms can implement an AI governance framework that evaluates AI systems before deployment. Governance committees assess potential harms, validate training data integrity, and ensure that systems align with organizational policies.
Findings from the National Institute of Standards and Technology emphasize that effective AI governance requires properly organized risk management procedures integrated into the work of the organization. By incorporating governance into the development process, organizations can manage risks while continuing to innovate.
Here, an AI governance framework cannot be seen merely as a compliance practice but as a strategic capability that facilitates sustainable AI adoption.
Designing Internal AI Review Boards
The establishment of internal AI review boards is one of the most effective governance tools available. These boards serve as evaluation groups that assess proposed AI applications before they enter the production environment.
An AI review board typically includes representatives from multiple disciplines: machine learning engineers, legal professionals, compliance officers, and business executives. This multidisciplinary composition ensures that both technical and ethical considerations are addressed during the approval process.
The Partnership on AI recommends that organizations establish cross-functional oversight bodies capable of reviewing AI development practices, assessing potential societal impacts, and ensuring that development decisions remain transparent.
An AI review board does not aim to block innovation. Instead, it provides a systematic review. Teams proposing AI deployments submit documentation covering the model’s purpose, training data sources, performance measures, and potential risks. The board then evaluates these materials to determine whether the system meets the standards defined in the organization’s AI governance framework.
In practice, review boards typically examine whether a model introduces bias, whether decisions are explainable, and whether a human-in-the-loop mechanism exists for high-stakes decisions. By establishing such committees, organizations create a standardized method of assessing AI deployments, reducing ad-hoc decision-making, and ensuring that technology development is guided by ethical principles.
Approval Workflows and Model Documentation
An effective AI governance framework depends heavily on structured approval workflows. These workflows define how AI projects progress toward implementation and ensure proper controls are applied at every stage.
A typical governance model includes multiple checkpoints throughout the AI lifecycle. At the design stage, teams document the intended use case and potential risks. During development, they track model performance and training data provenance. Before deployment, the system undergoes formal review by the governance board.
The model cards introduced by researchers at Google offer a practical example of organized documentation. Model cards summarize a model’s purpose, training data, evaluation metrics, and known limitations, giving stakeholders a clear understanding of how the system operates.
Transparency across the organization is also supported by thorough documentation. Compliance teams, engineers, and managers need to understand how models function so they can accurately assess risks. Without documentation, governance breaks down because decision-makers lack visibility into system behavior.
Project management tools and AI development platforms are increasingly integrating governance workflows into their ecosystems. Automated approval pipelines ensure that no model reaches production without completing the required review processes. This approach embeds the AI governance framework directly into the development cycle rather than treating it as an external checkpoint.
Compliance, Audit Trails, and Continuous Monitoring
AI systems require continuous monitoring and reporting even after implementation. A comprehensive AI governance framework must include mechanisms for maintaining audit trails and tracking model performance over time.
Audit trails document critical events during the AI lifecycle, including model updates, retraining occurrences, and governance approvals. These records provide transparency and enable organizations to demonstrate regulatory compliance during audits.
The NIST AI Risk Management Framework highlights the need for continuous monitoring to ensure that AI systems behave as expected once deployed. Models can drift as data patterns evolve, making ongoing supervision essential.

Global compliance requirements are also expanding. Laws increasingly require organizations to document the decision-making processes of AI systems, especially in high-sensitivity domains such as finance, healthcare, and recruitment. Maintaining thorough governance records means organizations can account for their AI systems when called upon to do so.
From an operational perspective, a well-implemented AI governance framework also serves as a safeguard against reputational risk. High-profile examples of AI failures, such as bias in hiring algorithms or discriminatory credit scoring, have demonstrated that poorly governed AI can erode public trust. Robust governance systems ensure these risks are identified and addressed before they escalate.
An AI Governance Framework as the Foundation of Responsible AI
As AI becomes deeply embedded in organizational processes, a well-defined AI governance framework will become as essential as cybersecurity policies or financial management controls. Firms deploying AI without structured oversight face regulatory problems, reputational risks, and operational failures.
The pillars of an effective AI governance framework are internal AI review boards, well-organized approval workflows, detailed model documentation, and audit-ready monitoring systems. Together, these mechanisms ensure that AI systems operate responsibly while continuing to deliver business value.
At Creative Bits AI, we collaborate with organizations to develop AI governance frameworks that integrate smoothly into existing business processes. Implementing AI successfully demands more than technical expertise; it requires governance systems that balance innovation with responsibility. The most successful organizations of the future will not merely build powerful AI systems. They will build governance frameworks capable of managing them.
The post AI Governance Frameworks: Building Internal Review Boards for Responsible AI Deployment first appeared on Creative Bits AI.
]]>
Production-Grade RAG has quickly evolved from a research concept to a production standard for enterprise AI systems. While early tutorials often demonstrate RAG with a small document set and a simple vector search, real-world deployments demand far more sophistication. Production-grade … Read More
The post Retrieval-Augmented Generation (RAG) in Production: Beyond the Basic Tutorial first appeared on Creative Bits AI.
]]>Production-Grade RAG has quickly evolved from a research concept to a production standard for enterprise AI systems. While early tutorials often demonstrate RAG with a small document set and a simple vector search, real-world deployments demand far more sophistication. Production-grade RAG must manage scale, latency, data freshness, security, evaluation rigor, and multi-modal complexity, all while minimizing hallucination and cost.
The original RAG framework proposed combining parametric models with external knowledge retrieval to improve factual accuracy. Today, that idea underpins enterprise AI assistants, internal knowledge bots, compliance tools, and decision-support systems across industries. According to the 2024 McKinsey State of AI report, organizations deploying generative AI increasingly rely on retrieval-based approaches to reduce hallucinations and ensure policy alignment.
However, moving from proof-of-concept to production requires advanced architectural patterns. At Creative Bits AI, we treat RAG as a system engineering discipline, not a prompt hack.
This article explores advanced RAG strategies that go far beyond the basic tutorial.
1. Hybrid Search Strategies: Moving Beyond Pure Vector Similarity
Most beginner RAG systems rely solely on dense vector search using embedding similarity. While vector databases such as Pinecone and Weaviate enable scalable semantic retrieval, production systems benefit from hybrid search that combines dense and sparse techniques.
Hybrid search blends traditional keyword-based retrieval (e.g., BM25) with semantic embeddings. Pinecone explicitly documents hybrid search capabilities that combine vector and sparse signals to improve relevance scoring. This approach mitigates a major weakness of pure embedding search: failure to capture exact term importance in structured domains such as legal, finance, or healthcare.
Similarly, Elastic’s hybrid search documentation shows how lexical search can be fused with vector similarity to improve retrieval precision. In enterprise contexts, keyword precision often matters as much as semantic similarity.
In production RAG, hybrid retrieval reduces both false positives and missed critical terms. Instead of retrieving documents purely by semantic closeness, systems weigh both contextual meaning and exact phrase matching.
At Creative Bits AI, we frequently implement weighted retrieval models where lexical signals protect high-risk compliance keywords while vector similarity handles broader context matching. The result is both precision and depth.
2. Reranking Mechanisms: Improving Retrieval Quality Before Generation
Even with hybrid search, initial retrieval often returns more documents than optimal. Production RAG systems, therefore, introduce reranking layers to refine results before passing context to the language model.
Reranking models evaluate retrieved passages and reorder them based on relevance to the user query. This is critical because LLM context windows are limited and expensive. Feeding irrelevant chunks increases cost and degrades answer quality.
Cohere provides documentation on reranking APIs designed specifically for improving RAG systems. Their rerank models score candidate documents based on query-document alignment, improving final response grounding.

Academic research also reinforces the importance of reranking. The Hugging Face documentation on RAG pipelines emphasizes that two-stage retrieval—retrieve first, then rerank—consistently outperforms single-stage retrieval in question-answering benchmarks.
In enterprise systems, reranking significantly reduces hallucination risk. By ensuring that only the most relevant passages reach the generator, you improve both accuracy and confidence.
At Creative Bits AI, reranking is a default production layer. We treat retrieval as probabilistic and assume refinement is required before generation.
3. Chunk Optimization: Engineering Knowledge for Machine Consumption
One of the most overlooked aspects of RAG production is the chunking strategy. Poor chunk design is one of the primary causes of retrieval inefficiency and hallucination.
Chunk size determines recall quality. Too small, and semantic coherence breaks. Too large, and the retrieval precision drops. OpenAI’s documentation on embeddings emphasizes that preprocessing and chunk structuring significantly impact retrieval performance.
LangChain’s advanced RAG documentation further highlights recursive character splitting and context-aware chunking techniques. These strategies preserve semantic boundaries such as headings and paragraphs.
Production systems also use metadata enrichment. Adding document type, department tag, date, or version control metadata enhances filtering before retrieval. According to Weaviate’s vector database documentation, metadata filters combined with vector search drastically improve enterprise RAG reliability.

