
Using Rcpp and QuantLib to build new R packages is straight forward on Unix/Linux. More steps are needed to achieve the same on Windows. Please find here a short manual taking the RHestonSLV packages as an example.
R/Finance 2016
Update 04.09.2016: Prebuild Windows x64 R package is available.
Please find here my talk about the Heston Stochastic Local Volatility Model at this year’s R/Finance 2016 conference in Chicago, USA. The source code of the RHestonSLV package including all examples is also available.
LSMC: Need for fast and accurate Generalized Least Squares
Update 21.02.2016: Added values for QR decomposition with pivoting and QuantLib performance improvements.
Least Squares Monte Carlo simulations spend a significant amount of the total computation time on the generalized least squares especially if the problem itself has a high dimensional state. Preferred techniques to solve the normal equations are the QR decomposition

where 


where 



where 


- Chlolesky Factorization: costs
flops
- QR decomposition: costs
flops
- Singular value decomposition: costs
flops
For LSMC simulations we have 

All three decomposition methods are available in QuantLib, in LAPACK (with or without optimized OpenBLAS library) and in Intel’s MKL library. A standard Swing option valuation via LSMC should serve as a test bed to measure the performance of the QR decomposition with and without column pivoting and of the SVD algorithm. For LAPACK and MKL the methods dgels and dgesvd have been used to implement the SVD and the QR decomposition without pivoting whereas QR with pivoting is based on dgeqp3, dormqr and dtrsm. In order to keep results comparable the single thread performance was measured in all cases. The reference prices are calculated via finite difference methods and all LSMC implementations have led to the same price in line with the reference price. The current QR implementation in QuantLib 1.7 has a performance issue if the number of rows is much larger than the number of columns. For these tests an improved version of QuantLib’s QR decomposition has been used.
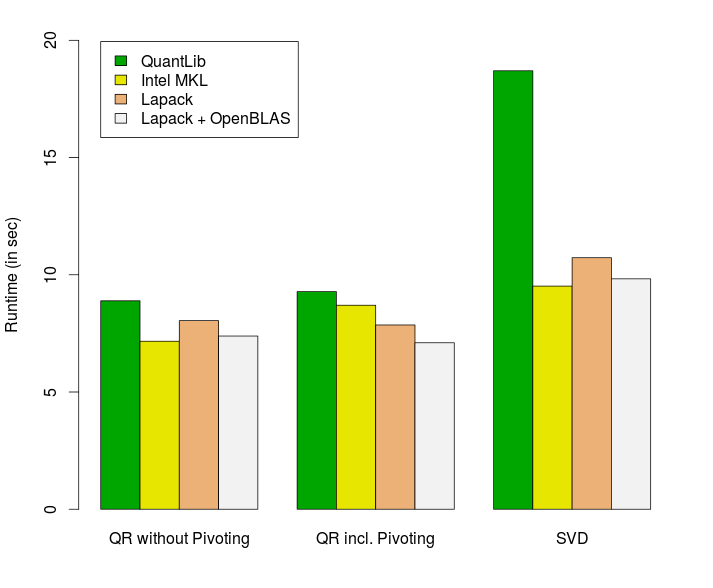
As expected MKL is often the fasted library but the difference between MKL and LAPACK plus OpenBLAS is small.
