En effet, lorsque vous travaillez avec des branches (quelque soit le SCM), une bonne pratique veut que chaque branche possède son propre numéro de version. Afin d’éviter des collisions de nommage, cette pratique devient indispensable lorsque vous utilisez un serveur d’intégration continue pour publier les artefacts construits dans un repo Maven.
Une fois une branche crée à partir d’une autre, chaque branche vit sa vie. Des releases Maven peuvent être réalisées de part et d’autre. Là où cela devient tendu, c’est lorsque vous devez reporter les commits d’une branche vers une autre. Des conflits de merge sur le numéro de version Maven apparaissent alors inévitablement. Lorsque votre application multi-modules comporte 15 pom.xml, c’est 15 conflits qu’il va falloir gérer manuellement. Il est effectivement risqué de conserver aveuglément la version du pom.xml local ou distant, car d’autres changements (et vrais conflits) peuvent se produire dans d’autres sections du pom.xml.
Comme cas d’études, prenons l’exemple du repo Git helloworld :
Une application HelloWorld construite avec Maven a été releasée avec Maven en version 1.0.0 sur la branche develop. La prochaine version renseignée sur develop est 1.1.0-SNAPSHOT.
Une branche de maintenance release/1.0.x a ensuite été créée à partir du tag pointant sur le commit « [maven-release-plugin] prepare release helloworld-1.0.0 ». Une faute d’orthographe a été corrigée. Afin de la livrer en production rapidement, une version 1.0.1 a été réalisée avec Maven.
Cette correction doit désormais être reportée sur la branche develop. Entre temps, 2 commits ont été réalisés sur celle-ci, dont l’un touchant au pom.xml.
Quelle solution adopter pour effectuer ce report ?
Une première solution consiste à utiliser un cherry-pick du commit « Fix spelling ». Pour rappel, cherry-pick permet de reporter commit par commit les différences entre branche. Le risque est d’oublier un commit. Et cette solution peut devenir laborieuse si beaucoup de commits séparent les 2 branches.
Une seconde solution consiste à merger la branche release/1.0.x dans la branche develop.
Apparaît alors le conflit sur le numéro de version du pom.xml évoqué en introduction :
git merge release/1.0.x
Auto-merging src/main/java/com/compagny/HelloWorld.java
Auto-merging pom.xml
CONFLICT (content): Merge conflict in pom.xml
Automatic merge failed; fix conflicts and then commit the result.
git diff
diff --cc pom.xml
index b43c671,01257f6..0000000
--- a/pom.xml
+++ b/pom.xml
@@@ -6,9 -6,9 +6,13 @@@
<groupId>com.mycompagny</groupId>
<artifactId>helloworld</artifactId>
++<<<<<<< HEAD
+ <version>1.1.0-SNAPSHOT</version>
++=======
+ <version>1.0.2-SNAPSHOT</version>
++>>>>>>> release/1.0.x
- <description>Hello World application</description>
+ <description>Git merge demonstration</description>
Le conflit doit être résolu manuellement : la version 1.1.0-SNAPSHOT de la branche develop est à conserver.
Une solution permettant d’éviter de résoudre ce genre de conflits consiste à utiliser un script que va utiliser Git pour merger 2 fichiers pom.xml. C’est précisément l’objectif du driver de merge mergepom.py écrit en Python et que vous pouvez récupérer sur le repo GitHub pom-merge-driver.
L’utilisation de ce script sous Linux et Mac est décrite dans le README.md.
Sur Windows, il est nécessaire de faire quelques adaptations :
- Télécharger et installer Python (la version portable est suffisante)
- Dans le script mergepom.py, supprimer la ligne d’en-tête #! /usr/bin/env python
- Dans le fichier .gitconfig, ajouter le chemin vers python.exe :
[merge "pommerge"]
name = A custom merge driver for Maven's pom.xml
driver = '/C/dev/python/python.exe' C:/dev/git/mergepom.py %O %A %B
Afin de laisser la liberté aux autres développeurs d’utiliser ce script ou non, j’ai ajouté le fichier attributes dans le répertoire .git/info de mon repo local :
pom.xml merge=pommerge
Remarque : alternativement, on peut également ajouter cette ligne dans le fichier .gitattributes situé dans le répertoire racine du repo Git. Tous les développeurs de l’application en profitent alors.
On relance la commande de merge. Cette fois-ci, le script détecte un conflit sur le numéro de version du pom.xml et décide de garder celui de la branche courante, à savoir 1.1.0-SNAPHSOT :
git merge release/1.0.x Merging pom version 1.0.2-SNAPSHOT into develop. Keeping version 1.1.0-SNAPSHOT Auto-merging src/main/java/com/compagny/HelloWorld.java Auto-merging pom.xml Merge made by the 'recursive' strategy. pom.xml | 2 +- src/main/java/com/compagny/HelloWorld.java | 2 +- 2 files changed, 2 insertions(+), 2 deletions(-)

