The post Un guide rapide pour la normalisation et la vérification des adresses appeared first on Data Ladder.
]]>La normalisation des adresses est le processus qui consiste à mettre à jour et à appliquer une norme ou un format à l’ensemble de vos données d’adresses.
Les mauvaises données d’adresses constituent un problème complexe de qualité des données qui affecte les clients, les entreprises et même le service postal. La quantité stupéfiante de données d’adresses médiocres a obligé les entreprises à investir dans des outils robustes de normalisation et de vérification des adresses qui les aideront à obtenir des adresses validées par USPS facilement et sans effort.
Nous vous aidons à comprendre :
- Le coût des mauvaises données
- Les problèmes liés aux données d’adresses
- Causes profondes de la mauvaise qualité des données
- Comment standardiser l’adresse
- Qu’est-ce que la normalisation des adresses CASS ?
- Comment valider une adresse ?
- Comment vérifier une adresse auprès d’USPS ?
- Correspondance des données – Le défi le plus important pour la normalisation et la vérification des adresses
- Une étude de cas – E-Ideas Limited
- Stratégies commerciales pour améliorer vos données d’adresses
Plongeons dans le vif du sujet !
Le coût des mauvaises données d’adresses
Chaque année, des millions de dollars sont gaspillés à cause de mauvaises données d’adresses. L’USPS rapporte que près de 6,6 milliards de pièces de courrier n’ont pas pu être distribuées au cours de la seule année 2016. Les expéditeurs dépensent plus de 20 milliards de dollars en courrier UAA, tandis que les coûts directs pour l’USPS s’élèvent à plus de 1,5 milliard de dollars par an. Tous ces coûts inutiles sont simplement dus au fait que les entreprises n’ont pas accès aux bonnes données d’adresse.

Si vous faites le calcul sur la base de ce seul coût préliminaire, vous dépensez probablement $$$$ rien qu’en gestion des frais de retour de courrier – sans parler du coût opérationnel de la vérification des informations fournies par les clients et du renvoi du colis.
Quelques chiffres à prendre en compte :

Les problèmes liés aux données d’adresses
C’est la nature humaine de faire des erreurs. La plupart du temps, les consommateurs sont laxistes lorsqu’il s’agit de fournir leurs coordonnées sur des formulaires physiques ou en ligne. Ils peuvent mal orthographier le nom d’un État, écrire des abréviations, omettre un numéro de rue ou oublier leur code postal. Il est inévitable que des erreurs soient commises et que des données incorrectes soient saisies.
Voici une image de ce à quoi ressemblent des données d’adresse brutes et non structurées. Les mauvaises données d’adresses sont un défi qui met à rude épreuve les entreprises et leurs employés. Imaginez devoir résoudre ces problèmes de base pour chaque campagne d’envoi, chaque activité promotionnelle et chaque rapport sur les clients que vous devez exécuter. C’est non seulement extrêmement frustrant, mais aussi contre-productif, car vous essayez de faire correspondre et de vérifier chaque adresse pour vous assurer qu’elle est exacte et complète. Les scientifiques et les analystes de données ou les utilisateurs professionnels qui ont besoin de ces données doivent passer des jours et des mois à résoudre ces problèmes.

On constate souvent que les données d’adresses souffrent de :
- Informations incomplètes (nom de la rue, numéro de l’îlot, code postal).
- Informations non valides (fausses adresses et codes postaux)
- Informations incorrectes (fautes de frappe, noms mal orthographiés, format médiocre tel que l’utilisation d’abréviations)
- Informations inexactes (numéros d’appartement ou de maison inexacts)
Tous ces problèmes font des données d’adresses l’une des plus difficiles à traiter dans une source de données. En outre, cela augmente considérablement le coût des courriers de retour, tout en empêchant une entreprise de s’appuyer sur les données d’adresses pour prendre des décisions commerciales cruciales.
La plupart de ces problèmes sont dus à des erreurs de saisie de l’utilisateur et à l’absence de contrôles appropriés des données.
Par exemple, certaines personnes choisiront d’écrire seulement le code postal mais pas l’adresse complète, d’autres oublieront simplement d’écrire le code postal, ou d’autres encore écriront une adresse incomplète. Certains donnent une fausse adresse. Quelles que soient les raisons des erreurs de données, une chose est sûre : pour qu’une entreprise puisse utiliser ses données, il faut que celles-ci soient propres et valides.
Mais les erreurs structurelles ne sont qu’une partie du problème que posent les mauvaises données d’adresse. D’autres questions pourraient être :
- Adresser les données qui sont valides, mais qui n’existent plus.
- Adresse qui est structurellement correcte mais qui n’appartient pas au client.
- Adresse qui n’existe pas dans la base de données de l’USPS.
Lorsque ces informations ne sont pas vérifiées à l’entrée, cela affecte toute la correspondance future, ainsi que la relation avec ce client. Pour y remédier, les entreprises devront passer du temps à appeler chaque client pour mettre à jour les données ou leur demander de fournir à nouveau les bonnes informations. Le problème est que les entreprises sont généralement à court de ressources et que ce mode de fonctionnement n’est pas très viable.
En fin de compte, tout se résume à une seule chose : les mauvaises données sont inévitables, mais elles peuvent être corrigées. Il existe de nombreux outils de normalisation d’adresses qui aident les entreprises à corriger les données de mauvaise qualité en corrigeant les problèmes de format et en nettoyant les données désordonnées. Le processus est moins long mais peut nécessiter une courbe d’apprentissage et une compréhension de base de la correspondance, de l’analyse et de la déduplication des données.
Causes profondes des mauvaises données d’adresse
Les erreurs humaines sont la principale, mais pas la seule, cause de la mauvaise qualité des adresses. Mis à part les difficultés liées à la saisie de données précises, les causes profondes sont bien plus nombreuses :
Décroissance de la base de données :
Selon le Bureau du recensement, un Américain type déménagera 11,7 fois dans sa vie. Comme le logement devient de plus en plus cher et que les Américains essaient de trouver des zones convenables pour vivre, ce chiffre va augmenter. Parmi ceux-ci, seuls 60% des déménageurs informent effectivement l’USPS de leur déménagement en temps voulu.
Les entreprises sont donc coincées avec des données d’adresses qui ne sont pas mises à jour. S’ils envoient un million de factures ou de courriers promotionnels par mois, ils peuvent recevoir 90 000 avis de déménagement au cours du même mois. Pire, selon ce pourcentage, 60 000 de ces millions de clients n’auront pas fourni les bonnes informations à l’USPS à temps.
En supposant que les mêmes clients soient toujours présents dans l’organisation, l’entreprise devra continuer à mettre à jour sa base de données et s’assurer qu’elle dispose de l’adresse la plus récente à utiliser.
Une mauvaise culture des données :
Ce n’est que récemment que les entreprises ont commencé à discuter de l’importance de l’exploitation des données, mais cela ne concerne que les dirigeants. L’employé à son bureau n’est pas conscient du niveau des problèmes de qualité des données auxquels il est confronté. En outre, il n’y a pas de règles commerciales à respecter en matière de qualité des données. Il n’y a pas de formation ou d’éducation pour que les employés soient orientés vers les données et il n’y a absolument aucun investissement dans les outils de gestion des données comme DataMatch Enterprise qui peut combler le fossé entre les applications informatiques et la gestion des données par les entreprises.
Fusions et acquisitions :
Lorsque les entreprises migrent des données lors d’une fusion ou d’une acquisition, la probabilité d’erreurs dans la qualité des données augmente. Ces fusions sont rapides et les problèmes sont parfois imprévus. La pression en faveur de la consolidation est de plus en plus forte, mais il n’y a pas de contrôle de la qualité – en fait, il y a rarement un cadre de gestion de la qualité en place.
Comment faire pour normaliser les adresses ?
Ok, donc définition, comment standardiser réellement les données ?
Il y a deux façons de faire : la plus facile et la plus difficile.
La méthode dure consiste à transporter ces données vers Excel, à appliquer des formules et des filtres pour corriger les données. Ne croyez pas les tutoriels qui vous disent que c’est « super facile », car ça ne l’est jamais.
Jetez un coup d’œil à cet article qui vous apprendra à corriger les erreurs dans Excel. Vous voyez la quantité de temps, d’efforts et de connaissances techniques que vous devez posséder pour effectuer des corrections de données de base ? Plus les problèmes sont complexes, plus cela prend du temps. Si vous devez traiter des millions de lignes de données, le nettoyage des données pourrait devenir votre emploi permanent.
La solution de facilité ?
Utilisez un logiciel de normalisation des adresses. Avant de rejeter cette idée, voici pourquoi.
Le logiciel permet évidemment de gagner un temps et des efforts considérables, mais il fait plus que cela.
Les enregistrements de données d’adresses ne sont pas de simples erreurs. Comme dans l’exemple ci-dessus, vous avez des milliers de lignes qui ont des problèmes. Vous avez besoin d’une solution qui vous permette de résoudre tous ces problèmes en une seule fois.
Si vous utilisez une solution de premier ordre, vous pouvez normaliser les données :
Évaluation des erreurs via le profilage des données : Imaginez que vous puissiez obtenir un aperçu consolidé de tout ce qui ne va pas dans vos données d’adresses. Vous pouvez voir des colonnes avec des caractères non imprimables, ou des colonnes avec des espaces négatifs ou même des colonnes avec des lettres dans des champs numériques. Le profilage des données vous permet d’effectuer des corrections en connaissance de cause. Si vous ne savez pas ce qui ne va pas, vous corrigez les problèmes à l’aveuglette.
Analyser les adresses pour résoudre des problèmes spécifiques : Une partie du nettoyage des adresses exige que vous analysiez ou décomposiez les différentes parties des adresses (ville, état, code postal, etc.) et que vous les fixiez à différents niveaux. Par exemple, avec DataMatch Enterprise, vous pouvez fixer spécifiquement les codes ZIP et vous assurer qu’ils correspondent aux codes postaux ZIP+4 ou ZIP+6.
Nettoyage des données désordonnées : Nettoyez les problèmes de formatage, supprimez les espaces négatifs et les caractères non imprimables en un seul coup de balai. Il est impératif de nettoyer vos données d’adresse et de les normaliser conformément aux directives de l’USPS (voir ci-dessous) avant de pouvoir les vérifier.
Suppression des doublons grâce à la mise en correspondance des données : le nettoyage des données désordonnées n’est qu’une partie de l’opération – la partie la plus stressante consiste à éliminer les doublons. Si vous avez des milliers de lignes de données clients qui n’ont pas été triées depuis longtemps, il y a de fortes chances que vous ayez des doublons et ils ne sont pas toujours de nature exacte.
Jetez un coup d’œil à ce tableau :
Vous voyez comment un client a cinq adresses différentes saisies de plusieurs façons ? Ce n’est pas quelque chose que vous pouvez trier facilement, à moins d’utiliser un puissant outil de qualité des données.
 Survivance et exportation des données : Vous devez être en mesure de créer facilement une fiche et de l’exporter sous forme de liste finale à votre équipe sans avoir à la copier/coller ou à la charger manuellement dans un format acceptable.
Survivance et exportation des données : Vous devez être en mesure de créer facilement une fiche et de l’exporter sous forme de liste finale à votre équipe sans avoir à la copier/coller ou à la charger manuellement dans un format acceptable.
Normalisation d’adresses CASS : Tout logiciel de normalisation d’adresses doit avoir la normalisation d’adresses CASS. DataMatch Enterprise, par exemple, est une solution de normalisation d’adresses certifiée CASS dont la base de données est mise à jour tous les mois.
Qu’est-ce que la normalisation des adresses CASS ?
Les logiciels qui corrigent ou font correspondre les adresses doivent être certifiés par l’USPS. Cela se fait par le biais du Coding Accuracy Support System (CASS) que l’USPS utilise pour vérifier l’exactitude du logiciel. Une certification CASS est une licence pour tous les fournisseurs de logiciels qui utilisent l’USPS pour évaluer la qualité de leurs données d’adresses et pour améliorer la précision du codage ZIP+4 et à cinq chiffres.
Comme l’USPS met régulièrement à jour ses données d’adresses, les fournisseurs de logiciels certifiés CASS sont tenus de renouveler chaque année leur certification auprès de l’USPS. Tous les produits certifiés CASS sont listés sur le site web de l’USPS.
Qu’est-ce que la directive de normalisation d’USPS ?
Les fournisseurs de logiciels de normalisation des données d’ adresses suivent la directive de normalisation de l’USPS qui exige que les adresses soient dans un format comme :

Voici les règles :
- Placez toujours l’adresse et l’affranchissement sur le même côté de votre envoi.
- Sur une lettre, l’adresse doit être parallèle au côté le plus long.
- Toutes les lettres majuscules.
- Pas de ponctuation.
- Au moins un caractère de 10 points.
- Un espace entre la ville et l’État.
- Deux espaces entre l’état et le code postal.
- Polices de caractères simples.
- justifié à gauche.
- Encre noire sur papier blanc ou clair.
- Pas de caractères inversés (impression blanche sur un fond noir).
- Si votre adresse apparaît à l’intérieur d’une fenêtre, assurez-vous qu’il y a au moins 1/8 de pouce d’espace libre autour de l’adresse. Parfois, des parties de l’adresse échappent à la vue derrière la fenêtre et les machines de traitement du courrier ne peuvent pas lire l’adresse.
- Si vous utilisez des étiquettes d’adresse, veillez à ne pas couper les informations importantes. Assurez-vous également que vos étiquettes sont bien droites. Les machines de traitement du courrier ont du mal à lire les informations tordues ou inclinées.
La normalisation des adresses est la condition préalable à une validation efficace des adresses. Vous devez vous assurer que votre adresse répond aux directives de l’USPS avant que vos données puissent être vérifiées auprès de l’USPS.
Vérification ou validation d’adresse – Quelle est la différence ?
Vous verrez souvent les termes « validation et vérification » mélangés lorsqu’il s’agit de données d’adresse. La différence est plus contextuelle que lexicale. Data Ladder utilise le terme » vérification d’adresse » pour vérifier les adresses par rapport à la base de données de l’USPS. D’autres organismes vérifient les adresses par rapport aux relevés de facturation, aux permis de conduire, aux relevés bancaires, etc. Il s’agit d’un service complètement différent, dont la plupart des entreprises n’ont pas besoin.
D’autres fournisseurs utilisent« Address Validation » pour effectuer le même rapprochement avec l’USPS afin de valider les données des clients. Dans le contexte de ce guide, nous nous en tiendrons à la vérification des adresses.
Normalisation et vérification des adresses – Comment vérifier les données d’adresse avec l’USPS
Le processus de vérification de l’adresse est simple. Vous comparez vos données désormais normalisées à la base de données gouvernementale ou à toute autre norme d’autorité. Si vous êtes aux États-Unis, l’USPS est la seule base de données à laquelle vous devez comparer vos données.
Si vos données d’adresse sont propres et normalisées, ce processus prend quelques minutes. Si vous utilisez DataMatch Enterprise, vous pouvez faire correspondre l’adresse entière ou seulement certaines parties de l’adresse qui est basée sur 50 éléments actifs, y compris les emplacements géocodés, ce qui signifie que vous pouvez vérifier les adresses jusqu’au T !
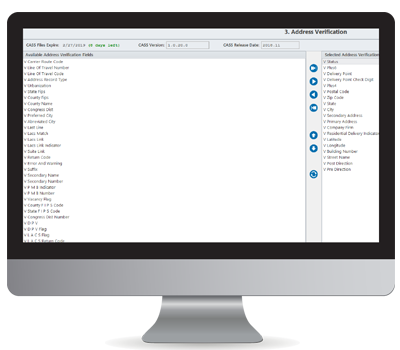
Parmi les domaines les plus populaires pour lesquels nos clients demandent souvent des vérifications, citons les suivants
-
V Statut – L’enregistrement est-il vérifié (oui/non) ?
-
V Indicateur de livraison résidentielle – Définit si l’adresse résidentielle peut recevoir des livraisons directes à la porte.
-
Société V Firm
-
V Adresse principale
-
V Adresse secondaire
-
Ville de V
-
V État
-
V Code postal – 5 chiffres (USA)
-
V Code postal (Canada)
-
V Plus4 – 4 chiffres supplémentaires associés au code postal à 5 chiffres.
Il existe 54 champs que vous pouvez utiliser pour valider vos données d’adresse.
Une fois que vous aurez fait correspondre la liste d’adresses avec ces composants, vous obtiendrez une valeur de retour qui indiquera :
- 10 = Adresse Invald
- 11 = Code ZIP invalide
- 12 = Code d’État non valide
- 13 = In invalid Ville
- 21 = l’adresse n’a pas été trouvée
Des avertissements vous seront également proposés :
-
-
A# ZIP
-
B# Ville/État corrigé
-
C# Ville/État/Zip non valide
-
D# Pas de ZIP attribué
-
E# ZIP attribué pour réponse multiple
-
F# Pas de ZIP disponible
-
G# Partie de l’entreprise déplacée à l’adresse
-
H# Numéro secondaire manquant
-
I# Données insuffisantes/incorrectes
-
J# Double entrée
-
Si vous souhaitez en savoir plus, n’hésitez pas à nous contacter pour une démonstration rapide !
Ok, alors on avance :
Correspondance des données – Le défi le plus important pour la normalisation et la vérification des adresses
Les clients qui s’adressent à nous n’ont qu’une seule plainte : ils ne parviennent jamais à obtenir un bon taux de correspondance. Et nous sommes d’accord !
Lerapprochement des données est encore un domaine à améliorer. Il y a très peu de vendeurs qui peuvent donner un taux de correspondance précis à 100%. Il vous faut vraiment ce chiffre, sinon, au moins 95%. La raison en est que pour que la vérification fonctionne, votre champ d’adresse doit trouver une correspondance avec l’USPS. Si la plupart de vos correspondances sont manquantes parce que le logiciel s’appuie sur des correspondances exactes ou déterministes, il ne jouera pas en votre faveur.
Par conséquent, lorsque vous choisissez un logiciel de normalisation et de vérification des adresses, vous devez être en mesure d’évaluer son taux de correspondance des données. Sur une centaine de rangs, combien de rangs l’outil a-t-il manqué, et pourquoi ? Il y a de fortes chances que vous constatiez que le logiciel ne parvient pas à détecter les correspondances proches ou étroites et qu’il se fie uniquement aux caractères exacts pour identifier une correspondance.
DataMatch Enterprise de Data Ladder est avant tout une solution de rapprochement de données qui a été utilisée par des institutions gouvernementales et des entreprises Fortune 500 comme HP, Coca Cola, Deloitte et bien d’autres. Nous sommes connus pour notre capacité à faire correspondre les données avec un taux de précision de 100 %. C’est parce que Data Ladder utilise une combinaison d’algorithmes de correspondance floue et ses algorithmes propriétaires établis pour identifier même les correspondances probables les plus éloignées.
P.S. – Le rapprochement des données demande beaucoup de ressources. Économisez le temps et les efforts manuels de votre équipe. Découvrez comment dans cet article de blog détaillé.
Voici une étude de cas qui révèle à quel point il est difficile, même pour un fournisseur de données, de garantir une correspondance précise des données.
Une étude de cas – E-Ideas Limited
Nous nous sommes entretenus avec Artem Axenov, directeur des opérations chez E-Ideas Limited, une agence de marketing B2B basée à Wellington. L’agence gère une importante base de données d’entreprises à des fins de marketing, ce qui signifie qu’elle doit accorder une attention particulière aux données d’adresses – un défi de taille qui implique beaucoup de travail manuel sur Excel.
1. Comment votre agence gère-t-elle le problème des mauvaises données ?
Nous avons souvent affaire à des clients qui disposent déjà d’une liste de clients, mais dont les données sont mal formatées. Il existe quelques tâches automatiques que vous pouvez effectuer pour résoudre ce problème, mais au final, c’est un travail manuel. Tout d’abord, vous devez décider du format que vous allez utiliser. La façon la plus simple de corriger des données mal formatées est de les trier une colonne à la fois, puis d’apporter les modifications nécessaires pour les remettre à niveau. Il existe certaines formules dans Excel qui permettent de diviser ou de combiner des données – pour diviser, vous pouvez utiliser MID et LEFT ensemble. Et pour combiner des données, vous pouvez utiliser CONCATENATE.
En triant d’abord les données, vous regroupez les ensembles d’adresses qui présentent les mêmes problèmes de formatage, ce qui facilite grandement leur traitement en une seule fois.
2. Quelle a été votre expérience des outils de vérification et de validation des adresses ?
Notre expérience avec tout type d’outil de validation ou de vérification d’adresse a toujours été mitigée. En fin de compte, aucun des outils que nous avons utilisés n’a réussi à produire une correspondance élevée. Et cela est dû à des méthodes très différentes de stockage des adresses. Ils sont utiles pour prendre une longueur d’avance sur le processus, mais en fin de compte, il faut toujours une quantité importante de travail manuel pour terminer le travail.
3. Quel est le problème de rapprochement de données le plus troublant ?
Le problème principal est que, quelle que soit la correspondance automatique effectuée, si les données ne sont pas formatées de la manière exacte dont l’outil est programmé pour les identifier, la correspondance ne se fait pas. Il peut s’agir par exemple d’une rue enregistrée comme St, d’une avenue comme Ave, etc.
4. Quel type de tâches manuelles devez-vous effectuer après avoir utilisé un logiciel de validation d’adresses ?
En général, il suffit d’examiner les données avec un œil humain pour repérer les éventuelles incohérences et les corriger. En Nouvelle-Zélande, par exemple, le service postal a un format très spécifique dans lequel les adresses doivent être conservées pour bénéficier de la remise sur les envois en nombre. Rien n’est compliqué mais, là encore, de petites choses comme le fait que la rue soit enregistrée comme St seront comptabilisées contre vous. Ou un autre exemple si votre boîte postale est enregistrée comme boîte postale – il ne le reconnaît pas comme correctement formaté. Même des éléments tels que les espaces avant ou arrière peuvent compter contre vous – et certains de ces éléments sont difficiles à repérer car, lorsque vous regardez l’adresse, vous ne voyez pas ce qui ne va pas !
5. Comment les mauvaises données d’adresses ont-elles affecté votre entreprise ?
Nous n’avons rencontré que des problèmes liés à la nécessité de consacrer des heures de travail supplémentaires à la mise à niveau des données pour bénéficier de la remise postale. Il existe un test à passer, appelé « déclaration d’exactitude », qui vérifie automatiquement les données pour s’assurer que 80 % d’entre elles sont correctement formatées. Dans un certain nombre de cas, nous avons fini par passer des jours de plus à formater manuellement les données pour nous assurer qu’elles sont correctement mises en forme.
La pratique que nous avons mise en place consiste à stocker toutes nos données dans le bon format. Il nous a fallu beaucoup de temps pour tout mettre en conformité avec cette norme, mais cela signifie maintenant que lorsque nous livrons des données à nos clients, elles sont prêtes pour la poste NZ et qu’il n’y a plus de travail à faire.
Les difficultés rencontrées par cette agence en raison de données d’adresses erronées entraînent des heures de travail supplémentaires qui affectent l’efficacité opérationnelle. Malgré l’utilisation d’outils de correspondance et de validation des adresses, l’incapacité à produire une correspondance élevée rend très difficile la validation des données d’adresses. Il est donc nécessaire de choisir un outil qui offre à l’utilisateur des capacités complètes de préparation et de normalisation des données tout en fournissant une correspondance élevée. Cela n’est possible qu’avec le meilleur logiciel de préparation et de rapprochement des données, tel que DataMatch Enterprise, qui permet à l’utilisateur de préparer et de nettoyer les données d’adresse tout en retournant un résultat de correspondance élevé, même avec du texte erroné.
Stratégies commerciales pour la gestion des données d’adresses
Les mauvaises données d’adresse sont un problème de qualité des données. Si vous pouvez utiliser des outils pour apporter des correctifs, vous devrez néanmoins mettre en œuvre des stratégies commerciales pour empêcher les mauvaises données d’affecter les processus opérationnels. Certaines de ces stratégies peuvent inclure :
Formations :
La première étape vers la qualité est la formation – il faut s’assurer que les personnes qui manipulent, interagissent, utilisent et saisissent les données connaissent l’impact qu’elles ont sur le processus et sur les applications en aval. Ils doivent comprendre les conséquences de mauvaises données sur l’ensemble de l’organisation et pas seulement sur un membre ou un client. Les employés qui appliquent les règles de qualité des données doivent être récompensés et appréciés.
Liste d’outils pour la gestion des données :
Il est essentiel de disposer d’outils qui peuvent aider les utilisateurs professionnels et les professionnels de l’informatique à gérer les données. Identifiez les outils dont vous avez besoin pour le nettoyage et la gestion des données afin d’aider les utilisateurs informatiques et commerciaux à avoir une relation non intimidante avec les données.
Impliquer les utilisateurs professionnels dans le processus de qualité :
Les données ne sont pas seulement un problème informatique. Les utilisateurs professionnels sont également responsables de la gestion des données. En effet, ils sont les seuls propriétaires des données clients qui sont souvent utilisées à des fins de marketing et de vente. C’est pourquoi ils doivent être impliqués dans le processus et doivent également être formés à l’utilisation des outils de gestion des données.
Gouvernance des données :
Mettez en place une équipe de gouvernance des données pour créer un plan de gestion des données et veillez à ce que l’organisation suive ce plan et que chaque employé le comprenne. Leur règle au sein du plan et les attentes qui accompagnent ce rôle.
