
丢掉脑袋,忘却时间
一双拖鞋,两只手
熟悉而陌生的小路,两侧路灯微弱
心无旁骛,夜慢行
每个灯的中心发散着纤细而明亮的线
随着慢行的节奏,左右定轴摇摆
思绪在空中飘荡,似有若无
只有慢慢变沉的双手
和渐渐发热的脚底板
让我察觉到我还在路上
直到行至起点
点亮回家的电梯
开门的声音忽然拉入另一个时空
脑袋和时间又回来了
丢掉脑袋,忘却时间
一双拖鞋,两只手
熟悉而陌生的小路,两侧路灯微弱
心无旁骛,夜慢行
每个灯的中心发散着纤细而明亮的线
随着慢行的节奏,左右定轴摇摆
思绪在空中飘荡,似有若无
只有慢慢变沉的双手
和渐渐发热的脚底板
让我察觉到我还在路上
直到行至起点
点亮回家的电梯
开门的声音忽然拉入另一个时空
脑袋和时间又回来了

分享一下经验:大概流程就是:数据集处理→参数调优→选择最佳模型。
数据集的质量直接影响到模型训练的效果,因此在数据集的选取上必须严格把控。
首先,图片质量是关键因素,优先选择写真原图,其分辨率高、细节丰富,能够为模型提供高质量的输入。如果无法获取写真原图,也应确保图片清晰度较高,单张图片大小最好在2MB以上,以满足训练对数据精度的要求。
其次,图片中人物的面部清晰度至关重要,无论是大头照还是全身图,面部都必须清晰无遮挡,不能被任何物体遮挡,以便模型能够准确地学习到面部特征。
此外,视角的覆盖范围也很重要,一个包含大头照、上半身照和全身照的数据集最为理想,这样能够使模型从不同角度学习人体特征,增强其泛化能力。
最后,图片风格的统一性也不容忽视,背景简单且带有景深的照片是最佳选择。如果背景较为复杂,则需要进行抠图处理,以避免背景对模型训练产生干扰。同时,应避免使用滤镜过重的图片,以免影响模型对真实特征的学习。
数据标注是模型训练的基础环节,虽然在实际操作中可以适当简化流程,但也不能完全忽视其重要性。在标注过程中,应尽量确保标注的准确性和一致性,以便为模型提供清晰明确的训练目标。虽然在一些情况下可以通过自动化工具生成标注,但人工审核和修正仍然是必要的,以确保标注质量。
参数调优是模型训练过程中的关键步骤,合理的参数设置能够显著提升模型的性能。以训练512×768分辨率的上半身图片为例,与网络相关的两个参数均设置为128,每张图片训练7步,总共训练25张图片。在学习率的调整方面,首先可以使用DAD优化器来寻找最佳的学习率。通过实验和观察,找到一个合适的学习率范围,然后根据经验公式lr=unet lr=8×text lr进行调整,以平衡不同模块的学习速度,确保模型能够稳定且高效地进行训练。
损失曲线是评估模型训练效果的重要指标之一,但并非损失值越低就越好。关键在于观察损失曲线是否呈现稳步下降的趋势,只要损失曲线能够持续下降,就说明模型在不断进步,正在逐步学习到数据中的特征和规律。在选择最佳模型时,不能仅仅依赖损失曲线,还需要结合其他评估指标。例如,可以使用XY图(即输入图片与生成图片的对比图)来进行直观的比较。通过观察XY图,可以直观地评估模型生成的图片与目标图片之间的相似度,从而更准确地判断模型的性能。
在模型选择阶段,需要综合考虑多个因素。首先,选取上半身图片作为测试样本,从中挑选出几个面部特征较为明显的图片进行XY图绘制,以评估模型对关键部位的生成效果。此外,还需要选择一些泛化性较强的样本,绘制全身照的XY图,以评估模型在不同场景下的表现。通过对比这些XY图,可以全面地评估模型的性能,最终选择出生成效果最佳、泛化能力最强的模型作为最终模型。
总之,数据集处理、参数调优和模型选择是深度学习模型训练过程中的关键环节,每个环节都至关重要,不容忽视。只有通过严谨的流程和科学的方法,才能训练出性能优异、泛化能力强的模型,为实际应用提供可靠的支持。
]]>Info Verifying wix package
Downloading https://github.com/wixtoolset/wix3/releases/download/wix3112rtm/wix311-binaries.zip
Error failed to bundle project: `Io Error: 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。 (os error 10060)`error Command failed with exit code 1.
解决办法:
先把这个文件下载下来
https://github.com/wixtoolset/wix3/releases/download/wix3112rtm/wix311-binaries.zip
在缓存目录下新建 tauri/WixTools 目录,放在wixtools目录下解压,再执行即可
平台目录例子
Linux$HOME/.cache/home/用户名/.cache
macOS$HOME/Library/Caches/Users/用户名/Library/Caches
Windows{FOLDERID_LocalAppData}C:\Users\用户名\AppData\Local
当然也可以设置代理处理
nsis 命令行下载失败 。先用迅雷或者其他方法下载下来
https://ghproxy.com/https://github.com/tauri-apps/binary-releases/releases/download/nsis-3/nsis-3.zip
在上面wixtools的目录新建 NSIS,也即tauri/NSIS
然后将nsis-3.zip 解压到nsis目录
https://github.com/tauri-apps/binary-releases/releases/download/nsis-plugins-v0/NSIS-ApplicationID.zip
下载后 解压到 nsis的plugins目录下
然后将releaseunicode 下的applicationid.dll 和nsis_tauri_utils.dll 两个文件复制到 x86-unicode 目录
nsis_tauri_utils.dll下载地址
nsis_tauri_utils.dll
上传一张图片,或者输入一些简单的关键词,系统就能自动生成一张卡通图像……最近一段时间,AI绘画开始在互联网社交平台走红。
AI绘画,顾名思义就是利用人工智能进行绘画,是人工智能生成内容的典型应用场景之一。其主要原理是收集大量已有作品,通过算法对其内容和风格特征进行解析,最后再生成新的作品,所以算法是AI绘画的核心。
当前,“凭空”生成图像的AI绘画,其实也会动辄“翻车”:也许上一秒AI通过你的照片绘出的是一张充满艺术感的二次元画像,下一秒你的宠物猫、狗则可能被画成可爱少女或肌肉猛男。
事实上,AI绘画早已火爆全球。第一张公开展出的、由人工智能创作的绘画作品《埃德蒙·贝拉米的肖像》曾于2018年在佳士得拍卖行以43.25万美元成交,那是一张由机器学习了从14世纪到20世纪的1.5万张肖像画之后自动生成的一张肖像画作品。
AI绘画是如何实现“凭空”生图的?除了娱乐外,AI绘画还有哪些潜在的应用前景?
2022年,由人工智能创作的《太空歌剧院》一度火出圈。在美国科罗拉多州举办的新兴数字艺术家竞赛中,《太空歌剧院》获得“数字艺术/数字修饰照片”类别一等奖。它的构图、配色以及画面的细节堪称精致。然而,这个作品的创作者不是艺术家,而是来自美国科罗拉多州的游戏设计师。
这位游戏设计师在一个名为“Midjourney”的AI创作工具里,先输入几个关键词,如光源、构图、氛围等,得到了100幅作品,再进行约80小时的修图修饰,最终选出3幅作品,最后把图像打印到画布上。
通过简单交互式对话在短时间内生成的“艺术”作品,让人类艺术家展开了一场关于“AI绘画作品参赛是否属于作弊”的争论。这场声势浩大的争论也令大众直观地意识到如今的AI绘画水平已经发展到了何种程度。
“人工智能在艺术方面的创作最早可以追溯到上个世纪末,当时的人工智能绘画技术叫作‘图像的风格化滤镜’。”中国科学院自动化研究所多模态人工智能系统全国重点实验室研究员董未名说,最初的AI绘画方法比较简单,比如一张普通的照片,通过一些图像处理的算法,把照片像素进行几何或者色彩上的变换,然后再调节不同参数,就可以模拟出类似油画或者水彩画的风格。
经过20年左右的发展,目前基于不同类型或者模态元素的AI绘画发展情况不尽相同,发展最久的是“以图生图”,再到近期火爆的“文+图”生图。当然,也有团队已经研发出由语音生成图像的技术。
董未名介绍,目前AI绘画主要借助图像风格迁移技术、图文预训练模型和扩散模型实现。
“图像风格迁移技术指的是图像处理算法通过对输入的真实图像内容特征和对参考的艺术图像风格特征的提取,实现真实图像内容特征和艺术图像风格特征的融合,从而生成新的艺术图像。”董未名举例,如果将美国旧金山艺术宫的外景照片和印象派创始人莫奈绘制的作品,通过图像风格迁移技术进行融合,就能得到一张看起来像是由莫奈绘制的美国旧金山艺术宫的绘画作品。最初的AI绘画采用的正是这种技术。
不过,在董未名看来,图像风格迁移技术大多依赖的是生成式对抗网络(GAN)算法,它最大的问题是生成的绘画作品艺术性不强,笔触和构图让人觉得与真实的绘画有差距,所以长久以来,AI绘画一直“籍籍无名”。
当图像风格迁移技术还在挣扎于输出作品的审美问题时,图文预训练模型的出现,加速了AI绘画的崛起。
“依托图文预训练模型,只要输入一句话或者上传一幅风格明显的图片,算法就能将图像特征和文字特征‘对齐’。生成的绘画作品的内容特征和上传图片的内容相似,艺术性也比图像风格迁移技术生成的图片强很多。”董未名举例,比如支撑图文预训练模型的可对比语言—图像预训练(CLIP)算法,就是利用图文特征“对齐”的能力,再结合已有的生成模型,实现“以图生图”或者“图+文”生图。
不过,董未名坦言,图文预训练模型的推广也存在一些争议,有部分人认为,该模型在训练前期,需要用大量的图形处理器(GPU)进行数据训练,耗电量大、成本很高,而该模型的应用场景却不够清晰。但也有人认为,也许该模型未来可以打造为通用的人工智能模型,用它完成更多的算法作业,只是这还需要时间的验证。
诚然没有一项技术是完美的,这也为人类探究更先进的技术提供了无限动力。当下最流行的扩散模型便是其中之一。
“目前最新的AI绘画技术采用的就是扩散模型,这种模型可以把一个随机采样的噪声输入模型,然后尝试通过去噪来生成图像。”董未名表示,扩散模型也存在弱点,由于模型对图片内容识别的能力不足,或者难以完全理解识别文字的意义,以及训练数据的偏差,有时便会生成“四不像”的作品。此外,扩散模型生成图片的速度比较慢,目前还达不到实时生成图片。
AI绘画目前的应用场景,更多聚焦于社交软件。近期在国内社交网络“火出天际”的AI绘画软件主要集中在小程序及App。随着AI绘画小程序的火爆,短视频平台抖音也迅速上线了AI绘画特效。同时,此前腾讯上线了“QQ小世界AI画匠”活动,百度也推出了首款AI艺术和创意辅助平台“文心一格”。
有了AI,人人都可以是艺术家。AI绘画的出现,恰如瑞士艺术家保罗·克利所言:“艺术不是再现可见,而是使不可见成为可见。”“AI现在已经完美实现了这一目标,人们可以通过机器计算来绘制出很多现实中见不到的场景。”董未名畅想,不远的将来,AI绘画或许还将展现更丰富的应用场景。
“现在网络上充斥着很多不良内容,这些内容为了逃避监管经常以绘画的形式出现,而当前很多内容识别模型对真实图片识别得很准确,但缺乏不良内容艺术作品的相关训练数据,所以对不良内容识别不准确。也许可以用AI绘画技术,积累不良内容艺术作品的数据,并用以训练识别模型,以提升互联网内容的安全监管能力和识别的准确率。”董未名建议。
在董未名看来,作为一种艺术呈现形式,AI绘画也将在元宇宙、设计、文旅等行业催生新的商业模式。例如AI绘画目前在AI辅助创作、短视频、影视制作和元宇宙等方面都有布局,因为这些赛道都离不开创意,AI绘画可以帮助创作者通过简单的特征输入,实现对其创意的预览,甚至可以直接进行创作。
不过,董未名并不讳言,当下AI绘画仍然存在版权争议问题。AI绘画的核心是模型,而训练模型需要使用大量图像、文本数据。对于未经授权的图片,经过运算之后所生成的图像版权归属尚难界定。“有的画家风格特别明显,如果用画家的画去训练算法模型生成作品,那最后的版权属于谁呢?”董未名提出的问题,正是多数AI绘画作品所面临的现实问题。
AI绘画掀起了一场资本的群体狂欢,希望有一天它能走出“照猫画虎”的尴尬,真正服务艺术创作、创造更多价值。
]]>由 apple 官方颁发, 用以证明开发者身份的特殊文件, 在 iOS 开发中主要用于代码签名, 保障 iOS 生态的健康安全, 分为开发者证书和发布者证书
只有在本机模拟器调试时无需代码签名, 当 App 需要在真机运行和发布时需要使用相应证书进行签名
首先需要拥有相应权限的开发者帐号, 通过在本地生成配对的密钥, 向 provisioning portal 提交公钥后换取, 后续证书在使用时会验证本地私钥
在 xcode 中, 使用描述文件(provision profile 包含调试者证书, 授权设备清单, 应用ID), 在 Build Settings 中选择存于 Keychain Access 中的证书文件设置调试和发布任务时的代码签名
在 Keychain Access 中找到导入的证书, 右击导出为包含私钥的 Personal Information Exchange(.p12)文件(导出时可以创建密码), 团队成员再导入 p12 证书后就完整包含了证书和私钥