[1] Do Q Lee, 2012, Numerically Efficient Methods for Solving Least Squares Problems
Monte-Carlo Calibration of the Heston Stochastic Local Volatiltiy Model
Solving the Fokker-Planck equation via finite difference methods is not the only way to calibrate the Heston stochastic local volatility model

The basic equation to calibrate the leverage function 


![L(S_t, t)=\frac{\sigma_{LV}(S_t, t)}{\sqrt{\mathop{\mathbb{E}}[\nu_t|S=S_t]}}= \sigma_{LV}(S_t, t)\sqrt{\frac{\int_{\mathop{\mathbb{R}}^+} p(S_t,\nu, t) d\nu}{\int_{\mathop{\mathbb{R}}^+}\nu p(S_t,\nu,t)d\nu}}](proxy.php?url=https://s0.wp.com/latex.php?latex=L%28S_t%2C+t%29%3D%5Cfrac%7B%5Csigma_%7BLV%7D%28S_t%2C+t%29%7D%7B%5Csqrt%7B%5Cmathop%7B%5Cmathbb%7BE%7D%7D%5B%5Cnu_t%7CS%3DS_t%5D%7D%7D%3D+%5Csigma_%7BLV%7D%28S_t%2C+t%29%5Csqrt%7B%5Cfrac%7B%5Cint_%7B%5Cmathop%7B%5Cmathbb%7BR%7D%7D%5E%2B%7D+p%28S_t%2C%5Cnu%2C+t%29+d%5Cnu%7D%7B%5Cint_%7B%5Cmathop%7B%5Cmathbb%7BR%7D%7D%5E%2B%7D%5Cnu+p%28S_t%2C%5Cnu%2Ct%29d%5Cnu%7D%7D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
Key problem here is to calculate the expectation value ![\mathop{\mathbb{E}}[\nu_t|S=S_t]](proxy.php?url=https://s0.wp.com/latex.php?latex=%5Cmathop%7B%5Cmathbb%7BE%7D%7D%5B%5Cnu_t%7CS%3DS_t%5D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)


The boost library supports the inverse of the cumulated non-central 
![\begin{array}{rcl} m &=& \theta+(\nu_t - \theta)e^{-\kappa \Delta t} \\[6pt] \nonumber \psi &=& \frac{\nu_t \frac{\eta^2\sigma^2 e^{-\kappa\Delta t}}{\kappa}\left(1-e^{-\kappa\Delta t} \right) + \frac{\theta\eta^2\sigma^2}{2\kappa}\left(1-e^{-\kappa\Delta t}\right)^2}{m^2}\\[6pt] \nonumber \beta &=& \frac{2}{\psi} - 1 + \sqrt{\frac{2}{\psi}\left(\frac{2}{\psi}-1 \right)} \\[6pt] \nonumber p &=& \frac{\psi-1}{\psi+1} \\[6pt] \nonumber Z_\nu &\sim& \mathcal{N}(0,1) , u \sim \mathcal{U}(0,1) \\[6pt] \nonumber \nu_{t+\Delta t} &=& \begin{cases} \frac{m}{1+\beta}\left(\sqrt{\beta}+Z_\nu\right)^2 & \text{if } \psi < 1.5 \\[6pt] \begin{cases} 0, & \text{if } u \leq p \\[6pt] \ln{\left(\frac{1-p}{1-u}\right)}\frac{m}{1-p} & \text{otherwise} \end{cases} & \text{if } \psi \geq 1.5 \end{cases} \end{array}](proxy.php?url=https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+m+%26%3D%26+%5Ctheta%2B%28%5Cnu_t+-+%5Ctheta%29e%5E%7B-%5Ckappa+%5CDelta+t%7D+%5C%5C%5B6pt%5D+%5Cnonumber+%5Cpsi+%26%3D%26+%5Cfrac%7B%5Cnu_t+%5Cfrac%7B%5Ceta%5E2%5Csigma%5E2+e%5E%7B-%5Ckappa%5CDelta+t%7D%7D%7B%5Ckappa%7D%5Cleft%281-e%5E%7B-%5Ckappa%5CDelta+t%7D+%5Cright%29+%2B+%5Cfrac%7B%5Ctheta%5Ceta%5E2%5Csigma%5E2%7D%7B2%5Ckappa%7D%5Cleft%281-e%5E%7B-%5Ckappa%5CDelta+t%7D%5Cright%29%5E2%7D%7Bm%5E2%7D%5C%5C%5B6pt%5D+%5Cnonumber+%5Cbeta+%26%3D%26+%5Cfrac%7B2%7D%7B%5Cpsi%7D+-+1+%2B+%5Csqrt%7B%5Cfrac%7B2%7D%7B%5Cpsi%7D%5Cleft%28%5Cfrac%7B2%7D%7B%5Cpsi%7D-1+%5Cright%29%7D+%5C%5C%5B6pt%5D+%5Cnonumber+p+%26%3D%26+%5Cfrac%7B%5Cpsi-1%7D%7B%5Cpsi