The post Eine Kurzanleitung zur Adressstandardisierung und -überprüfung appeared first on Data Ladder.
]]>Unter Adressstandardisierung versteht man den Prozess der Aktualisierung und Implementierung eines Standards oder Formats für Ihre Adressdaten.
Schlechte Adressdaten sind ein komplexes Problem der Datenqualität, das sich auf Kunden, Unternehmen und sogar den Versanddienstleister auswirkt. Die überwältigende Menge an unzureichenden Adressdaten hat es für Unternehmen zur Pflicht gemacht, in robuste Adressstandardisierungs- und Verifizierungstools zu investieren, die ihnen helfen, einfach und mühelos von USPS geprüfte Adressen zu erhalten.
Lesen Sie weiter, wir helfen Ihnen beim Verstehen:
- Die Kosten für schlechte Daten
- Die Probleme mit Adressdaten
- Ursachen für schlechte Datenqualität
- Wie standardisieren Sie Ihre Adresse?
- Was ist die CASS-Adressstandardisierung?
- Wie wird eine Adresse validiert?
- Wie überprüft man eine Adresse bei USPS?
- Datenabgleich – die größte Herausforderung für die Adressstandardisierung und -überprüfung
- Eine Fallstudie – E-Ideas Limited
- Geschäftsstrategien zur Verbesserung Ihrer Adressdaten
Tauchen wir gleich ein!
Die Kosten für schlechte Adressdaten
Jedes Jahr werden Millionen von Dollars aufgrund schlechter Adressdaten verschwendet. Der USPS berichtet, dass allein im Jahr 2016 fast 6,6 Milliarden Sendungen unzustellbar waren. Die Versender geben über 20 Milliarden Dollar für UAA-Sendungen aus, während die direkten Kosten für den USPS über 1,5 Milliarden Dollar pro Jahr betragen. All diese unnötigen Kosten sind einfach darauf zurückzuführen, dass die Unternehmen keinen Zugang zu den richtigen Adressdaten haben.

Wenn Sie allein diese vorläufigen Kosten ausrechnen, geben Sie wahrscheinlich $$$$ allein für die Verwaltung der Rücksendekosten aus – ganz zu schweigen von den Betriebskosten für die Überprüfung der Kundeninformationen und den erneuten Versand des Pakets.
Einige Zahlen zum Nachdenken:

Die Probleme mit Adressdaten
Es liegt in der menschlichen Natur, Fehler zu machen. Meistens sind die Verbraucher nachlässig, wenn es darum geht, ihre Adressdaten in physischen oder Webformularen anzugeben. Sie können den Namen eines Bundeslandes falsch schreiben, Abkürzungen verwenden, eine Hausnummer vergessen oder ihre Postleitzahl vergessen. Es ist unvermeidlich, dass einige Fehler gemacht werden und falsche Daten eingegeben werden.
Das folgende Bild zeigt, wie typische unstrukturierte Adressrohdaten aussehen. Unzureichende Adressdaten sind eine Herausforderung, die für Unternehmen und deren Mitarbeiter eine große Belastung darstellt. Stellen Sie sich vor, Sie müssten diese grundlegenden Probleme für jede Mailing-Kampagne, jede Werbeaktion und jeden Kundenbericht, den Sie erstellen müssen, lösen. Es ist nicht nur wahnsinnig frustrierend, sondern auch kontraproduktiv, wenn man versucht, jede Adresse abzugleichen und zu überprüfen, um sicherzustellen, dass sie korrekt und vollständig ist. Datenwissenschaftler und Analysten oder Geschäftsanwender, die diese Daten benötigen, müssen Tage und Monate damit verbringen, diese Probleme zu beheben.

Bei Adressdaten werden häufig Probleme festgestellt:
- Unvollständige Informationen (fehlender Straßenname, Blocknummer, Postleitzahl)
- Ungültige Informationen (gefälschte Adressen und Postleitzahlen)
- Falsche Informationen (Tippfehler, falsch geschriebene Namen, schlechtes Format wie die Verwendung von Abkürzungen)
- ungenaue Informationen (ungenaue Wohnungs- oder Hausnummern)
All diese Probleme machen die Adressdaten zu einer der am schwierigsten zu bearbeitenden Datenquellen. Außerdem werden dadurch die Kosten für die Rücksendung von Postsendungen erheblich erhöht, und die Unternehmen können sich nicht mehr auf die Adressdaten verlassen, um wichtige Geschäftsentscheidungen zu treffen.
Die meisten dieser Probleme sind auf Eingabefehler der Benutzer und das Fehlen einer angemessenen Datenkontrolle zurückzuführen.
Manche Leute schreiben zum Beispiel nur die Postleitzahl, aber nicht die vollständige Adresse, manche vergessen einfach die Postleitzahl oder schreiben eine unvollständige Adresse. Manche geben eine gefälschte Adresse an. Was auch immer die Gründe für Datenfehler sind, eines ist sicher: Damit ein Unternehmen seine Daten nutzen kann, müssen diese sauber und gültig sein.
Strukturelle Fehler sind jedoch nur ein Teil des Problems mit schlechten Adressdaten. Andere Themen könnten sein:
- Adressdaten, die zwar gültig sind, aber nicht mehr existieren.
- Adresse, die zwar strukturell richtig ist, aber nicht dem Kunden gehört.
- Adresse, die nicht in der USPS-Datenbank vorhanden ist.
Wenn diese Informationen in der Eingangsphase nicht überprüft werden, wirkt sich dies auf die gesamte künftige Korrespondenz sowie auf die Beziehung zu diesem Kunden aus. Um dies zu korrigieren, müssen die Unternehmen jeden einzelnen Kunden anrufen, um die Daten zu aktualisieren oder die richtigen Informationen erneut einzuholen. Das Problem ist, dass die Unternehmen in der Regel nicht über genügend Ressourcen verfügen und diese Arbeitsweise nicht sehr praktikabel ist.
Letztendlich läuft es auf eines hinaus: Schlechte Daten sind unvermeidlich, aber sie können behoben werden. Es gibt zahlreiche Tools zur Adressstandardisierung, die Unternehmen dabei helfen, schlechte Daten zu korrigieren, indem sie Formatprobleme beheben und unordentliche Daten bereinigen. Der Prozess ist weniger zeitaufwändig, erfordert jedoch eine gewisse Lernkurve und ein grundlegendes Verständnis von Datenabgleich, Parsing und Deduplizierung.
Ursachen für fehlerhafte Adressdaten
Menschliche Fehler sind die Haupt-, aber nicht die einzige Ursache für schlechte Adressqualität. Abgesehen von den Herausforderungen, die eine genaue Datenerfassung mit sich bringt, gibt es noch viele weitere Ursachen, wie zum Beispiel:
Datenbank-Verfall:
Nach Angaben des Census Bureau wird ein typischer Amerikaner im Laufe seines Lebens 11,7 Mal umziehen. Da Wohnraum immer teurer wird und die Amerikaner versuchen, geeignete Wohngegenden zu finden, wird diese Zahl weiter steigen. Davon informieren nur 60 % der Umzugsunternehmen den USPS tatsächlich rechtzeitig über ihren Umzug.
Die Unternehmen sitzen also auf Adressdaten fest, die nicht aktualisiert werden. Wenn sie monatlich eine Million Rechnungen oder Werbebriefe verschicken, erhalten sie im selben Monat vielleicht 90.000 Umzugsmitteilungen. Schlimmer noch, nach diesem Prozentsatz werden 60.000 dieser Millionen Kunden dem USPS nicht rechtzeitig die richtigen Informationen zur Verfügung gestellt haben.
Unter der Annahme, dass dieselben Kunden immer noch bei der Organisation sind, muss das Unternehmen seine Datenbank ständig aktualisieren und sicherstellen, dass es die aktuellste Adresse verwendet.
Schlechte Datenkultur:
Erst in jüngster Zeit beginnen Unternehmen, sich mit dem Thema Datenorientierung zu befassen – aber das beschränkt sich auf die Führungsebene. Der Mitarbeiter an seinem Schreibtisch ist sich nicht bewusst, mit welchen Datenqualitätsproblemen er es zu tun hat. Außerdem gibt es keine Geschäftsregeln, die bei der Datenqualität einzuhalten sind. Es gibt keine Schulung oder Ausbildung für Mitarbeiter, um datenorientiert zu arbeiten, und es gibt absolut keine Investitionen in Datenmanagement-Tools wie DataMatch Enterprise, die die Lücke zwischen IT-Anwendungen und Geschäftsmanagement von Daten schließen können.
Fusionen und Übernahmen:
Wenn Unternehmen im Zuge von Fusionen und Übernahmen Daten migrieren, steigt die Wahrscheinlichkeit von Fehlern in der Datenqualität. Diese Fusionen gehen schnell vonstatten und die Probleme sind manchmal unvorhersehbar. Der Druck zur Konsolidierung nimmt zu, aber es gibt keine Kontrolle und kein Gleichgewicht in Bezug auf die Qualität – tatsächlich gibt es nur selten einen Rahmen für das Qualitätsmanagement.
Wie führen Sie die Adressstandardisierung durch?
Also, Definition hin oder her, wie kann man eigentlich Daten standardisieren?
Nun, es gibt zwei Möglichkeiten – die einfache und die harte Variante.
Auf die harte Tour müssen Sie diese Daten nach Excel übertragen und Formeln und Filter anwenden, um die Daten zu korrigieren. Glauben Sie nicht den Anleitungen, die Ihnen sagen, dass es „super-einfach“ ist, denn das ist es nie.
In diesem Artikel erfahren Sie, wie Sie Fehler in Excel beheben können. Sehen Sie, wie viel Zeit, Mühe und technisches Wissen Sie aufbringen müssen, um grundlegende Datenkorrekturen durchzuführen? Je komplexer die Probleme werden, desto länger dauert es. Wenn Sie mit Millionen von Datenzeilen zu tun haben, könnte die Datenbereinigung zu Ihrer ständigen Aufgabe werden.
Der einfache Weg?
Verwenden Sie eine Adressstandardisierungssoftware. Bevor Sie die Idee verwerfen, hier die Gründe dafür.
Die Software spart natürlich viel Zeit und Mühe, aber sie kann noch mehr.
Adressdatensätze sind keine einfachen Fehler. Wie im obigen Beispiel haben Sie Tausende von Zeilen, die Probleme aufweisen. Sie brauchen eine Lösung, mit der Sie all diese Probleme auf einen Schlag lösen können.
Wenn Sie eine Best-in-Class-Lösung verwenden, können Sie Daten standardisieren:
Bewertung von Fehlern durch Datenprofilierung: Stellen Sie sich vor, Sie könnten sich einen konsolidierten Überblick über alle Fehler in Ihren Adressdaten verschaffen. Sie können Spalten mit nicht druckbaren Zeichen oder Spalten mit negativen Leerzeichen oder sogar Spalten mit Buchstaben in Zahlenfeldern sehen. Mit der Datenprofilerstellung können Sie fundierte Korrekturen vornehmen . Wenn Sie nicht wissen, was falsch ist, tappen Sie bei den Korrekturen im Dunkeln.
Parsing von Adressen zur Lösung spezifischer Probleme: Ein Teil der Adressbereinigung erfordert, dass Sie verschiedene Teile von Adressen (Stadt, Bundesland, Postleitzahl usw.) analysieren oder aufschlüsseln und sie auf verschiedenen Ebenen fixieren. Mit DataMatch Enterprise können Sie zum Beispiel Postleitzahlen gezielt korrigieren und sicherstellen, dass sie den Postleitzahlen ZIP+4 oder ZIP+6 entsprechen.
Bereinigung von unordentlichen Daten: Bereinigen Sie Formatierungsprobleme, entfernen Sie negative Leerzeichen und nicht druckbare Zeichen in einem Durchgang. Sie müssen Ihre Adressdaten unbedingt bereinigen und gemäß den USPS-Richtlinien (siehe unten) standardisieren, bevor Sie sie überprüfen können.
Entfernen von Duplikaten mit Datenabgleich : Das Bereinigen unordentlicher Daten ist nur ein Teil der Aufgabe – der anstrengende Teil ist das Aussortieren von Duplikaten. Wenn Sie Tausende von Kundendaten haben, die seit langem nicht mehr sortiert wurden, ist die Wahrscheinlichkeit groß, dass es Duplikate gibt, und diese sind nicht immer exakt.
Werfen Sie einen Blick auf diese Tabelle:
Sehen Sie, dass für einen Kunden fünf verschiedene Adressen auf unterschiedliche Weise eingegeben wurden? Das lässt sich nicht so einfach sortieren, es sei denn, Sie verwenden ein leistungsfähiges Datenqualitätstool.
 Datenübernahme und -export: Sie sollten in der Lage sein, einen Stammdatensatz zu erstellen und ihn als endgültige Liste an Ihr Team zu exportieren, ohne ihn kopieren/einfügen oder manuell in ein akzeptables Format laden zu müssen.
Datenübernahme und -export: Sie sollten in der Lage sein, einen Stammdatensatz zu erstellen und ihn als endgültige Liste an Ihr Team zu exportieren, ohne ihn kopieren/einfügen oder manuell in ein akzeptables Format laden zu müssen.
CASS-Adressstandardisierung: Jede Adressstandardisierungssoftware muss über die CASS-Adressstandardisierung verfügen. DataMatch Enterprise zum Beispiel ist eine CASS-zertifizierte Adressstandardisierungslösung mit einer CASS-Datenbank, die jeden Monat aktualisiert wird.
Was ist die CASS-Adressstandardisierung?
Software, die Adressen korrigiert oder abgleicht, muss vom USPS zertifiziert werden. Dies geschieht über das Coding Accuracy Support System (CASS), das der USPS zur Überprüfung der Genauigkeit der Software einsetzt. Eine CASS-Zertifizierung ist eine Lizenz für alle Software-Anbieter, die den USPS nutzen, um die Qualität ihrer Adressdaten zu bewerten und die Genauigkeit der ZIP+4- und fünfstelligen Kodierung zu verbessern.
Da der USPS seine Adressdaten regelmäßig aktualisiert, müssen Anbieter von CASS-zertifizierter Software ihre Zertifizierung jährlich beim USPS erneuern. Alle zertifizierten CASS-Produkte sind auf der Website des USPS aufgeführt.
Was ist die USPS-Standardisierungsrichtlinie?
Die Anbieter von Software zur Standardisierung von Adressdaten folgen der USPS-Standardisierungsrichtlinie, die vorschreibt, dass Adressen in einem Format wie folgt vorliegen müssen:

Hier sind die Regeln:
- Bringen Sie die Adresse und das Porto immer auf der gleichen Seite Ihres Poststücks an.
- Bei einem Brief sollte die Adresse parallel zur längsten Seite verlaufen.
- Alle Großbuchstaben.
- Keine Interpunktion.
- Mindestens 10-Punkt-Schrift.
- Ein Leerzeichen zwischen Stadt und Staat.
- Zwei Leerzeichen zwischen Staat und Postleitzahl.
- Einfache Schriftarten.
- Linksbündig.
- Schwarze Tinte auf weißem oder hellem Papier.
- Kein Rückseitendruck (weißer Druck auf schwarzem Hintergrund).
- Wenn Ihre Adresse innerhalb eines Fensters erscheint, stellen Sie sicher, dass um die Adresse herum mindestens 1/8-Zoll Platz ist. Manchmal verschwinden Teile der Adresse hinter dem Fenster und die Postbearbeitungsmaschinen können die Adresse nicht lesen.
- Wenn Sie Adressetiketten verwenden, achten Sie darauf, dass Sie keine wichtigen Informationen abschneiden. Achten Sie auch darauf, dass die Etiketten gerade angebracht sind. Postbearbeitungsmaschinen haben Schwierigkeiten, schiefe oder schräg stehende Informationen zu lesen.
Die Standardisierung von Adressen ist die Voraussetzung für eine effektive Adressprüfung. Sie müssen sicherstellen, dass Ihre Adresse den USPS-Richtlinien entspricht, bevor Ihre Daten mit dem USPS abgeglichen werden können.
Adressüberprüfung oder -validierung – Was ist der Unterschied?
Häufig werden die Begriffe „Validierung und Verifizierung“ vermischt, wenn es um Adressdaten geht. Der Unterschied ist eher kontextueller als lexikalischer Natur. Data Ladder verwendet den Begriff Adressverifizierung, um Adressen mit der USPS-Datenbank abzugleichen. Andere Organisationen überprüfen die Adressen anhand von Rechnungsunterlagen, Führerscheinen, Kontoauszügen usw. Das ist eine völlig andere Dienstleistung, die die meisten Unternehmen nicht brauchen.
Andere Anbieter verwenden die„Adressvalidierung“, um den gleichen Abgleich mit dem USPS vorzunehmen und die Kundendaten zu validieren. Im Rahmen dieses Leitfadens beschränken wir uns auf die Adressüberprüfung.
Adressstandardisierung und -überprüfung – Wie man Adressdaten mit dem USPS überprüft
Der Prozess der Adressüberprüfung ist einfach. Sie gleichen Ihre nun standardisierten Daten mit der staatlichen Datenbank oder einem anderen Behördenstandard ab. Wenn Sie in den USA leben, ist der USPS die einzige Datenbank, mit der Sie Ihre Daten abgleichen sollten.
Wenn Ihre Adressdaten sauber und standardisiert sind, dauert dieser Vorgang nur wenige Minuten. Wenn Sie DataMatch Enterprise verwenden, können Sie die gesamte Adresse oder nur Teile der Adresse abgleichen, die auf 50 aktiven Elementen einschließlich geocodierter Orte basiert, was bedeutet, dass Sie Adressen bis ins Detail überprüfen können!
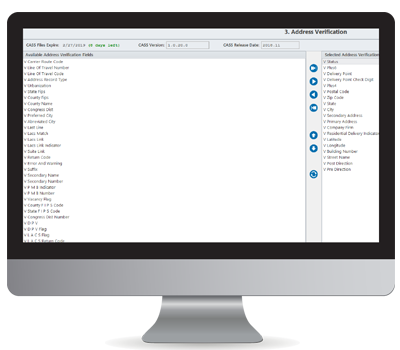
Zu den beliebtesten Feldern, für die unsere Kunden häufig eine Überprüfung verlangen, gehören:
-
V Status – Wird der Datensatz überprüft (Ja/Nein)
-
V Zustellungsindikator für Privatpersonen – Legt fest, ob die Privatadresse direkte Lieferungen an die Haustür erhalten kann.
-
V Unternehmen Firma
-
V Primäre Adresse
-
V Sekundäradresse
-
V Stadt
-
V Staat
-
V Postleitzahl – 5-stellig (USA)
-
V Postleitzahl (Kanada)
-
V Plus4 – Zusätzliche 4 Ziffern in Verbindung mit der 5-stelligen Postleitzahl
Es gibt 54 Felder, die Sie für die Überprüfung Ihrer Adressdaten verwenden können.
Sobald Sie die Adressliste mit diesen Komponenten abgeglichen haben, erhalten Sie einen Rückgabewert, der angibt:
- 10 = Invald Adresse
- 11 = Ungültige Postleitzahl
- 12 = Ungültiger Zustandscode
- 13 = Ungültige Stadt
- 21 = Adresse nicht gefunden
Sie werden auch mit Warnungen wie:
-
-
A# ZIP
-
B# Stadt/Staat Korrigiert
-
C# Ungültige Stadt/Staat/Zip
-
D# Keine Postleitzahl zugewiesen
-
E# ZIP zugewiesen für Mehrfachantwort
-
F# Kein ZIP verfügbar
-
G# Ein Teil der Firma ist an eine andere Adresse umgezogen
-
H# Sekundärnummer fehlt
-
I# Unzureichende/falsche Daten
-
J# Doppeleingang
-
Wenn Sie mehr darüber erfahren möchten, können Sie uns gerne für eine kurze Demo anrufen !
Okay, weiter geht’s:
Datenabgleich – die größte Herausforderung für die Adressstandardisierung und -überprüfung
Die Kunden, die sich an uns wenden, beschweren sich immer nur über eines – dass sie nie eine gute Trefferquote bekommen. Und wir sind einverstanden!
DerDatenabgleich muss noch verbessert werden. Es gibt nur sehr wenige Anbieter, die eine 100%ige Trefferquote angeben können. Sie brauchen diese Zahl wirklich, wenn nicht, dann zumindest 95 %. Der Grund dafür ist, dass Ihr Adressfeld eine Übereinstimmung mit dem USPS finden muss, damit die Überprüfung funktioniert. Wenn die meisten Ihrer Übereinstimmungen fehlen, weil die Software auf exakte oder deterministische Übereinstimmungen angewiesen ist, wird sie nicht zu Ihren Gunsten arbeiten.
Daher müssen Sie bei der Auswahl einer Software zur Adressennormung und -überprüfung in der Lage sein, deren Datenabgleichsrate zu beurteilen. Wie viele von hundert Zeilen hat das Tool übersehen, und warum? Wahrscheinlich werden Sie feststellen, dass die Software keine nahen oder ähnlichen Übereinstimmungen erkennt und sich ausschließlich auf exakte Zeichen verlässt, um eine Übereinstimmung zu identifizieren.
DataMatch Enterprise von Data Ladder ist in erster Linie eine Datenabgleichslösung, die von staatlichen Institutionen und Fortune-500-Unternehmen wie HP, Coca Cola, Deloitte und vielen anderen eingesetzt wird. Wir sind dafür bekannt, dass wir Daten mit einer Trefferquote von bis zu 100 % abgleichen. Das liegt daran, dass Data Ladder eine Kombination aus Fuzzy-Matching-Algorithmen und seinen bewährten proprietären Algorithmen verwendet, um selbst die entferntesten wahrscheinlichen Übereinstimmungen zu identifizieren.
P.S. – Der Datenabgleich ist ressourcenintensiv. Sparen Sie Ihrem Team Zeit und manuellen Aufwand. In diesem ausführlichen Blogbeitrag erfahren Sie, wie das geht.
Die folgende Fallstudie zeigt, wie schwierig es selbst für einen Datenlieferanten ist, einen genauen Datenabgleich zu gewährleisten.
Eine Fallstudie – E-Ideas Limited
Wir sprachen mit Artem Axenov, Operations Manager bei E-Ideas Limited, einer Boutique-Agentur für B2B-Marketing mit Sitz in Wellington. Die Agentur verwaltet eine große Datenbank von Unternehmen für Marketingzwecke, was bedeutet, dass sie sich besonders um die Adressdaten kümmern muss – eine große Herausforderung, die viel manuelle Arbeit mit Excel erfordert.
1. Wie geht Ihre Agentur mit dem Problem der schlechten Daten um?
Wir haben oft mit Kunden zu tun, die bereits eine Kundenliste haben, aber die Daten sind schlecht formatiert. Es gibt einige automatische Aufgaben, die Sie durchführen können, um das Problem zu lösen, aber letztendlich ist es eine manuelle Aufgabe. Zunächst müssen Sie entscheiden, welches Format Sie verwenden wollen. Der einfachste Weg, schlecht formatierte Daten zu korrigieren, besteht darin, sie spaltenweise zu sortieren und dann die erforderlichen Änderungen vorzunehmen, um sie auf den neuesten Stand zu bringen. In Excel gibt es einige Formeln, die dabei helfen, Daten aufzuteilen oder zu kombinieren – zum Aufteilen können Sie MID und LEFT zusammen verwenden. Und um Daten zu kombinieren, können Sie CONCATENATE verwenden.
Indem Sie die Daten zunächst sortieren, fassen Sie Adressensätze zusammen, die die gleichen Formatierungsprobleme aufweisen, was die gleichzeitige Bearbeitung wesentlich erleichtert.
2. Welche Erfahrungen haben Sie mit Tools zur Adressüberprüfung und -validierung gemacht?
Unsere Erfahrungen mit allen Arten von Adressvalidierungs- oder Verifizierungstools waren stets gemischt. Letzten Endes ist es keinem der von uns verwendeten Tools gelungen, eine hohe Übereinstimmung zu erzielen. Das liegt vor allem daran, dass die Adressen sehr unterschiedlich gespeichert werden. Sie sind nützlich, um sich einen Vorsprung zu verschaffen, aber am Ende ist immer ein erheblicher Anteil an manueller Arbeit erforderlich, um die Arbeit abzuschließen.
3. Welches ist das problematischste Problem beim Datenabgleich?
Das Hauptproblem besteht darin, dass der automatische Abgleich nicht funktioniert, wenn die Daten nicht genau so formatiert sind, wie das Programm sie erkennen soll. Das kann so klein sein, dass eine Straße als St, eine Avenue als Ave usw. erfasst wird.
4. Welche manuellen Aufgaben müssen Sie nach der Verwendung einer Adressvalidierungssoftware erledigen?
In der Regel genügt es, die Daten mit einem menschlichen Auge zu prüfen, um Unstimmigkeiten zu erkennen und zu korrigieren. In Neuseeland zum Beispiel hat die Post ein ganz bestimmtes Format, in dem die Adressen gehalten werden müssen, um den Rabatt für Massensendungen zu erhalten. Nichts ist kompliziert, aber auch hier gilt: Kleinigkeiten wie die Eintragung der Straße als St werden gegen Sie verwendet. Ein anderes Beispiel ist wenn Sie Ihr Postfach als Postfach registriert haben – es erkennt dies nicht als korrekt formatiert. Sogar Dinge wie führende oder nachfolgende Leerzeichen können gegen Sie zählen – und einige davon sind schwer zu erkennen, weil Sie, wenn Sie die Adresse betrachten, nicht sehen können, was falsch ist!
5. Wie haben sich schlechte Adressdaten auf Ihr Unternehmen ausgewirkt?
Wir sind nur insofern auf Probleme gestoßen, als wir zusätzliche Arbeitsstunden aufwenden mussten, um die Daten auf den neuesten Stand zu bringen, damit wir den Postrabatt in Anspruch nehmen konnten. Es gibt einen Test, den so genannten „Statement of Accuracy“, bei dem die Daten automatisch überprüft werden, um sicherzustellen, dass 80 % der Daten korrekt formatiert sind. Wir hatten eine Reihe von Fällen, in denen wir Tage länger mit der manuellen Formatierung von Daten verbracht haben, um sicherzustellen, dass sie korrekt formatiert sind.
Die Praxis, die wir jetzt eingeführt haben, besteht darin, alle unsere Daten im richtigen Format zu speichern. Es hat uns viel Zeit gekostet, alles auf diesen Standard zu bringen, aber jetzt bedeutet es, dass die Daten, die wir an unsere Kunden liefern, NZ Post-fertig sind und keine weitere Arbeit mehr erforderlich ist.
Die Probleme dieser Behörde mit fehlerhaften Adressdaten führen zu zusätzlichen Arbeitsstunden, die die operative Effizienz beeinträchtigen. Trotz des Einsatzes von Tools für den Adressabgleich und die Adressvalidierung ist es sehr schwierig, Adressdaten zu validieren, da keine hohe Übereinstimmung erzielt werden kann. Daher ist es notwendig, ein Tool zu wählen, das dem Benutzer umfassende Möglichkeiten der Datenaufbereitung und -standardisierung bietet und gleichzeitig eine hohe Trefferquote aufweist. Dies ist nur mit einer erstklassigen Datenaufbereitungs- und Abgleichsoftware wie DataMatch Enterprise möglich, die es dem Benutzer ermöglicht, Adressdaten aufzubereiten und zu bereinigen und dabei auch bei fehlerhaftem Text ein hohes Abgleichsergebnis zu erzielen.
Geschäftsstrategien für das Adressdatenmanagement
Schlechte Adressdaten sind ein Problem der Datenqualität. Auch wenn Sie mit Hilfe von Tools Korrekturen vornehmen können, müssen Sie dennoch Geschäftsstrategien implementieren, um zu verhindern, dass schlechte Daten die betrieblichen Abläufe beeinträchtigen. Einige dieser Strategien können sein:
Schulungen:
Der erste Schritt auf dem Weg zur Qualität ist die Schulung – stellen Sie sicher, dass die Personen, die Daten bearbeiten, mit ihnen interagieren, sie verwenden und eingeben, wissen, welchen Einfluss sie auf den Prozess und die nachgeschalteten Anwendungen haben. Sie müssen verstehen, welche Folgen schlechte Daten für das gesamte Unternehmen haben und nicht nur für ein Mitglied oder einen Kunden. Mitarbeiter, die sich an die Regeln der Datenqualität halten, sollten belohnt und gewürdigt werden.
Werkzeugliste für das Datenmanagement:
Die Verfügbarkeit von Tools, die sowohl Geschäftsanwendern als auch IT-Fachleuten bei der Verwaltung der Daten helfen können, ist von entscheidender Bedeutung. Ermitteln Sie die Tools, die Sie für die Datenbereinigung und das Datenmanagement benötigen, damit sowohl IT- als auch Geschäftsanwender einen reibungslosen Umgang mit Daten haben.
Einbindung der Geschäftsanwender in den Qualitätsprozess:
Daten sind nicht nur ein IT-Problem. Die Geschäftsanwender sind gleichermaßen für die Verwaltung der Daten verantwortlich. Sie sind nämlich die alleinigen Eigentümer der Kundendaten, die häufig für Marketing- und Vertriebszwecke verwendet werden. Deshalb müssen sie in den Prozess einbezogen und auch für die Verwendung von Datenmanagement-Tools geschult werden.
Datenverwaltung:
Stellen Sie ein Data-Governance-Team zusammen, das einen Datenverwaltungsplan erstellt und sicherstellt, dass das Unternehmen den Plan befolgt und jeder Mitarbeiter diesen Plan versteht. Ihre Rolle innerhalb des Plans und die Erwartungen, die mit der Rolle einhergehen.
Sperren von Daten und Benutzerrollen:
Wenn jeder in Ihrem Team das CRM oder die Datenquelle öffnen kann, mit den Daten herumhantiert und keine Spuren hinterlässt, haben Sie ernsthafte Probleme. Es ist notwendig, Stammdateninhaber zu schaffen, die die Rechte haben, auf kritische Daten zuzugreifen, sie einzugeben oder zu verarbeiten. Dies sollte in den Datenverwaltungsplan aufgenommen werden.
Sie sind kein Opfer von schlechten Daten. Akzeptieren Sie den Ernst der Lage, kultivieren Sie eine datengesteuerte Kultur und bemühen Sie sich, die mit der Datenverwaltung verbundenen Herausforderungen zu bewältigen. Es ist durchaus möglich, dass Sie Daten erhalten, die nur einer grundlegenden Bereinigung bedürfen, um sie nutzen zu können.
