The post Beta: How to Download the App on Your Android Device appeared first on Dreamfi.
]]>Here are instructions to download the app on Android devices.
Please check your email for a message from our developer, that looks like the image below.
The email will contain a link to download the app on the GooglePlay Store.
Please follow the instructions, and if you have any issues installing the app, please contact us at [email protected]
Once you’ve downloaded and launched the app, please complete sign up for your DreamFi account.

The post Beta: How to Download the App on Your Android Device appeared first on Dreamfi.
]]>The post Beta: How to Download the App on Apple/iOS Devices appeared first on Dreamfi.
]]>Here are instructions on how to download our app if you have an Apple/iOS mobile phone:
Step 1: Download TestFlight App
-
Open the App Store on your iPhone
-
Search for “TestFlight“
-
Download the official TestFlight app (it’s free and made by Apple)
-
Install it on your device
Step 2: Get Your Invitation
The app developer will send you an invitation in one of two ways:
-
Email invitation with a direct link
-
Invitation code that you’ll enter manually
Step 3: Accept the Invitation
If you received an email invitation:
-
Open the email on your iPhone
-
Tap the “Start Testing” or invitation link
-
This will automatically open TestFlight
-
Tap “Accept” to join the beta
Step 4: Install the Beta App
-
Once you’ve accepted the invitation, you’ll see the app in TestFlight
-
Tap “Install” next to the app name
-
Once installed, open the app to begin signing up.
-
Select “Sign Up” below the ‘Login’ button and follow the application steps through to completion.
-
If you have any questions or run into any issues, don’t hesitate to contact us at [email protected]
Important Things to Know
-
Use the same Apple ID that the developer invited
-
Check your spam folder if you don’t see the invitation email
-
Beta apps expire after 90 days (you’ll get updates before then)
-
You can provide feedback directly through TestFlight
-
Beta apps appear with an orange dot on your home screen
-
You can have both the beta and App Store versions installed simultaneously
If You Have Issues
-
Make sure your iOS version is compatible
-
Verify you’re signed in with the correct Apple ID
-
Contact the developer if the invitation isn’t working
-
Check that you have enough storage space on your device
If you have any issues downloading or accessing the app don’t hesitate to contact us at [email protected]!
The post Beta: How to Download the App on Apple/iOS Devices appeared first on Dreamfi.
]]>The post First Opportunities – “Get Your Foot in the Door” appeared first on Dreamfi.
]]>The Technical Challenge
Our use case presented several key technical requirements:
- High-bandwidth transfer between remote GPUs of non-contiguous memory chunks
- Ability to dynamically add or remove nodes from Kubernetes deployments without disrupting ongoing operations
- Support for peer-to-peer communication patterns
While NVIDIA’s NCCL library is the de facto standard for distributed deep learning, it wasn’t ideal for our use case:
- NCCL excels at collective communication but requires establishing a static “world”, which requires restarting the entire cluster when adjusting the participating nodes.
- NCCL’s synchronous communication model adds complexity for our asynchronous workload
- We wanted direct control over our memory transfer patterns for optimization
- Building our own solution provided valuable learning opportunities
Modern High-Performance Networks
To understand our solution, let’s first explore how modern high-performance networks differ from traditional networking.
Most networks we use daily rely on TCP/IP protocols, where applications communicate with the network card through the operating system kernel using sockets. However, high-performance networks use RDMA (Remote Direct Memory Access) – a completely different hardware and software stack that enables direct memory access between machines without involving the CPU.
AWS provides Elastic Fabric Adapter (EFA), a custom network interface that implements Amazon’s custom protocol called Scalable Reliable Datagram (SRD). Unlike traditional TCP/IP networking where data must be copied multiple times between user space, kernel space, and network buffers, EFA with RDMA allows direct data transfer between GPU memory and the network card, bypassing the CPU entirely.
Philosophy of High-Performance Network Design
Building high-performance networking systems requires rethinking several fundamental assumptions:
- Buffer Ownership: Unlike traditional sockets where the kernel manages network buffers and requires copying between user space and kernel space, RDMA requires applications to manage their own buffers. When an application initiates a network operation, it transfers buffer ownership to the network card until the operation completes, eliminating the need for data copying.
- Memory Registration: Applications must register memory regions with the operating system kernel. The kernel sets up virtual address mappings that allow the CPU, GPUs, and network cards to all understand the same virtual addresses. This registration is a one-time operation that enables subsequent zero-copy data transfers.
- Control Plane vs Data Plane: High-performance networks separate operations into two categories:
- Control plane operations (like connection setup and memory registration) go through the kernel to ensure security
- Data plane operations (actual data transfer) bypass the kernel for maximum performance
- Reception Before Transmission: Without kernel-managed buffers, applications must pre-post receive operations, specifying where incoming data should be placed. This is a fundamental shift from the socket model where applications can receive data at any time.
