
以下是我觉得还不错的训练计划:
- Marathon Handbook, 20 week version
- Garmin: Garmin 16 week plan, Garmin connect上也有每周3/5/7次训练的马拉松计划。
- ASICS Marathon Training Plans
- 马拉松终极训练指南 - 霍尔·希格登: training plans
目前决定使用Marathon Training : Novice 2来备战首马,希望自己能坚持,不要随意跳进度或偷懒。
The plan
| Week | Mon | Tue | Wed | Thu | Fri | Sat | Sun |
|---|---|---|---|---|---|---|---|
| 1 | Rest | ✅4.8 km run | ✅8.1 km pace | ✅4.8 km run | Rest | ✅12.9 | ✅Cross |
| 2 | Rest | ✅4.8 km run | ✅8.1 km run | ✅4.8 km run | Rest | ✅14.5 | ❌Cross |
| 3 | Rest | ✅4.8 km run | ✅8.1 km pace | ✅4.8 km run | Rest | ✅9.7 | ❌Cross |
| 4 | Rest | ✅4.8 km run | ✅9.7 km pace | ❌4.8 km run | Rest | ✅17.7 | ❌Cross |
| 5 | Rest | ✅4.8 km run | ❌9.7 km run | ✅4.8 km run | Rest | ✅19.3 | ✅Cross |
| 6 | Rest | ✅4.8 km run | ✅9.7 km pace | ✅4.8 km run | Rest | ⏳14.5 | ✅Cross |
| 7 | Rest | ✅6.4 km run | ❌11.3 km pace | ✅6.4 km run | Rest | ✅22.5 | ❌Cross |
| 8 | Rest | ✅6.4 km run | ❌11.3 km run | ⏳6.4 km run | Rest | ⏳24.1 | Cross |
| 9 | Rest | 6.4 km run | 11.3 km pace | 6.4 km run | Rest | Rest | Half Marathon |
| 10 | Rest | 6.4 km run | 12.9 km pace | 6.4 km run | Rest | 27.4 | Cross |
| 11 | Rest | 8.1 km run | 12.9 km run | 8.1 km run | Rest | 29.0 | Cross |
| 12 | Rest | 8.1 km run | 12.9 km pace | 8.1 km run | Rest | 21.0 | Cross |
| 13 | Rest | 8.1 km run | 8.1 km pace | 8.1 km run | Rest | 30.6 | Cross |
| 14 | Rest | 8.1 km run | 12.9 km run | 8.1 km run | Rest | 19.3 | Cross |
| 15 | Rest | 8.1 km run | 8.1 km pace | 8.1 km run | Rest | 32.2 | Cross |
| 16 | Rest | 8.1 km run | 6.4 km pace | 8.1 km run | Rest | 19.3 | Cross |
| 17 | Rest | 6.4 km run | 4.8 km run | 6.4 km run | Rest | 12.9 | Cross |
| 18 | Rest | 4.8 km run | 3.2 km run | Rest | Rest | 3.2 km run | Marathon |
Week 8
| Date | Dist. | Time | Pace | Note |
|---|---|---|---|---|
| 06/06 | 6.55 | 46:26 | 7:05 | 23⛰️ |
| 06/08 | 4.01 | 25:26 | 6:20 | |
| 06/10 | 21.03 | 2:22:07 | 6:46 | 81⛰️ |
Week 7
| Date | Dist. | Time | Pace | Note |
|---|---|---|---|---|
| 05/29 | 31:20 | 🤸 | ||
| 05/30 | 6.4 | 41:00 | 6:24 | Outdoor + Treadmill |
| 05/31 | 2.3 | 28:46 | 12:30 | Treadmill |
| 06/01 | 6.4 | 42:00 | 6:34 | Ourdoor + Treadmill |
| 06/03 | 17.20 | 2:17:15 | 7:59 | 767⛰️ |
Week 6
| Date | Dist. | Time | Pace | Note |
|---|---|---|---|---|
| 05/22 | 25:00 | 🏋️ | ||
| 05/23 | 4.81 | 36:43 | 7:38 | 12⛰️ |
| 05/24 | 9:60 | 1:02:59 | 6:33 | Treadmill |
| 05/26 | 4.81 | 33:26 | 6:57 | Treadmill |
| 05/27 | 7.55 | 57:57 | 7:40 | 118⛰️ |
Week 5
| Date | Dist. | Time | Pace | Note |
|---|---|---|---|---|
| 05/16 | 4.80 | 28:42 | 5:59 | Treadmill |
| 05/17 | 4.81 | 30:27 | 6:20 | Treadmill |
| 05/20 | 20.01 | 2:04:41 | 6:41 | 100⛰️ |
Week 4
| Date | Dist. | Time | Pace | Note |
|---|---|---|---|---|
| 05/09 | 4:82 | 31:26 | 6:32 | 92⛰️ |
| 05/10 | 10.08 | 59:07 | 5:52 | 142⛰️ |
| 05/13 | 18:01 | 1:57:26 | 6:31 | 208⛰️ |
Week 3
| Date | Dist. | Time | Pace | Note |
|---|---|---|---|---|
| 05/02 | 4.8 | 28:53 | 6:01 | 94⛰️; 15min strength training |
| 05/03 | 8.11 | 57:58 | 7:09 | 142⛰️ |
| 05/05 | 4.81 | 28:37 | 5:57 | Treadmill |
| 05/06 | 10.15 | 59:19 | 5:51 | 116⛰️ |
Week 2
| Date | Dist. | Time | Pace | Note |
|---|---|---|---|---|
| 04/24 | 1:55:22 | 🎾 | ||
| 04/25 | 4.96 | 25:43 | 5:11 | 68m ⛰️ |
| 04/26 | 8.11 | 52:32 | 6:29 | 135 ⛰️ |
| 04/27 | Schedule changed | |||
| 04/28 | 4.81 | 27:21 | 5:41 | Treadmill |
| 04/29 | 15.01 | 1:36:03 | 6:24 | 113 ⛰️ |
Week 1 (Year 2023)
| Date | Dist. | Time | Pace | Note |
|---|---|---|---|---|
| 04/17 | 2:03:05 | 🎾 | ||
| 04/18 | 6.02 | 33:22 | 5:32 | 65m ⛰️ |
| 04/19 | 8.01 | 59:17 | 7:24 | 120m ⛰️ |
| 04/20 | 5.01 | 34:13 | 6:50 | 47m ⛰️ |
| 04/21 | 23:13 | 🏋️ | ||
| 04/22 | 13.01 | 1:36:14 | 7:24 | 185 ⛰️ |
| 04/23 | 25:00 | 🤸🏻 |
Why Ph.D.?
25岁之前,我脑中几乎从未闪过读博的念头,甚至一度觉得读博是逃避现实的选择。媒体上“书呆子”、“不通人情世故”、“读书读傻了”的标签构成了我对博士的刻板印象。但人的本质是“真香”,“鸽子”和“复读机”。身边爱好广泛、多才多艺的博士们使我改变了偏见:硕士实验室中有爱摄影的文艺博士,认识的朋友里有运动达人+游戏高手博士,还有投身于创新创业或公益事业并取得瞩目成就的优秀博士。我觉得,有机构愿意资助我,使我可以专注于某个领域,甚至尝试拓展该领域知识的边界,是一件“真香”的事情。偶然的机会,我读到了韦伯的《以学术为志业》。韦伯提出,年轻人如果把学术作为谋生手段,性价比太低。
如果失败了呢?
引用罗曼·罗兰的一句话,“世界上只有一种真正的英雄主义,就是认清了生活的真相后还依然热爱它”。随着年龄的增长,我越来越认识到自己的平凡,选择读博士并不是因为我认为自己可以发表很多论文,收获鲜花、掌声和财富。我希望我能在5年后坦然面对平庸的博士生涯,与自己的失败和解。
未来职业规划
此时此刻,虽然意识到自己可能面临的失败,但我仍然忍不住上头了。如果有可能,我期待未来能在大学任教,继续从事科研方面的工作。
再见2019,拥抱2020。
]]>根据在网上的调研,猫咪长距离托运主要有两种方式:火车和飞机。两种方法各有优劣:火车费用低但时间长,且高铁不能托运;飞机费用贵但时间短,且比火车更危险。