不需要
描述文件(Provisioning Profiles)
开发者证书(ios_development.cer)
描述文件(Provisioning Profiles)
可用于发布的开发者证书(ios_distribution.cer)
用于换取证书的公钥文件, 实际是在本地基于 RSA 加密得到配对的密钥, 私钥存于 Keychain Access 用于签名, 公钥作为换取证书的凭证
OSX 系统自带的 Keychain Access
选择 “Request a Certificate From a Certificate Authority…”
输入 email 等信息后保存为 .certSigningRequest 文件
命令行下使用 openssl 生成
$ openssl genrsa -out private.key 2048$ openssl req -new -sha256 -key private.key -out my.certSigningRequest由 apple 官方颁发, 用来证明开发者资格的证书文件, 分开发(ios_development.cer)和发布(ios_distribution.cer)两种
cer 证书跟开发机(私钥)绑定只能在拥有私钥的机器上使用, 如果要迁移机器需要导出为 p12 文件
在 开发者中心 “certificates” 面板中添加 certificate 并上传刚刚生成的 CSR 文件, 获取 ios_development.cer
用于服务端消息推送, 类似 ssl 证书使用, 和 App 端的开发打包没有关系
在 开发者中心 “Identifiers” 面板中添加 App ID 并上传刚刚生成的 CSR 文件, 获取 aps_production.cer
p12 证书实际是包含了 cer 证书及私钥信息, 可以分发给团队成员
在 Keychain Access 中找到已经导入的 cer 证书, 点右键导出为 p12 格式
包含 certificate appID devices id 的文件用于在 xcode 调试打包时提供授权的配置信息
在 开发者中心 “Provisioning Profiles” 面板中添加 iOS Provisioning Profiles 并上传刚刚生成的 CSR 文件, 获取 .mobileprovision 文件
在 xcode 登录开发者帐号后可以连接开发者中心获取
开发者中心
https://developer.apple.com/devcenter/ios/index.actioniOS 描述管理(配置证书、描述文件、推送服务)
https://developer.apple.com/ios/manage/overview/index.action切换团队(在 web 界面上死活没有找到)
https://developer.apple.com/account/selectTeam.actioniOS 上架 Appstore
http://itunesconnect.apple.com/
真机调试指 mac 连上 iphone, xcode 可以直接以这台 iphone 设备为 build target, 能在 iphone 里执行编译结果
分为拥有独立开发者帐号(也包括公司帐号或企业帐号成员)和共享开发者帐号两种情况
iOS Team Provisioning Profile)如果无法在 xcode 登录一个开发者帐号, 也可以通过他人对你手机和应用 id 的授权, 得到 .mobileprovision 描述文件再导入其含私钥的证书(p12) 即可, 具体步骤如下:
udid (可以连上 mac, 在 itunes 中查看)udid (用以设备授权) 和 应用 idp12 证书, 再双击 mobileprovision 文件对刚入门的个人开发者而言, 可以在淘宝搜
iOS真机调试花几元购买一份授权, 包含(p12证书 和.mobileprovision描述文件)
当 App 开发进行到一定程度, 需要更多的人参与测试, 需要谋求一种方式方便应用能安装进更多的设备中
进行内测发布主要的关键点是:
.ipaxcode6 以后, 个人/公司帐号无法对应用打包为 .ipa, 要么用 xcode5 打包要么拥有企业帐号级别的授权
个人/公司帐号权限只有在 TestFlight / 越狱渠道下完成不授权安装; 企业帐号授权可以在 ad-hoc / in-house 渠道下分发, 完成不授权设备安装
打包时必须在登录企业帐号(或其成员)并已导入证书和描述文件的情况下, 任何用户(未授权)都可以在手机上用浏览器访问一个 url(例: itms-services://?action=download-manifest&url=https://example.com/manifest.plist) 完成安装
最大的问题是安装量有 100 的上限, 无法作为一个量很大的分发渠道
针对企业内部用户进行分发, 相比 ad-hoc 无安装量上限
iOS 8.1.3 开始不能企业证书 Iresign 方式重新签名的应用无法安装
https://support.apple.com/en-us/HT204245
仅支持 iOS8.0 以上, 不需要对设备 udid 进行授权, 适合个人 / 公司开发者, 在应用发布前可以开启 TestFlight Beta 测试并添加测试者的 iTunes Connect 帐号, 需要待测用户拥有 iTunes Connect 帐号并在设备安装 TestFlight 客户端
这种方式非常便于推送应用更新和收集测试信息
如果测试设备都越狱了, 这种方式非常灵活简单, 只有能导出 ipa 包就能通过 itools 等第三方工具安装
fir-第三方应用托管平台
http://fir.im/TestFlight
https://developer.apple.com/testflight/Agile-百度内部 ios 分发测试平台
http://agile.baidu.comfir-分发相关工具
http://fir.im/dev/toolsitools
http://www.itools.cn/
@TODO
@TODO
@TODO 待同步更新完善
]]>给openwrt安装软件的时候,出现提示需要5.10.92的kernel内核版本,然而当前系统版本内核只有5.4.52
opkg update后,内核是不会升级的。但是相应的kmod模块版本会更新到最新的依赖版本。这时候会出现这种问题。起初,想通过opkg降级安装,但是发现很难找到对应版本的kmod模块安装包。
下载内核更新包,在官网的包库中找到内核更新包,连接:https://downloads.openwrt.org/snapshots/targets/x86/64/packages/
搜索kernel,找到对应版本的安装包
复制这个包的下载地址或者直接下载下来。
openwrt系统终端里执行:
wget 这个包的下载地址然后执行opkg install安装这个包。
opkg install xxxx.ipk之后再次执行uname -a查看内核版本,还是5.4.52,但是安装软件是能正常进行的。固件内核版本,只会在固件升级的时候整体升级版本号。这边只是作为依赖包安装了下。
注:内核只能升级,不能降级,并且软件的版本要与内核版本要完全一致,
]]>
之前曝了一个核弹级的漏洞“log4j RCE”,官方的修补方案也逐渐完善。本篇就拿 log4j 作为主题讲一下几个发现。
log4j RCE 原理已经有挺多人发过了,本文不过多赘述。简单说就是日志在打印时遇到 ${ 后 Interpolator 类按照 : 分割出第一部分作为 prefix 第二部分作为 key。通过 prefix 去找对应的 lookup,再通过对应的 lookup 实例调用 lookup 方法传入 key 作为参数。
log4j-core 自带的 lookup 有很多实例,其中就包括了此次存在漏洞的 JndiLookup 实例。JndiLookup 则是直接把传进来的 key 当做 JNDI URL 用 InitialContext.lookup 去访问,从而造成了 JNDI 代码执行漏洞。
该漏洞曝光后各安全厂商也纷纷推出了解决方案,WAF、RASP、改源码、改配置文件、更新到rc2等。
在此次漏洞中最没有防御效果的就是 WAF 了。有提出 ${ 、jndi、ldap、rmi 等关键词规则的防护。但研究后发现都会存在被绕过问题。
首先是 jndi、ldap 简直太容易被绕过,只要用 lowerCase upperCase 就可以把关键词分割开。
如果是用了正则的话那还可以使用 upper 把 jndı 转成 jndi。
注意:这里的 ı(\u0131) 不是 i(\x69)和I(\x49),经过 toUpperCase 就会转变成 I。从而绕过了 jndi 关键词的拦截。
再就是 ${ 关键词的拦截了,虽然这个范围有点大可能会产生一些误报,但鉴于漏洞的严重性还是有很多人建议拦截 ${
但这样也未必能够真正的解决,因为漏洞的触发点是在打印日志的时候把可控内容携带进去了。那么可控内容从哪里来?
Header、URL、键值对参数、JSON参数、XML参数 ...
现在随着 JSON 数据格式的流行,很多系统都在使用 JSON 处理参数,JSON 处理库用的最多的就数 Jackson和fastjson。
而 Jackson 和 fastjson 又有 unicode 和 hex 的编码特性。
例如:
{"key":"\u0024\u007b"}{"key":"\x24\u007b"}这样就避开了数据包中有 ${ 的条件,所以 WAF 的防护规则还要多考虑几种编码。
sys、env 这两个 lookup 的 payload 也在讨论中被频繁提起,实际上他们分别对应的是 System.getProperty() 和 System.getenv(),能够获取一些环境变量和系统属性。部分内容是可以被携带在 dnslog 传出去的。
除了 sys、env 以外还发现 ResourceBundleLookup 也可以获取敏感信息,但没有看到有人讨论 Bundle,所以重点讲一下。
public String lookup(final LogEvent event, final String key) { if (key == null) { return null; } final String[] keys = key.split(":"); final int keyLen = keys.length; if (keyLen != 2) { LOGGER.warn(LOOKUP, "Bad ResourceBundle key format [{}]. Expected format is BundleName:KeyName.", key); return null; } final String bundleName = keys[0]; final String bundleKey = keys[1]; try { // The ResourceBundle class caches bundles, no need to cache here. return ResourceBundle.getBundle(bundleName).getString(bundleKey); } catch (final MissingResourceException e) { LOGGER.warn(LOOKUP, "Error looking up ResourceBundle [{}].", bundleName, e); return null; }}从代码上来看就很好理解,把 key 按照 : 分割成两份,第一个是 bundleName 获取 ResourceBundle,第二个是 bundleKey 获取 Properties Value
ResourceBundle 在 Java 应用开发中经常被用来做国际化,网站通常会给一段表述的内容翻译成多种语言,比如中文简体、中文繁体、英文。
那开发者可能就会使用 ResourceBundle 来分别加载 classpath 下的 zh_CN.properties、en_US.properties。并按照唯一的 key 取出对应的那段文字。例如: zh_CN.properties
LOGIN_SUCCESS=登录成功
那ResourceBundle.getBundle("zh_CN").getString("LOGIN_SUCCESS")
获取到的就是 登录成功
如果系统是 springboot 的话,它会有一个 application.properties 配置文件。里面存放着这个系统的各项配置,其中有可能就包含 redis、mysql 的配置项。当然也不止 springboot,很多其他类型的系统也会写一些类似 jdbc.properties 的文件来存放配置。
这些 properties 文件都可以通过 ResourceBundle 来获取到里面的配置项。所以在 log4j 中 Bundle 是比sys和env更严重的存在。

