Bryan Cantrill's talk Platform as a Reflection of Values gave me a lens I didn't know I needed. When platforms diverge, he argued, it's rarely about technical merit. It's about values misalignment. The things that matter most to one community simply rank differently for another.
I attended Remix Jam two weeks ago, then spent this past week watching React Conf 2025 videos. I have spent the last decade shipping production code on React and the last two years on Remix.
Now both ecosystems are shifting, and what seemed like different approaches has become incompatible visions.
React Conf's technical announcements were incremental: React 19.2 APIs, View Transitions experiments, the compiler getting more sophisticated. The message was clear: React is listening to the community while accepting complexity on your behalf. Stability, Composability, Capability: those are the values.
The Remix team announced something else entirely: they're breaking with React. The mental model shifts introduced by use client and the implementation complexity of Server Components forced a choice. And Remix 3 chose Simplicity. Remix 2 users pay the price; there's no upgrade path.
That choice, to sacrifice Stability for Simplicity, makes explicit what was already true: these values cannot coexist.
React's Values: Complexity as Capability
React's stated goal is to "raise the bar for responsive user experience." At React Conf 2025, the team demonstrated what that means in practice. They will accept tremendous complexity on developers' behalf if it delivers better experiences for end users.
The React Compiler is the clearest example. It analyzes your code, breaks components into smaller pieces of logic, and automatically optimizes rendering. In Meta's Quest store app, they saw 12% faster load times and interactions that were twice as fast, even though the app was already hand-optimized. The compiler isn't replacing developer skill; it's handling complexity that would be unrealistic to maintain manually. Joe Savona explained the challenge: in context-based apps where "every component has to update" the compiler now skips most of that work automatically.
This is React's value proposition: Stability (the compiler works with existing code), Composability (it integrates with concurrent rendering, Suspense, transitions), and Capability (it unlocks performance that manual optimization can't reach). When the team talked about their multi-year exploration into incremental computation, they weren't apologizing for the complexity. They were explaining the price of raising that bar.
The React team knows this makes React complicated. But the bet is clear: React falls on the sword of complexity so developers don't have to. That’s admirable, but it asks developers to trust React's invisible machinery more than ever.
Remix's Counter-Values: Simplicity as Liberation
The Remix team remembers when React was only a composable rendering library with few primitives. At Remix Jam, Ryan Florence demonstrated what Simplicity looks like when it becomes your organizing principle: explicit over implicit, traceable over automatic.
The clearest example is this.update(). When Ryan built a live drum machine on stage, every state change was manual: "In this code, the only time anything updates is because I told it to." No automatic reactivity graph, no hidden subscriptions, no debugging why something re-renders unexpectedly. If you're wondering why a component updated, "it's because you told it to somewhere."
This explicitness extends throughout Remix 3's design. Event handling uses the on property with native DOM events that bubble through normal DOM. AbortControllers (this.signal) wire cleanup explicitly. Context doesn't trigger re-renders. You set it, components read it, and you call this.update() when you want things to change.
After demonstrating the drum machine, Ryan explained the philosophy: "We've been chasing this idea that you construct things together, change values, and everything does what it's supposed to do. But my experience is getting it set up is difficult, and once it is set up, suddenly when something unexpected happens, you have to unravel it."
When Michael Jackson demonstrated server rendering with the <Frame> component, he showed how it uses plain HTML as its wire format. React Server Components solve real problems, but Remix believes it can solve them more simply by leaning on the Web Platform.
This is Remix's value proposition: Simplicity (explicitly control when things update), Web Platform Alignment (standard events, standard streams, cross-runtime compatibility), and Debuggability (trace every update back to a specific this.update() call). The team isn't rejecting React's goal of raising the UX bar, but they are rejecting the complexity tax React accepts to achieve it.
The Web Platform: Inevitable or Chosen?
There's an irony in using Cantrill's framework to analyze Remix's break from React: the Remix team doesn't see their Web Platform commitment as a values choice at all. They believe they're simply skating to where the puck is going. Every framework will embrace Web Platform APIs eventually. It is only a matter of timing.
But Cantrill's talk shows this is an explicit value choice, not an inevitable destination. He lamented Node.js choosing Approachability over Rigor, adopting Web Platform APIs to make it easier for browser developers to work with server-side JavaScript. The practitioners who brought those APIs to Node were the ones he felt were pushing out his values: robustness, debuggability, operational correctness. For Cantrill, aligning with the Web Platform meant sacrificing engineering rigor for developer convenience.
Remix 3 is building itself entirely on those same Web Platform APIs. Streams, fetch, the File API, every platform dependency behaves identically in browsers, Bun, Deno, and Node. Ryan and Michael demonstrated this throughout Remix Jam: standard HTML responses, native DOM events, cross-runtime compatibility. React respects Web Platform APIs too, but treats them as a foundation to build upon. Remix 3 treats them as the destination. This has always been a Remix value, evident in Remix 1 and 2, but Remix 3 makes it absolute.
And I love Remix for it.
I'm a huge fan of the open web, but I’m not convinced every server framework will, or should, fully align with the Web Platform. The browser and server live under different constraints that force different tradeoffs. The goal isn’t to erase the seam between them, but to make it visible and intentional. Remix 2 handles this tension elegantly. However, it's a result of taste in where to expose the platform, not an inherent outcome of aligning with it.
Remix 2 is dead. Long live react-router!
Despite Remix having one of the best upgrade policies in the industry with future flags, there will be no migration path from Remix 2 to Remix 3. The changes are just too fundamental. At Remix Jam, Michael Jackson was explicit: "We've been working on React Router for a decade now... A lot of people built on React Router. Shopify's built on React Router... We're not just going to abandon that thing." Remix 2 users get a maintained evolutionary path as react-router v7. But Remix 3 is taking the name in the divorce and moving in a new direction.
When Simplicity becomes the organizing principle, Stability becomes negotiable. The new on property can't coexist with React's legacy event system. The explicit this.update API replaces React's hooks entirely. Breaking backward compatibility isn't collateral damage, it's the point. It opens design space for tricks like overloading this (giving components an optional second parameter without relying on argument ordering), which feels Simple because it leans into JavaScript's existing capabilities.
An alpha is expected by year’s end, with a cohesive package to follow in 2026. But the warning is clear: Remix 3 isn't ready for production anytime soon. Everything is new and subject to change. In the meantime, we have react-router.
The Open Questions
Leaning on events as a communication backbone is clever, but it reminds me of complex Backbone.js apps that relied on a shared event bus to communicate across components. It worked for a time, but at a certain level of complexity, it became difficult for new developers to get up to speed on existing projects. Remix's explicitness and TypeScript support should help. But will it be enough to solve the challenges we couldn't in 2010?
this.update() makes for an easier mental model to grasp than React's hook system. But explicit rendering means more verbose code. AbortControllers require you to wire cleanup manually. The tradeoff is clear: you write more, but you understand more. Whether that's liberation or just shifted complexity depends on your team and your codebase.
The story of Remix 2 and react-router shows that Ryan and Michael are no strangers to pivoting toward what works. This is absolutely one of their strengths, but it's hard for large organizations to build on top of a shifting platform. How much will change before Remix 3 settles?
Living in the Divergence
Cantrill ended his talk with a warning: "Elections do not resolve differences in value. You can have as many votes as you want. If you are not actually changing people's minds, changing their values, you are not actually resolving anything."
The react-router fork exists because the Remix team knows values don’t change overnight. It's a maintained path for those who need Remix 2's stability while Remix 3 proves itself. That split acknowledges reality: production software doesn't adopt new frameworks on vision alone. Teams will make different choices based on different values. Some will stick with React and embrace the compiler's sophistication. Some will jump to Remix 3 early, betting that Simplicity is worth the migration cost and the uncertainty.
Both paths are valid. But they're valid for different values. When frameworks explicitly reprioritize what matters most, teams can't avoid choosing. Not based on features or performance benchmarks, but on what kind of complexity they're willing to accept and what kind of control they need to maintain. That's not a technical decision. It's a values decision.
The React ecosystem now has two incompatible visions of its future. Cantrill's framework helps us see why that's okay, even if it's uncomfortable. Choose your values, then choose your tools.
]]>It was a compliment, but also a diagnosis. It
]]>A Director walked up to our group in the hallway, our white StaffPlus lanyards clearly visible, and said something I'm still thinking about: "I came over because StaffPlus people have more interesting conversations than the LeadDev attendees."
It was a compliment, but also a diagnosis. It highlighted something the organizers had noticed: After four years, the overlap between Staff+ IC conversations and engineering leadership conversations has grown so much that running parallel conferences was a challenge. This was the last StaffPlus NYC. Next year the organizers replace it with LDX3, a three-track conference where the lines between IC and manager tracks blur deliberately.
Four years ago, Staff+ engineers needed their own space because so few people understood the role. Now the role has matured enough that the rest of leadership is catching up. Here's what stuck with me from the final StaffPlus NYC.
Understanding Staff+ superpowers
The conference chairs found the perfect talk to kick things off. Katie Sylor-Miller's talk was full of actionable blink-and-you'll-miss-it advice for growing into the Staff+ role. It's not just about deeper technical work. It's about recognizing that managers are your peers and your job is to help them help their team. Politics isn't a dirty word, it's a part of the job at the staff level. Her advice on the value of weekly emails over brag documents resonated too. I've learned that lesson from experience.
Kelly Moran's talk on what your VP is thinking explored their incentives and constraints and revealed the superpowers that Staff+ engineers have access to but aren't available to a VP. VPs have authority, they can shift headcount, remake teams, redirect entire roadmaps, but that power is blunt and disruptive. They don't have time to go deep on any one area because so much is competing for their attention. They're also responding to external forces: executives above them, market pressures, other divisions. Sometimes they miss internal feedback from within the division they control.
That's where Staff+ engineers come in. Our influence is more diffuse but can be precisely targeted. We have the ability to go deep, to listen to the internal voices, and to package that information in a way that's accessible to a VP. Kelly pointed out that one person can't know everything in a large organization and that is why different roles exist. If you watch just one talk from this year's Staff+ you should watch this one.
These talks named something important: Staff+ engineers occupy a unique position in the org. We're not managers, we're not VPs, but we're also not just senior ICs. We have different leverage points. We can go deep on technical problems, build trust across teams without the baggage of reporting structure or headcount, and say things VPs can't say. Understanding what makes the role distinct matters as much as technical skill.