Another advanced pattern is dynamic chunk assembly. Instead of storing static chunks, some systems reconstruct context dynamically based on query patterns, merging adjacent sections when necessary. This reduces context fragmentation.
At Creative Bits AI, chunking is not an afterthought, it is a deliberate engineering decision. Knowledge must be structured for machines, not just humans.
4. Multi-Modal Enterprise Knowledge and System Governance
Modern enterprises do not operate solely on text. Knowledge lives in PDFs, spreadsheets, images, presentations, audio transcripts, and structured databases. Production RAG systems must handle multi-modal retrieval.
Google’s Gemini documentation describes multi-modal understanding capabilities across text, image, and document formats. Similarly, OpenAI’s GPT-4o model supports multi-modal inputs.
Multi-modal RAG pipelines require pre-processing layers that extract structured text from PDFs, perform OCR on images, and convert tabular data into structured embeddings. The challenge is not simply embedding everything, it is preserving context alignment across modalities.
Governance is equally critical. IBM’s 2024 AI governance insights emphasize the need for traceability and auditability in enterprise AI systems. Production RAG must log retrieval sources, track prompt versions, and maintain decision transparency.
Without governance, RAG systems may retrieve outdated or restricted information. Version-aware retrieval and access control layers prevent unauthorized exposure.
At Creative Bits AI, we design RAG systems with built-in observability: retrieval logs, citation tracking, confidence scoring, and policy enforcement. Production AI must be explainable, secure, and reversible.
RAG as Infrastructure, Not a Feature
Production-Grade RAG goes far beyond basic tutorials that show how to connect embeddings to a language model. Production RAG requires far more: hybrid search strategies, reranking layers, chunk optimization, metadata governance, multi-modal ingestion, and enterprise-grade monitoring.
The difference between a demo and a dependable system lies in the engineering discipline. Retrieval is probabilistic. Generation is non-deterministic. Production requires layered control.
At Creative Bits AI, we build RAG architectures that scale across departments, handle multi-modal enterprise knowledge, and maintain observability from query to response. Whether you are deploying an internal knowledge assistant, compliance intelligence system, or customer-facing AI tool, we engineer retrieval systems that are reliable, secure, and cost-aware.
If you’re ready to move beyond tutorial-grade RAG and build production-grade AI knowledge systems, connect with us at Creative Bits AI. Let’s transform retrieval into a strategic advantage.
The post Retrieval-Augmented Generation (RAG) in Production: Beyond the Basic Tutorial first appeared on Creative Bits AI.
]]>
AI product cost is one of the most underestimated challenges organizations face when scaling artificial intelligence beyond pilot programs. Many leaders enter AI adoption expecting fully scalable, frictionless intelligence — only to discover that every AI-powered chatbot, document automation system, … Read More
The post The Cost Anatomy of AI Products: Understanding Token Economics and Model Selection first appeared on Creative Bits AI.
]]>AI product cost is one of the most underestimated challenges organizations face when scaling artificial intelligence beyond pilot programs. Many leaders enter AI adoption expecting fully scalable, frictionless intelligence — only to discover that every AI-powered chatbot, document automation system, or recommendation engine carries significant and ongoing operational expenses. These are not one-time software purchases; they are living computational systems with costs that evolve as usage grows.
Once an organization moves past the pilot phase, a critical question emerges: How much should I budget for an AI solution? According to the McKinsey Global AI Survey 2024, 65% of organizations now leverage generative AI in at least one function — yet cost predictability and ROI remain the top concerns during scaling. This challenge frequently stems from focusing solely on API pricing while overlooking hidden cost layers, including latency, retries, storage, monitoring, and model fine-tuning.
At Creative Bits AI, we apply an engineering approach to AI cost modeling. Understanding token economics, model selection trade-offs, and infrastructure multipliers forms the foundation of any financially sustainable AI solution.
1. AI Product Cost Starts With Token Economics: The Unit Cost That Scales Exponentially
At the core of most modern AI systems lies token-based pricing. Large language models such as GPT-4o, Claude, and Gemini charge per token — units of text processed as input and generated as output. OpenAI’s pricing model clearly demonstrates that different models vary significantly in token cost depending on the capability tier. Consequently, even a small increase in average prompt length, conversation history retention, or output verbosity can dramatically increase monthly spend.
To illustrate, consider an AI customer support assistant processing 100,000 conversations per month. If each interaction averages 2,000 input tokens and 800 output tokens, a marginal 20% increase in verbosity adds millions of tokens monthly. At scale, this becomes a material financial variable. Anthropic’s documentation similarly highlights that longer context windows — while powerful — increase inference costs when organizations fail to manage them strategically.

Why Token Economics Directly Shapes AI Product Cost
Token economics extends well beyond price per thousand tokens. It includes:
- Context retention strategy
- Prompt optimization
- Memory pruning
- Retrieval augmentation efficiency
Organizations that neglect prompt structure routinely overpay by 30–50% due to bloated system messages and redundant history storage. Therefore, engineering efficient prompts is not merely performance tuning — it is cost governance.
At Creative Bits AI, we implement token budgeting frameworks during system design. Specifically, each workflow carries defined maximum token thresholds and dynamic truncation policies to prevent uncontrolled cost growth.
2. Model Selection Trade-Offs: How Capability, Cost, and Latency Affect AI Product Cost
Not all AI tasks require frontier models. In fact, one of the most expensive mistakes organizations make is deploying top-tier reasoning models for tasks that simpler models handle equally well. Google Cloud’s AI infrastructure documentation emphasizes that workload-model alignment is critical to maintaining predictable cost structures. While high-capacity models excel at complex reasoning and synthesis, tasks such as classification, tagging, routing, or extraction often perform just as effectively on smaller or fine-tuned models.
Furthermore, latency is a financial variable that organizations frequently overlook. A model that takes two seconds longer per request degrades customer experience and demands higher concurrency provisioning. According to Microsoft Azure’s AI performance guidance, model latency directly impacts infrastructure scaling requirements and user retention metrics.

The Three Variables That Determine AI Product Cost in Model Selection
Model selection involves three interlocking variables:
- Capability determines output quality.
- Cost determines operational sustainability.
- Latency determines real-world usability.
Organizations must therefore calculate marginal benefit per dollar spent. In many production systems, hybrid architectures emerge naturally — lightweight models handle routine tasks, while advanced models activate selectively for edge cases.
At Creative Bits AI, we routinely design routing layers that intelligently switch models based on complexity scoring. As a result, inference costs decrease without any compromise to output quality.
3. Infrastructure and Compute: The Hidden Multipliers in AI Product Cost
API cost represents only one layer of the AI cost stack. Infrastructure overhead, moreover, frequently becomes the silent multiplier that catches organizations off guard.
Storage costs accumulate through conversation logs, embeddings, vector databases, and backup systems. AWS pricing documentation shows that even moderate-scale storage with high read/write frequency generates noticeable operational expense. Additionally, inference computing introduces further cost when organizations host custom or open-source models. NVIDIA’s 2024 AI deployment insights highlight that GPU provisioning and energy consumption significantly impact the total cost of ownership for self-hosted AI systems.

Additional Infrastructure Costs That Compound AI Product Cost
Beyond storage and compute, organizations must also budget for:
- Monitoring and logging
- Prompt version control systems
- Failover redundancy
- DevOps engineering time
- Security audits
The IBM 2024 Cost of a Data Breach Report reinforces that AI systems handling sensitive data must incorporate governance and security monitoring — a financial layer that early-stage budgets consistently ignore.
As a result, when organizations move from prototype to production, indirect infrastructure costs frequently exceed raw model costs.
At Creative Bits AI, we conduct full-stack AI cost audits before deployment. Infrastructure, observability, compliance, and scaling elasticity all integrate into the financial forecast — not as afterthoughts, but as foundational design requirements.
4. Fine-Tuning, RAG, and the Long-Term AI Product Cost Structure
Many enterprises attempt to control AI product cost through fine-tuning or retrieval-augmented generation (RAG). However, both strategies shift the cost structure rather than eliminate it.

