Amazon EKS Pod Identity 是 AWS 对 EKS 原有的 IAM roles for service accounts (IRSA) 功能的补充,通过新增的 EKS Pod Identity 功能, 用户可以用更简便的方式实现为 Pod 安全的授予 AWS API 访问权限, 并且所有的配置管理操作都可以通过 AWS API 或者控制台完成。
使用方法
- 新建个 IAM role,信任实体如下
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "pods.eks.amazonaws.com"
},
"Action": [
"sts:AssumeRole",
"sts:TagSession"
]
}
]
}分配策略比如:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::artifacts"
}
]
}- EKS 集群需要安装 eks-pod-identity-agent 组件(支持通过控制台安装)。
aws eks create-addon \
--cluster-name <CLUSTER_NAME> \
--addon-name eks-pod-identity-agent \
--addon-version v1.x.x-eksbuild.1- 创建 K8s Service Account
apiVersion: v1
kind: ServiceAccount
metadata:
name: my-service-account
namespace: default- 然后,需要配置应用 Pod 所使用的 Service Account 与 AWS IAM 角色之间的关联关系, 允许使用该 Service Account 的应用扮演特定的 IAM 角色(支持通过控制台配置)。
aws eks create-pod-identity-association \
--cluster-name <CLUSTER_NAME> \
--namespace <NAMESPACE> \
--service-account <SERVICE_ACCOUNT_NAME> \
--role-arn <IAM_ROLE_ARN>-
最关键的,应用 Pod 需要更新使用最新的支持 EKS Pod Identity 特性的 AWS SDK 比如应用 Pod 是 Java开发的,需要调用 S3 API,那么需要更新 pom.xml 文件,添加 AWS SDK,AWS SDK 中有一套获取凭证的默认搜索逻辑 或者显示调用 EKS Pod Identity 依赖的Container credential provide
-
运行应用 Pod, 我们来创建一个简单的应用 Pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
serviceAccountName: my-service-account
containers:
- name: my-app
image: public.ecr.aws/aws-cli/aws-cli:2.32.12
command:
- sh
- '-c'
- while true; do sleep 3600; done- 测试,发现有S3桶内容返回,如果把 s3:ListBucket action 拿掉则报错, 测试通过
kubectl exec -it deployment/my-app -- aws s3 ls s3://artifacts/
工作流程

-
当用户/Controller 向 apiserver 提交 Pod 时,会触发 eks-pod-identity-webhook 的 mutating webhook 流程。
-
eks-pod-identity-webhook 的 mutating webhook 流程会为 Pod 挂载 service account oidc token 文件以及配置环境变量 (AWS_CONTAINER_AUTHORIZATION_TOKEN_FILE, AWS_CONTAINER_CREDENTIALS_FULL_URI )。
通过 kubectl describe pod my-app-77f6749799-f26hf 可以看到
Environment:
AWS_STS_REGIONAL_ENDPOINTS: regional
AWS_DEFAULT_REGION: eu-west-1
AWS_REGION: eu-west-1
AWS_CONTAINER_CREDENTIALS_FULL_URI: http://169.254.170.23/v1/credentials
AWS_CONTAINER_AUTHORIZATION_TOKEN_FILE: /var/run/secrets/pods.eks.amazonaws.com/serviceaccount/eks-pod-identity-token
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-jtjst (ro)
/var/run/secrets/pods.eks.amazonaws.com/serviceaccount from eks-pod-identity-token (ro)打印 service account oidc token 文件,kubectl exec -it deployment/my-app -- cat /var/run/secrets/pods.eks.amazonaws.com/serviceaccount/eks-pod-identity-token
是 JWT 格式的,找一个在线解密 https://www.jwt.io/ 获得
## header
{
"alg": "RS256",
"kid": "167335cb436b4080252a64e070f6d3153f896845"
}
## payload
iss (Issuer):签发者
sub (Subject):主题
aud (Audience):接收者
exp (Expiration time):过期时间
nbf (Not Before):生效时间
iat (Issued At):签发时间
jti (JWT ID):编号
{
"aud": [
"pods.eks.amazonaws.com"
],
"exp": 1765334133,
"iat": 1765252458,
"iss": "https://oidc.eks.eu-west-1.amazonaws.com/id/43E064763DAXXXXD18392C7FC9CBEA3A",
"jti": "5e081212-fdf6-425c-9b32-c9a372112fd9",
"kubernetes.io": {
"namespace": "default",
"node": {
"name": "ip-172-31-77-99.eu-west-1.compute.internal",
"uid": "797b365b-3491-47a6-a222-ba5acf3276d8"
},
"pod": {
"name": "my-app-77f6749799-f26hf",
"uid": "8768b78a-298a-4bf5-95b4-07a181ccbc2a"
},
"serviceaccount": {
"name": "my-service-account",
"uid": "92a8c128-7c32-4199-be85-1f2669cf7914"
}
},
"nbf": 1765252458,
"sub": "system:serviceaccount:default:my-service-account"
}- Pod 容器内的应用使用的 AWS SDK 将使用通过环境变量 AWS_CONTAINER_AUTHORIZATION_TOKEN_FILE 获取的 service account oidc token 访问环境变量 AWS_CONTAINER_CREDENTIALS_FULL_URI 指向的地址 (http://169.254.170.23/v1/credentials)获取 AWS sts token。
curl $AWS_CONTAINER_CREDENTIALS_FULL_URI -H "Authorization: $(cat $AWS_CONTAINER_AUTHORIZATION_TOKEN_FILE)" 2>/dev/null | jq
{
"AccessKeyId": "ASXXXXXXXXXXXXX",
"SecretAccessKey": "zEuXXXXXXXX",
"Token": "IQoJb3JpXXXXXXX",
"AccountId": "5XXXXXXXXXXX",
"Expiration": "2025-12-09T09:54:37Z"
}等效写法
TOKEN=`kubectl exec -it deployment/my-app -- cat /var/run/secrets/pods.eks.amazonaws.com/serviceaccount/eks-pod-identity-token`
aws eks-auth assume-role-for-pod-identity --cluster-name cluter-name --token $TOKEN
{
"subject": {
"namespace": "default",
"serviceAccount": "my-service-account"
},
"audience": "pods.eks.amazonaws.com",
"podIdentityAssociation": {
"associationArn": "arn:aws:eks:eu-west-1:47111xxxxx:podidentityassociation/cluster-name/a-avrgufuj****",
"associationId": "a-avrgufuj****"
},
"assumedRoleUser": {
"arn": "arn:aws:sts::47111xxxxx:assumed-role/my-role/cluter-name-c-my-app-77f-8c3ec6dc-97****",
"assumeRoleId": "AROAW****:eks-cluster-eks-c-my-app-77f-8c3ec6dc-97****"
},
"credentials": {
"sessionToken": "IQoJb3JpZ2luX2VjEO///////////wEaCWV1LX****",
"accessKeyId": "ASIAW****",
"expiration": "2025-12-09T20:23:17+08:00"
}
}- AWS_CONTAINER_CREDENTIALS_FULL_URI 的值为 http://169.254.170.23/v1/credentials。 这个地址是固定的,是 EKS Pod Identity Agent 提供的本地 HTTP 端点。
- 169.254.170.23: EKS Pod Identity Agent 的固定端点
- 169.254.169.254: EC2 IMDS (Instance Metadata Service) 的固定端点
EKS Pod Identity Agent 作为 DaemonSet 运行在每个节点上,通过以下方式提供服务:
- HostNetwork 模式: Agent 使用主机网络
- 本地监听: 在节点上监听 169.254.170.23:80
- 所有 Pod 可访问: 节点上的所有 Pod 都可以访问这个 IP
eks-pod-identity-agent 收到请求后,将使用传递过来的 oidc token 访问 EKS 新增的 AssumeRoleForPodIdentity API 获取所需的 AWS sts token,然后将获取到的 sts token 返回给客户端。
- 应用调用的 AWS SDK 使用获取到的 sts token 访问应用所需的 AWS 云产品 API。
简单描述:
- Pod 读取 JWT 令牌文件 (/var/run/secrets/pods.eks.amazonaws.com/serviceaccount/eks-pod-identity-token)
- AWS SDK 将令牌发送到 http://169.254.170.23/v1/credentials
- EKS Pod Identity Agent 验证令牌并调用 AWS STS
- 返回临时 AWS 凭证 (AccessKeyId, SecretAccessKey, SessionToken)
参考
https://mozillazg.com/2023/12/security-deep-dive-into-aws-eks-pod-identity-feature.html
https://securitylabs.datadoghq.com/articles/eks-pod-identity-deep-dive/
]]>AWS S3 讲解
├── 1. S3 基础概念
│ ├── 什么是 S3
│ ├── 核心组件:Bucket + Object
│ └── 适用场景
│
├── 2. 存储类别 (Storage Classes)
│ ├── Standard (标准)
│ ├── Intelligent-Tiering (智能分层)
│ ├── Glacier (归档)
│ └── 成本优化对比
│
├── 3. 核心功能
│ ├── Versioning (版本控制)
│ ├── Lifecycle (生命周期)
│ ├── Encryption (加密)
│ └── Static Website Hosting
│
├── 4. 访问控制
│ ├── Bucket Policy
│ ├── IAM Policies
│ ├── ACLs
│ └── Block Public Access
│
├── 5. 数据保护
│ ├── Replication (复制)
│ ├── Object Lock (对象锁定)
│ └── 备份策略
│
└── 6. 最佳实践
├── 命名规范
├── 安全性
└── 成本优化详细大纲
- 什么是 Amazon S3?
- 对象存储服务:不同于块存储/文件存储
- 特点:无限容量、高持久性(11个9)、高可用
- 核心概念:
- Bucket(桶):容器,类似文件夹顶级目录
- Object(对象):文件 + 元数据 + 唯一键值
- 存储类别对比
| 存储类 | 适用场景 | 访问延迟 | 成本 |
|---|---|---|---|
| S3 Standard | 频繁访问的数据 | 毫秒级 | 高 |
| S3 Intelligent-Tiering | 访问模式未知/变化 | 毫秒级 | 中 |
| S3 Glacier Instant Retrieval | 极少访问,毫秒级检索 | 毫秒级 | 低 |
| S3 Glacier Flexible Retrieval | 长期归档 | 分钟级 | 更低 |
| S3 Glacier Deep Archive | 合规归档 | 小时级 | 最低 |
- 关键功能
版本控制 (Versioning)
- 保留对象多个版本
- 防止误删除、覆盖
生命周期策略 (Lifecycle)
- 自动将对象转移到低成本存储类
- 自动删除过期对象
静态网站托管
- 直接托管 HTML/CSS/JS
- 配合 CloudFront CDN
- 访问控制模型
安全层级(由外到内)
-
Block Public Access → 阻止公开访问
-
Bucket Policy → JSON 策略控制
-
IAM Policy → 用户/角色权限
-
ACL → 细粒度控制(较少用)
-
数据保护
- 跨区域复制 (CRR):多区域灾备
- 同区域复制 (SRR):合规/低延迟
- S3 Object Lock:WORM 保护,防删除
- 定价模式
- 存储费:按 GB/月
- 请求费:PUT/GET/DELETE
- 数据传出:出桶才收费
- S3 Glacier 检索费:注意隐藏成本
讲解建议
- 开场:用生活类比(Bucket = 仓库,Object = 箱子)
- 重点:存储类别选择 + 成本优化 + 安全性
- 互动:展示 AWS Console 实际操作
- 结尾:常见坑点 + 最佳实践清单
= 和 := 的区别
| 特性 | = |
:= |
|---|---|---|
| 用途 | 给已声明变量赋值 | 声明并赋值新变量 |
| 类型 | 需要预先声明类型 | 自动类型推断 |
| 使用范围 | 包级别和函数内 | 仅函数内 |
| 重复声明 | 可以重复赋值 | 不能重复声明同名变量 |
实际开发建议
- 优先使用 :=:在函数内部,:= 更简洁
- 包级别变量用 var:全局变量必须用 var 声明
- 需要零值初始化时用 var:如 var count int (自动为0)
- 明确指定类型时用 var:如 var pi float32 = 3.14
为什么结构体作为函数参数,前面要加 *
- 减少内存开销 如果不加 *,函数调用时会复制整个结构体,占用额外内存。 使用 * 可以传递结构体的地址,避免复制,提高性能,尤其是结构体较大时。
- 修改原始结构体 如果函数需要修改结构体的字段值,必须使用指针才能生效。 不使用指针(即传值方式),函数内部对结构体的修改不会影响原始结构体。
- 一致性 在 Go 中,方法可以有指针接收者(func (f *Family))或值接收者(func (f Family))。 如果你希望无论调用者是结构体变量还是指针,都能统一处理,通常会使用指针接收者。
下面两个写法等价吗
type Person struct {
Name string
Age int
}
// 方法 - 表示这是 Person 的行为
func (p Person) say() {
fmt.Println("hello world")
}
// 函数 - 表示这是一个独立的操作
func say(p Person) {
fmt.Println("hello world")
}
// 方法调用 - 面向对象风格
person.say()
// 函数调用 - 函数式风格
say(person)any
any 是 interface{} 的别名,Go 1.18+ 引入 any 类型,它表示任何类型,包括 nil。
]]>说明
- 节点大小:表示该主题的重要程度
- 节点标签:显示主题名称和文章数量
- 连线:表示主题之间的关联关系
- 交互:
- 拖拽节点调整位置
- 点击主题节点展开/收起文章列表
- 文章节点显示为绿色
统计数据
| 主题 | 文章数量 |
|---|---|
| Jenkins | 48 |
| K8s | 45 |
| Docker | 43 |
| Prometheus | 29 |
| Linux | 20 |
| GithubActions | 14 |
| Ansible2 | 11 |
| Terraform | 4 |
我对技术比较有热情。对CI/CD,容器化,云原生,微服务架构,自动化都有一定的了解。
目前在某传统行业外企担任 DevOps Specialist,10余年开发+运维经验
对文章有疑问的,欢迎加v讨论问题,也欢迎提issue
关于本站
- 2025.12.12 统一图床地址
- 2024.06.15 支持生成RSS
- 2023.12.31 从vuepress转移到vitepress,更快的构建速度
 ]]>
]]>animate API
$(selector).animate({params},[speed],[easing],[fn]);- params: 一组包含作为动画属性和终值的样式属性和及其值的集合
- speed: 可以填三种预定速度之一的字符串("slow" 600ms,"normal" 400ms, "fast" 200ms)或者直接填毫秒数值,默认400
- easing: 要使用的擦除效果的名称(需要插件支持). 默认jQuery提供"linear" 和 "swing".
- fn: 在动画完成时执行的函数,每个元素执行一次
例子,点击按钮让这个元素偏移一定像素
$("button").click(function(){
$("div").animate({left:'250px'});
});slideUp 等二次封装的方法
其中,jQuery还提供了方便的方法,其实是语法糖,对animate方法的二次封装
hide,show分别修改元素的display属性为none和block
slideUp(收缩高度),slideDown(还原高度),本质是随时间修改元素的高度
fadeIn(淡入), fadeOut(淡出),本质是随时间修改元素的opacity属性
详细的例子可以见w3school
jQuery自带效果有限,可以使用 jQuery Easing Plugin 另外jQuery UI 提供了更多的特效,如颤动,心跳,爆炸等
animate 队列
jQuery的animate还支持队列,逐帧播放
$("button").click(function(){
var div=$("div");
div.animate({left:'100px'},"slow");
div.animate({fontSize:'3em'},"slow");
});loop 循环播放
借助animate API最后一个callback参数,可以轻松实现无尽播放动画的效果。
<iframe height="265" style="width: 100%;" scrolling="no" title="jquery animation loop" src="https://codepen.io/mafeifan/embed/ExPJpRo?height=265&theme-id=light&default-tab=html,result" frameborder="no" allowtransparency="true" allowfullscreen="true">
See the Pen <a href='https://codepen.io/mafeifan/pen/ExPJpRo'>jquery animation loop</a> by finley
(<a href='https://codepen.io/mafeifan'>@mafeifan</a>) on <a href='https://codepen.io'>CodePen</a>.
</iframe>使用场景
- 不支持loop
- 不支持滚动条滚动播放
This page demonstrates usage of some of the runtime APIs provided by VitePress.
The main useData() API can be used to access site, theme, and page data for the current page. It works in both .md and .vue files:
<script setup>
import { useData } from 'vitepress'
const { theme, page, frontmatter } = useData()
</script>
## Results
### Theme Data
<pre>{{ theme }}</pre>
### Page Data
<pre>{{ page }}</pre>
### Page Frontmatter
<pre>{{ frontmatter }}</pre>Results
Theme Data
{{ theme }}
Page Data
{{ page }}
Page Frontmatter
{{ frontmatter }}
More
Check out the documentation for the full list of runtime APIs.
]]>This page demonstrates some of the built-in markdown extensions provided by VitePress.
Syntax Highlighting
VitePress provides Syntax Highlighting powered by Shiki, with additional features like line-highlighting:
Input
```js{4}
export default {
data () {
return {
msg: 'Highlighted!'
}
}
}
```<ul>
<li v-for="todo in todos" :key="todo.id">
{{ todo.text }}
</li>
</ul>Output
export default {
data () {
return {
msg: 'Highlighted!'
}
}
}Custom Containers
Input
::: info
This is an info box.
:::
::: tip
This is a tip.
:::
::: warning
This is a warning.
:::
::: danger
This is a dangerous warning.
:::
::: details
This is a details block.
:::Output
INFO
This is an info box.
TIP
This is a tip.
WARNING
This is a warning.
DANGER
This is a dangerous warning.
Details
This is a details block.
STOP
Danger zone, do not proceed
Click me to view the code
console.log('Hello, VitePress!')iframe
More
Check out the documentation for the full list of markdown extensions.
]]>使用 ChatGPT有几种方法
- 登录 openai.com,注册账号,然后点击左上角的“Log in”按钮,登录账号。
- 优点:简单,技术门栏低,目前ChatGPT3.5是免费的
- 缺点:需要开代理,国内无法直接使用
- 使用 ChatGPT API
- 优点:更安全,需要一定的技术能力和开发能力
- 缺点:ChatGPT API是需要付费
OpenRouter是一个开源的API代理服务,可以免费使用ChatGPT的API,支持自定义接口,模型等,关键你可以一个key同时调用多个模型
前提
- Visa信用卡
- 谷歌账号
- 已经部署了ChatGPTNextWeb,或支持自定义接口
- 打开 https://openrouter.ai 使用 google 账号登录
- 点顶部的 Credits 绑定信用卡,这里我充值 10 美元,注意 openrouter 会额外收一定的手续费

- 进到 https://openrouter.ai/keys 页面,点 create key,起个名字
最好也填上 Credit Limit, 这里我填5,超过5美元后就会自动停用
最终我们拿到 sk 开头的key

- 进到已经部署了ChatGPTNextWeb的配置页面
- 接口地址: https://openrouter.ai/api
- API Key: 填写 OpenRouter sk 开头的key

切换模型,验证是否生效



https://dev.amazoncloud.cn/experience/cloudlab?id=65fd7f888f852201f9704488
Titan Text G1 - Express 就是垃圾,根本不能用

aws bedrock-runtime invoke-model \
--model-id meta.llama2-13b-chat-v1 \
--body "{\"prompt\":\"[INST]Find the issue in this code below. Explain your reason\\nimport torch\\ntorch.device(\\\"cuda:0\\\" if torch.cuda.is_available() else \\\"cpu\\\")\\ndef run_som_func(a, b):\\nc = c*2\\nc=a+b\\nprint(c)\\nreturn c ^ 2\\nI get an error saying variable referred before[/INST]\",\"max_gen_len\":512,\"temperature\":0.5,\"top_p\":0.9}" \
--cli-binary-format raw-in-base64-out \
--region us-east-1 \
invoke-model-output.txtcurl 'https://dev-media.amazoncloud.cn/doc/workshop.zip' --output workshop.zip
unzip workshop.zip
pip3 install -r bedrock/workshop/setup/requirements.txt -U
# add code for labs/api/bedrock_api.py
python bedrock/workshop/labs/api/bedrock_api.py
streamlit run bedrock/workshop/labs/text/text_app.py --server.port 8080
streamlit run bedrock/workshop/labs/streaming/streaming_app.py --server.port 8080LangChain
LangChain可以抽象出使用Boto3客户端的许多细节,尤其是当你想专注于文本输入和文本输出时。
Bedrock Access Gateway
把 OpenAI API 的调用转发到 Amazon Bedrock,从而获得包括 Claude3 在内的多种 LLM 的优秀能力
https://docs.dify.ai/v/zh-hans/getting-started/readme/model-providers
]]>AWS 要授权给他人访问指定资源有哪几种方式呢?
- 在自己帐号下创建一个用户,把 Access Key ID 和 Secret Access Key 告诉别人。可为该用户限定权限,但任何获得那两个 Key 的人都能使用该用户。不够安全。
- 创建一个 IAM Role, 并指定谁(帐号或 Role) 能以该 Role 的身份来访问。被 Assume 的 Role 可限定权限和会话有效期。
所以,用 Assume Role 的方式具有更高的安全可控性,还不用维护 Access Key ID 和 Secret Access Key。
比如在构建和部署时通常是有一个特定的 Account, 然后 Assume 到别的 IAM Role 去操作资源。
本文将详细介绍在帐号 A 创建一个 IAM Role(标注为 R) 并分配一些权限,然后允许另一个帐号 B 以 IAM Role - R 的身份来访问帐号 A 下的资源。
IAM Role 将用 awscli 来创建,Assume Role 的过程用 awscli 和 boto3 Python 代码两种方式来演示。
已知两个账号A,B
~/.aws/credentials 添加好key
[a]
aws_access_key_id=AKIA5*****USBKPN4DIH
aws_secret_access_key=OdUsUew**********MEgoC8*****9LCvbqkaCQQS
[b]
aws_access_key_id=AKIA*****2USOGAHFVAU
aws_secret_access_key=b2nXQ**********7EuBO*****5ngKM3Msg2CLqma帐号 A 下创建 IAM Role
aws s3 ls --profile a
# 或者用环境变量,这是更推荐的方式
export AWS_DEFAULT_PROFILE=a
# 查看账户A下的S3资源
aws s3 ls
# 在账号A下创建 test-assumed-role
aws iam create-role --role-name test-assumed-role --assume-role-policy-document file://role-trust-policy.json
# 给新建的 test-assumed-role 加上 S3 的只读权限
aws iam attach-role-policy --role-name test-assumed-role --policy-arn arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess帐号 B Assume 帐号 A 的 role
export AWS_DEFAULT_PROFILE=b
# 924612875556是账户A的account id
# 这句话的意思是用,将账户B切换为账户A
aws sts assume-role --role-arn arn:aws:iam::924612875556:role/test-assumed-role --role-session-name awscli-session
返回内容:
{
"Credentials": {
"AccessKeyId": "ASIA*******O5OOFMMB",
"SecretAccessKey": "qLR4rNZ*******PPJAIBx22plNN8oWIRtp2bbq",
"SessionToken": "IQoJb3JpZ2luX2VjEPb//////////wEaDmFwLW5v*******xIkcwRQIgCKgl/h9gP4430qtSRfnp*******VddkekMUcN2ECIQC06q/7vYhcVMj7jujstIVzBhecnYQgB3bZf0l5qaxjzyqbAggwEAEaDDkyNDYxMjg3NTU1NiIMKP1BdAa6NQhoo2FYKvgBy5B1tyKn0GPz7DwG+YWxdfc9+ayNwzulKsF895wLpzuC9Hkyd2+KL22PgcaAOHV+PU3CPicDS8xTlanAQZvlPQy3egXv+JNOwlrJaVmyKuNbtzGCpYlBFs9TnC1sD+Uz0MGtXPh3GLhoZZ9gHt7fktDwohoz5+fbA+6zXUvO4xmFAicoYy7PCSM1v8weQ+oXqMAFREJ3Pd3Zs3y5adQYK100+reEJ1uvMIIdk3KSKYsF3T8ZByU+MdP+YBSgilfaY/YVgXExUp0B2dwWMRRh95FSdmmIfAtqSrt/0mXhah5zxTaoVxbPUT68A6Fj4Gecw+3iZiIeM2MwycSrlgY6nQGlo4fNrVvHEgw8yBFPE6wiY+jAi1vLNplxJ1WN59OMK+0rfdyBO91JFeoOEiQNXzbZJSorI2SuEUi3dVgVotvGwCMYsOYByM4zyJa9tdsjXTKX6UL2CdHyGKm6y5QK1DhXhl9mtEMqNqEWoQN4LkgGHv/4fzJLoFqKO2cC+VZDQ40AofaTVEsKaJjU3zt3NCUa+Ltq5qyfyTkHxoky",
"Expiration": "2022-07-10T15:29:29+00:00"
},
"AssumedRoleUser": {
"AssumedRoleId": "AROA5ORZY2USEASI2XI4F:awscli-session",
"Arn": "arn:aws:sts::924612875556:assumed-role/test-assumed-role/awscli-session"
}
}这时候得到一组新的 AccessKeyId, SecretAccessKey 和 SessionToken,可以在 ~/.aws/credentials 中配置一个新的 profile C, 然后 export AWS_DEFAULT_PROFILE=C 来使用。
或都用 export 分别导出三个环境变量 AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, 和 AWS_SESSION_TOKEN, 分别对应前面的三个值。
$ export AWS_ACCESS_KEY_ID=<Credentials.AccessKeyId>
$ export AWS_SECRET_ACCESS_KEY=<Credentials.SecretAccessKey>
$ export AWS_SESSION_TOKEN=<Credentials.SessionToken>aws s3 ls --profile c
# 想访问超出 test-assumed-role 之外的权限将被提示 Access Denied
aws s3 cp Desktop/jump-server.sh s3://blog.finleyma.ml --profile ty-assume
upload failed: Desktop/jump-server.sh to s3://blog.finleyma.ml/jump-server.sh An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
# 查看当前所使用的角色
aws sts get-caller-identity --profile c
{
"UserId": "AROA5ORZY2USEASI2XI4F:awscli-session",
"Account": "924612875556",
"Arn": "arn:aws:sts::924612875556:assumed-role/test-assumed-role/awscli-session"
}用 Python 的 boto3 包实现
帐号 B 登陆,调用 boto3 的 sts.assume_role() 函数切换到帐号 A 下的 IAM Role test-assumed-role,之后的操作就限定到 test-assumed-role 的约束中了。
import boto3
aws_credentials_b = {
'region_name': 'us-east-1',
'aws_access_key_id':'PNKDIESJGWAURFEWDLLT',
'aws_secret_access_key':'TdTMlDUSKecRadKeMlNIBEmIkRjmZOSvtnhgQDZc',
'aws_session_token':'IQoJb3JpZ2luX2VjEDYabEbMG5J2lzlv......IEQisSAwzmnkv7LNf+'
}
sts=boto3.client('sts', **aws_credentials_b)
stsresponse = sts.assume_role(
RoleArn="arn:aws:iam::123456789011:role/test-assumed-role", # under account A
RoleSessionName='assumed'
)
aws_credentials_assumed_role = {
'region_name':'us-east-1',
'aws_access_key_id':stsresponse["Credentials"]["AccessKeyId"],
'aws_secret_access_key':stsresponse["Credentials"]["SecretAccessKey"],
'aws_session_token':stsresponse["Credentials"]["SessionToken"]
}
boto3.setup_default_session(**aws_credentials_assumed_role)
s3 = boto3.client('s3')
buckets_of_a = [bucket['Name'] for bucket in s3.list_buckets()['Buckets']]当然,使用 Python 的话可以进一步封装,比如默认以帐号 B 登陆,然后执行一个函数 switch_role(role_arn) 后,后续的 boto3 client 就全部变成了 assumed role 的角色了
import boto3
def switch_role(assume_role_arn):
sts=boto3.client('sts')
sts_res = sts.assume_role(RoleArn=assume_role_arn, RoleSessionName='new_session')
new_credentials = {'aws' + re.sub('([A-Z]+)', r'_\1', key).lower(): value
for (key, value) in sts_res["Credentials"].items() if key != 'Expiration'}
boto3.setup_default_session(**new_credentials)
switch_role('arn:aws:iam::123456789011:role/test-assumed-role')
s3 = boto3.client('s3')
buckets_of_a = [bucket['Name'] for bucket in s3.list_buckets()['Buckets']]把 sts_res['Credentials'] 转换为 session 要求的格式是简化,但是要注意以后 assume_role() 响应格式的变化有可能影响到程序的正常执行。
参考
https://docs.aws.amazon.com/zh_cn/IAM/latest/UserGuide/tutorial_cross-account-with-roles.html
]]>有时候我们在云上部署一套高可用的系统往往需要创建很多资源,以在AWS部署一个Web服务为例:
- 2台EC2
- ALB(负载均衡)
- RDS(弹性数据库)
- Route53(域名解析)
- CloudFront(CDN)
- S3(管理静态资源)
- IAM(用户管理)
- SES(电子邮件服务)
- CloudWatch(监控)
光这么多资源,如果在页面上手动创建配置即便是再熟练,也会很累。 还有其他缺点: 手动部署,容易出错 无法进行版本化控制 需要专人部署,人员无法复用
如果使用CloudFormation,我们可以把这些资源都放在一个模板里,然后通过CloudFormation控制台来创建或者更新这些资源。
什么是CloudFormation

所谓堆栈资源,表示一种依赖关系,比如要使用ALB资源,那么就需要实例资源。使用实例要先创建安全组。 堆栈资源最终是一个资源集合。

CloudFormation模板
CloudFormation 模板是 JSON 或 YAML 格式的文本文件。 以下面为例。 表示创建一个EC2实例,指定了实例的AMI,类型,密钥对名称和数据卷。然后需要一个EIP来关联它。
AWSTemplateFormatVersion: "2010-09-09"
Description: A sample template
Resources:
MyEC2Instance:
Type: "AWS::EC2::Instance"
Properties:
ImageId: "ami-0ff8a91507f77f867"
AvailabilityZone: "ap-northeast-1a"
InstanceType: t2.micro
KeyName: testkey
BlockDeviceMappings:
- DeviceName: /dev/sdm
Ebs:
VolumeType: io1
Iops: 200
DeleteOnTermination: false
VolumeSize: 20
MyEIP:
Type: AWS::EC2::EIP
Properties:
# !Ref 等价 Fn::Ref
InstanceId: !Ref MyEC2Instance一个标准的模板由下面的部分组成,只有Resources是必需的
---
# 可选
AWSTemplateFormatVersion: "version date"
# 可选
Description:
String
# 可选
# Designer 添加的信息,或者注释
# CloudFormation 不会转换、修改或编辑在 Metadata 区段中包含的任何信息
Metadata:
template metadata
# 可选
Parameters:
# set of parameters
KeyName:
Type: "AWS::EC2::KeyPair::KeyName"
Description:
"Name of an existing EC2 KeyPair to enable SSH access to the instances"
Default:
"my-awesome-key-name"
SecurityGroupIDs:
Type: "List<AWS::EC2::SecurityGroup::Id>"
Description:
"Name of an existing security group"
Default:
"sg-1a2b3cd4"
EnvType:
Type: "String"
Description:
"The type of environment"
AllowableValues:
- "test"
- "prod"
- "staging"
Default:
"test"
# 可选
Rules:
set of rules
# 可选
# 创建一个名为InstanceType的映射,在美东区我们使用m1.small,美西区使用m1.nano
Mappings:
InstanceType:
us-east-1:
Type: "m1.small"
us-west-1:
Type: "m1.nano"
SubnetMap:
us-east-1:
SubnetID: "subnet-12345678"
us-west-1:
SubnetID: "subnet-7654321"
# 可选
# 比如测试环境用安全组A,正式环境用B
Conditions:
set of conditions
# 可选
Transform:
set of transforms
# 必需
Resources:
set of resources
# 可选
# 比如输出新创建的IP是什么
Outputs:
# set of outputs
KeyName
Description: "This is the EIP for EC2"
Value:
Ref: MyEIPAWS比较牛逼的是提供了AWS CloudFormation Designer可视化工具来拖拖拽拽资源生成模板。
并且官方提供了很多示例模板,你可以直接拿来改改就能用。

实战
如果已经有模板,可以直接上传到S3,然后填S3地址读取

参考
https://github.com/awslabs/aws-cloudformation-templates
https://docs.aws.amazon.com/zh_cn/AWSCloudFormation/latest/UserGuide/cfn-whatis-concepts.html
]]>下面是 user data 被执行时需知晓的一些知识
- 是脚本时必须以 #! 开始,俗称 Shebang, 如 #!/bin/bash
- user data 是以 root 身份执行,所以不要用 sudo, 当然创建的目录或文件的 owner 也是 root,需要 ec2-user 用* 户访问的话需要 chmod 修改文件权限,或者直接用 chown ec2-user:ec2-user -R abc 修改文件的所有者()
- 脚本不能交互,有交互时必须想办法跳过用户输入,如 apt install -y xzy, 带个 -y 标记
- 如果脚本中需访问 AWS 资源,权限由 Instance Profile 所指定的 IAM role 决定
- user data 中的脚本会被存储在
/var/lib/cloud/instances/<instance-id>/user-data.txt文件中,因此也* 可以从这里验证 user data 是否设置正确。或者在 EC2 实例上访问 http://169.254.169.254/latest/* user-data 也能看到 user data 的内容。并且在 EC2 实例初始化后不被删除,所以以此实例为基础来创建一个新的 * AMI 需把它删除了 - user data 的大小限制为 16 KB, 指 base64 编码前的大小
- cloud-init 的输出日志在
/var/log/cloud-init-output.log, 它会捕获 cloud-init 控制台的输出内容
user data 的内容通常在创建好实例后,还得等一会才完全生效,马上用 SSH 登陆新创建后的实例一般还看不到效果,有可能得等分把钟。
脚本的内容会存储在 EC2 实例上,但它执行的控制台输出却没地方找,如果脚本执行过程中有问题就难以诊断了,这里有个办法可记录下 user data 中脚本执行的控制台输出,需在 user data 中加上一行,最后把调试也打开
#!/bin/bash -ex
exec > >(tee /var/log/user-data.log|logger -t user-data -s 2>/dev/console) 2>&1
apt update
......对,你没有看错,上面的 exec > >(... 两个大括号之间有空格
这样就能在实例的 /var/log/user-data.log 中看到所有 user data 中脚本执行的控制台输出了,错在哪一步也就能有的放矢的修正。
如何修改Userdata
- 首先把实例停止
- 在实例仍被选中的情况下,依次选择操作、实例设置和编辑用户数据。
- 启动实例
参考
https://aws.amazon.com/cn/premiumsupport/knowledge-center/execute-user-data-ec2/
https://docs.amazonaws.cn/AWSEC2/latest/UserGuide/user-data.html#user-data-view-change
]]>- IAM > roles > create role
- custom trust policy > copy + paste
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {
"Service": "ecs-tasks.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}- Add permission > Create Policy
- JSON > replace YOUR_REGION_HERE & YOUR_ACCOUNT_ID_HERE & CLUSTER_NAME > copy + paste
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"ssmmessages:CreateControlChannel",
"ssmmessages:CreateDataChannel",
"ssmmessages:OpenControlChannel",
"ssmmessages:OpenDataChannel"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogGroups"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:YOUR_REGION_HERE:YOUR_ACCOUNT_ID_HERE:log-group:/aws/ecs/CLUSTER_NAME:*"
}
]
}- Give it a name
- go back to Add permissions > search by name > check > Next
- Give a role name > create role
ECS new task
- go back to ECS > go to task definition and create a new revision
- select your new role for "Task role" (different than "Task execution role") > update Task definition
- go to your service > update > ensure revision is set to latest > finish update of the service
- current task and it should auto provision your new task with its new role.
- try again
Commands I used to exec in
Option1
enables execute command
CLUSTER_NAME=node-red
REGION=cn-north-1
SERVICE_NAME=service-nodered
CONTAINER=nodered
aws ecs update-service --cluster $CLUSTER_NAME --service $SERVICE_NAME --region $REGION --enable-execute-command --force-new-deploymentadds ARN to environment for easier cli. Does assume only 1 task running for the service, otherwise just manually go to ECS and grab arn and set them for your cli
TASK_ARN=$(aws ecs list-tasks --cluster CLUSTER_NAME --service SERVICE_NAME --region REGION --output text --query 'taskArns[0]')
TASK_ARN=arn:aws-cn:ecs:cn-north-1:777702137755:task/node-red/417a6af0a8c447f9a57d8e49ba7cc84c
adds ARN to environment for easier cli. Does assume only 1 task running for the service, otherwise just manually go to ECS and grab arn and set them for your cli
aws ecs describe-tasks --cluster CLUSTER_NAME --region REGION --tasks $TASK_ARN
exec in
aws ecs execute-command --region $REGION --cluster $CLUSTER_NAME --task $TASK_ARN --container $CONTAINER --command "sh" --interactive
Option2
if you are using Jetbrains IDE, install plugin https://docs.aws.amazon.com/toolkit-for-jetbrains/latest/userguide/welcome.html
this plugin will help you to enables execute command and exec in
参考
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ecs-exec.html
https://github.com/aws/aws-cli/issues/6242#issuecomment-1079214960
https://issuecloser.com/blog/debugging-node-js-applications-running-on-ecs-fargate
]]>{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "MyListBucket",
"Effect": "Allow",
"Action": "S3:ListBucket",
"Resource": [
"arn:aws:s3:::com.demo.file"
],
"Condition": {"StringEquals": {"aws:username": "Bob"}}
}
]
}- 同一Condition名称不能出现两次,要合并
- IAM User 可以属于某个 IAM Group,甚至可以属于多个 Group
- IAM User 无法属于某个 IAM Role,必须透过”切换”的方式,在 AWS 中称为 “Assume Role”,而”切换”这个操作需要有权限才行
Assume Role 基本上是一种 Action("Action": "sts:AssumeRole"),因为 Assume Role 这个行为是从 AWS Security Token Service 中取得一个暂时的 token,藉此取得该 Role 所事先定义好的权限。(sts:AssumeRole Action & IAM Role 的对应关係可以从[此 AWS 官网文件](https://docs.aws.amazon.com/zh_cn/service-authorization/latest/reference/list_awssecuritytokenservice.html#awssecuritytokenservice-actions-as-permissions)找到)
assuming role
切换角色
参考
]]>-
不需要部署 or 管理 server
-
会根据需求自动的 scale out/in
-
不需要为 idle 资源支付费用
-
天生就具备的 HA & fault tolerance 等特性
目前 AWS 提供的 serverless service 其实很多,下图是目前比较常见的几个:

但要如何判断 AWS service 是否为 serverless? 只要评估一下上一个 section 提到的四个原则,如果都满足,表示这个服务属于 serverless(例如:Lambda、SNS、SQS),只要有一项不满足,则该服务不属于 serverless(例如:EC2、Kinesis)
Lambda
文件中提到可设定 Lambda Function 执行时使用的 memory 范围在 128MB ~ 10,240MB(10GB) 之间
比较需要注意的是,Lambda function 执行时 的vCPU core 的数量是根据 memory 的设定大小来决定,如果在设定最大 10GB memory 的情况下,可以取得最大 6 vCPU core;简单来说,就是 memory 设定越大,执行速度会越快,当然费用也会越高
]]>实际上就是只有 memory & timeout 设定可以调整而已
包含的产品多余牛毛

很多国外用户都在使用AWS的产品,著名的有S3,EC2,所有有必要了解一下。
这里介绍最基础的产品,VPC(Virtual Private Cloud),虚拟私有云。
先看下一些基础概念
地域 Region
AWS 在世界各地有很多数据中心,一个 Region 就是多个数据中心的集群
目前在中国大陆地区有北京和宁夏两个 Region
可用区 AZ(Availability Zone)
每个 Region 中包含数个独立的,物理分隔开的 AZ(Availability Zone),每个 AZ 有独立的供电,制冷,安保。
同一 Region 内 AZ 之间由高带宽,极低延时的光纤网络相连,数据以加密形式传输。
ap-northeast-1 是 region 名称
ap-northeast-1a,ap-northeast-1c,ap-northeast-1d 是 AZ
你可以理解为北京Region cn-north-1,朝阳区有个AZ:cn-north-1c,海淀区有个AZ:cn-north-1d 同一Region下的AZ之间由高速网络连接,重要的数据可以放到多AZ里,假如朝阳区机房停电或失火,通过配置流量和数据可以使用海淀区的。 这就是简单的容灾备份。
虚拟私有网络 VPC
VPC(Amazon Virtual Private Cloud)是用户在 Region 中自定义的虚拟网络,是一个整体概念。
用户可以在一个 Region 中创建多个 VPC。
我们可以在 VPC 中选择 IP 网段,创建 Subnet,指定 Route Table,控制 ACL(Access Control list),设置网关等。

多业务系统隔离
如果在一个地域的多个业务系统需要通过VPC进行严格隔离,例如,生产环境和测试环境,那么也需要使用多个VPC。
同样可以通过使用高速通道、VPN网关、云企业网等产品实现同地域VPC间互通。

多地域部署系统
VPC是地域级别的资源,不支持跨地域部署。当有多地域部署系统的需求时,必须使用多个VPC。 可以通过使用高速通道、VPN网关、云企业网等产品实现跨地域VPC间互通。


当 VPC 创建完成后主路由表 和 Main network ACL 会自动创建。
用户可以在公有云上创建一个或者多个VPC,比如,一个大公司里每个部门分配一个VPC。对于需要连通的部门创建VPC连接。
IP段用CIDR表示
CIDR
无类别域间路由(Classless Inter-Domain Routing、CIDR)是一个用于给用户分配IP地址以及在互联网上有效地路由IP数据包的对IP地址进行归类的方法。
遵从CIDR规则的地址有一个后缀说明前缀的位数,例如:192.168.0.0/16。这使得对日益缺乏的IPv4地址的使用更加有效。
也就是说,创建子网时要考虑你需要的资源数
| IP/CIDR | 掩码 | 主机数 |
|---|---|---|
| a.b.c.d/32 | 255.255.255.255 | 1 |
| a.b.c.0/28 | 255.255.255.240 | 16 |
| a.b.c.0/24 | 255.255.255.000 | 256 |
| a.b.0.0/16 | 255.255.000.000 | 65,536 |
Subnet
子网是 VPC 中的 IP 地址范围。在创建 VPC 之后,可以在每个可用区中添加一个或多个子网。
我们一般创建两种子网 Private Subnet 和 Public Subnet。
简单来说,不能直接访问 internet 互联网的 Subnet 就是 Private Subnet,能直接访问 internet 的就是 Public Subnet。
当然 Private Subnet 也可以通过 NAT 的方式访问 internet
当我们在一个 VPC 中创建 Subnet 时需要给 Subnet 选择一个 AZ(Availability Zone),一个 Subnet 只能选择建在一个 AZ 中。

实战

实现图上的功能,创建两个子网
- 一个是 Public Subnet,可以访问因特网,另一个是 Private Subnet
- 一个是 Private Subnet,不能访问因特网
创建VPC
IPv4 CIDR: 192.168.0.0/16
name: finley-vpc
创建互联网网关
name: finley-internet-gateway
并attach到finley-vpc上
创建三个子网
分别为 public, private, public&private(私网通过NAT访问公网)

| subnet id | IPV4 CIDR | AZ | 用途 | :-----| :---- | :---- | | finley-public | 192.168.0.0/24 | ap-northeast-1a | 部署web服务器 | finley-private| 192.168.2.0/24 | ap-northeast-1d | 部署数据库 | finley-private&public | 192.168.1.0/24| ap-northeast-1c| 部署应用程序

创建两个路由表
路由表包含一组称为路由的规则,用于确定来自子网或网关的网络流量定向到何处。
路由表必须属于某VPC
一个公有子网,一个私有子网但可通过NAT访问公网
name: finley-public
编辑路由表

# 第一条表示到192.168.*.*的请求会发送至VPC中
192.168.0.0/16 local
# 第二条表示到其它IP的请求会发送至IGW
0.0.0.0/0 igw-0d1092780f692f46f编辑子网关联

创建第二个路由
name: finley-private

编辑子网关联,选择finley-private&public
创建EC2
创建两个EC2,一个名为finley-public-ec2,一个finley-private-ec2
VPC选择finley-vpc

申请弹性IP,得到公网IP:52.197.152.165 并关联给 finley-public-ec2
| 实例名 | 公有 IPv4 地址 | 私有 IPv4 地址 |
|---|---|---|
| finley-public-ec2 | 52.197.152.165 | 192.168.0.107 |
| finley-private-ec2 | 无 | 192.168.2.197 |
EIP(Elastic IP)是AWS提供的静态公共IP,可以从internet上访问到。实例即便被删除IP也会保留

SSH ssh -i "aws-ty-2022.pem" [email protected] 登录实例
aws-ty-2022.pem 私钥是之前申请过的
检查网络配置,安装nginx或httpd,浏览器打开52.197.152.165,访问成功
ubuntu@ip-192-168-0-93:~$ ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 9001
inet 192.168.0.93 netmask 255.255.255.0 broadcast 192.168.0.255
inet6 fe80::4c3:76ff:feef:971 prefixlen 64 scopeid 0x20<link>
ether 06:c3:76:ef:09:71 txqueuelen 1000 (Ethernet)
RX packets 2795 bytes 2887062 (2.8 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1519 bytes 178671 (178.6 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisionsfinley-private-ec2 只有一个私网地址,由于我们选择private子网
会得到一个私网地址,如192.168.2.197,即使有公网IP,也无法通过互联网访问
可以通过finley-public-ec2登录这个私有子网的实例
# 在本机执行
## 上传私钥到public ec2
scp ~/.ssh/aws.pem 52.197.152.165:~
## 登录public ec2
ssh -i ~/.ssh/aws.pem 52.197.152.165
# 在 public ec2 上执行
chmod 400 aws.pem
## 登录private-ec2
ssh -i ~/.ssh/aws.pem 192.168.2.197
# 进到私网实例,确实无法访问互联网
wget www.baidu.com通过NAT网关使私有子网访问互联网
注意NAT是按小时收费的,用完及时释放
NAT 网关是一种网络地址转换 (NAT) 服务。可以使用 NAT 网关,以便私有子网中的实例可以连接到 VPC 外部的服务,但外部服务无法启动与这些实例的连接。
路由器将互联网流量从私有子网中的实例发送到 NAT 网关。NAT 网关通过使用自身的弹性 IP 地址作为源 IP 地址,将流量发送到互联网网关。
创建 NAT网关
NAT网关要创建在公有子网当中, 选择一个公有子网,创建成功后等待状态变为可用
参考:计算机网络

修改路由表,等状态变为available
| 目的地 | 目标 |
|---|---|
| 192.168.0.0/16 | 本地 |
| 0.0.0.0/02 | nat-gateway-id |
此时finley-private-ec2可以访问互联网了,是通过NAT关联的IP

通过终端节点让私有网络访问aws服务(S3)
VPC 终端节点使您能够在 Virtual Private Cloud (VPC) 与支持的服务和之间建立连接,而无需使用互联网网关、NAT 设备、VPN 连接或 AWS Direct Connect 连接。
因此,VPC 不会对公有 Internet 公开。
实现私有地址访问公有服务,这里我们让私有子网中的实例访问S3服务,首先创建终端节点

实际上是添加了一条路由表信息

访问S3并下载文件成功

VPC peering 对等连接
VPC 对等连接是两个 VPC 之间的网络连接
可以在自己的 VPC 之间创建 VPC 对等连接,或者在自己的 VPC 与其他AWS账户中的 VPC 之间创建连接
VPC 可位于不同区域内(也称为区域间 VPC 对等连接)。
例如,如果您有多个AWS账户,则可以通过在这些账户中的 VPC 间建立对等连接来创建文件共享网络。
您还可以使用 VPC 对等连接来允许其他 VPC 访问您某个 VPC 中的资源。
总结
- 首先我们选择Region,随后所有创建的内容都是存在此Region中
- 创建VPC,一个虚拟网络,在里面设置IP段,VPC是一个逻辑结构,并不和AZ(Availability Zone)直接相关
- 在VPC中创建Subnet,需指定IP段,并且指定所在的AZ,一个Subnet只能指定一个AZ,一个AZ可以容纳多个Subnet
- VPC中Subnet默认是可以相互访问的
- 新建的Subnet默认就是Private Subnet
- IGW(Internet gate way)是一个独立的组件配置在VPC上,使得VPC可以访问internet
- 在Private Subnet中配置了到IGW的路由后,就变成Public Subnet
- Public Subnet中的EC2还要再配置一个Public IP或者EIP就可以访问Internet
- 如果EC2可以访问internet,其关联的Security Group入站规则如果允许从internet访问,那么这个EC2就可以从internet中直接访问到
- 实践中我们把应用程序,数据库放在Private Subnet中,阻止从internet访问。把堡垒机和ALB(Application Load balancer)放在Public Subnet,允许从internet访问
- 配置了NAT路由的Private Subnet中EC2可以访问internet,但不能被internet访问到,因为这个EC2并没有IP,流量是通过NAT转换了,NAT有IP
- NAT gateway需要一个EIP(Elastic IP)并且把NAT配置在Public Subnet中
- 有时候Private Subnet中的EC2虽然不能访问外部internet,也需要访问特定服务如S3,RDS,这时候可以创建End Point
- 创建End Point需要选择Service种类,VPC,路由表,实际上会在选择的路由表上添加一条记录,前缀是vpce-
- 每个Subnet都必须关联一个路由表,创建的每个Subnet都会自动关联 VPC 的主路由表
- 创建Security Group时,只需指定VPC。之后可以把SG与EC2, RDS, VPC Endpoint相关连,用来控制这些服务的出入站IP和端口
- 所有 IPv4 流量 (0.0.0.0/0),IPv6 流量 (::/0)
参考
https://aws.amazon.com/cn/vpc/faqs/
https://help.aliyun.com/document_detail/54095.html
https://docs.aws.amazon.com/zh_cn/vpc/latest/userguide/VPC_Subnets.html
https://www.bilibili.com/video/BV1wk4y1r7gX
]]>
创建EC2
# https://docs.aws.amazon.com/zh_cn/zh_cn/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-rules.html
# 防止用户选择错误内容参数
# 每个模板规则由两个属性组成:
# 规则条件(可选)— 确定规则的生效时间。
# 断言(必选)— 描述用户可为特定参数指定的值。
AWSTemplateFormatVersion: "2010-09-09"
Resources:
MyInstance:
Type: AWS::EC2::Instance
Properties:
InstanceType: 't2.micro'
AvailabilityZone: 'ap-northeast-1a'
KeyName: 'aws-ty-2022'
ImageId: ami-03d79d440297083e3
UserData:
# 内部函数 Fn::Sub 将输入字符串中的变量替换为您指定的值
Fn::Base64: |
#!/bin/bash
yum update -y
timedatectl set-timezone "Asia/Shanghai"
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "/tmp/awscliv2.zip"
unzip /tmp/awscliv2.zip -d /tmp/awslicv2
/tmp/awslicv2/aws/install
curl -sL https://rpm.nodesource.com/setup_14.x | bash -
yum install -y gcc-c++ make
yum install -y nodejs
Tags:
- Key: Name
# Jack---Jones
Value: !Join ['-', ['Jack', '-', 'Jones']]安装 kinesis agent
yum install -y aws-kinesis-agent
https://docs.aws.amazon.com/zh_cn/firehose/latest/dev/writing-with-agents.html
配置firehose
# 配置凭证
cat /etc/sysconfig/aws-kinesis-agent
# AWS_ACCESS_KEY_ID=
# AWS_SECRET_ACCESS_KEY=
# AWS_DEFAULT_REGION=
cd /etc/aws-kinesis/
cat agent.json
{
"cloudwatch.emitMetrics": true,
"kinesis.endpoint": "",
"firehose.endpoint": "",
"flows": [
{
"filePattern": "/tmp/app.log*",
"kinesisStream": "yourkinesisstream",
"partitionKeyOption": "RANDOM"
},
{
"filePattern": "/var/log/kinesis-log*",
"deliveryStream": "yourdeliverystream"
}
]
}
# 修改为:
{
"cloudwatch.emitMetrics": true,
"kinesis.endpoint": "",
"firehose.endpoint": "firehose.cn-north-1.amazonaws.com.cn",
"flows": [
{
"filePattern": "/var/log/kinesis-log/*.log",
# Delivery stream 的名称
"kinesisStream": "KDS-S3-LogGenerator"
}
]
}重启服务并查看日志
service aws-kinesis-agent restart
tail -f /var/log/aws-kinesis-agent/aws-kinesis-agent.log
生成日志
mkdir -p /var/log/kinesis-log
参考
https://aws.amazon.com/cn/kinesis/data-firehose/faqs/?nc=sn&loc=5
生成日志程序
const LOG_LINE_COUNT = 5
// 名称,分类,年龄,语言,平台,是否免费
const gameList = [
["马里奥","动作","全年龄","日语", "Switch", 0]
["GTA5","暴力","18","英语", "Steam", 0]
["FIFA22","体育","9","英语", "Steam", 0]
["FIFA22","体育","9","英语", "Steam", 0]
]
function sleep(ms) {
return new Promise(resolve => {
setTimeout(resolve, ms)
})
}
function *myGenerator() {
let index = 1;
while(true) {
yield index++;
}
}
const logGenerator = async() => {
}
logGenerator()2022-05-29 22:10:51.123, "马里奥","动作","全年龄","日语", "Switch", 0
2022-05-29 22:10:51.243, "GTA5","暴力","18","英语", "Steam", 0
2022-05-29 22:10:51.312, "FIFA22","体育","9","英语", "Steam", 0
2022-05-29 22:10:51.567, "FIFA22","体育","9","英语", "Steam",
2022-05-29 22:10:51.123, "马里奥","动作","全年龄","日语", "Switch", 0
2022-05-29 22:10:51.243, "GTA5","暴力","18","英语", "Steam", 0
2022-05-29 22:10:51.312, "FIFA22","体育","9","英语", "Steam", 00logdate timestamp,
name string,
category string,
age string,
lang string,
platform string,
isfree tinyint
CREATE EXTERNAL TABLE IF NOT EXISTS `my_db`.`log-game` (
`logdate` timestamp,
`name` string,
`category` string,
`age` string,
`lang` string,
`platform` string,
`isfree` tinyint
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://finley-athena-logs/'
TBLPROPERTIES ('has_encrypted_data'='false');注意引号



- 进到 管理控制台,选择启动虚拟机

选择ES2,创建一台服务器实例

注意勾选“仅免费套餐”,这里选择的是比较新的Ubuntu Server 18.04
- 配置选1核1G就行,直接点击“审核和启动”
- 没有密钥对的话,先生成一个,会下载一个pem格式的文件,保存好,待会儿登录服务器要用到
- 如果是Windows系统,下载 MobaXterm 软件,根据提示连接主机

或者配置ssh config
Host aws-seoul
HostName ec2-170-82-55.ap-northeast-2.compute.amazonaws.com
User ubuntu
Port 22
IdentityFile ~/.ssh/aws-seoul.pem- 登录成功

- 依次执行下面的命令,会让你设置密码,端口和加密方式(默认)
sudo wget --no-check-certificate https://raw.githubusercontent.com/teddysun/shadowsocks_install/master/shadowsocks-go.sh
sudo chmod +x shadowsocks-go.sh
sudo ./shadowsocks-go.sh 2>&1 | tee shadowsocks-go.log安装成功后记录好信息 打开酸酸乳客户端,填入信息

-
连接成功!
-
如果无法连接,在AWS后台添加安全组,编辑入站规则,端口填写刚SSR设置的端口 在EC2控制面板,进入到了实例的安全组设置中。 在左下部点击 “入站” 标签页,并点击编辑。点击 “添加规则”,添加的规则中“类型”“协议” 都不需要改动。“端口范围”这里填上我们前面设置的端口,“来源”下拉框中选择“任何位置”。
-
接下来还需要给服务器申请一个固定IP。点击弹性IP -> 分配新地址 -> 操作 -> 关联地址 。选择自己的实例并关联。
]]>

例如,当前安全组、来自同一 VPC 的安全组或对等 VPC 的安全组。 这允许基于与指定安全组关联的资源的私有 IP 地址的流量。这并不会将指定安全组的规则添加到当前安全组。
]]>图形化工具:
- Windows平台: http://s3browser.com/
连接 bucket


- mac平台
推荐Transmit
命令行工具(awscli):
- Windows平台:
https://s3.amazonaws.com/aws-cli/AWSCLI64.msi
- Mac平台:
参考: https://github.com/aws/aws-cli
sudo easy_install pip
sudo pip install awscli --ignore-installed six
# 根据提示输入 Origin, AccessKey, AccessSecret
aws configureAWS Cli 操作文档:https://docs.aws.amazon.com/cli/latest/reference/s3/cp.html

开放访问权限
默认情况下文件对象和上传的文件不能公共下载的,比如访问 https://s3-us-west-1.amazonaws.com/yourbucketname/README.md 会提示 access deny。
如果需要对某目录下的文件开发公共访问权限,可以这么干,
打开 策略生成器

点击 generate policy,复制 json配置内容,粘贴到存储桶策略中
]]>

https://www.youtube.com/playlist?list=PLEiEAq2VkUULlNtIFhEQHo8gacvme35rz
https://www.bilibili.com/video/BV1vW411G75e
有用文档
]]>假设镜像源站点为:https://example.com/static,请求的对象 key 为:images/logo.png, 那么回源地址为:https://example.com/static/images/logo.png。
搜索 [https://hexo-blog.pek3b.qingstor.com] 替换为 [https://hexo-blog.pek3b.qingstor.com]
替换为
https://pek3b.qingstor.com/hexo-blog/20200720101157e0cb75757.jpg
]]>可转债
工具及网站
]]>之所以敢跟你聊它,是因为它几乎零风险,手续费低,收益率又比余额宝高,在一些特殊的时间点上还可能有很高的年化收益率,是我们普通人类的好朋友。
逆回购是个什么东西呢?它的全称是「债券质押式逆回购」。
简单来说,就是你在证券账户里借给别人一笔超短期贷款。谁把你的钱借走了你是不知道的,但他会用他所持有的合格债券来作为抵押。
在借款时间到期后,他会把本金和利息一起还给你,打回你账上。
在A股市场上,逆回购产品是可以像普通股票一样交易的。你需要的就是开有股票账户,以及账户里至少有1000.10元。
其中1000元是逆回购的最小参与金额,1毛钱是参与这笔逆回购的手续费。
一笔逆回购的收益是这么计算的:收益=交易金额*收益率*计息天数/365-手续费。手续费很低,最低是万分之零点一,最高也就是万分之三。
上交所有9个逆回购品种,分别是1天、2天、3天、4天、7天、14天、28天、91天、182天的逆回购,每一个都有自己独立的交易代码; 深交所有11个品种,比上交所多了63天和273天的2个品种。它们的名称和交易代码我放在文稿里,你可以备用。


你借出去的钱什么时候能回来呢?逆回购资金的到账日是T+N+0,提现日是T+N+1。N就是逆回购天数。
你逆回购1天,那么当天卖出,下一个交易日的开盘前,资金回到你的账户里,你可以进行股票交易,但是不能提现,要再过一天才能提现转出到自己的银行卡上。
上交所和深交所的逆回购产品参与门槛还不太一样,上交所的资金起点是10万,深交所是1000块,上交所产品的参与门槛高,参与人数也就比深交所要少。
所以同样期限的产品,上交所的利率有时会更高一些。比方说,同样在我写稿子这一天,11月23日,上交所的1天期逆回购产品GC001的收盘价格是2.595元,这就是年华收益率2.595%的意思;深交所的1天期逆回购产品R-001的收盘价格是1.99,年华收益率1.99%。怎么说呢,丰俭由人吧。
如果你账户里有笔1万块的闲钱想要借出去一天,你可以在交易日的15点半之前,在你的股票交易软件上输入131810,这就是R-001的交易代码,然后选择「卖出」10手,1000块一手,这笔钱就算借出去了。如果明天也是交易日的话,明天你就不用另外再进行反向操作了,在股市开盘之前,这笔钱就会连本带息回到你的账户上,不影响你明天买股票。
同样道理,你也可以卖出其他不同出借天数的逆回购产品。
你可能注意到刚才我说了一个奇怪的词,「卖出」。我们什么都没有,为什么不是买入这个逆回购品种呢?
话说到这儿,我为了给你解释为什么是「卖出」,捎带也要向你解释一下「逆回购」这个别扭的词。借钱就说借钱,为什么要用「逆回购」这个别扭的词呢?回购个什么?我来试着粗暴地解释一下:
在金融领域,「回购」这个词其实大家是跟着中央银行用的。央行发行的最基础产品是现金。所以,当央行想要收紧流动性,从商业银行收回现金这种产品的时候,这个操作就叫「正回购」,也就是相当于央行作为出品方要把现金这种产品买回来。那「逆回购」呢?就是把更多的现金产品投放到市场上。
所以我们只要记住,回购这个词的对象是「现金」。正回购就是回购现金,逆回购就是卖出现金,就可以了。
那正回购、逆回购里,央行和商业银行买卖现金这种产品的时候,双方用什么付账呢?暂时不付账,先欠着,但需要一个抵押品,这个抵押品通常是国债或者其他的合格债券。
拿一笔7天期限的逆回购来说,比如央行放出100亿现金给商业银行,银行你就要给我抵押品,这个抵押品通常就是国债。
7天后到期了,商业银行要把从我这儿拿走的100亿现金还回来,同时再加一笔利息。央行再把你押在我这儿的国债解除抵押,咱们就两清了。
这是央行的玩法。而我们普通人类虽然没有那么大的资金量,在股票交易平台上也是可以小规模体会一下当央行的感觉的,我们在放贷的时候,相当于也是在把现金卖给借款人,也是在给市场释放流动性。
一般来说,一笔逆回购交易,涉及三方参与者:
第一个是逆回购方,就是我们这样,手里有闲置现金,想要让它增值的人;
第二个是正回购方,也就是借款人,他手里有债券,现在着急用现金,想抵押债券来借钱。
多说一句,想做正回购的准入门槛是很高的,个人的话名下金融资产不能低于300万。还需要跟证券公司签特别的委托协议,今天我们就先不谈了。
第三个参与者,是监管和中介平台,在A股市场上就是上海证券交易所和深圳证券交易所。借款人的债券就抵押在交易所对应的电子平台上。
这个作为抵押品的债券,通常是国债或者企业的信用债,这些债券根据自己不同的信用等级,会折算成交易所承认的「标准券」。
有了这个抵押品,逆回购就几乎没有风险了。哪怕借款人真还不出钱,你的本息也是国家清算机构先垫付给你,然后它再去找借款人算账的。
那我为什么要选在新年前后提醒你特别注意这个品种呢?这是因为,在月底、年末、长假前后这种特殊时点上,市场的资金容易相对紧张,逆回购的年化收益率就会明显走高。
拿今年来说,10月9日也就是国庆节长假刚过,R-001的年化利率一开盘就冲到了6.2%,这背后一定是有借款人很急很缺钱,所以把利率开到了非常高。
我往回翻了翻数据,发现R-001在2016年2月27日的时候,年化收益率到过40%。
那什么时间的收益率会比较高呢?前面说了,在一年里,月末、年末、长假前后,因为这些时间点是银行要面对准备金率考核、或者企业要短期拆借的时候,市场上钱荒,所以每到这个时候,你就可以瞄一眼逆回购产品们。
如果你已经拿定主意在具体某一天里操作逆回购呢,那你也要注意了,一般上午的时间收益率会比下午高,因为急缺钱的借款人上午就把钱借走了。所以啊,具体到今年年底,要是12月31日是最后一个交易日,我建议你30号就开始留意一下逆回购的利率价格,如果合适的话就可以出手了。拿2019年的12月30日来说,深交所的1天逆回购产品R-001的最高年化收益率到了3.52%。
但你倒也不至于把茅台股票给卖了去操作逆回购,这个不值当的,把闲钱放进去就可以了。对我们普通人类来说,逆回购保本保收益,收益通常来说比余额宝高一点。
另外,长期投资也没必要考虑逆回购,用它来做1到7天的短期现金管理就可以了。逆回购的特殊吸引力主要是来自特殊时间点的收益率飙高,但在普通岁月里,逆回购的年化利率也就是2%到3%之间,吸引力不算大。
总之,周末或者假期之前的一两天,要是你的股票账户里有闲钱,可以把它扔进逆回购里去。对了,逆回购的交易时间比A股要长半小时,下午3点半才结束,所以平时股票收盘之后,你也可以把闲钱扔进去。熟悉逆回购的同学,肯定知道我还有好多细节和技巧没有来得及一一解释清楚,比如怎么选操作时间的收益率最大呀等等,所以也请各位学霸把你的秘笈敲在留言里,造福一下刚刚听说这个产品的同学。
购买方法如下,依然用东方财富举例,在「天天宝」下面就可以看到「国债逆回购」的选项,进去之后可以看到「沪市」和「深市」两个选项,门槛不同,一个是 10 万,一个是 1 千,酌情选择就好(选收益率高的)。
在这里,我们可以看到在12月12日 28天期的收益率达到了 5.1%,因为刚好跨过了年末这个关口,所以收益率也是不错的。

重点再强调一遍,每逢月末、季度末和年末,一定要看一下「国债逆回购」常常有惊喜哦。
]]>在书房2017年5月的《看得懂与看不懂》一文中,我曾写道:「当你能够回答下面四个问题时,就代表看懂了这家企业」:
- ①这家公司靠销售什么商品和服务获取利润?
- ②它的客户为何从它这里采购,而不选其他机构的商品或者服务?
- ③资本的天性是逐利。眼看这家公司坐享丰厚利润,为什么其他资本没有提供更高性价比的商品或服务,抢占了它的市场份额,或逼迫它降低利润空间呢? (更高性价比,即可以是同样质量/数量+更低价格,也可以是同样价格+更高质量/数量)
- ④假设同行挟巨资,或者其他产业巨头挟巨资参与竞争,该公司能否保住乃至继续扩张自己的市场份额? 其实这四个问题就是很多高人喜欢说的“商业模式”,老唐只是把它说的简单粗暴,显得稍微不那么高大上了
当我们能够回答以上四个问题后,就可以⑤给企业估值了。也就是说在我看来,研究一家企业的框架,就是上述①②③④⑤。 不管从哪个角度切入具体某家企业,总之万变不离其宗,就是想办法回答上述五个问题。
接下来,老唐以福寿园这只刚刚接触过的企业为例,分享一下从接触一家企业到得出研究结论,应该做的工作和大体的步骤,供朋友们参考。 需要提醒的是,老唐也是刚刚接触这家企业的财报,且由于手边琐事影响,到今天为止连财报都还没有看完。
所以,本系列主要谈框架和方法,是示范老唐本人所用的捕鱼之法(且不见得有多高明),不是介绍这条鱼。 尤其是文章中,完全可能包含老唐错误或片面的认识——烦请发现者直率指正,谢谢! 请千万不要将本系列文章理解为老唐建议在此位置买入福寿园,切记切记
利益声明:截止此刻,老唐本人及本人控制的账户,持有福寿园的数量为0。
一般来说,老唐喜欢投过去已经被证明能够赚到丰厚利润,且经过分析后,认为未来将继续赚到更丰厚利润的企业,不喜欢那些「虽然现在不赚钱,但是未来可能非常美好」的梦想窒息类企业。
因此,我通常用ROE作为筛选企业的第一项标准。
ROE是净利润与账面净资产的比值,它代表企业对掌控的资源的运用能力。
高的ROE说明企业利用当前掌控资源,获取了远超社会无风险收益率的回报水平。
高ROE是投资者的路标和指示牌。它的作用是指引我们去发现某种没有被记录在资产负债表、却能给公司带来收入的「经济商誉」资产。 具备高经济商誉的企业,往往都有某种竞争优势企业,值得投资的概率很大。
——注意,这个观点,老唐在2018年3月以《Roe指标的正确应用》和《Roe指标的正确应用(续)》为题,发表在书房。
这角度是老唐原创。以我的阅读经历,我从未见过(或至少没有在中文世界里见过)其他人做过如此阐述。
以福寿园2019年年报为例,公司净资产46亿(为行文简单,数据四舍五入,下同),当年净利润7.4亿,roe≈16%。 归母净资产40亿,归母净利5.8亿,归母roe≈15%。
还不错,但也不算特别出彩。
同时我们会发现少数股东权益5.4亿,带来约1.6亿少数股东损益,对于少数股东而言,roe≈1.6/5.4≈30%。
这意味着要么有关联人掏公司腰包,要么是少数股东带有某种没有体现在财报上的特殊资源。究竟是什么,暂且存疑。
老唐在《手把手教你读财报》32页第一行写过:
「经验丰富的投资者,首先看的报表一定是资产负债表。实际上,他们也许会翻阅利润表和现金流量表来相互印证,但最终总是聚焦在资产负债表上。」 长期跟踪书房的朋友们都知道,几乎分析任何企业,老唐都会首先搞出一份简化的资产负债表,福寿园也不例外。 福寿园2019年度资产负债表简化处理结果(单位人民币亿元):
读过《手把手教你读财报》的朋友,看到这份简化报表后,头脑里至少应该反映出以下企业特征:
- ①企业几乎没有有息负债;
- ②企业即占用上游资金,也占用下游资金,在产业链上相对强势;
- ③应收账款的数额很少,企业销售主要是预收或现款现货;
- ④公司有大量现金沉淀,账面类现金资产超过净资产的一半;
- ⑤商誉显示,企业发生过一次或多次溢价收购。
备注:当年营收18.5亿,有1亿应收账款。 在阅读过程会发现,这少量的应收款,是因为火化机销售、园林和景观设计以及向地方民政主管部门提供服务所产生的。 创造公司年度营业利润97%的墓地业务,几乎不产生应收账款。 沿着这五个要点展开思考,顺理成章地就会产生以下问题:
①企业的主营业务是卖墓穴,类似于房地产卖房子。为什么房地产企业普遍高负债,高杠杆运营,而福寿园却近于无杠杆状态运营。 它们之间存在什么样的差异? ②净资产回报率超过15%,盈利几乎全部为现金的生意,为什么要保留大量资金在手,且几乎完全不借款。 是什么制约着公司利用更多资本去获取更多利润的能力? ③企业为什么通过溢价收购来扩张,收购的出价是否有损害小股东利益的情况? 在上市公司下属非全资子公司中占少数股份的合作伙伴,凭什么可以得到比上市公司股东更高的回报率? 接下来就可以带着问题去阅读财报全文了,解开上述疑问的过程,就是我们通常所谈到的“企业研究”。 后文我不再一一引用原文和出处了,直接说我从财报阅读过程中的思考,大体考虑分为供应端、需求端、行业竞争、政策风险、发展空间、管理层风险以及估值前要做的工作七个角度展开。 不过,大家都知道,我写东西是兴趣驱动,不保证有兴趣和时间写完。也不保证一定从这七个角度,或只从这七个角度写。大家有多少看多少吧 从供应端看,这门生意和房地产似乎很像,都是从政府手中拿地、然后加工,卖给客户。
但按照我粗读财报的印象,它和房地产生意至少有以下五大区别: 第一,土地权属。 房地产行业是从政府手中买下土地50到70年的使用权,投入资金建房,然后将土地使用权和房屋一起卖给客户,结束。 未来若可以通过缴费延长土地使用权,由客户本人缴费,土地也归属于客户本人。 绝大部分城市商品房,客户支付的购房款,名义上是购“房”款,实际上主要款项是购买房子脚下的土地(以清水房论,房屋的建安成本大多介于800~3000之间,地区差异不大)。 严格的说,收钱卖掉房子后,房地产公司和这块地、地上的房产及其中的居住者,已经切断联系、分道扬镳了。 福寿园是从政府手中获得土地使用权,建墓穴,然后将墓穴的使用权租用给顾客。 注意土地使用权并没有转让给客户。客户购买的墓穴是不附带土地证的。 未来如果可以通过缴费或其他方式延长土地使用权,由福寿园缴费,土地继续属于福寿园。 如果同样用房子来类比说明的话,福寿园的客户相当于只是一次性交清了20年房租及物业费。 房子和脚下的土地,法律上的所有权依然属于开发商(福寿园)。
第二,后续黏性。 正因为上述土地权属问题,无论是躺在墓穴里的逝者还是其后人,将长期的、无可选择地与福寿园保持紧密的联系和商业往来。 如果未来不再续交租金的话,房东(福寿园)是有权力将租客(骨灰盒)驱逐,并将房子重新租给其他房客的。 (几十年后放弃缴费并失联的相关风险和处理方式,后面发展空间部分再聊)。 虽然房地产开发商一般也同时提供物业服务,但房地产行业的物业服务,本质上讲是任何主体都可以提供的,是红海里近于无差别的竞争。 而且物业管理工作琐碎复杂,对人力资源需求很大,很难有巨大的利润空间。 所以截至目前为止,房地产企业的物业部门,更侧重于为房屋销售服务,本身并没有什么利润甚至是赔钱的(当做销售费用看待)。 福寿园提供墓穴租用后,后续的物业服务只能由福寿园提供。 总体来说,墓园的维护工作,变量很少(享受服务的基本不再诞生新要求),大体标准化且极少有紧急事件发生,总体满意度常常超预期。 对此类物业服务费用,通常顾客是在办理“入住”手续时,就一次性预缴10~20年的费用。 这笔费用少则数百元/年,多则数千元/年,看似不高。但由于墓穴通常占地就1~3个平方,每平米收费标准常常是住宅物业标准的数倍甚至数十倍。 该款项中的少部分由监管部门监管使用,专项用于墓园管理,大部分收下就是利润。 第三,囤地待涨。 房地产行业的囤地行为,是政府层面打击的。 比如2020年9月成都市高新区财政局就下过一份文件,禁止高新区内金融机构向李嘉诚旗下的和记黄埔成都公司及其项目提供新增融资、贷款,禁止区内金融机构向和记黄埔进行重大资产重组提供帮助,原因是该公司存在捂地、捂盘等不良行为。 墓园的捂地行为几乎是政府要求的。 几乎所有的地区都有限制顾客购买墓穴资格的相关政策,例如去世后才能买,年龄超过70或80才能买,重病才能买,一人去世提前预留其他家庭成员墓穴才能买等等。 总之原则就是:只有在被证明有需要的时候,才允许购买,尽可能地禁止提前购买,同时也禁止转让。 而墓园土地(标准用语殡葬用地),是政府一次性划拨或出售给墓园经营者的,这就必然导致一种房地产行业里被禁止的获利模式,在墓园却是合理合法的,那就是:捂地。 而且奇妙的是,墓园土地可以超出土地使用权最后期限销售。 比如福寿园有些墓地的使用权已经卖超(意思就是假设土地使用权截止日期是2020年12月31日,但公司可以今天把墓穴卖给顾客,且将管理费用收到2040年),但政府相关部门出具书面函件确认不违规。 基本可以确定,未来土地到期后,适当续费就可以继续使用(续费的标准问题,我们放在政策风险部分谈)。 正因为这样,福寿园的土地大部分是未开发状态(即捂地)。 毕竟伴随着收入水平的提高,未来墓穴的价格几乎可以预期必然上涨(此处投资者可以做公司上市以来,各个墓园平均墓穴售价的数据统计和走势图)。 成本不变、售价上涨,无疑会给公司带来更多利润。 捂地也是福寿园账面ROE不够高的原因。 举个简化的例子说,就是公司买下100单位土地,成本全部计入ROE的分母。 产生的利润主要有一明一暗两块,明的是当年销售出去的5份土地带来的,记录在利润表里,是计算ROE的分子。 暗的是手中所捂的95份土地当年的增值,不记录在利润表里,不作为ROE的分子。 扩张过程中,不断有资本从产生利息收入的货币基金或金融资产,沉淀为只产生暗收益的墓地资产。正是这个原因,导致即使在超高毛利率的销售数据下,ROE看上去却并不怎么诱人。 第四,土地的主要获取方式。 房地产行业竞争者众多,土地拍卖是各地方政府主要财源,政策监管严格,地价高昂。 殡葬用地是受限制用地,是在当地民政部门和国土部门在按照死亡人数预期,规划出合适的数量后,划拨或者挂牌出让。 地方政府和媒体对于该类土地的关注度不够,接受划拨或者参与竞争的同行很少,土地基本上无需高价获得。 今天我们登陆自然资源部不动产登记中心旗下的中国土地市场网,查询殡葬用地,我们会发现绝大部分依然是划拨方式,拍卖和挂牌出让占比至今仍然极小。
正因为划拨方式为主,所以市场参与者基本上就是现有的业内人士。 说透彻一点,就是围绕在民政部门周围,长期与殡葬行业相关的小利益团体。 其他投资主体,根本无法预期能否获得经营原材料(殡葬用地),不可能提前进入这个行业去等地。结果就是真有地的时候,也很难及时参与竞争。 由于土地的划拨方式,加上殡葬用地主要以不适宜从事其他用途土地为主,所以大部分土地低廉的超乎想象。 比如我们点开上面截图的链接,看最近的土地划拨价格(只有部分划拨土地披露成交价格): 10月17日这块地,4.0481公顷(1公顷=15亩=1万平米)。位于新疆和田市外约75公里处,价格81620元,折合每亩1345元,每平米2元钱(你没有看错单位,就是2元钱/平米)。 但若是拍卖,成交价格立刻就不一样了。 还是上图,第一个拍卖出让的平阳县那块地5.3263公顷(53263平米=80亩),位于浙江温州市外约50公里处,成交价格4887万元,折合61万/亩或917.5元/㎡。付款要求为2020年11月11日付一半,2020年12月12日付一半。 当然,地价还受区域购买力和土地等级差异影响,但两地的墓穴价格差异不可能夸张到数百倍。区域购买力和土地等级解释不了大部分价差,只能归结为拿地模式的差异。 第五、土地供应量。 房地产的土地供应是源源不断的。政府在不断拓展城市空间,不断将生地变成适合房地产开发的熟地。 不仅如此,每一块土地的开发行为本身,实际上也在催熟隔壁地块的供应。 任何房地产商的每一份投入和努力,吸引到买房和入住客户的同时,也抬高着隔壁地块的价格,并给自己招来竞争对手。 这也是老唐五六年前于某论坛分享过的困惑,2017年6月27日的《生人勿近诞生记》一文引用过: 老唐对地产一直不感兴趣,原因是很多年前,一个做地产的熟人,曾经这样吐苦水:
3000万买一块地,求爷爷告奶奶地走通各个环节,起早贪黑担惊受怕的八个杯子五个盖,总算把房子修起来卖的七七八八了,一算账能赚好几千万。
但赚了钱,不能就这么回家抱娃吧,还得买地继续滚啊。隔壁去一看,本钱加上利润,也就勉强购买隔壁差不多大一块地。
这搞房地产的,终极形态到底是什么样子呢?
现金买地—建房换现金—现金买地—建房换现金—现金买地……周而复始。最终留给股东的,不知道是一堆现金,还是一大片荒地?
如果始终不产生或者很少产生现金流,投资者的回报,必须寄期望于牛市来临,这很难让我夜夜安枕。
殡葬用地不同。 每个地区人口的年度死亡人数,是有基本稳定的历史统计数据的。未来的预期,也可以根据年龄结构和平均寿命做大致准确的计算。 政府会根据这个计算,在土地规划中,规划出未来N年需要的殡葬用地,通过划拨或出售的方式释放,此时土地成本被提前锁定。 然后在该规划基本满足需求的时间跨度里,该城市很难再释放新的殡葬土地。 墓园经营者的每一分投入,除了提高自己所捂土地的附加值外,不会给自己增加竞争压力。 所以,从土地供应量角度看行业格局,墓园和房地产行业的原材料供应有天壤之别,这也决定了两者的经营方式有着巨大的差别。 当然,这并不意味着彻底杜绝竞争。 毕竟农村荒地、同区域其他墓园,甚至包括一些灵骨塔、庙宇、道观、商品房或小产权房屋以及天葬海葬不葬等多种方式,都有可能成为曲线的行业竞争对手。
]]>基金
]]>每张可转债的背后都对应的一家在A股上市的公司的股票,这个股票就叫做正股,比如深南转债对应的正股是深南电路。如果现在深南电路的股价是10元,则10元就是正股价,公司可以和股民约定,比如半年以后,可以拿着股民购买的可转债以12元每股的价格换成股票,这个12就是转股价,当然股民也可以选择不换股票,一年后直接拿连本带息。
这里面会有几个结果:
-
一年后公司股价涨到15元,超过了转股价,股民依然可以以12元的价格把可转债兑换成股票,这样股民赚到了15-12=3的差价
-
一年后公司股价跌到了5元,这时候显然没人去转换,因为换了就亏了,此时股民可以拿着不动,就等到期
所以可转债既有债券的属性,也有股票的属性,所以有人说可转债相当于保本的股票
解读
发行可转债必须公开一些信息,挑些不容易理解的解读下:

-
可转债的利息一般第一年最低,越往后越高,一般是6年,如上图第一年利息0.5%,最后一年3%,为了吸引投资者,大多数的转债都会在到期日前被收回。
-
转股溢价率:转股价/ 正股价 -1 是衡量可转债是否值得买的重要指标,一般来说,越低越好,最好是负数,这样上涨的概率会更大
-
债券评级,3A是最高级,安全性高,但收益水平也比较低
需要考虑的问题
- 作为债券,他的利息很低,一般1%的利息非常低,抵不过通货膨胀,换成股票赚差价是上选
- 上市公司还不起可转债怎么办?目前监管还是比较严格的,发债公司一般是优质公司,历史上没有发生过违约的可转债
注意事项
阅读募集说明书看清条款
转股价格的向下修正条款 如果正股价持续在转股价85%以下10到15天,上市公司有权下调转股价 目的:刺激股民买可转债 坏处:转股过多,可能会摊薄股东权益 这个是上市公司的权利,不是强制性的
强制赎回条款 一个非常美妙的条款 正股价维持在转股价130%(具体数值根据募集说明书)以上15个交易日,公司将以债券面值加应计利息的价格赎回可转债。 此时,可转债的持有人已经至少赚了30%的利润了
上市公司的终极目的是让全部股民全部转股,从债主变为股东,这样上市公司就不用还钱了,为达到此目的,需要正股价远高于转股价
有中国特色的赎回条款 回售期内的正股价持续低于转股价70%达30天,上市公司必须以债券面值加上应技利息的价格赎回可转债,大概101-103元 这个是义务,强制执行,为了保护股民,相当于硬性保底
四大要素
- 下调转股价和回售条款都是为了熊市准备的
- 强制赎回是为了牛市和反弹准备的
- 在牛市,正股价上涨,可转债的价格也会跟着上涨,不管你是卖出可转债还是转股继续持有股票,都可以享受收益。
- 在熊市,正股价下跌,可转债可以向下修正转股价,且战且退,一旦市场出现反弹,可以强制赎回条款来获得利益
实操
以东方财富APP为例,需要开户。 点新债申购

查看可购买的可转债

选择一个可转债,点申购,输入申购数量,默认10000,点确定,等待即可,一般1-2天就有结果,中签会收到短信通知,告诉你中签数量,比如这里我中了10张中投国债,需要交纳1000,只要保证可用资金里有就行了。


申购流程及常见问题



参考
]]>"浮盈"不是真实盈利。只有我们结束投资以后,才会变成真实的盈利。
情绪周期:利好来了(央视报道,合并,重组,收购),消息有一个发散的过程->开启阶段->大家蜂拥而至->爆发阶段->分歧阶段(利空和利好消息) ->龙回头(好看的人比较多,第二波...)-> ->没有回头->发酵结束
警惕噪音,没有核心东西支撑2019年拿着一万元冲入股市,能赚多少钱? 12.12股票学习公开课, 好的企业需要有业绩支撑
总的来说,两个方案各有利弊,基金账户方便,比较适合小资金,股票账户交易快速、费用低,比较适合大资金。我建议按照资金多少来决定,如果资金比较少(50 万以下)可以选择基金账户,如果资金量比较大推荐用股票账户。
基金账户 App 在申购、提现上有金额限制,想要完成大笔交易需要重复很多次;股票账户则没有限制,交易几百万也就分分钟;
股票账户的交易规则,必须以 100 份为单位购买,对小资金不友好,不能自由选择金额;
资金量越大,对佣金越敏感,以 50 万为例,股票账户(0.03% 佣金)和基金账户(0.12% 佣金)的手续费差异可以达到 450 元,如果资金更多的话,影响也会等比放大。
]]>

需要将需要部署到集群,但流水线环境不方便直接访问目标K8s集群,可以在K8s里安装runner
然后runner注册到gitlab站点,完成部署操作
helm repo add gitlab https://charts.gitlab.io
# 根据 gitlab 站点版本,挑选合适的 helm chart 版本
helm search repo -l gitlab/gitlab-runner
# 下载并解压
helm pull --untar gitlab/gitlab-runner --version=0.64.3
cd gitlab-runner
# 创建一个新的values文件,用来覆盖默认配置
vi values-nfm-dev.yaml内容如下:
gitlabUrl: https://gitlab.xxxx.cn/
runnerToken: "glrt-HVu1xxxxxyd"
tags: "aws,eit-nfm-dev,executor-k8s"
rbac:
create: true
clusterWideAccess: true
serviceAccountName: gitlab-runner
## Define list of rules to be added to the rbac role permissions.
## Each rule supports the keys:
## - apiGroups: default "" (indicates the core API group) if missing or empty.
## - resources: default "*" if missing or empty.
## - verbs: default "*" if missing or empty.
##
## Read more about the recommended rules on the following link
##
## ref: https://docs.gitlab.com/runner/executors/kubernetes.html#configure-runner-api-permissions
##
rules:
- resources: ["configmaps", "pods", "pods/attach", "secrets", "services"]
verbs: ["get", "list", "watch", "create", "patch", "update", "delete"]
- apiGroups: ['', 'apps', 'networking.k8s.io']
resources: ["*"]
verbs: ["*"]
# resources: ["deployments","services", "secrets","configmaps", "pods","pods/exec","nodes"]
# verbs: ["list", "create", "patch", "delete"]
runners:
# runner configuration, where the multi line string is evaluated as a
# template so you can specify helm values inside of it.
#
# tpl: https://helm.sh/docs/howto/charts_tips_and_tricks/#using-the-tpl-function
# runner configuration: https://docs.gitlab.com/runner/configuration/advanced-configuration.html
config: |
[[runners]]
[runners.kubernetes]
namespace = "{{.Release.Namespace}}"
service_account = "{{ .Release.Name }}"
image = "public.ecr.aws/docker/library/node:lts-alpine"
privileged = true
allow_privilege_escalation = true
helper_image = "public.ecr.aws/gitlab/gitlab-runner-helper:alpine3.19-x86_64-latest"安装 runner,
- values-nfm.yaml 要放在后面这样可以覆盖values.yaml
- upgrade --install 如果不存在就安装,存在就更新
helm upgrade --install --namespace gitlab-runner --create-namespace -f ./gitlab-runner/values.yaml -f ./gitlab-runner/values-nfm.yaml gitlab-runner ./gitlab-runner
k get pod -n gitlab-runnerservice: ['docker:dind'],不然 docker push 无法成功
典型的流水线例子如下:
stages:
- create-image
build-image-job:
stage: create-image
image: docker
services:
- docker:dind
script:
- echo $CI_REGISTRY_PASSWORD | docker Login -U $CI_REGISTRY_USER $CI_REGISTRY --password-stdin
- docker build -t $$CI_REGISTRY_IMAGE/myapp:1.2-
- docker push $$CI_REGISTRY_IMAGE/myapp:1.2-
- docker images为什么非得定义 services 呢?
这里先从Docker的 C/S 架构讲起
Docker 的 C/S(客户端/服务器)架构
Docker 采用典型的 C/S(客户端/服务器)架构
┌─────────────────┐ REST API ┌─────────────────────────────┐
│ Docker 客户端 │<─────────────────── │ Docker 服务器 │
│ (docker CLI) │ HTTP/UNIX Socket │ (Docker Daemon) │
└─────────────────┘ │ ┌─────────────────────┐ │
│ │ Containers │ │
│ │ Images │ │
│ │ Networks │ │
│ │ Volumes │ │
│ └─────────────────────┘ │
└─────────────────────────────┘组件说明
客户端 (Client)
- Docker CLI (docker 命令)
- Docker API 客户端
- Docker Compose
- 其他第三方工具
- 服务器 (Server)
服务端 Docker daemon (dockerd)
- 容器运行时 (containerd)
- 存储驱动
- 网络驱动
- 插件系统
工作流程
- 用户输入 docker 命令
- Docker CLI 解析命令
- 通过 API 发送请求到 daemon
- Daemon 处理请求
- 返回结果给客户端
示例:运行容器:
docker run nginx
│
├─► 1. CLI 解析命令
│
├─► 2. 发送 API 请求到 daemon
│
├─► 3. Daemon 检查本地是否有镜像
│
├─► 4. 如无镜像则从仓库拉取
│
├─► 5. 创建并启动容器
│
└─► 6. 返回容器 ID 给客户端客户端环境变量
# 指定 Docker daemon 地址
DOCKER_HOST=tcp://remote-host:2375
# 指定 TLS 设置
DOCKER_TLS_VERIFY=1
DOCKER_CERT_PATH=/path/to/certs优势
- 客户端和服务器可以分开部署
- 支持远程管理
- 便于第三方集成
- 支持 TLS 加密
- 可以通过 API 开发自定义工具
常见使用场景
本地开发:
docker ps远程管理:
# 通过 TCP 连接远程 daemon
docker -H tcp://remote:2375 ps进一步
深入了解镜像 docker 和 docker:dind 的具体区别
打开 https://hub.docker.com/_/docker 仔细阅读
发现 docker镜像 docker:28, docker:dind, docker:28-dind 是等价的
而 docker:cli, docker:28-cli 也是等价的,只不过 tag 不一样
进一步查看他们的 Dockerfile: docker:dind 和 docker:cli 直接扔给 Gemini 帮忙分析对比,对于 Docker28 版本的 Dockerfile 得出以下结论:
docker:cli
- docker:cli 是基于 alpine:3.21
- docker:cli 安装的有 docker 命令行工具, buildx插件,docker-compose插件
docker:dind
- docker:dind 是基于 docker:cli, 包含了 docker:cli 的所有功能,并在此基础上增加了运行 Docker daemon 所需的额外组件
- 额外组件有 git, iptables(IPv4 防火墙), ip6tables(IPv6 防火墙), openssl(SSL 支持), xz, zfs, pigz, e2fsprogs 等文件系统工具
- 额外组件还有 dockerd (Docker daemon), containerd, ctr, runc 这些容器运行时工具
- 暴露端口 EXPOSE 2375 2376 # Docker daemon API 端口
- 特有的存储卷, VOLUME /var/lib/docker # Docker 持久化存储
使用场景
-
docker:cli:
- 适用于只需要执行 Docker 命令的场景
- 需要连接外部 Docker daemon
-
docker:dind:
- 适用于需要完整 Docker 环境的场景
- 可以独立运行容器
- CI/CD 环境中的容器构建
网络配置
- docker:cli:
- 无特殊网络要求
- docker:dind:
- 需要暴露 Docker daemon 端口
- 需要配置网络隔离
参考
]]>动态名称
script:
# 动态生成时间戳
- export TIMESTAMP=$(date +'%Y%m%d%H%M%S')
# 动态生成文件名
- export ARTIFACT_NAME="${CI_JOB_NAME}-${TIMESTAMP}"
artifacts:
# 使用动态生成的制品名称
# 不生效,实际是 default.zip
name: $ARTIFACT_NAME
paths:
- "/target"参考:https://gitlab.com/gitlab-org/gitlab-runner/-/issues/1664
cache
Use separate caches for protected branches
By default, protected and non-protected branches do not share the cache. However, you can change this behavior.
so we run pipeline on cmss-web2321 branch, the cache url will be like http://minio.minio:9000/gitlab-runner/gitlab-cache/runner/-z_CiEf6/project/441/cmss-web-non_protected but on feature branch, the cache url will become to http://minio.minio:9000/gitlab-runner/gitlab-cache/runner/-z_CiEf6/project/441/cmss-web-non_protected

you can have all branches (protected and unprotected) use the same cache.
Clear the Use separate caches for protected branches checkbox.

script
use !reference to combine script
stages:
- demo
.setup:
script:
- echo creating environment
.teardown:
after_script:
- echo deleting environment
demo-reference:
stage: demo
script:
- !reference [.setup, script]
- echo running my own command
after_script:
- !reference [.teardown, after_script]output result:
creating environment
echo running my own command
deleting environment限制分支创建

- 只有 maintainers 才能合并代码到 develop 分支
- 只有 开发者才能合并代码到 feature 开头的分支
使用 $CI_JOB_TOKEN

project1
create_artifacts:
stage: demo
when: manual
artifacts:
paths:
- newfile.txt
expire_in: 1 week
script:
- CHILD_PROJECT_ID=493
- CHILD_REF_BRANCH_NAME=feature/cicd
- echo "CI_JOB_ID:$CI_JOB_ID" >> newfile.txt
- echo "CI_PIPELINE_ID:$CI_PIPELINE_ID" >> newfile.txt
# 触发下游项目流水线, 并传递 PROJECT_ID 和 JOB_ID
- curl --request POST --form "token=$CI_JOB_TOKEN" --form "variables[PARENT_JOB_ID]=$CI_JOB_ID" --form "variables[PARENT_PROJECT_ID]=$CI_PROJECT_ID" --form ref=${CHILD_REF_BRANCH_NAME} "${CI_SERVER_HOST}/api/v4/projects/${CHILD_PROJECT_ID}/trigger/pipeline"project2
download_upstream_artifacts:
# variables:
# CI_DEBUG_TRACE: "true"
stage: downstream_job
# download upstream pipeline artifacts:
needs:
- pipeline: $PARENT_PIPELINE_ID
job: create_artifacts
# 限制仅通过父流水线触发时运行
rules:
- if: $CI_PIPELINE_SOURCE == "pipeline"
script:
- git config --global user.name "gitlab-ci"
- git config --global user.email "[email protected]"
- git config --global --add safe.directory "*"
- mkdir -p ~/.ssh && chmod 700 ~/.ssh
- ssh-keyscan ${CI_SERVER_HOST} >> ~/.ssh/known_hosts && chmod 644 ~/.ssh/known_hosts
- cat "$SSH_PRIVATE_KEY" > ~/.ssh/gitlab && chmod 500 ~/.ssh/gitlab
- cat "$SSH_CONFIG" > ~/.ssh/config
- echo $PARENT_PROJECT_ID
- echo $PARENT_JOB_ID
# 下载 artifacts
# 会产生问题,因为 project1的流水线是先触发downstream才上传artifacts,有时间差问题,这个时候有可能取不到artifacts
# 解决方法:将artifacts存到外部存储,不使用 artifact
- curl --location --output artifacts.zip "${CI_SERVER_HOST}/api/v4/projects/${PARENT_PROJECT_ID}/jobs/${PARENT_JOB_ID}/artifacts?job_token=$CI_JOB_TOKEN"
- unzip -o artifacts.zip优化,支持传递 artifacts
project1
create_artifacts:
stage: demo
when: manual
artifacts:
paths:
- newfile.txt
expire_in: 1 week
script:
- CHILD_PROJECT_ID=493
- CHILD_REF_BRANCH_NAME=feature/cicd
- echo "CI_JOB_ID:$CI_JOB_ID" >> newfile.txt
- echo "CI_PIPELINE_ID:$CI_PIPELINE_ID" >> newfile.txt
trigger_downstream:
stage: deploy
trigger:
include:
- project: path_to/downstream/repo_name # Path to the project to trigger a pipeline in
ref: 'feature/cicd'
file: '.gitlab-ci.yml'- 创建密钥对,比如本地执行
ssh-keygen -t ed25519 -C "Keypair for FSD"' - 公钥做为部署key,存放到gitlab项目中
- 在项目中setting-cicd中定义一个类型为file的CICD变量,命名为
SSH_PRIVATE_KEY - 在 gitlab-ci.yml中使用这个文件变量
default:
tags: [ mnf, basic, global ]
image: $DEFAULT_IMAGE
before_script:
- git config --global user.name "gitlab-ci"
- git config --global user.email "[email protected]"
- mkdir -p ~/.ssh && chmod 700 ~/.ssh
- ssh-keyscan ${CI_SERVER_HOST} >> ~/.ssh/known_hosts && chmod 644 ~/.ssh/known_hosts
- eval $(ssh-agent -s)
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add -
- git checkout $CI_COMMIT_REF_NAME
- git submodule update --init
- git remote set-url origin git@$CI_SERVER_HOST:$CI_PROJECT_PATH.git ]]>
]]>We want to sync a private repo(https://github.com/mafeifan/vue-press.git) to gitlab
go to https://github.com/settings/tokens to generate a Personal access tokens (classic)
only check scope repo
remember the token: which like ghp_QabT1sLA*****d839uR1alj5S
you can make a test on your local
GITHUB_TOKEN=ghp_QabT1sLA*****j5S
git clone https://ghp_QabT1sLA*****j5S:[email protected]/mafeifan/vue-press.git
2. Create an empty project on gitlab
then go to Settings - repository - Mirroring repositories
fill in the below content in form
- Git repository URL: https://github.com/mafeifan/vue-press.git
- Authentication method: Username and Password
- Username: x-oauth-basic
- Password: ghp_QabT1sLA*****j5S

Alternative way
Not to use mirror feature, Use gitlab pipeline to sync code automatically
we need to generate a gitlab token to access gitlab repo

sync-code-from-github:
image: public.ecr.aws/bitnami/git:2
stage: sync
services: []
when: manual
script: |
set -x
# define $GITHUB_TOKEN and $GITLAB_TOKEN in gitlab pipeline variables first
git clone https://$GITHUB_TOKEN:[email protected]/mafeifan/vue-press.git
cd vue-press
ls
GITLAB_USERNAME=gitlab
git remote add gitlab https://$GITLAB_USERNAME:$GITLAB_TOKEN@gitlab.cn/cndevops/vue-press.git
git push gitlab master使用者在初次踏进 GitLab CI 的世界时,通常按着官方文件一步步照做,多半不会遇到什么问题。唯独有一项东西有可能让新手产生较大的疑惑,那就是该如何选择 Executor。
目前在官方文件上已经有提供了一份 Compatibility chart 帮助使用者选择 Executor。
GitLab Runner 与 Executor 的关系 首先,让我们先来解释 GitLab、GitLab Runner 与 Executor 的关系。
让我们拆开来说明,先从 GitLab 与 GitLab Runner 的关系开始。

如上图所示,我们都知道 GitLab Runner 是用来帮助我们执行 CI Job 的工人,而 GitLab 就是这些工人的老板。老板(GitLab)会去查看需求单(.gitlab-ci.yml)建立一张又一张有先后顺序的工单(CI Pipeline),而每一位工人(Runner)则是每隔固定的时间就去询问老板(GitLab)现在有分配给自己的工作(CI Job)吗?现在自己应该做哪一项工作?工人拿到工作后开始执行,并且在执行过程中将处理进度即时填写在工单上。
到这里为止,大部分的人都不太会有什么问题,让我们接着说明 GitLab Runner 与 Executor 的关系。
前面我们将 GitLab 与 GitLab Runner 比喻为老板与工人,那么 Executor 是什么?是工人的工具吗?从我的角度来看,Executor 反而更像是工人的「完成工作的方式」或「工作的环境」。
举例来说,就像我们都曾听过的都市传说,据说在国外有某知名企业的工程师,偷偷将自己的编程开发工作远程外包给印度工程师完成,借此实现上班摸鱼打混还能取得高绩效表扬的神奇故事。当然,偷偷把正职工作私下外包是不正确的行为,但在这个故事中,这就是这位工程师「完成工作的方式」;同理,用口头命令别人做事、自己亲力亲为的传统方法、善用自动化工具或高科技工具辅助、远程连接工作⋯⋯这些都是不同的「完成工作的方式」。
按照上面的比喻,根据您选择的 Executor,决定了 Runner 将会采用何种「方式」以及在哪个「工作环境」中来完成 CI Job。

因此我们可以理解,这意味着身为老板的我们,很可能需要雇佣多位不同的工人。举例来说,炒菜煮饭这种工作,我们就会安排给在厨房工作的厨师;闯入民宅开保险箱这种工作,我们就会安排给RPG游戏中的勇者。根据不同的CI Job,我们有可能需要准备设置了不同Executor的Runner来应对。
目前可选择的Executor
了解Runner与Executor的关系后,接着来认识目前GitLab Runner可选择的Executor有哪些。
【小提醒】目前GitLab官方已表示不会再增加更多的Executor,并且为了保留弹性与扩展性,改为提供Custom这项Executor,如果现有的Executor不能满足你的需求,那就自己定制处理吧!
目前可选择的Executor如下:
- Shell:即是Runner直接在自己的Local环境执行CI Job,因此如果你的CI Job要执行各种指令,例如make、npm、composer⋯⋯,则需要事先确定在此Runner的Local环境是否已具备执行CI Job所需的一切相关程序和依赖。
- SSH:Runner会通过SSH连接上目标主机,并且在目标主机上执行CI Job。因此你要提供Runner足以SSH连接目标主机的账号密码或SSH Key,也要提供足够的用户权限。当然目标主机上也要事先处理好执行CI Job所需的一切相关程序和依赖。
- Parallels:每次要执行CI Job时,Runner会先通过Parallels建立一个干净的VM,然后通过SSH登录此VM并在其中执行CI Job。所以同样的用来建立VM的Image是先要准备好执行CI Job所需的一切相依程式与套件,这样Runner建立好的环境才能正确地执行CI Job。另外,当然架设Runner的主机上,记得要安装好Parallels。
- VirtualBox:同上,只是改成用VirtualBox建立干净的VM。同样架设Runner的主机上,记得要安装好VirtualBox。
- Docker:Runner会通过Docker建立干净的Container,并且在Container内执行CI Job。因此架设Runner的主机上,记得要安装好Docker,另外在规划CI Pipeline时也要记得先准备能顺利执行CI Job的各种Docker image。在CI Pipeline中采用Container已是十分普遍的做法,建议大家可以优先评估Docker executor是否适合你的工作场景。
- Docker Machine:延续上一个 Executor,此种 Executor 一样会通过 Container 来执行 CI Job,但差别在于这次你原本的 Runner 将不再是一般的工人了,它已经摇身一变成为工头,每当有工作(CI Job)分派下来,工头就会去自行招募工人(auto-scaling)来执行工作。因此倘若在短时间内有大量的工作需要执行,工头就会去招募大量的工人迅速地将工作们全部搞定。需要注意的是因为招募工人需要一些时间,故有时此种 Executor 在启动时会需要多花费一些时间。
- Kubernetes:延续前两个与 Container 相关的 Executor,这次直接进入超级工头 K8s 的世界。与前两种 Executor 类似,但这次 Runner 操控的不是小小的 Docker engine 了,而是改为操控 K8s。此种 Executor 让 Runner 可以透过 K8s API 控制分配给 Runner 使用的 K8s Cluster 相关资源。每当有 CI Job 指派给 Runner 时,Runner 就会透过 K8s 先建立一个干净的 Pod,接着在其中执行 CI Job。当然使用此种 Executor 依然记得先准备好能顺利执行 CI Job 的各种 Container image。
- Custom:如果上面这七种 Executor 都不能让你满意,那就只好请客官您自行动手啦!Custom Executor 即是 GitLab 提供给使用者自行定制 Executor 的管道。
该选择哪一种 Executor?
简单来说就是根据你的需要来选择 Executor!
如果你的团队已经很熟悉 Container 技术,不论是开发、测试及 Production 环境都已全面拥抱 Container,那当然选择 Docker executor 是再正常不过了。更不用说如果 Production 环境已经采用 K8s,那么 CI/CD Pipeline 想必也离不开 K8s 的魔掌,Runner 势必会选用 Kubernetes executor。(但还是别忘了凡事都有例外。)
假如只有开发环境拥抱 Container,但实际上测试机与 Production 环境还是采用实体服务器或 VM,这时你可能就会准备多个 Runner 并搭配多种 Executor。例如 Build、Unit Testing 或某些自动化测试的 CI Job 让 Docker executor 去处理;而像是 Performance testing 则用 VirtualBox executor 开一台干净的 VM 并部署程序来执行测试。
又或者,你的公司有非常多项目正在同步进行中,同时需要执行的 CI Job 时多时少,那么可以 auto-scaling 的 Docker Machine executor 也许会是一个可以考虑的选择。事实上 gitlab.com 提供给大家免费使用的 Shared Runner,就有采用 Docker Machine executor。
再举例,假如有某个 CI Job 只能在某台主机上执行,也许是为了搭配实体服务器的某个硬件装置、也许是基于安全性或凭证的缘故,在这种情况下很可能你会用到 SSH executor,或甚至是在该主机上安装 Runner 并设置为 Shell executor,让特定的 CI Job 只能在该 Runner 主机上执行。
最后,也有可能你因为刚好身处在一个完全没有 Container 知识与技能的团队,所以才只好选择 Shell、SSH、VirtualBox 这些不需要碰到 Container 的 Executor。
【小提醒】由于 SSH、VirtualBox、Parallels 这三种 Executor,Runner 都是先连上别的主机或 VM 之后才执行 CI Job 的内容,因此都不能享受到 GitLab Runner 的 caching feature。
(官网文件也有特别提醒这件事。)
结语
GitLab Runner 及 Executor 与 CI/CD Pipeline 的规划密切相关,在实务上我们经常会准备多种 Runner 因应不同的情境,也许是类似下面这样常态准备 3 台 Runner。
- Docker executor|供一般的 CI Job 使用。
- Docker Machine executor|供 CI Job 大爆发堵车时使用。
- SSH 或 Shell executor|供 Production Deploy 或某些有较高安全性考量
前提
先阅读文档
https://github.com/sameersbn/docker-gitlab
https://www.damagehead.com/docker-gitlab/
测试环境下最简单的方式是使用 docker-compose
Amazon Linux 2023 下载安装docker
EC2 基本信息
- 系统: Amazon Linux 2023
- 磁盘: 100G
- 规格: t3.large 2核8G
sudo bash
cd ~
yum install docker -y
systemctl start docker
# 测试 docker
docker run hello-world
curl -SL https://github.com/docker/compose/releases/download/v2.29.6/docker-compose-linux-x86_64 -o /usr/local/bin/docker-compose
/usr/local/bin/docker-compose /usr/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
# 测试 docker-compose
docker-compose安装 gitlab
准备下面的yaml文件,执行 docker-compose up
浏览器打开http://localhost:10080并使用默认用户名和密码登录:
- username: root
- password: 5iveL!fe
docker-compose.yml
version: '2.3'
services:
redis:
restart: always
image: redis:6.2
command:
- --loglevel warning
volumes:
- redis-data:/data:Z
postgresql:
restart: always
image: sameersbn/postgresql:14-20230628
volumes:
- postgresql-data:/var/lib/postgresql:Z
environment:
- DB_USER=gitlab
- DB_PASS=password
- DB_NAME=gitlabhq_production
- DB_EXTENSION=pg_trgm,btree_gist
gitlab:
restart: always
image: sameersbn/gitlab:17.5.0
depends_on:
- redis
- postgresql
ports:
- "10080:80"
- "10022:22"
volumes:
- gitlab-data:/home/git/data:Z
healthcheck:
test: ["CMD", "/usr/local/sbin/healthcheck"]
interval: 5m
timeout: 10s
retries: 3
start_period: 5m
environment:
- DEBUG=false
- DB_ADAPTER=postgresql
- DB_HOST=postgresql
- DB_PORT=5432
- DB_USER=gitlab
- DB_PASS=password
- DB_NAME=gitlabhq_production
- REDIS_HOST=redis
- REDIS_PORT=6379
- TZ=Asia/Chongqing
- GITLAB_TIMEZONE=Chongqing
- GITLAB_HTTPS=false
- SSL_SELF_SIGNED=false
- GITLAB_HOST=localhost
- GITLAB_PORT=10080
- GITLAB_SSH_PORT=10022
- GITLAB_RELATIVE_URL_ROOT=
- GITLAB_SECRETS_DB_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_SECRETS_SECRET_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_SECRETS_OTP_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_ROOT_PASSWORD=
- GITLAB_ROOT_EMAIL=
- GITLAB_NOTIFY_ON_BROKEN_BUILDS=true
- GITLAB_NOTIFY_PUSHER=false
- [email protected]
- [email protected]
- [email protected]
- GITLAB_BACKUP_SCHEDULE=daily
- GITLAB_BACKUP_TIME=01:00
- SMTP_ENABLED=false
- SMTP_DOMAIN=www.example.com
- SMTP_HOST=smtp.gmail.com
- SMTP_PORT=587
- [email protected]
- SMTP_PASS=password
- SMTP_STARTTLS=true
- SMTP_AUTHENTICATION=login
- IMAP_ENABLED=false
- IMAP_HOST=imap.gmail.com
- IMAP_PORT=993
- [email protected]
- IMAP_PASS=password
- IMAP_SSL=true
- IMAP_STARTTLS=false
- OAUTH_ENABLED=false
- OAUTH_AUTO_SIGN_IN_WITH_PROVIDER=
- OAUTH_ALLOW_SSO=
- OAUTH_BLOCK_AUTO_CREATED_USERS=true
- OAUTH_AUTO_LINK_LDAP_USER=false
- OAUTH_AUTO_LINK_SAML_USER=false
- OAUTH_EXTERNAL_PROVIDERS=
- OAUTH_CAS3_LABEL=cas3
- OAUTH_CAS3_SERVER=
- OAUTH_CAS3_DISABLE_SSL_VERIFICATION=false
- OAUTH_CAS3_LOGIN_URL=/cas/login
- OAUTH_CAS3_VALIDATE_URL=/cas/p3/serviceValidate
- OAUTH_CAS3_LOGOUT_URL=/cas/logout
- OAUTH_GOOGLE_API_KEY=
- OAUTH_GOOGLE_APP_SECRET=
- OAUTH_GOOGLE_RESTRICT_DOMAIN=
- OAUTH_FACEBOOK_API_KEY=
- OAUTH_FACEBOOK_APP_SECRET=
- OAUTH_TWITTER_API_KEY=
- OAUTH_TWITTER_APP_SECRET=
- OAUTH_GITHUB_API_KEY=
- OAUTH_GITHUB_APP_SECRET=
- OAUTH_GITHUB_URL=
- OAUTH_GITHUB_VERIFY_SSL=
- OAUTH_GITLAB_API_KEY=
- OAUTH_GITLAB_APP_SECRET=
- OAUTH_BITBUCKET_API_KEY=
- OAUTH_BITBUCKET_APP_SECRET=
- OAUTH_BITBUCKET_URL=
- OAUTH_SAML_ASSERTION_CONSUMER_SERVICE_URL=
- OAUTH_SAML_IDP_CERT_FINGERPRINT=
- OAUTH_SAML_IDP_SSO_TARGET_URL=
- OAUTH_SAML_ISSUER=
- OAUTH_SAML_LABEL="Our SAML Provider"
- OAUTH_SAML_NAME_IDENTIFIER_FORMAT=urn:oasis:names:tc:SAML:2.0:nameid-format:transient
- OAUTH_SAML_GROUPS_ATTRIBUTE=
- OAUTH_SAML_EXTERNAL_GROUPS=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_EMAIL=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_NAME=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_USERNAME=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_FIRST_NAME=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_LAST_NAME=
- OAUTH_CROWD_SERVER_URL=
- OAUTH_CROWD_APP_NAME=
- OAUTH_CROWD_APP_PASSWORD=
- OAUTH_AUTH0_CLIENT_ID=
- OAUTH_AUTH0_CLIENT_SECRET=
- OAUTH_AUTH0_DOMAIN=
- OAUTH_AUTH0_SCOPE=
- OAUTH_AZURE_API_KEY=
- OAUTH_AZURE_API_SECRET=
- OAUTH_AZURE_TENANT_ID=
volumes:
redis-data:
postgresql-data:
gitlab-data:生产建议
postgresql 和 redis 不要和 gitlab 运行在同一台服务器,最好使用独立数据库,避免单点故障
]]>通过 IP:10080 访问 gitlab 站点不太优雅,也不方便识记 我们给 gitlab 站点绑定个域名并且带上SSL证书
申请免费SSL证书
由于我的 mafeifan.com 域名解析是托管在腾讯云, 可以在腾讯云的SSL证书服务里购买免费的域名证书
时长只有3个月


选择 nginx 类型,下载得到 gitlab.mafeifan.com_nginx.zip
登录服务器安装nginx
sudo yum install nginx -y
# 创建一个专门存放证书的目录
sudo mkdir -p /etc/nginx/my_certs将证书放到指定目录
- /etc/nginx/my_certs/gitlab.mafeifan.com_bundle.crt
- /etc/nginx/my_certs/gitlab.mafeifan.com.key
新建nginx配置文件 /etc/nginx/conf.d/gitlab.mafeifan.com-80-443.conf
内容如下:
server {
listen 80;
server_name gitlab.mafeifan.com;
rewrite ^(.*) https://$host$1 permanent;
}
server {
listen 443;
server_name gitlab.mafeifan.com;
ssl on;
ssl_certificate /etc/nginx/my_certs/gitlab.mafeifan.com_bundle.crt;
ssl_certificate_key /etc/nginx/my_certs/gitlab.mafeifan.com.key;
ssl_session_timeout 5m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE;
ssl_prefer_server_ciphers on;
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $http_host;
proxy_pass http://127.0.0.1:10080;
}
}修改docker-compose.yml
GITLAB_HTTPS=true
SSL_SELF_SIGNED=false
GITLAB_HOST=gitlab.mafeifan.com
GITLAB_PORT=443重启
docker-compose down && docker-compose up -d
问题
- gitlab 提供了一个 WebIDE 在线编辑代码的编辑器,发生了地址错误的情况

根据文档,把地址改为 https://gitlab.mafeifan.com/-/ide/oauth_redirect
参考文档
https://help.aliyun.com/document_detail/36576.html
- [email protected]
- [email protected]
- [email protected]
- SMTP_ENABLED=true
- SMTP_DOMAIN=www.aliyun.com
- SMTP_HOST=smtp.qiye.aliyun.com
- SMTP_PORT=465
- [email protected]
- SMTP_PASS=xxxxxxx
- SMTP_STARTTLS=false
- SMTP_TLS=true
- SMTP_AUTHENTICATION=login问题
]]>问题
]]>特别说明
- 极狐GitLab工作流是极狐GitLab团队内部的DevOps工作流,也是极狐GitLab面向企业推荐的参考工作流。本文将基于极狐GitLab企业版(专业版或旗舰版),参照极狐GitLab工作流,通过一个示例项目完整演示DevOps的全流程,覆盖权限管理、组织管理、需求管理、开发管理,并形成闭环。
- 由于DevOps是一项工程实践,需要结合企业的组织架构、业务流程、技术栈与工具链、人员能力进行落地。以上内容每家企业均存在较大差异,甚至同一家企业不同团队或不同时期也存在差异。故本文旨在向企业提供一个参考工作流,帮助企业快速了解极狐GitLab相关能力,也可用于改进企业内部的DevOps流程。
- 本文可面向企业DevOps工程师或熟悉DevOps的研发、运维团队成员及Leader。阅读以下内容需要至少了解Git的使用方式(代码推拉)、版本控制与分支策略、软件测试、CI/CD、制品库、容器技术(Docker)、监控运维等基础知识。需熟悉GitLab基本功能,如史诗议题、合并请求、GitLab CI脚本、GitLab Runner类型与部署方式。本文不会对上述内容进行深度展开,如果您对以上内容尚不熟悉,本文中的内容可能会对您造成较大困扰,建议您通过极狐GitLab原厂培训服务快速掌握极狐GitLab和DevOps的基础知识。
- 以下内容可在 https://presales-demo.jihulab.com/mycompany/project-x 中查看配套的demo示例
[TOC]
1 权限管理
1.1 用户角色
极狐GitLab内置6种用户角色,可根据不同的场景、用户职能进行分配。
| 用户角色 | 权限说明 | 场景示例 |
|---|---|---|
| Guest | 无法对私有化项目做贡献,只能查看议题和留言。 | 项目审计人员 |
| Reporters | 只读贡献者,可访问代码库但无法写入,可以编辑议题。 | 产品经理 |
| Developers | 直接贡献者,代码库可读写,受更高级权限管理(如保护分支)。 | 开发人员 |
| Maintainers | 项目维护者,可对代码库进行管理工作,如分配权限、项目设置。不具备删除权限。 | 项目负责人 |
| Owners | 项目管理员,能够对群组、项目进行全面管理。 | 部门总监 项目负责人 |
| Admin | 实例管理员,可对整个GitLab实例进行配置管理。 | 系统管理员 |
1.2 自定义角色[旗舰版]
极狐GitLab支持自定义角色,属于旗舰版功能,该功能正在持续完善。
2. 组织管理
2.1 群组
极狐GitLab的群组类似文件夹,可以包含多个项目(代码库),群组可以嵌套,类似文件夹、子文件夹。
群组可作为部门组织管理代码库,也可作为虚拟项目组织管理代码库。
操作步骤:
- 创建一级群组
项目X - 在群组
项目X下创建一个项目(代码库)子项目A,创建两个子群组子项目B、子项目C。 - 在子群组
子项目B、子项目C中创建项目(代码库)模块A、模块B、模块C
不同开发语言划分组织的参考经验:
- 若使用Java、Python等语言,能实现模块化开发,能通过流水线独立部署,或能打包成jar、pip等制品,通过包管理器向其他项目提供引用,这类项目建议参考
子项目B、子项目C,分成子群组和多个代码库来管理。 - 若使用C/CPP语言,没有太好的包管理工具,模块之间依靠完整源码编译,这类项目建议参考
子项目A,将整个C/CPP项目放到一个项目(代码库)中,通过文件夹来区分模块。
2.2 项目
极狐GitLab的项目就是指代码库,隶属于群组。
群组、项目与角色关系:
- 可将用户在群组级别进行角色授权,该用户具备该群组以及该群组的所有子群组、所有项目(代码库)的权限,即继承权限。
- 可将用户在项目级别进行角色授权,该用户只具备该项目(代码库)的权限。
2.3 范围标记[专业版]
极狐GitLab使用Label标记来给后续需求管理中使用到的史诗、议题赋予一些意义,可以理解为自定义字段。
操作步骤:
- 在群组项目X左侧边栏“管理——标记”中新建以下标记,这些标记可以在该群组以及该群组的所有子群组、所有项目(代码库)中使用。


- 管理员也可以参考文档在GitLab全局设置标记,GitLab中所有的群组、项目都可使用。
- 创建一组类型标记,用于标识议题的类型是“功能”还是“缺陷”。其中
::是用于设置范围标签,该标签是一组键值对,具有排他性。如下面例子中,某个议题同一时间只能具备其中一个type标记,即type要么是bug,要么是feature。
type::bug
type::feature- 创建一组状态标记,用于标识议题的状态是“待处理”、“进行中”还是“已完成”。
status::todo
status::doing
status::done- 创建一组优先级标记,用于标识议题的优先级是“高”、“中”还是“低”。
priority::high
priority::mid
priority::low2.4 群组/实例模板[专业版]
极狐GitLab支持使用模板来为后续需求管理中使用到的议题设置一些格式化内容,用来提高工作规范性和效率。
操作步骤:
- 在群组
项目X中创建一个项目(代码库)模板,创建两个文件.gitlab/issue_templates/feature.md、.gitlab/issue_templates/bug.md,用于作为“功能”和“缺陷”的标准模板
内容如下:
bug.md
### 步骤
1.
2.
3.
### 结果
### 期望
### 环境
- 机型:
- 版本:
/label ~"type::bug" ~"priority::low" ~"status::todo"feature.md
### 用户故事
作为 [角色],我 [想要实现/达到什么目的],[从而获得怎样的价值/解决什么问题]。
### 客户用例
1.
2.
3.
### 设计文档
1. 产品原型图见: xxxxxx
2. 产品设计图见: xxxxxx
/label ~"type::feature" ~"status::todo"- 在群组项目X的“设置——通用——模板”中,选择项目模板作为该群组的默认模板,该模板可以在该群组以及该群组的所有子群组、所有项目(代码库)中使用。

- 管理员也可以参考文档在GitLab全局设置模板,GitLab中所有的群组、项目都可使用。
3. 需求管理
说明:若您已经使用Jira、PingCode、Ones、LigaAI等国内外主流项目管理工具、或使用自研、定制开发的项目管理工具,以下内容仅供参考。您也可以直接跳到第4章了解开发管理的相关内容,在该章节中也会介绍极狐GitLab如何与这些第三方项目管理系统做集成,并打通整个流程。 若您没有使用线上化的项目管理工具,还在使用电子文档、聊天工具来进行需求管理,则建议您详细阅读以下内容。
3.1 史诗[专业版]

极狐GitLab使用Epic史诗来管理相对比较宏大的业务目标或原始需求,他一般由项目经理、产品经理负责创建并维护。
史诗是建立在群组上的。
操作步骤:
- 在群组项目X的“计划——史诗”中,创建两个史诗,并设置大致的时间计划

- 具备群组
项目X角色权限的用户都可以看到所有的史诗内容。 - 史诗将在后续阶段被拆分、细化、形成具体的研发任务,也就是
议题,史诗和议题是父子关系。
3.2 子史诗[旗舰版]
如果一项史诗任务过于复杂,可能还需拆分成多个依然比较宏大的史诗,这里就可以使用到子史诗
3.3 路线图 roadmap[专业版]
路线图是针对史诗的排期展示。设置史诗的时间计划后,项目经理、产品经理可以查看路线图。 操作步骤:
- 在群组项目X的“计划——路线图”中,通过甘特图来展示所有史诗的排期和进度。

- 史诗的进度依赖于与它关联的议题,如一个史诗关联了4个议题,其中2个议题已完成(已关闭),那么进度就是50%。
- 如果有子史诗,路线图中可会显示子史诗、史诗的排期和进度。

3.4 里程碑 Epic
 史诗和路线图是项目经理、产品经理对一些原始需求的大致排期。当某些原始需求已经有近期明确的开发计划后,应创建里程碑。
史诗和路线图是项目经理、产品经理对一些原始需求的大致排期。当某些原始需求已经有近期明确的开发计划后,应创建里程碑。
里程碑标识近期一段时间明确的开发计划,如一次版本发布、一次敏捷迭代等。
操作步骤:
- 在群组项目X的“计划——里程碑”中,创建两个里程碑,通过版本号进行命名,并设置里程碑的时间。

- 里程碑将关联一些具体的、细化的开发任务或者需要处理的缺陷,也就是下文中的议题。
3.4.1 燃起图、燃尽图[专业版]
当里程碑中的议题根据第3.5章节被创建,随后根据第4章节完成开发、集成、部署,最后议题被手动关闭或根据4.4.5.5在合并请求被执行后自动关闭,意味着这个功能开发完成。
议题在里程碑中会实时显示状态,并通过燃起图、燃尽图来展示整个里程碑的进展,也可以在里程碑结束后帮助团队回顾或用于帮助团队评估下一个里程碑的工作计划。

3.5 议题 issue

极狐GitLab使用Issue议题来管理需求任务、Bug缺陷。它一般由产品经理创建并由研发人员维护。
3.5.1 议题管理
议题是建立在项目(代码库)上的,它可以与史诗进行关联,也可以与史诗无关,即只与该项目(代码库)相关。 操作步骤:
- 拥有群组项目X角色权限的项目管理人员,可以查看该群组所有项目(代码库)的议题。

- 仅拥有项目(代码库)的开发人员,只可以查看与他工作相关的议题。

- 所以创建议题应明确该议题与哪一个项目(代码库)相关,如果议题创建到错误的项目(代码库)中,可以参考文档将议题移动到正确的项目中。
3.5.2 需求议题
用议题管理需求任务。
操作步骤:
- 在群组项目X下的项目(代码库)
子项目A的“计划——议题”中创建议题
- 选择之前创建的名为feature的模板来列出开发任务的描述格式。
- 将该议题关联到史诗“监控模块开发”,关联到里程碑“1.0.0”。
- 添加了其他几个议题,并与史诗、里程碑进行关联

- 添加了一个议题,只关联里程碑,不关联史诗。

3.5.3 缺陷议题
用议题管理缺陷,与管理开发任务没有什么不同,只是用Lable来标识这个议题是缺陷Bug。
- 另外缺陷议题一般不与史诗进行关联,只与各项目(代码库)相关。若项目为多模块模式进行开发,测试人员无法判断该缺陷属于哪个项目(代码库),可以向最终提测的应用项目(代码库)提交缺陷,研发团队内部定位后再通过移动议题将缺陷议题转移到对应的项目中。

- 通过选择之前创建的名为bug的模板来列出缺陷Bug的描述格式。
- 缺陷议题(缺陷)可以与需求议题(功能)进行关联。
3.6 议题权重[专业版]
在敏捷开发中,一般使用故事点、评估点来估算用户故事。在极狐GitLab中可使用权重来实现该功能。
操作步骤:
- 进入指定的议题,给议题设置权重。

- 在群组项目X的里程碑中,可查看该里程碑关联的议题的总权重。

3.7 工时统计
在瀑布开发中,或者对工时统计有要求的场景中,一般需要在开发前填写估算工时,开发结束后填写实际工时,用于做排期和分析。在极狐GitLab中可使用工时来实现该功能。
操作步骤:
- 进入指定的议题,给议题设置预估工时。

- 在议题处理过程中,可以多次给议题设置实际工时,如每天进行填写,最后实际工时将会累加。

- 在议题中可以查看时间追踪报告,看到实际工时的说明和累加历史。
 在群组
在群组项目X的里程碑中,可查看该里程碑关联的议题的总工时统计。
3.8 议题看板 issue board[专业版]
极狐GitLab支持灵活的自定义看板,来对议题进行管理、协作。
3.8.1 任务看板
操作步骤:
- 在群组项目X“计划——议题看板”中编辑“Development”看板。
- 设置
里程碑=1.0.0、标记=type::feature,即看板中只包含里程碑为1.0.0且类型为feature的议题。
- 创建列表,将标记为status::todo、status::doing、status::done的列表分别加入看板。

- 议题可在列表之间拖动。
- 后续只需要编辑看板的里程碑,即可用于不同里程碑周期下的任务看板管理。
3.8.2 缺陷看板
操作步骤:
- 在群组
项目X“计划——议题看板”中创建“Bug”看板。
- 设置
里程碑=1.0.0、标记=type::bug,即看板中只包含里程碑为1.0.0且类型为bug的议题。 - 参考任务看板,创建列表并进行管理。

3.9 指派议题[专业版]

将议题指派给一个或多个开发人员,用于分配开发任务、或处理Bug缺陷。
操作步骤:
- 进入指定的议题,给议题设置指派人。

- 被指派的人员可以收到邮件通知,并可在“代办事项列表”中进行展示和跟踪。

4 开发管理
4.1 创建分支

4.1.1 分支策略
极狐GitLab推荐的分支策略GitLab Flow提供了3种子模型来匹配不同的业务场景。

本文以第三种子模型,也就是多版本并行开发场景为例,它的完整分支模型如下:

- 新功能的开发应创建一个新的
feature分支,如feature/monitor-temperature,并创建从feature/monitor-temperature分支到main分支的合并请求。开发人员在该分支下开发,开发完成后通过流水线实现自动编译、打包、单元测试、质量扫描并发布到测试环境。测试人员进行该模块的功能测试,测试完成并通过评审后将该分支合并到main分支。合并结束后自动删除feature/monitor-temperature分支。 Bug的修复应创建一个新的fix分支,如fix/tag-version-diff,并创建从fix/tag-version-diff分支到main分支的合并请求。开发人员在该分支下修复Bug,开发完成后通过流水线实现自动编译、打包、单元测试、质量扫描并发布到测试环境。测试人员进行该模块的功能测试,测试完成并通过评审后将该分支合并到main分支。合并结束后自动删除fix/tag-version-diff分支。- 每个功能、每个
Bug都应创建新分支,并在新分支中独立开发,应避免多个功能、Bug在同一个feature分支或fix分支中开发,这样会导致管理混乱、难以回滚、容易冲突、不利于评审。 - 创建
release分支来管理版本,同一时间可能维护多个版本,如release/13.0.0分支、release/14.0.0分支、release/15.0.0分支。 - 当需要发版时,从
main分支向release/15.0.0分支发起合并请求。 - 基于
release分支编译、构建、打包,发布到测试环境,测试人员进行集成测试。 - 当
release分支发现有功能缺失或者存在缺陷,还应参照第1、2步的内容,创建feature或fix分支来开发新功能或修复缺陷,再向main分支合并。合并通过后使用cherry-pick拣选功能将这个合并请求拣选到指定的release分支,如release/13.0.0、release/14.0.0、release/15.0.0。 - 直到
release分支测试无误后,在release分支上打标签tag来标识一个新的小版本,如15.0.1。 - 可以在打标签
tag时触发流水线,基于tag编译、构建、打包,然后发布到生产环境。
需要注意,分支策略因研发流程而异,企业应该根据实际情况调整,但建议在企业在项目中尽可能推行统一的分支策略,以便于管理。
4.1.2 分支命名规则[专业版]
当确定分支策略后,应通过极狐GitLab推送规则来对分支命名进行校验,确保开发人员创建分支时能严格遵守分支策略,避免管理混乱。
操作步骤:
- 在子项目A“设置——仓库——推送规则”中配置分支名称校验规则
(cherry-pick|feature|fix|release)\/*。
- 可参考文档和文档,在GitLab实例级别或群组级别设置推送规则,这些推送规则仅对GitLab实例或群组中新创建的项目生效。
- 当创建的分支名称不符合校验规则,则提示无法创建分支

4.1.3 手动创建分支
在指定项目,如子项目A“代码——分支”中,新建分支feature/monitor-temperature,用来开发#2号需求“获取温度数据”


可在指定项目,如子项目A“代码——分支”查看并切换分支

创建合并请求,从feature/monitor-temperature合并到main。


4.1.4 基于议题创建分支[专业版]
极狐GitLab也支持基于议题快速创建分支和合并请求。
操作步骤:
- 在指定议题中,下拉“创建合并请求”,选择“创建合并请求和分支”,填写“分支名称”,即可快速创建分支和合并请求。

4.2 保护分支
当确定分支策略后,还应确保研发人员只能在开发分支如feature、 fix分支进行代码提交,应拒绝开发人员直接向主干分支如main分支或发版分支如release分支提交代码。开发分支和主干分支、发版分支之间必须通过合并请求,走评审或确认机制传递代码,避免管理混乱、引起冲突。在极狐GitLab中可以通过保护分支来达到以上目的。
4.2.1 角色级保护
基于用户角色设置保护分支,可能会导致管理失控。因为Maintainer角色具备的权限较多,除了基本的管理权限外,还能给项目设置新的人员及角色权限,即引入更多的Maintainer角色,无法满足企业合规管理的需求。
操作步骤:
-
在指定项目,如
子项目A“设置——仓库——受保护分支”中,新建保护分支,输入release*来匹配所有的release分支,包括后续创建的release分支也自动匹配为受保护分支。
-
由于GitLab项目中main分支是默认分支,所以本身已经是受保护分支。
-
调整受保护分支,允许
Maintainer角色可以合并,No One可以推送,即只有Maintainer角色通过确认合并请求,才能向受保护的main分支release*分支传递代码。
4.2.2 用户级保护[专业版]
基于用户设置保护分支,可将合并、推送权限进行细粒度控制,仅允许一个人或几个人具备合并、推送权限,可有效规避代码越权提交,管理失控等问题。
- 与“角色级保护”设置一样,可在“允许合并”、“允许推送和合并”处选择具体的用户,支持多选。

4.2.3 群组保护分支[专业版]
极狐GitLab支持在群组级别设置保护分支,将对该群组的所有项目(代码库)生效,且在项目中不能修改、覆盖群组级别的保护分支。
4.3 分支开发

4.3.1 代码推送规则[专业版]
在开发分支下提交代码,应遵循统一、规范的提交格式,否则容易导致管理混乱,降低协同效率。如下图:
- 左图是不规范的代码提交,意义不清、描述重复。
- 右图是知名项目Angular.js的代码提交,遵循统一的提交规范
类型(范围): 描述 (需求编号),该规范也被称为Angular规范,是业内使用比较普遍的提交规范 极狐GitLab推送规则可以对代码提交的格式、文件类型、文件大小以及提交人的身份进行校验,确保入库的代码符合企业统一的规范,为研发协同以及后续的代码评审打下良好的基础。
操作步骤:
极狐GitLab推送规则可以对代码提交的格式、文件类型、文件大小以及提交人的身份进行校验,确保入库的代码符合企业统一的规范,为研发协同以及后续的代码评审打下良好的基础。
操作步骤:
- 在
子项目A“设置——仓库——推送规则”中配置推送规则。 - 勾选“拒绝未经验证的用户 Reject unverified users”,即验证开发人员本地git配置的
user.email是不是当前执行代码推送的GitLab用户的已验证的邮箱。 - 勾选“拒绝不一致的用户名 Reject inconsistent user name”,即验证开发人员本地git配置的
user.name是不是当前执行代码推送的GitLab用户的用户名。
- 设置“提交信息中的要求表达式”为
(feat|fix|doc|style|refactor|pref|test|ci|revert):.+,您也可以自定义其他表达式。若提交信息格式不符合正则表达式,则拒绝推送。 - 根据需要设置“禁止的文件名”,如
(jar|exe|tar.gz|tar|zip)$。推送文件中若包含这些文件类型,则拒绝推送。 - 根据需要设置“最大文件大小”,如20。单个推送文件若超过该大小,则拒绝推送,除非使用LFS来进行推送。

- 可参考文档,在GitLab实例级别或群组级别设置推送规则,这些推送规则仅对GitLab实例或群组中新创建的项目生效。
4.3.2 代码开发与推送
在4.1章节中,新建了分支feature/monitor-temperature,用来开发#2号需求“获取温度数据”。现在可以模拟代码开发和提交推送过程。
- 将
子项目A的代码克隆到本地。 - 在本地将
子项目A的代码切换到feature/monitor-temperature分支。 - 新增一些代码文件,如
README.MD,并向文件中写入一些内容。 - 本地提交代码,代码提交格式应遵循4.3.1章节推送规则的规范,如
feat: #2 获取温度数据。 - 重复3-4步骤,直到功能开发完成。
- 向GitLab推送代码,在GitLab指定项目,如
子项目A“代码——提交”可切换分支并查看不同分支的提交记录。
4.3.3 代码提交关联GitLab议题
在4.3.1和4.3.2章节中,除了要求代码提交应遵循一些统一格式外,还可以将代码提交与需求任务、Bug缺陷进行关联,实现需求管理和代码开发的双向追溯。 将代码提交与GitLab议题关联,可参考以下步骤。 操作步骤:
- 在代码提交时,只需将议题ID号写入提交记录中,如
feat: #2 获取温度数据,其中#2就是需求“获取温度数据”的议题ID号。需注意代码提交仅能关联该代码所属项目(代码库)中的议题,不能关联其他项目(代码库)中的议题。
- 可以修改推送规则,如
^(feat|fix|doc|style|refactor|test|revert|ci): #[0-9]{1,4}.*$,这样可强制研发人员每次提交代码时都填写对应的议题ID号。 - 代码提交追溯需求、缺陷:在代码提交记录中,点击议题ID号,则会跳转到对应的议题

- 需求、缺陷追溯代码提交:在议题中也可查看该议题关联的代码提交记录

4.3.4 代码提交关联第三方项目管理系统
如果您已经使用Jira、PingCode、Ones、LigaAI等国内外主流项目管理工具,极狐GitLab的代码提交也可以关联这些主流第三方系统的任务ID,实现双向追溯。目前已经支持的有:
以Jira为例,实现的效果如下:
- 可以修改推送规则,如
^(feat|fix|doc|style|refactor|test|revert|ci): JIRA\-\d+ .+,其中JIRA是Jira议题的前缀,不同Jira项目的前缀不同,需要替换。这样可强制研发人员每次提交代码时都填写Jira的议题ID号。 - 代码提交追溯需求、缺陷:在代码提交记录中,点击议题ID号,则会跳转到对应的议题。

- 需求、缺陷追溯代码提交:在Jira议题中也可查看该议题关联的代码提交记录。

- 更多功能,请参见文档
4.4 持续集成、持续部署
代码推送到极狐GitLab后,应触发流水线实现自动化的编译、打包、部署。
4.4.1 配置流水线
 自动编译、构建、打包、单元测试、质量扫描、部署、发布都依赖于流水线的配置和编排,只有先配置好流水线才能再后续的开发过程中实现上述功能。
自动编译、构建、打包、单元测试、质量扫描、部署、发布都依赖于流水线的配置和编排,只有先配置好流水线才能再后续的开发过程中实现上述功能。
为降低流程复杂度,请参考4.2章节,临时关闭main分支的保护,用来配置、调试流水线(调试结束后开启保护分支)。需注意实际项目中不推荐直接修改main分支文件,依然是通过feature分支配置、调试流水线,再合并到main分支。
4.4.1.1 环境变量管理
如果需要将打包后的程序直接上传/部署到其他环境里,需要将不同环境的服务器的信息存储到GitLab环境变量中,并且确保GitLab Runner所在的服务器与上传/部署的目标服务器网络互通。
在本示例中,我们计划通过scp命令将软件包上传到不同环境的服务器中,那么在GitLab里,存储的变量可以为
# 生产环境的用户名、IP、PORT、路径
USERNAME_PROD: ubuntu
IP_PROD: 192.168.0.1
PORT_PROD: 22
PATH_PROD: /wwwroot/
# 测试环境的用户名、IP、PORT、路径
USERNAME_TEST: ubuntu
IP_TEST: 172.16.0.1
PORT_TEST: 22
PATH_TEST: /wwwroot/操作步骤:
- 在子项目A的“设置——CICD——变量”中,添加上述变量。

- 为了防止这些变量在流水线中被
echo命令打印出来导致信息泄露,可以在设置变量时勾选“隐藏变量”。
- 环境变量也可以设置在群组和实例级别,对群组和全局生效。
4.4.1.2 编译、打包、部署
进行这一步操作之前,需要根据不同语言、不同框架的代码项目,需要准备好编译服务器并安装好编译程序所需的环境,或准备好用于编译程序的Docker镜像。安装好GitLab Runner(如果您使用GitLab SaaS),然后参考以下内容基于GitLab CI关键字编写流水线脚本。
以一个C++的项目为例,通过指定的GitLab Runner完成自动编译、打包,根据流水线的触发条件来将软件包部署到指定的环境,如通过tag触发的流水线将软件包部署到生产环境(tag表示正式发版)同时将软件包上传到GitLab的制品库(软件包库),通过其他分支触发的流水线将软件包部署到测试环境。
操作步骤:
-
在子项目A的“构建——流水线编辑器”中,点击“配置流水线”。

-
流水线脚本内容如下:
stages:
- build
- upload
- deploy
# 编译任务,使用docker类型Runner
build-job:
stage: build
# 编译环境镜像
image: srzzumix/googletest
script:
# 编译打包
- mkdir build
- cd build
- cmake ..
- make
artifacts:
when: always
paths:
# 暂存打包程序,供upload-job使用
- build/libsqrt.so
# 上传任务,使用docker类型Runner
upload-job:
stage: upload
image: alpine/curl
rules:
# 如果是从tag触发,即生产版本,则执行上传到制品库任务
- if: '$CI_COMMIT_TAG =~ /^v?\d+\.\d+\.\d+$/'
script:
# 上传到软件包库
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./build/libsqrt.so "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/release/$CI_COMMIT_TAG/libsqrt.so"'
# 部署任务,使用shell类型Runner
deploy-job:
stage: deploy
tags:
- deploy_jump_server
# 用分支名称区分环境
environment: $CI_COMMIT_REF_NAME
script:
# 如果是从tag触发,使用生产环境变量,否则使用测试环境变量
- |
if echo "$CI_COMMIT_TAG" | grep -Eq '^v?[0-9]+\.[0-9]+\.[0-9]+$'; then
USERNAME=$USERNAME_PROD
IP=$IP_PROD
PORT=$PORT_PROD
PATH=$PATH_PROD
echo '生产环境'
else
USERNAME=$USERNAME_TEST
IP=$IP_TEST
PORT=$PORT_TEST
PATH=$PATH_TEST
echo '测试环境'
fi
# 通过scp命令传输到对应环境
#- scp -r ./build/libsqrt.so $USERNAME@$IP:@PATH -P $PORT
- echo "Deployment Complete!"需注意执行deploy-job的Runner需与部署环境网络互通,上述示例使用scp命令执行部署,还需参考以下方式配置该Runner到部署服务器的SSH Key:
-
可在
子项目A的“构建——流水线”中查看流水线运行状态和结果。
-
如果部署任务成功执行,可以看到对应的软件包库已经上传/部署到目标环境(此处应是测试环境)的服务器中,如果部署失败,应结合
deploy-job的日志进行排查。
4.4.1.3 单元测试
极狐GitLab支持与单元测试框架集成,不同语言、不同测试框架的集成方式见文档。 以上文C++的代码项目为例
操作步骤:
- 使用GoogleTest作为单元测试框架。
- 编写测试脚本,如
sqrt_test.cpp
- 修改
.gitlab-ci.yml,增加以下内容
stages:
- build
- test # 增加test阶段
- upload
- deploy
# 编译任务
build-job:
stage: build
# 编译环境镜像
image: srzzumix/googletest
script:
# 编译打包
- mkdir build
- cd build
- cmake ..
- make
# 运行单元测试
- ./sqrt_unittest --gtest_output="xml:report.xml"
# 生成覆盖率
- apt update
- apt install -y pip
- pip install gcovr --break-system-packages
- gcovr --xml-pretty --exclude-unreachable-branches --print-summary -o coverage.xml --root ${CI_PROJECT_DIR}
coverage: /^\s*lines:\s*\d+.\d+\%/
artifacts:
when: always
paths:
# 暂存打包程序,供upload-job使用
- build/libsqrt.so
reports:
# 单测报告
junit: build/report.xml
# 单测覆盖率报告
coverage_report:
coverage_format: cobertura
path: build/coverage.xml- 如果配置正确,可在子项目A的“构建——流水线”中看到流水线的状态为成功。进入流水线,可看到单元测试的报告

4.4.1.4 质量扫描[专业版]
极狐GitLab支持开箱即用的代码质量扫描,使用该功能需要Docker或K8S类型的Runner,且Runner需开启Docker-in-Docker模式,以Docker类型的Runner为例:
- 进入Runner的Docker容器。
- 修改
/etc/gitlab-runner/config.toml:
[[runners]]
url = xxxx
token = xxxx
executor = "docker"
[runners.docker]
tls_verify = xxx
image = xxx
# 仅修改privileged为true
privileged = true
disable_cache = xxx
volumes = xxx配置好Runner后,可以开启代码质量扫描,以上文C++的代码项目为例:
操作步骤:
- 在
子项目A代码库根目录创建文件.codeclimate.yml,内容如下:
plugins:
cppcheck:
enabled: true- 修改
.gitlab-ci.yml,增加以下内容:
include:
- template: Jobs/Code-Quality.gitlab-ci.yml
code_quality:
image: registry.gitlab.cn/gitlab-cn/docker:20.10.12
services:
- name: 'registry.gitlab.cn/gitlab-cn/docker:20.10.12-dind'
command: ['--tls=false', '--host=tcp://0.0.0.0:2375']
alias: docker
variables:
CODECLIMATE_PREFIX: "registry.gitlab.cn/"3.如果配置正确,可在子项目A的“构建——流水线”中看到流水线的状态为成功。进入流水线,可看到质量扫描的报告

4.4.1.5 安全扫描[旗舰版]
极狐GitLab旗舰版内置SAST、SCA、DAST、密钥检测、模糊测试等7种类型的安全扫描工具,覆盖软件全生命周期,配置简单,开箱即用。使用该功能需要Docker或K8S类型的Runner。
- 在
子项目A的“构建——流水线编辑器”中添加以下内容,以开启其中的4种静态安全扫描能力:
stages:
- test
include:
# 静态应用测试
- template: Security/SAST.gitlab-ci.yml
# 依赖扫描与许可证检测
- template: Security/Dependency-Scanning.gitlab-ci.yml
# 密钥检测
- template: Security/Secret-Detection.gitlab-ci.yml
variables:
# 安全扫描日志,有助于排查错误
SECURE_LOG_LEVEL: debug如果是扫描Maven项目,且需要自定义settings.xml文件,可参考4.4.1.1为该项目或群组创建环境变量,如名称为“MVN_SETTING”,类型为“文件”,内容为settings.xml文件中的内容

然后在流水线脚本中增加以下内容:
variables:
# 安全扫描日志,有助于排查错误
SECURE_LOG_LEVEL: debug
# 使用自定义MVN Settings
MAVEN_CLI_OPTS: "-s $MVN_SETTING"- 如果配置正确,可在子项目A的“构建——流水线”中看到流水线的状态为成功。进入流水线,可看到安全扫描和许可证报告

4.4.1.6 安全策略[旗舰版]
您也可以参考文档,在群组级别设置安全扫描策略,该群组的所有项目将会强制执行这个安全扫描策略,可实现安全扫描的批量设置、强制执行,并且无需修改项目自身的流水线脚本,减少侵入性。
4.4.2 单元测试

操作步骤:
- 接着4.3.2分支开发的内容,在
子项目A的feature/monitor-temperature分支增加一些单元测试的用例,用来体现差异。
#include "sqrt.h"
#include "gtest/gtest.h"
TEST(SquareRootTest, PositiveNos) // normal cases
{
ASSERT_EQ(6, squareRoot(36.0));
ASSERT_EQ(18.0, squareRoot(324.0));
ASSERT_EQ(25.4, squareRoot(645.16));
ASSERT_EQ(0, squareRoot(0.0));
}
// 增加测试用例
TEST(SquareRootTest, NegativeNos) // extreme cases
{
ASSERT_EQ(-1.0, squareRoot(-15.0));
ASSERT_EQ(-1.0, squareRoot(-0.2));
}
int main(int argc, char **argv)
{
testing::GTEST_FLAG(output) = "xml:report.xml";
testing::InitGoogleTest(&argc, argv);
return RUN_ALL_TESTS();
}-
提交代码后,自动触发
feature/monitor-temperature分支的流水线,等流水线执行完成,可在流水线中查看单元测试报告。
-
也可在4.1.3或4.1.4章节中创建的
feature/monitor-temperature到main的合并请求中查看单元测试报告以及单元测试覆盖率。
4.4.3 质量扫描[专业版]

操作步骤:
- 在
子项目A的feature/monitor-temperature分支人为引入一些代码质量问题。
#include "sqrt.h"
#include <iostream>
#include <cmath>
double squareRoot(const double a)
{
double b = sqrt(a);
if(b != b) return -1.0;// NaN check
else return sqrt(a);
}
// 人为引入代码质量问题
void decrease_code_quality() {
// introduce an out-of-bounds error to check code quality report
char a[10];
a[10] = 0;
return;
}-
提交代码后,自动触发
feature/monitor-temperature分支的流水线,等流水线执行完成,可在流水线中查看feature/monitor-temperature分支的全量代码质量报告。
-
也可在4.1.3或4.1.4章节中创建的
feature/monitor-temperature到main的合并请求中查看feature/monitor-temperature分支新引入的代码质量报告。
-
如果您使用极狐GitLab旗舰版,还可以在合并请求的变更页面查看代码质量问题,详见文档。
4.4.3 质量扫描[专业版]

操作步骤:
- 在子项目A的feature/monitor-temperature分支人为引入一些代码质量问题。
#include "sqrt.h"
#include <iostream>
#include <cmath>
double squareRoot(const double a)
{
double b = sqrt(a);
if(b != b) return -1.0;// NaN check
else return sqrt(a);
}
// 人为引入代码质量问题
void decrease_code_quality() {
// introduce an out-of-bounds error to check code quality report
char a[10];
a[10] = 0;
return;
}-
提交代码后,自动触发
feature/monitor-temperature分支的流水线,等流水线执行完成,可在流水线中查看feature/monitor-temperature分支的全量代码质量报告。
-
也可在4.1.3或4.1.4章节中创建的
feature/monitor-temperature到main的合并请求中查看feature/monitor-temperature分支新引入的代码质量报告。
-
如果您使用极狐GitLab旗舰版,还可以在合并请求的变更页面查看代码质量问题。
4.4.4 安全扫描[旗舰版]
扫描报告可通过以下途径查看
- 漏洞报告:指定项目“安全——漏洞报告”,显示默认分支如
main/master的全量漏洞报告:
- 依赖列表:指定项目“安全——依赖列表”,显示默认分支如main/master的全量依赖列表:

- 流水线安全报告:指定项目“流水线——安全/许可证”,显示当前分支的全量漏洞报告和许可证合规

- 合并请求安全报告:指定项目“合并请求——安全扫描/许可证”,显示源分支相较于目标分支的增量漏洞报告和许可证合规

4.4.5 代码评审

加速代码评审是提高软件交付效能最有效的途径之一。处于高效代码评审的团队,其软件交付效能有着50%的提升。 ——《2023 加速度 DevOps 全球状态报告》
如果您已参考4.1.3或4.1.4章节创建feature/monitor-temperature到main的合并请求,参考4.3章节推送了一些代码,参考4.4.1章节配置好流水线,那么此时您可以在合并请求中开展代码评审工作。
极狐GitLab专业版提供以下几种评审机制,可以帮助企业更好的开展代码评审工作。
4.4.5.1 合并请求批准[专业版]
多人多规则、自定义的流程化审批机制。
操作步骤:
- 在指定项目,如
子项目A的“设置——合并请求——合并请求批准”中,“添加批准规则”。 - 添加一个“规则名称”为
测试组的规则,“目标分支”为所有受保护的分支,“需要核准”为1,“添加审核人”中选择需要参与评审的测试人员。这条规则意思是所有向main、release分支发起的合并请求,都需要指定的测试人员参与评审,其中只要有1个人通过评审,则这条规则就算通过。
- 添加一个“规则名称”为
开发组的规则,“目标分支”为main,“需要核准”为1,“添加审核人”中选择需要参与评审的开发人员。这条规则意思是所有向main分支发起的合并请求,都需要指定的开发人员参与评审,其中只要有1个人通过评审,则这条规则就算通过。
- 考虑到代码提交人也可能是代码评审人,为了防止代码提交人自己给自己评审,可以:
- 勾选“阻止合并请求的创建者批准”。即如果评审人是合并请求的发起人,那么他不能参与评审。
- 勾选“阻止添加提交的用户批准”。即如果评审人是合并请求中代码的提交人,那么他不能参与评审。
- 选择“添加提交时:删除所有批准”。即评审过程中,如果有人评审通过,但开发人员提交了新的代码,则将所有通过的评审删除,应重新评审。

- 合并请求批准设置后仅对新发起的合并请求生效。为了验证效果,可以先将之前创建的合并请求删除,再重新创建从
feature/monitor-temperature到main的合并请求,即可在合并请求中看到需要评审人批准后,才能进行后续的合并动作。


评审人可以点击“批准”或“撤销批准”,来决定评审是否通过。评审人给出通过意见后,“核准”列会显示数据变化,“已核准人”列会显示对应的评审人。


4.4.5.2 代码所有者CodeOwner[专业版]
针对不同的文件夹、文件类型、文件名称设置负责人。当这些文件内容发生变化时,自动将对应的负责人纳入合并请求的代码评审流程。
CodeOwner可以有效防止在协同开发的过程中,因为研发人员无意或有意修改他人的代码,但又未通知到相关人员,最终导致代码冲突、程序异常甚至引起一些生产事故的问题。
操作步骤:
- 在指定项目,如
子项目A的默认分支,如main分支中创建名为CODEOWNERS的文件,或者通过feature分支创建文件然后合并到main分支。 CODEOWNERS文件的格式内容如下:
# 指定文件的负责人,@user1、@user2为GitLab的用户账号
file.md @user1
path/file.md @user1 @user2
# 指定文件类型的负责人
*.cpp @user1 @user2
# 指定文件路径的负责人
docs/ @user1
model/db/ @user2
# 将群组作为负责人,groupx、group-x/subgroup-y为群组路径
file.md @group-x @group-x/subgroup-y-
在
子项目A的“设置——仓库——受保护分支”中,开启需要代码所有者参与评审的分支
-
同合并请求批准一样,在合并请求中可以看到如果有人改了代码负责人的代码,那么这个负责人会被自动纳入代码评审流程。

4.4.5.3 单元测试覆盖率降低触发评审[专业版]
当合并请求的源分支(如feature/monitor-temperature)的单元测试覆盖率相较于目标分支(如main分支)降低时,触发评审。可以将代码的单元测试覆盖率始终维持在一个标准水平,从而提高代码的质量和可靠性。
操作步骤:
- 在
子项目A的“设置——合并请求——合并请求批准”中启用覆盖率检查。
- 同合并请求批准一样,配置“目标分支”、“需要核准”、“添加核准人”。
- 同合并请求批准一样,新的规则只对新的合并请求生效,删除并重新创建合并请求后可以看到该规则已生效

4.4.5.4 安全门禁[旗舰版]
根据漏洞类型、级别、数量、状态设置安全门禁,当合并请求中安全扫描报告不符合安全门禁设置的要求时触发强制评审。可以帮助研发人员在开发阶段发现潜在的安全风险,并要求他们在代码合并前处理这些安全漏洞,或者通过安全负责人的审批后才允许合并。快速、多类型的安全扫描加上安全门禁可以帮助企业更好的落地安全左移。
操作步骤:
- 在子项目A的“安全——策略——新建策略——扫描结果策略”。

- 根据需求自定义安全门禁策略和审核人。

- 当合并请求中,源分支相较于目标分支的
增量漏洞报告不满足安全门禁策略的要求,则无法进行代码合并,只有当开发人员解决相关漏洞问题,或通过审核人特批才能正常合并代码,从而实现安全卡点。
4.4.5.5 合并请求关闭GitLab议题
可以在合并请求中关联GitLab议题,当合并请求被执行合并后,该议题的状态自动变成关闭状态,即表示完成该议题。
操作步骤:
-
在指定的合并请求的描述中,添加
Closes #1、Closes #4, #6这种关键字加议题ID的格式内容
-
合并请求执行合并后,对应的议题变成已关闭状态。
4.4.6 测试验证

如4.1.1所提到的,测试人员开展工作可能分为两个阶段:
4.4.6.1 功能测试
在单个任务开发阶段,即单个feature分支或单个fix分支开发完成后,需向main分支发起合并请求。在代码合并前,代码已部署到测试环境,测试人员可以在测试环境通过自动化工具或手动测试验证这个单一个功能是否正常,并参与这个功能的代码评审。若发现缺陷Bug,则可拒绝代码合并,同时给出意见反馈,开发人员重新提交代码进行修复;若功能都正常,则可在合并请求中给出通过批准,随后可执行代码合并。 当一个里程碑的所有功能开发完成后,基于main分支创建release分支,并进入集成测试阶段。
操作步骤:
- 基于
main分支创建release分支,如release/1.0.0。
4.4.6.2 集成测试
在集成测试阶段,基于main分支创建release分支,release分支包含了多个feature分支集成后的代码,从release分支触发代码构建,发布到测试环境进行集成测试。如果测试人员在这个阶段发现缺陷,那么可参考3.5.3提交缺陷议题,创建新的feature或fix分支来开发新功能或修复缺陷,再向main分支合并(功能测试阶段)。合并通过后使用cherry-pick拣选功能将这个合并请求拣选到release分支(集成测试阶段)。如果通过这个阶段的测试,则可以进入后续的交付、部署阶段。 操作步骤:
- 在子项目A创建一个新的fix分支,如fix/tag-version-diff。
- 在fix/tag-version-diff分支下修改一些代码,模拟测试人员在集成测试中发现了一些缺陷,需要修复。

- 参考4.4.4章节,将
fix/tag-version-diff合并到main分支。 - 在
子项目A的“代码——提交”中,找到已从fix分支合并到main分支的代码提交,点击进入。
- 将该合并请求拣选到release/1.0.0分支。



4.4.7 交付、部署

4.4.7.1 测试环境交付
在集成测试阶段,也就是基于release分支触发流水线,可以看到:
- 在测试环境的服务器中,也能看到这个软件包被scp命令拷贝到了服务器中,这是
deploy-job实现的功能。本示例仅在deploy-job中打印“测试环境”字符。
4.4.7.2 生产环境交付
集成测试通过,就可以准备发布正式版本。
操作步骤:
- 在
子项目A“代码——标签”中新建标签(tag)。
- 填写“标签名称”,如1.0.1,“创建自”通过集成测试的
release分支,即release/1.0.0分支
- 在生产环境的服务器中,也能看到这个软件包被scp命令拷贝到了服务器中,这是
deploy-job实现的功能。本示例仅在deploy-job中打印“生产环境”字符。
- 在
子项目A“部署——软件包库”中,已经有生产环境的安装包了,这是upload-job实现的功能。
5. 监控反馈

当软件已经完成交付、部署,那么就进入了运维阶段,企业可以结合自己的实际情况采用不同的监控手段来了解软件的运行情况。 当软件发生故障时,运维人员、测试人员、开发人员再将问题进行定位,按照第3章节的步骤,创建新的需求或缺陷议题,并开始下一轮开发工作。
至此,极狐GitLab工作流已经完全跑通,并形成了闭环,感谢您的阅读。
]]>main分支
只存线上的代码,只有确定可以上线时的才合并到main上,并且在main的基础上打Tag。
develop分支
初次创建develop时,需要从main分支拉取,保持开发时代码和线上最新的代码相同。develop分支是在开发时的最终分支,具有所有当前版本需要上线的所有功能。
feature分支
用于开发功能的分支,必须从最新的develop分支代码拉取。分支命名基本上是feature/xxxxx(和功能相关的名字或JIRA Ticket ID带描述)。
不强制提交到远程仓库,可以本地创建。比如,某开发人员开发登录功能,开发人员从develop分支的最新代码创建新分支命名为feature/login,然后切换到这个新分支开始开发。
开发完成后,测试差不多完成,合并到develop分支。
TODO: 只要有代码合并到develop就要出发自动化测试
release分支
当develop分支已经有了本次上线的所有代码的时候,并且以通过全部测试的时候,可以从develop分支创建release分支了,release分支是为发布新的产品版本而设计的。
通过在release分支上进行这些工作可以让develop分支空闲出来以接受新的feature分支上的代码提交,进入新的软件开发迭代周期。
在这个分支上的代码允许做小的缺陷修正、准备发布版本所需的各项说明信息(版本号、发布时间、编译时间等等)。
比如,此次1.0版本所有的功能版本都已经合并到了develop上,并且所有测试都已经通过了测试,那就创建新的release分支release/v1.0。切换到新分支,修改最新的版本号等,不允许大的更改。
hotfix分支
当线上出现bug需要紧急修复时,从当前main分支派生hotfix分支。
修改线上bug,修改完成后合并回develop和main分支。
比如,在线上v1.0登录功能出现问题,我从main拉取代码创建新的分支hotfix/v1.0_login,修改完成后合并到main和develop上。
tag
上线合并到main以后,保留版本历史记录,从main创建tag版本
分支生命周期
| 分支 | 说明 | 创建来源 | 代码来源 | 目标分支 | 代码输入方式 | 生命周期 | 命名规则 |
|---|---|---|---|---|---|---|---|
| ★ main | 主干分支,通常作为代码基线,所有发布的代码最终都会合并到此分支。 | 无 | release, hotfix | 无 | Pull request | 长期 | main |
| ★ develop | 开发分支,通常作为其他分支的源分支,也最终会合并回此分支 | 无 | feature, release, hotfix | 无 | Pull request | 长期 | develop |
| feature | 功能分支,用于为未来的应用版本开发新的功能需求 | develop | develop | develop | Merge | 并入目标分支后,可以删除 | feature_ |
| ★ release | 发布分支,用于辅助新版本发布的准备工作,例如小bug的修复,或者版本号的修改等等 | develop | develop | develop, main | Merge | 并入目标分支后,可以删除 | release_ |
| hotfix | 修复分支,用于正式版本的紧急修复 | main | main | develop, main, release | Merge | 并入目标分支后,可以删除 | hotfix_ |
| tag | main发布版本快照 | main | main | 无 | 无 | 长期 | tag_ |
场景说明
正常的业务需求流程
当接收到正常的业务需求时,需要约定一个大的发布版本(一次迭代)以及这个发布版本包含的多个jira任务,一个发布版本必须在一个时间点上发布;如果jira上的任务粒度太大,则需要拆分细化成更小的jira子任务(工作量在1~2人日为准,最好控制在一天以内)。
以develop为基准创建一个分支,分支名称为“feature-jira编号-开发人员姓名全拼”,如“feature-ONC-21-zhangsan”,jira任务ONC-21的所有开发工作都在feature-ONC-21-zhangsan,所有开发过程的commit message需要填写具体的开发内容。
开发及单元测试工作完成后创建merge request合并到develop分支,合并请求消息同样需要复制jira的内容描述以及具体的开发内容。
开发人员的自测工作基于合并后的develop分支代码进行,如果这个发布版本所有jira任务全部自测通过后,基于测试通过的develop分支创建一个release分支,分支名称为“release-版本号”,如“release-ctrip1.0”,测试人员基于release分支进行测试。
测试人员继续在新建的release分支上进行回归测试和验证,如果存在bug直接在该分支修改并合并到develop分支;如果验证通过则准备生产上线,
生产上线时将release代码合并到main分支,并打tag,tag名称为“tag-版本号”,从release打包上线。
紧急bug修复流程
当发现线上bug需要紧急修复时(开发人员需要确保bug修复已经在jira录入),需要以main分支为基准创建一个hotfix分支,分支名称为“hotfix-jira编号-开发人员姓名全拼”;
bug修复代码直接在新建的hotfix分支上提交,commit message需要填写具体的开发内容。测试人员直接在hotfix分支测试测试
通过后,开发人员同时请求合并到main分支,release分支,develop分支,合并请求消息同样需要复制jira的任务描述以及具体的开发内容。
生产上线时将hotfix代码合并到main分支,并打tag,tag名称为“tag-版本号-jira编号”,从release打包上线。
高优先级开发任务流程
如果在其他发布版本或迭代在开发中,而优先级更高的迭代需要同时进行,则需要特别注意。在创建feature分支时,要确保develop分支和main分支时一致的没有被未上线甚至未测试的代码污染过的,如果是则直接以develop分支为基准创建新的分支,命名规范如同正常的业务需求流程; 如果develop分支上已经有其他未上线分支的代码且该分支代码上线优先级较低,则不能以develop分支为基准创建分支,需要以main分支为基准创建分支。
当更高优先级feature功能开发和自测完成后,需要上测试环境,这时,需要以main分支为基准创建一个release分支,release分支名称为“release-版本号”,所有较高优先级的feature分支合并到高优先级的release分支上,并在该分支进行测试。
release分支测试通过后,合并到main分支准备上生产,同时release合并到develop分支;main分支生产上线后打tag,tag名称为“tag-版本号”。
]]>前提
先阅读文档
https://github.com/sameersbn/docker-gitlab
https://www.damagehead.com/docker-gitlab/
测试环境下最简单的方式是使用 docker-compose
准备下面的yaml文件,执行 docker-compose up
浏览器打开http://localhost:10080并使用默认用户名和密码登录:
- username: root
- password: 5iveL!fe
docker-compose.yml
version: '2.3'
services:
redis:
restart: always
image: redis:6.2
command:
- --loglevel warning
volumes:
- redis-data:/data:Z
postgresql:
restart: always
image: sameersbn/postgresql:14-20230628
volumes:
- postgresql-data:/var/lib/postgresql:Z
environment:
- DB_USER=gitlab
- DB_PASS=password
- DB_NAME=gitlabhq_production
- DB_EXTENSION=pg_trgm,btree_gist
gitlab:
restart: always
image: sameersbn/gitlab:17.5.0
depends_on:
- redis
- postgresql
ports:
- "10080:80"
- "10022:22"
volumes:
- gitlab-data:/home/git/data:Z
healthcheck:
test: ["CMD", "/usr/local/sbin/healthcheck"]
interval: 5m
timeout: 10s
retries: 3
start_period: 5m
environment:
- DEBUG=false
- DB_ADAPTER=postgresql
- DB_HOST=postgresql
- DB_PORT=5432
- DB_USER=gitlab
- DB_PASS=password
- DB_NAME=gitlabhq_production
- REDIS_HOST=redis
- REDIS_PORT=6379
- TZ=Asia/Shanghai
- GITLAB_TIMEZONE=Shanghai
- GITLAB_HTTPS=false
- SSL_SELF_SIGNED=false
- GITLAB_HOST=localhost
- GITLAB_PORT=10080
- GITLAB_SSH_PORT=10022
- GITLAB_RELATIVE_URL_ROOT=
- GITLAB_SECRETS_DB_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_SECRETS_SECRET_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_SECRETS_OTP_KEY_BASE=long-and-random-alphanumeric-string
- GITLAB_ROOT_PASSWORD=
- GITLAB_ROOT_EMAIL=
- GITLAB_NOTIFY_ON_BROKEN_BUILDS=true
- GITLAB_NOTIFY_PUSHER=false
- [email protected]
- [email protected]
- [email protected]
- GITLAB_BACKUP_SCHEDULE=daily
- GITLAB_BACKUP_TIME=01:00
- SMTP_ENABLED=false
- SMTP_DOMAIN=www.example.com
- SMTP_HOST=smtp.gmail.com
- SMTP_PORT=587
- [email protected]
- SMTP_PASS=password
- SMTP_STARTTLS=true
- SMTP_AUTHENTICATION=login
- IMAP_ENABLED=false
- IMAP_HOST=imap.gmail.com
- IMAP_PORT=993
- [email protected]
- IMAP_PASS=password
- IMAP_SSL=true
- IMAP_STARTTLS=false
- OAUTH_ENABLED=false
- OAUTH_AUTO_SIGN_IN_WITH_PROVIDER=
- OAUTH_ALLOW_SSO=
- OAUTH_BLOCK_AUTO_CREATED_USERS=true
- OAUTH_AUTO_LINK_LDAP_USER=false
- OAUTH_AUTO_LINK_SAML_USER=false
- OAUTH_EXTERNAL_PROVIDERS=
- OAUTH_CAS3_LABEL=cas3
- OAUTH_CAS3_SERVER=
- OAUTH_CAS3_DISABLE_SSL_VERIFICATION=false
- OAUTH_CAS3_LOGIN_URL=/cas/login
- OAUTH_CAS3_VALIDATE_URL=/cas/p3/serviceValidate
- OAUTH_CAS3_LOGOUT_URL=/cas/logout
- OAUTH_GOOGLE_API_KEY=
- OAUTH_GOOGLE_APP_SECRET=
- OAUTH_GOOGLE_RESTRICT_DOMAIN=
- OAUTH_FACEBOOK_API_KEY=
- OAUTH_FACEBOOK_APP_SECRET=
- OAUTH_TWITTER_API_KEY=
- OAUTH_TWITTER_APP_SECRET=
- OAUTH_GITHUB_API_KEY=
- OAUTH_GITHUB_APP_SECRET=
- OAUTH_GITHUB_URL=
- OAUTH_GITHUB_VERIFY_SSL=
- OAUTH_GITLAB_API_KEY=
- OAUTH_GITLAB_APP_SECRET=
- OAUTH_BITBUCKET_API_KEY=
- OAUTH_BITBUCKET_APP_SECRET=
- OAUTH_BITBUCKET_URL=
- OAUTH_SAML_ASSERTION_CONSUMER_SERVICE_URL=
- OAUTH_SAML_IDP_CERT_FINGERPRINT=
- OAUTH_SAML_IDP_SSO_TARGET_URL=
- OAUTH_SAML_ISSUER=
- OAUTH_SAML_LABEL="Our SAML Provider"
- OAUTH_SAML_NAME_IDENTIFIER_FORMAT=urn:oasis:names:tc:SAML:2.0:nameid-format:transient
- OAUTH_SAML_GROUPS_ATTRIBUTE=
- OAUTH_SAML_EXTERNAL_GROUPS=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_EMAIL=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_NAME=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_USERNAME=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_FIRST_NAME=
- OAUTH_SAML_ATTRIBUTE_STATEMENTS_LAST_NAME=
- OAUTH_CROWD_SERVER_URL=
- OAUTH_CROWD_APP_NAME=
- OAUTH_CROWD_APP_PASSWORD=
- OAUTH_AUTH0_CLIENT_ID=
- OAUTH_AUTH0_CLIENT_SECRET=
- OAUTH_AUTH0_DOMAIN=
- OAUTH_AUTH0_SCOPE=
- OAUTH_AZURE_API_KEY=
- OAUTH_AZURE_API_SECRET=
- OAUTH_AZURE_TENANT_ID=
volumes:
redis-data:
postgresql-data:
gitlab-data:生产建议
postgresql 和 redis 不要和 gitlab 运行在同一台服务器,最好使用独立数据库,避免单点故障
]]>Live Expression
从 chrome70起,我们可以在控制台上方可以放一个动态表达式,用于实时监控它的值。
- 点击 "Create Live Expression" 眼睛图标,打开动态表达式界面。

- 输入要监控的表达式,比如查看当前的时间戳,输入 Date.now()
- 会发现当前时间戳会一直变动。也就是表示式被重新计算了,Live Expression 的执行频率是250毫秒。
下面是一些有用的表达式:
- document.activeElement 高亮当前focus的node
- document.querySelector(s) 高亮任意node,参数s是css选择器表达式,相当于在hover这个node。
- $0 高亮当前所选中的node
- $0.parentElement 高亮当前所选中的node的父节点
Store DOM nodes as global variables
我们可以把页面上的某元素节点作为全局变量。
- 比如当前页面有一个按钮,我们审核该元素,右键选择 "store as global variable"

- console面板中会显示该元素的引用名称,一般是 temp1 temp2。
- 在console中输入
monitorEvents(temp1)会监视并打印出该元素的所有事件。 - 这个你可以在按钮上点击,移动,甚至按键,会发现一系列的mouse, click等事件
- 使用
unmonitorEvents(temp1)停止记录事件。 - 使用
monitorEvents(temp1, ['mouse', 'focus'])只记录某类型的事件。可以填 mouse, key, click, touch和control等。
参考:
https://developers.google.com/web/updates/2018/08/devtools https://developers.google.com/web/updates/2018/10/devtools#bonus https://developers.google.com/web/tools/chrome-devtools/console/command-line-reference
]]>1. 截图
以前截取网页我都用qq,直接ctrl+alt+a。现在chrome自带了截图功能,可以截取指定区域或者指定dom元素。

截取指定区域:按ctrl+shift+c, 然后按住鼠标左键不放,选取网页区域,最后松手会下载截图的图片。 截取指定dom元素:右键检查元素,按ctrl+shift+P打开命令面板。输入"capture node"。然后回车,就会下载内容为指定元素的图片。
2. 新api
在console中,可以直接使用queryObjects查询特定的constructor
- queryObjects(Promise). 返回所有的 Promises.
- queryObjects(HTMLElement). 返回所有的 HTML elements.
- queryObjects(foo), foo是函数名。返回所有实例化new foo()后的对象。
console
大部分人经常用 console.log() 使用 keys(console) 打印所有方法,keys 和 values 类似 Object.keys,Object.values 只在调试面板有用。

各个方法的详细用法请查看 https://developers.google.com/web/tools/chrome-devtools/console/utilities
$
看到$大家不要以为是jquery,其实是浏览器自带的一些api。这个在调试上就比较方便!
$:返回第一个符合条件的元素,相当于document.querySelector
$$:返回所有符合条件的元素,相当于document.querySelectorAll
查找和监控事件
getEventListeners作用就是查找并获取选定元素的事件。用法如下

monitorEvents作用是监控你所选元素关联的所有事件,事件触发时,在控制台打印它们。


getEventListeners和monitorEvents感觉在开发上用得并不多了,至少我没用过。但是感觉会有用,就提及一下
类似可以使用 monitor 来监控函数,每次调用该函数,就会打印出传入的参数。
var func1 = function(x, y, z) {
//....
};输出:

参考:
]]>
- ip route show
- route -n
- netstat -r
使用 NAT 网络
- 偏好设置 - 添加 NAT 网络

- 对每一个虚拟机进行网络设置,选择 NAT 网络
这样就可以让虚拟机访问外网了。
但是宿主机无法通过ssh访问虚拟机。
因为 NAT 中的虚拟机对于外部网络以及主机本身是不可见的
- 解决方式是使用端口转发

不用重启虚拟机可以直接测试
宿主机 ssh -p 22224 <login>@127.0.0.1 可以访问虚拟机
宿主机浏览器访问 http://localhost:22225/ 可以看到nginx页面
ubuntu20.04 配置静态IP
sudo vi /etc/netplan/50-cloud-init.yaml
sudo netplan apply
sudo netplan --debug applynetwork:
ethernets:
enp0s3:
addresses: [192.168.1.2/24]
gateway4: 192.168.1.1
nameservers:
addresses: [8.8.8.8,8.8.4.4]
dhcp4: no
version: 2参考
]]>- Clash 等
以端口使用7890为例
安装浏览器代理插件
配置终端代理
MacOS
iterm终端
alias http_proxy="http_proxy=http://127.0.0.1:7890"
alias https_proxy="https_proxy=http://127.0.0.1:7890"
alias all_proxy="all_proxy=socks5://127.0.0.1:7890"
alias proxy_off="export https_proxy=;export http_proxy=;export all_proxy=;curl ipinfo.io;echo -e '\n终端代理已关闭'"
alias proxy_on="export https_proxy=http://127.0.0.1:7890;export http_proxy=http://127.0.0.1:7890;export all_proxy=socks5://127.0.0.1:7890;curl ipinfo.io;echo -e '\n终端代理已开启'"
alias proxy_check="curl -I --connect-timeout 10 -w %{http_code} https://facebook.com"
alias proxy_status="curl -I --connect-timeout 10 -w %{http_code} https://facebook.com"
alias ip="curl cip.cc"Git
配置拉取github仓库代码走代理
vi ~/.ssh/config
Host github.com
Hostname ssh.github.com
Port 443
ProxyCommand nc -v -x 127.0.0.1:7890 %h %p
User git
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa其他
排除 T3 打车 APP 的提示
Surge 及 Shadowrocket 在使用「 T3 出行」时遇到「检测到您正在使用网络代理,请关闭网络…」的,可以在文本编辑模式编辑,在 [General] 下的 skip-proxy 增加:passenger.t3go.cn 注意,passenger.t3go.cn 和原先内容之间要有英文逗号
]]>Mac
Raycast:
直接替代掉原生的 Spotlight 搜索
OrbStack:
替换掉Docker 原生的应用,这个速度比亲儿子强太多了
Warp:
https://warp.dev 很现代的一个 terminal,iterm2的替代品
Kap
https://getkap.co/ 录制视频和 gif 的轻量工具
linear
项目管理
Trello
项目管理
文件
Cyberduck
文件查看器 支持 FTP, SFTP, WebDAV, Amazon S3, OpenStack Swift, Backblaze B2, Microsoft Azure & OneDrive, Google Drive and Dropbox.
https://cyberduck.io/download/
OSSBrowser
专门查看阿里云OSS文件
https://help.aliyun.com/zh/oss/developer-reference/use-ossbrowser
PicGo
上传文件公有云对象存储服务,做为图床,我这个网站的图片都是存在了青云对象存储
https://github.com/Molunerfinn/PicGo
LocalSend
AirDrop的开源跨平台替代品 如果你同时有安卓,苹果手机,平板等设备,需要同一局域网内相互传文件,可以使用这个软件
https://github.com/localsend/localsend
安全
Bitwarden
密码管理器, 支持多设备之间互相同步
]]>根据官网介绍一个story是一个或多个UI组件的单一状态,基本上像一个可视化测试用例。 打开 这个,这是airbnb公司实现的一个react的datepicker组件。这个组件配置很多,怎么让大家直观的查看学习呢?他就利用storybook写了很多story,左侧的每一项点开后是datepicker组件不同的状态或配置,就是一个个story。
storybook本身提供了很多组件,也可以添加自己的组件作为story,方便他人查看,使用并测试。
使用storybook你需要有react或vue的开发经验,并且熟悉es6。
下来带大家简单使用一下:
- 首先全局安装storybook命令:
npm i -g @storybook/cli - 来到一个已存在的react项目,可以是由creat-react-app创建的
在根目录执行 getstorybook 命令
会出现如下画面

发现这个命令实际修改了package.json,对比如下

然后又多出来个名为.storybook的目录,里面有附件组件文件 addons.js 和 config.js
-
安装后根据提示执行
yarn run storybook启动storybook服务,浏览器打开 http://localhost:9009
-
这个页面是咋生成的呢,我们打开
\src\stories\index.js一看便知
import React from 'react';
import { storiesOf } from '@storybook/react';
import { action } from '@storybook/addon-actions';
import { linkTo } from '@storybook/addon-links';
import { Button, Welcome } from '@storybook/react/demo';
// 文档 https://storybook.js.org/basics/writing-stories/
// storiesOf应该是分组,每组添加一个个story
// 修改内容页面会实时发生变化
storiesOf('Welcome', module).add('to Storybook', () => <Welcome showApp={linkTo('Button')} />);
// 使用action让storybook去记录log,可以在页面的action logger中查看
storiesOf('Button', module)
.add('with text', () => <Button onClick={action('clicked')}>Hello Button</Button>)
.add('with some emoji', () => <Button onClick={action('clicked')}>😀 😎 👍 💯</Button>);今天就先研究到这里
]]>- 安装
npm install prettier --save-dev - 创建配置文件
.prettierrc放到项目根目录, prettier 的格式化风格 内容比如是:
{
"printWidth": 100,
"singleQuote": true,
"trailingComma": "es5"
}- commit 代码
- 按快捷键 Alt-Shift-Ctrl-P(macOS下是Alt-Shift-Cmd-P),你会发现所有的双引号字符串都变成单引号了
首先打开Sources面板,然后按快捷键 Ctrl + Shift + F (Cmd + Opt + F). 输入关键字即可在全部资源文件中搜索, 后面的选项支持大小写和正则

文件内快速跳转行号
打开一个源码文件后,输入 Ctrl + O (Cmd + O)
在输入如:200:10 回车,即可跳转到200行20列

切换颜色格式
按住shift键不放,左键颜色值的小方块,即可在RGBA,HSL和十六进制直接切换颜色格式


Preserve Log 保留日志
]]>一款识别并下载马蜂窝游记页面背景mp3音乐的chrome扩展程序
主要功能
当打开游记页面 比如 如果检测到有背景音乐, 会弹出包含歌曲信息的chrome桌面提醒,同时鼠标菜单右键有下载歌曲的选项。

安装
####源码
感谢
]]> "browserslist": [
"> 1%",
"last 2 versions",
"Android >= 3.2",
"Firefox >= 20",
"iOS 7"
]应该不难猜出来,这代表这个项目的浏览器兼容情况。
白话就是我这个项目兼容绝大多数的,最新的和iOS7系统下的浏览器。不兼容Android 3.2系统以下和Firefox20以下的浏览器
像这些"> 1%", "last 2 versions" 都是查询参数。
查询参数很强大,比如我想查看中国人使用浏览器的情况请输入 > 1% in CN。竟然还有IE8 ~>_<~。对比美国> 1% in US的。
具体参数列表见官方文档
那配这个除了说明我的项目支持情况,对开发有啥作用呢?
具体的影响到前端工具的编译情况,比如 Autoprefixer 可以给css加兼容性前缀 babel-preset-env , eslint-plugin-compat, stylelint-no-unsupported-browser-features 和 postcss-normalize 比如.babelrc文件你可以针对配置
{
"presets": [
["env", {
"targets": {
"browsers": ["last 2 versions"],
"node": "current"
},
}]
]
}
更进一步根据浏览器可以获得特性,比如最新的chrome浏览器支持原生的promise,而IE不支持,babel根据browserslist配置项就会动态的转义。不用在一个个进行配置了。
]]>原理:
Valet 为您的 Mac 设置了开机后始终在后台运行 Nginx 服务。 然后,Valet 使用 DnsMasq 将所有指向安装在本地的计算机站点请求代理到 *.test 结尾的域名上。
默认情况下,Valet 使用 .test 顶级域名为你的项目提供服务。例如,如果你要使用 .app 而不是 .test ,就运行 valet domain app ,Valet 会自动将站点域名改为 *.app 。
Valet 提供两个命令来为 Laravel 的站点提供服务:park 和 link 。
park 命令
- mkdir ~/projects, cd ~/projects
- 执行 valet park
- 在projects目录中新建site1,然后再往site1放个index.php
浏览器打开http://site1.test 就能访问到
link 命令
可以针对某目录中提供单个站点而不是整个目录。
比如切换到 /projects/symfony-demo。默认可以通过http://symfony-demo.test 打开该站点。
如果需要自定义,可以在该目录下执行 valet link my-symfony
会有提示 A [my-symfony] symbolic link has been created in [/Users/mafei/.config/valet/Sites/my-symfony].
然后就可以通过浏览器http://my-symfony.test 访问到了。不要忘了后缀。
支持Yii2项目
Valet 本身提供了很多开源项目,如Laravel,Lumen, Drupal,Wordpress等,但不支持Yii2项目。
网上有现成的 驱动 实际就是告诉Valet项目的项目的根目录在哪。
比如有一个Yii2的项目,绝对路径是~/sites/gee
来到~/sites/gee/frontend/web 这是Yii2项目默认的前台入口目录,执行 valet link gee
再来到~/sites/gee/backend/web 执行 valet link admin.gee
我们就可以通过http://gee.test打开前台,http://admin.gee.test打开后台
参考:
https://learnku.com/docs/laravel/5.6/valet/1356#the-park-command
]]>- Postman工具有chrome扩展和独立客户端,推荐安装独立客户端。
- Postman有个workspace的概念,workspace 分 personal 和 team类型。 personal workspace 只能查看和管理自己的的API,team workspace 可添加成员和设置成员权限,成员之间可共同管理API。

- 每个workspace可管理多个collection,我们可以发布collection,即生成在线API文档。

- collection及每个collection包含的API中的描述支持markdown
- 每个API支持写测试用例,下图 snippet 提供了很多测试示例

- Postman提供了一个专门跑API测试的GUI工具,叫 Runner, 配好循环次数,测试之间的时间间隔,然后针对某collection中的目录或上传collection就可以进行测试了。

- Postman本身提供了一套Postman API可以操作collection,environment等,不过要先申请一个api_key。通过他可以以请求的方式操作自己写的API。
- GUI工具需要我们手动点击触发跑测试,还无法做到完全自动化,好在Postman提供了CLI工具叫做 newman,是一个NodeJS项目。
- 下面的代码非常简单,配好要测试的collection和 environment,执行
node index.js就能看到测试用例的结果。这里配置的是在命令行和html中显示报告。

这里我找了漂亮的 Postman Report Html模板

- 这样基本可以实现了 API测试自动化
注意事项
- 使用Postman要注意有配额限制,尤其是team workspace和调用API。超出后需要掏钱升级。team 中的 member 越多,收费越高。

不过免费的一般基本够用。 2. Postman的功能不止如此,还支持Fork, pull request,monitor监控等功能,大家可以查看官方文档。 3. 关于免费和收费版的区别
]]>本地快速练习
docker run -p 8080:8080 -e KC_BOOTSTRAP_ADMIN_USERNAME=admin -e KC_BOOTSTRAP_ADMIN_PASSWORD=admin quay.io/keycloak/keycloak:26.0.7 start-dev适用于测试环境
services:
keycloak:
image: quay.io/keycloak/keycloak:26.0.7
container_name: keycloak
environment:
KC_BOOTSTRAP_ADMIN_USERNAME: ${KC_BOOTSTRAP_ADMIN_USERNAME:-admin}
KC_BOOTSTRAP_ADMIN_PASSWORD: ${KC_BOOTSTRAP_ADMIN_PASSWORD:-password}
KC_HOSTNAME: https://keycloak.mafeifan.com
KC_PROXY: edge
KC_PROXY_ADDRESS_FORWARDING: true # Crucial for correct protocol
KC_HTTP_ENABLED: "true"
KC_HOSTNAME_STRICT: "false"
KC_HOSTNAME_STRICT_HTTPS: "false"
KC_HTTP_HEADER_CONTENT_SECURITY_POLICY: "frame-src 'self' http://*.mafeifan.com https://*.mafeifan.com; object-src 'none';"
command:
- start-dev
ports:
- "8080:8080"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health/ready"]
interval: 30s
timeout: 10s
retries: 3nginx 配置
server {
listen 80;
server_name keycloak.mafeifan.com;
return 301 https://$host$request_uri; # Redirect to HTTPS
}
server {
listen 443 ssl http2;
server_name keycloak.mafeifan.com;
ssl_certificate /etc/nginx/my_certs/keycloak.mafeifan.com_bundle.crt;
ssl_certificate_key /etc/nginx/my_certs/keycloak.mafeifan.com.key;
ssl_session_timeout 5m;
ssl_protocols TLSv1.2 TLSv1.3; # Modernize protocols
ssl_ciphers TLS13-AES-256-GCM-SHA384:TLS13-CHACHA20-POLY1305-SHA256:TLS13-AES-128-GCM-SHA256:TLS13-AES-128-CCM-8-SHA256:TLS13-AES-128-CCM-SHA256; # Modernize ciphers
ssl_prefer_server_ciphers on;
location / {
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_pass http://127.0.0.1:8080;
}
}名词
- Realm:Keycloak中的一个 realm 领域相当于一个租户。
- Clients:客户端是能够请求用户身份验证的应用和服务。
Keycloak中的一个 realm 领域相当于一个租户。每个 realm 允许管理员创建隔离的应用程序和用户组。 最初,Keycloak包含一个名为 master 的单个 realm。仅使用此 realm 来管理Keycloak,不要用于管理任何应用程序。


使用PicUploader搭建个人图床
PicUploader 是一个用php编写的图床工具,它能帮助你快速上传你的图片到云图床,并自动返回Markdown格式链接到剪贴板。
但是我目前经使用客户端软件PicGo上传图片到青云了
使用frp搭建内网穿透工具
使用vuepress搭建个人博客
类似的工具很多,比如hexo, wordpress, Typora等
]]>最近用cordova开发app,客户希望用firebase带的消息推送功能,国内我们知道有激光推送,leancloud,而国外firebase非常出名。
cordova使用firebase需要注意以下几点:
-
因为firebase已被google收购,国内手机设备无法接收来自firebase的推送,除非开代理,要打开的端口和主机名见官方文档
-
手机上的app运行状态分前台和后台
- 前台运行时可以接收到消息推送,但是不会有消息栏的提醒(这是手机的默认行为),对于安卓,如果要在前台显示推送,推荐使用cordova-plugin-local-notification 插件
- 后台运行或关闭时,手机收到推送会显示消息栏,如果用户点击通知,app会显示在前台,通知内容会被JS回调接收。如果不点击或关闭,通知将一直存在。
-
我们项目中使用的是cordova-plugin-firebasex ,有个bug,手机息屏接收消息很快,亮屏app后台运行接收不稳定。
-
关于通知权限,对于安卓,不需要授权,但是对于apple,需要调用请求授权方法,如我们用到的
cordova-plugin-firebasex插件需要调用提供的grantpermission方法。
-
使用安卓模拟器时记得选用带GooglePlay标志的版本,然后需要在更多设置里更新GooglePlay的版本,并在虚拟机内部做一下接入点代理,记得勾选一下梯子的允许来自局域网的访问。

-
FCM发送推送分三种类型:
- 按设备ID(针对性强,可以只发给某几台设备),需要传
device token - 按
topic主题,比如定义一个名为ad的topic,只有订阅这个topic的设备才能接收到通知 - 按target目标,这应该是firebase的特色,你可以针对某平台(ios或android),某个国家,某目标人群等统计相关参数发推送,很灵活。但是需要创建firebase创建项目时候开启google analysis

- 按设备ID(针对性强,可以只发给某几台设备),需要传
-
APN(Apple Push Notification),不像安卓生态那么混乱,苹果生态中所有通知都走APN,大致流程:firebase通知APN,APN通知apple设备客户端。技术文档, firebase连APN需要我们在apple后台生成验权文件,就是P8或P12,后面会讲。
-
对于安卓,确保在firebase项目设置中生成了
google-services.json文件,对于ios,要生成GoogleService-Info.plist文件,生成文件在放到cordova项目根目录,对于ios,还需要到苹果开发者后后台生成p8或p12文件并上传到firebase项目ios集成页面中
强烈建议生成P8认证文件,P12文件有很多缺点: 流程繁琐,区分开发和正式环境,还有有效期。P8和P12文件生成流程参见:iOS 推送设置指南
- 消息推送内容可以带emoji
集成了如何测试?
如果是用的Cordova集成消息推送,建议先运行这个插件的demo项目
安卓手机模拟器可以收到推送消息,苹果的必须真机,收到推送消息的前提的运行获取FCM ID和FCM token成功(记得开代理,或者保证能访问google)


如何使用命令行发送消息
可以直接用curl命令调用https://fcm.googleapis.com/v1/projects/${project-id}/messages:send发送消息
${project-id} 替换成firebase中project setting页面中生成的
curl -X POST -H "Authorization: Bearer ya29.ElqKBGN2Ri_Uz...HnS_uNreA" -H "Content-Type: application/json" -d '{
"message": {
"topic" : "my-topic",
"notification": {
"body": "This is a Firebase Cloud Messaging Topic Message!",
"title": "FCM Message"
}
}
}' https://fcm.googleapis.com/v1/projects/myproject-b5ae1/messages:send HTTP/1.1参考
https://juejin.cn/post/6844904153274155022
https://github.com/katzer/cordova-plugin-local-notifications#readme
https://www.npmjs.com/package/cordova-plugin-fcm-with-dependecy-updated
]]>安装完nginx,会有sites-available和sites-enabled目录,只有在sites-enabled目录下创建的站点配置文件才会生效, 但是我们一般在sites-available目录下站点配置文件,然后软链接到sites-enabled, 这样有个好处是假设下面的 www.booking.com 站点不需要了,只需要删掉sites-enabled/www.booking.com文件即可,他只是链接文件,源文件还是在sites-available目录下面,方便还原。
basic认证
有些网站页面需要输入正确的用户名和密码才能打开
实现方法也比较简单
sudo apt-get install apache2-utils
cd /etc/nginx
# 使用htpasswd命令创建用户demo,密码123456文件名htpasswd的验证文件
sudo htpasswd -bc htpasswd demo 123456
# 编辑 nginx 站点配置文件
# 加入下面两行到 server 或 location 段中
auth_basic 'Restricted'; # 认证名称,随意填写
auth_basic_user_file /usr/local/nginx/htpasswd; # 认证的密码文件,需要生成。
# 重启 nginx
sudo nginx -t && sudo nginx -s reload显示目录文件列表
场景:有个存放每日备份数据库或日志的目录,希望显示列表,方便下载文件
location / {
root /data/www/file //指定实际目录绝对路径;
autoindex on; //开启目录浏览功能;
autoindex_exact_size off; //关闭详细文件大小统计,让文件大小显示MB,GB单位,默认为b;
autoindex_localtime on; //开启以服务器本地时区显示文件修改日期!
charset utf-8,gbk; //避免中文乱码
}另外,如果希望请求文件是下载而不是显示内容,可以通过添加下面参数实现:
add_header Content-Disposition attachment;
反向代理
我们只需要记得正向代理代理的对象是客户端,最常见的就是VPN软件
反向代理代理的对象是服务端
客户端本来可以直接通过HTTP协议访问某网站应用服务器,如果网站管理员在中间加上一个Nginx,客户端请求Nginx,Nginx请求应用服务器,然后将结果返回给客户端,此时Nginx就是反向代理服务器。
例子:Nginx监听来自外部访问80的请求,转发给自己服务器占用18083端口的服务
server {
listen 80;
index index.html index.htm index.nginx-debian.html;
server_name mqtt.demo.com;
location / {
proxy_pass http://127.0.0.1:18083;
}
}关于 try_files 指令
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
# $uri 是变量 如 www.xxx.com/aaa.php 则 $uri是aaa.php
# 假设我们访问/a.php 先判断 a.php是不是文件,是返回
# 如果不是再判断是不是目录($uri/),是返回
# 如果都不是则返回404
try_files $uri $uri/ =404;
}
# 所有的请求引导到index.php中
try_files $uri $uri/ /index.php?$query_string =404;@ 符号的使用
@用于定义一个 location 块,且该块不能被外部 Client 所访问,只能被 Nginx 内部配置指令所访问,比如 try_files
c49fb81c8f9141ae3fe7f9db2da60bd7.htm 实际上个不存在的文件, 下面的含义的如果访问项目根目录或blog目录底下的以php结尾的文件都走php fpm解析流程
location ~ \.php$ {
try_files /c49fb81c8f9141ae3fe7f9db2da60bd7.htm @php;
}
location /blog/\.php$ {
try_files /c49fb81c8f9141ae3fe7f9db2da60bd7.htm @php;
}
location @php {
try_files $uri =404;
include /etc/nginx/fastcgi_params;
fastcgi_pass unix:/var/lib/php7.2-fpm/web10.sock;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_intercept_errors on;
}使用Nginx解决跨域问题
当公司存在多个域名时,两个不同的域名相互访问就会存在跨域问题。
或者在进行前端开发时,通常前端代码在本地启动,而后端代码会部署在一台专用的后端开发服务器上,此时前端去调用后端接口时,就会出现跨域问题。
解决跨域的方法有很多,今天来说一下如何使用Nginx来解决跨域问题。
假设后端服务器,是使用Nginx作为对外统一入口的,在Nginx配置文件的server块中增加如下配置:
# 允许跨域请求的域名,*代表所有
add_header 'Access-Control-Allow-Origin' *;
# 允许带上cookie请求
add_header 'Access-Control-Allow-Credentials' 'true';
# 允许请求的方法,例如:GET、POST、PUT、DELETE等,*代表所有
add_header 'Access-Control-Allow-Methods' *;
# 允许请求的头信息,例如:DNT,X-Mx-ReqToken,Keep-Alive,User-Agent等,*代表所有
add_header 'Access-Control-Allow-Headers' *;重新加载Nginx,便发现,已经可以跨域访问了。
验证头信息中的 referer 参数
请求头信息中的 referer 参数,记录了上一个页面的地址,Nginx可以对其进行校验,达到防盗链的目的。
通常在配置文件的location块中增加配置。
server {
listen 80; # 端口
server_name www.osvlabs.com; # 服务名,可以是IP地址或者域名
location / { # 根路径
root html; # 对应nginx安装目标下的html文件夹
index hello.html; # 指定首页为 hello.html
}
location ~* \.(GIF|PNG|jpg|bmp|jpeg) { # *代表不区分大小写
# 校验请求是否来自于osvlabs.com这个站点,不是则返回404页面
valid_referers *.osvlabs.com;
if ($invalid_referer) {
return 404;
}
root /home/img;
}
error_page 500 502 503 504 /50x.html; # 指定这些状态码跳转的错误页
location = /50x.html {
root html;
}
}Nginx构建Tomcat集群
Nginx最常用的一个功能,就是为Tomcat构建集群,以达到实现高并发、高可用的目的。
首先在 upstream 块中,配置Tomcat集群中的服务地址,然后在location块中配置转发请求到此 upstream。
# 配置Tomcat集群中的服务器
upstream osvlabs {
server 192.168.1.101:8080;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
}
server {
listen 80;
server_name www.osvlabs.com;
location / {
proxy_pass http://osvlabs;
}
}默认按所有机器权重为1的轮询方式对集群服务进行访问,每个服务访问1次,然后访问下一个服务,适合集群中每台服务器性能差不多的情况。
权重配置也是经常用的,适用于机器性能有差异的情况。
upstream osvlabs {
server 192.168.1.101:8080 weight=1;
server 192.168.1.102:8080;
server 192.168.1.103:8080 weight=3;
}weight 就是权重配置,不配默认是1,按照以上配置,在5次请求中,101和102会被访问1次,103会被访问3次。
使用down,可以标识某个服务已停用,Nginx便不会去访问他了。
upstream osvlabs {
server 192.168.1.101:8080;
server 192.168.1.102:8080 down;
server 192.168.1.103:8080;
}使用backup,可以标识101是备用机,当102、103宕机后,101会进行服务。
upstream osvlabs {
server 192.168.1.101:8080 backup;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
}使用 max_fails 和 fail_timeout 将服务动态停用
max_fails 默认是1,fail_timeout默认是10s
upstream osvlabs {
server 192.168.1.101:8080 max_fails=2 fail_timeout=10s;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
}如此配置,101服务器在10秒内如果失败次数达到2次,会停用10秒。10秒后,会尝试连接101服务器,如果连接成功则恢复轮询方式,如果不成功,再等待10秒尝试。
使用keepalive设置长链接数量,提高吞吐量
upstream osvlabs {
server 192.168.1.101:8080;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
keepalive 50;
}
server {
listen 80;
server_name www.osvlabs.com;
location / {
proxy_pass http://osvlabs;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}需要在upstream块中增加 keepalive 配置,在server的location块中增加 proxy_http_version 和 proxy_set_header 配置。
这样设置可以减少连接断开、新建的损耗,增加吞吐量。
其他负载均衡策略
除了前面说到的轮询方式,Nginx在负载均衡时,还有其他策略。
- ip_hash:以客户端IP地址为依据,匹配服务器。
- hash $request_uri:以请求的URL为依据,匹配服务器。
- least_conn:以服务器连接数为依据,哪个服务器连接数少,匹配哪台服务器
upstream osvlabs {
# ip_hash;
# hash $request_uri;
least_conn;
server 192.168.1.101:8080;
server 192.168.1.102:8080;
server 192.168.1.103:8080;
}access_log过滤
一个网站,会包含很多元素,尤其是有大量的图片、js、css等静态元素。 这样的请求其实可以不用记录日志。
location ~* ^.+\.(gif|jpg|png|css|js)$
{
access_log off;
}
或
location ~* ^.+\.(gif|jpg|png|css|js)$
{
access_log /dev/null;
}github上面找到了这个不错的工具yt-dlp
他是基于大名鼎鼎的youtube-dl又额外添加了些功能。
前提
本地安装并开启代理,比如Clash,暴露代理地址,比如socks5://127.0.0.1:7890
会自动当列表下载
yt-dlp https://www.youtube.com/watch?v=MXdFMjm3vTs&list=PLliocbKHJNwslcXWGhQ7oaQSmw-MzLaXu&index=2 --proxy socks5://127.0.0.1:7890
先加--simulate尝试下载
yt-dlp --simulate https://www.youtube.com/watch?v=MXdFMjm3vTs --cookies-from-browser edge --proxy socks5://127.0.0.1:7890
下载付费课程
前提你可以正常播放该视频
yt-dlp https://www.youtube.com/watch?v=MXdFMjm3vTs --cookies-from-browser chrome --proxy socks5://127.0.0.1:7890
追加播放列表序号

yt-dlp --verbose -o "%(playlist)s/%(playlist_index)s - %(title)s.%(ext)s" "https://www.youtube.com/playlist?list=PLliocbKHJNwvBSh4DeBDHgq_8xINNzrt4" --cookies-from-browser chrome --proxy socks5://127.0.0.1:7890 --extractor-args youtubetab:skip=authcheck
]]>准备
- 公网服务器,假设 系统 Linux Ubuntu, 公网IP 140.140.192.192, 绑定了域名 www.good.com
- 本机 Mac 系统,跑着一个Angular程序,在本地访问,地址是 localhost:4200
效果
利用frp,可以实现任何人都可以通过配置的端口如 www.good.com:7001 访问我本机的Angular程序
方法
- 服务器和内网本机分别下载对应系统平台的frp, 这里ubuntu服务器需要下载linux_arm_64, mac本机是darwin_amd64。
- 先配服务端,在服务器上下载解压,编辑 frps.ini, 然后启动
./frps -c ./frps.ini后台启动命令nohup ./frps -c ./frps.ini &
[common]
bind_port = 7000
# 客户端定义的端口
vhost_http_port = 7001- 配置客户端,同样下载解压
wget https://github.com/fatedier/frp/releases/download/v0.23.1/frp_0.23.1_darwin_amd64.tar.gz
tar -zxvf frp_0.23.1_darwin_amd64.tar.gz编辑 frpc.ini
[common]
server_addr = 140.140.192.192 #公网服务器ip
server_port = 7001 #与服务端bind_port一致
#公网访问内部web服务器以http方式
[web]
type = http #访问协议
local_port = 4200 #内网web服务的端口号
custom_domains = www.good.com #所绑定的公网服务器域名,一级、二级域名都可以- 浏览器打开 www.good.com:4300 测试
进阶
修改服务端的 frps.ini, 添加 dashboard 信息,重启启动后可以通过140.140.192.192:7500打开控制面板
[common]
bind_port = 7000
# 客户端定义的端口
vhost_http_port = 7001
dashboard_port = 7500
# dashboard 用户名密码,默认都为 admin
dashboard_user = admin
dashboard_pwd = admin
注意事项
报 Invalid Host header
如果本机的web项目用了webpack server(目前vue cli, react cli, angular 本地开发用的都是这个)
这个是webpack server的安全策略,如果是angular项目,需要在启动配置中加上 --disable-host-check 类似 ng serve --open --host $IP --port $PORT --disable-host-check
参考
]]>- 自己做的网站系统需要一个公网地址,方便给客户演示,传统做法是买个有公网地址的服务器,可是手头上又没有服务器。即便有服务器还要搭建环境,同步代码啥的,非常不方便。关键只是演示,没必要大动干戈。
- 微信开发或聊天机器人开发等需要填写域名,比如微信窗口里打开IP地址会有警告提示,测试起来很麻烦。手头没有域名或者没有必要。
这时可以使用ngrok工具。他可以分配给你一个公网的二级域名,来绑定你本地的正在跑的http服务。
比如我本地跑了一个vue cli搭建的程序,跑起来后默认是 http://localhost:8080 。
当我安装 ngnok 后,执行 ./ngrok http 8080 (Windows系统下可能是ngrok.exe)

如图:工具随机分配给我了http和https两个地址,这个时候无论是手机还是电脑,还是其他地方的小伙伴访问 http://100a13a1.ngrok.io 就可以看到我本机上的 localhost:8080 打开web interface对应的地址,可以看到请求和响应内容,方便调试。
具体地址: https://ngrok.com/
注意:
- 对于免费用户,每次启动ngrok分配到的公网地址是会变的。 可以用国内的类似的服务,他提供了固定而且免费的地址。不过访问速度有点慢。毕竟是免费的。 https://ngrok.cc/
- 当页面显示Invalid Host header,因为vue cli使用的是webpack server,基于安全对访问做了限制。在 build/webpack.dev.conf.js 内
//追加配置
devServer: {
host: '0.0.0.0',
disableHostCheck: true
}我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=v7er73kcqd35
]]>默认主题
| 左对齐 | 右对齐 | 居中对齐 |
|---|---|---|
| 单元格 | 单元格 | 单元格 |
| 单元格 | 单元格 | 单元格 |
🎉 💯
TIP
This is a tip
WARNING
This is a warning
DANGER
This is a dangerous warning
STOP
Danger zone, do not proceed
点击查看代码
console.log('你好,VuePress!')Emoji
🎉 💯
代码高亮
export default {
name: 'MyComponent',
// ...
}<ul>
<li
v-for="todo in todos"
:key="todo.id"
>
{{ todo.text }}
</li>
</ul>代码 - 行高亮
export default {
data () {
return {
msg: 'Highlighted!'
}
}
}放入codepen,直接复制iframe即可
]]>说到后台技术栈,脑海中是不是浮现的是这样一幅图?