Wie kann DataMatch Enterprise helfen?
Unser Produkt ist CASS-zertifiziert, d. h. wir erfüllen und übertreffen die Anforderungen des USPS an die Qualität und Genauigkeit der Adressen. Wir helfen Ihnen auch beim Massenabgleich und der Validierung von Adressen und stellen sicher, dass Elemente wie Postleitzahlen, Orts- und Stadtnamen überprüft und validiert werden. Der größte Vorteil der Verwendung von DataMatch Enterprise von Data Ladder? Die Software findet und gleicht Daten ab, auch wenn sie unvollständig sind, und das mit einer Trefferquote von 96 %. Darüber hinaus können Sie mit der Software eine Adressüberprüfung in Echtzeit durchführen, um sicherzustellen, dass Sie korrekte Adressen in Ihrer Datenbank haben.
 Mithilfe von Algorithmen, die eine Übereinstimmung auf der Grundlage von Ähnlichkeitsbereichen ermitteln, macht unsere Plattform aus unbrauchbaren Daten einen Sinn und leitet Verbindungen zwischen Datensätzen ab. Ob es sich um Rechtschreibfehler oder unvollständige Postleitzahlen, Abkürzungen oder Tippfehler handelt. Wir sortieren große Datenmengen, um Ihnen zu helfen, Ihre Daten sinnvoll zu nutzen.
Mithilfe von Algorithmen, die eine Übereinstimmung auf der Grundlage von Ähnlichkeitsbereichen ermitteln, macht unsere Plattform aus unbrauchbaren Daten einen Sinn und leitet Verbindungen zwischen Datensätzen ab. Ob es sich um Rechtschreibfehler oder unvollständige Postleitzahlen, Abkürzungen oder Tippfehler handelt. Wir sortieren große Datenmengen, um Ihnen zu helfen, Ihre Daten sinnvoll zu nutzen.
Zum Abschluss
Schlechte Adressdaten sind unvermeidlich, aber das bedeutet nicht, dass Sie sich davon in Ihrer Unternehmensleistung beeinträchtigen lassen sollten. Die manuelle Korrektur von Adressdaten kostet Sie mehr Zeit und Mühe, und Sie können sie nicht standardisieren oder überprüfen, es sei denn, Sie verwenden eine CASS-zertifizierte Lösung.
Ertrinken Sie nicht in schlechten Daten. Wir sind hier, um zu helfen.
Wenn Sie wissen möchten, wie wir Sie bei der Adressstandardisierung und -überprüfung unterstützen können, nehmen Sie noch heute Kontakt mit einem unserer Lösungsexperten auf und erfahren Sie, wie wir Ihnen helfen können, Adressdaten zu erhalten, die Sie für den vorgesehenen Zweck verwenden können.
The post Eine Kurzanleitung zur Adressstandardisierung und -überprüfung appeared first on Data Ladder.
]]>The post 8 bewährte Verfahren zur Gewährleistung der Datenqualität auf Unternehmensebene appeared first on Data Ladder.
]]>Am 20. September 2021 räumte Facebook gegenüber drei Dutzend Forschern ein, dass der Datensatz schwerwiegende Fehler aufwies, und entschuldigte sich für die negativen Auswirkungen auf ihre Forschung. Es stellte sich heraus, dass Facebook es versäumt hatte, die Daten der Hälfte seiner US-Nutzer einzubeziehen, da diese im Vergleich zu den Nutzern insgesamt weniger politisch polarisiert waren. Eine Facebook-Sprecherin erklärte, dass dieser Vorfall auf einen technischen Fehler in ihrem URL-Shares-Datensatz zurückzuführen sei.
Heutzutage sind Daten zweifellos einer der größten Vermögenswerte eines Unternehmens. Sie wird überall eingesetzt – vom Tagesgeschäft eines Unternehmens bis hin zu Business-Intelligence-Initiativen – oder, wie im Fall von Facebook, zur Unterstützung von mehr als 100 Recherchen. Wenn jedoch Techniken und bewährte Verfahren für die Datenqualität fehlen (mit denen Datenqualitätsprobleme rechtzeitig erkannt und behoben werden), kann ein Unternehmen viel Geld verlieren und Gefahr laufen, ins Hintertreffen zu geraten.
In diesem Blog befassen wir uns mit einer Reihe von Best Practices und Prozessen zur Datenqualität, die eine hohe Datenqualität auf Unternehmensebene ermöglichen können. Ich werde nicht nur aufzeigen, was benötigt wird, sondern auch die Maßnahmen nennen, die Ihnen helfen können, diesen Zustand zu erreichen.
Darüber hinaus führen die unten genannten Praktiken zu den besten Ergebnissen, wenn sie in regelmäßigen Abständen in einem Unternehmen durchgeführt werden. Daten (in ihrer Definition und Verwendung) sind dem Wandel unterworfen. Wenn Ihr Unternehmen also diese Praktiken ständig überprüft, können Sie definitiv bessere und dauerhafte Ergebnisse erzielen.
Fangen wir an.
1. Ermitteln Sie den Zusammenhang zwischen Daten und Unternehmensleistung
Wir beginnen mit dieser Praxis, da sie der wichtigste und grundlegendste Teil einer ordnungsgemäßen Datenverwaltung, -übernahme und -nutzung in jedem Unternehmen ist. Zuallererst müssen Sie verstehen, wie Daten zu Ihren Unternehmenszielen beitragen.
Wie sieht sie aus?
Dies kann sowohl eine Analyse der Rolle von Daten auf hoher Ebene (z. B. Hervorhebung von Bereichen, in denen Daten genutzt werden) als auch eine detaillierte Analyse von Einzelheiten (z. B. der Rolle von Daten im Tagesgeschäft, in Geschäftsprozessen, beim Informationsaustausch zwischen Abteilungen usw.) umfassen.
Wenn Sie das erkannt haben, ist es an der Zeit, folgende Frage zu stellen: Wenn diese Prozesse oder Bereiche nicht durch Qualitätsdaten unterstützt wurden, welche Auswirkungen kann das auf die daraus resultierenden KPIs haben?
Ein Beispiel für eine solche Situation ist, wenn die Geschäftsleitung das Umsatzziel für das nächste Quartal auf der Grundlage der Verkaufsdaten des letzten Quartals festlegt, aber dann feststellt, dass der Datensatz, der für die Prognose des künftigen Ziels verwendet wurde, schwerwiegende Probleme mit der Datenqualität aufweist, was dazu führt, dass Ihre Verkaufsabteilung einem willkürlichen Wert nachjagt, der keine konkrete Bedeutung hat. Die daraus resultierende Situation hat massive negative Auswirkungen auf die Geschäftstätigkeit und den Ruf des Unternehmens, z. B. indem unrealistische Erwartungen an die Vertriebsmitarbeiter gestellt werden, ungenaue Umsatzzahlen versprochen werden und so weiter.
Wie hilft es?
Wenn Sie verstehen, welche Rolle Daten in allen laufenden Prozessen eines Unternehmens spielen, haben Sie immer ein Argument zur Hand, um Daten und ihrer Qualität Priorität einzuräumen. Dies wird Ihnen auch dabei helfen, die notwendige Zustimmung und Aufmerksamkeit der Beteiligten zu erhalten – etwas, das für die Durchführung und das Vorschlagen von Änderungen an bestehenden Prozessen entscheidend ist.
2. Messung und Pflege der Definition der Datenqualität
Sobald Sie wissen, welche Auswirkungen Daten auf Ihr Unternehmen haben, besteht der nächste Schritt darin, Datenqualität für alle Datensätze in Ihrem Unternehmen zu erreichen. Doch bevor wir das tun können, ist es wichtig, die Definition von Datenqualität zu verstehen, da sie für jedes Unternehmen etwas anderes bedeutet.
Die Datenqualität ist definiert als der Grad, in dem die Daten den beabsichtigten Zweck erfüllen. Um die Bedeutung der Datenqualität in Ihrem Fall zu verstehen, müssen Sie also wissen, was der beabsichtigte Zweck ist.
Wie sieht sie aus?
Um die Datenqualität für Ihr Unternehmen zu definieren, müssen Sie damit beginnen, die Daten zu identifizieren:
- Quellen, die Daten erzeugen, speichern oder manipulieren,
- Von jeder Quelle gespeicherte Attribute,
- Metadaten-Glossar, das jedes Attribut definiert,
- Akzeptanzkriterien für die in den Attributen gespeicherten Datenwerte, und
- Datenqualitätsmetriken, die die Qualität der gespeicherten Daten messen.
Ein Beispiel für die Definition der Datenqualität in Ihrem Unternehmen ist die Erstellung von Datenmodellen, in denen die notwendigen Datenbestandteile hervorgehoben werden (die Menge und Qualität der Daten, die als gut genug angesehen werden). Die folgende Abbildung zeigt, wie ein Datenmodell für ein Einzelhandelsunternehmen aussehen kann:
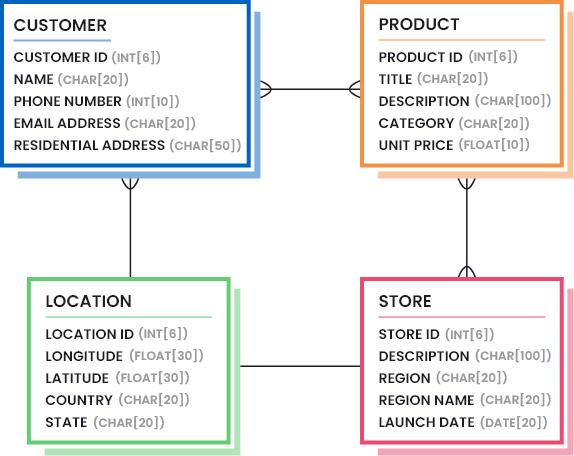
Außerdem müssen Sie nicht nur Datenmodelle entwerfen, sondern auch Datenqualitätsmetriken ermitteln, die das Vorhandensein eines akzeptablen Qualitätsniveaus in Ihren Datensätzen bestätigen. So können Sie beispielsweise verlangen, dass Ihr Datensatz genauer und zuverlässiger als vollständig ist.
Wie hilft es?
Eine standardisierte Definition von Datenqualität hilft dabei, alle Beteiligten auf den gleichen Stand zu bringen, damit sie verstehen, was Datenqualität bedeutet, wie sie aussieht und wie sie gemessen werden kann. Dies ermöglicht es jedem Einzelnen, die Anforderungen an die Datenqualität zu verstehen und zu erfüllen.
3. Festlegung von Rollen und Zuständigkeiten für Daten in der gesamten Organisation
Es wird allgemein davon ausgegangen, dass die Sicherstellung der Datenqualität auf Unternehmensebene die Beteiligung oder Zustimmungder obersten Führungsebene erfordert. Die Wahrheit ist, dass Sie nicht nur bestimmte Personen in Silo-Umgebungen einbeziehen, sondern Mitarbeiter in die bestehenden Prozesse einbinden und ihnen die Verantwortung für die Erreichung und Aufrechterhaltung der Datenqualität übertragen müssen – von der obersten Führungsebene bis hin zum Betriebspersonal.
Wie sieht sie aus?
Einige häufige, aber wichtige Datenrollen und ihre Zuständigkeiten sind:
- Chief Data Officer (CDO): Ein Datenbeauftragter der obersten Führungsebene, der für die Entwicklung von Strategien zur Gewährleistung eines effektiven Datenmanagements, der Verfolgung der Datenqualität und der Datenübernahme im gesamten Unternehmen verantwortlich ist.
- Datenverwalter: ein für die Datenqualität Verantwortlicher, der die Eignung der Daten für den vorgesehenen Zweck sicherstellt und die Metadaten verwaltet.
- Data and Analytics (D&A) Leader: ein Data Player, der für die Sicherstellung der Datenkompetenz im gesamten Unternehmen verantwortlich ist und dafür sorgt, dass Daten einen Mehrwert schaffen.
Wie hilft es?
Wenn Daten als Hauptquelle für zentrale Geschäftsprozesse behandelt werden, kommt es zu einem unternehmensweiten Wandel. Die Zuweisung von Rollen und Zuständigkeiten im Bereich der Daten und die Erteilung von Befugnissen an die Mitarbeiter, um Einfluss auf wichtige Datenfragen zu nehmen und sich zu diesen zu äußern, können eine wichtige Rolle bei der Gewährleistung einer erfolgreichen Datenkultur in jedem Unternehmen spielen.
4. Schulung und Aufklärung der Teams über Daten
In einer Umfrage unter 9000 Mitarbeitern, die verschiedene Funktionen in einem Unternehmen ausüben, waren nur 21 % von ihren Datenkenntnissen überzeugt.
Die Einführung von Datenrollen und -verantwortlichkeiten kann sich sehr positiv auf Ihr Unternehmen auswirken. Dennoch ist es wichtig zu bedenken, dass an einem modernen Arbeitsplatz jeder Einzelne im Rahmen seiner täglichen Arbeit Daten generiert, manipuliert oder mit ihnen umgeht. Aus diesem Grund ist es zwar wichtig, bestimmten Personen die Verantwortung für die Durchführung von Korrekturmaßnahmen zu übertragen, aber ebenso wichtig ist es, alle Teams im Umgang mit Unternehmensdaten zu schulen und zu schulen.
Wie sieht sie aus?
Dies kann die Erstellung von Plänen zur Datenkompetenz und die Entwicklung von Kursen beinhalten, die die Teams in die Unternehmensdaten einführen und erklären:
- Was es enthält,
- Was die einzelnen Datenattribute bedeuten,
- Welches sind die Akzeptanzkriterien für seine Qualität?
- Was ist der falsche und was der richtige Weg für die Eingabe/Manipulation von Daten?
- Welche Daten sind zu verwenden, um ein bestimmtes Ergebnis zu erzielen?
Außerdem können diese Kurse je nach Häufigkeit der Datennutzung durch bestimmte Rollen (täglich, wöchentlich oder jährlich) erstellt werden.
Wie hilft es?
Die Fähigkeit, Daten auf allen Ebenen korrekt und genau zu lesen, zu verstehen und zu analysieren, versetzt jeden Mitarbeiter in die Lage, die richtigen Fragen zu stellen – und zwar auf die bestmögliche Weise. Es gewährleistet auch die operative Effizienz Ihrer Mitarbeiter und reduziert Fehler bei der Kommunikation von Daten.
5. Kontinuierliche Überwachung des Datenzustands durch Datenprofiling
Datenqualität zu erreichen und sie über einen längeren Zeitraum aufrechtzuerhalten sind zwei verschiedene Dinge. Aus diesem Grund müssen Sie einen systematischen Prozess einführen, der den Zustand der Daten kontinuierlich überwacht und Profile erstellt, um verborgene Details über ihre Struktur und ihren Inhalt aufzudecken.
Der Umfang und der Prozess der Datenprofilerstellung können je nach der Definition der Datenqualität in Ihrem Unternehmen und der Art und Weise, wie sie gemessen wird, festgelegt werden.
Wie sieht sie aus?
Dies kann durch die Konfiguration und Planung von täglichen/wöchentlichen Datenprofilberichten erreicht werden. Darüber hinaus können Sie benutzerdefinierte Workflows entwerfen, um die Datenverantwortlichen in Ihrem Unternehmen zu alarmieren, wenn die Datenqualität unter einen akzeptablen Schwellenwert sinkt.
Ein Datenprofilbericht hebt in der Regel eine Reihe von Dingen über die untersuchten Datensätze hervor, zum Beispiel:
- Der Prozentsatz der fehlenden und unvollständigen Datenwerte,
- Die Anzahl der Datensätze, die möglicherweise Duplikate voneinander sind,
- Auswertung von Datentypen, -größen und -formaten zur Aufdeckung ungültiger Datenwerte,
- Statistische Analyse von numerischen Datenspalten zur Bewertung von Verteilungen.
Wie hilft es?
Auf diese Weise können Sie Datenfehler frühzeitig erkennen und verhindern, dass diese bis zum Kunden durchdringen. Darüber hinaus kann es den Chief Data Officers helfen, den Überblick über das Datenqualitätsmanagement zu behalten und die richtigen Entscheidungen zu treffen, z. B. wann und wie die in den Datenprofilen hervorgehobenen Probleme behoben werden sollen.
Lesen Sie mehr über Data Profiling: Umfang, Techniken und Herausforderungen.
6. Entwicklung und Pflege von Datenpipelines, um eine einzige Quelle der Wahrheit zu erhalten
Eine Datenpipeline bezieht sich auf einen systematischen Prozess, der Daten aus einer Quelle aufnimmt, die notwendigen Verarbeitungs- und Umwandlungstechniken an den Daten durchführt und sie dann in einen Zielspeicher lädt.
Es ist wichtig, dass Rohdaten eine Reihe von Validierungsprüfungen durchlaufen, bevor sie als brauchbar eingestuft und allen Benutzern im Unternehmen zur Verfügung gestellt werden können.
Wie sieht sie aus?
Um eine Datenpipeline zu erstellen, müssen Sie auf die in diesem Blog erwähnte Praxis Nr. 02 zurückgreifen: Definieren und pflegen Sie die Definition von Datenqualität. Entsprechend dieser Definition müssen Sie eine Liste von Operationen festlegen, die an den eingehenden Daten durchgeführt werden müssen, um das definierte Qualitätsniveau zu erreichen.
Eine Beispielliste von Vorgängen, die innerhalb Ihrer Datenpipeline durchgeführt werden können, umfasst
- Ersetzen von Null- oder Leerwerten durch einen Standardbegriff, z. B. „Nicht verfügbar“.
- Umwandlung von Datenwerten nach dem festgelegten Muster und Format.
- Parsing von Feldern in zwei oder mehr Spalten.
- Ersetzen von Abkürzungen durch richtige Wörter.
- Ersetzen von Spitznamen durch Eigennamen.
- Falls der eingehende Datensatz als potenzielles Duplikat vermutet wird, wird er mit dem bestehenden Datensatz zusammengeführt, anstatt als neuer Datensatz angelegt zu werden.

Wie hilft es?
Eine Datenpipeline fungiert als Firewall für die Datenqualität Ihrer Unternehmensdatenbestände. Die Entwicklung einer Datenpipeline trägt dazu bei, die Datenkonsistenz über alle Quellen hinweg zu gewährleisten und eventuelle Diskrepanzen zu beseitigen – noch bevor die Daten in die Zielquelle geladen werden.
7. Durchführung einer Ursachenanalyse von Datenqualitätsfehlern
Bisher haben wir uns vor allem darauf konzentriert, wie wir die Datenqualität nachverfolgen und vermeiden können, dass Fehler in die Datensätze gelangen, aber die Wahrheit ist: Trotz all dieser Bemühungen werden wahrscheinlich einige Fehler in das System gelangen. Sie müssen sie nicht nur beheben, sondern vor allem verstehen, wie diese Fehler entstanden sind, damit solche Szenarien verhindert werden können.
Wie sieht sie aus?
Eine Ursachenanalyse für Datenqualitätsfehler kann beinhalten, dass Sie sich den neuesten Datenprofilbericht besorgen und mit Ihrem Team zusammenarbeiten, um Antworten auf Fragen wie diese zu finden:
- Welche Datenqualitätsfehler sind aufgetreten?
- Woher stammen sie?
- Wann sind sie entstanden?
- Warum sind sie trotz aller Prüfungen der Datenqualität im System gelandet? Haben wir etwas verpasst?
- Wie können wir verhindern, dass solche Fehler erneut im System auftauchen?
Wie hilft es?
Wenn man den Problemen der Datenqualität auf den Grund geht, lassen sich Fehler langfristig vermeiden. Sie müssen nicht immer reaktiv arbeiten und Fehler beheben, sobald sie auftreten. Mit einem proaktiven Ansatz können Sie es Ihren Teams ermöglichen, ihren Aufwand für die Behebung von Datenqualitätsfehlern zu minimieren – und 99 % der Probleme im Zusammenhang mit Daten durch die verfeinerten Datenqualitätsprozesse beheben zu lassen.
8. Einsatz von Technologie zur Erreichung und Erhaltung der Datenqualität
Dies bringt uns zu unserer letzten Best Practice: die Nutzung von Technologie zur Erreichung eines nachhaltigen Datenqualitätsmanagement-Lebenszyklus. Kein Prozess verspricht eine gute Leistung und den besten ROI, wenn er nicht mit Hilfe von Technologie automatisiert und optimiert wird.
Wie sieht sie aus?
Investieren Sie in ein technologisches System, das über alle Funktionen verfügt, die Sie benötigen, um die Datenqualität in allen Datenbeständen zu gewährleisten. Zu diesen Funktionen gehört die Möglichkeit,:
- Datenimport: Importieren Sie Daten aus verschiedenen Quellen,
- Datenprofil: Bewerten Sie Daten, um Berichte zur Datenqualität zu erstellen,
- Datenbereinigung: Markieren Sie mögliche Bereiche, die eine Datenbereinigung, -standardisierung und -umwandlung erfordern, und implementieren Sie entsprechende Maßnahmen,
- Datenabgleich: Sie können Daten mit exakten und unscharfen Abgleichsalgorithmen mit hoher Genauigkeit abgleichen und die Algorithmen auf die Art Ihrer Daten abstimmen,
- Datendeduplizierung: Verknüpfen Sie Datensätze und finden Sie die einzige Quelle der Wahrheit,
- Daten exportieren: Ergebnisse exportieren/laden.
Zusätzlich zu den oben erwähnten Funktionen für das Datenqualitätsmanagement investieren einige Unternehmen in Technologien, die auch zentralisierte Datenverwaltungsfunktionen bieten. Ein Beispiel für ein solches System ist die Stammdatenverwaltung (MDM). Obwohl es sich bei einem MDM um eine vollständige Datenverwaltungslösung mit Datenqualitätsfunktionen handelt, benötigen nicht alle Unternehmen die umfangreiche Liste von Funktionen, die ein solches System bietet.
Um zu beurteilen, welche Art von Technologie für Sie die richtige Entscheidung ist, müssen Sie Ihre geschäftlichen Anforderungen kennen. Lesen Sie diesen Blog, um die wichtigsten Unterschiede zwischen einer MDM- und einer DQM-Lösung zu erfahren.
Wie hilft es?
Der Einsatz von Technologie bei der Umsetzung von Prozessen, die konsequent wiederholt werden müssen, um dauerhafte Ergebnisse zu erzielen, bietet zahlreiche Vorteile. Wenn Sie Ihrem Team Self-Service-Tools für das Datenqualitätsmanagement zur Verfügung stellen, können Sie die betriebliche Effizienz steigern, Doppelarbeit vermeiden, die Kundenerfahrung verbessern und zuverlässige Geschäftseinblicke gewinnen.
Schlussfolgerung
Die Implementierung konsistenter, automatisierter und wiederholbarer Datenqualitätsmaßnahmen kann Ihrem Unternehmen dabei helfen, Datenqualität über alle Datensätze hinweg zu erreichen und zu erhalten.
Data Ladder bietet seinen Kunden seit über einem Jahrzehnt Datenqualitätslösungen an. DataMatch Enterprise ist eines der führenden Datenqualitätsprodukte des Unternehmens, das sowohl als eigenständige Anwendung als auch als integrierbare API verfügbar ist und ein durchgängiges Datenqualitätsmanagement ermöglicht, einschließlich Datenprofilierung, -bereinigung, -abgleich, -deduplizierung und -bereinigung.
Sie können die kostenlose Testversion noch heute herunterladen oder eine persönliche Sitzung mit unseren Experten vereinbaren, um zu erfahren, wie unser Produkt bei der Implementierung der besten Verfahren zur Erreichung und Aufrechterhaltung der Datenqualität auf Unternehmensebene helfen kann.
The post 8 bewährte Verfahren zur Gewährleistung der Datenqualität auf Unternehmensebene appeared first on Data Ladder.
]]>The post Leitfaden zum Musterabgleich: Was bedeutet er und wie geht er? appeared first on Data Ladder.
]]>In jeder Art von datenreicher Umgebung ist es einfach, Muster zu finden; das ist es, was mittelmäßige Spieler tun. Der Schlüssel liegt in der Feststellung, ob die Muster ein Signal oder Rauschen darstellen.
Nate Silver
Jeder, der mit Daten arbeitet, weiß um die Bedeutung von Mustern. Ganz gleich, ob Sie große Datensätze ganzheitlich analysieren oder bis auf den kleinsten Wert herunterbrechen – Muster sind überall zu finden. Sie können allgemeingültig sein – wie das Muster einer Kreditkartennummer – oder sie können einzigartig für Ihr Unternehmen sein, z. B. das Muster, das für die Anzeige von Produktinformationen auf Ihrer Website verwendet wird.
Wenn Daten erfasst werden, folgen sie nicht immer dem richtigen Muster. Unternehmen müssen verschiedene Methoden für den Abgleich, die Validierung und die Umwandlung von Mustern implementieren, um die Daten in der gewünschten Form und dem gewünschten Format zu erhalten.
In diesem Blog werden wir einige wichtige Konzepte im Zusammenhang mit dem Musterabgleich und der Validierung kennenlernen, z. B:
- Was bedeutet der Musterabgleich?
- Wie unterscheidet sich der Musterabgleich vom Zeichenfolgenabgleich?
- Wie funktioniert der Musterabgleich?
- Was sind die häufigsten Gründe für den Abgleich und die Validierung von Mustern?
- Wie können Sie Ihre Daten in das von Ihnen benötigte Muster umwandeln?
Lassen Sie uns eintauchen.
Was ist ein Mustervergleich?
Ein Muster wird als etwas wahrgenommen, das das Gegenteil von Unordnung oder Chaos ist. Es handelt sich um ein sich wiederholendes Modell, das in einer großen Menge von Datenwerten, die zum selben Bereich gehören, identifiziert werden kann. Daher kann der Mustervergleich wie folgt definiert werden:
Der Prozess der Suche nach einer bestimmten Folge oder Platzierung von Zeichen in einem gegebenen Datensatz.
Der Musterabgleich liefert eindeutige Ergebnisse: Die Eingabezeichenfolge enthält entweder das Muster (ist gültig) oder nicht (ist ungültig). Für den Fall, dass die Zeichenkette nicht das erforderliche Muster enthält, wird der Abgleichprozess häufig um eine Mustertransformation erweitert, bei der Teildatenelemente aus dem Eingabewert extrahiert und dann neu formatiert werden, um das erforderliche Muster zu erstellen.
Musterabgleich versus Zeichenfolgenabgleich
Bevor wir die Funktionsweise von Algorithmen zum Musterabgleich erörtern, ist es wichtig, ihre Beziehung zu Algorithmen zum Abgleich von Zeichenfolgen zu verstehen. Diese beiden Begriffe werden oft als ein und dasselbe behandelt, aber sie sind in ihrem Zweck und ihrer Verwendung recht unterschiedlich. In der nachstehenden Tabelle sind einige der wichtigsten Unterschiede aufgeführt:
| Abgleich von Mustern | String-Abgleich | |
| Vergleich | Er vergleicht eine Zeichenkette mit einem Standardmuster, das Blöcke oder Token von Zeichen darstellt. | Er vergleicht zwei Zeichenketten Zeichen für Zeichen. |
| Beispiel | Vergleich von [email protected] mit [name]@[domain].[domain-extension]. | Vergleich von Elizabeth mit Alizabeth. |
| Ergebnisse | Berechnet endgültige Ergebnisse – entweder wird das Muster gefunden oder es ist nicht vorhanden. | Berechnet exakte Übereinstimmungen (Staub mit Staub) oder unscharfe Übereinstimmungen (Staub mit Rost). |
| Verwendet | Dient zum Parsen und Extrahieren von Werten oder zum Umwandeln von Werten in Standardmuster. | Dient der Korrektur von Rechtschreibfehlern, der Erkennung von Plagiaten und der Identifizierung von Werten mit ähnlicher Bedeutung oder Zeichenzusammensetzung. |
Wie funktioniert der Musterabgleich?
Einfach ausgedrückt, arbeiten Algorithmen für den Mustervergleich mit regulären Ausdrücken (oder regex). Um zu verstehen, was ein regulärer Ausdruck ist, stellen Sie sich vor, dass es sich um eine Sprache handelt, die Ihnen hilft, ein Muster zu definieren und es mit jemandem zu teilen – oder in unserem Fall mit einem Computerprogramm.
Reguläre Ausdrücke teilen Computerprogrammen mit, nach welchem Muster sie in Testdaten suchen sollen. Manchmal ist das Programm intelligent genug, um Muster aus einer Reihe von Datenwerten zu erkennen und automatisch eine Regex zu generieren. Einige Programme oder Tools verfügen über eine integrierte Regex-Bibliothek, die häufig verwendete Muster enthält, z. B. Kreditkartennummern, US-Telefonnummern, Datumsformate, E-Mail-Adressen usw.
Beispiel für ein passendes E-Mail-Adressmuster
Um herauszufinden, was ein Algorithmus zum Musterabgleich ist, nehmen wir das Beispiel der Validierung des Musters von E-Mail-Adressen. Der erste Schritt besteht darin, die Regex zu definieren, die das Muster einer gültigen E-Mail-Adresse angibt. Ein Beispiel für eine gültige E-Mail-Adresse könnte wie folgt aussehen:
[name]@[domain].[domain-extension]
In der Regex-Sprache wird dieses Muster wie folgt übersetzt:
^[\w-.]+@([\w-]+.)+[\w-]{2,3}$
Wo,
- ^ steht für den Anfang eines Satzes und $ für das Ende.
- [\w-.] bedeutet ein Wort, das alphanumerische Zeichen, einen Unterstrich, einen Bindestrich oder einen Punkt enthält.
- +@ bedeutet die Hinzufügung eines @-Symbols.
- ([\w-]+.) bezeichnet ein Wort, das alphanumerische Zeichen, Unterstriche oder Bindestriche enthält und mit einem Punkt endet.
- +[\w-]{2,3} bedeutet ein Wort, das alphanumerische Zeichen oder einen Bindestrich enthält, und dieses Wort darf nur mindestens zwei und höchstens drei Zeichen haben.
Unten sehen Sie eine Reihe von Test-E-Mail-Adressen, die durch dieses Regex-Muster laufen, und die Ergebnisse.
| Nein. | Test | Ergebnis | Grund für das Scheitern |
| 1. | [email protected] | Gültig | |
| 2. | pam.beesly_gmail.com | Ungültig | Fehlendes @-Symbol. |
| 3. | [email protected] | Ungültig | Die Domain hat einen unerwarteten Punkt. |
| 4. | [email protected] | Ungültig | Die Domainendung hat mehr als 3 Zeichen (z. B. com4). |
Es liegt auf der Hand, dass die manuelle Definition von Regexen mühsam ist und einiges an Fachwissen erfordert. Sie können sich auch für Datenstandardisierungstools entscheiden, die visuelle Regex-Designer anbieten (mehr dazu in einem späteren Abschnitt).