- Poll-based Completion: Instead of waiting for kernel notifications through mechanisms like epoll, applications directly poll hardware completion queues. This eliminates system call overhead and allows immediate reaction to completed operations.
- Hardware Topology Awareness: Understanding and optimizing for hardware topology is crucial for achieving maximum performance.
Understanding Hardware Topology
AWS p5 instances have a sophisticated internal architecture. As shown below, each instance contains two CPU sockets forming two NUMA nodes, with each NUMA node connecting to four PCIe switches:
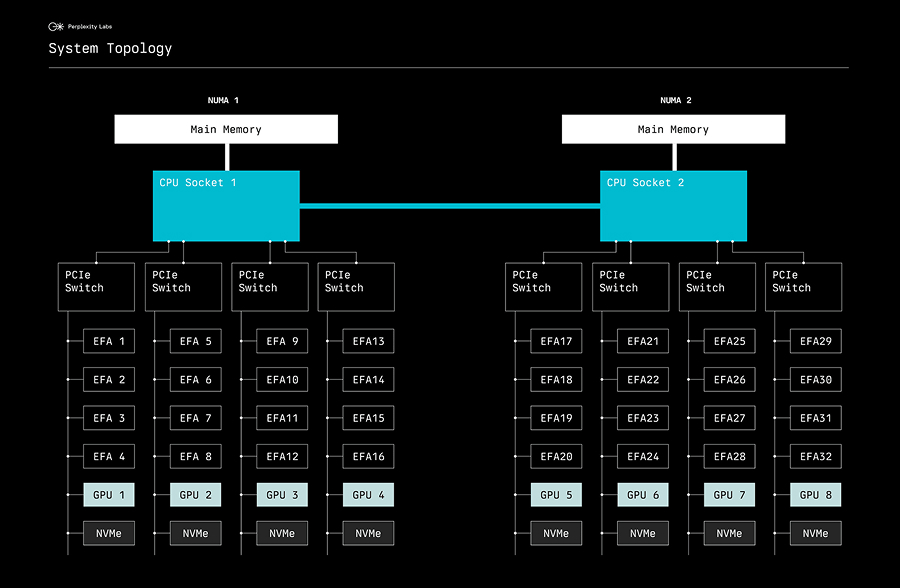
The post First Opportunities – “Get Your Foot in the Door” appeared first on Dreamfi.
]]>The post High-Performance GPU Memory Transfer on AWS Sage maker Hyperope appeared first on Dreamfi.
]]>The Technical Challenge
Our use case presented several key technical requirements:
- High-bandwidth transfer between remote GPUs of non-contiguous memory chunks
- Support for peer-to-peer communication patterns
While NVIDIA’s NCCL library is the de facto standard for distributed deep learning, it wasn’t ideal for our use case:
- NCCL excels at collective communication but requires establishing a static “world”, which requires restarting the entire cluster when adjusting the participating nodes.
- NCCL’s synchronous communication model adds complexity for our asynchronous workload
- We wanted direct control over our memory transfer patterns for optimization
Modern High-Performance Networks
Most networks we use daily rely on TCP/IP protocols, where applications communicate with the network card through the operating system kernel using sockets. However, high-performance networks use RDMA (Remote Direct Memory Access) – a completely different hardware and software stack that enables direct memory access between machines without involving the CPU.
- Buffer Ownership: Unlike traditional sockets where the kernel manages network buffers and requires copying between user space and kernel space, RDMA requires applications to manage their own buffers. When an application initiates a network operation, it transfers buffer ownership to the network card until the operation completes, eliminating the need for data copying.
- Memory Registration: Applications must register memory regions with the operating system kernel. The kernel sets up virtual address mappings that allow the CPU, GPUs, and network cards to all understand the same virtual addresses. This registration is a one-time operation that enables subsequent zero-copy data transfers.
- Control Plane vs Data Plane: High-performance networks separate operations into two categories:
- Control plane operations (like connection setup and memory registration) go through the kernel to ensure security
- Data plane operations (actual data transfer) bypass the kernel for maximum performance
- Reception Before Transmission: Without kernel-managed buffers, applications must pre-post receive operations, specifying where incoming data should be placed. This is a fundamental shift from the socket model where applications can receive data at any time.
AWS p5 instances have a sophisticated internal architecture. As shown below, each instance contains two CPU sockets forming two NUMA nodes, with each NUMA node connecting to four PCIe switches:
The post High-Performance GPU Memory Transfer on AWS Sage maker Hyperope appeared first on Dreamfi.
]]>The post Personal Finance appeared first on Dreamfi.
