llama.cpp, which seems more practical than vLLM for CPU-only setups. First, I need to compile a few dependencies (libuv, libarchive, and CMake). As described in the llama.cpp documentation, CMake is required to build the project.
I have prepare several Jenkins jobs via Ansible…




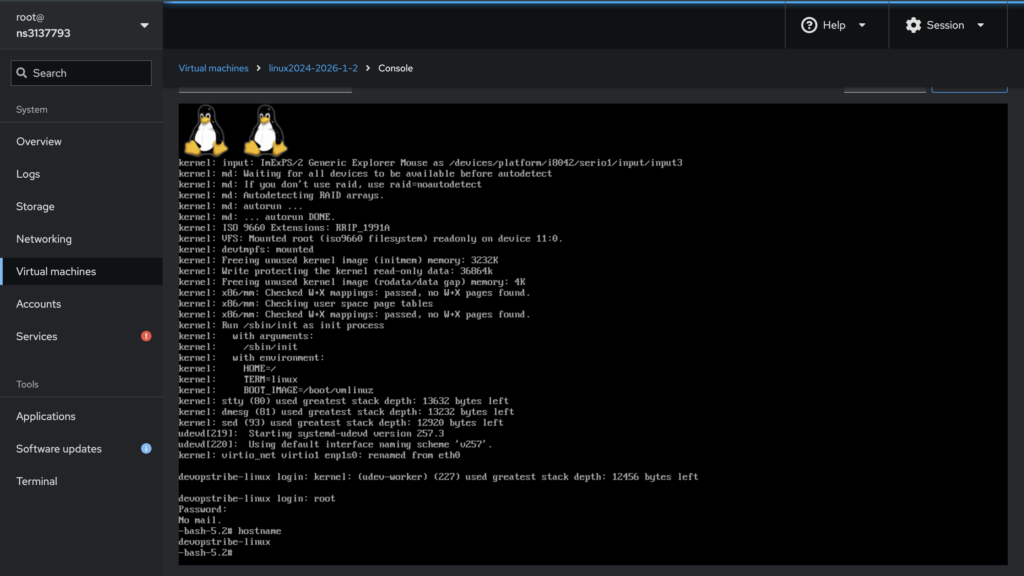
Chroot into the system to ensure the CMake binary is available
ubuntu@ns3137793:~/gdt$ sudo bash ./jenkins-lfs/chroot_in.sh
(lfs chroot) root:/# find / -name "cmake" -type f
/sources/cmake-4.2.1/Bootstrap.cmk/cmake
/sources/cmake-4.2.1/bin/cmakeBuild llama.cpp
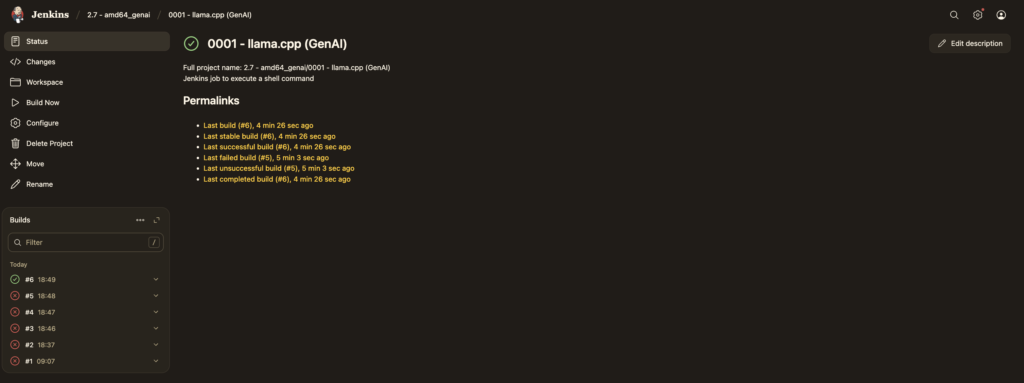
I’m now ready to load a lightweight model and launch llama-server. To conserve resources, I’ve bypassed systemd and written a custom init script to handle the startup process.
This is a video of an example of how to build an ISO, boot it, and test local AI inference.
I’m working on this repo: https://github.com/lucky-sideburn/generic-distro-toolkit. Anyone who wants to join is more than welcome!
]]>
My latest update was creating a .img file, which I run through Cockpit (using https://github.com/cockpit-project/cockpit-machines). Now, I would like to create a bootable operating system by generating an ISO image.
This process takes the previously created root filesystem, which contains a minimal structure to be executed.
root@ns3137793:/mnt/lfs# du -chs *
0 bin
28M boot
8.0K build
0 dev
4.0K dist
17M etc
4.0K home
0 lib
4.0K lib64
12K media
4.0K mnt
4.0K opt
4.0K proc
1.5M root
44K run
0 sbin
4.0K srv
4.0K sys
148K tmp
2.2G usr
84K var
Instead of using prepare_image.sh (https://github.com/lucky-sideburn/generic-distro-toolkit/blob/main/jenkins-lfs/playbooks/roles/ansible-gdt/files/prepare_image.sh), I need to create a prepare_iso.sh shell script. The initial concept is to maintain the entire root filesystem structure while creating custom grub.cfg, inittab, and fstab files.
# This is a temporary folder. I want to avoid corrupting my original /mnt/lfs
ISO_WORKSPACE="/tmp/lfs_iso_ws"
sudo mkdir -p $ISO_WORKSPACE
# I copy everything from /mnt/lfs but excluding sources directory
# Use -a to preserve permissions/symlinks which are critical for LFS
sudo rsync -a --progress --exclude='/mnt/lfs/sources' --exclude='/mnt/lfs/build' /mnt/lfs/ $ISO_WORKSPACE/
# Copy the Kernel
sudo cp /mnt/lfs/boot/vmlinuz-6.13.4-lfs-12.3 $ISO_WORKSPACE/boot/vmlinuz
# Create the GRUB config inside the workspace
# This is a live iso so my root is /dev/sr0
# I want to have tty console and serial console so I define both console=ttyS0,115200 console=tty1
# Use InitramFS
sudo mkdir -p $ISO_WORKSPACE/boot/grub
sudo tee $ISO_WORKSPACE/boot/grub/grub.cfg << EOF
set default=0
set timeout=10
menuentry "DevOpstribe Linux" {
linux /boot/vmlinuz root=/dev/sr0 ro rootfstype=iso9660 init=/sbin/init console=ttyS0,115200 console=tty1
initrd /boot/initrd.img-6.13.4
}
EOF
# I create an inittab file to define 3 as default runlevel (for production system use SystemD :D)
# Please pay attention to 1:2345:respawn:/sbin/agetty --autologin root --noclear -n tty1 9600, I do not want login with username and password but I want to start the installer script directly after the boot process
sudo tee $ISO_WORKSPACE/etc/inittab << 'EOF'
# Default Runlevel
id:3:initdefault:
# System initialization
si::sysinit:/etc/rc.d/init.d/rc S
# What to do in single-user mode
~:S:wait:/sbin/sulogin
# What to do when CTRL-ALT-DEL is pressed
ca::ctrlaltdel:/sbin/shutdown -t1 -a -r now
# Runlevels
l0:0:wait:/etc/rc.d/init.d/rc 0
l1:1:wait:/etc/rc.d/init.d/rc 1
l2:2:wait:/etc/rc.d/init.d/rc 2
l3:3:wait:/etc/rc.d/init.d/rc 3
l4:4:wait:/etc/rc.d/init.d/rc 4
l5:5:wait:/etc/rc.d/init.d/rc 5
l6:6:wait:/etc/rc.d/init.d/rc 6
# Consoles
1:2345:respawn:/sbin/agetty --autologin root --noclear -n tty1 9600
2:2345:respawn:/sbin/agetty tty2 9600
3:2345:respawn:/sbin/agetty tty3 9600
# End of /etc/inittab
EOF
sudo tee $ISO_WORKSPACE/etc/fstab << 'EOF'
# Begin /etc/fstab for Live ISO
# file system mount-point type options dump fsck
proc /proc proc nosuid,noexec,nodev 0 0
sysfs /sys sysfs nosuid,noexec,nodev 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
tmpfs /run tmpfs defaults 0 0
devtmpfs /dev devtmpfs mode=0755,nosuid 0 0
tmpfs /dev/shm tmpfs nosuid,nodev 0 0
cgroup2 /sys/fs/cgroup cgroup2 nosuid,noexec,nodev 0 0
# CD-ROM is already mounted as root, no need to mount it again
# /dev/sr0 / iso9660 ro 0 0
# End /etc/fstab
EOF
sudo rm $ISO_WORKSPACE/etc/rc.d/rcS.d/S45cleanfs
sudo rm $ISO_WORKSPACE/etc/rc.d/rcS.d/S40mountfs
echo "devopstribe-linux" | sudo tee $ISO_WORKSPACE/etc/hostname
# Also update /etc/hosts
sudo tee $ISO_WORKSPACE/etc/hosts << 'EOF'
# Begin /etc/hosts
127.0.0.1 localhost.localdomain localhost
127.0.1.1 lfs-live.localdomain lfs-live
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
# End /etc/hosts
EOF
# Make sure hostname is set at boot
# Check if you have a hostname init script
ls -l $ISO_WORKSPACE/etc/rc.d/init.d/hostname
# If it doesn't exist, create one
sudo tee $ISO_WORKSPACE/etc/rc.d/init.d/hostname << 'EOF'
#!/bin/sh
########################################################################
# Begin hostname
#
# Description : Set hostname
#
########################################################################
. /lib/lsb/init-functions
case "${1}" in
start)
log_info_msg "Setting hostname..."
hostname -F /etc/hostname
evaluate_retval
;;
*)
echo "Usage: ${0} {start}"
exit 1
;;
esac
# End hostname
EOF
sudo cp /mnt/lfs/sources/system-installer.sh $ISO_WORKSPACE/usr/local/bin/system-installer.sh
sudo chmod +x $ISO_WORKSPACE/usr/local/bin/system-installer.sh
> $ISO_WORKSPACE/root/.bashrc
> $ISO_WORKSPACE/root/.bash_profile
sudo tee -a $ISO_WORKSPACE/root/.bashrc << 'EOF'
#!/bin/bash
# 1. Stop kernel messages
dmesg -n 1
# Restore terminal settings
stty sane
# 2. Clear the screen completely
clear
# 4. Optional: Restore kernel logging on exit
dmesg -n 7
# Auto-start installer on first login
# It is important to use "exec" because we don't want that the user exit from the installer script
if [ -f /usr/local/bin/system-installer.sh ]; then
exec /usr/local/bin/system-installer.sh
fi
EOF
sudo tee -a $ISO_WORKSPACE/root/.bash_profile << 'EOF'
# Carica il bashrc se esiste
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
EOF
cat $ISO_WORKSPACE/root/.bash_profile
sudo chmod +x $ISO_WORKSPACE/etc/rc.d/init.d/hostname
# Link it to run early in boot
sudo ln -sf ../init.d/hostname $ISO_WORKSPACE/etc/rc.d/rcS.d/S02hostname
# 5. Generate the ISO
# WARNING: This ISO will be the size of your entire LFS install
sudo grub-mkrescue -o /var/lib/libvirt/images/lfs-system.iso $ISO_WORKSPACE -- -hfsplus off
sudo chown libvirt-qemu:kvm /var/lib/libvirt/images/lfs-system.iso
Now the system can boot from the lfs-system.iso image.
I want to provide a minimal graphical interface for my users, so I have chosen Dialog. It is very lightweight and is already used by several popular Linux distributions.
I will now add the Dialog compilation tasks to Jenkins by creating the job via Ansible. This is part of https://github.com/lucky-sideburn/generic-distro-toolkit that I use to automate some tasks.
- name: 0109 - Dialogs (Basic System Software) OPTIONAL
version: 2.15
archive_file: /sources/dialog.tar.gz
source_dir: /sources/dialog-1.3-20251223
description: |
Dialog is a tool for creating text-based user interfaces. This job builds Dialog, which is essential for managing file archives in the LFS environment.
category:
This job is part of the system configuration setup, specifically for building Dialog.
jenkins_job_url: http://localhost:8080/job/system_configuration/Dialogs-1.3-20251223
exec_command: echo
build_tool: true
build_command: |
{{ chroot_start_command }} -c '
cd /sources/dialog-1.3-20251223
./configure --prefix=/usr \
--with-ncursesw \
--enable-nls \
--with-libtool
make
make install
'
Once Dialogs is installed, you can use it at login configuring .bash_profile and .bashrc
sudo tee -a $ISO_WORKSPACE/root/.bashrc << 'EOF'
#!/bin/bash
# 1. Stop kernel messages
dmesg -n 1
# Restore terminal settings
stty sane
# 2. Clear the screen completely
clear
# 3. Run your dialog
dialog --msgbox "System Ready" 10 30
# 4. Optional: Restore kernel logging on exit
dmesg -n 7
# Auto-start installer on first login
if [ -f /usr/local/bin/system-installer.sh ]; then
#exec /usr/local/bin/system-installer.sh
/usr/local/bin/system-installer.sh
fi
EOF
sudo tee -a $ISO_WORKSPACE/root/.bash_profile << 'EOF'
# Carica il bashrc se esiste
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
EOF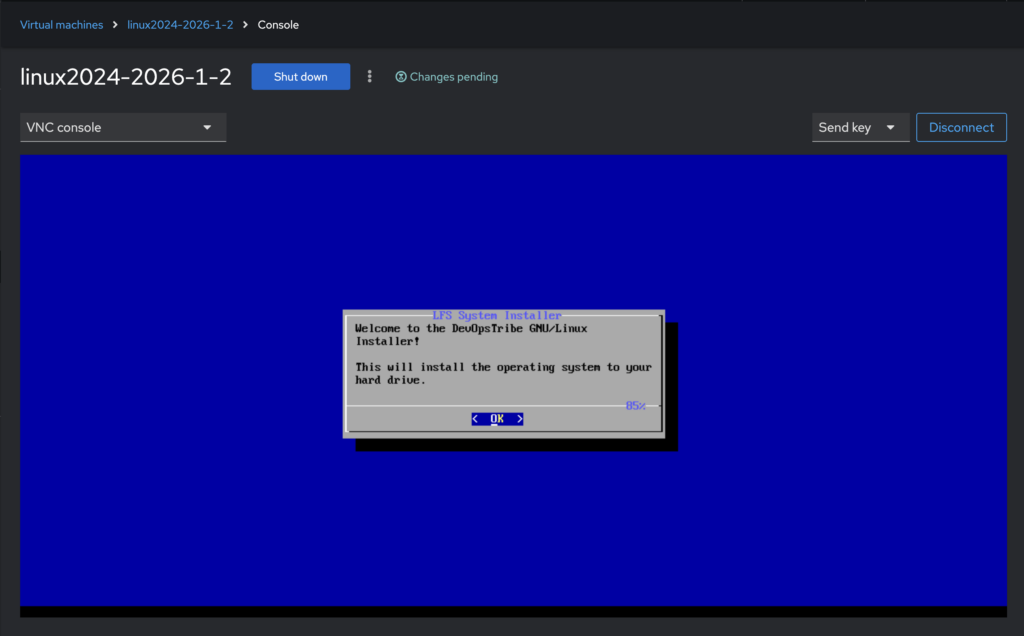
Version with initramfs made with Dracut
# 1. Create workspace
ISO_WORKSPACE="/tmp/lfs_iso_ws"
sudo mkdir -p $ISO_WORKSPACE
# 2. Copy EVERYTHING from your LFS root (except /proc, /sys, /dev)
# Use -a to preserve permissions/symlinks which are critical for LFS
sudo rsync -a --progress --exclude='/sources' --exclude='/build' /mnt/lfs/ $ISO_WORKSPACE/
# 3. Ensure the kernel is in the right place inside the workspace
sudo cp /mnt/lfs/boot/vmlinuz-6.13.4-lfs-12.3 $ISO_WORKSPACE/boot/vmlinuz
sudo mkdir dir -p $ISO_WORKSPACE/live
LFS_KERNEL_VERSION="6.13.4" # Change to your exact version
LFS_ROOT="/mnt/lfs" # Your LFS mount point
sudo dracut --force \
--kver $LFS_KERNEL_VERSION \
--kmoddir $LFS_ROOT/lib/modules/$LFS_KERNEL_VERSION \
--add "dmsquash-live bash kernel-modules rootfs-block base" \
--omit "systemd" \
--filesystems "iso9660 squashfs overlay" \
--drivers "sr_mod sd_mod usb_storage uas cdrom" \
/tmp/initrd
sudo cp /tmp/initrd $ISO_WORKSPACE/live/initrd
sudo cp /mnt/lfs/boot/vmlinuz-6.13.4-lfs-12.3 $ISO_WORKSPACE/live/vmlinuz
# 4. Create the GRUB config INSIDE the workspace
sudo mkdir -p $ISO_WORKSPACE/boot/grub
sudo tee $ISO_WORKSPACE/boot/grub/grub.cfg << EOF
insmod part_gpt
insmod part_msdos
insmod iso9660
insmod all_video
set default=0
set timeout=5
# GRUB cerca la partizione per caricare Kernel e Initrd
search --no-floppy --set=root --label DEVOPS_ISO
menuentry "DevOpsTribe GNU/Linux Live" {
set gfxpayload=keep
linux /live/vmlinuz boot=live root=LABEL=DEVOPS_ISO rootwait quiet splash
initrd /live/initrd
}
EOF
sudo tee $ISO_WORKSPACE/etc/inittab << 'EOF'
# Default Runlevel
id:3:initdefault:
# System initialization
si::sysinit:/etc/rc.d/init.d/rc S
# What to do in single-user mode
~:S:wait:/sbin/sulogin
# What to do when CTRL-ALT-DEL is pressed
ca::ctrlaltdel:/sbin/shutdown -t1 -a -r now
# Runlevels
l0:0:wait:/etc/rc.d/init.d/rc 0
l1:1:wait:/etc/rc.d/init.d/rc 1
l2:2:wait:/etc/rc.d/init.d/rc 2
l3:3:wait:/etc/rc.d/init.d/rc 3
l4:4:wait:/etc/rc.d/init.d/rc 4
l5:5:wait:/etc/rc.d/init.d/rc 5
l6:6:wait:/etc/rc.d/init.d/rc 6
# Consoles
1:2345:respawn:/sbin/agetty --autologin root --noclear -n tty1 9600
2:2345:respawn:/sbin/agetty tty2 9600
3:2345:respawn:/sbin/agetty tty3 9600
# End of /etc/inittab
EOF
sudo tee $ISO_WORKSPACE/etc/fstab << 'EOF'
# Begin /etc/fstab for Live ISO
# file system mount-point type options dump fsck
proc /proc proc nosuid,noexec,nodev 0 0
sysfs /sys sysfs nosuid,noexec,nodev 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
tmpfs /run tmpfs defaults 0 0
devtmpfs /dev devtmpfs mode=0755,nosuid 0 0
tmpfs /dev/shm tmpfs nosuid,nodev 0 0
cgroup2 /sys/fs/cgroup cgroup2 nosuid,noexec,nodev 0 0
# CD-ROM is already mounted as root, no need to mount it again
# /dev/sr0 / iso9660 ro 0 0
# End /etc/fstab
EOF
sudo rm $ISO_WORKSPACE/etc/rc.d/rcS.d/S45cleanfs
sudo rm $ISO_WORKSPACE/etc/rc.d/rcS.d/S40mountfs
sudo rm $ISO_WORKSPACE/etc/rc.d/rc3.d/S92kubelet
sudo rm $ISO_WORKSPACE/etc/rc.d/rc3.d/S91crio
sudo rm $ISO_WORKSPACE/etc/rc.d/rc3.d/S30sshd
echo "devopstribe-linux" | sudo tee $ISO_WORKSPACE/etc/hostname
# Also update /etc/hosts
sudo tee $ISO_WORKSPACE/etc/hosts << 'EOF'
# Begin /etc/hosts
127.0.0.1 localhost.localdomain localhost
127.0.1.1 lfs-live.localdomain lfs-live
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
# End /etc/hosts
EOF
# Make sure hostname is set at boot
# Check if you have a hostname init script
ls -l $ISO_WORKSPACE/etc/rc.d/init.d/hostname
# If it doesn't exist, create one
sudo tee $ISO_WORKSPACE/etc/rc.d/init.d/hostname << 'EOF'
#!/bin/sh
########################################################################
# Begin hostname
#
# Description : Set hostname
#
########################################################################
. /lib/lsb/init-functions
case "${1}" in
start)
log_info_msg "Setting hostname..."
hostname -F /etc/hostname
evaluate_retval
;;
*)
echo "Usage: ${0} {start}"
exit 1
;;
esac
# End hostname
EOF
sudo cp /mnt/lfs/sources/system-installer.sh $ISO_WORKSPACE/usr/local/bin/system-installer.sh
sudo chmod +x $ISO_WORKSPACE/usr/local/bin/system-installer.sh
> $ISO_WORKSPACE/root/.bashrc
> $ISO_WORKSPACE/root/.bash_profile
sudo tee -a $ISO_WORKSPACE/root/.bashrc << 'EOF'
#!/bin/bash
# 1. Stop kernel messages
dmesg -n 1
# Restore terminal settings
stty sane
# 2. Clear the screen completely
clear
# 3. Run your dialog
dialog --msgbox "System Ready" 10 30
# 4. Optional: Restore kernel logging on exit
dmesg -n 7
# Auto-start installer on first login
if [ -f /usr/local/bin/system-installer.sh ]; then
exec /usr/local/bin/system-installer.sh
fi
EOF
sudo tee -a $ISO_WORKSPACE/root/.bash_profile << 'EOF'
# Carica il bashrc se esiste
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
EOF
cat $ISO_WORKSPACE/root/.bash_profile
sudo chmod +x $ISO_WORKSPACE/etc/rc.d/init.d/hostname
sudo ln -sf ../init.d/hostname $ISO_WORKSPACE/etc/rc.d/rcS.d/S02hostname
sudo mksquashfs /mnt/lfs/ $ISO_WORKSPACE/live/filesystem.squashfs \
-e boot \
-e sources \
-e dev/* \
-e proc/* \
-e sys/* \
-e run/* \
-e tmp/* \
-comp xz
sudo grub-mkrescue --iso-level 3 \
-o /var/lib/libvirt/images/lfs-system.iso $ISO_WORKSPACE -- -volid "DEVOPS_ISO" \
-publisher "DevOpsTribe" \
-hfsplus off
sudo chown libvirt-qemu:kvm /var/lib/libvirt/images/lfs-system.iso
After preparing the iso you can burn to USB with different methods, my preferred are dd
root@datastore01:/home/eugenio/Downloads# sudo dd if=/home/eugenio/Downloads/lfs-system.iso of=/dev/sdc bs=4M status=progress conv=fsync
1035993088 bytes (1.0 GB, 988 MiB) copied, 79 s, 13.0 MB/sor Raspberry PI Imager

Of course, LFS is for manually setting up Linux and learning in depth how things work, but my focus is on the DevOps side, using tools like Jenkins and Ansible.
This is an example of a distribution for the x86_64 architecture that I started through virt-install by running the job “0004 – Prepare System Image (System Configuration).”
This post shows the journal of another experiment, where I created an aarch64 system. For this, I started directly on my MacBook Pro M3 using QEMU. The *.img file was passed through the synced folder of the LFS aarch64 build node, which was provisioned with Vagrant.
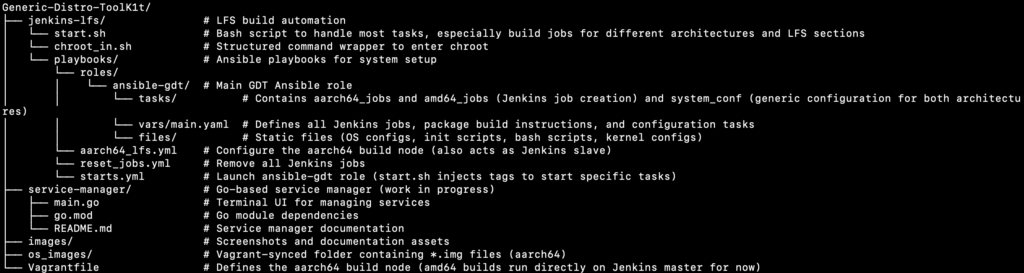
Project Structure
This is the start of VMs on AARCH64, the first one is an Alpine that I use for debugging, the second one is my (A)LFS
Prequisites
Before starting the operating system build, ensure you have a Jenkins server to coordinate the agent.
For building AMD64 or AARCH64, enable KVM and install libvirt, QEMU, and Cockpit.
For AMD64, I used a physical server with both the Jenkins Master and Agent running on the same node.
For AARCH64 (related to this article), I used my laptop with a VM acting as the Jenkins Agent, connected to a Jenkins Master (you can provision the master wherever you prefer)


Build AARCH64 – GNU/Linux Operating System
Clone https://github.com/lucky-sideburn/generic-distro-toolkit repo
Run start.sh and select “16) Provision an AARCH64 build node using Vagrant”
Run start.sh and create Jenkins folders:
0) Create Jenkins Folders
8) Build AARCH64 all Jenkins Jobs
9) Build AARCH64 cross_toolchain Jenkins Jobs
10) Build AARCH64 cross_compiling_temporary_tools Jenkins Jobs
11) Build AARCH64 chroot_and_building_additional_temporary_tools Jenkins Jobs
12) Build AARCH64 basic_system_software Jenkins Jobs
13) Build AARCH64 system_configuration Jenkins Jobs
14) Build AARCH64 containers Jenkins Jobs
Run Jenkins jobs in the order of the numbered folders and jobs.
Run start.sh and select 15) Start AARCH64 VM on QEMU to work on your GNU/Linux system.
Build AMD64 – GNU/Linux Operating System
Clone https://github.com/lucky-sideburn/generic-distro-toolkit repo
Run start.sh and select “17) Provision an AMD64 build node directly with Ansible”
Run start.sh and create Jenkins folders
0) Create Jenkins Folders
1) Build AMD64 all Jenkins Jobs
2) Build AMD64 cross_toolchain Jenkins Jobs
3) Build AMD64 cross_compiling_temporary_tools Jenkins Jobs
4) Build AMD64 chroot_and_building_additional_temporary_tools Jenkins Jobs
5) Build AMD64 basic_system_software Jenkins Jobs
6) Build AMD64 system_configuration Jenkins Jobs
7) Build AMD64 containers Jenkins Jobs
Run Jenkins jobs in the order of the numbered folders and jobs.
The job 0004 – Prepare System Image (System Configuration) will start the VMs, which can be monitored using Cockpit.
Wishing to build an ARM system, specifically AARCH64, I labeled a Jenkins slave as aarch64

In the definition of the jobs I will create automatically, I will therefore have an assignedNode set with the name of the chosen executor.
- name: "Create Jenkins Jobs - Cross Compiling Temporary Tools (aarch64)"
ansible.builtin.uri:
url: "{{ jenkins_url }}/job/aarch64_cross_compiling_temporary_tools/createItem?name={{ item.name | urlencode }}"
method: POST
user: "{{ jenkins_user }}"
password: "{{ jenkins_token }}"
force_basic_auth: yes
status_code: 200
headers:
Content-Type: "application/xml"
body: |
<project>
<actions/>
<description>Jenkins job to execute a shell command</description>
<keepDependencies>false</keepDependencies>
<properties/>
<scm class="hudson.scm.NullSCM"/>
<canRoam>false</canRoam>
<assignedNode>aarch64</assignedNode>
<disabled>false</disabled>
<blockBuildWhenDownstreamBuilding>false</blockBuildWhenDownstreamBuilding>
<blockBuildWhenUpstreamBuilding>false</blockBuildWhenUpstreamBuilding>
<triggers/>
<concurrentBuild>false</concurrentBuild>
<builders>
<hudson.tasks.Shell>
<command>{{ aarch64_common_build_start_command }}
if [ -d "{{ item.source_dir | basename }}" ]; then
rm -rf "{{ item.source_dir | basename }}"
fi
tar -xf "{{ item.archive_file | basename }}"
cd "{{ item.source_dir | basename }}"
pwd
{{ item.build_command }}
</command>
</hudson.tasks.Shell>
</builders>
<publishers/>
<buildWrappers/>
</project>
body_format: raw
timeout: 60
loop: "{{ jenkins_jobs.cross_compiling_temporary_tools }}"
ignore_errors: yes
tags:
- aarch64_jobs
- aarch64_cross_compiling_temporary_toolsJobs are configured for AMD64 and AARCH64 system and are defined in terms for build command in a Ansible Vars file. For example:
- name: 0009 - Grep (Cross Compiling Temporary Tools)
version: 3.11
archive_file: /mnt/lfs/sources/grep-3.11.tar.xz
source_dir: /mnt/lfs/sources/grep-3.11
description: |
Grep is a command-line utility for searching plain-text data for lines that match a regular expression. This job builds Grep, which is essential for text searching in the LFS environment.
category:
This job is part of the cross compiling temporary tools setup, specifically for building Grep.
jenkins_job_url: http://localhost:8080/job/cross_compiling_temporary_tools/job/Grep-3.11%20(Cross%20Compiling%20Temporary%20Tools)/
build_command: |
./configure --prefix=/usr \
--host=$LFS_TGT \
--build=$(./build-aux/config.guess)
make
make DESTDIR=$LFS installPrepare to the chroot…
I would say that the most fundamental tool, and the one I use the most during these activities, is the following.
sudo chroot "$LFS" /usr/bin/env -i \
HOME=/root \
TERM="$TERM" \
PS1='(lfs chroot) \u:\w\$ ' \
PATH=/usr/bin:/usr/sbin \
MAKEFLAGS="-j$(nproc)" \
TESTSUITEFLAGS="-j$(nproc)" \
/bin/bash
I place it with Ansible under Jenkins’ home directory...- name: Copy chroot_lfs.sh to /home/jenkins
ansible.builtin.copy:
src: chroot_lfs.sh
dest: /home/jenkins/chroot_lfs.sh
owner: jenkins
group: jenkins
mode: '0755'
It will be very common to have to enter the chroot environment to see what is not working inside the distro we are building.
Execution version-check.sh
Here https://www.linuxfromscratch.org/lfs/view/stable/chapter02/hostreqs.html a bash script is provided to check the versions of the tools present on the initial system. Running it, I see that everything is fine except for an issue related to Bash itself.
root@ubuntu-arm-lfs:~# /tmp/version-check.sh
OK: Coreutils 8.32 >= 8.1
OK: Bash 5.1.16 >= 3.2
OK: Binutils 2.38 >= 2.13.1
OK: Bison 3.8.2 >= 2.7
OK: Diffutils 3.8 >= 2.8.1
OK: Findutils 4.8.0 >= 4.2.31
OK: Gawk 5.1.0 >= 4.0.1
OK: GCC 11.4.0 >= 5.2
OK: GCC (C++) 11.4.0 >= 5.2
OK: Grep 3.7 >= 2.5.1a
OK: Gzip 1.10 >= 1.3.12
OK: M4 1.4.18 >= 1.4.10
OK: Make 4.3 >= 4.0
OK: Patch 2.7.6 >= 2.5.4
OK: Perl 5.34.0 >= 5.8.8
OK: Python 3.10.12 >= 3.4
OK: Sed 4.8 >= 4.1.5
OK: Tar 1.34 >= 1.22
OK: Texinfo 6.8 >= 5.0
OK: Xz 5.2.5 >= 5.0.0
OK: Linux Kernel 6.8.0 >= 5.4
OK: Linux Kernel supports UNIX 98 PTY
Aliases:
OK: awk is GNU
OK: yacc is Bison
ERROR: sh is NOT Bash
Compiler check:
OK: g++ works
OK: nproc reports 4 logical cores are available
To fix the error ERROR: sh is NOT Bash, I just need to force sh to point to bash. Do this only in your LFS machines.
ls -l /usr/bin/sh
ln /usr/bin/bash /usr/bin/sh
This should solve problems like the absence of pushd as a built-in in my bash interpreter.
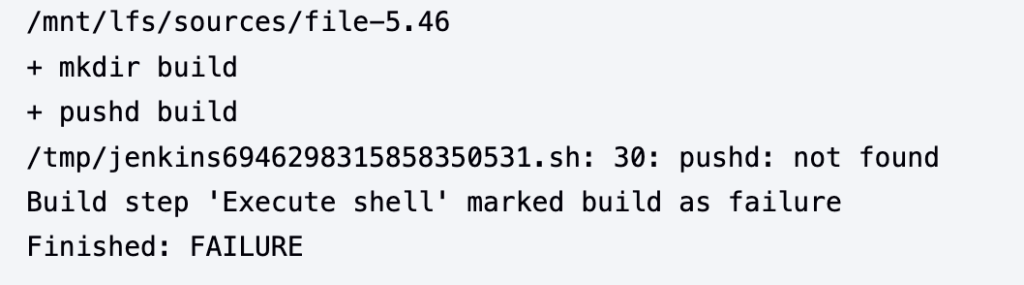
The Server Environment
On the server side, I installed Ansible, Jenkins, Cockpit, and Libvirt.
