The post Guía rápida para la normalización y verificación de direcciones appeared first on Data Ladder.
]]>La estandarización de las direcciones es el proceso de actualización e implementación de un estándar o formato en sus datos de direcciones.
Los datos de direcciones deficientes constituyen un complejo reto de calidad de datos que afecta a los clientes, a las empresas e incluso al servicio de correo. La asombrosa cantidad de datos de direcciones deficientes ha obligado a las empresas a invertir en sólidas herramientas de normalización y verificación de direcciones que les ayuden a obtener direcciones validadas por USPS de forma fácil y sin esfuerzo.
Lea mientras le ayudamos a entenderlo:
- El coste de los datos erróneos
- Los problemas con los datos de las direcciones
- Causas de la mala calidad de los datos
- ¿Cómo se estandariza la dirección?
- ¿Qué es la normalización de direcciones CASS?
- ¿Cómo validar una dirección?
- ¿Cómo verificar una dirección con USPS?
- Coincidencia de datos: el reto más importante para la normalización y verificación de direcciones
- Un estudio de caso – E-Ideas Limited
- Estrategias empresariales para mejorar sus datos de dirección
Vamos a sumergirnos de lleno.
El coste de los datos de direcciones erróneas
Cada año se desperdician millones de dólares por culpa de unos datos de direcciones deficientes. El USPS informa de que casi 6.600 millones de piezas de correo no se pudieron entregar solo en 2016. Los carteros gastan más de 20.000 millones de dólares en correo del SAU, mientras que los costes directos para el USPS son de más de 1.500 millones de dólares al año. Todo este coste innecesario se debe simplemente al hecho de que las empresas no tienen acceso a los datos de dirección correctos.

Si hace los cálculos basándose sólo en este coste preliminar, probablemente esté gastando $$$$ sólo en la gestión de los costes del correo de retorno, por no mencionar el coste operativo de verificar la información de los clientes y volver a enviar el paquete.
Algunas cifras a tener en cuenta:

Los problemas con los datos de las direcciones
Es de naturaleza humana cometer errores. La mayoría de las veces, los consumidores son poco rigurosos a la hora de facilitar sus datos de dirección en formularios físicos o web. Pueden escribir mal el nombre de un estado, escribir abreviaturas, omitir un número de calle u olvidar su código postal. Es inevitable que se cometan algunos errores y se introduzcan datos incorrectos.
Esta es una imagen de cómo son los típicos datos de direcciones sin estructurar y sin procesar. La falta de datos sobre las direcciones es un reto que provoca una gran tensión en las empresas y sus empleados. Imagínese tener que arreglar estos problemas tan básicos para cada campaña de correo, actividad promocional y cada informe de clientes que tenga que ejecutar. No sólo es alucinantemente frustrante, sino también contraproducente, ya que intentas cotejar y verificar cada dirección para asegurarte de que es exacta y completa. Los científicos de datos y los analistas o usuarios empresariales que necesitan estos datos deben pasar días y meses solucionando estos problemas.

Los datos de las direcciones suelen adolecer de:
- Información incompleta (falta el nombre de la calle, el número de manzana o el código postal)
- Información no válida (direcciones y códigos postales falsos)
- Información incorrecta (errores tipográficos, nombres mal escritos, mal formato como el uso de abreviaturas)
- Información inexacta (números de apartamento o casa inexactos)
Todos estos problemas hacen que los datos de direcciones sean uno de los más difíciles de abordar en una fuente de datos. Además, también aumenta significativamente el coste de las devoluciones de correo, a la vez que dificulta la confianza de una empresa en los datos de las direcciones para tomar decisiones comerciales cruciales.
La mayoría de estos problemas se deben a errores de introducción de datos por parte de los usuarios y a la falta de controles de datos adecuados.
Por ejemplo, algunas personas optarán por escribir sólo el código postal pero no la dirección completa, otras simplemente se olvidarán de escribir el código postal, o algunas escribirán una dirección incompleta. Algunos dan una dirección falsa. Sean cuales sean las razones de los errores de datos, una cosa es cierta: para que una empresa pueda utilizar sus datos, es necesario que éstos estén limpios y sean válidos.
Pero los errores estructurales son sólo una parte del problema de los datos de direcciones erróneas. Otras cuestiones podrían ser:
- Datos de la dirección que son válidos, pero que ya no existen.
- Dirección estructuralmente correcta pero que no pertenece al cliente.
- Dirección que no existe en la base de datos de USPS.
Cuando esta información no se comprueba en la fase de entrada, afecta a toda la correspondencia futura, así como a la relación con ese cliente. Para rectificar esto, las empresas tendrán que dedicar tiempo a llamar a cada cliente para actualizar los datos o hacer que proporcionen de nuevo la información correcta. El problema es que las empresas suelen tener pocos recursos y no es un modo de funcionamiento muy viable.
Al final, todo se reduce a una cosa: los datos deficientes son inevitables, pero se pueden arreglar. Existen muchas herramientas de estandarización de direcciones que ayudan a las empresas a corregir los datos deficientes, corrigiendo los problemas de formato y limpiando los datos desordenados. El proceso lleva menos tiempo, pero puede requerir una curva de aprendizaje y una comprensión básica de la concordancia, el análisis sintáctico y la deduplicación de datos.
Causas de los datos de direcciones erróneas
Los errores humanos son la causa principal, pero no la única, de la mala calidad de las direcciones. Aparte de los retos que plantea la captura de datos precisos, hay muchas más causas de fondo, como:
Decaimiento de la base de datos:
Según la Oficina del Censo, un estadounidense típico se mudará 11,7 veces en su vida. A medida que la vivienda se encarezca y los estadounidenses traten de encontrar zonas adecuadas para vivir, esta cifra aumentará. De ellos, sólo el 60% de los que hacen la mudanza informan al USPS de su traslado a tiempo.
Por lo tanto, las empresas se quedan con datos de direcciones que no están actualizados. Si envían un millón de facturas o folletos promocionales al mes, pueden recibir 90.000 avisos de mudanza en el mismo mes. Y lo que es peor, según este porcentaje, 60.000 de esos millones de clientes no habrán proporcionado la información correcta a USPS a tiempo.
Suponiendo que los mismos clientes sigan con la organización, la empresa tendrá que seguir actualizando su base de datos y asegurarse de que tiene la dirección más reciente para utilizarla.
Mala cultura de los datos:
Hace poco que las empresas están empezando a hablar sobre el uso de los datos, pero esto se limita a la dirección ejecutiva. El empleado en su mesa no es consciente del nivel de problemas de calidad de los datos al que se enfrenta. Además, no hay reglas de negocio a las que atenerse cuando se trata de la calidad de los datos. No hay formación ni educación para que los empleados se orienten hacia los datos y no hay absolutamente ninguna inversión en herramientas de gestión de datos como DataMatch Enterprise, que puede salvar la brecha entre las aplicaciones de TI y la gestión empresarial de los datos.
Fusiones y adquisiciones:
Cuando las empresas migran los datos durante una fusión y adquisición, aumenta la probabilidad de que se produzcan errores en la calidad de los datos. Estas fusiones se producen rápidamente y los problemas son a veces imprevistos. La presión por la consolidación es cada vez mayor, pero no hay control de la calidad; de hecho, rara vez existe un marco de gestión de la calidad.
¿Cómo se hace la normalización de direcciones?
Bien, entonces la definición, ¿cómo se estandarizan los datos?
Pues bien, hay dos maneras de hacerlo: la fácil y la difícil.
El camino difícil incluirá que transportes esos datos a Excel, aplicando fórmulas y filtros para arreglar los datos. No te creas los tutoriales que te dicen que es «superfácil», porque nunca lo es.
Echa un vistazo a este artículo, ya que te enseña cómo corregir errores en Excel. ¿Ves la cantidad de tiempo, esfuerzo y conocimientos técnicos que tendrás que poseer para hacer correcciones básicas de datos? Cuanto más complejos son los problemas, más tiempo se necesita. Si tiene que tratar con millones de filas de datos, la limpieza de datos puede convertirse en su trabajo permanente.
¿La manera fácil?
Utilice un programa de normalización de direcciones. Antes de que descartes la idea, te explicamos por qué.
Obviamente, el software ahorrará mucho tiempo y esfuerzo, pero hace más que eso.
Los registros de datos de direcciones no son simples errores. Como en el ejemplo anterior, tienes miles de filas que tienen problemas. Necesitas una solución que te permita arreglar todos esos problemas de una sola vez.
Si utiliza una solución de las mejores, puede estandarizar los datos:
Evaluación de los errores mediante la elaboración de perfiles de datos: Imagine que puede obtener una visión general consolidada de todo lo que está mal en sus datos de direcciones. Puede ver columnas con caracteres no imprimibles, o columnas con espacios negativos o incluso columnas con letras en campos numéricos. La elaboración de perfiles de datos le permite realizar correcciones con conocimiento de causa. A menos que no sepas qué es lo que está mal, estarás haciendo correcciones en la oscuridad.
Análisis de direcciones para resolver problemas específicos: Parte de la limpieza de direcciones requiere que se analicen o desglosen diferentes partes de las direcciones (ciudad, estado, código postal, etc.) y se fijen en diferentes niveles. Por ejemplo, con DataMatch Enterprise, puede fijar específicamente los códigos postales y asegurarse de que cumple con los códigos postales ZIP+4 o ZIP+6.
Limpieza de datos desordenados: Limpie los problemas de formato, elimine los espacios negativos y los caracteres no imprimibles de una sola vez. Es imperativo limpiar los datos de su dirección y estandarizarlos de acuerdo con las directrices de USPS (ver más abajo) antes de poder verificarlos.
Eliminación de duplicados con coincidencia de datos: La limpieza de datos desordenados es sólo una parte del proceso; la parte más estresante es eliminar los duplicados. Si tiene miles de filas de datos de clientes que no se han ordenado en mucho tiempo, lo más probable es que tenga duplicados y que éstos no siempre sean exactos.
Echa un vistazo a esta tabla:
¿Ves cómo un cliente tiene cinco direcciones diferentes introducidas de múltiples maneras? Ahora bien, esto no es algo que se pueda clasificar fácilmente a menos que se utilice una potente herramienta de calidad de datos.
 Supervisión y exportación de datos: Debería poder crear fácilmente un registro maestro y exportarlo como una lista final a su equipo sin tener que copiar/pegar o cargarlo manualmente en un formato aceptable.
Supervisión y exportación de datos: Debería poder crear fácilmente un registro maestro y exportarlo como una lista final a su equipo sin tener que copiar/pegar o cargarlo manualmente en un formato aceptable.
Normalización de direcciones CASS: Cualquier software de normalización de direcciones debe contar con la normalización de direcciones CASS. DataMatch Enterprise, por ejemplo, es una solución de normalización de direcciones certificada por CASS con una base de datos CASS que se actualiza cada mes.
¿Qué es la normalización de direcciones CASS?
Los programas informáticos que corrigen o hacen coincidir las direcciones deben estar certificados por el USPS. Esto se hace a través del sistema de apoyo a la exactitud de la codificación (CASS) que el USPS utiliza para verificar la exactitud del software. La certificación CASS es una licencia para todos los proveedores de software que utilizan el USPS para evaluar la calidad de sus datos de direcciones y mejorar la precisión de la codificación ZIP+4 y de cinco dígitos.
Dado que el USPS actualiza sus datos de direcciones con regularidad, los proveedores de software con certificación CASS deben renovar anualmente su certificación con el USPS. Todos los productos CASS certificados aparecen en el sitio web de USPS.
¿Qué es la directriz de normalización de USPS?
Los proveedores de software de estandarización de datos de direcciones siguen la directriz de estandarización de USPS que requiere que las direcciones tengan un formato como:

Estas son las reglas:
- Ponga siempre la dirección y el franqueo en el mismo lado de su pieza postal.
- En una carta, la dirección debe ser paralela al lado más largo.
- Todo en mayúsculas.
- No hay puntuación.
- Al menos con letra de 10 puntos.
- Un espacio entre la ciudad y el estado.
- Dos espacios entre el estado y el código postal.
- Fuentes tipográficas simples.
- Justificado a la izquierda.
- Tinta negra sobre papel blanco o claro.
- No hay tipo inverso (impresión blanca sobre fondo negro).
- Si su dirección aparece dentro de una ventana, asegúrese de que hay un espacio libre de al menos 1/8 de pulgada alrededor de la dirección. A veces, partes de la dirección se pierden de vista detrás de la ventana y las máquinas de procesamiento de correo no pueden leer la dirección.
- Si utiliza etiquetas de dirección, asegúrese de no cortar ninguna información importante. Asegúrate también de que las etiquetas están bien puestas. Las máquinas de procesamiento de correo tienen problemas para leer la información torcida o inclinada.
La normalización de las direcciones es el requisito previo para una validación eficaz de las mismas. Tiene que asegurarse de que su dirección cumple con la directriz de USPS antes de que sus datos puedan ser verificados con el USPS.
Verificación o validación de la dirección: ¿cuál es la diferencia?
A menudo verá el término «validación y verificación» entremezclado cuando se trata de datos de direcciones. La diferencia es más contextual que léxica. Data Ladder utiliza el término Verificación de Direcciones para verificar las direcciones con la base de datos de USPS. Otras organizaciones verifican las direcciones con los registros de facturación, los permisos de conducir, los extractos bancarios, etc. Ese es un servicio completamente diferente y que la mayoría de las empresas no necesitan.
Otros proveedores utilizanla «Validación de Direcciones», para hacer el mismo cotejo con el USPS para validar los datos del cliente. En el contexto de esta guía, lo mantendremos para la verificación de direcciones.
Normalización y verificación de direcciones – Cómo verificar los datos de las direcciones con el USPS
El proceso de verificación de la dirección es sencillo. Usted coteja sus datos, ahora estandarizados, con la base de datos del gobierno o con cualquier otra norma de la autoridad. Si está en Estados Unidos, el USPS es la única base de datos con la que debería cotejar sus datos.
Si sus datos de dirección están limpios y estandarizados, este proceso dura unos minutos. Si utiliza DataMatch Enterprise, puede cotejar toda la dirección o sólo partes de la misma, basándose en 50 elementos activos, incluidas las ubicaciones geocodificadas, lo que significa que puede verificar las direcciones al pie de la letra.
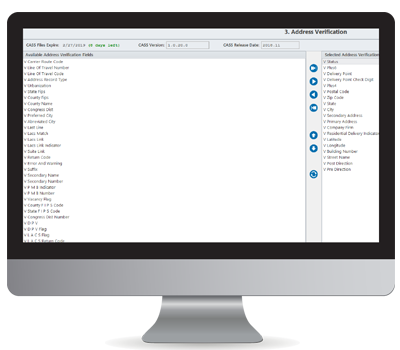
Algunos de los campos más populares contra los que nuestros clientes suelen requerir una verificación incluyen:
-
V Estado – El registro está verificado (Sí/No)
-
V Indicador de entrega residencial – Define si la dirección residencial puede recibir entregas directas en la puerta
-
V Empresa Empresa
-
V Dirección principal
-
V Dirección secundaria
-
V Ciudad
-
V Estado
-
V Código postal – 5 dígitos (USA)
-
V Código postal (Canadá)
-
V Plus4 – 4 dígitos adicionales asociados al código postal de 5 dígitos
Hay 54 campos que puede utilizar para validar sus datos de dirección.
Una vez que coincida con la lista de direcciones con estos componentes, se le dará un valor de retorno que indicará:
- 10 = Dirección Invald
- 11 = Código postal no válido
- 12 = Código de Estado inválido
- 13 = Ciudad inválida
- 21 = Dirección no encontrada
También te aparecerán advertencias como:
-
-
A# ZIP
-
B# Ciudad/Estado Corregido
-
C# Ciudad/estado/código postal no válidos
-
D# Sin ZIP asignado
-
E# ZIP asignado para respuesta múltiple
-
F# No hay ZIP disponible
-
G# Parte de la empresa trasladada a la dirección
-
H# Falta el número secundario
-
I# Datos insuficientes/incorrectos
-
J# Entrada doble
-
Si quieres saber más sobre esto, no dudes en pedirnos una demostración rápida.
Vale, pues a seguir adelante:
Coincidencia de datos: el reto más importante para la normalización y verificación de direcciones
Los clientes que acuden a nosotros siempre tienen una queja: nunca consiguen una buena tasa de coincidencia. Y estamos de acuerdo.
Elcotejo de datos sigue siendo un área de mejora. Hay muy pocos vendedores que puedan dar una tasa de coincidencia del 100%. Realmente necesitas esa cifra, si no, al menos el 95%. La razón es que para que la verificación funcione, su campo de dirección debe encontrar una coincidencia con el USPS. Si la mayoría de las coincidencias no se dan porque el software se basa en coincidencias exactas o deterministas, entonces no va a funcionar a su favor.
Por lo tanto, a la hora de elegir un software de normalización y verificación de direcciones, debe ser capaz de evaluar su tasa de coincidencia de datos. De un centenar de filas, ¿cuántas filas ha pasado por alto la herramienta y por qué? Lo más probable es que vea que el software no detecta las coincidencias cercanas o próximas y se basa únicamente en los caracteres exactos para identificar una coincidencia.
Data Ladder’s DataMatch Enterprise es principalmente una solución de cotejo de datos que ha sido utilizada por instituciones gubernamentales y empresas de Fortune 500 como HP, Coca Cola, Deloitte y muchas otras. Somos conocidos por hacer coincidir los datos con una tasa de precisión del 100%. Esto se debe a que Data Ladder utiliza una combinación de algoritmos de coincidencia difusa y sus algoritmos patentados establecidos para identificar incluso las coincidencias probables más distantes.
P.D. – La comparación de datos requiere muchos recursos. Ahorre tiempo y esfuerzo manual a su equipo. Aprenda a hacerlo en esta detallada entrada del blog.
Este es un estudio de caso que revela lo difícil que es, incluso para un proveedor de datos, garantizar una correspondencia de datos precisa.
Un estudio de caso – E-Ideas Limited
Hablamos con Artem Axenov, director de operaciones de E-Ideas Limited, una agencia de marketing B2B con sede en Wellington. La agencia gestiona una gran base de datos de empresas con fines de marketing, lo que significa que tienen que cuidar mucho los datos de las direcciones, un reto importante que implica mucho trabajo manual en Excel.
1. ¿Cómo afronta su agencia el problema de los datos erróneos?
A menudo tratamos con clientes que ya tienen una lista de clientes, pero los datos están mal formateados. Hay algunas tareas automáticas que puedes hacer para resolverlo pero al final, es un trabajo manual. En primer lugar, tienes que decidir qué formato vas a utilizar. Entonces, la forma más sencilla de arreglar los datos mal formateados es ordenarlos columna por columna y luego hacer los cambios necesarios para que queden bien. Hay algunas fórmulas en Excel que ayudan a dividir o combinar datos – para dividir puedes usar MID y LEFT juntos. Y para combinar datos se puede utilizar CONCATENAR.
Al clasificar los datos en primer lugar, se agrupan los conjuntos de direcciones que tienen los mismos problemas de formato, lo que facilita enormemente su tratamiento de una sola vez.
2. ¿Cómo ha sido su experiencia con las herramientas de verificación y validación de direcciones?
Nuestra experiencia con cualquier tipo de herramienta de validación o verificación de direcciones siempre ha sido desigual. A fin de cuentas, ninguna de las herramientas que hemos utilizado ha logrado producir una alta coincidencia. Y esto se debe a que las formas de almacenar las direcciones son muy diferentes. Son útiles para adelantarse al proceso, pero al final siempre hay una cantidad importante de trabajo manual para terminar el trabajo.