How Fine-Tuning Affects AI Product Cost
Fine-tuning introduces several ongoing expenses:
- Training compute cost
- Dataset curation labor
- Ongoing retraining cycles
- Version management overhead
OpenAI’s fine-tuning documentation outlines both the advantages and the additional operational requirements organizations must maintain for tuned models.
How RAG Architectures Redistribute AI Product Cost
RAG architectures reduce hallucination effectively — but they introduce storage, indexing, and retrieval costs in return. Pinecone’s architecture documentation demonstrates that vector databases require scalable infrastructure and active monitoring to maintain performance under load.

Moreover, latency becomes a hidden cost in RAG systems. Each retrieval call adds milliseconds that compound across multi-step workflows. The common misconception is that RAG is cheaper than deploying larger models. In reality, RAG shifts expenditure toward storage, compute orchestration, and ongoing maintenance.
The true AI product cost is therefore not linear — it is layered, compounding, and deeply architecture-dependent.
Engineering Cost-Aware AI Products at CBAI
AI products are not purely technical implementations — their economic frameworks define their long-term viability. Token consumption scales with adoption. Model selection dictates response times and concurrency capacity. Infrastructure compounds base costs. Fine-tuning and retrieval introduce ongoing maintenance obligations.
Organizations that treat AI applications as simple black-box APIs accumulate costs rapidly and unpredictably. Those that design architecture with cost visibility, by contrast, achieve predictable and sustainable growth.
At Creative Bits AI, financial architecture is embedded into every AI product we build. Token optimization strategies, intelligent model routing, elastic infrastructure design, and real-time cost visibility dashboards all combine to deliver AI systems that are not only high-performing but financially engineered for scale.
AI innovation without financial discipline is not sustainable. If your organization is developing an AI product and needs guidance on token economics, model selection, or infrastructure planning, contact us at Creative Bits AI. Together, we build intelligent, scalable, and cost-aware systems that deliver measurable business value.
The post The Cost Anatomy of AI Products: Understanding Token Economics and Model Selection first appeared on Creative Bits AI.
]]>
Multi-agent orchestration is redefining how enterprises deploy AI at scale. The first generation of AI applications concentrated on single-agent applications, a single model, a single prompt loop, and a single decision output. That works well for closed tasks such as … Read More
The post Multi-Agent Orchestration: When One AI Agent Isn’t Enough first appeared on Creative Bits AI.
]]>Multi-agent orchestration is redefining how enterprises deploy AI at scale. The first generation of AI applications concentrated on single-agent applications, a single model, a single prompt loop, and a single decision output. That works well for closed tasks such as summarization, classification, content writing, or structured extraction. But enterprise workflows are rarely one-step. They involve planning, verification, tool usage, constraint checking, human review, and conditional branching. As organizations move past AI experimentation, a consistent truth emerges: for AI to function as a practical operational layer, it needs more than a single agent.
Contemporary AI engineering is trending toward multi-agent orchestration patterns, in which a group of specialized agents is coordinated in a structured manner. A study by Google DeepMind on multi-agent systems demonstrates that distributed agent systems outperform monolithic models in challenging reasoning and task decomposition tasks. Similarly, Microsoft’s research on AutoGen shows that coordinated conversational agents increase reliability and reduce failure rates in lengthy workflows.
At CreativeBits AI, multi-agent orchestration is not a novelty experiment; it is a production necessity. Complex business processes require formalized collaboration between reasoning agents, validation agents, tool-execution agents, and governance layers.
1. The Supervisor–Worker Model: Centralized Coordination With Distributed Execution
The supervisor-worker architecture is one of the most widely adopted orchestration patterns. A central coordination agent breaks down a task into subtasks, assigns them to specialized worker agents, consolidates outputs, conducts quality control, and generates a final deliverable.

This mirrors classical distributed computing concepts and is well-documented in AI research. Microsoft’s AutoGen framework demonstrates how an orchestrating agent can manage specialized sub-agents — coding agents, retrieval agents, and validation agents — to complete complex tasks more reliably than a single agent attempting to handle the entire workflow.
The supervisor-worker model excels at accountability and structure. The supervisor enforces constraints, triggers rework on failed tasks, and maintains output consistency. Worker agents operate in narrower scopes, which improves determinism and reduces hallucination. OpenAI’s function-calling and tool-use capabilities further enable structured delegation, allowing agents to call APIs or external systems using explicit schemas.
This pattern is especially effective in enterprise contexts — compliance checks, financial reconciliation, legal drafting, and AI-assisted coding — where validation is as critical as generation. The supervisor is not just a generator; it is an orchestrator.
2. Peer Collaboration Frameworks: Decentralized Agent Cooperation
Not every workflow benefits from centralized control. For exploratory tasks or research-heavy processes, decentralized peer collaboration frameworks often outperform hierarchical designs. In this pattern, two or more agents engage each other conversationally, critiquing outputs, proposing revisions, and converging toward higher-quality results through structured dialogue.

Stanford’s research on multi-agent debate models shows that adversarial cooperation — where agents challenge and correct each other’s reasoning — meaningfully improves factual accuracy. The concept mirrors ensemble learning, where diversity across models reduces variance and error.
Peer collaboration models prove especially effective for creativity, brainstorming, policy analysis, or solving ambiguous problems. Rather than a single chain-of-thought, the system leverages parallel reasoning paths that are reconciled through consensus or voting.
That said, decentralized systems introduce coordination overhead. Without constraint mechanisms, conversations drift or become inefficient. Modern orchestration frameworks like LangGraph and CrewAI address this with structured dialogue policies and turn-taking logic to prevent looping and runaway execution.
At CreativeBits AI, we apply peer collaboration structures to high-uncertainty problems — strategic modeling, research synthesis, and multi-perspective evaluation — where diversity of reasoning enhances robustness.
3. Sequential vs. Parallel Execution: Designing Workflow Topology
A critical design decision in any multi-agent system is execution topology: do agents run in sequence or in parallel?

Sequential orchestration structures agents so that the output of one becomes the structured input for the next. This creates deterministic, traceable pipelines. For example, an intake agent classifies a request, a planning agent decomposes it, a retrieval agent collects context, a generation agent produces output, and a validation agent checks compliance. Each phase operates on pre-defined contracts.
Google’s MLOps guidance highlights the importance of modular pipelines for auditability and rollback control in production AI systems. Sequential architectures are especially appropriate in regulated industries where traceability is mandatory.
Parallel execution, by contrast, deploys multiple agents simultaneously on subtasks or alternative solution paths. Outputs are then aggregated or prioritized. Parallelism reduces latency in time-sensitive workflows and diversifies the solution space. This approach is increasingly common in compound AI systems, where specialized models handle retrieval, reasoning, and verification simultaneously before aggregation.
Parallel systems require robust arbitration logic. Without deterministic aggregation rules, conflicting outputs undermine reliability. Production systems address this through structured ranking, confidence scoring, and rule-based filtering layers.
At CreativeBits AI, we commonly hybridize both approaches, parallel generation for diversity, followed by sequential validation for safety and compliance.
4. Governance, Memory, and Failure Recovery in Multi-Agent Systems
Multi-agent systems expand capability, but they also multiply risk. When multiple agents interact dynamically, failure modes compound. Orchestration without governance is unpredictability at scale.