Understanding when change is possible
But having these superpowers doesn't mean using them constantly. Leaf Roy's talk had a poetic observation that even with greater power and influence, some problems simply aren't solvable within the current org structure and that's ok.
I thought it paired nicely with Carla Geisser's talk on the magic of a crisis. Carla's insight was that nothing really big changes unless there is a crisis. However, not every crisis is useful for driving change. She gave five properties that make a crisis actionable:
- Fundamental Surprise - everyone has to simultaneously deal with the new reality
- Broken Core Functions - change is no longer optional
- High Visibility - being seen as blocking progress is uncomfortable for those in the spotlight
- Perception Breakdown - different parts of the org have received different facts, creating a chance to build a new shared picture of the world
- Rigid timing - forces decisions
The key insight: you need 3 out of 5 for a useful crisis. Something with some of these properties might not be business ending, but it is an opportunity to radically alter priorities and disrupt communication patterns.
Todd Outten's closing talk brought this home by emphasizing how important it is to understand the business and its needs at the distinguished engineer level. Who are the key customers? What drives revenue growth? What drives excessive cost? It's important to have a view of why your group exists and how the company views your contribution. This business context is what tells you what changes are possible, not just theoretically desirable.
Question conventional wisdom with nuance
Knowing when change is possible also means knowing when the conventional wisdom applies and when it doesn't.
Travis Thieman's talk on Big Bang rewrites was unexpectedly good. I'm solidly in the "never rewrite" camp and figured I was ready to counter Travis's challenge. I loved his framing of the history of the common "never do a big bang rewrite" advice, tracing the knowledge back to Joel Spolsky's experience with Netscape Navigator, Martin Fowler's work on web monoliths and of course Fred Brooks' work on the IBM System/360. He observed that the common advice was given in the context of these large software projects and reminded us that we all have permission to perform rewrites for smaller more tractable systems. So yeah, I approached this talk expecting disagreement but it's hard to disagree with someone who points out RFC 2119 is in fact the #1 banger of 1997.
Hazel Weakly's talk on the art of strategy took a similar approach to challenging conventional thinking. I was expecting a review of Richard Rumelt's ideas from Good Strategy / Bad Strategy but Hazel took the concept in a very different direction. Focusing on Optionality + Confluence as the key leverage goals for an engineering strategy. Hazel observed that Optionality is secretly graceful extensibility. I liked the observation that strategy is 99% narrative but 99% not YOUR narrative.
Both talks were doing the same thing: taking widely-accepted advice and asking "but when does this actually apply?" That's a very Staff+ way of thinking. You've been around long enough to know the rules, and experienced enough to know when to break them.
Long-term thinking in a short-term world
This kind of nuanced judgment, knowing when the rules apply, extends to how Staff+ engineers think about time horizons too.
I loved Lauren Budorick's talk on building Figma Draw because it showed how to execute on a long term multi-year project, especially when the project is just a side project for the first couple of years. It's a masterclass in keeping a vision alive when it's not the org's priority, then knowing when the moment has arrived to push it across the finish line.
The Squarespace team's talk on reimagining their image pipeline told a similar story about evolution. Why change was needed, how the architecture adapted for scale and flexibility. This wasn't about a crisis forcing change or a big bang rewrite. This was about recognizing when foundations need to shift and actually doing the patient work to evolve them before they break.
Staff+ engineers operate on different timescales. You're not just thinking about this quarter's roadmap. You're thinking about what enables the next three years of work. What technical foundations will let the team move faster later, even if they slow us down now? What side project needs to be kept alive because it'll matter in two years? That long-term thinking is hard to maintain in organizations optimized for quarterly results, but it's essential.
After the conference, Krys Flores observed that a major theme this year was mentoring. Many of the speakers mentioned how important mentoring was for their growth, the growth of the teams they worked with and the growth of colleagues. Alex Poulos encouraged us to invest deeply in 2-3 engineers. This was an interesting callout because recently I've been spreading myself across a much broader range of engineers but as a result don't have as much time for each one.
On the train home, I tried to follow Alex's advice. I opened my notes app to list 2-3 engineers I should invest more deeply in. I gave up when my list hit 10+. Not because I'm bad at prioritization, but because I genuinely see potential everywhere in my area of influence. I'm wondering if that's not a mentorship problem but a systems design problem. Maybe I could try running small cohort where strong ICs pair with emerging ones to solve real problems together? Something to explore when I get back to the office. 🤔
Multiple speakers also mentioned offering bookable office hours as a way to be accessible to other engineers. That idea seems worth trying.
At the closing Tanya and Maude revealed that this year was the last StaffPlus NYC. There are now many more resources for Staff+ engineers today than existed when the conference first started. It was also pretty clear from the hallway track that there was quite a bit of overlap in interest between the talks at both LeadDev's more manager focused talks and Staff+'s IC talks. I myself, can't wait for the recording of Anil Dash's talk on power dynamics. I tried to sneak into the LeadDev room for that one but was turned away because of its popularity.
Instead LeadDev is going to run their LDX3 concept next year in NY, instead of the parallel two single-track conferences with a shared hallway track.
This makes sense. Both Managers and Staff+ are working with a definition of the system that is broader because they are modeling a more dynamic system that includes humans.
However, I'm going to miss the touch of whimsy that existed at the StaffPlus conference. I chuckled at some of the apologies by Akshay Shah and Kelly Moran about how they were former Staff+ engineers so it was ok they were let into the room despite currently holding people manager titles. I loved watching the community do what Staff+ engineers do best: sense-making. Attendees swapped tips about Rands' leadership slack, shared their favorite chapters of Tanya's book, and collectively bristled when Tanya revealed LeadDev had stolen one of OUR talks for their track. The possessiveness was both funny and touching but we didn't know yet that this was our space... for the last time.
Alas, time marches on. StaffPlus joins OpenVisConf, Deconstruct, and StrangeLoop in the pantheon of conferences that ended while they were still great. At least we have the videos and memories... and the knowledge that more will join them.
]]>Staff+ engineers aren't promoted so much as absorbed into the system. The system has its own logic, and once you're part of the machinery, you start to see how it really runs.
At this level, the work is less about code and more about context. You’re expected to navigate organizations as complex as the systems they build: networks of people, incentives, and constraints that are never written down. Success comes from recognizing how decisions actually get made, how priorities shift, and where influence lives. A shared canon equips us with the language, ideas, and tactics for an ecosystem bigger than any one person.
Books:
The Staff Engineer's Path by Tanya Reilly
The perfect starting point for understanding staff+ work. Reilly lays out the three pillars of staff engineering: big-picture thinking, project execution, and leveling others up. This book provides the foundational framework for understanding what staff+ work actually entails, beyond just "senior engineer++." It teaches tactics like: how to actually lead big projects, debug "why have we stopped?" moments, and working within the constraints of finite time and attention.
The Manager's Path by Camille Fournier
Even if you're committed to the IC track, understanding management is essential at staff+. Fournier shows us what manager's actually do. There's plenty of overlap with technical leadership, but managing people is its own skill tree. We don't need to master it, but understanding how managers think, what motivates them, and how they're incentivized makes us more effective partner across the organization.
Release It! by Michael Nygard
It's easy for staff+ engineers to slip into the role of on-call firefighter, constantly debugging outages and spinning plates. To be effective, we need to limit reactive work and create space for strategic thinking. Nygard provides the practical toolkit for building resilient systems that don't constantly scream for our attention. He teaches us to design for production, not QA environments, and gives us names for the failure patterns we keep encountering. If "circuit breaker" is already a part of your vocabulary, this book is a big reason why.
Domain-Driven Design by Eric Evans
Staff+ engineers translate between business reality and technical systems. As systems grow, the hard part shifts from the code to the problem space. DDD gives us language and patterns to make that translation without loss: ubiquitous language, bounded contexts, and clear seams. It helps us keep product needs and architecture in balance so today’s design doesn’t box in tomorrow’s business.
Kill It with Fire by Marianne Bellotti
Every staff+ engineer inherits legacy systems. Bellotti's tour-de-force teaches us "old systems are successful systems" that have survived because they deliver value. The book gives us the tools for protecting that value while modernizing strategically. Instead of a one-size-fits-all answer, she offers a menu of approaches, showing how to evolve systems without breaking what already works.
Thinking in Systems by Donella Meadows
Meadows teaches us to see the hidden structure behind complex systems. Stocks, flows, feedback loops, and delays are the building blocks of every complex system. With them, we gain a diagnostic toolkit to spot persistent issues and identify leverage points for maximum impact with minimal effort. Once we see these patterns, we’ll recognize them everywhere: in code, teams, and organizations.
The Pyramid Principle by Barbara Minto
Staff+ is scaled influence, and writing is our interface. Minto shows us how to make thinking legible: frame the Situation–Complication–Question, then deliver the Answer → Reasons → Evidence. These techniques have endured because they help busy readers decide fast. We use them for RFCs, strategy memos, and status updates when decisions, not prose, are the goal.
Good Strategy, Bad Strategy by Richard Rumelt
Everyone loves a good strategy, but this book earns its place because recognizing a bad one is high leverage. With endless priorities, backing a bad strategy, even from the top, is an unforced error. As staff+, we can choose our battles, and Rumelt shows how to pick the ones worth fighting.
The Unaccountability Machine by Dan Davies
I'll admit something, The Unaccountability Machine isn't a shared cultural touchstone for staff+ engineers yet. But it's my dark horse pick, and I believe it belongs here.
Davies reframes cybernetics as the “road not taken” after computer scientists chose to explore information theory. It offers an alternate lens for understanding complex organizations. One of its most powerful ideas is the Law of Requisite Variety: to steer a complex system, your responses must be as varied as the problems it throws at us. If a system can produce 100 different failure modes, operators need enough knobs to respond to all 100.
The concept that will really haunt you is the accountability sink. These structures divert blame, preventing feedback that would let the system address the root cause. Once you notice them, you’ll see them everywhere. It’s cursed knowledge, but the kind we need.
Essays and Articles:
Tanya Reilly's Being Glue
Reilly leads off the blog section just as she did with books. Glue work is a crucial concept for staff+ roles. We're often the only ones in the organization with enough context to understand why a particular piece of coordination, documentation, or process work is essential. Equally important is Tanya's insight about why glue work appears invisible and undervalued to others who lack that broader perspective.