3. ¿Cuál es el problema de concordancia de datos más preocupante?
El principal problema es que, sea cual sea el cotejo automático, si los datos no tienen el formato exacto que la herramienta está programada para identificar, el cotejo no se produce. Esto puede ser tan pequeño como que la calle se registre como St, la avenida como Ave, etc.
4. ¿Qué tipo de tareas manuales tiene que hacer después de utilizar un software de validación de direcciones?
Por lo general, sólo es cuestión de revisar los datos con un ojo humano para detectar cualquier incoherencia y corregirla. En Nueva Zelanda, por ejemplo, el servicio postal tiene un formato muy específico en el que deben mantenerse las direcciones para obtener el descuento por correo masivo. Nada es complicado pero, de nuevo, pequeñas cosas como que la calle se registre como St se contarán en tu contra. Otro ejemplo es si tiene su apartado de correos registrado como P.O. Box – no reconoce esto como correctamente formateado. Incluso los espacios iniciales o finales pueden contar en tu contra, y algunos de ellos son difíciles de detectar porque cuando miras la dirección no puedes ver lo que está mal.
5. ¿Cómo han afectado los datos de direcciones erróneas a su negocio?
Sólo hemos tenido problemas en cuanto a tener que dedicar horas extra para conseguir que los datos estén al día para poder optar al descuento postal. Hay una prueba que tiene que pasar, llamada Declaración de Exactitud, que verifica los datos automáticamente para garantizar que el 80% de ellos están correctamente formateados. Hemos tenido varios casos en los que hemos acabado pasando días más tiempo formateando manualmente los datos para asegurarnos de que están correctamente formateados.
La práctica que hemos implementado ahora es almacenar todos nuestros datos en el formato correcto. Nos ha llevado mucho tiempo conseguir que todo se ajuste a esta norma, pero ahora significa que cuando entregamos los datos a nuestros clientes ya están listos para NZ Post y no hay que hacer más trabajo.
Los problemas de esta agencia con los datos erróneos de las direcciones se traducen en horas de trabajo adicionales que afectan a la eficacia operativa. A pesar del uso de herramientas de cotejo y validación de direcciones, la incapacidad de producir una alta coincidencia hace que sea muy difícil validar los datos de las direcciones. Por lo tanto, es necesario elegir una herramienta que permita al usuario una completa capacidad de preparación y estandarización de los datos y que, al mismo tiempo, devuelva una alta coincidencia. Esto sólo es posible con el mejor software de preparación y cotejo de datos de su clase, como DataMatch Enterprise, que permite al usuario preparar y limpiar los datos de las direcciones al tiempo que devuelve un resultado de alta coincidencia incluso con texto erróneo.
Estrategias empresariales para la gestión de datos de direcciones
Los datos de direcciones erróneas son un problema de calidad de datos. Aunque puede utilizar herramientas para realizar correcciones, tendrá que aplicar estrategias empresariales para frenar los datos erróneos que afectan a los procesos operativos. Algunas de estas estrategias pueden ser:
Formaciones:
El primer paso hacia la calidad es la formación: asegúrese de que las personas que manipulan, interactúan, utilizan e introducen datos conocen el impacto que tienen en el proceso y en las aplicaciones posteriores. Deben comprender las consecuencias de los datos erróneos en toda la organización y no sólo en un miembro o cliente. Los empleados que practican las normas de calidad de datos deben ser recompensados y apreciados.
Lista de herramientas para la gestión de datos:
Es fundamental disponer de herramientas que ayuden a los usuarios de la empresa y a los profesionales de TI a gestionar los datos. Identifique las herramientas que necesita para la limpieza y la gestión de datos para ayudar tanto a los usuarios de TI como a los de la empresa a tener una relación no intimidatoria con los datos.
Implicar a los usuarios de la empresa en el proceso de calidad:
Los datos no son sólo un problema informático. Los usuarios empresariales son igualmente responsables de la gestión de los datos. De hecho, son los únicos propietarios de los datos de los clientes que a menudo se utilizan con fines de marketing y ventas. Por eso es necesario que participen en el proceso y que reciban formación para utilizar las herramientas de gestión de datos.
Gobernanza de los datos:
Establezca un equipo de gobernanza de datos para crear un plan de gestión de datos y asegúrese de que la organización sigue el plan en el que cada empleado entiende el plan. Su regla dentro del plan y las expectativas que vienen junto con el papel.
Bloqueo de datos y roles de usuario:
Si cualquier persona de su equipo puede abrir el CRM o la fuente de datos, trastear con los datos y no dejar ninguna huella, está usted en serios problemas. Es necesario crear titulares de datos maestros que tengan derechos para acceder, introducir o procesar datos críticos. Esto debería venir en el plan de gestión de datos.
No eres una víctima de los malos datos. Sólo hay que aceptar la gravedad de la situación, cultivar una cultura orientada a los datos y esforzarse por gestionar los retos que conlleva la gestión de los mismos. Es muy posible que se obtengan datos que sólo requieran una limpieza básica para ser utilizados.
¿Cómo ayuda DataMatch Enterprise?
Nuestro producto está certificado por CASS, lo que significa que cumplimos y superamos los requisitos de USPS en cuanto a calidad y precisión de las direcciones. También le ayudamos con la coincidencia y validación masiva de direcciones, asegurando que elementos como los códigos postales, los nombres de las ciudades y los pueblos sean verificados y validados. ¿La mejor ventaja de utilizar DataMatch Enterprise de Data Ladder? El programa encuentra y coteja los datos aunque estén incompletos con un índice de precisión del 96%. Además, puede utilizar el software para obtener una verificación de direcciones en tiempo real que garantice que tiene las direcciones correctas en su base de datos.
 Mediante algoritmos que determinan una coincidencia basada en áreas de similitud, nuestra plataforma da sentido a los datos inutilizables y deriva conexiones entre conjuntos de datos. Ya sean errores ortográficos o códigos postales incompletos, abreviaturas o erratas. Clasificamos grandes cantidades de datos para ayudarle a darles sentido.
Mediante algoritmos que determinan una coincidencia basada en áreas de similitud, nuestra plataforma da sentido a los datos inutilizables y deriva conexiones entre conjuntos de datos. Ya sean errores ortográficos o códigos postales incompletos, abreviaturas o erratas. Clasificamos grandes cantidades de datos para ayudarle a darles sentido.
Para concluir
Los datos de direcciones erróneas son inevitables, pero eso no significa que deba dejar que afecten al rendimiento de su empresa. Arreglar manualmente los datos de las direcciones le costará más tiempo y esfuerzo, y además no podrá estandarizarlos ni verificarlos a menos que utilice una solución con certificación CASS.
No te ahogues en los datos malos. Estamos aquí para ayudar.
Para ver cómo podemos ayudarle con la estandarización y verificación de direcciones, póngase en contacto con uno de nuestros expertos en soluciones hoy mismo y vea cómo podemos ayudarle a obtener datos de direcciones que pueda utilizar para el fin previsto.
The post Guía rápida para la normalización y verificación de direcciones appeared first on Data Ladder.
]]>The post 8 mejores prácticas para garantizar la calidad de los datos en la empresa appeared first on Data Ladder.
]]>El 2021 de septiembre, Facebook reconoció a tres docenas de investigadores que el conjunto de datos tenía graves errores y se disculpó por el impacto negativo que tuvo en sus investigaciones. Resulta que Facebook no incluyó los datos de la mitad de sus usuarios de EE.UU., ya que estaban menos polarizados políticamente en comparación con los usuarios en general. La portavoz de Facebook explicó que este incidente se debió a un error técnico que había surgido en su conjunto de datos de URLs compartidas.
Hoy en día, los datos son sin duda uno de los mayores activos de una organización. Se utiliza en todas partes, desde las operaciones cotidianas de una empresa hasta el impulso de sus iniciativas de inteligencia empresarial, o en el caso de Facebook, facilitando más de 100 investigaciones. Pero la ausencia de técnicas de calidad de datos y de mejores prácticas (que rastreen y solucionen a tiempo los problemas de calidad de datos) puede hacer que una empresa pierda mucho dinero y se arriesgue a quedarse atrás.
En este blog, examinaremos una serie de mejores prácticas y procesos de calidad de datos que pueden ayudar a conseguir una alta calidad de datos a nivel empresarial. Además de destacar lo que se necesita, también mencionaré los elementos procesables que pueden ayudarle a alcanzar ese estado.
Además, las prácticas que se mencionan a continuación darán los mejores resultados si se llevan a cabo de forma sistemática a intervalos regulares en una empresa. Los datos (en su definición y uso) son propensos a cambiar. Por lo tanto, si su empresa revisa constantemente estas prácticas, sin duda podrá conseguir resultados mejores y más duraderos.
Empecemos.
1. Averiguar la relación entre los datos y el rendimiento empresarial
Empezamos con esta práctica porque es la parte más importante y fundamental para permitir la gestión, adopción y uso adecuados de los datos en cualquier organización. En primer lugar, debe comprender cómo los datos contribuyen a sus metas y objetivos empresariales.
¿Qué aspecto tiene?
Esto puede implicar el análisis de la función de los datos a alto nivel (por ejemplo, destacando las áreas en las que se utilizan los datos), así como profundizar en detalles específicos (como el papel de los datos en las operaciones diarias, los procesos empresariales, el intercambio de información entre departamentos, etc.).
Una vez identificado esto, es el momento de plantear esta pregunta: si estos procesos o áreas no fueron facilitados por datos de calidad, ¿qué impacto puede tener en los KPIs resultantes?
Un ejemplo de esta situación es cuando los ejecutivos de nivel C establecen el objetivo de ingresos para el siguiente trimestre basándose en los datos de ventas del último trimestre, pero sólo para descubrir que el conjunto de datos utilizado para predecir el objetivo futuro tenía graves problemas de calidad de datos, lo que hace que su departamento de ventas persiga un valor arbitrario que no tiene ningún significado concreto. La situación resultante tiene un enorme impacto negativo en las operaciones y la reputación de la empresa, como el establecimiento de expectativas poco realistas de los representantes de ventas, la promesa de cifras de ingresos inexactas, etc.
¿Cómo ayuda?
Comprender el papel de los datos en todos los procesos que se llevan a cabo en una empresa permite tener siempre a mano un caso para priorizar los datos y su calidad. De hecho, esto también le ayudará a conseguir la aceptación y la atención necesarias de las partes interesadas, algo que es crucial para realizar y proponer cambios en los procesos existentes.
2. Medir y mantener la definición de la calidad de los datos
Una vez que conozca el impacto de los datos en su negocio, el siguiente paso es lograr la calidad de los datos en todos los conjuntos de datos de su organización. Pero antes de hacerlo, es importante entender la definición de calidad de datos, ya que significa algo diferente para cada empresa.
La calidad de los datos se define como el grado en que los datos cumplen con su propósito. Por lo tanto, para entender el significado de la calidad de los datos en su caso, es necesario saber cuál es el objetivo que se persigue.
¿Qué aspecto tiene?
Para definir la calidad de los datos de su empresa, debe empezar por identificar los:
- Fuentes que generan, almacenan o manipulan datos,
- Atributos almacenados por cada fuente,
- Glosario de metadatos que define cada atributo,
- Criterios de aceptabilidad de los valores de los datos almacenados en los atributos, y
- Métricas de calidad de datos que miden la calidad de los datos almacenados.
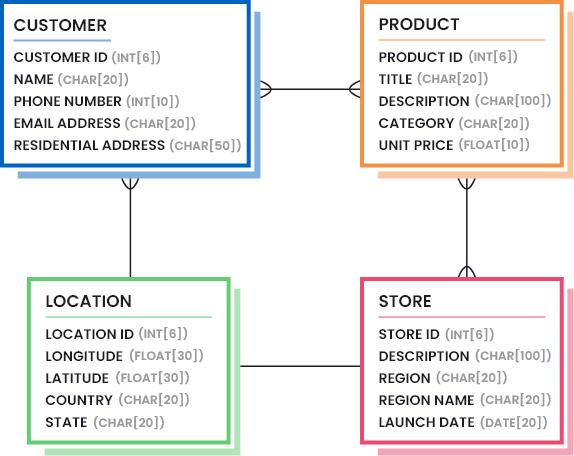
Un ejemplo de definición de la calidad de los datos en su empresa es la elaboración de modelos de datos que destaquen las partes necesarias de los mismos (la cantidad y la calidad de los datos que se consideran suficientemente buenos). Considere la siguiente imagen para entender cómo puede ser un modelo de datos para una empresa minorista:
Por otra parte, además de diseñar modelos de datos, también es necesario identificar métricas de calidad de datos que confirmen la presencia de un nivel de calidad aceptable en sus conjuntos de datos. Por ejemplo, puede exigir que su conjunto de datos sea más preciso y fiable, en lugar de completo.
¿Cómo ayuda?
Una definición estandarizada de la calidad de los datos ayuda a que todas las personas se pongan de acuerdo, de modo que puedan entender qué significa la calidad de los datos, qué aspecto tiene y cómo puede medirse. Esto permite que cada persona entienda y cumpla los requisitos de calidad de los datos.
3. Establecer las funciones y responsabilidades de los datos en toda la organización
Se suele considerar que para garantizar la calidad de los datos a nivel empresarial es necesario que la alta dirección se implique o participe. La verdad es que, más que implicar a determinadas personas en entornos aislados, hay que contratar a personas en los procesos existentes y hacerlas responsables de alcanzar y mantener la calidad de los datos, desde la alta dirección hasta el personal operativo.
¿Qué aspecto tiene?
Algunas de las funciones de datos más comunes e importantes y sus responsabilidades son:
- Chief Data Officer (CDO): representante de los datos en la alta dirección, responsable de diseñar estrategias para garantizar la gestión eficaz de los datos, el seguimiento de la calidad de los datos y su adopción en toda la organización.
- Administrador de datos: controlador de la calidad de los datos, responsable de garantizar la adecuación de los datos a su finalidad y de gestionar los metadatos.
- Líder de datos y análisis (D&A): un jugador de datos, responsable de garantizar la alfabetización de datos en toda la organización, y de permitir que los datos produzcan valor.
¿Cómo ayuda?
Cuando los datos se tratan como la fuente principal que alimenta los procesos empresariales básicos, se produce un cambio en toda la empresa. Aquí es donde la asignación de funciones y responsabilidades en el ámbito de los datos y el hecho de dar a las personas el poder de influir y hablar sobre cuestiones de datos cruciales puede desempeñar un papel importante para garantizar el éxito de la cultura de datos en cualquier organización.
4. Formar y educar a los equipos sobre los datos
En una encuesta realizada a 9.000 empleados que desempeñaban diversas funciones en una organización, sólo el 21% confiaba en sus conocimientos sobre datos.
La introducción de funciones y responsabilidades en materia de datos puede tener un gran impacto positivo en su empresa, pero aún así, es crucial tener en cuenta que en un lugar de trabajo moderno, cada individuo genera, manipula o trata con datos en sus operaciones diarias. Por ello, tan importante como responsabilizar a determinadas personas de la aplicación de medidas correctoras, es igualmente necesario formar y educar a todos los equipos en el manejo de los datos de la organización.
¿Qué aspecto tiene?
Esto puede implicar la creación de planes de alfabetización de datos y el diseño de cursos que introduzcan a los equipos en los datos de la organización y los expliquen:
- Lo que contiene,
- Qué significa cada atributo de los datos,
- Cuáles son los criterios de aceptabilidad de su calidad,
- ¿Cuál es la forma correcta e incorrecta de introducir/manipular datos?
- ¿Qué datos utilizar para conseguir un determinado resultado?
Además, estos cursos pueden crearse en función de la frecuencia con la que determinados roles utilizan los datos (diaria, semanal o anualmente).
¿Cómo ayuda?
La capacidad de leer, comprender y analizar los datos de forma correcta y precisa en todos los niveles permite a cada empleado formular las preguntas adecuadas, y de la forma más optimizada. También garantiza la eficacia operativa de su personal y reduce los errores al comunicar asuntos relacionados con los datos.
5. Supervisar continuamente el estado de los datos mediante la elaboración de perfiles de datos
Lograr la calidad de los datos y mantenerla en el tiempo son dos cosas diferentes. Por eso es necesario aplicar un proceso sistemático que supervise continuamente el estado de los datos y los perfile para descubrir detalles ocultos sobre su estructura y contenido.
El alcance y el proceso de la actividad de elaboración de perfiles de datos pueden establecerse en función de la definición de la calidad de los datos en su empresa y de cómo se mide.
¿Qué aspecto tiene?
Esto puede lograrse configurando y programando informes de perfil de datos diarios/semanales. Además, puede diseñar flujos de trabajo personalizados para alertar a los administradores de datos de su empresa en caso de que la calidad de los datos caiga por debajo de un umbral aceptable.
Un informe sobre el perfil de los datos suele poner de relieve una serie de aspectos sobre los conjuntos de datos examinados, por ejemplo:
- El porcentaje de valores de datos faltantes e incompletos,
- El número de registros que son posibles duplicados entre sí,
- Evaluación de los tipos, tamaños y formatos de los datos para descubrir valores de datos no válidos,
- Análisis estadístico de columnas de datos numéricos para evaluar las distribuciones.
¿Cómo ayuda?
Esta práctica le ayuda a detectar los errores de datos en una fase temprana del proceso y evita que lleguen a los clientes. Además, puede ayudar a los responsables de datos a estar al tanto de la gestión de la calidad de los datos y a tomar las decisiones correctas, como por ejemplo cuándo y cómo solucionar los problemas que se destacan en los perfiles de datos.
Más información sobre la elaboración de perfiles de datos: Alcance, técnicas y retos.
6. Diseñar y mantener canales de datos para lograr una única fuente de verdad
Una canalización de datos se refiere a un proceso sistemático que ingiere datos desde una fuente, realiza las técnicas de procesamiento y transformación necesarias en los datos y luego los carga en un repositorio de destino.
Es fundamental que los datos brutos pasen por una serie de comprobaciones de validación antes de que puedan considerarse utilizables y ponerse a disposición de todos los usuarios de la organización.
¿Qué aspecto tiene?
Para construir un pipeline de datos, hay que volver a la práctica#02 que mencionamos en este blog: Definir y mantener la definición de la calidad de los datos. Y de acuerdo con esa definición, hay que decidir la lista numerada de operaciones que deben realizarse con los datos entrantes para alcanzar el nivel de calidad definido.
Una lista de ejemplos de operaciones que se pueden realizar dentro de su canalización de datos incluye:
- Sustituir los valores nulos o vacíos por un término estándar, como «No disponible».
- Transformar los valores de los datos según el patrón y el formato definidos.
- Parsear campos en dos o más columnas.
- Sustituir las abreviaturas por palabras adecuadas.
- Sustituir los apodos por nombres propios.
- En caso de que se sospeche que el registro entrante es un posible duplicado, se fusiona con el registro existente, en lugar de crearlo como uno nuevo.

¿Cómo ayuda?
Una canalización de datos actúa como un cortafuegos de calidad de datos para sus conjuntos de datos organizativos. El diseño de una canalización de datos ayuda a garantizar la coherencia de los datos en todas las fuentes y elimina cualquier discrepancia que pueda existir, incluso antes de que los datos se carguen en la fuente de destino.