在不出网的环境下可以通过 dnslog 的方式来外带信息。
除了dnslog以外还可以通过这两种方法来获取信息。
ldap

dns
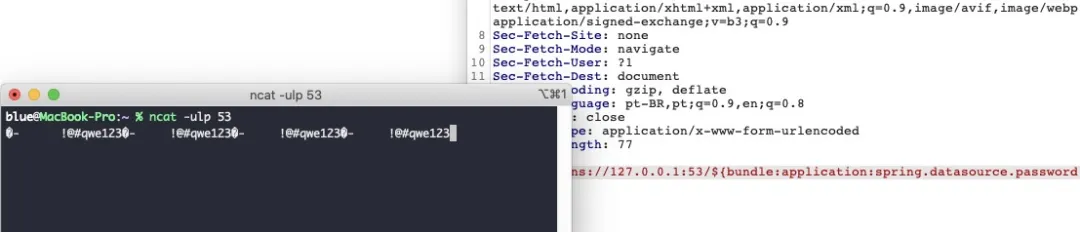
log4j 更新到最新版本
]]>
目前switch加速只有专用的游戏加速器,才是比较好的方案了。
好,要收费。
用游戏加速器的话,游戏加速线路都是iplc,直连不过墙的, 过墙的延迟太高了。
目前支持openwrt路由插件的:
网易uu加速器目前支持了梅林固件、小米路由器以及openwrt。
在app端操作,安装插件也很方便。
也有打包好的安装脚本,具体可参见官网说明。
具体参考:
灵缇路由器插件教程
Simulcast就是多播,在多人会议中,有时候大家网络状况并不相同,Simulcast能适配不同用户的网络和终端情况。
举个例子,3个人,有的是1Mbps网络,有的是2Mbps,有的是5Mbps。大家该推多少码率的流?
•如果推2Mbps的流,两个人会很Happy画质清晰很流畅,但是那个网络差的人就挂了,整个会议也开不下去。
•如果照顾比较差的网络,大家推1Mbps或更低码率的流,其他网络很好也只能看低码率的流,明明网络很好画质却很差。
Simulcast就是这个问题的解决方案之一,客户端只需要推一路流,但在服务器转发时(不用视频转码),可以出不同的码率的流,客户端根据自己的网络选择合适的流。
WebRTC 的 Simulcast , 在一个视频媒体行(MediaLine)中存在多个视频流(RTP Stream), 这些流来自相同的视频采集源, 其差别主要体现在视频编码,分辨率,码率等方面。
在 WebRTC 内部, Simulcast 会为每一个视频流分配一个编码器, 不同的编码器生成不同大小的码流, 这些码流经服务端转发, 最终达到用户播放器。
不过与普通单流转发不同, 因 Simulcast 推送多个码流的特点, 服务器可以为不同用户调度不同的码流。
比如, 考虑到播放端用户的 带宽 和 设备分辨率 的差异, 可以给部分用户推送高清码流, 另一部分推送低清码流.
代价是 推送端 需要更大的带宽, 更强的算力, 应付多码流的输出.
目前 WebRTC 源码为 Simulcast 提供了两种接口的API
SDP 示例
// SDP munging 风格a=ssrc-group:SIM 1390104252 1390104253 1390104254// RID based 风格a=rid:high senda=rid:mid senda=rid:low senda=simulcast:send high;mid;lowSDP munging 风格的 Simulcast 接口体现在sdp协商时,其视频媒体行会出现 a=ssrc-group:SIM 字样,其格式为
a=ssrc-group:SIM layer0 layer1 layer2...其中 SSRC 序列 即为 Simulcast 的多个层级, 序列长度通常不超过3.
它们按照分辨率大小从小到大依次排列; 假定 layer0 的分辨率为 w0xh0, 其他类推, 则:
分辨率满足:
layer0(w0xh0) < layer1(w1xh1) < layer2(w2xh2) ...
长宽比率满足:
w0 : w1 : w2 = 1: k: k^2h0 : h1 : h2 = 1: k: k^2(通常k = 2, 如果是源码开发,可自行修改)一份offer的某个视频媒体的部分片段
a=ssrc-group:FID 1390104252 2798384649a=ssrc:1390104252 cname:rsPDymoMnGBuVXTxa=ssrc:1390104252 msid:ez0lPBqQZbbAN0ImN4ZrrUCbshr2khvkB6ob 99528680-68d8-418b-afc6-205372e9cb6fa=ssrc:2798384649 cname:rsPDymoMnGBuVXTxa=ssrc:2798384649 msid:ez0lPBqQZbbAN0ImN4ZrrUCbshr2khvkB6ob 99528680-68d8-418b-afc6-205372e9cb6fa=ssrc-group:FID 1390104253 2798384650a=ssrc:1390104253 cname:rsPDymoMnGBuVXTxa=ssrc:1390104253 msid:ez0lPBqQZbbAN0ImN4ZrrUCbshr2khvkB6ob 99528680-68d8-418b-afc6-205372e9cb6fa=ssrc:2798384650 cname:rsPDymoMnGBuVXTxa=ssrc:2798384650 msid:ez0lPBqQZbbAN0ImN4ZrrUCbshr2khvkB6ob 99528680-68d8-418b-afc6-205372e9cb6fa=ssrc-group:FID 1390104254 2798384651a=ssrc:1390104254 cname:rsPDymoMnGBuVXTxa=ssrc:1390104254 msid:ez0lPBqQZbbAN0ImN4ZrrUCbshr2khvkB6ob 99528680-68d8-418b-afc6-205372e9cb6fa=ssrc:2798384651 cname:rsPDymoMnGBuVXTxa=ssrc:2798384651 msid:ez0lPBqQZbbAN0ImN4ZrrUCbshr2khvkB6ob 99528680-68d8-418b-afc6-205372e9cb6fa=ssrc-group:SIM 1390104252 1390104253 1390104254根据这个片段可以推测, 这个sdp里面视频媒体行是一个同播3个码流的 Simulcast
low: 1390104252 mid: 1390104253 high: 1390104254sudo yum install -y logrotate配置logrotate管理服务日志文件:
cat << END > /etc/logrotate.d/srs/usr/local/srs/objs/srs.log { daily dateext compress rotate 7 size 1024M sharedscripts postrotate kill -USR1 `cat /usr/local/srs/objs/srs.pid` endscript}END备注:可以手动执行命令触发日志切割
logrotate -f /etc/logrotate.d/srslogrotate还有一种方式是copytruncate, 墙裂不推荐这种方式因为会丢日志。可以作为workaround方案。
cat << END > /etc/logrotate.d/srs/usr/local/srs/objs/srs.log { daily dateext compress rotate 7 size 1024M copytruncate}END修改 .env文件的以下配置
SENTRY_EVENT_RETENTION_DAYS=7#登录worker容器docker exec -it sentry_onpremise_worker_1 /bin/bash #保留多少天的数据,cleanup使用delete命令删除postgresql数据,但对于delete,update等操作,只是将对应行标志为DEAD,并没有真正释放磁盘空间sentry cleanup --days 7#登录postgres容器docker exec -it sentry_onpremise_postgres_1 /bin/bash#运行清理vacuumdb -U postgres -d postgres -v -f --analyze0 1 * * * cd /root/onpremise && { time docker-compose run --rm worker cleanup --days 7; } &> /var/log/sentry-cleanup.log0 8 * * * { time docker exec -i $(docker ps --format "table {{.Names}}"|grep postgres) vacuumdb -U postgres -d postgres -v -f --analyze; } &> /var/logs/sentry-vacuumdb.log清理kafka占用磁盘过大的问题搜到可以配置 .env,如下:
KAFKA_LOG_RETENTION_HOURS=24KAFKA_LOG_RETENTION_BYTES=53687091200 #50GKAFKA_LOG_SEGMENT_BYTES=1073741824 #1GKAFKA_LOG_RETENTION_CHECK_INTERVAL_MS=300000KAFKA_LOG_SEGMENT_DELETE_DELAY_MS=60000如果已经占满100%,可以先去查找筛选出磁盘上其他占用很大的无用文件或者日志等,释放出一部分空间。
]]>使用constraints修改分辨率和帧速率FrameRate
https://webrtchacks.com/how-to-figure-out-webrtc-camera-resolutions/
获取当前的分辨率和帧速率FrameRate
https://stackoverflow.com/questions/26076259/get-media-detailsresolution-and-frame-rate-from-mediastream-object
https://github.com/webrtcHacks/WebRTC-Camera-Resolution
分辨率设置某些情况不兼容?
http://support.temasys.com.sg/support/solutions/articles/5000692251-how-do-i-set-a-fixed-video-resolution-
如何开始学习webrtc?
https://www.html5rocks.com/en/tutorials/webrtc/basics/
https://hpbn.co/webrtc/
https://webrtc.org/architecture/
如何控制修改带宽?
https://stackoverflow.com/questions/16712224/how-to-control-bandwidth-in-webrtc-video-call
webrtc最低带宽需求?
https://stackoverflow.com/questions/29854622/webrtc-bandwidth-requirements
能否修改摄像头视频质量和视频传输比特率?
答案是否,想看:https://stackoverflow.com/questions/24227705/change-the-quality-webrtc
其他常见问题:https://www.webrtc-experiment.com/webrtcpedia/
1.如何检测屏幕分享停止了或者摄像头停止了?
2.如何检测网页已经有权限访问麦克风或者摄像头?
3.如何管理音视频比特率?
4.如何设置音频sdp参数?
5.如何检测本地或者远程流?
6.如何在单个getUserMedia请求中捕获音频和屏幕?
7.如何不用重造getUserMedia请求而能修改流?
8.捕获前后端摄像头
9.选择第二个摄像头
10.其他最大带宽比特率数据值列表
如何修改sdp限制带宽?
https://webrtchacks.com/limit-webrtc-bandwidth-sdp/
约束以及统计实例
https://webrtc.github.io/samples/src/content/peerconnection/constraints/
webrtc支持视频适配的比特率流传输吗?
https://stackoverflow.com/questions/37128928/does-webrtc-support-adaptive-bitrate-streaming-for-video
1,ProductHunt, https://www.producthunt.com/ 每日新产品集合。
2,Twitter, https://twitter.com/ 在twitter上关注行业的各位大咖。
3,TechCrunch, https://techcrunch.com/ 国外每日创投方向的新闻和新产品。
4,36Kr, https://36kr.com/ 国内每日创投方向的新闻和新产品。
5,Google Groups, 行业相关的都有订阅,最新的feature和未来发展方向都能掌握。
6, V2ex, https://www.v2ex.com/ 国内小众分享和探索社区,社区质量非常高。
7, Cnbeta,https://www.cnbeta.com/ 老牌IT资讯网站,经久不衰。
8, 还有一些公众号。

其原理其实就是在客户端将文件分割成多个小的分片,然后再将这些分片一片一片的上传给服务端,服务端拿到所有分片后再将这些分片合并起来还原成原来的文件。那服务端怎么知道我合并出来的文件是否和服务端上传的文件完全一样呢?这就需要用到文件的MD5值了。文件的MD5值就相当于是这个文件的“数字指纹”,只有当两个文件内容完全一样时,他们的MD5值才会一样。所以在上传文件前,客户端需要先计算出文件的MD5值,并且把这MD5值传递给服务端。服务端在合并出文件后,在计算合并出的文件的MD5值,与客户端传递过来的进行比较,如果一致,则说明上传成功,若不一致,则说明上传过程中可能出现了丢包,上传失败。

断点续传其实是利用分片上传的特性,上次上传中断时,已经有部分分片已上传到服务端,这部分就可以不用重复上传了。

文件秒传其实是利用文件的MD5值作为文件的身份标识,服务端发现要上传的文件的MD5与附件库中的某个文件的MD5值完全一样,则要上传的文件已在附件库中,不用再重复上传。
]]>GPS模块在定位后会输出含有各项定位信息的NMEA语句,其中包括经纬度
信息。
$GPGGA,054514.000,2238.5260,N,11401.9686,E,1,7,1.27,89.2,M,-2.3,M,,7F
$GPGSA,A,3,08,23,10,28,09,04,02,,,,,,1.52,1.27,0.8401
$GPGSV,3,1,10,28,73,159,42,42,50,128,36,04,49,276,44,10,31,191,4375
$GPGSV,3,2,10,02,17,252,38,08,14,192,41,09,12,195,38,23,07,108,3574
$GPRMC,054514.000,A,2238.5260,N,11401.9686,E,0.14,183.83,270913,,,A*6B
详细的NEMA 0183协议解析访问网页NEMA 0183查询
以NMEA码RMC数据为例:$GPRMC,054514.000,A,2238.5260,N,11401.9686,E,0.14,183.83,270913,,,A*6B