Verrouiller les données et les rôles des utilisateurs :
Si n’importe qui dans votre équipe peut ouvrir le CRM ou la source de données, manipuler les données sans laisser d’empreintes, vous allez avoir de sérieux problèmes. Il est nécessaire de créer des détenteurs de données de base qui ont le droit d’accéder aux données critiques, de les saisir ou de les traiter. Cela devrait figurer dans le plan de gestion des données.
Vous n’êtes pas victime de mauvaises données. Il suffit d’accepter la gravité de la situation, de cultiver une culture axée sur les données et de s’efforcer de gérer les défis qui accompagnent la gestion des données. Vous pouvez très bien obtenir des données qui ne nécessitent qu’un nettoyage de base pour être mises à profit.
Comment DataMatch Enterprise peut-il vous aider ?
Notre produit est certifié CASS, ce qui signifie que nous respectons et dépassons les exigences de l’USPS en matière de qualité et de précision des adresses. Nous vous aidons également à faire correspondre et à valider les adresses en vrac, en veillant à ce que les éléments tels que les codes postaux, les noms des villes et des villages soient vérifiés et validés. Le meilleur avantage d’utiliser DataMatch Enterprise de Data Ladder? Le logiciel trouve et rapproche les données, même si elles sont incomplètes, avec un taux de précision de 96 %. En outre, vous pouvez utiliser le logiciel pour obtenir une vérification des adresses en temps réel, afin de vous assurer que votre base de données contient des adresses correctes.
 À l’aide d’algorithmes qui déterminent une correspondance sur la base de zones de similitude, notre plateforme donne un sens aux données inutilisables et établit des liens entre les ensembles de données. Qu’il s’agisse de fautes d’orthographe, de codes postaux incomplets, d’abréviations ou de fautes de frappe. Nous trions de grandes quantités de données pour vous aider à donner du sens à vos données.
À l’aide d’algorithmes qui déterminent une correspondance sur la base de zones de similitude, notre plateforme donne un sens aux données inutilisables et établit des liens entre les ensembles de données. Qu’il s’agisse de fautes d’orthographe, de codes postaux incomplets, d’abréviations ou de fautes de frappe. Nous trions de grandes quantités de données pour vous aider à donner du sens à vos données.
En conclusion
Les mauvaises données d’adresses sont inévitables, mais cela ne signifie pas que vous devez les laisser affecter les performances de votre entreprise. La correction manuelle des données d’adresses vous coûtera plus de temps et d’efforts, et vous ne pourrez pas non plus les normaliser ou les vérifier si vous n’utilisez pas une solution certifiée CASS.
Ne vous noyez pas dans les mauvaises données. Nous sommes là pour vous aider.
Pour savoir comment nous pouvons vous aider à normaliser et à vérifier les adresses, contactez dès aujourd’hui l’un de nos experts en solutions et voyez comment nous pouvons vous aider à obtenir des données d’adresses que vous pouvez utiliser aux fins prévues.
The post Un guide rapide pour la normalisation et la vérification des adresses appeared first on Data Ladder.
]]>The post 8 meilleures pratiques pour assurer la qualité des données au niveau de l’entreprise appeared first on Data Ladder.
]]>Le 20 septembre 21, Facebook a reconnu auprès de trois douzaines de chercheurs que l’ensemble de données comportait de graves erreurs et s’est excusé pour l’impact négatif qu’il a eu sur leurs recherches. Il s’avère que Facebook a omis d’inclure les données de la moitié de ses utilisateurs américains – car ils étaient moins polarisés politiquement par rapport à l’ensemble des utilisateurs. La porte-parole de Facebook a précisé que cet incident était dû à une erreur technique survenue dans son ensemble de données URL Shares.
Aujourd’hui, les données constituent sans aucun doute l’un des principaux atouts d’une organisation. Il est utilisé partout, qu’il s’agisse des opérations quotidiennes d’une entreprise, du renforcement de ses initiatives de veille stratégique ou, dans le cas de Facebook, de la facilitation de plus de 100 recherches. Mais en l’absence de techniques et de meilleures pratiques en matière de qualité des données (qui permettent de suivre et de résoudre les problèmes de qualité des données à temps), une entreprise peut perdre beaucoup d’argent et risquer de se retrouver à la traîne.
Dans ce blog, nous examinerons un certain nombre de bonnes pratiques et de processus de qualité des données qui peuvent contribuer à une qualité élevée des données au niveau de l’entreprise. En plus de souligner ce qui est nécessaire, je mentionnerai également les éléments réalisables qui peuvent vous aider à atteindre cet état.
En outre, les pratiques mentionnées ci-dessous donneront les meilleurs résultats si elles sont effectuées de manière cohérente à intervalles réguliers dans une entreprise. Les données (dans leur définition et leur utilisation) sont susceptibles de changer. Ainsi, si votre entreprise revoit constamment ces pratiques, vous pouvez certainement obtenir des résultats meilleurs et durables.
Commençons.
1. Déterminer la relation entre les données et les performances de l’entreprise
Nous commençons par cette pratique car il s’agit de l’élément le plus important et le plus fondamental pour permettre une gestion, une adoption et une utilisation appropriées des données dans toute organisation. Tout d’abord, vous devez comprendre comment les données contribuent à vos buts et objectifs commerciaux.
A quoi cela ressemble-t-il ?
Il peut s’agir d’analyser le rôle des données à un niveau élevé (par exemple, en mettant en évidence les domaines dans lesquels les données sont utilisées) ou d’aller plus loin dans les détails (comme le rôle des données dans les opérations quotidiennes, les processus commerciaux, l’échange d’informations entre les départements, etc.)
Une fois que vous avez identifié cela, il est temps de poser cette question : si ces processus ou domaines n’ont pas été facilités par des données de qualité, quel impact cela peut-il avoir sur les indicateurs clés de performance qui en résultent ?
Un exemple d’une telle situation est lorsque les cadres dirigeants fixent l’objectif de revenu pour le trimestre suivant en se basant sur les données de vente du trimestre précédent, mais qu’ils découvrent que l’ensemble de données utilisé pour prévoir l’objectif futur présente de sérieux problèmes de qualité des données, ce qui oblige votre département des ventes à poursuivre une valeur arbitraire qui n’a aucune signification concrète. La situation qui en résulte a un impact négatif massif sur les opérations et la réputation de l’entreprise, comme le fait de fixer des attentes irréalistes aux représentants commerciaux, de promettre des chiffres de revenus inexacts, etc.
Comment cela aide-t-il ?
Comprendre le rôle des données dans chaque processus de fonctionnement d’une entreprise vous permet d’avoir toujours sous la main un argumentaire pour hiérarchiser les données et leur qualité. En fait, cela vous aidera également à obtenir l’adhésion et l’attention nécessaires des parties prenantes, ce qui est crucial pour apporter et proposer des changements aux processus existants.
2. Mesurer et maintenir la définition de la qualité des données
Une fois que vous connaissez l’impact des données sur votre entreprise, l’étape suivante consiste à assurer la qualité des données dans tous les ensembles de données de votre organisation. Mais avant cela, il est important de comprendre la définition de la qualité des données, car elle a une signification différente pour chaque entreprise.
La qualité des données est définie comme le degré auquel les données remplissent l’objectif prévu. Ainsi, pour comprendre la signification de la qualité des données dans votre cas, vous devez savoir quel est l’objectif visé.
A quoi cela ressemble-t-il ?
Pour définir la qualité des données pour votre entreprise, vous devez commencer par identifier les :
- Sources qui génèrent, stockent ou manipulent des données,
- Attributs stockés par chaque source,
- Glossaire des métadonnées qui définit chaque attribut,
- les critères d’acceptabilité des valeurs de données stockées dans les attributs, et
- Les métriques de qualité des données qui mesurent la qualité des données stockées.
Un exemple de définition de la qualité des données dans votre entreprise consiste à dessiner des modèles de données qui mettent en évidence les parties nécessaires des données (la quantité et la qualité des données qui sont considérées comme suffisantes). Considérez l’image suivante pour comprendre à quoi peut ressembler un modèle de données pour une entreprise de vente au détail :
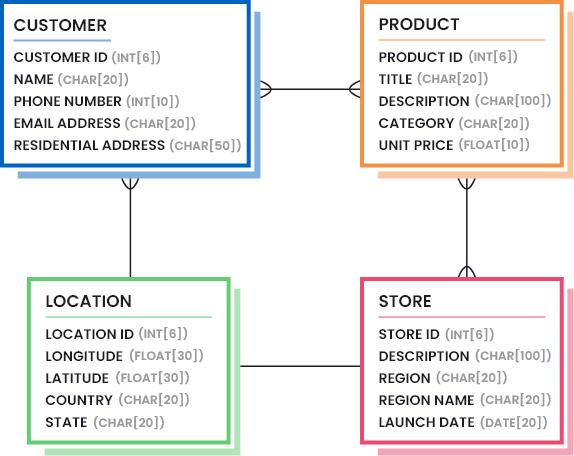
En outre, outre la conception de modèles de données, vous devez également identifier des mesures de qualité des données qui confirment la présence d’un niveau de qualité acceptable dans vos ensembles de données. Par exemple, vous pouvez exiger que votre ensemble de données soit plus précis et plus fiable que complet.
Comment cela aide-t-il ?
Une définition normalisée de la qualité des données permet de mettre tout le monde sur la même longueur d’onde, afin qu’ils puissent comprendre ce que signifie la qualité des données, à quoi elle ressemble et comment elle peut être mesurée. Cela permet à chaque personne de comprendre et de satisfaire les exigences en matière de qualité des données.
3. Définir les rôles et les responsabilités en matière de données dans l’ensemble de l’organisation
Il est communément admis que la garantie de la qualité des données au niveau de l’entreprise nécessite l’implication ou l’adhésionde la direction générale. En réalité, plus que d’impliquer certaines personnes dans des environnements cloisonnés, vous devez engager des personnes dans les processus existants, et rendre les gens responsables de l’obtention et du maintien de la qualité des données – de la direction de haut niveau au personnel opérationnel.
A quoi cela ressemble-t-il ?
Parmi les rôles courants mais importants en matière de données et leurs responsabilités, citons les suivants :
- Chief Data Officer (CDO) : un représentant des données au sein de la direction de haut niveau, chargé de concevoir des stratégies pour assurer une gestion efficace des données, un suivi de la qualité des données et l’adoption des données dans toute l’organisation.
- Intendant des données : contrôleur de la qualité des données, chargé de garantir l’adéquation des données à l’usage auquel elles sont destinées et de gérer les métadonnées.
- Responsable des données et de l’analyse (D&A) : un acteur des données, chargé d’assurer la maîtrise des données dans l’ensemble de l’organisation et de permettre aux données de produire de la valeur.
Comment cela aide-t-il ?
Lorsque les données sont traitées comme la source principale alimentant les processus commerciaux fondamentaux, un changement se produit à l’échelle de l’entreprise. C’est là que l’attribution de rôles et de responsabilités dans le domaine des données et le fait de donner aux gens le pouvoir d’avoir un impact et de s’exprimer sur les questions cruciales relatives aux données peuvent jouer un rôle important pour assurer une culture des données réussie dans toute organisation.
4. Former et éduquer les équipes sur les données
Dans une enquête menée auprès de 9000 employés jouant différents rôles dans une organisation, seuls 21 % d’entre eux avaient confiance dans leurs compétences en matière de données.
L’introduction de rôles et de responsabilités en matière de données peut avoir un impact positif énorme sur votre entreprise, mais il est néanmoins crucial de considérer que dans un lieu de travail moderne, chaque individu génère, manipule ou traite des données dans ses opérations quotidiennes. C’est pourquoi, s’il est important de confier à certaines personnes la responsabilité de mettre en œuvre des mesures correctives, il est tout aussi nécessaire de former et d’éduquer toutes les équipes sur la manière de traiter les données organisationnelles.
A quoi cela ressemble-t-il ?
Cela peut impliquer la création de plans de maîtrise des données et la conception de cours qui initient les équipes aux données et aux explications de l’organisation :
- Ce qu’il contient,
- La signification de chaque attribut de données,
- Quels sont les critères d’acceptabilité de sa qualité,
- Quelle est la bonne et la mauvaise manière de saisir/manipuler les données ?
- Quelles données utiliser pour atteindre un résultat donné ?
En outre, ces cours peuvent être créés en fonction de la fréquence d’utilisation des données par certains rôles (quotidienne, hebdomadaire ou annuelle).
Comment cela aide-t-il ?
La capacité de lire, de comprendre et d’analyser correctement et précisément les données à tous les niveaux permet à chaque employé de poser les bonnes questions, et ce de la manière la plus optimisée possible. Il garantit également l’efficacité opérationnelle de votre personnel et réduit les erreurs lors de la communication de questions impliquant des données.
5. Contrôler en permanence l’état des données grâce au profilage des données.
Obtenir la qualité des données et la maintenir dans le temps sont deux choses différentes. C’est pourquoi vous devez mettre en œuvre un processus systématique qui surveille en permanence l’état des données et les profile pour découvrir des détails cachés sur leur structure et leur contenu.
La portée et le processus de l’activité de profilage des données peuvent être définis en fonction de la définition de la qualité des données dans votre entreprise et de la manière dont elle est mesurée.
A quoi cela ressemble-t-il ?
Cela peut être réalisé en configurant et en programmant des rapports quotidiens/hebdomadaires sur le profil des données. En outre, vous pouvez concevoir des flux de travail personnalisés pour alerter les responsables des données de votre entreprise si la qualité des données passe en dessous d’un seuil acceptable.
Un rapport sur le profil des données met généralement en évidence un certain nombre d’éléments concernant les ensembles de données examinés, par exemple :
- Le pourcentage de valeurs de données manquantes et incomplètes,
- Le nombre d’enregistrements qui sont des doublons possibles les uns des autres,
- Évaluation des types, des tailles et des formats de données afin de découvrir des valeurs de données invalides,
- Analyse statistique de colonnes de données numériques pour évaluer les distributions.
Comment cela aide-t-il ?
Cette pratique vous permet de détecter les erreurs de données à un stade précoce du processus et d’éviter qu’elles ne se répercutent sur les clients. En outre, il peut aider les Chief Data Officers à rester au fait de la gestion de la qualité des données et à prendre les bonnes décisions, notamment quand et comment résoudre les problèmes mis en évidence dans les profils de données.
En savoir plus sur le profilage des données : Portée, techniques et défis.
6. Concevoir et maintenir des pipelines de données pour obtenir une source unique de vérité.
Un pipeline de données est un processus systématique qui ingère des données d’une source, exécute les techniques de traitement et de transformation nécessaires sur les données, puis les charge dans un référentiel de destination.
Il est essentiel que les données brutes passent par un certain nombre de contrôles de validation avant d’être jugées utilisables et mises à la disposition de tous les utilisateurs de l’organisation.
A quoi cela ressemble-t-il ?
Pour construire un pipeline de données, vous devez revenir à la pratique#02 que nous avons mentionnée dans ce blog : Définir et maintenir la définition de la qualité des données. Et selon cette définition, vous devez décider de la liste numérotée des opérations qui doivent être effectuées sur les données entrantes pour atteindre le niveau de qualité défini.
Voici une liste d’exemples d’opérations qui peuvent être effectuées dans votre pipeline de données :
- Remplacer les valeurs nulles ou vides par un terme standard, tel que « Non disponible ».
- Transformer les valeurs des données selon le modèle et le format définis.
- Analyse syntaxique des champs en deux colonnes ou plus.
- Remplacer les abréviations par des mots appropriés.
- Remplacer les surnoms par des noms propres.
- Si l’enregistrement entrant est suspecté d’être un doublon potentiel, il est fusionné avec l’enregistrement existant, plutôt que d’être créé comme un nouveau.

Comment cela aide-t-il ?
Un pipeline de données agit comme un pare-feu de qualité des données pour vos ensembles de données organisationnelles. La conception d’un pipeline de données permet de garantir la cohérence des données entre toutes les sources et d’éliminer toute divergence éventuelle, avant même que les données ne soient chargées dans la source de destination.
7. Effectuer une analyse des causes profondes des erreurs de qualité des données
Jusqu’à présent, nous nous sommes surtout concentrés sur la manière de suivre la qualité des données et d’éviter que des erreurs de qualité des données n’entrent dans les ensembles de données, mais la vérité est que, malgré tous ces efforts, certaines erreurs finiront probablement par se retrouver dans le système. Non seulement vous devrez les réparer, mais le plus important est de comprendre comment ces erreurs se sont produites afin d’éviter de tels scénarios.
A quoi cela ressemble-t-il ?
Une analyse des causes profondes des erreurs de qualité des données peut impliquer l’obtention du dernier rapport sur le profil des données et la collaboration avec votre équipe pour trouver des réponses à des questions telles que :
- Quelles erreurs de qualité des données ont été rencontrées ?
- D’où viennent-ils ?
- Quand ont-ils vu le jour ?
- Pourquoi se sont-ils retrouvés dans le système malgré tous les contrôles de validation de la qualité des données? On a raté quelque chose ?
- Comment éviter que de telles erreurs ne se reproduisent dans le système ?
Comment cela aide-t-il ?
Aller au cœur des problèmes de qualité des données peut contribuer à éliminer les erreurs à long terme. Vous ne devez pas toujours travailler selon une approche réactive et continuer à corriger les erreurs au fur et à mesure qu’elles se présentent. Grâce à une approche proactive, vous pouvez permettre à vos équipes de réduire au minimum les efforts qu’elles consacrent à la correction des erreurs de qualité des données – et laisser les processus affinés de qualité des données s’occuper de 99 % des problèmes associés aux données.
8. Utiliser la technologie pour atteindre et maintenir la qualité des données.
Ceci nous amène à notre dernière meilleure pratique : l’utilisation de la technologie pour atteindre un cycle de vie durable de la gestion de la qualité des données. Aucun processus n’est censé être performant et offrir le meilleur retour sur investissement s’il n’est pas automatisé et optimisé par la technologie.
A quoi cela ressemble-t-il ?
Investissez dans l’adoption d’un système technologique doté de toutes les fonctionnalités dont vous avez besoin pour garantir la qualité des données dans tous les ensembles de données. Ces caractéristiques comprennent la possibilité de :
- Importation de données: Intégrez des données provenant de plusieurs sources,
- Profil des données: Évaluer les données pour générer des rapports sur la qualité des données,
- Nettoyage des données: Mettez en évidence les domaines qui pourraient nécessiter un nettoyage, une normalisation et une transformation des données, et mettez en place des solutions,
- Correspondance des données: faites correspondre les données à l’aide d’algorithmes de correspondance exacte et floue avec un haut niveau de précision, et adaptez les algorithmes en fonction de la nature de vos données,
- Déduplication des données: Reliez les enregistrements et trouvez la source unique de vérité,
- Exportation de données : Exportation/chargement des résultats.
En plus des fonctions de gestion de la qualité des données mentionnées ci-dessus, certaines organisations investissent dans des technologies qui offrent également des capacités de gestion centralisée des données. Un exemple d’un tel système est la gestion des données de référence (MDM). Bien qu’un MDM soit une solution complète de gestion des données intégrant des fonctionnalités de qualité des données, toutes les organisations n’ont pas besoin de la liste exhaustive des fonctionnalités d’un tel système.
Vous devez comprendre les besoins de votre entreprise pour évaluer quel type de technologie est la bonne décision pour vous. Vous pouvez lire ce blog pour découvrir les différences fondamentales entre une solution MDM et DQM.
Comment cela aide-t-il ?
L’utilisation de la technologie pour la mise en œuvre de processus qui doivent être répétés régulièrement pour obtenir des résultats durables présente de nombreux avantages. En fournissant à votre équipe des outils de gestion de la qualité des données en libre-service, vous pouvez accroître l’efficacité opérationnelle, éliminer les efforts redondants, améliorer l’expérience client et obtenir des informations commerciales fiables.
Conclusion
La mise en œuvre de mesures de qualité des données cohérentes, automatisées et reproductibles peut aider votre organisation à atteindre et maintenir la qualité des données dans tous les ensembles de données.
Data Ladder offre des solutions de qualité des données à ses clients depuis plus d’une décennie maintenant. DataMatch Enterprise est l’un de ses principaux produits de qualité des données – disponible sous forme d’application autonome ou d’API intégrable – qui permet une gestion de la qualité des données de bout en bout, y compris le profilage, le nettoyage, la mise en correspondance, la déduplication et la purge par fusion des données.
Vous pouvez télécharger l’essai gratuit dès aujourd’hui ou programmer une session personnalisée avec nos experts pour comprendre comment notre produit peut aider à mettre en œuvre les meilleures pratiques pour atteindre et maintenir la qualité des données au niveau de l’entreprise.
The post 8 meilleures pratiques pour assurer la qualité des données au niveau de l’entreprise appeared first on Data Ladder.
]]>The post Guide du filtrage : ce que cela signifie et comment le faire ? appeared first on Data Ladder.
]]>Il est facile de trouver des modèles dans tout type d’environnement riche en données ; c’est ce que font les joueurs médiocres. La clé est de déterminer si les modèles représentent un signal ou du bruit.
Nate Silver
Toute personne qui travaille avec des données comprend l’importance des modèles. Qu’il s’agisse d’une analyse globale de grands ensembles de données ou de l’analyse la plus détaillée possible, les modèles sont partout. Ils peuvent être universels – comme le motif d’un numéro de carte de crédit – ou propres à votre entreprise, par exemple le motif utilisé pour afficher les informations sur les produits sur votre site web.
Lorsque les données sont saisies, elles ne suivent pas toujours le bon modèle. Les entreprises doivent mettre en œuvre différentes méthodes pour faire correspondre, valider et transformer les modèles afin d’obtenir les données dans la forme et le format requis.
Dans ce blog, nous allons apprendre quelques concepts importants liés au filtrage et à la validation, tels que :
- Que signifie la correspondance des modèles ?
- En quoi la correspondance de motifs diffère-t-elle de la correspondance de chaînes de caractères ?
- Comment fonctionne le filtrage ?
- Quelles sont les raisons les plus courantes de faire correspondre et de valider les modèles ?
- Comment pouvez-vous transformer vos données pour obtenir le modèle dont vous avez besoin ?
Plongeons dans le vif du sujet.
Qu’est-ce que le filtrage ?
Un modèle est perçu comme quelque chose qui est à l’opposé du désordre ou du chaos. Il s’agit d’un modèle répétitif qui peut être identifié dans un grand ensemble de valeurs de données appartenant au même domaine. Par conséquent, la correspondance des motifs peut être définie comme suit :
Le processus de recherche d’une séquence ou d’un placement spécifique de caractères dans un ensemble donné de données.
La correspondance de motifs produit des résultats définitifs: la chaîne en entrée contient le motif (elle est valide) ou ne le contient pas (elle est invalide). Si la chaîne de caractères ne contient pas le motif requis, le processus de mise en correspondance est souvent étendu à la transformation du motif, où les sous-éléments de données sont extraits de la valeur d’entrée, puis reformatés pour construire le motif requis.
Correspondance de motifs et correspondance de chaînes de caractères
Avant d’aborder le fonctionnement des algorithmes de filtrage, il est important de comprendre leur relation avec les algorithmes de filtrage de chaînes de caractères. Ces deux concepts sont souvent traités comme une seule et même chose, mais ils sont très différents dans leur objectif et leur utilisation. Le tableau ci-dessous met en évidence certaines des principales différences :
| Correspondance de motifs | Correspondance des chaînes de caractères | |
| Comparaison | Il compare une chaîne de caractères avec un modèle standard qui représente des blocs ou des tokens de caractères. | Il compare deux chaînes de caractères caractère par caractère. |
| Exemple | Comparaison de [email protected] avec [name]@[domain].[domain-extension]. | Comparaison entre Elizabeth et Alizabeth. |
| Résultats | Calcule les résultats définitifs – soit le motif est trouvé, soit il est absent. | Calcule les correspondances exactes (faire correspondre la poussière avec la poussière) ou les correspondances floues (faire correspondre la poussière avec la rouille). |
| Utilisations | Utilisé pour analyser et extraire des valeurs ou transformer des valeurs pour qu’elles suivent des modèles standard. | Utilisé pour corriger les fautes d’orthographe, détecter le plagiat et identifier les valeurs ayant une signification ou une composition de caractère similaire. |
Comment fonctionne le filtrage ?
En termes simples, les algorithmes de filtrage fonctionnent avec des expressions régulières (ou regex). Pour comprendre ce qu’est une expression régulière, pensez-y comme à un langage qui vous aide à définir un motif et à le partager avec quelqu’un – ou dans notre cas, un programme informatique.
Les expressions régulières indiquent aux programmes informatiques le modèle à rechercher dans les données à tester. Parfois, le programme est suffisamment intelligent pour sélectionner des modèles à partir d’un ensemble de valeurs de données et générer automatiquement une regex. Certains programmes ou outils disposent d’une bibliothèque d’expressions rationnelles intégrée qui contient des modèles couramment utilisés, tels que les numéros de carte de crédit, les numéros de téléphone américains, les formats de date, les adresses électroniques, etc.
Exemple de correspondance d’un modèle d’adresse électronique
Pour comprendre ce qu’est un algorithme de comparaison de motifs, prenons l’exemple de la validation du motif des adresses électroniques. La première étape consiste à définir l’expression rationnelle qui communique le modèle d’une adresse électronique valide. Un exemple de modèle d’adresse électronique valide peut ressembler à ceci :
[name]@[domain].[domain-extension]
Dans le langage regex, ce motif sera traduit par :
^[\w-.]+@([\w-]+.)+[\w-]{2,3}$
Où,
- ^ signifie le début d’une phrase et $ la fin.