7. Realizar un análisis de la causa raíz de los errores de calidad de los datos
Hasta ahora, nos hemos centrado sobre todo en cómo hacer un seguimiento de la calidad de los datos y evitar que los errores de calidad de los datos se introduzcan en los conjuntos de datos, pero la verdad es que, a pesar de todos estos esfuerzos, es probable que algunos errores acaben en el sistema. No sólo tendrá que solucionarlos, sino que lo más importante es entender cómo se produjeron esos errores para poder prevenirlos.
¿Qué aspecto tiene?
Un análisis de la causa raíz de los errores de calidad de los datos puede implicar la obtención del último informe sobre el perfil de los datos y la colaboración con su equipo para encontrar respuestas a preguntas como:
- ¿Qué errores de calidad de datos se han encontrado?
- ¿De dónde proceden?
- ¿Cuándo se originaron?
- ¿Por qué han acabado en el sistema a pesar de todos los controles de validación de la calidad de los datos? ¿Nos hemos perdido algo?
- ¿Cómo podemos evitar que estos errores vuelvan a aparecer en el sistema?
¿Cómo ayuda?
Llegar al núcleo de los problemas de calidad de los datos puede ayudar a eliminar los errores a largo plazo. No hay que trabajar siempre con un enfoque reactivo y seguir corrigiendo los errores a medida que surgen. Con un enfoque proactivo, puede permitir a sus equipos minimizar sus esfuerzos en la corrección de errores de calidad de datos, y dejar que los procesos refinados de calidad de datos se encarguen del 99% de los problemas asociados a los datos.
8. Utilizar la tecnología para conseguir y mantener la calidad de los datos
Esto nos lleva a nuestra última mejor práctica: utilizar la tecnología para lograr un ciclo de vida de gestión de calidad de datos sostenible. No se promete que ningún proceso funcione bien, ni que ofrezca el mejor rendimiento de la inversión, si no se automatiza y optimiza mediante la tecnología.
¿Qué aspecto tiene?
Invierta en la adopción de un sistema tecnológico que cuente con todas las funcionalidades que necesita para garantizar la calidad de los datos en todos los conjuntos de datos. Estas características incluyen la capacidad de:
- Importación de datos: Ingesta de datos de múltiples fuentes,
- Perfil de los datos: Evaluar los datos para generar informes de calidad de datos,
- Limpieza de datos: Destaca las posibles áreas que requieren limpieza, estandarización y transformación de datos, e implementa correcciones,
- Cotejo de datos: Haga coincidir los datos utilizando algoritmos de cotejo exactos y difusos con un alto nivel de precisión, así como ajustando los algoritmos según la naturaleza de sus datos,
- Deduplicación de datos: Vincule los registros y encuentre la única fuente de verdad,
- Exportación de datos: Exportación/carga de resultados.
Además de las funciones de gestión de la calidad de los datos mencionadas anteriormente, algunas organizaciones invierten en tecnologías que ofrecen también capacidades de gestión centralizada de datos. Un ejemplo de este sistema es la gestión de datos maestros (MDM). Aunque un MDM es una solución completa de gestión de datos que incluye funciones de calidad de datos, no todas las organizaciones necesitan la extensa lista de funciones que conlleva un sistema de este tipo.
Tiene que entender los requisitos de su negocio para evaluar qué tipo de tecnología es la decisión correcta para usted. Puede leer este blog para conocer las principales diferencias entre una solución MDM y DQM.
¿Cómo ayuda?
Son numerosas las ventajas de utilizar la tecnología para la aplicación de procesos que deben repetirse constantemente para lograr resultados duraderos. Proporcionar a su equipo herramientas de gestión de la calidad de los datos de autoservicio puede aumentar la eficiencia operativa, eliminar la duplicación de esfuerzos, mejorar la experiencia del cliente y obtener información empresarial fiable.
Conclusión:
La aplicación de medidas de calidad de datos coherentes, automatizadas y repetibles puede ayudar a su organización a alcanzar y mantener la calidad de los datos en todos los conjuntos de datos.
Data Ladder lleva más de una década ofreciendo soluciones de calidad de datos a sus clientes. DataMatch Enterprise es uno de sus principales productos de calidad de datos -disponible como aplicación independiente y como API integrable- que permite la gestión de la calidad de los datos de principio a fin, incluida la elaboración de perfiles de datos, la limpieza, la correspondencia, la deduplicación y la purga de fusiones.
Puede descargar la versión de prueba gratuita hoy mismo o programar una sesión personalizada con nuestros expertos para entender cómo nuestro producto puede ayudar a implementar las mejores prácticas para alcanzar y mantener la calidad de los datos a nivel empresarial.
The post 8 mejores prácticas para garantizar la calidad de los datos en la empresa appeared first on Data Ladder.
]]>The post Guía de concordancia de patrones: ¿Qué significa y cómo hacerlo? appeared first on Data Ladder.
]]>Encontrar patrones es fácil en cualquier tipo de entorno rico en datos; eso es lo que hacen los jugadores mediocres. La clave está en determinar si los patrones representan señal o ruido.
Nate Silver
Cualquiera que trabaje con datos entiende la importancia de los patrones. Tanto si se analizan grandes conjuntos de datos de forma holística como si se profundiza en el valor más granular, los patrones están en todas partes. Pueden ser universales -como el patrón de un número de tarjeta de crédito- o pueden ser exclusivos de su empresa, por ejemplo el patrón utilizado para mostrar la información de los productos en su sitio web.
Cuando se capturan los datos, no siempre siguen el patrón correcto. Las empresas tienen que aplicar diferentes métodos de cotejo, validación y transformación de patrones para obtener los datos en la forma y el formato requeridos.
En este blog, aprenderemos algunos conceptos importantes relacionados con la coincidencia de patrones y la validación, como por ejemplo
- ¿Qué significa la concordancia de patrones?
- ¿En qué se diferencia la concordancia de patrones de la concordancia de cadenas?
- ¿Cómo funciona la concordancia de patrones?
- ¿Cuáles son las razones más comunes para cotejar y validar patrones?
- ¿Cómo puede transformar sus datos en el patrón que necesita?
Vamos a sumergirnos.
¿Qué es la concordancia de patrones?
Un patrón se percibe como algo opuesto al desorden o al caos. Se trata de un modelo repetitivo que puede ser identificado a través de un gran conjunto de valores de datos pertenecientes al mismo dominio. Por lo tanto, la coincidencia de patrones puede definirse como:
Proceso de búsqueda de una secuencia o colocación específica de caracteres en un conjunto de datos determinado.
La concordancia de patrones produce resultados definitivos: la cadena de entrada contiene el patrón (es válida) o no lo contiene (es inválida). En caso de que la cadena no contenga el patrón requerido, el proceso de coincidencia suele ampliarse a la transformación de patrones, en la que se extraen subelementos de datos del valor de entrada y se reformulan para construir el patrón requerido.
Coincidencia de patrones frente a coincidencia de cadenas
Antes de hablar de cómo funcionan los algoritmos de concordancia de patrones, es importante entender su relación con los algoritmos de concordancia de cadenas. Ambos conceptos se tratan a menudo como la misma cosa, pero son bastante diferentes en su propósito y uso. El siguiente cuadro destaca algunas de las principales diferencias:
| Coincidencia de patrones | Coincidencia de cadenas | |
| Comparación | Compara una cadena con un patrón estándar que representa bloques o fichas de caracteres. | Compara dos cadenas carácter por carácter. |
| Ejemplo | Comparando [email protected] con [name]@[domain].[domain-extension]. | Comparando a Elizabeth con Alizabeth. |
| Resultados | Calcula los resultados definitivos: o se encuentra el patrón o está ausente. | Calcula las coincidencias exactas (coincidencia de polvo con polvo) o difusas (coincidencia de polvo con óxido). |
| Utiliza | Se utiliza para analizar y extraer valores o transformar valores para que sigan patrones estándar. | Se utiliza para corregir las faltas de ortografía, detectar el plagio e identificar los valores que tienen un significado o una composición de caracteres similar. |
¿Cómo funciona la concordancia de patrones?
En pocas palabras, los algoritmos de concordancia de patrones funcionan con expresiones regulares (o regex). Para entender lo que es una expresión regular, piense en ella como un lenguaje que le ayuda a definir un patrón y a compartirlo con alguien, o en nuestro caso, con un programa informático.
Las expresiones regulares indican a los programas informáticos qué patrón deben buscar en los datos de las pruebas. A veces, el programa es lo suficientemente inteligente como para recoger patrones de un conjunto de valores de datos y generar automáticamente una regex. Algunos programas o herramientas tienen una biblioteca regex incorporada que contiene patrones de uso común, como número de tarjeta de crédito, números de teléfono de Estados Unidos, formatos de fecha, direcciones de correo electrónico, etc.
Ejemplo de patrón de dirección de correo electrónico coincidente
Para saber qué es un algoritmo de concordancia de patrones, tomemos el ejemplo de la validación del patrón de las direcciones de correo electrónico. El primer paso es definir la regex que comunica el patrón de una dirección de correo electrónico válida. Un patrón de muestra de una dirección de correo electrónico válida puede ser el siguiente:
[name]@[domain].[domain-extension]
En el lenguaje regex, este patrón se traducirá como
^[\w-.]+@([\w-]+.)+[\w-]{2,3}$
Dónde,
- ^ significa el comienzo de una frase y $ el final.
- [Se trata de una palabra que contiene caracteres alfanuméricos, un guión bajo, un guión o un punto.
- +@ implica la adición de un símbolo @.
- ([\w-]+.) significa una palabra que contiene caracteres alfanuméricos, guiones bajos o guiones, y termina con un punto.
- +[\w-]{2,3} significa una palabra que contiene caracteres alfanuméricos o un guión, y esa palabra sólo puede tener al menos dos y como máximo 3 caracteres.
A continuación, puede ver una serie de direcciones de correo electrónico de prueba que se ejecutan a través de este patrón regex y los resultados producidos.
| No. | Prueba | Resultado | Motivo del fracaso |
| 1. | [email protected] | Válido | |
| 2. | pam.beesly_gmail.com | Inválido | Falta el símbolo @. |
| 3. | [email protected] | Inválido | El dominio tiene un punto final inesperado. |
| 4. | [email protected] | Inválido | La extensión del dominio tiene más de 3 caracteres (por ejemplo, com4). |
Es obvio que definir manualmente las expresiones regulares es tedioso y requiere cierta experiencia. También puede optar por herramientas de normalización de datos que ofrezcan diseñadores de regex visuales (más sobre esto en una sección posterior).
Casos de uso de la concordancia de patrones
Ahora que sabemos qué es la concordancia de patrones y cómo funciona el algoritmo, puede que se pregunte dónde se utiliza exactamente. La concordancia de patrones es uno de los conceptos más fundamentales en diferentes campos, como la programación informática, la ciencia y el análisis de datos, el procesamiento del lenguaje natural, etc.
Si hablamos específicamente de la concordancia de patrones y de la validación en el campo de los datos, he aquí algunas de sus aplicaciones más comunes:
1. Validación de los envíos de formularios
Como la concordancia de patrones de datos distingue entre información válida y no válida, se utiliza sobre todo para validar los formularios enviados en sitios web u otras aplicaciones de software. La regex se aplica en los campos del formulario según sea necesario; a continuación se ofrecen algunos ejemplos de validaciones:
- El nombre de una persona sólo contiene alfabetos o símbolos,
- La dirección de correo electrónico sigue el patrón correcto,
- El número de teléfono sólo contiene dígitos,
- El número de la tarjeta de crédito no tiene más de 16 dígitos, etc.
2. Realización de operaciones de búsqueda y sustitución
La concordancia de patrones también es útil en aplicaciones que tienen funciones de búsqueda y sustitución de información textual. Algunas aplicaciones básicas sólo ofrecen la coincidencia carácter por carácter (o coincidencia de cadenas), mientras que otras también ofrecen la función de búsqueda y sustitución regex, que permite buscar patrones en documentos de texto y no sólo coincidencias exactas de cadenas.
3. Limpieza y normalización de los conjuntos de datos
Se puede intentar validar la información en el momento de la entrada de datos, como el envío de formularios, pero debido a las diversas limitaciones y restricciones que se encuentran en los sistemas, los conjuntos de datos de la organización pueden acabar con múltiples representaciones de la misma información. Aquí es donde se hace imperativo limpiar y estandarizar los conjuntos de datos antes de que puedan ser utilizados para operaciones rutinarias o de BI.
4. Análisis y extracción de valores
Dado que la concordancia de patrones busca una secuencia específica de caracteres en un valor determinado, este proceso también es útil para emparejar y extraer tokens de valores que residen en formas extendidas de información. Por ejemplo, puede querer extraer los dominios de una lista de direcciones de correo electrónico de empresas para averiguar en qué compañía trabaja la persona, o puede extraer la ciudad y el país de residencia de los campos de dirección que contienen 3-4 líneas de información.
¿Cómo hacer coincidir los patrones?
Las empresas suelen adoptar dos enfoques a la hora de cotejar y validar patrones: uno es escribir scripts de código interno y el otro es utilizar herramientas de software de terceros. Analicemos la aplicación de ambos enfoques.
1. Comparación de patrones mediante código
Cuando se trata de limpiar y estandarizar datos, la solución por defecto de muchas organizaciones es crear aplicaciones internas personalizadas y codificar scripts para diversas operaciones de estandarización, incluyendo la coincidencia de patrones y la transformación. Aunque parezca interesante, puede ser todo un reto.
Why in-house data quality projects fail
Read this whitepaper to understand the consequences of ignoring poor data quality, gain insight on why in-house data quality solutions fail and at what costs.
DownloadVeamos un fragmento de código JavaScript que valida las direcciones de correo electrónico.
| function emailValidation(input) { var regex = /^\w+([.-]?\w+)@\w+([.-]?\w+)(.\w{2,3})+$/; if(input.value.match(regex)) { alert("Valid"); return true;} si no { alert("Invalid"); return false;} } |
Tenga en cuenta que este fragmento de código sólo valida las direcciones de correo electrónico y no las transforma en un patrón estandarizado en caso de que no sean válidas. Además, sólo valida el campo de la dirección de correo electrónico, por lo que para hacer coincidir diferentes patrones, se necesita una implementación de código similar para cada uno. Por último, la regex que valida las direcciones de correo electrónico sigue siendo un poco más fácil de descifrar. Si consideramos los campos de datos que tienen patrones complejos, las expresiones regulares pueden abarcar varias líneas. Por ejemplo, el siguiente fragmento de código busca coincidencias de patrones para las URL.
| function URLValidation(input) { var regex = /[-a-zA-Z0-9@:%.+~#=] {1,256}.[a-zA-Z0-9()]{1,6}\b ([-a-zA-Z0-9()@:%+.~#?&//=]*) …/gi; if(input.value.match(regex)) { alert("Valid"); return true;} si no { alert("Invalid"); return false;} } |
2. Comparación de patrones mediante herramientas informáticas
Por las razones mencionadas anteriormente, el mantenimiento de las aplicaciones personalizadas puede consumir muchos recursos. Requiere la contratación de un equipo de desarrolladores internos a los que los usuarios de la empresa se dirigen constantemente con peticiones de depuración y actualización de la funcionalidad del código.
Por ello, muchos directivos e ingenieros de datos de alto nivel se inclinan por la idea de adoptar herramientas sencillas para construir, cotejar y transformar patrones que puedan ser utilizadas fácilmente tanto por el personal de TI como por el que no lo es.
Dichos comparadores de patrones están empaquetados con diferentes características. A continuación se comentan las características más comunes.
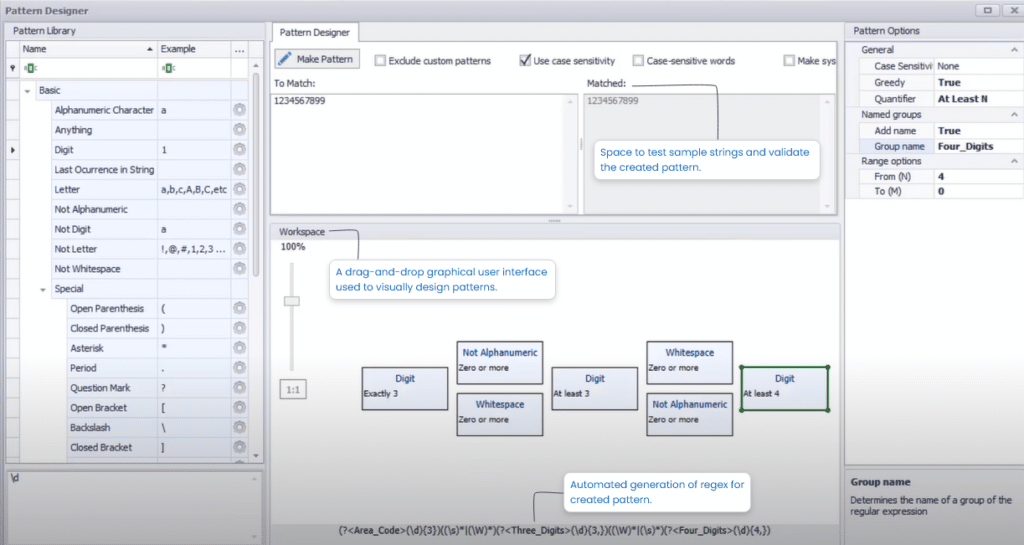
1. Creadores de patrones visuales
La función de creación de patrones visuales ofrece una interfaz gráfica de usuario de arrastrar y soltar que puede utilizarse para crear patrones. Mientras un usuario suelta bloques de patrones o tokens en el espacio de trabajo, se genera una regex equivalente en el backend. Esta característica elimina la necesidad de conocimientos técnicos y anima a los usuarios ingenuos a construir también patrones.
A continuación se muestra una captura de pantalla del diseñador de patrones visuales en DataMatch Enterprise:
2. Coincidencia de patrones por tipo de datos
Otra característica interesante de las herramientas de concordancia de patrones es la capacidad de perfilar columnas enteras por sus patrones de tipos de datos. Por ejemplo, puede perfilar la columna del número de teléfono por el tipo de datos entero, y la fracción de valores que contienen otros símbolos y caracteres además de los dígitos puede marcarse como no válida. Esto puede hacerse para obtener una evaluación rápida sobre el esfuerzo de normalización necesario para arreglar los patrones no válidos.
A continuación se muestra una captura de pantalla de los patrones de coincidencia por tipo de datos en DataMatch Enterprise:
3. Coincidencia de patrones mediante la biblioteca regex
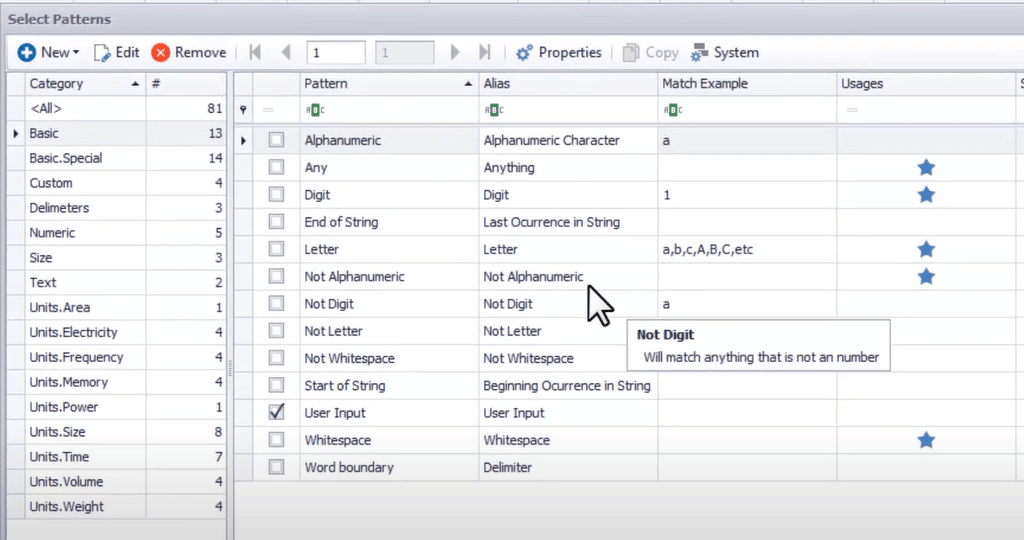
Muchas herramientas vienen con bibliotecas regex incorporadas llenas de patrones de uso común, como números de tarjetas de crédito, números de teléfono de Estados Unidos, formatos de fecha, direcciones de correo electrónico, etc. Además, también puede crear patrones personalizados (especializados para su uso empresarial) y guardarlos en la biblioteca para reutilizarlos.
