中文:https://kubevela.io/zh/blog/2023/05/30/lfx-cue-generator
英文:https://kubevela.io/blog/2023/05/30/lfx-cue-generator/
CNCF Blog: https://www.cncf.io/blog/2023/06/09/congratulations-to-57-cncf-term-1-lfx-program-mentees/
CNCF 公众号: https://mp.weixin.qq.com/s/RhaxpaLe4vdw9QOReaDBtw
大家好,我是刘俊余(GitHub: iyear),目前就读于软件工程专业大二。在这篇博客中,我将分享我作为 Linux Foundation Mentoship 学员的一些经历:从申请项目到成为社区的一份子。
我在 2023 年春季通过 LFX Mentoship 被选为 CNCF 基金会下 KubeVela 项目的学员,在该项目中,我负责从零开发基于 Golang 的 CUE 代码及文档生成器,为 KubeVela 的未来扩展性铺垫基础设施部分。
什么是 LFX Mentorship?
LFX Mentorship 是一个远程的学习项目,它为开源贡献者提供 12 周的学习机会,由特定的导师(他们通常是项目的主要维护者),帮助学员为社区和项目做出贡献。
许多开源组织或基金会都会通过 LFX Mentorship 为旗下项目发布项目并招募学员进行开发和贡献。我主要关注并工作在云原生领域,在今年二月份关注到 CNCF 在 LFX 上开始了 2023 年春季项目,我开始尝试申请自己感兴趣的项目。
什么是 KubeVela?
![]()
KubeVela 是一个开箱即用的现代化应用交付与管理平台,它使得应用在面向混合云环境中的交付更简单、快捷。
KubeVela 诞生自 2019 年年底阿里云联合微软共同推出的 Open Application Model(简称 OAM )模型基于 Kubernetes 的实现,在不断演进和迭代中融合了大量来自开源社区(尤其是微软、字节跳动、第四范式、腾讯和满帮集团的社区参与者们)的反馈与贡献,最终在 2020 年 KubeCon 北美峰会上以“KubeVela”的名字正式与开源社区见面。
KubeVela 项目发展迅速,其发展里程如下:
更值得一提的是,在今年3月,KubeVela 晋升为 CNCF 孵化项目,进一步证明了 KubeVela 在生产环境中的稳定性和灵活性。
项目详情
项目名称: Support auto generation of CUE schema and docs from Go struct
项目描述: In KubeVela's provider system, we can use our defined Go functions in CUE schema. The Go providers usually have a parameter and return. Fields in Go providers are the same as fields in CUE schema, so it is possible and important to support automatic generation of CUE schemas and documents from Go structs.
项目要求: Auto-generators of CUE schemas and docs from Go structs, the capabilities should be wrapped in vela cli command.
项目链接: https://mentorship.lfx.linuxfoundation.org/project/85f61cae-02d7-4931-8d87-d3da3128060e
申请及开发过程
在初步浏览项目列表时,KubeVela 就成为了我的候选项之一。在初步探索云原生领域之前我了解过 KubeVela 项目并尝试理解其理念和工作方式,但由于水平有限也便浅尝辄止。而这次如果能通过一个小的切入点最终熟悉 KubeVela 便是最好的贡献路径。同时元编程和代码生成是 Golang 的重要手段,我也想将此项目作为一次实践的机会。
项目涉及到 KubeVela 的核心部分:CUE。这是我第一时间需要去了解的部分,通过 KubeVela 官方文档 和 CUE Issues 我认识到 CUE 是一个为配置而生的语言,在可编程、自动化、Golang 集成度方面都有着其他语言不可比拟的优势,另一方面 KubeVela 在演进的过程中也不断为 CUE 提供实践案例和使用反馈。
在联系导师后,我的目标是先完成一个 DEMO 作为演示。整个项目的核心部分在于 Golang AST 和 CUE AST 的互转,我首先在 CUE 源代码中找到了一部分可以借鉴的代码,读通读懂后提取了核心部分并进行了修改和适配,实现了 DEMO 的结构体转换。
通过 DEMO 的编写,我对整体项目的目标有了更清晰的认知。CUE 作为面向用户和平台开发者的顶层语言,通过 Golang 作为中间媒介与云平台连接、控制,必然会出现大量的 CUE 与 Golang 的交互和转换。在许多场景中,CUE 需要与 Golang 代码保持维护一致性,否则将出现中间转换的错误。
这一过程耗时耗力且只在运行时出现问题,严重时可能会影响生产环境稳定性。这一项目即旨在解决该问题,使 Golang 代码作为单一事实来源,通过静态生成方式保持整体配置的一致性。
在项目描述的 Issue 中,导师以 provider 为例提供了生成预期。结合项目产出后一切都明朗了起来:
我将 CUE Generator 分为三层,最底层负责基础且核心的 AST 转换;中间层负责读取具体的 Golang 代码,例如 provider、policy,将 Golang 代码中的信息提取并写入 CUE 文件中;最上层即将生成能力以 CLI 形式暴露给用户和开发者,能够快捷地生成 CUE 和文档。在未来支持更多不同格式的 CUE 时,可以方便地复用底层转换能力。
在和导师进行了进一步沟通后,我对结构体 Tag 和注释做了进一步支持,并将一些想法总结为提案。在一系列的迭代和沟通后,项目已经初步成型,同时也非常荣幸地被成为 LFX Mentorship 的学员。

经过初期的交流和 DEMO 编写,正式开发的过程整体也比较顺畅,大多数沟通主要在用户体验和细节设计上。第一个 PR 由于没有拆分,收到了许多有价值的 review,经过了 50 个评论才最终合并。由于初期代码来自 DEMO 写的较为随意,最后一段时间也重点重构了部分代码,使代码更加清晰健壮。
自二月第一个 PR 到五月结项的第十五个 PR,项目基本完结且代码全部并入主分支。同时也通过了两次导师评估,即将从 LFX Mentorship 的第一个项目毕业?