综合比较,我选择带小龙虾坐飞机。经过4小时的颠簸,小龙虾和我一起安全抵达,下飞机后他的精神不错,在机场还引来了围观。
现在,本来说“暂时”帮我养猫的爸妈已经“和小龙虾有了感情”,“不同意把小龙虾再拿走”。不得不说,猫真是人见人爱啊。

为了给未来希望托运猫咪的朋友提供一些帮助,下面是我记录的托运准备事项,仅供参考。
-
联系航班,申请小动物托运
建议直接打电话到相应航空公司预定,客服会帮忙查询航班是否有空余有氧舱。最终搭乘时,可能因为临时因素取消(小概率)。 -
猫咪免疫及托运证明办理
下文所述是北京的要求,其他城市请咨询当地动物监督所。 宠物医院打狂犬疫苗和猫三联,要求疫苗接种时间在托运前21天-1年之内,开具“北京市动物健康免疫证”。
携带宠物及“北京市动物健康免疫证”,在符合资质的动物医院开具“宠物托运体检证明”(有效期24小时)。
携带“北京市动物健康免疫证”及“宠物托运体检证明”到对应区“动物监督所”办理动物托运证明(有效期:5天)。 -
准备航空箱
航空箱请参考对应航空公司的要求,特别需要注意的是,如果你的航班是小航空公司出售,搭乘的是大航空公司的飞机,一定要问清楚。一般购买最高标准航空箱的不会错。
国航航空箱标准 -
带猫咪上飞机

参考资料:
]]>新词挖掘可以分为两大类:
- 基于分词系统的新词挖掘
- 无监督、无知识的新词挖掘
BaizeNLP Open Web Demo
我正在开发的开源NLP工具集BaizeNLP中提供了无监督、无知识的新词挖掘工具,效果如下:(web demo »)
输入文本,自然语言处理的百度百科。
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分。
自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。
新词挖掘的结果
| # | New Word |
|---|---|
| 1 | 语言 |
| 2 | 自然语言 |
| 3 | 计算机 |
| 4 | 科学 |
| 5 | 领域 |
| 6 | 研究 |
| 7 | 自然语言处理 |
| 8 | 计算机科学 |
| 9 | 是计算机科学 |
| 10 | 重要 |