A continuación se muestra una captura de pantalla de la biblioteca regex en DataMatch Enterprise:
4. Paquete completo de limpieza y normalización de datos
Una de las mayores ventajas de este tipo de herramientas es que, en la mayoría de los casos, vienen acompañadas de otras funciones de limpieza y normalización de datos que son fundamentales para transformar los datos en una forma y un formato aceptables. Porque una vez que se tiene el informe de concordancia de patrones que muestra qué valores de datos son válidos y cuáles no, el siguiente paso importante es fijar los patrones también.
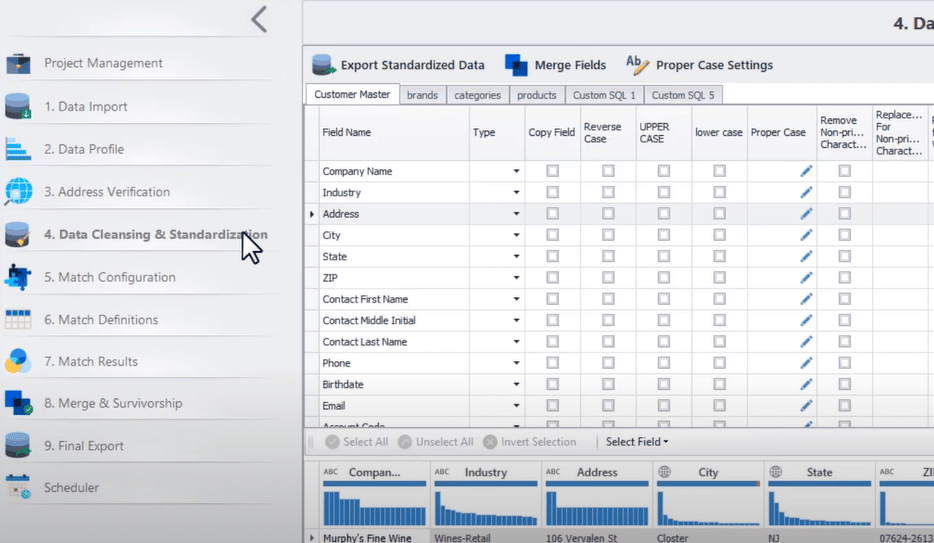
Por eso, adoptar un sistema integral que se encargue de varias disciplinas de gestión de la calidad de los datos -incluyendo la elaboración de perfiles de datos, la limpieza, la normalización, el cotejo y la fusión- puede ser una gran ventaja.
A continuación se muestra una captura de pantalla de varias funciones de calidad de datos que ofrece DataMatch Enterprise :
Optar por una solución sin código que construya, haga coincidir y transforme patrones
Aunque en este blog nos hemos centrado sobre todo en la coincidencia de patrones, el arte de la transformación de patrones es igual de interesante, aunque también supone un reto. Por esta razón, muchas organizaciones prefieren proporcionar a sus equipos herramientas de limpieza y estandarización de datos de autoservicio que están diseñadas con funciones de diseño, correspondencia y transformación de patrones. La adopción de este tipo de herramientas puede ayudar a su equipo a ejecutar complejas técnicas de limpieza y normalización de datos en millones de registros en cuestión de minutos.
DataMatch Enterprise es una de esas herramientas que facilita a los equipos de datos la rectificación de errores de patrón con rapidez y precisión, y les permite centrarse en tareas más importantes. Para saber más sobre cómo puede ayudar DataMatch Enterprise, puede descargar una prueba gratuita hoy mismo o reservar una demostración con un experto.
The post Guía de concordancia de patrones: ¿Qué significa y cómo hacerlo? appeared first on Data Ladder.
]]>The post Guía de normalización de datos: Tipos, beneficios y proceso appeared first on Data Ladder.
]]>Cuando se extraen datos de varias aplicaciones instaladas en la empresa, se espera recibir una definición y un formato coherentes de la misma información. Pero en la realidad, esto no suele ser así. Las variaciones presentes en los conjuntos de datos -entre aplicaciones e incluso dentro de la misma aplicación- hacen casi imposible utilizar los datos para cualquier propósito, desde las operaciones rutinarias hasta la inteligencia empresarial.
Hoy en día, una empresa media utiliza múltiples aplicaciones SaaS e internas. Cada sistema tiene sus propios requisitos, restricciones y limitaciones. Por ello, los datos alojados en las distintas aplicaciones están condenados a contener discrepancias. Y si tenemos en cuenta las faltas de ortografía, las abreviaturas, los apodos y los errores de escritura, nos damos cuenta de que los mismos valores pueden tener cientos de representaciones diferentes. Aquí es donde se hace imperativo estandarizar los datos para que sean utilizables para cualquier propósito.
En este blog, aprenderemos todo sobre la normalización de datos: qué es, por qué y cuándo se necesita, y cómo se puede hacer. Empecemos.
¿Qué es la estandarización de datos?
En el mundo de los datos, un estándar se refiere a un formato o representación al que debe ajustarse todo valor de un determinado dominio. Por lo tanto, normalizar los datos significa:
Proceso de transformación de una representación incorrecta o inaceptable de datos en una forma aceptable.
La forma más fácil de saber qué es «aceptable» es entender los requisitos de su empresa. Lo ideal es que las organizaciones se aseguren de que el modelo de datos utilizado por la mayoría de las aplicaciones -si no todas- se ajuste a sus necesidades empresariales. La mejor manera de lograr la estandarización de los datos es alinear su representación, estructura y definición con los requisitos de la organización.
Tipos y ejemplos de errores de normalización de datos
A continuación se ofrecen algunos ejemplos de cómo pueden acabar los datos no normalizados en el sistema:
- El número de teléfono del cliente se guarda como una cadena en un sistema, mientras que en otro sólo se permite que sea un número que contenga 8 dígitos, lo que provoca una incoherencia en el tipo de datos.
- El nombre del cliente se guarda como un solo campo en un sistema, mientras que el mismo se cubre como tres campos separados en otro sistema para el nombre, el segundo nombre y los apellidos, lo que lleva a una incoherencia estructural.
- La fecha de nacimiento del cliente tiene el formato MM/DD/AAAA en un sistema, mientras que la misma tiene el formato Mes Día, Año en otro sistema – lo que lleva a la inconsistencia del formato.
- El género del cliente se guarda como Mujer o Hombre en un sistema, mientras que el mismo se guarda como F o M en otro sistema, lo que lleva a la inconsistencia del valor del dominio.
Aparte de estas situaciones comunes, las faltas de ortografía, los errores de transcripción y la falta de restricciones de validación pueden aumentar los errores de normalización de datos en sus conjuntos de datos.
¿Por qué hay que normalizar los datos?
Cada sistema tiene su propio conjunto de limitaciones y restricciones, lo que da lugar a modelos de datos únicos y a sus definiciones. Por esta razón, puede ser necesario transformar los datos antes de que puedan ser consumidos correctamente por cualquier proceso de negocio.
Normalmente, se sabe que ha llegado el momento de normalizar los datos cuando se quiere:
1. Conformar los datos entrantes o salientes
Una organización tiene muchas interfaces que intercambian puntos de datos de partes interesadas externas, como proveedores o socios. Cada vez que los datos entran en una empresa o se exportan, es necesario ajustarlos a la norma requerida, pues de lo contrario el desorden de datos no estandarizados no hace más que crecer.
2. Preparar los datos para el BI o la analítica
Los mismos datos pueden representarse de múltiples maneras, pero la mayoría de las herramientas de BI no están especializadas para procesar todas las posibles representaciones de los valores de los datos y pueden acabar tratando los mismos datos con un significado diferente. Esto puede llevar a resultados de BI sesgados o inexactos. Por lo tanto, antes de alimentar los datos en sus sistemas de BI, deben ser limpiados, estandarizados y deduplicados, para que pueda obtener información correcta y valiosa.
3. Consolidar entidades para eliminar duplicidades
La duplicación de datos es uno de los mayores peligros para la calidad de los datos que afrontan las empresas. Para que las operaciones empresariales sean eficientes y sin errores, debe eliminar los registros duplicados que pertenezcan a la misma entidad (ya sea para un cliente, un producto, una ubicación o un empleado), y un proceso de deduplicación de datos eficaz requiere que se cumplan las normas de calidad de los datos.
4. Compartir datos entre departamentos
Para que los datos sean interoperables entre departamentos, tienen que estar en un formato comprensible para todos. Por lo general, las organizaciones tienen información de los clientes en los CRM que es entendida por la gente de ventas y marketing. Esto puede introducir retrasos en la finalización de las tareas y bloqueos en la productividad del equipo.
Limpieza de datos frente a estandarización de datos
Los términos limpieza de datos y normalización de datos suelen utilizarse indistintamente. Pero hay una pequeña diferencia entre ambos.
La limpieza de datos es el proceso de identificar datos incorrectos o sucios y sustituirlos por valores correctos, mientras que la normalización de datos es el proceso de transformar los valores de los datos de un formato inaceptable a un formato aceptable.
El objetivo y el resultado de ambos procesos es similar: se quiere eliminar la inexactitud y la incoherencia de los conjuntos de datos. Ambos procesos son vitales para su iniciativa de gestión de la calidad de los datos y deben ir de la mano.
¿Cómo normalizar los datos?
Un proceso de normalización de datos consta de cuatro sencillos pasos: definir, probar, transformar y volver a probar. Repasemos cada paso con un poco más de detalle.
1. Definir una norma
En el primer paso, debe identificar qué norma satisface las necesidades de su organización. La mejor manera de definir una norma es diseñar un modelo de datos para su empresa. Este modelo de datos representará el estado más ideal al que deben ajustarse los valores de los datos de una determinada entidad. Un modelo de datos puede ser diseñado como:
- Identifique los activos de datos cruciales para el funcionamiento de su empresa. Por ejemplo, la mayoría de las empresas capturan y gestionan datos de clientes, productos, empleados, ubicaciones, etc.
- Defina los campos de datos de cada activo identificado y decida también los detalles estructurales. Por ejemplo, puede querer almacenar el nombre, la dirección, el correo electrónico y el número de teléfono de un cliente, donde el campo nombre abarca tres campos y el campo dirección abarca dos.
- Asigne un tipo de datos a cada campo identificado en el activo. Por ejemplo, el campo Nombre es un valor de cadena, Número de teléfono es un valor entero, etc.
- Defina los límites de caracteres (mínimo y máximo) para cada campo. Por ejemplo, un nombre no puede tener más de 15 caracteres y el número de teléfono no puede tener más de 8 dígitos, etc.
- Defina el patrón al que deben atenerse los campos – puede que no sea aplicable a todos los campos. Por ejemplo, la dirección de correo electrónico de cada cliente debe ajustarse a la regex [chars]@[chars].[chars].
- Definir el formato en el que deben colocarse determinados elementos de datos dentro de un campo. Por ejemplo, la fecha de nacimiento de un cliente debe especificarse como MM/DD/AAAA.
- Defina la unidad de medida para los valores numéricos (si procede). Por ejemplo, la edad del cliente se mide por años.
- Definir el dominio de valores para los campos que deben derivarse de un determinado conjunto de valores. Por ejemplo, la edad del cliente debe ser un dígito entre 18 y 50, el sexo debe ser masculino o femenino, etc.
Un modelo de datos diseñado puede colocarse en un diagrama de clases ERD para ayudar a visualizar el estándar definido para cada activo de datos y cómo se relacionan entre sí. A continuación se muestra un ejemplo de modelo de datos para una empresa minorista:
2. Prueba de la norma
Las técnicas de estandarización de datos comienzan en el segundo paso, ya que el primero se centra en la definición de lo que debe ser, algo que se hace una vez o se revisa y actualiza de vez en cuando.
Ha definido la norma y ahora es el momento de ver si los datos actuales se ajustan a ella. A continuación, repasamos una serie de técnicas que comprueban los valores de los datos en busca de errores de estandarización y construyen un informe de estandarización que puede utilizarse para solucionar los problemas.
a. Análisis de registros y atributos
El diseño de un modelo de datos es la parte más crucial de la gestión de datos. Pero, por desgracia, muchas organizaciones no diseñan modelos de datos ni establecen estándares de datos comunes a tiempo, o las aplicaciones que utilizan no tienen modelos de datos personalizables, lo que les lleva a capturar datos con nombres de campos y estructuras diferentes.
Al consultar la información de diferentes sistemas, puede observar que algunos registros devuelven el nombre de un cliente como un solo campo, mientras que otros devuelven tres o incluso cuatro campos que cubren el nombre de un cliente. Por esta razón, antes de que cualquier conjunto de datos pueda ser examinado en busca de errores, hay que empezar por analizar los registros y los campos para obtener los componentes que deben ser probados para la normalización.
b. Informe sobre el perfil de los datos del edificio
El siguiente paso es pasar los componentes analizados por un sistema de perfiles. Una herramienta de perfilado de datos informa de diferentes estadísticas sobre los atributos de los datos, como
- ¿Cuántos valores de una columna siguen el tipo de datos, el formato y el patrón requeridos?
- ¿Cuál es el número medio de caracteres presentes en una columna?
- ¿Cuáles son los valores máximos y mínimos presentes en una columna numérica?
- ¿Cuáles son los valores más comunes presentes en una columna y cuántas veces aparecen?
c. Comparación y validación de patrones
Aunque las herramientas de perfilado de datos informan sobre las coincidencias de patrones, dado que es una parte importante de las pruebas de normalización de datos, lo discutiremos con un poco más de profundidad. Para hacer coincidir los patrones, es necesario definir primero una expresión regular estándar para un campo, por ejemplo, una expresión regular para las direcciones de correo electrónico puede ser ^[a-zA-Z0-9+_ .-]+@[a-zA-Z0-9 .-]+$. Todas las direcciones de correo electrónico que no sigan el patrón dado deben ser marcadas durante la prueba.
d. Uso de diccionarios
Se puede comprobar la normalización de determinados campos de datos cotejando los valores con diccionarios o bases de conocimientos. También puede ejecutarlas con diccionarios creados por el usuario. Esto se hace a menudo para coincidir con errores ortográficos, abreviaturas o nombres acortados. Por ejemplo, los nombres de empresas suelen incluir términos como LLC, Inc, Ltd. y Corp. Cotejarlos con un diccionario lleno de esos términos estándar puede ayudar a identificar cuáles no siguen la norma requerida o están mal escritos.
Más información sobre el uso de wordsmith para eliminar el ruido y normalizar los datos en masa.
e. Direcciones de prueba para la normalización
Mientras se prueban los datos para su estandarización, es posible que tenga que probar campos especializados, como ubicaciones o direcciones. La estandarización de direcciones es el proceso de cotejar el formato de las direcciones con una base de datos autorizada -como la de USPS en Estados Unidos- y convertir la información de las direcciones en un formato aceptable y estandarizado.
Una dirección estandarizada debe estar correctamente escrita, formateada, abreviada, geocodificada, así como adjuntada con valores ZIP+4 precisos. Todas las direcciones que no se ajustan a la norma requerida (especialmente las direcciones que se supone que reciben entregas y envíos) deben ser marcadas para que puedan ser transformadas según sea necesario.
Más información: Guía rápida para la normalización y verificación de direcciones.
Enterprise Content Solutions uses DataMatch Enterprise
Enterprise Content Solutions found 24% higher matches than other vendors for inconsistent address records.
Read case study3. Transformar
En el tercer paso del proceso de normalización de datos, llega finalmente el momento de convertir los valores no conformes en un formato normalizado. Esto puede incluir:
- Transformación de los tipos de datos de los campos, como la conversión de Número de teléfono de cadena a un tipo de datos entero y la eliminación de cualquier carácter o símbolo presente en los números de teléfono para obtener el número de 8 dígitos.
- Transformar patrones y formatos, como convertir las fechas presentes en el conjunto de datos al formato MM/DD/AAAA.
- Transformación de unidades de medida, como la conversión de los precios de los productos a USD.
- Ampliar los valores abreviados para completar las formas, como sustituir los estados de EE: NY a Nueva York, NJ a Nueva Jersey, etc.
- Eliminar el ruido presente en los valores de los datos para obtener una información más significativa, como eliminar LLC, Inc. y Corp. de los nombres de las empresas para obtener los nombres reales sin ningún ruido.
- Reconstruir los valores en un formato estandarizado en caso de que sea necesario asignarlos a una nueva aplicación o a un centro de datos, como un sistema de gestión de datos maestros.
Todas estas transformaciones se pueden hacer manualmente -lo que puede llevar mucho tiempo y ser improductivo- o se pueden utilizar herramientas automatizadas que pueden ayudar a limpiar los datos automatizando las fases de prueba y transformación estándar por usted.
4. Volver a probar la norma
Una vez finalizado el proceso de transformación, es una buena práctica volver a probar el conjunto de datos para detectar errores de estandarización. Los informes previos y posteriores a la estandarización pueden compararse para comprender en qué medida los errores de datos fueron corregidos por los procesos configurados y cómo pueden mejorarse para alcanzar mejores resultados.
Uso de herramientas de estandarización de datos de autoservicio
Hoy en día, los datos se introducen manualmente, así como se capturan y generan automáticamente. En medio del manejo de grandes volúmenes de datos, las organizaciones se encuentran con millones de registros que contienen patrones, tipos de datos y formatos incoherentes. Y cuando quieren utilizar estos datos, los equipos se ven bombardeados con horas de comprobación manual del formato y de corrección de cada pequeño detalle antes de que la información pueda considerarse útil.
Muchas empresas se están dando cuenta de la importancia de proporcionar a sus equipos herramientas de estandarización de datos de autoservicio que también vienen con funciones de limpieza de datos incorporadas. La adopción de este tipo de herramientas puede ayudar a su equipo a ejecutar complejas técnicas de limpieza y normalización de datos en millones de registros en cuestión de minutos.
DataMatch Enterprise es una de esas herramientas que facilita a los equipos de datos la rectificación de los errores de normalización de datos con rapidez y precisión, y les permite centrarse en tareas más importantes. Para saber más sobre cómo puede ayudar DataMatch Enterprise, puede descargar una prueba gratuita hoy mismo o reservar una demostración con un experto.
The post Guía de normalización de datos: Tipos, beneficios y proceso appeared first on Data Ladder.
]]>The post La integración de datos explicada: Definición, tipos, proceso y herramientas appeared first on Data Ladder.
]]>Los dirigentes suelen subestimar el tiempo y el esfuerzo necesarios para habilitar la inteligencia empresarial en toda la organización. Creen que es tan fácil como extraer datos de todas las fuentes, reunirlos en una hoja de cálculo y alimentar las herramientas de BI o, incluso más fácil, un analista de datos que pueda fabricar inteligencia a partir de los números. Al final de la misma, esperan recibir increíbles conocimientos sobre el rendimiento del negocio, las posibles oportunidades de mercado y las previsiones de ingresos para la próxima década.