- [\w-.] désigne un mot qui contient des caractères alphanumériques, un trait de soulignement, un trait d’union ou un point.
- +@ implique l’ajout d’un symbole @.
- ([\w-]+.) désigne un mot qui contient des caractères alphanumériques, un trait de soulignement ou un trait d’union, et qui se termine par un point.
- +[\w-]{2,3} signifie un mot qui contient des caractères alphanumériques ou un trait d’union, et ce mot ne peut avoir que deux caractères au minimum et trois au maximum.
Ci-dessous, vous pouvez voir un certain nombre d’adresses électroniques de test qui ont été soumises à ce modèle regex et les résultats obtenus.
| Non. | Test | Résultat | Raison de l’échec |
| 1. | [email protected] | Valable | |
| 2. | pam.beesly_gmail.com | Invalide | Symbole @ manquant. |
| 3. | [email protected] | Invalide | Le domaine a un point d’arrêt inattendu. |
| 4. | [email protected] | Invalide | L’extension du domaine comporte plus de 3 caractères (par exemple, com4). |
Il est évident que la définition manuelle des regex est fastidieuse et nécessite une certaine expertise. Vous pouvez également opter pour des outils de normalisation des données qui proposent des concepteurs visuels de regex (nous y reviendrons dans une section ultérieure).
Cas d’utilisation du filtrage
Maintenant que nous savons ce qu’est le filtrage et comment fonctionne l’algorithme, vous vous demandez peut-être à quoi il sert exactement. La correspondance des motifs est l’un des concepts les plus fondamentaux dans différents domaines, tels que la programmation informatique, la science et l’analyse des données, le traitement du langage naturel, etc.
Si nous parlons spécifiquement du filtrage et de la validation dans le domaine des données, voici quelques-unes de ses applications les plus courantes :
1. Validation des soumissions de formulaires
Comme la comparaison de modèles de données permet de distinguer les informations valides des informations non valides, elle est surtout utilisée pour valider les formulaires soumis sur des sites Web ou d’autres applications logicielles. L’expression rationnelle est appliquée aux champs du formulaire selon les besoins ; quelques exemples de validations sont donnés ci-dessous :
- Le nom d’une personne ne contient que des alphabets ou des symboles,
- L’adresse électronique suit le modèle correct,
- Le numéro de téléphone ne contient que des chiffres,
- Le numéro de la carte de crédit ne doit pas comporter plus de 16 chiffres, etc.
2. Effectuer des opérations de recherche et de remplacement
Le filtrage est également utile dans les applications qui disposent de fonctions de recherche et de remplacement d’informations textuelles. Certaines applications de base ne proposent que la correspondance caractère par caractère (ou correspondance de chaînes de caractères), tandis que d’autres offrent également la fonctionnalité de recherche et de remplacement regex, qui vous permet de rechercher des modèles dans les documents texte et pas seulement des correspondances exactes de chaînes de caractères.
3. Nettoyage et normalisation des ensembles de données
Vous pouvez essayer de valider les informations au moment de la saisie des données – comme les soumissions de formulaires, mais en raison des diverses limitations et restrictions rencontrées dans les systèmes, vos ensembles de données organisationnelles peuvent toujours se retrouver avec des représentations multiples des mêmes informations. C’est là qu’il devient impératif de nettoyer et de normaliser les ensembles de données avant de les utiliser pour les opérations de routine ou la BI.
4. Analyse syntaxique et extraction des valeurs
Étant donné que le filtrage par motif recherche une séquence spécifique de caractères dans une valeur donnée, ce processus est également utile pour faire correspondre et extraire des éléments de valeur qui se trouvent dans des formes d’information étendues. Par exemple, vous pouvez extraire les domaines d’une liste d’adresses électroniques professionnelles pour savoir dans quelle entreprise la personne travaille, ou vous pouvez extraire la ville et le pays de résidence des champs d’adresse qui contiennent 3-4 lignes d’informations.
Comment faire correspondre des modèles ?
Deux approches sont généralement adoptées par les entreprises lors de la comparaison et de la validation des modèles : l’une consiste à écrire des scripts de code internes et l’autre à utiliser des outils logiciels tiers. Discutons de la mise en œuvre de ces deux approches.
1. Correspondance de motifs à l’aide d’un code
Lorsqu’il s’agit de nettoyer et de normaliser des données, la solution par défaut pour de nombreuses organisations consiste à créer des applications internes personnalisées et des scripts de codage pour diverses opérations de normalisation, notamment le rapprochement et la transformation des modèles. Aussi intéressant que cela puisse paraître, cela peut être un véritable défi.
Why in-house data quality projects fail
Read this whitepaper to understand the consequences of ignoring poor data quality, gain insight on why in-house data quality solutions fail and at what costs.
DownloadJetons un coup d’œil à un extrait de code JavaScript qui valide les adresses électroniques.
| fonction emailValidation(input) { var regex = /^\w+([.-]?\w+)@\w+([.-]?\w+)(.\w{2,3})+$/ ; if(input.value.match(regex)) { alert("Valid"); return true;} sinon { alert("Invalid"); return false;} } |
Notez que cet extrait de code ne fait que valider les adresses électroniques et ne les transforme pas en un modèle standardisé au cas où elles ne seraient pas valides. En outre, il ne valide que le champ de l’adresse électronique, de sorte que pour faire correspondre différents modèles, vous devez mettre en œuvre un code similaire pour chacun d’eux. Enfin, la regex qui valide les adresses électroniques est encore un peu plus facile à décoder. Si nous considérons les champs de données qui ont des motifs complexes, les regex peuvent s’étendre sur un certain nombre de lignes. Par exemple, l’extrait de code suivant recherche des correspondances de motifs pour les URL.
| fonction URLValidation(input) { var regex = /[-a-zA-Z0-9@:%.+~#=] {1,256}.[a-zA-Z0-9()]{1,6}\b ([-a-zA-Z0-9()@:%+.~#?&//=]*) ?/gi ; if(input.value.match(regex)) { alert("Valid"); return true;} sinon { alert("Invalid"); return false;} } |
2. Correspondance de motifs à l’aide d’outils logiciels
Pour les raisons mentionnées ci-dessus, la maintenance des applications personnalisées peut être très gourmande en ressources. Il vous faut engager une équipe de développeurs internes qui sont constamment sollicités par les utilisateurs professionnels pour déboguer et mettre à jour les fonctionnalités du code.
C’est pourquoi de nombreux responsables et ingénieurs de données chevronnés penchent pour l’idée d’adopter des outils simples de création, de mise en correspondance et de transformation des modèles, qui peuvent être facilement utilisés par le personnel informatique et non informatique.
Ces apparieurs de motifs sont dotés de différentes caractéristiques. Les caractéristiques les plus courantes sont présentées ci-dessous.
1. Constructeurs de modèles visuels
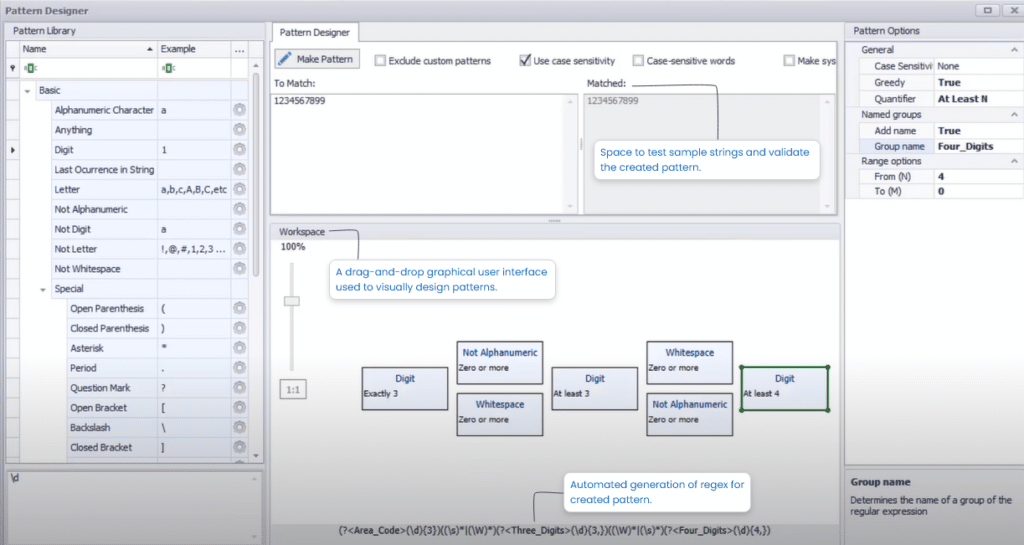
Une fonction de création de modèles visuels offre une interface utilisateur graphique de type glisser-déposer qui peut être utilisée pour créer des modèles. Lorsqu’un utilisateur dépose des blocs de motifs ou des jetons dans l’espace de travail, une expression rationnelle équivalente est générée en arrière-plan. Cette fonctionnalité élimine le besoin d’expertise technique et encourage les utilisateurs naïfs à construire eux aussi des modèles.
Une capture d’écran du concepteur de modèles visuels dans DataMatch Enterprise est présentée ci-dessous :
2. Correspondance de motifs par type de données
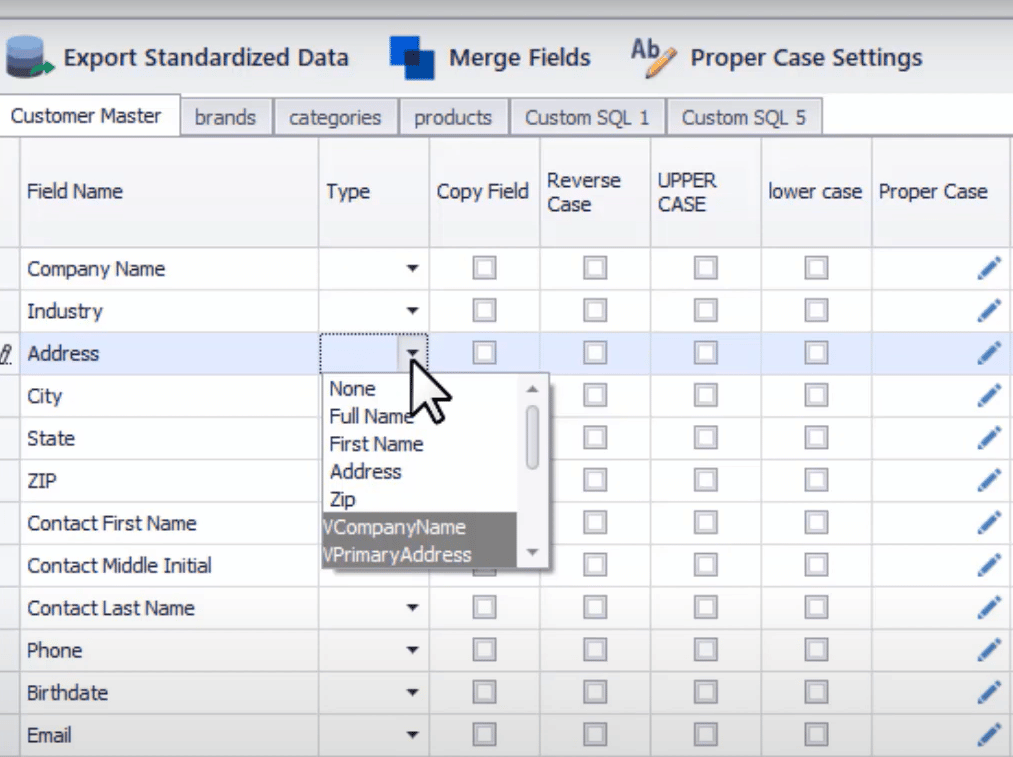
Une autre caractéristique intéressante des outils de comparaison de motifs est la possibilité de profiler des colonnes entières en fonction de leurs types de données. Par exemple, vous pouvez profiler la colonne des numéros de téléphone par le type de données entières, et la fraction des valeurs qui contiennent d’autres symboles et caractères en plus des chiffres peut être signalée comme non valide. Cela peut être fait pour obtenir une évaluation rapide de l’effort de normalisation nécessaire pour corriger les modèles invalides.
Une capture d’écran des modèles de correspondance par type de données dans DataMatch Enterprise est présentée ci-dessous :
3. Correspondance de motifs à l’aide de la bibliothèque regex
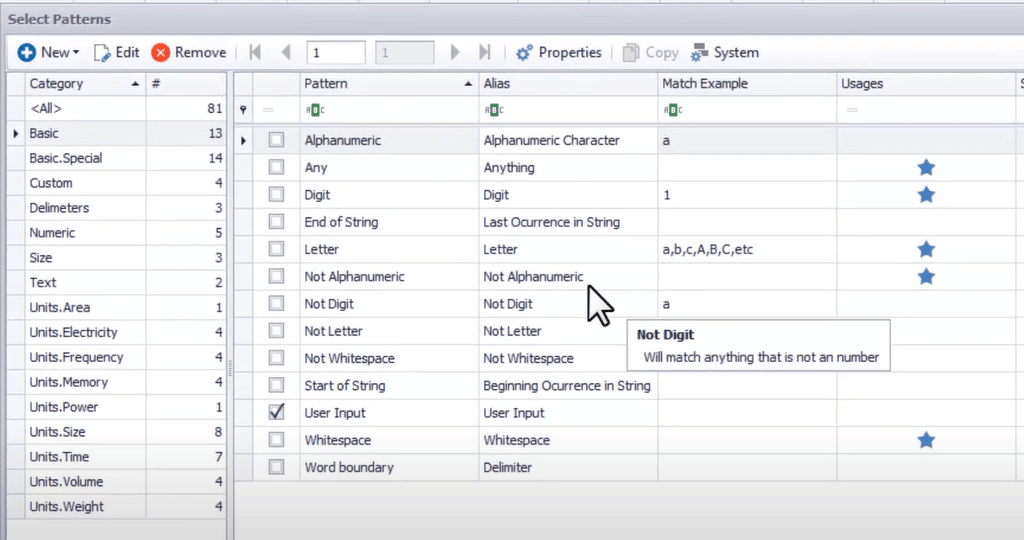
De nombreux outils sont dotés de bibliothèques d’expressions rationnelles intégrées contenant des modèles couramment utilisés, tels que les numéros de carte de crédit, les numéros de téléphone américains, les formats de date, les adresses électroniques, etc. En outre, vous pouvez également créer des modèles personnalisés (spécialisés pour votre usage professionnel) et les enregistrer dans la bibliothèque pour les réutiliser.
Une capture d’écran de la bibliothèque regex dans DataMatch Enterprise est présentée ci-dessous :
4. Ensemble complet de nettoyage et de normalisation des données
L’un des principaux avantages de ces outils est qu’ils sont généralement fournis avec d’autres fonctions de nettoyage et de normalisation des données, qui sont essentielles pour transformer vos données en une forme et un format acceptables. En effet, une fois que vous disposez d’un rapport sur le filtrage qui indique les valeurs de données valides et celles qui ne le sont pas, l’étape suivante consiste à corriger les modèles.
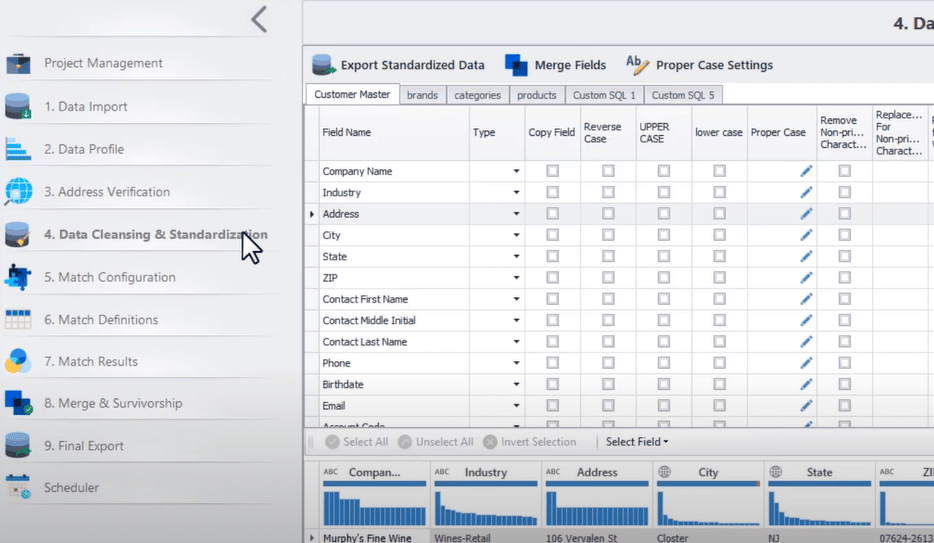
C’est pourquoi l’adoption d’un système de bout en bout qui prend en charge les diverses disciplines de la gestion de la qualité des données – y compris le profilage, le nettoyage, la normalisation, la mise en correspondance et la fusion des données – peut constituer un énorme avantage.
Une capture d’écran des diverses fonctions de qualité des données offertes par DataMatch Enterprise est présentée ci-dessous :
Opter pour une solution sans code qui construit, fait correspondre et transforme les modèles.
Bien que nous nous soyons surtout concentrés sur la correspondance des motifs dans ce blog, l’art de la transformation des motifs est tout aussi intéressant – et pourtant difficile. C’est pourquoi de nombreuses entreprises souhaitent fournir à leurs équipes des outils de nettoyage et de normalisation des données en libre-service, conçus avec des fonctions de conception, de mise en correspondance et de transformation de modèles. L’adoption de tels outils peut aider votre équipe à exécuter des techniques complexes de nettoyage et de normalisation des données sur des millions d’enregistrements en quelques minutes.
DataMatch Enterprise est l’un de ces outils qui permet aux équipes chargées des données de rectifier les erreurs de modèle avec rapidité et précision, et de se concentrer sur des tâches plus importantes. Pour en savoir plus sur la façon dont DataMatch Enterprise peut vous aider, vous pouvez télécharger un essai gratuit aujourd’hui ou réserver une démonstration avec un expert.
The post Guide du filtrage : ce que cela signifie et comment le faire ? appeared first on Data Ladder.
]]>The post Guide de la normalisation des données : Types, avantages et processus appeared first on Data Ladder.
]]>Lorsque vous extrayez des données de diverses applications installées dans toute l’entreprise, vous vous attendez à recevoir une définition et un format cohérents de ces mêmes informations. Mais en réalité, c’est rarement le cas. Les variations présentes dans les ensembles de données – entre les applications et même au sein d’une même application – rendent presque impossible l’utilisation des données à toutes fins – des opérations de routine à la veille économique.
Aujourd’hui, une entreprise moyenne utilise plusieurs applications SaaS et internes. Chaque système est assorti de son propre ensemble d’exigences, de restrictions et de limitations. C’est la raison pour laquelle les données hébergées dans différentes applications contiennent forcément des divergences. Et si l’on tient compte des fautes d’orthographe, des abréviations, des surnoms et des erreurs de frappe, on se rend compte que les mêmes valeurs peuvent avoir des centaines de représentations différentes. C’est là qu’il devient impératif de normaliser les données afin de les rendre utilisables à toutes fins utiles.
Dans ce blog, nous allons tout apprendre sur la normalisation des données : ce qu’elle est, pourquoi et quand vous en avez besoin, et comment vous pouvez la faire. Commençons.
Qu’est-ce que la normalisation des données ?
Dans le monde des données, une norme désigne un format ou une représentation auquel chaque valeur d’un certain domaine doit se conformer. Par conséquent, normaliser les données signifie :
Le processus de transformation d’une représentation incorrecte ou inacceptable de données en une forme acceptable.
Le moyen le plus simple de savoir ce qui est « acceptable » est de comprendre les exigences de votre entreprise. Idéalement, les organisations doivent veiller à ce que le modèle de données utilisé par la plupart – sinon toutes – les applications soit conforme à leurs besoins commerciaux. La meilleure façon de parvenir à la normalisation des données est d’aligner la représentation, la structure et la définition de vos données sur les exigences de l’organisation.
Types et exemples d’erreurs de normalisation des données
Voici quelques exemples de la façon dont des données non normalisées peuvent se retrouver dans le système :
- Le numéro de téléphone du client est enregistré sous forme de chaîne de caractères dans un système alors qu’il ne peut être qu’un numéro à 8 chiffres dans un autre système – ce qui entraîne une incohérence dans le type de données.
- Le nom du client est enregistré dans un seul champ dans un système alors qu’il est couvert par trois champs distincts dans un autre système pour le prénom, le second prénom et le nom de famille, ce qui entraîne une incohérence structurelle.
- La date de naissance du client a le format MM/JJ/AAAA dans un système, alors qu’elle a le format Mois Jour, Année dans un autre système – ce qui entraîne une incohérence de format.
- Le sexe du client est enregistré en tant que Female ou Male dans un système, alors qu’il est enregistré en tant que F ou M dans un autre système – ce qui entraîne une incohérence des valeurs du domaine.
Outre ces scénarios courants, les fautes d’orthographe, les erreurs de transcription et l’absence de contraintes de validation peuvent accroître les erreurs de normalisation des données dans vos ensembles de données.
Pourquoi devez-vous normaliser les données ?
Chaque système a son propre ensemble de limitations et de restrictions, ce qui conduit à des modèles de données uniques et à leurs définitions. C’est pourquoi il peut être nécessaire de transformer les données avant qu’elles ne puissent être consommées correctement par un processus métier.
En général, on sait qu’il est temps de normaliser les données quand on le souhaite :
1. Conformer les données entrantes ou sortantes
Une organisation possède de nombreuses interfaces qui permettent d’échanger des points de données provenant de parties prenantes externes, telles que des fournisseurs ou des partenaires. Chaque fois que des données entrent dans une entreprise ou sont exportées, il devient nécessaire de les conformer à la norme requise, sinon le fouillis de données non normalisées ne fait que s’amplifier.
2. Préparer les données pour la BI ou l’analytique
Les mêmes données peuvent être représentées de plusieurs façons, mais la plupart des outils de BI ne sont pas spécialisés pour traiter toutes les représentations possibles des valeurs de données et peuvent finir par traiter différemment des données de même signification. Cela peut conduire à des résultats BI biaisés ou inexacts. Par conséquent, avant de pouvoir alimenter vos systèmes de BI en données, celles-ci doivent être nettoyées, normalisées et dédupliquées, afin que vous puissiez obtenir des informations correctes et utiles.
3. Consolider les entités pour éliminer les doublons
La duplication des données est l’un des plus grands risques pour la qualité des données auxquels les entreprises sont confrontées. Pour des opérations commerciales efficaces et sans erreur, vous devez éliminer les enregistrements en double qui appartiennent à la même entité (qu’il s’agisse d’un client, d’un produit, d’un emplacement ou d’un employé). Un processus efficace de déduplication des données exige que vous vous conformiez aux normes de qualité des données.
4. Partager les données entre les départements
Pour que les données soient interopérables entre les départements, elles doivent être dans un format compréhensible par tous. Dans la plupart des cas, les organisations disposent d’informations sur les clients dans les systèmes de gestion de la relation client, qui sont comprises par les responsables des ventes et du marketing. Cela peut entraîner des retards dans l’accomplissement des tâches et bloquer la productivité de l’équipe.
Nettoyage des données ou normalisation des données
Les terminologies de nettoyage des données et de normalisation des données sont généralement utilisées de manière interchangeable. Mais il y a une légère différence entre les deux.
Le nettoyage des données est le processus qui consiste à identifier les données incorrectes ou sales et à les remplacer par des valeurs correctes, tandis que la normalisation des données est le processus qui consiste à transformer les valeurs des données d’un format inacceptable en un format acceptable.
L’objectif et le résultat de ces deux processus sont similaires : vous voulez éliminer les inexactitudes et les incohérences de vos ensembles de données. Ces deux processus sont essentiels à votre initiative de gestion de la qualité des données et doivent aller de pair.
Comment normaliser les données ?
Un processus de normalisation des données comporte quatre étapes simples : définir, tester, transformer et retester. Examinons chaque étape un peu plus en détail.
1. Définir une norme
Dans un premier temps, vous devez identifier la norme qui répond aux besoins de votre organisation. La meilleure façon de définir une norme est de concevoir un modèle de données pour votre entreprise. Ce modèle de données représente l’état le plus idéal auquel les valeurs des données d’une certaine entité doivent se conformer. Un modèle de données peut être conçu comme :
- Identifiez les données essentielles au fonctionnement de votre entreprise. Par exemple, la plupart des entreprises saisissent et gèrent des données relatives aux clients, aux produits, aux employés, aux sites, etc.
- Définissez les champs de données de chaque actif identifié et décidez également des détails structurels. Par exemple, vous pouvez souhaiter stocker le nom, l’adresse, l’adresse électronique et le numéro de téléphone d’un client, le champ Nom couvrant trois champs et le champ Adresse deux champs.
- Attribuez un type de données à chaque champ identifié dans le poste. Par exemple, le champ Nom est une valeur de type chaîne de caractères, le champ Numéro de téléphone est une valeur entière, et ainsi de suite.
- Définissez des limites de caractères (minimum et maximum) pour chaque champ. Par exemple, un nom ne peut pas comporter plus de 15 caractères et un numéro de téléphone ne peut pas comporter plus de 8 chiffres, etc.
- Définissez le modèle auquel les champs doivent se conformer – ce modèle peut ne pas être applicable à tous les champs. Par exemple, l’adresse électronique de chaque client doit respecter le regex : [chars]@[chars].[chars].