新词挖掘的原理
BaizeNLP中的新词挖掘算法原理来自Matrix67的互联网时代的社会语言学:基于SNS的文本数据挖掘。
不依赖于任何已有的词库,仅仅根据词的共同特征,将一段大规模语料中可能成词的文本片段全部提取出来,不管它是新词还是旧词。然后,再把所有抽出来的词和已有词库进行比较,不就能找出新词了吗?
Matrix认为,一段文本构成词语由它的内部凝固程度和它的自由运用程度构成。内部凝固程度衡量的是该词语的出现频率和该词语是有意义的搭配的程度,内部凝固程度越高,该文本片段越可能是一个词语;自由运用程度考察的是该词语左右邻字的丰富程度,自由运用程度越高,该文本片段越可能是一个词语。
在自然语言处理的百度百科语料中,部分文本片段的内部凝固程度和自由运用程度如下:
| 文本片段 | 内部凝固程度(bit) | 自由运用程度(bit) | 频率 |
|---|---|---|---|
| 自然 | 7.544 | 0.0 | 9 |
| 然语 | 7.014 | 0.0 | 9 |
| 语言 | 7.014 | 1.509 | 13 |
| 自然语 | 7.014 | 0.0 | 9 |
| 自然语言 | 7.014 | 2.281 | 9 |
| 然语言处 | 7.544 | 0.0 | 4 |
| 自然语言处 | 7.544 | 0.0 | 4 |
| 自然语言处理 | 7.544 | 0.811 | 4 |
| 然语言处理是 | 7.129 | 0.0 | 2 |
工程实现
BaizeNLP的新词挖掘工程实现可以参照源码。简单来说,核心实现包括:
- 由语料的ngram片段建立Trie树和逆序Trie树(
n=词语最大长度+1) - 由Trie树计算片段的出现频次、凝固程度和左邻字符集合熵
- 由逆序Trie树计算片段的右邻字符集合熵
- 计算片段成词的得分
在其他语料上的新词挖掘结果
《西游记》
行者,八戒,师父,三藏,行者道,大圣,一个,唐僧,菩萨,沙僧,和尚,怎么,者道,我们,不知,长老,那里,笑道,妖精,老孙,悟空,甚么,两个,八戒道,国王,徒弟,闻言,那怪,如何,呆子,只见,三藏道,与他,不敢,不曾,宝贝,小妖,原来,大王,道师父,今日,正是,等我,兄弟,出来,叫道,如今,一声,取经,铁棒
《资本论》
资本,生产,价值,劳动,商品,货币,这种,部分,形式,一个,00,工人,这个,利润,我们,作为,价格,因此,产品,剩余,流通,如果,资本家,已经,过程,他们,可以,土地,因为,社会,增加,但是,没有,就是,只是,情况,这样,自己,10,必须,地租,这些,银行
世界,中国,全球,人类,主义,共同,命运,发展,构建,时代,经济,推动,国际,多边,历史,20,治理,合作,多边主义
小说,斯通纳,生活,完美,威廉,力量,意义,是一,是一部,文学,的小说,这本,的一生,追求,或许,献给,艺术,语言,密苏里,勇者
参考资料
]]>下面以jieba的示例给读者一个对分词的感性认识。
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
中文分词的方法和评价指标
从20世纪80年代或更早的时候起,学者们研究了很多的分词方法,这些方法大致可以分为三大类:
- 基于词表的分词方法
- 正向最大匹配法(forward maximum matching method, FMM)
- 逆向最大匹配法(backward maximum matching method, BMM)
- N-最短路径方法
- 基于统计模型的分词方法
- 基于N-gram语言模型的分词方法
- 基于序列标注的分词方法
- 基于HMM的分词方法
- 基于CRF的分词方法
- 基于词感知机的分词方法
- 基于深度学习的端到端的分词方法
在中文分词领域,比较权威且影响深远的评测有 SIGHAN - 2nd International Chinese Word Segmentation Bakeoff。它提供了2份简体中文和2份繁体中文的分词评测语料。
| Corpus | Charset | Train Set Word Types/Counts | Test Set Word Count | OOV Rate |
|---|---|---|---|---|
| Academia Sinica | zh-CHT | 141K/5.45M | 19K/122K | 0.046 |
| City University of Hong Kong | zh-CHT | 69K/1.46M | 9K/41K | 0.074 |
| Peking University | zh-CHS | 55K/1.11M | 13K/104K | 0.058 |
| Microsoft Research | zh-CHS | 88K/2.37M | 13K/107K | 0.026 |
Sighan中采用的评价指标包括:
- 准确率(Precision)
- 召回率(Recall)
- F-测度(F-measure)
- 未登录词的召回率($R_{OOV}$)
- 词典词的召回率($R_{IV}$)
各指标计算公式如下:
\[Precision=\frac{WordCount(CorrectResults)}{WordCount(TrainSet)}\] \[Recall==\frac{WordCount(CorrectResults)}{WordCount(TestSet)}\] \[F1=\frac{2*P*R}{P+R}\]根据THULAC,目前各分词工具在sighan上的评测结果如下:
- msr_test
| Algorithm | Time | Precision | Recall | F-Measure |
|---|---|---|---|---|
| LTP-3.2.0 | 3.21s | 0.867 | 0.896 | 0.881 |
| ICTCLAS(2015版) | 0.55s | 0.869 | 0.914 | 0.891 |
| jieba(C++版) | 0.26s | 0.814 | 0.809 | 0.811 |
| THULAC_lite | 0.62s | 0.877 | 0.899 | 0.888 |
- pku_test
| Algorithm | Time | Precision | Recall | F-Measure |
|---|---|---|---|---|
| LTP-3.2.0 | 3.83s | 0.960 | 0.947 | 0.953 |
| ICTCLAS(2015版) | 0.53s | 0.939 | 0.944 | 0.941 |
| jieba(C++版) | 0.23s | 0.850 | 0.784 | 0.816 |
| THULAC_lite | 0.51s | 0.944 | 0.908 | 0.926 |
各分词方法的细节
正向最大匹配法(FMM)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 我 | 毕 | 业 | 于 | 北 | 京 | 邮 | 电 | ⼤ | 学 |
| pos | remain characters | start character | max matching |
|---|---|---|---|
| 0 | 我毕业于北京邮电⼤学 | 我 | 我 |
| 1 | 毕业于北京邮电⼤学 | 毕 | 毕业 |
| 3 | 于北京邮电⼤学 | 于 | 于 |
| 4 | 北京邮电⼤学 | 北 | 北京邮电⼤学 |
正向最大匹配法,顾名思义,对于输入的一段文本从左至右、以贪心的方式切分出当前位置上长度最大的词。正向最大匹配法是基于词典的分词方法,其分词原理是:单词的颗粒度越大,所能表示的含义越确切。
负向最大匹配法(BMM)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 我 | 毕 | 业 | 于 | 北 | 京 | 邮 | 电 | ⼤ | 学 |
| pos | remain characters | start character | max matching |
|---|---|---|---|
| 4 | 我毕业于北京邮电⼤学 | 北 | 北京邮电大学 |
| 3 | 我毕业于 | 于 | 于 |
| 1 | 我毕业 | 毕 | 毕业 |
| 0 | 我 | 我 | 我 |
反向最大匹配法的基本原理与正向最大匹配法类似,只是分词顺序变为从右至左。容易看出,FMM或BMM对于一些有歧义的词处理能力一般。举个例子:结婚的和尚未结婚的,使用FMM很可能分成结婚/的/和尚/未/结婚/的;为人民办公益,使用BMM可能会分成为人/民办/公益。
虽然在部分文献和软件实现中指出,由于中文的性质,反向最大匹配法优于正向最大匹配法。在成熟的工业界应用上几乎不会直接使用FMM、BMM作为分词模块的实现方法。
基于N-gram语言模型的分词方法
由于歧义的存在,一段文本存在多种可能的切分结果(切分路径),FMM、BMM使用机械规则的方法选择最优路径,而N-gram语言模型分词方法则是利用统计信息找出一条概率最大的路径。