有点眼晕,以上只是我们会用到的一些语言的合集,而且只是语言层面的一部分,就整个后台技术栈来说,这只是一个开始,从语言开始,还有很多很多的内容。今天要说的后台是大后台的概念,放在服务器上的东西都属于后台的东西,比如使用的框架,语言,数据库,服务,操作系统等等,整个后台技术栈我的理解包括4个层面的内容:
- 语言: 用了哪些开发语言,如:c++/java/go/php/python/ruby等等;
- 组件:用了哪些组件,如:MQ组件,数据库组件等等;
- 流程:怎样的流程和规范,如:开发流程,项目流程,发布流程,监控告警流程,代码规范等等;
- 系统:系统化建设,上面的流程需要有系统来保证,如:规范发布流程的发布系统,代码管理系统等等; 结合以上的的4个层面的内容,整个后台技术栈的结构如图2所示:

以上的这些内容都需要我们从零开始搭建,在创业公司,没有大公司那些完善的基础设施,需要我们从开源界,从云服务商甚至有些需要自己去组合,去拼装,去开发一个适合自己的组件或系统以达成我们的目标。咱们一个个系统和组件的做选型,最终形成我们的后台技术栈。
一、各系统组件选型
1、项目管理/Bug管理/问题管理
项目管理软件是整个业务的需求,问题,流程等等的集中地,大家的跨部门沟通协同大多依赖于项目管理工具。有一些 SAAS 的项目管理服务可以使用,但是很多时间不满足需求,此时我们可以选择一些开源的项目,这些项目本身有一定的定制能力,有丰富的插件可以使用,一般的创业公司需求基本上都能得到满足,常用的项目如下:
-
Redmine: 用 Ruby 开发的,有较多的插件可以使用,能自定义字段,集成了项目管理,BUG 问题跟踪,WIKI 等功能,不过好多插件 N 年没有更新了;
-
Phabricator: 用 PHP 开发的,facebook 之前的内部工具,开发这工具的哥们离职后自己搞了一个公司专门做这个软件,集成了代码托管, Code Review,任务管理,文档管理,问题跟踪等功能,强烈推荐较敏捷的团队使用;
-
Jira:用 Java 开发的,有用户故事,task 拆分,燃尽图等等,可以做项目管理,也可以应用于跨部门沟通场景,较强大;
-
悟空CRM :这个不是项目管理,这个是客户管理,之所以在这里提出来,是因为在 To B 的创业公司里面,往往是以客户为核心来做事情的,可以将项目管理和问题跟进的在悟空 CRM 上面来做,他的开源版本已经基本实现了 CR< 的核心 功能,还带有一个任务管理功能,用于问题跟进,不过用这个的话,还是需要另一个项目管理的软件协助,顺便说一嘴,这个系统的代码写得很难维护,只能适用于客户规模小(1万以内)时。
个人补充: 现在Jira分Cloud云端版和安装版,前者就是在线版,Jira会为你提供一个二级域名,省去了买服务器,维护数据库等运维成本,不过要每月付费,这也是以后的趋势。即服务及软件。 安装版就是在自己服务器上安装Jira JAVA程序包,网上有7.x破解版本的。已经够用,不过服务器配置低的话会比较卡。 另外 Jira 的社区也比较强大,支持插件扩展,有些很强大比如 Zephyr for Jira - Test Management 测试用例管理,tempo-timesheets 统计工作量,报表,财务,插件也是要每月付费的。 Jira 提供的定制化功能超强,比如 issue type, work flow, fields 都可以自己配,个人感觉安装版基本够用。
2、DNS
DNS 是一个很通用的服务,创业公司基本上选择一个合适的云厂商就行了,国内主要是两家:
-
阿里万网:阿里 2014 年收购了万网,整合了其域名服务,最终形成了现在的阿里万网,其中就包含 DNS 这块的服务;
-
腾讯 DNSPod: 腾讯 2012 年以 4000 万收购 DNSPod 100% 股份,主要提供域名解析和一些防护功能; 如果你的业务是在国内,主要就是这两家,选 一个就好,像今日头条这样的企业用的也是 DNSPod 的服务,除非一些特殊的原因才需要自建,比如一些 CDN 厂商,或者对区域有特殊限制的。要实惠一点用阿里最便宜的基础版就好了,要成功率高一些,还是用DNSPod 的贵的那种。
在国外还是选择亚马逊吧,阿里的 DNS 服务只有在日本和美国有节点,东南亚最近才开始部点, DNSPod 也只有美国和日本,像一些出海的企业,其选择的云服务基本都是亚马逊。
如果是线上产品,DNS 强烈建议用付费版,阿里的那几十块钱的付费版基本可以满足需求。如果还需要一些按省份或按区域调试的逻辑,则需要加钱,一年也就几百块,省钱省力。
如果是国外,优先选择亚马逊,如果需要国内外互通并且有自己的 APP 的话,建议还是自己实现一些容灾逻辑或者智能调度,因为没有一个现成的 DNS 服务能同时较好的满足国内外场景,或者用多个域名,不同的域名走不同的 DNS 。
3、LB(负载均衡)
LB(负载均衡)是一个通用服务,一般云厂商的 LB 服务基本都会如下功能:
- 支持四层协议请求(包括 TCP、UDP 协议);
- 支持七层协议请求(包括 HTTP、HTTPS 协议);
- 集中化的证书管理系统支持 HTTPS 协议;
- 健康检查;
如果你线上的服务机器都是用的云服务,并且是在同一个云服务商的话,可以直接使用云服务商提供的 LB 服务,如阿里云的 SLB,腾讯云的 CLB, 亚马逊 的 ELB 等等。如果是自建机房基本都是 LVS + Nginx。
4、CDN
CDN 现在已经是一个很红很红的市场,基本上只能挣一些辛苦钱,都是贴着成本在卖。国内以网宿为龙头,他们家占据整个国内市场份额的40%以上,后面就是腾讯,阿里。网宿有很大一部分是因为直播的兴起而崛起。
国外,Amazon 和 Akamai 合起来占比大概在 50%,曾经的国际市场老大 Akamai 拥有全球超一半的份额,在 Amazon CDN入局后,份额跌去了将近 20%,众多中小企业都转向后者,Akamai 也是无能为力。
国内出海的 CDN 厂商,更多的是为国内的出海企业服务,三家大一点的 CDN 服务商里面也就网宿的节点多一些,但是也多不了多少。阿里和腾讯还处于前期阶段,仅少部分国家有节点。
就创业公司来说,CDN 用腾讯云或阿里云即可,其相关系统较完善,能轻松接入,网宿在系统支持层面相对较弱一些,而且还贵一些。并且,当流量上来后,CDN 不能只用一家,需要用多家,不同的 CDN 在全国的节点覆盖不一样,而且针对不同的客户云厂商内部有些区分客户集群,并不是全节点覆盖(但有些云厂商说自己是全网节点),除了节点覆盖的问题,多 CDN 也在一定程度上起到容灾的作用。
5、RPC框架
维基百科对 RPC 的定义是:远程过程调用(Remote Procedure Call,RPC)是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。
通俗来讲,一个完整的RPC调用过程,就是 Server 端实现了一个函数,客户端使用 RPC 框架提供的接口,调用这个函数的实现,并获取返回值的过程。
业界 RPC 框架大致分为两大流派,一种侧重跨语言调用,另一种是偏重服务治理。
跨语言调用型的 RPC 框架有 Thrift、gRPC、Hessian、Hprose 等。这类 RPC 框架侧重于服务的跨语言调用,能够支持大部分的语言进行语言无关的调用,非常适合多语言调用场景。但这类框架没有服务发现相关机制,实际使用时需要代理层进行请求转发和负载均衡策略控制。
其中,gRPC 是 Google 开发的高性能、通用的开源 RPC 框架,其由 Google 主要面向移动应用开发并基于 HTTP/2 协议标准而设计,基于 ProtoBuf(Protocol Buffers) 序列化协议开发,且支持众多开发语言。本身它不是分布式的,所以要实现框架的功能需要进一步的开发。
Hprose(High Performance Remote Object Service Engine) 是一个 MIT 开源许可的新型轻量级跨语言跨平台的面向对象的高性能远程动态通讯中间件。
服务治理型的 RPC 框架的特点是功能丰富,提供高性能的远程调用、服务发现及服务治理能力,适用于大型服务的服务解耦及服务治理,对于特定语言(Java)的项目可以实现透明化接入。缺点是语言耦合度较高,跨语言支持难度较大。国内常见的冶理型 RPC 框架如下:
- Dubbo: Dubbo 是阿里巴巴公司开源的一个 Java 高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring 框架无缝集成。当年在淘宝内部,Dubbo 由于跟淘宝另一个类似的框架 HSF 有竞争关系,导致 Dubbo 团队解散,最近又活过来了,有专职同学投入。
- DubboX: DubboX 是由当当在基于 Dubbo 框架扩展的一个 RPC 框架,支持 REST 风格的远程调用、Kryo/FST 序列化,增加了一些新的feature。
- Motan: Motan 是新浪微博开源的一个 Java 框架。它诞生的比较晚,起于 2013 年,2016 年 5 月开源。Motan 在微博平台中已经广泛应用,每天为数百个服务完成近千亿次的调用。
- rpcx: rpcx 是一个类似阿里巴巴 Dubbo和微博Motan的分布式的 RPC 服务框架,基于 Golang net/rpc 实现。但是 rpcx 基本只有一个人在维护,没有完善的社区,使用前要慎重,之前做 Golang 的 RPC 选型时也有考虑这个,最终还是放弃了,选择了 gRPC,如果想自己自研一个 RPC 框架,可以参考学习一下。
6、名字发现/服务发现
名字发现和服务发现分为两种模式,一个是客户端发现模式,一种是服务端发现模式。
框架中常用的服务发现是客户端发现模式。
所谓服务端发现模式是指客户端通过一个负载均衡器向服务发送请求,负载均衡器查询服务注册表并把请求路由到一台可用的服务实例上。现在常用的负载均衡器都是此类模式,常用于微服务中。
所有的名字发现和服务发现都要依赖于一个可用性非常高的服务注册表,业界常用的服务注册表有如下三个:
- etcd,一个高可用、分布式、一致性、key-value方式的存储,被用在分享配置和服务发现中。两个著名的项目使用了它:k8s和Cloud Foundry。
- consul,一个发现和配置服务的工具,为客户端注册和发现服务提供了API,Consul还可以通过执行健康检查决定服务的可用性。
- Apache Zookeeper,是一个广泛使用、高性能的针对分布式应用的协调服务。Apache Zookeeper本来是 Hadoop 的子工程,现在已经是顶级工程了。 除此之外也可以自己实现服务实现,或者用 Redis 也行,只是需要自己实现高可用性。
7、关系数据库
关系数据库分为两种,一种是传统关系数据,如 Oracle, MySQL,Maria, DB2,PostgreSQL 等等,另一种是 NewSQL,即至少要满足以下五点的新型关系数据库:
-
完整地支持SQL,支持JOIN / GROUP BY /子查询等复杂SQL查询;
-
支持传统数据标配的 ACID 事务,支持强隔离级别。
-
具有弹性伸缩的能力,扩容缩容对于业务层完全透明。
-
真正的高可用,异地多活、故障恢复的过程不需要人为的接入,系统能够自动地容灾和进行强一致的数据恢复。
-
具备一定的大数据分析能力
传统关系数据库用得最多的是 MySQL,成熟,稳定,一些基本的需求都能满足,在一定数据量级之前基本单机传统数据库都可以搞定,而且现在较多的开源系统都是基于 MySQL,开箱即用,再加上主从同步和前端缓存,百万 pv 的应用都可以搞定了。不过 CentOS 7 已经放弃了 MySQL,而改使用 MariaDB。MariaDB 数据库管理系统是 MySQ L的一个分支,主要由开源社区在维护,采用GPL 授权许可。开发这个分支的原因之一是:甲骨文公司收购了 MySQL 后,有将 MySQ L闭源的潜在风险,因此社区采用分支的方式来避开这个风险。
在 Google 发布了F1: A Distributed SQL Database That Scales和Spanner: Google’s Globally-Distributed Databasa之后,业界开始流行起 NewSQL。于是有了 CockroachDB,于是有了 奇叔公司的 TiDB。国内已经有比较多的公司使用 TiDB,之前在创业公司时在大数据分析时已经开始应用 TiDB,当时应用的主要原因是 MySQL 要使用分库分表,逻辑开发比较复杂,扩展性不够。
8、NoSQL
NoSQL 顾名思义就是 Not-Only SQL,也有人说是 No – SQL, 个人偏向于Not – Only SQL,它并不是用来替代关系库,而是作为关系型数据库的补充而存在。
常见 NoSQL 有4个类型:
-
键值,适用于内容缓存,适合混合工作负载并发高扩展要求大的数据集,其优点是简单,查询速度快,缺点是缺少结构化数据,常见的有 Redis, Memcache, BerkeleyDB 和 Voldemort 等等;
-
列式,以列簇式存储,将同一列数据存在一起,常见于分布式的文件系统,其中以 Hbase,Cassandra 为代表。Cassandra 多用于写多读少的场景,国内用得比较多的有 360,大概 1500 台机器的集群,国外大规模使用的公司比较多,如 Ebay,Instagram,Apple 和沃尔玛等等;
-
文档,数据存储方案非常适用承载大量不相关且结构差别很大的复杂信息。性能介于 kv 和关系数据库之间,它的灵感来于 lotus notes,常见的有 MongoDB,CouchDB 等等;
-
图形,图形数据库擅长处理任何涉及关系的状况。社交网络,推荐系统等。专注于构建关系图谱,需要对整个图做计算才能得出结果,不容易做分布式的集群方案,常见的有 Neo4J,InfoGrid 等。
除了以上4种类型,还有一些特种的数据库,如对象数据库,XML 数据库,这些都有针对性对某些存储类型做了优化的数据库。
在实际应用场景中,何时使用关系数据库,何时使用 NoSQL,使用哪种类型的数据库,这是我们在做架构选型时一个非常重要的考量,甚至会影响整个架构的方案。
个人补充: NOSQL更适合哪种需要快速迭代,快速发布产品抢占市场的创业公司使用,比如MongoDB,你完全不用太关心字段类型,字段长度,索引,是否为空等。想存什么存什么。
9、消息中间件
消息中间件在后台系统中是必不可少的一个组件,一般我们会在以下场景中使用消息中间件:
-
异步处理:异步处理是使用消息中间件的一个主要原因,在工作中最常见的异步场景有用户注册成功后需要发送注册成功邮件、缓存过期时先返回老的数据,然后异步更新缓存、异步写日志等等;通过异步处理,可以减少主流程的等待响应时间,让非主流程或者非重要业务通过消息中间件做集中的异步处理。
-
系统解耦:比如在电商系统中,当用户成功支付完成订单后,需要将支付结果给通知ERP系统、发票系统、WMS、推荐系统、搜索系统、风控系统等进行业务处理;这些业务处理不需要实时处理、不需要强一致,只需要最终一致性即可,因此可以通过消息中间件进行系统解耦。通过这种系统解耦还可以应对未来不明确的系统需求。
-
削峰填谷:当系统遇到大流量时,监控图上会看到一个一个的山峰样的流量图,通过使用消息中间件将大流量的请求放入队列,通过消费者程序将队列中的处理请求慢慢消化,达到消峰填谷的效果。最典型的场景是秒杀系统,在电商的秒杀系统中下单服务往往会是系统的瓶颈,因为下单需要对库存等做数据库操作,需要保证强一致性,此时使用消息中间件进行下单排队和流控,让下单服务慢慢把队列中的单处理完,保护下单服务,以达到削峰填谷的作用。
业界消息中间件是一个非常通用的东西,大家在做选型时有使用开源的,也有自己造轮子的,甚至有直接用 MySQL 或 Redis 做队列的,关键看是否满足你的需求,如果是使用开源的项目,以下的表格在选型时可以参考:

以上图的纬度为:名字 成熟度所属社区/公司 文档 授权方式 开发语言支持的协议 客户端支持的语言 性能 持久化 事务 集群 负载均衡 管理界面 部署方式 评价
10 、代码管理
代码是互联网创业公司的命脉之一,代码管理很重要,常见的考量点包括两块:
- 安全和权限管理,将代码放到内网并且对于关系公司命脉的核心代码做严格的代码控制和机器的物理隔离;
- 代码管理工具,Git 作为代码管理的不二之选,你值得拥有。Gitlab 是当今最火的开源 Git 托管服务端,没有之一,虽然有企业版,但是其社区版基本能满足我们大部分需求,结合 Gerrit 做 Code review,基本就完美了。当然 Gitlab 也有代码对比,但没Gerrit 直观。Gerrit 比 Gitlab 提供了更好的代码检查界面与主线管理体验,更适合在对代码质量有高要求的文化下使用。
11 、持续集成
持续集成简,称 CI(continuous integration), 是一种软件开发实践,即团队开发成员经常集成他们的工作,每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽早地发现集成错误。持续集成为研发流程提供了代码分支管理/比对、编译、检查、发布物输出等基础工作,为测试的覆盖率版本编译、生成等提供统一支持。
业界免费的持续集成工具中系统我们有如下一些选择:
-
Jenkins:Jjava写的 有强大的插件机制,MIT协议开源 (免费,定制化程度高,它可以在多台机器上进行分布式地构建和负载测试)。Jenkins可以算是无所不能,基本没有 Jenkins 做不了的,无论从小型团队到大型团队 Jenkins 都可以搞定。 不过如果要大规模使用,还是需要有人力来学习和维护。
-
TeamCity: TeamCity与Jenkins相比使用更加友好,也是一个高度可定制化的平台。但是用的人多了,TeamCity就要收费了。
-
Strider: Strider 是一个开源的持续集成和部署平台,使用 Node.js 实现,存储使用的是 MongoDB,BSD 许可证,概念上类似 Travis 和Jenkins。
-
GitLabCI:从GitLab8.0开始,GitLab CI 就已经集成在 GitLab,我们只要在项目中添加一个 .gitlab-ci.yml 文件,然后添加一个Runner,即可进行持续集成。并且 Gitlab 与 Docker 有着非常好的相互协作的能力。免费版与付费版本不同可以参见这里:https://about.gitlab.com/products/feature-comparison/
-
Travis:Travis 和 Github 强关联;闭源代码使用 SaaS 还需考虑安全问题; 不可定制;开源项目免费,其它收费;
-
Go: Go是ThoughtWorks公司最新的Cruise Control的化身。除了 ThoughtWorks 提供的商业支持,Go是免费的。它适用于Windows,Mac和各种Linux发行版。
12 、日志系统
日志系统一般包括打日志,采集,中转,收集,存储,分析,呈现,搜索还有分发等。一些特殊的如染色,全链条跟踪或者监控都可能需要依赖于日志系统实现。日志系统的建设不仅仅是工具的建设,还有规范和组件的建设,最好一些基本的日志在框架和组件层面加就行了,比如全链接跟踪之类的。
对于常规日志系统ELK能满足大部分的需求,ELK 包括如下组件:
-
ElasticSearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
-
Logstash 是一个完全开源的工具,它可以对你的日志进行收集、分析,并将其存储供以后使用。
-
Kibana 是一个开源和免费的工具,它可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
-
Filebeat 已经完全替代了 Logstash-Forwarder 成为新一代的日志采集器,同时鉴于它轻量、安全等特点,越来越多人开始使用它。
因为免费的 ELK 没有任何安全机制,所以这里使用了 Nginx 作反向代理,避免用户直接访问 Kibana 服务器。加上配置 Nginx 实现简单的用户认证,一定程度上提高安全性。另外,Nginx 本身具有负载均衡的作用,能够提高系统访问性能。ELK 架构如图4所示:

对于有实时计算的需求,可以使用 Flume+Kafka+Storm+MySQL方案,一 般架构如图5所示:

其中:
- Flume 是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
- Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,由 Scala 和 Java 编写。其本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,它以可水平扩展和高吞吐率而被广泛使用。 Kafka 追求的是高吞吐量、高负载,Flume 追求的是数据的多样性,二者结合起来简直完美。
13、监控系统
监控系统只包含与后台相关的,这里主要是两块,一个是操作系统层的监控,比如机器负载,IO,网络流量,CPU,内存等操作系统指标的监控。另一个是服务质量和业务质量的监控,比如服务的可用性,成功率,失败率,容量,QPS 等等。常见业务的监控系统先有操作系统层面的监控(这部分较成熟),然后扩展出其它监控,如 zabbix,小米的 open-falcon,也有一出来就是两者都支持的,如 prometheus。如果对业务监控要求比较高一些,在创业选型中建议可以优先考虑 prometheus。这里有一个有趣的分布,如图6所示

亚洲区域使用 zabbix 较多,而美洲和欧洲,以及澳大利亚使用 prometheus 居多,换句话说,英文国家地区(发达国家?)使用prometheus 较多。
Prometheus 是由 SoundCloud 开发的开源监控报警系统和时序列数据库( TSDB )。Prometheus 使用 Go 语言开发,是 Google BorgMon 监控系统的开源版本。相对于其它监控系统使用的 push 数据的方式,prometheus 使用的是 pull 的方式,其架构如图7所示:

如上图所示,prometheus 包含的主要组件如下:
Prometheus Server 主要负责数据采集和存储,提供 PromQL 查询语言的支持。Server 通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。根据这些目标会,Server 定时去抓取 metric s数据,每个抓取目标需要暴露一个 http 服务的接口给它定时抓取。
客户端SDK:官方提供的客户端类库有 go、java、scala、python、ruby,其他还有很多第三方开发的类库,支持 nodejs、php、erlang 等。
-
Push Gateway 支持临时性 Job 主动推送指标的中间网关。
-
Exporter Exporter 是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为 Prometheus 支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。Prometheus提供多种类型的 Exporter 用于采集各种不同服务的运行状态。目前支持的有数据库、硬件、消息中间件、存储系统、HTTP服务器、JMX等。
-
alertmanager:是一个单独的服务,可以支持 Prometheus 的查询语句,提供十分灵活的报警方式。
-
Prometheus HTTP API的查询方式,自定义所需要的输出。
-
Grafana 是一套开源的分析监视平台,支持 Graphite, InfluxDB, OpenTSDB, Prometheus, Elasticsearch, CloudWatch 等数据源,其 UI 非常漂亮且高度定制化。
创业公司选择 Prometheus + Grafana 的方案,再加上统一的服务框架(如 gRPC ),可以满足大部分中小团队的监控需求。
14、配置系统
随着程序功能的日益复杂,程序的配置日益增多:各种功能的开关、降级开关,灰度开关,参数的配置、服务器的地址、数据库配置等等,除此之外,对后台程序配置的要求也越来越高:配置修改后实时生效,灰度发布,分环境、分用户,分集群管理配置,完善的权限、审核机制等等,在这样的大环境下,传统的通过配置文件、数据库等方式已经越来越无法满足开发人员对配置管理的需求,业界有如下两种方案:
-
基于 zk 和 etcd,支持界面和 api ,用数据库来保存版本历史,预案,走审核流程,最后下发到 zk 或 etcd 这种有推送能力的存储里(服务注册本身也是用 zk 或 etcd,选型就一块了)。客户端都直接和 zk 或 etcd 打交道。至于灰度发布,各家不同,有一种实现是同时发布一个需要灰度的 IP 列表,客户端监听到配置节点变化时,对比一下自己是否属于该列表。PHP 这种无状态的语言和其他 zk/etcd 不支持的语言,只好自己在客户端的机器上起一个 Agent 来监听变化,再写到配置文件或共享内存,如 360 的 Qconf。
-
基于运维自动化的配置文件的推送,审核流程,配置数据管理和方案一类似,下发时生成配置文件,基于运维自动化工具如Puppet,Ansible 推送到每个客户端,而应用则定时重新读取这个外部的配置文件,灰度发布在下发配置时指定IP列表。
创业公司前期不需要这种复杂,直接上 zk,弄一个界面管理 zk 的内容,记录一下所有人的操作日志,程序直连 zk,或者或者用Qconf 等基于 zk 优化后的方案。
15、发布系统/部署系统

从上图中可以看出,从开发人员写下代码到服务最终用户是一个漫长过程,整体可以分成三个阶段:
从代码(Code)到成品库(Artifact)这个阶段主要对开发人员的代码做持续构建并把构建产生的制品集中管理,是为部署系统准备输入内容的阶段。 从制品到可运行服务 这个阶段主要完成制品部署到指定环境,是部署系统的最基本工作内容。 从开发环境到最终生产环境 这个阶段主要完成一次变更在不同环境的迁移,是部署系统上线最终服务的核心能力。 发布系统集成了制品管理,发布流程,权限控制,线上环境版本变更,灰度发布,线上服务回滚等几方面的内容,是开发人员工作结晶最终呈现的重要通道。开源的项目中没有完全满足的项目,如果只是 Web 类项目,Walle、Piplin 都是可用的,但是功能不太满足,创业初期可以集成 Jenkins + Gitlab + Walle (可以考虑两天时间完善一下),以上方案基本包括 制品管理,发布流程,权限控制,线上环境版本变更,灰度发布(需要自己实现),线上服务回滚等功能。
16、跳板机
跳板机面对的是需求是要有一种能满足角色管理与授权审批、信息资源访问控制、操作记录和审计、系统变更和维护控制要求,并生成一些统计报表配合管理规范来不断提升IT内控的合规性,能对运维人员操作行为的进行控制和审计,对误操作、违规操作导致的操作事故,快速定位原因和责任人。其功能模块一般包括:帐户管理、认证管理、授权管理、审计管理等等
开源项目中,Jumpserver 能够实现跳板机常见需求,如授权、用户管理、服务器基本信息记录等,同时又可批量执行脚本等功能;其中录像回放、命令搜索、实时监控等特点,又能帮助运维人员回溯操作历史,方便查找操作痕迹,便于管理其他人员对服务器的操作控制。
17、机器管理
机器管理的工具选择的考量可以包含以下三个方面:
是否简单,是否需要每台机器部署agent(客户端)
语言的选择(puppet/chef vsansible/saltstack)开源技术,不看官网不足以熟练,不懂源码不足以精通;Puppet、Chef 基于 Ruby 开发,ansible、saltstack 基于 python 开发的
速度的选择(ansiblevssaltstack) ansible基于SSH协议传输数据,Saltstack使用消息队列zeroMQ传输数据;大规模并发的能力对于几十台-200台规模的兄弟来讲,ansible的性能也可接受,如果一次操作上千台,用salt好一些。

一般创业公司选择 Ansible 能解决大部问题,其简单,不需要安装额外的客户端,可以从命令行来运行,不需要使用配置文件。至于比较复杂的任务,Ansible 配置通过名为 Playbook 的配置文件中的 YAML 语法来加以处理。Playbook 还可以使用模板来扩展其功能。
二、创业公司的选择
1、选择合适的语言
选择团队熟悉的/能掌控的,创业公司人少事多,无太多冗余让研发团队熟悉新的语言,能快速上手,能快速出活,出了问题能快速解决的问题的语言才是好的选择。 选择更现代一些的,这里的现代是指语言本身已经完成一些之前需要特殊处理的特性,比如内存管理,线程等等。 选择开源轮子多的或者社区活跃度高的,这个原则是为了保证在开发过程中减少投入,有稳定可靠的轮子可以使用,遇到问题可以在网上快速搜索到答案。 选择好招人的 一门合适的语言会让创业团队减少招聘的成本,快速招到合适的人。 选择能让人有兴趣的 与上面一点相关,让人感兴趣,在后面留人时有用。
2、选择合适的组件和云服务商
- 选择靠谱的云服务商;
- 选择云服务商的组件;
- 选择成熟的开源组件,而不是最新出的组件;
- 选择采用在一线互联网公司落地并且开源的,且在社区内形成良好口碑的产品; 开源社区活跃度;
- 选择靠谱的云服务商,其实这是一个伪命题,因为哪个服务商都不靠谱,他们所承诺的那些可用性问题基本上都会在你的身上发生,这里我们还是需要自己做一些工作,比如多服务商备份,如用CDN,你一定不要只选一家,至少选两家,一个是灾备,保持后台切换的能力,另一个是多点覆盖,不同的服务商在CDN节点上的资源是不一样的。
选择了云服务商以后,就会有很多的产品你可以选择了,比较存储,队列这些都会有现成的产品,这个时候就纠结了,是用呢?还是自己在云主机上搭呢?在这里我的建议是前期先用云服务商的,大了后再自己搞,这样会少掉很多运维的事情,但是这里要多了解一下云服务商的组件特性以及一些坑,比如他们内网会经常断开,他们升级也会闪断,所以在业务侧要做好容错和规避。
关于开源组件,尽可能选择成熟的,成熟的组件经历了时间的考验,基本不会出大的问题,并且有成套的配套工具,出了问题在网上也可以很快的找到答案,你所遇到的坑基本上都有人踩过了。
3、制定流程和规范
- 制定开发的规范,代码及代码分支管理规范,关键性代码仅少数人有权限;
- 制定发布流程规范,从发布系统落地;
- 制定运维规范;
- 制定数据库操作规范,收拢数据库操作权限;
- 制定告警处理流程,做到告警有人看有人处理;
- 制定汇报机制,晨会/周报;
4、自研和选型合适的辅助系统
所有的流程和规范都需要用系统来固化,否则就是空中楼阁,如何选择这些系统呢?参照上个章节咱们那些开源的,对比一下选择的语言,组件之类的,选择一个最合适的即可。
比如项目管理的,看下自己是什么类型的公司,开发的节奏是怎样的,瀑布,敏捷的 按项目划分,还是按客户划分等等,平时是按项目组织还是按任务组织等等
比如日志系统,之前是打的文本,那么上一个 ELK,规范化一些日志组件,基本上很长一段时间内不用考虑日志系统的问题,最多拆分一下或者扩容一下。等到组织大了,自己搞一个日志系统。
比如代码管理,项目管理系统这些都放内网,安全,在互联网公司来说,属于命脉了,命脉的东西还是放在别人拿不到或很难拿到的地方会比较靠谱一些。
5、选择过程中需要思考的问题
技术栈的选择有点像做出了某种承诺,在一定的时间内这种承诺没法改变,于是我们需要在选择的时候有一些思考。
看前面内容,有一个词出现了三次,合适,选择是合适的,不是最好,也不是最新,是最合适,适合是针对当下,这种选择是最合适的吗?比如用 Go 这条线的东西,技术比较新,业界组件储备够吗?组织内的人员储备够吗?学习成本多少?写出来的东西能满足业务性能要求吗?能满足时间要求吗?
向未来看一眼,在一年到三年内,我们需要做出改变吗?技术栈要做根本性的改变吗?如果组织发展很快,在 200 人,500 人时,现有的技术栈是否需要大动?
创业过程中需要考虑成本,这里的成本不仅仅是花费多少钱,付出多少工资,有时更重要的是时间成本,很多业务在创业时大家拼的就是时间,就是一个时间窗,过了就没你什么事儿了。
三、基于云的创业公司后台技术架构
结合上面内容的考量,在对一个个系统和组件的做选型之后,以云服务为基础,一个创业公司的后台技术架构如图10所示:

参考资料
http://database.51cto.com/art/201109/291781.htm https://zh.wikipedia.org/wiki/Kafka https://prometheus.io/docs/introduction/overview/ http://deadline.top/2016/11/23/配置中心那点事/ http://blog.fit2cloud.com/2016/01/26/deployment-system.html
]]>小鹅通 专注内容付费的技术服务商。 netlify 快速的根据你的静态文件生成一个带https和域名的网站。教程见这篇 dzone 可以学到一些DevOps相关的教程和工具的国外网站 宜搭 阿里出的快速搭建应用平台。
- 一个提供pojie软件的国外网站推荐下载IDM,下东西比迅雷快
- 落尘之木作者维护着去广告版的迅雷
- 吾爱破解比较著名的站点了,不定期开放注册,有时能找到不错的资料或视频教程。
- PHP / Laravel 月刊
- https://smee.io/提供代理webhook请求并发送到本地,一般调试程序会用到
- SaaS微服务十二要素应用宣言 参考:https://www.jianshu.com/p/bbdccd020a1d
分享一个Skype彩蛋:在发过言的聊天窗口快速点击7次以上会出现一个会跳舞的猴子。具体哪个版本加上的未知。
想流畅观看youbute等国外网站的话。 有个比较好的做法是买个国外的vps,然后安装ssr。关于安装流程,非常简单有一键安装脚本。 可以去这买,搬瓦工。很便宜,只想做代理的话不用买配置很高的。 如果不想掏钱可以买 谷歌云 Google Cloud Platform。前提是有国际信用卡和google账号。 具体流程参见:isomeonegc,需要过墙才能打开。 全局富强软件: https://getoutline.org/en/home 教程: https://cyhour.com/697/ Dler Cloud 同事在用的科学上网 工具 https://getoutline.org/en/home 教程: https://free.com.tw/google-outline/
牛客网 收集各IT大厂的笔试面试题,没事做做上面的题全面提升IT编程能力
sourcegraph 装了chrome扩展之后,比如在github上分析源码的好伙伴。提供定义跳转,引用及搜索等功能。

bearychat 可以看成是国产简化版的slack吧

SSL/TLS安全评估报告 评估网站的ssl安全程度
]]>

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
</body>
</html>同理,当新建php文件,我希望是这样:
<?php
/**
* Created by PhpStorm
* Author Finley Ma <公司邮箱地址>
* Date: 2018/7/5
* Time: 下午11:56
*/其实 PHPStorm 已经预设了一些信息, Editor - File and Code Templates

关于 #parse("PHP File Header.php") 可以理解为一种语法指令
PHP File Header.php 在 Includes Tab 下面,一看就是方便复用的

比如,我在Files Tab下新建一个"JavaScript File", 内容照样填 #parse("PHP File Header.php")
这样,当新建一个JS文件的效果和PHP一样了。
-
有效的沟通是事业成功的必要条件。不管你的目标是成为一名卓越的管理者,还是成为某个领域的技术牛人,你都应该提高自己的沟通能力。
-
能把深奥,晦涩难懂的知识写得通俗易懂,只有真正的专家才可以做到。比如《从一到无穷大》有非常难以理解的爱因斯坦相对论,然而这本书却被作者写成了中学生都可以读懂的科普书。
-
这个世界上的学习只有两种,一种是被动学习,一种是主动学习。 听课,看书,看视频,看别人的演讲,这些统统都是被动学习,知识的留存度最多只有30%。而与别人讨论,实践和传授给别人,是主动学习,可以让你掌握知识的50%到90%以上。

- 这个世界不存在知识不够的情况,真的还没有到知识被少数精英的攥在手里面不给大家的情况,这个世界上的知识就像阳光和空气一样,根本不需要你付费,你就可以获得的。问题是,大多数人都失去了获取知识的能力,你就算把知识放在他们面前,他们也不会去学习,他们需要你喂,甚至需要你帮他们嚼碎了,帮他们消化过了,他们才能吃得到,消化得了。这才是最大的问题。 不好意思,我又说实话了,难听但是对你有用。
说的太对了,非常赞同
-
永远不要跟客户说不,要有条件地说是,告诉客户不同的期望要有不同的付出和不同的成本。不要帮客户做决定,而是给客户提供尽可能多的选项,让客户来做决定。
-
总结下来,在与客户沟通预期时,我通常会坚持以下几个原则。
* 一定要给客户选择权,永远不要说不,要有条件地说是。
* 降低期望的同时给予其他的补偿。
* 提高期望的同时附加更多的条件。
* 对于比较大的期望要分步骤达到客户的期望。
* 不要帮客户做决定,而是给客户提供尽可能多的选项,然后引导客户做决定。- 讨价还价是这个世界能运转的原因之一,要学会使用。
]]>这点我感触很深,我们目前的项目是每周一次迭代发布,有时候客户会添加进来一些临时任务,所以任务就很多,作为一名PM,每天和客户开会一定要跟客户确定任务的优先级,告诉他任务的预估工作量,最终本周的发布我们能做到什么程度,哪些任务能放到下周。
2018-08-27更新: 使用cookie前强烈建议先看下MDN的这篇基础文章 创建cookie可以配置的选项 Expires,Secure,HttpOnly,Domain,Path,SameSite。 为避免跨域脚本 (XSS) 攻击,通过JavaScript的 Document.cookie API无法访问带有 HttpOnly 标记的Cookie,它们只应该发送给服务端。
最近在开发一个前后台分离的项目。
前台是 localhost:8080,基于vue,请求用的axios库,后台是地址 localhost:8111,使用的是NodeJS。
也就是前台发起的请求是跨域的。
现在流程是这样的: 前台向后台请求接口,后台会看到set-cookie,可是我发现前端JS 怎么也拿不到 cookie(后来发现是cookie被设置了HttpOnly)。axios的response里没有。但是在chrome里可以看到设置的cookie。
查了文档,当需要跨域请求,前台需要设置 withCredentials 为 true。 这样每次请求会自动带上 cookie,但是后台也需要设置 Access-Control-Allow-Credentials: true, 就不能用*来设置Origin了,即 Access-Control-Allow-Origin:* , 而应该相应的改成Access-Control-Allow-Origin: localhost:8080,
这样就比较尴尬了,到时候前台是对大众开放,需要允许所有来源,难道没有别的办法了?相信标准这么做也是为了安全。
查了也有解决办法。都还没有尝试。
比如
- 可以在nginx中设置,对于过来的请求,让 nginx 自动加上请求头。下面的方法没试,不是嫌麻烦,是部署的工作不是自己的人来做。
if ($http_origin ~* ( https?://.*\.example\.com(:[0-9]+)?$)) {
add_header Access-Control-Allow-Origin: $http_origin;
}- 对于后端,比如express。每个请求都走一遍中间件, 取出 headers 里的域名, 写到 CORS 头部去:
app = express()
app.all('/*', (req, res, next) => {
if (req.headers.origin) {
res.header("Access-Control-Allow-Origin", req.headers.origin)
res.header("Access-Control-Allow-Credentials", true)
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS')
# 下面一行意义不明确...
res.header("Access-Control-Allow-Headers", "X-Requested-With, AUTHORIZATION")
}
next(); // pass control to the next handler
});
next()其实使用cookie做前后端分离真的没有 token 或 jwt 好用。机密的信息不要放到cookie中比较好。
==== 更新 使用下面的方法在本地可行
if (process.env.NODE_ENV == 'local') {
app.use(function(req, res, next) {
res.header("Access-Control-Allow-Credentials", true);
res.header("Access-Control-Allow-Origin", req.headers.origin);
res.header("Access-Control-Allow-Headers", "Origin, X-Requested-With, Content-Type, Accept");
next();
});
}else {
app.use(cors());
}
好吧,我不得不换成80端口。 然后我再刷新浏览器竟然显示 "File not found"。 下面是我的解决流程:
- 一般来说这是nginx配置文件中root的项目根目录路径不对所致,检查nginx配置文件无误,排除。
- 用
tail -n 20 /var/log/nginx/error查看错误日志,内容是FastCGI sent in stderr primary script unknown while reading response header from upstream - 查了一会网上说的,总结是俩原因: 一个是 nginx中的fastcgi_param段配置有误, 一个是文件权限问题。
- 先排除 fastcgi_param 问题,因为同样的配置在其他同样的操作系统运行时正常。唯一不同的是在其他主机默认是ubuntu用户,在这个上面是root用户。所以我觉得是文件权限问题。
- 先后给项目目录 加 www-data 用户组,给 /run/php/php-fpm.sock 提高权限。依然不行。
- 正一筹莫展之际,我发现项目的全路径是 /root/project 而并不是 /home/root/project。 而/root的权限是
drwx------当我执行完chmod 755 /root。 页面终于打开了,我只想说一句,Linux真难啊。
找到你想要的书名,然后去这搜 wowebook 。他提供了上面俩出版社的大部分书籍。比如我搜索下,正好有我感兴趣的。

但是提供的下载链接,是一个叫uploaded.net的网盘,在国内是被蔽了。 而且即便能打开也下载不了,除非是高级会员。这时候万能的某宝就派上用场了。
搜一下这个网盘名,有很多网盘中转站,1G 流量一块钱。还是比较划算的。
你只需要把类似 http://uploaded.net/file/ihghmpku 这种链接贴到中转站管理平台里。服务器就会下载。然后提供给你另一个速度还蛮不错的下载地址。
![YO6NH4{84N9OMMJ[QH]277Q.png](proxy.php?url=https://pek3b.qingstor.com/hexo-blog/upload_images/71414-8b92a798f0b7ba70.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
developers.google.com google开发者网站,了解google旗下产品最新开发动态。 尤其是Chome,Chrome作为市场份额最多也是最强的浏览器,他的版本更新非常频繁。 我的理念是:对于天天用到的工具,就要多去了解他。想尽办法提高效率。通过这个网站,我们可以第一时间了解google产品的最新动态,我主要学习Chome的新特性,怎么用到实际的开发中。
MDN Mozilla 开发者网络,学习web标准的好地方 Mozilla组织本身就参与标准的制定,权威性还是有的。
建议新人多逛上面的网站。
stackoverflow 我相信我们开发中遇到的90%的问题都能在上面找到答案,当然要善于搜索。
javascripting JS已经从web端延伸到移动端,甚至是桌面端。这个网站为你分门别类的列出了客户端用最流行的javascrpt类库,框架。
]]>说几个找老外聊天的途径,亲测有效
前提:有一定的英语基础和交流能力。
方法1:
在reddit的汉语板块找语言交换学习者
Reddit是一个社交新闻站点,类似百度贴吧,豆瓣小组,有很多各种板块,时事政治,游戏,文化等,汉语板块里面还有一群想学汉语的老外,可以找到各种各样的语言交换学习者。
比如我看到有个Bren开头的老外说自己通过了汉语等级考试,想进一步提高自己的汉语水平

然后我给他发了站内信,Reddit里叫DM,并且很快加到了他的微信

相同的方法我找到了3-4个聊友,我发现绝大多数是大学生,他们对中国文化比较感兴趣
比如这个brendan。是堪培拉一所大学的新生,护理专业,平时还在超市打零工,我们约定每周聊3-4次,互相教对方语言

这里我打错了,应该是 Do you allow pets in your university?
不过对方还是可以看懂的


方法2:
去专门的语言交换app上找聊友
这里推荐三款,Tandem, Italki和helloTalk
我建议尽量找母语是纯正英语国家的聊友


另外提醒app上也有骗子,说不定他会给你来句,我是乌克兰人,给我点钱吧
]]>技术是为业务服务的。不结合业务使用场景单纯进行框架,语言优劣对比都是扯淡。
技术是为业务服务的,只有当业务遇到发展瓶颈时,技术才能体现出它的价值。
造轮子就是一种知识变现。很多人光着急着去变现了,而忘记去积累。这些人,送他们一句话:先沸腾、再折腾。
理解需求是研发技术的第一步,你还需要具备非常深厚的专业知识和研发经验。
接上句,优化重构代码之前要先分析业务场景。
写组件时候要预留一些接口,考虑将来是否要求扩展,避免硬塞。
软件开发就是把一个复杂的问题分解成一系列简单的问题,再把一系列简单的解决方案组合成一个复杂的解决方案!
我们是用软件解决问题的工程师或程序员,不要自称为Java程序员,PHP程序员来限制自己的发展空间。了解语言的优缺点及使用场景,特定问题使用特定语言。
如果一个开发人员不清楚自己所做的产品盈利能力如何,是非常危险的,因为一旦这个产品不能盈利,他马上面临三个可能性:
- 这个产品被砍掉,这个人被安排其他工作
- 这个产品被砍掉,这个人失业了
- 老板很仁慈,一直维持这个亏损的产品,但公司会因为亏损而关门,大家还是失业了
学习新技术的小技巧。比如打算掌握node+moogodb。可按照如下步骤:
- 首先确立目标,确定时间及具体目标。采用项目驱动。如:一个月内使用 node+mogodb 做一个小型博客系统。如果按期完成奖励买电动牙刷,机械键盘等。
- 先去node和mongo官网看文档学习基础知识,并确定技术框架,比如使用流行的express和mongoose。
- 先自己大致写一些基础代码。
- github是个宝库,是学习他人源码的好地方,可以搜索关键字
express mongoose,express boilerplate或express skeleton等。选star比较多的项目。对比自己之前写的,边对比边重构。学习他人的代码组织,分层方式和结合自己习惯,不必完全照搬。 - 去v2ex或专门的社区论坛(如node就去node-china)发帖介绍项目。请别人点评,欢迎star。
提高代码水平,一、多看优秀的源码,JS推荐看lodash,PHP可以看Yii2的源码。二、看完自己写一遍,或者用其他语言实现一遍。
多人合作开发项目中,需要有一个人专门维护数据库,就是说除了这个人其他人不能随意操作正式数据库,定义新表或字段必须所有成员进行讨论包含字段名,类型,长度,索引等。表名和字段必须带有comment 将讨论结果转换为sql邮件抄送给相关人员。
有些开发人员很'自恋',就是学到了一点新技术就沾沾自喜,其实不过把官方的Demo例子照做了遍。最关键的话学到的新技术完全没有利用起来,要想方设法用到当前做的项目中,就是要产生最大的收益,其实对于客户来说,大多数时候并不关心你用的什么技术,他关心的时间和金钱。就是用最少的时间给我带来最大的收益。
持续有效的沟通
小的时候,你觉得孩子小,什么也不懂,只是帮他们做很多事,做饭、做衣服等。等到他们大了以后,比如到了青少年阶段,他们可能很忙,或者玩电脑,宁可跟同学朋友聊天,也不一定理你。
常常聊天是这样的,父母问,“学校怎么样啊?”孩子回答“很好”,然后就没有然后了。
但你想想,你在公司里,跟老板,跟同学,跟下属都不是这么沟通的。你不可能跟一个人说,“你怎么样?” 他回答 “很好”,就走了。
要把工作场合定期、保持交流的习惯,带回家,用在孩子身上。
至于具体怎么做,孩子不同的年龄阶段,可以有不同的方式。
-
婴幼儿的时候,爸爸妈妈能做的最好的方式是陪伴,是和他们一起去看这个有趣的世界。要多跟婴幼儿说话,不厌其烦地释看到的世界,哪怕你的孩子还不会说。
-
学龄前的孩子,讲故事是很好的方式你甚至可以跟孩子一起编故事,让他们做故事的主角。你不用怕编着编着就没话说了,我分享个我们家的聊天诀窍,跟孩子做各种问答,比如“我们来讲十个圆的东西”,“一起来说十件鱼不会做的事情”,这样的题目没有标准答案,既有趣,又可以教孩子一些概念。这个游戏,我们家很多年都玩得乐此不疲。
-
孩子上了小学以后,应该保持睡前谈话的习惯,听孩子分享他一天的见闻。这么做,能帮孩子整理他一天当中的经历,发现那些重要的事,既能帮他解决问题,还能发展他的表达能力。
-
孩子到了中学后,很多家长和孩子的沟通变得不是很通畅。这个时候,更加要让沟通变成习惯。比如说可以固定时间,每天晚上找一个睡觉前的时间聊一聊,或者周末找个时间聊一聊。
不要很刻意地一本正经地说,我们谈谈吧。我建议跟孩子一起做一些事情,比如说一起做饭,一起去买菜,一些日常的事情。你跟孩子一起做事,你会发现做事的时候,会自然而然地谈到一些关于学校的朋友的事,别人的事,他正在形成的世界观和看法。
- 和大孩子的沟通一定要注意几个方面:
多听少说,不要批评批判孩子的观点。
这点是很多家长都做不到的,他们都是忙于把自己的观点加在孩子头上。
不要有了问题才沟通
比如说学校学习不好,或者是跟别人有矛盾的时候再说,应该是在好的时候就随时沟通。很多时候大家就是讲一讲个人的生活,包括你自己的,你的工作,你遇到的问题也可以跟他聊一聊。养成这种习惯以后,当他真正遇到问题的时候,你自然而然就会了解了,就会这样做了。
持续不断的沟通非常重要,沟通要一直做,要很自然地去做。
我们在家里做父母,常常会认为孩子是自己的私有财产。虽然我们很爱孩子,很想保护他们,但是免不了就觉得他应该听我的,他应该跟我想的一样。
其实你退一步想,跟年轻的同事一样,孩子也是一个独立的人,在他有能力的事情上,父母应该让他独立运作,给他授权,你只定大方向就好了。
我家的老大其实小的时候蛮难管的,他很小就很有自己的想法,不爱听你的,尤其在细节上,你要去拧他,要阻止他做一件事,或者推他去做一件事,都是很难的这个也造成了很多的矛盾冲突。
但是从初中开始,我基本上就放手了。我定一些大的目标,比如学习要学好,体育锻炼要做,当然品德上不能有问题,大事情做好了,具体的东西我不管了。
后来发现这种平等的方法,非常有助于这个孩子的发展。
他很多事情都做得很好,很多事情他做的其实跟我想的不一样,他并没有去做我想让他做的事,但是他把他自己想做的事同时也是很正确的事情,做得非常好。父母应该这样想象,我们跟孩子也像在公司里跟其他人一样,是一个团队,大家是有共同目标的。这个共同目标包括孩子的成长,也包括我们自己的成长,要全家一起做,但是大家能力不同,分工不同,孩子并不需要要跟大人想的完全一样。
]]>1KB(kilobyte)=1000byte, 1KiB(kibibyte)=1024byte; 1MB(megabyte)=1000000byte, 1MiB(mebibyte)=1048576byte; 1GB(gigabyte)=1000000000byte, 1GiB(Gibibyte)=1073741824byte; 1Mbps = 1Mb/s = 1000Kbps ≈ 976.563 kibps;ps 为 per second 的缩写;
硬盘生产商是以GB(十进制,即10的3次方=1000,如1MB=1000KB)计算的,而电脑(操作系统)是以GiB(2进制,即2的10次方,如1MiB=1024KiB)计算的,但竖内用户一般理解为1MB=1024KB, 所以为了便于中文化的理解,翻译MiB为MB也是可以的。
1Mbps = 10的3次方Kbps;宽带网络中,运营商们所说的1M带宽是指1Mbps(megabits per second,兆比特每秒)。bps是bit per Second的缩写,也就是每秒多少“位”(bit)的意思。是用来计算资料传输速率的单“位”。
举例来说,电信局通常说的1M的带宽,所使用的单位就是bps,我们都知道一个字节等于8位(8个bit),而我们电脑的存储单位使用的是字节,也就是理论上每秒可以向硬盘下载1X1024/8=128KB/sec的数据。但这也只是理论上的速度。实际上则要再扣约12%的数据头信息(包Ethernet Header,IP Header,TCP Header,ATM Header等),各种各样的控制讯号。所以传输速度上限应112KB/sec左右,而不应该望文生义地理解为“每秒钟可以传送1M字节的数据。所以千万不要迷信广告,传输单位的写法上,B和b分别代表Bytes和bits,两者定义不同,差距是8倍。
1GB=1024MB,家里百兆带宽理论下载速度=100Mbps/8=12.5MB/s,下载1GB的电影仅需80秒;
]]>回答 how are you? / how you doing?
Couldn't be better 非常好 Can't complain 挺好的 Keeping busy 挺忙的 Been getting by 没什么特别的 Not so good 不怎么样
听不清
I'm losing you I can't hear you very well You're breaking up
Come again? Say that again ? Would you mind repeating that, please?
I've got bad reception/connection 我信号不好
赞同
I agree with you Well said Sounds good to me It works for me
商务常见缩写
COB -- close of business 工作日结束时间 COD -- cash on delivery 货到付款 N / A -- not applicable 不适用 BTW -- by the way 顺便说一下 FYI -- for your information 跟我说一下 ASAP -- as soon as possible 越快越好 TBD -- to be determined 还没决定 RSAP -- 请回复 please RSVP by COB Friday 请于周五下班前回复 APR -- Annual percentage rate 年利率 KPI -- key performance indicator 关键绩效指标 SOP -- standard operation procedure 标准操作规程 HQ -- Headquarter 公司总部 ETA -- estimated time of arrival 预计到达时间 YTD -- year to date 从开年到今天 EOM -- end of message 信息结束 ROI -- return of investment 投资回报 W/ -- with 有 W/O -- without 没有 FWIW -- for what it's worth 再说一句 KISS -- keep it simple stupid 保持简单易懂原则
辛苦了
对帮忙你的人
Thank you! I really appreciate it. I couldn't have done it without you. I don't know what I'd do without you.
对同学,同事
Good / great / fantastic job, guys! We did! 工作做完了 Keep up with the good work! 工作还没做完
夸人
He was born to do sth. Someone is a natural (at sth). Sth comes naturally to someone. Playing the piano comes naturally to him. Someone is a 'G' (gangster / badass) 某人超棒
我不打扰了 你忙你的吧
I 'll leave you to it. I gotta go back to work. I won't disturb you any further.
LA 要连读,不要两个分开读
参考:https://www.youtube.com/watch?v=N5fAaKm8y2k&list=PLYWlpZe1L2k3-ltN4XpDXpVP9PzzmW7bZ&index=19
]]>如果您的产品使用欧盟各国本地仓储进行发货或物品所在地为欧盟各国,就属于欧盟VAT销售增值税应缴范畴,即便您使用的海外仓储服务是由第三方物流公司提供,也从未在欧盟各国当地开设办公室或者聘用当地员工,您仍然需要交纳VAT增值税。
不缴纳 VAT 的危害: 1、货物出口无法享受进口增值税退税;
2、货物可能被扣无法清关;
3、难以保证电商平台正常销售;
4、不能提供有效的VAT发票,降低海外客户成交率及好评率...
在线验证:https://ec.europa.eu/taxation_customs/vies/?locale=en
使用代码
$client = new \SoapClient('http://ec.europa.eu/taxation_customs/vies/checkVatService.wsdl');
$a = $client->checkVat(array(
'countryCode' => 'NL',
'vatNumber' => '807705111B01',
));
var_dump($a->valid);
detect drift 偏差检测
CF生成的资源然后又手动做了修改,这时候就会出现偏差,就需要做偏差检测。
这里手动修改了tag name



Stack


修改 15_stack_root.yaml
更新根堆栈


更新成功

删除根堆栈,其使用的嵌套模板都被删除了

生产环境中开启终止保护
]]>一般我们在EKS上安装AWS Load Balancer Controller附加组件,然后定义ingress,AWS Load Balancer Controller会自动帮我们创建ALB或NLB了
传统ingress写法
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/healthcheck-interval-seconds: "300"
alb.ingress.kubernetes.io/healthcheck-path: /
alb.ingress.kubernetes.io/healthcheck-protocol: HTTP
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'
alb.ingress.kubernetes.io/load-balancer-name: alb-demo
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/success-codes: "200"
alb.ingress.kubernetes.io/target-type: ip
name: alb-demo
namespace: demo
spec:
ingressClassName: alb
rules:
- http:
paths:
- backend:
path: /*
pathType: ImplementationSpecific
service:
name: svc-nginx
port:
number: 80
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: alb-demo
namespace: demo
annotations:
alb.ingress.kubernetes.io/healthcheck-interval-seconds: "300"
alb.ingress.kubernetes.io/healthcheck-path: /
alb.ingress.kubernetes.io/healthcheck-protocol: HTTP
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'
alb.ingress.kubernetes.io/load-balancer-name: alb-demo
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/success-codes: "200"
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/conditions.rule-header: >
[{"field":"http-header","httpHeaderConfig":{"httpHeaderName": "X-Customer-Header", "values":["202405271135505"]}},{"field":"path-pattern","pathPatternConfig":{"values":["/*"]}}]
alb.ingress.kubernetes.io/conditions.default-header: >
{"type":"fixed-response","fixedResponseConfig":{"contentType":"text/plain","statusCode":"403","messageBody":"Access Deny, please contact to [email protected]"}}
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /*
backend:
pathType: Exact
service:
name: rule-header
port:
name: use-annotation
修改默认rule
default rule 总是一个返回固定响应404的text/plain
下面这个例子
- 添加一个 rule 并指定 target group
- 修改默认 rule,404 转为 403,并自定义响应内容
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: alb-demo
namespace: demo
annotations:
alb.ingress.kubernetes.io/healthcheck-interval-seconds: "300"
alb.ingress.kubernetes.io/healthcheck-path: /
alb.ingress.kubernetes.io/healthcheck-protocol: HTTP
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'
alb.ingress.kubernetes.io/load-balancer-name: alb-demo
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/success-codes: "200"
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/actions.rule-tg: >
{"type":"forward","forwardConfig":{"targetGroups":[{"serviceName":"svc-nginx","servicePort":"80"}]}}
alb.ingress.kubernetes.io/conditions.rule-tg: >
[{"field":"http-header","httpHeaderConfig":{"httpHeaderName": "X-DEMO-Header", "values":["1234567"]}}]
alb.ingress.kubernetes.io/actions.default: |
{"Type":"fixed-response","FixedResponseConfig":{"ContentType":"application/json","StatusCode":"403","MessageBody":"{ \"code\" : 403, \"message\" : \"Access deny, please contact to [email protected]\" }"}}
spec:
ingressClassName: alb
defaultBackend:
service:
name: default
port:
name: use-annotation
rules:
- http:
paths:
- path: /*
pathType: ImplementationSpecific
backend:
service:
name: rule-tg
port:
name: use-annotation使用 ingressgroup 合并多个 ingress, 使用支持多种协议
IngressGroup功能能够将多个Ingress资源分组在一起。
controller将自动合并IngressGroup内所有Ingress的Ingress规则,并创建单个ALB。
此外,Ingress上定义的大多数注释仅适用于该Ingress定义的路径。
默认情况下,Ingresses不属于任何IngressGroup,我们将其视为由Ingress本身组成的“隐式IngressGroup”。
比如,适用于一个LB关联多个目标组,一个目标组要支持grpc协议,另外一个支持http1协议
要建两个ingress,name不一样,但要有相同的annotation alb.ingress.kubernetes.io/group.name
第一个 ingress 支持 https
kind: Ingress
apiVersion: networking.k8s.io/v1
metadata:
name: nginx-http
namespace: demo
labels:
app: grpcserver
environment: dev
annotations:
alb.ingress.kubernetes.io/certificate-arn: >-
arn:aws-cn:acm:cn-north-1:xxxxxx:certificate/7010f433-9d60-xxxx-xxxx-ecbcd772e3ad
alb.ingress.kubernetes.io/group.name: demo-ingress-group
# 注意监听规则的优先级,值越高越靠前
alb.ingress.kubernetes.io/group.order: '10'
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}]'
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- host: grpcserver.dev.mafeifan.com
http:
paths:
- path: /hello
pathType: Prefix
backend:
service:
name: svc-nginx
port:
number: 80第二个 ingress 支持 grpc, 最终只创建一个 ALB
这种方法也适用于不同命名空间的ingress
kind: Ingress
apiVersion: networking.k8s.io/v1
metadata:
name: grpcserver
namespace: demo
labels:
app: grpcserver
environment: dev
annotations:
alb.ingress.kubernetes.io/backend-protocol-version: GRPC
# 注意监听规则的优先级,值越高越靠前
alb.ingress.kubernetes.io/group.order: '100'
alb.ingress.kubernetes.io/certificate-arn: >-
arn:aws-cn:acm:cn-north-1:xxxxxx:certificate/7010f433-9d60-xxxx-xxxx-ecbcd772e3ad
alb.ingress.kubernetes.io/group.name: demo-ingress-group
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS":443}]'
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/ssl-redirect: '443'
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- host: grpcserver.dev.mafeifan.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: grpcserver
port:
number: 50051最终生成LB效果如下:



https协议不使用443端口
上面的写法中,grpc 和 https 都占用了443端口,导致 https 不得不使用 /hello path 前缀,
我们继续优化, 修改 nginx-http 让https走8001端口,grpcserver保持不变
kind: Ingress
apiVersion: networking.k8s.io/v1
metadata:
name: nginx-http
namespace: demo
labels:
app: grpcserver
environment: dev
annotations:
alb.ingress.kubernetes.io/certificate-arn: >-
arn:aws-cn:acm:cn-north-1:xxxxxx:certificate/7010f433-9d60-xxxx-xxxx-ecbcd772e3ad
alb.ingress.kubernetes.io/group.name: demo-ingress-group
# 注意监听规则的优先级,值越高越靠前
alb.ingress.kubernetes.io/group.order: '10'
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":8001}]'
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- host: grpcserver.dev.mafeifan.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: svc-nginx
port:
number: 80
EKS外的ALB目标指向EKS集群内service对应的IP或Instance
流程:
- 不通过ingress方式创建ALB,绑定安全组
sg-08d041a8f0b0 - 创建ALB的监听,比如80
- 创建一个目标组,IP类型并绑定到这个ALB,拿到ARN:
arn:aws-cn:elasticloadbalancing:cn-north-1:xxxxx:targetgroup/mafei-demo/dec5f112d848f90c- 此时目标组的目标为空
- EKS 已存在service, svc-nginx
创建一个TargetGroupBinding,这样目标组的目标IP就是EKS中对应Pod的IP,如果扩缩Pod,目标组的IP会相应的发生变化
apiVersion: elbv2.k8s.aws/v1beta1
kind: TargetGroupBinding
metadata:
namespace: mafei
name: mafei-demo-tgb
spec:
serviceRef:
# route traffic to the k8s service
name: svc-nginx
# the port of service
port: 80
targetGroupARN: arn:aws-cn:elasticloadbalancing:cn-north-1:xxxxx:targetgroup/mafei-demo/dec5f112d848f90c
networking:
ingress:
- from:
- securityGroup:
# 一般写为ALB的SG
# EKS所在的安全组会添加一条规则,允许来自这个 ALB SG 的流量
groupID: sg-08d041a8f0b0
ports:
- port: 80
# Allow all TCP traffic from ALB SG
protocol: TCP参考
https://docs.amazonaws.cn/eks/latest/userguide/aws-load-balancer-controller.html
]]>将多个项目同时运行就称为聚合。
只需在 pom 中作如下配置即可实现聚合:
<modules>
<module>web-connection-pool</module>
<module>web-java-crawler</module>
</modules>继承
在聚合多个项目时,如果这些被聚合的项目中需要引入相同的Jar,那么可以将这些Jar写入父pom中,各个子项目继承该pom即可。
父 pom 配置如下
<dependencyManagement>
<dependencies>
<dependency>
<groupId>cn.missbe.web.search</groupId>
<artifactId>resource-search</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
</dependencyManagement>子项目 pom 配置
<parent>
<groupId>父pom所在项目的groupId</groupId>
<artifactId>父pom所在项目的artifactId</artifactId>
<version>父pom所在项目的版本号</version>
</parent>
<parent>
<artifactId>resource-search</artifactId>
<groupId>cn.missbe.web.search</groupId>
<version>1.0-SNAPSHOT</version>
</parent>int x = 10;
int y= 3;
// 13K, "K"是字符串,通过类型转换13被转成为"13", +是字符串连接符,最终输出13K
System.out.println(x+y+"K");
// ascii 和 数字互转
System.out.println((char)75);
System.out.println((byte)'K');
// 输出88, 88=13+75, (char)75 => 'K'
System.out.println(x+y+'K');
// 12aa66
System.out.println(6+6+"aa"+6+6);
// 12aa12
System.out.println(6+6+"aa"+(6+6));单机测试
环境 Ubuntu18.04
# 可选
$ export JAVA_HOME=/usr/java/jdk-11.0.10
## 安装 kafka
```bash
$ tar -zxf mv kafka_2.13-3.1.0.tgz
$ mv kafka_2.13-3.1.0.tgz /usr/local/kafka
$ mkdir /tmp/kafka-logs
# 生成随机cluster id
$ ./bin/kafka-storage.sh random-uuid
1QZShiaqQQCN8XE797uesg
# 格式化存储目录,注意我们使用的是kraft中的配置文件
./bin/kafka-storage.sh format -t 1QZShiaqQQCN8XE797uesg -c ./config/kraft/server.properties
Formatting /tmp/kraft-combined-logs
# 启动 kafka
$ ./bin/kafka-server-start.sh ./config/kraft/server.properties
# 创建名为test的topic
$ ./bin/kafka-topics.sh --create --topic test --partitions 1 --replication-factor 1 --bootstrap-server localhost:9092
Created topic test.
# 查看topic
$ ./bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic test
Topic: test TopicId: JyDAOV4AQ2mnCyD1Sh4DmA PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
# 生产消息到test主题(使用Ctrl-C停止生产者):
$ ./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
> test1
> test2
# 新开一个终端,消费来自test主题的消息:
# --from-beginning 是显示所有消息,而不是从最新的消息开始
$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginningpython客户端
生产者
# pip install kafka-python
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
for i in range(5):
future = producer.send('test', b'finley %d' % i)
result = future.get(timeout=10)
print(result)消费者还是有问题
疑问
消费者跟生产者不在同一台机器上该如何连接
./bin/kafka-console-consumer.sh --bootstrap-server 49.232.138.70:9092 --topic test --from-beginning [2022-03-16 22:22:50,436] WARN [Consumer clientId=console-consumer, groupId=console-consumer-26123] Connection to node 0 (localhost.localdomain/127.0.0.1:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) [2022-03-16 22:22:50,537] WARN [Consumer clientId=console-consumer, groupId=console-consumer-26123] Connection to node 0 (localhost.localdomain/127.0.0.1:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
在内网部署及访问kafka时,只需要配置listeners参数即可,比如
listeners=PLAINTEXT://192.168.133.11:9092
按照官网的参数说明,此时advertised.listeners默认值等于listeners参数的值,并被发布到zookeeper中,供客户端访问使用。 此时kafka服务、broker之间通信都是使用192.168.133.11:9092
在内网部署kafka服务,并且生产者或者消费者在外网环境时,需要添加额外的配置,比如
advertised_listeners 监听器会注册在 zookeeper 中;
总结:advertised_listeners 是对外暴露的服务端口,kafka组件之间通讯用的是 listeners。
其实listeners是真正决定kafka启动时候的监听端口。advertised_listeners可以看做类似nginx的端口代理。
参考
]]>单机测试
安装 zookeeper
环境 Ubuntu18.04
$ tar -zxf apache-zookeeper-3.8.0-bin.tar.gz
$ mv apache-zookeeper-3.5.9-bin /usr/local/zookeeper
$ mkdir -p /var/lib/zookeeper
$ cp > /usr/local/zookeeper/conf/zoo.cfg << EOF
> tickTime=2000
> dataDir=/var/lib/zookeeper
> clientPort=2181
> EOF# 可选
$ export JAVA_HOME=/usr/java/jdk-11.0.10
# 启动zookeeper
$ /usr/local/zookeeper/bin/zkServer.sh start
# 现在可以通过连接到客户端端口并发送四个字母的命令srvr来验证ZooKeeper是否在独立模式下正确运行。 这将返回运行服务器的基本ZooKeeper信息:
telnet localhost 2181
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
srvr
Zookeeper version: 3.8.0-5a02a05eddb59aee6ac762f7ea82e92a68eb9c0f, built on 2022-02-25 08:49 UTC
Latency min/avg/max: 0/0.0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 5
Connection closed by foreign host.安装 kafka
$ tar -zxf mv kafka_2.13-3.1.0.tgz
$ mv kafka_2.13-3.1.0.tgz /usr/local/kafka
$ mkdir /tmp/kafka-logs
# 启动 kafka
$ /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
# 创建名为test的topic
$ /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --replication-factor 1 --partitions 1 --topic test
Created topic test.
# 查看topic
$ /usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic test
Topic: test TopicId: GKrnmzgsTbSQNslvtKWkBw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
# 生产消息到test主题(使用Ctrl-C停止生产者):
$ /usr/local/kafka/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
> test1
> test2
# 新开一个终端,消费来自test主题的消息:
$ /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning疑问
消费者跟生产者不在同一台机器上该如何连接
./bin/kafka-console-consumer.sh --bootstrap-server 49.232.138.70:9092 --topic test --from-beginning [2022-03-16 22:22:50,436] WARN [Consumer clientId=console-consumer, groupId=console-consumer-26123] Connection to node 0 (localhost.localdomain/127.0.0.1:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient) [2022-03-16 22:22:50,537] WARN [Consumer clientId=console-consumer, groupId=console-consumer-26123] Connection to node 0 (localhost.localdomain/127.0.0.1:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
在内网部署及访问kafka时,只需要配置listeners参数即可,比如
listeners=PLAINTEXT://192.168.133.11:9092
按照官网的参数说明,此时advertised.listeners默认值等于listeners参数的值,并被发布到zookeeper中,供客户端访问使用。 此时kafka服务、broker之间通信都是使用192.168.133.11:9092
在内网部署kafka服务,并且生产者或者消费者在外网环境时,需要添加额外的配置,比如
advertised_listeners 监听器会注册在 zookeeper 中;
总结:advertised_listeners 是对外暴露的服务端口,kafka组件之间通讯用的是 listeners。
其实listeners是真正决定kafka启动时候的监听端口。advertised_listeners可以看做类似nginx的端口代理。
]]>基本概念
-
一台服务器就是一个broker,一个集群由多个broker组成,一个broker可以有多个topic,一个topic可以有多个partition分区,一个partition可以有多个segment
-
topic: 可以理解为一个队列或文件系统中的文件夹,所有的生产者和消费者都是面向topic的。每个partitions一般都会有一个消费者。
-
Kafka 通过分区来实现数据冗余和伸缩性。分区可以分布在不同的服务器上,也就是说,一个主题可以横跨多个服务器,以此来提供比单个服务器更强大的性能。
-
Kafka broker 默认的消息保留策略是这样的:要么保留一段时间(比如 7 天),要么保留到消息达到一定大小的字节数(比如 1GB)。当消息数量达到这些上限时,旧消息就会过期并被删除,所以在任何时刻,可用消息的总量都不会超过配置参数所指定的大小。
-
分区数的确定可以用主题吞吐量除以消费者吞吐量估算,如果每秒钟要从主题上写入和读取 1GB 的数据,并且每个消费者每秒钟可以处理 50MB 的数据,那么至少需要 20 个分区。这样就可以让 20 个消费者同时读取这些分区,从而达到每秒钟 1GB 的吞吐量。
-
主题可以配置自己的保留策略。例如,用于跟踪用户活动的数据可能需要保留几天,而应用程序的度量指标可能只需要保留几个小时。
-
Kafka 使用 Zookeeper 保存 Broker 的元数据,Kafka3 中使用Zookeeper已经不是必须的了

ack应答
三种qos:
-
级别0:不等待broker的ack回应,直接返回,毕竟没有经过leader与follower确认,优点是快,缺点是不可靠,生产环境很少使用
-
级别1:Producer发送消息到broker后,会等待leader落盘后再给producer返回信号,告诉producer数据已经收到了,但是也存在一种情况,那就是follower没有确认数据是否落盘,如果存在leader于follower数据不一致的情况,又碰巧leader挂了,选举了一个数据不健全的follower为新的leader,这就造成了数据丢失。所以它可靠性中等,性能不如0级。传输日志,允许丢失个别数据
-
级别-1:他要等leader与isr(可以看做一些比较活跃的follower集合)中follower确认全部落盘后在给producer回应,这种方式可靠,但是牺牲了性能,所以它是三种模式里最慢的。跟钱相关的数据,不允许丢失
-
数据完全可靠条件:ACK级别为-1 + 分区副本数>=2 + ISR 应答的最小副本数量>=2
-
精确一次 = 幂等性 + ACK级别为-1 + 分区副本数>=2 + ISR 应答的最小副本数量>=2


参考
]]>php artisan infyom:scaffold User --datatables=true
]]>原理也非常简单:
- 前天在请求头中添加 Authorization,如下

- 后台取到值,然后去用户表的api_token列进行匹配,如果查到说明验证成功,并且返回相关信息。
Laravel本身自带几种验证方式,下面介绍下token认证的实现的方法。
前台在向后台发起请求时要携带一个token
后台需要做一个返回当前登录用户的信息的api,地址是 /api/user
- 先添加路由,当给 route/api.php 添加
Route::middleware('auth:api')->get('/user', function (Request $request) {
echo $request->user();
});如果浏览器直接访问 http://mydomain.com/api/user 会返回 401 Unauthorized
原因是在config/auth.php中有下面的关键配置
'guards' => [
'web' => [
'driver' => 'session',
'provider' => 'users',
],
'api' => [
'driver' => 'token',
'provider' => 'users',
],
],可以看到通过api访问走的是token认证,这里没有提供token所以就认证失败返回401了。
'driver' => 'token'实际调用的是\vendor\laravel\framework\src\Illuminate\Auth\TokenGuard.php上面说到我们需要在request里提供api_token参数,为了区别是哪个用户,需要在user表添加api_token字段

- 认证过程调用的是getTokenForRequest方法
public function getTokenForRequest()
{
$token = $this->request->query($this->inputKey);
if (empty($token)) {
$token = $this->request->input($this->inputKey);
}
if (empty($token)) {
$token = $this->request->bearerToken();
}
if (empty($token)) {
$token = $this->request->getPassword();
}
return $token;
}这个bearerToken实际找header中是否存在Authorization
public function bearerToken()
{
$header = $this->header('Authorization', '');
if (Str::startsWith($header, 'Bearer ')) {
return Str::substr($header, 7);
}
}- 先给user表添加api_token字段
php artisan make:migration add_api_token_to_users --table=users内容
class AddApiTokenToUsers extends Migration
{
/**
* Run the migrations.
*
* @return void
*/
public function up()
{
Schema::table('users', function (Blueprint $table) {
$table->string('api_token', 60)->unique();
});
}
/**
* Reverse the migrations.
*
* @return void
*/
public function down()
{
Schema::table('users', function (Blueprint $table) {
$table->dropColumn('api_token');
});
}
}-
打开navicat进到user表里,更新users的api_token。

-
打开postman
 注意这里的header,key是Authorization,值就是Bearer+空格+刚才数据库里设的api_token
注意这里的header,key是Authorization,值就是Bearer+空格+刚才数据库里设的api_token
这样就能返回内容啦,修改其他用户的token能返回相应的用户信息,说明认证成功,功能基本完成! 下面完善细节
- 完善逻辑
修改
\app\Http\Controllers\Auth\RegisterController.php
protected function create(array $data)
{
return User::create([
'name' => $data['name'],
'email' => $data['email'],
'password' => bcrypt($data['password']),
// 添加这行
'api_token' => str_random(60),
]);
}User Model 的 $fillable也改下
protected $fillable = [
'name', 'email', 'password', 'api_token',
];- 如果在前台页面,发起请求时如何给后台传这个Authorization header? 方法如下 注意,下面的是Laravel5.4的修改方法。新版本可能有细微区别,只要知道原理就能自己改了。
打开 \resources\assets\js\bootstrap.js 参照着csrf-token。合适的地方添加下面的代码
let token = document.head.querySelector('meta[name="csrf-token"]');
let api_token = document.head.querySelector('meta[name="api-token"]');
if (token) {
// 这个要参考axios的文档
window.axios.defaults.headers.common['X-CSRF-TOKEN'] = Laravel.csrfToken =token.content;
// 如果用的jquery
// Fix jquery ajax crossDomain without Token
// jQuery.ajaxPrefilter(function (options, originalOptions, jqXHR) {
// // if (options.crossDomain) {
// jqXHR.setRequestHeader('Authorization', api_token.content);
// jqXHR.setRequestHeader('X-CSRF-TOKEN', token.content);
// //}
// });
} else {
console.error('CSRF token not found: https://laravel.com/docs/csrf#csrf-x-csrf-token');
}
if (api_token) {
window.axios.defaults.headers.common['Authorization'] = api_token.content;
} else {
console.error('Authorization token not found: https://laravel.com/docs/csrf#csrf-x-csrf-token');
}最后修改公共视图模版中 \views\layouts\app.blade.php
<meta name="csrf-token" content="{{ csrf_token() }}">
<meta name="api-token" content="{{ Auth::check() ? 'Bearer '.Auth::user()->api_token : 'Bearer ' }}">总结: 本质上给用户表添加api_token,后台根据这个字段判断是否是有效的用户,无效返回401,有效返回查询结果。 优点是容易理解,缺点太简单,安全也不够。 为了安全,可以实现下面的功能:
- 每次登录成功后刷新api_token为新值 其实 Laravel 官方提供了一个 Laravel Passport 的包。Laravel Passport is an OAuth2 server and API authentication package 。 具体使用请等更新。
问题: 如何修改默认的api_token列?
]]>-
新建middleware
php artisan make:middleware MustBeAdmin -
打开生成的
\app\Http\Middleware\MustBeAdmin.php修改handle方法 关于hasRole方法上一篇有讲解 这里在请求前判断用户角色是否是admin,如果条件满足进到下一个中间件。不满足返回首页。
public function handle($request, Closure $next)
{
// 前置
if ($request->user()->hasRole('admin')) {
return $next($request);
}
return redirect('/');
}-
让系统识别中间件。打开
\app\Http\Kernel在 $routeMiddleware 数组里追加'mustAdmin' => \App\Http\Middleware\MustBeAdmin::class, -
关于中间件的调用非常灵活,比如
- 在 routes\web.php 中
Route::resource('posts', 'PostsController')->middleware('mustAdmin'); - 在控制器中
class PostsController extends Controller
{
public function __construct()
{
$this->middleware('mustAdmin', ['only' => 'show']);
}
...- 项目中用到过的中间件
例1
在route中定义哪些角色可以访问,通过 role:ADMIN,TEACHER 知,role是中间件名字,后面的 ADMIN,TEACHER 是参数。
routes.php
Route::group(['middleware' => ['web', 'auth', 'role:ADMIN,TEACHER'], 'namespace' => '\StudentTrac\Guides\Controllers'],
function () {
Route::resource('guides', 'GuidesController', ['only' => ['index']]);
Route::resource('guides/admin', 'AdminController', ['only' => ['index', 'edit']]);
}
);/app/Http/Middleware/Role.php
public function handle($request, Closure $next, $role)
{
// ['ADMIN', 'TEACHER']
$roles = func_get_args();
$roleIds = [];
// 根据role名字拿到对应的id
foreach ($roles as $index => $role) {
// 为什么这么判断我也忘了
if ($index < 2) continue;
$roleIds[] = config('roles.' . trim($role));
}
// 判断当前用户的roleId是否存在
if (! in_array((int)$this->auth->user()->RoleId, $roleIds)) {
return response('Unauthorized', 403);
}
return $next($request);
}config/roles.php
return [
/*
* Role id for role.
*/
'ADMIN' => 1,
'STUDENT' => 2,
'GUARDIAN' => 3,
'TEACHER' => 4,
'SUPPORTSTAFF' => 5,
'AUDITOR' => 6,
'CURRICULUM' => 7,
'CLIENTADMINISTRATOR' => 8,
];<script>
var app = <?php echo json_encode($array); ?>;
</script>5.5以后可以这么写, 用 @json Blade 指令替代手动 json_encode
<script>
var app = @json($array);
</script>曾经在多语言项目中这么用过。
<script>
window.Laravel = {
csrfToken: '{{ csrf_token() }}',
Locale: '<?php echo \App::getLocale(); ?>',
Languages: <?php echo json_encode(
[
'scaffold' => __('scaffold::t'),
'module_dashboard' => __('module_dashboard::t'),
'module_user' => __('module_user::t'),
'setting' => __('setting::t'),
],
JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);?>
};
</script>Laravel变量传入在vue组件中
定义组件
<script>
export default {
props: ['surveyData'],
mounted () {
// Do something useful with the data in the template
console.dir(this.surveyData)
}
}
</script>注入变量
<survey-component :survey-data="'{!! json_encode($surveyData) !!}'"></survey-component>参考: https://medium.com/@m_ramsden/passing-data-from-laravel-to-vue-98b9d2a4bd23 https://laravel-china.org/docs/laravel/5.6/blade/1375
]]>这里已经建了一张表,叫 my_json,注意 meta 是 json 类型

建立相关的模型
<?php
namespace Modules\Models;
use Illuminate\Database\Eloquent\Model;
class MyJson extends Model
{
public $table = 'my_json';
public $fillable = [
'meta'
];
/**
* The attributes that should be casted to native types.
*
* @var array
*/
protected $casts = [
'id' => 'number',
'meta' => 'array',
];
}操作
// 新增
$model = new MyJson();
$model->meta =['name' => 'jack', 'age' => 18];
$model->save();
// 更新
$result = MyJson::query()
->where('id', 1)
->update(['meta->name' => 'lily', 'meta->age' => 28]);
// 可以插入复杂些的内容
$model = new MyJson();
$model->meta =[
'deviceInfo' => [
[
'name' => '消防栓',
'fields' => [
['id' => 1, 'type' => '1', 'label' => '消火栓箱体外观无破损现象'],
['id' => 2, 'type' => '2', 'label' => '消火栓箱箱门正面有标志牌,标注“消火栓”字样'],
['id' => 3, 'type' => '1', 'label' => '消火栓箱门开启角度可大于160度']
]
],
[
'name' => '灭火器',
'fields' => [
['id' => 1, 'type' => '1', 'label' => '灭火器外观无破损现象'],
['id' => 2, 'type' => '2', 'label' => '灭火器正面有标志牌'],
]
]
]
];
$model->save();
// 当然更新时候会稍微麻烦些
$model = MyJson::query()->find(4);
$tmp = $model->meta;
$tmp['deviceInfo'][0]['name'] = 'll';
$model->meta = $tmp;
$model->save();
$result = MyJson::query()->find(4)->meta;存到数据库里会自动转为JSON

总结:使用 Laravel 操作 MySQL 的 json类型还是很方便的,主要是建立表时要考虑好
参考
https://www.cnblogs.com/wshenjin/p/10276678.html https://learnku.com/laravel/t/13185/in-depth-understanding-of-json-data-type-of-mysql-nosql-in-relational-database
]]>我们有时候想测试一段代码生产的 SQL 语句,比如: 我们想看 App\User::all(); 产生的 SQL 语句,我们简单在 routes.php 做个实验即可:
//app/Http/routes.php
Route::get('/test-sql', function() {
DB::enableQueryLog();
$user = App\User::all();
return response()->json(DB::getQueryLog());
});然后我们在浏览器打开 http://www.yousite.com/test-sql 即可看到 $user = User::all(); 所产生的 SQL 了。
[
{
query: "select * from `users` where `users`.`deleted_at` is null",
bindings: [ ],
time: 1.37
}
]- Laravel 有 2 种主要方式来实现用户授权:gates 和策略。
- Gates 接受一个当前登录用户的实例作为第一个参数。并且接收可选参数,比如相关的Eloquent 模型。
- 用命令生成策略
php artisan make:policy PostPolicy --model=Post带--model参数生成的内容包含CRUD方法 - Gate用在模型和资源无关的地方,Policy正好相反。
<?php
namespace App\Policies;
use App\User;
use App\Post;
use Illuminate\Auth\Access\HandlesAuthorization;
class PostPolicy
{
use HandlesAuthorization;
/**
* Determine whether the user can view the post.
*
* @param \App\User $user
* @param \App\Post $post
* @return mixed
*/
public function view(User $user, Post $post)
{
//
}
/**
* Determine whether the user can create posts.
*
* @param \App\User $user
* @return mixed
*/
public function create(User $user)
{
//
}
/**
* Determine whether the user can update the post.
*
* @param \App\User $user
* @param \App\Post $post
* @return mixed
*/
public function update(User $user, Post $post)
{
//
}
/**
* Determine whether the user can delete the post.
*
* @param \App\User $user
* @param \App\Post $post
* @return mixed
*/
public function delete(User $user, Post $post)
{
//
}
}操作流程:
- 新建Post表及Model文件
php artisan make:migrate create_posts_tablephp artisan make:model Post表信息
public function up()
{
Schema::create('posts', function (Blueprint $table) {
$table->increments('id');
$table->string('title');
$table->integer('user_id')->unsigned();
$table->text('body');
$table->foreign('user_id')->references('id')->on('users')->onDelete('cascade');
$table->timestamps();
});
}填充数据,打开UserFactory添加
$factory->define(App\Post::class, function (Faker $faker) {
return [
'title' => $faker->sentence,
'body' => $faker->paragraph,
'user_id' => factory(\App\User::class)->create()->id,
];
});Post表内容

-
routes/web.php添加
Route::resource('posts', 'PostsController'); -
定义Gate 打开 Proviers/AuthServiceProvider.php,修改boot方法
public function boot()
{
$this->registerPolicies();
// Gates 接受一个用户实例作为第一个参数,并且可以接受可选参数,比如 相关的 Eloquent 模型:
Gate::define('update-post', function ($user, $post) {
// return $user->id == $post->user_id;
return $user->owns($post);
});
}这里,在User模型中定义了own方法
public function owns($post)
{
return $post->user_id === $this->id;
}- PostsController中,只写一个show方法
// Gate 演示
public function show($id)
{
$post = Post::findOrFail($id);
\Auth::loginUsingId(2);
$this->authorize('update-post', $post);
if (Gate::denies('update-post', $post)) {
abort(403, 'sorry');
}
// compact('post') 等价于 ['post' => $post]
return view('posts.view', compact('post'));
// return $post->title;
}- 访问
/posts/1。会报403。这是因为我们是用user_id为2登录。

-
如果注释
$this->authorize('update-post', $post);,就会显示:
-
视图中判断Policy,如果post的user_id是当前登录用户,显示编辑链接。
@can('update', $post)
<a href="proxy.php?url=#">编辑</a>
@endcan@can 和 @cannot 各自转化为如下声明:
@if (Auth::user()->can('update', $post))
<!-- 当前用户可以更新博客 -->
@endif
@unless (Auth::user()->can('update', $post))
<!-- 当前用户不可以更新博客 -->
@endunless- 建立这三个表及关联表
public function up()
{
Schema::create('roles', function (Blueprint $table) {
$table->increments('id');
$table->string('name');
$table->string('label')->nullable();
$table->timestamps();
});
Schema::create('permissions', function (Blueprint $table) {
$table->increments('id');
$table->string('name');
$table->string('label')->nullable();
$table->timestamps();
});
Schema::create('permission_role', function (Blueprint $table) {
$table->integer('permission_id')->unsigned();
$table->integer('role_id')->unsigned();
$table->foreign('permission_id')
->references('id')
->on('permissions')
->onDelete('cascade');
$table->foreign('role_id')
->references('id')
->on('roles')
->onDelete('cascade');
$table->primary(['permission_id', 'role_id']);
});
Schema::create('role_user', function (Blueprint $table) {
$table->integer('role_id')->unsigned();
$table->integer('user_id')->unsigned();
$table->foreign('user_id')
->references('id')
->on('users')
->onDelete('cascade');
$table->foreign('role_id')
->references('id')
->on('roles')
->onDelete('cascade');
$table->primary(['user_id', 'role_id']);
});
}- 建立模型关联
User模型
...
public function roles()
{
return $this->belongsToMany(Role::class);
}
...Role模型
class Role extends Model
{
public function permissions()
{
return $this->belongsToMany(Permission::class);
}
// $role = Role::first(); $p = Permission::first();
// $role->givePermission($p);
public function givePermission(Permission $permission)
{
return $this->permissions()->save($permission);
}
}Permission模型
class Permission extends Model
{
public function roles()
{
return $this->belongsToMany(Role::class);
}
}- 添加记录,这里我们添加一个admin的role和名为edit_form的permission,并且让admin拥有edit_form权限。

执行完 $role->givePermission($permission);会发现permission_role表多了一条记录

添加role和user的关系,将id为1的用户角色修改为admin。

会发现role_user表多了一条记录

$user->roles()->detach($role);可以删除这条记录$user->roles()->attach($role);新增记录
- 修改AuthServiceProvider.php,从数据库从读取所有的permission信息并设置Gate。让配置生效。
public function boot()
{
$this->registerPolicies();
// Gates 接受一个用户实例作为第一个参数,并且可以接受可选参数,比如 相关的 Eloquent 模型:
foreach($this->getPermission() as $permission) {
// dd($permission->roles);
Gate::define($permission->name, function($user) use ($permission) {
// 返回collection
return $user->hasRole($permission->roles);
});
}
}
public function getPermission()
{
return Permission::with('roles')->get();
}给User模型添加hasRole方法
public function hasRole($role)
{
if (is_string($role)) {
return $this->roles->contains('name', $role);
}
// intersect 移除任何指定 数组 或集合内所没有的数值。最终集合保存着原集合的键:
return !!$role->intersect($this->roles)->count();
}- 修改视图,测试,如果当前登录用户的id是1,就可以看到'编辑'链接
@can('edit_form')
<a href="proxy.php?url=#">编辑</a>
@endcan- 总结
$this->roles() 与 $this->roles 有什么不同,什么情况下使用呢? $this->roles() 返回 QueryBuilder ,$this->roles 返回一个 Collection
]]>-
新建laravel项目
laravel new zhihu-app -
配置.env,主要改下数据库连接信息
-
配置vhost,如果用的homestead,可能还要改他的配置文件
-
修改user表 打开
2014_10_12_000000_create_users_table.php添加一些字段
public function up()
{
Schema::create('users', function (Blueprint $table) {
$table->increments('id');
$table->string('name')->unique();
$table->string('email')->unique();
$table->string('password');
$table->string('avatar');
// 激活token
$table->string('confirmation_token');
// 是否激活邮箱
$table->smallInteger('is_active')->default(0);
$table->integer('questions_count')->default(0);
$table->integer('answers_count')->default(0);
$table->integer('comments_count')->default(0);
$table->integer('favorites_count')->default(0);
$table->integer('likes_count')->default(0);
$table->integer('followers_count')->default(0);
$table->integer('followings_count')->default(0);
$table->string('api_token', 64)->unique();
// 注意这里需要mysql5.7以上 支持json格式
$table->json('settings')->nullable();
$table->rememberToken();
$table->timestamps();
});
}- 执行
php artisan migrate生成user table
-
Laravel是自带登录,忘记密码,找回密码等auth相关的逻辑的,执行
php artisan make:auth就会多出来这些相关文件,具体 参见。页面的右上角就能看到注册,登录的链接了。 -
配置邮箱,使用上面的Laravel-SendCloud
-
修改注册逻辑,修改
RegisterController.php的create方法
protected function create(array $data)
{
$user = User::create([
'name' => $data['name'],
'email' => $data['email'],
// TODO 通过配置读取
'avatar' => '/images/avatars/default.png',
'confirmation_token' => str_random(40),
'password' => bcrypt($data['password']),
'api_token' => str_random(60),
'settings' => ['city' => '']
]);
// 发送激活邮件
$this->sendVerifyEmailToUser($user);
\Flash::success('一封激活邮件已发送到 '.$data['email'].' 请激活');
return $user;
}https://github.com/laracasts/flash
该扩展用于方便的输出提示信息

\app\Http\Controllers\Auth\LoginController.php
大致添加如下: /**
* Handle a login request to the application.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\RedirectResponse|\Illuminate\Http\Response
*/
public function login(Request $request)
{
$this->validateLogin($request);
// If the class is using the ThrottlesLogins trait, we can automatically throttle
// the login attempts for this application. We'll key this by the username and
// the IP address of the client making these requests into this application.
if ($this->hasTooManyLoginAttempts($request)) {
$this->fireLockoutEvent($request);
return $this->sendLockoutResponse($request);
}
if ($this->attemptLogin($request)) {
Flash::success('登录成功!');
return $this->sendLoginResponse($request);
}
// If the login attempt was unsuccessful we will increment the number of attempts
// to login and redirect the user back to the login form. Of course, when this
// user surpasses their maximum number of attempts they will get locked out.
$this->incrementLoginAttempts($request);
return $this->sendFailedLoginResponse($request);
}
/**
* Attempt to log the user into the application.
*
* @param \Illuminate\Http\Request $request
* @return bool
*/
protected function attemptLogin(Request $request)
{
$credentials = array_merge($this->credentials($request), ['is_active' => 1]);
return $this->guard()->attempt(
$credentials, $request->has('remember')
);
}默认下Laravel装好后使用的是英文
 错误消息也是英文的,如要翻译成中文其实非常简单。
复制/resouces/lang/en目录,在同级粘贴重命名为zh。
目录下有4个文件auth.php,validation.php等。你不用一个个翻译成中文,这里 有翻译好的,直接覆盖就可以了。
错误消息也是英文的,如要翻译成中文其实非常简单。
复制/resouces/lang/en目录,在同级粘贴重命名为zh。
目录下有4个文件auth.php,validation.php等。你不用一个个翻译成中文,这里 有翻译好的,直接覆盖就可以了。
app/Http/Middleware/VerifyCsrfToken.php]]>

总结 location目录后加"/",只能匹配目录,不加“/”不仅可以匹配目录还对目录进行模糊匹配。
而proxy_pass无论加不加“/”,代理跳转地址都直接拼接。为了加深大家印象可以用下面的配置实验测试下:
server {
listen 80;
server_name localhost;
# http://localhost/wddd01/xxx -> http://localhost:8080/wddd01/xxx
location /wddd01/ {
proxy_pass http://localhost:8080;
}
# http://localhost/wddd02/xxx -> http://localhost:8080/xxx
location /wddd02/ {
proxy_pass http://localhost:8080/;
}
# http://localhost/wddd03/xxx -> http://localhost:8080/wddd03*/xxx
location /wddd03 {
proxy_pass http://localhost:8080;
}
# http://localhost/wddd04/xxx -> http://localhost:8080//xxx,请注意这里的双斜线,好好分析一下。
location /wddd04 {
proxy_pass http://localhost:8080/;
}
# http://localhost/wddd05/xxx -> http://localhost:8080/hahaxxx,请注意这里的haha和xxx之间没有斜杠,分析一下原因。
location /wddd05/ {
proxy_pass http://localhost:8080/haha;
}
# http://localhost/api6/xxx -> http://localhost:8080/haha/xxx
location /wddd06/ {
proxy_pass http://localhost:8080/haha/;
}
# http://localhost/wddd07/xxx -> http://localhost:8080/haha/xxx
location /wddd07 {
proxy_pass http://localhost:8080/haha;
}
# http://localhost/wddd08/xxx -> http://localhost:8080/haha//xxx,请注意这里的双斜杠。
location /wddd08 {
proxy_pass http://localhost:8080/haha/;
}
}Let’s Encrypt 是一个非盈利的 CA 机构,目的是推动https的发展。 他们搞了一个非常有创意的事情,设计了一个 ACME 协议。 那为什么要创建 ACME 协议呢,传统的 CA 机构是人工受理证书申请、证书更新、证书撤销,完全是手动处理的。而 ACME 协议规范化了证书申请、更新、撤销等流程,只要一个客户端实现了该协议的功能,通过客户端就可以向 Let’s Encrypt 申请证书,也就是说 Let’s Encrypt CA 完全是自动化操作的。 任何人都可以基于 ACME 协议实现一个客户端,官方推荐的客户端是Certbot 。 Let’s Encrypt 支持两种证书,单域名和泛域名 为防止滥用,申请 Let’s Encrypt 证书的时候,需要校验域名的所有权,目前支持多种验证方式。 常见的是dns01:给域名添加一个 DNS TXT 记录
Certbot是可以生成的https证书的工具,要使用他,你需要保证:
- 懂一些命令行
- 一个http访问的站点,即已经安装并运行了服务器
- 80端口是开放的
- 可以通过SSH访问服务器
- 可以使用sudo 如果要配置泛域名证书,还需要知道域名的DNS提供商,并且可以修改DNS信息
- 安装 certbot
选择你的服务器和操作系统, 这里我选择Nginx服务器和Ubuntu18.04版本的操作系统 接着让你选择生成默认证书(单一域名)还是通配(泛域名)证书 这里我选择泛域名
sudo apt-get install software-properties-common
sudo add-apt-repository universe
sudo add-apt-repository ppa:certbot/certbot
sudo apt-get update
sudo apt-get install certbot- 生成证书
sudo certbot --server https://acme-v02.api.letsencrypt.org/directory -d *.example.com -d example.com --manual --preferred-challenges dns-01 certonly --agree-tos --manual-public-ip-logging-ok
修改example.com为实际的域名
会提示 ` Please deploy a DNS TXT record under the name _acme-challenge.example.com with the following value:
CqlWZaGWFSC1sj7Jww2juz9VJIzzJwWWoo-WUu-1Dow `
这时候需要去域名DNS管理后台添加相应记录,不要着急next回车,因为DNS生效可能要等5-10分钟 回车后,如果出现
` IMPORTANT NOTES:
-
Congratulations! Your certificate and chain have been saved at: /etc/letsencrypt/live/example.com/fullchain.pem Your key file has been saved at: /etc/letsencrypt/live/example.com/privkey.pem Your cert will expire on 2020-12-28. To obtain a new or tweaked version of this certificate in the future, simply run certbot again. To non-interactively renew all of your certificates, run "certbot renew"
-
If you like Certbot, please consider supporting our work by:
Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate Donating to EFF: https://eff.org/donate-le `
- 修改nginx配置,可以参考下面的配置,我的网站需要跑PHP
server {
root /var/html/www;
# Add index.php to the list if you are using PHP
index index.php index.html index.htm index.nginx-debian.html;
# 修改为泛域名
server_name *.example.com;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
# try_files $uri $uri/ =404;
try_files $uri $uri/ /index.php?$query_string;
}
location = /favicon.ico { access_log off; log_not_found off; }
location = /robots.txt { access_log off; log_not_found off; }
error_page 404 /index.php;
# pass PHP scripts to FastCGI server
#
location ~ \.php$ {
include snippets/fastcgi-php.conf;
#
# # With php-fpm (or other unix sockets):
fastcgi_pass unix:/var/run/php/php7.2-fpm.sock;
# # With php-cgi (or other tcp sockets):
# fastcgi_pass 127.0.0.1:9000;
}
listen [::]:443 ssl ipv6only=on; # managed by Certbot
listen 443 ssl; # managed by Certbot
# 注意路径,改为刚才生成后显示的
ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
}
server {
# http 转 https重定向
rewrite ^(.*) https://$host$1 permanent;
listen 80 default_server;
listen [::]:80 default_server;
server_name *.course.intogolf.nl;
return 404; # managed by Certbot
}-
sudo nginx -t 检查配置,无误后 sudo nginx -s reload
-
letsencrypt的证书有效期是三个月,可设置crontab自动任务进行更新
30 1 10 * * /usr/bin/certbot renew && /usr/sbin/nginx -s reload # 每月10日1点30分执行一次先which certbot确定certbot实际的位置
参考
https://certbot.eff.org/lets-encrypt/ubuntubionic-nginx
]]>覆盖发布和非覆盖发布的区别
- 覆盖发布: 前端项目打包后每次产生相同的文件名,发布至服务器时,同名文件直接替换,新文件添加。
- 非覆盖式发布: 采用更新文件名的形式,比如采用webpack的[id].[chunkhash].js的形式,这样更新文件后,新文件不会影响旧文件的存在。
覆盖式发布的缺点:
先更新页面再更新静态资源 新页面里加载旧的资源,页面和资源对应不上,会有页面混乱,还有执行会报错。 先更新静态资源再更新页面 在静态资源更新完成,页面没有被更新过程中,有缓存的用户是正常的。这个时候读本地的缓存,但是如果没有缓存的用户会怎样?依然是会页面混乱和执行错误,因为在旧的页面加载新资源。
无论如何,覆盖式发布都是能被用户感知到的,所以部分公司的发布是晚上上线。其中如果使用vue-cli直接生成webpack配置打包的话,直接发布dist文件夹下资源就会产生这种特殊的替换问题,因为在build.js文件中存在这么一行代码,初衷应该是防止dist文件夹越来越大,但是rimraf模块会递归删除目录所有文件,没有详细了解过vue-cli生成编译环境的人,就默认的采用了这种旧资源删除新资源生成。
// build.js
rm(path.join(config.build.assetsRoot, config.build.assetsSubDirectory), err => {
...
})接下来讲了下,我更新的发布模式。
nginx的静态文件缓存策略
静态资源html不使用缓存,每次加载均从服务器中拉取最新的html文件 静态资源js/css/图片资源,采取强缓存策略,这个时间可以尽可能的长一些,因为是非覆盖式发布,所以如果html中加载资源URI更新,那么资源也会统一的更新
nginx可以对不同文件进行不同的缓存策略,大致配置如下(需要注意location匹配的优先级):
location ~ .*\.(?:jpg|jpeg|gif|png|ico|cur|gz|svg|svgz|mp4|ogg|ogv|webm)$
{
expires 7d;
}
location ~ .*\.(?:js|css)$
{
expires 7d;
}
location ~ .*\.(?:htm|html)$
{
add_header Cache-Control "private, no-store, no-cache, must-revalidate, proxy-revalidate";
}然后发布的时候先将除html文件移动至发布路径,同名文件默认跳过,新生成的文件会产生新的hash,新旧文件不会冲突,共存在发布路径。 html文件的更新当时做了两种方案
- html完全由前端管理,前端发布的时候会有html文件,webpack打包时自动在html里写文件名;
- html由后端管理(服务器渲染),前端只负责发布js、css等资源文件。在前端发布之后,后端修改版本号再发布;
但一旦设置为监听其他端口,就一直跳转不正常;如,访问欢迎页面时应该是重定向到登录页面,在这个重定向的过程中端口丢失了。 这里给出一个简短的解决方案,修改nginx的配置文件。
- 一、配置文件
server {
listen 90;
server_name zxy1994.cn;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Server $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host:$server_port; # 这里是重点,这样配置才不会丢失端口
location / {
proxy_pass http://127.0.0.1:9001;
}
location = /50x.html {
root html;
}
}- 二、产生的原因
nginx没有正确的把端口信息传送到后端,没能正确的配置nginx,下面这行是关键
proxy_set_header Host $host:$server_port; 这一行是关键。
中间件的写法
支持 callback1,callback2、[callback1, callback2]、function callback(req, res, next) 或混合写法
function cb1(req, res, next) {
console.log('--cb1--');
next();
}
function cb2(req, res, next) {
console.log('--cb2--');
next();
}
app.get('/',
cb1, [cb2],
(req, res, next) => {
console.log('--cb3--');
next();
},
(req, res, next) => {
res.send('hello');
});middleware之间传值
使用 res.locals.key=value;
app.use(function(req, res, next) {
res.locals.user = req.user;
res.locals.authenticated = ! req.user.anonymous;
next();
});传给下一个
app.use(function(req, res, next) {
if (res.locals.authenticated) {
console.log(res.locals.user.id);
}
next();
});表单提交及json格式提交
var express = require('express');
var app = express();
var bodyParser = require('body-parser');
// 支持解析json格式
app.use(bodyParser.json());
// 支持解析 application/x-www-form-urlencoded 编码,就是表单提交
var urlencodedParser = bodyParser.urlencoded({ extended: false })
// 这个urlencodedParser必须带,不然 request.body 为 undefined
app.post('/', urlencodedParser, function(request, response) {
console.dir(request.body);
response.send('It works');
}
});-
不带 app.use(bodyParser.json()); 不支持下面的提交
 也就是
也就是
Content-Type: application/json -
带 var urlencodedParser = bodyParser.urlencoded({ extended: false })

参考: http://expressjs.com/en/resources/middleware/body-parser.html
]]>Node 单线程,远离多线程死锁,状态同步等问题。
利用异步io,让单线程远离阻塞,以更好的充分利用cpu。需要强调,这里得单线程仅仅是JS执行在单线程罢了。在node中,无论是*nix还是Windows平台,内部完成io任务的另有线程池。
Node的循环机制,启动时又一个死循环,每执行一次循环体称为Tick。每次循环处理事件。如果事件存在回调则处理回调。接着处理下一个事件。
在Node中,事件来源有网络请求,文件io等。
事件循环时典型的生产者/消费者模型,异步io,网络请求是生产者,源源不断等为node提供不同的事件,这次事件被传递导对应的观察者那里,事件循环则从观察者那里取出事件并处理
- Node8起新增了 util.promisify() 方法,可以快捷的把原来的异步回调方法改成返回 Promise 实例。
举例1
const util = require('util');
const fs = require('fs');
const readFileAsync = util.promisify(fs.readFile);
fileResult = await readFileAsync(sourcePathFile);举例2
/**
* 执行 shell 返回 Promise
*/
async function execShell(scriptPath) {
const execFile = require('util').promisify(require('child_process').execFile);
return await execFile('sh', [scriptPath]);
}- module.exports 与 exports 的区别 先看下面的例子
**test.js**
var a = {name: 1};
var b = a;
console.log(a);
console.log(b);
b.name = 2;
console.log(a);
console.log(b);
var b = {name: 3};
console.log(a);
console.log(b);
运行 test.js 结果为:
{ name: 1 }
{ name: 1 }
{ name: 2 }
{ name: 2 }
{ name: 2 }
{ name: 3 }解释:a 是一个对象,b 是对 a 的引用,即 a 和 b 指向同一块内存,所以前两个输出一样。当对 b 作修改时,即 a 和 b 指向同一块内存地址的内容发生了改变,所以 a 也会体现出来,所以第三四个输出一样。当 b 被覆盖时,b 指向了一块新的内存,a 还是指向原来的内存,所以最后两个输出不一样。
同理 exports 是 module.exports 的引用。 当 module.exports 属性被一个新的对象完全替代时,也会重新赋值 exports 如果你觉得用不好可以只使用module.exports
Event Loop
event loop是一个执行模型,在不同的地方有不同的实现。浏览器和NodeJS基于不同的技术实现了各自的 Event Loop。 可以简单理解为不断执行的死循环 浏览器的Event Loop是在 html5 的规范中明确定义。 NodeJS的Event Loop是基于libuv实现的。可以参考 Node 的官方文档以及 libuv 的官方文档。 libuv已经对Event Loop做出了实现,而HTML5规范中只是定义了浏览器中Event Loop的模型,具体的实现留给了浏览器厂商。
Events
Events 是 Node.js 中一个非常重要的 core 模块, 在 node 中有许多重要的 core API 都是依赖其建立的. 比如 Stream 是基于 Events 实现的, 而 fs, net, http 等模块都依赖 Stream, 所以 Events 模块的重要性可见一斑。
通过继承 EventEmitter 来使得一个类具有 node 提供的基本的 event 方法, 这样的对象可以称作 emitter,而触发(emit)事件的 cb 则称作 listener。与前端 DOM 树上的事件并不相同, emitter 的触发不存在冒泡, 逐层捕获等事件行为, 也没有处理事件传递的方法。
Node.js 中 Eventemitter 的 emit 是同步的。
例1:
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('myEvent', () => {
console.log('1');
});
emitter.on('myEvent', () => {
console.log('2');
});
emitter.emit('myEvent');执行结果是 1, 2
例2: 会发生死循环
const EventEmitter = require('events');
let emitter = new EventEmitter();
emitter.on('myEvent', () => {
console.log('hi');
emitter.emit('myEvent');
});
// 只出现一次
console.log("1")
emitter.emit('myEvent');
// 永远不会发生
console.log("down")例3 在使用node的mongoose模块中,项目中有如下代码: 如何实现的呢?
const mongoose = require('mongoose');
// MongoDB connect
function mongoDBConnect() {
mongoose.connect(`${config.mongo.url}${config.mongo.database}`);
return mongoose.connection;
}
mongoDBConnect()
.on('error', console.error.bind(console, 'connection error:'))
.on('disconnected', () => console.log('mongodb disconnected'))
.once('open', () => console.log('mongodb connection successful'));翻了 源码
最关键的一行是让Connection继承自EventEmitter。
Connection.prototype.__proto__ = EventEmitter.prototype;
const EventEmitter = require('events').EventEmitter;
// connectionState start
const STATES = Object.create(null);
const disconnected = 'disconnected';
const connected = 'connected';
const connecting = 'connecting';
STATES[0] = disconnected;
STATES[1] = connected;
STATES[2] = connecting;
STATES[disconnected] = 0;
STATES[connected] = 1;
STATES[connecting] = 2;
// connectionState end
function Connection() {
this.states = STATES;
this._readyState = STATES.disconnected;
}
// 这行非常关键,继承 EventEmitter
Connection.prototype.__proto__ = EventEmitter.prototype;
Object.defineProperty(Connection.prototype, 'readyState', {
get: function() {
return this._readyState;
},
set: function(val) {
if (!(val in STATES)) {
throw new Error('Invalid connection state: ' + val);
}
if (this._readyState !== val) {
this._readyState = val;
this.emit(STATES[val]);
}
}
});
Connection.prototype.onOpen = function() {
this.readyState = STATES.connected;
this.emit('open');
};
let conn = new Connection();
conn.on('connected', () => {
console.log("1");
});
conn.on('open', () => {
console.log("open!!");
});
conn.readyState = 1
conn.readyState = 2
conn.onOpen();面试相关
]]>PM2 的功能不多做介绍了,总之使用简单,功能强大。 今天实现了本地自动部署node项目到服务器的流程。简单总结下几个注意点。 建议先看 文档
- 先要保证要部署的服务器上(以下简称server)能直接ssh拉仓库代码,比如
git clone [email protected]:finley/demo.git。不行的话配下server生成ssh-key,然后把public key存到代码仓库服务商,比如coding.net, github。 - 权限问题,比如服务器的登录用户是ubuntu,将来项目要部署在/home/ubuntu下面,可以执行下
sudo chown ubuntu:ubuntu /home/ubuntu/.pm2/*不然可能会部署失败。 - 部署成功后会在配置的项目路径里出现以下三个目录:
current -- 当前服务运行的文件夹(是source的软链接) share -- log pid 等共享数据 source -- clone 下来的源代码
- 配置脚本
module.exports = {
/**
* Application configuration section
* http://pm2.keymetrics.io/docs/usage/application-declaration/
*/
apps : [
{
name : 'NODE-API',
script : 'server.js',
// 这里是公共变量
env: {
SERVER_PORT: 8081,
},
env_development: {
NODE_ENV: 'development',
},
env_production : {
NODE_ENV: 'production',
}
}
],
/**
* Deployment section
* http://pm2.keymetrics.io/docs/usage/deployment/
*/
deploy : {
// 项目信息
// 下面的配置是我用什么用户登录哪个服务器,从哪拉代码,项目存到什么位置。拉完执行的脚本是啥
'master' : {
user : 'ubuntu',
// 写成数组,可以同时部署到多台服务器
host : '119.254.xxx.xxx',
ref : 'origin/master',
repo : 'ssh://[email protected]/demo.git',
// 项目的存放地址,会生成current, source, share目录
path : '/home/ubuntu/node-project',
// "ssh_options": ["StrictHostKeyChecking=no", "PasswordAuthentication=no"],
"post-deploy" : 'npm install && pm2 startOrRestart ecosystem.config.js --env production'
}
}
};- 执行命令, 如果是windows,在CMD中执行没用,建议在 git bash下执行。
先初始化下,这里会尝试远程登录服务器并建立项目目录,如果失败通常是ssh问题。
所以先在服务器上试试git clone能否成功,如果拉不下来,考虑服务器防火墙限制或ssh配置
pm2 deploy ecosystem.config.js master setup这个命令只是拉仓库代码pm2 deploy ecosystem.config.js master这个命令会执行 配置文件的 post-deploy 部分,最终运行项目
pm2 reload 和pm2 restart 有啥区别
官方说明:As opposed to restart, which kills and restarts the process, reload achieves a 0-second-downtime reload. 简单理解: restart = stop+start reload 会更优雅一些 具体用哪个要根据项目运行实际情况,有些项目需要7*24运行,不得stop,这时候用reload比较好。
权限问题
使用 sudo pm2 start ecosystem.config.js 和 pm2 start ecosystem.config.js 启动项目是有区别的,前者用户可能是root,后者是当前用户。建议不加sudo启动。我们在服务器上操作pm2 list, pm2 logs非常频繁。如果非得加sudo和密码才能成功。
可以 sudo visudo 然后追加ubuntu ALL=(ALL) NOPASSWD:ALL ubuntu 是不希望输入密码的用户名。
默认morgan没有提供记录请求参数和请求内容的方法, 但是他提供了扩展方法,如下:
morgan.token('requestParameters', function(req, res){
return JSON.stringify(req.query) || '-';
});
morgan.token('requestBody', function(req, res){
return JSON.stringify(req.body) || '-';
});
// create custom format,includes the custom token
morgan.format('live-api', ':method :url :status :requestParameters :requestBody');
app.use(morgan('live-api'));输出日志到数据库或将日志作为参数发送到其他请求
默认日志信息是输出到命令行窗口中,能否输出到文件或数据库中呢?答案是肯定的 定义morgan的options中有个stream配置项,我们可以利用他做文章。
const request = require('request')
const split = require('split')
// 将日志信息作为请求参数传给其他地址,比如 Elasticsearch 日志分析系统
let httpLogStream = split().on('data', function (line) {
request({
url: 'localhost://192.168.1.1:8080',
method: 'POST',
body: line
})
.on('response', function(response) {
console.log(response.statusCode) // 200
})
});
app.use(morgan('common', {
stream: httpLogStream
}));
// 将日志写入数据库
// 带write方法的对象
let dbStream = {
write: function(line){
saveToDatabase(line); // 伪代码,保存到数据库
}
};
// 将 dbStream 作为 stream 配置项的值
app.use(morgan('short', {stream: dbStream}));node-modules/.bin/mocha --version, npx 的原理很简单,就是运行的时候,会到node_modules/.bin路径和环境变量$PATH里面,检查命令是否存在。npx create-react-app my-react-app1. 说说 PSR规范 (PHP Standard Recommendations)
https://learnku.com/docs/psr, 比较重要的规范是PSR-4 自动加载规范
2. new static() 和 new self() 的区别
两个都是new对象
- 他们的区别只有在继承中才能体现出来,如果没有任何继承,那么这两者是没有区别的。
- new self()返回的实例是万年不变的,无论谁去调用,都返回同一个类的实例,而new static()则是由调用者决定的。
class Father {
public function getNewFather() {
return new self();
}
public function getNewCaller() {
return new static();
}
}
class Sun1 extends Father {
}
class Sun2 extends Father {
}
$sun1 = new Sun1();
$sun2 = new Sun2();
// Father
print get_class($sun1->getNewFather());
// Sun1
print get_class($sun1->getNewCaller());
// Father
print get_class($sun2->getNewFather());
// Sun2
print get_class($sun2->getNewCaller());get_class()方法是用于获取实例所属的类名。
3. ...可变数量
<?php
function sum(...$numbers) {
$acc = 0;
foreach ($numbers as $n) {
$acc += $n;
}
return $acc;
}
echo sum(1, 2, 3, 4);
echo sum(1,2,3,4,5,6)4. 兼容数组和多参数的写法
这是Laravel文件系统中删除文件方法的源码 如果删除多个文件,可以传数组或多个参数
public function delete($paths)
{
$paths = is_array($paths) ? $paths : func_get_args();
$success = true;
foreach ($paths as $path) {
try {
if (! @unlink($path)) {
$success = false;
}
} catch (ErrorException $e) {
$success = false;
}
}
return $success;
}总结:该函数接受可变数量的参数。参数将作为数组传递给给定变量
]]>function setAge(int $age) {
var_dump($age);
}
// 要求传入参数是整型
// echo setAge('dwdw');
// Fatal error: Uncaught TypeError: Argument 1 passed to setAge() must be of the type integer, string given...
// 注意这么写不会报错
echo setAge('1');- 返回值类型声明
class User {}
function getUser() : array {
return new User;
}
// Fatal error: Uncaught TypeError: Return value of getUser() must be of the type array, object returned
var_dump(getUser());
// 改成下面不会报错
function getUser() : User {
return new User;
}
// 如果返回的类型不对
function getUser() : User {
return [];
}
// 会报
// Fatal error: Uncaught TypeError: Return value of getUser() must be an instance of User, array returned
// 再来个interface的例子, 执行下面的不会报错
interface SomeInterFace {
public function getUser() : User;
}
class User {}
class SomeClass implements SomeInterFace {
public function getUser() : User {
return [];
}
}
// 但是当调用的时候才会检查返回类型
// Fatal error: Uncaught TypeError: Return value of SomeClass::getUser() must be an instance of User, array returned
(new SomeClass)->getUser();- 太空船操作符(组合比较符)
太空船操作符用于比较两个表达式。当$a小于、等于或大于$b时它分别返回-1、0或1
// Integers
echo 1 <=> 1; // 0
echo 1 <=> 2; // -1
echo 2 <=> 1; // 1// 在usort自定义排序方法中很好用
$arr = ['c', 'd', 'b', 'a'];
// ['a', 'b', 'c', 'd']
usort($arr, function($a, $b) {
return $a <=> $b;
});- Null合并运算符
PHP7之前:
isset($_GET['id']) ? $_GET['id'] : 'err';
PHP7之后:
$_GET['id'] ?? 'err';
- use 批量声明
PHP7之前:
use App\Model\User;
use App\Model\Cart;
use App\Model\Base\BaseUser;PHP7之后:
use App\Model\{
User,
Cart,
Base\BaseUser
};- 匿名类
class SomeClass {}
interface SomeInterface {}
trait SomeTrait {}
var_dump(new class(10) extends SomeClass implements SomeInterface {
private $num;
public function __construct($num)
{
$this->num = $num;
}
use SomeTrait;
});
// 输出
object(class@anonymous)[1]
private 'num' => int 107.2 之后要注意的地方
- each 函数 在php7.2已经设定为过时
<?php
$b = array();
each($b);
// Deprecated: The each() function is deprecated. This message will be suppressed on further calls兼容方法
function fun_adm_each(&$array){
$res = array();
$key = key($array);
if($key !== null){
next($array);
$res[1] = $res['value'] = $array[$key];
$res[0] = $res['key'] = $key;
}else{
$res = false;
}
return $res;
}- count 函数在php7.2将严格执行类型区分. 不正确的类型传入, 会引发一段警告.
count方法使用非常广泛,升级7.2后多注意测试。
<?php
count('');
// Warning: count(): Parameter must be an array or an object that implements Countable兼容方法
function fun_adm_count($array_or_countable,$mode = COUNT_NORMAL){
if(is_array($array_or_countable) || is_object($array_or_countable)){
return count($array_or_countable, $mode);
}else{
return 0;
}
}- create_function创建匿名方法不鼓励使用。
参考:
https://laracasts.com/series/php7-up-and-running http://php.net/manual/zh/language.oop5.anonymous.php https://www.cnblogs.com/phpnew/p/7991572.html
]]>
假设用户在浏览器地址栏输入http://www.test.com/index.php发起一个请求, 然后:
- 域名被DNS解析到Nginx管理进程(Master process)所在的服务器IP。
- Nginx管理进程选择一个工作进程(Worker process)。
- Nginx工作进程把请求转发到PHP-FPM管理进程(默认是9000端口)。
- PHP-FPM管理进程分配一个工作进程处理index.php请求。
- 工作进程在服务器路径中找到index.php文件,解析编译。
- 执行PHP代码,可能还要请求后端存储等。
得到请求的结果,先返回给Nginx,然后再返回给用户浏览器。PHP-FPM管理进程不仅要负责分配PHP请求给工作进程,同时也要控制工作进程的创建、结束和启停。 单个PHP工作进程服务完若干个请求后会结束进程,释放资源,管理进程再启动新的工作进程。 PHP多进程模式中内存等资源管理将由工作进程自行分配,满足一定的条件后重启工作进程会自动释放内存,即使内存泄漏也不会造成严重的问题,也不会出现多线程死锁的问题。 所以PHP的可靠性较高,系统运行也更稳定,多进程需要不断地分配和回收进程资源,且需要消耗比线程模式更多的资源。 多进程在大规模集群下的可扩展性很好,只需要简单地增加机器或增加进程即可实现扩展。
]]> orm:
entity_managers:
default:
filters:
softdeleteable:
class: Gedmo\SoftDeleteable\Filter\SoftDeleteableFilter
enabled: true并且在最下面的启用
stof_doctrine_extensions:
orm:
default:
softdeleteable: true- 修改要使用软删除功能的setting 在Class上头添加
use Gedmo\Mapping\Annotation as Gedmo;
@Gedmo\SoftDeleteable(fieldName="deleted_at", timeAware=false)/然后配置字段, 注意字段名要一致
/**
* @ORM\Column(type="datetime", nullable=true)
*/
private $deleted_at;参考: https://symfony.com/doc/master/bundles/StofDoctrineExtensionsBundle/index.html https://www.cnblogs.com/wlemory/p/5224482.html
]]>Symfony中一般有两种方法:
- 使用 doctrine 的事件机制
- 使用 doctrine-extensions-bundle 类库提供的 timestampable 功能。
第一种,比较麻烦你需要在每个entity文件中定义时间类型的set,get方法还有,调用PrePersist 和 PreUpdate 生命周期钩子的方法。 例子如下:
<?php
namespace Finley\BlogBundle\Entity;
use Doctrine\ORM\Mapping as ORM;
/**
* Setting
*
* @ORM\Table(name="setting")
* @ORM\Entity(repositoryClass="Finley\BlogBundle\Repository\SettingRepository")
* 不要忘了这行, 表示启用声明周期钩子
* @ORM\HasLifecycleCallbacks
*/
class Setting
{
/**
* @var int
*
* @ORM\Column(name="id", type="integer")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
private $id;
/**
* @var \DateTime $created
*
* @ORM\Column(type="datetime", nullable=true)
*/
private $created;
/**
* @var \DateTime $updated
*/
private $updated;
public function setCreated($created)
{
$this->created = $created;
return $this;
}
public function getCreated()
{
return $this->created;
}
public function getUpdated()
{
return $this->updated;
}
public function setUpdated($updated)
{
$this->updated = $updated;
return $this;
}
/**
* 自动更新时间类型,不要忘了在 Class 上面加注解 ORM\HasLifecycleCallbacks
*
* @ORM\PrePersist
* @ORM\PreUpdate
*/
public function updatedTimestamps()
{
$this->setUpdated(new \DateTime('now'));
if ($this->getCreated() == null) {
$this->setCreated(new \DateTime('now'));
}
}
}第二种:
需要安装配置 doctrine-extensions-bundle
我因为对 Symfony 还不熟悉,所以花了一些时间。
在config.yml中,原来的内容是
orm:
auto_generate_proxy_classes: '%kernel.debug%'
naming_strategy: doctrine.orm.naming_strategy.underscore
auto_mapping: true # 默认是在 Entity 命名空间下找 entity 文件需要定义如何找entity文件,FinleyBlogBundle是我的自定义Bundle。
orm:
entity_managers:
default:
mappings: # php bin/console doctrine:mapping:info
FinleyBlogBundle:
type: annotation
prefix: Finley\BlogBundle\Entity
is_bundle: true
gedmo_translatable:
type: annotation
prefix: Gedmo\Translatable\Entity
dir: "%kernel.root_dir%/../vendor/gedmo/doctrine-extensions/lib/Gedmo/Translatable/Entity"
alias: GedmoTranslatable # (optional) it will default to the name set for the mapping
is_bundle: false
gedmo_translator:
type: annotation
prefix: Gedmo\Translator\Entity
dir: "%kernel.root_dir%/../vendor/gedmo/doctrine-extensions/lib/Gedmo/Translator/Entity"
alias: GedmoTranslator # (optional) it will default to the name set for the mapping
is_bundle: false
gedmo_loggable:
type: annotation
prefix: Gedmo\Loggable\Entity
dir: "%kernel.root_dir%/../vendor/gedmo/doctrine-extensions/lib/Gedmo/Loggable/Entity"
alias: GedmoLoggable # (optional) it will default to the name set for the mapping
is_bundle: false
gedmo_tree:
type: annotation
prefix: Gedmo\Tree\Entity
dir: "%kernel.root_dir%/../vendor/gedmo/doctrine-extensions/lib/Gedmo/Tree/Entity"
alias: GedmoTree # (optional) it will default to the name set for the mapping
is_bundle: false同时,记得在最下面添加,开启功能
stof_doctrine_extensions:
orm:
default:
timestampable: true然后entity文件就清爽了许多,只需为create和update添加注解。不需要set和get方法了。
/**
* @var \DateTime $created
*
* @Gedmo\Timestampable(on="create")
* @ORM\Column(type="datetime", nullable=true)
*/
private $created;
/**
* @var \DateTime $updated
*
* @Gedmo\Timestampable(on="update")
* @ORM\Column(type="datetime", nullable=true)
*/
private $updated;有个小细节: 使用第一种方法,只要执行update更新,updated字段的值就会改变。 而使用第二种方法,如果更新之后影响的行数 afftectd rows 是0,updated字段的值不会发生改变。
参考: https://www.doctrine-project.org/projects/doctrine-orm/en/current/tutorials/getting-started.html https://symfonycasts.com/screencast/symfony2-ep3/doctrine-extensions
]]>核心概念: bundle:类似插件
核心文件: app/AppKernel.php 查看注册的bundle,及在不同环境下加载的bundle
]]>概念理解: bundle entity doctrine
流程:
-
在配置文件配置数据库信息
-
命令生成bundle文件
-
命令生成bundle的entity文件
-
写CURD
-
配置数据库 /app/config/parameters.yml

为保证数据库字符集 app/config/config.yml

-
执行
php bin/console doctrine:database:create数据库就创建好啦~ -
创建一个 Entity 类 进到命令交互终端
php bin/console doctrine:generate:entity

首先让你输入Entity名称,输入首字母会有自动提示哦。 entity 有点类似模型, 表名 setting 字段 field, data,
不想添加新字段的话直接在 press <return> 处回车。
多了两个文件 /src/Finley/BlogBundle/Entity/Setting.php
<?php
namespace Finley\BlogBundle\Entity;
use Doctrine\ORM\Mapping as ORM;
/**
* Setting
*
* @ORM\Table(name="setting")
* @ORM\Entity(repositoryClass="Finley\BlogBundle\Repository\SettingRepository")
*/
class Setting
{
/**
* @var int
*
* @ORM\Column(name="id", type="integer")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
private $id;
/**
* @var string
*
* @ORM\Column(name="field", type="string", length=255, unique=true)
*/
private $field;
/**
* @var string
*
* @ORM\Column(name="data", type="string", length=255)
*/
private $data;
/**
* Get id
*
* @return int
*/
public function getId()
{
return $this->id;
}
/**
* Set field
*
* @param string $field
*
* @return Setting
*/
public function setField($field)
{
$this->field = $field;
return $this;
}
/**
* Get field
*
* @return string
*/
public function getField()
{
return $this->field;
}
/**
* Set data
*
* @param string $data
*
* @return Setting
*/
public function setData($data)
{
$this->data = $data;
return $this;
}
/**
* Get data
*
* @return string
*/
public function getData()
{
return $this->data;
}
}/src/Finley/BlogBundle/Repository/SettingRepository.php
<?php
namespace Finley\BlogBundle\Repository;
/**
* SettingRepository
*
* This class was generated by the Doctrine ORM. Add your own custom
* repository methods below.
*/
class SettingRepository extends \Doctrine\ORM\EntityRepository
{
}- 根据 entity 定义文件生成真正的表,
可以先用下面的命令打印出SQL,不真正执行
php bin/console doctrine:schema:create --dump-sql。 然后php bin/console doctrine:schema:create
官方建议如果后期要修改表结构,不建议直接修改entity文件,通过新建迁移文件的方式
问题:
- entity 加入 created_at, updated_at
- 定义 relation
参考: https://symfony.com/doc/3.4/doctrine.html https://symfony.com/doc/current/bundles/DoctrineMigrationsBundle/index.html
]]>假设 用户的权限 为 $myPrivilege = 15;
权限表为 array(8 => '增',4 => '改', 2 => '删', 1 => '查' );
8 =》 1 0 0 0
4 =》 0 1 0 0
2 =》 0 0 1 0
1 =》 0 0 0 1我们要知道用户有哪些权限,可以怎么做?
我们都知道 所有数据在计算机中都是二进制表示 15 换算成 二进制。就是 1111
1111 & 1000 只有最高位1相同,所以结果是 1000 即 8 同理 1111 & 0001 = 1 1111 & 0010 = 2 1111 & 0100 = 4 1111 & 1000 = 8
这里写的不太规范,注意二进制和十进制的转换
即用户拥有增删改查的权限。 我们可以展开 15 = 1 + 2 + 4 + 8;
那如果是 9 呢? 即 1 + 8。所以拥有查和赠权限
代码实现:
$myPrivilege = 15;
$privilegeArr = array(8=>'增', 4=>'删',2=>'改',1=>'查');
foreach($privilegeArr as $k => $v) {
$k * $myPrivilege && $Pri .= '我有' . $v . "权限<br>";
}
echo $Pri;Windows
在Windows,如果你是用的wamp。命令行模式用到的php.ini在apache2目录下,正常模式,如果你使用的php版本是7.2。则用到的php.ini在php7.2目录下。
MacOS
如果是用brew安装的PHP。跑的是fpm。
新建个test.php。内容 <?php phpinfo() ?>。浏览器运行。
会看到如下信息:
主配置文件是: /usr/local/etc/php/7.1/php.ini
额外的配置文件: /usr/local/etc/php/7.1/conf.d
 你还可以在
你还可以在 /usr/local/etc/php/7.1/php-fpm.d/www.conf 此文件下面定义配置项。这个文件被 [php-fpm.conf] 包含
- php-fpm.conf 是php-fpm进程服务的配置文件
######设置错误日志的路径
error_log = /var/log/php-fpm/error.log
######引入www.conf文件中的配置
include=/usr/local/php7.1/etc/php-fpm.d/*.confwww.conf这是php-fpm进程服务的扩展配置文件 (php-fpm.d目录下)

可修改范围

针对项目使用配置项
在项目入口目录新建 .user.ini
查看命令行模式下加载哪些ini文件

参考
http://php.net/configuration.file https://typecodes.com/web/php7configure.html
问题
mac下如何重启php-fpm?,我在
- /usr/local/etc/php/7.1/php-fpm.d/www.conf
- 项目入口目录下新建了 .user.ini
- /usr/local/etc/php/7.1/conf.d/php-memory-limits.ini
- /usr/local/etc/php/7.1/php.ini
- /usr/local/etc/php/7.1/conf.d/user.ini
上述5个配置文件都添加了 memory_limit 配置项,值分别是111M 到 555M
- 生效的是www.conf,然后去掉 www.conf 中的
memory_limit = 111M,重启brew services restart php71值依然是111,非常纳闷。要么不是这么重启,要么还有缓存? - 重启电脑后显示
memory_limit = 555M, 因为加载顺序。 user.ini 在 php-memory-limits.ini 后面把前面的覆盖了。
监测配置项是否被加载
var_dump(ini_get('curl.cainfo'));
- 开源,github上有源码
- 定制化比较高,特别是后台有个可视化功能很好用
而且还可以为页面添加自定义css和js。 直接线上编辑文件,添加 JS 或 CSS。
总结出的问题,针对7.1版本
- 编辑模板注意区分,桌面版和移动版

- 编辑移动版header的地址是 /system/tmp/template/mobile/block/header.html.php 比如想改logo,这里有个小bug

不过客户给我发了个 http://2070.wangzhan31.com/ 。。 一看就是流水线出来的,还有这个 http://m.hnjjjs.com/ 等于一个模子刻出来的。
]]>- 当做临时下载服务器
python -m http.server - 将JSON字符串换成JSON对象
echo '{"job":"developer","name":"lmx","sex":"male"}' I python -m json.tool, 其实没有浏览器console面板方便 - 检查第三方库是否安装
>>> import paramiko - 快速import
python -c 'import paramiko'
从源码安装第三方包
$ git clone https://github.com/paramilko/paramiko.git $ cd paramiko $ python setup.py install
IPython 交互式编程
特点:回车即显示结果,支持tab补全,语法高亮,行号显示
使用交互式编程,我们可以快速尝试不同的方案,先验证自己的想法是否正确,然后将代码拷贝到编辑器中,组成我们的 Python 程序文件。 通过这种方式,能够有效降低代码出错的概率,减少调试的时间,从而提高工作效率 。
IPython -- An enhanced Interactive Python - Quick Reference Card
================================================================
obj?, obj?? : Get help, or more help for object (also works as
?obj, ??obj).
?foo.*abc* : List names in 'foo' containing 'abc' in them.
%magic : Information about IPython's 'magic' % functions.
Magic functions are prefixed by % or %%, and typically take their arguments
without parentheses, quotes or even commas for convenience. Line magics take a
single % and cell magics are prefixed with two %%.
Example magic function calls:
%alias d ls -F : 'd' is now an alias for 'ls -F'
alias d ls -F : Works if 'alias' not a python name
alist = %alias : Get list of aliases to 'alist'
cd /usr/share : Obvious. cd -<tab> to choose from visited dirs.
%cd?? : See help AND source for magic %cd
%timeit x=10 : time the 'x=10' statement with high precision.
%%timeit x=2**100
x**100 : time 'x**100' with a setup of 'x=2**100'; setup code is not
counted. This is an example of a cell magic.学习模块
import os;
?os- %quickref 打开使用手册
- i, ii, iii 分别保存了最近的三次输入
- %lsmagic 列出所有的魔术函数
安装
本机环境 Mac 10.14, Python3
pip3 install scrapy
安装成功后 scrapy -h 查看包含的命令
安装过程中出现了一堆 error: unknown type name 'uint64_t' 错误
网上搜索 sudo mv /usr/local/include /usr/local/include_old
重新执行安装命令,安装成功后再恢复即可

创建一个项目
scrapy startproject tutorial
会生成以下文件
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py编写第一个爬虫
其实就是写一个类
创建文件 quotes_spider.py 放到 tutorial/spiders 目录
import scrapy
class QuotesSpider(scrapy.Spider):
# 爬虫名,唯一标示,会在命令行中用到
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)来到项目的根目录,执行scrapy crawl quotes
显示过程

结果:发现多出了两个 html 文件,等于我们把网页抓取下来了。
]]>scrapy shell 是 scrapy 提供的命令行工具,可以方便的调试
比如执行 scrapy shell "http://quotes.toscrape.com/page/1/"

提示我们会暴露出来很多有用的对象,比如response对象包含了css和xpath方法,可以进一步提取页面的title。

修改上节中建立的 quotes_spider.py
我们分别提取 text, author 和 tags
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
# ::text 选中文本节点
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}执行命令scrapy crawl quotes -o quotes.json
输出结果到 json 文件
结果类似:
[
{"text": "\u201cThe world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.\u201d", "author": "Albert Einstein", "tags": ["change", "deep-thoughts", "thinking", "world"]},
{"text": "\u201cIt is our choices, Harry, that show what we truly are, far more than our abilities.\u201d", "author": "J.K. Rowling", "tags": ["abilities", "choices"]},
{"text": "\u201cThere are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.\u201d", "author": "Albert Einstein", "tags": ["inspirational", "life", "live", "miracle", "miracles"]}, {"text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d", "author": "Jane Austen", "tags": ["aliteracy", "books", "classic", "humor"]}, {"text": "\u201cImperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.\u201d", "author": "Marilyn Monroe", "tags": ["be-yourself", "inspirational"]}, {"text": "\u201cTry not to become a man of success. Rather become a man of value.\u201d", "author": "Albert Einstein", "tags": ["adulthood", "success", "value"]}, {"text": "\u201cIt is better to be hated for what you are than to be loved for what you are not.\u201d", "author": "Andr\u00e9 Gide", "tags": ["life", "love"]}, {"text": "\u201cI have not failed. I've just found 10,000 ways that won't work.\u201d", "author": "Thomas A. Edison", "tags": ["edison", "failure", "inspirational", "paraphrased"]}, {"text": "\u201cA woman is like a tea bag; you never know how strong it is until it's in hot water.\u201d", "author": "Eleanor Roosevelt", "tags": ["misattributed-eleanor-roosevelt"]}, {"text": "\u201cA day without sunshine is like, you know, night.\u201d", "author": "Steve Martin", "tags": ["humor", "obvious", "simile"]}, {"text": "\u201cThis life is what you make it. No matter what, you're going to mess up sometimes, it's a universal truth. But the good part is you get to decide how you're going to mess it up. Girls will be your friends - they'll act like it anyway. But just remember, some come, some go. The ones that stay with you through everything - they're your true best friends. Don't let go of them. Also remember, sisters make the best friends in the world. As for lovers, well, they'll come and go too. And baby, I hate to say it, most of them - actually pretty much all of them are going to break your heart, but you can't give up because if you give up, you'll never find your soulmate. You'll never find that half who makes you whole and that goes for everything. Just because you fail once, doesn't mean you're gonna fail at everything. Keep trying, hold on, and always, always, always believe in yourself, because if you don't, then who will, sweetie? So keep your head high, keep your chin up, and most importantly, keep smiling, because life's a beautiful thing and there's so much to smile about.\u201d", "author": "Marilyn Monroe", "tags": ["friends", "heartbreak", "inspirational", "life", "love", "sisters"]}, {"text": "\u201cIt takes a great deal of bravery to stand up to our enemies, but just as much to stand up to our friends.\u201d", "author": "J.K. Rowling", "tags": ["courage", "friends"]}, {"text": "\u201cIf you can't explain it to a six year old, you don't understand it yourself.\u201d", "author": "Albert Einstein", "tags": ["simplicity", "understand"]}, {"text": "\u201cYou may not be her first, her last, or her only. She loved before she may love again. But if she loves you now, what else matters? She's not perfect\u2014you aren't either, and the two of you may never be perfect together but if she can make you laugh, cause you to think twice, and admit to being human and making mistakes, hold onto her and give her the most you can. She may not be thinking about you every second of the day, but she will give you a part of her that she knows you can break\u2014her heart. So don't hurt her, don't change her, don't analyze and don't expect more than she can give. Smile when she makes you happy, let her know when she makes you mad, and miss her when she's not there.\u201d", "author": "Bob Marley", "tags": ["love"]}, {"text": "\u201cI like nonsense, it wakes up the brain cells. Fantasy is a necessary ingredient in living.\u201d", "author": "Dr. Seuss", "tags": ["fantasy"]}, {"text": "\u201cI may not have gone where I intended to go, but I think I have ended up where I needed to be.\u201d", "author": "Douglas Adams", "tags": ["life", "navigation"]}, {"text": "\u201cThe opposite of love is not hate, it's indifference. The opposite of art is not ugliness, it's indifference. The opposite of faith is not heresy, it's indifference. And the opposite of life is not death, it's indifference.\u201d", "author": "Elie Wiesel", "tags": ["activism", "apathy", "hate", "indifference", "inspirational", "love", "opposite", "philosophy"]}, {"text": "\u201cIt is not a lack of love, but a lack of friendship that makes unhappy marriages.\u201d", "author": "Friedrich Nietzsche", "tags": ["friendship", "lack-of-friendship", "lack-of-love", "love", "marriage", "unhappy-marriage"]}, {"text": "\u201cGood friends, good books, and a sleepy conscience: this is the ideal life.\u201d", "author": "Mark Twain", "tags": ["books", "contentment", "friends", "friendship", "life"]},
{"text": "\u201cLife is what happens to us while we are making other plans.\u201d", "author": "Allen Saunders", "tags": ["fate", "life", "misattributed-john-lennon", "planning", "plans"]}
]也可以输出到 csv,如 scrapy crawl quotes -o quotes.csv

过程其实非常简单
- 新建项目
scrapy startproject book cd book; tree # 查看下项目结构- spiders 目录下新建文件
book_spider.py或者使用命令scrapy genspider books books.toscrape.com会生成 books.py文件
# -*- coding: utf-8 -*-
import scrapy
class BooksSpider(scrapy.Spider):
name = 'books'
allowed_domains = ['books.toscrape.com']
start_urls = ['http://books.toscrape.com/']
def parse(self, response):
pass- 分析 html 结构,先通过chrome的开发者工具的审查元素功能
结合命令行
scrapy shell "http://books.toscrape.com/"
更新 book_spider.py 为如下,内容非常简单
import scrapy
class BooksSpider(scrapy.Spider):
name = "books"
start_urls = [
'http://books.toscrape.com/',
]
def parse(self, response):
for book in response.css('article.product_pod'):
# 选择器可以通过命令行工具就行调试
yield {
# xpath 语法 @ATTR 为选中为名ATTR的属性节点
'name': book.xpath('h3/a/@title').get(),
'price': book.css('p.price_color::text').get(),
}- 测试输出结果
scrapy crawl books -o book.jl
jl 是 json line格式
- 为了完整抓取,来处理分页
class BooksSpider(scrapy.Spider):
# 爬取命令 scrapy crawl books
name = "books"
start_urls = [
'http://books.toscrape.com/',
]
def parse(self, response):
for book in response.css('article.product_pod'):
yield {
'name': book.xpath('h3/a/@title').get(),
'price': book.css('p.price_color::text').get(),
}
# 检查分页
# 提取下一页的链接
next_url = response.css('ul.pager li.next a::attr(href)').extract_first()
if next_url:
next_url = response.urljoin(next_url)
# 构造新的 Request 对象
yield scrapy.Request(next_url, callback=self.parse)解释 urljoin 是 response 对象提供的方法,传入相对地址生成绝对地址,然后再生成新的Request对象 Scrapy 本身不难,重点还是Python的基础
]]> def parse(self, response):
for book in response.css('article.product_pod'):
book_item = BookItem()
book_item['name'] = book.xpath('h3/a/@title').get(),
book_item['price'] = book.css('p.price_color::text').get(),
yield book_itemAnsible是用Python写的自动化运维工具,你如果需要管理维护好多主机,需要做批量操作,部署,任务等,他是个不错的选择。 Ansible是基于模块工作的,Ansible本身没有批量部署的能力。真正具有批量部署的是ansible所运行的模块。模块的内容会在后面重点介绍。

必备知识
想要高效的学习Ansible,必须熟悉某一发行的 Linux 系统 (Ubuntu, CentOS),至少需要了解以下内容。
- SSH连接远程服务器
- 基本的Bash命令
- 文件权限及处理
- 环境变量相关
- 简单的编写shell脚本
你还需要一台服务器,如果没有可以在本地新建虚拟机,我建议搭建至少两台,以便了解的Ansible的批处理能力。 搭建虚拟机非常简单,你可以搜一下VirtualBox和Vagrant。
Ansible特点
- 简单易学
- 使用SSH协议与受控机器进行通信,一般服务器默认有SSH服务,Ansible也被成为agentless(去客户端的)
- Ansible主要使用YAML格式作为自己的DSL格式及配置文件格式。
- Ansible自带很多模块,基于模块工作
Ansible将部署逻辑放在一个称为"playbook”的YAML文件中。通常,文件名是playbook.yml。
组织受控机器的逻辑被放在inventory文件中。它是ini格式的,默认文件名为hosts。
这两个文件构成了Ansible自动化部署的基础。
只要运行ansible-playbook --inventory hosts --user vagrant --ask pass playbook.ymI命令,输入SSH登录时用户vagrant的密码,就可以执行我们描述好的部署逻辑了。
为简单起见,我们使用用户名和密码的方式登录。更安全的方式是使用SSH密钥登录。
以上就是对Ansible的基本介绍。
如果想更深入地学习,请前往Ansible官网。
Ansible的隐喻
了解Ansible的隐喻对于了解Ansible背后的设计有一定的帮助。Ansible的隐喻很简单: Ansible是导演,受控机器列表(inventory) 为演员列表,开发者则是编剧。开发者只要把剧本(playbook.yml) 写好,Ansible拿着剧本与inventory一对上号,演员就会按照剧本如实表演,不会有任何个人发挥。
参考
]]>- 安装
brew install ansible或者使用pip3 install ansible
ansible --version
ansible [core 2.12.2]
config file = None
configured module search path = ['/Users/mafei/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/local/lib/python3.9/site-packages/ansible
ansible collection location = /Users/mafei/.ansible/collections:/usr/share/ansible/collections
executable location = /usr/local/bin/ansible
python version = 3.9.5 (default, May 4 2021, 03:36:27) [Clang 12.0.0 (clang-1200.0.32.29)]
jinja version = 3.0.3
libyaml = True- 创建主机清单文件
/etc/ansible/hosts - 添加要连接的 host 主机节点信息

格式如下: [主机组名称] ip:端口 ansible_user=登录的用户名 内容如下:
[cloud]
140.122.182.183:1234 ansible_user=ubuntu更高级的写法:
[dbs]
db-[a-f].example.com
[web]
www[1:100].example.comansible <host-pattern> [options]为一组主机运行单一task 下面的命令检查指定主机的连通性ansible all -m ping -vvv看能否访问到所有主机 也可以用指定主机ansible cloud -m ping -vvv
-m 等于 --module-name ping 就是模块名
可以使用
ansible-doc <模块名>查看模块的帮助信息。 如ansible-doc ping非常方便。
使用ping模块测试被管节点。能成功,说明ansible能控制该节点。
如果要指定非root用户运行ansible命令,则加上"--sudo"或"-s"来提升为sudo_user配置项所指定用户的权限。
ansible webservers -m ping -u ubuntu --sudo;或者使用 become 提升权限ansible webservers -m ping -b --become-user=root --become-method=sudo
- 我们更新下host文件,添加一组主机
[cloud]
140.122.182.183:1234 ansible_user=ubuntu
[fxa]
145.130.287.79:22 ansible_user=devuser
145.130.287.79:25 ansible_user=devuser
145.130.287.79:31 ansible_user=devuser也可以用下面的写法
[cloud]
40.122.182.183 ansible_port=1234 ansible_user=ubuntu
[merch]
mer22 ansible_host=145.130.287.79 ansible_port=22 ansible_user=devuser
mer25 ansible_host=145.130.287.79 ansible_port=25 ansible_user=devuser
mer31 ansible_host=145.130.287.79 ansible_port=31 ansible_user=devuser
[fuelx]
135.104.35.167 ansible_port=22 ansible_user=maf ansible_private_key_file=~/.ssh/github_id_rsa然后针对某主机进行操作
ansible mer31 -a uptime
mer31 | CHANGED | rc=0 >>
11:14:38 up 485 days, 15:52, 2 users, load average: 1.57, 0.58, 0.28
# 指定特定的hosts文件
ansible -i ~/.ansible/hosts cloud -a uptime相关工具

ansible安装完成后自带了很多工具,默认都保存在/usr/bin目录下 后面会介绍几个常用的
- ansible 主程序,临时命令执行工具
- ansible-playbook 命令,执行playbook
- ansible-doc 查看配置文档及模块使用
- ansible-galaxy 下载/上传优秀或Roles模块的官网平台 https://galaxy.ansible.com/
- ansible-playbook 定制自动化任务,编排剧本工具
- ansible-pull 远程执行命令的工具
- ansible-vault 文件加密工具
- ansible-console 基于Console界面与用户交互的工具
Ansible配置以ini格式存储配置数据,在 Ansible 中几乎所有配置都可以通过 Ansible 的 Playbook 或环境变量来重新赋值。 在运行 Ansible 命令时,命令将会按照以下优先级查找配置文件。
- ANSIBLE_CONFIG 这个环境变量所指向的配置文件。
- ./ansible.cfg:当前目录下的
ansible.cfg配置文件。 - ~/.ansible.cfg:检查当前用户家目录下的
.ansible.cfg配置文件。 - /etc/ansible/ansible.cfg:最后,将会检查在用软件包管理工具安装 Ansible 时自动产生的配置文件。
使用 ansible.cfg 来简化你的配置,使用
ansible-config dump查看配置信息 如果没有 ansible.cfg 文件,使用ansible-config init --disabled > ansible.cfg生成一个
大多数的Ansible参数可以通过设置带有 ANSIBLE_ 开头的环境变量进行配置,参数名称必须都是大写字母,如下配置:
export ANSIBLE_SUDO_USER=root
设置了环境变量之后, ANSIBLE_SUDO_USER 就可以在后续操作中直接引用。
ansible.cfg 配置文件
Ansible 有很多配置参数,以下是几个默认的配置参数:
inventory = /etc/ansible/hosts
library = /usr/share/my_modules/
forks = 5
sudo_user = root
remote_port = 22
host_key_checking = False
timeout = 20
log_path = /var/log/ansible.log- inventory :该参数表示inventory文件的位置,资源清单(inventory)就是Ansible需要连接管理的一些主机列表。
- library :Ansible的所有操作都使用模块来执行实现,这个library参数就是指向存放Ansible模块的目录。
- forks :设置默认情况下Ansible最多能有多少个进程同时工作,默认5个进程并行处理。具体需要设置多少个,可以根据控制端性能和被管理节点的数量来确定。
- sudo_user :设置默认执行命令的用户,也可以在playbook中重新设置这个参数。
- remote_port :指定连接被管理节点的管理端口,默认是22,除非设置了特殊的SSH端口,否则不需要修改此参数。
- host_key_checking :设置是否检查SSH主机的密钥。可以设置为True或False。即ssh的主机再次验证。
- timeout :设置SSH连接的超时间隔,单位是秒。
- log_path :Ansible默认不记录日志,如果想把Ansible系统的输出记录到日志文件中,需要设置log_path。需要注意,模块将会调用被管节点的(r)syslog来记录,执行Ansible的用户需要有写入日志的权限。
WARNING
建议使用Git等版本控制工具保管你的playbook和inventory文件
ansible 中的模块可以用在ansible命令行或后面要讲的playbook中。不同的模块提供不同的功能,官方提供的非常多,几千种,常用的有几十种,这里只介绍常见的几种模块。 模块是Ansible基本的可复用的单元。模块的功能范围很小,可能只针对某操作系统。
模块的幂等性
ansible绝大多数模块都天然具有 幂等 特性,只有极少数模块如shell和command模块不具备幂等性。所谓的幂等性是指多次执行同一个操作不会影响最终结果。例如,ansible的yum模块安装rpm包时,如果待安装的包已经安装过了,则再次或多次执行安装操作都不会真正的执行下去。再例如,copy模块拷贝文件时,如果目标主机上已经有了完全相同的文件,则多次执行copy模块不会真正的拷贝。ansible具有幂等性的模块在执行时,都会自动判断是否要执行。
自己编写的脚本有可能执行第二次的时候有可能带来不一样的意外或影响,而模块的幂等性可以降低一定的风险。
ansible-doc 命令

学习ansible模块时,可以先用ansible-doc命令,阅读相关模块的说明文档
比如我想通过ansible执行拷贝文件操作,先用ansible-doc -l | grep 'copy'过滤出所有包含copy的模块名。

ansible-doc copy 查看copy模块的使用详情

ansible-doc -s copy 查看copy模块的精简信息
常见模块命令

Ad-Hoc 执行方式,可以通过shell或者command模块来执行命令。一条条来执行
- -m 模块名称
- -a 模块参数
ansible-doc command
# 查看某服务器的内存使用情况
ansible myserver -m command -a "free -m"
# 可简写, 因为 command 是默认模块
ansible myserver -a "free -m"
# 模块包括 command, script(在远程主机执行主控端的shell脚本), shell (执行远程主机的shell脚本文件)
ansible myserver -m command -a "cat /etc/os-release"
# 先切换到目录再执行
ansible myserver -m command -a "chdir=/etc cat os-release"
# 用 command 模块执行不成功, shell 模块可以
ansible cloud -m command -a "sudo rm -rf /var/log/mysql/*.gz"
ansible cloud -m shell -a "sudo rm -rf /var/log/mysql/*.gz"
ansible myserver -m script -a "/home/local.sh"
ansible myserver -m shell -a "/home/server.sh"
# 实际上shell模块执行命令的方式是在远程使用/bin/sh来执行的
ansible merch -m shell -a "touch demo.txt"打开 ansible.cfg 搜索 module_name 可修改默认模块名
查看 shell 模块提供的参数
ansible-doc -s shell
- name: Execute commands in nodes.
shell:
chdir: # cd into this directory before running the command
# 执行命令前,先cd到指定目录
creates: # a filename, when it already exists, this step will *not* be run.
# 用于判断命令是否要执行。如果指定的文件(可以使用通配符)存在,则不执行。
executable: # change the shell used to execute the command. Should be an absolute path to the executable.
# 不再使用默认的/bin/sh解析并执行命令,而是使用此处指定的命令解析。例如使用expect解析expect脚本。必须为绝对路径。
free_form: # (required) The shell module takes a free form command to run, as a string. There's not an actual option
named "free form". See the examples!
removes: # a filename, when it does not exist, this step will *not* be run.
# 用于判断命令是否要执行。如果指定的文件(可以使用通配符)不存在,则不执行。
stdin: # Set the stdin of the command directly to the specified value.
warn: # if command warnings are on in ansible.cfg, do not warn about this particular line if set to no/false.例如:
tasks:
- shell: touch helloworld.txt creates=/tmp/hello.txt但建议,在参数可能产生歧义的情况下,使用args来传递ansible的参数。如:
- shell: touch helloworld.txt
args:
creates: /tmp/hello.txtCOPY 复制模块
实现主控端向目标主机拷贝文件,类似于scp的功能。 拷贝当前目录的 demo.png 到远程服务器的/home/ubuntu目录下,并修改文件权限
ansible cloud -m copy -a "src=demo.png dest=/home/ubuntu mode=755 owner=ubuntu"
# 指定内容,生成文件
ansible cloud -m copy -a "content='test line1\ntest line2' dest=/tmp/test.txt"
# src为本地文件内容 拷贝到远程服务器
ansible cloud -m copy -a "src=/etc/hosts dest=/tmp/test.txt"Fetch 模块
拷贝远程服务器的文件到本地, 会基于inventory创建目录
# 本地创建目录 `/Users/mafei/demo/49.232.138.70/etc`
ansible cloud -m fetch -a "src=/etc/hosts dest=~/demo"template 模块
template 模块用法和 copy 模块用法基本一致,它主要用于复制配置文件。
ansible-doc -s template
- name: Templates a file out to a remote server.
action: template
dest # 必填,拷贝到远程机器的目标路径
src # 必填,Ansible控制机模板文件所在位置
force # 是否覆盖同名文件
group # 设置远程文件的所属组
owner # 设置远程文件的所有者
mode # 设置远程文件权限,如 0644,'u+rw', 'u=rw,g=r,o=r' 等方式
backup # 拷贝的同时也创建一个包含时间戳信息的备份文件,默认为no类似的模块
- file # 文件处理模块,可以递归创建目录
- fetch # 拉取文件模块,从远程主机将文件拉取到本地端
- rsync # 实现rsync部分功能的模块
debug 模块
用于输出自定义的信息,类似于echo、print等输出命令。ansible中的debug主要用于输出变量值、表达式值,以及用于when条件判断时。使用方式非常简单。
ansible-doc -s debug
- name: Print statements during execution
debug:
msg: # The customized message that is printed. If omitted, prints a generic message.
# 输出自定义信息。如果省略,则输出普通字符。
var: # A variable name to debug. Mutually exclusive with the 'msg' option.
# 指定待调试的变量。只能指定变量,不能指定自定义信息,且变量不能加{{}}包围,而是直接的变量名。
verbosity: # A number that controls when the debug is run, if you set to 3 it will only run debug when -vvv or above
# 控制debug运行的调试级别,有效值为一个数值N。script 模块
script模块用于控制远程主机执行脚本。在执行脚本前,ansible会将本地脚本传输到远程主机,然后再执行。 在执行脚本的时候,其采用的是远程主机上的shell环境。
例如,将ansible端/tmp/a.sh发送到各被控节点上执行,但如果被控节点的/tmp下有hello.t xt ,则不执行。
- hosts: centos
remote_user: root
tasks:
- name: execute /tmp/a.sh,but only /tmp/hello.txt is not yet created
script: /tmp/a.sh hello
args:
creates: /tmp/hello.txtsetup 模块
自带模块,当执行playbook,会自动执行该模块,先收集主机信息过程,你会看到TASK [Gathering Facts]字样
这些不需要设置就可以直接使用的变量称为Facts变量
Facts变量可以实现更加个性化的功能需求,例如,将mysql的数据库备份到/var/db-<hostname>目录下
ansible cloud -m setup
# 列出很多服务器的系统信息
"ansible_distribution": "Ubuntu",
"ansible_distribution_file_parsed": true,
"ansible_distribution_file_path": "/etc/os-release",
"ansible_distribution_file_variety": "Debian",
"ansible_distribution_major_version": "20",
"ansible_distribution_release": "focal",
"ansible_distribution_version": "20.04",
"ansible_system_vendor": "Xen",
"ansible_uptime_seconds": 100758,
"ansible_user_dir": "/home/ubuntu",
"ansible_user_gecos": "Ubuntu",
"ansible_user_gid": 1000,
"ansible_user_id": "ubuntu",
"ansible_user_shell": "/bin/bash",
"ansible_user_uid": 1000,
"ansible_userspace_architecture": "x86_64",
"ansible_userspace_bits": "64",Facts:是由正在通信的远程目标主机发回的信息,这些信息被保存在ansible变量中。
后续学习playbook中,这些参数可以当做变量在yaml中使用,比如 include_vars: "{{ ansible_os_family }}.yml"
参考
模块非常多,有什么需求先去官网查,然后看文档,掌握常见的十来个模块即可 官方模块说明
]]>
使用 Ansible 时,绝大部分时间将花费在编写playbook上。 playbook 英文直译是剧本的意思,是一个Ansible术语,它指的是用于配置管理的脚本。
playbook 是 YAML 格式的,yaml格式可以很方便的被转换为json供开发语言使用
顺便推荐一个在线的 YAML转json服务
playbook是一个非常简单的配置管理和多主机部署系统,不同于任何已经存在的模式,可作为一个适合部署复杂应用程序的基础。playbook可以定制配置,可以按指定的操作步骤有序执行,支持同步及异步方式。
playbook是Ansible实现批量自动化最重要的手段。在其中可以使用变量、引用、循环等功能,功能比较强大。
一个playbook就是一组play组成的列表
每个play必须包含host和task,play就可以想象为连接到主机(host)上执行任务(task)的事物
host就是inventory中定义的主机
tasks下定义一系列的task任务列表,依次执行,如果执行某任务失败了,后续的任务不会执行

示例
playbook.yml
--- # yaml文件可以以 --- 开头
- name: the first demo # 使用 '-' 减号作为列表项,会被解析为json数组,注意在playbook中name属性不是必须的,表示描述,表示圈定一个范围,范围内的项都属于该列表。
hosts: cloud # cloud 是定义的主机,每一个playbook中必须包含"hosts"和"tasks"项
tasks:
- name: execute date command # 描述这个task
command: /bin/date # 本质是加载并执行ansible对应的模块转换为JSON
[ {
name: 'the first demo',
hosts: 'cloud',
tasks: [
{
name: 'execute date cmd',
command: '/bin/date'
}
]
} ]执行前先检查 ansible-playbook playbook.yml --check
有用的flag
--check 对支持check的大部分核心模块,输出真正执行会进行哪些更改 --diff 报告更改,比如操作文件,会告诉用户之前之后发生了哪些变化,由于会产生大量输出,最好在单一主机使用
另外例子
---
- hosts: localhost # 列表1
remote_user: root
tasks:
- name: test1 # 子列表,下面是shell模块,是一个动作,所以定义为列表,只不过加了个name
shell: echo /tmp/a.txt
register: hi_var
- debug: var=hi_var.stdout # 调用模块,这是动作,所以也是列表 # 同样是动作,包含文件
- include: /tmp/nginx.yml
- include: /tmp/mysql.yml
- copy: # 调用模块,定义为列表。但模块参数是虚拟性内容,应定义为字典而非列表
src: /etc/resolv.conf # 模块参数1
dest: /tmp # 模块参数2
- hosts: 192.168.100.65 # 列表2
remote_user: root
vars:
nginx_port: 80 # 定义变量,是虚拟性的内容,应定义为字典而非列表
mysql_port: 3306
vars_files:
- nginx_port.yml # 无法写成key/value格式,且是实体文件,因此定义为列表
tasks:
- name: test2
shell: echo /tmp/a.txt
register: hi_var # register是和最近一个动作绑定的
- debug: var=hi_var.stdout通过 ansible-playbook -h 获取所有参数列表
首先ansible-playbook -C playbook.yml检查语法。这里我故意写错了,在 -name同级添加了 hosts,这是不允许的,所以报错了。Ansible 的错误提示还是很方便的。

修改后:

playbook 中的配置项
playbook 除了hosts和tasks还有其他配置项:
- name play的描述,Ansible执行时会打印出来
- remote_user 指定在远程主机上执行任务的用户
- vars
- vars_files
配置 playbook 例子,包含了1个play,3个tasks,1个handlers

notify 和 handler
ansible中几乎所有的模块都具有幂等性,这意味着被控主机的状态是否发生改变是能被捕捉的,即每个任务的 changed=true或changed=false。 ansible在捕捉到changed=true时,可以触发notify组件(如果定义了该组件)。 notify是一个组件,并非一个模块,它可以直接定义action,其主要目的是调用handler。 例如:
tasks:
- name: copy template file to remote host
template: src=/etc/ansible/nginx.conf.j2 dest=/etc/nginx/nginx.conf
notify:
- restart nginx
- test web page
copy: src=nginx/index.html.j2 dest=/usr/share/nginx/html/index.html
notify:
- restart nginx
handlers:
- name: restart nginx
service: name=nginx state=restarted
- name: test web page
shell: curl -I http://192.168.100.10/index.html | grep 200 || /bin/false这表示当执行template模块的任务时,如果捕捉到changed=true,那么就会触发notify,如果分发的index.html改变了,那么也重启nginx(当然这是没必要的)。 notify下定义了两个待调用的handler。 handler主要用于重启服务或者触发系统重启,除此之外很少使用handler。
handler的定义和tasks的定义完全一样,唯一需要限定的是handler中task的name必须和notify中定义的名称相同。
注意,notify是在执行完一个play中所有task后被触发的,在一个play中也只会被触发一次。
意味着如果一个play中有多个task出现了changed=true,它也只会触发一次。例如上面的示例中,向nginx复制配置文件和复制 index.html时如果都发生了改变,都会触发重启nginx操作。但是只会在执行完play后重启一次,以避免多余的重启。
]]>使用 tag 为 task 分类
tasks:
- name: make sure apache is running
service: name=httpd state=started
tags: apache
- name: make sure mysql is running
service: name=mysqld state=started
tags: mysql以下是 ansible-playbook 命令关于tag的选项。
--list-tags # list all available tags
-t TAGS, --tags=TAGS # only run plays and tasks tagged with these values
--skip-tags=SKIP_TAGS # only run plays and tasks whose tags do not match these values使用 include,import 和 roles 提高 playbook 的复用性
如果playbook很大,task很多,或者某task要经常使用,可以考虑拆分位独立文件。
Ansible 2.4 起引入 include 和 import 的概念
- import 是静态导入,会在playbooks解析阶段将父和子task变量全部读取并加载 import_playbook, import_tasks 等
- include 是动态导入,执行play之前才加载变量 include_tasks, include_role 等
导入 task
导入task可以使用 import_tasks: include_tasks
# playbook.yaml
# -- task/ntupdate.yml
---
- hosts: centos7
tasks:
- import_tasks: task/ntupdate.yaml
# ntupdate.yml
---
- name: execute ntpdate
shell: /usr/sbin/ntpdate ntp1.aliyun.com虽然仍然可以用
include: task/ntupdate.yaml来直接导入 task 或 playbook 已经不推荐这么做,将来会被废弃
导入 playbook
即加载一个或多个play 导入playbook可以使用 import_playbook
---
- name: first demo
hosts: cloud
vars:
name: finley
tasks:
- name: execute date cmd
shell: echo date
- name: create hello
shell: touch helloworld.txt
args:
creates: /tmp/hello.txt # 存在此文件就不执行 shell
- include_tasks: tasks/task-hello.yml
- import_playbook: playbooks/web.yml参考
https://docs.ansible.com/ansible/latest/user_guide/playbooks_reuse.html
]]>无论多么复杂的程序,都是由条件,循环,顺序执行三种组合而成,yaml 本身不支持逻辑运算,运算符等功能。 ansible支持Jinja2模板引擎。 类似Laravel中的Blade模板引擎。
可以搜索 Online Jinja2 Parser 或在线体验 https://j2live.ttl255.com/
举个例子,创建 hello.yaml
- hosts: cloud
remote_user: root
vars:
ports:
- 8001
- 8002
nginx_conf_path: 'etc/nginx/nginx.conf'
tasks:
- name: hello
tags: demo
shell: echo "hello world"
- name: date
tags: date
shell: date -R
- name: jinja2 test
template:
src: demo.j2
dest: demo.confdemo.j2 内容
# {{ "hello world" | reverse | upper }}
<p>{{ 'hello every one' | truncate(9)}}</p>
Hi, {{ name | default("mafei")}}
{# 我是注释 #}
{% filter upper %}
hello world
{% endfilter %}
worker_processes {{ ansible_processor_vcpus }};
{# nginx.conf #}
{{nginx_conf_path | basename}}
{# etc/nginx #}
{{nginx_conf_path | dirname}}
{{ range(1, 51) | random }}
{% for port in ports %}
server {
listen localhost:{{ port }};
}
{% endfor %}
{% if ansible_os_family == 'Debian' %}
# This is a debian system
{% endif %}当执行ansible-playbook hello.yaml
cloud服务器就会多出一个 demo.conf 文件,内容:
# DLROW OLLEH
<p>hello...</p>
Hi, mafei
HELLO WORLD
worker_processes 2;
nginx.conf
etc/nginx
server {
listen localhost:8001;
}
server {
listen localhost:8002;
}
# This is a debian systemRole

role 需要一个特定的目录结构,执行时会自动加载定义好的文件如 vars_files,tasks,handles 等
通过role进行内容分组方便与其他用户分享role。
roles 可以解决文件混乱和 playbook 臃肿的问题
示例项目结构
site.yml
webservers.yml
fooservers.yml
roles/
common/
tasks/
handlers/
files/
templates/
vars/
defaults/
meta/
webservers/
tasks/
defaults/
meta/- tasks 目录:存放task列表。若role要生效,此目录必须要有一个主task文件main.yml,在main.yml中可以使用 include包含同目录(即tasks)中的其他文件。
- handlers 目录: 存放handlers的目录,若要生效,则文件必须名为main.yml文件。
- files目录:在task中执行copy或script模块时,如果使用的是相对路径,则会到此目录中寻找对应的文件。
- templates 目录:在task中执行template模块时,如果使用的是相对路径,则会到此目录中寻找对应的模块文件。
- vars目录:定义专属于该role的变量,如果要有var文件,则必须为main.yml文件。
- defaults 目录:定义角色默认变量,角色默认变量的优先级最低,会被任意其他层次的同名变量覆盖。如果要有var文件,则必须为main.yml文件。
- meta 目录:用于定义角色依赖(dependencies),如果要有角色依赖关系,则文件必须为main.yml。
实例
执行命令
ansible-galaxy install geerlingguy.redis
roles目录中多个为geerlingguy.redis的目录。可以在各种操作系统安装redis。
里面的 templates 目录中有redis.conf.j2文件,可以改变 redis 的配置。
我们可以研究别人写好的role

参考
]]>可以加密解密 yaml 文件,加密时提供口令,解密时提供口令
ansible-vault -h
usage: ansible-vault [-h] [--version] [-v] {create,decrypt,edit,view,encrypt,encrypt_string,rekey} ...
encryption/decryption utility for Ansible data files
positional arguments:
{create,decrypt,edit,view,encrypt,encrypt_string,rekey}
create Create new vault encrypted file
decrypt Decrypt vault encrypted file
edit Edit vault encrypted file
view View vault encrypted file
encrypt Encrypt YAML file
encrypt_string Encrypt a string
rekey Re-key a vault encrypted file
# 加密文件,记住口令
ansible-vault encrypt hello.yaml
New Vault password:
Confirm New Vault password:
Encryption successful本章内容
- 运维自动化发展历程及技术应用
- Ansible命令使用
- Ansible常用模块详解
- YAML语法简介
- Ansible playbook基础
- Playbook变量、tags、handlers使用
- Playbook模板templates
- Playbook条件判断 when
- Playbook字典 with_items
- Ansible Roles
企业实际应用场景分析
Dev开发环境
使用者:程序员
功能:程序员开发软件,测试BUG的环境
管理者:程序员
测试环境
使用者:QA测试工程师
功能:测试经过Dev环境测试通过的软件的功能
管理者:运维
说明:测试环境往往有多套,测试环境满足测试功能即可,不宜过多
1、测试人员希望测试环境有多套,公司的产品多产品线并发,即多个版本,意味着多个版本同步测试
2、通常测试环境有多少套和产品线数量保持一样
发布环境:代码发布机,有些公司为堡垒机(安全屏障)
使用者:运维
功能:发布代码至生产环境
管理者:运维(有经验)
发布机:往往需要有2台(主备)
生产环境
使用者:运维,少数情况开放权限给核心开发人员,极少数公司将权限完全
开放给开发人员并其维护
功能:对用户提供公司产品的服务
管理者:只能是运维
生产环境服务器数量:一般比较多,且应用非常重要。往往需要自动工具协助部署配置应用
灰度环境(生产环境的一部分)
使用者:运维
功能:在全量发布代码前将代码的功能面向少量精准用户发布的环境,可基
于主机或用户执行灰度发布
案例:共100台生产服务器,先发布其中的10台服务器,这10台服务器就是灰度服务器
管理者:运维
灰度环境:往往该版本功能变更较大,为保险起见特意先让一部分用户优化体验该功能,
待这部分用户使用没有重大问题的时候,再全量发布至所有服务器程序发布
程序发布要求:
不能导致系统故障或造成系统完全不可用
不能影响用户体验
预发布验证:
新版本的代码先发布到服务器(跟线上环境配置完全相同,只是未接入到调度器)
灰度发布:
基于主机,用户,业务
发布路径:
/webapp/tuangou
/webapp/tuangou-1.1
/webapp/tuangou-1.2
发布过程:在调度器上下线一批主机(标记为maintanance状态) --> 关闭服务 -->
部署新版本的应用程序 --> 启动服务 --> 在调度器上启用这一批服务器
自动化灰度发布:脚本、发布平台自动化运维应用场景
文件传输
应用部署
配置管理
任务流编排常用自动化运维工具
Ansible:python,Agentless,中小型应用环境
Saltstack:python,一般需部署agent,执行效率更高
Puppet:ruby, 功能强大,配置复杂,重型,适合大型环境
Fabric:python,agentless
Chef:ruby,国内应用少
Cfengine
func企业级自动化运维工具应用实战ansible
公司计划在年底做一次大型市场促销活动,全面冲刺下交易额,为明年的上市做准备。
公司要求各业务组对年底大促做准备,运维部要求所有业务容量进行三倍的扩容,
并搭建出多套环境可以共开发和测试人员做测试,运维老大为了在年底有所表现,
要求运维部门同学尽快实现,当你接到这个任务时,有没有更快的解决方案?Ansible发展史
Ansible
Michael DeHaan( Cobbler 与 Func 作者)
名称来自《安德的游戏》中跨越时空的即时通信工具
2012-03-09,发布0.0.1版,2015-10-17,Red Hat宣布收购
官网:https://www.ansible.com/
官方文档:https://docs.ansible.com/
同类自动化工具GitHub关注程度(2016-07-10)特性
1> 模块化:调用特定的模块,完成特定任务
2> Paramiko(python对ssh的实现),PyYAML,Jinja2(模板语言)三个关键模块
3> 支持自定义模块
4> 基于Python语言实现
5> 部署简单,基于python和SSH(默认已安装),agentless
6> 安全,基于OpenSSH
7> 支持playbook编排任务
8> 幂等性:一个任务执行1遍和执行n遍效果一样,不因重复执行带来意外情况
9> 无需代理不依赖PKI(无需ssl)
10> 可使用任何编程语言写模块
11> YAML格式,编排任务,支持丰富的数据结构
12> 较强大的多层解决方案ansible的作用以及工作结构
1、ansible简介:
ansible是新出现的自动化运维工具,基于Python开发,
集合了众多运维工具(puppet、cfengine、chef、func、fabric)的优点,
实现了批量系统配置、批量程序部署、批量运行命令等功能。
ansible是基于模块工作的,本身没有批量部署的能力。
真正具有批量部署的是ansible所运行的模块,ansible只是提供一种框架。
主要包括:
(1)、连接插件connection plugins:负责和被监控端实现通信;
(2)、host inventory:指定操作的主机,是一个配置文件里面定义监控的主机;
(3)、各种模块核心模块、command模块、自定义模块;
(4)、借助于插件完成记录日志邮件等功能;
(5)、playbook:剧本执行多个任务时,非必需可以让节点一次性运行多个任务。
2、ansible的架构:连接其他主机默认使用ssh协议Ansible主要组成部分
ANSIBLE PLAYBOOKS:任务剧本(任务集),编排定义Ansible任务集的配置文件,
由Ansible顺序依次执行,通常是JSON格式的YML文件
INVENTORY:Ansible管理主机的清单 /etc/anaible/hosts
MODULES: Ansible执行命令的功能模块,多数为内置核心模块,也可自定义
PLUGINS: 模块功能的补充,如连接类型插件、循环插件、变量插件、过滤插件等,该功能不常用
API: 供第三方程序调用的应用程序编程接口
ANSIBLE: 组合INVENTORY、API、MODULES、PLUGINS的绿框,可以理解为是ansible命令工具,其为核心执行工具Ansible命令执行来源:
1> USER,普通用户,即SYSTEM ADMINISTRATOR
2> CMDB(配置管理数据库) API 调用
3> PUBLIC/PRIVATE CLOUD API调用 (公有私有云的API接口调用)
4> USER-> Ansible Playbook -> Ansibile
利用ansible实现管理的方式:
1> Ad-Hoc 即ansible单条命令,主要用于临时命令使用场景
2> Ansible-playbook 主要用于长期规划好的,大型项目的场景,需要有前期的规划过程Ansible-playbook(剧本)执行过程
将已有编排好的任务集写入Ansible-Playbook
通过ansible-playbook命令分拆任务集至逐条ansible命令,按预定规则逐条执行
Ansible主要操作对象
HOSTS主机
NETWORKING网络设备
注意事项:
执行ansible的主机一般称为主控端,中控,master或堡垒机
主控端Python版本需要2.6或以上
被控端Python版本小于2.4需要安装python-simplejson
被控端如开启SELinux需要安装libselinux-python
windows不能做为主控端
ansible不是服务,不会一直启动,只是需要的时候启动安装
rpm包安装: EPEL源
yum install ansible
编译安装:
yum -y install python-jinja2 PyYAML python-paramiko python-babel
python-crypto
tar xf ansible-1.5.4.tar.gz
cd ansible-1.5.4
python setup.py build
python setup.py install
mkdir /etc/ansible
cp -r examples/* /etc/ansible
Git方式:
git clone git://github.com/ansible/ansible.git --recursive
cd ./ansible
source ./hacking/env-setup
pip安装: pip是安装Python包的管理器,类似yum
yum install python-pip python-devel
yum install gcc glibc-devel zibl-devel rpm-bulid openssl-devel
pip install --upgrade pip
pip install ansible --upgrade
确认安装:
ansible --version相关文件
配置文件
/etc/ansible/ansible.cfg 主配置文件,配置ansible工作特性(一般无需修改)
/etc/ansible/hosts 主机清单(将被管理的主机放到此文件)
/etc/ansible/roles/ 存放角色的目录
程序
/usr/bin/ansible 主程序,临时命令执行工具
/usr/bin/ansible-doc 查看配置文档,模块功能查看工具
/usr/bin/ansible-galaxy 下载/上传优秀代码或Roles模块的官网平台
/usr/bin/ansible-playbook 定制自动化任务,编排剧本工具
/usr/bin/ansible-pull 远程执行命令的工具
/usr/bin/ansible-vault 文件加密工具
/usr/bin/ansible-console 基于Console界面与用户交互的执行工具主机清单inventory
Inventory 主机清单
1> ansible的主要功用在于批量主机操作,为了便捷地使用其中的部分主机,可以在inventory file中将其分组命名
2> 默认的inventory file为/etc/ansible/hosts
3> inventory file可以有多个,且也可以通过Dynamic Inventory来动态生成
/etc/ansible/hosts文件格式
inventory文件遵循INI文件风格,中括号中的字符为组名。
可以将同一个主机同时归并到多个不同的组中;
此外,当如若目标主机使用了非默认的SSH端口,还可以在主机名称之后使用冒号加端口号来标明
ntp.magedu.com 不分组,直接加
[webservers] webservers组
www1.magedu.com:2222 可以指定端口
www2.magedu.com
[dbservers]
db1.magedu.com
db2.magedu.com
db3.magedu.com
如果主机名称遵循相似的命名模式,还可以使用列表的方式标识各主机
示例:
[websrvs]
www[1:100].example.com ip: 1-100
[dbsrvs]
db-[a:f].example.com dba-dbffansible 配置文件
Ansible 配置文件/etc/ansible/ansible.cfg (一般保持默认)
vim /etc/ansible/ansible.cfg
[defaults]
#inventory = /etc/ansible/hosts # 主机列表配置文件
#library = /usr/share/my_modules/ # 库文件存放目录
#remote_tmp = $HOME/.ansible/tmp # 临时py命令文件存放在远程主机目录
#local_tmp = $HOME/.ansible/tmp # 本机的临时命令执行目录
#forks = 5 # 默认并发数,同时可以执行5次
#sudo_user = root # 默认sudo 用户
#ask_sudo_pass = True # 每次执行ansible命令是否询问ssh密码
#ask_pass = True # 每次执行ansible命令是否询问ssh口令
#remote_port = 22 # 远程主机的端口号(默认22)
建议优化项:
host_key_checking = False # 检查对应服务器的host_key,建议取消注释
log_path=/var/log/ansible.log # 日志文件,建议取消注释
module_name = command # 默认模块ansible系列命令
Ansible系列命令
ansible ansible-doc ansible-playbook ansible-vault ansible-console
ansible-galaxy ansible-pull
ansible-doc: 显示模块帮助
ansible-doc [options] [module...]
-a 显示所有模块的文档
-l, --list 列出可用模块
-s, --snippet 显示指定模块的playbook片段(简化版,便于查找语法)
示例:
ansible-doc -l 列出所有模块
ansible-doc ping 查看指定模块帮助用法
ansible-doc -s ping 查看指定模块帮助用法ansible
ansible通过ssh实现配置管理、应用部署、任务执行等功能,
建议配置ansible端能基于密钥认证的方式联系各被管理节点
ansible <host-pattern> [-m module_name] [-a args]
ansible +被管理的主机(ALL) +模块 +参数
--version 显示版本
-m module 指定模块,默认为command
-v 详细过程 –vv -vvv更详细
--list-hosts 显示主机列表,可简写 --list
-k, --ask-pass 提示输入ssh连接密码,默认Key验证
-C, --check 检查,并不执行
-T, --timeout=TIMEOUT 执行命令的超时时间,默认10s
-u, --user=REMOTE_USER 执行远程执行的用户
-b, --become 代替旧版的sudo切换
--become-user=USERNAME 指定sudo的runas用户,默认为root
-K, --ask-become-pass 提示输入sudo时的口令ansible all --list 列出所有主机
ping模块: 探测网络中被管理主机是否能够正常使用 走ssh协议
如果对方主机网络正常,返回pong
ansible-doc -s ping 查看ping模块的语法
检测所有主机的网络状态
1> 默认情况下连接被管理的主机是ssh基于key验证,如果没有配置key,权限将会被拒绝
因此需要指定以谁的身份连接,输入用户密码,必须保证被管理主机用户密码一致
ansible all -m ping -k
2> 或者实现基于key验证 将公钥ssh-copy-id到被管理的主机上 , 实现免密登录
ansible all -m pingansible的Host-pattern
ansible的Host-pattern
匹配主机的列表
All :表示所有Inventory中的所有主机
ansible all –m ping
* :通配符
ansible "*" -m ping (*表示所有主机)
ansible 192.168.1.* -m ping
ansible "*srvs" -m ping
或关系 ":"
ansible "websrvs:appsrvs" -m ping
ansible “192.168.1.10:192.168.1.20” -m ping
逻辑与 ":&"
ansible "websrvs:&dbsrvs" –m ping
在websrvs组并且在dbsrvs组中的主机
逻辑非 ":!"
ansible 'websrvs:!dbsrvs' –m ping
在websrvs组,但不在dbsrvs组中的主机
注意:此处为单引号
综合逻辑
ansible 'websrvs:dbsrvs:&appsrvs:!ftpsrvs' –m ping
正则表达式
ansible "websrvs:&dbsrvs" –m ping
ansible "~(web|db).*\.magedu\.com" –m pingansible命令执行过程
ansible命令执行过程
1. 加载自己的配置文件 默认/etc/ansible/ansible.cfg
2. 加载自己对应的模块文件,如command
3. 通过ansible将模块或命令生成对应的临时py文件,
并将该文件传输至远程服务器的对应执行用户$HOME/.ansible/tmp/ansible-tmp-数字/XXX.PY文件
4. 给文件+x执行
5. 执行并返回结果
6. 删除临时py文件,sleep 0退出
执行状态:
绿色:执行成功并且不需要做改变的操作
黄色:执行成功并且对目标主机做变更
红色:执行失败ansible使用示例
示例
以wang用户执行ping存活检测
ansible all -m ping -u wang -k
以wang sudo至root执行ping存活检测
ansible all -m ping -u wang -k -b
以wang sudo至mage用户执行ping存活检测
ansible all -m ping -u wang -k -b --become-user=mage
以wang sudo至root用户执行ls
ansible all -m command -u wang -a 'ls /root' -b --become-user=root -k -K
ansible ping模块测试连接
ansible 192.168.38.126,192.168.38.127 -m ping -kansible常用模块
模块文档:https://docs.ansible.com/ansible/latest/modules/modules_by_category.html
Command:在远程主机执行命令,默认模块,可忽略-m选项
> ansible srvs -m command -a 'service vsftpd start'
> ansible srvs -m command -a 'echo adong |passwd --stdin 123456'
此命令不支持 $VARNAME < > | ; & 等,用shell模块实现
chdir: 进入到被管理主机目录
creates: 如果有一个目录是存在的,步骤将不会运行Command命令
ansible websrvs -a 'chdir=/data/ ls'
Shell:和command相似,用shell执行命令
> ansible all -m shell -a 'getenforce' 查看SELINUX状态
> ansible all -m shell -a "sed -i 's/SELINUX=.*/SELINUX=disabled' /etc/selinux/config"
> ansible srv -m shell -a 'echo magedu |passwd –stdin wang'
调用bash执行命令 类似 cat /tmp/stanley.md | awk -F'|' '{print $1,$2}' &> /tmp/example.txt
这些复杂命令,即使使用shell也可能会失败,
解决办法:写到脚本时,copy到远程执行,再把需要的结果拉回执行命令的机器
修改配置文件,使shell作为默认模块
vim /etc/ansible/ansible.cfg
module_name = shell
Script:在远程主机上运行ansible服务器上的脚本
> -a "/PATH/TO/SCRIPT_FILE"
> ansible websrvs -m script -a /data/test.sh
Copy:从主控端复制文件到远程主机
src : 源文件 指定拷贝文件的本地路径 (如果有/ 则拷贝目录内容,比拷贝目录本身)
dest: 指定目标路径
mode: 设置权限
backup: 备份源文件
content: 代替src 指定本机文件内容,生成目标主机文件
> ansible websrvs -m copy -a "src=/root/test1.sh dest=/tmp/test2.showner=wang mode=600 backup=yes"
如果目标存在,默认覆盖,此处指定先备份
> ansible websrvs -m copy -a "content='test content\nxxx' dest=/tmp/test.txt"
指定内容,直接生成目标文件
Fetch:从远程主机提取文件至主控端,copy相反,目前不支持目录,可以先打包,再提取文件
> ansible websrvs -m fetch -a 'src=/root/test.sh dest=/data/scripts'
会生成每个被管理主机不同编号的目录,不会发生文件名冲突
> ansible all -m shell -a 'tar jxvf test.tar.gz /root/test.sh'
> ansible all -m fetch -a 'src=/root/test.tar.gz dest=/data/'
File:设置文件属性
path: 要管理的文件路径 (强制添加)
recurse: 递归,文件夹要用递归
src: 创建硬链接,软链接时,指定源目标,配合'state=link' 'state=hard' 设置软链接,硬链接
state: 状态
absent 缺席,删除
> ansible websrvs -m file -a 'path=/app/test.txt state=touch' 创建文件
> ansible websrvs -m file -a "path=/data/testdir state=directory" 创建目录
> ansible websrvs -m file -a "path=/root/test.sh owner=wang mode=755" 设置权限755
> ansible websrvs -m file -a 'src=/data/testfile dest=/data/testfile-link state=link' 创建软链接
unarchive:解包解压缩,有两种用法:
1、将ansible主机上的压缩包传到远程主机后解压缩至特定目录,设置copy=yes.
2、将远程主机上的某个压缩包解压缩到指定路径下,设置copy=no
常见参数:
copy:默认为yes,当copy=yes,拷贝的文件是从ansible主机复制到远程主机上,
如果设置为copy=no,会在远程主机上寻找src源文件
src: 源路径,可以是ansible主机上的路径,也可以是远程主机上的路径,
如果是远程主机上的路径,则需要设置copy=no
dest:远程主机上的目标路径
mode:设置解压缩后的文件权限
示例:
ansible websrvs -m unarchive -a 'src=foo.tgz dest=/var/lib/foo'
#默认copy为yes ,将本机目录文件解压到目标主机对应目录下
ansible websrvs -m unarchive -a 'src=/tmp/foo.zip dest=/data copy=no mode=0777'
# 解压被管理主机的foo.zip到data目录下, 并设置权限777
ansible websrvs -m unarchive -a 'src=https://example.com/example.zip dest=/data copy=no'
Archive:打包压缩
> ansible all -m archive -a 'path=/etc/sysconfig dest=/data/sysconfig.tar.bz2 format=bz2 owner=wang mode=0777'
将远程主机目录打包
path: 指定路径
dest: 指定目标文件
format: 指定打包格式
owner: 指定所属者
mode: 设置权限
Hostname:管理主机名
ansible appsrvs -m hostname -a "name=app.adong.com" 更改一组的主机名
ansible 192.168.38.103 -m hostname -a "name=app2.adong.com" 更改单个主机名
Cron:计划任务
支持时间:minute,hour,day,month,weekday
> ansible websrvs -m cron -a "minute=*/5 job='/usr/sbin/ntpdate 172.16.0.1 &>/dev/null' name=Synctime"
创建任务
> ansible websrvs -m cron -a 'state=absent name=Synctime'
删除任务
> ansible websrvs -m cron -a 'minute=*/10 job='/usr/sbin/ntpdate 172.30.0.100" name=synctime disabled=yes'
注释任务,不在生效
Yum:管理包
ansible websrvs -m yum -a 'list=httpd' 查看程序列表
ansible websrvs -m yum -a 'name=httpd state=present' 安装
ansible websrvs -m yum -a 'name=httpd state=absent' 删除
可以同时安装多个程序包
Service:管理服务
ansible srv -m service -a 'name=httpd state=stopped' 停止服务
ansible srv -m service -a 'name=httpd state=started enabled=yes' 启动服务,并设为开机自启
ansible srv -m service -a 'name=httpd state=reloaded' 重新加载
ansible srv -m service -a 'name=httpd state=restarted' 重启服务
User:管理用户
home 指定家目录路径
system 指定系统账号
group 指定组
remove 清除账户
shell 指定shell类型
ansible websrvs -m user -a 'name=user1 comment="test user" uid=2048 home=/app/user1 group=root'
ansible websrvs -m user -a 'name=sysuser1 system=yes home=/app/sysuser1'
ansible websrvs -m user -a 'name=user1 state=absent remove=yes' 清空用户所有数据
ansible websrvs -m user -a 'name=app uid=88 system=yes home=/app groups=root shell=/sbin/nologin password="$1$zfVojmPy$ZILcvxnXljvTI2PhP2Iqv1"' 创建用户
ansible websrvs -m user -a 'name=app state=absent' 不会删除家目录
安装mkpasswd
yum insatll expect
mkpasswd 生成口令
openssl passwd -1 生成加密口令
删除用户及家目录等数据
Group:管理组
ansible srv -m group -a "name=testgroup system=yes" 创建组
ansible srv -m group -a "name=testgroup state=absent" 删除组ansible系列命令
可以通过网上写好的
ansible-galaxy
> 连接 https://galaxy.ansible.com
下载相应的roles(角色)
> 列出所有已安装的galaxy
ansible-galaxy list
> 安装galaxy
ansible-galaxy install geerlingguy.redis
> 删除galaxy
ansible-galaxy remove geerlingguy.redis
ansible-pull
推送命令至远程,效率无限提升,对运维要求较高
ansible-playbook 可以引用按照标准的yml语言写的脚本
执行playbook
示例:ansible-playbook hello.yml
cat hello.yml
#hello world yml file
- hosts: websrvs
remote_user: root
tasks:
- name: hello world
command: /usr/bin/wall hello world
ansible-vault (了解)
功能:管理加密解密yml文件
ansible-vault [create|decrypt|edit|encrypt|rekey|view]
ansible-vault encrypt hello.yml 加密
ansible-vault decrypt hello.yml 解密
ansible-vault view hello.yml 查看
ansible-vault edit hello.yml 编辑加密文件
ansible-vault rekey hello.yml 修改口令
ansible-vault create new.yml 创建新文件
Ansible-console:2.0+新增,可交互执行命令,支持tab (了解)
root@test (2)[f:10] $
执行用户@当前操作的主机组 (当前组的主机数量)[f:并发数]$
设置并发数: forks n 例如: forks 10
切换组: cd 主机组 例如: cd web
列出当前组主机列表: list
列出所有的内置命令: ?或help
示例:
root@all (2)[f:5]$ list
root@all (2)[f:5]$ cd appsrvs
root@appsrvs (2)[f:5]$ list
root@appsrvs (2)[f:5]$ yum name=httpd state=present
root@appsrvs (2)[f:5]$ service name=httpd state=startedplaybook
> playbook是由一个或多个"play"组成的列表
> play的主要功能在于将预定义的一组主机,装扮成事先通过ansible中的task定义好的角色。
Task实际是调用ansible的一个module,将多个play组织在一个playbook中,
即可以让它们联合起来,按事先编排的机制执行预定义的动作
> Playbook采用YAML语言编写playbook图解

用户通过 ansible 命令直接调用yml语言写好的 playbook,playbook 由多条 play 组成
每条play都有一个任务(task)相对应的操作,然后调用模块 modules,应用在主机清单上,通过 ssh 远程连接
从而控制远程主机或者网络设备Playbook核心元素
Hosts 执行的远程主机列表(应用在哪些主机上)
Tasks 任务集
Variables 内置变量或自定义变量在playbook中调用
Templates模板 可替换模板文件中的变量并实现一些简单逻辑的文件
Handlers 和 notify 结合使用,由特定条件触发的操作,满足条件方才执行,否则不执行
tags标签 指定某条任务执行,用于选择运行playbook中的部分代码。
ansible具有幂等性,因此会自动跳过没有变化的部分,
即便如此,有些代码为测试其确实没有发生变化的时间依然会非常地长。
此时,如果确信其没有变化,就可以通过tags跳过此些代码片断
ansible-playbook -t tagsname useradd.ymlplaybook基础组件
Hosts:
> playbook中的每一个play的目的都是为了让特定主机以某个指定的用户身份执行任务。
hosts用于指定要执行指定任务的主机,须事先定义在主机清单中
> 可以是如下形式:
one.example.com
one.example.com:two.example.com
192.168.1.50
192.168.1.*
> Websrvs:dbsrvs 或者,两个组的并集
> Websrvs:&dbsrvs 与,两个组的交集
> webservers:!phoenix 在websrvs组,但不在dbsrvs组
示例: - hosts: websrvs:dbsrvs
remote_user:
可用于Host和task中。
也可以通过指定其通过sudo的方式在远程主机上执行任务,其可用于play全局或某任务;
此外,甚至可以在sudo时使用sudo_user指定sudo时切换的用户
- hosts: websrvs
remote_user: root (可省略,默认为root) 以root身份连接
tasks: 指定任务
- name: test connection
ping:
remote_user: magedu
sudo: yes 默认sudo为root
sudo_user:wang sudo为wang
task 列表和 action
任务列表task:由多个动作,多个任务组合起来的,每个任务都调用的模块,一个模块一个模块执行
1> play的主体部分是task list,task list中的各任务按次序逐个在hosts中指定的所有主机上执行,
即在所有主机上完成第一个任务后,再开始第二个任务
2> task的目的是使用指定的参数执行模块,而在模块参数中可以使用变量。
模块执行是幂等的,这意味着多次执行是安全的,因为其结果均一致
3> 每个task都应该有其name,用于playbook的执行结果输出,建议其内容能清晰地描述任务执行步骤。
如果未提供name,则action的结果将用于输出tasks:任务列表
两种格式:
(1) action: module arguments
(2) module: arguments 建议使用 模块: 参数
注意:shell 和 command模块后面跟命令,而非key=value
某任务的状态在运行后为changed时,可通过"notify"通知给相应的handlers
任务可以通过"tags"打标签,可在ansible-playbook命令上使用-t指定进行调用
示例:
tasks:
- name: disable selinux 描述
command: /sbin/setenforce 0 模块名: 模块对应的参数如果命令或脚本的退出码不为零,可以使用如下方式替代
tasks:
- name: run this command and ignore the result
shell: /usr/bin/somecommand || /bin/true
转错为正 如果命令失败则执行 true
或者使用ignore_errors来忽略错误信息
tasks:
- name: run this command and ignore the result
shell: /usr/bin/somecommand
ignore_errors: True 忽略错误运行playbook
运行playbook的方式
ansible-playbook <filename.yml> ... [options]
常见选项
--check -C 只检测可能会发生的改变,但不真正执行操作
(只检查语法,如果执行过程中出现问题,-C无法检测出来)
(执行playbook生成的文件不存在,后面的程序如果依赖这些文件,也会导致检测失败)
--list-hosts 列出运行任务的主机
--list-tags 列出tag (列出标签)
--list-tasks 列出task (列出任务)
--limit 主机列表 只针对主机列表中的主机执行
-v -vv -vvv 显示过程
示例
ansible-playbook hello.yml --check 只检测
ansible-playbook hello.yml --list-hosts 显示运行任务的主机
ansible-playbook hello.yml --limit websrvs 限制主机Playbook VS ShellScripts
安装 httpd
SHELL脚本
#!/bin/bash
# 安装Apache
yum install --quiet -y httpd
# 复制配置文件
cp /tmp/httpd.conf /etc/httpd/conf/httpd.conf
cp/tmp/vhosts.conf /etc/httpd/conf.d/
# 启动Apache,并设置开机启动
service httpd start
chkconfig httpd onPlaybook定义
---
- hosts: all
remote_user: root
tasks:
- name: "安装Apache"
yum: name=httpd yum模块:安装httpd
- name: "复制配置文件"
copy: src=/tmp/httpd.conf dest=/etc/httpd/conf/ copy模块: 拷贝文件
- name: "复制配置文件"
copy: src=/tmp/vhosts.conf dest=/etc/httpd/conf.d/
- name: "启动Apache,并设置开机启动"
service: name=httpd state=started enabled=yes service模块: 启动服务示例:Playbook 创建用户
示例:sysuser.yml
---
- hosts: all
remote_user: root
tasks:
- name: create mysql user
user: name=mysql system=yes uid=36
- name: create a group
group: name=httpd system=yesPlaybook示例 安装httpd服务
示例:httpd.yml
- hosts: websrvs
remote_user: root
tasks:
- name: Install httpd
yum: name=httpd state=present
- name: Install configure file
copy: src=files/httpd.conf dest=/etc/httpd/conf/
- name: start service
service: name=httpd state=started enabled=yesPlaybook示例 安装nginx服务
示例 nginx.yml
- hosts: all
remote_user: root
tasks:
- name: add group nginx
user: name=nginx state=present
- name: add user nginx
user: name=nginx state=present group=nginx
- name: Install Nginx
yum: name=nginx state=present
- name: Start Nginx
service: name=nginx state=started enabled=yeshandlers 和 notify 结合使用触发条件
Handlers 实际上就是一个触发器
是 task 列表,这些 task 与前述的 task 并没有本质上的不同,用于当关注的资源发生变化时,才会采取一定的操作
Notify 此 action 可用于在每个 play 的最后被触发,
这样可避免多次有改变发生时每次都执行指定的操作,仅在所有的变化发生完成后一次性地执行指定操作。
在 notify 中列出的操作称为 handler,也即 notify 中调用 handler 中定义的操作Playbook中 handlers 使用
- hosts: websrvs
remote_user: root
tasks:
- name: Install httpd
yum: name=httpd state=present
- name: Install configure file
copy: src=files/httpd.conf dest=/etc/httpd/conf/
notify: restart httpd
- name: ensure apache is running
service: name=httpd state=started enabled=yes
handlers:
- name: restart httpd
service: name=httpd state=restarted示例
- hosts: webnodes
vars:
http_port: 80
max_clients: 256
remote_user: root
tasks:
- name: ensure apache is at the latest version
yum: name=httpd state=latest
- name: ensure apache is running
service: name=httpd state=started
- name: Install configure file
copy: src=files/httpd.conf dest=/etc/httpd/conf/
notify: restart httpd
handlers:
- name: restart httpd
service: name=httpd state=restarted示例
- hosts: websrvs
remote_user: root
tasks:
- name: add group nginx
tags: user
user: name=nginx state=present
- name: add user nginx
user: name=nginx state=present group=nginx
- name: Install Nginx
yum: name=nginx state=present
- name: config
copy: src=/root/config.txt dest=/etc/nginx/nginx.conf
notify:
- Restart Nginx
- Check Nginx Process
handlers:
- name: Restart Nginx
service: name=nginx state=restarted enabled=yes
- name: Check Nginx process
shell: killall -0 nginx > /tmp/nginx.logPlaybook中tags使用
tage: 添加标签
可以指定某一个任务添加一个标签,添加标签以后,想执行某个动作可以做出挑选来执行
多个动作可以使用同一个标签
示例:httpd.yml
- hosts: websrvs
remote_user: root
tasks:
- name: Install httpd
yum: name=httpd state=present
tags: install
- name: Install configure file
copy: src=files/httpd.conf dest=/etc/httpd/conf/
tags: conf
- name: start httpd service
tags: service
service: name=httpd state=started enabled=yes
ansible-playbook –t install,conf httpd.yml 指定执行install,conf 两个标签示例
//heartbeat.yaml
- hosts: hbhosts
remote_user: root
tasks:
- name: ensure heartbeat latest version
yum: name=heartbeat state=present
- name: authkeys configure file
copy: src=/root/hb_conf/authkeys dest=/etc/ha.d/authkeys
- name: authkeys mode 600
file: path=/etc/ha.d/authkeys mode=600
notify:
- restart heartbeat
- name: ha.cf configure file
copy: src=/root/hb_conf/ha.cf dest=/etc/ha.d/ha.cf
notify:
- restart heartbeat
handlers:
- name: restart heartbeat
service: name=heartbeat state=restartedPlaybook 中 tags 使用
- hosts: testsrv
remote_user: root
tags: inshttpd 针对整个playbook添加tage
tasks:
- name: Install httpd
yum: name=httpd state=present
- name: Install configure file
copy: src=files/httpd.conf dest=/etc/httpd/conf/
tags: rshttpd
notify: restart httpd
handlers:
- name: restart httpd
service: name=httpd status=restarted
ansible-playbook –t rshttpd httpd2.ymlPlaybook 中变量的使用
变量名:仅能由字母、数字和下划线组成,且只能以字母开头
变量来源:
1> ansible setup facts 远程主机的所有变量都可直接调用 (系统自带变量)
setup模块可以实现系统中很多系统信息的显示
可以返回每个主机的系统信息包括:版本、主机名、cpu、内存
ansible all -m setup -a 'filter="ansible_nodename"' 查询主机名
ansible all -m setup -a 'filter="ansible_memtotal_mb"' 查询主机内存大小
ansible all -m setup -a 'filter="ansible_distribution_major_version"' 查询系统版本
ansible all -m setup -a 'filter="ansible_processor_vcpus"' 查询主机cpu个数
2> 在/etc/ansible/hosts(主机清单)中定义变量
普通变量:主机组中主机单独定义,优先级高于公共变量(单个主机 )
公共(组)变量:针对主机组中所有主机定义统一变量(一组主机的同一类别)
3> 通过命令行指定变量,优先级最高
ansible-playbook –e varname=value
4> 在playbook中定义
vars:
- var1: value1
- var2: value2
5> 在独立的变量YAML文件中定义
6> 在role中定义
变量命名:
变量名仅能由字母、数字和下划线组成,且只能以字母开头
变量定义:key=value
示例:http_port=80
变量调用方式:
1> 通过{{ variable_name }} 调用变量,且变量名前后必须有空格,有时用“{{ variable_name }}”才生效
2> ansible-playbook –e 选项指定
ansible-playbook test.yml -e "hosts=www user=magedu"在主机清单中定义变量,在ansible中使用变量
vim /etc/ansible/hosts
[appsrvs]
192.168.38.17 http_port=817 name=www
192.168.38.27 http_port=827 name=web
调用变量
ansible appsrvs -m hostname -a'name={{name}}' 更改主机名为各自被定义的变量
针对一组设置变量
[appsrvs:vars]
make="-"
ansible appsrvs -m hostname -a 'name={{name}}{{mark}}{{http_port}}' ansible调用变量将变量写进单独的配置文件中引用
vim vars.yml
pack: vsftpd
service: vsftpd
引用变量文件
vars_files:
- vars.ymlAnsible基础元素
Facts:是由正在通信的远程目标主机发回的信息,这些信息被保存在ansible变量中。
要获取指定的远程主机所支持的所有facts,可使用如下命令进行
ansible websrvs -m setup
通过命令行传递变量
在运行playbook的时候也可以传递一些变量供playbook使用
示例:
ansible-playbook test.yml -e "hosts=www user=magedu"
register
把任务的输出定义为变量,然后用于其他任务
示例:
tasks:
- shell: /usr/bin/foo
register: foo_result
ignore_errors: True示例:使用setup变量
示例:var.yml
- hosts: websrvs
remote_user: root
tasks:
- name: create log file
file: name=/var/log/ {{ ansible_fqdn }} state=touch
ansible-playbook var.yml示例:变量
示例:var.yml
- hosts: websrvs
remote_user: root
tasks:
- name: install package
yum: name={{ pkname }} state=present
ansible-playbook –e pkname=httpd var.yml示例:变量
示例:var.yml
- hosts: websrvs
remote_user: root
vars:
- username: user1
- groupname: group1
tasks:
- name: create group
group: name={{ groupname }} state=present
- name: create user
user: name={{ username }} state=present
ansible-playbook var.yml
ansible-playbook -e "username=user2 groupname=group2” var2.yml变量
主机变量
可以在inventory中定义主机时为其添加主机变量以便于在playbook中使用
示例:
[websrvs]
www1.magedu.com http_port=80 maxRequestsPerChild=808
www2.magedu.com http_port=8080 maxRequestsPerChild=909
组变量
组变量是指赋予给指定组内所有主机上的在playbook中可用的变量
示例:
[websrvs]
www1.magedu.com
www2.magedu.com
[websrvs:vars]
ntp_server=ntp.magedu.com
nfs_server=nfs.magedu.com示例:变量
普通变量
[websrvs]
192.168.99.101 http_port=8080 hname=www1
192.168.99.102 http_port=80 hname=www2
公共(组)变量
[websvrs:vars]
http_port=808
mark="_"
[websrvs]
192.168.99.101 http_port=8080 hname=www1
192.168.99.102 http_port=80 hname=www2
ansible websvrs –m hostname –a ‘name={{ hname }}{{ mark }}{{ http_port }}’
命令行指定变量:
ansible websvrs –e http_port=8000 –m hostname –a'name={{ hname }}{{ mark }}{{ http_port }}'使用变量文件
cat vars.yml
var1: httpd
var2: nginx
cat var.yml
- hosts: web
remote_user: root
vars_files:
- vars.yml
tasks:
- name: create httpd log
file: name=/app/{{ var1 }}.log state=touch
- name: create nginx log
file: name=/app/{{ var2 }}.log state=touch
hostname app_81.magedu.com hostname 不支持"_",认为"_"是非法字符
hostnamectl set-hostname app_80.magedu.com 可以更改主机名变量
组嵌套
inventory中,组还可以包含其它的组,并且也可以向组中的主机指定变量。
这些变量只能在ansible-playbook中使用,而ansible命令不支持
示例:
[apache]
httpd1.magedu.com
httpd2.magedu.com
[nginx]
ngx1.magedu.com
ngx2.magedu.com
[websrvs:children]
apache
nginx
[webservers:vars]
ntp_server=ntp.magedu.cominventory 参数
invertory 参数:用于定义ansible远程连接目标主机时使用的参数,而非传递给playbook的变量
ansible_ssh_host
ansible_ssh_port
ansible_ssh_user
ansible_ssh_pass
ansbile_sudo_pass
示例:
cat /etc/ansible/hosts
[websrvs]
192.168.0.1 ansible_ssh_user=root ansible_ssh_pass=magedu
192.168.0.2 ansible_ssh_user=root ansible_ssh_pass=mageduinventory 参数
inventory参数
ansible基于ssh连接inventory中指定的远程主机时,还可以通过参数指定其交互方式;
这些参数如下所示:
ansible_ssh_host
The name of the host to connect to, if different from the alias you wishto give to it.
ansible_ssh_port
The ssh port number, if not 22
ansible_ssh_user
The default ssh user name to use.
ansible_ssh_pass
The ssh password to use (this is insecure, we strongly recommendusing --ask-pass or SSH keys)
ansible_sudo_pass
The sudo password to use (this is insecure, we strongly recommendusing --ask-sudo-pass)
ansible_connection
Connection type of the host. Candidates are local, ssh or paramiko.
The default is paramiko before Ansible 1.2, and 'smart' afterwards which
detects whether usage of 'ssh' would be feasible based on whether
ControlPersist is supported.
ansible_ssh_private_key_file
Private key file used by ssh. Useful if using multiple keys and you don't want to use SSH agent.
ansible_shell_type
The shell type of the target system. By default commands are formatted
using 'sh'-style syntax by default. Setting this to 'csh' or 'fish' will cause
commands executed on target systems to follow those shell's syntax instead.
ansible_python_interpreter
The target host python path. This is useful for systems with more
than one Python or not located at "/usr/bin/python" such as \*BSD, or where /usr/bin/python
is not a 2.X series Python. We do not use the "/usr/bin/env" mechanism as that requires the remote user's
path to be set right and also assumes the "python" executable is named python,where the executable might
be named something like "python26".
ansible\_\*\_interpreter
Works for anything such as ruby or perl and works just like ansible_python_interpreter.
This replaces shebang of modules which will run on that host.模板 templates
文本文件,嵌套有脚本(使用模板编程语言编写) 借助模板生成真正的文件
Jinja2语言,使用字面量,有下面形式
字符串:使用单引号或双引号
数字:整数,浮点数
列表:[item1, item2, ...]
元组:(item1, item2, ...)
字典:{key1:value1, key2:value2, ...}
布尔型:true/false
算术运算:+, -, *, /, //, %, **
比较操作:==, !=, >, >=, <, <=
逻辑运算:and,or,not
流表达式:For,If,WhenJinja2相关
字面量
1> 表达式最简单的形式就是字面量。字面量表示诸如字符串和数值的 Python对象。如“Hello World”
双引号或单引号中间的一切都是字符串。
2> 无论何时你需要在模板中使用一个字符串(比如函数调用、过滤器或只是包含或继承一个模板的参数),如4242.23
3> 数值可以为整数和浮点数。如果有小数点,则为浮点数,否则为整数。在Python 里, 42 和 42.0 是不一样的Jinja2:算术运算
算术运算
Jinja 允许你用计算值。这在模板中很少用到,但为了完整性允许其存在
支持下面的运算符
+:把两个对象加到一起。
通常对象是素质,但是如果两者是字符串或列表,你可以用这 种方式来衔接它们。
无论如何这不是首选的连接字符串的方式!连接字符串见 ~ 运算符。 {{ 1 + 1 }} 等于 2
-:用第一个数减去第二个数。 {{ 3 - 2 }} 等于 1
/:对两个数做除法。返回值会是一个浮点数。 {{ 1 / 2 }} 等于 {{ 0.5 }}
//:对两个数做除法,返回整数商。 {{ 20 // 7 }} 等于 2
%:计算整数除法的余数。 {{ 11 % 7 }} 等于 4
*:用右边的数乘左边的操作数。 {{ 2 * 2 }} 会返回 4 。
也可以用于重 复一个字符串多次。{{ ‘=’ * 80 }} 会打印 80 个等号的横条
**:取左操作数的右操作数次幂。 {{ 2**3 }} 会返回 8Jinja2
比较操作符
== 比较两个对象是否相等
!= 比较两个对象是否不等
> 如果左边大于右边,返回 true
>= 如果左边大于等于右边,返回 true
< 如果左边小于右边,返回 true
<= 如果左边小于等于右边,返回 true
逻辑运算符
对于 if 语句,在 for 过滤或 if 表达式中,它可以用于联合多个表达式
and
如果左操作数和右操作数同为真,返回 true
or
如果左操作数和右操作数有一个为真,返回 true
not
对一个表达式取反(见下)
(expr)
表达式组
['list', 'of', 'objects']:
一对中括号括起来的东西是一个列表。列表用于存储和迭代序列化的数据。
例如 你可以容易地在 for循环中用列表和元组创建一个链接的列表
<ul>
{% for href, caption in [('index.html', 'Index'), ('about.html', 'About'), ('downloads.html',
'Downloads')] %}
<li><a href="proxy.php?url={{ href }}">{{ caption }}</a></li>
{% endfor %}
</ul>
('tuple', 'of', 'values'):
元组与列表类似,只是你不能修改元组。
如果元组中只有一个项,你需要以逗号结尾它。
元组通常用于表示两个或更多元素的项。更多细节见上面的例子
{'dict': 'of', 'key': 'and', 'value': 'pairs'}:
Python 中的字典是一种关联键和值的结构。
键必须是唯一的,并且键必须只有一个 值。
字典在模板中很少使用,罕用于诸如 xmlattr() 过滤器之类
true / false:
true 永远是 true ,而 false 始终是 falsetemplate 的使用
template功能:根据模块文件动态生成对应的配置文件
> template文件必须存放于templates目录下,且命名为 .j2 结尾
> yaml/yml 文件需和templates目录平级,目录结构如下:
./
├── temnginx.yml
└── templates
└── nginx.conf.j2template示例
示例:利用template 同步nginx配置文件
准备templates/nginx.conf.j2文件
vim temnginx.yml
- hosts: websrvs
remote_user: root
tasks:
- name: template config to remote hosts
template: src=nginx.conf.j2 dest=/etc/nginx/nginx.conf
ansible-playbook temnginx.ymlPlaybook 中 template 变更替换
修改文件nginx.conf.j2 下面行为
worker_processes {{ ansible_processor_vcpus }};
cat temnginx2.yml
- hosts: websrvs
remote_user: root
tasks:
- name: template config to remote hosts
template: src=nginx.conf.j2 dest=/etc/nginx/nginx.conf
ansible-playbook temnginx2.ymlPlaybook中template算术运算
算法运算:
示例:
vim nginx.conf.j2
worker_processes {{ ansible_processor_vcpus**2 }};
worker_processes {{ ansible_processor_vcpus+2 }};when 实现条件判断
条件测试:如果需要根据变量、facts或此前任务的执行结果来做为某task执行与否的前提时要用到条件测试,
通过when语句实现,在task中使用,jinja2的语法格式
when语句
在task后添加when子句即可使用条件测试;when语句支持Jinja2表达式语法
示例:
tasks:
- name: "shutdown RedHat flavored systems"
command: /sbin/shutdown -h now
when: ansible_os_family == "RedHat" 当系统属于红帽系列,执行command模块
when语句中还可以使用Jinja2的大多"filter",
例如要忽略此前某语句的错误并基于其结果(failed或者success)运行后面指定的语句,
可使用类似如下形式:
tasks:
- command: /bin/false
register: result
ignore_errors: True
- command: /bin/something
when: result|failed
- command: /bin/something_else
when: result|success
- command: /bin/still/something_else
when: result|skipped
此外,when语句中还可以使用facts或playbook中定义的变量示例:when 条件判断
- hosts: websrvs
remote_user: root
tasks:
- name: add group nginx
tags: user
user: name=nginx state=present
- name: add user nginx
user: name=nginx state=present group=nginx
- name: Install Nginx
yum: name=nginx state=present
- name: restart Nginx
service: name=nginx state=restarted
when: ansible_distribution_major_version == "6"示例:when 条件判断
示例:
tasks:
- name: install conf file to centos7
template: src=nginx.conf.c7.j2 dest=/etc/nginx/nginx.conf
when: ansible_distribution_major_version == "7"
- name: install conf file to centos6
template: src=nginx.conf.c6.j2 dest=/etc/nginx/nginx.conf
when: ansible_distribution_major_version == "6"Playbook 中 when 条件判断
---
- hosts: srv120
remote_user: root
tasks:
- name:
template: src=nginx.conf.j2 dest=/etc/nginx/nginx.conf
when: ansible_distribution_major_version == "7"迭代:with_items
迭代:当有需要重复性执行的任务时,可以使用迭代机制
> 对迭代项的引用,固定变量名为"item"
> 要在task中使用with_items给定要迭代的元素列表
> 列表格式:
字符串
字典示例
示例: 创建用户
- name: add several users
user: name={{ item }} state=present groups=wheel #{{ item }} 系统自定义变量
with_items: # 定义{{ item }} 的值和个数
- testuser1
- testuser2
上面语句的功能等同于下面的语句:
- name: add user testuser1
user: name=testuser1 state=present groups=wheel
- name: add user testuser2
user: name=testuser2 state=present groups=wheel
with_items中可以使用元素还可为hashes
示例:
- name: add several users
user: name={{ item.name }} state=present groups={{ item.groups }}
with_items:
- { name: 'testuser1', groups: 'wheel' }
- { name: 'testuser2', groups: 'root' }
ansible的循环机制还有更多的高级功能,具体请参见官方文档
http://docs.ansible.com/playbooks_loops.html示例:迭代
示例:将多个文件进行copy到被控端
---
- hosts: testsrv
remote_user: root
tasks
- name: Create rsyncd config
copy: src={{ item }} dest=/etc/{{ item }}
with_items:
- rsyncd.secrets
- rsyncd.conf示例:迭代
- hosts: websrvs
remote_user: root
tasks:
- name: copy file
copy: src={{ item }} dest=/tmp/{{ item }}
with_items:
- file1
- file2
- file3
- name: yum install httpd
yum: name={{ item }} state=present
with_items:
- apr
- apr-util
- httpd示例:迭代
- hosts:websrvs
remote_user: root
tasks
- name: install some packages
yum: name={{ item }} state=present
with_items:
- nginx
- memcached
- php-fpm示例:迭代嵌套子变量
- hosts:websrvs
remote_user: root
tasks:
- name: add some groups
group: name={{ item }} state=present
with_items:
- group1
- group2
- group3
- name: add some users
user: name={{ item.name }} group={{ item.group }} state=present
with_items:
- { name: 'user1', group: 'group1' }
- { name: 'user2', group: 'group2' }
- { name: 'user3', group: 'group3' }with_items 嵌套子变量
with_itmes 嵌套子变量
示例
---
- hosts: testweb
remote_user: root
tasks:
- name: add several users
user: name={{ item.name }} state=present groups={{ item.groups }}
with_items:
- { name: 'testuser1' , groups: 'wheel'}
- { name: 'testuser2' , groups: 'root'}Playbook字典 with_items
- name: 使用ufw模块来管理哪些端口需要开启
ufw:
rule: “{{ item.rule }}”
port: “{{ item.port }}”
proto: “{{ item.proto }}”
with_items:
- { rule: 'allow', port: 22, proto: 'tcp' }
- { rule: 'allow', port: 80, proto: 'tcp' }
- { rule: 'allow', port: 123, proto: 'udp' }
- name: 配置网络进出方向的默认规则
ufw:
direction: "{{ item.direction }}"
policy: "{{ item.policy }}"
state: enabled
with_items:
- { direction: outgoing, policy: allow }
- { direction: incoming, policy: deny }Playbook 中 template for if when 循环
{% for vhost in nginx_vhosts %}
server { #重复执行server代码
listen {{ vhost.listen | default('80 default_server') }};
{% if vhost.server_name is defined %}
server_name {{ vhost.server_name }};
{% endif %}
{% if vhost.root is defined %}
root {{ vhost.root }};
{% endif %}
{% endfor %}示例
// temnginx.yml
---
- hosts: testweb
remote_user: root
vars: # 调用变量
nginx_vhosts:
- listen: 8080 #列表 键值对
//templates/nginx.conf.j2
{% for vhost in nginx_vhosts %}
server {
listen {{ vhost.listen }}
}
{% endfor %}
生成的结果
server {
listen 8080
}示例
// temnginx.yml
---
- hosts: mageduweb
remote_user: root
vars:
nginx_vhosts:
- web1
- web2
- web3
tasks:
- name: template config
template: src=nginx.conf.j2 dest=/etc/nginx/nginx.conf
// templates/nginx.conf.j2
{% for vhost in nginx_vhosts %}
server {
listen {{ vhost }}
}
{% endfor %}
生成的结果:
server {
listen web1
}
server {
listen web2
}
server {
listen web3
}roles
roles
ansible自1.2版本引入的新特性,用于层次性、结构化地组织playbook。
roles能够根据层次型结构自动装载变量文件、tasks以及handlers等。
要使用roles只需要在playbook中使用include指令即可。
简单来讲,roles就是通过分别将变量、文件、任务、模板及处理器放置于单独的目录中,
并可以便捷地include它们的一种机制。
角色一般用于基于主机构建服务的场景中,但也可以是用于构建守护进程等场景中
复杂场景:建议使用roles,代码复用度高
变更指定主机或主机组
如命名不规范维护和传承成本大
某些功能需多个Playbook,通过includes即可实现Roles
角色(roles):角色集合
roles/
mysql/
httpd/
nginx/
memcached/
可以互相调用roles目录结构
每个角色,以特定的层级目录结构进行组织
roles目录结构:
playbook.yml 调用角色
roles/
project/ (角色名称)
tasks/
files/
vars/
templates/
handlers/
default/ 不常用
meta/ 不常用Roles各目录作用
/roles/project/ :项目名称,有以下子目录
files/ :存放由copy或script模块等调用的文件
templates/:template模块查找所需要模板文件的目录
tasks/:定义task,role的基本元素,至少应该包含一个名为main.yml的文件;
其它的文件需要在此文件中通过include进行包含
handlers/:至少应该包含一个名为main.yml的文件;
其它的文件需要在此文件中通过include进行包含
vars/:定义变量,至少应该包含一个名为main.yml的文件;
其它的文件需要在此文件中通过include进行包含
meta/:定义当前角色的特殊设定及其依赖关系,至少应该包含一个名为main.yml的文件,
其它文件需在此文件中通过include进行包含
default/:设定默认变量时使用此目录中的main.yml文件
roles/appname 目录结构
tasks目录:至少应该包含一个名为main.yml的文件,其定义了此角色的任务列表;
此文件可以使用include包含其它的位于此目录中的task文件
files目录:存放由copy或script等模块调用的文件;
templates目录:template模块会自动在此目录中寻找Jinja2模板文件
handlers目录:此目录中应当包含一个main.yml文件,用于定义此角色用到的各handler;
在handler中使用include包含的其它的handler文件也应该位于此目录中;
vars目录:应当包含一个main.yml文件,用于定义此角色用到的变量;
meta目录:应当包含一个main.yml文件,用于定义此角色的特殊设定及其依赖关系;
ansible1.3及其以后的版本才支持;
default目录:为当前角色设定默认变量时使用此目录;应当包含一个main.yml文件
roles/example_role/files/ 所有文件,都将可存放在这里
roles/example_role/templates/ 所有模板都存放在这里
roles/example_role/tasks/main.yml: 主函数,包括在其中的所有任务将被执行
roles/example_role/handlers/main.yml:所有包括其中的 handlers 将被执行
roles/example_role/vars/main.yml: 所有包括在其中的变量将在roles中生效
roles/example_role/meta/main.yml: roles所有依赖将被正常登入创建role
创建role的步骤
(1) 创建以roles命名的目录
(2) 在roles目录中分别创建以各角色名称命名的目录,如webservers等
(3) 在每个角色命名的目录中分别创建files、handlers、meta、tasks、templates和vars目录;
用不到的目录可以创建为空目录,也可以不创建
(4) 在playbook文件中,调用各角色实验: 创建 httpd 角色
1> 创建 roles 目录
mkdir roles/{httpd,mysql,redis}/tasks -pv
mkdir roles/httpd/{handlers,files}
查看目录结构
tree roles/
roles/
├── httpd
│ ├── files
│ ├── handlers
│ └── tasks
├── mysql
│ └── tasks
└── redis
└── tasks
2> 创建目标文件
cd roles/httpd/tasks/
touch install.yml config.yml service.yml
3> vim install.yml
- name: install httpd package
yum: name=httpd
vim config.yml
- name: config file
copy: src=httpd.conf dest=/etc/httpd/conf/ backup=yes
vim service.yml
- name: start service
service: name=httpd state=started enabled=yes
4> 创建main.yml主控文件,调用以上单独的yml文件,
main.yml定义了谁先执行谁后执行的顺序
vim main.yml
- include: install.yml
- include: config.yml
- include: service.yml
5> 准备httpd.conf文件,放到httpd单独的文件目录下
cp /app/ansible/flies/httpd.conf ../files/
6> 创建一个网页
vim files/index.html
<h1> welcome to weixiaodong home <\h1>
7> 创建网页的yml文件
vim tasks/index.yml
- name: index.html
copy: src=index.html dest=/var/www/html
8> 将网页的yml文件写进mian.yml文件中
vim mian.yml
- include: install.yml
- include: config.yml
- include: index.yml
- include: service.yml
9> 在handlers目录下创建handler文件mian.yml
vim handlers/main.yml
- name: restart service httpd
service: name=httpd state=restarted
10> 创建文件调用httpd角色
cd /app/ansidle/roles
vim role_httpd.yml
---
# httpd role
- hosts: appsrvs
remote_user: root
roles: #调用角色
- role: httpd
11> 查看目录结构
tree
.
httpd
├── files
│ ├── httpd.conf
│ └── index.html
├── handlers
│ └── main.yml
└── tasks
├── config.yml
├── index.yml
├── install.yml
├── main.yml
└── service.yml
12> ansible-playbook role_httpd.yml针对大型项目使用Roles进行编排
roles目录结构:
playbook.yml
roles/
project/
tasks/
files/
vars/
templates/
handlers/
default/ # 不经常用
meta/ # 不经常用
示例:
nginx-role.yml
roles/
└── nginx
├── files
│ └── main.yml
├── tasks
│ ├── groupadd.yml
│ ├── install.yml
│ ├── main.yml
│ ├── restart.yml
│ └── useradd.yml
└── vars
└── main.yml示例
roles的示例如下所示:
site.yml
webservers.yml
dbservers.yml
roles/
common/
files/
templates/
tasks/
handlers/
vars/
meta/
webservers/
files/
templates/
tasks/
handlers/
vars/
meta/实验: 创建一个nginx角色
建立nginx角色在多台主机上来部署nginx需要安装 创建账号
1> 创建nginx角色目录
cd /app/ansible/role
mkdir nginx{tesks,templates,hanslers} -pv
2> 创建任务目录
cd tasks/
touch insatll.yml config.yml service.yml file.yml user.yml
创建main.yml文件定义任务执行顺序
vim main.yml
- include: user.yml
- include: insatll.yml
- include: config.yml
- include: file.yml
- include: service.yml
3> 准备配置文件(centos7、8)
ll /app/ansible/role/nginx/templates/
nginx7.conf.j2
nginx8.conf.j2
4> 定义任务
vim tasks/install.yml
- name: install
yum: name=nginx
vim tasks/config.yml
- name: config file
template: src=nginx7.conf.j2 dest=/etc/nginx/nginx.conf
when: ansible_distribution_major_version=="7"
notify: restrat
- name: config file
template: src=nginx8.conf.j2 dest=/etc/nginx/nginx.conf
when: ansible_distribution_major_version=="8"
notify: restrat
vim tasks/file.yml 跨角色调用file.yum文件,实现文件复用
- name: index.html
copy: src=roles/httpd/files/index.html dest=/usr/share/nginx/html/
vim tasks/service.yml
- nmae: start service
service: name=nginx state=started enabled=yes
vim handlers/main.yml
- name: restrat
service: name=nginx state=restarted
vim roles/role_nginix.yml
---
#test rcle
- hosts: appsrvs
roles:
- role: nginx
5> 测试安装
ansible-playbook role_nginx.ymlplaybook调用角色
调用角色方法1:
- hosts: websrvs
remote_user: root
roles:
- mysql
- memcached
- nginx
调用角色方法2:
传递变量给角色
- hosts:
remote_user:
roles:
- mysql
- { role: nginx, username: nginx } #不同的角色调用不同的变量
键role用于指定角色名称
后续的k/v用于传递变量给角色
调用角色方法3:还可基于条件测试实现角色调用
roles:
- { role: nginx, username: nginx, when: ansible_distribution_major_version == '7' }通过roles传递变量
通过roles传递变量
当给一个主机应用角色的时候可以传递变量,然后在角色内使用这些变量
示例:
- hosts: webservers
roles:
- common
- { role: foo_app_instance, dir: '/web/htdocs/a.com', port: 8080 }向roles传递参数
而在playbook中,可以这样使用roles:
---
- hosts: webservers
roles:
- common
- webservers
也可以向roles传递参数
示例:
---
- hosts: webservers
roles:
- common
- { role: foo_app_instance, dir: '/opt/a', port: 5000 }
- { role: foo_app_instance, dir: '/opt/b', port: 5001 }条件式地使用roles
甚至也可以条件式地使用roles
示例:
---
- hosts: webservers
roles:
- { role: some_role, when: "ansible_os_family == 'RedHat'" }Roles条件及变量等案例
When条件
roles:
- {role: nginx, when: "ansible_distribution_major_version == '7' " ,username: nginx }
变量调用
- hosts: zabbix-proxy
sudo: yes
roles:
- { role: geerlingguy.php-mysql }
- { role: dj-wasabi.zabbix-proxy, zabbix_server_host: 192.168.37.167 }完整的roles架构
// nginx-role.yml 顶层任务调用yml文件
---
- hosts: testweb
remote_user: root
roles:
- role: nginx
- role: httpd 可执行多个role
cat roles/nginx/tasks/main.yml
---
- include: groupadd.yml
- include: useradd.yml
- include: install.yml
- include: restart.yml
- include: filecp.yml
// roles/nginx/tasks/groupadd.yml
---
- name: add group nginx
user: name=nginx state=present
cat roles/nginx/tasks/filecp.yml
---
- name: file copy
copy: src=tom.conf dest=/tmp/tom.conf
以下文件格式类似:
useradd.yml,install.yml,restart.yml
ls roles/nginx/files/
tom.confroles playbook tags使用
roles playbook tags使用
ansible-playbook --tags="nginx,httpd,mysql" nginx-role.yml 对标签进行挑选执行
// nginx-role.yml
---
- hosts: testweb
remote_user: root
roles:
- { role: nginx ,tags: [ 'nginx', 'web' ] ,when: ansible_distribution_major_version == "6“ }
- { role: httpd ,tags: [ 'httpd', 'web' ] }
- { role: mysql ,tags: [ 'mysql', 'db' ] }
- { role: marridb ,tags: [ 'mysql', 'db' ] }
- { role: php }实验: 创建角色memcached
memcacched 当做缓存用,会在内存中开启一块空间充当缓存
cat /etc/sysconfig/memcached
PORT="11211"
USER="memcached"
MAXCONN="1024"
CACHESIZE="64" # 缓存空间默认64M
OPTIONS=""
1> 创建对用目录
cd /app/ansible
mkdir roles/memcached/{tasks,templates} -pv
2> 拷贝memcached配置文件模板
cp /etc/sysconfig/memcached templates/memcached.j2
vim templates/memcached.j2
CACHESIZE="{{ansible_memtotal_mb//4}}" #物理内存的1/4用做缓存
3> 创建对应yml文件,并做相应配置
cd tasks/
touch install.yml config.yml service.yml
创建main.yml文件定义任务执行顺序
vim main.yml
- include: install.yml
- include: config.yml
- include: service.yml
vim install.yml
- name: install
yum: name=memcached
vim config.yml
- name: config file
template: src=memcached.j2 dets=/etc/sysconfig/memcached
vim service.yml
- name: service
service: name=memcached state=started enabled=yes
4> 创建调用角色文件
cd /app/ansible/roles/
vim role_memcached.yml
---
- hosts: appsrvs
roles:
- role: memcached
5> 安装
ansible-playbook role_memcached.yml
memcached端口号11211其它功能
委任(指定某一台机器做某一个task)
delegate_to
local_action (专指针对ansible命令执行的机器做的变更操作)
交互提示
prompt
*暂停(java)
wait_for
Debug
debug: msg="This always executes."
Include
Template 多值合并
Template 动态变量配置Ansible Roles
委任
delegate_to
交互提示
prompt
暂停
wait_for
Debug
debug: msg="This always executes."
Include
Template 多值合并
Template 动态变量配置推荐资料
http://galaxy.ansible.com
https://galaxy.ansible.com/explore#/
http://github.com/
http://ansible.com.cn/
https://github.com/ansible/ansible
https://github.com/ansible/ansible-examples实验: 实现二进制安装mysql的卸载
cat remove_mysql.yml
---
# install mariadb server
- hosts: appsrvs:!192.168.38.108
remote_user: root
tasks:
- name: stop service
shell: /etc/init.d/mysqld stop
- name: delete user
user: name=mysql state=absent remove=yes
- name: delete
file: path={{item}} state=absent
with_items:
- /usr/local/mysql
- /usr/local/mariadb-10.2.27-linux-x86_64
- /etc/init.d/mysqld
- /etc/profile.d/mysql.sh
- /etc/my.cnf
- /data/mysql
ansible-playbook remove_mysql.ymlFROM alpine:lts
# 替换为阿里源
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories
# 设置时区为上海
RUN apk add tzdata && cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \
&& echo "Asia/Shanghai" > /etc/timezone \
&& apk del tzdata还有一种方法是映射宿主机的/etc/localtime文件到容器内,权限设置为只读,当然宿主机的时区要配置正确
K8s的写法是
volumes:
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: frontend
image: $IMAGE_NAME:$BUILD_NUMBER
ports:
- name: tcp-80
containerPort: 80
protocol: TCP
resources: {}
volumeMounts:
- name: host-time
readOnly: true
mountPath: /etc/localtime最近有一个新的后台API项目需要运行在PHP5.3环境中,软件行业有个特点,版本更新快,工具层出不穷。PHP5.3至少是5年前的版本了。 PHP官方早已不维护,虽然提供源码,但是安装配置也很麻烦,又不想污染目前机器上PHP7环境。
所以想到了Docker,通过这篇 文章 我很快的就利用Docker解决了我的问题,我直接利用别人提供好的Docker镜像,可以快速实现PHP版本切换
我觉得Docker适合以下情况:
- 运行特定的开发环境,比如要运行两个项目。一个要求PHP5.6,一个PHP7.0。不想来回切换。或者同时运行多个Node版本等等。
- 喜欢尝鲜,折腾,docker有很强的隔离性。在docker里搞坏也不会破坏本地,用到的时候docker run 启动镜像和容器,不想用了
docker rm [容器名]删掉即可。
以ThinkPHP3.2框架为例,通过docker跑起来,可以按如下步骤:
-
安装 Docker,略 记得一定要切换为国内源,不然速度巨慢,还容易报错,推荐免费的 https://www.daocloud.io/mirror#accelerator-doc 或者搜索阿里docker镜像源。
-
下载镜像
docker pull eriksencosta/php-dev -
项目目录是已经存在的 路径是
D:/projects/live-ranking-api -
运行容器 其中参数:
- -p 端口映射
- -v 或者 --volume,挂载目录,冒号前是宿主机目录,后面的是容器内目录
- -t 或者 --tty 分配一个伪终端
- -i 或者 --interactive, 就是表示已交互方式运行容器,啥是交互方式?就是你输入命令,就返回命令的结果,
- -d 或者 --detach, 在容器在后台运行,并返回容器ID,这样可以不用再新开一个窗口 运行成功后会执行 /bin/bash 就是进去终端
docker run 后面可以带很多参数,见官网
完整的命令如下:
docker run -t -i -p 8088:80 -v D:/projects/live-ranking-api:/var/www -d "eriksencosta/php-dev:latest" /bin/bash

- 打开浏览器输入
localhost:8088正常的话项目已经成功跑起来了 - 切换PHP版本,在容器内的终端内输入
phpenv命令列出当前可选择的PHP版本
# phpenv versions
5.3
5.3.29
5.4
5.4.35
5.5
5.5.19
5.6
* 5.6.3 (set by /opt/phpenv/version)执行 phpenv global 5.4
# phpenv global 5.4
# php -v
PHP 5.4.35 (cli) (built: Dec 14 2014 00:35:12)
Copyright (c) 1997-2014 The PHP Group
Zend Engine v2.4.0, Copyright (c) 1998-2014 Zend Technologies
with Zend OPcache v7.0.3, Copyright (c) 1999-2014, by Zend Technologies
with Xdebug v2.2.6, Copyright (c) 2002-2014, by Derick Rethans启动 nginx
# webserver start
Starting PHP-FPM (PHP version 5.3) server.
Starting Nginx server.
Done.参考:
]]>2019-11-6 更新 lazydocker 终端UI的docker和docker-compose
2019-3-8 更新 dockstation Docker的GUI管理工具


为什么需要docker图形化管理平台?
命令行虽然效率高,但太专业,不够直观,而且多主机管理不方便。 图形化管理系统还可以和用户角色管理等关联起来。不用太多的专业知识也能很快上手。
都有哪些开源免费的docker图形化管理平台?
截至当前(2018年) Rancher 和 portainer 比较火,star数量都将近1w。还有个shipyard,但是作者已经停止维护,并推荐使用前面两款。
Portainer 比 Rancher 要轻量,如果刚接触 Docker,建议先使用这个。如果要图形化管理 Kubernetes 就用 Rancher。
Portainer - 轻量的 Docker UI管理系统


先看下 Portainer ,以 Windows 为例,Portainer 可以运行在容器中,也可以下载编译后的包。比如这里我下载的是 portainer-1.19.2-windows-amd64.tar.gz
下载最新的发行版本 https://github.com/portainer/portainer/releases
解压到新建的portainer目录中,这个目录底下再新建保存数据的目录 portainer_data
打开命令行执行下面的命令,然后浏览器就可以访问了
./portainer.exe -p :9000 --template-file templates.json --data ./portainer_data/
具体细节参考: https://portainer.readthedocs.io/en/latest/deployment.html#quick-start 关于在Windows运行的教程 http://blog.airdesk.com/2017/10/windows-containers-portainer-gui.html
Rancher - 针对 Kubernetes 企业级管理系统
文档: Rancher 。
下面放几张图:
- 装好后,打开先让设置管理员密码:

- 然后让添加一个集群,先修改语言为中文。

- 填写信息,呃,好像是配置Kubernates。还没有研究到这里 先到这里吧。有空再研究。


cadvisor - 容器监控工具
有时候需要监控每个容器的运行情况。 google出品了cAdvisor 运行后,可打开web界面查看所有的容器, 镜像。

点击某容器,可查看具体的CPU,内存,网络,文件系统的运行情况


cAdvisor提供的页面非常简洁。 页面上的数据可以通过他暴露的API直接获取,可以把 cAdvisor 定位为一个监控数据收集器,收集和导出数据是它的强项,而非展示数据。所以可以结合其他工具一块使用。
lazydocker - 终端用户界面
lazydocker,一个简单的 docker 和 docker-compose 终端用户界面,用更懒惰的方式来管理所有的 docker。
其界面采用 gocui 开发。
]]>

17.05.0-ce开始,就支持了一种新的构建镜像的方法,叫做:多阶段构建(Multi-stage builds),旨在解决Docker构建应用容器中的一些痛点。
在日常构建容器的场景中,经常会遇到在同一个容器中进行源码的获取,编译和生成,最终才构建为镜像。这样做的劣势在于:
- 不得不在容器中安装构建程序所必须的运行时环境
- 不得不在同一个容器中,获取程序的源码和构建所需的一些生态工具
- 构建出的镜像甚至包含了程序源码和一些不必要的文件,导致容器镜像尺寸偏大
当然,还有一种稍微优雅的方式,就是我们事先在外部将项目及其依赖库编译测试打包好后,再将其拷贝到构建目录中,这种虽然可以很好地规避第一种方式存在的风险点,但是也需要考虑不同镜像运行时,对于程序运行兼容性所带来的差异。
其实,这些痛点,Docker也想到了,官方提供了简便的多阶段构建 (multi-stage build) 方案。所谓多阶段构建,也即将构建过程分为多个阶段,在同一个Dockerfile中,通过不同的阶段来构建和生成所需要的应用文件,最终将这些应用文件添加到一个release的镜像中。这样做能完全规避上面所遇到的一系列问题。
实现多阶段构建,主要依赖于新提供的关键字:from和as。
下面举个前端的例子:
# build stage
FROM node:9.11.1-alpine as build-stage
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
RUN npm run build
# production stage
FROM nginx:1.13.12-alpine as production-stage
COPY --from=build-stage /app/dist /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]第一阶段:拷贝源文件到镜像中,生成用于生产环境需要的静态资源文件 第二阶段:启动一个nginx容器,托管第一阶段的静态文件
# 编译阶段
FROM golang:1.10.3
COPY server.go /build/
WORKDIR /build
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 GOARM=6 go build -ldflags '-w -s' -o server
# 运行阶段
FROM scratch
# 从编译阶段的中拷贝编译结果到当前镜像中
COPY --from=0 /build/server /
ENTRYPOINT ["/server"]这个 Dockerfile 的玄妙之处就在于 COPY 指令的 --from=0 参数,从前边的阶段中拷贝文件到当前阶段中,多个FROM语句时,0代表第一个阶段。 除了使用数字,我们还可以给阶段命名,比如:
# 编译阶段 命名为 builder
FROM golang:1.10.3 as builder
# ... 省略
# 运行阶段
FROM scratch
# 从编译阶段的中拷贝编译结果到当前镜像中
COPY --from=builder /build/server /更为强大的是,COPY --from 不但可以从前置阶段中拷贝,还可以直接从一个已经存在的镜像中拷贝。比如,
FROM ubuntu:16.04
COPY --from=quay.io/coreos/etcd:v3.3.9 /usr/local/bin/etcd /usr/local/bin/我们直接将etcd镜像中的程序拷贝到了我们的镜像中,这样,在生成我们的程序镜像时,就不需要源码编译etcd了,直接将官方编译好的程序文件拿过来就行了。
有些程序要么没有apt源,要么apt源中的版本太老,要么干脆只提供源码需要自己编译,使用这些程序时,我们可以方便地使用已经存在的Docker镜像作为我们的基础镜像。
但是我们的软件有时候可能需要依赖多个这种文件,我们并不能同时将 nginx 和 etcd 的镜像同时作为我们的基础镜像(不支持多根),这种情况下,使用 COPY --from 就非常方便实用了。
多阶段构建的Dockerfile看起来像是把两个或者更多的Dockerfile合并在了一起,这也即多阶段的意思。
as关键字用来为构建阶段赋予一个别名,这样,在另外一个构建阶段中,可以通过from关键字来引用和使用对应关键字阶段的构建输出,并打包到容器中。
甚至,我们还可以使用更多的构建阶段来构建不同的应用,最终将这些构建产出的应用,合并到一个最终需要发布的镜像中。 我们可以看一个更复杂一点的栗子:
from debian as build-essential
arg APT_MIRROR
run apt-get update
run apt-get install -y make gcc
workdir /src
from build-essential as foo
copy src1 .
run make
from build-essential as bar
copy src2 .
run make
from alpine
copy --from=foo bin1 .
copy --from=bar bin2 .
cmd ...再来一个Laravel项目的多阶段构建( 自己加的内容) 第一阶段:使用compose安装PHP依赖 第二阶段:安装node,并安装前端依赖然后生成编译后的文件 第三阶段:拷贝PHP依赖及前端build后的文件到项目运行目录
#
# PHP Dependencies
#
FROM composer:1.7 as vendor
COPY database/ database/
COPY composer.json composer.json
COPY composer.lock composer.lock
RUN composer install \
--ignore-platform-reqs \
--no-interaction \
--no-plugins \
--no-scripts \
--prefer-dist
#
# Frontend
#
FROM node:8.11 as frontend
RUN mkdir -p /app/public
COPY package.json webpack.mix.js yarn.lock /app/
COPY resources/assets/ /app/resources/assets/
WORKDIR /app
RUN yarn install && yarn production
#
# Application
#
FROM php:7.2-apache-stretch
COPY . /var/www/html
COPY --from=vendor /app/vendor/ /var/www/html/vendor/
COPY --from=frontend /app/public/js/ /var/www/html/public/js/
COPY --from=frontend /app/public/css/ /var/www/html/public/css/
COPY --from=frontend /app/mix-manifest.json /var/www/html/mix-manifest.json多阶段构建的好处不言而喻,既可以很方便地将多个彼此依赖的项目通过一个Dockerfile就可轻松构建出期望的容器镜像,并且不用担心镜像太大、源码泄露等风险。 不得不说,这是一个非常不错的改进。
参考:
]]>关于主从同步的流程图,放张网上找的流程图

以mysql5.7为例
- 创建 mysql-master-slave 目录,比如完整路径是 D:/docker/mysql-master-slave 目录结构如下:
-- master
-- data
mysqld.cnf
-- slave
-- data
mysqld.cnf- 其中master目录底下的 mysqld.cnf 配置文件内容为
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# 以下是新增内容
# 标识不同的数据库服务器,而且唯一
server-id=1
# 启用二进制日志
log-bin=mysql-bin
log-slave-updates=1
innodb_flush_log_at_trx_commit = 2
innodb_flush_method = O_DIRECT
skip-host-cache
skip-name-resolveslave 目录底下的 mysqld.cnf 内容为
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
# 以下是新增内容
server-id=2
log-bin=mysql-bin
log-slave-updates=1
# 多主的话需要注意这个配置,防止自增序列冲突。
auto_increment_increment=2
auto_increment_offset=2
read-only=1
slave-skip-errors = 1062
skip-host-cache
skip-name-resolve- 基于官方mysql镜像,运行两个容器并指定一些参数 启动 名称为mysql_master的容器作为master数据库
docker run --name mysql_master -d -p 3307:3306 -e MYSQL_ROOT_PASSWORD=123456 \
-v D:/docker/mysql-master-slave/master/data:/var/lib/mysql \
-v D:/docker/mysql-master-slave/master/mysqld.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf mysql:5.7
docker run --name mysql_slave -d -p 3308:3306 -e MYSQL_ROOT_PASSWORD=123456 \
-v D:/docker/mysql-master-slave/slave/data:/var/lib/mysql \
-v D:/docker/mysql-master-slave/slave/mysqld.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf mysql:5.7这个时候宿主机的 Navicat 应该可以连上容器里的两个数据库了。
- 配置主从同步,新开终端进入容器
docker exec -it mysql_master bashmysql -u root -p创建一个同步数据权限的用户GRANT REPLICATION SLAVE ON *.* to 'backup'@'%' identified by '123456';查看状态,记住File、Position的值,在 Slave 中将用到show master status;

进入slave容器
docker exec -it mysql_slave bash
mysql -u root -p
设置主库链接
change master to master_host='172.17.0.2',master_user='backup',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=0,master_port=3306;
启动从库同步
start slave
查看状态,如果 Slave_SQL_Running_State 是 Slave has read all relay log; waiting for more updates 表示正常运行。
show slave status \G

- 测试同步,在master上新建一个数据库
docker exec mysql_master mysql -uroot -p123456 -e "CREATE DATABASE test"docker exec mysql_slave mysql -uroot -p123456 -e "SHOW DATABASES"
总结:
-
mysqld.cnf 文件的由来? 答:就是从容器内的
/etc/mysql/mysql.conf.d/mysqld.cnf拷贝出来的 -
主从同步的简单原理? 答: MySQL的主从复制是一个异步的复制过程,数据库从一个Master复制到Slave数据库,在Master与Slave之间实现整个主从复制的过程是由三个线程参与完成的,其中有两个线程(SQL线程和IO线程)在Slave端,另一个线程(IO线程)在Master端。 master 数据变化时会产生bin log日志,slave上的线程拉去bin log,然后在slave上重新执行日志。这样就保证了数据一致性。
-
show slave status 中的Slave_IO_Running和Slave_SQL_Running的含义? 答:Slave 上会同时有两个线程在工作, I/O 线程从 Master 得到数据(Binary Log 文件),放到被称为 Relay Log 文件中进行记录。另一方面,SQL 线程则将 Relay Log 读取并执行。 为什么要有两个线程?这是为了降低同步的延迟。因为 I/O 线程和 SQL 线程都是相对很耗时的操作。
-
从服务器同步失败? 答:看错误日志
tail /var/log/mysql/error.log重新执行同步stop slave;change master to master_log_file='mysql-bin.000100,master_log_pos=123'关于 file 和 pos,需在master上执行show master status获得。 或者使用mysqlbinlog命令分析。 -
如何添加多个从节点? 和添加第一个从节点类似,先导出master的数据,复制第一个slave配置文件,唯一要改变的是server-id,不能和其他的重复。之后启动新的容器,进到容器内执行
change master to ...。 还需要注意当前master没有写入等操作,最好先锁表,同步设置好后在解锁。参考
问题:
- 如何添加slave节点服务器,如何主主备份 更多细节还得啃官方文档
- 使用 docker compose 配置 mysql 主从 http://tarunlalwani.com/post/mysql-master-slave-using-docker/
参考:
]]>MySQL本身是开源的,有些公司或社区基于MySQL发布了新的分支,如有名的MariaDB。
在介绍 Percona 之前,首要要介绍的是XtraDB存储引擎,在MYSQL中接触比较多的是MyISAM 和 InnoDB这两个存储引擎。
MySQL 4 和 5 使用默认的 MyISAM 存储引擎安装每个表。从5.5开始,MySQL已将默认存储引擎从 MyISAM 更改为 InnoDB。MyISAM 没有提供事务支持,而 InnoDB 提供了事务支持。与 MyISAM 相比,InnoDB 提供了许多细微的性能改进,并且在处理潜在的数据丢失时提供了更高的可靠性和安全性。
Percona Server由领先的MySQL咨询公司Percona发布。Percona Server是一款独立的数据库产品,其可以完全与MySQL兼容,可以在不更改代码的情况了下将存储引擎更换成XtraDB 。
Percona XtraDB Cluster 完全兼容MySQL。
常见MySQL集群方案

Percona XtraDB Cluster优缺点
优点: 1.当执行一个查询时,在本地节点上执行。因为所有数据都在本地,无需远程访问。 2.无需集中管理。可以在任何时间点失去任何节点,但是集群将照常工作。 3.良好的读负载扩展,任意节点都可以查询。
缺点: 1.加入新节点,开销大。需要复制完整的数据。 2.不能有效的解决写缩放问题,所有的写操作都将发生在所有节点上。 3.有多少个节点就有多少重复的数据。
基于Docker的实现流程
- 拉镜像
docker pull percona/percona-xtradb-cluster:5.7 - 镜像名字有点长,起个短点的
docker tag percona/percona-xtradb-cluster:5.7 pxc - 出于安全考虑,针对PXC集群实例创建内部网络
创建的时候通过参数指定IP段和子网掩码,Docker默认使用的IP 172.17.0.1,我们换个别的。
docker network create --subnet=172.18.0.0/24 pxc-network - 创建第一个节点
docker run -d -p 33010:3306 -e MYSQL_ROOT_PASSWORD=root -e CLUSTER_NAME=pxc_cluster --name=pxc_node1 --net=pxc-network --ip=172.18.0.2 pxc执行 docker logs pxc_node1 查看执行状态,如果看到 mysqld: ready for connections. 就可以使用navicat等工具测试连接。 - 创建第二个数据库节点,并加入到第一个集群中,注意多了 CLUSTER_JOIN 参数
docker run -d -p 33011:3306 -e MYSQL_ROOT_PASSWORD=root -e CLUSTER_NAME=pxc_cluster -e CLUSTER_JOIN=pxc_node1 --name=pxc_node2 --net=pxc-network --ip=172.18.0.3 pxc - 创建第三个数据库节点,并加入到第一个集群中,注意多了 CLUSTER_JOIN 参数
docker run -d -p 33012:3306 -e MYSQL_ROOT_PASSWORD=root -e CLUSTER_NAME=pxc_cluster -e CLUSTER_JOIN=pxc_node1 --name=pxc_node3 --net=pxc-network --ip=172.18.0.4 pxc - 接下来可以创建第N个节点,注意参数如容器名称 --name 和映射的端口别冲突;
- 测试:本地连接这三个节点,在其中一个创建demo数据,其他节点都自动同步数据过去了

注意
- 启动第一个节点后记得使用docker logs查看启动状态,然后使用navicat等工具测试连接,等第一个mysql运行成功后再运行第二个容器。否则第二个起不来,需要重新启动容器。
- 如果停掉某一节点
docker stop pxc_node1再启动时docker start pxc_node1可能会发现连接不上了。这时候可以删除容器,重新运行,命令类似docker run -d -p 33010:3306 -e MYSQL_ROOT_PASSWORD=root -e CLUSTER_NAME=pxc_cluster -e CLUSTER_JOIN=pxc_node2 --name=pxc_node1 --net=pxc-network --172.18.0.2 pxc
参考
]]>
在这里我们使用haproxy作为负载均衡的中间件,类似的还有LVS,但是好像不支持虚拟机,在docker中用不了。

实现流程:
- 下载镜像
docker pull haproxy - 宿主机创建 haproxy 的配置文件,比如路径是 D:\Docker\haproxy\haproxy.cfg
- 最重要的就是配置文件了。这里内容如下:
global
daemon
# nbproc 1
# pidfile /var/run/haproxy.pid
# 工作目录
chroot /usr/local/etc/haproxy
defaults
log 127.0.0.1 local0 err #[err warning info debug]
mode http #默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK
retries 2 #两次连接失败就认为是服务器不可用,也可以通过后面设置
option redispatch #当serverId对应的服务器挂掉后,强制定向到其他健康的服务器
option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
option dontlognull #日志中不记录负载均衡的心跳检测记录
maxconn 4096 #默认的最大连接数
timeout connect 5000ms #连接超时
timeout client 30000ms #客户端超时
timeout server 30000ms #服务器超时
#timeout check 2000 #=心跳检测超时
######## 监控界面配置 #################
listen admin_status
# 监控界面访问信息
bind 0.0.0.0:8888
mode http
# URI相对地址
stats uri /dbs
# 统计报告格式
stats realm Global\ statistics
# 登录账户信息
stats auth admin:123456
########frontend配置##############
######## mysql负载均衡配置 ###############
listen proxy-mysql
bind 0.0.0.0:3306
mode tcp
# 负载均衡算法
# static-rr 权重, leastconn 最少连接, source 请求IP, 轮询 roundrobin
balance roundrobin
# 日志格式
option tcplog
# 在 mysql 创建一个没有权限的haproxy用户,密码为空。 haproxy用户
# create user 'haproxy'@'%' identified by ''; FLUSH PRIVILEGES;
option mysql-check user haproxy
# 这里是容器中的IP地址,由于配置的是轮询roundrobin,weight 权重其实没有生效
server MYSQL_1 172.18.0.2:3306 check weight 1 maxconn 2000
server MYSQL_2 172.18.0.3:3306 check weight 1 maxconn 2000
server MYSQL_3 172.18.0.4:3306 check weight 1 maxconn 2000
# 使用keepalive检测死链
# option tcpka
#########################################- 启动 haproxy 的容器,镜像名称为 h1,网络名称使用上节中创建的 pxc-network,就是和 mysql 集群处于同一网络。
docker run -it -d -p 4001:8888 -p 4002:3306 -v D:/Docker/haproxy:/usr/local/etc/haproxy --name h1 --net=pxc-network - 进去容器,并让 haproxy 加载配置
docker exec -it h1 bashhaproxy -f /usr/local/etc/haproxy/ - 宿主机打开
http://localhost:4001/dbs这是haproxy 提供的图形界面

可以看到每个mysql节点运行状态是绿色,说明正常。
7. 测试,停掉一个数据库节点 docker stop pxc_node1 ,发现有一个变红了。

- 项目中可以使用配置的 4002 来连接数据库,这样请求会被分发到各个子节点。
总结:
- 数据库的负载均衡配置还是比较简单的,关键是负载均衡算法,如果每个数据库节点配置都一样,可以使用轮询算法,如果不一样,可以使用权重算法,让配置高的多接收请求。
- 官方的教程
下面介绍怎么通过PHPStorm创建并运行一个docker容器项目并启用xdebug,以Windows系统为例
- 运行 Docker for Windows,Docker运行成功后桌面右下角有图标,右键选择Settings
勾选
"Expose daemon on tcp://localhost:2375"就是暴露守护进程。

-
比如有一个空项目叫 Docker-compose-demo,用PHPStorm打开 新建
docker-compose.yml文件 -
内容如下:
version: '2'
services:
webserver:
image: phpstorm/php-71-apache-xdebug-26
ports:
- "6080:80"
volumes:
- ./:/var/www/html
environment:
#change the line below with your IP address
XDEBUG_CONFIG: remote_host=host.docker.internalhost.docker.internal 指运行IDE的本机IP
4. PHPStorm 中菜单项 'Run - Edit Configurations' 配置Docker信息。因为之前我们开放了docker的守护进行,可以通过TCP协议,地址localhost:2372进行连接。PHPStorm连接上会显示 success

- 鼠标右键选择
Run 'docker-compose.yml',通过PHPStorm下载镜像并运行容器

可以看到本机安装过的Docker的容器和镜像。 当前正在执行 docker-compose.yml

运行成功了,可以直观的看到容器的相关信息

- 项目根目录创建index.php,浏览器打开
localhost:6080查看效果 - 因为已经配置了xdebug,直接就可以用。 具体 chrome浏览器安装 xdebug helper 新建index.php 内容:
$arr = ['jack', 'smith', 'www'];
foreach ($arr as $item) {
# 在下面的 echo 处打断点
echo $item;
}
如图,每点一次步进就显示当前运行时的相关变量信息。非常方便。
总结:
使用docker大大方便了咱们的环境搭建流程。
这篇文章我是看了官方的视频 后写的。
还有配置文件只配置了apache服务器,关于mysql等官方镜像中其实也提供了。请自行修改docker-compose.yml。
PHPStorm官方镜像: https://github.com/JetBrains/phpstorm-docker-images/blob/master/docker-compose.yml
]]> --- backend
-- model
-- controller如果执行
WORKDIR /app
COPY backend .容器内app底下会是model和controller目录,并不是backend目录。
如果要拷贝整个目录,应该:
COPY backend ./backend
-
如果修改了 Dockerfile,记得要重新执行build,即生成新的镜像。这样启动后才能看到效果。
-
打包node项目中的node_modules问题。 某node项目结构:
src
node_modules
package.json
package-lock.jsondockerfile部分代码
FROM node:8.12-alpine
RUN mkdir -p /app
WORKDIR /app
COPY package.json .
COPY package-lock.json .
RUN npm install
...我们在容器内生成了项目所依赖的node_modules文件。这是docker的build阶段。 之后在run启动阶段时,在mouted共享目录时要特别小心,如果挂载整个项目,容器内的node_modules会被项目中的覆盖。 最好把需要挂载的文件单独放到一个目录中。
- 关于项目目录是挂载好,还是COPY ADD好,stackoverflow上有人也问过
- COPY/ADD 文件是镜像的一部分,在docker构建阶段执行。比较适合项目的生产环境,比如自动化。对于成熟稳定的项目,把编译后的可以直接运行的代码打包进镜像内也利于分发。
- volumn 是在docker运行阶段,本地文件变化能方便的反应到容器中,比较适合项目的开发阶段。 要根据实际情况,挂载可以节省空间,便于修改。如果是想文件COPY到容器,每次修改文件都需要重新制作镜像。
- 关于 docker-compose,对于镜像的版本,数据库密码等不建议直接写死到 docker-compose.yml 中,可以新建.env文件。 docker-compose部分
mysql:
build: ./docker-build/mysql
ports:
- "33060:3306"
volumes:
- ./docker-build/mysql/data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: ${DOCKER_MYSQL_PASSPORD-123456}.env文件
DOCKER_MYSQL_PASSPORD=mypassord
比如下面的${DOCKER_MYSQL_PASSPORD-123456}表示优先去.env文件找定义的key值,如果没有则使用默认值,即123456。
docker-compose.yml 受版本控制,.env不受。更多细节参考
- 在 Laravel 项目中,如果数据库跑在容器里,在宿主机直接执行
php aritsan是不行的,
需要进到容器里执行,或者在宿主机执行docker-compose exec <mycontainer> php artisan或者是docker exec -it <mycontainer> php artisan
-
如果php项目用的nginx的php-fpm容器,想重启php-fpm,容器内使用
kill -USR2 1,容器外执行docker exec -it <mycontainer> kill -USR2 1\ -
docker-compose down要慎用,他会销毁所有容器和网络等。如果你之前在容器里修改过文件,都会没有。当然docker也不推荐直接在容器动手脚,建议写个shell脚本,启动之后在容器内执行。
-
还是 mysql 数据库问题,如果容器启动了 mysql,之后通过配置修改了密码,可能会造成重新连接后死活显示"Access denied"。 这是因为如果建立了共享卷volume,里面存的还是老的user信息,需要
docker-compose rm -v清除卷然后重连。 -
删除日志
find /var/lib/docker/containers/ -type f -name "*.log" -delete -
删除所有停止的容器
docker rm $(docker ps -a -q) -
Docker 提供了方便的
docker system prune命令来删除那些已停止的容器、dangling 镜像、未被容器引用的 network 和构建过程中的 cache. 安全起见,这个命令默认不会删除那些未被任何容器引用的数据卷,如果需要同时删除这些数据卷,你需要显式的指定 --volumns 参数。比如你可能想要执行下面的命令:docker system prune --all --force --volumns
注意,使用 --all 参数后会删除所有未被引用的镜像而不仅仅是 dangling 镜像。
何为 dangling images,其实可以简单的理解为未被任何镜像引用的镜像。比如在你重新构建了镜像后,那些之前构建的且不再被引用的镜像层就变成了 dangling images
我们还可在不同在子命令下执行 prune,这样删除的就是某类资源:
docker container prune # 删除所有退出状态的容器
docker volume prune # 删除未被使用的数据卷
docker image prune # 删除 dangling 或所有未被使用的镜像- docker diff 容器名或ID,可以查看容器发生的文件系统的变化信息 如下图,我在容器里新建了个demo.txt文件,在docker diff中可以查看出来 A 添加, C 修改, D 删除
]]>

- docker save保存的是镜像(image),docker export保存的是容器(container);
- docker load用来载入镜像包,docker import用来载入容器,但两者都会恢复为镜像;
- docker load不能对载入的镜像重命名,而docker import可以为镜像指定新名称。
比如我本机上有一个 finleyma/express的镜像,容器ID为4a655b443069
使用如下命令分别导出镜像和容器
docker save -o image-express-save.tar finleyma/express
docker export -o container-express-export.tar 4a655b443069
发现如下特点:
- 镜像压缩包比容器要大。
- 目录结构不太一样

- 容器压缩包 是很典型的Linux目录结构,还找到当初build时被ADD进的源码文件

- 镜像压缩包 其实就是分层的文件系统。Docker镜像就是由这样一层层的文件叠加起来。
打开压缩包内的 repositories,
内容为
{"finleyma/express":{"latest":"dda6ce6f2c43f673353e2ce232b31d11ff15b444e338a0ef8f34b6ef74093d6c"}}既这个镜像的名称,tag是latest,id为dda6ce6f2c43f673353e2ce232b31d11ff15b444e338a0ef8f34b6ef74093d6c 而且tar内有相同ID的目录。

json文件的内容如下:里面记录着这一层容器文件的元信息,通过parent,还能知道依赖的上一层的文件系统是什么。
{
"id": "dda6ce6f2c43f673353e2ce232b31d11ff15b444e338a0ef8f34b6ef74093d6c",
"parent": "b75acde96878455ce36208008bb1143d4ea17723257c991f8bfb33ad9e27251d",
"created": "2018-09-19T15:41:54.6130547Z",
"container": "3cd78865317bce73179abc7d21fcbe860a96d14fc980c01566fa2c9412b17d7d",
"container_config": {
"Hostname": "3cd78865317b",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"ExposedPorts": {
"8081/tcp": {}
},
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": ["PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin", "NODE_VERSION=8.9.4", "YARN_VERSION=1.3.2"],
"Cmd": ["/bin/sh", "-c", "#(nop) ", "CMD [\"npm\" \"start\"]"],
"ArgsEscaped": true,
"Image": "sha256:91f850e6adbd56df68088dffe63c56e6f48fc24f763ff9d22c739742be71212a",
"Volumes": null,
"WorkingDir": "/usr/src/app",
"Entrypoint": null,
"OnBuild": [],
"Labels": {}
},
"docker_version": "18.06.1-ce",
"config": {
"Hostname": "",
"Domainname": "",
"User": "",
"AttachStdin": false,
"AttachStdout": false,
"AttachStderr": false,
"ExposedPorts": {
"8081/tcp": {}
},
"Tty": false,
"OpenStdin": false,
"StdinOnce": false,
"Env": ["PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin", "NODE_VERSION=8.9.4", "YARN_VERSION=1.3.2"],
"Cmd": ["npm", "start"],
"ArgsEscaped": true,
"Image": "sha256:91f850e6adbd56df68088dffe63c56e6f48fc24f763ff9d22c739742be71212a",
"Volumes": null,
"WorkingDir": "/usr/src/app",
"Entrypoint": null,
"OnBuild": [],
"Labels": null
},
"architecture": "amd64",
"os": "linux"
}打开lay.tar, 对于的原来就是当初dockerfile中的ADD . /app/

那 node_modules 跑哪了,你很快就能猜测到,肯定在上一层文件中。事实确实是这样的。ADD . /app/ 之前对于的命令是 RUN npm install

所以写dockerfile时,一行命令对于一层文件系统,要充分利用这样机制,层的数量尽可能少,只安装必要的依赖包。
参考:
]]>近几天打算用Docker跑一个需要PHP5.6的项目,然后发现Docker官方提供的PHP镜像中,只有PHP7.0以上的介绍。没有PHP5.5及PHP5.6的(tag还有,只不过主页中没有) 感到比较纳闷,官方github也移除了相关的代码。 搜索发现原来是PHP官方团队已经不再维护5.6。 也就是说,既然官方都不管了,Docker更不没有必要继续维护相关分支。 然后去PHP官方公告查看从2019年1月1日起PHP5.6已经不再维护支持,就连PHP7.1都只进行安全支持。

这样可以倒逼企业进行系统版本更新换代。对开发人员绝对是好事,虽然企业主出于成本考虑不愿意进行升级。 最后如果想查看之前5.6及5.5的Dockerfile细节,可以查看这个PR。
]]>开发阶段
- 项目根目录添加
Dockerfile文件
# base image
FROM circleci/node:10.14-browsers
USER root
# set working directory
RUN mkdir -p /usr/src/app
WORKDIR /usr/src/app
# 如果觉得 npm install 慢可以使用淘宝源
RUN npm config set registry https://registry.npm.taobao.org
# install and cache app dependencies
COPY package*.json /usr/src/app/
RUN npm install
RUN npm install -g @angular/cli
# add `/usr/src/app/node_modules/.bin` to $PATH
ENV PATH /usr/src/app/node_modules/.bin:$PATH
# add app
COPY . /usr/src/app
# start app 根据实际情况修改配置
# CMD ng serve --host 0.0.0.0
CMD ng serve --port=4201 --proxy-config=proxy.conf.json --configuration=local --host 0.0.0.0- 然后再添加
.dockerignore文件,指定构建docker镜像时不希望发送给Docker daemon的文件。也就是不希望被打包进镜像的文件。防止镜像过大。
node_modules
.git- 构建镜像
docker build -t angular-demo . - 根据刚创建好的镜像启动一个容器
docker run -it \
-d # 加这个参数表示后台运行
-v ${PWD}:/usr/src/app \
-v /usr/src/app/node_modules \ #挂载依赖目录
-p 4201:4201 \
--rm \
angular-demo- 浏览器打开
http://localhost:4201,然后修改本地的某个文件,如src/app/app.component.html你会发现浏览器会自动刷新。 - 基础镜像
circleci/node:10.14-browsers已经包含了chrome浏览器,我们可以直接跑unit test。先修改src/karma.conf.js添加ChromeHeadless配置。
// Karma configuration file, see link for more information
// https://karma-runner.github.io/1.0/config/configuration-file.html
module.exports = function (config) {
config.set({
basePath: '',
frameworks: ['jasmine', '@angular-devkit/build-angular'],
plugins: [
require('karma-jasmine'),
require('karma-chrome-launcher'),
require('karma-jasmine-html-reporter'),
require('karma-coverage-istanbul-reporter'),
require('@angular-devkit/build-angular/plugins/karma'),
],
client: {
clearContext: false // leave Jasmine Spec Runner output visible in browser
},
files: [
{ pattern: '../node_modules/rxjs/**/*.js.map', included: false, watched: false },
{ pattern: '../node_modules/@angular/**/*.js.map', included: false, watched: false },
],
browserConsoleLogOptions: {
terminal: true,
level: config.LOG_INFO
},
coverageIstanbulReporter: {
dir: require('path').join(__dirname, '../coverage'),
reports: ['html', 'lcovonly'],
fixWebpackSourcePaths: true
},
reporters: ['progress', 'kjhtml'],
port: 9876,
colors: true,
logLevel: config.LOG_INFO,
autoWatch: true,
browsers: ['Chrome'],
// 加入下面的参数配置
customLaunchers: {
ChromeHeadless: {
base: 'Chrome',
flags: [
'--headless',
'--disable-gpu',
'--no-sandbox',
'--remote-debugging-port=9222'
]
}
},
// if true, Karma will start and capture all configured browsers, run tests and then exit
singleRun: true
});
};- 执行
docker exec -it angular-demo-container ng test --watch=false,注意替换下容器名 - 推荐使用docker-compose,好处是把运行参数记录在docker-compose.yml文件中。
version: '3.5'
services:
node:
container_name: angular-demo
build:
context: .
dockerfile: Dockerfile
volumes:
- '.:/usr/src/app'
- '/usr/src/app/node_modules'
ports:
- '4209:4201'请留意下匿名卷/usr/src/app/node_modules。
该目录是在docker build构建阶段创建的,在Run启动阶段需要手动挂载该目录。
9. docker-compose相关命令
# build镜像并后台启动
docker-compose up -d --build
docker-compose run angular-demo ng test --watch=false
ng e2e
docker-compose stop生产环境
- 创建一个生产环境用的Docker配置文件,Dockerfile-prod
#########################
### build environment ###
#########################
# base image
FROM circleci/node:10.14-browsers as builder
# set working directory
RUN mkdir /usr/src/app
WORKDIR /usr/src/app
# add `/usr/src/app/node_modules/.bin` to $PATH
ENV PATH /usr/src/app/node_modules/.bin:$PATH
# install and cache app dependencies
COPY package.json /usr/src/app/package.json
RUN npm install
RUN npm install -g @angular/cli
# add app
COPY . /usr/src/app
# run tests
RUN ng test --watch=false
# generate build
RUN npm run build
##################
### production ###
##################
# base image
FROM nginx:1.13.9-alpine
# copy artifact build from the 'build environment'
COPY --from=builder /usr/src/app/dist /usr/share/nginx/html
# expose port 80
EXPOSE 80
# run nginx
CMD ["nginx", "-g", "daemon off;"]这里用到了Dockerfile支持的多阶段构建,首先利用临时Node镜像生成静态资源,然后将静态资源拷贝到nginx镜像中进行托管。
2. 打包镜像-f表示指定文件,docker build -f Dockerfile-prod -t angular-demo-prod .
3. 运行 docker run -it -p 80:80 --rm angular-demo-prod
4. 对应的docker-compose-prod.yml
version: '3.5'
services:
angular-demo-prod:
container_name: something-clever-prod
build:
context: .
dockerfile: Dockerfile-prod
ports:
- '80:80'docker-compose -f docker-compose-prod.yml up -d --build
参考
]]>Docker容器虽然运行起来了。
但遇到了新的问题:
- 容器内安装的服务器是nginx,对于ThinkPHP项目,还需要一些额外的配置,简单的说在apache服务器下运行 http://localhost:8088/home/Index/index 能正常返回结果,而nginx下返回404,必须要写成 http://localhost:8088/index.php?m=home&c=Index&a=demo 所以我需要修改nginx配置文件,使其支持。
- 由于容器本身是无状态的,如果进到容器里修改完配置文件,关闭docker,下次在启动后还是原样,我需要保存修改。
下面是解决方法:
- 镜像为了精简并没有安装VIM编辑器,编辑文件不方便,要先安装
apt-get update; apt-get install vim注意,如果执行 apt-get update 超时了,试试翻墙。或者替换为国内源。 vi /etc/nginx/sites-enabled/default编辑并修改配置文件,记得最好先备份- 修改完新开个窗口
先执行
docker ps查看正在运行的容器,复制 container id。 然后docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]如 docker commit cb439fb2c714 finley/phpenv:tp3.2 commit 会基于对container的修改创建一个新的镜像 具体用法请参见官方文档:commit
WARNING
经查,不推荐更改运行中的容器配置,容器本身是无状态的,当然也可以通过进入容器内部的方式进行更改: docker exec -it 这样的更改是无法持久化保存的,当容器重启后,更改就丢失了,正确的做法是将需要持久化保存的数据放在挂载的存储卷中,当配置需要改变时直接删除重建。
回顾:
# 从仓库拉镜像
docker pull eriksencosta/php-dev
# 基于上面的镜像加入了自己的修改并提交为自己的镜像,还打了tag
docker commit cb439fb2c714 finleyma/php-dev:tp3.2问题: 这个项目的环境是有了,但是是多人开发,我如何将我的配好的镜像分享给他人呢? 请见下篇
]]>FROM node:10.8.0-alpine
MAINTAINER www.mafeifan.com
# 设置工作目录,下面的RUN命令会在工作目录执行
WORKDIR /app
# 先拷贝本地的 package.json 和 package-lock 到容器内
# 这样是利用docker的镜像分层机制
COPY package*.json ./
# 安装项目依赖包
# 生产环境可以运行 RUN npm install --only=production 只按照 package.json 中dependencies定义的模块
RUN npm install
# 将根目录下的文件都copy到container(运行此镜像的容器)文件系统的app文件夹下
ADD . /app/
# 暴露容器内的3000端口
EXPOSE 3000
# 容器启动时执行的命令,类似npm run start
CMD ["npm", "start"]当我们执行docker build 生成镜像的时候,实际上每行命令产生的文件会存到一个目录中,即一层,Dockerfile 最佳实践 也建议我们
镜像层数尽可能少
这里推荐一款工具 dive 可以方便的查看镜像层详情,评估镜像的质量,如浪费了多少空间


如果作为镜像审查之后,可以进行如下命令操作:
$: CI=true dive <image-id>
Fetching image... (this can take a while with large images)
Parsing image...
Analyzing image...
efficiency: 95.0863 %
wastedBytes: 671109 bytes (671 kB)
userWastedPercent: 8.2274 %
Run CI Validations...
Using default CI config
PASS: highestUserWastedPercent
SKIP: highestWastedBytes: rule disabled
PASS: lowestEfficiency从输出信息可以得到很多有用的信息,集成到CI过程也就非常容易了。 dive本身支持添加.dive-ci 配置文件作为项目的CI配置,具体配置规则见文档。
rules:
# If the efficiency is measured below X%, mark as failed.
# Expressed as a percentage between 0-1.
lowestEfficiency: 0.95
# If the amount of wasted space is at least X or larger than X, mark as failed.
# Expressed in B, KB, MB, and GB.
highestWastedBytes: 20MB
# If the amount of wasted space makes up for X% or more of the image, mark as failed.
# Note: the base image layer is NOT included in the total image size.
# Expressed as a percentage between 0-1; fails if the threshold is met or crossed.
highestUserWastedPercent: 0.20集成到CI中,增加以下命令即可:
$: CI=true dive <image-id>
镜像审查和代码审查类似,是一件开始抵制,开始后就欲罢不能的事。这件事宜早不宜迟,对于企业与个人而言均百利而无一害。
随着容器化的普及,个人觉得这个工具很有前途
另外推荐一个容器的静态分析工具 clair
参考
]]>-
服务端为 docker daemon (daemon是守护进程的意思,进程名叫dockerd)。 docker daemon 支持三种方式的连接(unix,tcp 和 fd)。默认只使用第一种,监听
/var/run/docker.sockunix套接字文件。 -
客户端为docker.service。 一般情况下客户端和服务端运行在同一主机上,但有时候我们需要连接远程某服务器的Docker,其实和mysql有点类似。比如mysql的守护进程叫mysqld。监听3306端口,跑在一台服务器上,我们本地客户端通过IP及3306端口连接mysqld服务端,就可以操作他了。 类似的,这就需要docker daemon开放tcp,要做如下设置。
注意,这样会不安全,如果你的docker daemon运行在公网上面,一旦开了监听端口,任何人都可以远程连接到docker daemon服务器进行操作)
配置远程访问Docker官方文档有详细教程 https://docs.docker.com/install/linux/linux-postinstall/
有两种方法一种是修改系统的 systemd 另一种是修改 Docker 的 daemon.json 两种方式选择一种即可,都修改会有冲突,官方建议使用第二种方式。
修改 systemd unit 文件允许远程访问
sudo systemctl edit docker.service打开文件- 添加或修改下面的
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd -H fd:// -H tcp://127.0.0.1:2375- 保存,重启Docker
sudo systemctl daemon-reloadsudo systemctl restart docker.service - 检查
sudo netstat -lntp | grep dockerd会发现 Dockerd正在监听 2375 端口
修改 daemon.json 允许远程访问
- 打开Docker守护端的配置文件
sudo vi /etc/docker/daemon.json,检查host配置 - 讲host部分内容修改如下
{
"hosts": ["unix:///var/run/docker.sock", "tcp://127.0.0.1:2375"]
}- 同上,重启,然后检查端口
在 daemon.json 中设置 hosts 并不支持Windows和Mac Docker 桌面版
关于daemon.json 的具体配置,见官方文档
在任何装了docker客户端的机器上,测试 docker -H tcp://192.168.3.201:2375 ps
192.168.3.201 是刚才运行docker daemon的机器,如果连不上,检查防火墙是否开放了2375端口
注意
如果你修改了daemon.json,手动重启dockerd进程时也带了参数,比如dockerd --debug \ --host tcp://192.168.59.3:2376 可能会报错,即配置冲突,这时就需要用上面提到的方法,即创建docker.conf文件
另外查看日志分析错误的命令:
sudo dockerd --debug
sudo journalctl -r -u docker错误记录
failed to start daemon: error while opening volume store metadata database: timeout
ps axf | grep docker | grep -v grep | awk '{print "kill -9 " $1}' | sudo sh
sudo dockerd --debug
# 其他方法
sudo systemctl start docker
sudo kill -SIGHUP $(pidof dockerd)你会发现dockerd其实暴露了很多API接口,比如获取和操作images,container的,还暴露了一个_ping接口,用于测试连通性,直接使用

curl http://ip:2375/_ping 如果连通正常,返回OK
具体API参见:https://docs.docker.com/engine/api/v1.40
安全性
允许Docker远程访问后一定要设置好防火墙或者用nignx加一层反向代理,也可以开启https访问,不过要生成证书,具体见下面参考中的链接。
参考
]]>为了加快构建速度,Docker实现了缓存: 如果Dockerfile和相关文件未更改,则重建(rebuild)时可以重用本地镜像缓存中的某些现有层。 但是,为了利用此缓存,您需要了解它的工作方式,这就是我们将在本文中介绍的内容。
我们来看一个使用以下Dockerfile的示例:
FROM python:3.7-slim-buster
COPY . .
RUN pip install --quiet -r requirements.txt
ENTRYPOINT ["python", "server.py"]第一次运行时,所有命令都会运行:
$ docker build -t example1 .
Sending build context to Docker daemon 5.12kB
Step 1/4 : FROM python:3.7-slim-buster
---> f96c28b7013f
Step 2/4 : COPY . .
---> eff791eb839d
Step 3/4 : RUN pip install --quiet -r requirements.txt
---> Running in 591f97f47b6e
Removing intermediate container 591f97f47b6e
---> 02c7cf5a3d9a
Step 4/4 : ENTRYPOINT ["python", "server.py"]
---> Running in e3cf483c3381
Removing intermediate container e3cf483c3381
---> 598b0340cc90
Successfully built 598b0340cc90
Successfully tagged example1:latest第二次构建时,因为没有任何改变,docker构建将使用镜像缓存:
$ docker build -t example1 .
Sending build context to Docker daemon 5.12kB
Step 1/4 : FROM python:3.7-slim-buster
---> f96c28b7013f
Step 2/4 : COPY . .
---> Using cache
---> eff791eb839d
Step 3/4 : RUN pip install --quiet -r requirements.txt
---> Using cache
---> 02c7cf5a3d9a
Step 4/4 : ENTRYPOINT ["python", "server.py"]
---> Using cache
---> 598b0340cc90
Successfully built 598b0340cc90
Successfully tagged example1:latest请注意,上面显示的Using cache加快了构建速度(无需从网络下载任何pip依赖包)
如果我们删除镜像,则后续构建将从头开始(没有层缓存了):
$ docker image rm example1
Untagged: example1:latest
Deleted: sha256:598b0340cc90967501c5c51862dc586ca69a01ca465f48232fc457d3ab122a73
Deleted: sha256:02c7cf5a3d9af1939b9f5286312b23898fd3ea12b7cb1d7a77251251740a806c
Deleted: sha256:d9e9602d9c3fd7381a8e1de301dc4345be2eb2b8488b5fc3e190eaacbb2f9596
Deleted: sha256:eff791eb839d00cbf46d139d8595b23867bc580bb9164b90253d0b2d9fcca236
Deleted: sha256:53d34b2ead0a465d229a4260fee2a845fb8551856d4019cd2e608dfe0e039e77
$ docker build -t example1 .
Sending build context to Docker daemon 5.12kB
Step 1/4 : FROM python:3.7-slim-buster
---> f96c28b7013f
Step 2/4 : COPY . .
---> 63c32b9b1af6
...缓存算法还有一个更重要的规则:
如果某层无法应用层缓存,则后续层都不能从层缓存加载
在以下示例中,前后两次构建过程的C层均未更改,尽管如此,由于上层并不是从层缓存中加载,因此后置的C层仍然无法从缓存中加载:

层缓存对下面的Dockerfile意味着什么?
FROM python:3.7-slim-buster
COPY requirements.txt .
COPY server.py .
RUN pip install --quiet -r requirements.txt
ENTRYPOINT ["python", "server.py"]如果COPY命令的任何文件改变了,则会使后续所有层缓存失效:我们需要重新运行pip install。 但是,如果server.py更改了,但requirements.txt却没有更改,为什么我们必须重做pip安装?毕竟,pip安装仅使用requirements.txt。
推及到现代编程语言:前端的依赖包文件package.json, dotnet的项目管理文件dotnetdemo.csproj等,一般很少变更;随时变动的业务代码,导致后续的层缓存失效(后续层每次都要重新下载&安装依赖)。
因此,要做的是仅复制实际需要运行下一步的那些文件,以最大程度地减少缓存失效的机会。
FROM python:3.7-slim-buster
COPY requirements.txt .
RUN pip install --quiet -r requirements.txt
COPY server.py .
ENTRYPOINT ["python", "server.py"]如果想通过重用之前缓存的层来进行快速构建,则需要适当地编写Dockerfile:
- 仅复制下一步所需的文件,以最大程度地减少构建过程中的缓存失效。
- 尽量将文件可能变更的新增(ADD命令)、拷贝(COPY命令) 延迟到Dockerfile的后部。
Docker 容器的部署有一种在手机上装 App 的感觉,但 Docker 容器并不会像手机 App 那样会自动更新,而如果我们需要更新容器一般需要以下四个步骤:
停止容器:docker stop <CONTAINER>
删除容器:docker rm <CONTAINER>
更新镜像:docker pull <IMAGE>
启动容器:docker run <ARG> ... <IMAGE>停止容器这个步骤可以在删除容器时使用 -f 参数来代替,即使这样还是需要三个步骤。如果部署了大量的容器需要更新使用这种传统的方式工作量是巨大的。
Watchtower 是一个可以实现自动化更新 Docker 基础镜像与容器的实用工具。它监视正在运行的容器以及相关的镜像,当检测到 registry 中的镜像与本地的镜像有差异时,它会拉取最新镜像并使用最初部署时相同的参数重新启动相应的容器,一切好像什么都没发生过,就像更新手机上的 App 一样。
快速开始
Watchtower 本身被打包为 Docker 镜像,因此可以像运行任何其他容器一样运行它:
docker run -d \
--name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower然后所有容器都会自动更新,也包括 Watchtower 本身。
选项参数
$ docker run --rm containrrr/watchtower -h
Watchtower automatically updates running Docker containers whenever a new image is released.
More information available at https://github.com/containrrr/watchtower/.
Usage:
watchtower [flags]
Flags:
-a, --api-version string api version to use by docker client (default "1.24")
-c, --cleanup remove previously used images after updating
-d, --debug enable debug mode with verbose logging
--enable-lifecycle-hooks Enable the execution of commands triggered by pre- and post-update lifecycle hooks
-h, --help help for watchtower
-H, --host string daemon socket to connect to (default "unix:///var/run/docker.sock")
-S, --include-stopped Will also include created and exited containers
-i, --interval int poll interval (in seconds) (default 300)
-e, --label-enable watch containers where the com.centurylinklabs.watchtower.enable label is true
-m, --monitor-only Will only monitor for new images, not update the containers
--no-pull do not pull any new images
--no-restart do not restart any containers
--notification-email-delay int Delay before sending notifications, expressed in seconds
--notification-email-from string Address to send notification emails from
--notification-email-server string SMTP server to send notification emails through
--notification-email-server-password string SMTP server password for sending notifications
--notification-email-server-port int SMTP server port to send notification emails through (default 25)
--notification-email-server-tls-skip-verify
Controls whether watchtower verifies the SMTP server's certificate chain and host name.
Should only be used for testing.
--notification-email-server-user string SMTP server user for sending notifications
--notification-email-subjecttag string Subject prefix tag for notifications via mail
--notification-email-to string Address to send notification emails to
--notification-gotify-token string The Gotify Application required to query the Gotify API
--notification-gotify-url string The Gotify URL to send notifications to
--notification-msteams-data The MSTeams notifier will try to extract log entry fields as MSTeams message facts
--notification-msteams-hook string The MSTeams WebHook URL to send notifications to
--notification-slack-channel string A string which overrides the webhook's default channel. Example: #my-custom-channel
--notification-slack-hook-url string The Slack Hook URL to send notifications to
--notification-slack-icon-emoji string An emoji code string to use in place of the default icon
--notification-slack-icon-url string An icon image URL string to use in place of the default icon
--notification-slack-identifier string A string which will be used to identify the messages coming from this watchtower instance (default "watchtower")
-n, --notifications strings notification types to send (valid: email, slack, msteams, gotify)
--notifications-level string The log level used for sending notifications. Possible values: panic, fatal, error, warn, info or debug (default "info")
--remove-volumes remove attached volumes before updating
--revive-stopped Will also start stopped containers that were updated, if include-stopped is active
-R, --run-once Run once now and exit
-s, --schedule string the cron expression which defines when to update
-t, --stop-timeout duration timeout before a container is forcefully stopped (default 10s)自动清除旧镜像
官方给出的默认启动命令在长期使用后会堆积非常多的标签为 none 的旧镜像,如果放任不管会占用大量的磁盘空间。要避免这种情况可以加入 --cleanup 选项,这样每次更新都会把旧的镜像清理掉。
docker run -d \
--name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower \
--cleanup--cleanup 选项可以简写为 -c
docker run -d \
--name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c选择性自动更新
某些容器可能需要稳定的运行,经常更新或重启可能会造成一些问题,这时我们可以使用一些选项参数来选择与控制容器的更新。
容器更新列表 假设我们只想更新 nginx、redis 这两个容器,我们可以把容器名称追加到启动命令的最后面,就像下面这个例子:
docker run -d \
--name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c \
nginx redis博主觉得把需要更新的容器名称写在启动命令中不利于管理,于是想了个更好的方法,建立一个更新列表文件。
$ cat ~/.watchtower.list
aria2-pro
unlockmusic
mtg
...通过变量的方式去调用这个列表:
docker run -d \
--name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c \
$(cat ~/.watchtower.list)这样只需要调整列表后删除 Watchtower 容器并重新执行上面的命令重新启动 Watchtower 即可。
- 设置单个容器自动更新特征
给容器添加 com.centurylinklabs.watchtower.enable 这个 LABEL 并设置它的值为 false,或者在启动命令中加入 --label com.centurylinklabs.watchtower.enable=false 参数可以排除相应的容器。下面这个例子是博主的 openwrt-mini 镜像的容器启动命令,Watchtower 将永远忽略它的更新,即使它包含在自动更新列表中。
docker run -d \
--name openwrt-mini \
--restart always \
--network openwrt \
--privileged \
--label com.centurylinklabs.watchtower.enable=false \
p3terx/openwrt-mini \
/sbin/init当容器启动命令中加入 --label com.centurylinklabs.watchtower.enable=true 参数,并且给 Watchtower 加上 --label-enable 选项时,Watchtower 将只更新这些包含此参数的容器。
docker run -d \
--name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c \
--label-enable--label-enable 可以简写为 -e
docker run -d \
--name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -ce因为需要在容器启动时进行设置,且设置后就无法直接更改,只能重建容器,所以这种方式的灵活性不如更新列表法。尤其是在设置 com.centurylinklabs.watchtower.enable=false 参数后容器将永远被 Watchtower 忽略,也包括后面将要提到的手动更新方式,所以一般不推荐这样做,除非你愿意手动重建的原生方式更新。
设置自动更新检查频率
默认情况下 Watchtower 每 5 分钟会轮询一次,如果你觉得这个频率太高了可以使用如下选项来控制更新检查的频率,但二者只能选择其一。
--interval, -i - 设置更新检测时间间隔,单位为秒。比如每隔 1 个小时检查一次更新:
docker run -d \
--name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c \
--interval 3600--schedule, -s - 设置定时检测更新时间。格式为 6 字段 Cron 表达式,而非传统的 5 字段,即第一位是秒。比如每天凌晨 2 点检查一次更新:
docker run -d \
--name watchtower \
--restart unless-stopped \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c \
--schedule "0 0 2 * * *"手动更新
前面的使用方式都是让 Watchtower 以 detached(后台)模式在运行并自动更新容器,而 Watchtower 也支持以 foreground(前台)模式来使用,即运行一次退出并删掉容器,来实现手动更新容器。这对于偶尔更新一次那些不在自动更新列表中的容器非常有用。
对于 foreground 模式,需要加上 --run-once 这个专用的选项。下面的例子 Docker 会运行一次 Watchtower 并检查 aria2-pro 容器的基础镜像更新,最后删掉本次运行创建的 Watchtower 容器。
docker run --rm \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -c \
--run-once \
aria2-pro--run-once 可以简写为 -R
docker run --rm \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower -cR \
aria2-pro需要注意的是当这个容器设置过 com.centurylinklabs.watchtower.enable=false 参数时不会更新。
尾巴
以上是博主在使用 Watchtower 中总结的一些使用方式和方法,当然它还有一些其它的功能与使用方式,比如电子邮件通知、监视私人注册表的镜像、更新远程主机上的容器等,这些对于一般用户来说可能很少会用到,所以这里就不赘述了,感兴趣的小伙伴可以去研究 Watchtower 官方文档。
参考
]]>官方文档 有介绍
# 创建名为docker的用户组
sudo groupadd docker
# 把当前用户加入到这个用户组中
sudo usermod -aG docker $USER
# 重登session
# 测试,不带sudo跑一个测试镜像
docker run hello-world跟随系统自自动docker
sudo systemctl enable docker
- Docker Machine 的目的是简化 Docker 的安装和远程管理。 通过 docker-machine 命令我们可以轻松的在远程主机上安装 Docker。
- pull 镜像的时候最好指定tag,不然默认会用latest。会导致版本问题。 如 pull mysql 会拉最新的8.0
CMD echo $HOME, 在实际执行中,会将其变更为:CMD [ "sh", "-c", "echo $HOME" ], 所以CMD service nginx start不对,要使用CMD ["nginx", "-g", "daemon off;"]
docker build 会加入上下文 如果加入
.dockerignore 指定忽略目录文件
实用的命令
根据容器名称查询容器ID并删除
# 第一种写法
docker stop `docker ps -a| grep test-project | awk '{print $1}' `
docker rm `docker ps -a| grep test-project | awk '{print $1}' `
# 第二种写法
docker stop `docker ps -aq --filter name=test-project`
docker rm `docker ps -aq --filter name=test-project`根据镜像名称查询容器ID并删除
# 第一种写法
docker stop `docker ps -a| grep ygsama/test-project:1.0.2 | awk '{print $1}' `
docker rm `docker ps -a| grep ygsama/test-project:1.0.2 | awk '{print $1}' `
# 第二种写法
docker stop `docker ps -aq --filter ancestor=ygsama/test-project:1.0.2`
docker rm `docker ps -aq --filter ancestor=ygsama/test-project:1.0.2`根据镜像名称查询镜像ID并删除
docker images -q --filter reference=ygsama/test-project*:*
docker image rm `docker images -q --filter reference=10.2.21.95:10001/treasury-brain*:*`docker-compose
- env问题
- 重启 php-fpm
- 慎用 docker-compose down
- 环境变量 优先级 shell > .env
- 执行
docker-compose up之前执行先执行docker-compose config就是把实际要运行的docker-compose.yml内容打印出来
Windows 操作系统底下经常会有文件字符集问题,比如报
<input>:1:13: illegal character NUL,需要转换成unix文件格式
可以打开 git bash 运行 dos2unix 后跟文件名
参考:
]]>Dockerfile 中提供了两个非常相似的命令 COPY 和 ADD,本文尝试解释这两个命令的基本功能,以及其异同点,然后总结其各自适合的应用场景。
Build 上下文的概念
在使用 docker build 命令通过 Dockerfile 创建镜像时,会产生一个 build 上下文(context)。所谓的 build 上下文就是 docker build 命令的 PATH 或 URL 指定的路径中的文件的集合。在镜像 build 过程中可以引用上下文中的任何文件,比如我们要介绍的 COPY 和 ADD 命令,就可以引用上下文中的文件。
默认情况下 docker build -t testx . 命令中的 . 表示 build 上下文为当前目录。
当然我们可以指定一个目录作为上下文,比如下面的命令:
docker build -t testx /home/nick/hc
我们指定 /home/nick/hc 目录为 build 上下文,默认情况下 docker 会使用在上下文的根目录下找到的 Dockerfile 文件。
COPY 和 ADD 命令不能拷贝上下文之外的本地文件
对于 COPY 和 ADD 命令来说,如果要把本地的文件拷贝到镜像中,那么本地的文件必须是在上下文目录中的文件。 其实这一点很好解释,因为在执行 build 命令时,docker 客户端会把上下文中的所有文件发送给 docker daemon。 考虑 docker 客户端和 docker daemon 不在同一台机器上的情况,build 命令只能从上下文中获取文件。 如果我们在 Dockerfile 的 COPY 和 ADD 命令中引用了上下文中没有的文件,就会收到类似下面的错误:

与 WORKDIR 协同工作
WORKDIR 命令为后续的 RUN、CMD、COPY、ADD 等命令配置工作目录。 在设置了 WORKDIR 命令后,接下来的 COPY 和 ADD 命令中的相对路径就是相对于 WORKDIR 指定的路径。 比如我们在 Dockerfile 中添加下面的命令:
WORKDIR /app
COPY checkredis.py .然后构建名称为 testx 的容器镜像,并运行一个容器查看文件路径:

checkredis.py 文件就是被复制到了 WORKDIR /app 目录下。
COPY 命令的简单性
如果仅仅是把本地的文件拷贝到容器镜像中,COPY 命令是最合适不过的。其命令的格式为:
COPY <src> <dest>
除了指定完整的文件名外,COPY 命令还支持 Go 风格的通配符,比如:
COPY check* /testdir/ # 拷贝所有 check 开头的文件
COPY check?.log /testdir/ # ? 是单个字符的占位符,比如匹配文件 check1.log对于目录而言,COPY 和 ADD 命令具有相同的特点:**只复制目录中的内容而不包含目录自身。**比如我们在 Dockerfile 中添加下面的命令:
WORKDIR /app
COPY nickdir .其中 nickdir 目录的结构如下:

重新构建镜像 testx,运行一个容器并查看 /app 目录下的内容:

这里只有 file1 和 file2,少了一层目录 nickdir。如果想让 file1 和 file2 还保存在 nickdir 目录中,需要在目标路径中指定这个目录的名称,比如:
WORKDIR /app
COPY nickdir ./nickdir**COPY 命令区别于 ADD 命令的一个用法是在 multistage 场景下。**关于 multistage 的介绍和用法请参考笔者的《Dockerfile 中的 multi-stage》一文。在 multistage 的用法中,可以使用 COPY 命令把前一阶段构建的产物拷贝到另一个镜像中,比如:
FROM golang:1.7.3
WORKDIR /go/src/github.com/sparkdevo/href-counter/
RUN go get -d -v golang.org/x/net/html
COPY app.go .
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o app .
FROM alpine:latest
RUN apk --no-cache add ca-certificates
WORKDIR /root/
COPY --from=0 /go/src/github.com/sparkdevo/href-counter/app .
CMD ["./app"]这段代码引用自《Dockerfile 中的 multi-stage》一文,其中的 COPY 命令通过指定 --from=0 参数,把前一阶段构建的产物拷贝到了当前的镜像中。
ADD 命令还可以干其它事情
ADD 命令的格式和 COPY 命令相同,也是:
ADD <src> <dest>
除了不能用在 multistage 的场景下,ADD 命令可以完成 COPY 命令的所有功能,并且还可以完成两类超酷的功能:
- 解压压缩文件并把它们添加到镜像中
- 从 url 拷贝文件到镜像中
当然,这些功能也让 ADD 命令用起来复杂一些,不如 COPY 命令那么直观。
解压压缩文件并把它们添加到镜像中 如果我们有一个压缩文件包,并且需要把这个压缩包中的文件添加到镜像中。需不需要先解开压缩包然后执行 COPY 命令呢?当然不需要!我们可以通过 ADD 命令一次搞定:
WORKDIR /app
ADD nickdir.tar.gz .这应该是 ADD 命令的最佳使用场景了!
从 url 拷贝文件到镜像中 这是一个更加酷炫的用法!但是在 docker官方文档的最佳实践中却强烈建议不要这么用!!docker 官方建议我们当需要从远程复制文件时,最好使用 curl 或 wget 命令来代替 ADD 命令。 原因是,当使用 ADD 命令时,会创建更多的镜像层,当然镜像的 size 也会更大(下面的两段代码来自 docker 官方文档):
ADD http://example.com/big.tar.xz /usr/src/things/
RUN tar -xJf /usr/src/things/big.tar.xz -C /usr/src/things
RUN make -C /usr/src/things all如果使用下面的命令,不仅镜像的层数减少,而且镜像中也不包含 big.tar.xz 文件:
RUN mkdir -p /usr/src/things \
&& curl -SL http://example.com/big.tar.xz \
| tar -xJC /usr/src/things \
&& make -C /usr/src/things all好吧,看起来只有在解压压缩文件并把它们添加到镜像中时才需要 ADD 命令!
加速镜像构建的技巧
在使用 COPY 和 ADD 命令时,我们可以通过一些技巧来加速镜像的 build 过程。 比如把那些最不容易发生变化的文件的拷贝操作放在较低的镜像层中,这样在重新 build 镜像时就会使用前面 build 产生的缓存。 比如笔者构建镜像时需要用到下面几个文件:

其中 myhc.py 文件不经常变化,而 checkmongo.py、checkmysql.py 和 checkredis.py 这三个文件则经常变化,那么我们可这样来设计 Dockerfile 文件:
WORKDIR /app
COPY myhc.py .
COPY check* ./让 COPY myhc.py . 单独占据一个镜像层,当 build 过一次后,每次因 checkmongo.py、checkmysql.py 和 checkredis.py 这三个文件变化而导致的重新 build 都不会重新 build COPY myhc.py . 镜像层:

如上图所示,第二步和第三步都没有重新 build 镜像层,而是使用了之前的缓存,从第四步才开始重新 build 了镜像层。 当文件 size 比较大且文件的数量又比较多,尤其是需要执行安装等操作时,这样的设计对于 build 速度的提升还是很明显的。 所以我们应该尽量选择能够使用缓存的 Dockerfile 写法。
当第一次看到 COPY 和 ADD 命令时不免让人感到疑惑。但分析之后大家会发现 COPY 命令是为最基本的用法设计的,概念清晰,操作简单。而 ADD 命令基本上是 COPY 命令的超集(除了 multistage 场景),可以实现一些方便、酷炫的拷贝操作。ADD 命令在增加了功能的同时也增加了使用它的复杂度,比如从 url 拷贝压缩文件时弊大于利。希望本文能够解去大家对 Dockerfile 中 COPY 和 ADD 命令的疑惑。
参考
]]>除了将 Docker Engine 更新至 v20.10.0 外,还新增了一个Docker Hub CLI 工具
直接hub-tool -h
本文已hub-tool v0.2.0为准
A tool to manage your Docker Hub images
Usage:
hub-tool
hub-tool [command]
Available Commands:
account Manage your account
help Help about any command
login Login to the Hub
logout Logout of the Hub
org Manage organizations
repo Manage repositories
tag Manage tags
token Manage Personal Access Tokens
version Version information about this tool
Flags:
-h, --help help for hub-tool
--verbose Print logs
--version Display the version of this tool
Use "hub-tool [command] --help" for more information about a command.从一级菜单来看,主要功能包括:
- 登录/登出 DockerHub;
- 账户相关管理功能;
- 组织相关管理功能;
- 仓库和 tag 的相关管理功能;
- token 的相关管理功能;
但这里需要注意的是 Hub Tool 并没有使用 Docker Desktop 默认的用户凭证,也就是说,即使你在 Docker Desktop 中已经登录了帐号,你同样还是需要再次在终端下执行 login 操作。
account 账户管理
包含info和rate-limiting两个子命令
对于免费用户每 6 小时只允许 pull 200 次 200 container image requests per 6 hours
详情或最新政策见官网
> hub-tool account info
Username: finleyma
Full name:
Company:
Location:
Joined: 3 years ago
Plan: free
Limits:
Seats: 1
Private repositories: 1
Parallel builds: 1
Collaborators: unlimited
Teams: unlimited> hub-tool account rate-limiting
Limit: 200, 6 hours window
Remaining: 200, 6 hours windowrepo 仓库和tag管理
查看repo列表和删除repo
> hub-tool repo ls
REPOSITORY DESCRIPTION LAST UPDATE PULLS STARS PRIVATE
finleyma/simplewhale 7 weeks ago 9 0 false
finleyma/express 16 months ago 61 0 false
finleyma/yapi 16 months ago 10 0 false
finleyma/circleci-nodejs-browser-awscli 23 months ago 331 0 false
finleyma/phpenv 2 years ago 24 0 false
finleyma/my-first-flask-app 3 years ago 58 0 false列出repo的所有tag
> hub-tool tag ls finleyma/express查看镜像详情
> hub-tool tag inspect finleyma/expressorg 组织和token管理
这个比较简单,
hub-tool org展示一些组织和成员相关信息。
hub-tool token对个人 Token 的创建/删除,激活/失效,列表,查询详细等功能。
参考
]]>就是在docker内运行Docker,一个常用的场景是我们用Docker起了一个Jenkins,Jenkins构建项目的时候,为了保证项目环境是干净的, 也需要拉一个docker镜像,把项目放到干净的容器中。
在Docker容器中运行Docker
在Docker中实现Docker的三种方法
- 通过挂载docker.sock(DooD方法)运行docker
- dind 方法
- 使用Nestybox sysbox Docker运行时
方法1:使用[/var/run/docker.sock]的Docker中运行Docker
/var/run/docker.sock是默认的Unix套接字。套接字用于在同一主机上的进程之间进行通信。
Docker守护程序默认情况下侦听docker.sock。
如果您在运行Docker守护程序的主机上,则可以使用/var/run/docker.sock管理容器。
例如,如果运行以下命令,它将返回docker engine的版本。
curl --unix-socket /var/run/docker.sock http://localhost/version
要在docker内部运行docker,要做的只是在默认Unix套接字docker.sock作为卷的情况下运行docker。
-v /var/run/docker.sock:/var/run/docker.sock
WARNING
如果您的容器可以访问docker.sock,则意味着它具有对docker守护程序的更多特权。因此,在实际项目中使用时,请了解并使用安全隐患。 因为容器的docker可以访问并删除宿主机的所有镜像
现在,从容器中应该能够执行docker命令来构建镜像并将其推送到镜像仓库。 在这里,实际的docker操作发生在运行docker容器的VM主机上,而不是在容器内部进行。 意思是,即使您正在容器中执行docker命令,也指示Docker客户端通过以下docker.sock方式连接到VM主机docker-engine。
上面的意思是,假如Jenkins是运行在容器中,在Jenkins中执行docker run...和在服务器上(就是宿主机)直接执行docker run效果一样。
这样很方便,但是也比较危险。
方法2:Docker In Docker
此方法实际上在容器内部创建一个子容器。仅当确实要在容器中包含容器和镜像时才使用此方法。 否则,建议使用第一种方法。为此,只需要使用带有dind标签的官方docker镜像即可。
建立一个以docker:dind为镜像,名字为some-docker的docker容器
docker run --privileged --name some-docker -v /my/own/var-lib-docker:/var/lib/docker -d docker:dind
使用exec登录到容器。
docker exec -it some-docker /bin/sh
登录后可以执行docker build等docker命令了
WARNING
为了对主机环境的完全访问,--privileged 特权模式是必须的
方法3:使用Sysbox运行时的Docker中的Docker
Sysbox 是nestybox公司旗下的一款产品,当允许Docker容器充当虚拟服务器, 能够在其中运行Systemd、Docker和Kubernetes等软件,操作容易且具有适当的隔离。
比前两种好处是避免了访问宿主机
- 安装sysbox运行时环境
- 使用sysbox运行时标志启动docker容器,还使用官方的docker:dind镜像
docker run --runtime=sysbox-runc --name sysbox-dind -d docker:dind - 进入sysbox-dind容器 `docker exec -it sysbox-dind /bin/sh
- 可以在里面构建docker镜像了
总结
使用docker.sock和dind方法在docker中运行docker的安全性较差,因为它具有对docker守护程序的完全特权
参考
]]>网络问题是我们使用容器技术时候经常碰到的问题,容器明明启动成功了就是ping不通,为了使容器尽量精简,有时并没有top,ps,netstat等网络命令, 有一个方法是再启动一个包含很多工具命令的容器连接到出问题的容器同一网络进行调试,netshoot就是这样的工具
源码其实非常简单,可以把他想象成一个调试外挂,哪个容器出问题了,就把他挂到同一网络。
FROM debian:stable-slim as fetcher
COPY build/fetch_binaries.sh /tmp/fetch_binaries.sh
RUN apt-get update && apt-get install -y \
curl \
wget
RUN /tmp/fetch_binaries.sh
FROM alpine:3.13
RUN set -ex \
&& echo "http://nl.alpinelinux.org/alpine/edge/main" >> /etc/apk/repositories \
&& echo "http://nl.alpinelinux.org/alpine/edge/testing" >> /etc/apk/repositories \
&& echo "http://nl.alpinelinux.org/alpine/edge/community" >> /etc/apk/repositories \
&& apk update \
&& apk upgrade \
&& apk add --no-cache \
apache2-utils \
bash \
bind-tools \
bird \
bridge-utils \
busybox-extras \
conntrack-tools \
curl \
dhcping \
drill \
ethtool \
file\
fping \
iftop \
iperf \
iproute2 \
ipset \
iptables \
iptraf-ng \
iputils \
ipvsadm \
jq \
libc6-compat \
liboping \
mtr \
net-snmp-tools \
netcat-openbsd \
nftables \
ngrep \
nmap \
nmap-nping \
openssl \
py3-pip \
py3-setuptools \
scapy \
socat \
speedtest-cli \
strace \
tcpdump \
tcptraceroute \
tshark \
util-linux \
vim \
git \
zsh \
websocat
# Installing httpie ( https://httpie.io/docs#installation)
RUN pip3 install --upgrade httpie
# Installing ctop - top-like container monitor
COPY --from=fetcher /tmp/ctop /usr/local/bin/ctop
# Installing calicoctl
COPY --from=fetcher /tmp/calicoctl /usr/local/bin/calicoctl
# Installing termshark
COPY --from=fetcher /tmp/termshark /usr/local/bin/termshark
# Setting User and Home
USER root
WORKDIR /root
ENV HOSTNAME netshoot
# ZSH Themes
RUN wget https://github.com/robbyrussell/oh-my-zsh/raw/master/tools/install.sh -O - | zsh || true
RUN git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions
RUN git clone --depth=1 https://github.com/romkatv/powerlevel10k.git ${ZSH_CUSTOM:-$HOME/.oh-my-zsh/custom}/themes/powerlevel10k
COPY zshrc .zshrc
COPY motd motd
# Fix permissions for OpenShift
RUN chmod -R g=u /root
# Running ZSH
CMD ["zsh"]容器网络基础
Docker
bridge 模式是 Docker 默认的网络设置,此模式会为每一个容器分配 Network Namespace、设置 IP 等,并将一个主机上的 Docker 容器连接到一个虚拟网桥上。
当 Docker server 启动时,会在主机上创建一个名为 docker0 的虚拟网桥,此主机上启动的 Docker 容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
接下来就要为容器分配 IP 了,Docker 会从 RFC1918 所定义的私有 IP 网段中,选择一个和宿主机不同的IP地址和子网分配给 docker0,连接到 docker0 的容器就从这个子网中选择一个未占用的 IP 使用。
如一般 Docker 会使用 172.17.0.0/16 这个网段,并将 172.17.42.1/16 分配给 docker0 网桥(在主机上使用 ifconfig 命令是可以看到 docker0 的,可以认为它是网桥的管理接口,在宿主机上作为一块虚拟网卡使用)
Kubernetes
Kubernetes也使用Network Namespace概念。 Kubernetes为每个pod创建一个Network Namespace,其中该pod中的所有容器共享相同的网络名称空间(IP, tcp sockets等)。 这是Docker容器和Kubernetes之间的一个关键区别。
举例
这个例子来自docker官网 https://docs.docker.com/get-started/07_multi_container/
下面的命令,创建了名称为todo-app的网络,起了个mysql容器,这个容器在网络中的名称是mysql,由--network-alias指定
docker network create todo-app
docker run -d \
--network todo-app --network-alias mysql \
-v todo-mysql-data:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=secret \
-e MYSQL_DATABASE=todos \
mysql:5.7
docker exec -it <mysql-container-id> mysql -u root -p下面我们启动netshoot容器并加入同一网络,进入容器,使用dig命令来通过主机名查看IP地主
docker run -it --network todo-app nicolaka/netshoot
dig mysql返回内容类似
; <<>> DiG 9.14.1 <<>> mysql
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 32162
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;mysql. IN A
;; ANSWER SECTION:
mysql. 600 IN A 172.23.0.2
;; Query time: 0 msec
;; SERVER: 127.0.0.11#53(127.0.0.11)
;; WHEN: Tue Oct 01 23:47:24 UTC 2019
;; MSG SIZE rcvd: 44还有种更简单的方式
docker run -it --net container:<container_name> nicolaka/netshoot
如果要排查宿主机的网络问题
docker run -it --net host nicolaka/netshoot
参考
https://docs.docker.com/get-started/07_multi_container/
https://docs.docker.com/engine/reference/commandline/network_create/#bridge-driver-options
https://www.huaweicloud.com/articles/5bb8f4efe7aaca9d4332750d73876db8.html
]]>网址:https://github.com/moby/buildkit
需要注意的是,该功能仅适用于 Docker v19.03+ 版本。
本文将讲解如何使用 Buildx 构建多种系统架构的镜像。 在开始之前,已经默认你在 Linux 系统(各大发行版)下安装好了 64 位的 Docker。 在写本文时,Docker 最新版本号是 20.10.0。
$ docker version
Client: Docker Engine - Community
Version: 20.10.0
API version: 1.41
Go version: go1.13.15
Git commit: 7287ab3
Built: Tue Dec 8 18:59:53 2020
OS/Arch: linux/amd64
Context: default
Experimental: true
Server: Docker Engine - Community
Engine:
Version: 20.10.0
API version: 1.41 (minimum version 1.12)
Go version: go1.13.15
Git commit: eeddea2
Built: Tue Dec 8 18:57:44 2020
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.4.3
GitCommit: 269548fa27e0089a8b8278fc4fc781d7f65a939b
runc:
Version: 1.0.0-rc92
GitCommit: ff819c7e9184c13b7c2607fe6c30ae19403a7aff
docker-init:
Version: 0.19.0
GitCommit: de40ad0
ubuntu@VM-16-4-ubuntu:~$1. 启用 Buildx
buildx 命令属于实验特性,因此首先需要开启该特性。
上面的查看 Docker 版本返回的内容中,如果出现Experimental: true字样就代表已经开启该特性了。
下面的这一步骤就可以省略。
编辑~/.docker/config.json 文件,新增如下内容(以下的演示适用于事先不存在 .docker 目录的情况下)
$ mkdir ~/.docker
$ cat > ~/.docker/config.json <<EOF
{
"experimental": "enabled"
}
EOFLinux/macOS 下或者通过设置环境变量的方式(不推荐):
$ export DOCKER_CLI_EXPERIMENTAL=enabled
2. 新建 builder 实例
在 Docker 19.03+ 版本中可以使用 docker buildx build 命令使用 BuildKit 构建镜像。该命令支持 --platform 参数可以同时构建支持多种系统架构的 Docker 镜像,大大简化了构建步骤。
由于 Docker 默认的 builder 实例不支持同时指定多个 --platform ,我们必须首先创建一个新的 builder 实例。
$ docker buildx create --name mybuilder --driver docker-container
返回新的 builder 实例名,为「mybuilder」
mybuilder
使用新创建好的 builder 实例
$ docker buildx use mybuilder
查看已有的 builder 实例
$ docker buildx ls
NAME/NODE DRIVER/ENDPOINT STATUS PLATFORMS
mybuilder * docker-container
mybuilder0 unix:///var/run/docker.sock inactive
default docker
default default running linux/amd64, linux/386Docker 在 linux/amd64 系统架构下是不支持 arm 架构镜像,因此我们可以运行一个新的容器(emulator)让其支持该特性,Docker 桌面版则无需进行此项设置。
- 方法一:
$ docker run --rm --privileged docker/binfmt:a7996909642ee92942dcd6cff44b9b95f08dad64
注:docker/binfmt 可以参考网址:https://hub.docker.com/r/docker/binfmt/tags 获取最新镜像
- 方法二(推荐):
$ docker run --rm --privileged tonistiigi/binfmt --install all
去参考网址:https://hub.docker.com/r/tonistiigi/binfmt 获取最新镜像。目前(2021/09/02 更新)的 Qemu version: 6.0.0
3. 新建 Dockerfile 文件
要想构建多种系统架构的镜像,还需要一个支持的 Dockerfile 文件。 以下是一个示例的 Dockerfile 文件。 参考链接:https://github.com/teddysun/across/blob/master/docker/kms/Dockerfile.architecture
该 Dockerfile 文件内容如下:
FROM --platform=$TARGETPLATFORM alpine:latest AS builder
WORKDIR /root
RUN apk add --no-cache git make build-base && \
git clone --branch master --single-branch https://github.com/Wind4/vlmcsd.git && \
cd vlmcsd/ && \
make
FROM --platform=$TARGETPLATFORM alpine:latest
LABEL maintainer="Teddysun <[email protected]>"
COPY --from=builder /root/vlmcsd/bin/vlmcsd /usr/bin/vlmcsd
EXPOSE 1688
CMD [ "vlmcsd", "-D", "-e" ]$TARGETPLATFORM 是内置变量,由 --platform 参数来指定其值。
由于是基于 alpine 的镜像来制作的,而 alpine 是支持以下 7 种系统架构的,因此我们制作的镜像也就跟着支持这 7 种系统架构。
linux/amd64, linux/arm/v6, linux/arm/v7, linux/arm64, linux/386, linux/ppc64le, linux/s390x
更友好一点的架构名称如下:
amd64, arm32v6, arm32v7, arm64v8, i386, ppc64le, s390x
这里穿插一句吐槽。 简单统计了一下,ARM 的系统架构有如下各种简称:
arm64, armv8l, arm64v8, aarch64
arm, arm32, arm32v7, armv7, armv7l, armhf
arm32v6, armv6, armv6l, arm32v5, armv5, armv5l, armel, aarch32看完了是不是很想打人? 而对比 Intel 和 AMD 的就简单多了:
x86, 386, i386, i686
x86_64, x64, amd644. 构建镜像
先来本地构建一个。
git clone 刚才的示例 Dockerfile 文件,并进入其目录下
$ cd ~ && git clone https://github.com/teddysun/across.git && cd across/docker/kms/
在本地构建支持 7 种 platform 的镜像
$ docker buildx build --platform linux/amd64,linux/arm/v6,linux/arm/v7,linux/arm64,linux/ppc64le,linux/s390x,linux/386 -t teddysun/kms -o type=local,dest=.docker -f ./Dockerfile.architecture .
docker buildx build 的具体参数含义,参考下面的官方文档 https://docs.docker.com/engine/reference/commandline/buildx_build/
做完上面的那一步,实际上是把构建好的镜像放在了本地路径下。 此时我们再来查看一下已有的 builder 实例。
$ docker buildx ls
NAME/NODE DRIVER/ENDPOINT STATUS PLATFORMS
mybuilder * docker-container
mybuilder0 unix:///var/run/docker.sock running linux/amd64, linux/arm64, linux/riscv64, linux/ppc64le, linux/s390x, linux/386, linux/arm/v7, linux/arm/v6
default docker
default default running linux/amd64, linux/386你会发现 mybuilder 下存在 8 种支持的架构(riscv64 目前还用不上,但是已经支持)。
此时查看一下 docker image 的运行情况,会发现存在一个名为 buildx_buildkit_mybuilder0 的容器在运行。
这是刚才在本地构建时,自动创建的,切记不要将其停止,也不要删除。
$ docker ps -as
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE
be753fa16090 moby/buildkit:buildx-stable-1 "buildkitd" 15 minutes ago Up 15 minutes buildx_buildkit_mybuilder0 0B (virtual 78.6MB)再来构建一个多系统架构镜像,并将构建好的镜像推送到 Docker 仓库(也就是 hub.docker.com)。
在此操作之前,你需要事先注册一个账号(演示过程省略),并登录。 登录命令如下:
$ docker login
输入你的用户名和密码即可登录。
注意,以下演示的命令中 tag 的前面是我的用户名 finley,如果你想制作自己的镜像,请自行替换为你自己的用户名。
使用 --push 参数构建好的镜像推送到 Docker 仓库。
此时仍然是在刚才的 ~/across/docker/kms 目录下,文件 Dockerfile.architecture 是为多系统架构构建准备的。
命令如下:
$ docker buildx build --platform linux/386,linux/amd64,linux/arm/v6,linux/arm/v7,linux/arm64,linux/ppc64le,linux/s390x -t finley/kms --push -f ./Dockerfile.architecture .
命令执行成功后,你就会在 Docker Hub 看到你上传的镜像啦。
5. 写在最后
在制作多系统架构的 Docker 镜像时,建议使用 CPU 比较强或者多核心的 VPS 来构建,否则会非常耗时。
参考
https://github.com/moby/buildkit
https://kubesphereio.com/post/docker-image-operation-guide-for-building-arm-x86-architecture/
]]>
Docker官方提供了类似 github的平台,叫 https://hub.docker.com 可以 pull 官方或第三方提供的镜像,当然也可以发布自己的镜像供别人下载,互相学习。
大致流程:
docker hub 平台注册账号 -> docker login (登录) -> docker image ls (查看本地镜像) -> docker push (如 docker push finleyma/phpenv:tp3.2)
注册完成后如果要发布本地自己制作好的镜像,要执行命令
先执行 docker image ls 查看本地存在的镜像
然后 docker push 某镜像 , 比如提交上篇制作好的镜像

刷新docker hub的个人 REPOSITORY 页面,会看到已经存在了
https://hub.docker.com/r/finleyma/phpenv/
这样的话其他项目成员可以直接执行
docker run -it -p 8089:80 -v [本地项目路径]:/var/www "finleyma/phpenv:tp3.2" /bin/bash