%2B1%7D+%5C%5C%5B6pt%5D+%5Cnonumber+Z_%5Cnu+%26%5Csim%26+%5Cmathcal%7BN%7D%280%2C1%29+%2C+u+%5Csim+%5Cmathcal%7BU%7D%280%2C1%29+%5C%5C%5B6pt%5D+%5Cnonumber+%5Cnu_%7Bt%2B%5CDelta+t%7D+%26%3D%26+%5Cbegin%7Bcases%7D+%5Cfrac%7Bm%7D%7B1%2B%5Cbeta%7D%5Cleft%28%5Csqrt%7B%5Cbeta%7D%2BZ_%5Cnu%5Cright%29%5E2+%26+%5Ctext%7Bif+%7D+%5Cpsi+%3C+1.5+%5C%5C%5B6pt%5D+%5Cbegin%7Bcases%7D+0%2C+%26+%5Ctext%7Bif+%7D+u+%5Cleq+p+%5C%5C%5B6pt%5D+%5Cln%7B%5Cleft%28%5Cfrac%7B1-p%7D%7B1-u%7D%5Cright%29%7D%5Cfrac%7Bm%7D%7B1-p%7D+%26+%5Ctext%7Botherwise%7D+%5Cend%7Bcases%7D+%26+%5Ctext%7Bif+%7D+%5Cpsi+%5Cgeq+1.5+%5Cend%7Bcases%7D+%5Cend%7Barray%7D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
The authors in [2] suggesting a sampling scheme for 
![\begin{array}{rcl} X_{t+\Delta t} &=& X_t + \left(r_t - q_t - \frac{1}{4}\left(\nu_t+\nu_{t+\Delta t}\right)L(S_t, t)^2 \right)\Delta t \\[6pt] \nonumber &&+ \frac{\rho}{\sigma}L(S_t, t) \left(\nu_{t+\Delta t} -\nu_t - \kappa\theta\Delta t + \frac{1}{2}\left(\nu_t + \nu_{t + \Delta t}\right)\kappa\Delta t\right) \\[6pt] \nonumber &&+\sqrt{\frac{1}{2}\left(1-\rho^2\right)\left(\nu_t + \nu_{t+\Delta t}\right) Z_x \Delta t} \\[6pt] \nonumber Z_x &\sim& \mathcal{N}(0,1) \end{array}](proxy.php?url=https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+X_%7Bt%2B%5CDelta+t%7D+%26%3D%26+X_t+%2B+%5Cleft%28r_t+-+q_t+-+%5Cfrac%7B1%7D%7B4%7D%5Cleft%28%5Cnu_t%2B%5Cnu_%7Bt%2B%5CDelta+t%7D%5Cright%29L%28S_t%2C+t%29%5E2+%5Cright%29%5CDelta+t+%5C%5C%5B6pt%5D+%5Cnonumber+%26%26%2B+%5Cfrac%7B%5Crho%7D%7B%5Csigma%7DL%28S_t%2C+t%29+%5Cleft%28%5Cnu_%7Bt%2B%5CDelta+t%7D+-%5Cnu_t+-+%5Ckappa%5Ctheta%5CDelta+t+%2B+%5Cfrac%7B1%7D%7B2%7D%5Cleft%28%5Cnu_t+%2B+%5Cnu_%7Bt+%2B+%5CDelta+t%7D%5Cright%29%5Ckappa%5CDelta+t%5Cright%29+%5C%5C%5B6pt%5D+%5Cnonumber+%26%26%2B%5Csqrt%7B%5Cfrac%7B1%7D%7B2%7D%5Cleft%281-%5Crho%5E2%5Cright%29%5Cleft%28%5Cnu_t+%2B+%5Cnu_%7Bt%2B%5CDelta+t%7D%5Cright%29+Z_x+%5CDelta+t%7D+%5C%5C%5B6pt%5D+%5Cnonumber+Z_x+%26%5Csim%26+%5Cmathcal%7BN%7D%280%2C1%29+%5Cend%7Barray%7D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
To get from the Monte-Carlo paths to the leverage function the authors in [2] using a binning technique in every time step. QuantLib supports two ways to generate the random draws, either based on i.i.d normal variables or based on Sobol quasi Monte-Carlo simulations with brownian bridges.
Test case definition: Feller constraint is violated.

Effectively the leverage function 
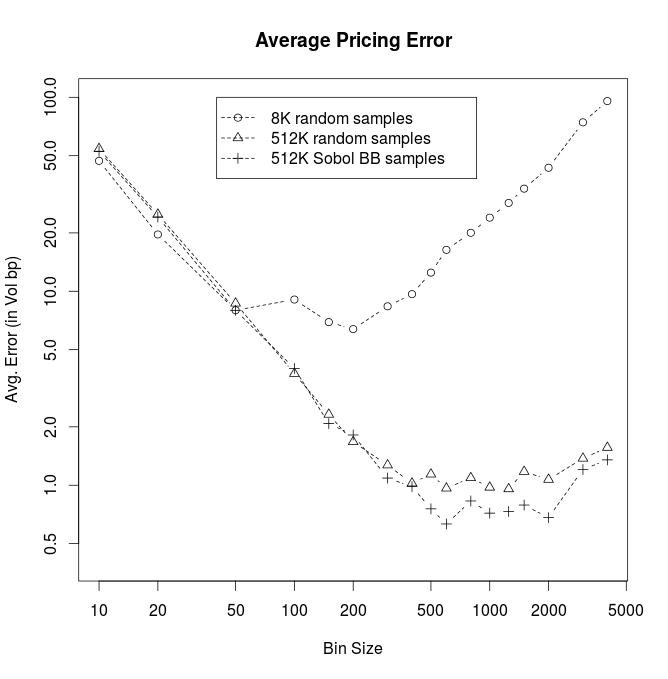
The diagram above shows the average pricing error for different number of Monte-Carlo calibration paths and for different bin sizes. As expected the optimal bin size depends on the number of Monte-Carlo simulations. Especially deep OTM options benefit from a large number of bins. The usage of Sobol quasi Monte-Carlo simulations with brownian bridges does not give a significant advantage.