Will Larson's Staff Engineer Archetypes
Larson has an excellent blog, and choosing just one article was difficult, but Staff Engineer Archetypes is the clear winner. He explains why the staff+ role takes so many different forms and how two people with the same title at the same company can have completely different day-to-day responsibilities. Understanding these archetypes: Tech Lead, Architect, Solver, and Right Hand, helps us figure out which path fits our strengths and your organization's needs.
Charity Majors' The Engineer/Manager Pendulum
Majors does an excellent job laying out the differences between individual contributor and management tracks, and the benefits of experiencing both sides. She makes the case that switching between IC and management roles throughout our career creates better leaders in both paths. I suspect this is the most widely read post on this entire list, and for good reason.
Patrick McKenzie's Don't Call Yourself a Programmer
McKenzie's article targets a junior audience, but it's worth revisiting with the perspective of experience. He makes a compelling case that engineering work isn't about writing code - it's about creating valuable software and operating it economically. The fundamentals of business value, communication skills, and strategic thinking become even more relevant as we advance to staff+ levels.
Dan McKinley's Choose Boring Technology
McKinley reframes “boring” as well-understood, operable tech. Boring frees attention for the truly new by keeping everything else legible and predictable. His “innovation tokens” give us a budget for novelty: pick one new piece and keep adjacent layers stable. That constraint lowers risk and speeds delivery when we adopt unfamiliar tools.
Richard I. Cook's How Complex Systems Fail
No Staff+ reading list would be complete without How Complex Systems Fail. Cook’s treatise explains why failure isn’t an edge case but the natural state of complex systems. For Staff+ engineers working to evolve the system, this perspective is essential. It reminds us that forgotten failures resurface, that resilience is built in layers, and that our real influence comes from shaping how the system adapts, not pretending it won’t break.
Steve Yegge’s Google Platforms Rant
If only we all had the wit and clarity of Steve Yegge in our writing. His Google platform rant is an instant classic. Part organizational case study, part culture critique, part technical architecture lesson. Yegge shows you how Amazon transformed itself through sheer organizational will (and fear), then dissects why Google failed to learn the same lessons. His insights about how technical choices reflect and reinforce company culture will change how we see every architectural decision. Oh yeah, he also explains why platforms are overpowered, which, despite being in the title, almost feels like a bonus insight compared to everything else he unpacks.
Newsletters:
Staff+ engineers operate at the intersection of technology and business strategy, where the landscape shifts constantly. While books and essays provide timeless wisdom, newsletters give us the ongoing context to apply that wisdom effectively.
The best newsletters do something books can't: they recursively build on themselves. When events validate or challenge previous ideas, authors link back to earlier issues with updated commentary. This creates a living knowledge base where important concepts are constantly resurfaced and pressure-tested against current reality. For staff+ engineers making decisions that will play out over years, watching these ideas evolve in real-time is invaluable.
Pragmatic Engineer by Gergely Orosz
Orosz has become the definitive voice for engineering in today's tech industry. His level of access to companies is unprecedented, providing insider perspectives on everything from layoffs to compensation trends to organizational changes. Every staff+ engineer should subscribe for situational awareness, knowing what's happening across companies is essential. That context helps us separate structural headwinds from local problems and pick the right fights.
Lenny's Newsletter by Lenny Rachitsky
Lenny writes for PMs, but we should read him to level up product literacy. His frameworks turn “what’s the user problem?” into testable hypotheses, experiments, and metrics. His guests, operators across growth, research, product and yes even engineering bring battle-tested playbooks. It helps us show up as credible cross-functional partners who align on outcomes, not outputs.
Stratechery by Ben Thompson
Stratechery is the macro lens for engineering decisions. Thompson ties industry structure to the constraints that show up in our roadmaps. He connects historical precedent to current events, revealing how earlier strategic bets shape today’s competition. The context shows the incentives and constraints driving technology choices, so the “irrational” starts to look inevitable and we can plan accordingly.
What's Not Here (And Why)
You won't find deep technical books on distributed systems, programming languages, or specific technologies in this list. No Designing Data-Intensive Applications, Effective TypeScript, or Database Internals. This is intentional.
By the time we reach staff+, we've already proven our technical depth. We know how to learn new technologies when needed. What differentiates staff+ engineers isn't technical excellence, that's table stakes, but the ability to navigate the organizational, strategic, and human complexities that surround technical decisions.
This list also skips the pure leadership and management books that dominate airport bookstores. While valuable, they're written for a different audience with different constraints. Staff+ engineers need resources that acknowledge our unique position: technical leaders without formal authority, architects who must consider organizational dynamics, strategists who still write code.
Read Write Execute
This is my proposal for the staff+ canon. I'll admit it's biased. My selections reflect a belief that staff+ engineering is fundamentally about executing in complex sociotechnical systems rather than just technical depth. This reflects my current role and experience. But as Will Larson shows us, there are many shapes of staff engineer, and different archetypes might benefit from different foundational knowledge.
Canons aren’t fixed — they are read, argued over, rewritten, and revised. What did I miss from this list? What would you add or remove? I'd love to hear how your experience as a staff+ engineer shapes your perspective on what belongs here.
The canon compiles, but it’s not bug-free. Patches welcome.
]]>test is a classic, vi.fn might have the best name, and expect is a great Swiss Army knife. Like a proud parent, I have trouble choosing my favorite. But I know which API I]]>Which Vitest API is your favorite? There are so many great ones to choose from. test is a classic, vi.fn might have the best name, and expect is a great Swiss Army knife. Like a proud parent, I have trouble choosing my favorite. But I know which API I hate the most: vi.mock. It creates more confusion than clarity and encourages mocking that’s too broad and brittle for maintainable codebases.
And if you're using Jest, yes, this applies to jest.mock too. The APIs are identical, and so are the problems.
Let me start with a confession: I am a recovering vi.mock abuser. I enjoy the mockist style of TDD, so naturally every time I needed to isolate my code from a dependency, I'd reach for that sledgehammer. After all, it says "mock" right on the tin, what's not to love?
But I've seen the light, and I'm here to show you why vi.spyOn should be your preferred choice. It's a sharper, safer tool that gives you precision without the pitfalls.
Understanding Mock Mechanics: What's Actually Happening Under the Hood
When you see vi.mock('./someModule') in a test file, it may look like a simple inline method call but under the hood your test runner is breaking the rules. Before a single line of code is executed, vitest pre-parses the test file and hoists all vi.mock(...) calls to the top. It then evaluates every vi.mock before any imports or any other code in the file has a chance to run. This behavior applies globally, affecting every test in the file.
This might be surprising to those of you who've studied the ES modules spec, which requires static imports to be evaluated before any code runs. Vitest, like Jest before it, cheats. It makes mocking work by bending the rules. In every other JavaScript runtime, imports happen first, then code runs, just as the spec demands. But with vi.mock, that flow is flipped: your mocks run before anything else, no matter where they appear. That inversion breaks your mental model, making tests harder to follow and easier to misuse.
Once you understand how the test runner works, this behavior might feel manageable. But that’s the problem, it’s inside baseball. You might know what's going on, but it's risky to assume the next developer will. Tests that rely on this behavior depend on deep, tool-specific knowledge that most people don’t carry around in their heads.
In contrast, vi.spyOn(module, 'method') runs at runtime, exactly where you put it. It patches a specific method on an already imported module. Thanks to ES modules' live bindings, you get a precise override without affecting the rest of the module. It’s surgical, predictable, and plays by the rules.
Let's compare them side-by-side with a simple example:
// The vi.mock approach
import { vi, test } from 'vitest';
import { getUser } from './userService';
// vi.mock lives in the root scope. But this line is evaluated first before the imports above.
vi.mock('./userService');
test('fetches and displays user data', async () => {
// We have to manually configure the mock after importing
vi.mocked(getUser).mockResolvedValue({ id: 117, name: 'John' });
// Rest of test...
});
// The vi.spyOn approach
import { vi, test } from 'vitest';
import * as userService from './userService';
test('fetches and displays user data', async () => {
// Mocking happens where you expect it to
vi.spyOn(userService, 'getUser').mockResolvedValue({ id: 117, name: 'John' });
// Rest of test...
});
At first glance, both tests have a similar shape. The main difference is the vi.mock call in the root scope in the first example and the star import in the second. However, beyond these superficial differences there is a bigger behavioral one. vi.mock is affecting every test in the file, while vi.spyOn is local to your test. It’s manageable with one test, but quickly becomes a liability as your file grows.
The Problem of Module-Wide Replacement
vi.mock always replaces the entire module, even parts you might want to keep real. This behavior can be surprising in larger test files, especially when the vi.mock call has scrolled off screen.
Consider this simplified (and yes, slightly contrived) scenario:
import { vi, test } from 'vitest';
import { getUser } from './userService';
vi.mock('./userService');
test('getUser test 1', () => {
vi.mocked(getUser).mockResolvedValue({ id: 1, name: 'John' });
// Tests here...
});
test('getUser test 2', () => {
vi.mocked(getUser).mockResolvedValue({ id: 2, name: 'Jane' });
// More tests...
});
We start with two tests mocking the userService module. Later, we modify this test file to add a new test for the gravatarUrl method from the same module:
// Later, we add a new function from the same module
import { getUser, gravatarUrl } from './userService';
vi.mock('./userService');
// ... existing tests
test('gravatarUrl', () => {
// This will fail because gravatarUrl is undefined in the mocked module
expect(gravatarUrl('[email protected]')).toBe('https://gravatar.com/avatar/b4c9a...');
});
Suddenly, gravatarUrl is always returning undefined! While this example is simplified, it illustrates a real problem: in long test files, it's not always obvious that vi.mock('./userService') is silently replacing everything, even code that was never meant to be mocked.
The problem gets worse as your test file grows. Different tests may rely on different aspects of the same module. vi.mock introduces implicit coupling between them. As the number of tests increases, you end up with a tangled web of mock state that’s hard to reason about and even harder to maintain.
Remember: that innocent-looking vi.mock call has global effects. Because it’s hoisted to the top of the file (before any imports!), it can lead to a confusing and brittle execution order. Using vi.mocked can help annotate intent, but it can’t undo the global scope of the mock itself.