El proceso de BI no es tan sencillo, y a menudo se pasa por alto el componente más crítico para su éxito: la integración de datos. Para que los datos funcionen sin problemas en cualquier empresa, primero deben estar disponibles en el lugar adecuado, en el momento adecuado y en el formato adecuado. Los datos dispersos -que residen en silos- son la causa principal de la incoherencia, la ineficacia y la inexactitud de sus esfuerzos de BI y otras operaciones de datos.
En este blog, aprenderemos qué es la integración de datos y discutiremos sus diferentes tipos, procesos y herramientas. Comencemos.
¿Qué es la integración de datos?
La integración de datos se define como:
El proceso de combinar, consolidar y fusionar datos procedentes de múltiples fuentes dispares para obtener una visión única y uniforme de los datos y permitir una gestión, un análisis y un acceso eficaces a los mismos.
La captura y el almacenamiento son el primer paso del ciclo de vida de la gestión de datos. Pero los datos dispares -que residen en varias bases de datos, hojas de cálculo, servidores locales y aplicaciones de terceros- no sirven de nada hasta que se reúnen. La integración de datos permite a su empresa aplicar de forma práctica y global la información capturada y responder a las preguntas críticas de la empresa.
Considere la integración de los datos de los clientes como un ejemplo. En cualquier organización, los datos de los clientes se almacenan y alojan en múltiples ubicaciones: herramientas de seguimiento de sitios web, CRM, software de automatización de marketing y contabilidad, etc. Para dar sentido a la información de los clientes y extraer información útil, su equipo no puede cambiar constantemente entre aplicaciones. Necesitan un acceso único y uniforme a los registros de datos de los clientes, donde los datos se mantengan limpios y sin ambigüedades.
Del mismo modo, existen otras innumerables ventajas de la integración de datos que permiten una gestión eficaz de los mismos, la inteligencia empresarial y otras operaciones de datos.
5 tipos de integración de datos
La integración de los datos puede lograrse de múltiples maneras. Comúnmente denominados métodos, técnicas, enfoques o tipos de integración de datos, existen 5 formas diferentes de integrar los datos.
1. Integración de datos por lotes
En este tipo de integración de datos, los datos pasan por el proceso ETL en lotes en momentos programados (semanal o mensualmente). Se extrae de fuentes dispares, se transforma en una vista coherente y estandarizada, y luego se carga en un nuevo almacén de datos, como un almacén de datos o múltiples marts de datos. Esta integración es sobre todo útil para el análisis de datos y la inteligencia empresarial, ya que una herramienta de BI o un equipo de analistas pueden simplemente observar los datos almacenados en el almacén.
2. Integración de datos en tiempo real
En este tipo de integración de datos, los datos entrantes o en flujo se integran en los registros existentes casi en tiempo real a través de conductos de datos configurados. Las empresas emplean canalizaciones de datos para automatizar el movimiento y la transformación de los datos, y dirigirlos al destino deseado. Los procesos para integrar los datos entrantes (como un nuevo registro o la actualización/aplicación de la información existente) se incorporan a la cadena de datos.
3. Consolidación de datos
En este tipo de integración de datos, se crea una copia de todos los conjuntos de datos de origen en un entorno o aplicación de preparación, se consolidan los registros de datos para representar una única vista y, finalmente, se trasladan a un origen de destino. Aunque este tipo es similar al ETL, tiene algunas diferencias clave como:
- La consolidación de datos se centra más en conceptos como la limpieza y normalización de datos y la resolución de entidades, mientras que la ETL se centra en la transformación de datos.
- Mientras que el ETL es una mejor opción para el big data, la consolidación de datos es un tipo más adecuado para vincular registros e identificar de forma única los principales activos de datos, como el cliente, el producto y la ubicación.
- Los almacenes de datos ayudan sobre todo al análisis de datos y al BI, mientras que la consolidación de datos también es útil para mejorar las operaciones comerciales, como utilizar el registro consolidado de un cliente para contactar con él o crear facturas, etc.
4. Virtualización de datos
Como su nombre indica, este tipo de integración de datos no crea realmente una copia de los datos ni los traslada a una nueva base de datos con un modelo de datos mejorado, sino que introduce una capa virtual que se conecta con todas las fuentes de datos y ofrece un acceso uniforme como una aplicación front-end.
Dado que no tiene un modelo de datos propio, el propósito de la capa virtual es aceptar las solicitudes entrantes, crear resultados consultando la información requerida de las bases de datos conectadas y presentar una vista unificada. La virtualización de datos reduce el coste del espacio de almacenamiento y la complejidad de la integración, ya que los datos sólo parecen estar integrados, pero residen por separado en los sistemas de origen.
5. Federación de datos
La federación de datos es similar a la virtualización de datos y suele considerarse como su subtipo. De nuevo, en la federación de datos, los datos no se copian ni se trasladan a una nueva base de datos, sino que se diseña un nuevo modelo de datos que representa una visión integrada de los sistemas de origen.
Proporciona una interfaz de consulta y, cuando se solicitan datos, los extrae de las fuentes conectadas y los transforma en el modelo de datos mejorado antes de presentar los resultados. La federación de datos es útil cuando los modelos de datos subyacentes de los sistemas de origen son demasiado diferentes y deben adaptarse a un modelo más reciente para utilizar la información de forma más eficaz.
Proceso de integración de datos
Independientemente del tipo de integración de datos, el flujo del proceso de integración de datos es similar para todos, ya que el objetivo es combinar y reunir los datos. En esta sección, repasamos un marco general de integración de datos empresariales que puede utilizar al implementar cualquier técnica de integración de datos.

1. Recogida de requisitos
El primer paso en cualquier proceso de integración de datos es reunir y evaluar los requisitos empresariales y técnicos. Esto le ayudará a planificar, diseñar y aplicar un marco que produzca los resultados esperados. Entre las áreas que hay que cubrir mientras se recopilan los requisitos se incluyen:
- ¿Necesita integrar los datos en tiempo real o por lotes en momentos programados?
- ¿Necesita crear una copia de los datos y luego integrarlos, o implementar una capa virtual que integre los datos sobre la marcha sin replicar las bases de datos?
- ¿Deben los datos integrados seguir un nuevo modelo de datos mejorado?
- ¿Qué fuentes hay que integrar?
- ¿Cuál será el destino de los datos integrados?
- ¿Qué departamentos funcionales de la organización necesitan acceder a la información integrada?
2. Perfiles de datos
Otro paso inicial del proceso de integración de datos es generar informes de perfilado o evaluación de los datos que deben integrarse. Esto le ayudará a comprender el estado actual de los datos y a descubrir detalles ocultos sobre su estructura y contenido. Un informe de perfilado de datos identifica los valores en blanco, los tipos de datos de los campos, los patrones recurrentes y otras estadísticas descriptivas que ponen de manifiesto posibles oportunidades de limpieza y transformación de datos.
3. Revisión de los perfiles en función de los requisitos
Con los requisitos de integración y los informes de evaluación en la mano, ahora es el momento de identificar la brecha entre ambos. Habrá muchas funcionalidades solicitadas en la fase de requisitos que no son válidas o no cuadran con los informes perfilados de los datos existentes. Pero la comparación entre ambos le ayudará a planificar un diseño de integración que cumpla el mayor número de requisitos posible.
4. Diseñar
Esta es la fase de planificación del proceso en la que hay que diseñar algunos conceptos clave sobre la integración de datos, como por ejemplo
- El diseño arquitectónico que muestra cómo se moverán los datos entre los sistemas,
- Los criterios de activación que deciden cuándo tendrá lugar la integración o qué la activará,
- El nuevo modelo de datos mejorado y las asignaciones de columnas que definen el proceso de consolidación,
- Las reglas de limpieza de datos, normalización, cotejo y garantía de calidad que deben configurarse para una integración sin errores, y
- La tecnología que se utilizará para implementar, verificar, supervisar e iterar el proceso de integración.
5. Implementar
Una vez diseñado el proceso de integración, es el momento de la ejecución. La ejecución puede producirse de forma incremental, es decir, integrando bajos volúmenes de datos procedentes de fuentes menos conflictivas, y aumentando iterativamente los volúmenes y añadiendo más fuentes. Esto puede ser útil para detectar cualquier error inicial que pueda surgir. Una vez completada la integración de los datos existentes, puede centrarse en la integración de los nuevos flujos de datos entrantes.
6. Verificar, validar y controlar
Durante la fase de verificación, hay que comprobar la precisión y la eficacia del proceso de integración de datos. La elaboración de perfiles de la fuente de destino puede ser una buena manera de detectar errores y validar la integración. Antes de poder confiar la configuración de la integración a las actividades futuras, hay que probar una serie de áreas, como por ejemplo
- La pérdida de datos es nula o mínima,
- La calidad de los datos no se deterioró tras la integración,
- El proceso de integración funciona siempre como se espera,
- El significado de los datos no cambió durante la integración,
- Las medidas mencionadas anteriormente siguen siendo válidas después de que haya pasado algún tiempo.
Integración y calidad de los datos: Demasiado integrados para ser diferenciados
Antes de seguir adelante, vamos a discutir un concepto importante relacionado con la integración de datos que a menudo confunde a la gente: la relación entre la integración de datos y la calidad de los datos.
Desde un punto de vista holístico, tanto la integración como la calidad de los datos tienen el mismo objetivo: facilitar el uso de los datos y hacerlo más eficiente. Para lograr este objetivo, no se puede hablar de integración de datos sin calidad de los mismos, y viceversa. Puede resultar confuso si se intenta entender dónde acaba uno y empieza el otro. Lo cierto es que ambos conceptos están demasiado integrados como para diferenciarlos y deben manejarse sin fisuras.
Los esfuerzos de integración de datos sin tener en cuenta la calidad de los mismos están abocados al fracaso. La gestión de la calidad de los datos es un catalizador de su proceso de integración de datos, ya que mejora y acelera la consolidación de los mismos.
Otra distinción entre ambos es que la calidad de los datos no es una iniciativa, sino un hábito o ejercicio que debe ser supervisado constantemente. Aunque en el caso de los almacenes de datos, la integración de datos puede producirse en momentos concretos de la semana o del mes, no se puede olvidar la calidad de los datos ni siquiera durante esa espera. Por lo tanto, la calidad de los datos es primordial para que los resultados de la integración de datos sean satisfactorios y utilizables.
Herramientas y soluciones de integración de datos
Teniendo en cuenta los grandes volúmenes de datos que las organizaciones almacenan e integran, los esfuerzos manuales están fuera de la ecuación para la mayoría de las iniciativas de integración. Utilizar la tecnología para integrar y consolidar los datos que residen en fuentes separadas puede resultar más eficaz, eficiente y productivo. Analicemos cuáles son algunas de las características comunes que puede buscar en una plataforma de integración de datos:
- La capacidad de extraer datos de una amplia variedad de fuentes, como bases de datos SQL u Oracle, hojas de cálculo y aplicaciones de terceros.
- La capacidad de perfilar conjuntos de datos y generar un informe exhaustivo sobre su estado en términos de integridad, reconocimiento de patrones, tipos y formatos de datos, etc.
- La capacidad de eliminar ambigüedades, como valores nulos o basura, eliminar el ruido, corregir errores ortográficos, sustituir abreviaturas, transformar el tipo de datos y el patrón, y mucho más.
- La posibilidad de asignar atributos pertenecientes a fuentes de datos distintas para resaltar el flujo de integración.
- La capacidad de ejecutar algoritmos de coincidencia de datos e identificar los registros que pertenecen a la misma entidad.
- La capacidad de sobrescribir valores siempre que sea necesario y fusionar registros entre fuentes para obtener el registro de oro.
- La capacidad de ejecutar la integración de datos en momentos programados o de integrarlos en tiempo real mediante llamadas a la API u otros mecanismos similares.
- La capacidad de cargar los datos integrados en cualquier base de datos de destino.
Unificación de la integración, la limpieza y el cotejo de datos
La integración de grandes cantidades de datos puede ser una iniciativa abrumadora, especialmente si se opta por una configuración de ETL o de virtualización de datos. Un entorno básico de integración de datos que reúna los datos y minimice los defectos intolerables de calidad de datos puede ser un buen punto de partida para la mayoría de las empresas. Dar prioridad al aspecto de integración de datos más importante de la consolidación de datos puede ayudarle a empezar por lo bajo y a mejorar gradualmente según sea necesario.
Puede empezar por emplear una solución de integración de datos unificada que ofrezca una variedad de conectores comunes, así como funciones incorporadas para el perfilado, la limpieza, la estandarización, el cotejo y la fusión de datos. Además, una función de programación que integra los datos por lotes en momentos configurados puede poner en marcha su iniciativa en pocos días.
DataMatch Enterprise es una de estas herramientas de consolidación de datos que puede ayudar a integrar sus datos que residen en fuentes separadas. Descargue una prueba hoy mismo o reserve una demostración con nuestros expertos para ver cómo podemos ayudarle a ejecutar su iniciativa de integración de datos.
The post La integración de datos explicada: Definición, tipos, proceso y herramientas appeared first on Data Ladder.
]]>The post Cómo afecta la mala calidad de los datos a un plan de supervivencia ante la recesión appeared first on Data Ladder.
]]>«Hay recesiones, hay caídas de la bolsa. Si no entiendes que eso va a ocurrir, entonces no estás preparado. No te irá bien en los mercados. Si vas a Minnesota en enero, debes saber que va a hacer frío. No te asustas cuando el termómetro baja de cero».
Peter Lynch
Predicción sobre la recesión mundial
Los economistas advierten de ambas cosas: una recesión en Estados Unidos y otra a nivel mundial. El descenso de las cotizaciones bursátiles -especialmente en la tecnología y el comercio minorista-, el aumento de los tipos de interés y los crecientes problemas con la cadena de suministro son los principales indicadores que influyen en esta predicción.
Ante la inminente sensación de fatalidad en el mercado, las empresas están tomando decisiones precipitadas e impulsivas. Los nuevos proyectos se detienen, los gastos se reducen demasiado y los empleados son despedidos brutalmente. La imprevisibilidad de los acontecimientos futuros se suma a la preocupación de los dirigentes empresariales que intentan sortear una posible recesión.
En medio de todo esto, los datos demuestran ser el activo más valioso de una organización que ofrece un valor real en una recesión económica.
Datos: La verdad está ahí fuera
Los datos se convierten en un salvador en los momentos en que todo lo demás falla. Un rápido vistazo a lo que ocurrió durante las anteriores recesiones económicas puede ayudarle a navegar por el presente con confianza. Los datos ofrecen un colchón a las empresas y les permiten tomar decisiones con una sensación de familiaridad y comodidad que es necesaria en tiempos sin precedentes. Pero es obvio que los datos en bruto no ofrecen la información necesaria, y deben transformarse en inteligencia empresarial y elementos procesables.
Ciclo de inteligencia empresarial
Investigación sobre Datos y catástrofes describe un ciclo de inteligencia empresarial sencillo pero potente:
El ciclo muestra cómo los datos sin procesar se convierten en información práctica:
- Una vez recogidos los datos brutos , se convierten en información verificando sus metadatos y comprobando su calidad para descartar imprecisiones e incoherencias.
- La información se convierte en conocimiento alimentando las herramientas de inteligencia empresarial.
- El conocimiento se gestiona entonces para formar planes y objetivos empresariales.
- Los líderes se reúnen para convertir esos planes y objetivos en elementos prácticos.
- Los nuevos datos brutos se recogen de nuevo tras la adopción de medidas y se convierten en información.
6 formas en que los datos ayudan en la recesión
Una inteligencia empresarial precisa y fiable ayuda a las empresas a tomar decisiones basadas en datos reales, en lugar de en conjeturas y suposiciones. He aquí 6 formas en que los datos ayudan a las empresas a mantenerse a flote durante una recesión.
1. Minimizar el riesgo
Dos decisiones pueden llevarle por caminos distintos, pero ¿cómo saber cuál de ellas tendrá un impacto mejor y más positivo para su negocio? La respuesta está en los datos del pasado. El análisis de la información del pasado puede ayudarle a evitar decisiones costosas y a medir los costes de oportunidad de las distintas vías, lo que le permitirá elegir las alternativas que ofrecen más valor a corto plazo.
2. Planificar los recursos
Una de las primeras decisiones que toman los empresarios en una crisis económica es despedir a un gran número de empleados. Pero los datos históricos han demostrado que esas decisiones se toman siempre demasiado pronto. Por ejemplo, con el inicio de la pandemia de COVID-19, el mundo experimentó la recesión más corta de la historia, que sólo duró 3 meses. Y los líderes empresariales pronto se dieron cuenta de que los recortes de personal se hicieron demasiado pronto, ya que descubrieron que la recontratación, la incorporación y la formación de los empleados era un reto mucho mayor que el de retenerlos.
3. Predecir la gravedad de la recesión
Las recesiones siempre resultan sombrías, largas y severas. Pero los datos del pasado demuestran que no es tan malo como se puede sentir al pasar por uno. Porque los plazos de cuándo llegará la recesión, cuánto tiempo se mantendrá y con qué severidad afectará a las pequeñas y grandes empresas no se ajustaban a lo que los gurús de la economía predecían. El uso de datos para comprender realmente estos aspectos de la recesión puede ayudar a basar las decisiones en información más precisa.
4. Lea las historias de éxito anteriores
Por muy mal que suenen las recesiones, ha habido historias de éxito de empresas que no sólo han sobrevivido a una, sino que han prosperado durante y después de ella. El secreto está en las decisiones que tomaron antes de la recesión. Puedes empezar por hacerte con esos casos de éxito del pasado o incluso conectar con líderes que hayan superado crisis económicas anteriores y aprender cómo lo hicieron.
5. Observar el comportamiento del consumidor
Las empresas de la cadena de suministro o del sector minorista son las que más se quejan de la recesión. Pero la verdad es que ha habido historias de éxito de cómo los pequeños minoristas crecieron en tiempos difíciles. El principal secreto aquí es entender el comportamiento del consumidor. No es que los consumidores no compren durante una crisis económica, es que pueden comprar algo diferente y en cantidades variables según la situación económica de su país.
Este es el mejor momento para invertir en plataformas de inteligencia de mercado que le proporcionen los últimos datos del mercado. Lea más sobre cómo los minoristas pueden seguir aprovechando la ola del comercio electrónico durante las recesiones económicas.
The role of data quality in the world of retail
Download this whitepaper to find out how retailers can identify if they have poor retail data quality and the most common issues associated with retail data and how to fix them.
Download6. Invertir en la mejora del funcionamiento
Los datos pueden ayudarle a comprender qué áreas de negocio requieren mejoras operativas. Dado que el negocio es lento, es un buen momento para analizar las transacciones operativas pasadas y diseñar nuevos procesos empresariales mejorados para diferentes áreas, como la experiencia y el compromiso del cliente, el ciclo de ventas, la gestión de la cadena de suministro, etc.
Mala calidad de los datos: La verdad no está ahí fuera
Es imprescindible que los datos utilizados para elaborar un plan de supervivencia a la recesión sean precisos, válidos y coherentes. Pero, en realidad, los datos están llenos de errores y defectos intolerables que hacen que la inteligencia empresarial sea bastante difícil, si no imposible. La mala calidad de los datos -si no se gestiona a tiempo- ha demostrado producir resultados poco fiables y tener un impacto devastador en una empresa.