Anwendungsfälle für den Musterabgleich
Nachdem wir nun wissen, was der Musterabgleich ist und wie der Algorithmus funktioniert, fragen Sie sich vielleicht, wo genau er eingesetzt wird. Der Musterabgleich ist eines der grundlegendsten Konzepte in verschiedenen Bereichen wie der Computerprogrammierung, der Datenwissenschaft und -analyse, der Verarbeitung natürlicher Sprache und vielen mehr.
Wenn wir speziell über den Musterabgleich und die Validierung im Datenbereich sprechen, finden sich hier einige der häufigsten Anwendungen:
1. Validierung von Formularübermittlungen
Da der Datenmusterabgleich zwischen gültigen und ungültigen Informationen unterscheidet, wird er meist zur Überprüfung von Formularen verwendet, die auf Websites oder in anderen Softwareanwendungen eingereicht werden. Der Regex wird je nach Bedarf auf die Formularfelder angewendet; einige Beispiele für Validierungen sind unten aufgeführt:
- Der Name einer Person enthält nur Alphabete oder Symbole,
- Die E-Mail-Adresse entspricht dem richtigen Muster,
- Die Rufnummer enthält nur Ziffern,
- Die Kreditkartennummer darf nicht mehr als 16 Ziffern haben und so weiter.
2. Durchführen von Such- und Ersetzungsoperationen
Der Musterabgleich ist auch in Anwendungen nützlich, die über Funktionen zum Suchen und Ersetzen von Textinformationen verfügen. Einige Basisanwendungen bieten nur den Abgleich von Zeichen für Zeichen (oder den Abgleich von Zeichenketten), während andere auch Regex-Such- und Ersetzungsfunktionen bieten, mit denen Sie Muster in Textdokumenten suchen können und nicht nur exakte Übereinstimmungen mit Zeichenketten.
3. Bereinigung und Standardisierung von Datensätzen
Sie können versuchen, die Informationen bei der Dateneingabe zu validieren, z. B. bei der Übermittlung von Formularen, aber aufgrund der verschiedenen Beschränkungen und Einschränkungen, die in den verschiedenen Systemen auftreten, können Ihre Unternehmensdatensätze immer noch mehrere Darstellungen derselben Informationen enthalten. An dieser Stelle ist es unerlässlich, Datensätze zu bereinigen und zu standardisieren, bevor sie für Routinevorgänge oder BI verwendet werden können.
4. Parsing und Extraktion von Werten
Da der Musterabgleich nach einer bestimmten Zeichenfolge in einem bestimmten Wert sucht, ist dieses Verfahren auch für den Abgleich und die Extraktion von Wert-Tokens nützlich, die sich in erweiterten Informationsformen befinden. Sie können zum Beispiel die Domänen aus einer Liste von geschäftlichen E-Mail-Adressen extrahieren, um herauszufinden, bei welchem Unternehmen die Person arbeitet, oder Sie können die Stadt und das Land des Wohnsitzes aus Adressfeldern extrahieren, die 3-4 Zeilen an Informationen enthalten.
Wie lassen sich Muster abgleichen?
Beim Abgleich und bei der Validierung von Mustern verfolgen die Unternehmen in der Regel zwei Ansätze: Zum einen schreiben sie eigene Code-Skripte, zum anderen verwenden sie Software-Tools von Drittanbietern. Lassen Sie uns die Umsetzung beider Ansätze diskutieren.
1. Mustervergleich mit Code
Wenn es um die Bereinigung und Standardisierung von Daten geht, besteht die Standardlösung für viele Unternehmen darin, benutzerdefinierte interne Anwendungen und Codierungsskripte für verschiedene Standardisierungsvorgänge, einschließlich Musterabgleich und Transformation, zu erstellen. So interessant das auch klingen mag, es kann eine ziemliche Herausforderung sein.
Why in-house data quality projects fail
Read this whitepaper to understand the consequences of ignoring poor data quality, gain insight on why in-house data quality solutions fail and at what costs.
DownloadWerfen wir einen Blick auf einen JavaScript-Codeausschnitt, der E-Mail-Adressen validiert.
| function emailValidation(input) { var regex = /^\w+([.-]?\w+)@\w+([.-]?\w+)(.\w{2,3})+$/; if(input.value.match(regex)) { alert("Valid"); return true;} sonst { alert("Invalid"); return false;} } |
Beachten Sie, dass dieses Codeschnipsel nur die E-Mail-Adressen validiert und sie nicht in ein standardisiertes Muster umwandelt, falls sie ungültig sind. Außerdem wird nur das E-Mail-Adressfeld überprüft, so dass Sie für verschiedene Muster jeweils eine ähnliche Code-Implementierung benötigen. Schließlich ist die Regex zur Überprüfung von E-Mail-Adressen noch etwas einfacher zu entschlüsseln. Wenn es sich um Datenfelder mit komplexen Mustern handelt, können sich Regexe über mehrere Zeilen erstrecken. Der folgende Codeschnipsel findet beispielsweise Musterübereinstimmungen für URLs.
| function URLValidation(input) { var regex = /[-a-zA-Z0-9@:%.+~#=] {1,256}.[a-zA-Z0-9()]{1,6}\b ([-a-zA-Z0-9()@:%+.~#?&//=]*) ?/gi; if(input.value.match(regex)) { alert("Valid"); return true;} sonst { alert("Invalid"); return false;} } |
2. Musterabgleich mit Software-Tools
Aus den oben genannten Gründen kann die Pflege benutzerdefinierter Anwendungen sehr ressourcenintensiv sein. Sie müssen ein Team von internen Entwicklern einstellen, die ständig von Geschäftsanwendern um Fehlerbehebung und Aktualisierung von Codefunktionen gebeten werden.
Aus diesem Grund tendieren viele Manager und leitende Dateningenieure dazu, einfache Tools für die Erstellung, den Abgleich und die Umwandlung von Mustern zu verwenden, die sowohl von IT- als auch von Nicht-IT-Mitarbeitern leicht genutzt werden können.
Solche Mustervergleiche sind mit verschiedenen Funktionen ausgestattet. Die häufigsten Merkmale werden im Folgenden erläutert.
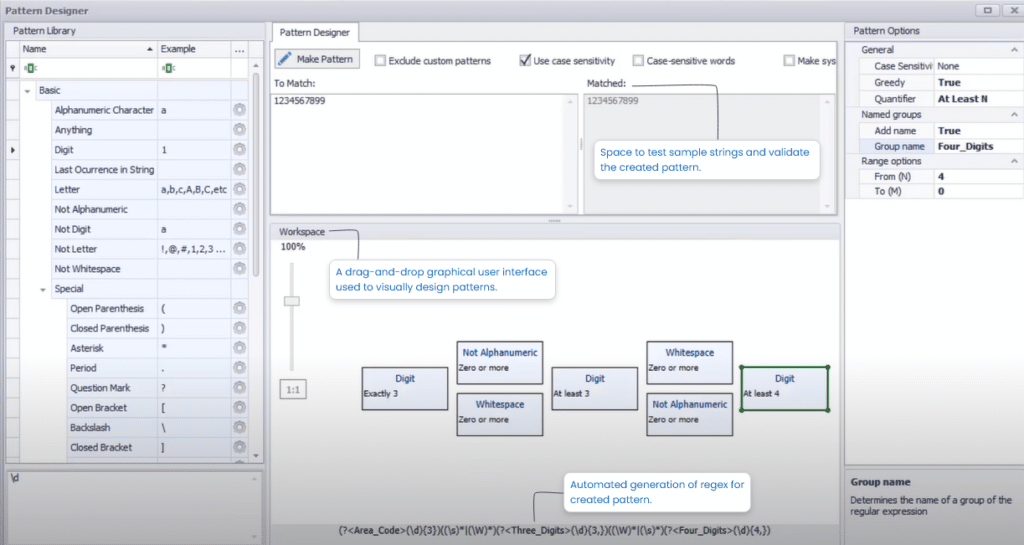
1. Visuelle Musterersteller
Eine visuelle Mustererstellungsfunktion bietet eine grafische Drag-and-Drop-Benutzeroberfläche, die für die Erstellung von Mustern verwendet werden kann. Während ein Benutzer Pattern-Blöcke oder Token im Arbeitsbereich ablegt, wird eine entsprechende Regex im Backend generiert. Diese Funktion macht technische Fachkenntnisse überflüssig und ermutigt auch unbedarfte Benutzer, Muster zu erstellen.
Ein Screenshot des visuellen Musterdesigners in DataMatch Enterprise ist unten abgebildet:
2. Mustervergleich nach Datentyp
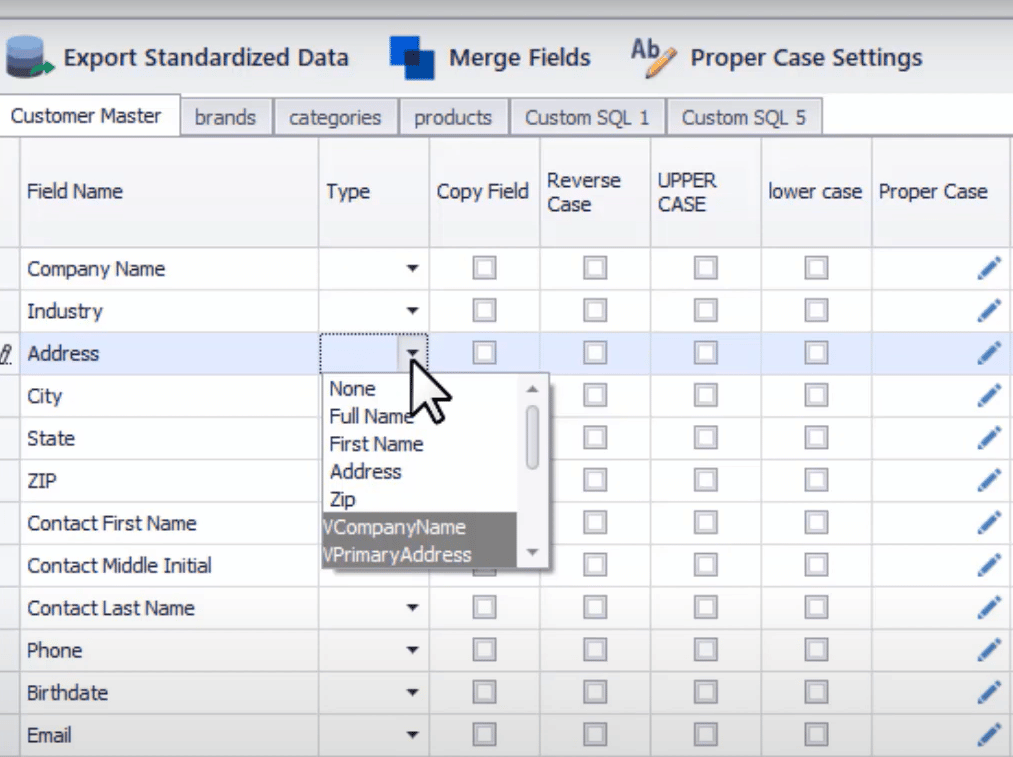
Ein weiteres interessantes Merkmal von Tools für den Musterabgleich ist die Möglichkeit, ganze Spalten nach ihren Datentypmustern zu profilieren. So können Sie z. B. die Telefonnummernspalte nach dem ganzzahligen Datentyp profilieren, und der Anteil der Werte, die neben Ziffern auch andere Symbole und Zeichen enthalten, kann als ungültig gekennzeichnet werden. Auf diese Weise lässt sich schnell abschätzen, welcher Standardisierungsaufwand zur Behebung der ungültigen Muster erforderlich ist.
Nachfolgend sehen Sie einen Screenshot der Musterübereinstimmung nach Datentyp in DataMatch Enterprise:
3. Mustervergleich mit der Regex-Bibliothek
Viele Tools verfügen über integrierte Regex-Bibliotheken mit häufig verwendeten Mustern, z. B. Kreditkartennummern, US-Telefonnummern, Datumsformate, E-Mail-Adressen usw. Darüber hinaus können Sie auch benutzerdefinierte Muster (speziell für Ihre geschäftlichen Zwecke) erstellen und in der Bibliothek zur Wiederverwendung speichern.
Ein Bildschirmfoto der Regex-Bibliothek in DataMatch Enterprise ist unten abgebildet:
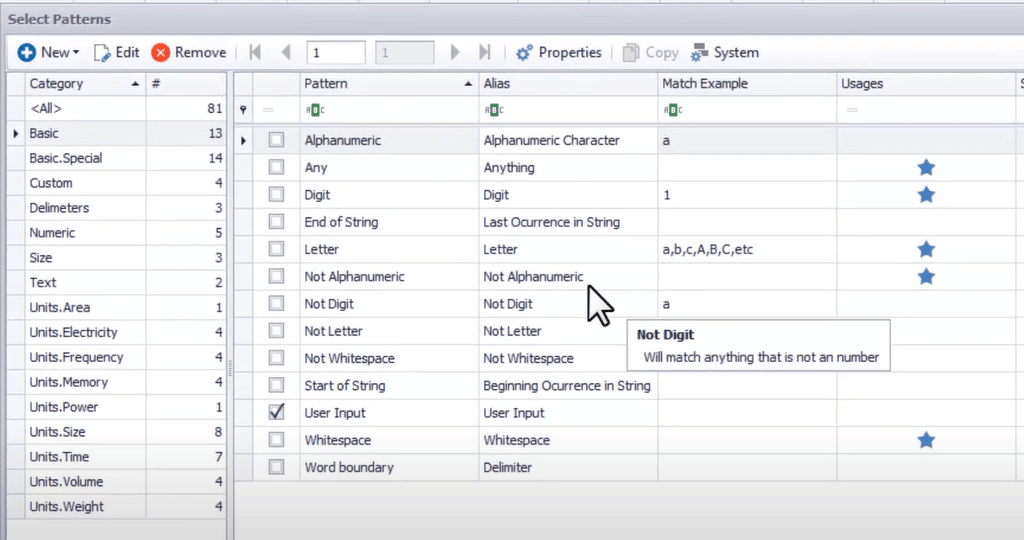
4. Komplettes Datenbereinigungs- und Standardisierungspaket
Einer der größten Vorteile solcher Tools ist, dass sie meist mit anderen Datenbereinigungs- und Standardisierungsfunktionen geliefert werden, die für die Umwandlung Ihrer Daten in eine akzeptable Form und ein akzeptables Format entscheidend sind. Sobald Sie den Bericht zum Musterabgleich haben, der zeigt, welche Datenwerte gültig sind und welche nicht, ist der nächste wichtige Schritt, auch die Muster zu korrigieren.
Aus diesem Grund kann die Einführung eines End-to-End-Systems, das die verschiedenen Disziplinen des Datenqualitätsmanagements – einschließlich Datenprofilierung, -bereinigung, -standardisierung, -abgleich und -zusammenführung – übernimmt, von großem Nutzen sein.
Nachfolgend sehen Sie einen Screenshot der verschiedenen Datenqualitätsfunktionen von DataMatch Enterprise :
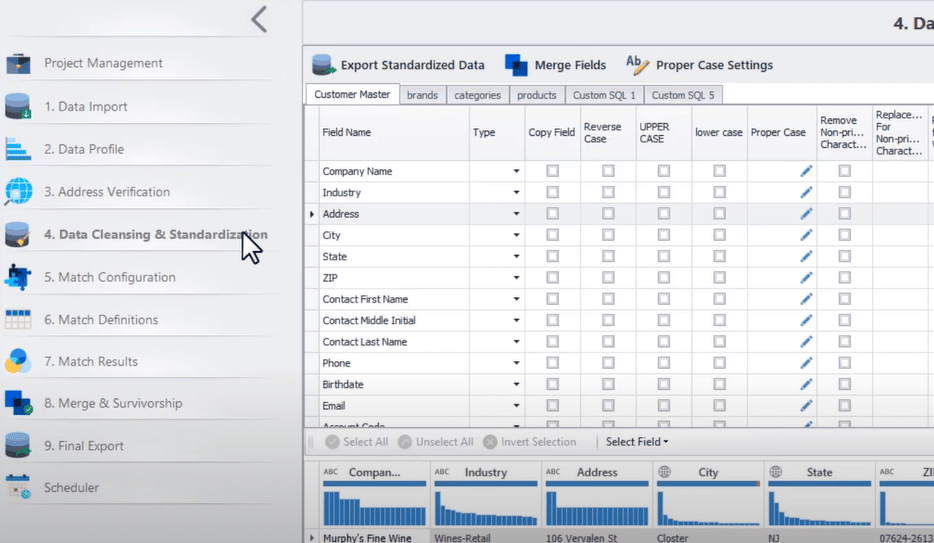
Entscheidung für eine codefreie Lösung, die Muster erstellt, abgleicht und umwandelt
Obwohl wir uns in diesem Blog hauptsächlich auf den Musterabgleich konzentriert haben, ist die Kunst der Mustertransformation ebenso interessant – und eine Herausforderung. Aus diesem Grund stellen viele Unternehmen ihren Teams gerne Self-Service-Tools für die Datenbereinigung und -standardisierung zur Verfügung, die über Funktionen für den Entwurf, den Abgleich und die Umwandlung von Mustern verfügen. Mit solchen Tools kann Ihr Team komplexe Datenbereinigungs- und Standardisierungstechniken für Millionen von Datensätzen innerhalb weniger Minuten durchführen.
DataMatch Enterprise ist ein solches Tool, das es den Datenteams erleichtert, Musterfehler schnell und präzise zu korrigieren und sich auf wichtigere Aufgaben konzentrieren zu können. Um mehr darüber zu erfahren, wie DataMatch Enterprise helfen kann, können Sie noch heute eine kostenlose Testversion herunterladen oder eine Demo mit einem Experten buchen.
The post Leitfaden zum Musterabgleich: Was bedeutet er und wie geht er? appeared first on Data Ladder.
]]>The post Leitfaden zur Datenstandardisierung: Arten, Vorteile und Verfahren appeared first on Data Ladder.
]]>Wenn Sie Daten aus verschiedenen Anwendungen im gesamten Unternehmen abrufen, erwarten Sie eine einheitliche Definition und ein einheitliches Format der gleichen Informationen. In der Realität ist dies jedoch selten der Fall. Die Unterschiede in den Datensätzen – über verschiedene Anwendungen hinweg und sogar innerhalb derselben Anwendung – machen es fast unmöglich, Daten für jeden Zweck zu nutzen – von Routinevorgängen bis hin zu Business Intelligence.
Ein durchschnittliches Unternehmen nutzt heute mehrere SaaS- und interne Anwendungen. Jedes System hat seine eigenen Anforderungen, Einschränkungen und Begrenzungen. Aus diesem Grund sind bei Daten, die in verschiedenen Anwendungen gehostet werden, Diskrepanzen vorprogrammiert. Und wenn wir Rechtschreibfehler, Abkürzungen, Spitznamen und Tippfehler in Betracht ziehen, stellen wir fest, dass ein und derselbe Wert Hunderte von verschiedenen Darstellungen haben kann. An dieser Stelle ist es zwingend erforderlich, Daten zu standardisieren, um sie für jeden beabsichtigten Zweck nutzbar zu machen.
In diesem Blog erfahren Sie alles über die Datenstandardisierung: was sie ist, warum und wann Sie sie brauchen und wie Sie sie durchführen können. Fangen wir an.
Was ist Datenstandardisierung?
In der Datenwelt bezieht sich ein Standard auf ein Format oder eine Darstellung, der jeder Wert eines bestimmten Bereichs entsprechen muss. Standardisierung von Daten bedeutet also:
Der Prozess der Umwandlung einer falschen oder inakzeptablen Darstellung von Daten in eine akzeptable Form.
Der einfachste Weg, um herauszufinden, was „akzeptabel“ ist, besteht darin, Ihre geschäftlichen Anforderungen zu verstehen. Im Idealfall müssen Unternehmen sicherstellen, dass das Datenmodell, das von den meisten – wenn nicht sogar allen – Anwendungen verwendet wird, ihren Geschäftsanforderungen entspricht. Der beste Weg zur Standardisierung von Daten ist die Anpassung der Datendarstellung, -struktur und -definition an die organisatorischen Anforderungen.
Arten und Beispiele von Datenstandardisierungsfehlern
Im Folgenden werden einige Beispiele dafür angeführt, wie nicht standardisierte Daten in das System gelangen können:
- Die Telefonnummer des Kunden wird in einem System als Zeichenkette gespeichert, während sie in einem anderen System nur als 8-stellige Zahl zulässig ist, was zu Inkonsistenzen beim Datentyp führt.
- Der Kundenname wird in einem System als ein einziges Feld gespeichert, während er in einem anderen System in drei separaten Feldern für Vor-, Mittel- und Nachnamen erfasst wird, was zu struktureller Inkonsistenz führt.
- Das Geburtsdatum des Kunden hat in einem System das Format MM/TT/JJJ, während es in einem anderen System das Format Monat-Tag-Jahr hat, was zu Formatinkonsistenz führt.
- Das Geschlecht des Kunden wird in einem System als „weiblich“ oder „männlich“ gespeichert, während es in einem anderen System als „F“ oder „M“ gespeichert wird, was zu einer Inkonsistenz der Domänenwerte führt.
Abgesehen von diesen häufigen Szenarien können Rechtschreibfehler, Transkriptionsfehler und fehlende Validierungsbeschränkungen die Datenstandardisierungsfehler in Ihren Datensätzen erhöhen.
Warum müssen Sie Daten standardisieren?
Jedes System hat seine eigenen Beschränkungen und Einschränkungen, die zu einzigartigen Datenmodellen und deren Definitionen führen. Aus diesem Grund müssen Sie die Daten möglicherweise umwandeln, bevor sie von einem Geschäftsprozess korrekt verarbeitet werden können.
Normalerweise wissen Sie, dass es an der Zeit ist, Daten zu standardisieren, wenn Sie dies wollen:
1. Konformität eingehender oder ausgehender Daten
Ein Unternehmen hat viele Schnittstellen, über die Datenpunkte von externen Akteuren, wie z. B. Lieferanten oder Partnern, ausgetauscht werden. Wann immer Daten in ein Unternehmen gelangen oder aus einem Unternehmen exportiert werden, ist es notwendig, die Daten an den erforderlichen Standard anzupassen, da sonst das nicht standardisierte Datenchaos immer größer wird.
2. Daten für BI oder Analytik vorbereiten
Dieselben Daten können auf verschiedene Weise dargestellt werden, aber die meisten BI-Tools sind nicht darauf spezialisiert, alle möglichen Darstellungen von Datenwerten zu verarbeiten, und es kann vorkommen, dass Daten mit derselben Bedeutung unterschiedlich behandelt werden. Dies kann zu verzerrten oder ungenauen BI-Ergebnissen führen. Bevor Sie also Daten in Ihre BI-Systeme einspeisen können, müssen diese bereinigt, standardisiert und dedupliziert werden, damit Sie korrekte, wertvolle Erkenntnisse gewinnen können.
3. Konsolidierung von Einheiten zur Beseitigung von Doppelspurigkeiten
Die Duplizierung von Daten ist eine der größten Gefahren für die Datenqualität, mit der Unternehmen zu kämpfen haben. Für einen effizienten und fehlerfreien Geschäftsbetrieb müssen Sie doppelte Datensätze, die zur selben Entität gehören, eliminieren (sei es für einen Kunden, ein Produkt, einen Standort oder einen Mitarbeiter), und ein effektiver Datendeduplizierungsprozess erfordert die Einhaltung von Datenqualitätsstandards.
4. Datenaustausch zwischen Abteilungen
Damit die Daten zwischen den Abteilungen interoperabel sind, müssen sie in einem Format vorliegen, das für alle verständlich ist. Meistens haben Unternehmen Kundeninformationen in CRMs, die von den Vertriebs- und Marketingmitarbeitern verstanden werden. Dies kann zu Verzögerungen bei der Erledigung von Aufgaben und zu Produktivitätseinbußen im Team führen.
Datenbereinigung versus Datenstandardisierung
Die Begriffe “ Datenbereinigung“ und “ Datenstandardisierung “ werden in der Regel synonym verwendet. Es gibt jedoch einen kleinen Unterschied zwischen den beiden.
Bei der Datenbereinigung werden fehlerhafte oder unsaubere Daten identifiziert und durch korrekte Werte ersetzt, während bei der Datenstandardisierung die Datenwerte von einem inakzeptablen Format in ein akzeptables Format umgewandelt werden.
Zweck und Ergebnis dieser beiden Prozesse sind ähnlich: Sie wollen Ungenauigkeiten und Inkonsistenzen in Ihren Datensätzen beseitigen. Beide Prozesse sind für Ihre Initiative zum Datenqualitätsmanagement unerlässlich und müssen Hand in Hand gehen.
Wie können Daten standardisiert werden?
Ein Datenstandardisierungsprozess besteht aus vier einfachen Schritten: definieren, testen, transformieren und erneut testen. Gehen wir die einzelnen Schritte etwas ausführlicher durch.
1. Definieren Sie eine Norm
In einem ersten Schritt müssen Sie herausfinden, welcher Standard den Anforderungen Ihres Unternehmens entspricht. Der beste Weg, einen Standard zu definieren, ist der Entwurf eines Datenmodells für Ihr Unternehmen. Dieses Datenmodell stellt den idealsten Zustand dar, dem die Datenwerte für eine bestimmte Entität entsprechen müssen. Ein Datenmodell kann wie folgt gestaltet werden:
- Identifizieren Sie die für Ihren Geschäftsbetrieb wichtigen Datenbestände . Die meisten Unternehmen erfassen und verwalten zum Beispiel Daten über Kunden, Produkte, Mitarbeiter, Standorte usw.
- Definieren Sie die Datenfelder jedes identifizierten Vermögenswerts und entscheiden Sie auch über die strukturellen Details. Sie möchten beispielsweise den Namen, die Adresse, die E-Mail-Adresse und die Telefonnummer eines Kunden speichern, wobei sich das Feld „Name“ über drei Felder und das Feld „Adresse“ über zwei Felder erstreckt.
- Weisen Sie jedem im Asset identifizierten Feld einen Datentyp zu. Das Feld „Name“ ist beispielsweise eine Zeichenkette, „Telefonnummer“ ist eine ganze Zahl usw.
- Definieren Sie Zeichengrenzen (Minimum und Maximum) für jedes Feld. Zum Beispiel darf ein Name nicht länger als 15 Zeichen und eine Telefonnummer nicht länger als 8 Ziffern sein, usw.
- Definieren Sie das Muster, dem die Felder entsprechen müssen – dies gilt möglicherweise nicht für alle Felder. Zum Beispiel sollte die E-Mail-Adresse eines jeden Kunden der Regex entsprechen: [chars]@[chars].[chars].
- Definieren Sie das Format, in dem bestimmte Datenelemente in ein Feld eingefügt werden müssen. Das Geburtsdatum eines Kunden sollte zum Beispiel als MM/TD/JJJJ angegeben werden.
- Definieren Sie die Messeinheit für numerische Werte (falls zutreffend). Zum Beispiel wird das Alter des Kunden in Jahren gemessen.
- Definieren Sie den Wertebereich für Felder, die aus einer bestimmten Menge von Werten abgeleitet werden müssen. Zum Beispiel muss das Alter des Kunden eine Zahl zwischen 18 und 50 sein, das Geschlecht muss männlich oder weiblich sein, und so weiter.
Ein entworfenes Datenmodell kann dann in ein ERD-Klassendiagramm eingefügt werden, um den definierten Standard für jeden Datenbestand und dessen Beziehung zueinander zu veranschaulichen. Ein Beispiel für ein Datenmodell für ein Einzelhandelsunternehmen ist unten dargestellt:
2. Test für Standard
Datenstandardisierungstechniken beginnen mit dem zweiten Schritt, da sich der erste Schritt auf die Definition dessen konzentriert, was sein soll – etwas, das einmalig gemacht oder inkrementell überprüft und von Zeit zu Zeit aktualisiert wird.
Sie haben den Standard definiert, und nun ist es an der Zeit zu prüfen, inwieweit die aktuellen Daten mit diesem übereinstimmen. Im Folgenden werden einige Techniken erläutert, mit denen Datenwerte auf Standardisierungsfehler geprüft und ein Standardisierungsbericht erstellt werden kann, der zur Behebung der Probleme verwendet werden kann.
a. Parsing von Datensätzen und Attributen
Der Entwurf eines Datenmodells ist der wichtigste Teil der Datenverwaltung. Doch leider entwerfen viele Unternehmen nicht rechtzeitig Datenmodelle und legen gemeinsame Datenstandards fest, oder die von ihnen verwendeten Anwendungen verfügen nicht über anpassbare Datenmodelle, was dazu führt, dass sie Daten mit unterschiedlichen Feldnamen und Strukturen erfassen.
Wenn Sie Informationen aus verschiedenen Systemen abfragen, stellen Sie vielleicht fest, dass einige Datensätze den Namen eines Kunden als ein einziges Feld zurückgeben, während andere drei oder sogar vier Felder für den Namen eines Kunden zurückgeben. Aus diesem Grund müssen Sie, bevor ein Datensatz auf Fehler geprüft werden kann, zunächst die Datensätze und Felder analysieren, um die Komponenten zu ermitteln, die auf Standardisierung geprüft werden müssen.
b. Bericht zum Gebäudedatenprofil
Der nächste Schritt besteht darin, die geparsten Komponenten durch ein Profiling-System laufen zu lassen. Ein Datenprofilierungstool liefert verschiedene Statistiken über Datenattribute, wie z. B.
- Wie viele Werte in einer Spalte entsprechen dem erforderlichen Datentyp, Format und Muster?
- Wie hoch ist die durchschnittliche Anzahl der Zeichen in einer Spalte?
- Welches sind die meisten Mindest- und Höchstwerte in einer numerischen Spalte?