进到终端只需 webserver start 启动服务。
-
提前用
docker pull把镜像拉到本地 -
搭建内部使用的镜像仓库,把镜像同步进来
流程也非常简单,docker pull先拉下来,然后重新打tag,最后push到我们自己的仓库
sudo docker pull registry.cn-hangzhou.aliyuncs.com/lfy_ruoyi/ruoyi-visual-monitor:v2
docker images
docker tag eb5aeb93fe3b finleyma/ruoyi-visual-monitor:v2
docker login
docker push finleyma/ruoyi-visual-monitor:v2更进一步,创建俩文件一个是待同步的镜像列表,一个是脚本文件,执行后会同步镜像
run.sh
#!/bin/bash
file="images.txt"
username="finleyma"
while read -r line
do
new_image=`echo ${line#*/} | sed 's|/|-|g'`
echo "docker pull ${line}"
echo "docker tag ${line} ${username}/${new_image}"
echo "docker push v5cn/${new_image}"
done < "$file"images.txt
k8s.gcr.io/defaultbackend-amd64:1.5
k8s.gcr.io/ingress-nginx/controller:v0.46.0
k8s.gcr.io/pause:3.2
k8s.gcr.io/kube-controller-manager:v1.19.7
k8s.gcr.io/kube-scheduler:v1.19.7
k8s.gcr.io/kube-proxy:v1.19.7
k8s.gcr.io/kube-apiserver:v1.19.7
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns:1.7.0
quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.26.1- 其实harbor自带了镜像同步功能
以一个把dockerhub的名称为finleyma/raco-bird的镜像同步到harbor为例
左侧菜单:仓库管理 - 创建目标,弹出的对话框中
目标名: hub.docker.com
目标URL: https://hub.docker.com
左侧菜单:复制管理 - 添加规则
- 名称: raco-bird
- 描述: 同步docker hub的finleyma/raco-bird到harbor

- 源资源过滤器: finleyma/raco-bird
- Ta: latest
- 触发模式: 手动
- 勾选: 覆盖和启动规则
点击"复制"按钮

- 使用工具 image-syncer
涉及到下载和上传,注意服务器上传带宽限制
参考
]]>这个是我自己常用的镜像,作者制作的很优秀,有以下特点:
- 基于官方的node基础镜像,加入了git,bash,openssh这三个常用的工具
- 支持多个arm64,armv7,amd64等5种架构
- 基于Github actions同步官方镜像的tag,每小时重新制作,举个例子,目前node的文档版本是v14,
我如果
docker run tarampampam/node:lts-alpine,node -v会返回14,这样没错。 但是如果第二天官方的lts变为了node16。tarampampam/node:lts-alpine也需要更新为16。 Github actions支持定时任务的,作者写了个脚本, 每小时去Dockerhub抓tag,和上游保持更新。
阅读他的代码可以学习github actions一些知识,回头我再详细介绍
]]>事故缘由
version: "2.3"
services:
wordpress:
image: wordpress
restart: always
ports:
- "127.0.0.1:8090:80"
environment:
WORDPRESS_DB_PASSWORD: root
mysql:
image: mysql:5.7
restart: always
environment:
MYSQL_ROOT_PASSWORD: root为了给容器添加healthcheck,添加了以下几行
@@ -8,6 +8,12 @@
- "127.0.0.1:8090:80"
environment:
WORDPRESS_DB_PASSWORD: root
+ healthcheck:
+ test: "curl -f http://127.0.0.1"
+ interval: 30s
+ timeout: 5s
+ retries: 1
+ start_period: 10s
mysql:
image: mysql:5.7
restart: always由于此前多次重启机器,容器均会自动重启(restart: always),放低了警惕,没有考虑到更新 docker-compose.yml 后重启服务会删除之前容器。
于是运行了 docker-compose down && docker-compose up -d,此时原容器被删除了(访问 127.0.0.1 显示 Wordpress 安装界面,使用 mysql 工具打开数据库显示 wordpress 数据库为空)。
数据找回
这时候不要慌,/var/lib/docker/volumes/ 下查找是否有尚未删除的 volume。
查看了一下每个 volume,发现了两个 wordpress 目录和一个 mysql 目录。最终通过 mtime 确定了两个最后修改于当日的 volume,且 cd 进去后发现确实一个是 Wordpress,一个是 MySQL
- 复制 volume 数据到 named volume。我使用了 docker_clone_volume.sh,这个 Shell Script 创建了一个 Alpine 容器,将原 volume 和新 volume 挂载到容器内,使用 cp -av src dst 直接复制。
- 修改 docker-compose.yml 文件挂载新的 named volume
@@ -14,8 +14,17 @@
timeout: 5s
retries: 1
start_period: 10s
+ volumes:
+ - wordpress:/var/www/html
mysql:
image: mysql:5.7
restart: always
environment:
MYSQL_ROOT_PASSWORD: root
+ volumes:
+ - mysql:/var/lib/mysql
+volumes:
+ wordpress:
+ external: true
+ mysql:
+ external: true- 重启并恢复服务 docker-compose up -d
总结
- 运维角度最好从 Docker 级别也做好备份
- 对于有状态的服务,比如站点目录,和数据库数据目录,创建volume,并定时备份
- volume放到宿主机也是100%安全,可以备份到云服务对象存储
- 使用官方的镜像作为基础镜像

- 基础镜像的标签不要使用latest
- 使用.dockerignore 文件
- 最经常变化的命令越往后执行 充分利用缓存机制
把 copy myapp /app 放到后面,因为myapp是源码目录,是会经常发生变动的,一旦该层内容发生变动,那么后续的层都会重新执行

这是优化后的执行顺序

- dockerfile中每行命令产生一层,请最大限度减少层数
- 当Dockerfile的指令修改了,复制的文件变化了,或者构建镜像时指定的变量不同了,对应的镜像层缓存就会失效。某一层的镜像缓存失效之后,它之后的镜像层缓存都会失效
- 使用CMD和ENTRYPOINT时,请务必使用数组语法。CMD /bin/echo 会在你的命令前面加上/bin/sh -c 可能导致意想不到的问题
- 使用多步构建 multi staging
- 不要使用root用户 避免潜在的风险
- 使用 docker scan 命令扫描风险
参考
]]>/var/run/docker.sock挂载在容器里, 然后在容器里构建镜像。
导致我们可以直接执行docker images看到所有镜像,甚至删除他们!
在多人开发中这是非常危险的!
这里推荐使用kaniko, 它是一个非常好的选择。
Kaniko使用自己的“executor”执行构建步骤
下面我们来举个例子
1.首先创建一个secret,类型为docker-creds
export REGISTRY_SERVER=https://index.docker.io/v1/
# Replace `[...]` with the registry username
export REGISTRY_USER=[...]
# Replace `[...]` with the registry password
export REGISTRY_PASS=[...]
kubectl create secret \
docker-registry regcred \
--docker-server=$REGISTRY_SERVER \
--docker-username=$REGISTRY_USER \
--docker-password=$REGISTRY_PASS2.创建一个pod,挂载刚创建的secret
Pod 是 K8s 中的概念
---
apiVersion: v1
kind: Pod
metadata:
namespace: kaniko
name: kaniko
spec:
containers:
- name: kaniko
image: gcr.io/kaniko-project/executor:debug
args:
- '--context=git://github.com/mafeifan/kaniko-demo'
- '--destination=finleyma/devops-toolkit:1.0.0'
volumeMounts:
- name: kaniko-secret
mountPath: /kaniko/.docker
restartPolicy: Never
volumes:
- name: kaniko-secret
secret:
secretName: regcred
items:
- key: .dockerconfigjson
path: config.json镜像名称:gcr.io/kaniko-project/executor:debug
注意镜像参数
--context上下文,可以是仓库地址,压缩包,对象存储地址(S3等),git仓库,本地路径等。--destination目标镜像地址。默认是docker hub,我们还看到它使用了一个secret来获取docker配置文件,然后把它挂载到容器里。
大致流程:
启动 pod,挂载 secret
去github.com/mafeifan/kaniko-demo拉代码,里面有一个Dockerfile,构建镜像。上传到 docker hub,名称为 finleyma/devops-toolkit:1.0.0。
pod退出
3.打开docker hub,确实发现我们的镜像已经创建成功了
https://hub.docker.com/repository/docker/finleyma/devops-toolkit
参考
]]>默认情况下,捕获的日志显示命令输出是在本地运行容器时在交互式终端上通常看到的内容,即 STDOUT 和 STDERR I/O 流,
Docker 支持的日志驱动
Docker默认支持如下日志驱动。有直接写文件的,有使用云服务的。下面简单介绍下。
https://docs.docker.com/config/containers/logging/configure/

AWS ECS
awslogs 日志驱动程序只是将 Docker 中的这些日志传递到 CloudWatch Logs。这个也是默认的驱动
由于 AWS ECS 底层用到 Docker 技术,所以 Docker 支持的日志驱动也是 ECS 支持的。
- For tasks on AWS Fargate, the supported log drivers are awslogs, splunk, and awsfirelens.
- For tasks hosted on Amazon EC2 instances, the supported log drivers are awslogs, fluentd, gelf, json-file, journald, logentries,syslog, splunk, and awsfirelens.
json-file - Docker 默认的日志驱动
json-file 是默认的 docker 日志驱动, docker info可以查看
全局的日志驱动设置,可以修改daemon配置文件 /etc/docker/daemon.json。
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}写入文件的日志格式长这样:{"log":"java.lang.InterruptedException\n","stream":"stderr","time":"2022-08-14T00:43:00.360028811Z"},
每一行是一个json文件,log字段为容器原来输出的每行内容。
# 查看正在运行的docker
docker ps
# 复制 CONTAINER ID,比如 3b0949ac59d6
dockder logs 3b0949ac59d6
cd /var/lib/docker/containers/3b0949*
tree
root@ip-172-31-30-158:/var/lib/docker/containers/3b0949ac59d63ca27c668fea87a1a1375bae9dde1fa8ee816d2c4961017110c7# tree
.
├── 3b0949ac59d63ca27c668fea87a1a1375bae9dde1fa8ee816d2c4961017110c7-json.log
├── checkpoints
├── config.v2.json
├── hostconfig.json
├── hostname
├── hosts
├── mounts
├── resolv.conf
└── resolv.conf.hash
-json.log 结尾的就是 json 日志文件怎么记录更多上下文信息
json-file本身是没有记录上下文信息的。集中存储到日志中心服务器,就无法区分具体是哪个应用产生的日志了。
fluentd也有不少通过docker daemon查询或是解析容器目录下config.v2.json获取metadata的 filter 插件。

参考 https://www.fluentd.org/plugins
比如这个 https://github.com/zsoltf/fluent-plugin-docker_metadata_elastic_filter
{
"log": "2015/05/05 19:54:41 \n",
"stream": "stderr",
"docker": {
"id": "df14e0d5ae4c07284fa636d739c8fc2e6b52bc344658de7d3f08c36a2e804115",
"name": "k8s_fabric8-console-container.efbd6e64_fabric8-console-controller-9knhj_default_8ae2f621-f360-11e4-8d12-54ee7527188d_7ec9aa3e",
"container_hostname": "fabric8-console-controller-9knhj",
"image": "fabric8/hawtio-kubernetes:latest",
"image_id": "b2bd1a24a68356b2f30128e6e28e672c1ef92df0d9ec01ec0c7faea5d77d2303",
"labels": {}
}
}新增了docker结构体,镜像名称也能收集到了
日志量大了,用docker logs看历史数据不大合适。我们就需要考虑将日志存储到日志中心去。
local
--log-driver指定日志驱动。
cat输出local文件,部分结果乱码。挺不方便日志解析的。
实验
root@ubuntu-parallel:~# docker run --name local_logging_driver --log-driver local hello-world
root@ubuntu-parallel:~# cd /var/lib/docker/containers/$(docker ps --no-trunc -aqf "name=local_logging_driver")
root@ubuntu-parallel:~# cat local-logs/container.log
stdout�������&
stdout�������Hello from Docker!&^
stdout˧�����JThis message shows that your installation appears to be working correctly.^none
不生成日志文件,docker logs也拿不到日志。实际使用不会考虑
syslog
因为日志被写入了syslog,并混在其他应用的日志中,docker logs没办法工作了。
实验
# 观察syslog
root@ubuntu-parallel:~# tail -f /var/log/syslog
root@ubuntu-parallel:~# docker run --name syslog_logging_driver --log-driver syslog hello-world
# 日志不会写本地
root@ubuntu-parallel:~# cd /var/lib/docker/containers/$(docker ps --no-trunc -aqf "name=syslog_logging_driver")
root@ubuntu-parallel:~# docker logs syslog_logging_driver
Error response from daemon: configured logging driver does not support readingjournald
写入syslog和journald,应用日志与系统日志混在一起,难以辨认了。
倒是journald驱动下,可以使用docker logs。
参考:https://wiki.archlinux.org/index.php/Systemd/Journal
实验
root@ubuntu-parallel:~# docker run --name journald_logging_driver --log-driver journald hello-world
root@ubuntu-parallel:~# journalctl
Apr 02 10:30:36 ubuntu-parallel 4b948bf091a8[999]: To try something more ambitious, you can run an Ubuntu container with:
Apr 02 10:30:36 ubuntu-parallel 4b948bf091a8[999]: $ docker run -it ubuntu bash
Apr 02 10:30:36 ubuntu-parallel 4b948bf091a8[999]:
Apr 02 10:30:36 ubuntu-parallel 4b948bf091a8[999]: Share images, automate workflows, and more with a free Docker ID:
Apr 02 10:30:36 ubuntu-parallel 4b948bf091a8[999]: https://hub.docker.com/
root@ubuntu-parallel:~# cd /var/lib/docker/containers/$(docker ps --no-trunc -aqf "name=journald_logging_driver")
# docker logs管用
root@ubuntu-parallel:~# docker logs journald_logging_driverFluentd
通过服务请求,让docker吐日志到fluentd进程。https://docs.docker.com/config/containers/logging/fluentd/
使用包括fluentd在很多日志驱动,因为日志写入到远程服务器,会导致docker logs, kubectl logs不可用。
Fluentd是一个挺灵活的工具,可以让fluentd主动监听容器目录下的日志文件。参考另一篇文章 https://xujiahua.github.io/posts/use-fluentd/
比如利用Fluentd将日志打进elasticsearch。
总结
为了兼容可使用docker logs ,kubectl logs,必须使用写本地文件的日志驱动。而json格式更方便工具(比如fluentd,logstash)解析,所以json-file是首选。
然后使用日志收集工具集中采集docker容器日志。k8s中日志收集策略,一般是在每台服务器上以DaemonSet的形式安装logging agent,监听本地文件、文件夹,将日志转发到日志中心。
当然这个前提条件是,应用日志是输出到标准输出和标准错误的。这对应用日志的规范有一定要求:
- 不输出多行日志。比如panic、exception。
- 应用日志使用JSON格式输出,方便后续的日志分析。
- 应用日志中加入更多的上下文信息。用于问题定位,维度分析。
- Go应用开发,使用logrus日志库,加字段,以JSON格式输出都很方便。
- 应用不关注日志该如何收集这个问题。不在应用层写日志到kafka、redis等中间件,让基础设施层处理。
- 应用要么写入文件、要么写入标准输出,这个应该很方便做成可配置的。对程序来说,都有共同的抽象,io.Writer。
- 应用日志如果是写到文件的,需要考虑通过数据卷,挂载等将日志与容器分离。采集挂载目录上的日志文件,以前怎么收集,现在还是怎么收集。还是建议写标准输出,这是目前的最佳实践。
参考
https://xujiahua.github.io/posts/20200403-docker-logging/
https://docs.docker.com.zh.xy2401.com/config/containers/logging/configure/
]]>本章基于容器镜像服务实践所编写,将一个单体应用进行容器改造为例,展示如何写出可读性更好的Dockerfile,从而提升镜像构建速度,构建层数更少、体积更小的镜像。
下面是一个常见企业门户网站架构,由一个Web Server和一个数据库组成,Web Server提供Web服务,数据库保存用户数据。通常情况下,这样一个门户网站安装在一台服务器上。

如果把应用运行在一个Docker容器中,那么很可能写出下面这样的Dockerfile来。
FROM ubuntu
ADD . /app
RUN apt-get update
RUN apt-get upgrade -y
RUN apt-get install -y nodejs ssh mysql
RUN cd /app && npm install
# this should start three processes, mysql and ssh
# in the background and node app in foreground
# isn't it beautifully terrible? <3
CMD mysql & sshd & npm start当然这样Dockerfile有很多问题,这里CMD命令是错误的,只是为了说明问题而写。
下面的内容中将展示对这个Dockerfile进行改造,说明如何写出更好的Dockerfile,共有如下几种处理方法。
一个容器只运行一个进程
从技术角度讲,Docker容器中可以运行多个进程,您可以将数据库、前端、后端、ssh等都运行在同一个Docker容器中。但是,这样跟未使用容器前没有太大区别,且这样容器的构建时间非常长(一处修改就要构建全部),镜像体积大,横向扩展时非常浪费资源(不同的应用需要运行的容器数并不相同)。
通常所说的容器化改造是对应用整体微服务进行架构改造,改造后,再容器化。这样做可以带来如下好处:
- 单独扩展:拆分为微服务后,可单独增加或缩减每个微服务的实例数量。
- 提升开发速度:各微服务之间解耦,某个微服务的代码开发不影响其他微服务。
- 通过隔离确保安全:整体应用中,若存在安全漏洞,一旦被攻击,所有功能的权限都可能会被窃取。微服务架构中,若攻击了某个服务,只可获得该服务的访问权限,无法入侵其他服务。
- 提升稳定性:如果其中一个微服务崩溃,其他微服务还可以持续正常运行。
因此,上述企业门户网站可以进行如下改造,Web应用和MySQL运行在不同容器中。

MySQL运行在独立的镜像中,这样的好处就是,我们可以对它们分别进行修改,且不会牵一发而动全身。如下面这个例子所示,我们可以删除MySQL,只安装node.js。
FROM ubuntu
ADD . /app
RUN apt-get update
RUN apt-get upgrade -y
RUN apt-get install -y nodejs
RUN cd /app && npm install
CMD npm start不要在构建中升级版本
为了降低复杂性、减少依赖、减小文件大小、节约构建时间,你应该避免安装任何不必要的包。例如,不要在数据库镜像中包含一个文本编辑器。
如果基础镜像中的某个包过时了,但你不知道具体是哪一个包,你应该联系它的维护者。如果你确定某个特定的包,比如foo需要升级,使用apt-get install -y foo就行,该指令会自动升级foo包。
apt-get upgrade会使得镜像构建过程非常不稳定,在构建时不确定哪些包会被安装,此时可能会产生不一致的镜像。因此通常我们会删掉apt-get upgrade。
删掉apt-get upgrade后,Dockerfile如下:
FROM ubuntu
ADD . /app
RUN apt-get update
RUN apt-get install -y nodejs
RUN cd /app && npm install
CMD npm start将变化频率一样的RUN指令合一
Docker镜像是分层的,类似于洋葱,它们都有很多层,为了修改内层,则需要将外面的层都删掉。Docker镜像有如下特性:
- Dockerfile中的每个指令都会创建一个新的镜像层。
- 镜像层将被缓存和复用。
- Dockerfile修改后,复制的文件变化了或者构建镜像时指定的变量不同了,对应的镜像层缓存就会失效。
- 某一层的镜像缓存失效之后,它之后的镜像层缓存都会失效。
- 镜像层是不可变的,如果我们在某一层中添加一个文件,然后在下一层中删除它,则镜像中依然会包含该文件,只是这个文件在Docker容器中不可见。
将变化频率一样的指令合并在一起,目的是为了更好的将镜像分层,避免带来不必要的成本。如本例中将node.js安装与npm模块安装放在一起的话,则每次修改源代码,都需要重新安装node.js,这显然不合适。
FROM ubuntu
ADD . /app
RUN apt-get update \
&& apt-get install -y nodejs \
&& cd /app \
&& npm install
CMD npm start因此,正确的写法是这样的:
FROM ubuntu
RUN apt-get update && apt-get install -y nodejs
ADD . /app
RUN cd /app && npm install
CMD npm start使用特定的标签
当镜像没有指定标签时,将默认使用latest标签。因此,FROM ubuntu指令等同于FROM ubuntu:latest。当镜像更新时,latest标签会指向不同的镜像,这时构建镜像有可能失败。
如下示例中使用16.04作为标签。
FROM ubuntu:16.04
RUN apt-get update && apt-get install -y nodejs
ADD . /app
RUN cd /app && npm install
CMD npm start删除多余文件
假设我们更新了apt-get源,下载解压并安装了一些软件包,它们都保存在/var/lib/apt/lists/目录中。
但是,运行应用时Docker镜像中并不需要这些文件。因此最好将它们删除,因为它会使Docker镜像变大。
示例Dockerfile中,删除/var/lib/apt/lists/目录中的文件。
FROM ubuntu:16.04
RUN apt-get update \
&& apt-get install -y nodejs \
&& rm -rf /var/lib/apt/lists/*
ADD . /app
RUN cd /app && npm install
CMD npm start选择合适的基础镜像
在示例中,我们选择了ubuntu作为基础镜像。但是我们只需要运行node程序,没有必要使用一个通用的基础镜像,node镜像应该是更好的选择。
更好的选择是alpine版本的node镜像。alpine是一个极小化的Linux发行版,只有4MB,这让它非常适合作为基础镜像。
FROM node:7-alpine
ADD . /app
RUN cd /app && npm install
CMD npm start设置WORKDIR和CMD
WORKDIR指令可以设置默认目录,也就是运行RUN / CMD / ENTRYPOINT指令的地方。
CMD指令可以设置容器创建时执行的默认命令。另外,您应该将命令写在一个数组中,数组中每个元素为命令的每个单词
FROM node:7-alpine
WORKDIR /app
ADD . /app
RUN npm install
CMD ["npm", "start"]使用ENTRYPOINT(可选)
ENTRYPOINT指令并不是必须的,因为它会增加复杂度。ENTRYPOINT是一个脚本,它会默认执行,并且将指定的命令作为其参数。它通常用于构建可执行的Docker镜像。
FROM node:7-alpine
WORKDIR /app
ADD . /app
RUN npm install
ENTRYPOINT ["./entrypoint.sh"]
CMD ["start"]ENTRYPOINT脚本中使用exec
在前文的ENTRYPOINT脚本中,使用了exec命令运行node应用。不使用exec的话,我们则不能顺利地关闭容器,因为SIGTERM信号会被bash脚本进程吞没。exec命令启动的进程可以取代脚本进程,因此所有的信号都会正常工作。
优先使用COPY
COPY指令非常简单,仅用于将文件拷贝到镜像中。ADD相对来讲复杂一些,可以用于下载远程文件以及解压压缩包。
FROM node:7-alpine
WORKDIR /app
COPY . /app
RUN npm install
ENTRYPOINT ["./entrypoint.sh"]
CMD ["start"]合理调整COPY与RUN的顺序
将变化最少的部分放在Dockerfile的前面,这样可以充分利用镜像缓存。
示例中,源代码会经常变化,则每次构建镜像时都需要重新安装NPM模块,这显然不是我们希望看到的。因此我们可以先拷贝package.json,然后安装NPM模块,最后才拷贝其余的源代码。这样的话,即使源代码变化,也不需要重新安装NPM模块。
FROM node:7-alpine
WORKDIR /app
COPY package.json /app
RUN npm install
COPY . /app
ENTRYPOINT ["./entrypoint.sh"]
CMD ["start"]设置默认的环境变量、映射端口和数据卷
运行Docker容器时很可能需要一些环境变量。在Dockerfile设置默认的环境变量是一种很好的方式。另外,我们应该在Dockerfile中设置映射端口和数据卷。示例如下:
FROM node:7-alpine
ENV PROJECT_DIR=/app
WORKDIR $PROJECT_DIR
COPY package.json $PROJECT_DIR
RUN npm install
COPY . $PROJECT_DIR
ENTRYPOINT ["./entrypoint.sh"]
CMD ["start"]ENV指令指定的环境变量在容器中可以使用。如果你只是需要指定构建镜像时的变量,你可以使用ARG指令。
使用VOLUME管理数据卷
VOLUME指令用于暴露任何数据库存储文件、配置文件或容器创建的文件和目录。强烈建议使用VOLUME来管理镜像中的可变部分和用户可以改变的部分。
下面示例中填写一个媒体目录。
FROM node:7-alpine
ENV PROJECT_DIR=/app
WORKDIR $PROJECT_DIR
COPY package.json $PROJECT_DIR
RUN npm install
COPY . $PROJECT_DIR
ENV MEDIA_DIR=/media \
APP_PORT=3000
VOLUME $MEDIA_DIR
EXPOSE $APP_PORT
ENTRYPOINT ["./entrypoint.sh"]
CMD ["start"]使用LABEL设置镜像元数据 你可以给镜像添加标签来帮助组织镜像、记录许可信息、辅助自动化构建等。每个标签一行,由LABEL开头加上一个或多个标签对。
WARNING
如果你的字符串中包含空格,必须将字符串放入引号中或者对空格使用转义。如果字符串内容本身就包含引号,必须对引号使用转义。
FROM node:7-alpine
LABEL com.example.version="0.0.1-beta"添加HEALTHCHECK
运行容器时,可以指定--restart always选项。这样的话,容器崩溃时,docker daemon会重启容器。对于需要长时间运行的容器,这个选项非常有用。但是,如果容器的确在运行,但是不可用怎么办?使用HEALTHCHECK指令可以让Docker周期性的检查容器的健康状况。我们只需要指定一个命令,如果一切正常的话返回0,否则返回1。当请求失败时,curl --fail命令返回非0状态。示例如下:
FROM node:7-alpine
LABEL com.example.version="0.0.1-beta"
ENV PROJECT_DIR=/app
WORKDIR $PROJECT_DIR
COPY package.json $PROJECT_DIR
RUN npm install
COPY . $PROJECT_DIR
ENV MEDIA_DIR=/media \
APP_PORT=3000
VOLUME $MEDIA_DIR
EXPOSE $APP_PORT
HEALTHCHECK CMD curl --fail http://localhost:$APP_PORT || exit 1
ENTRYPOINT ["./entrypoint.sh"]
CMD ["start"]编写.dockerignore文件
.dockerignore的作用和语法类似于.gitignore,可以忽略一些不需要的文件,这样可以有效加快镜像构建时间,同时减少Docker镜像的大小。
构建镜像时,Docker需要先准备context,将所有需要的文件收集到进程中。默认的context包含Dockerfile目录中的所有文件,但是实际上,我们并不需要.git目录等内容。
示例如下:
.git/
node_modules# 只查看一级目录统计的空间占用
alias dud="du -d 1 -h"
# 查看一级和二级目录的占用
alias du1="du -h --max-depth=1 *"
alias duf="du -sh"
cd /
du -sh *
31G var
14G opt
# 有时候 ISPconfig 开启自动备份,会导致磁盘空间占用过大,请登录 IPSconfig 后台检查
root@jira:/var/backup# du -sh *
1.7G web10
5.4G web3
1.7G web5
784M web7清理Docker镜像及日志
默认情况下,docker的日志是在/var/lib/docker/containers/<container_id>/<container_id>-json.log中
使用sudo docker info 发现日志驱动是Logging Driver: json-file,也应证了此点
有些json.log文件很大,记得清除掉
执行docker images列出本机存在的镜像,最后一列SIZE是镜像大小
强制删除多个镜像
sudo docker rmi --force f439bc73d690 fa440e89e4c2
删除那些已停止的容器、dangling 镜像、未被容器引用的 network 和构建过程中的 cache
docker system prune
删除 24 小时前下载的镜像
docker image prune -a --filter "until=24h"
安全起见,这个命令默认不会删除那些未被任何容器引用的数据卷,如果需要同时删除这些数据卷,你需要显式的指定 --volumns 参数。比如你可能想要执行下面的命令:
docker system prune --all --force --volumns
清理 Containerd 镜像
k8s 1.24版本后容器运行时从Docker换为了Containerd,所以当你登录到节点后会发现已经没有Docker命令了,换为了 ctr 或 crictl
crictl rmi --prune使用 ncdu 查看磁盘占用情况
该命令默认会统计当前目录的文件占用情况,并直观的显示出来 我现在要查看整个磁盘个目录的占用情况
cd /
ncdu

删除 journal 日志
# 查看磁盘占用
journalctl --disk-usage
# 清理日志
journalctl --vacuum-size=10M
# 只保留一周的日志
journalctl --vacuum-time=1w删除系统日志文件
cd /var/log
# 删除 /var/log 下的日志压缩包
rm -rf /var/log/*.gz
# 删除 /var/log 轮转日志
rm -rf /var/log/*.1- 安装Docker,略过,请自行去官方文档查
- 执行
docker pull busybox去官方拉镜像 BusyBox 是一个集成了三百多个最常用Linux命令和工具的软件。 简单的说BusyBox就好像是个大工具箱,它集成压缩了 Linux 的许多工具和命令,也包含了 Android 系统的自带的shell。 - 使用
docker images查看镜像 - 创建容器启动
docker run busybox会看到啥都没有发生,因为没有提供任何命令,容器启动后,运行个空命令就退出了。 - 如果提供个命令呢
docker run busybox echo "hello from busybox"这个能看到输出了,但是容器执行完依然退出了。 - 我想查看正在运行的容器
docker ps没有任何输出 试试docker ps -a可以看到刚刚运行过的容器了,注意 status 列

- 如果想以交互式方式运行容器,并进入容器终端,就用
docker run -it busybox sh注意 -it 一般是同时出现的

TIP
-ttty的缩写 终端控制台-iinteractive 可交互缩写
如果想知道 run 后面都能带什么参数及含义,请使用 docker run --help
- 一些术语:
- Docker Daemon - Docker为C/S架构,服务端为docker daemon,在后台运行,用于管理,构建,分发容器
- Docker Client - 就是经常用的命令行工具
- Docker Hub - 分享,查找镜像资源的网站
WEBAPPS WITH DOCKER
- 我们运行一个容器
docker run --rm prakhar1989/static-site
prakhar1989/static-site 是作者维护的镜像--rm 当退出容器时自动移除这里容器启动会显示了 nginx is running,但没有告诉更多的信息
按 ctrl+c 退出
- 使用
docker run -d -P --name static-site prakhar1989/static-site-d 放到后台运行 -P 将容器内应用运行使用的端口暴露出来 ( Publish all exposed ports to random ports) --name 给容器起个名字

端口有了,可以打开站点了,还可以使用 docker run -p 8888:80 prakhar1989/static-site 指定端口

同时运行了两个容器

- 暂停容器用
docker stop static-sitestatic-site 是我们给运行时给容器起的名字,也可以用ID - 后面内容是使用 Dockerfile 构建自己的镜像并上传到AWS。由于之前讲过而且aws国内使用不方便,此处略过。
- 当docker安装后,会自动创建三个网络
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
c2c695315b3a bridge bridge local
a875bec5d6fd host host local
ead0e804a67b none null local默认使用的是 bridge 桥接。使用 docker network inspect bridge 在 Containers 下面看到正在使用该网络方式的所有容器。默认所有的容器都会使用bridge,通过刚才的命令还可以看到每个容器分配到的内部IP。 一般是 172.17.0.xx。 为了安全及方便,我们需要使某几个容器之间使用自己的桥接网络,如何做到呢?
- 使用
docker network创建一个新的bridge网络,比如docker network create foodtrucks-net

- 运行 Elasticsearch 容器并把刚创建的网络分配给他
docker run -d --name es --net foodtrucks-net -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.3.2 - 然后运行Python Flask 容器,并进到bash终端
docker run -it --rm --net foodtrucks-net finleyma/foodtrucks-web bash来测试下能否访问到 Elasticsearch 容器curl es:9200
TIP
访问容器网络没有输入容器的IP地址,用的容器名称表示,这种能力叫 automatic service discovery,自动服务发现,原理也比较简单 /etc/hosts 里有条记录,es为键名,值就是实际IP,由于IP是动态的,使用名字更不容易出错。
备注:elasticsearch挺占内存的,我服务器4G内存,在docker运行启动后出现了警告
]]>- 运行容器
docker run --name my-nginx -d -p 8088:80 --rm nginx:1.15
- -d:在后台运行
- -p:容器的80端口映射到 宿主机的 8088 端口
- --rm:容器停止运行后,自动删除容器文件
- --name:容器的名字为 my-nginx

docker run 其实等于 docker create + start 因为tag为 1.15 的 nginx 镜像并不在本地,会先下载再运行
浏览器打开 locahost:8088 就能看到默认页面了
- 官方推荐通过 Dockerfile 的方式制作镜像并运行容器
新建static-pages目录,结构如下:
static-pages
-- index.html
-- Dockerfileindex.html
<h1>Hello World</h1>Dockerfile
FROM nginx:1.15
COPY . /usr/share/nginx/html切换到Dockerfile所在路径
制作镜像 docker build -t my-nginx .,名称为 my-nginx,完整镜像名格式是:name:tag
参见 文档

根据镜像运行一个容器
docker run --name my-nginx -d -p 8088:80 my-nginx:latest
浏览器打开 locahost:8088 就能看到 hello-world 了
3.如果要修改nginx配置文件,我们把容器里面的 Nginx 配置文件拷贝到本地的当前目录。
执行 docker container cp my-nginx:/etc/nginx .
不要漏掉最后那个点。执行完成后,当前目录应该多出一个nginx子目录。
修改Dockerfile
FROM nginx:1.15
COPY index.html /usr/share/nginx/html
COPY nginx /etc/然后修改 static-pages\nginx\conf.d\default.conf
server {
listen 80;
server_name ng.test;
}C:\Windows\System32\drivers\etc\HOSTS
需要添加 127.0.0.10 ng.test 保持和localhost一致即可
重新制作镜像 docker build -t my-nginx:ng-test .
运行容器 docker run -d -p 80:80 my-nginx:ng-test 注意我映射的端口不再是8088,这样本地浏览器就能访问 ng.test 了
细节
- 停止容器: 先 docker ps 获取容器ID,比如是 934f93002018 然后 docker stop 934f93002018
- 重启容器
docker exec -it <mycontainer> kill -USR2 1
Compose项目由 Python 编写 ,实现上调用了 Docker服务提供的 API 来对容器进行管理。 因此只要所操作的平台支持 Docker,就可以在其上利用 Compose 来进行编排管理。
本人提炼出了几点技巧:
- 多用
docker-compose config命令校验和查看配置信息, 当修改了docker-compose.yml文件,不要急于执行docker-compose up启动,可以先检查下配置。很多时候是yml格式不规范导致的。 docker-compose up包含了构建镜像,创建服务,启动服务等一系列操作。一般配好文件执行这个命令就可以了。- 使用
.env环境变量配置文件 一些敏感信息如,数据库密码等不建议写死到docker-compose.yml中,可以写在.env环境配置文件中(使用Laravel的同学对这个文件肯定不陌生)。
因为docker-compose.yml一般跟随项目受版本控制,.env可以不受版本控制。
优化前:
- docker-compose.yml
mysql:
build: ./docker-build/mysql
ports:
- "33060:3306"
volumes:
- ./docker-build/mysql/data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: 123456优化后:
- docker-compose.yml
- .env
同级目录建立.env文件
mysql:
build: ./docker-build/mysql
ports:
- "33060:3306"
volumes:
- ./docker-build/mysql/data:/var/lib/mysql
environment:
# 先从.env找DOCKER_MYSQL_PASSPORD,找不到使用后面的默认值
MYSQL_ROOT_PASSWORD: ${DOCKER_MYSQL_PASSPORD-123456}.env
# define env var default value.
DOCKER_MYSQL_PASSPORD=root- 使用
docker-compose.yml中的env_file语法
service节点下支持 env_file属性,即环境变量从额外的文件中读取。 如下面的例子,如果local.env和common.env有相同key。则下面的优先级高。
php:
build:
context: ./docker-build/php
args:
- INSTALL_COMPOSER=${PHP_INSTALL_COMPOSER}
- INSTALL_MONGO=${PHP_INSTALL_MONGO}
- INSTALL_REDIS=${PHP_INSTALL_REDIS}
- INSTALL_XDEBUG=${PHP_INSTALL_XDEBUG}
ports:
- "9001:9000"
links:
- "mysql"
volumes:
- .:/www
env_file:
- ./common.env
- ./local.env假设 local.env 中内容是A:1,common.env 是 A:2
environment:
A: 3
env_file:
- ./common.env
- ./local.env最终生效的是 A:3
- 配置不同场景下的环境变量
我们可以把不同场景下的环境变量定义在不同的 shell 脚本中并导出,
然后在执行
docker-compose命令前先执行 source 命令把 shell 脚本中定义的环境变量导出到当前的 shell 中。 通过这样的方式可以减少维护环境变量的地方,下面的例子中我们分别在docker-compose.yml文件所在的目录创建test.sh和prod.sh。
test.sh 的内容如下:
#!/bin/bash
# define env var default value.
export IMAGETAG=web:v1
export APPNAME=HelloWorld
export AUTHOR=Nick Li
export VERSION=1.0prod.sh 的内容如下:
#!/bin/bash
# define env var default value.
export IMAGETAG=webpord:v1
export APPNAME=HelloWorldProd
export AUTHOR=Nick Li
export VERSION=1.0LTS在测试环境下,执行下面的命令:
$ source test.sh
$ docker-compose config
此时 docker-compose.yml 中的环境变量应用的都是测试环境相关的设置。 而在生产环境下,执行下面的命令:

此时 docker-compose.yml 中的环境变量应用的都是生产环境相关的设置。
- 环境变量的优先级 docker-compose.yml 文件中引用的环境变量,它们的优先级如下:
- Compose file
- Shell environment variables
- Environment file
- Dockerfile
- Variable is not defined
首先,在 docker-compose.yml 文件中直接设置的值优先级是最高的。 然后是在当前 shell 中 export 的环境变量值。 接下来是在环境变量文件中定义的值。 再接下来是在 Dockerfile 中定义的值。 最后还没有找到相关的环境变量就认为该环境变量没有被定义。
额外内容,使用 extends 继承扩展docker-compose.yml
基于其他模板文件进行扩展 。 例如,我们已经有了一个 webapp 服务,定义一个基础模板文件为 common.yml,如下所示:
common.yml:
webapp
build : . /webapp
environment:
- DEBUG=false
- SEND EMAILS=false再编写一个新的 development .yml 文件,使用 common.yml 中的 webapp 服务进行扩展:
development.yml:
web:
extends:
file: common .yml
service: webapp
ports :
- "8000:8000"
links:
- db environment:
- DEBUG=true
db:
image : postgres后者会自动继承common.yml中的webapp服务及环境变量定义。 使用extends需要注意以下两点:
- 要避免出现循环依赖,例如 A 依赖 B, B 依赖 C, C 反过来依赖 A 的情况 。
- extends 不会继承 links 和 volumes_from 中定义的容器和数据卷资源 。 一般情况下,推荐在基础模板中只定义一些可以共享的镜像和环境变量,在扩展模板中 具体指定应用变量、链接、数据卷等信息 。
TIP
- Dockerfile中,在基础镜像上安装软件使用 RUN
- CMD命令是当Docker镜像被启动后Docker容器将会默认执行的命令。一个Dockerfile中只能有一个CMD命令。通过执行
docker run $image $other_command启动镜像可以重载CMD命令。 - 使用 docker-compose run 命令可以在服务上运行一次性命令,如
docker-compose run web env查看服务为web的环境变量

参考:
]]>docker run -d -p 3000:3000 finleyma/express 就可以访问一个简单的express程序了。
需要你有简单的express使用经验 实现过程非常简单:
- 本地全局安装
npm install express-generator -g - 初始化一个express项目
express myapp - cd myapp,然后 npm run start,项目就在本地运行了。
- 我们在项目内建立Dockerfile,内容如下:
FROM node:10.8.0-alpine
MAINTAINER www.mafeifan.com
# 设置工作目录,下面的RUN命令会在工作目录执行
WORKDIR /app
# 先拷贝本地的 package.json 和 package-lock 到容器内
# 这样是利用docker的镜像分层机制
COPY package*.json ./
# 安装项目依赖包
# 生产环境可以运行 RUN npm install --only=production 只按照 package.json 中dependencies定义的模块
RUN npm install
# 将根目录下的文件都copy到container(运行此镜像的容器)文件系统的app文件夹下
ADD . /app/
# 暴露容器内的3000端口
EXPOSE 3000
# 容器启动时执行的命令,类似npm run start
CMD ["npm", "start"]- 构建镜像
docker build -t finleyma/express .别忘了最后的点,表示当前目录 - 启动容器
docker run -d -p 3000:3000 finleyma/express - 可选,登录docker hub, 并提交镜像。
docker login,docker push finleyma/express - 进入容器
docker run -it --rm finleyma/express:1.0 ash简要说下参数:
- -it:这是两个参数,一个是 -i:交互式操作,一个是 -t 终端。我们这里打算进入 容器 执行一些命令并查看返回结果,因此我们需要交互式终端。
- --rm:这个参数是说容器退出后随之将其删除。默认情况下,为了排障需求,退出的容器并不会立即删除,除非手动 docker rm。我们这里只是随便执行个命令,看看结果,不需要排障和保留结果,因此使用 --rm 可以避免浪费空间。
- ash:因为我们的Node的基础镜像是10.8.0-alpine, alpine的交互式 Shell是ash不是bash,使用bash会提示not found。注意这个细节。 会发现整个项目文件都在容器内。

简单总结使用Docker的好处:
- 使用版本方便,比如服务器上跑着node6,而你的项目需要node8以上。使用docker因为是隔离环境
- 部署分享也方便,一行命令完事
问题:容器内的 node_modules 是本来就有还是容器执行 npm install 产生的呢? 答案:是构建的时候打包进镜像内了。我们看一下体积,有20M而且进到容器内, ls -l node_modules 时间也是打包的什么,并不是当前时间。

参考:
]]>docker run -d -p 3000:3000 finleyma/express,就会部署并运行项目
然后浏览器中输入154.8.100.100:3000 就可以访问了。
这里牵涉到两个问题:
- 每次修改了项目代码需要重新构建新的镜像,然后push到仓库。
- 每次还得登录服务器从仓库拉最新的镜像重新运行 ,这样才能反映出变化。
持续集成就能帮我们做到自动化。 不过有几个条件:
- 需要一个提供持续集成服务的平台,这里我使用国内的 daocloud 他可以接入我们的主机,提供在线 web 的方式管理运行在主机上面的容器。
- 需要一台能访问的且安装了docker的主机(最好是Linux)。
- 代码要部署到 github,coding 等 daocloud 支持的代码托管商。
下面介绍下流程: 去daocloud绑定仓库,和主机 根据仓库构建镜像 配置

- 查看主机上运行的 docker相关的信息 在主机上我们得敲 docker info, docker inspect 等。这里直观的多。

- 添加应用

- 添加项目,需要绑定 github 或 coding代码源 代码源就是上节的express项目,仓库地址是:https://coding.net/u/finley/p/docker-express-demo。 里面有Dockerfile。我们让daocloud帮忙构建,并且发布到主机上面。

在流程定义中构建阶段后面添加发布阶段,选择发布到自有主机

这个过程就是push代码之后,daocloud要根据Dockerfile去构建镜像,构建之前可以要运行测试脚本,构建成功之后可能要发送提醒。 默认是图形化的配置,也可以切换到yaml形式,编写流程定义 daocloud.yml 文件。 这里有个细节,如果你切换到了yaml格式,内容为空。push代码不会触发自动构建的。 稍微吐槽下daocloud做的不够人性化,流程定义没有帮助提示。比如匹配分支,满足条件那块,我不知道能填哪些,你弄个问号,鼠标指上去显示几行描述也好啊

- 这样就实现了,每当本地push代码到仓库,daocloud会重新构建镜像然后发布到主机。

有很多细节没有讲到,请自行查看提供的文档。
参考:
]]>Docker的技术原理介绍
Docker就是虚拟化的一种轻量级替代技术。Docker的容器技术不依赖任何语言、框架或系统,可以将App变成一种 标准化的、可移植的、自管理的组件,并脱离服务器硬件在任何主流系统中开发、调试和运行。 简单的说就是,在 Linux 系统上迅速创建一个容器(类似虚拟机)并在容器上部署和运行应用程序,并通过配置文件 可以轻松实现应用程序的自动化安装、部署和升级,非常方便。因为使用了容器,所以可以很方便的把生产环境和开 发环境分开,互不影响,这是 docker 最普遍的一个玩法。
Docker相关的核心技术之cgroups
Linux系统中经常有个需求就是希望能限制某个或者某些进程的分配资源。于是就出现了cgroups的概念, cgroup就是controller group ,在这个group中,有分配好的特定比例的cpu时间,IO时间,可用内存大小等。 cgroups是将任意进程进行分组化管理的Linux内核功能。最初由google的工程师提出,后来被整合进Linux内 核中。 cgroups中的 重要概念是“子系统”,也就是资源控制器,每种子系统就是一个资源的分配器,比如cpu子系 统是控制cpu时间分配的。首先挂载子系统,然后才有control group的。比如先挂载memory子系统,然后在 memory子系统中创建一个cgroup节点,在这个节点中,将需要控制的进程id写入,并且将控制的属性写入, 这就完成了内存的资源限制。 cgroups 被Linux内核支持,有得天独厚的性能优势,发展势头迅猛。在很多领域可以取代虚拟化技术分割资源。 cgroup默认有诸多资源组,可以限制几乎所有服务器上的资源:cpu mem iops,iobandwide,net,device acess等。
Docker相关的核心技术之LXC
LXC是Linux containers的简称,是一种基于容器的操作系统层级的虚拟化技术。借助于namespace的隔离机制 和cgroup限额功能,LXC提供了一套统一的API和工具来建立和管理container。LXC跟其他操作系统层次的虚 拟化技术相比,最大的优势在于LXC被整合进内核,不用单独为内核打补丁
LXC 旨在提供一个共享kernel的 OS 级虚拟化方法,在执行时不用重复加载Kernel, 且container的kernel与host 共享,因此可以大大加快 container 的启动过程,并显著减少内存消耗,容器在提供隔离的同时,还通过共享这 些资源节省开销,这意味着容器比真正的虚拟化的开销要小得多。 在实际测试中,基于LXC的虚拟化方法的IO和 CPU性能几乎接近 baremetal 的性能。
备注:最初实现是基于 LXC,从 0.7 版本以后开始去除 LXC,转而使用自行开发的 libcontainer,从 1.11 开始,则进一步演进为使用 runC 和 containerd。
虽然容器所使用的这种类型的隔离总的来说非常强大,然而是不是像运行在hypervisor上的虚拟机那么强壮仍具有 争议性。如果内核停止,那么所有的容器就会停止运行。 • 性能方面:LXC>>KVM>>XEN • 内存利用率:LXC>>KVM>>XEN • 隔离程度: XEN>>KVM>>LXC
备注:XEN,KVM有些同学对这个名词不会陌生,所谓虚拟主机,就是采用了这个技术,在一台物理主机上面,采用这种技术再划分N多台虚拟主机去售卖。可以搜下KVM或XEN虚拟主机。
Docker相关的核心技术之AUFS
什么是AUFS? AuFS是一个能透明覆盖一或多个现有文件系统的层状文件系统。 支持将不同目录挂载到同一 个虚拟文件系统下,可以把不同的目录联合在一起,组成一个单一的目录。这种是一种虚拟的文件系统,文 件系统不用格式化,直接挂载即可。 Docker 一直在用 AuFS 作为容器的文件系统(注意:目前好像不是这样的)。当一个进程需要修改一个文件时,AuFS 创建该文件的一个副本。 AuFS 可以把多层合并成文件系统的单层表示。这个过程称为写入复制( copy on write )。 AuFS 允许Docker把某些镜像作为容器的基础。例如,你可能有一个可以作为很多不同容器的基础的CentOS 系统镜像。多亏 AuFS,只要一个CentOS镜像的副本就够了,这样既节省了存储和内存,也保证更快速的容 器部署。 使用AuFS的另一个好处是Docker的版本容器镜像能力。每个新版本都是一个与之前版本的简单差异改动, 有效地保持镜像文件最小化。但,这也意味着你总是要有一个记录该容器从一个版本到另一个版本改动的 审计跟踪。
Docker原理之App打包
LXC的基础上, Docker额外提供的Feature包括:标准统一的 打包部署运行方案。 为了最大化重用Image,加快运行速度,减少内存和磁盘footprint, Docker container运行时所构造的运行环境,实际上是由具有依赖关系的多个Layer组成的。例如一个apache的运行环境可能是在基础的rootfs image的基础上,叠加了包含例如Emacs等各种工具的image,再叠加包含apache及其相关依赖library的image,这些image由AUFS文件系统加载合并到统一路径中,以只读的方式存在,最后再叠加加载一层可写的空白的Layer用作记录对当前运行环境所作的修改。 有了层级化的Image做基础,理想中,不同的APP就可以既可能的共用底层文件系统,相关依赖工具等,同一个APP的不同实例也可以实现共用绝大多数数据,进而以copy on write的形式维护自己的那一份修改过的数据等。
备注:简单说Docker是基于Linux的虚拟化技术,又加入了image,Dockerfile等概念。又整了个类似github的docker hub。等发展起来了自己的生态系统。Docker本身提供的命令非常简单,Dockerfile,Docker compose又便于学习及运用,这是Docker火起来的一大原因。
Docker和传统虚拟化方式的不同之处
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
]]>部署私有仓库
-
https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
-
Awesome Compose) 收集的一些常见的语言框架的docker-compose示例
Docker开源公共镜像提供商
推荐几个好用的 Docker 开源公共镜像提供商,还可以学习他们打包镜像的思路
-
Bitnami,提供wordpress, Laravel, Magento, Sonarqube, Redmine,Joomla 等镜像。
-
CircleCI images CircleCI 本身提供的是CI/CD服务。针对不同语言和工具,自己维护了一些常用的镜像。
而且所有镜像都预装了常用工具,如git, gzip, unzip, sudo, wget, zip 等。
-
thecodingmachine/docker-images-php 提供了很多PHP相关的镜像
-
鼎鼎有名的JetBrains公司维护的PHP相关镜像 https://github.com/JetBrains/phpstorm-docker-images
-
提供支持很多Laravel版本的PHP+nginx镜像 https://github.com/dwchiang/nginx-php-fpm
-
亚马逊的公有镜像仓库,速度还不错
使用容器时,要尽量使用单进程容器,所谓单进程容器,是指在容器运行时,只有一个工作进程。
如果需要存在多个进程协作的时候,要部署为两个容器,比如 PHP 一个容器,MySQL 一个容器,而不要在一个容器中运行这两者。
因为,Docker本身就是一个非常好的守护进程,它可以完美地管理一个进程,但是如果一个容器中存在多个进程时,你就需要自己维护两个进程的运行状态,比如使用 supervisord ,但这就大大增加了容器维护的难度和不稳定性。
比如在一个容器中同时运行 PHP 和 MySQL,那么如果PHP异常退出了,容器该不该连同MySQL一起退出?如果不退出,而是不断重启PHP,那么在容器之外,比如运行 docker ps 是无法了解到PHP运行状态的。
所以,使用docker,就要习惯于单进程容器的方式,既简单,又稳健。
为什么使用无状态容器
所谓状态,是指程序在执行过程中生成的中间数据,而无状态容器,是指容器在运行时,不在容器中保存任何数据,而将数据统一保存在容器外部,比如数据库中。
因为有状态的容器异常重启就会造成数据丢失,也无法多副本部署,无法实现负载均衡。
比如PHP的Session数据默认存储在磁盘上,比如 /tmp 目录,而多副本负载均衡时,多个PHP容器的目录是彼此隔离的。比如存在两个副本A和B,用户第一次请求时候,流量被转发到A,并生成了SESSION,而第二次请求时,流量可能被负载均衡器转发到B上,而B是没有SESSION数据的,所以就会造成会话超时等BUG。
如果采用主机卷的方式,多个容器挂载同一个主机目录,就可以共享SESSION数据,但是如果多主机负载均衡场景,就需要将SESSION存储于外部数据库或Redis中了。
除了文件,还有内存数据,比如Node.js项目中使用了全局变量暂存数据,那么这个容器也是有状态的,也会出现类似BUG,所以要使用无状态容器。
为什么要避免使用latest
docker镜像的tag部分可以省略,默认为latest,比如:
docker pull ubuntu
这当然非常方便,但是请不要这样操作。在部署镜像时或Dockerfile的FROM中,请不要省略Tag,也不要使用latest作为Tag。
首先,这样非常不直观,ubuntu:16.04 要比 ubuntu:latest 更加明确,使用 latest 作为标签时,我们经常需要进行思考甚至查阅仓库文档才能确定具体的版本号。
更重要的,latest 引用是经常变化的,随着时间的推移,此时的latest可能和下个月的latest是完全不同的版本,比如 ubuntu:latest 刚刚从 16.04 升级为 18.04,使用 latest 会给未来增加非常多的不确定性隐患,此时能部署成功,下个月也许就会出现各种问题。
所以,请一定避免使用latest标签,而使用稳定的、明确的、具体的版本号来标明你的依赖项。
RUN cd
WORKDIR 指定工作目录(或称当前目录),以后各层的当前目录就被改为指定的目录,如该目录不存在,WORKDIR 会自行创建。 WORKDIR 在 Dockerfile可以多次使用
WARNING
Dockerfile 不能等同于 Shell 脚本来书写,下面是错误写法:
RUN cd /app
RUN echo "hello" > world.txt此 Dockerfile 构建镜像,会发现找不到 /app/world.txt 文件,或者其内容不是 hello 。
在 Shell 中,连续两行是同一个进程执行环境,因此前一个命令修改的内存状态,会直接影响后一个命令;
而在 Dockerfile 中,这两行 RUN 命令的执行环境根本不同,是两个完全不同的容器。
每一个 RUN 都会启动一个容器、执行命令、然后提交存储层文件变更。
第一层 RUN cd /app 的执行仅仅是当前进程的工作目录变更,一个内存上的变化而已,其结果不会造成任何文件变更。
第二层启动的是一个全新的容器,跟第一层的容器更完全没关系,自然不可能继承前一层构建过程中的内存变化。
因此如果需要改变以后各层的工作目录的位置,那么应该使用 WORKDIR 指令。
]]>在使用Docker的过程中,必然会涉及到容器的数据管理操作,例如查看容器内应用生成或更新的数据,容器内数据的备份/恢复,容器之间进行数据共享等操作。Docker中数据管理等方式主要有两种:
-
数据卷(Data volumes)
-
数据卷容器(Data volume containers)
数据卷和数据卷容器
数据卷是一个供容器使用的特殊目录,用来存放持久化或共享数据的地方,而数据卷容器其实就是一个普通容器,只是这个容器专门提供数据卷给其它容器挂载使用,因此,数据卷和数据卷容器之间有着密切的联系,并不是两个完全不相关的概念。
当使用docker run或者docker create命令时,使用-v就可以在容器内创建一个数据卷,默认情况下,Docker Engine会在宿主机上的/var/lib/docker/volumes/目录下创建一个特殊目录,供容器挂载使用,而挂载了这个数据卷的容器便可以称为数据卷容器。我们将这种方式,称为在容器里创建一个数据卷,此外,我们还可以指定挂载一个宿主机的本地目录到容器中作为数据卷。

如上图所示,volume container1分别挂载了容器内创建的数据卷/vol1以及指定挂载了一个宿主机中的本地目录作为数据卷/vol2。而volume container2则只挂载了数据卷/vol2。通过这样,当我们修改Docker默认数据目录以及修改挂载的本地宿主机目录时,数据卷容器中挂载的数据卷/vol1和数据卷vol2中的数据也都会进行变更,反之亦然。
除了上述创建数据卷的方式外,我们还可以使用--volume-from的方式,指定数据卷容器,从而挂载其中的数据卷。还是上图中,containerA和containerB在使用docker run创建容器时,通过--volume-from选项指定直接使用volume container2中的数据卷/vol2。
数据卷的特性
通过前面所述,我们理解了什么是数据卷和数据卷容器,接下来,简要总结数据卷的特性:
-
当我们在创建容器时,数据卷就会自动初始化。
-
数据卷可以在容器之间共享和复用。
-
对数据卷的数据的更新,不会影响到镜像。
-
对数据卷的修改会立刻生效。
-
数据卷中的数据会一直存在,直到删除最后一个挂载该数据卷的容器被删除时,还需要显示指定删除关联的数据卷。
通过Docker提供的数据卷和数据卷容器的特性和机制,我们可以对容器内的数据进行共享、备份和恢复,增加了容器的容灾能力。即使容器在运行过程中发生故障也不用担心,只需要快速重新创建容器,挂载数据卷即可。当然,在实际生产环境中,还是需要配合支持诸如RAID、DRBD、以及ceph和HDFS等分布式存储技术来的达到数据的安全性和高可用性。
]]>可以直接fork这个项目练习
这里假设你已有docker hub账号,先登录,进到https://hub.docker.com/settings/security生成access token,注意好记好。
然后打开Github到Settings > Secrets > New secret添加两条记录:
- 键名:DOCKER_HUB_USERNAME,值是Docker hub的用户名
- 键名:DOCKER_HUB_ACCESS_TOKEN,值是刚才复制的access token,值类似c292155d-1bd7-xxxx-xxxx-4da75bedb178
关于参见 buildx
修改.github/workflows/main.yml文件
name: CI to Docker Hub
on:
push:
branches: [ master ]
# tags:
# - "v*.*.*"
jobs:
build:
runs-on: ubuntu-latest
steps:
-
name: Set up Docker Buildx
uses: docker/setup-buildx-action@v1
-
name: Login to DockerHub
uses: docker/login-action@v1
with:
username: ${{ secrets.DOCKER_HUB_USERNAME }}
password: ${{ secrets.DOCKER_HUB_ACCESS_TOKEN }}
-
name: Build and push
id: docker_build
uses: docker/build-push-action@v2
with:
push: true
tags: finleyma/simplewhale:latest
build-args: |
arg1=value1
arg2=value2
-
name: Image digest
run: echo ${{ steps.docker_build.outputs.digest }}参考
]]># main.yml
# Workflow's name
name: Build Electron App For Win/Mac
# Workflow's trigger
on:
push:
tags:
- "v*.*.*"
# Workflow's jobs
jobs:
# job's id
release:
# job's name
name: build and release electron app
# the type of machine to run the job on
runs-on: ${{ matrix.os }}
# create a build matrix for jobs
strategy:
fail-fast: false
matrix:
os: [windows-2019, macos-10.15]
# create steps
steps:
# step1: check out repository
- name: Check out git repository
uses: actions/checkout@v2
# step2: install node env
- name: Install Node.js
uses: actions/setup-node@v2-beta
# step3: npm install
- name: npm install
run: |
npm install
# step4: build app for mac/win
- name: build windows app
if: matrix.os == 'windows-2019'
run: |
npm run electron:build-win
env:
GH_TOKEN: bef0b46667d2b13f8asdasdasd762873af59f71c
- name: build mac app
if: matrix.os == 'macos-10.15'
run: |
npm run electron:build
env:
GH_TOKEN: bef0b46667d2b13f8asdasdasd762873af59f71c
# step5: cleanup artifacts in dist_electron
- name: cleanup artifacts for windows
if: matrix.os == 'windows-2019'
run: |
npx rimraf "dist_electron/!(*.exe)"
- name: cleanup artifacts for macosZ
if: matrix.os == 'macos-10.15'
run: |
npx rimraf "dist_electron/!(*.dmg)"
# step6: upload artifacts
- name: upload artifacts
uses: actions/upload-artifact@v2
with:
name: ${{ matrix.os }}
path: dist_electron
# step7: create release
- name: release
uses: softprops/action-gh-release@v1
if: startsWith(github.ref, 'refs/tags/')
with:
files: "dist_electron/**"
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}https://github.com/<OWNER>/<REPOSITORY>/workflows/<WORKFLOW_NAME>/badge.svg?branch=<branch-name>
<OWNER>:所有者的用户名<REPOSITORY>:项目仓库名称<WORKFLOW_NAME>:工作流名称<branch-name>:分支名称,如果不写默认是master分支
本项目的图标地址就是:https://github.com/mafeifan/vue-press/workflows/CI/badge.svg
https://github.com/mafeifan/vue-press/workflows/CI/badge.svg
]]>开箱即用的环境。从 GitHub 官方的虚拟环境仓库可以看到,Ubuntu 20.04 的环境中自带了 Java 11,Kotlin 1.6.0,Gradle 7.3,和 Android SDK 的常用版本。相比上面的传统方法,Ubuntu 这套环境其实已经解决了很多编译环境问题了,且合适大部分的 Android 项目的构建,如果遇到不满足的地方,下面也有方法告诉你怎么轻易地解决。
足够的免费配额。GitHub Actions 对于免费的账户也是有一定的限制的,具体表现在:每个仓库的构建产物限制是 500MB,每个月的运行时长是 2000 分钟。对于我们只是构建一个普通的 Android 项目安装包来说,也够用了,运行时长也是绰绰有余。
如何使用 GitHub Actions
下面就通过实战来看看如何方便快捷地用 GitHub Actions 来构建一个开源 Android 项目的 APK 安装包吧。 我这里选择的是 FolioReader,一个 Java 编写的 ePub 阅读器,在 GitHub 上开源并获得 2k ⭐。
这里是我编写的 GitHub Actions 运行的配置文件并开源在 Wsine/android_builder,我会详细地说明一下每个步骤都做了什么。
name: android_build
on:
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout the code
# 拉取 android_builder 的源代码
uses: actions/checkout@v2
- name: Set up JDK
# 设置 Java 运行环境
uses: actions/setup-java@v1
with:
java-version: 1.8
# 用 1.8 版本覆盖环境中自带的 Java 11 版本
- id: get-project
# 读取项目地址
name: Get project name
run: echo "::set-output name=PROJECT::$(cat project-to-build)"
- name: Clone project
# 拉取项目源码到虚拟环境
run: git clone --depth=1 ${{ steps.get-project.outputs.PROJECT }} project
- name: Build the app
# 构建调试版 APK
working-directory: ./project
run: |
if [ ! -f "gradlew" ]; then gradle wrapper; fi
chmod +x gradlew
./gradlew assembleDebug --stacktrace
- name: Upload APK
# 打包上传生成的 APK 到的网页端
uses: actions/upload-artifact@v2
with:
name: my-build-apk
path: ./**/*.apk这个 Workflow 的触发条件设置为手动触发,因为还需要一些修改才能满足目标 Android 项目的构建条件,因此没有设置为常规的基于文件改动就触发。
虚拟环境这里我使用的是 ubuntu-latest,在此时就是指向 Ubuntu 20.04 这个 LTS 版本,日常开发中可能不建议使用这种不确定的版本,但在我们的场景中还是毕竟合适的,因为一个还在维护的 Android 项目一般都会适配较新的 LTS 版本的。
第一步是拉取 android_builder 的源代码,主要目的是获取 project-to-build 这份文件,里面包含了我们的目标 Android 项目的 GitHub 地址。在我们这个实战中就是 https://github.com/FolioReader/FolioReader-Android 这个地址,如需编译其它的项目,把该地址替换为其相应的 GitHub 地址即可。
第二步是设置运行环境,这里是重点。一般情况下,Android 项目中的 Java 代码语法需要一定的 Java 编译器版本,因此我这里引入了 actions/setup-java 这个 action 来快捷地设置 Java 的版本,比如这里我使用了 1.8 版本(Java 8)覆盖环境中自带的 Java 11 版本。同样地,设置 Gradle 和 Android SDK 也有快捷的 action 可以复用,分别为 gradle/gradle-build-action 和 android-actions/setup-android。GitHub 官方的 Ubuntu 20.04 的环境中自带的版本已经是比较高的版本了,一般情况下程序都有后向兼容,所以大部分的情况下你其实可以完全不用设置。这里仅是一个例子来展示如何轻松地修改版本。
第三步的目标是从 project-to-build 这份文件中读取 Android 项目的开源地址并传递给下一步进行拉取Android 项目源码。注意,目标 Android 项目要开源并且是处于公开的状态。cat
project-to-build可以读取这份文件包含的地址,然后通过 GitHub Actions 中特殊的语法 ::set-output name=PROJECT::XXX设置地址为该步骤的输出。
第四步是拉取目标 Android 项目源码到虚拟环境中准备编译。首先通过
${{ steps.get-project.outputs.PROJECT }}
获取上一步的输出地址,然后用 Git 命令克隆 Android 项目源码到虚拟环境的本地中。至此,编译前的准备工作已完成。
第五步是构建 APK 的关键步骤,这里假设目标 Android 项目是已经能够编译通过的了。gradlew 是 Gradle 包管理工具自己产生的一个 bash
脚本,用于命令行环境下的自动构建,绝大部分的开源项目已经包含了该文件,因此我加了个判断,如果不存在该文件则用 Gradle 生成出来,并赋予执行权限。得益于优秀的包管理器,Android 项目下只需要一句命令即可构建出 APK
安装包——./gradlew assembleDebug --stacktrace,该命令用于构建调试版 APK,调试版本已满足个人的使用,折腾应用签名就没有必要了。后面的 stacktrace 参数只是为了显示更多的运行信息。执行完这步,
APK 就已经生成好了。
最后一步,把生成的 APK 文件打包上传到 GitHub Actions 的网页端,方便下载。你也可以上这里看看我构建的 APK 输出,最后会得到一个 zip 压缩包,包含了最终生成的 APK 文件。
整个构建过程只需要 2m 47s,就得到了我们的 APK 文件,其中包含了下载全部依赖库和从零开始编译两个过程,相比自己下载到本地编译从运行速度和网速两个角度来说,整个过程就显得非常快了。然后就可以把 APK 文件传输到自己的手机,在设置中打开「允许安装未知来源应用」的选项,就能够顺利安装到手机中。
如何复刻该 Workflow
首先 fork 一下 Wsine/android_builder 这个仓库,根据上面第三步的操作,修改 project-to-build 这个文件改为你需要编译的 Android 项目的 GitHub 地址,然后如下图所示点击,即可运行该 Workflow。 运行完毕后点开 Workflow 在 Summary 的选项卡中找到 Artifacts,即可下载带 APK 的压缩包。


感谢 GitHub Actions 让以往相对复杂、也有不低上手门槛的事情变得更加简单、快捷,如果你也有过类似的需求,不妨现在就找个项目上手试试吧。
参考
]]>Github Action 是什么?
是 Github 推出的持续集成工具
持续集成是什么?
简单说就是自动化的打包程序——如果是前端程序员,这样解释比较顺畅:
每次提交代码到 Github 的仓库后,Github 都会自动创建一个虚拟机(Mac / Windows / Linux 任我们选),来执行一段或多段指令(由我们定),例如:
npm install npm run build
关于虚拟机的目前是 Microsoft Azure 提供的Standard_DS2型号,硬件配置是2核7G内存,14G的SSD硬盘,详见
Yaml 是什么?
我们集成 Github Action 的做法,就是在我们仓库的根目录下,创建一个 .github 文件夹,里面放一个 *.yaml 文件——这个 Yaml 文件就是我们配置 Github Action 所用的文件。
它是一个非常容易地脚本语言,如果我们不会的话,也没啥大事继续往下看就成了。
Github Action 的使用限制
每个 Workflow 中的 job 最多可以执行 6 个小时 每个 Workflow 最多可以执行 72 小时 每个 Workflow 中的 job 最多可以排队 24 小时 在一个存储库的所有 Action 中,一个小时最多可以执行 1000 个 API 请求 并发工作数:Linux:20,Mac:5(专业版可以最多提高到 180 / 50)
什么是 Workflow?
Workflow 是由一个或多个 job 组成的可配置的自动化过程。我们通过创建 YAML 文件来创建 Workflow 配置。
一、如何定义 Workflow 的名字?
name
Workflow 的名称,Github 在存储库的 Action 页面上显示 Workflow 的名称。
如果我们省略 name,则 Github 会将其设置为相对于存储库根目录的工作流文件路径。
name: Greeting from Mona on: push
二、如何定义 Workflow 的触发器?
on
触发 Workflow 执行的 event 名称,比如:每当我提交代码到 Github 上的时候,或者是每当我打 TAG 的时候。
// 单个事件
on: push
// 多个事件
on: [push,pull_request]三、Workflow 的 job 是什么?
答:一个 Workflow 由一个或多个 jobs 构成,含义是一次持续集成的运行,可以完成多个任务。
1、如何定义一个 job?
jobs:
my_first_job:
name: My first job
my_second_job:
name: My second job答:通过 job 的 id 定义。
每个 job 必须具有一个 id 与之关联。
上面的 my_first_job 和 my_second_job 就是 job_id。
2、如何定义 job 的名称?
jobs.<job_id>.name
name 会显示在 Github 上
3、如何定义 job 的依赖?job 是否可以依赖于别的 job 的输出结果?
jobs.<job_id>.needs
答:needs 可以标识 job 是否依赖于别的 job——如果 job 失败,则会跳过所有需要该 job 的 job
jobs:
job1:
job2:
needs: job1
job3:
needs: [job1, job2]jobs.<jobs_id>.outputs:用于和 need 打配合,outputs 输出=》need 输入
jobs:
job1:
runs-on: ubuntu-latest
# Map a step output to a job output
outputs:
output1: ${{ steps.step1.outputs.test }}
output2: ${{ steps.step2.outputs.test }}
steps:
- id: step1
run: echo "::set-output name=test::hello"
- id: step2
run: echo "::set-output name=test::world"
job2:
runs-on: ubuntu-latest
needs: job1
steps:
- run: echo ${{needs.job1.outputs.output1}} ${{needs.job1.outputs.output2}}4、如何定义 job 的运行环境?
jobs.<job_id>.runs-on
指定运行 job 的运行环境,Github 上可用的运行器为:
- windows-2019
- ubuntu-20.04
- ubuntu-18.04
- ubuntu-16.04
- macos-10.15
而且这些操作系统上面已经预装了一些常用的软件开发工具,如Ubuntu 20.04.1 LTS安装的软件
jobs:
job1:
runs-on: macos-10.15
job2:
runs-on: windows-20195、如何给 job 定义环境变量?
jobs.<jobs_id>.env
jobs:
job1:
env:
FIRST_NAME: Mona6、如何使用 job 的条件控制语句?
jobs.<job_id>.if
我们可以使用 if 条件语句来组织 job 运行
四、Step 属性是什么?
答:每个 job 由多个 step 构成,它会从上至下依次执行。
step 运行的是什么? step 可以运行:
commands:命令行命令 setup tasks:环境配置命令(比如安装个 Node 环境、安装个 Python 环境) action(in your repository, in public repository, in Docker registry):一段 action(Action 是什么我们后面再说) 每个 step 都在自己的运行器环境中运行,并且可以访问工作空间和文件系统。
因为每个 step 都在运行器环境中独立运行,所以 step 之间不会保留对环境变量的更改。
# 定义 Workflow 的名字
name: Greeting from Mona
# 定义 Workflow 的触发器
on: push
# 定义 Workflow 的 job
jobs:
# 定义 job 的 id
my-job:
# 定义 job 的 name
name: My Job
# 定义 job 的运行环境
runs-on: ubuntu-latest
# 定义 job 的运行步骤
steps:
# 定义 step 的名称
- name: Print a greeting
# 定义 step 的环境变量
env:
MY_VAR: Hi there! My name is
FIRST_NAME: Mona
MIDDLE_NAME: The
LAST_NAME: Octocat
# 运行指令:输出环境变量
run: |
echo $MY_VAR $FIRST_NAME $MIDDLE_NAME $LAST_NAME.五、Action 是什么?
我们可以直接打开的 Action 市场来看看 Action 其实就是命令,比如 Github 官方给了我们一些默认的命令: 比如最常用的,check-out 代码到 Workflow 工作区: https://github.com/marketplace/actions/checkout
1、我们应该如何使用 Action?
jobs.<job_id>.steps.uses
比如我们可以 check-out 仓库中最新的代码到 Workflow 的工作区:
steps:
- uses: actions/checkout@v2当然,我们还可以给它添加个名字:
steps:
- name: Check out Git repository
uses: actions/checkout@v2再比如说,我们如果是 node 项目,我们可以安装 Node.js 与 NPM:
steps:
- uses: actions/checkout@v2
- uses: actions/setup-node@v2-beta
with:
node-version: '12'2、上面我们为什么要用:@v2 和 @v2-beta 呢?
答:首先,正如大家所想,这个 @v2 和 @v2-beta 的意思都是 Action 的版本。
我们如果不带版本号的话,其实就是默认使用最新版本的了。
但是 Github 官方强烈要求我们带上版本号——这样子的话,我们就不会出现:写好一个 Workflow,但是由于某个 Action 的作者一更新,我们的 Workflow 就崩了的问题
3、上面的 with 参数是什么意思?
答:有的 Action 可能会需要我们传入一些特定的值:比如上面的 node 版本啊之类的,这些需要我们传入的参数由 with 关键字来引入。
具体的 Action 需要传入哪些参数,还请去 Github Action Market 中 Action 的页面中查看。
具体库的使用和参数,我们可以去官方的 Action 市场查看:
六、我们如何运行命令行命令?
jobs.<job_id>.steps.run
上文说到,steps 可以运行:action 和 command-line programs。
我们现在已经知道可以使用 uses 来运行 action 了,那么我们该如何运行 command-line programs 呢?
答案是:run
run 命令在默认状态下会启动一个没有登录的 shell 来作为命令输入器。
1、如何运行多行命令?
每个 run 命令都会启动一个新的 shell,所以我们执行多行连续命令的时候需要写在同一个 run 下:
单行命令
- name: Install Dependencies
run: npm install
多行命令
- name: Clean install dependencies and build
run: |
npm ci
npm run build2、如何指定 command 运行的位置?
使用 working-directory 关键字,我们可以指定 command 的运行位置:
- name: Clean temp directory
run: rm -rf *
working-directory: ./temp3、如何指定 shell 的类型?(使用 cmd or powershell or python??)
使用 shell 关键字,来指定特定的 shell:
steps:
- name: Display the path
run: echo $PATH
shell: bash七、什么是矩阵?
答:就是有时候,我们的代码可能编译环境有多个。比如 electron 的程序,我们需要在 macos 上编译 dmg 压缩包,在 windows 上编译 exe 可执行文件。
这种时候,我们使用矩阵就可以啦~
比如下面的代码,我们使用了矩阵指定了:2 个操作系统,3 个 node 版本。
这时候下面这段代码就会执行 6 次—— 2 x 3 = 6!!!
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-16.04, ubuntu-18.04]
node: [6, 8, 10]
steps:
- uses: actions/setup-node@v1
with:
node-version: ${{ matrix.node }}八、跳过Github Actions
在 commit 信息中只要包含了下面几个关键词就会跳过 CI,不会触发 CI Build
[skip ci]
[ci skip]
[no ci]
[skip actions]
[actions skip]参考
]]>Github Actions 支持 jobs.<job_id>.if 语法
Github Actions运行中我们可以拿到一些当前的环境信息,比如git的提交内容信息,通过这些内容来控制actions的执行
比如,当git message不包含wip才触发构建
jobs:
format:
runs-on: ubuntu-latest
if: "! contains(github.event.head_commit.message, 'wip')"同理,下面的workflow表示,只有git message中包含[build]才触发构建,否则跳过
jobs:
format:
runs-on: ubuntu-latest
if: "contains(github.event.head_commit.message, '[build]')"具体的信息我们可以全部打印出来,修改workflow文件,添加steps
on: push
jobs:
one:
runs-on: ubuntu-latest
steps:
- name: Dump GitHub context
env:
GITHUB_CONTEXT: ${{ toJson(github) }}
run: echo "$GITHUB_CONTEXT"
- name: Dump job context
env:
JOB_CONTEXT: ${{ toJson(job) }}
run: echo "$JOB_CONTEXT"
- name: Dump steps context
env:
STEPS_CONTEXT: ${{ toJson(steps) }}
run: echo "$STEPS_CONTEXT"
- name: Dump runner context
env:
RUNNER_CONTEXT: ${{ toJson(runner) }}
run: echo "$RUNNER_CONTEXT"
- name: Dump strategy context
env:
STRATEGY_CONTEXT: ${{ toJson(strategy) }}
run: echo "$STRATEGY_CONTEXT"
- name: Dump matrix context
env:
MATRIX_CONTEXT: ${{ toJson(matrix) }}
run: echo "$MATRIX_CONTEXT"push和pull request动作才会触发构建
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]最简单的做法,添加workflow_dispatch动作
on:
workflow_dispatch:
push:
branches: [ main ]
pull_request:
branches: [ main ]这样在actions页面可以看到执行构建的按钮,选择分支后可以执行手动构建。

on:
workflow_dispatch:
inputs:
name:
description: 'Person to greet'
required: true
default: 'Mona the Octocat'
home:
description: 'location'
required: false
jobs:
say_hello:
runs-on: ubuntu-latest
steps:
- run: |
echo "Hello ${{ github.event.inputs.name }}!"
echo "- in ${{ github.event.inputs.home }}!"关于手动触发还支持自定义输入文本,也就是输入文本当成传入的参数,用在后续的构建命令中

参考
https://p3terx.com/archives/github-actions-manual-trigger.html
]]>如果需要开启runner的运行日志,只需要在settings中添加一对secret,key为ACTIONS_RUNNER_DEBUG,值为true
如果需要开启step的运行日志,只需要在settings中添加一对secret,key为ACTIONS_STEP_DEBUG,值为true
下图开启debug前后的输出信息对比

另外在action运行中会带有一些诸如执行环境,当前job,当前runner,当前仓库,执行用户等上下文变量。 想查看都有哪些集具体的变量可以加入steps
steps:
- name: Dump GitHub context
env:
GITHUB_CONTEXT: ${{ toJson(github) }}
run: echo "$GITHUB_CONTEXT"
- name: Dump job context
env:
JOB_CONTEXT: ${{ toJson(job) }}
run: echo "$JOB_CONTEXT"
- name: Dump steps context
env:
STEPS_CONTEXT: ${{ toJson(steps) }}
run: echo "$STEPS_CONTEXT"
- name: Dump runner context
env:
RUNNER_CONTEXT: ${{ toJson(runner) }}
run: echo "$RUNNER_CONTEXT"
- name: Dump strategy context
env:
STRATEGY_CONTEXT: ${{ toJson(strategy) }}
run: echo "$STRATEGY_CONTEXT"
- name: Dump matrix context
env:
MATRIX_CONTEXT: ${{ toJson(matrix) }}
run: echo "$MATRIX_CONTEXT"https://docs.github.com/en/actions/guides/deploying-to-google-kubernetes-engine
]]>通过ssh登录服务器,然后执行git pull, npm build等构建命令 需要提前在github仓库的setting页面配置ssh host,password,user等环境变量
优点:简单粗暴
缺点:直接在服务器上拉代码并不是最好的办法,而且还需要配置ssh,对于前端项目一般只需要构建后的dist目录。而且有时候国内服务器直接拉github仓库的代码会超时。
# This is a basic workflow to help you get started with Actions
name: CI
# Controls when the action will run. Triggers the workflow on push or pull request
# events but only for the master branch
on:
push:
branches: [ master, develop ]
pull_request:
branches: [ master ]
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Runs a single command using the runners shell
- name: Run a one-line script
run: echo Hello, world!
# Runs a set of commands using the runners shell
- name: SSH Remote Commands
uses: appleboy/[email protected]
with:
host: ${{ secrets.HOST }}
username: ${{ secrets.USERNAME }}
key: ${{ secrets.PRIVATE_KEY }}
port: ${{ secrets.PORT }}
script: cd /home/mafei20191103/IntoGolfV3 && git reset --hard origin/develop && git pull && npm run prod && php artisan migrate && composer install && php artisan telescope:prune && composer dump-autoload -o;
# Slack Notification
- name: Slack Notification
uses: 8398a7/action-slack@v3
with:
status: ${{ job.status }}
fields: repo,message,commit,author,action,eventName,ref,workflow,job,took # selectable (default: repo,message)
env:
GITHUB_TOKEN: ${{ secrets.PERSONAL_TOKEN }} # optional
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }} # required
if: always() # Pick up events even if the job fails or is canceled.优化方案,使用rsync 同步文件
基于ssh deploy 原理是在action的机器中拉代码,构建,然后使用rsync命令将产物同步到目标服务器的指定目录中
好处:解决了超时问题,同步速度也不慢
待优化,如果文件非常多,是否可以压缩后然后再目标服务器上解压。
]]>Github 提交代码 -> 触发WebHook -> 触发Jenkins 执行 build
Github 部分:
-
建立仓库: https://github.com/mafeifan/docker-express-demo 这是一个非常简单的Node Express的项目,自带Dockerfile文件,我们需要每次push代码,在Jenkins服务器上构建新的Docker镜像和容器。
-
生成 personal access token (如果是私有项目)

- 配置项目的Webhook地址

地址获取在Jenkins系统设置页面,还可以覆盖默认的地址

Jenkins 部分
- 安装 Github 插件 (一般默认就会安装)
- 添加 Jenkins credentials

我们发现credentials分好几种,对于公有仓库,选择用户名和密码即可,如果是私有仓库可以选择“ssh username with private key” 或者 "Secret" (内容填入刚生成的Github token) ID 自己起,要唯一,创建后无法修改 3. 创建Item,类型选择"FreeStyle Project"

- 配置


总结
- 流程非常简单,只是个人练习,不要运用在正式项目中
- 有很多优化的地方,比如build后需要执行的shell脚本完全可以放入到项目仓库中受版本控制
这个插件可以触发基于某一个job的构建结果触发一个新的构建,而且支持传入参数
https://stackoverflow.com/questions/9704677/jenkins-passing-variables-between-jobs
]]>Linux中,系统在启动一个进程的同时会为该进程打开三个文件:标准输入(stdin)、标准输出(stdout)和标准错误输出(stderr),分别用 文件标识符0,1,2来标识。如果要为进程打开其他的输入输出,则需要从整数3开始标识。默认情况下,标准输入为键盘,标准输出和错误输出为显示器。
输入输出可以重定向,如 ls -l 会在显示器上看到结果,为了将结果输出到文件中,可以改为 ls -l /user > result.txt
如果ls命令后面跟的指定文件不存在呢?
标准输出覆盖重定向(>) 其实是默认将文件标识符为1的内容重定向到指定文件中,所以下面两种写法等价
ls -l /user > result.txt
ls -l /user 1 > result.txt可以通过指定将文件标识符为2的内容重定向到指定文件,这样错误输出就不会出现在显示器上。
ls -l /noExist 2 > no_exist_result.txt
标识输出重定向 >&
将一个标准的输出重定向到另一个标识的输入。
如果想要将标准输出和标准错误同时定向到同一个文件,可使用下面命令
COMMAND > stout_stderr.txt 2 > &1
举例:
find / -type f -name *.txt 会报权限问题,如果使用find / -type f -name *.txt > result.txt 只能将标准输出重定向到result文件,
错误输出依然会出现在显示器上,使用 find / -type f -name *.txt 2 > &1 可避免类似问题
而且不需要记录错误记录,可以将错误输出到'黑洞'里,常见的是 nohup command >/dev/null 2>&1 &
参考
https://jenkins.io/doc/pipeline/steps/workflow-durable-task-step/#-sh-%20shell%20script
sh: Shell Script
-
scriptRuns a Bourne shell script, typically on a Unix node. Multiple lines are accepted.
An interpreter selector may be used, for example:
#!/usr/bin/perlOtherwise the system default shell will be run, using the
-xeflags (you can specifyset +eand/orset +xto disable those).- Type:
String
- Type:
-
encoding(optional)Encoding of process output. In the case of
returnStdout, applies to the return value of this step; otherwise, or always for standard error, controls how text is copied to the build log. If unspecified, uses the system default encoding of the node on which the step is run. If there is any expectation that process output might include non-ASCII characters, it is best to specify the encoding explicitly. For example, if you have specific knowledge that a given process is going to be producing UTF-8 yet will be running on a node with a different system encoding (typically Windows, since every Linux distribution has defaulted to UTF-8 for a long time), you can ensure correct output by specifying:encoding: 'UTF-8'- Type:
String
- Type:
-
label(optional)Label to be displayed in the pipeline step view and blue ocean details for the step instead of the step type. So the view is more meaningful and domain specific instead of technical.
- Type:
String
- Type:
-
returnStatus(optional)Normally, a script which exits with a nonzero status code will cause the step to fail with an exception. If this option is checked, the return value of the step will instead be the status code. You may then compare it to zero, for example.
- Type:
boolean
- Type:
-
returnStdout(optional)If checked, standard output from the task is returned as the step value as a
String, rather than being printed to the build log. (Standard error, if any, will still be printed to the log.) You will often want to call.trim()on the result to strip off a trailing newline.
- http://docs.idevops.site/jenkins/
- https://zeyangli.github.io/
- https://blog.csdn.net/u011541946/category_7175041.html
监控工具
代码质量
- Allure 生成更美观的测试报告
- SonarQube 质量检查
- PMD 静态代码分析
- 通过docker 跑的 Jenkins 安装插件失败
Also: java.lang.Throwable: HttpInput failure可能是Docker配置的网络问题 第二天,又自己好了。。
插件
Remote directory参数问题
Publish Over SSH是款很常用的插件,一般用于通过SSH将构建后的文件传到远程主机上。
其中的Remote directory选项是相对的登录后的路径。而不是远程主机的全路径
比如你登录主机后的pwd是/home/mafei/。即便你在Jenkins配置中填的Remote directory是/var/www。
执行后的实际路径是 /home/mafei/var/www
- execCommand 是要在远程主机上执行的shell命令
有两种方式:
第一种,在远程主机上放一个sh文件里面包含所有要在主机上执行的操作,比如deploy.sh
execCommand: '''sh deploy.sh'''
第二种,把具体命令都写execCommand里面 下面的脚本有一定的通用性,首先将之前步骤构建的dist压缩,上传到远程服务器,然后在远程上执行下面的命令,先重命名老的dist,然后将新的压缩包解压
execCommand: '''
# sh deploy.sh
# 这里可以定义变量
# DEST_PATH 项目的发布路径
DEST_PATH=/var/www/web/
TODAY=$(date +%Y%m%d-%H%M%S)
cp -rf dist.gz $DEST_PATH
cd $DEST_PATH
tar -zcvf $TODAY-dist.gz dist
rm -rf dist
tar -xzvf dist.gz
'''- 使用注意事项:
- Source files(要上传的文件) 和 Exec command(要在远程服务器执行的命令) 至少有一个必填的, 如果 Source files 为空,什么也不会传
- Source files, Remove prefix, Remote directory 和 Exec command 这几个参数,可以使用 Jenkins 的environment variables 和 build parameters.
Extended E-mail Notification
配置Gmail 勾选 SSL,端口填写 465

首次登陆 Google 会阻止,建议调低安全
]]>

#!groovy
import hudson.model.*;
println env.JOB_NAME
println env.BUILD_NUMBER
pipeline{
agent any
stages{
stage("Check file download") {
steps {
script {
try{
// 第二种写法
// 把linux执行打印结果存在一个字符串中,通过字符串包含的方法去判断文件是否存在
// out = sh(script: "ls /tmp/test ", returnStdout: true).toString().trim()
out = sh(script: "[ -f /tmp/test1/Python-3.7.1.tgz ] && echo 'true' || echo 'false' ", returnStdout: true)
println out
// if(out.contains("Python-3.7.1.tgz")) {
if(out == "true") {
println "file download successfully."
} else {
// 进入异常
sh("exit 1")
}
} catch(Exception e) {
println e
error("fond error during check file download.")
}
}
}
}
}
}参考
]]>下面的操作是当执行 docker 或 docker-compose 不用带 sudo
# 创建名为docker的用户组
sudo groupadd docker
# 把当前用户加入到这个用户组中
sudo usermod -aG docker $USER
# 重登session
# 测试,不带sudo跑一个测试镜像
docker run hello-world新建 jenkins 用户
# 创建jenkins用户并添加同名组、创建用户目录,默认shell为bash
$ sudo useradd -mU jenkins -s /bin/bash
$ sudo passwd jenkins #重置密码
$ su jenkins #使用jenkins用户登录
$ cd ~ #进入/home/jenkins目录新建 jenkins-compose目录并在里面添加docker-compose.yml 文件,内容如下:
version: '3'
services:
jenkins-compose:
# 注意镜像名称,lts表示长期支持版
image: jenkins/jenkins:lts
privileged: true # 解决权限问题
restart: always
ports:
- "8088:8080"
- "50000:50000"
environment:
- JAVA_OPTS=-Duser.timezone=Asia/Shanghai
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /usr/bin/docker:/usr/bin/docker
- /home/ubuntu/jenkins-compose:/var/jenkins_home执行 docker-compose up -d jenkins-compose 会下载镜像并在后台启动
然后 docker-compose logs 查看日志
留意并复制红框中的密码
浏览器打开Jenkins地址,地址应该是服务器ip:8088
TIP
打不开的话检查下防火墙开放8088端口
粘贴刚复制的密码,点Continue
安装插件,建议选第一个
安装完成后会自动跳转到管理员用户界面
最终来到了欢迎页面
修改时区
在【系统管理】-【脚本命令行】里运行
System.setProperty('org.apache.commons.jelly.tags.fmt.timeZone', 'Asia/Shanghai')
修改Jenkins插件为国内源
首页 --> configure --> Manage Jenkins --> Advanced --> Update Site(页面最下方‘升级站点’)
替换URL为 清华大学仓库地址:
https://updates.jenkins.io/update-center.json 改为 https://mirror.tuna.tsinghua.edu.cn/jenkins/updates/update-center.json
如果插件页面为空,把https改为http
问题:
- Jenkins更新比较频繁,如何更新版本? 见 medium 的这篇 文章
如果希望通过 Webhook 触发 multibranch pipeline 项目需要安装 multibranch-scan-webhook-trigger-plugin 插件 安装完之后,配置界面多出一个 Scan by webhook 选项

实际中一个项目的代码仓库可能会有很多分支,比如develop,master等。Jenkins 支持创建多分支pipeline的任务。
创建多分支项目
新建 "Item" 直接选择 "Multibranch Pipeline" 即可 Tab中有很多配置项,比如 General,Branch Sources,Build Configuration等
- Scan Multibranch Pipeline Triggers 触发 扫描分支频率,最低是1分钟

- Orphaned Item 孤儿任务,所谓孤儿任务即代码仓库中该分支被删除,但是Jenkins分支中还保留着。


- Health metric 健康指标 我也不清楚有什么用,望指教
WARNING
配置完成后,Jenkins就会自动执行首次构建,首先扫描所有的分支,如果根据配置的路径去找Jenkinsfile,找到后就立即执行。
根据发现的分支数量,比如这里3个就自动创建了3个pipeline项目,点进去后可以像pipeline任务一样进行详细配置。

使用 when 指令判断多分支
我们需要判断针对不同分支做不同事情,使用 if else 比较low,不够优雅
stage("deploy to test") {
steps {
script {
if (env.GIT_NAME == 'testing') {
echo 'deploy to test'
}
}
}
}可以使用 when 指令
stage("deploy to test") {
when {
branch 'testing'
}
steps {
echo 'deploy to test'
}
}
stage("deploy to prod") {
when {
branch 'production'
}
steps {
echo 'deploy to prod'
}
}when指令的用法
when指令允许pipeline根据给定的条件,决定是否执行阶段内的步骤。when指令必须至少包含一个条件。when指令除了支持branch判断条件,还支持多种判断条件。
- changelog:如果版本控制库的changelog符合正则表达式,则执行
- changeset:如果版本控制库的变更集合中包含一个或多个文件符合给定的Ant风格路径表达式,则执行
when {
changeset "**/*.js"
}- environment:如果环境变量的值与给定的值相同,则执行
when {
environment name: 'DEPLOY_TO', value: 'production'
}- equals:如果期望值与给定的值相同,则执行
when {
equals expected: 2, actual: currentBuild.number
}- expression:如果Groovy表达式返回的是true,则执行 当表达式返回的是字符串时,它必须转换成布尔类型或null;否则,所有的字符串都被当作true处理。
when {
expression {
return env.BRANCH_NAME != 'master'
}
}- building Tag:如果pipeline所执行的代码被打 了tag,则执行
- tag:如果pipeline所执行的代码被打了tag,且tag名称符合规则,则执行 如果tag的参数为空,即tag (),则表示不论tag名称是什么都执行,与buildingTag的效果相同。
when {
tag "release-*"
}tag 条件支持comparator参数,支持的值如下: -- EQUALS:简单的文本比较。
when {
tag "release-3.1", comparator: "EQUALS"
}-- GLOB (默认值):Ant风格路径表达式。由于是默认值,所以使用时一般省略。完整写法如下:
when {
tag "release-*", comparator: "GLOB"
}-- REGEXP:正则表达式。使用方法如下:
when {
tag "release-\\d+", comparator: "REGEXP"
}tag条件块非常适合根据tag进行发布的发布模式。
以上介绍的都是单条件判断,when指令还可以进行多条件组合判断。
- allOf:所有条件都必须符合。下例表示当分支为master且环境变量DEPLOY TO的值为production时,才符合条件。
allOf {
branch "master";
environment name: 'DEPLOY_TO', value: 'production'
}注意,多条件之间使用分号分隔。
- anyOf:其中一个条件为true, 就符合。下例表示master分支或staging分支都符合条件。
anyOf {
branch "master";
branch "staging";
}Generic Webhook Trigger 插件在多分支pipeline场景下的应用
Generic Webhook Trigger 在之前已经介绍过,可以这么传参
triggers {
GenericTrigger(
genericVariables: [
[key: 'ref', value: '$. ref']
],
token: env.JOB_NAME ,
regexpFilterText: '$ref',
regexpFilterExpression: 'refs/heads/' + env.BRANCH_NAME,
)
}env.BRANCH_NAME 为当前 pipeline 的分支名
问题
Multibranch Pipeline Events 的作用是什么

参考
]]>比如,我们知道sh "printenv"会打印所有的环境变量方便调试,但是如果写死在pipeline里,每次构建
console output都会输出大量内容。
比如现在
stage('debug') {
steps {
sh "printenv"
}
}我希望构建时可以手动控制是否输出调试信息。默认为关闭,即不输出,打钩后才输出信息。
下面的例子就讲解如何实现
当我们新建的项目为freestyle或pipeline类型,在配置页面的General的tab中会发现有一个选项为 "This project is parameterized" 表示该项目类型为可参数化的,勾选之后,可以添加很多类型的参数,如下图

比如我这里添加一个Boolean Parameter,参数名称为is_print_env,默认不显示环境变量信息,即不希望执行sh "printenv"

修改之前的pipeline,根据is_print_env的取值走不同的逻辑。
stage('debug') {
steps {
// echo env.is_print_env
script {
if (env.is_print_env) {
sh "printenv"
} else {
echo "no execute 'sh printenv'"
}
}
}
}保存之后来到该项目的首页,左侧功能列表中会发现之前的"Build now"变为了"Build with parameters"。点击后,刚才的Boolean Parameter参数配置就可视化了。

如果勾选了,就会输出所有的环境变量
Pipeline Parameter
上面的参数是在页面上手动添加,实际上如果是pipeline类型的job,可以用代码的方式是实现,这样更灵活,更容易版本化管理 pipeline语法支持传入parameters指令,parameter 包括 string, text(多行文本), boolean, choice(下拉),file 文件类型(很少用), password(密码类型)等。
pipeline {
agent any
parameters {
booleanParam(defaultValue: true, description: '', name: 'p_userFlag')
choice(
choices: 'dev\nprod',
description: 'choose deploy environment',
name: 'p_deploy_env'
)
string (name: 'p_version', defaultValue: '1.0.0', description: 'build version')
text (name: 'p_deploy_text', defaultValue: 'One\nTwo\nThree', description: '')
password (name: 'p_password', defaultValue: '', description: '')
}
}保存后需要手动执行一次,才能在页面中看到效果

被传入的参数会放到名为params的对象中,在pipeline中可以直接使用,比如params.userFlag就是引用parameters指令中定义的userFlag参数
根据参数进行逻辑判断
stage('debug') {
steps {
script {
if (params.p_deploy_env == 'dev') {
echo "deploy to dev"
}
}
}
}可以安装 Conditional BuildStep 像使用 when 指令一样进行条件判断。 下面安装插件后的写法
pipeline {
agent any
parameters {
choice(name: 'CHOICES', choices: 'dev\nstaging', description: '请选择部署环境')
}
stages {
stage('deploy test') {
when {
expression( return params.CHOICES == 'test')
}
scripts {
echo 'deploy to test'
}
}
stage('deploy staging') {
when {
expression( return params.CHOICES == 'staging')
}
scripts {
echo 'deploy to staging'
}
}
}
}expression 本质是Groovy代码块,可以写出更复杂的逻辑判断
when {
expression { return A || B || C && D }
}从文件中提取
when {
expression { return readFile('pom.xml'.contains('foo')) }
}正则
when {
expression { return return token ==~ /(?i)(Y|YES|TRUE)/) }
}input 步骤
执行 input 步骤会暂停pipeline,直到用户输入参数。 场景: 1 审批流程,pipeline暂停在部署前的stage,由负责人点击确定后才能部署。 2 手动测试,增加一个手动测试stage,该阶段只有一个input步骤,当手动测试通过后才可以通过这个input步骤。
pipeline中添加input的step
pipeline {
agent any
stages {
stage('deploy') {
steps {
input message: '发布或停止' // 如果只有一个messge参数,可以简写为 input '发布或停止'
}
}
}
无论是中止还是通过,job日志中都记录了谁操作的,这对审计非常友好
]]>

pipeline {
agent any
stages {
stage ('build') {
steps {
// 输出 当前日期和构建编号
echo "${createVersion(BUILD_NUMBER)}"
}
}
}
}
def createVersion(String BUILD_NUMBER) {
return new Date().format('yyyy-MM-dd') + "-${BUILD_NUMBER}"
}还有一种更优雅的写法,将变量定义在environment内
pipeline {
agent any
environment {
_version = createVersion()
}
stages {
stage ('build') {
steps {
echo "${_version}"
}
}
}
}
def createVersion() {
return new Date().format('yyyy-MM-dd') + "-${env.BUILD_NUMBER}"
}使用共享库
大致流程:
- 新建个代码仓库,里面包含共享库代码 目录结构类似
(root)
+- src # Groovy source files
| +- org
| +- foo
| +- Bar.groovy # for org.foo.Bar class
+- vars
| +- foo.groovy # for global 'foo' variable
| +- foo.txt # help for 'foo' variable
+- resources # resource files (external libraries only)
| +- org
| +- foo
| +- bar.json # static helper data for org.foo.Bar这里已经建好 jenkins-shared-library,文件结构如下:

vars 目录下的全局变量可以直接在pipeline中使用,即当写sayHello('world'),实际调用的是sayHello.groovy中的call函数
src 目录是标准的Java源码结构,目录中的类被称为类库(Library class),而 @Library('global-shared-library@master')
就是一次性静态加载src目录下所有代码到classpath中。
TIP
src目录中的类,可以使用Groovy中的@Grab注解,自动下载第三方依赖包
- Jenkins 管理后台配置仓库地址和版本等 进入 Jenkins 的Manage Jenkins -> Configure System -> Global Pipeline Libraries 配置页面

- Jenkins 项目的pipeline中引入共享库(可以指定仓库版本和具体class) 新建一pipeline类型的job。 Pipeline内容如下:
// 配置页面开启隐式加载后,可以直接使用共享库
// 定义library,命名为_
@Library('global-shared-library@master') _
pipeline {
agent any
environment {
_version = createVersion()
}
stages {
stage ('build') {
steps {
script {
def util = new com.mafeifan.Utils()
def version = util.createVersion("${BUILD_NUMBER}")
echo "${version}"
sayHello 'yes'
echo "${_version}"
}
}
}
}
}
def createVersion() {
return new Date().format('yyyyMM') + "-${env.BUILD_NUMBER}"
}查看构建日志,发现Jenkins首先拉取共享库代码,执行成功。

指定加载
后台配置共享库是非必须的,我们可以直接在pipeline中指定共享库的位置,如下面的例子,指定共享库的位置是https://gitee.com/finley/devops-jenkins-shared-library.git
引入后直接调用共享库中的方法
library identifier: 'devops-ws-demo@master', retriever: modernSCM([
$class: 'GitSCMSource',
remote: 'https://gitee.com/finley/devops-jenkins-shared-library.git',
traits: [[$class: 'jenkins.plugins.git.traits.BranchDiscoveryTrait']]
])
// 另外的写法,需要在后台配置,注意名称要一致
//@Library('devops-ws-demo') _
//@Library('devops-ws-demo@test') _
pipeline {
agent any
stages {
stage('Demo') {
steps {
script {
mvn.fake()
}
}
}
}
}使用共享库实现Pipeline模板
// vars/generatePipeline.groovy
def call(String lang) {
if (lang == 'go') {
pipeline {
agent any
stages {
stage ('set go path') {
steps {
echo "GO path is ready"
}
}
}
}
} else if (lang == 'java') {
pipeline {
agent any
stages {
stage ('clean install') {
steps {
sh "mvn clean install"
}
}
}
}
}
// 其他语言
}使用时,Jenkinsfile 只有两行
@Library['global-shared-library'] _
generatePipeline('go')如果大多数项目都是标准化的,可以利用共享库的pipeline模块技术来降低维护成本。
这里只是抛砖引玉,想写出更强大的共享库需要多了解Groovy。
TIP
优先考虑使用自定义函数,如果此函数出现在了至少三个项目中,考虑移到共享库里,当发现项目的pipeline非常相似,考虑使用pipeline模块。
参考
]]>EXECUTED: Job \' ${env.JOB_NAME}:${env.BUILD_NUMBER}\'
View console output at " ${env.JOB_NAME}:${env.BUILD_NUMBER}"
(Build log is attached.)
""", attachLog: true, compressLog: true } ``` 效果如下: >  你也可以使用全局配置默认subject和content,使用方法如下: ```groovy post { always { emailext ( to: '[email protected]', replyTo: '[email protected]', subject: '$DEFAULT_SUBJECT', body: '$DEFAULT_CONTENT', mimeType: 'text/html' ); } } ``` 主要要用单引号包裹变量,否则groovy会尝试扩展变量 关于一些参数 * attachLog(可选):将构建日志以附件形式发送 * compressLog(可选):压缩日志 * recipientProviders(可选): List 类型,收件人列表类型 * replyTo(可选):回复邮箱 * recipientProviders (可选):收件人列表类型 类型名称 | helper方法名 | 描述 ]]>邮件通知
这个需要在Jenkins中配置发件人的信息,如SMTP服务器,默认的邮件内容等 来到Jenkins的Configure System
- 首先在配置页面搜索 Location 配置 Jenkins 管理员的邮箱

- 搜索'E-mail Notification'
可能会发现有两个E-mail Notification,一个是Extended E-mail Notification另一个是E-mail Notification。前者是安装Jenkins时顺便安装的插件,后者是自带的。
自带的E-mail Notification功能较弱,我们配置 Extended E-mail Notification,配置项比较多,不懂的点问号图标。

- 来到Pipeline项目的配置页面, 通过点击 Pipeline Syntax 来到 Snippet Generator, 生成pipeline脚本。 Step 选择 mailtext: Extended Email。

修改pipeline,添加发送邮件的步骤,放到pipeline的post部分的always块内,你也可以改为failure
post {
always {
emailext to: '[email protected]', subject: "Job [${env.JOB_NAME}] - Status: ${currentBuild.result?: 'success'}", body:
"""
<p>EXECUTED: Job <b>\' ${env.JOB_NAME}:${env.BUILD_NUMBER}\'
</b></p><p>View console output at "<a href= "${env.BUILD_URL}">
${env.JOB_NAME}:${env.BUILD_NUMBER}</a>"</p>
<p><i>(Build log is attached.)</i></p>
""", attachLog: true, compressLog: true
}效果如下:

你也可以使用全局配置默认subject和content,使用方法如下:
post {
always {
emailext (
to: '[email protected]',
replyTo: '[email protected]',
subject: '$DEFAULT_SUBJECT',
body: '$DEFAULT_CONTENT',
mimeType: 'text/html'
);
}
}主要要用单引号包裹变量,否则groovy会尝试扩展变量
关于一些参数
- attachLog(可选):将构建日志以附件形式发送
- compressLog(可选):压缩日志
- recipientProviders(可选): List 类型,收件人列表类型
- replyTo(可选):回复邮箱
- recipientProviders (可选):收件人列表类型
| 类型名称 | helper方法名 | 描述 |
|---|---|---|
| Culprits | culprits() | 引发构建失败的人。最后一次构建成功和最后一次构建失败之间的变更提交者列表 |
| Developers | developers() | 此次构建所涉及的变更的所有提交者列表 |
| Requestor | requestor() | 请求构建的人,一般指手动触发构建的人 |
| Upstream Committers | upstreamDevelopers() | 上游job变更提交者的列表 |
更多参数见文档
Slack 通知
Slack 号称邮件杀手,是一款国外很火的消息聚合平台服务,通过建立不同的频道降低团队沟通的干扰。
-
Jenkins 安装 Slack Notification Plugin
-
打开插件Github官网 根据提示没有账号的话先申请账号
-
Slack 端集成 Jenkin CI,首先,网页端登录slack,进到自己的workspace,然后添加Jenkins应用,需要选择一个要推送通知的频道

- 根据指引配置就可以了,非常人性,下图在FreeStyle类型的项目中可配


- 如果需要通过Pipeline代码触发
post {
always {
slackSend channel: "#机器人", message: "Build Started: ${env.JOB_NAME} ${env.BUILD_NUMBER}"
}更多参数还是参见非常好用的Pipeline Syntax 的 Snippet Generator

效果:

钉钉通知
Slack 有时候国内速度访问比较慢,如果公司喜欢用钉钉,也可以集成钉钉通知。 步骤是类似的,不再赘述,见文档
问题
使用邮件,想把构建日志作为邮件内容发送出去,但是使用 ${env.BUILD_LOG} 返回 null,可以改为\${BUILD_LOG} groovy 会展开所有的变量,然后留给email ext 处理这个变量
网上也有人问了类似的问题,可以使用 currentBuild.rawBuild.getLog(15) 获取最后的15行日志,不过需要在 scriptApproval 页面批准下 method org.jenkinsci.plugins.workflow.support.steps.build.RunWrapper getRawBuild

参考
]]>emailext (
to: '[email protected]',
subject: "Job [${env.JOB_NAME}] - Status: ${currentBuild.result?: 'success'}",
body:
"""
<p>EXECUTED: Job <b>\' ${env.JOB_NAME}:${env.BUILD_NUMBER}\'
</b></p><p>View console output at "<a href= "${env.BUILD_URL}">
${env.JOB_NAME}:${env.BUILD_NUMBER}</a>"</p>
<p><i>(Build log is attached.)</i></p>
""")这里我们通过 Config File Provider 插件,创建邮件模板,然后实现复用的目的,具体步骤:
- 安装插件,略
- 安装后管理页面多了 "Managed files" 菜单项, 进入后点 Add a new Config

Type 选择 "Extended Email Publisher Groovy Template"

ID 可以自行填写

Content 填写如下
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>${ENV, var="JOB_NAME"}-第${BUILD_NUMBER}次构建日志</title>
</head>
<body leftmargin="8" marginwidth="0" topmargin="8" marginheight="4"
offset="0">
<table width="95%" cellpadding="0" cellspacing="0"
style="font-size: 11pt; font-family: Tahoma, Arial, Helvetica, sans-serif">
<tr>
<td>(本邮件是程序自动下发的,请勿回复!)</td>
</tr>
<tr>
<td><br />
<b><font color="#0B610B">构建信息</font></b>
<hr size="2" width="100%" align="center" /></td>
</tr>
<tr>
<td>
<ul>
<li>项目名称 : ${JOB_NAME}</li>
<li>构建编号 : 第${BUILD_NUMBER}次构建</li>
<li>触发原因 : ${CAUSE}</li>
<li>构建日志 : <a href="${BUILD_URL}console">${BUILD_URL}console</a></li>
<li>工作目录 : <a href="${PROJECT_URL}">${PROJECT_URL}</a></li>
</ul>
</td>
</tr>
<tr>
<td><b style="color='#0B610B'">历史变更记录:</b>
<hr size="2" width="100%" align="center" /></td>
</tr>
<tr>
<td>
${CHANGES_SINCE_LAST_SUCCESS,reverse=true, format="Changes for Build #%n:<br />%c<br />",showPaths=true,changesFormat="<pre>[%a]<br />%m</pre>",pathFormat=" %p"}
</td>
</tr>
<tr>
<td><b style="color='#0B610B'">构建日志(最后100行):</b>
<hr size="2" width="100%" align="center" /></td>
</tr>
<tr>
<td><p><pre>${BUILD_LOG, maxLines=100}</pre></p></td>
</tr>
</table>
</body>
</html>- 最后修改流水线脚本,通过插件提供的configFileProvider实现获取文件 如果是脚本式流水线。
node () {
stage('email'){
echo "测试发送邮件"
// 设置生成模板文件
configFileProvider([configFile(fileId: '0ad43176-c202-4ebc-aaff-441ef79f49d8',
targetLocation: 'email.html',
variable: 'failt_email_template')]) {
// 读取模板
template = readFile encoding: 'UTF-8', file: "${failt_email_template}"
// 发送邮件
emailext(subject: '任务执行失败',
attachLog: true,
recipientProviders: [requestor()],
to: '32*****[email protected]',
body: """${template}""")
}
}
}如果是声明式流水线
post {
always {
configFileProvider([configFile(fileId: 'email-groovy-template-cn', targetLocation: 'email.html', variable: 'content')]) {
script {
template = readFile encoding: 'UTF-8', file: "${content}"
emailext(
to: "${email_to}",
subject: "Job [${env.JOB_NAME}] - Status: ${currentBuild.result?: 'success'}",
body: """${template}"""
)
}
}
}
}
}大致流程,configFileProvider 通过传入的 fileId 读取具体文件,然后通过 targetLocation 给模板起起名,假如 WORKSPACE=/var/jenkins_home/workspace/email-test,targetLocation: 'email.html',执行时,通过构建日志你会发现 copy managed file [Groovy Email Template] to file:/var/jenkins_home/workspace/email-test/email.html
参考
]]>pipeline {
agent any
stages {
stage('example') {
steps {
script {
def browsers = ['chrome', 'firefox']
for (int i = 0; i < browsers.size(); i ++) {
echo "testing ${browsers[i]}"
}
}
}
}
}
}绝大多数时候没有必要写script,建议都提取到不同的stage或使用共享库
pipeline内置了一些step
文件相关的有deleteDir, dir, fileExists, isUnix, pwd, writeFile,readFile
steps {
script {
println pwd()
json_file = "${env.WORKSPACE}/testdata/test_json.json"
if (fileExists(json_file) == true && isUnix()) {
echo("json file is exists")
} else {
error("here haven't find json file")
}
dir ("/var/logs") {
deleteDir()
}
}
}命令相关的有
error主动报错,中止pipelineerror('there is an error')sh执行shell命令 支持参数有script(必填,shell脚本),encoding(执行后输出日志的编码),returnStatus(布尔类型,默认返回的是状态码,如果是一个非0的状态码,则会引发pipeline执行失败。 如果returnStatus参数为true,则无论状态码是什么,pipeline的执行不受影响),returnStdout(布尔类型,如果为true,则任务的标准输出将作为步骤的返回值,而不是打印到构建日志中)
returnStatus 和 returnStdout 参数一般不会同时使用,因为返回值只能有一个,如果同时存在则只有returnStatus生效
bat和powershell在Windows系统上执行的批处理
其他:
withEnv: 设置环境变量 在代码块中设置环境变量,仅在该代码块中生效,注意下面例子中sh被包裹的是单引号,说明变量解析是由shell完成而不是Jenkins。
withEnv(['MYTOOL_HOME=/usr/local/mytool']) {
sh '$MYTOOL_HOME/bin/start'
}timeout: 代码块的超时时间waitUnit: 等待条件满足,不断重复waitUnit内的代码直到为true,最好和timeout结合使用,避免死循环
timeout(50) {
waitUnit {
script {
def r = sh script: 'curl http://example', returnStatus: true
return (r == 0)
}
}
}retry: 重复代码块,如果某次执行抛出异常,则中止本次执行,不会中止整个retry执行sleep: 暂停指定时间再执行
echo "hello"
sleep(120) // 休眠120秒
sleep(time: '2', unit: 'HOURS') //单位有 NANOSECONDS, MICROSECONDS, MILLISECONDS, SECONDS, MINUTES, HOURS, DAYS
echo "hello again"参考
]]>使用Role-based Authorization Strategy插件,使得不同的账号有不同的权限,不同的项目。可以非常轻松实现上面的需求。
- 安装过程略,安装后来到Jenkins管理,发现了很多选项,勾选"Role-Based Strategy"并保存

- 安装成功后会多出一个"Manage and Assign Roles"菜单项

点击后,有三个选项,分别表示管理角色,分配用户给角色和角色策略宏

- 我们先添加一个角色,可以添加三种类型的角色,分别是全局角色(比较简单粗暴),基于项目的(常用) 和 基于节点的(不常用)
注意Pattern可以使用正则,如果需要过滤已sinuo开头的项目,可以填写
sinuo.*填写sinuo*会不生效,点击后会列出匹配到的项目
注意,如果一个用户及时全局角色又是项目角色,默认全局角色优先级更高,如果希望基于项目维度进行权限控制,除了admin角色,其他全局角色的Job权限及SCM权限留空
列下不易看懂的权限:
Overall: 特殊的权限类,系统级别权限
- Adminster 允许用户更改Jenkins系统级别的配置,开放后可进入Jenkins管理页面
- Read 全局读权限
Job:任务相关的权限
- Discover:如果匿名用户没有Discover权限,直接在浏览器中输入Jenkins任务URL(真实存在)时,会直接跳转到404页面,如果有该权限,则跳转到登录页面
- Workspace:允许查看Jenkins任务的工作空间内容的权限
- Update:允许用户更新构建历史的属性,如手动更新某次构建失败的原因

-
然后我们来到分配角色,已经提前创建好了名为sinuo-admin用户,然后把他分配给project-admin角色

-
浏览器新开一个隐身窗口,使用sinuo-admin测试登录,正常的话,他应该只能看到以sinuo开头的项目名称
TIP
- 测试时,浏览器开俩窗口,一个正常一个隐藏,一个修改权限,另一个刷新查看权限效果
- 如果Role-based Authorization Strategy仍然无法满足复杂的权限控制,多搭建几套Jenkins分配给不同团队也未尝不可
Dockerfile的文件。
第二步把文件存为制品。
#!groovy
pipeline {
agent any
stages {
stage('checkout') {
steps {
git 'https://git.dev.tencent.com/finley/angular-js.git'
archiveArtifacts 'Dockerfile'
}
}
}
}然后在Jenkins 构建页面中就可以直接查看和下载制品

archiveArtifacts 指令
参数:
- artifacts 只有这一个参数是必填的,需要归档的文件路径,可以是Ant文件风格的路径表达式
- fingerprint | 布尔 | 是否对归档文件进行签名
- excludes 需要排除的文件路径,可以是Ant文件风格的路径表达式
- onlyIfSuccessful | 布尔 | 只在构建成功时进行归档
- allowEmptyArchive | 布尔 | 如果归档文件没有返回任何结果,不构建失败

制品管理软件
制品多了话需要管理,单靠Jenkins有点力不从心了,需要专门的制品管理软件,目前流行的有Nexus Repository OSS 和 Artifactory 他们都提供免费的社区版和收费的专业版,安装可以使用Docker镜像,省时省力。
以Nexus为例,制品软件系统到底有啥用呢,通过官方文档,通过Nexus制品管理软件。有以下功能 可以方便的搭建使用自己的私有Docker仓库,Composer, NPM,Raw(任何文件格式) 等。 更好的文件分类,更好的角色权限控制 支持REST API 更好的备份恢复机制 所以个人觉得大公司很有必要建立的自己制品管理系统。
缺点: 自己搭建和维护,需要一定服务器运行成本
制品管理软件详细的使用本文不再展开,大家参照文档即可,大致流程是: 搭建制品仓库系统,Jenkins安装对应的插件,修改pipeline通过插件提供的指令上传制品到制品仓库。供系统项目或人员使用
如果只是为了Docker私有仓库,不用搭建Nexus,阿里云,腾讯云等公有云提供的有类似服务而且是免费的。
使用 nexus3 搭建 私有Docker仓库
最快的方法使
docker run -d --name nexus3 --restart=always \
-p 8081:8081 \
--mount src=nexus-data,target=/nexus-data \
sonatype/nexus3等待 3-5 分钟,如果 nexus3 容器没有异常退出,那么你可以使用浏览器打开 http://YourIP:8081 访问 Nexus 了。
第一次启动 Nexus 的默认帐号是 admin 密码是 通过 docker exec -it nexus3 cat /nexus-data/admin.password 获取,登录以后点击页面上方的齿轮按钮进行设置。

创建一个私有仓库的方法: Repository->Repositories 点击右边菜单 Create repository 选择 docker (hosted)
Name: 仓库的名称 HTTP: 仓库单独的访问端口 Enable Docker V1 API: 如果需要同时支持 V1 版本请勾选此项(不建议勾选)。 Hosted -> Deployment policy: 请选择 Allow redeploy 否则无法上传 Docker 镜像。 其它的仓库创建方法请各位自己摸索,还可以创建一个 docker (proxy) 类型的仓库链接到 DockerHub 上。再创建一个 docker (group) 类型的仓库把刚才的 hosted 与 proxy 添加在一起。主机在访问的时候默认下载私有仓库中的镜像,如果没有将链接到 DockerHub 中下载并缓存到 Nexus 中。
详细内容请自行查看 Nexus 文档

参考
]]>凭证可以是一段字符串如密码,私钥文件等,是Jenkins进行受限操作时的凭据。比如SSH登录远程服务器,用户名,密码或SSH key就是凭证。这些凭据不要明文写在Jenkinsfile中,Jenkins有专门管理凭证的地方和插件。
添加凭证
添加凭证步骤(需要有凭证权限,这里使用超级管理员身份)



参数:
- Kind | 凭证类型
- Scope | 凭证作用域,分Global,用于pipeline就选这个,System,用于Jenkins系统本身,如电子邮件身份验证,代理连接等。
- ID | 在pipeline中使用凭证的唯一标识 | 可以自己起,如果不填Jenkins会分配一个,必须唯一,而且创建后无法修改。建议自己起成容易识别的,比如 xxx-project-dingtalk-robot-token
关于Kind凭证类型,有如下几种:
- Username with password | 用户名和密码
- Docker Host Certificate Authentication
- SSH Username with private key | 一对SSH用户名和密钥
- Secret file | 需要保密的文本文件,使用时Jenkins会将文件复制到一个临时目录中,再将文件路径设置到一个变量中,等构件结束后,所复制的Secret file就会被删除。
- Secret text | 需要保存的一个保密的文本串,如钉钉机器人或Github的api token
- Certificate
添加凭证后,需要安装"Credentials Binding Plugin"插件,就可以在pipeline中使用withCredentials步骤使用凭证了。
pipeline中使用凭证
- withCredentials
// 通过 credentialsId 取出对应凭证,然后赋值给名为'my_dingtalk_token'(自己起)的变量
// 根据变量在其他step中使用
withCredentials([string(credentialsId: 'dingding-robot-token', variable: 'my_dingtalk_token')]) {
// 注意:构建记录中只会输出 ****
echo "${my_dingtalk_token}"
}比如钉钉讨论组建立机器人后会提供给你webhook的地址https://oapi.dingtalk.com/robot/send?access_token=123456789abcde,将后面的access_token 存到 Secret text 中。
- credentials
如果觉得withCredentials比较麻烦,声明式pipeline还提供了 helper 方法,在environment中使用credentials('credentials-id')就可以方便取出。
注意:credentials 指令只能使用在 environment 段中,而且目前只支持Secret text,Username with password 和 Secret file 三种。
#!groovy
pipeline {
agent any
environment {
ding_robot_token = credentials('dingding-robot-token')
}
stages {
stage('debug') {
steps {
sh "printenv"
}
}
}
post {
success {
script {
// 输出 **** ,即在console中看不到真实信息
echo "${env.ding_robot_token}"
}
// 通知钉钉机器人,需要安装dingtalk插件
dingTalk accessToken: "${env.ding_robot_token}", imageUrl: '', jenkinsUrl: '', message: '构建成功', notifyPeople: ''
}
}
}进阶:使用 Vault
如果你要管理很多服务器密钥,数据库密码,用户密码或token等敏感信息,可以使用 Vault 他是hashicorp公司出品的专业管理机密和保护敏感数据的工具。
他有以下功能:
- 提供 图形化界面,CLI命令和HTTP API
- 方便的密码维护和变更管理功能,比如密码需要定期更换,使用Vault只需要在vault端更新密码,通知应用重新拉取就可以了
- 动态定期生成唯一密码,省去人工维护麻烦
- 支持 ACL,角色,策略,认证等
安装非常简单,就一个二进制包,直接运行即可。具体使用请参考官方文档写的非常清晰,再结合Jenkins的vault插件。就可以方便的管理凭证了。
]]>通过脚本命令行批量修改Jenkins任务
最近,笔者所在团队的 Jenkins 所在的服务器经常报硬盘空间不足。经查发现很多任务没有设置“丢弃旧的构建”。通知所有的团队检查自己的 Jenkins 任务有没有设置丢弃旧的构建,有些不现实。
一开始想到的是使用 Jenkins 的 API 来实现批量修改所有的 Jenkins 任务。笔者对这个解决方案不满意,经 Google 发现有同学和我遇到了同样的问题。
他使用的更“技巧”的方式:在 Jenkins 脚本命令行中,通过执行 Groovy 代码操作 Jenkins 任务。
Script Console 需要对Java和Jenkins相关的API比较熟悉,除了进行管理操作还可以诊断调式Jenkins。建议执行危险操作前先备份好数据。
总的来说,就两步:
- 进入菜单:系统管理 –> 脚本命令行

- 在输入框中,粘贴如下代码:

import jenkins.model.Jenkins
import hudson.model.Job
import jenkins.model.BuildDiscarderProperty
import hudson.tasks.LogRotator
// 遍历所有的任务
Jenkins.instance.allItems(Job).each { job ->
if ( job.isBuildable() && job.supportsLogRotator() && job.getProperty(BuildDiscarderProperty) == null) {
println " \"${job.fullDisplayName}\" 处理中"
job.addProperty(new BuildDiscarderProperty(new LogRotator (2, 10, 2, 10)))
println "$job.name 已更新"
}
}
return;
/**
LogRotator构造参数分别为:
daysToKeep: If not -1, history is only kept up to this days.
numToKeep: If not -1, only this number of build logs are kept.
artifactDaysToKeep: If not -1 nor null, artifacts are only kept up to this days.
artifactNumToKeep: If not -1 nor null, only this number of builds have their artifacts kept.
**/脚本命令行介绍
脚本命令行(Jenkins Script Console),它是 Jenkins 的一个特性,允许你在 Jenkins master 和 Jenkins agent 的运行时环境执行任意的 Groovy 脚本。
这意味着,我们可以在脚本命令行中做任何的事情,包括关闭 Jenkins,执行操作系统命令rm -rf /(所以不能使用 root 用户运行 Jenkins agent)等危险操作。
除了上文中的,使用界面来执行 Groovy 脚本,还可以通过 Jenkins HTTP API:/script执行。
具体操作,请参考官方文档。
问题:代码执行完成后,对任务的修改有没有被持久化?
当我们代码job.addProperty(new BuildDiscarderProperty(new LogRotator (2, 10, 2, 10)))执行后,这个修改到底有没有持久化到文件系统中呢 (Jenkins 的所有配置默认都持久化在文件系统中)?我们看下 hudson.model.Job 的源码,在addProperty方法背后是有进行持久化的:
public void addProperty(JobProperty<? super JobT> jobProp) throws IOException {
((JobProperty)jobProp).setOwner(this);
properties.add(jobProp);
save();
}小结
本文章只介绍了批量修改“丢弃旧的构建”的配置,如果还希望修改其它配置,可以参考 hudson.model.Job 的源码
不得不提醒读者朋友,Jenkins 脚本命令行是一把双刃剑,大家操作前,请考虑清楚影响范围。如果有必要,请提前做好备份。
]]>从某种抽象层次上讲,部署流水线(Deployment pipeline)是指从软件版本控制库到用户手中这一过程的自动化表现形式。
Jenkins 2.x 支持 pipeline as code,可以通过”代码“来描述部署流水线。
使用"代码”而不是UI的意义在于:
- 更好地版本化:将pipeline提交到软件版本库中进行版本控制。
- 更好地协作: pipeline的每次修改对所有人都是可见的。除此之外,还可以对pipeline进行代码审查。
- 更好的重用性:手动操作没法重用,但是代码可以重用。
TIP
总结:创建Jenkins 项目尽量使用 pipeline 风格。是2.x最大特别,也是官方主推的特性,是发展趋势。
Jenkinsfile 是什么
Jenkinsfile就是一个文本文件,也就是部署流水线概念在Jenkins中的表现形式。像Dockerfile之于Docker。所有部署流水线的逻辑都写在Jenkinsfile中。 建议把Jenkinsfile跟项目源码一块加入到版本控制中,这样方便项目成员了解构建构建和流程。当然出于安全,有些环境变量和参数等可以管理在Jenkins管理平台上。具体后续会有介绍。
pipeline 基本构成
写 pipeline 就是写 Groovy 代码,Jenkins pipeline 其实就是基于Groovy语言实现的一种领域DSL(Domain Specific Language)。
Jenkins pipeline支持两种语法,声明式和脚本式,前者简单,结构化好,后者灵活,扩展性好,但是需要对Groovy比较熟练。 声明式语法更符合阅读习惯,所有示例都会使用声明式语法。
pipeline的内容包含执行编译、打包、测试、输出测试报告等步骤。
如下图,声明式pipeline的语法结构概览,粗线边框的表示必需的

例1 一个最简单的声明式pipeline
pipeline {
agent any
// stages 包含一个或多个阶段(stage)的容器
stages {
// stage 阶段,pipleline流水线由一个或多个阶段(stage)组成,每个阶段必须有名称,这里build就是此阶段的名称
stage('build') {
// steps,阶段中的一个或多个具体步骤(step)的容器
steps {
# 这是是具体的步骤,真正”做事“的,不可再拆分的最小操作
echo "hello world"
}
}
}
}- 所有的声明必须包含在 pipeline 语句块中。
- 块只能由 stage, directives (指令,后续会讲到) 或 steps 组成。
- agent:指定流水线的执行位置,流水线中的每个阶段都必须在某个地方(物理机,虚拟机或 Docker 容器)执行,agent 部分即指定具体在哪里执行。
- echo 是内置命令,用来输出一段文本,还有些命令是安装插件后才有的,参见官方文档。
- step: 步骤,可拆分最小单元,真正“做事”的语句。如
echo "hello world"表示输出一句话。
TIP
有些插件安装后可以直接在pipeline中使用,如发送邮件的Extended E-mail Notification,安装后可以直接
steps {
emailext to: '[email protected]', subject: "test", body: "email content"
}来发送邮件
参考
]]>节点
节点分为主节点master和代理节点agent。 在Jenkins 2中,节点是一个基础概念,代表了任何可以执行Jenkins任务的系统。节点中包含主节点和代理节点,有的时候也用于指代这些概念。此外,节点也可以是一个容器,比如Docker。
主节点 master
Jenkins主节点是一个Jenkins实例(instance) 的主要控制系统。它能够完全访问所有Jenkins配置选项和任务(job) 列表。如果没有指定其他系统(system) ,它也是默认的任务执行节点。
Jenkins设计之初就支持master-slave的分支式架构。最佳实践是不要在master上跑业务job,而在slave上跑,这样不会拖累master,任何需要大量处理的任务都应该在主节点之外的系统上运行。性能与隔离两不误。
这样做的另一个原因是,凡是在主节点上执行的任务,都有权限访问所有的数据、配置和操作,这会构成潜在的安全风险。同样值得注意的是,在主系统上不应该执行任何包含潜在阻塞的操作,因为主系统需要持续响应和管理各类操作过程。
此外,基于容器技术,可以轻松实现slave的标准化、集群化、弹性化,从而保障构建环境的一致性和资源有效利用率。这点后续文章我会介绍。
agent 代理节点
在早先版本的Jenkins中,代理节点被称为从节点(slave) ,其代表了所有非主节点的系统。这类系统由主系统管理,按需分配或指定执行特定的任务。例如,我们可以分配不同的代理节点针对不同的操作系统构建任务,或者可以分配多个代理节点并发地运行测试任务。 为了减少系统负载,降低安全风险,通常在子系统上只会安装一个轻量级的Jenkins客户端应用来处理任务,这个客户端应用对资源访问是受限的。

Jenkins支持创建传统Slave,比如通过SSH方式添加一个机器作为Slave,配置一个或多个Executor,此Slave一般保持长连接状态,等待构建任务的分配和运行。这种类型的Slave往往直接挂载物理机或虚拟机,通过Jenkins UI可以查看Slave的状态,并对Slave进行管理。
除此之外,Jenkins对容器化Slave支持也很好,通过Docker插件,Kubernetes插件等根据构建需求动态提供容器作为Jenkins Slave,运行构建任务后及时销毁容器Slave。这种方式在Slave的自动扩容缩容上弹性比较好,也能大幅提高资源利用率。
添加agent可以通过JNLP协议,SSH协议
我们这里介绍如何添加另外一台物理机作为Master的Slave节点,两台都是Linux ubuntu 系统
添加物理机节点
实际就是让master jenkins用户可无密码访问slave
- Slave 机器
创建 jenkins 用户并设置密码 sudo useradd jenkins
- Master 机器
- 登录master机器
- 设置 jenkins 用户的密码,一般master上既然跑着Jenkins,安装时候就已经创建了jenkins用户
sudo passwd jenkins - 切换到 jenkins 用户
su - jenkins路径一般是/var/lib/jenkins - 生成 ssh key
ssh-keygen -t rsa -b 4096 -C "[email protected]"邮箱可不配,得到 id_rsa 和 id_rsa.pub 俩文件 - 复制 id_rsa 中的内容
- Jenkins 中创建SSH类型的凭证,username 填 jenkins, private内容粘贴 id_rsa 中的内容
- 上传 id_rsa.pub 到 slave 机器,
ssh-copy-id -p 4522 jenkins@slave机器的IP-p是端口,如果是22可不加此参数。 - 检查连通性,
ssh -p 4522 jenkins@slave机器的IP - Jenkins - manage - manage nodes 添加节点


成功的话可以看到Slave机器的信息

并且Slave的/home/jenkins中你会看到remoting.jar和remoting目录
我们来验证一下让新添加的slave工作,创建一个freestyle的job,
General 选项卡:勾选"Restrict where this project can be run",Label Expression 中填写我们起的label,如linux,会有自动提示。
Build 选项卡:添加 Execute shell,内容填在slave中执行的命令,如ps -ef
最后保存,build,查看 Console Output 结果。应该和直接在slave上执行的结果一致。

如果新建的job类型是pipeline,等价的写法如下:
pipeline {
agent {
label 'linux'
}
stages {
stage ('testing') {
steps {
sh "ps -ef"
}
}
}
}下篇文章会有更多的pipeline agent语法介绍
参考
]]>- 进入 Manage Jenkins 页面 -> Configure Global Security -> Agents 勾选固定端口,填一个端口数字

-
进入 Manage Jenkins -> Manage Nodes -> New Node 勾选 Permanent Agent ,即设置为固定节点
-
配置页面 Remote root directory 远程根目录,指连接 slave节点后使用的目录,相关文件会存放于此 Launch method 选择 "Launch agent by connecting it to the master"

- 添加节点后,点击名称进入连接页面
提示连接agent有两种方式:
- 直接在 agent 的浏览器上打开此页面,单击 Launch 按钮
- slave 需要安装java,复制页面上的地址
sudo nohup java -jar agent.jar -jnlpUrl http://xx.xx.xx.xx:xx/computer/new/slave-agent.jnlp -secret ef6bedd1dfc7001077179aa6888e02078d4187aa28f4edfe8be23a7f796528a5 -workDir "/home" &然后运行

SSH 登录 slave 机器上,然后运行master上提供的连接命令

连接成功
]]>

当agnet数量变多时,如何区分这些agnet有哪些特点呢?比如哪些环境是node10,哪些是JDK8,为了区分,我们可以给不同的agent打标签(也叫tag)。一个agent可以拥有多个标签,为避免冲突,标签名不能包含空格,!&<>()|等这些特殊符号。打标签时可以考虑以下维度: 工具链: jdk, node, php 语言或工具的版本 操作系统:linux, windows, osx 系统位数: 32bit, 64bit
定义好标签后,可以在pipeline中指定他了,你可能见过
pipeline {
agent any
}agent any 告诉 Jenkins master 任意可用的agent都可以执行
agent 必须放在pipeline的顶层定义或stage中可选定义,放在stage中就是不同阶段使用不同的agent
通过标签指定 agent,比如某项目需要在JDK8中环境中构建
pipeline {
agent {
label 'jdk8'
}
stages {
stage ('build') {
steps {
echo 'build'
}
}
}
}实际上 agent { label 'jdk8' }是 agent { node { label 'jdk8' } } 的简写。
label 支持过滤多标签
agent {
label 'windows && jdk8'
}node 除了 label 选项,还支持自定义工作目录
agent {
node {
label 'jdk8'
customWorkspace '/var/lib/custom'
}
}不分配 agent
agent none ,这样可以在具体的stages中定义
agent:指定流水线的执行位置,流水线中的每个阶段都必须在某个地方(物理机,虚拟机或 Docker 容器)执行,agent 部分即指定具体在哪里执行。
指定在Docker镜像中运行
如下面例子,首先pull一个我打包好的docker镜像,这个镜像里面已经包含了nodejs10,npm和浏览器,可以方便的在里面执行npm install, npm test 跑测试等。
pipeline {
agent {
docker {
image 'finleyma/circleci-nodejs-browser-awscli'
}
}
stage('Checkout') {
steps {
git branch: 'develop', credentialsId: 'github-private-key', url: '[email protected]:your-name/angular-web.git'
}
}
stage('Node modules') {
steps {
sh 'npm install'
}
}
stage('Code Lint') {
steps {
sh 'npm run lint'
}
}
stage('Unit Test') {
steps {
sh 'npm run test'
}
}
// .... build, delpoy
}when 指令中的 beforeAgent 选项
pipeline {
agent none
stages {
stage ('example build') {
steps {
echo 'hello world'
}
}
stage ('example deploy') {
agent {
label 'some-label'
}
when {
beforeAgent true
branch 'production'
}
steps {
echo 'deploying'
}
}
}
}只有当分支为 production时,才会进入 'example deploy' 阶段,这样避免了agent中拉取代码,从而达到加速pipeline执行的目的。
参考
]]>/var/lib/jenkins,或者到Jenkins的配置文件中查看cat /etc/default/jenkins | grep "home"。
JENKINS_HOME目录 结构如下:

其中 workspace, builds 和 fingerprints目录是不需要备份的
定期备份是个好习惯,备份功能通过安装插件实现。
thin-backup 备份插件
比较流行的插件有 periodicbacku 和 thin-backup ,发现无论是Github中更新时间还是star数量 thin-backup都更好些,所以选择了 thin-backup
thin-backup 安装好后,管理页面会多出一个菜单项,进入后是 thin-backup 设置页面, 非常简答,立即备份,恢复和配置

配置页面中可以设置备份路径,备份周期,最大备份数量等等

备份周期的填写要符合Jenkins trigger cron语法,我填写的是 H 23 * * 6 即每周6的23点任意分钟执行
关于 Jenkins trigger cron
类似UNIX cron语法,一段 cron 包含5个字段。使用空格或tab分隔
格式为: 分钟:0~59 小时:0~23 一月某一天:1~31 月份:1~12 星期几:0~7 还可以使用以下字符,一次性指定多个值 *:匹配所有值 M-N:匹配M到N之间的值 M-N/X:指定M到N范围内,以X值为步长 A,B,C:逗号分隔枚举多个值
有时候存在大量同一时刻执行的定时任务,比如N个半夜零点(0 0 * * *)执行的任务,这样会产生负载不均衡,Jenkins提供了H字符来解决这一问题,H表示hash,(0 0 * * *)表示零点0分至0点59分之间任何一个时间点
Jenkins trigger cron 提供了更便捷的写法 @yearly, @monthly,@weekly, @daily,@hourly
| 缩写 | 等价写法 | 描述 |
|---|---|---|
| @daily 或 @midnight | 0 0 * * * | 每天午夜0点执行 |
| @hourly | 0 * * * * | 每个整点0分执行 |
| @monthly | 0 0 1 * * | 每月1号的午夜执行 |
| @weekly | 0 0 * * 0 | 每周日午夜执行 |
| @yearly 或 @annually | 0 0 1 1 * | 每年1月1日的午夜执行 |
进阶
无意看到一篇文章,把 JENKINS_HOME 放到Git版本控制中管理,这样省去了频繁备份的烦恼。
参考
]]>面向读者:需要了解 Jenkins 流水线的基本语法。
Electron 是由 Github 开发,用 HTML,CSS 和 JavaScript 来构建跨平台桌面应用程序的一个开源库。
本文将介绍 Electron 桌面应用的流水线的设计。
但是如何介绍呢?倒是个大问题。笔者尝试直接贴代码,在代码注释中讲解。这是一次尝试,希望得到你的反馈。
完整代码
pipeline {
// 我们决定每一个阶段指定 agent,所以,
// 流水线的 agent 设置为 none,这样不会占用 agent
agent none
// 指定整条流水线的环境变量
environment {
APP_VERSION = ""
APP_NAME = "electron-webpack-quick-start"
}
stages {
stage("生成版本号"){
agent {label "linux" }
steps{
script{
APP_VERSION = generateVersion("1.0.0")
echo "version is ${APP_VERSION}"
}}
}
stage('并行构建') {
// 快速失败,只要其中一个平台构建失败,
// 整次构建算失败
failFast true
// parallel 闭包内的阶段将并行执行
parallel {
stage('Windows平台下构建') {
agent {label "windows && nodejs" }
steps {
echo "${APP_VERSION}"
}
}
stage('Linux平台下构建') {
agent {label "linux && nodejs" }
// 不同平台可能存在不同的环境变量
// environment 支持阶段级的环境变量
environment{
SUFFIX = "tar.xz"
APP_PLATFORM = "linux"
ARTIFACT_PATH = "dist/${APP_NAME}-${APP_PLATFORM}-${APP_VERSION}.${SUFFIX}"
}
steps {
script{
// Jenkins nodejs 插件提供的 nodejs 包装器
// 包装器内可以执行 npm 命令。
// nodejs10.15.2 是在 Jenkins 的全局工具配置中添加的 NodeJS 安装器
nodejs(nodeJSInstallationName: 'nodejs10.15.2') {
// 执行具体的构建命令
sh "npm install yarn"
sh "yarn version --new-version ${APP_VERSION}"
sh "yarn install"
sh "yarn dist --linux deb ${SUFFIX}"
// 上传制品
uploadArtifact("${APP_NAME}", "${APP_VERSION}", "${ARTIFACT_PATH}")
}}} // 将括号合并是为了让代码看起来紧凑,提升阅读体验。下同。
}
stage('Mac平台下构建') {
agent {label "mac && nodejs" }
stages {
stage('mac 下阶段1') {
steps { echo "staging 1" }
}
stage('mac 下阶段2') {
steps { echo "staging 2" }
}
}
} } }
stage("其它阶段,读者可根据情况自行添加"){
agent {label "linux"}
steps{
echo "发布"
} }
}
post {
always { cleanWs() } } // 清理工作空间
}
def generateVersion(def ver){
def gitCommitId = env.GIT_COMMIT.take(7)
return "${ver}-${gitCommitId}.${env.BUILD_NUMBER}"
}
def uploadArtifact(def appName, def appVersion, def artifactPath){
echo "根据参数将制品上传到制品库中,待测试"
}代码补充说明
因为 Electron 是跨平台的,我们需要将构建过程分别放到 Windows、Linux、Mac 各平台下执行。所以,不同平台的构建任务需要执行在不同的 agent 上。我们通过在 stage 内定义 agent 实现。如在“Mac平台下构建”的阶段中,agent {label "mac && nodejs" } 指定了只有 label 同时包括了 mac 和 nodejs 的 agent 才能执行构建。
多平台的构建应该是并行的,以提升流水线的效率。我们通过 parallel 指令实现。
另外,默认 Electron 应用使用的三段式版本号设计,即 Major.Minor.Patch。但是笔者认为三段式的版本号信息还不够追踪应用与构建之间的关系。笔者希望版本号能反应出构建号和源代码的 commit id。函数 generateVersion 用于生成此类版本号。生成的版本号,看起来类似这样:1.0.0-f7b06d0.28。
完整源码地址:https://github.com/zacker330/electronjs-pipeline-demo
小结
上例中,Electron 应用的流水线设计思路,不只是针对 Electron 应用,所有的跨平台应用的流水线都可以参考此思路进行设计。设计思路大概如下:
多平台构建并行化。本文只有操作系统的类型这个维度进行了说明。现实中,还需要考虑其它维度,如系统位数(32位、64位)、各操作系统下的各版本。 各平台下的构建只做一次编译打包。并将制品上传到制品库,以方便后续步骤或阶段使用。 全局变量与平台相关变量进行分离。 最后,希望能给读者带来一些启发。
参考:
- 持续交付的八大原则:https://blog.csdn.net/tony1130/article/details/6673741
- Jenkins nodejs 插件:https://plugins.jenkins.io/nodejs
- Electron 版本管理:https://electronjs.org/docs/tutorial/electron-versioning#semver
- 如何在 Jenkins 中添加一个远程 Docker 作为构建项目的 Cloud
- 如何在这个 Cloud 中指定代码仓库并打包 Docker 镜像
- 将镜像 push 到官方的 Docker Hub 仓库
实验前提:
两台服务器,一个跑Jenkins,另一台运行Docker服务端(注意需要开放远程访问)
目前Docker已经成为众多流水线中关键的组成部分之一。 容器化具有的简单性,灵活性以及隔离性可以让我们定制特定的而且能够精确重复的环境。容器化部署也越来越流行。
关于Docker的基本概念和使用方法,可以参见我写的系列。
这里我需要两台主机(测试时可以是同一个机器),一台运行Jenkins,另一台运行Docker,作为Jenkins的代理节点。
当Jenkins启动pipeline工作时,同时连接并启动这个代理节点,由他完成构建镜像的工作,当流水线完成之后,Jenkins会停止并删除运行这些镜像的容器,使用这种方法需要配置Docker插件
好处:Jenkins master 节点只负责调控,具体的构建任务下放到Docker代理节点中去,解决master空间不够等问题
安装插件之后Jenkins的系统配置页面会多出一个Cloud部分。
需要填写连接Docker的配置信息
Name: 给Docker主机起个别名
Docker Host URI: 如 tcp://192.168.10.10:2375 ,连接本机Docker,如果连其他主机上的Docker服务端,需要Docker宿主机开放远程访问,具体见Docker 学习系列21 远程连接Docker

集成Docker插件后,在管理Jenkins页面中会多出一个Docker入口

点击后能看到配置过的分配给Jenkins实例的Docker服务器列表

再点进去能看到正在运行的容器和拥有的镜像

Cloud 构建Docker镜像并上传到指定仓库
接下来我们新建一个 freestyle 项目
-
配置代码仓库,注意仓库中要有Dockerfile,以我的这个公开仓库为例
-
Build - Add build step 添加新的构建步骤 - Build / Publish Docker Image
- Directory for Dockerfile: 因为Dockerfile就在代码中的根目录,这里不填
- Cloud:选择刚刚配置的 Docker Cloud 名字
- Image: 要打包上传的镜像名
- Registry Credentials: 注意这里,要添加一个类型是username/password的可以登录docker仓库的credentials

- 构建,查看输出信息

- 检查 Docker Hub 可以看到刚刚上传的镜像

同时Docker Cloud中也多出了一个刚刚打包的镜像

参考
https://docs.docker.com/engine/reference/commandline/dockerd/#daemon-configuration-file https://www.jianshu.com/p/2ad009ae95ad jenkins slave docker容器化
]]>- 阿里云设置容器镜像服务
- Jenkins 指定 Docker agent 拉代码基于 Dockerfile 构建镜像并上传到阿里云镜像仓库
- 登录阿里云账号,在产品服务中搜索“容器镜像服务”,首先我们先创建一个命名空间,一个命名空间可以包含多个镜像仓库,你可以理解为项目组

- 然后来到镜像仓库,创建一个新的镜像仓库,一个镜像仓库其实对应一个项目的代码仓库

- 这里拉仓库代码和Docker构建,我不希望让阿里云帮我构建,而是在Jenkins完成,只是构建完成后并上传到这个刚创建的镜像仓库中。 所以选择“本地仓库”

至此,我们获得了一个阿里云提供的私有仓库地址,点击操作的管理页面,会有具体的操作指南

-
复制镜像地址
registry.cn-zhangjiakou.aliyuncs.com/fineyma/node-demo -
Jenkins 中新建一个 freestyle 项目,填写Git仓库地址,添加构建步骤,Build - Add build step - Publish Docker Image
-
Image: 粘贴刚复制的地址,同时勾选 push image,这里表示构建完成,推到我们刚创建的镜像仓库中
-
Registry Credentials 需针对阿里云容器仓库新建凭证,就是 docker login 时输入的账号和密码,可以先到阿里云-容器镜像服务-访问凭证中设置固定的密码。

需要注意镜像名称要填写完整 registry.cn-zhangjiakou.aliyuncs.com/fineyma/node-demo:${BUILD_NUMBER}-${GIT_PREVIOUS_COMMIT}
格式是 registry地址/命名空间/镜像仓库名:tag
其中 tag 为了保证唯一,使用了 Jenkins 提供的GIT_PREVIOUS_COMMIT和BUILD_NUMBER环境变量
- 点击构建,查看日志,看到 Docker Build Done
阿里云中也可以看到刚刚构建的镜像,注意查看版本

版本号其实就是自增的构建次数+commit_id,是和仓库的提交id一致的 https://github.com/mafeifan/docker-express-demo/commit/c5636e58f3603e8a40fed6dd8d991db09f80b156
所以在任何装有Docker的主机上,根据提交id,我们就可以方便的docker run部署和回滚项目
怎么用pipeline实现同样的操作呢,请见下篇
心得
生成环境部署Docker容器还是方便非常的, 比较费时的是寻找好的Docker基础镜像和写好Dockerfile,尽量让Dockerfile打包生成的镜像小些,而Dockerfile一般基于Linux,所以掌握好Linux基础知识是关键。
]]>如下面例子,首先pull一个我打包好的基于ubuntu的node镜像,这个镜像里面已经包含了nodejs10, wget, zip, curl, python,chrome,firefox, aws-cli 等常用工具,可以方便的在里面执行npm install,npm run test 启动浏览器跑测试等。
pipeline {
agent {
docker {
image 'finleyma/circleci-nodejs-browser-awscli'
}
}
stage('Checkout') {
steps {
git branch: 'develop', credentialsId: 'github-private-key', url: '[email protected]:your-name/angular-web.git'
}
}
stage('Node modules') {
steps {
sh 'npm install'
}
}
stage('Code Lint') {
steps {
sh 'npm run lint'
}
}
stage('Unit Test') {
steps {
sh 'npm run test'
}
}
// .... build, delpoy
}pipeline 中操作镜像
需要安装 Jenkins docker workflow 插件, 下面的例子展示了:
- 连接远程Docker主机
- 登录私有Docker 仓库(阿里云镜像服务)
- 根据代码中的 Dockerfile 构建镜像并push
- 删除Docker远程主机中构建好的镜像,不占用空间
- 不包含目标主机中部署镜像 其实就说上篇文章中的pipeline版本
#!groovy
pipeline {
agent any
environment {
// PATH="/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin"
_docker_remote_server='tcp://192.100.155.155:2375'
_aliyun_registry='https://registry.cn-zhangjiakou.aliyuncs.com'
}
stages {
stage('debug') {
steps {
script {
sh "printenv"
}
}
}
stage('connect remote docker') {
steps {
// 注意 代码是先拉到了Jenkins主机上,但是构建镜像在Docker远程
git 'https://github.com/mafeifan/docker-express-demo.git'
script {
docker.withServer("${env._docker_remote_server}") {
// 第一个参数是私有仓库地址,注意要带http(s),第二个参数是账号密码登录凭证,需要提前创建
docker.withRegistry("${env._aliyun_registry}", 'aliyun-docker-registry') {
// 使用 ${GIT_PREVIOUS_COMMIT} 取不到 commint_id
// https://stackoverflow.com/questions/35554983/git-variables-in-jenkins-workflow-plugin
git_commit = sh(returnStdout: true, script: "git rev-parse HEAD").trim()
echo git_commit
def customImage = docker.build("fineyma/node-demo:${env.BUILD_NUMBER}-${git_commit}")
/* Push the container to the custom Registry */
customImage.push()
// 可以优化,用匹配搜索并删除
sh "docker rmi fineyma/node-demo:${env.BUILD_NUMBER}-${git_commit}"
}
}
}
// clean workspace
cleanWs()
}
}
}
}这里 customImage.push() 貌似有个bug,构建之后的镜像有两个一样的,一个带registry name一个不带
关于 docker.build, docker.withRegistry 等是Jenkins docker workflow 插件提供的, 可以看源码,其实是封装了docker build, docker login,你完全可以写原生的docker 命令
关于远程容器部署
既然镜像已经成功上传到阿里云的镜像服务,理论上任何装有Docker的主机只要docker run就可以完成部署了(需要网络通)。 实现方法我想到有几种:
- 阿里云的镜像服务提供触发器,即每当push新的镜像上去,可以发送一个post请求到配置的地址,这样可以完成容器部署操作。Jenkins可以添加一个job,暴露一个触发地址给阿里云镜像服务的触发器。
- 在pipeline中添加ssh登录目标主机,然后添加
docker run --rm fineyma/node-demo:${env.BUILD_NUMBER}-${git_commit}step 步骤 - 目标主机也开放dockerd,这样连登录都不需要了,直接docker client 操作远程Docker完成部署。
参考
]]>之前的做法:项目代码的每个分支有维护单独的Jenkinsfile,这样不但麻烦而且冗余。
我们知道pipeline流水线由若干个stage阶段组成,其实stage中支持写when指令,即根据条件执行这个stage。
when 支持的条件有 branch, environment, express, not, anyOf, allOf 具体使用可参见官方文档
下面是个使用when选项优化后的Jenkinsfile,所有分支使用一份Jenkinsfile即可:
有几点细节说下:
changset是提交中的变更的文件列表,这里项目中即包含后台PHP代码也包含前端的 JS 和 CSS文件,只有当提交中包含了JS或CSS文件才触发npm run build,加速构建,因为如果提交了 PHP 文件,没有必要构建前端资源
when {
anyOf {
// 是 ant 路径写法
changeset "**/*.js"
changeset "**/*.css"
}
}-
如果两次push代码间隔很短,有可能造成同时出现多个的
npm run build,为避免这种情况加上了disableConcurrentBuilds() -
通过使用when, 只有往master分支提交代码才触发邮件step,post指令也可以写在stage中
-
默认情况下,stage内的所有代码都将在指定的Jenkins agent上执行,when指令提供 beforeAgent选项,当他的值为true时,只有符合when条件时才会进入该Jenkins agent,这样就避免的没有必要的工作空间的分配
// https://jenkins.io/zh/doc/book/pipeline/syntax
pipeline {
agent {
// 在Docker容器里跑Job,跑完Jenkins会自动删除容器
docker {
image 'node:8.15.0-alpine'
}
}
// 避免 npm install 报权限问题
environment {
HOME = '.'
_EMAIL_TO='[email protected]'
}
options {
// 不允许同时执行流水线, 防止同时访问共享资源等
disableConcurrentBuilds()
// 显示具体的构建流程时间戳
timestamps()
}
stages {
// 只有修改 JS 或 CSS 资源文件才触发 Build 步骤
stage('Build') {
when {
anyOf {
changeset "**/*.js"
changeset "**/*.css"
}
}
steps {
sh 'npm install'
sh 'npm run build'
}
}
// 只有触发 Master 分支才发邮件
stage('Master') {
when {
beforeAgent true
branch 'master'
}
steps {
echo 'master branch'
}
post {
always {
configFileProvider([configFile(fileId: 'email-groovy-template-cn', targetLocation: 'email.html', variable: 'content')]) {
script {
template = readFile encoding: 'UTF-8', file: "${content}"
emailext(
to: "${env._EMAIL_TO}",
subject: "Job [${env.JOB_NAME}] - Status: ${currentBuild.result?: 'success'}",
body: """${template}"""
)
}
}
}
}
}
stage('Staging') {
when {
beforeAgent true
branch 'staging'
}
steps {
echo 'This is staging branch'
}
}
stage('Develop') {
when {
beforeAgent true
branch 'develop'
}
steps {
echo 'This is develop branch'
}
}
}
}具体方法: 系统管理 >> 管理插件 >> 高级 将 [升级站点] 更换为 https://mirrors.tuna.tsinghua.edu.cn/jenkins/updates/current/update-center.json 上面配置的是 清华大学开源软件镜像站
类似的还有 https://jenkins-zh.gitee.io/update-center-mirror/tsinghua/update-center.json
jenkins镜像地址列表 http://mirrors.jenkins-ci.org/status.html
指定插件版本
最新全新安装的Jenkins并安装相关插件后发现执行流水线后报错,经过排查,是钉钉通知插件版本导致,最新的2.0在pipeline中不支持 dingtalk,需要降级使用1.9版本,具体方法:
打开 http://updates.jenkins-ci.org/download/plugins 这里列出了所有可安装的插件,然后搜索ding,进到 http://updates.jenkins-ci.org/download/plugins/dingding-notifications/

点1.9下载,得到文件dingding-notifications.hpi
然后回到Jenkins插件管理页面上传即可
]]>

Groovy是一门同时具有静态和动态特定的脚本语言,或者胶水语言,也是面向对象的。非常适合编写简洁容易的自动化测试代码,例如我再次强调的pipeline的构建任务,就是一个典型的使用领域。
Groovy是apache下的一个产品,所以叫Apache Groovy,官网地址是http://groovy-lang.org/
Groovy是由 James Strachan 设计,第一个发布版本在2003年。
核心特点就是Java平台的多面语言,下面特点就是描述这个多面。
Flat learning curve
- 直接翻译就是平坦的学习曲线,什么可读性强,简洁,表达性强的,易于Java开发人员学习的编程语言。
Powerful features
- 功能强大,支持闭包,构建器,运行时和编译时元编程,函数编程,类型推断和静态编译。
Smooth Java integration
- 就是无缝和Java集成,Java的语法Groovy都支持。
Domain-Specific Languages
- 特定领域语言,灵活的语法,高度集成和自定义机制。这个我使用来看,由于Jenkins平台Pipeline插件是采用Groovy开发,在特定领域语言,我认为就是指pipeline。
Vibrant and rich ecosystem
- 充满活力和丰富的生态系统,这个,我学习比较基础,理解不了。在测试工具中,有一个很强大的框架spcok就能测试Java和groovy开发的项目,这个我认为是一个生态。
Scripting and testing glue
不想本地安装Groovy环境的话,可以打开 groovy-playground 运行线上groovy代码,查看结果 该网站可能需要会科学上网。

必要的Groovy语法知识
- 定义变量和方法用def关键字,
def name="jack" - 语句最后的分号不是必需的
- 方法调用时可以省略括号
def say(String name = "world") {
return "hi " + name
}
// 调用
say name = "jack"- 双引号支持插值,单引号不会解析变量,原样输出
def name = 'world'
// 结果: hello world
print "hello ${name}"
// 结果: hello ${name}
print 'hello ${name}'- 三双引号和三单引号都支持换行,只有三双引号支持插值
def foo = """ line one
line two
${name}
"""- 支持闭包
// 定义闭包
def codeBlack = {print "hello closure"}
// 闭包当做函数调用
codeBlack
// 闭包可以赋值给变量,或者作为参数传递
def pipeline(closure) {
closure()
}
pipeline(codeBlack)因为括号是非必需的,下面几种写法结果是一样的,是不是和Jenkins pipeline很像呢
pipeline( {print "hello closure"} )
pipeline {
print "hello closure"
}
pipeline codeBlack- 闭包的另一个用法
def stage(String name, closure) {
println name
closure()
}
// 正在情况下,我们这样使用stage函数
stage("stage name", {
println "closure"
})
// 最终打印
/*
stage name
closure
*/
// 但是,在Groovy里,可以直接这么写
stage("stage name") {
print "closure"
}比起Jenkins的优势:
- 比起自己搞服务器,安装部署Jenkins省事多了
- 免费提供了每月2000分钟构建时长,和2核7G内存硬件配额,算是非常大方了。
- Actions workflow 语法简单,如果你懂Jenkins pipeline几分钟就可以转移过去。
关于Jenkins pipeline和Action的语法区别。官方文档有表格
Github Action 使用非常简单,我专门录制了视频-Github Action 实现SSH登录部署和Slack通知
这里贴下我正在使用的workflow脚本。具体讲解可以见Github Actions系列
流程非常简单 本地提交代码 -> SSH登录到远程服务器 -> 执行构建命令 -> 执行成功发送Slack通知
# This is a basic workflow to help you get started with Actions
name: CI
# Controls when the action will run. Triggers the workflow on push or pull request
# events but only for the master branch
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Runs a single command using the runners shell
- name: Run a one-line script
run: echo Hello, world!
# Runs a set of commands using the runners shell
- name: SSH Remote Commands
uses: appleboy/[email protected]
with:
host: ${{ secrets.HOST }}
username: ${{ secrets.USERNAME }}
key: ${{ secrets.PRIVATE_KEY }}
port: ${{ secrets.PORT }}
script: cd /var/www/vue-press && git pull && npm i && npm run build
# Slack Notification
- name: Slack Notification
uses: 8398a7/action-slack@v3
with:
status: ${{ job.status }}
fields: repo,message,commit,author,action,eventName,ref,workflow,job,took # selectable (default: repo,message)
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} # optional
SLACK_WEBHOOK_URL: ${{ secrets.SLACK_WEBHOOK_URL }} # required
if: always() # Pick up events even if the job fails or is canceled.更多信息见官方文档,这是个好习惯
参考
]]>原因:Jenkins本身是运行在容器中的,但是没有安装Docker,所以找不到命令
解决方案:把宿主机的docker和docker.sock映射到运行Jenkins的容器内,通过挂载卷的方式把/usr/bin/docker,/var/run/docker.sock挂载出来。 修改Dockerfile或者docker-compose文件
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /usr/bin/docker:/usr/bin/docker报错:libltdl.so.7 cannot open shared object
原因:容器内 /usr/lib缺少这个libltdl.so.7
解决方案:安装即可
apt-get install -y libltdl7.*
这里牵涉到两个问题:
- 我如何知道宿主机的IP
- 我如何通过IP访问宿主机
第1个问题,获取宿主机的IP
方法1:宿主机执行ifconfig
br-afd31e8abae9: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.22.0.1 netmask 255.255.0.0 broadcast 172.22.255.255
inet6 fe80::42:a9ff:fea7:24d4 prefixlen 64 scopeid 0x20<link>
ether 02:42:a9:a7:24:d4 txqueuelen 0 (Ethernet)
RX packets 5566 bytes 1789941 (1.7 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8811 bytes 75927547 (75.9 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:63ff:fe9f:9251 prefixlen 64 scopeid 0x20<link>
ether 02:42:63:9f:92:51 txqueuelen 0 (Ethernet)
RX packets 18693 bytes 5563196 (5.5 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 23271 bytes 122914964 (122.9 MB)
TX errors 0 dropped 0 overr+uns 0 carrier 0 collisions 0会看到docker0中的inet,172.17.0.1就是docker中的IP。而宿主机的内部IP是172.22.0.1
如果进到Jenkins容器,直接ping这个地址是通的。
但问题是这个IP不一定是固定的,我们需要在启动Jenkins容器时将当前的宿主IP告诉容器。
方法2:容器内执行ip route show | awk '/default/ {print $3}'
方法3:解决方案
如果在MacOS或Windows运行docker,尝试直接在容器内运行ping host.docker.internal返回的是宿主机IP
对于Linux,在docker-compose.yaml加入
注:需要docker版本在20.04及以上
我们更新docker-compose.yml
extra_hosts:
- "host.docker.internal:host-gateway"重新进到容器内,查看hosts文件
cat /etc/hosts
就会发现新增了一条172.17.0.1 host.docker.internal
直接ping host.docker.internal可以连通
如果docker-compose.yml
extra_hosts:
- "somehost:162.242.195.82"
- "otherhost:50.31.209.229"/etc/hosts 就会看到
162.242.195.82 somehost
50.31.209.229 otherhost第2个问题,通过SSH协议访问宿主机
这个简单,我们需要进到容器内,只需要生成一对密钥。然后再将ssh目录映射出来
假设有一正在运行的容器,名称为: jenkins_jenkins-compose
登录宿主机,将容器内的ssh目录拷贝到宿主机中
docker cp jenkins_jenkins-compose:/root/.ssh ssh
设置权限和所属
chown root:root -R ~/.ssh/
chmod 600 ~/.ssh/config修改docker-compose
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- /usr/bin/docker:/usr/bin/docker
# 加入这行
- /home/ubuntu/docker/jenkins/ssh:/root/.ssh关于ssh/config文件
Host cloud2
HostName host.docker.internal
User ubuntu
Port 22
IdentityFile ~/.ssh/id_rsa测试: 在容器内执行 ssh cloud2 ls,相当于进到cloud2主机,并执行ls命令,返回结果正常
参考
https://github.com/qoomon/docker-host
https://stackoverflow.com/questions/32163955/how-to-run-shell-script-on-host-from-docker-container
]]>流程
- Build Triggers 下开启 Generic Webhook Trigger
- 配置token
- Post content parameters 部分表示从payload中提取commit message,并赋给变量。
Expression 填写$.commits[0].message
name 起做 commit_message的变量名
假设payload:
{
"commits": [
{
"message": "CI: build"
}
]
}则$commit_message = "CI: build"
可以这么理解

- Optional filter 部分是可选的,如果指定了,则只有匹配到的才会触发构建。
这里我们为了实现,只有commit message中带有[CI]才触发构建
Expression填写: 正则^\[CI]
Text填写上面指定的变量:$commit_message

参考
https://stackoverflow.com/questions/7293008/display-last-git-commit-comment
]]>流程
- Build Triggers 下开启 Generic Webhook Trigger
- 配置全局唯一token
- 开启 Print post content 和 Print contributed variables in job log选项,可以看到接收到的payload和自定义变量
- gitlab或github配置merge request事件的webhook
 5. 创建merge request,观察数据
5. 创建merge request,观察数据
合并后GitLab的webhook触发了, 我们需要对比开启请求和合并请求的数据。找不同,找特点。
# approved状态
$.event_type = merge_request
$.object_attributes.state = opened
$.object_attributes.action = approved
# merge状态
$.event_type = merge_request
$.object_attributes.state = merged
$.object_attributes.action = merge
#拿到source和target分支
$.object_attributes.source_branch
$.object_attributes.target_branch- 此部分都是在jenkins上面配置的 配置Generic Webhook的过滤没用的请求,实现精准触发
currentBuild.description = "Trigger: ${source_branch} > ${target_branch} \n${event_type} \n ${state} \n ${action}"
pipeline {
agent any
triggers {
GenericTrigger(causeString: 'Generic Cause',
genericVariables: [[defaultValue: '', key: 'event_type', regexpFilter: '', value: '$.event_type'],
[defaultValue: 'NULL', key: 'state', regexpFilter: '', value: '$.object_attributes.state'],
[defaultValue: 'NULL', key: 'action', regexpFilter: '', value: '$.object_attributes.action'],
[defaultValue: 'NULL', key: 'source_branch', regexpFilter: '', value: '$.object_attributes.source_branch'],
[defaultValue: 'NULL', key: 'target_branch', regexpFilter: '', value: '$.object_attributes.target_branch']],
printContributedVariables: true,
printPostContent: true,
regexpFilterExpression: '^merge_request\\smerged\\smerge$',
regexpFilterText: '$event_type $state $action',
token: 'devops-merge-trigger',
tokenCredentialId: '')
}
stages {
stage('Hello') {
steps {
echo 'Hello World'
}
}
}
}- 完成
参考
]]>docker-host:
image: qoomon/docker-host
cap_add: [ 'NET_ADMIN', 'NET_RAW' ]
restart: on-failure
environment:
- PORTS=999
some-service:
image: ...
environment:
SERVER_URL: "http://docker-host:999"
command: ...
depends_on:
- docker-hostpost 步骤在Jenkins pipeline语法中是可选的,包含的是整个pipeline或阶段完成后一些附加的步骤。 比如我们希望整个pipeline执行完成之后或pipeline的某个stage执行成功后发生一封邮件,就可以使用post,可以理解为”钩子“。
根据 pipeline 或阶段的完成状态,post 部分分成多种条件块,包括:
- always:不论当前完成状态是什么,都执行。
- changed:只要当前完成状态与上一次完成状态不同就执行。
- fixed:上一次完成状态为失败或不稳定(unstable),当前完成状态为成功时执行。
- regression:上一次完成状态为成功,当前完成状态为失败、不稳定或中止(aborted)时执行。
- aborted:当前执行结果是中止状态时(一般为人为中止)执行。
- failure:当前完成状态为失败时执行。
- success:当前完成状态为成功时执行。
- unstable:当前完成状态为不稳定时执行。
- cleanup:清理条件块。不论当前完成状态是什么,在其他所有条件块执行完成后都执行。post部分可以同时包含多种条件块。
以下是 post 部分的完整示例:
pipeline {
agent any
stages {
stage('build') {
steps {
echo "build stage"
}
post {
always {
echo 'stage post always'
}
}
}
}
post {
changed {
echo 'pipeline post changed'
}
always {
echo 'pipeline post always'
}
success {
echo 'pipeline post success'
}
// 省略其他条件块
}
}技巧,分组判断多个状态:
post {
always {
script{
if (currentBuild.currentResult == "ABORTED" || currentBuild.currentResult == "FAILURE" || currentBuild.currentResult == "UNSTABLE" ){
slackSend channel: "#机器人", message: "Build failure: ${env.JOB_NAME} -- No: ${env.BUILD_NUMBER}, please check detail in email!"
} else {
slackSend channel: "#机器人", message: "Build Success: ${env.JOB_NAME} -- Build No: ${env.BUILD_NUMBER}, please check on http://www.yourwebsite.com"
}
}
}
}又因为script内可以直接写Groovy代码,上面的判断可以进一步优化
["ABORTED", "FAILURE", "UNSTABLE"].contains(currentBuild.currentResult)
参考
]]>
System Configuration - Configuration as Code

参考
https://opensource.com/article/20/4/jcasc-jenkins
https://blog.csdn.net/weixin_40046357/article/details/104549031
]]>- 拥有正在运行的Jenkins,并且有管理员权限
- 拥用一个Kubernetes集群
- Jenkins 安装 Kubernetes 插件

安装后系统设置里Configure Clouds - Add new cloud 选择Kubernetes

参考
https://www.jenkins.io/zh/blog/2018/09/14/kubernetes-and-secret-agents/
]]>基本结构满足不了现实多变的需求。所以,Jenkins pipeline通过各种指令(directive) 来丰富自己。指令可以被理解为对Jenkins pipeline基本结构的补充。
Jenkins pipeline支持的指令有:
- environment: 用于设置环境变量,可定义在stage或pipeline部分。
- tools: 可定义在pipeline或stage部分。它会自动下载并安装我们指定的工具,并将其加入PATH变量中。
- input: 定义在stage部分,会暂停 pipeline,提示你输入内容。
- options: 用于配置 Jenkins pipeline 本身的选项,比如
options {retry (3) }指当pipeline失败时再重试2次。options指令 可定义在stage或pipeline部分。 - parallel: 并行执行多个step。在pipeline插件 1.2版本后,parallel开始支 持对多个阶段进行并行执行。
- parameters: 与input不同,parameters是 执行pipeline前传入的一些参数。
- triggers: 用于定义执行pipeline的触发器。
- when: 当满足when定义的条件时,阶段才执行。
TIP
parameters 和 when 的使用会在后面详情介绍
在使用指令时,需要注意的是每个指令都有自己的"作用域"。如果指令使用的位置不正确,Jenkins将会报错。
options指令用于配置整个Jenkins pipeline本身的选项
例子
pipeline {
agent any
options {
timeout(time: 1, unit: 'HOURS')
disableConcurrentBuilds()
}
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}- 整个pipeline执行超过一个小时将中止
- 禁止pipeline同时执行,避免抢占资源或调用冲突
stage 的 options 指令类似于流水线根目录上的 options。
pipeline {
agent any
stages {
stage('Example') {
options {
timeout(time: 1, unit: 'HOURS')
}
steps {
echo 'Hello World'
}
}
}
}- 指定 Example 阶段的执行超时时间, 在此之后,Jenkins 将中止流水线运行。
options指令具体包含的参数比较多,不一一介绍了,见文档
参考
]]>Jenkins内置变量
在pipeline执行时,Jenkins通过一个名为env的全局变量,将Jenkins内置环境变量暴露出来。其使用方法有多种,示例如下:
pipeline {
agent any
stages {
stage('debug-列出当前流水线的所有环境变量) {
setps {
sh "printenv | sort"
}
}
stage('Example') {
steps {
echo "Running ${env.BUILDNUMBER} on ${env.JENKINS_URL}" # 方法1
echo "Running $env.BUILDNUMBER on $env.JENKINS_URL" # 方法2
echo "Running ${BUILDNUMBER} on ${JENKINS_URL}" # 方法3 简写版本不推荐,难排查
}
}
}
}默认env的属性可以直接在pipeline中引用。所以以上方法都是合法的。但是不推荐方法三,因为出现变量冲突时,非常难查问题。
那么,env变量都有哪些可用属性呢?
通过访问<Jenkins master的地址>/pipeline-syntax/globals#env来获取完整列表。
在列表中,当一个变量被声明为"For a multibranch project"时,代表只有多分支项目才会有此变量。

下面我们简单介绍几个在实际工作中经常用到的变量:
- BUILD_ NUMBER:构建号,累加的数字。在打包时,它可作为制品名称的一部分,比如server-2.jar。
- BRANCH_ NAME:多分支pipeline项目支持。当需要根据不同的分支做不同的事情时就会用到,比如通过代码将release分支发布到生产环境中、master分支发布到测试环境中。
- BUILD_ URL:当前构建的页面URL。如果构建失败,则需要将失败的构建链接放在邮件通知中,这个链接就可以是BUILD _URL。
- GIT BRANCH:通过git拉取的源码构建的项目才会有此变量。
在使用env变量时,需要注意不同类型的项目,env变量所包含的属性及其值是不一样的。
比如普通pipeline任务中的GIT BRANCH变量的值为origin/master,而在多分支pipeline任务中GIT BRANCH变量的值为master。
所以,在pipeline中根据分支进行不同行为的逻辑处理时,需要留意。
自定义变量
- pipeline提供的environment指令中定义
pipeline {
agent any
environment {
// 覆盖默认的PATH变量值
PATH="/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin"
name='jack'
}
stages {
stage("test env") {
steps {
sh "printenv" #调试,打印所有env变量
echo "${name}" # jack
echo "${env.name}" # jack
}
}
}
}pipeline {
agent any
environment {
FOO = "bar"
}
stages {
stage("Env Variables") {
environment {
NAME = "Alan"
}
steps {
echo "FOO = ${env.FOO}"
echo "NAME = ${env.NAME}"
script {
env.TEST_VARIABLE = "some test value"
}
echo "TEST_VARIABLE = ${env.TEST_VARIABLE}"
withEnv(["ANOTHER_ENV_VAR=here is some value"]) {
echo "ANOTHER_ENV_VAR = ${env.ANOTHER_ENV_VAR}"
}
}
}
}
}覆盖环境变量
Jenkins Pipeline支持覆盖环境变量。您需要注意一些规则。
- 使用
withEnv(["env=value]) { }语句块可以覆盖任何环境变量。 - 使用
environment {}语句块设置的变量不能使用命令式env.VAR = "value"赋值覆盖。 - 命令式
env.VAR = "value"分配只能覆盖使用命令式创建的环境变量。
这是一个示例性的Jenkinsfile,显示了所有三种不同的用例。
pipeline {
agent any
environment {
FOO = "bar"
NAME = "Joe"
}
stages {
stage("Env Variables") {
environment {
NAME = "Alan" // overrides pipeline level NAME env variable
BUILD_NUMBER = "2" // overrides the default BUILD_NUMBER
}
steps {
echo "FOO = ${env.FOO}" // prints "FOO = bar"
echo "NAME = ${env.NAME}" // prints "NAME = Alan"
echo "BUILD_NUMBER = ${env.BUILD_NUMBER}" // prints "BUILD_NUMBER = 2"
script {
env.SOMETHING = "1" // creates env.SOMETHING variable
}
}
}
stage("Override Variables") {
steps {
script {
env.FOO = "IT DOES NOT WORK!" // it can't override env.FOO declared at the pipeline (or stage) level
env.SOMETHING = "2" // it can override env variable created imperatively
}
echo "FOO = ${env.FOO}" // prints "FOO = bar"
echo "SOMETHING = ${env.SOMETHING}" // prints "SOMETHING = 2"
withEnv(["FOO=foobar"]) { // it can override any env variable
echo "FOO = ${env.FOO}" // prints "FOO = foobar"
}
withEnv(["BUILD_NUMBER=1"]) {
echo "BUILD_NUMBER = ${env.BUILD_NUMBER}" // prints "BUILD_NUMBER = 1"
}
}
}
}
}environment指令可以用在pipeline中定义,作用域就是整个pipeline,当定义在stage阶段,只在当前stage有效。
环境变量的互相引用
environment {
__server_name = 'email-server'
__version = "${BUILD_NUMBER}"
__artifact_name = "${__server_name}-${__version}.jar"
}将布尔值存储在环境变量中
关于使用环境变量,存在一种普遍的误解。存储为环境变量的每个值都将转换为String。
当您存储布尔false值时,它将转换为"false"。如果要在布尔表达式中正确使用该值,则需要调用"false".toBoolean()method。
pipeline {
agent any
environment {
IS_BOOLEAN = false
}
stages {
stage("Env Variables") {
steps {
script {
if (env.IS_BOOLEAN) {
echo "You can see this message, because \"false\" String evaluates to Boolean.TRUE value"
}
if (env.IS_BOOLEAN.toBoolean() == false) {
echo "You can see this message, because \"false\".toBoolean() returns Boolean.FALSE value"
}
}
}
}
}
}使用sh捕获环境变量
您还可以将shell命令的输出捕获为环境变量。
请记住,需要使用sh(script: 'cmd', returnStdout:true)格式来强制sh步骤返回输出,以便可以捕获它并将其存储在变量中。
pipeline {
agent any
environment {
LS = "${sh(script:'ls -lah', returnStdout: true)}"
}
stages {
stage("Env Variables") {
steps {
echo "LS = ${env.LS}"
}
}
}
}TIP
- 在调试pipeline时,可以再开始阶段加一句
sh 'printenv'将所有env变量打印出来。 - 自定义变量时,为避免命名冲突,可根据项目或公司加上统一前缀,如
__server_name,__就是前缀。
自定义全局环境变量
定义全局环境变量可以跨pipeline使用 进入Jenkins -- Manage Jenkins -- 找到Global properties -- 勾选Environment variables

自定义全局环境变量会被加入env属性列表中,所以使用时可以直接用${env.g_name}引用。
脚本式pipeline
上面的例子都是定义式pipeline,下面的例子是脚本式
node {
/* .. snip .. */
withEnv(["PATH+MAVEN=${tool 'M3'}/bin"]) {
sh 'mvn -B verify'
}
}构建是指将源码转换成一个可使用的二进制程序的过程。这个过程可以包括但不限于这几个环节:下载依赖、编译、打包。构建过程的输出一比如一 个zip包,我们称之为制品(有些书籍也称之为产出物)。而管理制品的仓库,称为制品库。 在没有Jenkins的情况下,构建过程通常发生在某个程序员的电脑上,甚至只能发生在某台特定的电脑上。这会给软件的质量带来很大的不确定性。想想软件的可靠性(最终是老板的生意)依赖于能进行构建的这台电脑的好坏,就觉得很可怕。 解决这问题的办法就是让构建每一步都是可重复的,尽量与机器无关。 所以,构建工具的安装、设置也应该是自动化的、可重复的。 虽然Jenkins只负责执行构建工具提供的命令,本身没有实现任何构建功能,但是它提供了构建工具的自动安装功能。
构建工具的选择
对构建工具的选择,很大一部分因素取决于你所使用的语言。比如构建Scala使用SBT, JavaScript的Babel、 Browserify、 Webpack、 Grunt以及Gulp等。 当然,也有通用的构建工具,比如Gradle,它不仅支持Java、Groovy、 Kotlin等语言,通过插件的方式还可以实现对更多语言的支持。 对构建工具的选择,还取决于团队对工具本身的接受程度。建议团队中同一技术栈的所有项目都使用同一个构建工具。
tools指令介绍
tools指令能帮助我们自动下载并安装所指定的构建工具,并将其加入PATH变量中。这样,我们就可以在sh步骤里直接使用了。但在agent none的情况下不会生效。 tools指令默认支持3种工具: JDK、Maven、Gradle。 通过安装插件,tools指令还可以支持更多的工具。
搭建Python环境
- 在Jenkins机器上安装python和virtualenv(Python的虚拟环境管理工具)
- 安装pyenv-pipeline插件
- 在pipeline中使用pyenv-pipeline插件提供的withPythonEnv方法,第一个参数是可执行Python的执行路径,在当前工作空间下创建一个virtualenv环境。第二个参数是一个闭包,闭包内的代码就执行在新建的virtualenv环境下。
withPythonEnv('/usr/bin/python3.5') {
// Uses the specific python3.5 executable located in /usr/bin
...
}
// 使用方法见文档
withPythonEnv('python') {
// Uses the default system installation of Python
// Equivalent to withPythonEnv('/usr/bin/python')
...
}利用环境变量支持更多构建工具
是不是所有的构建工具都需要安装相应的Jenkins插件才可以使用呢?当然不是。 平时,开发人员在搭建开发环境时做的就是:首先在机器上安装好构建工具,然后将这个构建工具所在目录加入PATH环境变量中。 如果想让Jenkins支持更多的构建工具,也是同样的做法:在Jenkins agent上安装构建工具,并记录下它的可执行命令的目录,然后在需要使用此命令的Jenkins pipeline 的PATH环境变量中加入该可执行命令的目录。示例如下:
pipeline {
agent any
environment {
PATH = "/user/lib/custom_tool/bin:$PATH"
}
stages {
stage('build') {
steps {
sh "custom_tool -v"
}
}
}
}还可以有另一种写法:
pipeline {
agent any
environment {
CUSTOM_TOOL_HOME = "/user/lib/custom_tool/bin"
}
stages {
stage('build') {
steps {
sh "${CUSTOM_TOOL_HOME}/custom_tool -v"
}
}
}
}利用tools作用域实现多版本编译
在实际工作中,有时需要对同一份源码使用多个版本的编译器进行编译。tools指令除了支持pipeline作用域,还支持stage作用域。 所以,我们可以在同一个pipeline中实见多版本编译。代码如下:
pipeline {
agent any
stages {
stage('build with jdk-10.0.2') {
tools {
jdk "jdk --10.0.2"
}
steps {
sh "printenv"
}
}
stage('build with jdk-9.0.4') {
tools {
jdk "jdk --9.0.4"
}
steps {
sh "printenv"
}
}
}
}在打印出来的日志中,会发现每个stage下的JAVA_ HOME变量的值都不一样。
总结:
- 使用tools指令指定或切换要使用的构建工具。
- 如果没有就先找相应的插件,如果没有插件就在Jenkins机器上安装,然后加入到环境变量中,最后在pipeline中使用。
更新 2021-06-15 为防止恶意触发,建议在Jenkins->configure Generic Webhook Trigger 中配置white list 添加IP地址,即只接受这个IP去请求webhook地址
更新 2019-07-14
关于 webhook 触发job,其实有更简单的办法,在job的配置页面
勾选Build Triggers选项卡的Trigger builds remotely (e.g., from scripts),填入一个token,但是有时候会报
"Error 403 No valid crumb was included in the request"个人觉得还是Generic Webhook Trigger插件好用

比如job名称是foo,token是123456,webhook地址就是JENKINS_URL/job/=foo/build?token=123456
经测无论是get还是post请求都可以成功触发。当然如果你的需求更高,需要根据请求头请求或地址中的参数有条件的触发,就可以用Generic Webhook Trigger插件。
如果返回'Authentication required'请检查地址中的token是否正确,还需要保证在Jenkins的'Configure Global Security'配置页面勾选了'Allow anonymous read access'。
使用参数化构建完成流水线动态传参
-
Generic Webhook Trigger中定义一个Request parameters,name 填 env_name env_name 是参数,值可以是qa或dev -
开启参数化流水线,为了接收参数,作为流水线变量

-
流水线脚本中要接收这个参数
以 powershell 为例,当然也可以是 shell
cd C:\JenkinsWorkSpace\CKFM\Framework
C:\Users\k64145621\AppData\Local\anaconda3\envs\pyAppium312\python.exe run.py %ENV_NAME%- 最终效果
- 当触发地址
http://JENKINS_URL/generic-webhook-trigger/invoke?token=Mobile_UI_GITLAB-20240927&env_name=qa运行 python run.py qa - 当触发地址
http://JENKINS_URL/generic-webhook-trigger/invoke?token=Mobile_UI_GITLAB-20240927&env_name=dev运行 python run.py dev
使用Generic Webhook Trigger完成提交代码自动触发流水线
需求:我的博客是用 hexo 搭建的,每次提交完代码都需要在托管的服务器上执行手动发布命令
deploy.sh
git pull
npm install
hexo g # 生成静态文件现在我需要Jenkins的Generic Webhook Trigger插件来帮我自动完成这些工作。
Generic Webhook Trigger是 Jenkins 提供的一款插件,装好这个插件后会暴露出一个URL地址,格式如 JENKINS_URL/generic-webhook-trigger/invoke。
我们往这个地址发请求,请求体或请求头带上要构建的job名称,分支名称等信息,这个插件可以正则提取出这些信息,当作变量进而触发构建。
大致流程如下图:

-
在 Jenkins 插件管理页面搜索该插件

-
安装之后新建一个item,类型选freestyle,pipeline都行,在 Build Trigger 选项卡中会看到多出了一项 "Generic Webhook Trigger",勾选之后多出了很多信息。这里只填写Token

-
这里我创建的是个Pipeline的job,pipeline script 就是调用
deploy.sh。注意这里我的博客和Jenkins都部署在了同一台服务器上面。
pipeline {
agent any
// 避免 npm install 报权限问题
environment {
PATH="/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin"
}
stages {
stage('build') {
steps {
sh 'node -v'
sh 'npm -v'
dir ("/var/www/www.mafeifan.com/") {
sh 'git pull'
sh 'npm install'
sh 'hexo g'
}
}
}
}
}-
来到Gitee/Github,添加一个webhook地址,如果你的Jenkins地址是
http://110.110.110.110:8080,job名称为gitee-hexo-blog-pipeline, 那么根据规则,Generic Webhook Trigger的地址是http://110.110.110.110:8080/generic-webhook-trigger/invoke?token=gitee-hexo-blog-pipeline配置完成,点测试,看返回内容是否是成功的。
-
测试,我们修改代码内容,并且push,发现Jenkins果然自动触发了build。

- 如果我们需要限制分支,比如只有往develop上push代码才触发,
在 Build Triggers 选项卡中填写 Post content parameters 内容。
即将请求体中的ref内容提取出来赋给$ref

然后在 Optional filter 选项卡中填写要过滤的分支名称。 Expression 填写正则 ^(refs/heads/develop)$, Text 可以填写变量 $ref

测试时候建议用Postman。触发地址 GWT 会告诉咱们,请求体可以在仓库托管平台获取,然后手动修改内容进行测试

插件安装后在Job配置页面会多出一个"Generic WebHook Trigger"选项 勾选后有很多参数配置,详细介绍GWT各参数的含义我们下面会讲到

插件安装后在pipeline也可以使用 GenericTrigger 指令完成相同的配置
现在,我们创建一个普通的pipeline项目。代码如下:
#!groovy
pipeline {
agent {
node {
label 'master'
}
}
triggers {
GenericTrigger(
genericVariables: [
[key: 'ref', value: '$.ref']
],
token: 'secret' ,
causeString: ' Triggered on $ref' ,
printContributedVariables: true,
printPostContent: true
)
}
stages {
stage('GWT env') {
steps {
sh "echo $ref"
sh "printenv"
}
}
}
}注意:在创建完成后,需要手动执行一次, 这样pipeline的触发条件オ会生效。
然后我们用 Postman 发起一次 HTTP POST 请求。

或者直接用curl命令 curl -vs http://140.xxx.xxx.xxx/generic-webhook-trigger/invoke\?token\=first-pipeline\&foo\=bar
接着,我们就看到 pipeline 被触发!
GenericTrigger 触发条件由GWT插件提供。此触发条件可以说是GWT的所有内容。 GenericTrigger 触发条件分为5部分,这样更易于理解各参数的作用。
- 从 HTTP POST 请求中提取参数值。
- token, GWT 插件用于标识Jenkins项目的唯一性。
- 根据清求参数值判断是否触发Jenkins项目的抗行。
- 日志打印控制。
- WebHook 响应控制。 一个 HTTP POST 请求可以从三个维度提取参数,即 POST Body、URL参数和header。 GWT 插件提供了三个参数分别从这三个维度的数据进行提取。
- genericVariables: 提取POST body 中的参数
genericVariables: [
[
key: 'before',
value: '$.before',
expressionType: 'JSONPath',
regularFilter: '',
defaultValue: ''
],
[key: 'ref', value: '$.ref']
],- value: JSONPath 或 XPath 表达式,取决于 expressType 参数值,用于从 POST body 中提取值。
- key: 从 POST Body 中提取出的值的新变量名,可用于pipeline其他步骤。
- expressType: 可选, value的表达式类型,默认为JSONPath,当请求为XML内容时,必须指定 XPath 值。
- defaultValue:可选,当提取不到值,且defaultValue不为空时,则使用defaultValue作为返回值。
- regexpFilter:可选,过滤表达式,对提取出来的值进行过滤。regexpFilter做的事情其实就是
string.replaceAll(regexpFilter,"");。string是从HTTP请求中提取出来的值。
- genericRequestVariables:从URL参数中提取值。
genericRequestVariables: [
[
key: 'requestWithNumber',
regexpFilter: '[^0-9]',
],
[key: 'requestWithString', regexpFilter: '']
],• key:提取出的值的新变量名,可用于pipeline其他步骤。 • regexpFilter:对提取出的值进行过滤。
- genericHeaderVariables:从HTTP header 中提取值。用法和genericRequestVariables一样。
token 参数
标识唯一性,值可以使用项目+时间 当Jenkins接收到 GWT 接口的请求时,会将请求代理给GWT插件处理。GWT插件内部会从Jenkins实例对象中取出所有的参数化Jenkins项目,包括pipeline, 然后进 行遍历。如果在参数化项目中GenericTrigger配置的token的值与Webhook请求时的token的值 致,则触发此参数化项目。 如果多个项目的此参数值一样,都会被触发。
实际上,GWT并不只是根据 token 值来判断是否触发,还可以根据我们提取出的值进行判断。示例如下:
- regexpFilterText:需要进行匹配的key。例子中,我们使用从POST body中提取出的refValue变量值。
- regexpFilterExpression:正则表达式。 如果 regexpFilterText 参数的值符合 regexpFilterExpression 参数的正则表达式,则触发执行。
打印内容
GWT 插件提供了三个供日调试打印日志的参数
- Silent response 当为true,只返回http 200 状态码,不返回触发结果
- Print post content 将 webhook 请求的内容打印到日志上
- Print contributed variables 将 提取后的变量打印到日志上
实例
只有commit message 包含 new build 才触发


测试,触发成功,payload 从 gitee 的webhook中复制

测试
修改请求,header头添加信息,地址添加参数,发现 GWT 返回的结果中已经成功识别了。 至于多了0的参数,原因未详。

apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkins
spec:
replicas: 1
selector:
matchLabels:
app: jenkins
template:
metadata:
labels:
app: jenkins
spec:
containers:
- name: jenkins
image: jenkins/jenkins:lts
ports:
- name: http-port
containerPort: 8080
- name: jnlp-port
containerPort: 50000
volumeMounts:
- name: jenkins-vol
mountPath: /var/jenkins_vol
volumes:
- name: jenkins-vol
emptyDir: {}所以只要把这个文件替换掉即可。
比较省事的做法是进到 console 镜像所在的 node 节点,然后docker exec进到容器,替换掉svg文件即可
需要注意的是要使用 root 用户进到容器,不然没有操作权限
注意:容器重启了 logo 还会还原
商业用途请联系 kubesphere 商务,这里只是本地实验
查看 ks-console 在哪个节点上运行
kubectl describe pods -l app=ks-console -n kubesphere-system | grep "Node"
比如显示 master
ssh 登录到 master 机器节点,进入到容器
# 查看console的容器ID
sudo docker ps | grep "console"
834fe7c6a782 kubespheredev/ks-console "docker-entrypoint.s…" 2 weeks ago Up 2 weeks k8s_ks-console_ks-console-7684cb7965-jwl9z_kubesphere-system_17a82fb7-b315-4ba5-a518-580ec8caa5fc_0
# 进入容器
sudo docker exec -it -u root 834fe7c6a782 /bin/ash以下是容器内执行
cd dist/
mv assets/logo.svg assets/logo2.svg
wget https://www.osvlabs.com/static/icons/logo.svg
mv logo.svg assets/关于语言文本
kubesphere本身支持多语言,语言文件在dist目录。以locale开头,比如打开locale-en.6ea577bc5b07101a8d52.json 搜索'KS_DESCRIPTION'替换掉描述文本



参考
https://stackoverflow.com/questions/42793382/exec-commands-on-kubernetes-pods-with-root-access
]]>现象:文档说的是执行kubectl edit ks-console将 service 类型NodePort 更改为LoadBalancer,完成后保存文件
可是当修改可插拔组件后,ks-console service就又恢复成NodePort了
为彻底解决,可以新建一个LoadBalancer类型的service,既让他支持NodePort又支持LoadBalancer
cat <<EOF | kubectl apply -f -
kind: Service
apiVersion: v1
metadata:
name: ks-console-loadbalancer
namespace: kubesphere-system
labels:
app: ks-console-loadbalancer
tier: frontend
version: v3.1.0
spec:
ports:
- name: nginx
protocol: TCP
port: 80
targetPort: 8000
nodePort: 30888
selector:
app: ks-console
tier: frontend
type: LoadBalancer
sessionAffinity: None
EOFkubesphere自带的本身提供了nodejs,maven,go,base等4种agent,参见,对应于不同的语言构建。
但是nodejs的版本是9,我希望是目前比较流行的16版本。
所以我打算新添加一个agent。
前置条件
- kubesphere管理员
- kubesphere开启Jenkins界面后台访问
- 熟悉Jenkins的kubernetes插件
制作agent镜像
对照着官方的Dockerfile和base制作新的agent
FROM kubespheredev/builder-base:v3.1.0
ENV NODE_VERSION 16.13.0
RUN ARCH=x64 \
# gpg keys listed at https://github.com/nodejs/node#release-keys
&& set -ex \
&& for key in \
4ED778F539E3634C779C87C6D7062848A1AB005C \
94AE36675C464D64BAFA68DD7434390BDBE9B9C5 \
74F12602B6F1C4E913FAA37AD3A89613643B6201 \
71DCFD284A79C3B38668286BC97EC7A07EDE3FC1 \
8FCCA13FEF1D0C2E91008E09770F7A9A5AE15600 \
C4F0DFFF4E8C1A8236409D08E73BC641CC11F4C8 \
C82FA3AE1CBEDC6BE46B9360C43CEC45C17AB93C \
DD8F2338BAE7501E3DD5AC78C273792F7D83545D \
A48C2BEE680E841632CD4E44F07496B3EB3C1762 \
108F52B48DB57BB0CC439B2997B01419BD92F80A \
B9E2F5981AA6E0CD28160D9FF13993A75599653C \
; do \
gpg --batch --keyserver sks.srv.dumain.com --recv-keys "$key"; \
done \
&& curl -fsSLO --compressed "https://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION-linux-$ARCH.tar.xz" \
&& curl -fsSLO --compressed "https://nodejs.org/dist/v$NODE_VERSION/SHASUMS256.txt.asc" \
&& gpg --batch --decrypt --output SHASUMS256.txt SHASUMS256.txt.asc \
&& grep " node-v$NODE_VERSION-linux-$ARCH.tar.xz\$" SHASUMS256.txt | sha256sum -c - \
&& tar -xJf "node-v$NODE_VERSION-linux-$ARCH.tar.xz" -C /usr/local --strip-components=1 --no-same-owner \
&& rm "node-v$NODE_VERSION-linux-$ARCH.tar.xz" SHASUMS256.txt.asc SHASUMS256.txt \
&& ln -s /usr/local/bin/node /usr/local/bin/nodejs \
&& yum install -y nodejs gcc-c++ make bzip2 GConf2 gtk2 chromedriver chromium xorg-x11-server-Xvfb
# Yarn
ENV YARN_VERSION 1.22.17
RUN curl -f -L -o /tmp/yarn.tgz https://github.com/yarnpkg/yarn/releases/download/v${YARN_VERSION}/yarn-v${YARN_VERSION}.tar.gz && \
tar xf /tmp/yarn.tgz && \
mv yarn-v${YARN_VERSION} /opt/yarn && \
ln -s /opt/yarn/bin/yarn /usr/local/bin/yarn && \
yarn config set cache-folder /root/.yarn
# https://www.npmjs.com/package/npm-config-china
RUN yarn config set registry https://registry.npmmirror.com -g
RUN npm config set registry https://registry.npmmirror.com
CMD ["node","-v"]镜像我托管在了https://hub.docker.com/repository/docker/finleyma/node16
配置jenkins agent
登录kubesphere,进入【配置中心】-【配置】,搜索 jenkins-casc-config ,修改配置。此文件是Jenkins的配置文件,描述了安装Jenkins时要顺带哪些插件和插件配置 在clouds-kubernetes-templates添加的新的agent描述信息 当然你也可以复制nodejs的配置信息
- name: "nodejs16"
namespace: "kubesphere-devops-worker"
label: "nodejs16"
nodeUsageMode: "EXCLUSIVE"
idleMinutes: 0
containers:
- name: "nodejs16"
image: "registry.cn-zhangjiakou.aliyuncs.com/finleyma/jenkins-agent-node16"
command: "cat"
args: ""
ttyEnabled: true
privileged: false
resourceRequestCpu: "100m"
resourceLimitCpu: "4000m"
resourceRequestMemory: "100Mi"
resourceLimitMemory: "8192Mi"
- name: "jnlp"
image: "jenkins/jnlp-slave:3.27-1"
command: "jenkins-slave"
args: "^${computer.jnlpmac} ^${computer.name}"
resourceRequestCpu: "50m"
resourceLimitCpu: "500m"
resourceRequestMemory: "400Mi"
resourceLimitMemory: "1536Mi"
workspaceVolume:
emptyDirWorkspaceVolume:
memory: false
volumes:
- hostPathVolume:
hostPath: "/var/run/docker.sock"
mountPath: "/var/run/docker.sock"
- hostPathVolume:
hostPath: "/var/data/jenkins_nodejs_yarn_cache"
mountPath: "/root/.yarn"
- hostPathVolume:
hostPath: "/var/data/jenkins_nodejs_npm_cache"
mountPath: "/root/.npm"
- hostPathVolume:
hostPath: "/var/data/jenkins_sonar_cache"
mountPath: "/root/.sonar/cache"
yaml: "spec:\r\n affinity:\r\n nodeAffinity:\r\n preferredDuringSchedulingIgnoredDuringExecution:\r\n - weight: 1\r\n preference:\r\n matchExpressions:\r\n - key: node-role.kubernetes.io/worker\r\n operator: In\r\n values:\r\n - ci\r\n tolerations:\r\n - key: \"node.kubernetes.io/ci\"\r\n operator: \"Exists\"\r\n effect: \"NoSchedule\"\r\n - key: \"node.kubernetes.io/ci\"\r\n operator: \"Exists\"\r\n effect: \"PreferNoSchedule\"\r\n containers:\r\n - name: \"nodejs16\"\r\n resources:\r\n requests:\r\n ephemeral-storage: \"1Gi\"\r\n limits:\r\n ephemeral-storage: \"10Gi\"\r\n securityContext:\r\n fsGroup: 1000\r\n "WARNING
java.net.ProtocolException: Expected HTTP 101 response but was '400 Bad Request'
当遇到这个错误,是因为容器名不一致导致的,Pod template中containers/name 和 yaml/spec/containers/name 要设为一致,一开始我一个设的nodejs16另一个设置的nodejs
打开你的Jenkins,点击“Manage Jenkins->Configuration as Code->Apply new configuration”。
等待一会儿,如果没有报错,则配置完成。可以点击此页下的“View Configuration”检查配置是否生效。
如果还没生效,Path中填写/var/jenkins_home/casc_configs/jenkins.yaml 重新apply

检查agent
Manage Jenkins - Manage Nodes and Clouds - Configure Clouds
发现nodejs16配置项已经有了,内容就是之前yaml中描述的那样

参考
https://github.com/kubesphere/devops-agent/blob/v3.2.0/nodejs/Dockerfile
https://segmentfault.com/a/1190000039311627
https://kubesphere.io/zh/docs/devops-user-guide/how-to-use/jenkins-setting/
https://kubesphere.com.cn/forum/d/3384-kubespheredevopsdotnet-core
]]>搜索名称为 devops-jenkins的deployment,编辑yaml,在env添加-Dorg.apache.commons.jelly.tags.fmt.timeZone=Asia/Shanghai
containers:
- name: devops-jenkins
image: 'kubesphere/ks-jenkins:v3.2.0-2.249.1'
args:
- '--argumentsRealm.passwd.$(ADMIN_USER)=$(ADMIN_PASSWORD)'
- '--argumentsRealm.roles.$(ADMIN_USER)=admin'
ports:
- name: http
containerPort: 8080
protocol: TCP
- name: slavelistener
containerPort: 50000
protocol: TCP
env:
- name: JAVA_TOOL_OPTIONS
value: >-
-Xms512m -Xmx512m -XX:MaxRAM=2g
-Dorg.apache.commons.jelly.tags.fmt.timeZone=Asia/Shanghai对于Kubersphere来说。替换分为几个方面:
第一步
kubectl -n kubesphere-system patch cc ks-installer -p '{"spec":{"local_registry":"registry.cn-beijing.aliyuncs.com"}}' --type=merge
基本能替换 kubesphere-system 命名空间的镜像
对于 kubesphere-monitoring-system 由于Kubersphere整合了开源的prometheus-operator,直接改deployment或stateful的image是不生效的, 要改CRD,原因这个配置项应该是PrometheusOperator在控制,具体可以参考文档看看 api-reference
修改 prometheus 用到的镜像地址
kubectl edit prometheus -n kubesphere-monitoring-system k8s
# 修改image部分
# 注意版本,替换为正在使用的
containers:
- image: 'registry.cn-beijing.aliyuncs.com/kubesphereio/prometheus:v2.39.1'
name: prometheus
- image: >-
registry.cn-beijing.aliyuncs.com/kubesphereio/prometheus-config-reloader:v0.55.1
name: config-reloader
evaluationInterval: 1m
image: 'registry.cn-beijing.aliyuncs.com/kubesphereio/prometheus:v2.39.1'
initContainers:
- image: >-
registry.cn-beijing.aliyuncs.com/kubesphereio/prometheus-config-reloader:v0.55.1
name: init-config-reloader直接在界面里编辑也可以

同样的,修改 alertmanager 用到的镜像地址
kubectl edit alertmanager -n kubesphere-monitoring-system main
containers:
- image: 'registry.cn-beijing.aliyuncs.com/kubesphereio/alertmanager:v0.23.0'
name: alertmanager
- image: >-
registry.cn-beijing.aliyuncs.com/kubesphereio/prometheus-config-reloader:v0.55.1
name: config-reloader
image: 'registry.cn-beijing.aliyuncs.com/kubesphereio/alertmanager:v0.23.0'参考
https://prometheus-operator.dev/docs/api-reference/api/#monitoring.coreos.com/v1.Prometheus
]]>-
[TOC]
账户问题
重置管理员密码
kubectl patch users <USERNAME> -p '{"spec":{"password":"<YOURPASSWORD>"}}' --type='merge' && kubectl annotate users <USERNAME> iam.kubesphere.io/password-encrypted-
# 请将命令中的 <USERNAME> 修改为实际的帐户名称,将 <YOURPASSWORD> 修改为实际的新密码。检查密码是否正确
curl -u <USERNAME>:<PASSWORD> "http://`kubectl -n kubesphere-system get svc ks-apiserver -o jsonpath='{.spec.clusterIP}'`/api/v1/nodes"创建
创建服务
Invalid Service "blog-mysql" is invalid: spec.clusterIPs[0]: Invalid value: "None": may not be set to 'None' for NodePort services

服务启动
Caused by: org.quartz.impl.jdbcjobstore.LockException: Failure obtaining db row lock: Table 'mega-admin.QRTZ_LOCKS' doesn't exist

问题原因
微服务模块启动时,报表不存在,检测 mysql 后发现配置无异常,数据库中也有该表。仔细观察上面报错内容,发现其找的是大写字母的表名,这是由于 mysql 配置中未忽略大小写造成。
解决办法
在 mysql 的配置文件中my.ini,配置如下
...
[mysqld]
lower_case_table_names=1
...查看是否生效
在 mysql 图形界面执行
SHOW VARIABLES LIKE '%case%'流水线报错
java.net.ProtocolException: Expected HTTP 101 response but was '400 Bad Request'
at okhttp3.internal.ws.RealWebSocket.checkResponse(RealWebSocket.java:229)
at okhttp3.internal.ws.RealWebSocket$2.onResponse(RealWebSocket.java:196)
at okhttp3.RealCall$AsyncCall.execute(RealCall.java:203)
at okhttp3.internal.NamedRunnable.run(NamedRunnable.java:32)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
io.fabric8.kubernetes.client.KubernetesClientException: container base is not valid for pod nodejs-qvtv0原因agent的label要与step-container中保持一致
pipeline {
agent {
node {
label 'nodejs'
}
}
stage('打包镜像') {
steps {
container('nodejs') {
sh 'docker build -f Dockerfile -t $ARTIFACT_IMAGE/$NAMESPACE/$PROJECT:prod-$BUILD_NUMBER .'
}
}
}
}以 wordpress 包为例
wordpress/
Chart.yaml # 包含有关chart信息的YAML文件
LICENSE # OPTIONAL: 包含chart许可证的纯文本文件
README.md # OPTIONAL: 一个可读的README文件
requirements.yaml # OPTIONAL: 一个YAML文件,列出了chart的依赖关系
values.yaml # 该chart的默认配置值
charts/ # OPTIONAL: 包含此chart所依赖的任何chart的目录。
templates/ # OPTIONAL: 一个模板目录,当与values相结合时,
# 将生成有效的Kubernetes清单文件
templates/NOTES.txt # OPTIONAL: 包含简短使用说明的纯文本文件
templates/_helpers.tpl # OPTIONAL:通过define 函数定义命名模板
crds/ # OPTIONAL: 自定义资源以下说明chart包内容 Chart.yaml文件内容格式
name: chart的名称 (required)
version: 一个SemVer 2(语义化版本)版本(required)
description: 这个项目的单句描述 (optional)
keywords:
- 关于此项目的关键字列表 (optional)
home: 该项目主页的URL(optional)
sources:
- 此项目的源代码URL列表 (optional)
dependencies: chart依赖关系 (optional)
- name: chart名字 (nginx)
version: chart版本 ("1.2.3")
repository: url仓库 ("https://example.com/charts")
condition: (optional) 布尔值的yaml路径,用于启用/禁用图表
maintainers: # (optional)
- name: 维护者的名称 (每个维护者都需要)
email: 维护者的email (optional for each maintainer)
url: 维护者的url (optional for each maintainer)
engine: gotpl#模板引擎的名称(可选,默认为gotpl)
icon: 要用作图标的SVG或PNG图像的URL (optional)
appVersion: 包含的应用程序版本(可选)这个不一定是SemVer
deprecated: 此chart是否已被弃用(可选,布尔型)README.md内容
- Introduction
- Prerequisites
- Installing the Chart
- Uninstalling the Chart
- Configuration
requirements.yaml介绍
在Helm中,一个chart可能取决于任何数量的其他chart。
这些依赖关系可以通过requirements.yaml文件动态链接,或者引入charts/目录并手动管理。
dependencies:
- name: apache
version: 1.2.3
repository: http://example.com/charts
alias: new-subchart-1- Name: 你想要的chart的名称。
- Version: 你想要的chart的版本。
- repository字段是图表存储库的完整URL。 请注意,您还必须使用helm repo add在本地添加该repository。
- alias:别名。 一旦有一个依赖关系文件,可以运行
helm dependency update,它会使用你的依赖关系文件为你下载所有指定的chart到你的charts/目录中。 可以在values.yaml定义true/false判断依赖包是否被启用,如
apache:
enabled: true依赖关系可以是chart压缩包(foo-1.2.3.tgz),也可以是未打包的chart目录。 依赖执行顺序:参考k8s负载自启动原理,所以我们可以不关心执行顺利。实际上交叉执行。
说明:helm2是通过requirements.yaml文件描述依赖关系,helm3直接在Chart.yaml描述
templates/k8s资源
templates下有多个deployment对象,可以命名不同名字。 执行顺序:参考k8s负载自启动原理,所以我们可以不关心执行顺利。 实际执行顺序为:
var InstallOrder KindSortOrder = []string{
"Namespace",
"NetworkPolicy",
"ResourceQuota",
"LimitRange",
"PodSecurityPolicy",
"PodDisruptionBudget",
"Secret",
"ConfigMap",
"StorageClass",
"PersistentVolume",
"PersistentVolumeClaim",
"ServiceAccount",
"CustomResourceDefinition",
"ClusterRole",
"ClusterRoleList",
"ClusterRoleBinding",
"ClusterRoleBindingList",
"Role",
"RoleList",
"RoleBinding",
"RoleBindingList",
"Service",
"DaemonSet",
"Pod",
"ReplicationController",
"ReplicaSet",
"Deployment",
"HorizontalPodAutoscaler",
"StatefulSet",
"Job",
"CronJob",
"Ingress",
"APIService",
}两种方式可以提前执行,一种设置pre-install,另一种是设置权重: pre-install hooks,如:
apiVersion: v1
kind: Service
metadata:
name: foo
annotations:
"helm.sh/hook": "pre-install"定义权重,如:
annotations:
"helm.sh/hook-weight": "5"values.yaml
- Release.Name: release的名称(不是chart的名称!)
- Release.Namespace: chart release的名称空间。
- Release.Service: 进行release的服务。 通常这是Tiller。
- chart版本可以作为Chart.Version获得。Chart:Chart.yaml 的内容。
- templates下有多个deployment对象,可以命名不同名字,然后在values.yaml以不同名字打头定义值。如以下格式定义:
mysql:
name:
image:
repository:
tag:
pullPolicy:
redis:
name:
image:
repository:
tag:
pullPolicy:helm模板
helm模板语法嵌套在{{和}}之间,有三个常见的
.Values.*
从value.yaml文件中读取或者--set获取(--set优先级最大)。
.Release.*
从运行Release的元数据读取,每次安装均会生成一个新的release
template * .
从_helpers.tpl文件中读取,通过define 函数定义命名模板
.Chart.*
从Chart.yaml文件中读取模板函数和管道
* | 管道,类似linux下的管道,以下实例效果是一样的。
{{ quote .Values.favorite.drink }}与 {{ .Values.favorite.drink | quote }}
* default制定默认值
drink: {{ .Values.favorite.drink | default “tea” | quote }}
* indent 模板函数,对左空出空格,左边空出两个空格
{{ include "mychart_app" . | indent 2 }}
include 函数,与 template 类似功能
如实例,在_helpers.tpl中define模板,在资源对象中引用。
{{- define "mychart.labels" }}
labels:
generator: helm
date: {{ now | htmlDate }}
{{- end }}
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
{{- template "mychart.labels" }}
data:在模板中使用文件
apiVersion: v1
kind: ConfigMap
metadata:
name: conf
data:
{{ (.Files.Glob "foo/*").AsConfig | indent 2 }}chart根目录下foo目录的所有文件配置为configmap的内容
模板流程控制
常用的有 if/else 条件控制 with 范围控制 range 循环控制 如:values.yaml中定义变量,ConfigMap中.Values.favorite循环控制参数。
favorite:
drink: coffee
food: pizza
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}-configmap
data:
myvalue: "Hello World"
{{- range $key, $val := .Values.favorite }}
{{ $key }}: {{ $val | quote }}
{{- end}}在deployment.yaml文件中使用if/else语法,如:- end结束标志,双括号都有“-”。
{{- if .Values.image.repository -}}
image: {.Values.image.repository}
{{- else -}}
image: "***/{{ .Release.Name }}:{{ .Values.image.version }}"
{{- end -}}数据键值对,作为Pod的配置文件或环境变量。
configmap的数据可以来自三种类型:字面量,文件和目录
mkdir primary
echo g > primary/green
echo r > primary/red
echo y > primary/yellow
echo k > primary/black
echo "known as key" >> primary/black
echo blue > favorite
kubectl create configmap colors \
--from-literal=text=black \
--from-file=./favorite \
--from-file=./primary/
kubectl get configmap colors
kubectl get configmap colors -o yamlconfigMap作为环境变量传入Pod
simpleshell.yaml
apiVersion: v1
kind: Pod
metadata:
name: shell-demo
spec:
containers:
- name: nginx
image: nginx
env:
- name: ilike
valueFrom:
configMapKeyRef:
name: colors
key: favoritekubectl create -f simpleshell.yaml
kubectl exec shell-demo -- /bin/bash -c 'echo $ilike'
kubectl delete pod shell-demo也可以把全部的文件内容作为环境变量传入Pod。稍微修改下simpleshell2.yaml
apiVersion: v1
kind: Pod
metadata:
name: shell-demo2
spec:
containers:
- name: nginx
image: nginx
# env:
# - name: ilike
# valueFrom:
# configMapKeyRef:
# name: colors
# key: favorite
envFrom:
- configMapRef:
name: colorskubectl exec shell-demo -- /bin/bash -c 'env'
作为挂载卷
kind: ConfigMap
apiVersion: v1
metadata:
name: redis-conf
namespace: iot-ningxia
annotations:
kubesphere.io/creator: admin
data:
redis.conf: |-
appendonly yes
port 6379
bind 0.0.0.0挂载到StatefulSet的Pod中
kind: StatefulSet
apiVersion: apps/v1
metadata:
name: redis
namespace: iot-ningxia
labels:
app: redis
annotations:
kubesphere.io/creator: mafei
spec:
serviceName: redis
replicas: 1
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
volumes:
- name: volume-redis-conf
configMap:
name: redis-conf
containers:
- name: redis
image: 'redis:6'
command:
- redis-server
args:
- /etc/redis/redis.conf
ports:
- name: tcp-6379
containerPort: 6379
protocol: TCP
volumeMounts:
- name: volume-redis-conf
readOnly: true
mountPath: /etc/redis
imagePullPolicy: IfNotPresent创建流程:创建两个 deployment 和对应的 service,最后基于这两个service创建ingress。 最终实现效果,当访问
-
当客户端将请求发送到网址路径为 "/" 的负载平衡器时,请求将被转发到端口 60000 上的 hello-world Service。
-
当客户端将请求发送到网址路径为 "/kube" 的负载平衡器时,请求将被转发到端口 80 上的 hello-kubernetes Service。
大致流程:
deployment -> service -> ingress
hello-kubernetes-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-kubernetes-deployment
spec:
selector:
matchLabels:
greeting: hello
department: kubernetes
replicas: 3
template:
metadata:
labels:
greeting: hello
department: kubernetes
spec:
containers:
- name: hello-again
image: "gcr.io/google-samples/node-hello:1.0"
env:
- name: "PORT"
value: "8080"hello-kubernetes-service.yaml
apiVersion: v1
kind: Service
metadata:
name: hello-kubernetes
spec:
# 同时具有 greeting: hello 标签和 department: kubernetes 标签的任何 Pod 都是 Service 的成员。
type: NodePort
selector:
greeting: hello
department: kubernetes
ports:
# 当请求发送到 TCP 端口 80 上的 Service 时,它将被转发到 TCP 端口 8080 上的某个成员 Pod。
- protocol: TCP
port: 80
targetPort: 8080hello-world-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-world-deployment
spec:
selector:
matchLabels:
greeting: hello
department: world
replicas: 3
template:
metadata:
labels:
greeting: hello
department: world
spec:
containers:
- name: hello
image: "gcr.io/google-samples/hello-app:2.0"
env:
- name: "PORT"
value: "50000"hello-world-service.yaml
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
type: NodePort
selector:
greeting: hello
department: world
ports:
- protocol: TCP
port: 60000
# 当请求发送到 TCP 端口 60000 上的 Service 时,它将被转发到 TCP 端口 50000 上的某个成员 Pod
targetPort: 50000选中刚创建的两个service

配置路径

最后我们可以预览yaml
---
apiVersion: "extensions/v1beta1"
kind: "Ingress"
metadata:
name: "my-ingress"
namespace: "default"
spec:
rules:
- http:
paths:
- path: "/*"
backend:
serviceName: "hello-world"
servicePort: 60000
- path: "/kube"
backend:
serviceName: "hello-kubernetes"
servicePort: 80查看刚创建的ingress
kubectl get ingress my-ingress --output yaml
status:
loadBalancer:
ingress:
- ip: 34.117.148.159google cloud会自动创建负载均衡器并暴露一个IP地址,比如 34.117.148.159,访问根路径和/kube会返回期望的结果拉
PS:真实情况是我怎么访问这个IP都显示超时,检查了防火墙也没有问题,无奈我联系Google cloud人工客服,虽然他们只能看懂英文,不过很好沟通。 最终确认是IP被墙了,在外国访问是正常的... 你可以打开浏览器的代理
参考
https://cloud.google.com/kubernetes-engine/docs/tutorials/http-balancer
https://cloud.google.com/kubernetes-engine/docs/how-to/load-balance-ingress#gcloud
]]>cat /usr/lib/systemd/system/kubelet.service
[Unit] Description=kubelet: The Kubernetes Node Agent Documentation=https://kubernetes.io/docs/home/ Wants=network-online.target After=network-online.target
[Service] ExecStart=/usr/bin/kubelet Restart=always StartLimitInterval=0 RestartSec=10
[Install] WantedBy=multi-user.target
]]>springboot 的配置文件是 application.yml 里面会有连接数据库的配置信息,在仓库里明文显示是不行的
部署到k8s里要替换掉,url, username, password 等
server:
port: 8040
spring:
application:
name: demo
jackson:
default-property-inclusion: non_null
locale: zh
time-zone: GMT+8
date-format: yyyy-MM-dd HH:mm:ss
datasource:
druid:
url: jdbc:mysql://localhost:23306/demo?characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=false&allowMultiQueries=true
username: root
password: root使用环境变量替换
- 首先创建secret,包含键值对,值会自动经过base64处理
kind: Secret
apiVersion: v1
metadata:
name: demo-secret
namespace: demo
data:
rds_conn_str: >-
amRiYzpteXNFyYWN0ZXJFbmNvZGluZz1VVEYtOCZ1c2VTU0w9ZmFsc2UmdXNlSkRCQ0NvbXBsaWFudFRpbWV6b25lU2hpZnQ9dHJ1ZSZhbGxvd011bHRpUXVlcmllcz10cnVl
rds_password: aDg2YkNBOUZQOA==
rds_username: a2Zwcy1ydw==
type: Opaque- 修改 deployment
env 部分是从secret中读取键,对应的值存到环境变量中,这时候登录容器,就是可以查看到环境变量RDS_CONN_STR,RDS_USERNAME和RDS_PASSWORD
然后在args中,使用$(RDS_CONN_STR),$(RDS_USERNAME),$(RDS_PASSWORD)覆盖掉application.yml中的值
spec:
containers:
- name: demo
image: >-
demo-image:latest
command:
- java
- '-jar'
args:
- '-Dfile.encoding=UTF-8'
- '-Dspring.profiles.active=pt'
- '-Dspring.datasource.url=$(RDS_CONN_STR)'
- '-Dspring.datasource.username=$(RDS_USERNAME)'
- '-Dspring.datasource.password=$(RDS_PASSWORD)'
- /opt/app/app.jar
env:
- name: RDS_CONN_STR
valueFrom:
secretKeyRef:
name: demo-secret
key: rds_conn_str
- name: RDS_USERNAME
valueFrom:
secretKeyRef:
name: demo-secret
key: rds_username
- name: RDS_PASSWORD
valueFrom:
secretKeyRef:
name: demo-secret
key: rds_password更进一步
spec:
containers:
- name: demo
image: >-
demo-image:latest
command:
- java
- '-jar'
args:
- '-Dfile.encoding=UTF-8'
- '-Dspring.profiles.active=pt'
- /opt/app/app.jar
env:
- name: SPRING.DATASOURCE.URL
valueFrom:
secretKeyRef:
name: demo-secret
key: rds_conn_str
- name: SPRING.DATASOURCE.USERNAME
valueFrom:
secretKeyRef:
name: demo-secret
key: rds_username
- name: SPRING.DATASOURCE.PASSWORD
valueFrom:
secretKeyRef:
name: demo-secret
key: rds_password使用新的配置文件替换,配置文件存到secret中
-
把整个application.yml 存到secret中
-
deployment 添加环境变量
spec:
containers:
- name: your-app
image: your-image:tag
command:
- java
- '-jar'
args:
- '-Dfile.encoding=UTF-8'
- '-Dspring.config_location=$(SPRING_CONFIG_LOCATION)'
ports:
- containerPort: 8080
env:
- name: SPRING_CONFIG_LOCATION
value: "file:/path/to/application.yaml"
volumeMounts:
- name: config-volume
mountPath: /path/to/application.yaml
volumes:
- name: config-volume
secret:
secretName: demo-secret在 Kubernetes 中有几种不同的方式发布应用,所以为了让应用在升级期间依然平稳提供服务,选择一个正确的发布策略就非常重要了,本篇文章将讲解如何在 Kubernetes 使用滚动更新的方式更新镜像。
原理
策略定义为 RollingUpdate 的 Deployment。滚动更新通过逐个替换实例来逐步部署新版本的应用,直到所有实例都被替换完成为止,会有新版旧版同时存在的情况。
spec:
replicas: 4
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 0 # 决定了配置中期望的副本数之外,最多允许超出的 pod 实例的数量
maxUnavailable: 25% # 决定了在滚动升级期间,相对于期望副本数能够允许有多少 pod 实例处于不可用状态上述更新策略执行结果如下图所示

使用 Kubernetes 原生方式升级应用
准备
image
bebullish/demo:v1
bebullish/demo:v2deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo-dp
spec:
selector:
matchLabels:
app: demo
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
metadata:
labels:
app: demo
spec:
containers:
- name: demo
image: bebullish/demo:v1
ports:
- containerPort: 8080service
apiVersion: v1
kind: Service
metadata:
name: demo-service
spec:
selector:
app: demo
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
protocol: TCP将上述 deployment 以及 service 保存为 yaml 文件,使用 kubectl apply -f 命令创建 yaml 资源,等待创建成功后,使用 kubectl get svc 获取 EXTERNAL-IP。
测试
如果使用浏览器测试的话,你会发现每次调用都会返回同一个 pod 的名字,那是因为浏览器发出的请求包含 keepAlive,所以需要使用 curl 来保证每次发出的请求都是重新创建的。
curl -X GET http://${EXTERNAL-IP}

升级
升级之前先执行命令,以便查看镜像更新过程
while true; do curl -X GET http://49.232.125.218 ; done
更新镜像
kubectl set image deployment demo-dp demo=bebullish/demo:v2
查看日志
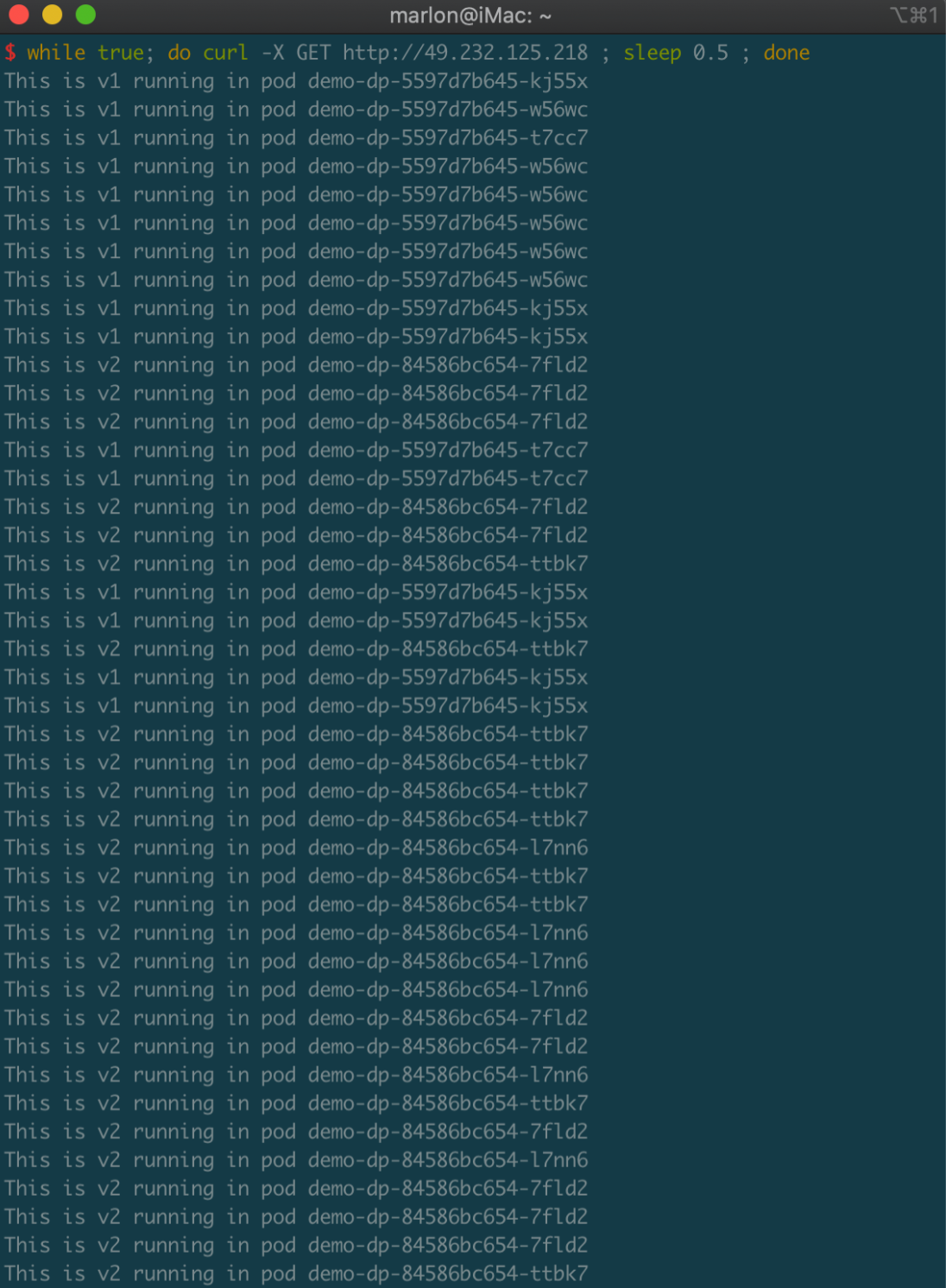
结论
首先可以发现在更新过程中,程序保持一直可用的状态,在出现了 v2 版本之后,还会出现 v1 版本的日志,说明在这个期间 v1 和 v2 版本是同时存在的,等到 v2 版本的 pod 全部处于就绪状态之后,可以看到所有的请求就都是 v2 版本的了。
参考
https://help.coding.net/docs/best-practices/cd/rolling-release.html
]]>蓝绿(blue/green):
一句话:新版本与旧版本一起存在,然后切换流量
详细说明: 蓝绿发布,是在生产环境稳定集群之外,额外部署一个与稳定集群规模相同的新集群,并通过流量控制,逐步引入流量至新集群直至 100%,原先稳定集群将与新集群同时保持在线一段时间,期间发生任何异常,可立刻将所有流量切回至原稳定集群,实现快速回滚。直到全部验证成功后,下线老的稳定集群,新集群成为新的稳定集群。
蓝绿部署流程图

蓝绿发布的流程,包括:蓝绿发布开始、蓝绿初始化、蓝绿验证、蓝绿取消或完成上线。
K8S中如何实现蓝绿部署
- 通过k8s service label标签来实现蓝绿发布
- 通过Ingress 控制器来实现蓝绿发布
- 通过Istio来实现蓝绿发布,或者像Istio类似的服务
K8S中如何实现蓝绿部署
service.yaml 文件
apiVersion: v1
kind: Service
metadata:
name: demo
namespace: default
labels:
app: demo
spec:
ports:
- port: 80
targetPort: http
protocol: TCP
name: http
# 注意这里我们匹配 app 和 version 标签,当要切换流量的时候,我们更新 version 标签的值,比如:v2
selector:
app: demo
version: v1蓝 v1-deploy.yaml 文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo1-deployment
namespace: default
labels:
app: demo
version: v1
spec:
replicas: 1
revisionHistoryLimit: 3
## 滚动发布策略
strategy:
rollingUpdate:
maxSurge: 30%
maxUnavailable: 30%
selector:
matchLabels:
app: demo
version: v1
template:
metadata:
labels:
app: demo
version: v1
spec:
containers:
- name: demo1
image: mritd/demo
## 存活探针
## https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/#configure-probes
livenessProbe:
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
periodSeconds: 30
successThreshold: 1
failureThreshold: 5
# 就绪探针
readinessProbe:
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 5
ports:
- name: http
containerPort: 80
protocol: TCP绿 v2-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo2-deployment
namespace: default
labels:
app: demo
version: v2
spec:
replicas: 1
revisionHistoryLimit: 3
strategy:
rollingUpdate:
maxSurge: 30%
maxUnavailable: 30%
selector:
matchLabels:
app: demo
version: v2
template:
metadata:
labels:
app: demo
version: v2
spec:
containers:
- name: demo2
image: mritd/demo
livenessProbe:
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
periodSeconds: 30
successThreshold: 1
failureThreshold: 5
readinessProbe:
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 30
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 5
ports:
- name: http
containerPort: 80
protocol: TCP上面定义的资源对象中,最重要的就是Service 中 label selector的定义:
selector:
app: demo
version: v1部署与测试
部署v1 v2 deploy服务 和 service服务
$ kubectl apply -f service.yaml -f v1-deploy.yaml -f v2-deploy.yaml
测试流量是否到v1版本
# 登陆任意一个pod,向 demo service 发起请求
$ while sleep 0.3; do curl http://demo; done
# 输出日志
Host: demo1-deployment-b5bd596d8-dw27b, Version: v1
Host: demo1-deployment-b5bd596d8-dw27b, Version: v1切换入口流量从v1 到 v2
$ kubectl patch service demo -p '{"spec":{"selector":{"version":"v2"}}}'
测试流量是否到v2版本
# 登陆任意一个pod,向 demo service 发起请求
$ while sleep 0.3; do curl http://demo; done
# 输出日志
Host: demo2-deployment-b5bd596d8-dw27b, Version: v2
Host: demo2-deployment-b5bd596d8-dw27b, Version: v2参考
]]>当流量突然增大,会导致CPU使用率或内存突然增高,为保证业务不中断,可以通过设置自动调整的Horizontal Pod Autoscaler 来解决这个问题。
HPA (Horizontal Pod Autoscaler) 可以根据 CPU 利用率自动扩缩 ReplicationController、 Deployment、ReplicaSet 或 StatefulSet 中的 Pod 数量
原理
使用HPA,必须先安装metrics-server服务 工作原理: 使用metrics-server持续采集所有Pod副本的指标数据,HPA Controller 通过metrics-server提供的API获取这些数据,基于用户自定义的扩缩容规则进行计算,得到目标副本数量。
如果得出结果与当前副本数不符,HPA Controller向副本控制器发起scale操作,调转
然后通过HPA来调整副本数量
创建测试用的 deployment 和 service
其中 hpa-example 镜像只包含了一个index.php,模拟 CPU 密集型计算,内容如下:
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
}
echo "OK!";
?>apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: mirrorgooglecontainers/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache创建水平自动伸缩器 Horizontal Pod Autoscaler
# 大致来说,HPA 将(通过 Deployment)增加或者减少 Pod 副本的数量以保持所有 Pod 的平均 CPU 利用率在 50% 左右。
# 由于每个 Pod 请求 200 毫核的 CPU,这意味着平均 CPU 用量为 100 毫核。
$ kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=3
$ kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 3 1 17s
# 打开另一个终端发起更多请求,模拟压力测试,提高CPU负载
$ kubectl run -i --tty load-generator --rm --image=busybox --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
# 这时,由于请求增多,CPU 利用率已经升至请求值的 305%。 可以看到,Deployment 的副本数量已经增长到了3:
k get deployment -w
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 2/3 3 2 10m
# 停掉模拟请求,deployment副本数会在数分钟内自动将至为1多项度量维度
上面的例子,只有一个度量维度,即CPU利用率。 如果需要更多的度量维度,可以使用平均值
参考
https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
]]>所以K8引入了Network Policy网络策略的概念,网络策略可以设置Pod之间的访问权限,只有被授权的Pod才能访问其他Pod。
原理
网络策略的实现是通过网络策略的规则来实现的,规则的实现需要策略控制器,策略控制器由第三方网络组件提供,目前有Calico, Weave, Cilium等。
网络策略的规则是一个YAML文件,
实例
只允许拥有role=nginx-client标签的 Pod 访问某些容器
这里创建三个 Pod 和一个网络策略 pc-network-policy
## 访问目标的nginx pod
k run np-target --image=nginx --labels="app=nginx" --port=80
# 两个访问源,一个带标签role=nginx-client,可以访问np-target,不带的访问不了
k run np-source-1 --image=busybox --labels="role=nginx-client" --command -- sleep 3600
k run np-source-2 --image=busybox --command -- sleep 3600apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: pc-network-policy
namespace: default
spec:
podSelector:
matchLabels:
app: nginx
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
role: nginx-client
ports:
- protocol: TCP
port: 80# 记下 np-target 的 IP,比如是 10.233.68.42
k get po -o wide
# 分别登录 np-source-1 和 np-source-2 去访问 np-target
mafei@master:~/app$ k exec -it np-source-1 -- sh
/ # curl 10.233.68.42
sh: curl: not found
/ # wget 10.233.68.42
Connecting to 10.233.68.42 (10.233.68.42:80)
saving to 'index.html'
index.html 100% |*****************************************************************************************| 615 0:00:00 ETA
'index.html' saved
/ # exit
mafei@master:~/app$ k exec -it np-source-2 -- sh
/ # wget --timeout=5 10.233.68.42
Connecting to 10.233.68.42 (10.233.68.42:80)
wget: download timed out
/ #证实了网络策略生效了,对没有role: nginx-client标签的 Pod 拒绝访问
CKA考题
Run an nginx Pod in the default namespace. Also run a busybox Pod in the secure namespace.
Create a NetworkPolicy that only allows access to the nginx Pod from the busybox Pod in the secure namespace and denies all other access.
创建一个网络策略,只允许命名空间为 secure 的 busybox Pod 访问 nginx Pod,其他的都拒绝访问
k create ns secure
k run nginx --image=nginx --port=80 --labels="app=nginx"# touch b1.yaml
apiVersion: v1
kind: Pod
metadata:
name: busybox1
namespace: secure
labels:
type: monitoring1
spec:
containers:
- name: busybox1
image: busybox
command: [ "sleep", "3600"]apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: only-allow-from-busybox-secure-ns
namespace: default
spec:
podSelector:
matchLabels:
app: nginx
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: secure
- podSelector:
matchLabels:
type: monitoring1默认拒绝所有入站流量
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
spec:
podSelector: {}
policyTypes:
- Ingress更多例子参考官网文档:https://kubernetes.io/docs/concepts/services-networking/network-policies/
参考
https://kubernetes.io/zh/docs/concepts/services-networking/network-policies/
https://github.com/mafeifan/kubernetes-network-policy-recipes
https://faun.pub/cka-exercises-network-policy-namespace-843bfead629e
]]>卷的核心是一个目录,其中可能存有数据,Pod 中的容器可以访问该目录中的数据。
所采用的特定的卷类型将决定该目录如何形成的、使用何种介质保存数据以及目录中存放的内容。
数据卷(Volume)
我们对数据的要求:
- pod 或 node 挂了,数据依然存在;
- pod 或 node 重启,数据依然存在。
- 数据保存在 Pod 外部
查看k8s支持的存储类型
kubectl explain pod.spec.volumes
数据卷(Volume)是Pod与外部存储设备进行数据传递的通道,也是Pod内部容器间、Pod与Pod间、Pod与外部环境进行数据共享的方式。
数据卷(Volume)定义了外置存储的细节,并内嵌到Pod中作为Pod的一部分。其实质是外置存储在Kubernetes 系统的一个资源映射,当负载需要使用外置存储的时候,可以从数据卷(Volume)中查到相关信息并进行存储挂载操作。
数据卷(Volume)生命周期和Pod一致,即Pod被删除的时候,数据卷(Volume)也一起被删除(Volume中的数据是否丢失取决于Volume的具体类型)。
Kubernetes提供了非常丰富的Volume类型,常用的Volume类型分类如下:
| 数据卷(Volume)分类 | 描述 |
|---|---|
| 本地存储 | 适用于本地存储的数据卷,例如HostPath、emptyDir等。本地存储卷的特点是数据保存在集群的特定节点上,并且不能随着应用漂移,节点停机时数据即不再可用。 |
| 网络存储 | 适用于网络存储的数据卷,例如Ceph、GlusterFS、NFS、iSCSI等。网络存储卷的特点是数据不在集群的某个节点上,而是在远端的存储服务上,使用存储卷时需要将存储服务挂载到本地使用。 |
| Secret和ConfigMap | Secret和ConfigMap是特殊的数据卷,其数据是集群的一些对象信息,该对象数据以卷的形式被挂载到节点上供应用使用。 |
| PVC | 一种数据卷定义方式,将数据卷抽象成一个独立于Pod的对象,这个对象定义(关联)的存储信息即存储卷对应的真正存储信息,供Kubernetes负载挂载使用。 |
卷类型 - emptyDir
emptyDir类型的Volume在Pod分配到Node上时被创建,Kubernetes会在Node上自动分配一个目录,因此无需指定宿主机Node上对应的目录文件。 这个目录的初始内容为空,当Pod从Node上移除时,emptyDir中的数据会被永久删除。
常见场景: 作为从崩溃中恢复的备份点; 存储那些那些需要长久保存的数据,例web服务中的数据
我们定义了2个容器,其中一个容器是输入日期到index.html中,然后验证访问nginx的html是否可以获取日期。以验证两个容器之间挂载的emptyDir实现共享。
# vim pod-vol-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels:
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
volumeMounts: #在容器内定义挂载存储名称和挂载路径
- name: html
mountPath: /usr/share/nginx/html/
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: html
mountPath: /data/ #在容器内定义挂载存储名称和挂载路径
command: ['/bin/sh','-c','while true;do echo $(date) >> /data/index.html;sleep 2;done']
volumes: #定义存储卷
- name: html #定义存储卷名称
emptyDir: {} #定义存储卷类型卷类型 - hostPath
hostPath类型则是映射node文件系统中的文件或者目录到pod里。在使用hostPath类型的存储卷时,也可以设置type字段,支持的类型有文件、目录、File、Socket、CharDevice和BlockDevice。
常见场景: 挂载宿主机的时区文件到容器内,保持和宿主机时区一致。
在使用hostPath volume卷时,即便pod已经被删除了,volume卷中的数据还在!
emptyDir和hostPath在功能上的异同分析
二者都是node节点的本地存储卷方式;
emptyDir可以选择把数据存到tmpfs类型的本地文件系统中去,hostPath并不支持这一点;
emptyDir是临时存储空间,完全不提供持久化支持;
hostPath的卷数据是持久化在node节点的文件系统中的,即便pod已经被删除了,volume卷中的数据还会留存在node节点上;
卷类型 - local 卷
local 卷仍然取决于底层节点的可用性,并不适合所有应用程序。 如果节点变得不健康,那么local 卷也将变得不可被 Pod 访问。使用它的 Pod 将不能运行。
如果不使用外部静态驱动来管理卷的生命周期,用户需要手动清理和删除 local 类型的持久卷
更多卷类型及具体用法见文档:https://kubernetes.io/zh/docs/concepts/storage/volumes/#volume-types
数据卷(Volume)使用原则
- 一个Pod可以挂载多个数据卷(Volume)。
- 一个Pod可以挂载多种类型的数据卷(Volume)。
- 每个被Pod挂载的Volume卷,可以在不同的容器间共享。
- Kubernetes 环境推荐使用PVC和PV方式挂载数据卷(Volume)。
- 虽然单Pod可以挂载多个数据卷(Volume),但是并不建议给一个Pod挂载过多数据卷。
PV和PVC
并非所有的Kubernetes数据卷(Volume)具有持久化特征,为了实现持久化的实现,容器存储需依赖于一个远程存储服务。
为此Kubernetes引入了PV和PVC两个资源对象,将存储实现的细节从其如何被使用中抽象出来,并解耦存储使用者和系统管理员的职责。
PV和PVC的概念如下:
- PV,PV是PersistentVolume的缩写,译为持久化存储卷。
PV在Kubernetes中代表一个具体存储类型的卷,其对象中定义了具体存储类型和卷参数。即目标存储服务所有相关的信息都保存在PV中,Kubernetes引用PV中的存储信息执行挂载操作
PV是一个集群级别的概念,其对象作用范围是整个Kubernetes集群,而不是一个节点。PV可以有自己的独立生命周期,不依附于Pod。
PVC 属于某命名空间
$ kubectl get pv -A
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-018f32f6-2b7c-455f-98d3-1a483759856a 1Gi RWO Delete Bound harbor/database-data-harbor-mi6d6k-harbor-database-0 local 194d
pvc-02180b8b-e3ab-4dde-b047-c716519e58e3 20Gi RWO Delete Bound iot-ningxia/pvc-pg-data local 136d
pvc-07d5ba11-8ab5-446c-b7bc-add960c3a15c 20Gi RWO Delete Bound monitor/pvc-prometheus
$ kubectl get pvc -A
NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
cosmota db Bound pvc-9acde447-b380-4609-be24-c837ce983e13 40Gi RWO local 81d
cosmota web-storage Bound pvc-e095b626-0abb-498b-be8b-8365a35073f9 5Gi RWO local 78d
cosmota web-uploads Bound pvc-e49627ba-9fde-4ef3-b5ec-7a0f6ad8a840 5Gi RWO local 78- PVC, PVC是PersistentVolumeClaim的缩写,译为存储声明。
PVC是在Kubernetes中一种抽象的存储卷类型,代表了某个具体类型存储的数据卷表达。其设计意图是分离存储与应用编排,将存储细节抽象出来并实现存储的编排。这样Kubernetes中存储卷对象独立于应用编排而单独存在,在编排层面使应用和存储解耦。

PV和PVC使用说明
PVC和PV的绑定
PVC与PV是一一对应关系,不能一个PVC挂载多个PV,也不能一个PV挂载多个PVC。
为应用配置存储时,需要声明一个存储需求声明(PVC),而Kubernetes会通过最佳匹配的方式选择一个满足PVC需求的PV,并与之绑定。
所以从职责上PVC是应用所需要的存储对象,属于应用作用域。PV是存储平面的存储对象,属于整个存储域。
PVC只有绑定了PV之后才能被Pod使用,而PVC绑定PV的过程即是消费PV的过程,这个过程是有一定规则的,以下规则都满足的PV才能被PVC绑定:
- VolumeMode:被消费PV的VolumeMode需要和PVC一致。
- AccessMode:被消费PV的AccessMode需要和PVC一致。
- StorageClassName:如果PVC定义了此参数,PV必须有相关的参数定义才能进行绑定。
- LabelSelector:通过标签(labels)匹配的方式从PV列表中选择合适的PV绑定。
- Size:被消费PV的capacity必须大于或者等于PVC的存储容量需求才能被绑定。
PV和PVC定义中的size字段
PVC和PV里面的size字段作用如下:
- PVC、PV绑定时,会根据各自的size进行筛选。
- 通过PVC、StorageClass动态创建PV时,有些存储类型会参考PVC的size创建相应大小的PV和后端存储。
- 对于支持Resize操作的存储类型,PVC的size作为扩容后PV、后端存储的容量值。
一个PVC、PV的size值只是在执行一些PVC和PV管控操作的时候,作为配置参数来使用。
真正的存储卷数据流写数据的时候,不会参考PVC和PV的size字段,而是依赖底层存储介质的实际容量。
两种PV的提供方式:静态分配或者动态分配
静态分配:
- 集群管理员预先创建一些 PV。它们携带可供集群用户使用的真实存储的详细信息。 它们存在于Kubernetes API中,可用于消费。
- 用户创建PVC与PV绑定
动态分配:
通过存储类进行动态创建存储空间,当管理员创建的静态 PV 都不匹配用户的 PVC 时,集群可能会尝试动态地为 PVC 配置卷。此配置基于 StorageClasses:PVC 必须请求存储类,并且管理员必须已创建并配置该类才能进行动态配置。
用户创建PVC即可自动创建PV并绑定
参考
]]>k run --image=nginx --port=80 pod1
k exec -it pod1 -- curl -s http://localhost:80root@pod1:/var/run/secrets/kubernetes.io# tree
.
`-- serviceaccount
|-- ca.crt -> ..data/ca.crt
|-- namespace -> ..data/namespace
`-- token -> ..data/token
1 directory, 3 files- namespace内容就是pod所在的ns名称,default
- token 内容吗, 是和 default ns 的 token一致的
eyJhbGciOiJSUzI1NiIsImtpZCI6IlV3YVRlU216QlVRV2ZGZkhCcGhtZmcwLUtJLU5rdk9MYWdkMFFyWDdmbDAifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjc3NTc5MTM1LCJpYXQiOjE2NDYwNDMxMzUsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJkZWZhdWx0IiwicG9kIjp7Im5hbWUiOiJwb2QxIiwidWlkIjoiZDEyOTFiYzEtMjI1MC00ZmVlLWJkN2ItYjk0YzdmYTdhZjE1In0sInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJkZWZhdWx0IiwidWlkIjoiNTYxN2EyYzYtMTA4OC00ZGNlLTk0MDUtMDU0NTJjODdiYmRlIn0sIndhcm5hZnRlciI6MTY0NjA0Njc0Mn0sIm5iZiI6MTY0NjA0MzEzNSwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50OmRlZmF1bHQ6ZGVmYXVsdCJ9.3wa7U8pthVdyFCUHStaQ7KLW1Bu01uKFj1dGry-latvj7jZZyrBn_6ELW0akdH-lZ0Zbqq0zZsCxTL2sIA0aAibb8o1iyPdtVkeJPtqRZW9lZXkGpCVy9B9dpxzjO88D7Gd_Y0azBqNnE5XLocsOtht8foyI4qeDmbNT_5W3VMOHMcJYGfweK3PAS8P1GRkGgNj3zKZ8At_Dr9d4-toFUVwHvOsr49XMsUaORCnk8zujW_Aap0tK3sdeb58QIIwUL318Zg-goYx7lOojpPg9FIoIZJsYEG5a5iFbeWn1NDQrg_w7mIrDv3FJTrCmYbY0tn2OdNmrJ_tHjw4kbydAYQ查看 default namespace 下的 default service account名称
kubectl get sa default -n default -o yaml
apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2022-02-28T05:58:01Z"
name: default
namespace: default
resourceVersion: "450"
uid: 5617a2c6-1088-4dce-9405-05452c87bbde
secrets:
- name: default-token-224g4查看 secret 的内容
kubectl describe secret default-token-224g4
Name: default-token-224g4
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name: default
kubernetes.io/service-account.uid: 5617a2c6-1088-4dce-9405-05452c87bbde
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1066 bytes
namespace: 7 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IlV3YVRlU216QlVRV2ZGZkhCcGhtZmcwLUtJLU5rdk9MYWdkMFFyWDdmbDAifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJkZWZhdWx0Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImRlZmF1bHQtdG9rZW4tMjI0ZzQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGVmYXVsdCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjU2MTdhMmM2LTEwODgtNGRjZS05NDA1LTA1NDUyYzg3YmJkZSIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDpkZWZhdWx0OmRlZmF1bHQifQ.VRfS_Kbz_xEd1aFbJsJap1LnrUKIFRdMF3lei_ODZ2H5ao4EnKjccdCmWLZHOBHWKLBbtTKX0c4iHoHMxBgOF8WOK2NdUS90DsdIrHx0wwHe9r2dPeqyETz8QpEu6ahRs40Rz23o8T62wJZ_VU5dW38c2tYZyeFWV9UCiFCpTovouHvP5DYNzw-O31UCABtQzLKiy6R3pjl8f_Z0_RQgiPlBHM17n7Zmqt_9f8kOS7Uf2ofyZXVAZKCNo-bmy_uMcL-XIpt0tTqN_-1JlTOmsoh8Q6N75W-3PQ1P3f57lQKkK96vO_CsuD0u3_Kvt1wcPBa5QsqiuAIbKEUJlcjrtQK8s集群对外暴露服务的方式目前只有三种:Loadbalancer;NodePort;Ingress
- Loadbalancer 缺点:需要阿里云等公有云支持,而且需要额外支付费用
- NodePort 缺点:要暴露端口,端口默认是 30000-32767
- Ingress 好处:Ingress 不会公开任意端口或协议。可能就是带来一些学习成本,需要了解 Traefik 和 Nginx 的常用配置和反向代理。
一图看 Ingress 流程,由图可知,ingress 充当的是代理的角色,把外部来的请求,根据路由地址转发到k8s中匹配到的后端service,而且service又连接了deployment,一个deployment又跑了N个Pod,达到了流量转发的目的。
知识点:
- 为了让 Ingress 资源工作,集群必须有一个正在运行的 Ingress Controller。
- 可以在集群中部署任意数量的 ingress 控制器。 创建 ingress 时,应该使用适当的 ingress.class 注解每个 Ingress 以表明在集群中如果有多个 Ingress 控制器时,应该使用哪个 Ingress 控制器。
- 比较流行的Ingress 控制器有nginx-ingress-controller 和 Traefik & Kubernetes
- Traefik是用Go编写的边缘路由程序,自带UI界面,有反向代理,负载均衡,自动配置并SSL证书,最近很火,但是官方文档比较垃圾,配置很灵活,使用起来有些难度。


平台
- MacOS 11.2.3
- Docker Desktop 3.3.3
- Docker Engine: 20.10.6
- Kubernetes: v1.19.7
坑
目前常用的K8S镜像库有
- docker.io (docker hub公共镜像库)
- gcr.io (Google container registry)
- k8s.gcr.io (等同于 gcr.io/google-containers)
- quay.io (Red Hat运营的镜像库)
k8s.gcr.io 被墙,拉image可能会失败而且阿里云啥的没有最新的镜像库,没办法,我是去docker hub找别人的。具体参见
步骤
- 本地启动docker,检查k8s版本,是1.19.7
- 版本
kubectl version
Client Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.7", GitCommit:"1dd5338295409edcfff11505e7bb246f0d325d15", GitTreeState:"clean", BuildDate:"2021-01-13T13:23:52Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.7", GitCommit:"1dd5338295409edcfff11505e7bb246f0d325d15", GitTreeState:"clean", BuildDate:"2021-01-13T13:15:20Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"linux/amd64"}- 安装NGINX Ingress Controller,打开官网
提示安装kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.46.0/deploy/static/provider/cloud/deploy.yaml
先浏览器打开https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.46.0/deploy/static/provider/cloud/deploy.yaml搜image:
会搜到这个镜像地址k8s.gcr.io/ingress-nginx/controller:v0.46.0@sha256:....
本地先尝试拉下docker pull k8s.gcr.io/ingress-nginx/controller:v0.46.0... 发现失败,很简单,这个镜像地址被墙了,得找替换!
打开 docker hub 搜 ingress-nginx-controller, 只找到了最新的v0.45.0
猜测差距不大,把文件下载到并编辑器打开
https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.45.0/deploy/static/provider/cloud/deploy.yaml
把
image: k8s.gcr.io/ingress-nginx/controller:v0.45.0 替换为
image: willdockerhub/ingress-nginx-controller:v0.45.0
这步非常重要哦
- 我重命名为了
v0.45.0-deploy.yaml接下来运行他!kubectl apply -f v0.45.0-deploy.yaml
验证一下
kubectl get pods --all-namespaces -l app.kubernetes.io/name=ingress-nginx
kubectl describe pod
- 跑一个例子
准备文件,下载三个实例文件,镜像hashicorp/http-echo就是个http服务器
# apple.yaml
kind: Pod
apiVersion: v1
metadata:
name: apple-app
labels:
app: apple
spec:
containers:
- name: apple-app
image: hashicorp/http-echo
args:
- "-text=apple"
---
kind: Service
apiVersion: v1
metadata:
name: apple-service
spec:
selector:
app: apple
ports:
- port: 5678 # Default port for image# banana.yaml
kind: Pod
apiVersion: v1
metadata:
name: banana-app
labels:
app: banana
spec:
containers:
- name: banana-app
image: hashicorp/http-echo
args:
- "-text=banana"
---
kind: Service
apiVersion: v1
metadata:
name: banana-service
spec:
selector:
app: banana
ports:
- port: 5678 # Default port for image# ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: example-ingress
annotations:
kubernetes.io/ingress.class: "nginx"
ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: ingress.finley.demo
http:
paths:
- path: /apple
backend:
serviceName: apple-service
servicePort: 5678
- path: /banana
backend:
serviceName: banana-service
servicePort: 5678service不作解释。ingress就是定义一个地址,当访问/apple就调用apple-service中暴露的5678端口,而apple-service是为apple-app这个pod提供网络服务的
运行他们
kubectl apply -f sample/apple.yaml
kubectl apply -f sample/banana.yaml
kubectl apply -f sample/ingress.yaml注意ingress.yaml我配置的域名是ingress.finley.demo需要让本地访问
- 打开 /etc/hosts
添加127.0.0.1 ingress.finley.demo
- 见证奇迹时刻
浏览器打开 http://ingress.finley.demo/apple 页面显示 apple
浏览器打开 http://ingress.finley.demo/banana 页面显示 banana
其实ingress就是个代理功能,可以作为Service的统一网关入口
各个 Kubernetes Ingress Controllers 的对比: https://docs.google.com/spreadsheets/d/191WWNpjJ2za6-nbG4ZoUMXMpUK8KlCIosvQB0f-oq3k/htmlview
参考
https://docs.google.com/spreadsheets/d/191WWNpjJ2za6-nbG4ZoUMXMpUK8KlCIosvQB0f-oq3k/htmlview
https://kubernetes.io/zh/docs/concepts/services-networking/ingress/
https://kubernetes.github.io/ingress-nginx/deploy/#docker-desktop
https://developer.aliyun.com/article/759310
]]>虽然我们知道K8s的集群数据是保存在ETCD上面,但很难针对单个namespace进行备份及恢复。
这里推荐使用Velero
Velero 可以干什么
- 灾备场景,提供备份恢复k8s集群的能力
- 迁移场景,提供拷贝集群资源到其他集群的能力(复制同步开发,测试,生产环境的集群配置,简化环境配置)
另外各大公有云厂商提供了 Velero 插件,比如安装了阿里云 velero ACK plugin 可以直接将数据备份到阿里云对象存储上。
Velero 的组成
Velero 由运行在集群上的服务端和一个运行在本地的命令行客户端组成。
与etcd的区别
与 Etcd 备份相比,直接备份 Etcd 是将集群的全部资源备份起来。而 Velero 就是可以对 Kubernetes 集群内对象级别进行备份。除了对 Kubernetes 集群进行整体备份外,Velero 还可以通过对 Type、Namespace、Label 等对象进行分类备份或者恢复。
备份原理和流程图
- 本地 Velero 客户端发送备份指令。
- Kubernetes 集群内就会创建一个 Backup 对象。
- BackupController 监测 Backup 对象并开始备份过程。
- BackupController 会向 API Server 查询相关数据。
- BackupController 将查询到的数据备份到远端的对象存储。

安装
这里,我已经有AWS账号并创建了S3存储桶,可以直接使用Velero插件
创建一个配置文件,里面放可以操作S3的AWS凭证信息
$ cat > ~/.credentials-velero << EOF
[default]
accessKeyID: AKIAIOSFODNN7EXAMPLE
secretAccessKey: *****SECRET*****
EOF
# 安装 velero
$ export BUCKET=finley007
$ export REGION=ap-northeast-1
$ velero install \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.4.0 \
--bucket $BUCKET \
--backup-location-config region=$REGION \
--snapshot-location-config region=$REGION \
--secret-file ./.credentials-velero
# 等待状态变为running
Velero is installed! ⛵ Use 'kubectl logs deployment/velero -n velero' to view the status.备份及恢复
# 测试备份,这里我只备份命名空间为secure的资源,里面就跑了一个Pod
$ k get po -n secure
NAME READY STATUS RESTARTS AGE
busybox1 1/1 Running 23 5d21h
$ velero backup create nginx-backup --include-namespaces secure --wait
Backup request "nginx-backup" submitted successfully.
Waiting for backup to complete. You may safely press ctrl-c to stop waiting - your backup will continue in the background.
...
Backup completed with status: Completed. You may check for more information using the commands `velero backup describe nginx-backup` and `velero backup logs nginx-backup`打开S3页面查看备份结果

# 测试恢复,恢复之前我已经把里面的Pod删除了
$ k delete po busybox1 -n secure
$ velero restore create --from-backup nginx-backup --wait
Restore request "nginx-backup-20220310221931" submitted successfully.
Waiting for restore to complete. You may safely press ctrl-c to stop waiting - your restore will continue in the background.
.
Restore completed with status: Completed. You may check for more information using the commands `velero restore describe nginx-backup-20220310221931` and `velero restore logs nginx-backup-20220310221931`.
k get po -n secure
NAME READY STATUS RESTARTS AGE
busybox1 1/1 Running 0 5s注意:velero restore 的行为不是覆盖,恢复不会覆盖已有的资源,只恢复当前集群中不存在的资源。已有的资源不会回滚到之前的版本,如需要回滚,需在restore之前提前删除现有的资源。
更多命令
# 查看备份位置
$ velero get backup-locations
NAME PROVIDER BUCKET/PREFIX PHASE LAST VALIDATED ACCESS MODE DEFAULT
default aws finley007 Available 2022-03-10 22:23:28 +0800 CST ReadWrite true
# 查看已有恢复
velero get restores
# 查看 velero 插件
velero get plugins
# 删除 velero 备份
velero backup delete nginx-backup
# 持久卷备份
velero backup create nginx-backup-volume --snapshot-volumes --include-namespaces nginx-example
# 持久卷恢复
velero restore create --from-backup nginx-backup-volume --restore-volumes
# 创建集群所有namespaces备份,但排除 velero,metallb-system 命名空间
velero backup create all-ns-backup --snapshot-volumes=false --exclude-namespaces velero,metallb-system
# 周期性定时备份
# 每日3点进行备份
$ velero schedule create <SCHEDULE NAME> --schedule "0 3 * * *"
# 每日3点进行备份,备份保留48小时,默认保留30天
$ velero schedule create <SCHEDULE NAME> --schedule "0 3 * * *" --ttl 48
# 每6小时进行一次备份
$ velero create schedule <SCHEDULE NAME> --schedule="@every 6h"
# 每日对 web namespace 进行一次备份
$ velero create schedule <SCHEDULE NAME> --schedule="@every 24h" --include-namespaces web迁移场景
# 在集群1上做一个备份:
$ velero backup create <BACKUP-NAME> --snapshot-volumes
# 在集群2上做一个恢复:
$ velero restore create --from-backup <BACKUP-NAME> --restore-volumes
# velero 清理
$ kubectl delete namespace/velero clusterrolebinding/velero
$ kubectl delete crds -l component=veleroVelero 作为一个免费的开源组件,其能力基本可以满足容器服务的灾备和迁移的场景,推荐用户将velero日常备份作为运维的一部分,未雨绸缪,防患未然。
参考
https://github.com/vmware-tanzu/velero
https://www.imooc.com/article/310069
]]>Hello, World!
]]>
Argo CD 是一个声明式、GitOps 持续交付的 Kubernetes 工具,它的配置和使用分非常简单,并且自带一个简单一用的 Dashboard 页面,更重要的是 Argo CD 支持 kustomzie、helm、ksonnet 等多种工具。应用程序可以通过 Argo CD 提供的 CRD 资源对象进行配置,可以在指定的目标环境中自动部署所需的应用程序。关于 Argo CD 更多的信息可以查看官方文档了解更多。
Argo CD 的主要职责是 CD(Continuous Delivery,持续交付),将应用部署到 Kubernetes 等环境中
更多功能:https://argo-cd.readthedocs.io/en/stable/#features
Argo CD 会自动和代码仓库的内容进行校验,当代码仓库中应用属性等信息发生变化时,Argo CD 会自动同步更新 Kubernetes 集群中的应用。
使用条件
- 准备好的k8s集群
- git仓库,demo地址是:https://gitee.com/finley/argocd-demo, 该仓库的demo目录下存在两个k8s清单文件,用于跑一个web项目
安装并配置 argocd
配合文档 https://argo-cd.readthedocs.io/en/stable/getting_started/
图形化界面是可选安装的,如果不安装,可以直接使用命令行操作。 这里我们安装
kubectl create namespace argocd
# 处理访问github慢的问题
kubectl apply -f https://ghproxy.com/https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml -n argocd
# 设置 Argo CD API Server
kubectl patch svc argocd-server -n argocd -p '{"spec": {"type": "NodePort"}}'
# 获取端口
kubectl get svc -n argocd
# 获取登录密码
kubectl -n argocd get secret \
argocd-initial-admin-secret \
-o jsonpath="{.data.password}" | base64 -d
登录并创建新app。登录名默认是admin


除了dashboard图形创建,也可以使用yaml文件创建
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: myapp
namespace: argocd
spec:
destination:
namespace: devops # 部署应用的命名空间
server: https://kubernetes.default.svc # API Server 地址
project: default # 项目名
source:
path: demo # 资源文件路径
repoURL: https://gitee.com/finley/argocd-demo.git # Git 仓库地址
targetRevision: master # 分支名点击sync,同步app,然后看到已经执行成功了,也就是说argocd帮我们运行了git仓库中的k8s清单文件。

检查下
k get -n devops all
NAME READY STATUS RESTARTS AGE
pod/myapp-865f9f464f-7q72s 1/1 Running 0 75s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/myapp NodePort 10.233.61.10 <none> 80:32060/TCP 75s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/myapp 1/1 1 1 75s
NAME DESIRED CURRENT READY AGE
replicaset.apps/myapp-865f9f464f 1 1 1 75
# 访问程序,看到此时是v1版本
curl 10.0.2.5:32060
this is app v1同步仓库
开启自动同步,点击 APP DETAILS -> SYNC POLICY,点击 ENABLE AUTO-SYNC

编辑 myapp 资源文件,将镜像的版本从 v1 改为 v2,点击 Commit changes,提交更改。
等待一会 Argo CD 会自动更新应用,如果你等不及可以点击 Refresh,Argo CD 会去立即获取最新的资源文件。可以看到此时 myapp Deployment 会新创建 v2 版本的 Replicaset,v2 版本的 Replicaset 会创建并管理 v2 版本的 Pod。
# 新版本部署成功
curl <节点 IP>:32060
this is app v2回滚
细心的同学应该会发现升级到 v2 版本以后, v1 版本的 Replicaset 并没有被删除,而是继续保留,这是为了方便我们回滚应用。在 myapp 应用中点击 HISTORY AND ROLLBACK 查看历史记录,可以看到有 2 个历史记录。
假设我们刚刚上线的 v2 版本出现了问题,需要回滚回 v1 版本,那么我们可以选中 v1 版本,然后点击 Rollback 进行回滚。
在回滚的时候需要禁用 AUTO-SYNC 自动同步,点击 OK 确认即可。

等待一会可以看到此时已经回滚成功,此时 Pod 是 v1 版本的,并且由于此时线上的版本并不是 Git 仓库中最新的版本,因此此时同步状态是 OutOfSync。
至此,argocd初步使用完毕。 但是依然存在一些问题:
- 我们的需求是每次提交到代码,可以自动发布到线上,目前是在页面点击,效率太低了。
看下面的两个示例
示例1
测试仓库:https://github.com/mafeifan/argocd-in-action
如果拉取github仓库慢,可以使用:https://mirror.ghproxy.com/https://github.com/mafeifan/argocd-in-action.git
分为了两个目录,flask-demo源码目录和kustomize配置清单目录。
实际中,要分成两个仓库,因为源码目录是开发团队负责,配置清单目录是部署团队负责。
argocd创建app:
- project: default
- namespace: flask-demo
- repo url: https://github.com/mafeifan/argocd-in-action
- revision: HEAD
- path: kustomize
# 检查执行情况,并获取暴露的端口
k get all -n flask-demo -o wide
# 测试,返回正常
curl vm2:30688
<p>Hello, World!</p>
<p>---something important from environ---</p>
<p>DB_NAME=demo</p>
<p>DB_NAME=root</p>
<p>DB_PASSWORD=password</p>
<p>DB_HOST=127.0.0.1</p>
<p>DB_PORT=9527</p>示例2

优化后的工作流:
- 创建两个仓库,分别是代码仓库Flask-demo和清单仓库Flask-demo-kustomize
- 开发团队提交业务业务代码到Flask-demo仓库,触发Actions
- Flask-demo仓库的actions会构建docker镜像并推送到docker hub,同时会触发清单仓库的Actions,Flask-demo-kustomize清单仓库的Actions会执行set image即更新镜像为最新tag,并提交git commit
- argocd会执行监控Flask-demo-kustomize仓库的变动更新应用的镜像为最新tag
argocd新建app
project: default
source:
repoURL: >-
https://mirror.ghproxy.com/https://github.com/mafeifan/flask-demo-kustomize.git
path: secret
targetRevision: HEAD
destination:
server: 'https://kubernetes.default.svc'
namespace: flask-demo
syncPolicy:
automated: {}
syncOptions:
- CreateNamespace=true使用sealed-secrets为清单加密
这里牵涉到一个问题是secret.yaml中的内容不能直接暴露,需要加密。
这里我们使用https://github.com/bitnami-labs/sealed-secrets这个工具实现加密和解密
工作流程是:
- k8s集群需要安装sealed-secrets-controller
- 使用sealed-secrets客户端工具将secret.yaml加密成secret-seal.yaml
- 提交加密后的文件到集群中,controller会监控并自动解密
# 安装sealed-secrets服务端controller
kubectl apply -f https://github.com/bitnami-labs/sealed-secrets/releases/download/v0.17.5/controller.yaml
k get all -n kube-system -A | grep "sealed"
# 安装客户端工具
brew install kubeseal
# 如果是Linux系统
wget https://github.com/bitnami-labs/sealed-secrets/releases/download/v0.17.5/kubeseal-0.17.5-linux-amd64.tar.gz
# 获取公钥文件,注意备份
kubeseal --fetch-cert public-cert.pem
# 加密secret.yaml并输出secret-seal.yaml
kubeseal --scope cluster-wide --format=yaml --cert .public-cert.pem < secret.yaml > secret-seal.yaml遇到 Error updating flask-demo/db-connection, will retry: no key could decrypt secret (DB_HOST, DB_NAME, DB_PASSWORD, DB_PORT, DB_USERNAME) 使用 kubeseal --scope cluster-wide --format=yaml --cert public-cert.pem < secret.yaml > secret-seal.yaml 就可以了 原因是kubeseal加密时有scope参数,详见:https://github.com/bitnami-labs/sealed-secrets#scopes
参考
https://argo-cd.readthedocs.io/en/stable/
https://www.qikqiak.com/post/gitlab-ci-argo-cd-gitops/
https://blog.csdn.net/cr7258/article/details/122028096
]]>QoS Class: BestEffort
对于一个 pod 来说,服务质量体现在两个具体的指标:CPU 和内存。
当节点上内存资源紧张时,kubernetes 会根据预先设置的不同 QoS 类别进行相应处理。
当 Kubernetes 创建一个 Pod 时,它就会给这个 Pod 分配一个 QoS 等级,可以是以下等级之一:
- Guaranteed(有保证的):Pod 里的每个容器都必须有内存/CPU 限制和请求,而且值必须相等。如果一个容器只指明limit而未设定request,则request的值等于limit值。
- Burstable(不稳定的):Pod 里至少有一个容器有内存或者 CPU 请求且不满足 Guarantee 等级的要求,即内存/CPU 的值设置的不同。
- BestEffort(尽最大努力):容器必须没有任何内存或者 CPU 的限制或请求。
该配置不是通过一个配置项来配置的,而是通过配置 CPU/MEM的 limits 与 requests 值的大小来确认服务质量等级。
实例
下面是 Guaranteed 例子:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
spec:
containers:
- name: qos-demo
image: busybox
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
command: [ "sleep", "3600"]下面是 Guaranteed 例子:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
spec:
containers:
- name: qos-demo-2
image: busybox
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 10m
memory: 10Mi
command:下面是 BestEffort 例子:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-3
spec:
containers:
- name: qos-demo-3
image: busybox
command:QoS 优先级
三种 QoS 优先级,从高到低(从左往右)
Guaranteed –> Burstable –> BestEffort
资源限制 Limits 和 资源需求 Requests
-
对于CPU:如果pod中服务使用CPU超过设置的 limits,pod不会被kill掉但会被限制。如果没有设置limits,pod可以使用全部空闲的cpu资源。
-
对于内存:当一个pod使用内存超过了设置的 limits,pod中 container 的进程会被 kernel 因OOM kill掉。当container因为OOM被kill掉时,系统倾向于在其原所在的机器上重启该container或其他重新创建一个pod。
Kubernetes 资源回收策略
Kubernetes 通过cgroup给pod设置QoS级别,当资源不足时先kill优先级低的 pod,在实际使用过程中,通过OOM分数值来实现,OOM分数值范围为0-1000。OOM 分数值根据OOM_ADJ参数计算得出。
对于Guaranteed级别的 Pod,OOM_ADJ参数设置成了-998,对于Best-Effort级别的 Pod,OOM_ADJ参数设置成了1000,对于Burstable级别的 Pod,OOM_ADJ参数取值从2到999。
对于 kuberntes 保留资源,比如kubelet,docker,OOM_ADJ参数设置成了-999,表示不会被OOM kill掉。OOM_ADJ参数设置的越大,计算出来的OOM分数越高,表明该pod优先级就越低,当出现资源竞争时会越早被kill掉,对于OOM_ADJ参数是-999的表示kubernetes永远不会因为OOM将其kill掉。
当集群监控到 node 节点内存或者CPU资源耗尽时,为了保护node正常工作,就会启动资源回收策略,通过驱逐节点上Pod来减少资源占用。
三种 QoS 策略被驱逐优先级,从高到低(从左往右)
BestEffort –> Burstable –> Guaranteed
系统用完了全部内存时,BestEffort类型 pods 会最先被kill掉, 如果内存还不够kill掉Burstable,最后Guaranteed
使用建议
- 如果资源充足,可以将 pod QoS 设置为 Guaranteed
- 不是很关键的服务 pod QoS 设置为 Burstable 或者 BestEffort。比如 filebeat、logstash、fluentd等
]]>建议:k8s 安装时,建议把 Swap 关闭,虽然 Swap 可以解决内存不足问题,但当内存不足使用Swap时,系统负载会出现过高,原因是 swap 大量 占用磁盘IO
kubectl api-resources 查看k8s内置的资源类型, 那么如何创建自己的资源类型?
K8s支持自定义类型 Custom Resource Definition,让开发者去自定义资源(如Deployment,StatefulSet等),其实可以把CRD想象为类,对象就是类的实例。
Kubernetes Operator 是一种封装、部署和管理 Kubernetes 应用的方法。
Operator = CRD + Controller;
Controller:监听CRD实例(以及关联的资源)的 CRUD 事件,然后执行相应的业务逻辑;
这里创建了一个名为crontab的资源类型,缩写为ct,创建ct需要配置几个参数,image,cronSpec,replicas
# vi crd.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# name must match the spec fields below, and be in the form: <plural>.<group>
name: crontabs.stable.example.com
spec:
# group name to use for REST API: /apis/<group>/<version>
group: stable.example.com
# list of versions supported by this CustomResourceDefinition
versions:
- name: v1
# Each version can be enabled/disabled by Served flag.
served: true
# One and only one version must be marked as the storage version.
storage: true
schema:
# 定义参数及校验规则
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
# either Namespaced or Cluster
# 作用范围,类似 role和clusterrole
scope: Namespaced
names:
# plural name to be used in the URL: /apis/<group>/<version>/<plural>
plural: crontabs
# singular name to be used as an alias on the CLI and for display
singular: crontab
# kind is normally the CamelCased singular type. Your resource manifests use this.
kind: CronTab
# shortNames allow shorter string to match your resource on the CLI
shortNames:
- ctkubectl apply -f crd.yaml
customresourcedefinition.apiextensions.k8s.io/crontabs.stable.example.com created
kubectl get crd
kubectl describe crd crontab我们已经把资源创建成功了,下面基于资源类型创建具体的对象。
# vi new-crontab.yaml
apiVersion: "stable.example.com/v1"
# This is from the group and version of new CRD
kind: CronTab
# The kind from the new CRD
metadata:
name: new-cron-object
spec:
cronSpec: "*/5 * * * *"
image: some-cron-image
replicas: 2# 执行成功
kubectl apply -f new-crontab.yaml
kubectl get ct
NAME AGE
new-cron-object 7s
kubectl describe ct
# 尝试添加replicas属性
kubectl edit ct new-cron-object
kubectl delete -f crd.yaml
# 返回 not found
kubectl get ct这里只是演示,并没有具体的实现。
kubernetes 的 controller-manager 通过 APIServer 实时监控内部资源的变化情况,通过各种操作将系统维持在一个我们预期的状态上。
比如当我们将 Deployment 的副本数增加时,controller-manager 会监听到此变化,主动创建新的 Pod。
对于通过 CRD 创建的资源,也可以创建一个自定义的 controller 来管理。
具体的实现需要对k8s的api 和 go 语言比较熟悉,官方也提供了例子,有空再做详解。
参考
https://jimmysong.io/kubernetes-handbook/concepts/crd.html
https://python.iitter.com/other/231069.html
]]>帮忙创建快速、高持久、可靠和可伸缩的容器附加存储。
这里介绍在一个纯净的K8s集群中安装 OpenEBS。Linux 平台是 Ubuntu
OpenEBS 依赖 iSCSI 服务,默认未开启
# active iSCSI service
sudo cat /etc/iscsi/initiatorname.iscsi
systemctl status iscsid
sudo systemctl enable --now iscsid
# 如果没有则安装 iscsi
sudo apt-get update
sudo apt-get install open-iscsi
sudo systemctl enable --now iscsid
OpenEBS 提供了三种存储引擎选择:Jiva,cStor 和 Local PV。
这里我们只介绍 Local PV
Local PV
其中 Local PV 默认的存储路径为 /var/openebs/local
kubectl apply -f https://openebs.github.io/charts/openebs-operator.yaml
# Storage Class
```yaml
# local-hostpath-sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-hostpath
annotations:
openebs.io/cas-type: local
cas.openebs.io/config: |
- name: StorageType
value: hostpath
- name: BasePath
value: /var/local-hostpath
provisioner: openebs.io/local
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer# local-hostpath-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: local-hostpath-pvc
spec:
storageClassName: openebs-hostpath
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5G# local-hostpath-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: hello-local-hostpath-pod
spec:
volumes:
- name: local-storage
persistentVolumeClaim:
claimName: local-hostpath-pvc
containers:
- name: hello-container
image: busybox
command:
- sh
- -c
- 'while true; do echo "`date` [`hostname`] Hello from OpenEBS Local PV." >> /mnt/store/greet.txt; sleep $(($RANDOM % 5 + 300)); done'
volumeMounts:
- mountPath: /mnt/store
name: local-storagek exec -it hello-local-hostpath-pod --- cat /mnt/store/greet.txt
Tue Mar 1 13:17:43 UTC 2022 [hello-local-hostpath-pod] Hello from OpenEBS Local PV.
Tue Mar 1 13:22:46 UTC 2022 [hello-local-hostpath-pod] Hello from OpenEBS Local PV.
Tue Mar 1 13:27:47 UTC 2022 [hello-local-hostpath-pod] Hello from OpenEBS Local PV.
Tue Mar 1 13:32:48 UTC 2022 [hello-local-hostpath-pod] Hello from OpenEBS Local PV.Pod 所在的节点,确实生成了类似 /var/openebs/local/pvc-098878b6-32f2-4920-811c-d2f3064c44c0/greet.txt 的目录。
我们的卷也可以在这个目录中找到。
参考
]]>kubectl top node命令
执行后发现报如下错误,这是因为没有安装 Metrics 服务
W0228 15:00:55.748791 2774 top_node.go:119] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
error: Metrics API not available阅读文档,安装服务:https://github.com/kubernetes-sigs/metrics-server
打开 components.yaml 搜 image 发现镜像源是 k8s.gcr.io/metrics-server/metrics-server, 国内不下来
fuck!! 去 docker hub 搜索个其他的镜像源 dyrnq/metrics-server, 将 components.yaml 中的 k8s.gcr.io/metrics-server/metrics-server 替换为 dyrnq/metrics-server
修改启动参数
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostnamekubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml# 检查执行,确保出现了 metrics-server
mafei@master:~$ k get po -A | grep "metrics"
# top 命令正常了, 完工
mafei@master:~$ k top pod -A
W0228 15:32:42.454163 35558 top_pod.go:140] Using json format to get metrics. Next release will switch to protocol-buffers, switch early by passing --use-protocol-buffers flag
NAMESPACE NAME CPU(cores) MEMORY(bytes)
kube-system calico-kube-controllers-846b5f484d-xd9rc 1m 17Mi
kube-system calico-node-hdg2c 35m 122Mi
kube-system calico-node-rwk2k 33m 122Mi
kube-system coredns-b5648d655-n6sff 3m 11Mi
kube-system coredns-b5648d655-st4nj 2m 11Mi
kube-system kube-apiserver-master 58m 436Mi
kube-system kube-controller-manager-master 19m 52Mi
kube-system kube-proxy-jft2t 4m 21Mi
kube-system kube-proxy-qbzdv 1m 21Mi
kube-system kube-scheduler-master 3m 18Mi
kube-system metrics-server-6647799c9-4c65s 3m 15Mi
kube-system nodelocaldns-59d8n 3m 12Mi
kube-system nodelocaldns-px57k 2m 13Mi/var/lib/docker/containers/<container_id>/<container_id>-json.log中。
使用 sudo docker info 发现日志驱动是Logging Driver: json-file,也应证了此点。
root@master:/var/lib/docker/containers/41181a3291527e# tail 41181a3291527e7-json.log
{"log":"AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.233.70.57. Set the 'ServerName' directive globally to suppress this message\n","stream":"stderr","time":"2022-03-14T10:59:59.582206712Z"}
{"log":"AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.233.70.57. Set the 'ServerName' directive globally to suppress this message\n","stream":"stderr","time":"2022-03-14T10:59:59.603628054Z"}通过我们是用kubectl logs或docker logs来查看日志的,这样的弊端是效率低,如果容器或节点挂了就没法查看了。
我们希望有套独立于k8s集群的日志系统,供查询,分析或可视化展示。
下面的教程是根据搭建 EFK 日志系统的建议来做的。
总结几点:
- 在我本地的虚拟机集群测试成功,我的本地k8s集群版本是1.22
- elasticsearch的运行环境对硬件要求比较高,最好2核4G以上,日志文件可能占据大量磁盘容量
- 关于storageClassName的填写,建议看看之前我写的安装OpenEBS,我填写的是
openebs-hostpath - 关于elaasticsearch stateful,我填写的replicas和discovery.zen.minimum_master_nodes都是1,因为本地集群中我只配了一个master节点,一个worker节点
- 示例中的镜像版本并非最新稳定,回头再出一版最新版本的实验下
安装 elasticsearch
k8s官方推荐做法是采用 fluentd-elasticsearch
你可以把整个addon目录拷贝下来,官方也提到这只是测试目的,生产环境可以去Helm中搜索。
首先创建一个名为 elasticsearch 的无头服务,新建文件 elasticsearch-svc.yaml,文件内容如下:
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: logging
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node定义了一个名为 elasticsearch 的 Service,指定标签app=elasticsearch,当我们将 Elasticsearch StatefulSet 与此服务关联时,服务将返回带有标签app=elasticsearch的 Elasticsearch Pods 的 DNS A 记录,然后设置clusterIP=None,将该服务设置成无头服务。
最后,我们分别定义端口9200、9300,分别用于与 REST API 交互,以及用于节点间通信。
kubectl get services --namespace=logging
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 43现在我们已经为 Pod 设置了无头服务和一个稳定的域名.elasticsearch.logging.svc.cluster.local,接下来我们通过 StatefulSet 来创建具体的 Elasticsearch 的 Pod 应用。
Kubernetes StatefulSet 允许我们为 Pod 分配一个稳定的标识和持久化存储,Elasticsearch 需要稳定的存储来保证 Pod 在重新调度或者重启后的数据依然不变,所以需要使用 StatefulSet 来管理 Pod。
新建名为 elasticsearch-statefulset.yaml 的资源清单文件,首先粘贴下面内容:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: logging
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.ping.unicast.hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: discovery.zen.minimum_master_nodes
value: "2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: es-data-db
resources:
requests:
storage: 100Gi该内容中,我们定义了一个名为 es-cluster 的 StatefulSet 对象,然后定义serviceName=elasticsearch和前面创建的 Service 相关联,这可以确保使用以下 DNS 地址访问 StatefulSet 中的每一个 Pod:es-cluster-[0,1,2].elasticsearch.logging.svc.cluster.local,其中[0,1,2]对应于已分配的 Pod 序号。
然后指定3个副本,将 matchLabels 设置为app=elasticsearch,所以 Pod 的模板部分.spec.template.metadata.lables也必须包含app=elasticsearch标签。
k get all -n logging
NAME READY STATUS RESTARTS AGE
pod/es-cluster-0 1/1 Running 0 23m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 65m
NAME READY AGE
statefulset.apps/es-cluster 1/1 23mPods 部署完成后,我们可以通过请求一个 REST API 来检查 Elasticsearch 集群是否正常运行。使用下面的命令将本地端口9200转发到 Elasticsearch 节点(如es-cluster-0)对应的端口:
$ kubectl port-forward es-cluster-0 9200:9200 --namespace=logging
Forwarding from 127.0.0.1:9200 -> 9200
Forwarding from [::1]:9200 -> 9200然后,在另外的终端窗口中,执行如下请求:
$ curl http://localhost:9200/_cluster/state?pretty
{
"cluster_name" : "k8s-logs",
"compressed_size_in_bytes" : 234,
"cluster_uuid" : "rRNQupGlS4yda89jFs2acg",
"version" : 2,
"state_uuid" : "I6PjJTTdRLKLeHL5qGPQBg",
"master_node" : "h7r9E6wwTKiEo2GBj6yx2Q",
"blocks" : { },
"nodes" : {
"h7r9E6wwTKiEo2GBj6yx2Q" : {
"name" : "es-cluster-0",
"ephemeral_id" : "zcjn6Z0jQ4CwRIASTbEbKQ",
"transport_address" : "10.233.68.102:9300",
"attributes" : { }
}
},
"metadata" : {
"cluster_uuid" : "rRNQupGlS4yda89jFs2acg",
"templates" : { },
"indices" : { },
"index-graveyard" : {
"tombstones" : [ ]
}
},
"routing_table" : {
"indices" : { }
},
"routing_nodes" : {
"unassigned" : [ ],
"nodes" : {
"h7r9E6wwTKiEo2GBj6yx2Q" : [ ]
}
},
"snapshot_deletions" : {
"snapshot_deletions" : [ ]
},
"snapshots" : {
"snapshots" : [ ]
},
"restore" : {
"snapshots" : [ ]
}
}安装 Kibana
Elasticsearch 集群启动成功了,接下来我们可以来部署 Kibana 服务,新建一个名为 kibana.yaml 的文件,对应的文件内容如下:
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
ports:
- port: 5601
type: NodePort
selector:
app: kibana
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: logging
labels:
app: kibana
spec:
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana-oss:6.4.3
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601上面我们定义了两个资源对象,一个 Service 和 Deployment
唯一需要注意的是我们使用 ELASTICSEARCH_URL 这个环境变量来设置Elasticsearch 集群的端点和端口,直接使用 Kubernetes DNS 即可,此端点对应服务名称为 elasticsearch,由于是一个 headless service,所以该域将解析为3个 Elasticsearch Pod 的 IP 地址列表。
浏览器访问 Kibana