上图为南京市长江大桥的全切分有向无环图(DAG)。可以看到,可能的切分路径有:
- 南京/市/长江/大桥
- 南京/市/长江大桥
- 南京市/长江/大桥
- 南京市/长江大桥
- 南京/市长/江/大桥
- 南京/市长/江大桥
- 南京市长/江/大桥
- 南京市长/江大桥
- …
假设随机变量$S$为一个汉字序列,$W$是$S$上所有可能的切分路径。对于分词,实际上就是求解使条件概率$P(W|S)$最大的切分路径$W^{*}$,即
根据贝叶斯公式,
\[W^{*}=\arg\max_\W \frac{P(W)P(S|W)}{P(S)}\]由于$P(S)$为归一化因子,$P(S|W)$恒为1,因此只需要求解$P(W)$。
$P(W)$使用N-gram语言模型建模,定义如下(以Bi-gram为例):
\[P(W)=P(w_{1}w_{2}\cdots w_{T})= P(w_{1})*P(w_{2}|w_{1})\cdots *P(w_{T}|w_{T-1}) =\prod_{t=1}^{T}\widehat{P}(w_{t}|w_{1}^{t-1})\]至此,各切分路径的好坏程度(条件概率$P(W|S)$)可以求解。简单的,可以根据DAG枚举全路径,暴力求解最优路径;也可以使用动态规划的方法求解,jieba中不带HMM新词发现的分词,就是DAG + Uni-gram的语言模型 + 后向DP的方式进行的。
基于HMM的分词方法
接下来介绍的几种分词方法都属于由字构词的分词方法,由字构词的分词方法思想并不复杂,它是将分词问题转化为字的分类问题(序列标注问题)。从某些层面讲,由字构词的方法并不依赖于事先编制好的词表,但仍然需要分好词的训练语料。
规定每个字有4个词位:
- 词首 B
- 词中 M
- 词尾 E
- 单字成词 S
| X | 我 | 毕 | 业 | 于 | 北 | 京 | 邮 | 电 | ⼤ | 学 |
|---|---|---|---|---|---|---|---|---|---|---|
| Y | S | B | E | S | B | M | M | M | M | E |
由于HMM是一个生成式模型,X为观测序列,Y为隐序列。
\[P(X\ ,\ Y)=\prod_{t=1}^{T} P(y_{t}|y_{t-1})*P(x_{t}|y_{t})\]
熟悉HMM的同学都知道,HMM有三类基本问题:
- 预测(filter):已知模型参数和某一特定输出序列,求最后时刻各个隐含状态的概率分布,即求
$P(x(t)\ |\ y(1),\cdots,y(t))$。通常使用前向算法解决. - 平滑(smoothing):已知模型参数和某一特定输出序列,求中间时刻各个隐含状态的概率分布,即求
$P(x(k)\ |\ y(1),\cdots,y(t)), k<t$。通常使用forward-backward 算法解决. - 解码(most likely explanation): 已知模型参数,寻找最可能的能产生某一特定输出序列的隐含状态的序列. 即求
$P([x(1)\cdots x(t)]\ |\ [y(1)\cdots ,y(t)])$, 通常使用Viterbi算法解决.
分词就对应着HMM的解码问题,模型参数(转移矩阵,发射矩阵)可以使用统计方法计算得到,原始文本为输出序列,词位是隐状态序列,使用Viterbi算法求解即可。具体方法请参照参考资料#2。
jieba的新词模式就是使用HMM识别未登录词的,具体做法是:针对不在词表中的一段子文本,使用HMM分词,并把HMM的分词结果加入到原始分词结果中。
基于CRF的分词方法
与HMM不同,CRF是一种判别式模型,CRF通过定义条件概率$P(Y|X)$来描述模型。基于CRF的分词方法与传统的分类模型求解很相似,即给定feature(字级别的各种信息)输出label(词位)。
简单来说,分词所使用的是Linear-CRF,它由一组特征函数组成,包括权重$\lambda$和特征函数$f$,特征函数$f$的输入是整个句子$s$、当前pos$i$、前一个词位$l_{i-1}$,当前词位$l_{i}$。

引自参考资料#3,以CRF在词性标注上的应用,给大家一个特征函数的感性认识。
- $f_1(s, i, l_i, l_{i-1}) = 1$,如果$l_i$是副词且第i个单词以”-ly”结尾;否则$f_1=0$。该特征函数实际上描述了英语中副词“常常以-ly结尾”的特点,对应的权重$\lambda_1$应该是个较大的正数。
- $f_4(s, i, l_i, l_{i-1}) = 1$,如果$l_{i-1}$是介词且$l_{i}$也是介词,否则$f_4=0$。对应的权重$\lambda_4$是个较大的负数,表明英语语法中介词一般不连续出现。
感性地说,CRF的一组特征函数其实就对应着一组判别规则(特征函数),并且该判别规则有不同的重要度(权重)。在CRF的实现中,特征函数一般为二值函数,其量纲由权重决定。在开源实现CRF++中,使用者需要规定一系列特征模板,然后CRF++会自动生成特征函数并训练、收敛权重。
与HMM比,CRF存在以下优点:
- CRF可以使用输入文本的全局特征,而HMM只能看到输入文本在当前位置的局部特征
- CRF是判别式模型,直接对序列标注建模;HMM则引入了不必要的先验信息
基于深度学习的端到端的分词方法
最近,基于深度神经网络的序列标注算法在词性标注、命名实体识别问题上取得了优秀的进展。词性标注、命名实体识别都属于序列标注问题,这些端到端的方法可以迁移到分词问题上,免去CRF的特征模板配置问题。但与所有深度学习的方法一样,它需要较大的训练语料才能体现优势。