Ciclo de inteligencia empresarial sin calidad de datos
Veamos cómo se comporta un ciclo de inteligencia empresarial cuando se le suministran datos erróneos:

- Se salta el paso más importante de convertir los datos en información.
- Los analistas y las herramientas de BI tratan de extraer directamente el conocimiento de los datos sucios.
- El «conocimiento» se convierte entonces en objetivos y planes empresariales.
- Los líderes diseñan elementos de acción a partir del plan de negocios contaminado.
Así, los líderes ordenan a sus equipos que actúen basándose en un plan que no tiene nada que ver con la realidad. Y no sólo eso, todo el tiempo y los recursos invertidos en este ciclo de BI se desperdiciaron, ya que la entrada estaba corrupta para empezar.
4 formas en que la mala calidad de los datos arruina un plan de supervivencia ante la recesión
Veamos cómo la mala calidad de los datos puede arruinar el plan de supervivencia de una empresa ante la recesión.
1. Información poco fiable de las herramientas de BI
Acabamos de ver cómo los datos sucios pueden destruir sus conocimientos de inteligencia empresarial. Si sus herramientas de BI reciben datos erróneos, los líderes pueden experimentar sugerencias inconsistentes y confusas de sus herramientas de BI o de su equipo de analistas. Basar las decisiones en este tipo de información puede llevar a su organización a perder oportunidades críticas de mercado y a perder ingresos en tiempos difíciles. Esto puede ser devastador para su negocio, ya que puede no estar preparado para soportar tales pérdidas.
2. Descompromiso con los clientes
Las empresas que compiten en un mercado desde hace décadas conocen bien a sus consumidores, en términos de demografía, sus preferencias y elecciones. Pero una inminente recesión puede cambiar eso. Observar el comportamiento de los consumidores a partir de datos obsoletos o malinterpretados puede ser perjudicial para su reputación en el mercado. Sus clientes pueden tener la sensación de que está perdiendo el contacto con ellos y de que no cumple sus expectativas. Esto puede hacer que sus competidores le roben clientes al tratar de reducir los servicios y la asistencia al cliente.
How to build a unified, 360 customer view
Download this whitepaper to learn why it’s important to consolidate your customer data and how you can get a 360 view of your customers.
Download3. Obstáculos en el cambio a la tecnología digital
Las empresas suelen detener sus iniciativas de transformación digital por miedo a una posible recesión. Pero los economistas han predicho que las recesiones son un buen momento para acelerar los proyectos de transformación digital, ya que sus costes de oportunidad son bajos. Esto sucede porque el negocio ya es lento y la contratación de profesionales técnicos es más fácil y menos costosa, ya que están siendo despedidos en toda la industria tecnológica.
A pesar de sus ventajas, las empresas se encuentran atascadas en su cambio a lo digital debido a las montañas de información que faltan, están incompletas, son incoherentes y no están estandarizadas. Cuando la calidad de los datos no alcanza el nivel requerido, se producen grandes retrasos cuando las empresas intentan digitalizar los procesos o introducir nuevas tecnologías.
4. Reducción de la eficiencia operativa y la productividad
Dado que el negocio es lento durante estos tiempos, las empresas tienden a centrarse en la mejora de la eficiencia operativa en toda la organización para centrarse en nuevas oportunidades de expansión en el mercado. Pero la mala calidad de los datos provoca serios cuellos de botella en el trabajo de todos, ya que tienen que volver a comprobar las fuentes y el contenido de los datos antes de utilizarlos en las operaciones rutinarias. La baja eficiencia operativa y los niveles de productividad son el resultado de estos problemas en el momento en que su empresa menos puede tolerarlos.
Un plan de calidad de datos antes de que llegue la recesión
No hay duda de que sus análisis deben ser oportunos y precisos para sobrevivir a una recesión. Pero la mala calidad de los datos puede destruir tanto la puntualidad como la exactitud de sus conocimientos. Por esta razón, es imperativo invertir en la gestión de la calidad de los datos ahora mismo para poder esquivar las posibles caídas de los datos defectuosos cuando llegue la recesión. Veamos los 3 pasos más importantes para hacer frente a la mala calidad de los datos cuando nos acercamos a una recesión.
1. Identificar los problemas de calidad de los datos
El primer paso es obvio: averiguar a qué se enfrenta. No todas las empresas tienen el mismo conjunto de problemas de calidad de datos. La calidad de los datos se define como la aptitud de los datos para cualquier fin previsto. Dependiendo de cómo se utilicen los datos en su empresa, puede encontrar muchas discrepancias en la gestión de la calidad de los datos. A continuación se ofrece una lista de los problemas de calidad de datos más comunes. Para saber más, consulte los 12 problemas de calidad de datos más comunes y su origen.
| No. | Data quality issue | Explanation | Example of data quality issue |
|---|---|---|---|
| 1 | Column duplication | Multiple columns are present that have the same logical meaning. | Product category is stored in two columns that logically mean the same: Category and Classification. |
| 2 | Record duplication | Multiple records are present for the same individual or entity. | Every time a customer interacts with your brand, a new row is created in the database rather than updating the existing one. |
| 3 | Invalid data | Data values are present in an incorrect format, pattern, data type or size. | Customer Phone Numbers are present in varying formats – some are stored as flat 10 digits, while others have hyphens, some are saved as a string, while others as numbers, and so on. |
| 4 | Inaccurate data | Data values do not conform to reality. | Customer Name is incorrectly stored: Elizabeth is stored as Aliza, or Matt is stored as Mathew. |
| 5 | Incorrect formulae | Data values are calculated using incorrect formulae. | Customer Age is calculated from their Date of Birth but the formula used is incorrect. |
| 6 | Inconsistency | Data values that represent the same information vary across different datasets and sources. | Customer record stored in the CRM represents a different Email Address than the one present in accounts application. |
| 7 | Missing data | Data is missing or is filled with blank values. | The Job Title of most customers is missing from the dataset. |
| 8 | Outdated data | Data is not current and represents outdated information. | Customer Mailing Addresses are years old leading to returned packages. |
| 9 | Unverified domain data | Data does not belong to a range of acceptable values. | Customer Mailing Addresses are years old leading to returned packages. |
2. Aplicar un plan de calidad de datos en semanas
Si sus conjuntos de datos están contaminados con errores, necesita utilizar una plataforma de calidad de datos, pero nada demasiado grande, algo que pueda estar en funcionamiento en cuestión de semanas y no de meses. Hay múltiples formas en que los proveedores empaquetan varios procesos de gestión de la calidad de los datos en sus herramientas, como por ejemplo
- Perfiles de datos para evaluar el estado actual de la calidad de los datos,
- Limpieza y normalización de datos para eliminar los valores nulos y el ruido, y transformar los datos en una vista estándar,
- Cotejo de datos para identificar los registros que pertenecen a la misma entidad,
- Deduplicación de datos para eliminar los registros duplicados,
- Fusión y depuración de datos para conservar la información útil y fusionar los registros para obtener el conjunto de datos de oro, libre de errores.
The definitive buyer’s guide to data quality tools
Download this guide to find out which factors you should consider while choosing a data quality solution for your specific business use case.
Download3. Acortar el ciclo acción-impacto
A la hora de implantar una herramienta de calidad de datos, muchas empresas se quedan atascadas en sistemas avanzados de gestión de datos que se encargan de principios complejos de gestión de datos, como la gobernanza de datos, la gestión centralizada, la gestión de datos maestros, así como la protección y la seguridad de los datos. Aunque estas funciones son estupendas para integrarlas en sus sistemas de datos, puede llevar mucho tiempo implantarlas y que resulten beneficiosas para su empresa.
Concéntrese en minimizar su ciclo de acción-impacto. Durante las crisis económicas, probablemente quiera algo que le ofrezca una visión rápida pero detallada de los errores de calidad de datos existentes en sus conjuntos de datos y la forma más fácil de resolverlos.
Reflexiones finales
La imprevisibilidad económica hace que los empresarios teman los acontecimientos futuros. La inteligencia empresarial y de mercado puede ofrecerles la comodidad necesaria para tomar decisiones cruciales. Invertir en herramientas de BI y en un equipo de analistas es perjudicial en estos tiempos sin precedentes, pero no podemos socavar el valor de los datos limpios, el activo que se transforma en conocimientos procesables.
Para empezar, proporcionar a sus equipos herramientas de limpieza y cotejo de datos de autoservicio puede ser muy beneficioso para producir resultados rápidos. Una herramienta de autoservicio «todo en uno» que perfile los datos, realice diversas actividades de limpieza de datos, coteje los duplicados y genere una única fuente de verdad puede convertirse en un gran diferenciador en el rendimiento de las herramientas de BI y los analistas de datos.
DataMatch Enterprise es una de esas herramientas que facilita a los equipos de datos la rectificación de los errores de calidad de datos con rapidez y precisión, y les permite centrarse en tareas más importantes. Los equipos de calidad de datos pueden perfilar, limpiar, cotejar, fusionar y purgar millones de registros en cuestión de minutos, y ahorrar mucho tiempo y esfuerzo que normalmente se desperdicia en estas tareas.
Para saber más sobre cómo puede ayudar DataMatch Enterprise, puede descargar una prueba gratuita hoy mismo o reservar una demostración con un experto.
Getting Started with DataMatch Enterprise
Download this guide to find out the vast library of features that DME offers and how you can achieve optimal results and get the most out of your data with DataMatch Enterprise.
DownloadThe post Cómo afecta la mala calidad de los datos a un plan de supervivencia ante la recesión appeared first on Data Ladder.
]]>The post 8 principios de la gestión de datos appeared first on Data Ladder.
]]>Una empresa media -con 200-500 empleados- utiliza unas 123 aplicaciones SaaS para digitalizar sus procesos empresariales. Con las grandes cantidades de datos que se generan cada día, definitivamente se necesita una forma sistemática de manejar los datos. Esto incluye la adopción de prácticas y estrategias modernas para capturar, procesar, compartir, almacenar y recuperar datos minimizando la pérdida de datos y los errores. Cualquier laguna presente en estos procesos puede poner en peligro su negocio con graves riesgos.
En este blog, hablamos de lo que significa la gestión de datos y de los principios clave de la gestión de datos que debe conocer al gestionar los datos de su organización. Empecemos.
¿Qué es la gestión de datos?
La gestión de datos es la práctica de adoptar principios, reglas, estrategias y metodologías que pueden ayudar a garantizar una utilización máxima y óptima de los datos de una organización.
Los conceptos y principios de la gestión de datos son bastante diversos, ya que se centran en una serie de procesos de datos en una empresa, como por ejemplo
- Captura e integración de datos: Garantiza la captura, integración y consolidación de los datos necesarios para que puedan utilizarse para todos los fines previstos.
- Almacenamiento de datos: Garantiza que los datos se almacenen donde sea necesario, ya sea un almacenamiento local, una nube pública o privada, o una configuración híbrida.
- Seguridad de los datos: Garantiza que los datos están a salvo de accesos no autorizados y que se aplican políticas para acceder y compartir los datos de forma segura.
- Gestión de la calidad de los datos: Garantiza que los datos se perfilan continuamente en busca de errores y se ejecutan a través de una canalización de datos para la comprobación y corrección de la calidad de los datos.
- Disponibilidad de los datos: Garantiza que los datos sean accesibles para las personas siempre que los necesiten, y que existan planes de copia de seguridad y recuperación de desastres.
8 principios de la gestión de datos
El diseño de sus procesos de gestión de datos puede ser difícil, ya que se centra en una variedad de dominios de datos. Aquí descubrirá qué son los principios de gestión de datos, ya que vemos los 8 principios de gestión de datos más importantes que debe administrar.
1. Modelado de datos
El primer y principal principio rector de la gestión de datos es el modelado de datos. El modelado de datos significa diseñar y estructurar sus activos de datos, sus propiedades y sus interrelaciones de manera lógica. A continuación se muestra un ejemplo de modelo de datos para un negocio minorista:
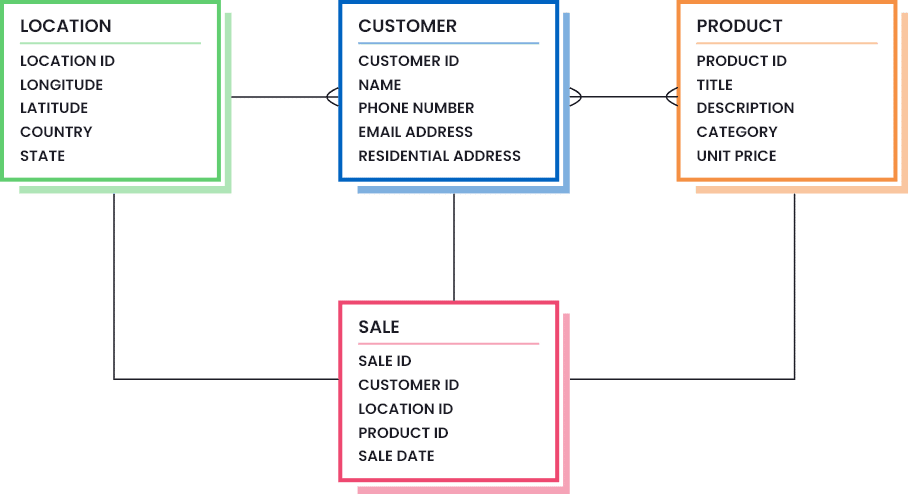
Un modelo de datos representa simplemente lo siguiente (como puede verse en el diagrama anterior):
- Los activos de datos que una organización almacena y gestiona (por ejemplo, Cliente, Producto, Ubicación y Ventas),
- Las propiedades del mundo real que almacena cada activo (por ejemplo El activo de datos del cliente tiene el ID del cliente, el nombre, el número de teléfono, la dirección de correo electrónico y la dirección residencial),
- El tipo de datos y el tamaño de cada propiedad (por ejemplo, el ID del cliente debe ser un entero con un número máximo de 12 dígitos),
- Las restricciones de relación que dos o más activos de datos tienen entre sí (por ejemplo, el cliente tiene la ubicación, el cliente compra el producto, etc.)
- La cardinalidad de la relación que muestra el número máximo de relaciones que un activo puede tener con otro (por ejemplo, un Cliente sólo puede tener una Ubicación a la vez),
- La integridad referencial que define a qué registros se puede hacer referencia a través de los activos (por ejemplo, un registro de Ventas debe referirse siempre a un ID de Cliente que exista en la tabla de Clientes).
Una organización nunca podrá gestionar sus datos de forma eficiente si no consigue relacionar con precisión los requisitos de los datos con los modelos de datos estructurados. Por este motivo, es importante recoger primero los requisitos de datos de las partes interesadas necesarias y, a continuación, iniciar el proceso de diseño. Una vez que conozca las expectativas que su equipo tiene de los datos que utiliza, podrá diseñar modelos de datos que capturen la información necesaria.
2. Funciones y responsabilidades en materia de datos
Los responsables de las empresas suelen cometer el error de responsabilizar a los usuarios de los datos de una gestión eficaz de los mismos. Pero, en realidad, hay que nombrar a varios profesionales de los datos en distintos niveles de la empresa. Esto garantiza que todos los esfuerzos e inversiones realizados para la gestión de datos no sólo se apliquen, sino que se mantengan bien durante años. Echemos un vistazo a las funciones de datos más importantes y a sus responsabilidades que debe tener en cuenta al crear un equipo de datos.
- Director de Datos (CDO): Un Chief Data Officer (CDO) es un cargo de nivel ejecutivo, único responsable de diseñar estrategias que permitan la utilización de los datos, la supervisión de la calidad de los mismos y la gobernanza de los datos en toda la empresa.
- Administrador de datos: Un administrador de datos es la persona a la que se recurre en una empresa para cualquier asunto relacionado con los datos. Están completamente al tanto de cómo la organización captura los datos, dónde los almacenan, qué significan para los diferentes departamentos y cómo se mantiene su calidad a lo largo de su ciclo de vida.
- Custodio de datos: Un custodio de datos es responsable de la estructura de los campos de datos – incluyendo las estructuras y modelos de las bases de datos.
- Ingeniero de datos: Un ingeniero de datos es responsable del modelado de datos y de la creación de sistemas que capturen, almacenen y analicen los datos con precisión.
- Analista de datos: Un analista de datos es alguien que es capaz de tomar los datos en bruto y convertirlos en ideas significativas – especialmente en dominios específicos. Una parte principal del analista de datos es preparar, limpiar y filtrar los datos necesarios.
- Otros equipos: Estos roles se consideran consumidores de datos, lo que significa que utilizan los datos – ya sea en su forma cruda o cuando se convierten en conocimientos procesables, como los equipos de ventas y marketing, los equipos de productos, los equipos de desarrollo de negocios, etc.
3. Diseño del sistema de datos
Este es otro aspecto importante de la gestión de datos que le ayuda a averiguar:
¿Dónde y cómo se recopilan, integran y alojan los datos para garantizar la máxima utilización y disponibilidad de los mismos y la mínima pérdida de datos y tiempo de inactividad?
El diseño del sistema de datos se refiere a múltiples disciplinas, como las fuentes de datos, la arquitectura, la sincronización y el alojamiento. Veamos qué cubre cada uno de ellos:
a. Entradas y salidas de datos
La primera parte del diseño del sistema consiste en identificar las fuentes de entrada y salida de datos, es decir, desde dónde se capturan los datos y a dónde se transfieren. Las organizaciones utilizan múltiples aplicaciones para capturar datos, como rastreadores de sitios web, automatización de marketing, CRM, software de contabilidad, formularios web, etc. Es necesario identificar todas esas fuentes y ver cómo se transfieren los datos entre las fuentes o a un nuevo destino.
b. Topología del sistema de datos
La topología de datos se refiere a la forma en que los sistemas de datos están interconectados entre sí. A alto nivel, puedes diseñar tu topología utilizando uno de los siguientes enfoques:
- Enfoque centralizado en el que todos los sistemas de datos se conectan a un eje central e inteligente,
- Enfoque descentralizado en el que los sistemas de datos se comunican entre sí para obtener la información necesaria.

c. Sincronización de datos
Se refiere a la forma en que los datos se mantienen actualizados a través de las fuentes. Los sistemas de gestión de datos, especialmente las soluciones MDM, se implementan en diferentes estilos arquitectónicos, dependiendo de los requisitos de la organización. Los estilos arquitectónicos más comunes para la sincronización incluyen:
- Estilo consolidado
- Los datos procedentes de diversas fuentes se introducen en un núcleo central que almacena una visión consolidada de los datos, pero no los transfiere a los sistemas de origen. Cualquier aplicación de BI o posterior puede obtener los datos del centro de operaciones según sea necesario.
- Convivencia o estilo híbrido
- Los datos procedentes de diversas fuentes se introducen en un eje central que almacena una visión consolidada de los datos, y las actualizaciones se transfieren también a todas las aplicaciones fuente conectadas.
- Estilo centralizado
- Los datos procedentes de diversas fuentes se introducen en un núcleo central que almacena una visión consolidada de los datos, pero no los transfiere a los sistemas de origen. Sin embargo, los sistemas de origen pueden consultar los datos actualizados cuando lo necesiten desde el núcleo central.
d. Alojamiento de datos
Se refiere al lugar donde se alojan o almacenan los datos. Dependiendo de las necesidades de una organización, los datos pueden almacenarse localmente en las instalaciones o guardarse en una nube pública o privada. También puede optar por una configuración híbrida en la que algunos datos se mantienen en las instalaciones y otros se alojan en la nube.