Le script Python respecte le workflow git-flow. De ce fait, les merge dans le master des branches de release et de hotfix conservent le numéro de version de ces dernières.
Comme moi, j’espère que l’existence de ce driver de merge Git vous simplifiera vos merges. Ne prenant en compte que les fichiers pom.xml encodé en UTF-8, j’ai fait une demande d’évolution. En attendant, vous pouvez changer l’encodage en dur dans le script ou bien, encore mieux, soumettre une pull request.
Enfin, sachez que d’autres drivers de merge Git existent. pomutils est écrit en Java. Si vous en avez testé, n’hésitez pas à laisser un feedback.
]]>Pour être certain de ne pas faire chauffer sa carte de paiement, une bonne pratique consiste à exécuter une ligne de commande maven (ou gradle) avant chaque commit dans le gestionnaire de code source. Cependant, sur certains changements que l’on juge mineur, il peut être tentant de passer outre. Aujourd’hui, les PC ou les Mac multi-coeurs avec SSD permettent de lancer un build sans freezer le poste de développement. C’est donc davantage par excès de confiance qu’à cause du temps d’attente qu’il arrive de casser Jenkins, Bamboo ou bien encore TeamCity.
Pour contrer tout oubli, il est possible de systématiser l’exécution du build Maven avant de commiter. Les outils de gestion de configuration SVN et Git offrent un mécanisme de hook. Lors de la phase de pre-commit, on va demander au SCM d’exécuter un script de hook chargé de vérifier le code source. En cas d’erreur, le commit est refusé.
Ecrire de tels scripts n’est pas compliqué sous Linux car beaucoup d’exemples existent. Par contre, sous Windows, c’est plus rare. L’objet de cet article est donc de vous donner des exemples de scripts de hook de pre-commit et de vous expliquer comment les configurer dans Tortoise SVN et Git.
Hook SVN
![]() Deux types de hook existent dans Subversion : des hooks clients et des hooks serveurs.
Deux types de hook existent dans Subversion : des hooks clients et des hooks serveurs.
Pour ne pas transformer le serveur SVN en serveur d’intégration continue, ce sont les hooks clients qui vont ici nous intéresser.
Le script appelé par le hook n’est rien d’autre qu’un .bat.
L’exemple de script pre-commit.bat ci-dessous est localisé dans le même répertoire que le POM reactor du projet. Un pré-requis est que Maven et Java sont dans le PATH de Windows.
@echo on call mvn clean –f myapp-parent\pom.xml > target\pre-commit.log if not exist target mkdir target call mvn install sonar:sonar -Dsonar.analysis.mode=preview -Dsonar.issuesReport.html.enable=true -Dsonar.buildbreaker.skip=false –f myapp-parent\pom.xml > target\pre-commit.log echo Maven error code: %ERROR_CODE% cmd /C exit /B %ERROR_CODE%
Afin de pouvoir être consultée en cas d’échec du build, la sortie console est redirigée dans un fichier de logs. Le code d’erreur de maven est retourné à SVN qui sait l’interpréter. Tout code différent de 0 fait échouer le commit.
Exécuté dans à la racine de l’arborescence, le paramètre –f myapp-parent\pom.xml permet de spécifier à maven où se trouve le POM parent (structure de type flat module). Nul besoin d’ajouter ce paramètre lorsque le POM parent se situe à la racine du projet.
TortoiseSVN permet de configurer un hook client à 2 niveaux :
- De manière globale pour tous les repos SVN du poste de dév. Chaque développeur doit individuellement configurer TortoiseSVN. Cette configuration peut être problématique lorsqu’un développeur est amené à travailler sur plusieurs repos et que le script de hook n’est pas assez générique. Le script précédent devra être généralisé pour fonctionner avec l’ensemble des projets.
- De manière unitaire pour chaque repo SVN. A l’instar d’une propriété svn:ignore, TortoiseSVN ajoute récursivement une propriété tsn:precommithook au niveau du repository SVN. Tous les développeurs bénéficient alors de ce hook.
Etapes de configuration du mode global :
- Depuis n’importe quel répertoire, sélectionner le menu contextuel TortoiseSVN > Settings
- Se rendre dans le menu Hook Scripts
- Renseigner les champs suivants :
- Hook type : pre-commit
- Woking copy path : chemin vers le pom parent de l’application
- Command line to execute : pre-commit.bat

Etapes de configuration du mode local :
- Sélectionner le répertoire racine du projet SVN
- Ouvrir le menu contextuel et sélectionner le menu TortoiseSVN > Properties
- Cliquer sur le bouton New > Local Hooks (création d’une property tsvn:precommithook)
- Choisir les paramètres suivants :
- Hook Type : Start Commit Hook
- Command Line to Execute : %REPOROOT+%/myproject-parent/pre-commit.bat
- Cocher les options suivantes :
- Wait for the script to finish
- Always execute the script
- Apply property recursively
- Commiter ces modifications de manière récursive sur l’ensemble des sous répertoires du projet SVN