BiLSTM-CRF(参考资料#4)的网络结构如上图所示,输入层是一个embedding层,经过双向LSTM网络编码,输出层是一个CRF层。下图是BiLSTM-CRF各层的物理含义,可以看见经过双向LSTM网络输出的实际上是当前位置对于各词性的得分,CRF层的意义是对词性得分加上前一位置的词性概率转移的约束,其好处是引入一些语法规则的先验信息。
从数学公式的角度上看:
\[S(X, y)=\sum_{i=0}^{n}A_{y_i,y_{i+1}}+\sum_{i=1}^{n}P_{i,y_i}\]其中,A是词性的转移矩阵,P是BiLSTM网络的判别得分。
\[P(y|X)=\frac{e^{s(X,y)}}{\sum_{\widetilde{y}\in Y_{x}}e^{s(X,y)}}\]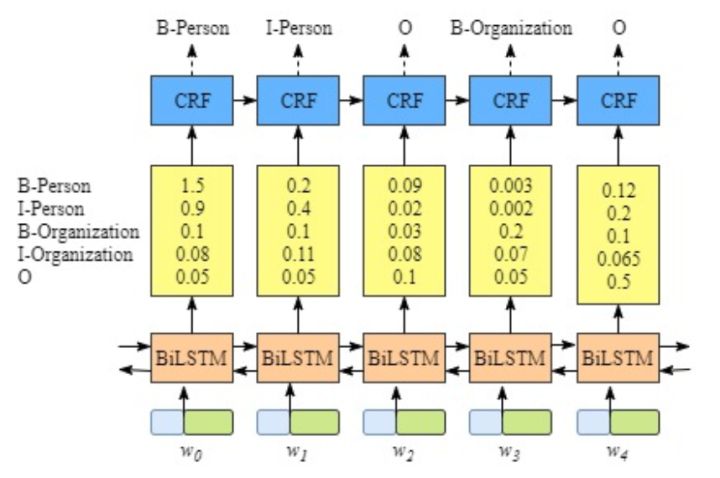
因此,训练过程就是最大化正确词性序列的条件概率$P(y|X)$。
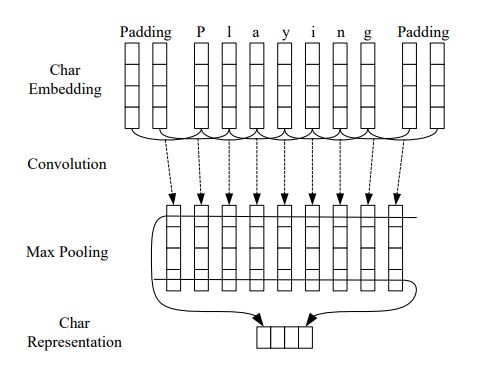
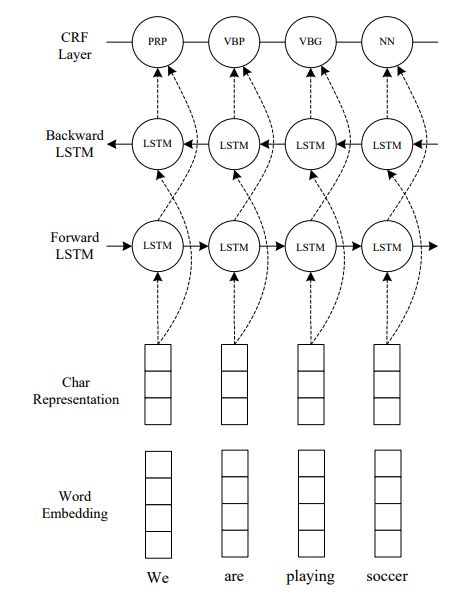
类似的工作还有LSTM-CNNs-CRF(参考资料#5)。
参考资料
- 成庆, 宗. 统计自然语言处理[M]. 清华大学出版社, 2008.
- Itenyh版-用HMM做中文分词
- Introduction to Conditional Random Fields
- Lample G, Ballesteros M, Subramanian S, et al. Neural Architectures for Named Entity Recognition[J]. 2016:260-270.
- Ma X, Hovy E. End-to-end sequence labeling via bi-directional lstm-cnns-crf[J]. arXiv preprint arXiv:1603.01354, 2016.
随着年龄越来越大,欲望也越来越多。书买了不少,但拿起来之前总担心自己精力不济,或者害怕草草浏览而没有收获。这可能跟逐渐养成的碎片阅读习惯有关,简单粗暴的情节,短小的文本腐蚀了我的注意力。想读书又不敢读,形成了恶性循环。
于是下定决心,不想着要学到什么,要总结什么,要输出什么,回归阅读最原始的快乐。开卷有益,希望能逐渐找回以前的自己。
今年印象最深的书是《宽客人生》,是一个物理学博士追求教职失败最后去华尔街的故事。作者虽然获得了世俗意义上的成功,但诺贝尔奖的梦想却失败了,而自始至终作者都在追求着学术或精神上的东西。于我个人而言,在工作了一年之后回头看这本书有了很深的共鸣。
“生活太具体了“,希望我能坚持自己的梦想。
]]>
今年终于正式开启职业生涯,选择了大厂核心广告部门的算法工程师作为起点,历经前几个月的踌躇满志,到最后的心灰意冷,乃至离职。不得不说,社会给我好好地上了一课。此外,基于这件事我修改了未来几年的人生规划,新的计划更加关注成长性和天花板,同时也更加注重work-life balance,具体成功与否就看18年前几个月的努力了。失败的话就老老实实继续搬砖。
工作
简单说离职的原因吧:
- 工作内容螺丝钉化,且日常工作中涉及的技术算法严重落后于业界。
- 加班严重。
这份工作意味着我必须付出大量的额外时间来跟上部门的节奏,但技术上却会进步缓慢。我反思过为什么当时会选择这个offer?答案是被名气迷惑了。事实上,部门的名气与个人的关系不大,日常的工作内容和朝夕相处的同事才会决定业务和技术上的成长。
最后,结合新规划,我选择了年前离职,并且从广告算法转到自然语言处理方向。我个人比较看好NLP未来的发展以及技术壁垒。我之前的技术积累主要在CTR预估和特征工程上,NLP方向上只掌握了词向量和序列标注等Topic,还需好好努力。
新工作做了很多权衡,最后的选择依据是:WLB > 技术方向 > 薪酬。
生活
生活方面,今年添了新家庭成员:小龙虾。 刚到家时,他整晚都不安静,一直哭闹,适应了两周才和我们的生活节奏一致。我们还为他买了特质的baby食物,给他洗澡,真是操碎了心。
等等,先别急着恭喜我。小龙虾其实是一只暹罗猫,目前9个月大~
工作后最大的好处是生活便利了很多,想养猫也不用人批准就养了,衣服全部交给洗衣机。
感情方面进展平稳,可能明年就告别未婚啦。
其他
此外,入职后尝试了写公众号、搭建垂类网站等项目,计算投入产出比不太合算,并且和主业难以形成合力。考虑到职业发展前期,还是投注主要精力在主业比较稳妥。 最终,副业还是只有投资。今年的投资品类从基金扩展到了基金、A股和区块链。投资的基金是指数基金,A股是蓝筹股,综合来看年化收益在20%左右。区块链投资了BTC、BCH、ETH,入场时间较晚,目前亏损,打算加仓并继续持有。其实今年年初的时候身边就已经有人在投资BTC了,限于资金和眼界,没有深究。“有些钱放在你面前你也赚不到”,说白了,还是能力圈不够大。
今年读完的书不多,8本,还有几本正在读。感触最大的是《宽客人生》,在物理学博士眼里去华尔街赚钱是下下选择,天才们还是更愿意和上帝玩游戏。深感上班后时间不属于自己,需要对生活做减法,少刷朋友圈少做碎片阅读,少看网络小说。
目标回顾
- 升职加薪:未完成
- 追求技术之外的视野:完成
- 锻炼身体:完成
明年新目标
- 为新规划而努力
- 扩大能力圈:读其他领域的书;接触其他行业的朋友,并弄懂背后的商业规律
- 保持投资和锻炼身体
- 提高行动力:做事速度提高;生活中做减法
- 去一趟美国
照惯例,打鸡血:
]]>生活是一种永恒的沉重的努力。 —《被背叛的遗嘱》米兰•昆德拉
- 使用训练出的词向量作为输入特征,提升现有系统,如应用在情感分析、词性标注、语言翻译等神经网络中的输入层。
- 直接从语言学的角度对词向量进行应用,如使用向量的距离表示词语相似度、query相关性等。
本文试图以词向量的发展为脉络,从早期Bengio的Neural Probabilistic Language Models[1],到Mikolov关于Word2Vec的两篇论文Efficient Estimation of Word Representations in Vector Space[2]和Distributed Representations of Words and Phrases and their Compositionality[3],介绍涉及的网络结构、公式原理和开源工具。
Why Word Embedding?
机器学习模型要求输入是数字,因此自然语言处理问题要转化为机器学习的问题首先需要把自然语言数学符号化。NLP早期最常见的方法是One-hot Representation,这种方法把词转化成一个很长的稀疏向量,向量的维度等于词表大小,在向量中只有一个维度是1,其他都是0。One-hot稀疏表示法简洁,但也导致任意两个词之间都是孤立的。