项目产出
近三个月的开发,项目主要产出了三个能力和两个 CLI 用户接口,所有代码测试覆盖率均达到 90% 以上。
项目核心能力处于 references/cuegen 目录下,实现了从 Go AST 转换到 CUE AST 的基础能力,并配以 README 文档供开发者了解具体转换规则。中间层的代码放置于 references/cuegen/generators 目录下,目前已经实现了针对 provider 格式的生成器。文档生成部分位于 references/docgen/provider.go ,复用了 docgen 的能力为 CUE 自动生成文档。
项目增加了两个 CLI 子命令,分别为 vela def gen-cue 与 vela def gen-doc。前者将 Golang 代码生成为对应格式的 CUE 文件,即将中间层能力暴露为 CLI 接口,后者将 CUE 生成为对应的文档。
由于 vela def gen-cue 单次只支持一个文件,通过编写 Shell 脚本为其实现了遍历目录批量生成的功能:#6009
以 kubevela/pkg/providers/kube 的代码片段为例,进行改造与验证。
先将 kube.go 转换为 kube.cue :
$ vela def gen-cue \
-t provider \
--types *k8s.io/apimachinery/pkg/apis/meta/v1/unstructured.Unstructured=ellipsis \
--types *k8s.io/apimachinery/pkg/apis/meta/v1/unstructured.UnstructuredList=ellipsis \
kube.go > kube.cue再将 kube.cue 转换为 kube.md
$ vela def gen-doc -t provider kube.cue > kube.md最终效果如下:

未来展望
虽然本次 LFX Mentorship 的期望产出已经全部实现,但这只是 cuegen 的第一步,其衍生工作对 KubeVela 的未来发展也将起到重要作用。
例如,基于 cuegen 我们可以对当前依赖手工维护的 policy 规则进行自动生成化改造;对 kubevela/pkg 中已有的 providers 进行迁移和验证;对用户自定义 provider 的脚手架生成工具等等都需要依赖于 cuegen 的转换能力。这也是我未来在社区工作的重点方向。
除了 cuegen 生态的相关工作,我也将深入 KubeVela 的其他方面,比如对 OAM 生产实践和用户社群的熟悉深入、阅读 Workflow 组件源码探索新特性的可能性……我也发起了对 KubeVela Reviewer 的申请,尝试为项目代码质量控制做出一些贡献。
这是我第一次参加 LFX Mentorship 项目,在为期三个月的沟通和交流中,两位导师在细节和决策上都给予了我许多帮助和指导,结项前我们也通过线上 Meeting 完整演示了功能、讨论了未来社区的工作方向和规划。
开源是一个兴趣主导,自驱力推动的过程。开发者能在不同社区工作的经历中不断提高自己,与社区共同成长。开源就是对有兴趣的项目都应该勇于迈出第一步,去尝试读一读项目的源码。学生参与开源更多的是一个学习的过程,在开源道路上的每一步都会有不同的收获和感悟。非常感谢能在 LFX Mentorship 与 KubeVela 社区相遇,期待未来对社区的进一步深入和贡献!
]]>2023.4.27 一年过去了,细节忘光了,摆了
]]>原本稀薄的得以聚合,曾经蜷曲的得以伸展,容易被忽略的得以显现,可能被排斥的获得接纳:孤独的不再孤独,卑微的不再卑微,每一个生命绽放的声音,从来没有像这样韵味深长。
前些日子,阅读《Kubernetes权威指南》到网络原理部分,涉及到了Docker虚拟网桥部分,对于计算机网络这块内容属实没有系统学习过,等学校开课是来不及的,于是开出一条支线任务,先把计网的整体体系与框架搞清楚。
从4.18-4.28花了十天左右时间,阅读完了《图解TCP/IP》,对计网做了一个整体的了解。
这几天可谓收益良多。我之前也尝试看过《TCP/IP详解卷》,但实在是枯燥乏味了些,并不太适合入门。这本书相对来说以科普、自顶向下的方式将计网发展史与协议簇娓娓道来,用词也很接地气,非常推荐的一本书。
对于计网,我其实一直非常感兴趣,有很大的驱动力去学习相关知识。容我多写几句废话~刨除小时候最简单意义的“上网”,正经去了解“网络”这件事还是在小学五六年级,那个时候有一部非常经典的纪录片 《互联网时代》,甚至他的实体书版本都还放在家里。
开头的引言也来自这部纪录片,它没有去讲协议、讲细节,而是以历史的视角纵观互联网变迁。让我印象最深的是万维网的创立、雅虎的诞生、谷歌的席卷全球、北京暴雨时微博的接送大军。也被 IP 设计的理念深深震撼——在IP协议中,网络中的每一个节点都拥有完全平等的地位。《互联网时代》算是我的计算机网络启蒙了
初中以后接触网络便越来越多了,一直在应用层玩个不停:浏览器抓抓包、玩玩公共API、写了个云便签服务(甚至是拿FTP作为存储的)、玩了SMTP和POP3、买过服务器和域名自己搭网站、买证书、用梯子
后来还玩起了路由器,不过整个过程都囫囵吞枣,不懂的概念也就草草略过。
前面所说的这段经历虽然寥寥几句,但是在我阅读《图解TCP/IP》时,不断的看到这些经历的影子,一切的底层协议和设计仿佛都回荡着中学时代的回忆,同时又是构建人类互联与自由的一部恢宏史诗。于我堪比《三体》的时空跨越与史诗感。
我想用一句话总结,计算机网络不仅是计算机专业的一门专业课,更是对人类自由、平等、互通之理念长达半个世纪的深刻贯彻,是技术人对整个世界发起的革命性颠覆。至此,人类以一种全新的组织、连接方式,迸发出无数钻石般的光辉。
]]>Redis 时认为奇怪的数字&HashSlot引出浅析
Redis Slot 采用的是 CRC16 算法,输出集合有 2^16-1=65535 种结果。而 16384 = 2^14,为什么要少两位?