经纬度格式为:
Latitude: ddmm.mmmm
Longitude: dddmm.mmm
转换成度:
方法是dd作整数位,(mm.mmmm÷60)作小数位
上例可得 01.9686÷60=0.03281;38.5260÷60=0.6421
所以:
11401.9686 = 114.03281
2238.5260 = 22.6421
出于安全的考虑,国家不允许直接使用GPS坐标。GCJ-02坐标系又称为火星坐标系。腾讯地图,高德地图,谷歌中国地图使用的是GCJ-02坐标系,百度地图和搜狗地图使用的是在GCJ-02基础上再加密的坐标。
地图公司测绘得到原始的GPS地图后,要上交给国家测绘局,测绘局给GPS坐标加上偏移(不是线性偏移),得到GCJ-02坐标,测绘局要收钱的,然后再交给地图公司。地图公司可以直接发行或者再做一次偏移后发行。一般的偏移是在几百米,对于精度要求不高的定位,这个误差无所谓。
坐标系转换的方式就不赘述了。
已经有很多算法和公开的api了。
去噪 -> 滤波 -> 抽稀
去噪
轨迹去噪,删除垂距大于mNoiseThreshholdm的点
滤波
轨迹多点滤波,卡尔曼滤波
抽稀
抽稀算法,删除垂距小于mThreshhold的点
import android.util.Log;import com.amap.api.maps.AMapUtils;import com.amap.api.maps.model.LatLng;import java.util.ArrayList;import java.util.List;/** * 轨迹优化工具类 Android * <p> * 使用方法: * <p> * PathSmoothTool pathSmoothTool = new PathSmoothTool(); * pathSmoothTool.setIntensity(2);//设置滤波强度,默认3 * List<LatLng> mList = LatpathSmoothTool.kalmanFilterPath(list); */public class PathSmoothTool { private int mIntensity = 3; private float mThreshhold = 0.3f; private float mNoiseThreshhold = 10; public PathSmoothTool(){ } public int getIntensity() { return mIntensity; } public void setIntensity(int mIntensity) { this.mIntensity = mIntensity; } public float getThreshhold() { return mThreshhold; } public void setThreshhold(float mThreshhold) { this.mThreshhold = mThreshhold; } public void setNoiseThreshhold(float mnoiseThreshhold) { this.mNoiseThreshhold = mnoiseThreshhold; } /** * 轨迹平滑优化 * @param originlist 原始轨迹list,list.size大于2 * @return 优化后轨迹list */ public List<LatLng> pathOptimize(List<LatLng> originlist){ List<LatLng> list = removeNoisePoint(originlist);//去噪 List<LatLng> afterList = kalmanFilterPath(list,mIntensity);//滤波 List<LatLng> pathoptimizeList = reducerVerticalThreshold(afterList,mThreshhold);//抽稀// Log.i("MY","originlist: "+originlist.size());// Log.i("MY","list: "+list.size());// Log.i("MY","afterList: "+afterList.size());// Log.i("MY","pathoptimizeList: "+pathoptimizeList.size()); return pathoptimizeList; } /** * 轨迹线路滤波 * @param originlist 原始轨迹list,list.size大于2 * @return 滤波处理后的轨迹list */ public List<LatLng> kalmanFilterPath(List<LatLng> originlist) { return kalmanFilterPath(originlist,mIntensity); } /** * 轨迹去噪,删除垂距大于20m的点 * @param originlist 原始轨迹list,list.size大于2 * @return */ public List<LatLng> removeNoisePoint(List<LatLng> originlist){ return reduceNoisePoint(originlist,mNoiseThreshhold); } /** * 单点滤波 * @param lastLoc 上次定位点坐标 * @param curLoc 本次定位点坐标 * @return 滤波后本次定位点坐标值 */ public LatLng kalmanFilterPoint(LatLng lastLoc, LatLng curLoc) { return kalmanFilterPoint(lastLoc,curLoc,mIntensity); } /** * 轨迹抽稀 * @param inPoints 待抽稀的轨迹list,至少包含两个点,删除垂距小于mThreshhold的点 * @return 抽稀后的轨迹list */ public List<LatLng> reducerVerticalThreshold(List<LatLng> inPoints) { return reducerVerticalThreshold(inPoints,mThreshhold); } /********************************************************************************************************/ /** * 轨迹线路滤波 * @param originlist 原始轨迹list,list.size大于2 * @param intensity 滤波强度(1—5) * @return */ private List<LatLng> kalmanFilterPath(List<LatLng> originlist,int intensity) { List<LatLng> kalmanFilterList = new ArrayList<LatLng>(); if (originlist == null || originlist.size() <= 2) return kalmanFilterList; initial();//初始化滤波参数 LatLng latLng = null; LatLng lastLoc = originlist.get(0); kalmanFilterList.add(lastLoc); for (int i = 1; i < originlist.size(); i++) { LatLng curLoc = originlist.get(i); latLng = kalmanFilterPoint(lastLoc,curLoc,intensity); if (latLng != null) { kalmanFilterList.add(latLng); lastLoc = latLng; } } return kalmanFilterList; } /** * 单点滤波 * @param lastLoc 上次定位点坐标 * @param curLoc 本次定位点坐标 * @param intensity 滤波强度(1—5) * @return 滤波后本次定位点坐标值 */ private LatLng kalmanFilterPoint(LatLng lastLoc, LatLng curLoc, int intensity) { if (pdelt_x == 0 || pdelt_y == 0 ){ initial(); } LatLng kalmanLatlng = null; if (lastLoc == null || curLoc == null){ return kalmanLatlng; } if (intensity < 1){ intensity = 1; } else if (intensity > 5){ intensity = 5; } for (int j = 0; j < intensity; j++){ kalmanLatlng = kalmanFilter(lastLoc.longitude,curLoc.longitude,lastLoc.latitude,curLoc.latitude); curLoc = kalmanLatlng; } return kalmanLatlng; } /***************************卡尔曼滤波开始********************************/ private double lastLocation_x; //上次位置 private double currentLocation_x;//这次位置 private double lastLocation_y; //上次位置 private double currentLocation_y;//这次位置 private double estimate_x; //修正后数据 private double estimate_y; //修正后数据 private double pdelt_x; //自预估偏差 private double pdelt_y; //自预估偏差 private double mdelt_x; //上次模型偏差 private double mdelt_y; //上次模型偏差 private double gauss_x; //高斯噪音偏差 private double gauss_y; //高斯噪音偏差 private double kalmanGain_x; //卡尔曼增益 private double kalmanGain_y; //卡尔曼增益 private double m_R= 0; private double m_Q= 0; //初始模型 private void initial(){ pdelt_x = 0.001; pdelt_y = 0.001;// mdelt_x = 0;// mdelt_y = 0; mdelt_x = 5.698402909980532E-4; mdelt_y = 5.698402909980532E-4; } private LatLng kalmanFilter(double oldValue_x, double value_x, double oldValue_y, double value_y){ lastLocation_x = oldValue_x; currentLocation_x= value_x; gauss_x = Math.sqrt(pdelt_x * pdelt_x + mdelt_x * mdelt_x)+m_Q; //计算高斯噪音偏差 kalmanGain_x = Math.sqrt((gauss_x * gauss_x)/(gauss_x * gauss_x + pdelt_x * pdelt_x)) +m_R; //计算卡尔曼增益 estimate_x = kalmanGain_x * (currentLocation_x - lastLocation_x) + lastLocation_x; //修正定位点 mdelt_x = Math.sqrt((1-kalmanGain_x) * gauss_x *gauss_x); //修正模型偏差 lastLocation_y = oldValue_y; currentLocation_y = value_y; gauss_y = Math.sqrt(pdelt_y * pdelt_y + mdelt_y * mdelt_y)+m_Q; //计算高斯噪音偏差 kalmanGain_y = Math.sqrt((gauss_y * gauss_y)/(gauss_y * gauss_y + pdelt_y * pdelt_y)) +m_R; //计算卡尔曼增益 estimate_y = kalmanGain_y * (currentLocation_y - lastLocation_y) + lastLocation_y; //修正定位点 mdelt_y = Math.sqrt((1-kalmanGain_y) * gauss_y * gauss_y); //修正模型偏差 LatLng latlng = new LatLng(estimate_y,estimate_x); return latlng; } /***************************卡尔曼滤波结束**********************************/ /***************************抽稀算法*************************************/ private List<LatLng> reducerVerticalThreshold(List<LatLng> inPoints, float threshHold) { if (inPoints == null) { return null; } if (inPoints.size() <= 2) { return inPoints; } List<LatLng> ret = new ArrayList<LatLng>(); for (int i = 0; i < inPoints.size(); i++) { LatLng pre = getLastLocation(ret); LatLng cur = inPoints.get(i); if (pre == null || i == inPoints.size() - 1) { ret.add(cur); continue; } LatLng next = inPoints.get(i + 1); double distance = calculateDistanceFromPoint(cur, pre, next); if (distance > threshHold){ ret.add(cur); } } return ret; } private static LatLng getLastLocation(List<LatLng> oneGraspList) { if (oneGraspList == null || oneGraspList.size() == 0) { return null; } int locListSize = oneGraspList.size(); LatLng lastLocation = oneGraspList.get(locListSize - 1); return lastLocation; } /** * 计算当前点到线的垂线距离 * @param p 当前点 * @param lineBegin 线的起点 * @param lineEnd 线的终点 * */ private static double calculateDistanceFromPoint(LatLng p, LatLng lineBegin, LatLng lineEnd) { double A = p.longitude - lineBegin.longitude; double B = p.latitude - lineBegin.latitude; double C = lineEnd.longitude - lineBegin.longitude; double D = lineEnd.latitude - lineBegin.latitude; double dot = A * C + B * D; double len_sq = C * C + D * D; double param = dot / len_sq; double xx, yy; if (param < 0 || (lineBegin.longitude == lineEnd.longitude && lineBegin.latitude == lineEnd.latitude)) { xx = lineBegin.longitude; yy = lineBegin.latitude;// return -1; } else if (param > 1) { xx = lineEnd.longitude; yy = lineEnd.latitude;// return -1; } else { xx = lineBegin.longitude + param * C; yy = lineBegin.latitude + param * D; } return AMapUtils.calculateLineDistance(p,new LatLng(yy,xx)); } /***************************抽稀算法结束*********************************/ private List<LatLng> reduceNoisePoint(List<LatLng> inPoints, float threshHold) { if (inPoints == null) { return null; } if (inPoints.size() <= 2) { return inPoints; } List<LatLng> ret = new ArrayList<LatLng>(); for (int i = 0; i < inPoints.size(); i++) { LatLng pre = getLastLocation(ret); LatLng cur = inPoints.get(i); if (pre == null || i == inPoints.size() - 1) { ret.add(cur); continue; } LatLng next = inPoints.get(i + 1); double distance = calculateDistanceFromPoint(cur, pre, next); if (distance < threshHold){ ret.add(cur); } } return ret; }}function LatLng(var1, var3, var5 = true) { if (!var5) { return { "latitude": var1, "longitude": var3 } } else { let longitude = null, latitude = null if (-180.0 <= var3 && var3 < 180.0) { longitude = var3; } else { longitude = ((var3 - 180.0) % 360.0 + 360.0) % 360.0 - 180.0; } if (var1 < -90.0 || var1 > 90.0) { console.error("非法坐标值") throw new Error('非法坐标值') } latitude = Math.max(-90.0, Math.min(90.0, var1)); return { "latitude": latitude, "longitude": longitude } }}let mIntensity = 5;let mThreshhold = 0.3;let mNoiseThreshhold = 10;/** * 轨迹平滑优化 * @param originlist 原始轨迹list,list.size大于2 * @return 优化后轨迹list */function pathOptimize(originlist) { let list = removeNoisePoint(originlist);//去噪 let afterList = kalmanFilterPath(list, mIntensity);//滤波 let pathoptimizeList = reducerVerticalThreshold(afterList, mThreshhold);//抽稀// Log.i("MY","originlist: "+originlist.size());// Log.i("MY","list: "+list.size());// Log.i("MY","afterList: "+afterList.size());// Log.i("MY","pathoptimizeList: "+pathoptimizeList.size()); return pathoptimizeList;}/** * 轨迹去噪,删除垂距大于20m的点 * @param originlist 原始轨迹list,list.size大于2 * @return */function removeNoisePoint(originlist) { return reduceNoisePoint(originlist, mNoiseThreshhold);}function reduceNoisePoint(inPoints, threshHold) { if (inPoints == null) { return null; } if (inPoints.length <= 2) { return inPoints; } let ret = [] for (let i = 0; i < inPoints.length; i++) { let pre = getLastLocation(ret); let cur = inPoints[i]; if (pre == null || i == inPoints.length - 1) { ret.push(cur); continue; } let next = inPoints[i + 1]; let distance = calculateDistanceFromPoint(cur, pre, next); if (distance < threshHold) { ret.push(cur); } } return ret;}function getLastLocation(oneGraspList) { if (oneGraspList == null || oneGraspList.length == 0) { return null; } let locListSize = oneGraspList.length; let lastLocation = oneGraspList[locListSize - 1]; return lastLocation;}/** * 计算当前点到线的垂线距离 * @param p 当前点 * @param lineBegin 线的起点 * @param lineEnd 线的终点 * */function calculateDistanceFromPoint(p, lineBegin, lineEnd) { let A = p.longitude - lineBegin.longitude; let B = p.latitude - lineBegin.latitude; let C = lineEnd.longitude - lineBegin.longitude; let D = lineEnd.latitude - lineBegin.latitude; let dot = A * C + B * D; let len_sq = C * C + D * D; let param = dot / len_sq; let xx, yy; if (param < 0 || (lineBegin.longitude == lineEnd.longitude && lineBegin.latitude == lineEnd.latitude)) { xx = lineBegin.longitude; yy = lineBegin.latitude;// return -1; } else if (param > 1) { xx = lineEnd.longitude; yy = lineEnd.latitude;// return -1; } else { xx = lineBegin.longitude + param * C; yy = lineBegin.latitude + param * D; } return calculateLineDistance(p, LatLng(yy, xx));}function calculateLineDistance(var0, var1) { if (var0 != null && var1 != null) { try { let var2 = var0.longitude; let var4 = var0.latitude; let var6 = var1.longitude; let var8 = var1.latitude; var2 *= 0.01745329251994329; var4 *= 0.01745329251994329; var6 *= 0.01745329251994329; var8 *= 0.01745329251994329; let var10 = Math.sin(var2); let var12 = Math.sin(var4); let var14 = Math.cos(var2); let var16 = Math.cos(var4); let var18 = Math.sin(var6); let var20 = Math.sin(var8); let var22 = Math.cos(var6); let var24 = Math.cos(var8); let var28 = []; let var29 = []; var28[0] = var16 * var14; var28[1] = var16 * var10; var28[2] = var12; var29[0] = var24 * var22; var29[1] = var24 * var18; var29[2] = var20; return (Math.asin(Math.sqrt((var28[0] - var29[0]) * (var28[0] - var29[0]) + (var28[1] - var29[1]) * (var28[1] - var29[1]) + (var28[2] - var29[2]) * (var28[2] - var29[2])) / 2.0) * 1.27420015798544E7); } catch (var26) { console.error(var26) return 0.0; } } else { console.error("非法坐标值"); return 0.0; }}/***************************卡尔曼滤波开始********************************/let lastLocation_x; //上次位置let currentLocation_x;//这次位置let lastLocation_y; //上次位置let currentLocation_y;//这次位置let estimate_x; //修正后数据let estimate_y; //修正后数据let pdelt_x; //自预估偏差let pdelt_y; //自预估偏差let mdelt_x; //上次模型偏差let mdelt_y; //上次模型偏差let gauss_x; //高斯噪音偏差let gauss_y; //高斯噪音偏差let kalmanGain_x; //卡尔曼增益let kalmanGain_y; //卡尔曼增益let m_R = 0;let m_Q = 0;//初始模型function initial() { pdelt_x = 0.001; pdelt_y = 0.001;// mdelt_x = 0;// mdelt_y = 0; mdelt_x = 5.698402909980532E-4; mdelt_y = 5.698402909980532E-4;}/** * 轨迹线路滤波 * @param originlist 原始轨迹list,list.size大于2 * @param intensity 滤波强度(1—5) * @return */function kalmanFilterPath(originlist, intensity) { let kalmanFilterList = [] if (originlist == null || originlist.length <= 2) return kalmanFilterList; initial();//初始化滤波参数 let latLng = null; let lastLoc = originlist[0]; kalmanFilterList.push(lastLoc); for (let i = 1; i < originlist.length; i++) { let curLoc = originlist[i]; latLng = kalmanFilterPoint(lastLoc, curLoc, intensity); if (latLng != null) { kalmanFilterList.push(latLng); lastLoc = latLng; } } return kalmanFilterList;}/** * 单点滤波 * @param lastLoc 上次定位点坐标 * @param curLoc 本次定位点坐标 * @param intensity 滤波强度(1—5) * @return 滤波后本次定位点坐标值 */function kalmanFilterPoint(lastLoc, curLoc, intensity) { if (pdelt_x == 0 || pdelt_y == 0) { initial(); } let kalmanLatlng = null; if (lastLoc == null || curLoc == null) { return kalmanLatlng; } if (intensity < 1) { intensity = 1; } else if (intensity > 5) { intensity = 5; } for (let j = 0; j < intensity; j++) { kalmanLatlng = kalmanFilter(lastLoc.longitude, curLoc.longitude, lastLoc.latitude, curLoc.latitude); curLoc = kalmanLatlng; } return kalmanLatlng;}function kalmanFilter(oldValue_x, value_x, oldValue_y, value_y) { lastLocation_x = oldValue_x; currentLocation_x = value_x; gauss_x = Math.sqrt(pdelt_x * pdelt_x + mdelt_x * mdelt_x) + m_Q; //计算高斯噪音偏差 kalmanGain_x = Math.sqrt((gauss_x * gauss_x) / (gauss_x * gauss_x + pdelt_x * pdelt_x)) + m_R; //计算卡尔曼增益 estimate_x = kalmanGain_x * (currentLocation_x - lastLocation_x) + lastLocation_x; //修正定位点 mdelt_x = Math.sqrt((1 - kalmanGain_x) * gauss_x * gauss_x); //修正模型偏差 lastLocation_y = oldValue_y; currentLocation_y = value_y; gauss_y = Math.sqrt(pdelt_y * pdelt_y + mdelt_y * mdelt_y) + m_Q; //计算高斯噪音偏差 kalmanGain_y = Math.sqrt((gauss_y * gauss_y) / (gauss_y * gauss_y + pdelt_y * pdelt_y)) + m_R; //计算卡尔曼增益 estimate_y = kalmanGain_y * (currentLocation_y - lastLocation_y) + lastLocation_y; //修正定位点 mdelt_y = Math.sqrt((1 - kalmanGain_y) * gauss_y * gauss_y); //修正模型偏差 let latlng = LatLng(estimate_y, estimate_x); return latlng;}function reducerVerticalThreshold(inPoints, threshHold) { if (inPoints == null) { return null; } if (inPoints.length <= 2) { return inPoints; } let ret = [] for (let i = 0; i < inPoints.length; i++) { let pre = getLastLocation(ret); let cur = inPoints[i]; if (pre == null || i == inPoints.length - 1) { ret.push(cur); continue; } let next = inPoints[i + 1]; let distance = calculateDistanceFromPoint(cur, pre, next); if (distance > threshHold) { ret.push(cur); } } return ret;}export { pathOptimize}
坐标采集频率问题:轨迹线是由轨迹点连接组成,而轨迹点一定都是离散的,离散程度取决于坐标获取的频率。频率高,设备耗电,轨迹存储增大,但是轨迹特征明显;频率低,轨迹线特征容易丢失。如何能够比较智能的调整坐标上报频率?
坐标采集保活问题:移动设备普遍具有省电模式、息屏功能等,这些场景均容易导致GPS采集程序被系统清除,从而导致坐标在某段时间突然无法采集、信号中断。而互联网APP却往往早已被设备添加至白名单(与厂商有合作关系等),并不会有此问题。
轨迹坐标转换问题:GPS是WGS84坐标,北斗是CGCS2000坐标,而轨迹展示依托的地图往往是各种不同坐标系的地图,两者直接需要进行坐标转换。而且不同于互联网应用只采用一种地图,只需解决一种坐标类型的转换,城市管理中需要解决的坐标转换具有地图类型多、地图精度不可控(如脱密地图)等问题。而坐标转换的准确度将直接影响轨迹展示的效果。
坐标准确度问题:卫星定位最少要求4颗星同时观测(由于其三球定位原理,再加上把时间作为变量,所以至少需要4颗星来观测),而在不少情况下,移动设备并不能满足同时接收到4颗以上卫星的信号(比如:室内、高层建筑遮挡等),这将导致此时的卫星定位误差很大。如何可以提高卫星定位的准确度?
轨迹坐标去噪问题:坐标准确度问题是一个不可避免的问题,在此情况下,需要一套可以对坐标异常点进行去除的方法,从而保证轨迹展示的效果不受异常点的影响。
轨迹线连接问题:轨迹线的逐点连接必然会导致线和线之间过渡不平滑,并且单纯的轨迹点直连,还容易出现轨迹线“穿墙”问题(A点和B点分别在十字路口不同地方,AB直连将导致线条穿越中间的非路面建筑)。
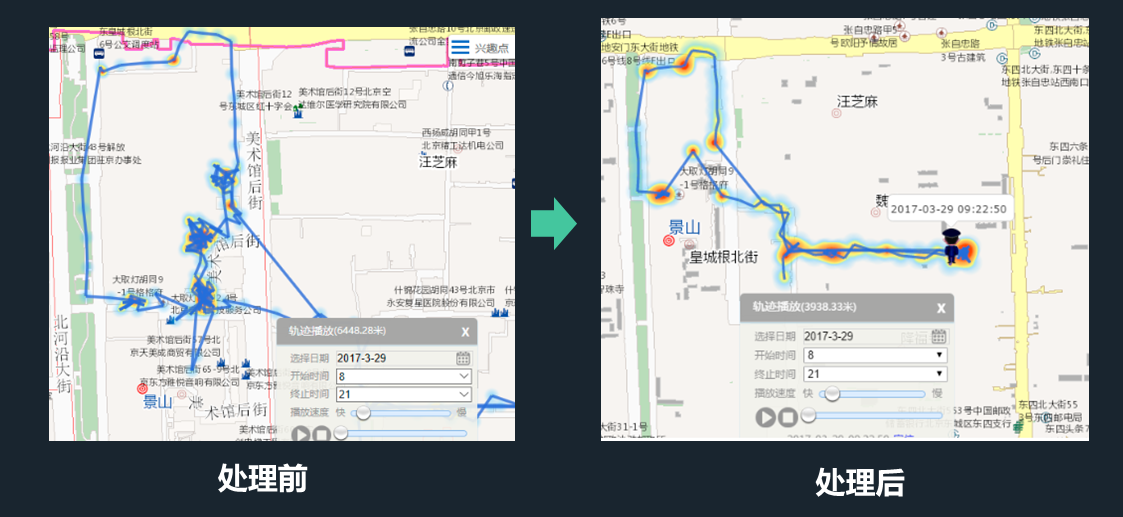
轨迹播放问题:轨迹天然是动态的,仅仅以轨迹线描述不能真实展现轨迹的时空特征。如何优美的展示轨迹动态,让用户具有看动画片一样的观感?
系统有设置的默认采集频率,针对人员和车辆是不同的。
当连续多个采集点为静止或相差不大时(在阈值范围内),此时可以将坐标采集频率适当调慢。
当连续多个采集点的距离大于阈值范围时,此时可以将坐标采集频率适当调快。
保活机制为:常驻通知栏,双进程守护,广播锁屏,自定义锁屏
坐标信号强度对定位准确度影响十分大,比如当设备在室内或者高楼下时,坐标信号是明显减弱的。可采用了如下优化策略:
记录信号强弱作为后续轨迹奇异点(问题点)的筛选条件之一。
当信号弱的超过一定阈值时,切换成百度定位方案。
从算法层面上对轨迹点进行优化的策略。依据实施条件不同,展示要求不同,这里从三个不同方向进行轨迹点拟合研究。

