-
-

Landing page heros
-

Landing page grid
-

Projects Page



Inspiration
Over the past summer, I had an internship at Persistent Systems. During my time there, I saw an important bottleneck in the software development lifecycle that seemed outmoded in the modern era. The frontend team was blocked, waiting while the backend engineers finalized API contracts and their database schemas. We were building extremely fast-paced application prototypes, but the friction between data definition and the UI created a big desynchronization.
I realized that, for frontend engineers, the database is more times than not, a black box. It is an abstract concept that is buried behind ORMs and SQL migrations. We wanted to break that. We didn't just want a database client. We wanted a visual application that filled in the gap between designing schemas and also prototyping. Backplane was born from the desire to decouple frontend velocity from the boilerplate of backend code, allowing developers to write complex data relationships visually and also derive immediate utility without ever having to write a single line of server-sided code.
What it does
Backplane is an intelligent visual interface for relational databases. It turns the annoying command-line experience of using PostgreSQL and MySQL into a node-based graph topology. At the core, it performs immediate introspection. All you have to do is feed it a connection string and the app is able to reverse engineer the entire schema, map foreign key constraints, column types, and also indices into a navigable graph. Instead of users having to manually write DDL scripts, users are able to drag and drop to create tables, modify columns, and also build their own relationships, with the system tracking these actions as "pending state" which can be reviewed and adjusted. Once the visual design is complete, Backplane compiles the graph changes into raw SQL execution plans, and applies them to the live database with rollback protection. Most powerfully, Backplane can instantly spin up as secure, ephemeral REST API for any table in the graph. This allows frontend teams to start fetching, posting, and manipulating data against a real schema, which removes the backend bottleneck. Backplane also bundles with Real Time Collaboration (RTC) through Liveblocks. This makes our application akin to "Figma for databases".
How we built it
We built Backplane as a highly performant Turbo monorepo, which ensures strict type safety between the client and the backend engine. The backend bypasses the typical Node.js runtime concepts in favor of Bun and Elysia.js. This decision was extremely important for achieving sub-millisecond latency during schema parsing. We used a double-layer approach where we use Prisma for our application state, while we maintain a raw Knex.js instance for user-project connections. This allows us to execute raw DDL commands directly against the user's infrastructure without the overhead of an ORM. On the frontend, the UI is built on Next.js 15 using React Server Components, but I believe the true complexity is behind our visualization core. We used React Flow for rendering, and we engineered our own Directed Acyclic Graph (DAG) layout engine that performs topological sorting on the database schema. This engine calculates node depth based on foreign key dependencies to build a "layered" graph that visually represents the overall hierarchy of data flow.
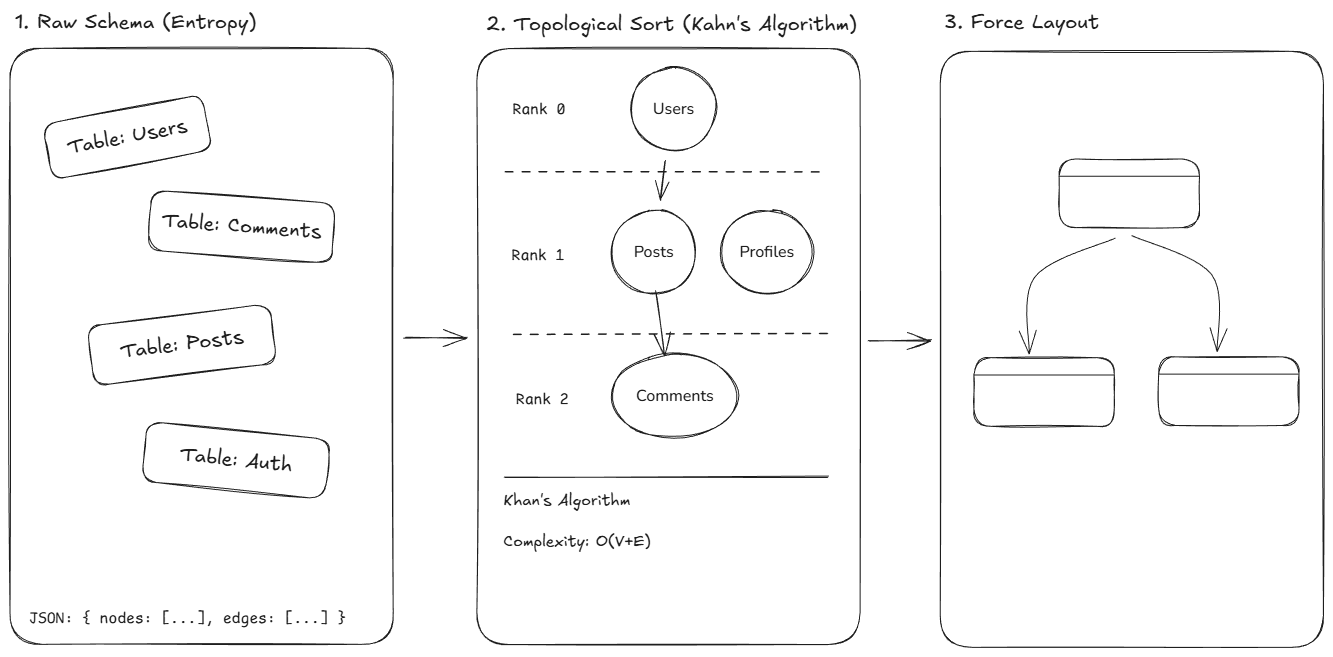
To visualize the schema without "edge crossings," we parse the SQL introspection result into an adjacency matrix. We then apply Kahn's Algorithm to perform a Topological Sort, and assign a dependency rank to each table.
$$ \text{Rank}(v) = 1 + \max({ \text{Rank}(u) \mid (u, v) \in E}) $$
This ensures that tables are rendered in a hierarchy where upstream dependencies (like Users) always appear above downstream consumers like Orders. This converts a chaotic relational set into a readable DAG.
Our RTC relies on Liveblocks for syncing. Liveblocks is a CRDT library, which stands for Conflict-free Replicated Data Type, which is a datatype bundled with an algorithm to resolve conflicts between clients. What this means is that each client has its own data, and the algorithm will merge and sync inconsistencies to one converged result. The following is a flowchart that displays this.