- Définir le format dans lequel certains éléments de données doivent être placés dans un champ. Par exemple, la date de naissance d’un client doit être spécifiée sous la forme MM/JJ/AAAA.
- Définissez l’unité de mesure des valeurs numériques (le cas échéant). Par exemple, l’âge du client est mesuré en années.
- Définissez le domaine de valeurs pour les champs qui doivent être dérivés d’un certain ensemble de valeurs. Par exemple, l’âge du client doit être un chiffre compris entre 18 et 50, le sexe doit être Masculin ou Féminin, et ainsi de suite.
Un modèle de données conçu peut ensuite être placé dans un diagramme de classe ERD pour aider à visualiser la norme définie pour chaque actif de données et comment ils sont liés les uns aux autres. Un exemple de modèle de données pour une entreprise de vente au détail est présenté ci-dessous :
2. Test de la norme
Les techniques de normalisation des données commencent à la deuxième étape, puisque la première étape se concentre sur la définition de ce qui devrait être – quelque chose qui est fait une fois ou revu et mis à jour de façon incrémentielle de temps en temps.
Vous avez défini la norme et il est maintenant temps de voir dans quelle mesure les données actuelles s’y conforment. Nous examinons ci-dessous un certain nombre de techniques qui permettent de tester les valeurs de données pour détecter les erreurs de normalisation et de créer un rapport de normalisation qui peut être utilisé pour résoudre les problèmes.
a. Analyse syntaxique des enregistrements et des attributs
La conception d’un modèle de données est la partie la plus cruciale de la gestion des données. Mais malheureusement, de nombreuses organisations ne conçoivent pas de modèles de données et ne définissent pas de normes de données communes à temps, ou encore les applications qu’elles utilisent ne disposent pas de modèles de données personnalisables – ce qui les conduit à capturer des données sous des noms de champs et des structures variables.
Lorsque vous interrogez des informations provenant de différents systèmes, vous pouvez remarquer que certains enregistrements renvoient le nom d’un client sous la forme d’un champ unique, tandis que d’autres renvoient trois, voire quatre champs couvrant le nom du client. C’est pourquoi, avant de pouvoir rechercher les erreurs dans un ensemble de données, vous devez commencer par analyser les enregistrements et les champs pour obtenir les composants qui doivent être testés pour la normalisation.
b. Rapport sur le profil des données du bâtiment
L’étape suivante consiste à faire passer les composants analysés par un système de profilage. Un outil de profilage des données présente différentes statistiques sur les attributs des données, telles que
- Combien de valeurs dans une colonne respectent le type, le format et le modèle de données requis ?
- Quel est le nombre moyen de caractères présents dans une colonne ?
- Quelles sont les valeurs minimales et maximales présentes dans une colonne numérique ?
- Quelles sont les valeurs les plus courantes présentes dans une colonne et combien de fois apparaissent-elles ?
c. Correspondance et validation des modèles
Bien que les outils de profilage des données fassent état des correspondances de motifs, étant donné qu’il s’agit d’une partie importante des tests de normalisation des données, nous allons en parler un peu plus en profondeur. Pour faire correspondre des motifs, vous devez d’abord définir une expression régulière standard pour un champ. Par exemple, une expression régulière pour les adresses électroniques peut être : ^[a-zA-Z0-9+_ .-]+@[a-zA-Z0-9 .-]+$. Toutes les adresses électroniques qui ne suivent pas le modèle donné doivent être signalées pendant le test.
d. Utilisation des dictionnaires
La normalisation de certains champs de données peut être testée en comparant les valeurs avec des dictionnaires ou des bases de connaissances. Vous pouvez également les exécuter contre des dictionnaires créés sur mesure. Il s’agit souvent de faire correspondre des fautes d’orthographe, des abréviations ou des noms raccourcis. Par exemple, les noms de sociétés comprennent généralement des termes tels que LLC, Inc, Ltd, et Corp, etc. En les comparant à un dictionnaire rempli de ces termes standard, vous pourrez identifier ceux qui ne respectent pas la norme requise ou qui sont mal orthographiés.
En savoir plus sur l’utilisation de wordsmith pour éliminer le bruit et normaliser les données en vrac.
e. Adresses de test pour la normalisation
Lorsque vous testez des données à des fins de normalisation, vous pouvez être amené à tester des champs spécialisés, tels que des lieux ou des adresses. La normalisation des adresses est le processus qui consiste à vérifier le format des adresses par rapport à une base de données faisant autorité – comme l’USPS aux États-Unis – et à convertir les informations relatives aux adresses dans un format acceptable et normalisé.
Une adresse normalisée doit être correctement orthographiée, formatée, abrégée, géocodée, ainsi que complétée par des valeurs ZIP+4 précises. Toutes les adresses qui ne sont pas conformes à la norme requise (en particulier les adresses qui sont censées recevoir des livraisons et des envois) doivent être signalées afin qu’elles puissent être transformées si nécessaire.
Lire la suite : Un guide rapide de la normalisation et de la vérification des adresses.
Enterprise Content Solutions uses DataMatch Enterprise
Enterprise Content Solutions found 24% higher matches than other vendors for inconsistent address records.
Read case study3. Transformer
Dans la troisième étape du processus de normalisation des données, il est enfin temps de convertir les valeurs non conformes dans un format normalisé. Cela peut inclure :
- Transformer les types de données des champs, par exemple convertir le numéro de téléphone d’une chaîne de caractères en un type de données entier et éliminer tous les caractères ou symboles présents dans les numéros de téléphone pour obtenir un numéro à 8 chiffres.
- Transformer les modèles et les formats, par exemple en convertissant les dates présentes dans l’ensemble de données au format MM/JJ/AAAA.
- Transformation des unités de mesure, comme la conversion des prix des produits en USD.
- Expansion des valeurs abrégées pour compléter les formulaires, par exemple en remplaçant les états américains abrégés : NY pour New York, NJ pour New Jersey, et ainsi de suite.
- Suppression du bruit présent dans les valeurs des données pour obtenir des informations plus significatives, par exemple en supprimant les termes LLC, Inc. et Corp. des noms de sociétés pour obtenir les noms réels sans aucun bruit.
- Reconstruire les valeurs dans un format standardisé au cas où elles devraient être mises en correspondance avec une nouvelle application ou un hub de données, comme un système de gestion des données de base.
Toutes ces transformations peuvent être effectuées manuellement – ce qui peut prendre du temps et être improductif – ou vous pouvez utiliser des outils automatisés qui peuvent vous aider à nettoyer les données en automatisant pour vous les phases de test et de transformation standard.
4. Retester pour la norme
Une fois le processus de transformation terminé, il est bon de tester à nouveau l’ensemble de données pour détecter les erreurs de normalisation. Les rapports avant et après normalisation peuvent être comparés pour comprendre dans quelle mesure les erreurs de données ont été corrigées par les processus configurés et comment ils peuvent être améliorés pour obtenir de meilleurs résultats.
Utilisation d’outils de normalisation des données en libre-service
Aujourd’hui, les données sont saisies manuellement, mais aussi capturées et générées automatiquement. Dans le cadre du traitement de grands volumes de données, les organisations se retrouvent avec des millions d’enregistrements contenant des modèles, des types de données et des formats incohérents. Et chaque fois qu’elles veulent utiliser ces données, les équipes sont bombardées d’heures de vérification manuelle du format et de correction des moindres détails avant que les informations puissent être jugées utiles.
De nombreuses entreprises se rendent compte de l’importance de fournir à leurs équipes des outils de normalisation des données en libre-service, avec des fonctions intégrées de nettoyage des données. L’adoption de tels outils peut aider votre équipe à exécuter des techniques complexes de nettoyage et de normalisation des données sur des millions d’enregistrements en quelques minutes.
DataMatch Enterprise est l’un de ces outils qui aide les équipes chargées des données à rectifier les erreurs de normalisation des données avec rapidité et précision, et leur permet de se concentrer sur des tâches plus importantes. Pour en savoir plus sur la façon dont DataMatch Enterprise peut vous aider, vous pouvez télécharger un essai gratuit aujourd’hui ou réserver une démonstration avec un expert.
The post Guide de la normalisation des données : Types, avantages et processus appeared first on Data Ladder.
]]>The post L’intégration des données expliquée : Définition, types, processus et outils appeared first on Data Ladder.
]]>Les dirigeants sous-estiment souvent le temps et les efforts nécessaires à la mise en place de l’informatique décisionnelle au sein d’une organisation. Ils pensent que c’est aussi simple que de rassembler des données de toutes les sources, de les réunir sur une feuille de calcul et de les transmettre à des outils de veille stratégique ou, encore plus simple, de faire appel à un analyste de données capable de produire de l’intelligence à partir de chiffres. À la fin du projet, ils s’attendent à recevoir des informations incroyables sur les performances de l’entreprise, les opportunités de marché potentielles et les prévisions de revenus pour la prochaine décennie.
Le processus de BI n’est pas si simple, et l’élément le plus critique pour sa réussite est souvent négligé : l’intégration des données. Pour que l’exploitation des données se déroule sans heurts dans une entreprise, celles-ci doivent d’abord être disponibles au bon endroit, au bon moment et dans le bon format. La dispersion des données – qui résident dans des silos – est la cause première de l’incohérence, de l’inefficacité et de l’inexactitude de vos efforts de veille stratégique et autres opérations sur les données.
Dans ce blog, nous allons apprendre ce qu’est l’intégration des données, et discuter de ses différents types, processus et outils. Commençons.
Qu’est-ce que l’intégration des données ?
L’intégration des données est définie comme suit :
Le processus de combinaison, de consolidation et de fusion de données provenant de multiples sources disparates afin d’obtenir une vue unique et uniforme des données et de permettre une gestion, une analyse et un accès efficaces aux données.
La capture et le stockage constituent la première étape du cycle de vie de la gestion des données. Mais des données disparates – résidant dans diverses bases de données, feuilles de calcul, serveurs locaux et applications tierces – ne sont d’aucune utilité tant qu’elles ne sont pas regroupées. L’intégration des données permet à votre entreprise d’appliquer de manière pratique et holistique les informations capturées et de répondre aux questions commerciales essentielles.
Prenons l’exemple de l’intégration des données clients. Dans toute organisation, les données clients sont stockées et hébergées à de multiples endroits – notamment dans les outils de suivi des sites web, les CRM, les logiciels d’automatisation du marketing et de comptabilité, etc. Pour donner du sens aux informations sur les clients et en extraire des informations utiles, votre équipe ne peut pas passer constamment d’une application à l’autre. Ils ont besoin d’un accès unique et uniforme aux enregistrements des données des clients – où les données sont propres et sans ambiguïté.
De même, il existe d’innombrables autres avantages de l’intégration des données qui permettent une gestion efficace des données, une veille économique et d’autres opérations sur les données.
5 types d’intégration de données
L’intégration des données peut être réalisée de plusieurs façons. Communément appelées méthodes, techniques, approches ou types d’intégration de données, il existe 5 façons différentes d’intégrer vos données.
1. Intégration de données par lots
Dans ce type d’intégration de données, les données passent par le processus ETL par lots à des moments programmés (hebdomadaires ou mensuels). Elles sont extraites de sources disparates, transformées en une vue cohérente et normalisée, puis chargées dans un nouveau magasin de données, tel qu’un entrepôt de données ou plusieurs marts de données. Cette intégration est surtout utile pour l’analyse des données et la veille stratégique, car un outil de veille stratégique ou une équipe d’analystes peut simplement observer les données stockées dans l’entrepôt.
2. Intégration des données en temps réel
Dans ce type d’intégration de données, les données entrantes ou en continu sont intégrées aux enregistrements existants en quasi temps réel par le biais de pipelines de données configurés. Les entreprises utilisent des pipelines de données pour automatiser le mouvement et la transformation des données, et les acheminer vers la destination ciblée. Les processus d’intégration des données entrantes (en tant que nouvel enregistrement ou mise à jour/application des informations existantes) sont intégrés dans le pipeline de données.
3. Consolidation des données
Dans ce type d’intégration de données, une copie de tous les ensembles de données sources est créée dans un environnement ou une application de transit, les enregistrements de données sont ensuite consolidés pour représenter une vue unique, puis finalement déplacés vers une source de destination. Bien que ce type soit similaire à l’ETL, il présente quelques différences essentielles telles que :
- La consolidation des données se concentre davantage sur des concepts tels que le nettoyage et la normalisation des données et la résolution des entités, tandis que l’ETL se concentre sur la transformation des données.
- Alors que l’ETL est une meilleure option pour le big data, la consolidation des données est un type plus approprié pour relier les enregistrements et identifier de manière unique les principaux actifs de données, tels que le client, le produit et l’emplacement.
- Les entrepôts de données aident principalement à l’analyse des données et à la BI, tandis que la consolidation des données est également utile pour améliorer les opérations commerciales, comme l’utilisation du dossier consolidé d’un client pour le contacter ou créer des factures, etc.
4. La virtualisation des données
Comme son nom l’indique, ce type d’intégration de données ne crée pas réellement une copie des données ou ne les déplace pas vers une nouvelle base de données avec un modèle de données amélioré. Il introduit plutôt une couche virtuelle qui se connecte à toutes les sources de données et offre un accès uniforme comme une application frontale.
Comme elle ne dispose pas de son propre modèle de données, la couche virtuelle a pour but d’accepter les demandes entrantes, de créer des résultats en interrogeant les informations requises dans les bases de données connectées et de présenter une vue unifiée. La virtualisation des données réduit le coût de l’espace de stockage et la complexité de l’intégration, puisque les données semblent intégrées mais résident séparément dans les systèmes sources.
5. Fédération de données
La fédération de données est similaire à la virtualisation des données et est souvent considérée comme son sous-type. Encore une fois, dans la fédération de données, les données ne sont pas copiées ou déplacées vers une nouvelle base de données, mais un nouveau modèle de données est conçu qui représente une vue intégrée des systèmes sources.
Il fournit une interface frontale d’interrogation et, lorsque des données sont demandées, il les extrait des sources connectées et les transforme en modèle de données amélioré avant de présenter les résultats. La fédération de données est utile lorsque les modèles de données sous-jacents des systèmes sources sont trop différents et doivent être mis en correspondance avec un modèle plus récent afin d’utiliser les informations plus efficacement.
Processus d’intégration des données
Quel que soit le type d’intégration de données, le flux du processus d’intégration de données est similaire pour tous, car l’objectif est de combiner et de rassembler les données. Dans cette section, nous examinons un cadre général d’intégration de données d’entreprise que vous pouvez utiliser lors de la mise en œuvre de toute technique d’intégration de données.

1. Collecte des besoins
La première étape de tout processus d’intégration de données consiste à recueillir et à évaluer les exigences commerciales et techniques. Cela vous aidera à planifier, concevoir et mettre en œuvre un cadre qui produira les résultats escomptés. Voici un certain nombre de domaines à couvrir lors de la collecte des exigences :
- Avez-vous besoin d’intégrer des données en temps réel ou par lots à des moments programmés ?
- Devez-vous créer une copie des données pour ensuite les intégrer, ou mettre en place une couche virtuelle qui intègre les données à la volée sans répliquer les bases de données ?
- Les données intégrées doivent-elles suivre un nouveau modèle de données amélioré ?
- Quelles sources doivent être intégrées ?
- Quelle sera la destination des données intégrées ?
- Quels départements fonctionnels de l’organisation ont besoin d’accéder aux informations intégrées ?
2. Profilage des données
Une autre étape initiale du processus d’intégration des données consiste à générer des rapports de profilage ou d’évaluation des données qui doivent être intégrées. Cela vous aidera à comprendre l’état actuel des données et à découvrir des détails cachés sur leur structure et leur contenu. Un rapport sur le profilage des données identifie les valeurs vides, les types de données des champs, les modèles récurrents et d’autres statistiques descriptives qui mettent en évidence les possibilités de nettoyage et de transformation des données.
3. Examen des profils par rapport aux exigences
Avec les exigences d’intégration et les rapports d’évaluation en main, il est maintenant temps d’identifier l’écart entre les deux. De nombreuses fonctionnalités demandées lors de la phase de définition des besoins ne sont pas valables ou ne correspondent pas aux rapports profilés des données existantes. Mais la comparaison entre les deux vous aidera à planifier une conception de l’intégration qui répond à autant d’exigences que possible.
4. Conception
Il s’agit de la phase de planification du processus au cours de laquelle vous devez concevoir certains concepts clés sur l’intégration des données, tels que :
- La conception architecturale qui montre comment les données vont circuler entre les systèmes,
- Les critères de déclenchement qui décident quand l’intégration aura lieu ou ce qui la déclenchera,
- Le nouveau modèle de données amélioré et les mappages de colonnes qui définissent le processus de consolidation,
- Les règles de nettoyage, de normalisation, de mise en correspondance et d’assurance qualité des données qui doivent être configurées pour une intégration sans erreur, et
- La technologie qui sera utilisée pour mettre en œuvre, vérifier, surveiller et itérer le processus d’intégration.
5. Mettre en œuvre
Une fois le processus d’intégration conçu, il est temps de l’exécuter. L’exécution peut se faire de manière incrémentielle – en intégrant de faibles volumes de données provenant de sources moins conflictuelles, puis en augmentant itérativement les volumes et en ajoutant d’autres sources. Cela peut être utile pour détecter les erreurs initiales qui peuvent survenir. Une fois l’intégration des données existantes terminée, vous pouvez maintenant vous concentrer sur l’intégration des nouveaux flux de données entrants.
6. Vérifier, valider et contrôler
Au cours de la phase de vérification, vous devez tester l’exactitude et l’efficacité du processus d’intégration des données. Le profilage de la source de destination peut être un bon moyen de détecter les erreurs et de valider l’intégration. Un certain nombre de domaines doivent être testés avant que l’installation d’intégration ne puisse être confiée à des activités futures, comme par exemple :
- La perte de données est minime ou nulle,
- La qualité des données ne s’est pas détériorée après l’intégration,
- Le processus d’intégration fonctionne systématiquement comme prévu,
- La signification des données n’a pas changé pendant l’intégration,
- Les mesures mentionnées ci-dessus sont toujours valables après un certain temps.
Intégration et qualité des données : Trop intégrées pour être différenciées
Avant de poursuivre, discutons d’un concept important lié à l’intégration des données qui sème souvent la confusion : la relation entre l’intégration des données et la qualité des données.
D’un point de vue global, l’intégration des données et la qualité des données ont le même objectif : rendre l’utilisation des données plus facile et efficace. Pour atteindre cet objectif, on ne peut mentionner l’intégration des données sans la qualité des données, et vice versa. Cela peut devenir confus si vous essayez de comprendre où finit l’un et où commence l’autre. La vérité est que ces deux concepts sont trop intégrés pour être différenciés et doivent être traités de manière transparente.
Les efforts d’intégration de données qui ne tiennent pas compte de la qualité des données sont voués à l’échec. La gestion de la qualité des données est un catalyseur de votre processus d’intégration de données car elle améliore et accélère la consolidation des données.
Une autre distinction entre les deux est que la qualité des données n’est pas une initiative – mais une habitude ou un exercice qui doit être constamment contrôlé. Bien que dans le cas des entrepôts de données, l’intégration des données puisse se faire à des moments précis de la semaine ou du mois, vous ne pouvez pas oublier la qualité des données même pendant cette attente. La qualité des données est donc primordiale pour obtenir des résultats d’intégration de données réussis et utilisables.
Outils et solutions d’intégration de données
Compte tenu des grands volumes de données que les organisations stockent et intègrent, les efforts manuels sont hors de question pour la plupart des initiatives d’intégration. L’utilisation de la technologie pour intégrer et consolider les données résidant dans des sources distinctes peut s’avérer plus efficace, efficiente et productive. Voyons maintenant quelles sont les caractéristiques communes que vous pouvez rechercher dans une plateforme d’intégration de données :
- La possibilité d’extraire des données d’une grande variété de sources, telles que des bases de données SQL ou Oracle, des feuilles de calcul et des applications tierces.
- La possibilité de profiler des ensembles de données et de générer un rapport complet sur leur état en termes d’exhaustivité, de reconnaissance des formes, de types et de formats de données, etc.
- La possibilité d’éliminer les ambiguïtés, telles que les valeurs nulles ou les valeurs résiduelles, de supprimer le bruit, de corriger les fautes d’orthographe, de remplacer les abréviations, de transformer le type et le modèle de données, etc.
- La possibilité de mapper des attributs appartenant à des sources de données distinctes pour mettre en évidence le flux d’intégration.
- La capacité d’exécuter des algorithmes de comparaison de données et d’identifier les enregistrements appartenant à la même entité.
- La possibilité d’écraser les valeurs lorsque cela est nécessaire et de fusionner les enregistrements entre les sources afin d’obtenir le disque d’or.
- La possibilité d’exécuter l’intégration des données à des moments planifiés ou de les intégrer en temps réel via des appels API ou d’autres mécanismes similaires.
- La possibilité de charger les données intégrées dans n’importe quelle base de données ciblée.
Unifier l’intégration, le nettoyage et le rapprochement des données
L’intégration de grandes quantités de données peut s’avérer être une initiative écrasante, surtout si vous optez pour une configuration ETL ou de virtualisation des données. Un environnement d’intégration de données de base qui rassemble les données tout en minimisant les défauts intolérables de qualité des données peut être un bon point de départ pour la plupart des entreprises. En donnant la priorité à l’aspect unique et le plus important de l’intégration des données pour la consolidation des données, vous pouvez commencer à un niveau bas et l’améliorer progressivement si nécessaire.
Vous pouvez commencer par utiliser une solution d’intégration de données unifiée qui offre une variété de connecteurs communs ainsi que des fonctions intégrées pour le profilage, le nettoyage, la normalisation, la mise en correspondance et la fusion des données. En outre, une fonction de planification qui intègre les données par lots à des moments configurés peut donner le coup d’envoi de votre initiative en quelques jours.
DataMatch Enterprise est l’un de ces outils de consolidation de données qui peut vous aider à intégrer vos données résidant dans des sources distinctes. Téléchargez une version d’évaluation dès aujourd’hui ou réservez une démonstration avec nos experts pour voir comment nous pouvons vous aider à mener à bien votre initiative d’intégration de données.
The post L’intégration des données expliquée : Définition, types, processus et outils appeared first on Data Ladder.
]]>The post L’impact d’une mauvaise qualité des données sur un plan de survie en période de récession appeared first on Data Ladder.
]]>« Vous avez des récessions, vous avez des baisses de la bourse. Si vous ne comprenez pas que cela va se produire, alors vous n’êtes pas prêt. Vous n’aurez pas de bons résultats sur les marchés. Si vous allez au Minnesota en janvier, vous devez savoir qu’il va faire froid. Vous ne paniquez pas lorsque le thermomètre descend en dessous de zéro ».
Peter Lynch
Prévision de la récession mondiale
Les économistes mettent en garde contre les deux : une récession aux États-Unis et une récession mondiale. La baisse du prix des actions – en particulier dans les secteurs de la technologie et du commerce de détail, la hausse des taux d’intérêt – et les problèmes croissants liés à la chaîne d’approvisionnement sont les principaux indicateurs qui gonflent cette prédiction.
Avec un sentiment de malheur imminent sur le marché, les entreprises prennent des décisions irréfléchies et impulsives. Les nouveaux projets sont arrêtés, les dépenses sont réduites à un niveau trop bas et les employés sont licenciés brutalement. L’imprévisibilité des événements futurs ajoute à l’inquiétude des chefs d’entreprise qui tentent de naviguer à travers une éventuelle récession.
Au milieu de tout cela, les données s’avèrent être l’atout le plus précieux d’une organisation qui offre une valeur réelle en période de ralentissement économique.
Data : La vérité est là
Les données deviennent un sauveur dans les moments où tout le reste échoue. Un rapide coup d’œil à ce qui s’est passé lors des précédents ralentissements économiques peut vous aider à naviguer dans le présent avec confiance. Les données offrent un coussin aux entreprises et leur permettent de prendre des décisions avec un sentiment de familiarité et de confort qui est nécessaire dans une période sans précédent. Mais il est évident que les données brutes n’offrent pas les perspectives requises et qu’elles doivent être transformées en informations commerciales et en éléments exploitables.
Cycle de l’intelligence économique
Recherche sur Données et catastrophes décrit un cycle de veille économique simple mais puissant :
Ce cycle montre comment les données brutes sont transformées en informations exploitables :
- Une fois les données brutes collectées, elles sont converties en informations en vérifiant leurs métadonnées et en testant la qualité des valeurs pour exclure les inexactitudes et les incohérences.
- Les informations sont ensuite converties en connaissances en les alimentant en outils de business intelligence.
- Les connaissances sont ensuite gérées pour élaborer des plans et des objectifs commerciaux.
- Les dirigeants se réunissent pour convertir ces plans et ces objectifs en éléments concrets.
- De nouvelles données brutes sont à nouveau collectées après la réalisation d’actions, puis converties en informations.
6 façons dont les données aident en période de récession
Une veille économique précise et fiable aide les entreprises à prendre des décisions fondées sur des données réelles, plutôt que sur des suppositions et des hypothèses. Voici six façons dont les données aident les entreprises à se maintenir à flot en période de récession.
1. Minimiser le risque
Deux décisions peuvent vous conduire sur des voies différentes, mais comment savoir laquelle aura un impact meilleur et plus positif sur votre entreprise ? La réponse se trouve dans les données du passé. L’analyse des informations passées peut vous aider à éviter des décisions coûteuses et à mesurer les coûts d’opportunité de diverses voies – ce qui vous permet de choisir les alternatives qui offrent plus de valeur à court terme.