相关讨论: https://github.com/redis/redis/issues/2576
1 缩减通讯消息体
https://github.com/redis/redis/blob/a642947e04168b40aea6cec666927a9e653035e6/src/cluster.h#L120
Redis Cluster 定义的 clusterNode 需要携带自己的 slots 以及一定数量其他节点的信息(包括 slots)
solts 相当于一个 BitMap, 16384b = 2KB , 65535b = 8KB
Redis Cluster 需要发送心跳包通讯,在节点数量较大时,过大的消息体会导致节点通讯较慢且浪费带宽
2 Master不应当过多的前提
At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
作者认为,Redis Cluster 的 Master Node 架构设计时不应当超过1000个,否则节点间的通信将占用大量的网络IO,导致整体性能反而下降
在这一前提下,过多的插槽是没有必要的。反而如果大量的插槽占据 slots,会导致其压缩率下降
参考
]]>Kitex文档的一致性哈希实现负载均衡,好吧,我连什么是一致性哈希都不知道一、传统哈希取模算法的局限性
1.1 节点增加、减少
任何节点的故障或临时增加我们都只希望性能上有所降低,而不是服务受到影响。
对于传统哈希算法,节点的增加、减少会导致键与节点的映射关系发生变化。对于已有的键来说,将导致节点映射错误。
1.2 结论
当集群中节点的数量发生变化时,之前的映射规则就可能发生变化。
对于分布式缓存,映射规则失效意味着之前缓存的失效,若同一时刻出现大量的缓存失效,则可能会出现 “缓存雪崩”,这将会造成灾难性的后果。
要解决此问题,我们必须在其余节点上重新分配所有现有键,这是非常昂贵的操作,并且可能对正在运行的系统产生不利影响。
二、一致性哈希算法
Wiki: https://zh.wikipedia.org/wiki/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C
一致性哈希算法是在哈希算法基础上提出的
哈希算法应该满足的几个条件:
- 平衡性:是指 Hash 的结果应该平均分配到各个节点
- 单调性:是指在新增或者删减节点时,不影响系统正常运行
- 分散性:是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据
2.1 对象、服务器哈希
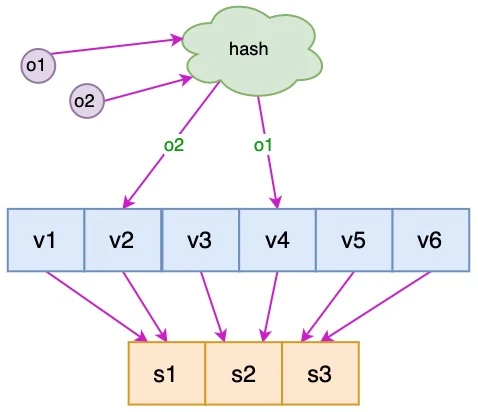
通过一致性哈希环(Hash Ring)实现。这个环的起点是 0,终点是 2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是 [0, 2^32-1]
其实终点可以自定义,或许这个数字来源为IP地址为32位
点由哈希函数再取模得出
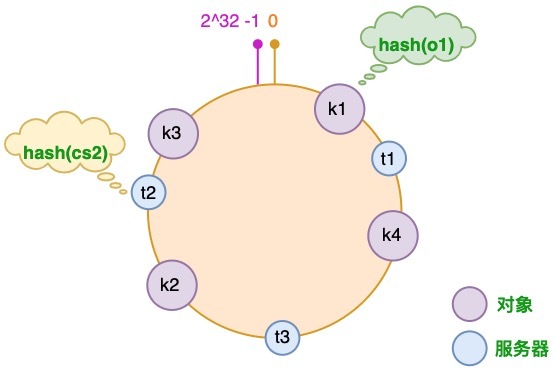
k1 k2 k3 k4 为四个对象哈希后的位置
t1 t2 t3 为三个服务器哈希后的位置,可以选择服务器的IP或主机名等等作为键
2.2 映射规则
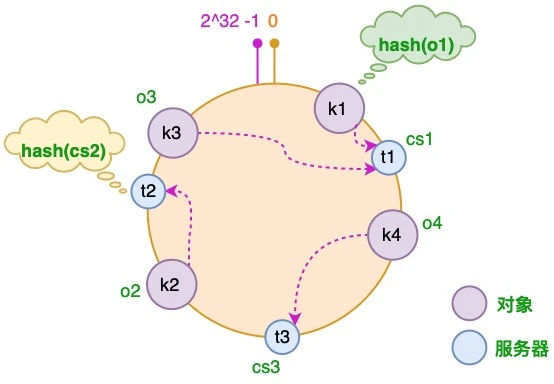
将对象和服务器都放置到同一个哈希环后,在哈希环上顺时针查找距离这个对象的 hash 值最近的机器,即是这个对象所属的机器。
以 o2 对象为例,顺序针找到最近的机器是 cs2,故服务器 cs2 会缓存 o2 对象。
而服务器 cs1 则缓存 o1,o3 对象,
服务器 cs3 则缓存 o4 对象。
2.3 服务器增加
假设由于业务需要,我们需要增加一台服务器 cs4
经过同样的 hash 运算,该服务器最终落于 t1 和 t2 服务器之间
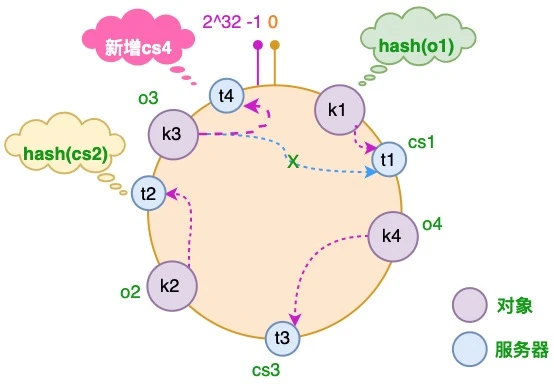
可见,只有 t1 和 t2 之间的对象需要重新分配
2.4 服务器减少
假设 cs3 服务器出现故障导致服务下线
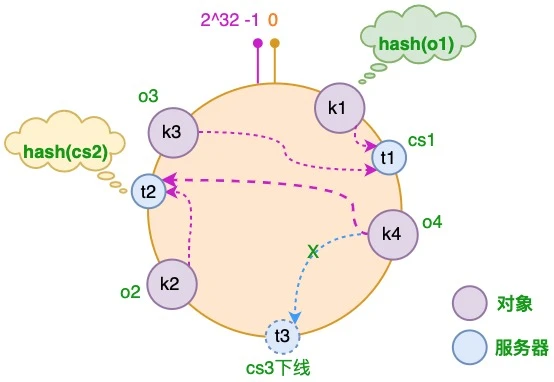
可见,只有 t2 和 t3 之间的对象需要重新分配
2.5 数据倾斜与解决方案
当物理节点数量较少时,一致性哈希的平衡性是有问题的
- 某些节点承担的
key非常多,一些节点却非常少。一旦负载较多的物理节点挂了,容易造成缓存雪崩。 - 纯物理节点无法实现权重分配
我们可以创造出一组虚拟节点,再让虚拟节点向物理节点映射,解决了以上两点
虚拟节点数越大,内存和计算代价越大,负载越均衡
在 Kitex 的文档中
推荐 VirtualFactor * Weight(如果 Weighted 为 true)的中位数在 1000 左右,负载应当已经很均衡了
推荐 总虚拟节点数 在 2000W 以内(1000W 情况之下 build 一次需要 250ms,不过为后台 build 理论上 3s 内均无问题)
2.6 依旧存在的缺点
- 哈希环结构的存在,无法手动管理和精细化控制
- 哈希环上的虚拟节点非常多或者更新频繁时,查找和迁移计算性能会比较低下
Redis 作为著名的分布式缓存系统,其 Sharding 采用的并不是一致性哈希,而是哈希槽,在一定程度上解决了以上问题
开源库实现
参考
相关文章实在是太多了
]]>已经使用了将近一个月了,整体体验比笔记本确实高太多了,虚拟机和IDE随便开,根本不用考虑内存不够的情况。
机箱的大小刚好放在桌面显示器的后面,充分利用了空间。
这台主机配完,自己装完,对整个主机市场也有了一个大概的了解,算是一次有趣的探索吧。
1
高考完买的联想小新Pro16 挺好用的,为啥还要再买一台主机?