As you can see, each client starts with their own data, then eventually merges with other branches to achieve a unified result. Our Liveblocks CRDT holds each user's cursor position, pending table and column changes, as well as the layout of the graph, ensuring that coworkers can see exactly what other team members are working on. When publishing, we use an event broadcast to sync database changes across all clients.
For security, we also have a backend endpoint for users to access a Liveblocks collaboration room. This means that our secret key is never shared with the frontend, and each user has to send a request to the backend, which checks the session for authorization. If successful, the backend will send a JSON Web Token back, authorizing them to access the room.
Challenges we ran into
The biggest problem we faced was the topological layout problem. Automating the visualization of a database schema is mathematically equivalent to a graph drawing problem, which can potentially be NP-hard depending on the constraints faced. We had to implement heuristic algorithms that prevent "edge crossing" and visual clutter. We wrote a custom layout engine that calculates the dimensions of nodes before rendering, and then positions them based on their dependency depth using a modified topological sort, and it handles edge cases like cyclic dependencies where the 2 tables reference each other. At the same time, we also had issues building the "Pending State" diffing engine. This is basically a specialized Version Control System for database schemas that are running entirely in the browser. We had to build an Event Sourcing pattern where every action performed by a user (for example, creating a column or dropping a table) is stored as a discrete event. Then, reconciling this linear queue against the complex reality of a live database schema to generate valid SQL involved handling complex dependency resolution. For example, we had to ensure a table exists before attempting to create a foreign key constraint against it, or even handling the renaming of a column that is part of a composite primary key index. Additionally, the mock server also posed a considerable challenge regarding type isomorphism. Basically, we had to build a runtime translation layer that maps incoming JSON primitives to SQL data types, for example distinguishing whether a string payload should be cast to a UUID, VARCHAR, or TXT based on the schema definition. Also, implementing the API key infrastructure required some cryptographic knowledge. We couldn't simply just store mock API tokens. We had to implement a secure issuance strategy where we generate 256-bit entropy buffers, and return the raw key to the user only once while storing a SHA-256 hash in our database. Reconciling this stateless authentication with stateful database connections required a separate and crucial middleware layer that validates headers in O(1) time while also preventing any sort of timing attacks.
Accomplishments that we're proud of
What we are extremely proud of is our JIT architecture of our Mock Engine. Unlike existing mocking tools that use configuration files or code gen, our engine uses runtime reflection to serve its requests. This means that just milliseconds after a user creates a node on the canvas, the API endpoint automatically adapts to accept this new field, and it auto handles type validation and also all the constraints dynamically. We are also proud of the cryptographic nature in our security implementation. We used AES-256-GCM authenticated encryption for all of our stored connection strings and made sure that user credentials are NEVER exposed at rest. This involved managing distinct initialization vectors (IV) and authentication tags for EVERY SINGLE encryption operation, which made sure that even identical outputs produce unique ciphertexts.
We are also extremely proud of our cursor syncing system, which calculates the zoom of each user and scales the movement of the cursor's based off that. This ensures that even if a user is zoomed in more than other users in the same room, the cursors will always be synced relative to the graph, ensuring seamless collaboration.
What we learned
This project helped us fully understand the internal workings of relational databases. Something funny I learned is that information_schema isn't a reference, it's a programmable API that can be exploited to build meta tools. We also learned to normalize the metadata formats of PostgreSQL's pg_catalog and MySQL's information_schema into an interface. By building a tool that is specifically intended to solve the friction between frontend and backend, we also gained a deeper understanding and appreciation for API contract design, and we learned that visual tools are also important for seniors to visualize their architecture's complexity, not just for beginners. Also, migrating from Node to Bun's runtime showed us that the future of JavaScript backend engineering is extremely fast, with startup times and request throughput we achieved with Elysia representing order-of-magnitude improvements over traditional frameworks like Express and Nest (regarding the serialization cost of JSON responses).
What's next for Backplane
Our roadmap will focus on intelligent automation and also real time collaboration. We want to integrate AI-driven query optimization to analyze the schema graph and suggest missing indices or denormalization strategies based on query access patterns. We are also working on a collaborative schema design, which uses WebSockets and CRDTs allowing multiple engineers to change the schema graph all at the same time, which effectively creates a "Figma for Databases." Also, we want to integrate directly with GitHub to implement migration version control, automatically generating .sql migration files and also opening PRs when users publish changes from their editor, which effectively closes the loop behind design and code defined infrastructure.




Log in or sign up for Devpost to join the conversation.