Observability and control layers are becoming a cornerstone of enterprise AI best practices. Microsoft’s responsible AI documentation emphasizes that production AI systems must include logging, auditing, and fallback mechanisms to ensure reliability. This requirement becomes even more critical in multi-agent environments.
Memory layers — capturing agent interactions, decision paths, and versioning — must be actively managed. Without persistent state management, agents cannot coordinate across long workflows. Systems also need timeout enforcement, retry logic, and circuit breakers to prevent cascading failures.
Failure recovery patterns are particularly important. If a worker agent produces invalid output, the supervisor can re-run the task with modified parameters, route the output to a validation agent, or escalate to a human-in-the-loop. These redundancy schemes are what separate brittle experimental systems from resilient production architectures.
At CreativeBits AI, we treat multi-agent orchestration as software architecture, not prompt experimentation. Every agent has defined responsibilities, explicit contracts, and observability hooks. All orchestration pathways are version-controlled and measured against performance KPIs.
The Future of AI Is Coordinated, Not Singular
Single-agent AI is rapidly being superseded by multi-agent systems. As enterprise workflows grow in complexity, orchestration patterns define whether AI functions as a tool or as infrastructure.
Supervisor-worker hierarchies provide structure. Peer collaboration improves reasoning quality. Sequential pipelines ensure traceability. Parallel execution accelerates resolution. Governance layers guarantee reliability. Together, these patterns form the engineering foundation of production-grade AI systems.
At CreativeBits AI, we build AI ecosystems where agents operate within deterministic structures, guided by observability, validation, and measurable business outcomes. In production environments, intelligence alone is not enough — coordination is what scales.
If your AI system still relies on a single monolithic agent, it may be time to architect something stronger.
The post Multi-Agent Orchestration: When One AI Agent Isn’t Enough first appeared on Creative Bits AI.
]]>
AI agents have moved from experimental to essential. But how are enterprises actually building and deploying them? In partnership with research firm Material, Claude surveyed over 500 technical leaders across industries and company sizes to understand how organizations are deploying … Read More
The post How Enterprises Are Building AI Agents in 2026 first appeared on Creative Bits AI.
]]>AI agents have moved from experimental to essential. But how are enterprises actually building and deploying them?
In partnership with research firm Material, Claude surveyed over 500 technical leaders across industries and company sizes to understand how organizations are deploying AI agents today, and where they see opportunity ahead.
The findings reveal a clear pattern: organizations are shifting from simple task automation to complex, multi-step workflows that span teams and business functions.
What the Data Shows About Enterprise AI Agent Adoption
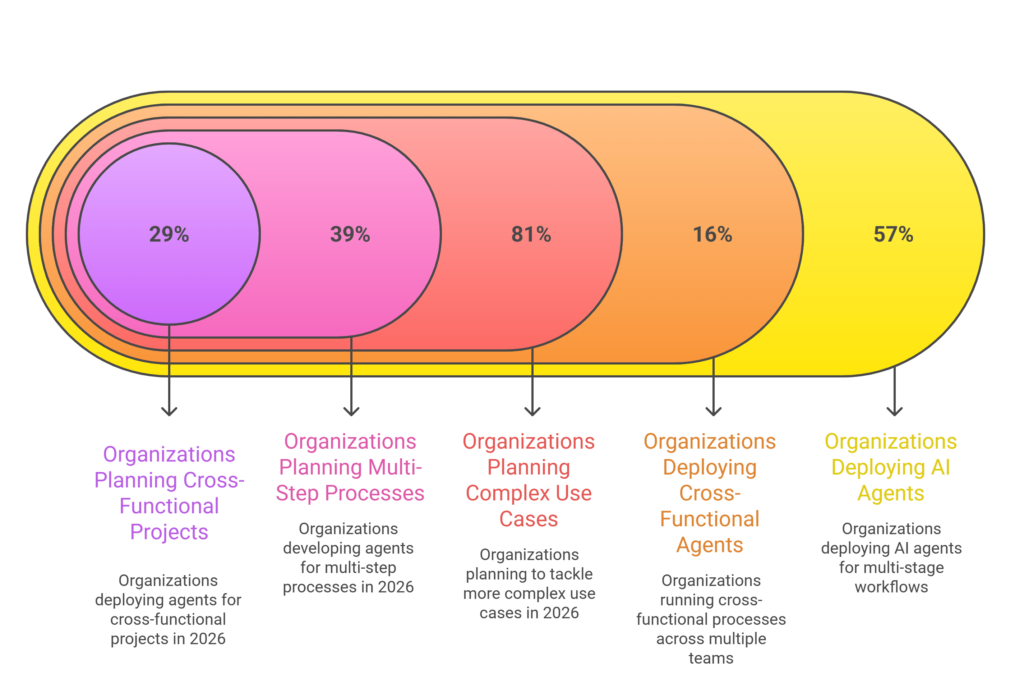
More than half of organizations (57%) now deploy AI agents for multi-stage workflows, with 16% running cross-functional processes across multiple teams. In 2026, 81% plan to tackle more complex use cases, including 39% developing agents for multi-step processes and 29% deploying them for cross-functional projects.
Coding leads adoption. Nearly 90% of organizations use AI to assist with development, and 86% deploy agents for production code. Organizations report time savings across the entire development lifecycle: planning and ideation (58%), code generation (59%), documentation (59%), and code review and testing (59%).
But the impact extends well beyond engineering. Data analysis and report generation (60%) and internal process automation (48%) rank among the highest-impact use cases. Looking ahead, 56% plan to implement agents for research and reporting over the next year.
Perhaps most notably, 80% of organizations report their AI agent investments are already delivering measurable economic returns.
What AI Agents Look Like in Practice
The organizations seeing results are treating agents as core infrastructure — not experiments.

Thomson Reuters uses Claude to power CoCounsel, their AI legal platform. Lawyers who once spent hours manually searching through documents can now access 150 years of case law and 3,000 domain experts in minutes.
Cybersecurity company eSentire compressed expert threat analysis from 5 hours to 7 minutes, with AI-driven analysis aligning with their senior security experts 95% of the time. In healthcare, Doctolib rolled out Claude Code across its entire engineering team, replacing legacy testing infrastructure in hours rather than weeks and shipping features 40% faster.
The retail sector is seeing similar gains. L’Oréal achieved 99.9% accuracy in conversational analytics, enabling 44,000 monthly users to query data directly rather than wait for custom dashboards.
The Path Forward for Enterprise AI Agents
The question for leaders in 2026 isn’t whether to adopt AI agents — it’s how to scale them strategically. The data points to three primary challenges: integration with existing systems (46%), data access and quality (42%), and change management needs (39%).
Nine in ten leaders report that agents are shifting how their teams work, with employees spending more time on strategic activities, relationship building, and skill development rather than routine execution.
This transition requires purpose-built infrastructure: models optimized for coding and enterprise workflows, frameworks like the Agent SDK, and tools like Claude Code that help teams move from prototype to production faster.
At Creative Bits AI, we’re seeing the same trajectory with our enterprise clients. While coding has been the proving ground for AI agents, it’s just the beginning. As agents expand into research, customer service, financial planning, and supply chain operations, the organizations that build expertise now will capture disproportionate value as the technology matures.
Are you ready to move from AI experimentation to enterprise-scale deployment? Contact Creative Bits AI to build your AI agent strategy.
The post How Enterprises Are Building AI Agents in 2026 first appeared on Creative Bits AI.
]]>
The data flywheel is the engine behind the world’s most successful AI products. Unlike traditional software that remains static after deployment, AI systems built with a data flywheel get better as they learn—both directly through users and indirectly through outcomes … Read More
The post The Data Flywheel Effect: How Your AI Products Get Smarter with Every Customer Interaction first appeared on Creative Bits AI.
]]>The data flywheel is the engine behind the world’s most successful AI products. Unlike traditional software that remains static after deployment, AI systems built with a data flywheel get better as they learn—both directly through users and indirectly through outcomes and feedback loops designed into the product. The largest language models and corporate copilots now operate on this principle: a reinforcing cycle in which usage creates data, data enhances models, better models increase adoption, and increased adoption generates even more data.
This data flywheel effect explains why early traction is such a crucial element in AI markets—and why companies that view AI as a fixed implementation cannot compete. The McKinsey State of AI report suggests that organizations incorporating continuous learning loops within AI systems have a much higher chance of reporting material business impact compared to those that deployed only one model. This is a pattern we see repeatedly at Creative Bits AI: AI products that gain ground in production perform better than the ones that reach their peak at launch.
1. Understanding the Data Flywheel in AI Systems
The data flywheel is not merely an architectural metaphor; it is an operational reality. Every significant interaction between a user and an AI system produces signals: prompts, responses, corrections, choices, rejections, time-to-completion, downstream task success, and escalations. When these signals are captured, labeled (explicitly or implicitly), and re-integrated into training or tuning pipelines, the system evolves.

This phenomenon has been widely reported in platform economics and AI product design. Andreessen Horowitz (a16z) defines the data flywheel as self-reinforcing loops in which improved products attract more users, generating better data that further enhances the product. The flywheel effect is amplified in artificial intelligence due to the ability to learn not only at the model level but also across prompts, routing logic, retrieval layers, and decision policies.
More importantly, data alone is insufficient. Without proper instrumentation, governance, and learning pipelines, interaction data becomes exhaust instead of fuel. The data flywheel only rotates when data is intentionally organized into feedback loops.
2. Feedback Loops: Turning User Behavior Into Learning Signals
Feedback loops—mechanisms that transform human interaction into machine improvement—form the core of the data flywheel. These loops may be explicit or implicit. Explicit feedback includes thumbs-up/down ratings, corrections, annotations, and human review. Implicit feedback encompasses abandonment rates, retries, follow-up prompts, task completion success, and latency tolerance.