- 一直用的 4K 显示器,笔记本每次带回来都要外接两根线(typec+电源)。嫌麻烦。(有点扯)
- 小新Pro16板载16G内存,日常开发其实有点不够,要把 WSL 的内存给限制一些。
- 一直没有自己DIY主机的经历,很想试试。
所以说干就干,先花了一些时间看了一些B乎文章和B站视频,了解了整个主机DIY的基础知识和大概市场。
2
因为要配的是一台开发机,所以内存肯定是32G起步,直接16Gx2走一个双通道。硬盘1TSSD起步。这些是开发机的硬性需求。显卡我不需要。CPU为了成本缩减考虑AMD。散热能用就行。电源不能省,尽量给多点冗余。机箱我一开始想要组ITX,这种短小精悍的东西我特别喜欢,但是看完价格直接劝退了。所以机箱直接不算钱,真不行直接堆桌子上也可以。
预算就3000左右,基本把之前攒的+红包花完了。
因为是第一次配,完全没有概念,花了30块钱去知乎付费咨询了一下,给自己一个基础模板。
付费咨询结束,感觉这套配的不是很合我的口味,不过大致的品牌和价位都可以摸清楚了。最后淘宝、咸鱼、评测文章反复对比,搞出下面这套配置。没有杂牌,尽可能都是大牌保证了。
CPU R5-5600G 散片 1289r
主板 微星B450m迫击炮max 闲鱼 200r
内存 科赋普条 16Gx2 790r
硬盘 西数SN570 1T 595r
散热 利民AX120RSE ARGB 69r
电源 航嘉冷静王蓝钻白牌 400w 200r
机箱 P6 matx 机箱 35.9r
共3179元对这套选型做逐一讲解。
3
CPU
预算限制,AMD YES!
由于不需要显卡,所以想要独显稍微强点,5600G的显卡相当于 GTX-750Ti ,非常够用。
CPU选择其实也不是很多,1500元的预算已经是最多了,再加上这几个原因,很快就确定了这个型号。只不过1289的价格是我找了一会儿才有的。
主板
B450m是老款主板,要刷BIOS才能用上锐龙五代。但是B550m的价格比较高,而且我后续再升级大件硬件的可能性比较小,所以预算优先,就不上新主板了。
200元的价格是咸鱼找到的,这个价格我是有点顾虑的,但是因为预算本来就有点超了,只能上了。不过最后没啥问题。
内存
32G内存便宜不下来的,只能上比较普通的内存条,不过不打游戏,影响估计不会太大,科赋算是二三线品牌,这块如果有预算可以上更好点的内存条。
硬盘
西数SN570的性价比我个人认为是挺高的。经过各种观摩评测文章,总结就是:500G选铠侠RC10,1T选SN570。没啥好说的,SSD就是爽。
散热
我这配置和日常使用基本不怎么发热,PDD随便找一个高度低点的就行,有点牌子的就行。
电源
这个不能省,经过计算,日常大概200W可能就够了,但是我还是上了400W的电源,安全第一,而且也要考虑到后续加装扩展和转手。
机箱
我是想越小越好,可以放在显示器后面的吃灰区域。最后发现了这款垃圾佬专用机箱,想要多好是没有的,不过该有的都有,满足了。
]]>目前还没研究具体的协议实现,只实现了二进制还原JSON的过程。
因为 pure-live 项目,开始对企鹅电竞进行分析。直播流的获取还是比较简单的,参考 real-url 项目,发几个HTTP请求就拿到了。难的是 websocket 协议的破解。
看了 real-url 的实现是模拟了 js 的过程,但是模拟的过程非常抽象,无法理解其宏观实现。本来也打算跟着写下来,但是 python 和 golang 的太多地方不同了,python 随便返回,对象里嵌套对象。但是 golang 却无法这么轻松的做到,模仿实现实在是困难。
既然无法模仿 python 代码,但是其又来自于网页的 js 代码。不如直接找 js 代码,直接用 goja 在 golang 里跑这段 js 不就行了?
这段未完成的模拟实现代码放到了 gist ,等待大佬完成它,效率肯定更高。
https://gist.github.com/iyear/b580a87c1a76c564c77783e02b98a364