在虚拟机里设置了端口转发,所以宿主机访问地址是:localhost:32256

部署 Fluentd
Fluentd 是一个高效的日志聚合器,是用 Ruby 编写的,并且可以很好地扩展。对于大部分企业来说,Fluentd 足够高效并且消耗的资源相对较少,另外一个工具Fluent-bit更轻量级,占用资源更少,但是插件相对 Fluentd 来说不够丰富,所以整体来说,Fluentd 更加成熟,使用更加广泛,所以我们这里也同样使用 Fluentd 来作为日志收集工具。
Fluentd 通过一组给定的数据源抓取日志数据,处理后(转换成结构化的数据格式)将它们转发给其他服务,比如 Elasticsearch、对象存储等等。Fluentd 支持超过300个日志存储和分析服务,所以在这方面是非常灵活的。主要运行步骤如下:
- 首先 Fluentd 从多个日志源获取数据
- 结构化并且标记这些数据
- 然后根据匹配的标签将数据发送到多个目标服务去

配置
一般来说我们是通过一个配置文件来告诉 Fluentd 如何采集、处理数据的,下面简单和大家介绍下 Fluentd 的配置方法。
日志源配置
比如我们这里为了收集 Kubernetes 节点上的所有容器日志,就需要做如下的日志源配置:
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
tag raw.kubernetes.*
format json
read_from_head true
</source>- id:表示引用该日志源的唯一标识符,该标识可用于进一步过滤和路由结构化日志数据
- type:Fluentd 内置的指令,tail表示 Fluentd 从上次读取的位置通过 tail 不断获取数据,另外一个是http表示通过一个 GET 请求来收集数据。
- path:tail类型下的特定参数,告诉 Fluentd 采集/var/log/containers目录下的所有日志,这是 docker 在 Kubernetes 节点上用来存储运行容器 stdout 输出日志数据的目录。
- pos_file:检查点,如果 Fluentd 程序重新启动了,它将使用此文件中的位置来恢复日志数据收集。
- tag:用来将日志源与目标或者过滤器匹配的自定义字符串,Fluentd 匹配源/目标标签来路由日志数据。
路由配置
上面是日志源的配置,接下来看看如何将日志数据发送到 Elasticsearch:
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
type_name fluentd
host "#{ENV['OUTPUT_HOST']}"
port "#{ENV['OUTPUT_PORT']}"
logstash_format true
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size "#{ENV['OUTPUT_BUFFER_CHUNK_LIMIT']}"
queue_limit_length "#{ENV['OUTPUT_BUFFER_QUEUE_LIMIT']}"
overflow_action block
</buffer>- match:标识一个目标标签,后面是一个匹配日志源的正则表达式,我们这里想要捕获所有的日志并将它们发送给 Elasticsearch,所以需要配置成**。
- id:目标的一个唯一标识符。
- type:支持的输出插件标识符,我们这里要输出到 Elasticsearch,所以配置成 elasticsearch,这是 Fluentd 的一个内置插件。
- log_level:指定要捕获的日志级别,我们这里配置成info,表示任何该级别或者该级别以上(INFO、WARNING、ERROR)的日志都将被路由到 Elsasticsearch。
- host/port:定义 Elasticsearch 的地址,也可以配置认证信息,我们的 Elasticsearch 不需要认证,所以这里直接指定 host 和 port 即可。
- logstash_format:Elasticsearch 服务对日志数据构建反向索引进行搜索,将 logstash_format 设置为true,Fluentd 将会以 logstash 格式来转发结构化的日志数据。
- Buffer: Fluentd 允许在目标不可用时进行缓存,比如,如果网络出现故障或者 Elasticsearch 不可用的时候。缓冲区配置也有助于降低磁盘的 IO。
安装
要收集 Kubernetes 集群的日志,直接用 DasemonSet 控制器来部署 Fluentd 应用,这样,它就可以从 Kubernetes 节点上采集日志,确保在集群中的每个节点上始终运行一个 Fluentd 容器。
当然可以直接使用 Helm 来进行一键安装,为了能够了解更多实现细节,我们这里还是采用手动方法来进行安装。
首先,我们通过 ConfigMap 对象来指定 Fluentd 配置文件,新建 fluentd-configmap.yaml 文件,文件内容如下:
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
# Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
# Logs from systemd-journal for interesting services.
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
@type forward
</source>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host elasticsearch
port 9200
logstash_format true
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>上面配置文件中我们配置了 docker 容器日志目录以及 docker、kubelet 应用的日志的收集,收集到数据经过处理后发送到 elasticsearch:9200 服务。
然后新建一个 fluentd-daemonset.yaml 的文件,文件内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
version: v2.0.4
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v2.0.4
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v2.0.4
# This annotation ensures that fluentd does not get evicted if the node
# supports critical pod annotation based priority scheme.
# Note that this does not guarantee admission on the nodes (#40573).
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
image: cnych/fluentd-elasticsearch:v2.0.4
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluentd-config我们将上面创建的 fluentd-config 这个 ConfigMap 对象通过 volumes 挂载到了 Fluentd 容器中,另外为了能够灵活控制哪些节点的日志可以被收集,所以我们这里还添加了一个 nodSelector 属性:
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"另外由于我们的集群使用的是 kubeadm 搭建的,默认情况下 master 节点有污点,所以要想也收集 master 节点的日志,则需要添加上容忍:
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule来看下完整的输出
$ k get all -n logging -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/es-cluster-0 1/1 Running 0 72m 10.233.68.102 vm2 <none> <none>
pod/fluentd-es-hdt2t 1/1 Running 0 58s 10.233.68.104 vm2 <none> <none>
pod/fluentd-es-t8f7j 1/1 Running 0 58s 10.233.70.66 master <none> <none>
pod/kibana-7dfb9d8bc5-xrxs7 1/1 Running 0 42m 10.233.68.103 vm2 <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 114m app=elasticsearch
service/kibana NodePort 10.233.42.144 <none> 5601:32236/TCP 42m app=kibana
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE CONTAINERS IMAGES SELECTOR
daemonset.apps/fluentd-es 2 2 2 2 2 beta.kubernetes.io/fluentd-ds-ready=true 59s fluentd-es cnych/fluentd-elasticsearch:v2.0.4 k8s-app=fluentd-es,version=v2.0.4
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/kibana 1/1 1 1 42m kibana docker.elastic.co/kibana/kibana-oss:6.4.3 app=kibana
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replicaset.apps/kibana-7dfb9d8bc5 1 1 1 42m kibana docker.elastic.co/kibana/kibana-oss:6.4.3 app=kibana,pod-template-hash=7dfb9d8bc5
NAME READY AGE CONTAINERS IMAGES
statefulset.apps/es-cluster 1/1 72m elasticsearch docker.elastic.co/elasticsearch/elasticsearch-oss:6.4.3Fluentd 启动成功后,我们可以前往 Kibana 的 Dashboard 页面中,点击左侧的Discover,可以看到如下配置页面:

在这里可以配置我们需要的 Elasticsearch 索引,前面 Fluentd 配置文件中我们采集的日志使用的是 logstash 格式,这里只需要在文本框中输入logstash-*即可匹配到 Elasticsearch 集群中的所有日志数据,然后点击下一步,进入以下页面:

在该页面中配置使用哪个字段按时间过滤日志数据,在下拉列表中,选择@timestamp字段,然后点击Create index pattern,创建完成后,点击左侧导航菜单中的 Discover,然后就可以看到一些直方图和最近采集到的日志数据了:

发现日志集中时间在晚上9点多,因为我这是本地虚拟机里的测试集群,随用随开。
测试
现在我们来将上一节课的计数器应用部署到集群中,并在 Kibana 中来查找该日志数据。
新建 counter.yaml 文件,文件内容如下:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']该 Pod 只是简单将日志信息打印到 stdout,所以正常来说 Fluentd 会收集到这个日志数据,在 Kibana 中也就可以找到对应的日志数据了,创建该 Pod
Pod 创建并运行后,回到 Kibana Dashboard 页面,在上面的Discover页面搜索栏中输入kubernetes.pod_name:counter,就可以过滤 Pod 名为 counter 的日志数据:

我们也可以通过其他元数据来过滤日志数据,比如 您可以单击任何日志条目以查看其他元数据,如容器名称,Kubernetes 节点,命名空间等。
到这里,我们就在 Kubernetes 集群上成功部署了 EFK ,要了解如何使用 Kibana 进行日志数据分析,可以参考 Kibana 用户指南文档:https://www.elastic.co/guide/en/kibana/current/index.html
当然对于在生产环境上使用 Elaticsearch 或者 Fluentd,还需要结合实际的环境做一系列的优化工作.
参考
]]>Kubernetes中所有的访问,无论外部内部,都会通过API Server处理,访问Kubernetes资源前需要经过认证与授权。
- Authentication:用于识别用户身份的认证,Kubernetes分外部服务帐号和内部服务帐号,采取不同的认证机制。
- Authorization:用于控制用户对资源访问的授权,对访问的授权目前主要使用RBAC机制,将在RBAC介绍。

Kubernetes的用户分为服务帐户(ServiceAccount)和普通帐户两种类型。
- ServiceAccount与Namespace绑定,关联一套凭证,存储在Secret中,Pod创建时挂载Secret,从而允许与API Server之间调用。
- Kubernetes中没有代表普通帐户的对象,这类帐户默认由外部服务独立管理,比如在华为云上CCE的用户是由IAM管理的。
ServiceAccount同样是Kubernetes中的资源,与Pod、ConfigMap类似,且作用于独立的命名空间,也就是ServiceAccount是属于命名空间级别的,创建命名空间时会自动创建一个名为default的ServiceAccount。
使用下面命令可以查看ServiceAccount。
$ kubectl get sa
NAME SECRETS AGE
default 1 30d同时Kubernetes还会为ServiceAccount自动创建一个Secret,使用下面命令可以查看到。
$ kubectl describe sa default
Name: default
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: default-token-6r7dm
Tokens: default-token-6r7dm
Events: <none>在Pod的定义文件中,可以用指定帐户名称的方式将一个ServiceAccount赋值给一个Pod,如果不指定就会使用默认的ServiceAccount。 当API Server接收到一个带有认证Token的请求时,API Server会用这个Token来验证发送请求的客户端所关联的ServiceAccount是否允许执行请求的操作。
继续探究token
$ kubectl get secret default-token-6r7dm -o yaml
apiVersion: v1
data:
ca.crt: LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0t....
namespace: ZGVmYXVsdA==
token: ZXlKaGJHY2lPaUpTVXpJ....
kind: Secret
metadata:
annotations:
kubernetes.io/service-account.name: default
kubernetes.io/service-account.uid: 4943cbdb-453f-4ae6-b768-a53363178828
creationTimestamp: "2022-07-20T11:39:38Z"
name: default-token-6r7dm
namespace: default
resourceVersion: "460"
uid: 55d3e935-a4c9-484f-aa5d-6ef8e54bf329
type: kubernetes.io/service-account-token其中 data 中的 ca.crt,token 和 namespace 是被 base64 过的
# 解码namespace: 输出 default
echo ZGVmYXVsdA== |base64 -d
# 我们解码 ca.crt 可以得到证书信息,包含过期时间,发行人,加密算法等细节
kubectl get secret default-token-6r7dm -n default -o jsonpath="{['data']['ca\.crt']}" | base64 -d | openssl x509 -text
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 0 (0x0)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN = kubernetes
Validity
Not Before: Jul 20 11:39:05 2022 GMT
Not After : Jul 17 11:39:05 2032 GMT
Subject: CN = kubernetes
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:a7:20:5d:b1:72:ee:cc:e1:c5:b0:77:4c:aa:97:
26:c0:b1:e4:54:38:62:72:6e:31:58:89:e0:54:c0:
3e:88:e3:66:0c:85:1f:bc:5c:2c:8f:65:66:16:78:
55:29:09:58:1b:73:c6:17:03:f4:4c:28:36:94:4b:
6d:91:e6:a1:dc:45:7b:11:cd:d7:72:a1:ff:16:27:
60:e0:02:d3:81:cc:4c:a1:de:98:14:d0:6d:a7:ae:
d2:28:c7:aa:d4:bf:7f:e9:12:4b:95:70:80:b5:a4:
f2:06:58:28:c8:27:b9:82:17:50:63:62:f6:26:93:
93:59:28:64:15:b4:97:4f:4c:37:51:6c:65:e1:d7:
a3:a7:a5:b6:2a:b0:0b:3c:38:3a:c5:20:fe:ba:ec:
59:70:8a:45:af:18:64:ed:81:e4:6d:35:f3:2b:3f:
48:49:fb:44:fe:2b:04:e7:2b:75:a4:5c:b9:40:6b:
14:da:b3:9a:5b:f9:27:db:fb:81:a2:16:4a:9d:05:
73:4d:78:74:01:e9:2d:2b:7d:52:58:9b:7b:84:a3:
2a:02:18:7b:d7:b7:96:3e:d3:1b:d9:67:f1:f1:48:
c4:cc:e5:9d:09:2a:e5:e7:c1:8c:af:d7:db:6d:85:
b7:c5:f7:8d:4f:86:1d:43:92:62:ba:8e:9c:54:5b:
53:81
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Encipherment, Certificate Sign
X509v3 Basic Constraints: critical
CA:TRUE
X509v3 Subject Key Identifier:
E6:22:94:7C:38:17:5A:43:C8:27:93:B9:49:88:85:7D:CB:B9:92:75
X509v3 Subject Alternative Name:
DNS:kubernetes
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
03:b8:28:fa:26:f5:f9:45:0a:05:0a:ff:ff:97:51:51:fa:08:
84:5b:8d:4f:98:11:44:d3:a1:18:c1:ae:15:29:ed:b3:a7:7d:
85:dc:8a:07:e8:ea:ac:65:0c:66:b4:16:4f:b2:d5:99:6d:d6:
44:11:4e:5f:32:cf:c8:47:c1:f9:77:c6:51:01:84:8f:5a:3d:
c3:50:1d:43:8c:2d:51:4b:36:00:e2:d7:ca:64:d5:c1:0d:db:
ed:e0:87:53:8f:1d:a0:a2:0b:6e:6a:7d:cf:fb:05:96:be:b7:
16:22:e5:b6:67:13:db:7c:51:3a:5d:88:ca:27:ee:5c:48:cc:
5c:d6:4d:94:1e:c1:0b:99:48:1c:2b:a3:6e:22:e6:8c:ed:ae:
ca:37:5a:8b:ae:de:91:74:17:a8:c1:3a:c4:43:3a:1e:49:3a:
c2:28:72:b4:fd:21:ed:1e:82:00:c6:c6:77:1e:14:2c:a0:db:
0c:c2:56:4f:23:da:ae:e6:5e:be:fc:81:8e:40:63:a7:9a:36:
df:39:35:7d:20:90:ce:46:b5:fd:2a:b4:13:ee:08:04:18:b5:
22:64:7b:1a:a3:a1:00:2f:91:15:d9:1c:ef:5f:dd:03:7f:ee:
08:85:2e:56:17:28:9f:00:f9:81:79:c0:9c:0b:42:a1:00:e9:
5d:76:77:5a
-----BEGIN CERTIFICATE-----
MIIC/jCCAeagAwIBAgIBADANBgkqhkiG9w0BAQsFADAVMRMwEQYDVQQDEwprdWJl
cm5ldGVzMB4XDTIyMDcyMDExMzkwNVoXDTMyMDcxNzExMzkwNVowFTETMBEGA1UE
AxMKa3ViZXJuZXRlczCCASIwDQYJKoZIhvcNAQEBBQADggEPADCCAQoCggEBAKcg
XbFy7szhxbB3TKqXJsCx5FQ4YnJuMViJ4FTAPojjZgyFH7xcLI9lZhZ4VSkJWBtz
xhcD9EwoNpRLbZHmodxFexHN13Kh/xYnYOAC04HMTKHemBTQbaeu0ijHqtS/f+kS
S5VwgLWk8gZYKMgnuYIXUGNi9iaTk1koZBW0l09MN1FsZeHXo6eltiqwCzw4OsUg
/rrsWXCKRa8YZO2B5G018ys/SEn7RP4rBOcrdaRcuUBrFNqzmlv5J9v7gaIWSp0F
c014dAHpLBBBBBBBWWWWWWCCCVVVVV7TG9ln8fFIxMzlnQkq5efBjK/X222Ft8X3
jU+GHUOSYrqOnFRbU4ECAwEAAaNZMFcwDgYDVR0PAQH/BAQDAgKkMA8GA1UdEwEB
/wQFMAMBAf8wHQYDVR0OBBYEFOYilHw4F1pDyCeTuUmIhX3LuZJ1MBUGA1UdEQQO
MAyCCmt1YmVybmV0ZXMwDQYJKoZIhvcNAQELBQADggEBAAO4KPom9flFCgUK//+X
UVH6CIRbjU+YEUTToRjBrhUp7bOnfYXcigfo6qxlDGa0Fk+y1Zlt1kQRTl8yz8hH
wfl3xlEBhI9aPcNQHUOMLVFLNgDi18pk1cEN2+3gh1OPHaCiC25qfc/7BZa+txYi
5bZnE9t8UTpdiMon7lxIzFzWTZQewQuZSBwro24i5oztrso3Wouu3pF0F6jBOsRD
Oh5JOsIocrT9Ie0eggDGxnceFCyg2wzCVk8j2q7mXr78gY5AY6eaNt85NX0gkM5G
tf0qtBPuCAQYtSJkexqjoQAvkRXZHO9f3QN/7giFLlYXKJ8A+YF5wJwLQqEA6V12
d1o=
-----END CERTIFICATE-----实战
创建ServiceAccount
$ k create serviceaccount sa-example
# 可以看到已经创建了与ServiceAccount相关联的Token。
$ k describe sa sa-example
Name: sa-example
Namespace: default
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: sa-example-token-gpgcf
Tokens: sa-example-token-gpgcf
Events: <none>
# 查看Secret的内容,可以发现ca.crt、namespace和token三个数据。
$ k describe secret sa-example-token-gpgcf
Name: sa-example-token-gpgcf
Namespace: default
Labels: <none>
Annotations: kubernetes.io/service-account.name: sa-example
kubernetes.io/service-account.uid: 7e6ef492-25b0-4d67-a74d-4277e45c8032
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1099 bytes
namespace: 7 bytes
token: eyJhbGciOiJSUzI1NiIsI...
# 查看详细数据
$ k get secret sa-example-token-gpgcf -o yaml在Pod中使用ServiceAccount
Pod中使用ServiceAccount非常方便,只需要指定ServiceAccount的名称即可。
apiVersion: v1
kind: Pod
metadata:
name: sa-example
spec:
serviceAccountName: sa-example
containers:
- image: nginx:alpine
name: container-0
resources:
limits:
cpu: 100m
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi创建并查看这个Pod,可以看到Pod挂载了sa-example-token-c7bqx,也就是sa-example这个ServiceAccount对应的Token,即Pod使用这个Token来做认证。
$ kubectl create -f pod-sa-example
# Pod 挂载了sa
$ kubectl describe pod sa-example
...
Containers:
sa-example:
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-2ps8d
readOnly: true
....
volumes:
- name: kube-api-access-2ps8d
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace如果你的K8S版本低于1.21,执行同样的指令得到的结果与上图完全不同,在1.21及更新的版本中,这种service account token被叫做Bound Service Account,比起之前的service account token,这种实际上更具安全性。
由上看一共三个volumes,其中serviceAccountToken是真正包含有token内容的volume,可以看到它有一个'expirationSeconds'的属性,上图显示是3607,代表着这个volume包含的内容会在1个小时的时间范围过期,每隔一个小时,这个pod会自动更新这个token来维持有效性。
第二个configmap的volume包含有CA的证书内容,最后一个downwardAPI里面则是包含有这个service account所属的namespace信息。这三个projected volume都会被自动mount在如下文件路径下:
/var/run/secrets/kubernetes.io/serviceaccount
# 进入Pod内部,还可以看到对应的文件,如下所示。
$ kubectl exec -it pod-sa-example -- /bin/sh
/ # cd /run/secrets/kubernetes.io/serviceaccount
/run/secrets/kubernetes.io/serviceaccount # ls
ca.crt namespace token
# 经过对比和sa-example的sa内容是一致的!
# 由于在Kubernetes集群中,默认为API Server创建了一个名为kubernetes的Service,通过这个Service可以访问API Server。
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 78d
# 我们来实验下
$ kubectl exec -it pod-sa-example -- /bin/sh
# 使用curl命令直接访问会得到如下返回信息,表示并没有权限。
/run/secrets/kubernetes.io/serviceaccount # curl https://kubernetes
curl: (60) SSL certificate problem: unable to get local issuer certificate
More details here: https://curl.se/docs/sslcerts.html
curl failed to verify the legitimacy of the server and therefore could not
establish a secure connection to it. To learn more about this situation and
how to fix it, please visit the web page mentioned above.
# 使用ca.crt和Token做认证,先将ca.crt放到CURL_CA_BUNDLE这个环境变量中,curl命令使用CURL_CA_BUNDLE指定证书;再将Token的内容放到TOKEN中,然后带上TOKEN访问API Server。
# export CURL_CA_BUNDLE=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
# curl -H "Authorization: Bearer $TOKEN" https://kubernetes
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "forbidden: User \"system:serviceaccount:default:sa-example\" cannot get path \"/\"",
"reason": "Forbidden",
"details": {},
"code": 403
}
# 可以看到,已经能够通过认证了,但是API Server返回的是cannot get path \"/\"",表示没有权限访问,这说明还需要得到授权后才能访问,授权机制将在RBAC中介绍。RBAC(Role-Based Access Control)
Kubernetes中完成授权工作的就是RBAC机制,RBAC授权规则是通过四种资源来进行配置。
- Role:角色,其实是定义一组对Kubernetes资源(命名空间级别)的访问规则。
- RoleBinding:角色绑定,定义了用户和角色的关系。
- ClusterRole:集群角色,其实是定义一组对Kubernetes资源(集群级别,包含全部命名空间)的访问规则。
- ClusterRoleBinding:集群角色绑定,定义了用户和集群角色的关系。
- Role和ClusterRole指定了可以对哪些资源做哪些动作,RoleBinding和ClusterRoleBinding将角色绑定到特定的用户、用户组或ServiceAccount上。如下图所示。

