Over the past few years, we have been running a research collaboration between MTG and the recommender systems team at Kakao who are behind Melon, one of the major music streaming services in Korea. One of its outcomes is Melon Playlist Dataset, a new public dataset for music audio tagging, music recommendation and playlist generation, and representation learning. It contains mel-spectrograms for 649K tracks annotated by 149K playlists and 31K tags, based on music consumption patterns in Korea. Interestingly, it is the first research dataset representing listening patterns outside of the platforms with a predominantly Western audience.
https://mtg.github.io/melon-playlist-dataset/
Read our ICASSP 2021 paper for more details:
Melon Playlist Dataset: a public dataset for audio-based playlist generation and music tagging. Ferraro A., Kim Y., Lee S., Kim B., Jo N., Lim S., Lim S., Jang J., Kim S., Serra X., & Bogdanov, D. In 20th International Society for Music Information Retrieval Conference. In IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2021), 2021.
One of the main limitations in the field of audio signal processing is the lack of large public datasets with audio representations and high-quality annotations due to restrictions of copyrighted commercial music. We present Melon Playlist Dataset, a public dataset of mel-spectrograms for 649,091 tracks and 148,826 associated playlists annotated by 30,652 different tags. All the data is gathered from Melon, a popular Korean streaming service. The dataset is suitable for music information retrieval tasks, in particular, auto-tagging and automatic playlist continuation. Even though the latter can be addressed by collaborative filtering approaches, audio provides opportunities for research on track suggestions and building systems resistant to the cold-start problem, for which we provide a baseline. Moreover, the playlists and the annotations included in the Melon Playlist Dataset make it suitable for metric learning and representation learning.
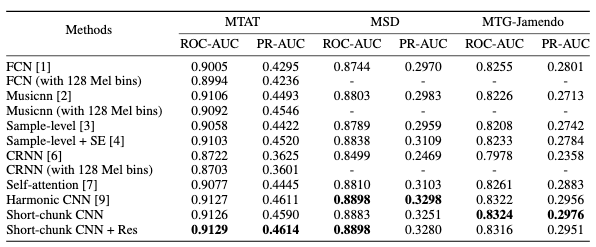
One of the challenges in making the distribution of this data possible was to identify the trade-off settings for the mel-spectrograms frequency/temporal resolution, which would allow to significantly reduce the data size with only minor or negligible loss in performance. To this end, we did a preliminary study, analyzing the performance of several music auto-tagging models under different resolutions:
How low can you go? Reducing frequency and time resolution in current CNN architectures for music auto-tagging. Ferraro A., Bogdanov D., Serra X., Jeon J. H., & Yoon J. The 28th European Signal Processing Conference (EUSIPCO 2020), 2020.
Automatic tagging of music is an important research topic in Music Information Retrieval and audio analysis algorithms proposed for this task have achieved improvements with advances in deep learning. In particular, many state-of-the-art systems use Convolutional Neural Networks and operate on mel-spectrogram representations of the audio. In this paper, we compare commonly used mel-spectrogram representations and evaluate model performances that can be achieved by reducing the input size in terms of both lesser amount of frequency bands and larger frame rates. We use the MagnaTagaTune dataset for comprehensive performance comparisons and then compare selected configurations on the larger Million Song Dataset. The results of this study can serve researchers and practitioners in their trade-off decision between accuracy of the models, data storage size and training and inference times.
As Melon Playlist Dataset contains different types of metadata (playlists, tags, and genres), it is suitable for multi-modal learning. We have explored that applying contrastive learning using playlist and genre information to generate audio embeddings:
Enriched music representations with multiple cross-modal contrastive learning. Ferraro A., Favory X., Drossos K., Kim Y., & Bogdanov D. IEEE Signal Processing Letters. 28.
Modeling various aspects that make a music piece unique is a challenging task, requiring the combination of multiple sources of information. Deep learning is commonly used to obtain representations using various sources of information, such as the audio, interactions between users and songs, or associated genre metadata. Recently, contrastive learning has led to representations that generalize better compared to traditional supervised methods. In this paper, we present a novel approach that combines multiple types of information related to music using cross-modal contrastive learning, allowing us to learn an audio feature from heterogeneous data simultaneously. We align the latent representations obtained from playlists-track interactions, genre metadata, and the tracks’ audio, by maximizing the agreement between these modality representations using a contrastive loss. We evaluate our approach in three tasks, namely, genre classification, playlist continuation and automatic tagging. We compare the performances with a baseline audio-based CNN trained to predict these modalities. We also study the importance of including multiple sources of information when training our embedding model. The results suggest that the proposed method outperforms the baseline in all the three downstream tasks and achieves comparable performance to the state-of-the-art.
]]>