Remarque : les hooks clients sont une fonctionnalité propre à TortoiseSVN. De ce fait, le client en ligne de commande svn.exe ou bien encore le plugin Subversive d’Eclipse ne reconnaissent pas la propriété tsvn:precommithook.
Hook Git
![]() Git appartenant à la catégorie des DVCS, il n’existe pas de hook server. La configuration s’effectue donc au niveau du repository Git local. Les scripts de hook sont à positionner dans le sous-répertoire .git\hooks. Par défaut, ce répertoire contient des exemples post-fixés par l’extension .sample. Le nom des scripts est conventionné et correspond au nom de la phase à laquelle il est exécuté. Ainsi, le script de hook exécuté avant le commit se nomme pre-commit.
Git appartenant à la catégorie des DVCS, il n’existe pas de hook server. La configuration s’effectue donc au niveau du repository Git local. Les scripts de hook sont à positionner dans le sous-répertoire .git\hooks. Par défaut, ce répertoire contient des exemples post-fixés par l’extension .sample. Le nom des scripts est conventionné et correspond au nom de la phase à laquelle il est exécuté. Ainsi, le script de hook exécuté avant le commit se nomme pre-commit.
Sous Windows, Msysgit est le client Git le plus populaire. Basé sur les utilitaires Msys, le script ne doitpas être écrit en script batch comme c’est le cas avec SVN, mais en bash Linux.
Voici un exemple de sript shell pre-commit :
#!/bin/sh
echo "Executing pre-commit"
# Set Java and Maven:
export JAVA_HOME="C:/dev/jdk/1.7.0_45"
export MAVEN_OPTS="-Xmx1024m -XX:MaxPermSize=256m"
export MAVEN_HOME="C:/dev/maven/apache-maven-3.2.3"
echo "Running Maven clean install for errors and Sonar for testing if the project fails its quality gate."
# Retrieving current working directory
CWD=`pwd`
MAIN_DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
# Go to main project dir
cd $MAIN_DIR/../../myapp-parent
# Running Maven clean install and Sonar
$MAVEN_HOME/bin/mvn clean install -U sonar:sonar -Dsonar.analysis.mode=preview -Dsonar.issuesReport.html.enable=true -Dsonar.buildbreaker.skip=false
if [ $? -ne 0 ]; then
echo "Error while compiling or testing the code"
# Go back to current working dir
cd $CWD
exit 1
fi
# Go back to current working dir
cd $CWD
exit 0
La commande cd $MAIN_DIR/../../myapp-parent permet de positionner dans le répertoire contenant le POM parent. Ce chemin est à adapter selon la structure du projet.
Conclusion
Que ce soit avec Git ou avec TortoiseSVN, il est possible de systématiser l’appel à commande mvn clean install (ou à tout autre script) avant de commiter. Cette bonne pratique fait en sorte que le code historisé dans le gestionnaire de code source est toujours stable. L’intérêt de maintenir un serveur d’intégration continue peut donc se poser. Dès 2009, David Gageot montrait d’ailleurs qu’il était possible de monter une intégration continue sans serveur. Pour autant, les serveurs d’intégration continue tels que Jenkins ont aujourd’hui davantage de responsabilités que par le passé : exécution des tests d’intégration, des tests Selenium et des tests de montée en charge, packaging, déploiement d’applications sur les différents environnements … Leurs jours ne sont donc pas comptés !
]]>Mise en scène
L’historique de commits ci-dessous illustre les explications qui suivront :

Cet historique des commits commence par la branche master sur laquelle les fonctionnalités A et B ont été commitées. La branche maBranche est alors créée à partir du commit de la fonctionnalité B. Un premier merge no fast-forward est créé pour récupérer la fonctionnalité E de master dans maBranche : le commit de merge « Merge branch ‘master’ into maBranche » est créé.
A partir de là, les nouvelles fonctionnalités F, G et H sont développées sur maBranche. Ne pouvant attendre la fin des développements de la fonctionnalité G qui résoudrait proprement le problème rencontré par les utilisateurs, est créé sur le master un contournement permettant d’y palier temporairement. Ce Hotfix est déployé en production. N’ayant aucun intérêt dans les prochaines versions de l’application, ce Hotfix ne doit être en aucun cas mergé sur maBranche. Une fois les développements de la fonctionnalité H terminés et déployés en production, l’équipe décide de faire revenir sur le master les développements de maBranche.
Les 2 derniers commits de l’historique mettent en œuvre cette opération.
Commandes
Voici les 4 lignes de commandes à exécuter pour réaliser cet écrasement de branche :
- Se placer sur la branche à conserver
git checkout maBranche - Demander une fusion avec la stratégie ours (attention, ceci est différent d’un merge avec stratégie recursive et l’option ours) qui va uniquement conserver le contenu de la branche actuelle. En effet, l’option -s ours indique à Git de fusionner la branche source dans la branche cible mais sans aucunement modifier la branche cible. Cette stratégie est habituellement utilisée pour ne pas reporter un commit d’une branche de maintenance sur le master.
git merge -s ours master -m « Merge avec stratégie ours » - Repasser sur la branche master
git checkout master - Demander une fusion de la branche maBranche vers le master tout en conservant 2 branches distinctes (un fast-forward aurait été réalisé puisque que le dernier commit n’est autre que notre fusion de la commande n°2).
git merge –no-ff maBranche
Sortie console sur notre exemple de la commande Git n°4 :