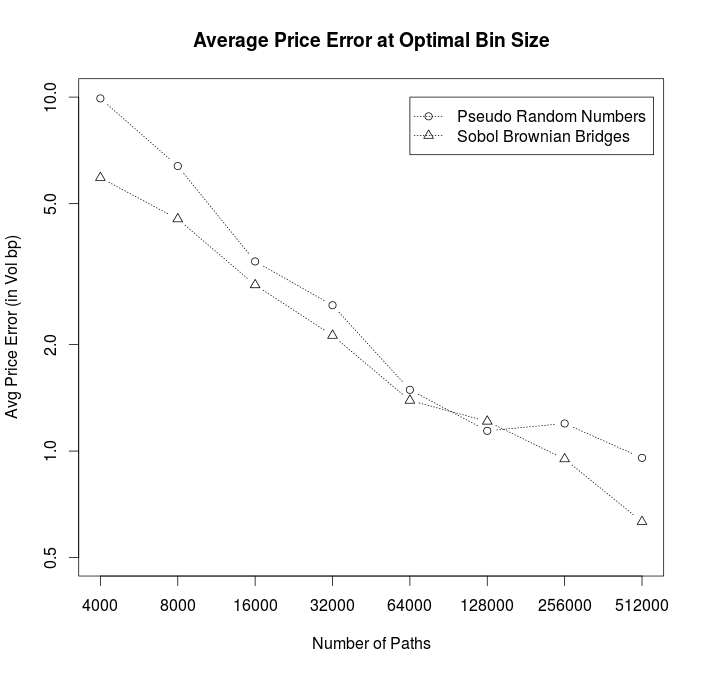
The average pricing error is decreasing with the square root of the number of Monte-Carlo calibration paths if one always choses the optimal bin size as shown in the diagram below. Quasi Mont-Carlo path generation with brownian bridges gives a small advanage.
As expected the leverage function itself exposes some Monte-Carlo noise, see diagram below. The corresponding leverage function based on the finite difference method is smooth but the overall calibration error is of the same size.
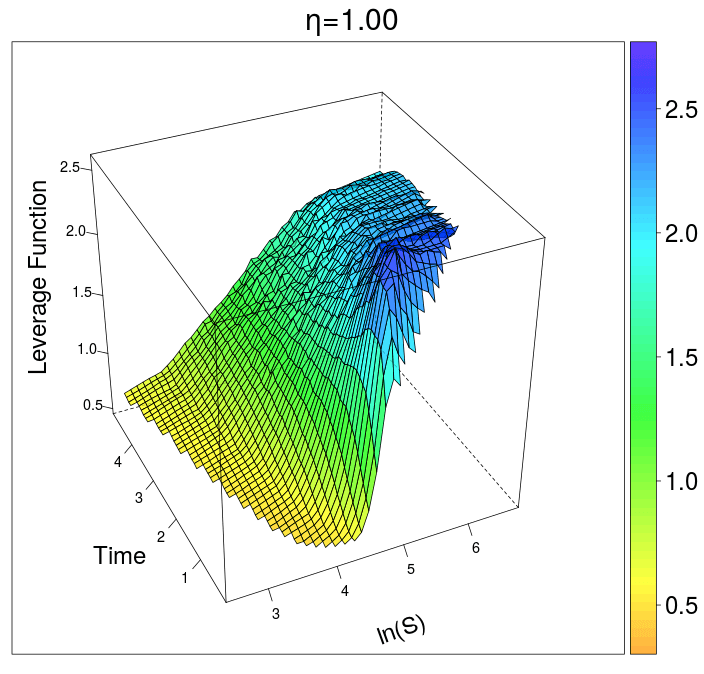
The calibration for different mixing factors 
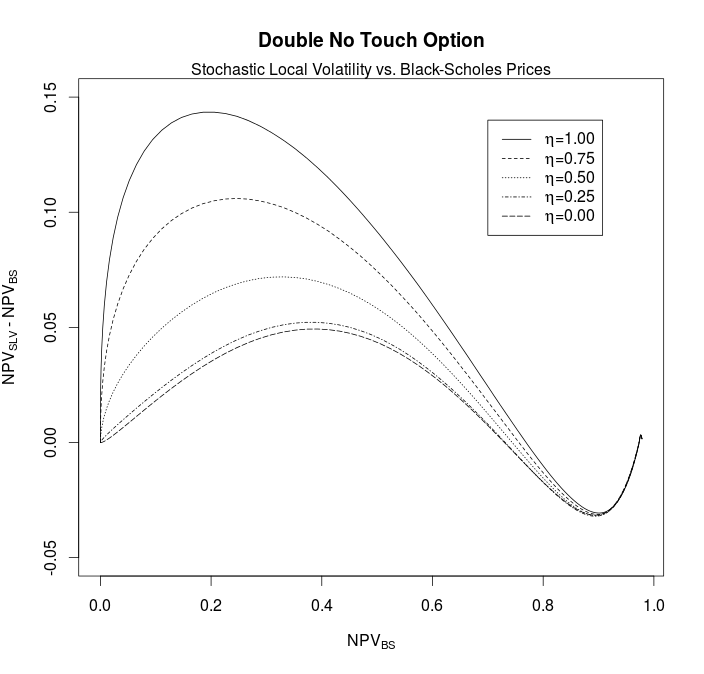
The source code is available on github as part of the test suite HestonSLVModelTest.
[1] Leif Andersen, Efficient Simulation of the Heston Stochastic Volatility Model
[2] Anthonie Van der Stoep, Lech Grzelak, Cornelis Oosterlee,
The Heston Stochastic-Local Volatility Model: Efficient Monte Carlo Simulation
[3] Johannes Goettker-Schnetmann, Klaus Spanderen, Calibrating the Heston Stochastic Local Volatility Model using the Fokker-Planck Equation
[4] Iain J. Clark, Foreign Exchange Option Pricing: A Practitioner’s Guide
Parallel Unit Test Runner using MPI
Update: 10.03.2016: added performance results of latest QuantLib test-suite build on a 32 Core SMP machine using boost interprocess instead of MPI.
Running QuantLib’s test suite on a recent computer takes around 10min. The situation will improve a lot if the test runner utilises more than one core of today’s multi-core CPUs to run the tests in parallel. Unfortunately multi-threading won’t work because the boost unit test framework is not thread safe. A reasonable way forward to speed-up the test suite is via multiprocessing using message passing between the compute nodes based on the master-slave paradigm. The cross platform standard MPI together with boost::mpi is tailor-made for this task.
The missing piece is an external, parallel unit test runner, which uses MPI for load balancing and to collect the test results. The runner for QuantLib ‘s test suite needs boost version 1.59 or higher and can be found here. Please replace in quantlibtestsuite.cpp line 24
#include <boost/test/unit_test.hpp>
by
#include <mpiparalleltestrunner.hpp>
and do not link the executable with libboost_unit_test_framework.so because the new header file includes the header only version of the boost test framework (Thanks to Peter Caspers for the hint). Load balancing is a crucial point for the overall speed-up because QuantLib’s test suite has a handful of long running tests (max. around 90 seconds), which should be scheduled first. Therefore the MPI test runner collects the statistics of every unit-test’s runtime and stores these in a local file to plan the schedule of the next runs.