创建Role
Role的定义非常简单,指定namespace,然后就是rules规则。如下面示例中的规则就是允许对default命名空间下的Pod进行GET、LIST操作。
kubectl create role role-pod-reader --verb=get --verb=list --resource=pods
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: default # 命名空间
name: role-pod-reader
rules:
- apiGroups: [""]
resources: ["pods"] # 可以访问pod
verbs: ["get", "list"] # 可以执行GET、LIST操作创建RoleBinding
有了Role之后,就可以将Role与具体的用户绑定起来,实现这个的就是RoleBinding了。如下所示。
命令式写法,注意--serviceaccount要求<namespace>:<ServiceAccount>
k create rolebinding rolebinding-example --user=user-example --serviceaccount=default:sa-example --role=role-pod-reader
声明式写法
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rolebinding-example
namespace: default
subjects: # 指定用户
- kind: User # 普通用户
name: user-example
apiGroup: rbac.authorization.k8s.io
- kind: ServiceAccount # ServiceAccount
name: sa-example
namespace: default
roleRef: # 指定角色
kind: Role
name: role-pod-reader
apiGroup: rbac.authorization.k8s.io这里的subjects就是将Role与用户绑定起来,用户可以是外部普通用户,也可以是ServiceAccount,这两种用户类型在ServiceAccount有过介绍。
下面来验证一下授权是否生效。
$ kubectl exec -it pod-sa-example -- /bin/sh
# export CURL_CA_BUNDLE=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
# curl -H "Authorization: Bearer $TOKEN" https://kubernetes/api/v1/namespaces/default/pods
{
"kind": "PodList",
"apiVersion": "v1",
"metadata": {
"selfLink": "/api/v1/namespaces/default/pods",
"resourceVersion": "10377013"
},
"items": [
{
"metadata": {
"name": "sa-example",
"namespace": "default",
"selfLink": "/api/v1/namespaces/default/pods/sa-example",
"uid": "c969fb72-ad72-4111-a9f1-0a8b148e4a3f",
"resourceVersion": "10362903",
"creationTimestamp": "2020-07-15T06:19:26Z"
},
"spec": {
...
# 返回结果正常,说明sa-example是有LIST Pod的权限的。再查询一下Deployment,返回如下,说明没有访问Deployment的权限。
# curl -H "Authorization: Bearer $TOKEN" https://kubernetes/api/v1/namespaces/default/deployments
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {},
"status": "Failure",
"message": "deployments is forbidden: User \"system:serviceaccount:default:sa-example\" cannot list resource \"deployments\" in API group \"\" in the namespace \"default\"",
"reason": "Forbidden",
"details": {
"kind": "deployments"
},
"code": 403
}Role和RoleBinding作用的范围是命名空间,能够做到一定程度的权限隔离,如下图所示,上面定义role-example就不能访问kube-system命名空间下的资源。

在上面Pod中继续访问,返回如下,说明确实没有权限。
# curl -H "Authorization: Bearer $TOKEN" https://kubernetes/api/v1/namespaces/kube-system/pods
...
"status": "Failure",
"message": "pods is forbidden: User \"system:serviceaccount:default:sa-example\" cannot list resource \"pods\" in API group \"\" in the namespace \"kube-system\"",
"reason": "Forbidden",
...在RoleBinding中,还可以绑定其他命名空间的ServiceAccount,只要在subjects字段下添加其他命名空间的ServiceAccount即可。
subjects: # 指定用户
- kind: ServiceAccount # ServiceAccount
name: kube-sa-example
namespace: kube-system加入之后,kube-system下kube-sa-example这个ServiceAccount就可以GET、LIST命名空间default下的Pod了,如下图所示。

ClusterRole和ClusterRoleBinding
相比Role和RoleBinding,ClusterRole和ClusterRoleBinding有如下几点不同:
- ClusterRole和ClusterRoleBinding不用定义namespace字段
- ClusterRole可以定义集群级别的资源
可以看出ClusterRole和ClusterRoleBinding控制的是集群级别的权限。
在Kubernetes中,默认定义了非常多的ClusterRole和ClusterRoleBinding,如下所示。
其中,最重要最常用的是如下四个ClusterRole。
- view:拥有查看命名空间资源的权限
- edit:拥有修改命名空间资源的权限
- admin:拥有命名空间全部权限
- cluster-admin:拥有集群的全部权限
使用kubectl describe clusterrole命令能够查看到各个规则的具体权限。
通常情况下,使用这四个ClusterRole与用户做绑定,就可以很好的做到权限隔离。 这里的关键一点是理解到Role(规则、权限)与用户是分开的,只要通过Rolebinding来对这两者进行组合就能做到灵活的权限控制。
参考
]]>topology 就是拓扑的意思,是一个范围的概念,比如一个 Node、一个机柜、一个机房或者是一个地区(如杭州、上海)等,实际上对应的还是 Node 上的标签。
这里的 topologyKey 对应的是 Node 上的标签的 Key(没有Value)
# 这是master节点拥有的标签
k get nodes --show-labels
beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=master
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
node-role.kubernetes.io/master=其实 topologyKey 就是用于筛选 Node 的。通过这种方式,我们就可以将各个 Pod 进行跨集群、跨机房、跨地区的调度了。
比如 topologyKey: "kubernetes.io/hostname" 按照节点名称的不同,分散Pod到各个节点上面。
这里 Pod 的亲和性规则是:
这个 Pod 要调度到的 Node 必须有一个标签为 app:dp-demo 的 Pod(说白了,每个Node要保证只有一个app:dp-demo的Pod)。
且该 Node 必须有一个 Key 为 kubernetes.io/hostname 的标签,即 Node 必须属于 kubernetes.io/hostname 拓扑域。
这里有个有趣的现象,由于我这里只有两个 node,而 replicas: 3,造成一个Pod始终处于 pending 状态
dp-demo-6544cdf96-bscdt 1/1 Running 0 15m 10.233.70.5 master <none> <none>
dp-demo-6544cdf96-kzwlv 1/1 Running 0 15m 10.233.68.62 vm2 <none> <none>
dp-demo-6544cdf96-zgqd2 0/1 Pending 0 15m <none> <none> <none> <none>apiVersion: apps/v1
kind: Deployment
metadata:
name: dp-demo
spec:
selector:
matchLabels:
app: dp-demo
replicas: 3
template:
metadata:
labels:
app: dp-demo
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- dp-demo
topologyKey: "kubernetes.io/hostname"
# 反亲和度
podAntiAffinity:
# 尽量让 Pod 不要调度到这样的 Node
# 其中包含一个 Key 为 kubernetes.io/hostname 的标签,且该 Node 上有标签为 security: S2 的 Pod。
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security
operator: In
values:
- S2
topologyKey: kubernetes.io/hostname
containers:
- name: nginx
image: nginx-alpineDeployment 译名为 部署。在k8s中,通过发布 Deployment,可以创建应用程序 (docker image) 的实例 (docker container),这个实例会被包含在称为 Pod 的概念中,Pod 是 k8s 中最小可管理单元。
在 k8s 集群中发布 Deployment 后,Deployment 将指示 k8s 如何创建和更新应用程序的实例,master 节点将应用程序实例调度到集群中的具体的节点上。
创建应用程序实例后,Kubernetes Deployment Controller 会持续监控这些实例。如果运行实例的 worker 节点关机或被删除,则 Kubernetes Deployment Controller 将在群集中资源最优的另一个 worker 节点上重新创建一个新的实例。这提供了一种自我修复机制来解决机器故障或维护问题。
本教程教你跑一个Web NodeJS项目在google cloud k8s集群上面。
GKE 是 Google Kubernetes Engine (GKE) 集群
前提
- 已经在GKE上面创建好了k8s集群

- 本地安装好了gcloud cli,并且可以管理集群
kubecl get nodes 查看所有节点

- 制作好的镜像
源码在github上面非常简单,镜像也放到了docker hub
- 本地运行
docker run -p 3000:3000 -d finleyma/express可以成功
浏览器打开 http://localhost:3000, 可以看到内容,说明我们的镜像运行成功,可以分发部署了
部署应用到GKE
创建k8s的deployment
kubectl create deployment express-demo-deployment --image=finleyma/express
设置基准数量为3,因为我们有3个节点机器,所以每个节点跑一个
kubectl scale deployment express-demo-deployment --replicas=3
(可选)创建一个水平自动扩展调节器, 根据 CPU 负载将 Pod 数量从 3 个扩缩为 1 到 5 个之间
kubectl autoscale deployment express-demo-deployment --cpu-percent=80 --min=1 --max=5
查看已创建的Pod
kubectl get pods

程序跑起来了,google cloud 也可以看到

虽然 Pod 确实具有单独分配的 IP 地址,但这些 IP 地址只能从集群内部访问。此外,GKE Pod 设计是临时的,可根据扩缩需求启动或关闭。当 Pod 因错误而崩溃时,GKE 会自动重新部署该 Pod,并且每次都会为 Pod 分配新的 IP 地址。
我们需要将集群外部公开 Kubernetes 服务,创建 LoadBalancer 类型的服务。此类型的服务会为可通过互联网访问的一组 Pod 生成外部负载平衡器 IP 地址。
kubectl expose deployment express-demo-deployment --name=express-demo-deployment --type=LoadBalancer --port 80 --target-port 3000
--port 标志指定在负载平衡器上配置的端口号
--target-port 标志指定 hello-app 容器正在侦听的端口号查看服务,会看到 EXTERNAL-IP 列会自动分配一个IP,访问IP,和本地效果一样
kubectl get service 或 kubectl get svc

至此部署完成
虽然部署完了,如果代码更新了,我们怎么发布新版本到k8s集群呢?
之前我们用k8s创建了一个deployment,deployment很强大,可以指定镜像版本,实现不停机逐渐替换镜像的Pod。
- 更新代码,比如将 server.js中输入内容那行更新为
res.send('Hello world222\n'); - 重新生成镜像并推到仓库
docker build -t finleyma/express:v2 .
docker push finleyma/express:v2docker hub上可以看到我们新的tag名为v2的镜像

使用 kubectl set image 命令通过镜像更新将滚动更新应用于现有的名为 express-demo-deployment的Deployment
kubectl set image deployment/[deployment名称] [容器名]=[镜像名:tag名]
kubectl set image deployment/express-demo-deployment express-demo=finleyma/express:v2
监控 pods的运行状况, 旧的pod被依次删除,新的被依次创建了,因为连pod的名字都变了
kubectl get pods -w

再次刷新页面,内容已经变了!滚动更新成功。
deployment对于发布应用到k8s集群非常有用,我们还可以方便的回滚到某个历史版本
其他命令
查看详情
kubectl describe deployment/express-demo-deployment
验证发布
kubectl rollout status deployment/express-demo-deployment
查看pod中的容器的打印日志(和命令docker logs 类似)
kubectl logs -f express-demo-deployment-XXXXXXX
pod中的容器环境内执行命令(和命令docker exec 类似)
kubectl exec -it express-demo-deployment-XXXXXXX -- /bin/bash
参考
]]>helm create my-nginx
Creating my-nginx会生成同名目录,打开后,里面有一些配置文件

helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
helm search repo bitnamihelm show chart bitnami/nginx
annotations:
category: Infrastructure
apiVersion: v2
appVersion: 1.21.3
dependencies:
- name: common
repository: https://charts.bitnami.com/bitnami
tags:
- bitnami-common
version: 1.x.x
description: Chart for the nginx server
home: https://github.com/bitnami/charts/tree/master/bitnami/nginx
icon: https://bitnami.com/assets/stacks/nginx/img/nginx-stack-220x234.png
keywords:
- nginx
- http
- web
- www
- reverse proxy
maintainers:
- email: [email protected]
name: Bitnami
name: nginx
sources:
- https://github.com/bitnami/bitnami-docker-nginx
- http://www.nginx.org
version: 9.5.8| 命令实例 | 对应功能介绍 |
|---|---|
| helm repo add bitnami https://charts.bitnami.com/bitnami | 添加有效的 Helm-chart 仓库 |
| helm repo list | 查看配置的 chart 仓库 |
| helm search repo wordpress | 从添加的仓库中查找 chart 的名字 |
| helm install happy-panda bitnami/wordpress | 安装一个新的 helm 包 |
| helm status happy-panda | 来追踪展示 release 的当前状态 |
| helm show values bitnami/wordpress | 查看 chart 中的可配置选项 |
| helm uninstall happy-panda | 从集群中卸载一个 release |
| helm list | 看到当前部署的所有 release |
| helm pull bitnami/wordpress | 下载和查看一个发布的 chart |
| helm upgrade | 升级 release 版本 |
| helm rollback | 恢复 release 版本 |
helm install release bitnami/nginx
NAME: release
LAST DEPLOYED: Sun Oct 17 11:24:26 2021
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
** Please be patient while the chart is being deployed **
NGINX can be accessed through the following DNS name from within your cluster:
release-nginx.default.svc.cluster.local (port 80)
To access NGINX from outside the cluster, follow the steps below:
1. Get the NGINX URL by running these commands:
NOTE: It may take a few minutes for the LoadBalancer IP to be available.
Watch the status with: 'kubectl get svc --namespace default -w release-nginx'
export SERVICE_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[0].port}" services release-nginx)
export SERVICE_IP=$(kubectl get svc --namespace default release-nginx -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
echo "http://${SERVICE_IP}:${SERVICE_PORT}"
helm create my-nginx
helm install full-coral ./my-nginx
helm get manifest my-nginx
helm install --debug --dry-run full-coral ./my-nginx
helm install --debug --dry-run funny my-nginxHelm debug 命令
- helm template --debug
- helm install --dry-run --debug
- helm get manifest
关于 Helm upgrade
实际工作中,CICD流水线,实现k8s滚动更新的核心命令就是 helm upgrade
解释下各个flag
- --install 如果集群没这个chart就安装,否则执行更新操作
- --version 指定 Helm chart 版本
- --wait 等待直到容器状态变为running才结束, --timeout 5m 最大等待时间
- --set 覆盖默认参数,每次更新其实就是更新image.tag
helm upgrade --version $HELM_CHART_VERSION \
--namespace $EKS_NS --install \
--wait --timeout 5m \
--set image.tag=$ACR_IMAGE_TAG \
$MODULE_NAME $HELM_REPO_NAME/$MODULE_NAME- 在实际的chart中,所有的静态默认值应该设置在 values.yaml 文件中,且不应该重复使用 default 命令 (否则会出现冗余)。
- 使用
--set覆盖默认值helm install solid-vulture ./mychart --dry-run --debug --set favoriteDrink=slurm - 使用
-f参数(helm install -f myvals.yaml ./mychart)传递到 helm install 或 helm upgrade 的 values 文件
参考
]]>用户可以用 Kubernetes Dashboard 部署容器化的应用、监控应用的状态、执行故障排查任务以及管理 Kubernetes 各种资源。
先检查dashboard版本与kubernetes版本兼容性:https://github.com/kubernetes/dashboard/releases
这里安装最新的 dashboard v2.6.1
执行yaml文件直接部署:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.6.1/aio/deploy/recommended.yaml
k8s中,创建资源需要一个配置文件,配置文件的格式要求是yaml
当然我们也可以把这个yaml文件先下载下来,编辑后再执行。
检查 kubernetes-dashboard 应用状态
kubectl get pod -n kubernetes-dashboard
开启 API Server 访问代理
kubectl proxy
通过如下 URL 访问 Kubernetes dashboard
创建cluster-admin并获取token
这里我们创建一个SA并绑定为cluster级别的admin
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard获得token并复制
kubectl get secret | grep admin-user -n kubernetes-dashboard
kubectl describe secret admin-user-token-swjwl -n kubernetes-dashboard
Name: admin-user-token-swjwl
Namespace: kubernetes-dashboard
Labels: <none>
Annotations: kubernetes.io/service-account.name: admin-user
kubernetes.io/service-account.uid: 9d723616-7051-4a42-81c7-0cf04d74dbda
Type: kubernetes.io/service-account-token
Data
====
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IkE4bElfczJzaWJRdXZWYk5OZVN6RjhubHRCbGxBNWlRLUwza2l4UVRuOFUifQ.eyJpc3MiOiJrdWJl***********2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0***********c2VyLXRva2VuLXN3andsIi****************C9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI5ZDcyMzYxNi03MDUxLTRhNDItODFjNy0wY2YwNGQ3NGRiZGEiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.LWdMu6V3iBlNJ9***********4CGKi_AR-e-MApqJ364yXq4EpO5Teq5K_XoOM8oZBI1_HgfsQ-65SFsz60sDaqE8UR23UeFnBlJmXgfHibM6H6kNUz2wtTGxsOaXlA2iNlHy7tYhkZHQivARfLqH6PqaVeU3mOHiBW8TK4***********rozE4sZe8m0cAMqv1LOctuGOrWqgR73trmm3WPam925gBOJKWvN5z_UDwmf9M_QSfz5XTmKAw0CvFxksOuMao8numCumnvhZN2j2ch1qgkGHZZIARn1N8c-kuvWaf2iPHnnN0fns5RIOBGsH2Xw
ca.crt: 1099 bytes
namespace: 20 bytes登录dashboard的时候,选择令牌,粘贴刚才的token

或者选择 Kubeconfig 文件,路径如下:
- Mac: $HOME/.kube/config
- Win: %UserProfile%.kube\config
点击登陆,进入Kubernetes Dashboard
]]># 起别名,缩短命令
alias k=kubectl
alias kd="kubectl describe"
export do="--dry-run=client -o yaml" # k get pod x $do # 只运行不真正生成资源
export now="--force --grace-period 0" # k delete pod x $now # 立刻强制删除pod
# yaml 缩进
# vi 打开文件,按 esc 并输入 :set shiftwidth=2 来设置缩进空格数
# 缩进多行
# shift+v 并按上下键,选中多行,再按 > 或 < 将选中的内容缩进集群命令
k get nodes
k config get-clusters
k cluster-info
k create ns demo
# 设置默认命名空间
k config set-context $(kubectl config current-context) --namespace=demo
k run nginx --image=nginx
kd pod/nginx
k exec nginx -it -- curl localhost
k create deployment nginx --image=nginx --replicas=2
k get deployments
kd deployment nginx
k get events
k get events --sort-by=.metadata.creationTimestamp
k get deployment nginx -o yaml
k get deployment nginx -o yaml > first.yaml
k delete deployment nginx
k create -f first.yaml
k get deployment nginx -o yaml > second.yaml
diff first.yaml second.yaml
# 只查看不运行
k create deployment two --image=nginx --dry-run=client -o yaml
k get deploy,pod
k expose deployment nginx --port=80
# (可选)创建一个水平自动扩展调节器, 根据 CPU 负载将 Pod 数量从 3 个扩缩为 1 到 5 个之间
k autoscale deployment nginx --cpu-percent=80 --min=1 --max=5
k get deploy,pod,svc
# 记住 10.76.2.119
k get ep nginx
# 扩容
k scale deployment nginx --replicas=3
# 变为了三个endpoint
k get ep nginx
k get pod -o wide
k exec nginx-6799fc88d8-7z8w7 -i -t -- bash
# 容器内执行
curl 10.76.2.119
printenv
KUBERNETES_SERVICE_PORT_HTTPS=443
KUBERNETES_SERVICE_PORT=443
HOSTNAME=nginx-6799fc88d8-7z8w7
PWD=/
PKG_RELEASE=1~bullseye
HOME=/root
KUBERNETES_PORT_443_TCP=tcp://10.80.0.1:443
NJS_VERSION=0.7.0
TERM=xterm
SHLVL=1
KUBERNETES_PORT_443_TCP_PROTO=tcp
KUBERNETES_PORT_443_TCP_ADDR=10.80.0.1
KUBERNETES_SERVICE_HOST=10.80.0.1
KUBERNETES_PORT=tcp://10.80.0.1:443
KUBERNETES_PORT_443_TCP_PORT=443
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
NGINX_VERSION=1.21.4
_=/usr/bin/printenv
# 新建一个deployment以供实验
kubectl create deployment redis --image=redis:3.2
# 修改deployment的image版本
kubectl set image deployment redis redis=redis:latest --record
# 查看redis的历史版本
kubectl rollout history deployment redis
# 修改deployment的版本,退回到上一个版本
kubectl rollout undo deployment redis
# 修改deployment的版本,退回到指定的版本
kubectl rollout undo deployment redis --to-revision=1
# 输出deployment的spec信息拿出来。
kubectl get deployment redis -o=custom-columns=NAME:spec > aim.txt
# kubectl replace用提供的规范定义的资源完全替换现有资源。 希望输入完整的规范,删除老的,创建新的
# kubectl apply使用提供的规范来创建资源(如果该资源不存在)并进行更新(即修补)(如果存在的话),提供给apply的规范仅需包含规范的必需部分
# kubectl patch 更新字段
# 忘了 yaml 中某资源或参数的用法,使用 explain 现学现卖
k explain jobs
k explain jobs.spec关于 -o 输出选项参数
参考:https://kubernetes.io/docs/reference/kubectl/overview/#output-options
k get pods
NAME READY STATUS RESTARTS AGE
nginx-6799fc88d8-7z8w7 1/1 Running 0 13d
k get pods nginx-6799fc88d8-7z8w7
NAME READY STATUS RESTARTS AGE
nginx-6799fc88d8-7z8w7 1/1 Running 0 13d
k get pods nginx-6799fc88d8-7z8w7 -o=name
pod/nginx-6799fc88d8-7z8w7
# -o=wide 输出更多信息
k get pods nginx-6799fc88d8-7z8w7 -o=wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-6799fc88d8-7z8w7 1/1 Running 0 13d 10.76.2.119 gke-cluster-1-default-pool-2d9ab2a3-ynnj <none> <none>
# 输出格式
k get pods nginx-6799fc88d8-7z8w7 -o=json
k get pods nginx-6799fc88d8-7z8w7 -o=yaml
# 提取行
k get pods -A -o=custom-columns=time:.metadata.creationTimestamp
# 输出
time
2022-02-21T13:58:14Z
2022-02-21T15:01:21Z
2022-02-21T13:58:14Z
2022-02-21T13:58:14Z
2022-02-21T13:58:14Z
k get pods nginx-6799fc88d8-7z8w7 -o=custom-columns=IP:.status.podIP,c2:.status.startTime
IP c2
10.76.2.119 2021-12-17T15:06:16Z# 新建 column.txt,内容如下,用来定义要显示的列
Pod的IP 启动时间
.status.podIP .status.startTime
k get pods nginx-6799fc88d8-7z8w7 -o=custom-columns-file=column.txt
Pod的IP 启动时间
10.76.2.119 2021-12-17T15:06:16Z节点的启停
为了确保重启Master节点期间Kubernetes集群能够使用,集群中master节点数量要大于等于3
# 备份数据,关于备份看我写的其他章节
velero backup create
# 设置为不可调度
k cordon master
# 驱逐上面的工作负载
# delet-local-data 会删除Pod的临时数据,不会删除持久化数据
k drain master --ignore-damonsets --delet-local-data
# 停止kubelet etcd docker
systemctl stop kubelet
systemctl stop etcd
systemctl stop docker节点打标签
k get nodes --show-labels
# 添加标签
k label node vm2 beta.kubernetes.io/fluentd-ds-ready=true
# 移除标签
k label node vm2 beta.kubernetes.io/fluentd-ds-ready-集群停止与恢复
kubectl get nodes -o name
node/master
node/vm2
# 停止顺序 kubelet etcd docker
# 启动时顺序相反 启动顺序 docker -> etcd -> kubelet
nodes=$(kubectl get nodes -o name | aws -F[/] '{print $2}')
for node in ${nodes[@]}
do
echo "==STOP kubelet on $node=="
ssh root@$node systemctl stop kubelet && systemctl stop etcd && systemctl stop docer
done查看组件状态
# 缩写 k get cs
k get componentstatuses
# 由于本身服务是正常的,只是健康检查的端口没启,所以不影响正常使用
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
# 开启 scheduler, control-manager的10251,10252端口
# 修改以下配置文件:
# 静态pod的路径:/etc/kubernetes/manifests
vi kube-scheduler.yaml,把port=0那行注释
vi kube-controller-manager.yaml,把port=0那行注释
# 这时候再检查,正常了
k get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}etcd
检查 etcd 状态
source /etc/etcd.env
etcdctl --endpoints=${ETCD_LISTEN_CLIENT_URLS} \
--cacert=${ETCD_TRUSTED_CA_FILE} \
--cert=${ETCD_CERT_FILE} \
--key=${ETCD_KEY_FILE} \
endpoint health
https://127.0.0.1:2379 is healthy: successfully committed proposal: took = 30.02469ms
https://192.168.50.111:2379 is healthy: successfully committed proposal: took = 53.164703ms查看日志
journalctl -u etcd.service
taint 污点
默认情况下,master节点存在以下污点:
Taints: node-role.kubernetes.io/master:NoSchedule
导致Pod不会被分配到master节点上面
移除污点
k taint node master node-role.kubernetes.io/master:NoSchedule-
如果要设置回来
k taint node master node-role.kubernetes.io/master=:NoSchedule
证书解密
kubeconfig 文件保存着集群、用户和上下文信息,这些信息都是加密的,需要解密
kubectl config view --minify --raw --output 'jsonpath={..cluster.certificate-authority-data}'
输出类似,一看就是base64编码过的
LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSUM1ekNDQWMrZ0F3SUJBZ0lCQU....URS0tLS0tCg==解码
sudo cat ~/kube/config | grep client-certificate-data | cut -f2 -d : | tr -d ' ' | base64 -d | openssl x509 -text -in -输出
Certificate:
Data:
Version: 3 (0x2)
Serial Number: 931386242226475695 (0xcecf2da449852af)
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN = kubernetes
Validity
Not Before: Feb 28 05:57:26 2022 GMT
Not After : Feb 28 05:57:28 2023 GMT
Subject: O = system:masters, CN = kubernetes-admin
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
RSA Public-Key: (2048 bit)
Modulus:
00:bb:e5:be:e2:4e:5f:06:1d:b6:4b:59:b4:d7:a9:
fd:dc:01:5b:5d:26:bd:ce:02:50:0b:b9:eb:cd:b6:
b7:35:f8:a6:da:1d:68:c5:49:f4:c4:48:2f:14:ad:
81:17:da:9e:99:78:97:6c:36:ae:ba:bc:ce:99:90:
89:80:4f:4e:19:d4:b4:46:07:da:9c:27:a8:50:23:
1b:be:e3:26:be:36:37:ab:af:0b:ce:49:2b:66:15:
a2:2a:2a:c3:8a:4d:1a:a5:9d:a2:c2:b2:4c:3b:65:
4a:2d:99:2e:25:d5:fa:1f:8a:69:e3:63:62:9a:92:
5d:82:e4:d5:6b:82:bf:56:6c:5d:fc:6a:4e:5a:08:
82:68:1b:3a:25:ce:ec:1e:c1:47:a8:0b:44:48:44:
5c:28:da:8e:e6:22:39:07:45:e1:bb:9a:33:3d:2a:
0a:0d:05:d9:22:76:35:3c:6b:be:c4:cc:d9:7c:72:
96:fa:b7:55:3e:95:ea:98:81:7b:f9:92:af:47:13:
1c:96:ce:08:ea:b8:41:50:fd:94:45:19:30:8c:6f:
a8:ee:1d:c6:d2:d0:4d:ce:d9:7e:19:16:44:76:31:
e5:e7:78:6c:49:d1:58:ce:cb:4a:5c:c7:ef:db:1f:
79:cc:e7:12:d4:c9:9a:9b:d9:9a:ad:2b:72:55:eb:
8d:cb
Exponent: 65537 (0x10001)
X509v3 extensions:
X509v3 Key Usage: critical
Digital Signature, Key Encipherment
X509v3 Extended Key Usage:
TLS Web Client Authentication
X509v3 Basic Constraints: critical
CA:FALSE
X509v3 Authority Key Identifier:
keyid:8F:AF:E7:AF:07:48:02:10:DE:C2:B7:63:35:EA:A8:F4:A3:38:A4:3B
Signature Algorithm: sha256WithRSAEncryption
1a:65:09:3f:3f:13:14:b2:c6:7e:5f:7a:2e:14:47:80:c9:6f:
1a:5d:c7:54:04:3a:dd:59:17:24:64:57:50:37:40:1a:23:86:
42:3d:94:c3:2d:d6:08:89:66:2c:2d:01:0f:56:54:9d:1a:93:
e9:c7:20:f1:5d:fc:d6:52:b4:2b:91:07:c7:c1:e0:f8:7b:4d:
98:b8:06:7b:5c:19:d1:1d:d5:45:29:e9:12:c8:da:83:fe:12:
28:e0:ea:28:1e:77:64:b3:91:b1:25:b5:8b:19:2a:77:f5:50:
3b:29:90:fd:65:36:93:e7:98:ec:ab:c5:57:03:ca:92:26:7f:
56:b7:a8:89:a2:cb:6e:c3:6d:cc:93:cd:33:c7:f7:79:65:d3:
22:2d:16:08:b4:f1:dd:15:77:74:b6:5b:c8:82:ab:ff:72:d3:
82:c0:31:12:e8:6e:1e:ea:48:be:be:bc:f0:4b:83:c8:a1:7d:
df:57:bb:8e:b5:70:95:78:25:27:5c:e4:b9:d6:68:c6:f6:1d:
9d:b9:52:c5:4d:94:36:45:7d:e7:85:19:d3:93:26:08:66:b4:
1c:86:05:54:48:6c:a9:c2:84:d3:ef:54:97:67:2a:f8:ca:0b:
fb:5d:95:1b:5a:90:c9:27:3e:e7:95:a4:35:c1:54:a5:bd:33:
cd:66:bb:3b
-----BEGIN CERTIFICATE-----
MIIDITCCAgmgAwIBAgIIDOzy2kSYUq8wDQYJKoZIhvcNAQELBQAwFTETMBEGA1UE
AxMKa3ViZXJuZXRlczAeFw0yMjAyMjgwNTU3MjZaFw0yMzAyMjgwNTU3MjhaMDQx
FzAVBgNVBAoTDnN5c3RlbTptYXN0ZXJzMRkwFwYDVQQDExBrdWJlcm5ldGVzLWFk
bWluMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAu+W+4k5fBh22S1m0
16n93AFbXSa9zgJQC7nrzba3Nfim2h1oxUn0xEgvFK2BF9qemXiXbDauurzOmZCJ
gE9OGdS0RgfanCeoUCMbvuMmvjY3q68LzkkrZhWiKirDik0apZ2iwrJMO2VKLZku
JdX6H4pp42NimpJdguTVa4K/Vmxd/GpOWgiCaBs6Jc7sHsFHqAtESERcKNqO5iI5
B0Xhu5ozPSoKDQXZInY1PGu+xMzZfHKW+rdVPpXqmIF7+ZKvRxMcls4I6rhBUP2U
RRkwjG+o7h3G0tBNztl+GRZEdjHl53hsSdFYzstKXMfv2x95zOcS1Mmam9marSty
VeuNywIDAQABo1YwVDAOBgNVHQ8BAf8EBAMCBaAwEwYDVR0lBAwwCgYIKwYBBQUH
AwIwDAYDVR0TAQH/BAIwADAfBgNVHSMEGDAWgBSPr+evB0gCEN7Ct2M16qj0ozik
OzANBgkqhkiG9w0BAQsFAAOCAQEAGmUJPz8TFLLGfl96LhRHgMlvGl3HVAQ63VkX
JGRXUDdAGiOGQj2Uwy3WCIlmLC0BD1ZUnRqT6ccg8V381lK0K5EHx8Hg+HtNmLgG
e1wZ0R3VRSnpEsjag/4SKODqKB53ZLORsSW1ixkqd/VQOymQ/WU2k+eY7KvFVwPK
kiZ/VreoiaLLbsNtzJPNM8f3eWXTIi0WCLTx3RV3dLZbyIKr/3LTgsAxEuhuHupI
vr688EuDyKF931e7jrVwlXglJ1zkudZoxvYdnblSxU2UNkV954UZ05MmCGa0HIYF
VEhsqcKE0+9Ul2cq+MoL+12VG1qQySc+55WkNcFUpb0zzWa7Ow==
-----END CERTIFICATE-----https://kubernetes.io/zh/docs/tasks/access-application-cluster/configure-access-multiple-clusters/
参考
]]>kubectl get clusterrole system:node -o yaml返回内容
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:node
rules:
- apiGroups:
- authentication.k8s.io
resources:
- tokenreviews
verbs:
- create
- apiGroups:
- authorization.k8s.io
resources:
- localsubjectaccessreviews
- subjectaccessreviews
verbs:
- create
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch这个 apiGroups: "" 是指 Kubernetes 中所有 API 组的默认值。
apiGroup字段为空字符串("")时,这代表这个资源属于Kubernetes API的核心组(Core Group),每个API所在的Groups可以参考以下文档
例如 Container、Pod、Endpoints都属于core group;
但是 Deployment 属于 apps group。
怎么哪个资源属于哪个组呢?
定义资源时,需要指定其所属的 API 组。例如,定义一个 Deployment 资源时,需要指定其所属的 API 组为 apps/v1。
- pods 和 services 的 APIGROUP 列为空,这意味着它们属于 core 组,其 APIVERSION 是 v1。
- deployments 的 APIGROUP 是 apps,这表示它属于 apps 组
apiVersion: apps/v1
kind: Deploymentkubectl api-resources 命令返回的 APIVERSION 列中的 v1 表示该资源属于 core API 组(也称为 core group 或 legacy group)。
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
limitranges limits v1 true LimitRange
namespaces ns v1 false Namespace
nodes no v1 false Node
persistentvolumeclaims pvc v1 true PersistentVolumeClaim
persistentvolumes pv v1 false PersistentVolume
pods po v1 true Pod
podtemplates v1 true PodTemplate
replicationcontrollers rc v1 true ReplicationController
resourcequotas quota v1 true ResourceQuota
secrets v1 true Secret
serviceaccounts sa v1 true ServiceAccount
services svc v1 true Service
mutatingwebhookconfigurations admissionregistration.k8s.io/v1 false MutatingWebhookConfiguration
validatingwebhookconfigurations admissionregistration.k8s.io/v1 false ValidatingWebhookConfiguration
customresourcedefinitions crd,crds apiextensions.k8s.io/v1 false CustomResourceDefinition
apiservices apiregistration.k8s.io/v1 false APIService
controllerrevisions apps/v1 true ControllerRevision
daemonsets ds apps/v1 true DaemonSet
deployments deploy apps/v1 true Deployment
replicasets rs apps/v1 true ReplicaSet
statefulsets sts apps/v1 true StatefulSet
selfsubjectreviews authentication.k8s.io/v1 false SelfSubjectReview
tokenreviews authentication.k8s.io/v1 false TokenReview
localsubjectaccessreviews authorization.k8s.io/v1 true LocalSubjectAccessReview
selfsubjectaccessreviews authorization.k8s.io/v1 false SelfSubjectAccessReview
selfsubjectrulesreviews authorization.k8s.io/v1 false SelfSubjectRulesReview
subjectaccessreviews authorization.k8s.io/v1 false SubjectAccessReview
horizontalpodautoscalers hpa autoscaling/v2 true HorizontalPodAutoscaler
cronjobs cj batch/v1 true CronJob
jobs batch/v1 true Job
certificatesigningrequests csr certificates.k8s.io/v1 false CertificateSigningRequest
amazoncloudwatchagents otelcol,otelcols cloudwatch.aws.amazon.com/v1alpha1 true AmazonCloudWatchAgent
dcgmexporters dcgmexp,dcgmexps cloudwatch.aws.amazon.com/v1alpha1 true DcgmExporter
instrumentations otelinst,otelinsts cloudwatch.aws.amazon.com/v1alpha1 true Instrumentation
neuronmonitors neuronexp,neuronexps cloudwatch.aws.amazon.com/v1alpha1 true NeuronMonitor
leases coordination.k8s.io/v1 true Lease
eniconfigs crd.k8s.amazonaws.com/v1alpha1 false ENIConfig
endpointslices discovery.k8s.io/v1 true EndpointSlice
ingressclassparams elbv2.k8s.aws/v1beta1 false IngressClassParams
targetgroupbindings elbv2.k8s.aws/v1beta1 true TargetGroupBinding
events ev events.k8s.io/v1 true Event
flowschemas flowcontrol.apiserver.k8s.io/v1 false FlowSchema
prioritylevelconfigurations flowcontrol.apiserver.k8s.io/v1 false PriorityLevelConfiguration
policyendpoints networking.k8s.aws/v1alpha1 true PolicyEndpoint
ingressclasses networking.k8s.io/v1 false IngressClass
ingresses ing networking.k8s.io/v1 true Ingress
networkpolicies netpol networking.k8s.io/v1 true NetworkPolicy
runtimeclasses node.k8s.io/v1 false RuntimeClass
poddisruptionbudgets pdb policy/v1 true PodDisruptionBudget
clusterrolebindings rbac.authorization.k8s.io/v1 false ClusterRoleBinding
clusterroles rbac.authorization.k8s.io/v1 false ClusterRole
rolebindings rbac.authorization.k8s.io/v1 true RoleBinding
roles rbac.authorization.k8s.io/v1 true Role
priorityclasses pc scheduling.k8s.io/v1 false PriorityClass
csidrivers storage.k8s.io/v1 false CSIDriver
csinodes storage.k8s.io/v1 false CSINode
csistoragecapacities storage.k8s.io/v1 true CSIStorageCapacity
storageclasses sc storage.k8s.io/v1 false StorageClass
volumeattachments storage.k8s.io/v1 false VolumeAttachment
cninodes cnd vpcresources.k8s.aws/v1alpha1 false CNINode
securitygrouppolicies sgp vpcresources.k8s.aws/v1beta1 true SecurityGroupPolicyUser "system:serviceaccount:gitlab-runner:default" cannot list resource "pods" in API group "" in the namespace "gov-cn"
system:serviceaccount:gitlab-runner:default 是一个 Kubernetes 中标识用户身份的完整名称,用于表示在集群中的 ServiceAccount(服务账号)。
让我们逐个解释这个名称的各个部分:
-
system:这是 Kubernetes 中预定义的特殊命名空间之一。它包含了用于 Kubernetes 系统组件和核心资源的 ServiceAccount 和角色(Role)。
-
serviceaccount:这是指 ServiceAccount(服务账号)的类型。
-
gitlab-runner:这是 ServiceAccount 的命名空间(Namespace)。在此例中,ServiceAccount "gitlab-runner" 属于 "default" 命名空间。
-
default:这是 ServiceAccount 的名称。在 "default" 命名空间中,有一个名为 "gitlab-runner" 的 ServiceAccount。
这篇文章的目的是让大家利用 Docker Desktop 跑一个单节点的 k8s, 需要说明的是单节点无法满足生产环境高可用的要求,但是对于个人来说成本比较高,生产环境至少需要三个节点
这里主要为了熟悉常用概念和命令,有一个大概的认识。
k8s 安装
k8s 由 controller-manager, scheduler, api server, coreDNS 等组件组成。还需要容器运行时环境。
这里容器运行时就是 docker。
这些组件被制作成了镜像,镜像仓库在k8s.gcr.io 是 google 的镜像仓库,国内无法直接访问。
我们可以参考这个项目提供的脚本, 从阿里源下载并安装镜像。
注意 Docker Desktop 带的 k8s 版本要和 images.properties 文件中提供的一致

命令介绍
k8s 启动成功后打开终端,我们的练习全部通过终端进行
kubectl 是 k8s 命令行工具,可以使用 kubectl 来部署应用、监测和管理集群资源以及查看日志。
# 查看节点信息
kubectl get nodes
# 输出节点名称,状态,角色,启动时间和版本
NAME STATUS ROLES AGE VERSION
docker-desktop Ready control-plane,master 14d v1.22.5
# 查看命名空间
# namespace 用来区分不同团队或项目,有隔离资源的作用
# 以`kube-`开头的是k8s自己占用的命名空间,如果创建的资源不指定 namespace 则默认使用 default
# 或者使用 kubectl get namespace, ns 是缩写
kubectl get ns
# 创建一个 namespace,我们在这个 namespace 下面创建资源
kubectl create namespace demo
# 指定默认命名空间为demo, 执行该操作会修改`~/.kube/config`配置文件
kubectl config set-context $(kubectl config current-context) --namespace=demo
# 创建一个 Pod,镜像为 nginx
# Pod 是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
# 一个 Pod 可以包含多个容器,这些容器共享存储,网络
kubectl run nginx --image=nginx
# 查看 Pod
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 45s
# 查看 Pod 具体信息, 留意生成的Pod IP
kubectl describe pod/nginx
# 进入容器
kubectl exec nginx -it -- bash
# 在容器内执行命令,会返回nginx欢迎页面的html,最后exit退出容器
root@nginx:/# curl localhost
root@nginx:/# curl nginx
# 刚才的 Pod IP 会被记录在hosts文件里,记下内网IP:如 172.31.56.149
root@nginx:/# cat /etc/hosts
# nginx version: nginx/1.21.5
root@nginx:/# nginx -v
root@nginx:/# exit如果我们ssh登录k8s所在的任一节点,
curl 172.31.56.149是有nginx内容返回的,说明 Pod 在k8s在整个集群内部是通的
# 销毁 Pod
kubectl delete pod/nginx
# 实际上,我们很少通过 Pod 来跑服务,通常使用 Deployment,StatefulSet 和 DaemonSet 来替代
# 因为 Pod 一旦出现问题,比如资源不足,网络不通等,无法自动重启,扩容,转移等
# 先看帮助文档里提供了哪些参数
kubectl create deployment -h
# 创建一个 deployment,名为 nginx,副本数为2
# 假设有两个工作节点,每个节点运行一个同样的 Pod,这样即便其中一个节点挂掉了,另给一个还能正常工作,达到高可用的目的
kubectl create deployment nginx --image=nginx --replicas=2
# 观察资源情况,我们看到可用数 0/2 变为 1/2 最终 2/2
kubectl get deployment nginx --watch
# 查看 Pod,和期望的一致,运行了两个 Pod
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-6799fc88d8-r8lmj 1/1 Running 0 2m49s
nginx-6799fc88d8-t9pms 1/1 Running 0 2m49s
# 假设我们删除其中一个, 再次观察,会发现又启动了一个新的 Pod
kubectl delete pod/nginx-6799fc88d8-t9pms
# --watch 的简写
kubectl get pods -wkubernetes 会始终保持预期创建的对象存在和集群运行在预期的状态下。
# 我们现在编辑 deployment, 此时会呼出编辑器或vim,修改 replicas 为 1
kubectl edit deployment nginx
# pod 数量会和 replicas 保持一致
kubectl get pods -w
# 如果只想改副本数,可以使用 scale
kubectl scale deployment nginx --replicas=3
# 修改 image 版本
kubectl set image deployment/nginx nginx=nginx:1.16.1 --record
# 注意观察
kubectl get pods -w
# 如果我们细心观察,假设当前副本数3,每个 Pod 里面跑着 nginx/1.21.5,当 set image为 nginx=nginx:1.16.1
# k8s 会先启动一个新的 Pod,里面运行着1.16.1,此时有4个 Pod 正在运行
# 只有新的 Pod 运行成功才会销毁一个旧的 Pod, 会这样依次滚动更新,新旧版本会平滑过渡,直到全部更新完成,可以保证我们的服务不被中断。
NAME READY STATUS RESTARTS AGE
nginx-6799fc88d8-bcfpz 1/1 Running 0 51s
nginx-6799fc88d8-msgkf 1/1 Running 0 51s
nginx-6799fc88d8-r8lmj 1/1 Running 0 19m
nginx-6889dfccd5-t52mv 0/1 ContainerCreating 0 6s
# 查看 deployment 的版本更新历史
deployment.apps/nginx
REVISION CHANGE-CAUSE
1 kubectl.exe scale deployment nginx --replicas=3 --record=true
2 kubectl.exe set image deployment/nginx nginx=nginx:1.16.1 --record=true
# 回退到上一个版本
kubectl rollout undo deployment nginx
# 回退到 to-revision 指定的版本
kubectl rollout undo deployment redis --to-revision=1服务暴露
k8s 并没有docker -p那样直接将容器端口暴露出来的参数,要通过创建 service 的方式
service 分 "ClusterIP", "LoadBalancer", "NodePort" 等类型
- ClusterIP: 默认类型,k8s分配一个集群内可访问固定虚拟IP,实现集群内访问,外部无法访问。
- NodePort: 跟docker的-p最类似,将容器端口映射到每个节点的端口上面,实现
nodeIP:nodePort从集群外部访问, 弊端是为了避免冲突,默认端口范围是30000-32767,比较难记。安装时k8s可修改此参数。 - LoadBalancer: 只在公有云上有效,比如阿里云提供的k8s服务,使用该类型后,阿里云会自动创建一个负载均衡器, 这个负载均衡器的后端映射到各节点的nodePort,一般创建完成后会给我们提供一个公网IP, 可以通过service的external IP查看, 访问该IP,流量经过负载均衡,再到节点中的容器里,除了需要额外支付负载均衡器和静态IP的费用没什么弊端。
# 将 Pod 中的 80 端口暴露出来,此命令会创建一条 service
kubectl expose deployment nginx --port=80 --name=svc-nginx
# 查看 service, cluster-ip 是 k8s 集群IP,只能在集群内访问,外界无法访问
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc-nginx ClusterIP 10.108.193.18 <none> 80/TCP 19s
# ssh登录到任意集群节点,curl 10.108.193.18 也是通的
# kubectl port-forward 通过端口转发映射本地端口到指定的应用端口,从而访问集群中的应用程序(Pod).
# 这个命令一般适用于本地调试,比如数据库连接
# 这里没有指定本地的端口,让 k8s 分配一个可用的端口
kubectl port-forward service/svc-nginx :80
# 当然也可以手动指定
kubectl port-forward service/svc-nginx 8099:80
> Forwarding from 127.0.0.1:8099 -> 80
> Forwarding from [::1]:8099 -> 80
> Handling connection for 8099
# 创建一个 NodePort 类型的 service
kubectl expose deployment nginx --port=80 --name=svc-nginx-nodetype --type NodePort
# 32031就是 nodeType 暴露的端口,本地浏览器打开 localhost:32031 可以看到 nginx 欢迎页面
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc-nginx ClusterIP 10.108.193.18 <none> 80/TCP 16m
svc-nginx-nodetype NodePort 10.103.213.244 <none> 80:32031/TCP 7s销毁
k delete svc svc-nginx
k delete deployment nginxingress
ingress 是入口的意思,ingress 可以调度不同的业务领域,不同URL访问路径的业务流量。
比如我们有一个域名www.localdev.me
现在有俩项目,demo1 和 demo2,对应的 deployment 和 service 都创建好了,如果使用NodeType 之前访问地址可能是www.localdev.me:32102和www.localdev.me:36321
使用 ingress 之后,就可以是demo1.localdev.me和demo2.localdev.me, 域名和业务结合起来了,还便于识记
当然也可以配为www.localdev.me/demo1,当访问此域名,流量会被转发到名为 demo1 的 deployment 应用
你会说这不是 nginx 反向代理干的事情吗,对的,ingress是个概念,具体干活的叫ingress controller,比如现在流行的有 Nginx Ingress Controller ,
Traefik Ingress Controller, Kong Ingress Controller
比如 Nginx Ingress Controller,安装后其实就是运行了个 nginx 的Pod,提供了反向代理,负载均衡,Basic认证,Oauth认证,流量控制,路由重写等功能
参考
]]>组件图


- Control Plane组件:etcd, kube-controller-manager, kube-scheduler, kube-apiserver
- node组件:kubelet, kube-proxy, container runtime
- 额外的:DNS, Web UI, Monitoring, Logging
Kubernetes组件
我们平时做开发的过程中所使用的服务器(即宿主机),在Kubernetes集群中被称为Node节点。
同时在Kubernetes中存在一个或者多个Master节点控制多个宿主机实现集群,整个Kubernetes的核心调度功能基本都在Master节点上。
Kubernetes的主要功能通过五个大组件组成:
- kubelet:安装在Node节点上,用以控制Node节点中的容器完成Kubernetes的调度逻辑
- ControllerManager:是我们上述所讲的控制器模式的核心管理组件,管理了所有Kubernetes集群中的控制器逻辑
- API Server:服务处理集群中的api请求,我们一直写的kubectl,其实就是发送给API Server的请求,请求会在其内部进行处理和转发
- Scheduler:负责Kubernetes的服务调度,比如控制器只是控制Pod的编排,最后的调度逻辑是由Scheduler所完成并且发送请求给kubelet执行的
- Etcd:这是一个分布式的数据库存储项目,由CoreOS开发,最终被RedHat收购成为Kubernetes的一部分,它里面保存了Kubernetes集群中的所有配置信息,比如所有集群对象的name,IP,secret,configMap等所有数据,其依靠自己的一致性算法可以保证在系统中快速稳定的返回各种配置信息,因此这也是Kubernetes中的核心组件
kube-controller-manager,kube-apiserver,kube-scheduler,etcd是以静态Pod方式运行,kubelet是系统进程
定制化功能
除了各种强大的组件功能之外,Kubernetes也给用户提供了极高的自由度。
为了实现这种高度的自由,Kubernetes给用户提供了三个公开的接口,分别是:
- CNI(Container Networking Interface,容器网络接口):其定义了Kubernetes集群所有网络的链接方式,整个集群的网络都通过这个接口实现。只要实现了这个接口内所有功能的网络插件,就可以作为Kubernetes集群的网络配置插件,其内部包括宿主机路由表配置、7层网络发现、数据包转发等等都有各式各样的小插件,这些小插件还可以随意配合使用,用户可以按照自己的需求自由定制化这些功能
- CSI(Container Storage Interface,容器存储接口)定义了集群持久化的一些规范,只要是实现这个接口的存储功能,就可以作为Kubernetes的持久化插件
- CRI(Container Runtime Interface,容器运行时接口):在Kubernetes的容器运行时,比如默认配置的Docker在这个集群的容器运行时,用户可以自由选择实现了这个接口的其他任意容器项目,比如之前提到过的 containerd 和 rkt
这里讲一个有趣的点:CRI。
Kubernetes的默认容器是Docker,但是由于项目初期的竞争关系,Docker其实并不满足Kubernetes所定义的CRI规范,那怎么办呢?
为了解决这个问题,Kubernetes专门为Docker编写了一个叫DockerShim的组件,即Docker垫片,用来把CRI请求规范,转换成为Docker操作Linux的OCI规范(对,就是第二部分提到的那个OCI基金会的那个规范)。但是这个功能一直是由Kubernetes项目维护的,只要Docker发布了新的功能Kubernetes就要维护这个DockerShim组件。
于是,这个近期的消息——Kubernetes将在明年的版本v1.20中删除删除DockerShim组件,意味着从明年的新版本开始,Kubernetes将全面不支持Docker容器的更新了。
但其实这对我们普通开发者来说可能并没有什么影响,最坏的结果就是我们的镜像需要从Docker换成其他Kubernetes支持的容器镜像。
不过根据这这段时间各个云平台放出的消息来看,这些平台都会提供对应的转换措施,比如我们还是提供Docker镜像,平台在发布运维的时候会把这些镜像转换成其他镜像;又或者这些平台会自行维护一个DockerShim来支持Docker,都是有解决方案的。
Pod
- Pod里的容器运行在一个逻辑上的"主机"上,它们使用相同的网络名称空间(也就是说,同一Pod里的容器使用相同的IP和相同的端口段区间)和相同的进程间通信(IPC)名称空间. 它们也可以共享存储卷.这些特性使它们可以更有效的通信.并且pod可以使你把紧密耦合的应用容器作为一个单元来管理.
- 这就意味着同一个Pod内的容器可以通过localhost来连接对方的端口
- 每个Pod都拥有一个独立的IP地址,并假定所有Pod都在一个可以直接连通的、扁平的网络空间中
- 为了使Pod保持运行,Pod应该执行某些任务,否则Kubernetes会发现它是不必要的,因此退出。有很多方法可以使Pod保持运行。
- 在运行容器时发出睡眠命令。
- 在容器内运行无限循环。
睡眠命令
apiVersion: v1
kind: Pod
metadata:
name: busybox
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
ports:
- containerPort: 80
command: ["/bin/sh", "-ec", "sleep 1000"]无限循环
apiVersion: v1
kind: Pod
metadata:
name: busybox
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
ports:
- containerPort: 80
command: ["/bin/sh", "-ec", "while :; do echo '.'; sleep 5 ; done"]Just sleep forever
apiVersion: v1
kind: Pod
metadata:
name: ubuntu
spec:
containers:
- name: ubuntu
image: ubuntu:latest
# Just sleep forever
command: [ "sleep" ]
args: [ "infinity" ]Pod控制器
Pod控制器是Pod启动的一种模板,来保证K8S里启动的Pod应始终按照预期运行(副本数,生命周期,健康状态检查等)
在生产环境,我们一般不会直接创建Pod,通常使用Deployment和StatefulSet来替代。因为Pod一旦出现问题,比如资源不足,网络不通等,无法自动重启,扩容,转移等。
K8S内提供了众多的Pod控制器,常用的有:
- Deployment (最常用的Pod控制器,可以指定副本数,健康状态检查,Deployment 创建的 Pod 并不是唯一的,也不会保留它们的状态,因此可以简化无状态应用的扩缩和更新过程。)
- StatefulSet (有状态应用要求保存或永久保存其状态。有状态应用使用永久性存储空间(例如永久性卷)保存数据,以供服务器或其他用户使用。可以创建 Kubernetes StatefulSet,以部署有状态应用。StatefulSet 创建的 Pod 具有唯一标识符,可以安全有序地进行更新。)
- ReplicaSet (已废弃,被Deployment取代)
- DaemonSet (守护程序在分配的节点中持续执行后台任务,而无需用户干预。守护进程示例包括像 Fluentd 之类的日志收集器和监控服务。可以创建 Kubernetes DaemonSet,以在集群上部署守护进程。DaemonSet 在每个节点创建一个 Pod,您可以选择 DaemonSet 应部署的一个特定节点)
- Job (创建一个或多个Pod可靠的执行任务,任务完成Pod会被终止,失败才会自动创建新的Pod。跟Deployment不同,假如某Deployment的副本数为3,Deployment会始终保持这个数量,而对于Job,Pod执行完就完了,不会始终保持)
- CronJob (按指定的时间计划去执行Job)
- 创建Pod 会以
pod-ip-address.my-namespace.pod.cluster.local这种形式被指派一个 DNS A 记录。[Pod-name].[Service-name-ClusterIP].[namespace].cluster.local
静态Pod
静态 Pod 在指定的节点上由 kubelet 守护进程直接管理,不需要 API Server 监管
静态 Pod 永远都会绑定到一个指定节点上的 Kubelet。
特点: 名称以连字符开头的节点主机名作为后缀。如 kube-controller-manager,kube-apiserver-master,kube-scheduler-master,根据名称判断是静态Pod还是普通Pod。
kubectl delete pod 删除无效,需要转移定义文件,kubelet 会定期扫描配置的目录,如 mv /etc/kubelet.d/static-web.yaml /tmp
DaemonSet
随着node的新增而创建或node的移除而销毁,就是说确保node上运行相同的pod,适合监控或日志收集。
DaemonSet的Pod必须有RestartPolicy值必须是Always或空
存活探针livenessProbe和就绪探针readiness的区别
有些pod可能需要时间来加载配置或数据,或者可能需要执行预热过程以防止第一个用户请求时间太长影响了用户体验。在这种情况下,不希望该pod立即开始接收请求,尤其是在运行的实例可以正确快速地处理请求的情况下。不要将请求转发到正在启动的pod中,直到完全准备就绪。
与存活探针不同,如果容器未通过准备检查,则不会被终止或重新启动。这是存活探针与就绪探针之间的重要区别。
解释有状态和无状态
容器化应⽤程序最困难的任务之⼀,就是设计有状态分布式组件的部署体系结构
由于⽆状态组件可能没有预定义的启动顺序、集群要求、点对点 TCP 连接、唯⼀的⽹络标识符、正常的启动和终⽌要求等,因此可以很容易地进⾏容器化
有状态诸如数据库,⼤数据分析系统,分布式key/value 存储和 message brokers 可能有复杂的分布式体系结构
特点:有状态的pod挂了之后会恢复,恢复的时候名称的生成总是和原先挂之前保持一模一样,无状态的Pod名字后缀是随机的,挂了之后会被重新命名。
Namespace
命名空间,隔离K8S资源的方法。比如有两个项目,都想运行名为backend的deployment,那么可以创建两个namespace,隔离这两个deployment
Service
- 在K8S的世界里,虽然每个Pod会被分配一个单独的IP地址,但是这个IP地址会随着Pod的销毁而消失
- Service(服务)就是解决这个问题的核心概念
- 一个Service可以看做一组提供相同服务Pod的对外访问接口
- Service作用于哪些Pod是通过标签选择器来定义的(这个非常灵活,他把一些复杂的东西解耦了,也是K8S设计强大的地方之一,后续会讲到)
- 当你创建一个服务 时, Kubernetes 会创建一个相应的 DNS 条目。该条目的形式是
<服务名称>.<名字空间名称>.svc.cluster.local
Service类型
- ClusterIP: 在群集中的内部IP上公布服务,外界无法访问,集群内可访问(默认)
- LoadBalance:在云环境中(需要云供应商可以支持)创建一个集群外部的负载均衡器,并为使用该负载均衡器的 IP 地址作为服务的访问地址。此时 ClusterIP 和 NodePort 的访问方式仍然可用。
- NodePort:使用 NAT 在集群中每个的同一端口上公布服务。这种方式下,可以通过访问集群中任意节点+端口号的方式访问服务
<NodeIP>:<NodePort>。此时 ClusterIP 的访问方式仍然可用
Service 中的 port
- port是暴露在cluster ip上的端口,:port提供了集群内部客户端访问service的入口
- nodePort 提供了集群外部客户端访问 Service 的一种方式
- targetPort 是 pod 上的端口
Ingress
- Ingress是K8S集群里工作的OSI网络参考模型下,第7层的应用,对外暴露的接口
- Service只能进行L4流量调度,表现形式是IP+Port
- Ingress则可以调度不同的业务领域,不同URL访问路径的业务流量,比如可以配置访问backend.aa.com,转发到名为backend的deployment应用, 访问frontend.aa.com,转发到名为访问frontend的deployment应用
configmap
configmap的数据可以来自三种类型:字面量,文件和目录
Role 和 ClusterRole的区别
在 Role 中,定义的规则只适⽤于单个命名空间,也就是和 namespace 关联的 ⽽ClusterRole 是集群范围内的,因此定义的规则不受命名空间的约束
Subject
分三种,user account,group,service account
RoleBinding 和 ClusterRoleBinding
简单来说就是把声明的 Subject 和我们的 Role 进⾏绑定的过程(给某个⽤户绑定上操作的权限)
RoleBinding 只会影响到当前 namespace 下⾯的资源操作权限 ClusterRoleBinding 会影响到所有的 namespace。
命令行
kubectl scale 不止Deployment,还能对ReplicaSet, Replication Controller, or StatefulSet设置副本数
参考
]]>写下心得和最佳实践
考试前
- 等黑五大概11月份在买,应该是最便宜的,原价2498,我买的CKA&LFS258套购1498.
- 购买后一个月内需要激活,激活后一年内考试都有效
- 考试有中文和英文选择,题目一样,看个人选择
- 远程考试,提前把桌面和房间整理干净,不能有纸笔,水杯必须是透明的,考官会让开摄像头检查房间四角和整个桌面
- 可以用笔记本外接显示器考试,但是只能运行浏览器程序
- 不要报班,自己用虚拟机搭建集群练习就行
- 名字要一致,可以填中文全称,考试前会检查身份证,英文的话可能要看护照,需要和报名网站一致
备考
- 自己用虚拟机运行 kubeadm 或 kubekey 搭建集群
- 看视频 https://www.bilibili.com/video/BV13Q4y1C7hS
- 或买书,只推荐一本《Kubernetes权威指南》
- 做模拟题,github 或闲鱼上搜 kubernetes-cka,开始感觉会比较难,直到熟练为止
考试中
- 只能开两个浏览器标签,一个是答题页面,一个可以打开K8s官方文档,等于是开卷考试
- 所以文档要勤阅
- 把有用的文档存为书签
- 答题页面可以打开一个笔记本,建议每个题目运行的命令都存上面,方便做完检查
- 注意考试环境提供了3-5个集群,每个题目都要求切换到指定集群上面
必考的题目
- etcd 的备份和还原
- network policy 的创建
- ingress 的创建
- service 的创建
- pod 的创建
- role, serviceaccount, rolebinding的创建
- deployment 的创建及 scale 伸缩
- pv,pvc的创建
- kubelet 和 kubectl 的升级
- 设置某节点为不可调度并驱逐上面的pod
强烈建议把常考的题目存为书签

选择考试时间





有用的链接
https://www.reddit.com/r/kubernetes/comments/rzpu5i/i_just_passed_the_cka_here_are_some_tips_2022/
https://github.com/David-VTUK/CKA-StudyGuide
https://github.com/ahmetb/kubernetes-network-policy-recipes
https://github.com/kabary/kubernetes-cka/wiki/CKA-Killer-20-Questions
]]>**污点(Taint)**表示此节点已被 key=value 污染,容器组调度不允许(PodToleratesNodeTaints 策略)或尽量不(TaintTolerationPriority 策略)调度到此节点,除非是能够容忍(Tolerations)key=value 污点的容器组。
- 不允许调度 (NoSchedule)
- 尽量不调度 (PreferNoSchedule)
- 不允许并驱逐已有容器组 (NoExecute)

master nodes上有个污点
kubectl describe node master | grep Taint
`Taints: node-role.kubernetes.io/master:NoSchedule`去除污点
#!/bin/bash
read -p "请输入要去除污点的master节点的hostname(比如: master1):" node
kubectl taint nodes $node node-role.kubernetes.io/master:NoSchedule-所以默认创建的Pod不会被调度master节点,除非被设置了容忍tolerations
# pod_toleration.yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: pod1
spec:
containers:
- image: httpd:2.4.41-alpine
name: pod1-container
command: ["sleep", "3600"]
# 容忍这个污点
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
nodeSelector:
node-role.kubernetes.io/master: ""参考
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/taint-and-toleration/
]]>wget https://github.do/https://github.com/kubesphere/kubekey/releases/download/v2.0.0-rc.3/kubekey-v2.0.0-rc.3-linux-64bit.deb
sudo dpkg -i kubekey-v2.0.0-rc.3-linux-64bit.deb
export KKZONE=cn
# 生成配置文件 sample.yaml
kk create config --from-cluster编辑配置文件,主要修改IP,密码,这里只按照k8s,没有安装kubersphere
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: sample
spec:
hosts:
##You should complete the ssh information of the hosts
- {name: master, address: 192.168.50.111, internalAddress: 192.168.50.111}
- {name: node1, address: 192.168.50.111, internalAddress: 192.168.50.111}
roleGroups:
etcd:
- SHOULD_BE_REPLACED
master:
- master
worker:
- master
controlPlaneEndpoint:
##Internal loadbalancer for apiservers
#internalLoadbalancer: haproxy
##If the external loadbalancer was used, 'address' should be set to loadbalancer's ip.
domain: lb.kubesphere.local
address: ""
port: 6443
kubernetes:
version: v1.21.5
clusterName: cluster.local
proxyMode: ipvs
masqueradeAll: false
maxPods: 110
nodeCidrMaskSize: 24
network:
plugin: calico
kubePodsCIDR: 10.233.64.0/18
kubeServiceCIDR: 10.233.0.0/18
registry:
privateRegistry: ""等待完成
kk create cluster -f sample.yaml前提
安装步骤到网络源配置时,输入阿里源 http://mirrors.aliyun.com/ubuntu/
几个显示切换快捷键 Host + F – 切换到全屏模式 Host + L – 切换到无缝模式 Host + C – 切换到比例模式 Host + Home – 显示控制菜单
Host为键盘上右边的ctrl键
我这里是把网络改为桥接,然后设置静态IP
- master 192.168.50.66
- vm2 192.168.50.49
cat /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
enp0s3:
dhcp4: false
addresses: [192.168.50.66/24]
gateway4: 192.168.50.1
nameservers:
addresses: [192.168.50.1,143.143.143.143]
version: 2应用网络配置 sudo netplan apply
然后路由器绑定MAC地址
修改配置
以下命令每个节点都需要执行
# 禁止swap分区,这个是暂时关闭
sudo swapoff -a
# 永久关闭,注释swap那行
sudo vi /etc/fstab
#
sudo apt-get install openssh-server
sudo/etc/init.d/ssh start
# 关闭防火墙
sudo ufw disable
# 移除ubuntu自带的snapd
sudo apt remove snapd
# 确保每个机器不会自动suspend(待机/休眠)
sudo systemctl mask sleep.target suspend.target hibernate.target hybrid-sleep.target
# 修改时区
sudo timedatectl set-timezone Asia/Shanghai
date -R
# 确认Linux内核加载了br_netfilter模块
lsmod | grep br_netfilter
# 确保sysctl配置中net.bridge.bridge-nf-call-iptables的值设置为了1。
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 修改/etc/sysctl.d/10-network-security.conf
sudo vi /etc/sysctl.d/10-network-security.conf
# 将下面两个参数的值从2修改为1
# net.ipv4.conf.default.rp_filter=1
# net.ipv4.conf.all.rp_filter=1
# 然后使之生效
sudo sysctl --system
# 加入k8s下载阿里源
curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
sudo tee /etc/apt/sources.list.d/kubernetes.list <<EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
# 安装依赖组件
sudo apt-get update && sudo apt-get install -y docker.io openssh-server net-tools ca-certificates curl software-properties-common apt-transport-https kubelet kubeadm kubectl && sudo apt-mark hold kubelet kubeadm kubectl
# 修改docker配置文件 vi /etc/docker/daemon.json文件如下所示
# 驱动改为systemd
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": ["https://c1iu8k4x.mirror.aliyuncs.com"]
}
# 检查驱动
sudo systemctl restart docker
sudo systemctl enable docker
sudo docker info | grep -i cgroup
# 输出类型
WARNING: No swap limit support
Cgroup Driver: systemd
Cgroup Version: 1
# 开机自启动
sudo systemctl enable kubelet && systemctl start kubeletmaster 节点命令
sudo kubeadm init --pod-network-cidr 172.16.0.0/16 \
--apiserver-advertise-address=192.168.50.66 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--ignore-preflight-errors=all
# 这时看到master已经出现,但是status为 not ready,需要安装网络插件,可以是Flannel,Calico等
kubectl get node
# 安装 flannel
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.ymlnode 节点命令
sudo swapoff -a
sudo systemctl restart kubelet
sudo systemctl status kubelet
sudo kubeadm join 192.168.50.66:6443 --token ygwpny.2lj1tj2njduj6qjg \
--discovery-token-ca-cert-hash sha256:b7fe3d7806fcf74a9742a67f8259e7f22edcbd284429cf439e04dda96f3c4a70排错
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
检查并保证kubelet运行
sudo systemctl restart kubelet
sudo systemctl status kubeleterror execution phase preflight: [preflight] Some fatal errors occurred: [ERROR Port-6443]: Port 6443 is in use
加入 --ignore-preflight-errors=all或者kubeadm reset 重置后再次执行
重启主机后CoreDNS启动失败
检查日志
journalctl -u kubelet -n 1000
后续
每添加一个node节点,设置为work节点,注意替换vm1为你实际的节点名
mafei@master:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 3h12m v1.23.1
vm2 Ready <none> 148m v1.23.1
mafei@master:~$ kubectl label node vm2 node-role.kubernetes.io/worker=worker
node/vm2 labeled
mafei@master:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 3h30m v1.23.1
vm2 Ready worker 166m v1.23.1
mafei@master:~$参考
https://www.bilibili.com/video/BV1P5411r78j
]]>1.1 非对称加密基础知识
对称加密:加密和解密使用一样的算法,只要解密时提供与加密时一致的密码就可以完成解密。例如QQ登录密码,银行卡密码,只要保证密码正确就可以。
非对称加密:通过公钥(public key)和私钥(private key)来加密、解密。公钥加密的内容可以使用私钥解密,私钥加密的内容可以使用公钥解密。一般使用公钥加密,私钥解密,但并非绝对如此,例如CA签署证书时就是使用自己的私钥加密。在接下来介绍的SSH服务中,虽然一直建议分发公钥,但也可以分发私钥。
所以,如果A生成了(私钥A,公钥A),B生成了(私钥B,公钥B),那么A和B之间的非对称加密会话情形包括:
(1).A将自己的公钥A分发给B,B拿着公钥A将数据进行加密,并将加密的数据发送给A,A将使用自己的私钥A解密数据。
(2).A将自己的公钥A分发给B,并使用自己的私钥A加密数据,然后B使用公钥A解密数据。
(3).B将自己的公钥B分发给A,A拿着公钥B将数据进行加密,并将加密的数据发送给B,B将使用自己的私钥B解密数据。
(4).B将自己的公钥B分发给A,并使用自己的私钥B加密数据,然后A使用公钥B解密数据。
虽然理论上支持4种情形,但在SSH的身份验证阶段,SSH只支持服务端保留公钥,客户端保留私钥的方式,所以方式只有两种:客户端生成密钥对,将公钥分发给服务端;服务端生成密钥对,将私钥分发给客户端。只不过出于安全性和便利性,一般都是客户端生成密钥对并分发公钥。后文将给出这两种分发方式的示例。
1.2 SSH概要
(1).SSH是传输层和应用层上的安全协议,它只能通过加密连接双方会话的方式来保证连接的安全性。当使用ssh连接成功后,将建立客户端和服务端之间的会话,该会话是被加密的,之后客户端和服务端的通信都将通过会话传输。
(2).SSH服务的守护进程为sshd,默认监听在22端口上。
(3).所有ssh客户端工具,包括ssh命令,scp,sftp,ssh-copy-id等命令都是借助于ssh连接来完成任务的。也就是说它们都连接服务端的22端口,只不过连接上之后将待执行的相关命令转换传送到远程主机上,由远程主机执行。
(4).ssh客户端命令(ssh、scp、sftp等)读取两个配置文件:全局配置文件/etc/ssh/ssh_config和用户配置文件~/.ssh/config。实际上命令行上也可以传递配置选项。它们生效的优先级是:命令行配置选项 > ~/.ssh/config > /etc/ssh/ssh_config。
(5).ssh涉及到两个验证:主机验证和用户身份验证。通过主机验证,再通过该主机上的用户验证,就能唯一确定该用户的身份。一个主机上可以有很多用户,所以每台主机的验证只需一次,但主机上每个用户都需要单独进行用户验证。
(6).ssh支持多种身份验证,最常用的是密码验证机制和公钥认证机制,其中公钥认证机制在某些场景实现双机互信时几乎是必须的。虽然常用上述两种认证机制,但认证时的顺序默认是gssapi-with-mic,hostbased,publickey,keyboard-interactive,password。注意其中的主机认证机制hostbased不是主机验证,由于主机认证用的非常少(它所读取的认证文件为/etc/hosts.equiv或/etc/shosts.equiv),所以网络上比较少见到它的相关介绍。总的来说,通过在ssh配置文件(注意不是sshd配置文件)中使用指令PreferredAuthentications改变认证顺序不失为一种验证的效率提升方式。
(7).ssh客户端其实有不少很强大的功能,如端口转发(隧道模式)、代理认证、连接共享(连接复用)等。
(8).ssh服务端配置文件为/etc/ssh/sshd_config,注意和客户端的全局配置文件/etc/ssh/ssh_config区分开来。
(9).很重要却几乎被人忽略的一点,ssh登录时会请求分配一个伪终端。但有些身份认证程序如sudo可以禁止这种类型的终端分配,导致ssh连接失败。例如使用ssh执行sudo命令时sudo就会验证是否要分配终端给ssh。
1.3 SSH认证过程分析
假如从客户端A(172.16.10.5)连接到服务端B(172.16.10.6)上,将包括主机验证和用户身份验证两个过程,以RSA非对称加密算法为例。
[root@xuexi ~]# ssh 172.16.10.6
服务端B上首先启动了sshd服务程序,即开启了ssh服务,打开了22端口(默认)。
1.3.1 主机验证过程
当客户端A要连接B时,首先将进行主机验证过程,即判断主机B是否是否曾经连接过。
判断的方法是读取~/.ssh/known_hosts文件和/etc/ssh/known_hosts文件,搜索是否有172.16.10.6的主机信息(主机信息称为host key,表示主机身份标识)。如果没有搜索到对应该地址的host key,则询问是否保存主机B发送过来的host key,如果搜索到了该地址的host key,则将此host key和主机B发送过来的host key做比对,如果完全相同,则表示主机A曾经保存过主机B的host key,无需再保存,直接进入下一个过程——身份验证,如果不完全相同,则提示是否保存主机B当前使用的host key。
询问是否保存host key的过程如下所示:
[root@xuexi ~]# ssh 172.16.10.6
The authenticity of host '172.16.10.6 (172.16.10.6)' can't be established.
RSA key fingerprint is f3:f8:e2:33:b4:b1:92:0d:5b:95:3b:97:d9:3a:f0:cf.
Are you sure you want to continue connecting (yes/no)? yes或者windows端使用图形界面ssh客户端工具时:
 在说明身份验证过程前,先看下known_hosts文件的格式。以~/.ssh/known_hosts为例。
在说明身份验证过程前,先看下known_hosts文件的格式。以~/.ssh/known_hosts为例。
[root@xuexi ~]# cat ~/.ssh/known_hosts
172.16.10.6 ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC675dv1w+GDYViXxqlTspUHsQjargFPSnR9nEqCyUgm5/32jXAA3XTJ4LUGcDHBuQ3p3spW/eO5hAP9eeTv5HQzTSlykwsu9He9w3ee+TV0JjBFulfBR0weLE4ut0PurPMbthE7jIn7FVDoLqc6o64WvN8LXssPDr8WcwvARmwE7pYudmhnBIMPV/q8iLMKfquREbhdtGLzJRL9DrnO9NNKB/EeEC56GY2t76p9ThOB6ES6e/87co2HjswLGTWmPpiqY8K/LA0LbVvqRrQ05+vNoNIdEfk4MXRn/IhwAh6j46oGelMxeTaXYC+r2kVELV0EvYV/wMa8QHbFPSM6nLz该文件中,每行一个host key,行首是主机名,它是搜索host key时的索引,主机名后的内容即是host key部分。以此文件为例,它表示客户端A曾经试图连接过172.16.10.6这个主机B,并保存了主机B的host key,下次连接主机B时,将搜索主机B的host key,并与172.16.10.6传送过来的host key做比较,如果能匹配上,则表示该host key确实是172.16.10.6当前使用的host key,如果不能匹配上,则表示172.16.10.6修改过host key,或者此文件中的host key被修改过。
那么主机B当前使用的host key保存在哪呢?在/etc/ssh/ssh_host*文件中,这些文件是服务端(此处即主机B)的sshd服务程序启动时重建的。以rsa算法为例,则保存在/etc/ssh/ssh_host_rsa_key和/etc/ssh/ssh_host_rsa_key.pub中,其中公钥文件/etc/ssh/ssh_host_rsa_key.pub中保存的就是host key。
[root@xuexi ~]# cat /etc/ssh/ssh_host_rsa_key.pub # 在主机B上查看
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC675dv1w+GDYViXxqlTspUHsQjargFPSnR9nEqCyUgm5/32jXAA3XTJ4LUGcDHBuQ3p3spW/eO5hAP9eeTv5HQzTSlykwsu9He9w3ee+TV0JjBFulfBR0weLE4ut0PurPMbthE7jIn7FVDoLqc6o64WvN8LXssPDr8WcwvARmwE7pYudmhnBIMPV/q8iLMKfquREbhdtGLzJRL9DrnO9NNKB/EeEC56GY2t76p9ThOB6ES6e/87co2HjswLGTWmPpiqY8K/LA0LbVvqRrQ05+vNoNIdEfk4MXRn/IhwAh6j46oGelMxeTaXYC+r2kVELV0EvYV/wMa8QHbFPSM6nLz发现/etc/ssh/ssh_host_rsa_key.pub文件内容和~/.ssh/known_hosts中该主机的host key部分完全一致,只不过~/.ssh/known_hosts中除了host key部分还多了一个主机名,这正是搜索主机时的索引。
综上所述,在主机验证阶段,服务端持有的是私钥,客户端保存的是来自于服务端的公钥。注意,这和身份验证阶段密钥的持有方是相反的。 实际上,ssh并非直接比对host key,因为host key太长了,比对效率较低。所以ssh将host key转换成host key指纹,然后比对两边的host key指纹即可。指纹格式如下:
[root@xuexi ~]# ssh 172.16.10.6
The authenticity of host '172.16.10.6 (172.16.10.6)' can't be established.
RSA key fingerprint is f3:f8:e2:33:b4:b1:92:0d:5b:95:3b:97:d9:3a:f0:cf.
Are you sure you want to continue connecting (yes/no)? yeshost key的指纹可由ssh-kegen计算得出。例如,下面分别是主机A(172.16.10.5)保存的host key指纹,和主机B(172.16.10.6)当前使用的host key的指纹。可见它们是完全一样的。
[root@xuexi ~]# ssh-keygen -l -f ~/.ssh/known_hosts
2048 f3:f8:e2:33:b4:b1:92:0d:5b:95:3b:97:d9:3a:f0:cf 172.16.10.6 (RSA)
[root@xuexi ~]# ssh-keygen -l -f /etc/ssh/ssh_host_rsa_key
2048 f3:f8:e2:33:b4:b1:92:0d:5b:95:3b:97:d9:3a:f0:cf (RSA)其实ssh还支持host key模糊比较,即将host key转换为图形化的指纹。这样,图形结果相差大的很容易就比较出来。之所以说是模糊比较,是因为对于非常近似的图形化指纹,ssh可能会误判。图形化指纹的生成方式如下:只需在上述命令上加一个"-v"选项进入详细模式即可。
[root@xuexi ~]# ssh-keygen -lv -f ~/.ssh/known_hosts
2048 f3:f8:e2:33:b4:b1:92:0d:5b:95:3b:97:d9:3a:f0:cf 172.16.10.6 (RSA)
+--[ RSA 2048]----+
| |
| |
| . |
| o |
| S. . + |
| . +++ + . |
| B.+.= . |·
| + B. +. |
| o.+. oE |
+-----------------+更详细的主机认证过程是:先进行密钥交换(DH算法)生成session key(rfc文档中称之为shared secret),然后从文件中读取host key,并用host key对session key进行签名,然后对签名后的指纹进行判断。(In SSH, the key exchange is signed with the host key to provide host authentication.来源:https://tools.ietf.org/html/rfc4419) 过程如下图:

#####1.3.2 身份验证过程 主机验证通过后,将进入身份验证阶段。SSH支持多种身份验证机制,它们的验证顺序如下:gssapi-with-mic,hostbased,publickey,keyboard-interactive,password,但常见的是密码认证机制(password)和公钥认证机制(public key)。当公钥认证机制未通过时,再进行密码认证机制的验证。这些认证顺序可以通过ssh配置文件(注意,不是sshd的配置文件)中的指令PreferredAuthentications改变。
如果使用公钥认证机制,客户端A需要将自己生成的公钥(~/.ssh/id_rsa.pub)发送到服务端B的~/.ssh/authorized_keys文件中。当进行公钥认证时,客户端将告诉服务端要使用哪个密钥对,并告诉服务端它已经访问过密钥对的私钥部分~/.ssh/id_rsa(客户端从自己的私钥中推导,或者从私钥同目录下读取公钥,计算公钥指纹后发送给服务端。所以有些版本的ssh不要求存在公钥文件,有些版本的ssh则要求私钥和公钥同时存在且在同目录下),然后服务端将检测密钥对的公钥部分,判断该客户端是否允许通过认证。如果认证不通过,则进入下一个认证机制,以密码认证机制为例。
当使用密码认证时,将提示输入要连接的远程用户的密码,输入正确则验证通过。 #####1.3.3 验证通过 当主机验证和身份验证都通过后,分两种情况:直接登录或执行ssh命令行中给定某个命令。如:
[root@xuexi ~]# ssh 172.16.10.6
[root@xuexi ~]# ssh 172.16.10.6 'echo "haha"'(1).前者ssh命令行不带任何命令参数,表示使用远程主机上的某个用户(此处为root用户)登录到远程主机172.16.10.6上,所以远程主机会为ssh分配一个伪终端,并进入bash环境。
(2).后者ssh命令行带有命令参数,表示在远程主机上执行给定的命令【echo "haha"】。ssh命令行上的远程命令是通过fork ssh-agent得到的子进程来执行的,当命令执行完毕,子进程消逝,ssh也将退出,建立的会话和连接也都将关闭。(之所以要在这里明确说明远程命令的执行过程,是为了说明后文将介绍的ssh实现端口转发时的注意事项)
实际上,在ssh连接成功,登录或执行命令行中命令之前,可以指定要在远程执行的命令,这些命令放在~/.ssh/rc或/etc/ssh/rc文件中,也就是说,ssh连接建立之后做的第一件事是在远程主机上执行这两个文件中的命令。
1.4 各种文件分布
以主机A连接主机B为例,主机A为SSH客户端,主机B为SSH服务端。
在服务端即主机B上:
- /etc/ssh/sshd_config :ssh服务程序sshd的配置文件。
- /etc/ssh/ssh_host_* :服务程序sshd启动时生成的服务端公钥和私钥文件。如ssh_host_rsa_key和ssh_host_rsa_key.pub。 :其中.pub文件是主机验证时的host key,将写入到客户端的~/.ssh/known_hosts文件中。 :其中私钥文件严格要求权限为600,若不是则sshd服务可能会拒绝启动。
- ~/.ssh/authorized_keys:保存的是基于公钥认证机制时来自于客户端的公钥。在基于公钥认证机制认证时,服务端将读取该文件。
在客户端即主机A上:
- /etc/ssh/ssh_config :客户端的全局配置文件。
- ~/.ssh/config :客户端的用户配置文件,生效优先级高于全局配置文件。一般该文件默认不存在。该文件对权限有严格要求只对所有者有读/写权限,对其他人完全拒绝写权限。
- ~/.ssh/known_hosts :保存主机验证时服务端主机host key的文件。文件内容来源于服务端的ssh_host_rsa_key.pub文件。
- /etc/ssh/known_hosts:全局host key保存文件。作用等同于~/.ssh/known_hosts。
- ~/.ssh/id_rsa :客户端生成的私钥。由ssh-keygen生成。该文件严格要求权限,当其他用户对此文件有可读权限时,ssh将直接忽略该文件。
- ~/.ssh/id_rsa.pub :私钥id_rsa的配对公钥。对权限不敏感。当采用公钥认证机制时,该文件内容需要复制到服务端的~/.ssh/authorized_keys文件中。
- ~/.ssh/rc :保存的是命令列表,这些命令在ssh连接到远程主机成功时将第一时间执行,执行完这些命令之后才开始登陆或执行ssh命令行中的命令。
- /etc/ssh/rc :作用等同于~/.ssh/rc。
1.5 配置文件简单介绍
分为服务端配置文件/etc/ssh/sshd_config和客户端配置文件/etc/ssh/ssh_config(全局)或~/.ssh/config(用户)。
虽然服务端和客户端配置文件默认已配置项虽然非常少非常简单,但它们可配置项非常多。sshd_config完整配置项参见金步国翻译的sshd_config中文手册,ssh_config也可以参考sshd_config的配置,它们大部分配置项所描述的内容是相同的。
1.5.1 sshd_config
简单介绍下该文件中比较常见的指令。
[root@xuexi ~]# cat /etc/ssh/sshd_config
#Port 22 # 服务端SSH端口,可以指定多条表示监听在多个端口上
#ListenAddress 0.0.0.0 # 监听的IP地址。0.0.0.0表示监听所有IP
Protocol 2 # 使用SSH 2版本
#####################################
# 私钥保存位置 #
#####################################
# HostKey for protocol version 1
#HostKey /etc/ssh/ssh_host_key # SSH 1保存位置/etc/ssh/ssh_host_key
# HostKeys for protocol version 2
#HostKey /etc/ssh/ssh_host_rsa_key # SSH 2保存RSA位置/etc/ssh/ssh_host_rsa _key
#HostKey /etc/ssh/ssh_host_dsa_key # SSH 2保存DSA位置/etc/ssh/ssh_host_dsa _key
###################################
# 杂项配置 #
###################################
#PidFile /var/run/sshd.pid # 服务程序sshd的PID的文件路径
#ServerKeyBits 1024 # 服务器生成的密钥长度
#SyslogFacility AUTH # 使用哪个syslog设施记录ssh日志。日志路径默认为/var/log/secure
#LogLevel INFO # 记录SSH的日志级别为INFO
#LoginGraceTime 2m # 身份验证阶段的超时时间,若在此超时期间内未完成身份验证将自动断开
###################################
# 以下项影响认证速度 #
###################################
#UseDNS yes # 指定是否将客户端主机名解析为IP,以检查此主机名是否与其IP地址真实对应。默认yes。
# 由此可知该项影响的是主机验证阶段。建议在未配置DNS解析时,将其设置为no,否则主机验证阶段会很慢
###################################
# 以下是和安全有关的配置 #
###################################
#PermitRootLogin yes # 是否允许root用户登录
#MaxSessions 10 # 最大客户端连接数量
#GSSAPIAuthentication no # 是否开启GSSAPI身份认证机制,默认为yes
#PubkeyAuthentication yes # 是否开启基于公钥认证机制
#AuthorizedKeysFile .ssh/authorized_keys # 基于公钥认证机制时,来自客户端的公钥的存放位置
PasswordAuthentication yes # 是否使用密码验证,如果使用密钥对验证可以关了它
#PermitEmptyPasswords no # 是否允许空密码,如果上面的那项是yes,这里最好设置no
###################################
# 以下可以自行添加到配置文件 #
###################################
DenyGroups hellogroup testgroup # 表示hellogroup和testgroup组中的成员不允许使用sshd服务,即拒绝这些用户连接
DenyUsers hello test # 表示用户hello和test不能使用sshd服务,即拒绝这些用户连接
###################################
# 以下一项和远程端口转发有关 #
###################################
#GatewayPorts no # 设置为yes表示sshd允许被远程主机所设置的本地转发端口绑定在非环回地址上
# 默认值为no,表示远程主机设置的本地转发端口只能绑定在环回地址上,见后文"远程端口转发"一般来说,如非有特殊需求,只需修改下监听端口和UseDNS为no以加快主机验证阶段的速度即可。
配置好后直接重启启动sshd服务即可
[root@xuexi ~]# service sshd restart
1.5.2 ssh_config
需要说明的是,客户端配置文件有很多配置项和服务端配置项名称相同,但它们一个是在连接时采取的配置(客户端配置文件),一个是sshd启动时开关性的设置(服务端配置文件)。例如,两配置文件都有GSSAPIAuthentication项,在客户端将其设置为no,表示连接时将直接跳过该身份验证机制,而在服务端设置为no则表示sshd启动时不开启GSSAPI身份验证的机制。即使客户端使用了GSSAPI认证机制,只要服务端没有开启,就绝对不可能认证通过。
下面也简单介绍该文件。
# Host * # Host指令是ssh_config中最重要的指令,只有ssh连接的目标主机名能匹配此处给定模式时,
# 下面一系列配置项直到出现下一个Host指令才对此次连接生效
# ForwardAgent no
# ForwardX11 no
# RhostsRSAAuthentication no
# RSAAuthentication yes
# PasswordAuthentication yes # 是否启用基于密码的身份认证机制
# HostbasedAuthentication no # 是否启用基于主机的身份认证机制
# GSSAPIAuthentication no # 是否启用基于GSSAPI的身份认证机制
# GSSAPIDelegateCredentials no
# GSSAPIKeyExchange no
# GSSAPITrustDNS no
# BatchMode no # 如果设置为"yes",将禁止passphrase/password询问。比较适用于在那些不需要询问提供密
# 码的脚本或批处理任务任务中。默认为"no"。
# CheckHostIP yes
# AddressFamily any
# ConnectTimeout 0
# StrictHostKeyChecking ask # 设置为"yes",ssh将从不自动添加host key到~/.ssh/known_hosts文件,
# 且拒绝连接那些未知的主机(即未保存host key的主机或host key已改变的主机)。
# 它将强制用户手动添加host key到~/.ssh/known_hosts中。
# 设置为ask将询问是否保存到~/.ssh/known_hosts文件。
# 设置为no将自动添加到~/.ssh/known_hosts文件。
# IdentityFile ~/.ssh/identity # ssh v1版使用的私钥文件
# IdentityFile ~/.ssh/id_rsa # ssh v2使用的rsa算法的私钥文件
# IdentityFile ~/.ssh/id_dsa # ssh v2使用的dsa算法的私钥文件
# Port 22 # 当命令行中不指定端口时,默认连接的远程主机上的端口
# Protocol 2,1
# Cipher 3des # 指定ssh v1版本中加密会话时使用的加密协议
# Ciphers aes128-ctr,aes192-ctr,aes256-ctr,arcfour256,arcfour128,aes128-cbc,3des-cbc # 指定ssh v1版本中加密会话时使用的加密协议
# MACs hmac-md5,hmac-sha1,[email protected],hmac-ripemd160
# EscapeChar ~
# Tunnel no
# TunnelDevice any:any
# PermitLocalCommand no # 功能等价于~/.ssh/rc,表示是否允许ssh连接成功后在本地执行LocalCommand指令指定的命令。
# LocalCommand # 指定连接成功后要在本地执行的命令列表,当PermitLocalCommand设置为no时将自动忽略该配置
# %d表本地用户家目录,%h表示远程主机名,%l表示本地主机名,%n表示命令行上提供的主机名,
# p%表示远程ssh端口,r%表示远程用户名,u%表示本地用户名。
# VisualHostKey no # 是否开启主机验证阶段时host key的图形化指纹
Host *
GSSAPIAuthentication yes如非有特殊需求,ssh客户端配置文件一般只需修改下GSSAPIAuthentication的值为no来改善下用户验证的速度即可,另外在有非交互需求时,将StrictHostKeyChecking设置为no以让主机自动添加host key。
1.6 ssh命令简单功能
此处先介绍ssh命令的部分功能,其他包括端口转发的在后文相关内容中解释,关于连接复用的选项本文不做解释。
语法:
ssh [options] [user@]hostname [command]
参数说明:
-b bind_address :在本地主机上绑定用于ssh连接的地址,当系统有多个ip时才生效。
-E log_file :将debug日志写入到log_file中,而不是默认的标准错误输出stderr。
-F configfile :指定用户配置文件,默认为~/.ssh/config。
-f :请求ssh在工作在后台模式。该选项隐含了"-n"选项,所以标准输入将变为/dev/null。
-i identity_file:指定公钥认证时要读取的私钥文件。默认为~/.ssh/id_rsa。
-l login_name :指定登录在远程机器上的用户名。也可以在全局配置文件中设置。
-N :显式指明ssh不执行远程命令。一般用于端口转发,见后文端口转发的示例分析。
-n :将/dev/null作为标准输入stdin,可以防止从标准输入中读取内容。ssh在后台运行时默认该项。
-p port :指定要连接远程主机上哪个端口,也可在全局配置文件中指定默认的连接端口。
-q :静默模式。大多数警告信息将不输出。
-T :禁止为ssh分配伪终端。
-t :强制分配伪终端,重复使用该选项"-tt"将进一步强制。
-v :详细模式,将输出debug消息,可用于调试。"-vvv"可更详细。
-V :显示版本号并退出。
-o :指定额外选项,选项非常多。
user@hostname :指定ssh以远程主机hostname上的用户user连接到的远程主机上,若省略user部分,则表示使用本地当前用户。
:如果在hostname上不存在user用户,则连接将失败(将不断进行身份验证)。
command :要在远程主机上执行的命令。指定该参数时,ssh的行为将不再是登录,而是执行命令,命令执行完毕时ssh连接就关闭。几个有用的文件大小查看命令
# 只查看一级目录统计的空间占用
alias dud="du -d 1 -h"
# 查看一级和二级目录的占用
alias du1="du -h --max-depth=1 *"
alias duf="du -sh"
cd /
du -sh *
31G var
14G opt
# 有时候 ISPconfig 开启自动备份,会导致磁盘空间占用过大,请登录 IPSconfig 后台检查
root@jira:/var/backup# du -sh *
1.7G web10
5.4G web3
1.7G web5
784M web7首先来到 Jenkins 目录,发现占用最多的是 workspace 目录,达到了6.9G
cd /var/lib/jenkins

workspace 是 Jenkins 的工作目录,当流水线执行 git pull,项目源码就存放在里面,流水线执行完成后没有及时清理
清理Jenkins的workspace
流水线添加清理工作区步骤
stage('清理工作目录') {
steps {
cleanWs()
}
}或者添加流水线完成钩子
stages {
// ...
}
post {
always {
cleanWs()
}
}清理Docker镜像及日志
默认情况下,docker的日志是在/var/lib/docker/containers/<container_id>/<container_id>-json.log中。
使用 sudo docker info 发现日志驱动是Logging Driver: json-file,也应证了此点。
有些json.log文件很大,记得清除掉。
执行docker images列出本机存在的镜像,最后一列SIZE是镜像大小
强制删除多个镜像
sudo docker rmi --force f439bc73d690 fa440e89e4c2
删除那些已停止的容器、dangling 镜像、未被容器引用的 network 和构建过程中的 cache
docker system prune
删除 24 小时前下载的镜像
docker image prune -a --filter "until=24h"
安全起见,这个命令默认不会删除那些未被任何容器引用的数据卷,如果需要同时删除这些数据卷,你需要显式的指定 --volumns 参数。比如你可能想要执行下面的命令:
docker system prune --all --force --volumns
清理 Containerd 镜像
k8s 1.24版本后容器运行时从Docker换为了Containerd,所以当你登录到节点后会发现已经没有Docker命令了,换为了 ctr 或 crictl
crictl rmi --prune使用 ncdu 查看磁盘占用情况
该命令默认会统计当前目录的文件占用情况,并直观的显示出来 我现在要查看整个磁盘个目录的占用情况
cd /
ncdu
删除 journal 日志
# 查看磁盘占用
journalctl --disk-usage
# 清理日志
journalctl --vacuum-size=10M
# 只保留一周的日志
journalctl --vacuum-time=1w删除系统日志文件
cd /var/log
# 删除 /var/log 下的日志压缩包
rm -rf /var/log/*.gz
# 删除 /var/log 轮转日志
rm -rf /var/log/*.1最后差不多清理大概10G文件
]]>在自定义安装软件的时候,经常需要配置环境变量,下面列举出各种对环境变量的配置方法。
下面所有例子的环境说明如下:
- 系统:Ubuntu 16.0
- 用户名:ubuntu
- 需要配置MySQL环境变量路径:/home/ubuntu/mysql/bin
Linux读取环境变量
读取环境变量的方法:
export命令显示当前系统定义的所有环境变量echo $PATH命令输出当前的PATH环境变量的值
这两个命令执行的效果如下
ubuntu@VM-16-4-ubuntu:~$ export
declare -x HISTSIZE="3000"
declare -x HISTTIMEFORMAT="%F %T "
declare -x HOME="/home/ubuntu"
declare -x LANG="C.UTF-8"
declare -x LC_CTYPE="C.UTF-8"
declare -x LC_TERMINAL="iTerm2"
declare -x LC_TERMINAL_VERSION="3.4.8"
declare -x LOGNAME="ubuntu"
declare -x MAIL="/var/mail/ubuntu"
declare -x OLDPWD
declare -x PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin"
declare -x PROMPT_COMMAND="history -a; history -a; history -a; "
declare -x PWD="/home/ubuntu"
declare -x SHELL="/bin/bash"
declare -x SHLVL="1"
declare -x SSH_TTY="/dev/pts/3"
declare -x TERM="xterm-256color"
declare -x USER="ubuntu"
declare -x XDG_DATA_DIRS="/usr/local/share:/usr/share:/var/lib/snapd/desktop"
declare -x XDG_RUNTIME_DIR="/run/user/500"
declare -x XDG_SESSION_ID="143335"
ubuntu@VM-16-4-ubuntu:~$ echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin其中PATH变量定义了运行命令的查找路径,以冒号:分割不同的路径,使用export定义的时候可加双引号也可不加。
Linux环境变量配置方法一:export PATH
使用export命令直接修改PATH的值,配置MySQL进入环境变量的方法:
export PATH=/home/ubuntu/mysql/bin:$PATH
# 或者把PATH放在前面
export PATH=$PATH:/home/ubuntu/mysql/bin注意事项:
- 生效时间:立即生效
- 生效期限:当前终端有效,窗口关闭后无效
- 生效范围:仅对当前用户有效
- 配置的环境变量中不要忘了加上原来的配置,即$PATH部分,避免覆盖原来配置
Linux环境变量配置方法二:vim ~/.bashrc
通过修改用户目录下的~/.bashrc文件进行配置:
vim ~/.bashrc
# 在最后一行加上
export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:使用相同的用户打开新的终端时生效,或者手动
source ~/.bashrc生效 - 生效期限:永久有效
- 生效范围:仅对当前用户有效
- 如果有后续的环境变量加载文件覆盖了PATH定义,则可能不生效
Linux环境变量配置方法三:vim ~/.bash_profile
和修改~/.bashrc文件类似,也是要在文件最后加上新的路径即可:
vim ~/.bash_profile
# 在最后一行加上
export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:使用相同的用户打开新的终端时生效,或者手动
source ~/.bash_profile生效 - 生效期限:永久有效
- 生效范围:仅对当前用户有效
- 如果没有
~/.bash_profile文件,则可以编辑~/.profile文件或者新建一个
Linux环境变量配置方法四:vim /etc/bashrc
该方法是修改系统配置,需要管理员权限(如root)或者对该文件的写入权限:
# 如果/etc/bash.bashrc文件不可编辑,需要修改为可编辑
chmod -v u+w /etc/bash.bashrc
vim /etc/bash.bashrc
# 在最后一行加上
export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:新开终端生效,或者手动
source /etc/bash.bashrc生效 - 生效期限:永久有效
- 生效范围:对所有用户有效
WARNING
如果系统是 ubuntu 或者 debian 的话, 就不会有 /etc/bashrc 而会有 /etc/bash.bashrc 文件.
Linux环境变量配置方法五:vim /etc/profile
该方法修改系统配置,需要管理员权限或者对该文件的写入权限,和vim /etc/bash.bashrc类似:
# 如果/etc/profile文件不可编辑,需要修改为可编辑
chmod -v u+w /etc/profile
vim /etc/profile
# 在最后一行加上
export PATH=$PATH:/home/uusama/mysql/bin注意事项:
- 生效时间:新开终端生效,或者手动source /etc/profile生效
- 生效期限:永久有效
- 生效范围:对所有用户有效
Linux环境变量加载原理解析
上面列出了环境变量的各种配置方法,那么Linux是如何加载这些配置的呢?是以什么样的顺序加载的呢?
特定的加载顺序会导致相同名称的环境变量定义被覆盖或者不生效。
环境变量的分类 环境变量可以简单的分成用户自定义的环境变量以及系统级别的环境变量。
- 用户级别环境变量定义文件:
~/.bashrc、~/.profile(部分系统为:~/.bash_profile) - 系统级别环境变量定义文件:
/etc/bashrc、/etc/profile(部分系统为:/etc/bash_profile) 另外在用户环境变量中,系统会首先读取~/.bash_profile(或者~/.profile)文件,如果没有该文件则读取~/.bash_login,根据这些文件中内容再去读取~/.bashrc。
Linux环境变量文件加载详解
打开/etc/profile文件你会发现,该文件的代码中会加载/etc/bash.bashrc文件,然后检查/etc/profile.d/目录下的.sh文件并加载。
/etc/profile源码
# /etc/profile: system-wide .profile file for the Bourne shell (sh(1))
# and Bourne compatible shells (bash(1), ksh(1), ash(1), ...).
if [ "${PS1-}" ]; then
if [ "${BASH-}" ] && [ "$BASH" != "/bin/sh" ]; then
# The file bash.bashrc already sets the default PS1.
# PS1='\h:\w\$ '
if [ -f /etc/bash.bashrc ]; then
. /etc/bash.bashrc
fi
else
if [ "`id -u`" -eq 0 ]; then
PS1='# '
else
PS1='$ '
fi
fi
fi
if [ -d /etc/profile.d ]; then
for i in /etc/profile.d/*.sh; do
if [ -r $i ]; then
. $i
fi
done
unset i
fi技巧:我在/etc/profile.d创建了finley.sh,方便任何登录用户使用
内容:
alias ll='ls -alhS'
alias la='ls -A'
alias l='ls -CF'
alias k='kubectl'理解 bashrc 和 profile
Shell 的模式
系统的 shell 有很多种, 比如 bash, sh, zsh 之类的, 如果要查看某一个用户使用的是什么 shell 可以通过 finger [USERNAME] 命令来查看. 我们这里只说 shell 是 bash 的情况, 因为如果是 sh 或者其他 shell 显然不会运行 bashrc 的.
login shell 和 no-login shell
login shell代表用户登入, 比如使用su -命令, 或者用 ssh 连接到某一个服务器上, 都会使用该用户默认 shell 启动 login shell 模式.
该模式下的 shell 会去自动执行/etc/profile和~/.profile文件, 但不会执行任何的bashrc文件, 所以一般在/etc/profile或者 ~/.profile里我们会手动去source bashrc文件.
而 no-login shell 的情况是我们在终端下直接输入bash或者bash -c "command"来启动的 shell.
该模式下是不会自动去运行任何的 profile 文件
interactive shell 和 non-interactive shell
interactive shell 是交互式shell, 顾名思义就是用来和用户交互的, 提供了命令提示符可以输入命令.
该模式下会存在一个叫 PS1 的环境变量, 如果还不是login shell的则会去source /etc/bash.bashrc和~/.bashrc文件
non-interactive shell 则一般是通过bash -c "command"来执行的bash.
bashrc和profile的用途和区别
- ~/.profile: executed by Bourne-compatible login shells.
其实看名字就能了解大概了, profile 是某个用户唯一的用来设置环境变量的地方 因为用户可以有多个 shell 比如 bash, sh, zsh 之类的, 但像环境变量这种其实只需要在统一的一个地方初始化就可以了, 而这就是 profile.
- ~/.bashrc: executed by bash(1) for non-login shells.
bashrc 也是看名字就知道, 是专门用来给 bash 做初始化的比如用来初始化 bash 的设置, bash 的代码补全, bash 的别名, bash 的颜色. 以此类推也就还会有 shrc, zshrc 这样的文件存在了, 只是 bash 太常用了而已.
cat ~/.profile查看该文件的源码
# ~/.profile: executed by Bourne-compatible login shells.
if [ "$BASH" ]; then
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
fi
mesg n || true结论:
- profile是包含bashrc
~/.profile文件只在用户登录的时候读取一次,profile是在用户登录后才会运行。有些Linux的发行版本不一定有profile这个文件~/.bashrc会在每次运行Shell脚本的时候读取一次。bashrc是在系统启动后就会自动运行
一些小技巧
可以自定义一个环境变量文件,比如在某个项目下定义uusama.profile,在这个文件中使用export定义一系列变量,然后在~/.profile文件后面加上:sourc uusama.profile,这样你每次登陆都可以在Shell脚本中使用自己定义的一系列变量。
也可以使用alias命令定义一些命令的别名,比如alias rm="rm -i"(双引号必须),并把这个代码加入到~/.profile中,这样你每次使用rm命令的时候,都相当于使用rm -i命令,非常方便。
参考
]]>-
执行ssh-keygen命令生成ssh密钥对 执行后~/.ssh/目录下,会新生成两个文件:id_rsa.pub和id_rsa
ssh-keygen -
执行ssh-copy-id命令将公钥传送到服务器
ssh-copy-id root@host -
测试免密码登陆
ssh root@host
二、添加变量
gitlab项目/群组 -> 设置 -> CI/CD -> 变量
SSH_USER = 服务器的用户名
SSH_HOST = 服务器ip
SSH_KNOWN_HOSTS = 文件 ~/.ssh/known_host 有你服务器ip的一行
SSH_PRIVATE_KEY = 文件 ~/.ssh/id_rsa 里的内容三、添加.gitlab-ci.yml
stage:
- Deploy
Deplpy:
stage: Deploy
only:
- master
before_script:
- 'which ssh-agent || ( apt-get update -y && apt-get install openssh-client -y )'
- eval $(ssh-agent -s)
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add - > /dev/null
- mkdir -p ~/.ssh
- chmod 700 ~/.ssh
- echo "$SSH_KNOWN_HOSTS" > ~/.ssh/known_hosts
- chmod 644 ~/.ssh/known_hosts
when: manual #手动确认之后才能构建
script:
- pwd
- ls -l
#主要同步代码的命令,可以在这里排除一些文件,同步权限,配置服务器的项目路径等。重点参考rsync命令的用法。
- rsync -aztp --exclude ".gitlab-ci.yml" ./ $SSH_USER@$SSH_HOST:/data/wwwroot/laravel四、记得配置runner
]]>一般情况下我们可以通过 ssh [email protected] 登录远程服务器,如果要管理多台服务器,这样太长了。
可以在家目录的.ssh中新建config文件,设置别名。
比如我有一台个人的云主机。IP是120.163.163.163,端口是4722(一般都是22,这里为了安全我改为了其他),登录用户名是ubuntu,登录方式是私钥登录。
# Host 可跟多个表示别名
Host cloud alias
HostName 120.163.163.163
User ubuntu
Port 4722
# 私钥路径
IdentityFile ~/.ssh/id_rsa这样执行 ssh cloud 或 ssh alias 就无密码登录云主机了
执行远程命令
ssh cloud "df -h"

用分号分隔多个命令,用引号引起来
ssh cloud "df -h; ps;"
遇到需要交互的命令,加 -t 参数
$ ssh -t cloud top比如 sudo 开头的可能需要用户输入密码,需要 TTY。
添加 -t 参数后,ssh 会保持登录状态,直到你退出需要交互的命令。

再举个实际例子:
ssh -t flux sudo -u fueladminprd ssh 192.168.1.100
这句话实际执行了两步:
- ssh -t flux # 登录名为flux的服务器,因为需要交互式,加上-t
- sudo -u fueladminprd ssh 192.168.1.100 # 以 fueladminprd 用户在 flux 上执行 ssh 192.168.1.100 为了安全,flux 就是跳板机,192.168.1.100 为实际测试服务器。
使用RemoteCommand登录后执行自定义命令
Host target
HostName xx.xx.xx.202
User client_admin
# 使用RemoteCommand登录后执行自定义命令(需要SSH版本大于等于7.6,可用ssh -V查看)
RemoteCommand cd /data/www/clients/client3/web160 && /bin/bash
# 其中RequestTTY为了避免执行ssh target之后hang住
RequestTTY yes
Port 22
IdentityFile ~/.ssh/id_rsa如果RemoteCommand不生效, 可把ssh config中的RemoteCommand和RequestTTY删除,用如下方式:
ssh -t target "cd xxx; bash"
执行多行命令
$ ssh cloud "echo 'haha'
> pwd
> ls "可以用单引号或双引号开头,然后写上几行命令,最后再用相同的引号来结束。
> 开头的就是输入下一行命令
如果需要在命令中使用引号,可以混合使用单双引号。

在命令中使用变量
在远程服务器执行 ls node,本地定义变量a,传入到命令中。达到一样的效果。
在下图的命令中为 bash 指定了 -c 参数
$ a=node
$ ssh cloud bash -c " '
> ls $a
> ' "
执行本地脚本
本地创建demo.sh,内容是:ls node
运行 ssh cloud < demo.sh
通过重定向 stdin,本地的脚本 demo.sh 在远程服务器上被执行。

为脚本传入参数
修改 demo.sh 内容为:
ls node
echo $0
echo $1
echo $2执行 ssh cloud 'bash -s'< demo.sh aa bb cc
bash 就是 $0 第一个参数。

想查看更多配置,打man ssh_config
跳板
有跳板机配置在某些场景下,往往是不能直接访问目标机器的,通常是用先登录一台机器(此机器通常被称为跳板机/堡垒机/gateway),然后再在这台机器上登录目标机器, 我们可以借助ssh config来简化这种操作。
在~/.ssh/config中配置:Host gateway
HostName $GATEWAY_HOST
Port $GATEWAY_PORT
IdentityFile ~/.ssh/id_rsa
User $GATEWAY_USER
Host target
HostName $TARGET_HOST
User $TARGET_USER
IdentityFile ~/.ssh/id_rsa
ProxyCommand ssh gateway nc %h %p 2> /dev/null # 或者 ProxyCommand ssh gateway -W %h:%p其中:
%h 表示 hostname
%p 表示 port然后配置免密登录,和上面一样,也只需要第一次输入密码:ssh target 'mkdir -p .ssh && cat > .ssh/authorized_keys' < ~/.ssh/id_rsa.pub
然后可以无感知地ssh/scp/rsync到目标机器,在终端中也只需要输入目标机器的别名就行:
ssh target
scp some_file target:/home/user
rsync -avP * target:/home/user/some_dir端口转发功能
ssh -L
设有三台主机: A, B, C. 其对应ip为 ip_A, ip_B, ip_C.
如果在主机A上执行:
ssh -L 1234:ip_C:5678 root@ip_B
那么访问主机A的1234端口就等价于访问主机 C 的 5678 端口(两者直接会通过主机B作为中介建立一个隧道)
这种转发方式的应用场景为: A可以访问B, B可以访问C, 但是A不能直接访问C.
ssh -R
设有两台主机: A, B. 其对应ip为 ip_A, ip_B.
如果在主机A上执行:
ssh -R 1234:127.0.0.1:5678 root@ip_B
注意: 这儿一定要是root用户
那么此时在B上访问 localhost:1234 就等价于访问 A 的 5678 端口.
若想实现可以通过ip_B:1234访问主机A的127.0.0.1:5678还需要配置一层代理, 具体方式后面关于内网穿透的章节会说
这种转发方式的应用场景为: A是一个内网主机, B 是一个公网主机. 用户想随时随地可以访问A, 就需要做一个反向代理实现内网穿透, 使得用户可以通过 B 作为中介访问 A.
ssh -D
设有两台主机: A, B. 其对应ip为 ip_A, ip_B.
如果在主机A上执行:
ssh -D 1234 root@ip_B
那么主机A的 localhost:1234 就会有一个socks代理, 所有走这个代理的流量都会通过主机B转发出去.
这种转发方式的应用场景为: 懒得安装/启动socks代理软件客户端.
autossh + xinetd 实现内网穿透
设有两台主机: A, B. 其对应ip为 ip_A, ip_B, A是一个内网主机, B 是一个公网主机. 我们的需求是随时随地可以访问A上的资源.
我们可以使用前面提到的 ssh -R 转发方式, 在A上执行:
ssh -R 1234:127.0.0.1:22 root@ip_B
注意: 22是ssh server的端口
此时我们若在B上执行
ssh [email protected] -p 1234
并输入A上root用户的密码, 我们就可以成功登录主机A.
但是B的127.0.0.1只有自己能访问, 别的主机想访问B上的1234端口只能通过ip_B进行访问, 所以我们这儿可以在B上启动一个转发服务: 将ip_B:5678来的流量转发至127.0.0.1:1234(两个端口建议不相同, 避免可能的冲突). 我这儿用的是 xinetd:
$ sudo apt install xinetd
$ cat ./proxy
service http-switch
{
disable = no
type = UNLISTED
socket_type = stream
protocol = tcp
wait = no
redirect = 127.0.0.1 1234
bind = 0.0.0.0
port = 5678
user = nobody
}
$ cp ./proxy /etc/xinetd.d/
$ sudo /etc/init.d/xinetd restart
[ ok ] Restarting xinetd (via systemctl): xinetd.service.此时我们在任何一台可以访问外网的主机上执行如下命令:
ssh root@ip_B -p 5678
并输入A上root用户的密码, 就可以登录上A了.
autossh和ssh功能差不多, 但是多一个自动断线重连功能, 因此搭建内网穿透服务的时候稳定性更好.
使用命令和ssh类似:
$ sudo apt install autossh
$ autossh -M 7788 -NfR 1234:127.0.0.1:22 root@ip_B-M 参数声明一个没有被占用的端口, autossh 会使用这个端口检测连接是否存在, 如果断掉的话就需要进行重连操作.
-N 和 -f 参数是让 autossh 不打印信息, 在后台运行. (ssh同样可以加上这两个参数.)
参考:
https://www.cnblogs.com/sparkdev/p/6842805.html
]]>
虎符: 古代皇帝调兵遣将用的兵符,用青铜或者黄金做成伏虎形状的令牌,劈为两半,其中一半交给将帅,另一半由皇帝保存。只有两个虎符同时合并使用,持符者即获得调兵遣将权。

ssh key跟虎符类似
通过ssh-keygen命令生成公钥文件和私玥文件,私玥存本地,不告诉其他人。 把公钥放到需要认证的服务器。然后通过ssh登录,会进行公私钥认证。匹配成功即实现无密码登录。 同理把公钥放到如github,码云等提供git仓库的服务商。就能实现ssh协议非账号密码pull push代码。
机器A 向 机器B 进行免密码登陆
流程
1. 生成公私钥对
机器A执行,修改邮箱
ssh-keygen -t rsa -b 4096 -C "[email protected]"
一般一路回车,默认会在当前用户目录创建.ssh目录并生成id_ras私钥和id_ras.pub公钥
为了无密码登录服务器,需要将公钥上传到服务器的authorized_keys的文件中
就是说我用ssh方式敲你的门,我提供私钥,你提供公钥,算法匹配成功,就让我进去。
2. 添加公钥到机器B
不推荐手动拷贝,建议使用ssh-copy-id命令
如果对方机器SSH端口是22,不用特别指定
ssh-copy-id -i ~/.ssh/id_rsa.pub 用户名@对方机器IP
指定端口
ssh-copy-id -i ~/.ssh/id_rsa.pub -p 5722 用户名@对方机器IP
这个过程是将本地公钥加写到机器B的 ~/.ssh/authorized_keys 文件 这次需要输入机器B的登录密码
修改本地的~/.ssh/config添加连接配置项
Host cloud my
HostName 140.xxx.xxx.183
User ubuntu
Port 22
IdentityFile ~/.ssh/id_rsa测试
机器A执行ssh cloud或ssh my查看是否可以顺利登录
排错
1.公钥拷贝成功了,还让输入帐号密码
答:尝试设置文件权限
//用户权限
chmod 700 /home/username
//.ssh文件夹权限
chmod 700 ~/.ssh/
// ~/.ssh/authorized_keys 文件权限
chmod 600 ~/.ssh/authorized_keys2.检查ssh服务配置文件
vim /etc/ssh/sshd_config
// 这行可能被注释了,开启
RSAAuthentication yes
PubkeyAuthentication yes
#禁用root账户登录,如果是用root用户登录请开启
PermitRootLogin yes重启服务sudo systemctl restart sshd.service
3.加 -v 参数,查看调试信息 ssh cloud -vvv
参考
]]>$ ssh -R remote-port:target-host:target-port -N remotehost
# 访问 my.public.server:8080 相当于访问 内网服务器的 80 端口
ssh -R 8080:localhost:80 -N my.public.server
ssh -R 22:localhost:80 -N 52.81.89.90- -R 远程端口转发
| 格式 | 说明 |
|---|---|
${string: start :length} |
从 string 字符串的左边第 start 个字符开始,向右截取 length 个字符。 |
${string: start} |
从 string 字符串的左边第 start 个字符开始截取,直到最后。 |
${string: 0-start :length} |
从 string 字符串的右边第 start 个字符开始,向右截取 length 个字符。 |
${string: 0-start} |
从 string 字符串的右边第 start 个字符开始截取,直到最后。 |
${string#*chars} |
从 string 字符串第一次出现 *chars 的位置开始,截取 *chars 右边的所有字符。 |
${string##*chars} |
从 string 字符串最后一次出现 *chars 的位置开始,截取 *chars 右边的所有字符。 |
${string%*chars} |
从 string 字符串第一次出现 *chars 的位置开始,截取 *chars 左边的所有字符。 |
${string%%*chars} |
从 string 字符串最后一次出现 *chars 的位置开始,截取 *chars 左边的所有字符。 |
GITHUB_REF=refs/tags/v1.3.0
# 按长度截取,格式 ${string: start :length}
# 从第10个字符截取,直到最后
# 输出 v1.3.0
echo ${GITHUB_REF:10}
# # 是截取
# 输出tags/v1.3.0
echo ${GITHUB_REF#refs/}GITHUB_REF=refs/heads/main
# 输出 heads/main
echo ${GITHUB_REF#*/}
# 输出 main
echo ${GITHUB_REF##*/}使用%号可以截取指定字符(或者子字符串)左边的所有字符,具体格式如下:
${string%chars*}
请注意*的位置,因为要截取 chars 左边的字符,而忽略 chars 右边的字符,所以*应该位于 chars 的右侧。其他方面%和#的用法相同,这里不再赘述,仅举例说明:
url="http://c.biancheng.net/index.html"
# 结果为 http://c.biancheng.net
echo ${url%/*}
# 结果为 http:
echo ${url%//*}
#结果为 http:
echo ${url%%/*}
#结果为 http://
echo ${url%%c*}参考
]]>使用方法 check.sh baidu.com 输出剩余天数
#! /usr/bin/env bash
# host baidu.com,不用带 https://www
host=$1
port=${2:-"443"}
end_date=`timeout 6 openssl s_client -host $host -port $port -showcerts </dev/null 2>/dev/null |
sed -n '/BEGIN CERTIFICATE/,/END CERT/p' |
openssl x509 -text 2> /dev/null |
sed -n 's/ *Not After : *//p'`
if [ -n "$end_date" ];then
# 把时间转换为时间戳
end_date_seconds=`date '+%s' --date "$end_date"`
# 获取当前时间
now_seconds=`date '+%s'`
echo "($end_date_seconds-$now_seconds)/24/3600" | bc
fi#! /usr/bin/env bash
host=$1
port=${2:-"443"}
end_date=`echo | timeout 6 openssl s_client -servername ${host} -connect ${host}:${port} 2>/dev/null |
openssl x509 -noout -dates | grep notAfter | awk -F "=" '{print $NF}'`
if [ -n "$end_date" ];then
# 把时间转换为时间戳
end_date_seconds=`date '+%s' --date "$end_date"`
# 获取当前时间
now_seconds=`date '+%s'`
echo "($end_date_seconds-$now_seconds)/24/3600" | bc
fi环境
- 服务端 Ubuntu20.04 IP 49.111.111.111
- 客户端 Mac Big Sur
服务端
# 安装NFS服务
sudo apt-get install nfs-kernel-server
# 创建共享目录
sudo mkdir -p /nfsboot/
# 设置权限
sudo chmod -R 777 /nfsroot
# ubuntu为当前用户
sudo chown ubuntu:ubuntu /nfsroot/ -R
# 编译NFS配置we你按
sudo vim /etc/exports
# 在该文件末尾添加下面的一行,注意:你可以创建多个共享文件夹,在/etc/exports下添加多个条目。
# 格式 `NFS共享目录路径 客户机IP或者名称(参数1,参数2,...,参数n)`
# *:表示允许任何网段 IP 的系统访问该 NFS 目录
# no_root_squash:访问nfs server共享目录的用户如果是root的话,它对该目录具有root权限
# no_all_squash:保留共享文件的UID和GID(默认)
# rw:可读可写
# sync:请求或者写入数据时,数据同步写入到NFS server的硬盘中后才会返回,默认选项
# secure:NFS客户端必须使用NFS保留端口(通常是1024以下的端口),默认选项。
# insecure:允许NFS客户端不使用NFS保留端口(通常是1024以上的端口)
/nfsroot/ *(rw,sync,no_root_squash,insecure)
# 下面命令慎用,导致客户端被挂起
sudo systemctl restart rpcbind
sudo systemctl restart nfs-server
sudo systemctl status nfs-server
# 最好使用下面命令来重新加载配置
# -a 全部挂载或者全部卸载
# -r 重新挂载
# -u 卸载某一个目录
# -v 显示共享目录
sudo exportfs -arv
# 显示挂载目录
sudo exportfs -v
/nfsroot <world>(rw,wdelay,insecure,no_root_squash,no_subtree_check,sec=sys,rw,insecure,no_root_squash,no_all_squash)| 参数 | 说明 |
|---|---|
| ro | 只读访问 |
| rw | 读写访问 |
| sync | 所有数据在请求时写入共享 |
| async | nfs在写入数据前可以响应请求 |
| secure | nfs通过1024以下的安全TCP/IP端口发送 |
| insecure | nfs通过1024以上的端口发送 |
| wdelay | 如果多个用户要写入nfs目录,则归组写入(默认) |
| no_wdelay | 如果多个用户要写入nfs目录,则立即写入,当使用async时,无需此设置 |
| hide | 在nfs共享目录中不共享其子目录 |
| no_hide | 共享nfs目录的子目录 |
| subtree_check | 如果共享/usr/bin之类的子目录时,强制nfs检查父目录的权限(默认) |
| no_subtree_check | 不检查父目录权限 |
| all_squash | 共享文件的UID和GID映射匿名用户anonymous,适合公用目录 |
| no_all_squash | 保留共享文件的UID和GID(默认) |
| root_squash | root用户的所有请求映射成如anonymous用户一样的权限(默认) |
| no_root_squash | root用户具有根目录的完全管理访问权限 |
| anonuid=xxx | 指定nfs服务器/etc/passwd文件中匿名用户的UID |
| anongid=xxx | 指定nfs服务器/etc/passwd文件中匿名用户的GID |
WARNING
- 注1:尽量指定主机名或IP或IP段最小化授权可以访问NFS 挂载的资源的客户端;注意如果在k8s集群中配合nfs-client-provisioner使用的话,这里需要指定pod的IP段,否则nfs-client-provisioner pod无法启动,报错 mount.nfs: access denied by server while mounting
- 注2:经测试参数insecure必须要加,否则客户端挂载出错mount.nfs: access denied by server while mounting
- 注3:NFS服务不能随便重启,要重启,就需要先去服务器上,把挂载的目录卸载下来
Mac客户端
首先需要确保网络能够ping通。
# 检查挂载
showmount -e 49.111.111.111
Exports list on 49.111.111.111:
/nfsboot
# 创建本地挂载目录
mkdir ~/nfs
sudo mount -t nfs -o nolock 49.111.111.111:/nfsroot/ /Users/mafei/nfs
umount /Users/mafei/nfsMac永久挂载NFS
- 打开System Preferences > Users & Groups
- 点击右侧的Login Items,系统启动项
- 点击下面的+号,添加一个新的挂载,位置是已经挂载的目录

Linux客户端挂载
Ubuntu 16.04,首先需要安装 nfs-common 包
apt install nfs-commonCentOS 7, 需要安装 nfs-utils 包
yum install nfs-utils另一个挂载NFS 共享的方式就是在 /etc/fstab 文件中添加一行。该行必须指明 NFS 服务器的主机名、服务器输出的目录名以及挂载 NFS 共享的本机目录。
以下是在 /etc/fstab 中的常用语法:
example.hostname.com:/ubuntu /local/ubuntu nfs rsize=8192,wsize=8192,timeo=14,intr参数优化
NFS高并发下挂载优化常用参数(mount -o选项)
async:异步同步,此参数会提高I/O性能,但会降低数据安全(除非对性能要求很高,对数据可靠性不要求的场合。一般生产环境,不推荐使用)。
noatime:取消更新文件系统上的inode访问时间,提升I/O性能,优化I/O目的,推荐使用。
nodiratime:取消更新文件系统上的directory inode访问时间,高并发环境,推荐显式应用该选项,提高系统性能,推荐使用。
参考
https://www.cnblogs.com/operationhome/p/11700700.html
https://www.cnblogs.com/keystone/p/12699479.html
https://www.cnblogs.com/me80/p/7464125.html
https://xiaozhuanlan.com/topic/8560297431
https://github.com/easzlab/kubeasz/blob/master/docs/guide/nfs-server.md
]]>Kali Linux 号称道德黑客的操作系统,支持超过 500 种渗透测试和网络安全相关的应用程序。
下面介绍几款简单的网络安全相关的工具
docker 方式安装 Kali Linux
docker pull kalilinux/kali-rolling docker run --tty --interactive kalilinux/kali-rolling /bin/bash cat /etc/os-release apt update -y apt upgrade -y exit
Nmap
Network Mapper,是Linux下的网络扫描和嗅探工具包。
扫描目标可以是主机名、ip地址或网络地址等,多个目标以空格分隔;常用的选项有”-p”、”-n”,分别用来指定扫描的端口、禁止反向解析(以加快扫描速度);扫描类型决定着扫描的方式,也直接影响扫描结果。
apt install -y nmap
# 对本机进行扫描,检测开放了哪些常用的TCP端口、UDP端口
nmap 127.0.0.1
Starting Nmap 7.91 ( https://nmap.org ) at 2022-04-18 11:50 CST
Nmap scan report for ingress.finley.demo (127.0.0.1)
Host is up (0.000081s latency).
Not shown: 993 closed ports
PORT STATE SERVICE
53/tcp open domain
80/tcp open http
443/tcp open https
3306/tcp open mysql
5000/tcp open upnp
7000/tcp open afs3-fileserver
49165/tcp open unknown
Nmap done: 1 IP address (1 host up) scanned in 0.15 seconds
# 扫描百度
nmap www.baidu.com
Starting Nmap 7.92 ( https://nmap.org ) at 2022-04-13 09:57 CST
Nmap scan report for www.baidu.com (103.235.46.39)
Host is up (0.22s latency).
Not shown: 998 filtered tcp ports (no-response)
PORT STATE SERVICE
80/tcp open http
443/tcp open https
Nmap done: 1 IP address (1 host up) scanned in 73.88 seconds
# 扫描一个IP的多个端口
nmap 10.0.1.161 -p20-200,7777,8888
# 扫描多个IP用法
nmap 10.0.1.161 10.0.1.162
# 扫描一个子网网段所有IP
nmap 10.0.3.0/24
# 扫描连续的ip地址
nmap 10.0.1.161-162whatweb 下一代网络扫描程序 - 快速分析网站信息
特点:
- 超过1800个插件
- 性能调整。 控制要同时扫描的网站数量
- 多种日志格式:简要(可摘要),详细(人类可读),XML,JSON,MagicTree,RubyObject,MongoDB,SQL。
- 自定义HTTP标头
- HTTP身份验证
- 代理支持,包括TOR
- 控制网页重定向
- IP地址范围
- 模糊匹配
- 在命令行上定义的自定义插件
sudo apt-get install whatweb
whatweb https://www.mafeifan.com
https://www.mafeifan.com [200 OK] Country[CHINA][CN], HTML5, HTTPServer[Ubuntu Linux][nginx/1.14.0 (Ubuntu)], IP[49.232.138.70], Meta-Author[FinleyMa], MetaGenerator[VuePress 1.8.2], Script, Title[hello world! | mafeifan 的技术博客], nginx[1.14.0]
# 列出所有插件
whatweb --list-plugins
# 列出详情
# 会看到把nginx版本也打印出来了,暴露版本号这是一种不安全的做法
whatweb -v https://www.mafeifan.com
WhatWeb report for https://www.mafeifan.com
Status : 200 OK
Title : hello world! | mafeifan 的技术博客
IP : 49.232.138.70
Country : CHINA, CN
Summary : MetaGenerator[VuePress 1.8.2], Meta-Author[FinleyMa], Script, HTTPServer[Ubuntu Linux][nginx/1.14.0 (Ubuntu)], nginx[1.14.0], HTML5
Detected Plugins:
[ HTML5 ]
HTML version 5, detected by the doctype declaration
[ HTTPServer ]
HTTP server header string. This plugin also attempts to
identify the operating system from the server header.
OS : Ubuntu Linux
String : nginx/1.14.0 (Ubuntu) (from server string)
[ Meta-Author ]
This plugin retrieves the author name from the meta name
tag - info:
http://www.webmarketingnow.com/tips/meta-tags-uncovered.html
#author
String : FinleyMa
[ MetaGenerator ]
This plugin identifies meta generator tags and extracts its
value.
String : VuePress 1.8.2
[ Script ]
This plugin detects instances of script HTML elements and
returns the script language/type.
[ nginx ]
Nginx (Engine-X) is a free, open-source, high-performance
HTTP server and reverse proxy, as well as an IMAP/POP3
proxy server.
Version : 1.14.0
Website : http://nginx.net/
HTTP Headers:
HTTP/1.1 200 OK
Server: nginx/1.14.0 (Ubuntu)
Date: Thu, 14 Apr 2022 02:18:26 GMT
Content-Type: text/html
Last-Modified: Wed, 06 Apr 2022 03:53:33 GMT
Transfer-Encoding: chunked
Connection: close
ETag: W/"624d0ebd-b2bf"
Content-Encoding: gzip隐藏nginx版本号
vim /etc/nginx/conf/nginx.conf
# 在http段中加入
server_tokens off;theHarvester 用户信息收集工具
theHarvester是一款信息收集工具,它可以通过搜索引擎等公开库去收集用户的email,子域名,主机IP,开放端口等等信息。
https://github.com/laramies/theHarvester
-
-d:用来确定搜索的域或网址,也就是你要收集哪个目标的信息,这个参数的作用就是确定目标(d指的就是domain,域名的意思)。
-
-b:用来确定收集信息的来源,比如:baidu, bing, google等等,这个参数是确定从哪里收集信息,信息的来源可以是baidu,也可以是bing或者google。
-
-l:该选项用来设置theHarvester要收集多少信息,用来限制要收集信息的数量,量越大速度也就越慢。
-
-f:用来保存收集到的所有信息,可以保存为HTML文件,也可以是XML文件。如果不想保存,只是想看一遍结果,就不需要添加这个参数。
apt install theharvester
# -d 搜索域名 -l 搜索结果数 -b 搜索引擎
theHarvester -d apple.com -l 100 -b baidu
[*] Target: apple.com
[*] Searching Baidu.
[*] No IPs found.
[*] Emails found: 15
----------------------
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[email protected]
[*] Hosts found: 21
---------------------
apple-lists.apple.com
appleid.apple.com:17.111.105.242
communities.apple.com:113.24.194.97, 150.138.167.141
connect.apple.com
developer.apple.com:17.253.83.204, 17.253.118.202
devforums.apple.com:118.214.35.197
discussions.apple.com:23.47.242.238
discussionschinese.apple.com:103.254.191.161, 124.236.67.184
email.apple.com
forums.developer.apple.com:23.37.149.157
group.apple.com
help.apple.com:23.217.250.176
id.apple.com:17.179.252.3
iforgot.apple.com:17.111.105.243
lists.apple.com:17.179.124.160, 17.32.208.205
mfi.apple.com:17.179.124.158
mysupport.apple.com:104.123.24.25
store.apple.com:61.147.219.208
support.apple.com:113.24.194.97, 124.236.67.184
www.apple.com:221.194.155.186
# 通过所有来源来扫码网站
theHarvester -d apple.com -l 100 -b allRED HAWK 网站信息收集及漏洞扫描工具
基于PHP的网站信息收集及漏洞扫描工具,提供的功能有
- 网站title
- 服务器检测
- CMS检测
- Cloudflare检测
- robots.txt 扫描
- 物理IP地址
- nmap端口扫描
等等,详见官网
https://github.com/Tuhinshubhra/RED_HAWK
使用方法非常简单。
执行以下步骤,并按提示操作即可
git clone https://github.com/Tuhinshubhra/RED_HAWK.git
cd RED_HAWK
php rhawk.php
nikto 网站脆弱性检测
https://github.com/sullo/nikto
使用
sudo apt install -y nikto
nikto -host www.mafeifan.com
- Nikto v2.1.5
---------------------------------------------------------------------------
+ Target IP: 49.232.138.70
+ Target Hostname: www.mafeifan.com
+ Target Port: 80
+ Start Time: 2022-04-14 16:50:29 (GMT8)
---------------------------------------------------------------------------
+ Server: nginx
+ The anti-clickjacking X-Frame-Options header is not present.
+ Root page / redirects to: https://www.mafeifan.com/
+ No CGI Directories found (use '-C all' to force check all possible dirs)
+ 6544 items checked: 0 error(s) and 1 item(s) reported on remote host
+ End Time: 2022-04-14 16:50:40 (GMT8) (11 seconds)
---------------------------------------------------------------------------
+ 1 host(s) tested
nikto -host www.osvlabs.com
- Nikto v2.1.5
---------------------------------------------------------------------------
+ Target IP: 39.100.198.227
+ Target Hostname: www.osvlabs.com
+ Target Port: 80
+ Start Time: 2022-04-14 16:52:15 (GMT8)
---------------------------------------------------------------------------
+ Server: nginx/1.14.0 (Ubuntu)
+ The anti-clickjacking X-Frame-Options header is not present.
+ Root page / redirects to: https://www.osvlabs.com/
+ No CGI Directories found (use '-C all' to force check all possible dirs)
+ Server leaks inodes via ETags, header found with file /, fields: 0x5dceb91d 0x264
+ 6544 items checked: 0 error(s) and 2 item(s) reported on remote host
+ End Time: 2022-04-14 16:53:05 (GMT8) (50 seconds)
---------------------------------------------------------------------------
+ 1 host(s) tested参考
]]>更新
证书过期续期方法
执行sudo /snap/bin/certbot renew --force-renewal
提示
Saving debug log to /var/log/letsencrypt/letsencrypt.log
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Processing /etc/letsencrypt/renewal/course.intogolf.nl.conf
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Could not choose appropriate plugin: The manual plugin is not working; there may be problems with your existing configuration.
The error was: PluginError('An authentication script must be provided with --manual-auth-hook when using the manual plugin non-interactively.')
Failed to renew certificate course.intogolf.nl with error: The manual plugin is not working; there may be problems with your existing configuration.
The error was: PluginError('An authentication script must be provided with --manual-auth-hook when using the manual plugin non-interactively.')
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
All renewals failed. The following certificates could not be renewed:
/etc/letsencrypt/live/course.intogolf.nl/fullchain.pem (failure)
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
1 renew failure(s), 0 parse failure(s)经查,不管是申请还是续期,只要是通配符证书,只能采用 dns-01 的方式校验申请者的域名,也就是说 certbot 操作者必须手动添加 DNS TXT 记录。
certbot 提供了一个 hook,可以编写一个 Shell 脚本,让脚本调用 DNS 服务商的 API 接口,动态添加 TXT 记录,这样就无需人工干预了。
--manual-auth-hook:在执行命令的时候调用一个 hook 文件
安装生成工具
sudo apt update
sudo apt-get install letsencrypt生成证书文件
sudo certbot --server https://acme-v02.api.letsencrypt.org/directory -d *.example.com --manual --preferred-challenges dns-01 certonly --agree-tos --manual-public-ip-logging-ok为了证明域名是属于你的,需要进行验证,其中preferred-challenges=dns表示使用dns验证方式
参数解释:
certonly: 只生成证书
–manual: 使用交互方式
–preferred-challenges=dns: 使用dns验证方式
–server: 指定要用于生成证书的服务器地址
–agree-tos: 同意条款
-d: 指定要生成证书的域名回车后,会出现类似如下提示
Please deploy a DNS TXT record under the name
_acme-challenge.example.com with the following value:
x4MrZ6y-JqFJQRmq_lGi9ReRQHPa1aTC9J2O7wDKzq8
Before continuing, verify the record is deployed.需要在你的域名DNS中添加一条txt类型的记录,名为_acme-challenge.example.com值为x4MrZ6y-JqFJQRmq_lGi9ReRQHPa1aTC9J2O7wDKzq8
添加后先不要急着回车,等几分钟后回车,会出现成功提示
IMPORTANT NOTES:
- Congratulations! Your certificate and chain have been saved at:
/etc/letsencrypt/live/example.com/fullchain.pem
Your key file has been saved at:
/etc/letsencrypt/live/example.com/privkey.pem
Your cert will expire on 2020-01-09. To obtain a new or tweaked
version of this certificate in the future, simply run certbot
again. To non-interactively renew *all* of your certificates, run
"certbot renew"
- Your account credentials have been saved in your Certbot
configuration directory at /etc/letsencrypt. You should make a
secure backup of this folder now. This configuration directory will
also contain certificates and private keys obtained by Certbot so
making regular backups of this folder is ideal.
- If you like Certbot, please consider supporting our work by:
Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate
Donating to EFF: https://eff.org/donate-le会告诉你证书的生成地址
使用sudo certbot certificates来查看证书的过期时间和存放路径
Found the following certs:
Certificate Name: example.com
Domains: *.example.com
Expiry Date: 2020-01-05 07:48:04+00:00 (VALID: 85 days)
Certificate Path: /etc/letsencrypt/live/example.com/fullchain.pem
Private Key Path: /etc/letsencrypt/live/example.com/privkey.pem默认情况,证书的有效时间是三个月,为了防止过期,添加一条计划任务,自动续签,先编辑sudo crontab -e添加下行
0 1 * * * /usr/bin/certbot renew >> /var/log/letsencrypt/renew.log最后打开nginx配置,引入证书,站点路径需要改为你实际的
server {
root /home/example/;
# Add index.php to the list if you are using PHP
index index.php index.html index.htm index.nginx-debian.html;
server_name *.example.com;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
# try_files $uri $uri/ =404;
try_files $uri $uri/ /index.php?$query_string;
}
location = /favicon.ico { access_log off; log_not_found off; }
location = /robots.txt { access_log off; log_not_found off; }
error_page 404 /index.php;
# pass PHP scripts to FastCGI server
#
location ~ \.php$ {
include snippets/fastcgi-php.conf;
#
# # With php-fpm (or other unix sockets):
fastcgi_pass unix:/var/run/php/php7.2-fpm.sock;
# # With php-cgi (or other tcp sockets):
# fastcgi_pass 127.0.0.1:9000;
}
listen [::]:443 ssl ipv6only=on; # managed by Certbot
listen 443 ssl; # managed by Certbot
ssl_certificate /etc/letsencrypt/live/example.com/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/example.com/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
}参考
https://github.com/ywdblog/certbot-letencrypt-wildcardcertificates-alydns-au
]]>- 安装过程略,建议用Docker
- sites-enabled 下新建配置文件,如 proxy 编辑内容如下:
resolver 8.8.8.8;
server {
listen 8888;
location / {
proxy_pass http://$http_host$request_uri;
}
}- 重启 nginx
sudo nginx -s reload
- 注意, resolver是必填的
- 仅供演示,有安全隐患,建议加上用户密码限制
使用Python测试
import urllib.request
import urllib.parse
# proxy练习
# 可以找些免费的代理IP
# https://www.xicidaili.com/2019-06-01/henan
req_url = "http://www.baidu.com"
# 改为列表,当作代理池
proxy_addr = "163.204.240.138:8090"
def use_proxy(req_url, proxy_addr):
proxy = urllib.request.ProxyHandler({"http": proxy_addr})
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data = urllib.request.urlopen(req_url).read().decode("utf-8", "ignore")
return data
data = use_proxy(req_url, proxy_addr)
print(len(data))root:x:0:0:root:/root:/usr/bin/zsh
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync# -F 指定分隔符为:然后提取第一个字段。
awk -F ':' '{ print $1 }' awk1.txt
root
daemon
bin
sys
sync
# 提取最后一个字段
awk -F ":" '{print $NF}' awk1.txt
/usr/bin/zsh
/usr/sbin/nologin
/usr/sbin/nologin
/usr/sbin/nologin
/bin/sync
# 提取倒数第二字段
awk -F ":" '{print $(NF-1)}' awk1.txt
/root
/usr/sbin
/bin
/dev
/bin
# 带上行号和分隔符
awk -F ":" '{print NR ")" $1}' awk1.txt
1)root
2)daemon
3)bin
4)sys
5)sync
# 输出最后一行
awk 'END {print}' awk1.txt
tail -n 1 filename
1)root
2)daemon
3)bin
4)sys
5)sync
# awk提供了函数
awk -F ':' '{ print toupper($1) }' awk1.txt
ROOT
DAEMON
BIN
SYS
SYNC
# print命令前面是一个正则表达式,只输出包含usr的行。
awk -F ':' '/usr/ {print $1}' awk1.txt
# 也可以结合 grep 达到同样的效果
cat awk1.txt | grep "/usr/" | awk -F ':' '{print $1}'
# 输出奇数行, NR 理解成 number row
awk -F ':' 'NR % 2 == 1 {print $1}' awk1.txt
# 输出第三行以后的行
awk -F ':' 'NR >3 {print $1}' awk1.txt
输出第一个字段等于指定值的行
awk -F ':' '$1 == "root" || $1 == "bin" {print $1}' awk1.txt
root
bin
# 输出第一个字段的第一个字符大于m的行
awk -F ':' '{if ($1 > "m") print $1}' awk1.txt
root
sys
sync
cat test
a
aa
ab
b
$ awk '{if ($1>"a") print $1}' test
aa
ab
b
c
$ awk '{if ($1>"aa") print $1}' test
ab
b
c
# 使用else
awk -F ':' '{if ($1 > "m") print $1; else print "---"}' awk1.txt
root
---
---
sys
sync动态实时查看日志
tail -f test.log
如果想在日志中出现 Failed 等信息时立刻停止 tail 监控,可以通过如下命令来实现:
tail -f test.log | sed '/Failed/ q'
查看自己的公网IP
curl ip.sb
文件大小
du -h --max-depth=1 | grep G | sort -n
查看一级目录大小
du -hd 1
显示文件大小单位, 并按大小排序
ls -alhS
]]>if [ "id -u" -eq 0 ]; 判断是否是root用户/etc/sudoers 判断该用户是否有执行sudo的权限/etc/sudoers 文件要使用 visudo 命令,好处退出时会自动检查语法设置,防止配置错误早产无法使用sudocrontab -e 来编辑自己定义的任务,系统级也有定时任务,其配置文件是 /etc/cron.hourly, /etc/cron.daily, /etc/cron.weekly等tail -f /var/log/message名称 宏定义 隔离内容
Cgroup CLONE_NEWCGROUP Cgroup root directory (since Linux 4.6)
IPC CLONE_NEWIPC System V IPC, POSIX message queues (since Linux 2.6.19)
Network CLONE_NEWNET Network devices, stacks, ports, etc. (since Linux 2.6.24)
Mount CLONE_NEWNS Mount points (since Linux 2.4.19)
PID CLONE_NEWPID Process IDs (since Linux 2.6.24)
User CLONE_NEWUSER User and group IDs (started in Linux 2.6.23 and completed in Linux 3.8)
UTS CLONE_NEWUTS Hostname and NIS domain name (since Linux 2.6.19)
# 查看当前bash进程所属的namespace
ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 500 ubuntu 0 Mar 12 12:07 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 500 ubuntu 0 Mar 12 12:07 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 500 ubuntu 0 Mar 12 12:07 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 500 ubuntu 0 Mar 12 12:07 net -> 'net:[4026531993]'
lrwxrwxrwx 1 500 ubuntu 0 Mar 12 12:07 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 500 ubuntu 0 Mar 12 12:07 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 500 ubuntu 0 Mar 12 12:07 user -> 'user:[4026531837]'
lrwxrwxrwx 1 500 ubuntu 0 Mar 12 12:07 uts -> 'uts:[4026531838]'Kubernetes 要求所有的网络插件实现必须满足如下要求:
- 一个Pod一个IP
- 所有的 Pod 可以与任何其他 Pod 直接通信,无需使用 NAT 映射
- 所有节点可以与所有 Pod 直接通信,无需使用 NAT 映射
- Pod 内部获取到的 IP 地址与其他 Pod 或节点与其通信时的 IP 地址是同一个。
1、Docker容器网络模型
先看下Linux网络名词:
-
网络的命名空间: Linux在网络栈中引入网络命名空间,将独立的网络协议栈隔离到不同的命令空间中,彼此间无法通信;Docker利用这一特性,实现不同容器间的网络隔离。
-
Veth设备对: Veth设备对的引入是为了实现在不同网络命名空间的通信。
-
Iptables/Netfilter: Docker使用Netfilter实现容器网络转发。
-
网桥: 网桥是一个二层网络设备,通过网桥可以将Linux支持的不同的端口连接起来,并实现类似交换机那样的多对多的通信。
-
路由: Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里。
Docker容器网络示意图如下:

2、Pod 网络
问题: Pod是K8S最小调度单元,一个Pod由一个容器或多个容器组成,当多个容器时,怎么都用这一个Pod IP?
实现: k8s会在每个Pod里先启动一个infra container小容器,然后让其他的容器连接进来这个网络命名空间,然后其他容器看到的网络试图就完全一样了。即网络设备、IP地址、Mac地址等。这就是解决网络共享的一种解法。在Pod的IP地址就是infra container的IP地址。

在 Kubernetes 中,每一个 Pod 都有一个真实的 IP 地址,并且每一个 Pod 都可以使用此 IP 地址与其他 Pod 通信。
Pod 之间通信会有两种情况:
- 两个Pod在同一个Node上
- 两个Pod在不同Node上
先看下第一种情况:两个Pod在同一个Node上
同节点Pod之间通信道理与Docker网络一样的,如下图:

- 对 Pod1 来说,eth0 通过虚拟以太网设备(veth0)连接到 root namespace;
- 网桥 cbr0 中为 veth0 配置了一个网段。一旦数据包到达网桥,网桥使用ARP 协议解析出其正确的目标网段 veth1;
- 网桥 cbr0 将数据包发送到 veth1;
- 数据包到达 veth1 时,被直接转发到 Pod2 的 network namespace 中的 eth0 网络设备。
再看下第二种情况:两个Pod在不同Node上
K8S网络模型要求Pod IP在整个网络中都可访问,这种需求是由第三方网络组件实现。

3、CNI(容器网络接口)
CNI(Container Network Interface,容器网络接口):是一个容器网络规范,Kubernetes网络采用的就是这个CNI规范,CNI实现依赖两种插件,一种CNI Plugin是负责容器连接到主机,另一种是IPAM负责配置容器网络命名空间的网络。
CNI插件默认路径:
# ls /opt/cni/bin/地址:https://github.com/containernetworking/cni
当你在宿主机上部署Flanneld后,flanneld 启动后会在每台宿主机上生成它对应的CNI 配置文件(它其实是一个 ConfigMap),从而告诉Kubernetes,这个集群要使用 Flannel 作为容器网络方案。
CNI配置文件路径:
/etc/cni/net.d/10-flannel.conflist当 kubelet 组件需要创建 Pod 的时候,先调用dockershim它先创建一个 Infra 容器。然后调用 CNI 插件为 Infra 容器配置网络。
这两个路径在kubelet启动参数中定义:
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin4.3 Kubernetes网络组件之 Flannel
Flannel是CoreOS维护的一个网络组件,Flannel为每个Pod提供全局唯一的IP,Flannel使用ETCD来存储Pod子网与Node IP之间的关系。flanneld守护进程在每台主机上运行,并负责维护ETCD信息和路由数据包。
1、Flannel 部署
https://github.com/coreos/flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml2、 Flannel工作模式及原理
Flannel支持多种数据转发方式:
- UDP:最早支持的一种方式,由于性能最差,目前已经弃用。
- VXLAN:Overlay Network方案,源数据包封装在另一种网络包里面进行路由转发和通信
- Host-GW:Flannel通过在各个节点上的Agent进程,将容器网络的路由信息刷到主机的路由表上,这样一来所有的主机都有整个容器网络的路由数据了。
VXLAN
# kubeadm部署指定Pod网段
kubeadm init --pod-network-cidr=10.244.0.0/16
# 二进制部署指定
cat /opt/kubernetes/cfg/kube-controller-manager.conf
--allocate-node-cidrs=true \
--cluster-cidr=10.244.0.0/16 \# kube-flannel.yml
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。下图flannel.1的设备就是VXLAN所需的VTEP设备。示意图如下:

如果Pod 1访问Pod 2,源地址10.244.1.10,目的地址10.244.2.10 ,数据包传输流程如下:
-
**容器路由:**容器根据路由表从eth0发出
/ # ip route default via 10.244.0.1 dev eth0 10.244.0.0/24 dev eth0 scope link src 10.244.0.45 10.244.0.0/16 via 10.244.0.1 dev eth0 -
**主机路由:**数据包进入到宿主机虚拟网卡cni0,根据路由表转发到flannel.1虚拟网卡,也就是,来到了隧道的入口。
# ip route default via 192.168.31.1 dev ens33 proto static metric 100 10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1 10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink 10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink -
**VXLAN封装:**而这些VTEP设备(二层)之间组成二层网络必须要知道目的MAC地址。这个MAC地址从哪获取到呢?其实在flanneld进程启动后,就会自动添加其他节点ARP记录,可以通过ip命令查看,如下所示:
# ip neigh show dev flannel.1 10.244.1.0 lladdr ca:2a:a4:59:b6:55 PERMANENT 10.244.2.0 lladdr d2:d0:1b:a7:a9:cd PERMANENT -
**二次封包:**知道了目的MAC地址,封装二层数据帧(容器源IP和目的IP)后,对于宿主机网络来说这个帧并没有什么实际意义。接下来,Linux内核还要把这个数据帧进一步封装成为宿主机网络的一个普通数据帧,好让它载着内部数据帧,通过宿主机的eth0网卡进行传输。

-
**封装到UDP包发出去:**现在能直接发UDP包嘛?到目前为止,我们只知道另一端的flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。
flanneld进程也维护着一个叫做FDB的转发数据库,可以通过bridge fdb命令查看:
bridge fdb show dev flannel.1
d2:d0:1b:a7:a9:cd dst 192.168.31.61 self permanent ca:2a:a4:59:b6:55 dst 192.168.31.63 self permanent
可以看到,上面用的对方flannel.1的MAC地址对应宿主机IP,也就是UDP要发往的目的地。使用这个目的IP进行封装。
6. **数据包到达目的宿主机:**Node1的eth0网卡发出去,发现是VXLAN数据包,把它交给flannel.1设备。flannel.1设备则会进一步拆包,取出原始二层数据帧包,发送ARP请求,经由cni0网桥转发给container。
#### Host-GW
host-gw模式相比vxlan简单了许多, 直接添加路由,将目的主机当做网关,直接路由原始封包。
下面是示意图:
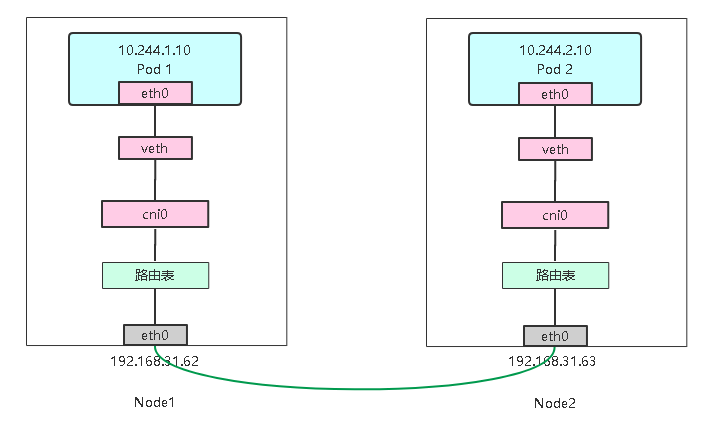kube-flannel.yml
net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "host-gw" } }
当你设置flannel使用host-gw模式,flanneld会在宿主机上创建节点的路由表:ip route
default via 192.168.31.1 dev ens33 proto static metric 100 10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1 10.244.1.0/24 via 192.168.31.63 dev ens33 10.244.2.0/24 via 192.168.31.61 dev ens33 192.168.31.0/24 dev ens33 proto kernel scope link src 192.168.31.62 metric 100
目的 IP 地址属于 10.244.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即:dev eth0);并且,它下一跳地址是 192.168.31.63(即:via 192.168.31.63)。
一旦配置了下一跳地址,那么接下来,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址。
而 Node 2 的内核网络栈从二层数据帧里拿到 IP 包后,会“看到”这个 IP 包的目的 IP 地址是 10.244.1.20,即 container-2 的 IP 地址。这时候,根据 Node 2 上的路由表,该目的地址会匹配到第二条路由规则(也就是 10.244.1.0 对应的路由规则),从而进入 cni0 网桥,进而进入到 container-2 当中。
- 路由器: 网络出口
- 核心层: 主要完成数据高效转发、链路备份等
- 汇聚层: 网络策略、安全、工作站交换机的接入、VLAN之间通信等功能
- 接入层: 工作站的接入
交换技术
有想过局域网内主机怎么通信的?主机访问外网又是怎么通信的?
想要搞懂这些问题得从交换机、路由器讲起。

交换机工作在OSI参考模型的第二次,即数据链路层。交换机拥有一条高带宽的背部总线交换矩阵,在同一时间可进行多个端口对之间的数据传输。
交换技术分为2层和3层:
-
2层:主要用于小型局域网,仅支持在数据链路层转发数据,对工作站接入。
-
3层:三层交换技术诞生,最初是为了解决广播域的问题,多年发展,三层交换机书已经成为构建中大型网络的主要力量。
广播域
交换机在转发数据时会先进行广播,这个广播可以发送的区域就是一个广播域。交换机之间对广播帧是透明的,所以交换机之间组成的网络是一个广播域。
路由器的一个接口下的网络是一个广播域,所以路由器可以隔离广播域。
ARP(地址解析协议,在IPV6中用NDP替代)
发送这个广播帧是由ARP协议实现,ARP是通过IP地址获取物理地址的一个TCP/IP协议。
通过发送arp请求获取局域网内所有的主机信息
比如在家中输入arp -a
使用此命令可以查询本机ARP缓存中IP地址和MAC地址的对应关系
ac68u 是家里的路由器型号
arp -a
rt-ac68u-6490 (192.168.50.1) at 4:92:26:6b:64:90 on en0 ifscope [ethernet]
shuuseikiiphone (192.168.50.65) at 1a:cc:5f:c5:91:f2 on en0 ifscope [ethernet]
? (192.168.50.146) at b6:4:a4:dd:41:de on en0 ifscope [ethernet]
ipad (192.168.50.197) at 8e:ef:98:a2:b7:de on en0 ifscope [ethernet]
? (224.0.0.251) at 1:0:5e:0:0:fb on en0 ifscope permanent [ethernet]
? (239.255.255.250) at 1:0:5e:7f:ff:fa on en0 ifscope permanent [ethernet]三层交换机
前面讲的二层交换机只工作在数据链路层,路由器则工作在网络层。而功能强大的三层交换机可同时工作在数据链路层和网络层,并根据 MAC地址或IP地址转发数据包。
VLAN(Virtual Local Area Network):虚拟局域网
VLAN是一种将局域网设备从逻辑上划分成一个个网段。
一个VLAN就是一个广播域,VLAN之间的通信是通过第3层的路由器来完成的。VLAN应用非常广泛,基本上大部分网络项目都会划分vlan。
VLAN的主要好处:
- 分割广播域,减少广播风暴影响范围。
- 提高网络安全性,根据不同的部门、用途、应用划分不同网段
路由技术

路由器主要分为两个端口类型:LAN口和WAN口
-
WAN口:配置公网IP,接入到互联网,转发来自LAN口的IP数据包。
-
LAN口:配置内网IP(网关),连接内部交换机。
路由器是连接两个或多个网络的硬件设备,将从端口上接收的数据包,根据数据包的目的地址智能转发出去。
路由器的功能:
- 路由
- 转发
- 隔离子网
- 隔离广播域
路由器是互联网的枢纽,是连接互联网中各个局域网、广域网的设备,相比交换机来说,路由器的数据转发很复杂,它会根据目的地址给出一条最优的路径。那么路径信息的来源有两种:动态路由和静态路由。
静态路由: 指人工手动指定到目标主机的地址然后记录在路由表中,如果其中某个节点不可用则需要重新指定。
动态路由: 则是路由器根据动态路由协议自动计算出路径永久可用,能实时地 适应网络结构 的变化。
常用的动态路由协议:
-
RIP( Routing Information Protocol ,路由信息协议)
-
OSPF(Open Shortest Path First,开放式最短路径优先)
-
BGP(Border Gateway Protocol,边界网关协议)
OSI七层模型
OSI(Open System Interconnection)是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,一般称为OSI参考模型或七层模型。
| 层次 | 名称 | 功能 | 协议数据单元(PDU) | 常见协议 |
|---|---|---|---|---|
| 7 | 应用层 | 为用户的应用程序提供网络服务,提供一个接口。 | 数据 | HTTP、FTP、Telnet |
| 6 | 表示层 | 数据格式转换、数据加密/解密 | 数据单元 | ASCII |
| 5 | 会话层 | 建立、管理和维护会话 | 数据单元 | SSH、RPC |
| 4 | 传输层 | 建立、管理和维护端到端的连接 | 段/报文 | TCP、UDP |
| 3 | 网络层 | IP选址及路由选择 | 分组/包 | IP、ICMP、RIP、OSPF |
| 2 | 数据链路层 | 硬件地址寻址,差错效验等。 | 帧 | ARP、WIFI |
| 1 | 物理层 | 利用物理传输介质提供物理连接,传送比特流。 | 比特流 | RJ45、RJ11 |

TCP/UDP协议
TCP(Transmission Control Protocol,传输控制协议),面向连接协议,双方先建立可靠的连接,再发送数据。适用于传输数据量大,可靠性要求高的应用场景。
UDP(User Data Protocol,用户数据报协议),面向非连接协议,不与对方建立连接,直接将数据包发送给对方。适用于一次只传输少量的数据,可靠性要求低的应用场景。相对TCP传输速度快。
以太网桥管理 bridge-utils
$ sudo apt-get install bridge-utils
$ brctl show
bridge name bridge id STP enabled interfaces
br-126eacc1ebd7 8000.0242da05696d no vethf00f161
br-2db339edd793 8000.024244dac6b8 no vethd6cf56e
br-cf45f7e667f5 8000.02426949a50f no veth5a4160b
br-eb62880fbd29 8000.0242576f0396 no
docker0 8000.024219279906 nonmap 网络扫描工具
Nmap可以检测目标主机是否在线、端口开放情况、侦测运行的服务类型及版本信息、侦测操作系统与设备类型等信息。 它是网络管理员必用的软件之一,用以评估网络系统安全。
$ nmap 127.0.0.1
Starting Nmap 6.40 ( http://nmap.org ) at 2022-02-01 05:41 UTC
Nmap scan report for localhost (127.0.0.1)
Host is up (0.00070s latency).
Not shown: 997 closed ports
PORT STATE SERVICE
22/tcp open ssh
25/tcp open smtp
111/tcp open rpcbind
Nmap done: 1 IP address (1 host up) scanned in 0.08 secondPrometheus是一款近年来非常火热的容器监控系统,它使用go语言开发,设计思路来源于Google的Borgmom(一个监控容器平台的系统)。
产品由前谷歌SRE Matt T.Proudd发起开发,并在其加入SoundCloud公司后,与另一位工程师Julius Volz合伙推出,将其开源发布。
2016年,由Google发起的原生云基金会(Cloud Native Computing Foundation)将Prometheus纳入麾下,成为该基金会继Kubernetes后第二大开源项目。
Prometheus天然具有对容器的适配性,可非常方便的满足容器的监控需求,也可用来监控传统资源。近年来随着kubernetes容器平台的火爆,Prometheus的热度也在不断上升,大有超越老牌监控系统Zabbix成为No.1的趋势,目前已在众多公司得到广泛的使用。
二.Prometheus的特点
- 多维度数据模型
- 灵活的查询语言
- 不依赖分布式存储,单个服务器节点是自主的
- 通过基于HTTP的pull方式采集时序数据
- 可以通过中间网关进行数据推送
- 通过服务发现或者静态配置来发现目标服务对象
- 支持多种多样的图表和界面展示,比如Grafana 等
三. Prometheus相关组件
- Prometheus Server:服务端,用于处理和存储监控数据
- Exporter:监控客户端,用于收集各类监控数据,不同的监控需求由不同的exporter处理,如node-exporter、mysql-exporter、blackbox-exporter等。
- Pushgateway:在不支持pull 拉取监控数据的场景中,可通过部署Pushgateway的方式,由监控源主动上报到Promtehus。
- Alertmanager:独立组件,用于处理告警信息。
- Web-UI:Prometheus自带的web界面,可进行监控数据的展示与查询。
四. 工作原理
1.服务发现
Prometheus可通过多种方式来发现要监控的资源列表,包括:
用户提供的静态资源列表。
基于文件的发现。
自动发现,例如使用DNS SRV记录来生成列表或通过查询Consul等配置中心获取信息。
2. 指标收集
Prometheus根据配置的Job定时去拉取各个监控节点的数据,任何组件只要提供对应的HTTP接口就可以接入监控,不需要任何SDK或其他集成过程,非常适合虚拟化环境的监控,如Kubernetes、Docker等。
默认的拉取方式为pull,也可以使用pushgateway提供的push 方式获取各个监控节点的数据,并将获取到的数据存入TSDB(一种时序型数据库)。
3. 数据查询
Prometheus提供一套内置的PromQL语言,其自带的Web-UI查询数据支持按条件表达式的方式,查询相关的监控数据。
4. 可视化
Prometheus自带的Web-UI可支持图表展示 ,但功能及界面较简陋,常规方案是接入到grafana进行展示管理。
5. 聚合告警
Prometheus Server没有内置告警工具,程序基于配置的rules发送告警信息到Alertmanager,由Alertmanager对告警信息进行统一处理。
Alertmanger支持对告警信息进行聚合和收敛,并通过邮箱、短信、微信、钉钉等多种告警方式发送给相关的接收人。
]]>本文将对Prometheus相关的主机监控指标进行介绍。
一. CPU监控
CPU负载
node_load1
node_load5
node_load15以上三个指标为主机的CPU平均负载,分别对应一分钟、五分钟和十五分钟的时间间隔。
CPU负载是指某段时间内占用CPU时间的进程和等待CPU时间的进程数之和。
一般来说,cpu负载数/cpu核数如果超过0.7,应该开始关注机器性能情况 ,如果超过1的话,运维人员应该介入处理。
CPU使用率
node_cpu_seconds_total
该指标包括了多个标签,分别标记每种处理模式使用的CPU时间,该指标为counter类型。
这个指标不适合直接拿来使用,可通过前面学习的PromQL,将其转化成CPU使用率的指标 。
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 3.56934038e+06
node_cpu_seconds_total{cpu="0",mode="iowait"} 6208.33
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 398.62
node_cpu_seconds_total{cpu="0",mode="softirq"} 2759.47
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 65250.09
node_cpu_seconds_total{cpu="0",mode="user"} 190913.76
node_cpu_seconds_total{cpu="1",mode="idle"} 3.56738873e+06
node_cpu_seconds_total{cpu="1",mode="iowait"} 8643.69
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 378.03
node_cpu_seconds_total{cpu="1",mode="softirq"} 2633.77
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 65323.76
node_cpu_seconds_total{cpu="1",mode="user"} 190535.96mode="idle"代表CPU 的空闲时间,所以我们只需要算出空闲的时间占比,再以总数减去该值 ,便可知道CPU的使用率,此处使用irate方法。
由于现有的服务器一般为多核,所以加上avg求出所有cpu的平均值,便是CPU的使用率情况 ,如下 :
100 -avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)* 100
二. 内存监控
物理内存使用率 对于内存,我们一般会关注内存的使用率,但node-exporter并不直接进行计算,我们需要根据node-exporter返回的内存指标自己写计算公式 。
需要用到的内存指标有下列几个:
node_memory_MemTotal_bytes #总内存大小
node_memory_MemFree_bytes #空闲内存大小
node_memory_Buffers_bytes #缓冲缓存大小
node_memory_Cached_bytes #页面缓存大小计算的公式为:(总内存 -(空闲内存 + 缓冲缓存 + 页面缓存))/ 总内存 * 100
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes+node_memory_Cached_bytes ))/node_memory_MemTotal_bytes * 100
swap内存使用率
Swap为交换内存分区,它使用磁盘上的部分空间来充当服务器内存,当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务。而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
swap内存用到的指标如下:
node_memory_SwapTotal_bytes #swap内存总大小
node_memory_SwapFree_bytes #swap空闲内存大小计算的公式如下:(node_memory_SwapTotal_bytes - node_memory_SwapFree_bytes)/node_memory_SwapTotal_bytes * 100
三. 磁盘监控
分区使用率
分区使用率的指标可以通过分区空间总容器和分区空闲容量计算出来
node_filesystem_size_bytes # 分区空间总容量
node_filesystem_free_bytes # 分区空闲容量由于主机一般会有多个分区 ,需要通过指标的标签mountpoint 进行区分 ,如 获取 / 分区磁盘使用率可使用下列公式
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"})/node_filesystem_size_bytes{mountpoint="/"} * 100
磁盘吞吐量
node_disk_read_bytes_total #分区读总字节数
node_disk_written_bytes_total #分区写总字节数上面两个指标分别对应了分区读写的总字节数,指标为counter类型。前面文章讲过,counter类型会不断的累加,该指标直接使用对于监控没有意义,但可通过下面公式转化为磁盘的每秒读写速率。device代表对应的磁盘分区。
irate(node_disk_read_bytes_total{device="vda"}[5m])
irate(node_disk_written_bytes_total{device="vda"}[5m])磁盘IOPS
IOPS表示每秒对磁盘的读写次数,它与吞吐量都是衡量磁盘的重要指标。对于IOPS的监控,可通过下面两个指标算得出
node_disk_reads_completed_total #分区读总次数
node_disk_writes_completed_total #分区写总次数计算公式与上面相似,使用我们熟悉的irate或rate函数来处理
irate(node_disk_reads_completed_total{device="vda"}[5m])
irate(node_disk_writes_completed_total{device="vda"}[5m])四. 网络监控
网卡流量 网卡流量一般分为上传和下载流量,下面两个指标分别为总的字节数,可通过这两个指标计算出来网卡每秒流量
node_network_receive_bytes_total #下载流量总字节数
node_network_transmit_bytes_total #上传流量总字节数计算公式如下,此处排除Loopback 网卡
irate(node_network_receive_bytes_total{device != "lo"}[1m]
除了监控主机的性能参数外,我们还需要关注实例的可用性情况,比如是否关机、exporter是否正常运行等。
在exporter返回的指标,有一个up指标,可用来实现这类监控需求。
up{job="node-exporter"}
结语
主机监控是监控平面中最底层的一类,虽然基础但是非常重要,只有在主机层面稳定了,上层应用才能更好的运行。 本文讲解的内容只是主机监控中的基本指标,node-exporter自身还提供不少有用的指标,包括支持textfile的自定义指标。 在生产环境中,需要根据实际情况进行调试。
]]>对此,Prometheus官方推荐的可视化方案是与Grafana结合,来实现丰富的监控展示效果。
一. Grafana简介
Grafana是一个开源的可视化和分析工具,它支持Prometheus、elasticsearch、graphite、influxdb 等众多的数据源,并提供了强大的界面编辑器和可视化模板。
该产品具有以下几个特点:
- 可视化:快速灵活的图形类型和多种选项,面板插件支持多种不同的方式来可视化指标和日志,例如:热图、折线图、图表等多种展示方式;
- 混合展示:在同一个图表中混合不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
- 数据源支持:支持Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,Mysql等多种数据源;
- 告警通知:支持以可视化方式定义警报规则,并会不断的计算数据,在指标达到阀值时通过Slack、PagerDuty、VictorOps等系统发送通知。
二. 安装部署
下载二进制包,运行安装
$ wget https://dl.grafana.com/oss/release/grafana-7.5.10-1.x86_64.rpm
$ sudo yum install grafana-7.5.10-1.x86_64.rpm启动服务
$ sudo systemctl start grafana-server
grafana默认端口为3000,打开浏览器输入 http://ip:3000 访问, 默认账号密码都为admin。

登录系统后,可看到左边一排功能键,分别对应着Dashboard搜索、Dashboard创建、Dashboard管理、Explore、告警管理、系统配置、管理员选项等功能,具体的功能这里不做详细介绍,
感兴趣的话可以上官网自行查阅:https://grafana.com/docs/grafana/latest/。

三. Grafana使用方法
下面我们以Prometheus为例,讲解关于Grafana的使用方法。
在列表中可以看到grafana支持多种数据源,此处选择Prometheus

填写数据源名称与URL,完成后点击“save&test”按键,如果正常会收到Success提示。

点击“Add an empty panel”,添加一个新的面板
点击Panel Title选择Edit
选择数据源名称“Prometheus”,在metrics处填写监控指标的PromQL语句,此处以上篇文章中的CPU使用率公式为例。在
图表右边处提供了丰富的功能,用于自定义图表类型,此处我们选择Graph类型图表。
完成后,点击右上角"Apply”按键,一个简单的图表就做好了。如果需要在仪表盘中增加更多展示图表,可点击右上角的“Add panel”继续添加。

如果需要对Dashboard进行配置,可点击右上角的“Dashboard setting”按键,进入配置界面 。
在配置界面可设置Dashboard名称等基础信息,还有配置变量、权限管理、版本管理等多个功能。 配置完成后,点击“save dashboard"保存并退出。
四. 下载Dashboard模板
上面介绍了关于Dashboard的配置,但考虑到监控的图表很多,如果全部手动去配置,无疑是件耗时耗力的事。
在这点上,Grafana官网很贴心的提供了不少Dashboard的模板,可以下载即用,极大的提升了我们的工作效率。 浏览器打开官网:https://grafana.com,点击 “Grafana”-“Dashboards”,
按需要的模板类型进行搜索,如node。搜索后一般会出现较多的可选模板,这里可根据下载量和星数判断,推荐选择受欢迎的模板。
https://grafana.com/grafana/dashboards/?search=node

点击模板后,进入介绍页面,会有该模板的详细介绍。在右边会看到该模板的ID号,这个很重要,Grafana需要根据这个ID号进行模板下载。
拷贝该ID号(8919),回到grafana系统,选择”Create"-"import" ,进入模板导入界面
下载加载。(grafana也支持json文件导入的方式,可将Dashboard导出为json备份,需要时再选择“Upload Json file”进行模板导入)

选择Prometheus的数据源,点击"import",完成导入
查看新生成的Dashboard,顺利完成。

在Prometheus的架构中,告警功能由Prometheus Server和Alertmanager 协同完成,Prometheus Server负责收集目标实例的指标,定义告警规则以及产生警报,并将相关的警报信息发送到Alertmanager。
Alertmanager则负责对告警信息进行管理 ,根据配置的接收人信息,将告警发送到对应的接收人与介质 。
一. 添加告警规则
告警规则配置在独立的文件中,文件格式为yml,并在prometheus.yml文件的rule_files模块中进行引用。如下
rule_files:
- "/etc/prometheus/rules/myrules.yml"引用的文件路径支持正则表达式方式,如果有多个文件时,可以用下列的方式匹配
rule_files:
- "/etc/prometheus/rules/*.yml"
- "/data/prometheus/rules/prd-*.yml"默认情况下,Prometheus会每隔一分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,可在global 模块中配置evaluation_interval参数来控制。
global:
evaluation_interval: 15s在告警规则文件中, 可以将一组相关的规则设置定义在一个group下,在每一个group中我们可以定义多个告警规则。
如下是一条标准的告警规则,用于检测实例状态是否正常。
groups:
- name: node_alert
rules:
- alert: node_down
expr: up{job="node-exporter"} != 1
for: 1m
labels:
level: critical
annotations:
description: "The node is Down more than 1 minute!"
summary: "The node is down"一条告警规则由以下几部分组成:
- alert:告警规则的名称,在每一个group中,规则名称必须是唯一的。
- expr:基于PromQL表达式配置的规则条件,用于计算相关的时间序列指标是否满足规则。
- for :评估等待时间,可选参数。当相关指标触发规则后,在for定义的时间区间内该规则会处于Pending状态,在达到该时间后规则状态变成Firing,并发送告警信息到Alertmanager。
- labels:自定义标签, 允许用户指定要添加到告警信息上的一组附加标签。
- annotations: 用于指定一组附加信息,如用于描述告警的信息文字等,本示例中 summary用于描述主要信息,description用于描述详细的告警内容。
二. 使用模板
模板(template)是一种在警报中使用时间序列数据的标签和值的方法,可用于告警中的注解和标签。模板使用标准的Go模板语法,并暴露一些包含时间序列的标签和值的变量。
通过
{{ $lable.<lablename>}}
变量可以访问当前告警实例中指定标签的值,
{{ $value }}
则可以获取当前PromQL表达式计算的样本值。
# To insert a firing element's label values:
{{ $labels.<labelname> }}
# To insert the numeric expression value of the firing element:
{{ $value }}在实际使用中,可以通过模板的方式优化summary与description内容的可读性。比如,在描述中插入了实例信息以及PromQL表达式计算的样本值。 如下:
groups:
- name: node_alert
rules:
- alert: cpu_alert
expr: 100 -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)* 100 > 85
for: 5m
labels:
level: warning
annotations:
description: "instance: {{ $labels.instance }} ,cpu usage is too high ! value: {{$value}}"
summary: "cpu usage is too high"三. 规则应用
配置好规则文件后,可以使用 curl -X POST http://localhost:9090/-/reload 或者重启Prometheus的方式让规则更新。
当顺利加载规则后,可以在Prometheus的“Status”- “Rules”页面查看到相关的规则状态信息。

当告警规则生效后,可以在Alerts页面查看警报状态。

四. 警报状态
Prometheus的警报有如下几种状态:
- inactive :警报未被触发。
- Pending:警报已被触发,但还未满足for参数定义的持续时间。
- Firing:警报被触发警,并满足for定义的持续时间的
告警规则的状态变化如下所示,默认状态为inactive,当规则被触发后将变为Pending,在达到持续时间后变成Firing状态。如果配置的规则没有for子句,那么当规则触发时,警报会自动从inactive转换为Firing,而没有任何的等待周期。
如果配置了Alertmanager的地址,当警报状态为Firing时,Prometheus会将相关的告警信息转发到Alertmanager,并由其进行告警信息的发送。在恢复正常后,警报状态重新变回inactive。
结语
本文介绍了关于Prometheus告警规则的配置,到目前为止,我们只能通过Prometheus UI查看当前警报的活动状态。 Prometheus自身并不提供告警发送功能,其需要与Alertmanager结合,才能实现警报的管理与发送。 限制篇幅原因,Alertmanager的讲解放到下一篇文章中介绍。
]]>在Prometheus的整体方案中,告警管理功能主要通过Alertmanager来完成,本文将接着上篇,讲解使用Alertmanager来实现警报的发送与管理。
一. Alertmanager简介
Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息。
Alertmanager可以对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方。
Alertmanager内置了对邮件,Slack等多种通知方式的支持,同时还支持通过Webhook的方式接入企业微信、钉钉等国内IM工具。

Alertmanager除了提供基本告警通知能力以外,还具有以下几个特点:
1. 分组
分组机制可以将相同性质的警报合并为一个通知。比如在某些故障场景中,可能导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受收大量的通知信息,而无法对问题进行快速定位。
例如:当一台宿主机上运行着数十个虚拟机,如果机器发生网络或硬件故障,运维人员可能收到数十个告警,包括物理机与上面的所有虚拟机。而逐个查看这些故障本身是个耗时的工作,也容易导致对主要问题的忽略。
作为告警接收人,我们希望可以在一个通知中就能查看到受影响的所有实例信息,这时可以按照告警名称或所属宿主机对告警进行分组,而将这些告警合并到一个通知中查收。
告警分组功能可以通过Alertmanager的配置文件进行配置。
2. 抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
例如:当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。
抑制机制同样通过Alertmanager的配置文件进行设置。
3. 静默
静默提供了一种简单的方法对特定的告警在特定时间内进行静音处理,它根据标签进行匹配。如果Alertmanager接收到的告警信息符合静默的配置,它将不会发送告警通知。静默功能适合在机器进行维护等场景下,暂时屏蔽告警通知。
静默设置需要在Alertmanager的Web页面上进行设置。
二. 安装部署
下载安装包并解压
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
$ tar -xvf alertmanager-0.21.0.linux-amd64.tar.gz拷贝文件到bin目录
$ cd alertmanager-0.21.0.linux-amd64
$ sudo cp alertmanager /usr/local/bin/
$ sudo cp amtool /usr/local/bin/注:amtool是一个Alertmanager管理工具,支持用命令行方式进行管理。 查看版本号验证安装是否正常
$ alertmanager --version
alertmanager, version 0.21.0 (branch: HEAD, revision: 4c6c03ebfe21009c546e4d1e9b92c371d67c021d)
build user: root@dee35927357f
build date: 20200617-08:54:02
go version: go1.14.4三. 配置介绍
Alertmanager与Prometheus Server一样,也是通过yml格式的配置文件进行配置。下面是一个基本的配置文件模板:
global:
resolve_timeout: 3m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '[email protected]'
smtp_require_tls: false
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
receiver: 'admin'
group_by: ['alertname']
group_wait: 20s
group_interval: 10m
repeat_interval: 3h
receivers:
- name: 'admin'
email_configs:
- to: '[email protected]'该配置文件总共定义了四个模块,global、templates、route和receivers。
global
用于定义Alertmanager的全局配置。
在示例中我们只配置几个参数,其中resolve_timeout定义持续多长时间未接收到告警标记后,就将告警状态标记为resolved。 而smtp_smarthost指定SMTP服务器地址,smtp_from定义了邮件发件的的地址,smtp_require_tls配置禁用TLS的传输方式。
templates
用于指定告警通知时的模板,如邮件模板等。
由于Alertmanager的信息可以发送到多种接收介质,如邮件、Slack等,我们通常需要能够自定义警报所包含的信息,这个就可以通过模板来实现。
限于篇幅原因,相关模板的配置方式本文不做介绍,有兴趣的朋友可上官网查看:https://prometheus.io/docs/alerting/latest/notifications/。
route
用于定义Alertmanager接收警报的处理方式,根据规则进行匹配并采取相应的操作。
路由是一个基于标签匹配规则的树状结构,所有的告警信息都会从配置中的顶级路由(route)进入路由树。从顶级路由开始,根据标签匹配规则进入到不同的子路由,并且根据子路由设置的接收者发送告警。在示例配置中只定义了顶级路由,并且配置的接收者为admin,因此,所有的告警都会发送给到admin的接收者。
- group_by 用于定义分组规则,前面讲过Alertmanager支持告警分组功能,这里使用告警名称做为规则,满足规则的告警将会被合并到一个通知中;
- group_wait 配置分组等待的时间间隔,在这个时间内收到的告警,会根据前面的规则做合并;
- group_interval 定义相同group间发送告警通知的时间间隔;
- repeat_interval 用于定义重复警报发送间隔,默认为3小时。
receivers
用于定义接收者的地址信息。
由于我们示例配置是邮件告警的方式,这里email_configs参数配置相关的邮件地址信息,另外还支持wechat_configs、webhook_configs等方式。
四. 启动Alertmanager
启动Alertmanager时可使用参数修改相关配置,--config.file用于指定配置文件路径,--storage.path用于指定数据存储路径。
$ alertmanager --config.file alertmanager.yml --storage.path /data/alertmanager/ &
启动完成后,打开浏览器,访问http://:9093$IP,可看到UI界面

五. Prometheus关联Alertmanager
Prometheus的配置文件中,alerting模块用于配置Alertmanager地址。当配置完成后,Prometheus会将触发告警规则的警报发送到Alertmanager。
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']我们可以试着将上篇文章中的cpu告警规则调低,触发Prometheus告警规则来验证配置,此处我们改为CPU使用率大于1%触发告警。
groups:
- name: node_alert
rules:
- alert: cpu_alert
expr: 100 -avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)* 100 > 1
for: 5m
labels:
level: warning
annotations:
description: "instance: {{ $labels.instance }} ,cpu usage is too high ! value: {{$value}}"
summary: "cpu usage is too high"在Prometheus界面看到已成功触发告警规则

打开Alertmanager,可看到接收到的警报信息。

六. 标签路由
在前面的示例中,我们只定义了一个顶级路由,这意味着所有的告警都由admin的接收者获取。但在实际环境中,告警的需求往往要比这个来得复杂。
例如:我们需要根据资源类型,将数据库的告警发送给DBA团队,将服务器的告警发送给运维团队;或者根据告警的严重级别,普通告警发送给技术人员,严重告警还需要通知到领导层等等。
对于此类需求,我们可以使用子路由的方式来实现,这些Route支持通过标签的方式进行匹配,并发送给相关的receiver。
route:
receiver: 'admin'
group_by: ['alertname']
group_wait: 20s
group_interval: 10m
repeat_interval: 3h
routes:
- receiver: 'database'
continue: true
match_re
type: mysql|mongodb
- receiver: 'devops'
continue: true
match:
type: server
receivers:
- name: 'admin'
email_configs:
- to: '[email protected]'
- name: 'database'
email_configs:
- to: '[email protected] |[email protected]'
- name: 'devops'
email_configs:
- to: '[email protected] |[email protected]'在上面的这个示例中,我们配置了顶级路由,然后又根据不同的标签,定义了两个子路由和相关的接收者。 其中continue的值如果为false,那么告警在匹配到第一个子节点之后就直接停止,如果continue为true,报警则会继续进行后续子节点的匹配。
对于告警信息的匹配,可以通过match和match_re进行标签的匹配,其中match匹配字符,而match_re支持正则表达式的方式。
七. 静默告警
在某些情况下,我们可能希望对告警信息进行屏蔽,不收到相关的告警信息。例如对服务器进行关机维护、实例重启等场景。对此,Alertmanager提供了静默功能,用于处理此类需求。
静默功能的配置可以UI界面上进行,点击页面右上角的 "Silence"按键。
在"New Silence“页面进行配置,Matchers通过标签配置需要屏蔽的告警,如果勾上Regex,则可以在Value处使用正则表达式做匹配。
在Start处填写开始时间,然后在End或Duration中填写一处即可,另外一个会自动计算出来。

配置完成后,点击 "Create”完成创建。此时点击”Silence”,可看到已经生成的Silence。当需要提前中止该Silence时,可点击旁边的Expire红色字体,让其过期即可。
]]>Pushgateway为Prometheus整体监控方案的功能组件之一,并做为一个独立的工具存在。
它主要用于Prometheus无法直接拿到监控指标的场景,如监控源位于防火墙之后,Prometheus无法穿透防火墙;目标服务没有可抓取监控数据的端点等多种情况。在类似场景中,可通过部署Pushgateway的方式解决问题。
当部署该组件后,监控源通过主动发送监控数据到Pushgateway,再由Prometheus定时获取信息,实现资源的状态监控。

工作流程:
- 监控源通过Post方式,发送数据到Pushgateway,路径为/metrics。
- Prometheus服务端设置任务,定时获取Pushgateway上面的监控指标。
- Prometheus获取监控指标后,会根据告警规则进行计算,如果匹配将触发告警到Alertmanager;同时,Grafana可配置数据源调用Prometheus数据,做为数据展示。
二. 安装部署
1、二进制安装
下载安装包
$ wget https://github.com/prometheus/pushgateway/releases/download/v1.4.1/pushgateway-1.4.1.linux-amd64.tar.gz
$ tar -xvf pushgateway-1.4.1.linux-amd64.tar.gz
$ cd pushgateway-1.4.1.linux-amd64
$ sudo cp pushgateway /usr/local/bin/查看版本号验证是否正常
$ pushgateway --version
pushgateway, version 1.4.1 (branch: HEAD, revision: 6fa509bbf4f082ab8455057aafbb5403bd6e37a5)
build user: root@da864be5f3f0
build date: 20210528-14:30:10
go version: go1.16.4
platform: linux/amd64启动服务,默认端口为9091,可通过--web.listen-address更改监听端口
pushgateway &
2、docker安装
$ docker pull prom/pushgateway
$ docker run -d --name=pushgateway -p 9091:9091 prom/pushgateway部署完成后,在浏览器输入 http://:9091$IP 即可看到程序界面

三. 数据推送Pushgateway
pushgateway的数据推送支持两种方式,Prometheus Client SDK推送和API推送。
1. Client SDK推送
Prometheus本身提供了支持多种语言的SDK,可通过SDK的方式,生成相关的数据,并推送到pushgateway,这也是官方推荐的方案。
目前的SDK覆盖语言有官方的:
- Go
- Java or Scala
- Python
- Ruby
也有许多第三方的,详情可参见此链接:https://prometheus.io/docs/instrumenting/clientlibs/
示例:
本示例以python为例,讲解SDK的使用
from prometheus_client import Counter,Gauge,push_to_gateway
from prometheus_client.core import CollectorRegistry
registry = CollectorRegistry()
data1 = Gauge('gauge_test_metric','This is a gauge-test-metric',['method','path','instance'],registry=registry)
data1.labels(method='get',path='/aaa',instance='instance1').inc(3)
push_to_gateway('10.12.61.3:9091', job='alex-job',registry=registry)注解:
第一、二行代码:引入Python的Prometheus SDK;
第五行代码:创建相关的指标,类型为Gauge。其中“gauge_test_metric”为指标名称,'This is a gauge-test-metric'为指标注释,['method','path','instance'] 为指标相关的label。
第六行代码:添加相关的label信息和指标value 值。
第七行代码:push数据到pushgateway,'10.12.61.3:9091'为发送地址,job指定该任务名称。
以上代码产生的指标数据等同如下 :
# HELP gauge_test_metric This is a gauge-test-metric
# TYPE gauge_test_metric gauge
gauge_test_metric{instance="instance1",method="get",path="/aaa"} 3.02. API推送
通过调用pushgateway API的方式实现数据的推送。
请求格式:/metrics/job/<jobname>{/instance/instance_name}
<jobname>将用作Job标签的值,然后是其他指定的标签。
示例:
本例中定义了两个标签 job=alex-job和instance=instance1,并推送了指标 http_request_total 及其value值,10.12.61.1 为pushgateway地址。
echo 'http_request_total 12' | http://10.12.61.3:9091/metrics/job/alex-job/instance/instance1
复杂数据发送:
$ cat <<EOF | curl --data-binary @- http://10.12.61.3:9091/metrics/job/alex-job/instance/10.2.10.1
# TYPE http_request_total counter
http_request_total{code="200",path="/aaa"} 46
http_request_total{code="200",path="/bbb"} 15
EOF数据推送完成后,可登录pushgateay地址查看指标情况

假如需要删除pushgateway上面存储的指标信息,可通过如下方式操作:
删除某个组下某个实例的所有数据
curl -X DELETE http://10.12.61.3:9091/metrics/job/alex-job/instance/10.2.10.1
删除某个job下所有的数据
curl -X DELETE http://10.12.61.3:9091/metrics/job/alex-job
四. prometheus抓取数据
Pushgateway只是指标的临时存放点,最终我们需要通过Prometheus将其存放到时间序列数据库里。对此,我们需要在Prometheus上面创建一个job。
- job_name: 'pushgateway'
honor_labels: true
static_configs:
- targets:
- '10.12.61.3:9091'目标任务正常启动后,可在prometheus查看到相关的指标数据
五. 注意事项
通过Pushgateway方式,Prometheus无法直接检测到监控源服务的状态,故此种方式不适用于监控服务的存活状态等场景。
Pushgateway属于静态代理,它接收的指标不存在过期时间,故会一直保留直到该指标被更新或删除。此种情况下,不再使用的指标可能存在于网关中。
如上所言,Pushgateway并不算是完美的解决方案,在监控中更多做为辅助方案存在,用于解决Prometheus无法直接获取数据的场景。
]]>这些Exporter不仅类型丰富,功能上也很强大,通过合理的使用可以极大的方便我们的运维监控工作。除此之外,Prometheus还提供了支持多种开发语言的Clinet Libraries,用于满足Exporter的定制化开发需求。
本文将对Exporter进行介绍,包括工作中常用到的Exporter,以及如何通过Client Libraries开发自定义的Exporter。
一. Exporter运行方式
1. 独立运行
以前面使用过的node_exporter为例,由于操作系统本身并不直接支持Prometheus,因此,只能通过一个独立运行的程序,从操作系统提供的相关接口将系统的状态参数转换为可供Prometheus读取的监控指标。
除了操作系统外,如Mysql、kafka、Redis等介质,都是通过这种方式实现的。这类Exporter承担了一个中间代理的角色。
2. 应用集成
由于Prometheus项目的火热,目前有部分开源产品直接在代码层面使用Prometheus的Client Library,提供了在监控上的直接支持,如kubernetes、ETCD等产品。
这类产品自身提供对应的metrics接口,Prometheus可通过接口直接获取相关的系统指标数据。这种方式打破了监控的界限,应用程序本身做为一个Exporter提供功能。
二. 常用的Exporter
下面表格是一些较常使用到的Exporter,内容覆盖了数据库、主机、HTTP、云平台等多个层面。

除以上这些外,还有很多其他用途的Exporter,有兴趣的朋友可以自行查看官网:https://prometheus.io/docs/instrumenting/exporters/。
三. 自定义Exporter
虽然Prometheus社区提供了丰富多样的Exporter给用户使用,但由于各家公司的环境都有自身的特点,有时候可能无法在现有资源中找到合适的工具。对此,我们可以利用Prometheus的Clinet Libraries,开发符合实际需要的自定义Exporter。
Client Libraries支持的语言版本非常丰富,除了官方提供了Go、Java or Scala、Python和Ruby几种外,还有很多第三方开发的其他语言版本。
本文我们将以Python为例,演示Exporter的开发。
示例:开发一个exporter,并用于获取系统网络连数状态为TIME_WAIT的数量指标。
本次将调用到的Linux的命令如下 ,用于获取系统的TIME_WAIT连接数量
$ netstat -an |grep TIME_WAIT |wc -l
36使用pip安装python的prometheus-client库
$ pip install prometheus-client
在Python开发中引入prometheus-client和commands库,command库用于执行Linux系统命令。
from prometheus_client import Gauge
import commands定义一个Gauge指标,名称为time_wait_count,并添加标签type。
time_wait_count = Gauge('time_wait_count', 'time_wait count of system',['type'])
定义执行函数,函数调用上面的Linux命令,用于获取相关的指标信息
def get_time_wait_count():
number=commands.getoutput('netstat -an |grep TIME_WAIT |wc -l')
time_wait_count.labels('Linux').set(int(number))现在,我们可以通过执行get_time_wait_count函数获取到time_wait_count的指标value,但要做为一个exporter运行,我们还得支持http协议。
此处,可以用到prometheus_client的start_http_server模块,该模块支持做为http服务启动。 完整的代码如下:
from prometheus_client import start_http_server,Gauge
import commands
time_wait_count = Gauge('time_wait_count', 'time_wait count of system',['type'])
def get_time_wait_count():
number=commands.getoutput('netstat -an |grep TIME_WAIT |wc -l')
time_wait_count.labels('Linux').set(int(number))
if __name__ == '__main__':
# Start up the server to expose the metrics.
start_http_server(8090)
# Generate some requests.
while True:
get_time_wait_count()将代码保存为mytest_exporter.py,在需要监控的服务器上运行该程序
$ python mytest_exporter.py
访问http://IP:8090/metrics,可看到该Exporter已经获取到系统的相关指标。

关于容器的开源产品,目前知名的有Docker、Containerd、CoreOS rkt、LXC 等,在这其中Docker占据了绝对的统治地位,也是当前使用最广泛的容器产品。
本文将介绍通过Prometheus实现Docker容器监控的方案,关于Docker的技术本文不做讲解,不熟悉的朋友可先自行查阅相关资料。
一. CAdvisor工具
CAdvisor为Google开源的一款用于监控和展示容器运行状态的可视化工具。CAdvisor可直接运行在主机上,它不仅可以搜集到机器上所有运行的容器信息,还提供查询界面和http接口,方便如Prometheus等监控系统进行数据的获取。 CAdvisor的安装很简单,可通过容器的方式进行部署。
- 下载镜像
$ docker pull google/cadvisor:latest
- 启动容器
$ docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged=true \
google/cadvisor:latest注解:该命令在容器中挂载了几个目录,ro代表只读,CAdvisor将从其中收集数据。 rw代表可读写,此处指定/var/run目录,用于Docker套接字的挂载; --detach将以守护进程的方式运行; --name对生成的容器进行命名; 在Ret Hat,CentOS, Fedora 等发行版上需要传递如下参数--privileged=true。
- 查看容器状态,已正常启动
$ docker ps |grep cadvisor
13eb99bc02ce google/cadvisor:latest "/usr/bin/cadvisor -…" 19 minutes ago Up 19 minutes 0.0.0.0:8080->8080/tcp cadvisor- 访问页面
浏览器打开http://:8080$ip ,可查看CAdvisor的web界面


访问http://:8080$ip/metrics,可看到相关的metrics指标信息
二. 容器指标
以下是比较常用到的一些容器指标:
CPU指标
container_cpu_load_average_10s #最近10秒容器的CPU平均负载情况
container_cpu_usage_seconds_total #容器的CPU累积占用时间内存指标
container_memory_max_usage_bytes #容器的最大内存使用量(单位:字节)
container_memory_usage_bytes #容器的当前内存使用量(单位:字节)
container_spec_memory_limit_bytes #容器的可使用最大内存数量(单位:字节)网络指标
container_network_receive_bytes_total #容器网络累积接收字节数据总量(单位:字节)
container_network_transmit_bytes_total #容器网络累积传输数据总量(单位:字节)三. Prometheus集成
CAdvisor是一个简单易用的工具,它除了有详细的监控指标,也提供了可供查看的WEB图表界面。但CAdvisor本身的数据保存时间只有2分钟,而且在多主机的情况下,要单独去登录每台机器查看docker数据也是一件麻烦的事情。
对此,更好的方法是与Prometheus集成,实现Docker容器数据的收集与保存。由于CAdvisor提供了支持Prometheus的metrics格式接口,所以Prometheus只需要按照获取Exporter指标的方式,创建相关的Job即可。 示例:
- job_name: 'docker'
static_configs:
- targets:
- '192.168.214.108:8080'
labels:
group: docker任务正常启动后,我们可以在Prometheus查看到相关的指标
四. Grafana展示
Grafana提供了不少Docker相关的Dashboard,可根据自己情况选择合适模板导入。 填写需要导入的Dashboard ID号(193),点击Load

导入完成后,可看到新的Dashboard已生效。

白盒监控通过获取目标的内部信息指标,实现对目标状态的监控,我们前面介绍的主机监控、容器监控都属于此类监控。
而黑盒监控指在程序外部通过探针的方法模拟访问,获取程序的响应指标来监控应用状态,如请求处理时间、状态码等。在实际生产环境中, 往往会将两种监控方式混合使用,以实现对应用的全方位监控。
本篇我们将介绍Prometheus如何通过Blackbox exporter的探针检测功能,来实现对应用的外部监控。
一.Blackbox exporter
Blackbox exporter使用go语言开发,它支持通过HTTP、HTTPS、DNS、TCP和ICMP的方式来探测目标端点。
Blackbox exporter的使用方式与其他exporter不太一样,在Blackbox exporter的内部需要定义好检查的模块,如HTTP检测模块。
Prometheus将目标和模块名做为URL的参数传递给Blackbox exporter,再由exporter 生成对应的探测请求到目标端点,根据返回的请求状态生成对应的时间序列指标,并传递给Prometheus。

探针检测非常有用,比如我们可以在多个分散的地点部署探针检测,来了解公司提供对外服务的站点在该地区的访问是否正常。
目前有不少商业机构在提供专业的探针检测服务,如听云、博睿、监控宝等。当然 ,你也可以通过Blackbox exporter来搭建自己的探针监控。
二. 安装配置
Blackbox exporter提供了支持不同平台的安装文件 ,包括Linux、Windows、Max OS等,本文我们使用Linux版本的安装文件来演示。
1. 安装Blackbox exporter
$ cd /opt/
$ wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.19.0/blackbox_exporter-0.19.0.linux-amd64.tar.gz
$ tar -xvf blackbox_exporter-0.19.0.linux-amd64.tar.gz
$ sudo cp blackbox_exporter-0.19.0.linux-amd64/blackbox_exporter /usr/local/bin/
# 查看版本
$ blackbox_exporter --version
blackbox_exporter, version 0.19.0 (branch: HEAD, revision: 5d575b88eb12c65720862e8ad2c5890ba33d1ed0)
build user: root@2b0258d5a55a
build date: 20210510-12:56:44
go version: go1.16.4
platform: linux/amd642. 配置Blackbox exporter
blackbox exporter需要在配置文件中定义模块,每个模块有特定的名称和探针,如用于检查HTTP服务的http探针、用于检查TCP连接的TCP探针等。此处我们以HTTP模块为例,来演示配置的操作。(其他更多配置,可参见Prometheus的示例文件 :https://github.com/prometheus/blackbox_exporter/blob/master/example.yml。)
创建 blackbox.yml配置文件,包含以下内容:
modules:
http_2xx:
prober: http
timeout: 5s
http:
valid_status_codes: [200]
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
method: GET注释:此处我们定义了一个模块名为http_2xx,使用http探针,探针检测超过5秒会被当成超时; valid_status_codes定义返回的响应码; valid_http_versions定义探针的http版本; method则定义了请求模式,可支持GET和POST。
3. 启动Blackbox exporter
启动exporter,并加载指定配置文件
$ sudo blackbox_exporter --config.file=blackbox.yml &
三.配置Prometheus
我们在Prometheus上面配置一个示例任务,以百度和163网站为例,演示对于网站的HTTP检测 。
- job_name: 'blackbox_http'
metrics_path: /probe
params:
module: [http_2xx]
static_configs:
- targets:
- http://www.baidu.com
- http://www.163.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
#blackbox exporter 所在节点
replacement: 192.168.214.108:9115配置完成后,等Prometheus加载新配置后,可看到相关的Targets已生成。
在任务生效后,可以看到与该任务相关的探测指标。
四. Grafana展示
选择"Create"-"Import"
填写Dashboard模板ID号(7587),点击Load
选择对应的Prometheus 数据源,点击import
导入完成后,即可在新的Dashboard查看数据指标。

但在大规模的监控环境中,基于文件的方式往往会面临较多的挑战。首先,由于有大量的实例需要进行监控,运维人员得频繁地对 Prometheus 配置文件进行修改,这会给工作带来很大的负担,同时也容易出现人为的失误。
另外,在大型企业中往往会有细致的分工,服务器部署与监控的管理可能是由不同的团队成员在负责,每当实例部署完成后还需要在人员之间进行信息的传递,这更进一步增加了操作的复杂性。
对此,Prometheus提供了多种动态服务发现的功能,而基于Consul的服务发现即是其中较为常见的一种方案。
一. Consul简介
Consul 是HashiCorp 公司推出的开源工具,产品基于GO 语言开发,主要面向分布式、服务化的系统提供服务注册、服务发现和配置管理的功能。

产品具有以下特点:
- 服务发现
Consul 的客户端可以注册一个服务,例如 api 或 mysql,其他客户端可以使用 Consul 来发现给定服务的提供者。
- 健康检查
Consul 可以根据给定的信息,对服务的状态进行检查,并获取服务的健康状态。
- Key/Value存储
通过HTTP API的方式实现Key/Value存储,可用于动态配置、功能标记、协商等多种场景。
- 多数据中心支持
支持多数据中心的分布式架构。
二. Consul安装
- 下载二进制文件,并解压缩。
$ wget https://releases.hashicorp.com/consul/1.10.4/consul_1.10.4_linux_amd64.zip
$ unzip consul_1.10.4_linux_amd64.zip
$ mv consul /usr/local/bin/- 启动Consul
$ consul agent -dev -client 0.0.0.0 &
注:本文以dev方式启动,用于测试。该模式不适合用于生产环境,因为不会持久化任何状态。
- 打开浏览器,访问
http://<cousul_ip>:8500,可看到Consul已经正常启动,目前只有默认的consul服务。

三. 注册服务
现在我们可以使用Consul的register API 接口,注册相关的服务信息。
示例:本文将演示通过注册node_exporter的实例信息,实现Prometheus的自动发现。
我们在下面两台服务器上安装好node_exporter,端口为9100。
node1: 192.168.214.100 node2: 192.168.214.108
此处通过curl 命令调用register API接口,并将实例信息注册到Consul,服务名称为node_exporter。 node1注册:
$ curl -X PUT -d '{
"id": "node1",
"name": "node_exporter",
"address": "192.168.214.100",
"port": 9100,
"tags": ["prometheus"],
"checks": [{"http": "http://192.168.214.100:9100/metrics","interval": "15s"}]}' \
http://<cousul_ip>:8500/v1/agent/service/registernode2注册:
$ curl -X PUT -d '{
"id": "node2",
"name": "node_exporter",
"address": "192.168.214.108",
"port": 9100,
"tags": ["prometheus"],
"checks": [{"http": "http://192.168.214.108:9100/metrics","interval": "15s"}]}' \
http://<cousul_ip>:8500/v1/agent/service/register完成后,打开Consul可以看到服务已经注册成功,服务中包含相关的实例信息。

四. Prometheus配置
在Prometheus配置Job,这里使用Consul的服务发现方式,并配置好Consul接口地址,用于发现Consul中的node_exporter节点。
- job_name: 'consul-prom'
consul_sd_configs:
- server: '<cousul_ip>:8500'
services: ['node_exporter']注释 :services 用于过滤Consul服务,如果为空,则会获取全部服务信息。
重新加载配置后,可看到Prometheus已自动获取实例目标,并进行监控。

五. 添加自定义标签
使用上面的方式,我们已经可以通过Prometheus自动发现实例并进行监控。但这种方式默认只有instance和job的标签。而在实际环境中,往往还需要增加自定义的标签,用于从不同维度区分实例,并且在alertmanager告警时也需要依赖标签来分组。
对于自定义标签的添加,可通过json文件的方式进行操作。
- 创建json文件
node1的json文件 :
$ vi node1.json
{
"ID": "node1",
"Name": "node_exporter",
"Tags": ["prometheus"],
"Address": "192.168.214.100",
"Port": 9100,
"Meta": {
"group": "kafka",
"env": "dev"
},
"EnableTagOverride": false,
"Check": {
"Http": "http://192.168.214.100:9100/metrics",
"Interval": "15s"
}
}node2的json文件 :
$ vi node2.json
{
"ID": "node2",
"Name": "node_exporter",
"Tags": ["prometheus"],
"Address": "192.168.214.108",
"Port": 9100,
"Meta": {
"group": "mysql",
"env": "dev"
},
"EnableTagOverride": false,
"Check": {
"Http": "http://192.168.214.108:9100/metrics",
"Interval": "15s"
}
}注释:
- ID 指定实例的唯一ID名称;
- Name 指定服务名,可以多个实例共用服务名;
- Tags 指定服务的标签列表,这些标签可用于过滤服务,并通过API进行公开;
- Address 指定服务的实例地址;
- Port 指定实例的端口号;
- Meta 指定服务的元数据,格式为key:value,此处用于保存我们的标签信息;
- EnableTagOverride 此处禁用服务标签的反熵功能;
- Check 服务的检查列表,Consul会根据配置信息定时发起检查,确定服务是否正常;
- 通过json文件注册服务
$ curl --request PUT --data @node1.json http://<cousul_ip>:8500/v1/agent/service/register
$ curl --request PUT --data @node2.json http://<cousul_ip>:8500/v1/agent/service/register- 查看Consul,可看到实例的元数据中已包含标签信息

- 元数据在Prometheus自动发现的过程中,会变成以__meta_consul_service_metadata_开头的标签,如下图所示。

我们可以通过前面介绍的Relabeling(标签重写)功能,将其转换为我们需要的标签。 将job进行如下修改:
- job_name: 'consul-prom'
consul_sd_configs:
- server: '192.168.214.108:8500'
services: ['node_exporter']
relabel_configs:
- regex: __meta_consul_service_metadata_(.+)
action: labelmap- 重新加载配置后,可看到标签已经生成。