Comme attendu, le fichier Hotfix.txt ayant été ajouté lors du commit Hotfix est supprimé du master. Si, dans un autre exemple, le commit Hotfix avait modifié une ligne du fichier FeatureE.txt, un revert de cette modification aurait alors été effectué.
Conclusion
Cet article explique comment Git permet d’écraser le contenu de la branche A par une branche B lorsque la branche B a pris le pas sur la branche A et qu’aucune des modifications présente dans le branche A n’a besoin d’être conservée (tout a été préalablement fusionné, reporté par cherry-pick, copié à la main ou volontairement ignoré car à ne pas reporter).
Cerise sur le gâteau : ces opérations sont applicables entre 2 branches SVN par le biais du bridge git-svn.
Pour resituer le contexte, ce chantier dura plus de 6 mois. Entre le début et la fin de la migration, l’application a été livrée plusieurs fois en production, embarquant à chaque fois de nombreuses évolutions fonctionnelles. Nous avons donc dû nous organiser pour migrer l’application sans pénaliser l’avancement du reste de l’équipe.
Les changements techniques étant bien trop transverses à l’application, la stratégie de Feature Toggle ne pouvait s’appliquer. Nous nous sommes donc dirigés vers une technique assimilable au Feature Branch ; notre migration technique n’étant rien d’autre qu’une feature comme une autre. Logiquement, une branche dédiée à la migration a été créée.
Notre stratégie fut de merger régulièrement dans cette branche le code issu de la branche de développement. Une fois la migration terminée, la branche de migration a été à son tour mergée dans la branche de développement.

Git svn à la rescousse
Comme c’est encore le cas dans de nombreuses entreprises, SVN est l’unique outil de versioning proposé dans l’usine de développement. La plateforme d’intégration continue s’appuie dessus et, installés sur une infrastructure de production, les repos SVN présentent l’intérêt d’être archivés quotidiennement.
C’est là que la passerelle git-svn intervient en mettant à la portée des utilisateurs SVN la puissance et la facilité des merges apportées par Git. Git-svn permet en effet de maintenir à jour la branche svn avec le trunk.
Cette facilité a un prix : une vigilance accrue et une grande rigueur lors des opérations en ligne de commande. En effet, une erreur d’inattention et vous pouvez vous retrouver à commiter le code de la branche de migration sur le trunk SVN. C’est pourquoi, au cours de la migration, le mode opératoire présenté ci-dessus a été scrupuleusement suivi.
Mode opératoire
Les instructions suivantes permettent de récupérer dans la branche de migration SVN, les développements commités sur le trunk SVN.
L’exemple illustrant ces instructions concerne une application Java. Maven est l’outil de build utilisé pour compiler, exécuter les tests unitaires et vérifier ainsi l’état du merge.
Les 2 branches Git manipulées sont associées aux branches SVN suivantes :
- master (git) => trunk (svn)
- local-feature-migration (branche locale git)=> feature-migration (branche distance svn)
Depuis la précédente opération de merge, nous partons du principe que des commits ont pu ou non avoir eu lieu dans le trunk. De la même manière, des modifications ont pu ou non avoir été commitées et poussées dans la branche de migration.
Avant de commencer, s’assurer que toutes les modifications sont commitées dans le repo SVN et l’intégration continue est au vert, à la fois sur le trunk et la branche.
Enfin, cette opération de merge est à réaliser de préférence depuis le même repo git local. Ce dernier possède l’historique des merges réalisés précédemment. Il faut en effet garder à l’esprit que, une fois commité dans SVN, le commit ancêtre entre le trunk et la branche est perdu. Même avec git-svn, un autre développeur ne pourrait le récupérer.
1. Faire pointer le master au niveau du trunk
git checkout master git svn rebase
2. Effectuer un checkout de la branche locale (et non distante)
git checkout local-feature-migration
Avec le pont git-svn, les merges ne fonctionnent que dans un sens. Il faut donc veiller à se placer sur la branche sur laquelle on veut créer le commit de merge.
3. Merger le master vers la branche locale
git merge --no-ff master
Remarque : l’option –no-ff (no fast-forward) est très importante : elle force git à créer un commit dit de « merge ». Lorsque la branche ou le master n’ont pas bougé, cela évite que la référence HEAD de la branche local-feature-migration soit déplacée pour pointer sur le dernier commit de la branche master. En résumé, cela permet de conserver 2 branches distinctes, comme dans SVN. La conséquence désastreuse de cet oubli est qu’un svn dcommit de la branche local-feature-migrationserait pourrait être réalisé sur le trunk.
4. Régler les éventuels conflits
git mergetool git rebase --continue
Utiliser son outil de merge préféré, par exemple kdiff3 ou TortoiseMerge.
5. Exécuter le build maven
mvn clean install
Permet de s’assurer que le code compile et que les tests unitaires passent.
6. Commiter dans SVN
git svn dcommit
Sous peine de corrompre votre repo git, attention à ne pas effectuer de git svn rebase entre le merge et le svn dcommit.
Clonage d’un repo SVN existant, création d’une branche Git et liaison avec une branche SVN distante sont expliqués dans la documentation de git-svn.
Bénéfices
Voici une liste non exhaustive des bénéfices apportés par cette méthode de travail :
- Le report des commits au fil de l’eau permet de régler au plus tôt d’éventuels problèmes de merge. L’effet tunnel est évité. Les conflits sont résolus plus rapidement car les modifications sont encore toutes fraiches dans la tête des développeurs (du trunk comme de la branche).
- Cette stratégie permet de déployer en dual-run les 2 versions de l’application, sans perte de fonctionnalités puisqu’elles sont iso-fonctionnelles (à la migration technique prêt). La comparaison de comportements et les bascules en sont facilitées.
Conclusion
Après quelques essais, la fréquence retenue pour réaliser ces opérations de merge fut d’une fois par semaine.
Au final, ce n’est pas une application, mais dix qui ont été migrées à l’aide de cette stratégie. Au total, 2 millions de ligne de code ont ainsi été promues.
Bien entendu, ce procédé peut être appliqué avec d’autres technologies que maven et Java.
Dans ce billet, je vais donc vous expliquer comment créer votre propre usine logicielle. Déployée à cheval sur GitHub et l’offre DEV@Cloud de CloudBees, vous y retrouverez les briques les plus classiques : SCM, intégration continue, dépôt de binaires, bug tracker, wiki …
Le gain : à chaque commit poussé dans GitHub, votre code est compilé, testé unitairement puis déployé dans un repository maven public dédié aux Snapshots. Par ailleurs, vous pourrez effectuer des releases maven en local depuis votre poste de développement ; les artefacts construits seront mis à disposition dans un repository maven dédié. Tout développeur pourra librement référencer l’un ou l’autre de ces repository et utiliser votre code.
En bonus, si vous développez des projets open source, vous n’aurez même pas à sortir votre carte bancaire.