分析
real-url 项目也没有说 js 的位置,所以我们自己抓抓看。
由于并不会 js 逆向,只能用一些土办法找到相关代码。
随便点开一个直播间,F12,Search。
根据 python 代码,就用 event_id 作为关键词搜索整个网页。结果就三个。依次查看上下逻辑,找到最像 python 实现的代码。
发现 https://static.egame.qq.com/pgg_pcweb/v2/7873f0f1dec453d99a98.js
复制到 webstorm 中,查看上下导出模块,发现应该逻辑都在 725 这个 id 中,把 725 的复制出来。
发现 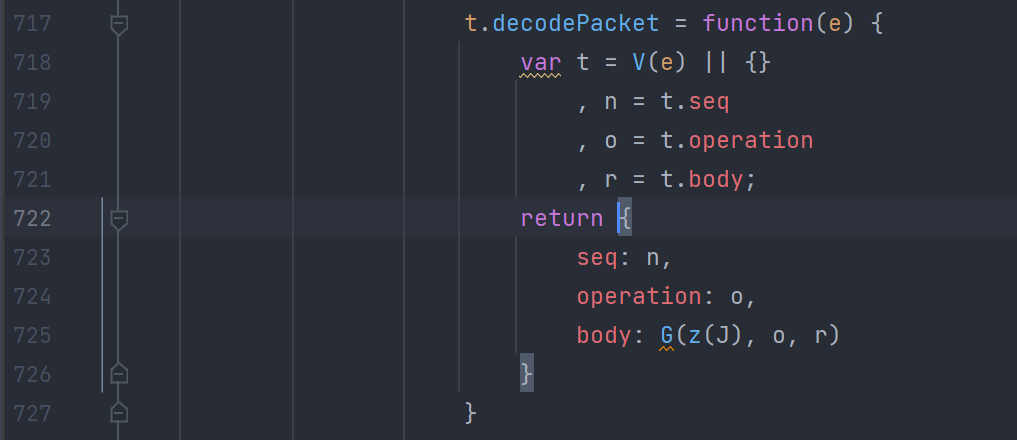
这里和 python 代码非常像了,大概率就是了。去除与t赋值相关的模块导出代码,把 decodePacket 写成单独的函数,然后把整个实现逻辑单独拎出来。
先去掉那些 encode 的代码,把代码内含 encode set 等字样的代码都去掉。
写个 hex2ArrayBuffer 函数,把抓到的 websocket 包以十六进制字符串扔进去看看能解析出啥东西。 为了还原运行环境,所以先放到浏览器运行。
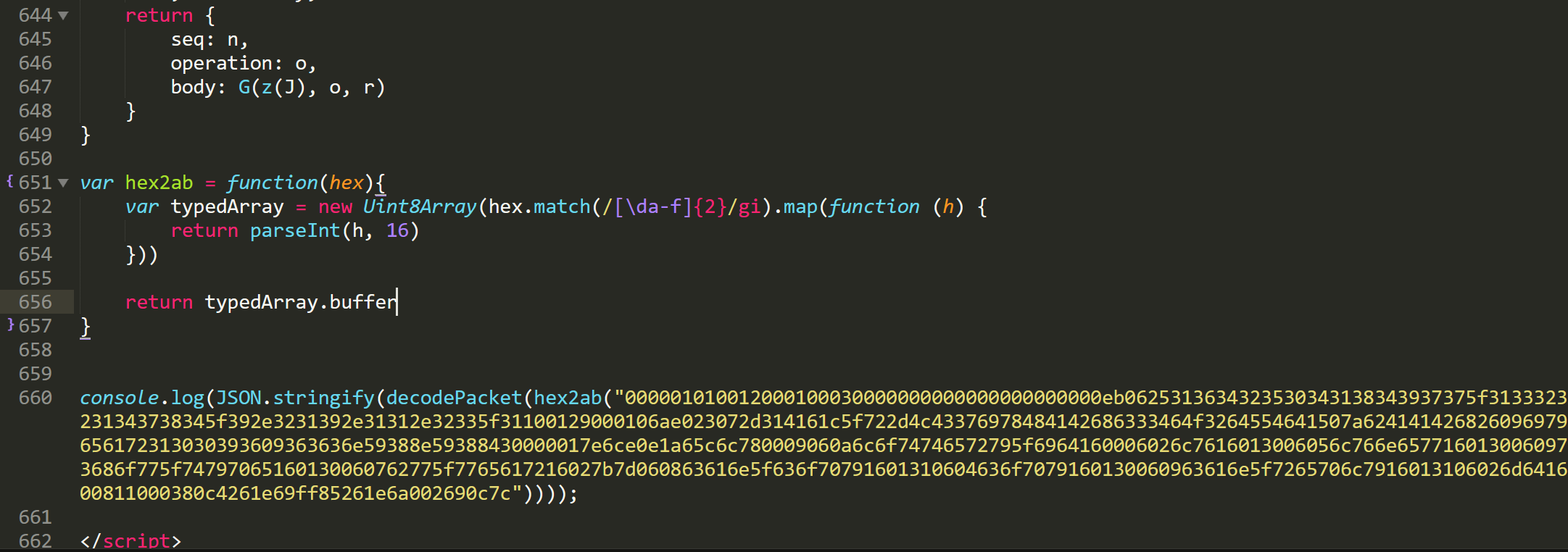

完美解析,但是浏览器提供的库比本地多得多,那么再在 webstorm 中运行这段代码,果然报错了。
ReferenceError: e is not defined
开始分析
b = "undefined" != typeof window ? window : void 0 !== e ? e : "undefined" != typeof self ? self : {}发现这段代码似乎可以直接去除,直接给 b 空对象即可。去除,再次运行,报了另一个错。
Error: TextDecoder is required
跳转到代码处,查看文档,发现 TextDecoder 并非 js 原生提供的库,而是浏览器提供的。但是把整个 TextDecoder 的代码再嵌入进去就太重了。如何解决 utf8 解码?
想了很久,想到一个做法,学 golang 的时候,都知道 golang 中的 string 都是 utf8 编码的。那我把 buffer 传给 golang 转成 string 再传回来不就可以了吗?
这点用 goja 可以方便地实现(感谢这么好,实现这么全的 js 引擎库)。把 ArrayBuffer 传进来,string(buf) 即可。
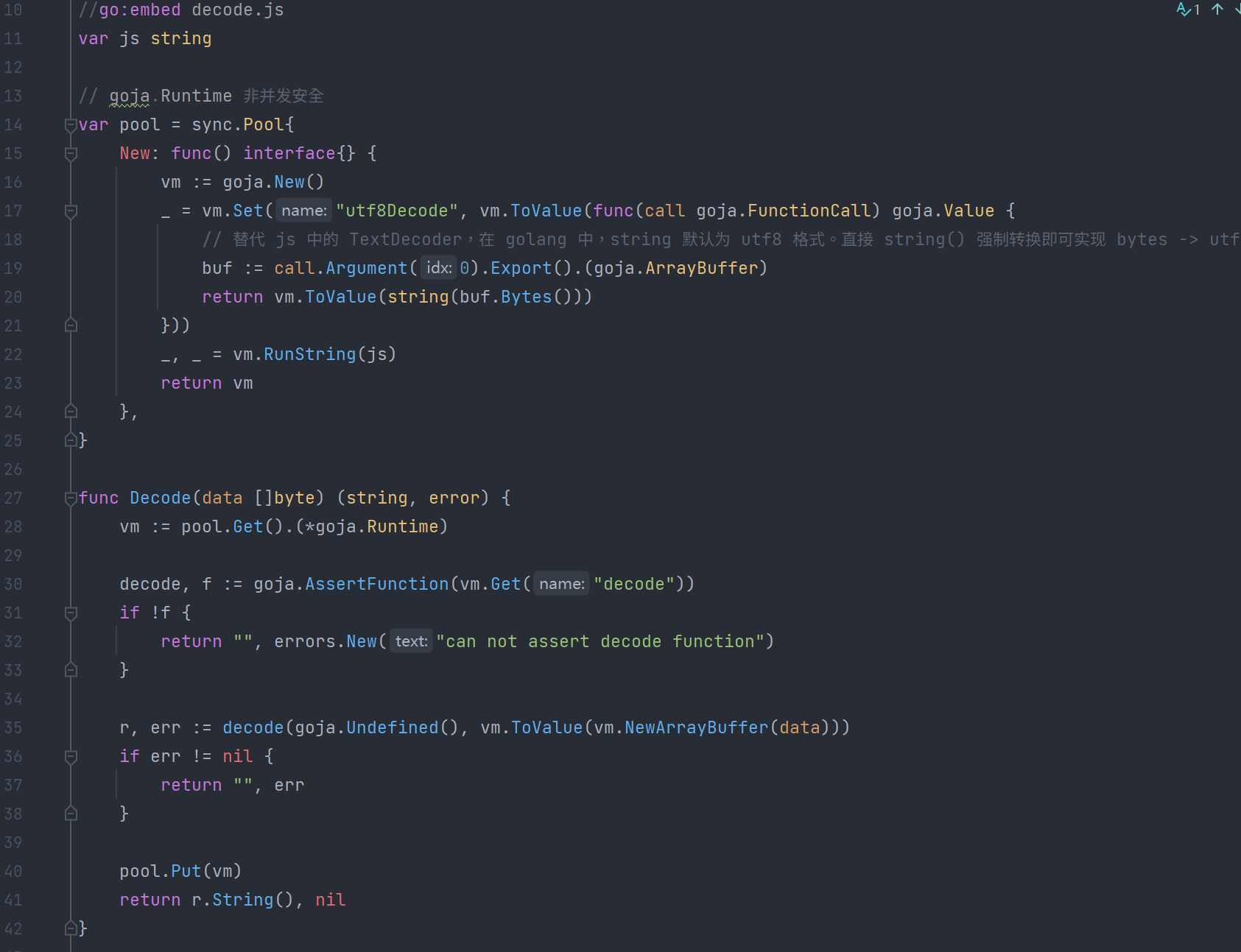
vm.Set("utf8Decode", vm.ToValue(func(call goja.FunctionCall) goja.Value {
// 替代 js 中的 TextDecoder,在 golang 中,string 默认为 utf8 格式。直接 string() 强制转换即可实现 bytes -> utf8 string
buf := call.Argument(0).Export().(goja.ArrayBuffer)
return vm.ToValue(string(buf.Bytes()))
}))于是,js 中直接调用 utf8Decode 就可以解码了。
把原来代码中 I() 的实现替换成 utf8Decode
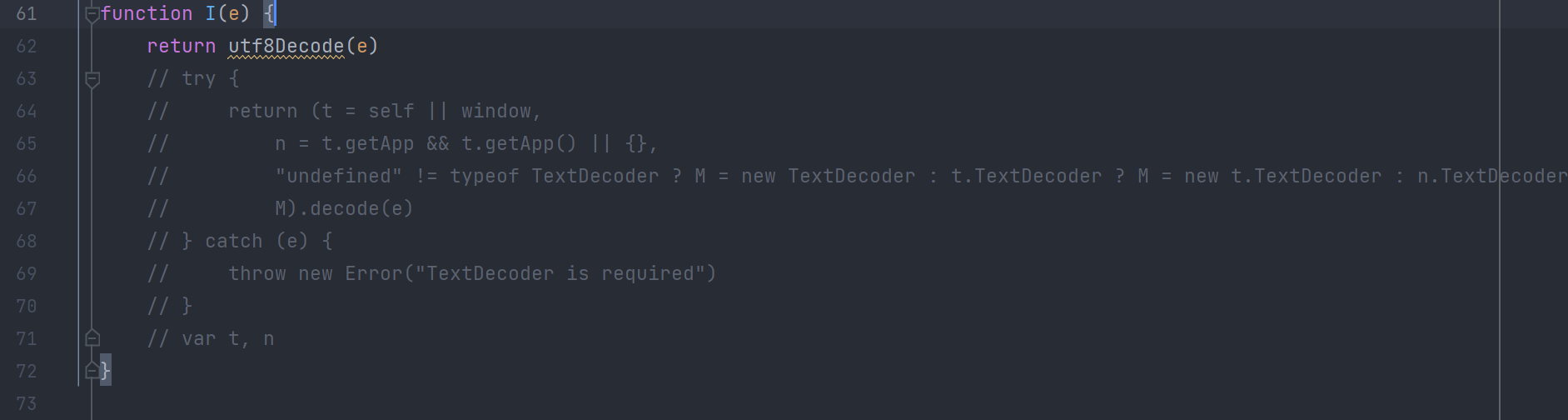
因为有外部函数,直接放到 goja 里跑

完美解析。
再稍微封装和完善一下整个 Decode 过程。
js 代码放在外部文件 decode.js 中,用 embed 引进 golang 。
由于 goja.Runtime 是非并发安全的,但是每次解析都 New 一个太浪费时间和内存了,就用 sync.Pool 实现 Runtime 的复用。