语音、图像数据可以编码为高维度、稠密的向量,并且编码方式会影响语音、图像任务的性能。基于此,Hinton、Bengio、Milokov等提出了自然语言的Distributed representation,这种表示法可以把词映射到连续实数向量空间,且相似词在该空间中位置相近。有两种常见的途径获得Distributed representation,一种是 count-based方法( Latent Semantic Analysis),一种是predictive方法(neural probabilistic language models)。简单来说,Count-based方法在大语料集上计算词语的共现统计特征,然后把这些统计特征映射到低维空间成为低维、稠密向量;Predictive方法训练语言模型,直接尝试从学习词向量(是模型的参数)来通过邻居词估计目标词。

前世
Word2Vec算法使Distributed representation真正受到学术界、工业界的认可,它属于predictive方法,传承自Bengio的”Neural Probabilistic Language Models”[1]。NNLM是Distributed representation for words早期的重要工作,Word2Vec的很多方面受到该篇论文启发。文章提出了一个3层的网络结构(embedding输入层,tanh隐层,softmax输出层),通过最大化词序列的联合概率来学习word embedding。
背景知识
NNLM的目标函数是给定上文时下一个词的条件概率,该目标函数源于统计语言模型(statistical model of language)。一般地,统计语言模型将一个句子(由多个词构成的序列)的出现概率建模为:
\[\widehat{P}(w_{1}^{T})= \prod_{t=1}^{T}\widehat{P}(w_{t}|w_{1}^{t-1})\]计算统计语言模型的句子概率的计算复杂度是$O(N^T)$,N为语料中词的个数(vocabulary size,中文一般是2万~4万),T为句子长度(一般小于20)。
统计语言模型的计算复杂度太高,在早期实践中采用的是简化版本n-gram语言模型。n-gram模型可直接通过统计词频来计算,计算复杂度 - ,n一般取值2、3、4。n-gram模型的缺点是需要事先保存所有的概率值,工程上还涉及到对稀疏组合平滑化的操作。
\[\widehat{P}(w_{t}|w_{1}^{t-1})\approx \widehat{P}(w_{t}|w_{t-n+1}^{t-1})\]使用机器学习的观点看待求解给定上下文求下一个词的条件概率,目标函数为:
\[\widehat{P}(w|Context(w))=F(w,Context(w),\theta)\]使用对数最大似然算法(Maximum Log-Likelihood Esimation)进行参数估计:
\[L(\theta)=\sum_{w\in C}log p(w|Context(w))\]因此,通过选择合适的模型可以减小参数 - 的尺寸。事实上,Word2Vec受到广泛认可正是因为它在大幅提高了模型训练速度的同时,保证了较好的模型精度。从统计语言模型到NNLM,再到Word2Vec的过程也是一个以精度为约束提高训练速度的过程。
NNLM