In Jenkins, I created all the jobs needed to build the projects that are part of the GNU/Linux ecosystem using Ansible. They are defined in the vars of a role that you can find here: https://github.com/lucky-sideburn/Generic-Distro-ToolK1t/blob/main/jenkins-lfs/playbooks/roles/ansible-gdt/vars/main.yml
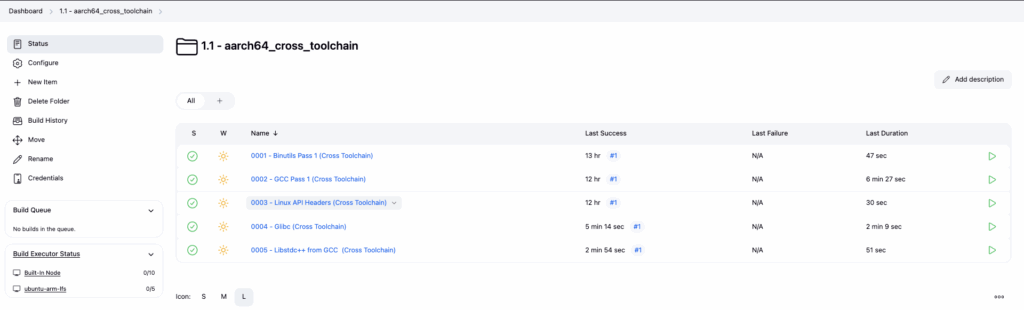
I am very satisfied with a simple bash script that wraps the playbooks to be called with the relevant tags. I use it for any modifications in the Jenkins folder and jobs or test OS image via QEMU.
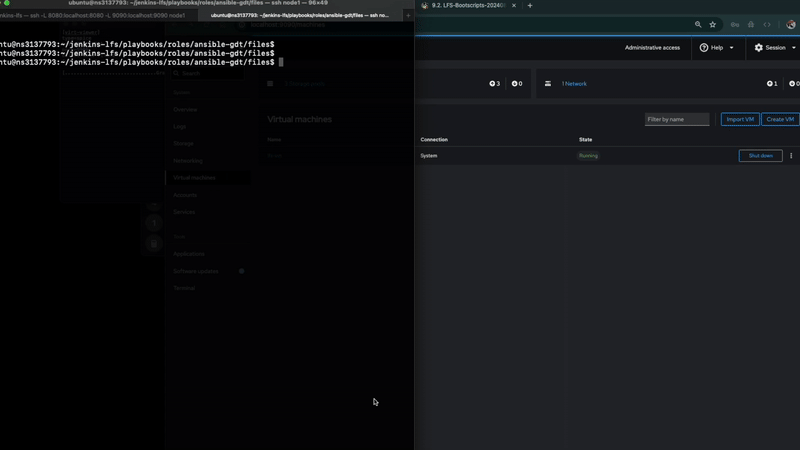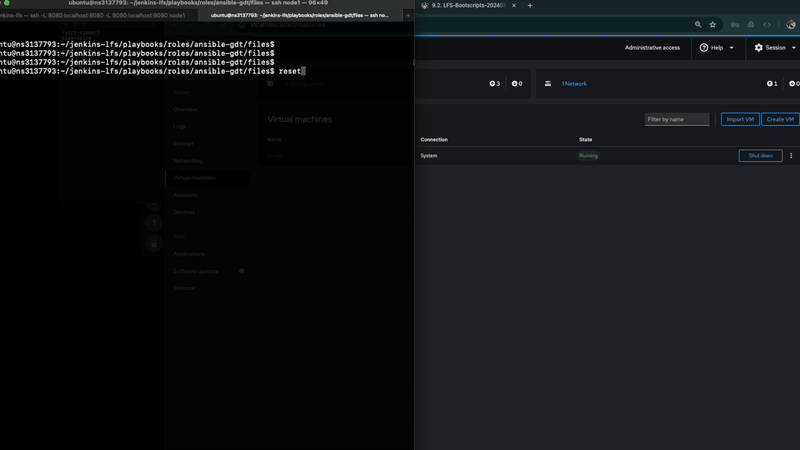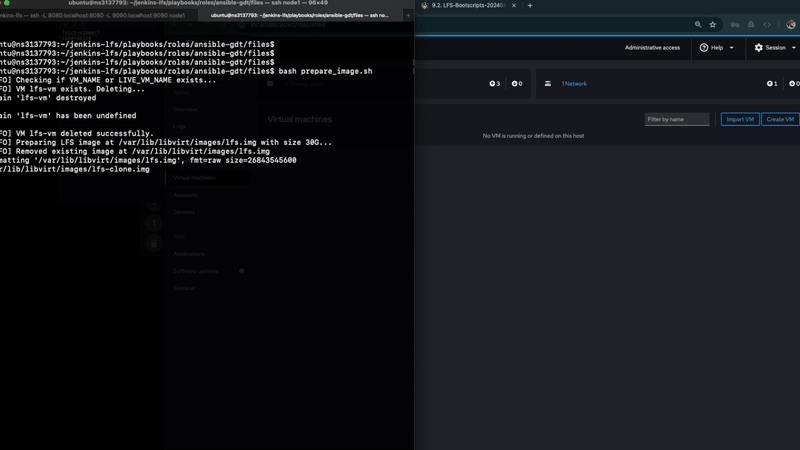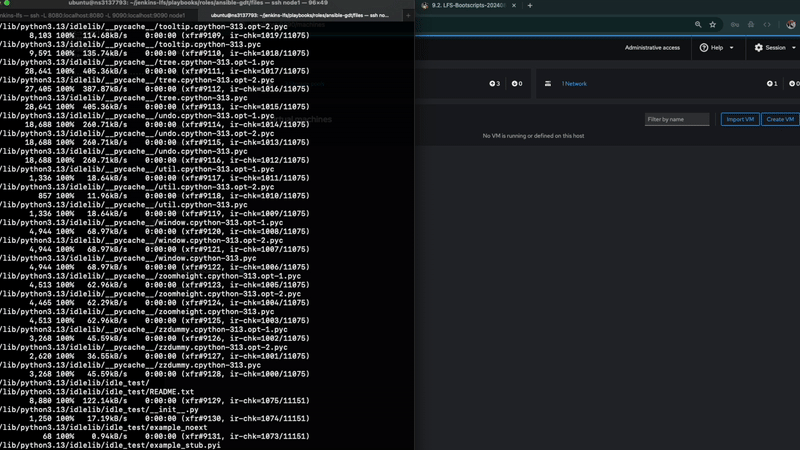
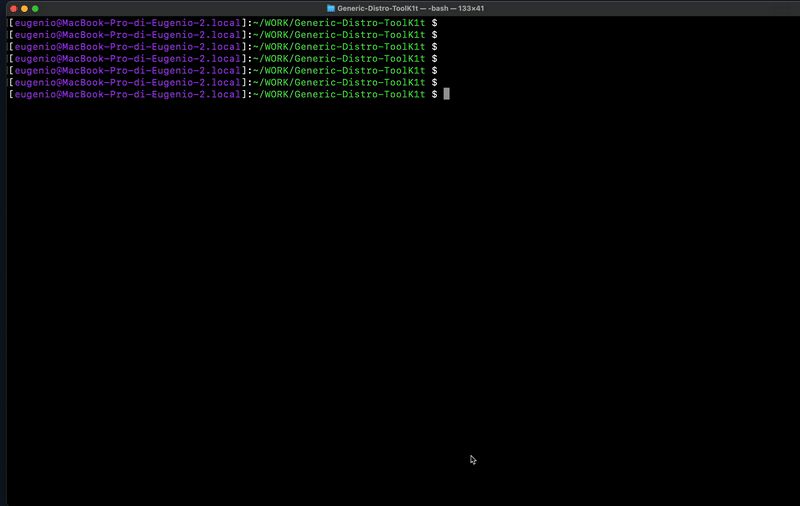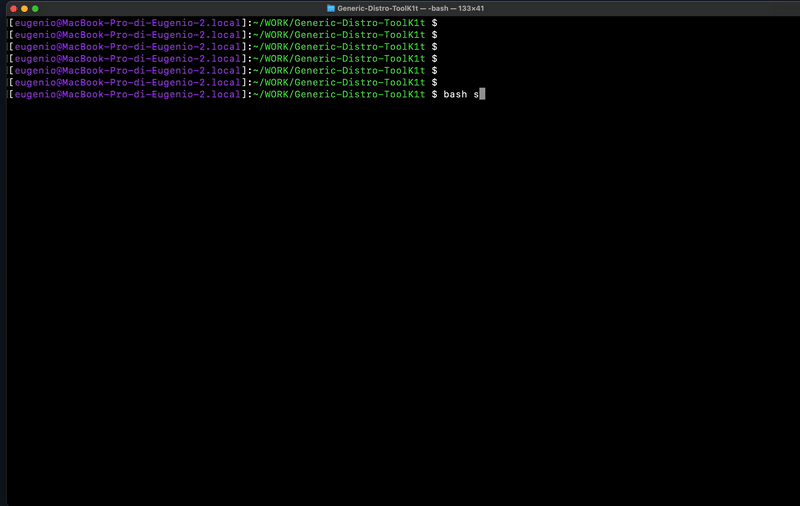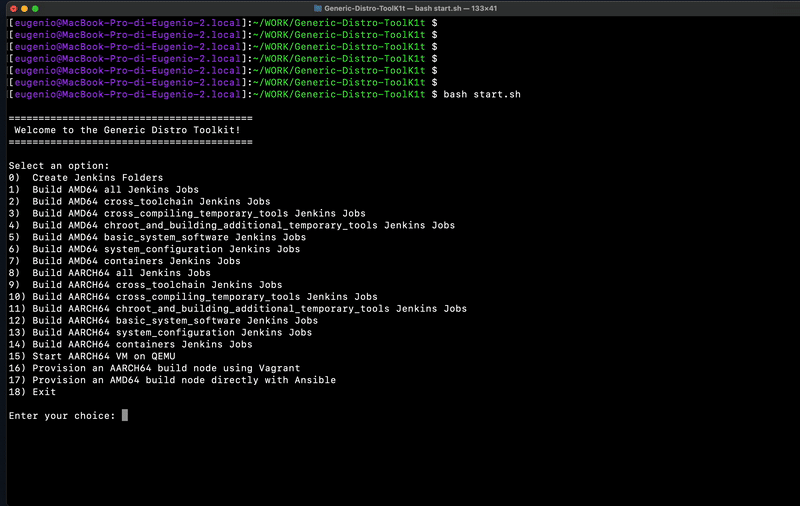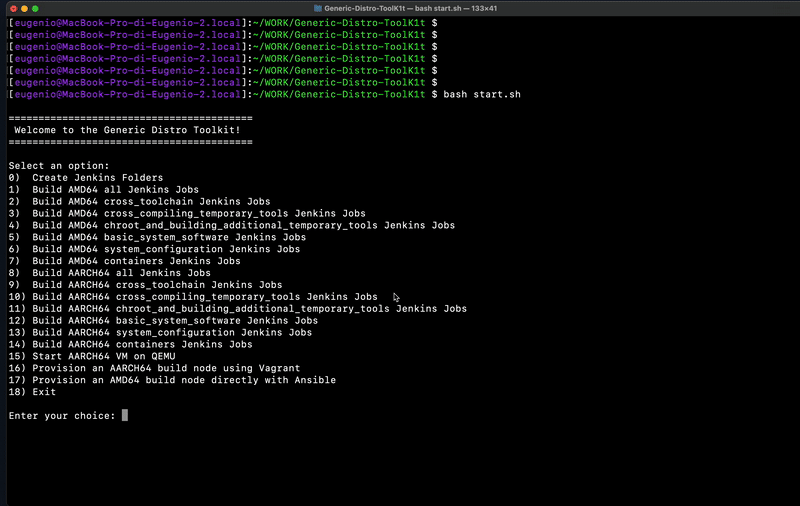
ubuntu@ns3137793:~/gdt$ bash start.sh
=========================================
Welcome to the Generic Distro Toolkit!
=========================================
Select an option:
0) Create Jenkins Folders
1) Build AMD64 all Jenkins Jobs
2) Build AMD64 cross_toolchain Jenkins Jobs
3) Build AMD64 cross_compiling_temporary_tools Jenkins Jobs
4) Build AMD64 chroot_and_building_additional_temporary_tools Jenkins Jobs
5) Build AMD64 basic_system_software Jenkins Jobs
6) Build AMD64 system_configuration Jenkins Jobs
7) Build AMD64 containers Jenkins Jobs
8) Build AARCH64 all Jenkins Jobs
9) Build AARCH64 cross_toolchain Jenkins Jobs
10) Build AARCH64 cross_compiling_temporary_tools Jenkins Jobs
11) Build AARCH64 chroot_and_building_additional_temporary_tools Jenkins Jobs
12) Build AARCH64 basic_system_software Jenkins Jobs
13) Build AARCH64 system_configuration Jenkins Jobs
14) Build AARCH64 containers Jenkins Jobs
15) Start AARCH64 VM on QEMU
16) Exit
Enter your choice:
Enter your choice: 9
Building AARCH64 cross_toolchain Jenkins Jobs...
On Cockpit, I test the newly created VMs from the images built through Jenkins.
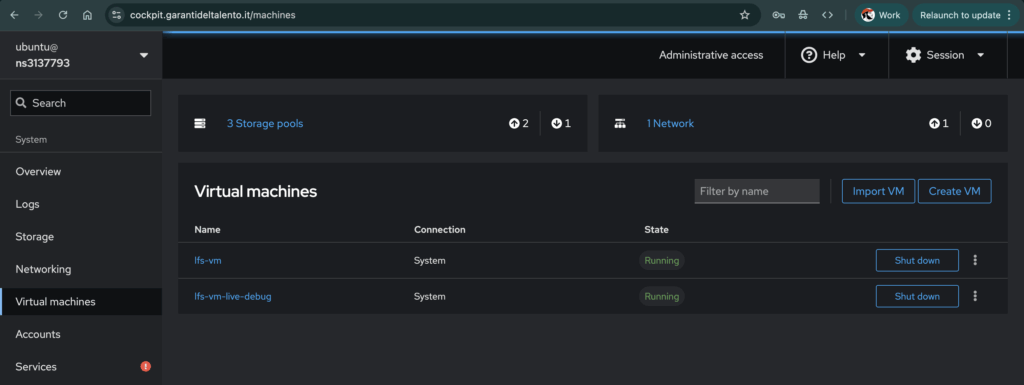
On ARM (my MacBook M3), I don’t have Cockpit and KVM, so I will use QEMU.
The AARCH64 (ARM) build node
I’m using my work Apple MacBook Pro M3, on which I provisioned a VM via Vagrant. As you can see, the node is also a slave of my Jenkins, which I manually labeled as aarch64.
# Vagrantfile for Ubuntu ARM
Vagrant.configure("2") do |config|
config.vm.box = "arm64-boxes/ubuntu-22.04"
config.vm.box_version = "0.2"
config.vm.hostname = "ubuntu-arm-lfs"
config.vm.define "ubuntu-arm-lfs"
config.vm.provider "virtualbox" do |vb|
vb.memory = "12288"
vb.cpus = 4
end
config.vm.provision "ansible" do |ansible|
ansible.playbook = "./jenkins-lfs/playbooks/aarch64_lfs.yml"
ansible.become = true
ansible.extra_vars = {
"jenkins_agent_jar" => "/opt/jenkins/agent/agent.jar",
"jenkins_master_url" => "https://jenkins.garantideltalento.it",
"jenkins_user" => "jenkins",
"jenkins_group" => "jenkins",
"jenkins_agent_workdir" => "/opt/jenkins/workdir",
"jenkins_agent_home" => "/opt/jenkins/home",
"jenkins_agent_name" => "ubuntu-arm-lfs",
"jenkins_agent_secret" => ENV['JENKINS_AGENT_SECRET'],
"lfs_repo_url" => "http://repo.garantideltalento.it",
}
end
config.vm.network "private_network", type: "dhcp"
endI created a dedicated Ansible playbook to provision the node. It does very simple tasks and you can find it here: https://github.com/lucky-sideburn/Generic-Distro-ToolK1t/blob/main/jenkins-lfs/playbooks/roles/ansible-gdt/tasks/aarch64_lfs.yml
Basically, the tasks are very simple:
[[email protected]]:~/WORK/Generic-Distro-ToolK1t $ vagrant provision
==> ubuntu-arm-lfs: Running provisioner: ansible...
ubuntu-arm-lfs: Running ansible-playbook...
PLAY [Print node name] *********************************************************
TASK [Gathering Facts] *********************************************************
ok: [ubuntu-arm-lfs]
TASK [Display the node name] ***************************************************
ok: [ubuntu-arm-lfs]
TASK [Start arm_node.yml task of ansible-gdt role] *****************************
TASK [ansible-gdt : Show machine architecture] *********************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Ensure user 'jenkins' exists] ******************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create Jenkins Workdir] ************************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create Jenkins Agent Home] *********************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create Jenkins Agent Workdir] ******************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Update apt cache] ******************************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Install Java] **********************************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Copy agent.jar to Jenkins home] ****************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create SystemD unit for start Jenkins agent] ***************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Start and enable Jenkins agent service] ********************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create /mnt/lfs directory] *********************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Set LFS environment variable] ******************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Set LFS environment variable for jenkins] ******************
changed: [ubuntu-arm-lfs]
TASK [ansible-gdt : Set LFS environment variable for root] *********************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create /mnt/lfs/sources directory] *************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create directories under $LFS] *****************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create symbolic links for bin, lib, and sbin] **************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create lib directory for ARM architecture] *****************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create $LFS/tools directory] *******************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create 'lfs' group] ****************************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Create 'lfs' user] *****************************************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Change ownership of lib for aarch64 architecture] **********
changed: [ubuntu-arm-lfs]
TASK [ansible-gdt : Configure environment variables for LFS] *******************
ok: [ubuntu-arm-lfs]
TASK [ansible-gdt : Configure environment variables for Jenkins] ***************
changed: [ubuntu-arm-lfs]
TASK [ansible-gdt : Install additional packages] *******************************
After I prepared the build node and joined it to my Jenkins server as an executor, it is time to create all Jenkins jobs via Ansible, and then run them in the specific order, following the numbered names.
Cross Tool Chain
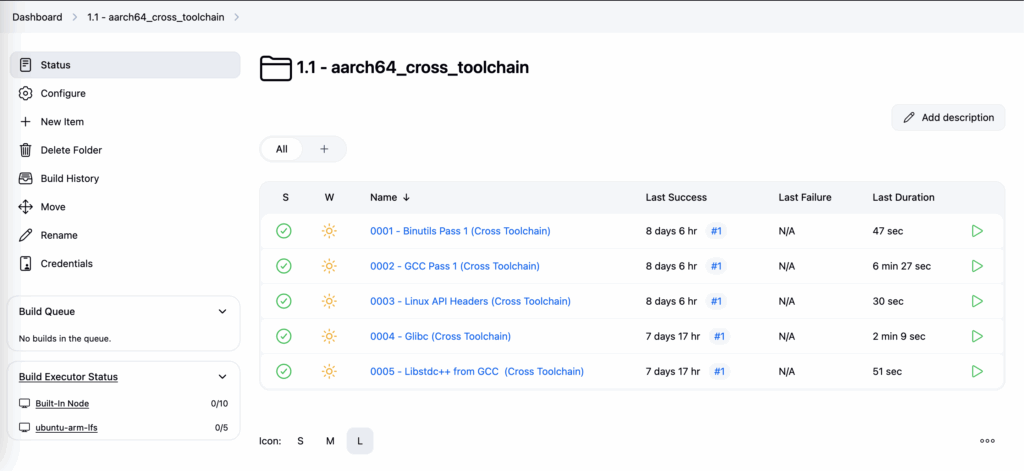
aarch64_cross_toolchain - amd64_cross_toolchain
└─0001 - Binutils Pass 1 (Cross Toolchain)
└─0002 - GCC Pass 1 (Cross Toolchain)
└─0003 - Linux API Headers (Cross Toolchain)
└─0004 - Glibc (Cross Toolchain)
└─0005 - Libstdc++ from GCC (Cross Toolchain)Cross Compiling Temporary Tools
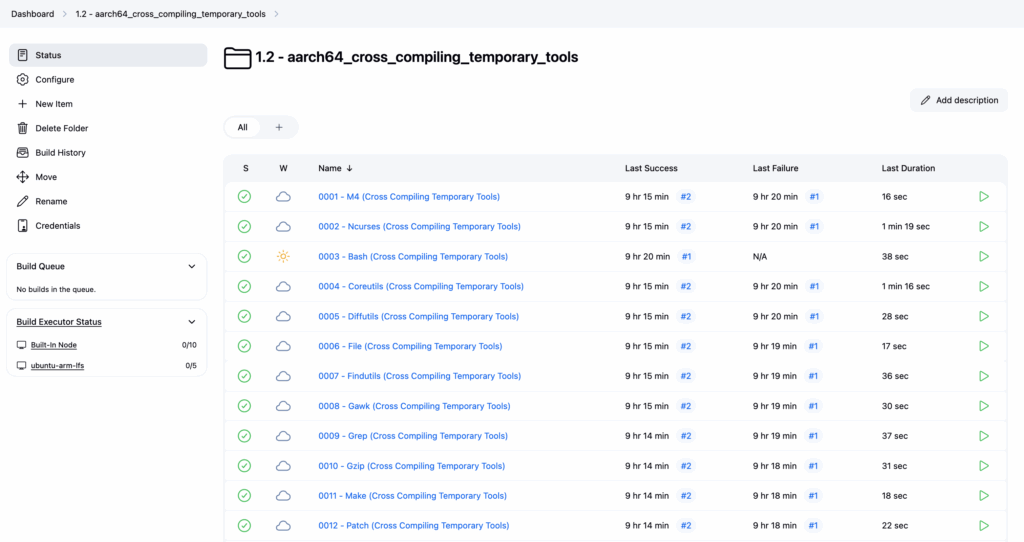

aarch64_cross_compiling_temporary_tools - amd64_cross_compiling_temporary_tools
└─0001 - M4 (Cross Compiling Temporary Tools)
└─0002 - Ncurses (Cross Compiling Temporary Tools)
└─0003 - Bash (Cross Compiling Temporary Tools)
└─0004 - Coreutils (Cross Compiling Temporary Tools)
└─0005 - Diffutils (Cross Compiling Temporary Tools)
└─0006 - File (Cross Compiling Temporary Tools)
└─0007 - Findutils (Cross Compiling Temporary Tools)
└─0008 - Gawk (Cross Compiling Temporary Tools)
└─0009 - Grep (Cross Compiling Temporary Tools)
└─0010 - Gzip (Cross Compiling Temporary Tools)
└─0011 - Make (Cross Compiling Temporary Tools)
└─0012 - Patch (Cross Compiling Temporary Tools)
└─0013 - Sed (Cross Compiling Temporary Tools)
└─0014 - Tar (Cross Compiling Temporary Tools)
└─0015 - Xz (Cross Compiling Temporary Tools)
└─0016 - Binutils (Cross Compiling Temporary Tools)
└─0017 - GCC Pass 2 (Cross Compiling Temporary Tools)
Entering Chroot and Building Additional Temporary Tools
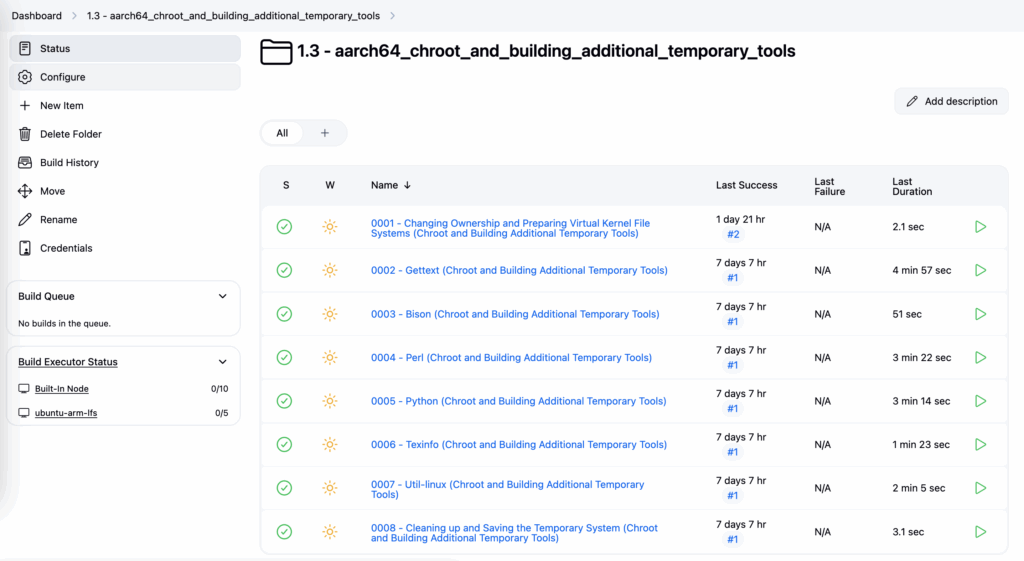
aarch64_chroot_and_building_additional_temporary_tools - amd64_chroot_and_building_additional_temporary_tools
└─0001 - Changing Ownership and Preparing Virtual Kernel File Systems (Chroot and Building Additional Temporary Tools)
└─0002 - Gettext (Chroot and Building Additional Temporary Tools)
└─0003 - Bison (Chroot and Building Additional Temporary Tools)
└─0004 - Perl (Chroot and Building Additional Temporary Tools)
└─0005 - Python (Chroot and Building Additional Temporary Tools)
└─0006 - Texinfo (Chroot and Building Additional Temporary Tools)
└─0007 - Util-linux (Chroot and Building Additional Temporary Tools)
└─0008 - Cleaning up and Saving the Temporary System (Chroot and Building Additional Temporary Tools)Installing Basic System Software
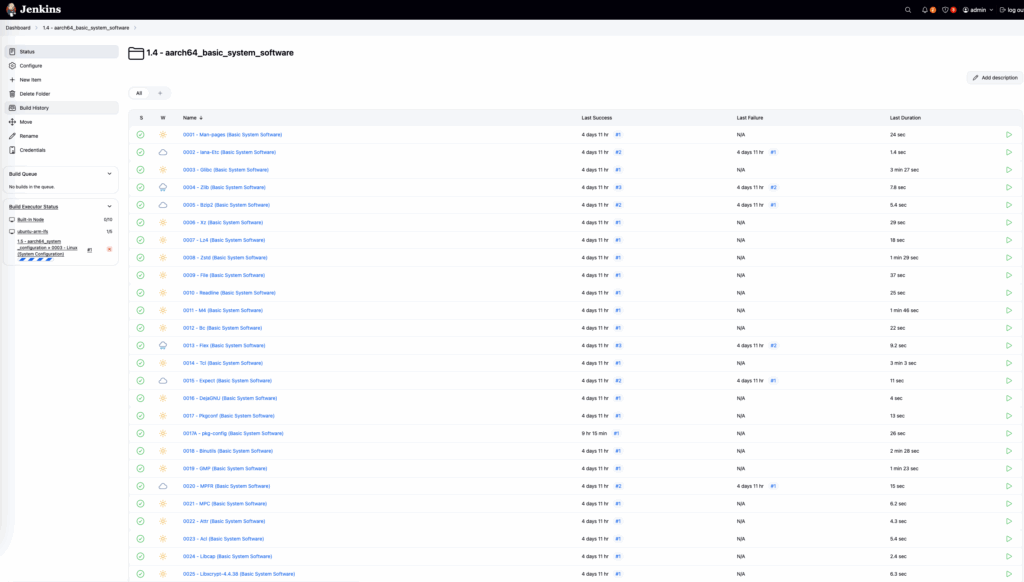
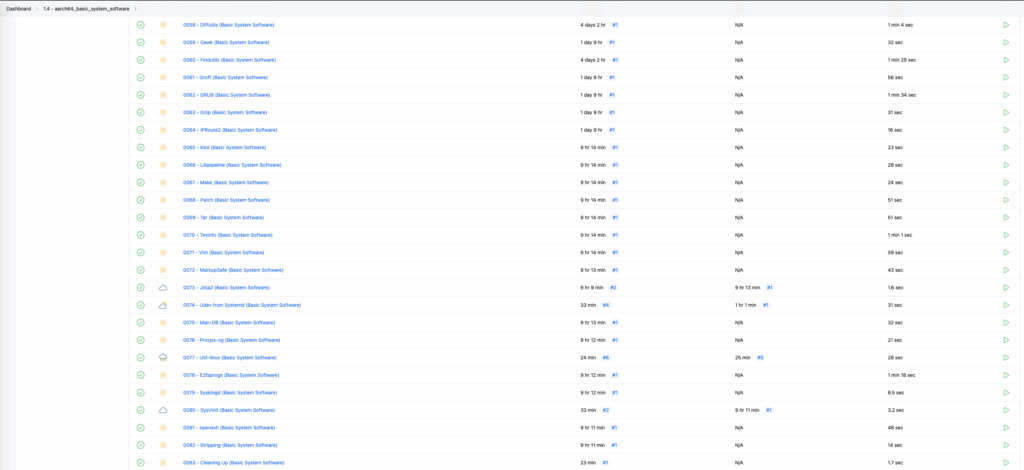
aarch64_basic_system_software - amd64_basic_system_software
└─0001 - Man-pages (Basic System Software)
└─0002 - Iana-Etc (Basic System Software)
└─0003 - Glibc (Basic System Software)
└─0004 - Zlib (Basic System Software)
└─0005 - Bzip2 (Basic System Software)
└─0006 - Xz (Basic System Software)
└─0007 - Lz4 (Basic System Software)
└─0008 - Zstd (Basic System Software)
└─0009 - File (Basic System Software)
└─0010 - Readline (Basic System Software)
└─0011 - M4 (Basic System Software)
└─0012 - Bc (Basic System Software)
└─0013 - Flex (Basic System Software)
└─0014 - Tcl (Basic System Software)
└─0015 - Expect (Basic System Software)
└─0016 - DejaGNU (Basic System Software)
└─0017 - Pkgconf (Basic System Software)
└─0017A - pkg-config (Basic System Software)
└─0018 - Binutils (Basic System Software)
└─0019 - GMP (Basic System Software)
└─0020 - MPFR (Basic System Software)
└─0021 - MPC (Basic System Software)
└─0022 - Attr (Basic System Software)
└─0023 - Acl (Basic System Software)
└─0024 - Libcap (Basic System Software)
└─0025 - Libxcrypt-4.4.38 (Basic System Software)
└─0026 - Shadow (Basic System Software)
└─0027 - GCC (Basic System Software)
└─0028 - Ncurses (Basic System Software)
└─0029 - Sed (Basic System Software)
└─0030 - Psmisc (Basic System Software)
└─0031 - Gettext (Basic System Software)
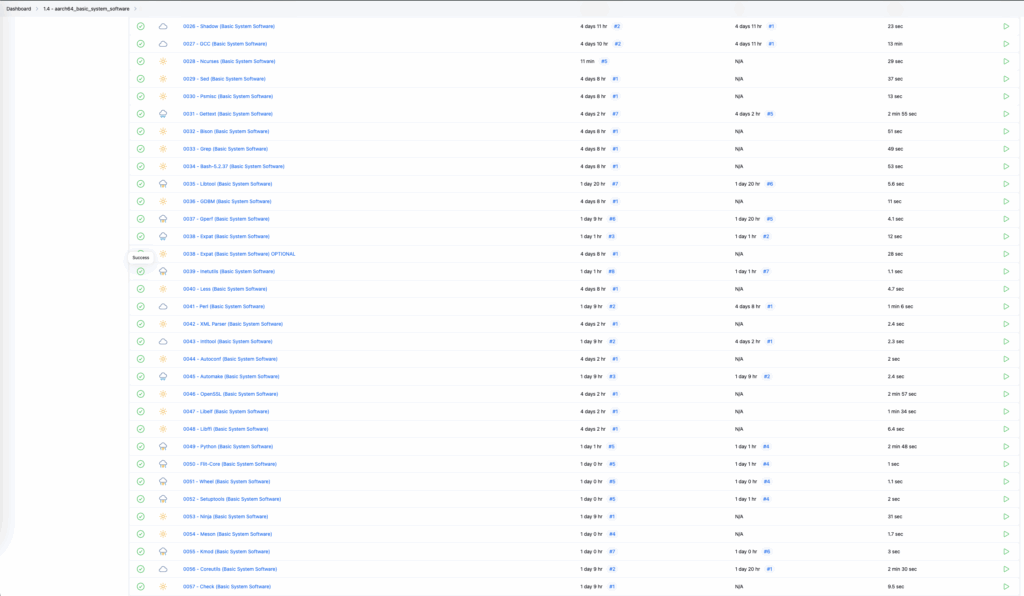
└─0032 - Bison (Basic System Software)
└─0033 - Grep (Basic System Software)
└─0034 - Bash-5.2.37 (Basic System Software)
└─0035 - Libtool (Basic System Software)
└─0036 - GDBM (Basic System Software)
└─0037 - Gperf (Basic System Software)
└─0038 - Expat (Basic System Software)
└─0039 - Inetutils (Basic System Software)
└─0040 - Less (Basic System Software)
└─0041 - Perl (Basic System Software)
└─0042 - XML Parser (Basic System Software)
└─0043 - Intltool (Basic System Software)
└─0044 - Autoconf (Basic System Software)
└─0045 - Automake (Basic System Software)
└─0046 - OpenSSL (Basic System Software)
└─0047 - Libelf (Basic System Software)
└─0048 - Libffi (Basic System Software)
└─0049 - Python (Basic System Software)
└─0050 - Flit-Core (Basic System Software)
└─0051 - Wheel (Basic System Software)
└─0052 - Setuptools (Basic System Software)
└─0053 - Ninja (Basic System Software)
└─0054 - Meson (Basic System Software)
└─0055 - Kmod (Basic System Software)
└─0056 - Coreutils (Basic System Software)
└─0057 - Check (Basic System Software)
└─0058 - Diffutils (Basic System Software)
└─0059 - Gawk (Basic System Software)
└─0060 - Findutils (Basic System Software)
└─0061 - Groff (Basic System Software)
└─0062 - GRUB (Basic System Software)
└─0063 - Gzip (Basic System Software)
└─0064 - IPRoute2 (Basic System Software)
└─0065 - Kbd (Basic System Software)
└─0066 - Libpipeline (Basic System Software)
└─0067 - Make (Basic System Software)
└─0068 - Patch (Basic System Software)
└─0069 - Tar (Basic System Software)
└─0070 - Texinfo (Basic System Software)
└─0071 - Vim (Basic System Software)
└─0072 - MarkupSafe (Basic System Software)
└─0073 - Jinja2 (Basic System Software)
└─0074 - Udev from Systemd (Basic System Software)
└─0075 - Man-DB (Basic System Software)
└─0076 - Procps-ng (Basic System Software)
└─0077 - Util-linux (Basic System Software)
└─0078 - E2fsprogs (Basic System Software)
└─0079 - Sysklogd (Basic System Software)
└─0080 - SysVinit (Basic System Software)
└─0081 - openssh (Basic System Software)
└─0082 - Stripping (Basic System Software)
└─0083 - Cleaning Up (Basic System Software)System Configuration
This set of Jenkins jobs automates the complete system configuration and image preparation process. It includes setting up LFS and optional BLFS boot scripts, configuring the core Linux system components, and creating a ready-to-use system image. Together, these jobs ensure a fully configured, functional, and deployable operating system.
