Moving files with SSIS
June 28, 2013 3 Comments
In the last few weeks, I’ve seen the ugly side of being a DBA: Server maintenance. Most of the time this is only needed when things go wrong, checking the backups, etc. But last week I had something that makes every DBA on earth shiver: diskspace shortage.
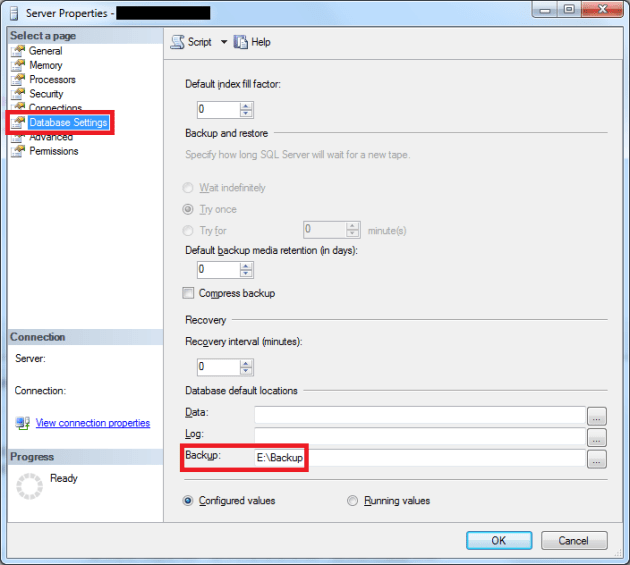
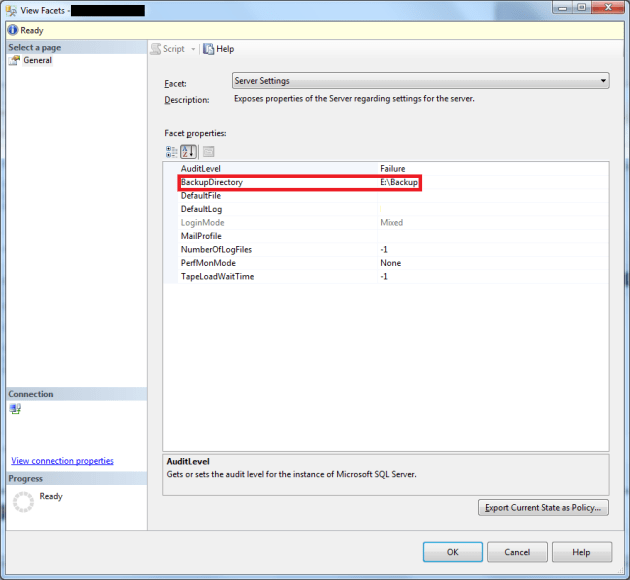
One of the ETL processes that runs on our server, downloads a bunch of XML files from an external source, and stores those on local disk. After that, the XML files are imported into a database, so our business analysts can use the content for their analysis. After the import, the XML files are zipped, and stored in a folder called “Backup”. But because the files are never deleted after the imported (they might want to audit the data and files), the disk they were stored on was running low on diskspace.
Thinking about the options
As a DBA, it’s your job make your own life as easy as possible. So moving the files by hand is okay if you only need to do it once. But I’d rather solve this once and for all, because maybe next time the disk will run out of space in the middle of the night, instead of during the day like this time.
So to prevent this issue in the future, I’ve created an SSIS solution to run directly after the import. This SSIS package moves the files from local disk to SAN storage. This way, we’re getting rid of the local files, but the files are still available when needed.
Creating your test environment
The first thing I did was create a copy of the directory structure that exists on the server, on my local machine. I’ve just copied the structure, and put a single .txt file in every directory. You can download the “test environment” setup here. Unzip the contents of the folder to “C:\Temp”, so you can use the SSIS package like described below, without making changes to it.
Creating the package
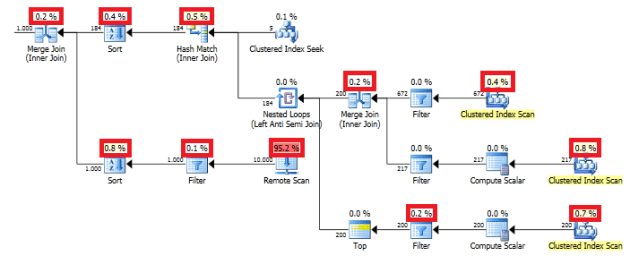
I started by creating a new package, and added a “Foreach Loop Container” for every folder that contains XML- and text-files. In every “Foreach Loop Container” I’ve placed a “File System Task”. After that, I’ve created the variables needed for this package:

Some of the variables are created just for the scope of the corresponding “Foreach Loop Container”. So if you want to see all variables in one overview, click the “Show All Variables” button that I’ve marked in the image above.
Configuring the components
Now you can start configuring the components. The “Foreach Loop Container” needs to be configured like this:

And:

And the “File System Task” needs to be configured like this:

You can also download the SSIS package as shown above, directly here (save the XML as dtsx file).
Test run
Now you’re ready for a test run! If you didn’t download the directories and files (the “test environment”) above, make sure you create all the destination directories. If you don’t, the package will fail. I didn’t build it into this version, but you might want to add a feature like that to the package.