| 上图是NNLM的网络结构图,输入是target word的context(前n个词在矩阵C中的index,等价于在vocabulary中的index),输出是一个长度为$ | V | $的向量,其中第i维代表target word为$i$ ($i$同样是词在vocabulary中的index)在当前context下的条件概率。矩阵$C$是NNLM的关键部分,论文中原文是: |
In practice, $C$ is represented by a $ V $ * m matrix of free parameters. $C$ being shared across all the words in the context.
| 实际上,$C$矩阵存储的就是语料中所有词的词向量,它的行数$ | V | $是语料中词的个数,列数m为词向量的长度。上图$g$代表的是神经网络的映射(mapping),由图可知它包括了tanh层和softmax层。NNLM的目标函数为: |
其中,$b$是output层的bias;$W$是当词向量和output层有直接连接(direct connections)时的weight,对应NNLM网络结构图中的虚线,一般为0;$H, d$是tanh层(hidden层)的weight、bias;$U$是tanh层到output层的weight。(注意,隐藏层可以有多个神经元)
损失函数为:$L(\theta)=-\frac{1}{T}\sum_{t}logf(w_{t},w_{t-1},…,w_{t-n+1};\theta)+R(\theta)$, 其中 $R(\theta)$是正则惩罚项。
因此,$\theta=(b,d,W,U,H,C)$,对应的计算复杂度为:
\[|V|(1 + nm + h) + h(1 + (n - 1)m)=O(N(nm+h))\]其中,$N$为语料中词的个数,$h$为神经网络中隐藏层神经元的个数,$n$为context window的大小,$m$为词向量的维度。由此可见,NNLM将模型训练的计算复杂度由$O(N^n)$降低到$O(N*nm)$。论文中提到,在Associated Press 新闻数据集(1400w words),使用NNLM在40个CPU上训练5个epoch耗时约3周。
今生
2013年word2vec横空出世,背后的原理在Mikolov的两篇论文”Efficient Estimation of Word Representations in VectorSpace”[2], “Distributed Representations of Words and Phrases and their Compositionality”[3]中有详细的介绍。
论文[2]主要提出了CBOW和Skip-gram两种网络结构来训练词向量,并使用语义word relationship test和语法word relationship两种测试集来评估模型的有效性。
语义word relationship:$V(Athens)-V(Greece)+V(Norway)=V(Oslo)$
语法word relationship:$V(apparent)-V(apparently)+V(rapid)=V(rapidly)$

论文[3]提出了一些方法拓展CBOW和Skip-gram(为主)的词向量质量和训练速度,主要有:subsampling of frequent words;hierarchial softmax、negative sampling。Mikolov还指出Word2Vec的主要缺陷是无法感知语序和无法表达习惯用语(idiomatic phrases,即由若干个单词组成的约定俗成的短语,如 NewYork),对于idiomatic phrases,文中提出了一种简单的方法使得其词向量可训练(短语作为一个整体去训练)。
关于word2vec的数学原理请参考word2vec中的数学原理详解,讲得很详细也很透彻。
延续上文的思路,从目标函数和计算复杂度的角度看word2vec的发展。
CBOW的目标函数是:
\[\widehat{P}(w_{t}|w_{c})=\frac{e^{v_{w_{t}}^{T}v_{w_{c}}}}{\sum_{w=1}^{N}{v_{w}^{T}v_{w_{c}}}},\ where\ v_{w_{c}}=\sum_{i\in context(w_{t})}C(w_{i})\]损失函数是:
\[L(\theta)=-\frac{1}{T}\sum_{t}log\ \widehat P(w_{t}|w_{c})+R(\theta)\]计算复杂度是:
\[nm+mlog_{2}(N)=O(mlog_{2}(N))\]论文原文 $N\times D+D\times log_{2}(V)$
上式中N为语料中词的个数,N为语料中词的个数。
Skip-gram的目标函数是:
\[\prod_{-c\leq j\leq c, j\ne t}\widehat{P}(w_{j}|w_{t})=\frac{e^{v_{w_{j}}^{T}v_{w_{t}}}}{\sum_{w=1}^{N}{v_{w}^{T}v_{w_{t}}}}\]损失函数是:
\[L(\theta)=-\frac{1}{T}\sum_{t}\sum_{-c\leq j\leq c, j\ne t}log\ \widehat{P}(w_{j}|w_{t})+R(\theta)\]计算复杂度是:
\[n(m+nlog_{2}(N))=O(nmlog_{2}(N))\]论文原文 $C\times (D+D\times log_{2}(V))$
结论
NNLM到word2vec的发展使得计算复杂度由O(N)的线性级降低到对数级。
目前有很多开源工具提供词向量训练的功能:
- fasttext: facebookresearch/fastText, PS: fasttext是mikolov跳槽到facebook后开发的。
- gensim: gensim: topic modelling for humans
使用主流的深度学习框架训练词向量也并不困难:
- tensorflow的官方教程:Vector Representations of Words Tutorial
- Pytorch的官方教程:Word Embeddings: Encoding Lexical Semantics
未来
自从2013年Mikolov出词向量的概念后,NLP领域仿佛一下子进入了embedding的世界,Sentence2Vec、Doc2Vec、Everything2Vec。另一方面,研究人员也尝试使用其他的方法生成词向量,比如斯坦福NLP小组提出的Global Vectors for Word Representation 。
参考文献
[1] Bengio Y, Schwenk H, Senécal J S, et al. Neural Probabilistic Language Models[J]. Journal of Machine Learning Research, 2003, 3(6):1137-1155.
[2] Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
[3] Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2013:3111-3119.
- 使用训练出的词向量作为输入特征,提升现有系统,如应用在情感分析、词性标注、语言翻译等神经网络中的输入层。
- 直接从语言学的角度对词向量进行应用,如使用向量的距离表示词语相似度、query相关性等。
MovieTaster
MovieTaster是我用Item2Vec实现的电影推荐demo,它可以针对输入的一个或多个电影,基于豆瓣用户UGC内容(豆列)产生推荐列表。Github Repo