4. Calidad de los datos
Uno de los principales aspectos de la gestión de datos es la gestión de la calidad de los mismos. La presencia de defectos intolerables en su conjunto de datos demuestra que no se aplican las prácticas de gestión de datos necesarias. Si sus equipos no pueden confiar en los datos que tienen, esto afecta a su productividad y eficiencia en el trabajo. Para evitar que los errores de calidad de los datos entren en el sistema, es necesario tratar los datos entrantes a los pipelines de datos donde se realizan una serie de operaciones, como la limpieza de datos, la estandarización y el cotejo.
a. Medición de la calidad de los datos
La calidad de los datos suele indicarse en los conjuntos de datos a través de una serie de características de los mismos. Suelen llamarse dimensiones de calidad de los datos. Los indicadores de calidad de datos más comunes son:
- Exactitud: Los datos representan la realidad y la verdad.
- Validación: Los datos están presentes en el patrón y el formato correctos, y pertenecen al dominio correcto.
- Exhaustividad: Los datos son tan completos como sea necesario.
- Moneda: Los datos están actualizados o son lo más actuales posible.
- Coherencia: Los datos son los mismos (tanto en términos de significado como de representación) en diferentes fuentes de datos.
- Identificabilidad: Los datos representan identidades únicas y no contienen duplicados.
- Usabilidad: Los datos están presentes en un formato comprensible para los que pretenden utilizarlos.
b. Gestión de la calidad de los datos
Para adoptar sin problemas los principios de gestión de la calidad de los datos, hay que poner en marcha una serie de procesos de calidad de los datos, como por ejemplo
- Perfiles de datos para evaluar el estado actual de sus datos e identificar oportunidades de limpieza,
- Técnicas de limpieza y estandarización de datos para conseguir una visión estandarizada en todas las fuentes de datos,
- Cotejo de datos para identificar los registros duplicados que representan a la misma entidad,
- Deduplicación de datos para eliminar los registros duplicados,
- Purga de fusión de datos para consolidar los registros duplicados en uno solo y sobrescribir los datos siempre que sea necesario y conseguir el registro de oro.
5. Gobernanza de los datos
El término gobierno de los datos se refiere a un conjunto de funciones, políticas, flujos de trabajo, normas y métricas que garantizan un uso eficiente de la información y la seguridad, y permiten a una empresa alcanzar sus objetivos empresariales. La gobernanza de los datos está relacionada con los siguientes ámbitos:
- Implantar un control de acceso basado en funciones para garantizar que sólo los usuarios autorizados puedan acceder a los datos confidenciales,
- Diseñar flujos de trabajo para verificar las actualizaciones de la información,
- Limitar el uso y el intercambio de datos,
- Colaborar y coordinar la actualización de los datos con los compañeros de trabajo o las partes interesadas externas,
- Permitir la procedencia de los datos mediante la captura de metadatos, su origen, así como la actualización del historial.
6. Educación en materia de datos
Puedes diseñar perfectamente modelos de datos, sistemas de datos y marcos de calidad de datos, y ocuparte de todos los principios básicos de la gestión de datos, pero aun así fracasar en la consecución de tus objetivos de datos, y el principal culpable de ello es la falta de educación en materia de datos entre los miembros de tu equipo. Si su equipo no entiende cómo funcionan los sistemas de datos en su organización, probablemente los manejará mal o los utilizará de manera ineficiente.
Para que los miembros de su equipo puedan aprender a manejar los datos, debe empezar por documentarlo todo. Y difundir ese conocimiento a través de planes de aprendizaje que destaquen diversos aspectos de los datos, como:
- Lo que contiene,
- Qué significa cada atributo de los datos,
- Cuáles son los criterios de aceptabilidad de su calidad,
- ¿Cuál es la forma correcta e incorrecta de introducir/manipular datos?
- ¿Qué datos utilizar para conseguir un determinado resultado?
Además, estos cursos pueden crearse en función de la frecuencia con la que determinados roles utilizan los datos (diaria, semanal o anualmente).
7. Protección de datos
Las estrategias de protección de datos abarcan algunas de las medidas de seguridad más importantes. Los tres ámbitos principales que se incluyen en la protección de datos son:
- Seguridad de los datos: Salvaguardar los datos de la manipulación de ataques maliciosos,
- Control de acceso a los datos: Controlar quién puede acceder a los datos y cuándo,
- Disponibilidad de los datos: Garantizar la copia de seguridad de los datos y su restauración en caso de pérdida o indisponibilidad de los mismos.
Los términos «protección de datos» y «seguridad de los datos» suelen utilizarse indistintamente, pero en realidad ambos se refieren a conceptos ligeramente diferentes. La protección de datos se refiere a la protección de los datos contra la pérdida, el daño o la corrupción, y a la garantía de la disponibilidad de los datos, mientras que la seguridad de los datos se refiere a la protección de los datos contra los ataques maliciosos y la manipulación.
Sin embargo, ambos son cruciales para permitir una gestión de datos de calidad.
8. Cumplimiento de los datos
Las normas de cumplimiento de datos (como el GDPR, la HIPAA y la CCPA, etc.) están obligando a las empresas a revisar sus estrategias de gestión de datos. Según estas normas de cumplimiento de datos, las empresas están obligadas a proteger los datos personales de sus clientes y a garantizar que los propietarios de los datos (los propios clientes) tengan derecho a acceder a ellos, modificarlos o borrarlos.
Además de estos derechos concedidos a los propietarios de los datos, las normas también responsabilizan a las empresas de seguir los principios de transparencia, limitación de la finalidad, minimización de los datos, exactitud, limitación del almacenamiento, seguridad y responsabilidad. Es muy difícil cumplir estas normas si los datos subyacentes no están bien gestionados. Y la falta de cumplimiento puede limitar las operaciones de su empresa, especialmente desde el punto de vista geográfico.
Envoltura
Y ahí lo tiene: los 8 principios principales de gestión de datos que debe adoptar para maximizar la eficacia de los datos en toda su organización. Dado que los datos son una parte integral de una empresa, la gestión de datos bien hecha le ayuda a alcanzar sus metas y objetivos de forma eficaz y sencilla.
Si su empresa aún no ha adoptado ningún principio de gestión de datos, está bien empezar por un lugar y potencialmente crecer a través de las disciplinas a medida que las cosas caen en su lugar. La gestión de la calidad de los datos es una de esas áreas que puede tener un gran impacto positivo en el menor tiempo posible.
Después de haber proporcionado soluciones de limpieza y cotejo de datos a empresas de la lista Fortune 500 en la última década, entendemos la importancia de mantener los datos libres de errores. Nuestro producto, DataMatch Enterprise, le ayuda a limpiar y estandarizar sus conjuntos de datos, y a eliminar los registros duplicados que representan la misma entidad.
Puede descargar la versión de prueba gratuita hoy mismo o programar una sesión personalizada con nuestros expertos para entender cómo nuestro producto puede ayudar a implementar las mejores prácticas para alcanzar y mantener la calidad de los datos a nivel empresarial.
The post 8 principios de la gestión de datos appeared first on Data Ladder.
]]>The post Gestión de la calidad de los datos: Qué, por qué, cómo y mejores prácticas appeared first on Data Ladder.
]]>The post Gestión de la calidad de los datos: Qué, por qué, cómo y mejores prácticas appeared first on Data Ladder.
]]>The post Cómo mejorar la calidad de los datos en los servicios financieros appeared first on Data Ladder.
]]>El 24% de las aseguradoras afirma que «no confía mucho» en los datos que utiliza para evaluar y fijar el precio del riesgo.
Inteligencia Corinium
La recesión económica y los problemas financieros a los que se enfrentan las empresas hoy en día indican la importancia de utilizar los datos para predecir acontecimientos futuros. Pero las ambigüedades presentes en los datos financieros pueden llevar a las empresas a basar decisiones cruciales en datos inexactos y a sufrir las consecuencias. Los bancos, las aseguradoras, las empresas hipotecarias y otras empresas que ofrecen servicios financieros no son inmunes a la pesadilla de la calidad de los datos. De hecho, estas empresas experimentan los mayores costes derivados de la mala calidad de la información financiera.
En este blog, trataremos el significado de la calidad de los datos en los servicios financieros, cómo beneficia a las personas y a las organizaciones, los problemas comunes de calidad de datos presentes en los datos financieros y cómo mejorar la calidad de la información financiera.
¿Qué es la calidad de los datos en los servicios financieros?
La calidad de los datos en los servicios financieros significa que los datos financieros capturados, almacenados, procesados y presentados por las instituciones financieras cumplen su objetivo. Se sabe que cualquier dato que no cumpla su propósito es de mala calidad y debe ser probado y verificado antes de que pueda ser utilizado eficazmente.
Las instituciones financieras -como los bancos, las compañías de seguros, las empresas hipotecarias o de corretaje, los inversores, los acreedores o los prestamistas- utilizan datos en casi todos los procesos empresariales. Los datos financieros se utilizan para:
- Preparar estados financieros e informes para uso interno y para los clientes,
- Aprobar los préstamos y completar el proceso de suscripción,
- Detectar o prevenir actividades fraudulentas, como el robo de datos o las solicitudes falsas,
- Identificar a las personas que tienen más probabilidades de no pagar sus préstamos,
- Evaluar los riesgos asociados a las decisiones financieras, como el riesgo operativo o de crédito, etc.
Es obvio que la mala calidad de los datos puede afectar negativamente a la ejecución y los resultados de estos procesos. Alimentar estos procesos con datos precisos y limpios es perjudicial para proteger la credibilidad de las instituciones financieras.
¿Por qué es importante la calidad de los datos en los servicios financieros?
Dado que los datos están estrechamente integrados en el sector de los servicios financieros, es muy importante que los datos estén libres de errores. Los datos de alta calidad, limpios y sin errores, permiten a los clientes confiar en sus bancos de inversión y compañías de seguros. Veamos la importancia de la calidad de los datos en el sector de los servicios financieros y los beneficios que puede obtener al garantizar la calidad de sus datos financieros.
1. Evaluar, planificar y mitigar el riesgo
El riesgo es inevitable en ciertas actividades financieras, ya sea para invertir en una empresa, prestar dinero a un prestatario o aprobar préstamos o solicitudes de hipotecas. Pero una planificación inteligente del riesgo es crucial para sobrevivir en el mundo financiero. Con un cuidadoso análisis de los datos y una evaluación del riesgo, se puede mitigar el riesgo y tomar mejores decisiones sobre los rendimientos esperados, la rentabilidad y otras alternativas. Pero para ello, necesita datos correctos, precisos y relevantes que le ayuden a esquivar los riesgos financieros y las posibles pérdidas que puedan existir.
2. Detectar y prevenir las actividades fraudulentas
Los bancos, las compañías de seguros y los inversores que tienen una mala calidad de datos son más susceptibles de sufrir comportamientos fraudulentos y bajas. Esto se debe a que las lagunas en la calidad de los datos permiten a los defraudadores robar la identidad, hacer solicitudes falsas, eludir los controles de reapertura y realizar ataques maliciosos a los datos sensibles almacenados por las organizaciones financieras. Los datos limpios, precisos y consolidados le permiten detectar anomalías a tiempo y evitar actividades fraudulentas.
3. Permitir la digitalización de los procesos financieros
La banca digital, los pagos en línea y las solicitudes de crédito en línea están revolucionando el sector financiero. Pero el éxito de la implantación y ejecución de estos servicios digitales sólo es posible con datos de alta calidad. Muchos banqueros e inversores siguen manteniendo archivos físicos, ya que los datos están dispersos en diferentes fuentes y requieren una intervención manual para ser comprendidos según sea necesario. La gestión de la calidad de los datos permite a las instituciones financieras digitalizar cualquier aspecto de su negocio u oferta de servicios.
4. Garantizar la fidelidad de los clientes
Cuando los registros de los clientes se cotejan, fusionan y consolidan para representar una visión completa de 360 grados, resulta más fácil aprovechar las experiencias personalizadas de los clientes, así como garantizar su privacidad y seguridad. Cuando los datos están dispersos en diferentes fuentes -incluidos los archivos locales y físicos, las aplicaciones de terceros y los envíos de formularios web- resulta imposible ofrecer una experiencia conectada a sus clientes y generar confianza y fidelidad.
5. Permitir una puntuación de crédito precisa para la aprobación de préstamos
Cuando se trata de prestar dinero a los prestatarios, es crucial que los inversores y los banqueros comprendan la responsabilidad de sus decisiones. Deben validar la identidad y la puntuación de crédito del solicitante, así como calcular el valor y el tipo de interés que se utilizará para el préstamo. Una buena calidad de los datos puede eliminar cualquier discrepancia o retraso que pueda surgir en el proceso de suscripción y asegurarse de que está invirtiendo en la persona adecuada en el momento adecuado.
6. Cumplir con las normas reglamentarias
Las normas de cumplimiento, como la lucha contra el blanqueo de capitales (AML) y la lucha contra la financiación del terrorismo (CFT), obligan a las instituciones financieras a revisar su gestión de datos en los servicios financieros. Para cumplir estas normas, estas empresas deben supervisar las transacciones de sus clientes para detectar delitos financieros, como el blanqueo de capitales y la financiación de actividades terroristas. Con una información inexacta y de mala calidad, las instituciones financieras no informan a tiempo de las actividades anormales o inusuales a las autoridades pertinentes.
7. Facilitar el análisis predictivo
La ciencia de los datos ha evolucionado para permitir predicciones y conocimientos en tiempo real en el mundo de las finanzas y los posibles riesgos asociados a las actividades de financiación. Los inversores predicen la viabilidad de la inversión en un determinado mercado, o qué acciones serán más rentables a largo plazo. Estos cálculos no serán precisos ni pertinentes si los datos utilizados para estas estadísticas son de mala calidad. Por lo tanto, otra gran ventaja de la calidad de los datos es permitir a los analistas y científicos de datos hacer predicciones precisas sobre los beneficios financieros.
Problemas comunes de calidad de datos en los servicios financieros
Hablamos de cómo la calidad de los datos ofrece un gran valor a las instituciones financieras. En esta sección, veremos cómo se ve la mala calidad de los datos en diferentes instituciones financieras, como los problemas de calidad de datos en la banca o los problemas de calidad de datos en las compañías de seguros. Puede leer más sobre los problemas de calidad de datos más comunes y su origen.
| Problema de calidad de los datos | Explicación | Ejemplo de mala calidad de datos en los servicios financieros |
| Datos inexactos | Los datos no representan la realidad ni la verdad. | El nombre legal completo de un cliente está mal escrito en el contrato de préstamo. |
| Datos que faltan | Los datos no son tan completos como se necesitan. | 2 de cada 15 cláusulas de un contrato de préstamo se dejan en blanco. |
| Registros duplicados | Los datos contienen duplicados y no representan identidades únicas. | La presencia de registros de clientes duplicados permite la solicitud de múltiples préstamos. |
| Unidades de medida variables | Los datos se almacenan en distintas unidades de medida. | Las transacciones internacionales almacenan los valores monetarios en las monedas locales, en lugar de una unidad comercial estándar, como el dólar estadounidense. |
| Formatos y patrones variables | Los datos se almacenan en diferentes formatos y patrones. | Los números de teléfono de los clientes se almacenan en diferentes patrones: algunos tienen códigos internacionales, mientras que otros ni siquiera tienen códigos de área. |
| Información obsoleta | Los datos no están actualizados o no son lo más actuales posible. | Las transacciones tardan demasiado en aparecer en los registros de los clientes, lo que hace que los procesos del sistema sean susceptibles de un cálculo incorrecto. |
| Dominio incorrecto | Los datos no pertenecen a un dominio de valores correctos. | Los códigos de moneda utilizados no pertenecen al dominio ISO. |
| Inconsistencia | Los datos no son los mismos en las distintas fuentes. | Se utilizan diferentes tipos de cambio para los distintos segmentos de clientes de la organización. |
| Irrelevancia | Los datos no ofrecen ningún valor a sus usuarios. | Los empleados obtienen la información requerida después de aplicar múltiples filtros, clasificaciones y reglas de priorización. |
¿Cómo mejorar la calidad de la información financiera?
Los problemas de calidad de los datos pueden costarle mucho dinero, especialmente si se encuentra en el sector financiero. Las empresas que ofrecen servicios financieros necesitan probar y verificar sus datos antes de alimentar los procesos empresariales críticos. Deben tomarse medidas calculadas para evitar que se produzcan problemas de calidad de datos en el sistema, así como para remediar los problemas que ya existen. A continuación, veremos las iniciativas más importantes que las organizaciones financieras pueden adoptar para garantizar la calidad de los datos.
1. Conseguir la aprobación de la dirección y la gerencia
El primer paso para hacer posible la cultura de la calidad de los datos en cualquier organización es involucrar a los líderes empresariales y al resto del personal directivo. Puede empezar por llamar su atención sobre los problemas de calidad de los datos que están presentes en los conjuntos de datos. Los informes sobre la calidad de los datos generados mediante la elaboración de perfiles de datos pueden ser útiles para informar a la alta dirección y a otros miembros del personal sobre el tipo de problemas de calidad de los datos a los que se enfrenta su institución.
Además, puede obtener una muestra de datos de actividades financieras recientes y calcular el coste de la mala calidad de los datos utilizando el método de la Medición del Viernes por la Tarde. Esto le ayudará a construir un caso contra la mala calidad de los datos y a obtener las aprobaciones y los compromisos necesarios para ejecutar las medidas de calidad de los datos.
2. Aplicar tres niveles de control de calidad de los datos
El control de calidad de los datos es cada vez más avanzado a medida que surgen nuevas técnicas y tecnologías. Esto ayuda a los bancos y a las compañías de seguros a permitir múltiples niveles de control de calidad de los datos. Por ejemplo, en el primer nivel y en el inicial, se puede empezar haciendo una rápida comprobación de los hechos y solucionando los problemas de calidad de los datos que pueda haber. A este nivel, hay que asegurarse de que el conjunto de datos está completo, es preciso y está normalizado.
En el segundo nivel, usted desea implementar un análisis estadístico más profundo de su conjunto de datos. Esto le ayudará a calcular las variaciones estándar de los valores numéricos y a detectar las anomalías que puedan producirse. La elaboración de perfiles de datos es una buena técnica para realizar este tipo de análisis estadístico de los datos. En el tercer y último nivel, puede utilizar herramientas complejas de aprendizaje automático e IA que pueden predecir los posibles problemas de calidad de los datos en tiempo de ejecución que sus fuentes son propensas a tener.
3. Conciliar y consolidar los registros duplicados
La duplicación de datos es uno de los mayores problemas de calidad de datos a los que se enfrentan los bancos y las compañías de seguros. Deben emplear un marco de calidad de datos que coteje los duplicados y los consolide en uno solo. Los registros pueden cotejarse en tiempo de ejecución con cada actualización o procesarse en lotes a intervalos regulares. Más información sobre el procesamiento por lotes frente a la validación de la calidad de los datos en tiempo real.
El proceso de reconciliación de registros o deduplicación de datos consiste en los siguientes pasos:
- Perfilar los datos para resaltar los errores,
- Ejecución de técnicas de análisis, limpieza y normalización de datos para lograr una visión coherente,
- Coincidencia de registros que pertenecen a la misma entidad (exactamente en un identificador único o coincidencia difusa en una combinación de campos),
- Fusionar los registros para eliminar la información innecesaria y conseguir una única fuente de verdad.
