A few months ago I started working with spatial data in SQL Server. From that moment on, and I’ve said this before, I’m hooked!
And since my daily work includes more and more work regarding spatial data, I’m trying to write some posts about querying spatial data.
Yet another source of information???
If you want to start with spatial data, and you try to find information about this subject, you’ll probably encounter the same problem I had: there’s too much information. Almost all examples are based on real-life polygons and spatial data, and in my opinion way over-engineered to start with or to answer basic questions.
That’s why I’ll try to cover the basics in this post, and maybe create a series about spatial data, without trying to reinvent the wheel.
What is spatial data?
Spatial data represents information about the physical location and shape of geometric objects
If we analyse this quote taken from TechNet, it tells us that every object can be visualized with spatial data? As a matter of fact, yes you can!
Every object around you, ranging from a tree to a city or country region, can be represented by one of 3 basic types. The image below (from MSDN) shows these 3 basic types:
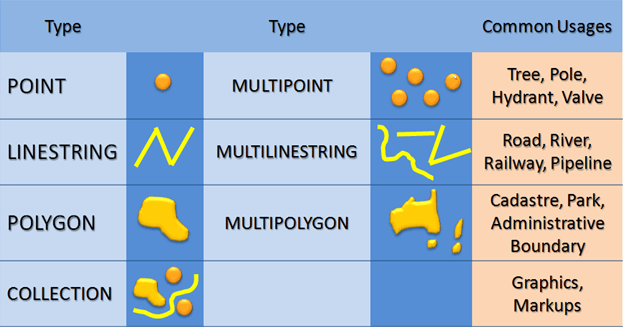
And from these 3 types (or collections of types) you can create every spatial object you want.
Geometry vs Geography
In SQL Server you have the option to use 2 spatial types. The main difference between these 2, is that Geometry only stores 2D objects, and Geography can store 3D (and even 4D) objects. Also, Geometry and Geography don’t support the same exact methods. For example, Geography can’t calculate a center-point of a shape.
Another big difference is that Geometry calculates straight lines, and Geography actually compensates for the curvature of the earth.
In order to keep things simple, I created the examples in this post all in Geometry data.
Drawing your first object
To start off basic, what is easier then drawing a simple square? A square consists of 4 coordinates, and is one of the most basic forms you can draw. An example of a square looks like this:
DECLARE @Square geometry;
SET @Square = geometry::STGeomFromText('LINESTRING (0 0, 0 100, 100 100, 100 0, 0 0)', 4326);
SELECT @Square
But what if you want a solid square, instead of an outline? In that case, you need to change the type you’re drawing into a polygon. Where the 4 lines in the example above just draw the outline of the object, a polygon (like the example below) will also contain everything within the lines you draw:
DECLARE @SquareFilled geometry;
SET @SquareFilled = geometry::STGeomFromText('POLYGON((0 0, 0 100, 100 100, 100 0, 0 0))', 4326);
SELECT @SquareFilled
Layers
Okay, let’s take this one step further. You can also draw multiple objects in one context. These objects can be drawn next to each other, or on top of each other. Every object you draw will be drawn in a “separate layer”. Objects that don’t overlap are just 2 shapes (polygons). But if you draw 2 shapes on top of each other, it’s a whole different story. Both objects can actually aggregate into 1 big shape, or exclude each other. First, an example with 2 separate shapes:
DECLARE @Square geometry,
@Triangle geometry;
SET @Square = geometry::STGeomFromText('POLYGON((0 0, 0 100, 100 100, 100 0, 0 0))', 4326);
SET @Triangle = geometry::STGeomFromText('POLYGON((50 50,100 150,150 50, 50 50))', 4326);
SELECT @Square
UNION ALL
SELECT @Triangle
If you run the query above, you’ll see 2 objects appear: a square and a triangle. Both object overlap at a certain point, but they’re still 2 independent shapes.
Layer aggregation
Until now it’s just child’s play. Now we’re getting to the exiting stuff! How about combining the 2 previous objects into one big shape?
DECLARE @Square geometry,
@Triangle geometry;
SET @Square = geometry::STGeomFromText('POLYGON((0 0, 0 100, 100 100, 100 0, 0 0))', 4326);
SET @Triangle = geometry::STGeomFromText('POLYGON((50 50,100 150,150 50, 50 50))', 4326);
SELECT @Square.STUnion(@Triangle)
Now you’ll see that both objects merged into one single object. This is a result of “joining” 2 objects or layers. By using the extended method STUnion on one of your shapes, you can add another shape to it. So in the case, the triangle is added to the square.
Layer intersection
But what if you want to know the part of the polygon that intersects? So which part of object 1 overlaps object 2? You can do this by using the STIntersection method:
DECLARE @Square geometry,
@Triangle geometry;
SET @Square = geometry::STGeomFromText('POLYGON((0 0, 0 100, 100 100, 100 0, 0 0))', 4326);
SET @Triangle = geometry::STGeomFromText('POLYGON((50 50,100 150,150 50, 50 50))', 4326);
SELECT @Square.STIntersection(@Triangle)
Or maybe you want to know which part doesn’t overlap. Then you can query the difference of both objects:
DECLARE @Square geometry,
@Triangle geometry;
SET @Square = geometry::STGeomFromText('POLYGON((0 0, 0 100, 100 100, 100 0, 0 0))', 4326);
SET @Triangle = geometry::STGeomFromText('POLYGON((50 50,100 150,150 50, 50 50))', 4326);
SELECT @Square.STSymDifference(@Triangle)
Center
As you see, there are many really cool things you can do with spatial data. One other I want to show you is how to determine the center of your object. Instead of calculating it yourself, you can use a method called STCentroid:
DECLARE @Square geometry;
SET @Square = geometry::STGeomFromText('POLYGON((0 0, 0 100, 100 100, 100 0, 0 0))', 4326);
SELECT @Square
UNION ALL
SELECT @Square.STCentroid().STBuffer(10)
Just to keep it visual, I’ve added a buffer to the center point. What STBuffer does, is adding a radial to the selected object. So in this case, it created a radial around the center point.
If you didn’t draw that extra radial, it would literally just be a pixel on your screen. So by adding a buffer around the center, it’s still visible. But it’s only for visual purposes, and isn’t required to make this query work.
Other possibilities
Another thing I wanted to show, is a really awesome polygon made by one of my colleagues: Johannes Tedjaatmadja (@JTedjaatmadja). You have to see it for yourself, because posting it would spoil the surprise. You can download it from here. And I must say, this’ll be one to make Mladen Prajdic (Blog | @MladenPrajdic) proud! 😉