Composants de l’usine de développement
Le tableau ci-dessous liste les différentes briques de l’usine de développement ainsi que les motivations qui m’ont poussé à les choisir.
| Brique de l’usine logicielle | Outil | Plateforme | Raisons |
| Gestionnaire de Code Source (SCM) | Git | GitHub | Pour utiliser la pleine puissance de Git, bridé jusque-là par l’utilisation en entreprise du bridge git-svn. |
| Outil de build | Maven | Poste de Dev + Cloudbees |
L’incontournable maven. Mais cela aurait pu être l’occasion de tester Gradle. |
| Intégration Continue | Jenkins | CloudBees | Un comble : probablement celui que je connaissais le moins par rapport à Continium, Bamboo et TeamCity. |
| Dépôt de binaires | Repository Maven | Cloudbees | Offre de base de CloudBees suffisante. Accès par webdav |
| Espace documentaire | Wiki | GitHub | Pages versionnées avec Git Syntaxte MarkDown Le XWiki de CloudBees aurait pu être une alternative |
| BugTracker | Navigateur Web | GitHub | Projets OSS personnels pas suffisamment actifs pour bénéficier d’un Jira (ni même d’une licence JRebel) |
Afin de vous donner une idée du résultat, je vous invite à jeter un coup d’œil aux différentes URLs :
- Jenkins DEV@Cloud : https://javaetmoi.ci.cloudbees.com
- Repository maven : https://repository-javaetmoi.forge.cloudbees.com/
- Compte github : https://github.com/arey
Pré-requis
2 prérequis sont nécessaires au déploiement d’une telle usine de développement :
- Disposer d’un compte GitHub et d’un repository contenant un projet java déjà mavenisé
- Avoir accès à la plateforme de build de CloudBees, soit en souscrivant à l’une des offres gratuites ou payantes, soit en souscrivant au Free FOSS Programm
Configuration Maven
Afin de pouvoir intégrer un projet mavenisé dans l’usine de développement, il est préalablement nécessaire de compléter sa configuration maven pour prendre en compte :
- Le gestionnaire de code source pour que maven ait accès en lecture / écriture au repository git distant (hébergé ici sur GitHub), ce qui est par exemple nécessaire pour tagger et faire des releases maven.
- Les repository maven des releases et des snapshots, ce qui est utile à Jenkins ou au plugin release de maven pour déployer un artefact, et par maven pour télécharger des artefacts.
- La configuration de l’extension maven wagon-webdav, utile lors du déploiement d’un artefact sur le repo maven CloudBees utilisant le protocole webdav.
- Les credentials d’accès en écriture au webdav, là encore utile pendant la phase de déploiement d’un artefact.
Toute cette configuration est détaillée dans un précédent billet intitulé Release Maven sous Windows d’un projet GitHub déployé sur CloudBees. Vous y trouverez notamment comment configurer les différentes balises maven au travers 2 fichiers :
- pom.xml : <scm>, <distributionManagement>, <repositories> et <extensions>
- settings.xml : <servers>
Gage de son intérêt, le projet github maven-config-github-cloudbees à l’origine de l’article a été forké par Ryan Cambell et est désormais proposé dans la Cloudbees Community de GitHub.
Une fois le pom.xml commité dans GitHub avec le reste du code source, le build Jenkins correspondant peut être configuré.
Configuration Jenkins
Depuis la console d’administration de Jenkins, vérifier que le Jenkins GIT plugin soit installé puis installer le GitHub plugin.
Dans la section CloudBees DEV@Cloud Authorization, configurer l’URL du chemin d’accès au repository Github qui sera utilisée par le plugin GitHub:

Dans la section Gestion de code source du build Jenkins, sélectionner l’option Git Repositories puis renseigner le Repository URL.
La syntaxe à utiliser est la suivante : https://github.com/<username>/<repository name>.git
Exemple : https://github.com/arey/hibernate-hydrate.git

Afin que Jenkins lance le build lors de la réception d’un hook en provenance de GitHub, sélectionner la case Build when a change is pushed to GitHub dans le panneau ci-dessous :

La version de maven, le chemin vers le pom.xml racine ainsi que le goal à exécuter peuvent être configurés dans la section Build :

Lorsqu’aucun goal n’est précisé, Jenkins exécute un install.
A la fin du build, on indique à Jenkins de déployer les artefacts dans le repository CloudBees des Snapshots :
![]()
Afin d’exploiter au mieux le plugin GitHub de Jenkins et laisser Jenkins configurer les hooks dans GitHub, il est possible de renseigner votre login / mot de passe dans l’encart GitHub Web Hook accessible depuis le menu Administration Jenkins > Configurer le Système.
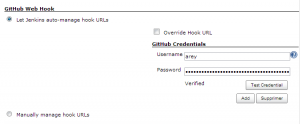
Dernière étape de la mise en place de notre usine de développement : la configuration de GitHub.
Configuration GitHub
Pour que Jenkins soit notifié à chaque push dans GitHub et relancer ainsi le build maven configuré précédemment, il est nécessaire de configurer un Hook web dans GitHub.
La WebHook URL doit référencer votre forge logicielle CloudBees.
Syntaxe : https://<cloudbees username>.ci.cloudbees.com/github-webhook/
Exemple : https://javaetmoi.ci.cloudbees.com/github-webhook/

Cette configuration n’est a priori pas nécessaire si vous utilisez le plugin GitHub Jenkins. Ce dernier se charge en effet d’ajouter les WebHooks pour vous.
Pour que CloudBees ait les habilitations nécessaires pour accéder à l’ensemble de vos repository GitHub, sa clé publique doit être ajoutée dans la partie SSH Keys accessible via le menu d’administration de GitHub :
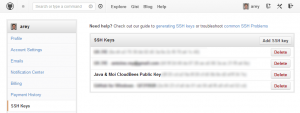
En principe, si je n’ai rien omis de mentionner dans ce guide, tout est prêt. Et pour vérifier que votre usine de développement est opérationnelle, vous avez le choix entre :
- pousser une modification dans votre repository GitHub
- ou simuler un hook depuis GitHub.
Conclusion
Suivant CloudBees depuis son lancement il y’a plus de 2 ans, j’ai eu la chance de pouvoir bénéficier début 2012 de l’offre gratuite Free and Open-Source Software. Après avoir passé un peu de temps au départ pour mettre en place mon usine, j’en suis aujourd’hui pleinement satisfait et je serais prêt à l’expérimenter en entreprise.
N’ayant utilisé qu’une infime partie des services proposés par CloudBees, de nombreuses découvertes s’offrent encore à moi : utiliser le plugin release de Jenkins, tester SauceLabs ou bien encore déployer une application web sur la plateforme RUN@CloudBees.
Apparu quelques mois après mes débuts sur DEV@cloud, CloudBees propose le produit BuildHive aux développeurs utilisant GitHub et qui souhaitent mettre en place de l’intégration continue sur leur projet. Non seulement ce produit est gratuit, mais il simplifie considérablement la configuration de votre build, à la fois côté Jenkins que côté GitHub grâce au protocole OAuth. Tout est automatisé. Je me suis inscrit et j’ai créé mon premier build en à peine 2 minutes. Un hook sur les pull request permet même de lancer un build afin de valider le code soumis. Néanmoins, il y’a tout de même quelques limitations par rapport à la solution que vous ai proposée : pas de repository maven, impossibilité d’installer des plugins Jenkins … A vous de décider lequel vous convient !
]]>Pour rappel, lors d’une release, le plugin maven accède au gestionnaire de code source pour commiter les modifications effectuées sur les pom.xml et créer un tag. Il déploie ensuite les artefacts sur le repo maven distant.
Mes contraintess techniques étaient les suivantes :
- Plateforme de développement : Windows 7, JDK 6, mSysGit
- Code source Java mavenisé et hébergé sur GitHub
- Le repo maven sur lequel déployer les artefacts maven est hébergé par CloudBees et accessible par le protocople Webdav [2]
Les réponses apportées par ce billet sont :
- Configuration maven pour GitHub
- Problème de passphrase SSH spécifique à Windows
- Configuration maven du repo CloudBees
Configuration maven pour GitHub
Pour permettre à maven d’accéder en lecture et en écriture à votre repo GitHub, vous devez tout d’abord configurer comme suit la balise <scm> de votre pom.xml :
<scm> <url>https://github.com/arey/maven-config-github-cloudbees</url> <connection>scm:git:ssh://[email protected]/arey/maven-config-github-cloudbees.git</connection> <developerConnection>scm:git:ssh://[email protected]/arey/maven-config-github-cloudbees.git</developerConnection> </scm>
L’accès en écriture sur un repo GitHub requière l’utilisation du protocole SSH. L’URL est conforme à ce qui est spécifié dans la documentation de référence maven [3] :
scm:git:ssh://server_name[:port]/path_to_repository
A noter une syntaxe légèrement différent au chemin SSH affiché sur GitHub : /arey et non :arey, le caractère : étant utilisé pour préciser le port de connexion.