With vi.spyOn, you only mock what you need, leaving the rest of the module intact:
import * as userService from './userService';
test('getUser test', () => {
const getUserSpy = vi.spyOn(userService, 'getUser')
.mockResolvedValue({ id: 1, name: 'John' });
// Test logic...
});
test('gravatarUrl', () => {
// This works normally because we didn't mock it
expect(userService.gravatarUrl('[email protected]')).toBe('https://gravatar.com/avatar/b4c9a...');
});
Each test only affects what it explicitly mocks, making tests more isolated and predictable.
Type Safety: Less Accounting Work, More Reliable Tests
One of the most compelling reasons to favor vi.spyOn is type safety. When mocking an entire module with vi.mock, TypeScript loses track of the type contract for that module's functions, requiring you to use the vi.mocked helper.
import { add } from './calculator';
vi.mock('./calculator');
test('addition works', () => {
// TypeScript will complain without vi.mocked
add.mockReturnValue(5); // ❌ Error: Property 'mockReturnValue' does not exist on type...
// This makes TypeScript happy, but it's a kludge
vi.mocked(add).mockReturnValue(5);
expect(add(2, 3)).toBe(5);
});
The vi.mocked API exists to patch over this exact problem. And it kinda works? It infers the original types of the mocked module, which can save time. But I think it's a bit of a kludge. It relies on the developer to remember to use it everywhere. At its core, it’s a type assertion: you’re telling TypeScript, “Trust me, this is a mock function.” But that trust is fragile, if you forget, TypeScript won’t have your back. Worse, if someone later removes or moves the vi.mock call, your vi.mocked code will quietly stop working, and TypeScript won’t say a word, because past you already swore everything was fine.
Now compare with vi.spyOn:
import * as calculator from './calculator';
test('addition works', () => {
const spy = vi.spyOn(calculator, 'add').mockReturnValue(5);
// TypeScript knows exactly what's going on here
expect(calculator.add(2, 3)).toBe(5);
// TypeScript will even catch errors in mock implementations
vi.spyOn(calculator, 'add').mockReturnValue("not a number"); // ❌ Type error!
});
With vi.spyOn, TypeScript enforces both parameter types and return types, catching errors before your tests even run. This means fewer bugs and faster test development cycles.
The vi.mock + vi.requireActual Anti-pattern
If you've been using vi.mock for a while, you've probably run into this situation: you want to mock just one function from a module while keeping the rest of it real. So you reach for the old trick:
// The dreaded mock + requireActual pattern
vi.mock('./utils', () => {
const actual = vi.requireActual('./utils');
return {
...actual,
formatDate: vi.fn().mockReturnValue('2025-03-15')
};
});
import * as utils from './utils';
test('uses formatted date', () => {
// Your test logic...
});
This is a red flag! It’s complex, fragile, and easy to get wrong. If the formatDate function signature changes, this test might silently break in confusing ways.
Compare with the vi.spyOn approach:
// Clean and clear with vi.spyOn
import * as utils from './utils';
test('uses formatted date', () => {
const formatSpy = vi.spyOn(utils, 'formatDate').mockReturnValue('2025-03-15');
// Your test logic...
});
This is cleaner, safer, and TypeScript has your back. If the API changes, you’ll know. No spread hacks, no runtime indirection, just one line where you say exactly what you want to override.
So if you ever catch yourself reaching for vi.requireActual, take it as a sign: you're fighting your tools. Switch to vi.spyOn instead.
Live Bindings and Closures: The Edge Cases
I love an exception that proves the rule and with spyOn that is live bindings.
I’ll admit it: in this specific case, vi.mock has the edge on usability. But once you understand what’s happening, it’s easy to fix.
vi.spyOn works by modifying an ES module’s live binding, a concept where the imported value stays linked to the original export. When the exporting module updates that value, the change is visible to the importer. That’s what makes spying possible in the first place.
But there’s a catch: if your code saves a direct reference to an imported function, like when wrapping it in a higher-order function, the spy won’t affect it. You’ve captured a value, not a binding.
This shows up a lot with utilities like debounce or throttle:
// In your module
import { debounce } from 'lodash';
import { expensiveOperation } from './operations';
// This won't be affected by spying on operations.expensiveOperation
const debouncedOperation = debounce(expensiveOperation, 315);
export function performOperation() {
return debouncedOperation();
}
Here, debouncedOperation has closed over the original function. So if you spy on operations.expensiveOperation, it won’t change what debouncedOperation does.
The fix? Use a closure to defer the reference:
// Better approach
import { debounce } from 'lodash';
import { expensiveOperation } from './operations';
// This preserves the live binding
const debouncedOperation = debounce(() => expensiveOperation(), 300);
export function performOperation() {
return debouncedOperation();
}
Now, when you spy on operations.expensiveOperation, the debounced version respects the override, because it accesses the function through the live binding.
Tips for Using vi.spyOn
To get the most out of vi.spyOn, follow these best practices:
- Restore your spies after each test:
afterEach(() => {
vi.restoreAllMocks(); // Clean up all spies at once
});
This prevents test bleed and ensures each test starts fresh. In most projects, you’ll want to add this to your global test setup file and forget about it.
- Import modules as namespaces:
import * as userService from './userService';
This gives you a reference to the module object, which you need for vi.spyOn.
- Keep spy creation close to where it's used:
test('specific test case', () => {
const spy = vi.spyOn(module, 'method').mockImplementation(() => 'mock value');
// Test that directly uses this mock
});
This maintains the locality principle and makes tests easier to understand.
When vi.mock Is Appropriate (The Exception)
I'll admit it, vi.mock does have its place. Sometimes you genuinely want to turn off a dependency completely, especially when it introduces noise or side effects that aren’t relevant to the behavior under test.
Good candidates include:
- Logging libraries that clutter your test output
- Analytics trackers that fire background events
- Expensive but non-essential computations that slow down your tests (yes, I’m looking at you,
popper.js)
For example:
// An appropriate use of vi.mock
vi.mock('./logger');
The key is that these dependencies aren’t what you’re testing. They’re distractions, runtime noise that you want to eliminate so your test stays focused and fast.
Conclusion
vi.mock has its place, but it belongs deep in the back of the toolbox. For most situations, vi.spyOn is the better default. It gives you:
- Better type safety and compile-time error checking
- Clearer, more predictable test structure
- Fine-grained control without wiping out the whole module
- Freedom from
vi.requireActualhacks and global side effects
So the next time you're about to reach for vi.mock, stop and ask:
Am I trying to disable this dependency entirely, or just control its behavior?
If it's the latter, give vi.spyOn a chance. Your future self, and your teammates, will thank you when when it’s time to debug.
I love a good test. No, scratch that, I love a laconic test! There's an art to it: the eloquent test name, the crisp setup that establishes context, the succinct action that triggers only what needs testing, and finally a few pithy assertions. A truly great test is verbal economy in executable form, a dozen sharp lines that speak volumes without wasting a character.
You can imagine my heartbreak when I open a test file and spot an ugly blemish staring back at me from the very top:
vi.mock('@remix-run/react', () => {
useLoaderData: vi.fn(),
});
Mocking a framework dependency? How unsightly! This test suite may as well be mocking me.
Mocking your framework might seem expedient today, but tomorrow it will cause pain in the form of brittle tests, high upgrade friction, and hidden integration issues.
Where It All Started: "Don't Mock What You Don't Own"
The principle "Don't mock what you don't own" originated from the London School of Test-Driven Development (TDD), particularly in Steve Freeman and Nat Pryce's excellent book Growing Object-Oriented Software, Guided by Tests (2009). This guideline advises against mocking interfaces or types that you don't control. This covers any external code like third-party libraries.
Google's Testing Blog later gave this concept a URL in a 2020 "Testing on the Toilet" article titled Don't Mock Types You Don't Own which warned:
The expectations of an API hardcoded in a mock can be wrong or get out of date. This may require time-consuming work to manually update your tests when upgrading the library version.
In theory, this advice seems rather obvious. Yet when deadlines approach and test suites need completing, mocking a framework dependency becomes irresistibly tempting. The promise is alluring: isolate your code, control all inputs, test only what you wrote. Experience tells a different story: what begins as a clever shortcut inevitably becomes tomorrow's maintenance nightmare.
Fast forward to today's TypeScript landscape, and this principle becomes not just good advice but essential survival wisdom for maintaining modern codebases and products.
Why You Shouldn't Mock Your Framework (React, Remix, Next.js)
When you mock React, Remix, or similar frameworks, you're creating problems for your future self:
Problem 1: Brittle Tests Due to Framework Updates
Imagine you're testing a React component that uses hooks. You might be tempted to mock useState to control their behavior in tests. Your tests pass, you ship the code, and all seems well. Then some other dependency releases an update with internal implementation changes, suddenly your tests are broken, but your actual code still works fine! What changed? The other dependency's update relied on useState under the hood, the same API your test mocked out.
Frameworks aren't just libraries, they're ecosystems where many dependencies coexist and interact. When you mock out framework internals, you're not just tampering with one API; you're potentially disrupting an entire habitat of interdependent modules that expect the framework to behave consistently.
Problem 2: Framework Coupling Increases Upgrade Friction
When you mock framework APIs, you are hardcoding assumptions about their behavior. This increases your tests coupling on the framework because you are coupling to both the API interface and the internal algorithm details. This creates a maintenance burden during upgrades:
- You must painstakingly update all your mocks to match the new API
- You lose the ability to detect actual regressions during upgrades
- The time spent fixing mock-related test failures distracts from addressing real issues
For example, when Remix updated its API to support the V2 data APIs, many tests that mocked loaders and actions needed significant rewrites—not because the application logic changed, but because the tests were coupled to the framework's implementation details.
Problem 3: Library Mocks Hide Integration Issues
This principle isn't just for UI frameworks, it applies to all external dependencies, just as Steve Freeman and Nat Pryce predicted. Whether it's validation libraries like Zod, state managers, or any other third-party code, the same caution applies: mock what you own, respect what you don't.