完整代码(把 js 的 decodePacket 改成了 decode):
其实最后代码很少,但是实现的过程其实走了很多弯路,单单模拟实现就耗费了许多时间,结果最后还没用上。后来的 js 解决错误又花了很多时间(不太熟悉 js),最后才想到用 golang 解决 utf8 问题。不过最后解析成功还是很有成就感的,
Benchmark
func BenchmarkDecode(b *testing.B) {
data, _ := hex.DecodeString("000001010012000100030000000000000000000000eb0625313634323530343138343937375f3133323231343738345f392e3231392e31312e32335f31100129000106ae023072d314161c5f722d4c43376978484142686333464f3264554641507a624141426826096979656172313030393609363636e59388e59388430000017e6ce0e1a65c6c780009060a6c6f74746572795f6964160006026c7616013006056c766e6577160130060973686f775f74797065160130060762775f7765617216027b7d060863616e5f636f70791601310604636f7079160130060963616e5f7265706c7916013106026d641600811000380c4261e69ff85261e6a002690c7c")
for i := 0; i < b.N; i++ {
if _, err := Decode(data); err != nil {
b.Error(err)
return
}
}
}goos: windows
goarch: amd64
cpu: AMD Ryzen 7 5800H with Radeon Graphics
BenchmarkDecode
BenchmarkDecode-16 1275 826234 ns/op
PASS速度还是不错的,相对于网络传输已经可以忽略不计了,基本上解析都可以在 1ms 内完成。
完整代码等我提交到 https://github.com/iyear/pure-live-core 即可查看。
越发地对 goja 感兴趣了,有空观摩一下源码,说不定自己也能搞个小脚本语言地引擎~。
耳机中放着陈奕迅的《人来人往》,却迟迟下不了手来写2021的年度总结,今年发生的事情实在太多,每件事情又那么深印在脑海中。即使在DDL的压迫下,我还是想把今年叙一叙。
以流水账的形式写下2021的这篇总结会不会太过平庸?
现在回忆起来,惊讶于第一次选考竟是今年第一件大事,地理的100分让我足够满意,也是三年里唯二让我能够喜欢的一门课。地理背后的社会、人文和自然比其他学科有着更高的魅力。
选考后的我已经完全厌恶了学校日复一日的复习节奏,最后的一个月我看完了刘慈欣的《三体》三册、毕淑敏的《非洲三万里》、熊培云的《重新发现社会》。借着同学的电子书把网上公开的几乎所有技术电子书都翻了翻。
《三体》我在初中便已经看过一次,但是第一册对历史的叙述让我完全没法看下去。但是在最后一个月,我竟然能静下心来看完完整三册。《三体》看完后的震撼是无法言表的,那种跨越时间,置于时间之外的格局和冲突的人性将我从焦虑中拔了出来。星际穿越和三体的内核又是如此的相似,人性与科幻的结合总是能结合出完全不一样的效果。
Do not go gentle into that good night,
Old age should burn and rave at close of day;
Rage, rage against the dying of the light.