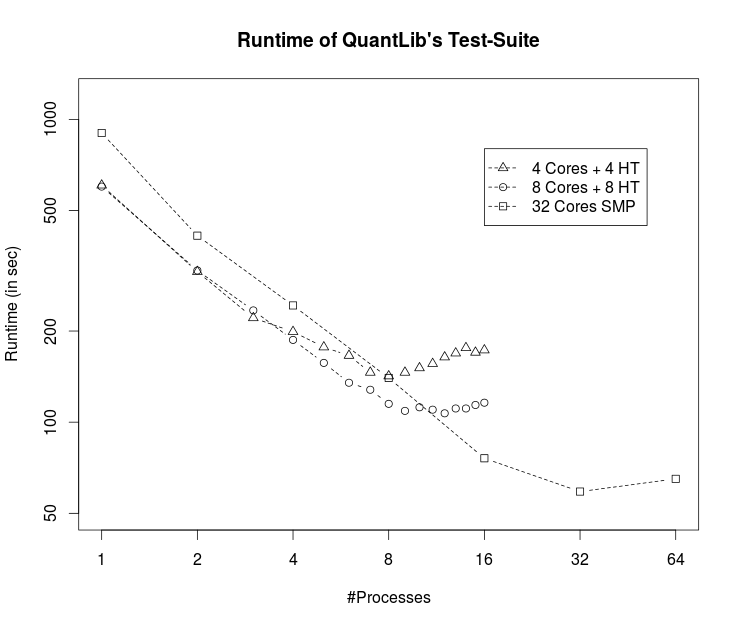
The diagram above shows the runtime of QuantLib’s test suite for a different number of parallel processes and CPU configurations. The minimum runtime is set by the longest running test case, which is around 50 seconds. On a single CPU the performance scales pretty linear with the number of cores being utilised and also hyper-threading cores help. Using more than sixteen real cores does not improve the situation any further because the overall runtime is already dominated by the longest running test case.
QuantLib User Meeting 2015
Please find here Johannes and my talk about “Calibration of Heston Local Volatility Models ” given at year’s QuantLib User Meeting in Düsseldorf. The zip file contains the PDF and the animations.
Calibration of Heston Stochastic Local Volatility Models
QuantLib 1.6.2 Multithreading Patch for JVM/.NET
Update 23.11.2015: A modified version of the patch is now part of the official QuantLib Release 1.7.
The implementation of QuantLib’s observer pattern does not tolerate a parallel garbage collector running in a different thread. This can lead to random crashes or producing “pure virtual function calls” when using QuantLib in JVM and .NET languages (e.g. Java/Scala and C#/F#) via the SWIG interface. An original description of this problem can be found e.g. here and within the references.
With the version 1.58 and higher the boost library has extended the interface of class boost::enable_shared_from_this<T> by the method
weak_ptr<T> weak_from_this() noexcept;
which gives access to the underlying weak pointer used to implement the “shared pointer from this” functionality. This method now allows for a much cleaner and easier to install patch to make QuantLib’s observer pattern thread safe. Especially it is no longer necessary to define preprocessor defines or to edit boost files.
The implementation is backed by boost::signals2 to get the observer pattern working in a thread safe manner. The boost::signals2 library works purely based on shared_ptr. Therefore the first step is to add an Observer::Proxy class to QuantLib’s Observer, which can be registered with boost::signals2 and which forwards the update calls to the corresponding observer. In addition the class Observer is now derived from boost::enable_shared_from_this.
class Observer : public boost::enable_shared_from_this<Observer> {
friend class Observable;
public:
// public interface remains untouched
virtual ~Observer() {
boost::lock_guard<boost::recursive_mutex> lock(mutex_);
if (proxy_) {
proxy_->deactivate();
for (iterator i=observables_.begin();
i!=observables_.end(); ++i)
(*i)->unregisterObserver(proxy_);
}
}
private:
class Proxy {
public:
Proxy(Observer* const observer)
: active_ (true),
observer_(observer) {
}
void update() const {
boost::lock_guard<boost::recursive_mutex> lock(mutex_);
if (active_) {
const boost::weak_ptr<Observer> o
= observer_->weak_from_this();
if (!o._empty()) {
boost::shared_ptr<Observer> obs(o.lock());
if (obs)
obs->update();
}
else {
observer_->update();
}
}
}
void deactivate() {
boost::lock_guard<boost::recursive_mutex> lock(mutex_);
active_ = false;
}
private:
bool active_;
mutable boost::recursive_mutex mutex_;
Observer* const observer_;
};
boost::shared_ptr<Proxy> proxy_;
mutable boost::recursive_mutex mutex_;
std::set<boost::shared_ptr<Observable> > observables_;
typedef std::set<boost::shared_ptr >::iterator
iterator;
};
The critical path for the race condition in the original implementation is when the destructor of an observer is called while an observable triggers an update call. Now the destructor of an observer deactivates the proxy if the destructor is able to get the same mutex lock as the update method of the proxy acquires. If the proxy gets deactivated it will not forward any update calls to the observer which is about to be deleted.
If the update call manages to acquire the mutex lock then it will delay any concurrent observer destructor calls. Therefore it is safe trying to get the underlying weak pointer from the observer linked to the proxy in line 27. This weak pointer can be empty if no shared pointer has been created from the observer in the past. If a weak pointer exists then the proxy tries to get the shared pointer and calls the update methods from there. This part follows the same methodology as outlined in [1}. The rest of the implementation inherits the thread safeness from the boost signals2 library.
