Using SQLCMD to your advantage
May 28, 2012 1 Comment
A few weeks ago, I came across something called SQLCMD (or SQLCommand). I’ve never heard of this, so the curious developer in me wanted to know what it was. The official definition according to MSDN is this:
The sqlcmd utility lets you enter Transact-SQL statements, system procedures, and script files at the command prompt, in Query Editor in SQLCMD mode, in a Windows script file or in an operating system (Cmd.exe) job step of a SQL Server Agent job. This utility uses ODBC to execute Transact-SQL batches.
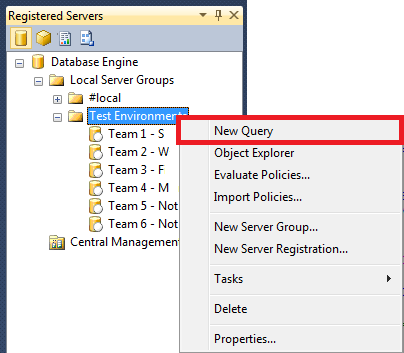
You can either run a SQLCMD query via command-line or in SQL Server Management Studio (SSMS). If you want to run it via SSMS, open a new query and press the hotkey combination: ALT+Q, ALT+M. You could also use the menu Query -> SQLCMD Mode.
Once you’ve done that, you can run queries in SQLCMD mode. This means you can use your query window as a commandline tool. The advantage of this, is that you can query multiple servers and instances in one query.
To run queries in SQLCMD mode you need the commands listed below:
| Command | Parameters | Description |
| :!! | <command> | Directly executes a cmd command from SQLCMD |
| :CONNECT | <server>(\instance) | Connects to the specified servers default or specified instance |
| [-l timeout] | ||
| [-U user] | ||
| [-P password] | ||
| :ERROR | <destination> | Redirects error output to a file, stderr or stdout |
| :EXIT | Quits SQLCMD immediately | |
| (<query>) | Executes the specified query and returens numeric result | |
| GO | [n] | Executes the specified query (parameter: x times) |
| :ONERROR | <exit / ignore> | Specifies which action to take if the query encounteres error |
| :OUT | <filename> | Redirects query output to a file, stderr or stdout |
| [stderr / stdout] | ||
| : PERFTRACE | <filename> | Redirects timing output to a file, stderr or stdout |
| [stderr / stdout] | ||
| :QUIT | Quits SQLCMD immediately | |
| :R | <filename> | Append a file to statement cache (ready to execute) |
| :RESET | Discards the statement cache (reset session) | |
| :SERVERLIST | Lists local and network SQL servers | |
| :SETVAR | <varname> <"value"> | Sets a SQLCMD scripting variable |
Remember, not all commands are listed above, but just the once I found usefull at this time. Parameters listed in are mandatory, and in [ ] are optional.
To write all queries out would be too much, so I created some scripts for you to download. Here’s a list of files you can download and try on your local SQL server:
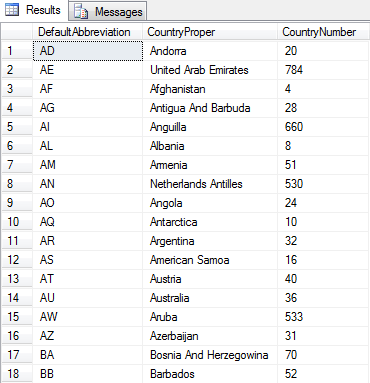
Get database info with screen output, from multiple SQL servers
Execute script file, and output to file
Get directory content via commandline
Collection of commands in 1 script file
Script file used in the example above
The first script file is the most interesting if you ask me. In this script, I connect to multiple instances of SQL server to retrieve data. You can use this instead of a Multiserver query I blogged about earlier. Instead of registering a group of servers and running your query against that, you can now specify the servers you want by server name or IP-address.
With this information you could start writing your own SQLCMD queries. If you want, you can do this via SSMS or command line. The command line utility can be found at this location:
C:\Program Files\Microsoft SQL Server\100\Tools\Binn\SQLCMD.exe
If you have any questions or need some help, just contact me. I’d love to help you out! 🙂