- Welches sind die häufigsten Werte in einer Spalte und wie oft kommen sie vor?
c. Abgleich und Validierung von Mustern
Obwohl Datenprofilierungstools über Musterübereinstimmungen berichten, werden wir sie etwas ausführlicher besprechen, da sie ein wichtiger Bestandteil der Datenstandardisierungstests sind. Um Muster abzugleichen, müssen Sie zunächst einen regulären Ausdruck für ein Feld definieren, z. B. kann ein regulärer Ausdruck für E-Mail-Adressen lauten: ^[a-zA-Z0-9+_ .-]+@[a-zA-Z0-9 .-]+$. Alle E-Mail-Adressen, die nicht dem vorgegebenen Muster entsprechen, müssen bei der Prüfung markiert werden.
d. Verwendung von Wörterbüchern
Bestimmte Datenfelder können auf Standardisierung geprüft werden, indem die Werte mit Wörterbüchern oder Wissensdatenbanken verglichen werden. Sie können sie auch mit selbst erstellten Wörterbüchern abgleichen. Dies wird oft gemacht, um Rechtschreibfehler, Abkürzungen oder verkürzte Namen zu finden. So enthalten Firmennamen in der Regel Begriffe wie LLC, Inc, Ltd. und Corp. usw. Ein Abgleich mit einem Wörterbuch, das solche Standardbegriffe enthält, kann dabei helfen, festzustellen, welche Begriffe nicht der geforderten Norm entsprechen oder falsch geschrieben sind.
Lesen Sie mehr über die Verwendung von Wordsmith zur Entfernung von Störungen und zur Standardisierung von Daten in großen Mengen.
e. Prüfadressen für die Normung
Beim Testen von Daten für die Standardisierung müssen Sie möglicherweise auch spezielle Felder testen, z. B. Orte oder Adressen. Bei der Adressstandardisierung wird das Format der Adressen mit einer maßgeblichen Datenbank – z. B. dem USPS in den USA – abgeglichen und die Adressdaten in ein akzeptables, standardisiertes Format umgewandelt.
Eine standardisierte Adresse sollte korrekt geschrieben, formatiert, abgekürzt, geokodiert und mit genauen ZIP+4-Werten versehen sein. Alle Adressen, die nicht dem geforderten Standard entsprechen (insbesondere Adressen, die Lieferungen und Sendungen erhalten sollen), müssen gekennzeichnet werden, damit sie bei Bedarf umgestaltet werden können.
Lesen Sie weiter: Eine Kurzanleitung zur Adressennormung und -überprüfung.
Enterprise Content Solutions uses DataMatch Enterprise
Enterprise Content Solutions found 24% higher matches than other vendors for inconsistent address records.
Read case study3. Transformieren
Im dritten Schritt des Datenstandardisierungsprozesses ist es schließlich an der Zeit, die nicht konformen Werte in ein standardisiertes Format umzuwandeln. Dies kann Folgendes beinhalten:
- Umwandlung der Felddatentypen, z. B. Konvertierung der Telefonnummer von einer Zeichenkette in einen Ganzzahldatentyp und Eliminierung von Zeichen oder Symbolen in Telefonnummern, um eine 8-stellige Nummer zu erhalten.
- Umwandlung von Mustern und Formaten, wie z. B. die Konvertierung von Datumsangaben im Datensatz in das Format MM/TT/JJJJ.
- Umwandlung von Maßeinheiten, z. B. Umrechnung von Produktpreisen in USD.
- Erweitern von abgekürzten Werten zu vollständigen Formularen, z. B. Ersetzen der abgekürzten US-Bundesstaaten: NY zu New York, NJ zu New Jersey usw.
- Entfernen von Rauschen in Datenwerten, um aussagekräftigere Informationen zu erhalten, z. B. Entfernen von LLC, Inc. und Corp. aus Firmennamen, um die tatsächlichen Namen ohne Rauschen zu erhalten.
- Rekonstruktion der Werte in einem standardisierten Format für den Fall, dass sie in eine neue Anwendung oder eine Datendrehscheibe, z. B. ein Stammdatenverwaltungssystem, übertragen werden müssen.
Alle diese Transformationen können manuell durchgeführt werden – was zeitaufwändig und unproduktiv sein kann – oder Sie können automatisierte Tools verwenden, die Ihnen bei der Datenbereinigung helfen, indem sie die Standardtest- und Transformationsphasen für Sie automatisieren.
4. Wiederholungsprüfung für Standard
Nach Abschluss des Transformationsprozesses ist es ratsam, den Datensatz erneut auf Standardisierungsfehler zu prüfen. Die Berichte vor und nach der Standardisierung können verglichen werden, um zu verstehen, inwieweit Datenfehler durch die konfigurierten Prozesse behoben wurden und wie sie verbessert werden können, um bessere Ergebnisse zu erzielen.
Verwendung von Self-Service-Tools zur Datenstandardisierung
Heutzutage werden die Daten sowohl manuell eingegeben als auch automatisch erfasst und generiert. Bei der Verarbeitung großer Datenmengen haben Unternehmen mit Millionen von Datensätzen zu kämpfen, die inkonsistente Muster, Datentypen und Formate enthalten. Und wann immer sie diese Daten nutzen wollen, werden die Teams mit stundenlangen manuellen Formatprüfungen und der Korrektur jedes noch so kleinen Details bombardiert, bevor die Informationen als nützlich eingestuft werden können.
Viele Unternehmen haben erkannt, wie wichtig es ist, ihren Teams Self-Service-Tools zur Datenstandardisierung zur Verfügung zu stellen, die auch über integrierte Datenbereinigungsfunktionen verfügen. Mit solchen Tools kann Ihr Team komplexe Datenbereinigungs- und Standardisierungstechniken für Millionen von Datensätzen innerhalb weniger Minuten durchführen.
DataMatch Enterprise ist ein solches Tool, das es den Datenteams erleichtert, Fehler bei der Datenstandardisierung schnell und präzise zu beheben und sich auf wichtigere Aufgaben konzentrieren zu können. Um mehr darüber zu erfahren, wie DataMatch Enterprise helfen kann, können Sie noch heute eine kostenlose Testversion herunterladen oder eine Demo mit einem Experten buchen.
The post Leitfaden zur Datenstandardisierung: Arten, Vorteile und Verfahren appeared first on Data Ladder.
]]>The post Datenintegration erklärt: Definition, Arten, Verfahren und Tools appeared first on Data Ladder.
]]>Führungskräfte unterschätzen oft den Zeit- und Arbeitsaufwand, der erforderlich ist, um Business Intelligence im gesamten Unternehmen zu aktivieren. Sie glauben, dass es so einfach ist, Daten aus allen Quellen zu sammeln, sie in einer Tabelle zusammenzufassen und in BI-Tools einzuspeisen, oder – noch einfacher – einen Datenanalysten zu haben, der aus Zahlen Intelligenz fabrizieren kann. Am Ende erwarten sie unglaubliche Einblicke in die Unternehmensleistung, potenzielle Marktchancen und Umsatzprognosen für das nächste Jahrzehnt.
Der BI-Prozess ist nicht so einfach, und die wichtigste Komponente für seinen Erfolg wird oft übersehen – die Datenintegration. Für einen reibungslosen Datenbetrieb in einem Unternehmen müssen die Daten zunächst am richtigen Ort, zur richtigen Zeit und im richtigen Format verfügbar sein. Verstreute Daten – die sich in Silos befinden – sind die Hauptursache für Inkonsistenz, Ineffizienz und Ungenauigkeit Ihrer BI-Bemühungen und anderer Datenoperationen.
In diesem Blog erfahren wir, was Datenintegration ist, und diskutieren die verschiedenen Arten, Prozesse und Tools. Fangen wir an.
Was ist Datenintegration?
Datenintegration ist definiert als:
Der Prozess des Kombinierens, Konsolidierens und Zusammenführens von Daten aus mehreren unterschiedlichen Quellen, um eine einzige, einheitliche Sicht auf die Daten zu erhalten und eine effiziente Datenverwaltung, -analyse und -zugriff zu ermöglichen.
Das Erfassen und Speichern ist der erste Schritt im Lebenszyklus der Datenverwaltung. Ungleiche Daten, die sich in verschiedenen Datenbanken, Tabellenkalkulationen, lokalen Servern und Anwendungen von Drittanbietern befinden, sind jedoch nutzlos, wenn sie nicht zusammengeführt werden. Die Datenintegration ermöglicht es Ihrem Unternehmen, die erfassten Informationen praktisch und ganzheitlich zu nutzen und wichtige Geschäftsfragen zu beantworten.
Nehmen wir als Beispiel die Integration von Kundendaten. Kundendaten werden in jedem Unternehmen an mehreren Orten gespeichert und gehostet – einschließlich Website-Tracking-Tools, CRMs, Marketing-Automatisierungs- und Buchhaltungssoftware und so weiter. Um Kundeninformationen sinnvoll auszuwerten und nützliche Erkenntnisse zu gewinnen, kann Ihr Team nicht ständig zwischen verschiedenen Anwendungen wechseln. Sie benötigen einen einzigen, einheitlichen Zugang zu den Kundendatensätzen, bei dem die Daten sauber und frei von Unklarheiten sind.
Darüber hinaus bietet die Datenintegration unzählige weitere Vorteile, die eine effiziente Datenverwaltung, Business Intelligence und andere Datenoperationen ermöglichen.
5 Arten der Datenintegration
Die Datenintegration kann auf verschiedene Weise erreicht werden. Allgemein als Datenintegrationsmethoden, -techniken, -ansätze oder -typen bezeichnet, gibt es 5 verschiedene Möglichkeiten, wie Sie Ihre Daten integrieren können.
1. Integration von Stapeldaten
Bei dieser Art der Datenintegration durchlaufen die Daten den ETL-Prozess in Stapeln zu geplanten Zeiten (wöchentlich oder monatlich). Die Daten werden aus unterschiedlichen Quellen extrahiert , in eine konsistente und standardisierte Ansicht umgewandelt und dann in einen neuen Datenspeicher, z. B. ein Data Warehouse oder mehrere Data Marts, geladen . Diese Integration ist vor allem für die Datenanalyse und Business Intelligence nützlich, da ein BI-Tool oder ein Analystenteam die im Warehouse gespeicherten Daten einfach beobachten kann.
2. Datenintegration in Echtzeit
Bei dieser Art der Datenintegration werden eingehende oder strömende Daten über konfigurierte Datenpipelines nahezu in Echtzeit in bestehende Datensätze integriert. Unternehmen setzen Datenpipelines ein, um die Bewegung und Umwandlung von Daten zu automatisieren und sie an das gewünschte Ziel zu leiten. Prozesse zur Integration eingehender Daten (als neuer Datensatz oder zur Aktualisierung/Ergänzung bestehender Informationen) sind in die Datenpipeline integriert.
3. Datenkonsolidierung
Bei dieser Art der Datenintegration wird eine Kopie aller Quelldatensätze in einer Staging-Umgebung oder -Anwendung erstellt, die Datensätze werden dann konsolidiert, um eine einzige Ansicht darzustellen, und schließlich in eine Zielquelle verschoben. Obwohl dieser Typ dem ETL ähnlich ist, gibt es einige wichtige Unterschiede, wie z.B:
- Die Datenkonsolidierung konzentriert sich mehr auf Konzepte wie Datenbereinigung und -standardisierung und Entitätsauflösung, während ETL sich auf die Datentransformation konzentriert.
- Während ETL eine bessere Option für große Datenmengen ist, eignet sich die Datenkonsolidierung besser für die Verknüpfung von Datensätzen und die eindeutige Identifizierung der wichtigsten Datenbestände, z. B. Kunde, Produkt und Standort.
- Data Warehouses helfen vor allem bei der Datenanalyse und BI, während die Datenkonsolidierung auch zur Verbesserung der Geschäftsabläufe beiträgt, z. B. bei der Verwendung des konsolidierten Datensatzes eines Kunden zur Kontaktaufnahme oder bei der Erstellung von Rechnungen usw.
4. Datenvirtualisierung
Wie der Name schon sagt, wird bei dieser Art der Datenintegration nicht wirklich eine Kopie der Daten erstellt oder in eine neue Datenbank mit einem erweiterten Datenmodell verschoben, sondern es wird eine virtuelle Schicht eingeführt, die eine Verbindung zu allen Datenquellen herstellt und einen einheitlichen Zugriff als Front-End-Anwendung bietet.
Da sie über kein eigenes Datenmodell verfügt, besteht der Zweck der virtuellen Schicht darin, eingehende Anfragen entgegenzunehmen, Ergebnisse durch Abfragen der erforderlichen Informationen aus den angeschlossenen Datenbanken zu erstellen und eine einheitliche Ansicht zu präsentieren. Die Datenvirtualisierung senkt die Kosten für Speicherplatz und die Komplexität der Integration, da die Daten nur scheinbar integriert sind, aber separat in den Quellsystemen gespeichert werden.
5. Datenföderation
Die Datenföderation ähnelt der Datenvirtualisierung und wird oft als deren Unterform betrachtet. Auch bei der Datenföderation werden die Daten nicht kopiert oder in eine neue Datenbank verschoben, sondern es wird ein neues Datenmodell entworfen, das eine integrierte Sicht der Quellsysteme darstellt.
Es bietet eine Front-End-Schnittstelle für Abfragen, und wenn Daten angefordert werden, zieht es Daten aus den verbundenen Quellen und wandelt sie in das erweiterte Datenmodell um, bevor es die Ergebnisse präsentiert. Datenföderation ist sinnvoll, wenn die zugrunde liegenden Datenmodelle der Quellsysteme zu unterschiedlich sind und auf ein neueres Modell abgebildet werden müssen, um die Informationen effizienter nutzen zu können.
Prozess der Datenintegration
Unabhängig von der Art der Datenintegration ist der Ablauf des Datenintegrationsprozesses bei allen ähnlich, da das Ziel darin besteht, Daten zu kombinieren und zusammenzuführen. In diesem Abschnitt wird ein allgemeiner Rahmen für die Integration von Unternehmensdaten vorgestellt, den Sie bei der Implementierung beliebiger Datenintegrationstechniken verwenden können.

1. Erfassen von Anforderungen
Der erste Schritt in jedem Datenintegrationsprozess ist die Erfassung und Bewertung der geschäftlichen und technischen Anforderungen. Dies wird Ihnen helfen, einen Rahmen zu planen, zu gestalten und umzusetzen, der die erwarteten Ergebnisse bringt. Zu den Bereichen, die bei der Erfassung der Anforderungen zu berücksichtigen sind, gehören:
- Müssen Sie Daten in Echtzeit integrieren oder eine Batch-Integration zu geplanten Zeiten durchführen?
- Müssen Sie eine Kopie der Daten erstellen und diese dann integrieren oder eine virtuelle Schicht implementieren, die Daten im laufenden Betrieb integriert, ohne Datenbanken zu replizieren?
- Sollen die integrierten Daten einem neuen, erweiterten Datenmodell folgen?
- Welche Quellen müssen integriert werden?
- Wohin sollen die integrierten Daten gelangen ?
- Welche funktionalen Abteilungen im Unternehmen benötigen Zugang zu integrierten Informationen?
2. Datenprofilierung
Ein weiterer erster Schritt des Datenintegrationsprozesses ist die Erstellung von Datenprofilen oder Bewertungsberichten der zu integrierenden Daten. Dies hilft Ihnen, den aktuellen Stand der Daten zu verstehen und verborgene Details über deren Struktur und Inhalt aufzudecken. Ein Bericht zur Datenprofilerstellung identifiziert leere Werte, Felddatentypen, wiederkehrende Muster und andere beschreibende Statistiken, die potenzielle Möglichkeiten zur Datenbereinigung und -umwandlung aufzeigen.
3. Überprüfung der Profile anhand der Anforderungen
Mit den Integrationsanforderungen und den Bewertungsberichten in der Hand ist es nun an der Zeit, die Lücke zwischen den beiden zu ermitteln. In der Anforderungsphase werden viele Funktionen gefordert, die nicht gültig sind oder nicht mit den profilierten Berichten über die vorhandenen Daten übereinstimmen. Der Vergleich zwischen beiden hilft Ihnen jedoch bei der Planung eines Integrationsdesigns, das so viele Anforderungen wie möglich erfüllt.
4. Entwurf
Dies ist die Planungsphase des Prozesses, in der Sie einige Schlüsselkonzepte zur Datenintegration entwickeln müssen, wie z. B.:
- Der architektonische Entwurf, der zeigt, wie die Daten zwischen den Systemen übertragen werden,
- Die Auslösekriterien, die entscheiden, wann die Integration stattfindet oder wodurch sie ausgelöst wird,
- Das neue, erweiterte Datenmodell und die Spaltenzuordnungen, die den Konsolidierungsprozess definieren,
- die Regeln für Datenbereinigung, -standardisierung, -abgleich und -qualitätssicherung, die für eine fehlerfreie Integration konfiguriert werden müssen, und
- Die Technologie , die für die Implementierung, Überprüfung, Überwachung und Wiederholung des Integrationsprozesses eingesetzt wird.
5. Umsetzung
Nachdem der Integrationsprozess entworfen wurde, ist es an der Zeit, ihn auszuführen. Die Ausführung kann inkrementell erfolgen, d. h. Sie integrieren geringe Datenmengen aus weniger widersprüchlichen Quellen und erhöhen iterativ das Volumen und fügen weitere Quellen hinzu. Dies kann nützlich sein, um eventuelle anfängliche Fehler zu erkennen. Sobald die Integration bestehender Daten abgeschlossen ist, können Sie sich nun auf die Integration neuer eingehender Datenströme konzentrieren.
6. Überprüfen, validieren und überwachen
In der Überprüfungsphase müssen Sie die Genauigkeit und Effizienz des Datenintegrationsprozesses testen. Ein Profiling der Zielquelle kann eine gute Möglichkeit sein, um Fehler zu finden und die Integration zu validieren. Eine Reihe von Bereichen muss getestet werden, bevor die Integrationseinrichtung für künftige Aktivitäten eingesetzt werden kann, z. B:
- Es gibt keinen/kaum Datenverlust,
- Die Qualität der Daten hat sich nach der Integration nicht verschlechtert,
- Der Integrationsprozess verläuft durchweg wie erwartet,
- Die Bedeutung der Daten hat sich während der Integration nicht geändert,
- Die oben genannten Maßnahmen sind auch nach einiger Zeit noch gültig.
Datenintegration und Datenqualität: Zu integriert, um differenziert zu sein
Bevor wir fortfahren, wollen wir ein wichtiges Konzept im Zusammenhang mit der Datenintegration erörtern, das oft für Verwirrung sorgt: die Beziehung zwischen Datenintegration und Datenqualität.
Aus ganzheitlicher Sicht haben sowohl die Datenintegration als auch die Datenqualität das gleiche Ziel: die Datennutzung einfacher und effizienter zu gestalten. Bei den Bemühungen, dieses Ziel zu erreichen, kann man nicht von Datenintegration ohne Datenqualität sprechen, und umgekehrt. Es kann verwirrend werden, wenn man versucht zu verstehen, wo das eine aufhört und das andere beginnt. Die Wahrheit ist, dass beide Konzepte zu sehr miteinander verwoben sind, um voneinander unterschieden werden zu können, und dass sie nahtlos gehandhabt werden müssen.
Datenintegrationsbemühungen, die keine Rücksicht auf die Datenqualität nehmen, sind zwangsläufig umsonst. Das Datenqualitätsmanagement ist ein Katalysator für Ihren Datenintegrationsprozess, denn es verbessert und beschleunigt die Datenkonsolidierung.
Ein weiterer Unterschied besteht darin, dass Datenqualität keine Initiative ist, sondern eine Gewohnheit oder Übung, die konsequent überwacht werden muss. Obwohl die Datenintegration bei Data Warehouses zu bestimmten Zeiten in der Woche oder im Monat erfolgen kann, darf die Datenqualität auch während dieser Wartezeit nicht vergessen werden. Daher ist die Datenqualität für erfolgreiche und brauchbare Datenintegrationsergebnisse entscheidend.
Tools und Lösungen zur Datenintegration
In Anbetracht der großen Datenmengen, die Unternehmen speichern und integrieren, ist manuelle Arbeit bei den meisten Integrationsinitiativen nicht mehr möglich. Der Einsatz von Technologie zur Integration und Konsolidierung von Daten aus verschiedenen Quellen kann sich als effektiver, effizienter und produktiver erweisen. Lassen Sie uns erörtern, welche gemeinsamen Merkmale Sie in einer Datenintegrationsplattform suchen können:
- Die Möglichkeit, Daten aus einer Vielzahl von Quellen wie SQL- oder Oracle-Datenbanken, Tabellenkalkulationen und Anwendungen von Drittanbietern zu beziehen.
- Die Möglichkeit, Profile von Datensätzen zu erstellen und einen umfassenden Bericht über deren Zustand in Bezug auf Vollständigkeit, Mustererkennung, Datentypen und -formate usw. zu erstellen.
- Die Fähigkeit, Mehrdeutigkeiten zu beseitigen, wie z. B. Null- oder Müllwerte, Rauschen zu entfernen, Rechtschreibfehler zu korrigieren, Abkürzungen zu ersetzen, Datentypen und -muster umzuwandeln und vieles mehr.
- Die Möglichkeit, Attribute, die zu separaten Datenquellen gehören, zuzuordnen, um den Integrationsfluss hervorzuheben.
- Die Fähigkeit, Datenabgleichsalgorithmen auszuführen und Datensätze zu identifizieren, die zur gleichen Entität gehören.
- Die Möglichkeit, Werte bei Bedarf zu überschreiben und Datensätze aus verschiedenen Quellen zusammenzuführen , um den goldenen Datensatz zu erhalten.
- Die Möglichkeit, die Datenintegration zu geplanten Zeiten durchzuführen oder sie in Echtzeit über API-Aufrufe oder ähnliche Mechanismen zu integrieren.
- Die Möglichkeit, integrierte Daten in jede beliebige Zieldatenbank zu laden.
Vereinheitlichung von Datenintegration, -bereinigung und -abgleich
Die Integration großer Datenmengen kann ein überwältigendes Unterfangen sein – insbesondere, wenn Sie sich für eine ETL- oder Datenvirtualisierungseinrichtung entscheiden. Eine grundlegende Datenintegrationsumgebung, die Daten zusammenführt und gleichzeitig untragbare Datenqualitätsmängel minimiert, ist für die meisten Unternehmen ein guter Ausgangspunkt. Die Priorisierung des wichtigsten Aspekts der Datenintegration im Rahmen der Datenkonsolidierung kann Ihnen dabei helfen, niedrig anzusetzen und schrittweise Verbesserungen vorzunehmen.
Sie können damit beginnen, eine einheitliche Datenintegrationslösung einzusetzen, die eine Vielzahl gängiger Konnektoren sowie integrierte Funktionen für Datenprofilierung, -bereinigung, -standardisierung, -abgleich und -zusammenführung bietet. Darüber hinaus kann eine Zeitplanungsfunktion, die Daten zu konfigurierten Zeiten integriert, Ihre Initiative innerhalb weniger Tage in Gang setzen.
DataMatch Enterprise ist ein solches Tool zur Datenkonsolidierung, das Sie bei der Integration Ihrer Daten aus verschiedenen Quellen unterstützen kann. Laden Sie noch heute eine Testversion herunter oder buchen Sie eine Demo mit unseren Experten, um herauszufinden, wie wir Sie bei der Umsetzung Ihrer Datenintegrationsinitiative unterstützen können.
The post Datenintegration erklärt: Definition, Arten, Verfahren und Tools appeared first on Data Ladder.
]]>The post Wie sich schlechte Datenqualität auf einen Überlebensplan für die Rezession auswirkt appeared first on Data Ladder.
]]>„Es gibt Rezessionen, es gibt Börsenrückgänge. Wenn Sie nicht verstehen, dass das passieren wird, dann sind Sie nicht bereit. Sie werden an den Märkten nicht gut abschneiden. Wenn Sie im Januar nach Minnesota fahren, sollten Sie wissen, dass es kalt sein wird. Man gerät nicht in Panik, wenn das Thermometer unter Null sinkt.“
Peter Lynch
Vorhersage der weltweiten Rezession
Wirtschaftswissenschaftler warnen vor beidem: einer Rezession in den USA und einer weltweiten Rezession. Sinkende Aktienkurse – vor allem in der Technologiebranche und im Einzelhandel -, steigende Zinsen und zunehmende Probleme in der Lieferkette sind die Hauptindikatoren, die diese Vorhersage verstärken.
Die drohende Untergangsstimmung auf dem Markt veranlasst die Unternehmen zu überstürzten, impulsiven Entscheidungen. Neue Projekte werden gestoppt, die Ausgaben werden zu niedrig angesetzt und Mitarbeiter werden brutal entlassen. Die Unvorhersehbarkeit künftiger Ereignisse verstärkt die Sorgen der Unternehmer, die versuchen, sich durch eine mögliche Rezession zu navigieren.
Inmitten all dessen erweisen sich Daten als das wertvollste Kapital eines Unternehmens, das in Zeiten des wirtschaftlichen Abschwungs einen echten Wert darstellt.
Daten: Die Wahrheit ist da draußen
Daten werden zum Retter in Zeiten, in denen alles andere versagt. Ein kurzer Blick darauf, was bei früheren Konjunkturabschwüngen geschah, kann Ihnen helfen, die Gegenwart mit Zuversicht zu meistern. Daten bieten den Unternehmen einen Puffer und ermöglichen es ihnen, Entscheidungen mit einem Gefühl der Vertrautheit und des Komforts zu treffen, das in Zeiten, in denen es so etwas noch nie gegeben hat, notwendig ist. Es liegt jedoch auf der Hand, dass Rohdaten nicht die erforderlichen Erkenntnisse liefern, sondern in Business Intelligence und umsetzbare Elemente umgewandelt werden müssen.
Business Intelligence-Zyklus
Forschung über Daten und Katastrophen beschreibt einen einfachen, aber leistungsstarken Business Intelligence-Zyklus:
Der Zyklus zeigt, wie Rohdaten in verwertbare Erkenntnisse umgewandelt werden:
- Nach der Erfassung der Rohdaten werden diese in Informationen umgewandelt, indem ihre Metadaten überprüft und die Werte auf ihre Qualität hin untersucht werden, um Ungenauigkeiten und Unstimmigkeiten auszuschließen.
- Die Informationen werden dann in Wissen umgewandelt, indem sie in Business Intelligence Tools eingespeist werden.
- Das Wissen wird dann verwaltet, um Geschäftspläne und Ziele zu erstellen.
- Die Führungskräfte kommen zusammen, um diese Pläne und Ziele in umsetzbare Dinge zu verwandeln.
- Nach der Durchführung von Maßnahmen werden wieder neue Rohdaten gesammelt und in Informationen umgewandelt.
6 Wege, wie Daten in der Rezession helfen
Genaue und zuverlässige Business Intelligence hilft Unternehmen, Entscheidungen auf der Grundlage realer Daten zu treffen, statt auf der Basis von Vermutungen und Annahmen. Hier sind 6 Möglichkeiten, wie Daten Unternehmen helfen, sich in einer Rezession über Wasser zu halten.
1. Risiko minimieren
Zwei Entscheidungen können Sie in unterschiedliche Richtungen führen; aber woher wissen Sie, welche von beiden eine bessere, positivere Auswirkung auf Ihr Unternehmen haben wird? Die Antwort liegt in den Daten der Vergangenheit. Die Analyse von Informationen aus der Vergangenheit kann Ihnen dabei helfen, kostspielige Entscheidungen zu vermeiden und die Opportunitätskosten verschiedener Wege zu messen – so können Sie sich für Alternativen entscheiden, die auf kurze Sicht mehr Wert bieten.
2. Ressourcen planen
Eine der ersten Entscheidungen, die Unternehmensleiter in einer Wirtschaftskrise treffen, ist die Entlassung einer großen Zahl von Mitarbeitern. Die Vergangenheit hat jedoch gezeigt, dass solche Entscheidungen immer zu früh getroffen werden. Zum Beispiel erlebte die Welt mit dem Ausbruch der COVID-19-Pandemie die kürzeste Rezession aller Zeiten, die nur 3 Monate dauerte. Und die Unternehmensleiter erkannten bald, dass der Personalabbau zu früh erfolgte, da sie feststellten, dass die Neueinstellung, Einarbeitung und Schulung von Mitarbeitern eine weitaus größere Herausforderung darstellte als deren Bindung.
3. Vorhersage der Schwere der Rezession
Rezessionen fühlen sich immer düster, lang und schwer an. Die Daten aus der Vergangenheit zeigen jedoch, dass es nicht so schlimm ist, wie Sie sich vielleicht fühlen, wenn Sie eine solche Phase durchlaufen. Denn die Zeitpläne, wann die Rezession eintritt, wie lange sie andauern wird und wie stark sie kleine und große Unternehmen treffen wird, entsprachen nicht den Vorhersagen der Wirtschaftsgurus. Die Verwendung von Daten, um diese Aspekte der Rezession wirklich zu verstehen, kann helfen, Entscheidungen auf genauere Informationen zu stützen.
4. Lesen Sie vergangene Erfolgsgeschichten
So schlimm Rezessionen auch klingen mögen, es gibt Erfolgsgeschichten von Unternehmen, die eine Rezession nicht nur überlebt haben, sondern auch während und nach der Rezession florieren! Das Geheimnis liegt in den Entscheidungen, die sie vor dem Einsetzen der Rezession getroffen haben. Sie können damit beginnen, indem Sie sich über vergangene Erfolgsgeschichten informieren oder sogar mit Führungskräften in Kontakt treten, die frühere Wirtschaftskrisen überstanden haben, um zu erfahren, wie sie es geschafft haben.
5. Beobachten Sie das Verbraucherverhalten
Unternehmen in der Lieferkette oder im Einzelhandel beklagen sich über die größten Rezessionsausfälle. Aber es gibt tatsächlich Erfolgsgeschichten, in denen kleine Einzelhändler in schwierigen Zeiten groß geworden sind. Das wichtigste Geheimnis dabei ist, das Verhalten der Verbraucher zu verstehen. Es ist nicht so, dass die Verbraucher während einer Wirtschaftskrise nichts kaufen – sie kaufen nur je nach der wirtschaftlichen Lage ihres Landes etwas anderes und in unterschiedlichem Umfang.
Dies ist der beste Zeitpunkt, um in Marktintelligenzplattformen zu investieren, die Ihnen die neuesten Marktkenntnisse vermitteln. Lesen Sie mehr darüber, wie Einzelhändler in Zeiten des wirtschaftlichen Abschwungs weiterhin auf der E-Commerce-Welle reiten können.
The role of data quality in the world of retail
Download this whitepaper to find out how retailers can identify if they have poor retail data quality and the most common issues associated with retail data and how to fix them.