The significance of feedback-driven improvement is explicitly emphasized in OpenAI’s documentation on training and model evaluation, noting that real-world usage cues are essential to improving reliability and model compliance over time. Similarly, Google highlights continuous assessment through live traffic signals as a best practice for deployed ML systems.
Effective feedback loops powering your data flywheel are not simply about training the model. They record learning as a by-product of regular usage. When users rephrase prompts, override suggestions, or escalate to a human, they create high-value signals of model failure modes. Signal capture and routing systems can systematically capture these inputs, enhancing improvement speed compared to systems that depend solely on offline retraining cycles.
3. RLHF and Beyond: Learning From Humans at Scale
Reinforcement Learning from Human Feedback (RLHF) has emerged as one of the most powerful methods for designing modern AI systems. RLHF enables models to optimize not only for likelihood or accuracy but also for human preference, safety, and usefulness. OpenAI’s original research on RLHF demonstrates how human rankings and evaluations can be converted to reward models and used to optimize policies.
However, in production AI products, RLHF represents only one component of the learning ecosystem that powers the data flywheel. According to Microsoft, enterprise AI systems increasingly integrate RLHF with continuous fine-tuning, retrieval-augmented learning, and post-deployment feedback loops to meet evolving user demands. This hybrid methodology enables systems to improve without causing behavioral breaks or regressions.
The critical engineering shift is treating human feedback as infrastructure, not annotation. Feedback pipelines must be versioned, auditable, bias-conscious, and aligned with business goals. At Creatuve Bits AI, we build RLHF-inspired loops where improvement is tied to operational KPIs—accuracy, resolution time, and cost per task—not abstract benchmarks.
4. Continuous Improvement Cycles: From Static Models to Living Systems
The most advanced AI products are living systems, not static models. Continuous improvement cycles unite monitoring, evaluation, learning, and redeployment in a closed loop that keeps the data flywheel spinning. Stanford’s AI Index report demonstrates that the most successful AI applications focus on post-deployment monitoring and iteration as core deployment practices, not optional features.

These cycles typically involve performance monitoring, error clustering, purposeful data collection, controlled updates, and rollback capabilities. Notably, not all improvements require retraining a foundation model. Prompt refinement, retrieval optimization, tool routing, and policy constraints often deliver faster, more cost-effective results.
Amazon Web Services (AWS) reinforces this principle by highlighting constant experimentation and iteration based on feedback as best practices for maintaining AI system performance at scale. Organizations lacking these cycles typically experience model drift, reduced user confidence, and escalating operational expenses.
Why the Data Flywheel Is a Strategic Advantage
The data flywheel effect explains why AI leaders continue to extend their lead. Learning systems that improve with each interaction compound their advantage, while non-adaptive deployments stagnate. This isn’t about gathering more data—it’s about engineering learning into the product itself.
At Creative Bits AI, we help organizations design AI systems where feedback is deliberate, learning is governed, and improvement is measurable. With RLHF-inspired pipelines, real-time evaluation, and controlled iteration, we approach AI products as evolving platforms, not static artifacts.
If your AI system looks the same as it did six months ago, then your data flywheel isn’t spinning. And in today’s AI landscape, standing still means falling behind.
Book a session with us at Creative Bits AI to build AI systems that get smarter with every interaction and turn usage into a sustainable competitive advantage.
The post The Data Flywheel Effect: How Your AI Products Get Smarter with Every Customer Interaction first appeared on Creative Bits AI.
]]>
Generative AI and large language models (LLMs) have transformed the capabilities of various industries, from contract summaries to AI assistant prompting. These models, however, are non-deterministic in nature, even with their power, i.e., identical prompts will yield varying outputs when … Read More
The post From Prompt to Pipeline: Engineering Deterministic Outputs from Non-Deterministic AI Models first appeared on Creative Bits AI.
]]>Generative AI and large language models (LLMs) have transformed the capabilities of various industries, from contract summaries to AI assistant prompting. These models, however, are non-deterministic in nature, even with their power, i.e., identical prompts will yield varying outputs when triggered. This variability may be tolerable in experimentation or prototypes; however, in a production system driving workflows in an enterprise, uncertainty is a grave threat. Building deterministic AI pipelines ensures that systems provide predictable and consistent business output and traceable results that meet the business demands and regulatory requirements.
The key aspects of filling this gap are AI observability and pipeline engineering. Instead of considering models more like low-level box models that autogenerate results, forward-looking engineering teams are building deterministic AI pipelines – overlay systems that restrict, validate, and control AI behavior in such a way that behaviors are predictable even as models are probabilistic at their core. Such pipelines are necessary to minimize error rates, increase reliability, and scale AI to make it a trusted system.
This article unboxes the movement of the organizations from frenzied experimentation to deterministic AI pipelines that are engineered, and our strategies to promptly and successfully handle constraints to enable the prompting of outputs, parsing, and validation to create reliable and enterprise-ready AI outputs.
Why Prompt Engineering Alone Cannot Guarantee Determinism
Classical prompt engineering – writing the text you are sending to an LLM – is a significant first step, but not enough to be a production control mechanism. Some prompts affect the model but compel no strict behavior. Despite having well-thought-out prompts, sampling temperature, context drift, or even minor shifts in input distribution can change the outputs in an unpredictable way. This is why deterministic AI pipelines require more than just well-crafted prompts.

The insights on AI observability frameworks have come about at exactly the time when it is necessary to know what occurs within deterministic AI pipelines, not only what users feed in, but what they need to be reliable. Observability means constant monitoring of the quality of data input, model output, decision route, and drifted trajectory with time to identify silent failures before they can influence business metrics, as per Actian Corporation. In the absence of this visibility, the organization is left with systems that may seem healthy on the infrastructure layer, but silently degenerate in terms of model performance or quality of output.
Therefore, it is impossible to construct deterministic AI pipelines only by means of prompts. As an alternative, prompts are viewed as interfaces (similar to API contracts) that should be verified against schemas, filtered through logic layers, and verified against the operation of drift detection systems to verify that outputs are of a quality expected by the user.
Engineering Deterministic Outputs: Constraint-Based Prompting and Structured Parsing
The key first ingredient of deterministic AI pipelines is constraint-based prompting, in combination with structured output parsing. Instead of creating text freely, prompts are required to support a format, which can be programmatically verified, e.g., JSON, XML, or domain-specific vernacular.

Formatted output types enable the developer to specify what a valid output should resemble and deny any possible output that does not match. The following is an example where the generative systems can be programmed to produce JSON with predetermined fields like status, confidence, and payload. The downstream systems have the ability to interpret this organization and correct any discrepancies or format breaches immediately they receive the answer from the AI.
Besides schema enforcement, observability frameworks like Arize AI and Maxim AI also offer specific drift detection and performance monitoring of model predictions in production systems. Such tools track not only error rates but also distributional changes in input features and output semantics, both important when model behavior is expected to go wrong according to Monte Carlo and GetMaxim.ai. It is proven that constraint-based prompting, along with strict parsing, can convert an unpredictable generative output into a deterministic contract that can be enforced and reasoned about by systems.
This is consistent with current ML observability practices, in which outputs are processed in a similar way as telemetry: they are logged, timed, and sent into monitoring layers, which raise an alert when a deviation is detected.
Validation Chains and Guardrails: Ensuring Quality and Compliance

Still, in structured outputs, deterministic AI pipelines should have validation chains, which are modular checks that verify all outputs against a chain of business and technical requirements before production systems use them. These chains usually consist of:
- Schema validation: Ensuring the output matches the expected format and required fields.
- Semantic checks: Confirming that values make sense within the business domain (e.g., risk scores within expected ranges).
- Model confidence and metadata: Leveraging confidence scores or other internal signals to determine reliability.
- Cross-model verification: Running secondary models or heuristics to verify critical outputs.
Such a system of checks and balances creates strength. Outputs that fail to pass the validation may be retriggered with modified prompts or sent to fallback processes that a human can inspect or to logic-based fallback.
Moreover, a vital guardrail of validation chains is drift detection. One of the most commonly known problems that present themselves in production AI systems is model drift. The statistical properties of data tend to change over time, and studies have demonstrated that in the absence of control, the error rates of such models may skyrocket in just a few months after implementation, as per OpenLayer. Observability systems identify the drift at runtime so that deterministic AI pipelines can indicate and repair poor performance.
Combined, these validation and observability layers avoid silent failures such that AI responses are not only likely but also reliable and predictable.
Fallback Mechanisms: Graceful Degradation and Human-in-the-Loop
The most sophisticated deterministic AI pipelines have to make assumptions that there are going to be occasions when models will not give us any businessable results. Good AI engineering has fallback mechanisms – alternative paths that will keep the continuity in case primary generative paths fail.