六. 注销服务
当我们某个实例下线后,我们需要把Consul的服务信息清理掉,可通过deregister API 接口+ID号进行删除。
示例:curl -X PUT http://<cousul_ip>:8500/v1/agent/service/deregister/node1
查看Cousul ,原有的node1实例已经被清理。
在Consul清理后,Prometheus也会进行同步,实现监控实例的自动清理。
]]>使用Consul的好处很多,不用手动修改配置文件了只需要一个请求就行了
Prometheus是一款近年来非常火热的容器监控系统,它使用go语言开发,设计思路来源于Google的Borgmom(一个监控容器平台的系统)。 2016年,云原生基金会将其纳入麾下,成为该基金会继Kubernetes后,第二大开源项目。因此,Prometheus天然具有对容器的适配性,可非常方便的满足容器的监控需求,目前已成为监控Kubernetes的主要工具。
本文将介绍如何通过Prometheus监控Kubernetes集群状态的方案,限于篇幅原因会分为上、下两个篇章进行。 (对于Kubernetes的技术细节本文不做讲解,不熟悉的朋友可先自行查阅相关资料。)
一.安装Prometheus
Prometheus支持基于Kubernetes的服务发现,通过<kubernetes_sd_config> 配置允许从 Kubernetes 的API 检索抓取目标,并始终与集群状态保持同步。
我们需要在被监控集群上安装Prometheus,本文将使用YAML文件的方式进行部署。
- 创建命名空间 创建namespace.yml文件,内容如下
apiVersion: v1
kind: Namespace
metadata:
name: monitoring执行该yml文件
$ kubectl apply -f namespace.yml
namespace/monitoring created查看命名空间,已成功创建。
$ kubectl get ns monitoring
NAME STATUS AGE
monitoring Active 2m53s- 创建RBAC规则 RBAC为Kubernetes的授权认证方式,包括 ServiceAccount、ClusterRole、ClusterRoleBinding三类YAML文件。该规则用于授权Prometheus获取资源信息。
创建prometheus-rbac.yml文件,内容如下:
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources: ["nodes", "nodes/proxy", "services", "endpoints", "pods"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring执行该yml文件
$ kubectl apply -f prometheus-rbac.yml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created查看RBAC是否创建成功
$ kubectl get sa prometheus -n monitoring
NAME SECRETS AGE
prometheus 1 77s
$ kubectl get ClusterRole prometheus
NAME CREATED AT
prometheus 2021-10-24T04:30:33Z
$ kubectl get ClusterRoleBinding prometheus -n monitoring
NAME ROLE AGE
prometheus ClusterRole/prometheus 2m20s- 创建Configmap 我们使用Configmap来管理Prometheus的配置文件,此处先使用默认的配置,用于启动Prometheus,后面再根据需要进行修改。
创建prometheus-config.yml文件,内容如下
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']执行该yml文件
$ kubectl apply -f prometheus-config.yml
configmap/prometheus-config created查看configmap资源是否生成
$ kubectl get configmap prometheus-config -n monitoring
NAME DATA AGE
prometheus-config 1 84s- 部署Deployment
在完成Configmap资源创建后,我们可以开始部署Prometheus的实例了。此处,我们使用Deployment来部署Prometheus,并通过Volume挂载的方式,将Prometheus的配置文件挂载到Pod内。另外,在正式环境中建议通过PVC的方式,将收集的监控数据挂载到外部存储,避免因Pod被删除而造成数据丢失。
创建prometheus-deployment.yml文件,内容如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitoring
labels:
app: prometheus
spec:
strategy:
type: Recreate
replicas: 1
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
containers:
- image: prom/prometheus:v2.20.0
name: prometheus
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/config/prometheus.yml"
- "--storage.tsdb.path=/data"
- "--web.enable-lifecycle"
securityContext:
runAsUser: 0
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/etc/prometheus/config/"
name: config
- name: host-time
mountPath: /etc/localtime
serviceAccountName: prometheus
volumes:
- name: config
configMap:
name: prometheus-config
- name: host-time
hostPath:
path: /etc/localtime执行该yml文件
$ kubectl apply -f prometheus-deployment.yml
deployment.apps/prometheus created查看Prometheus实例状态
$ kubectl get deploy -n monitoring
NAME READY UP-TO-DATE AVAILABLE AGE
prometheus 1/1 1 1 4m53s
$ kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
prometheus-fcfb4bbd7-4vgl9 1/1 Running 0 69s- 创建Service 创建Prometheus的Service,用于集群内外部访问。默认情况下,Service只能在集群内访问,如果希望开放给集群外部,可选方案有Ingress、NodePort、ExternalIPs、LoadBalancer等几种。此处使用LoadBalancer方式。
创建prometheus-service.yml,内容如下:
apiVersion: v1
kind: Service
metadata:
labels:
app: prometheus
name: prometheus
namespace: monitoring
spec:
ports:
- name: "web"
port: 9090
protocol: TCP
targetPort: 9090
selector:
app: prometheus
type: LoadBalancer执行该yml文件
$ kubectl apply -f prometheus-service.yml
service/prometheus created查看Service状态,Service已创建完成,其中Cluster-ip用于集群内部访问,External-ip则是给到集群外部访问。
$ kubectl get service prometheus -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus LoadBalancer 10.220.57.72 10.12.61.202 9090:31183/TCP 56s浏览器打开http://$ip:9090,可看到Prometheus已部署完成。
查看Targets目标,当前除了监控Prometheus自身实例,还未有其他Kubernetes资源。
二. 基于Kubernetes的服务发现
在监控Kubernetes集群的过程中,我们需要使用到针对Kubernetes的服务发现功能,这个在Prometheus的原生功能中已经支持。
以下几种类型的资源角色可被配置为服务发现的目标,对于集群的监控即是通过有效利用这些角色及标签来实现。
- node角色
该node 角色发现用于检索集群中的节点目标信息,其地址默认为节点kubelet的HTTP访问端口。目标地址的默认顺序为NodeInternalIP,NodeExternalIP,NodeLegacyHostIP和NodeHostName中的第一个现有地址。
该角色可获取到的元数据标签如下:
• __meta_kubernetes_node_name:节点对象的名称。
• __meta_kubernetes_node_label_labelname:节点对象所定义的各个label
• __meta_kubernetes_node_labelpresent_labelname:节点对象所定义的各个label,value固定为true。
• _meta_kubernetes_node_annotation_annotationname:来自节点对象的每个注释
• _meta_kubernetes_node_annotationpresent_annotationname:来自节点对象的每个注释,value固定为true。
• _meta_kubernetes_node_address_address_type:每个节点地址类型的第一个地址(如果存在)
此外,节点的instance标签将被设置为从API服务检索到的节点名称。
- service角色 该角色发现用于检索集群中每个service目标,并且将该服务开放的端口做为目标端口。该地址将设置为服务的Kubernetes DNS名称以及相应的服务端口。
该角色可获取到的元数据标签如下:
- __meta_kubernetes_namespace: 服务对象的名称空间。
- __meta_kubernetes_service_annotation_annotationname:服务对象的每个注释。
- __meta_kubernetes_service_annotationpresent_annotationname: 服务对象的每个注释,value固定为true。
- __meta_kubernetes_service_cluster_ip: 服务对象的集群IP。
- __meta_kubernetes_service_external_name: 服务的DNS名称。
- __meta_kubernetes_service_label_labelname: 服务对象中的每个label。
- __meta_kubernetes_service_labelpresent_labelname: 服务对象中的每个label,value固定为true。
- __meta_kubernetes_service_name: 服务对象的名称。
- __meta_kubernetes_service_port_name: 目标服务端口的名称。
- __meta_kubernetes_service_port_protocol: 目标服务端口的协议。
- __meta_kubernetes_service_type: 服务的类型。
- Pod角色
该pod角色发现用于发现所有Pod并将其容器做为目标访问,对于容器的每个声明的端口,将生成一个目标。如果容器没有指定的端口,则会为每个容器创建无端口目标。
该角色可获取到的元数据标签如下:
- __meta_kubernetes_namespace: pod对象的命名空间。
- __meta_kubernetes_pod_name: pod对象的名称。
- __meta_kubernetes_pod_ip: pod对象的pod IP。
- __meta_kubernetes_pod_label_labelname: 来自pod对象的每个标签。
- __meta_kubernetes_pod_labelpresent_labelname: 来自pod对象的每个标签,value固定为true。
- __meta_kubernetes_pod_annotation_annotationname: 来自pod对象的每个注释。
- __meta_kubernetes_pod_annotationpresent_annotationname: 来自pod对象的每个注释,value固定为true。
- __meta_kubernetes_pod_container_init: 如果容器是初始化容器,则value为true。
- __meta_kubernetes_pod_container_name: 目标地址指向的容器的名称。
- __meta_kubernetes_pod_container_port_name: 容器端口的名称。
- __meta_kubernetes_pod_container_port_number: 容器端口号。
- __meta_kubernetes_pod_container_port_protocol: 容器端口的协议。
- __meta_kubernetes_pod_ready: 代表pod状态是否就绪,value为true或false。
- __meta_kubernetes_pod_phase: Pod的生命周期,Value值为Pending,Running,Succeeded,Failed或Unknown 。
- __meta_kubernetes_pod_node_name: Pod所在节点的名称。
- __meta_kubernetes_pod_host_ip: pod所在节点的IP。
- __meta_kubernetes_pod_uid: pod对象的UID。
- __meta_kubernetes_pod_controller_kind: pod控制器的对象种类。
- __meta_kubernetes_pod_controller_name: pod控制器的名称。
- endpoints角色
该endpoints角色发现用于检索服务的endpoints目标,且每个endpoints的port地址会生成一个目标。 如果端点由Pod支持,则该Pod的所有其他容器端口(包括未绑定到endpoints的端口)也将作为目标。
该角色可获取到的元数据标签如下:
- __meta_kubernetes_namespace: endpoints对象的命名空间
- __meta_kubernetes_endpoints_name: endpoints对象的名称
对于直接从端点列表中发现的所有目标(不包括由底层pod推断出来的目标),将附加以下标签:
- __meta_kubernetes_endpoint_hostname: 端点的主机名
- __meta_kubernetes_endpoint_node_name: 托管endpoints的节点名称
- __meta_kubernetes_endpoint_ready: 代表endpoint 状态是否就绪,value为true或false。
- __meta_kubernetes_endpoint_port_name: endpoint 端口的名称。
- __meta_kubernetes_endpoint_port_protocol: endpoint 端口的协议。
- __meta_kubernetes_endpoint_address_target_kind: endpoint地址目标的类型,如deployment、DaemonSet等。
- __meta_kubernetes_endpoint_address_target_name: endpoint地址目标的名称。
- ingress角色 该ingress角色发现用于发现ingress的每个地址目标。该地址将设置为ingress的spec配置中指定的host。
可使用的元数据标签如下:
结语:
本篇我们主要介绍了Prometheus实例在 Kubernetes 中的部署方式,以及监控集群所需要的服务发现功能。 下篇我们将讲解如何通过这些功能,来实现对 Kubernetes 集群的监控。
]]>当然,做为与容器有着紧密联系的监控系统,Promethesu也可以很方便的通过docker、kubernetes等容器平台进行部署。
Prometheus的部署安装非常简单,本文将演示通过二进制文件以及Docker的部署方式,部署环境操作系统为Centos7.8,其他环境的安装方式可自行参考官网的安装文档。
一.二进制安装
1. 下载安装包
$ cd /opt
$ wget https://github.com/prometheus/prometheus/releases/download/v2.20.0/prometheus-2.20.0.linux-386.tar.gz2. 解压tar包,拷贝二进制文件到bin目录
$ tar -xvf prometheus-2.20.0.linux-386.tar.gz
$ cd prometheus-2.20.0.linux-386
$ sudo cp prometheus /usr/local/bin/
$ sudo cp promtool /usr/local/bin/3. 运行--version 检查版本
$ prometheus --version
prometheus, version 2.20.0 (branch: HEAD, revision: e5a06b483527d4fe0704b8fa3a2b475b661c526f)
build user: root@ac954b6d5c6e
build date: 20200722-18:56:15
go version: go1.14.64. 启动
在本例中我们使用默认的配置文件来启动prometheus。 创建/etc/prometheus目录,并移动安装包的配置文件到此路径
``bash $ sudo mkdir /etc/prometheus $ sudo cp prometheus.yml /etc/prometheus/
通过promtool工具,检测配置文件是否正确。
```bash
$ promtool check config /etc/prometheus/prometheus.yml
Checking /etc/prometheus/prometheus.yml
SUCCESS: 0 rule files found启动Prometheus,并指定配置文件。
prometheus --config.file /etc/prometheus/prometheus.yml &
说明:Prometheus默认只保留15天的监控数据,可通过--storage.tsdb.retention选项控制时间序列的保留时间;--storage.tsdb.path选项可用于控制时间序列数据库位置,默认数据目录位于运行Prometheus的目录中。
二. Docker安装
docker的安装方式很简单,只需要一条命令即可
$ docker run --name prometheus -d -p 9090:9090 prom/prometheus
如果要将配置文件与容器分离,可将prometheus.yml文件保存在本地目录 ,在启动时通过-v参数挂载到容器上面
mkdir /etc/prometheus
$ vi /etc/prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']$ docker run --name prometheus -d -p 9090:9090 -v /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
启动完成后,打开浏览器,访问http://:9090$IP 可看到系统界面。
]]>在监控策略上,我们将混合使用白盒监控与黑盒监控两种模式,建立起包括基础设施(Node)、应用容器(Docker)、Kubernetes组件和资源对象等全方位的监控覆盖。
一. 监控Node节点
- Daemonset部署node-exporter 创建node_exporter-daemonset.yml文件,内容如下。在spec配置中添加了tolerations,用于污点容忍,保证master节点也会部署。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
tolerations: # 污点容忍
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- image: prom/node-exporter
name: node-exporter
ports:
- name: scrape
containerPort: 9100
hostPort: 9100
hostNetwork: true
hostPID: true
securityContext:
runAsUser: 0执行该yml文件
$ kubectl apply -f node_exporter-daemonset.yml
daemonset.apps/prometheus-node-exporter created确认Daemonset及Pod状态正常
$ kubectl get daemonset -n monitoring
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
node-exporter 3 3 3 3 3 <none> 13m
$ kubectl get pod -n monitoring |grep node-exporter
node-exporter-76qz8 1/1 Running 0 14m
node-exporter-8fqmm 1/1 Running 0 14m
node-exporter-w9jxd 1/1 Running 0 2m6s- Prometheus配置任务
在prometheus-config.yml文件中添下如下任务,并执行生效。
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)注解:该任务通过node角色发现动态获取节点地址信息,并使用标签重写(Relabeling)功能重写targets目标端口为node-exporter端口,从而实现自动监控集群节点功能。
任务生效后,可看到Prometheus已自动获取到节点信息并监控。
二. 监控容器
Kubernetes各节点的kubelet除包含自身的监控指标信息以外,还内置了对CAdviosr的支持。在前面的容器监控篇中,我们知道可以通过安装CAdviosr来监控节点上的容器状态。而在Kuberentes集群中,通过Kubelet可实现类似的效果,不需要再额外安装CAdviosr。
Prometheus配置任务 prometheus-config.yml文件中添下如下任务,并执行生效。
- job_name: 'kubernetes-cadvisor'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)注解:该任务通过node角色发现动态获取节点地址信息。由于直接访问kubelet地址会有证书验证问题,这里使用标签重写(Relabeling)功能重写targets目标地址和地址,通过API Server提供的代理地址访问kubelet的/metrics/cadvisor。
任务生效后,可看到Prometheus已自动生成相关目标信息

三. 监控Kube API Server
Kube API Server做为整个Kubernetes集群管理的入口服务,负责对外暴露Kuberentes API,服务的稳定与否影响着集群的可用性。通过对Kube API Server的监控,我们能够清楚API的请求处理延迟、错误和可用性等参数。
Kube API Server组件一般独立部署在集群外部,并运行在Master的主机上,为了使集群内部的应用能够与API进行交互,Kubernetes会在default的命名空间下创建一个kubernetes的Service,用于集群内部访问。
$ kubectl get service kubernetes -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.220.0.1 <none> 443/TCP 77d <none>该kubernetes服务代理的后端实际地址通过endpoints进行维护,该endpoints代理地址指向了master节点的6443端口,也即是Master上运行的Kube API Server服务端口。
$ kubectl get endpoints kubernetes
NAME ENDPOINTS AGE
kubernetes 10.12.61.1:6443 77d
$ netstat -lnpt |grep 6443
tcp6 0 0 :::6443 :::* LISTEN 30458/kube-apiserver因此,我们可通过Prometheus的endpoints角色发现功能,来实现Kube API Server的目标发现并监控。
Prometheus配置任务
prometheus-config.yml文件中添下如下任务,并执行生效。
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- target_label: __address__
replacement: kubernetes.default.svc:443注解:该任务通过endpoints角色发现动态获取endpoints信息,并使用标签重写(Relabeling)功能只保留符合正则表达式匹配的endpoints目标。
任务生效后,查看Prometheus已自动生成相关目标信息。
四. 监控Kubelet组件
Kubelet组件运行在集群中每个worker节点上,用于处理Master下发到本节点的任务,包括管理Pod和其中的容器。Kubelet会在Kube API Server上注册节点信息,并定期向集群汇报节点资源使用情况。
Kubelet的运行状态关乎着该节点的是否可以正常工作,基于该组件的重要性,我们有必要对各个节点的kubelet进行监控。
Prometheus配置任务
prometheus-config.yml文件中添下如下任务,并执行生效。
- job_name: 'k8s-kubelet'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics注解:该任务通过node角色发现动态获取节点地址信息。由于直接访问kubelet地址会有证书验证问题,这里使用标签重写(Relabeling)功能重写targets目标地址和地址,通过API Server提供的代理地址访问kubelet的/metrics路径。
任务生效后,查看Prometheus已自动生成相关目标信息。
五. 监控Kubernetes资源
Kubernetes资源对象包括Pod、Deployment、StatefulSets等,我们需要知道相关资源的使用情况和状态,如Pod是否正常运行。由于并不是所有资源都支持Prometheus的监控, 因此,我们需要使用开源的kube-state-metrics方案来获取监控指标。
1. 部署kube-state-metrics
kube-state-metrics对Kubernetes有版本要。我们环境的Kubernetes为1.18,所以需要下载V2.0.0及以上版本。
kube-state-metrics是Kubernetes组织下的一个项目,它通过监听Kube API收集相关资源和对象的最新信息,并提供接口地址给到Prometheus获取指标。
下载项目仓库并部署安装
$ git clone https://github.com/kubernetes/kube-state-metrics.git
$ cd kube-state-metrics/
$ kubectl apply -f examples/standard/
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
serviceaccount/kube-state-metrics created
service/kube-state-metrics created查看服务状态
$ kubectl get deploy kube-state-metrics -n kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
kube-state-metrics 1/1 1 1 6m20s2. Prometheus配置任务
prometheus-config.yml文件中添下如下任务,并执行生效。
- job_name: kube-state-metrics
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_label_app_kubernetes_io_name]
regex: kube-state-metrics
replacement: $1
action: keep
- source_labels: [__address__]
regex: '(.*):8080'
action: keep任务生效后,查看Prometheus已自动生成相关目标信息。
六. 监控service访问
在Kubernetes集群中,我们可以采用黑盒监控的模式,由Prometheus通过探针的方式对service进行访问探测,以便及时了解业务的可用性。
要实现探针检测,我们需要在集群中安装Blackbox Exporter。
1. 部署Blackbox Exporter
创建blackbox-exporter.yml文件,内容如下:
apiVersion: v1
kind: Service
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
spec:
ports:
- name: blackbox
port: 9115
protocol: TCP
selector:
app: blackbox-exporter
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: blackbox-exporter
template:
metadata:
labels:
app: blackbox-exporter
spec:
containers:
- name: blackbox-exporter
image: prom/blackbox-exporter
imagePullPolicy: IfNotPresent执行yml文件
$ kubectl apply -f temp.yml
service/blackbox-exporter created
deployment.apps/blackbox-exporter created查看blackbox-exporter服务状态,已正常运行。
$ kubectl get svc blackbox-exporter -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blackbox-exporter ClusterIP 10.220.50.176 <none> 9115/TCP 11m
$ kubectl get deploy blackbox-exporter -n monitoring
NAME READY UP-TO-DATE AVAILABLE AGE
blackbox-exporter 1/1 1 1 12m2. Prometheus配置任务
在部署Blackbox Exporter后,Prometheus可通过集群内部的访问地址:blackbox-exporter.monitoring.svc.cluster.local 对其进行调用。
- job_name: 'kubernetes-services'
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module: [http_2xx]
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_probe]
action: keep
regex: true
- source_labels: [__address__]
target_label: __param_target
- target_label: __address__
replacement: blackbox-exporter.monitoring.svc.cluster.local:9115
- source_labels: [__param_target]
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
target_label: kubernetes_name注释 :该任务通过service角色发现的方式,获取集群中的service对象;并使用“prometheus.io/probe: true”标签进行过滤,只有包含此注解的service才纳入监控;另外,__address__执行Blackbox Exporter实例的访问地址,并且重写了标签instance的内容。
任务生效后,查看Prometheus已自动生成相关目标信息。
]]>本文主要介绍Prometheus的存储机制以及对存储容量的评估方法。
一. 内部存储机制
Prometheus内置了一个本地的时间序列数据库,通过该数据库进行样本数据的存储,这种设计方式较大地简化了产品部署与管理的复杂性。 从2.x版本开始,Prometheus采用了更加高效的存储机制。
系统采集的样本数据会按照两个小时为一个时间窗口,将期间产生的数据存储在一个块(Block)中,每个块目录包含该时间窗口内所有的样本数据(chunks),一个元数据文件(meta.json)和一个索引文件(index)。 当通过API删除时间序列指标时,删除记录会存储在单独的墓碑(tombstone )文件中,而不会立即从文件中删除。
存储根目录:
$ ls -l ./data/
total 20
drwxr-xr-x. 3 root root 68 Jan 7 13:33 01FRSGF2NBJ21HZW1QM2594CB9 # 块目录
drwxr-xr-x. 3 root root 68 Jan 7 15:00 01FRSNCMS0Q1Y9Q9KKT6TTXH3C # 块目录
drwxr-xr-x. 2 root root 34 Jan 7 15:00 chunks_head
-rw-r--r--. 1 root root 0 Jan 7 10:33 lock
-rw-r--r--. 1 root root 20001 Jan 7 15:19 queries.active
drwxr-xr-x. 2 root root 54 Jan 7 15:00 wal块目录内容:
$ ls -l 01FRSGF2NBJ21HZW1QM2594CB9
total 1532
drwxr-xr-x. 2 root root 20 Jan 7 13:33 chunks # 样本数据
-rw-r--r--. 1 root root 1560504 Jan 7 13:33 index # 索引文件
-rw-r--r--. 1 root root 280 Jan 7 13:33 meta.json # 元数据文件
-rw-r--r--. 1 root root 9 Jan 7 13:33 tombstones # 墓碑文件在当前时间窗口内正在收集的样本数据,则会被Prometheus保存到内存中。同时 ,为了确保系统在出现意外崩溃后数据依然能够恢复,Prometheus会通过预写日志(WAL)的方式进行临时保存,在重新启动后会从WAL目录进行加载,从而恢复数据。预写日志以128MB 的段存储在WAL目录中,这些文件包含尚未压缩的原始数据,因此你会看到它们将明显大于块文件。
WAL目录内容:
ls -l ./wal/ total 38048 -rw-r--r--. 1 root root 23625728 Jan 7 13:33 00000000 -rw-r--r--. 1 root root 11206656 Jan 7 15:00 00000001 -rw-r--r--. 1 root root 3064462 Jan 7 15:23 00000002 通过时间窗口的方式保存样本数据,可以较好地提升Prometheus的查询效率,当系统查询一段时间范围内所有的样本数据时,只需要简单的从落在该范围内的块中查询数据即可。同时,这种方式也可以简化历史数据的删除逻辑,当一个块的时间范围超过需要保留的范围后,直接清理该块即可。
二. 容量管理
在了解系统的存储机制后,我们可以开始对Prometheus的容量来进行评估 。
按照官方数据,每个样本指标平均占用存储空间为1-2 字节,我们通过下面的公式可对总容量进行粗略的计算:
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample
注:retention_time_seconds 为数据保留时间范围内的总时间数;ingested_samples_per_second为平均每秒获取的指标数量;bytes_per_sample为每条样本数据占用的空间大小,此处取2 字节。
ingested_samples_per_second的数量可以采用下面的PromQL表达式获取,该表达式会计算出最近5分钟平均每秒获取的样本数量
rate(prometheus_tsdb_head_samples_appended_total[5m])
假设系统平均每秒获取的指标数量为10万个,按照默认样本保留 15天计算,那么需要的空间至少为259G。
(3600*24*15)* 100000 * 2 ≈ 259G
从上面的公式中也可以看出,容量的大小取决于样本保留时间(retention_time_seconds)和指标的样本数量。对于样本保留时间,可以在系统启动时通过--storage.tsdb.retention 参数进行修改。而样本数量的控制有两种方式,一种是减少目标的指标数量,另一种则是增加采集样本的时间间隔,考虑到Prometheus会对时间序列进行压缩,所以减少时间序列数量的效果会更明显。
结语
Prometheus原生的TSDB存储具有简单易用、方便快捷等特点,但其自身也存在着不少短板。
该数据库本身不适用于大数据量的存储与查询,并且不支持集群模式,这使得该架构不适合用在大规模的监控环境中。
对此,更好的方案是通过外置存储的方式来保存,关于这块内容我们将在下篇的“远程存储“一文中讲解。
]]>Prometheus默认将数据储存在本地的TSDB(时序数据库)中,这种设计较大地简化了Promethes的部署难度,但与此同时也存在着一些问题。
首先是数据持久化的问题,原生的TSDB对于大数据量的保存及查询支持不太友好 ,并不适用于保存长期的大量数据;另外,该数据库的可靠性也较弱,在使用过程中容易出现数据损坏等故障,且无法支持集群的架构。
为了满足这方面的需求,Prometheus提供了remote_write和remote_read的特性,支持将数据存储到远端和从远端读取数据的功能。当配置remote_write特性后,Prometheus会将采集到的指标数据通过HTTP的形式发送给适配器(Adaptor),由适配器进行数据的存入。而remote_read特性则会向适配器发起查询请求,适配器根据请求条件从第三方存储服务中获取响应的数据。

使用接口的存储方式,符合Prometheus追求简洁的设计理念,一方面可以减少与远程存储的耦合性,避免因存储问题而导致服务中断;另一方面通过将监控与数据分离,Prometheus也降低了自身设计的复杂性,能够更好地进行弹性扩展。 在Prometheus社区中,目前已经有不少远程存储的支持方案,下面列出了其中的部分方案,完整内容可参见官网。 AppOptics: write
Chronix: write
Cortex: read and write
CrateDB: read and write
Elasticsearch: write
Gnocchi: write
Graphite: write
InfluxDB: read and write
Kafka: write
OpenTSDB: write
PostgreSQL/TimescaleDB: read and write
Splunk: read and write
在这些解决方案中,有些只支持写入操作,不支持读取,有些则支持完整的读写操作。
在本文的示例中,我们将使用InfluxDB来做为我们远程存储的方案。
二. InfluxDB简介
InfluxDB是业界流行的一款时间序列数据库,其使用go语言开发。InfluxDB以性能突出为特点,具备高效的数据处理和存储能力,目前在监控和IOT 等领域被广泛应用。

产品具有以下特点: 自定义的TSM引擎,数据高速读写和压缩等功能。
简单、高性能的HTP查询和写入API。
针对时序数据,量身打造类似SQL的查询语言,轻松查询聚合数据。
允许对tag建索引,实现快速有效的查询。
通过保留策略,可有效去除过期数据。
与传统关系数据库的名词对比:
| influxDB | 传统关系数据库 |
|---|---|
| database | database |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
关于InfluxDB的更多内容可参见官文文档:https://docs.influxdata.com/influxdb/v1.8,本文不做过多介绍。
三. 安装InfluxDB
1. 配置yum源
$ cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxDB Repository - RHEL \$releasever
baseurl = https://repos.influxdata.com/rhel/\$releasever/\$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
EOF2. 安装InfluxDB
$ sudo yum install influxdb
3. 启动InfluxDB
$ sudo systemctl start influxdb
4. 查看进程状态,已启动
$ ps aux |grep influxdb
influxdb 2404 0.0 1.9 595132 35848 ? Sl 11:21 0:01 /usr/bin/influxd -config /etc/influxdb/influxdb.conf
$ netstat -lnpt |grep 8086
tcp6 0 0 :::8086 :::* LISTEN 3163/influxd5 .登录InfluxDB
$ influx
Connected to http://localhost:8086 version 1.8.10
InfluxDB shell version: 1.8.106. 创建名称为prometheus的库
create database prometheus
查看数据库已生成,目前为空库,还未有数据。
> show databases
name: databases
name
----
_internal
prometheus注意:默认情况下,InfluxDB会禁用身份验证,并且所有用户都具有全部权限,这样并不安全。在正式环境中,建议启用InfluxDB的身份验证功能。
四. 安装适配器
- 下载Prometheus源码文件
$ git clone https://github.com/prometheus/prometheus.git
- 使用go编译remote_storage_adapter源码文件,并将生成的二进制文件拷贝到bin目录。
$ cd ./prometheus/documentation/examples/remote_storage/remote_storage_adapter
$ go build
$ mv remote_storage_adapter /usr/local/bin/- 启动适配器,并连接influxdb。
$ remote_storage_adapter --influxdb-url=http://localhost:8086/ --influxdb.database=prometheus --influxdb.retention-policy=autogen &
- 默认端口为9201,查看端口状态可看到实例已正常启动。
$ netstat -lnpt |grep 9201
tcp6 0 0 :::9201 :::* LISTEN 3428/remote_storage五. Prometheus配置
完成前面组件的部署后,我们只要在Prometheus中配置远程读写功能,并指定对应的url和端口即可。
remote_write和remote_read的具体配置可参见如下内容:
remote_write:
url: <string>
[ remote_timeout: <duration> | default = 30s ]
write_relabel_configs:
[ - <relabel_config> ... ]
basic_auth:
[ username: <string> ]
[ password: <string> ]
[ bearer_token: <string> ]
[ bearer_token_file: /path/to/bearer/token/file ]
tls_config:
[ <tls_config> ]
[ proxy_url: <string> ]
remote_read:
url: <string>
required_matchers:
[ <labelname>: <labelvalue> ... ]
[ remote_timeout: <duration> | default = 30s ]
[ read_recent: <boolean> | default = false ]
basic_auth:
[ username: <string> ]
[ password: <string> ]
[ bearer_token: <string> ]
[ bearer_token_file: /path/to/bearer/token/file ]
[ <tls_config> ]
[ proxy_url: <string> ]注释 :其中url用于指定远程读写的HTTP服务地址,如果该URL启动了认证则可以通过basic_auth进行安全认证配置;对于https的支持需要设定tls_concig;proxy_url主要用于Prometheus无法直接访问适配器服务的情况下;write_relabel_configs用于标签重写功能。
修改prometheus.yml文件,添加远程读写的配置内容:
remote_write:
- url: "http://192.168.214.108:9201/write"
remote_read:
- url: "http://192.168.214.108:9201/read"配置完成后,重启Prometheus。在实例启动后,我们可以看到InfluxDB已经开始存储监控指标。

在数据写入成功后,我们可以试着停止Prometheus服务,同时删除本地data目录的监控数据,模拟Prometheus数据丢失的情况后重启服务。
重新打开Prometheus后,如果还可以正常查询到本地存储已删除的历史数据记录,则代表配置正常。
]]>一. Prometheus高可用
在官方的推荐方案中,对于高可用的处理是通过部署两套Prometheus,配置同样的目标实例来实现的。在这个方案里面,两套Prometheus会获取相同的监控指标,并且触发同样的告警规则,而对于警报的去重工作则由Alertmanager来负责。

但此方案也存在着明显缺点,比如当某个Prometheus出现故障或中断时,那么该节点将会出现数据丢失的情况,并与另一个节点存在数据差异。当在该节点上进行查询操作时,就会遇到这个问题。
对此,我们可以与远程存储方案结合起来,将Prometheus的读写放到远程存储端,通过高可用 +远程存储的方式来解决上面的问题。

此优化方案在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当某个Promthues 节点发生宕机的情况时,由于还有另一个节点在获取数据,这样可以保证在查询时不会遇到数据丢失的问题。
该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时确保Promthues服务高可用性的场景。
二. 联邦模式
在大规模的监控环境中,当单个Prometheus无法处理大量的监控采集任务时,我们可以基于联邦的模式将采集任务划分到不同的Prometheus实例中,再由顶层的Prometheus进行数据的统一管理。

在此方案中,工作节点的Prometheus根据拆分原则,负责指定目标的数据采集及规则告警工作,而主节点则通过/federate接口从工作节点获取数据指标,并写入到远程存储中,同时对接Grafana实现监控展示。
1. 任务拆分
在任务的拆分上,我们可以从两个维度来考虑,一种是按功能进行拆分,一种则是水平的拆分。
功能拆分
功能拆分可按资源类型或区域等维度,将不同的任务划分到不同的Prometheus节点上,如下图所示

这种方式简单且易于理解,在此架构中每个Prometheus都有明确的目标实例且配置独立,当监控的实例指标出现错误时,用户可以清楚定位到相应的Prometheus节点。通过功能拆分的方式,可以有效分散Prometheus的负载压力,提升监控系统的整体容量规模。 不过在某些场景下,通常是大规模的部署环境中,功能拆分依然会出现瓶颈。例如:在一个存在着上万台主机的环境中,即使单独监控主机任务,对于单个Prometheus实例也将面临巨大的压力。而如果要靠人为来划分每个监控实例对应的目标主机节点,则会给运维人员增加很多工作量和复杂性。在这种场景下,我们可以考虑水平拆分的方式。
水平拆分
在水平拆分的场景下,每个Prometheus节点配置相同的目标实例信息,并通过HASH规则的方式,计算自身负责的目标实例,从而实现横向的扩展。

配置示例:
scrape_configs:
- job_name: 'node'
file_sd_configs:
- files:
- /etc/prometheus/node/*.yml
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep注释:本示例中我们负责抓取监控指标的工作节点为两台,所以在modulus处标记数量为2,并根据每个实例的[address]标签值 ,生成一个临时标签[__tmp_hash]及对应的值,该值内容包含0或1。然后根据正则匹配机制,保留符合正则表达则的实例。在两个工作节点中,regex处分别配置为^0$和^1$。如果后续工作节点的数量增加,则需要修改modulus值为新的节点数量 ,并在新的节点中配置对应的regex。
在每个Worker节点的配置中,可以插入一个worker:<value>的标签,这样方便在主节点处可以知道相关指标来源于哪个worker。
global:
external_labels:
worker: 02. 主节点配置
在worker配置完成正常运行后,我们可以开始配置主节点的任务,用于抓取工作节点的时间序列。集群中的工作节点都是我们Targets的目标地址,本示例为两个worker节点,相关配置如下 :
- scrape_config:
- job_name: node-workers
honor_labels: true
metrics_path: /federate
params:
match[]:
- '{job="node"}'
static_configs:
- targets:
- worker-0:9090
- worker-1:9090注释 :honor_labels需配置为true,这样可保证主节点不会覆盖工作节点的序列标签;metrics_path指定federate API路径;params指定match[]参数,匹配我们想要获取的特定时间序列,可以指定多个条件,Prometheus将返回所有条件的并集;targets指定工作节点的目标地址。
如下所示,在任务正常启动后,我们就可以在主节点的上查询到Worker节点收集的监控指标。

结语:
目前Prometheus在集群与扩展性方面的功能并不算强大,通过分级联邦的方式虽然可以解决扩展性的问题,但依然存着的一些不足之处 。例如:多层结构使得Prometheus之间的网络变得复杂,我们不止要关注工作节点和目标之间的连接,也要关注主节点与工作节点的连接;工作节点根据设定的间隔获取目标指标,而主节点对于工作节点数据的抓取也存在着时间间隔,这可能导致主节点出现数据延迟的情况;最后,当所有的指标汇总到主节点时,可能会对其造成较大的压力,在资源的调配上需做好分配,以免引起主节点的崩溃。
基于以上的短板,在采用分级联邦时,建议尽量遵循下列的规范:
-
将告警的规则配置在worker节点,而不是主节点。
-
在主节点抓取worker节点指标时,通过match参数筛选过滤指标。
-
整体分层架构最多不要超过三层。
-
将分级联邦模式做为最后的选择,只有在大规模的监控环境中才考虑使用。
本文我们将讲解关于Alertmanager的集群方案。
一. 功能概述
Alertmanager使用 HashiCorp 公司的 Memberlist 库来实现集群功能。Memberlist 使用Go语言开发,并基于Gossip的协议来管理集群成员和成员故障检测。 Gossip协议(Gossip protocol)是一种去中心化、容错并保证最终一致性的协议,被广泛应用于分布式系统中。
Gossip的原理是由网络中的某个节点,通过一种随机的方式向集群中的N个节点同步信息,相关节点在收到消息后,又会重复相同的工作,最终达到整个集群所有节点的统一。

Gossip协议具有以下优点:
- 扩展性强,可以允许集群内节点任意增加或者减少。
- 协议操作简单,实现起来简单方便。
- 容错性强,节点之间是平等关系,任何节点出现问题都不影响集群。
- 最终一致性,可以在较短时间内快速将变化覆盖到全局节点。
二. Alertmanager配置
在本次配置中,我们通过三个Alertmanager来进行演示,分别为am1、am2和am3,其中am1主机做为集群的启动节点。每台alertmanager必须保证配置文件的一致性,否则集群实际上并不是高可用的效果。
am1: 192.168.214.100
am2: 192.168.214.108
am3: 192.168.214.109Gossip的传播需要指定特定端口,此处我们使用8001为监听端口。为了能够让Alertmanager节点之间进行通讯,需要在Alertmanager启动时设置相应的参数。其中主要的参数包括:
- --cluster.listen-address string: 当前实例集群服务监听地址
- --cluster.peer value: 初始化时关联的其它实例的集群服务地址
am1启动配置:
$ alertmanager --config.file alertmanager.yml --storage.path /data/alertmanager/ --cluster.listen-address="192.168.214.100:8001" &
am2与am3启动配置:
alertmanager --config.file alertmanager.yml --storage.path /data/alertmanager/ --cluster.listen-address="0.0.0.0:8001" --cluster.peer=192.168.214.100:8001 &
在配置完成后,我们可以在任意一个Alertmanager中看到如下状态,证明三个节点已加入到集群中。

在集群启动后,我们可以在其中一个Alertmanager上设置silence,并查看配置是否复制到其他Alertmanager节点,以此来验证集群是否正常工作。如下图所示,现在集群已经在正常运行,接下来可以开始进行Prometheus的设置。

三.Prometheus设置
对于Alertmanager集群,我们不需要在集群前面额外增加负载均衡器。在Prometheus的配置文件中,只需要将所有Alertmanager的地址配置进去,这样当集群中的某个Alertmanager发生故障时,Prometheus会自动找寻另一个来发送警报。而收到警报Alertmanager节点,自身会负责与集群中的其他活动成员共享所有收到的警报。
alerting:
alertmanagers:
- static_configs:
- targets:
- '192.168.214.100:9093'
- '192.168.214.108:9093'
- '192.168.214.109:9093'启动Prometheus后,我们在Status页面会看到相关的Alertmanager信息,代表配置成功。

Thanos(灭霸)即是其中之一,也是目前较为流行的解决方案,本文将对其进行介绍。
一. 产品介绍
Thanos为英国游戏技术公司Improbable 开源的一套监控解决方案,它包含多个功能组件,可以使用无侵入的方式与Prometheus配合部署,从而实现全局查询 、跨集群存储等能力,能够较好地的提升Prometheus的高可用性与扩展性。 源码地址仓库:https://github.com/thanos-io/thanos
该产品具有以下特点:
- 1、可实现跨集群的全局查询功能;
- 2、兼容现有的Prometheus API 接口 ,从而实现无缝集成;
- 3、提供数据压缩和降准采样功能,提升查询速度;
- 4、重复数据删除与合并,可从Pormetheus HA 集群中收集指标;
- 5、支持多种对象存储系统,包括S3、微软Azure、腾讯COS、Google GCP、Openstack Swift 等,可支撑大规模数据的长期存储;

二. 功能组件
Thanos包含以下主要功能组件:
-
Sidecar(边车组件) Thanos通过该组件实现与Prometheus的集成,配置Sidecar连接Prometheus后,可读取数据给到Querier进行实时查询。另外,通过Sidecar还可以将Prometheus采集的数据上传到对象存储进行保存。 该组件必须与Prometheus运行在同一台机器或同一个Pod中。
-
Querier(查询组件) 该组件具有与Prometheus兼容的API并支持Prom语法,与其他组件(Sidecar或Store Gateway)一起协同工作,用于查询Prometheus的数据指标和做为Grafana的监控展示数据源。
-
Store Gateway(存储网关) 该组件实现与Sidercar一致的API提供给Querier进行查询,当Sidecar将数据存储到对象存储后,Prometheus会清理掉本地数据保证本地空间可用。当Querier需要调取历史数据时,则会通过Store Gateway读取对象存储中保存的数据。
-
Comactor(压缩组件) 主要用于对采集到的数据进行压缩和降采样,以提升对长期数据的查询效率。
-
Ruler(规则组件) 用于对多个Alertmanager的告警规则进行统一管理 。
-
Receiver(接收器) 接收Promehtus的 remote-write数据,用于Receiver模式下的数据收集。
Thanos有两种运行模式,分别为Sidecar和Receiver,区别在于Sidercar主动获取Prometheus数据,而Receiver则是被动接收remote-write传送的数据。由于Receiver模式很少使用,本文不做介绍,只讲解Sidercar模式。 Sidercar模式官方架构图:

三. Prometheus配置
Thanos本身并不从目标实例处采集指标,监控指标的采集依然由Prometheus来完成。Thanos对Prometheus的版本有要求,需要部署2.21版本以上。 在本文示例中,我们部署两个Prometheus节点,分别为prom1和prom2,用于实现高可用的功能。 Prometheus相关的安装部署方法可参见前面的文章 ,此处不再过多叙述。
prom1:192.168.214.101
prom2: 192.168.214.102在高可用的情况下,由于数据会有重复,需要在external_labels的标签集区分不同的实例。本文通过增加replica标签做区分 ,在不同的实例填不同的值,如0或1。 注意:标签区分这一步非常重要,因为Thanos的数据去重功能依赖external_labels来区分不同的实例。
global:
scrape_interval: 30s
evaluation_interval: 60s
external_labels:
env: dev
replica: 0启动Prometheus
prometheus \
--config.file=/etc/prometheus/prometheus.yml \
--storage.tsdb.path=/data/prometheus \
--web.listen-address='0.0.0.0:9090' \
--storage.tsdb.max-block-duration=2h \
--storage.tsdb.min-block-duration=2h \
--storage.tsdb.retention.time=2h \
--web.enable-lifecycle注释:--storage.tsdb.min-block-duration和--storage.tsdb.min-block-duration参数必须添加且配置相同的值,用于关闭Prometheus的本地压缩功能,否则在使用compactor在压缩数据时会出现问题,并且会在Sidecar启动时报错;--storage.tsdb.retention.time配置本地只保留两小时数据,减少空间占用;--web.enable-lifecycle 用于支持Webhook方式重新加载Prometheus配置。
Sidercar会关注Prometheus的配置文件,并在出现变化时通过Webhook方式让Prometheus自动更新配置。
打开浏览器,访问http://:9090$IP,可以看到Prometheus已正常启动。
四. 部署Thanos
1. 集群架构
我们在上面的两个Prometheus的节点服务器中部署Sidercar,用于获取监控数据。同时,配置历史数据写入到对象存储中进行持久化保存。部署一个Store Gateway对接对象存储,而Compactor组件会定时对存储中数据进行压缩索引及降采样操作。
Querier做为面向用户的组件,对接Sidercar和Store Gateway获取数据并进行展示。(另外还有的Receiver和ruler组件由于使用不是很多,本文不做介绍,有需要可自行查阅。

2. 下载安装包
Thanos虽然有多个功能组件,但都是使用同一个二进制文件进行部署,通过不同的启动命令启用不同的功能,非常方便。 此处我们下载当前的v0.23.1版本,并将解压的二进制文件放到bin目录中。
$ wget https://github.com/thanos-io/thanos/releases/download/v0.23.1/thanos-0.23.1.linux-amd64.tar.gz
$ tar -xvf thanos-0.23.1.linux-amd64.tar.gz
$ cd thanos-0.23.1.linux-amd64
$ mv thanos /usr/local/bin/3. Sidecar部署
Sidercar为Thanos的关键组件,通过Sidercar实现了与Prometheus的无缝集成。Sidercar对Prometheus的实例几乎没有任何影响,Prometheus依然做为一个独立的实例运行,你不需要对其配置进行修改。 Siderca提供了一个数据API,用于我们查询Prometheus中的指标数据,同时默认会将超过两个小时的数据上传到对象存储 ,进行备份保存。 Sidercar组件必须与Prometheus运行在同一台机器或同一个Kubernetes Pod中,启动命令如下所示:
thanos sidecar \
--tsdb.path /data/prometheus \
--prometheus.url http://localhost:9090 \
--objstore.config-file bucket_config.yaml \
--http-address 0.0.0.0:19191 \
--grpc-address 0.0.0.0:19091注释:--tsdb.path 用于指定Prometheus 数据存储路径;--prometheus.url 指定Prometheus访问地址;--objstore.config-file 设置上传数据的对象存储信息;--http-address 配置http端口,用于提供Sidercar的metrics信息;--grpc-address 配置grpc端口,用于与其他Thanos组件通信;
Thanos支持多种对象存储及本地文件系统,如下列表所示:

以阿里云的oss为例,如下为bucket.yml配置格式:
type: ALIYUNOSS
config:
endpoint: ""
bucket: ""
access_key_id: ""
access_key_secret: ""Sidecar默认会每隔两个小时备份数据到对象存储,当Sidercar运行超过两个小时后,我们可以在对象存储中看到备份的数据。

4. Store Gateway部署
当Sidercar把监控数据备份到对象存储后,我们只需要在Prometheus中保留短期的数据,如数个小时。这样可以减少Prometheus的压力,也可用于应付大部分的查询。当需要查询历史数据时,我们可以通过Store Gateway来查询对象存储中保存的数据。
Store Gateway 主要与对象存储交互,从对象存储获取已经保存的数据。Store Gateway实现与Sidecar一样的数据api,Querier组件可以从Store Gateway 查询历史数据。Store Gateway支持横向扩展,可配置多个Store Gateway拉取多个对象存储数据。 启动命令:
thanos store \ --data-dir /data/thanos/store \ --objstore.config-file bucket_config.yaml \ --http-address 0.0.0.0:19194 \ --grpc-address 0.0.0.0:19094
注释 :--data-dir 配置缓存目录地址,Store Gateway会在本地磁盘上保留有关所有远程块的少量信息,并使其与存储桶保持同步;--objstore.config-file 设置对象存储信息,与Sidercar的配置一致;--http-address 配置http端口,用于提供访问界面和metrics信息;--grpc-address 配置grpc端口,用于与其他Thanos组件通信。
程序启动后,打开浏览器访问http://:19191$IP,可以看到对象存储中已存储的块信息

5. Querier部署
前面我们已经配置好Sidercar和Store Gateway组件,接下来我们为Thanos配置一个全局查询界面,即Querier组件。Querier连接Sidercar后,会根据给定的PromQL查询自动检测需要联系哪些Prometheus服务器,当要查询历史数据时,则是通过Store Gateway查询对象存储内容。 Querier还提供与Prometheus官方一致的HTTP API,可以接入Grafana进行监控展示,并支持PromQL语法。 启动命令如下所示:
thanos query \
--http-address 0.0.0.0:19192 \
--grpc-address 0.0.0.0:19092 \
--query.replica-label replica \
--store 192.168.214.101:19091 \ #prom1实例Sidercar地址
--store 192.168.214.102:19091 \ #prom2实例Sidercar地址
--store 192.168.214.102:19094 #Store Gateway地址注释 :--query.replica-label 指定重复数据删除的标记label,query在查询数据时,将根据此label评估是否重复数据;--store 用于指定Sidercar和Store Gateway的连接地址,此示例前两个store配置了prom1和prom2的Sidercar地址,第三个则是连接到store gateway;--http-address 指定Querier的UI界面访问地址;
启动完成后,打开浏览器,访问http://:19192$IP 即可查看Querier的UI界面。
“Use Deduplication”项默认已勾选,Querier会根据指定的扩展标签进行数据去重,这保证了在用户层面不会因为高可用模式而出现重复数据的问题。 “Use Partial Response”选项用于允许部分响应的情况,这要求用户在一致性与可用性之间做选择。当某个store出现故障而无法响应时,此时是否还需要返回其他正常store的数据。如果对可用性要求更高的场景,可以勾选此项。

Querier兼容Prometheus的API接口,因此,Grafana可直接添加Querier组件地址做为Prometheus数据源。


6. Compactor 部署
在默认情况下,Prometheus会定期压缩旧数据以提升查询效率,但在前面的操作中,我们关闭了此功能。因此,我们需要使用Compactor组件对存储中的数据进行类似操作。 Compactor会为以下数据进行降采样操作,降采样有利于对大时间范围的查询提供快速获取结果的能力:
- 为大于 40 小时 (2d, 2w) 的块创建 5m 降采样;
- 为大于 10 天 (2w) 的块创建 1 小时降采样。
同时,Compactor也将对索引进行压缩,包括将来自同个Prometheus实例的多个块压缩为一个,这有利于对提升数据的查询效率。Compactor通过扩展标签集来区分不同的Prometheus实例,所以,在Thanos集群中不同实例的Prometheus 扩展标签集必须是唯一的,否则会导致Compactor出现错误。
启动命令如下所示:
thanos compact \ --data-dir /var/thanos/compact \ --objstore.config-file bucket_config.yaml \ --http-address 0.0.0.0:19191
注释:--data-dir 指定用于数据处理的临时工作空间,为保证Compactor正常工作,建议提供100-300G的容量;--objstore.config-file 指定对象存储的信息,Thanos的其他组件如Sdiercar、Store Gateway只需要提供对象存储的读写权限即可,但Compactor还需要提供删除权限,因为它会对数据进行操作;--http-address compact的http地址,用于提供metrics指标。
目前,Thanos还不支持多个Compactor对单个存储对象存储并发进行操作的功能,必须以单实例的方式运行compact。
在任务完成后,Compactor的程序会退出,我们可将其做为定时任务的方式来运行。如果需要程序保持运行,可使用--wait和--wait-interval 参数实现。
由于对象存储本身对于数据是永久保留,如果希望只保留指定时间内的数据,可以通过配置Compactor的--retention.resolution-raw 、--retention.resolution-5m 和 --retention.resolution-1h 三个参数来实现,分别为原始数据的保留时间、5m分钟降采样数据的保留时间和1小时降采样数据保留时间,其中--retention.resolution-raw 不能小于其他两个时间段,否则会影响compact的降采样操作。
结语:
当前中文网上对于Thanos产品组件介绍的相关资料较少,并且由于产品还在不断迭代中,原有的文档往往已经不再适用。在研究的过程中笔者也只能依赖于官网的英文资料,并在实际使用中做验证。本文应该算是目前比较系统性介绍产品的一份资料,按照文中的操作方法,可以搭建出满足实际需要的集群架构。 目前产品依然处于快速迭代中,更多的使用内容,读者可自行参见官方文档学习。
]]>包含功能:
- The Prometheus Operator
- Highly available Prometheus
- Highly available Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
前提
Desktop 4.12.0 开启 K8s 1.25
安装
# clone 对应的版本 release v0.11.0
git clone [email protected]:prometheus-operator/kube-prometheus.git
# 先安装CRD资源
kubectl apply --server-side -f manifests/setup
# 检查CRD安装情况
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
# 替换为国内镜像,搜索 quay.io,如 image: quay.io/prometheus/node-exporter:v1.5.0,
# 替换为 quay.dockerproxy.com/prometheus/node-exporter:v1.5.0
# 参见: https://dockerproxy.com/docs
# 如果是Mac系统,注释 nodeExporter-daemonset.yaml 中的 mountPropagation: HostToContainer
kubectl apply -f manifests/
# 检查安装情况
kubectl get pod -n monitoring
# 进到dashboard页面
# kubectl --namespace monitoring port-forward svc/prometheus-k8s 9090
# grafana 用户名密码 admin admin
kubectl --namespace monitoring port-forward svc/grafana 3000
kubectl --namespace monitoring port-forward svc/alertmanager-main 9093
Grafana 已经内置了很多面板


报错
failed to try resolving symlinks in path "/var/log/pods/monitoring_node-exporter-6hq8f_433e74b9-f343-42da-9293-beca9bdb6987/node-exporter/4.log": lstat /var/log/pods/monitoring_node-exporter-6hq8f_433e74b9-f343-42da-9293-beca9bdb6987/node-exporter/4.log: no such file or directory
k logs node-exporter-6hq8f -n monitoring kube-rbac-proxy
Flag --logtostderr has been deprecated, will be removed in a future release, see https://github.com/kubernetes/enhancements/tree/master/keps/sig-instrumentation/2845-deprecate-klog-specific-flags-in-k8s-components
W0108 10:10:43.193481 63974 kube-rbac-proxy.go:152]
==== Deprecation Warning ======================
Insecure listen address will be removed.
Using --insecure-listen-address won't be possible!
The ability to run kube-rbac-proxy without TLS certificates will be removed.
Not using --tls-cert-file and --tls-private-key-file won't be possible!
For more information, please go to https://github.com/brancz/kube-rbac-proxy/issues/187
===============================================
I0108 10:10:43.193618 63974 kube-rbac-proxy.go:272] Valid token audiences:
I0108 10:10:43.193682 63974 kube-rbac-proxy.go:363] Generating self signed cert as no cert is provided
I0108 10:11:38.849433 63974 kube-rbac-proxy.go:414] Starting TCP socket on [192.168.65.4]:9100
I0108 10:11:38.849787 63974 kube-rbac-proxy.go:421] Listening securely on [192.168.65.4]:9100
I0108 10:11:41.850336 63974 log.go:198] http: proxy error: dial tcp 127.0.0.1:9100: connect: connection refused
I0108 10:11:52.534207 63974 log.go:198] http: proxy error: dial tcp 127.0.0.1:9100: connect: connection refused
I0108 10:11:56.079702 63974 log.go:198] http: proxy error: dial tcp 127.0.0.1:9100: connect: connection refused
I0108 10:12:07.346623 63974 log.go:198] http: proxy error: dial tcp 127.0.0.1:9100: connect: connection refused在Mac或Win上安装会有一些问题
需要注释 mountPropagation: HostToContainer
阅读本文需要对Prometheus及相关组件有所了解,请先熟悉之前的教程。
在学习Prometheus Operator前,我们有必要先来了解一下:什么是Operator?
当在Kuberentes平台上部署和管理某些复杂应用时,往往会面临不少挑战。
为了简化这个过程,CoreOS公司推出了Operator的概念,这可以理解为是一种自动化的部署与管理工具。
Operator可扩展 Kubernetes API,通过自定义资源(CRD)来封装对于应用的管理方法,从而实现软件配置的代码化管理。
Prometheus Operator顾名思义是针对Prometheus及其相关组件的管理工具,通过对其有效使用,可实现监控系统的快速搭建和高效管理。
本文将为你介绍相关的使用方法。
部署Prometheus Operator
Prometheus Operator对Kubernetes的版本有所要求,需要不低于1.16.x。
$ git clone https://github.com/coreos/prometheus-operator.git
$ cd prometheus-operator
$ kubectl create -f bundle.yaml
# 查看服务实例状态,已部署完成
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
prometheus-operator-98d4cf976-djvvr 1/1 Running 0 15mOperator的部署非常简单,在创建完成后,我们可以开始来部署应用服务。
在Prometheus Operator创建的自定义资源(CRD)中,与Prometheus相关资源的主要有以下几种:
- Prometheus
- ServiceMonitor
- PodMonitor
- PrometheusRule
其中Prometheus资源用于声明Prometheus的部署,ServiceMonitor 和 PodMonitor用于配置监控任务,而PrometheusRule则用于告警规则配置。 如下图所示,Operator将会监测相关对象资源的变动,并根据资源设置对Prometheus Server进行管理

部署Prometheus
下面,我们先来部署Prometheus实例,这里需创建一个Prometheus资源。
- 创建namespace。
$ kubectl create ns demo
- 配置RBAC授权。 创建SA
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: demo
# 创建集群角色
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/metrics
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
# 绑定账号
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: demo将上面内容保存为yml格式文件,并执行。
$ kubectl apply -f rbac.yml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created- 部署prometheus实例,并指定匹配的ServiceMonitors。
prometheus.yml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: monitor
namespace: demo
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
group: demo
resources:
limits:
memory: 4Gi
requests:
memory: 0.5Gi
enableAdminAPI: false注释:此处匹配标签为“group: demo”的ServiceMonitors,符合该条件的ServiceMonitors配置会被获取。 默认情况下,Prometheus只会在当前namespace查找,如果需要从其他namespace选择,可以在spec中添加serviceMonitorNamespaceSelector字段。
将内容保存为yml格式文件,并执行 kubectl create -f prometheus.yml
查看prometheus服务,确认实例已正常启动。
$ kubectl get pod -n demo
NAME READY STATUS RESTARTS AGE
prometheus-monitor-0 2/2 Running 0 17m- 配置prometheus service,并用nodeport的方式开放外部访问。
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
type: NodePort
ports:
- name: web
nodePort: 30900
port: 9090
protocol: TCP
targetPort: web
selector:
prometheus: monitor执行文件后,查看service已创建完成
$ kubectl get svc prometheus -n demo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.220.105.76 <none> 9090:30900/TCP 13s- 此时,我们打开浏览器访问prometheus服务,正常情况下会看到系统已正常运行。

配置监控任务
在完成了Prometheus的部署后,下面我们来了解如何配置监控任务。
- 先部署一个测试服务example-app,用于验证功能。
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
namespace: demo
spec:
replicas: 3
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: fabxc/instrumented_app
ports:
- name: web
containerPort: 8080
---
kind: Service
apiVersion: v1
metadata:
name: example-app
namespace: demo
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080执行部署文件后,可看到相关的pod实例已正常运行。
$ kubectl get pod -l app=example-app -n demo
NAME READY STATUS RESTARTS AGE
example-app-bb759dfcc-4hfl4 1/1 Running 0 16m
example-app-bb759dfcc-9lmzt 1/1 Running 0 16m
example-app-bb759dfcc-wxgwq 1/1 Running 0 16m- 创建ServiceMonitor对象,用于监控该服务。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
namespace: demo
labels:
group: demo
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web- 在前面的Prometheus配置中,我们已经配置自动关联标签为“group: demo”的ServiceMonitor。 现在,查看Prometheus 的configuration页面,可以发现已生成名为:serviceMonitor/demo/example-app/0 的监控Job。

查看Targets页面,可看到example-app的相关实例已在监控中。

除了ServiceMonitor,还有PodMonitor也可以用于配置监控任务。两者的使用方法类似,PodMonitor主要用于Pod的服务发现,适用于对没有配置service的服务进行监控。限于篇幅原因,此处不展开细说,有兴趣的朋友可自行查看官网。
配置告警规则
现在,我们已配置好监控Job并完成了对目标的监控,接下来可以开始配置告警规则了。 告警规则使用PrometheusRule对象来进行设置。
- 创建PrometheusRule对象,并配置监控规则。
# demo-rule.yml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: example
role: alert-rules
name: prometheus-demo-rules
namespace: demo
spec:
groups:
- name: demo.rule
rules:
- alert: up监控
expr: up{job="example-app"} != 1保存上面文件为yml格式,并执行。
- 此时需要修改prometheus配置,添加ruleSelector项,使其与PrometheusRule对象关联。
# prometheus.yml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: monitor
namespace: demo
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
group: demo
ruleSelector:
matchLabels:
role: alert-rules
prometheus: example
resources:
limits:
memory: 4Gi
requests:
memory: 0.5Gi
enableAdminAPI: false- 执行完成后,查看Prometheus的rules面板,可看到已自动生成相关的告警规则。

管理 Alertmanager
至此,我们完成了关于Prometheus的配置工作,包括创建实例、配置监控任务和告警规则。
当然,整个告警流程除了Prometheus以外,还离不开Alertmanager的支持。在这一点上,Prometheus Operator也可以帮助你实现。
在Prometheus Operator的自定义资源(CRD)中,与Alertmanager管理相关的资源有以下两种:
- Alertmanager
- AlertmanagerConfig 其中Alertmanager资源用于创建服务实例,AlertmanagerConfig则用于创建Alertmanager的配置。

创建Alertmanager实例
下面,我们来演示如何创建Alertmanager实例。
- 创建Alertmanager资源。
# alert.yml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: alert
namespace: demo
spec:
replicas: 3当replicas数量大于1时,Prometheus Operator会自动创建Alertmanager的集群。 查看状态,可看到实例已正常运行。
$ kubectl get pod -n demo |grep alertmanager
alertmanager-alert-0 2/2 Running 0 11m
alertmanager-alert-1 2/2 Running 0 11m
alertmanager-alert-2 2/2 Running 0 11m- 创建service对象,并用nodeport方式开放外部访问。
# alert-svc.yml
apiVersion: v1
kind: Service
metadata:
name: alertmanager-alert
namespace: demo
spec:
type: NodePort
ports:
- name: web
nodePort: 30905
port: 9093
protocol: TCP
targetPort: web
selector:
alertmanager: alert执行alert-svc.yml文件后,查看service可看到已创建完成。
- 打开浏览器,访问alertmanager服务,可看到已正常启动。

此时,我们查看alertmanager配置,可发现默认使用了最小化的配置。这个配置对于告警而言没有什么用途,需要定制化配置

配置Alertmanager
下面,我们使用AlertmanagerConfig资源来定制化配置。
- 创建AlertmanagerConfig对象,添加配置。
# alert-config.yml
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: alert-config
namespace: demo
labels:
alertmanagerConfig: demo
spec:
route:
groupBy: ['job']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'webhook'
receivers:
- name: 'webhook'
webhookConfigs:
- url: 'http://example.com/'- 修改alertmanager对象,添加alertmanagerConfigSelector项,并匹配AlertmanagerConfig的label。
# alert.yml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: alert
namespace: demo
spec:
replicas: 3
alertmanagerConfigSelector:
matchLabels:
alertmanagerConfig: demo- 现在重新登录alertmanager,可查看到配置已更新。

在配置好Alertmanager后,下面我们需要让Prometheus将触发的告警信息发送到Alertmanager ,并由其进行通知。
Prometheus关联Alertmanager
- 修改Prometheus,添加alerting项,指定alertmanager服务名称。
# prometheus.yml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: monitor
namespace: demo
spec:
serviceAccountName: prometheus
alerting:
alertmanagers:
- namespace: demo
name: alertmanager-alert
port: web
serviceMonitorSelector:
matchLabels:
group: demo
ruleSelector:
matchLabels:
role: alert-rules
prometheus: example
resources:
limits:
memory: 4Gi
requests:
memory: 0.5Gi
enableAdminAPI: false- 查看prometheus信息,可发现已配置相关的告警地址。prometheus在此处是基于服务自动发现方式,获取到alertmanger地址信息。

总结:
如文章如示,使用Prometheus Operator可将配置的工作进行代码化实现,从而较好的简化整个部署和管理过程,让我们得以简单高效的完成工作。 另外,这种方式也有利于我们进行定制化管理,如与第三方系统相结合来实现自动化监控,不失为一个很实用的方案。
]]>API格式
目前,Prometheus API 的稳定版本为V1,针对该API的访问路径为 /api/v1。API支持的请求模式有GET和POST两种,当正常响应时,会返回2xx的状态码。 反之,当API调用失败时,则可能返回以下几种常见的错误提示码:
- 400 Bad Request 参数丢失或不正确时出现。
- 422 Unprocessable Entity 当表达无法被执行时。
- 503 Service Unavailable 查询超时或中止时。
在功能上,Prometheus API 提供了丰富的接口类型,包括表达式查询、元数据查询、配置查询、规则查询等多个功能,甚至还有清理数据的接口。 当API正常响应后,将返回如下的Json数据格式。
{
"status": "success" | "error",
"data": <data>,
// Only set if status is "error". The data field may still hold
// additional data.
"errorType": "<string>",
"error": "<string>",
// Only if there were warnings while executing the request.
// There will still be data in the data field.
"warnings": ["<string>"]
}API调用
下面,我们将以两个样例来演示关于API的调用,方便大家理解掌握。
即时查询
说明:该接口属于表达式查询,将根据表达式返回单个时间点的数据。
GET /api/v1/query
POST /api/v1/query该接口可使用如下参数进行查询,其中time为需要获取值的时间戳,如果不填则默认返回最新的值 。
query=<string>:Prometheus 表达式查询字符串。time=<rfc3339 | unix_timestamp>:评估时间戳,可选参数。timeout=<duration>: 查询超时设置,可选参数,默认将使用-query.timeout的全局参数。
示例:
获取实例"192.168.214.108"的 node_load5 值。
请求的参数如下:
curl http://localhost:9090/api/v1/query?query=node_load5{instance="192.168.214.108:9100"}
返回数据:
status 字段为success,表明请求成功;data字段包括了数据的相关参数,其中value为对应的时间戳和数据值 ,也即是node_load5的值。
{
"status": "success",
"data": {
"resultType": "vector",
"result": [
{
"metric": {
"__name__": "node_load5",
"instance": "192.168.214.108:9100",
"job": "node"
},
"value": [
1666865246.993, # 时间戳
"0.04" # 数据值
]
}
]
}
}范围查询
GET /api/v1/query_range
POST /api/v1/query_range该接口支持如下参数查询:
* query=<string>:Prometheus 表达式查询字符串。
* start=<rfc3339 | unix_timestamp>:开始时间戳。
* end=<rfc3339 | unix_timestamp> :结束时间戳。
* step=<duration | float>:查询分辨率步长。
* timeout=<duration>:查询超时设置,可选参数,默认将使用-query.timeout的全局参数。示例:
获取实例"192.168.214.108"在某段时间内 node_load5 的所有值。
请求的参数如下:
curl http://localhost:9090/api/v1/query_range?query=node_load5{instance="192.168.214.108:9100"}&start=2022-10-28T02:10:10.000Z&end=2022-10-28T02:13:00.000Z&step=60s返回数据:
以下示例为3分钟范围内的表达式返回值,查询步长为60秒,故返回三次值
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "node_load5",
"instance": "192.168.214.108:9100",
"job": "node"
},
"values": [
[
1666923010,
"0.04"
],
[
1666923070,
"0.04"
],
[
1666923130,
"0.03"
]
]
}
]
}
}获取数据
上面的curl访问方式更多是用于测试,在实际应用中,我们通常会用代码的方式来获取数据并进行处理。
此处以Python为例,演示关于代码调用接口的应用方法。(PS:这里需要具备一点Python编程基础)
安装requests库,用于url访问。
$ pip install requests
编写python脚本test_api.py
# -*- coding: utf-8 -*-
import requests
# 定义参数
url = 'http://192.168.214.108:9090'
query_api = '/api/v1/query'
params = 'query=node_load5{instance="192.168.214.108:9100"}'
# 访问prometheus API获取数据
res = requests.get(url + query_api, params)
metrics = res.json().get("data").get("result")
# 判断结果是否为空
if metrics:
value = metrics[0].get('value')[1]
print('服务器 192.168.214.108的node_load5值为 %s' % value)
else:
print('无法获取有效数据')脚本运行结果:
$ python test_api.py
服务器 192.168.214.108的node_load5值为 0.01结语
本文仅展示了Prometheus API的简单应用,更多的接口使用可参考官方文献:https://prometheus.io/docs/prometheus/latest/querying/api/。
]]>该配置文件分为四个模块:global(全局配置)、alerting(告警配置)、rule_files(规则配置)、scrape_configs(目标拉取配置),本文将分别对其进行讲解介绍。
一. global
用于定义prometheus的全局配置。
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_timeout: 10sscrape_interval :用来指定Prometheus从监控端抓取数据的时间间隔(默认为15s),如果在特定的job指定时间间隔指标,则该job的配置会覆盖全局设置。
evaluation_interval:用于指定检测告警规则的时间间隔,每15s重新检测告警规则,并对变更进行更新。
scrape_timeout:定义拉取实例指标的超时时间。
二. alerting
用于设置Prometheus与Alertmanager的通信,在Prometheus的整体架构中,Prometheus会根据配置的告警规则触发警报并发送到独立的Alertmanager组件,Alertmanager将对告警进行管理并发送给相关的用户。
alerting:
alertmanagers:
- scheme: http
timeout: 10s
static_configs:
- targets:
- localhost:9093- scheme:配置如何访问alertmanager,可使用http或https。
- timeout:配置与alertmanager连接的超时时间。
- static_configs:配置alertmanager的地址信息,关于Alertmanager的内容会在后续的文档中介绍。
三. rule_files
用于指定告警规则的文件路径,文件格式为yml。
rule_files:
- "rule_cpu.yml"
- "rule_memory.yml"Prometheus的告警规则都是通过yml文件进行配置,对于用惯了zabbix完善图形界面的人来说,一开始可能不会太习惯。 但这也是Promthesu的特点之一,这种方式提供了开放性的定制化功能,可以根据自己需要进行各类规则的定制化配置。
四. scrape_configs
用于指定Prometheus抓取的目标信息。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']Prometheus对于监控数据的抓取,通过配置job的方式进行操作。在job里面指定了一组目标抓取所必须的信息,例如目标地址、端口、标签和验证信息等。抓取的时间间隔使用上面global模块配置的时间,也可在该job中单独指定。 在实际环境中,通常会根据抓取目标的类型不同,如Mysql、mongodb、kafka等,分成多个job来进行。
默认配置只有一个监控目标,即prometheus server本身,端口为9090,如果不指定路径,默认会从/metrics路径抓取。
]]>metrics指标为时间序列数据,它们按相同的时序,以时间维度来存储连续数据的集合。
metrics有自定义的一套数据格式,不管对于日常运维管理或者监控开发来说,了解并对其熟练掌握都是非常必要的,本文将对此进行详细介绍。
一. Mtrics组成
每个metrics数据都包含几个部分:指标名称、标签和采样数据。
指标名称
用于描述收集指标的性质,其名称应该具有语义化,可以较直观的表示一个度量的指标。名称格式可包括ASCII字符、数字、下划线和冒号。
如:
node_cpu_seconds_total
node_network_receive_bytes_total标签
时间序列标签为key/value格式,它们给Prometheus数据模型提供了维度,通过标签可以区分不同的实例,
如: node_network_receive_bytes_total{device="eth0"} #表示eth0网卡的数据
通过标签 ,Prometheus可以在不同维度上对一个或一组数据进行查询处理。标签名称由 ASCII 字符,数字,以及下划线组成, 其中 __ 开头属于 Prometheus 保留,标签的值可以是任何 Unicode 字符,支持中文。标签可来自被监控的资源,也可由Prometheus在抓取期间和之后添加。
采样数据
按照某个时序以时间维度采集的数据,其值包含:
一个float64值
一个毫秒级的unix时间戳
二. Metrics格式
结合以上这些元素,Prometheus的时间序列统一使用以下格式来表示。
<metric name>{<label name>=<label value>, ...}
下面为一个node-exporter暴露的数据指标样本:

第一个#是指标的说明介绍,第二个# 代表指标的类型,此为必须项且格式固定,TYPE+指标名称+类型。node_cpu_seconds_total为指标名称,{}里面为标签, 它标明了当前指标样本的特征和维度,最后面的数值则是该样本的具体值。
三. Metric类型
Prometheus的时序数据分为Counter(计数器),Gauge(仪表盘),Histogram(直方图),Summary(摘要)四种类型。
Counter类型
counter类型的指标与计数器一样,会按照某个趋势一直变化(一般是增加),我们往往用它记录服务请求总量、错误总数等。
如下图展示就是一个counter类型的metrics数据采集,采集的是Prometheus的接口访问量,可看到数值一直在向上增加。

基于counter类型的数据,我们可以清楚某些事件发生的次数,由于数据是以时序的方式进行存储,我们也可以轻松了解该事件产生的速率变化。
例如,通过rate()函数,获取api请求量每分钟的增长率:rate(apiserver_request_total[1m])
Gauge类型
与Counter不同,Gauge类型的指标用于展示瞬时的值,与时间没有关系,可增可减。该类型值可用来记录CPU使用率、内存使用率等参数,用来反映目标在某个时间点的状态。
以下是一个关于内存使用量的数据展示,可以看到每个时间点的数据具有随机性,不与其他数据有关联。

Gauge指标简单且易于理解,对于该类型的指标,我们可以直观的查看目标在当前的状态。
node_memory_MemFree_bytes
Summary和Histogram类型
在大多数情况下,我们可以计算指标某个时间段内的平均值来了解情况,如需要知道每分钟CPU使用率,可通过计算该时间段内采集的数据平均值来获取。
但在某些场景中,这种方式并不合适。假设某个接口一分钟内的请求为1万次,采用平均值的方式计算出响应时间为2s,通过该值我们无法判断是所有请求都不超过2s,还是有部分较高延迟被平均值拉低,该方法缺乏对于全局的观察性。对此,Prometheus通过Summary和Histogram类型来解决这样的问题。
Summary 通过计算分位数(quantile)显示指标结果,可用于统计一段时间内数据采样结果 ,如中位数(quantile=0.5)、9分位数(quantile=0.9)等。
下面是一个Summary类型的指标prometheus_tsdb_wal_fsync_duration_seconds,通过该指标我们可以得知,Prometheus进行wal_fsync操作的数据结果中,50%(quantile=0.5)的耗时小于0.051406522,90%(quantile=0.9)的耗时小于0.053670506。

Histogram类型与Summary类型的指标相似之处在于同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义,通常它采集的数据展示为直方图。
Histogram可用于请求耗时、响应时间等数据的统计,例如指标prometheus_tsdb_compaction_chunk_range_bucket即为Histogram类型。

本文将通过Prometheus内置的表达式浏览器来演示PromQL语言的使用,考虑篇幅原因,本次内容会分为两篇文章进行讲解。
一. 基础查询
Prometheus的基础查询一般表达式格式为<metric name>{label=value},通过指标名称加标签的方式进行查询,如查看Prometheus更新接口的请求次数。
promhttp_metric_handler_requests_total

查询表达式也可以支持通过指标名称(例如http_request_total),或者一个不会匹配到空字符串的标签过滤器(例如{code="200"})来进行查询。
promhttp_metric_handler_requests_total #合法
promhttp_metric_handler_requests_total{} #合法
{handler="/api/v1/query"} #合法PromQL支持使用=和!=两种匹配模式,通过使用label=value 可以查询那些标签满足表达式的时间序列,而与之相反使用label !=value则会排除满足条件的时间序列。以上面的查询为例,假如我们只想关注非正常响应的请求,可使用下列表达式
promhttp_metric_handler_requests_total{code!="200",job="阿里云-演示"}

此时,查询结果会排除code=200的时间序列,并返回其他类型的数据。
除了使用完全匹配的方式的进行查询外,PromQL还支持使用正则表达式作为匹配条件,书写格式为label =~regx,其中~为表示符,regx为正则内容。
promhttp_metric_handler_requests_total{handler=~".*reload"}
如需要同时查询多个接口的时间序列的话,可使用如下正则表达式
promhttp_metric_handler_requests_total{handler=~"/graph|/rules|/metrics"}
查询包含job包含pro且code为200的结果
promhttp_metric_handler_requests_total{job=~".*pro.*",code="200"}

二. 时间范围查询
在上述的基础查询案例中,我们通过<metric name>{label=value}方式进行查询时,返回结果中只会包含该时间序列的最新一个值,这样的结果类型称为瞬时向量(instant vector )。除了瞬时向量,PromQL也支持返回时间序列在某个时间范围内的一组数据,这种称为范围向量(range vector )。
范围向量表达式需要定义时间选择的范围,时间范围被包含在[]号中,例如查询5分钟内的样本数据,可用下列表达式
promhttp_metric_handler_requests_total{code="200"}[5m]
在Prometheus的表达式浏览器中,我们可以看到,返回的数据包含了5分钟内的所有采样结果。

除了使用m表示分钟以外,PromQL的时间范围选择器支持其它时间单位:
- s - 秒
- m - 分钟
- h - 小时
- d - 天
- w - 周
- y - 年
在时间序列的查询上,除了以当前时间为基准,也可以使用offset进行时间位移的操作。如以1小时前的时间点为基准,查询瞬时向量和5分钟内的范围向量:
promhttp_metric_handler_requests_total{code="200"} offset 1h
promhttp_metric_handler_requests_total{code="200"}[5m] offset 1h三. 聚合操作
PromQL语言提供了不少内置的聚合操作符,用于对瞬时向量的样本进行聚合操作 ,形成一个新的序列。目前支持的聚合操作符如下:
- sum (求和)
- min (最小值)
- max (最大值)
- avg (平均值)
- stddev (标准差)
- stdvar (标准方差)
- count (计数)
- count_values (对value进行计数)
- bottomk (后n条时序)
- topk (前n条时序)
- quantile (分位数)
聚合操作符有非常多的用途,例如可使用sum对返回结果进行汇总,得到一个总值 。
例如要计算所有接口的请求数量总和,可以用如下表达式:
sum(promhttp_metric_handler_requests_total{})
使用max,匹配其中样本值为最大的时间序列
max(promhttp_metric_handler_requests_total{})
使用topk ,可显示匹配的前N条时间序列数据
topk(5,promhttp_metric_handler_requests_total{})
在聚合操作中,还可以在表达式中加上without或 by ,其中without用于在计算样本中移除列举的标签,而by正相反,结果向量中只保留列出的标签,其余标签则移除。
sum(promhttp_metric_handler_requests_total{}) without (code,handler,job)
sum(promhttp_metric_handler_requests_total{}) by (instance)

参考
]]>一. 操作符
在PromQL的查询中,还可以通过表达式操作符,进行更加复杂的结果查询,常见的操作有下列几种。
数学运算符
数据运算符使用的加、减、乘、除等方式,对样本值进行计算,并返回计算后的结果。
例如,通过process_virtual_memory_bytes获取到的内存值单位为byte,我们希望转换为GB为单位时,只需要使用下列表达式处理
process_virtual_memory_bytes/(1024*1024*1024)
PromQL支持的所有数学运算符如下所示:
-
- (加法)
-
- (减法)
-
- (乘法)
- / (除法)
- % (求余)
- ^ (幂运算)
比较运算符
比较运算符支持用户根据时间序列样本的值,对时间序列进行过滤。
例如,我们只想查询Prometheus请求量大于1千的接口数据,则可以使用下列比较表达式进行过滤。
promhttp_metric_handler_requests_total{code="200"} > 1000
比较表达式还可以与bool修饰符进行搭配,添加bool后表达式将不再对数据进行过滤,而是根据比较结果返回1(true)或0(false)。
例如 :
promhttp_metric_handler_requests_total{code="200"} > bool 1000

Prometheus支持的比较运算符如下:
== (相等)
!= (不相等)
> (大于)
< (小于)
>= (大于等于)
<= (小于等于)逻辑运算符
逻辑运算符支持的操作有 and、or、unless(排除)三种,其中and为并集,用于匹配表达式中相同的结果。
如下示例,该表达式将匹配大于100小于1000区间的时间序列样本
promhttp_metric_handler_requests_total < 1000 or promhttp_metric_handler_requests_total > 100
其中,表达式1为显示所有小于1千的样本,而表达式2则是显示所有大于100的样本,在并集匹配后,将会显示两者间相同的数据,即小于1千大于100这个区间的样本。
unless与and正好相反,匹配结果将会排除两者中相同的样本,只显示其中对方互不包含部分的合集;而or的匹配范围最广,它除了会匹配表达式1所有的数据外,还会匹配表达式2中与其不相同的样本。
注意:Prometheus 的运算符之间存在着优先级,其中由高到低依次为
(^)> (*, /, %) > (+, -) > (==, !=, <=, <, >=, >) > (and, unless) > (or),在使用过程中需要注意优先级关系,避免出现错误结果。
promhttp_metric_handler_requests_total{code="200"} > 20000 and promhttp_metric_handler_requests_total{code="200"} < 100000

二. 内置函数
Prometheus内置不少函数,通过灵活的应用这些函数,可以更方便的查询及数据格式化。本文将选取其中较常使用到的几个函数进行讲解。
ceil 函数
ceil函数会将返回结果的值向上取整数。
ceil(avg(promhttp_metric_handler_requests_total{code="200"}))
floor 函数
floor 函数与ceil相反,将会进行向下取整的操作。
rate函数
rate函数是使用频率最高,也是最重要的函数之一。rate用于取某个时间区间内每秒的平均增量数,它会以该时间区间内的所有数据点进行统计。rate函数通常作用于Counter类型的指标,用于了解增量情况。
示例:获取http_request_total在1分钟内,平均每秒新增的请求数
rate(promhttp_metric_handler_requests_total{handler="/rules"}[1m])

irate函数
相比rate函数,irate提供了更高的灵敏度。irate函数是通过时间区间中最后两个样本数据来计算区间向量的增长速率,从而避免范围内的平均值拉低峰值的情况。
示例:该函数用法与rate相同
irate(promhttp_metric_handler_requests_total{handler="/rules"}[1m])
其它内置函数
除了上面提到的这些函数外,PromQL还提供了大量的其他函数供使用,功能范围涵盖了日常所需的功能,如用于标签替换的label_replace函数、统计Histogram指标分位数的histogram_quantile函数
更多信息可参阅官方文档:https://prometheus.io/docs/prometheus/latest/querying/functions/。
]]>一. 功能概述
任务与实例,是Prometheus监控中经常会提到的词汇。在其术语中,每一个提供样本数据的端点称为一个实例(instance),它可以是各种exporter,如node-exporter、mysql-exporter,也可以是你自己开发的一个服务。只要提供符合prometheus要求的数据格式 ,并允许通过HTTP请求获取信息的端点都可称为实例。而对于实例数据的采集,则是通过一个个任务(job)来进行管理,每个任务会管理一类相同业务的实例。
在前面"配置介绍“一文中,我们对Prometheus的配置文件prometheus.yml进行过讲解,其中scrape_configs模块即是管理任务的配置。
如下是Prometheus默认配置的Job,用于获取Prometheus自身的状态信息,这是一个格式最精简的Job。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']当Job生效后,我们可以在Prometheus的Status - Targets页面看到相关的任务实例,其中Endpoint项代表该实例的采集地址;State项为实例状态,状态为UP表示可正常采集;Labels为实例所拥有的标签 ,标签会包含在获取到的所有时间序列中。

二. 配置参数
Job_name(任务名称)
Job_name定义了该job的名称,这会生成一个标签{job="xxx"},并插入到该任务所有获取指标的标签列中。如上面的Prometheus任务指标,我们可以在表达式浏览器中查询 {job="腾讯云-重庆"},即可看到与该job相关的指标。

此外,Job也支持自定义标签的方式。如下所示,将在该Job获取的指标中添加{group="dev"}的标签。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
labels:
group: 'dev'配置完成后,重启Prometheus可看到标签 已生效。
static_configs(静态配置)
static_configs为静态配置,需要手动在配置文件填写target的目标信息,格式为域名/IP + 端口号。当有多个目标实例时,书写格式如下 :
scrape_configs:
- job_name: 'myjob'
static_configs:
- targets:
- '192.168.0.1:9100'
- '192.168.0.2:9100'
- '192.168.0.3:9100'Prometheus对于监控实例的加载,除了静态配置,还可以使用文件配置的方式。
操作方式很简单,只需要在一个文件中填好相关的实例信息,然后在Job中加载该文件即可,文件的格式必须是yaml或json格式。
如:
$ vi /opt/prom/nodex-info.yml
- targets:
- '192.168.0.1:9100'
- '192.168.0.2:9100'
- '192.168.0.3:9100'配置Job加载该文件
scrape_configs:
- job_name: 'myjob'
file_sd_configs:
- files:
- /opt/prom/nodex-info.yml另外,Prometheus也支持基于kubernetes、DNS或配置中心的服务自动发现方式,这个会在后面的文档做介绍。
scrape_interval和scrape_timeout
scrape_interval代表抓取间隔,scrape_timeout代替抓取的超时时间,它们默认继承来global全局配置的设置。但如果有特殊需求,也可以对单个Job单独定义自己的参数。
示例:
scrape_configs:
- job_name: 'myjob'
scrape_interval:15s
scrape_timeout: 10s
static_configs:
- targets: ['192.168.0.1:9100']注意:scrape_timeout时间不能大于scrape_interval,否则Prometheus将会报错。
metric_path
指定抓取路径,可以不配置,默认为/metrics。
scheme
指定采集使用的协议,http或者https,默认为http。
params
某些特殊的exporter需要在请求中携带url参数,如Blackbox_exporter ,可以通过params进行相关参数配置。
scrape_configs:
- job_name: 'myjob'
params:
module: [http_2xx]
static_configs:
- targets: ['192.168.0.1:9100']basic_auth
默认情况下,exporter不需要账号密码即可获取到相关的监控数据。在某些安全程度较高的场景下,可能验证通过后才可获取exporter信息,此时可通过basic_auth配置Prometheus的获取exporter信息时使用的账密。
scrape_configs:
- job_name: 'myjob'
static_configs:
- targets: ['192.168.0.1:9100']
basic_auth:
username: alex
password: mypassword该功能在日常的监控中常常会使用到,值得我们好好了解。
一. 默认标签
默认情况下,Prometheus加载targets后,都会包含一些默认的标签,其中以__作为前置的标签是在系统内部使用的,因此这些标签不会写入到样本数据中。

如:
- address:当前Target实例的访问地址
- scheme:采集目标服务访问地址的HTTP Scheme,HTTP或者HTTPS;
- metrics_path:采集目标服务访问地址的访问路径;
上面这些标签将会告诉Prometheus如何从该目标实例中获取监控数据,而通过标签重写功能,我们可以对这些标签进行重写,从而实现对Target目标的控制。
二. relabel_config
标签重写的配置参数为relabel_config,其完整的配置格式如下 :
#源标签,需要在现有标签中已存在
[ source_labels: '[' <labelname> [, ...] ']' ]
# 多个源标签的分隔符;
[ separator: <string> | default = ; ]
# 要替换的目标标签;
[ target_label: <labelname> ]
# 正则表达式,用于匹配源标签的值
[ regex: <regex> | default = (.*) ]
# 源标签值取hash的模块;
[ modulus: <uint64> ]
# 当正则表达式匹配时,用于替换的值,$1代替正则匹配到的值;
[ replacement: <string> | default = $1 ]
# 基于正则匹配的动作
[ action: <relabel_action> | default = replace ]其中,相关的action类型有如下几种:
- replace:正则匹配源标签的值用来替换目标标签,如果有replacement,使用replacement替换目标标签;
- keep: 如果正则没有匹配到源标签的值,删除该targets ,不进行采集;
- drop: 与keep相反,正则匹配到源标签,删除该targets;
- labelmap:正则匹配所有标签名,将匹配的标签值部分做为新标签名,原标签值 做为新标签的值;
- labeldrop:正则匹配所有标签名,匹配则移除标签;
- labelkeep:正则匹配所有标签名,不匹配的标签会被移除;
注意:重定义标签并应用后,__开头的标签会被删除; 要临时存储值用于下一阶段的处理,使用__tmp开头的标签名,这种标签不会被Prometheus使用;
三. 功能操作
在开始测试前,我们先配置一个测试Job,该Job包含两个实例,实例分别包含了两个标签,__machine_hostname和__machine_idc__。
scrape_configs:
- job_name: 'myjob'
static_configs:
- targets:
- '10.12.61.1:9100'
labels:
__machine_hostname__: 'node-01'
__machine_idc__: 'idc-01'
- targets:
- '10.12.61.2:9100'
labels:
__machine_hostname__: 'node-02'
__machine_idc__: 'idc-02'replace操作
将__machine_hostname__的值替换到新标签hostname
scrape_configs:
- job_name: 'myjob'
static_configs:
- targets:
- '10.12.61.1:9100'
labels:
__machine_hostname__: 'node-01'
__machine_idc__: 'idc-01'
- targets:
- '10.12.61.2:9100'
labels:
__machine_hostname__: 'node-02'
__machine_idc__: 'idc-02'
relabel_configs:
- source_labels: [__machine_hostname__]
regex: "(.*)"
target_label: "hostname"
action: replace
replacement: '$1'重启Prometheus后,查看target信息如下:

keep/drop操作
排除标签值不匹配正则的targets 目标,此处正则匹配__machine_hostname__: 'node-01' 。
scrape_configs:
- job_name: 'myjob'
static_configs:
- targets:
- '10.12.61.1:9100'
labels:
__machine_hostname__: 'node-01'
__machine_idc__: 'idc-01'
- targets:
- '10.12.61.2:9100'
labels:
__machine_hostname__: 'node-02'
__machine_idc__: 'idc-02'
relabel_configs:
- source_labels: [__machine_hostname__]
regex: "(.*)-01"
target_label: "hostname"
action: keep
replacement: '$1'重启后,会发现只有一个__machine_hostname__: 'node-01'的实例了
如果将上面配置的action改为drop,则结果相反,将删除正则匹配到标签的实例。
labelmap操作
重写新的标签hostname和idc,使用原有__machine_hostname__和__machine_idc__标签的值。
scrape_configs:
- job_name: 'myjob'
static_configs:
- targets:
- '10.12.61.1:9100'
labels:
__machine_hostname__: 'node-01'
__machine_idc__: 'idc-01'
- targets:
- '10.12.61.2:9100'
labels:
__machine_hostname__: 'node-02'
__machine_idc__: 'idc-02'
relabel_configs:
- action: labelmap
regex: __machine_(.+)__查看target信息,可看到重写的新标签。
两个实例的标签
hostname="node-01",idc="idc-01",instance="10.12.61.1:9100",job="myjob"
hostname="node-02",idc="idc-02",instance="10.12.61.2:9100",job="myjob"Prometheus使用各种Exporter来监控资源。Exporter可以看成是监控的agent端,它负责收集对应资源的指标,并提供接口给到Prometheus读取。不同资源的监控对应不同的Exporter,如node-exporeter、mysql-exporter、kafka-exporter等,在这其中最常用的当属node_exporter。
node-exporter使用Go语言编写,它主要用来监控主机系统的各项性能参数,可收集各种主机指标的库,还提供了textfile功能,用于自定义指标。
一. 安装node-exporter
二进制安装
下载安装包并解压
$ wget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz
$ tar -xvf tar -xvf node_exporter-1.1.2.linux-amd64.tar.gz
$ cd node_exporter-1.1.2.linux-amd64启动 Node Exporter
$ ./node_exporter &
查看服务器,可看到端口已启动(默认端口9100)
$ netstat -lnpt |grep ":9100"
docker安装
官方不建议通过Docker方式部署node-exporter,因为它需要访问主机系统。 通过docker部署的方式,需要把任何非根安装点都绑定到容器中,并通过--path.rootfs参数指定。
docker run -d --net="host" --pid="host" -v "/:/host:ro,rslave" prom/node-exporter --path.rootfs=/host
部署完成后,访问节点地址:http://ip:9100/metrics ,可看到node-exporter获取的指标。
二. 配置node-exporter
node-exporter提供不少配置参数,可使用 --help 进行查看。
$ ./node_exporter --help
例如:通过--web.listen-address 改变监听的端口
$ ./node_exporter --web.listen-address=":8080" &
如果需要收集主机上面运行服务的状态,可启用systemd收集器。由于systemd指标较多,可以用--collector.systemd.unit-include参数配置只收集指定的服务,减少无用数据,该参数支持正则表达式匹配。如docker和ssh服务状态,
示例:./node_exporter --collector.systemd --collector.systemd.unit-include="(docker|sshd).service" &
如果只想启用需要的收集器,其他的全部禁用,可用如下格式配置
--collector.disable-defaults --collector.<name>
三. textfile收集器
textfile是一个特定的收集器,它的功能非常有用,textfile允许我们暴露自定义的指标。这些指标或者是没有相关的exporter可以使用,或者是你自己开发的应用指标。
textfile通过扫描指定目录中的文件,提取所有符合Prometheus数据格式的字符串,然后暴露它们给到Prometheus进行抓取。
示例:
创建指标文件保存目录 mkdir /opt/prom
$ cat <<EOF | tee /opt/prom/metadata.prom
# HELP alex_test this is a test
# TYPE alex_test gauge
alex_test{server="test",idc="bj"} 1
EOF启用textfile ./node_exporter --collector.textfile.directory="/opt/prom" &
访问node-exporter的地址,可看到指标已生效

四. Prometheus抓取指标
在Prometheus配置关于node-exporter节点的target,即可抓取相关节点指标数据。
scrape_configs:
- job_name: 腾讯云-重庆
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
basic_auth:
username: prometheus
password: <secret>
follow_redirects: true
static_configs:
- targets:
- xx.xx.xx.xx:xxxx
- job_name: 阿里云-演示
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
basic_auth:
username: prometheus
password: <secret>
follow_redirects: true
static_configs:
- targets:
- xx.xx.xx.xx:xxxx
- job_name: 阿里云-张家口-devops
honor_timestamps: true
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
basic_auth:
username: prometheus
password: <secret>
follow_redirects: true
static_configs:
- targets:
- xx.xx.xx.xx:xxxx在表达式浏览器中搜索 {job="阿里云-张家口-devops"},可看到相关指标已被收集到Prometheus。
]]>官方的Terraform教程真的写的很好,把官方学一遍也基本掌握的差不多了。
我学习Terraform有以下原因:
- 本身工作要求需要经常在aws上面进行资源操作
- 不喜欢aws的cloudformation
- terraform可以满足多云需求
参考
]]>dynamic 支持在 resource, data, provider 和 provisioner blocks 内使用
举例
下列的 subnet 定义是重复的
resource "azurerm_virtual_network" "dynamic_block" {
name = "vnet-dynamicblock-example-centralus"
resource_group_name = azurerm_resource_group.dynamic_block.name
location = azurerm_resource_group.dynamic_block.location
address_space = ["10.10.0.0/16"]
subnet {
name = "snet1"
address_prefix = "10.10.1.0/24"
}
subnet {
name = "snet2"
address_prefix = "10.10.2.0/24"
}
subnet {
name = "snet3"
address_prefix = "10.10.3.0/24"
}
subnet {
name = "snet4"
address_prefix = "10.10.4.0/24"
}
}使用 dynamic 进行封装
resource "azurerm_virtual_network" "dynamic_block" {
name = "vnet-dynamicblock-example-centralus"
resource_group_name = azurerm_resource_group.dynamic_block.name
location = azurerm_resource_group.dynamic_block.location
address_space = ["10.10.0.0/16"]
dynamic "subnet" {
for_each = var.subnets
iterator = item #optional
content {
name = item.value.name
address_prefix = item.value.address_prefix
}
}
}subnets 改为通过变量传入
variable "subnets" {
description = "list of values to assign to subnets"
type = list(object({
name = string
address_prefix = string
}))
}实际的值类似
subnets = [
{ name = "snet1", address_prefix = "10.10.1.0/24" },
{ name = "snet2", address_prefix = "10.10.2.0/24" },
{ name = "snet3", address_prefix = "10.10.3.0/24" },
{ name = "snet4", address_prefix = "10.10.4.0/24" }
]Dynamic 支持多级嵌套
dynamic "origin_group" {
for_each = var.load_balancer_origin_groups
iterator = outer_block
content {
name = outer_block.key
dynamic "origin" {
for_each = outer_block.value.origins
iterator = inner_block
content {
hostname = inner_block.value.hostname
}
}
}
}再举例
Cloudfront 在prod下绑定的域名是https,有个cloudfront_default_certificate属性需要是false,其他环境需要是true,所以我们可以这么写
resource "aws_cloudfront_distribution" "govplt-s3-website-distribution" {
// .....
dynamic "viewer_certificate" {
for_each = var.env_name == "prod" ? [1] : []
content {
cloudfront_default_certificate = false
iam_certificate_id = data.aws_iam_server_certificate.govplt-management-domain.id
minimum_protocol_version = "TLSv1.2_2021"
ssl_support_method = "sni-only"
}
}
dynamic "viewer_certificate" {
for_each = var.env_name != "prod" ? [1] : []
content {
cloudfront_default_certificate = true
}
}
}terraform plan和terraform apply是希望terraform配置文件和实际资源保持一致terraform refresh是希望state文件和实际资源保持一致- 当执行
terraform plan,terraform apply和terraform destroy会自动先执行terraform refresh
state管理
简单来说,Terraform 将每次执行基础设施变更操作时的状态信息保存在当前目录的叫做terraform.tfstate的状态文件中。
当我们创建,销毁,更新resource基础设施资源,该文件会被同步更新。
为了解决多人状态文件的存储和共享问题,Terraform引入了远程状态存储机制, 将这个文件存储到远程数据库或对象存储。
以AWS为例
state从local改为AWS S3后端
当前目录新建 module-tf-state-backend-s3 目录, 里面的 main.tf 内容是
module-tf-state-backend-s3
--- main.tf
--- variables.tfresource "aws_s3_bucket" "terraform_state" {
bucket = var.bucket_name
lifecycle {
prevent_destroy = true
ignore_changes = [tags]
}
}
resource "aws_s3_bucket_versioning" "terraform_s3_bucket_versioning" {
bucket = aws_s3_bucket.terraform_state.id
versioning_configuration {
status = "Enabled"
}
}
resource "aws_s3_bucket_server_side_encryption_configuration" "terraform_state_encryption" {
bucket = aws_s3_bucket.terraform_state.bucket
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
resource "aws_dynamodb_table" "terraform_locks" {
name = var.aws_dynamodb_table_name
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
lifecycle {
ignore_changes = [tags]
}
}variables.tf
variable "bucket_name" {
type = string
default = "terraform-state"
description = "the unique bucket name"
}
variable "aws_dynamodb_table_name" {
type = string
default = "terraform-locks"
description = "the unique bucket name"
}## 引入module-tf-state-backend-s3, 执行 tf apply, 创建好S3和dynamodb
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.16"
}
}
required_version = ">= 1.2.0"
# backend "s3" {
# bucket = "terraform-state-655418457877"
# // S3 bucket 中 Terraform 状态文件写入的文件路径
# key = "global/terraform.tfstate"
# region = "cn-north-1"
# // 用于锁定的 DynamoDB 表
# dynamodb_table = "terraform-locks"
# // Terraform 状态文件将以加密格式存储在S3的磁盘上
# encrypt = true
# }
}
module "backend_s3" {
source = "../modules/module-tf-state-backend-s3"
bucket_name = "terraform-state-${local.account_id}"
}
## 2. 更新TF后端,去掉backend "s3" 的整块注释,注意S3的bucket名称,由于在region是唯一的,不能重名,故修改后缀数字改为account_id
## 3. 执行 terraform init -migrate-state查看受到 terraform state 管理的资源列表
terraform state list
从 state 管理中排除资源,使其不受 terraform 维护,但是不会删除该资源,只是改为手动维护
terraform state rm module.eks-aws-lb-controller
terraform state rm module.module-eks-aws-load-balancer-controller导入已存在的基础设施资源到 state
terraform import module.eks.aws_iam_role.gitlab-deploy-role gitlab-deployment-eks-role指定具体模块 apply 或 plan
terraform plan -target=module.mymodule.aws_instance.myinstance
terraform apply -target=module.mymodule.aws_instance.myinstance
terraform plan -target=aws_instance.myinstance
terraform apply -target=aws_instance.myinstancealias tf="terraform"
alias tfa="terraform apply"
alias tfp="terraform plan"加速 tf init
执行 tf init 时,让 provider 从本地目录搜索安装,解决因为联网超时,导致init失败
- 创建TF配置文件,参数说明
Windows 系统: C:\Users\your_user_name\AppData\Roaming\terraform.rc MacOS: ~/.terraformrc
disable_checkpoint = true
disable_checkpoint_signature = true
plugin_cache_dir = "D:/terraform-providers"
provider_installation {
filesystem_mirror {
path = "D:/terraform-providers"
include = ["registry.terraform.io/*/*"]
}
}- 创建缓存目录
mkdir -p ~/.terraform.d/plugin-cache
.terraform.d
├── checkpoint_cache
├── checkpoint_signature
├── credentials.tfrc.json
└── plugin-cache
└── registry.terraform.io
└── hashicorp
├── archive
│ └── 2.2.0
│ └── darwin_amd64
│ └── terraform-provider-archive_v2.2.0_x5
├── aws
│ ├── 4.35.0
│ │ └── darwin_amd64
│ │ └── terraform-provider-aws_v4.35.0_x5
│ ├── 4.38.0
│ │ └── darwin_amd64
│ │ └── terraform-provider-aws_v4.38.0_x5
│ ├── 4.40.0
│ │ ├── 4.40.0.json
│ │ └── darwin_amd64
│ │ └── terraform-provider-aws_v4.40.0_x5
│ ├── 4.44.0
│ │ └── darwin_amd64
│ │ └── terraform-provider-aws_v4.44.0_x5
│ └── index.json- 这样
terraform init就会使用本地目录,或者 显式指定terraform init -plugin-dir=~/.terraform.d/plugin-cache
修改 module 名字
需求: 要改代码中 module 的名字, module-demo-1 为 module-demo-2
module "module-demo-1" {
// ....
}- 指令先执行 tf init
- 再执行 tf state mv module.module-demo-1 module.module-demo-2
- 这样 plan 后不会发生变化
根据变量动态创建 resource
resource "aws_route53_record" "gov-apigw-inout-dns-record" {
count = var.env_name == "prod" ? 1 : 0
zone_id = data.aws_route53_zone.primary.id
name = var.acm_domain_name
type = "CNAME"
ttl = 300
records = [aws_api_gateway_domain_name.gov-apigw-inout-domain.regional_domain_name]
}关于 aws 的 tags 和 tags_all
Tag属性表示在 Terraform 状态文件中的特定 resource 的 tag,而tag_all是在 provider 上指定的 resource tag 和 default tag 的总和。
举个例子,如果我们想给asg创建出来的ec2添加默认tag,需要这么写
provider "aws" {
profile = "default"
region = "us-east-2"
default_tags {
tags = {
Environment = "Test"
Service = "Example"
HashiCorp-Learn = "aws-default-tags"
}
}
}
data "aws_default_tags" "current" {}
resource "aws_autoscaling_group" "example" {
availability_zones = data.aws_availability_zones.available.names
desired_capacity = 1
max_size = 1
min_size = 1
launch_template {
id = aws_launch_template.example.id
version = "$Latest"
}
# 这里使用dynamic关键字动态给resource添加tag
dynamic "tag" {
for_each = data.aws_default_tags.current.tags
content {
key = tag.key
value = tag.value
propagate_at_launch = true
}
}
}使用 terraform console 调试函数
$ terraform console
> concat(["a"], ["b"])
[
"a",
"b",
]
> max(4,12,7)
12有用的站点
]]>基金的种类?
(1)主动型股票、混合基金:以股票、债基等作为持仓,具体看持仓比例,很多混合型其实相当于股票型。 (2)债券型基金:以国债、海外债、企业债为主,部分会持仓可转债及少量股票。 (3)LOF基金:上市型开放式基金,可在场内交易,也可在场外购买,场内实时净值,场外净值要等待发布,而场外场内的净值会有所偏差,偏差幅度有时较大。 (4)FOF基金:一篮子基金组合,具体看2楼。 (5)货币型基金:就是余额宝啦,余额宝界面可以点基金详情,进行更换,我用的是兴全。 (6)ETF链接:就是场内ETF的链接拉。(余额宝的黄金,比如博时,就是场内黄金ETF的链接) (7)指数型(及增强)链接:指数链接型。包括行业指数,以中证指数有限公司制定的指数相关联。而增强型是经理会进行主动的微幅调仓。 (8)分级基金以及其他类型没研究过。
基金的A类C类有什么区别?
A类基本上买入、卖出(按时长) 收手续费,不收管理费。适合长期持有。 C类基本上买入卖出不收手续费,管理费在每天净值里扣。适合短线。 这里是大致描述,具体看基金买卖规则(有时C类也收买卖手续费的,要看清楚)。
基金当天买有效嘛?
当天15点前购买,按照收盘价结算,15点后就是成交状态,不可撤销。不到15点可以撤销。 当天15点后购买,是按照明天15点结算,在明天15点前,都可以撤销。
基金的单位净值和累计净值
基金的单位净值,其实就是每份基金的价格。 计算公式是:基金的总净资产/基金份额总数。 假设说,现在基金的总净资产有15亿,而现在基金的份额总数有10亿份,那么计算下来每一份的单位净值也就是1.5元。
只是大家需要注意的是,通常我们在基金销售软件上,所看到的基金的单位净值,是前一个交易日的基金单位净值,并不是我买入时候的单位净值。 因为基金的净值,是在交易日晚上才会公布的。 我们买基金的时候,并不知道它当天的单位净值是多少。 也就是说,我们是盲买的。如果我们在交易当天下午三点之前买入,那么真正成交的净值会是当天晚上的公布的净值。 如何超过三点了,那么就是第二个交易日晚上公布的净值了。
举个例子:假设我们是在周五下午3点之前买入的基金,那么是按照当日晚上的基金单位净值进行结算。 如果我们是在周五下午三点之后买入的基金,那么会按下一个交易日,也就是下周一晚上的基金单位净值进行结算的。 (同样周末买的基金,和星期一下午3点之前买入的基金一样,都是按照周一晚上的基金净值结算的。)
基金的单位净值讲完了,我们再来聊聊累计净值。 其实累计净值就是单位净值加上基金所有历史分红。 用基金的累计净值减去1得到的就是这只基金成立以来,给我们创造的总收益。所以,这个数值是越高越好。
有一些朋友喜欢买“便宜”的基金,觉得基金的单位净值越低越好,但是事实上基金的单位净值也是越高越好。 有的基金为了迎合某些人买“便宜”基金的心态,就多一些分红,把基金的单位净值给降低。 但其实基金的分红,就是就是把我们基金里面的钱,又还给我们而已,我们的总资产,并没有因为基金的分红而增加或者减少。 如果基金没有分红,那么基金的单位净值和累计净值,就是一样的。
不是说基金不分红就不是好基金,基金经常分红就是好基金。判断基金好坏,和基金分红没有关关系。 在上面的那张截图当中,除去单位净值和累计净值之外,还有一个净值估算。这又是什么意思呢?
前面我们说了,我们当天看到的是基金前一个交易日的净值。 而基金当天的净值,一般是在当天晚上才会公布。 那么在这之前,我们能不能提前知道该基金当天晚上的净值呢?可以的,这就是净值估算的作用。 当然,这个功能不是每一个平台都有,目前只有少部分平台有这个功能,是平台根据基金的持仓情况,结合当天的市场情况,再结合自己的大数据最后预估出来的。 一般来说指数基金的估算会比较准确一些,而主动管理型基金的估算通常不会太准。因此,这个数据也只是作为一个参考。
哪里购买比较好?
各大平台都可以,我主要在支付宝买。 其他平台有东方财富的天天基金,雪球的蛋卷基金等 另外有些基金只能在特定的app上购买,比如易方达推出的某些基金只能在易方达e钱包app上的购买
晨星评级
晨星评级是一个相对的评价标准,在过去 24 个月中,前 10% 的基金可以获得 5 星标准 评级可以参考,但是不要完全依赖评级。关于评级的主要方法可以浏览官方文档:晨星中国基金评级说明 。 https://cn.morningstar.com/Localization/CN/Products/IndexHelp/晨星中国基金评级说明.pdf
股票基金不要完全根据评级购买
挑选基金建议
-
新人的话建议先买指数基金,比如上证50,深沪300。因为操作简单不用怎么操作。不需要多少专业知识。 然后是混合行业基金,比如三大黄金赛道,消费,医疗和科技。 对于单一成分基金要足够重视。 比如诺安成长混合虽然带混合二字,但看持仓,清一色的芯片科技行业,这种基金在顺周期涨的时候非常猛,但可能过几个月跌的时候也非常快。
-
买行业指数基金要操心,行业具有周期性,比如生物医疗行业受疫情影响在2020年上半年表现非常优异, 但到了下半年回撤很多,要么要有耐心。或者每隔几个月转移到其他板块。
-
看基金公司和基金经理,建议至少3年从业经验吧
私募公募有什么区别?
私募一般起点较高,我见过最低的是31万起步。 一般是各大平台的专享专区,比如余额宝财富页面的尊享。 私募这块我很少研究。 个人不推荐。
ETF
交易型开放式指数基金,通常又被称为交易所交易基金(Exchange Traded Fund,简称ETF) 大家只要记住,ETF 是「用股票账户购买的基金」就可以了。 ETF就是股票市场交易的基金,里面有一篮子股票,比例由基金经理调整。又分指数被动基金和主动基金,前者跟踪中证公司公布的指数成分股,后者由基金经理根据自己的判断调整。
挑选ETF,直接登录上交所网站
ETF基金特点: 流动性强,ETF 可以即时成交,非常快速;而普通基金申购需要 1 天,赎回需要 3 天左右;
佣金便宜,ETF 的费率等同于佣金费率,现在普遍在 0.03%;相比之下,蚂蚁财富的费率是 0.12%,相差了 4 倍
特点:
- 可以像股票一样日内买卖的基金
- 买入ETF就相当于买入一个指数投资组合。例如,对于以上证50指数为标的的ETF,其价格走势应会与上证50指数走势一致,所以买入上证50指数ETF,就等于买进五十只绩优的股票,对中小投资人来说可达到分散风险的效果。
新基金为什么会有封闭期
一般新成立的基金会有3个月的封闭期,封闭期内无法申购和赎回。 新基金之所以要有一个封闭期,一方面是为了方便基金的后台(登记注册中心)为日常申购、赎回做好最充分的准备; 另一方面基金管理人则利用这段时间,开始初步用募集来的资金购买股票、债券,进行投资准备,在这段时间内,如果仍然有频繁的申购和赎回,势必对基金经理的建仓策略造成影响。 为了让基金管理人在不受外界干扰的情况下逐步建仓,新基金成立之后,一般都会有一段时间不接受投资人的申购和赎回。封闭期相对长一点,才能保障基金管理人的建仓步骤不受资金进出的影响,当然,根据《证券投资基金运作管理办法》规定,基金封闭期最长也就是3个月。 封闭期内不能申购、转换或赎回。在发行期间,即在结束发售前购买叫认购。封闭期过了,重新开放,就称为申购了。
一般来说,基金在发行期内仍可获得资金利息,封闭期内收益多少要看基金操作如何。
操作类
基金定投和一次性买入
区别在于风险高低,定投降低风险但并不会增加收益的数学期望.在涨多跌少的情况下一次性早买入收益比定投高,在长期低位震荡的情况下更适合选择定投?
(1)如果你会择时择势,一次性买入收益要比定投高,特别是买在牛市起步阶段。 (2)如果你择时能力差,建议定投,因为基金定投就是做微笑曲线。
同样市场大盘行情下,涨跌幅度股票型>混合型>指数型?
首先,股票型以及混合型的区别不大,主要还是看持仓,所以建议都称为主动型基金。 其次,主动型股票基金在绝大多数情况下,涨幅程度依赖经理操作以及持仓风格。
在初期投资已到达自己的盈利期望的情况下,应当减持观望,如果继续涨则择机撤,跌则定投买入?
前面提到的两本书,里面有教你止盈,但是还是要自己择时择势。
基金准备中长期持有的话,应该优先考虑指数型、混合型,而非股票型?
这里涉及到一个选基的问题。
如果追求高收益(伴随高风险), 中长期持有的话,还是建议做风口主题的基金,具体用天天基金APP的主题选基、股票选基等工具,看基金的持仓股票、持仓比例、持仓历史,再结合4433法则(新基则参考其经理其他管理基金),最后看经理是不是穿越过牛熊。
什么是4433法则
选基金的4433法则: 步骤1:选取一年期绩效前四分之一基金 步骤2:选取两年、三年、以及成立以来,基金绩效排名也在前四分之一的基金,其中在某期间内无基金绩效者亦予以保留。 步骤3:再从步骤2筛选的名单中,删除三个月与六个月不在前三分之一的基金,符合中长期绩效稳健的四四三三标准。 “4433”选基法则提供了一种兼顾长短期业绩的选基方法,虽简单却经过了严格的层层过滤。层层过滤,长短期收益益兼优。
同一个基金经理、相同方向,新基金比老基金收益更大?
没必要买新基。 (1) 配售的话,达不到资产管理需要。 (2) 新基金经常给同一经理的旧基金抬轿子。 (3) 封闭期3个月起步,有些长达3年。
工具
如果你打算买多个基金,为了防止重复,可以用天天基金的比较工具


癌股:这是我们股市的一种调侃的称呼,大跌的时候就说我们这个股市就像得了癌症,不行了。
涨停/跌停:我们股市是有涨跌幅限制的,有的10%,有的20%,意思就是当天不能波动超过这个幅度。
涨停板/跌停板:涨、跌到了规定的最大幅度,在这个上面股价成为了一个横线,比较像地板与天花板,所以就叫做板。
多头:就是看涨的投资者。
空头:看跌的投资者。
回调:回调就是跌了的意思,因为一般股市大趋势是往上的,涨起来跌下去就叫做回调。
崩盘:就是指跌了很多,崩掉了的意思,没有具体的一个数值。
跳水:就是本来平稳运行的股价突然下跌。
拉升:平稳运行的股价突然被拉起来。
洗盘:就是主力故意制造跌下去的假象,让散户误以为还会跌,然后卖出股票、基金。
砸盘:就是主力出货,砸跌了股价。
诱多:主力拉升,让散户以为是要涨了,让进场接盘。
诱空:类似于洗盘,只要跌的假象让人割肉。
阴跌:就是一天跌一点,慢刀子慢慢折磨人。
仓位:意思就是现在你的基金、股票里面的市值、份额是多少。
持仓:意思跟仓位差不多的。都是指你拿着的股票、基金的多少。持仓不动指拿着这个仓位不要动。
重仓:一般仓位较重指重仓,比如7成以上。
轻仓:一般仓位较轻指轻仓,比如3成以下。
清仓:意思就是卖掉了所有的仓位,把手里的股票、基金清了。
满仓/全仓:意思就是把手里用来投资的钱全部放进了股票、基金里面。
梭哈:这个不只是股市的名词,在赌场里面也是这样称呼,就是把剩余筹码一次性全部买进去,就叫做梭哈。
空仓/空手:就是没有仓位的意思,没有股票、基金持仓。
建仓:就是原来没有买入,现在开始买入的意思。
减仓:就是减一下仓位,卖出一些份额。
加仓:加一下仓位,买一些基金、股票的份额。
补仓:持仓是亏损的情况下,进行买入。
止盈:把盈利的股票、基金卖掉。
落袋为安:就是把股票、基金的份额换成现金,一般是指盈利的。
止损:把觉得还要下跌的股票、基金及时卖掉,止住损失不扩大。
踏空:就是想买没有买的股票、基金涨了很多,就是踏空了行情。
卖飞:就是持有的股票、基金卖掉了,然后涨了很多,卖早了。
逼空:就是一直强势上涨,逼着空头越来越难受
认购:在募集期买基金。
申购:在开放期买基金。
韭菜:就是指市场里面比较菜的人,在里面总是连续亏钱的投资者。就像韭菜一样,割了涨,涨了割。
做多:就是买入股票、基金,把股价买上去,就叫做做多。
做空:A股没有这个做法,但是单纯卖股票、基金也可以说做空。
上车:就是买了某个股票、基金,跟上了老司机的车。
大盘:一般就是指上证指数。
大盘股:就是市值很大的股票。
小盘股:市值比较小的股票。
绩优股:业绩优良公司的股票。
白马股:指长期绩优、回报率高并具有较高投资价值的股票。
蓝筹股:指长期稳定增长的、大型的、传统工业股及金融股。
成长股:有前途的产业中利润增长率较高的企业股票。
妖股:通常把那些股价走势奇特、怪异的股票称为“妖股”。
接盘:指买下别人卖出的股票。
打新:新股、新债上市时候申购,就叫做打新。一般都是稳赚的。
支撑位:就是在某个点位买盘很多,支撑力很强,股价跌不下去。
压力位:就是在某个点位卖盘很多,压力很大,股价上不去。
破位:就是突破了支撑位或者压力位,股价会继续上涨or下跌。
牛市:就是指07、15年那样的牛市,随便买都赚钱。
熊市:就是不赚钱时期的市场或者平淡时期的市场。
套牢:就是买在了高位,损失很大不舍得止损了。
割肉:就是把亏损的股票、基金赎回,钱就真的亏在了里面。
吃肉:就是今天大涨,有了很多盈利。
浮盈:没有取出来的盈利,可能能亏掉,没有落袋为安。
浮亏:没有卖掉股票、基金,这时候的亏损叫做浮亏,可能能涨回来。
关灯吃面:最早出现在股吧里一条发帖中所描述出的情景,用以表达发帖人股票投资失利后极度痛苦与绝望的心情。
追涨杀跌:就是在金融市场(股票,期货,外汇等)价格上涨的时候买入金融产品,以期待涨得更多,然后以更高的价格卖出获利了结。在金融市场价格下跌的时候卖出金融产品,以更低的价格买入回来,以获取价格下跌的收益。
高抛低吸:从最高点抛出,最低点吸收进来,从而做到高抛低吸。
主力:指主要的力量,一般也指股票中的庄家。形容市场上或一只股票里有一个或多个操纵价格的人或机构,以引导市场或股价向某个方向运行。
机构:指以证券、股票买卖交易为主要业务的公司或团体,一般也是大资金用户跟主力具有很高的重合度。
出货:指卖出股票获得收益,一般主力出货就是主力高位套现
游资:迅速移向能提供更好回报的任何国家的流动性极高的短期资本
北向资金:就是国外投资者通过香港投资内地的资金。
标的:就是股票、基金,对象的意思。
超跌反弹:跌的太多了,需要反弹一下释放一下多头力量。
抬轿:指后期买入的投资者为前面买入的人抬股价的行为。比如冯柳重仓90亿安防,知道消息后散户疯狂买入,就为冯柳抬轿了。
回踩:股票要上涨之前,主力为了验证某一个价位的支撑确实有效,主动回到(下跌)到那个地方重新验证是否支撑有效。
市盈率:股票的价格和每股收益的比率,大白话的讲就是按照目前的盈利,多少年能把当前公司股票市值买下来。
市净率:每股股价与每股净资产的比率。
估值:就是对市盈率、市净率、市盈率百分比、市净率百分比等分析,来判断这个股票、基金值不值得买。
基本面:公司角度,运营状况如何,主营业务、财务状况、盈利水平等。国家角度,影响公司发展前景的宏观经济运行情况,包括银行利率、财政政策、汇率波动等。
技术面:股价波动,进而通过各种方式计算出的能够判断未来可能涨跌的技术指标。
消息面:就是可能影响股价的消息。
]]>如果你正在做一个复杂项目,必然会需要自定义表单控件,这个控件主要需要实现ControlValueAccessor接口(译者注:该接口定义方法可参考**API 文档说明,也可参考Angular 源码定义**)。网上有大量文章描述如何实现这个接口,但很少说到它在 Angular 表单架构里扮演什么角色,如果你不仅仅想知道如何实现,还想知道为什么这样实现,那本文正合你的胃口。
首先我解释下为啥需要ControlValueAccessor接口以及它在 Angular 中是如何使用的。然后我将展示如何封装第三方组件作为 Angular 组件,以及如何使用输入输出机制实现组件间通信(译者注:Angular 组件间通信输入输出机制可参考**官网文档),最后将展示如何使用ControlValueAccessor来实现一种针对 Angular 表单**新的数据通信机制。
FormControl 和 ControlValueAccessor
如果你之前使用过 Angular 表单,你可能会熟悉**FormControl,Angular 官方文档将它描述为追踪单个表单控件值和有效性的实体对象。需要明白,不管你使用模板驱动还是响应式表单(译者注:即模型驱动),FormControl都总会被创建。如果你使用响应式表单,你需要显式创建FormControl对象,并使用formControl或formControlName指令来绑定原生控件;如果你使用模板驱动方法,FormControl对象会被NgModel指令隐式创建(译者注:可查看 Angular 源码这一行**):
@Directive({
selector: '[ngModel]...',
...
})
export class NgModel ... {
_control = new FormControl(); <---------------- here不管formControl是隐式还是显式创建,都必须和原生 DOM 表单控件如input,textarea进行交互,并且很有可能需要自定义一个表单控件作为 Angular 组件而不是使用原生表单控件,而通常自定义表单控件会封装一个使用纯 JS 写的控件如**jQuery UI's Slider。本文我将使用原生表单控件**术语来区分 Angular 特定的formControl和你在html使用的表单控件,但你需要知道任何一个自定义表单控件都可以和formControl指令进行交互,而不是原生表单控件如input。
原生表单控件数量是有限的,但是自定义表单控件是无限的,所以 Angular 需要一种通用机制来桥接原生/自定义表单控件和formControl指令,而这正是**ControlValueAccessor**干的事情。这个对象桥接原生表单控件和formControl指令,并同步两者的值。官方文档是这么描述的(译者注:为清晰理解,该描述不翻译):
ControlValueAccessoracts as a bridge between the Angular forms API and a native element in the DOM.
任何一个组件或指令都可以通过实现ControlValueAccessor接口并注册为NG_VALUE_ACCESSOR,从而转变成ControlValueAccessor类型的对象,稍后我们将一起看看如何做。另外,这个接口还定义两个重要方法——writeValue和registerOnChange(译者注:可查看 Angular 源码**这一行**):
interface ControlValueAccessor {
writeValue(obj: any): void
registerOnChange(fn: any): void
registerOnTouched(fn: any): void
...
}formControl指令使用writeValue方法设置原生表单控件的值(译者注:你可能会参考**L186和L41);使用registerOnChange方法来注册由每次原生表单控件值更新时触发的回调函数(译者注:你可能会参考这三行,L186和L43,以及L85),你需要把更新的值传给这个回调函数,这样对应的 Angular 表单控件值也会更新(译者注:这一点可以参考 Angular 它自己写的DefaultValueAccessor的写法是如何把 input 控件每次更新值传给回调函数的,L52和L89);使用registerOnTouched方法来注册用户和控件交互时触发的回调(译者注:你可能会参考L95**)。
下图是Angular 表单控件如何通过ControlValueAccessor来和原生表单控件交互的(译者注:formControl和**你写的或者 Angular 提供的CustomControlValueAccessor**两个都是要绑定到 native DOM element 的指令,而formControl指令需要借助CustomControlValueAccessor指令/组件,来和 native DOM element 交换数据。):

再次强调,不管是使用响应式表单显式创建还是使用模板驱动表单隐式创建,ControlValueAccessor都总是和 Angular 表单控件进行交互。
Angular 也为所有原生 DOM 表单元素创建了Angular表单控件(译者注:Angular 内置的 ControlValueAccessor):
| Accessor | Form Element |
|---|---|
| DefaultValueAccessor | input,textarea |
| CheckboxControlValueAccessor | input[type=checkbox] |
| NumberValueAccessor | input[type=number] |
| RadioControlValueAccessor | input[type=radio] |
| RangeValueAccessor | input[type=range] |
| SelectControlValueAccessor | select |
| SelectMultipleControlValueAccessor | select[multiple] |
从上表中可看到,当 Angular 在组件模板中中遇到input或textareaDOM 原生控件时,会使用DefaultValueAccessor指令:
@Component({
selector: 'my-app',
template: `
<input [formControl]="ctrl">
`
})
export class AppComponent {
ctrl = new FormControl(3);
}所有表单指令,包括上面代码中的formControl指令,都会调用**setUpControl函数来让表单控件和DefaultValueAccessor实现交互(译者注:意思就是上面代码中绑定的formControl指令,在其自身实例化时,会调用setUpControl()函数给同样绑定到input的DefaultValueAccessor指令做好安装工作,如L85**,这样formControl指令就可以借助DefaultValueAccessor来和input元素交换数据了)。细节可参考formControl指令的代码:
export class FormControlDirective ... {
...
ngOnChanges(changes: SimpleChanges): void {
if (this._isControlChanged(changes)) {
setUpControl(this.form, this);还有setUpControl函数源码也指出了原生表单控件和 Angular 表单控件是如何数据同步的(译者注:作者贴的可能是 Angular v4.x 的代码,v5 有了点小小变动,但基本相似):
export function setUpControl(control: FormControl, dir: NgControl) {
// initialize a form control
// 调用 writeValue() 初始化表单控件值
dir.valueAccessor.writeValue(control.value);
// setup a listener for changes on the native control
// and set this value to form control
// 设置原生控件值更新时监听器,每当原生控件值更新,Angular 表单控件值也更新
valueAccessor.registerOnChange((newValue: any) => {
control.setValue(newValue, {emitModelToViewChange: false});
});
// setup a listener for changes on the Angular formControl
// and set this value to the native control
// 设置 Angular 表单控件值更新监听器,每当 Angular 表单控件值更新,原生控件值也更新
control.registerOnChange((newValue: any, ...) => {
dir.valueAccessor.writeValue(newValue);
});只要我们理解了内部机制,就可以实现我们自定义的 Angular 表单控件了。
组件封装器
由于 Angular 为所有默认原生控件提供了控件值访问器,所以在封装第三方插件或组件时,需要写一个新的控件值访问器。我们将使用上文提到的 jQuery UI 库的**slider**插件,来实现一个自定义表单控件吧。
简单的封装器
最基础实现是通过简单封装使其能在屏幕上显示出来,所以我们需要一个NgxJquerySliderComponent组件,并在其模板里渲染出slider:
@Component({
selector: 'ngx-jquery-slider',
template: `
<div #location></div>
`,
styles: ['div {width: 100px}']
})
export class NgxJquerySliderComponent {
@ViewChild('location') location;
widget;
ngOnInit() {
this.widget = $(this.location.nativeElement).slider();
}
}这里我们使用标准的jQuery方法在原生 DOM 元素上创建一个slider控件,然后使用widget属性引用这个控件。
一旦简单封装好了slider组件,我们就可以在父组件模板里使用它:
@Component({
selector: 'my-app',
template: `
<h1>Hello {{name}}</h1>
<ngx-jquery-slider></ngx-jquery-slider>
`
})
export class AppComponent { ... }为了运行程序我们需要加入jQuery相关依赖,简化起见,在index.html中添加全局依赖:
<script src="proxy.php?url=https://code.jquery.com/jquery-3.2.1.js"></script>
<script src="proxy.php?url=https://code.jquery.com/ui/1.12.1/jquery-ui.js"></script>
<link rel="stylesheet" href="proxy.php?url=//code.jquery.com/ui/1.12.1/themes/smoothness/jquery-ui.css">这里是安装依赖的**源码**。
交互式表单控件
上面的实现还不能让我们自定义的slider控件与父组件交互,所以还得使用输入/输出绑定来是实现组件间数据通信:
export class NgxJquerySliderComponent {
@ViewChild('location') location;
@Input() value;
@Output() private valueChange = new EventEmitter();
widget;
ngOnInit() {
this.widget = $(this.location.nativeElement).slider();
this.widget.slider('value', this.value);
this.widget.on('slidestop', (event, ui) => {
this.valueChange.emit(ui.value);
});
}
ngOnChanges() {
if (this.widget && this.widget.slider('value') !== this.value) {
this.widget.slider('value', this.value);
}
}
}一旦slider组件创建,就可以订阅slidestop事件获取变化的值,一旦slidestop事件被触发了,就可以使用输出事件发射器valueChanges通知父组件。当然我们也可以使用ngOnChanges生命周期钩子来追踪输入属性value值的变化,一旦其值变化,我们就将该值设置为slider控件的值。
然后就是父组件中如何使用slider组件的代码实现:
<ngx-jquery-slider
[value]="sliderValue"
(valueChange)="onSliderValueChange($event)">
</ngx-jquery-slider>**源码**在这里。
但是,我们想要的是,使用slider组件作为表单的一部分,并使用模板驱动表单或响应式表单的指令与其数据通信,那就需要让其实现ControlValueAccessor接口了。由于我们将实现的是新的组件通信方式,所以不需要标准的输入输出属性绑定方式,那就移除相关代码吧。(译者注:作者先实现标准的输入输出属性绑定的通信方式,又要删除,主要是为了引入新的表单组件交互方式,即ControlValueAccessor。)
实现自定义控件值访问器
实现自定义控件值访问器并不难,只需要两步:
- 注册
NG_VALUE_ACCESSOR提供者 - 实现
ControlValueAccessor接口
NG_VALUE_ACCESSOR提供者用来指定实现了ControlValueAccessor接口的类,并且被 Angular 用来和formControl同步,通常是使用组件类或指令来注册。所有表单指令都是使用NG_VALUE_ACCESSOR标识来注入控件值访问器,然后选择合适的访问器(译者注:这句话可参考这两行代码,L175和L181)。要么选择DefaultValueAccessor或者内置的数据访问器,否则 Angular 将会选择自定义的数据访问器,并且有且只有一个自定义的数据访问器(译者注:这句话参考**selectValueAccessor源码实现**)。
让我们首先定义提供者:
@Component({
selector: 'ngx-jquery-slider',
providers: [{
provide: NG_VALUE_ACCESSOR,
useExisting: NgxJquerySliderComponent,
multi: true
}]
...
})
class NgxJquerySliderComponent implements ControlValueAccessor {...}我们直接在组件装饰器里直接指定类名,然而 Angular 源码默认实现是放在类装饰器外面:
export const DEFAULT_VALUE_ACCESSOR: any = {
provide: NG_VALUE_ACCESSOR,
useExisting: forwardRef(() => DefaultValueAccessor),
multi: true
};
@Directive({
selector:'input',
providers: [DEFAULT_VALUE_ACCESSOR]
...
})
export class DefaultValueAccessor implements ControlValueAccessor {}放在外面就需要使用forwardRef,关于原因可以参考**What is forwardRef in Angular and why we need it**。当实现自定义controlValueAccessor,我建议还是放在类装饰器里吧(译者注:个人建议还是学习 Angular 源码那样放在外面)。
一旦定义了提供者后,就让我们实现controlValueAccessor接口:
export class NgxJquerySliderComponent implements ControlValueAccessor {
@ViewChild('location') location;
widget;
onChange;
value;
ngOnInit() {
this.widget = $(this.location.nativeElement).slider(this.value);
this.widget.on('slidestop', (event, ui) => {
this.onChange(ui.value);
});
}
writeValue(value) {
this.value = value;
if (this.widget && value) {
this.widget.slider('value', value);
}
}
registerOnChange(fn) { this.onChange = fn; }
registerOnTouched(fn) { }由于我们对用户是否与组件交互不感兴趣,所以先把registerOnTouched置空吧。在registerOnChange里我们简单保存了对回调函数fn的引用,回调函数是由formControl指令传入的(译者注:参考**L85**),只要每次slider组件值发生改变,就会触发这个回调函数。在writeValue方法内我们把得到的值传给slider组件。
现在我们把上面描述的功能做成一张交互式图:

如果你把简单封装和controlValueAccessor封装进行比较,你会发现父子组件交互方式是不一样的,尽管封装的组件与slider组件的交互是一样的。你可能注意到formControl指令实际上简化了与父组件交互的方式。这里我们使用writeValue来向子组件写入数据,而在简单封装方法中使用ngOnChanges;调用this.onChange方法输出数据,而在简单封装方法中使用this.valueChange.emit(ui.value)。
现在,实现了ControlValueAccessor接口的自定义slider表单控件完整代码如下:
@Component({
selector: 'my-app',
template: `
<h1>Hello {{name}}</h1>
<span>Current slider value: {{ctrl.value}}</span>
<ngx-jquery-slider [formControl]="ctrl"></ngx-jquery-slider>
<input [value]="ctrl.value" (change)="updateSlider($event)">
`
})
export class AppComponent {
ctrl = new FormControl(11);
updateSlider($event) {
this.ctrl.setValue($event.currentTarget.value, {emitModelToViewChange: true});
}
}你可以查看程序的**最终实现**。
Github
项目的**Github 仓库**。
]]>{{a | currency:'USD':true:'1.0-0'}}
如果变量a的值是2345。格式化后会显示成$2,345。非常方便。
如果需要在component内使用原生pipe,可以用下面的方法:
- 打开component所属的module文件,添加提供器,供依赖注入
import {CurrencyPipe} from '@angular/common'
.....
providers: [CurrencyPipe]- 打开要使用的component文件,往构造函数中注入刚才定义的提供器
import {CurrencyPipe} from '@angular/common'
....
constructor(private currencyPipe: CurrencyPipe) { ... }- 在component也就是ts中,就可以直接使用了
// $12,345
this.value = this.cp.transform(this.value, 'USD': true: '1.0-0')参考:
http://ngninja.com/posts/angular2-builtin-pipes-in-typescript
]]>Angular 扩展了ngIf 指令, 加入了两个新伙伴 else 和 then。
ngIf 内的 expression并会对expression进行求值,如果为真,则在原地渲染then模板,否则渲染else模板。通常:
then模板就是ngIf中内联的模板 —— 除非你指定了另一个值。else模板是空白的 —— 除非你另行指定了。
else
当表达式为false,用于显示的模板。
注意,else绑定指向的是一个带有#elseBlock标签的<ng-template>元素。 该模板可以定义在此组件视图中的任何地方,但为了提高可读性,通常会放在 ngIf的紧下方。
<button (click)="show = !show">{{show ? 'hide' : 'show'}}</button>
<div *ngIf="show; else elseBlock">to show</div>
<ng-template #elseBlock>Alternate text while primary text is hidden</ng-template>then
<div *ngIf="show; then thenBlock; else elseBlock">this is ignored</div>
<ng-template #primaryBlock>Primary text to show</ng-template>
<ng-template #secondaryBlock>Secondary text to show</ng-template>
<ng-template #elseBlock>Alternate text while primary text is hidden</ng-template>总结:
你完全写一堆ngIf进行判断分支判断,这样会导致代码可读性比较差。
]]>要创建一个管道,必须实现 PipeTransform 接口。这个接口非常简单,只需要实现transform方法即可。
使用管道的几个注意事项:
- 管道可以链式使用,还可以传参
{{date | date: 'fullDate' | uppercase}}- 管道分两种 纯(pure)管道与非纯(impure)管道 默认是pure的。 Angular 只有在它检测到输入值发生了纯变更时才会执行纯管道。 纯变更是指对原始类型值(String、Number、Boolean、Symbol)的更改, 或者对对象引用(Date、Array、Function、Object)的更改。
使用 impure 管道时候要小心,很可能触发非常频繁。
- 也是出于性能的考虑。Angular并没有提供 angularjs 自带的 Filter 和 OrderBy 过滤器,Angular官方推荐把过滤和排序放到组件中实现,比如对外提供
filteredHeroes或sortedHeroes属性
Angular提供了json和async管道,我们来分析下源码
源码解析
json管道
/node_modules/@angular/common/esm5/src/pipes/json_pipe.js非常简单,就一行话。
JsonPipe.prototype.transform = function (value) {
return JSON.stringify(value, null, 2);
};async管道
这个是Angular特有的管道,可以多使用 其实会处理两种对象类型,Observable或Promise,简单说如果是Observable会执行subscription方法,如果是Promise会调用then方法。如果是Observable当组件销毁时执行unsubscribe方法取消订阅。 node_modules/@angular/common/esm5/src/pipes/async_pipe.js:11
参考
]]>- 新建Resolve文件,这里起名 FxAccountListResolverService 要求实现Resolve方法,该方法可以返回一个 Promise、一个 Observable 来支持异步方式,或者直接返回一个值来支持同步方式。
import { Injectable } from '@angular/core';
import { Router, Resolve, } from '@angular/router';
import { AccountService } from '../_services';
import { map } from 'rxjs/operators';
@Injectable({
providedIn: 'root'
})
export class FxAccountListResolverService implements Resolve<any> {
constructor(
public service: AccountService,
public router: Router,
) {
}
resolve() {
return this.service.getAccountList()
.pipe(map(response => {
if (response.success) {
if (response.data.length && response.data.length === 1) {
this.router.navigate(['/pageB']);
} else {
return response.data;
}
} else {
return [];
}
}));
}
}- 修改路由,添加 resolve 配置
{
path: 'accounts',
component: FxAccountListComponent,
resolve: {
data: FxAccountListResolverService,
}
},- 修改 FxAccountListComponent 中的 ngOnInit 之前代码,我们是在组件中取数据,因为以为改成了从 resolve 中取数据
this.service.getAccountList().subscribe( (res: Account) => {
// ...
});改为如下,这里route.snapshot.data 就是后台返回的数据 import { ActivatedRoute, Router } from '@angular/router';
constructor(
private route: ActivatedRoute,
) { }
ngOnInit() {
let result = this.route.snapshot.data.data;
}参考:https://angular.cn/guide/router#resolve-pre-fetching-component-data
]]>import { Component } from '@angular/core';
import { HttpClient } from '@angular/common/http';
@Component({
selector: 'app-root',
templateUrl: 'app/app.component.html'
})
export class AppComponent {
constructor(private http: HttpClient) { }
ngOnInit() {
// 发起一个get请求
this.http.get('/api/people/1').subscribe(json => console.log(json));
}
}注意:上面的this.http.get... 处理HTTP最好放到单独的Service文件中,再注入到Component。这里为了演示没有这么做。
优化有顺序依赖的多个请求
有些时候我们需要按顺序发起多个请求,根据第一个请求返回的结果中的某些内容,作为第二个请求的参数,比如下面代码。
ngOnInit() {
this.http.get('/api/people/1').subscribe(character => {
this.http.get(character.id).subscribe(homeworld => {
character.homeworld = homeworld;
this.loadedCharacter = character;
});
});
}上面的嵌套写法可读性不那么好,我们可以使用RxJS提供的mergeMap操作符来优化上述代码
import { Component } from '@angular/core';
import { Http } from '@angular/http';
import { Observable } from 'rxjs/Observable';
import { mergeMap } from 'rxjs/operators';
@Component({
selector: 'app-root',
templateUrl: 'app/app.component.html'
})
export class AppComponent {
homeworld: Observable<{}>;
constructor(private http: HttpClient) { }
ngOnInit() {
this.homeworld = this.http.get('/api/people/1')
.pipe(
mergeMap(character => this.http.get(character.homeworld))
);
}
}mergeMap 操作符用于从内部的 Observable 对象中获取值,然后返回给父级流对象。 可以合并 Observable 对象
处理并发请求
forkJoin 是 Rx 版本的 Promise.all(),即表示等到所有的 Observable 都完成后,才一次性返回值。
import { Component } from '@angular/core';
import { HttpClient } from '@angular/common/http';
import { Observable } from 'rxjs/Observable';
import { forkJoin } from "rxjs/observable/forkJoin";
@Component({
selector: 'app-root',
templateUrl: 'app/app.component.html'
})
export class AppComponent {
loadedCharacter: {};
constructor(private http: HttpClient) { }
ngOnInit() {
let character = this.http.get('https://swapi.co/api/people/1');
let characterHomeworld = this.http.get('http://swapi.co/api/planets/1');
forkJoin([character, characterHomeworld]).subscribe(results => {
// results[0] is our character
// results[1] is our character homeworld
results[0].homeworld = results[1];
this.loadedCharacter = results[0];
});
}
}错误处理请求
使用 catchError 处理observable中的错误,需要返回一个新的 observable 或者直接抛出error
例1 ,在请求方法内部处理错误,若请求失败返回一个默认值,看起来用户也感知不到发生了错误
// http.service.ts
getPostDetail(id) {
return this.http
.get<any>(`https://jsonplaceholder.typicode.com/posts/${id}`)
.pipe(
// catchError 需要 returning a new observable or throwing an error.
catchError(err => {
// 如果发生错误,用缺省值,(尝试修改为错误地址)
return of({
userId: 1,
id: 1,
title: '-occaecati excepturi optio reprehenderit-',
body: '-eveniet architecto-'
});
})
)
}
// component 中调用
getPostDetail() {
this.postDetail$ = this.service.getPostDetail(1)
.subscribe(val => {
console.log(val);
});
}例2 直接把错误抛出来,在外部处理错误,比如来个弹窗,提示告诉用户
getPostDetail(id) {
return this.http
.get<any>(`${this.endpoint}/posts2/${id}`)
.pipe(
// catchError returning a new observable or throwing an error.
catchError(err => {
throw err;
})
)
}
// 改造调用方法
getPostDetail() {
this.postDetail$ = this.service.getPostDetail(1)
.subscribe(
(next) => {
},
// 这里接收内部抛出的错误
err => {
// 可以加入自己的错误处理逻辑,搞个弹窗,notify等
console.log(err);
}
)
}参考
]]>比如 ng-zorro项目中的 BackTop回到顶部 组件就支持自定义模板。
默认时可以使用<nz-back-top></nz-back-top>。获得这个图标。

也可以通过
<nz-back-top [nzTemplate]="tpl" [nzVisibilityHeight]="100" (nzOnClick)="notify()">
<ng-template #tpl>
<div class="ant-back-top-inner">UP</div>
</ng-template>
</nz-back-top>添加自定义模板。

核心是 ngTemplateOutlet
我们通过源码来看是如何实现的。 关键字 ngTemplateOutlet
- 先看模板,ngTemplateOutlet 是一个指令,它接收模板变量,可以实现模板的动态渲染, 在这里,如果定义了 nzTemplate 变量就使用它,否则用默认的defaultContent。

- nzTemplate 是输入变量,类型是TemplateRef, 即模板引用。

- 使用自定义模板
]]>

ngx服务是什么概念?可以简单地认为它是一个功能模块,重要在于它是单例对象,并且可以注入到其他的地方使用。
依赖注入(Dependency Injection 简称 DI)是来自后端的概念,其实就是自动创建一个实例,省去每次需要手动创建的麻烦。
在 Angular 中定义一个服务很简单,主要在类之前加上 @Injectable 装饰器的功能。这是最常见的依赖注入方式 useClass,其他具体参见这里。
import { Injectable } from '@angular/core';
@Injectable()
export class Service {
counter: number = 0;
getData(){
return this.counter++;
}
}然后在模块的providers中声明:
import { Service } from './service';
...
@NgModule({
imports: [
...
],
declarations: [
...
],
providers: [ Service ], // 注入服务
bootstrap: [...]
})
export class AppModule {
}使用的时候需要在构造器中建立关联:
import { Component } from '@angular/core';
import { Service } from './service';
...
@Component({
selector: 'my-app',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
constructor(public service: Service) {
// this.service被成功注入
// 相当于 this.service = new Service();
// 然后可以调用服务
this.service.getData();
}
}由于该服务是在模块中注入,所以该模块中的所有组件使用这个服务时,使用的都是同一个实例。
除了在模块中声明,还可以在组件中声明。假设AppComponent下还有组件HomeComponent,此时我们在AppComponent中注入这个服务:
import { Component } from '@angular/core';
import { Service } from './service';
...
@Component({
selector: 'my-app',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css'],
providers: [ Service ], // 注入服务
})
export class AppComponent {
constructor(public service: Service) {
// this.service被成功注入
// 相当于 this.service = new Service();
// 然后可以调用服务
this.service.getData();
}
}如果HomeComponent也使用了这个服务,那它使用的将是同一个实例。这个可以从Service中的数据变化来看出。
Angular还有个分层依赖注入的概念,也就是说,你可以为任一组件创建自己独立的服务。就像上面的例子,如果想要HomeComponent不和它的父组件同使用一个服务实例的话,只要在该组件中重新注入即可:
...
@Component({
selector: 'home',
templateUrl: './home.component.html',
styleUrls: ['./home.component.css'],
providers: [ Service ], // 重新注入服务
})
export class HomeComponent {
...
}对于前后端的接口,通常会写成服务。下面说下请求后端数据这块应该怎么写。在模块这节中提过,http有专门的HttpModule模块处理请求。首先要在模块中导入HttpModule,然后引入http服务,调用相应的请求方法即可。
import { Injectable } from '@angular/core';
import { Http } from '@angular/http';
@Injectable()
export class HttpService {
constructor(private http: Http) {}
getFromServer(): any {
return this.http.get(`/data`)
}
}Service 服务
Service 的表现形式是一个class,可以用来在组件中复用 比如 Http 请求获取数据,日志处理,验证用户输入等都写成Service,供组件使用。
import { Injectable } from '@angular/core';
// 在 Angular 中,要把一个类定义为服务,就要用`@Injectable` 装饰器来提供元数据
@Injectable({
// we declare that this service should be created
// by the root application injector.
providedIn: 'root',
})
export class LoggerService {
warn(msg) {
return console.warn(msg);
}
}Injector 注入器
一般不用自己手动注入,Angular 会在启动过程中为你创建全应用级注入器以及所需的其它注入器。
Provider 提供商
是一个对象,告诉 Injector 应该如何获取或创建依赖。
打开Angular看下面的代码片段 app.module.ts
@NgModule({
declarations: [
....
],
imports: [
....
],
// providers 告诉 Angular 应用哪些对象需要依赖注入
// providers 是个数组,每一项都是provider
providers: [
// 简写,等价 {provider: LoggerService, useClass: LoggerService}
LoggerService,
{
provide: RequestCache,
useClass: RequestCacheWithLocalStorage
},
{
provide: HTTP_INTERCEPTORS,
useClass: UrlInterceptor,
multi: true
},
],
bootstrap: [AppComponent]
})DI token(令牌)
provide 属性提供了provider 的token,也叫令牌,表示在构造函数中指定的类型。 也就是说,当constructor(private productService: ProductService){...} 指定了ProductService,就会去找token是productService的provider。

Provider 的几种写法
- useClass
providers: [{provide: ProductService, useClass: ProductService} ]的简写是providers: [ ProductService ]useClass属性指定实例化方式,表示是 new 一个 ProductService,如果userClass" AnotherProductService真正实例化的就是 AnotherProductService。 - userFactory
除了useClass写法,还可以使用 userFactory 工厂方法,这个方法返回的实例作为构造函数中productService参数的内容。
providers: [{provide: ProductService, userFactory: () => {}} ]这样可以根据条件具体实例化某对象,更加灵活
providers: [{
provide: ProductService,
userFactory: () => {
let logger = new LoggerService();
let dev = Math.random() > 0.5;
if (dev) {
return new ProductService(logger);
} else {
return new AnotherProductService(logger);
}
}
}, LoggerService ]上面的写法有个弊端LoggerService和ProductService耦合太强 进一步优化,利用deps参数,指工厂声明所依赖的参数。
providers: [{
provide: ProductService,
userFactory: (logger: LoggerService) => {
let dev = Math.random() > 0.5;
if (dev) {
return new ProductService(logger);
} else {
return new AnotherProductService(logger);
}
},
deps: [ LoggerService ]
},
LoggerService
]再次优化,定义第三个提供器,token是IS_DEV_ENV,值是具体的false
providers: [{
provide: ProductService,
// 注入的 顺序和deps对应
userFactory: (logger: LoggerService, isDev) => {
if (isDev) {
return new ProductService(logger);
} else {
return new AnotherProductService(logger);
}
},
deps: [ LoggerService, 'IS_DEV_ENV' ]
},
LoggerService,
{provide: 'IS_DEV_ENV', useValue: false}
]一般来说可以创建一个类型为对象的提供器供注入
providers: [{
provide: ProductService,
// 注入的 顺序和deps对应
userFactory: (logger: LoggerService, appConfig) => {
if (appConfig.isDev) {
return new ProductService(logger);
} else {
return new AnotherProductService(logger);
}
},
deps: [ LoggerService, 'APP_CONFIG' ]
},
LoggerService,
{ provide: 'APP_CONFIG', useValue: {isDev: false }}
]提供器的作用域

provide声明在App模块中,则对所有模块可见
provide声明在某组件中,只对该组件及其子组件可见。其他组件不可以注入。 当声明在组件和模块中的提供器具有相同的token时,声明在组件中的提供器会覆盖模块中的那个提供器。
@Injectable 装饰器
表示FooService可以通过构造函数注入其他服务 举个例子,如果注释掉
// @Injectable({
// providedIn: 'root'
// })就会报错


为什么在组件中没有写@Injectable也能直接注入service? 我们知道定义组件要写@Component装饰器,定义管道要写@Pipe装饰器,他们都是Injectable的子类。 同时Component又是Directive的子类,所以所有的组件都是指令。
手动注入
import { Component, OnInit, Injector } from '@angular/core';
import { LoggerService } from '../_service/logger.service';
@Component({
selector: 'app-di',
templateUrl: './di.component.html',
styleUrls: ['./di.component.styl']
})
export class DIComponent implements OnInit {
logger: LoggerService;
// 手动注入
constructor(
private injector: Injector
) {
this.logger = injector.get(LoggerService);
}
ngOnInit() {
this.logger.log()
}
}angular-quick-start执行ng build后,静态资源会输出到dist/angular-quick-start,angular-quick-start是项目名。

如果你不喜欢这个路径,可以打开angular.json,找到build--options--outputPath。
把值从"dist/angular-quick-start"改为"dist"
另外通过ng build --help可以查看有个--output-path参数,通过ng build --output-path=dist可以动态的指定文件输出路径
- 修改
app-routing.module.ts开启hash模式
@NgModule({
imports: [
// 加入 {useHash: true}
RouterModule.forRoot(routes, {useHash: true})
],
exports: [
RouterModule
]
})- 然后修改相关的module文件,比如ad页面的链接需要支持,组件所属于app-ad.module.ts 则打开这个文件
import { NgModule } from '@angular/core';
import { CommonModule, LocationStrategy, HashLocationStrategy } from '@angular/common';
......
@NgModule({
....
// 加入这个提供器,
providers: [
{
provide: LocationStrategy,
useClass: HashLocationStrategy
},
]
})
export class AppAdModule { }官方文档 有说明: RouterModule.forRoot 函数把 LocationStrategy 设置成了 PathLocationStrategy,使其成为了默认策略。 你可以在启动过程中改写(override)它,来切换到 HashLocationStrategy 风格。
延伸 -- 关于前端路由
页面地址中的 # 叫 hash,可以通过hashchange事件监听hash后面的地址内容发生变化。这个是Html5才有的API。也是各个前端路由类库的基础。 见例子
关于不刷新页面实现浏览器历史的前进后退,也是利用H5的History API
this.route.push('login') 和 this.route.replace('login') 实际上是调用的是History.pushState() 和 History.replaceState()
1. 父到子 -- Input
使用 @Input() 装饰器 通过模板把数据传到子组件中
This is probably the most common and straightforward method of sharing data. It works by using the @Input() decorator to allow data to be passed via the template.
parent.component.ts
import { Component } from '@angular/core';
@Component({
selector: 'app-parent',
template: `
<app-child [childMessage]="parentMessage"></app-child>
`,
styleUrls: ['./parent.component.css']
})
export class ParentComponent{
parentMessage = "message from parent"
constructor() { }
}child.component.ts
import { Component, Input } from '@angular/core';
@Component({
selector: 'app-child',
template: `
Say {{ message }}
`,
styleUrls: ['./child.component.css']
})
export class ChildComponent {
// https://angular.cn/api/core/Input
// Input 装饰器,用来把某个类字段标记为输入属性,并提供配置元数据。
// 该输入属性会绑定到模板中的某个 DOM 属性。当变更检测时,Angular 会自动使用这个 DOM 属性的值来更新此数据属性。
@Input() childMessage: string;
constructor() { }
}2. 子到父 -- ViewChild
ViewChild 装饰器可以将一个组件注入到另一个组件中,使得父组件访问子组件的属性和方法。 但是,需要注意的是,在初始化视图之前,子视图ViewChild是不可用的,这时,需要我们在父组件实现 ngAfterViewInit 生命周期钩子来接收来自子组件的数据。
ViewChild allows a one component to be injected into another, giving the parent access to its attributes and functions. One caveat, however, is that child won’t be available until after the view has been initialized. This means we need to implement the AfterViewInit lifecycle hook to receive the data from the child.
parent.component.ts
import { Component, ViewChild, AfterViewInit } from '@angular/core';
import { ChildComponent } from "../child/child.component";
@Component({
selector: 'app-parent',
template: `
Message: {{ message }}
<app-child></app-child>
`,
styleUrls: ['./parent.component.css']
})
export class ParentComponent implements AfterViewInit {
@ViewChild(ChildComponent) child;
constructor() { }
message:string;
ngAfterViewInit() {
this.message = this.child.message
}
}child.component.ts
import { Component} from '@angular/core';
@Component({
selector: 'app-child',
template: `
`,
styleUrls: ['./child.component.css']
})
export class ChildComponent {
message = 'Hola Mundo!';
constructor() { }
}3. 子到父 -- Output() 和 EventEmitter
当我们需要通过事件触发,提交表单将子组件数据传递给父组件时,使用Output()装饰器和EventEmitter共享数据是不错的方法。 在父组件中,我们创建一个方法来接收消息,并将其设置为消息变量。 在子组件中,定义一个名称为messageEvent的变量,类型为EventEmitter,使用Output装饰器标记为输出属性,又定义了名为sendMessage的方法,当点击按钮时调用这个方法,向外发送数据。 父组件订阅了来自子组件发出的messageEvent。
Another way to share data is to emit data from the child, which can be listed to by the parent. This approach is ideal when you want to share data changes that occur on things like button clicks, form entires, and other user events.
In the parent, we create a function to receive the message and set it equal to the message variable.
In the child, we declare a messageEvent variable with the Output decorator and set it equal to a new event emitter. Then we create a function named sendMessage that calls emit on this event with the message we want to send. Lastly, we create a button to trigger this function.
The parent can now subscribe to this messageEvent that’s outputted by the child component, then run the receive message function whenever this event occurs.
parent.component.ts
import { Component } from '@angular/core';
@Component({
selector: 'app-parent',
template: `
Message: {{message}}
<app-child (messageEvent)="receiveMessage($event)"></app-child>
`,
styleUrls: ['./parent.component.css']
})
export class ParentComponent {
constructor() { }
message:string;
receiveMessage($event) {
this.message = $event
}
}child.component.ts
import { Component, Output, EventEmitter } from '@angular/core';
@Component({
selector: 'app-child',
template: `
<button (click)="sendMessage()">Send Message</button>
`,
styleUrls: ['./child.component.css']
})
export class ChildComponent {
message: string = "Hola Mundo!"
@Output() messageEvent = new EventEmitter<string>();
constructor() { }
sendMessage() {
this.messageEvent.emit(this.message)
}
}4. 使用Service在不相关的组件中共享数据
由于Service是单例的,可以在不相干的组件(兄弟组件,孙子组件)中传递数据,只需要把这个Service注入到用到的组件中。
如果需要保持同步数据,在此场景下,RxJS的BehaviorSubject非常好用。 优点如下:
- 总是在订阅时返回当前值,不需要调用onnext
- 提供getValue()方法来获取最后值作为原始数据
- 确认组件总是收到最新值
在下面的例子中, data.service.ts
首先创建一个私有BehaviorSubject类型的变量,名为messageSource,初始值为'default message',又基于他创建了一个Observable类型的变量, 名为currentMessage。供在组件中使用。最后定义一个方法changeMessage来修改值。
parent.component.ts, sibling.component.ts
父组件、子组件和兄弟组件都是相同的处理。将DataService注入构造函数,然后订阅currentMessage,如果要修改值,只需调用changeMessage方法 这样其他组件会显示最新的修改值。
When passing data between components that lack a direct connection, such as siblings, grandchildren, etc, you should you a shared service. When you have data that should aways been in sync, I find the RxJS BehaviorSubject very useful in this situation.
You can also use a regular RxJS Subject for sharing data via the service, but here’s why I prefer a BehaviorSubject.
It will always return the current value on subscription - there is no need to call onnext It has a getValue() function to extract the last value as raw data. It ensures that the component always receives the most recent data.
In the service, we create a private BehaviorSubject that will hold the current value of the message. We define a currentMessage variable handle this data stream as an observable that will be used by the components. Lastly, we create function that calls next on the BehaviorSubject to change its value.
The parent, child, and sibling components all receive the same treatment. We inject the DataService in the constructor, then subscribe to the currentMessage observable and set its value equal to the message variable.
Now if we create a function in any one of these components that changes the value of the message. when this function is executed the new data it’s automatically broadcast to all other components.
data.service.ts
import { Injectable } from '@angular/core';
import { BehaviorSubject } from 'rxjs';
@Injectable()
export class DataService {
private messageSource = new BehaviorSubject('default message');
currentMessage = this.messageSource.asObservable();
constructor() { }
changeMessage(message: string) {
this.messageSource.next(message)
}
}parent.component.ts
import { Component, OnInit } from '@angular/core';
import { DataService } from "../data.service";
@Component({
selector: 'app-parent',
template: `
{{message}}
`,
styleUrls: ['./sibling.component.css']
})
export class ParentComponent implements OnInit {
message:string;
constructor(private data: DataService) { }
ngOnInit() {
this.data.currentMessage.subscribe(message => this.message = message)
}
}sibling.component.ts
import { Component, OnInit } from '@angular/core';
import { DataService } from "../data.service";
@Component({
selector: 'app-sibling',
template: `
{{message}}
<button (click)="newMessage()">New Message</button>
`,
styleUrls: ['./sibling.component.css']
})
export class SiblingComponent implements OnInit {
message:string;
constructor(private data: DataService) { }
ngOnInit() {
this.data.currentMessage.subscribe(message => this.message = message)
}
newMessage() {
this.data.changeMessage("Hello from Sibling")
}
}WARNING
如果你发现sharedService不生效,尝试把service放到组件对应的module的provider中而不是组件的provider中
@Component({
providers: [SharedDataService] <--- remove this line from both of your components, and add that line to your NgModule configuration instead
})
### 参考
* https://angularfirebase.com/lessons/sharing-data-between-angular-components-four-methods/
* https://stackoverflow.com/questions/40468172/how-to-share-data-between-components-using-a-service-properly
* https://stackoverflow.com/questions/42860896/angular-2-shared-data-service-is-not-working// https://stackoverflow.com/questions/49507928/how-to-inject-httpclient-in-static-method-or-custom-class
export function httpManual() {
const injector = Injector.create({
providers: [
{ provide: HttpClient, deps: [HttpHandler] },
{ provide: HttpHandler, useValue: new HttpXhrBackend({ build: () => new XMLHttpRequest }) },
],
});
const http = injector.get(HttpClient);
return http.get(`https://jsonplaceholder.typicode.com/todos`);
}https://stackblitz.com/edit/base-dialog
点击按钮,出现弹窗,背后还有遮盖层,弹窗的内容可以自定义
- 打开一个全新的 Angular 项目,然后执行创建组件命令
ng g c --name base-dialog得到三个初始化的文件

- 首先制作遮盖层,就是铺满整个屏幕的div
base-dialog.component.html
<div class="modal-overlay" *ngIf="visible"></div>对应的样式 base-dialog.component.scss
.overlay {
position: fixed;
top: 0;
right: 0;
bottom: 0;
left: 0;
width: 100%;
height: 100%;
z-index: 1200;
background-color: rgba(0, 0, 0, 0.3);
touch-action: none; /* 不触发任何事件 */
-ms-touch-action: none;
}效果:遮盖整个屏幕

默认情况下,遮盖层是不显示的
@Input() dialogTitle = '';
/*
* 显示/隐藏
* */
_visible = false;
constructor() { }
ngOnInit() {
}
show() {
this._visible = true;
}
close() {
this._visible = false;
}- 制作弹窗Dialog区域
<div class="overlay"></div>
<div class="dialog-container">
<div class="dialog-content">
<div class="dialog-header">{{dialogTitle}}</div>
<div class="dialog-body">
<ng-content select=".dialog-body"></ng-content>
</div>
<div class="dialog-footer">
<ng-content select=".dialog-footer"></ng-content>
</div>
</div>
</div>补充样式
.overlay {
....
}
.dialog-container {
position: fixed;
z-index: 1300;
left: 50%;
top: 50%;
background-color: #fff;
.dialog-content {
border-radius: 8px;
padding: 10px;
}
.dialog-body {
}
.dialog-footer {
text-align: right;
}
}这里有一个细节是base-dialog的z-index一定要大于overlay的,已保证dialog能显示在遮盖层上方。
- 打开
app.component.html, 加入下面的代码
<button (click)="dialogRef.show()">Show</button>
<app-my-dialog class="dialog-container" dialogTitle="这是标题" #dialogRef>
<ng-container class="dialog-body">
<div>
<p>这是内容</p>
</div>
</ng-container>
<ng-container class="dialog-footer">
<button (click)="dialogRef.close()">关闭</button>
</ng-container>
</app-my-dialog>- dialogRef 是这个组件的引用别名
<ng-container class="dialog-body">类似Vue中的插槽,之内的html会替换组件内部的<ng-content select=".dialog-body"></ng-content>效果如下,点击show按钮,显示弹窗,点击弹窗中的关闭按钮,恢复原样。

- 其实大部分功能已经完成了,剩下的是样式美化和添加一些额外功能,比如现在是居中显示,示例中加入了从底部显示,用到了CSS3中的动画。
- 直接把 *ngFor 中的index传给[matDatepicker],用来引用组件
*ngFor="let editItem of budget.edits; index as j;index as k;"j是组件的引用,k是循环索引。支持这种写法,把k传到方法里,方便操作哪一个日期组件。 实例 看代码
import { Component, OnInit } from '@angular/core';
@Component({
selector: 'app-muldatepicker',
templateUrl: './muldatepicker.component.html',
styleUrls: ['./muldatepicker.component.styl']
})
export class MuldatepickerComponent implements OnInit {
result = {
budgets: []
};
constructor() {
}
ngOnInit() {
this.result = {
'budgets': [{
id: 1,
edits: [
{
'id': 10,
'date': new Date('2019-01-01 00:00:00'),
amount: 100,
},
{
'id': 11,
'date': new Date('2019-01-18 00:00:00'),
amount: 150,
}
]
},
{
id: 2,
edits: [
{
'id': 21,
'date': new Date('2019-02-10 00:00:00'),
amount: 0,
}
]
}
]
}
}
onAddOrUpdate() {
console.log(arguments);
}
}模板
<pre>{{result.budgets|json}}</pre>
<mat-list *ngFor="let budget of result.budgets;index as i;">
<div *ngFor="let editItem of budget.edits; index as j;index as k;">
<mat-form-field>
<input matInput [matDatepicker]="j" [(ngModel)]="editItem.date" placeholder="Choose a date">
<mat-datepicker-toggle matSuffix [for]="j"></mat-datepicker-toggle>
<mat-datepicker #j></mat-datepicker>
</mat-form-field>
<mat-form-field>
<input type="number" min="0" matInput placeholder="amount" [(ngModel)]="editItem.amount">
</mat-form-field>
<button mat-icon-button color="primary" (click)="onAddOrUpdate(budget.id, editItem, i, k)">
<mat-icon>edit</mat-icon>
</button>
</div>
</mat-list>如果是用angular-cli生成的项目,可以在angular.json中配置你喜欢的样式预处理器
"schematics": {
"@schematics/angular:component": {
// 指定组件生成的默认前缀
"prefix": "fx",
// 定义样式预处理器,可选值 css, scss, less 或 stylus, 无需安装其他依赖
"styleext": "scss"
}
},:host
如果需要指定组件宿主元素的样式,可以使用:host选择器
:host来指定它,这也是在组件内部样式规则中选择宿主元素的唯一方式。:host {
border: 1px solid #00f;
}
::ng-deep
在Angular中,对组件的样式规则进行了内部封装,即为组件定义的样式规则都只在组件内部才能生效,不进不出,所以组件样式通常只会作用于组件自身的 HTML 上。因此可以使用::ng-deep来强制一个样式对各级子组件的视图也生效。
比如子组件和父组件中都有h4标签,假设我们在父组件的css文件中写入
::ng-deep h4{
color: #00f;
}可以看到不止父组件中的h4标签中的字体颜色改变了,子组件中的也改变了。

但是需要注意的是,在我们的项目中,不止写入上面样式代码相关的组件和其子组件样式改变了,其他的不相关的组件h4标签颜色也发生了改变。:ng-deep 等于污染了全局样式
:host ::ng-deep
那这样该怎么办呢,我们并不想改变全局的h4标签的字体颜色,那么只需要在::ng-deep前面加上:host就可以把当前样式限制在当前组件和其子组件内部了。
:host ::ng-deep h4 {
color: #00f;
}@component 的 encapsulation
默认情况下,你看发现 angular 生成的 html 自带一堆类外的属性
<hero-details _nghost-pmm-5>
<h2 _ngcontent-pmm-5>Mister Fantastic</h2>
<hero-team _ngcontent-pmm-5 _nghost-pmm-6>
<h3 _ngcontent-pmm-6>Team</h3>
</hero-team>
</hero-detail>这是因为默认情况下组件的encapsulation属性值为Emulated,即模拟浏览器的支持的Shadow DOM,目的把 CSS 样式局限在组件视图。(只进不出,全局样式能进来,组件样式出不去) encapsulation可选值为 Emulate | Native | None | ShadowDom 如果你希望样式可进可出,设置为None,详情的使用参见官方文档,这里不细致展开。
@Component({
selector: 'fx-button',
// 指定组件的样式封装性
encapsulation: ViewEncapsulation.None,
templateUrl: './fx-button.component.html',
styleUrls: ['./fx-button.component.scss']
})关于 :host 和 :host-context 属于 Shadow DOM 的内容
什么是Shadow DOM
总结
- 默认情况下,组件的样式文件只会影响对于的组件,比如
-- fx-button.component.ts
-- fx-button.component.scss
-- fx-button.component.html
在
fx-button.component.scss中定义的样式只会影响fx-button.component.html。 记忆只进不出 - 可以使用
::ng-deep影响组件包含的子组件的样式
参考
]]>模板引用变量通常用来引用模板中的某个 DOM 元素,它还可以引用 Angular 组件或指令或Web Component。 注意:模板引用变量的作用范围是整个模板。 不要在同一个模板中多次定义同一个变量名,否则它在运行期间的值是无法确定的。
- 模板变量可以循环
<div class="device-wrapper">
<div
class="device-item-wrapper"
*ngFor="let device of listService.activeNode.items_mapping; let i = index"
[ngStyle]="{ 'top.%': device.y * 100, 'left.%': device.x * 100 }"
>
<img
[src]="'https://s2.ax1x.com/2019/12/23/lpUFje.png'"
alt=""
class="device"
nz-tooltip
[nzTooltipTitle]="titleTemplate"
/>
<ng-template #titleTemplate>
<p>{{ device.info.name }}</p>
<p>{{ device.info.category }}</p>
</ng-template>
</div>
</div>- 可以通过方法传给后台
demo.html
<fx-ad-group-private-deal *fxPermissions="['Internal Team Views']" #private_deal_editor
[cgid]="cid"
[private_deal]="formData.private_deal"
[private_deal_list]="formData.private_deal_list">
</fx-ad-group-private-deal>
<fx-ad-group-targeting [ngClass]="{'hide': this.isSMB}" #targeting_editor [cgid]="cid"
[data]="formData.targeting"
[is_create]="createOrEdit"
[audience_id]="formData?.content.audienceType.id">
</fx-ad-group-targeting>
<button mat-raised-button color="primary" [disabled]="totalForm.invalid"
(click)="createAdGroup(private_deal_editor, targeting_editor )">
Next
</button>demo.ts
createAdGroup(private_deal_editor, targeting_editor) {
if (private_deal_editor) {
Object.assign(payload, private_deal_editor.getPayload());
console.log(payload);
}
if (targeting_editor) {
Object.assign(payload, targeting_editor.getPayload());
}
}
如果不想一个个删掉console.log,需要在正式环境屏蔽log信息。可按如下方法: 修改根目录的main.ts文件,添加disableConsole方法
import { enableProdMode } from '@angular/core';
import { platformBrowserDynamic } from '@angular/platform-browser-dynamic';
import { AppModule } from './app/app.module';
import { environment } from './environments/environment';
import 'hammerjs';
if (environment.production) {
enableProdMode();
// 只在正式正式环境调用
disableConsole();
}
platformBrowserDynamic().bootstrapModule(AppModule)
.catch(err => console.error(err));
// 覆盖console方法为空函数
function disableConsole() {
Object.keys(window.console).forEach(v => {
window.console[v] = function() { };
});
}这个教程适合初学者看,这里介绍的是最常见的三种通信方式。
如图,下面的页面里有个名为side-bar的组件,组件内部有个toggle方法,可以控制显示或隐藏,这个需要其他组件来调用toggle的方法。
 我们可以通过以下三种方式来实现:
我们可以通过以下三种方式来实现:
- 传递一个组件的引用给另一个组件
- 通过子组件发送EventEmitter和父组件通信
- 通过service通信
每个例子都会有StackBlitz在线演示地址
1. 传递一个组件的引用给另一个组件
模板引用变量通常用来引用模板中的某个 DOM 元素,它还可以引用 Angular 组件或指令或Web Component。 使用井号 (#) 来声明引用变量。 #phone 的意思就是声明一个名叫 phone 的变量来引用 元素
这种方式适合组件间有依赖关系。 app component
<app-side-bar-toggle [sideBar]="sideBar"></app-side-bar-toggle>
<app-side-bar #sideBar></app-side-bar>@Component({
selector: 'app-side-bar-toggle',
templateUrl: './side-bar-toggle.component.html',
styleUrls: ['./side-bar-toggle.component.css']
})
export class SideBarToggleComponent {
@Input() sideBar: SideBarComponent;
@HostListener('click')
click() {
this.sideBar.toggle();
}
}@Component({
selector: 'app-side-bar',
templateUrl: './side-bar.component.html',
styleUrls: ['./side-bar.component.css']
})
export class SideBarComponent {
@HostBinding('class.is-open')
isOpen = false;
toggle() {
this.isOpen = !this.isOpen;
}
}2. 通过子组件发送EventEmitter和父组件通信
Demo2 这种方式利用事件传播,需要在子组件中写 app.component.html
<app-side-bar-toggle (toggle)="toggleSideBar()"></app-side-bar-toggle>
<app-side-bar [isOpen]="sideBarIsOpened"></app-side-bar>@Component({
selector: 'my-app',
templateUrl: './app.component.html',
styleUrls: [ './app.component.css' ]
})
export class AppComponent {
sideBarIsOpened = false;
toggleSideBar(shouldOpen: boolean) {
this.sideBarIsOpened = !this.sideBarIsOpened;
}
}@Component({
selector: 'app-side-bar-toggle',
templateUrl: './side-bar-toggle.component.html',
styleUrls: ['./side-bar-toggle.component.css']
})
export class SideBarToggleComponent {
@Output() toggle: EventEmitter<null> = new EventEmitter();
@HostListener('click')
click() {
this.toggle.emit();
}
}@Component({
selector: 'app-side-bar',
templateUrl: './side-bar.component.html',
styleUrls: ['./side-bar.component.css']
})
export class SideBarComponent {
@HostBinding('class.is-open') @Input()
isOpen = false;
}3. 通过service进行通信
Demo3 这里需要新建side-bar.service,我们把toggle方法写到service文件中, 然后将service注入到side-bar-toggle.component和side-bar-toggle.component,前者调用toggle方法,发送事件流,后者订阅事件
<app-side-bar-toggle></app-side-bar-toggle>
<app-side-bar></app-side-bar>@Component({
selector: 'app-side-bar-toggle',
templateUrl: './side-bar-toggle.component.html',
styleUrls: ['./side-bar-toggle.component.css']
})
export class SideBarToggleComponent {
constructor(
private sideBarService: SideBarService
) { }
@HostListener('click')
click() {
this.sideBarService.toggle();
}
}@Component({
selector: 'app-side-bar',
templateUrl: './side-bar.component.html',
styleUrls: ['./side-bar.component.css']
})
export class SideBarComponent {
@HostBinding('class.is-open')
isOpen = false;
constructor(
private sideBarService: SideBarService
) { }
ngOnInit() {
this.sideBarService.change.subscribe(isOpen => {
this.isOpen = isOpen;
});
}
}@Injectable()
export class SideBarService {
isOpen = false;
@Output() change: EventEmitter<boolean> = new EventEmitter();
toggle() {
this.isOpen = !this.isOpen;
this.change.emit(this.isOpen);
}
}import { Component } from '@angular/core';
import { FormBuilder, FormGroup, Validators } from '@angular/forms';
import { Observable } from 'rxjs';
import { tap } from 'rxjs/operators';
import { UserService, User } from './user.service';
@Component({
selector: 'my-app',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
form: FormGroup;
user$: Observable<User>;
constructor(
private formBuilder: FormBuilder,
private userService: UserService) { }
ngOnInit() {
this.form = this.formBuilder.group({
firstName: ['Jack', Validators.required],
lastName: ['Jones', Validators.required],
about: []
});
}
submit() {
if (this.form.valid) {
console.log(this.form.value);
}
}
}app-component.html
<form [formGroup]="form" (ngSubmit)="submit()">
<label for="firstname">First Name</label>
<input id="firstname" formControlName="firstName" />
<div *ngIf="form.controls.firstName.errors?.required && form.controls.firstName.touched" class="error">
*Required
</div>
<label for="lastname">Last Name</label>
<input id="lastname" formControlName="lastName" />
<div *ngIf="form.controls.lastName.errors?.required && form.controls.lastName.touched" class="error">
*Required
</div>
<label for="about">About</label>
<textarea id="about" formControlName="about"></textarea>
<button [disabled]="!form.valid">Save Profile</button>
</form>需要注意的几点:
- 使用响应式表单,需要组件所在的module引入ReactiveFormsModule 该module提供了很多指令。比如已Accessor结尾的,如
NumberValueAccessor是专门处理,RadioControlValueAccessor处理 等等。 - 模板中表单元素需要绑定FormControlName属性与TS中定义的FormControl匹配。 TS中的定义表单可以使用FormControl,如果嫌麻烦,有更简便的FormBuilder.group
this.personForm = this.formBuilder.group({
username: ['', Validators.required],
email: ['', [Validators.required, Validators.email]],
age: ['', Validators.required],
...
});
// 也可以写成
this.personForm = new FormGroup({
username: new FormControl('', Validators.required),
email: new FormControl('', Validators.required),
});- 表单元素上面不要同时出现formControlName和ngModel
如
<input formControlName="first" [(ngModel)]="value">。使用formControlName实际已经隐含绑定了ngModel。
- 请求HTTP拿到数据。
- 根据数据修改表单中字段的值,最终体现在页面上。 我们改造上一节的例子,成为异步获取数据。 我们先创建service文件, 写一个loadUser方法,模拟HTTP请求
import { Injectable } from '@angular/core';
import { of } from 'rxjs';
import { delay } from 'rxjs/operators';
// /api/users/1
export interface User {
id: number;
firstName: string;
lastName: string;
about: string;
}
const fakeData = {
id: 0,
firstName: 'Cory',
lastName: 'Rylan',
about: 'Web Developer'
};
@Injectable()
export class UserService {
constructor() { }
loadUser() {
return of<User>(fakeData).pipe(
delay(2000)
);
}
}组件中,调用该方法
import { Component } from '@angular/core';
import { FormBuilder, FormGroup, Validators } from '@angular/forms';
import { Observable } from 'rxjs';
import { tap } from 'rxjs/operators';
import { UserService, User } from './user.service';
@Component({
selector: 'my-app',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
form: FormGroup;
user$: Observable<User>;
constructor(
private formBuilder: FormBuilder,
private userService: UserService) { }
ngOnInit() {
this.form = this.formBuilder.group({
firstName: ['', Validators.required],
lastName: ['', Validators.required],
about: []
});
this.user$ = this.userService.loadUser().pipe(
// tap 返回的还是 Observable 这里我们不订阅,我们在模板中使用 async pipe 和 if else 语句实现有条件的显示表单
tap(user => this.form.patchValue(user))
);
// .subscribe();
}
submit() {
if (this.form.valid) {
console.log(this.form.value);
}
}
}修改模板
<form *ngIf="user$ | async; else loading" [formGroup]="form" (ngSubmit)="submit()">
<label for="firstname">First Name</label>
<input id="firstname" formControlName="firstName" />
<div *ngIf="form.controls.firstName.errors?.required && form.controls.firstName.touched" class="error">
*Required
</div>
<label for="lastname">Last Name</label>
<input id="lastname" formControlName="lastName" />
<div *ngIf="form.controls.lastName.errors?.required && form.controls.lastName.touched" class="error">
*Required
</div>
<label for="about">About</label>
<textarea id="about" formControlName="about"></textarea>
<button [disabled]="!form.valid">Save Profile</button>
</form>
<ng-template #loading>
Loading User...
</ng-template>你会发现页面打开后一开始显示 Loading User...过了大概2s后文字消失并显示表单。
- 验证要求: name: 必填 Category: 必填,只能输入大小写,字符长度3到10 Price:必填,只能输入不超过100的数字
- 显示要求: 错误在表单上放统一显示

我们可以借助Angular的formControl来实现,这里我们基于FormControl创建一个子类ProductFormControl来提高可复用性
核心代码: form.model.ts 该文件是表单模型文件,与业务无关。只包含一个收集表单错误信息的方法
import { FormControl, FormGroup, Validators } from "@angular/forms";
// 自定义验证器
import { LimitValidator } from "./limit.formvalidator";
export class ProductFormControl extends FormControl {
label: string;
modelProperty: string;
constructor(label:string, property:string, value: any, validator: any) {
super(value, validator);
this.label = label;
this.modelProperty = property;
}
// 此方法用于收集错误信息,然后在模板中遍历输出,
getValidationMessages() {
let messages: string[] = [];
if (this.errors) {
for (let errorName in this.errors) {
switch (errorName) {
case "required":
messages.push(`You must enter a ${this.label}`);
break;
case "minlength":
messages.push(`A ${this.label} must be at least
${this.errors['minlength'].requiredLength}
characters`);
break;
case "maxlength":
messages.push(`A ${this.label} must be no more than
${this.errors['maxlength'].requiredLength}
characters`);
break;
case "limit":
messages.push(`A ${this.label} cannot be more
than ${this.errors['limit'].limit}`);
break;
case "pattern":
messages.push(`The ${this.label} contains
illegal characters`);
break;
}
}
}
return messages;
}
}
// 业务相关,专门验证 Product Form
// 注意 new ProductFormControl() 不是 new FormControl()
export class ProductFormGroup extends FormGroup {
constructor() {
super({
name: new ProductFormControl("Name", "name", "", Validators.required),
category: new ProductFormControl("Category", "category", "",
Validators.compose([Validators.required,
Validators.pattern("^[A-Za-z ]+$"),
Validators.minLength(3),
Validators.maxLength(10)])),
price: new ProductFormControl("Price", "price", "",
Validators.compose([Validators.required,
LimitValidator.Limit(100),
Validators.pattern("^[0-9\.]+$")]))
});
}
get productControls(): ProductFormControl[] {
return Object.keys(this.controls)
.map(k => this.controls[k] as ProductFormControl);
}
getFormValidationMessages(form: any) : string[] {
let messages: string[] = [];
this.productControls.forEach(c => c.getValidationMessages()
.forEach(m => messages.push(m)));
return messages;
}
}其中 limit.formvalidator.ts 封装了一个验证长度限制的自定义验证器
import { FormControl } from "@angular/forms";
export class LimitValidator {
static Limit(limit:number) {
return (control:FormControl) : {[key: string]: any} => {
let val = Number(control.value);
if (val != NaN && val > limit) {
return {"limit": {"limit": limit, "actualValue": val}};
} else {
return null;
}
}
}
}最后在用到的组件中,直接引入 form.model
import { Component } from "@angular/core";
import { NgForm } from "@angular/forms";
import { Product } from "./product.model";
import { ProductFormGroup } from "./form.model";
@Component({
selector: "app",
templateUrl: "template.html"
})
export class ProductComponent {
form: ProductFormGroup = new ProductFormGroup();
newProduct: Product = new Product();
get jsonProduct() {
return JSON.stringify(this.newProduct);
}
addProduct(p: Product) {
console.log("New Product: " + this.jsonProduct);
}
formSubmitted: boolean = false;
submitForm(form: NgForm) {
this.formSubmitted = true;
if (form.valid) {
this.addProduct(this.newProduct);
this.newProduct = new Product();
form.reset();
this.formSubmitted = false;
}
}
}完整实例可以参见: https://stackblitz.com/edit/angular-advance-form-control
]]>https://github.com/Tencent/omi/blob/master/tutorial/shadow-dom-in-depth.cn.md
]]>RxJS 已于上月2019.4.23发布。 来看下带来了哪些新功能
New Fetch Observable
基于原生的 fetch API,RxJS 进行了封装并提供了 fromFetch 方法,也就是利用原生的fetch发http请求并返回为Observable 类型。而且还支持通过基于原生的FetchController 实现取消发送中的请求。
在线例子:https://stackblitz.com/edit/fromfetch
import { of } from 'rxjs';
import { switchMap, catchError } from 'rxjs/operators';
import { fromFetch } from 'rxjs/fetch';
const users$ = fromFetch('https://reqres.in/api/users').pipe(
switchMap(response => {
if (response.ok) {
return response.json();
} else {
return of({ error: true, message: `Error ${response.status}` });
}
}),
catchError((error) => of({ error: true, message: error.message }))
);
users$.subscribe({ next(data) { ... }, complete() { ... } });forkJoin 增强
forkJoin 类似 promise.all() 用于同时处理多个 Observable 在v6.5中可以支持传入对象类型了
import { forkJoin, timer } from 'rxjs';
import { take, mapTo } from 'rxjs/operators';
const source = forkJoin({
todos: timer(500).pipe(mapTo([{ title: 'RxJS'}])),
user: timer(500).pipe(mapTo({ id: 1 }))
});
source.subscribe({
next({ todos, user }) { }
});此外,不再支持 forkJoin(a, b, c, d) 形式,建议传入数组,如 forkJoin([a, b, c, d])。 译者注: 增强了可读性
// DEPRECATED
forkJoin(of(1), of(2)).subscribe();
// use an array instead
forkJoin([of(1), of(2)]).subscribe();在线例子:https://stackblitz.com/edit/forkjoin-65
Partition Observable
Partition 能够将 source observable 分成两个 observables, 一个利用放满足时的预测值,一个是不满足时候的值。
比如页面中,当鼠标点击 h1 标题区域才是我们想要的值,点击其他区域我们依然做处理。
import { fromEvent, partition } from 'rxjs';
const clicks$ = fromEvent(document, 'click');
const [clicksOnH1$, clicksElsewhere$] =
partition(clicks$, event => event.target.tagName === 'H1');
clicksOnH1$.subscribe({
next() { console.log('clicked on h1') }
});
clicksElsewhere$
.subscribe({
next() {
console.log('Other clicked')
}
});在线例子:https://stackblitz.com/edit/partition-65
combineLatest 被废弃
combineLatest 目前只会保留 combineLatest([a, b, c]) 这一种使用方法,原因可以看这里.
Schedulers
添加 scheduled 函数来创建 a scheduled observable of values。from、range等其他方法被废弃
import { of, scheduled, asapScheduler } from 'rxjs';
console.log(1);
// DEPRECATED
// of(2, asapScheduler).subscribe({
// next(value) {
// console.log(value);
// }
// });
scheduled(of(2), asapScheduler).subscribe({
next(value) {
console.log(value);
}
});
console.log(3)输出结果是 1 3 2 在线例子:https://stackblitz.com/edit/scheduled65
]]>关于 Schedulers 的使用我会在后续文章中介绍
- 启动项目本地开发
npm start - 开发完成,跑代码语法及规范检测
npm run lint - 跑单元测试
npm run test - 构建生产静态资源
npm run build - 打包然后上传到服务器
tar -zcvf oneportal.gz -C dist .
每处理完一个任务都得搞一遍是不是很麻烦?重复而且效率低
这种事情完全可以交给CircleCI来处理。不用自己买服务器,比Jenkins简单。省去了维护和部署。 CircleCI的好处(截止当前的政策2019.2):
- 每月构建时长1000分钟以内免费 (基本够用)
- 提供的构建环境配置2核CPU / 4G内存,(算是很慷慨了) 据测试如果是在1核1G的主机下执行npm run build很容易报内存不足
- 有专门的配置文件来定义work flow,而且还很强大。
具体实现
Angular项目根目录新建.circleci目录(注意以点开头),然后在这个目录里面再新建config.yml文件
下面是我正在使用的配置,具体语法可以见官方介绍
# Check https://circleci.com/docs/2.0/language-javascript/ for more details
#
# See: https://github.com/ci-samples/angular-cli-circleci/blob/master/.circleci/config.yml
version: 2
jobs:
build:
docker:
# Specify service dependencies here if necessary
# CircleCI maintains a library of pre-built images
# documented at https://circleci.com/docs/2.0/circleci-images/
# specify the version you desire here
# - image: circleci/node:10.14-browsers
- image: finleyma/circleci-nodejs-browser-awscli
working_directory: ~/repo
# https://circleci.com/docs/2.0/env-vars/
environment:
ANGULAR_BUILD_DIR: ~/repo/dist
steps:
- checkout
# Download and cache dependencies
- restore_cache:
keys:
- v1-dependencies-{{ checksum "package.json" }}
# fallback to using the latest cache if no exact match is found
- v1-dependencies-
- run:
name: install-dependencies
command: npm install
- run: node -v
- run: npm -v
- run: npm run lint
- run: npm run ci-test
- run: npm run ci-build
- run: tar -zcvf oneportal.gz -C dist .
- save_cache:
paths:
- node_modules
key: v1-dependencies-{{ checksum "package.json" }}
- run: aws --version
- run:
name: upload-to-aws-s3
command: 'aws s3 cp oneportal.gz s3://your-aws-bucket/path/ --region us-east-1'
workflows:
version: 2
build-deploy:
jobs:
- build:
filters:
branches:
only: daily-build需要解释几点:
- 使用的Docker镜像是finleyma/circleci-nodejs-browser-awscli,这是我基于CircleCI的镜像又加入了awscli工具。这个镜像包含了node10, Chrome(为了跑单元测试), Python2.7(为了安装AWS CLI), AWS CLI(为了上传打包后的静态资源)
- 大致流程就是开头说的,只不过为了统一环境我们的项目是在Docker容器里跑测试和构建。通过之后将打包的待发布的静态资源上传到AWS存储。 还有配置文件里限制了分支,只有往daily-build分支上合并代码才会触发CircleCI的构建。
- 其中
npm run ci-test和npm run ci-build需要在项目的package.json定义好,加入了一些参数,比如不输出过程,和加入环境参数配置
"start": "npm run proxy",
...
"build": "ng build --prod",
"test": "ng test --configuration=testing",
"ci-build": "node --max_old_space_size=4096 node_modules/@angular/cli/bin/ng build --configuration=dev --watch=false --progress=false",
"ci-test": "ng test --configuration=testing --watch=false --browsers=ChromeHeadless --progress=false",
"lint": "ng lint",- 需要在CircleCI后台配置AWS的Key和Secret。
当然,你可以直接通过SSH将项目传到站点服务器部署。也需要在后台配置下访问服务器的Key。
效果:
]]>

1. 起步,用express实现最简单的例子
运行一个GraphQL API Server
GraphiQL is a great tool for debugging and inspecting a server, so we recommend running it whenever your application is in development mode.

index.js
const express = require('express');
const graphqlHTTP = require('express-graphql');
const schema = require('./schema');
const app = express();
// 具体选项含义见文档
// https://github.com/graphql/express-graphql
app.use('/graphql', graphqlHTTP({
schema: schema,
graphiql: true,
}));
app.listen(12580);
console.log("please open http://localhost:12580/graphql")schema.js
const {
GraphQLObjectType,
GraphQLSchema,
GraphQLString,
} = require('graphql');
const Query = new GraphQLObjectType({
name: 'BlogSchema',
description: 'Root of the Blog Schema',
fields: () => ({
echo: {
type: GraphQLString,
description: '回应你输入的内容',
args: {
message: {type: GraphQLString}
},
resolve: function(source, {message}) {
return `hello: ${message}`;
}
},
})
});
const Schema = new GraphQLSchema({
query: Query,
});
module.exports = Schema;注意点:
-
上篇讲过GraphQL只是一套规范,目前官方只提供了JS版本,其他PHP,Go等其他语言都是社区实现的。
-
当只有一种操作,并且是query,可以省去query操作名关键字

-
可以看到字段和字段参数要指定类型,因为GraphQL是强类型的。
-
因为指定了参数类型是string,输入时必须要用双引号
-
注意看调试面板的请求
GraphQL API server运行时,只要构造http请求就可以,传入不同的query参数,也能得到和在GraphiQL同样的结果

2. 查询
2.1 变量
所有声明的变量都必须是标量、枚举型或者输入对象类型。

默认变量
使用默认值


覆盖默认值

类型后面带个感叹号表示参数必填

2.2 别名

2.3 片段
提取公众的部分
上面的查询,将共同的字段:id和name,提取成fragment

2.4 指令
GraphQL内置两个核心指令,@skip 和 @include
@skip(if: Boolean) 如果参数为 true,跳过此字段。
? 貌似参数必须要写默认值 ?


3. 修改 Mutation
4. 分页
分页的原理:定义一个Edges类型,包含node和cursor字段,Node保存查询列表内容,Cursor记录分页。以下面的Github例子
5. GitHub GraphQL API
打开 https://developer.github.com/v4/explorer/
先打开右侧的Docs浏览所有Query,发现有个名为search的query
 他返回的是个 SearchResultItemConnection!类型,接着点进去
他返回的是个 SearchResultItemConnection!类型,接着点进去

你会发现所有已Connection结尾的类型,其结果都包含pageInfo, edges, nodes
输入下面的内容,这个查询是返回包含"graphql"关键字的前三个仓库,并显示每个仓库的前3个issues的作者,头像信息。
{
search(first: 3, query: "graphql", type: REPOSITORY) {
codeCount
pageInfo {
startCursor
endCursor
hasNextPage
hasPreviousPage
}
edges {
cursor
node {
... on Repository {
nameWithOwner
issues(first: 3) {
nodes {
author {
avatarUrl
login
resourcePath
url
}
title
}
}
}
}
}
}
rateLimit {
cost
limit
nodeCount
resetAt
remaining
}
}返回的结果类似
{
"data": {
"search": {
"codeCount": 16287,
"pageInfo": {
"startCursor": "Y3Vyc29yOjE=",
"endCursor": "Y3Vyc29yOjM=",
"hasNextPage": true,
"hasPreviousPage": false
},
"edges": [
{
"cursor": "Y3Vyc29yOjE=",
"node": {
"nameWithOwner": "facebook/graphql",
"issues": {
"nodes": [
{
"author": {
"avatarUrl": "https://avatars0.githubusercontent.com/u/540892?v=4",
"login": "raymondfeng",
"resourcePath": "/raymondfeng",
"url": "https://github.com/raymondfeng"
},
"title": "Possibility of collaboration with LoopBack framework?"
},
{
"author": {
"avatarUrl": "https://avatars1.githubusercontent.com/u/825073?v=4",
"login": "luisobo",
"resourcePath": "/luisobo",
"url": "https://github.com/luisobo"
},
"title": "Pagination?"
},
{
"author": {
"avatarUrl": "https://avatars3.githubusercontent.com/u/71047?v=4",
"login": "KyleAMathews",
"resourcePath": "/KyleAMathews",
"url": "https://github.com/KyleAMathews"
},
"title": "Custom Sorting"
}
]
}
}
},
{
"cursor": "Y3Vyc29yOjI=",
"node": {
"nameWithOwner": "graphql-go/graphql",
"issues": {
"nodes": [
{
"author": {
"avatarUrl": "https://avatars0.githubusercontent.com/u/78585?v=4",
"login": "sogko",
"resourcePath": "/sogko",
"url": "https://github.com/sogko"
},
"title": "Suggestion: Improve package discovery"
},
{
"author": {
"avatarUrl": "https://avatars2.githubusercontent.com/u/1064547?v=4",
"login": "ptomasroos",
"resourcePath": "/ptomasroos",
"url": "https://github.com/ptomasroos"
},
"title": "Why not wrap the C lib?"
},
{
"author": {
"avatarUrl": "https://avatars0.githubusercontent.com/u/1000404?v=4",
"login": "chris-ramon",
"resourcePath": "/chris-ramon",
"url": "https://github.com/chris-ramon"
},
"title": "Using graphql-go in other programs throws various errors."
}
]
}
}
},
{
"cursor": "Y3Vyc29yOjM=",
"node": {
"nameWithOwner": "Youshido/GraphQL",
"issues": {
"nodes": [
{
"author": {
"avatarUrl": "https://avatars2.githubusercontent.com/u/2429244?v=4",
"login": "mrbarletta",
"resourcePath": "/mrbarletta",
"url": "https://github.com/mrbarletta"
},
"title": "How to manage a List of Posts"
},
{
"author": {
"avatarUrl": "https://avatars2.githubusercontent.com/u/2429244?v=4",
"login": "mrbarletta",
"resourcePath": "/mrbarletta",
"url": "https://github.com/mrbarletta"
},
"title": "No way to get requested fields of the object inside `resolve`"
},
{
"author": {
"avatarUrl": "https://avatars0.githubusercontent.com/u/971254?v=4",
"login": "larswolff",
"resourcePath": "/larswolff",
"url": "https://github.com/larswolff"
},
"title": "Minor documentation issue?"
}
]
}
}
}
]
},
"rateLimit": {
"cost": 1,
"limit": 5000,
"nodeCount": 12,
"resetAt": "2018-03-31T01:47:34Z",
"remaining": 4995
}
}
}- 每个node包含一个cursor游标,不是数字,是唯一字符串
- 如果想查下一页,直接修改query search,添加after参数。
search(first: 3, after:"Y3Vyc29yOjM=", query: "graphql", type: REPOSITORY) { - 关于实现原理,参考
最后欢迎 clone 我的仓库, 里面包含了所有例子。
]]>目前项目开发比较流行的是前台后分离模式,后台提供接口,前台调用接口,接口书写遵循流行的RESTful API规范
- REST 由 Roy Thomas Fielding 在他2000年的博士论文中提出的。
- REST,即 Representational State Transfer(表述性状态传递) 的缩写。
- 如果一个架构符合 REST 原则, 就称它为 RESTful 架构
RESTful API 特点
- 每一个 URI 代表一种资源;
- 充分利用 HTTP 协议本身语义;
- 客户端和服务器器之间,传递这种资源的某种表现层;
- 客户端通过四个 HTTP 动词,对服务器器端资源进行操作,实现 " 表现层状态转化 " 。
RESTful API 缺陷
- 一个接口仅操作单一资源
- 各个资源是独立的,完成一个页面需要调用多个接口
- 数据冗余,灵活性差
- 需专门维护文档 (v1, v2)
有时候打开某个页面,我们需要调用多个接口。 有时候我们不需要的字段后台也给我们返回了,这是由后台控制的。
而GraphQL可以完美的解决上面的问题
GraphQL是….
- Facebook 2012年开发,2015年开源
- 应用层的API查询语言
- 在服务端的运行数据查询语言的规范 (我建议你先抽半个小时浏览下心里有个大概)
GraphQL的特点
- 强类型
- 单一入口
- 一个请求获取所有所需资源
- 内省系统
为什么叫GraphQL
图(Graph)是一种复杂的非线性结构,在图结构中,每个元素都可以有零个或多个前驱,也可以有零个或多个后继,也就是说,元素之间的关系是任意的。
使用GraphQL 注意的问题
- 性能问题 (请求少了,但查询多了)
- GraphQL 在前端如何与视图层、状态管理方案结合
- 安全, Limit, timeout N+1 查询
关于从规范里提炼的
- GraphQL是一种数据描述语言,而非编程语言,因此GraphQL缺乏用于描述数学表达式的标点符号。
- 注释只能用 # ,可以使用末尾的逗号提高可读性。
- GraphQL的命名是大小写敏感的,也就是说name,Name,和NAME是不同的名字。
- 一个文档可以包含多个操作和片段的定义。一个查询文档只有包含操作时,服务器才能执行。
- 如果一个文档只有一个操作,那这个操作可以不带命名或者简写,省略掉query关键字和操作名。
下一篇 实战
]]>ps:不考虑兼容问题(下次会写js实现元素的水平and垂直居中 )
css3的transform
.box {
/* 设置元素绝对定位 */
position: absolute;
top: 50%;
left: 50%;
/* css3 transform 实现 */
transform: translate(-50%, -50%);
}flex盒子布局
.box {
/* 弹性盒模型 */
display: flex;
/* 主轴居中对齐 */
justify-content: center;
/* 侧轴居中对齐 */
align-items: center;
}display的table-cell
.box{
/* 让元素渲染为表格单元格 */
display: table-cell;
/* 设置文本水平居中 */
text-align: center;
/* 设置文本垂直居中 */
vertical-align: middle;
}参考
https://codingwithalice.github.io/2019/07/07/子盒子在父盒子中水平垂直居中有几种方法/
]]>定义语法:--variableName: value;
变量名称(variableName)使用规范:
- 以"--"开头,后面可以是数字、字母、下划线、连字符、汉字等,但不能包含$、[、^、(、%等字符
- 大小写敏感(另:CSS中,书写属性名时大小写不敏感,但是书写选择器时大小写敏感)
- 定义只能出现在块{}内
- 可以使用**!important**修饰
- 作用域就是选择器的选定范围,作用域出现交叉时,同名变量覆盖规则取决于选择器权重
<style type="text/css">
/* 这里定义的变量是全局的 */
:root {
--main-bg-color: brown;
--1: red;
--_: blue;
--飞: green;
}
/* -fz1 相当于局部变量,在其他地方不能用 */
p {
--fz14: 14px;
color: var(--1);
}
em {
color: var(--飞);
/* 第二个参数是默认值 */
font-size: var(--fz14, 16px);
}
</style>使用限制
- CSS自定义属性变量是不能用作CSS属性名称的,比如:
var(--color): red; - 不能用作背景地址,比如:
url(var(--url)); - 由于var()后面会默认跟随一个空格,因此在其后面加单位是无效的,比如:
--size:20; font-size: var(--size)px会解析成font-size: 20 px;
不能直接和数值单位连用
.foo {
--gap: 20;
/* 无效 */
margin-top: var(--gap)px;
}使用 calc() 函数,将它们连接。
.foo {
--gap: 20;
margin-top: calc(var(--gap) * 1px);
}兼容性
目前现代浏览器都支持 检测方法
- 使用 @supports方法
@supports ( (--size: 0)) {
/* 支持 */
}
@supports ( not (--size: 0)) {
/* 不支持 */
}- 使用 JavaScript
if (window.CSS && window.CSS.supports && window.CSS.supports('--size', 0)) {
/* 支持 */
}作用域
与 CSS 的"层叠"(cascade)规则是一致的。 看例子
JavaScript 操作
varrootStyles = getComputedStyle(document.documentElement);
varvalue = rootStyles.getPropertyValue('--variableName');
// 获取某个元素中定义的属性变量
value = element.style.getPropertyValue('--variableName');
// 设置变量
document.body.style.setProperty('--primary', '#7F583F');
// 读取变量
document.body.style.getPropertyValue('--primary').trim();
// '#7F583F'
// 删除变量
document.body.style.removeProperty('--primary');操作前

操作后

响应式布局
可以结合媒体查询实现不同的尺寸采用不同的变量值
/* 先定义一些变量,如主配色和次要配色 */
body {
--primary: red;
--secondary: blue;
}
/* 为元素应用配色 */
a {
color: var(--primary);
text-decoration-color: var(--secondary);
}
/* 当小屏幕使用另外一套配色方案 */
@media screen and (min-width: 768px) {
body {
--primary: black;
--secondary: orange;
}
}
参考
https://www.cnblogs.com/bibibobo/p/6140659.html http://www.ruanyifeng.com/blog/2017/05/css-variables.html
]]>flex: 1 1 auto;的缩写,flex-grow:1; flex-shrink:1; flex-basis:1css中box-sizing的属性
应该如何计算一个元素的总宽度和总高度。
content-box 是默认值。如果你设置一个元素的宽为100px,那么这个元素的内容区会有100px 宽,并且任何边框和内边距的宽度都会被增加到最后绘制出来的元素宽度中。
border-box 告诉浏览器:你想要设置的边框和内边距的值是包含在width内的。 也就是说,如果你将一个元素的width设为100px,那么这100px会包含它的border和padding,内容区的实际宽度是width减去(border + padding)的值。 大多数情况下,这使得我们更容易地设定一个元素的宽高。
]]>reset.css
先来看看早先 YUI 的一个版本的 reset.css,这是一份历史比较悠久的 RESET 方案:
body, div, dl, dt, dd, ul, ol, li, h1, h2, h3, h4, h5, h6, pre, form, fieldset, input, textarea, p, blockquote, th, td {
margin: 0;
padding: 0;
}
table {
border-collapse: collapse;
border-spacing: 0;
}
fieldset, img {
border: 0;
}
address, caption, cite, code, dfn, em, strong, th, var {
font-style: normal;
font-weight: normal;
}
ol, ul {
list-style: none;
}
caption, th {
text-align: left;
}
h1, h2, h3, h4, h5, h6 {
font-size: 100%;
font-weight: normal;
}
q:before, q:after {
content: '';
}
abbr, acronym {
border: 0;
}reset.css 存在的问题
看看第一段:
body, div, dl, dt, dd, ul, ol, li, h1, h2, h3, h4, h5, h6, pre, form, fieldset, input, textarea, p, blockquote, th, td {
margin: 0;
padding: 0;
}这一条样式的目的是在于,清除元素的默认 margin 和 padding 。
但是这一段代码是充满问题的。
- 诸如 div 、dt、li 、th、td 等标签是没有默认 padding 和 margin 的;
- 如果我现在问你 fieldset 是什么标签,可能没几个人知道,相似的还有如 blockquote 、acronym 这种很生僻的标签,在 html 代码中基本不会出现的,其实没太大必要 RESET ,只会给每个项目徒增冗余代码; 上面的意思是,这一段代码其实做了很多无用功!
要知道,CSS RESET 的作用域是全局的。我们都知道在脚本代码中应该尽量避免滥用全局变量,但是在 CSS 上却总是会忘记这一点,大量的全局变量会导致项目大了之后维护起来非常的棘手。
再看看这一段:
h1, h2, h3, h4, h5, h6 {
font-size: 100%;
font-weight: normal;
}
ol, ul {
list-style: none;
}这一段代码,目的是统一了 h1~h6 的表现,取消了标题的粗体展示,取消了列表元素的项目点。
好像没什么问题,但是诸如 h1~h6、ol、ul 这些拥有具体语义化的元素,一旦去掉了它们本身的特性,而又没有赋予它们本身语义化该有的样式(经常没有),导致越来越多人弄不清它们的语义,侧面来说,这也是现在越来越多的页面上 div 满天飞,缺乏语义化标签的一个重要原因。
YUI 版本的 reset 不管高矮胖瘦,一刀切的方式,看似将所有元素统一在同一起跑线上,实则是多了很多冗余代码,得不偿失。
所以,YUI 的 reset.css 的诸多问题,催生出了另一个版本的 reset.css ,名为 Normalize.css。
Normalize.css 有着详尽的注释,由于篇幅太长,可以点开网址看看,本文不贴出全部代码。
Normalize.css 与 reset.css 的风格恰好相反,没有不管三七二一的一刀切,而是注重通用的方案,重置掉该重置的样式(例如body的默认margin),保留该保留的 user agent 样式,同时进行一些 bug 的修复,这点是 reset 所缺乏的。
Normalize.css 做了什么:
- Preserves useful defaults, unlike many CSS resets.
- Normalizes styles for a wide range of elements.
- Corrects bugs and common browser inconsistencies.
- Improves usability with subtle modifications.
- Explains what code does using detailed comments.
简单翻译一下,大概是:
- 统一了一些元素在所有浏览器下的表现,保护有用的浏览器默认样式而不是完全清零它们,让它们在各个浏览器下表现一致;
- 为大部分元素提供一般化的表现;
- 修复了一些浏览器的 Bug ,并且让它们在所有浏览器下保持一致性;
- 通过一些巧妙的细节提升了 CSS 的可用性;
- 提供了详尽的文档让开发者知道,不同元素在不同浏览器下的渲染规则;
- 真心建议各位抽时间读一读 Normalize.css 的源码,加上注释一共就 460 行,多了解了解各个浏览器历史遗留的一些坑
关于取舍
那么,最后再讨论下取舍问题。是否 Normalize.css 就真的比 reset.css 好呢?
也不见得,Normalize.css 中重置修复的很多 bug ,其实在我们的项目中十个项目不见得有一个会用得上,那么这些重置或者修复,某种意义上而言也是所谓的冗余代码。
我觉得最重要的是,拒绝拿来主义,不要人云亦云,看见别人说这个 reset.css 好用,也不了解一下,拿来就上到项目中。又或者说写代码几年了,知道每次都引用一个 reset ,却从没有去细致了解其中每一句的含义。
关于维护
当团队根据项目需要(可能混合部分了 reset 或者 normalize )编写了一份适合团队项目的 reset 之后,随着不断的迭代或者说是复用,很有可能这个版本的 reset.css 会逐渐添加许多其他的全局性的样式,从而又重新陷入上面说的那些问题。
所以我觉得,reset.css 也是需要维护的,关于最佳的 reset.css ,没有一劳永逸的方案,根据项目灵活配置,做出取舍微调,适量裁剪和修改后再使用。
]]>第一章
- W3C 并不“生产”标准。W3C 以工作组的方式,把某项技术的相关各方聚 集起来,最终由他们来产出标准。
- CSS 规范通常是由 CSS 工作组的成员来编写的。在编写本书时,CSS
工作组共有 98 名成员,人员结构如下:
- 86 名来自 W3C 会员公司的成员(88%)
- 7 名特邀专家(笔者有幸在列)(7%)
- 5 名 W3C 工作人员(5%)
- 对于哪些东西该进入标准,浏览器厂商比 W3C 有更多的发言权,上面列出的人员结构 已经证明了这一点。
- 每项规范从最初启动到最终成熟,都会经过以下阶段。 编辑草案(ED) -> 首个公开工作草案(FPWD) -> 工作草案(WD)-> 候选推荐规范(CR) -> 提名推荐规范(PR) -> 正式推荐规范(REC)。
- 编码技巧 尽量减少代码重复
bad
font-size: 20px;
line-height: 30px;当某些值相互依赖时,应该把它们的相互关系用代码表达出来。在这个例子中,行高是字号的 1.5 倍。因 此,把代码改成下面这样会更易维护: good
font-size: 20px;
line-height: 1.5;跨站脚本攻击。 缩写不是CSS,避免与层叠样式表混淆,
攻击手段: 盗用cookie,获取敏感信息。
最常用的,留言板中输入<script>alert1</script>
CSP (Content Security Policy)
CSP的主要目标是减少和报告XSS攻击 可以重新约束内容被下载的域名
X-XSS-Protection
X-XSS-Protection
通过浏览器是开启XSS过滤的,比如地址栏中直接输入<script>alert(1)<script>是无效的
当然PHP中,可以设置header('X-XSS-Protection', 0)关闭保护
例子
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; script-src 'self' https://ajax.googleapis.com; style-src 'self'; img-src 'self' data:">
指定脚本的,图片和样式的来源
CSRF 或 XSRF (Cross Site Request forgery) 跨站请求伪造
XSS 利用的是用户对指定网站的信任,CSRF 利用的是网站对用户网页浏览器的信任。
通常情况下,CSRF 攻击是攻击者借助受害者的 Cookie 骗取服务器的信任,在受害者毫不知情的情况下以受害者名义伪造请求发送给受攻击服务器,从而在并未授权的情况下执行在权限保护之下的操作。
防御方法
-
Cookie 的 SameSite 属性用来限制第三方 Cookie, Set-Cookie: CookieName=CookieValue; SameSite=Strict; Strict:这个规则过于严格,可能造成非常不好的用户体验。比如,当前网页有一个 GitHub 链接,用户点击跳转就不会带有 GitHub 的 Cookie,跳转过去总是未登陆状态。 Lax: Lax 规则稍稍放宽,大多数情况也是不发送第三方 Cookie,但是导航到目标网址的 Get 请求除外。
-
同源检测 在 HTTP 协议中,每一个异步请求都会携带两个 Header ,用于标记来源域名:
Origin Header, Referer Header
这两个 Header 在浏览器发起请求时,大多数情况会自动带上,并且不能由前端自定义内容。 服务器可以通过解析这两个 Header 中的域名,确定请求的来源域。 通过校验请求的该字段,我们能知道请求是否是从本站发出的。 我们可以通过拒绝非本站发出的请求,来避免了 CSRF 攻击。
-
验证 Referer 或 Origin 这种方法不是非常可靠,下面两种更常见。
-
添加token验证 服务器将 Token 返回到前端,前端可以作为隐藏字段放到表单中,前端发请求时携带这个 Token,服务器验证 Token 是否正确
-
验证码
CSRF 攻击往往是在用户不知情的情况下成功伪造请求。而验证码会强制用户必须与应用进行交互,才能完成最终请求,而且因为 CSRF 攻击无法获取到验证码,因此通常情况下,验证码能够很好地遏制 CSRF 攻击。 但验证码并不是万能的,因为出于用户体验考虑,不能给网站所有的操作都加上验证码。 因此,验证码只能作为防御 CSRF 的一种辅助手段,而不能作为最主要的解决方案。
参考
]]>使用Vue做前后端分离项目时,通常前端是单独部署,用户访问的也是前端项目地址,因此前端开发人员很有必要熟悉一下项目部署的流程与各类问题的解决办法了。Vue项目打包部署本身不复杂,不过一些前端同学可能对服务器接触不多,部署过程中还是会遇到这样那样的问题。本文介绍一下使用nginx服务器代理前端项目的方法以及项目部署的相关问题,内容概览:
一、准备工作——服务器和nginx使用
1. 准备一台服务器
我的是ubuntu系统,linux系统的操作都差不多。没有服务器怎么破?
如果你只是想体验一下,可以尝试各大厂的云服务器免费试用套餐,比如华为云免费试用,本文相关操作即是在华为云上完成的。 不过如果想时常练练手,我觉得可以购买一台云服务器,比如上面的华为云或者阿里云都还挺可靠。
2. nginx安装和启动
轻装简行,这部分不作过多赘述(毕竟网上相关教程一大堆),正常情况下仅需下面两个指令:
# 安装,安装完成后使用nginx -v检查,如果输出nginx的版本信息表明安装成功
sudo apt-get install nginx
# 启动
sudo service nginx start
启动后,正常情况下,直接访问 http://服务器ip 或 http://域名 (本文测试用的服务器没有配置域名,所以用ip,就本文而言,域名和ip没有太大区别)应该就能看到nginx服务器的默认页面了——如果访问不到,有可能是你的云服务器默认的http服务端口(80端口)没有对外开放,在服务器安全组配置一下即可。3. 了解nginx: 修改nginx配置,让nginx服务器代理我们创建的文件
查看nginx的配置,linux系统下的配置文件通常会存放在/etc目录下,nginx的配置文件就在/etc/nginx文件夹,打开文件/etc/nginx/sites-available/default(nginx可以有多个配置文件,通常我们配置nginx也是修改这个文件):
可以看到默认情况下,nginx代理的根目录是/var/www/html,输入 http://服务器ip会访问这个文件夹下的文件,会根据index的配置值来找默认访问的文件,比如index.html、index.htm之类。
我们可以更改root的值来修改nginx服务代理的文件夹:
创建文件夹/www,并创建index.html,写入"Hello world"字符串 mkdir /www echo 'Hello world' > /www/index.html 修改root值为 /www
sudo nginx -t 检查nginx配置是否正确
加载nginx配置:sudo nginx -s reload 再次访问页面,发现页面内容已经变成了我们创建的index.html:
二、Vue项目打包同步文件到远程服务器
1. 打包
默认情况下,使用vue-cli创建的项目,package.json里的script应该已经配置了build指令,直接执行yarn build 或者 npm run build即可。
2. 同步到远程服务器
我们使用nginx部署Vue项目,实质上就是将Vue项目打包后的内容同步到nginx指向的文件夹。之前的步骤已经介绍了怎样配置nginx指向我们创建的文件夹,剩下的问题就是怎么把打包好的文件同步到服务器上指定的文件夹里,比如同步到之前步骤中创建的/www。 同步文件可以在git-bash或者powershell使用scp指令,如果是linux环境开发,还可以使用rsync指令:
scp -r dist/* [email protected]:/www
或
rsync -avr --delete-after dist/* [email protected]:/www注意这里以及后续步骤是root使用用户远程同步,应该根据你的具体情况替换root和ip(ip换为你自己的服务器IP)。
为了方便,可以在package.json脚本中加一个push命令,以使用yarn为例(如果你使用npm,则push命令中yarn改成npm run即可):
"scripts": {
"build": "vue-cli-service build",
"push": "yarn build && scp -r dist/* [email protected]:/www"
},这样就可以直接执行yarn push 或者npm run push直接发布了。不过还有一个小问题,就是命令执行的时候要求输入远程服务器的root密码(这里使用root来连接远程的,你可以用别的用户,毕竟root用户权限太高了)。
为了避免每次执行都要输入root密码,我们可以将本机的ssh同步到远程服务器的authorized_keys文件中。
3. 同步ssh key
生成ssh key:使用git bash或者powershell执行ssh-keygen可以生成ssh key。
会询问生成的key存放地址,直接回车就行,如果已经存在,则会询问是否覆盖:
-同步ssh key
同步ssh key到远程服务器,使用ssh-copy-id指令同步
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
输入密码后,之后再次同步就不需要输入密码了。 其实ssh_key是同步到了服务器(此处是root用户家目录)~/.ssh/authorized_keys文件里:
当然你也可以手动复制本地~/.ssh/id_rsa.pub(注意是pub结尾的公钥)文件内容追加到服务器~/.ssh/authorized_keys的后面(从命名可以看出该文件可以存储多个ssh key)
注意: 这里全程使用的是root用户,所以没有文件操作权限问题。如果你的文件夹创建用户不是远程登录用户,或许会存在同步文件失败的问题,此时需要远程服务器修改文件夹的读写权限(命令 chmod)。
创建了一个测试项目(点击本链接可以在gihub查看)试一下,打包、文件上传一句指令搞定啦:
访问一下,果然看到了我们熟悉的界面:
至此,常规情况下发布Vue项目就介绍完了,接下来介绍非域名根路径下发布以及history路由模式发布方法。
三、非域名根路径发布
有时候同一台服务器同一端口下可能会根据目录划分出多个不同的项目,比如我们希望项目部署到http://a.com/test下,这样访问http://a.com/test访问到的是项目的首页,而非test前缀的地址会访问到其它项目。此时需要修改nginx配置以及Vue打包配置。
1. nginx配置
只需要添加一条location规则,分配访问路径和指定访问文件夹。我们可以把/test指向之前创建的/www文件夹,这里因为文件夹名称和访问路径不一致,需要用到alias这个配置:

如果文件夹名称与访问路径一致都为test,那这里可以用root来配置:

这里要将/test配置放到/之前,意味着在路由进入的时候,会优先匹配/test。如果根路径/下的项目有子路由/test,那http://xxxx/test只会访问到/www里的项目,而不会访问该子路由。
2. 项目配置
为了解决打包后资源路径不对的问题,需要在vue.config.js中配置publicPath,这里有两种配置方式,分别将publicPath配置为./和/test:

更新nginx配置,发布后即可正常访问啦。这里的两种配置方式是有区别的,接下来会看一下它们的区别。 如果不进行项目配置,直接发布访问会出现JS、CSS等资源找不到导致页面空白的问题:
该问题原因是资源引用路径不对,页面审查元素可以看到,页面引用的js都是从根路径下引用的:
查看打包后的文件结构,可以看到js/css/img/static等资源文件是与index.html处于同级别的:
对于两种配置方式,看看都是怎么生效的:
publicPath配置为./, 打包后资源引用路径为相对路径:
publicPath配置为/test,打包后资源相对路径为从域名根目录开始的绝对路径:
两种配置都可以正确地找到JS、CSS等资源。不过还有个问题,那就是static中的静态资源依旧会找不到。
3. 绝对路径引用的静态资源找不到的问题
因为在打包过程中,public下的静态资源都不会被webpack处理,我们需要通过绝对路径来引用它们。当项目部署到非域名根路径上时,这点非常头疼,你需要在每个引用的URL前面加上process.env.BASE_URL(该值即对应上文配置的publicPath),以使得资源能被正常访问到。 我们可以在main.js把这个变量值绑定到Vue.prototype,这样每个Vue组件都可以使用它:
Vue.prototype.$pb = process.env.BASE_URL
在模板中使用:
<img :src="${$pb}static/logo.png">
然而,更加头疼并且没有良好解决方案的问题是在组件style部分使用public文件夹下的静态资源:
如果需要使用图片等作为背景图片等,尽量使用内联方式使用吧,像在模板中使用一样。 如果需要引入样式文件,则在index.html中使用插值方式引入吧。 关于静态资源的问题,vue-cli的推荐是尽量将资源作为你的模块依赖图的一部分导入(即放到assets中,使用相对路径引用),避免该问题的同时也带来其它好处:

四、history模式部署
默认情况下,Vue项目使用的是hash路由模式,就是URL中会包含一个#号的这种形式。#号以及之后的内容是路由地址的hash部分。正常情况下,当浏览器地址栏地址改变,浏览器会重新加载页面,而如果是hash部分修改的话,则不会,这就是前端路由的原理,允许根据不同的路由页面局部更新而不刷新整个页面。H5新增了history的pushState接口,也允许前端操作改变路由地址但是不触发页面刷新,history模式即利用这一接口来实现。因此使用history模式可以去掉路由中的#号。
1. 项目配置
在vue-router路由选项中配置mode选项和base选项,mode配置为'history';如果部署到非域名根目录,还需要配置base选项为前文配置的publicPath值(注意:此情况下,publicPath必须使用绝对路径/test的配置形式,而不能用相对路径./)
2. nginx配置
对于history模式,假设项目部署到域名下的/test目录,访问http://xxx/test/about的时候,服务器会去找/test指向的目录下的about子目录或文件,很显然因为是单页面应用,并不会存在a这个目录或者文件,就会导致404错误:
Vue项目部署后页面找不到
我们要配置nginx让这种情况下,服务器能够返回单页应用的index.html,然后剩下的路由解析的事情就交给前端来完成即可。
history模式nginx配置
这句配置的意思就是,拿到一个地址,先根据地址尝试找对应文件,找不到再试探地址对应的文件夹,再找不到就返回/test/index.html。再次打开刚才的about地址,刷新页面也不会404啦:

3. history模式部署到非域名根路径下
非域名根目录下部署,首先肯定要配置publicPath。需要注意的点前面其实已经提过了,就是这种情况下不能使用相对路径./或者空串配置publicPath。为什么呢? 原因是它会导致router-link等的表现错乱,使用测试项目分别使用两种配置打包发布,审查元素就能看出区别。在页面上有两个router-link,Home和About:
两种配置打包后的结果如下。
publicPath配置为./或者空串:
publicPath配置为/test:
publicPath配置为相对路径的router-link打包后地址变成了相对根域名下地址,很明显是错误的,所以非域名根路径部署应该将publicPath配置为完整的前缀路径。
五、结语
关于Vue项目发布的相关问题就先总结这么多,几乎在每一步都踩过坑才有所体会,有问题欢迎各位同学一起探讨。 写博客很累,不过收获也很多,还是要坚持;有时候别人转载自己的原创文章也不标明出处,竟然将写文章日期改得比原创还早,有点心累。本文中使用到的图片都加了个自己的水印,是前端实现的,原理也很简单,之后写一篇简短的文章分享一下。 (完)
]]>注意: 若表单提交时,checkbox未勾选,则提交的值并非为value=unchecked;此时的值不会被提交到服务器
但是我们想实现不勾选也能提交到后台呢。 发现了一个利用hidden巧妙提交的办法。
<form method="post">
<input type="hidden" name="foo" value="0">
<input type="checkbox" name="foo" id="foo" value="1">
<input type="submit" value="submit">
</form>生成这样的表单,当checkbox未选中的时候,提交的是hidden表单。值0就被提交到服务器了。 当checkbox都选中的时候,hidden和checkbox表单都被提交了,但是因为它们的name是一样的,所以hidden的值被checkbox覆盖了。所以就得到了数值1。
在PHP中,如果有多个name相同的表单,都可以post到服务器
参考
]]><button>
<svg>
<use xlink:href="#gear"></use>
</svg>
</button>当用户点击齿轮图标,必然要触发 click 事件,但你并不会直接绑定事件到 svg 或 use 元素上,而是绑定到它们的父元素 button 上。即:
document.querySelector('button').addEventListener('click', function (e) {
console.log('点击了按钮');
// 查看 事件具体是发生在哪个元素上面
console.log(e.target);
})这时会产生一个问题,根据用户点击的位置,e.target 可能是下面三种情况:
BUTTON 元素 SVG 元素 USE 元素 实际的情况是这样的

我们真正的意图是,只要点击是发生在按钮上面,不论是按钮的哪个位置,我们都应视为按钮被点击了。 嗯,简单,我们再改一下,这样写:
document.documentElement.addEventListener('click', function (e) {
if (['BUTTON', 'SVG', 'USE'].includes(e.target.tagName.toUpperCase())) {
// 点击的是按钮
}
})这样似乎没什么问题,也确实可以达到目的,但看上去总是有些别扭。因为这种情况对于最上层的 document 来说,得知道每个子元素的情况,本来我只需要关心离我最近的 button 元素就可以了。
根据 OOP 对内封装的思想,button 元素内部的事情应该在内部消化掉,其子元素对外不可见,应该只暴露 button 元素本身。依据这个思想和事件冒泡的特点,我们就有了比较好的解决办法:只需要禁止 button 内部元素的事件响应(包括事件冒泡)而只允许 button 元素本身的事件发生就行。有两种方式可以实现这个目的。
一种是使用 CSS 禁止 button 内部元素的事件响应:
pointer-events
button > * {
pointer-events: none;
}stopPropagation
document.querySelector('button > svg').addEventListener('click', function (e) {
e.stopPropagation()
e.preventDefault()
})
document.querySelector('button').addEventListener('click', function (e) {
console.log(e.target.tagName)
})ParentNode
查询点击的父节点判断是不是在button节点内部
参考
]]>数据收集原理分析
简单来说,网站统计分析工具需要收集到用户浏览目标网站的行为(如打开某网页、点击某按钮、将商品加入购物车等)及行为附加数据(如某下单行为产生的订单金额等)。早期的网站统计往往只收集一种用户行为:页面的打开。而后用户在页面中的行为均无法收集。这种收集策略能满足基本的流量分析、来源分析、内容分析及访客属性等常用分析视角,但是,随着ajax技术的广泛使用及电子商务网站对于电子商务目标的统计分析的需求越来越强烈,这种传统的收集策略已经显得力不能及。
后来,Google在其产品谷歌分析中创新性的引入了可定制的数据收集脚本,用户通过谷歌分析定义好的可扩展接口,只需编写少量的javascript代码就可以实现自定义事件和自定义指标的跟踪和分析。目前百度统计、搜狗分析等产品均照搬了谷歌分析的模式。
其实说起来两种数据收集模式的基本原理和流程是一致的,只是后一种通过javascript收集到了更多的信息。下面看一下现在各种网站统计工具的数据收集基本原理。
流程概览
首先通过一幅图总体看一下数据收集的基本流程。

图1. 网站统计数据收集基本流程
首先,用户的行为会触发浏览器对被统计页面的一个http请求,这里姑且先认为行为就是打开网页。当网页被打开,页面中的埋点javascript片段会被执行,用过相关工具的朋友应该知道,一般网站统计工具都会要求用户在网页中加入一小段javascript代码,这个代码片段一般会动态创建一个script标签,并将src指向一个单独的js文件,此时这个单独的js文件(图1中绿色节点)会被浏览器请求到并执行,这个js往往就是真正的数据收集脚本。数据收集完成后,js会请求一个后端的数据收集脚本(图1中的backend),这个脚本一般是一个伪装成图片的动态脚本程序,可能由php、python或其它服务端语言编写,js会将收集到的数据通过http参数的方式传递给后端脚本,后端脚本解析参数并按固定格式记录到访问日志,同时可能会在http响应中给客户端种植一些用于追踪的cookie。
上面是一个数据收集的大概流程,下面以谷歌分析为例,对每一个阶段进行一个相对详细的分析。
埋点脚本执行阶段
若要使用谷歌分析(以下简称GA),需要在页面中插入一段它提供的javascript片段,这个片段往往被称为埋点代码。下面是我的博客中所放置的谷歌分析埋点代码截图:

图2. 谷歌分析埋点代码
其中_gaq是GA的的全局数组,用于放置各种配置,其中每一条配置的格式为:
_gaq.push(['Action', 'param1', 'param2', ...]);Action指定配置动作,后面是相关的参数列表。GA给的默认埋点代码会给出两条预置配置,_setAccount用于设置网站标识ID,这个标识ID是在注册GA时分配的。_trackPageview告诉GA跟踪一次页面访问。更多配置请参考:https://developers.google.com/analytics/devguides/collection/gajs/。实际上,这个_gaq是被当做一个FIFO队列来用的,配置代码不必出现在埋点代码之前,具体请参考上述链接的说明。
就本文来说,_gaq的机制不是重点,重点是后面匿名函数的代码,这才是埋点代码真正要做的。这段代码的主要目的就是引入一个外部的js文件(ga.js),方式是通过document.createElement方法创建一个script并根据协议(http或https)将src指向对应的ga.js,最后将这个element插入页面的dom树上。
注意ga.async = true的意思是异步调用外部js文件,即不阻塞浏览器的解析,待外部js下载完成后异步执行。这个属性是HTML5新引入的。
数据收集脚本执行阶段
数据收集脚本(ga.js)被请求后会被执行,这个脚本一般要做如下几件事:
1、通过浏览器内置javascript对象收集信息,如页面title(通过document.title)、referrer(上一跳url,通过document.referrer)、用户显示器分辨率(通过windows.screen)、cookie信息(通过document.cookie)等等一些信息。
2、解析_gaq收集配置信息。这里面可能会包括用户自定义的事件跟踪、业务数据(如电子商务网站的商品编号等)等。
3、将上面两步收集的数据按预定义格式解析并拼接。
4、请求一个后端脚本,将信息放在http request参数中携带给后端脚本。
这里唯一的问题是步骤4,javascript请求后端脚本常用的方法是ajax,但是ajax是不能跨域请求的。这里ga.js在被统计网站的域内执行,而后端脚本在另外的域(GA的后端统计脚本是http://www.google-analytics.com/__utm.gif),ajax行不通。一种通用的方法是js脚本创建一个Image对象,将Image对象的src属性指向后端脚本并携带参数,此时即实现了跨域请求后端。这也是后端脚本为什么通常伪装成gif文件的原因。通过http抓包可以看到ga.js对__utm.gif的请求:

图3. 后端脚本请求的http包
可以看到ga.js在请求__utm.gif时带了很多信息,例如utmsr=1280×1024是屏幕分辨率,utmac=UA-35712773-1是_gaq中解析出的我的GA标识ID等等。
值得注意的是,__utm.gif未必只会在埋点代码执行时被请求,如果用_trackEvent配置了事件跟踪,则在事件发生时也会请求这个脚本。
由于ga.js经过了压缩和混淆,可读性很差,我们就不分析了,具体后面实现阶段我会实现一个功能类似的脚本。
后端脚本执行阶段
GA的__utm.gif是一个伪装成gif的脚本。这种后端脚本一般要完成以下几件事情:
1、解析http请求参数的到信息。
2、从服务器(WebServer)中获取一些客户端无法获取的信息,如访客ip等。
3、将信息按格式写入log。
5、生成一副1×1的空gif图片作为响应内容并将响应头的Content-type设为image/gif。
5、在响应头中通过Set-cookie设置一些需要的cookie信息。
之所以要设置cookie是因为如果要跟踪唯一访客,通常做法是如果在请求时发现客户端没有指定的跟踪cookie,则根据规则生成一个全局唯一的cookie并种植给用户,否则Set-cookie中放置获取到的跟踪cookie以保持同一用户cookie不变(见图4)。

图4. 通过cookie跟踪唯一用户的原理
这种做法虽然不是完美的(例如用户清掉cookie或更换浏览器会被认为是两个用户),但是是目前被广泛使用的手段。注意,如果没有跨站跟踪同一用户的需求,可以通过js将cookie种植在被统计站点的域下(GA是这么做的),如果要全网统一定位,则通过后端脚本种植在服务端域下(我们待会的实现会这么做)。
系统的设计实现
根据上述原理,我自己搭建了一个访问日志收集系统。总体来说,搭建这个系统要做如下的事:

图5. 访问数据收集系统工作分解
下面详述每一步的实现。我将这个系统叫做MyAnalytics。
确定收集的信息
为了简单起见,我不打算实现GA的完整数据收集模型,而是收集以下信息。
| 名称 | 途径 | 备注 | | 访问时间 | web server | Nginx $msec | | IP | web server | Nginx $remote_addr | | 域名 | javascript | document.domain | | URL | javascript | document.URL | | 页面标题 | javascript | document.title | | 分辨率 | javascript | window.screen.height & width | | 颜色深度 | javascript | window.screen.colorDepth | | Referrer | javascript | document.referrer | | 浏览客户端 | web server | Nginx $http_user_agent | | 客户端语言 | javascript | navigator.language | | 访客标识 | cookie | | | 网站标识 | javascript | 自定义对象 |
埋点代码
埋点代码我将借鉴GA的模式,但是目前不会将配置对象作为一个FIFO队列用。一个埋点代码的模板如下:
<script type="text/javascript">
var _maq = _maq || [];
_maq.push(['_setAccount', '网站标识']);
(function() {
var ma = document.createElement('script'); ma.type = 'text/javascript'; ma.async = true;
ma.src = ('https:' == document.location.protocol ? 'https://analytics' : 'http://analytics') + '.codinglabs.org/ma.js';
var s = document.getElementsByTagName('script')[0]; s.parentNode.insertBefore(ma, s);
})();
</script>这里我启用了二级域名analytics.codinglabs.org,统计脚本的名称为ma.js。当然这里有一点小问题,因为我并没有https的服务器,所以如果一个https站点部署了代码会有问题,不过这里我们先忽略吧。
前端统计脚本
我写了一个不是很完善但能完成基本工作的统计脚本ma.js:
(function () {
var params = {};
//Document对象数据
if(document) {
params.domain = document.domain || '';
params.url = document.URL || '';
params.title = document.title || '';
params.referrer = document.referrer || '';
}
//Window对象数据
if(window && window.screen) {
params.sh = window.screen.height || 0;
params.sw = window.screen.width || 0;
params.cd = window.screen.colorDepth || 0;
}
//navigator对象数据
if(navigator) {
params.lang = navigator.language || '';
}
//解析_maq配置
if(_maq) {
for(var i in _maq) {
switch(_maq[i][0]) {
case '_setAccount':
params.account = _maq[i][1];
break;
default:
break;
}
}
}
//拼接参数串
var args = '';
for(var i in params) {
if(args != '') {
args += '&';
}
args += i + '=' + encodeURIComponent(params[i]);
}
//通过Image对象请求后端脚本
var img = new Image(1, 1);
img.src = 'http://analytics.codinglabs.org/1.gif?' + args;
})();整个脚本放在匿名函数里,确保不会污染全局环境。功能在原理一节已经说明,不再赘述。其中1.gif是后端脚本。
日志格式
日志采用每行一条记录的方式,采用不可见字符^A(ascii码0x01,Linux下可通过ctrl + v ctrl + a输入,下文均用“^A”表示不可见字符0x01),具体格式如下:
时间^AIP^A域名^AURL^A页面标题^AReferrer^A分辨率高^A分辨率宽^A颜色深度^A语言^A客户端信息^A用户标识^A网站标识
后端脚本
为了简单和效率考虑,我打算直接使用nginx的access_log做日志收集,不过有个问题就是nginx配置本身的逻辑表达能力有限,所以我选用了OpenResty做这个事情。OpenResty是一个基于Nginx扩展出的高性能应用开发平台,内部集成了诸多有用的模块,其中的核心是通过ngx_lua模块集成了Lua,从而在nginx配置文件中可以通过Lua来表述业务。关于这个平台我这里不做过多介绍,感兴趣的同学可以参考其官方网站http://openresty.org/,或者这里有其作者章亦春(agentzh)做的一个非常有爱的介绍OpenResty的slide:http://agentzh.org/misc/slides/ngx-openresty-ecosystem/,关于ngx_lua可以参考:https://github.com/chaoslawful/lua-nginx-module。
首先,需要在nginx的配置文件中定义日志格式:
log_format tick "$msec^A$remote_addr^A$u_domain^A$u_url^A$u_title^A$u_referrer^A$u_sh^A$u_sw^A$u_cd^A$u_lang^A$http_user_agent^A$u_utrace^A$u_account";注意这里以u_开头的是我们待会会自己定义的变量,其它的是nginx内置变量。
然后是核心的两个location:
location /1.gif {
#伪装成gif文件
default_type image/gif;
#本身关闭access_log,通过subrequest记录log
access_log off;
access_by_lua "
-- 用户跟踪cookie名为__utrace
local uid = ngx.var.cookie___utrace
if not uid then
-- 如果没有则生成一个跟踪cookie,算法为md5(时间戳+IP+客户端信息)
uid = ngx.md5(ngx.now() .. ngx.var.remote_addr .. ngx.var.http_user_agent)
end
ngx.header['Set-Cookie'] = {'__utrace=' .. uid .. '; path=/'}
if ngx.var.arg_domain then
-- 通过subrequest到/i-log记录日志,将参数和用户跟踪cookie带过去
ngx.location.capture('/i-log?' .. ngx.var.args .. '&utrace=' .. uid)
end
";
#此请求不缓存
add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT";
add_header Pragma "no-cache";
add_header Cache-Control "no-cache, max-age=0, must-revalidate";
#返回一个1×1的空gif图片
empty_gif;
}
location /i-log {
#内部location,不允许外部直接访问
internal;
#设置变量,注意需要unescape
set_unescape_uri $u_domain $arg_domain;
set_unescape_uri $u_url $arg_url;
set_unescape_uri $u_title $arg_title;
set_unescape_uri $u_referrer $arg_referrer;
set_unescape_uri $u_sh $arg_sh;
set_unescape_uri $u_sw $arg_sw;
set_unescape_uri $u_cd $arg_cd;
set_unescape_uri $u_lang $arg_lang;
set_unescape_uri $u_utrace $arg_utrace;
set_unescape_uri $u_account $arg_account;
#打开日志
log_subrequest on;
#记录日志到ma.log,实际应用中最好加buffer,格式为tick
access_log /path/to/logs/directory/ma.log tick;
#输出空字符串
echo '';
}要完全解释这段脚本的每一个细节有点超出本文的范围,而且用到了诸多第三方ngxin模块(全都包含在OpenResty中了),重点的地方我都用注释标出来了,可以不用完全理解每一行的意义,只要大约知道这个配置完成了我们在原理一节提到的后端逻辑就可以了。
日志轮转
真正的日志收集系统访问日志会非常多,时间一长文件变得很大,而且日志放在一个文件不便于管理。所以通常要按时间段将日志切分,例如每天或每小时切分一个日志。我这里为了效果明显,每一小时切分一个日志。我是通过crontab定时调用一个shell脚本实现的,shell脚本如下:
_prefix="/path/to/nginx"
time=`date +%Y%m%d%H`
mv ${_prefix}/logs/ma.log ${_prefix}/logs/ma/ma-${time}.log
kill -USR1 `cat ${_prefix}/logs/nginx.pid`这个脚本将ma.log移动到指定文件夹并重命名为ma-{yyyymmddhh}.log,然后向nginx发送USR1信号令其重新打开日志文件。
然后再/etc/crontab里加入一行:
59 * * * * root /path/to/directory/rotatelog.sh在每个小时的59分启动这个脚本进行日志轮转操作。
测试
下面可以测试这个系统是否能正常运行了。我昨天就在我的博客中埋了相关的点,通过http抓包可以看到ma.js和1.gif已经被正确请求:

图6. http包分析ma.js和1.gif的请求
同时可以看一下1.gif的请求参数:

图7. 1.gif的请求参数
相关信息确实也放在了请求参数中。
然后我tail打开日志文件,然后刷新一下页面,因为没有设access log buffer, 我立即得到了一条新日志:
1351060731.360^A0.0.0.0^Awww.codinglabs.org^Ahttp://www.codinglabs.org/^ACodingLabs^A^A1024^A1280^A24^Azh-CN^AMozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4^A4d612be64366768d32e623d594e82678^AU-1-1注意实际上原日志中的^A是不可见的,这里我用可见的^A替换为方便阅读,另外IP由于涉及隐私我替换为了0.0.0.0。
看一眼日志轮转目录,由于我之前已经埋了点,所以已经生成了很多轮转文件:

图8. 轮转日志
关于分析
通过上面的分析和开发可以大致理解一个网站统计的日志收集系统是如何工作的。有了这些日志,就可以进行后续的分析了。本文只注重日志收集,所以不会写太多关于分析的东西。
注意,原始日志最好尽量多的保留信息而不要做过多过滤和处理。例如上面的MyAnalytics保留了毫秒级时间戳而不是格式化后的时间,时间的格式化是后面的系统做的事而不是日志收集系统的责任。后面的系统根据原始日志可以分析出很多东西,例如通过IP库可以定位访问者的地域、user agent中可以得到访问者的操作系统、浏览器等信息,再结合复杂的分析模型,就可以做流量、来源、访客、地域、路径等分析了。当然,一般不会直接对原始日志分析,而是会将其清洗格式化后转存到其它地方,如MySQL或HBase中再做分析。
分析部分的工作有很多开源的基础设施可以使用,例如实时分析可以使用Storm,而离线分析可以使用Hadoop。当然,在日志比较小的情况下,也可以通过shell命令做一些简单的分析,例如,下面三条命令可以分别得出我的博客在今天上午8点到9点的访问量(PV),访客数(UV)和独立IP数(IP):
awk -F^A '{print $1}' ma-2012102409.log | wc -l
awk -F^A '{print $12}' ma-2012102409.log | uniq | wc -l
awk -F^A '{print $2}' ma-2012102409.log | uniq | wc -l其它好玩的东西朋友们可以慢慢挖掘。
参考
GA的开发者文档:https://developers.google.com/analytics/devguides/collection/gajs/
一篇关于实现nginx收日志的文章:http://blog.linezing.com/2011/11/%E4%BD%BF%E7%94%A8nginx%E8%AE%B0%E6%97%A5%E5%BF%97
关于Nginx可以参考:http://wiki.nginx.org/Main
OpenResty的官方网站为:http://openresty.org
ngx_lua模块可参考:https://github.com/chaoslawful/lua-nginx-module
]]>合并功能
例1
let state = { name: "jack" }
{...state, { name: "finley" }}
// 返回
{name: "finley"}例2
var arr1 = ['two', 'three'];
var arr2 = ['one', ...arr1, 'four', 'five'];
// 结果
["one", "two", "three", "four", "five"]拷贝功能
var arr = [1,2,3];
var arr2 = [...arr]; // 和arr.slice()差不多
arr2.push(4)
// arr2 此时变成 [1, 2, 3, 4]
// arr 不受影响记住:数组中的对象依然是引用值,所以不是任何东西都“拷贝”过去了。
例3
let ab = { ...a, ...b };
// 等同于
let ab = Object.assign({}, a, b);
// 实际上, 展开语法和 Object.assign() 行为一致, 执行的都是浅拷贝(只遍历一层)。
{...{name: "finley"}, ...{name: "xx"}} 结果 {name: "xx"}module 模块
用default导出的话,import时就不用大括号,因为default只有一个。
async 和 await
async 表示函数里有异步操作 await 表示紧跟在后面的表达式需要等待结果。 async 函数返回一个 Promise 对象
例1
const demo = async function() {
// await 后面接表达式
await alert(1);
}
// async 函数返回一个 Promise 对象
demo().then(res => console.log(1))链判断运算符
在项目开发中,我们经常会遇到要取结构深层数据的情况,下面的一行代码就在所难免:
const price = data.result.redPacket.price
那么当某一个key不存在时,undefined.key就会报错,通常我们会优化成下面的样子:
const price = (data && data.result && data.result.redPacket && data.result.redPacket.price)||'default'
es6提供链判断运算符:
const price = data?.result?.redPacket?.price||'default'
这样即使某一个key不存在,也不会报错,只会返回undefined。
相关语法:
a?.b // 等同于 a == null ? undefined : a.b
a?.[x] // 等同于 a == null ? undefined : a[x]
a?.b() // 等同于 a == null ? undefined : a.b()
a?.() // 等同于 a == null ? undefined : a()参考
]]>- debounce 防抖:类似游戏施法条,读条过程中再按技能,就会重新读条
- throttle 节流:一直按技能键,但是单位时间内只有一次生效
JS为什么是单线程?
由于浏览器可以渲染DOM,JS也可以修改DOM结构,未避免冲突,JS执行的时候,浏览器DOM渲染会停止。 两段JS不能同时执行。
虽然 HTML5 中新引入的webworker支持多线程,但是不能访问DOM
浏览器允许的并发资源数限制,如何突破?
不同浏览器的并发请求数目限制不同

因为浏览器的并发请求数目限制是针对同一域名的。
- 所以可以多设置子个域名来突破限制,比如简书的图片子域名
upload-images.jianshu.io, - 把资源文件放到CDN上,如
https://cdn2.jianshu.io/assets/web-f5f4ced5c8b8a95fc8b4.js
单线程的解决方案,异步
和PHP不一样,写的代码顺序和执行的顺序是不一致的,PHP是同步。
console.log(100)
// 等其他JS代码执行完才开始执行
setTimeout(()=> {
console.log(200)
}, 10000)
console.log(300)类似的ajax也是
console.log(100)
// 等其他JS代码执行完才开始执行
$.ajax({
url: 'xxx',
success: res => {
console.log(res)
}
})
console.log(300)这样有个弊端,可读性差
event loop 事件轮询
- 同步代码,直接执行
- 异步函数先放到异步队列中,待同步函数执行完毕,轮询执行异步队列的函数
- 触发异步函数有 setTimeout,setImmediate,setInterval
实例1
setTimeout(() => console.log(1), 100)
setTimeout(() => console.log(2))
console.log(3)显示顺序是: 3 2 1

实例2

显示顺序: d c a b 或 d c a b 这是由于ajax的success回调函数被放入异步队列的时间是不确定的,当然如果是本地测试,有可能的顺序是 d a...

关于$ajax的底层
jquery的 $ajax 实际上是对 XMLHttpRequest 对象的封装
xmlhttp.open( "GET", "some/ur/1", true );
xmlhttp.onreadystatechange = function( data ) {
if ( xmlhttp.readyState === 4 ) {
console.log( data );
}
};
xmlhttp.send( null );底层的XmlHttpRequest对象发起请求,设置回调函数用来处理XHR的readystatechnage事件。 然后执行XHR的send方法。在XHR运行中,当其属性readyState改变时readystatechange事件就会被触发, 只有在XHR从远端服务器接收响应结束时回调函数才会触发执行。
jQuery的$ajax的async 参数设置同步或异步的本质是?
关于$ajax 中的 async 参数 async默认的设置值为true,这种情况为异步方式,就是说当ajax发送请求后,在等待server端返回的这个过程中,前台会继续执行ajax块后面的脚本,直到server端返回正确的结果才会去执行success。 其本质是 xhrReq.open(method, url, async)
JS 异常有做上报处理吗?是什么实现的
- 捕获异常的方法通过使用 try...catch
try {
var a = 1;
var b = a + c;
} catch (e) {
// 捕获处理
console.log(e); // ReferenceError: c is not defined
}缺点:增加代码量和维护性,不适用于整个项目的异常捕获。
- window.onerror 相比try catch来说window.onerror提供了全局监听异常的功能:
window.onerror = function(errorMessage, scriptURI, lineNo, columnNo, error) {
console.log('errorMessage: ' + errorMessage); // 异常信息
console.log('scriptURI: ' + scriptURI); // 异常文件路径
console.log('lineNo: ' + lineNo); // 异常行号
console.log('columnNo: ' + columnNo); // 异常列号
console.log('error: ' + error); // 异常堆栈信息
};
console.log(a);
提交异常
window.onerror = function(errorMessage, scriptURI, lineNo, columnNo, error) {
// 构建错误对象
var errorObj = {
errorMessage: errorMessage || null,
scriptURI: scriptURI || null,
lineNo: lineNo || null,
columnNo: columnNo || null,
stack: error && error.stack ? error.stack : null
};
if (XMLHttpRequest) {
var xhr = new XMLHttpRequest();
xhr.open('post', '/middleware/errorMsg', true); // 上报给node中间层处理
xhr.setRequestHeader('Content-Type', 'application/json'); // 设置请求头
xhr.send(JSON.stringify(errorObj)); // 发送参数
}
}- Vue 的捕获异常 在MVVM框架中如果你一如既往的想使用window.onerror来捕获异常,那么很可能会竹篮打水一场空,或许根本捕获不到,因为你的异常信息被框架自身的异常机制捕获了。使用Vue.config.errorHandler这样的Vue全局配置,可以在Vue指定组件的渲染和观察期间未捕获错误的处理函数。这个处理函数被调用时,可获取错误信息和Vue实例。
Vue.config.errorHandler = function (err, vm, info) {
// handle error
// `info` 是 Vue 特定的错误信息,比如错误所在的生命周期钩子
// 只在 2.2.0+ 可用
}- React 的 异常处理 -- Error Boundary 同样的在react也提供了异常处理的方式,在 React 16.x 版本中引入了 Error Boundary
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
componentDidCatch(error, info) {
this.setState({ hasError: true });
// 将异常信息上报给服务器
logErrorToMyService(error, info);
}
render() {
if (this.state.hasError) {
return '出错了';
}
return this.props.children;
}
}使用
<ErrorBoundary>
<MyWidget />
</ErrorBoundary>ES6部分
var 和 let的区别
let声明的变量只在它所在的代码块有效,不存在变量提升 let实际上为 JavaScript 新增了块级作用域
async, await
- async 返回一个
Promise对象,可以用then方法添加回调函数 - 最好把
await命令放到try...catch代码块中 await命令只能放到async函数中
箭头函数
函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。 箭头函数可以让this指向固定化,这种特性很有利于封装回调函数。
参考
]]>ES7 中的 decorator 同样借鉴了这个语法糖,不过依赖于 ES5 的 Object.defineProperty 方法 。
使用babel转换 步骤 :
- npm install -g babel-cli
- npm init; npm install --save-dev babel-plugin-transform-decorators-legacy
- babel --plugins transform-decorators-legacy 1.js > 1.es5.js
例1
@eat
class Person {
constructor() {}
}
function eat(target, key, descriptor) {
console.log('吃饭');
console.log(target);
console.log(key);
console.log(descriptor);
target.prototype.act = '我要吃饭';
}
const jack = new Person();
console.log(jack.act);转换后
var _class;
let Person = eat(_class = class Person {
constructor() {}
}) || _class;
function eat(target, key, descriptor) {
console.log('吃饭');
console.log(target);
console.log(key);
console.log(descriptor);
target.prototype.act = '我要吃饭';
}
const jack = new Person();
console.log(jack.act);
// 吃饭
// [Function: Person]
// undefined
// undefined
// 我要吃饭例2
function mixins(...list) {
return function (target) {
Object.assign(target.prototype, ...list);
};
}
const Foo = {
foo() { console.log('foo') }
};
@mixins(Foo)
class MyClass {}
let obj = new MyClass();
obj.foo() // "foo"babel 后
var _dec, _class;
function mixins(...list) {
return function (target) {
Object.assign(target.prototype, ...list);
};
}
const Foo = {
foo() {
console.log('foo');
}
};
let MyClass = (_dec = mixins(Foo), _dec(_class = class MyClass {}) || _class);
let obj = new MyClass();
obj.foo(); // "foo"reduce 方法是对数组中的每个元素执行一个由您提供的reducer函数(升序执行),将其结果汇总为单个返回值。
reducer 函数接收4个参数:
- Accumulator (acc) (累计器)
- Current Value (cur) (当前值)
- Current Index (idx) (当前索引)
- Source Array (src) (源数组)
语法
arr.reduce(callback(accumulator, currentValue[, index[, array]])[, initialValue])
举例
- 计算数组中每个元素出现的次数
let names = ['Alice', 'Bob', 'Tiff', 'Bruce', 'Alice'];
let nameNum = names.reduce((res, cur)=>{
if (cur in res){
res[cur]++
} else{
res[cur] = 1
}
return res
},{})
// { Alice: 1 }
// { Alice: 1, Bob: 1 }
// { Alice: 1, Bob: 1, Tiff: 1 }
// { Alice: 1, Bob: 1, Tiff: 1, Bruce: 1 }
// { Alice: 2, Bob: 1, Tiff: 1, Bruce: 1 }
// {Alice: 2, Bob: 1, Tiff: 1, Bruce: 1}
console.log(nameNum);- 对象里的属性求和
var result = [
{
subject: 'math',
score: 10
},
{
subject: 'chinese',
score: 20
},
{
subject: 'english',
score: 30
}
];
var sum = result.reduce(function(prev, cur) {
return cur.score + prev;
}, 0);
console.log(sum) // 60- 聚合
// 已知
let data = [
{id: 1, name: 'jack'},
{id: 2, name: 'jack'},
{id: 3, name: 'andy'},
];
/**
* 期望结果,name一样的话,合并重复的id
* [
{id: 1|2, name: 'jack'},
{id: 3, name: 'andy'},
]
*/
// 首先初始 res 为空数组
// cur 为当前元素,检查累加后的res是否存在重复的name,有的话,把id拼接起来
const result = data.reduce((res, cur) => {
const need = res.find(item => item.name === cur.name);
if (need && need.id) {
// 避免重复id,不拼接已有的
if (!(need.id + '').includes(cur.id)) {
need.id = need.id + '|' + cur.id;
}
} else {
res.push(cur)
}
return res;
}, []);
console.log(result)- 来个稍微复杂的例子
已知,源数据,三列分别表示 中心编号,受试者代码,受试结果
var data = [
['CHN001', 'CHN001014', true ],
['CHN002', 'CHN002001', true ],
['CHN002', 'CHN002001', false ],
['CHN002', 'CHN002002', true ],
['CHN002', 'CHN002002', false ],
['CHN002', 'CHN002003', true ],
['CHN002', 'CHN002004', true ],
['CHN002', 'CHN002005', true ],
['CHN002', 'CHN002007', false ],
['CHN002', 'CHN002008', false ],
['CHN003', 'CHN003001', true ],
['CHN003', 'CHN003001', false ],
['CHN005', 'CHN005001', true ],
['CHN005', 'CHN005001', false ],
['CHN005', 'CHN005002', true ],
['CHN005', 'CHN005003', true ],
['CHN005', 'CHN005004', true ],
['CHN007', 'CHN007001', true ],
['CHN007', 'CHN007001', false ],
['CHN007', 'CHN007001', false ],
['CHN007', 'CHN007002', true ],
['CHN007', 'CHN007003', true ],
['CHN007', 'CHN007003', false ],
['CHN007', 'CHN007004', true ],
['CHN007', 'CHN007004', true ],
['CHN007', 'CHN007004', false ],
['CHN007', 'CHN007007', true ],
['CHN007', 'CHN007008', true ],
['CHN007', 'CHN007009', false ]
]要求: 按照,中心编号和受试者代码分组, 比如 CHN005 下面包含了4个受试者,为CHN005001,CHN005002,CHN005003,CHN005004
['CHN005', 'CHN005001', true ],
['CHN005', 'CHN005001', false ],
['CHN005', 'CHN005002', true ],
['CHN005', 'CHN005003', true ],
['CHN005', 'CHN005004', true ],CHN005001 下面又有两条记录,只有同时都是true,才按累加1处理
['CHN005', 'CHN005001', true ],
['CHN005', 'CHN005001', false ],所以 CHN005001 为0 CHN005002,CHN005003,CHN005004都为1,最终
CHN005结果 为3
期望输出结果:
"CHN001" "1"
"CHN002" "3"
"CHN005" "3"
"CHN007" "4"求解:
function computeScore(list) {
const results = list.reduce((res, [no,code,result]) => {
res[no] = res[no]||{};
res[no][code] = (typeof res[no][code] == 'undefined' ? true : res[no][code])&&result;
return res;
}, {});
return Object.keys(results).reduce((res,key) => {
res[key] = Object.values(results[key]).reduce((acc,bol) => acc+bol,0)
return res;
}, {})
}第一步消重
第二步累加个数
]]>我们知道HTML中的元素是可以嵌套的,形成类似于树的层次关系。比如下面的代码:
<div id="outA" style="height:300px;width:300px;padding:50px;background:gray;">A
<div id="outB" style="height:200;width:200px;padding:50px;background:blue;"> B
<div id="outC" style="height:100px;width:100px;background:yellow;">C</div>
</div>
</div>然后效果如下:

如果点击了最里面的outC,那么外层的outB和outC算不算被点击了呢?很显然算,不然就没有必要区分事件冒泡和事件捕获了,这一点各个浏览器厂家也没有什么疑义。假如outA、outB、outC都注册了click类型事件处理函数,当点击outC的时候,触发顺序是A-->B-->C,还是C-->B-->A呢?
如果浏览器采用的是事件冒泡,那么触发顺序是C-->B-->A,由内而外,像气泡一样,从水底浮向水面;如果采用的是事件捕获,那么触发顺序是A-->B-->C,从上到下,像石头一样,从水面落入水底。
一般来说事件冒泡机制,用的更多一些,所以在IE8以及之前,IE只支持事件冒泡。IE9+/FF/Chrome这2种模型都支持,可以通过addEventListener((type, listener, useCapture)的useCapture来设定,useCapture=false代表着事件冒泡,useCapture=true代表着采用事件捕获。
DOM事件流
假如我们在outC元素上同时绑定了冒泡和捕获两种阶段的事件
window.onload = function(){
var outC = document.getElementById("outC");
// 目标(自身触发事件,是冒泡还是捕获无所谓)
outC.addEventListener('click',function(){alert("target1");},false);
outC.addEventListener('click',function(){alert("target2");},true);
};是冒泡先执行还是会捕获先执行呢。答案:对于自身触发事件,是冒泡还是捕获无所谓。先注册的先执行,后注册的后执行。
另外要理解DOM事件流,DOM事件流:将事件分为三个阶段:捕获阶段、目标阶段、冒泡阶段。先调用捕获阶段的处理函数,其次调用目标阶段的处理函数,最后调用冒泡阶段的处理函数。
更近一步,给三个div都绑定冒泡和捕获事件。想想,如果分别点击ABC三个div,执行顺序是什么呢?
window.onload = function(){
var outA = document.getElementById("outA");
var outB = document.getElementById("outB");
var outC = document.getElementById("outC");
// 目标(自身触发事件,是冒泡还是捕获无所谓)
outC.addEventListener('click',function(){alert("target2");},true);
outC.addEventListener('click',function(){alert("target1");},false);
// 事件冒泡
outA.addEventListener('click',function(){alert("bubble1");},false);
outB.addEventListener('click',function(){alert("bubble2");},false);
// 事件捕获
outA.addEventListener('click',function(){alert("capture1");},true);
outB.addEventListener('click',function(){alert("capture2");},true);
};点击C
分析:
- 捕获阶段:从最外层到元素C,先执行各个元素上的点击事件capture1->capture2
- 目标阶段:C上绑定了两个单击事件,按绑定顺序依次执行target2->target1
- 冒泡阶段:从内到外bubble2->bubble1
最终的执行顺序: capture1->capture2->target2->target1->bubble2->bubble1
点击B,执行顺序: capture1->bubble2->capture2->bubble1 点击A,执行顺序: bubble1->capture1
阻止事件冒泡和捕获
默认情况下,多个事件处理函数会按照DOM事件流模型中的顺序执行。如果子元素上发生某个事件,不需要执行父元素上注册的事件处理函数,那么我们可以停止捕获和冒泡,避免没有意义的函数调用。
IE8以及以前可以通过 window.event.cancelBubble=true阻止事件的继续传播;IE9+/FF/Chrome通过event.stopPropagation()阻止事件的继续传播。
修改代码
// 目标
outC.addEventListener('click',function(event){
alert("target");
event.stopPropagation();
},false);
// 事件冒泡
outA.addEventListener('click',function(){alert("bubble");},false);
// 事件捕获
outA.addEventListener('click',function(){alert("capture");},true);当点击outC的时候,只会打印出capture->target,不会打印出bubble。因为当事件传播到outC上的处理函数时,通过stopPropagation阻止了事件的继续传播,所以不会继续传播到冒泡阶段。
继续修改代码
// 目标
outC.addEventListener('click',function(event){ alert("target");}, false);
// 事件冒泡
outA.addEventListener('click',function(){ alert("bubble");}, false);
// 事件捕获
outA.addEventListener('click',function(event){
alert("capture");
event.stopPropagation();
}, true);当点击outC的时候,只会打印出capture而没有触发outC上的事件处理函数。 因为outA上的捕获事件是先执行的,触发了里面event.stopPropagation()就不会再执行任何传播事件了。
引申
preventDefault, stopPropagation, stopImmediatePropagation和return false的区别
preventDefault, stopPropagation, stopImmediatePropagation都是event提供的方法
event.stopPropagation
event.stopPropagation阻止捕获和冒泡阶段中当前事件的进一步传播。
event.preventDefault
如果事件可取消,则取消该事件,而不停止事件的进一步传播。 它可以阻止事件触发后默认动作的发生。
可用来阻止input框非法内容的输入,checkbox被选中等
WARNING
注意:preventDefault 方法不会阻止该事件的进一步冒泡。stopPropagation 方法才有这样的功能.
event.stopImmediatePropagation
这个方法会做两件事情:
Keeps the rest of the handlers from being executed and prevents the event from bubbling up the DOM tree.
第一件事:阻止绑定在事件触发元素的其他同类事件的运行,看下面的例子就很明白:
$("p").click(function(event) {
event.stopImmediatePropagation();
});
$("p").click(function(event) {
// 不会执行以下代码
$(this).css("background-color", "#f00");
});第二件事,阻止事件传播到父元素,这跟stopPropagation的作用是一样的。
stopImmediatePropagation比stopPropagation多做了第一件事情,这就是他们之间的区别。
WARNING
注意:不要用return false;来阻止event的默认行为,原因请见
关于 addEventListener 和 on
使用on后面的会覆盖前面事件,而addEventListener不会
比如页面上有 <div id="box">追梦子</div>
window.onload = function(){
var box = document.getElementById("box");
box.onclick = function(){
console.log("我是box1");
}
box.onclick = function(){
box.style.fontSize = "18px";
console.log("我是box2");
}
}运行结果:"我是box2"
window.onload = function(){
var box = document.getElementById("box");
box.addEventListener("click",function(){
console.log("我是box1");
})
box.addEventListener("click",function(){
console.log("我是box2");
})
}运行结果:我是box1, 我是box2
关于addEventListener的第三个参数,true代表捕获阶段处理, false代表冒泡阶段处理。不写默认false。
参考
]]>for(let i = 0 ; i < 5 ; i++){
setTimeout(function(){
console.log(i);
}, i * 1000);
}- 结合promise写法
function sleep(millis) {
return new Promise(resolve => setTimeout(resolve, millis));
}
for(let i = 0 ; i < 5 ; i++){
sleep(i * 1000).then(() => {
console.log(i);
})
}在 JavaScript 中,像这样用字面量初始化对象的写法十分常见:
let foo = {};
foo.bar = 123;
foo.bas = 'Hello World';但在 TypeScript 中,同样的写法就会报错:
let foo = {};
foo.bar = 123; // Error: Property 'bar' does not exist on type '{}'
foo.bas = 'Hello World'; // Error: Property 'bas' does not exist on type '{}'这是因为 TypeScript 在解析let foo = {}这段赋值语句时,会进行“类型推断”:它会认为等号左边foo的类型即为等号右边{}的类型。
由于{}本没有任何属性,因此,像上面那样给foo添加属性时就会报错。
最好的解决方案就是在为变量赋值的同时,添加属性及其对应的值:
let foo = {
bar: 123,
bas: 'Hello World'
};快速解决方案
let foo = {} as any;
foo.bar = 123;
foo.bas = 'Hello World';折中的解决方案 当然,总是用 any 肯定是不好的,因为这样做其实是在想办法绕开 TypeScript 的类型检查。 那么,折中的方案就是创建 interface,这样的好处在于:
方便撰写类型文档 TypeScript 会参与类型检查,确保类型安全 请看以下的示例:
interface Foo {
bar: number;
bas: string;
}
let foo = {} as Foo;
foo.bar = 123;
foo.bas = 'Hello World';
// 使用 interface 可以确保类型安全,比如我们尝试这样做:
foo.bar = 'Hello Stranger'; // 错误:你可能把 `bas` 写成了 `bar`,不能为数字类型的属性赋值字符串如果实在不想写interface,为避免object.p找不到属性,可以尝试使用 object['p']即对象的数组取值写法,
2. 关于interface
TS 中的 interface 接口和 Java,PHP等语言中的接口不太一样。 在 TS 中接口可以确保类拥有指定的结构。
interface LoggerInterface {
log(arg: any) : void;
}
class Logger implements LoggerInterface {
log (arg) {
console.log(arg);
}
}也可以使用接口来约束对象
interface Person {
name: string;
// 只能在对象刚刚创建的时候修改其值
readonly age: number;
// 可选属性
hobby?: string;
}
let zhangsan = {} as Person;错: zhangsan.age = 10; age 是只读属性,只能get不能set
对: let zhangsan = {age: 10} as Person;
错: let zhangsan = {nickname: 'xx'} as Person; nickname不属于Person类型。
readonly vs const 最简单判断该用readonly还是const的方法是看要把它做为变量使用还是做为一个属性。 做为变量使用的话用 const,若做为属性则使用readonly。
有时候我们希望一个接口允许有任意的属性,可以使用如下方式:
interface Person {
name: string;
readonly age: number;
hobby?: string;
[propName: string]: any;
}使用 [propName: string] 定义了任意属性取 string 类型的值。
需要注意的是,一旦定义了任意属性,那么确定属性和可选属性都必须是它的子属性:
所以 let zhangsan = { name: 'xx', age: 18, nickname: 'xx'} as Person; 不会报错。
也可以这么写 let lisi: Person = { name: 'lisi', age: 20 }
这个功能在有些地方很有用,比如一个组件的config对象类型。可允许传入任意名称的属性。当然属性值得是字符串。
3. 枚举类型
当我们需要定义一组有共同特点的变量,可以使用枚举类型。 比如我们要实现下面的页面,这个页面有两处地方要实现点击切换视图的效果,一个是包含Ad Creative,Images和Videos分类的Tab,一个是显示方式Grid还是table。 点击不同的按钮,页面切换不同的效果。


代码实现
export enum DisplayTab {
Creative,
Image,
Video,
}
export enum DisplayMode {
Table,
Grid,
}默认下 DisplayTab.Creative 等于 0,即起始从0开始。 也可以改变起始值
export enum DisplayTab {
Creative = 3,
Image, // 4
Video, // 5
}4. 使用泛型提高重用性
比如后台的API中返回的格式是规定的
{
success: true,
data: [{id:1, name: 'aa'}, {id:2, name: 'bb'}]
}刚开始我们可能会这么写,为每一个API的返回定义一种类型
interface AccountInfo {
'id': number;
'name': string;
}
// success 和 data 具有普遍性,应该进一步封装
interface AccountInfoResp {
success: boolean;
data: AccountInfo;
}
getAccountInfo(id) {
return this.http.get<AccountInfoResp>(`/api/accounts/info/${id}`);
}使用泛型进行优化 T 代表我们传入的类型
// 可以提取到一个result.ts文件
export interface Result<T> {
success?: boolean;
data?: T;
}
getAccountInfo(bid) {
return this.http.get<Result<AccountInfo>>(`/api/accounts/xhr/info`);
}参考
]]>使用StorageEvent非常简单,代码如下:
window.addEventListener('storage', () => {
// When local storage changes, dump the list to
// the console.
console.log(JSON.parse(window.localStorage.getItem('sampleList')));
});其他写法:
window.onstorage = () => {
// When local storage changes, dump the list to
// the console.
console.log(JSON.parse(window.localStorage.getItem('sampleList')));
};购物车的完整例子,你可以开多个tab实验: https://jsbin.com/radekilosu/1/edit?html,css,js,output

另外事件e上还带有很多信息,方便做更多控制。
| 字段 | 含义 |
|---|---|
| key | 发生变化的storageKey |
| newValue | 变换后新值 |
| oldValue | 变换前原值 |
| storageArea | 相关的变化对象 |
| url | 触发变化的URL,如果是frameset内,则是触发帧的URL |
关于兼容性:最新的火狐,Chrome,Edge的支持,IE未知
]]>for...in, for...of和forEach
- forEach遍历数组的时候是无法通过break或return false来中断。
var arr = [3, 5, 7];
arr.forEach(value => {
console.log(value);
if (value == 5) {
// 无效
return false;
}
});
// 结果是:
// 3
// 5
// 7可以使用for...of
var arr = [3, 5, 7];
for (let value of arr) {
console.log(value);
if (value === 5) {
break;
}
}
// 结果是:
// 3
// 5for...of循环可以使用的范围包括数组、Set 和 Map 结构、某些类似数组的对象(比如arguments对象、DOM NodeList 对象)、后文的 Generator 对象,以及字符串。
let str = 'boo';
for (let value of str) {
console.log(value);
}
// 结果是:
// "b"
// "o"
// "o"总结
- 对于对象遍历,用for...in
- 对于数组遍历,如果不需要知道索引,for..of迭代更合适,因为还可以中断;如果需要知道索引,则forEach()更合适;
- 对于字符串,类数组,arguments对象、DOM NodeList 对象等只要部署了Symbol.iterator属性,用for...of循环遍历它的成员。
iterator 就是迭代器或遍历器,任何数据结构只要部署 Iterator 接口,就可以完成遍历操作(即依次处理该数据结构的所有成员)。具体参见
用 for...of 遍历对象需要配合 Object.keys / Object.values / Object.entries
let obj = {name: 'xx', age: 18}
for(let [key, value] of Object.entries(obj)) {
console.log(key, value);
}参考
https://www.zhangxinxu.com/wordpress/2018/08/for-in-es6-for-of/
]]>本文主要讲两种主流方式实现前端路由。
Hash 模式
浏览器提供了一些 api 可以让我们获取到URL中带“#”的标识。比如 URL.hash、location.hash。
如 网址 https://www.vip.com/#drop-item-2
通过location.hash可以获取#drop-item-2
同时我们可以通过 hashchange 事件来监听hash值的改变,这样就能通过事件监听 url 中 hash 的改变从而改变特定页面元素的显示内容,从而实现前端路由。
简单实现代码如下:
<body>
<div id="app">
<a href="/home">home</a>
<a href="/about">about</a>
<div class="router-view"></div>
</div>
<script>
// 1.获取路由显示元素
const routerViewEl = document.querySelector('.router-view');
// 2.监听 hashchange 事件
window.addEventListener('hashchange', () => {
// 3.判断 hash 的改变值,修改路由显示元素的 innerHTMl
switch (location.hash) {
case '#/home':
routerViewEl.innerHTML = 'Home';
break;
case '#/about':
routerViewEl.innerHTML = 'about';
break;
default:
routerViewEl.innerHTML = 'default';
}
});
</script>
</body>另外一个例子
切换hash,执行对应名称的方法,达到修改背景色的目的
History API
History 接口是 HTML5 新增的, 它有六种模式改变 URL 而不刷新页面。
- pushState:使用新的路径;
- replaceState:替换原来的路径;
- popState:路径的回退;
- go:向前或向后改变路径;
- forward:向前改变路径;
- back:向后改变路径;
其中比较重要的两个 api 是 pushState 和 replaceState 是比较重要的,是实现 history 模式的重要 api。
这两个 API 都接收三个参数,分别是
- 状态对象(state object) — 一个JavaScript对象,与用pushState()方法创建的新历史记录条目关联。无论何时用户导航到新创建的状态,popstate事件都会被触发,并且事件对象的state属性都包含历史记录条目的状态对象的拷贝。
- 标题(title) — FireFox浏览器目前会忽略该参数,虽然以后可能会用上。考虑到未来可能会对该方法进行修改,传一个空字符串会比较安全。或者,你也可以传入一个简短的标题,标明将要进入的状态。
- 地址(URL) — 新的历史记录条目的地址。浏览器不会在调用pushState()方法后加载该地址,但之后,可能会试图加载,例如用户重启浏览器。新的URL不一定是绝对路径;如果是相对路径,它将以当前URL为基准;传入的URL与当前URL应该是同源的,否则,pushState()会抛出异常。该参数是可选的;不指定的话则为文档当前URL。
首先我们用 pushState 来简单实现下,代码如下:
<body>
<div id="app">
<a href="/home">home</a>
<a href="/about">about</a>
<div class="router-view"></div>
</div>
<script>
// 1.获取路由显示元素
const routerViewEl = document.querySelector('.router-view');
// 2.获取所有路由跳转元素
const aEls = document.getElementsByTagName('a');
// 3.遍历所有 a 元素,注册事件监听点击
for (let aEl of aEls) {
aEl.addEventListener('click', (e) => {
// 4.阻止默认跳转
e.preventDefault();
// 5.获取 href 属性
const href = aEl.getAttribute('href');
// 6.执行 history.pushState
history.pushState({}, '', href);
//
// history.replaceState({}, '', href);
// 7.判断 pathname 路径的改变
switch (location.pathname) {
case '/home':
routerViewEl.innerHTML = 'Home';
break;
case '/about':
routerViewEl.innerHTML = 'about';
break;
default:
routerViewEl.innerHTML = 'default';
}
});
}
</script>
</body>如果把代码改成 replaceState 实现。那么就不能操作浏览器上面的前进后退操作。
对比
hash 方案更常见些,也是前端框架,如Vue,Angular的默认路由模式, hash模式的缺点就是路径比较丑,总是多了一个#!,优点是浏览器兼容性强
history模式是,URL就像一个正常的url,例如http://yoursite.com/user/id,更顺眼些。
缺点是需要后台配置支持,否则可能会出现404的情况
所以呢,使用history模式要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app 依赖的页面。
具体配置方法
参考
https://segmentfault.com/a/1190000007238999
https://www.cnblogs.com/cqkjxxxx/p/15253331.html
https://router.vuejs.org/zh/guide/essentials/history-mode.html
]]>导读
变量和类型是学习JavaScript最先接触到的东西,但是往往看起来最简单的东西往往还隐藏着很多你不了解、或者容易犯错的知识,比如下面几个问题:
-
JavaScript中的变量在内存中的具体存储形式是什么? -
0.1+0.2为什么不等于0.3?发生小数计算错误的具体原因是什么? -
Symbol的特点,以及实际应用场景是什么? -
[] == ![]、[undefined] == false为什么等于true?代码中何时会发生隐式类型转换?转换的规则是什么? -
如何精确的判断变量的类型?
如果你还不能很好的解答上面的问题,那说明你还没有完全掌握这部分的知识,那么请好好阅读下面的文章吧。
本文从底层原理到实际应用详细介绍了JavaScript中的变量和类型相关知识。
一、JavaScript数据类型
ECMAScript标准规定了7种数据类型,其把这7种数据类型又分为两种:原始类型和对象类型。
原始类型
-
Null:只包含一个值:null -
Undefined:只包含一个值:undefined -
Boolean:包含两个值:true和false -
Number:整数或浮点数,还有一些特殊值(-Infinity、+Infinity、NaN) -
String:一串表示文本值的字符序列 -
Symbol:一种实例是唯一且不可改变的数据类型
(在es10中加入了第七种原始类型BigInt,现已被最新Chrome支持)
对象类型
Object:自己分一类丝毫不过分,除了常用的Object,Array、Function等都属于特殊的对象
二、为什么区分原始类型和对象类型
2.1 不可变性
上面所提到的原始类型,在ECMAScript标准中,它们被定义为primitive values,即原始值,代表值本身是不可被改变的。
以字符串为例,我们在调用操作字符串的方法时,没有任何方法是可以直接改变字符串的:
varstr='ConardLi';
str.slice(1);str.substr(1);
str.trim(1);
str.toLowerCase(1);
str[0]=1;
console.log(str);
//ConardLi在上面的代码中我们对str调用了几个方法,无一例外,这些方法都在原字符串的基础上产生了一个新字符串,而非直接去改变str,这就印证了字符串的不可变性。
那么,当我们继续调用下面的代码:
str+='6';
console.log(str);
//ConardLi6你会发现,str的值被改变了,这不就打脸了字符串的不可变性么?其实不然,我们从内存上来理解:
在JavaScript中,每一个变量在内存中都需要一个空间来存储。
内存空间又被分为两种,栈内存与堆内存。
栈内存:
-
存储的值大小固定
-
空间较小
-
可以直接操作其保存的变量,运行效率高
-
由系统自动分配存储空间
JavaScript中的原始类型的值被直接存储在栈中,在变量定义时,栈就为其分配好了内存空间。
由于栈中的内存空间的大小是固定的,那么注定了存储在栈中的变量就是不可变的。
在上面的代码中,我们执行了str += '6'的操作,实际上是在栈中又开辟了一块内存空间用于存储'ConardLi6',然后将变量str指向这块空间,所以这并不违背不可变性的特点。
2.2 引用类型
堆内存:
-
存储的值大小不定,可动态调整
-
空间较大,运行效率低
-
无法直接操作其内部存储,使用引用地址读取
-
通过代码进行分配空间
相对于上面具有不可变性的原始类型,我习惯把对象称为引用类型,引用类型的值实际存储在堆内存中,它在栈中只存储了一个固定长度的地址,这个地址指向堆内存中的值。
varobj1={name:"ConardLi"}
varobj2={age:18}
varobj3=function(){...}
varobj4=[1,2,3,4,5,6,7,8,9]由于内存是有限的,这些变量不可能一直在内存中占用资源,这里推荐下这篇文章JavaScript中的垃圾回收和内存泄漏,这里告诉你
JavaScript是如何进行垃圾回收以及可能会发生内存泄漏的一些场景。
当然,引用类型就不再具有不可变性了,我们可以轻易的改变它们:
obj1.name="ConardLi6";obj2.age=19;obj4.length=0;console.log(obj1);//{name:"ConardLi6"}console.log(obj2);//{age:19}console.log(obj4);//[]以数组为例,它的很多方法都可以改变它自身。
-
pop()删除数组最后一个元素,如果数组为空,则不改变数组,返回undefined,改变原数组,返回被删除的元素 -
push()向数组末尾添加一个或多个元素,改变原数组,返回新数组的长度 -
shift()把数组的第一个元素删除,若空数组,不进行任何操作,返回undefined,改变原数组,返回第一个元素的值 -
unshift()向数组的开头添加一个或多个元素,改变原数组,返回新数组的长度 -
reverse()颠倒数组中元素的顺序,改变原数组,返回该数组 -
sort()对数组元素进行排序,改变原数组,返回该数组 -
splice()从数组中添加/删除项目,改变原数组,返回被删除的元素
下面我们通过几个操作来对比一下原始类型和引用类型的区别:
2.3 复制
当我们把一个变量的值复制到另一个变量上时,原始类型和引用类型的表现是不一样的,先来看看原始类型:
varname='ConardLi';
varname2=name;name2='code秘密花园';
console.log(name);
//ConardLi;内存中有一个变量name,值为ConardLi。我们从变量name复制出一个变量name2,此时在内存中创建了一个块新的空间用于存储ConardLi,虽然两者值是相同的,但是两者指向的内存空间完全不同,这两个变量参与任何操作都互不影响。
复制一个引用类型:
varobj={name:'ConardLi'};
varobj2=obj;
obj2.name='code秘密花园';
console.log(obj.name);
//code秘密花园当我们复制引用类型的变量时,实际上复制的是栈中存储的地址,所以复制出来的obj2实际上和obj指向的堆中同一个对象。因此,我们改变其中任何一个变量的值,另一个变量都会受到影响,这就是为什么会有深拷贝和浅拷贝的原因。
2.4 比较
当我们在对两个变量进行比较时,不同类型的变量的表现是不同的:
varname='ConardLi';
varname2='ConardLi';
console.log(name===name2);
//truevarobj={name:'ConardLi'};
varobj2={name:'ConardLi'};
console.log(obj===obj2);//false对于原始类型,比较时会直接比较它们的值,如果值相等,即返回true。
对于引用类型,比较时会比较它们的引用地址,虽然两个变量在堆中存储的对象具有的属性值都是相等的,但是它们被存储在了不同的存储空间,因此比较值为false。
2.5 值传递和引用传递
借助下面的例子,我们先来看一看什么是值传递,什么是引用传递:
letname='ConardLi';
functionchangeValue(name){
name='code秘密花园';
}
changeValue(name);
console.log(name);执行上面的代码,如果最终打印出来的name是'ConardLi',没有改变,说明函数参数传递的是变量的值,即值传递。如果最终打印的是'code秘密花园',函数内部的操作可以改变传入的变量,那么说明函数参数传递的是引用,即引用传递。
很明显,上面的执行结果是'ConardLi',即函数参数仅仅是被传入变量复制给了的一个局部变量,改变这个局部变量不会对外部变量产生影响。
letobj={ name:'ConardLi' };
functionchangeValue(obj){
obj.name='code秘密花园';
}
changeValue(obj);
console.log(obj.name);
//code秘密花园上面的代码可能让你产生疑惑,是不是参数是引用类型就是引用传递呢?
首先明确一点,ECMAScript中所有的函数的参数都是按值传递的。
同样的,当函数参数是引用类型时,我们同样将参数复制了一个副本到局部变量,只不过复制的这个副本是指向堆内存中的地址而已,我们在函数内部对对象的属性进行操作,实际上和外部变量指向堆内存中的值相同,但是这并不代表着引用传递,下面我们再按一个例子:
letobj={};
functionchangeValue(obj){
obj.name='ConardLi';
obj={
name:'code秘密花园'
};
}
changeValue(obj);
console.log(obj.name);//ConardLi可见,函数参数传递的并不是变量的引用,而是变量拷贝的副本,当变量是原始类型时,这个副本就是值本身,当变量是引用类型时,这个副本是指向堆内存的地址。所以,再次记住:
ECMAScript中所有的函数的参数都是按值传递的。
三、分不清的null和undefined
在原始类型中,有两个类型Null和Undefined,他们都有且仅有一个值,null和undefined,并且他们都代表无和空,我一般这样区分它们:
null
表示被赋值过的对象,刻意把一个对象赋值为null,故意表示其为空,不应有值。
所以对象的某个属性值为null是正常的,null转换为数值时值为0。
undefined
表示“缺少值”,即此处应有一个值,但还没有定义,
如果一个对象的某个属性值为undefined,这是不正常的,如obj.name=undefined,我们不应该这样写,应该直接delete obj.name。
undefined转为数值时为NaN(非数字值的特殊值)
JavaScript是一门动态类型语言,成员除了表示存在的空值外,还有可能根本就不存在(因为存不存在只在运行期才知道),这就是undefined的意义所在。对于JAVA这种强类型语言,如果有"undefined"这种情况,就会直接编译失败,所以在它不需要一个这样的类型。
四、不太熟的Symbol类型
Symbol类型是ES6中新加入的一种原始类型。
每个从Symbol()返回的symbol值都是唯一的。一个symbol值能作为对象属性的标识符;这是该数据类型仅有的目的。
下面来看看Symbol类型具有哪些特性。
4.1 Symbol的特性
1.独一无二
直接使用Symbol()创建新的symbol变量,可选用一个字符串用于描述。当参数为对象时,将调用对象的toString()方法。
varsym1=Symbol();
//Symbol()varsym2=Symbol('ConardLi');
//Symbol(ConardLi)varsym3=Symbol('ConardLi');
//Symbol(ConardLi)
varsym4=Symbol({name:'ConardLi'});
//Symbol([objectObject])console.log(sym2===sym3);//false我们用两个相同的字符串创建两个Symbol变量,它们是不相等的,可见每个Symbol变量都是独一无二的。
如果我们想创造两个相等的Symbol变量,可以使用Symbol.for(key)。
使用给定的key搜索现有的symbol,如果找到则返回该symbol。否则将使用给定的key在全局symbol注册表中创建一个新的symbol。
varsym1=Symbol.for('ConardLi');
varsym2=Symbol.for('ConardLi');
console.log(sym1===sym2);//true2.原始类型
注意是使用Symbol()函数创建symbol变量,并非使用构造函数,使用new操作符会直接报错。
newSymbol();//UncaughtTypeError:Symbolisnotaconstructor我们可以使用typeof运算符判断一个Symbol类型:
typeofSymbol()==='symbol'typeofSymbol('ConardLi')==='symbol'3.不可枚举
当使用Symbol作为对象属性时,可以保证对象不会出现重名属性,调用for...in不能将其枚举出来,另外调用Object.getOwnPropertyNames、Object.keys()也不能获取Symbol属性。
可以调用Object.getOwnPropertySymbols()用于专门获取Symbol属性。
varobj={
name:'ConardLi',
[Symbol('name2')]:'code秘密花园'
}
Object.getOwnPropertyNames(obj);//["name"]
Object.keys(obj);//["name"]
for(variinobj){
console.log(i);//name
}
Object.getOwnPropertySymbols(obj) //[Symbol(name)]4.2 Symbol的应用场景
下面是几个Symbol在程序中的应用场景。
应用一:防止XSS
在React的ReactElement对象中,有一个$$typeof属性,它是一个Symbol类型的变量:
varREACT_ELEMENT_TYPE=
(typeofSymbol==='function'&&Symbol.for&&Symbol.for('react.element'))
||0xeac7;ReactElement.isValidElement函数用来判断一个React组件是否是有效的,下面是它的具体实现。
ReactElement.isValidElement=function(object){
returntypeofobject==='object'&&object!==null
&&object.$$typeof===REACT_ELEMENT_TYPE;
};可见React渲染时会把没有$$typeof标识,以及规则校验不通过的组件过滤掉。
如果你的服务器有一个漏洞,允许用户存储任意JSON对象, 而客户端代码需要一个字符串,这可能会成为一个问题:
//JSON
letexpectedTextButGotJSON={
type:'div',
props:{
dangerouslySetInnerHTML:{
__html:'/*putyourexploithere*/'
},
},
};
letmessage={text:expectedTextButGotJSON};
<p>{message.text}</p>而JSON中不能存储Symbol类型的变量,这就是防止XSS的一种手段。
应用二:私有属性
借助Symbol类型的不可枚举,我们可以在类中模拟私有属性,控制变量读写:
constprivateField=Symbol();
classmyClass{
constructor(){
this[privateField]='ConardLi';
}
getField(){
returnthis[privateField];
}
setField(val){
this[privateField]=val;
}
}应用三:防止属性污染
在某些情况下,我们可能要为对象添加一个属性,此时就有可能造成属性覆盖,用Symbol作为对象属性可以保证永远不会出现同名属性。
例如下面的场景,我们模拟实现一个call方法:
Function.prototype.myCall = function (context) {
if (typeofthis !== 'function') {
returnundefined; //用于防止Function.prototype.myCall()直接调用
}
context=context||window;
constfn=Symbol();
context[fn]=this;
constargs=[...arguments].slice(1);
constresult=context[fn](...args);
deletecontext[fn];
returnresult;
}我们需要在某个对象上临时调用一个方法,又不能造成属性污染,Symbol是一个很好的选择。
五、不老实的Number类型
为什么说Number类型不老实呢,相信大家都多多少少的在开发中遇到过小数计算不精确的问题,比如0.1+0.2!==0.3,下面我们来追本溯源,看看为什么会出现这种现象,以及该如何避免。
下面是我实现的一个简单的函数,用于判断两个小数进行加法运算是否精确:
function judgeFloat(n, m) {
const binaryN = n.toString(2);
const binaryM = m.toString(2);
console.log(`${n}的二进制是 ${binaryN}`);
console.log(`${m}的二进制是 ${binaryM}`);
const MN = m + n;
const accuracyMN = (m * 100 + n * 100) / 100;
const binaryMN = MN.toString(2);
const accuracyBinaryMN = accuracyMN.toString(2);
console.log(`${n}+${m}的二进制是${binaryMN}`);
console.log(`${accuracyMN}的二进制是 ${accuracyBinaryMN}`);
console.log(`${n}+${m}的二进制再转成十进制是${to10(binaryMN)}`);
console.log(`${accuracyMN}的二进制是再转成十进制是${to10(accuracyBinaryMN)}`);
console.log(`${n}+${m}在js中计算是${(to10(binaryMN) === to10(accuracyBinaryMN)) ? '' : '不'}准确的`);
}
function to10(n) {
const pre = (n.split('.')[0] - 0).toString(2);
const arr = n.split('.')[1].split('');
let i = 0;
let result = 0;
while (i < arr.length) {
result += arr[i] * Math.pow(2, -(i + 1));
i++;
}
return result;
}
judgeFloat(0.1, 0.2);
judgeFloat(0.6, 0.7);5.1 精度丢失
计算机中所有的数据都是以二进制存储的,所以在计算时计算机要把数据先转换成二进制进行计算,然后在把计算结果转换成十进制。
由上面的代码不难看出,在计算0.1+0.2时,二进制计算发生了精度丢失,导致再转换成十进制后和预计的结果不符。
5.2 对结果的分析—更多的问题
0.1和0.2的二进制都是以1100无限循环的小数,下面逐个来看JS帮我们计算所得的结果:
0.1的二进制:
0.00011001100110011001100110011001100110011001100110011010.2的二进制:
0.001100110011001100110011001100110011001100110011001101理论上讲,由上面的结果相加应该::
0.0100110011001100110011001100110011001100110011001100111实际JS计算得到的0.1+0.2的二进制
0.0100110011001100110011001100110011001100110011001101看到这里你可能会产生更多的问题:
为什么 js计算出的 0.1的二进制 是这么多位而不是更多位???
为什么 js计算的(0.1+0.2)的二进制和我们自己计算的(0.1+0.2)的二进制结果不一样呢???
为什么 0.1的二进制 + 0.2的二进制 != 0.3的二进制???
5.3 js对二进制小数的存储方式
小数的二进制大多数都是无限循环的,JavaScript是怎么来存储他们的呢?
在ECMAScript®语言规范中可以看到,ECMAScript中的Number类型遵循IEEE 754标准。使用64位固定长度来表示。
事实上有很多语言的数字类型都遵循这个标准,例如JAVA,所以很多语言同样有着上面同样的问题。
所以下次遇到这种问题不要上来就喷JavaScript…
有兴趣可以看看下这个网站http://0.30000000000000004.com/,是的,你没看错,就是http://0.30000000000000004.com/!!!
5.4 IEEE 754
IEEE754标准包含一组实数的二进制表示法。它有三部分组成:
-
符号位
-
指数位
-
尾数位
三种精度的浮点数各个部分位数如下:
JavaScript使用的是64位双精度浮点数编码,所以它的符号位占1位,指数位占11位,尾数位占52位。
下面我们在理解下什么是符号位、指数位、尾数位,以0.1为例:
它的二进制为:0.0001100110011001100...
为了节省存储空间,在计算机中它是以科学计数法表示的,也就是
1.100110011001100...X 2-4
如果这里不好理解可以想一下十进制的数:
1100的科学计数法为11X 102
所以:
符号位就是标识正负的,1表示负,0表示正;
指数位存储科学计数法的指数;
尾数位存储科学计数法后的有效数字;
所以我们通常看到的二进制,其实是计算机实际存储的尾数位。
5.5 js中的toString(2)
由于尾数位只能存储52个数字,这就能解释toString(2)的执行结果了:
如果计算机没有存储空间的限制,那么0.1的二进制应该是:
0.00011001100110011001100110011001100110011001100110011001...科学计数法尾数位
1.1001100110011001100110011001100110011001100110011001...但是由于限制,有效数字第53位及以后的数字是不能存储的,它遵循,如果是1就向前一位进1,如果是0就舍弃的原则。
0.1的二进制科学计数法第53位是1,所以就有了下面的结果:
0.00011001100110011001100110011001100110011001100110011010.2有着同样的问题,其实正是由于这样的存储,在这里有了精度丢失,导致了0.1+0.2!=0.3。
事实上有着同样精度问题的计算还有很多,我们无法把他们都记下来,所以当程序中有数字计算时,我们最好用工具库来帮助我们解决,下面是两个推荐使用的开源库:
-
number-precision
-
mathjs/
5.6 JavaScript能表示的最大数字
由与IEEE 754双精度64位规范的限制:
指数位能表示的最大数字:1023(十进制)
尾数位能表达的最大数字即尾数位都位1的情况
所以JavaScript能表示的最大数字即位
1.111...X 21023这个结果转换成十进制是1.7976931348623157e+308,这个结果即为Number.MAX_VALUE。
5.7 最大安全数字
JavaScript中Number.MAX_SAFE_INTEGER表示最大安全数字,计算结果是9007199254740991,即在这个数范围内不会出现精度丢失(小数除外),这个数实际上是1.111...X 252。
我们同样可以用一些开源库来处理大整数:
-
node-bignum
-
node-bigint
其实官方也考虑到了这个问题,bigInt类型在es10中被提出,现在Chrome中已经可以使用,使用bigInt可以操作超过最大安全数字的数字。
六、还有哪些引用类型
在
ECMAScript中,引用类型是一种数据结构,用于将数据和功能组织在一起。
我们通常所说的对象,就是某个特定引用类型的实例。
在ECMAScript关于类型的定义中,只给出了Object类型,实际上,我们平时使用的很多引用类型的变量,并不是由Object构造的,但是它们原型链的终点都是Object,这些类型都属于引用类型。
-
Array数组 -
Date日期 -
RegExp正则 -
Function函数
6.1 包装类型
为了便于操作基本类型值,ECMAScript还提供了几个特殊的引用类型,他们是基本类型的包装类型:
-
Boolean -
Number -
String
注意包装类型和原始类型的区别:
true === new Boolean(true); // false
123 === new Number(123); // false
'ConardLi' === new String('ConardLi'); // false
console.log(typeof new String('ConardLi')); // object
console.log(typeof 'ConardLi'); // string引用类型和包装类型的主要区别就是对象的生存期,使用new操作符创建的引用类型的实例,在执行流离开当前作用域之前都一直保存在内存中,而自基本类型则只存在于一行代码的执行瞬间,然后立即被销毁,这意味着我们不能在运行时为基本类型添加属性和方法。
varname='ConardLi'
name.color='red';
console.log(name.color);//undefined6.2 装箱和拆箱
-
装箱转换:把基本类型转换为对应的包装类型
-
拆箱操作:把引用类型转换为基本类型
既然原始类型不能扩展属性和方法,那么我们是如何使用原始类型调用方法的呢?
每当我们操作一个基础类型时,后台就会自动创建一个包装类型的对象,从而让我们能够调用一些方法和属性,例如下面的代码:
var name = "ConardLi";