如果让我给我的2021选一个词,我希望是“纯粹”
愿世界上还能有一群纯粹的人。
《非洲三万里》读的很快,但是又那么放松。可能是我喜欢地理的关系,看到世界上的多元社会和文化,总会觉得很美好。我也不知为何熊培云被定为公知,《重新发现社会》让我真的看到了十年前的笔墨依旧真实地发生在了十年后的现实中。国家与民族需要分清,国家的制度仍然需要完善,地区间的不平等依旧存在,小地方的贪污和称霸还藏在角落。如今的舆论环境也是太迷幻,一边润,一边爱国,仿佛一个国家的人存在于两个平行世界里。
然后就高考了,似乎没有慌张,就这么过去了。考完浪了浪,成绩出来没有惊喜也没有意外,和模拟考差不多。于是来到还挺想来的HDU,毕竟曾经听学长说过这里计算机的氛围很不错。
2
暑假到来。
考前发誓一定要把 E5SubBot 重构一下,毕竟几百star的项目写成这样太丢脸了。结果到了7月份才写了并发版本(之前居然从来没学过 goroutine ),八月份重构了一下发了 pure go sqlite 的版本,至此这个 bot 基本没有特别需要添加的功能了。
每天半划水半学技术的节奏到了快开学,发现了 https://github.com/SocialSisterYi/bilibili-API-collect ,于是开始准备 bilibili api go 的编写,写完了基础结构以后,上层的 api 基本就是照着文档重新实现和验证一遍。过程有点无聊,不过最后做出了100多个api还是挺有成就感的。开源后似乎也没有多少人用,可能还是 gopher 太少吧?
可能是我先入 golang 的原因,我对 golang 的编程思想和代码风格尤其喜欢,希望能为 golang 的开源生态做出一点点贡献。
3
9月来到校园。
一切都还挺顺的,室友都很不错。
开学几天没课,闲来无事研究了一下学校的健康打卡。这也是第一次做 Web 逆向,不过逆向的过程还是挺快的,把 sign参数的加密方式破解完以后就很顺了。
再研究了一下学校 cas 登录的鉴权,也没啥意思,就一个常规的抓包,只是一路的重定向是真的多。然后闲得慌就成文发博客了。
开启了自己的 Telegram 频道,作为一个不喜欢发朋友圈的人,很喜欢频道记录生活的方式,仿佛每天与自己对话,没有评价没有点赞。
也就那段时间在杭电助手的招新群混,由于表现突出(每天水群)被叫到线下私面,然后交流了一下技术栈基本就等于进去了。招新的小任务还是参加了,写了一个简单的 CRUD Web 项目,恰好总结一下以前杂乱的项目结构,确定自己 Web 开发的基本项目结构。之后的项目都能看到这个项目的影子。
进去的比较早,所以早早就分配了一些 Github 组织权限,写了简单的一点微信公众号后台功能感觉没啥意思,就半拖半写的混到大家都差不多进来了。然后这边微信公众号后台的业务基本都交给他们了。大家基本都在写微信公众号后台,进展还算快,两个月差不多把微擎上的服务都迁移过来了。
不得不说,真正热爱技术的人是与周围人不同的,仅仅一个月后零基础的两个人已经完全不是一个水平了。
十一月份基本都在维护 biligo 和 biligo-live ,十一月底的时候就已经基本完善了。
课余买了几个 N1 当服务器玩,目前已经有4个 N1 ,一个刷了小钢炮当 nas,另外三个刷了 armbian,作为 k3s 集群学习 k8s ,1 master 2 node 。
12月初作为负责人在带一个新的项目,一个类似B站动态社区的坑。技术栈选的比较激进,也因此看了许多书。野心不止于将项目落地上线,希望最后能够作为一个完整的开源项目向社区开放。
12月初同时也在写一个聚合直播的项目,野心也很大,希望能做成一套完整的直播生态。然而自己把前端、客户端都学个遍很不现实,但愿能借助社区的力量共同维护。pure-live 发布两天后被 github 大V点了个star,瞬间 star 暴增,5天已经达到了 400 star,实在惊喜,不过现在也放缓到正常速度了。
因为 pure-live 的 docker 部署,仔细研究了一下 docker buildx 和 github action ,两者的结合真的解放生产力,否则让我自己的电脑跑40分钟的编译实在难受。
4
说说理论上的东西都学了啥。
不得不说学校图书馆的书还是挺新的,甚至可以找到两个月前刚出版的书。这点对于技术学习来说非常重要。
因为社团的项目看了 《redis 开发与维护》《深入 redis 原理和源码》的前半本(后面集群还没实践过实在看不下去)
中途穿插在看 k8s 的书,深有感触的是,如果不一边看一边做,k8s 学着几乎没效果。因为 k8s 还看了一些分布式系统和一致性算法的书,只能说略微了解了。
还有一些 《代码重构之道》等等杂书。
5
这么一看,寒假可能会很忙了。
动态社区项目才写完框架,业务部分几乎还没开始做。 pure-live 的平台支持和生态搭建都还需要很多时间。
还要深入 k8s,参加明年 GSOC 的 k8s 组,如果有幸能够参加,对自己会是很大的提升和对大型项目维护的理解。
写到这,已经是2021年12月31日的下午2点57分,耳边响起的依旧是陈奕迅的《人来人往》
6
“难道生命这漫长进程中所有的努力和希望,都是为了那飞娥扑火的一瞬间?”