2. Planifier les ressources
L’une des premières décisions que prennent les chefs d’entreprise en cas de crise économique est de licencier un grand nombre de leurs employés. Mais les données historiques ont montré que de telles décisions sont toujours prises trop tôt. Par exemple, avec le début de la pandémie de COVID-19, le monde a connu la plus courte récession de son histoire, qui n’a duré que 3 mois. Les chefs d’entreprise se sont vite rendu compte que les réductions d’effectifs avaient été effectuées trop tôt, car ils ont constaté que le réembauchage, l’intégration et la formation des employés constituaient un défi bien plus important que leur maintien en poste.
3. Prévoir la gravité de la récession
Les récessions sont toujours lugubres, longues et graves. Mais les données passées montrent que ce n’est pas aussi grave que ce que l’on peut penser en passant par là. En effet, le moment où la récession va frapper, sa durée et la gravité de son impact sur les petites et grandes entreprises ne correspondent pas aux prévisions des gourous de l’économie. L’utilisation de données pour comprendre réellement ces aspects de la récession peut aider à fonder les décisions sur des informations plus précises.
4. Lire les succès passés
Même si les récessions peuvent sembler désastreuses, il existe des exemples d’entreprises qui ont non seulement survécu à une récession, mais qui ont également prospéré pendant et après celle-ci. Le secret réside dans les décisions qu’ils ont prises avant que la récession ne frappe. Vous pouvez commencer par mettre la main sur des exemples de réussites passées ou même vous mettre en relation avec des dirigeants qui ont réussi à traverser les crises économiques précédentes et apprendre comment ils s’y sont pris.
5. Observer le comportement des consommateurs
Les entreprises de la chaîne d’approvisionnement ou du commerce de détail se plaignent des plus gros inconvénients de la récession. Mais la vérité, c’est qu’il y a eu des histoires à succès sur la façon dont les petits détaillants sont devenus grands pendant les périodes difficiles. Le principal secret ici est de comprendre le comportement des consommateurs. Ce n’est pas que les consommateurs n’achètent pas pendant une crise économique – c’est qu’ils peuvent acheter quelque chose de différent et en quantité variable selon l’état économique de leur pays.
C’est le meilleur moment pour investir dans des plates-formes d’intelligence économique qui vous donnent les dernières informations sur le marché. En savoir plus sur la façon dont les détaillants peuvent continuer à surfer sur la vague du commerce électronique en période de ralentissement économique.
The role of data quality in the world of retail
Download this whitepaper to find out how retailers can identify if they have poor retail data quality and the most common issues associated with retail data and how to fix them.
Download6. Investir dans l’amélioration des opérations
Les données peuvent vous aider à comprendre quels domaines d’activité nécessitent une amélioration opérationnelle. Puisque les affaires sont au ralenti, c’est le bon moment pour analyser les transactions opérationnelles passées et concevoir de nouveaux processus opérationnels améliorés pour différents domaines, tels que l’expérience et l’engagement des clients, le cycle des ventes, la gestion de la chaîne d’approvisionnement, etc.
La mauvaise qualité des données : La vérité n’existe pas
Il est impératif que les données utilisées pour élaborer un plan de survie à la récession soient précises, valides et cohérentes. Mais en réalité, les données sont pleines d’erreurs et de défauts intolérables qui rendent la business intelligence assez difficile, voire impossible. La mauvaise qualité des données – si elle n’est pas gérée à temps – s’est avérée produire des résultats peu fiables et avoir un impact dévastateur sur une entreprise.
Cycle d’intelligence économique sans qualité des données
Voyons comment un cycle de veille stratégique se comporte lorsqu’il est alimenté par de mauvaises données :

- L’étape la plus importante de la conversion des données en informations est sautée.
- Les analystes et les outils de BI tentent d’extraire directement des connaissances à partir de données sales.
- Les « connaissances » sont ensuite converties en objectifs et plans d’entreprise.
- Les dirigeants conçoivent des éléments exploitables à partir du plan d’affaires pollué.
Ainsi, les leaders ordonnent à leurs équipes d’agir en fonction d’un plan qui n’a rien à voir avec la réalité. De plus, tout le temps et les ressources consacrés à ce cycle de BI ont été gaspillés puisque les données étaient déjà corrompues.
4 façons dont une mauvaise qualité des données ruine un plan de survie à la récession
Voyons comment une mauvaise qualité des données peut ruiner le plan de survie d’une entreprise en cas de récession.
1. Des informations peu fiables grâce aux outils de BI
Nous venons de voir comment des données sales peuvent détruire vos informations de business intelligence. Si vos outils de BI sont alimentés par de mauvaises données, les dirigeants risquent de recevoir des suggestions incohérentes et confuses de la part de leurs outils de BI ou de leur équipe d’analystes. Si vous fondez vos décisions sur de telles informations, votre organisation risque de manquer des opportunités de marché cruciales et de perdre des revenus en période difficile. Cela peut être dévastateur pour votre entreprise, car elle n’est peut-être pas prête à supporter de telles pertes.
2. Désengagement vis-à-vis des clients
Les entreprises qui sont en concurrence sur un marché depuis des décennies ont une bonne connaissance de leurs consommateurs – en termes de démographie, de préférences et de choix. Mais une récession imminente pourrait changer la donne. Observer le comportement des consommateurs à partir de données périmées ou mal interprétées peut nuire à votre réputation sur le marché. Vos clients peuvent avoir l’impression que vous perdez le contact avec eux et que vous ne répondez pas à leurs attentes. Cela peut conduire vos concurrents à vous voler vos clients alors que vous essayez de réduire les services et l’assistance à la clientèle.
How to build a unified, 360 customer view
Download this whitepaper to learn why it’s important to consolidate your customer data and how you can get a 360 view of your customers.
Download3. Obstacles au passage au numérique
Les entreprises interrompent souvent leurs initiatives de transformation numérique par crainte d’une éventuelle récession. Mais les économistes ont prédit que les récessions sont un bon moment pour accélérer les projets de transformation numérique car leurs coûts d’opportunité sont faibles. Cela s’explique par le fait que les affaires sont déjà au ralenti et qu’il est plus facile et moins coûteux d’embaucher des professionnels techniques qui sont licenciés dans tout le secteur de la technologie.
Malgré ses avantages, les entreprises sont bloquées dans leur passage au numérique en raison de montagnes d’informations manquantes, incomplètes, incohérentes et non standardisées. Lorsque la qualité des données n’est pas conforme aux normes requises, cela entraîne des retards importants lorsque les entreprises tentent de numériser les processus ou d’introduire de nouvelles technologies.
4. Réduction de l’efficacité opérationnelle et de la productivité
Comme les affaires sont lentes pendant ces périodes, les entreprises ont tendance à se concentrer sur l’amélioration de l’efficacité opérationnelle dans l’ensemble de l’organisation pour se concentrer sur de nouvelles opportunités d’expansion sur le marché. Mais la mauvaise qualité des données entraîne de sérieux goulots d’étranglement dans le travail de chacun, car il faut vérifier les sources et le contenu des données avant de les utiliser dans les opérations de routine. De tels problèmes entraînent une baisse de l’efficacité opérationnelle et des niveaux de productivité à un moment où votre entreprise peut le moins les tolérer.
Un plan de qualité des données avant la récession
Il ne fait aucun doute que vos analyses doivent être opportunes et précises pour survivre à une récession. Mais une mauvaise qualité des données peut détruire à la fois la rapidité et la précision de vos informations. C’est pourquoi il est impératif d’investir dès maintenant dans la gestion de la qualité des données afin d’éviter les conséquences potentielles de mauvaises données lorsque la récession se produira. Examinons les 3 étapes les plus importantes pour faire face à une mauvaise qualité des données lorsque nous sommes proches d’une récession.
1. Identifier les problèmes de qualité des données
La première étape est évidente : déterminer à quoi vous avez affaire. Toutes les entreprises n’ont pas les mêmes problèmes de qualité des données. La qualité des données est définie comme l’adéquation des données à tout objectif prévu. Selon la manière dont les données sont utilisées dans votre entreprise, vous pouvez trouver de nombreuses divergences dans la manière dont la qualité des données est gérée. Une liste des problèmes courants de qualité des données est donnée ci-dessous. Pour en savoir plus, consultez les 12 problèmes de qualité des données les plus courants et leur origine.
| No. | Data quality issue | Explanation | Example of data quality issue |
|---|---|---|---|
| 1 | Column duplication | Multiple columns are present that have the same logical meaning. | Product category is stored in two columns that logically mean the same: Category and Classification. |
| 2 | Record duplication | Multiple records are present for the same individual or entity. | Every time a customer interacts with your brand, a new row is created in the database rather than updating the existing one. |
| 3 | Invalid data | Data values are present in an incorrect format, pattern, data type or size. | Customer Phone Numbers are present in varying formats – some are stored as flat 10 digits, while others have hyphens, some are saved as a string, while others as numbers, and so on. |
| 4 | Inaccurate data | Data values do not conform to reality. | Customer Name is incorrectly stored: Elizabeth is stored as Aliza, or Matt is stored as Mathew. |
| 5 | Incorrect formulae | Data values are calculated using incorrect formulae. | Customer Age is calculated from their Date of Birth but the formula used is incorrect. |
| 6 | Inconsistency | Data values that represent the same information vary across different datasets and sources. | Customer record stored in the CRM represents a different Email Address than the one present in accounts application. |
| 7 | Missing data | Data is missing or is filled with blank values. | The Job Title of most customers is missing from the dataset. |
| 8 | Outdated data | Data is not current and represents outdated information. | Customer Mailing Addresses are years old leading to returned packages. |
| 9 | Unverified domain data | Data does not belong to a range of acceptable values. | Customer Mailing Addresses are years old leading to returned packages. |
2. Mettre en œuvre un plan de qualité des données en semaines
Si vos ensembles de données sont pollués par des erreurs, vous devez utiliser une plateforme de qualité des données – mais rien de trop grandiose, quelque chose qui peut être opérationnel en quelques semaines et non en quelques mois. Il existe de multiples façons pour les fournisseurs d’intégrer divers processus de gestion de la qualité des données dans leurs outils, par exemple :
- Profilage des données pour évaluer l’état actuel de la qualité des données,
- Nettoyage et normalisation des données pour éliminer les valeurs nulles et le bruit, et transformer les données en une vue standard,
- Correspondance de données permettant d’identifier les enregistrements appartenant à la même entité,
- Déduplication des données pour éliminer les enregistrements en double,
- Fusion et épuration des données pour conserver les informations utiles et fusionner les enregistrements afin d’obtenir l’ensemble de données idéal, exempt d’erreurs.
The definitive buyer’s guide to data quality tools
Download this guide to find out which factors you should consider while choosing a data quality solution for your specific business use case.
Download3. Raccourcir le cycle action-impact
Lorsqu’il s’agit de mettre en œuvre un outil de qualité des données, de nombreuses entreprises s’enlisent dans des systèmes avancés de gestion des données qui prennent en charge des principes complexes de gestion des données, tels que la gouvernance des données, la gestion centralisée, la gestion des données de référence, ainsi que la protection et la sécurité des données. Bien qu’il s’agisse d’excellentes fonctionnalités à intégrer dans vos systèmes de données, leur mise en œuvre peut prendre beaucoup de temps et s’avérer bénéfique pour votre entreprise.
Concentrez-vous sur la réduction du cycle action-impact. En période de ralentissement économique, vous souhaitez probablement disposer d’un outil qui vous donne un aperçu rapide mais détaillé des erreurs de qualité des données existant dans vos ensembles de données et de la manière la plus simple de les résoudre.
Dernières réflexions
L’imprévisibilité économique fait que les chefs d’entreprise craignent les événements futurs. L’intelligence économique et commerciale peut leur offrir le confort nécessaire pour prendre des décisions cruciales. Investir dans des outils de BI et une équipe d’analystes est préjudiciable en ces temps sans précédent, mais nous ne pouvons pas minimiser la valeur des données propres – l’actif qui est transformé en informations exploitables.
Pour commencer, fournir des outils de nettoyage et de rapprochement des données en libre-service à vos équipes peut être très bénéfique pour produire des résultats rapides. Un outil tout-en-un, en libre-service, qui permet de profiler les données, d’effectuer diverses activités de nettoyage des données, de faire correspondre les doublons et de produire une source unique de vérité peut devenir un facteur de différenciation important dans les performances des outils de BI et des analystes de données.
DataMatch Enterprise est l’un de ces outils qui aide les équipes chargées des données à rectifier les erreurs de qualité des données avec rapidité et précision, et leur permet de se concentrer sur des tâches plus importantes. Les équipes chargées de la qualité des données peuvent profiler, nettoyer, faire correspondre, fusionner et purger des millions d’enregistrements en quelques minutes, et économiser beaucoup de temps et d’efforts qui sont habituellement gaspillés pour de telles tâches.
Pour en savoir plus sur la façon dont DataMatch Enterprise peut vous aider, vous pouvez télécharger un essai gratuit aujourd’hui ou réserver une démonstration avec un expert.
Getting Started with DataMatch Enterprise
Download this guide to find out the vast library of features that DME offers and how you can achieve optimal results and get the most out of your data with DataMatch Enterprise.
DownloadThe post L’impact d’une mauvaise qualité des données sur un plan de survie en période de récession appeared first on Data Ladder.
]]>The post 8 principes de gestion des données appeared first on Data Ladder.
]]>Une entreprise moyenne – de 200 à 500 employés – utilise environ 123 applications SaaS pour numériser ses processus commerciaux. Avec les grandes quantités de données générées chaque jour, vous avez certainement besoin d’une manière systématique de traiter les données. Il s’agit notamment d’adopter des pratiques et des stratégies modernes pour capturer, traiter, partager, stocker et récupérer les données tout en minimisant les pertes de données et les erreurs. Toute faille présente dans ces processus peut faire courir de graves risques à votre entreprise.
Dans ce blog, nous abordons ce que signifie la gestion des données et les principes clés de la gestion des données que vous devez connaître lorsque vous gérez les données de votre organisation. Commençons.
Qu’est-ce que la gestion des données ?
La gestion des données est la pratique consistant à adopter des principes, des règles, des stratégies et des méthodologies qui peuvent contribuer à garantir une utilisation maximale et optimale des données d’une organisation.
Les concepts et principes de la gestion des données sont assez diversifiés car ils se concentrent sur un certain nombre de processus de données dans une entreprise, tels que :
- Capture et intégration des données : S’assurer que les données requises sont capturées, intégrées et consolidées afin qu’elles puissent être utilisées à toutes les fins prévues.
- Stockage des données : Assure que les données sont stockées là où elles sont nécessaires – qu’il s’agisse d’un stockage sur site, d’un cloud public ou privé, ou d’une configuration hybride.
- Sécurité des données : Assure que les données sont protégées contre tout accès non autorisé et que des politiques sont mises en œuvre pour un accès et un partage sécurisés des données.
- Gestion de la qualité des données : Assure que les données sont continuellement profilées pour détecter les erreurs et qu’elles passent par un pipeline de données pour vérifier et corriger leur qualité.
- Disponibilité des données : Elle garantit que les données sont accessibles aux personnes qui en ont besoin et que des plans de sauvegarde et de reprise après sinistre sont en place.
8 principes de gestion des données
La conception de vos processus de gestion des données peut s’avérer difficile car elle porte sur divers domaines de données. Vous découvrirez ici ce que sont les principes de gestion des données et vous verrez les 8 principes de gestion des données les plus importants que vous devez administrer.
1. Modélisation des données
Le premier et le plus important principe directeur de la gestion des données est la modélisation des données. La modélisation des données consiste à concevoir et à structurer vos actifs de données, leurs propriétés et leurs interrelations de manière logique. Un exemple de modèle de données pour un commerce de détail est présenté ci-dessous :
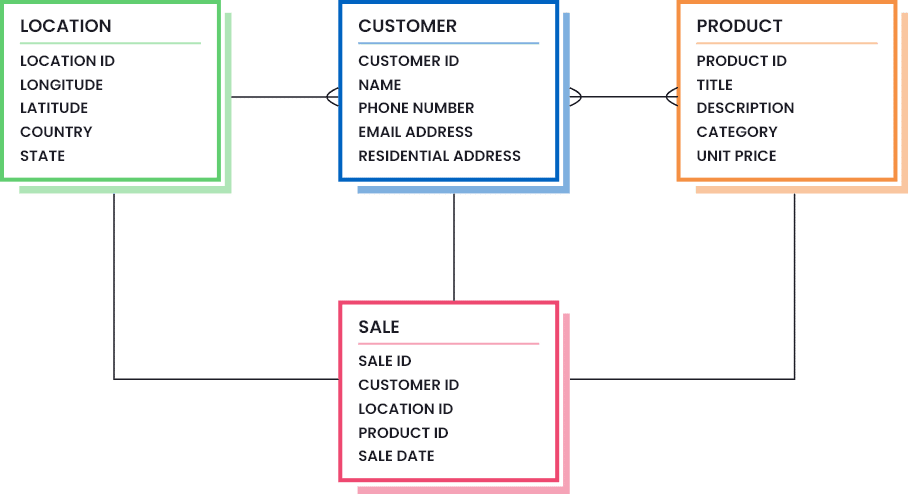
Un modèle de données représente simplement ce qui suit (comme on peut le voir dans le diagramme ci-dessus) :
- Les actifs de données qu’une organisation stocke et gère (par exemple, client, produit, emplacement et ventes),
- Les propriétés du monde réel que chaque actif stocke (par exemple : L’actif de données client contient l’identifiant, le nom, le numéro de téléphone, l’adresse électronique et l’adresse résidentielle du client),
- Le type de données et la taille de chaque propriété (par exemple, l’ID du client doit être un nombre entier avec un maximum de 12 chiffres),
- Les contraintes relationnelles que deux ou plusieurs actifs de données ont entre eux (par exemple, le client a un emplacement, le client achète un produit, etc.)
- La cardinalité de la relation qui indique le nombre maximum de relations qu’un actif peut avoir avec un autre (par exemple, un client ne peut avoir qu’un seul emplacement à la fois),
- L’intégrité référentielle qui définit quels enregistrements peuvent être référencés entre les actifs (par exemple, un enregistrement de ventes doit toujours faire référence à un ID de client qui existe dans la table des clients).
Une organisation ne pourra jamais gérer efficacement ses données si elle ne parvient pas à établir un lien précis entre les exigences en matière de données et les modèles de données structurés. C’est pourquoi il est important de recueillir d’abord les besoins en données auprès des parties prenantes nécessaires, puis de commencer le processus de conception. Une fois que vous connaissez les attentes de votre équipe vis-à-vis des données qu’elle utilise, vous pouvez alors concevoir des modèles de données qui capturent les informations requises.
2. Rôles et responsabilités en matière de données
Les chefs d’entreprise commettent souvent l’erreur de tenir les utilisateurs de données pour responsables d’une gestion efficace des données. Mais en réalité, vous devez nommer plusieurs professionnels des données à différents niveaux de votre entreprise. Cela permet de s’assurer que tous les efforts et investissements consentis pour la gestion des données ne sont pas seulement mis en œuvre, mais qu’ils sont bien entretenus pour les années à venir. Examinons les rôles les plus importants en matière de données et leurs responsabilités que vous devez prendre en compte lors de la constitution d’une équipe de données.
- Chief Data Officer (CDO) : Un Chief Data Officer (CDO) est un poste de direction, uniquement chargé de concevoir des stratégies permettant l’utilisation des données, le contrôle de la qualité des données et la gouvernance des données dans toute l’entreprise.
- Responsable des données : Un responsable des données est la personne à contacter dans une entreprise pour toute question relative aux données. Ils sont totalement impliqués dans la manière dont l’organisation capture les données, où elle les stocke, ce qu’elles signifient pour les différents départements et comment leur qualité est maintenue tout au long de leur cycle de vie.
- Dépositaire des données : Le gardien des données est responsable de la structure des champs de données, y compris des structures et des modèles de base de données.
- Ingénieur en données : Un ingénieur en données est responsable de la modélisation des données et de la construction de systèmes qui capturent, stockent et analysent les données avec précision.
- Analyste de données : Un analyste de données est une personne capable de prendre des données brutes et de les convertir en informations significatives, notamment dans des domaines spécifiques. L’une des principales tâches de l’analyste de données consiste à préparer, nettoyer et filtrer les données requises.
- Autres équipes : Ces rôles sont considérés comme des consommateurs de données, ce qui signifie qu’ils utilisent les données – soit sous leur forme brute, soit lorsqu’elles sont converties en informations exploitables, comme les équipes de vente et de marketing, les équipes de produits, les équipes de développement commercial, etc.
3. Conception du système de données
C’est un autre aspect important de la gestion des données qui vous aide à comprendre :
Où et comment les données sont-elles collectées, intégrées et hébergées pour garantir une utilisation et une disponibilité maximales des données et un minimum de pertes de données et de temps d’arrêt ?
La conception de systèmes de données fait référence à de multiples disciplines, telles que les sources de données, l’architecture, la synchronisation et l’hébergement. Voyons ce que chacun d’entre eux couvre :
a. Entrées et sorties de données
La première partie de la conception du système consiste à identifier les sources d’entrée et de sortie des données – d’où les données sont capturées et vers où elles sont transférées. Les organisations utilisent de multiples applications pour capturer les données, telles que les trackers de sites web, l’automatisation du marketing, les CRM, les logiciels de comptabilité, les formulaires web, etc. Vous devez identifier toutes ces sources et voir comment les données sont transférées entre les sources ou vers une nouvelle destination.
b. Topologie du système de données
La topologie des données désigne la manière dont les systèmes de données sont interconnectés entre eux. À un haut niveau, vous pouvez concevoir votre topologie en utilisant l’une des approches suivantes :
- Approche centralisée où chaque système de données se connecte à un hub central et intelligent,
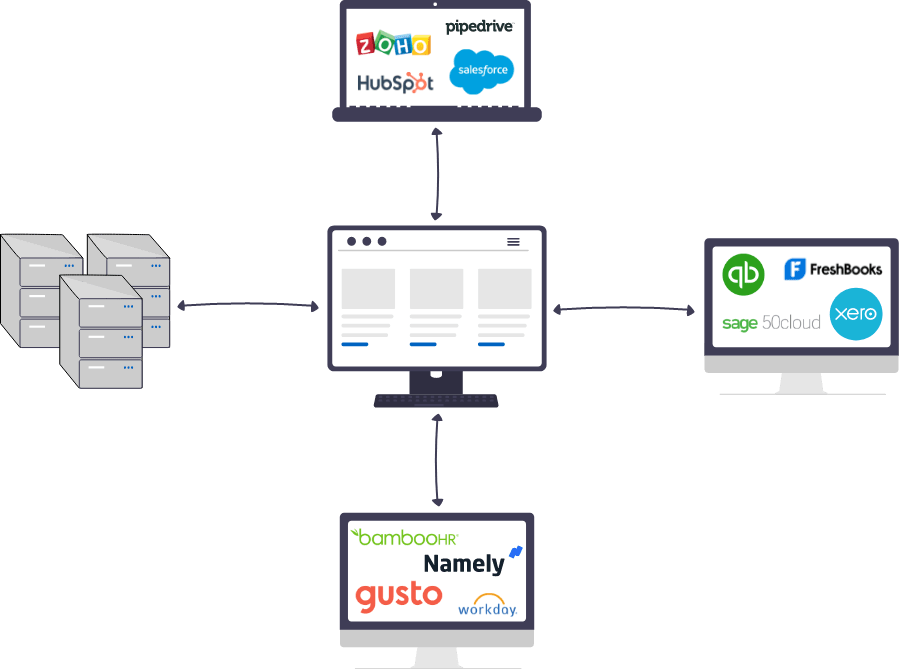
- Approche décentralisée où les systèmes de données communiquent entre eux pour obtenir les informations requises.

c. Synchronisation des données
Il s’agit de la façon dont les données sont mises à jour à travers les sources. Les systèmes de gestion des données, en particulier les solutions MDM, sont mis en œuvre dans différents styles architecturaux, en fonction des exigences de l’organisation. Les styles architecturaux les plus courants pour la synchronisation sont les suivants :
- Style consolidé
- Les données provenant de diverses sources sont acheminées vers un hub central qui stocke une vue consolidée des données, mais ne les retransmet pas aux systèmes sources. Toutes les applications de BI ou en aval peuvent récupérer des données à partir de la plate-forme centrale, selon les besoins.
- Coexistence ou style hybride
- Les données provenant de diverses sources sont transmises à un concentrateur central qui stocke une vue consolidée des données, et les mises à jour sont également transférées à toutes les applications sources connectées.
- Style centralisé
- Les données provenant de diverses sources sont acheminées vers un hub central qui stocke une vue consolidée des données, mais ne les retransmet pas aux systèmes sources. Cependant, les systèmes sources peuvent interroger les données mises à jour en fonction des besoins à partir du centre de données.
d. Hébergement de données
Il s’agit de l’endroit où les données sont hébergées ou stockées. Selon les besoins d’une organisation, les données peuvent être stockées localement dans les locaux, ou sauvegardées sur un nuage public ou privé. Vous pouvez également opter pour une configuration hybride dans laquelle certaines données sont conservées sur place et d’autres sont hébergées dans le nuage.