A Better Way: What You Actually Own
So what's the alternative? Instead of mocking frameworks directly, focus on what you own:
1. Create Thin Adapters Around Libraries
Wrap external dependencies in your own abstractions that match your domain language, this is a core principle of hexagonal architecture. These adapters not only decouple your code from third-party implementations but also create perfect test seams where mocking becomes both safe and effective:
// Instead of directly using Remix's useLoaderData in components
// Create a domain-specific adapter
// Your adapter
export const getUserProfile = () => {
const data = useLoaderData<typeof loader>();
return {
username: data.user.username,
displayName: data.user.displayName,
isVerified: data.user.emailVerified && data.user.phoneVerified,
permissions: mapPermissions(data.user.roles)
};
};
// In tests, you can mock your own function
import * as profile from '../user/profile';
vi.spyOn(profile, 'getUserProfile').mockReturnValue({
username: 'testuser',
displayName: 'Test User',
isVerified: true,
permissions: ['read:content', 'edit:profile']
});
By mocking your adapter instead of Remix's useLoaderData directly, you're working with interfaces you control, creating tests that bend without breaking when the framework evolves. Your components can also remain focused on presentation rather than data transformation logic.
2. Use Real Implementations in Integration Tests
I love mocks as much as the next dev to ensure my tests run fast and the behavior under test remains isolated. However, when your code integrates directly with a framework there is no replacement for integration tests that exercise the real thing.
test('should show an error message for invalid emails', async () => {
// Testing Library's render method integrates directly with React
render(<UserForm />);
// Interact with actual components
fireEvent.change(screen.getByLabelText('Email'), {
target: { value: 'invalid-email' }
});
fireEvent.click(screen.getByRole('button', { name: /submit/i }));
// Test actual validation behavior
await screen.findByText('Please enter a valid email address');
});
3. Use Official Testing Utilities
Many frameworks provide official testing utilities that are designed to work with the framework:
// Using React Router's MemoryRouter instead of mocking
test('navigation works correctly', () => {
render(
<MemoryRouter initialEntries={['/start']}>
<App />
</MemoryRouter>
);
// Test navigation without mocking router internals
fireEvent.click(screen.getByText('Go to Dashboard'));
expect(screen.getByRole('heading')).toHaveTextContent('Dashboard');
});
These utilities are maintained alongside the framework and are designed to be used in tests without exposing internal implementation details. This means you can rely on them to be a stable foundation that will continue to work as the framework updates and evolves.
Beyond reliability, using these official utilities signals to other developers that your tests follow community standards, making your codebase more approachable for newcomers and easier to maintain as your team grows.
The Exception That Proves the Rule: Disabling Non-Essential Behavior
While "Don't Mock What You Don't Own" is generally good advice, there is one exception where I've found it's ok to bend the rules a bit. I typically feel comfortable mocking a 3rd party dependency only if I am completely disabling behavior that isn't a part of the behavior I'm testing.
My go-to example of this is Popper.js. Popper.js is a UI library for making floating elements like tooltips, popovers or drop-downs. Because of the nature of floating elements popper.js often makes some relatively expensive layout calculations when the component is rendered, but many integration tests of UI components that contain informational tooltips aren't actually testing the behavior of the tooltip.
In cases like this, I'll disable Popper.js in the test suite because it can provide a significant speedup to unit test execution time.
// Disable Popper.js because we're not testing
// tooltip positioning
vi.mock('@popperjs/core');
This simple change reduced our test suite execution time from 15 seconds to 11 seconds on my local machine. More importantly, on our congested CI workers during peak hours, it decreased test timeouts by nearly 40% by eliminating calculations irrelevant to what we were actually testing.
So why is mocking Popper.js an acceptable exception to our rule? Because we're completely disabling functionality peripheral to our test's purpose. We're not testing tooltip positioning - we're testing the component that happens to use tooltips. By removing these expensive layout calculations, we dramatically improve test reliability without compromising correctness.
However, remember to document this exception clearly in your test setup and consider having at least one integration test that uses the real implementation to ensure it works as expected.
Conclusion
We began with the heartbreak of discovering an unsightly mock blemishing our test file. Now you have the antidote: draw clear boundaries, respect what others own, and mock only what's truly yours. The next time you open a test file, it won't mock you with its fragility, it will greet you with the same elegance that makes testing an art form. After all, test files should be collections of wit and wisdom, not monuments to the framework APIs we once thought we understood.
Your future self will thank you for making your test suite a sharper tool. After all, the beauty of a great test isn't just in what it verifies, but in how gracefully it evolves alongside your code.
]]>For example, the feed&
]]>Ben Thompson likes to point out that early websites were essentially static copies of physical world artifacts like newspapers and brochures. The web only reached its potential during the Web 2.0 era when developers discovered truly native capabilities that previous mediums couldn't match.
For example, the feed's infinite scrolling experience created a new canvas for Facebook and others to display ads. Real-time collaboration breathed life into once-solitary documents, enabling Google Docs, Trello, and others to create virtual workshops where teams create together. On-demand resource access enabled streaming services like Netflix to provide thousands of content options without waiting 3-5 days for a red envelope full of bits.
The emergence of LLMs has opened up new design space for products, enabling features that were previously impossible. Since ChatGPT made its splash in late 2022, we've had about two years of product teams experimenting with LLMs to see what would stick. Today, we are starting to see the shape of LLM-native capabilities that bring real value to users.
Let's explore 6 LLM-native capabilities that have emerged, how they're being used today, and where opportunities remain to deploy them in building better products.
1. Content Generation

Google Search's AI Overview demonstrates how LLMs excel at generating comprehensive content about given topics (even if they occasionally hallucinate details). Companies like Copy.ai and Jasper have embraced LLM-powered content generation to help create marketing materials.
Personalization through memory and context represents one of the most promising frontiers for LLM-powered products. ChatGPT's conversation memory showed us just the beginning, the ability to maintain context and adapt responses based on user history opens up new possibilities for user experience. Imagine hotel listings that don't just filter results, but completely reframe their content based on your preferences: highlighting the quiet workspace for business travelers, emphasizing the kid-friendly amenities for families, or focusing on nearby nightlife for young tourists. This kind of dynamic, personalized content generation could transform how users expect to interact with products across every industry.


If I'm searching for a hotel in Vermont in February, I care about skiing not ice cream.
Personalization extends far beyond individual user preferences. Enterprise tools like Glean are pioneering organization-wide personalization by tapping into company wikis, internal documentation, and proprietary data. This creates an entirely new category of contextual intelligence. Where responses aren't just personalized to you, but to your role, your team's terminology, your company's processes, and your organization's collective knowledge. A developer asking about 'deployment' gets answers specific to their company's CI/CD pipeline, while a sales rep sees information about their team's deployment playbooks.
2. Pattern Parsing
The second key capability is extracting information from unstructured documents. The chat transcript titles on ChatGPT or Claude.ai offer excellent examples of this functionality.

While Google Docs had a pre-LLM version of this (suggesting document titles based on first sentences), it relied on simple context clues. LLMs enable more sophisticated parsing. Imagine automatically extracting the purpose of a SQL worksheet, using the existing select queries to give it a meaningful name like "May 2024 visitor count exploration" instead of "2024-06-05 11:12:03am". That will be vastly more helpful months later when you are looking through your past worksheets to reconstruct a similar query.
Less visible but equally important are the various libraries and APIs that make it easy to extract structured information from LLM-generated content, bridging the gap to traditional programming tools and existing services.
Quick wins in this space could include helping to name scratchpad worksheets, providing context for screenshots in macOS, or upgrading any automatically generated filename (timestamps, hashes or ids) with richer context.
3. Intent Translation
Intent Translation helps users achieve their goals by converting natural language descriptions into precise commands supported by the system. GitHub Copilot exemplifies this, helping developers write code based on descriptions and context. Any tool with a complex query language can benefit from Intent Translation, helping both newcomers and experts become productive faster.
While many focus on how this helps non-experts access complex tools with less training, Intent Translation may prove even more valuable for experts who deeply understand the capabilities and limitations of underlying commands, enabling them to work faster and more easily transfer skills to adjacent domains.

As LLM interfaces become standard for complex business tools, we might see them visually de-emphasized in UIs but always available via quick shortcuts. This could spark a renaissance in command palettes for power users, as the work to expose and document commands for LLMs can be repurposed to provide shortcuts for experts who prefer not to wait for LLM processing.
4. Conversational Interfaces

ChatGPT's explosive success, despite the underlying model existing for six months prior without much interest, parallels early computing history. One-shot LLM generation resembles batch processing, requiring all inputs upfront. In contrast, chat provides all the power of a REPL, allowing users to iteratively refine results and discover possibilities they hadn't initially considered.
Beyond ChatGPT, conversational interfaces have become ubiquitous in customer support and show promise in educational contexts, particularly for interactive tutoring and language learning.
While chat was LLM's first killer app and won't disappear, conversational interfaces may become one of the less frequent LLM-powered features users interact with in the future. This shift could occur as other LLM capabilities, such as intent translation and content generation, provide faster and more seamless ways to achieve results without requiring extended dialogue. The time required for interaction make it difficult to compete with more attention efficient LLM features.
5. Evaluators

The current generation of LLMs show potential at assessment, comparison, and structured feedback. Given appropriate rubrics, they can even provide scoring or grading. While companies like Greptile.com leverage LLMs for automated code review, others are applying this capability in novel ways. Educational platforms use LLMs to provide detailed essay feedback, recruitment tools employ them to screen resumes against job requirements, and content platforms utilize them to assess user-generated content for quality and policy compliance.
However, modern LLMs aren't always the optimal tool for evaluation. They can struggle with consistency across evaluations, may miss edge cases, and often require significant prompt engineering to maintain reliability. While they can serve as an interim solution, many evaluation tasks may ultimately be better handled by deterministic algorithms or dedicated ML models trained on specific evaluation criteria.
6. Agents

Agents combine many of the capabilities above into systems that dynamically direct their own processes and tool usage to accomplish tasks. They're gaining significant attention in 2025, and I expect substantial product growth as teams become more familiar with AI capabilities and grow more ambitious. Anthropic has published useful documentation on techniques for building effective agents and advanced workflows.
Looking ahead, I'm particularly excited about personal assistant agents that can automatically follow up on meeting action items or proactively invite relevant people into incident Slack channels based on context.