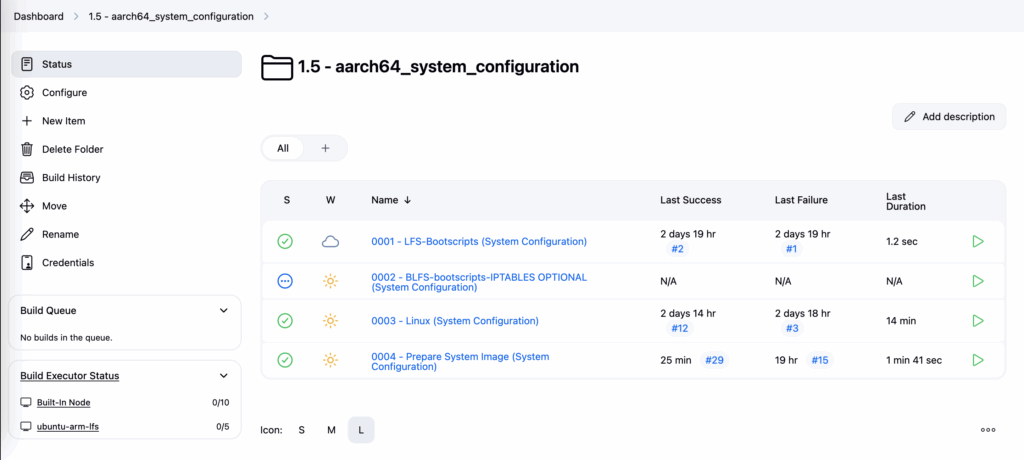
Run OS via qemu-system-aarch64
For troubleshooting my operating system (in case of a broken boot, filesystem, or configuration problem), I used the following strategy:
During the image preparation, I create lfs.img as well as lfs-clone.img, which is a clone, as suggested by the name. I run an Alpine Linux live instance to mount the image of the OS that I built.
qemu-system-aarch64 \
-M virt \
-cpu host \
-accel hvf \
-smp 2 \
-m 2048 \
-drive file=$OS_IMAGE_BASE_DIR/alpine.iso,if=virtio,media=cdrom \
-drive file=$OS_IMAGE_BASE_DIR/lfs-clone.qcow2,if=virtio,format=qcow2 \
-netdev user,id=net0,hostfwd=tcp::2222-:22 \
-device virtio-net-device,netdev=net0 \
-device virtio-gpu-pci \
-device usb-ehci \
-device usb-kbd \
-display cocoa \
-bios /opt/homebrew/Cellar/qemu/10.0.3/share/qemu/edk2-aarch64-code.fd \
-serial mon:stdio \
-boot dThis permits me to mount the disk and check if everything is fine
Welcome to Alpine Linux 3.22
Kernel 6.12.38-0-lts on aarch64 (/dev/ttyAMA0)
localhost login: root
Welcome to Alpine!
The Alpine Wiki contains a large amount of how-to guides and general
information about administrating Alpine systems.
See <https://wiki.alpinelinux.org/>.
You can setup the system with the command: setup-alpine
You may change this message by editing /etc/motd.
localhost:~# mount /dev/vdb
vdb vdb1 vdb2
localhost:~# mount /dev/vdb2 /mnt/
localhost:~# ls /mnt/
bin home mnt right srv var
boot lib opt root sys
dev lost+found posix run tmp
etc media proc sbin usr
localhost:~#
After checking everything, I can start my image
# echo "Starting the AARCH64 VM with the LFS image..."
qemu-system-aarch64 \
-M virt \
-cpu host \
-accel hvf \
-smp 2 \
-m 2048 \
-drive file=$OS_IMAGE_BASE_DIR/lfs.qcow2,if=virtio,format=qcow2 \
-netdev user,id=net0,hostfwd=tcp::2222-:22 \
-device virtio-net-device,netdev=net0 \
-device virtio-gpu-pci \
-device usb-ehci \
-device usb-kbd \
-display cocoa \
-bios /opt/homebrew/Cellar/qemu/10.0.3/share/qemu/edk2-aarch64-code.fd \
-serial mon:stdio \
-boot c
EFI stub: Booting Linux Kernel...
EFI stub: EFI_RNG_PROTOCOL unavailable
EFI stub: Generating empty DTB
EFI stub: Exiting boot services...
[ 0.000000] Booting Linux on physical CPU 0x0000000000 [0x610f0000]
[ 0.000000] Linux version 6.13.4 (root@ubuntu-arm-lfs) (gcc (GCC) 14.2.0, GNU ld (GNU Binutils) 2.44) #1 SMP PREEMPT Fri Aug 15 21:55:14 UTC 2025
[ 0.000000] KASLR disabled due to lack of seed
[ 0.000000] efi: EFI v2.7 by EDK II
[ 0.000000] efi: SMBIOS 3.0=0xbfed0000 MEMATTR=0xbef84018 ACPI 2.0=0xbcb43018 MEMRESERVE=0xbc696e98
[ 0.000000] ACPI: Early table checksum verification disabled
[ 0.000000] ACPI: RSDP 0x00000000BCB43018 000024 (v02 BOCHS )
[ 0.000000] ACPI: XSDT 0x00000000BCB43F18 00006C (v01 BOCHS BXPC 00000001 01000013)
[ 0.000000] ACPI: FACP 0x00000000BCB43B18 000114 (v06 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: DSDT 0x00000000BCB41018 001468 (v02 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: APIC 0x00000000BCB43C98 0000FC (v04 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: PPTT 0x00000000BCB43E18 000060 (v02 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: GTDT 0x00000000BCB43098 000068 (v03 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: MCFG 0x00000000BCB43A98 00003C (v01 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: SPCR 0x00000000BCB43818 000050 (v02 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: DBG2 0x00000000BCB43A18 000057 (v00 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: IORT 0x00000000BCB43898 000080 (v03 BOCHS BXPC 00000001 BXPC 00000001)
[ 0.000000] ACPI: BGRT 0x00000000BCB43998 000038 (v01 INTEL EDK2 00000002 01000013)
[ 0.000000] ACPI: SPCR: console: pl011,mmio32,0x9000000,9600
[ 0.000000] ACPI: Use ACPI SPCR as default console: Yes
[ 0.000000] NUMA: Faking a node at [mem 0x0000000040000000-0x00000000bfffffff]
[ 0.000000] NODE_DATA(0) allocated [mem 0xbfa589c0-0xbfa5afff]
[ 0.000000] Zone ranges:
[ 0.000000] DMA [mem 0x0000000040000000-0x00000000bfffffff]
[ 0.000000] DMA32 empty
[ 0.000000] Normal empty
[ 0.000000] Movable zone start for each node
[ 0.000000] Early memory node ranges
[ 0.000000] node 0: [mem 0x0000000040000000-0x00000000bc55ffff]
[ 0.000000] node 0: [mem 0x00000000bc560000-0x00000000bc56ffff]
[ 0.000000] node 0: [mem 0x00000000bc570000-0x00000000bc67ffff]
[ 0.000000] node 0: [mem 0x00000000bc680000-0x00000000bc68ffff]
[ 0.000000] node 0: [mem 0x00000000bc690000-0x00000000bc76ffff]
[ 0.000000] node 0: [mem 0x00000000bc770000-0x00000000bcb3ffff]
[ 0.000000] node 0: [mem 0x00000000bcb40000-0x00000000bfe1ffff]
[ 0.000000] node 0: [mem 0x00000000bfe20000-0x00000000bfeaffff]
[ 0.000000] node 0: [mem 0x00000000bfeb0000-0x00000000bfebffff]
[ 0.000000] node 0: [mem 0x00000000bfec0000-0x00000000bffdffff]
[ 0.000000] node 0: [mem 0x00000000bffe0000-0x00000000bfffffff]
[ 0.000000] Initmem setup node 0 [mem 0x0000000040000000-0x00000000bfffffff]
[ 0.000000] cma: Reserved 32 MiB at 0x00000000ba400000 on node -1
[ 0.000000] psci: probing for conduit method from ACPI.
[ 0.000000] psci: PSCIv1.1 detected in firmware.
[ 0.000000] psci: Using standard PSCI v0.2 function IDs
[ 0.000000] psci: Trusted OS migration not required
[ 0.000000] psci: SMC Calling Convention v1.0
[ 0.000000] percpu: Embedded 23 pages/cpu s54552 r8192 d31464 u94208
[ 0.000000] pcpu-alloc: s54552 r8192 d31464 u94208 alloc=23*4096
[ 0.000000] pcpu-alloc: [0] 0 [0] 1
[ 0.000000] Detected PIPT I-cache on CPU0
[ 0.000000] CPU features: detected: Spectre-v4
[ 0.000000] alternatives: applying boot alternatives
[ 0.000000] Kernel command line: BOOT_IMAGE=/vmlinuz-6.13.4-lfs-12.3 root=/dev/vda2 ro console=ttyAMA0 nomodeset debug earlyprintk=efi,keep
[ 0.000000] Booted with the nomodeset parameter. Only the system framebuffer will be available
[ 0.000000] Unknown kernel command line parameters "BOOT_IMAGE=/vmlinuz-6.13.4-lfs-12.3 earlyprintk=efi,keep", will be passed to user space.
[ 0.000000] printk: log buffer data + meta data: 131072 + 458752 = 589824 bytes
[ 0.000000] Dentry cache hash table entries: 262144 (order: 9, 2097152 bytes, linear)
[ 0.000000] Inode-cache hash table entries: 131072 (order: 8, 1048576 bytes, linear)
[ 0.000000] Fallback order for Node 0: 0
[ 0.000000] Built 1 zonelists, mobility grouping on. Total pages: 524288
[ 0.000000] Policy zone: DMA
[ 0.000000] mem auto-init: stack:all(zero), heap alloc:off, heap free:off
[ 0.000000] software IO TLB: SWIOTLB bounce buffer size adjusted to 2MB
[ 0.000000] software IO TLB: area num 2.
[ 0.000000] software IO TLB: mapped [mem 0x00000000bf514000-0x00000000bf714000] (2MB)
[ 0.000000] SLUB: HWalign=64, Order=0-3, MinObjects=0, CPUs=2, Nodes=1
[ 0.000000] rcu: Preemptible hierarchical RCU implementation.
[ 0.000000] rcu: RCU event tracing is enabled.
[ 0.000000] rcu: RCU restricting CPUs from NR_CPUS=512 to nr_cpu_ids=2.
[ 0.000000] Trampoline variant of Tasks RCU enabled.
[ 0.000000] Tracing variant of Tasks RCU enabled.
[ 0.000000] rcu: RCU calculated value of scheduler-enlistment delay is 25 jiffies.
[ 0.000000] rcu: Adjusting geometry for rcu_fanout_leaf=16, nr_cpu_ids=2
[ 0.000000] RCU Tasks: Setting shift to 1 and lim to 1 rcu_task_cb_adjust=1 rcu_task_cpu_ids=2.
[ 0.000000] RCU Tasks Trace: Setting shift to 1 and lim to 1 rcu_task_cb_adjust=1 rcu_task_cpu_ids=2.
[ 0.000000] NR_IRQS: 64, nr_irqs: 64, preallocated irqs: 0
[ 0.000000] Root IRQ handler: gic_handle_irq
[ 0.000000] GICv2m: ACPI overriding V2M MSI_TYPER (base:80, num:64)
[ 0.000000] GICv2m: range[mem 0x08020000-0x08020fff], SPI[80:143]
[ 0.000000] rcu: srcu_init: Setting srcu_struct sizes based on contention.
[ 0.000000] arch_timer: cp15 timer(s) running at 24.00MHz (virt).
[ 0.000000] clocksource: arch_sys_counter: mask: 0xffffffffffffff max_cycles: 0x588fe9dc0, max_idle_ns: 440795202592 ns
[ 0.000000] sched_clock: 56 bits at 24MHz, resolution 41ns, wraps every 4398046511097ns
[ 0.000029] Console: colour dummy device 80x25
[ 0.000038] ACPI: Core revision 20240827
[ 0.000057] Calibrating delay loop (skipped), value calculated using timer frequency.. 48.00 BogoMIPS (lpj=96000)
[ 0.000058] pid_max: default: 32768 minimum: 301
[ 0.000065] LSM: initializing lsm=capability
[ 0.000093] Mount-cache hash table entries: 4096 (order: 3, 32768 bytes, linear)
[ 0.000099] Mountpoint-cache hash table entries: 4096 (order: 3, 32768 bytes, linear)
[ 0.029540] rcu: Hierarchical SRCU implementation.
[ 0.029541] rcu: Max phase no-delay instances is 1000.
[ 0.029584] Timer migration: 1 hierarchy levels; 8 children per group; 1 crossnode level
[ 0.029620] Remapping and enabling EFI services.
[ 0.029700] smp: Bringing up secondary CPUs ...
[ 0.029913] Detected PIPT I-cache on CPU1
[ 0.029968] CPU1: Booted secondary processor 0x0000000001 [0x610f0000]
[ 0.030048] smp: Brought up 1 node, 2 CPUs
[ 0.030049] SMP: Total of 2 processors activated.
[ 0.030050] CPU: All CPU(s) started at EL1
[ 0.030050] CPU features: detected: ARMv8.4 Translation Table Level
[ 0.030051] CPU features: detected: Data cache clean to the PoU not required for I/D coherence
[ 0.030052] CPU features: detected: Common not Private translations
[ 0.030052] CPU features: detected: CRC32 instructions
[ 0.030052] CPU features: detected: Data independent timing control (DIT)
[ 0.030052] CPU features: detected: E0PD
[ 0.030053] CPU features: detected: Enhanced Privileged Access Never
[ 0.030053] CPU features: detected: RCpc load-acquire (LDAPR)
[ 0.030053] CPU features: detected: LSE atomic instructions
[ 0.030054] CPU features: detected: Privileged Access Never
[ 0.030054] CPU features: detected: RAS Extension Support
[ 0.030054] CPU features: detected: Speculation barrier (SB)
[ 0.030054] CPU features: detected: TLB range maintenance instructions
[ 0.030088] alternatives: applying system-wide alternatives
[ 0.030265] Memory: 1975484K/2097152K available (16832K kernel code, 4874K rwdata, 11828K rodata, 2816K init, 738K bss, 85280K reserved, 32768K cma-reserved)
[ 0.030435] devtmpfs: initialized
[ 0.030636] clocksource: jiffies: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 7645041785100000 ns
[ 0.030637] futex hash table entries: 512 (order: 3, 32768 bytes, linear)
[ 0.030689] 23440 pages in range for non-PLT usage
[ 0.030690] 514960 pages in range for PLT usage
[ 0.030702] pinctrl core: initialized pinctrl subsystem
[ 0.030868] SMBIOS 3.0.0 present.
[ 0.030870] DMI: QEMU QEMU Virtual Machine, BIOS edk2-stable202408-prebuilt.qemu.org 08/13/2024
[ 0.030872] DMI: Memory slots populated: 1/1
[ 0.031591] NET: Registered PF_NETLINK/PF_ROUTE protocol family
[ 0.031717] DMA: preallocated 256 KiB GFP_KERNEL pool for atomic allocations
[ 0.031768] DMA: preallocated 256 KiB GFP_KERNEL|GFP_DMA pool for atomic allocations
[ 0.031841] DMA: preallocated 256 KiB GFP_KERNEL|GFP_DMA32 pool for atomic allocations
[ 0.031846] audit: initializing netlink subsys (disabled)
[ 0.031914] audit: type=2000 audit(0.000:1): state=initialized audit_enabled=0 res=1
[ 0.031980] thermal_sys: Registered thermal governor 'step_wise'
[ 0.031980] thermal_sys: Registered thermal governor 'power_allocator'
[ 0.031986] cpuidle: using governor menu
[ 0.032002] hw-breakpoint: found 6 breakpoint and 4 watchpoint registers.
[ 0.032042] ASID allocator initialised with 256 entries
[ 0.032185] acpiphp: ACPI Hot Plug PCI Controller Driver version: 0.5
[ 0.032226] Serial: AMBA PL011 UART driver
[ 0.032401] HugeTLB: registered 1.00 GiB page size, pre-allocated 0 pages
[ 0.032402] HugeTLB: 0 KiB vmemmap can be freed for a 1.00 GiB page
[ 0.032402] HugeTLB: registered 32.0 MiB page size, pre-allocated 0 pages
[ 0.032402] HugeTLB: 0 KiB vmemmap can be freed for a 32.0 MiB page
[ 0.032403] HugeTLB: registered 2.00 MiB page size, pre-allocated 0 pages
[ 0.032403] HugeTLB: 0 KiB vmemmap can be freed for a 2.00 MiB page
[ 0.032403] HugeTLB: registered 64.0 KiB page size, pre-allocated 0 pages
[ 0.032403] HugeTLB: 0 KiB vmemmap can be freed for a 64.0 KiB page
[ 0.032691] ACPI: Added _OSI(Module Device)
[ 0.032691] ACPI: Added _OSI(Processor Device)
[ 0.032692] ACPI: Added _OSI(3.0 _SCP Extensions)
[ 0.032692] ACPI: Added _OSI(Processor Aggregator Device)
[ 0.032883] ACPI: 1 ACPI AML tables successfully acquired and loaded
[ 0.032925] ACPI: Interpreter enabled
[ 0.032925] ACPI: Using GIC for interrupt routing
[ 0.032928] ACPI: MCFG table detected, 1 entries
[ 0.033347] ACPI: CPU0 has been hot-added
[ 0.033356] ACPI: CPU1 has been hot-added
[ 0.033401] ARMH0011:00: ttyAMA0 at MMIO 0x9000000 (irq = 12, base_baud = 0) is a SBSA
[ 0.033403] printk: legacy console [ttyAMA0] enabled
[ 0.058298] ACPI: PCI: Interrupt link L000 configured for IRQ 35
[ 0.058461] ACPI: PCI: Interrupt link L001 configured for IRQ 36
[ 0.058610] ACPI: PCI: Interrupt link L002 configured for IRQ 37
[ 0.058757] ACPI: PCI: Interrupt link L003 configured for IRQ 38
[ 0.058907] ACPI: PCI Root Bridge [PCI0] (domain 0000 [bus 00-ff])
[ 0.059063] acpi PNP0A08:00: _OSC: OS supports [ExtendedConfig ASPM ClockPM Segments MSI HPX-Type3]
[ 0.059298] acpi PNP0A08:00: _OSC: platform does not support [LTR]
[ 0.059467] acpi PNP0A08:00: _OSC: OS now controls [PME AER PCIeCapability]
[ 0.059688] acpi PNP0A08:00: ECAM area [mem 0x4010000000-0x401fffffff] reserved by PNP0C02:00
[ 0.059903] acpi PNP0A08:00: ECAM at [mem 0x4010000000-0x401fffffff] for [bus 00-ff]
[ 0.060094] ACPI: Remapped I/O 0x000000003eff0000 to [io 0x0000-0xffff window]
[ 0.060291] PCI host bridge to bus 0000:00
[ 0.060396] pci_bus 0000:00: root bus resource [mem 0x10000000-0x3efeffff window]
[ 0.060576] pci_bus 0000:00: root bus resource [io 0x0000-0xffff window]
[ 0.060746] pci_bus 0000:00: root bus resource [mem 0x8000000000-0xffffffffff window]
[ 0.060938] pci_bus 0000:00: root bus resource [bus 00-ff]
[ 0.061091] pci 0000:00:00.0: [1b36:0008] type 00 class 0x060000 conventional PCI endpoint
[ 0.061367] pci 0000:00:01.0: [1af4:1050] type 00 class 0x038000 conventional PCI endpoint
[ 0.062027] pci 0000:00:01.0: BAR 1 [mem 0x10002000-0x10002fff]
[ 0.062760] pci 0000:00:01.0: BAR 4 [mem 0x8000000000-0x8000003fff 64bit pref]
[ 0.063227] pci 0000:00:02.0: [8086:24cd] type 00 class 0x0c0320 conventional PCI endpoint
[ 0.063542] pci 0000:00:02.0: BAR 0 [mem 0x10001000-0x10001fff]
[ 0.064318] pci 0000:00:03.0: [1af4:1001] type 00 class 0x010000 conventional PCI endpoint
[ 0.064632] pci 0000:00:03.0: BAR 0 [io 0x0000-0x007f]
[ 0.064868] pci 0000:00:03.0: BAR 1 [mem 0x10000000-0x10000fff]
[ 0.065310] pci 0000:00:03.0: BAR 4 [mem 0x8000004000-0x8000007fff 64bit pref]
[ 0.065689] pci 0000:00:01.0: BAR 4 [mem 0x8000000000-0x8000003fff 64bit pref]: assigned
[ 0.066077] pci 0000:00:03.0: BAR 4 [mem 0x8000004000-0x8000007fff 64bit pref]: assigned
[ 0.066283] pci 0000:00:01.0: BAR 1 [mem 0x10000000-0x10000fff]: assigned
[ 0.066599] pci 0000:00:02.0: BAR 0 [mem 0x10001000-0x10001fff]: assigned
[ 0.066769] pci 0000:00:03.0: BAR 1 [mem 0x10002000-0x10002fff]: assigned
[ 0.066943] pci 0000:00:03.0: BAR 0 [io 0x1000-0x107f]: assigned
[ 0.067201] pci_bus 0000:00: resource 4 [mem 0x10000000-0x3efeffff window]
[ 0.067367] pci_bus 0000:00: resource 5 [io 0x0000-0xffff window]
[ 0.067519] pci_bus 0000:00: resource 6 [mem 0x8000000000-0xffffffffff window]
[ 0.068087] iommu: Default domain type: Translated
[ 0.068242] iommu: DMA domain TLB invalidation policy: strict mode
[ 0.068487] SCSI subsystem initialized
[ 0.068679] libata version 3.00 loaded.
[ 0.068895] ACPI: bus type USB registered
[ 0.069000] usbcore: registered new interface driver usbfs
[ 0.069138] usbcore: registered new interface driver hub
[ 0.069276] usbcore: registered new device driver usb
[ 0.069434] pps_core: LinuxPPS API ver. 1 registered
[ 0.069571] pps_core: Software ver. 5.3.6 - Copyright 2005-2007 Rodolfo Giometti <[email protected]>
[ 0.069810] PTP clock support registered
[ 0.069924] EDAC MC: Ver: 3.0.0
[ 0.070617] scmi_core: SCMI protocol bus registered
[ 0.070833] efivars: Registered efivars operations
[ 0.071109] FPGA manager framework
[ 0.071261] Advanced Linux Sound Architecture Driver Initialized.
[ 0.071644] vgaarb: loaded
[ 0.071863] clocksource: Switched to clocksource arch_sys_counter
[ 0.072074] VFS: Disk quotas dquot_6.6.0
[ 0.072178] VFS: Dquot-cache hash table entries: 512 (order 0, 4096 bytes)
[ 0.072405] pnp: PnP ACPI init
[ 0.072509] system 00:00: [mem 0x4010000000-0x401fffffff window] could not be reserved
[ 0.072716] pnp: PnP ACPI: found 1 devices
[ 0.078669] NET: Registered PF_INET protocol family
[ 0.078956] IP idents hash table entries: 32768 (order: 6, 262144 bytes, linear)
[ 0.079485] tcp_listen_portaddr_hash hash table entries: 1024 (order: 2, 16384 bytes, linear)
[ 0.080003] Table-perturb hash table entries: 65536 (order: 6, 262144 bytes, linear)
[ 0.080216] TCP established hash table entries: 16384 (order: 5, 131072 bytes, linear)
[ 0.080435] TCP bind hash table entries: 16384 (order: 7, 524288 bytes, linear)
[ 0.080723] TCP: Hash tables configured (established 16384 bind 16384)
[ 0.080932] UDP hash table entries: 1024 (order: 4, 65536 bytes, linear)
[ 0.081118] UDP-Lite hash table entries: 1024 (order: 4, 65536 bytes, linear)
[ 0.081342] NET: Registered PF_UNIX/PF_LOCAL protocol family
[ 0.081679] RPC: Registered named UNIX socket transport module.
[ 0.081831] RPC: Registered udp transport module.
[ 0.081948] RPC: Registered tcp transport module.
[ 0.082067] RPC: Registered tcp-with-tls transport module.
[ 0.082205] RPC: Registered tcp NFSv4.1 backchannel transport module.
[ 0.082446] PCI: CLS 0 bytes, default 64
[ 0.082813] Initialise system trusted keyrings
[ 0.083041] workingset: timestamp_bits=42 max_order=19 bucket_order=0
[ 0.083255] squashfs: version 4.0 (2009/01/31) Phillip Lougher
[ 0.083506] NFS: Registering the id_resolver key type
[ 0.083708] Key type id_resolver registered
[ 0.083954] Key type id_legacy registered
[ 0.084085] nfs4filelayout_init: NFSv4 File Layout Driver Registering...
[ 0.084254] nfs4flexfilelayout_init: NFSv4 Flexfile Layout Driver Registering...
[ 0.084490] 9p: Installing v9fs 9p2000 file system support
[ 0.090011] Key type asymmetric registered
[ 0.090115] Asymmetric key parser 'x509' registered
[ 0.090250] Block layer SCSI generic (bsg) driver version 0.4 loaded (major 245)
[ 0.090441] io scheduler mq-deadline registered
[ 0.090555] io scheduler kyber registered
[ 0.090659] io scheduler bfq registered
[ 0.091238] ledtrig-cpu: registered to indicate activity on CPUs
[ 0.091712] input: Power Button as /devices/LNXSYSTM:00/LNXSYBUS:00/PNP0C0C:00/input/input0
[ 0.092066] ACPI: button: Power Button [PWRB]
[ 0.096215] ACPI: \_SB_.L001: Enabled at IRQ 36
[ 0.096889] ACPI: \_SB_.L003: Enabled at IRQ 38
[ 0.097004] virtio-pci 0000:00:03.0: enabling device (0005 -> 0007)
[ 0.099091] Serial: 8250/16550 driver, 4 ports, IRQ sharing enabled
[ 0.099820] msm_serial: driver initialized
[ 0.100120] SuperH (H)SCI(F) driver initialized
[ 0.100244] STM32 USART driver initialized
[ 0.101242] loop: module loaded
[ 0.101376] virtio_blk virtio2: 2/0/0 default/read/poll queues
[ 0.101732] virtio_blk virtio2: [vda] 52428800 512-byte logical blocks (26.8 GB/25.0 GiB)
[ 0.102671] vda: vda1 vda2
[ 0.102960] megasas: 07.727.03.00-rc1
[ 0.103498] tun: Universal TUN/TAP device driver, 1.6
[ 0.104054] thunder_xcv, ver 1.0
[ 0.104138] thunder_bgx, ver 1.0
[ 0.104218] nicpf, ver 1.0
[ 0.104367] hns3: Hisilicon Ethernet Network Driver for Hip08 Family - version
[ 0.104545] hns3: Copyright (c) 2017 Huawei Corporation.
[ 0.104676] hclge is initializing
[ 0.104758] e1000: Intel(R) PRO/1000 Network Driver
[ 0.104876] e1000: Copyright (c) 1999-2006 Intel Corporation.
[ 0.105025] e1000e: Intel(R) PRO/1000 Network Driver
[ 0.105151] e1000e: Copyright(c) 1999 - 2015 Intel Corporation.
[ 0.105309] igb: Intel(R) Gigabit Ethernet Network Driver
[ 0.105452] igb: Copyright (c) 2007-2014 Intel Corporation.
[ 0.105600] igbvf: Intel(R) Gigabit Virtual Function Network Driver
[ 0.105764] igbvf: Copyright (c) 2009 - 2012 Intel Corporation.
[ 0.105939] sky2: driver version 1.30
[ 0.106389] VFIO - User Level meta-driver version: 0.3
[ 0.106971] usbcore: registered new interface driver usb-storage
[ 0.107055] ehci-pci 0000:00:02.0: EHCI Host Controller
[ 0.107368] ehci-pci 0000:00:02.0: new USB bus registered, assigned bus number 1
[ 0.108057] ehci-pci 0000:00:02.0: irq 46, io mem 0x10001000
[ 0.111606] rtc-efi rtc-efi.0: registered as rtc0
[ 0.111995] rtc-efi rtc-efi.0: setting system clock to 2025-08-18T12:58:55 UTC (1755521935)
[ 0.112273] i2c_dev: i2c /dev entries driver
[ 0.112834] sdhci: Secure Digital Host Controller Interface driver
[ 0.112987] sdhci: Copyright(c) Pierre Ossman
[ 0.113142] Synopsys Designware Multimedia Card Interface Driver
[ 0.113353] sdhci-pltfm: SDHCI platform and OF driver helper
[ 0.113642] pstore: Using crash dump compression: deflate
[ 0.113776] pstore: Registered efi_pstore as persistent store backend
[ 0.114064] usbcore: registered new interface driver usbhid
[ 0.114262] usbhid: USB HID core driver
[ 0.115006] NET: Registered PF_PACKET protocol family
[ 0.115205] 9pnet: Installing 9P2000 support
[ 0.115376] Key type dns_resolver registered
[ 0.116210] registered taskstats version 1
[ 0.116334] Loading compiled-in X.509 certificates
[ 0.117012] Demotion targets for Node 0: null
[ 0.117233] clk: Disabling unused clocks
[ 0.117332] PM: genpd: Disabling unused power domains
[ 0.117458] ALSA device list:
[ 0.117537] No soundcards found.
[ 0.120423] ehci-pci 0000:00:02.0: USB 2.0 started, EHCI 1.00
[ 0.120654] hub 1-0:1.0: USB hub found
[ 0.120749] hub 1-0:1.0: 6 ports detected
[ 0.121876] EXT4-fs (vda2): mounted filesystem df86d824-3058-48bd-9515-24ac42491dc6 ro with ordered data mode. Quota mode: none.
[ 0.122316] VFS: Mounted root (ext4 filesystem) readonly on device 254:2.