Download6. Investitionen in operative Verbesserungen
Daten können Ihnen helfen zu verstehen, in welchen Geschäftsbereichen operative Verbesserungen erforderlich sind. Da das Geschäft nur schleppend läuft, ist dies ein guter Zeitpunkt, um vergangene betriebliche Vorgänge zu analysieren und neue, verbesserte Geschäftsprozesse für verschiedene Bereiche zu entwickeln, z. B. Kundenerfahrung und -bindung, Verkaufszyklus, Lieferkettenmanagement usw.
Schlechte Datenqualität: Die Wahrheit ist nicht da draußen
Die Daten, die zur Erstellung eines Überlebensplans für die Rezession verwendet werden, müssen unbedingt genau, gültig und konsistent sein. Doch in Wirklichkeit sind die Daten voller Fehler und untragbarer Mängel, die Business Intelligence erschweren, wenn nicht gar unmöglich machen. Schlechte Datenqualität – wenn sie nicht rechtzeitig behoben wird – führt nachweislich zu unzuverlässigen Ergebnissen und hat verheerende Auswirkungen auf ein Unternehmen.
Business Intelligence-Zyklus ohne Datenqualität
Werfen wir einen Blick darauf, wie ein Business Intelligence-Zyklus funktioniert, wenn er mit schlechten Daten gefüttert wird:

- Der wichtigste Schritt der Umwandlung von Daten in Informationen wird übersprungen.
- Analysten und BI-Tools versuchen, Wissen direkt aus verschmutzten Daten zu gewinnen.
- Das „Wissen“ wird dann in Unternehmensziele und -pläne umgesetzt.
- Die Führungskräfte entwickeln aus dem belasteten Geschäftsplan umsetzbare Maßnahmen.
So befehlen die Führungskräfte ihren Teams, nach einem Plan zu handeln, der nichts mit der Realität zu tun hat. Und nicht nur das: Die gesamte Zeit und die Ressourcen, die für diesen BI-Zyklus aufgewendet wurden, waren umsonst, da der Input von vornherein beschädigt war.
4 Wege, wie schlechte Datenqualität einen Überlebensplan für die Rezession ruiniert
Werfen wir einen Blick darauf, wie schlechte Datenqualität den Überlebensplan eines Unternehmens für die Rezession zunichte machen kann.
1. Unzuverlässige Erkenntnisse aus BI-Tools
Wir haben gerade gesehen, wie schmutzige Daten Ihre Business-Intelligence-Erkenntnisse zerstören können. Wenn Ihre BI-Tools mit unzureichenden Daten gespeist werden, kann es vorkommen, dass Führungskräfte inkonsistente und verwirrende Vorschläge von ihren BI-Tools oder ihrem Analystenteam erhalten. Entscheidungen, die auf solchen Erkenntnissen beruhen, können dazu führen, dass Ihr Unternehmen in schwierigen Zeiten wichtige Marktchancen verpasst und Einnahmen verliert. Dies kann für Ihr Unternehmen verheerend sein, da es möglicherweise nicht in der Lage ist, solche Verluste zu verkraften.
2. Loslösung von den Kunden
Unternehmen, die seit Jahrzehnten auf einem Markt konkurrieren, kennen ihre Verbraucher gut – in Bezug auf Demografie, Vorlieben und Wahlmöglichkeiten. Aber eine drohende Rezession könnte das ändern. Die Beobachtung des Verbraucherverhaltens anhand veralteter oder falsch interpretierter Daten kann Ihrem Ruf auf dem Markt schaden. Ihre Kunden könnten das Gefühl haben, dass Sie den Kontakt zu ihnen verlieren und ihre Erwartungen nicht erfüllen. Dies kann dazu führen, dass Ihre Konkurrenten Ihnen die Kunden wegnehmen, wenn Sie versuchen, den Kundenservice und -support zu reduzieren.
How to build a unified, 360 customer view
Download this whitepaper to learn why it’s important to consolidate your customer data and how you can get a 360 view of your customers.
Download3. Hindernisse beim Übergang zur Digitalisierung
Unternehmen stoppen ihre Initiativen zur digitalen Transformation oft aus Angst vor einer möglichen Rezession. Wirtschaftswissenschaftler haben jedoch vorausgesagt, dass Rezessionen ein guter Zeitpunkt sind, um Projekte zur digitalen Transformation zu beschleunigen, da die Opportunitätskosten niedrig sind. Dies geschieht, weil das Geschäft bereits langsam ist und die Einstellung von technischen Fachkräften einfacher und weniger kostspielig ist, da sie in der gesamten Technologiebranche entlassen werden.
Trotz der Vorteile, die sich daraus ergeben, stecken Unternehmen bei der Umstellung auf die Digitalisierung fest, weil Berge von fehlenden, unvollständigen, inkonsistenten und nicht standardisierten Informationen vorliegen. Wenn die Datenqualität nicht dem erforderlichen Standard entspricht, führt dies zu langen Verzögerungen, wenn Unternehmen versuchen, Prozesse zu digitalisieren oder neue Technologien einzuführen.
4. Geringere betriebliche Effizienz und Produktivität
Da das Geschäft in solchen Zeiten eher schleppend verläuft, konzentrieren sich die Unternehmen auf die Verbesserung der betrieblichen Effizienz im gesamten Unternehmen, um sich auf neue Expansionsmöglichkeiten auf dem Markt zu konzentrieren. Eine schlechte Datenqualität führt jedoch zu ernsthaften Engpässen bei der Arbeit aller Beteiligten, da sie Datenquellen und -inhalte vor der Verwendung in Routinevorgängen doppelt überprüfen müssen. Geringe betriebliche Effizienz und Produktivität sind die Folge solcher Probleme zu einem Zeitpunkt, an dem Ihr Unternehmen sie am wenigsten vertragen kann.
Ein Plan zur Datenqualität vor der Rezession
Es besteht kein Zweifel, dass Ihre Analysen zeitnah und genau sein müssen, um eine Rezession zu überstehen. Eine schlechte Datenqualität kann jedoch sowohl die Aktualität als auch die Genauigkeit Ihrer Erkenntnisse beeinträchtigen. Aus diesem Grund ist es unerlässlich, jetzt in das Datenqualitätsmanagement zu investieren, damit Sie den potenziellen Nachteilen schlechter Daten ausweichen können, wenn die Rezession tatsächlich eintritt. Werfen wir einen Blick auf die 3 wichtigsten Schritte im Umgang mit schlechter Datenqualität, wenn wir uns einer Rezession nähern.
1. Identifizierung von Datenqualitätsproblemen
Der erste Schritt ist offensichtlich: Finden Sie heraus, womit Sie es zu tun haben. Nicht jedes Unternehmen hat die gleichen Probleme mit der Datenqualität. Datenqualität ist definiert als Eignung der Daten für einen bestimmten Zweck. Je nachdem, wie die Daten in Ihrem Unternehmen verwendet werden, können Sie viele Diskrepanzen bei der Verwaltung der Datenqualität feststellen. Nachstehend finden Sie eine Liste der häufigsten Probleme mit der Datenqualität. Weitere Informationen finden Sie in den 12 häufigsten Datenqualitätsproblemen und deren Ursachen.
| No. | Data quality issue | Explanation | Example of data quality issue |
|---|---|---|---|
| 1 | Column duplication | Multiple columns are present that have the same logical meaning. | Product category is stored in two columns that logically mean the same: Category and Classification. |
| 2 | Record duplication | Multiple records are present for the same individual or entity. | Every time a customer interacts with your brand, a new row is created in the database rather than updating the existing one. |
| 3 | Invalid data | Data values are present in an incorrect format, pattern, data type or size. | Customer Phone Numbers are present in varying formats – some are stored as flat 10 digits, while others have hyphens, some are saved as a string, while others as numbers, and so on. |
| 4 | Inaccurate data | Data values do not conform to reality. | Customer Name is incorrectly stored: Elizabeth is stored as Aliza, or Matt is stored as Mathew. |
| 5 | Incorrect formulae | Data values are calculated using incorrect formulae. | Customer Age is calculated from their Date of Birth but the formula used is incorrect. |
| 6 | Inconsistency | Data values that represent the same information vary across different datasets and sources. | Customer record stored in the CRM represents a different Email Address than the one present in accounts application. |
| 7 | Missing data | Data is missing or is filled with blank values. | The Job Title of most customers is missing from the dataset. |
| 8 | Outdated data | Data is not current and represents outdated information. | Customer Mailing Addresses are years old leading to returned packages. |
| 9 | Unverified domain data | Data does not belong to a range of acceptable values. | Customer Mailing Addresses are years old leading to returned packages. |
2. Umsetzung eines Datenqualitätsplans in Wochen
Wenn Ihre Datensätze mit Fehlern behaftet sind, müssen Sie eine Datenqualitätsplattform einsetzen – aber nichts allzu Großes, etwas, das in wenigen Wochen und nicht Monaten einsatzbereit ist. Es gibt mehrere Möglichkeiten, wie Anbieter verschiedene Datenqualitätsmanagementprozesse in ihren Tools verpacken, z. B:
- Erstellung von Datenprofilen zur Bewertung des aktuellen Stands der Datenqualität,
- Datenbereinigung und -standardisierung zur Beseitigung von Nullwerten und Rauschen sowie zur Umwandlung von Daten in eine Standardansicht,
- Datenabgleich zur Identifizierung von Datensätzen, die zu ein und derselben Entität gehören,
- Datendeduplizierung zur Beseitigung doppelter Datensätze,
- Zusammenführen und Bereinigen von Daten, um nützliche Informationen zu erhalten und Datensätze zusammenzuführen, um den goldenen Datensatz zu erhalten – frei von Fehlern.
The definitive buyer’s guide to data quality tools
Download this guide to find out which factors you should consider while choosing a data quality solution for your specific business use case.
Download3. Verkürzung des Zyklus von der Aktion bis zur Auswirkung
Wenn es um die Implementierung eines Datenqualitäts-Tools geht, bleiben viele Unternehmen in fortgeschrittenen Datenmanagementsystemen stecken, die sich um komplexe Datenmanagement-Prinzipien wie Data Governance, zentralisierte Verwaltung, Stammdatenmanagement sowie Datenschutz und -sicherheit kümmern. Obwohl dies großartige Funktionen sind, die in Ihre Datensysteme integriert werden können, kann es lange dauern, bis sie implementiert sind und sich für Ihr Unternehmen als vorteilhaft erweisen.
Konzentrieren Sie sich auf die Minimierung des Zyklus zwischen Handlung und Auswirkung. In Zeiten des wirtschaftlichen Abschwungs möchten Sie wahrscheinlich etwas haben, das Ihnen einen schnellen und dennoch detaillierten Überblick über die in Ihren Datensätzen vorhandenen Datenqualitätsfehler und die einfachste Möglichkeit, diese zu beheben, bietet.
Abschließende Gedanken
Die Unvorhersehbarkeit der wirtschaftlichen Entwicklung macht den Unternehmern Angst vor zukünftigen Ereignissen. Geschäfts- und Marktinformationen können ihnen die nötige Sicherheit für wichtige Entscheidungen bieten. Investitionen in BI-Tools und ein Analystenteam sind in diesen Zeiten von Nachteil, aber wir dürfen den Wert von sauberen Daten nicht untergraben – das Kapital, das in umsetzbare Erkenntnisse umgewandelt wird.
Zunächst einmal kann die Bereitstellung von Self-Service-Tools für die Datenbereinigung und den Datenabgleich für Ihre Teams sehr vorteilhaft sein, um schnelle Ergebnisse zu erzielen. Ein All-in-One-Selbstbedienungstool, das Datenprofile erstellt, verschiedene Datenbereinigungsaktivitäten durchführt, Duplikate abgleicht und eine einzige Quelle der Wahrheit ausgibt, kann zu einem wichtigen Unterscheidungsmerkmal für die Leistung von BI-Tools und Datenanalysten werden.
DataMatch Enterprise ist ein solches Tool, das es den Datenteams erleichtert, Datenqualitätsfehler schnell und präzise zu beheben und sich auf wichtigere Aufgaben konzentrieren zu können. Datenqualitätsteams können innerhalb weniger Minuten Profile erstellen, bereinigen, abgleichen, zusammenführen und Millionen von Datensätzen bereinigen und so viel Zeit und Mühe sparen, die normalerweise für solche Aufgaben verschwendet wird.
Um mehr darüber zu erfahren, wie DataMatch Enterprise helfen kann, können Sie noch heute eine kostenlose Testversion herunterladen oder eine Demo mit einem Experten buchen.
Getting Started with DataMatch Enterprise
Download this guide to find out the vast library of features that DME offers and how you can achieve optimal results and get the most out of your data with DataMatch Enterprise.
DownloadThe post Wie sich schlechte Datenqualität auf einen Überlebensplan für die Rezession auswirkt appeared first on Data Ladder.
]]>The post 8 Grundsätze der Datenverwaltung appeared first on Data Ladder.
]]>Ein durchschnittliches Unternehmen – mit 200-500 Mitarbeitern – nutzt etwa 123 SaaS-Anwendungen, um seine Geschäftsprozesse zu digitalisieren. Angesichts der großen Datenmengen, die täglich generiert werden, brauchen Sie auf jeden Fall einen systematischen Umgang mit Daten. Dazu gehört die Einführung moderner Verfahren und Strategien zur Erfassung, Verarbeitung, gemeinsamen Nutzung, Speicherung und Abfrage von Daten bei gleichzeitiger Minimierung von Datenverlusten und Fehlern. Jede Lücke in diesen Prozessen kann Ihr Unternehmen in ernste Gefahr bringen.
In diesem Blog erörtern wir, was Datenmanagement bedeutet und welche Grundsätze Sie bei der Verwaltung Ihrer Unternehmensdaten beachten müssen. Fangen wir an.
Was ist Datenmanagement?
Unter Datenmanagement versteht man die Anwendung von Grundsätzen, Regeln, Strategien und Methoden, die eine maximale und optimale Nutzung der Daten eines Unternehmens gewährleisten können.
Die Konzepte und Grundsätze des Datenmanagements sind sehr vielfältig, da sie sich auf eine Reihe von Datenprozessen in einem Unternehmen konzentrieren, wie z. B.:
- Datenerfassung und -integration: Stellt sicher, dass die erforderlichen Daten erfasst, integriert und konsolidiert werden, damit sie für alle vorgesehenen Zwecke verwendet werden können.
- Datenspeicherung: Stellt sicher, dass die Daten dort gespeichert werden, wo sie benötigt werden – sei es in einem lokalen Speicher, in einer öffentlichen oder privaten Cloud oder in einem hybriden System.
- Datensicherheit: Gewährleistet, dass die Daten vor unbefugtem Zugriff geschützt sind und dass Richtlinien für den sicheren Datenzugriff und die gemeinsame Nutzung umgesetzt werden.
- Verwaltung der Datenqualität: Stellt sicher, dass die Daten kontinuierlich auf Fehler geprüft werden und eine Datenpipeline zur Überprüfung und Korrektur der Datenqualität durchlaufen.
- Datenverfügbarkeit: Stellt sicher, dass die Daten jederzeit für die Mitarbeiter zugänglich sind und dass Pläne für die Sicherung und Wiederherstellung im Notfall vorhanden sind.
8 Grundsätze der Datenverwaltung
Die Gestaltung Ihrer Datenverwaltungsprozesse kann schwierig sein, da sie sich auf eine Vielzahl von Datenbereichen konzentriert. Hier erfahren Sie, was die Grundsätze des Datenmanagements sind, und wir stellen Ihnen die 8 wichtigsten Grundsätze des Datenmanagements vor, die Sie verwalten müssen.
1. Datenmodellierung
Das erste und wichtigste Prinzip der Datenverwaltung ist die Datenmodellierung. Datenmodellierung bedeutet, dass Sie Ihre Datenbestände, ihre Eigenschaften und ihre Beziehungen untereinander in einer logischen Weise entwerfen und strukturieren. Ein Beispiel für ein Datenmodell für ein Einzelhandelsgeschäft ist unten dargestellt:
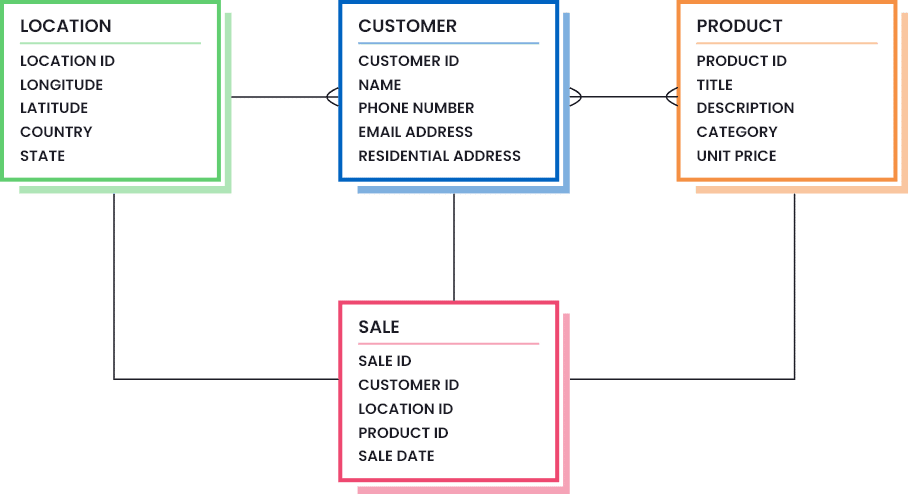
Ein Datenmodell stellt einfach Folgendes dar (wie aus dem obigen Diagramm ersichtlich):
- Die Datenbestände, die ein Unternehmen speichert und verwaltet (z. B. Kunde, Produkt, Standort und Umsatz),
- Die realen Eigenschaften , die jedes Asset speichert (z. B.: Kundendaten-Asset hat die Kunden-ID, den Namen, die Telefonnummer, die E-Mail-Adresse und die Wohnadresse),
- Datentyp und Größe jeder Eigenschaft (z. B. sollte die Kunden-ID eine ganze Zahl mit maximal 12 Ziffern sein),
- Die Beziehungseinschränkungen, die zwei oder mehr Datenbestände untereinander haben (z. B. Kunde hat Standort, Kunde kauft Produkt usw.)
- Die Beziehungskardinalität, die die maximale Anzahl der Beziehungen anzeigt, die ein Asset mit einem anderen haben kann (z. B. kann ein Kunde immer nur einen Standort haben),
- Die referentielle Integrität, die festlegt, auf welche Datensätze in verschiedenen Assets verwiesen werden kann (z. B. muss ein Verkaufsdatensatz immer auf eine Kunden-ID verweisen, die in der Tabelle Kunde vorhanden ist).
Ein Unternehmen kann seine Daten niemals effizient verwalten, wenn es nicht in der Lage ist, die Datenanforderungen genau mit den strukturierten Datenmodellen zu verknüpfen. Aus diesem Grund ist es wichtig, zunächst die Datenanforderungen von den erforderlichen Interessengruppen zu sammeln und dann mit dem Entwurfsprozess zu beginnen. Sobald Sie wissen, welche Erwartungen Ihr Team an die von ihm verwendeten Daten hat, können Sie Datenmodelle entwerfen, die die erforderlichen Informationen erfassen.
2. Rollen und Verantwortlichkeiten für Daten
Unternehmensleiter machen oft den Fehler, die Datennutzer für eine effiziente Datenverwaltung verantwortlich zu machen. In Wirklichkeit müssen Sie jedoch verschiedene Datenexperten auf unterschiedlichen Ebenen in Ihrem Unternehmen einsetzen. Dadurch wird sichergestellt, dass alle Bemühungen und Investitionen in die Datenverwaltung nicht nur umgesetzt, sondern auch über Jahre hinweg aufrechterhalten werden. Werfen wir einen Blick auf die wichtigsten Datenrollen und ihre Aufgaben, die Sie beim Aufbau eines Datenteams berücksichtigen müssen.
- Leiter der Datenabteilung (CDO): Ein Chief Data Officer (CDO) ist eine Position auf Führungsebene, die ausschließlich für die Entwicklung von Strategien für die Datennutzung, die Überwachung der Datenqualität und die Datenverwaltung im gesamten Unternehmen zuständig ist.
- Datenverwalter: Ein Datenverwalter ist der Ansprechpartner in einem Unternehmen für alle Fragen im Zusammenhang mit Daten. Sie wissen genau, wie das Unternehmen Daten erfasst, wo sie gespeichert werden, welche Bedeutung sie für die verschiedenen Abteilungen haben und wie die Qualität der Daten während ihres gesamten Lebenszyklus gewährleistet wird.
- Datenverwalter: Ein Datenverwalter ist für die Struktur der Datenfelder verantwortlich – einschließlich der Datenbankstrukturen und -modelle.
- Dateningenieur: Ein Dateningenieur ist für die Datenmodellierung und den Aufbau von Systemen zur genauen Erfassung, Speicherung und Analyse von Daten zuständig.
- Datenanalyst: Ein Datenanalyst ist jemand, der in der Lage ist, Rohdaten in aussagekräftige Erkenntnisse umzuwandeln – insbesondere in bestimmten Bereichen. Eine Hauptaufgabe des Datenanalysten ist die Vorbereitung, Bereinigung und Filterung der benötigten Daten.
- Andere Teams: Diese Rollen werden als Datenkonsumenten betrachtet, d. h. sie verwenden Daten – entweder in ihrer Rohform oder wenn sie in verwertbare Erkenntnisse umgewandelt werden, z. B. Vertriebs- und Marketingteams, Produktteams, Geschäftsentwicklungsteams usw.
3. Entwurf des Datensystems
Dies ist ein weiterer wichtiger Aspekt der Datenverwaltung, der Ihnen hilft, herauszufinden:
Wo und wie werden die Daten erfasst, integriert und gehostet, um eine maximale Datennutzung und -verfügbarkeit sowie einen minimalen Datenverlust und Ausfallzeiten zu gewährleisten?
Der Entwurf von Datensystemen bezieht sich auf mehrere Disziplinen, wie Datenquellen, Architektur, Synchronität und Hosting. Werfen wir einen Blick auf die einzelnen Bereiche:
a. Dateneingänge und -ausgänge
Der erste Teil des Systementwurfs besteht darin, die Quellen der Dateneingänge und -ausgänge zu ermitteln – von wo aus die Daten erfasst werden und wohin sie übertragen werden. Unternehmen verwenden mehrere Anwendungen zur Datenerfassung, z. B. Website-Tracker, Marketingautomatisierung, CRM, Buchhaltungssoftware, Webformulare usw. Sie müssen alle diese Quellen identifizieren und sehen, wie Daten zwischen den Quellen oder zu einem neuen Ziel übertragen werden.
b. Topologie des Datensystems
Die Datentopologie bezieht sich darauf, wie die Datensysteme miteinander verbunden sind. Auf einer hohen Ebene können Sie Ihre Topologie mit einem der folgenden Ansätze entwerfen:
- Zentralisierter Ansatz, bei dem jedes Datensystem mit einem zentralen, intelligenten Knotenpunkt verbunden ist,
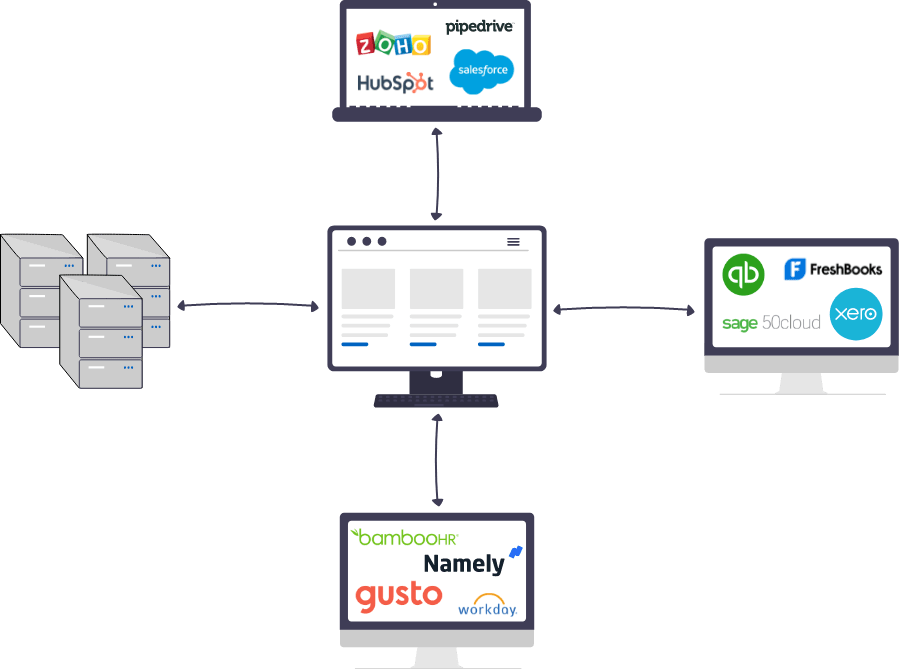
- Dezentraler Ansatz , bei dem die Datensysteme miteinander kommunizieren, um die benötigten Informationen zu erhalten.

c. Daten-Synchronisation
Dies bezieht sich auf die Art und Weise, wie die Daten über verschiedene Quellen hinweg aktualisiert werden. Datenmanagementsysteme, insbesondere MDM-Lösungen, werden je nach den Anforderungen des Unternehmens in unterschiedlichen Architekturen implementiert. Die gebräuchlichsten Architekturstile für die Synchronisierung sind:
- Konsolidierter Stil
- Die aus verschiedenen Quellen stammenden Daten werden an einen zentralen Knotenpunkt weitergeleitet, der eine konsolidierte Ansicht der Daten speichert, sie aber nicht an die Quellsysteme zurücküberträgt. Alle BI- oder nachgelagerten Anwendungen können bei Bedarf Daten vom zentralen Hub abrufen.
- Koexistenz oder hybrider Stil
- Die aus verschiedenen Quellen stammenden Daten werden an einen zentralen Knotenpunkt weitergeleitet, der eine konsolidierte Ansicht der Daten speichert, und die Aktualisierungen werden auch an alle angeschlossenen Quellanwendungen übertragen.
- Zentralisierter Stil
- Die aus verschiedenen Quellen stammenden Daten werden an einen zentralen Knotenpunkt weitergeleitet, der eine konsolidierte Ansicht der Daten speichert, sie aber nicht an die Quellsysteme zurücküberträgt. Die Quellsysteme können jedoch die aktualisierten Daten bei Bedarf vom zentralen Hub abfragen.
d. Daten-Hosting
Dies bezieht sich auf den Ort, an dem die Daten gehostet oder gespeichert werden. Je nach den Bedürfnissen eines Unternehmens können die Daten lokal vor Ort oder in einer öffentlichen oder privaten Cloud gespeichert werden. Sie können sich auch für ein hybrides System entscheiden, bei dem ein Teil der Daten vor Ort und ein Teil in der Cloud gehostet wird.
4. Datenqualität
Einer der wichtigsten Aspekte des Datenmanagements ist das Datenqualitätsmanagement. Das Vorhandensein von untragbaren Mängeln in Ihrem Datensatz zeigt, dass die erforderlichen Datenverwaltungspraktiken nicht vorhanden sind. Wenn Ihre Teams den Daten nicht vertrauen können, beeinträchtigt dies ihre Arbeitsproduktivität und -effizienz. Um zu verhindern, dass Datenqualitätsfehler in das System gelangen, müssen Sie eingehende Daten in Datenpipelines verarbeiten, in denen eine Reihe von Operationen wie Datenbereinigung, Standardisierung und Abgleich durchgeführt werden.
a. Messung der Datenqualität
Die Datenqualität wird in der Regel durch eine Reihe von Datenmerkmalen angezeigt. Diese werden in der Regel als Datenqualitätsdimensionen bezeichnet. Zu den häufigsten Indikatoren für die Datenqualität gehören:
- Exaktheit: Die Daten geben die Realität und die Wahrheit wieder.
- Validierung: Die Daten sind im richtigen Muster und Format vorhanden und gehören zum richtigen Bereich.
- Vollständig: Die Daten sind so umfassend wie nötig.
- Währung: Die Daten sind aktuell oder so aktuell wie möglich.
- Konsistenz: Die Daten sind über verschiedene Datenquellen hinweg gleich (sowohl in Bezug auf die Bedeutung als auch auf die Darstellung).
- Identifizierbarkeit: Die Daten stellen eindeutige Identitäten dar und enthalten keine Duplikate.
- Benutzerfreundlichkeit: Die Daten liegen in einem Format vor, das für diejenigen, die sie nutzen wollen, verständlich ist.
b. Verwaltung der Datenqualität
Um die Grundsätze des Datenqualitätsmanagements reibungslos zu übernehmen, müssen Sie eine Reihe von Datenqualitätsprozessen implementieren, wie z. B.:
- Erstellung von Datenprofilen zur Bewertung des aktuellen Zustands Ihrer Daten und zur Ermittlung von Bereinigungsmöglichkeiten,
- Datenbereinigungs- und Standardisierungstechniken , um eine standardisierte Ansicht über alle Datenquellen hinweg zu erhalten,
- Datenabgleich , um doppelte Datensätze zu identifizieren, die dieselbe Einheit repräsentieren,
- Datendeduplizierung zur Beseitigung doppelter Datensätze,
- Bereinigung von Daten, um doppelte Datensätze zu einem einzigen zu konsolidieren und Daten bei Bedarf zu überschreiben und den goldenen Datensatz zu erreichen.
5. Datenverwaltung
Der Begriff Data Governance bezieht sich auf eine Sammlung von Rollen, Richtlinien, Arbeitsabläufen, Standards und Metriken, die eine effiziente Informationsnutzung und -sicherheit gewährleisten und es einem Unternehmen ermöglichen, seine Geschäftsziele zu erreichen. Data Governance bezieht sich auf die folgenden Bereiche:
- Implementierung einer rollenbasierten Zugriffskontrolle, um sicherzustellen, dass nur autorisierte Benutzer auf vertrauliche Daten zugreifen können,
- Gestaltung von Arbeitsabläufen zur Überprüfung von Informationsaktualisierungen,
- Begrenzung der Datennutzung und -freigabe,
- Zusammenarbeit und Koordinierung bei Datenaktualisierungen mit Mitarbeitern oder externen Beteiligten,
- Ermöglichung der Datenprovenienz durch Erfassung von Metadaten, ihrer Herkunft und der Aktualisierungshistorie.