4. Qualité des données
L’un des principaux aspects de la gestion des données est la gestion de la qualité des données. La présence de défauts intolérables dans votre ensemble de données montre que les pratiques de gestion des données requises ne sont pas en place. Si vos équipes ne peuvent pas faire confiance aux données dont elles disposent, cela affecte leur productivité et leur efficacité au travail. Pour empêcher les erreurs de qualité des données de pénétrer dans le système, vous devez traiter les données entrantes dans des pipelines de données où un certain nombre d’opérations sont effectuées, telles que le nettoyage, la normalisation et la mise en correspondance des données.
a. Mesure de la qualité des données
La qualité des données est généralement indiquée dans les ensembles de données par un certain nombre de caractéristiques des données. On les appelle généralement les dimensions de la qualité des données. Les indicateurs de qualité des données les plus courants comprennent :
- Exactitude : Les données dépeignent la réalité et la vérité.
- Validation : Les données sont présentes dans le bon modèle et format, et appartiennent au bon domaine.
- Complétude: Les données sont aussi complètes que nécessaire.
- Monnaie : Les données sont à jour ou aussi actuelles que possible.
- Cohérence : Les données sont les mêmes (en termes de signification et de représentation) dans les différentes sources de données.
- Identifiabilité : Les données représentent des identités uniques et ne contiennent pas de doublons.
- Facilité d’utilisation : Les données sont présentées dans un format compréhensible par ceux qui ont l’intention de les utiliser.
b. Gestion de la qualité des données
Pour adopter en douceur les principes de gestion de la qualité des données, vous devez mettre en œuvre un certain nombre de processus de qualité des données, tels que :
- Profilage des données pour évaluer l’état actuel de vos données et identifier les possibilités de nettoyage,
- Techniques de nettoyage et de normalisation des données pour obtenir une vue standardisée de toutes les sources de données,
- Comparaison des données pour identifier les enregistrements en double représentant la même entité,
- Déduplication des données pour éliminer les enregistrements en double,
- La fusion des données permet de regrouper les enregistrements en double en un seul et d’écraser les données partout où cela est nécessaire pour atteindre l’enregistrement d’or.
5. La gouvernance des données
Le terme de gouvernance des données désigne un ensemble de rôles, de politiques, de flux de travail, de normes et d’indicateurs qui garantissent une utilisation et une sécurité efficaces des informations et permettent à une entreprise d’atteindre ses objectifs commerciaux. La gouvernance des données concerne les domaines suivants :
- Mise en œuvre d’un contrôle d’accès basé sur les rôles pour garantir que seuls les utilisateurs autorisés peuvent accéder aux données confidentielles,
- Concevoir des flux de travail pour vérifier les mises à jour des informations,
- Limiter l’utilisation et le partage des données,
- Collaborer et coordonner les mises à jour des données avec les collègues ou les parties prenantes externes,
- Permettre la provenance des données en capturant les métadonnées, leur origine, ainsi que l’historique des mises à jour.
6. Éducation aux données
Vous pouvez parfaitement concevoir des modèles de données, des systèmes de données et des cadres de qualité des données, et prendre soin de tous les principes de base de la gestion des données, mais vous ne parviendrez toujours pas à atteindre vos objectifs en matière de données – et le principal responsable de cette situation est le manque d’éducation en matière de données parmi les membres de votre équipe. Si votre équipe ne comprend pas comment les systèmes de données fonctionnent dans votre organisation, elle les manipulera probablement mal ou les utilisera de manière inefficace.
Pour permettre aux membres de votre équipe de maîtriser les données, vous devez commencer par tout documenter. Et diffusez ces connaissances par le biais de plans d’apprentissage qui mettent en avant divers aspects des données, tels que :
- Ce qu’il contient,
- La signification de chaque attribut de données,
- Quels sont les critères d’acceptabilité de sa qualité,
- Quelle est la bonne et la mauvaise manière de saisir/manipuler les données ?
- Quelles données utiliser pour atteindre un résultat donné ?
En outre, ces cours peuvent être créés en fonction de la fréquence d’utilisation des données par certains rôles (quotidienne, hebdomadaire ou annuelle).
7. Protection des données
Les stratégies de protection des données englobent certaines des mesures de sécurité les plus importantes. Les trois principaux domaines qui relèvent de la protection des données sont les suivants :
- Sécurité des données : Protection des données contre les attaques malveillantes et la manipulation,
- Contrôle de l’accès aux données : Contrôle de qui peut accéder aux données et quand,
- Disponibilité des données : Garantir que les données sont sauvegardées et restaurées en cas de perte ou d’indisponibilité des données.
Les termes « protection des données » et « sécurité des données » sont souvent utilisés de manière interchangeable, mais ils renvoient en fait à des concepts légèrement différents. La protection des données consiste à protéger les données contre la perte, l’endommagement ou la corruption, et à garantir leur disponibilité, tandis que la sécurité des données consiste à protéger les données contre les attaques malveillantes et la manipulation.
Cependant, les deux sont essentiels pour permettre une gestion des données de qualité.
8. Conformité des données
Les normes de conformité des données (telles que GDPR, HIPAA et CCPA, etc.) obligent les entreprises à revoir et à réviser leurs stratégies de gestion des données. En vertu de ces normes de conformité des données, les entreprises sont tenues de protéger les données personnelles de leurs clients et de veiller à ce que les propriétaires des données (les clients eux-mêmes) aient le droit d’accéder à leurs données, de les modifier ou de les effacer.
Outre ces droits accordés aux propriétaires de données, les normes obligent également les entreprises à respecter les principes de transparence, de limitation de la finalité, de minimisation des données, d’exactitude, de limitation du stockage, de sécurité et de responsabilité. Il est très difficile de se conformer à ces normes si les données sous-jacentes ne sont pas bien gérées. Et un manque de conformité peut limiter les activités de votre entreprise, notamment sur le plan géographique.
Récapitulation
Et voilà, les 8 principes de gestion des données que vous devez adopter pour maximiser l’efficacité des données dans votre organisation. Les données faisant partie intégrante d’une entreprise, une gestion des données bien menée vous aide à atteindre vos buts et objectifs efficacement et facilement.
Si votre entreprise n’a encore adopté aucun principe de gestion des données, il est bon de commencer par un endroit et de s’étendre éventuellement à d’autres disciplines au fur et à mesure que les choses se mettent en place. La gestion de la qualité des données est l’un de ces domaines qui peut avoir un impact positif majeur en un minimum de temps.
Ayant fourni des solutions de nettoyage et de rapprochement des données à des entreprises du classement Fortune 500 au cours de la dernière décennie, nous comprenons l’importance de préserver les données de toute erreur. Notre produit, DataMatch Enterprise, vous aide à nettoyer et à normaliser vos ensembles de données, et à éliminer les enregistrements en double qui représentent la même entité.
Vous pouvez télécharger l’essai gratuit dès aujourd’hui ou programmer une session personnalisée avec nos experts pour comprendre comment notre produit peut aider à mettre en œuvre les meilleures pratiques pour atteindre et maintenir la qualité des données au niveau de l’entreprise.
The post 8 principes de gestion des données appeared first on Data Ladder.
]]>The post Gestion de la qualité des données : Quoi, pourquoi, comment et meilleures pratiques appeared first on Data Ladder.
]]>La qualité n’est jamais un accident ; elle est toujours le résultat d’une intention élevée, d’un effort sincère, d’une direction intelligente et d’une exécution habile ; elle représente le choix judicieux de nombreuses alternatives.
Le problème le plus courant auquel les entreprises sont confrontées est celui de la qualité des données. Vous avez déployé les bonnes applications de données, les sources capturent le type de données dont vous avez besoin, il existe un système complet qui utilise et analyse les données collectées, et pourtant, les résultats ne sont pas satisfaisants. Lors d’une analyse plus poussée, vous constatez des différences entre les données attendues et la réalité ; les ensembles de données sont remplis de champs vides, d’abréviations et de formats incohérents, de modèles invalides, d’enregistrements en double et d’autres anomalies de ce type.
Pour éliminer ces problèmes, vous devez mettre en œuvre des mesures correctives qui valident et corrigent systématiquement les problèmes de qualité des données. Mais pour faire du rêve de la qualité des données une réalité, il est nécessaire de comprendre les bases de la qualité des données – sa signification, son impact et comment planifier l’amélioration. C’est pourquoi nous partageons avec vous un guide complet qui couvre tout ce qui a trait à la gestion de la qualité des données : ce qu’elle signifie, comment elle peut avoir un impact sur une entreprise, comment elle peut être gérée, à quoi elle ressemble dans divers secteurs verticaux, et plus encore.
Ce guide est divisé en trois parties :
- La qualité des données : Qu’est-ce que c’est et pourquoi est-ce important ?
- Les problèmes de qualité des données : Quels sont-ils, d’où viennent-ils et quel est leur impact sur l’entreprise ?
- Gestion de la qualité des données : Ce qu’elle signifie, ses piliers et ses meilleures pratiques, et quelques exemples concrets dans divers secteurs.
Commençons.
Qualité des données
Qu’est-ce que la qualité des données ?
La mesure dans laquelle les données répondent aux exigences d’une finalité prévue.
Les organisations stockent, gèrent et utilisent chaque jour de grands volumes de données. Si les données ne remplissent pas leur fonction, elles sont considérées comme étant de mauvaise qualité. Cette définition de la qualité des données implique que sa signification diffère selon l’organisation à laquelle elle appartient et l’objectif qu’elle sert.
Pour certaines entreprises, l’exhaustivité des données peut être un meilleur indicateur de la qualité des données que leur exactitude.

Cela conduit les entreprises à définir leur propre ensemble de caractéristiques et d’exigences pour maintenir la qualité des données dans toute l’organisation. Il existe une autre façon de définir la qualité des données :
Le degré auquel les données sont exemptes de défauts intolérables.
Les données ne peuvent jamais être exactes à cent pour cent et exemptes de défauts. Il y aura forcément des erreurs et c’est acceptable. Mais le fait d’avoir des défauts intolérables dans votre ensemble de données – qui nuisent à l’exécution de processus critiques – indique une mauvaise qualité des données. Vous devez vous assurer que la structure des données est conforme aux besoins et que son contenu est aussi exempt de défauts que possible.
Pourquoi la qualité des données est-elle importante ?
Le maintien de la propreté des données doit être un effort collectif entre les utilisateurs professionnels, le personnel informatique et les professionnels des données. Mais souvent, elle est simplement perçue comme un problème informatique, c’est-à-dire que les données deviennent sales lorsque certains processus techniques de capture, de stockage et de transfert des données ne fonctionnent pas correctement. Bien que cela puisse être le cas, les données nécessitent l’attention de tous les bonnes parties prenantes pour maintenir sa qualité dans le temps. Pour cette raison, il devient impératif de
établir un argumentaire en faveur de la qualité des données
devant les décideurs nécessaires, afin qu’ils puissent contribuer à sa mise en œuvre dans tous les services et à tous les niveaux.
Nous avons répertorié ci-dessous les avantages les plus courants de la qualité des données.
01. Prise de décision précise
Les chefs d’entreprise ne s’appuient plus sur des hypothèses, mais mais utilisent plutôt des techniques de business intelligence pour prendre de meilleures décisions. C’est… où
une bonne qualité des données peut permettre
une prise de décision précise
prise de décision précise
tandis qu’une mauvaise qualité des données peut fausser les résultats de l’analyse des données et conduire les entreprises à fonder des décisions cruciales sur des prévisions erronées.
02. Efficacité opérationnelle
Les données font partie de toutes les opérations, petites et grandes, d’une entreprise. Qu’il s’agisse du produit, du marketing, des ventes ou des finances – exploiter efficacement les données dans tous les domaines est la clé. L’utilisation de données de qualité dans ces services peut amener votre équipe à éliminer les efforts redondants, à obtenir rapidement des résultats précis et à être productive tout au long de la journée.
03. Conformité
Conformité des données
normes
(telles que le GDPR, l’HIPAA et le CCPA) exigent des entreprises qu’elles suivent les principes de minimisation des données, de limitation de la finalité, de transparence, d’exactitude, de sécurité, de limitation du stockage et de responsabilité.
La conformité à ces normes de qualité des données
de données
est n’est possible qu’avec des données propres et fiables.
04. Opérations financières
Les entreprises encourent d’énormes
coûts financiers dus à la mauvaise qualité des données
. Des opérations telles que le versement des paiements en temps voulu, la prévention des incidents de sous-paiement et de surpaiement, l’élimination des transactions incorrectes et l’élimination des risques d’erreur. la fraude dues à la duplication des données ne sont possibles qu’avec des données propres et de qualité.
05. Personnalisation et fidélisation des clients
Offrir des expériences personnalisées aux clients est le seul moyen de les convaincre d’acheter auprès de votre marque plutôt que d’un concurrent. Les entreprises utilisent une tonne de données pour comprendre le comportement et les préférences des clients. Grâce à des données précises, vous pouvez découvrir des acheteurs pertinents et leur offrir exactement ce qu’ils recherchent – ce qui garantit la fidélité des clients à long terme tout en leur donnant l’impression que votre marque les comprend comme personne d’autre.
06. Avantage concurrentiel
Presque tous les acteurs du marché ont utilisé les données pour comprendre la croissance future du marché et les éventuelles possibilités de vente incitative et croisée. L’alimentation de cette analyse en données de qualité provenant du passé vous aidera à
créer un avantage concurrentiel
sur le marché, convertir plus de clients et
augmentez
votre part de marché.
07. Numérisation
Numérisation des processus cruciaux peut vous aider à éliminer le travail manuel, à accélérer le temps de traitement et à réduire les erreurs humaines. Mais avec des données de mauvaise qualité, ces attentes ne peuvent être satisfaites. Au contraire, une mauvaise qualité des données vous obligera à vous retrouver dans un désastre numérique où la migration et l’intégration des données semblent impossibles en raison de structures de bases de données variables et de formats incohérents.
Problèmes de qualité des données
Un problème de qualité des données est défini comme suit :
un défaut intolérable dans un ensemble de données, tel qu’il affecte gravement la fiabilité de ces données.
Avant de passer à la mise en œuvre de mesures correctives pour valider, corriger et améliorer la qualité des données, il est impératif de comprendre ce qui pollue les données en premier lieu.. C’est pourquoi nous allons d’abord nous pencher sur la question :
- Les problèmes de qualité des données les plus courants présents dans les ensembles de données d’une organisation,
- D’où viennent ces problèmes de qualité des données ?
- Comment ces problèmes de qualité des données peuvent-ils engendrer de graves dangers pour les entreprises ?
Quels sont les problèmes de qualité des données les plus courants ?
| No. | Data quality issue | Explanation | Example of data quality issue |
|---|---|---|---|
| 1 | Column duplication | Multiple columns are present that have the same logical meaning. | Product category is stored in two columns that logically mean the same: Category and Classification. |
| 2 | Record duplication | Multiple records are present for the same individual or entity. | Every time a customer interacts with your brand, a new row is created in the database rather than updating the existing one. |
| 3 | Invalid data | Data values are present in an incorrect format, pattern, data type or size. | Customer Phone Numbers are present in varying formats – some are stored as flat 10 digits, while others have hyphens, some are saved as a string, while others as numbers, and so on. |
| 4 | Inaccurate data | Data values do not conform to reality. | Customer Name is incorrectly stored: Elizabeth is stored as Aliza, or Matt is stored as Mathew. |
| 5 | Incorrect formulae | Data values are calculated using incorrect formulae. | Customer Age is calculated from their Date of Birth but the formula used is incorrect. |
| 6 | Inconsistency | Data values that represent the same information vary across different datasets and sources. | Customer record stored in the CRM represents a different Email Address than the one present in accounts application. |
| 7 | Missing data | Data is missing or is filled with blank values. | The Job Title of most customers is missing from the dataset. |
| 8 | Outdated data | Data is not current and represents outdated information. | Customer Mailing Addresses are years old leading to returned packages. |
| 9 | Unverified domain data | Data does not belong to a range of acceptable values. | Customer Mailing Addresses are years old leading to returned packages. |
Comment les problèmes de qualité des données entrent-ils dans le système ?
Il existe de multiples moyens les erreurs de qualité des données peuvent se retrouver dans votre système. Voyons de quoi il s’agit.
01. Absence de modélisation appropriée des données
C’est la première et la plus importante raison des erreurs de qualité des données. Votre équipe informatique ne consacre pas le temps et les ressources nécessaires à l’adoption d’une nouvelle technologie, qu’il s’agisse d’une nouvelle application web, d’un système de base de données ou de l’intégration/migration entre des systèmes existants.
La modélisation des données permet d’organiser et de structurer vos actifs et éléments de données. Vos modèles de données peuvent être exposés à l’un des problèmes suivants :
a)
Absence de contraintes hiérarchiques :
Cela concerne les cas où il n’y a pas relation appropriée contraintes dans votre modèle de données. Par exemple, vous avez un ensemble de champs différents pour Clients existants et Nouveaux clientsmais vous utilisez un générique Client modèle pour les deux, plutôt que d’avoir Clients existants et Nouveaux clients en tant que sous-types du super-type Client.
b)
Absence de cardinalité de la relation :
Il s’agit du cas où aucun nombre n’est défini pour représenter le nombre de relations qu’une entité peut avoir avec une autre. Par exemple, un
Commande
ne peut avoir qu’une seule
Remise
à la fois.
c)
Manque d’intégrité référentielle
:
Cela concerne le cas où un enregistrement dans un ensemble de données fait référence à un enregistrement dans un autre ensemble de données qui n’est pas présent. Par exemple, le
Ventes
fait référence à une liste de
IDs de produits
qui ne sont pas présents dans la table
Produits
des produits.
02. Manque d’identifiants uniques
C’est le cas lorsqu’il n’y a aucun moyen d’identifier de manière unique un enregistrement, ce qui vous amène à stocker des enregistrements en double pour la même entité. Les enregistrements sont identifiés de manière unique en stockant des attributs tels que
Numéro de sécurité sociale
pour les clients,
Numéro de pièce du fabricant
pour les produits, etc.
03. Absence de contraintes de validation
Il s’agit du cas où les valeurs de données ne sont pas soumises aux contrôles de validation requis avant d’être stockées dans la base de données. Par exemple, il s’agit de vérifier que les champs obligatoires ne sont pas manquants, de valider le modèle, le type de données, la taille et le format des valeurs de données, et de s’assurer également qu’elles appartiennent à une plage de valeurs acceptables.
04. Manque de qualité de l’intégration
Il s’agit du cas où votre entreprise dispose d’une base de données centrale qui se connecte à plusieurs sources et intègre les données entrantes pour représenter une source d’information unique. Si cette configuration ne dispose pas d’un moteur central de qualité des données pour nettoyer, normaliser et fusionner les données, elle peut donner lieu à de nombreuses erreurs de qualité des données.
05. Manque de compétences en matière de données
Malgré tous les efforts déployés pour protéger les données et leur qualité dans tous les ensembles de données, un manque de compétences en matière de données dans une organisation peut encore causer beaucoup de dommages à vos données. Les employés stockent souvent des informations erronées car ils ne comprennent pas la signification de certains attributs. De plus, ils ne sont pas conscients des conséquences de leurs actions, comme par exemple les implications de la mise à jour des données dans un certain système ou pour un certain enregistrement.
06. Erreurs de saisie des données
Les fautes de frappe ou d’orthographe sont l’une des sources les plus courantes d’erreurs de qualité des données. On sait que les humains commettent au moins 400 erreurs lors de la saisie de 10 000 données. Cela montre que même avec la présence d’identifiants uniques, de contrôles de validation et de contraintes d’intégrité, il est possible que l’erreur humaine intervienne et que la qualité de vos données se détériore.
Comment les questions de qualité des données sont-elles liées aux dangers de l’entreprise ?
Pour embarquer les décideurs concernés, il est important de leur expliquer comment les problèmes de qualité des données, petits et grands, ont un impact sur l’entreprise. impactent des affaires. A
faille dans les données – matrice des risques commerciaux
comme celle présentée ci-dessous, peut vous aider à le faire.
| Problem | Issue | Business risk | Quantifier | Cost |
|---|---|---|---|---|
| This is the data quality problem that resides in your dataset. | These are the various issues that can arise due to the data problem. | This is the impact the issue can have on the business. | This quantifies the impact in terms of a business measure. | This provides a periodic estimated cost incurred due to the business impact. |
| Example | ||||
| Misspelled customer name and contact information | Duplicate records created for the same customer | Customer service: Increased number of inbound calls | Increased staff time | $30,000.00 worth more staff time required |
| Customer service: Decreased customer satisfaction | Order reduction, lost customers | ~500 less orders this year (as compared to estimated) | ||
Gestion de la qualité des données
Nous avons abordé les principes fondamentaux de la qualité des données, les problèmes de qualité des données et leur lien avec les risques commerciaux. Maintenant il est temps de voir ce que la gestion de la qualité des données plan La question qui se pose est la suivante : comment fixer et gérer de manière cohérente la qualité des données au fil du temps et en tirer tous les avantages possibles pour votre entreprise ? Commençons.
Qu’est-ce que la gestion de la qualité des données ?
La gestion de la qualité des données est définie comme suit : La mise en œuvre d’un cadre systématique qui profile en permanence les sources de données, vérifie la qualité des informations et exécute un certain nombre de processus pour éliminer les erreurs de qualité des données – dans le but de rendre les données plus précises, correctes, valides, complètes et fiables. Étant donné que les exigences et les caractéristiques de la qualité des données sont différentes pour chaque organisation, la gestion de la qualité des données diffère également entre les entreprises. Les types de personnes dont vous avez besoin pour gérer la qualité des données, les paramètres dont vous avez besoin pour la mesurer, les processus de qualité des données que vous devez mettre en œuvre – tout dépend de multiples facteurs, tels que la taille de l’entreprise, la taille de l’ensemble de données, les sources concernées, etc. Nous abordons ici les principaux piliers de la mise en œuvre et de la gestion de la qualité des données, qui vous donneront une bonne idée de la manière de garantir la qualité des données dans votre entreprise en fonction de vos besoins spécifiques.
Quels sont les 5 piliers de la gestion de la qualité des données ?
Dans cette section, nous examinons les piliers les plus importants de la gestion de la qualité des données : les personnes, la mesure, les processus, le cadre et la technologie.
01. Les personnes : Qui est impliqué dans la gestion de la qualité des données ?
Il est communément admis que pour gérer la qualité des données dans l’ensemble de l’organisation, vous devez obtenir l’approbation et l’adhésion des décideurs. Mais la vérité est que vous avez besoin de professionnels des données nommés à différents niveaux d’ancienneté pour garantir que vos investissements dans les initiatives de qualité des données portent leurs fruits.
Voici quelques rôles qui sont soit responsables, soit redevables, soit consultés, soit informés sur le contrôle de la qualité des données dans une organisation :
a) Chief Data Officer (CDO) :
Un Chief Data Officer (CDO) est un poste de direction, uniquement chargé de concevoir des stratégies permettant l’utilisation des données, le contrôle de la qualité des données et la gouvernance des données dans toute l’entreprise.
b)
Responsable des données :
Un responsable des données est la personne à contacter dans une entreprise pour toute question relative aux données. Ils sont totalement impliqués dans comment l’organisation saisit les données, où elle les stocke, ce qu’elles signifient pour les différents départements et comment leur qualité est maintenue tout au long de leur cycle de vie.
c) Dépositaire des données:
A
dépositaire des données est responsable de la structure des champs de données – y compris les structures et les modèles de base de données.
d)
Analyste de données :
Un analyste de données est une personne capable de prendre des données brutes et de les convertir en informations significatives, notamment dans des domaines spécifiques. L’une des principales tâches de l’analyste de données consiste à préparer, nettoyer et filtrer les données requises.
e) Autres équipes :
Ces rôles sont considérés comme des consommateurs de données, ce qui signifie qu’ils utilisent les données – soit sous leur forme brute, soit lorsqu’elles sont converties en informations exploitables, comme les équipes de vente et de marketing, les équipes de produits, les équipes de développement commercial, etc.
En savoir plus sur
Constituer une équipe de qualité des données : rôles et responsabilités à prendre en compte
.
02. Mesure : Comment la qualité des données est-elle mesurée ?
Le deuxième aspect le plus important de la gestion de la qualité des données est sa mesure. Il s’agit de caractéristiques de données et d’indicateurs de performance clés qui valident la présence de la qualité des données dans les ensembles de données organisationnelles. Selon la façon dont votre entreprise utilise les données, ces indicateurs clés de performance peuvent différer. J’ai listé les données les plus importantes qualité et la métrique de qualité qu’ils représentent :

- Exactitude : Dans quelle mesure les valeurs des données représentent-elles la réalité ou l’exactitude ?
- Lignage : Dans quelle mesure la source d’origine des valeurs des données est-elle digne de confiance ?
- Sémantique : Les valeurs des données sont-elles fidèles à leur signification ?
- Structure : Les valeurs des données existent-elles dans le bon modèle et/ou format ?
- Exhaustivité : Vos données sont-elles aussi complètes que vous le souhaitez ?
- Cohérence : Les magasins de données disparates ont-ils les mêmes valeurs de données pour les mêmes enregistrements ?
- La monnaie : Vos données sont-elles acceptables et à jour ?
- Rapidité : Dans quel délai les données demandées sont-elles mises à disposition ?
- Caractère raisonnable : Les valeurs des données ont-elles le bon type et la bonne taille ?
- Identifiabilité : Chaque enregistrement représente-t-il une identité unique et n’est pas un doublon ?
Plus d’informations sur
Les dimensions de la qualité des données – 10 paramètres que vous devriez mesurer
.