[ 0.123100] devtmpfs: mounted
[ 0.123527] Freeing unused kernel memory: 2816K
[ 0.123736] Run /sbin/init as init process
[ 0.123910] with arguments:
[ 0.123983] /sbin/init
[ 0.124050] with environment:
[ 0.124128] HOME=/
[ 0.124186] TERM=linux
[ 0.124253] BOOT_IMAGE=/vmlinuz-6.13.4-lfs-12.3
[ 0.124372] earlyprintk=efi,keep
INIT: version 3.14 booting
* Mounting virtual file systems: /run /proc /sys /dev/shm /sys/fs/c[ OK ]
* Create symlinks in /dev targeting /proc: /dev/stdin /dev/stdout /[ OK ]rr /dev/fd
* Bringing up the loopback interface... [ OK ]
Setting hostname to # Hostname configuration
# This file is written and managed by Ansible of Generic Distro Toolkit
* ... [ OK ]
Populating /dev with device nodes... [ 0.197662] udevd[177]: Starting systemd-udevd version 257.3
[ 0.198802] udevd[178]: Using default interface naming scheme 'v257'.
[ 0.371879] usb 1-1: new high-speed USB device number 2 using ehci-pci
[ 0.530167] input: QEMU QEMU USB Keyboard as /devices/pci0000:00/0000:00:02.0/usb1/1-1/1-1:1.0/0003:0627:0001.0001/input/input1
[ 0.655926] hid-generic 0003:0627:0001.0001: input: USB HID v1.11 Keyboard [QEMU QEMU USB Keyboard] on usb-0000:00:02.0-1/input0
* [ OK ]
* Activating all swap files/partitions... [ OK ]
Mounting root file system in read-only mode... [ 1.232877] EXT4-fs (vda2): re-mounted df86d824-3058-48bd-9515-24ac42491dc6 ro. Quota mode: none.
* [ OK ]
* Checking file systems... [ OK ]
Remounting root file system in read-write mode...[ 1.247071] EXT4-fs (vda2): re-mounted df86d824-3058-48bd-9515-24ac42491dc6 r/w. Quota mode: none.
* [ OK ]
* Mounting remaining file systems... [ OK ]
* Cleaning file systems: /tmp [ OK ]
* Retrying failed uevents, if any... [ OK ]
* Setting kernel runtime parameters... [ OK ]
INIT: Entering runlevel: 3
* Starting system log daemon... [ OK ]
devbox-aarch4 login: root
Password:
No mail.
-bash-5.2#
-bash-5.2# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enx525400123456
-bash-5.2#
-bash-5.2# echo "test"
test
-bash-5.2# uname -a
Linux 0xHrtz 6.13.4 #1 SMP PREEMPT Fri Aug 15 21:55:14 UTC 2025 aarch64 GNU/Linux
-bash-5.2# uname -n
devbox-aarch4
-bash-5.2# uname -m
aarch64
-bash-5.2# uname -a
Linux devbox-aarch4 6.13.4 #1 SMP PREEMPT Fri Aug 15 21:55:14 UTC 2025 aarch64 GNU/LinuxA Londra mi sembrano tutti molto educati e in presa bene, e poi sono stati 5 giorni di sole. Quest’anno anche al Fosdem c’era il sole. Insomma, dal punto di vista metereologico sono stato fortunato ad entrambi gli eventi dell’anno (considero questi due gli “eventi dell’anno”, ma ce ne sono tanti altri interessanti).
La conferenza si è tenuta ad ExCeL London di cui adoro il mix tra location dell’evento ed esercizi commerciali “embedded”. I panini della KubeCon sono buoni, ma anche farsi dei noodles in pausa pranzo fa piacere. L’organizzazione dell’evento è stata perfetta, non ci sono mai state code per i talk, le presentazioni molto chiare.
Naturalmente, il mio viaggio, essendo stato sponsorizzato da parte della mia società, Sourcesense (che ringrazio), ho avuto il piacevole mandato di non presidiare la conferenza solo per accumulare gadget (tema su cui dopo scriverò qualche riga) ma anche per carpire quelli che sono i trend tecnologici, le soluzioni e gli spunti per architetture e tool-chain nuove.
Kubernetes ha da poco compiuto 10 anni e devo dire che la community è ancora molto attiva e determinata.
Ogni tanto si è parlato di una grande numerosità di progetti nella tool-chain presente nel CNCF. Questo aspetto genera complessità, ma credo che sia facile individuare i tool su cui puntare grazie alle attività di divulgazione che i membri della community svolgono. L’anno scorso, a Parigi, ricordo che si parlò di era dell’AI e in effetti anche in questa KubeCon si è ripreso il tema. Come eseguire i modelli, containerizzarli, distribuire i carichi a seconda delle risorse all’interno di Kubernetes, sono alcuni punti di vari talk a cui ho partecipato. Come l’anno scorso, il tema su cui ci è si è soffermati parecchio è quello della osservabilità. Kubernetes e le architetture a microservizi (tanti microservizi) possono risultare complessi da osservare. Ma è un problema che grazie a Prometheus e Open Telemetry è risolvibile a mio parere. Naturalmente, senza farsi sommergere dalle metriche e applicando una selezione di quest’ultime che abbia senso. Anche perchè tali metriche allertano i reperibili ed è necessario svegliarli veramente quando serve! 
L’aspetto interessante di KubeCon sono i talk di ingegneri che lavorano in grandi realtà dove hanno grandi (ma veramente grandi) cluster Kubernetes e risorse a disposizione. Sono spunti interessanti per capire se la tool-chain, i pattern di CI/CD e Observability, la distro Kubernetes scelta, sono in linea con chi affronta sfide simili (e a volte più grandi, come nel caso del CERN).
Si è parlato anche di Rust e della sua presenza sempre più crescente all’interno del progetto Linux. Si è anche un po’ scherzato sullo spirito di repulsione che gli sviluppatori della vecchia scuola, amanti e utilizzatori ormai abitudinari del C, hanno nei confronti di Rust. Non scenderò nel dettaglio ma ricordo come sono state visionate alcune CVE del Kernel che banalmente sono state prodotte da una dimenticanza dei programmatori nel valutare correttamente i ritorni di funzioni. Rust non impone il controllo su tutti i ritorni sempre, ma lo fa in modo intelligente grazie a tipi come Result e Option combinati con annotazioni tipo #[must_use]. Insomma, il messaggio che è arrivato è che il compilatore non risolve qualsiasi problema ma facilità la vita degli sviluppatori.
Ho trovato i soliti cloni di KubeInvaders e quest’anno ce n’era uno nuovo! Ho postato qui le foto. Devo dire che preferivo SpotInvaders di AWS a questo punto  Naturalmente lo dico in modo scherzoso.
Naturalmente lo dico in modo scherzoso.
Andiamo ora su alcuni aspetti ludici degli eventi tech..
Stickers
A livello di sticker ce ne sono veramente tanti. Ci sono degli Stickers Wall dove accollandosi un po’ di fila è possibile fare scorta. Credo però che sia possibile prenderne uno per tool (ricordo che a Parigi venni ripreso…). Tuttavia, a questa KubeCon non ci sono andato allo Stickers Wall.
Ci sono anche gli sticker che distribuiscono nei vari banchetti e chioschi dell’area Solutions Showcase. I vendor più grandi e potenti hanno chioschi che sembrano delle “micro discoteche”. C’è anche spesso un qualcuno microfonato che fa molto “venghino signori!”.
I progetti che seguo io, di solito, hanno il banchetto piccolo e una persona sola a presidiare.
Gadgets
Quelli non li ho proprio presi. Gadget uguale “tonnellate di email quando torno” (scherzo naturalmente).
In sostanza, quest’anno non ho rimediato gadget e ho portato con me veramente pochissimi sticker. Non so perchè, ma mi sento molto più a mio agio al FOSDEM sul tema dell’acquisizione compulsiva degli adesivi… Lì, basta una stretta di mano e un’occhiata per ottenerli mentre a KubeCon, giustamente, un po’ di chiacchiere in più è gradito che ci siano. Ripeto, non è una critica. Il mercato va alimentato in qualche modo e le aziende (anche quelle che lavorano a contatto con l’open-source) devono promuoversi come è giusto che sia.
Quindi, il FOSDEM rimane l’unico luogo dove puoi prendere tonnellate di sticker in tranquillità (non frequento troppe conferenze per cui perdonatemi se ci sono posti in cui è possibile prenderne di più).
Il bilancio di questo viaggio
Veramente super positivo. Ho assistito a talk di persone che seguo e che per me sono i punti di riferimento su Kubernetes e sull’ecosistema che si è creato intorno.
Torno con qualche informazione in più sui trend, le architetture di riferimento e progetti di rilievo. Torno anche con qualche accordo interessante :D.
È importante sapere che Kubernetes è supportato da una community enorme e distribuita a livello globale perchè ormai lo utilizziamo per esercire molte delle infrastrutture su cui lavoriamo. Presidiare tali eventi è fondamentale.
]]>The steps are quite simple.
python3 -m venv /opt/prometheus-pve-exporter
/opt/prometheus-pve-exporter/bin/pip install prometheus-pve-exporter
# Check the installation with: /opt/prometheus-pve-exporter/bin/pve_exporter --helpOnce the Python module is installed, I can set up the configuration file for the exporter, and I also need a user dedicated to read-only access.
I have created a prometheus user
As described in the exporter’s documentation, it’s fine to assign the PVEAuditor role to the user, and I have configured the pve.yml file

Now, I can create the pve.yml file in /etc/prometheus/pve.yml.
$ root@ns304365 (~) > cat /etc/prometheus/pve.yml
$ root@ns304365 (~) > cat /etc/prometheus/pve.yml
default:
user: prometheus@pve
password: ****
verify_ssl: false
# I used the password but you can use also an API tokenThis is the SystemD service unit, located at /etc/systemd/system/prometheus-pve-exporter.service.
$ root@ns304365 (~) > cat /etc/systemd/system/prometheus-pve-exporter.service
[Unit]
Description=Prometheus exporter for Proxmox VE
Documentation=https://github.com/znerol/prometheus-pve-exporter
[Service]
Restart=always
User=prometheus
ExecStart=/opt/prometheus-pve-exporter/bin/pve_exporter --config.file /etc/prometheus/pve.yml
[Install]
WantedBy=multi-user.targetOnce the file is created, you need to reload the daemon’s configuration and start the service.
systemctl daemon-reload
systemctl start prometheus-pve-exporterYou can test if the exporter is working properly using curl.
$ root@ns304365 (~) > curl localhost:9221/pve
# HELP pve_up Node/VM/CT-Status is online/running
# TYPE pve_up gauge
pve_up{id="node/ns304365"} 1.0
pve_up{id="qemu/100"} 1.0
pve_up{id="qemu/101"} 1.0
pve_up{id="qemu/9000"} 0.0
pve_up{id="storage/ns304365/local"} 1.0
# HELP pve_disk_size_bytes Storage size in bytes (for type 'storage'), root image size for VMs (for types 'qemu' and 'lxc').
# TYPE pve_disk_size_bytes gauge
pve_disk_size_bytes{id="qemu/100"} 3.221225472e+010
pve_disk_size_bytes{id="qemu/101"} 5.36870912e+010
pve_disk_size_bytes{id="qemu/9000"} 1.073741824e+010
pve_disk_size_bytes{id="node/ns304365"} 2.0940804096e+010
pve_disk_size_bytes{id="storage/ns304365/local"} 2.7177187328e+011
# HELP pve_disk_usage_bytes Used disk space in bytes (for type 'storage'), used root image space for VMs (for types 'qemu' and 'lxc').
# TYPE pve_disk_usage_bytes gauge
pve_disk_usage_bytes{id="qemu/100"} 0.0
pve_disk_usage_bytes{id="qemu/101"} 0.0
pve_disk_usage_bytes{id="qemu/9000"} 0.0
pve_disk_usage_bytes{id="node/ns304365"} 1.9636924416e+010
pve_disk_usage_bytes{id="storage/ns304365/local"} 1.93465360384e+011
# HELP pve_memory_size_bytes Number of available memory in bytes (for types 'node', 'qemu' and 'lxc').
# TYPE pve_memory_size_bytes gauge
pve_memory_size_bytes{id="qemu/100"} 4.294967296e+09
pve_memory_size_bytes{id="qemu/101"} 1.2884901888e+010
pve_memory_size_bytes{id="qemu/9000"} 8.589934592e+09
pve_memory_size_bytes{id="node/ns304365"} 1.6759209984e+010
# HELP pve_memory_usage_bytes Used memory in bytes (for types 'node', 'qemu' and 'lxc').
# TYPE pve_memory_usage_bytes gauge
pve_memory_usage_bytes{id="qemu/100"} 3.226718208e+09
pve_memory_usage_bytes{id="qemu/101"} 1.0086023168e+010
pve_memory_usage_bytes{id="qemu/9000"} 0.0
pve_memory_usage_bytes{id="node/ns304365"} 1.569089536e+010
# HELP pve_network_transmit_bytes The amount of traffic in bytes that was sent from the guest over the network since it was started. (for types 'qemu' and 'lxc')
# TYPE pve_network_transmit_bytes gauge
pve_network_transmit_bytes{id="qemu/100"} 8.446923247e+010
pve_network_transmit_bytes{id="qemu/101"} 1.2573177635e+010
pve_network_transmit_bytes{id="qemu/9000"} 0.0
# HELP pve_network_receive_bytes The amount of traffic in bytes that was sent to the guest over the network since it was started. (for types 'qemu' and 'lxc')
# TYPE pve_network_receive_bytes gauge
pve_network_receive_bytes{id="qemu/100"} 2.1083896353e+010
pve_network_receive_bytes{id="qemu/101"} 7.7540201276e+010
pve_network_receive_bytes{id="qemu/9000"} 0.0
# HELP pve_disk_write_bytes The amount of bytes the guest wrote to its block devices since the guest was started. This info is not available for all storage types. (for types 'qemu' and 'lxc')
# TYPE pve_disk_write_bytes gauge
pve_disk_write_bytes{id="qemu/100"} 1.91578735104e+011
pve_disk_write_bytes{id="qemu/101"} 5.312994432e+011
pve_disk_write_bytes{id="qemu/9000"} 0.0
# HELP pve_disk_read_bytes The amount of bytes the guest read from its block devices since the guest was started. This info is not available for all storage types. (for types 'qemu' and 'lxc')
# TYPE pve_disk_read_bytes gauge
pve_disk_read_bytes{id="qemu/100"} 1.578918018804e+012
pve_disk_read_bytes{id="qemu/101"} 5.544803722e+09
pve_disk_read_bytes{id="qemu/9000"} 0.0
# HELP pve_cpu_usage_ratio CPU utilization (for types 'node', 'qemu' and 'lxc').
# TYPE pve_cpu_usage_ratio gauge
pve_cpu_usage_ratio{id="qemu/100"} 0.0685821712501984
pve_cpu_usage_ratio{id="qemu/101"} 0.132691592201471
pve_cpu_usage_ratio{id="qemu/9000"} 0.0
pve_cpu_usage_ratio{id="node/ns304365"} 0.148930720962991
# HELP pve_cpu_usage_limit Number of available CPUs (for types 'node', 'qemu' and 'lxc').
# TYPE pve_cpu_usage_limit gauge
pve_cpu_usage_limit{id="qemu/100"} 1.0
pve_cpu_usage_limit{id="qemu/101"} 6.0
pve_cpu_usage_limit{id="qemu/9000"} 4.0
pve_cpu_usage_limit{id="node/ns304365"} 8.0
# HELP pve_uptime_seconds Uptime of node or virtual guest in seconds (for types 'node', 'qemu' and 'lxc').
# TYPE pve_uptime_seconds gauge
pve_uptime_seconds{id="qemu/100"} 8.069085e+06
pve_uptime_seconds{id="qemu/101"} 5.448312e+06
pve_uptime_seconds{id="qemu/9000"} 0.0
pve_uptime_seconds{id="node/ns304365"} 8.069122e+06
# HELP pve_storage_shared Whether or not the storage is shared among cluster nodes
# TYPE pve_storage_shared gauge
pve_storage_shared{id="storage/ns304365/local"} 0.0
# HELP pve_ha_state HA service status (for HA managed VMs).
# TYPE pve_ha_state gauge
pve_ha_state{id="qemu/100",state="stopped"} 0.0
pve_ha_state{id="qemu/100",state="request_stop"} 0.0
pve_ha_state{id="qemu/100",state="request_start"} 0.0
pve_ha_state{id="qemu/100",state="request_start_balance"} 0.0
pve_ha_state{id="qemu/100",state="started"} 0.0
pve_ha_state{id="qemu/100",state="fence"} 0.0
pve_ha_state{id="qemu/100",state="recovery"} 0.0
pve_ha_state{id="qemu/100",state="migrate"} 0.0
pve_ha_state{id="qemu/100",state="relocate"} 0.0
pve_ha_state{id="qemu/100",state="freeze"} 0.0
pve_ha_state{id="qemu/100",state="error"} 0.0
pve_ha_state{id="qemu/101",state="stopped"} 0.0
pve_ha_state{id="qemu/101",state="request_stop"} 0.0
pve_ha_state{id="qemu/101",state="request_start"} 0.0
pve_ha_state{id="qemu/101",state="request_start_balance"} 0.0
pve_ha_state{id="qemu/101",state="started"} 0.0
pve_ha_state{id="qemu/101",state="fence"} 0.0
pve_ha_state{id="qemu/101",state="recovery"} 0.0
pve_ha_state{id="qemu/101",state="migrate"} 0.0
pve_ha_state{id="qemu/101",state="relocate"} 0.0
pve_ha_state{id="qemu/101",state="freeze"} 0.0
pve_ha_state{id="qemu/101",state="error"} 0.0
pve_ha_state{id="qemu/9000",state="stopped"} 0.0
pve_ha_state{id="qemu/9000",state="request_stop"} 0.0
pve_ha_state{id="qemu/9000",state="request_start"} 0.0
pve_ha_state{id="qemu/9000",state="request_start_balance"} 0.0
pve_ha_state{id="qemu/9000",state="started"} 0.0
pve_ha_state{id="qemu/9000",state="fence"} 0.0
pve_ha_state{id="qemu/9000",state="recovery"} 0.0
pve_ha_state{id="qemu/9000",state="migrate"} 0.0
pve_ha_state{id="qemu/9000",state="relocate"} 0.0
pve_ha_state{id="qemu/9000",state="freeze"} 0.0
pve_ha_state{id="qemu/9000",state="error"} 0.0
pve_ha_state{id="node/ns304365",state="online"} 0.0
pve_ha_state{id="node/ns304365",state="maintenance"} 0.0
pve_ha_state{id="node/ns304365",state="unknown"} 0.0
pve_ha_state{id="node/ns304365",state="fence"} 0.0
pve_ha_state{id="node/ns304365",state="gone"} 0.0
# HELP pve_lock_state The guest's current config lock (for types 'qemu' and 'lxc')
# TYPE pve_lock_state gauge
pve_lock_state{id="qemu/100",state="backup"} 0.0
pve_lock_state{id="qemu/100",state="clone"} 0.0
pve_lock_state{id="qemu/100",state="create"} 0.0
pve_lock_state{id="qemu/100",state="migrate"} 0.0
pve_lock_state{id="qemu/100",state="rollback"} 0.0
pve_lock_state{id="qemu/100",state="snapshot"} 0.0
pve_lock_state{id="qemu/100",state="snapshot-delete"} 0.0
pve_lock_state{id="qemu/100",state="suspended"} 0.0
pve_lock_state{id="qemu/100",state="suspending"} 0.0
pve_lock_state{id="qemu/101",state="backup"} 0.0
pve_lock_state{id="qemu/101",state="clone"} 0.0
pve_lock_state{id="qemu/101",state="create"} 0.0
pve_lock_state{id="qemu/101",state="migrate"} 0.0
pve_lock_state{id="qemu/101",state="rollback"} 0.0
pve_lock_state{id="qemu/101",state="snapshot"} 0.0
pve_lock_state{id="qemu/101",state="snapshot-delete"} 0.0
pve_lock_state{id="qemu/101",state="suspended"} 0.0
pve_lock_state{id="qemu/101",state="suspending"} 0.0
pve_lock_state{id="qemu/9000",state="backup"} 0.0
pve_lock_state{id="qemu/9000",state="clone"} 0.0
pve_lock_state{id="qemu/9000",state="create"} 0.0
pve_lock_state{id="qemu/9000",state="migrate"} 0.0
pve_lock_state{id="qemu/9000",state="rollback"} 0.0
pve_lock_state{id="qemu/9000",state="snapshot"} 0.0
pve_lock_state{id="qemu/9000",state="snapshot-delete"} 0.0
pve_lock_state{id="qemu/9000",state="suspended"} 0.0
pve_lock_state{id="qemu/9000",state="suspending"} 0.0
# HELP pve_guest_info VM/CT info
# TYPE pve_guest_info gauge
pve_guest_info{id="qemu/100",name="web01",node="ns304365",tags="",template="0",type="qemu"} 1.0
pve_guest_info{id="qemu/101",name="k8s1",node="ns304365",tags="",template="0",type="qemu"} 1.0
pve_guest_info{id="qemu/9000",name="VM 9000",node="ns304365",tags="",template="1",type="qemu"} 1.0
# HELP pve_storage_info Storage info
# TYPE pve_storage_info gauge
pve_storage_info{content="iso,backup,rootdir,snippets,vztmpl,images",id="storage/ns304365/local",node="ns304365",plugintype="dir",storage="local"} 1.0
# HELP pve_node_info Node info
# TYPE pve_node_info gauge
pve_node_info{id="node/ns304365",level="",name="ns304365",nodeid="0"} 1.0
# HELP pve_version_info Proxmox VE version info
# TYPE pve_version_info gauge
pve_version_info{release="8.3",repoid="c1689ccb1065a83b",version="8.3.0"} 1.0
# HELP pve_onboot_status Proxmox vm config onboot value
# TYPE pve_onboot_status gauge
# HELP pve_replication_duration_seconds Proxmox vm replication duration
# TYPE pve_replication_duration_seconds gauge
# HELP pve_replication_last_sync_timestamp_seconds Proxmox vm replication last_sync
# TYPE pve_replication_last_sync_timestamp_seconds gauge
# HELP pve_replication_last_try_timestamp_seconds Proxmox vm replication last_try
# TYPE pve_replication_last_try_timestamp_seconds gauge
# HELP pve_replication_next_sync_timestamp_seconds Proxmox vm replication next_sync
# TYPE pve_replication_next_sync_timestamp_seconds gauge
# HELP pve_replication_failed_syncs Proxmox vm replication fail_count
# TYPE pve_replication_failed_syncs gauge
# HELP pve_replication_info ProxmoxNow, I need to add the job to my Prometheus configuration. I use Podman, so after modifying the config file, I restart Prometheus with podman restart prometheus.
- job_name: 'pve'
static_configs:
- targets:
- 10.10.10.1:9221 # Proxmox VE node with PVE exporter.
metrics_path: /pve
params:
module: [default]
cluster: ['1']
node: ['1']
The next step is to check if the metrics are being scraped by Prometheus. In my case, I start an SSH tunnel to reach Prometheus with the command: ssh -L 9090:localhost:9090 web01.
It’s time to get a Grafana dashboard. I found one here: https://grafana.com/grafana/dashboards/10347-proxmox-via-prometheus/, which is linked in the exporter’s GitHub repo.
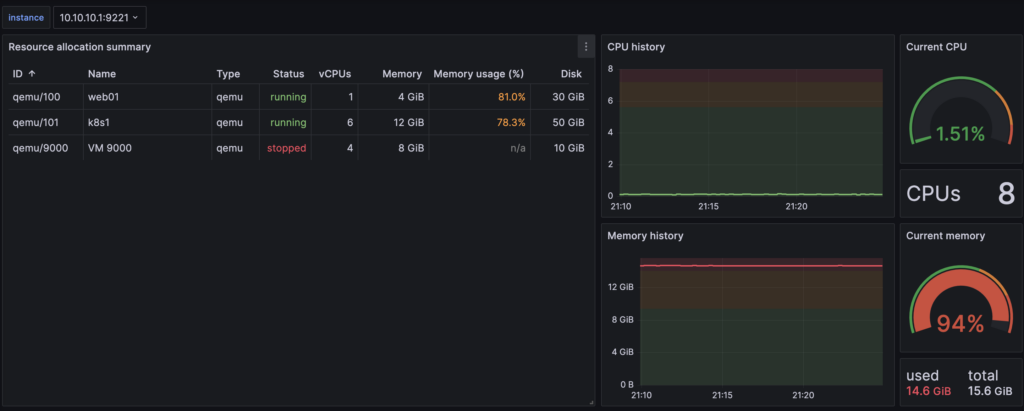
Okay, the dashboard looks good, but alerts matter, so I need to configure Prometheus rules. I tried using an LLM to help me and used GPT-4 via Copilot on VSCode. The results were partially okay, so I had to adjust a few things, like the indentation.
To trigger instantanly the alerts I set to 1 Byte the threshold of some expresions in order to see the firing alerts.
groups:
- name: pve_alerts
rules:
- alert: NodeDown
expr: pve_up{id=~"node/.*"} == 0
for: 1s
labels:
severity: critical
annotations:
summary: "Node {{ $labels.id }} is down"
description: "Node {{ $labels.id }} has been down for more than 5 minutes."
- alert: VMDown
expr: pve_up{id=~"qemu/.*"} == 0
for: 1s
labels:
severity: critical
annotations:
summary: "VM {{ $labels.id }} is down"
description: "VM {{ $labels.id }} has been down for more than 5 minutes."
- alert: HighCPUUsage
expr: pve_cpu_usage_ratio > 0.9
for: 1s
labels:
severity: warning
annotations:
summary: "High CPU usage on {{ $labels.id }}"
description: "CPU usage on {{ $labels.id }} is above 90%."
- alert: HighMemoryUsage
expr: (pve_memory_usage_bytes / pve_memory_size_bytes) > 0.9
for: 1s
labels:
severity: warning
annotations:
summary: "High memory usage on {{ $labels.id }}"
description: "Memory usage on {{ $labels.id }} is above 90%."
- alert: HighNetworkTransmit
expr: pve_network_transmit_bytes{id=~"qemu/.*"} > 1.0
for: 1s
labels:
severity: warning
annotations:
summary: "High network transmit on VM {{ $labels.id }}"
description: "Network transmit on VM {{ $labels.id }} is above 1 Byte."
- alert: HighNetworkReceive
expr: pve_network_receive_bytes{id=~"qemu/.*"} > 1.0
for: 1s
labels:
severity: warning
annotations:
summary: "High network receive on VM {{ $labels.id }}"
description: "Network receive on VM {{ $labels.id }} is above 1 Byte."
- alert: HighDiskWrite
expr: pve_disk_write_bytes{id=~"qemu/.*"} > 1.0
for: 1s
labels:
severity: warning
annotations:
summary: "High disk write on VM {{ $labels.id }}"
description: "Disk write on VM {{ $labels.id }} is above 1 Byte."
- alert: HighDiskRead
expr: pve_disk_read_bytes{id=~"qemu/.*"} > 1.0
for: 1s
labels:
severity: warning
annotations:
summary: "High disk read on VM {{ $labels.id }}"
description: "Disk read on VM {{ $labels.id }} is above 1 Byte."Obviously, some metrics and rules are already included in Node Exporter, but it’s interesting to have a single view that monitors the hypervisor.
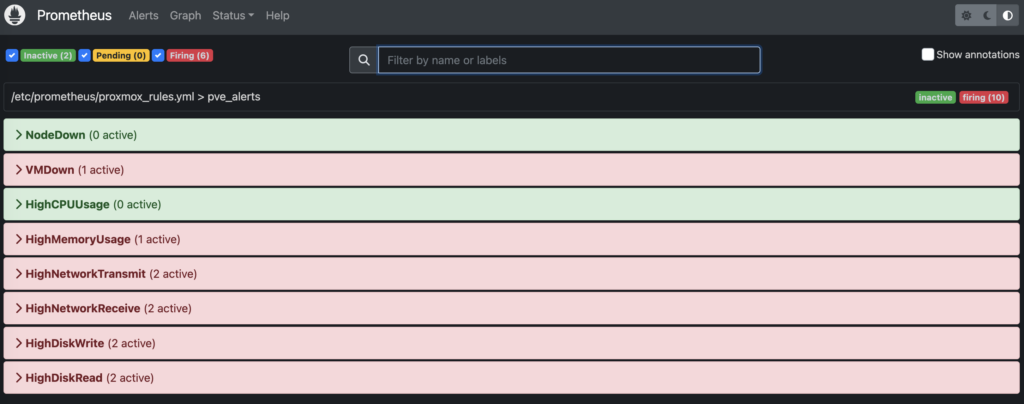
Conclusions
In conclusion, I can say that monitoring Proxmox hypervisors via Prometheus is a great idea for gaining additional controls beyond Node Exporter and other exporters. Naturally, I recommend using a Prometheus + Alertmanager cluster in HA, located outside the monitored hypervisors. Perhaps the exporter could be expanded with additional metrics, and it would be useful to experiment with automated actions triggered by certain alerts.
]]>First of all, I needed to check the KubeVirt API, which I found here: https://kubevirt.io/api-reference/
For my purpose I need https://kubevirt.io/api-reference/v1.4.0/operations.html#_v1restart
PUT /apis/subresources.kubevirt.io/v1/namespaces/{namespace}/virtualmachines/{name}/restart
Description
Restart a VirtualMachine object.The other API function I need is the list of virtual machines for a namespace, in order to discover all the virtual machines during the game.
GET /apis/kubevirt.io/v1/namespaces/{namespace}/virtualmachines
Description
Get a list of VirtualMachine objects.Then, I needed to create a role to allow my service account to reboot the VMs.
I like Kubernetes RBAC, as it allows me to grant permissions specifically for rebooting VMs. Below is the ClusterRole:
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
namespace: default
name: kubevirt-vm-restart-role
rules:
- apiGroups: ["subresources.kubevirt.io"]
resources: ["virtualmachines/restart"]
verbs: ["update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubevirt-vm-restart-binding
namespace: default
subjects:
- kind: ServiceAccount
name: kubeinvaders
namespace: kubeinvaders
roleRef:
kind: ClusterRole
name: kubevirt-vm-restart-role
apiGroup: rbac.authorization.k8s.io
Because the game will now support both pods and VMs, I decided to add a legend to represent the different statuses of the objects I want to observe and add some special keys for set the game for discovery virtual machines
# Controls and Options
h => Enable or disable help
s => Enable or disable shuffle for aliens
n => Change the namespace
p => Display pods switch
c => Display nodes switch
v => Display virtual machines (kubevirt) switchObviously, it is important to press ‘p’ to disable the discovery of the pods in order to avoid killing the virt-launcher pod and to focus only on the VMs.
I have prepared two VMs in my first post related to KubeVirt that I used for testing this feature. During the test, I observed this command.
[root@node1 ~]# kubectl get vms
NAME AGE STATUS READY
ubuntu-bionic 23d Running True
vm-d9f5z 23d Stopped FalseI recorded this short video where I have a shell on the right in which I observe the list and status of the VMs in the default namespace. I position myself on the game console, removing the pods from the visualization (by pressing the “p” key) and enabling the virtual machines (by pressing the “v” key). Then, I launched some missiles towards the alien representing my running VM called “ubuntu-bionic,” and I saw its state change (i.e., the color of the alien changes).
Naturally, performing chaos engineering on the pods makes much more sense, but I believe setting up resilience tests for virtual machines in Kubernetes also makes sense to observe the reboot and scheduling speed, as well as to test distributed systems migrated to Kubernetes.
I released this new feature that you can use by installing k-inv through Helm.
helm repo add kubeinvaders https://lucky-sideburn.github.io/helm-charts/
helm repo update
kubectl create namespace kubeinvaders
# With ingress and TLS enabled
helm install --set-string config.target_namespace="default\,namespace1\,namespace2" --set ingress.enabled=true --set ingress.hostName=kubeinvaders.local --set deployment.image.tag=latest -n kubeinvaders kubeinvaders kubeinvaders/kubeinvaders --set ingress.tls_enabled=true
Thank you for your attention!
]]>
[root@node1 opt]# cat /etc/redhat-release
Rocky Linux release 9.4 (Blue Onyx)
[root@node1 opt]# free -m
total used free shared buff/cache available
Mem: 31781 4160 20486 5 7594 27620
Swap: 0 0 0
[root@node1 opt]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel(R) Corporation
Model name: Intel(R) Xeon(R) CPU E3-1230 v6 @ 3.50GHz
BIOS Model name: Intel(R) Xeon(R) CPU E3-1230 v6 @ 3.50GHz
CPU family: 6
Model: 158
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
Stepping: 9
CPU(s) scaling MHz: 93%
CPU max MHz: 3900.0000
CPU min MHz: 800.0000
BogoMIPS: 6999.82
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_ts
c art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pd
cm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb pti ssbd ibrs ibpb stibp tpr_sh
adow flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dt
herm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp vnmi md_clear flush_l1d arch_capabilities
Firstly, I’m installing k8s through KubeSpray (single-node) along with kube-ovn and multus for the SDN component. Here are some attributes and the inventory.
