
AI Blind Spots: How Enterprises Detect Hidden Model Failures
AI systems can fail due to hidden blind spots. Learn how enterprises detect edge cases and structural gaps before deployment.
The post AI Blind Spots: How Enterprises Detect Hidden Model Failures appeared first on Innodata.
]]>

The post AI Blind Spots: How Enterprises Detect Hidden Model Failures appeared first on Innodata.
]]>The post Trace Datasets for Agentic AI: Structuring and Optimizing Traces for Automated Agent Evaluation appeared first on Innodata.
]]>

The post Trace Datasets for Agentic AI: Structuring and Optimizing Traces for Automated Agent Evaluation appeared first on Innodata.
]]>The post Turning Human Motion into Better AI: How Kinematics Improves Data Labeling and Model Quality appeared first on Innodata.
]]>

The post Turning Human Motion into Better AI: How Kinematics Improves Data Labeling and Model Quality appeared first on Innodata.
]]>The post Innodata Selected by Palantir to Accelerate Advanced Initiatives in AI-Powered Rodeo Modernization appeared first on Innodata.
]]>AI systems can fail due to hidden blind spots. Learn how enterprises detect edge cases and structural gaps before deployment.
Trace datasets reveal how AI agents behave and enable automated agentic AI evaluation for reliability, safety, and compliance.

How kinematics-based motion analysis improves data labeling, automated quality control, and computer vision models for fitness and robotics.
The post Innodata Selected by Palantir to Accelerate Advanced Initiatives in AI-Powered Rodeo Modernization appeared first on Innodata.
]]>The post AI Evaluation: 7 Core Components Enterprises Must Get Right appeared first on Innodata.
]]>

The post AI Evaluation: 7 Core Components Enterprises Must Get Right appeared first on Innodata.
]]>The post Innodata Awarded Prime Contract Position on U.S. Missile Defense Agency’s IDIQ SHIELD Program appeared first on Innodata.
]]>AI systems can fail due to hidden blind spots. Learn how enterprises detect edge cases and structural gaps before deployment.
Trace datasets reveal how AI agents behave and enable automated agentic AI evaluation for reliability, safety, and compliance.
How kinematics-based motion analysis improves data labeling, automated quality control, and computer vision models for fitness and robotics.
The post Innodata Awarded Prime Contract Position on U.S. Missile Defense Agency’s IDIQ SHIELD Program appeared first on Innodata.
]]>The post Achieving State-of-the-Art UAV Tracking on the Anti-UAV Benchmark: Innodata Results appeared first on Innodata.
]]>


The post Achieving State-of-the-Art UAV Tracking on the Anti-UAV Benchmark: Innodata Results appeared first on Innodata.
]]>The post Domain-Specific AI: Smarter, Safer, and Built for Your Industry appeared first on Innodata.
]]>Domain-specific AI models are fine-tuned on industry data. Contrary to general-purpose Large Language Models, they are precise, know the specifics of your industry, and context-aware. Generic LLMs often misinterpret specialized workflows, leading to unexpected outcomes and poor performance in high-stakes domains.

So, enterprises need AI models that are trained specifically on quality data and specific industry use cases. Making AI models aware of an enterprise’s context helps them solve common problems in their domain during training itself.
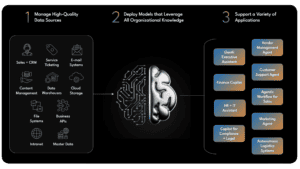
1. Healthcare, Life Sciences & Pharmaceuticals
2. Banking, Financial Services & Fintech
3. E-Commerce, Manufacturing & Transportation
The post Domain-Specific AI: Smarter, Safer, and Built for Your Industry appeared first on Innodata.
]]>The post Implementing AI TRiSM in Agentic AI Systems: A Guide to Enterprise Risk Management appeared first on Innodata.
]]> The post Implementing AI TRiSM in Agentic AI Systems: A Guide to Enterprise Risk Management appeared first on Innodata.
]]>The post Why Did My AI Lie? Understanding and Managing Hallucinations in Generative AI appeared first on Innodata.
]]> The post Why Did My AI Lie? Understanding and Managing Hallucinations in Generative AI appeared first on Innodata.
]]>