Fallbacks can include:
- Rule-based logic: Simple deterministic rules to cover edge cases.
- Cached responses: Pre-validated outputs for frequently asked or critical queries.
- Secondary lightweight models: Smaller, specialized models that verify or replace LLM outputs in constrained scenarios.
- Human-in-the-loop escalation: Routing uncertain cases to human experts for final judgment, especially in regulated domains.
Fallback strategies are particularly crucial during work in the high-risk areas of industry, like finance, healthcare, and compliance, where the wrong choice can be extremely expensive. The observability systems assist in fallback mechanisms with real-time signals of the point at which the outputs are to be escalated or rerouted. Consider the case of observability tools identifying an anomaly or drift pattern above an established threshold; deterministic AI pipelines can automatically revert to slower, but more reliable, fallback paths.
Fallback mechanisms in the real world reduce unpredictability to controlled risk and make systems both dynamic and reliable.
From Prompt to Pipeline with CBAI
The implementation of AI in deterministic production systems needs to be a planned engineering process instead of a non-deterministic research undertaking. The engineering should be timely. Deterministic outputs are obtained by properly designed deterministic AI pipelines, which impose structure, test semantics, and watch drift, and combine fallback layers. We design these pipelines for clients of Creative Bits AI (CBAI) who require compliant, scalable, and reliable AI. We ensure that probabilistic models are made a reliable business infrastructure by integrating observability across the lifecycle – between ingesting data and tracking inferences. When your AI systems, in theory, work on trials but act unpredictably when you put them on production load, it is not only the model that is the problem; it is the pipeline—partner with CBAI to create production-scale deterministic AI pipelines that provide confident yet deterministic output.
The post From Prompt to Pipeline: Engineering Deterministic Outputs from Non-Deterministic AI Models first appeared on Creative Bits AI.
]]>
The uptake of artificial intelligence has been fast, yet the success of AI projects is disproportional. Most organisations invest a lot in pilots, chatbots, and recommendation engines, but many of them are unable to stabilise these systems in a scalable … Read More
The post AI Observability: The Missing Link Between AI Pilots and Production Deployments first appeared on Creative Bits AI.
]]>The uptake of artificial intelligence has been fast, yet the success of AI projects is disproportional. Most organisations invest a lot in pilots, chatbots, and recommendation engines, but many of them are unable to stabilise these systems in a scalable production environment. According to Gartner, over half of AI projects do not reach the pilot stage because of operational risks, and not the model performance problem. It is not the intelligence, but the invisibility, which is the core problem.
AI systems do not act in a way that is similar to regular software. Their outputs are context-dependent, probabilistic, and responsive to data, prompts, and user behaviour changes. Lacking tools to observe, track, and interpret such behaviours, AI deployments will be black boxes that harm trust and lead to systemic risk. AI observability has thus become the lost middle ground operational layer, between the success of experiments and the reliability of an enterprise-scale.
Why Traditional Monitoring Breaks Down in AI Systems
Conventional observability tools emphasise the health of infrastructure in terms of latency, uptime, and error rates. These signals are still significant, but they do not indicate whether an AI system is making good decisions. A model can be technically healthy, but because of either data drift or changing user intent will silently become inaccurate in its predictions. According to McKinsey, one of the most frequent factors leading to the underperformance of AI systems in production settings is model decay due to uncontrolled data drift.

Generative AI and agentic systems exacerbate this. Even in large language models (LLM) applications, prompt updates, changes in retrieval logic, or tool orchestration can result in a dramatic behaviour change, and no model weights change. According to OpenAI, the timely change in prompts and contextual features has become one of the main causes of unintended regressions in applications based on the use of LLM. The classical monitoring is unable to identify these semantic failures since the system has not technically crashed.
AI observability redefines monitoring in terms of the quality of decisions. Rather than answering the question of system running, it assesses whether the output is as per the expectation, policies, and business objectives. The shift to AI observability is critical for organisations that want to scale AI responsibly and sustainably.
Core Pillars of AI Observability at Scale

Successful AI observability is based on ongoing transparency on model behaviour, data integrity, and its relevance. The first pillar is model and data drift detection, which detects the dissimilarity between the training data and the actual inputs of the world. WhyLabs shows that early warning of feature drift and prediction drift can be used to eliminate downstream failure and expensive retraining loops by a significant margin. Drift monitoring makes models proactive and not reactive.
The second pillar is prompt and workflow version control that has become inseparable in the systems of generative AI. According to Datadog, which considers prompts as versioned artefacts (as with code), the risk of regression is minimized, and the reproducibility of production deployments is enhanced. Teams can analyse and recreate decision trails and accurately identify failures by recording timely versions, retrieval sources, and tool calls.
The third pillar is real-time monitoring of performance and business results. AWS states that the production AI systems should not be measured solely based on accuracy but rather on the metrics of real impact (i.e., the rate of task completion, cost-efficiency, and user satisfaction) on a real-world scale. By combining technical telemetry and business KPIs, AI observability platforms help an organisation constantly confirm that AI systems are providing quantifiable value.
Embedding AI Observability from Pilot to Production
The decision to add AI observability later is one of the most frequently used reasons behind AI failure. According to Forrester research, retrofitting governance and monitoring into production AI systems is a highly costly and ineffective strategy compared to production AI systems built with AI observability in mind. Engineering Production-grade AI Production-grade AI engineering considers all model invocations to be traceable.
This refers to recording the inputs, outputs, the confidence scores, and the intermediate reasoning steps into organised formats, which are replayable and auditable. Observability-by-design is a requirement that Google Cloud underlines as a prerequisite to the deployment of AI systems in regulated and safety-critical settings. The non-negotiableness of the possibility to explain and audit decisions increases with increasing autonomy of the AI agent, which performs multi-step plans across APIs.

Organisational readiness is also of the essence. The engineering, data science, product, and risk teams will have to work together to achieve AI observability. Shared dashboards, ownership frameworks, and escalation procedures can ensure that anomalies lead to action as opposed to confusion. With AI observability insights directly into retraining pipelines, timely updates, and enforcement of policies, AI systems evolve as they go, rather than becoming stagnant, silent observers.
The Future of AI Observability and Enterprise Readiness
With the transition of enterprises to compound and agentic AI architectures, AI observability will set the border between experimental innovation and mission-critical infrastructure. According to Gartner, AI observability platforms will become the standard feature of enterprise AI stacks as organisations aim to operate risk, compliance, and operational resilience at scale.
The AI observability systems of the future will be able to include automated root-cause analysis, second-level AI models that identify the reason behind anomalies, and real-time policy enforcement tools that can stop or reroute decisions when risk thresholds are met. This development is an extension of DevOps and cloud observability and is an indication that AI observability is not an option, but a prerequisite.

The Creative Bits AI Perspective
AI observability is the foundation of production-grade AI systems at Creative Bits AI. It is not about being smart that generates value, but visibility. All of our AI systems are designed with timely versioning, drift identification, and performance-based monitoring baked in since the first day, so that it keeps transparency and accountability at scale.
This will help us to get organisations out of flashy demonstrations and into reliable production systems, AI that works in the real world and not just in a lab. When your AI programs are not just scaling effectively or are black boxes when deployed, then AI observability is what you need.
The post AI Observability: The Missing Link Between AI Pilots and Production Deployments first appeared on Creative Bits AI.
]]>
During most of the previous ten years, the development of artificial intelligence was determined by the volume and capacity of specific models. Big data, greater model dimensions, and more exact benchmarks became colloquially referred to as innovation. Since the first … Read More
The post The Compound AI Systems Revolution: Why Single-Model Solutions Are Already Obsolete first appeared on Creative Bits AI.
]]>During most of the previous ten years, the development of artificial intelligence was determined by the volume and capacity of specific models. Big data, greater model dimensions, and more exact benchmarks became colloquially referred to as innovation. Since the first machine learning pipelines, up to the latest large language models (LLMs), organizations have believed that more intelligent models were better. But with AI entering the field of experimentation to mission-critical enterprise use, this assumption is crumbling fast. Issues of regulatory compliance, multi-step reasoning, real-time decision-making, domain specificity, and system reliability that are part of the problems a real-world business must solve are becoming inaccessible to single-model architectures.
A new paradigm emerged in 2024 and 2025: compound AI systems. Compound systems combine multiple specialized models, tools, memory layers, and control logic into cohesive, production-grade integration solutions, as opposed to relying on a single, monolithic model to perform all tasks. The change represents the precedent shifts in software engineering, whereby monoliths were replaced by microservices to allow scalability, resiliency, and maintainability. The forces exist in AI.
The leading companies like IBM, Google Cloud, Databricks, and OpenAI have started promoting multi-model, orchestrated AI systems, pointing to the fact that enterprise-grade intelligence needs more than basic generative capability, as per IBM and Databricks. With AI being pushed into customer operations by businesses, supply chain, finance, healthcare, and controlled environments, the shortcomings of single-model systems, hallucinations, brittleness, lack of traceability, and the lack of grounding into domain are becoming hard to ignore.
This piece examines the reasons why single-model AI solutions are already becoming outdated, why compound AI systems are transforming the nature of large-scale intelligence, and what this implies for organizations developing AI systems that should be reliable in production, not only in demos.
1) The Reason behind the single-model AI Architectures hitting their limits
Even highly trained LLMs are single-model AI, generalized reasoning engines that are trained to give approximations of intelligence on a broad set of tasks. Though this generality is robust, it also comes with inherent weak points when applied in complicated and high-risk business situations. Context fragility is one of the significant limitations. LLMs think in a probabilistic way after the patterns of training data, and as such, they are also susceptible to hallucinations when acting beyond their well-defined bounds or when having partial information.