[root@ns3137793 kubespray]# cat inventory/local/group_vars/k8s_cluster/k8s-cluster.yml | grep -i kube_netwo
kube_network_plugin: kube-ovn
kube_network_plugin_multus: true
[root@ns3137793 kubespray]# cat inventory/local/hosts.ini
node1 ansible_connection=local local_release_dir={{ansible_env.HOME}}/releases
[kube_control_plane]
node1
[etcd]
node1
[kube_node]
node1I’m going straight with Podman to get a Python and Ansible setup ready for KubeSpray. I like using an image that already has everything I need for a certain version of KubeSpray.
podman run --rm -it -v /opt/kubespray/inventory/local:/kubespray/inventory quay.io/kubespray/kubespray:v2.25.0 ansible-playbook -i /kubespray/inventory/hosts.ini -b /kubespray/upgrade-cluster.yml
[root@node1 ~]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-d665d669-g7hpq 1/1 Running 0 16s
kube-system dns-autoscaler-597dccb9b9-wwmf2 1/1 Running 0 31h
kube-system kube-apiserver-node1 1/1 Running 1 31h
kube-system kube-controller-manager-node1 1/1 Running 2 31h
kube-system kube-multus-ds-amd64-gmbs9 1/1 Running 2 (31h ago) 31h
kube-system kube-ovn-cni-2p26b 1/1 Running 0 31h
kube-system kube-ovn-controller-6bd964f544-7hghj 1/1 Running 0 31h
kube-system kube-ovn-monitor-6974f7f95f-djlmv 1/1 Running 0 31h
kube-system kube-ovn-pinger-jwpkw 1/1 Running 0 31h
kube-system kube-proxy-5rpf5 1/1 Running 0 31h
kube-system kube-scheduler-node1 1/1 Running 1 31h
kube-system nodelocaldns-g6w2m 1/1 Running 0 31h
kube-system ovn-central-799c6555b6-xxvsg 1/1 Running 0 31h
kube-system ovs-ovn-dwwb9 1/1 Running 0 31h
[root@node1 ~]# kubectl version
Client Version: v1.31.3
Kustomize Version: v5.4.2
Server Version: v1.31.3
For first, let’s check out https://kubevirt.io/user-guide/cluster_admin/installation/ for a step-by-step guide. Just to be safe, I’ll update the KubeSpray cluster.
[root@k8s1 kubespray]# podman run --rm -it -v /opt/kubespray/inventory/kimsufi:/kubespray/inventory quay.io/kubespray/kubespray:v2.14.0 ansible-playbook -i /kubespray/inventory/inventory.ini -b /kubespray/upgrade-cluster.yml
Trying to pull quay.io/kubespray/kubespray:v2.14.0...
...
.....I’m validating that the API server has the –allow-privileged=true parameter enabled.
root@node1 ~]# ps -ef | grep allow-privileged
root 1661 1473 12 Dec02 ? 06:30:06 kube-apiserver --advertise-address=10.10.10.4 --allow-privileged=trueSo, KubeVirt suggests using cri-o or containerd. I’m pretty sure it’ll work fine, but let’s double-check with ‘grep containerd systemctl list-unit-files’
[root@node ~]# systemctl list-unit-files | grep containerd.service
containerd.service enabled disabledI’ll run virt-host-validate qemu to check for hardware virtualization. It’s missing on my server, so I’ll install libvirt-clients to enable it
[root@node1 ~]# virt-host-validate qemu
QEMU: Checking for hardware virtualization : PASS
QEMU: Checking if device /dev/kvm exists : PASS
QEMU: Checking if device /dev/kvm is accessible : PASS
QEMU: Checking if device /dev/vhost-net exists : PASS
QEMU: Checking if device /dev/net/tun exists : PASS
QEMU: Checking for cgroup 'cpu' controller support : PASS
QEMU: Checking for cgroup 'cpuacct' controller support : PASS
QEMU: Checking for cgroup 'cpuset' controller support : PASS
QEMU: Checking for cgroup 'memory' controller support : PASS
QEMU: Checking for cgroup 'devices' controller support : PASS
QEMU: Checking for cgroup 'blkio' controller support : PASS
QEMU: Checking for device assignment IOMMU support : PASS
QEMU: Checking if IOMMU is enabled by kernel : WARN (IOMMU appears to be disabled in kernel. Add intel_iommu=on to kernel cmdline arguments)
QEMU: Checking for secure guest support : WARN (Unknown if this platform has Secure Guest support)Add container-selinux
dnf install container-selinux -yI am ready to initiate the KubeVirt installation process. I will follow the exact steps provided below, which I’ll incorporate into a bash script for streamlined execution https://kubevirt.io/user-guide/cluster_admin/installation/#installing-kubevirt-on-kubernetes
# Point at latest release
export RELEASE=$(curl https://storage.googleapis.com/kubevirt-prow/release/kubevirt/kubevirt/stable.txt)
# Deploy the KubeVirt operator
kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${RELEASE}/kubevirt-operator.yaml
# Create the KubeVirt CR (instance deployment request) which triggers the actual installation
kubectl apply -f https://github.com/kubevirt/kubevirt/releases/download/${RELEASE}/kubevirt-cr.yaml
# wait until all KubeVirt components are up
kubectl -n kubevirt wait kv kubevirt --for condition=AvailableI’m verifying that KubeVirt has started
[root@node1 opt]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-d665d669-g7hpq 1/1 Running 0 13m
kube-system dns-autoscaler-597dccb9b9-wwmf2 1/1 Running 0 31h
kube-system kube-apiserver-node1 1/1 Running 1 31h
kube-system kube-controller-manager-node1 1/1 Running 2 31h
kube-system kube-multus-ds-amd64-gmbs9 1/1 Running 2 (31h ago) 31h
kube-system kube-ovn-cni-2p26b 1/1 Running 0 31h
kube-system kube-ovn-controller-6bd964f544-7hghj 1/1 Running 0 31h
kube-system kube-ovn-monitor-6974f7f95f-djlmv 1/1 Running 0 31h
kube-system kube-ovn-pinger-jwpkw 1/1 Running 0 31h
kube-system kube-proxy-5rpf5 1/1 Running 0 31h
kube-system kube-scheduler-node1 1/1 Running 1 31h
kube-system nodelocaldns-g6w2m 1/1 Running 0 31h
kube-system ovn-central-799c6555b6-xxvsg 1/1 Running 0 31h
kube-system ovs-ovn-dwwb9 1/1 Running 0 31h
kubevirt virt-api-5f9f64fd4d-bwcqc 1/1 Running 0 114s
kubevirt virt-controller-7c8d6577b6-6p26s 1/1 Running 0 88s
kubevirt virt-controller-7c8d6577b6-fm4tc 1/1 Running 0 88s
kubevirt virt-handler-746wz 1/1 Running 0 88s
kubevirt virt-operator-79456d8689-tddjr 1/1 Running 0 2m23s
kubevirt virt-operator-79456d8689-v9nnh 1/1 Running 0 2m23sI’ve realized that it creates extra replicas by default. While this is beneficial for production setups, I don’t require high availability and my resources are limited. I’m going to remove all extra replicas and scale down to the minimum
The initial step is to adjust the replicas parameter within the kubevirt-operator.yaml file and subsequently scale down to a single replica
[root@k8s1 opt]# for i in $(kubectl get deployment -n kubevirt | grep -v NAME | awk '{ print $1}'); do kubectl scale deployment $i --replicas=1 -n kubevirt; done
deployment.apps/virt-api scaled
deployment.apps/virt-controller scaled
deployment.apps/virt-operator scaledThe operator is correctly resetting the replicas for the controller and APIs to 2. I’m going to check the kube-virt code, specifically the ‘virt-operator’ part. It seems I can’t modify the number of replicas due to a hardcoded minReplicas value. I’ll revisit this later
$ > cat resource/apply/apps.go | grep -i minReplicas
const minReplicas = 2
if replicas < minReplicas {
replicas = minReplicas
Alright, it’s time to create my first VM. I’m going to install virtctl (https://kubevirt.io/user-guide/user_workloads/virtctl_client_tool/) to do so.
[root@node1 ~]# virtctl version
Client Version: version.Info{GitVersion:"v1.4.0", GitCommit:"9b9b3d4e7b681af96ca1b6b6a5cea75e2f05ce5b", GitTreeState:"clean", BuildDate:"2024-11-13T08:23:36Z", GoVersion:"go1.22.8 X:nocoverageredesign", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{GitVersion:"v1.4.0", GitCommit:"9b9b3d4e7b681af96ca1b6b6a5cea75e2f05ce5b", GitTreeState:"clean", BuildDate:"2024-11-13T09:51:17Z", GoVersion:"go1.22.8 X:nocoverageredesign", Compiler:"gc", Platform:"linux/amd64"}
I found this Git repo https://github.com/Tedezed/kubevirt-images-generator and decided to use it as a starting point for applying my first virtual machine manifest!
kind: VirtualMachine
metadata:
name: ubuntu-bionic
spec:
runStrategy: Always
template:
metadata:
labels:
kubevirt.io/size: small
kubevirt.io/domain: ubuntu-bionic
spec:
domain:
cpu:
cores: 1
devices:
disks:
- name: containervolume
disk:
bus: virtio
- name: cloudinitvolume
disk:
bus: virtio
interfaces:
- name: default
masquerade: {}
resources:
requests:
memory: 2048M
networks:
- name: default
pod: {}
volumes:
- name: containervolume
containerDisk:
image: tedezed/ubuntu-container-disk:20.0
- name: cloudinitvolume
cloudInitNoCloud:
userData: |-
#cloud-config
chpasswd:
list: |
ubuntu:ubuntu
root:toor
expire: False
[root@node1 ~]# kubectl create -f myvm.yml
virtualmachine.kubevirt.io/ubuntu-bionic created
State is Scheduling...
[root@node1 ~]# kubectl get vmis -A -o wide
NAMESPACE NAME AGE PHASE IP NODENAME READY LIVE-MIGRATABLE PAUSED
default ubuntu-bionic 9s Scheduling FalseListing vmis…
[root@k8s1 kubespray]# kubectl get vmis -A -o wide
NAMESPACE NAME AGE PHASE IP NODENAME READY LIVE-MIGRATABLE PAUSED
default my-vm 5m38s Running 10.233.88.188 k8s3 True False
[root@node1 ~]# kubectl get vmis -A -o wide
NAMESPACE NAME AGE PHASE IP NODENAME READY LIVE-MIGRATABLE PAUSED
default ubuntu-bionic 36s Running 10.233.64.20 node1 True True
[root@node1 ~]# ping 10.233.64.20
PING 10.233.64.20 (10.233.64.20) 56(84) bytes of data.
64 bytes from 10.233.64.20: icmp_seq=1 ttl=62 time=0.750 ms
64 bytes from 10.233.64.20: icmp_seq=2 ttl=62 time=0.537 msNow that the VM is pingable, it’s time to SSH into it.
By default, this image doesn’t have SSH enabled (password authentication on the SSH daemon is probably disabled). So I connect to via console to change PasswordAuthentication in /etc/ssh/sshd_config
[root@node1 ~]# kubectl get vmis
NAME AGE PHASE IP NODENAME READY
ubuntu-bionic 10m Running 10.233.64.20 node1 True
[root@node1 ~]# virtctl console 10.233.64.20
virtualmachineinstance.kubevirt.io "10.233.64.20" not found
[root@node1 ~]#
[root@node1 ~]#
[root@node1 ~]# kubectl get vmis
NAME AGE PHASE IP NODENAME READY
ubuntu-bionic 10m Running 10.233.64.20 node1 True
[root@node1 ~]# virtctl console ubuntu-bionic
Successfully connected to ubuntu-bionic console. The escape sequence is ^]
Password:
Login incorrect
ubuntu-bionic login: ubuntu
Password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-73-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Sat Dec 7 18:08:04 UTC 2024
System load: 0.0 Processes: 105
Usage of /: 63.9% of 1.96GB Users logged in: 0
Memory usage: 9% IPv4 address for enp1s0: 10.0.2.2
Swap usage: 0%
1 update can be applied immediately.
To see these additional updates run: apt list --upgradable
The list of available updates is more than a week old.
To check for new updates run: sudo apt update
Failed to connect to https://changelogs.ubuntu.com/meta-release-lts. Check your Internet connection or proxy settings
Last login: Sat Dec 7 18:01:04 UTC 2024 on ttyS0
ubuntu@ubuntu-bionic:~$ sudo su -
root@ubuntu-bionic:~# systemctl restart sshd
root@ubuntu-bionic:~#
root@ubuntu-bionic:~# cat /etc/ssh/sshd_config | grep -i password
#PermitRootLogin prohibit-password
# To disable tunneled clear text passwords, change to no here!
PasswordAuthentication yesI can try using SSH now
[root@node1 ~]# kubectl get vmis
NAME AGE PHASE IP NODENAME READY
ubuntu-bionic 12m Running 10.233.64.20 node1 True
[root@node1 ~]# ssh [email protected]
[email protected]'s password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 5.4.0-73-generic x86_64)Thank you for having been there. I will continue with part 2!
La cosa mi crea un senso di confusione per cui meglio procedere sistemando la situazione.
Inizierò usando podman-generate-systemd ma è deprecato (lo trovavo molto comodo) in favore di Podman Quadlet dalla versione 4.4 di Podman. In realtà mi ci devo abituare perché in effetti è molto più sensato e ci permette di definire il container stesso nella unit Systemd. Come riportato nell’articolo https://blogs.gnome.org/alexl/2021/10/12/quadlet-an-easier-way-to-run-system-containers/ di Alexander Larsson verrebbe più o meno così:
[Unit]
Description=Redis container
[Container]
Image=docker.io/redis
PublishPort=6379:6379
User=999
[Service]
Restart=always
[Install]
WantedBy=local.targetAlla vecchia maniera ho dovuto svolgere i seguenti passi che lascio per chi dovesse avere una versione antecedente alla 4.4 di Podman.
Prima di tutto prendere la lista di tutti in container running sul nodo con un for per generare i file .service.
[root@web01]:~ >> mkdir my_systemd_units
[root@web01]:~ >>
[root@web01]:~ >>
[root@web01]:~ >>
[root@web01]:~ >> cd my_systemd_units/
[root@web01]:~/my_systemd_units >> for i in $(podman ps --format '{{.Names}}' | grep -v infra); do podman generate systemd --restart-policy=always --new --files --name -t 1 $i; done
Please refer to podman-systemd.unit(5) for details.
/root/container-mysql.service
Please refer to podman-systemd.unit(5) for details.
/root/container-devopstribe.service
Please refer to podman-systemd.unit(5) for details.
/root/container-cartediaccollo2.service
Please refer to podman-systemd.unit(5) for details.
/root/container-mongodb.service
Please refer to podman-systemd.unit(5) for details.
/root/container-grafana.service
Please refer to podman-systemd.unit(5) for details.
/root/container-registry.service
Please refer to podman-systemd.unit(5) for details.
/root/container-prometheus.service
[root@web01]:~/my_systemd_units >> cp *.service /usr/lib/systemd/system/
[root@web01]:~/my_systemd_units >> Riavvio i servizi e li abilito al boot
[root@web01]:~/my_systemd_units >> for i in $(ls -lart /usr/lib/systemd/system/ | grep 'container-' | awk '{ print $9}'); do systemctl restart $i && systemctl enable $i; done
See system logs and 'systemctl status [email protected]' for details.
Created symlink /etc/systemd/system/default.target.wants/container-registry.service → /usr/lib/systemd/system/container-registry.service.
Created symlink /etc/systemd/system/default.target.wants/container-prometheus.service → /usr/lib/systemd/system/container-prometheus.service.
Created symlink /etc/systemd/system/default.target.wants/container-mysql.service → /usr/lib/systemd/system/container-mysql.service.
Created symlink /etc/systemd/system/default.target.wants/container-mongodb.service → /usr/lib/systemd/system/container-mongodb.service.
Created symlink /etc/systemd/system/default.target.wants/container-grafana.service → /usr/lib/systemd/system/container-grafana.service.
Created symlink /etc/systemd/system/default.target.wants/container-devopstribe.service → /usr/lib/systemd/system/container-devopstribe.service.
Created symlink /etc/systemd/system/default.target.wants/container-cartediaccollo2.service → /usr/lib/systemd/system/container-cartediaccollo2.service.Controllo che sia tutto running da systemctl
[root@web01]:~/my_systemd_units >> for i in $(ls -lart /usr/lib/systemd/system/ | grep 'container-' | awk '{ print $9}'); do systemctl status $i; done
Failed to get properties: Unit name [email protected] is neither a valid invocation ID nor unit name.
● container-registry.service - Podman container-registry.service
Loaded: loaded (/usr/lib/systemd/system/container-registry.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-11-12 17:58:46 UTC; 2min 6s ago
Docs: man:podman-generate-systemd(1)
Main PID: 2542077 (conmon)
Tasks: 1 (limit: 22914)
Memory: 1.3M
CGroup: /system.slice/container-registry.service
└─2542077 /usr/bin/conmon --api-version 1 -c 91c8e4006588b0c0595660280cde6b54560e5896cbeec7ce2e2d56ec739052f1 -u 91c8e4006588b0c0595660280cde6b54560e5896cbeec7ce2e2d56ec739052f1 -r /usr/bin/runc -b /var/lib/con>
Nov 12 17:58:45 web01 systemd[1]: Starting Podman container-registry.service...
Nov 12 17:58:46 web01 systemd[1]: Started Podman container-registry.service.
Nov 12 17:58:46 web01 podman[2541923]: 91c8e4006588b0c0595660280cde6b54560e5896cbeec7ce2e2d56ec739052f1
● container-prometheus.service - Podman container-prometheus.service
Loaded: loaded (/usr/lib/systemd/system/container-prometheus.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-11-12 17:58:48 UTC; 2min 8s ago
Docs: man:podman-generate-systemd(1)
Main PID: 2542169 (conmon)
Tasks: 1 (limit: 22914)
Memory: 1.7M
CGroup: /system.slice/container-prometheus.service
└─2542169 /usr/bin/conmon --api-version 1 -c 6c3bd4ffe7195989b448ffa6bed8891812912398b39ac4d8a5e6bf278ff64d9f -u 6c3bd4ffe7195989b448ffa6bed8891812912398b39ac4d8a5e6bf278ff64d9f -r /usr/bin/runc -b /var/lib/con>
Nov 12 17:58:47 web01 systemd[1]: Starting Podman container-prometheus.service...
Nov 12 17:58:48 web01 systemd[1]: Started Podman container-prometheus.service.
Nov 12 17:58:48 web01 podman[2542127]: 6c3bd4ffe7195989b448ffa6bed8891812912398b39ac4d8a5e6bf278ff64d9f
● container-mysql.service - Podman container-mysql.service
Loaded: loaded (/usr/lib/systemd/system/container-mysql.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-11-12 17:58:52 UTC; 2min 5s ago
Docs: man:podman-generate-systemd(1)
Main PID: 2542262 (conmon)
Tasks: 1 (limit: 22914)
Memory: 1.2M
CGroup: /system.slice/container-mysql.service
└─2542262 /usr/bin/conmon --api-version 1 -c b8279692cb99652dedfa4d59b88d2ec4d50d8e1c4541e4cc5bf00ad1e32062b2 -u b8279692cb99652dedfa4d59b88d2ec4d50d8e1c4541e4cc5bf00ad1e32062b2 -r /usr/bin/runc -b /var/lib/con>
Nov 12 17:58:49 web01 systemd[1]: Starting Podman container-mysql.service...
Nov 12 17:58:52 web01 systemd[1]: Started Podman container-mysql.service.
Nov 12 17:58:52 web01 podman[2542221]: b8279692cb99652dedfa4d59b88d2ec4d50d8e1c4541e4cc5bf00ad1e32062b2
● container-mongodb.service - Podman container-mongodb.service
Loaded: loaded (/usr/lib/systemd/system/container-mongodb.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-11-12 17:58:56 UTC; 2min 1s ago
Docs: man:podman-generate-systemd(1)
Main PID: 2542589 (conmon)
Tasks: 1 (limit: 22914)
Memory: 1.2M
CGroup: /system.slice/container-mongodb.service
└─2542589 /usr/bin/conmon --api-version 1 -c 289a78dcf214c4c27dac624d4c74a44037697a85f954bb63212c51d15565d99e -u 289a78dcf214c4c27dac624d4c74a44037697a85f954bb63212c51d15565d99e -r /usr/bin/runc -b /var/lib/con>
Nov 12 17:58:53 web01 systemd[1]: Starting Podman container-mongodb.service...
Nov 12 17:58:56 web01 systemd[1]: Started Podman container-mongodb.service.
Nov 12 17:58:56 web01 podman[2542345]: 289a78dcf214c4c27dac624d4c74a44037697a85f954bb63212c51d15565d99e
● container-grafana.service - Podman container-grafana.service
Loaded: loaded (/usr/lib/systemd/system/container-grafana.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-11-12 17:59:00 UTC; 1min 58s ago
Docs: man:podman-generate-systemd(1)
Main PID: 2542713 (conmon)
Tasks: 1 (limit: 22914)
Memory: 1.2M
CGroup: /system.slice/container-grafana.service
└─2542713 /usr/bin/conmon --api-version 1 -c bc437bff8a6a9548d72f22d75dc9bfb97cf60d1f9b1bd5b5add5b3197e3778c9 -u bc437bff8a6a9548d72f22d75dc9bfb97cf60d1f9b1bd5b5add5b3197e3778c9 -r /usr/bin/runc -b /var/lib/con>
Nov 12 17:58:57 web01 systemd[1]: Starting Podman container-grafana.service...
Nov 12 17:59:00 web01 systemd[1]: Started Podman container-grafana.service.
Nov 12 17:59:00 web01 podman[2542652]: bc437bff8a6a9548d72f22d75dc9bfb97cf60d1f9b1bd5b5add5b3197e3778c9
● container-devopstribe.service - Podman container-devopstribe.service
Loaded: loaded (/usr/lib/systemd/system/container-devopstribe.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-11-12 17:59:05 UTC; 1min 53s ago
Docs: man:podman-generate-systemd(1)
Main PID: 2542851 (conmon)
Tasks: 1 (limit: 22914)
Memory: 2.6M
CGroup: /system.slice/container-devopstribe.service
└─2542851 /usr/bin/conmon --api-version 1 -c c044fc2a723700585572e34d889425266f12b9c226b3f86dd8921c0b54979aed -u c044fc2a723700585572e34d889425266f12b9c226b3f86dd8921c0b54979aed -r /usr/bin/runc -b /var/lib/con>
Nov 12 17:59:00 web01 systemd[1]: Starting Podman container-devopstribe.service...
Nov 12 17:59:05 web01 systemd[1]: Started Podman container-devopstribe.service.
Nov 12 17:59:05 web01 podman[2542771]: c044fc2a723700585572e34d889425266f12b9c226b3f86dd8921c0b54979aed
● container-cartediaccollo2.service - Podman container-cartediaccollo2.service
Loaded: loaded (/usr/lib/systemd/system/container-cartediaccollo2.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2024-11-12 17:59:10 UTC; 1min 48s ago
Docs: man:podman-generate-systemd(1)
Main PID: 2543177 (conmon)
Tasks: 1 (limit: 22914)
Memory: 1.2M
CGroup: /system.slice/container-cartediaccollo2.service
└─2543177 /usr/bin/conmon --api-version 1 -c fc9be83b3cc3514d0439a47badc195c358c14f77e6c209c77394281255327f57 -u fc9be83b3cc3514d0439a47badc195c358c14f77e6c209c77394281255327f57 -r /usr/bin/runc -b /var/lib/con>
Nov 12 17:59:08 web01 systemd[1]: container-cartediaccollo2.service: Failed with result 'exit-code'.
Nov 12 17:59:08 web01 systemd[1]: Stopped Podman container-cartediaccollo2.service.
Nov 12 17:59:08 web01 systemd[1]: Starting Podman container-cartediaccollo2.service...
Nov 12 17:59:10 web01 systemd[1]: Started Podman container-cartediaccollo2.service.
Nov 12 17:59:10 web01 podman[2543019]: fc9be83b3cc3514d0439a47badc195c358c14f77e6c209c77394281255327f57Come sarebbe usando Podman Quadlet?
Come riportato anche in questo articolo https://www.redhat.com/en/blog/quadlet-podman con Quadlet è possibile istrumentare delle unit Systemd che abbiano al loro interno direttamente i parametri che esprimono i nostri container… Ne riporto di seguito un estratto.
| ContainerName=name | –name name |
| ContainersConfModule=/etc/nvd.conf | –module=/etc/nvd.conf |
| DNS=192.168.55.1 | –dns=192.168.55.1 |
| DNSOption=ndots:1 | –dns-option=ndots:1 |
| DNSSearch=example.com | –dns-search example.com |
| DropCapability=CAP | –cap-drop=CAP |
| Entrypoint=/foo.sh | –entrypoint=/foo.sh |
| Environment=foo=bar | –env foo=bar |
| EnvironmentFile=/tmp/env | –env-file /tmp/env |
| EnvironmentHost=true | –env-host |
| Exec=/usr/bin/command | Command after image specification – /usr/bin/command |
Ricapitolando, una unit system verrebbe più o meno così:
[Unit]
Description=The sleep container
After=local-fs.target
[Container]
Image=registry.access.redhat.com/ubi9-minimal:latest
Exec=sleep 1000
[Install]
# Start by default on boot
WantedBy=multi-user.target default.targetSupporta file .kube (manifest di pod Kubernetes) .network (container network) .container (definizione container) .volume (volumi per la persistenza dei container)
Non andiamo più a definire nelle unit .service dei container espandendo il comando “podman run… ” sostanzialmente, ma andiamo ad esprimere una unit che definisce i parametri necessari al container.
Direi che è molto utile e come sempre, per alcuni tipi di workload e quando non è necessario usare Kubernetes, anche delle VMs con Podman vanno più che bene.
A presto!
]]>Lo scopo è molto semplice, vorrei una notifica qualora qualcuno creasse una carta di accollo al fine di capire se mi stanno dossando (non è vero, per quello uso altri strumenti ma mi serve una scusa per impostare il tutto).
Siccome espongo i miei servizi con HaProxy direi che potrei usare le loggate per individuare le chiamate POST che creano le card. Il Grok Exporter è un progetto molto utile: trasforma in metriche per Prometheus il parsing dei log.
Per prima cosa lo installo in /opt/grok e gli do un file di configurazione molto semplice…
global:
config_version: 3
input:
type: file
path: /var/log/haproxy.log
readall: true
imports:
- type: grok_patterns
dir: ./logstash-patterns-core/patterns
metrics:
- type: counter
name: grok_post_cartadiaccollo_lines_total
help: Counter metric example with labels.
match: '.*302.*POST /cartadiaccollo.*'
server:
port: 9144
Poi creo una unit Systemd di tipo service per trattarlo come un servizio Linux (file grok_exporter.service)
[Unit]
Description=Grok Exporter Service
After=network.target
[Service]
User=root
Group=root
WorkingDirectory=/opt/grok_exporter
ExecStart=/opt/grok_exporter -config /opt/config.yml
Restart=on-failure
[Install]
WantedBy=multi-user.targetLo avvio con systemctl start grok_exporter e controllo se il servizio è running.
$ root@ns304365 (~) > systemctl status grok_exporter.service
● grok_exporter.service - Grok Exporter Service
Loaded: loaded (/etc/systemd/system/grok_exporter.service; disabled; preset: enabled)
Active: active (running) since Sun 2024-09-01 08:20:53 UTC; 1 day 10h ago
Main PID: 4039639 (grok_exporter)
Tasks: 13 (limit: 19100)
Memory: 9.4M
CPU: 7min 1.362s
CGroup: /system.slice/grok_exporter.service
└─4039639 /opt/grok_exporter -config /root/grok_exporter/config.yml
Sep 01 08:20:53 ns304365 systemd[1]: Started grok_exporter.service - Grok Exporter Service.
Sep 01 08:20:53 ns304365 grok_exporter[4039639]: Starting server on http://ns304365:9144/metricsPer provare il suo funzionamento basta un curl verso localhost su porta 9144
$ root@ns304365 (~) > curl http://localhost:9144/metrics -s | grep accollo
grok_exporter_line_processing_errors_total{metric="grok_post_cartadiaccollo_lines_total"} 0
grok_exporter_lines_matching_total{metric="grok_post_cartadiaccollo_lines_total"} 8
grok_exporter_lines_processing_time_microseconds_total{metric="grok_post_cartadiaccollo_lines_total"} 169
# HELP grok_post_cartadiaccollo_lines_total Counter metric example with labels.
# TYPE grok_post_cartadiaccollo_lines_total counter
grok_post_cartadiaccollo_lines_total 8Al cambiamento di stato, ovvero all’aggiunta di una nuova riga di log in haproxy.log intercettata da Grok, la metrica grok_post_cartadiaccollo_lines_total cambia per cui mi basta confrontarla con quella ottenuta in un controllo precedente.
Non ho voglia di scrivere troppo codice, basteranno un po’ di righe di bash
$ root@ns304365 (~) > cat telegram_notifications/notify.sh
#!/bin/bash
# Set the API token and chat ID
API_TOKEN="***"
CHAT_ID="***"
check_cartadiaccollo=$(curl -s http://localhost:9144/metrics | grep '^grok_post_cartadiaccollo_lines_total\ [0-9]*')
ls check_cartadiaccollo.lock || echo $check_cartadiaccollo > check_cartadiaccollo.lock
check_cartadiaccollo_lock=$(cat check_cartadiaccollo.lock)
while true
do
if [ "$check_cartadiaccollo" != "$check_cartadiaccollo_lock" ]; then
echo "Metrica grok_post_cartadiaccollo_lines_total cambiata, inviare notifica Telegram"
MESSAGE='Warning, a new carta di accollo has just been issued!'
curl -s -X POST https://api.telegram.org/bot$API_TOKEN/sendMessage -d chat_id=$CHAT_ID -d text="$MESSAGE"
echo $check_cartadiaccollo > check_cartadiaccollo.lock
fi
sleep 2
done
A questo punto creo una unit Systemd anche per il mio script bash per gestire il servizio notify_telegram.service
$ root@ns304365 (~) > cat /etc/systemd/system/notify_telegram.service
[Unit]
Description=My Telegram Notifications
After=network.target
[Service]
User=root
Group=root
WorkingDirectory=/root/telegram_notifications
ExecStart=/root/telegram_notifications/notify.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target$ root@ns304365 (~) > systemctl status notify_telegram.service
● notify_telegram.service - My Telegram Notifications
Loaded: loaded (/etc/systemd/system/notify_telegram.service; disabled; preset: enabled)
Active: active (running) since Sun 2024-09-01 20:16:28 UTC; 22h ago
Main PID: 376330 (notify.sh)
Tasks: 2 (limit: 19100)
Memory: 1.1M
CPU: 32min 52.345s
CGroup: /system.slice/notify_telegram.service
├─ 376330 /bin/bash /opt/telegram_notifications/notify.sh
└─1255329 sleep 2

L’obiettivo di questo elaborato è fornire al lettore un percorso che spieghi il perché il software open-source e la collaborazione fra individui liberi è l’elemento chiave per proteggere e tenere al sicuro i dati personali e la propria privacy. L’ambito “sicurezza” nel mondo IT ha molte sfaccettature per cui non avrebbe senso fornire al lettore una visione d’insieme a 360°. Vengono quindi declinati concetti, pratiche e tool dal punto di vista di chi gestisce ed evolve infrastrutture più o meno complesse ed ha solide basi di networking, amministrazioni di sistemi e integrazioni tramite automatismi. L’elemento cardine che sarà presente in molti dei prossimi capitoli è la filosofia open-source che ha svolto un ruolo chiave nella diffusione di internet fin dai suoi albori e che ad oggi, nel 2023, sta mutando alcune sue forme per adattarsi alle sfide che il progresso tecnologico sta attualmente presentando.