“飞蛾并不觉得阴暗,它至少享受了短暂的光明。” ——刘慈欣《朝闻道》
❤ BE PURE BE COOL
]]>高中开始一直有一个 Sony Walkman A55 ,里面放着不同平台聚合的喜欢的歌,但是一到大学就难受了,一个一半手机大小的砖一直要带着跑来跑去。但是在每个设备上都同步一遍几十G的音乐不现实,所以想着怎么在云端搭一个私人音乐库,所有新歌只需要在上面传一次就行。
选择
SMB。这是我一开始的选择,也是我认为最理想的。因为这样我就可以用foobox无缝切换,手机再搞个支持SMB的文件浏览器就实现了这个功能。
但是暴露 SMB 竟然成为了最麻烦的地方,由于 445 端口成为众多病毒的攻击点,运营商基本关闭了公网 445 端口,所以要暴露,必须在服务端和客户端各转发一次端口,而 Windows 又无法修改 SMB 的默认端口。所以这个计划真的要实行也很麻烦了。
WebDavFTP,最大的弱点就是没有支持良好的播放器,暴露倒是不难。Web Player,所以只能找私人音乐库的在线播放器,最终找到了开源中还算不错的koel(虽然功能其实也挺简陋的,性能可能因为PHP写的,也不太行)。
所需
- 安装了小钢炮的
N1(armbianopenwrt都可以,只要能装docker) - 一个外接硬盘,并且已经挂载(自带8G Flash太小了)
目标
- 完整的
koel安装,使用轻量的sqlite数据库,官方推荐的docker-compose用的mysql,N1可能会跑不动 - 白嫖钉钉内网穿透暴露公网
- 写个
golang小脚本批量导入Sony A55的歌单
安装
踩了不少坑,一定要按顺序操作
把官方提供的 https://github.com/koel/docker 跑起来
docker run -d --name koel -v 媒体目录(外接硬盘挂载点):/music -p 本地端口:80 hyzual/koel
# docker run -d --name koel -v /media/music:/music -p 7777:80 hyzual/koel进入小钢炮 docker 控制面板,进入容器内部命令行,以下均在容器内执行
安装 vim ,编辑 .env 文件
apt-get install -y vim && vi .env修改为以下内容
# 不要随便动KEY
APP_KEY=rUvKWgs38Fe/jJfnzWHVJEBg4gRBRlvUe392MsWMgIc=
DB_CONNECTION=sqlite-persistent
# 数据库位置
DB_DATABASE=/var/www/html/database/data.db
APP_NAME=Koel
# 指定容器内的读取目录
MEDIA_PATH=/music
APP_ENV=production
APP_DEBUG=true
# 同步目录歌曲时内存限制 MB
MEMORY_LIMIT=512
# hyzual/koel镜像自带ffmpeg
FFMPEG_PATH=/usr/bin/ffmpeg
# 输出比特率
OUTPUT_BIT_RATE=320
# 允许下载
ALLOW_DOWNLOAD=true创建数据库
touch database/data.db给予文件夹权限
chmod -R 777 .初始化 koel
php artisan koel:init --no-assets重新生成 APP_KEY
php artisan key:generate --force打开 <ip>:<port> ,默认账号密码如下:
Email: [email protected]
Password: KoelIsCool成功登录!记得修改默认密码
同步媒体文件夹
php artisan koel:sync重建搜索索引
php artisan koel:search:import设置管理员密码
php artisan koel:admin:change-password内网穿透
以下在 ssh 小钢炮后台操作
下载钉钉内网穿透 arm64 版及配置文件: https://github.com/open-dingtalk/pierced/tree/113bab7e397a6471775f6534f4b277961b7a345f/linux_arm
通过各种途径上传到小钢炮中
安装 screen
https://www.right.com.cn/forum/thread-801304-1-1.html
启动 ding
./ding -config=./ding.cfg -subdomain=<子域名> <启动容器的宿主机端口号>
# ./ding -config=./ding.cfg -subdomain=mykoel 7777
# Ctrl + A + D 然后就可以从外网访问了
迁移歌单
TODO
]]>( 这个系列文档够我水好几篇文章
前后端分离网络知识
概念与历史
这是 Web 项目开发中必需的一种思想。
下面是一些网络上的文章
https://cloud.tencent.com/developer/article/1520380
https://www.infoq.cn/article/mnftt4ubk5pql3jpnt6m
我对前后端分离的理解就是页面和接口的分离。在以前 asp jsp 等不分离的状态下,后端一人扛起页面渲染和数据库交互等责任,前端和后端的耦合度极高,导致开发效率低下。
后来随着 ajax 等技术的出现,前端请求接口越来越方便,为了解耦前端和后端,发展到了后端提供接口,前端渲染页面,也就是前后端分离。
比如 golang 的 HTML 模板渲染就是一种前后端不分离的形式,渲染页面时直接输出 HTML 代码而不是通过接口去解耦。
前后端分离不是一门技术,而是工程领域中的一个经验和实践,随着前后端各自的技术发展,这个趋势是自然形成的。
虽然前后端分离有一定的缺点,但是依旧利大于弊,这种思想应当在实践中贯彻和理解。
优点
- 节省流量。
分离时服务端和客户端只传输数据,不分离时传输整个 HTML 。
- 解耦公司内的前后端职位,提高开发效率。
不再是前后端岗位揉成一团,而是以接口为桥梁各司其职。
- 局部性能提升。
通过前端路由的配置,我们可以实现页面的按需加载,无需一开始加载首页便加载网站的所有的资源,服务器也不再需要解析前端页面,在页面交互及用户体验上有所提升。
- 部署体验提高。
前端的代码有问题只需要改动前端再上线,后端有问题只需改动后端,不会一个小改动导致整个项目重新上线。
缺点
- 前端的代码量增大,招聘门槛变高。
但对于前端和后端却是好事,一方面前端从以往后端的“附属品”逐渐拥有话语权,另一方面前端的门槛提高有助于降低后端的心智负担,不至于对接的前端都是阿猫阿狗。
- 网站SEO效果变差。
前端 DOM 动态渲染导致对搜索引擎的友好度降低,不过这可以通过 SSR 解决。
- 文档重要性提升。
因为要按照接口去编写代码,前后端对接的接口文档显得十分重要,所以项目最好的方式是前后端先共同商议文档,而后再各自编写代码。但是由于大部分人并不喜欢写文档,所以对接有时显得混乱。
前后端交互
协议
Web 项目大部分使用 HTTP 协议,毕竟是跑在浏览器上的,HTTP 支持最好
像 APP 或 桌面应用也可以采用 RPC 协议远程调用,RPC 相对 HTTP 的开销更小
协议不是交互的重点,主要根据项目的设计和框架走
序列化格式
序列化通俗的讲就是把代码中复杂或者简单的结构体转化为可传输的二进制或文本
反序列化即把可传输的二进制和文本变为代码中的结构体
常见序列化如下,这些格式在:(助手项目中大多采用 JSON 和 Protobuf)
JSON教程
常用于前后端数据传输,体积小、可读性好。由于大部分情况下不支持注释,很少用做配置文件。
YAML教程
常用于程序的配置文件,支持注释,可读性好。但是语法的缩进敏感对新手不太友好,经常写出错误语法。
TOML教程
Github 创始人与前 CEO 提出的格式,比较新的一种格式。通常用作程序的配置文件,对新手比较友好,但是写多层嵌套的时候可读性会变得很差。
Protobuf教程
需要使用 .proto 文件定义结构。速度快体积小,但是因为用二进制表示,可读性较差,常用于微服务中 RPC调用,有时也用于 Web 传输。当然目前 Protobuf 的应用范畴已经不局限于序列化了,也用于微服务的 service 定义等等。
Msgpack教程
类似 Protobuf ,但是因为没有一个好爹所以干不过 Protobuf
- ......
等待补充
其他
不要有一把锤子,看什么都是钉子
在Web项目开发前应当预估项目规模、技术栈等等需求再去决定开发模式,而不是无脑前后端分离。在一些开发时间紧的项目里,PHP (不分离)显然是比 Golang (分离) 更好的选择。当然,在时间允许的情况下,尽量采取前后端分离的开发模式,这在后续团队规模扩大、项目复杂度变高后会体现出非常大的优势。