顾名思义,本方案必须有道路线数据,其原理为将各轨迹点匹配至与道路垂直距离最近的节点上,并且将前后两点沿道路顺势连接。
优点:轨迹全部在道路上,展示美观。
缺点:依赖于道路数据的完整性,并且展示有失真实。
此算法的思路为在尽量不改变轨迹点的特征情况下,通过轨迹的时空聚类,将某些特征相似的点聚在一处,从而减小由于轨迹点打结导致的轨迹杂乱。但是本算法并不仅仅是常规的空间聚类算法,由于轨迹具有天然的时间属性,不考虑轨迹的时间属性进行聚类则会丢失轨迹的许多特征信息。例如,双行道道路,来回分别在不同的行道路上,如果不考虑时间维度,则会出现将双行道上的轨迹点聚类到一个行道上。
优点:解决了轨迹点打结展示问题。
缺点:对于轨迹点之间的连接并没有平滑处理。

卡尔曼滤波(Kalman filtering)一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。其在轨迹处理中,可以达到通过预测轨迹点与实际轨迹点之间的偏差来进行轨迹位置的调整,实现轨迹的平滑。
优点:轨迹线变的曲线平滑,更加美观。
缺点:平滑度很难控制,导致轨迹有失真实,轨迹特征变模糊,并且轨迹噪声点对整体平滑效果影响很大。
以上方案各有优劣,但是如果能够进行有效的综合,并且再加上其他的数据处理流程,轨迹点的质量将会提升更多。具体描述如下:
通过坐标的准确度参数,去除一部分误差特别大的轨迹点。
通过计算轨迹点速率异常变化,去除一部分“飞点”。
基于时空聚类算法,进行轨迹点聚合。
通过卡尔曼滤波进行轨迹平滑美化,且控制平滑度过大。
针对车辆轨迹,在存在完好的道路线数据时,采用路网匹配算法。

静止的人(车)图标无法表示真实的变化,随着位置坐标的获取而跳跃变化的人(车)图标又颇显突兀,如果能实时的、平滑的显示人(车)位置变化将会使用户具有更强的“参与”感。以人的展示为例,为实现该目标,设计16个方向的人员图标,根据坐标点之间的角度计算来选择不同的人员图标,并且通过计算两点距离和播放速度来计算人员前进时的图标变化,最终实现诸如前进时人手的左右摇摆效果等。
轨迹箭头的流动除了可以增加整体轨迹展示的动效,更能够表示出轨迹的方向特征。但是轨迹箭头过于密集,也会影响轨迹的美观。综合设计,当地图缩放到一定级别后,此时出现轨迹箭头流动特效。

“滴滴”这类互联网轨迹展示方案已经越来越被大众所接受,尤其是多车辆(人员)的实时轨迹展示上。通过在轨迹大数据存储、轨迹信息流、前端展示算法的不断研究下,目前展示上基本可与之靠齐,并且也先后得到了实际项目的验证,其中某扬尘项目为监控整个城市1.6万辆车24小时的实时轨迹。