Terminologia
Si ritiene opportuno fornire al lettore una visione di insieme della terminologia utilizzata in questo elaborato o relativo alle aree prese in considerazione.
| Acronimo / Termine | Definizione |
| AFS | Apache Software Foundation |
| BSD | Berkeley Software Distribution o Berkeley Standard Distribution |
| CI/CD | Continuous Integration and Delivery |
| CNCF | Cloud Native Computing Foundation |
| DevSecOps | Development, Security, and Operations |
| FOSS | Free and open-source software |
| FSF | Free Software Foundation |
| GNU | GNU’s not Unix |
| GPG | GNU Privacy Guard |
| GPL | General Public License |
| HTTP | Hypertext Transfer Protocol (HTTP) |
| K8S | Kubernetes |
| NIST | National Institute of Standards and Technology |
| OCI | Open Container Initiative |
| PMC | Project Management Committee |
| TOCP | Technical Oversight Committee |
Dal progetto GNU/Linux alla Cloud Native Computing Foundation
Scrivere codice open-source significa distribuire pubblicamente il codice sorgente di un progetto software per godere dei vantaggi derivanti da una comunità di utenti che contribuiscono all’evoluzione del progetto stesso. All’interno di questo elaborato viene spiegato perché il software open source è sicuro e in quali ambiti del mondo DevOps viene utilizzato per effettuare enforcing di piattaforme entreprise.
Non è possibile parlare di open-source senza citare alcune persone (programmatori, filosofi e pionieri) e tecnologie che hanno sicuramente segnato la storia di questo movimento culturale e rivoluzionario.
Il progetto GNU/Linux è probabilmente la massima espressione ed è bassato fondamentalmente su due progetti che hanno segnato la storia dei sistemi operativi liberi, di internet e del pensiero filosofico che ruota attorno al software libero.
In rete è presente una grande raccolta di materiale dedicato al progetto GNU/Linux ma si è scelto all’interno di questo elaborato di consigliare al lettore la visione di Revolution OS, film documentario che descrive la storia e l’evoluzione del progetto.
In particolare Linuxs Torvalds descrive lo sviluppo del Kernel Linux, la controversia sul nome GNU/Linux, l’ulteriore evoluzione di Linux e la sua commercializzazione.
Non mancano riferimenti ad altri progetti importanti, sempre open source, come Apache HTTP Server, il primo web server che fu largamente distribuito e tuttora utilizzato.
L’intero film mostra in progressione le linee del kernel Linux di codice che incrementano negli anni.
Possiamo immaginare Linux Torvald e Richard Stallman come facenti parte di un binomio tecnologico e culturale che ha dato il via a quello che è attualmente il sistema operativo più usato in ambito server e in realtà enterprise.
Viene anche segnalato questo il TED talk “The mind behind Linux” reperibile al seguente indirizzo https://youtu.be/o8NPllzkFhE?si=8kbVbjFZsPVMn9QW
Linus Torvalds, oltre ad aver creato il Kernel Linux e diretto la community di sviluppatori attorno al progetto è stato anche il creatore di GIT, il tool di versioning del codice standard de-facto utilizzato dalla maggior parte dei programmatori di tutto il mondo. Il concetto chiave è che Torvalds per gestire in modo distribuito il suo progetto (dal punto di vista dello sviluppo) ha creato un ulteriore elemento chiave per le comunità, ovvero GIT.
Nel suo TED Talk, Linus Torvalds, il creatore del kernel Linux e di Git, ci offre uno spaccato della sua mente e del suo approccio al lavoro e alla vita. Non si definisce un visionario, ma piuttosto un ingegnere pragmatico, con i piedi ben piantati a terra. Il suo obiettivo è risolvere problemi concreti, “sistemare la buca davanti a me prima di finirci dentro”, come lui stesso dice.
Linux e GIT
Il pragmatismo di Torvalds ha dato vita a due progetti rivoluzionari: Linux e Git. Il kernel Linux, rilasciato come software open source nel 1991, ha dato vita a una famiglia di sistemi operativi che oggi alimenta la maggior parte dei server e dei dispositivi embedded del mondo. Git, nato nel 2005, ha rivoluzionato il modo in cui gli sviluppatori collaborano ai progetti software, diventando il sistema di gestione del codice sorgente più utilizzato al mondo. Torvalds è noto per il suo stile di leadership diretto e schietto. Non ha paura di criticare le idee che ritiene sbagliate, e crede fermamente nel merito e nella collaborazione aperta. Il suo pragmatismo si traduce in un approccio all’innovazione basato sul fare, sul risolvere problemi concreti, senza perdersi in visioni grandiose ma poco realistiche. Il suo lavoro ha avuto un impatto enorme sull’industria tecnologica. Ha contribuito a rendere il software più libero, aperto e accessibile, dimostrando che la perseveranza e una genialità nella scrittura del codice sorgente possono portare a grandi successi. Il TED Talk sopracitato è una fonte di ispirazione per chiunque voglia avere un impatto positivo sul mondo, un invito a rimboccarsi le maniche e a concentrarsi sul fare, passo dopo passo. Le idee di Torvalds sono semplici, ma potenti. Ci insegnano che non è necessario essere un visionario per fare la differenza. Il pragmatismo, la dedizione al lavoro e la collaborazione aperta sono armi potenti che possono portare a grandi risultati. Il suo esempio ci dimostra che è possibile cambiare il mondo, un problema alla volta, con tenacia e umiltà.
La Free Software Foundation (FSF)
La Free Software Foundation (FSF) è un’organizzazione senza scopo di lucro che si impegna a promuovere la libertà degli utenti di computer in tutto il mondo. La missione principale della FSF è difendere i diritti di tutti gli utenti di software.
Con il crescente ruolo della tecnologia informatica nella nostra società, i software che utilizziamo giocano un ruolo cruciale nel determinare il futuro di una società libera. La FSF sostiene che il software libero permette di mantenere il controllo sulla tecnologia utilizzata nelle nostre case, scuole e luoghi di lavoro. Questo implica che i computer lavorano per il beneficio individuale e collettivo degli utenti, e non sono soggetti al controllo di compagnie di software proprietari o governi che potrebbero cercare di limitare o monitorare le attività. La Free Software Foundation si impegna a utilizzare esclusivamente software libero per svolgere il proprio lavoro. L’organizzazione lavora attivamente per garantire la libertà degli utenti informatici promuovendo lo sviluppo e l’uso di software e documentazione liberi. Questo include in particolare il sistema operativo GNU. La FSF conduce campagne contro minacce alla libertà degli utenti informatici, come le Restrizioni dei Diritti Digitali (DRM) e i brevetti sui software.
Supporta finanziariamente il progetto GNU, che rappresenta un costante sforzo nel fornire un sistema operativo distribuito con licenze di software libero. L’organizzazione sponsorizza e promuove importanti sviluppi nel software libero e fornisce servizi di sviluppo ai manutentori del software GNU, inclusi servizi di posta elettronica, shell e mailing list. La FSF è impegnata a facilitare il contributo volontario al lavoro, anche attraverso la sponsorizzazione di Savannah (https://savannah.gnu.org/), il repository del codice sorgente e il centro per gli sviluppi del software libero. La FSF detiene il copyright su gran parte del sistema operativo GNU e su altri software liberi. Questo copyright è utilizzato per difendere il software libero da tentativi di rendere il software proprietario. Ogni anno, l’organizzazione riceve migliaia di assegnazioni di copyright da parte di sviluppatori individuali e organizzazioni che lavorano sul software libero. La FSF registra questi copyright attraverso l’ufficio copyright degli Stati Uniti e applica le licenze, tipicamente la GNU General Public License, sotto cui distribuisce il software libero. Questo lavoro è svolto attraverso il Free Software Licensing and Compliance Lab.
La FSF pubblica alcune delle licenze software libero più importanti, tra cui:
- GNU General Public License (GNU GPL)
- GNU Lesser General Public License (GNU LGPL)
- GNU Affero General Public License (GNU AGPL)
- GNU Free Document License (GNU FDL)
Queste licenze sono progettate per promuovere e preservare la libertà del software. Per ulteriori informazioni sulle licenze e questioni correlate, è possibile consultare il sito web della FSF (https://www.fsf.org/). Offre inoltre risorse significative alla comunità, tra cui la FSF/UNESCO Free Software Directory, che rappresenta un’importante fonte di informazioni sul software libero.
Il movimento del software libero si distingue come uno dei movimenti sociali più riusciti nati dalla cultura informatica. È guidato da una comunità internazionale di programmatori etici dedicati alla causa della libertà e della condivisione. Tuttavia, il successo finale del movimento del software libero dipende dalla consapevolezza diffusa tra amici, vicini e colleghi riguardo ai pericoli connessi all’uso di software non libero e alla minaccia di una società che perde il controllo dei propri computer.
Progetti notevoli della Free Software Foundation
– GNU Compiler Collection (GCC): un compilatore per diversi linguaggi di programmazione, tra cui C, C++, Java, Fortran e Ada. È utilizzato per creare software libero e open source per una varietà di piattaforme.
– GNU Debugger (GDB): un debugger utilizzato per trovare e correggere bug nei programmi. Permette di esaminare il codice sorgente, impostare breakpoint e valutare le variabili.
– GNU Binutils: una suite di strumenti per il lavoro con file binari. Include programmi per l’assemblaggio, il disassemblaggio, il linking e l’analisi di file binari.
– GNU Make: un programma utilizzato per automatizzare la costruzione di software. Permette di definire le dipendenze tra i file e di specificare le istruzioni per la compilazione e l’assemblaggio.
– GNU Autotools: una suite di strumenti per la creazione di software portabile. Permette di scrivere script che configurano automaticamente il software per diverse piattaforme.
– Emacs: un editor di testo potente e personalizzabile. È utilizzato da sviluppatori e sysadmin per la sua efficienza e flessibilità.
– GIMP: un programma di editing di immagini gratuito e open source. Offre una vasta gamma di funzionalità per la modifica di foto, la creazione di grafiche e il disegno.
– Inkscape: un programma di grafica vettoriale gratuito e open source. Permette di creare illustrazioni, loghi, icone e altri tipi di grafica vettoriale.
– LibreOffice: una suite per ufficio gratuita e open source che comprende un elaboratore di testi, un foglio di calcolo, un programma di presentazione e altro ancora. È compatibile con Microsoft Office e offre una vasta gamma di funzionalità.
Altri strumenti notevoli:
- GNU grep: tool per la ricerca di stringhe di testo in file.
- GNU sed: tool per la modifica di file di testo.
- GNU diff: tool per confrontare due file di testo.
- GNU patch: tool per applicare patch a file di testo.
- GNU wget: tool per scaricare file da Internet.
- GNU curl: tool per trasferire dati tra computer.
- GNU tar: tool per archiviare e comprimere file.
Questi sono solo alcuni degli strumenti notevoli presenti nella Free Software Foundation. Per un elenco completo, visitare il sito web della Free Software Foundation.
L’Apache Software Foundation
Dagli umili inizi con meno di una dozzina di ingegneri del software che condividevano patch di codice via e-mail nel febbraio del 1995, alla costituzione dell’ASF nel giugno del 1999, agli anni di lenta crescita quando il concetto di open source si è diffuso nel gergo quotidiano, all’ASF di oggi con centinaia di progetti che abbracciano lo spettro tecnologico, la storia dell’ASF riguarda davvero la crescita delle sue comunità.
L’ASF è stata costituita nel 1999 come organizzazione no-profit dagli otto sviluppatori originali noti collettivamente come “il gruppo Apache”. Ciò ha garantito che il progetto HTTP originale e tutti i progetti successivi continuassero ad esistere al di là della partecipazione dei singoli volontari. Il cofondatore di ASF Brian Behlendorf ha utilizzato per primo il nome “Apache” per il server. L’uso del nome “Apache” dimostra apprezzamento per le persone e le tribù che si definiscono “Apache”. Man mano che il server HTTP Apache cresceva dalle patch applicate al server NCSA, un gioco di parole sul nome si diffuse rapidamente tra i membri della comunità, con la voce che “Apache” in realtà stava per “un server ‘irregolare'”. Con il passare del tempo, la popolarità della storia di “A Patchy Server” è cresciuta: le voci sono diventate tradizione, e la tradizione è diventata leggenda.
Il successo della tecnologia collaborativa e meritocratica dell’ASF e il processo di sviluppo comunitario noto come “The Apache Way” sono altamente emulati da altre fondazioni open source e oggetto di numerosi casi di studio del settore e programmi di studio delle business school. Ogni progetto Apache è supervisionato da un Project Management Committee (PMC), un team auto selezionato di contributori attivi che guida le operazioni quotidiane del progetto, compreso lo sviluppo della comunità e il rilascio dei prodotti.
Miliardi di utenti beneficiano del software open source disponibile gratuitamente di ASF: innumerevoli applicazioni software non sviluppate da ASF sono state distribuite secondo i termini della popolare licenza Apache business-friendly. Consentendo l’utilizzo del codice sorgente per lo sviluppo di qualsiasi software, sia open source che proprietario, la licenza Apache semplifica l’implementazione e la distribuzione dei prodotti Apache per tutti gli utenti. La Fondazione fornisce supporto organizzativo, legale e finanziario per l’incubazione e lo sviluppo di nuovi progetti e riduce al minimo la potenziale esposizione legale della proprietà intellettuale e dei contributi finanziari.
La comunità Apache partecipa attivamente alle mailing list ASF, alle iniziative di mentoring e ad ApacheCon, la conferenza ufficiale degli utenti, i corsi di formazione e l’esposizione. Questo evento di punta, ora noto come Community Over Code, insieme a eventi più piccoli come Apache Roadshow, continua ad attirare partecipanti da tutto il mondo per abbracciare la “tecnologia di domani” attraverso opportunità educative, di collaborazione e di networking senza precedenti.
In quanto organizzazione di beneficenza, l’ASF è finanziata attraverso contributi deducibili dalle tasse di società, fondazioni e privati. L’ASF gestisce un’operazione molto snella, spendendo il 10% o meno in spese generali. I servizi di supporto per le infrastrutture critiche mantengono la larghezza di banda, la connettività, i server e l’hardware Apache in esecuzione 24 ore su 24, 7 giorni su 7, 365 giorni all’anno con un tempo di attività prossimo al 100%. Le donazioni all’ASF aiutano anche a compensare le spese operative quotidiane come servizi legali e contabili, gestione del marchio, pubbliche relazioni e spese generali d’ufficio.
Progetti notevoli dell’Apache Software Foundation
– Apache HTTP Server: il server web più utilizzato al mondo, utilizzato da siti web come Google, Facebook e Wikipedia.
– Apache Tomcat: un server di applicazioni Java open source utilizzato per la distribuzione di applicazioni web Java.
– Apache Hadoop: un framework open source per l’elaborazione distribuita di grandi volumi di dati.
– Apache Spark: un framework open source per l’elaborazione distribuita di dati su cluster di computer.
– Apache Kafka: una piattaforma di streaming di dati distribuita open source.
– Apache Cassandra: un database NoSQL distribuito open source.
– Apache Solr: un motore di ricerca open source basato su Apache Lucene.
– Apache Maven: un tool di gestione delle build per progetti Java.
– Apache Ant: un altro tool di gestione delle build per progetti Java.
– Apache Subversion: un sistema di controllo delle versioni open source.
Altri strumenti notevoli:
- Apache Commons: una libreria di utilità Java open source.
- Apache Axis: un framework per la creazione di Web service.
- Apache CXF: un altro framework per la creazione di Web service.
- Apache James: un server di posta elettronica open source.
- Apache SpamAssassin: un filtro antispam open source.
- Apache OpenOffice: una suite per ufficio open source.
- Apache POI: una libreria Java per la lettura e la scrittura di file di Microsoft Office.
Questi sono solo alcuni degli strumenti notevoli dell’Apache Software Foundation. Per un elenco completo, visitare il sito web dell’Apache Software Foundation.
Note:
- La Apache Software Foundation ospita oltre 350 progetti software open source.
- I progetti Apache sono utilizzati da milioni di persone in tutto il mondo.
- I progetti Apache sono rilasciati sotto la licenza Apache, una licenza open source permissiva.
La Linux Foundation
La Linux Foundation (LF) è un’organizzazione senza scopo di lucro fondata nel 2000 per supportare lo sviluppo di Linux e progetti di software open source. Oltre a fornire un luogo neutrale in cui promuovere lo sviluppo del kernel Linux, LF si dedica alla costruzione di ecosistemi sostenibili attorno a progetti open source per accelerare lo sviluppo tecnologico e incoraggiare l’adozione commerciale. Fondata inizialmente per standardizzare e promuovere il sistema operativo open source kernel Linux come Open Source Development Labs nel 2000, LF è stato formata dalla fusione con Free Standards Group nel 2007. Da allora la fondazione si è evoluta oltre Linux per diventare una “fondazione di fondazioni” che ospita una varietà di progetti che abbracciano argomenti come cloud, networking, blockchain e hardware. La fondazione ospita anche eventi formativi annuali tra la comunità Linux per risolvere le questioni urgenti che affliggono Linux e l’open source, tra cui il Linux Kernel Developers Summit e l’Open Source Summit.
La Cloud Native Computing Foundation
Come parte della Linux Foundation, il CNCF (Cloud Native Computing Foundation) fornisce supporto, supervisione e direzione per progetti cloud nativi in rapida crescita, tra cui Kubernetes, Envoy e Prometheus. Non è possibile non citare la Cloud Native Computing Foundation (CNCF) parlando dell’ecosistema open source attuale. La missione della Fondazione è rendere onnipresente il cloud computing nativo. La definizione nativa del cloud CNCF v1.0 afferma:
Le tecnologie native del cloud consentono alle organizzazioni di creare ed eseguire applicazioni scalabili in ambienti moderni e dinamici come cloud pubblici, privati e ibridi. Containers, mesh di servizi, microservizi, infrastruttura immutabile e API dichiarative esemplificano questo approccio.
Queste tecniche consentono sistemi liberamente accoppiati che sono resilienti, gestibili e osservabili. Combinati con una solida automazione, consentono agli ingegneri di apportare modifiche ad alto impatto frequentemente e in modo prevedibile con il minimo sforzo.
La Cloud Native Computing Foundation cerca di promuovere l’adozione di questo paradigma promuovendo e sostenendo un ecosistema di progetti open source e indipendenti dal fornitore. Democratizziamo modelli all’avanguardia per rendere queste innovazioni accessibili a tutti.
Il ruolo del CNCF
Gestione dei progetti
- Garantire che le tecnologie siano disponibili alla comunità e libere da influenze di parte
- Garantire che il marchio delle tecnologie (marchio e logo) venga curato e utilizzato in modo appropriato dai membri della comunità, con un’enfasi specifica sull’esperienza utente uniforme e su elevati livelli di compatibilità delle applicazioni
La crescita e l’evoluzione dell’ecosistema del CNCF
- Valutare quali tecnologie aggiuntive dovrebbero essere aggiunte per soddisfare la visione delle applicazioni cloud native e lavorare per incoraggiare la comunità a fornirle e integrarle se e solo se avanzano l’agenda generale
- Fornire un modo per promuovere standard tecnici comuni tra i vari pezzi
- Eventi e conferenze, marketing, corsi di formazione e certificazione degli sviluppatori
- Servire la comunità rendendo la tecnologia accessibile e affidabile
La fondazione cerca di offrire una costruzione completamente integrata e qualificata di ciascuno dei pezzi costitutivi, secondo una cadenza ben definita attraverso l’architettura di riferimento.
Il CNCF si impegna quindi a rispettare i seguenti principi:
(a) Veloce è meglio che lento. La fondazione consente ai progetti di progredire ad alta velocità per supportare l’adozione aggressiva da parte degli utenti.
(b) Aperto. La fondazione è aperta e accessibile e opera indipendentemente da specifici interessi di parte. La fondazione accetta tutti i contributori in base al merito dei loro contributi e la tecnologia della fondazione deve essere disponibile a tutti secondo i valori open source. La comunità tecnica e le sue decisioni devono essere trasparenti.
(c) Giusto. La fondazione evita influenze indebite, cattivi comportamenti o processi decisionali “pay-to-play”.
(d) Forte identità tecnica. La fondazione raggiunge e mantiene un elevato grado di identità tecnica condivisa tra i progetti.
(e) Confini chiari. La fondazione deve stabilire obiettivi chiari e, in alcuni casi, quali siano i non-obiettivi della fondazione per consentire ai progetti di coesistere efficacemente e per aiutare l’ecosistema a capire dove concentrarsi per la nuova innovazione.
(f) Scalabile. Capacità di supportare tutte le scale di implementazione, dai piccoli ambienti incentrati sugli sviluppatori alla scala delle imprese e dei fornitori di servizi. Ciò implica che in alcune distribuzioni alcuni componenti opzionali potrebbero non essere distribuiti, ma la progettazione e l’architettura complessive dovrebbero comunque essere applicabili.
(g) Indipendente dalla piattaforma. Le specifiche sviluppate non saranno specifiche della piattaforma in modo tale da poter essere implementate su una varietà di architetture e sistemi operativi.
Il Consiglio di amministrazione del CNCF
Il consiglio di amministrazione della CNCF è responsabile del marketing e di altre attività di supervisione aziendale e delle decisioni di bilancio per la CNCF. Il consiglio di amministrazione non prende decisioni tecniche per il CNCF, oltre a collaborare con il TOC per definire l’ambito generale del CNCF. È responsabile delle seguenti punti.
- Definire e far rispettare la politica relativa all’uso dei marchi e dei diritti d’autore della fondazione
- Dirigere il marketing, inclusa l’evangelizzazione, gli eventi e il coinvolgimento dell’ecosistema
- Creazione ed esecuzione di un programma di conformità del marchio, se lo si desidera
- Supervisionare le operazioni e gli sforzi di qualificazione
- Raccolta fondi e governance finanziaria in generale
Personalità notevoli presenti nel TOC del CNCF
– Amy Unruh: Direttrice esecutiva della Cloud Native Computing Foundation (CNCF). – Dan Kohn: Direttore tecnico della CNCF
– Chris DiBona: Ambasciatore Open Source presso Google e membro del Governing Board della CNCF
– Sam Ramji: CTO di Red Hat e membro del Governing Board della CNCF
– Priyanka Sharma: VP of Developer Relations presso IBM e membro del Governing Board della CNCF
– Matt Farina: VP of Engineering presso Red Hat e membro del Governing Board della CNCF
– Arpit Shrivastava: Chief Architect presso VMware e membro del Governing Board della CNCF
– Michael Hausenblas: Senior Staff Engineer presso Google e membro del Governing Board della CNCF
– Tim Hockin: Principal Engineer presso Google e membro del Governing Board della CNCF
– Liz Fong-Jones: Senior Engineer presso Microsoft e membro del Governing Board della CNCF.
Altri personaggi notevoli:
- Brendan Burns: Creatore di Kubernetes.
- Kelsey Hightower: Co-fondatore di Kubernetes e CNCF Ambassador.
- Craig McLuckie: CTO di Weaveworks e CNCF Ambassador.
- Cornelia Davis: Principal Engineer presso VMware e CNCF Ambassador.
- Michelle Noorali: Senior Engineer presso Google e CNCF Ambassador.
- Aaron Crickenberger: Staff Engineer presso Google e CNCF Ambassador.
- Michael Irwin: Senior Engineer presso Microsoft e CNCF Ambassador.
Note:
- Il CNCF TOC è composto da oltre 300 membri.
- I membri del TOC sono leader di aziende tecnologiche, organizzazioni no-profit e comunità open source.
- Il TOC è responsabile della governance del CNCF e dei suoi progetti.
Inoltre, il TOC del CNCF include diverse personalità notevoli provenienti da diverse aree del mondo, tra cui:
- Europa: Kelsey Hightower (Regno Unito), Craig McLuckie (Regno Unito), Cornelia Davis (Germania), Michelle Noorali (Germania), Aaron Crickenberger (Germania), Michael Irwin (Germania).
- Asia: Priyanka Sharma (India), Arpit Shrivastava (India).
- America Latina: Liz Fong-Jones (Brasile).
Le varie tipologie di licenze software
La prima distinzione importante sulle tipologie di licenze software è applicabile al concetto di software aperto o chiuso. In entrambi i casi la “proprietà intellettuale” è tutelata da delle apposite licenze. Ebbene anche in caso di software aperto è possibile tutelare il lavoro e il riconoscimento dell’autore di un progetto.
Prima di elencare le varie tipologie di licenze è importante chiarire uno dei concetti chiave come il copyleft.
Il copyleft è la tecnica legale che prevede la concessione di alcune libertà sulle copie di opere protette da copyright, con l’obbligo di mantenere gli stessi diritti nelle opere derivate. In questo senso, le libertà si riferiscono all’uso dell’opera per qualsiasi scopo e alla possibilità di modificare, copiare, condividere e distribuire l’opera, con o senza compenso. Le licenze che implementano il copyleft possono essere utilizzate per mantenere le condizioni di copyright per opere che vanno dal software per computer, ai documenti, all’arte, alle scoperte scientifiche e persino ad alcuni brevetti. Vengono di seguito riportate alcune delle licenze più popolari e più usate dalle community.
| Nome Licenza | Breve descrizione |
| GNU AGPLv3 | I permessi di questa licenza copyleft più forte sono condizionati alla messa a disposizione del codice sorgente completo delle opere concesse in licenza e delle modifiche, che includono opere più ampie che utilizzano un’opera concessa in licenza, sotto la stessa licenza. Gli avvisi di copyright e di licenza devono essere conservati. I collaboratori concedono espressamente i diritti di brevetto. Quando una versione modificata viene utilizzata per fornire un servizio in rete, il codice sorgente completo della versione modificata deve essere reso disponibile. |
| GNU GPLv3 | I permessi di questa licenza con copyleft forte sono condizionati alla messa a disposizione del codice sorgente completo delle opere concesse in licenza e delle modifiche, che includono opere più ampie che utilizzano un’opera concessa in licenza, sotto la stessa licenza. Gli avvisi di copyright e di licenza devono essere conservati. I collaboratori concedono espressamente i diritti di brevetto. |
| GNU LGPLv3 | I permessi di questa licenza copyleft sono condizionati alla messa a disposizione del codice sorgente completo delle opere concesse in licenza e delle modifiche sotto la stessa licenza o la GNU GPLv3. Gli avvisi di copyright e di licenza devono essere conservati. I collaboratori concedono espressamente i diritti di brevetto. Tuttavia, un’opera più ampia che utilizza l’opera concessa in licenza attraverso le interfacce fornite dall’opera concessa in licenza può essere distribuita secondo termini diversi e senza il codice sorgente dell’opera più ampia. |
| Mozilla Public License 2.0 | I permessi di questa licenza con copyleft debole sono condizionati alla messa a disposizione del codice sorgente dei file concessi in licenza e delle modifiche di tali file sotto la stessa licenza (o in alcuni casi, una delle licenze GNU). Gli avvisi di copyright e di licenza devono essere conservati. I collaboratori concedono espressamente i diritti di brevetto. Tuttavia, un’opera più ampia che utilizza il lavoro concesso in licenza può essere distribuita secondo termini diversi e senza il codice sorgente dei file aggiunti nell’opera più ampia. |
| Apache License 2.0 | Una licenza permissiva le cui condizioni principali richiedono la conservazione del copyright e degli avvisi di licenza. I collaboratori concedono espressamente i diritti di brevetto. Le opere concesse in licenza, le modifiche e le opere più ampie possono essere distribuite secondo termini diversi e senza codice sorgente. |
| MIT License | Una licenza permissiva breve e semplice con condizioni che richiedono solo la conservazione del copyright e degli avvisi di licenza. Le opere concesse in licenza, le modifiche e le opere più ampie possono essere distribuite secondo termini diversi e senza codice sorgente. |
| The Unlicense | Una licenza priva di qualsiasi condizione, che dedica le opere al pubblico dominio. Le opere senza licenza, le modifiche e le opere più ampie possono essere distribuite con termini diversi e senza codice sorgente. |
| BSD Lincenses | Le licenze BSD sono una famiglia di licenze di software libero permissive, che impongono restrizioni minime all’uso e alla distribuzione del software coperto. Questo è in contrasto con le licenze copyleft, che hanno requisiti di condivisione. La licenza BSD originale è stata utilizzata per il suo omonimo, la Berkeley Software Distribution (BSD), un sistema operativo simile a Unix. La versione originale è stata successivamente rivista e i suoi discendenti sono chiamati licenze BSD modificate. BSD è sia una licenza che una classe di licenze (generalmente definita BSD-like). La licenza BSD modificata (oggi ampiamente utilizzata) è molto simile alla licenza originariamente utilizzata per la versione BSD di Unix. La licenza BSD è una licenza semplice che richiede semplicemente che tutto il codice mantenga l’avviso di licenza BSD se distribuito in formato di codice sorgente, o che riproduca l’avviso se distribuito in formato binario. La licenza BSD (a differenza di altre licenze, come la GPL) non richiede la distribuzione del codice sorgente. |
Vengono di seguito elencate alcune licenze software più orientate alla protezione della proprietà intellettuale e del business che ruota attorno al progetto. Alcune di esse sono state recentemente applicate a progetti dai vari vendor che detengono il nucleo principale di sviluppatori dei progetti stessi.
| Nome Licenza | Breve Descrizione |
| Business Source License (BSL) | La Business Source License (BSL) è una sorta di via di mezzo tra le licenze open source e quelle per gli utenti finali. La BSL (talvolta abbreviata anche in BUSL) è considerata una licenza source-available, in quanto chiunque può visualizzare o utilizzare il codice concesso in licenza per scopi interni o di test, ma ci sono limitazioni all’uso commerciale. A differenza delle licenze open source, la BSL proibisce che il codice concesso in licenza venga utilizzato in produzione, senza l’esplicita approvazione del licenziante. Tuttavia, analogamente alle licenze open source, il codice sorgente con licenza BSL è pubblicamente disponibile e chiunque è libero di utilizzarlo, modificarlo e/o copiarlo per scopi non produttivi. |
| Server Side Public License (SSPL) | La Server Side Public License (SSPL) è una licenza software disponibile alla fonte introdotta da MongoDB Inc. nel 2018. Include la maggior parte del testo e delle disposizioni della GNU Affero General Public License versione 3 (AGPL v3), ma ne modifica le disposizioni per il software veicolato in rete, richiedendo che chiunque offra le funzionalità di un software con licenza SSPL a terzi come servizio debba rilasciare l’intero codice sorgente, compresi tutti i software, le API e altri software che sarebbero necessari a un utente per eseguire un’istanza del servizio stesso, sotto la SSPL. Al contrario, la disposizione equivalente dell’AGPL v3 copre solo l’opera stessa concessa in licenza. La SSPL non è riconosciuta come software libero da molte parti, tra cui l’Open Source Initiative (OSI) e molti dei principali venditori di Linux, in quanto la suddetta disposizione è discriminatoria nei confronti di specifici campi di utilizzo. |
| European Union Public Licence | L’EUPL (informazioni presenti in https://commission.europa.eu/content/european-union-public-licence_en) è la prima licenza europea per il software libero/open source (FOSS) creata su iniziativa della Commissione europea. È uno strumento legale unico sviluppato in 22 lingue europee e può essere utilizzato da chiunque per la distribuzione di software. Esistono più di 100 altre licenze FOSS. Lo scopo dell’EUPL non è quello di competere con nessuna di queste licenze, ma di incoraggiare una nuova ondata di amministrazioni pubbliche ad abbracciare il modello Free/Open Source per valorizzare il proprio software e la propria conoscenza, a partire dalle stesse istituzioni europee. |
L’Agenzia Per L’Italia Digitale
Lavorando sul mercato italiano è doveroso citare AgID ovvero L’Agenzia Per L’Italia Digitale. È un’agenzia pubblica sottoposta ai poteri di indirizzo e vigilanza del presidente del Consiglio dei ministri o del ministro da lui delegato, svolge le funzioni ed i compiti ad essa attribuiti dalla legge al fine di perseguire il massimo livello di innovazione tecnologica nell’organizzazione e nello sviluppo della pubblica amministrazione e al servizio dei cittadini e delle imprese, nel rispetto dei principi di legalità, imparzialità e trasparenza e secondo criteri di efficienza, economicità ed efficacia.
Compito rilevante dell’AgID è di accreditare o autorizzare i soggetti (pubblici o privati) che svolgono talune attività in ambito digitale (ad esempio conservazione sostitutiva, certificati digitali, marche temporali, PEC, intermediario PagoPA, ecc.).
All’interno della sezione per il design dei servizi sono presenti delle linee guida proprio sull’utilizzo consapevole del software libero.
Le linee guida vertono su acquisizione e riuso di software per le pubbliche amministrazioni indirizzando le amministrazioni nel processo decisionale per l’acquisto di software, la condivisione e il riuso delle soluzioni open source. Promuovono un cambio culturale verso un più ampio utilizzo del software di tipo aperto facendo sì che qualsiasi investimento di una PA sia messo a fattor comune delle altre amministrazioni e della collettività e consentendo di semplificare le scelte di acquisto e gli investimenti in tema di servizi digitali.