MovieTaster-demo-输入多个电影

MovieTaster-demo-输入单个电影
Item2Vec
MovieTaster是Item2Vec在电影推荐上的实现,下面简单介绍一下Item2Vec的内容。
Item2Vec是由O Barkan,N Koenigstein在他们2016年的论文“Item2Vec: Neural Item Embedding for Collaborative Filtering“[3]中提出的。论文把Word2vec的Skipgram with Negative Sampling (SGNS)的算法思路迁移到基于物品的协同过滤(item-based CF)上,以物品的共现性作为自然语言中的上下文关系,构建神经网络学习出物品在隐空间的向量表示。论文中还比较了Item2Vec和SVD在微软Xbox音乐推荐服务和Windows 10商店的商品推荐的效果,结果显示Item2Vec效果有所提升。
总的来说,这篇论文的算法创新性不高,但把Word2Vec迁移到item-based CF的脑洞令人耳目一新。在Item2Vec中,一个物品集合被视作自然语言中的一个段落,物品集合的基本元素-物品等价于段落中的单词。因此在论文中,一个音乐物品集合是用户对某歌手歌曲的播放行为,一个商品集合是一个订单中包含的所有商品。
从自然语言序列迁移到物品集合,丢失了空间/时间信息,还无法对用户行为程度建模(喜欢和购买是不同程度的强行为)。好处是可以忽略用户-物品关系,即便获得的订单不包含用户信息,也可以生成物品集合。而论文的结论证明,在一些场景下序列信息的丢失是可忍受的。

skipgram网络结构
Item2Vec的网络结构与Word2Vec Skipgram的结构基本一致,只是输入的w(t)替换为i(t)。论文中还提到,由于训练数据迁移到物品集合,模型需要进行调整才能保证效果:
(1) 把Word2Vec的上下文窗口(window size)由定长的修改为变长的,长度由当前训练的物品集合长度决定。此方法需要修改网络结构。
(2) 不修改网络结构,而在训练神经网络时对物品集合做shuffle操作,变相地起到忽略序列带来对影响。
论文提出两种方法的实验效果基本一致。
MovieTaster是如何实现的
MovieTaster的训练数据(我爬的)是豆友们的电影豆列共6万个,其中包括10万+部电影。训练item向量使用的工具是fasttext,训练方式是skipgram、50个epoch,并滤去出现次数低于10次的电影。
我还尝试了其它训练参数,推荐结果如下:

skipgram-vs-cbow
从结果中可以观察出一些有意思的结论。战狼2是最近刚出的电影(此文作于2017/08),包含战狼2的大多是“暑期国产电影合集”,“2017年不得不看的国产电影“这类豆列;美国往事属于经典老片,训练语料足够多,skipgram和cbow的推荐结果各有千秋;小时代在豆瓣中属于不受待见的一类电影,包含小时代的豆列较少,skipgram的推荐结果优于cbow。
大家关于Item2Vec有什么脑洞,欢迎讨论。文章后续会公开部分源码和数据集,并尝试更多不同算法和参数的效果。
参考资料:
[1] Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
[2] word2vec 中的数学原理详解
[3] Barkan O, Koenigstein N. Item2Vec: Neural Item Embedding for Collaborative Filtering[J]. 2016:1-6.
虽然老觉得在颁奖典礼上说谢谢很俗,但自己能走到现在这一步多亏了大家的帮助。感谢导师,谢谢您的指导与信任,帮助我顺利地度过研究生生涯;感谢mentor,带我走好职场第一步;感谢室友,感谢家人,感谢女朋友。
2016年的三个关键词
- 坚持
实验室是做传统通信方向,但通过坚持自己学习、借助身边的资源,目前已上车机器学习。 转型这方面可以多说两句,目前网络上资源很多,特别推荐CS231n;学好了基本知识后去打kaggle、天池比赛,可以弥补一些实习经历的缺陷。
- 选择
找工作时获得了一些offer,各有优劣,最后选择了广告方向,这个方向是mentor一直推荐我的,也是所谓的”互联网变现“的主要方向。预期工作会以工程性的任务为主,搞算法的情况较少。其他的offer有一个推荐方向,且偏算法更多,遗憾。广告和推荐是我认为的前景比较广阔的方向,欢迎拍砖。 更大的遗憾是,最终没能加入微软,连面试都没有机会,执行力不够,ACM题刷的太少。
- 谦逊
自己身上学生气较重,自负,希望能通过”做一些微小的工作”改掉这些毛病。 竞争意识过强,不能正视别人的成绩。自我反思,之前一直以学生作为主要身份,学生的任务较少涉及到合作,只需要独立获得优秀的成绩。在考试之外的领域,能感受到自己推动事情落实的能力较差,惧怕向人低头,惧怕发展关系。希望在新的人生阶段,能够理解竞争与合作的关系。
2017年对自己的要求
- 好好赚钱,好好努力。具体的KPI就是升职加薪。
- 追求技术之外的视野,争取在房市早日上车,让家人过上好生活。KPI:尝试1-2个副业,盈利能cover买礼物的钱。
- 锻炼身体,戴好口罩,保证牙齿健康。KPI:保持健身频率,体检,洗牙。
最后给自己打点鸡血。
]]>一个悲哀的事实是,但凡靠卖时间来赚钱的人,想要赚的比同行多,就只能在睡眠时间上打主意。 —“月入十万,难吗?” @肥肥猫的回答