The patch for QuantLib 1.6.2 can be found here. It also contains Riccardo’s thread-safe singleton patch and it requires boost version 1.58 or higher.
[1] Shuo Chen, Where Destructors meet Threads
Heston Model Calibration using Adjoint Algorithmic Differentiation
Algorithmic Differentiation becomes more and more popular in financial engineering since the method was first brought to the attention of a wider audience in [1]. Key factors for the popularity are
- Adjoint Algorithmic Differentiation (AAD): computational cost to calculate all first order partial derivatives of a function (or a computer program) with this method is loosely speaking three to six times larger than the cost of evaluating the function itself. If the function has a large number of first order partial derivatives then this method clearly overtakes the finite difference method, for which the computational cost is proportional to the number of partial derivatives.
- Easy to use C++ libraries, among others e.g. CppAD or ADOL-C
- Accuracy: The partial derivatives are the direct result of a function evaluation and do not depend on an arbitrary bumping parameter.
Adjoint Algorithmic Differentiation was first mentioned in conjunction with QuantLib in Sebastian and Jan’s talk at the 2013 User Group Meeting [2]. The topic has gain further momentum with Peter’s initial blog on Adjoint Greeks and with Alexander’s announcement that CompatibL is working on an AAD port of QuantLib. Alexander will give a talk at this years Global Derivatives Conference on the techniques involved to port QuantLib.
Almost all efficient local optimisation algorithms used for model calibration like the Levenberg-Marquardt algorithm are based on gradient methods and therefore need to calculate the Jacobian matrix of the target function Z. The target function for the Heston model calibration is defined by the goodness of fit measure

for the model parameters

The model prices of the calibration options are evaluated using Gauss-Laguerre integration of the characteristic functions 
![\begin{array}{rcl} \displaystyle \Pi_j &=& \displaystyle \frac{1}{2} + \frac{1}{\pi} \int_0^\infty\Re\left[\frac{\phi_j(u)\mathrm{e}^{-iu \ln K}}{iu}\right]\mathrm{d}u \\[0.9em] \nonumber \displaystyle P_j(\varphi) &=& \displaystyle \frac{1-\varphi}{2} + \varphi \Pi_j \\[0.9em] \nonumber \displaystyle \mathrm{NPV} &=& \varphi\left[\mathrm{e}^{-qT}SP_1(\varphi) - \mathrm{e}^{-rT}KP_2(\varphi)\right] \end{array}](proxy.php?url=https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+%5Cdisplaystyle+%5CPi_j+%26%3D%26+%5Cdisplaystyle+%5Cfrac%7B1%7D%7B2%7D+%2B+%5Cfrac%7B1%7D%7B%5Cpi%7D+%5Cint_0%5E%5Cinfty%5CRe%5Cleft%5B%5Cfrac%7B%5Cphi_j%28u%29%5Cmathrm%7Be%7D%5E%7B-iu+%5Cln+K%7D%7D%7Biu%7D%5Cright%5D%5Cmathrm%7Bd%7Du+%5C%5C%5B0.9em%5D+%5Cnonumber+%5Cdisplaystyle+P_j%28%5Cvarphi%29+%26%3D%26+%5Cdisplaystyle+%5Cfrac%7B1-%5Cvarphi%7D%7B2%7D+%2B+%5Cvarphi+%5CPi_j+%5C%5C%5B0.9em%5D+%5Cnonumber+%5Cdisplaystyle+%5Cmathrm%7BNPV%7D+%26%3D%26+%5Cvarphi%5Cleft%5B%5Cmathrm%7Be%7D%5E%7B-qT%7DSP_1%28%5Cvarphi%29+-+%5Cmathrm%7Be%7D%5E%7B-rT%7DKP_2%28%5Cvarphi%29%5Cright%5D+%5Cend%7Barray%7D+&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
with the binary variable 

template <class F>
CppAD::AD<Real> GaussianADQuadrature::operator()(const F& f)
const {
CppAD::AD<Real> sum = 0.0;
for (Integer i = order()-1; i >= 0; --i) {
sum += w_[i] * f(x_[i]);
}
return sum;
}
Using this AAD version of the Gauss-Laguerre integration the method
CppAD::AD<Real>; AnalyticHestonADEngine::Fj_Helper::operator()(Real phi) const;
can be ported in a similar manner and the AnalyticHestonADEngine::doCalculation method now reads
std::vector<CppAD::AD<Real> > params;
params += spotPrice, v0, kappa, theta, sigma, rho;
CppAD::Independent(params);
std::vector<CppAD::AD<Real> > y(1);
// untouched code ...