在三维场景中实现对轨迹的展示,将更加具有视觉的直观性、冲击力。并且借助游戏场景展示的思路,将会让用户有更好的互动感。
]]>

蓝天金楼古道街,老少幼比肩叠迹。

寻街走巷茶话弄,

柳暗花明博古雅。

小小商店搅搅糖,啥也不是没童年。

青年客栈撒哈拉,

大夫及第忆回坊。

借问老外把糕舔,

红枣绿糕惹人馋。

东巷西街寻无路,

愕然回首闫师傅。

千年古阶滑滑梯,

回眸一笑金海湾。

穷途末路乘晚风,

不到半坡夜不归。

大唐雁塔人从众,

不及耳东送我情。
1:查看防火状态
systemctl status firewalld
service iptables status
2:暂时关闭防火墙
systemctl stop firewalld
service iptables stop
3:永久关闭防火墙
systemctl disable firewalld
chkconfig iptables off
4:重启防火墙
systemctl enable firewalld
service iptables restart
5:永久关闭后重启
chkconfig iptables on
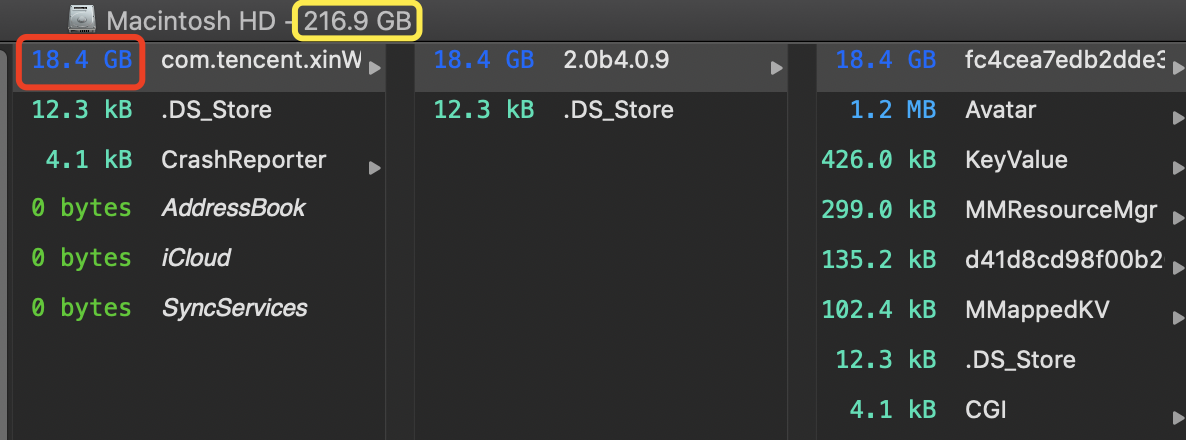
微信聊天记录中产生的文件,图片以及音视频都会缓存在本地磁盘,长时间不清理,就会占用很大存储空间。
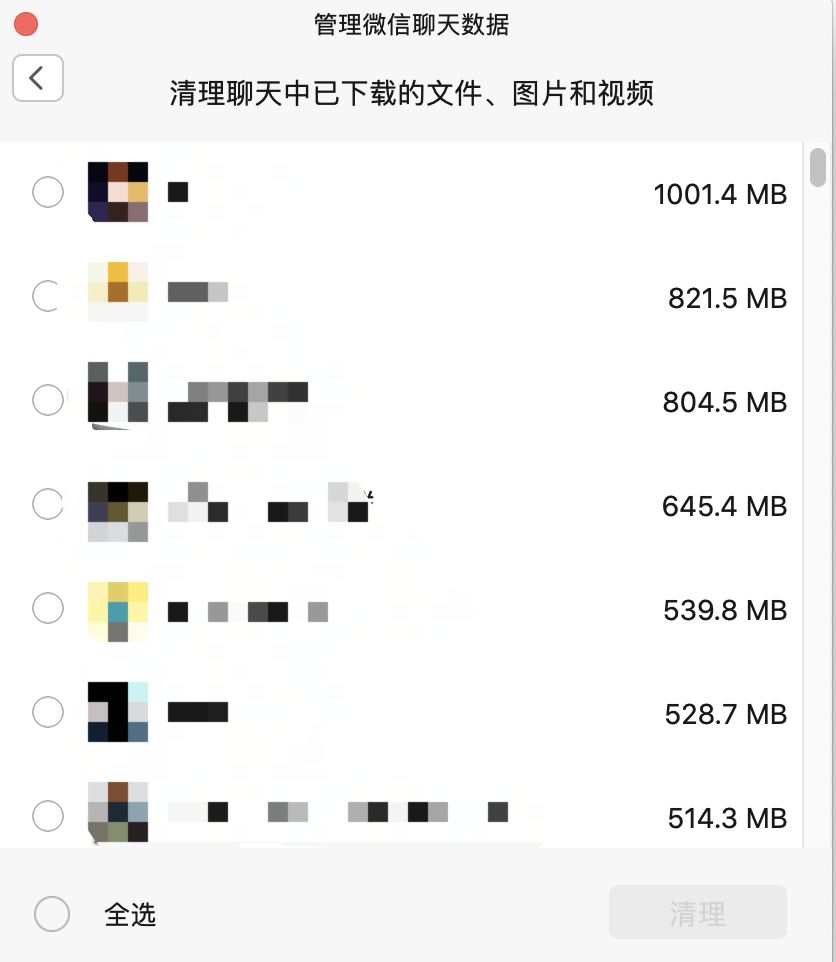
虽然微信mac端版本有一个清理空间的功能,可以单独直接删除与某一个人或群的所有聊天文件,但是是直接删除,没得选择和备份的机会。
这个事情就很尴尬了。网上搜了一圈也没找到比较好的清理归档方案。大多是教你怎么清理掉释放空间,没什么意义。
清理比较简单,更想要的是能够归档备份,因为有些聊天文件,会比较重要或者后面真的会有需要。聊天的文字倒不会占用多大空间,主要是缓存的各种文件。
如果只是把本地微信缓存目录直接同步到某个同步盘或者nas之类的,也不能很好地归档管理。
这里简单介绍一个方案吧。
写一个简单的shell脚本,根据文件时间筛选需要归档的比较老的文件。
Mac微信聊天文件目录是:~/Library/Containers/com.tencent.xinWeChat/Data/Library/Application\ Support/com.tencent.xinWeChat/2.0b4.0.9
然后下面,在电脑上登录过的微信账户,都会生成一个id目录,例如:fc4cea7edb2dde38c6ba91c9f1a5f288。
该目录下Message/MessageTemp里的就是各聊天单位所产生的聊天文件。
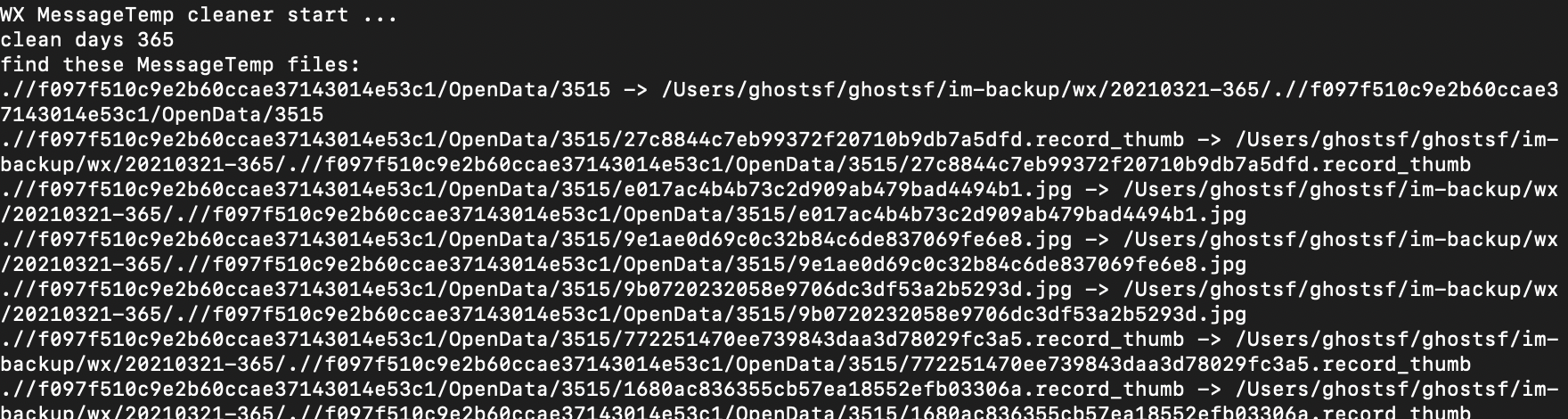
就在这个目录下搜索筛选:find ./ -mtime "+$clean_days"
这个命令就能筛选出超过clean_days天的文件,可以将这些文件归档到nas或者其他存储盘。
find ./ -mtime "+$clean_days" -exec sh -c ' mkdir -p "$0/${1%/*}" mv -v "$1" "$0/$1"' "$backupDir" {} \;这里就是将筛选出的文件同步到备份盘,同时会创建好文件的层级目录。这里层级目录的创建也很关键,便于后面恢复查询这些文件。
backupDir 备份目录,我这简单利用afp,挂载了nas上的一个共享文件夹。
相关知识,了解下https://support.apple.com/zh-cn/HT202181。
这里贴一个挂载命令供参考:mount_afp afp://username:password@host:port/volume backupDir
这样就可以做清楚删选归档还有备份恢复了。
看下效果:
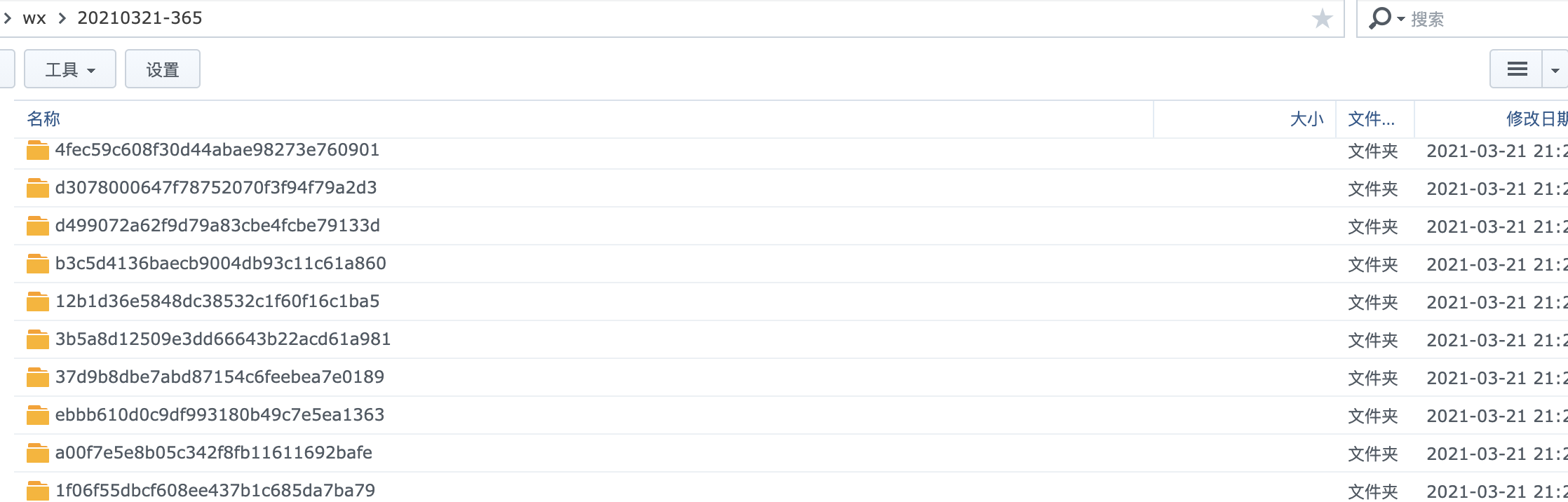
可以按自己需要的时间段或者其他筛选条件归档。
用rsync之类的远程同步也可以,但是可能相对不是很灵活。不过后续也可以进一步研究完善一下。
有需要完整方案脚本代码的或者完整程序的可以关注一波abitmean公众号,留言索取。😝