4. Utilizar la tecnología para la gestión de la calidad de los datos
La utilización de la tecnología para lograr un ciclo de vida sostenible de la gestión de la calidad de los datos es el núcleo de la mejora de la calidad de los datos en cualquier institución financiera. No se promete que ningún proceso funcione bien, ni que ofrezca el mejor rendimiento de la inversión, si no se automatiza y optimiza mediante la tecnología. Invierta en la adopción de un sistema tecnológico que cuente con todas las funcionalidades que necesita para garantizar la calidad de los datos en todos los conjuntos de datos.
Por muy capacitado que esté su equipo de calidad de datos, seguirá teniendo dificultades para mantener unos niveles aceptables de calidad de datos hasta que se les proporcione las herramientas adecuadas. Aquí es donde una herramienta de gestión de la calidad de los datos puede resultar útil. Una herramienta de autoservicio «todo en uno» que perfile los datos, realice varias actividades de limpieza de datos, coteje los duplicados y genere una única fuente de verdad puede convertirse en un gran diferenciador en el desempeño de los administradores de datos, así como de los analistas de datos.
Conclusión:
Comprender los problemas de calidad de los datos financieros y elegir un marco adecuado para rectificar estos errores es una tarea difícil. En muchas situaciones, una sola técnica no es suficiente, y se utiliza una combinación de técnicas para solucionar con precisión los problemas de calidad de los datos. Por ello, la necesidad de herramientas digitales es cada vez mayor. Herramientas que no sólo optimizan el tiempo y el esfuerzo, sino que también seleccionan inteligentemente las técnicas de calidad de datos en función de la naturaleza de su estructura y valores.
DataMatch Enterprise es una de estas herramientas que le ayuda a limpiar y cotejar sus datos para permitir un análisis preciso y una visión completa. Ofrece una serie de módulos que admiten datos procedentes de distintas fuentes, limpian y estandarizan valores, permiten la asignación de campos, sugieren una combinación de definiciones de coincidencias específicas para sus datos y fusionan datos para obtener una visión completa de sus finanzas.
Para saber más, inscríbase en una prueba gratuita hoy mismo o reserve una demostración con nuestros expertos para empezar a arreglar la calidad de su información financiera.
The post Cómo mejorar la calidad de los datos en los servicios financieros appeared first on Data Ladder.
]]>The post Calidad de los datos en la sanidad: retos, limitaciones y medidas para mejorar la calidad appeared first on Data Ladder.
]]>Por desgracia, ma mayoría de los centros sanitarios se ven acosados por la mala calidad de los datos y el gran retraso de las historias clínicas, que deben mejorarse para que sean accesibles y utilizable. Los sistemas anticuados, la escasa cultura de datos y la reticencia a incorporar nuevas tecnologías son algunos de los mayores obstáculos para data calidad en la asistencia sanitaria.
La regla es sencilla: si las autoridades sanitarias quieren mantener y mejorar la asistencia sanitaria a un nivel óptimo, deben garantizar el cumplimiento de las normas de calidad de los datos.
En este rápido post, trataremos lo que significa la calidad de los datos para la sanidad, sus retos, limitaciones y los pasos inmediatos que pueden dar los líderes del sector para mejorar la calidad de los datos.
¿Qué significa la calidad de los datos para la sanidad?
 Los datos sanitarios organizados, agregados y transformados en un formato significativo proporcionan
Los datos sanitarios organizados, agregados y transformados en un formato significativo proporcionan
información sanitaria
que puede utilizarse para:
- Oomentar la atención al paciente con datos precisos
- Consolidar los datos para obtener una visión precisa de los pacientes
- Permitir la confianza en la fiabilidad de los datos
- Crear informes con estadísticas fiables
- Permitir a los empleados y al personal tomar decisiones críticas basadas en datos precisos
Dado que es mucho lo que está en juego, es de suma importancia que los datos sanitarios sean
organizados, válidos, precisos y accesibles.
.
¿Cómo se determina la calidad de los datos?
En el ámbito sanitario, la calidad de los datos se refiere a de los usuarios nivel de confianza en los datos. Esta confianza es máxima si se mantienen las siguientes normas.
Exactitud y validez: La fuente de datos original no es engañosa ni está corrupta
Ejemplo de precisión y validez:
- Los datos de identificación y la dirección del paciente son válidos
- Los signos vitales se registran dentro de los parámetros de valores aceptables
- Los códigos utilizados en los hospitales para clasificar las enfermedades y los procedimientos se ajustan a normas predefinidas
Fiabilidad y coherencia:
La información sigue una norma establecida en toda la organización
Ejemplos de fiabilidad y coherencia:
- La edad del paciente registrada en un registro es la misma en todos los demás registros
- El nombre/sexo/estado civil correcto es el mismo en todos los registros
- El formato correcto del número de teléfono/dirección es el mismo en todos los registros
Exhaustividad:
Todos los campos de datos requeridos están presentes
Ejemplos de exhaustividad:
- Las notas de enfermería, incluyendo el plan de enfermería, las notas de progreso, la presión arterial, la temperatura y otros gráficos están completos con las firmas y la fecha de entrada
- Para todos los registros médicos/sanitarios, los formularios pertinentes están completos, con firmas y fechas de asistencia.
- En el caso de los pacientes ingresados, la historia clínica contiene un registro preciso de la enfermedad principal y otros diagnósticos y procedimientos relevantes, así como la firma del médico que los atiende.
Actualidad y oportunidad:
los datos están actualizados
Ejemplos de puntualidad:
- Los datos de identificación del paciente se registran en el momento de la primera asistencia y están fácilmente disponibles para identificar al paciente en cualquier momento.
- El historial médico del paciente, la historia de la enfermedad/problema actual detallada por el paciente y los resultados de la exploración física se registran en la primera asistencia a una clínica o ingreso en el hospital.
- Los informes estadísticos están listos en un plazo determinado, tras haber sido comprobados y verificados.
Accesibilidad:
Los datos están disponibles para las personas autorizadas como y cuando sea necesario
Ejemplos de accesibilidad:
- Los registros médicos/sanitarios están disponibles cuando y donde se necesiten en todo momento.
- Los datos extraídos están disponibles para su revisión cuando y donde sea necesario.
- En un sistema de registro electrónico de pacientes, la información clínica está fácilmente disponible cuando se necesita.
La calidad de los datos en la sanidad es de vital importancia no sólo para la atención a los pacientes, sino también para controlar el rendimiento de los servicios sanitarios y los empleados. Los datos recogidos y presentados deben cumplir estas normas. ¿El problema? La dependencia de los métodos tradicionales de gestión de datos hace que los hospitales y los intercambios de información (HIE) tengan problemas de correspondencia con los pacientes, algoritmos deficientes, procesos caóticos, ineficacia operativa, escaso conocimiento de los datos y mala calidad de los mismos.
Los datos de alta calidad incorporan estos estándares internacionalesnormas internacionalmente seguidasSin embargo, las limitaciones actuales en términos de tecnología, recursos y procesos han hecho que los centros sanitarios tengan dificultades para alcanzar estos objetivos.
Tl COVID-19 es un ejemplo perfecto de cómo los retos en la calidad de los datos afectan a la gestión de la pandemia. Organizaciones que fueron impulsados por los datos respondieron rápidamente con aplicaciones, análisis predictivos y modelos de atención al paciente que ayudaron al mundo a hacer frente. Los que anteriormente transformaciones digitales ignoradas fueron sacudidas para que se dieran cuenta de la necesidad de adaptarse a las tecnologías ML/AI (para las que los datos precisos son la base).
Cómo el COVID-19 ha puesto de manifiesto los retos y limitaciones de la calidad de los datos en el sector sanitario
Las pandemias siempre han supuesto un reto para la infraestructura del sector sanitario, pero el COVID-19 ha añadido un nuevo reto: el de la transformación digital y la necesidad de mejorar los datos agregados.
Los centros de salud están en el punto de mira‘ de la cabeza tratando de aprovechar el en tiempo real de datos para tomar decisiones críticas. Parte de lo que hace que esto sea tan difícil es la actual infraestructura de datos anticuada que todavía depende de métodos manuales para la entrada y agregación de datos. El complejo almacenamiento de datos, unido a la disparidad de las fuentes de datos y a la falta de formación del personal en materia de datos, dificulta la recopilación, el tratamiento y la consolidación de los datos para ofrecer el imagen completa de un paciente – las implicaciones de lo que da lugar a análisis sesgados y datos parcheados que proporcionan una visión nada precisa de la pandemia.
En un brillante artículo sobre el impacto de la mala calidad de los datos en la respuesta de COVID-19,
Datanami
informa de que los recuentos de nuevos casos y los datos de las camas de hospitalización son manualmente por los hospitales y que crea un reto para conseguir la alta confianza en esos datos actuales de «cabezas y camas».
El volumen y la variedad de datos generados durante esta pandemia son inimaginables. Los centros sanitarios se ven presionados a dar sentido a estos datos con rapidez para hacer frente a los retos, pero la dependencia de los procesos manuales, un enfoque generalmente lento de las iniciativas impulsadas por la tecnología y el uso existente de sistemas heredados han dificultado la toma de decisiones en tiempo real.
Afortunadamente, no todo está condenado. La pandemia ha acelerado el uso de herramientas y tecnologías que permiten a hospitales, centros sanitarios, gobiernos, empresas farmacéuticas y organizaciones de investigación agregar y analizar una multitud de conjuntos de datos diversos para producir soluciones (como aplicaciones móviles que predicen los riesgos), directrices de atención al paciente y la creación de vacunas en un tiempo récord.
¿Qué medidas inmediatas puede tomar el sector para alcanzar los objetivos de calidad de los datos?
Liderazgo, formación, cambio de cultura son algunos de los consejos más comunes que dan los expertospero estos pasos requieren a largo plazo a largo plazo. En un momento en el que los líderes se ven presionados para dar prioridad a la calidad de los datos, necesitan tomar medidas inmediatas y procesables. Entre ellas se encuentran:
Realización de una auditoría de calidad de datos:
Las soluciones sólo pueden derivarse si se conoce exactamente el problema al que se enfrenta la organización. Por ejemplo:
- A¿Sus equipos tienen dificultades para consolidar los datos de los pacientes procedentes de varios recursos para la elaboración de un informe?
- I¿tiene su centro problemas con los errores al introducir los datos?
- ¿Tiene controles de datos deficientes?
- ¿Cuáles son los errores más comunes que se encuentran en sus registros?
Hay que plantearse estas y otras muchas preguntas. Los registros deben ser extraídos y evaluados para ver si cumplen con los estándares de calidad definidos.
Invertir en una herramienta de calidad de datos de autoservicio:
Lo más probable es que su equipo siga confiando en la herramienta ETL para limpiar y transformar los datos. Los métodos manuales no pueden utilizarse para procesar datos con un volumen y una variedad exponenciales. volumen y variedad. Aquí es donde las herramientas de calidad de datos de autoservicio basadas en ML resultan útiles. Ellos reemplazarmanual la limpieza de datos o la estandarización esfuerzos con procesos rápidos y automatizados. Por ejemplo, la normalización de los datos hospitalarios lleva meses de esfuerzo e implica procesos complejos como garantizar los formatos correctos de [name] [date] [phone number] . Con una herramienta de autoservicio, se lleva a sólo unos minutos parapara poner los nombres en mayúsculas, eliminar los espacios en blanco, los errores de dedo gordo y mucho más para un millón de filas.
Con la herramienta de calidad de datos adecuada, puede realizar la limpieza de datos, la deduplicación de datos, la correspondencia de datos y la consolidación de datos, todo dentro de una plataforma, sin código, utilizando una interfaz de apuntar y hacer clic.
Automatice la preparación de los datos:
La automatización es el futuro. Para el sector sanitario, la automatización es una necesidad que puede repercutir positivamente en la atención al paciente, la gestión de recursos, la gestión de sistemas, las estadísticas, la financiación y mucho más. Las viejas creencias y la dependencia de procesos obsoletos deben ser sustituidas por la innovación y la automatización con el objetivo fundamental de permitir que los recursos humanos se centren más en el análisis y la toma de decisiones.
Definir las normas de calidad de los datos:
Los datos deben medirse para reflejar las dimensiones de las normas de calidad de los datos. Para empezar, las organizaciones deben asegurarse de que sus datos actuales son precisos, completos y válidos.
Haga de la calidad de los datos un hábito organizativo:
Las funciones de la calidad de los datos, como la limpieza de datos o la normalización de los mismos, no deben realizarse sólo cuando sean necesarias. Las organizaciones deben desarrollar una rutina para limpiar y mantener los datos actualizados. Los empleados con acceso a estos datos deben recibir formación para comprender la calidad de los datos y las implicaciones que tiene en las aplicaciones posteriores. Este paso en particular no requiere un cambio organizativo, sino que puede llevarse a cabo simplemente creando un calendario, asignando un recurso y dotándolo de la herramienta adecuada para realizar el trabajo.
¿Cómo ayuda Data Ladder?
Escalera de datos DataMatch Enterprise es la mejor solución de su clase diseñada para ayudar al sector sanitario en la gestión de la calidad de los datos. Con Data Ladder, su equipo puede procesar terabytes de datos, consolidar múltiples fuentes de datos, limpiar y transformar millones de filas de datos en sólo 45 minutos.
El ISD es la herramienta elegida por las organizaciones sanitarias debido a su interfaz fácil de usar, 100% de vinculación de registros y su capacidad para realizar transformaciones de datos. SIN CÓDIGO.
El ISD puede ayudar a los sistemas sanitarios con:
Vinculación de registros para estudios longitudinales
La vinculación de datos es el proceso de vincular/combinar/reunir múltiples fuentes de información sobre un individuo o entidad. La combinación de información tiene varias ventajas:
- Se pueden realizar estudios longitudinales de poblaciones enteras para comprender las tendencias de la enfermedad y los retos correlativos.
- Aplicar cambios o desarrollar nuevas políticas sanitarias a la luz de los datos disponibles.
- Los expertos pueden descubrir o resolver preguntas con respuestas que un solo conjunto de datos no puede proporcionar.
- La información histórica, como los datos administrativos, los datos de acontecimientos vitales, etc., recopilados a lo largo de la vida de una población, es valiosa para estudiar las enfermedades e identificar a las poblaciones susceptibles.
- La combinación de múltiples conjuntos de datos permite a las organizaciones evaluar el estado de la calidad de sus datos a un nivel más profundo e identificar las posibles lagunas que hay que cubrir.
- Se pueden desarrollar modelos de simulación para estudiar diferentes poblaciones
También conocida como «vinculación deregistros«, la vinculación de datos fue propuesta por primera vez por Halbert L. Dunn en 1946 en su artículo titulado «Record Linkage», en el
American Journal of Public Health,
donde sugirió la creación de un «libro de la vida» para cada individuo desde su nacimiento hasta su muerte, incorporando los principales acontecimientos sanitarios y sociales. Este libro sería una recopilación de todos los registros existentes para crear un archivo singular para su uso en la planificación de los servicios sanitarios.
Desde entonces, los centros sanitarios de todo el mundo, incluidos los de Estados Unidos, Canadá, Inglaterra, Dinamarca y Australia, se han esforzado por crear sistemas de vinculación de datos. Estos sistemas contienen conjuntos de datos sobre nacimientos, defunciones, ingresos hospitalarios, asistencias a urgencias y mucho más. Algunos países tienen incluso amplios registros sobre salud mental, educación, genealogía y datos de investigación específicos.
En Estados Unidos, la preocupación por la privacidad, la confidencialidad y la seguridad de la información de los pacientes ha dado lugar a políticas y normativas cada vez más estrictas , siendo la HIPAA la política de privacidad del paciente más conocida. Con estas políticas en vigor, las organizaciones no tienen acceso a identificadores únicos que puedan utilizarse fácilmente para vincular los registros. Cuando esto ocurre, se utilizan otros componentes de la fuente de datos para identificar los registros. En este caso, la vinculación de registros implica varias etapas y el uso de la concordancia probabilística para cotejar los datos.
Existe un gran abismo entre el sistema de datos ideal y el actual sistema federal de datos sanitarios. La escasa calidad de los datos almacenados en sistemas fragmentados y la ausencia de un control de la calidad hacen que los centros sanitarios se enfrenten a importantes retos a la hora de prestar una asistencia sanitaria de alto valor.
Además, la expansión sin precedentes de los datos de los pacientes procedentes de fuentes como Internet y los móviles ha aumentado el volumen y la variedad de los datos de forma exponencial, lo que dificulta a las organizaciones la vinculación de las historias clínicas electrónicas (HCE) a través de los sistemas y entre ellos, una actividad necesaria para una serie de fines que incluyen la investigación sanitaria, los estudios longitudinales de poblaciones, la prevención y el control de enfermedades, la atención al paciente y mucho más.
Análisis, limpieza y normalización de datos sin código
El ISD permite una limpieza de datos fácil y con un solo clic. A diferencia de las herramientas ETL o de Excel, no hay ningún esfuerzo manual. Con el ISD, los usuarios pueden:
- Transforme los datos deficientes simplemente haciendo clic en las casillas de verificación.
- Normalizar el estilo del texto.
- Eliminar los caracteres no deseados
- Eliminar las erratas accidentales durante la introducción de datos (¡son difíciles de detectar!)
- Limpiar los espacios entre letras/palabras
- Transformar los apodos en nombres reales (Juan en lugar de Johnny)
El ISD permite uniformar fácilmente los datos al permitir al usuario elegir entre más de una docena de opciones de normalización que pueden aplicarse a
cientos de millones de registros a la vez (probado con más de 2.000 millones de
+ registros).
Permitir la implantación de un marco de calidad de datos
La plataforma DME es un marco que permite a las organizaciones encontrar un punto de partida para sus objetivos de mejora de la calidad de los datos. No sólo pueden limpiar y preparar sus datos, sino que también pueden convertirlo en una parte consistente de su rutina diaria a la mitad del coste. Los datos sanitarios deben cumplir las normas de calidad de datos descritas anteriormente, lo que significa que las instituciones sanitarias deben aplicar un marco de calidad de datos que garantice la uniformidad, la precisión y la coherencia. Y deben cumplir estas normas rápidamente.
DME, al ser una solución de gestión de la calidad de los datos, permite a los usuarios perfilar, estandarizar y limpiar miles de millones de registros de múltiples fuentes de datos a una velocidad y precisión récord. Además, con la capacidad de integrar más de 500 fuentes de datos, los usuarios pueden actualizar y modificar directamente sus fuentes de datos sin la molestia de las herramientas de terceros.
Conclusión – Ayude a su organización a obtener datos precisos y fiables para mejorar la calidad de la atención al paciente
Para ser útiles, los datos deben ser correctos, completos, fiables y precisos. Los datos defectuosos conducen a errores en la toma de decisiones, errores letales en la atención al paciente (como diagnosticar al paciente equivocado), cifras sesgadas en la investigación y otros problemas críticos.
Aunque muchos centros sanitarios han recopilado datos sobre los pacientes, todavía no han desarrollado sistemas actualizados para mantener la calidad de los servicios prestados. Una herramienta de calidad de datos de autoservicio como DataMatch Enterprise permite a los usuarios autorizados preparar los datos para sus múltiples usos sin tener que depender de TI o de conocimientos específicos de SQL.
Y lo que es más importante, da a las organizaciones una cabeza iniciar en el viaje de mejora de los datos. Una vez que la organización entiende los problemas que afectan a la calidad de los datos, puede estar en mejor posición para hacer las modificaciones necesarias, elaborando un plan de gestión de datos más sólido.
Descargue nuestra prueba gratuita para ver cómo puede limpiar y vincular los registros de su organización de forma fácil y sin códigos.
The post Calidad de los datos en la sanidad: retos, limitaciones y medidas para mejorar la calidad appeared first on Data Ladder.
]]>