Pour tester la configuration maven, vous pouvez par exemple utiliser le plugin scm pour créer un tag. C’est ce plugin qui est utilisé par le plugin release.
mvn org.apache.maven.plugins:maven-scm-plugin:1.6:tag -Dtag=test -Dbasedir=.
Vous devriez obtenir les logs suivants :
[INFO] --- maven-scm-plugin:1.6:tag (default-cli) @ maven-config-github-cloudbees --- [INFO] Final Tag Name: 'test' [INFO] Executing: cmd.exe /X /C "git tag -F D:\tmp\maven-scm-1264232534.commit test" [INFO] Working directory: D:\dev\workspaces\WS_GitHub\maven-config-github-cloudbees [INFO] Executing: cmd.exe /X /C "git push ssh://[email protected]/arey/maven-config-github-cloudbees.git test" [INFO] Working directory: D:\dev\workspaces\WS_GitHub\maven-config-github-cloudbees
1 minute. 2 minutes. Le plugin s’arrête là, comme bloqué. L’occupation CPU est à 0%. Ne cherchez pas, vous êtes sous Windows.
Problème SSH spécifique à Windows
En interne, le plugin scm exécute des lignes de commandes git.
Sous Windows, la ligne de commande git est exécutée par l’interpréteur de commandes cmd.exe en mode non interactif.
Or, lorsque vous essayez manuellement de pousser vos modifications vers GitHub depuis un bash git ou une ligne de commande avec git dans le path, Git vous demande systématiquement votre passphrase :
git push Enter passphrase for key '/c/Users/Antoine/.ssh/id_rsa':
L’explication est là : lors d’un tag ou d’un push, le plugin scm est bloqué car il attend votre passphrase. Pour autant, il ne vous demande jamais de le saisir. Vous vous retrouvez bloqué.
L’une des solutions permettant de résoudre ce problème est de répondre à la question : « Comment faire pour que Windows retienne ma passphrase ? » Stackoverflow.com vous donne la réponse [4].
En résumé, vous allez demander à git d’utiliser PuTTY pour communiquer en SSH avec GitHub. L’agent d’authentification SSH Pageant sera utilisé pour conserver votre clés privée Github en mémoire pour que vous puissiez vous authentifier sans avoir besoin de retaper votre phrase de passe à chaque fois. Voici le mode opératoire :
- Télécharger puis décompresser l’archive putty.zip librement téléchargeable depuis le site de Putty [5].
- Utiliser PuTTYGen.exe [6] pour convertir au format PuTTY (.ppk) votre clé RSA GitHub généré avec open SSH.
- Exécuter pageant.exe [7], ajouter la clé au format PuTTY and saisir le passphrase