The Path Forward
As we witness these native LLM capabilities mature, we're seeing an evolution from simple text generation to sophisticated features that enhance existing products and enable new ones. The most successful implementations share a common thread: they don't just replicate human tasks but augment human capabilities in ways that weren't previously possible.
For product teams, the challenge isn't just implementing these capabilities, but identifying where they can provide real value instead of novelty. The most successful products will be those that subtlety use LLMs to solve problems on top of the existing web platform capabilities.
As we move further into 2025 and beyond, we'll likely see these capabilities become more refined and specialized for specific domains. The winners won't be those who simply add LLM features to existing products, but those who reimagine their products with LLM-native thinking from the ground up, just as the most successful web products weren't digitized magazines, but entirely new experiences that leveraged the web's unique capabilities.
]]>But
]]>Ever feel like updating your Remix app's UI is a circus act? One small change, and suddenly everything's breaking? You're not alone. This fragility often comes from tightly coupled components – a change in one place triggers a domino effect throughout your code.
But there's a solution: hexagonal architecture. This pattern, also known as ports and adapters, helps you build Remix apps that are flexible, maintainable, and resilient to change. How? By clearly separating your core business logic from the nitty-gritty details of UI components, databases, and external services.
With hexagonal architecture, you'll be able to:
- Make UI changes with confidence: No more worrying about breaking unrelated parts of your app.
- Test components in isolation: Simplify your testing process and catch bugs early.
- Swap out dependencies easily: Keep your app up-to-date without major refactoring.
- Reuse your code like Lego blocks: Build a modular system where components can be easily repurposed.
Principles of Hexagonal Architecture
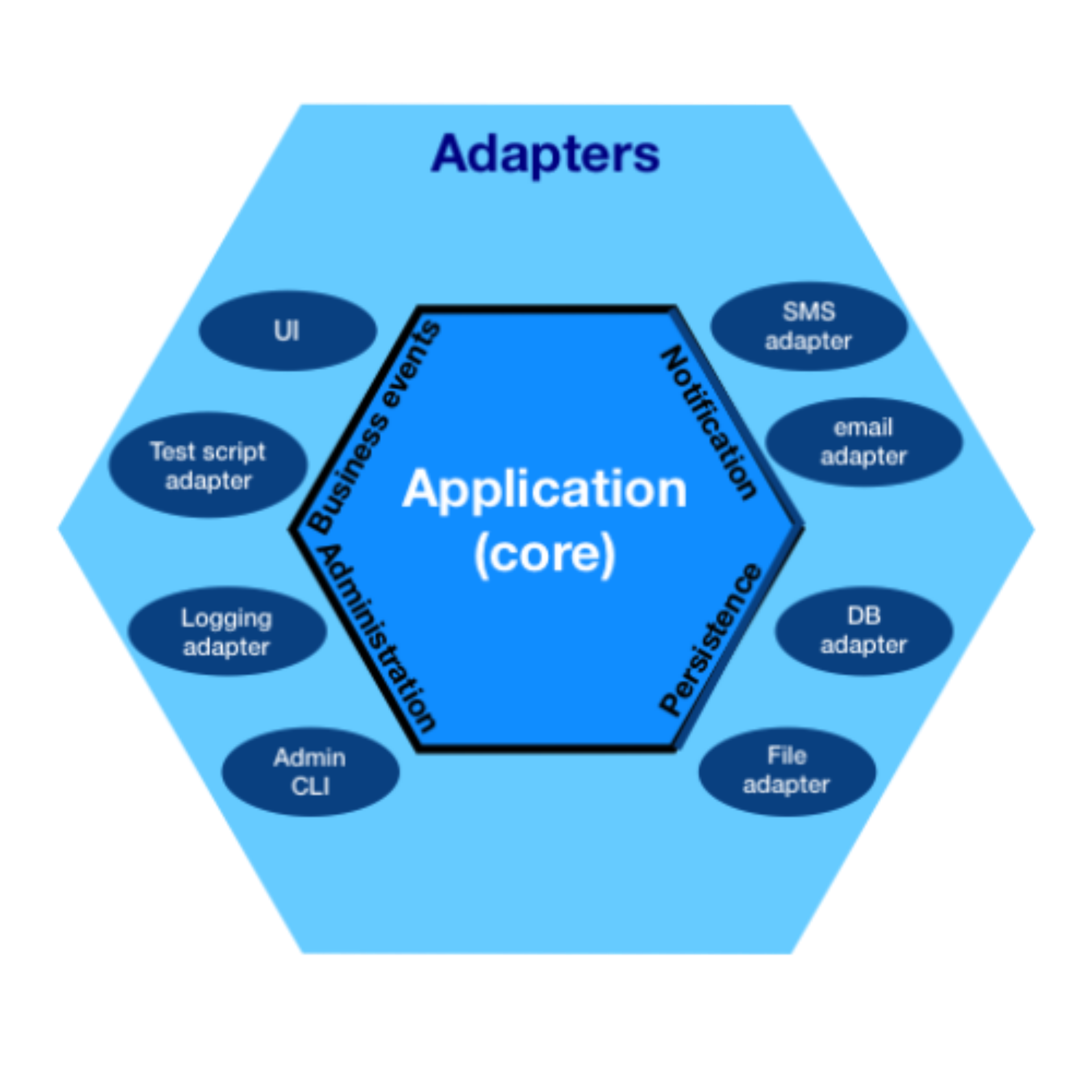
Hexagonal architecture is usually depicted using a similar image to the one above[1]. In the center, we have application code. This is where your business logic lives. A well-structured application will use Domain-driven design to model and build a software system that matches the business problem. In hexagonal architecture, this DDD-inspired system lives within the application core, where it can focus on implementing business logic without having to deal with the idiosyncrasies of outside systems or dependencies.
Surrounding the application core is a solid hexagon-shaped border called "ports." The application core communicates with external systems by passing messages or value objects across the ports. Despite the name, the six-sided shape isn't inherently meaningful[2]. What's important is that ports are simply interfaces acting as a boundary between the core and the adapters. The interfaces exposed by ports should match the domain model of your application core and encapsulate implementation details of the external systems.
Adapters live on the other side of the "ports." They are the concrete implementations of the port interface. Their job is to convert a domain object into a message on some external protocol and generate a new domain object from the response.
Application Core
This is all a bit abstract. Let's look at a concrete example. Imagine our application, jester.codes, needs to show a list of the top 10 gists for a user ordered by the number of stars each gist has. In this scenario, our application core might look something like this:
export const topGistsForUser = async (username: string) => {
const gists = await getGistsForUser(username);
return gists
.sort((a, b) => {
return b.stargazerCount - a.stargazerCount;
}).slice(0, 10);
};The core of our business logic is sorting a list of gists and taking the first 10. But to achieve this, we need to interface with a couple of ports. The first port invokes our business logic and passes in the username as a value. In our example, this port is the function signature. We also leverage a port to fetch the list of gists for the user via the getGistsForUser interface.
// port
export const topGistsForUser = async (username: string) => {
// port
const gists = await getGistsForUser(username);
// business logic
return gists
.sort((a, b) => {
return b.stargazerCount - a.stargazerCount;
}).slice(0, 10);
};
Since this function just accepts a username as the input and returns a list of Gists as the output, its logic and behavior are only limited to our application domain. This enables easy reuse of the core logic in different contexts because we don't have any direct coupling to any one specific Remix loader or action. These properties also simplify unit testing. Let's look at the tests now.
describe("gistService", () => {
it("should return sorted gists", async () => {
const oneStarGist = stub<Gist>({ stargazerCount: 1 });
const threeStarGist = stub<Gist>({ stargazerCount: 3 });
const fiveStarGist = stub<Gist>({ stargazerCount: 5 });
vi.spyOn(githubClient, "getGistsForUser").mockResolvedValue([
threeStarGist,
fiveStarGist,
oneStarGist,
]);
const topGists = await gistService.topGistForUser("octocat");
expect(topGists[0]).toBe(fiveStarGist);
expect(topGists[1]).toBe(threeStarGist);
expect(topGists[2]).toBe(oneStarGist);
});
it("returns at most 10 gists", async () => {
const aDozenGists = Array.from({length: 12}).map(() => stub<Gist>({}));
vi.spyOn(githubClient, "getGistsForUser").mockResolvedValue(aDozenGists);
const topGists = await gistService.topGistForUser("octocat");
expect(topGists.length).toBe(10);
});
});
We have two tests for our core logic. The first test ensures we are sorting our gists correctly, and our second test asserts that we only return the first 10 results.
We can use an outside-in approach to testing and mock out our external dependency at the getGistsForUser port. Hexagonal architecture promotes decoupling because our application core is only coupled to the interface exposed by the port and not the implementation-specific details of interfacing with GitHub directly. This makes it painless to create a test mock along this boundary.
Adapters
We've seen how ports help hide the complexities of external systems from our core application logic. But experience tells us that complexity has to live somewhere. Only toy software systems can remain blissfully ignorant of the outside world. In hexagonal architecture, these complexities live in adapters. An adapter's job is to translate our domain objects into an external protocol so our system can interact with the outside world. It also converts the responses back into domain objects that the core system can understand. Adapters encapsulate logic and decisions specific to the external dependency/protocol, but they should not perform any business logic.
import { graphql } from "@octokit/graphql";
export const getGistsForUser = async (username: string) => {
const response = await graphql<GistResponse>(`<long graphql string>`,
{
headers: {
authorization: `token ${process.env.GITHUB_TOKEN}`,
},
},
);
return response.user.gists.nodes;
};Our adapter implementation above conforms to the getGistsForUser port while hiding the complexities of talking to the GitHub API, providing authentication, and unwrapping the response envelope. Since it integrates with an external service, we want an integration test for this component. Integration tests are painful to work with because they can be slow to execute and depend on external state. But since this adapter is relatively limited in scope and our core business logic lives outside of the adapter, we can get away with just a single test for this behavior.
import { getGistsForUser } from "./githubClient";
describe("githubClient", () => {
it("it should fetch gits from the github api", async () => {
const gists = await getGistsForUser("octocat");
expect(gists).toHaveLength(8);
expect(gists[0].description).toBe(
"Some common .gitignore configurations",
);
});
});
Tightly focused adapters are not just important for testing they are also are much easier to maintain and evolve over time. If the external system changes, you only need to update the relevant adapter. Its also easy to swap out adapters if needed. For example, if we decide to switch from GitHub's GraphQL interface to its REST API for fetching gist, we could re-write this adapter without impacting the rest of the application.