6. Datenerziehung
Sie können Datenmodelle, Datensysteme und Datenqualitäts-Frameworks perfekt entwerfen und sich um alle grundlegenden Prinzipien des Datenmanagements kümmern, aber trotzdem Ihre Datenziele nicht erreichen – und der Hauptschuldige dafür ist die mangelnde Datenausbildung Ihrer Teammitglieder. Wenn Ihr Team nicht versteht, wie Datensysteme in Ihrem Unternehmen funktionieren, wird es sie wahrscheinlich falsch handhaben oder ineffizient nutzen.
Um Ihren Teammitgliedern Datenkompetenz zu vermitteln, müssen Sie damit beginnen, alles zu dokumentieren. Und verbreiten Sie dieses Wissen durch Lernpläne, die verschiedene Datenaspekte beleuchten, wie z. B.:
- Was es enthält,
- Was die einzelnen Datenattribute bedeuten,
- Welches sind die Akzeptanzkriterien für seine Qualität?
- Was ist der falsche und was der richtige Weg für die Eingabe/Manipulation von Daten?
- Welche Daten sind zu verwenden, um ein bestimmtes Ergebnis zu erzielen?
Außerdem können diese Kurse je nach Häufigkeit der Datennutzung durch bestimmte Rollen (täglich, wöchentlich oder jährlich) erstellt werden.
7. Schutz der Daten
Datenschutzstrategien umfassen einige der wichtigsten Sicherheitsmaßnahmen. Zu den drei Hauptbereichen, die unter den Datenschutz fallen, gehören:
- Datensicherheit: Schutz der Daten vor böswilligen Angriffen und Manipulation,
- Kontrolle des Datenzugriffs: Kontrolle darüber, wer wann auf Daten zugreifen kann,
- Datenverfügbarkeit: Sicherstellen, dass die Daten gesichert und im Falle eines Datenverlusts oder einer Nichtverfügbarkeit wiederhergestellt werden.
Die Begriffe „Datenschutz“ und „Datensicherheit“ werden oft synonym verwendet, aber beide beziehen sich auf leicht unterschiedliche Konzepte. Der Datenschutz bezieht sich auf den Schutz von Daten vor Verlust, Beschädigung oder Verfälschung und die Gewährleistung der Datenverfügbarkeit, während sich die Datensicherheit auf den Schutz von Daten vor böswilligen Angriffen und Manipulationen bezieht.
Beide sind jedoch entscheidend für eine qualitativ hochwertige Datenverwaltung.
8. Einhaltung der Daten
Normen zur Einhaltung von Datenschutzbestimmungen (wie GDPR, HIPAA und CCPA usw.) zwingen Unternehmen dazu, ihre Datenverwaltungsstrategien zu überdenken und zu überarbeiten. Im Rahmen dieser Daten-Compliance-Standards sind die Unternehmen verpflichtet, die personenbezogenen Daten ihrer Kunden zu schützen und sicherzustellen, dass die Dateneigentümer (die Kunden selbst) das Recht haben, auf ihre Daten zuzugreifen, sie zu ändern oder zu löschen.
Neben diesen Rechten, die den Dateneigentümern zugestanden werden, machen die Standards die Unternehmen auch für die Einhaltung der Grundsätze Transparenz, Zweckbindung, Datenminimierung, Richtigkeit, Speicherbegrenzung, Sicherheit und Rechenschaftspflicht verantwortlich. Es ist sehr schwierig, diese Normen einzuhalten, wenn die zugrunde liegenden Daten nicht gut verwaltet werden. Und ein Mangel an Konformität kann Ihre Geschäftstätigkeit einschränken – insbesondere in geografischer Hinsicht.
Einpacken
Das sind die 8 wichtigsten Grundsätze für das Datenmanagement, die Sie anwenden müssen, um die Effektivität Ihrer Daten in Ihrem Unternehmen zu maximieren. Da Daten ein integraler Bestandteil eines Unternehmens sind, hilft Ihnen die richtige Datenverwaltung dabei, Ihre Ziele effizient und einfach zu erreichen.
Wenn Ihr Unternehmen noch keine Datenverwaltungsprinzipien eingeführt hat, ist es in Ordnung, an einer Stelle zu beginnen und möglicherweise über verschiedene Disziplinen hinweg zu wachsen, wenn sich die Dinge eingespielt haben. Das Datenqualitätsmanagement ist ein solcher Bereich, der in kürzester Zeit einen großen positiven Einfluss haben kann.
Da wir in den letzten zehn Jahren Datenbereinigungs- und -abgleichslösungen für Fortune-500-Unternehmen geliefert haben, wissen wir, wie wichtig es ist, Daten fehlerfrei zu halten. Unser Produkt DataMatch Enterprise hilft Ihnen, Ihre Datensätze zu bereinigen und zu standardisieren und doppelte Datensätze zu eliminieren, die dieselbe Entität repräsentieren.
Sie können die kostenlose Testversion noch heute herunterladen oder eine persönliche Sitzung mit unseren Experten vereinbaren, um zu erfahren, wie unser Produkt bei der Implementierung der besten Verfahren zur Erreichung und Aufrechterhaltung der Datenqualität auf Unternehmensebene helfen kann.
The post 8 Grundsätze der Datenverwaltung appeared first on Data Ladder.
]]>The post Datenqualitätsmanagement: Was, warum, wie und beste Praktiken appeared first on Data Ladder.
]]>Qualität ist nie ein Zufall; sie ist immer das Ergebnis einer hohen Absicht, aufrichtiger Bemühungen, intelligenter Leitung und geschickter Ausführung; sie ist die kluge Wahl unter vielen Alternativen.
Das häufigste Problem, mit dem Unternehmen zu kämpfen haben, ist die Qualität der Daten. Sie haben die richtigen Datenanwendungen im Einsatz, die Quellen erfassen die Art von Daten, die Sie benötigen, es gibt ein ganzes System, das die gesammelten Daten nutzt und analysiert, und dennoch sind die Ergebnisse nicht zufriedenstellend. Bei der weiteren Analyse stellen Sie Unterschiede zwischen den Datenerwartungen und der Realität fest; die Datensätze sind mit leeren Feldern, inkonsistenten Abkürzungen und Formaten, ungültigen Mustern, doppelten Datensätzen und anderen Unstimmigkeiten gefüllt.
Um diese Probleme zu beseitigen, müssen Sie Korrekturmaßnahmen einführen, die Datenqualitätsprobleme konsequent validieren und beheben. Um den Traum von der Datenqualität Wirklichkeit werden zu lassen, ist es jedoch notwendig, die Grundlagen der Datenqualität zu verstehen – ihre Bedeutung, ihre Auswirkungen und wie man Verbesserungen plant. Aus diesem Grund stellen wir Ihnen einen umfassenden Leitfaden zur Verfügung, der alle Aspekte des Datenqualitätsmanagements abdeckt: was es bedeutet, wie es sich auf ein Unternehmen auswirken kann, wie es verwaltet werden kann, wie es in verschiedenen Branchen aussieht und vieles mehr.
Dieser Leitfaden ist in drei Teile gegliedert:
- Datenqualität: Was ist das und warum ist sie wichtig?
- Probleme mit der Datenqualität: Was sind sie, woher kommen sie, und wie wirken sie sich auf das Geschäft aus?
- Datenqualitätsmanagement: Was es bedeutet, seine Säulen und Best Practices sowie einige Beispiele aus der Praxis in verschiedenen Branchen.
Dann fangen wir mal an.
Qualität der Daten
Was ist Datenqualität?
Der Grad, in dem die Daten die Anforderungen eines bestimmten Zwecks erfüllen.
Unternehmen speichern, verwalten und nutzen täglich große Mengen an Daten. Wenn die Daten ihren Zweck nicht erfüllen, wird davon ausgegangen, dass sie von schlechter Qualität sind. Diese Definition von Datenqualität impliziert, dass ihre Bedeutung je nach Organisation und Zweck, dem sie dienen, unterschiedlich ist.
Für einige Unternehmen kann die Vollständigkeit der Daten ein besserer Indikator für die Datenqualität sein als die Genauigkeit der Daten.

Dies führt dazu, dass Unternehmen ihre eigenen Merkmale und Anforderungen für die Aufrechterhaltung der Datenqualität im gesamten Unternehmen definieren. Es gibt eine weitere Möglichkeit, Datenqualität zu definieren:
Der Grad, in dem die Daten frei von unzulässigen Mängeln sind.
Daten können nie hundertprozentig genau und fehlerfrei sein. Sie wird zwangsläufig einige Fehler enthalten, und das ist akzeptabel. Aber untragbare Mängel in Ihrem Datensatz – die die Ausführung kritischer Prozesse beeinträchtigen – deuten auf eine schlechte Datenqualität hin. Sie müssen sicherstellen, dass die Datenstruktur den Anforderungen entspricht und ihr Inhalt so fehlerfrei wie möglich ist.
Warum ist Datenqualität wichtig?
Die Aufrechterhaltung der Datenreinheit sollte eine gemeinsame Anstrengung von Geschäftsanwendern, IT-Mitarbeitern und Datenexperten sein. Oft wird es jedoch nur als IT-Panne wahrgenommen – in dem Glauben, dass Daten schmutzig werden, wenn einige technische Prozesse zur Erfassung, Speicherung und Übertragung von Daten nicht korrekt funktionieren. Obwohl dies der Fall sein kann, müssen die Daten die Aufmerksamkeit der alle die richtigen Stakeholder, um die Qualität auf Dauer zu erhalten. Aus diesem Grund ist es unerlässlich, dass
eine Argumentation für Datenqualität aufbauen
die notwendigen Entscheidungsträger zu überzeugen, damit sie dazu beitragen können, dass sie in allen Abteilungen und auf allen Ebenen umgesetzt wird.
Im Folgenden haben wir die häufigsten Vorteile der Datenqualität aufgeführt.
01. Genaue Entscheidungsfindung
Wirtschaftsführer verlassen sich nicht mehr auf Annahmen, sondern sondern nutzen Business Intelligence-Techniken, um bessere Entscheidungen zu treffen. Dies ist wobei
Eine gute Datenqualität kann Folgendes ermöglichen
Genauigkeit
Entscheidungsfindung
Eine schlechte Datenqualität hingegen kann die Ergebnisse der Datenanalyse verfälschen und dazu führen, dass Unternehmen wichtige Entscheidungen auf falschen Prognosen aufbauen.
02. Operative Effizienz
Daten sind Teil jeder kleinen und großen Operation in einem Unternehmen. Ob es um Produkte, Marketing, Verkauf oder Finanzen geht – Daten effizient nutzen in jedem Bereich ist der Schlüssel. Die Verwendung von Qualitätsdaten in diesen Abteilungen kann dazu führen, dass Ihr Team Doppelarbeit vermeidet, schnell genaue Ergebnisse erzielt und den ganzen Tag über produktiv ist.
03. Einhaltung der Vorschriften
Einhaltung von Daten
Normen
(z. B. GDPR, HIPAA und CCPA) verlangen von Unternehmen die Einhaltung der Grundsätze der Datenminimierung, Zweckbindung, Transparenz, Genauigkeit, Sicherheit, Speicherbegrenzung und Rechenschaftspflicht.
Konformität mit solchen Datenqualitäts
Standards
ist nur mit sauberen und zuverlässigen Daten möglich.
04. Finanzielle Transaktionen
Den Unternehmen entstehen enorme
finanzielle Kosten aufgrund schlechter Datenqualität
. Vorgänge wie z. B. rechtzeitige Zahlungen, Vermeidung von Unter- und Überzahlungen, Beseitigung fehlerhafter Transaktionen und Vermeidung der Gefahr von Betrug aufgrund von Datenduplikationen sind nur mit sauberen und qualitativ hochwertigen Daten möglich.
05. Personalisierung und Kundentreue
Personalisierte Erlebnisse für Kunden anbieten ist die einzige Möglichkeit, sie davon zu überzeugen, bei Ihrer Marke und nicht bei einem Konkurrenten zu kaufen. Unternehmen nutzen eine Vielzahl von Daten, um das Verhalten und die Vorlieben ihrer Kunden zu verstehen. Mit präzisen Daten können Sie relevante Käufer erkennen und ihnen genau das anbieten, wonach sie suchen. So sichern Sie sich langfristig die Loyalität Ihrer Kunden und geben ihnen das Gefühl, dass Ihre Marke sie wie kein anderer versteht.
06. Wettbewerbsvorteil
Fast jeder Marktteilnehmer nutzte die Daten, um das zukünftige Marktwachstum und mögliche Chancen für Upselling und Cross-Selling zu verstehen. Die Einspeisung von Qualitätsdaten aus der Vergangenheit in diese Analyse wird Ihnen helfen
einen Wettbewerbsvorteil aufbauen
auf dem Markt, konvertieren mehr Kunden und
wachsen
Ihren Marktanteil.
07. Digitalisierung
Digitalisierung von wichtigen Prozessen kann Ihnen helfen, manuellen Aufwand zu vermeiden, die Bearbeitungszeit zu verkürzen und menschliche Fehler zu reduzieren. Bei schlechter Datenqualität können diese Erwartungen jedoch nicht erfüllt werden. Vielmehr führt eine schlechte Datenqualität zu einem digitalen Desaster, bei dem Datenmigration und -integration aufgrund unterschiedlicher Datenbankstrukturen und inkonsistenter Formate unmöglich erscheinen.
Probleme mit der Datenqualität
Ein Datenqualitätsproblem ist definiert als:
ein nicht tolerierbarer Mangel in einem Datensatz, der die Vertrauenswürdigkeit und Zuverlässigkeit dieser Daten stark beeinträchtigt.
Bevor wir mit der Umsetzung von Korrekturmaßnahmen zur Validierung, Korrektur und Verbesserung der Datenqualität fortfahren können, müssen wir unbedingt verstehen, was die Daten überhaupt verschmutzt. Aus diesem Grund werden wir zunächst einen Blick darauf werfen:
- Die häufigsten Datenqualitätsprobleme in den Datenbeständen eines Unternehmens,
- Woher kommen diese Probleme mit der Datenqualität?
- Wie können diese Datenqualitätsprobleme zu ernsthaften Geschäftsrisiken führen?
Was sind die häufigsten Probleme mit der Datenqualität?
| No. | Data quality issue | Explanation | Example of data quality issue |
|---|---|---|---|
| 1 | Column duplication | Multiple columns are present that have the same logical meaning. | Product category is stored in two columns that logically mean the same: Category and Classification. |
| 2 | Record duplication | Multiple records are present for the same individual or entity. | Every time a customer interacts with your brand, a new row is created in the database rather than updating the existing one. |
| 3 | Invalid data | Data values are present in an incorrect format, pattern, data type or size. | Customer Phone Numbers are present in varying formats – some are stored as flat 10 digits, while others have hyphens, some are saved as a string, while others as numbers, and so on. |
| 4 | Inaccurate data | Data values do not conform to reality. | Customer Name is incorrectly stored: Elizabeth is stored as Aliza, or Matt is stored as Mathew. |
| 5 | Incorrect formulae | Data values are calculated using incorrect formulae. | Customer Age is calculated from their Date of Birth but the formula used is incorrect. |
| 6 | Inconsistency | Data values that represent the same information vary across different datasets and sources. | Customer record stored in the CRM represents a different Email Address than the one present in accounts application. |
| 7 | Missing data | Data is missing or is filled with blank values. | The Job Title of most customers is missing from the dataset. |
| 8 | Outdated data | Data is not current and represents outdated information. | Customer Mailing Addresses are years old leading to returned packages. |
| 9 | Unverified domain data | Data does not belong to a range of acceptable values. | Customer Mailing Addresses are years old leading to returned packages. |
Wie gelangen Probleme mit der Datenqualität in das System?
Es gibt mehrere Möglichkeiten können Fehler in der Datenqualität in Ihr System gelangen. Werfen wir einen Blick darauf, was sie sind.
01. Mangel an angemessener Datenmodellierung
Dies ist der erste und wichtigste Grund für Fehler in der Datenqualität. Ihr IT-Team wendet bei der Einführung einer neuen Technologie – sei es eine neue Webanwendung, ein Datenbanksystem oder die Integration/Migration zwischen bestehenden Systemen – nicht die richtige Menge an Zeit und Ressourcen auf.
Die Datenmodellierung hilft bei der Organisation und Strukturierung Ihrer Datenbestände und -elemente. Ihre Datenmodelle können für eines der folgenden Probleme anfällig sein:
a)
Fehlen von hierarchischen Zwängen:
Dies ist der Fall, wenn es keine geeignete Beziehung Beschränkungen innerhalb Ihres Datenmodells. Sie haben zum Beispiel einen anderen Satz von Feldern für Bestehende Kunden und Neue Kundenaber Sie verwenden eine generische Kunde Modell für beide, anstatt ein Bestehende Kunden und Neue Kunden als Subtypen des Supertyps Kunde.
b)
Fehlende Kardinalität der Beziehung:
Dies ist der Fall, wenn es keine Zahl gibt, die die Anzahl der Beziehungen einer Einheit zu einer anderen darstellt. Zum Beispiel, ein
Bestellung
kann nur einen
Rabatt
zur gleichen Zeit haben.
c)
Fehlende referenzielle Integrität
:
Dies ist der Fall, wenn ein Datensatz in einem Datensatz auf einen Datensatz in einem anderen Datensatz verweist, der nicht vorhanden ist. Zum Beispiel, die
Verkäufe
Tabelle bezieht sich auf eine Liste von
Produkt-IDs
die sich nicht in der Tabelle
Produkte
Tabelle enthalten sind.
02. Fehlen eindeutiger Identifikatoren
Dies ist der Fall, wenn es keine Möglichkeit gibt, einen Datensatz eindeutig zu identifizieren, was dazu führt, dass Sie doppelte Datensätze für dieselbe Entität speichern. Datensätze werden eindeutig identifiziert, indem Attribute gespeichert werden wie
Sozialversicherungsnummer
für Kunden,
Hersteller-Teilenummer
für Produkte, etc.
03. Fehlen von Validierungsauflagen
Dies ist der Fall, wenn Datenwerte vor der Speicherung in der Datenbank nicht den erforderlichen Validierungsprüfungen unterzogen werden. So wird z. B. geprüft, ob die erforderlichen Felder vorhanden sind, ob Muster, Datentyp, Größe und Format der Datenwerte validiert werden und ob sie zu einem Bereich akzeptabler Werte gehören.
04. Mangelnde Qualität der Integration
Dies ist der Fall, wenn Ihr Unternehmen über eine zentrale Datenbank verfügt, die eine Verbindung zu mehreren Quellen herstellt und die eingehenden Daten integriert, um eine einzige Informationsquelle darzustellen. Fehlt bei diesem Aufbau eine zentrale Datenqualitätsmaschine zur Bereinigung, Standardisierung und Zusammenführung von Daten, können viele Datenqualitätsfehler entstehen.
05. Mangelnde Datenkompetenz
Trotz aller Bemühungen um den Schutz von Daten und deren Qualität in allen Datenbeständen kann ein Mangel an Datenkompetenz in einem Unternehmen Ihren Daten großen Schaden zufügen. Die Mitarbeiter speichern oft falsche Informationen, da sie nicht verstehen, was bestimmte Attribute bedeuten. Außerdem sind sie sich der Folgen ihrer Handlungen nicht bewusst, z. B. welche Auswirkungen die Aktualisierung von Daten in einem bestimmten System oder für einen bestimmten Datensatz hat.
06. Fehler bei der Dateneingabe
Tipp- oder Rechtschreibfehler sind eine der häufigsten Ursachen für Datenqualitätsfehler. Es ist bekannt, dass Menschen bei der Eingabe von 10.000 Daten mindestens 400 Fehler machen. Dies zeigt, dass selbst bei Vorhandensein eindeutiger Bezeichner, Validierungsprüfungen und Integritätsbeschränkungen die Möglichkeit besteht, dass menschliches Versagen eingreift und die Datenqualität beeinträchtigt.
Wie hängen Datenqualitätsprobleme mit geschäftlichen Gefahren zusammen?
Um relevante Entscheidungsträger einzubinden, ist es wichtig, sie darüber aufzuklären, wie sich große und kleine Datenqualitätsprobleme auswirken Geschäft. A
Datenfehler – Geschäftsrisikomatrix
wie die unten abgebildete, kann Ihnen dabei helfen.
| Problem | Issue | Business risk | Quantifier | Cost |
|---|---|---|---|---|
| This is the data quality problem that resides in your dataset. | These are the various issues that can arise due to the data problem. | This is the impact the issue can have on the business. | This quantifies the impact in terms of a business measure. | This provides a periodic estimated cost incurred due to the business impact. |
| Example | ||||
| Misspelled customer name and contact information | Duplicate records created for the same customer | Customer service: Increased number of inbound calls | Increased staff time | $30,000.00 worth more staff time required |
| Customer service: Decreased customer satisfaction | Order reduction, lost customers | ~500 less orders this year (as compared to estimated) | ||
Verwaltung der Datenqualität
Wir befassten uns mit den Grundlagen der Datenqualität, mit Problemen der Datenqualität und deren Zusammenhang mit Geschäftsrisiken. Jetzt ist es an der Zeit zu sehen, was das Datenqualitätsmanagement Plan ist: Wie können Sie die Datenqualität im Laufe der Zeit verbessern und konsistent verwalten und alle Vorteile nutzen, die Ihr Unternehmen daraus ziehen kann. Fangen wir an.
Was ist Datenqualitätsmanagement?
Datenqualitätsmanagement ist definiert als: Die Implementierung eines systematischen Rahmens, der kontinuierlich Datenquellen profiliert, die Qualität der Informationen überprüft und eine Reihe von Prozessen zur Beseitigung von Datenqualitätsfehlern durchführt – in dem Bestreben, die Daten genauer, korrekter, gültiger, vollständiger und zuverlässiger zu machen. Da die Anforderungen und Merkmale der Datenqualität in jedem Unternehmen anders sind, unterscheidet sich auch das Datenqualitätsmanagement von Unternehmen zu Unternehmen. Die Art der Mitarbeiter, die Sie für die Verwaltung der Datenqualität benötigen, die Metriken, die Sie zur Messung benötigen, die Datenqualitätsprozesse, die Sie implementieren müssen – all das hängt von verschiedenen Faktoren ab, z. B. von der Unternehmensgröße, der Größe der Datenmenge, den beteiligten Quellen usw. Im Folgenden werden die wichtigsten Säulen der Datenqualitätsimplementierung und des Datenqualitätsmanagements erörtert, die Ihnen eine gute Vorstellung davon vermitteln, wie Sie die Datenqualität in Ihrem Unternehmen für Ihre spezifischen Anforderungen sicherstellen können.
Was sind die 5 Säulen des Datenqualitätsmanagements?
In diesem Abschnitt befassen wir uns mit den wichtigsten Säulen des Datenqualitätsmanagements: Menschen, Messung, Prozesse, Rahmenbedingungen und Technologie.
01. Die Menschen: Wer ist am Datenqualitätsmanagement beteiligt?
Es ist eine weit verbreitete Meinung, dass man bei der Verwaltung der Datenqualität im gesamten Unternehmen die Zustimmung und das Einverständnis der Entscheidungsträger einholen muss. Die Wahrheit ist jedoch, dass Sie Datenexperten auf verschiedenen Führungsebenen benötigen, um sicherzustellen, dass sich Ihre Investitionen in Datenqualitätsinitiativen auszahlen.
Im Folgenden sind einige Rollen aufgeführt, die entweder für die Kontrolle der Datenqualität in einem Unternehmen verantwortlich, rechenschaftspflichtig, beratend tätig oder darüber informiert sind:
a) Leiter der Datenabteilung (CDO):
Ein Chief Data Officer (CDO) ist eine Position auf Führungsebene, die ausschließlich für die Entwicklung von Strategien für die Datennutzung, die Überwachung der Datenqualität und die Datenverwaltung im gesamten Unternehmen zuständig ist.
b)
Datenverwalter:
Ein Datenverwalter ist der Ansprechpartner in einem Unternehmen für alle Fragen im Zusammenhang mit Daten. Sie sind sehr praktisch veranlagt in wie das Unternehmen Daten erfasst, wo sie gespeichert werden, welche Bedeutung sie für die verschiedenen Abteilungen haben und wie die Qualität der Daten während ihres gesamten Lebenszyklus gewährleistet wird.
c) Verwahrer der Daten:
A
Datenverwalter ist für die Struktur der Datenfelder verantwortlich – einschließlich Datenbankstrukturen und -modelle.
d)
Datenanalytiker:
Ein Datenanalyst ist jemand, der in der Lage ist, Rohdaten in aussagekräftige Erkenntnisse umzuwandeln – insbesondere in bestimmten Bereichen. Eine Hauptaufgabe des Datenanalysten ist die Vorbereitung, Bereinigung und Filterung der benötigten Daten.
e) Andere Teams:
Diese Rollen werden als Datenkonsumenten betrachtet, d. h. sie nutzen Daten – entweder in ihrer Rohform oder wenn sie in umsetzbare Erkenntnisse umgewandelt werden, wie z. B. Vertriebs- und Marketingteams, Produktteams, Geschäftsentwicklungsteams usw.
Lesen Sie mehr über
Aufbau eines Datenqualitätsteams: Zu beachtende Rollen und Verantwortlichkeiten
.
02. Die Messung: Wie wird die Datenqualität gemessen?
Der zweitwichtigste Aspekt des Datenqualitätsmanagements ist seine Messung. Dabei handelt es sich um Datenmerkmale und wichtige Leistungsindikatoren, die das Vorhandensein von Datenqualität in Unternehmensdatensätzen bestätigen. Je nachdem, wie Ihr Unternehmen Daten nutzt, können diese KPIs unterschiedlich ausfallen. Ich habe die wichtigsten Daten aufgelistet Qualität Dimensionen und die Qualitätsmetrik, die sie darstellen:

- Genauigkeit: Wie gut bilden die Datenwerte die Realität oder die Richtigkeit ab?
- Herkunft: Wie vertrauenswürdig ist die ursprüngliche Quelle der Datenwerte?
- Semantisch: Entsprechen die Datenwerte ihrer Bedeutung?
- Struktur: Sind die Datenwerte im richtigen Muster und/oder Format vorhanden?
- Vollständigkeit: Sind Ihre Daten so umfassend, wie Sie sie benötigen?
- Konsistenz: Haben die verschiedenen Datenspeicher die gleichen Datenwerte für die gleichen Datensätze?
- Währung: Ist die Aktualität Ihrer Daten akzeptabel?
- Rechtzeitigkeit: Wie schnell werden die angeforderten Daten zur Verfügung gestellt?
- Angemessenheit: Haben die Datenwerte den richtigen Datentyp und die richtige Größe?
- Identifizierbarkeit: Stellt jeder Datensatz eine eindeutige Identität dar und ist kein Duplikat?
Lesen Sie mehr über
Dimensionen der Datenqualität – 10 Metriken, die Sie messen sollten
.
03. Prozess: Was sind Datenqualitätsprozesse?
Da die Datenmenge in den letzten Jahrzehnten massiv zugenommen hat, sind sie multivariat und werden in mehreren Dimensionen gemessen. Um Datenqualitätsprobleme zu finden, zu beheben und zu verbessern, müssen Sie eine Vielzahl von Datenqualitätsprozessen implementieren, von denen jeder einzelne einen anderen, wertvollen Zweck erfüllt. Werfen wir einen Blick auf die häufigsten Datenqualitätsprozesse, die Unternehmen zur Verbesserung ihrer Datenqualität einsetzen.
a) Erstellung von Datenprofilen
Es geht darum, den aktuellen Zustand Ihrer Daten zu verstehen, indem verborgene Details über ihre Struktur und ihren Inhalt aufgedeckt werden. Ein Algorithmus zur Erstellung von Datenprofilen analysiert die Spalten des Datensatzes und berechnet Statistiken für verschiedene Dimensionen, wie Vollständigkeit, Eindeutigkeit, Häufigkeit, Charakter und Musteranalyse usw.
b) Datenbereinigung und -standardisierung
Es handelt sich um den Prozess der Beseitigung falscher und ungültiger Informationen in einem Datensatz, um eine konsistente und nutzbare Ansicht über alle Datenquellen hinweg zu erhalten. Dazu gehören das Entfernen und Ersetzen falscher Werte, das Parsen längerer Spalten, die Umwandlung von Groß- und Kleinschreibung, das Zusammenführen von Spalten usw.
Auch bekannt als
Datensatzverknüpfung
und
Entitätsauflösung
ist es der Vorgang, bei dem zwei oder mehr Datensätze verglichen werden, um festzustellen, ob sie zu ein und derselben Entität gehören. Sie umfasst die Kartierung die gleichen Spalten, die Auswahl der abzugleichenden Spalten, die Ausführung von Abgleichsalgorithmen, die Analyse der Abgleichsergebnisse und die Abstimmung der Abgleichsalgorithmen, um genaue Ergebnisse zu erzielen.
Dabei werden mehrere Datensätze, die zur selben Entität gehören, eliminiert und nur ein Datensatz pro Entität beibehalten. Dazu gehört die Analyse der doppelten Datensätze in einer Gruppe, die Markierung der doppelten Datensätze und deren anschließende Löschung aus dem Datensatz.
e)
Datenzusammenführung und Überlebensfähigkeit
Sie ist der Prozess der Erstellung von Regeln, die doppelte Datensätze durch bedingte Auswahl und Überschreiben zusammenführen. Dies hilft Ihnen, Datenverluste zu vermeiden und ein Maximum an Informationen von Duplikaten zu erhalten. Dazu gehörten die Definition von Regeln für die Auswahl und das Überschreiben von Stammsätzen, die Ausführung von Regeln und deren Abstimmung, um genaue Ergebnisse zu erzielen.
f)
Daten
Governance
Der Begriff Data Governance bezieht sich in der Regel auf eine Sammlung von Rollen, Richtlinien, Arbeitsabläufen, Standards und Metriken, die eine effiziente Datennutzung und -sicherheit gewährleisten und es einem Unternehmen ermöglichen, seine Geschäftsziele zu erreichen. Dazu gehören die Erstellung von Datenrollen und die Zuweisung von Berechtigungen, die Entwicklung von Arbeitsabläufen zur Überprüfung von Informationsaktualisierungen, die Gewährleistung des Schutzes der Daten vor Sicherheitsrisiken usw.
Dabei werden die Adressen mit einer maßgeblichen Datenbank abgeglichen – z. B. mit der des USPS in den USA – und es wird überprüft, ob es sich bei der Adresse um einen für die Postzustellung geeigneten, genauen und gültigen Ort innerhalb des Landes handelt.
Lesen Sie mehr über die
5 Datenqualitätsprozesse, die Sie kennen sollten, bevor Sie ein DQM-Rahmenwerk entwerfen
.