const std::vector<Real> moreResults
= CppAD::ADFun<Real>(params, y)
.Reverse(1, std::vector<Real>(1, 1.0));
results.value = CppAD::Value(y[0]);
results.additionalResults["v0"] = moreResults[1];
results.additionalResults["kappa"] = moreResults[2];
results.additionalResults["theta"] = moreResults[3];
results.additionalResults["sigma"] = moreResults[4];
results.additionalResults["rho"] = moreResults[5];
All first order Greeks for the calibration instruments can now be calculated using AAD. The Jacobian of the target function Z w.r.t. the first order Greeks is given by
![\begin{array}{rcl} \displaystyle\frac{\partial Z_i}{\partial x_j} &=& \displaystyle \frac{\partial \sigma_i^{model}(\Theta)}{\partial x_j} = \displaystyle \frac{1}{\frac{\partial NPV_i}{\partial \sigma_i}}\frac{\partial NPV_i}{\partial x_j} \\[0.9em] \nonumber &=& \displaystyle \frac{1}{\nu_{BS}}\frac{\partial NPV_i}{\partial x_j} \end{array}](proxy.php?url=https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+%5Cdisplaystyle%5Cfrac%7B%5Cpartial+Z_i%7D%7B%5Cpartial+x_j%7D+%26%3D%26+%5Cdisplaystyle+%5Cfrac%7B%5Cpartial+%5Csigma_i%5E%7Bmodel%7D%28%5CTheta%29%7D%7B%5Cpartial+x_j%7D+%3D+%5Cdisplaystyle+%5Cfrac%7B1%7D%7B%5Cfrac%7B%5Cpartial+NPV_i%7D%7B%5Cpartial+%5Csigma_i%7D%7D%5Cfrac%7B%5Cpartial+NPV_i%7D%7B%5Cpartial+x_j%7D+%5C%5C%5B0.9em%5D+%5Cnonumber+%26%3D%26+%5Cdisplaystyle+%5Cfrac%7B1%7D%7B%5Cnu_%7BBS%7D%7D%5Cfrac%7B%5Cpartial+NPV_i%7D%7B%5Cpartial+x_j%7D+%5Cend%7Barray%7D&bg=ffffff&fg=5e5e5e&s=0&c=20201002)
The advantage of using AAD for the Heston model is not calculation speed but precision. In fact the AAD version of the Heston model calibration is slower than the finite difference based method but the AAD method does not need an arbitrary, fine-tuned bumping parameter or any higher order finite difference schemes to come up with high precision first order derivatives. The diagram below shows the relative difference between the AAD value and several finite difference approximations for 

Only the six point central finite difference scheme with optimal bumping size gives the AAD value within/close to machine precision. The two point forward scheme, which is used by default in the MINPACK implementation of the Levenberg-Marquardt algorithm, reproduces only the first eight digits. A more detailed analysis for the forward scheme can be found in [3] or [4]. Especially the latter paper calculates the values for the optimal choice of the bumping size for the different schemes. Please find the source code for the AAD pricing engine here.
The rate of convergence can be improved by using the Richardson extrapolation. For the diagram below the same analysis was repeated including a Richardson extrapolation step.

[1] Giles, M. and Glasserman, P., (2006) Smoking adjoints: fast Monte Carlo Greeks. Risk, 19:88–92. 1
[2] Schlenkrich, S. and Riehme J., (2013) Design Patterns for Algorithmic Differentiation
[3] Kopecky, K. (2007) Numerical Differentiation, Lecture Notes
[4] Numerical Differentiation in Integration, Lecture Notes
QuantLib-1.5 SWIG Patch for JVM/.NET
Update 23.11.2015: A modified version of the patch is now part of the official QuantLib Release 1.7.
Update 22.09.2015: Please find the latest and improved version of the patch for QuantLib 1.6.2 here.
The usage of QuantLib in JVM and .NET languages (e.g. Java/Scala and C#/F#) via the SWIG interface has a known shortcoming. The implementation of QuantLib’s observer pattern does not tolerate a parallel garbage collector running in a different thread. As a result programs are randomly crashing or producing “pure virtual function calls”. A detailed description of this problem can be found e.g. here and within the references.
Please find here a patch for QuantLib 1.5 to fix this issue.