The Role of Remix in Hexagonal Architecture
We are four sections into this blog post, and we've barely talked about Remix. Where does it fit into this architecture?
The secret is Remix is just another adapter for our core business logic. Its job is to translate incoming HTTP requests into domain objects for our system and translate the resulting entities into HTTP responses for the browser.
This job primarily falls on the loader/action functions in a Remix app. So let's take a look at one now.
export async function loader({ params }: LoaderFunctionArgs) {
try {
const topGists = topGistForUser(params.username || "");
return json({
topGists: await topGists,
});
} catch (error) {
throw json({}, 404);
}
}In the code above, the Remix loader works as an adapter by grabbing the username out of the incoming request and passing it into our core application logic via the topGistForUser port. It also takes the resulting list of top gists and transforms it into an HTTP response object that serializes our data as JSON. In some cases, it might also be responsible for some error handling, transforming our domain exception into an HTTP 404 page.
loader/action layer is the only part of your codebase that should be touching the incoming Request and outgoing Response. You will want to unwrap any data from this request and transform it into a more concrete domain object before passing it down into your core application. If your port interface functions take a Request or FormData object as a parameter, that is usually a sign you are leaking some of your adapter implementation details into your core app logic.Additionally, since
Request and FormData are envelopes that can hold lots of different data, passing them around between different layers of the system means losing an opportunity for TypeScript to enforce correctness in our system. TypeScript usually doesn't know what kind of data they hold in the body. By unwrapping these objects early and converting them into well-defined types, you can leverage TypeScript's type-checking capabilities to ensure data integrity and consistency throughout your application.Testing the Remix Adapter
Testing this adapter is fairly straightforward using the same outside-in approach we used for the application core.
describe("loader", () => {
it("should return the top gists for the username", async () => {
const gists = [stub<Gist>({ id: "gist" })];
vi.spyOn(gistService, "topGistForUser").mockResolvedValue(gists);
const response = await loader(stub<LoaderFunctionArgs>({
params: { username: "octocat" }
}));
const data = await response.json();
expect(data.topGists).toEqual(gists);
});
it("should reject with a 404 if the user name is invalid", async () => {
vi.spyOn(gistService, "topGistForUser").mockRejectedValue(
new Error("no such user"),
);
const response = await loader(stub<LoaderFunctionArgs>({
params: { username: "no_such_user" }
}));
expect(response).rejects.toMatchObject({
status: 404,
});
});
});
Once again, we can mock out our dependencies on the core application logic at the topGistForUser port. This lets us focus on testing only the behavior of this adapter and not other parts of the system. TypeScript guarantees the topGistForUser interface stays in sync and alerts us to any changes in the contract that might break our test or production code.
Conclusion
The hexagonal architecture, with its emphasis on ports and adapters, offers several advantages for developing a maintainable Remix application. Think of ports as walls between different parts of your app. They keep the messy details of how you talk to external systems separate from the core logic. This means you can swap out those external parts without tearing your whole app apart. This isolation significantly simplifies the process of evolving the user interface, as UI changes can be made without the need to rewrite the underlying domain logic. Additionally, updating dependencies becomes more manageable because they are confined to isolated adapters rather than being spread across the entire application. The use of ports also provides excellent test seams, allowing for fast and isolated unit tests that ensure the reliability and stability of your codebase. Let's take a closer look at how to implement these principles effectively within your Remix application.
- Remix is the Adapter: Your Remix loaders and actions are your HTTP translators. Keep them lean, focused on request/response handling, and let your core business logic shine elsewhere.
- Unwrap and Conquer: Before you pass data into the heart of your application, take the time to unwrap those
RequestandFormDataobjects. Your domain objects will thank you, and so will your type checker. - Keep Adapters Pure: Think of your client adapters like diplomats: they facilitate communication, but they don't make policy decisions. Leave the business logic to your core domain.
- Test with Confidence: Embrace the test seams that ports provide. By mocking dependencies at these boundaries, you unlock the power of isolated, focused unit tests.
Additional Resources
Alistair Cockburn's writings
Both the user-side and the server-side problems actually are caused by the same error in design and programming — the entanglement between the business logic and the interaction with external entities. The asymmetry to exploit is not that between ‘’left’’ and ‘’right’’ sides of the application but between ‘’inside’’ and ‘’outside’’ of the application. The rule to obey is that code pertaining to the ‘’inside’’ part should not leak into the ‘’outside’’ part.
AWS prescriptive guidance
Use the hexagonal architecture pattern when:You want to decouple your application architecture to create components that can be fully tested.Multiple types of clients can use the same domain logic.Your UI and database components require periodical technology refreshes that don't affect application logic.
Jester
The example remix project reference by this blogpost.
Call to Action
Adopting a hexagonal architecture in your Remix applications can transform the way you build, test, and maintain your software. By decoupling your core business logic from external dependencies, you create a more modular, maintainable, and testable codebase. Experiment with this architecture pattern in your projects. Explore the example project Jester to see these principles in action, and check out the source code for more insights. If you have any questions or want to share your experiences, feel free to leave a comment below or reach out on social media. Let's build better websites!
?ref=laconicwit.com#/media/File:Hexagonal_Architecture.svg){kind=link}
[2] It was just picked so the author could leave enough space to represent the different interfaces needed between the component and the external world.
]]>Welcome, brave souls, to a realm where the ordinary meets the supernatural, where lines of code transform into incantations. Today, I extend an invitation to journey with me into the depths of arcane knowledge, armed with a dusty tome retrieved from the restricted section of the Miskatonic University. This hallowed grimoire is none other than the enigmatic Necronomicon ECMAScript 2023 specification.
As you gather around, let the flickering candlelight cast eerie shadows upon the walls, for what we are about to explore is not just a collection of spooky tales—it's a journey into the spectral corners of JavaScript language. I want you to know with certainty, dear readers, that as with the best ghost stories these tales are all 100% true. So, steel yourselves, for the phantoms of JavaScript await their awakening, and our expedition into the unknown commences now.
The Cursed Legacy of undefined
Our first tale today is an oldie but a goodie. Let us turn to section 12.7.2 Keywords and Reserved Words.
Here we find a list of all the reserved words in JavaScript.
Syntax
ReservedWord :: one of
await break case catch class const continue debugger default delete do else enum export extends
false finally for function if import in instanceof new null return super switch this throw
true try typeof var void while with yield
The scary part about this list isn't what is there but what is missing. Keen readers may notice that null is a reserved word but it's diabolical double undefined is missing from this list. This is because undefined is implemented as a variable. If we turn to section 19.1.4 we can see the undefined is defined as a property of the global object that is neither writable nor configurable.
But it wasn't always that way. Some of the most ancient among you may remember these chaotic days before ECMAScript 5 (2009). Until that version of the language undefined was still a writeable object on the global scope. So the variable undefined could in fact be redefined.
Not the concept of undefined, mind you. Just its variable binding in most JavaScript scopes. This led to many defensive coding techniques, such as libraries creating their own undefined variables or comparing values against the void 0 statement which always returns undefined. This has become much less of an issue recently. Every modern JavaScript runtime now follows a version of the ECMAScript spec which prevents users from casually re-writing the undefined variable.
undefined = 'Boooooooooooo!';
console.log({ undefined }); // { undefined: undefined }However, if on a dark moonlit night you find yourself wanting to give your colleagues a fright, you can still invoke a bit of the chaotic times of the past by wrapping your code in a function with a parameter binding named undefined.
(function (undefined) {
undefined = 'Boooooooooooo!';
console.log({ undefined }); // { undefined: "Boooooooooooo!" }
})();Just be careful how you use this power...
The primitive monster
Our next tale is another classic. First we need to check out the dog eared pages of section 7.1.1.1. Here lies the abstract incantation for the ToPrimitive spell that is used to convert objects into primitives such as strings or numbers.
We learn from these pages that one can define a method named with the built in symbol Symbol.toPrimitive on an object that will be used by the JavaScript runtime to convert the object to a primitive value.
This spell says JavaScript will attempt to call the Symbol.toPrimitive method on an object if it thinks the object should be converted to a number or string. Conversion happens in a number of places but the most common is when comparing a value with == or !=. It can also happen when using the value as a key to another object otherObject[myValue].
One thing keen readers might notice is the JavaScript doesn't require us to always return the same value. We can use this unfortunate knowledge to create a most sinister object. An object that can be used in illogical statements such as (a == 1 && a == 2) by introducing some mutation into our Symbol.toPrimitive method.
let evil = {
index: 0,
[Symbol.toPrimitive](hint) {
return this.index++;
}
};
console.log(evil == 0 && evil == 1); // trueNow, this may be a fine parlor trick, but with the dark magic of Symbol.toPrimitive we can go deeper and build a chameleon object that adapts to the shape of its surroundings.
let evil = {
[Symbol.toPrimitive](hint) {
switch (hint) {
case 'number':
return 333;
case 'string':
return 'boo';
case 'default':
return Date.now();
}
}
};
console.log(2 * evil); // 666
console.log((evil in {'boo': 1})); // true
console.log(evil == +new Date()); // true
with(evil) {}
with is an ancient word of power. Deemed to be too error-prone by the elders and too hard to optimize by the engine implementers it has been banished from modern JavaScript. If you try to invoke it in a strict mode function or a JavaScript module you will be met with a SyntaxError. However, it is still possible for stict mode functions or modules to tap into its power by calling a function defined outside of strict mode.
with adds a new object to the scope chain whose properties automatically become global variables that can be referred to without qualifiers.
let myContext = {
evil: 'demon',
macabre: 'ghost',
nocturnal: 'vampire',
};
with (myContext) {
console.log(evil); // 'demon'
console.log(macabre); // 'ghost'
}
console.log(nocturnal); // ReferenceError: nocturnal is not definedwith can be used in a pinch for making a quick templating library.
function interpolate(context, template) {
with (context) {
return eval('`' + template + '`');
}
}
interpolate(
{ ghost: 'Slimer', place: 'hotel' },
'The ${ghost} haunted the ${place}.'
); // 'The Slimer haunted the hotel.'