04. Rahmen: Was ist ein Datenqualitätsrahmen?
Neben den Datenqualitätsprozessen ist ein weiterer wichtiger Aspekt, der bei der Entwicklung einer Datenqualitätsstrategie zu berücksichtigen ist, ein Datenqualitäts Rahmenwerk. Die Prozesse stellen eigenständige Techniken dar, die zur Beseitigung von Datenqualitätsproblemen in Ihren Datensätzen eingesetzt werden. A Datenqualität Rahmenwerk ist ein systematischer Prozess, der die Datenqualität konsequent überwacht, eine Vielzahl von Datenqualitätsprozessen (in einer bestimmten Reihenfolge) implementiert und sicherstellt, dass sie nicht unter festgelegte Schwellenwerte sinkt. Sie enthält weitere Einzelheiten über den Prozessablauf des Datenqualitätsmanagements.
Ein einfacher Rahmen für die Datenqualität besteht aus vier Stufen:
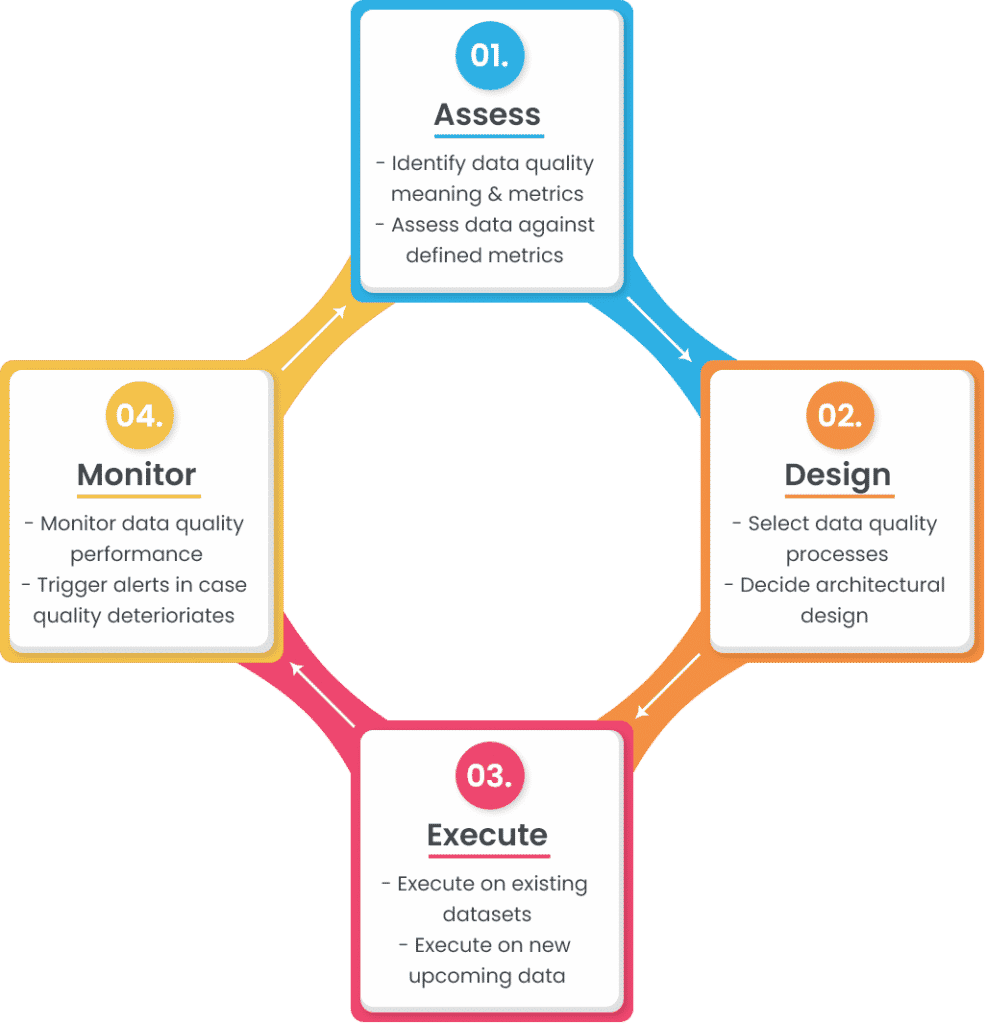
a) Bewerten:
Dies ist der erste Schritt des Rahmens, in dem Sie die beiden Hauptkomponenten bewerten müssen: die Bedeutung der Datenqualität für Ihr Unternehmen und die Bewertung der aktuellen Daten im Vergleich dazu.
b) Entwurf:
Der nächste Schritt im Datenqualitäts-Framework besteht darin, die erforderlichen Geschäftsregeln zu entwerfen, indem die benötigten Datenqualitätsprozesse ausgewählt und auf Ihre Daten abgestimmt werden, sowie das architektonische Design der Datenqualitätsfunktionen festzulegen.
c)
Ausführen:
Die dritte Phase des Zyklus ist die Phase der Ausführung. In den beiden vorangegangenen Schritten haben Sie die Bühne vorbereitet, nun ist es an der Zeit zu sehen, wie gut das System tatsächlich funktioniert.
d)
Überwachen:
Dies ist die letzte Phase des Rahmens, in der die Ergebnisse überwacht werden. Sie können fortgeschrittene Datenprofilierungstechniken verwenden, um detaillierte Leistungsberichte zu erstellen.
Lesen Sie mehr über
Entwurf eines Rahmens für das Datenqualitätsmanagement
.
05. Technologie: Was sind Datenqualitätsmanagement-Tools?
Obwohl Datenqualitätsprobleme von Natur aus recht komplex sind, validieren viele Unternehmen die Datenqualität immer noch manuell, was zu zahlreichen Fehlern führt. Die Einführung einer technologischen Lösung für dieses Problem ist der beste Weg, um die Produktivität Ihres Teams und die reibungslose Umsetzung eines Datenqualitätsrahmens zu gewährleisten. Es gibt viele Anbieter, die Datenqualitätsfunktionen in verschiedenen Angeboten bündeln, z. B:
a)
Eigenständige Datenqualitätssoftware zur Selbstbedienung
Software
:
Mit dieser Art von Datenqualitätsmanagement-Software können Sie eine Vielzahl von Datenqualitätsprozessen für Ihre Daten durchführen. Sie verfügen in der Regel über ein automatisiertes Datenqualitätsmanagement oder Stapelverarbeitungsfunktionen zum Bereinigen, Abgleichen und Zusammenführen großer Datenmengen zu bestimmten Zeiten am Tag. Es ist eine der schnellsten und sichersten Methoden zur Konsolidierung von Datensätzen, ohne dass wichtige Informationen verloren gehen, da alle Prozesse auf einer Kopie der Daten ausgeführt werden und die endgültige Datenansicht an eine Zielquelle übertragen werden kann.
b)
Datenqualität API oder SDK:
Einige Anbieter stellen die erforderlichen Datenqualitätsfunktionen über
APIs oder SDKs
. So können Sie alle Funktionen des Datenqualitätsmanagements in Echtzeit oder zur Laufzeit in Ihre bestehenden Anwendungen integrieren. Lesen Sie mehr über Datenqualitäts-API: Funktionen, Architektur und Vorteile.
c)
Datenqualität eingebettet in Datenmanagement-Tools
Einige Anbieter betten Datenqualitäts
Fähigkeiten
in
zentralisierten Datenmanagement-Plattformen
so dass alles in der gleichen Datenpipeline erledigt werden kann. Die Entwicklung eines durchgängigen Datenverwaltungssystems mit eingebetteter Datenqualitätsfunktion erfordert eine detaillierte Planung und Analyse sowie die Einbeziehung der wichtigsten Interessengruppen bei jedem Schritt des Prozesses. Solche Systeme werden oft als Paket angeboten
Stammdaten-Management
Lösungen.
Wie unterscheidet sich das Datenqualitätsmanagement vom Stammdatenmanagement?
- Der Begriff „Stammdatenmanagement“ bezieht sich auf eine Sammlung von Best Practices für das Datenmanagement, die Datenintegration, Datenqualität und Data Governance umfassen. Das bedeutet, dass Datenqualität und Stammdatenmanagement keine Gegensätze sind, sondern sich vielmehr ergänzen. MDM-Lösungen enthalten neben den Funktionen für das Datenqualitätsmanagement einige zusätzliche Funktionen. Dies macht MDM definitiv zu einer komplexeren und ressourcenintensiveren Lösung, was bei der Wahl zwischen den beiden Ansätzen zu berücksichtigen ist.

c)
Kundenspezifische interne Lösungen
Obwohl es auf dem Markt verschiedene Lösungen für Datenqualität und Stammdatenmanagement gibt, investieren viele Unternehmen in die Entwicklung einer eigenen Lösung für ihre individuellen Datenanforderungen. Auch wenn dies sehr vielversprechend klingt, verschwenden die Unternehmen bei diesem Prozess oft eine große Anzahl von Ressourcen – Zeit und Geld -. Die Entwicklung einer solchen Lösung mag zwar einfacher zu implementieren sein, aber es ist fast unmöglich, sie auf Dauer zu erhalten.
Wenn Sie mehr darüber erfahren möchten, lesen Sie unser Whitepaper:
Warum interne Datenqualitätsprojekte scheitern
.
Was sind die besten Praktiken für das Datenqualitätsmanagement?
Werfen wir einen kurzen Blick auf die bewährten Verfahren zur Datenqualität:
a)
Ermitteln Sie die Beziehung zwischen
Daten und Unternehmensleistung
und welche genauen Auswirkungen eine schlechte Datenqualität auf Ihre Unternehmensziele hat.
b)
Messung und Pflege der
Definition von Datenqualität
Wählen Sie eine Liste von Metriken aus, die Ihnen und Ihren Teams helfen, sich über die Datenqualität und ihre Bedeutung für Ihr Unternehmen einig zu werden.
c)
Einrichtung von
Rollen und Verantwortlichkeiten für Daten
in der gesamten Organisation, um die Verantwortung für die Erreichung und Aufrechterhaltung der Datenqualität zu übertragen – von der obersten Ebene bis zum Betriebspersonal.
d)
Schulung und Ausbildung von Teams
über Datenbestände und deren Eigenschaften, den Umgang mit Daten und die Auswirkungen ihres Handelns auf das gesamte Datenökosystem.
e)
Kontinuierlich
überwachen den Zustand der Daten
durch Datenprofilierung und
verborgene Details über ihre Struktur und ihren Inhalt aufdecken.
f)
Entwurf und
pflegen Datenpipelines
die eine nummerierte Liste von
Operationen
auf eingehende Daten ausführt, um eine einzige Quelle der Wahrheit zu erhalten.
g)
durchführen
Ursachenanalyse
von Datenqualitätsfehlern, um zu verstehen, woher die Datenqualitätsfehler kommen, und diese Probleme an der Quelle zu beheben.
h)
Nutzung der Technologie
um
zu erreichen
Datenqualität zu erreichen und zu erhalten, denn
kein
Denn kein Prozess verspricht eine gute Leistung und den besten ROI, wenn er nicht durch Technologie automatisiert und optimiert wird.
Wenn Sie mehr über jede dieser Praktiken erfahren möchten, lesen Sie unseren ausführlichen Blog
8 Best Practices zur Sicherung der Datenqualität auf Unternehmensebene
.
Beispiele aus der Praxis für das Datenqualitätsmanagement
In diesem letzten Abschnitt unseres Leitfadens werden wir uns einige Anwendungsfälle für die Datenqualität ansehen und herausfinden, wie renommierte Marken die folgenden Tools einsetzen
Tools für Datenbereinigung und -abgleich
für das Management der Qualität ihrer Daten einsetzen und was sie darüber zu sagen haben.
01. Datenqualitätsmanagement im Einzelhandel

Der größte Vorteil von DataMatch Enterprise war die Fuzzy-Logik und der synthetische Abgleich. Es war einfach etwas, das ich selbst nicht nachmachen konnte.
war die Fuzzy-Logik und der synthetische Abgleich. Es war einfach etwas, das ich selbst nicht nachmachen konnte.

Marty YantzieManager für PC-Support und Systementwicklung, Buckle
Schnalle ist ein führender Einzelhändler für Denim, Sportbekleidung, Oberbekleidung, Schuhe und Accessoires mit über 450 Geschäften in 43 Staaten. Buckle stand vor der Herausforderung, große Mengen von Datensätzen aus Hunderten von Geschäften zu sortieren. Die Hauptaufgabe bestand darin, alle doppelten Informationen zu beseitigen, die in das aktuelle iSeries DB2-System geladen worden waren. Man suchte nach einer effizienten Methode, um doppelte Daten zu entfernen, die etwa 10 Millionen Datensätze ausmachten.
DataMatch Enterprise bot eine brauchbare und effizientere Lösung für Buckle. Das Unternehmen war in der Lage, eine große Anzahl von Datensätzen durch das
Deduplizierungsprozess
als ein Projekt unter Verwendung eines einzigen Softwaretools im Gegensatz zur Verwendung mehrerer verschiedener Methoden.
02. Datenqualitätsmanagement im Gesundheitswesen
DataMatch Enterprise war viel einfacher zu verwenden als die anderen Lösungen, die wir uns angesehen haben. Die Möglichkeit, die Datenbereinigung und den Abgleich zu automatisieren, hat uns jedes Jahr Hunderte von Personenstunden eingespart.
Shelley Hahn Geschäftsentwicklung, St. John Associates
St. John Associates bietet Vermittlungs- und Rekrutierungsdienste in den Bereichen Kardiologie, Notfallmedizin, Gastroenterologie, neurologische Chirurgie, Neurologie, orthopädische Chirurgie und anderen Bereichen. Mit einer wachsenden Datenbank von Bewerbern benötigte St. John Associates eine Möglichkeit zum Deduplizieren, Bereinigen und Abgleichen von Datensätzen. Nachdem diese Aufgabe mehrere Jahre lang manuell ausgeführt wurde, beschloss das Unternehmen, dass es an der Zeit war, ein Tool einzusetzen, das den Zeitaufwand für die
Reinigungsprotokolle
.
Mit DataMatch Enterprise war St. John Associates in der Lage, eine erste Datenbereinigung vorzunehmen, bei der Daten gefunden wurden, Zusammenführen und Bereinigung von Hunderttausende von Datensätzen in einem kurzen Zeitraum. DataMatch half, den Prozess der Deduplizierung durch Fuzzy-Matching-Algorithmen zu beschleunigen und erleichterte das Sortieren von Datenfeldern, um ungültige Informationen zu finden. Außerdem entfällt die Notwendigkeit der manuellen Eingabe, da die Benutzer Änderungen exportieren und bei Bedarf hochladen können.
03. Datenqualitätsmanagement bei Finanzdienstleistungen
Das schrittweise und assistentenähnliche Tool, das Sie durch den Prozess der Einrichtung eines Projekts führt. Es ist sehr intuitiv und ermöglicht es uns, alle Arten von Projekten zu erstellen und alle Arten von Datenquellen einzubinden. Einer der Gründe, warum wir uns für DL entschieden haben, war, dass es eine DB2-Importfunktion gibt, mit der wir direkt in unsere DB2-Datenbank gehen können. Mit der Schnittstelle konnten wir gute Ergebnisse erzielen und sie ist sehr einfach zu bedienen.
Scott FordIT-Lösungsarchitekt, Bell Bank
Glockenbank ist eine der größten unabhängigen Banken des Landes mit einer Bilanzsumme von mehr als 6 Milliarden Dollar und ist in allen 50 Bundesstaaten vertreten. Als große Privatbank arbeitet die Bell Bank mit vielen Anbietern und Dutzenden von Dienstleistungssparten zusammen – von Hypotheken bis zu Versicherungen, von der Altersvorsorge bis zur Vermögensverwaltung und vielen mehr. Mit Informationen, die isoliert und in verschiedenen
unterschiedlichen Datenquellen
war es für die Bank schwierig, einen einzigen, konsolidierten Überblick über ihre Kunden zu erhalten; ganz zu schweigen davon, dass ihr durch das Versenden mehrerer E-Mails an einen Anbieter oder Kunden unnötige Kosten entstanden.
DataMatch Enterprise ist ein wichtiger Bestandteil der bankinternen Datenmanagementlösung Datenmanagement-LösungDadurch können sie die Ergebnisse leicht gruppieren und die Liste aller Kundendatensätze zurückgeben, von denen angenommen wird, dass sie zu einer Einheit gehören. Diese
konsolidierte Ansicht
hilft der Bank, die Verbindung ihrer Kunden mit der Bank wirklich zu verstehen und die Maßnahmen zu ergreifen, die sie ergreifen kann, um diese Verbindung weiter zu stärken.
04. Datenqualitätsmanagement in Vertrieb und Marketing
DataMatch macht es mir viel einfacher, Spalten in Excel abzugleichen. Der einzige Grund, warum ich mir die Software zugelegt habe, war, verkaufte Fahrzeuge mit den von uns bearbeiteten Leads abzugleichen.
Matt GriffinVP Betrieb, TurnKey Auto Events
TurnKey Auto Veranstaltungen führt landesweit groß angelegte Autokaufkampagnen für Autohändler durch. Sie organisieren Veranstaltungen, die Autokäufer zum Besuch und zum Kauf von Fahrzeugen bewegen. Als Dienstleister, der Vertriebskontakte für Automobilhändler vermittelt, wollte TurnKey Marketing eine Gutschrift für zusätzliche Verkäufe erhalten, die mit den verschiedenen Autohäusern, mit denen sie zusammenarbeiten, getätigt wurden.
Da sie in der Lage sind, den Vertrieb mit der Vielzahl potenzieller Interessenten, die sie täglich ansprechen, abzustimmen, erhalten sie für jeden Lead eine Umsatzgutschrift (und verdienen Geld). Mit DataMatch, dem hochentwickelten Data Ladder Datenabgleich Produkt war das Unternehmen in der Lage, Datensätze aus verschiedenen Quellen abzugleichen. Von dort aus konnten sie eine Vogelperspektive eines potenziellen Autoverkaufs im Laufe der Zeit erstellen.
05. Datenqualitätsmanagement im Bildungswesen
Die Idee, zwei Gruppen von Datensätzen miteinander zu verknüpfen, war für die Forschungsabteilung überwältigend. Das Verfahren wäre sehr zeitaufwändig und würde die Rechtzeitigkeit und den Ablauf der Forschungsaktivitäten gefährden.
Universität West Virginia
Universität West Virginia ist die einzige Forschungsuniversität des Bundesstaates, die einen Doktortitel vergibt und eine staatliche Zulassung besitzt. Die Schule bietet fast 200 Studiengänge für Studierende, Graduierte, Doktoranden und Fachleute an. Sie hatten die Aufgabe, die langfristigen Auswirkungen bestimmter medizinischer Erkrankungen auf die Patienten über einen längeren Zeitraum hinweg zu bewerten. Die Daten für die medizinischen Bedingungen und die aktuellen Gesundheitsdaten, die vom Staat zur Verfügung gestellt werden, sind in getrennte Systeme.
Mit DataMatch, dem Vorzeigeprodukt von Data Ladder zur Datenbereinigung, konnte die Universität Datensätze bereinigen aus mehreren Systemen, die die erforderlichen Informationen enthalten. Von dort aus konnten sie Folgendes schaffen eine einheitliche Sicht des Patienten im Laufe der Zeit.
Das letzte Wort
Führungskräfte wissen um die Bedeutung von Daten – von Routinevorgängen bis hin zu fortschrittlicher Business Intelligence werden sie überall genutzt. Die meisten Teams, die mit Daten arbeiten, verbringen jedoch zusätzliche Stunden mit Doppelarbeit, mangelndem Datenwissen und fehlerhaften Ergebnissen. Und all diese Probleme entstehen durch ein schlechtes oder fehlendes Management der Datenqualität.
Investitionen in Datenqualitätstools, wie
DataMatch Enterprise
wird Ihnen auf jeden Fall helfen, mit dem Datenqualitätsmanagement zu beginnen. DataMatch führt Sie durch verschiedene Phasen der Datenbereinigung und des Datenabgleichs. Angefangen beim Importieren von Daten aus verschiedenen Quellen, führt es Sie durch
Datenprofilierung
,
Bereinigung
,
Standardisierung
und
Deduplizierung
. Darüber hinaus ist die
Adressüberprüfung
hilft Ihnen bei der Überprüfung von Adressen anhand der offiziellen USPS-Datenbank.
DataMatch bietet auch Planungsfunktionen für die Stapelverarbeitung von Datensätzen oder Sie können seine API nutzen, um Datenbereinigungs- oder Abgleichfunktionen in benutzerdefinierte Anwendungen zu integrieren und sofortige Ergebnisse zu erhalten.
Buchen Sie noch heute eine Demo oder laden Sie eine kostenlose Testversion herunter, um mehr darüber zu erfahren, wie wir Ihnen helfen können, das Beste aus Ihren Daten herauszuholen.
The post Datenqualitätsmanagement: Was, warum, wie und beste Praktiken appeared first on Data Ladder.
]]>The post Wie man die Datenqualität bei Finanzdienstleistungen verbessert appeared first on Data Ladder.
]]>24 Prozent der Versicherer geben an, dass sie „nicht sehr zuversichtlich“ sind, was die Daten angeht, die sie zur Risikobewertung und -bewertung verwenden.
Corinium Intelligenz
Der wirtschaftliche Abschwung und die finanziellen Probleme, mit denen Unternehmen heute konfrontiert sind, zeigen, wie wichtig die Nutzung von Daten für die Vorhersage künftiger Ereignisse ist. Die Unklarheiten in den Finanzdaten können jedoch dazu führen, dass Unternehmen wichtige Entscheidungen auf der Grundlage ungenauer Daten treffen und die Konsequenzen tragen. Banken, Versicherungen, Hypothekenbanken und andere Unternehmen, die Finanzdienstleistungen anbieten, sind gegen den Alptraum der Datenqualität nicht gefeit. In der Tat entstehen diesen Unternehmen die höchsten Kosten durch die schlechte Qualität der Finanzinformationen.
In diesem Blog befassen wir uns mit der Bedeutung von Datenqualität im Finanzdienstleistungsbereich, dem Nutzen für Einzelpersonen und Unternehmen, häufigen Datenqualitätsproblemen in Finanzdaten und der Verbesserung der Qualität von Finanzinformationen.
Was ist Datenqualität bei Finanzdienstleistungen?
Datenqualität bei Finanzdienstleistungen bedeutet, dass die von den Finanzinstituten erfassten, gespeicherten, verarbeiteten und präsentierten Finanzdaten ihren Zweck erfüllen. Alle Daten, die ihren Zweck nicht erfüllen, sind bekanntermaßen von schlechter Qualität und müssen getestet und überprüft werden, bevor sie effektiv genutzt werden können.
Finanzinstitute – wie Banken, Versicherungen, Hypotheken- oder Maklerfirmen, Investoren, Kreditgeber oder Darlehensgeber – nutzen Daten in fast jedem Geschäftsprozess. Die Finanzdaten werden verwendet, um:
- Erstellung von Jahresabschlüssen und Berichten für den internen Gebrauch und für Kunden,
- Bewilligung von Krediten und Abschluss des Underwriting-Prozesses,
- Erkennen oder verhindern Sie betrügerische Aktivitäten wie gestohlene Daten oder gefälschte Anträge,
- Identifizierung von Personen, bei denen die Wahrscheinlichkeit höher ist, dass sie ihren Kredit nicht zurückzahlen können,
- Bewertung der mit Finanzentscheidungen verbundenen Risiken, wie z. B. Betriebs- oder Kreditrisiko usw.
Es liegt auf der Hand, dass sich eine schlechte Datenqualität negativ auf die Ausführung und die Ergebnisse dieser Prozesse auswirken kann. Die Einspeisung genauer und sauberer Daten in diese Prozesse ist für den Schutz der Glaubwürdigkeit der Finanzinstitute von großer Bedeutung.
Warum ist Datenqualität bei Finanzdienstleistungen wichtig?
Da Daten in der Finanzdienstleistungsbranche eng miteinander verknüpft sind, ist es sehr wichtig, dass die Daten fehlerfrei sind. Hochwertige, saubere und fehlerfreie Daten ermöglichen es den Kunden, ihren Investmentbanken und Versicherungsgesellschaften zu vertrauen. Werfen wir einen Blick auf die Bedeutung der Datenqualität in der Finanzdienstleistungsbranche und die Vorteile, die Sie durch die Gewährleistung der Qualität Ihrer Finanzdaten erzielen können.
1. Bewertung, Planung und Minderung von Risiken
Das Risiko ist bei bestimmten Finanzaktivitäten unvermeidlich – ganz gleich, ob Sie in ein Unternehmen investieren, einem Kreditnehmer Geld leihen oder Darlehen oder Hypothekenanträge bewilligen wollen. Eine intelligente Risikoplanung ist jedoch entscheidend für das Überleben in der Finanzwelt. Mit einer sorgfältigen Datenanalyse und Risikobewertung können Sie das Risiko mindern und bessere Entscheidungen über die erwarteten Erträge, die Rentabilität und andere Alternativen treffen. Dafür benötigen Sie jedoch korrekte, genaue und relevante Daten, die Ihnen helfen, finanzielle Risiken und potenzielle Verluste zu vermeiden, die möglicherweise bestehen.
2. Betrügerische Aktivitäten aufdecken und verhindern
Banken, Versicherungen und Anleger, die eine schlechte Datenqualität aufweisen, sind anfälliger für betrügerisches Verhalten und Verluste. Denn die Lücken in der Datenqualität ermöglichen es Betrügern, Identitäten zu stehlen, gefälschte Anträge zu stellen, Wiederholungsprüfungen zu umgehen und bösartige Angriffe auf sensible Daten durchzuführen, die von Finanzorganisationen gespeichert werden. Saubere, genaue und konsolidierte Daten ermöglichen es Ihnen, Anomalien rechtzeitig zu erkennen und betrügerische Aktivitäten zu verhindern.
3. Ermöglichung der Digitalisierung von Finanzprozessen
Digitales Banking, Online-Zahlungen und Online-Kreditanträge revolutionieren die Finanzbranche. Die erfolgreiche Umsetzung und Ausführung dieser digitalen Dienste ist jedoch nur mit qualitativ hochwertigen Daten möglich. Viele Banker und Investoren führen immer noch physische Akten, da die Daten über verschiedene Quellen verstreut sind und manuelle Eingriffe erfordern, um sie bei Bedarf zu erfassen. Managed Data Quality ermöglicht es Finanzinstituten, jeden Aspekt ihres Geschäfts oder ihrer Dienstleistungsangebote zu digitalisieren.
4. Kundentreue sicherstellen
Wenn Kundendatensätze abgeglichen, zusammengeführt und konsolidiert werden, um eine vollständige 360°-Ansicht darzustellen, wird es einfacher, personalisierte Kundenerfahrungen zu nutzen und gleichzeitig den Datenschutz und die Sicherheit der Kunden zu gewährleisten. Wenn Daten über verschiedene Quellen verstreut sind – einschließlich lokaler und physischer Dateien, Anwendungen von Drittanbietern und Webformular-Eingaben – wird es unmöglich, Ihren Kunden ein zusammenhängendes Erlebnis zu bieten und Vertrauen und Loyalität aufzubauen.
5. Ermöglichung einer genauen Kreditwürdigkeitsprüfung für die Kreditvergabe
Wenn es darum geht, Kreditnehmern Geld zu leihen, ist es für Investoren und Banker von entscheidender Bedeutung, die Haftung ihrer Entscheidungen zu kennen. Sie müssen die Identität und die Kreditwürdigkeit des Antragstellers überprüfen sowie den Wert und den Zinssatz für den Kredit berechnen. Eine gute Datenqualität kann Unstimmigkeiten oder Verzögerungen, die im Underwriting-Prozess auftreten können, beseitigen und sicherstellen, dass Sie zum richtigen Zeitpunkt in die richtige Person investieren.
6. Einhaltung der gesetzlichen Normen
Compliance-Standards wie die Bekämpfung der Geldwäsche (AML) und der Terrorismusfinanzierung (CFT) zwingen die Finanzinstitute, ihr Datenmanagement im Bereich der Finanzdienstleistungen zu überdenken und zu überarbeiten. Um diese Standards einzuhalten, müssen diese Unternehmen ihre Kundentransaktionen überwachen, um Finanzverbrechen wie Geldwäsche und Finanzierung terroristischer Aktivitäten aufzudecken. Da die Informationen ungenau und von schlechter Qualität sind, gelingt es den Finanzinstituten nicht, anormale oder ungewöhnliche Aktivitäten rechtzeitig den zuständigen Behörden zu melden.
7. Erleichterung der prädiktiven Analytik
Die Datenwissenschaft hat sich weiterentwickelt, um Echtzeit-Vorhersagen und Einblicke in die Finanzwelt und potenzielle Risiken im Zusammenhang mit Finanzierungsaktivitäten zu ermöglichen. Die Anleger sagen voraus, ob es sich lohnt, in einen bestimmten Markt zu investieren, oder welche Aktien langfristig rentabler sein werden. Diese Berechnungen sind ungenau und nicht aussagekräftig, wenn die Daten, die für diese Statistiken verwendet werden, von schlechter Qualität sind. Ein weiterer großer Vorteil der Datenqualität besteht also darin, dass Datenanalysten und Datenwissenschaftler genaue Vorhersagen über finanzielle Gewinne machen können.