]]>The Technical Challenge
Our use case presented several key technical requirements:
- High-bandwidth transfer between remote GPUs of non-contiguous memory chunks
- Support for peer-to-peer communication patterns
While NVIDIA’s NCCL library is the de facto standard for distributed deep learning, it wasn’t ideal for our use case:
- NCCL excels at collective communication but requires establishing a static “world”, which requires restarting the entire cluster when adjusting the participating nodes.
- NCCL’s synchronous communication model adds complexity for our asynchronous workload
- We wanted direct control over our memory transfer patterns for optimization
Modern High-Performance Networks
To understand our solution, let’s first explore how modern high-performance networks differ from traditional networking.
Most networks we use daily rely on TCP/IP protocols, where applications communicate with the network card through the operating system kernel using sockets. However, high-performance networks use RDMA (Remote Direct Memory Access) – a completely different hardware and software stack that enables direct memory access between machines without involving the CPU.
- Buffer Ownership: Unlike traditional sockets where the kernel manages network buffers and requires copying between user space and kernel space, RDMA requires applications to manage their own buffers. When an application initiates a network operation, it transfers buffer ownership to the network card until the operation completes, eliminating the need for data copying.
- Memory Registration: Applications must register memory regions with the operating system kernel. The kernel sets up virtual address mappings that allow the CPU, GPUs, and network cards to all understand the same virtual addresses. This registration is a one-time operation that enables subsequent zero-copy data transfers.
- Control Plane vs Data Plane: High-performance networks separate operations into two categories:
- Control plane operations (like connection setup and memory registration) go through the kernel to ensure security
- Data plane operations (actual data transfer) bypass the kernel for maximum performance
- Reception Before Transmission: Without kernel-managed buffers, applications must pre-post receive operations, specifying where incoming data should be placed. This is a fundamental shift from the socket model where applications can receive data at any time.
- Poll-based Completion: Instead of waiting for kernel notifications through mechanisms like epoll, applications directly poll hardware completion queues. This eliminates system call overhead and allows immediate reaction to completed operations.
- Hardware Topology Awareness: Understanding and optimizing for hardware topology is crucial for achieving maximum performance.
Understanding Hardware Topology
AWS p5 instances have a sophisticated internal architecture. As shown below, each instance contains two CPU sockets forming two NUMA nodes, with each NUMA node connecting to four PCIe switches:
The post Personal Finance appeared first on Dreamfi.
]]>The post How to Improve Current Situation – “Ask for Raise or Promotion” appeared first on Dreamfi.
]]>
The Technical Challenge
Our use case presented several key technical requirements:
- High-bandwidth transfer between remote GPUs of non-contiguous memory chunks
- Support for peer-to-peer communication patterns
While NVIDIA’s NCCL library is the de facto standard for distributed deep learning, it wasn’t ideal for our use case:
- NCCL excels at collective communication but requires establishing a static “world”, which requires restarting the entire cluster when adjusting the participating nodes.
- NCCL’s synchronous communication model adds complexity for our asynchronous workload
- We wanted direct control over our memory transfer patterns for optimization
Modern High-Performance Networks
Most networks we use daily rely on TCP/IP protocols, where applications communicate with the network card through the operating system kernel using sockets. However, high-performance networks use RDMA (Remote Direct Memory Access) – a completely different hardware and software stack that enables direct memory access between machines without involving the CPU.
- Buffer Ownership: Unlike traditional sockets where the kernel manages network buffers and requires copying between user space and kernel space, RDMA requires applications to manage their own buffers. When an application initiates a network operation, it transfers buffer ownership to the network card until the operation completes, eliminating the need for data copying.
- Memory Registration: Applications must register memory regions with the operating system kernel. The kernel sets up virtual address mappings that allow the CPU, GPUs, and network cards to all understand the same virtual addresses. This registration is a one-time operation that enables subsequent zero-copy data transfers.
- Control Plane vs Data Plane: High-performance networks separate operations into two categories:
- Control plane operations (like connection setup and memory registration) go through the kernel to ensure security
- Data plane operations (actual data transfer) bypass the kernel for maximum performance
- Reception Before Transmission: Without kernel-managed buffers, applications must pre-post receive operations, specifying where incoming data should be placed. This is a fundamental shift from the socket model where applications can receive data at any time.
AWS p5 instances have a sophisticated internal architecture. As shown below, each instance contains two CPU sockets forming two NUMA nodes, with each NUMA node connecting to four PCIe switches:
The post How to Improve Current Situation – “Ask for Raise or Promotion” appeared first on Dreamfi.
]]>The post Hello world! appeared first on Dreamfi.
]]>The post Hello world! appeared first on Dreamfi.
]]>