But with is usually best avoided because it is hard for a human reader to decide whether an unqualified name will be found along the scope chain, and if so, in which object.
function printGhost(ghost, graveyard) {
with (graveyard) {
console.log(ghost);
}
}
printGhost('Banquo', {}); // Banquo
printGhost('Banquo', { ghost: 'Brom Bones'}); // ???Try to wrap your head around that, just don't lose it in the process.
The Haunted Annex
For our final story we will venture into my favorite section of the ECMAScript spec, the dreaded Annex B.
But first a test for those of you who have been studying. What doesn't the following code do? No cheating and typing it into a console. Try and reason through it on your own.
let a = 0;
a = a<!--10;
console.log(a); // ?
Before we learn the answer we must look back in time. Back to the earliest days of browser magic, back before the ECMAScript spec catalogued all of the arcane sorcery of the open web. The sorcerers at Netscape created JavaScript but the warlocks and witches of Microsoft were a jealous bunch. They coveted Netscape's power and sought to copy it for their own purposes. And copy they did, emulating it exactly down to the most minor spell and incantation.
Netscape was alarmed at this development and turned to the acolytes at ECMA for help. They wished to bind the magic of JavaScript into a specification to make it more predictable and useful to all. But when they started drafting the first spec Microsoft appeared and insisted the spec include every last minor spell that Microsoft had worked so hard to copy.
The sorcerers at Netscape did not like many of the minor spells they created in haste, but Microsoft insisted, until a compromise was reached. It was agreed to include these hacky cantrips, but hide them very back of the ledger. In a section called Annex B Additional ECMAScript Features for Web Browsers to dissuade all but the most curious from reading.
Annex B contains all of the dark and unsavory kludges the sorcerers at Netscape were too embarrassed to admit they unleashed upon the world but the witches and warlocks of Microsoft were too prideful at copying to let them forget.
Now with this history lesson over let us return to our test for it helps us to remember the context of the earliest JavaScript spells.
<script>
let a = 0;
a = a<!--10;
console.log(a); // 0
<!-- html comment -->
</script>The old masters at Netscape had included <!-- in their grammar as an alias for the start of a comment block // to facilitate html comments inside script tags. So our humble <!-- operator is a simple comment.
Sometimes the ghosts of the pasts can be scary, and other times they are just pragmatic.
Thanks to Ingrid for feedback and reading drafts and Mike Pennisi for sharing many of these spooky tales with me.
Photo credit: https://www.flickr.com/photos/9741459@N07/6522146791/
]]> The loader API is the best thing about Remix.
Some background: A loader is a custom defined function that is responsible for "loading" all of
This is an uncontroversial opinion for people using Remix, but it needs to be said:
The loader API is the best thing about Remix.
Some background: A loader is a custom defined function that is responsible for "loading" all of the data that is required to render a route. It's often paired with a React component that I will refer to as the RouteComponent which is responsible for using that data to render a HTML page.
In Remix, by convention, both of these live in the same file in the app/routes directory. Remix auto discovers files in this directory to build up the supported url paths in an application based on their filename.
Love is simple
Let's start with the simplicity. The Remix loader is a function that takes a Request (and a few other arguments) and returns a promise that resolves to a Response. That's it!
The loader's primary job is to "load" all of the data required to render this route. Pretty good name huh? Let's look at a concrete example. Here is a simple loader that returns search results:
export async function loader({
request,
}: LoaderFunctionArgs) {
const query = new URL(request.url).searchParams.get('s');
const results = await searchService.search(query);
return json({
query,
results,
});
}The result of the loader function is automatically made available to the route component and can be accessed using the useLoaderData hook.
export async function loader({
request,
}: LoaderFunctionArgs) {
const query = new URL(request.url).searchParams.get('s');
const results = await searchService.search(query);
return json({
query,
results,
});
}
export default function Search() {
const {query, results} = useLoaderData<typeof loader>();
return (
<div>
<h1>Search: {query}</h1>
{results.map((result) => (
<div key={result.id}>{result.name}</div>
))}
</div>
);
}That is the gist of the loader function. Conceptually its pretty simple. One thing to know is the loader is only ever run on the server. On the initial server render, the response will be embedded in the HTML document. On the client, navigation changes in the browser, Remix will call the loader via fetch to avoid a full page reload.
Now let's look at some of the more powerful things we can do with it.
Love brings data together
Firstly, the loader is a great place to aggregate data from across multiple different sources. If we structure our code right we can even fetch data in parallel to speed up our response. The RouteComponent won't load until all of the data is resolved which can simplify some client scenarios since we don't have to worry about partial data.
export async function loader({
request,
}: LoaderFunctionArgs) {
const query = new URL(request.url).searchParams.get('s');
const results = searchService.search(query);
const recommendations = recommendationsService.search(query);
return json({
query,
results: await results,
recommendations: await recommendations,
});
}The loader is also a great place to filter and process the data so we aren't bloating the network or client with irrelevant information.
Love finds its own logic in the language of the web
Since the loader's promise only needs to resolve to a Response object it's also great for doing some light business logic related to the web requests. This includes returning redirects, 404s, or other errors.
export async function loader({
request,
}: LoaderFunctionArgs) {
const id = new URL(request.url).searchParams.get('id');
const result = await entityService.find({id});
if (result === null) {
throw new Response(null, {
status: 404,
statusText: "Not Found",
});
}
if (result.id !== id) {
return redirect(`?id=${result.id}`);
}
return json({
result,
});
}If our loader returns a rejected promise, Remix will recognize that as an error and render a special ErrorComponent instead of our RouteComponent. This lets us focus on handling the happy path in our RouteComponent.
Love is dynamic
So far we've only used the loader to pull down data for the initial page load. It may not be obvious but the loader is also a great place for dynamically loading data in response to user input. This is because by default Remix will re-run the loader every time our url changes.
This makes it a great place to load dynamic data in response to user input. All we have to do is tie the data to the url.
So next time we find ourselves reaching for a useEffect to fetch data from an API every-time the user changes some state.
export default function DateSelector() {
const [date, setDate] = useState(null);
const [results, setResults] = useState([]);
useEffect(() => {
fetch(`/myDataAPI?date=${date}`).then(r => r.json()).then(setResults);
}, [date]);
return (
<>
<DatePicker date={date} setDate={setDate} />
<ResultsList results={results} />
</>
)
}Instead try pushing some of that logic into the Remix loader.
export async function loader({
request,
}: LoaderFunctionArgs) {
const date = new URL(request.url).searchParams.get('date');
const results = await fetch(`/myDataAPI?date=${date}`).then(r => r.json());
return json(results);
}
export default function DateSelector() {
const date = new URLSearchParams(location.search).get('date');
const results = useLoaderData();
return (
<>
<DatePicker date={date} setDate={(newDate) => history.push(`?date=${newDate}`)} />
<ResultsList results={results} />
</>
)
}This change reduces the complexity of our <DateSelector /> component by pushing some of that complexity into Remix and our url. It also makes things easier to test since the loader is a simple Request -> Response function and our <DateSelector /> no longer has its own state.
This results in less work for us developers but as an added bonus we now have a better user experience for our customer since the state is now tied to the url, they can bookmark the page, share the link or just get back to where they are without extra hassle if their mobile phone unloads the tab.
In addition to url changes, Remix also re-runs the loader automatically after the user performs a <form> posts. This keeps our UI up to date with the latest data for free. Thanks loader! This behavior sounds simple but once you start using it you will be surprised at how much less often you find yourself reaching for a client side state management library like redux since the Remix loader handles the grunt work of syncing state with the server.
Love has a type
The decision to keep the loader function and RouteComponent in the same file creates some really great TypeScript support.
export async function loader({
request,
}: LoaderFunctionArgs) {
const query = new URL(request.url).searchParams.get('s');
const results = await searchService.search(query);
return json({
query,
results,
});
}
export default function Search() {
const {query, results} = useLoaderData<typeof loader>();
return (<>...</>);
}Look at that! It feels almost unfair that we can just add a typeof loader in the same file. No need to name a type. No need for an extra import/export. Things just work! Over the network! It almost feels unfair to other TypeScript code we write that Remix makes this so easy. Our editor/tools knows about any and all changes in the return value of the loader function.
Love's path may be parallel
In Remix, it is possible to have multiple routes active at one time when a UI is nested. This is useful when multiple pages share a common header or footer. When this happens, Remix will run the loader functions for each active route in parallel. This avoids accidentally introducing chained request sequences for independent data and ensures our user gets a quick response without requiring us to think about performance.
Love's pain, a bitter reminder of its depth
Whenever there is a super power it casts a shadow, and the Remix loader is absolutely a super power. But it does have its challenges.
Magic splits frontend code and backend code
The loader function runs on the server, but the RouteComponent runs on the client. For the developer, both of these functions live in the same file. The Remix compiler has to be pretty smart to figure out what code to pull into the client bundle and what should stay on the server.
Luckily, it works! And works surprisingly well! However, the complexity needed to make it work still makes me nervous. Is there a gap in all that complexity? Will Remix make a mistake one day and include something in a client bundle that it shouldn't?
A simpler model of all server code using a convention of ending with.server.ts would give me more confidence, however it would also degrade Remix's great dev experience.
useLoaderData() is a bit clunky
This is mainly a complaint about testing. Since useLoaderData() is a hook and relies on Remix wiring up its engine around the component it can be a bit awkward to test a RouteComponent and inject some mocked data. It would be nicer if we had a different interface for injecting the server state into the client, but the hook is probably the most appropriate and familiar approach for React developers in 2023.
Easy to introduce waterfalls in async loader functions
If we naively add await to every function call that returns a promise it's a bit too easy to accidentally introduce a waterfall where we are waiting for one async request to complete before starting another async request in a sequence chain. This is a problem with all async functions and not a Remix specific issue. However, Remix could help address the issue by automatically unwrapping some promises and showcasing patterns for parallel loading in the loader documentation.
Love is gratitude in action
So thank you, humble Remix loader, for being the catalyst of my creativity, the backbone of my projects, and my only true love of the Remix API.
Thanks to Ingrid, Ryan Canulla and Clayton Phillips-Dorsett for feedback and for reading drafts.
]]>This is Laconic Wit, a brand new site by Brendan McLoughlin that's just getting started. Things will be up and running here shortly, but you can subscribe in the meantime if you'd like to stay up to date and receive emails when new content is published!
]]>