03. Processus : Quels sont les processus de qualité des données ?
Comme les données ont augmenté massivement au cours des dernières décennies, elles sont devenues multi-variables et sont mesurées dans de multiples dimensions. Pour récupérer, corriger et améliorer les problèmes de qualité des données, vous devez mettre en œuvre une variété de processus de qualité des données – où chacun d’entre eux sert un objectif différent et précieux. Examinons les processus de qualité des données les plus courants utilisés par les entreprises pour améliorer la qualité de leurs données.
Il s’agit de comprendre l’état actuel de vos données en découvrant des détails cachés sur leur structure et leur contenu. Un algorithme de profilage des données analyse les colonnes d’un ensemble de données et calcule des statistiques pour diverses dimensions, telles que l’exhaustivité, l’unicité, la fréquence, le caractère et l’analyse des modèles, etc.
b) Nettoyage et normalisation des données
Il s’agit du processus d’élimination des informations incorrectes et invalides présentes dans un ensemble de données afin d’obtenir une vue cohérente et utilisable de toutes les sources de données. Il s’agit de supprimer et de remplacer les valeurs incorrectes, d’analyser des colonnes plus longues, de transformer les majuscules et les modèles, de fusionner des colonnes, etc.
c)
Mise en correspondance des données
Également connu sous le nom de
couplage de documents
et
résolution d’entités
c’est le processus consistant à comparer deux ou plusieurs enregistrements et à déterminer s’ils appartiennent à la même entité. Il s’agit de cartographier les mêmes les colonnes, la sélection des colonnes à comparer, l’exécution des algorithmes de comparaison, l’analyse des résultats de la comparaison et le réglage des algorithmes de comparaison pour obtenir des résultats précis.
C’est le processus qui consiste à éliminer les enregistrements multiples qui appartiennent à la même entité et à ne conserver qu’un seul enregistrement par entité. Il s’agit notamment d’analyser les enregistrements en double dans un groupe, de marquer les enregistrements qui sont des doublons, puis de les supprimer de l’ensemble de données.
e)
Fusion de données et survivance
Il est le processus d’élaboration de règles qui fusionnent les enregistrements en double par le biais d’une sélection et d’un écrasement conditionnels. Cela vous permet d’éviter la perte de données et de conserver un maximum d’informations à partir des doublons. Il s’agissait de définir des règles de sélection et d’écrasement des fiches, d’exécuter les règles et de les ajuster pour obtenir des résultats précis.
f)
Données
gouvernance
Le terme de gouvernance des données fait généralement référence à un ensemble de rôles, de politiques, de flux de travail, de normes et de mesures qui garantissent une utilisation et une sécurité efficaces des données et permettent à une entreprise d’atteindre ses objectifs commerciaux. Il s’agit de créer des rôles de données et d’attribuer des autorisations, de concevoir des flux de travail pour vérifier les mises à jour des informations, de s’assurer que les données sont à l’abri des risques de sécurité, etc.
Il s’agit du processus consistant à comparer les adresses à une base de données faisant autorité – telle que celle de l’USPS aux États-Unis – et à valider que l’adresse est un lieu de distribution du courrier précis et valide dans le pays.
En savoir plus sur les
5 processus de qualité des données à connaître avant de concevoir un cadre DQM
.
04. Cadre : Qu’est-ce qu’un cadre de qualité des données ?
Outre les processus de qualité des données, un autre aspect important à prendre en compte lors de la conception d’une stratégie de qualité des données est un cadre de qualité des données. de données. Les processus représentent des techniques autonomes utilisées pour éliminer les problèmes de qualité des données de vos ensembles de données. Une qualité de données cadre est un processus systématique qui permet de surveiller en permanence la qualité des données, de mettre en œuvre divers processus de qualité des données (dans un ordre défini) et de s’assurer qu’elle ne se détériore pas en dessous de seuils définis. Il donne plus de détails sur le déroulement du processus de gestion de la qualité des données.
Un cadre simple de qualité des données se compose de quatre étapes :
a) Évaluer :
Il s’agit de la première étape du cadre dans laquelle vous devez évaluer les deux principaux éléments : la signification de la qualité des données pour votre entreprise et la façon dont les données actuelles s’y comparent.
b) Conception :
L’étape suivante du cadre de qualité des données consiste à concevoir les règles métier requises, en sélectionnant les processus de qualité des données dont vous avez besoin et en les adaptant à vos données, ainsi qu’en décidant de la conception architecturale des fonctions de qualité des données.
c)
Exécuter :
La troisième étape du cycle est celle de l’exécution. Vous avez préparé la scène dans les deux étapes précédentes, il est maintenant temps de voir comment le système fonctionne réellement.
d)
Moniteur :
Il s’agit de la dernière étape du cadre où les résultats sont contrôlés. Vous pouvez utiliser des techniques avancées de profilage des données pour générer des rapports de performance détaillés.
Plus d’informations sur
Conception d’un cadre pour la gestion de la qualité des données
.
05. Technologie : Quels sont les outils de gestion de la qualité des données ?
Bien que la nature des problèmes de qualité des données soit assez complexe, de nombreuses entreprises continuent de valider manuellement la qualité des données, ce qui donne lieu à de multiples erreurs. L’adoption d’une solution technologique à ce problème est le meilleur moyen de garantir la productivité de votre équipe et la bonne mise en œuvre d’un cadre de qualité des données. Il existe de nombreux fournisseurs qui proposent des fonctions de qualité des données dans différentes offres, par exemple :
a)
Qualité des données autonome et en libre-service
logiciel
:
Ce type de logiciel de gestion de la qualité des données vous permet d’exécuter une variété de processus de qualité des données sur vos données. Ils sont généralement dotés de fonctions automatisées de gestion de la qualité des données ou de traitement par lots permettant de nettoyer, de rapprocher et de fusionner de grandes quantités de données à des moments précis de la journée. C’est l’un des moyens les plus rapides et les plus sûrs de consolider des enregistrements de données, sans perdre aucune information importante puisque tous les processus sont exécutés sur une copie des données et que la vue finale des données peut être transférée vers une source de destination.
b)
API ou SDK de qualité des données :
Certains fournisseurs exposent les fonctions nécessaires à la qualité des données par le biais
API ou SDK
. Cela vous permet d’intégrer toutes les fonctions de gestion de la qualité des données dans vos applications existantes en temps réel ou en cours d’exécution. Plus d’informations sur API de qualité des données : Fonctions, architecture et avantages.
c)
Qualité des données intégrée dans les outils de gestion des données
Certains fournisseurs intègrent la qualité des données
de données
au sein de
plateformes centralisées de gestion des données
afin que tout soit pris en charge dans le même pipeline de données. La conception d’un système de gestion des données de bout en bout avec une fonction intégrée de qualité des données nécessite une planification et une analyse détaillées, ainsi que l’implication des principales parties prenantes à chaque étape du processus. Ces systèmes sont souvent présentés sous forme de
gestion des données de base
solutions.
En quoi la gestion de la qualité des données diffère-t-elle de la gestion des données de référence ?
- Le terme « gestion des données de référence » fait référence à un ensemble de bonnes pratiques en matière de gestion des données, ce qui implique l’intégration des données, leur qualité et leur gouvernance. Cela signifie que la qualité des données et la gestion des données de référence ne sont pas opposées l’une à l’autre ; elles sont plutôt complémentaires. Les solutions MDM contiennent quelques capacités supplémentaires en plus des fonctions de gestion de la qualité des données. Cela fait de MDM une solution plus complexe et plus gourmande en ressources à mettre en œuvre – un élément à prendre en compte lors du choix entre les deux approches.

c)
Solutions internes personnalisées
Malgré les diverses solutions de qualité des données et de gestion des données de référence présentes sur le marché, de nombreuses entreprises investissent dans le développement d’une solution interne pour leurs besoins en données personnalisées. Bien que cela puisse sembler très prometteur, les entreprises finissent souvent par gaspiller un grand nombre de ressources – temps et argent – dans ce processus. L’élaboration d’une telle solution peut être plus facile à mettre en œuvre, mais elle est presque impossible à maintenir dans le temps.
Pour en savoir plus, vous pouvez lire notre livre blanc :
Pourquoi les projets internes de qualité des données échouent
.
Quelles sont les meilleures pratiques en matière de gestion de la qualité des données ?
Jetons un coup d’œil rapide aux meilleures pratiques en matière de qualité des données :
a)
Déterminez la relation entre
les données et les performances de l’entreprise
et l’impact exact d’une mauvaise qualité des données sur vos buts et objectifs commerciaux.
b)
Mesurer et maintenir la
définition de la qualité des données
en sélectionnant une liste de mesures qui vous permettront, à vous et à vos équipes, d’être sur la même longueur d’onde en ce qui concerne la qualité des données et ce qu’elle signifie pour votre organisation.
c)
Établir
rôles et responsabilités en matière de données
dans l’ensemble de l’organisation afin de rendre les personnes responsables de l’obtention et du maintien de la qualité des données – du niveau supérieur au personnel opérationnel.
d)
Former et éduquer les équipes
sur les actifs de données et leurs attributs, sur la manière de traiter les données et sur l’impact de leurs actions sur l’ensemble de l’écosystème de données.
e)
En permanence
surveiller l’état des données
grâce au profilage des données et
découvrir des détails cachés sur leur structure et leur contenu.
f)
Concevoir et
maintenir des pipelines de données
qui exécute une liste numérotée d’opérations
opérations
sur les données entrantes pour obtenir une source unique de vérité.
g)
Effectuer
analyse des causes profondes
des erreurs de qualité des données afin de comprendre d’où proviennent ces erreurs et de résoudre ces problèmes à la source.
h)
Utiliser la technologie
pour
atteindre
et maintenir la qualité des données car
aucun
processus n’est promis à une bonne performance, et à un meilleur retour sur investissement, s’il n’est pas automatisé et optimisé par la technologie.
Vous voulez en savoir plus sur chacune de ces pratiques, lisez notre blog détaillé
8 meilleures pratiques pour assurer la qualité des données au niveau de l’entreprise
.
Exemples concrets de gestion de la qualité des données
Dans cette dernière partie de notre guide, nous allons examiner quelques cas d’utilisation de la qualité des données et voir comment des marques renommées utilisent
outils de nettoyage et de rapprochement des données
pour gérer la qualité de leurs données et voir ce qu’elles ont à dire à ce sujet.
01. Gestion de la qualité des données dans le commerce de détail

Le principal avantage de DataMatch Enterprise était la logique floue et la correspondance synthétique. C’était juste quelque chose que je ne pouvais pas reproduire moi-même.
était la logique floue et la correspondance synthétique. C’était juste quelque chose que je ne pouvais pas reproduire moi-même.

Marty YantzieResponsable du support PC et du développement des systèmes, Buckle
Boucle est l’un des principaux détaillants haut de gamme de jeans, de vêtements de sport, de vêtements d’extérieur, de chaussures et d’accessoires, avec plus de 450 magasins dans 43 États. Buckle était confronté au défi de trier de grandes quantités d’enregistrements de données provenant de centaines de magasins. La principale tâche à accomplir était d’éliminer toutes les informations en double qui avaient été chargées dans leur système DB2 iSeries actuel. Ils cherchaient un moyen efficace de supprimer les données en double, qui représentaient environ 10 millions d’enregistrements.
DataMatch Enterprise a fourni une solution utilisable et plus efficace pour Buckle. L’entreprise a pu faire passer un grand nombre d’enregistrements par l’intermédiaire du
processus de déduplication
comme un seul projet utilisant un seul outil logiciel, plutôt que d’utiliser plusieurs méthodes différentes.
02. Gestion de la qualité des données dans les soins de santé
DataMatch Enterprise était beaucoup plus facile à utiliser que les autres solutions que nous avons examinées. Pouvoir automatiser le nettoyage et la correspondance des données nous a permis d’économiser des centaines d’heures-personnes chaque année.
Shelley Hahn Développement commercial, St. John Associates
St. John Associates fournit des services de placement et de recrutement en cardiologie, médecine d’urgence, gastro-entérologie, chirurgie neurologique, neurologie, chirurgie orthopédique, et dans d’autres domaines. Avec une base de données croissante de candidats au recrutement, St. John Associates avait besoin d’un moyen de déduire, nettoyer et faire correspondre les enregistrements. Après plusieurs années d’exécution manuelle de cette tâche, l’entreprise a décidé qu’il était temps de déployer un outil permettant de réduire le temps passé à
Dossiers de nettoyage
.
Grâce à DataMatch Enterprise, St. John Associates a pu effectuer une première opération de nettoyage des données, en trouvant , fusionner et purger des centaines de milliers d’enregistrements en un court laps de temps. DataMatch a permis d’accélérer le processus de déduplication grâce à des algorithmes de correspondance floue et a facilité le tri des champs de données pour trouver les informations nulles. Il a également éliminé la nécessité d’une saisie manuelle, permettant aux utilisateurs d’exporter les modifications et de les télécharger selon les besoins.
03. Gestion de la qualité des données dans les services financiers
Cet outil, qui ressemble à un assistant, vous guide pas à pas dans la mise en place d’un projet. Il est très intuitif et nous a permis d’élaborer toutes sortes de projets et d’intégrer toutes sortes de sources de données. L’une des raisons pour lesquelles nous avons choisi DL est qu’il existe une fonction d’importation DB2 qui nous permet d’accéder directement à notre base de données DB2. L’interface nous a permis d’obtenir de bons résultats et elle est très simple à utiliser.
Scott FordArchitecte de solutions informatiques, Bell Bank
Banque Bell est l’une des plus grandes banques indépendantes du pays, avec des actifs de plus de 6 milliards de dollars et des activités dans les 50 États. En tant que grande banque privée, la Banque Bell traite avec de nombreux fournisseurs partenaires et des dizaines de lignes de services – du prêt hypothécaire à l’assurance, de la retraite à la gestion de patrimoine et bien d’autres encore. Avec des informations cloisonnées et stockées dans
sources de données disparates
la banque avait du mal à obtenir une vue unique et consolidée de ses clients, sans parler des dépenses inutiles liées à l’envoi de plusieurs courriers à un même fournisseur ou client.
DataMatch Enterprise est un élément essentiel de la solution interne de gestion des données de la banque. solution de gestion des donnéesCe qui leur permet de regrouper facilement les résultats et de remettre la liste des enregistrements de tous les clients qui semblent appartenir à une seule et même entité. Ce site
vue consolidée
aidera la banque à comprendre réellement l’association de son client avec la banque et les mesures qu’elle peut prendre pour renforcer cette association.
04. Gestion de la qualité des données dans les ventes et le marketing
DataMatch me facilite grandement la tâche pour faire correspondre les colonnes dans Excel. La raison pour laquelle j’ai acheté le logiciel était de faire correspondre les véhicules vendus avec les pistes que nous travaillons.
Matt GriffinVice-président des opérations, TurnKey Auto Events
TurnKey Auto Events mène des campagnes d’achat de voitures à fort volume pour des concessionnaires automobiles dans tout le pays. Ils produisent des événements qui incitent les acheteurs de voitures à y assister et à acheter des véhicules. En tant que prestataire de services qui fournit des pistes de vente aux vendeurs automobiles, TurnKey Marketing cherchait à recevoir des crédits pour les ventes supplémentaires réalisées auprès des différents concessionnaires avec lesquels il est en partenariat.
En étant en mesure de faire correspondre les ventes avec la multitude de prospects potentiels auxquels ils parlent quotidiennement, ils reçoivent un crédit de vente (et gagnent de l’argent) pour chaque piste. En utilisant DataMatch, le système sophistiqué de Data Ladder mise en correspondance des données l’entreprise a pu faire correspondre des enregistrements provenant de plusieurs sources. À partir de là, ils ont pu créer une vue d’ensemble de la vente potentielle d’une voiture au fil du temps.
05. Gestion de la qualité des données dans l’éducation
L’idée de relier deux groupes d’enregistrements était bouleversante pour le service de recherche. Ce processus prendrait beaucoup de temps et menacerait la rapidité et le déroulement des activités de recherche.
Université de Virginie occidentale
Université de Virginie occidentale est la seule université de recherche de l’État qui délivre des diplômes de doctorat. L’école propose près de 200 programmes diplômants au niveau du premier cycle, du deuxième cycle, du doctorat et des professions libérales. Ils ont été chargés d’évaluer les effets à long terme de certaines conditions médicales sur les patients pendant une période prolongée. Les données relatives aux conditions médicales et les dossiers de santé actuels fournis par l’État existent en systèmes séparés.
Grâce à DataMatch, le produit phare de Data Ladder pour le nettoyage des données, l’université a pu nettoyer les enregistrements provenant de plusieurs systèmes et contenant les informations requises. A partir de là, ils ont pu créer une vue unifiée du patient au fil du temps.
Le mot de la fin
Les chefs d’entreprise comprennent l’importance des données – des opérations de routine à la veille stratégique avancée, elles sont utilisées partout. Mais la plupart des équipes qui travaillent avec des données passent des heures supplémentaires à cause du travail en double, du manque de connaissance des données et de résultats erronés. Et tous ces problèmes sont dus à une gestion médiocre ou inexistante de la qualité des données.
Investir dans des outils de qualité des données, tels que
DataMatch Enterprise
vous aidera certainement à vous lancer dans la gestion de la qualité des données. DataMatch vous fera passer par les différentes étapes du nettoyage et du rapprochement des données. En commençant par l’importation de données à partir de diverses sources, il vous guide à travers
profilage de données
,
nettoyage
,
normalisation
et
déduplication
. En plus de cela, son
vérification des adresses
vous permet de vérifier les adresses par rapport à la base de données officielle de l’USPS.
DataMatch offre également des fonctions de planification pour le traitement des enregistrements par lots. Vous pouvez également utiliser son API pour intégrer des fonctions de nettoyage ou de rapprochement des données dans des applications personnalisées et obtenir des résultats instantanés.
Réservez une démonstration aujourd’hui ou téléchargez une version d’essai gratuite pour en savoir plus sur la façon dont nous pouvons vous aider à tirer le meilleur parti de vos données.
The post Gestion de la qualité des données : Quoi, pourquoi, comment et meilleures pratiques appeared first on Data Ladder.
]]>The post Comment améliorer la qualité des données dans les services financiers appeared first on Data Ladder.
]]>24 % des assureurs se disent « peu confiants » dans les données qu’ils utilisent pour évaluer et tarifer les risques.
Corinium Intelligence
Le ralentissement économique et les problèmes financiers auxquels sont confrontées les entreprises aujourd’hui montrent l’importance d’utiliser les données pour prévoir les événements futurs. Mais les ambiguïtés présentes dans les données financières peuvent conduire les entreprises à fonder des décisions cruciales sur des données inexactes et à en subir les conséquences. Les banquiers, les assureurs, les sociétés de crédit hypothécaire et les autres entreprises offrant des services financiers ne sont pas à l’abri du cauchemar de la qualité des données. En effet, ces entreprises subissent les coûts les plus élevés résultant de la mauvaise qualité des informations financières.
Dans ce blog, nous aborderons la signification de la qualité des données dans les services financiers, les avantages qu’elle présente pour les individus et les organisations, les problèmes courants de qualité des données financières et la manière d’améliorer la qualité des informations financières.
Qu’est-ce que la qualité des données dans les services financiers ?
La qualité des données dans les services financiers signifie que les données financières saisies, stockées, traitées et présentées par les institutions financières répondent à l’objectif visé. Toute donnée qui ne remplit pas son objectif est réputée être de mauvaise qualité et doit être testée et vérifiée avant de pouvoir être utilisée efficacement.
Les institutions financières – telles que les banques, les compagnies d’assurance, les sociétés de crédit hypothécaire ou de courtage, les investisseurs, les créanciers ou les prêteurs – utilisent des données dans presque tous les processus commerciaux. Les données financières sont utilisées pour :
- Préparer les états financiers et les rapports pour l’usage interne et les clients,
- Approuver les prêts et mener à bien le processus de souscription,
- Détecter ou prévenir les activités frauduleuses telles que le vol de données ou les fausses demandes,
- Identifier les personnes qui sont plus susceptibles de ne pas rembourser leurs prêts,
- Évaluer les risques associés aux décisions financières, tels que le risque opérationnel ou de crédit, etc.
Il est évident qu’une mauvaise qualité des données peut avoir un impact négatif sur l’exécution et les résultats de ces processus. L’alimentation de ces processus en données précises et propres est préjudiciable à la protection de la crédibilité des institutions financières.
Pourquoi la qualité des données est-elle importante dans les services financiers ?
Les données étant étroitement intégrées dans le secteur des services financiers, il est très important que les données soient exemptes d’erreurs. Des données de haute qualité, propres et sans erreur permettent aux clients de faire confiance à leurs banques d’investissement et aux compagnies d’assurance. Examinons l’importance de la qualité des données dans le secteur des services financiers et les avantages que vous pouvez retirer en garantissant la qualité de vos données financières.
1. Évaluer, planifier et atténuer les risques
Le risque est inévitable dans certaines activités financières – que vous souhaitiez investir dans une entreprise, prêter de l’argent à un emprunteur ou approuver des prêts ou des demandes de crédit hypothécaire. Mais une planification intelligente des risques est essentielle pour survivre dans le monde financier. En analysant soigneusement les données et en évaluant les risques, vous pouvez atténuer les risques et prendre de meilleures décisions concernant les rendements attendus, la rentabilité et d’autres alternatives. Mais pour cela, vous avez besoin de données correctes, précises et pertinentes qui vous aident à éviter les risques financiers et les pertes potentielles qui peuvent exister.
2. Détecter et prévenir les activités frauduleuses
Les banques, les compagnies d’assurance et les investisseurs dont les données sont de mauvaise qualité sont plus exposés aux comportements frauduleux et aux pertes. En effet, les failles dans la qualité des données permettent aux fraudeurs d’usurper des identités, de faire de fausses demandes, de contourner les contrôles de renouvellement des demandes et d’effectuer des attaques malveillantes sur les données sensibles stockées par les organismes financiers. Des données propres, précises et consolidées vous permettent de détecter les anomalies à temps et de prévenir les activités frauduleuses.
3. Permettre la numérisation des processus financiers
Les services bancaires numériques, les paiements en ligne et les demandes de crédit en ligne révolutionnent le secteur financier. Mais la mise en œuvre et l’exécution réussies de ces services numériques ne sont possibles qu’avec des données de haute qualité. De nombreux banquiers et investisseurs conservent encore des dossiers physiques, car les données sont dispersées entre différentes sources et nécessitent une intervention manuelle pour être appréhendées selon les besoins. La gestion de la qualité des données permet aux institutions financières de numériser tout aspect de leurs activités ou de leurs offres de services.
4. Assurer la fidélité des clients
Lorsque les dossiers des clients sont appariés, fusionnés et consolidés pour représenter une vue complète à 360°, il devient plus facile de tirer parti des expériences personnalisées des clients et de garantir leur confidentialité et leur sécurité. Lorsque les données sont éparpillées entre différentes sources – y compris les fichiers locaux et physiques, les applications tierces et les soumissions de formulaires web – il devient impossible d’offrir une expérience connectée à vos clients et d’instaurer la confiance et la fidélité.
5. Permettre un scoring précis du crédit pour l’approbation des prêts
Lorsqu’il s’agit de prêter de l’argent à des emprunteurs, il est crucial pour les investisseurs et les banquiers de comprendre la responsabilité de leurs décisions. Ils doivent valider l’identité et la cote de crédit du demandeur, ainsi que calculer la valeur et le taux d’intérêt à utiliser pour le prêt. Une bonne qualité des données permet d’éliminer les divergences ou les retards qui peuvent survenir dans le processus de souscription et de s’assurer que vous investissez dans la bonne personne au bon moment.
6. Respecter les normes réglementaires
Les normes de conformité, telles que la lutte contre le blanchiment d’argent (AML) et la lutte contre le financement du terrorisme (CFT), obligent les institutions financières à revoir et à réviser leur gestion des données dans les services financiers. Pour se conformer à ces normes, ces entreprises doivent surveiller les transactions de leurs clients afin de détecter les délits financiers, tels que le blanchiment d’argent et le financement d’activités terroristes. En raison de l’inexactitude et de la mauvaise qualité des informations, les institutions financières ne signalent pas à temps les activités anormales ou inhabituelles aux autorités compétentes.
7. Faciliter l’analyse prédictive
La science des données a évolué pour permettre des prédictions et des aperçus en temps réel dans le monde de la finance et des risques potentiels associés aux activités de financement. Les investisseurs prédisent la faisabilité d’un investissement sur un certain marché, ou les actions qui seront les plus rentables à long terme. Ces calculs ne seront pas précis et pertinents si les données utilisées pour ces statistiques sont de mauvaise qualité. Par conséquent, un autre grand avantage de la qualité des données est de permettre aux analystes et aux scientifiques des données de faire des prédictions précises sur les bénéfices financiers.