- Allegato B: Guida alla pubblicazione open source di software realizzato per la PA (https://docs.italia.it/italia/developers-italia/lg-acquisizione-e-riuso-software-per-pa-docs/it/stabile/attachments/allegato-b-guida-alla-manutenzione-di-software-open-source.html)
- Allegato C: Guida alla manutenzione di software open source (https://docs.italia.it/italia/developers-italia/lg-acquisizione-e-riuso-software-per-pa-docs/it/stabile/attachments/allegato-c-guida-alle-licenze-open-source.html)
- Allegato E: Guida alla modifica di software open source preso a riuso o di terzi (https://docs.italia.it/italia/developers-italia/lg-acquisizione-e-riuso-software-per-pa-docs/it/stabile/attachments/allegato-e-tabella-sinottica-degli-elementi-necessari-al-percorso-decisionale.html)
I concetti chiave esposti in tali linee guida rappresentando un insieme di best practice che sono diffuse tra chi opera nel settore e delineano, le ormai standard, linee guida per mantainer e utilizzatori di progetti open source.
Di seguito quelle più importanti:
- Necessario il controllo delle dipendenze software utilizzate e aggiornarle a seguito di vulnerabilità emerse ed individuate
- Individuazione di un soggetto definito come “mantainer” che avrà quindi la responsabilità dell’evoluzione e del mantenimento del progetto. È necessario che il mantainer interagisca con le commuity afferenti ai tool utilizzati.
- Interagire nei repository GIT dei tool utilizzati aprendo issue o pull request. Questo elemento è fondamentale proprio in ottica di evoluzione comunitaria al software libero.
- Attenta valutazione a seguito di richieste di nuove feature
La scelta della giusta licenza software
Le persone che intendono sviluppare un nuovo tool open source, spesso si chiedono quale licenza si consiglia di utilizzare per il loro progetto. Viene di seguito presentato un modello preso dalla Free Software Foundation. I consigli si applicano alla concessione in licenza di un’opera creata da un individuo, sia che si tratti di una modifica di un’opera esistente o di una nuova opera originale. Non viene affrontato il problema della combinazione di materiale esistente con licenze diverse. Per la maggior parte dei programmi, viene consigliato di utilizzare la versione più recente della GNU General Public License (GPL) . Il suo forte copyleft è appropriato per tutti i tipi di software e include numerose protezioni per la libertà degli utenti.
Per consentire futuri aggiornamenti della licenza, si consiglia di specificare “versione 3 o qualsiasi versione successiva” in modo che il programma sia compatibile con la licenza con il codice che potrebbe essere rilasciato, in futuro, sotto le successive versioni GPL. Non vale la pena usare il copyleft per la maggior parte dei piccoli programmi. Si può fare riferimento a 300 righe di codice. Quando il codice sorgente di un pacchetto software è più breve, i vantaggi forniti dal copyleft sono solitamente troppo piccoli per giustificare l’inconveniente di assicurarsi che una copia della licenza accompagni sempre il software. Per questi programmi consigliamo la licenza Apache 2.0. Si tratta di una licenza software debole, permissiva, “pushover” (senza copyleft) che prevede termini per impedire a contributori e distributori di intentare causa per violazione di brevetto. Ciò non rende il software immune alle minacce derivanti dai brevetti (nessuna licenza software può raggiungere questo obiettivo), ma impedisce ai titolari dei brevetti di istituire un “esca e scambio” in cui rilasciano il software a condizioni libere e richiedono quindi ai destinatari di accettare termini non liberi in una licenza di brevetto.
Tra le licenze deboli (pushover), Apache 2.0 è la migliore; quindi se si intente utilizzare una licenza debole, qualunque sia il motivo, viene quindi consigliata tale licenza.
Si consiglia la GNU Free Documentation License (GFDL) per tutorial, manuali di riferimento e altri grandi lavori di documentazione. Si tratta di una forte licenza copyleft per opere didattiche, inizialmente scritta per manuali di software, e include termini che affrontano specificamente problemi comuni che sorgono quando tali opere vengono distribuite o modificate.
Per brevi lavori di documentazione secondaria, come ad esempio una scheda di riferimento, è meglio utilizzare la licenza GNU onnipermissiva, poiché una copia della GFDL difficilmente potrebbe entrare in una scheda di riferimento.
Alcune controversie recenti nel mondo del software opensource
A fine estate del 2023, HashiCorp (vendor molto noto per lo sviluppo di tool fortemente usati in ambito entreprise) ha apportato significative modifiche alle licenze dei suoi software open-source di punta, tra cui Terraform, Vault e Vagrant. L’introduzione della nuova licenza, denominata Business Source License (BSL), ha scatenato un acceso dibattito all’interno della comunità open-source. Le motivazioni di HashiCorp di proteggere gli investimenti in ricerca e sviluppo, generare maggiori profitti e mantenere il controllo sul proprio codice sorgente sono state accolte con critiche e preoccupazioni.
La BSL, benché miri a tutelare gli interessi aziendali, ha suscitato controversie in quanto non è riconosciuta come licenza open-source dalla Free Software Foundation (FSF) e dalla Open Source Initiative (OSI). Le restrizioni imposte dalla BSL, come il limite sull’utilizzo del codice sorgente per scopi commerciali e il divieto di distribuzione di prodotti derivati a pagamento senza una licenza specifica, hanno sollevato interrogativi sulla sua compatibilità con i principi dell’open source.
Le critiche rivolte alla BSL includono il timore che essa limiti l’innovazione e lo sviluppo di fork e prodotti derivati, concentrandosi eccessivamente il potere decisionale nelle mani di HashiCorp. Come risposta a tali cambiamenti, alcune aziende hanno optato per alternative con licenze open-source più permissive, mentre la Linux Foundation ha creato un fork di Terraform denominato OpenTofu per mantenere una versione open-source del tool.
La controversia in corso sull’evoluzione delle licenze nel panorama open-source sottolinea la sfida di bilanciare la sostenibilità aziendale e l’innovazione con i principi fondamentali di accessibilità e libertà che caratterizzano l’ecosistema open-source. La discussione è ancora in corso, e l’impatto a lungo termine di queste decisioni rimane incerto.
Anche Red Hat in passato ha annunciato la fine del ciclo di vita di CentOS Stream 8, una distribuzione Linux ampiamente utilizzata per la sua stabilità e compatibilità con Red Hat Enterprise Linux (RHEL). Le motivazioni di Red Hat riguardavano la mancata soddisfazione degli obiettivi utente previsti da CentOS Stream e l’inefficienza derivante dalla duplicazione degli sforzi tra CentOS Stream e RHEL.
Questa decisione ha comportato la necessità per gli utenti di CentOS Stream 8 di migrare verso alternative, tra cui RHEL (a pagamento), AlmaLinux (gratuita e compatibile con RHEL), Rocky Linux (gratuita e compatibile con RHEL) e Oracle Linux (gratuita, con alcune differenze da RHEL).
Il futuro di RHEL rimane solido, con Red Hat che continua ad investire nella sua piattaforma Linux enterprise di punta, offrendo supporto ufficiale, funzionalità avanzate e stabilità a lungo termine.
In conclusione, il termine del ciclo di vita di CentOS Stream 8 ha rappresentato un cambiamento significativo nella comunità open-source, portando ad una serie di alternative gratuite per gli utenti di CentOS. Nonostante ciò, RHEL resta una scelta eccellente per le aziende che richiedono una piattaforma Linux entreprise affidabile e stabile. La comunità open-source continua a valutare e adattarsi a queste dinamiche, cercando soluzioni che rispettino i principi fondamentali della libertà del software. Per ulteriori approfondimenti, è possibile consultare il sito web di Red Hat e gli articoli di miamammausalinux.
L’open-source come modello vincente per lo sviluppo software sicuro
Questo paragrafo descrive le principali motivazioni per cui il software libero è in grado di produrre codice sicuro rispetto agli standard di sicurezza necessari per gli ambienti anteprise o per gli utenit. Naturalmente l’elemento principale che determina il livello di sicurezza di un tool è derivante da molti aspetti il che rende complesso decretare il livello di sicurezza in modo definito.
Per prima cosa quindi è necessario definire cosa vuol dire “sicuro” in relazione ad un peogetto software. Sicurezza è unione di più elementi quali: stabilità, sostenibilità, conformità e utilizzo consapevole del software. Sicurezza implica che sia applicata a tutta la catena: dagli utenti, dalle infrastrutture di chi eroga servizi (quindi DevOps e SysAdmin), dagli sviluppatori del software.
Quando il codice sorgente di un progetto è disponibile a tutti, la questione della sicurezza non è molto lontana.
Come può essere sicuro qualcosa se chiunque può esaminare il codice e cercare falle nella sicurezza?
Per sommi capi vengono riportati alcuni aspetti che definiscono una comunità che ha accesso al codice sorgente come elemento chiave per il mantenimento di un software sicuro.
- Si può iniziare con la definizione di “opensource” non come software “gratis” ma come software libero (che dichiarato da Richart Stallman “free is not a free beer”). Questo dettaglio implica che il software libero porta con sé diritti e doveri. Il diritto di poterlo usare, maneggiare e distribuire secondo le regole definite dalle licenze associate, ma il dovere di partecipare all’ecosistema delle comunità che ruotano attorno ai progetti. Gli utenti che usufruiscono di software libero partecipano, quindi, attivamente all’individuazione di tutti gli aspetti migliorativi da applicare (quindi anche in ambito di sicurezza).
- Essendo il codice aperto, è senza dubbio visibile da attaccanti pronti a sfruttare eventuali falle, ma anche osservabile da chi è pronto ad apportare nuove funzionalità o correzioni volte a ridurre i rischi.
- Il software libero ha cicli di rilascio molto veloci per cui è importante mantenerlo aggiornato. Occorre che i software developer usino sempre libreria aggiornate e che gli admin eseguano tool e sistemi operativi aggiornati.
Gli aspiranti aggressori possono setacciare il codice sorgente per trovare falle nella sicurezza. A volte ci riescono, ma ciò permette anche ai “white hat” di esaminare i progetti open source per cercare di trovare e correggere le vulnerabilità prima che gli aggressori le trovino e le usino. Permette alle organizzazioni di identificare le potenziali vulnerabilità, segnalarle e applicare le correzioni senza dipendere da un singolo fornitore.
Alcuni utenti trovano e sfruttano continuamente vulnerabilità nel software proprietario.
In termini assoluti, nessun software dovrebbe essere considerato privo di vulnerabilità. Ma, in termini relativi, si può dire di sì. Il software open source è sicuro rispetto al software proprietario – e in alcuni casi, diremmo più sicuro del software proprietario.
In tutti i casi, il software open source consente a chiunque di esaminare il software e di cercare di fornire correzioni se scopre una vulnerabilità. Il software open source non dipende da un unico fornitore che controlla interamente il software.
Riportiamo di seguito lo State Of Enterprise Open Source Report del 2022 rilasciato da Red Hat (azienda molto importante che tra i vari prodotti distribuisce Red Hat Enterprise Linux). In questo report si affronta il tema di due anni di lavoro attraverso la pandemia e le organizzazioni di tutto il mondo che si stanno adattando a nuovi modi di operare. Il COVID-19 ha costretto le aziende a capire come lavorare a distanza. Hanno dovuto imparare a soddisfare le esigenze immediate dei clienti, aggiungendo al contempo l’agilità necessaria per adattarsi a un futuro ancora sconosciuto. Tuttavia, questo modo di lavorare è qualcosa che le comunità open source fanno da più di 25 anni. Queste comunità, così come le aziende che vi partecipano, hanno avuto un vantaggio sulla collaborazione distribuita.
Viene anche spiegato che il contributo dei fornitori (vendor o aziende di consulenza) all’open source è importante. È stato chiesto ad aziende leader nel settore IT se si preoccupassero del contributo dei loro fornitori ai progetti open source. È emerso che gli intervistati erano molto più propensi a scegliere fornitori che contribuivano alle comunità open source (quasi l’82% degli intervistati).
Infatti se raccogliamo le ragioni per cui i vendor open source sono i più selezionati emergono dati molto interessanti.
- Hanno familiarità con i processi dell’open source – 49%
- Aiutano a sostenere comunità open source sane – 49%
- Possono influenzare lo sviluppo di funzionalità di cui abbiamo bisogno – 48%
- Saranno più efficaci se devono affrontare sfide tecniche – 46%
L’89% degli intervistati ritiene che il software open source aziendale sia altrettanto o più sicuro del software proprietario. Nel complesso, i numeri raccontano una storia simile a quella del sondaggio dello scorso anno, anche se la scelta “più sicuro” è aumentata di quattro punti percentuali. Chiunque abbia trascorso del tempo nell’industria IT riconoscerà che si tratta di un cambiamento significativo rispetto alla percezione mainstream del software open source di una decina di anni fa, quando la sicurezza del software open source veniva spesso considerata un punto debole.
Di seguito altri punti forza relativi ai benefici nell’utilizzo di software libero.
- Il mio team può utilizzare codice open source ben collaudato per le nostre applicazioni interne – 55%
- Le patch di sicurezza sono ben documentate e possono essere scansionate – 52%
- I venditori rendono prontamente disponibili le patch di vulnerabilità per l’open source aziendale – 51%
- Un numero maggiore di persone ha avuto modo di vedere il codice rispetto al software proprietario – 44%
- Il mio team può verificare il codice – 38%
La cultura DevOps come metodologia e insieme di tool
Questo elaborato affronta il tema sicurezza e relazione con il software open source dal punto di vista DevOps, quindi da chi implementa, supporta, automatizza infrastrutture e rilascia il software prodotto dagli sviluppatori software.
La cultura DevOps è nata circa tra il 2007 e il 2008 con l’esigenza di rendere ripetibili e automatizzabili le configurazioni prima manuali. Gli amministratori di sistema con skill di sviluppo hanno sempre cercato di automatizzare processi e configurazioni ma con la definizione di questo movimento si è tirata di netto una linea di confine che “imponeva” pratiche e tool al fine di evitare quelli che venivano chiamati in gergo “snowflakes”. Ovvero porzioni di infrastrutture non ripetibili e con una memoria storica che ne impediva la piena comprensione e funzionamento. Tramite l’approccio DevOps sono nati strumenti di configuration management come Chef, Ansible o Puppet che hanno permesso di definire le configurazioni tramite codice per poi passare al concetto di IaC (infrastrure as code) che ha definito tale approccio anche alle stesse infrastrutture cloud o on-premise. Inoltre, lo scopo di chi lavora in un reparto DevOps è quello di rilasciare il software nel minor tempo possibile, in sicurezza e in modo automatico. Per questo i DevOps Engineer vengono visti come l’anello di congiunzione tra sistemi e sviluppo.
I punti fondamentali della cultura DevOps
- Continuous Integration e Continuous Delivery: Adozione di tool e pratiche volte ad automatizzare, standardizzare e centralizzare il progetto di build del software e di rilascio equipaggiando il tutto con test unitari e di integrazione, code quality, vulnerability scanning.
- IaC: Infrastructure as code: Ovvero la creazione di infrastrutture tramite codice
- Configuration Management: Configurazione dei workload (containerizzati o non) tramite approccio deterministico e quindi tramite codice
- Monitoring & Observability: Consente ai team (ops & dev) di comprendere meglio le prestazioni dei loro sistemi durante l’intero ciclo di sviluppo e nell’erogazione. Ciò consente di risolvere immediatamente i difetti e i bug, possibilità di tuning delle configurazioni. Vengono utilizzate metriche, “trace” e logs centralizzando il tutto e utilizzando strumenti per “graficare” e quindi osservarne il loro andamento oltre che ad allarmare a seguito del raggiungimento di soglie definite in fase di progettazione.
È ragionevole pensare che dal movimento DevOps siano nate svariate aree che hanno esteso alcuni concetti chiave ed evoluto o specializzato un determinato approccio.
SRE – Site Reliability Engineer
SRE è un approccio di ingegneria del software alle operation IT. I team SRE utilizzano il software come strumento per gestire i sistemi, risolvere i problemi e automatizzare le attività operative.
Si individuano i compiti che storicamente sono stati svolti dai team operativi, spesso manualmente, e si affidano agli ingegneri o ai team operativi che utilizzano il software e l’automazione per risolvere i problemi e gestire i sistemi di produzione.
I team SRE sono responsabili del modo in cui il codice viene distribuito, configurato e monitorato, nonché della disponibilità, della latenza, della gestione delle modifiche, della risposta alle emergenze e della gestione della capacità dei servizi in produzione.
I team SRE determinano il lancio di nuove funzionalità utilizzando gli accordi di livello di servizio (SLA) per definire l’affidabilità richiesta del sistema attraverso indicatori di livello di servizio (SLI) e obiettivi di livello di servizio (SLO).
Lo SLI misura aspetti specifici dei livelli di servizio forniti. I principali SLI includono la latenza della richiesta, la disponibilità, il tasso di errore e il throughput del sistema. Uno SLO si basa sul valore obiettivo o sull’intervallo per un livello di servizio specifico basato sullo SLI. Lo SLO per l’affidabilità del sistema richiesto si basa sul tempo di inattività ritenuto accettabile. Questo livello di downtime viene definito error budget, ovvero la soglia massima consentita per errori e interruzioni.
Con SRE, non ci si aspetta il 100% di affidabilità, ma si pianificano e si prevedono i guasti.
Si consiglia il libro “Site Reliability Engineering: How Google Runs Production Systems” di Jennifer Petoff, Niall Murphy, Betsy Beyer, e Chris Jones.
Platform Engineering
Il Platform Engineering migliora l’esperienza e la produttività degli sviluppatori fornendo funzionalità self-service con operazioni infrastrutturali automatizzate. È di tendenza per la sua promessa di ottimizzare l’esperienza degli sviluppatori e accelerare la fornitura di valore ai clienti da parte dei team di prodotto.
Inoltre, è in linea con il modello di apertura del lavoro e delle conoscenze tecniche a un’ampia gamma di ruoli e funzioni aziendali. L’intelligenza artificiale generativa ha contribuito a livellare il campo di gioco in questo modo.
“L’ingegneria della piattaforma è emersa in risposta alla crescente complessità delle moderne architetture software. Oggi, agli utenti finali non esperti viene spesso chiesto di gestire un insieme di complicati servizi arcani”, afferma Paul Delory, VP Analyst di Gartner “per aiutare gli utenti finali e ridurre l’attrito per il prezioso lavoro che svolgono, le aziende più lungimiranti hanno iniziato a costruire piattaforme operative che si frappongono tra l’utente finale e i servizi di supporto su cui si basano”.
Entro il 2026, l’80% delle grandi organizzazioni di ingegneria del software creerà team di ingegneria delle piattaforme come fornitori interni di servizi, componenti e strumenti riutilizzabili per la distribuzione delle applicazioni. L’ingegneria delle piattaforme risolverà in ultima analisi il problema centrale della cooperazione tra sviluppatori di software e operatori.
Chaos Engineering
Il Chaos Engineering è un approccio disciplinato per identificare i guasti prima che diventino interruzioni. Testando in modo proattivo la risposta di un sistema sotto stress, è possibile identificare e risolvere i guasti prima che finiscano sui giornali.
L’ingegneria del caos consente di confrontare ciò che si pensa possa accadere con ciò che accade effettivamente nei sistemi. Si possono letteralmente “rompere le cose di proposito” per imparare a costruire sistemi più resistenti.
Uno dei tool noti in ambito Chaos Engineering per Kubernetes è Kubeinvaders (https://github.com/lucky-sideburn/kubeinvaders) creato dall’autore di questo elaborato (Eugenio Marzo)
DevSecOps
DevSecOps, abbreviazione di sviluppo, sicurezza e operazioni, automatizza l’integrazione della sicurezza in ogni fase del ciclo di vita dello sviluppo del software, dalla progettazione iniziale fino all’integrazione, al test, alla distribuzione e alla distribuzione del software. DevSecOps rappresenta un’evoluzione naturale e necessaria nel modo in cui le organizzazioni di sviluppo affrontano la sicurezza. In passato, la sicurezza veniva “aggiungeta” al software alla fine del ciclo di sviluppo (quasi come ripensamento) da un team di sicurezza separato ed era testata da un team di garanzia della qualità (QA) separato. Ciò era gestibile quando gli aggiornamenti software venivano rilasciati solo una o due volte l’anno. Ma quando gli sviluppatori di software hanno adottato pratiche Agile e DevOps, con l’obiettivo di ridurre i cicli di sviluppo del software a settimane o addirittura giorni, il tradizionale approccio “aggiunto” alla sicurezza ha creato un collo di bottiglia inaccettabile. DevSecOps integra perfettamente la sicurezza delle applicazioni e dell’infrastruttura nei processi e negli strumenti Agile e DevOps. Affronta i problemi di sicurezza non appena emergono, quando è più facile, veloce e meno costoso risolverli (e prima che vengano messi in produzione). Inoltre, DevSecOps rende la sicurezza delle applicazioni e dell’infrastruttura una responsabilità condivisa dei team di sviluppo, sicurezza e operazioni IT, anziché una responsabilità esclusiva di un silo di sicurezza. Rende possibile “software più sicuro, prima” (il motto di DevSecOps) automatizzando la distribuzione di software sicuro senza rallentare il ciclo di sviluppo del software
Affondo sulle metodologia DevSecOps
Uno degli aspetti che potrebbe distogliere dalla sostanza in favore della forma è il concetto di “buzzword”. Vengono quindi assegnati a toolchain, movimenti culturali tecnologici e trend delle denominazioni significative che a volte rischiano di raccogliere troppi concetti in un’unica atomica descrizione. È invece utile dare un nome alle cose per poterle identificare e raggruppare, a patto che si scenda poi nel dettaglio per comprenderne a fondo l’essenza. Nel caso di DevSecOps in quanto derivazione del movimento DevOps è facile cadere nel tranello della semplificazione. Soprattutto in ambito sicurezza in quanto scenario multiforme e dispersivo talvolta.
Quindi, cosa si intende più nello specifico? Quali sono le metodologie da applicare per rendere sicuri quelle che sono le pratiche e i tool aderenti ai pattern DevOps ormai consolidati?
DevSecOps include: sviluppo, sicurezza e operation. È un approccio alla cultura dell’automazione e alla progettazione delle piattaforme integrando sicurezza come responsabilità condivisa nell’intero ciclo di vita dell’IT.
Come riportato nella definizione di DevSecOps data da Red Hat in questo articolo https://www.redhat.com/en/topics/devops/what-is-devsecops possiamo racchiudere pratiche e metodologie per aree.
Ambienti e sicurezza dei dati
- Standardizzare e automatizzare l’ambiente: Ogni servizio deve avere il minor numero di privilegi possibile per ridurre al minimo le connessioni e gli accessi non autorizzati.
- Centralizzare le funzionalità di controllo dell’identità e dell’accesso degli utenti: Il controllo degli accessi e i meccanismi di autenticazione centralizzati sono essenziali per proteggere i microservizi, poiché l’autenticazione viene avviata in più punti.
- Isolare i container che eseguono microservizi tra loro e dalla rete: Questo include sia i dati in transito che quelli a riposo, poiché entrambi possono rappresentare obiettivi di alto valore per gli aggressori.
- Crittografare i dati tra applicazioni e servizi: Una piattaforma di orchestrazione di container con funzioni di sicurezza integrate aiuta a ridurre al minimo le possibilità di accesso non autorizzato.
- Introdurre gateway API sicuri: Le API sicure aumentano la visibilità delle autorizzazioni e del routing. Riducendo le API esposte, le organizzazioni possono ridurre le superfici di attacco.
Pratiche DevSecOps innestati nei flussi di CI/CD
Vengono di seguito descritte alcune metodologie con cui equipaggiare flussi e piattaforme dedicate alla build e al rilascio del codice sorgente.
Integrare gli scanner di sicurezza per i container: Utilizzare tool che possano individuare vulnerabilità all’interno di registry delle immagini Docker (qui si intende Docker come standard OCI – https://opencontainers.org/)
Automatizzare i test di sicurezza nel processo di CI: Esecuzione di strumenti di analisi statica della sicurezza come parte delle build, nonché la scansione di qualsiasi immagine di container pre-costruita per le vulnerabilità di sicurezza conosciute quando vengono inserite nella pipeline di build.
Aggiungere test automatizzati per le funzionalità di sicurezza nel processo di test di accettazione: Automatizzare i test di convalida degli input e le funzioni di verifica dell’autenticazione e dell’autorizzazione.
Automatizzare gli aggiornamenti di sicurezza, come le patch per le vulnerabilità note: Questo avviene tramite la pipeline DevOps. Dovrebbe eliminare la necessità per gli amministratori di accedere ai sistemi di produzione, creando al contempo un registro delle modifiche documentato e tracciabile.
Automatizzare le funzionalità di gestione della configurazione dei sistemi e dei servizi: Ciò consente di rispettare le politiche di sicurezza e di eliminare gli errori manuali. Anche l’audit e la correzione dovrebbero essere automatizzati.
Information security standards
Questo capitolo ha lo scopo di raccogliere gli standard, le certificazioni e le normative in ambito sicurezza decretate da enti governativi e comunità no-profit. Viene principalmente introdotto il tema facendo riferimento al seguente materiale https://en.wikipedia.org/wiki/Information_security_standards che raccoglie una chiara visione sul tema.
- National Institute of Standards and Technology (NIST, providing guidelines on technology-related matters)
- Payment Card Industry Data Security Standard (PCI-DSS, for protecting yourself and customers when taking payments)
- The Centre of Internet Security (CIS) standard is our focus in this article.
Sostanzialmente per Information Security Standard si intende un insieme di materiali (che al loro interno raccolgono metodologie e pratiche) volti a proteggere infrastrutture e servizi IT dal punto di vista degli utenti e delle aziende.
Sono infatti inclusi:
- Gli utenti stessi
- Le reti
- I dispositivi hardware
- Software
- Processi
- Dati in transito
L’obiettivo principale è quello di ridurre i rischi, compresa la prevenzione o la mitigazione degli attacchi informatici. Questi materiali pubblicati consistono in strumenti, politiche, concetti di sicurezza, salvaguardie di sicurezza, linee guida, approcci alla gestione del rischio, azioni, formazione, best practice, garanzie e tecnologie.
Il National Institute of Standards and Technology (NIST)
Tra gli attori più importanti non possiamo non citare in National Institute of Standards and Technology (NIST) in quanto agenzia del Dipartimento del Commercio degli Stati Uniti la cui missione è promuovere l’innovazione e la competitività industriale americana.
Ne deriva quindi il NIST Cybersecurity Framework come insieme di linee guida per la mitigazione dei rischi di cybersecurity delle organizzazioni, pubblicato dal NIST per l’appunto. Fornisce una tassonomia di alto livello dei risultati della cybersecurity e una metodologia per valutare e gestire tali risultati oltre a indicazioni sulla protezione della privacy e delle libertà civili nel contesto della cybersecurity
Il materiale stato tradotto in molte lingue ed è utilizzato da diversi governi e da un’ampia gamma di aziende e organizzazioni.
Esistono moltissime pubblicazione emesse dal NIST ma all’interno di questo documento dovendo avendo ristretto il campo di azione in ambito DevOps e soprattutto Cloud Native viene scelto come esempio di materiale prodotto la pubblicazione NIST 800-53 sponsorizzata e messa in rilievo anche dall’azienda Sysdig (https://sysdig.com/) che per l’appunto tratta temi in ambito sicurezza su ambienti Cloud Native.
Riportiamo i punti cardine delle linee guida.
- Access Controls:
- Generazione di account utente e regole di autorizzazione.
- Rilevamento di processi che tentano di superare i vincoli di sicurezza.
- Implementazione a livello di build o runtime dei container.
- Audit and Accountability:
- Intercettazione e archiviazione delle attività del sistema.
- Auditing degli eventi Kubernetes e problemi di sicurezza.
- Generazione di report sullo stato generale di sicurezza.
- Comunicazione tra i Sistemi:
- Utilizzo di meccanismi di cifratura per le comunicazioni.
- Implementazione di meccanismi per rilevare e contrastare tentativi di impersonificazione o modifiche nei container.
- Configuration Management:
- Mantenimento della configurazione di base del sistema.
- Test delle immagini dei container per sicurezza e configurazioni errate nelle pipeline CI.
- System and Information Integrity:
- Identificazione, correzione e segnalazione di difetti di sistema.
- Implementazione di pipeline centralizzate per CI/CD con scansione delle immagini.
- Rilevamenti a runtime per comportamenti anomali e meccanismi di notifica.
- System and Services Acquisition:
- Metriche di qualità e garanzie da parte degli sviluppatori.
- Controllo di configurazioni errate e vulnerabilità del software distribuito nei container.
- Incident Response:
- Caratteristiche della politica di risposta agli incidenti.
- Notifica corretta degli eventi di sicurezza nei container e in Kubernetes.
- Security Assessment and Authorization:
- Esecuzione di controlli di conformità della sicurezza prima della connessione dei sistemi interni.
- Mappatura dei controlli di sicurezza rispetto alle famiglie di NIST 800-53.
L’automazione degli standard di conformità e configurazione dei container è raccomandata per garantire la sicurezza e la conformità alle normative, come NIST SP 800-53.
Il Center for Internet Security (CIS)
È doveroso all’interno di questo capitolo citare anche il Center for Internet Security (CIS), un’organizzazione statunitense senza scopo di lucro, costituita nell’ottobre 2000.
La sua dichiarazione di missione afferma che la funzione del CIS è quella di “aiutare le persone, le aziende e i governi a proteggersi dalle minacce informatiche pervasive”.
L’organizzazione ha sede a East Greenbush, New York, Stati Uniti, e tra i suoi membri figurano grandi aziende, agenzie governative e istituzioni accademiche.
Viene citato il CIS in quanto vengono usati spesso i benchmark di sicurezza da essa pubblicati. All’interno della sezione presente a questo indirizzo https://www.cisecurity.org/cis-benchmarks sono elencate per tecnologie tutte le linee guida necessarie all’enforcing di sicurezza.
Certamente, è possibile implementare le regole dettate dai documenti del CIS (Center for Internet Security) utilizzando strumenti open source. Nel caso specifico menzionato nell’articolo, vengono utilizzati OpenSCAP ed Ansible per applicare le CIS Benchmarks.
- OpenSCAP:
- Descrizione: OpenSCAP è uno strumento open source che implementa gli standard di sicurezza aperti, inclusi i benchmark CIS. Esso fornisce un framework per la gestione della sicurezza, che include la valutazione della conformità e la scansione di configurazioni di sicurezza.
- Utilizzo: Puoi utilizzare OpenSCAP per valutare e verificare la conformità dei tuoi sistemi rispetto alle regole CIS Benchmarks.
- Ansible:
- Descrizione: Ansible è una piattaforma di automazione open source utilizzata per orchestrare, automatizzare e gestire configurazioni di sistema. Viene spesso utilizzato nel contesto di DevSecOps per automatizzare attività legate alla sicurezza.
- Utilizzo: Puoi utilizzare Ansible per automatizzare l’applicazione delle regole CIS Benchmarks su una vasta gamma di sistemi.
- Approccio DevSecOps:
- Descrizione: DevSecOps integra la sicurezza nelle pratiche di sviluppo e operazioni (DevOps). In questo contesto, Ansible può essere utilizzato per automatizzare e integrare test di sicurezza e applicazione di configurazioni sicure all’interno dei processi di sviluppo e distribuzione.
- Utilizzo: Puoi incorporare controlli di sicurezza basati su CIS Benchmarks nelle pipeline di automazione con Ansible, garantendo che gli ambienti siano configurati in modo sicuro fin dalla fase di sviluppo.
- Approfondimenti:
- Articolo di Red Hat: L’articolo menzionato fornisce una guida dettagliata sull’implementazione di CIS Benchmarks utilizzando Ansible Automation Platform. Esso copre i passaggi specifici per l’automazione delle regole di sicurezza.
L’utilizzo di strumenti open source per implementare le regole CIS Benchmarks offre un approccio flessibile, trasparente e modificabile secondo le esigenze specifiche dell’organizzazione. È possibile adattare gli script Ansible e le configurazioni OpenSCAP in base ai requisiti di sicurezza unici dell’ambiente target
Payment Card Industry Data Security Standard (PCI-DSS)
Il PCI DSS (Payment Card Industry Data Security Standard) è uno standard globale di sicurezza dei dati adottato dalle principali società emittenti di carte di credito per tutte le organizzazioni che processano, memorizzano o trasmettono dati di carte di pagamento, tra cui dati di autenticazione sensibili. Lo scopo del PCI DSS è proteggere i dati dei titolari di carte da accessi non autorizzati, divulgazione, modifica o distruzione, e ridurre il rischio di frodi con carta di credito.
Il PCI DSS è composto da 12 requisiti di sicurezza che le organizzazioni devono implementare per garantire la sicurezza dei dati delle carte di credito. Questi requisiti si concentrano su aspetti come:
- Implementare controlli di accesso fisici e logici per proteggere i sistemi e le reti che trattano dati di carte di pagamento.
- Proteggere i dati di carte di pagamento durante la trasmissione, lo storage e la lavorazione utilizzando crittografia e altre misure di sicurezza.
- Formare i dipendenti sulle pratiche di sicurezza dei dati e sulle segnalazioni di violazioni dei dati.