Domain misalignment is another problem that is a critical challenge. Businesses work in tightly-tight areas, such as finance, healthcare, logistics, and legal compliance, where precision, traceability, and policy compliance are inarguable. One general-purpose model is not highly specialized in all these aspects at once, and thus cannot give reliable results, unless highly constrained or additionalized. According to Google Cloud research, the error rate in production workflows is much higher with models whose operations are not grounded or have no policy layers.
Monolithic AI systems also have problems with scalability and maintainability. When one model performs all the reasoning, retrieval, decision-making, and execution, then a small modification can only be achieved through a long retraining or immediate reengineering. This brings about brittle systems that are hard to debug and even audit. Databricks emphasizes that a single-model pipeline-based enterprise finds it challenging to scale its AI systems with business fluctuation, leading to an increase in technical debt but not a compounding value.
Above all, single-model systems do not represent the way the intelligence works within organizations. There is an intrinsic distribution in human decision-making, that is, various teams, tools, and processes have different parts of a problem. Assuming that one model can produce this complexity, it would mean disregarding decades of organizational design and systems engineering knowledge. With the maturity of AI implementation, companies are finding that intelligence should be engineered, rather than being trained.
2) What Compound AI Systems Are- and Why They Work Better
Compound AI systems are a paradigm of transition to system-centric intelligence instead of model-centric thinking. Compound systems do not consider models and AI as subsystems of the larger architecture, but they view models as a part of it. These systems usually bring together various AI models, deterministic logic, and external tools, layers of memory, and orchestration to resolve problems in a complex manner, as per IBM.

The functional specialization is at the center of the compound systems. Various models are charged with differing tasks; one model could be used to do natural language understanding, another to do classification or prediction, yet the aspect of retrieval will be the task of retrieving confirmed information in a structured or unstructured data source. These components are then organized by orchestration layers that guarantee that tasks are executed in the appropriate order instead of using ad-hoc chaining of prompts. Such a method has a significant positive impact on reliability, interpretability, and control.
Databricks defines compound AI as the logical next step of enterprise AI, in which generalist LLMs are enhanced with specialist models and controlled by workflow logic, which ensures correctness and consistency. IBM also stresses that compound systems enable enterprises to integrate symbolic reasoning, statistical learning, and generative capabilities, which cannot be effectively applied by any model alone.
This shift is supported by empirical evidence. According to the 2025 Google Cloud AI Infrastructure Report, organizations that build their AI infrastructure with retrieval-augmented generation (RAG), policy enforcement, and orchestration layers achieve a larger than 40% reduction in hallucination levels in production settings. The gains are not incremental; they are radical in nature and ensure the reliability of AI systems at scale.

Systems based on compounds make evolution and modularity possible as well. Single aspects may be improved, changed, or dialed without causing instability to the whole system. This is a best practice in contemporary software development and enables AI solutions to evolve in tandem with business requirements, rules, and technologies.
3) The Foundation of Large-Scale, Production-Grade Intelligence Compound AI
The true strength of the compound AI systems is apparent in the large scope. With the emerging organizations using AI to implement thousands of users, departments, and varied geographies, the issue of governance, observability, and resilience becomes critical. These requirements are inherently supported in terms of compound architectures through the separation of concerns at different layers.

Memory layers and governance are essential in a system at production-grade. The long-term memory stores, audit logs, and controls that are rule-based make sure that AI decisions can be reversed and traced, which are essential conditions in regulated industries. The 2024 AI Risk Management Survey conducted by Forrester also suggests that enterprises that have layered governance architectures have a significantly higher probability of passing internal compliance audits in comparison to enterprises that use standalone AI models.
The emerging agentic AI, where autonomous agents perform tasks, engage with tools, and coordinate towards goals, is also consistent with compound systems. Such agents are not monoliths but coordinated systems that depend on various elements to think, plan, and behave securely. Studies published in 2025 by Cornell University point to the fact that the agentic systems that lack orchestration and policy layers have much higher chances to fail or act unpredictably in the real-life context.
Compound AI allows quantifiable ROI, as far as the business is concerned. Organizations will be able to measure performance at every level, such as retrieval accuracy, decision latency, error rates, and business performance, instead of the general gains in productivity. This openness makes AI more of an experimental feature than a responsible infrastructure. According to Artefact, compound systems enable companies to tie the performance of AI to the KPI of the business instead of artificial standards.

Simply, compound AI systems are not only better scaled, but they are also better-behaved in the real world.
4) Why the Switch to Compound AI Is Unavoidable?
The shift towards compound AI systems is not a fad, but a structural reaction to the facts of enterprise complexity. Since AI will be ingrained in business processes, failure, ambiguity, and even opaqueness become unacceptable. These expectations cannot be fulfilled on a regular basis by single-model systems.

Ecosystems of technology are already becoming more adaptive. OpenAI, Anthropic, and Google are increasingly trying to establish their models as part of a larger system, not as solutions on their own. Systems like LangChain, LlamaIndex, and CrewAI do exist because orchestration, memory, and control cannot be added later to the system; they need to be built into it.
This change is enhanced by economic pressures. Raising bigger models is costly and unsustainable as the key to improvement. Compound architectures are more intelligent combinations of existing models, which means that they will make more sense by tapping into existing models and reducing marginal costs, yet they will be more reliable. According to Databricks, larger systems with monolithic models usually cost more to operate compared to smaller ones composed of multiple systems.
Lastly, it is required by organizational maturity. Businesses that have been able to scale software systems are aware that intelligence, just as software, needs to be modular, testable, and governable. AI is no exception. It is not the largest model that will have its future, but the best-designed system.
Compound AI– The CBAI View of Building the Future
The mono-model AI dominance has faded away. With organizations moving out of experimentation into actual implementation, it is becoming obvious that intelligence is something that must be designed and not something that has to be improvised. Inspired by specialised models, coordination layers, governance structures, and quantifiable results, compound AI systems comprise the architecture of scalable, trustworthy, enterprise-grade intelligence.
At Creative Bits AI, we develop AI systems in the way modern software must be developed, i.e., modular, observable, governed, and aligned with business reality. We do not pursue models of larger size just because it is bigger. Rather, we design scalable AI systems that run consistently in the business, develop along with your company, and provide quantifiable benefits.
When your AI projects are failing to scale out of pilots, or you are willing to create systems that can scale without collapsing, it is time to reconsider your architecture.
Partner with Creative Bits AI to develop competitive advantage compound AI systems.
Let’s Engage Via A Meeting Session: https://outlook.office.com/book/[email protected]/s/XpIkeeYl5kKf1lwuHiyiig2?ismsaljsauthenabled
The post The Compound AI Systems Revolution: Why Single-Model Solutions Are Already Obsolete first appeared on Creative Bits AI.
]]>
The artificial intelligence landscape is evolving rapidly, with generative AI vs traditional AI becoming a critical decision point for businesses. According to a McKinsey report, nearly 40% of new AI investments target generative AI, yet traditional AI still powers over … Read More
The post Understanding the Difference Between Generative AI and Traditional AI first appeared on Creative Bits AI.
]]>The artificial intelligence landscape is evolving rapidly, with generative AI vs traditional AI becoming a critical decision point for businesses. According to a McKinsey report, nearly 40% of new AI investments target generative AI, yet traditional AI still powers over 80% of production systems today.
At Creative Bits AI, we specialize in hybrid AI architectures that combine the reliability of traditional AI with the creative power of generative systems. This comprehensive guide explains the key differences between generative AI and traditional AI to help you make informed implementation decisions.
Quick Comparison: Generative AI vs Traditional AI
| Aspect | Traditional AI | Generative AI |
|---|---|---|
| Primary Function | Prediction & Classification | Content Creation & Generation |
| Data Requirements | Labeled, structured data | Unlabeled, unstructured data |
| Training Approach | Supervised learning | Foundation models with fine-tuning |
| Interpretability | High (explainable decisions) | Lower (post-hoc explanations) |
| Use Cases | Fraud detection, risk scoring | Content creation, conversational AI |
1. Core Functional Difference: Prediction vs Creation
How Traditional AI Works
Traditional AI excels at pattern recognition and prediction. These systems analyze historical data to:
- Assess credit risk
- Detect fraudulent transactions
- Forecast demand
- Diagnose medical conditions
- Score customer behavior
Traditional AI relies on structured data and statistical correlations to make deterministic decisions based on predefined rules.
How Generative AI Works
Generative AI creates new, original content by learning from vast datasets. Unlike traditional AI that predicts outcomes, generative systems:
- Generate text, images, code, and multimedia
- Use unstructured data for training
- Employ abductive inference to reason through ambiguous situations
- Create content never seen before
According to Google DeepMind, generative models can “infer plausible explanations of events based on the absence of evidence,” making them ideal for scenarios requiring creativity and contextual reasoning.
The Key Distinction
Traditional AI asks: “What will happen based on historical patterns?”
Generative AI asks: “What could we create that doesn’t exist yet?”
2. Data Requirements: Labeled vs Unlabeled Training