Problèmes courants de qualité des données dans les services financiers
Nous avons discuté de la manière dont la qualité des données offre une grande valeur aux institutions financières. Dans cette section, nous allons voir à quoi ressemble la mauvaise qualité des données pour différentes institutions financières, comme les problèmes de qualité des données dans le secteur bancaire ou les problèmes de qualité des données dans les compagnies d’assurance. Vous pouvez en savoir plus sur les problèmes de qualité des données les plus courants et sur leur origine.
| Problème de qualité des données | Explication | Exemple de mauvaise qualité des données dans les services financiers |
| Données inexactes | Les données ne dépeignent pas la réalité ou la vérité. | Le nom légal complet d’un client est mal orthographié dans le contrat de prêt. |
| Données manquantes | Les données ne sont pas aussi complètes que nécessaire. | 2 des 15 clauses restrictives d’un contrat de prêt sont laissées en blanc. |
| Enregistrements en double | Les données contiennent des doublons et ne représentent pas des identités uniques. | La présence de dossiers de clients en double permet des demandes de prêts multiples. |
| Unités de mesure variables | Les données sont stockées dans différentes unités de mesure. | Les transactions internationales enregistrent les valeurs monétaires dans les monnaies locales, plutôt que dans une unité commerciale standard, telle que le dollar américain. |
| Formats et motifs variables | Les données sont stockées sous différents formats et modèles. | Les numéros de téléphone des clients sont stockés selon différents schémas – certains ont des codes internationaux, tandis que d’autres n’ont même pas d’indicatif régional. |
| Informations obsolètes | Les données ne sont pas à jour ou aussi actuelles que possible. | Les transactions mettent un peu trop de temps à apparaître dans les dossiers des clients, ce qui rend les processus du système susceptibles d’effectuer des calculs incorrects. |
| Domaine incorrect | Les données n’appartiennent pas à un domaine de valeurs correctes. | Les codes monétaires utilisés n’appartiennent pas au domaine ISO. |
| Incohérence | Les données ne sont pas les mêmes selon les différentes sources. | Des taux de change différents sont utilisés pour les différents segments de clientèle de l’organisation. |
| Irrelevance | Les données n’offrent aucune valeur à leurs utilisateurs. | Les employés obtiennent les informations requises après avoir appliqué de multiples filtres, règles de tri et de hiérarchisation. |
Comment améliorer la qualité de l’information financière ?
Les problèmes de qualité des données peuvent vous coûter très cher, surtout si vous êtes dans le secteur financier. Les entreprises qui proposent des services financiers doivent tester et vérifier leurs données avant qu’elles ne soient transmises aux processus opérationnels critiques. Des mesures calculées doivent être prises pour empêcher les problèmes de qualité des données de se produire dans le système, ainsi que pour remédier aux problèmes qui existent déjà. Nous examinerons ci-dessous les initiatives les plus importantes que les organisations financières peuvent prendre pour garantir la qualité des données.
1. Obtenir l’adhésion des dirigeants et de la direction
La première étape pour instaurer une culture de la qualité des données dans une organisation consiste à impliquer les chefs d’entreprise et les autres cadres. Vous pouvez commencer par attirer leur attention sur les problèmes de qualité des données qui sont présents dans les ensembles de données. Les rapports sur la qualité des données générés par le profilage des données peuvent être utiles pour informer les cadres supérieurs et les autres membres du personnel sur le type de problèmes de qualité des données auxquels votre institution est confrontée.
En outre, vous pouvez obtenir un échantillon de données provenant d’activités financières récentes et calculer le coût d’une mauvaise qualité des données en utilisant la méthode de mesure du vendredi après-midi. Cela vous permettra d’établir un argumentaire contre la mauvaise qualité des données et d’obtenir les approbations et l’adhésion nécessaires à l’exécution des mesures de qualité des données.
2. Mettre en œuvre trois niveaux de contrôle de la qualité des données
Le contrôle de la qualité des données se perfectionne au fur et à mesure que de nouvelles techniques et technologies apparaissent. Cela permet aux banques et aux compagnies d’assurance d’activer plusieurs niveaux de contrôle de la qualité des données. Par exemple, au premier niveau, vous pouvez commencer par effectuer une vérification rapide des faits et résoudre les problèmes de qualité des données qui peuvent être présents. À ce niveau, vous voulez vous assurer que l’ensemble de données est complet, précis et normalisé.
Au deuxième niveau, vous souhaitez mettre en œuvre une analyse statistique plus approfondie de votre ensemble de données. Cela vous aidera à calculer les variations standard des valeurs numériques et à détecter les anomalies qui peuvent se produire. Le profilage des données est une bonne technique pour effectuer une telle analyse statistique sur vos données. Au troisième et dernier niveau, vous pouvez utiliser des outils complexes d’apprentissage automatique et d’IA qui peuvent prédire les éventuels problèmes de qualité des données au moment de l’exécution que vos sources sont susceptibles d’avoir.
3. Rapprocher et consolider les enregistrements en double
La duplication des données est l’un des principaux problèmes de qualité des données auxquels sont confrontées les banques et les compagnies d’assurance. Ils doivent utiliser un cadre de qualité des données qui permet de repérer les doublons et de les regrouper en un seul. Les enregistrements peuvent être mis en correspondance au moment de l’exécution avec chaque mise à jour ou traités par lots à intervalles réguliers. En savoir plus sur le traitement par lots par rapport à la validation de la qualité des données en temps réel.
Le processus de rapprochement des enregistrements ou de dédoublonnage des données comprend les étapes suivantes :
- Profiler les données pour mettre en évidence les erreurs,
- Exécuter des techniques d’analyse, de nettoyage et de normalisation des données pour obtenir une vue cohérente,
- Correspondance des enregistrements qui appartiennent à la même entité (correspondance exacte sur un identifiant unique ou correspondance floue sur une combinaison de champs),
- Fusionner les enregistrements pour supprimer les informations inutiles et obtenir une source unique de vérité.
4. Utiliser la technologie pour la gestion de la qualité des données
L’utilisation de la technologie pour atteindre un cycle de vie durable de gestion de la qualité des données est au cœur de l’amélioration de la qualité des données dans toute institution financière. Aucun processus n’est censé être performant et offrir le meilleur retour sur investissement s’il n’est pas automatisé et optimisé par la technologie. Investissez dans l’adoption d’un système technologique doté de toutes les fonctionnalités dont vous avez besoin pour garantir la qualité des données dans tous les ensembles de données.
Quelle que soit la compétence de votre équipe chargée de la qualité des données, elle aura toujours du mal à maintenir des niveaux acceptables de qualité des données tant qu’elle ne disposera pas des bons outils. C’est là qu’un outil de gestion de la qualité des données peut s’avérer utile. Un outil tout-en-un, en libre-service, qui permet de profiler les données, d’effectuer diverses activités de nettoyage des données, de faire correspondre les doublons et de produire une source unique de vérité, peut devenir un facteur de différenciation important dans la performance des gestionnaires de données ainsi que des analystes de données.
Conclusion
Comprendre les problèmes de qualité de vos données financières et choisir un cadre approprié pour rectifier ces erreurs est une tâche difficile. Dans de nombreuses situations, une seule technique ne suffit pas, et une combinaison de techniques est utilisée pour résoudre avec précision les problèmes de qualité des données. C’est pourquoi le besoin d’outils numériques augmente. Des outils qui non seulement optimisent le temps et l’effort, mais aussi sélectionnent intelligemment les techniques de qualité des données en fonction de la nature de la structure et des valeurs de vos données.
DataMatch Enterprise est l’un de ces outils qui vous aide à nettoyer et à faire correspondre vos données pour permettre une analyse précise et une vision globale. Il offre une gamme de modules qui prennent en charge les données provenant de différentes sources, nettoient et normalisent les valeurs, permettent le mappage des champs, suggèrent une combinaison de définitions de correspondance spécifiques à vos données et fusionnent les données pour obtenir une vue complète à 360° de vos finances.
Pour en savoir plus, inscrivez-vous à un essai gratuit dès aujourd’hui ou réservez une démonstration avec nos experts pour commencer à améliorer la qualité de vos informations financières.
The post Comment améliorer la qualité des données dans les services financiers appeared first on Data Ladder.
]]>The post Qualité des données dans les soins de santé – Défis, limites et mesures à prendre pour améliorer la qualité appeared first on Data Ladder.
]]>Malheureusement, ma plupart des établissements de soins de santé sont confrontés à une mauvaise qualité des données et à d’importants arriérés de dossiers médicaux qui doivent être améliorés pour être accessibles. et utilisable. Les systèmes obsolètes, la mauvaise culture des données et la réticence à adopter les nouvelles technologies sont quelques-uns des principaux obstacles à l’intégration des données dans les systèmes de gestion de l’information.la qualité des soins de santé.
La règle est simple : si les autorités sanitaires veulent maintenir et améliorer les soins de santé à un niveau optimal, elles doivent veiller au respect des normes de qualité des données.
Dans ce bref article, nous allons expliquer ce que signifie la qualité des données pour les soins de santé, ses défis, ses limites et les mesures immédiates que les leaders du secteur peuvent prendre pour améliorer la qualité des données.
Que signifie la qualité des données pour les soins de santé ?
 Les données de santé organisées, agrégées et transformées dans un format significatif fournissent
Les données de santé organisées, agrégées et transformées dans un format significatif fournissent
informations sur la santé
qui peuvent être utilisées pour:
- Optimiser les soins aux patients avec des données précises
- Consolider les données pour obtenir une vue d’ensemble précise des patients
- Permettre la confiance dans la fiabilité des données
- Créer des rapports avec des statistiques fiables
- Donner aux employés et au personnel les moyens de prendre des décisions cruciales sur la base de données précises.
Les enjeux étant très élevés, il est de la plus haute importance que les données sur les soins de santé soient
factuelles, organisées, valides, précises et accessibles.
.
Comment la qualité des données est-elle déterminée ?
Dans le domaine de la santé, la qualité des données se réfère à des utilisateurs niveau de confiance dans le site données. Cette confiance est maximale si les normes suivantes sont respectées.
Exactitude et validité : La source originale des données n’est pas trompeuse ou corrompue.
Exemple d’exactitude et de validité :
- Les données d’identification et l’adresse du patient sont valides.
- Les signes vitaux sont enregistrés dans des paramètres de valeurs acceptables
- Les codes utilisés dans les hôpitaux pour classer les maladies et les procédures sont conformes à des normes prédéfinies.
Fiabilité et cohérence :
Les informations suivent une norme établie dans toute l’organisation
Exemples de fiabilité et de cohérence :
- L’âge du patient enregistré dans un dossier est le même dans tous les autres dossiers.
- Le nom, le sexe et l’état civil corrects sont les mêmes dans tous les dossiers.
- Le format correct du numéro de téléphone et de l’adresse est le même dans tous les enregistrements.
Complétude :
Tous les champs de données obligatoires sont présents
Exemples d’exhaustivité :
- Les notes infirmières, y compris le plan de soins infirmiers, les notes d’évolution, la pression artérielle, la température et les autres tableaux sont complets avec les signatures et la date d’entrée.
- Pour tous les dossiers médicaux/de santé, les formulaires pertinents sont complets, avec les signatures et les dates de présence.
- Pour les patients hospitalisés, le dossier médical contient un enregistrement précis de l’état principal et des autres diagnostics et procédures pertinents, ainsi que la signature du médecin traitant.
Monnaie et actualité :
les données sont à jour
Exemples de respect des délais :
- Les informations d’identification d’un patient sont enregistrées au moment de la première consultation et sont facilement disponibles pour identifier le patient à tout moment.
- Les antécédents médicaux du patient, l’historique de la maladie ou du problème actuel tel que détaillé par le patient, et les résultats de l’examen physique, sont enregistrés lors de la première visite dans une clinique ou de l’admission à l’hôpital.
- Les rapports statistiques sont prêts dans un délai déterminé, après avoir été contrôlés et vérifiés.
Accessibilité :
Les données sont disponibles pour les personnes autorisées selon les besoins.
Exemples d’accessibilité :
- Les dossiers médicaux/de santé sont disponibles à tout moment, au moment et à l’endroit voulus.
- Les données résumées sont disponibles pour examen quand et où cela est nécessaire.
- Dans un système de dossier électronique du patient, les informations cliniques sont facilement accessibles en cas de besoin.
La qualité des données dans le domaine des soins de santé est d’une importance cruciale, non seulement pour les soins aux patients, mais aussi pour le suivi des performances des services de santé et des employés. Les données collectées et présentées doivent répondre à ces normes. Le problème ? En s’appuyant sur des méthodes traditionnelles de gestion des données, les hôpitaux et les échanges d’informations (HIE) sont confrontés à des problèmes de correspondance entre les patients, à des algorithmes médiocres, à des processus chaotiques, à l’inefficacité opérationnelle, à une mauvaise connaissance des données et à une mauvaise qualité des données.
Les données de haute qualité reflètent ces normes internationales.tandardsCependant, les limites actuelles en termes de technologie, de ressources et de processus font que les établissements de santé ont du mal à atteindre ces objectifs.
Te COVID-19 est un parfait exemple de la façon dont les problèmes de qualité des données affectent le traitement des pandémies. Les organisations qui ont répondu rapidement par des applications, des analyses prédictives et des modèles de soins aux patients qui ont aidé le monde à faire face à la situation.. Ceux qui précédemment transformations numériques ignorées ont pris conscience de la nécessité de s’adapter aux technologies ML/AI (dont les données précises constituent le fondement).
Comment le COVID-19 a mis en évidence les défis et les limites de l’industrie des soins de santé en matière de qualité des données
Les pandémies ont toujours mis au défi l’infrastructure du secteur de la santé, mais le COVID-19 a ajouté un nouveau défi – celui de la transformation numérique et de la nécessité de disposer de données améliorées et agrégées.
Les établissements de santé sont à bout de souffle‘ d’essayer de tirer parti temps réel des informations fondées sur des données pour prendre des décisions cruciales. Ce défi est en partie dû à l’infrastructure de données actuelle, qui est dépassée et repose encore sur des méthodes manuelles pour la saisie et l’agrégation des données. Le stockage complexe des données, associé à des sources de données disparates et à un personnel manquant de formation en matière de données, rend difficile la collecte, le traitement et la consolidation des données afin de fournir le site image complète d’un patient – les implications de ce qui se traduit par des analyses faussées et des données corrigées qui donnent une vision loin d’être exacte de la pandémie.
Dans un article brillant sur l’impact de la mauvaise qualité des données sur la réponse à COVID-19,
Datan
ami
rapporte que les données sur les nouveaux cas et les lits d’hospitalisation sont déclarées manuellement par les hôpitaux et que crée un défi pour obtenir une confiance élevée dans les données actuelles « têtes et lits ».
Le volume et la variété des données générées pendant cette pandémie sont inimaginables. Les établissements de soins de santé sont pressés de donner un sens à ces données rapidement pour relever les défis, mais le recours à des processus manuels, une approche généralement lente des initiatives technologiques et l’utilisation actuelle de systèmes hérités ont rendu difficile la prise de décision en temps réel.
Heureusement, tout n’est pas condamné. La pandémie a déclenché une accélération des efforts en faveur de l’utilisation d’outils et de technologies permettant aux hôpitaux, aux établissements de soins, aux gouvernements, aux entreprises pharmaceutiques et aux organismes de recherche d’agréger et d’analyser une multitude d’ensembles de données pour produire des solutions (telles que des applications mobiles permettant de prédire les risques), des directives de soins aux patients et la création de vaccins en un temps record.
Quelles mesures immédiates l’industrie peut-elle prendre pour atteindre les objectifs de qualité des données ?
Leadership, formation, changement de culture est l’un des conseils les plus courants donnés par les expertsmais ces étapes nécessitent long terme une refonte à long terme. À l’heure où les dirigeants sont pressés de donner la priorité à la qualité des données, ils doivent prendre des mesures concrètes et immédiates. Il s’agit notamment de :
Réaliser un audit de la qualité des données :
Les solutions ne peuvent être trouvées que si vous connaissez exactement le problème auquel votre organisation est confrontée. Par exemple:
- Aos équipes ont-elles du mal à consolider les données sur les patients provenant de plusieurs ressources pour établir un rapport ?
- IVotre établissement est confronté à des erreurs lors de la saisie des données ?
- Avez-vous mis en place des contrôles de données insuffisants ?
- Quelles sont les erreurs les plus courantes trouvées dans vos dossiers ?
Ces questions et bien d’autres encore doivent être posées. Les dossiers doivent être extraits et évalués pour voir s’ils répondent aux normes de qualité définies.
Investir dans un outil de qualité des données en libre-service :
Il y a de fortes chances que votre équipe s’appuie encore sur un outil ETL pour nettoyer et transformer les données. Les méthodes manuelles ne peuvent pas être utilisées pour traiter des données dont le volume et la variété sont exponentiels. volume et la variété. C’est là que les outils de qualité des données en libre-service basés sur le ML se révèlent utiles. Ils replacmanuel nettoyage ou normalisation des données s avec des processus rapides et automatisés. Par exemple, la normalisation des données hospitalières demande des mois d’efforts et implique des processus complexes comme la garantie des bons formats [name] [date] [phone number] . Avec un outil en libre-service, il prend quelques minutes seulementpour mettre les noms en majuscules, supprimer les espaces blancs, les fautes de frappe et bien d’autres choses encore. pour un million de lignes.
Avec le bon outil de qualité des données, vous pouvez effectuer le nettoyage des données, la déduplication des données, la mise en correspondance des données et la consolidation des données, le tout sur une seule plateforme, sans code, en utilisant une interface de type pointer-cliquer.
Automatiser la préparation des données:
L’automatisation est l’avenir. Pour le secteur des soins de santé, l’automatisation est une nécessité qui peut avoir un impact positif sur les soins aux patients, la gestion des ressources, la gestion des systèmes, les statistiques, le financement et bien plus encore. Les vieilles croyances et le recours à des processus dépassés doivent être remplacés par l’innovation et l’automatisation, l’objectif fondamental étant de permettre aux ressources humaines de se concentrer davantage sur l’analyse et la prise de décision.
Définir des normes de qualité des données :
Les données doivent être mesurées pour refléter les dimensions des normes de qualité des données. Pour commencer, les organisations doivent s’assurer que leurs données actuelles sont exactes, complètes et valides.
Faites de la qualité des données une habitude organisationnelle :
Les fonctions de qualité des données, telles que le nettoyage des données et la normalisation des données, ne doivent pas être exécutées uniquement en cas de besoin. Les organisations doivent développer une routine pour nettoyer et mettre à jour les données. Les employés ayant accès à ces données doivent être formés pour comprendre la qualité des données et les implications qu’elle a sur les applications en aval. Cette étape particulière ne nécessite pas de changement organisationnel. Elle peut être accomplie tout simplement en créant un calendrier, en affectant une ressource et en dotant cette dernière du bon outil pour accomplir le travail.
Comment Data Ladder vous aide-t-il ?
Data Ladder DataMatch Enterprise est une solution de premier ordre conçue pour aider le secteur des soins de santé à gérer la qualité des données. Avec Data Ladder, votre équipe peut traiter des téraoctets de données, consolider des sources de données multiples, nettoyer et transformer des millions de lignes de données en un temps record. seulement 45 minutes.
DME est l’outil de choix des organismes de soins de santé en raison de son interface facile à utiliser, de sa capacité à relier les dossiers à 100%. lien entre les enregistrements et sa capacité à effectuer des transformations de données CODE-FREE.
Les DME peuvent aider les systèmes de santé dans les domaines suivants :
Couplage d’enregistrements pour les études longitudinales
La liaison de données est le processus qui consiste à relier/combiner/constituer plusieurs sources d’information sur un individu ou une entité. La combinaison des informations présente plusieurs avantages :
- Des études longitudinales portant sur des populations entières peuvent être menées afin de comprendre les tendances des maladies et les défis qui y sont liés.
- Mettre en œuvre des changements ou élaborer de nouvelles politiques de santé à la lumière des données disponibles.
- Les experts peuvent découvrir ou résoudre des questions pour obtenir des réponses qu’un seul ensemble de données ne peut fournir.
- Les informations historiques telles que les données administratives, les données sur les événements vitaux, etc., recueillies au cours de la vie d’une population sont précieuses pour étudier les maladies et identifier les populations sensibles.
- La combinaison de plusieurs ensembles de données permet aux organisations d’évaluer l’état de la qualité de leurs données à un niveau plus profond et d’identifier les lacunes potentielles à combler.
- Des modèles de simulation peuvent être développés pour étudier différentes populations.
Également connu sous le nom de « couplage d’enregistrements« , le couplage de données a été proposé pour la première fois par Halbert L. Dunn en 1946 dans son article intitulé » Record Linkage » (couplage d’enregistrements) publié dans l’American Journal of Public Health.
American Journal of Public Health,
où il a suggéré la création d’un « livre de vie » pour chaque individu, de la naissance à la mort, intégrant les principaux événements sanitaires et sociaux. Ce livre serait une compilation de tous les dossiers existants afin de créer un dossier unique à utiliser pour la planification des services de santé.
Depuis lors, les établissements de soins de santé du monde entier, y compris les États-Unis, le Canada, l’Angleterre, le Danemark et l’Australie, se sont efforcés de créer des systèmes de liaison des données. Ces systèmes contiennent des ensembles de données sur les naissances, les décès, les admissions à l’hôpital, les visites aux urgences, et bien plus encore. Certains pays disposent même de dossiers complets sur la santé mentale, l’éducation, la généalogie et des données de recherche spécifiques.
Aux États-Unis, les préoccupations concernant le respect de la vie privée, la confidentialité et la sécurité des informations relatives aux patients ont conduit à des politiques et des réglementations de plus en plus strictes , l’HIPAA étant la politique la plus connue en la matière. Avec ces politiques en place, les organisations n’ont pas accès à des identifiants uniques qui peuvent facilement être utilisés pour relier les enregistrements. Lorsque cela se produit, d’autres composants de la source de données sont utilisés pour identifier les enregistrements. Dans ce cas, le couplage d’enregistrements implique plusieurs étapes et l’utilisation d’une correspondance probabiliste pour apparier les données.
Il existe un large fossé entre le système de données idéal et le système fédéral actuel de données sur les soins de santé. En raison de la mauvaise qualité des données stockées dans des systèmes fragmentés et de l’absence de contrôle de la qualité, les établissements de soins de santé sont confrontés à des défis importants pour fournir des soins de santé de grande qualité.
En outre, l’expansion sans précédent des données sur les patients provenant de sources telles que l’internet et le mobile a augmenté le volume et la variété des données de manière exponentielle, ce qui rend difficile pour les organisations de relier les dossiers de santé électroniques (DSE) entre les systèmes et à travers ceux-ci – une activité nécessaire pour une série d’objectifs, notamment la recherche sur les soins de santé, les études longitudinales des populations, la prévention et le contrôle des maladies, les soins aux patients et bien plus encore.
Analyse, nettoyage et normalisation des données sans code
DME permet un nettoyage des données facile, par pointer-cliquer. Contrairement aux outils ETL ou à Excel, aucun effort manuel n’est nécessaire. Avec DME, les utilisateurs peuvent :
- Transformez les données pauvres en cliquant simplement sur les cases à cocher.
- Normaliser le style du texte.
- Supprimer les caractères indésirables
- Supprimez les fautes de frappe accidentelles lors de la saisie des données (elles sont difficiles à repérer !).
- Nettoyer les espaces entre les lettres/mots
- Transformer les surnoms en noms réels (John au lieu de Johnny)
DME permet d’uniformiser facilement les données en laissant l’utilisateur choisir parmi plus d’une douzaine d’options de normalisation qui peuvent être appliquées à
des centaines de millions d’enregistrements à la fois (testé avec plus de 2 milliards d’enregistrements).
+ d’enregistrements).
Permettre la mise en œuvre d’un cadre de qualité des données
La plateforme de DME est un cadre qui permet aux organisations de trouver un point de départ à leurs objectifs d’amélioration de la qualité des données. Non seulement ils peuvent nettoyer et préparer leurs données, mais ils peuvent aussi en faire une partie intégrante de leur routine quotidienne, et ce à moitié prix. Les données relatives aux soins de santé doivent répondre aux normes de qualité des données décrites ci-dessus, ce qui signifie que les établissements de soins de santé doivent mettre en œuvre un cadre de qualité des données qui garantit l’uniformité, l’exactitude et la cohérence. Et ils doivent répondre à ces normes rapidement.
DME, qui est une solution de gestion de la qualité des données, permet aux utilisateurs de profiler, normaliser et nettoyer des milliards d’enregistrements provenant de sources de données multiples à une vitesse et une précision record. En outre, grâce à la possibilité d’intégrer plus de 500 sources de données, les utilisateurs peuvent directement mettre à jour et modifier leurs sources de données sans avoir à recourir à des outils tiers.
Conclusion – Aidez votre organisation à obtenir des données précises et fiables pour améliorer la qualité des soins aux patients
Pour être utiles, les données doivent être correctes, complètes, fiables et précises. Les données erronées entraînent des erreurs dans la prise de décision, des erreurs fatales dans les soins aux patients (comme le diagnostic du mauvais patient), des chiffres faussés dans la recherche et d’autres problèmes critiques.
Si de nombreux établissements de soins de santé ont collecté des données sur les patients, ils doivent encore développer des systèmes actualisés pour maintenir la qualité des services fournis. Un outil de qualité des données en libre-service tel que DataMatch Enterprise permet aux utilisateurs autorisés de préparer les données en vue de leurs multiples utilisations sans avoir à recourir à l’informatique ou à une expertise SQL spécifique.
Plus important encore, cela donne aux organisations une tête commencer dans le parcours d’amélioration des données. Une fois que l’organisation a compris les problèmes affectant la qualité des données, elle est mieux à même d’apporter les modifications nécessaires et d’élaborer un plan de gestion des données plus solide.
Téléchargez notre version d’essai gratuite pour voir comment vous pouvez nettoyer et relier les dossiers de votre organisation de manière simple et sans code.
The post Qualité des données dans les soins de santé – Défis, limites et mesures à prendre pour améliorer la qualité appeared first on Data Ladder.
]]>