Häufige Probleme mit der Datenqualität bei Finanzdienstleistungen
Wir haben erörtert, inwiefern Datenqualität für Finanzinstitute von großem Wert ist. In diesem Abschnitt werden wir sehen, wie schlechte Datenqualität bei verschiedenen Finanzinstituten aussieht, z. B. bei Banken oder Versicherungen. Lesen Sie mehr über die häufigsten Datenqualitätsprobleme und deren Ursachen.
| Problem der Datenqualität | Erläuterung | Beispiel für schlechte Datenqualität bei Finanzdienstleistungen |
| Ungenaue Daten | Daten stellen nicht die Realität oder Wahrheit dar. | Der vollständige juristische Name eines Kunden ist im Kreditvertrag falsch geschrieben. |
| Fehlende Daten | Die Daten sind nicht so umfassend wie nötig. | 2 von 15 Klauseln in einem Kreditvertrag bleiben leer. |
| Doppelte Datensätze | Die Daten enthalten Duplikate und stellen keine eindeutigen Identitäten dar. | Das Vorhandensein von doppelten Kundendatensätzen ermöglicht mehrfache Kreditanträge. |
| Variable Messeinheiten | Die Daten werden in unterschiedlichen Maßeinheiten gespeichert. | Bei internationalen Transaktionen wird der Geldwert in der jeweiligen Landeswährung und nicht in einer Standardhandelseinheit wie dem US-Dollar gespeichert. |
| Variable Formate und Muster | Die Daten werden in unterschiedlichen Formaten und Mustern gespeichert. | Die Telefonnummern der Kunden werden in unterschiedlichen Mustern gespeichert – einige haben internationale Vorwahlen, andere nicht einmal Ortsvorwahlen. |
| Überholte Informationen | Die Daten sind nicht aktuell oder so aktuell wie möglich. | Es dauert etwas zu lange, bis Transaktionen in den Kundendatensätzen auftauchen, wodurch die Systemprozesse anfällig für falsche Berechnungen sind. |
| Falsche Domäne | Die Daten gehören nicht zu einem Bereich mit korrekten Werten. | Die verwendeten Währungscodes gehören nicht zum ISO-Bereich. |
| Inkonsistenz | Die Daten sind in den verschiedenen Quellen nicht identisch. | Für die verschiedenen Kundensegmente innerhalb des Unternehmens werden unterschiedliche Wechselkurse verwendet. |
| Irrelevanz | Daten bieten ihren Nutzern keinen Wert. | Die Mitarbeiter erhalten die gewünschten Informationen nach Anwendung mehrerer Filter, Sortier- und Priorisierungsregeln. |
Wie lässt sich die Qualität der Finanzinformationen verbessern?
Probleme mit der Datenqualität können Sie eine Menge Geld kosten – vor allem, wenn Sie in der Finanzbranche tätig sind. Unternehmen, die Finanzdienstleistungen anbieten, müssen ihre Daten testen und verifizieren, bevor sie in kritische Geschäftsprozesse eingespeist werden. Es müssen kalkulierte Schritte unternommen werden, um zu verhindern, dass Probleme mit der Datenqualität im System auftreten, und um bereits bestehende Probleme zu beheben. Im Folgenden werden die wichtigsten Initiativen vorgestellt, die Finanzunternehmen zur Sicherung der Datenqualität ergreifen können.
1. Zustimmung von Führung und Management einholen
Der erste Schritt zur Schaffung einer Datenqualitätskultur in einem Unternehmen besteht darin, die Unternehmensleitung und andere Führungskräfte einzubeziehen. Sie können damit beginnen, sie auf die in den Datensätzen vorhandenen Probleme mit der Datenqualität aufmerksam zu machen. Durch die Erstellung von Datenprofilen erstellte Datenqualitätsberichte können nützlich sein, um die obere Führungsebene und andere Mitarbeiter über die Art der Datenqualitätsprobleme in Ihrer Einrichtung zu informieren.
Darüber hinaus können Sie eine Stichprobe von Daten aus den jüngsten Finanzaktivitäten erhalten und die Kosten einer schlechten Datenqualität mit der Friday Afternoon Measurement-Methode berechnen. Auf diese Weise können Sie eine Argumentation gegen schlechte Datenqualität aufbauen und die für die Durchführung von Datenqualitätsmaßnahmen erforderlichen Genehmigungen und Zustimmungen einholen.
2. Implementierung von drei Ebenen der Datenqualitätskontrolle
Die Kontrolle der Datenqualität wird mit dem Aufkommen neuer Techniken und Technologien immer fortschrittlicher. Dies hilft Banken und Versicherungsunternehmen, die Datenqualität auf mehreren Ebenen zu kontrollieren. In der ersten Stufe können Sie zum Beispiel mit einer schnellen Überprüfung der Fakten beginnen und die eventuell vorhandenen Probleme mit der Datenqualität beheben. Auf dieser Ebene wollen Sie sicherstellen, dass der Datensatz vollständig, genau und standardisiert ist.
Auf der zweiten Ebene möchten Sie eine tiefergehende statistische Analyse Ihres Datensatzes durchführen. So können Sie die Standardabweichungen numerischer Werte berechnen und eventuell auftretende Anomalien erkennen. Data Profiling ist eine gute Technik, um eine solche statistische Analyse Ihrer Daten durchzuführen. Auf der dritten und letzten Ebene können Sie komplexe maschinelle Lern- und KI-Tools einsetzen, die mögliche Datenqualitätsprobleme zur Laufzeit vorhersagen können, für die Ihre Quellen anfällig sind.
3. Abgleich und Konsolidierung von doppelten Datensätzen
Die Duplizierung von Daten ist eines der größten Probleme für die Datenqualität bei Banken und Versicherungen. Sie sollten einen Datenqualitätsrahmen verwenden, der Duplikate abgleicht und zu einem einzigen konsolidiert. Die Datensätze können zur Laufzeit bei jeder Aktualisierung abgeglichen oder in regelmäßigen Abständen in Stapeln verarbeitet werden. Lesen Sie mehr über die Stapelverarbeitung im Vergleich zur Validierung der Datenqualität in Echtzeit.
Der Prozess des Datensatzabgleichs oder der Datendeduplizierung besteht aus den folgenden Schritten:
- Profiling von Daten zur Hervorhebung von Fehlern,
- Analysieren, Bereinigen und Standardisieren von Daten, um eine einheitliche Ansicht zu erhalten,
- Abgleich von Datensätzen, die zur gleichen Entität gehören (genau auf Basis eines eindeutigen Bezeichners oder unscharfer Abgleich auf Basis einer Kombination von Feldern),
- Zusammenführung von Datensätzen, um unnötige Informationen zu entfernen und eine einzige Quelle der Wahrheit zu schaffen.
4. Einsatz von Technologie für das Datenqualitätsmanagement
Der Einsatz von Technologie zur Erreichung eines nachhaltigen Datenqualitätsmanagement-Lebenszyklus ist der Kern der Verbesserung der Datenqualität in jedem Finanzinstitut. Kein Prozess verspricht eine gute Leistung und den besten ROI, wenn er nicht mit Hilfe von Technologie automatisiert und optimiert wird. Investieren Sie in ein technologisches System, das über alle Funktionen verfügt, die Sie benötigen, um die Datenqualität in allen Datenbeständen zu gewährleisten.
Ganz gleich, wie gut Ihr Datenqualitätsteam ausgebildet ist, es wird dennoch Schwierigkeiten haben, ein akzeptables Niveau der Datenqualität aufrechtzuerhalten, solange es nicht mit den richtigen Tools ausgestattet ist. An dieser Stelle kann ein Datenqualitätsmanagement-Tool sehr nützlich sein. Ein All-in-One-Tool zur Selbstbedienung, das Datenprofile erstellt, verschiedene Datenbereinigungsaktivitäten durchführt, Duplikate abgleicht und eine einzige Quelle der Wahrheit ausgibt, kann ein großer Unterschied in der Leistung von Datenverantwortlichen und Datenanalysten sein.
Schlussfolgerung
Es ist eine schwierige Aufgabe, die Probleme mit der Datenqualität in Ihren Finanzdaten zu verstehen und einen geeigneten Rahmen zur Behebung dieser Fehler zu wählen. In vielen Situationen reicht eine Technik nicht aus, und es wird eine Kombination von Techniken verwendet, um Datenqualitätsprobleme genau zu beheben. Aus diesem Grund steigt der Bedarf an digitalen Werkzeugen. Tools, die nicht nur den Zeit- und Arbeitsaufwand optimieren, sondern auch die Datenqualitätstechniken je nach Art der Datenstruktur und -werte intelligent auswählen.
DataMatch Enterprise ist ein solches Tool, das Ihnen hilft, Ihre Daten zu bereinigen und abzugleichen, um genaue Analysen und umfassende Einblicke zu ermöglichen. Es bietet eine Reihe von Modulen, die Daten aus verschiedenen Quellen unterstützen, Werte bereinigen und standardisieren, die Zuordnung von Feldern ermöglichen, eine Kombination von Abgleichsdefinitionen vorschlagen, die für Ihre Daten spezifisch sind, und Daten zusammenführen, um eine vollständige 360°-Sicht auf Ihre Finanzen zu erhalten.
Wenn Sie mehr wissen möchten, melden Sie sich noch heute für eine kostenlose Testversion an oder buchen Sie eine Demo mit unseren Experten, um die Qualität Ihrer Finanzinformationen zu verbessern.
The post Wie man die Datenqualität bei Finanzdienstleistungen verbessert appeared first on Data Ladder.
]]>The post Datenqualität im Gesundheitswesen – Herausforderungen, Beschränkungen und Schritte zur Qualitätsverbesserung appeared first on Data Ladder.
]]>Leider ist mie meisten Einrichtungen des Gesundheitswesens leiden unter einer schlechten Datenqualität und großen Rückständen bei den Krankenakten, die verbessert werden müssen, damit sie zugänglich sind. & brauchbar. Veraltete Systeme, eine unzureichende Datenkultur und die mangelnde Bereitschaft, neue Technologien einzuführen, sind einige der größten Hindernisse für dieta Qualität im Gesundheitswesen.
Die Regel ist einfach: Wenn die Gesundheitsbehörden die Gesundheitsversorgung auf einem optimalen Niveau halten und verbessern wollen, müssen sie die Einhaltung von Datenqualitätsstandards sicherstellen.
In diesem kurzen Beitrag erfahren Sie, was Datenqualität für das Gesundheitswesen bedeutet, welche Herausforderungen und Einschränkungen sie mit sich bringt und welche Maßnahmen Branchenführer zur Verbesserung der Datenqualität ergreifen können.
Welche Bedeutung hat Datenqualität für das Gesundheitswesen?
 Organisierte, aggregierte und in ein aussagekräftiges Format umgewandelte Gesundheitsdaten liefern
Organisierte, aggregierte und in ein aussagekräftiges Format umgewandelte Gesundheitsdaten liefern
Gesundheitsinformationen
die genutzt werden können, um:
- Optimieren Sie die Patientenversorgung mit genauen Daten
- CDaten konsolidieren, um einen genauen Überblick über die Patienten zu erhalten
- Vertrauen schaffen in die Zuverlässigkeit der Daten
- Berichte mit zuverlässigen Statistiken erstellen
- Mitarbeiter und Personal in die Lage versetzen, wichtige Entscheidungen auf der Grundlage genauer Daten zu treffen
Da so viel auf dem Spiel steht, ist es von äußerster Wichtigkeit, dass die Daten im Gesundheitswesen
sachlich, organisiert, gültig, genau und zugänglich sind
.
Wie wird die Datenqualität bestimmt?
Im Gesundheitswesen bezieht sich die Datenqualität bezieht sich auf die Benutzer Grad des Vertrauen in die Daten. Dieses Vertrauen ist am höchsten, wenn die folgenden Standards eingehalten werden.
Korrektheit und Gültigkeit: Die ursprüngliche Datenquelle ist nicht irreführend oder fehlerhaft
Beispiel für Genauigkeit und Gültigkeit:
- Die Ausweisdaten und die Adresse des Patienten sind gültig
- Vitalparameter werden innerhalb akzeptabler Werte aufgezeichnet
- Die in Krankenhäusern verwendeten Codes zur Klassifizierung von Krankheiten und Verfahren entsprechen vordefinierten Standards
Verlässlichkeit und Konsistenz:
Die Informationen folgen in der gesamten Organisation einem bestimmten Standard
Beispiele für Zuverlässigkeit und Konsistenz:
- Das in einem Datensatz erfasste Alter des Patienten ist in allen anderen Datensätzen identisch
- Korrekter Name/Geschlecht/Familienstand ist in allen Datensätzen identisch
- Das korrekte Format der Telefonnummer/Adresse ist in allen Datensätzen gleich.
Vollständig:
Alle erforderlichen Datenfelder sind vorhanden
Beispiele für Vollständigkeit:
- Pflegedokumente, einschließlich Pflegeplan, Verlaufsnotizen, Blutdruck- und Fieberkurven und andere Aufzeichnungen sind vollständig mit Unterschriften und Eintragungsdatum versehen
- Für alle medizinischen/gesundheitlichen Unterlagen sind die entsprechenden Formulare vollständig, mit Unterschriften und Anwesenheitsdaten.
- Bei stationären Patienten enthält die Krankenakte eine genaue Aufzeichnung der Hauptkrankheit und anderer relevanter Diagnosen und Verfahren sowie die Unterschrift des behandelnden Arztes.
Aktualität und Rechtzeitigkeit:
Daten sind auf dem neuesten Stand
Beispiele für Rechtzeitigkeit:
- Die Identifizierungsdaten eines Patienten werden bei der ersten Behandlung erfasst und sind jederzeit verfügbar, um den Patienten zu identifizieren.
- Bei der ersten Vorstellung in einer Klinik oder bei der Aufnahme ins Krankenhaus werden die Vorgeschichte des Patienten, die vom Patienten geschilderte aktuelle Erkrankung/Problem und die Ergebnisse der körperlichen Untersuchung erfasst.
- Die statistischen Berichte werden innerhalb eines bestimmten Zeitraums fertiggestellt, nachdem sie kontrolliert und überprüft wurden.
Zugänglichkeit:
Daten sind bei Bedarf für autorisierte Personen verfügbar
Beispiele für Barrierefreiheit:
- Medizinische/gesundheitliche Unterlagen sind jederzeit verfügbar, wenn und wo sie benötigt werden.
- Die abstrahierten Daten stehen bei Bedarf zur Überprüfung zur Verfügung.
- In einem elektronischen Patientendatensystem sind die klinischen Informationen bei Bedarf sofort verfügbar.
Die Datenqualität im Gesundheitswesen ist nicht nur für die Patientenversorgung von entscheidender Bedeutung, sondern auch für die Überwachung der Leistung von Gesundheitsdiensten und Mitarbeitern. Die gesammelten und präsentierten Daten müssen diesen Standards entsprechen. Das Problem? Die Abhängigkeit von traditionellen Methoden der Datenverwaltung führt dazu, dass Krankenhäuser und Informationsaustauschstellen (HIEs) mit Problemen beim Patientenabgleich, schlechten Algorithmen, chaotischen Prozessen, betrieblicher Ineffizienz, mangelnder Datenkompetenz und schlechter Datenqualität zu kämpfen haben.
Hochwertige Daten verkörpern diese international befolgten standardsAufgrund der derzeitigen Beschränkungen in Bezug auf Technologie, Ressourcen und Verfahren ist es für die Gesundheitseinrichtungen jedoch eine Herausforderung, diese Ziele zu erreichen.
Tas COVID-19 ist ein perfektes Beispiel dafür, wie sich Herausforderungen bei der Datenqualität auf den Umgang mit Pandemien auswirken. Organisationen, die datengesteuert waren, reagierten schnell mit Apps, prädiktiven Analysen und Modellen für die Patientenversorgung, die der Welt halfen, mit den Problemen fertig zu werden.. Diejenigen, die bisher ignorierte digitale Umwälzungen wurden aufgerüttelt und erkannten die Notwendigkeit, sich an ML/AI-Technologien anzupassen (für die genaue Daten die Grundlage sind).
Wie die COVID-19 die Herausforderungen und Grenzen der Datenqualität im Gesundheitswesen aufgedeckt hat
Pandemien waren schon immer eine Herausforderung für die Infrastruktur des Gesundheitswesens, aber das COVID-19 ist eine neue Herausforderung hinzugekommen – die digitale Transformation und der Bedarf an verbesserten, aggregierten Daten.
Gesundheitseinrichtungen stehen vor einem Rätsel‚ dem Versuch, die Vorteile von Echtzeit datengestützte Erkenntnisse, um wichtige Entscheidungen zu treffen. Dies ist unter anderem deshalb so schwierig, weil die derzeitige Dateninfrastruktur veraltet ist und noch immer auf manuelle Methoden für die Dateneingabe und -aggregation angewiesen ist. Eine komplexe Datenspeicherung, gepaart mit unterschiedlichen Datenquellen, und ein Personal, dem es an Datenschulung mangelt, machen es schwierig, Daten zu sammeln, zu verarbeiten und zu konsolidieren, um die vollständiges Bild eines Patienten – die Auswirkungen von Dies führt zu verzerrten Analysen und gefälschten Daten, die kein genaues Bild der Pandemie vermitteln.
In einem brillanten Artikel über die Auswirkungen einer schlechten Datenqualität auf die COVID-19-Reaktion, Datanami berichtet Datan ami, dass neue Fallzahlen und Krankenhausbetten von den Krankenhäusern manuell gemeldet werden und dass stellt eine Herausforderung dar, wenn es darum geht, das hohe Vertrauen in die aktuellen „Kopf- und Bettdaten“ zu erhalten.
Die Menge und Vielfalt der Daten, die während dieser Pandemie erzeugt werden, ist unvorstellbar. Die Einrichtungen des Gesundheitswesens stehen unter dem Druck, diese Daten schnell zu nutzen, um die Herausforderungen zu meistern, aber die Abhängigkeit von manuellen Prozessen, eine allgemein langsame Herangehensweise an technologiegesteuerte Initiativen und die Verwendung von Altsystemen haben die Entscheidungsfindung in Echtzeit erschwert.
Glücklicherweise ist nicht alles dem Untergang geweiht. Die Pandemie hat die Bemühungen um den Einsatz von Instrumenten und Technologien beschleunigt, die es Krankenhäusern, Gesundheitseinrichtungen, Regierungen, Pharmaunternehmen und Forschungseinrichtungen ermöglichen, eine Vielzahl von Datensätzen zu sammeln und zu analysieren, um in Rekordzeit Lösungen (z. B. mobile Apps zur Risikovorhersage), Richtlinien für die Patientenversorgung und die Entwicklung von Impfstoffen zu entwickeln.
Welche unmittelbaren Schritte kann die Branche unternehmen, um die Ziele der Datenqualität zu erreichen?
Führung, Ausbildung, Kulturwandel ist einer der häufigsten Ratschläge, die Experten gebenaber diese Schritte erfordern langfristige Überholung. In einer Zeit, in der Führungskräfte unter Druck stehen, der Datenqualität Priorität einzuräumen, müssen sie sofort umsetzbare Maßnahmen ergreifen. Dazu gehören:
Durchführung eines Datenqualitätsaudits:
Lösungen lassen sich nur dann ableiten, wenn Sie das Problem, mit dem Ihr Unternehmen konfrontiert ist, genau kennen. Zum Beispiel:
- AHaben Ihre Teams Schwierigkeiten, Patientendaten aus verschiedenen Quellen für einen Bericht zu konsolidieren?
- Ist Ihre Einrichtung mit Fehlern bei der Dateneingabe konfrontiert?
- Haben Sie unzureichende Datenkontrollen eingerichtet?
- Was sind die häufigsten Fehler, die in Ihren Unterlagen gefunden werden?
Diese und viele weitere Fragen müssen gestellt werden. Die Aufzeichnungen müssen abgerufen und bewertet werden, um zu sehen, ob sie den festgelegten Qualitätsstandards entsprechen.
Investition in ein Self-Service-Tool für Datenqualität:
Wahrscheinlich verlässt sich Ihr Team immer noch auf ein ETL Werkzeugum Daten zu bereinigen und umzuwandeln. Manuelle Methoden können nicht verwendet werden, um Daten mit exponentiellem Volumen und Vielfalt. Hier kommen ML-basierte Self-Service-Tools für die Datenqualität ins Spiel. Sie ersetzenmanuelle Datenbereinigung oder Standardisierung Aufwands mit schnellen, automatisierten Prozessen. Die Normalisierung von Krankenhausdaten beispielsweise erfordert monatelange Bemühungen und komplexe Prozesse wie die Sicherstellung der richtigen [name] [date] [phone number] Formate. Mit einem Self-Service-Tool kann es dauert nur wenige Minutendie Großschreibung von Namen, das Entfernen von Leerzeichen, Fettfingerfehler und vieles mehr für eine Million Zeilen.
Mit dem richtigen Datenqualitätstool können Sie Datenbereinigung, Datendeduplizierung, Datenabgleich und Datenkonsolidierung auf einer einzigen Plattform durchführen, ohne Code, mit einer Point-and-Click-Schnittstelle.
Automatisieren Sie die Datenaufbereitung:
Der Automatisierung gehört die Zukunft. Für das Gesundheitswesen ist die Automatisierung eine Notwendigkeit, die sich positiv auf die Patientenversorgung, das Ressourcenmanagement, die Systemverwaltung, Statistiken, die Finanzierung und vieles mehr auswirken kann. Altbewährte Überzeugungen und das Vertrauen auf veraltete Prozesse müssen durch Innovation und Automatisierung ersetzt werden, mit dem grundlegenden Ziel, dass sich die Mitarbeiter stärker auf Analysen und Entscheidungen konzentrieren können.
Definition von Datenqualitätsstandards:
Die Daten müssen so gemessen werden, dass sie die Dimensionen der Datenqualitätsstandards widerspiegeln. Zunächst einmal müssen die Unternehmen sicherstellen, dass ihre aktuellen Daten korrekt, vollständig und gültig sind.
Machen Sie Datenqualität zu einer organisatorischen Gewohnheit:
Funktionen der Datenqualität wie Datenbereinigung und Datenstandardisierung sollten nicht nur bei Bedarf durchgeführt werden. Unternehmen müssen eine Routine entwickeln, um Daten zu bereinigen und auf dem neuesten Stand zu halten. Mitarbeiter, die Zugang zu diesen Daten haben, müssen geschult werden, um die Datenqualität und ihre Auswirkungen auf nachgelagerte Anwendungen zu verstehen. Dieser Schritt erfordert keine organisatorische Veränderung, sondern kann ganz einfach durch die Erstellung eines Zeitplans, die Zuweisung einer Ressource und die Ausstattung der Ressource mit dem richtigen Werkzeug für die Erledigung der Aufgabe erfolgen.
Wie hilft die Data Ladder?
Data Ladder’s DataMatch Enterprise ist eine erstklassige Lösung, die das Gesundheitswesen beim Datenqualitätsmanagement unterstützt. Mit Data Ladder kann Ihr Team Terabytes an Daten verarbeiten, mehrere Datenquellen konsolidieren, Millionen von Datenzeilen bereinigen und umwandeln. nur 45 Minuten.
DME ist das Tool der Wahl für Organisationen im Gesundheitswesen aufgrund seiner benutzerfreundlichen Oberfläche, der 100%igen Datensatzverknüpfung und seiner Fähigkeit, Datentransformationen durchzuführen CODE-FREE.
DME kann den Gesundheitssystemen dabei helfen:
Datensatzverknüpfung für Längsschnittstudien
Datenverknüpfung ist der Prozess der Verknüpfung/Kombination/Zusammenführung mehrerer Informationsquellen zu einer Person oder Einheit. Die Kombination von Informationen hat mehrere Vorteile:
- Längsschnittstudien für ganze Bevölkerungsgruppen können durchgeführt werden, um Krankheitstrends und damit zusammenhängende Herausforderungen zu verstehen.
- Durchführung von Änderungen oder Entwicklung neuer gesundheitspolitischer Maßnahmen im Lichte der verfügbaren Daten.
- Experten können Fragen entdecken oder lösen, auf die ein einzelner Datensatz keine Antwort geben kann.
- Historische Informationen wie Verwaltungsdaten, Daten zu lebenswichtigen Ereignissen usw., die über die gesamte Lebenszeit einer Bevölkerung gesammelt werden, sind für die Untersuchung von Krankheiten und die Identifizierung anfälliger Bevölkerungsgruppen sehr wertvoll.
- Die Kombination mehrerer Datensätze ermöglicht es Unternehmen, den Zustand ihrer Datenqualität auf einer tieferen Ebene zu bewerten und potenzielle Lücken zu erkennen, die es zu schließen gilt.
- Es können Simulationsmodelle entwickelt werden, um verschiedene Populationen zu untersuchen
Die auch als „Record Linkage“ bezeichnete Datenverknüpfung wurde erstmals 1946 von Halbert L. Dunn in seinem Artikel „Record Linkage“ in der Zeitschrift
American Journal of Public Health,
in dem er vorschlug, ein „Buch des Lebens“ für jeden Menschen von der Geburt bis zum Tod zu erstellen, das die wichtigsten gesundheitlichen und sozialen Ereignisse enthält. Dieses Buch wäre eine Zusammenstellung aller vorhandenen Datensätze, um eine einzigartige Datei zur Verwendung bei der Planung von Gesundheitsdiensten zu erstellen.
Seitdem haben sich Gesundheitseinrichtungen in der ganzen Welt, darunter in den USA, Kanada, England, Dänemark und Australien, um die Einrichtung von Datenverknüpfungssystemen bemüht. Diese Systeme enthalten Datensätze über Geburten, Sterbefälle, Krankenhauseinweisungen, Notfalleinsätze und vieles mehr. In einigen Ländern gibt es sogar umfangreiche Aufzeichnungen über psychische Gesundheit, Bildung, Genealogie und spezifische Forschungsdaten.
In den Vereinigten Staaten hat die Sorge um den Schutz der Privatsphäre, die Vertraulichkeit und die Sicherheit von Patientendaten zu immer strengeren Richtlinien und Vorschriften geführt , wobei HIPAA die bekannteste Datenschutzrichtlinie für Patienten ist. Mit diesen Richtlinien haben Organisationen keinen Zugang zu eindeutigen Identifikatoren, die leicht zur Verknüpfung von Datensätzen verwendet werden können. In diesem Fall werden andere Komponenten in der Datenquelle verwendet, um Datensätze zu identifizieren. In diesem Fall umfasst die Verknüpfung von Datensätzen mehrere Stufen und die Verwendung eines probabilistischen Abgleichs, um Daten abzugleichen.
Zwischen dem idealen Datensystem und dem derzeitigen föderalen Gesundheitsdatensystem besteht eine große Kluft. Die schlechte Qualität der in fragmentierten Systemen gespeicherten Daten und das Fehlen einer Qualitätsüberwachung stellen die Gesundheitseinrichtungen vor große Herausforderungen bei der Bereitstellung einer hochwertigen Gesundheitsversorgung.
Darüber hinaus hat die beispiellose Zunahme von Patientendaten aus Quellen wie dem Internet und dem Mobilfunk das Volumen und die Vielfalt der Daten exponentiell erhöht, so dass es für Organisationen schwierig ist, elektronische Gesundheitsdatensätze (EHR) systemübergreifend miteinander zu verknüpfen – ein Vorgang, der für eine Reihe von Zwecken wie Gesundheitsforschung, Längsschnittstudien über Bevölkerungsgruppen, Krankheitsvorbeugung und -bekämpfung, Patientenversorgung und vieles mehr erforderlich ist.
Codefreies Parsen, Bereinigen und Standardisieren von Daten
DME ermöglicht eine einfache Datenbereinigung per Mausklick. Im Gegensatz zu ETL-Tools oder Excel ist kein manueller Aufwand erforderlich. Mit DME können Benutzer:
- Transformieren Sie schlechte Daten durch einfaches Anklicken von Kontrollkästchen.
- Textstil normalisieren.
- Unerwünschte Zeichen entfernen
- Beseitigung versehentlicher Tippfehler bei der Dateneingabe (diese sind schwer zu erkennen!)
- Leerzeichen zwischen Buchstaben/Wörtern bereinigen
- Spitznamen in richtige Namen umwandeln (John statt Johnny)
DME ermöglicht eine einfache Vereinheitlichung der Daten, indem der Benutzer aus mehr als einem Dutzend Standardisierungsoptionen wählen kann, die sich auf
Hunderte von Millionen von Datensätzen gleichzeitig angewendet werden können (getestet mit 2 Milliarden + Datensätze).
Ermöglichen Sie die Implementierung eines Datenqualitätsrahmens
Die DME-Plattform ist ein Rahmenwerk, das es Unternehmen ermöglicht, einen Ausgangspunkt für ihre Ziele zur Verbesserung der Datenqualität zu finden. Sie können ihre Daten nicht nur bereinigen und aufbereiten, sondern dies auch zu einem festen Bestandteil ihrer täglichen Routine machen – und das zur Hälfte der Kosten. Gesundheitsdaten müssen den oben beschriebenen Datenqualitätsstandards entsprechen, was bedeutet, dass Gesundheitseinrichtungen einen Datenqualitätsrahmen einführen müssen, der Einheitlichkeit, Genauigkeit und Konsistenz gewährleistet. Und sie müssen diese Standards schnell erfüllen .
DME ist eine Lösung für das Datenqualitätsmanagement, die es den Anwendern ermöglicht, Milliarden von Datensätzen aus verschiedenen Datenquellen in Rekordgeschwindigkeit und mit hoher Genauigkeit zu profilieren, zu standardisieren und zu bereinigen. Dank der Möglichkeit, über 500 Datenquellen zu integrieren, können die Nutzer ihre Datenquellen direkt aktualisieren und ändern, ohne dass sie sich mit Tools von Drittanbietern herumschlagen müssen.
Fazit – Helfen Sie Ihrer Organisation, genaue und zuverlässige Daten zu erhalten, um die Qualität der Patientenversorgung zu verbessern
Um nützlich zu sein, müssen die Daten korrekt, vollständig, zuverlässig und genau sein. Fehlerhafte Daten führen zu Fehlern bei der Entscheidungsfindung, tödlichen Fehlern bei der Patientenversorgung (z. B. Diagnose des falschen Patienten), verzerrten Zahlen in der Forschung und anderen kritischen Problemen.
Viele Einrichtungen des Gesundheitswesens haben zwar Daten über Patienten gesammelt, müssen aber noch aktuelle Systeme entwickeln, um die Qualität der erbrachten Leistungen zu gewährleisten. Ein Self-Service-Datenqualitäts-Tool wie DataMatch Enterprise ermöglicht es autorisierten Anwendern, Daten für ihre vielfältigen Verwendungszwecke vorzubereiten, ohne sich auf die IT-Abteilung oder spezielle SQL-Kenntnisse verlassen zu müssen.
Noch wichtiger ist, dass sie den Organisationen einen Kopf Start auf dem Weg zur Datenverbesserung. Sobald die Organisation die Probleme, die die Datenqualität beeinträchtigen, versteht, ist sie in einer besseren Position, um die notwendigen Änderungen vorzunehmen und einen robusteren Datenverwaltungsplan zu erstellen.
Laden Sie unsere kostenlose Testversion herunter und erfahren Sie, wie Sie die Datensätze Ihres Unternehmens einfach und ohne Code bereinigen und verknüpfen können.
Kostenlose Testversion herunterladen
The post Datenqualität im Gesundheitswesen – Herausforderungen, Beschränkungen und Schritte zur Qualitätsverbesserung appeared first on Data Ladder.
]]>