Traditional AI Data Challenges
IBM’s AI Adoption Index reveals that 73% of enterprise teams cite data labeling as their biggest barrier to AI deployment. Traditional AI requires:
✓ Massive volumes of labeled data
✓ Correctly structured inputs mapped to outputs
✓ Clean, high-quality datasets
✓ Supervised learning approaches
✓ Significant data preparation investment
Example: Training a fraud detection model requires thousands of labeled transactions marked as “fraudulent” or “legitimate.”
Generative AI Data Advantages
Generative AI democratizes AI adoption by learning from unlabeled data:
✓ Trains on trillions of tokens from web text, code, books
✓ Foundation models (GPT-4o, Gemini, Llama 3) understand natural language
✓ Fine-tuning or RAG adds domain specificity
✓ No need for millions of labeled examples
✓ Faster deployment cycles
Trade-off: While generative AI reduces labeling costs, AWS’s 2025 Enterprise AI Survey shows businesses must invest more in governance and oversight to prevent hallucinations and ensure factual accuracy.
3. Interpretability and Control: Transparency vs Flexibility

Traditional AI: Explainable and Auditable
Traditional AI systems offer:
- Fixed decision rules and transparent logic
- Defined thresholds and feature weights
- Predictable, repeatable outputs
- Full auditability for regulatory compliance
- Clear cause-and-effect relationships
Industries with strict regulations (finance, healthcare, insurance) rely on traditional AI’s interpretability.
Generative AI: Powerful but Opaque
Generative AI uses neural networks for implicit reasoning through multiple processing layers. Challenges include:
⚠ Less interpretable decision-making
⚠ “Post-hoc” explanations that aren’t verifiable traces
⚠ Requires guardrails and governance frameworks
⚠ Needs structured oversight mechanisms
Microsoft’s 2025 Responsible AI research shows that combining LLMs with structured governance layers reduces unsafe outputs by 61% but requires engineered oversight.
Enterprise Control Mechanisms
At Creative Bits AI, we implement:
- RAG-pipelined processes
- Policy-based governance systems
- Deterministic tool enforcement
- Output filtering mechanisms
- Constrained memory and permission boundaries
- Complete audit trails
Our agentic orchestration frameworks ensure generative AI operates under enterprise-grade controls.
4. Deployment Architecture: Single-Task vs Ecosystem

Traditional AI Deployment
Traditional AI systems are typically:
- Single-purpose (classification, scoring, ranking)
- API-integrated or embedded in backend systems
- Predictable lifecycle with periodic retraining
- Straightforward monitoring and maintenance
- Lower operational complexity
Generative AI Deployment Complexity
Generative AI exists within complex ecosystems comprising:
🔧 Vector databases for knowledge retrieval
🔧 API routing and orchestration layers
🔧 Long-term memory systems
🔧 Safety validators and guardrails
🔧 Multi-agent coordination frameworks
🔧 Tool integration and monitoring
Critical Insight: Deloitte’s 2025 State of AI Platforms Report found that 95% of generative AI pilots fail due to architectural misalignment—not model performance. Teams consistently underestimate the engineering complexity of agentic operations.
CBAI’s Agentic Infrastructure Approach
Our deployment framework includes:
- Comprehensive action logging
- Real-time tool usage monitoring
- Business logic governance
- Compliance-ready architectures
- Production reliability safeguards
- Reduced operational risk
5. Use Cases: Where Each AI Paradigm Excels

Best Use Cases for Traditional AI
Deploy traditional AI when you need:
✅ Fraud Detection – Pattern recognition in transaction data
✅ Risk Scoring – Credit assessments with explainable decisions
✅ Predictive Maintenance – Equipment failure forecasting
✅ Medical Diagnostics – Image classification with high accuracy requirements
✅ Demand Forecasting – Inventory and supply chain optimization
When to choose traditional AI: Mission-critical operations requiring accuracy, explainability, and regulatory compliance where creative variation poses risks.
Best Use Cases for Generative AI
Deploy generative AI for:
🚀 Autonomous Customer Support – Conversational agents handling complex queries
🚀 Knowledge Retrieval – Semantic search across enterprise documents
🚀 Meeting Summarization – Automated documentation and insights
🚀 Content Generation – Marketing copy, reports, and creative assets
🚀 Workflow Automation – Processing ambiguous, unstructured inputs
With multimodal capabilities (text, images, audio, charts), generative AI has become the primary human-system interface for enterprise applications.
The Hybrid Future: Best of Both Worlds
Gartner’s AI Infrastructure Forecast predicts that by 2027, 60% of enterprise AI workloads will combine generative and predictive components, enabling systems that both identify and automatically resolve issues.
Example Hybrid Workflow:
- Traditional AI detects anomalies in customer behavior
- Generative AI drafts personalized outreach message
- Traditional AI scores the likelihood of successful intervention
- Generative AI adapts communication based on feedback
The Future: Hybrid Intelligence for Enterprise Success
Generative AI doesn’t replace traditional AI—they’re complementary technologies that deliver maximum value when integrated:
Traditional AI provides:
- Mathematical foundation
- Controlled predictability
- Operational trust
- Regulatory compliance
Generative AI provides:
- Contextual reasoning
- Creative problem-solving
- Natural language interfaces
- Adaptive workflows
How Creative Bits AI Delivers Hybrid Solutions
At Creative Bits AI, we bridge the gap between experimentation and production-ready AI systems through:
✓ Deterministic Logic Integration – Structured reasoning engines
✓ Knowledge Retrieval Systems – RAG-powered information access
✓ Policy-Driven Oversight – Governance frameworks for safety
✓ Observable Behaviors – Full traceability and monitoring
✓ Agentic Orchestration – Self-governed, coordinated AI agents
Our hybrid approach combines traditional AI’s reliability with generative AI’s innovation, delivering scalable, production-grade intelligent automation.
Making the Right Choice: Generative AI vs Traditional AI
Choose your AI approach based on:
Traditional AI when:
- Decisions must be explainable to regulators
- Historical patterns accurately predict outcomes
- Accuracy is non-negotiable
- Creative variation introduces risk
Generative AI when:
- Tasks involve natural language processing
- Requirements are ambiguous or evolving
- Creative solutions add value
- Human-like interaction is needed
Hybrid AI when:
- Complex workflows need both prediction and creation
- Systems must detect issues AND propose solutions
- Enterprise-scale automation requires governance + flexibility
If Ready to Implement AI That Delivers Results?
The future belongs to organizations that master both traditional and generative AI paradigms. Whether you need predictive analytics, generative workflows, or hybrid intelligent automation, Creative Bits AI has the expertise to guide your AI transformation.
Contact us today to discuss how we can architect AI solutions that combine reliability, creativity, and production-grade performance for your enterprise.
The post Understanding the Difference Between Generative AI and Traditional AI first appeared on Creative Bits AI.
]]>