- Eseguire regolarmente test di penetrazione e audit per rilevare e correggere vulnerabilità.
- Documentare e mantenere le politiche e le procedure di sicurezza dei dati.
Open Source Security Foundation
La Open Source Security Foundation (OpenSSF) si propone di semplificare la protezione sostenibile dello sviluppo, della manutenzione e del consumo di software open source (OSS). Questo impegno comprende la promozione della collaborazione, la definizione di best practice e lo sviluppo di soluzioni innovative.
Riconoscendo l’OSS come un bene pubblico digitale, l’industria ha l’obbligo di affrontare le sfide di sicurezza insieme alla comunità. L’obiettivo è immaginare un futuro in cui l’OSS sia universalmente affidabile, sicuro e affidabile. Questa visione collaborativa permette a individui e organizzazioni, all’interno di un ecosistema globale, di sfruttare i vantaggi dell’OSS in modo sicuro e contribuire in modo significativo alla comunità OSS.
OpenSSF agisce come partner fidato per le fondazioni e i progetti open source affiliati, offrendo indicazioni e strumenti preziosi, come i primi dieci principi guida per lo sviluppo di software sicuro. Le iniziative di OpenSSF mirano a semplificare la sicurezza per i manutentori e i contributori open source, fornendo agli utenti OSS segnali chiari per comprendere il profilo di sicurezza dei contenuti OSS.
L’impegno di OpenSSF è coinvolgere tutte le parti interessate nella fondazione e nelle sue iniziative tecniche. OpenSSF è un influente sostenitore di sforzi esterni reciprocamente vantaggiosi e svolge un ruolo educativo nei confronti dei decisori politici.
Oltre a promuovere la diversità, l’equità e l’inclusione (DEI), OpenSSF facilita un ambiente che supporta tutte le prospettive e i background, offrendo opportunità eque per il tutoraggio e l’istruzione globali. L’impegno di OpenSSF è continuare a sviluppare iniziative per offrire un’educazione sulla sicurezza software più inclusiva e diversificata, garantendo opportunità di condivisione delle parti interessate per impegnarsi e ricevere valore dalle iniziative tecniche di OpenSSF.
La strategia OpenSSF si basa su una serie di obiettivi finalizzati a migliorare la sicurezza dell’OSS attraverso lo sviluppo di strumenti e processi. Questi obiettivi comprendono la formazione e la comunicazione mirata, la facilitazione della collaborazione, l’innovazione tecnica sostenibile, il patrocinio e la politica, e il coinvolgimento della comunità. Questi sforzi mirano a garantire coerenza, integrità e valutazione del rischio per rafforzare la sicurezza complessiva dell’ecosistema OSS.
Antologia Tool Open Source DevSecOps
Software Composition Analysis (SCA) Tools
I Software Composition Analysis (SCA) Tools sono strumenti progettati per identificare e gestire le dipendenze del software e le componenti di terze parti utilizzate in un’applicazione. Questi strumenti aiutano a identificare potenziali vulnerabilità di sicurezza, licenze software e altre informazioni critiche nelle librerie e nei framework utilizzati nello sviluppo del software.
OWASP Dependency-Check
- Repository GIT: https://github.com/jeremylong/DependencyCheck.git
- Licenza: Apache 2.0
- Descrizione:
L’OWASP Dependency-Check è uno strumento essenziale per l’analisi delle composizioni software, identificando vulnerabilità note nelle dipendenze di progetti.
Retire.js
- Repository GIT: https://github.com/retirejs/retire.js
- Licenza: Apache 2.0
- Descrizione:
Retire.js è uno scanner che rileva l’utilizzo di librerie JavaScript con vulnerabilità note. Inoltre, ha la capacità di generare un SBOM (Software Bill of Materials) delle librerie individuate.
Dependency-Track
- Repository GIT: https://github.com/DependencyTrack/dependency-track
- Licenza: Apache 2.0
- Descrizione:
Dependency-Track è una piattaforma open-source che traccia e monitora le dipendenze di un progetto, fornendo informazioni sulle vulnerabilità conosciute di tali dipendenze.
OSSIndex
- Repository GIT: https://github.com/sonatype/ossindex-public
- Licenza: Apache 2.0
- Descrizione:
OSSIndex è un database di vulnerabilità open-source e una piattaforma di analisi che si integra con vari strumenti di sviluppo per fornire informazioni in tempo reale sulla sicurezza delle dipendenze dei progetti.
Static Application Security Testing (SAST) Tools
Gli strumenti di Static Application Security Testing (SAST) sono progettati per individuare potenziali vulnerabilità di sicurezza nel codice sorgente di un’applicazione durante la fase di sviluppo. Questi strumenti esaminano il codice senza eseguirlo e identificano problemi di sicurezza, consentendo agli sviluppatori di risolverli prima che l’applicazione venga rilasciata.
SonarQube
- Repository GIT: https://github.com/SonarSource/sonarqube
- Licenza: Apache 2.0
- Descrizione:
SonarQube offre la capacità non solo di mostrare lo stato di salute di un’applicazione, ma anche di evidenziare i problemi introdotti di recente. Con un Quality Gate in atto, è possibile raggiungere il “Clean Code” e quindi migliorare sistematicamente la qualità del codice.
Container Security Tools
Gli strumenti di sicurezza dei container sono progettati per individuare e mitigare le vulnerabilità di sicurezza nelle immagini e nei Runtime dei container. Con l’ampia adozione di container, questi strumenti sono essenziali per garantire la sicurezza delle applicazioni distribuite in ambienti basati su container
Clair
- Repository GIT: https://github.com/quay/clair
- Licenza: Apache 2.0
- Descrizione:
Clair è uno strumento open-source di analisi delle vulnerabilità per container. Progettato per essere integrato nelle pipeline di sviluppo e distribuzione dei container, Clair analizza le immagini dei container per identificare e segnalare le vulnerabilità di sicurezza presenti nelle librerie e nelle dipendenze utilizzate nell’applicazione.
Clair è spesso utilizzato in combinazione con strumenti di orchestrazione dei container, come Kubernetes, per garantire che le immagini dei container utilizzate siano sicure e conformi alle politiche di sicurezza dell’organizzazione. Utilizzando un database di vulnerabilità regolarmente aggiornato, Clair fornisce informazioni dettagliate sulla sicurezza delle immagini dei container.
Trivy
- Repository GIT: https://github.com/aquasecurity/trivy
- Licenza: Apache 2.0
- Descrizione:Trivy è uno scanner di vulnerabilità open-source specializzato per container e immagini di container. È progettato per identificare e segnalare le vulnerabilità di sicurezza nelle immagini dei container, inclusi pacchetti di sistema operativo, librerie e dipendenze applicative.
Trivy supporta varie fonti di database di vulnerabilità, tra cui database pubblici e privati, e offre un’analisi rapida e dettagliata delle immagini dei container. È spesso utilizzato durante il processo di sviluppo e distribuzione dei container per garantire la sicurezza delle applicazioni containerizzate.
Anchore
- Repository GIT: https://github.com/anchore/anchore-engine
- Licenza: Apache 2.0
- Descrizione:
Anchore Engine è un motore open-source di analisi delle immagini dei container e di valutazione della sicurezza. È progettato per esaminare le immagini dei container e identificare vulnerabilità di sicurezza, configurazioni non sicure e altre potenziali minacce.
Le funzionalità di Anchore Engine includono la valutazione delle immagini rispetto a politiche di sicurezza definite, l’analisi delle vulnerabilità, la gestione delle politiche e delle whitelist. Questo strumento è spesso utilizzato nel processo di sviluppo e distribuzione dei container per garantire che le immagini utilizzate siano sicure e conformi alle politiche di sicurezza.
Falco
- Repository GIT: https://github.com/falcosecurity/falco
- Licenza: Apache 2.0
- Descrizione:
Falco è uno strumento di sicurezza open-source progettato per la rilevazione di comportamenti anomali e attività minacciose nei sistemi Linux. È particolarmente adatto per il monitoraggio e la sicurezza in ambienti containerizzati e Kubernetes.
Le funzionalità di Falco includono il rilevamento di eventi come chiamate di sistema, accessi alla rete e attività del file system, consentendo agli amministratori di sistema di identificare potenziali minacce alla sicurezza. Falco può essere integrato nelle pipeline di sicurezza e può notificare o rispondere automaticamente a comportamenti sospetti.
Infrastructure Security Tools
Gli strumenti di sicurezza dell’infrastruttura sono progettati per garantire la protezione e la robustezza delle componenti fisiche e virtuali all’interno di un ambiente IT. Questi strumenti coprono diverse aree della sicurezza dell’infrastruttura, tra cui monitoraggio della rete, gestione delle configurazioni, sicurezza dei dispositivi di rete e altro ancora.
OpenVAS
- Repository GIT: https://github.com/greenbone/openvas
- Licenza: GNU General Public License (GPL)
- Descrizione:
OpenVAS (Open Vulnerability Assessment System) è un framework open-source per la valutazione della sicurezza e la scansione delle vulnerabilità. Fornisce strumenti per identificare e gestire le vulnerabilità di sicurezza in reti e sistemi.
Le funzionalità di OpenVAS includono la scansione automatica di reti per individuare vulnerabilità, la valutazione del rischio, la generazione di report dettagliati e la gestione delle vulnerabilità. OpenVAS è spesso utilizzato come parte di una strategia di sicurezza per identificare e mitigare le minacce alla sicurezza nei sistemi e nelle reti.
La licenza GNU GPL consente l’utilizzo, la modifica e la distribuzione del software, seguendo i principi del software open source.
OpenSCAP
- Repository GIT: https://github.com/ComplianceAsCode/content (OpenSCAP fa parte di ComplianceAsCode, un progetto che integra diverse basi di sicurezza, inclusa OpenSCAP)
- Licenza: Apache 2.0 per il progetto ComplianceAsCode
- Descrizione:
OpenSCAP (Security Content Automation Protocol) è uno standard open-source per l’automazione delle attività di conformità, sicurezza e valutazione dei rischi. OpenSCAP fornisce un framework per la creazione, la gestione e la distribuzione di contenuti di sicurezza standardizzati.
ComplianceAsCode, che include OpenSCAP, è un progetto che offre contenuti di sicurezza standardizzati basati su OpenSCAP. Il progetto comprende regole e profili di sicurezza predefiniti, consentendo agli utenti di automatizzare la valutazione della sicurezza dei sistemi.
Lynis
- Repository GIT: https://github.com/CISOfy/lynis
- Licenza: GNU General Public License (GPL)
- Descrizione:
Lynis è uno strumento open-source di audit di sicurezza progettato per sistemi Unix e Linux. Il suo scopo principale è condurre un audit di sicurezza del sistema operativo e fornire raccomandazioni per migliorare la sicurezza generale.
Le funzionalità di Lynis includono la scansione di configurazioni di sistema, la valutazione della sicurezza del kernel, l’analisi dei file di log e la rilevazione di vulnerabilità potenziali. Lynis è spesso utilizzato per identificare e mitigare rischi di sicurezza in ambienti Unix e Linux.
Dashboard Tools
Gli strumenti di creazione di dashboard consentono di visualizzare in modo chiaro e intuitivo dati e informazioni provenienti da diverse fonti. Questi strumenti sono utilizzati in vari contesti, come il monitoraggio delle prestazioni, la visualizzazione dei dati aziendali o la presentazione di report.
Grafana
- Repository GIT: https://github.com/grafana/grafana
- Licenza: Apache License 2.0
- Descrizione:
Grafana è una piattaforma open-source di analisi e monitoraggio che integra diverse fonti di dati per la creazione di dashboard interattive. Essa offre la possibilità di visualizzare dati provenienti da vari sistemi, inclusi database, sistemi di monitoraggio e altre fonti di dati.
Le funzionalità di Grafana includono la creazione di grafici, dashboard personalizzate, allerte e la possibilità di esplorare e analizzare i dati in modo interattivo. È ampiamente utilizzata nella comunità DevOps e nell’ambito del monitoraggio di sistemi.
Kibana
- Repository GIT: https://github.com/elastic/kibana
- Licenza: Server Side Public License (SSPL)
- Descrizione:
Kibana è una piattaforma open-source di visualizzazione dei dati, sviluppata da Elastic, progettata per funzionare con il motore di ricerca Elasticsearch. Essa fornisce un’interfaccia utente web per l’analisi e la visualizzazione dei dati immagazzinati in Elasticsearch.
Le funzionalità di Kibana includono la creazione di dashboard interattive, la visualizzazione di log, la navigazione e l’esplorazione dei dati, nonché la creazione di visualizzazioni personalizzate. È spesso utilizzata in combinazione con Elasticsearch e Logstash come parte dell’ELK (Elasticsearch, Logstash, Kibana) stack per l’analisi dei log e il monitoraggio.
La licenza Server Side Public License (SSPL) è stata introdotta da Elastic come una licenza di sorgente pubblica, con alcune specifiche che si applicano quando si fornisce il servizio come servizio gestito. Assicurati di comprendere le implicazioni della licenza SSPL prima di utilizzare il software.
Kubernetes Policy e Compliance
La gestione delle politiche e la conformità in Kubernetes sono aspetti cruciali per garantire la sicurezza e la coerenza delle distribuzioni di container. Diverse soluzioni sono disponibili per implementare politiche e assicurare la conformità nei cluster Kubernetes.
Kyverno
- Repository GIT: https://github.com/kyverno/kyverno
- Licenza: Apache License 2.0
- Descrizione:
Kyverno è uno strumento open-source di gestione delle politiche per Kubernetes. È progettato per consentire agli utenti di definire, dichiarare e applicare politiche di ammissione e governance delle risorse in un cluster Kubernetes.
Le funzionalità di Kyverno includono la possibilità di definire politiche tramite risorse di Kubernetes, la validazione delle risorse in base a tali politiche e la generazione di risorse conformi alle politiche specificate. È spesso utilizzato per garantire che le risorse Kubernetes siano create e mantenute in conformità con le politiche di sicurezza e governance dell’organizzazione.
Mandatory Access Control (MAC)
Il Mandatory Access Control (MAC) è una categoria di strumenti e tecniche di sicurezza informatica utilizzati per implementare un controllo degli accessi più rigoroso rispetto ai tradizionali sistemi di Discretionary Access Control (DAC). Mentre nel DAC i proprietari delle risorse decidono chi può accedere a tali risorse, nel MAC le decisioni sono prese centralmente da un’autorità di controllo, spesso basata su criteri di sicurezza o politiche aziendali.
Ecco una breve descrizione del concetto e delle caratteristiche principali del Mandatory Access Control:
- Controllo Centrale: Nel MAC, l’autorità di controllo (solitamente implementata nel sistema operativo) determina e impone regole di accesso su tutte le risorse del sistema. Gli utenti e i proprietari delle risorse non hanno il potere di sovrascrivere queste regole.
- Etichettatura delle Risorse: Una delle tecniche comuni utilizzate nel MAC è l’etichettatura delle risorse. Ciascuna risorsa (file, processo, oggetto di sistema) è contrassegnata con un’etichetta di sicurezza che rappresenta i suoi livelli di riservatezza, integrità o altri attributi di sicurezza.
- Ruoli e Categorie: Gli utenti e i processi sono assegnati a ruoli e categorie che determinano le azioni e le risorse alle quali possono accedere. Queste assegnazioni sono generalmente fisse e basate su politiche di sicurezza.
- Principio di Minimizzazione dei Privilegi: Nel MAC, il principio di minimizzazione dei privilegi è applicato rigorosamente. Gli utenti e i processi ottengono solo i privilegi necessari per eseguire le loro attività specifiche.
- Implementazioni Comuni: Tra le implementazioni di MAC più note ci sono SELinux (Security-Enhanced Linux), AppArmor e TOMOYO Linux. Questi strumenti forniscono meccanismi avanzati di controllo degli accessi su sistemi Linux.
- Sicurezza del Sistema: Il MAC è spesso utilizzato in ambienti in cui la sicurezza è una priorità critica, come nel governo, nell’industria della difesa e in altri settori sensibili.
- Prevenzione degli Attacchi: Poiché il MAC impone un controllo centrale e limita i privilegi degli utenti, è più resistente a determinati tipi di attacchi informatici, come quelli basati sulla compromissione di account utente.
Il Mandatory Access Control è una componente fondamentale delle strategie di sicurezza avanzate e contribuisce a mitigare rischi di sicurezza associati a accessi non autorizzati e violazioni della sicurezza informatica.
AppArmor
- Repository GIT: https://gitlab.com/apparmor/apparmor
- Licenza: GNU General Public License (GPL)
- Descrizione:
AppArmor è un sistema di controllo degli accessi basato sul kernel del sistema operativo Linux. Il suo obiettivo principale è fornire un framework per la limitazione delle risorse e la restrizione delle attività di processi specifici, contribuendo così a rafforzare la sicurezza del sistema.
Le funzionalità di AppArmor includono la definizione di profili di sicurezza per i processi, consentendo di specificare quali risorse possono essere accessibili e quali operazioni possono essere eseguite. Ciò fornisce un livello aggiuntivo di protezione contro potenziali minacce di sicurezza e limita l’impatto delle violazioni di sicurezza.
SELinux
- Repository GIT: https://github.com/SELinuxProject/selinux
- Licenza: Licenza Pubblica Generica GNU (GNU General Public License – GPL)
- Descrizione:
SELinux, che sta per Security-Enhanced Linux, è un framework di sicurezza per il sistema operativo Linux. La sua implementazione è una estensione del kernel Linux che aggiunge funzionalità di controllo degli accessi obbligatori basati su politiche.
Le funzionalità di SELinux includono l’applicazione di politiche di sicurezza basate su etichette su processi e file di sistema. Questo permette di limitare l’accesso di processi e utenti a risorse specifiche del sistema, contribuendo a rafforzare la sicurezza del sistema operativo
Tool centralizzazione autenticazione
FreeIPA
- Repository GIT: https://github.com/freeipa/freeipa
- Licenza: Licenza Pubblica Generica GNU (GNU General Public License – GPL)
- Descrizione:
FreeIPA è un progetto open-source che fornisce un insieme di servizi di gestione di identità e sicurezza basati su standard aperti. È progettato per semplificare la gestione delle identità, delle autenticazioni e delle autorizzazioni in ambienti di rete basati su Linux.
Le funzionalità di FreeIPA includono la gestione centralizzata degli utenti, la gestione dei gruppi, la politica di sicurezza, il servizio di autenticazione Kerberos, il servizio di directory LDAP e altro ancora. FreeIPA è spesso utilizzato nelle infrastrutture IT aziendali per fornire un’ampia gamma di funzionalità di gestione delle identità e di sicurezza.
Keycloak
- Repository GIT: https://github.com/keycloak/keycloak
- Licenza: Apache License 2.0
- Descrizione:
Keycloak è un sistema open-source per la gestione delle identità e degli accessi (Identity and Access Management – IAM). È progettato per fornire funzionalità di autenticazione, autorizzazione e gestione delle identità in applicazioni e servizi web.
Le funzionalità di Keycloak includono la gestione centralizzata degli utenti, la federazione delle identità, l’autenticazione Single Sign-On (SSO), la gestione dei ruoli e delle autorizzazioni. Può essere utilizzato come servizio indipendente o integrato in applicazioni esistenti come componente IAM.
Privacy Dati Personali
Tool dedicati ad incrementare il livello di sicurezza su aspetti che potrebbero anche essere relativi agli ambienti non entreprise ma all’utilizzo comune di workstation di lavoro o uso personale. Vengono di seguito raccolti tool per protezione del traffico rete, crittografia di messaggi e controllo delle risoluzioni DNS.
OpenVPN
- Repository Git: https://github.com/OpenVPN/openvpn
- Licenza: GNU General Public License version 2.0 (GPL-2.0)
- Descrizione:
OpenVPN è una soluzione open source per la creazione di reti private virtuali (VPN). La sua architettura sicura e flessibile lo rende ampiamente utilizzato per implementare connessioni VPN sicure su reti pubbliche, come Internet.
GnuPG
- Repository GIT: https://gnupg.org/git/gnupg.git
- Licenza: GNU General Public License (GPL)
- Descrizione:
GnuPG, o GNU Privacy Guard, è un programma open-source per la crittografia di dati e la sicurezza della comunicazione. Fornisce implementazioni gratuite e open source degli standard OpenPGP (Pretty Good Privacy), consentendo agli utenti di cifrare e firmare digitalmente dati e comunicazioni.
Le funzionalità di GnuPG includono la cifratura dei dati, la firma digitale, la gestione delle chiavi crittografiche e la verifica dell’integrità dei dati. È ampiamente utilizzato per garantire la privacy e la sicurezza delle comunicazioni e dei dati sensibili.
Pi-hole
- Repository GIT: https://github.com/pi-hole/pi-hole
- Licenza: GNU General Public License (GPL)
- Descrizione:
Pi-hole è un progetto open-source che funge da server DNS e blocca gli annunci pubblicitari su una rete, filtrando i domini associati agli annunci. È progettato per funzionare come un filtro DNS centrale, impedendo agli annunci di essere visualizzati su tutti i dispositivi collegati alla rete.
Le funzionalità di Pi-hole includono il blocco degli annunci pubblicitari su dispositivi come computer, telefoni, tablet e smart TV, contribuendo a migliorare l’esperienza di navigazione. Può anche fornire statistiche e report sulla quantità di annunci bloccati.
Zero Trust – Approccio moderno alla sicurezza
La metodologia Zero Trust è un approccio alla sicurezza informatica che si basa sulla premessa che le organizzazioni non devono implicitamente fidarsi di nulla all’interno o all’esterno della loro rete. Invece, ogni utente, dispositivo e sistema deve essere verificato e autorizzato prima di essere concesso l’accesso alle risorse. L’obiettivo è mitigare i rischi associati alle minacce interne ed esterne, riducendo la superficie di attacco e migliorando la sicurezza complessiva.
Principi chiave della metodologia Zero Trust:
- Nessuna fiducia implicita: Nessun utente o dispositivo viene automaticamente considerato attendibile. Ogni richiesta di accesso deve essere autenticata e autorizzata.
- Accesso minimo privilegiato: Gli utenti ottengono solo i privilegi di accesso necessari per svolgere il loro lavoro, riducendo il rischio di abusi.
- Verifica continua: La verifica dell’identità e dei dispositivi avviene in modo continuo durante l’intera sessione di accesso, anziché solo all’inizio.
- Microsegmentazione: La rete è suddivisa in segmenti più piccoli, limitando la comunicazione solo a quei segmenti necessari per svolgere una specifica funzione.
- Monitoraggio dettagliato: Viene implementato un monitoraggio approfondito delle attività degli utenti e dei dispositivi per rilevare eventuali comportamenti anomali.
- Applicazione rigorosa delle politiche di sicurezza: Le politiche di sicurezza vengono applicate rigorosamente, ad esempio attraverso l’uso di firewall, sistemi di rilevamento delle minacce e analisi comportamentale.
Strumenti Open Source correlati alla Metodologia Zero Trust:
- BeyondCorp (progetto di Google): Un approccio Zero Trust sviluppato da Google per garantire la sicurezza dei suoi utenti e dispositivi, senza affidarsi a una rete aziendale tradizionale.
- Jericho Forum: Un gruppo di esperti in sicurezza che promuove l’approccio Zero Trust attraverso il concetto di “perimetro mobile”.
- OSSIM (Open Source Security Information and Event Management): Non specificamente legato al Zero Trust, ma può essere utilizzato per monitorare e analizzare gli eventi di sicurezza nell’ambito di una strategia di sicurezza completa.
- NIST Special Publication 800-207 Zero Trust Architecture: Non uno strumento, ma una guida del National Institute of Standards and Technology (NIST) sugli aspetti architetturali e concettuali dell’approccio Zero Trust.
Conclusioni
DevSecOps, acronimo di Development, Security e Operations, rappresenta una pratica che integra la sicurezza in ogni fase del ciclo di vita dello sviluppo di applicazioni o software. L’approccio si concentra sull’automazione dei processi di sicurezza e sulla minimizzazione delle vulnerabilità per soddisfare gli obiettivi di sicurezza e conformità dell’IT e del business. Introducendo la sicurezza fin dalle prime fasi del ciclo di sviluppo e integrandola con le pipeline di integrazione continua, distribuzione continua e distribuzione continua (CI/CD), DevSecOps assiste le organizzazioni nell’assicurare la sicurezza delle proprie applicazioni.
L’approccio DevSecOps richiede l’utilizzo di vari strumenti e strategie per identificare e affrontare i rischi per la sicurezza. In questo articolo, esploreremo alcuni dei migliori strumenti DevSecOps open source disponibili nel 2022.
I sistemi aperti non sono intrinsecamente meno sicuri delle loro controparti proprietarie, e il codice open source non è intrinsecamente meno sicuro del codice proprietario. Invece, il software Open Source (OSS) presenta sfide familiari alla sicurezza informatica. Nonostante ciò, concentrarsi sulla sicurezza degli OSS è ampiamente vantaggioso.
La recente diffusione della vulnerabilità Log4Shell ha riportato in primo piano i dibattiti sulla sicurezza e sul software Open Source (OSS), che è pubblicato con una licenza che consente a chiunque di utilizzare, studiare, copiare, modificare e ridistribuire liberamente i programmi per computer. Per alcuni, Log4Shell ha rafforzato la percezione comune secondo cui l’OSS è, per definizione, un problema di sicurezza informatica di notevole preoccupazione. Hanno indicato, ad esempio, i manutentori volontari che “stanno cercando disperatamente di affrontare una vasta vulnerabilità che ha messo a rischio miliardi di macchine”. Altre valutazioni sulla sicurezza si sono affrettate a difendere l’OSS, citando preoccupazioni di sicurezza equivalenti nel software proprietario e sottolineando l’importanza delle migliori pratiche di sicurezza informatica a tutti i livelli. Per loro, queste vulnerabilità e i relativi sforzi per affrontarle erano in gran parte “business as usual”.
Cosa rappresenta questo? L’OSS costituisce un problema di sicurezza informatica particolarmente impegnativo per l’industria e i decisori politici? Oppure i problemi di sicurezza legati all’OSS riflettono principalmente preoccupazioni più ampie in materia di sicurezza informatica a tutti i livelli? La nostra risposta: dipende.
Il termine “software open source” (OSS) è definito e utilizzato in vari contesti, dalle comunità software agli esperti di sicurezza e oltre. Al livello più basilare, l’Open Source Initiative definisce l’OSS come un software pubblicato con una licenza che consente a chiunque di utilizzare, studiare, copiare, modificare e ridistribuire liberamente i programmi per computer. L’OSS può riferirsi al codice, al software, ai pacchetti e ai sistemi; il “codice” costituisce gli elementi fondamentali, simili a un insieme di mattoncini Lego, mentre il “software” è semplicemente il codice utilizzabile. Un “pacchetto” è un codice in una forma distribuibile che ha un significato, analogamente a una costruzione Lego. Il “sistema” è ciò che tiene insieme tutti i diversi pacchetti, consentendo loro di interagire e avere un significato commerciale, come un villaggio Lego con case e marciapiedi che collega questi pezzi separati.
Grazie alle licenze permissive, il codice viene spesso modificato e combinato in nuovi modi per creare applicazioni, programmi e addirittura attività commerciali innovative.
La natura permissiva delle licenze OSS crea un modello di sviluppo software che incoraggia – e, in definitiva, si basa sulla collaborazione di molteplici attori. Molti contributori lavorano sia indipendentemente che in collaborazione, con pezzi di codice modulari che vengono combinati e ricombinati da numerosi utenti per vari scopi. Ciò vale sia per lo sviluppo del software che, soprattutto, per la manutenzione continua del software lungo tutto il suo ciclo di vita.
L’apertura e la relativa facilità d’uso hanno reso gli OSS ampiamente adottati, sia come codice, pacchetti e sistemi, sia in contesti aperti che proprietari. Un recente rapporto della Linux Foundation e del Laboratory for Innovation Science di Harvard stima che l’OSS costituisca l’80-90% di tutto il software, con la probabilità di un aumento futuro. Secondo il rapporto “The State of Enterprise Open Source” di Redhat, il 79% degli intervistati prevede un aumento dell’uso di software open source aziendale per tecnologie emergenti nei prossimi due anni. Aziende come Soundcloud e Netflix contribuiscono attivamente a progetti open source come Prometheus per il monitoraggio delle applicazioni e React per la creazione di interfacce utente.
Le sfide di sicurezza informatica sono familiari sia per il software open source che per quello proprietario. Le vulnerabilità possono derivare dalla gestione delle dipendenze e dall’azione di attori in malafede. Esistono migliori pratiche per migliorare la sicurezza del software, applicabili a entrambi i modelli di sviluppo.
Il modello di responsabilità nell’OSS è un’area critica in cui l’intervento governativo può essere significativo. La mancanza di una governance centrale nell’OSS crea un modello di responsabilità poco definito quando le cose vanno male.
L’apertura può essere vista su uno spettro, dalle collaborazioni aziendali controllate ai progetti interamente gestiti dalla comunità. Progetti come Linux, completamente gestiti dalla comunità, richiedono approcci diversi rispetto a quelli controllati dalle aziende.
L’ampia adozione dell’OSS rende la sicurezza informatica più impegnativa. L’esempio di Log4j2 evidenzia la complessità di tracciare e correggere le vulnerabilità in un ambiente in cui l’OSS è diffuso.
Le lezioni per i policy maker seguono schemi simili tra software open source e proprietario. Affrontare le preoccupazioni sulla sicurezza richiede una comprensione delle sfide comuni e l’implementazione di migliori pratiche già esistenti.
L’OSS offre un vantaggio unico nella sicurezza informatica grazie a una comunità attiva pronta ad avvisare, correggere e mitigare gli exploit. Tuttavia, la manutenzione a lungo termine può essere problematica senza adeguati incentivi finanziari e umani.
La responsabilità della sicurezza dovrebbe essere condivisa e incentivare le migliori pratiche per garantire un ambiente sicuro per tutti.
Bibliografia
- Wikipedia Contributors. (2022). Revolution OS. In: Wikipedia. Recuperato il 23 febbraio 2024, da https://en.wikipedia.org/wiki/Revolution_OS
- The Linux Foundation. (s.d.). Sito web della Linux Foundation. Recuperato da https://www.linuxfoundation.org/
- The Apache Software Foundation. (s.d.). Sito web della Apache Software Foundation. Recuperato da https://www.apache.org/
- Cloud Native Computing Foundation (CNCF). (s.d.). Sito web della CNCF. Recuperato da https://www.cncf.io/
- Red Hat. (s.d.). What is DevSecOps? Recuperato da https://www.redhat.com/en/topics/devops/what-is-devsecops
- Red Hat. (2022). Enterprise Open Source Report 2022. Recuperato da https://www.redhat.com/en/enterprise-open-source-report/2022
- Mia Mamma Usa Linux. (2022, luglio). Per i professionisti, il software opensource è sicuro e affidabile secondo un sondaggio: non tutti la pensano così. Recuperato da https://www.miamammausalinux.org/2022/07/per-i-professionisti-il-software-opensource-e-sicuro-e-affidabile-secondo-un-sondaggio-non-tutti-a-pensano-cosi/
- Awesome DevSecOps. (s.d.). GitHub repository. Recuperato da https://github.com/devsecops/awesome-devsecops
- Wikipedia Contributors. (2022). Information security standards. In: Wikipedia. Recuperato il 23 febbraio 2024, da https://en.wikipedia.org/wiki/Information_security_standards
- Agenzia per l’Italia Digitale (AGID). (s.d.). Sito web dell’AGID. Recuperato da https://www.agid.gov.it/it/
- Torvalds, L. (2007, aprile). Linus Torvalds: The mind behind Linux. TED. Recuperato da https://www.ted.com/talks/linus_torvalds_the_mind_behind_linux?language=en
- Wikipedia Contributors. (2022). Zero Trust Security Model. In: Wikipedia. Recuperato il 23 febbraio 2024, da https://en.wikipedia.org/wiki/Zero_trust_security_model
- Mia Mamma Usa Linux. (2023, agosto). HashiCorp cambia la licenza dei propri prodotti da Mozilla Public License a Business Source License: che di open source ha poco e niente. Recuperato da https://www.miamammausalinux.org/2023/08/hashicorp-cambia-la-licenza-dei-propri-prodotti-da-mozilla-public-license-a-business-source-license-che-di-open-source-ha-poco-e-niente/
- Choose a License. (s.d.). Recuperato da https://choosealicense.com/
- National Institute of Standards and Technology (NIST). (s.d.). Sito web del NIST. Recuperato da https://www.nist.gov/
- Open Source Security Foundation (OpenSSF). (s.d.). Sito web dell’OpenSSF. Recuperato da https://openssf.org/
- Center for Internet Security (CIS). (s.d.). Sito web del CIS. Recuperato da https://www.cisecurity.org