- Déclarer la variable d’environnement GIT_SSH en spécifiant le chemin vers plink.exe [8], outil de connexion en ligne de commande utilisé pour automatiser des connexions.
Pour tester la configuration, ouvrir une nouvelle fenêtre de commande et exécuter la commande suivante :
C:\Software\Dev\Putty>plink.exe [email protected] Using username "git". Server refused to allocate pty Hi arey! You've successfully authenticated, but GitHub does not provide shell access.
La création d’un tag par le plugin scm de maven doit désormais aboutir.
Configuration des repository Cloudbees
Avant de pouvoir effectuer une release, il est encore nécessaire de configurer les repository maven de votre forge CloudBees. Il s’agit ici de configuration maven relativement ordinaire.
Lors de la phase de déploiement d’un artefact, 2 repositories sont nécessaires, l’un pour déployer des releases,et l’autre pour déployer des snapshots :
<distributionManagement> <downloadUrl>https://github.com/arey/maven-config-github-cloudbee</downloadUrl> <repository> <id>javaetmoi-cloudbees-release</id> <name>javaetmoi-cloudbees-release</name> <url>dav:https://repository-javaetmoi.forge.cloudbees.com/release/</url> </repository> <snapshotRepository> <id>javaetmoi-cloudbees-snapshot</id> <name>javaetmoi-cloudbees-snapshot</name> <url>dav:https://repository-javaetmoi.forge.cloudbees.com/snapshot/</url> </snapshotRepository> </distributionManagement>
Point d’attention : les repositories CloudBees ne sont accessibles en écriture que par le prococole WebDAV. Les URL des repository doivent donc être préfixées par un dav:
L’extension maven wagon-webddav est requis pour que maven puisse interprêtrer le dav:. A ajouter dans la balise <build> de votre configuration :
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-webdav</artifactId>
<version>1.0-beta-2</version>
</extension>
</extensions>
Afin que maven puisse accéder à ces repository pour télécharger les snapshots et les releases, il est nécessaire de les déclarer, soit dans le pom.xml de votre projet, soit dans le fichier setting.xml global ou local à l’utilisateur (ce qui est une bien meilleure pratique) :
<repositories> <repository> <id>javaetmoi-cloudbees-release</id> <name>javaetmoi-cloudbees-release</name> <url>https://repository-javaetmoi.forge.cloudbees.com/release/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> <repository> <id>javaetmoi-cloudbees-snapshot</id> <name>javaetmoi-cloudbees-snapshot</name> <url>https://repository-javaetmoi.forge.cloudbees.com/snapshot/</url> <releases> <enabled>false</enabled> </releases> <snapshots> <enabled>true</enabled> </snapshots> </repository> </repositories>
Lors d’un déploiement distant (ex : mvn deploy), maven doit disposer des paramètres de connexion pour écrire dans l’un ou l’autre des repository. A configurer dans le fichier setting.xml global ou local de l’utilisateur :
<servers> <server> <id>javaetmoi-cloudbees-snapshot</id> <username>javaetmoi</username> <password>Mot de passe CloudBees</password> </server> <server> <id>javaetmoi-cloudbees-release</id> <username>javaetmoi</username> <password>Mot de passe CloudBees </password> </server>

Attention, bien que le mot de passe soit celui que vous utilisez pour vous connecter à vore compte CloudBees, le username ne correspond pas à votre adresse email, mais celui spécifié dans la forge CloudBees comme le montre la capture d’écran ci-contre.
Pour figer sa version, le plugin maven release peut également être déclaré dans votre pom.xml :
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-release-plugin</artifactId>
<version>2.2.2</version>
</plugin>
Ca y’est, toute la configuration est en place. A vous de jouer :
mvn release:prepare release:perform
Conclusion
Afin d’avoir sous la main un squelette pour un prochain projet, j’ai initié un projet GitHub regroupant toute la configuration maven nécessaire : https://github.com/arey/maven-config-github-cloudbees [9]. Vous pouvez y télécharger l’intégralité du pom.xml et du settings.xml décrits dans cet article]. Ce projet a fait des émules puisque le code a été forké par la CloudBees-Community [10] de Github.
Pour ne plus avoir besoin à configurer PuTTY, un axe d’amélioration du plugin release serait de pouvoir s’appuyer un provider Git en full java, basé par exemple sur JGit [11] (projet utilisé par le plugin Eclipse EGit). Initié par Olivier Lamy, le projet maven-scm-provider-jgit [12] semble malheureusement s’être arrêté avant que jgit ne bascule sous le giron de la fondation Eclipse. Avis aux contributeurs !!
Références :
- Projet Hibernate Hydrate hébergé sur Github
- Définition du protocole WebDAV sur Wikipédia
- Apache Maven SCM Git Implementation dans la documentation de référence maven
- Why git can’t remembrer my passphrase under Windows sur stackoverflow.com
- Télechargement de PuTTY
- Manuel utilisateur de PuTTYgen
- Manuel utilisateur de Pageant
- Manuel utilisateur de plink
- Projet Maven Config pour GitHub & CloudBees hébergé sur GitHub
- Communauté CloudBees sur GitHub
- Site officiel du projet JGit hébergé sur Eclipse.org
- Site officiel du projet maven-scm-provider-jgit hébergé sur Google Code