var name2 = name.substring(2);实际上发生了以下几个过程:
-
创建一个
String的包装类型实例 -
在实例上调用
substring方法 -
销毁实例
也就是说,我们使用基本类型调用方法,就会自动进行装箱和拆箱操作,相同的,我们使用Number和Boolean类型时,也会发生这个过程。
从引用类型到基本类型的转换,也就是拆箱的过程中,会遵循ECMAScript规范规定的toPrimitive原则,一般会调用引用类型的valueOf和toString方法,你也可以直接重写toPeimitive方法。一般转换成不同类型的值遵循的原则不同,例如:
-
引用类型转换为
Number类型,先调用valueOf,再调用toString -
引用类型转换为
String类型,先调用toString,再调用valueOf
若valueOf和toString都不存在,或者没有返回基本类型,则抛出TypeError异常。
const obj = {
valueOf: () => { console.log('valueOf'); return 123; },
toString: () => { console.log('toString'); return 'ConardLi'; },
};
console.log(obj - 1); // valueOf 122
console.log(`${obj}ConardLi`); // toString ConardLiConardLi
const obj2 = {
[Symbol.toPrimitive]: () => { console.log('toPrimitive'); return 123; },
};
console.log(obj2 - 1); // valueOf 122
const obj3 = {
valueOf: () => { console.log('valueOf'); return {}; },
toString: () => { console.log('toString'); return {}; },
};
console.log(obj3 - 1);
// valueOf
// toString
// TypeError除了程序中的自动拆箱和自动装箱,我们还可以手动进行拆箱和装箱操作。我们可以直接调用包装类型的valueOf或toString,实现拆箱操作:
var num = new Number("123");
console.log( typeof num.valueOf() ); //number
console.log( typeof num.toString() ); //string七、类型转换
因为JavaScript是弱类型的语言,所以类型转换发生非常频繁,上面我们说的装箱和拆箱其实就是一种类型转换。
类型转换分为两种,隐式转换即程序自动进行的类型转换,强制转换即我们手动进行的类型转换。
强制转换这里就不再多提及了,下面我们来看看让人头疼的可能发生隐式类型转换的几个场景,以及如何转换:
7.1 类型转换规则
如果发生了隐式转换,那么各种类型互转符合下面的规则:
7.2 if 语句和逻辑语句
在if语句和逻辑语句中,如果只有单个变量,会先将变量转换为Boolean值,只有下面几种情况会转换成false,其余被转换成true:
null
undefined
''
NaN
0
false7.3 各种运数学算符
我们在对各种非Number类型运用数学运算符(- * /)时,会先将非Number类型转换为Number类型;
1 - true // 0
1 - null // 1
1 * undefined // NaN
2 * ['5'] // 10注意+是个例外,执行+操作符时:
-
1.当一侧为
String类型,被识别为字符串拼接,并会优先将另一侧转换为字符串类型。 -
2.当一侧为
Number类型,另一侧为原始类型,则将原始类型转换为Number类型。 -
3.当一侧为
Number类型,另一侧为引用类型,将引用类型和Number类型转换成字符串后拼接。
123 + '123' // 123123 (规则1)
123 + null // 123 (规则2)
123 + true // 124 (规则2)
123 + {} // 123[object Object] (规则3)7.4 ==
使用==时,若两侧类型相同,则比较结果和===相同,否则会发生隐式转换,使用==时发生的转换可以分为几种不同的情况(只考虑两侧类型不同):
- 1.NaN
NaN和其他任何类型比较永远返回false(包括和他自己)。
NaN==NaN//false- 2.Boolean
Boolean和其他任何类型比较,Boolean首先被转换为Number类型。
true == 1 // true
true == '2' // false
true == ['1'] // true
true == ['2'] // false这里注意一个可能会弄混的点:
undefined、null和Boolean比较,虽然undefined、null和false都很容易被想象成假值,但是他们比较结果是false,原因是false首先被转换成0:
undefined == false // false
null == false // false- 3.String和Number
String和Number比较,先将String转换为Number类型。
123=='123'//true''==0//true- 4.null和undefined
null == undefined比较结果是true,除此之外,null、undefined和其他任何结果的比较值都为false。
null == undefined // true
null == '' // false
null == 0 // false
null == false // false
undefined == '' // false
undefined == 0 // false
undefined == false // false- 5.原始类型和引用类型
当原始类型和引用类型做比较时,对象类型会依照ToPrimitive规则转换为原始类型:
'[object Object]' == {} // true
'1,2,3' == [1, 2, 3] // true来看看下面这个比较:
[]==![]//true!的优先级高于==,![]首先会被转换为false,然后根据上面第三点,false转换成Number类型0,左侧[]转换为0,两侧比较相等。
[null] == false // true
[undefined] == false // true根据数组的ToPrimitive规则,数组元素为null或undefined时,该元素被当做空字符串处理,所以[null]、[undefined]都会被转换为0。
所以,说了这么多,推荐使用===来判断两个值是否相等…
7.5 一道有意思的面试题
一道经典的面试题,如何让:a == 1 && a == 2 && a == 3。
根据上面的拆箱转换,以及==的隐式转换,我们可以轻松写出答案:
const a = {
value:[3,2,1],
valueOf: function () {return this.value.pop(); },
}八、判断JavaScript数据类型的方式
8.1 typeof
适用场景
typeof操作符可以准确判断一个变量是否为下面几个原始类型:
typeof 'ConardLi' // string
typeof 123 // number
typeof true // boolean
typeof Symbol() // symbol
typeof undefined // undefined你还可以用它来判断函数类型:
typeoffunction(){}//function不适用场景
当你用typeof来判断引用类型时似乎显得有些乏力了:
typeof [] // object
typeof {} // object
typeof new Date() // object
typeof /^\d*$/; // object除函数外所有的引用类型都会被判定为object。
另外typeof null === 'object'也会让人感到头痛,这是在JavaScript初版就流传下来的bug,后面由于修改会造成大量的兼容问题就一直没有被修复…
8.2 instanceof
instanceof操作符可以帮助我们判断引用类型具体是什么类型的对象:
[] instanceof Array // true
new Date() instanceof Date // true
new RegExp() instanceof RegExp // true我们先来回顾下原型链的几条规则:
-
1.所有引用类型都具有对象特性,即可以自由扩展属性
-
2.所有引用类型都具有一个
**proto**(隐式原型)属性,是一个普通对象 -
3.所有的函数都具有
prototype(显式原型)属性,也是一个普通对象 -
4.所有引用类型
**proto**值指向它构造函数的prototype -
5.当试图得到一个对象的属性时,如果变量本身没有这个属性,则会去他的
**proto**中去找
[] instanceof Array实际上是判断Foo.prototype是否在[]的原型链上。
所以,使用instanceof来检测数据类型,不会很准确,这不是它设计的初衷:
[]instanceofObject//truefunction(){}instanceofObject//true另外,使用instanceof也不能检测基本数据类型,所以instanceof并不是一个很好的选择。
8.3 toString
上面我们在拆箱操作中提到了toString函数,我们可以调用它实现从引用类型的转换。
每一个引用类型都有
toString方法,默认情况下,toString()方法被每个Object对象继承。如果此方法在自定义对象中未被覆盖,toString()返回"[object type]",其中type是对象的类型。
constobj={};obj.toString()//[objectObject]注意,上面提到了如果此方法在自定义对象中未被覆盖,toString才会达到预想的效果,事实上,大部分引用类型比如Array、Date、RegExp等都重写了toString方法。
我们可以直接调用Object原型上未被覆盖的toString()方法,使用call来改变this指向来达到我们想要的效果。
8.4 jquery
我们来看看jquery源码中如何进行类型判断:
var class2type = {};
jQuery.each( "Boolean Number String Function Array Date RegExp Object Error Symbol".split( " " ),
function( i, name ) {
class2type[ "[object " + name + "]" ] = name.toLowerCase();
} );
type: function( obj ) {
if ( obj == null ) {
return obj + "";
}
return typeof obj === "object" || typeof obj === "function" ?
class2type[Object.prototype.toString.call(obj) ] || "object" :
typeof obj;
}
isFunction: function( obj ) {
return jQuery.type(obj) === "function";
}原始类型直接使用typeof,引用类型使用Object.prototype.toString.call取得类型,借助一个class2type对象将字符串多余的代码过滤掉,例如[object function]将得到array,然后在后面的类型判断,如isFunction直接可以使用jQuery.type(obj) === "function"这样的判断。
参考
小结
希望你阅读本篇文章后可以达到以下几点:
-
了解
JavaScript中的变量在内存中的具体存储形式,可对应实际场景 -
搞懂小数计算不精确的底层原因
-
了解可能发生隐式类型转换的场景以及转换原则
-
掌握判断
JavaScript数据类型的方式和底层原理
scrollHeight 和 clientHeight 值是固定的
scrollTop 是滚动条的高度,越往下值越大
${target.scrollTop} - ${target.scrollHeight} - ${target.clientHeight}
let obj = {};
let obj = new Object;
let obj = Object.create();如果我们直接为对象添加一个属性,比如 obj.a = 10 我们说 a 是 普通属性,他的值既可以被改变,也可以被删除,还可以被for..in 或 Object,keys 枚举遍历。
如果需要精确的添加或修改对象的属性。就可以使用Object.defineProperty()。
Object.defineProperty(obj, prop, descriptor) 接收三个参数:
obj: 要在其上定义属性的对象。 prop: 要定义或修改的属性的名称。 descriptor: 将被定义或修改的属性描述符。
默认情况下,使用 Object.defineProperty() 添加的属性值是不可修改的。
descriptor 是重点,它是个对象,包含的键值比较多; 我们可以这样:
// 在对象中添加一个属性与数据描述符的示例
Object.defineProperty(obj, "a", {
value : 20, // 属性 a 的初始化值是37
writable : true, // 可修改值内容
enumerable : true, // 可枚举,默认 false
configurable : true // 可删除,默认 false
});这种效果和 obj.a = 20 一样 还可以这么写
var bValue;
Object.defineProperty(obj, "a", {
get : function(){
return bValue;
},
set : function(newValue){
bValue = newValue;
},
writable : true, // 可修改值内容
enumerable : true, // 可枚举,默认 false
configurable : true // 可删除,默认 false
});
o.a = 20;set,get 叫做存取描述符,这时不能出现 value 或 write 键,因为会冲突.
Writable 属性
默认 false 如下:
let obj = new Object;
obj.a = 10;
obj.a = 20;
console.log(obj.a) // 20
Object.defineProperty(obj, 'b', {}) // 属性 b 默认值为 'undefined'
obj.b = 20
console.log(obj.b) // 依然是 undefined,而且不会报错Enumerable 属性
默认 false
enumerable定义了对象的属性是否可以在 for...in 循环和 Object.keys() 中被枚举。
var o = {};
Object.defineProperty(o, "a", { value : 1, enumerable:true });
Object.defineProperty(o, "b", { value : 2, enumerable:false });
Object.defineProperty(o, "c", { value : 3 }); // enumerable defaults to false
o.d = 4; // 如果使用直接赋值的方式创建对象的属性,则这个属性的enumerable为true
for (var i in o) {
console.log(i);
}
// 打印 'a' 和 'd' (in undefined order)
Object.keys(o); // ["a", "d"]
o.propertyIsEnumerable('a'); // true
o.propertyIsEnumerable('b'); // false
o.propertyIsEnumerable('c'); // falseConfigurable 属性
configurable特性表示对象的属性是否可以被删除,以及除value和writable特性外的其他特性是否可以被修改。
var o = {};
Object.defineProperty(o, "a", { get : function(){return 1;},
configurable : false } );
// throws a TypeError
Object.defineProperty(o, "a", {configurable : true});
// throws a TypeError
Object.defineProperty(o, "a", {enumerable : true});
// throws a TypeError (set was undefined previously)
Object.defineProperty(o, "a", {set : function(){}});
// throws a TypeError (even though the new get does exactly the same thing)
Object.defineProperty(o, "a", {get : function(){return 1;}});
// throws a TypeError
Object.defineProperty(o, "a", {value : 12});
console.log(o.a); // logs 1
delete o.a; // Nothing happens
console.log(o.a); // logs 1function LateBloomer() {
this.petalCount = Math.ceil(Math.random() * 12) + 1;
}
// Declare bloom after a delay of 2 second
LateBloomer.prototype.bloom = function() {
// 这个写法会报 I am a beautiful flower with undefined petals!
// 原因:在setInterval和setTimeout中传入函数时,函数中的this会指向window对象
window.setTimeout(this.declare, 2000);
// 如果写成 window.setTimeout(this.declare(), 2000); 会立即执行,就没有延迟效果了。
};
LateBloomer.prototype.declare = function() {
console.log('I am a beautiful flower with ' +
this.petalCount + ' petals!');
};
var flower = new LateBloomer();
flower.bloom(); // 二秒钟后, 调用'declare'方法解决办法:
推荐用下面两种写法
- 将bind换成call,apply也会导致立即执行,延迟效果会失效
window.setTimeout(this.declare.bind(this), 2000); - 使用es6中的箭头函数,因为在箭头函数中this是固定的。
// 箭头函数可以让setTimeout里面的this,绑定定义时所在的作用域,而不是指向运行时所在的作用域。
// 参考:箭头函数
语法
fun.bind(thisArg[, arg1[, arg2[, ...]]])
参数
thisArg
当绑定函数被调用时,该参数会作为原函数运行时的this指向。当使用new操作符调用绑定函数时,该参数无效。 this将永久地被绑定到了bind的第一个参数,无论这个函数是如何被调用的。
arg1, arg2, ...
当绑定函数被调用时,这些参数将置于实参之前传递给被绑定的方法。
返回值
返回由指定的this值和初始化参数改造的原函数拷贝
例1
window.color = 'red';
var o = {color: 'blue'};
function sayColor(){
alert(this.color);
}
var func = sayColor.bind(o);
// 输出 "blue", 因为传的是对象 o,this 始终指向 o
func();
var func2 = sayColor.bind(this);
// 输出 "red", 因为传的是this,在全局作用域中this代表 window。等于传的是 window。
func2();例2
注意:bind只生效一次
function f(){
return this.a;
}
//this被固定到了传入的对象上
var g = f.bind({a:"azerty"});
console.log(g()); // azerty
var h = g.bind({a:'yoo'}); //bind只生效一次!
console.log(h()); // azerty
var o = {a:37, f:f, g:g, h:h};
console.log(o.f(), o.g(), o.h()); // 37, azerty, azerty例3
var myObj = {
specialFunction: function () {
},
anotherSpecialFunction: function () {
},
getAsyncData: function (cb) {
cb();
},
render: function () {
// 注意这里,写成 this.specialFunction() 会报错
var that = this;
this.getAsyncData(function () {
that.specialFunction();
that.anotherSpecialFunction();
});
}
};
myObj.render();
// 使用 bind 优化
// 当myObj 调用,this就指向了myObj
render: function () {
this.getAsyncData(function () {
this.specialFunction();
this.anotherSpecialFunction();
}.bind(this));
}例4
使用bind可少写匿名函数
<button>Clict Me!</button>
<script>
var logger = {
x: 0,
updateCount: function(){
this.x++;
console.log(this.x);
}
}
// document.querySelector('button').addEventListener('click', function(){
// logger.updateCount();
// });
// 优化后
// 因为bind返回就是新的函数,不用再写匿名函数了。
document.querySelector('button').addEventListener('click', logger.updateCount.bind(logger))参考
]]>JSON(JavaScript Object Notation) 和 JSONP(JSON with Padding) 虽然只有一个字母的差别,但其实他们根本不是一回事儿:JSON是一种数据交换格式,而JSONP是一种依靠开发人员的聪明才智创造出的一种非官方跨域数据交互协议。我们拿最近比较火的谍战片来打个比方,JSON是地下党们用来书写和交换情报的“暗号”,而JSONP则是把用暗号书写的情报传递给自己同志时使用的接头方式。看到没?一个是描述信息的格式,一个是信息传递双方约定的方法。
既然随便聊聊,那我们就不再采用教条的方式来讲述,而是把关注重心放在帮助开发人员理解是否应当选择使用以及如何使用上。
什么是JSON
前面简单说了一下,JSON是一种基于文本的数据交换方式,或者叫做数据描述格式,你是否该选用他首先肯定要关注它所拥有的优点。
JSON的优点:
- 1、基于纯文本,跨平台传递极其简单;
- 2、Javascript原生支持,后台语言几乎全部支持;
- 3、轻量级数据格式,占用字符数量极少,特别适合互联网传递;
- 4、可读性较强,虽然比不上XML那么一目了然,但在合理的依次缩进之后还是很容易识别的;
- 5、容易编写和解析,当然前提是你要知道数据结构; JSON的缺点当然也有,但在作者看来实在是无关紧要的东西,所以不再单独说明。
JSON的格式或者叫规则:
JSON能够以非常简单的方式来描述数据结构,XML能做的它都能做,因此在跨平台方面两者完全不分伯仲。
- 1、JSON只有两种数据类型描述符,大括号{}和方括号[],其余英文冒号:是映射符,英文逗号,是分隔符,英文双引号""是定义符。
- 2、大括号{}用来描述一组“不同类型的无序键值对集合”(每个键值对可以理解为OOP的属性描述),方括号[]用来描述一组“相同类型的有序数据集合”(可对应OOP的数组)。
- 3、上述两种集合中若有多个子项,则通过英文逗号,进行分隔。
- 4、键值对以英文冒号:进行分隔,并且建议键名都加上英文双引号”",以便于不同语言的解析。
- 5、JSON内部常用数据类型无非就是字符串、数字、布尔、日期、null 这么几个,字符串必须用双引号引起来,其余的都不用,日期类型比较特殊,这里就不展开讲述了,只是建议如果客户端没有按日期排序功能需求的话,那么把日期时间直接作为字符串传递就好,可以省去很多麻烦。
JSONP是怎么产生的
其实网上关于JSONP的讲解有很多,但却千篇一律,而且云里雾里,对于很多刚接触的人来讲理解起来有些困难,小可不才,试着用自己的方式来阐释一下这个问题,看看是否有帮助。
- 1、一个众所周知的问题,Ajax直接请求普通文件存在跨域无权限访问的问题,甭管你是静态页面、动态网页、web服务、WCF,只要是跨域请求,一律不准;
- 2、不过我们又发现,Web页面上调用js文件时则不受是否跨域的影响(不仅如此,我们还发现凡是拥有”src”这个属性的标签都拥有跨域的能力,比如
<script>、<img>、<iframe>); - 3、于是可以判断,当前阶段如果想通过纯web端(ActiveX控件、服务端代理、属于未来的HTML5之Websocket等方式不算)跨域访问数据就只有一种可能,那就是在远程服务器上设法把数据装进js格式的文件里,供客户端调用和进一步处理;
- 4、恰巧我们已经知道有一种叫做JSON的纯字符数据格式可以简洁的描述复杂数据,更妙的是JSON还被js原生支持,所以在客户端几乎可以随心所欲的处理这种格式的数据;
- 5、这样子解决方案就呼之欲出了,web客户端通过与调用脚本一模一样的方式,来调用跨域服务器上动态生成的js格式文件(一般以JSON为后缀),显而易见,服务器之所以要动态生成JSON文件,目的就在于把客户端需要的数据装入进去。
- 6、客户端在对JSON文件调用成功之后,也就获得了自己所需的数据,剩下的就是按照自己需求进行处理和展现了,这种获取远程数据的方式看起来非常像AJAX,但其实并不一样。
- 7、为了便于客户端使用数据,逐渐形成了一种非正式传输协议,人们把它称作JSONP,该协议的一个要点就是允许用户传递一个callback参数给服务端,然后服务端返回数据时会将这个callback参数作为函数名来包裹住JSON数据,这样客户端就可以随意定制自己的函数来自动处理返回数据了。
简单总结:
由于浏览器有同略策略,但是<script>标签的src可以跨域,利用这个"漏洞"搞事,具体做法是:
服务端地址(比如 http://api.xxx.com/jsonp.php?callback?callbackFunction) 返回 json 数据的包装(故称为 jsonp,即json padding),形如 callback({"name":"Finley","gender":"Male"}), 可以直接运行的 JS 脚本
浏览器提供一个回调函数(callbackFunction)来接收数据。
因为 script 标签只支持get请求,故JSONP只能用GET请求
JSONP的客户端具体实现
例子1
后台 PHP 代码,返回一段可 JS 运行的脚本,供前台调用
header('Content-type: application/json');
// 获取回调函数名
$jsoncallback = htmlspecialchars($_GET['jsoncallback']);
//json数据, 可以从数据库总获得
$json_data = '["customername1","customername2"]';
// 输出jsonp格式的数据
// callbackFunction(["customername1","customername2"]) 共前台js调用
echo $jsoncallback . "(" . $json_data . ")";前台
<div id="divCustomers"></div>
<script type="text/javascript">
function callbackFunction(result, methodName) {
var html = '<ul>';
for (var i = 0; i < result.length; i++) {
html += '<li>' + result[i] + '</li>';
}
html += '</ul>';
document.getElementById('divCustomers').innerHTML = html;
}
</script>
<script src="http://localhost/finley/PHP/jsonp/jsonp.php?jsoncallback=callbackFunction"></script>例子1中script标签是自己创建的,不方便,可以改为自动动态创建 参见一个开源库,代码非常简单 https://github.com/webmodules/jsonp/blob/master/index.js
jsonp 源码实现

- 1、ajax和jsonp这两种技术在调用方式上“看起来”很像,目的也一样,都是请求一个url,然后把服务器返回的数据进行处理,因此jquery和ext等框架都把jsonp作为ajax的一种形式进行了封装;
- 2、但ajax和jsonp其实本质上是不同的东西。ajax的核心是通过XmlHttpRequest获取非本页内容,而jsonp的核心则是动态添加
<script>标签来调用服务器提供的js脚本。 - 3、所以说,其实ajax与jsonp的区别不在于是否跨域,ajax通过服务端代理一样可以实现跨域,jsonp本身也不排斥同域的数据的获取。
- 4、还有就是,jsonp是一种方式或者说非强制性协议,如同ajax一样,它也不一定非要用json格式来传递数据,如果你愿意,字符串都行,只不过这样不利于用jsonp提供公开服务。
总而言之,jsonp不是ajax的一个特例,哪怕jquery等巨头把jsonp封装进了ajax,也不能改变这一点!
JSONP的总结:
-
- 只能用GET请求
-
- 核心是动态添加
script标签来调用服务器提供的js脚本
- 核心是动态添加
-
- JSONP不是ajax的特例,只不过经常被封装进了ajax
动画是使网络应用和网站吸引人的重要因素。用户希望有快速响应和高度交互的用户界面。但是,为界面设置动画未必很简单。什么应设置动画,何时显示,以及动画应有哪种感觉?
TL;DR
- 使用动画方式给项目增加活力。
- 动画应支持用户交互。
- 要小心选择您为其设置动画的属性;有些属性比其他属性开销更大
选择合适的内容来设置动画
出色的动画可增添一层乐趣,增加项目对用户的吸引力。可以将您喜欢的几乎所有内容设置动画,不管是宽度、高度、位置、颜色,还是背景,但您需要注意潜在的性能瓶颈,以及动画如何影响您的应用的个性。卡顿或选择不当的动画可能对用户体验产生负面影响,因此动画需要高性能并且恰当。
使用动画来支持交互
不要仅仅因为您可以做动画就随便做;它只会惹恼用户并妨碍操作。相反,要有策略地放置动画以增强用户交互。如果用户点击菜单图标,滑动以显示抽屉式导航栏,或者点击按钮,则可以使用少量辉光或弹跳来确认交互。避免不必要地打断或妨碍用户活动的动画。
避免为开销大的属性设置动画
唯一比放置不当的动画更糟的事情是导致页面卡顿的动画。这种类型的动画让用户感到沮丧和不快,并且可能希望你没有设置动画。
某些属性做出改变所花费的开销比其他属性要多,因此更可能使动画卡顿。例如,与改变元素的文本颜色相比,改变元素的 box-shadow 需要开销大很多的绘图操作。同样,改变元素的 width 可能比改变其 transform 要多一些开销。
您可以在动画与性能指南中阅读有关动画性能考虑事项的更多内容,但是如果想要 TL;DR(太长;未读),则坚持使用转换和透明度改变,以及使用 will-change。如果想确切知道给指定的属性设置动画会触发什么效果,请参阅 CSS 触发器。
]]>CSS 对比 JavaScript 动画
在网页上创建动画有两种主要方法:使用 CSS 和使用 JavaScript。您选择哪种方法实际上取决于项目的其他依赖关系,以及您尝试实现什么类型的效果。
TL;DR
- 使用 CSS 动画来实现较简单的“一次性”转换,例如切换 UI 元素状态。
- 当您需要高级效果(例如弹跳、停止、暂停、倒退或减速)时,请使用 JavaScript 动画。
- 如果选择使用 JavaScript 来编写动画,可选用 Web Animations API 或用起来顺手的现代框架。
大多数基本动画可以使用 CSS 或 JavaScript 来创建,但工作量和时间将有所不同(另请参考 CSS 对比 JavaScript 的性能)。每一种方法都有其优点和缺点,但以下内容是很好的指导原则:
- 当您为 UI 元素采用较小的独立状态时,使用 CSS。 CSS 变换和动画非常适合于从侧面引入导航菜单,或显示工具提示。最后,可以使用 JavaScript 来控制状态,但动画本身是采用 CSS。
- 在需要对动画进行大量控制时,使用 JavaScript。 Web Animations API 是一个基于标准的方法,现已在 Chrome 和 Opera 中提供。该方法可提供实际对象,非常适合复杂的对象导向型应用。在需要停止、暂停、减速或倒退时,JavaScript 也非常有用。
- 如果您需要手动协调整个场景,可直接使用 requestAnimationFrame。这属于高级 JavaScript 方法,但如果您构建游戏或绘制到 HTML 画布,则该方法非常有用。
或者,如果您已使用包括动画功能的 JavaScript 框架,比如通过 jQuery 的 .animate() 方法或 GreenSock 的 TweenMax,则可能发现继续使用该方法实现动画在总体上更方便。
使用 CSS 编写动画
使用 CSS 编写动画是使内容在屏幕上移动的最简单方式。此方法被称为声明式,因为您可以指定您想要的结果。
以下是一些 CSS 代码,让一个元素同时在 X 轴和 Y 轴上移动 100px。其实现方法是使用 CSS 变换,用时设置为 500 毫秒。当添加了 move 类时,transform 值被改变并且变换开始。
.box {
-webkit-transform: translate(0, 0);
-webkit-transition: -webkit-transform 500ms;
transform: translate(0, 0);
transition: transform 500ms;
}
.box.move {
-webkit-transform: translate(100px, 100px);
transform: translate(100px, 100px);
}除了变换的持续时间之外,还有针对缓动的选项,缓动基本上是动画表现的方式。如需详细了解关于缓动的信息,请参阅缓动基础知识指南。
如果在上述代码段中,您创建单独的 CSS 类来管理动画,则可以使用 JavaScript 来打开和关闭每个动画:
box.classList.add('move');此操作将给您的应用带来良好的平衡。您可以侧重于使用 JavaScript 来管理状态,只需在目标元素上设置相应的类,让浏览器去处理动画。如果您按照这种方法,则可以侦听元素的 transitionend 事件,但前提是您能够放弃对 Internet Explorer 较旧版本的支持;IE 10 是支持这些事件的首个版本。所有其他浏览器均已支持此事件有一段时间了。
侦听变换结束所需的 JavaScript 如下所示:
var box = document.querySelector('.box');
box.addEventListener('transitionend', onTransitionEnd, false);
function onTransitionEnd() {
// Handle the transition finishing.
}除了使用 CSS 变换之外,还可以使用 CSS 动画,这允许您对单个动画关键帧、持续时间和迭代进行更多控制。
TIP
Note: 如果您是动画初学者,那么说明一下,关键帧是来自手绘动画的老术语。动画设计者为一个片段创建多个特定帧,称为关键帧,关键帧将提供某个动作的起止状态,然后它们开始绘出关键帧之间的所有单个帧。现在我们使用 CSS 动画也有相似的过程,我们指示浏览器,CSS 属性在指定时点需要什么值,然后浏览器填充其中的间隔。
例如,可以使用与变换相同的方式为方框设置动画,但是设置动画时没有任何用户交互(例如点击),而是采用无限重复。还可以同时更改多个属性:
/**
* This is a simplified version without
* vendor prefixes.With them included
* (which you will need), things get far
* more verbose!
*/
.box {
/* Choose the animation */
animation-name: movingBox;
/* The animation’s duration */
animation-duration: 1300ms;
/* The number of times we want
the animation to run */
animation-iteration-count: infinite;
/* Causes the animation to reverse
on every odd iteration */
animation-direction: alternate;
}
@keyframes movingBox {
0% {
transform: translate(0, 0);
opacity: 0.3;
}
25% {
opacity: 0.9;
}
50% {
transform: translate(100px, 100px);
opacity: 0.2;
}
100% {
transform: translate(30px, 30px);
opacity: 0.8;
}
}借助 CSS 动画,可独立于目标元素来定义动画本身,并且使用 animation-name 属性来选择所需的动画。
CSS 动画在某种程度上仍采用浏览器厂商前缀,在 Safari、Safari Mobile 和 Android 浏览器中使用-webkit-。Chrome、Opera、Internet Explorer 和 Firefox 均不采用前缀。许多工具可帮助您创建所需的 CSS 前缀版本,使您能够在源文件中编写无前缀的版本。
使用 JavaScript 和 Web Animations API 编写动画
比较而言,使用 JavaScript 创建动画比编写 CSS 变换或动画更复杂,但它一般可为开发者提供更多功能。您可以使用 Web Animations API 给特定的 CSS 属性设置动画,或构建可组合的效果对象。
JavaScript 动画是命令式,因为您将它们作为代码的一部分嵌入代码中。您还可以将它们封装在其他对象内。以下是在重新创建我们之前所讨论的 CSS 变换时需要编写的 JavaScript:
var target = document.querySelector('.box');
var player = target.animate([
{transform: 'translate(0)'},
{transform: 'translate(100px, 100px)'}
], 500);
player.addEventListener('finish', function() {
target.style.transform = 'translate(100px, 100px)';
});默认情况下,Web Animations 仅修改元素的呈现形式。如果您想让您的对象保持在它已移动到的位置,则应在动画完成时,按照我们的示例修改其底层样式。
Web Animations API 是来自 W3C 的新标准,在 Chrome 和 Opera 中受原生支持,且正在进行针对 Firefox 的开发。对于其他的现代浏览器,提供 polyfill。
使用 JavaScript 动画,您可以完全控制元素在每个步骤的样式。这意味着您可以在您认为合适时减慢动画、暂停动画、停止动画、倒退动画和操纵元素。如果您正在构建复杂的对象导向型应用,则此方法特别有用,因为您可以正确封装您的行为。
]]>缓动的基础知识
自然界中没有东西是从一点呈线性地移动到另一点。现实中,物体在移动时往往会加速或减速。我们的大脑习惯于期待这种运动,因此在做动画时,应利用此规律。自然的运动会让用户对您的应用感觉更舒适,从而产生更好的总体体验。
TL;DR
- 缓动使您的动画感觉更自然。
- 为 UI 元素选择缓出动画。
- 避免缓入或缓入缓出动画,除非可以使其保持简短;这类动画可能让最终用户觉得很迟钝。
在经典动画中,缓慢开始然后加速的动画术语是“慢入”,快速开始然后减速的动画被称为“慢出”。网络上对于这些动画最常用的术语分别是“缓入”和“缓出”。有时两种动画相组合,称为“缓入缓出”。缓动实际上是使动画不再那么尖锐或生硬的过程。
缓动关键字
CSS 变换和动画都允许您选择要为动画使用的缓动类型。您可以使用影响相关动画的缓动(或有时称为 timing)的关键字。还可以完全自定义您的缓动,借此方式更自由地表达应用的个性。
以下是可在 CSS 中使用的一些关键字:
- linear
- ease-in
- ease-out
- ease-in-out
还可以使用 steps 关键字,它允许您创建具有离散步骤的变换,但上面列出的关键字对于创建感觉自然的动画最有用,并且这绝对是您要的效果。
线性动画
没有任何缓动的动画称为线性动画。线性变换的图形看起来像这样:
随着时间推移,其值以等量增加。采用线性运动时,动画内容往往显得很僵硬,不自然,让用户觉得不协调。一般来说,应避免线性运动。
不管通过 CSS 还是 JavaScript 来编写动画代码,您将发现始终有线性运动的选项。
要通过 CSS 实现上述效果,代码将类似下面这样:
transition: transform 500ms linear;
缓出动画
缓出使动画在开头处比线性动画更快,还会在结尾处减速。
缓出一般最适合界面,因为开头时快速使动画有反应快的感觉,同时在结尾仍允许有一点自然的减速。
有很多方法来实现缓出效果,但最简单的方法是 CSS 中的 ease-out 关键字:
transition: transform 500ms ease-out;
缓入动画
缓入动画开头慢结尾快,与缓出动画正好相反。
这种动画像沉重的石头掉落一样,开始时很慢,然后快速地重重撞击地面,突然沉寂下来。
但是,从交互的角度来看,缓入可能让人感觉有点不寻常,因为结尾很突然;在现实中移动的物体往往是减速,而不是突然停止。缓入还有让人感觉行动迟缓的不利效果,这会对网站或应用的响应速度给人的感觉产生负面影响。
要使用缓入动画,与缓出和线性动画类似,可以使用其关键字:
transition: transform 500ms ease-in;
缓入缓出动画
缓入并缓出与汽车加速和减速相似,使用得当时,可以实现比单纯缓出更生动的效果。
由于缓入开头让动画有迟钝感,因此动画持续时间不要过长。300-500 毫秒的时间范围通常比较合适,但实际的数量主要取决于项目的感觉。也就是说,由于开头慢、中间快和结尾慢,动画将有更强的对比,可能让用户感到非常满意。
要设置缓入缓出动画,可以使用 ease-in-out CSS 关键字:
transition: transform 500ms ease-in-out;
自定义缓动
有时您不想使用 CSS 随附的缓动关键字,或者要使用 Web Animations 或 JavaScript 框架。在这些情况下,一般可以定义自己的曲线(或公式),这让您能更好地控制项目动画的感觉。
TL;DR
- 自定义缓动使您能够给项目提供更多个性。
- 您可以创建与默认动画曲线(缓出、缓入等)相似的三次贝塞尔曲线,只是重点放在不同的地方。
- 当需要对动画时间和行为(例如弹性或弹跳动画)进行更多控制时,请使用 JavaScript。
如果使用 CSS 编写动画,您将发现可以通过定义三次贝塞尔曲线来定义时间。事实上,关键字 ease、ease-in、ease-out 和 linear 映射到预定义的贝塞尔曲线,详细说明请参考 CSS 变换规范 和 Web Animations 规范。
这些贝塞尔曲线有四个值,即两对数字,每对数字描述三次贝塞尔曲线的控制点的 X 和 Y 坐标。贝塞尔曲线的起点坐标为 (0, 0),终点坐标为 (1, 1);由您设置两个控制点的 X 和 Y 值。两个控制点的 X 值必须在 0 到 1 之间,每个控制点的 Y 值可以超过 [0, 1] 限制,但此规范未说明可超过多少。
更改每个控制点的 X 和 Y 值将实现截然不同的曲线,从而使动画有截然不同的感觉。例如,如果第一个控制点在右下角,则动画在开头缓慢。如果它在左上角,动画在开头会显得很快。相反,如果第二控制点在网格的右下角,则动画在结尾处变快;而在左上角时,动画将在结尾处变慢。
为了对比,以下有两条曲线:一条典型的缓入缓出曲线和一条自定义曲线:
此自定义曲线的 CSS 为:
transition: transform 500ms cubic-bezier(0.465, 0.183, 0.153, 0.946);
前两个数字是第一个控制点的 X 和 Y 坐标,后两个数字是第二个控制点的 X 和 Y 坐标。
制作自定义曲线很有趣,您可以有效控制对动画的感觉。以上述曲线为例,您可以看到曲线与经典的缓入缓出曲线相似,但缓入即“开始”部分缩短,而结尾减速部分拉长。
使用此动画曲线工具进行试验,并查看此曲线如何影响动画的感觉。
使用 JavaScript 框架实现更多控制
有时您需要三次贝塞尔曲线未能提供的更多控制。如果您需要弹跳的感觉,您可以考虑使用 JavaScript 框架,因为使用 CSS 或 Web Animations 很难实现这个效果。
TweenMax
GreenSock 的 TweenMax(或 TweenLite,如果您想要超轻量版本)是一个强大的框架,您可以在小型 JavaScript 库中获得很多控制,它是一个非常成熟的代码库。
要使用 TweenMax,请在页面中包括此脚本:
<script src="https://cdnjs.cloudflare.com/ajax/libs/gsap/latest/TweenMax.min.js"></script>
将该脚本放到合适位置后,您可以对元素调用 TweenMax,并且告诉它您想要的任何缓动,以及您想要哪些属性。有大量缓动选项可供使用;以下代码使用一个弹性缓出:
var box = document.getElementById('my-box');
var animationDurationInSeconds = 1.5;
TweenMax.to(box, animationDurationInSeconds, {
x: '100%',
ease: 'Elastic.easeOut'
});TweenMax 文档重点说明了您使用的所有选项,非常值得一读。
]]>选择合适的缓动
前面已经讨论了可在动画中实现缓动的各种选项,您应当在项目中使用哪种?您的动画应采用哪种持续时间?
TL;DR
- 为 UI 元素使用缓出动画;Quintic 缓出是一个非常好(虽然比较快速)的缓动。
- 一定要使用动画持续时间;缓出和缓入应为 200 毫秒 - 500 毫秒,而弹跳和弹性缓动的持续时间应更长,为 800 毫秒 - 1200 毫秒。
一般来说,缓出将是正确的选择,当然也是很好的默认选择。它开头较快,使动画有反应快速的感觉,这一点很受欢迎,但在结尾有一个不错的减速。
除了在 CSS 中通过 ease-out 关键字指定的公式之外,还有一组知名的缓出公式,它们按其“攻击性”排列。想要快速的缓出效果,请考虑 Quintic 缓出。
其他缓动公式应谨慎使用,特别是弹跳或弹性缓动,并且仅在适合于项目时才使用。很少有东西会像不协调的动画那样让用户体验很差。如果您的项目不是为了追求乐趣,那么就无需使元素在 UI 周围进行弹跳。相反,如果您将要创建一个轻松欢乐的网站,那么请务必使用弹跳!
试试各种缓动,看看哪些与项目的个性匹配,然后以此为起点。关于缓动类型的完整列表及其演示,请参阅 easings.net。
选择合适的动画持续时间
给项目添加的任何动画均须有正确的持续时间。若太短,动画让人感觉有攻击性和突然;若太长,则让人觉得很卡和讨厌。
- 缓出:约 200 毫秒 - 500 毫秒。这让眼睛有机会看到动画,但不会觉得卡顿。
- 缓入:约 200 毫秒 - 500 毫秒。请记住,它在结尾将晃动,没有时间量变化将缓和这种影响。
- 弹跳或弹性效果:约 800 毫秒 - 1200 毫秒。您需要留出时间让弹性或弹跳效果“停下”。若没有这点额外时间,动画的弹性跳动部分看上去比较有攻击性,让人感觉不舒服。
当然,这些只是指导原则。用您自己的缓动做试验,然后选择觉得适合于项目的缓动。
]]>当我们谈起React的时候,多半会将注意力集中在组件之上,思考如何将页面划分成一个个组件,以及如何编写可复用的组件。但对于接触React不久,还没有真正用它做一个完整项目的人来说,理解如何创建一个组件也并不那么简单。在最开始的时候我以为创建组件只需要调用createClass这个api就可以了;但学习了ES6的语法后,又知道了可以利用继承,通过extends React.component来创建组件;后来在阅读别人代码的时候又发现了PureComponent以及完全没有继承,仅仅通过返回JSX语句的方式创建组件的方式。下面这篇文章,就将逐一介绍这几种创建组件的方法,分析其特点,以及如何选择使用哪一种方式创建组件。
几种方法
1.createClass
如果你还没有使用ES6语法,那么定义组件,只能使用React.createClass这个helper来创建组件,下面是一段示例:
var React = require("react");
var Greeting = React.createClass({
propTypes: {
name: React.PropTypes.string //属性校验
},
getDefaultProps: function() {
return {
name: 'Mary' //默认属性值
};
},
getInitialState: function() {
return {count: this.props.initialCount}; //初始化state
},
handleClick: function() {
//用户点击事件的处理函数
},
render: function() {
return <h1>Hello, {this.props.name}</h1>;
}
});
module.exports = Greeting;这段代码,包含了组件的几个关键组成部分,这种方式下,组件的props、state等都是以对象属性的方式组合在一起,其中默认属props和初始state都是返回对象的函数,propTypes则是个对象。这里还有一个值得注意的事情是,在createClass中,React对属性中的所有函数都进行了this绑定,也就是如上面的hanleClick其实相当于handleClick.bind(this)。
2.component
因为ES6对类和继承有语法级别的支持,所以用ES6创建组件的方式更加优雅,下面是示例:
import React from 'react';
class Greeting extends React.Component {
constructor(props) {
super(props);
this.state = {count: props.initialCount};
this.handleClick = this.handleClick.bind(this);
}
//static defaultProps = {
// name: 'Mary' //定义defaultprops的另一种方式
//}
//static propTypes = {
//name: React.PropTypes.string
//}
handleClick() {
//点击事件的处理函数
}
render() {
return <h1>Hello, {this.props.name}</h1>;
}
}
Greeting.propTypes = {
name: React.PropTypes.string
};
Greeting.defaultProps = {
name: 'Mary'
};
export default Greating;可以看到Greeting继承自React.component,在构造函数中,通过super()来调用父类的构造函数,同时我们看到组件的state是通过在构造函数中对this.state进行赋值实现,而组件的props是在类Greeting上创建的属性,如果你对类的属性和对象的属性的区别有所了解的话,大概能理解为什么会这么做。对于组件来说,组件的props是父组件通过调用子组件向子组件传递的,子组件内部不应该对props进行修改,它更像是所有子组件实例共享的状态,不会因为子组件内部操作而改变,因此将props定义为类Greeting的属性更为合理,而在面向对象的语法中类的属性通常被称作静态(static)属性,这也是为什么props还可以像上面注释掉的方式来定义。对于Greeting类的一个实例对象的state,它是组件对象内部维持的状态,通过用户操作会修改这些状态,每个实例的state也可能不同,彼此间不互相影响,因此通过this.state来设置。
用这种方式创建组件时,React并没有对内部的函数进行this绑定,所以如果你想让函数在回调中保持正确的this,就要手动对需要的函数进行this绑定,如上面的handleClick,在构造函数中对this 进行了绑定。
3.PureComponet
我们知道,当组件的props或者state发生变化的时候:React会对组件当前的Props和State分别与nextProps和nextState进行比较,当发现变化时,就会对当前组件以及子组件进行重新渲染,否则就不渲染。有时候为了避免组件进行不必要的重新渲染,我们通过定义shouldComponentUpdate来优化性能。例如如下代码:
class CounterButton extends React.Component {
constructor(props) {
super(props);
this.state = {count: 1};
}
shouldComponentUpdate(nextProps, nextState) {
if (this.props.color !== nextProps.color) {
return true;
}
if (this.state.count !== nextState.count) {
return true;
}
return false;
}
render() {
return (
<button
color={this.props.color}
onClick={() => this.setState(state => ({count: state.count + 1}))}>
Count: {this.state.count}
</button>
);
}
}shouldComponentUpdate通过判断props.color和state.count是否发生变化来决定需不需要重新渲染组件,当然有时候这种简单的判断,显得有些多余和样板化,于是React就提供了PureComponent来自动帮我们做这件事,这样就不需要手动来写shouldComponentUpdate了:
class CounterButton extends React.PureComponent {
constructor(props) {
super(props);
this.state = {count: 1};
}
render() {
return (
<button
color={this.props.color}
onClick={() => this.setState(state => ({count: state.count + 1}))}>
Count: {this.state.count}
</button>
);
}
}大多数情况下, 我们使用PureComponent能够简化我们的代码,并且提高性能,但是PureComponent的自动为我们添加的shouldComponentUpate函数,只是对props和state进行浅比较(shadow comparison),当props或者state本身是嵌套对象或数组等时,浅比较并不能得到预期的结果,这会导致实际的props和state发生了变化,但组件却没有更新的问题,例如下面代码有一个ListOfWords组件来将单词数组拼接成逗号分隔的句子,它有一个父组件WordAdder让你点击按钮为单词数组添加单词,但他并不能正常工作:
class ListOfWords extends React.PureComponent {
render() {
return <div>{this.props.words.join(',')}</div>;
}
}
class WordAdder extends React.Component {
constructor(props) {
super(props);
this.state = {
words: ['marklar']
};
this.handleClick = this.handleClick.bind(this);
}
handleClick() {
// 这个地方导致了bug
const words = this.state.words;
words.push('marklar');
this.setState({words: words});
}
render() {
return (
<div>
<button onClick={this.handleClick} />
<ListOfWords words={this.state.words} />
</div>
);
}
}这种情况下,PureComponent只会对this.props.words进行一次浅比较,虽然数组里面新增了元素,但是this.props.words与nextProps.words指向的仍是同一个数组,因此this.props.words !== nextProps.words 返回的便是flase,从而导致ListOfWords组件没有重新渲染,笔者之前就因为对此不太了解,而随意使用PureComponent,导致state发生变化,而视图就是不更新,调了好久找不到原因~。
最简单避免上述情况的方式,就是避免使用可变对象作为props和state,取而代之的是每次返回一个全新的对象,如下通过concat来返回新的数组:
handleClick() {
this.setState(prevState => ({
words: prevState.words.concat(['marklar'])
}));
}你可以考虑使用Immutable.js来创建不可变对象,通过它来简化对象比较,提高性能。
这里还要提到的一点是虽然这里虽然使用了Pure这个词,但是PureComponent并不是纯的,因为对于纯的函数或组件应该是没有内部状态,对于stateless component更符合纯的定义,不了解纯函数的同学,可以参见这篇文章。
4.Stateless Functional Component
上面我们提到的创建组件的方式,都是用来创建包含状态和用户交互的复杂组件,当组件本身只是用来展示,所有数据都是通过props传入的时候,我们便可以使用Stateless Functional Component来快速创建组件。例如下面代码所示:
import React from 'react';
const Button = ({
day,
increment
}) => {
return (
<div>
<button onClick={increment}>Today is {day}</button>
</div>
)
}
Button.propTypes = {
day: PropTypes.string.isRequired,
increment: PropTypes.func.isRequired,
}这种组件,没有自身的状态,相同的props输入,必然会获得完全相同的组件展示。因为不需要关心组件的一些生命周期函数和渲染的钩子,所以不用继承自Component显得更简洁。
对比
createClass vs Component
对于React.createClass和extends React.Component本质上都是用来创建组件,他们之间并没有绝对的好坏之分,只不过一个是ES5的语法,一个是ES6的语法支持,只不过createClass支持定义PureRenderMixin,这种写法官方已经不再推荐,而是建议使用PureComponent。
pureComponent vs Component
通过上面对PureComponent和Component的介绍,你应该已经了解了二者的区别:PureComponent已经定义好了shouldUpdateComponent而Component需要显示定义。
Component vs Stateless Functional component
-
Component包含内部state,而Stateless Functional Component所有数据都来自props,没有内部state; -
Component包含的一些生命周期函数,Stateless Functional Component都没有,因为Stateless Functional component没有shouldComponentUpdate,所以也无法控制组件的渲染,也即是说只要是收到新的props,Stateless Functional Component就会重新渲染。 -
Stateless Functional Component不支持Refs
选哪个?
这里仅列出一些参考:
-
createClass, 除非你确实对ES6的语法一窍不通,不然的话就不要再使用这种方式定义组件。
-
Stateless Functional Component, 对于不需要内部状态,且用不到生命周期函数的组件,我们可以使用这种方式定义组件,比如展示性的列表组件,可以将列表项定义为Stateless Functional Component。
-
PureComponent/Component,对于拥有内部state,使用生命周期的函数的组件,我们可以使用二者之一,但是大部分情况下,我更推荐使用PureComponent,因为它提供了更好的性能,同时强制你使用不可变的对象,保持良好的编程习惯。
参考文章
optimizing-performance.html#shouldcomponentupdate-in-action pureComponent介绍 react-functional-stateless-component-purecomponent-component-what-are-the-dif 4 different kinds of React component styles react-without-es6 react-create-class-versus-component
]]>- 注释要用
{/* 这是注释 */}注意前后的空格
组件篇
- 纯文本组件
const Comment = ({ text }) => text.replace(':)', '[smile]');
class App extends Component {
render() {
return (
<div>
<Comment text="Text only components are awesome :)" />
</div>
);
}
}- 返回数组的纯文本组件 元素类型可不相同
const Fruits = () => [
<li key="1">Pear</li>,
<li key="2">Weater Melon</li>,
];
class App extends Component {
render() {
// 注意返回的是个数组,减少嵌套层级
return [
<ul>
<li>Apple</li>
<li>Banana</li>
<Fruits />
</ul>,
<div>this is a div</div>,
];
}
}- ReactDOM.createPortal(child, container) 他可以将子组件直接渲染到当前容器组件 DOM 结构之外的任意 DOM 节点中,这将使得开发对话框,浮层,提示信息等需要打破当前 DOM 结构的组件更为方便。例子
资料
https://doc.react-china.org/ 翻译后的官方文档,学技术一定要多看几遍文档
React小书 强烈推荐,由浅入深,循序渐进
http://reactpatterns.com/ 由于react本身 API 比较简单,贴近原生。通过组件变化产生一系列模式
https://github.com/CompuIves/codesandbox-client
react在线编辑器,方便的分享你的react项目


js.coach
找js包的网站

视频
基础的免费,高级的收费 https://egghead.io
工具
sublime 支持jsx语法高亮。
不要安装 sublime-react 那个已被弃用了。
安装 babel,然后按照上面的教程,完美支持

要学源码其实主要关心components目录即可。 我会根据 使用文档 一个个组件的去研究。从小到大,从简单到复杂。
需要注意的是:
- 很多组件是基于 基础组件 构造的,我不会对基础组件做深入研究。
- 源码中组件的扩展名是tsx,说明是用TypeScript写的。使用TypeScript有个非常大的好处。比如打开row.tsx
- 我在会仿照省略一个代码并转换成es6写法去运行。地址
export interface RowProps {
className?: string;
gutter?: number;
type?: 'flex';
align?: 'top' | 'middle' | 'bottom';
justify?: 'start' | 'end' | 'center' | 'space-around' | 'space-between';
style?: React.CSSProperties;
prefixCls?: string;
}
...
static defaultProps = {
gutter: 0,
};
static propTypes = {
type: PropTypes.string,
align: PropTypes.string,
justify: PropTypes.string,
className: PropTypes.string,
children: PropTypes.node,
gutter: PropTypes.number,
prefixCls: PropTypes.string,
};这里RowProps定义的row的属性信息。看到这些立马就能知道Row组件可以接收的各个属性信息,其中gutter是数字类型,type的默认值flex,align可以写top,middle,bottom三者其一。等等,非常方便。
脑海中就知道实际项目中可以这么写<Row gutter={16} align="top" style={color: "red"}></Row>
关于入口文件 index.js。
主要作用做了两件事。
- 收集components目录下的每个组件的style文件,最终应该汇总成一个样式文件。
- 将每个组件的index.tsx挂到export下。方便import。比如
import { Table, Card } from 'antd';
/* eslint no-console:0 */
// 字符串转驼峰
// camelCase('dwdDdwdS') => "DwdDdwdS"
// camelCase('abc-de-FghiJ') => "AbcDeFghiJ"
function camelCase(name) {
return name.charAt(0).toUpperCase() +
name.slice(1).replace(/-(\w)/g, (m, n) => {
return n.toUpperCase();
});
}
// Just import style for https://github.com/ant-design/ant-design/issues/3745
// https://webpack.js.org/guides/dependency-management/#require-context
// 通过正则批量匹配引入相应的文件模块。
// 第二个参数指包含子目录
const req = require.context('./components', true, /^\.\/[^_][\w-]+\/style\/index\.tsx?$/);
req.keys().forEach((mod) => {
let v = req(mod);
if (v && v.default) {
v = v.default;
}
// 匹配类似 './input/index.tsx'
const match = mod.match(/^\.\/([^_][\w-]+)\/index\.tsx?$/);
if (match && match[1]) {
if (match[1] === 'message' || match[1] === 'notification') {
// message & notification should not be capitalized
exports[match[1]] = v;
} else {
exports[camelCase(match[1])] = v;
}
}
});
module.exports = require('./components');grid/index.tsx
import Row from './row';
import Col from './col';
export {
Row,
Col,
};grid/row.js
export default class Row extends React.Component {
static defaultProps = {
// gutter是col之间的间隔,默认0
// <Row gutter={24}>
// 生成 <div class="ant-row" style="margin-left: -8px; margin-right: -8px"></div>
gutter: 0,
};
render() {
const { type, justify, align, className, gutter, style, children,
prefixCls = 'ant-row', ...others } = this.props;
// https://ant.design/components/grid-cn/#components-grid-demo-gutter
// 默认class只有一个ant-row
// type 一般是flex
// 如果传入<Row justify="center"> 则输出 ant-row-flex-center
const classes = classNames({
[prefixCls]: !type,
[`${prefixCls}-${type}`]: type,
[`${prefixCls}-${type}-${justify}`]: type && justify,
[`${prefixCls}-${type}-${align}`]: type && align,
}, className);
// 汇总style,如果gutter属性大于0设置marginLeft,marginRight。gutter最好满足(16+8n)px
const rowStyle = gutter > 0 ? {
marginLeft: gutter / -2,
marginRight: gutter / -2,
...style
} : style;
// 下面的比较简单,对每一个col设置 paddingLeft 和 paddingRight
const cols = Children.map(children, (col) => {
if (!col) {
return null;
}
if (col.props && gutter > 0) {
return cloneElement(col, {
style: {
paddingLeft: gutter / 2,
paddingRight: gutter / 2,
...col.props.style
},
});
}
})
return(
<div {...others} className={classes} style={rowStyle}>{cols}</div>
)
}
}###grid/col.js col也比较简单,需要对 flex布局 比较熟悉
export default class Col extends React.Component {
render() {
const props = this.props;
const { span, order, offset, push, pull, className, children, prefixCls = 'ant-col', ...others } = props;
let sizeClassObj = {};
['xs', 'sm', 'md', 'lg', 'xl'].forEach(size => {
let sizeProps = {};
if (typeof props[size] === 'number') {
sizeProps.span = props[size];
} else if (typeof props[size] === 'object') {
sizeProps = props[size] || {};
}
delete others[size];
sizeClassObj = {
...sizeClassObj,
[`${prefixCls}-${size}-${sizeProps.span}`]: sizeProps.span !== undefined,
[`${prefixCls}-${size}-order-${sizeProps.order}`]: sizeProps.order || sizeProps.order === 0,
[`${prefixCls}-${size}-offset-${sizeProps.offset}`]: sizeProps.offset || sizeProps.offset === 0,
[`${prefixCls}-${size}-push-${sizeProps.push}`]: sizeProps.push || sizeProps.push === 0,
[`${prefixCls}-${size}-pull-${sizeProps.pull}`]: sizeProps.pull || sizeProps.pull === 0,
};
});
// 汇总style,如果gutter属性大于0,gutter最好满足(16+8n)px
// const colStyle = span > 0 ? {
// marginLeft: gutter / -2,
// marginRight: gutter / -2,
// ...style
// } : style;
const classes = classNames({
[`${prefixCls}-${span}`]: span !== undefined,
[`${prefixCls}-order-${order}`]: order,
[`${prefixCls}-offset-${offset}`]: offset,
[`${prefixCls}-push-${push}`]: push,
[`${prefixCls}-pull-${pull}`]: pull,
}, className, sizeClassObj);
return(
<div className={classes}>{children}</div>
)
}
}默认情况下webpack配置文件不会暴露出来,这不满足我当前的需求,比如这里我喜欢用 stylus(一个类似less,sass的样式预处理器)。stylus 和 sass 类似,支持变量,mixin,函数等功能,而且连括号,分号都不用写。用缩进区分。
create-react-app 支持执行 npm run reject 将相关配置文件释放到根目录下。注意这里是不可逆操作。
官网的 readme 中有怎么添加 sass 和 less 的教程 没有讲如何添加 stylus 支持,其实这也难不倒咱。 具体步骤如下:
- 项目根目录执行
npm run reject,会发现多出来个 config 目录,里面的各个配置文件都带有详尽的注释 - 安装 stylus 相关依赖,执行
npm install stylus stylus-loader --save-dev或yarn add stylus stylus-loader - 打开
config\webpack.config.dev.js我们让webpack支持解析 styl 格式的文件 在 module->rules->oneOf 组下面添加
{
test: /\.styl$/,
use: [
require.resolve('style-loader'),
require.resolve('css-loader'),
require.resolve('stylus-loader')
]
}, 4. 打开
4. 打开 webpack.config.prod.js 添加如下(这是我参考下面的针对的css配置,需要更进一步测试)这是因为prod环境下,所有的css都被 ExtractTextPlugin 插件提取到同一个样式文件中,开发环境则是动态的创建style标签并插入到html的header中。
{
test: /\.styl$/,
loader: ExtractTextPlugin.extract(
Object.assign(
{
fallback: require.resolve('style-loader'),
use: [
{
loader: require.resolve('css-loader'),
options: {
importLoaders: 1,
minimize: true,
sourceMap: shouldUseSourceMap,
},
},
{
loader: require.resolve('stylus-loader'),
}
],
},
extractTextPluginOptions
)
),
// Note: this won't work without `new ExtractTextPlugin()` in `plugins`.
},- 新建目录
src\static\styl并创建 base.styl 内容如下:
body
margin: 0
padding: 0
background-color: #f1f1f1
*
margin: 0
padding: 0
box-sizing: border-box
font-family: "微软雅黑","Times New Roman",Georgia,Serif
a
text-decoration: none- 打开
src\index.js,添加import './static/styl/index.styl'; - 最后重新执行
npm run start或yarn start就能看到样式变化了。
问:react-router,react-router-native 和 react-router-dom 的区别 答:react-router是核心。react-router-native 和 react-router-dom是在 react-router 的基础上针对不同运行环境做为额外补充。对于web环境使用 react-router-dom。对于开发 react-native,使用 react-router-native 即可。
例子:手动跳转
路由文件 routerMap
import React from 'react'
import { BrowserRouter as Router, Route, Link, Switch } from 'react-router-dom'
import Home from '../Pages/Home/'
import List from '../Pages/List/'
import Detail from '../Pages/Detail/'
import NoMatch from './404'
// 下面几行是老式写法,可以忽略
// import createBrowserHistory from 'history/createBrowserHistory';
// 是个用于浏览器导航#的历史对象
// const history = createBrowserHistory()
// <BrowserRouter /> 其实就是<Router history={history} />
export class RouterMap extends React.Component {
render() {
return (
<Router>
<div>
<ul>
<li><Link to="/">Home</Link></li>
<li><Link to="/list">List</Link></li>
</ul>
<hr/>
<Switch>
<Route exact path="/" component={Home} />
<Route exact path="/list" component={List} />
<Route path="/detail/:id" component={Detail} />
<Route component={NoMatch}/>
</Switch>
</div>
</Router>
);
}
}入口文件
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import {RouterMap} from "./Router/routerMap";
ReactDOM.render(<div>
<App />
<RouterMap />
</div>, document.getElementById('root'));List页面
import React from 'react'
export default class List extends React.Component {
constructor({ match }) {
super();
this.state = {
match
}
}
clickHandle(item) {
//关于history
// http://www.jianshu.com/p/e3adc9b5f75c
this.props.history.push('/detail/' + item)
}
render() {
const arr = [1,2,3]
console.log(this.state.match)
return (
<div>
<h3>List Page</h3>
<ul>
{
arr.map((item, index) =>
<li key={index} onClick={this.clickHandle.bind(this, item)}>{item}</li>
)
}
</ul>
</div>
)
}
}Detail 页面
import React from 'react'
export default class Detail extends React.Component {
constructor({ match }) {
super();
this.state = {
match
}
}
render() {
console.log(this.state.match)
return (
<div>Detail Page {this.state.match.params.id}</div>
)
}
}实现方法如下:
-
安装koa和koa-router。注意我的当前版本是最新的 koa2.3.0 和 koa-router7.2.1
yarn add koa koa-router -
项目根目录创建一个mock目录,并新建一个server.js 内容如下:
var Koa = require('koa');
var Router = require('koa-router');
var app = new Koa();
var router = new Router();
router.get('/', function (ctx, next) {
console.log('say');
ctx.body = 'hello koa !'
});
// 加前缀
router.prefix('/api');
// 模拟json数据
var todo = require('./todo.js')
router.get('/todos', function (ctx, next) {
console.log('--todo--')
ctx.body = todo
});
// 开始服务并生成路由
app.use(router.routes())
.use(router.allowedMethods());
app.listen(4000);todo.js
module.exports = [
{
title: 'title1',
},
{
title: 'title2',
}
]-
package.json 添加代理信息
"proxy": "http://localhost:4000",这样当我们在create-react-app的代码里调用fetch('api/todos')会被代理执行http://localhost:4000/api/todos并且在 script 节点下添加"mock": "node ./mock/server.js"这样执行yarn mock就启动了这个后台服务 -
在 react 中比如入口的 index.js 中添加测试代码。 我们使用 fetch ,发起客户端请求。
fetch('/api/todos')
.then(res => res.json())
.then(res => {
console.log(res)
})参考:
]]>
需要注意几点:
- 初始化阶段的getInitialState()方法在es6里的写法中被constructor()取代。详见
- 方法中带有前缀 will 的在特定环节之前被调用,而带有前缀 did 的方法则会在特定环节之后被调用。特定环节我的理解就是render方法。 未完待续
参考: http://www.jianshu.com/p/c36a0601b00c https://doc.react-china.org/docs/react-component.html http://www.cnblogs.com/twobin/p/4949888.html
]]>如果使用的是react-router,官网文档给出的 方案 是用webpack的bundle-loader
你可能也见过require.ensure。这是webpack的旧式写法,现在已不推荐。
我倾向于使用import(),这也是webpack推荐的。因为更符合规范。 这篇 我有专门的介绍,社区中也有专门的 方案。
我也用到项目中,代码如下 其中City和Login页面是按需加载中的,你可以在network中看到进入这俩页面浏览器会先加载类似 1.chunk.js文件。
import React from 'react'
import { BrowserRouter as Router, Route, Link, Switch } from 'react-router-dom'
import Home from '$pages/Home/'
import List from '$pages/List/'
// import City from '$pages/City/'
// import Login from '$pages/Login/'
import Detail from '$pages/Detail/'
import Search from '$pages/Search/'
import UserCenter from '$pages/UserCenter/'
import Demo from '$pages/Demo/'
import NoMatch from './404'
// 异步按需加载component
function asyncComponent(getComponent) {
return class AsyncComponent extends React.Component {
static Component = null;
state = { Component: AsyncComponent.Component };
componentWillMount() {
if (!this.state.Component) {
getComponent().then(({default: Component}) => {
AsyncComponent.Component = Component
this.setState({ Component })
})
}
}
render() {
const { Component } = this.state
if (Component) {
return <Component {...this.props} />
}
return null
}
}
}
function load(component) {
return import(`$pages/${component}/`)
}
const Login = asyncComponent(() => load('Login'));
const City = asyncComponent(() => load('City'));
export class RouterMap extends React.Component {
render() {
return (
<Router>
<div>
{ /*
<ul>
<li><Link to="/">Home</Link></li>
<li><Link to="/list">List</Link></li>
</ul>
<hr/>
*/ }
<Switch>
<Route exact path="/" component={Home} />
<Route path="/login/:refer?" component={Login} />
<Route path="/city" component={City} />
<Route path="/user" component={UserCenter} />
<Route path="/list" component={List} />
<Route exact path="/demo" component={Demo} />
<Route path="/search/:category/:keyword?" component={Search} />
<Route path="/detail/:id" component={Detail} />
<Route component={NoMatch}/>
</Switch>
</div>
</Router>
);
}
}如果感觉这篇对你有用的朋友给我的 项目 点个star
]]>function getDisplayName(component) {
return component.displayName || component.name || 'Component';
}
export function withHeader(WrappedComponent) {
return class HOC extends React.Component {
// 在React组件查看中显示Hoc(被传入的组件名)
static displayName = `HOC(${getDisplayName(WrappedComponent)})`
render() {
return <div>
<div className="demo-header">
我是标题
</div>
<WrappedComponent {...this.props}/>
</div>
}
}
}调用
class Demo extends React.Component {
constructor() {
super();
this.state = {
}
}
static displayName = 'I am demo component'
render() {
return <div>我是一个普通组件</div>
}
}
const EnhanceDemo = withHeader(Demo);调试面板 react 显示类似如下

我加上了自己的理解并进行了结构代码调整和优化,而且用的版本都升级到最新。
目前是 react16, redux3.7.2, react-router v4, webpack 3.5, koa 2.3
比如有个列表加载更多的功能,好多页面需要代码严重重复,我给封装成了通用组件,放到了src\components\base\ListLoadingMoreComponent
并加入了支持stylus等功能,并写了一系列文章。见 react学习系列1 修改create-react-app配置支持stylus
这是我第一个用react做的小项目,有空就会优化,有不足之处还请见谅。 项目地址: https://github.com/mafeifan/react-dianping 欢迎star
]]>- 简单,非加密,持久化的key-value存储系统,旨在替代LocalStorage
- 每个api返回Promise对象,操作方便。
npm run eject后根目录会产生一个andriod目录和ios目录。里面就是运行打包的配置文件。
如果你是用react-native-cli 开发RN的应该一开始就有这俩目录。
比如 android 目录里面会有build.gradle,gradle.properties 等 简单说 gradle 是一个依赖管理/自动化编译测试部署打包工具。
首先生成签名key
.\keytool.exe -genkey -v -keystore D:/my-release-key.keystore -alias my-key-a lias -keyalg RSA -keysize 2048 -validity 10000
有个小坑是生成key的路径是D盘,因为在当前C盘生成的话在windows下可能会有权限问题。

然后按照这个 教程,改动一些配置文件。
修改相关配置文件
在根目录的android目录下执行 ./gradlew assembleRelease
后面就踩了很多坑,大多数版本问题。
比如java jdk从最新的9改为了8
gradle版本改为了最新的4.3
还报了一些缺少npm包的错误,直接npm install缺哪个装哪个就行了。
具体的见下面的文件改动
android/build.gradle
// Top-level build file where you can add configuration options common to all sub-projects/modules.
buildscript {
repositories {
jcenter()
}
dependencies {
/*
这里之前是 2.2.3
卡在这里半天,老是报 com.android.build.gradle.tasks.factory.AndroidJavaCompile.setDependencyCacheDir(Ljava/io/File;)V
*/
classpath 'com.android.tools.build:gradle:2.3.2'
// NOTE: Do not place your application dependencies here; they belong
// in the individual module build.gradle files
}
}
allprojects {
repositories {
mavenLocal()
jcenter()
maven {
// All of React Native (JS, Obj-C sources, Android binaries) is installed from npm
url "$rootDir/../node_modules/react-native/android"
}
}
}android/app/build.gradle
android {
// 这里之前是
// compileSdkVersion 23
// buildToolsVersion "23.0.1
compileSdkVersion 25
buildToolsVersion "25.0.1"
...android\gradle\wrapper
distributionBase=GRADLE_USER_HOME
distributionPath=wrapper/dists
zipStoreBase=GRADLE_USER_HOME
zipStorePath=wrapper/dists
# distributionUrl=https\://services.gradle.org/distributions/gradle-2.14.1-all.zip
distributionUrl=https\://services.gradle.org/distributions/gradle-4.3-all.zip执行最后的打包命令 ./gradlew assembleRelease
切换到android目录 打包成功画面

注意事项:打包过程会占用大量内存,把WebStorm等大的程序关掉。
]]>- 引入FlatList
- 写一个 getPageHomeList 方法,可以看到FlatList接收的data属性表示数据源 renderItem表示渲染每条数据的回调方法。这里用Text组件包裹下每条数据。
getPageHomeList() {
return (
<FlatList
data={[
{key: 'Devin'},
{key: 'Jackson'},
{key: 'James'},
{key: 'Joel'},
{key: 'John'},
{key: 'Jillian'},
{key: 'Jimmy'},
{key: 'Julie'},
]}
renderItem={({item}) => <Text style={styles.item}>{item.key}</Text>}
/>
);
} 3. 最终把这个方法嵌到View中展示
完整代码如下:
3. 最终把这个方法嵌到View中展示
完整代码如下:
import React from 'react';
import TabNavigator from 'react-native-tab-navigator';
import { StyleSheet, Text, TextInput, View, Image, FlatList } from 'react-native';
export default class App extends React.Component {
constructor(props) {
super(props);
this.state = {selectedTab: 'home'};
}
getPageHomeList() {
return (
<FlatList
data={[
{key: 'Devin'},
{key: 'Jackson'},
{key: 'James'},
{key: 'Joel'},
{key: 'John'},
{key: 'Jillian'},
{key: 'Jimmy'},
{key: 'Julie'},
]}
renderItem={({item}) => <Text style={styles.item}>{item.key}</Text>}
/>
);
}
render() {
return (
<View style={styles.container}>
<TabNavigator>
<TabNavigator.Item
selected={this.state.selectedTab === 'home'}
title="最热"
renderIcon={() => <Image style={styles.image} source={require('./res/images/ic_polular.png')} />}
renderSelectedIcon={() => <Image style={styles.image} source={require('./res/images/ic_polular.png')} />}
badgeText="1"
onPress={() => this.setState({ selectedTab: 'home' })}>
<View style={styles.page1}>
{this.getPageHomeList()}
</View>
</TabNavigator.Item>
<TabNavigator.Item
selected={this.state.selectedTab === 'profile'}
title="趋势"
renderIcon={() => <Image style={styles.image} source={require('./res/images/ic_trending.png')} />}
renderSelectedIcon={() => <Image style={styles.image} source={require('./res/images/ic_trending.png')} />}
onPress={() => this.setState({ selectedTab: 'profile' })}>
<View style={styles.page2}></View>
</TabNavigator.Item>
</TabNavigator>
</View>
);
}
}
const styles = StyleSheet.create({
container: {
flex: 1,
backgroundColor: '#F5FCFF',
},
page1: {
flex: 1,
backgroundColor: 'red'
},
page2: {
flex: 1,
backgroundColor: 'yellow'
},
item: {
padding: 10,
fontSize: 18,
height: 44,
},
image: {
height: 22,
width: 22
}
});文章里还介绍了比FlatList稍微复杂些的 SectionList 组件。当需要对item进行分组,支持设置每个分组的header,footer。
这个非常适合用来做通讯录,城市地址

参考文档:
参考: http://facebook.github.io/react-native/docs/using-a-listview.html http://blog.csdn.net/mengks1987/article/details/70229918
]]>我的电脑及软件环境 系统: windows10 64 Node:8.5.0 然后安装下面的工具,不分先后。
首先说下 create-react-native-app
npm install -g create-react-native-app
并按照教程 尝试启动,执行完执行npm start会出现个二维码,让我们在手机里安装expo,扫一扫就可以打开react native应用。注意要处在同一网络。经常会出现timeout。
Android Studio 3.0 (注意这个不是必须的,我主要是用他来安装android sdk)
这个安装过程会比较慢,而且加上sdk等大约会占2G的空间。按照网站的视频安装就行,安装完就可以启动一个安卓程序了。

注意sdk的安装路径,我们要保证命令行可以直接运行adb。
我是在环境变量里添加了C:\Users\{替换成你的计算机名}\AppData\Local\Android\Sdk\platform-tools
genymotion 这个需要注册帐号,然后按照expo的推荐,安装安卓虚拟设备,可以是Nexus5。
安装 expo XDE
简单说expo是一个工具,可以运行react native,并且在genymotion模拟器里打开,提供live reload等功能,还可以发布你的程序。类似开发微信小程序那个工具。
具体文档
实测发现不太稳定。可能会受到不同的电脑环境和环境变量的影响。
这里要注意一点ADB的配置

大致流程:
-
用
create-react-native-app创建一个项目,比如名叫RN_First
-
用Expo XDE打开这个项目并运行 运行后界面如下,

-
打开Genymotion并运行安卓模拟器

- 然后在expo里选择Device-Open on Android,成功的话可以在安卓模拟器看到启动expo并打开了我们的RN项目
如果修改代码,比如App.js,会立即发生变化。


遇到的坑:
ADB server didn't ACK, failed to start daemon
答: 发现adb的环境变量设的不对,之前装过安卓sdk造成有两个adb。expo找的是老的adb。 参考
Error running adb: Error running app. Error: Activity not started, unable to resolve Intent
答: 检查adb配置,最后重装expo解决。
原谅我用了粗话,因为第一次接触,走了不少弯路。
关于模拟器里调试:
ios里按cmd+R,对于安卓,点击菜单按钮

总结:
- 最好用mac开发react native,毕竟这个工具的开发者很多都用的MBP,坑会少一些。
- 工具尽量从官方下载,不要胡乱从第三方网站下载
- 开发前建议多看几遍 expo 文档。清楚你每步的操作是什么。
相关工具官方下载地址: Android Studio genymotion
]]> 完整代码如下,其实就是把文档中的例子稍微调整下。
完整代码如下,其实就是把文档中的例子稍微调整下。
import React from 'react';
import TabNavigator from 'react-native-tab-navigator';
import { StyleSheet, Text, Button, TextInput, View, Alert, Image } from 'react-native';
export default class App extends React.Component {
constructor(props) {
super(props);
this.state = {selectedTab: 'home'};
}
render() {
return (
<View style={styles.container}>
<TabNavigator>
<TabNavigator.Item
selected={this.state.selectedTab === 'home'}
title="最热"
renderIcon={() => <Image style={styles.image} source={require('./res/images/ic_polular.png')} />}
renderSelectedIcon={() => <Image style={styles.image} source={require('./res/images/ic_polular.png')} />}
badgeText="1"
onPress={() => this.setState({ selectedTab: 'home' })}>
<View style={styles.page1}></View>
</TabNavigator.Item>
<TabNavigator.Item
selected={this.state.selectedTab === 'profile'}
title="趋势"
renderIcon={() => <Image style={styles.image} source={require('./res/images/ic_trending.png')} />}
renderSelectedIcon={() => <Image style={styles.image} source={require('./res/images/ic_trending.png')} />}
onPress={() => this.setState({ selectedTab: 'profile' })}>
<View style={styles.page2}></View>
</TabNavigator.Item>
</TabNavigator>
</View>
);
}
}
const styles = StyleSheet.create({
container: {
flex: 1,
backgroundColor: '#F5FCFF',
},
page1: {
flex: 1,
backgroundColor: 'red'
},
page2: {
flex: 1,
backgroundColor: 'yellow'
},
image: {
height: 22,
width: 22
}
});默认选中名为home的tab。点击可以切换。 通过StyleSheet给元素设置样式。 需要注意的:
- 尺寸不要设置单位,在RN中尺寸与设备无关。
- 图片是透明png,可在这下载
- 如ic_polular.png的尺寸是5757, [email protected]的尺寸是114114。只引入最基本的ic_polular.png,只要按这种命名规则在不同设备会自动适配(待验证)。
image: {
height: 22,
width: 22
}在网页的世界存取任何资源都是非同步(Async)的,比如说我们希望拿到一个档案,要先发送一个请求,然后必须等到档案回来,再执行对这个档案的操作。这就是一个非同步的行为,而随著网页需求的复杂化,我们所写的 JavaScript 就有各种针对非同步行为的写法,例如使用 callback 或是 Promise 对象甚至是新的语法糖 async/await —— 但随著应用需求越来越复杂,编写非同步的代码仍然非常困难。
非同步常见的问题
- 竞态条件 (Race Condition)
- 内存泄漏 (Memory Leak)
- 复杂的状态 (Complex State)
- 异常处理 (Exception Handling)
竞争条件 Race Condition
每当我们对同一个资源同时做多次的非同步存取时,就可能发生 Race Condition 的问题。比如说我们发了一个 Request 更新使用者资料,然后我们又立即发送另一个 Request 取得使用者资料,这时第一个 Request 和第二个 Request 先后顺序就会影响到最终接收到的结果不同,这就是 Race Condition。
内存泄漏 Memory Leak
Memory Leak 是最常被大家忽略的一点。原因是在传统网站的行为,我们每次换页都是整页重刷,并重新执行 JavaScript,所以不太需要理会内存的问题!但是当我们希望将网站做得像应用时,这件事就变得很重要。例如做 SPA (单页应用) 网站时,我们是透过 JavaScript 来达到切换页面的内容,这时如果有对 DOM 注册监听事件,而没有在适当的时机点把监听的事件移除,就有可能造成 Memory Leak 内存泄漏。比如说在 A 页面监听 body 的 scroll 事件,但页面切换时,没有把 scroll 的监听事件移除。
Complex State
当有非同步行为时,应用程式的状态就会变得非常复杂!比如说我们有一支付费用户才能播放的影片,首先可能要先抓取这部影片的资讯,接著我们要在播放时去验证使用者是否有权限播放,而使用者也有可能再按下播放后又立即按了取消,而这些都是非同步执行,这时就会各种复杂的状态需要处理。
Exception Handling
JavaScript 的 try/catch 可以捕捉同步的例外,但非同步的程式就没这么容易,尤其当我们的非同步行为很复杂时,这个问题就愈加明显。
各种不同的 API
我们除了要面对非同步会遇到的各种问题外,还需要烦恼很多不同的 API
- DOM Events
- XMLHttpRequest
- fetch
- WebSockets
- Server Send Events
- Service Worker
- Node Stream
- Timer
上面列的 API 都是非同步的,但他们都有各自的 API 及写法!如果我们使用 RxJS,上面所有的 API 都可以通过 RxJS 来处理,就能用同样的 API 操作 (RxJS 的 API)。
这里我们举一个例子,假如我们想要监听点击事件(click event),但点击一次之后不再监听。
原生 JavaScript
var handler = (e) => { console.log(e); document.body.removeEventListener('click', handler); // 结束监听 }
// 注册监听 document.body.addEventListener('click', handler);
使用 Rx 大概的样子
Rx.Observable
.fromEvent(document.body, 'click') // 注册监听
.take(1) // 只取一次
.subscribe(console.log);大致上能看得出来我们在使用 RxJS 后,不管是针对 DOM Event 还是上面列的各种 API 我们都可以通过 RxJS 的 API 来做操作,像是范例中用 take(n) 来设定只取一次,之后就释放内存。
RxJS 基本介绍
RxJS 是一套藉由 Observable sequences 来组合非同步行为和事件基础程序的类库!
可以把 RxJS 想成处理 非同步行为 的 Lodash。
Rx 最早是由微软开发的 LinQ 扩展出来的开源程序,之后主要由社群的工程师贡献,有多种语言支援,也被许多科技公司所採用,如 Netflix, Trello, Github, Airbnb...等。
ReactiveX.io (官网)给的定义是,Rx 是一个使用可观察数据流进行异步编程的编程接口,ReactiveX 结合了观察者模式、迭代器模式和函数式编程的精华!
RxJS 使用场景及注意事项
RxJS 提供大量的操作符,用于处理不同的业务需求。对于同一个场景来说,可能实现方式会有很多种,需要在写代码之前仔细斟酌。由于 RxJS 的抽象程度很高,所以,可以用很简短代码表达很复杂的含义,这对开发人员的要求也会比较高,需要有比较强的归纳能力。
]]>throttle 预先设定一个执行周期,当调用动作的时刻大于等于执行周期则执行该动作,然后进入下一个新周期。
debounce 和 throttle 他们两个的作用都是要降低事件的触发頻率,但行为上有很大的不同。throttle 比较像是控制行为的最高頻率,也就是说如果我们设定 1000 毫秒,那该事件频率的最大值就是每秒触发一次不会再更快,debounce 则比较像要等到一定的时间过了才会收到元素。
debounce: 接收一个返回Observable的方法,可以传入interval,timer等 debounce会根舍弃掉在两次输出之间小于指定时间的发出值。 debounceTime: 接收毫秒数,舍弃掉在两次输出之间小于指定时间的发出值。 适用场景:搜索栏输入关键词请求后台拿数据,防止频繁发请求。 debounceTime 比 debounce 使用更频繁
throttle 节流: 接收一个返回Observable的方法,可以传入interval,timer等 throttleTime: 接收毫秒数,经过指定的这个时间后发出最新值。
const { interval, timer } = rxjs;
const { debounce } = rxjs.operators;
// 每1秒发出值, 示例: 0...1...2
const interval$ = interval(1000);
// 每1秒都将 debounce 的时间增加200毫秒
const debouncedInterval = interval$.pipe(debounce(val => timer(val * 200)));
/*
5秒后,debounce 的时间会大于 interval 的时间,之后所有的值都将被丢弃
输出: 0...1...2...3...4......(debounce 的时间大于1秒后则不再发出值)
*/
const subscribe = debouncedInterval.subscribe(val =>
console.log(`Example Two: ${val}`)
);debounceTime 例子
<body>
<input type="text" id="example">
</body>
<script src='../lib/rxjs6.3.3.umd.js'></script>
<script>
// https://rxjs-cn.github.io/learn-rxjs-operators/operators/filtering/debouncetime.html
// debounceTime
// 舍弃掉在两次输出之间小于指定时间的发出值
// 此操作符在诸如预先知道用户的输入频率的场景下很受欢迎!
const { fromEvent, timer } = rxjs;
const { debounceTime, map } = rxjs.operators;
const input = document.getElementById('example');
// 对于每次键盘敲击,都将映射成当前输入值
const example = fromEvent(input, 'keyup').pipe(map(i => i.currentTarget.value));
// 在两次键盘敲击之间等待0.5秒方才发出当前值,
// 并丢弃这0.5秒内的所有其他值
const debouncedInput = example.pipe(debounceTime(500));
// 输出值
const subscribe = debouncedInput.subscribe(val => {
console.log(`Debounced Input: ${val}`);
});
</script>concat
首先登场的是concat,用来连接多个 observable。并顺序依次执行 特点:按照顺序,前一个 observable 完成了再订阅下一个 observable 并发出值 注意事项:此操作符可以既有静态方法,又有实例方法 Marble Diagram:
source : ----0----1----2|
source2: (3)|
source3: (456)|
concat()
example: ----0----1----2(3456)|例子:
const { concat } = rxjs.operators;
const { of } = rxjs;
const sourceOne = of(1, 2, 3);
const sourceTwo = of(4, 5, 6);
const sourceThree = of(7, 8);
// 先发出 sourceOne 的值,当完成时订阅 sourceTwo
// 输出: 1,2,3,4,5,6,7,8
// 特点: 必须先等前一个 observable 完成(complete),才会继续下一个
sourceOne
.pipe(
concat(sourceTwo, sourceThree)
)
.subscribe(val =>
console.log('Example: Basic concat:', val)
);
// 等价写法, 把 concat 作为静态方法使用,这样更直观
rxjs
.concat(sourceOne, sourceTwo)
.subscribe(val =>
console.log(val)
);merge
特点:merge 把多个 observable 同时处理,这跟 concat 一次处理一个 observable 是完全不一样的,由于是同时处理行为会变得较为复杂。 merge 的逻辑有点像是 OR(||),就是当两个 observable 其中一个被触发时都可以被处理,这很常用在一个以上的按钮具有部分相同的行为。 同样 既有静态方法,又有实例方法
rxjs
.merge(
interval(500).pipe(take(3)),
interval(300).pipe(take(6)),
)
.subscribe(val =>
console.log(val)
);
sourceOne
.pipe(
merge(sourceTwo)
)
.subscribe(val =>
console.log(val)
);Marble Diagram:
source : ----0----1----2|
source2: --0--1--2--3--4--5|
merge()
example: --0-01--21-3--(24)--5|例如一个影片播放器有两个按钮,一个是暂停(II),另一个是结束播放(口)。这两个按钮都具有相同的行为就是影片会被停止,只是结束播放会让影片回到 00 秒,这时我们就可以把这两个按钮的事件 merge 起来处理影片暂停这件事。
var stopVideo = rxjs.merge(stopButton, endButton);
stopVideo.subscribe(() => {
// 暂停播放影片
})concatAll
有时我们的 Observable 送出的元素又是一个 observable,就像是二维数组,数组里面的元素是数组,这时我们就可以用 concatAll 把它摊平成一维数组,大家也可以直接把 concatAll 想成把所有元素 concat 起来。 特点:摊平 Observable
// 我们每点击一次 body 就会立刻送出 1,2,3
fromEvent(document.body, 'click')
.pipe(
// 内部发出值是 observable 类型
map(e => of(1,2,3)),
// 取 observable 的值
concatAll(),
)
.subscribe(val =>
console.log(val)
);Observable<Observable<T>>
通常我们需要的是第二层 Observable 送出的元素,所以我们希望可以把二维的 Observable 改成一维的,像是下面这样
Observable<Observable<T>> => Observable<T>
其实想要做到这件事有三个方法 switchAll、mergeAll 和 concatAll,其中 concatAll 我们在上节已经稍微讲过了,今天这篇文章会讲解这三个 operators 各自的效果跟差异。
先看各自最重要的特点:
- concatAll: 处理完前一个 observable 才会在处理下一个 observable。依次按顺序执行一个个observable 。
- switchAll:新的 observable 送出后直接处理新的 observable 不管前一个 observable 是否完成,每当有新的 observable 送出就会直接把旧的 observable 退订(unsubscribe),永远只处理最新的 observable!
注意:RxJS5 中叫switch,由于与Javascript保留字冲突,RxJS 6中对以下运算符名字做了修改:do -> tap, catch ->catchError, switch -> switchAll, finally -> finalize
- mergeAll:并且能够同时并行处理所有的 observable
看下面的例子,我们可以切换为 concatAll,mergeAll,switchAll 体验区别
const example = fromEvent(document.body, 'click')
.pipe(
// map 把送出的event事件转换为 Observable
// 每次点击送出一个新的 Observable
map(e => {
// console.log(e);
// 生成新的 Observable,点击一次输出0,1,2
return interval(1000).pipe(take(3))
}),
// concatAll 比如快速点击三次,会按顺序输出三次0,1,2
// switchAll 快速点击,只输出一次0,1,2,也就是说老的舍去只保留最新的
// mergeAll 快速点击,会重复的输出多次0,1等。点击越多下,最后送出的频率就会越快。不会舍去,每次都会输出
switchAll()
);
example.subscribe({
next: (value) => { console.log(value); },
error: (err) => { console.log('Error: ' + err); },
complete: () => { console.log('complete'); }
});switchMap = map + switchAll mergeMap = map + mergeMap concatMap = map + concatMap
我们可以使用mergeMap优化上节的例子
fromEvent(document.body, 'click')
.pipe(
map(e => {
return interval(1000)
.pipe(
take(3)
)
}),
mergeAll()
)
.subscribe(val => console.log(val));
// 简写
fromEvent(document.body, 'click')
.pipe(
mergeMap(e => {
return interval(1000)
.pipe(
take(3)
)
}),
)
.subscribe(val => console.log(val));使用场景
switchMap: input的搜索框,typehead,当有新的输入舍去之前的请求,switchMap 同一时间只维护一个内部订阅。记忆switch切换新的。 mergeMap:同时维护多个活动的内部订阅,第二个参数传入数字,可以控制并发数量。如果需要考虑顺序性,concatMap 会是更好的选择。为防止内存泄漏,如果将 observable 映射成内部的定时器或 DOM 事件流。如果仍然想用 mergeMap 的话,应该利用另一个操作符来管理内部订阅的完成,比如 take 或 takeUntil。 concatMap:合并observable,前一个内部 observable 完成后才会订阅下一个。
]]> const source = rxjs.interval(1000).pipe(take(3));
// observer 其实就是实现了next方法,error 方法和 complete 方法的对象
const observerA = {
next: value => {
console.log(`A:` + value )
},
error: error => {
console.log('Error:', error);
},
complete: () => {
console.log('complete');
}
};
const observerB = {
next: value => {
console.log(`B:` + value)
},
error: error => {
console.log('Error:', error);
},
complete: () => {
console.log('complete');
}
};
source.subscribe(observerA);
source.subscribe(observerB);
// "A: 0"
// "B: 0"
// "A: 1"
// "B: 1"
// "A: 2"
// "A complete!"
// "B: 2"
// "B complete!"上面这段代码,分别用 observerA 跟 observerB 订阅了 source,从 log 可以看出来 observerA 跟 observerB 都各自收到了元素,但请记得这两个 observer 其实是分开执行的也就是说他们是完全独立的,我们把 observerB 延迟订阅来证明看看。
const source = rxjs.interval(1000).pipe(take(3));
const observerA = {
next: value => console.log('A next: ' + value),
error: error => console.log('A error: ' + error),
complete: () => console.log('A complete!')
}
const observerB = {
next: value => console.log('B next: ' + value),
error: error => console.log('B error: ' + error),
complete: () => console.log('B complete!')
}
source.subscribe(observerA);
setTimeout(() => {
source.subscribe(observerB);
}, 1000);
// "A next: 0"
// "A next: 1"
// "B next: 0"
// "A next: 2"
// "A complete!"
// "B next: 1"
// "B next: 2"
// "B complete!"这里我们延迟一秒再用 observerB 订阅,可以从 log 中看出 1 秒后 observerA 已经打印到了 1,这时 observerB 开始打印却是从 0 开始,而不是接著 observerA 的进度,代表这两次的订阅是完全分开来执行的,或者说是每次的订阅都建立了一个新的执行。 这样的行为在大部分的情景下使用,但有些情况下我们会希望第二次订阅 source 不会从头开始接收元素,而是从第一次订阅到当前处理的元素开始发送,我们把这种处理方式称为组播(multicast),那我们要如何做到组播呢?
手动实现 subject
或许已经有读者想到解法了,其实我们可以建立一个中间人来订阅 source 再由中间人转送数据出去,就可以达到我们想要的效果
const source = rxjs.interval(1000).pipe(take(3));
const observerA = {
next: value => console.log('A next: ' + value),
error: error => console.log('A error: ' + error),
complete: () => console.log('A complete!')
}
const observerB = {
next: value => console.log('B next: ' + value),
error: error => console.log('B error: ' + error),
complete: () => console.log('B complete!')
}
const subject = {
observers: [],
addObserver: function(observer) {
this.observers.push(observer)
},
next: function(value) {
this.observers.forEach(o => o.next(value))
},
error: function(error){
this.observers.forEach(o => o.error(error))
},
complete: function() {
this.observers.forEach(o => o.complete())
}
}
subject.addObserver(observerA)
source.subscribe(subject);
setTimeout(() => {
subject.addObserver(observerB);
}, 1000);
// "A next: 0"
// "A next: 1"
// "B next: 1"
// "A next: 2"
// "B next: 2"
// "A complete!"
// "B complete!"从上面的代码可以看到,我们先建立了一个对象叫 subject,这个对象具备 observer 所有的方法(next, error, complete),并且还有一个 addObserver 方法,是把 observer 加到内部的清单中,每当有值送出就会遍历清单中的所有 observer 并把值再次送出,这样一来不管多久之后加进来的 observer,都会是从当前处理到的元素接续往下走,就像范例中所示,我们用 subject 订阅 source 并把 observerA 加到 subject 中,一秒后再把 observerB 加到 subject,这时就可以看到 observerB 是直接收 1 开始,这就是组播或多播(multicast)的行为。 让我们把 subject 的 addObserver 改名成 subscribe。
const subject = {
observers: [],
subscribe: function(observer) {
this.observers.push(observer)
},
next: function(value) {
this.observers.forEach(o => o.next(value))
},
error: function(error){
this.observers.forEach(o => o.error(error))
},
complete: function() {
this.observers.forEach(o => o.complete())
}
}虽然上面是我们自己手写的 subject,但运行方式跟 RxJS 的 Subject 实例是几乎一样的,我们把前面的代码改成 RxJS 提供的 Subject 试试
const source = rxjs.interval(1000).pipe(take(3));
const subject = new rxjs.Subject();
const observerA = {
next: value => {
console.log(`A:` + value )
},
error: error => {
console.log('Error:', error);
},
complete: () => {
console.log('complete');
}
};
const observerB = {
next: value => {
console.log(`B:` + value)
},
error: error => {
console.log('Error:', error);
},
complete: () => {
console.log('complete');
}
};
// 不会执行,相当于注册 observer
subject.subscribe(observerA);
subject.subscribe(observerB);
source.subscribe(subject);大家会发现使用方式跟前面是相同的,建立一个 subject 先拿去订阅 observable(source),再把我们真正的 observer 加到 subject 中,这样一来就能完成订阅,而每个加到 subject 中的 observer 都能整组的接收到相同的元素。
什么是 Subject?
首先 Subject 可以拿去订阅 Observable(source) 代表他是一个 Observer,同时 Subject 又可以被 Observer(observerA, observerB) 订阅,代表他是一个 Observable。
总结成两句话
- Subject 同时是 Observable 又是 Observer
- Subject 会对内部的 observers 清单列表进行组播(multicast)
参考: https://blog.jerry-hong.com/series/rxjs/thirty-days-RxJS-22/
]]>例1 理解 Subject 的组播
const subject = new rxjs.Subject();
// subject.subscribe 可以理解成 Event.AddListener 注意只是注册不会去执行
// subscriber 1
subject.subscribe((data) => {
console.log(data); // 0.24957144215097515 (random number)
});
// subscriber 2
subject.subscribe((data) => {
console.log(data); // 0.24957144215097515 (random number)
});
// 执行每个注册的 Listener
// 注意 输出的随机数值是一样的
subject.next(Math.random());Subject 是一个特殊的对象,即可以是数据生产者也同时是消费者,通过使用 Subject 作为数据消费者,可以使用它们将 Observables 从单播转换为多播。下面是一个例子:
例2 使用 Subject 将 Observables 从单播转换为多播
const observable = rxjs.Observable
.create((observer) => {
observer.next(Math.random());
});
const subject = new rxjs.Subject();
// subscriber 1
subject.subscribe((data) => {
console.log(data); // 0.24957144215097515 (random number)
});
// subscriber 2
subject.subscribe((data) => {
console.log(data); // 0.24957144215097515 (random number)
});
observable.subscribe(subject);结合 Angular 中的例子
例1
实现文本框传送输入内容并防抖
部分关键代码, TS 部分
nameChange$ = new Subject<string>();
// val 就是 input 输入的值
this.nameChange$.pipe(debounceTime(800)).subscribe(val => {
// 交互后台
this.service.searchName(val).subscribe(
// ....
);
});模板
<input matInput type="text" placeholder="Search Keyword" name="keyword"
(input)="nameChange$.next($event.target.value)" [(ngModel)]="formData.keyword">Subject 实际上就是 Observer Pattern 的实现,他会在内部管理一份 observer 的清单,并在接收到值时遍历这份清单并送出值,所以我们可以直接用 subject 的 next 方法传送值,所有订阅的 observer 就会接收到值了。
例2
使用 subject 可以实现局部刷新页面功能,假设有一List列表组件,单击列表中的某按钮弹出Model,操作完Model要刷新List数据。 我们可以按如下操作:
// 第一步 先在 service 文件中定义一个 subject
export class ListService {
listUpdated$ = new Subject();
}
// 第二步 在列表组件中 ,组件初始化时把要执行的事件放到 subject 中
// 非常类似 DOM addEventListener
export class ListComponent implements OnInit {
ngOnInit() {
this.service.listUpdated$.subscribe(() => {
this.getListData();
});
}
// 从后台获取数据的方法
private getListData() {
}
}
// 第三步 在需要的地方调用定义的subject
export class InfoModalComponent implements OnInit {
onAddClick(): void {
// 重新获取最新数据
this.service.listUpdated$.next();
}
}总结:
- Subject 是一个特殊的对象,即可以是数据生产者也同时是消费者,通过使用 Subject 作为数据消费者,可以使用它们将 Observables 从单播转换为多播。下面是一个例子:
- Subject 很像 EventEmitter,用来维护注册的 Listener, 当对 Subject 调用 subscribe 时,不会执行发送数据,只是在 维护的 Observers 中注册新的 Observer。
BehaviorSubject 是 Subject 的一个变种,他的特点是会存储当前值,
const subject = new rxjs.Subject();
subject.subscribe((next => {
console.log(next);
}));
// 去掉下面的注释才会输出结果
// subject.next(1);而 BehaviorSubject 一旦 subscribe 就会执行,可以在定义时要初始化值。
const subject = new rxjs.BehaviorSubject(0);
// 会输出 0
subject.subscribe((next => {
console.log(next);
}));ReplaySubject
在某些时候我们会希望 Subject 代表事件,但又能在新订阅时重新发送最后的几个元素,这时我们就可以用 ReplaySubject,范例如下
const count = 1;
const subject = new rxjs.ReplaySubject(count);
var observerA = {
next: value => console.log('A next: ' + value),
error: error => console.log('A error: ' + error),
complete: () => console.log('A complete!')
}
var observerB = {
next: value => console.log('B next: ' + value),
error: error => console.log('B error: ' + error),
complete: () => console.log('B complete!')
}
subject.subscribe(observerA);
subject.next(1);
// "A next: 1"
subject.next(2);
// "A next: 2"
subject.next(3);
// "A next: 3"
setTimeout(() => {
subject.subscribe(observerB);
// 根据传入 n 的不同
// "B next: 2"
// "B next: 3"
},3000)ReplaySubject(1) 不等同于 BehaviorSubject,BehaviorSubject 在建立时就会有起始值,比如 BehaviorSubject(0) 起始值就是 0,BehaviorSubject 是代表着状态而 ReplaySubject 只是事件的重放而已。
AsyncSubject
AsyncSubject 是最怪的一个变形,他有点像是 operator last,会在 subject 结束后送出最后一个值,范例如下
const subject = new rxjs.AsyncSubject();
var observerA = {
next: value => console.log('A next: ' + value),
error: error => console.log('A error: ' + error),
complete: () => console.log('A complete!')
}
var observerB = {
next: value => console.log('B next: ' + value),
error: error => console.log('B error: ' + error),
complete: () => console.log('B complete!')
}
subject.subscribe(observerA);
// 执行 next 并不会输出值
subject.next(1);
subject.next(2);
subject.next(3);
// 必须执行 complete 才会输出值
subject.complete();
setTimeout(() => {
subject.subscribe(observerB);
// "B next: 2"
// "B next: 3"
},3000)AsyncSubject 会在 Subject 结束后才送出最后一个值,其实这个行为跟 Promise 很像,都是等到事情结束后送出一个值,实际上我们非常少用到 AsyncSubject,绝大部分的时候都是使用 BehaviorSubject 跟 ReplaySubject 或 Subject。
参考:
]]>什么是 函数式编程 Functional Programming
简单说 Functional Programming 核心思想就是做运算处理,并用 function 来思考问题,例如像以下的算数运算式:
例如像以下的算数运算式:
(5 + 6) - 1 * 3
我们可以写成
const add = (a, b) => a + b
const mul = (a, b) => a * b
const sub = (a, b) => a - b
sub(add(5, 6), mul(1, 3))我们把每个运算包成一个个不同的 function,并用这些 function 组合出我们要的结果,这就是最简单的 Functional Programming。
函数式编程是一种编程范式,最主要的特征是,函数是第一等公民。
特点:
- 函数可以被赋值给变量
var hello = function() {} - 函数能被当作参数传入
fetch('www.google.com').then(function(response) {}) // 匿名 function 被传入 then() - 函数能被当作返回值
var a = function(a) {
return function(b) {
return a + b;
};
// 可以回传一个 function
}- 函数式编程强调 function 要保持纯粹,只做运算并返回一个值,没有其他额外的行为。 纯函数 (Pure function 是指 一个 function 给予相同的参数,永远会回传相同的返回值,并且没有任何显著的副作用(Side Effect))
var arr = [1, 2, 3, 4, 5];
arr.slice(0, 3); // [1, 2, 3]
arr.slice(0, 3); // [1, 2, 3]
arr.slice(0, 3); // [1, 2, 3]这里可以看到 slice 不管执行几次,返回值都是相同的,并且除了返回一个值(value)之外并没有做任何事,所以 slice 就是一个 pure function。
var arr = [1, 2, 3, 4, 5];
arr.splice(0, 3); // [1, 2, 3]
arr.splice(0, 3); // [4, 5]
arr.slice(0, 3); // []这里我们换成用 splice,因为 splice 每执行一次就会影响 arr 的值,导致每次结果都不同,这就很明显不是一个 pure function。
函数式编程好处
- 可读性高
[9, 4]
.concat([8, 7]) // 合并数组
.sort() // 排序
.filter(x => x > 5) // 过滤出大于 5 的- 可维护性高 因为纯函数等特性,执行结果不依赖外部状态,且不会对外部环境有任何操作
- 易于平行/并行处理 因为我们基本上只做运算不碰 I/O,再加上没有 Side Effect 的特性,所以较不用担心死锁等问题。 这节我们了解了函数式编程,下节讲下观察者模式
- 什么是观察者(Observer)模式及代码实现
- 什么是 Iterator (迭代器) 模式及代码实现
- 什么是 Observable
观察者模式
发布—订阅模式又叫观察者模式,它定义对象间的一种一对多的依赖关系,当一个对象的状 态发生改变时,所有依赖于它的对象都将得到通知。在 JavaScript 开发中,我们一般用事件模型 来替代传统的发布—订阅模式。
现实中的发布-订阅模式
不论是在程序世界里还是现实生活中,发布—订阅模式的应用都非常之广泛。我们先看一个 现实中的例子。 小明最近看上了一套房子,到了售楼处之后才被告知,该楼盘的房子早已售罄。好在售楼MM 告诉小明,不久后还有一些尾盘推出,开发商正在办理相关手续,手续办好后便可以购买。但到底是什么时候,目前还没有人能够知道。 于是小明记下了售楼处的电话,以后每天都会打电话过去询问是不是已经到了购买时间。除了小明,还有小红、小强、小龙也会每天向售楼处咨询这个问题。一个星期过后,售楼 MM 决定辞职,因为厌倦了每天回答 1000 个相同内容的电话。 当然现实中没有这么笨的销售公司,实际上故事是这样的:小明离开之前,把电话号码留在了售楼处。售楼 MM 答应他,新楼盘一推出就马上发信息通知小明。小红、小强和小龙也是一样,他们的电话号码都被记在售楼处的花名册上,新楼盘推出的时候,售楼 MM 会翻开花名册,遍历上面的电话号码,依次发送一条短信来通知他们。
现实中的发布-订阅模式
在刚刚的例子中,发送短信通知就是一个典型的发布—订阅模式,小明、小红等购买者都是 订阅者,他们订阅了房子开售的消息。售楼处作为发布者,会在合适的时候遍历花名册上的电话 号码,依次给购房者发布消息。 可以发现,在这个例子中使用发布—订阅模式有着显而易见的优点。
- 购房者不用再天天给售楼处打电话咨询开售时间,在合适的时间点,售楼处作为发布者会通知这些消息订阅者。
- 购房者和售楼处之间不再强耦合在一起,当有新的购房者出现时,他只需把手机号码留在售楼处,售楼处不关心购房者的任何情况,不管购房者是男是女还是一只猴子。 而售楼处的任何变动也不会影响购买者,比如售楼 MM 离职,售楼处从一楼搬到二楼,这些改变都跟购房者无关,只要售楼处记得发短信这件事情。
第一点说明发布—订阅模式可以广泛应用于异步编程中,这是一种替代传递回调函数的方案。 比如,我们可以订阅 ajax 请求的 error、success 等事件。 或者如果想在动画的每一帧完成之后做一些事情,那我们可以订阅一个事件,然后在动画的每一帧完成之后发布这个事件。在异步编程中使用发布—订阅模式,我们就无需过多关注对象在异步运行期间的内部状态,而只需要订阅感兴趣的事件发生点。
第二点说明发布—订阅模式可以取代对象之间硬编码的通知机制,一个对象不用再显式地调用另外一个对象的某个接口。发布—订阅模式让两个对象松耦合地联系在一起,虽然不太清楚彼此的细节,但这不影响它们之间相互通信。当有新的订阅者出现时,发布者的代码不需要任何修改;同样发布者需要改变时,也不会影响。
DOM 事件
实际上,只要我们曾经在 DOM 节点上面绑定过事件函数,那我们就曾经使用过发布—订阅 模式,来看看下面这两句简单的代码发生了什么事情:
document.body.addEventListener( 'click', function(){
alert(2);
}, false );
document.body.click(); // 模拟用户点击在这里需要监控用户点击 document.body 的动作,但是我们没办法预知用户将在什么时候点击。所以我们订阅 document.body 上的 click 事件,当 body 节点被点击时,body 节点便会向订阅者发布这个消息。这很像购房的例子,购房者不知道房子什么时候开售,于是他在订阅消息后等待售楼处发布消息。 当然我们还可以随意增加或者删除订阅者,增加任何订阅者都不会影响发布者代码的编写:
document.body.addEventListener( 'click', function(){
alert(2);
}, false );
document.body.addEventListener( 'click', function(){
alert(3);
}, false );
document.body.addEventListener( 'click', function(){
alert(4);
}, false );
document.body.click(); // 模拟用户点击实现 观察者模式
分别用 es5 和 es6 实现 下面是es5写法
function Producer() {
// 这个 if 只是避免使用者不小心把 Producer 当作函式来调用
if(!(this instanceof Producer)) {
throw new Error('请用 new Producer()!');
// 仿 ES6 行为可用: throw new Error('Class constructor Producer cannot be invoked without 'new'')
}
this.listeners = [];
}
// 加入监听的方法
Producer.prototype.addListener = function(listener) {
if(typeof listener === 'function') {
this.listeners.push(listener)
} else {
throw new Error('listener 必须是 function')
}
}
// 移除监听的方法
Producer.prototype.removeListener = function(listener) {
this.listeners.splice(this.listeners.indexOf(listener), 1)
}
// 发送通知的方法
Producer.prototype.notify = function(message) {
this.listeners.forEach(listener => {
listener(message);
})
}es6版本
class Producer {
constructor() {
this.listeners = [];
}
addListener(listener) {
if(typeof listener === 'function') {
this.listeners.push(listener)
} else {
throw new Error('listener 必须是 function')
}
}
removeListener(listener) {
this.listeners.splice(this.listeners.indexOf(listener), 1)
}
notify(message) {
this.listeners.forEach(listener => {
listener(message);
})
}
}有了上面的方法,可以实例化了
var egghead = new Producer();
// new 出一个 Producer 实例叫 egghead
function listener1(message) {
console.log(message + 'from listener1');
}
function listener2(message) {
console.log(message + 'from listener2');
}
egghead.addListener(listener1); // 注册监听
egghead.addListener(listener2);
egghead.notify('A new course!!') // 当某件事情方法时,执行会输出
a new course!! from listener1
a new course!! from listener2每当 egghead.notify 执行一次,listener1 跟 listener2 就会被通知,而这些 listener 可以额外被添加,也可以被移除! 虽然我们的实现很简单,但它很好的说明了 Observer Pattern 如何在事件(event)跟监听者(listener)的互动中做到去藕合(decoupling)。
迭代器模式 Iterator Pattern
迭代器模式是指提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示。 迭代器模式可以把迭代的过程从业务逻辑中分离出来,在使用迭代器模式之后,即使不关心对象的内部构造,也可以按顺序访问其中的每个元素。
JavaScript 原有的表示“集合”的数据结构,主要是数组(Array)和对象(Object),ES6 又添加了Map和Set。这样就有了四种数据集合,用户还可以组合使用它们,定义自己的数据结构,比如数组的成员是Map,Map的成员是对象。这样就需要一种统一的接口机制,来处理所有不同的数据结构。
遍历器(Iterator)就是这样一种机制。它是一种接口,为各种不同的数据结构提供统一的访问机制。任何数据结构只要部署 Iterator 接口,就可以完成遍历操作(即依次处理该数据结构的所有成员)。 迭代器 Iterator 本质是一个指针(pointer)对象。 Iterator 的遍历过程是这样的。 (1)创建一个指针对象,指向当前数据结构的起始位置。也就是说,遍历器对象本质上,就是一个指针对象。 (2)第一次调用指针对象的next方法,可以将指针指向数据结构的第一个成员。 (3)第二次调用指针对象的next方法,指针就指向数据结构的第二个成员。 (4)不断调用指针对象的next方法,直到它指向数据结构的结束位置。 先让我们来看看原生的 JS 要怎么建立 iterator
var arr = [1, 2, 3];
var iterator = arr[Symbol.iterator]();
iterator.next();
// { value: 1, done: false }
iterator.next();
// { value: 2, done: false }
iterator.next();
// { value: 3, done: false }
iterator.next();
// { value: undefined, done: true }自己实现 Iterator
function IteratorFromArray(arr) {
if(!(this instanceof IteratorFromArray)) {
throw new Error('请用 new IteratorFromArray()!');
}
this._array = arr;
this._cursor = 0;
}
IteratorFromArray.prototype.next = function() {
return this._cursor < this._array.length ?
{ value: this._array[this._cursor++], done: false } :
{ done: true };
}es6版本
class IteratorFromArray {
constructor(arr) {
this._array = arr;
this._cursor = 0;
}
next() {
return this._cursor < this._array.length ?
{ value: this._array[this._cursor++], done: false } :
{ done: true };
}
}迭代器模式虽然很单纯,但同时带来了两个优势,第一它渐进式取得数据的特性可以拿来做延迟运算(Lazy evaluation),让我们能用它来处理数据结构。第二因为 iterator 本身是序列,所以可以实现所有数组的运算方法像 map, filter... 等!
class IteratorFromArray {
constructor(arr) {
this._array = arr;
this._cursor = 0;
}
next() {
return this._cursor < this._array.length ?
{ value: this._array[this._cursor++], done: false } :
{ done: true };
}
map(callback) {
const iterator = new IteratorFromArray(this._array);
return {
next: () => {
const { done, value } = iterator.next();
return {
done: done,
value: done ? undefined : callback(value)
}
}
}
}
}
var iterator = new IteratorFromArray([1,2,3]);
var newIterator = iterator.map(value => value + 3);
newIterator.next();
// { value: 4, done: false }
newIterator.next();
// { value: 5, done: false }
newIterator.next();
// { value: 6, done: false }补充: 延迟运算(Lazy evaluation)
延迟运算,或说 call-by-need,是一种运算策略(evaluation strategy),简单来说我们延迟一个表达式的运算时机直到真正需要它的值在做运算。 以下我们用 generator 实作 iterator 来举一个例子
function* getNumbers(words) {
for (let word of words) {
if (/^[0-9]+$/.test(word)) {
yield parseInt(word, 10);
}
}
}
const iterator = getNumbers('30 天精通 RxJS (04)');
iterator.next();
// { value: 3, done: false }
iterator.next();
// { value: 0, done: false }
iterator.next();
// { value: 0, done: false }
iterator.next();
// { value: 4, done: false }
iterator.next();
// { value: undefined, done: true }
}这么我们写了一个函数用来抓取字串中的数字,在这个函数中我们用 for...of 的方式来取得每个字符并用正则表示式来判断是不是数值,如果为真就转成数值并回传。当我们把一个字串丢进 getNumbers 函式时,并没有马上运算出字串中的所有数字,必须等到我们执行 next() 时,才会真的做运算,这就是所谓的延迟运算(evaluation strategy)
Observable
在了解 Observer 跟 Iterator 后,不知道大家有没有发现其实 Observer 跟 Iterator 有个共通的特性,就是他们都是渐进式(progressive) 的取得数据,差别只在于 Observer 是生产者(Producer)推送数据(push),而 Iterator 是消费者(Consumer)拉数据(pull)!

Observable 其实就是这两个 Pattern 思想的结合,Observable 具备生产者推送数据的特性,同时能像数组,拥有数组处理数据的方法(map, filter...)!
下节讲 如何创建 Observable 。
]]>Observer 和 Observable: 在ReactiveX中,一个观察者(Observer)订阅一个可观察对象(Observable)。观察者对Observable发射的数据或数据序列作出响应。这种模式可以极大地简化并发操作,因为它创建了一个处于待命状态的观察者哨兵,在未来某个时刻响应Observable的通知,不需要阻塞等待Observable发射数据。
RxJS: 刚才说了Rx是抽象的东西,RxJS 就是使用JavaScript语言实现rx接口的类库。 它通过使用 observable 序列来编写异步和基于事件的程序。它提供了一个核心类型Observable,附属类型 (Observer、 Schedulers、 Subjects) 和受 [Array#extras] 启发的操作符 (map、filter、reduce、every, 等等),这些数组操作符可以把异步事件作为集合来处理。
ReactiveX 结合了观察者模式、迭代器模式和使用集合的函数式编程,以满足以一种理想方式来管理事件序列所需要的一切。
在 RxJS 中用来解决异步事件管理的的基本概念是:
- **Observable (可观察对象)😗*表示一个概念,这个概念是一个可调用的未来值或事件的集合。
- **Observer (观察者)😗*一个回调函数的集合,它知道如何去监听由 Observable 提供的值。
- **Subscription (订阅)😗*表示 Observable 的执行,主要用于取消 Observable 的执行。
- **Operators (操作符)😗*采用函数式编程风格的纯函数 (pure function),使用像
map、filter、concat、flatMap等这样的操作符来处理集合。 - **Subject (主体)😗*相当于 EventEmitter,并且是将值或事件多路推送给多个 Observer 的唯一方式。
- **Schedulers (调度器)😗*用来控制并发并且是中央集权的调度员,允许我们在发生计算时进行协调,例如
setTimeout或requestAnimationFrame或其他。
注意:网上很多例子都是基于 RxJS5 版本,而最新的 RxJS6 变化很大,具体参见和中文,后面的例子中都会基于 RxJS6 来实现。
另外学习 RxJS 建议直接看官方文档,毕竟是最新的。
- http://reactivex.io/documentation
- https://rxjs-dev.firebaseapp.com/guide/overview 可结合中文文档 (注意例子中的版本)
- https://mcxiaoke.gitbooks.io/rxdocs/content/
- https://rxjs-cn.github.io
下节介绍如何创建 Observable
]]>注册事件监听器的常规写法。
var button = document.querySelector('button');
button.addEventListener('click', () => console.log('Clicked!'));使用 RxJS 的话,创建一个 observable 来代替(基于最新的Rxjs6版本写法)
<script src='https://cdn.bootcss.com/rxjs/6.5.1/rxjs.umd.js'></script>
<script>
const { fromEvent } = rxjs;
const button = document.querySelector('button');
fromEvent(button, 'click')
.subscribe(() => console.log('Clicked!'));
</script>上面例子中的fromEvent就是基于Event 建立 Observable,fromEvent 的第一个参数要传入 DOM 对象,第二个参数传入要监听的事件名。
创建 Observable 有很多操作符

使用Create操作符从头开始创建一个Observable, 这个接收一个回调函数,把observer作为参数
// Observer 是一个对象,这个对象具有三个方法,分别是 next, error, complete
// 建立 Observable 最简单方法是用 create 方法
// create 接收一个回调函数,把 observer 作为参数
const observer = {
next: value => {
console.log(`observer:` + value)
},
error: error => {
console.log('Error:', error);
},
complete: () => {
console.log('complete');
}
}
var observable = rxjs.Observable
.create(observer => {
observer.next('Jerry');
observer.next('Anna');
observer.complete();
observer.next('not work');
})
// 建立观察者来订阅 observable
// 订阅一个 Observable 就像是执行一个 function
observable.subscribe(
observer
)from操作符:将对象、字符串,数组,promise 等其他类型转换为Observable。
请自己敲一遍看结果。
const {from} = rxjs;
function f() {
return from(arguments);
}
const observer = {
next: value => {
console.log('Next: ' + value);
},
error: error => {
console.log('Error:', error);
},
complete: () => {
console.log('Complete');
}
}
// Array Like Object
f(1, 2, 3).subscribe(observer);
// string
from('foo').subscribe(observer);
// Set, any iterable object
const s = new Set(['foo', window]);
from(s).subscribe(observer);
// Promise
const source = from(new Promise((resolve, reject) => {
setTimeout(() => {
resolve('Hello RxJS!');
}, 3000)
}))
source.subscribe(observer);- 延迟运算
- 渐进式取值
延迟运算
延迟运算很好理解,所有 Observable 一定会等到订阅后才开始对元素做运算,如果没有订阅就不会有运算的行为
var source = Rx.Observable.from([1,2,3,4,5]);
var example = source.map(x => x + 1);上面这段代码因为 Observable 还没有被订阅,所以不会真的对元素做运算,这跟数组的操作不一样,如下
var source = [1,2,3,4,5];
var example = source.map(x => x + 1);上面这段代码执行完,example 就已经取得所有元素的返回值了。
数组的运算都必须完整的运算出每个元素的返回值并组成一个新数组,再做下一个运算。
渐进式取值
数组的 operators 都必须完整的运算出每个元素的返回值并组成一个数组,再做下一个 operator 的运算,我们看下面这段程式码
var source = [1,2,3];
var example = source
.filter(x => x % 2 === 0) // 这裡会运算并返回一个完整的数组
.map(x => x + 1) // 这裡也会运算并返回一个完整的数组上面这段代码,相信读者们都很熟悉了,大家应该都有注意到 source.filter(...)就会返回一整个新数组,再接下一个 operator 又会再返回一个新的数组,这一点其实在我们实现 map 跟 filter 时就能观察到
Array.prototype.map = function(callback) {
var result = []; // 建立新数组
this.forEach(function(item, index, array) {
result.push(callback(item, index, array))
});
return result; // 返回新数组
}每一次的 operator 的运算都会建立一个新的数组,并在每个元素都运算完后返回这个新数组,我们可以用下面这张动态图表示运算过程

Observable operator 的运算方式跟数组的是完全的不同,虽然 Observable 的 operator 也都会回传一个新的 observable,但因为元素是渐进式取得的关系,所以每次的运算是一个元素运算到底,而不是运算完全部的元素再返回。
var source = Rx.Observable.from([1,2,3]);
var example = source
.filter(x => x % 2 === 0)
.map(x => x + 1)
example.subscribe(console.log);上面这段程式码运行的方式是这样的
- 送出
1到 filter 被过滤掉 - 送出
2到 filter 在被送到 map 转成3,送到 observerconsole.log印出 - 送出
3到 filter 被过滤掉
每个元素送出后就是运算到底,在这个过程中不会等待其他的元素运算。这就是渐进式取值的特性,不知道读者们还记不记得我们在讲 Iterator 跟 Observer 时,就特别强调这两个 Pattern 的共同特性是渐进式取值,而我们在实现 Iterator 的过程中其实就能看出这个特性的运作方式
class IteratorFromArray {
constructor(arr) {
this._array = arr;
this._cursor = 0;
}
next() {
return this._cursor < this._array.length ?
{ value: this._array[this._cursor++], done: false } :
{ done: true };
}
map(callback) {
const iterator = new IteratorFromArray(this._array);
return {
next: () => {
const { done, value } = iterator.next();
return {
done: done,
value: done ? undefined : callback(value)
}
}
}
}
}
var myIterator = new IteratorFromArray([1,2,3]);
var newIterator = myIterator.map(x => x + 1);
newIterator.next(); // { done: false, value: 2 }虽然上面这段代码是一个非常简单的示范,但可以看得出来每一次 map 虽然都会返回一个新的 Iterator,但实际上在做元素运算时,因为渐进式的特性会使一个元素运算到底,Observable 也是相同的概念,我们可以用下面这张动态图表示运算过程

渐进式取值的观念在 Observable 中其实非常的重要,这个特性也使得 Observable 相较于 Array 的 operator 在做运算时来的高效很多,尤其是在处理大量资料的时候会非常明显! (想像一下我们今天要切五万个大蛋糕,你会选择切完一个请一个人拿走,还是全部切完再拿给所有人呢?哪个会比较有效率呢?)
]]>学好 RxJS 的关键是对 Operators (操作符)的灵活使用,操作符大多是纯函数,我们使用操作符创建,转换,过滤,组合,错误处理,辅助操作 Observables。具体参见 不同的操作符有不同的使用场景,有些名字容易混淆,可以对比的学习。
下面介绍几个可以创建 Observable 的运算符,具体的介绍请问官网 例子:https://codepen.io/mafeifan/pen/eQKNvN
const {from, of, range, interval, timer, empty} = rxjs;
function f() {
return from(arguments);
}
const observer = {
next: value => {
console.log('Next: ' + value);
},
error: error => {
console.log('Error:', error);
},
complete: () => {
console.log('Complete');
}
}
// Array Like Object
f(1, 2, 3).subscribe(observer);
// string
// from 接收数组
// 如果是字符串,会打印每一个字符
from('foo').subscribe(observer);
// Set, any iterable object
const s = new Set(['foo', window]);
from(s).subscribe(observer);
// Promise
const source = from(new Promise((resolve, reject) => {
setTimeout(() => {
resolve('Hello RxJS!');
},3000)
}));
source.subscribe(observer);
// 传啥输出啥
/*
Next: 1
Next: 2
Next: 3
*/
of(1, 2, 3).subscribe(observer);
// Next: 4,5,6
of([4, 5, 6]).subscribe(observer);
// https://rxjs-dev.firebaseapp.com/api/index/function/range
// 从10开始递增+1连续发射两次, 输出 10, 11
/*
Next: 10,
Next: 11
*/
range(10, 2).subscribe(observer);
// 从0开始计数,每间隔num ms秒发射一次
const num = 1000;
interval(num).subscribe(observer);
// 延迟2秒发射
timer(2000).subscribe(observer);
// 不会执行 next,直接执行 complete
empty().subscribe({
next: () => console.log(`empty`),
complete: () => console.log('empty Complete!')
});
// 延迟5秒发射, 间隔1秒发射一次
const subscription = timer(5000, 1000).subscribe(observer);<script src='https://cdn.bootcss.com/rxjs/6.5.1/rxjs.umd.js'></script>
<script>
const { from } = rxjs;
const { filter, take, last, startWith, skip } = rxjs.operators;
// 发出(1, 2, 3, 4, 5)
const source = from([1, 2, 3, 4, 5]);
const example = source.pipe(
// 开头追加 6, 8 得 6, 8, 1, 2, 3, 4, 5
startWith(6, 8),
// 舍弃第一个 得 8, 1, 2, 3, 4, 5
skip(1),
// 只取偶数得 8, 2, 4
filter(num => num % 2 === 0),
// 再取前俩得 8, 2
take(2),
// 只取最后一个得 2
last()
);
example.subscribe(val => {
console.log(`The number: ${val}`)
});
</script>skip 跳过开头的N个值,需要传入数字类型 skipUntil,skipWhile 都是 skip 的变种 skipUntil 接收的是 Observable 类型,当这个Observable发出值才完成 skipWhile 接收的是 function ,一旦返回值为false 就完成
总结:take 和 skip 互逆
<script src='../lib/rxjs6.3.3.umd.js'></script>
<script>
// https://rxjs-cn.github.io/learn-rxjs-operators/operators/filtering/filter.html
// filter
// 发出符合给定条件的值
const { from, interval, timer } = rxjs;
const { filter, take, last, startWith, skip, takeUntil, takeWhile, skipWhile } = rxjs.operators;
interval(1000)
.pipe(
// timer(5000) 是等待5s发出值
// takeUntil 只取timer(5000)开始发出之前的那些值
takeUntil(timer(5000))
)
// 输出 0,1,2,3
.subscribe(val => console.log(val));
interval(1000)
.pipe(
// timer(5000) 是等待5s发出值
// takeWhile 只取timer(5000)开始发出之前的那些值
takeWhile((val) => val < 5)
)
// 输出 -0,-1,-2,-3, -4
.subscribe(val => console.log(`-${val}`));
</script>来看下skip操作,我们只替换take为skip,显示的内容刚好相反
const { from, interval, timer } = rxjs;
const { filter, take, last, startWith, skip, takeUntil, takeWhile, skipWhile, skipUntil } = rxjs.operators;
interval(1000)
.pipe(
// timer(5000) 是等待5s发出值
// skipUntil 舍弃timer(5000)开始发出之前的那些值
skipUntil(timer(5000))
)
// 从 4 开始输出 每秒1发送一次,4, 5, 6, 7...
.subscribe(val => console.log(val));
interval(1000)
.pipe(
// timer(5000) 是等待5s发出值
// skipWhile 舍弃timer(5000)开始发出之前的那些值
// 输出
skipWhile((val) => val < 5)
)
// 从 -5 开始输出 每秒1发送一次,如 -5, -6, -7 ...
.subscribe(val => console.log(`-${val}`));修改import路径
建议TypeScript开发人员使用rxjs-tslint来重构import路径。 RxJS团队设计了以下规则来帮助JavaScript开发人员重构import路径:
- rxjs: 包含创建方法,类型,调度程序和工具库。
import { Observable, Subject, asapScheduler, pipe, of, from, interval, merge, fromEvent } from 'rxjs';
- rxjs/operators: 包含所有的管道操作符
import { map, filter, scan } from 'rxjs/operators';
- rxjs/webSocket: 包含websocket subject实现.
import { webSocket } from 'rxjs/webSocket';
- rxjs/ajax: 包含Rx ajax实现.
import { ajax } from 'rxjs/ajax';
- rxjs/testing: 包含RxJS的测试工具库.
import { TestScheduler } from 'rxjs/testing';
使用管道操作而不是链式操作
请按照如下步骤将您的链式操作替换为管道操作:
- 从rxjs-operators中引入您需要的操作符
注意:由于与Javascript保留字冲突,以下运算符名字做了修改:do -> tap, catch -> catchError, switch -> switchAll, finally -> finalize
import { map, filter, catchError, mergeMap } from 'rxjs/operators';
- 使用pipe()包裹所有的操作符方法。确保所有操作符间的.被移除,转而使用,连接。 记住!!!有些操作符的名称变了!!! 以下为升级示例:
// Rxjs5写法,操作符链
source
.map(x => x + x)
.mergeMap(n => of(n + 1, n + 2)
.filter(x => x % 1 == 0)
.scan((acc, x) => acc + x, 0)
)
.catch(err => of('error found'))
.subscribe(printResult);
// Rxjs写法,需要用pipe包一下所有的操作符
source.pipe(
map(x => x + x),
mergeMap(n => of(n + 1, n + 2).pipe(
filter(x => x % 1 == 0),
scan((acc, x) => acc + x, 0),
)),
catchError(err => of('error found')),
).subscribe(printResult);注意我们在以上代码中嵌套使用了pipe()。 Ben Lesh在ng-conf 2018上解释了为什么我们应该使用管道操作符。
其他RxJs6弃用
Observable.if and Observable.throw Observable.if已被iif()取代,Observable.throw已被throwError()取代。您可使用rxjs-tslint将这些废弃的成员方法修改为函数调用。
代码示例如下:
OBSERVABLE.IF > IIF()
// deprecated
Observable.if(test, a$, b$);
// use instead
iif(test, a$, b$);
OBSERVABLE.ERROR > THROWERROR()
// deprecated
Observable.throw(new Error());
//use instead
throwError(new Error());已弃用的方法
根据迁移指南,以下方法已被弃用或重构:
- merge
import { merge } from 'rxjs/operators';
a$.pipe(merge(b$, c$));
// becomes
import { merge } from 'rxjs';
merge(a$, b$, c$);- concat
import { concat } from 'rxjs/operators';
a$.pipe(concat(b$, c$));
// becomes
import { concat } from 'rxjs';
concat(a$, b$, c$);- combineLatest
import { combineLatest } from 'rxjs/operators';
a$.pipe(combineLatest(b$, c$));
// becomes
import { combineLatest } from 'rxjs';
combineLatest(a$, b$, c$);- race
import { race } from 'rxjs/operators';
a$.pipe(race(b$, c$));
// becomes
import { race } from 'rxjs';
race(a$, b$, c$);- zip
import { zip } from 'rxjs/operators';
a$.pipe(zip(b$, c$));
// becomes
import { zip } from 'rxjs';
zip(a$, b$, c$);总结
RxJS 6带来了一些重大改变,但是通过添加rxjs-compat软件包可以缓解这一问题,该软件包允许您在保持v5代码运行的同时逐渐迁移。对于Typescript用户,其他中包括大多数Angular开发人员,tslint提供了大量的自动重构功能,使转换变得更加简单。
任何升级与代码修改都会引入一些bug到代码库中。因此请务必测试您的功能以确保您的终端用户最终接受到相同的质量体验。
]]>个人备注,现在网上大部分教程还是rxjs5的,rxjs6变化还是蛮大的,学习时候要留意区别。
FormControl的valueChanges属性和statusChanges属性包含了会发出变更事件的可观察对象。
例子
import { Component, OnInit } from '@angular/core';
import { FormBuilder, FormGroup, Validators, FormControl, AbstractControl } from '@angular/forms';
import { concat, merge, zip, combineLatest, race } from 'rxjs/index';
import { filter, map, startWith, } from 'rxjs/internal/operators';
@Component({
selector: 'my-app',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent implements OnInit {
form: FormGroup;
constructor(
private formBuilder: FormBuilder,
) { }
ngOnInit() {
this.form = this.formBuilder.group({
username: ['', Validators.required],
hobby: [''],
});
// 监听整个表单
this.form.valueChanges
.subscribe( res => console.log(res));
}
}HTML
<form [formGroup]="form">
username: <input type="text" name="username" formControlName="username">
hobby:
<select name="hobby">
<option value="sleep">sleep</option>
<option value="play">play</option>
</select>
</form>完善验证,只有通过验证才输出内容 filter 是rxjs提供的运算符
this.form.valueChanges
.pipe(
filter(() => this.form.valid)
)
.subscribe(res => console.log(res));如果需要额外的逻辑,只需要在pipe添加相应的运算符。比如这里在结果里追加上次更新时间,字段名为lastTime
this.form.valueChanges
.pipe(
filter(() => this.form.valid),
map(data => {
data.lastTime = new Date();
return data
})
)
.subscribe(res => console.log(res));另一种写法,监听各个元素
// 如果要监听单个表单元素
const username$ = this.form.get('username').pipe(startWith(this.form.get('username').value))
const hobby$ = this.form.get('hobby').pipe(startWith(this.form.get('hobby').value))
// combineLatest,它会取得各个 observable 最后送出的值,再输出成一个值
// 这个有个问题是只有合并的元素都产生值才会输出内容,所以在上面使用startWith赋初始化值
combineLatest(username$, status$)
.pipe(
map(([username, status]) => ({username, status}))
)
.subscribe(res => console.log(res));结合返回Observable的组件 Angular Material
Angular Material 是基于Angular的前端框架,国外使用度高。 他提供的组件有些方法返回的是Observable,比如Dialog的afterAllClosed,SnackBar的afterOpened, afterDismissed 比如某需要,提示消失1s后跳转页面 优化前的代码:
this.snackbar.success(response);
setTimeout(function () {
this.router.navigate([`/login`]);
}, 1000);优化后的代码:
import { delay } from 'rxjs/operators';
...
this.snack.success(response).afterDismissed()
.pipe(delay(1000))
.subscribe(() => {
this.router.navigate([`/login`]);
});例1:
async testOf() {
return await this.service.getUserList().toPromise().then(res => {
return res;
})
}读数据
ngOnInit() {
this.testOf().then(res => {
console.log(res);
})
}例2
ngOnInit() {
this.initData(response.creativeId)
}
async initData(creativeId) {
const detailResponse = await this.service.getCreativeDetail(creativeId).toPromise();
const assetResponse = await this.service.getCreativeVideoImageUrl(creativeId).toPromise();
const {data: detailData} = detailResponse;
const {data: assetData} = assetResponse;另外谈谈个人对于学习新知识的方法。
首先对于陌生的技术名词要先去官方的网站看介绍,因为官方的教程是最新的,而且的写的人一般是技术的作者本人。 官方的教程一定要先多看几遍。
其次官方的教程可能写的比较晦涩,或者例子太少,这个时候可以搜些网友写的文章或者书籍看。 对于技术文章,要留意是否是转载,很多是不负责任的转载,没有加入自己的理解。
最后,对于编程光看是不行的,有时候看完感觉是会了,但是不看教程一行都敲不出来,这是因为思路是被别人引领着,自己没有在脑子里过一遍,建议看懂后自己再敲一便,也是理顺自己思路的过程。
]]><!DOCTYPE html>
<html>
<body>
<div id="app">
<input type="text" id="txt">
<p id="show"></p>
</div>
<script type="text/javascript">
var obj = {}
Object.defineProperty(obj, 'txt', {
// get: function () {
// return obj
// },
set: function (newValue) {
document.getElementById('txt').value = newValue
document.getElementById('show').innerHTML = newValue
}
})
document.getElementById('txt').addEventListener('keyup', function (e) {
obj.txt = e.target.value
})
</script>
</body>
</html>DevTools中随便输入 obj.txt = '12321z@2',页面两处会相应的发生变化。
参考
]]>
关于JS文件的后缀 cjs表示构建出来的文件遵循CommonJS规范, es 表示构建出来的文件遵循ES Module规范。 umd 表示构建出来的文件遵循UMD规范。
Runtime Only 与 Runtime + Compiler
]]>
import { initMixin } from './init'
import { stateMixin } from './state'
import { renderMixin } from './render'
import { eventsMixin } from './events'
import { lifecycleMixin } from './lifecycle'
import { warn } from '../util/index'
// 模拟类,只能通过new Vue去实例化
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)
) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}
// 把对象传进去,然后给对象的原型挂载方法
initMixin(Vue)
stateMixin(Vue)
eventsMixin(Vue)
lifecycleMixin(Vue)
renderMixin(Vue)
export default Vue它本质上就是⼀个⽤ Function 实现的 Class,然后它的原型 prototype 以及它本⾝都扩展了⼀系列的 ⽅法和属性
]]>main.js
new Vue({
data(){
return{
loading:true
}
},
router,
store,
render: h => h(App)
}).$mount('#app')a.vue
created(){
console.log(this.$root.loading) //获取loading的值
}b.vue
created(){
this.$root.loading = false; //设置loading的属性
}动态给body添加class
方法1:使用 document.body.classList
mounted () {
document.body.classList.add('bg-light')
},
destroyed () {
document.body.classList.remove('bg-light')
}上面的代码会在组件创建时动态给body添加bg-lightclass,组件销毁时移除class
如果需要添加多个class,可以以逗号分隔
mounted () {
document.body.classList.add('bg-light', 'login')
},
destroyed () {
document.body.classList.remove('bg-light', 'login')
},方法2:
使用包 vue-body-class
这个需要在配合vue-router 3.x使用
{
path: '/login',
name: 'login',
component: Login,
meta: { bodyClass: 'bg-light' }
}参考
]]>传统上可以这样做:
子组件,发射事件
<template>
<div class="child" style="border: 1px dotted red">
<input type="text" @input="handleOuter" v-model="innerText">
<div>等待被内部组件修改</div>
</div>
</template>
<script>
export default {
name: 'Child',
data () {
return {
innerText: '',
}
},
methods: {
// 修改内容时发射事件,然后在父组件接收
handleOuter(e) {
console.log(e);
this.$emit('update:outer', this.innerText);
},
},
}
</script>父组件:
<template>
<div style="border: 1px dotted blue">
<h1>父子组件数据传递</h1>
<h3>Parent:</h3>
<div v-text="fromInner"></div>
<h3>Child:</h3>
<!-- 接收事件并实时更新父组件的 fromInner 属性 -->
<i-child @update:outer="val => fromInner = val"/>
</div>
</template>
<script>
import Child from './child';
export default {
name: 'Parent',
components: {
'i-child': Child
},
data () {
return {
fromInner: '',
}
},
methods: {
},
}
</script>使用 .sync后
<i-child :outer.sync="fromInner"/>
需要注意的是sync要写在子组件上面
]]>下面的例子需要通过服务器打开才生效哦,比如本地localhost开头的..
例1
有一个 js 文件和 html 文件,现在可以实现不借助任何东西在浏览器里实现点击页面上的按钮加载该 js。
export default {
open() {
return alert('I am opening')
}
}html文件
<button id="btn">点击动态加载js</button>
<script>
const btn = document.querySelector("#btn")
btn.addEventListener('click', event => {
import('./dialogBox.js')
.then(dialogBox => {
dialogBox.default.open();
})
.catch(error => {
/* Error handling */
});
});
</script>注意:import方法 返回的是一个promise对象
例2 vue加载动态路由组件
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<div id="app">
<nav>
<!-- lazy load component -->
<a href="proxy.php?url=/pages/BooksPage.js" @click.prevent="navigate">Books</a>
<a href="proxy.php?url=/pages/MoviesPage.js" @click.prevent="navigate">Movies</a>
<a href="proxy.php?url=/pages/GamesPage.js" @click.prevent="navigate">Games</a>
</nav>
<component :is="page"></component>
</div>
<script src="proxy.php?url=node_modules/vue/dist/vue.js"></script>
<!-- 必须加上 type="module" -->
<script type="module">
import BooksPage from './pages/BooksPage.js';
new Vue({
el: '#app',
data: {
page: BooksPage
},
methods: {
navigate(event) {
this.page = () => import(`./${event.target.pathname}`)
// 如果 Vue.js < 2.5.0
// .then(m => m.default)
}
}
});
</script>
</body>
</html>注意,这里使用了vue的内置 component组件,依 is 的值,来决定哪个组件被渲染。
BookPage的内容
export default {
name: 'BooksPage',
template: `
<div>
<h1>Books Page</h1>
<p>{{ message }}</p>
</div>
`,
data() {
return {
message: 'Oh hai from the books page'
}
}
};完整的代码已放到了 GitHub 上面 如果觉得文章对你有帮助,请点下下方的喜欢,谢谢!
]]>开发网页经常遇到分享功能,这时候可以利用现成的工具比如 JiaThis,通过几步简单配置就实现分享共享功能啦。
比如我想生成图标式的分享

得到的基础代码如下:
<!-- JiaThis Button BEGIN -->
<div class="jiathis_style">
<span class="jiathis_txt">分享到:</span>
<a class="jiathis_button_qzone">QQ空间</a>
<a class="jiathis_button_tsina">新浪微薄</a>
<a class="jiathis_button_tqq">腾讯微薄</a>
<a class="jiathis_button_renren">人人网</a>
<a class="jiathis_button_kaixin001">开心网</a>
<a href="proxy.php?url=http://www.jiathis.com/share" class="jiathis jiathis_txt jiathis_separator jtico jtico_jiathis" target="_blank">更多</a>
<a class="jiathis_counter_style"></a>
</div>
<script type="text/javascript" >
var jiathis_config={
url:"http://www.jianshu.com",
summary:"分享摘要",
title:"分享标题 ##",
shortUrl:false,
hideMore:false
}
</script>
<script type="text/javascript" src="proxy.php?url=http://v3.jiathis.com/code/jia.js" charset="utf-8"></script>
<!-- JiaThis Button END -->大概分成三部分
分享图标html模版,jiathis_config 配置对象, http://v3.jiathis.com/code/jia.js类库
根据Vue组件的思想,现在封装成一个组件,方便将来在其他项目中使用。
如果是vue-cli,新建一个Share.vue,内容如下很简单。template为空,因为可能是自定义需要外部传入,组件必须带一个config属性,是配置项对象,我把config挂到了window下,这样可能有风险。但是目前找不到更好的办法。
<template>
</template>
<script>
// JiaThis 按钮自定义大全
// http://www.jiathis.com/customize
export default {
name: 'share',
props: {
config: {
type: Object,
required: true
},
},
mounted: function () {
// 这里需要优化
window.jiathis_config = Object.assign({
url: "http://www.jiathis.com",
summary: "分享摘要",
title: "分享标题",
shortUrl: false,
hideMore: false
}, this.config)
// 这里需要vue引入jquery
// http://api.jquery.com/jquery.getscript/
$.getScript('http://v3.jiathis.com/code/jia.js')
},
computed: {
},
methods: {
}
}
</script>
<!-- Add "scoped" attribute to limit CSS to this component only -->
<style scoped>
</style>在需要用到分享的地方 template内,注意 inline-template,这样会把组件将把它的内容当作它的模板,这部分需要自定义不能写死在share组件内。
<share :config="shareConfig" inline-template>
<div class="jiathis_style_32x32">
<a class="jiathis_button_tqq"></a>
<a class="jiathis_button_cqq"></a>
<a class="jiathis_button_qzone"></a>
<a class="jiathis_button_tsina"></a>
<a href="proxy.php?url=http://www.jiathis.com/share" class="jiathis jiathis_txt jiathis_separator jtico jtico_jiathis" target="_blank"></a>
<a class="jiathis_counter_style"></a>
</div>
</share>
import()函数,完成动态加载。
import(specifier)上面代码中,import函数的参数specifier,指定所要加载的模块的位置。import命令能够接受什么参数,import()函数就能接受什么参数,两者区别主要是后者为动态加载。
import()返回一个 Promise 对象。下面是一个例子。
const main = document.querySelector('main');
import(`./section-modules/${someVariable}.js`)
.then(module => {
module.loadPageInto(main);
})
.catch(err => {
main.textContent = err.message;
});import()函数可以用在任何地方,不仅仅是模块,非模块的脚本也可以使用。它是运行时执行,也就是说,什么时候运行到这一句,也会加载指定的模块。另外,import()函数与所加载的模块没有静态连接关系,这点也是与import语句不相同。
import()类似于 Node 的require方法,区别主要是前者是异步加载,后者是同步加载。
syntax-dynamic-import
这种方式chrome63后已经原生支持了,但是如果是不支持浏览器就需要babel了。 看这里 https://babeljs.io/docs/plugins/syntax-dynamic-import/
运用
- vue的router.js中
import Vue from 'vue'
import Router from 'vue-router'
Vue.use(Router)
function load(component) {
// '@' is aliased to src/components
return () => import(`@/pages/${component}/index.vue`)
}
export default new Router({
routes: [
{
path: '/',
name: 'HelloWorld',
component: load('HelloPage')
},
{
path: '/tree',
name: 'TreePage',
component: load('TreePage')
}
]
})- vue加载多components
// http://www.css88.com/doc/lodash/#_kebabcasestring
// UploadFile => upload-file
import { kebabCase } from 'lodash'
const load = (component) => {
return () => import(`../components/${component}.vue`)
}
const commonComponents = [
'BaseFormDialog',
'Datepicker',
'HeaderContent',
'UploadFile',
'FullScreenButton',
'RouterTreeview',
'RouterLinkBack',
'ModalDialog',
'vSelect'
]
commonComponents.forEach(component => {
Vue.component(kebabCase(component), load(component));
})- 最常见的就是使用debug节点,可以勾选讲消息输出到调试窗口还是控制台
控制台查看和node-red安装有关,我的node-red是用pm2运行的,所以直接pm2 logs就可以查看node-red的日志

- 使用 node.warn() 和 node.error() 方法
好处是会看到黄色和红色标记,以及node的名称和时间戳

Git 是目前业界最流行的版本控制系统(Version Control System),而 GitHub 是开源代码托管平台的翘楚。越来越多的从业者、从业团队以及开源贡献者首选二者用于管理项目代码。本文首先从概念的角度介绍版本控制系统、Git 和 GitHub,并着重通过一些实验来演示 Git 的基础特性,使您能够对 Git 和 GitHub 有更清晰的认识。
Git 和 GitHub 区别和联系
一些初次接触 Git 和 GitHub 的从业者常常将 Git 和 GitHub 二者混淆而谈。二者虽然联系甚紧,但从本质上是两个不同的概念。
Git 是一个开源的分布式版本控制系统。而 GitHub 本质上是一个代码托管平台,它提供的是基于 Git 的代码托管服务。对于一个团队来说,即使不使用 GitHub,他们也可以通过自己搭建和管理 Git 服务器来进行代码库的管理,甚至还有一些其它的代码托管商可供选择,如 GitLab,BitBucket 等。值得一提的是 Git 作为一个开源项目,其代码本身就被托管在 GitHub 上,如果您感兴趣,可以上去一观其真容。Git 项目地址:https://github.com/git
版本控制系统简介
在现代软件项目中,版本控制系统是项目配置管理不可或缺的一部分,甚至是其核心工具。版本控制最主要的任务是追踪文件的变更,无论是应用系统源代码、项目配置文件,还是项目过程的开发文档,甚至是网站界面图片、Logo,都可以且应该被版本控制系统所管理起来,以方便我们在项目的生命各周期能够追踪、查看到软件系统的变更和演进。版本控制系统另一个重要的作用是方便开发者进行协同开发,使得项目中各开发者能够在本地完成开发而最终通过版本控制系统将各开发者的工作合并在一起进行管理。
集中式版本控制系统
早期的版本控制系统大多是集中式(Centralized)版本控制系统。所谓集中式,即是此类系统都有一个单一的集中管理的服务器。在该服务器上保存着项目所有文件以及文件的历史版本,而各开发者可以通过连接到该服务器读取并下载到文件的最新版本,也可以检索文件的历史版本。开发者常常可以只需要下载他们所需要的文件。通过连接集中式服务器来获取文件和文件更新是集中式版本控制系统的标准做法。业界主流的集中式版本控制系统包括 CVS、SVN、Perforce 等。
集中式版本控制很大程度上解决了版本控制和协同开发的问题,但是它也有重大的缺点。如果中央服务器出现宕机,那么开发者将无法提交代码,也无法进行协同工作,更无法查看文件历史。如果服务器出现更严重的磁盘损坏,又没有进行恰当的备份,那么很大可能将丢失掉项目文件以及项目的变更历史。而各协同开发者在自己本地因为也只有当前版本的文件,或者只有部分文件,很难根据各开发者的本地库对项目的历史记录进行恢复。
分布式版本控制系统
相比较集中式的版本控制,目前业界最流行的版本控制系统是分布式(Distributed)版本控制系统,其最大的特点是各开发者本地所复制的不仅仅是当前最新版本的文件,而是把代码仓库完整地从服务器上克隆了下来。各开发者本地拥有代码仓库所有的文件以及文件历史和变更信息。这样即使服务器出现宕机,也不影响开发者本地开发,开发者也可以随时查看文件的各历史版本。甚至服务器出现故障导致数据丢失时,项目组也很容易根据开发者的本地代码库恢复出所有文件和文件的历史变更记录。
Git 是业界目前最为流行的分布式版本控制系统,除此之外还有 Mercurial、BitKeeper 等。Git 其实就是 Linus Torvalds 根据 BitKeeper 的设计理念而重新设计并主导开发而成的。在随后的章节中会以 Git 为例进一步介绍分布式版本控制系统的机制。如果您感兴趣可以去查阅一下 Linus Torvalds、BitKeeper 和 Git 之间的趣事。
理解 Git 的分布式版本控制
早期我在接触 Git 时,常常为其所谓的分布式感到困惑。大部分人心目中的分布式的概念可能更多来自于分布式计算。分布式计算使得程序可以通过某种机制分布地运行在多台计算机上从而最大化地利用多台计算机的计算能力、存储能力。分布式计算是将计算任务分割成多个可以独立运行的子任务,然后将子任务分布在多台计算机独立并行运行,最后通过某种合并机制将所有计算机的计算结果最终合并起来。因此单独来看这多台计算机中其中某一台,它并没有拥有程序的所有数据和所需资源。从表面看这似乎和分布式版本控制系统中的分布式概念截然相反。毕竟分布式版本控制系统"号称"克隆一次代码库本地就拥有了一个完整的代码库副本,这听起来有些骇人听闻。
其实我们可以尝试从以下两个方面来理解:
- 其一,在分布式版本控制系统中,克隆了代码库的各本地开发者拥有了服务器分发过来(Distributed)的完整的代码库副本,使得开发者们可以独立于主服务器之外进行开发任务,这和分布式计算概念中,各计算机独立进行计算任务的理念不谋而合。同时也符合分布式存储的理念:一个文件多份副本。
- 其二,各开发者在完成开发任务后又需要将自己本地修改后的代码库合并(Merge)到主服务器上。这也与分布式计算概念中最终需要将各计算机的计算结果合并起来的概念是相符的。
因此这也就不难理解分布式版本控制中的分布式概念了。
下面通过 Git 的一个实验来尝试理解什么是克隆了完整的代码库副本。
首先我在 GitHub 上建立了一个用于实验的公开代码库。代码库中目前只包含有少量的源文件和提交记录,如清单 1 所示。实验仓库地址:https://github.com/caozhi/repo-for-developerworks
清单 1. 查看本地代码库中所拥有的文件
caozhi @ repo-for-developerworks$ ls -al
total 24
drwxr-xr-x 7 caozhi staff 224 8 4 23:43 .
drwxr-xr-x 3 caozhi staff 96 8 4 23:43 ..
drwxr-xr-x 13 caozhi staff 416 8 4 23:43 .git
-rw-r--r-- 1 caozhi staff 278 8 4 23:43 .gitignore
-rw-r--r-- 1 caozhi staff 39 8 4 23:43 README.md
-rw-r--r-- 1 caozhi staff 56 8 4 23:43 helloworld.sh
drwxr-xr-x 3 caozhi staff 96 8 4 23:43 src注意代码库中.git目录中包含了代码库所有的存储对象和记录。如果想要备份或复制一个代码库,则只需要将这个目录拷贝下来即可。
因此该代码库中只有.gitignore、README.md、helloworld.sh以及src目录是代码库所管理的源文件。我们将除.git目录之外的所有文件全部删除,如清单 2 所示:
清单 2. 删除除.git目录之外的全部源文件
caozhi@ repo-for-developerworks$ rm -rf .gitignore README.md helloworld.sh src
接下来我们断掉电脑的网络连接使得本地代码库无法与服务器进行交互,以验证是否所有的文件可以只从本地就进行恢复。断网之后执行git pull尝试与服务器进行同步,命令结果提示:Network is down,如清单 3 所示:
清单 3. 断网之后尝试git pull同步代码
caozhi@ repo-for-developerworks$ git pull
ssh: connect to host github.com port 22: Network is down
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.不用担心代码库被破坏,如前所述,.git目录中包含有代码库所有的文件对象和记录,因此我们可以很容易的通过命令将其进行恢复。
首先,虽然文件被删除且网络无法连接,我们依然可以查询到历史提交记录,如图 1 所示:
图 1. 查看提交历史

然后我们可以通过git reset --hard commit_id命令恢复当前代码库到目标 commit 的状态,如清单 4 所示:
清单 4. 执行git reset --hard命令
caozhi@ repo-for-developerworks$ git reset --hard d774ecf5575bd5434e0cfadfcda0aef0ab147c92
HEAD is now at d774ecf changes
caozhi@ repo-for-developerworks$ ll -a
total 24
drwxr-xr-x 7 caozhi staff 224 8 5 10:48 .
drwxr-xr-x 3 caozhi staff 96 8 4 23:43 ..
drwxr-xr-x 15 caozhi staff 480 8 5 10:48 .git
-rw-r--r-- 1 caozhi staff 278 8 5 10:48 .gitignore
-rw-r--r-- 1 caozhi staff 39 8 5 10:48 README.md
-rw-r--r-- 1 caozhi staff 56 8 5 10:48 helloworld.sh
drwxr-xr-x 3 caozhi staff 96 8 5 10:48 src从运行结果我们可以看出,代码库中被删除的文件已经被恢复回来,而且是在无任何网络连接、没有和服务器进行交互的情况下进行的恢复!
通过这个实验相信您对 Git 克隆了完整的代码库副本有更加直观的理解。如有兴趣,您也可尝试通过git reset命令将代码库恢复到任意目标 commit 的状态。本文就不再赘述。
Git 基础特性
本章将会介绍 Git 作为版本控制系统的几大基础特性并会借助一些实验来帮助理解这些特性。注意:本章节介绍的基础特性其内容总结自 ProGit 这本书,如有兴趣您也可自行查阅原文。
克隆一次即获得代码库的完整副本
这个特性是所有分布式版本控制系统的特性之一。Git 也不例外。本文在上一个章节中已经对该特性进行了详细的描述和分析,在此就不再赘述。
直接记录快照而非差异比较
版本控制系统中采取何种策略来管理文件的历史版本是系统的核心技术之一。目前很多传统的版本控制系统如 SVN、Perforce 等采用基于增量的方式来记录每次变更。每次变更产生即生成一个差异对象,最终最新版本的文件可以由最初的基础文件和这个文件所累积的差异来组成。如图 2 所示(截取自 ProGit 一书):
图 2. 增量方式

而 Git 采用的是类似于快照流(Streams of Snapshot)的方式来存储数据。Git 在一个文件发生修改时会生成一个新的完整的文件对象,当然旧的文件对象也会保留下来作为历史版本。对于未发生更改的文件,Git 在新版本的代码库中只是保留了一个链接指向之前存储的文件。例如图 3 (截取自 ProGit 一书)所示版本 2 中,对 A 文件和 C 文件都进行了修改,Git 生成了两个新的完整的文件对象 A1 和 C1,而 B 文件未发生更改,那么版本 2 中就只记录了一个指向 B 文件的链接。基于文件对象 A1 和 C1 以及连接 B,Git 就生成了一个版本 2 的快照。
图 3. 快照方式

代码库的存储和复制并非版本控制系统的瓶颈所在,分析文件的差异、查看代码库的各历史版本常常是真正的瓶颈所在。基于这种快照流的设计,Git 可以快速地获取到某一时刻的代码库所有文件,同时也可以快速地进行文件各个历史版本的差异比对,甚至是各历史版本或者各分支的代码库整体差异比对。想像一下如果是传统的增量存储方式,一个代码库经过长期的开发,假设代码库已经有 10 万个文件,每个文件平均经历了 100 次修改,那么要检索最新的代码库和原始的代码库的差异,就需要检索出 1000 万个增量才能最终成功比对,这需要难以想象的时间成本。而 Git 就不存在这个问题,Git 只需要检索出最新的代码库快照和原始代码库快照直接进行比对即可,再依托于 Git 的 diff 算法(Myers 算法),Git 可以高效快速地检索出二者的差异来。
近乎所有操作都是本地执行
Git 另一个十分高效的原因是它几乎所有的操作都是在本地执行,除了几个极少的需要跟服务器同步代码的操作(push、pull、fetch)。这种本地执行的能力正是来自于克隆一次即获得代码库的完整副本这一特性。在本文前面的章节中对 Git 的本地操作也进行了实验,所以在此亦不进行赘述。
诚然,类似 SVN 和 Perforce 一类的集中式分布系统,当没有网络连接时我们依然可以对本地代码进行修改,但却无法提交代码,更不用说查询提交历史,比对版本差异。在日常的开发工作中,修改代码只是工作的一部分,还有很大部分工作需要不断与代码库各历史版本进行交互。在集中式分布系统中,当发生网络异常时,这类工作就几乎无法进行从而很可能导致开发中断。即使是网络正常的情况下,集中式分布系统的工作效率也远低于 Git 的本地化执行。
使用 SHA-1 哈希值保证完整性
Git 中所有数据对象(详见下文)在存储前都会计算 SHA-1 校验和,生成一个 40 位的十六进制的哈希值字符串。基于此校验和,就不可能在 Git 不知情的情况下更改任何文件内容。Git 中很多地方会使用到这种哈希值,如前面实验中我们实际上就用到了 commit 的哈希值 id 来还原代码库。
接下来我们用另一系列小实验来演示并验证 Git 的部分基础特性:
- 记录的快照和各历史的完整内容,而非记录差异比较
- 哈希值在 Git 中的重要作用
本节仍然以 repo-for-developerworks 为例子。
前文提到,代码库中.git 目录存储了代码库的所有文件和信息。我们可以查看.git目录结构,如清单 5 所示:
清单 5. 查看 Git 目录结构
[email protected]$ tree -L 1
.
├── FETCH_HEAD
├── HEAD
├── ORIG_HEAD
├── branches
├── config
├── description
├── hooks
├── index
├── info
├── logs
├── objects
├── packed-refs
└── refs在本系列的随后文章中会对该目录每个子项进行深入介绍,您现在只需关注objects目录。objects目录存储了本地仓库的所有数据对象,Git 存储的数据对象一共有以下四种:
- Tree:类似 Unix 文件系统的文件组织方式,Tree 对象中记录了多个 Blob 对象或者其它子 Tree 对象哈希值、文件名目录名等元数据。通过 Tree 对象可以还原出代码库的目录结构。
- Commit:记录一个 commit 的所有信息。
- Blob:记录了代码库源文件的内容,不记录源文件的如文件名一类的元数据。
- Tag:为某一个时刻的代码库打一个 Tag,方便检索特定的版本。Tag 在 Git 中也是以一种数据对象的方式进行存储。
objects目录下存放了多个以 2 位字符命名的目录,在这些目录下又存放了 38 位字符命名的文件,2 位的前缀和 38 位的文件名就组成了 Git 中的一个数据对象的哈希值,如清单 6 所示:
清单 6. 查看objects目录结构
caozhi@ objects $ tree -L 2
.
├── 06
│ └── dad60f87d28d220216f5891dddfdfe4af5f1a0
├── 07
│ └── 5c1307a44bae63a2d37c4819502c6ffdb6141b
├── 16
│ └── d0e292c43ca35d4ab36da6b3e1913288477076
├── 22
│ └── 783d07955986cab0d2195eb131d8e0047acb59
├── 40
│ └── 6714df7708534f67d9373821de5948ab3f5d9a
├── 6d
│ └── 1f98e1a9bede453ab16d6ba90428a994ebf147
├── ae
│ └── e311888e5572cc3d7d8b00e8f400216d26d320
├── b3
│ └── adac68e8b6a22f88003c226fc4746a5269a496
├── b8
│ └── 74d57c1df33902acb74f85d05bb5dcbb44c30a
├── d4
│ └── eec9c19502086dd0f42f8bb7f26feb77377d5c
├── d6
│ └── 96feb980566a3c03fd0f22c4b806e34a312de6
├── info ## can be ignored right now
└── pack ## can be ignored right now
├── pack-eff5463c4b0c56c3ea5e5c381941541d76d8e143.idx
└── pack-eff5463c4b0c56c3ea5e5c381941541d76d8e143.pack
8 directories, 8 files清单 7 的脚本核心使用了git cat-file -t命令来查看对象文件的类型。由此可以看出,在 Git 内部使用哈希值作为文件名来存储所有的数据对象。
清单 7. 执行脚本列出对象文件及其对应的类型
caozhi@ objects$ find . -type f | grep -v pack | \
while read line; \
do \
var=${line//"."/""}; \
var=${var////""}; \
echo $line `git cat-file -t $var`; \
done
./b3/adac68e8b6a22f88003c226fc4746a5269a496 tree
./d6/96feb980566a3c03fd0f22c4b806e34a312de6 tree
./ae/e311888e5572cc3d7d8b00e8f400216d26d320 tree
./16/d0e292c43ca35d4ab36da6b3e1913288477076 commit
./07/5c1307a44bae63a2d37c4819502c6ffdb6141b commit
./6d/1f98e1a9bede453ab16d6ba90428a994ebf147 blob
./06/dad60f87d28d220216f5891dddfdfe4af5f1a0 blob
./d4/eec9c19502086dd0f42f8bb7f26feb77377d5c blob
./b8/74d57c1df33902acb74f85d05bb5dcbb44c30a commit
./40/6714df7708534f67d9373821de5948ab3f5d9a tree
./22/783d07955986cab0d2195eb131d8e0047acb59 tag另外可以看到16d0e292…这个对象表示其是一个 commit。结合提交历史记录可以看到,这个哈希值确实对应于一个 commit id,如清单 8 所示:
清单 8. 查看提交历史
caozhi@ repo-for-developerworks/.git/objects$ git log
commit d774ecf5575bd5434e0cfadfcda0aef0ab147c92
(HEAD -> master, origin/master, origin/HEAD)
Author: caozhi <[email protected]>
Date: Sat Aug 4 23:22:17 2018 +0800
changes
… ## Ignored some useless history
commit 16d0e292c43ca35d4ab36da6b3e1913288477076
Author: Zhi Cao <[email protected]>
Date: Fri Aug 3 22:15:02 2018 +0800
Create a shell script
… ## Ignored some useless history在清单 9 中可以看到6d1f98e1…这个对象是一个 blob 对象:
清单 9. 查看 blob 对象的类型和内容
caozhi@ objects$ git cat-file -t 6d1f98e1a9bede453ab16d6ba90428a994ebf147
blob
caozhi@ objects$ git cat-file -p 6d1f98e1a9bede453ab16d6ba90428a994ebf147
#!/bin/bash
echo hello world!
caozhi@ objects$ git cat-file -t d4eec9c19502086dd0f42f8bb7f26feb77377d5c
blob
caozhi@ objects$ git cat-file -p d4eec9c19502086dd0f42f8bb7f26feb77377d5c
#!/bin/bash
echo hello world!
echo hello world again!查看该文件内容,可以看到6d1f98e1…其实是helloworld.sh这个源代码的内容,但对象6d1f98e1…是helloworld.sh的上一个版本,而在随后查看的d4eec9c1…才是其最新版本。从这里也能看到 Git 在存储文件不同版本时,确实是存储了各历史版本全量的文件而非其增量。
注意:实际操作中也可以使用哈希值的前八位缩写,如:git cat-file -t 6d1f98e1。如有兴趣,您可以尝试一下。
至此,我们看到 SHA1 哈希值在 Git 底层的巨大作用,所有对象都以哈希值来命名并存储,所有对象也可以通过哈希值来进行检索。同时我们也从 Git 底层再次验证了 Git 在本地存储了文件的所有全量历史版本。
Git 一般只添加数据
这个特性指的是正常情况下我们执行的 Git 操作,几乎只往 Git 里增加数据。因此很难让 Git 执行任何不可逆的操作,或者让它以任何方式清除数据。同其它版本控制系统一样,没有提交的更新有可能出现丢失的情况,但是一旦我们将更改提交到 Git 中之后,就很难再丢失数据。
这个特性使得我们可以放心且愉悦地使用 Git,我们可以尽情地做任何尝试。即使误操作出现数据丢失,我们也可以通过各种手段将其进行快速恢复。
在 ProGit 一书中还提到了 Git 的另一个特性"三种状态",该特性是指 Git 中的文件一般有三种状态:已提交(committed)、已修改(modified)和已暂存(staged)。在随后的系列文章中将会结合 Git 的日常使用来着重介绍以帮助您理解这三种状态,还会对 Git 目录以及 Git 的对象存储模型进行详细地分析和讲解。
GitHub 简介
GitHub 是全球最大的开源代码托管平台,在开源界有着不可撼动的定位,也深受开源爱好者的喜爱。GitHub 平台本身十分直观易用,其使用方法在此就不进行详述。本章简单列举一下我认为的 GitHub 一些很有意思或者很有用的功能:
- 如果只使用免费版,那么无法创建私人仓库(Repository),只能创建开放仓库;开放仓库可被任何人克隆或 Fork。
- 可以作为独立开发者建立自己的代码仓库,团队协作的话也可以通过建立组织(Organization)来管理组织下的仓库、团队、成员、权限等。如图 4 所示:
图 4. 添加仓库或组织

- 如果是开源项目,可以很容易 Fork 其它开源项目的代码库到自己的账号下;也可以向别人发起 Pull Request 请求,请求作者将 Fork 下来之后的代码修改合并到原代码库中。如图 5 和图 6 所示,我们可以将 Linux 的源码库 Fork 到自己的账户或组织下。
图 5. Fork Linux 代码库

图 6. 选择 Fork 的目标

- Pull Request 提供了强大的代码评审、代码合并的机制。通过创建 Pull Request 向开源项目的作者或者管理者发起合并自己代码的请求,我们可以轻松地向开源项目贡献代码。代码评审和 Pull Request 将在随后的系列文章中详细介绍。
- 使用 Gist 可以管理一些自己常用的代码片段、常用的命令,也可以分享给其他开发者。
- GitHub 上也可以管理钩子(Hook),可用于自动构建过程,例如引入 Jenkins 的 WebHook,使得 Jenkins 可以在每次发现代码提交后立即触发一次项目构建。
- GitHub 也提供了很多可选的集成服务(Integration & Service)使用,例如集成 ZenHub 插件,可以进行敏捷式项目管理。
本章简单罗列了部分 GitHub 的特点,在随后的系列文章中,我将会对 GitHub 不同的主题进行详细的介绍,例如权限控制、Pull Request 等。
结束语
Git 和 GitHub 都是现在业界最流行的代码管理工具。Git 提供了强大的版本控制功能,而 GitHub 作为最大的开源代码代码托管平台,提供了强大的托管能力、协同合作能力。GitHub 的蓬勃发展与开源项目的蓬勃发展息息相关,GitHub 拥抱开源的开放态度使其成为了开发者心目中最为喜爱的代码托管平台。希望您在读完本文之后对 Git 和 GitHub 能有清晰的理解,同时在今后的工作中享受到 Git 和 GitHub 带来的乐趣。
]]>在本系列的第一篇文章中着重介绍了 Git 的基础特性。本文作为本系列的第二篇文章将介绍 Git 和 GitHub 的基础配置,包括 Git 安装、使用 Git 克隆 GitHub 上的代码库、使用 Git 克隆远端代码仓库、Git 的基本配置和设置忽略提交规则。您在阅读完本文将有能力完成本地 Git 环境的基础配置,为接下来的 Git 日常使用做基础。
GitHub 是一个代码托管平台,如果开发者想要在本地进行开发工作,那么就需要使用到 Git 的客户端工具来连接到 GitHub,再克隆代码到本地。如果您是重度的 GUI 使用者,那么有很多 GUI 客户端可以选择,在 Git 的官网就专门有个页面列出了业内的GUI 客户端。
但遗憾的是往往 GUI 客户端只能提供 Git 部分的功能,如果想要享受到 Git 自底向上强大的功能,使用命令行的方式来操作 Git 是不二之选。建议无论您是否擅长使用命令行工作,都可以尝试使用命令行方式来操作 Git。本文将只介绍如何从命令行来连接到 GitHub。
安装 Git
使用命令行方式操作 Git 工具,需要本地安装 Git。注意,这里没有使用 "Git 客户端" 一词,因为 Git 作为一个开源版本控制系统,本身既可以作为客户端工具,也可以用于建立服务器端代码库,所以本质上 Git 作为工具来讲没有客户端和服务器端之分。
本地安装 Git 十分简单。
对于 Windows 用户,可以下载Git For Windows工具。下载安装成功之后,我们可以得到一个 Git Bash 工具,它是一个类 Linux Bash 工具。在该工具中我们可以直接执行 Git 相关命令。如图 1 所示:
图 1. Git Bash

对于 Mac 和 Linux 用户,只需通过对应的包管理工具安装即可,如清单 1 所示: 清单 1. Mac 和 Linux 下安装 Git
$ brew install git # For Mac
$ apt-get install git # For Ubuntu
# yum install git # For RedHat EL, CentOS使用 Git 克隆 GitHub 代码库
安装 Git 成功之后,我们就可以使用 Git 克隆 GitHub 上的代码库,本节仍然以我的代码库repo-for-developerworks为例。
GitHub 提供了两种克隆方式:HTTPS 和 SSH。我们可以点击仓库页面上的Clone or download按钮来查看用于克隆的链接,同时可以点击浮动框右上角的Use SSH/Use HTTPS换我们想要克隆的 link,如图 2 和 图 3 所示。注意,这里只是切换查看不同的链接,而不是设置代码库不同的链接方式。
图 2. 查看 HTTPS 克隆链接

图 3. 查看 SSH 克隆链接

由此我们可以获得两个 URL:
- HTTPS 链接:
https://github.com/caozhi/repo-for-developerworks.git - SSH 链接:
[email protected]:caozhi/repo-for-developerworks.git
使用 HTTPS 进行克隆
由于代码库是开放的,因此使用 HTTPS 方式克隆时,无需 GitHub 用户名密码,如清单 2 所示:
清单 2. 使用 HTTPS 进行克隆
caozhi@ clone$ git clone https://github.com/caozhi/repo-for-developerworks.git
Cloning into 'repo-for-developerworks'...
remote: Counting objects: 14, done.
remote: Compressing objects: 100% (9/9), done.
remote: Total 14 (delta 3), reused 5 (delta 1), pack-reused 0
Unpacking objects: 100% (14/14), done.顺便提一下,进行 pull 和 fetch 操作时也无需用户名密码认证。因为 GitHub 的机制允许随意免费下载任何公开的代码库,如若要 push 代码需经过认证或者经过作者同意才可。当要进行 push 时,会出现提示要求输入用户名密码,如清单 3 所示: 清单 3. HTTPS 方式下 push 代码
caozhi@ repo-for-developerworks$ echo change >> README.md ## make some modification
caozhi@ repo-for-developerworks$ git add .
caozhi@ repo-for-developerworks$ git commit -m "changes"
[master d774ecf] changes
1 file changed, 1 insertion(+)
caozhi@ repo-for-developerworks$ git push
Username for 'https://github.com': [email protected] ## Enter GitHub account name
Password for 'https://[email protected]@github.com': ## Enter Password
Counting objects: 6, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (4/4), done.
Writing objects: 100% (6/6), 528 bytes | 528.00 KiB/s, done.
Total 6 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), completed with 1 local object.
To https://github.com/caozhi/repo-for-developerworks.git
075c130..d774ecf master -> master使用 SSH 进行克隆 使用 SSH 方式进行克隆,需要一步额外的配置 SSH-KEY 的操作。首先需要本地生成一个 SSH Key。我们可以借助 ssh-keygen 工具生成一对 RSA 的秘钥:私钥 id_rsa 和公钥 id_rsa.pub。生成的秘钥文件会默认放在 home 目录下的 .ssh 目录下,如图 4 所示:
图 4. 使用 ssh-keygen 生成 RSA 秘钥

先将id_rsa.pub公钥文件的内容复制到剪贴板,如图 5 所示,使用cat id_rsa.pub命令可以查看公钥内容,随后将该公钥导入到 GitHub 里的账户之下。
图 5. 查看 id_rsa.pub 公钥文件

在 GitHub 页面右上角的头像里点击展开一个下拉菜单,点击Settings可以打开个设置页面,如图 6 所示:
图 6. 打开 GitHub 设置

打开SSH and GPG keys的配置页面,点击右上角的New SSH key按钮,如图 7 所示:
图 7. 打开 SSH and GPG keys 的配置页面

在打开的页面中先设置一个您想导入的公钥的名称,再将前面复制的公钥内容粘贴到大文本框中,点击Add SSH key即可,如图 8 所示:
图 8. 输入 Key 的名称及其内容

页面自动跳转回SSH and GPG keys设置页面,您可以看到在我的账号下成功新增了一个 SSH Key,如图 9 所示:
图 9. 查看已经添加的 Key

此时我们可以使用 SSH 的方式进行代码克隆,还可以使用ssh -T命令检测是否配置成功, 如清单 4 和 5 所示:
清单 4. 使用 SSH 方式克隆
caozhi@ $ git clone [email protected]:caozhi/repo-for-developerworks.git
Cloning into 'repo-for-developerworks'...
remote: Counting objects: 20, done.
remote: Compressing objects: 100% (12/12), done.
remote: Total 20 (delta 5), reused 10 (delta 2), pack-reused 0
Receiving objects: 100% (20/20), done.
Resolving deltas: 100% (5/5), done.清单 5. 检测 SSH 是否配置成功
caozhi@bogon:~$ ssh -T [email protected]
Hi caozhi! You've successfully authenticated, but GitHub does not provide shell access.使用 SSH 的方式进行克隆,将使得我们本地与 GitHub 之间建立了信任连接,也就意味着之后所有需要进行用户认证的地方都不再需要显式地用户名密码认证。例如git push会直接通过 SSH 进行认证。经验表明,使用 SSH 的另一个好处是在网络环境较差的情况下,其稳定性要高于 HTTPS 连接。
至此,我们成功地使用 Git 命令行方式克隆了代码库,之后就可以进行正常的日常开发。
使用 Git 克隆远程仓库
当一个开发者刚进入某一项目,一般来说他所要做的第一件事是克隆远程仓库到本地,以进行本地开发工作。远程仓库可以是来自于 GitHub 或者 GitLab 等代码托管服务,也可以是项目组自己所搭设的 Git 服务器。无论是哪种远程仓库,都可以使用git clone命令git clone <repository> [local_path]将其从远端克隆到本地。命令中间的<repository>根据远端仓库提供的连接方式不同,其形式可能不同,例如:
- GitHub 的 HTTPS 连接:
https://github.com/caozhi/repo-for-developerworks.git - GitHub 的 SSH 连接:
[email protected]:caozhi/repo-for-developerworks.git - 自建仓库的 SSH 连接:
[email protected]:/usr/local/repo-for-developerworks.git
其中前两种 GitHub 的连接方式,其仓库的连接字符串可以在 GitHub 的对应仓库页面中找到,如前图 2和图 3所示。
第三种自建仓库的 URL 一般需要提供远端服务器上的账号、host 和路径。以上面例子中的连接字符串[email protected]:/usr/local/repo-for-developerworks.git为例:
git_user是服务器上对代码库目录有访问权限的账号。192.168.0.1是远端服务器的 IP,也可以是主机名或者 URL。/usr/local/repo-for-developerworks.git是服务器上代码库的根目录。
git clone命令中的local_path指定了本地想要存放代码库的地址。该参数是可选参数,如果不指定该参数就会在本地新建一个以远程仓库名为命名的目录,然后以该目录为代码库根目录。图 10 展示了在空目录clone_demo中执行不带local_path参数的 clone 命令:
图 10. local_path 为空

从截图可以看到,git clone命令在clone_demo目录中创建了一个repo-for-developerworks的代码库目录。
图 11 展示了在目录clone_demo中执行带local_path参数的 clone 命令:
图 11. local_path 参数为指定路径

从截图可以看到,git clone命令在clone_demo目录中新建了一个我们指定的local_dev-repo目录,并将其作为本地代码库的根目录。
图 12 展示了在空目录clone_demo2中执行local_path为当前目录的 clone 命令:
图 12. local_path 参数为当前目录

我们知道一般操作系统将一个英文句点表示当前目录,因此从截图可以看出,当local_path指定为当前目录时,git clone命令会直接将当前目录作为本地代码库的根目录。
当然 Git 还提供其它的连接方式如 File、FTP。感兴趣的读者可以自己使用 Git 搭一个 Git 服务器尝试使用 File 和 FTP 方式进行连接。
默认情况下,git clone会将远端代码库全部克隆到本地。Git 还支持只克隆特定分支到本地。我们可以使用git clone -b**branchname**--single-branch git@URL local_path命令, 如图 13 所示:
图 13. 克隆特定分支

Git 的基本配置
在克隆了代码库之后,我们一般仍需要对 Git 做一些基本的配置才能使用 Git 进行日常工作。Git 配置的作用域主要有三种:System、Global 和 Local,分别对应的配置文件地址为:
- System:
/etc/gitconfig。系统级别有效。 - Global:home 目录下的
~/.gitconfig文件。用户级别有效。 - Local:代码库目录的
.git/config文件。代码库级别有效。
另外我们也可以使用git config --system -l,git config --global -l,git config --local -l命令分别列出三个作用域下的配置。跟 Linux 操作系统的环境变量配置类似,Git 在执行命令中会首先查看 local 配置,如果没有找到所需配置会再查看 global 配置,最后再查看 system 配置。
在使用git config命令进行配置的时候,也可以使用git config --system,git config --global,git config --local三种不同的选项来修改不同作用域的配置。
下面介绍一些重要或有用的 Git 配置。
配置 user 信息
配置 user 信息在 Git 中是十分重要的一个步骤, username 和 email 不能为空,它们将会被记录在每一条该 user 的 commit 信息中,如图 14 所示:
图 14. 查看 commit 的 user 信息

我们可以配置user.name和user.email的值来配置 user 信息,如清单 6 所示:
清单 6. 配置 user.name 和 user.email
git config --global user.name "caozhi"
git config --global user.email "[email protected]"也可以将上述命令中的 --global改成 --local来修改只对代码库作用域有效的配置。
配置命令的别名 Git 提供了很多有用的命令,我们可以将一些比较常用的命令设置上别名,提高工作效率。例如我们可以将 git log --abbrev-commit 设置一个别名 lg,使得查看 log 时只需要显示 commit id 的短名称,如: git config --global alias.lg "log --abbrev-commit"
设置成功后就可以使用 git lg 来查看 commit 日志,如图 15 所示:
图 15. 短名称的日志

当然还可以设置一些其它的别名,如清单 7 所示:
清单 7. 配置 st 和 cm 别名
git config --global alias.st "status"
git config --global alias.cm "commit"别名可以根据自己的喜好和习惯去设置。将常用的命令设为短别名将大大提高工作效率。
查看配置
配置成功后可以使用git config --global -l命令查看配置,如图 16 所示:
图 16. 查看配置

使用 Config 文件进行配置
除了使用命令之外,也可以直接编辑 config 文件进行相关配置,如图 17 所示:
图 17. ~/.gitconfig 文件里的配置

设置 Git 忽略提交规则
在进行完代码库克隆和简单的配置之后,接下来我们可以根据项目需要配置一些文件忽略规则。跟大多数的代码库管理工具一样,Git 也可以对不需要被代码库所管理的文件或文件类型进行配置,使得提交代码时,这些文件不会被提交到代码库中。Git 是通过忽略清单.gitignore文件进行配置的。
通常我们会考虑将如下类型的文件添加到忽略清单中:
- 编译过程的中间文件,例如
*.class文件、*.o文件、*.obj文件等。 - 外部依赖的包或者工程编译的包,例如 jar 包、lib 包、dll 包或 war 包等。在有的项目实践中,可能会将这类依赖包也放到代码库中进行管理,通常这不是一个很好的策略,因为这样会显著地增加代码库的大小,降低开发者的工作效率。比较合理的方式是通过构建工具的依赖管理功能来管理这些依赖包,例如 Maven、Gradle 等。
- 编译过程中,通过某种机制自动生成的代码。某些项目中,可能会使用脚本或者
xsd schema文件来生成代码;这类代码只需要将用于自动生成的脚本或者 schema 文件管理起来即可。 - 项目的配置文件。同一项目组的不同开发者可能有不同的项目配置,或者配置中包含敏感信息,例如账号密码等,这类配置文件也应该放到 ignore 清单里。
- 某些 IDE 的工程配置文件,例如 Eclipse 的
setting和project文件、Idea 的.idea目录等。 - 一些自动生成的系统文件,例如 Windows 的
Thumbs.db或者 MacOS 的.DS_Store文件等。 - 项目或者 IDE 的日志文件。
.gitignore文件每行表示一个匹配模式(#开头的行或者空行除外,#用于注释)。它使用 glob 模式来进行匹配,glob 模式是一种简化的正则表达式,常用于来进行路径的模式匹配。我们可以在代码库的根目录或者任意子目录添加.gitignore文件,特定目录下的.gitignore文件使得忽略规则只在该目录及其子目录下有效。表 1 列出了常用的一些匹配模式的写法:
表 1. 常用匹配模式
| 模式 | 含义 | 示例 |
|---|---|---|
| 完整路径 | 忽略完整路径所定义的文件 | dev/dev.conf |
| /path | 以 / 开头,只匹配当前目录下路径为 path 的文件 | `/a.java |
| /a.cpp` | ||
| path | 不以 / 开头,匹配当前目录及其子目录下所有文件 | `*.o |
| web.xml` | ||
| path/ | 以 / 结尾,用以只匹配目录;path 目录及其子目录和文件会被忽略;如果 path 是个文件,则不会被忽略 | .settings/ |
| 带 * 号的模式 | 置于文件中,用于匹配所有满足规则的文件 | `*.zip |
| *.jar` | ||
| 带 ** 的模式 | 置于路径中,用于匹配满足 ** 前后的所有路径 | `Dev/**/dev.conf |
| **/*.jar` | ||
| !path | 在 ignore 文件中如果前面已经定义了某个模式,但是又有一些特殊文件我们不想被忽略,我们可以用 ! 来匹配 | *.jar ##忽略所有 jar 包 !server.jar ##希望server.jar仍被跟踪 |
注意:
- 当某个文件已经被提交到代码库中被 Git 所管理起来之后,将该文件再添加进
.gitignore文件是无效的,对该文件进行修改时,执行git status操作之后仍然会提示该文件已被修改。针对已经提交代码库的文件我们又想忽略其修改的场景,将会在本系列第四篇文章中介绍。 - 每个目录下都可以放单独的
.gitignore文件以控制子目录的忽略规则。 - 即使已经在忽略列表里,当我们确实想要提交一些符合忽略规则的文件时,仍可以使用
git -f add加具体的文件路径的方式将这些文件提交到库中。如图 18 所示:
图 18. 强制添加被忽略的文件

- GitHub 有一个十分详细的针对数十种项目及语言的
.gitignore文件列表模板,可以在https://github.com/github/gitignore找到它。
结束语
为使用 Git 和 GitHub 进行日常开发做准备,本文详细通过一些列演示向读者讲解了如何采用 SSH 和 HTTPS 两种方式从 GitHub 克隆代码库,如何进行本地 Git 开发环境的基础配置,如何配置.gitignore文件等。相信您在阅读完本文之后将有能力自己初始化一套本地的 Git 环境。
参考资源
- 访问我的 GitHub 主页,可以获取文章中所涉及的代码库repo-for-developerworks。
- 查看 Git 官网Git-SCM,可获得 Git 相关的资源。
- 可从Git-For-Windows官网上下载 Git Windows 版的安装包。
- 参考ProGit(中文版)、ProGit(英文版)一书,可以了解 Git 操作使用详细的讲解。
- 访问GitHub Online Help可检索关于 GitHub 的相关帮助。
- 访问GitHub gitignore查看 GitHub 提供的
.gitignore文件示例。
从本篇文章开始,我将结合实验和实际的场景详细讲解如何在日常工作中使用 Git 和 GitHub。
Git 有六大特性,第一篇中介绍了前五个特性,本文将介绍 Git 的最后一个特性:三种状态和三个工作区,然后介绍 Git 的核心功能:Git 分支,最后介绍 Git 的一些日常操作,例如如何进行一次完整的代码提交以及其它常用操作 log、status 等。
Git 的三种状态和三个工作区域
一个文件在 Git 中被管理时有三种状态以及对应所处的三种工作区域,理解这一特性将有助于我们更好的理解 Git 的常用命令的原理。在随后的 Git 操作介绍中,也会经常提到文件的各种状态变化和所处的工作区域。
三种状态
- 已修改(Modified):表示代码被修改了,但还没有被保存到代码库中被管理起来。
- 已暂存(Staged):表示将修改保存到暂存区(Staging Area)。对应于
add/rm/mv命令(添加/删除/移动)。git add/rm/mv可将对应的修改保存到暂存区。 - 已提交(Committed):表示已经将修改提交至代码库中被管理起来。对应于 commit 命令。
git commit命令可将已暂存的修改提交到代码库中。
三个工作区域
Git 中有三个工作区域与上述三种状态相对应,如下图 1 所示:
图 1. 三个工作区域和三种状态

- 工作目录(Working Directory):工作目录是我们常用的使用或修改代码的目录,它可以从 Git 仓库目录中 checkout 出特定的分支或者版本来使用。在工作目录的修改如果未添加到暂存区,那么该修改仍处在已修改状态。
- 暂存区域(Staging Area):当我们在工作目录中修改了文件,我们需要先将修改添加到暂存区。暂存区的修改就是已暂存状态。
- Git 仓库目录(.git directory):Git 仓库目录就是真正存储和管理代码库的目录。提交修改到代码库本质上就是将暂存区的修改提交(commit)到代码库中。处在 Git 仓库目录中的修改就是已提交状态。
总结下来,一次完整的提交包含以下操作:
- 修改文件。
- 将修改的文件保存到暂存区(
git add/rm/mv)。 - 将暂存区的文件提交(
git commit)到代码库中。
当然如果需要将本地代码库的修改同步到远程代码库中(例如 GitHub),还需要将本地修改 push 到远程。
为什么要有暂存区?
暂存区是 Git 另一个区别于传统版本控制系统的概念之一。传统的版本控制系统例如 SVN、Perforce,提交代码时直接将修改提交到了代码库中。暂存区相当于在工作目录和代码仓库之间建立了一个缓冲区,在真正 commit 之前,我们可以做任意的修改,先将修改保存到暂存区,待所有修改完成之后就可以将其完整的 commit 进代码库,这样可以保证提交的历史是干净清晰的;保存到暂存区的修改也可以被撤销,而不会影响到现有的版本库和提交历史。暂存区另一个作用是在进行多分支工作时,我们常常在某一分支上进行了修改,但又不想提交到代码库中,这时候我们可以使用git stash命令将暂存的和未暂存的修改保存到一个缓冲栈里,使得当前工作分支恢复到干净的状态;待我们想再次恢复工作时,只需要将缓冲栈的修改恢复到暂存区即可。
Git 分支
理解了 Git 的工作区和几个状态之后,我们来看一下 Git 另一重要概念:分支。Git 的分支技术是 Git 的核武器,理解并合理的使用 Git 分支,将大大的提升我们的工作效率。本章将会通过一系列实验来讲解 Git 的分支技术。
理解 Git 分支
在 Git 中,分支本质上是指向提交对象的可变指针。首先我们可以使用git branch或者git branch -a命令列出本地所有的分支。如图 2 所示,git branch 列出了本地已经被 check out 分支,其中带星号的绿色标注的分支是当前的 check out 出来的工作分支。而git branch -a除了列出本地已经被 check out 分支,还列出了所有本地仓库中与远端相对应的分支,即图中的红色标注的分支。
图 2. 查看分支

注意:
- 不像其它的 SCM 创建的分支是物理复制出额外的文件夹来创建分支,Git 的所有分支都在同一个目录之下,我们一般只需要将正在进行开发的分支 check out 出来并切换成当前工作分支即可,如上图中的 dev 分支。
- 虽然上图显示出来红色的分支是 remote 分支,但它们本质上还是存储于本地的分支,只是这些分支是指向对应的远端分支。后面会再详细说明该类分支。
接下来使用 git log 命令可以查看每个分支所指向的提交。如图 3 所示,可以看到绿色标注的两个本地分支 dev 和 master 分别指向的 commit。
图 3. 查看分支对应的 commit

理解 origin
从上图 3 可以看到,有些红色标注的分支名称前带有 origin 的前缀。origin 实际上是 git 默认生成的一个仓库名称,在每次 clone 的时候 git 会生成一个 origin 仓库,该仓库是一个本地仓库,它指向其对应的远程仓库。前面提到的 remote 分支remotes/origin/*,实际上就是储存于 origin 仓库的本地分支,它只是与对应的远端分支具有映射关系。通过git remote -v命令可以查看本地所有的仓库所指向的远程仓库。如图 4 所示:
图 4. 查看本地仓库指向的远端仓库

基于此机制,我们也可以 clone 其它的仓库到同一个本地目录。如图 5 所示,执行git remote add remote-sample [email protected]:caozhi/sample-project.git命令添加一个本地仓库 remote-sample 向我的另一个远端仓库[email protected]:caozhi/sample-project.git,再通过git remote -v命令我们可以看到新建的本地仓库 remote-sample 向以及指向的远端仓库。
图 5. 添加本地仓库

注意,在本地代码库中建立多个 remote 仓库的映射对于大多数开发者来说,不是一个最佳实践,因为这样会使得本地开发环境比较混乱。一般只有在做持续集成时,为了方便在同一个代码目录下编译打包项目,才推荐在本地建立多个远端仓库的映射。
理解 HEAD 指针
HEAD 针是指向当前工作分支中的最新的分支或者 commit。Git 通过 HEAD 知道当前工作分支指向的哪条 commit 上。HEAD 针存在的意义在于我们可以通过设定 HEAD 针指向的 commit 来灵活地设定我们当前的工作分支,由于 HEAD 针并不仅仅指向实际存在的分支,也可以指向任意一条 commit,因此我们可以任意地设定当前工作分支指向任一历史 commit。
首先我们通过 checkout 操作切换当前工作分支来查看 HEAD 针的变化,如图 6 所示,我们当前的分支是 dev 分支,HEAD 针就指向了 dev 分支,我们再 checkout master 分支,当前工作分支变为了 master 分支,而 HEAD 针就指向了 master 分支对应的 commit。
图6. 切换HEAD指针指向的分支

我们再执行git checkout 075c130尝试 checkout 一个历史 commit,如图 7 所示,此时可以看到 Git 会为我们创建一个 detached 的分支,该分支并不指向一个实际存在的分支。执行git log命令也能看到,HEAD 针指向了075c130这个 commit,而非一个分支。
图7. 切换HEAD指针指向任意 commit

理解 push
当我们完成了本地的代码提交,需要将本地的 commit 提交到远端,我们会使用git push命令。Push 操作实际上是先提交代码到本地的remote/**分支中,再将remote/**分支中的代码上传至对应的远端仓库。
当远端仓库的提交历史要超前于本地的remote/**提交历史,说明本地的 remote 分支并不是远端最新的分支,因此这种情况下 push 代码,Git 会提交失败并提示fetch first要求我们先进行同步,下图 8 所示:
图 8. push 失败

理解 fetch, pull
fetch 和 pull 操作都可以用来同步远端代码到本地。在多数开发者的实践中,可能更习惯使用git pull去同步远端代码到本地, 但是 git fetch 也可以用于同步远端代码到本地,那二者的区别是什么呢?
- fetch 操作是将远端代码同步到本地仓库中的对应的 remote 分支,即我们执行
git fetch操作时,它只会将远端代码同步到本地的remote/**分支中,而本地已经 checkout 的分支是不会被同步的。 - pull 操作本质上是一条命令执行了两步操作,
git fetch和git merge。执行一条git pull命令,首先它会先执行 fetch 操作将远端代码同步到本地的 remote 分支,然后它会执行git merge操作将本地的 remote 分支的 commits 合并到本地对应的已经 check out 的分支。这也是为什么在 pull 时常常会出现 merge 的冲突,这是在执行 merge 操作时,git 无法自动的完成 merge 操作而提示冲突。另一种经常出现的情况是,pull 会自动产生一条 merge 的 commit,这是因为本地工作分支出现了未提交的 commit,而在 pull 时 Git 能够自动完成合并,因此合并之后会生成一条 merge 的 commit。
让 Git 自动为我们去生成这样的 merge commit 可能会打乱我们的提交历史,因此比较好的实践方式是先git fetch同步代码到本地 remote 分支再自己执行git merge来合并代码到本地工作分支,通过这种方式来代替git pull命令去同步代码。
Git 的日常操作
通过前文介绍,相信您对 Git 工作区和 Git 分支技术已经有了更深入的了解,下面我再介绍一些日常使用的 Git 和 GitHub 操作。
Git 分支操作
- 查看本地分支:
git branch [-av]
git branch可以用于查看本地分支。-a选项会列出包括本地未 checkout 的远端分支。-v选项会额外列出各分支所对应的 commit,如下图 9 所示:
图 9. 查看分支

- 创建本地分支:
git branch branchname,如图 10 所示。创建本地分支时时会基于当前的分支去创建,因此需要注意当前工作分支是什么分支。
图 10. 创建本地分支

- 推送本地分支到远端:
git push origin branchname:remote_branchname,如图 11 和 图 12 所示。技术上本地分支branchname和远端分支remote_branchname必是相同的名字,但实践中为了方便记忆,最好使用相同的名字。
图 11. 推送本地分支到远端

图 12. 在 GitHub 上查看推送的分支

- 切换工作分支:
git checkout branchname,如图 13 所示:
图 13. 切换工作分支

- 删除本地分支:git branch -d branchname,如图 14 所示:
图 14. 删除本地分支

- 删除远端分支:git push :remote_branchname,如图 15 和图 16 所示:
图 15. 删除远端分支

图 16. 在 GitHub 上查看被删除的分支

GitHub 分支操作
除了本地创建,然后推送到远端的方式之外,我们也可以直接在 GitHub 上创建远程分支,本地只需要 fetch 下来即可。如图 17 和图 18 所示:
图 17. GitHub 中创建分支

图 18. 查看创建的分支

在 GitHub 上我们也可以直接删除分支。首先我们进入代码库的branches页面,该页面列出了我们所有的分支, 如图 19 和图 20 所示:
图 19. 进入 branches 页面

在branches页面,我们找到想要删除的分支,点击分支条目后方的垃圾箱按钮,即可删除该分支,如图 20、图 21 和 图 22 所示:
图 20. 在 GitHub 上删除分支

图 21. 删除分支后

图 22. 代码库主界面再次查看该分支

分支的其它进阶操作,如合并分支、比较分支差异等我们将在下一篇进行介绍。
从远端同步代码
在前面章节 Git 分支的介绍时已经讲解了 pull 和 fetch 区别。二者都可以用来从远端同步代码到本地。本处不再赘述。
一次完整的提交
下面列出了一次完成的提交流程:
- 总是先同步远端代码到本地:一个 Git 的最佳实践是,在每次正式提交代码前都先将远端最新代码同步到本地。同步代码使用
git pull或者git fetch&git merge。 - 将本地修改提交到暂存区:使用
git add/rm/mv命令将本地修改提交到暂存区中。此处需要注意,为了使 Git 能够完整的跟踪文件的历史,使用对应的 git rm/mv 命令去操作文件的删除、移动和复制,而不要使用操作系统本身的删除、移动和复制操作之后再进行git add。 - 将暂存区的修改提交到本地仓库:使用
git commit命令将暂存区中的修改提交到本地代码库中。 - 使用
git push命令提交本地 commit 到远端。
Git 其它常用操作
Log 操作
Log 命令用于查看代码库的提交历史。结合 log 命令提供的各种选项,可以帮助我们查看提交历史中有用的提交信息。
--oneline选项:不显示详细信息,只列出 commit 的 id 和标题, 如图 23 所示:
图 23. log 的 --oneline 选项

-p选项:列出 commit 里的文件差异,如图 24 所示:
图 24. log 的 -p 选项

-number选项:只列出 number 数的 commit 历史,如图 25 所示:
图 25. log 的-number 选项

--name-only选项:列出每条 commit 所修改的文件名。此选项只列出修改的文件名,不列出修改类型,如图 26 所示:
图 26. log 的 --name-only 选项

--name-status选项:列出每条 commit 所修改的文件名和对应的修改类型,如图 27 所示:
图 27. log 的 --name-status 选项

--stat选项:列出每条 commit 所修改的统计信息,如图 28 所示:
图 28. log 的 --stat 选项

Blame 操作
Blame 命令是一个非常实用但是鲜为人知的命令,它可以用来查看单个文件中每行代码所对应的最新的提交历史。为了展现更多的提交历史,本操作是在我的另一个代码库devops-all-in-one中进行的实验。如图 29 所示,可以看到每行代码都列出了对应的最新的 commit、文件名、提交者、时间等信息。
图 29. git blame 操作

我们也可以添加-L选项控制只显示我们所关心的行。如清单 1 所示:
清单 1. Blame 命令的 -L 选项
git blame -L 10,20 filename
git blame -L 10,+10 filename
git blame -L 20,-5 filename10,20即显示第 10 行到第 20 行代码的信息;10,+10即显示第 10 行开始往后 10 行代码的信息;10,-5即显示第 10 行开始往前 5 行代码的信息。如图 30 所示:
图 30. 执行 git blame -L

Status 操作
git status是另一个常用的命令,用于查看当前分支的修改状态。当前分支没有任何修改时,执行git status命令会显示working tree clean,如图 31 所示:
图 31. 无修改时执行 git status 操作

当我们对当前分支进行了更改时,git status会根据被修改文件的状态显示不同的信息,如图 32 所示:
- 红色框的修改表明这些修改已经提交到了暂存区。
- 蓝色框的修改表示它们还在工作区未被提交到暂存区。
- 绿色框的修改表示是新文件,这些文件没有被代码库所跟踪。
图 32. 有修改时执行 git status

Diff 操作
Diff 操作用于查看比较两个 commit 或者两个不同代码区域的文件异同。
git diff:默认比较工作区和暂存区,如图 33 所示:
图 33. 比较工作区和暂存区

--cached选项:比较暂存区和代码库的差异,例如图 34 所示:
图 34. 比较暂存区和本地代码库

- 在命令后面指定特定的文件名,也可以比较特定文件的差异,如图 35 所示:
图 35. 比较工作区和暂存区

结束语
本文重点介绍了 Git 的分支,讲解了一些不容易理解的概念如 HEAD 指针、origin 仓库等,并通过实验介绍了分支的常用操作:创建、删除、切换等。同时,本文还介绍了 Git 的日常常用操作。相信您在阅读完本文之后将有能力使用 Git 和 GitHub 进行日常开发。在下一篇文章中将会通过一系列实验和实际应用场景讲解一些我们在日常工作中经常遇到的 Git 进阶操作,例如撤销、回滚、分支比较等。
参考资源
- 访问我的 GitHub 主页,可以获取文章中所涉及的代码库repo-for-developerworks和devops-all-in-one。
- 查看 Git 官网Git-SCM,可获得 Git 相关的资源。
- 可从Git-For-Windows官网上下载 Git Windows 版的安装包。
- 参考ProGit(中文版)、ProGit(英文版)一书,可以了解 Git 操作使用详细的讲解。
- 访问GitHub Online Help可检索关于 GitHub 的相关帮助。
- 访问Git Cheat Sheat获得 Git 命令的快捷帮助。
比较
比较操作是开发过程中最常用的操作之一,场景包括通过比较来查看本地修改了哪些代码,比较特定分支之间的代码,或者 Tag 与 Tag 之间、Tag 与分支之间的比较。Git 中比较操作可以通过 diff 操作和 log 完成,diff 主要用于比较文件内容的差异,而 log 操作主要比较 commit 的差异。在本系列的第三篇文章中 Diff 操作中已经简单介绍了工作区、暂存区和代码库之间的比较。这里我将会详细介绍其它各种对象之间的比较。
Diff 命令的基本格式是 git diff <src> <dst> 。其作用是相比 src ,列出目标对象 dst 的差异。例如图 1 和图 2 所示,分别执行 git diff dev master 和 git diff master dev 来查看 dev 分支和 master 分支的差异,两次执行结果显示的是相反的结果。
图 1. 执行 git diff dev master

图 2. 执行 git diff master dev

Git 中 Tag 和分支本质上都是指向对应 commit 的指针。因此 Tag、分支、commit 三者之间可以很平滑的进行比较操作。 例如图 3 进行了 tag 和分支之间的比较、图 4 进行了 Tag 和 Tag 之间的比较、图 5 进行了分支和 commit 之间的比较。
图 3. tag 和分支的比较

图 4. Tag 和 Tag 之间的比较

图 5. 分支和 Commit 之间的比较

使用 git diff 也可以查看单个文件的差异。例如图 6 所示:
图 6. 比较单个文件的差异

在实际项目中,只通过命令行的方式来展示差异在某些场景下可能不是特别友好,比如想要比较两个相隔时间较远、差异特别多的分支,通过命令行的方式可能较难定位到我们关心的修改。因此我在实际项目中也会使用 IDE 或其它图形化 Git 客户端进行比较。例如图 7 展示了如果在 Eclipse 的 EGit 插件中比较两个 commit:
图 7. Eclipse EGit 中比较两个 commit

回滚和撤销
回滚
回滚(Rollback)操作指的是将已经提交到代码库的 commit 生成一个与对应 commit 完全相反的 commit,相当于是对目标 commit 进行一次代码修改的逆向操作。在实际项目中,经常用于进行版本的回滚或对某些错误提交进行回滚。Git 中是使用 revert 命令进行回滚操作,它会生成一条新的反向 commit,同时保留目标 commit。下面我将演示进行 revert 的一个小实验。
首先我先进行了一些代码修改并进行了提交。提交的 commit 包含新增文件、删除文件以及代码修改,如下图 8 所示:
图 8. 提交 commit

然后我们再利用 git revert 进行回滚,如图 9 所示。可以看到回滚之后,Git 生成了一条新的 commit,这条 commit 的提交内容与被回滚的 commit 完全相反:
图 9. 执行 revert 操作

撤销
撤销操作指的是丢弃我们的代码修改。实际开发中撤销通常包含多种情况:
- 撤销未保存至暂存区的代码。
- 撤销已保存至暂存区但是还未提交到代码库的代码。
- 撤销已提交到本地代码库但还未 push 到远端进行同步的代码。
- 撤销已提交到远端的代码。
不同的情况可能采取不同办法来解决。
撤销未保存到暂存区的代码
当我们只需要撤销并丢弃到某个文件的修改时,我们可以使用 git checkout -- filepath 命令来进行撤销。如图 10 所示:
图 10. 撤销单个文件的修改

本地修改太多,我们又想完全丢弃掉本地修改时,使用 git checkout -- filepath 命令会显得十分麻烦。此时可以使用 git reset -- hard HEAD 命令来丢弃本地所有修改,如图 11 所示:
图 11. 丢弃本地修改

对于下面两种情况,我们也都可以使用 git reset 命令结合不同的选项来进行操作。
撤销已保存至暂存区但是还未提交到代码库的代码 当我们不想完全丢弃掉代码修改,而只是想将暂存的修改撤销到工作区,我们可以使用 git reset HEAD 命令来完成。由图 12 可以看到,此时暂存区的修改被恢复到了工作区。
图 12. 从暂存区恢复到工作区

撤销已提交到本地代码库但还未 push 到远端进行同步的代码 例如我们已经将修改 commit 到了本地代码库,如图 13 所示,可以看到 HEAD 指针已经指向了本地最新的修改。当我们想要撤销掉该 commit 时,可以使用 git reset [–hard] commit_id 命令来操作。同样的,如果我们只是想保留修改,我们可以使用 git reset commit_id 命令来使得 HEAD 指针指向对应的 commit,这样在其之后 commit 的代码修改会被撤销到工作区,如图 13 所示:
图 13. 将已提交 commit 恢复到工作区

当我们不需要保留修改,而想要完全丢弃掉 commit 时,我们可以使用 git reset --hard commit_id 命令,这样对应 commit 之后的 commit 将会完全被丢弃。如图 14 所示:
图 14. 完全丢弃已提交 commit

撤销已提交到远端的代码
而对于已经提交到远端的 commit,此时我们没有办法再使用 reset 命令撤销掉原先的 commit,即使在本地用 reset 进行了撤销,再进行同步拉取代码时,仍然会将远端的 commit 拉回本地。因此这种情况我们只有通过 revert 进行回滚。
由此我们也可以看到,revert 和 reset 命令都可以用于撤销 commit,它们最大的不同在于 revert 会生成一条与之前完全相反的 commit 同时保留原先的 commit,而 reset 则是抛弃掉原先的 commit。
Reset 命令的本质
Reset 命令本质上是重置工作区的 HEAD 指针使其指向对应位置,当重置 HEAD 指针之后,会将 HEAD 指针之后的 commit 丢弃掉从而也达到了撤销修改的目的。reset 命令有三个参数:
--soft 选项:重置 HEAD 之后,将重置 HEAD 之后的 commit 的代码变更还原到暂存区。 --hard 选项:重置 HEAD 之后完全丢弃 HEAD 之后的代码。 --mixed 选项:默认选项。重置 HEAD 之后,将重置 HEAD 之后的 commit 的代码变更还原到 工作区 。 理解 reset 命令的三个选项的本质不同,需要理解 Git 的三个工作区的不同:工作区、暂存区和代码库。您可以参考本系列的 第三篇 文章的相关简介来了解这三个工作区。下列实验(图 15 到图 18)演示了使用 reset 命令三个选项重设 head 到 e6ea793 时,commit b772c6e 中的代码的不同状态。如果您想要自己尝试重现该实验,那么在两次 reset 之间为了恢复到相同的状态,需要执行 git reset --hard e6ea793 && git pull 来进行代码同步。
图 15. 执行 reset 前的两个 commit

图 16. 使用 –mixed 选项执行 reset

图 17. 使用 –soft 选项执行 reset

图 18. 使用 –hard 选项执行 reset

合并分支 在本系列 第三篇 文章中已经介绍了分支的基本操作,包括创建分支、删除分支等。本节将会介绍实际开发中分支的另一个重要操作:合并分支。
合并分支是将目标分支的 commit 合并到当前分支的操作。一般使用 git merge 命令来完成。在进行 merge 实验之前,首先我将 master 分支和 dev 分支的代码进行了同步,并切换到了 dev 分支,如图 19 所示:
图 19. 同步 master 和 dev 代码

然后我在 dev 分支上进行一次提交,如图 20 所示:
图 20. 在 dev 分支进行一次提交

接下来我们切换到 master 分支使用 git merge branchname 命令进行合并,如下图 21 所示:
图 21. 将 dev 分支合并到 master

可以看到 master 分支成功合并了 dev 分支的那条 commit。
Fast-forward 观察可以看到上面的实验 Git 是以 Fast-forward 方式进行的合并。Fast-forward 是指快进合并,它是直接将 master 分支指针直接指向了 dev 分支的 commit,而并没有在 master 分支上产生新的 merge commit。我们再执行一次相同的操作来演示非快进合并模式的效果。执行 git merge 命令时通过加上 --no-ff 选项来禁止 Fast-forward。如图 22 示,可以看到非快进合并模式下,git 会产生一条新的 merge commit 。使用 Fast-forward 模式的好处是可以快速的进行合并且不会产生 merge commit,但其缺点在于它不会保留合并分支的信息,因此当合并分支被删除时,也就不知道对应的提交是来自于哪个分支。
图 22. 非快进方式合并

Squash 选项 有时候我们实际项目中在自己的开发分支上可能会提交很多跟业务意义关系不大的 commit,例如格式修改、删除空格、撤销前次提交等等,执行 git merge 操作时默认情况下会将合并分支上这些原始 commit 直接合并过来,在目标分支上保留了详细的提交历史,往往这些无意义的提交历史会导致主分支的历史显得杂乱。这种情况下我们可以使用 squash 选项将待合并的所以 commit 重新替换成一条新的 commit。如图 23-24 所示,我们将 dev 分支的三条 commit 合并成了一条 commit。
图 23. Dev 分支上的三个 commit

图 24. 将 dev 分支使用 Squash 方式合并到 master

图 25. 查看 master 上的 squashed commit

Cherry-pick 除了使用 git merge 命令来合并分支之外,我们还可以通过 cherry-pick 命令来检出特定的一个或多个 commit 进行合并。首先我们先在 dev 分支上提交 3 条 commit,如图 26 所示:
图 26. Dev 分支上的三个 commit

然后我们切换到 master 分支使用 cherry-pick 来合并第二个 commit,如图 27 所示:
图 27. 在 master 上 cherry-pick dev 分支的 commit

查看 log 发现第二个 commit 被合并到了 master 分支,如图 28 所示:
图 28. 查看 cherry-pick 结果

冲突的产生与解决冲突 冲突的产生 在实际项目中,冲突是不可避免的问题。冲突可能出现在很多情况下,例如使用 pull 去同步代码时、多个分支之间进行合并时,甚至在进行 cherry-pick 时都可能产生冲突。例如下面实验(图 29-31)中,我们分别在 dev 和 master 分支上同时修改了 helloworld.sh 的同一段代码,然后从 dev 分支往 master 上进行合并,Git 会提示我们产生了冲突同时无法自动合并。
图 29. dev 分支中的代码修改

图 30. master 分支中的代码修改

图 31. 合并时产生冲突

解决冲突 无论是什么情况下产生的冲突,Git 一般会直接将冲突信息输出到冲突文件中,并使用 <<<<<< 、 ===== 、 >>>>>> 符号来标注产生冲突的位置以及两个分支的冲突代码。我们需要解决冲突再进行下一步合并或者代码提交的操作,如图 32 所示:
图 32. 源文件中显示冲突位置

我们可以直接编辑该冲突文件,保留我们感兴趣的内容,同时删除 Git 自动生成的标识行 <<<<<< 、 ===== 、 >>>>>> 。也可以借用 GUI Git 客户端、IDE 或者其它合并工具进行冲突解决。下图展示了 Eclipse(图 33)、VSCode(图 34)和 GitHub Desktop(图 35)的冲突解决。=
图 33. Eclipse 里解决冲突

图 34. VSCode 里解决冲突

图 35. GitHub Desktop 里解决冲突

当在代码中解决了冲突之后,我们需要将修改后的代码重新使用 git add/rm/mv 提交到暂存区,并重新 commit 到代码库中。
避免产生冲突 现代软件开发项目中,代码冲突是不可避免的,但我们应该尽量减少冲突的产生,避免不必要的冲突。下面列举一下实践经验:
工作在不同的分支上,并经常性的同步主代码,如果由于项目要求,比如长期开发一个功能使得该功能代码在开发完成之前合并到主分支,此时我们虽然没有办法经常合并代码到主分支,也至少需要经常性的同步主分支代码到开发分支上,避免在最终合并到主分支上时产生过多冲突。 尽量使用短生命周期分支而非长期分支。 除了技术层面的手段,也可以通过项目管理上的手段来尽量避免,例如:
不要同时将相同组件开发的不同任务分给不同的开发者,否则在合并代码时该组件将会产生过多的冲突。 各组件开发小组之间经常性的沟通,互相了解各自的开发状态,在可能产生冲突的时候及时采取手段。
结束语
本篇文章通过一些演示讲解了 Git 在日常项目中的常用进阶操作,包括使用 diff 命令进行比较,使用 revert 命令进行回滚,使用 reset 进行撤销以及分支之间的合并等。本篇文章的思路并没有从 Git 命令本身出发,而是从使用场景出发进行讲解,旨在结合实际项目场景来解决开发者经常遇到的问题。当然这种思路也使得有些操作的介绍不尽详实。对此建议您在了解了具体场景如何进行操作的同时,也可翻阅 Git 的官方文档来查看各个命令更详细的参数及其作用。
]]>在本系列的前面四篇文章中已经介绍了 Git 和 GitHub 的一些特性和常用操作。本篇文章中我将介绍分支管理策略。 分支管理在代码管理中可以保证代码版本管理的清晰合理,同时也对生产版本提供有效的保护。 良好的分支管理也可以最大化的保证团队协同合作的有效进行。 本文将介绍为什么我们需要使用合理的分支策略,以及两种常见的工作流分支管理策略。
为什么需要分支管理
一个产品的生命周期里往往同时存在多个不同的发行版本,同时也存在着诸如开发版本、预生产版本等多个版本。 我们需要设计一个良好的分支管理策略来有效管理同时存在的多个版本,同时,实际项目中往往需要多个开发者协同开发,多名开发者之间的工作又往往互相依赖。 如何保证提交的代码的完整性,同时又能让某一功能开发者在不受其他功能开发影响的情况下自己也能独立开发,此时我们需要分支管理策略来更好的保证协同开发和独立开发互不冲突。
根据我的实践经验总结下来,分支管理的作用大致包含:代码管理与产品生命周期相结合、分支保护、协同合作与独立开发互不冲突。
代码管理与产品生命周期相结合
不同的分支往往代表着产品的不同生命周期阶段。图 1 展示了一个简单的产品新版本发布的生命周期模型和下文 Git Flow 分支管理策略 章节中不同类型分支的对应关系。
图 1. 产品生命周期模型和分支管理对应关系

只有将不同的分支类型与产品的生命周期对应起来,才能更好的对不同周期的代码进行不同的策略管理。
- 开发阶段:在 Dev 分支或 Feature 分支开发,最大程度的实现协同合作。
- 测试阶段:产品进入预发布阶段,预发布版本的功能都已实现,需要进行完整的系统测试以及测试报出的 bug 修复,此时在 release 分支上进行测试和 bug 修复,既保证了未来新版本发布的质量又不会影响其他 Dev 分支或 Feature 分支的开发。
- 产品上线:产品上线通过 Master 分支管理生产版本,保证产品的发布版本历史和代码历史清晰。
- 线上修复:通过 Master 分支创建出 Hotfix 分支来进行修复再发布到 Master 分支,确保提交的修复不包含任何其它无关代码,最大程度地保护生产版本。
分支保护
产品不同生命周期也往往需要不同的保护策略来确保代码的版本管理清晰,各版本之间的代码不会混淆甚至于破坏了生产环境的代码。分支管理的重要意义在于生产版本、预生产版本、开发版本的代码隔离,使得版本的完整性和质量都得到保证。由此我们也可以看到分支管理的保护作用可归纳为:
- 通过严格的提交和合并策略来确保生产分支的稳定及不被破坏。
- 功能分支开发完成之后再提交到主开发分支,确保主开发分支和生产分支不包含未完成功能的不完整代码。
- 通过在预生产分支上进行严格测试,来保证产品发布版本的质量稳定。
协同合作与独立开发互不冲突
设想如果我们没有不同类型的分支管理策略,而只使用一个 master 分支来管理代码库,这时当我们需要发布新版本时,为了保证新发布版本不包含多余的代码,我们需要开发者禁止向 master 分支提交代码直到版本发布成功,这样严重影响了开发者对未来版本的功能开发。但是通过不同类型的分支管理,开发者既可以在 dev 分支上进行常规提交,又可以灵活地在功能分支上进行独立开发。团队内成员的各项开发工作也不会受到互相依赖,使得协同合作与独立开发互不冲突的进行下去。
Git Flow 分支管理策略
Vincent Driessen 在 2010 年提出了一种 Git 工作流的分支管理模型。这种模型考虑了产品生命周期中的多种代码版本形态,能够很好地适用于大部分企业级产品中。本节我将简单介绍该分支管理策略,如果感兴趣,您也可以去阅读 Vincent Driessen 的原文:A successful Git branching model 。
图 2. Git Flow 分支管理

我们从上图 2 可以看到该策略一共有五种不同的分支类型,其中根据他们的生命周期又可以分为两大类:
长生命周期分支:项目开始一直存在的分支。
- master:master 分支是一个生产主分支。它的 HEAD 指针永远指向最新的稳定生产版本。它使用 Tag 来管理历史生产版本。它的代码来源只有 release 预生产分支和 hotfix 修复分支。
- dev:dev 分支是一个开发主分支。它的 HEAD 指针永远指向的是最新的在开发版本。它的代码来源可以是开发者直接提交,或者是 release 预生产分支、feature 功能分支和 hotfix 修复分支的合并。
短生命周期分支:根据不同需求创建的分支,在合并到 master 或 dev 分支之后需要删除的分支。
- release:release 分支是预生产分支。当项目完成了某一个完整周期的开发,准备对产品发布新版本时,我们可以创建一个预生产分支。创建预生产分支之后,产品进入测试阶段,测试阶段发现的 bug 经修复后直接提交到该预生产分支。当测试完整正式发布新版本时,我们需要将该分支合并到 master 分支,同时删除该预生产分支并在 master 分支上创建相应的 tag。Release 分支根据实际项目情况可以有一个或多个,因此分支命名建议使用 release 为前缀,加上版本号后缀作为分支名,例如 release-v1 、 release-v1.1 等。
- feature:feature 分支是功能开发分支。项目中可能会出现比较大的功能需要较长的周期进行开发。此时为了避免开发分支或者生产分支上出现不完整的该功能代码,我们可以单独从 dev 分支创建出一个功能分支。多个开发者可以协同在该分支上进行功能开发。功能代码都先提交到该分支上。当功能开发完成之后再合并回 dev 分支,同时删除该功能分支。Feature 分支根据实际项目情况可以有一个或多个,因此分支命名建议使用 feature 为前缀,加上功能名缩写或者该功能在项目管理工具(JIRA、GitHub Issues 等)中的 ticket id 作为后缀,例如 feature-login 、 feature-211 等。
- hotfix:hotfix 分支是修复分支。产品上线后仍可能报出 bug。当报出 bug 时,我们可以从 master 的 tag 创建出 hotfix 分支,针对该 bug 的修复直接提交到该 hotfix 分支上。当修复经过测试之后,我们需要将该 hotfix 分支合并到 master 分支和 dev 分支,合并后同时删除该 hotfix 分支。合并到 master 分支之后可以创建 tag 来生成新的生产小版本号。合并回 dev 分支可以保证未来的发布版本不再出现该 bug。Hotfix 分支根据实际项目情况可以有一个或多个,因此分支命名建议使用 hotfix 为前缀,加上功能名缩写或者该功能在项目管理工具(JIRA、GitHub Issues 等)中的 ticket id 作为后缀,例如 feature-login_defect 、 feature-311 等。
注意 : 虽然在创建 Git 或 GitHub 仓库时,Git 或 GitHub 为我们创建了一个默认的 master 分支(现在改为了main),但是该 master 分支与其它分支并没有任何本质上的区别。在实践中我们可以使用任何的名字来替代 master、dev 分支等。例如使用 stable 表示生产分支、使用 new 表示在开发分支等。
从不同的分支类型可以看到,该策略覆盖了产品生命周期的各个阶段:开发、测试、版本发布、修复等等。因此该分支策略可以适用于大部分企业产品。下表 1 总结了 5 种分支类型的创建时间、代码来源等特点。
表 1. 5 种分支类型总结
| 类型 | 从哪个分支创建 | 什么时候创建 | 合并到哪个分支 | 什么时候删除 | 分支数量 |
|---|---|---|---|---|---|
| master | NA | 项目最开始 | NA | 永不删除 | 一个 |
| dev | NA | 项目最开始 | NA | 永不删除 | 一个 |
| release | dev 分支 | 准备发布新版本 | dev, master | 正式发布新版本,代码合并到 dev 和 master 之后 | 数量不定 |
| feature | dev 分支 | 新功能需要较长时间的协同开发 | dev | 新功能开发完成,合并到 dev 之后 | 数量不定 |
| hotfix | master 分支 | 当生产版本报出 bug | dev, master | 修复经过测试,代码合并到 dev 和 master 之后 | 数量不定 |
实际上我的项目情况相比该策略会更复杂,例如我们的产品会同时存在多个不同的生产版本,针对不同的版本可能会提交不同的修复,因此这要求我们的生产版本需要一直存在,而我们的 release 分支不再是预生产分支而是生产分支,同时也不会随着合并到 master 而消亡,而根据生产版本在线上情况会长时间存在。同时我们的 hotfix 分支是直接提交到生产版本中。当然我们也要认识到,出现这种复杂情况的原因在于我们的产品历史比较长,在采用 GitHub 作为版本控制工具以前,产品的生命周期模型就已经定义下来并被长期采用。因此我们需要尽量设计一种既符合该分支策略同时又能适用于我们产品生命周期的一种策略。
GitHub Flow 分支管理策略
GitHub Flow 是 GitHub 推出的一种更加简便、敏捷并适合快速持续部署项目的分支管理策略。如图 3 所示。图 3 截取自 GitHub 官网关于 GitHub Flow 的介绍。

该工作流只有一个长期分支 master 分支,master 分支的 HEAD 指针同时也指向了最新的生产版本分支。 日常开发通过创建不同的功能分支来进行,在开发完成后通过创建 Pull Request 来尝试合并代码到 master 分支。Pull Request 是一种代码评审和代码合并的机制。经过评审通过之后的代码,才真正的合并到 master 分支,随后进行发布。(我将在本系列的第六篇文章中专门讲解代码评审和 Pull Request 的内容。)这种工作流的特点是简单、高效,特别适用于发布十分频繁的项目。
两种方法各自适用的场景
两种 Flow 的管理策略各有优缺点,也各自有不同的适用场景。
- Git Flow:分支类型太多,不利于管理。适用于发布周期较长,项目规模较大的产品。
- GitHub Flow:工作流非常简单,管理也很容易。它引入 Pull Request 进行代码评审,一定程度上保证了代码质量。但是它只有一个 master 分支,不适用于多个生产版本并存的项目。GitHub Flow 被广泛用于开源项目中。 在实际项目中,我结合了两种策略进行的分支管理。由于产品特性,我们必须采用 Git Flow 来保证多个生产版本都能够独立的发布,同时在向生产版本和 Dev 版本合并代码时,我们又要求团队成员必须提交 Pull Request 来进行代码评审。
结束语
我在本篇文章中介绍了分支管理策略的重要意义,同时介绍了两种业界流行的基于 Git 或 GitHub 工作流的分支管理策略。 Git 的分支技术极大的提高了分支管理的效率。但是如何将分支管理能够更好的应用到具体的项目中,是我们从业者们需要认真思考的问题。我认为,分支策略需要服务于产品的生命周期特点。基于产品生命周期特点,选择合适产品的分支管理策略,同时我们还可能需要进行必要的改进以能够达到产品发布和产品质量的要求。
]]>使用 git push --force 可以覆盖上一次的push提交。不过一般不推荐这么做
git rebase
合并本地多个还没有push过的commit
使用 git rebase , 比如合并最近两次的commit 。git rebase HEAD~2

-i 出现交互界面
- pick:正常选中
- reword:选中,并且修改提交信息;
- edit:选中,rebase时会暂停,允许你修改这个commit(参考这里)
- squash:选中,会将当前commit与上一个commit合并
- fixup:与squash相同,但不会保存当前commit的提交信息
- exec:执行其他shell命令
git commit --amend
- 修改commit信息
git commit --amend - 修改commit的author
git commit --amend --author "New Author Name " - 修改commit的提交时间
git commit --amend --date="$(date -R)"
git pull
git pull = git fetch + git merge , 所以 fetch 更安全些
git diff --name-only <commit-id>
需求: 某次远程提交的文件列表,并判断是否包含某文件类型
# 更新远程的变更
git fetch
# 查看提交历史,获取最后一次提交的commit id
git log origin/develop
# 查看具体的提交内容
git show 2678b99db5be1d6870feecde243dffb6e59d4bcd
# 只查看更新的文件
git diff --name-only 2678b99db5be1d6870feecde243dffb6e59d4bcd
结果只会列出 `app.js`gitignore_global 全局忽略文件
不需要在每一个仓库中添加.gitignore文件,只需要在家目录下建立.gitignore_global文件就可以忽略我们想忽略的内容
touch ~/.gitignore_global
git config --global core.excludesfile ~/.gitignore内容为:
*~
.DS_Store
.ideaincludeif 根据目录统一配置
问题:每次新建一个仓库,都得使用git config user.email配置邮箱和用户名而且,项目分公司的个人的,公司项目要使用公司邮箱[email protected],个人邮箱是[email protected]。
方案:gitconfig中有includeIf指令,使用他可以根据条件导入额外的配置
维护全局配置文件
我的是在~/.gitconfig,也可能/etc/gitconfig也会存在一个系统级别的配置文件,这个文件可以设置全局的配置,比如邮箱,用户名等。
使用命令git config --global core.editor emacs本质就是编辑这个文件
使用git config --list查看当前git的配置信息,注意配置文件可能存在多处
使用git config --list --show-origin显示文件出处
快速重写 git history
有时候 git commit 会不一致,公司邮箱和个人邮箱容器混用,最简单方法是使用 git-filter-repo
pip3 install git-filter-repo --break-system-packages
git filter-repo --force --email-callback 'return b"[email protected]"'
git filter-repo --force --name-callback 'return b"mafeifan"'git submodule add [email protected]:cndevops/ci/components.git
git add .
git commit -m "init"
git push --set-upstream origin feature-submodule使用submodule
git clone [email protected]:cndevops/gitlab-pipeline-examples/demo-pipeline.git
cd demo-pipeline
git checkout feature-submodule
## 注意区别! ##
## 初始化并拉取子模块内容
git submodule update --init
## 更新子模块,该命令会将子模块的 HEAD 指针更新为远程分支的最新提交。
git submodule update --remote
## 返回初始提交的内容
git submodule update --init --recursiveIDEA系列好像有个bug,检测不到submodule的变更,需要执行下菜单栏 git-update project
区别
git submodule sync --init:
- 更新 所有 子模块及其子模块(递归)。
- 将每个子模块重置为 父模块中指定的提交(使用 .gitmodules 文件中的 branch 字段)。
- 不会 从远程仓库获取更新(除非使用 --fetch 选项)。
- 更适合 同步多个子模块 并确保它们与父模块保持一致。
git submodule update --init:
- 只更新 指定的子模块(不递归)。
- 将子模块重置为其 远程分支的最新的提交。
- 会从远程仓库 获取更新。
- 更适合 单独更新单个子模块 到最新状态。
大致要执行下面的命令
# 创建一个名为git的用户,专门访问仓库,这里会问一系列问题,包括设置用户密码,请牢记
sudo adduser git
# 配置SSH,无密码访问服务器,这里不是本文重点,关于SSH配置请自行搜索,要创建 home/git/.ssh 目录,并设置权限
sudo chmod 700 /home/git/.ssh
chmod 600 authorized_keys
# 创建项目目录,这里没有放到用户目录下
mkdir -p /usr/git_repo/gittest.git && cd ..
# 建立一个裸仓库并设置该仓库目录的组权限为可写。
# 裸仓库就是一个只包含.git子目录的内容,不包含其他资料。
git init --bare --shared
# 好,服务端的仓库已经创建,下面是本地操作
# 开发人员小马先在本地创建一个git项目,将刚才创建的仓库设置为项目的远程仓库并推送分支。
git init
touch readme && vi readme
git add .
git commit -m 'add readme'
git remote add origin git@cloud:/usr/git_repo/gittest.git
git push origin master
# 小张作为另外一个开发人员,可以直接clone项目,并推送自己的改动
# 本地尝试访问并拉仓库。cloud是我配置ssh主机名称,也可以是IP地址或域名
# 如果不成功检查SSH的配置
git clone git@cloud:/usr/git_repo/gittest.git
cd gittest
vi readme
git commit -am 'fix the readme file'
git push origin master是不是和Github的 git clone [email protected]:mafeifan/smzdm.git 很类似?但是Github还支持HTTP协议,比如 https://github.com/mafeifan/smzdm.git 想达到同样的目的,需要在服务器上针对apache或nginx配置 git-http-backend。
使用服务器的hook
每当本地push代码,还得在服务器上git pull。这样太麻烦了。git支持hook机制,类似事件通知,比如git服务器收到push请求,并且接受完代码提交时触发。需要在hooks目录下创建post-receive文件 服务器操作
cd /usr/git_repo/gittest.git/hooks
sudo cp post-update.sample post-receive
# 编辑post-receive内容为
echo $(date) >> hook.log这样push代码到服务器,就会多出一个记录时间的hook.log 你可以优化内容,比如执行代码检查,git pull代码到/var/www,npm install,等操作。
使用托管网站的web-hook
以bitbucket为例,我在上面创建一个nodejs项目叫git-deploy-demo,暴露一个接口叫deploy,必须是post方法。项目跑在我自己的主机叫cloud。每次push代码,我让他调用这个deploy接口
 关于deploy接口,接收调用后执行update.sh脚本
关于deploy接口,接收调用后执行update.sh脚本
const exec = require('child_process').exec;
app.post('/deploy', (req, res) => {
const commands = 'sh ./update.sh';
exec(commands, (err, out, code) => {
if (res.statusCode === 200) {
res.send('deploy done');
}else {
res.send(out)
}
})update.sh内容如下:
#!/bin/bash
git pull
npm install
sudo pm2 restart git-deploy-demo参考:
]]>- 一个邮箱,未被注册apple id
- gift card,淘宝上搜 apple gift card,充值app store用,5美元即可,大概30多人民币
步骤:
- 打开 https://appleid.apple.com/ 注册,国家选美国,手机号可以填国内的,需要短信验证
- iPhone 设置,先退出老apple id(如何退出见最下面的图),打开 app store 登录新的美区账号,要求补全个人信息
- 搜 美国地址生成器,添加 街区,城市,洲 等信息,付款方式不用填
- 打开 淘宝,购买gift card,自动发货那种,其实就是 一串字符,类似 XN54Z5JQ9VYDTVHC,充值成功
- 使用新注册的美区账号登录app store, 搜索下载 ShadowRockets, YouTube,Netflix,Twitter,Facebook,NiceGram,Feedly,Potatso,Instagram,Reddit,CNN等国内区无法上架的app。
如何切换apple id

完工
]]>正常安装JDK 1.8和JDK 9即可,JAVA 8对应的就是JDK 1.8,JAVA 9对应的JDK 9。
安装地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
查看版本,终端输入java -version
切换
安装好之后,可以使用如下命令找到JAVA 8和JAVA 9的位置。
- JAVA 8
/usr/libexec/java_home -v 1.8
输出
/Library/Java/JavaVirtualMachines/jdk-9.0.4.jdk/Contents/Home
- JAVA 9
/usr/libexec/java_home -v 9
输出
/Library/Java/JavaVirtualMachines/jdk1.8.0_211.jdk/Contents/Home
在 .zshrc 或 .bashrc 中,添加如下内容:
# 设置 JDK 8
export JAVA_8_HOME=`/usr/libexec/java_home -v 1.8`
# 设置 JDK 9
export JAVA_9_HOME=`/usr/libexec/java_home -v 9.0`
# 默认用 JDK 8
export JAVA_HOME=$JAVA_8_HOME
# export PATH=$JAVA_HOME/bin:$PATH
# 切换 Java 版本命令
alias jdk8="export JAVA_HOME=$JAVA_8_HOME"
alias jdk9="export JAVA_HOME=$JAVA_9_HOME"保存后重新打开终端或 source ~/.zshrc 或 source ~/.bashrc
效果

参考
]]>新Mac买来了,如何配置软件安装配置流程
学习了几个思路:
- ~/.zshrc 放到 github gist
- 几个小工具
磁盘文件分析 http://www.derlien.com/
 窗口管理 https://github.com/rxhanson/Rectangle
Video Speed Controller https://chrome.google.com/webstore/detail/video-speed-controller/nffaoalbilbmmfgbnbgppjihopabppdk?hl=en
窗口管理 https://github.com/rxhanson/Rectangle
Video Speed Controller https://chrome.google.com/webstore/detail/video-speed-controller/nffaoalbilbmmfgbnbgppjihopabppdk?hl=en
推荐这篇文章 只说几个爽的地方:
2019.06.04
- 安装
brew install tree - 查看命令
tree -h - 查看树形文件目录
快速跳转
Zsh支持目录的快速跳转,我们可以使用 d 这个命令,列出最近访问过的各个目录,然后选择目录前面的数字进行快速跳转:

重复上一条命令
输入 r ,可以很便捷的重复执行上一条命令。
通过插件
web-search
一个方便的终端搜索工具,支持大多常用的搜索引擎,比如:
输入 baidu hhkb pro2 直接在浏览器打开百度搜索关键字”hhkb pro2” 输入 google minila air 直接在浏览器打开Google搜索关键字”minila air”
快捷键
另外请记住并常用这些快捷键
- ctrl+p shell中上一个命令,或者 文本中移动到上一行
- ctrl+n shell中下一个命令,或者 文本中移动到下一行
- ctrl+r 往后搜索历史命令
- ctrl+s 往前搜索历史命令
- ctrl+f 光标前移
- ctrl+b 光标后退
- ctrl+a 到行首
- ctrl+e 到行尾
- ctrl+d 删除一个字符,删除一个字符,相当于通常的Delete键
- ctrl+h 退格删除一个字符,相当于通常的Backspace键
- ctrl+u 删除到行首
- ctrl+k 删除到行尾
- ctrl+l 类似 clear 命令效果
- ctrl+y 粘贴
参考
https://www.swyx.io/new-mac-setup-2021/
https://xiaozhou.net/learn-the-command-line-iterm-and-zsh-2017-06-23.html
]]>MQTT 协议 因为其轻量、灵活等特点成为了当今世界上最受欢迎的物联网协议,它已经广泛应用于车联网、智能家居、物流、即时聊天应用和移动消息推送等领域,连接了数以亿计的设备,并且每时每刻都有无数设备开始使用和接入 MQTT 协议。MQTT 协议为这些设备提供了稳定、可靠的通信基础,这些设备庞大的接入数量也向 MQTT 协议规范提出了挑战,MQTT 5.0 的诞生便是为了更好地满足这一需求。
MQTT 历史
MQTT(消息队列遥测传输)最初由 IBM 于上世纪 90 年代晚期发明。它最初的用途是将石油管道上的传感器与卫星相链接,所以 MQTT 从诞生之初就是专为受限设备和低带宽、高延迟或不可靠的网络而设计,它使用了发布订阅模型,在空间和时间上解耦了消息的发送者与接收者,并且基于 TCP/IP 提供稳定可靠的网络连接,拥有非常轻量的报头以减少传输开销,支持可靠消息传输,可以说天生就满足了物联网场景的各种需求。在 MQTT 3.1.1 发布并成为 OASIS 标准的四年后,MQTT 5.0 正式发布,这是一次重大的改进和升级,它的目的不仅仅是满足现阶段的行业需求,更是为行业未来的发展变化做了充足的准备。2019 年 3 月,MQTT 5.0 成为了新的 OASIS 标准。
MQTT 5.0 设计目标
面对迅速增长的设备数量和层出不穷的需求,OASIS MQTT 技术委员会需要从繁杂的需求中提取出通用部分,将其纳入标准规范,并且尽可能不增加开销或降低易用性,在不增加不必要的复杂性的前提下提高性能和易用性。
最终,OASIS MQTT 技术委员会为 MQTT 5.0 添加了大量的全新功能与特性,5.0 成为 MQTT 有史以来变化最大的一个版本。在这里,我们将列举一些比较重要的特性:
- 改进的错误报告。现在,所有响应报文都将包含原因码和可选的人类易读的原因字符串。
- 规范通用模式,包括能力发现和请求响应等。
- 对共享订阅的协议支持,此前标准无共享订阅的内容,共享订阅由各个软件厂商自已定义,不具备通用性。
- 新的扩展机制,包括用户属性。
- 引入主题别名等新特性进一步减小传输开销
- 增加了会话过期间隔和消息过期间隔,用以改善老版本中 Clean Session 不够灵活的地方。
完整的新属性列表包含在协议标准的附录C,您可以访问以下网址了解详情:https://docs.oasis-open.org/mqtt/mqtt/v5.0/cs02/mqtt-v5.0-cs02.html#AppendixC。
拥抱 MQTT 5.0
随着各 MQTT 服务器 厂商不断加入 MQTT 5.0 的支持阵营(例如 EMQ 在 2018 年 9 月就已经完整支持了 MQTT 5.0 协议),整个行业生态逐步迁移至 MQTT 5.0 已经成为大的趋势,MQTT 5.0 也将是未来绝大多数物联网企业的首选。我们也希望用户能够尽早拥抱 MQTT 5.0 并且享受到它带来的便利,这也是这篇文章的目的。如果您已经对 MQTT 5.0 产生了一些兴趣,但还想了解更多,您可以尝试阅读以下文章,我们将以通俗易懂的方式为您介绍 MQTT 5.0 的重要特性:
- 全新开始标识与会话过期间隔
- 消息过期间隔
- 原因码与 ACK
- 载荷格式和内容类型
- 请求响应
- 共享订阅
- 订阅标识符与订阅选项
- 主题别名
- 流量控制
- 用户属性
- 增强认证
MQTT v5.0 中的 Clean Start 与 Session Expiry Interval,对于有 MQTT v3.1.1 版本协议使用经验的朋友,一定不会感觉陌生,因为这两个字段与之前版本中的 Clean Session 非常相似。但它们在实际使用中远比 Clean Session 灵活,下文将详细介绍这几个字段的作用与区别。
MQTT v3.1.1 版本的 Clean Session
如果 Clean Session 设置为 0,服务端必须使用与 Client ID 关联的会话来恢复与客户端的通信。如果不存在这样的会话,服务器必须创建一个新会话。客户端和服务器在断开连接后必须存储会话的状态。
如果 Clean Session 设置为 1,客户端和服务器必须丢弃任何先前的会话并创建一个新的会话。该会话的生命周期将和网络连接保持一致,其会话状态一定不能被之后的任何会话重用。

可以看出,MQTT 期望通过这种持久会话的机制避免客户端掉线重连后消息的丢失,并且免去客户端连接后重复的订阅流程。这一功能在带宽小,网络不稳定的物联网场景中非常实用。但 Clean Session 同时限定了客户端和服务器在连接和断开连接两种状态下的行为,这并不是一个很好的实现。此外,在某些场景下会话并不需要服务器永久保留自己的状态时,这个机制将会导致服务器资源的浪费。
MQTT v5.0 版本的 Clean Start 与 Session Expiry Interval
如果 CONNECT 报文中的 Clean Start 为 1,客户端和服务端必须丢弃任何已存在的会话,并开始一个新的会话。
如果 CONNECT 报文中的 Clean Start 为 0 ,并且存在一个关联此客户端标识符的会话,服务端必须基于此会话的状态恢复与客户端的通信。如果不存在任何关联此客户端标识符的会话,服务端必须创建一个新的会话。
Session Expiry Interval 以秒为单位,如果 Session Expiry Interval 设置为 0 或者未指定,会话将在网络连接关闭时结束。
如果 Session Expiry Interval 为 0xFFFFFFFF ,则会话永不过期。
如果网络连接关闭时(DISCONNECT 报文中的 Session Expiry Interval 可以覆盖 CONNECT 报文中的设置) Session Expiry Interval 大于0,则客户端与服务端必须存储会话状态 。

现在,Clean Start 替代了原先的 Clean Session,但不再用于指示是否存储会话状态,仅用于指示服务端在连接时应该尝试恢复之前的会话还是直接创建全新的会话。会话状态在服务端的存储时长则完全交给 Session Expiry Interval 决定。
前面还提到,MQTT v5.0 支持客户端在断开连接时重新指定 Seesion Expiry Interval。这样我们可以非常容易地满足类似客户端网络连接异常断开时会话状态被服务器保留,客户端正常下线时会话则随着连接关闭而结束的场景,只需要客户端在断开连接时将 Session Expiry Interval 设置为 0 即可。即便是一个已经永不过期的会话,客户端也可以在下一次连接中通过设置 Clean Start 为 1 来 "反悔"。
Clean Start 与 Session Expiry Interval 不仅解决了 Clean Session 的遗留问题,同时也扩展了客户端的使用场景,使 MQTT 协议在受限的网络环境下更加实用。
]]>为了提高消息吞吐效率和减少网络波动带来的影响,EMQ X 消息服务器允许多个未确认的 QoS 1 和 QoS 2 报文同时存在于网路链路上。这些已发送但未确认的报文将被存放在 inflight Window 中直至完成确认。
当网络链路中同时存在的报文超出限制,即 Inflight Window 到达长度限制(见 max_inflight)时,EMQ X 消息服务器将不再发送后续的报文,而是将这些报文存储在 Message Queue 中。一旦 Inflight Window 中有报文完成确认,Message Queue 中的报文就会以先入先出的顺序被发送,同时存储到 Inflight Window 中。
当客户端离线时,Message Queue 还会被用来存储 QoS 0 消息,这些消息将在客户端下次上线时被发送。这功能默认开启,当然你也可以手动关闭,见 mqueue_store_qos0。
需要注意的是,如果 Message Queue 也到达了长度限制,后续的报文将依然缓存到 Message Queue,但相应的 Message Queue 中最先缓存的消息将被丢弃。如果队列中存在 QoS 0 消息,那么将优先丢弃 QoS 0 消息。因此,根据你的实际情况配置一个合适的 Message Queue 长度限制(见 max_mqueue_len)是非常重要的。
Inflight Window 与 Receive Maximum
MQTT v5.0 协议为 CONNECT 报文新增了一个 Receive Maximum 的属性,官方对它的解释是:客户端使用此值限制客户端愿意同时处理的 QoS 为 1 和 QoS 为 2 的发布消息最大数量。没有机制可以限制服务端试图发送的 QoS 为 0 的发布消息。也就是说,服务端可以在等待确认时使用不同的报文标识符向客户端发送后续的 PUBLISH 报文,直到未被确认的报文数量到达 Receive Maximum 限制。
不难看出,Receive Maximum 其实与 EMQ X 消息服务器中的 Inflight Window 机制如出一辙,只是在 MQTT v5.0 协议发布前,EMQ X 就已经对接入的 MQTT 客户端提供了这一功能。现在,使用 MQTT v5.0 协议的客户端将按照 Receive Maximum 的规范来设置 Inflight Window 的最大长度,而更低版本 MQTT 协议的客户端则依然按照配置来设置。
配置项
| 配置项 | 类型 | 可取值 | 默认值 | 说明 |
|---|---|---|---|---|
| max_inflight | integer | >= 0 | 32 (external), 128 (internal) |
Inflight Window 长度限制,0 即无限制 |
| max_mqueue_len | integer | >= 0 | 1000 (external), 10000 (internal) |
Message Queue 长度限制,0 即无限制 |
| mqueue_store_qos0 | enum | true, false |
true | 客户端离线时 EMQ X 是否存储 QoS 0 消息至 Message Queue |
共享订阅是 MQTT 5.0 协议引入的新特性,相当于是订阅端的负载均衡功能。
我们知道一般的非共享订阅的消息发布流程是这样的:

在这种结构下,如果订阅节点发生故障,就会导致发布者的消息丢失(QoS 0)或者堆积在 Server 中(QoS 1, 2)。一般情况下,解决这个问题的办法都是直接增加订阅节点,但这样又产生了大量的重复消息,不仅浪费性能,在某些业务场景下,订阅节点还需要自行去重,进一步增加了业务的复杂度。
其次,当发布者的生产能力较强时,可能会出现订阅者的消费能力无法及时跟上的情况,此时只能由订阅者自行实现负载均衡来解决,又一次增加了用户的开发成本。
协议规范
现在,在 MQTT 5.0 协议中,你可以通过共享订阅特性解决上面提到的问题。当你使用共享订阅时,消息的流向就会变为:

同非共享订阅一样,共享订阅包含一个主题过滤器和订阅选项,唯一的区别在于共享订阅的主题过滤器格式必须是 $share/{ShareName}/{filter} 这种形式。这几个的字段的含义分别是:
$share前缀表明这将是一个共享订阅{ShareName}是一个不包含 "/", "+" 以及 "#" 的字符串。订阅会话通过使用相同的{ShareName}表示共享同一个订阅,匹配该订阅的消息每次只会发布给其中一个会话{filter}即非共享订阅中的主题过滤器
需要注意的是,如果服务端正在向其选中的订阅端发送 QoS 2 消息,并且在分发完成之前网络中断,服务端会在订阅端重新连接时继续完成该消息的分发。如果订阅端的会话在其重连之前终止,服务!端将丢弃该消息而不尝试发送给其他订阅端。如果是 QoS 1 消息,服务端可以等订阅端重新连接之后继续完成分发,也可以在订阅端断开连接时就立即尝试将消息分发给其他订阅端,MQTT 协议没有强制规定,因此需要视服务器的具体实现而定。但如果在等待订阅端重连期间其会话终止,服务端则会将消息尝试发送给其他订阅端。
共享策略
虽然共享订阅使得订阅端能够负载均衡地消费消息,但 MQTT 协议并没有规定 Server 应当使用什么负载均衡策略。作为参考,EMQ X 提供了 random, round_robin, sticky, hash 四种策略供用户自行选择。
- random: 在所有共享订阅会话中随机选择一个发送消息
- round_robin: 按照订阅顺序轮流选择
- sticky: 使用 random 策略随机选择一个订阅会话,持续使用至该会话取消订阅或断开连接再重复这一流程
- hash: 对发送者的 ClientID 进行 hash 操作,根据 hash 结果选择订阅会话
效果演示
最后,我们通过一个综合性的示例来演示共享订阅的效果。
服务端使用 emqx-v3.2.4,客户端使用 emqtt,emqx 的共享订阅分发策略为默认的 random:
broker.shared_subscription_strategy = random
使用 ./emqx start 启动 emqx,然后使用 emqtt 启动三个订阅客户端,分别订阅 $share/a/topic, $share/a/topic, $share/b/topic

启动一个发布客户端,向 topic 主题发布消息。

$share/a/topic 与 $share/b/topic 属于不同的会话组,非共享订阅主题 topic 会在所有的会话组中进行负载均衡。客户端 sub3 因为组内只有自己一个会话,所以收到了所有消息,而客户端 sub1 与 sub2 则是遵循我们配置的 random 策略随机接收消息。
在物联网的应用场景中,安全设计是非常重要的一个环节,敏感数据泄露或是边缘设备被非法控制等事故都是不可接受的,但是相比于其他应用场景,物联网项目还存在着以下局限:
- 安全性与高性能之间不可以兼顾;
- 加密算法需要更多的算力,而物联网设备的性能往往非常有限;
- 物联网的网络条件常常要比家庭或者办公室的网络条件差许多。
为了解决上述问题,MQTT 协议 提供了简单认证和增强认证,方便在应用层验证设备。
简单认证
MQTT CONNECT 报文使用用户名和密码支持基本的网络连接认证,这个方法被称为简单认证。该方法也可以被用来承载其他形式的认证,例如把密码作为令牌(Token)传递。
服务器在收到 CONNECT 报文后,可以通过其包含的用户名和密码来验证客户端的合法性,保障业务的安全。
相比于增强认证,简单认证对于客户端和服务器的算力占用都很低,对于安全性要求不是那么高,计算资源紧张的业务,可以使用简单认证。
但是,在基于用户名和密码这种简单认证模型的协议中,客户端和服务器都知道一个用户名对应一个密码。在不对信道进行加密的前提下,无论是直接使用明文传输用户名和密码,还是给密码加个哈希的方法都很容易被攻击。
增强认证
基于更强的安全性考虑,MQTT v5 增加了新特性 增强认证,增强认证包含质询/响应风格的认证,可以实现对客户端和服务器的双向认证,服务器可以验证连接的客户端是否是真正的客户端,客户端也可以验证连接的服务器是否是真正的服务器,从而提供了更高的安全性。
增强认证依赖于认证方法和认证数据来完成整个认证过程,在增强认证中,认证方法通常为 SASL( Simple Authentication and Security Layer ) 机制,使用一个注册过的名称便于信息交换。但是,认证方法不限于使用已注册的 SASL 机制,服务器和客户端可以约定使用任何质询 / 响应风格的认证。
认证方法
认证方法是一个 UTF-8 的字符串,用于指定身份验证方式,客户端和服务器需要同时支持指定的认证方法。客户端通过在 CONNECT 报文中添加认证方法字段来启动增强认证,增强认证过程中客户端和服务器交换的报文都需要包含认证方法字段,并且认证方法必须与 CONNECT 报文保持一致。
认证数据
认证数据是二进制信息,用于传输加密机密或协议步骤的多次迭代。认证数据的内容高度依赖于认证方法的具体实现。
增强认证流程
相比于依靠 CONNECT 报文和 CONNACK 报文一次交互的简单认证,增强认证需要客户端与服务器之间多次交换认证数据,因此,MQTT v5 新增了 AUTH 报文来实现这个需求。增强认证是基于 CONNECT 报文、CONNACK 报文以及 AUTH 报文三种 MQTT 报文类型实现的,三种报文都需要携带认证方法与认证数据达成双向认证的目的。
要开启增强认证流程,需要客户端向服务器发送包含了认证方法字段的 CONNECT 报文,服务器收到了 CONNECT 报文后,它可以与客户端通过 AUTH 报文继续交换认证数据,在认证完成后向客户端发送 CONNACK 报文。
SCRAM 认证非规范示例
-
客户端到服务端: CONNECT 认证方法="SCRAM-SHA-1",认证数据=client-first-data
-
服务端到客户端: AUTH 原因码=0x18,认证方法="SCRAM-SHA-1",认证数据=server-first-data
-
客户端到服务端: AUTH 原因码=0x18,认证方法="SCRAM-SHA-1",认证数据=client-final-data
-
服务端到客户端: CONNACK 原因码=0,认证方法="SCRAM-SHA-1",认证数据=server-final-data
Kerberos 认证非规范示例
- 客户端到服务端: CONNECT 认证方法="GS2-KRB5"
- 服务端到客户端: AUTH 原因码=0x18,认证方法="GS2-KRB5"
- 客户端到服务端: AUTH 原因码=0x18,认证方法="GS2-KRB5",认证数据=initial context token
- 服务端到客户端: AUTH 原因码=0x18,认证方法="GS2-KRB5",认证数据=reply context token
- 客户端到服务端: AUTH 原因码=0x18,认证方法="GS2-KRB5"
- 服务端到客户端: CONNACK 原因码=0,认证方法="GS2-KRB5",认证数据=outcome of authentication
在增强认证的过程中,客户端与服务器需要进行多次认证数据的交换,每次交换都需要通过认证算法对认证数据进行加解密的计算,所以它需要更多的计算资源以及更稳定的网络环境,因此它并不适合算力薄弱、网络波动大的边缘设备,而支持增强认证的 MQTT 服务器 也需要准备更多的计算资源来应对大量的连接。
重新认证
增强认证完成之后,客户端可以在任意时间通过发送 AUTH 报文发起重新认证,重新认证开始后,同增强认证一样,客户端与服务器通过交换 AUTH 报文来交换认证数据,直到服务器向客户端发送原因码为 0x00( 成功) 的 AUTH 报文表示重新认证成功。需要注意的是,重新认证的认证方法必须与增强认证一致。
在重新认证的过程中,客户端和服务器的其他报文流可以继续使用之前的认证。
]]>MQTT 5.0 协议中携带有效载荷的报文有 CONNECT 报文,PUBLISH 报文,SUBSCRIBE 报文,SUBACK 报文,UNSUBSCRIBE 报文和 UNSUBACK 报文。
PUBLISH 报文的有效载荷负责存储消息内容,与 MQTT 3.1.1 协议相同。
CONNECT 报文
CONNECT 报文的可变头部新增的属性有:

在 CONNECT 报文的 Payload 中,部分字段发生了变化,遗嘱消息(Will Message)变成了遗嘱载荷(Will Payload)。Payload 中新增了遗嘱属性(Will Properties),用于定义遗嘱消息的行为。
新增的遗嘱属性有:

CONNACK 报文
CONNACK 报文没有 Payload,在可变头部中包含的属性有:

PUBLISH 报文
PUBLISH 报文可变头部的属性有:

PUBACK, PUBREC, PUBREL, PUBCOMP, SUBACK, UNSUBACK 报文
PUBACK, PUBREC, PUBREL, PUBCOMP, SUBACK, UNSUBACK 都具备以下三个属性:

SUBSCRIBE 报文
SUBSCRIBE 报文的属性同样存在可变头部中。

MQTT 5.0 中 SUBSCRIBE 报文中的 Payload 包含了订阅选项(Subscription Options)。

订阅选项(Subscription Options)的第 0 位和第 1 位表示 QoS 最大值。该字段给出了服务器可以发送给客户端应用消息的最大 QoS 等级。如果 QoS 值为 3,就会触发协议错误。
订阅选项第 2 位表示非本地选项(No Local)。如果值为 1,应用消息就不会发布给订阅发布主题的发布者本身,如果在共享订阅中将该选项设置为 1 的话,就会触发协议错误。
订阅选项的第 3 位表示保留为已发布(Retain As Published)。若该值为 1,服务器须将转发消息的 RETAIN flag 设为与接收到的 PUBLISH 报文的 RETAIN flag 一致。若该值为 0,不管接收到的 PUBLISH 报文中的 RETAIN flag 是何值,服务器都需将转发消息的 RETAIN flag 置为 0。
订阅选项的第 4 第 5 位表示保留处理 (Retain Handling)。该选项是用来控制保留消息 (retained message) 的发送。当保留处理的值为 0 时,服务器须将保留消息转发到与订阅匹配的主题上去。当该值为 1 时,如果订阅已经不存在了,那么服务器需要将保留消息转发给与订阅匹配的主题上,但是如果订阅存在,服务器就无法再转发保留消息。当该值为 2 时,服务器不转发保留消息。
订阅选项的第 6 第 7 位是预留给未来使用的。如果有效载荷的任何一个预留位非零,那么服务器就会将该报文视为格式错误的报文。
UNSUBSCRIBE 报文
UNSUBSCRIBE 报文仅有两个属性:属性长度和用户属性。
UNSUBSCRIBE 报文的载荷相比 SUBSCRIBE 的载荷要简单很多,它仅仅只是包含主题过滤器的列表,并不包含各种各样的订阅选项。
服务器就会将该报文视为格式错误的报文。
DISCONNECT 报文(新增)
DISCONNECT 报文是 MQTT 5.0 新增的报文,它的引入意味着 mqtt broker 拥有了主动断开连接的能力。DISCONNECT 报文所具备的属性有:

流量控制
通常服务端的资源都是固定且有限的,而客户端的流量则可能是随时随地变化的。正常业务(用户集中访问、设备大量重启)、被恶意攻击、网络波动,都会导致流量出现激增,如果服务端没有对其进行任何限制,就会导致负载迅速上升,进而导致响应速度下降,影响其他业务,甚至导致系统瘫痪。

因此,我们需要流量控制,可以是限制发送端的发送速率,也可以是限制接收端的接收速率,但最终目的都是保证系统的稳定。常用的流控算法有滑动窗口计数法、漏桶算法以及令牌桶算法。
MQTT v3 没有规范流量控制行为,导致客户端和服务端在实现上百花齐放,进而影响了设备的接入和管理。不过现在,MQTT v5 已经引入了流量控制功能,这也是我们接下来将要探讨的内容。
MQTT v5 中的流量控制
在 MQTT v5 中,发送端会有一个初始的发送配额,每当它发送一个 QoS 大于 0 的 PUBLISH 报文,发送配额就相应减一,而每当收到一个响应报文(PUBACK、PUBCOMP 或 PUBREC),发送配额就会加一。如果接收端没有及时响应,导致发送端的发送配额减为 0,发送端应当停止发送所有 QoS 大于 0 的 PUBLISH 报文直至发送配额恢复。我们可以将其视为变种的令牌桶算法,它们之间的区别仅仅是增加配额的方式从以固定速率增加变成了按实际收到响应报文的速率增加。
这种算法能够更加积极和充分地利用资源,因为它没有在发送速率的层面上进行限制,发送速率完全取决于对端的响应速率和网络情况,如果接收端空闲且网络良好,那么发送端可以得到比较高的发送速率,反之则会被限制到一个比较低的发送速率上。
Receive Maximum 属性
为了支持流量控制,MQTT v5 新增了一个 Receive Maximum 属性,它存在于 CONNECT 报文与 CONNACK 报文,表示客户端或服务端愿意同时处理的 QoS 为 1 和 2 的 PUBLISH 报文最大数量,即对端可以使用的最大发送配额。如果接收端已收到但未发送响应的 QoS 大于 0 的 PUBLISH 报文数量超过 Receive Maximum 的值,接收端将断开连接避免受到更严重的影响。

为什么没有 QoS 0 ?
也许你已经发现,前文所有提到 PUBLISH 报文的地方都使用了定语: QoS 大于 0。QoS 0 消息的特性决定了它不存在响应报文,也许是觉得 QoS 0 消息的重要性不高,接收端可以通过强制的接收速率限制来约束 QoS 0 消息,也许是其他原因,总之最后我们看到的 MQTT v5 的流量控制机制完全依赖响应报文,这就导致它的流量控制只能局限在 QoS 1,2 消息中。
聊胜于无,MQTT v5 给出了一个并不完美的解决方案,或者说仅仅只是一个建议:当发送配额减为 0 时,发送端可以选择继续发送 QoS 为 0 的 PUBLISH 报文,也可以选择暂停发送。其中暂停发送的行为逻辑是,如果 QoS 1,2 的 PUBLISH 报文的应答速度变慢,通常意味着接收端的消费能力已经下降,继续发送 QoS 0 消息只会令情况变得更糟。
结论
尽管 MQTT v5 的流量控制机制依然存在一些不足,但我们依然建议用户尽可能地使用它。基于响应报文的发送配额算法使得发送端能够最大程度地利用资源,Receive Maximum 使得通信双方不再需要事先协商发送配额,从而获得更高的透明度和灵活性,这在需要接入多厂商设备时是很有帮助的。
]]>订阅标识符
客户端可以在订阅时指定一个订阅标识符,服务端将在订阅成功创建或修改时建立并存储该订阅与订阅标识符的映射关系。当有匹配该订阅的 PUBLISH 报文要转发给此客户端时,服务端会将与该订阅关联的订阅标识符随 PUBLISH 报文一并返回给客户端。
因此,客户端可以建立订阅标识符与消息处理程序的映射,以在收到 PUBLISH 报文时直接通过订阅标识符将消息定向至对应的消息处理程序,这会远远快于通过主题匹配来查找消息处理程序的速度。

由于 SUBSCRIBE 报文支持包含多个订阅,因此可能出现多个订阅关联到同一个订阅标识符的情况。即便是分开订阅,也可能出现这种情况,但这是被允许的,只是用户应当意识到这样使用可能引起的后果。根据客户端的实际订阅情况,最终客户端收到的 PUBLISH 报文中可能包含多个订阅标识符,这些标识符可能完全不同,也可能有些是相同的,以下是几种常见的情况:
- 客户端订阅主题
a并指定订阅标识符为 1,订阅主题b并指定订阅标识符为 2。由于使用了不同的订阅标识符,主题为a和b的消息能够被定向至不同的消息处理程序。 - 客户端订阅主题
a并指定订阅标识符为 1,订阅主题b并指定订阅标识符为 1。由于使用了相同的订阅标识符,主题为a和b的消息都将被定向至同一个消息处理程序。 - 客户端订阅主题
a/+并指定订阅标识符为 1,订阅主题a/b并指定订阅标识符为 1。主题为a/b的 PUBLISH 报文将会携带两个相同的订阅标识符,对应的消息处理程序将被触发两次。 - 客户端订阅主题
a/+并指定订阅标识符为 1,订阅主题a/b并指定订阅标识符为 2。主题为a/b的 PUBLISH 报文将会携带两个不同的订阅标识符,一个消息将触发两个不同的消息处理程序。

这种 PUBLISH 报文中携带多个订阅标识符的情况,在消息速率低的时候通常不成问题,但在消息速率高时可能会引发一些性能问题,因此我们建议您尽量确保这种情况的出现都是您有意为之。
订阅选项
在 MQTT v5 中,你可以使用更多的订阅选项来改变服务端的行为。

QoS
参见 MQTT 消息服务质量等级。
No Local
在 MQTT v3.1.1 中,如果你订阅了自己发布消息的主题,那么你将收到自己发布的所有消息。
而在 MQTT v5 中,如果你在订阅时将此选项设置为 1,那么服务端将不会向你转发你自己发布的消息。
Retain As Publish
这一选项用来指定服务端向客户端转发消息时是否要保留其中的 RETAIN 标识,注意这一选项不会影响保留消息中的 RETAIN 标识。因此当 Retain As Publish 选项被设置为 0 时,客户端直接依靠消息中的 RETAIN 标识来区分这是一个正常的转发消息还是一个保留消息,而不是去判断消息是否是自己订阅后收到的第一个消息(转发消息甚至可能会先于保留消息被发送,视不同 Broker 的具体实现而定)。
Retain Handling
这一选项用来指定订阅建立时服务端是否向客户端发送保留消息:
- Retain Handling 等于 0,只要客户端订阅成功,服务端就发送保留消息。
- Retain Handling 等于 1,客户端订阅成功且该订阅此前不存在,服务端才发送保留消息。毕竟有些时候客户端重新发起订阅可能只是为了改变一下 QoS,并不意味着它想再次接收保留消息。
- Retain Handling 等于 2,即便客户订阅成功,服务端也不会发送保留消息。
请求响应
我们知道,在 MQTT 中客户端可以向指定主题发布消息,也可以订阅指定主题以接收感兴趣的消息。在明确有人订阅的情况下,大于 0 的 QoS 可以保证消息送达至订阅端 [^1]。但如果结合一些业务场景,即不仅仅是将消息投递至订阅端,可能需要订阅端触发一些行为并返回结果,又或者是需要向订阅端请求一些信息,发布订阅模式下的实现就会稍显笨重,通信双方需要事先协商好请求主题和响应主题。
如果同一个请求主题存在多个请求方,为了将响应正确地返回给请求方,需要多个不同的响应主题,最常见的办法就是在 Payload 首部或是其他位置插入客户端标识符(Client ID)等能够唯一标识该请求客户端的字段,响应方在收到请求后按照事先约定的规则提取这些字段以及真正的 Payload,并将这些字段用于构造响应主题。

但显然这不是一个好的实现,我们期望请求接收方只需要关注怎么处理请求即可,而不用花费额外的精力考虑怎么将响应正确返回给请求方。因此,MQTT 5.0 新增了 响应主题(Response Topic) 属性,并定义了以下请求响应交互过程:
- MQTT 客户端(请求方)向请求主题发布包含 响应主题 属性的请求消息。
- 假如有其他 MQTT 客户端(响应方)订阅了与请求消息发布时使用的主题名相匹配的主题过滤器,那么将收到该请求消息。
- 响应方根据请求消息采取适当的操作,然后向该 响应主题 属性指定的主题发布响应消息。

对比数据
与 HTTP 的请求响应模式不同,MQTT 的请求响应是异步的,这带来了一个问题,即响应消息与请求消息如何关联。最常用的办法就是在请求消息中携带一个特征字段,响应方在响应时将收到的字段原封不动地返回,请求方在收到响应消息时就可以根据其中的特征字段来匹配相应的请求。很显然 MQTT 也是这么考虑的,所以为 PUBLISH 报文新增了一个 对比数据(Correlation Data) 属性。

响应信息
前面已经提到,可能存在多个请求方同时发起请求的情况,为避免不同请求方之间的冲突,请求方客户端使用的响应主题最好对于该客户端是唯一的。由于请求方和响应方通常都需要对这些主题进行授权,因此使用随机主题名称将会对授权造成挑战。
为了解决此问题,MQTT 5.0 在 CONNACK 报文中定义了一个名为响应信息的属性。服务端可以使用此属性指导客户端如何选择使用的响应主题。此机制对于服务端和客户端都是可选的。连接时,客户端通过设置 CONNECT 报文中的请求响应信息属性来请求服务端发送响应信息。这会导致服务端在 CONNACK 报文中插入响应信息属性,请求方可以使用响应信息来构建响应主题。

使用建议
-
由于发布订阅模式本身的一些局限性,使用大于 0 的 QoS 也只能保证消息到达了对端而不是订阅端,如果发布消息时订阅端还未完成订阅,那么消息就会丢失,但发布方却无法得知。因此,对于一些投递要求比较严格的消息,可以通过请求响应来确认消息是否到达订阅端。
-
某些数据上报类的应用,当你感觉上报时间间隔设置得太长太短都不合适时,也许你可以尝试改成通过请求响应主动请求数据。但需要注意,如果请求方过多,导致数据实际上报频率大大超过原先的话,反而得不偿失,所以还是需要根据实际场景进行考量。
-
如果你已经正确地使用了 对比数据 属性,那么你可以放心地为响应方使用共享订阅。
-
要特别注意多个响应方订阅同一个请求主题和多个请求方订阅同一个响应主题的情况,请确保你能够正确处理这些情况。
[^1]: QoS 大于 0 时,发布者保证消息投递给服务端,服务端保留消息投递给订阅者。
]]>- 实现简单
- 提供数据传输的 QoS
- 轻量、占用带宽低
- 可传输任意类型的数据
- 可保持的会话(session)
之后 IBM 一直将 MQTT 作为一个内部协议在其产品中使用,直到 2010 年,IBM 公开发布了 MQTT 3.1 版本。 在 2014 年,MQTT 协议正式成为了 OASIS(结构化信息标准促进组织)的标准协议。简单地来说MQTT协议具有以下特性:
基于 TCP 协议的应用层协议;
- 采用 C/S 架构;
- 使用订阅/发布模式,将消息的发送方和接受方解耦;
- 提供 3 种消息的 QoS(Quality of Service): 至多一次,最少一次,只有一次;
- 收发消息都是异步的,发送方不需要等待接收方应答。
下文将从以下四个方面对MQTT的基础概念进行介绍:
- MQTT 协议的通信模型
- MQTT Client
- MQTT Broker
- MQTT协议数据包
1. MQTT 协议的通信模型
MQTT 的通信是通过发布/订阅的方式来实现的,订阅和发布又是基于主题(Topic)的。 发布方和订阅方通过这种方式来进行解耦,它们没有直接地连接,它们需要一个中间方。 在 MQTT 里面我们称之为 Broker,用来进行消息的存储和转发。一次典型的 MQTT 消息通信流程如下所示:

- 发布方(Publisher)连接到Broker;
- 订阅方(Subscriber)连接到Broker,并订阅主题Topic1;
- 发布方(Publisher)发送给Broker一条消息,主题为Topic1;
- Broker收到了发布方的消息,发现订阅方(Subscriber)订阅了Topic1,然后将消息转发给订阅方(Subscriber);
- 订阅方从Broker接收该消息;
MQTT通过订阅与发布模型对消息的发布方和订阅方进行解耦后,发布方在发布消息时并不需要订阅方也连接到Broker,只要订阅方之前订阅过相应主题,那么它在连接到Broker之后就可以收到发布方在它离线期间发布的消息。我们可以称这种消息为离线消息。
在该通信模型中,有两组身份需要区别:
- 一组是发布方Publisher和订阅方Subscriber
- 另一组是发送方Sender和接收方Receiver
1.1. Publisher和Subscriber
publisher和subscriber是相对于Topic来说的身份,如果一个Client向某个Topic发布消息,那么这个Client就是publisher; 如果一个Client订阅了某个Topic,那么它就是Subscriber。
1.2. Sender和Receiver
Sender和Receiver则是相对于消息传输方向的身份。当publisher向Broker发送消息时,那么此时publisher是sender,Broker是receiver; 当Broker转发消息给subscriber时,此时Broker是sender,subscriber是receiver。
2. MQTT Client
Publisher 和 Subscriber 都属于 Client,Publisher 或者 Subscriber 只取决于该 Client 当前的状态——是在发布消息还是在订阅消息。 当然,一个 Client 可以同时是 Publisher 和 Subscriber。 client的范围很广,任何终端、嵌入式设备、服务器只要运行了MQTT的库或者代码,都可以称为MQTT Client。 MQTT Client库很多语言都有实现,可以在这个网址中找到:MQTT Client库大全
3. MQTT Broker
MQTT Broker负责接收Publisher的消息,并发送给相应的Subscriber,是整个MQTT 订阅/发布的核心。 现在很多云服务器提供商都有提供MQTT 服务,比如阿里云、腾讯云等。 当然我们自己也可以搭建一个MQTT Broker
TIP
常见的MQTT Broker有Eclipse Mosquitto , EMQ X Broker和 HiveMQ等 个人推荐EMQ X Broker,国人开发,开源,自带一个web管理界面,非常方便。 更多客户端和服务端参见:https://github.com/mqtt/mqtt.org/wiki/libraries
4. MQTT协议数据包
MQTT 协议数据包的消息格式为:固定头|可变头|消息体
由下面三个部分组成:
- 固定头(Fixed header): 存在于所有的MQTT数据包中,用于表示数据包类型及对应标志、数据包大小等;
- 可变头(Variable header): 存在于部分类型的MQTT数据包中,具体内容是由相应类型的数据包决定的;
- 消息体(Payload): 存在于部分的MQTT数据包中,存储消息的具体数据。
4.1. 固定头
固定头格式:

固定头的第一个字节的高4位Bit用于表示该数据包的类型,MQTT的数据包有以下一些类型:
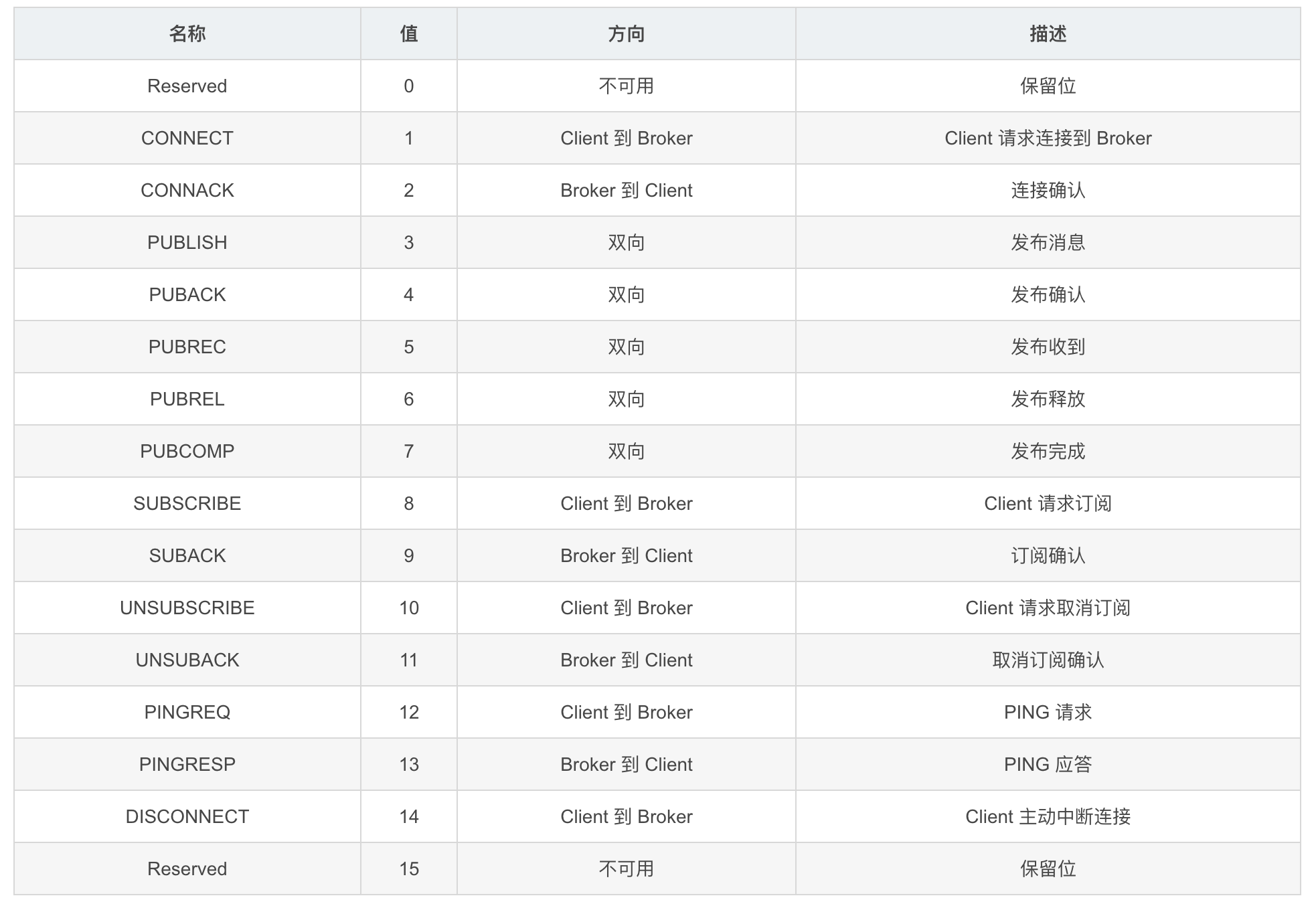
4.2. 可变头
可变报文头主要包含协议名、协议版本、连接标志(Connect Flags)、心跳间隔时间(Keep Alive timer)、连接返回码(Connect Return Code)、主题名(Topic Name)等,后面会针对此部分进行具体讲解。
4.3. 消息体
当MQTT发送的消息类型是CONNECT(连接)、PUBLISH(发布)、SUBSCRIBE(订阅)、SUBACK(订阅确认)、UNSUBSCRIBE(取消订阅)时,则会带有负荷。
参考
]]>MQTT设计了一套保证消息稳定传输的机制,包括消息应答、存储和重传。 为了保证消息被正确的接收 在这套机制下,提供了三种不同层次QoS(Quality of Service):
- QoS0,At most once,至多一次;
- QoS1,At least once,至少一次;
- QoS2,Exactly once,确保只有一次。
QoS 是消息的发送方(Sender)和接受方(Receiver)之间达成的一个协议:
- QoS0 代表,Sender 发送的一条消息,Receiver 最多能收到一次,也就是说 Sender 尽力向 Receiver 发送消息,如果发送失败,也就算了;
- QoS1 代表,Sender 发送的一条消息,Receiver 至少能收到一次,也就是说 Sender 向 Receiver 发送消息,如果发送失败,会继续重试,直到 Receiver 收到消息为止,但是因为重传的原因,Receiver 有可能会收到重复的消息;
- QoS2 代表,Sender 发送的一条消息,Receiver 确保能收到而且只收到一次,也就是说 Sender 尽力向 Receiver 发送消息,如果发送失败,会继续重试,直到 Receiver 收到消息为止,同时保证 Receiver 不会因为消息重传而收到重复的消息。
WARNING
QoS是Sender和Receiver之间的协议,而不是Publisher和Subscriber之间的协议。 换句话说,Publisher发布了一条QoS1的消息,只能保证Broker能至少收到一次这个消息;
而对于Subscriber能否至少收到一次这个消息,还要取决于Subscriber在Subscribe的时候和Broker协商的QoS等级。
1.1. QoS0
QoS0等级下,Sender和Receiver之间一次消息的传递流程如下:

Sender向Receiver发送一个包含消息数据的PUBLISH包,然后不管结果如何,丢掉已发送的PUBLISH包,一条消息的发送完成。
1.2. QoS1
QoS1要保证消息至少到达一次,所以有一个应答的机制。Sender和Receiver的一次消息的传递流程如下:

1.Sender向Receiver发送一个带有数据的PUBLISH包,并在本地保存这个PUBLISH包; 2.Receiver收到PUBLISH包以后,向Sender发送一个PUBACK数据包,PUBACK数据包没有消息体(Payload),在可变头中有一个包标识(Packet Identifier),和它收到的PUBLISH包中的Packet Identifier一致。 3.Sender收到PUBACK之后,根据PUBACK包中的Packet Identifier找到本地保存的PUBLISH包,然后丢弃掉,一次消息的发送完成。
但是消息传递流程中可能会出现问题:
- 如果Sender在一段时间内没有收到PUBLISH包对应的PUBACK,它将该PUBLISH包的DUP标识设为1(代表是重新发送的PUBLISH包),然后重新发送该PUBLISH包。
- Receiver可能会重复收到消息,需自行去重。
1.3. QoS2
相比QoS0和QoS1,QoS2不仅要确保Receiver能收到Sender发送的消息,还需要确保消息不重复。它的重传和应答机制就要复杂一些,同时开销也是最大的。QoS2下,一次消息的传递流程如下所示:

1.Sender发送QoS为2的PUBLISH数据包,数据包 Packet Identifier 为 P,并在本地保存该PUBLISH包;
2.Receiver收到PUBLISH数据包后,在本地保存PUBLISH包的Packet Identifier P,并回复Sender一个PUBREC数据包,PUBREC数据包可变头中的Packet Identifier为P,没有消息体(Payload);
3.当Sender收到PUBREC,它就可以安全的丢弃掉初始Packet Identifier为P的PUBLISH数据包。同时保存该PUBREC数据包,并回复Receiver一个PUBREL数据包,PUBREL数据包可变头中的Packet Identifier为P,没有消息体;
4.当Receiver收到PUBREL数据包,它可以丢掉保存的PUBLISH包的Packet Identifier P,并回复Sender一个可变头中 Packet Identifier 为 P,没有消息体(Payload)的PUBCOMP数据包;
5.当Sender收到PUBCOMP包,那么认为传输已完成,则丢掉对应的PUBREC数据包;
上面是一次完整无误的传输过程,然而传输过程中可能会出现以下情况:
- 情况1:Sender发送PUBLISH数据包给Receiver的时候,发送失败;
- 情况2:Sender已经成功发送PUBLISH数据包给Receiver了,但是Receiver发送PUBREC数据包失败;
- 情况3:Sender已经成功收到了PUBREC数据包,但是PUBREL数据包发送失败;
- 情况4:Receiver已经收到了PUBREL数据包,但是发送PUBCOMP数据包时发送失败
针对上述的问题,较为详细的处理方法如下:
-
不管是情况1还是情况2,因为Sender在一定时间内没有收到PUBREC,那么它会把PUBLISH包的DUP标识设为1,重新发送该PUBLISH数据包;
-
不管是情况3还是情况4,因为Sender在一定时间内没有收到PUBCOMP包,那么它会重新发送PUBREL数据包;
-
针对情况2,Receiver可能会收到多个重复的PUBLISH包,更加完善的处理如下:
-
Receiver在收到PUBLISH数据包之后,马上回复一个PUBREC数据包。并会在本地保存PUBLISH包的Packet Identifier P,不管之后因为重传多少次这个Packet Identifier 为P的数据包,Receiver都认为是重复的,丢弃。同时Receiver接收到QoS为2的PUBLISH数据包后,**并不马上投递给上层,**而是在本地做持久化,将消息保存起来(这里需要是持久化而不是保存在内存)。
-
针对情况4,更加完善的处理如下:
Receiver收到PUBREL数据包后,正式将消息递交给上层应用层,投递之后销毁Packet Identifier P,并发送PUBCOMP数据包,销毁之前的持久化消息。 之后不管接收到多少个PUBREL数据包,因为没有Packet Identifier P,直接回复PUBCOMP数据包即可。
2. QoS降级
在 MQTT 协议中,从 Broker 到 Subscriber 这段消息传递的实际 QoS 等于:Publisher 发布消息时指定的 QoS 等级和 Subscriber 在订阅时与 Broker 协商的 QoS 等级,这两个 QoS 等级中的最小那一个。
Actual Subscribe QoS = MIN(Publish QoS, Subscribe QoS)
3. QoS和会话
如果 Client 想接收离线消息,必须使用持久化的会话(Clean Session = 0)连接到 Broker,这样 Broker 才会存储 Client 在离线期间没有确认接收的 QoS 大于 等于1 的消息。
在发送QoS为1或2的情况,Broker(此时为Sender)会将发送的PUBLISH数据包保存到本地,直到收到一系列回复的数据包, 然而Client(此时为Receiver)在离线期间无法回复相应的数据包,所以会一直存储。
4. QoS等级使用建议
在以下情况下你可以选择 QoS0:
- Client 和 Broker 之间的网络连接非常稳定,例如一个通过有线网络连接到 Broker 的测试用 Client;
- 可以接受丢失部分消息,比如你有一个传感器以非常短的间隔发布状态数据,所以丢一些也可以接受;
- 你不需要离线消息。
在以下情况下你应该选择 QoS1:
- 你需要接收所有的消息,而且你的应用可以接受并处理重复的消息;
- 你无法接受 QoS2 带来的额外开销,QoS1 发送消息的速度比 QoS2 快很多。
在以下情况下你应该选择 QoS2:
- 你的应用必须接收到所有的消息,而且你的应用在重复的消息下无法正常工作,同时你也能接受 QoS2 带来的额外开销。
参考
]]>MQTT 协议 通过网络传输应用消息,应用消息通过 MQTT 传输时,它们有关联的服务质量(QoS)和主题(Topic)。主题本质上是一个字符串,MQTT 协议规定主题是 UTF-8 编码的字符串,这意味着,主题过滤器和主题名的比较可以通过比较编码后的 UTF-8 字节或解码后的 Unicode 字符。
主题名和主题过滤器
- 主题名 附加在应用消息上的一个标签,服务端已知且与订阅匹配。服务端发送应用消息的一个副本给每一个匹配的客户端订阅。
- 主题过滤器 订阅中包含的一个表达式,用于表示相关的一个或多个主题。主题过滤器可以使用通配符。
如果订阅的主题过滤器与消息的主题名匹配,应用消息会被发送给每一个匹配的客户端订阅。主题资源可以是管理员在服务端预先定义好的,也可以是服务端收到第一个订阅或使用那个主题名的应用消息时动态添加的。服务端可以使用一个安全组件有选择地授权客户端使用某个主题资源。
主题和主题过滤器命名的规则
- 所有的主题名和主题过滤器必须至少包含一个字符。
- 主题名和主题过滤器是大小写敏感的。
ACCOUNTS和Accounts是不同的主题名。 - 主题名和主题过滤器可以包含空格字符。
Accounts payable是合法的主题名 - 主题名或主题过滤器以前置或后置斜杠
/区分。/finance和finance是不同的。 - 只包含斜杠
/的主题名或主题过滤器是合法的。 - 主题名和主题过滤器不能包含
null字符(Unicode U+0000)。 - 主题名和主题过滤器是 UTF-8 编码字符串,除了不能超过 UTF-8 编码字符串的长度限制之外,主题名或主题过滤器的层级数量没有其它限制。
主题层级
主题层级分隔符
斜杠(“/” U+002F)用于分割主题的每个层级,为主题名提供一个分层结构。分隔符用于将结构化引入主题名。如果存在分隔符,它将主题名分割为多个主题层级,是消息主题层级设计中很重要的符号。 比方说:aaa/bbb、aaa/bbb/ccc 和 aaa/bbb/ccc/ddd 这样的消息主题格式,是一个层层递进的关系,可通过多层通配符同时匹配两者,或者单层通配符只匹配一个。 这在现实场景中,可以应用到:公司的部门层级推送、国家城市层级推送等包含层级关系的场景。
MQTT 订阅报文包含一个主题过滤器(Topic Filter)和一个最大的服务质量(QoS)等级。订阅的主题过滤器可以包含特殊的通配符,允许客户端一次订阅多个主题。当客户端订阅指定的主题过滤器包含两种通配符时,主题层级分隔符就很有用了。主题层级分隔符可以出现在主题过滤器或主题名字的任何位置。相邻的主题层次分隔符表示一个零长度的主题层级。
主题过滤器中可以使用通配符,但是主题名不能使用通配符。单层通配符和多层通配符只能用于订阅 (subscribe) 消息而不能用于发布 (publish) 消息,层级分隔符两种情况下均可使用。
多层通配符
井字符号(“#” U+0023)是用于匹配主题中任意层级的通配符。多层通配符表示它的父级和任意数量的子层级。
例如,如果客户端订阅主题 sport/tennis/player1/#,它会收到使用下列主题名发布的消息:
sport/tennis/player1sport/tennis/player1/rankingsport/tennis/player1/score/wimbledon
因为多层通配符包括它自己的父级,所以 sport/# 也匹配单独的 sport 主题名,sport/tennis/player1/# 也可以匹配 sport/tennis/player1。
单独的多层通配符 # 是有效的,它会收到所有的应用消息。
多层通配符必须单独指定,或者跟在主题层级分隔符后面。多层通配符必须是主题过滤器的最后一个字符。因此,sport/tennis# 和 sport/tennis/#/ranking 都是无效的多层通配符。
单层通配符
加号 (“+” U+002B) 是只能用于单个主题层级匹配的通配符。例如,sport/tennis/+ 匹配 sport/tennis/player1 和 sport/tennis/player2 ,但是不匹配 sport/tennis/player1/ranking。同时,由于单层通配符只能匹配一个层级,sport/+ 不匹配 sport 但是却匹配 sport/。
在主题过滤器的任意层级都可以使用单层通配符,包括第一个和最后一个层级,可以在主题过滤器中的多个层级中使用它,也可以和多层通配符一起使用,+、+/tennis/# 、sport/+/player1 都有有效的。在使用单层通配符时,单层通配符占据过滤器的整个层级,sport+ 是无效的。
以 $ 开头的主题
服务端不能将 $ 字符开头的主题名匹配通配符 (#或+) 开头的主题过滤器, 订阅 # 的客户端不会收到任何发布到以 $ 开头主题的消息,订阅 +/monitor/Clients 的客户端也不会收到任何发布到 $SYS/monitor/Clients 的消息。服务端应该阻止客户端使用这种主题名与其他客户端交换消息,客户端注意不能使用 $ 字符开头的主题。
服务端实现可以将 $ 开头的主题名用作其他目的。,例如 $SYS/ 被广泛用作包含服务器特定信息或控制接口的主题的前缀。订阅 $SYS/# 的客户端会收到发布到以 $SYS/ 开头主题的消息,订阅 $SYS/monitor/+ 的客户端会收到发布到 $SYS/monitor/Clients 主题的消息,如果客户端想同时接受以 $SYS/ 开头主题的消息和不以 $ 开头主题的消息,它需要同时订阅 # 和 $SYS/#。
举个例子
比如我们用传感器监视家里的卧室、客厅以及厨房的温度、湿度和空气质量,可以设计一下几个主题:
myhome/bedroom/temperaturemyhome/bedroom/humiditymyhome/bedroom/airqualitymyhome/livingroom/temperaturemyhome/livingroom/humiditymyhome/livingroom/airqualitymyhome/kitchen/temperaturemyhome/kitchen/humiditymyhome/kitchen/airquality
当我们想获取卧室的所有数据时,可以订阅 myhome/bedroom/+ 主题,当我们想获取三个房间的温度数据的时候,可以订阅 myhome/+/temperature 主题,当我们想获取所有的数据的时候,可以订阅 myhome/# 或者 #。
服务端每1分钟给客户端发消息,会造成一个问题,新来的订阅者最极端情况可能无法第一时间获取到信息,需要等1分钟。这样对体验非常不友好。
如何做到订阅后立马收到消息呢?
其实也简单,让服务器保留最后一条最新消息就行了,发送端发送消息的时候带上一个标志,服务端收到后,会把消息存储起来
保留消息存在的意义是为了订阅者能够立即收到消息而无须等待发布者发布下一条消息。
保留消息
发送一条保留消息
从开发者的角度来说,发送一条保留消息是最简单直接的办法。你只需要将一条MQTT发布消息的保留标志(retained flag)置为true。每一个典型的客户端库文件都提供了一个简单方法来实现此操作。
对于paho客户端,发送时候带上-r参数就行了
paho_c_pub -t presence --connection ws://192.168.100.1:8083/mqtt -r -m "test223334567"
如果是用mqttx客户端发送,勾选retain即可

如果你是用MQTT X broker,我们可以设置保留的消息的存储类型,存到内存还是硬盘,保留数量,保留时间等等 文档
删除一条保留消息
保留消息虽然存储在服务端中,但它并不属于会话的一部分。也就是说,即便发布这个保留消息的会话终结,保留消息也不会被删除。
删除保留消息只有两种方式:
前文已经提到过的,客户端往某个主题发送一个 Payload 为空的保留消息,服务端就会删除这个主题下的保留消息。 消息过期间隔属性在保留消息中同样适用,如果客户端设置了这一属性,那么保留消息在服务端存储超过过期时间后就会被删除。
参考
https://www.jianshu.com/p/701ef52c62fd
https://www.emqx.com/zh/blog/message-retention-and-message-expiration-interval-of-emqx-mqtt5-broker
https://www.emqx.com/zh/blog/mqtt5-features-retain-message
https://www.hivemq.com/blog/mqtt-essentials-part-8-retained-messages/
]]>各种语言的客户端
https://github.com/mqtt/mqtt.org/wiki/libraries
工具
https://www.hivemq.com/mqtt-toolbox/
公开的 MQTT broker
]]>客户端
我们所说的客户端泛指MQTT的客户端,包含发布者和订阅者,分别负责发布消息和订阅消息。 (通常情况下,一个MQTT实体同时具备发布者和订阅者两重功能)。 任何包含了MQTT运行库并且通过任意网路类型连接到MQTT broker的且具备微控制器的设备都称为MQTT客户端。
它可以是一个用于测试的小型设备,包含一个小型计算机系统,同时可以接入无线网络,最重要的是其支持TCP/IP协议从而允许MQTT在其上运行。
在客户端上实现MQTT协议非常直观方便,基于此,可以说MQTT非常适合小型设备。
MQTT客户端运行库支持大部分编程语言和平台,例如,Android,Arduino,C,C++,C#,Go,iOS,Java,Javascript,.Net。
完整的支持列表可以参考
中间人(Broker)
和MQTT客户端协作的另一部分是MQTT broker,其被称为发布/订阅协议的心脏部分。 根据具体的实现不同,一个broker可以支持数以千计的客户端并发连接。
broker的主要职责是接受所有消息,并将其过滤后分发给不同的消息订阅者。
它也可以根据订阅内容和未送达的消息来保持持久的会话。
broker的另一个职责是验证和授权客户端。在大多数时候,broker是可扩展的,我们可以将其整合进后台系统,整合进系统显得尤为重要,因为大多数时候,broker只是一个网络通信系统的组件。
我们之前的一篇文章提到订阅所有消息并不是很好的选择。
总而言之,broker是一个中心交换机,交换所有数据。因此高扩展性,可集成到后台系统,易于监控当然还包括不出错误对broker来说尤为重要。

各个broker对比,参见
客户端以一个CONNECT消息初始化连接 让我们来看一下MQTT连接消息,正如前面提到的,客户端发送消息给broker以初始化连接。
如果CONNET消息是畸形的,或者由建立socket连接到发送消息中间等待的时间过长,broker都会关闭连接。 这是一个较好的避免恶意客户端攻击服务器的处理方式。一个正常的客户端将会按照下面的内容发送连接消息。

此外,CONNECT消息还包含了一些其他信息,这些信息与MQTT库的制定者有更多关系,实际使用者则不必关心,如果你感兴趣,请参考官方MQTT 3.1.1 说明 下面让我们逐个了解一下这些信息的含义。
ClientId
ClientId是连接到broker的每个MQTT客户端的唯一标识符。根据场景不同,broker制定的ID规则也可以不同。 broker使用此标识符来识别客户端以及客户端的当前状态。 如果你不需要broker记录客户端的状态,也可以发送一个空的ClientId,这样将会创建一个无状态的连接,此功能适用于MQTT 3.1.1版本。 这样做的一个前提条件是cleanSession字段需要置为true,否则连接将会被拒绝。
Clean Session
Clean session 字段表明客户端是否想与broker建立持久的会话。 一个持久的会话(cleanSession为false)意味着,当使用QoS级别为1或2时,broker将会存储所有的客户端订阅的消息,和尚未送达的消息。 如果cleanSession为true时,broker不会存储任何客户端订阅的消息,并会将之前所存的内容清空。
Username/Password
MQTT允许发送用户名和密码来鉴定和授权客户端身份。然而,如果未使用TLS加密,用户名和密码将会以明文的方式传输。 我们强烈建议使用安全传输协议来传输用户名和密码。HiveMQ broker也支持使用SSL验证客户端身份,此时用户名和密码不再必须。
Will Message(遗嘱)
遗嘱是MQTT的一大特色,它允许broker在发现一台设备意外断开时发送通告给其他相关设备。 客户端在建立CONNECT连接时会将遗嘱打包在消息体里。如果这个客户端在没有通知的情况下意外断开连接,broker将会发送遗嘱消息给其他关联设备。我们将会在单独一章讨论此话题。
KeepAlive(心跳)
心跳是指客户端周期性地发送PING请求给broker,broker也会应答此心跳,这种机制可以保证双方知道对方是否还在线。我们将会在单独一章讨论此话题。
最主要的是所有消息都由MQTT客户端向broker建立连接,有一些定制化的库文件还会附加其他选项,例如规定消息如何排序和存储等。
Broker以CONNACK消息应答
当broker收到一个CONNECT消息时,broker有义务应答一个CONNACK消息,CONNACK只包含两个数据字段,一个是Session present flag(当前会话标志),另一个是Return code(返回码)。
Session Present Flag(当前会话标志)
当前会话标识可以表明broker是否在之前已经和客户端建立过持久会话。 如果客户端连上来并且将cleanSession字段置为true,那么当前会话标志将始终为false,因为会话都已经被清空了。 如果客户端在连上来时将cleanSession置为false,那么flag的状态决定于当前针对此客户端是否有可用的会话。 如果有已有存储的会话消息,那么false将会为true,否则为false。这个flag标志在MQTT 3.1.1中被添加,以帮助客户端来确定是否需要订阅主题或判断当前是否有待处理的消息。
参考
]]>当客户端断开连接时,发送给相关的订阅者的遗嘱消息。以下情况下会发送 Will Message:
- 服务端发生了I/O 错误或者网络失败;
- 客户端在定义的心跳时期失联;
- 客户端在发送下线包之前关闭网络连接;
- 服务端在收到下线包之前关闭网络连接。
遗嘱消息一般通过在客户端 CONNECT 的时候指定。如下所示,在连接的时候通过调用 MqttConnectOptions 实例的 setWill 方法来设定。任何订阅了下面的主题的客户端都可以收到该遗嘱消息。
//方法1MqttConnectOptions.setWill(MqttTopic topic, byte[] payload, int qos, boolean retained)//方法2MqttConnectOptions.setWill(java.lang.String topic, byte[] payload, int qos, boolean retained)使用场景
在客户端 A 进行连接时候,遗嘱消息设定为”offline“,客户端 B 订阅这个遗嘱主题。当 A 异常断开时,客户端 B 会收到这个”offline“的遗嘱消息,从而知道客户端 A 离线了。
Connect Flag 报文字段
| Bit | 7 | 6 | 5 | 4 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|
| User Name Flag | Password Flag | Will Retain | Will QoS | Will Flag | Clean Start | Reserved | |
| byte 8 | X | X | X | X | X | X | X |
遗嘱消息在客户端正常调用 disconnect 方法之后并不会被发送。
Will Flag 作用
简而言之,就是客户端预先定义好,在自己异常断开的情况下,所留下的最后遗愿(Last Will),也称之为遗嘱(Testament)。这个遗嘱就是一个由客户端预先定义好的主题和对应消息,附加在CONNECT的可变报文头部中,在客户端连接出现异常的情况下,由服务器主动发布此消息。
当Will Flag位为1时,Will QoS和Will Retain才会被读取,此时消息体中要出现Will Topic和Will Message具体内容,否则Will QoS和Will Retain值会被忽略掉。
当Will Flag位为0时,则Will Qos和Will Retain无效。
命令行示例
下面是一个Will Message的示例:
-
Sub端clientid=sub预定义遗嘱消息:
mosquitto_sub --will-topic test --will-payload die --will-qos 2 -t topic -i sub -h 192.168.1.1 -
客户端 clientid=alive 在 192.168.1.1(EMQ服务器) 订阅遗嘱主题
mosquitto_sub -t test -i alive -q 2 -h 192.168.1.1 -
异常断开Sub端与Server端(EMQ服务器)连接,Pub端收到Will Message 。
高级使用场景
这里介绍一下如何将 Retained 消息与Will 消息结合起来进行使用。
- 客户端 A 遗嘱消息设定为”offline“,该遗嘱主题与一个普通发送状态的主题设定成同一个
A/status; - 当客户端 A 连接时,向主题
A/status发送 “online” 的 Retained 消息,其它客户端订阅主题A/status的时候,获取 Retained 消息为 “online” ; - 当客户端 A 异常断开时,系统自动向主题
A/status发送”offline“的消息,其它订阅了此主题的客户端会马上收到”offline“消息;如果遗嘱消息被设定了 Retained 的话,这时有新的订阅A/status主题的客户端上线的时候,获取到的消息为“offline”。
近年来随着 Web 前端的快速发展,浏览器新特性层出不穷,越来越多的应用可以在浏览器端通过浏览器渲染引擎实现,Web 应用的即时通信方式 WebSocket 也因此得到了广泛的应用。
WebSocket 是一种在单个 TCP 连接上进行全双工通讯的协议。WebSocket 通信协议于2011年被 IETF 定为标准 RFC 6455,并由 RFC 7936 补充规范。WebSocket API 也被 W3C 定为标准。
WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。 ^1
MQTT 协议第 6 章 详细约定了 MQTT 在 WebSocket [RFC6455] 连接上传输需要满足的条件,协议内容不在此详细赘述。
两款客户端比较
Paho.mqtt.js
Paho 是 Eclipse 的一个 MQTT 客户端项目,Paho JavaScript Client 是其中一个基于浏览器的库,它使用 WebSockets 连接到 MQTT 服务器。相较于另一个 JavaScript 连接库来说,其功能较少,不推荐使用。
MQTT.js
MQTT.js 是一个完全开源的 MQTT 协议的客户端库,使用 JavaScript 编写,可用于 Node.js 和浏览器。在 Node.js 端可以通过全局安装使用命令行连接,同时支持 MQTT/TCP、MQTT/TLS、MQTT/WebSocket 连接;值得一提的是 MQTT.js 还对微信小程序有较好的支持。
本文将使用 MQTT.js 库进行 WebSocket 的连接讲解。
安装 MQTT.js
如果读者机器上装有 Node.js 运行环境,可直接使用 npm 命令安装 MQTT.js。
在当前目录安装
npm install mqtt --saveCDN 引用
或免安装直接使用 CDN 地址
<script src="https://unpkg.com/mqtt/dist/mqtt.min.js"></script>
<script>
// 将在全局初始化一个 mqtt 变量
console.log(mqtt)
</script>连接至 MQTT 服务器
本文将使用 EMQ X 提供的 免费公共 MQTT 服务器,该服务基于 EMQ X 的 MQTT 物联网云平台 创建。服务器接入信息如下:
- Broker: broker.emqx.io
- TCP Port: 1883
- Websocket Port: 8083
EMQ X 使用 8083 端口用于普通连接,8084 用于 SSL 上的 WebSocket 连接。
为了简单起见,让我们将订阅者和发布者放在同一个文件中:
const clientId = 'mqttjs_' + Math.random().toString(16).substr(2, 8)
const host = 'ws://broker.emqx.io:8083/mqtt'
const options = {
keepalive: 60,
clientId: clientId,
protocolId: 'MQTT',
protocolVersion: 4,
clean: true,
reconnectPeriod: 1000,
connectTimeout: 30 * 1000,
will: {
topic: 'WillMsg',
payload: 'Connection Closed abnormally..!',
qos: 0,
retain: false
},
}
console.log('Connecting mqtt client')
const client = mqtt.connect(host, options)
client.on('error', (err) => {
console.log('Connection error: ', err)
client.end()
})
client.on('reconnect', () => {
console.log('Reconnecting...')
})连接地址
上文示范的连接地址可以拆分为: ws: // broker . emqx.io : 8083 /mqtt
即 协议 // 主机名 . 域名 : 端口 / 路径
初学者容易出现以下几个错误:
- 连接地址没有指明协议:WebSocket 作为一种通信协议,其使用
ws(非加密)、wss(SSL 加密) 作为协议标识。MQTT.js 客户端支持多种协议,连接地址需指明协议类型; - 连接地址没有指明端口:MQTT 并未对 WebSocket 接入端口做出规定,EMQ X 上默认使用
80838084分别作为非加密连接、加密连接端口。而 WebSocket 协议默认端口同 HTTP 保持一致 (80/443),不填写端口则表明使用 WebSocket 的默认端口连接;而使用标准 MQTT 连接时则无需指定端口,如 MQTT.js 在 Node.js 端可以使用mqtt://localhost连接至标准 MQTT 1883 端口,当连接地址是mqtts://localhost则连接到 8884 端口; - 连接地址无路径:MQTT-WebSoket 统一使用
/path作为连接路径,连接时需指明,在 EMQ X 上使用的路径为/mqtt; - 协议与端口不符:使用了
wss连接却连接到8083端口; - 在 HTTPS 下使用非加密的 WebSocket 连接: Google 等机构在推进 HTTPS 的同时也通过浏览器约束进行了安全限定,即 HTTPS 连接下浏览器会自动禁止使用非加密的
ws协议发起连接请求; - 证书与连接地址不符: 篇幅较长,详见下文 EMQ 启用 SSL/TLS 加密连接。
连接选项
上面代码中, options 是客户端连接选项,以下是主要参数说明,其余参数详见https://www.npmjs.com/package/mqtt#connect。
- keepalive:心跳时间,默认 60秒,设置 0 为禁用;
- clientId: 客户端 ID ,默认通过
'mqttjs_' + Math.random().toString(16).substr(2, 8)随机生成; - username:连接用户名(可选);
- password:连接密码(可选);
- clean:true,设置为 false 以在离线时接收 QoS 1 和 2 消息;
- reconnectPeriod:默认 1000 毫秒,两次重新连接之间的间隔,客户端 ID 重复、认证失败等客户端会重新连接;
- connectTimeout:默认 30 * 1000毫秒,收到 CONNACK 之前等待的时间,即连接超时时间;
- will:遗嘱消息,当客户端严重断开连接时,Broker 将自动发送的消息。 一般格式为:
- topic:要发布的主题
- payload:要发布的消息
- qos:QoS
- retain:保留标志
订阅/取消订阅
连接成功之后才能订阅,且订阅的主题必须符合 MQTT 订阅主题规则;
注意 JavaScript 的异步非阻塞特性,只有在 connect 事件后才能确保客户端已成功连接,或通过 client.connected 判断是否连接成功:
client.on('connect', () => {
console.log('Client connected:' + clientId)
// Subscribe
client.subscribe('testtopic', { qos: 0 })
})// Unsubscribe
client.unubscribe('testtopic', () => {
console.log('Unsubscribed')
})发布/接收消息
发布消息到某主题,发布的主题必须符合 MQTT 发布主题规则,否则将断开连接。发布之前无需订阅该主题,但要确保客户端已成功连接:
// Publish
client.publish('testtopic', 'ws connection demo...!', { qos: 0, retain: false })// Received
client.on('message', (topic, message, packet) => {
console.log('Received Message: ' + message.toString() + '\nOn topic: ' + topic)
})微信小程序
MQTT.js 库对微信小程序特殊处理,使用 wxs 协议标识符。注意小程序开发规范中要求必须使用加密连接,连接地址应类似为 wxs://broker.emqx.io:8084/mqtt。
EMQ X 启用 SSL/TLS 加密连接
EMQ 内置自签名证书,默认已经启动了加密的 WebSocket 连接,但大部分浏览器会报证书无效错误如 net::ERR_CERT_COMMON_NAME_INVALID (Chrome、360 等 webkit 内核浏览器在开发者模式下, Console 选项卡 可以查看大部分连接错误)。导致该错误的原因是浏览器无法验证自签名证书的有效性,读者需从证书颁发机构购买可信任证书,并参考该篇文章中的相应部分进行配置操作:EMQ X MQTT 服务器启用 SSL/TLS 安全连接。
这里就总结启用 SSL/TLS 证书需要具备的条件是:
- 将域名绑定到 MQTT 服务器公网地址:CA 机构签发的证书签名是针对域名的;
- 申请证书:向 CA 机构申请所用域名的证书,注意选择一个可靠的 CA 机构且证书要区分泛域名与主机名;
- 使用加密连接的时候选择
wss协议,并 使用域名连接 :绑定域名-证书之后,必须使用域名而非 IP 地址进行连接,这样浏览器才会根据域名去校验证书以在通过校验后建立连接。
EMQ X 配置
打开 etc/emqx.conf 配置文件,修改以下配置:
# wss 监听地址
listener.wss.external = 8084
# 修改密钥文件地址
listener.wss.external.keyfile = etc/certs/cert.key
# 修改证书文件地址
listener.wss.external.certfile = etc/certs/cert.pem完成后重启 EMQ X 即可。
可以使用你的证书与密钥文件直接替换到 etc/certs/ 下。
在 Nginx 上配置反向代理与证书
使用 Nginx 来反向代理并加密 WebSocket 可以减轻 EMQ X 服务器计算压力,同时实现域名复用,同时通过 Nginx 的负载均衡可以分配多个后端服务实体。
# 建议 WebSocket 也绑定到 443 端口
listen 443, 8084;
server_name example.com;
ssl on;
ssl_certificate /etc/cert.crt; # 证书路径
ssl_certificate_key /etc/cert.key; # 密钥路径
# upstream 服务器列表
upstream emq_server {
server 10.10.1.1:8883 weight=1;
server 10.10.1.2:8883 weight=1;
server 10.10.1.3:8883 weight=1;
}
# 普通网站应用
location / {
root www;
index index.html;
}
# 反向代理到 EMQ X 非加密 WebSocket
location / {
proxy_redirect off;
# upstream
proxy_pass http://emq_server;
proxy_set_header Host $host;
# 反向代理保留客户端地址
proxy_set_header X-Real_IP $remote_addr;
proxy_set_header X-Forwarded-For $remote_addr:$remote_port;
# WebSocket 额外请求头
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection “upgrade”;
}其它资源
项目完整代码请见:https://github.com/emqx/MQTT-Client-Examples/tree/master/mqtt-client-WebSocket
一款在线的 MQTT WebSocket 连接测试工具:https://www.emqx.cn/mqtt/mqtt-websocket-toolkit
]]>- Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核 心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引 擎的功能都在这一层实现,比如存储过程、触发器、视图等。
- 存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、 MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
一条查询语句的执行过程一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎。
在 MySQL 中,索引是在存储引擎层实现的,所以并没有统一的索引标准,即不同存储引擎的索引的工作方式并不一样。
索引类型分为主键索引和非主键索引。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index),非主键索引也被称为二级索引(secondary index)。
基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
开启慢查询
查看慢查询状态 show variables like 'slow_query_log'
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
# 无论是否超时,未被索引的记录也会记录下来。
SET GLOBAL log_queries_not_using_indexes = 'ON';
# 慢查询阈值(秒),SQL 执行超过这个阈值将被记录在日志中。
SET SESSION long_query_time = 1;
# 慢查询仅记录扫描行数大于此参数的 SQL。
SET SESSION min_examined_row_limit = 100;最好将配置写入配置文件
sudo vi /etc/mysql/my.cnf
[mysqld]
slow-query-log = 1
slow-query-log-file = /var/log/mysql/localhost-slow.log
long_query_time = 1
log-queries-not-using-indexes使用 mysqldumpslow 慢查询工具
使用 explain 分析SQL
EXPLAIN SELECT * FROM res_user ORDER BY modifiedtime LIMIT 0,1000
常见慢查询的优化
- 拆解关联查询
- 讲字段很多的表分解为多个表
- 增加中间表
- 优化limit
在 MySQL 中,索引是在存储引擎层实现的,所以并没有统一的索引标准,即不同存储引擎的索引的工作方式并不一样。 索引其实是一种数据结构,能够帮助我们快速的检索数据库中的数据,常见的MySQL主要有两种结构:Hash索引和B+ Tree索引,我们使用的是InnoDB引擎,默认的是B+树 在InnoDB存储引擎中,主键索引是作为聚簇索引存在的,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
-
Hash索引底层是哈希表,哈希表是一种以key-value存储数据的结构,所以多个数据在存储关系上是完全没有任何顺序关系的,所以,对于区间查询是无法直接通过索引查询的,就需要全表扫描。 所以,哈希索引只适用于等值查询的场景。
-
B+ 树是一种多路平衡查询树,所以他的节点是天然有序的(左子节点小于父节点、父节点小于右子节点),所以对于范围查询的时候不需要做全表扫描。
-
有序数组在等值查询和范围查询场景中的性能就都非常优秀。有序数组索引只适用于静态存储引擎,比如你要保存的是 2017 年某个城市的所有人口信息,这类不会再修改的数据。
最左前缀匹配
根据业务需求,where子句中使用最频繁的一列放在最左边,因为MySQL索引查询会遵循最左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。 所以当我们创建一个联合索引的时候,如(key1,key2,key3),相当于创建了(key1)、(key1,key2)和(key1,key2,key3)三个索引,这就是最左匹配原则
B+ Tree
InnoDB的B+ Tree可能存储的是整行数据(主键索引,聚簇索引),也有可能是主键的值(非主键索引,非聚簇索引),聚簇索引查询会更快? 因为主键索引树的叶子节点直接就是我们要查询的整行数据了。而非主键索引的叶子节点是主键的值,查到主键的值以后,还需要再通过主键的值再进行一次查询(过程叫回表)
B+树和二叉树有什么区别和优劣?
B+树是多叉树,深度更小,B+树可以对叶子节点进行顺序遍历,B+树能够更好地利用磁盘扇区;二叉树:实现简单
TIP
哈希索引适合等值查询,做区间查询的速度很慢
哈希索引没办法利用索引完成排序
哈希索引不支持多列联合索引的最左匹配规则
如果有大量重复键值的情况下,哈希索引的效率会很低,因为存在哈希碰撞问题
在建立索引的时候,都有哪些需要考虑的因素呢?
定义主键的数据列一定要建立索引。
定义有外键的数据列一定要建立索引。
对于经常查询的数据列最好建立索引。
对于需要在指定范围内的快速或频繁查询的数据列;
经常用在WHERE子句中的数据列。
经常出现在关键字order by、group by、distinct后面的字段,建立索引。如果建立的是复合索引,索引的字段顺序要和这些关键字后面的字段顺序一致,否则索引不会被使用。
对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
对于定义为text、image和bit的数据类型的列不要建立索引。
对于经常存取的列避免建立索引
限制表上的索引数目。对一个存在大量更新操作的表,所建索引的数目一般不要超过3个,最多不要超过5个。索引虽说提高了访问速度,但太多索引会影响数据的更新操作。
对复合索引,按照字段在查询条件中出现的频度建立索引。在复合索引中,记录首先按照第一个字段排序。对于在第一个字段上取值相同的记录,系统再按照第二个字段的取值排序,以此类推。因此只有复合索引的第一个字段出现在查询条件中,该索引才可能被使用,因此将应用频度高的字段,放置在复合索引的前面,会使系统最大可能地使用此索引,发挥索引的作用。
参考
https://mp.weixin.qq.com/s/_bk2JVOm2SkXfdcvki6-0w
https://www.cnblogs.com/williamjie/p/11187470.html
]]>若想实现聚合查询,需要把fielddata改为true, 但是text会被分词,最好还是使用keyword。
{
"properties": {
"tags": {
"type": "text",
"fielddata": true
}
}
}-
fielddata是基于内存的正排索引(快但耗资源),doc_values是基于磁盘的
-
基于聚合结果的聚合
{
"size": 0,
"aggs": {
"<agg_name1>": {
"<agg_type>": {
"field": "<field_name1>"
},
"aggs": {
"<agg_name2>": {
"<agg_type>": {
"field": "<field_name2>"
}
}
}
}
}
}- 基于查询结果的聚合
{
"size": 0,
"query": {
"bool": {
"filter": [
{
"match_all": {}
},
{
"range": {
"metadata.ts": {
"format": "strict_date_optional_time",
"gte": "2022-07-08T00:32:25.354Z",
"lte": "2022-07-10T02:32:25.354Z"
}
}
}
],
"must": [],
"must_not": [],
"should": []
}
},
"aggs": {
"<agg_name1>": {
"<agg_type>": {
"field": "<field_name1>",
"order": {
"_count": "desc"
}
},
"aggs": {
"<agg_name2>": {
"<agg_type>": {
"field": "<field_name2>",
"order": {
"_key": "desc"
}
}
}
}
}
}
}举例:
{
"size": 0,
"query": {
"range": {
"metadata.ts": {
"format": "strict_date_optional_time",
"gte": "2022-07-08T00:32:25.354Z",
"lte": "2022-07-10T02:32:25.354Z"
}
}
},
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
}
}- 基于聚合结果的过滤查询
对聚合的结果没有影响对,过滤的是hits中的原数据
{
"aggs": {
"tags_bucket": {
"terms": {
"field": "tags.keyword"
}
}
},
"post_filter": {
"term": {
"tags.keyword": "性价比"
}
}
}- 高级排序
按照计算后的结果排序

- 为Index patterns起ID
Index patterns的ID用于visualize的引用,建议自己指定,系统自己指定的是一个uuid,建议自动指定,这样识别度比较高。 我的做法是和 alias 或 index 名字一致

- 修改Index patterns的Time Field
查询所有index-pattern
GET /.kibana_1/_search修改指定index-pattern的Time field,注意替换_id
POST /.kibana_1/_update/index-pattern:<_id>
{
"doc": {
"index-pattern": {
"timeFieldName" : "timestamp"
}
}
}- 关于 alias 注意的问题
alias 是 index 的别名,比如当前有两个index, demo-2022-07 和 demo-2022-08
创建 alias,只包含指定条件的记录
POST /_aliases
{
"actions": [
{
"add": {
"index": "demo-2022-*",
"alias": "demo-fault",
"filter": {
"bool": {
"should": [
{
"match": {
"faultType": "fault"
}
}
]
}
}
}
}
]
}然后我们就可以根据 alias 进行查询
GET /demo-fault/_search但是如果我们又创建了新的index,名称为demo-2022-09,demo-fault是感知不到的。 我们需要重新执行创建 alias 动作。
解决办法是使用 index-template
在index-template中指定aliases,这样每当产生新的index,就会自动套用index-template
PUT /_template/demo_template
{
"template" : "demo*",
"aliases" : {
"demo-fault": { }
}
}{
"query": {
"bool": {
"filter": [
{
"match_all": {}
},
{
"match_phrase":
{
"metadata.ss_address.keyword": "无锡凯旸置业有限公司, 214028, 无锡"
}
},
{
"exists": {
"field": "metadata.ss_address.keyword"
}
},
{
"range": {
"metadata.ts": {
"format": "strict_date_optional_time",
"gte": "2022-07-10T02:03:26.766Z",
"lte": "2022-07-10T02:18:26.766Z"
}
}
}
],
"must": [],
"must_not": [],
"should": []
}
},
"script_fields": {},
"size": 50,
"sort": [
{
"metadata.ts": {
"order": "desc"
}
}
],
"_source": {
"excludes": []
}
}ISO-8601标准格式
其中一种常见的格式形如:
- 2018-04-08T11:38:39+08:00 // 日期用'-'相隔,与时间用'T'连接
- 2018-04-08T11:38:39Z // Z代表UTC时间,Z也可写成+00:00
- 2022-07-21T00:00:00.000Z
- 2022-07-21T00:00:00.000+08:00
创建 index 并指定字段
PUT /demo
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"title": {
"type": "keyword"
},
"timestamp": {
"type": "date"
}
}
}
}插入测试数据
POST demo/_doc
{
"title": "lucy",
"timestamp" : "2022-08-01T10:55:22.043+08:00"
}
POST demo/_doc
{
"title": "jack",
"timestamp" : "2022-08-01T11:55:22.043+08:00"
}
POST demo/_doc
{
"title": "james",
"timestamp" : "2022-08-01T12:17:22.043Z"
}
POST demo/_doc
{
"title": "finley",
// 不指定时区就是+00:00,跟 2022-08-01T13:17:22.043Z 效果一致。
"timestamp" : "2022-08-01T13:17:22.043"
}查询
GET demo/_search
{
"query": {
"range": {
"timestamp": {
"gte": "now-10m",
"lte": "now",
"time_zone": "Asia/Shanghai"
}
}
}
}我们发现,即便不指定time_zone也是可以的,这应该是opensearch配置了时区是浏览器时区的原因。

参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html
]]>让我加载一个新的数据集(汽车的数据不太适用于百分位)。我们要索引一系列网站延时数据然后运行一些百分位操作进行查看:
POST /website/logs/_bulk
{ "index": {}}
{ "latency" : 100, "zone" : "US", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 80, "zone" : "US", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 99, "zone" : "US", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 102, "zone" : "US", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 75, "zone" : "US", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 82, "zone" : "US", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 100, "zone" : "EU", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 280, "zone" : "EU", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 155, "zone" : "EU", "timestamp" : "2014-10-29" }
{ "index": {}}
{ "latency" : 623, "zone" : "EU", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 380, "zone" : "EU", "timestamp" : "2014-10-28" }
{ "index": {}}
{ "latency" : 319, "zone" : "EU", "timestamp" : "2014-10-29" }数据有三个值:延时、数据中心的区域以及时间戳。让我们对数据全集进行 百分位 操作以获得数据分布情况的直观感受:
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"load_times" : {
"percentiles" : {
"field" : "latency"
}
},
"avg_load_time" : {
"avg" : {
"field" : "latency"
}
}
}
}默认情况下,percentiles 度量会返回一组预定义的百分位数值: [1, 5, 25, 50, 75, 95, 99] 。它们表示了人们感兴趣的常用百分位数值,极端的百分位数在范围的两边,其他的一些处于中部。在返回的响应中,我们可以看到最小延时在 75ms 左右,而最大延时差不多有 600ms。与之形成对比的是,平均延时在 200ms 左右, 信息并不是很多:
...
"aggregations": {
"load_times": {
"values": {
"1.0": 75.55,
"5.0": 77.75,
"25.0": 94.75,
"50.0": 101,
"75.0": 289.75,
"95.0": 489.34999999999985,
"99.0": 596.2700000000002
}
},
"avg_load_time": {
"value": 199.58333333333334
}
}所以显然延时的分布很广,让我们看看它们是否与数据中心的地理区域有关:
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"zones" : {
// 首先根据区域我们将延时分到不同的桶中。
"terms" : {
"field" : "zone"
},
"aggs" : {
"load_times" : {
// 再计算每个区域的百分位数值。
"percentiles" : {
"field" : "latency",
// percents 参数接受了我们想返回的一组百分位数,因为我们只对长的延时感兴趣。
"percents" : [50, 95.0, 99.0]
}
},
"load_avg" : {
"avg" : {
"field" : "latency"
}
}
}
}
}
}在响应结果中,我们发现欧洲区域(EU)要比美国区域(US)慢很多,在美国区域(US),50 百分位与 99 百分位十分接近,它们都接近均值。
与之形成对比的是,欧洲区域(EU)在 50 和 99 百分位有较大区分。现在,显然可以发现是欧洲区域(EU)拉低了延时的统计信息,我们知道欧洲区域的 50% 延时都在 300ms+。
...
"aggregations": {
"zones": {
"buckets": [
{
"key": "eu",
"doc_count": 6,
"load_times": {
"values": {
"50.0": 299.5,
"95.0": 562.25,
"99.0": 610.85
}
},
"load_avg": {
"value": 309.5
}
},
{
"key": "us",
"doc_count": 6,
"load_times": {
"values": {
"50.0": 90.5,
"95.0": 101.5,
"99.0": 101.9
}
},
"load_avg": {
"value": 89.66666666666667
}
}
]
}
}
...百分位等级
这里有另外一个紧密相关的度量叫 percentile_ranks 。 percentiles 度量告诉我们落在某个百分比以下的所有文档的最小值。例如,如果 50 百分位是 119ms,那么有 50% 的文档数值都不超过 119ms。 percentile_ranks 告诉我们某个具体值属于哪个百分位。119ms 的 percentile_ranks 是在 50 百分位。 这基本是个双向关系,例如:
- 50 百分位是 119ms。
- 119ms 百分位等级是 50 百分位。 所以假设我们网站必须维持的服务等级协议(SLA)是响应时间低于 210ms。然后,开个玩笑,我们老板警告我们如果响应时间超过 800ms 会把我开除。可以理解的是,我们希望知道有多少百分比的请求可以满足 SLA 的要求(并期望至少在 800ms 以下!)。
为了做到这点,我们可以应用 percentile_ranks 度量而不是 percentiles 度量:
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"zones" : {
"terms" : {
"field" : "zone"
},
"aggs" : {
"load_times" : {
// percentile_ranks 度量接受一组我们希望分级的数值。
"percentile_ranks" : {
"field" : "latency",
"values" : [210, 800]
}
}
}
}
}
}在聚合运行后,我们能得到两个值:
"aggregations": {
"zones": {
"buckets": [
{
"key": "eu",
"doc_count": 6,
"load_times": {
"values": {
"210.0": 31.944444444444443,
"800.0": 100
}
}
},
{
"key": "us",
"doc_count": 6,
"load_times": {
"values": {
"210.0": 100,
"800.0": 100
}
}
}
]
}
}这告诉我们三点重要的信息:
- 在欧洲(EU),210ms 的百分位等级是 31.94% 。
- 在美国(US),210ms 的百分位等级是 100% 。
- 在欧洲(EU)和美国(US),800ms 的百分位等级是 100% 。
通俗的说,在欧洲区域(EU)只有 32% 的响应时间满足服务等级协议(SLA),而美国区域(US)始终满足服务等级协议的。但幸运的是,两个区域所有响应时间都在 800ms 以下,所以我们还不会被炒鱿鱼(至少目前不会)。
percentile_ranks 度量提供了与 percentiles 相同的信息,但它以不同方式呈现,如果我们对某个具体数值更关心,使用它会更方便。
参考
https://www.elastic.co/guide/cn/elasticsearch/guide/current/percentiles.html
]]>导图



5个类型
string(字符串)、list(链表)、set(集合)、zset(有序集合)和 hash(散列表)
命令
字符串
优点:二进制安全,意味着该类型可以接受任何格式的数据,如JPEG图像数据或Json对象描述信息等。 在Redis中字符串类型的Value最多可以容纳的数据长度是512M。
# 选择一个数据库
> select 2
OK
> keys *
(empty array)
> set name finley
OK
> keys *
1) "name"
> get name
"finley"
> exists name
(integer) 1
> strlen name
(integer) 9
> set name "finley"
OK
> strlen name
(integer) 6
> set age 18
OK
> incr age
(integer) 19
> get age
"19"
# 从当前数据库中随机选择的一个key
> randomkey
"age"
# 重命名一个key
> rename name name2
OK
> get name
(nul)
> get name2
"finley"
# 追加字符串, 返回新字符串值的长度。
> append name hello
(integer) 11
> get name
"finleyhello"
> getrange name 6 10
"hello"
> set json '{"name":"finley","age":18}'
OK
# 设置多个键值
> mset name finley age 18
OK
> mget name age
1) "finley"
2) "18"
# 设置指定Key的过期时间为10秒。
> setex mykey 10 "hello"
OK
# 通过ttl命令查看一下指定Key的剩余存活时间(秒数),0表示已经过期,-1表示永不过期。
> ttl mykey
(integer) 4列表(List)
类似JS中的数组。 List类型是按照插入顺序排序的字符串链表. 如果我们是在链表的两头插入或删除元素,这将会是非常高效的操作. 如果元素插入或删除操作是作用于链表中间,那将会是非常低效的.
散列类型(Hash)
> hset car:2 color "白色" name "奥迪" price 90
(integer) 3
> hmget car:2 name price
1) "\xe5\xa5\xa5\xe8\xbf\xaa"
2) "90"
> hgetall car:2
1) "color"
2) "\xe7\x99\xbd\xe8\x89\xb2"
3) "name"
4) "\xe5\xa5\xa5\xe8\xbf\xaa"
5) "price"
6) "90"Sorted Set(有序集合)
> zadd myzset 79 Jack 56 Lucy 93 Finley
(integer) 3
# 0表示第一个成员,-1表示最后一个成员。
# WITHSCORES选项表示返回的结果中包含每个成员及其分数,否则只返回成员。
> zrange myzset 0 -1 WITHSCORES
1) "Lucy"
2) "56"
3) "Jack"
4) "79"
5) "Finley"
6) "93"
# 获取成员Finley在Sorted-Set中的位置索引值。0表示第一个位置。
> zrank myzset Finley
(integer) 2
# 获取成员Finley的分数。返回值是字符串形式。
> zscore myzset Finley
"93"
# 将成员Finley的分数增加2,并返回该成员更新后的分数。
> zincrby myzset 2 Finley
"95"
# 将成员Finley的分数增加-20,并返回该成员更新后的分数。
> zincrby myzset -20 Finley
"75"
# 查看在更新了成员的分数后是否正确。
> zrange myzset 0 -1 WITHSCORES
1) "Lucy"
2) "56"
3) "Finley"
4) "75"
5) "Jack"
6) "79"
# 以位置索引从高到低的方式获取并返回此区间内的成员。
> zrevrange myzset 0 -1 WITHSCORES
1) "Jack"
2) "79"
3) "Finley"
4) "75"
5) "Lucy"
6) "56"
# 删除分数满足表达式1 <= score <= 100的成员,并返回实际删除的数量
> zremrangebyscore myzset 1 100
(integer) 3
> del myzet
(empty array)字符串类型是 Redis 中最基本的数据类型,可以存储二进制数据、图片和 Json 的对象。
字符串类型也是其他 4 种数据库类型的基础,其它数据类型可以说是从字符串类型中进行组织的,如:列表类型是以列表的形式组织字符串,集合类型是以集合的形式组织字符串。
命名
建议:“对象类型:对象ID:对象属性”命名一个键,如:“user:1:friends”存储 ID 为 1 的用户的的好友列表。对于多个单词则推荐使用 “.” 进行分隔。
应用:
- 访问量统计:每次访问博客和文章使用 INCR 命令进行递增;
- 将数据以二进制序列化的方式进行存储。
散列类型(Hash)
散列类型采用了字典结构(k-v)进行存储。
散列类型适合存储对象。可以采用这样的命名方式:对象类别和 ID 构成键名,使用字段表示对象的属性,而字段值则存储属性值。
如:存储 ID 为 2 的汽车对象
hset car:2 color "白色" name "奥迪" price 90
hset post:2 title "Redis 学习笔记" content "Redis 是一个高性能的数据库"
列表类型(List)
列表类型(list)可以存储一个有序的字符串列表,常用的操作是向两端添加元素。
列表类型内部是使用双向链表实现的,也就是说,获取越接近两端的元素速度越快,代价是通过索引访问元素比较慢
应用
- 显示社交网站的新鲜事、热门评论和新闻等;
- 推特的粉丝列表,关注列表;
- 当队列使用;
- 记录日志。
集合(Set)
字符串的无序集合,不允许存在重复的成员。
多个集合类型之间可以进行并集、交集和差集运算。
应用
- 文章标签
- 社交中共同关注的人
- 你关注的人也关注了哪些人
有序集合(SortedSet)
在集合类型的基础上添加了排序的功能。
应用
- 排行榜
参考
]]>key的一个格式约定:object-type🆔field。用":"分隔域,用"."作为单词间的连接,如"comment:12345:reply.to"。 不推荐含义不清的key和特别长的key。
一般的设计方法如下:
- 把表名转换为key前缀 如, tag:
- 第2段放置用于区分区key的字段--对应mysql中的主键的列名,如userid
- 第3段放置主键值,如2,3,4...., a , b ,c 4: 第4段,写要存储的列名
例如用户表 user, 转换为key-value存储:
set user:userid:9:username lisi
set user:userid:9:password 111111
set user:userid:9:email [email protected]例如,查看某个用户的所有信息为:
keys user:userid:9*
如果另一个列也常常被用来查找,比如username,则也要相应的生成一条按照该列为主的key-value,例如:
set user:username:lisi:userid 9
此时相当于RDBMS中在username上加索引,我们可以根据 username:lisi:uid,查出userid=9,再查user:9:password/email ...
注意事项
- 从业务需求逻辑和内存的角度,尽可能的设置key存活时间。
- 程序应该处理如果redis数据丢失时的清理redis内存和重新加载的过程。
- 只要有可能的话,就尽量使用散列键而不是字符串键来储存键值对数据,因为散列键管理方便、能够避免键名冲突、并且还能够节约内存
- 尽量使用批量操作命令,如用mget、hmget而不是get和hget,对于set也是如此,lpush向一个list一次性导入多个元素,而不用lset一个个添加
- 尽可能的把redis和APP SERVER部署在一个网段甚至一台机器。
- 由于redis单线程的,所以长时间的排序操作会阻塞其他client的请求
- 对于数据量较大的集合,不要轻易进行删除操作,这样会阻塞服务器,一般采用重命名+批量删除的策略
列表:
# Rename the key
newkey = "gc:hashes:" + redis.INCR("gc:index")
redis.RENAME("my.list.key", newkey)
# Trim off elements in batche of 100s
while redis.LLEN(newkey) > 0
redis.LTRIM(newkey, 0, -99)
end集合:
# Rename the key
newkey = "gc:hashes:" + redis.INCR("gc:index")
redis.RENAME("my.set.key", newkey)
# Delete members from the set in batches of 100
cursor = 0
loop
cursor, members = redis.SSCAN(newkey, cursor, "COUNT", 100)
if size of members > 0
redis.SREM(newkey, members)
end
if cursor == 0
break
end
end排序集合:
# Rename the key
newkey = "gc:hashes:" + redis.INCR("gc:index")
redis.RENAME("my.zset.key", newkey)
# Delete members from the sorted set in batche of 100s
while redis.ZCARD(newkey) > 0
redis.ZREMRANGEBYRANK(newkey, 0, 99)
endHash:
# Rename the key
newkey = "gc:hashes:" + redis.INCR( "gc:index" )
redis.RENAME("my.hash.key", newkey)
# Delete fields from the hash in batche of 100s
cursor = 0
loop
cursor, hash_keys = redis.HSCAN(newkey, cursor, "COUNT", 100)
if hash_keys count > 0
redis.HDEL(newkey, hash_keys)
end
if cursor == 0
break
end
end参考
]]>配置
- windows建议安装service方式,省的每次通过命令行启动server端。
- 对比mysql 大部分人都有mysql的使用经验,对比着学习也是种不错的方法。 具体区别见官方文档 非常详细。
- 比如mongo里没有table和row的概念,而是对应的collection和document。
- mongo非常灵活,当执行插入语句,如果collection不存在会自动创建,
如
db.people.insertOne( { user_id: "bcd001", age: 45, status: "A" } )不存在会自动创建名为people的collection。
导入导出
- 导出有 mongoexport和mongodump工具。
mongodump和mongodrestore对应
mongoexport和mongoimport对应
mongoexport 必须指定collection,但是可以导出来json或csv格式可读性好,使用 mongodump 可直接将整个库都导出来。
先
.\mongoexport.exe --help
- 假设要导出database是blog,collection是post。
.\mongoexport.exe -d blog -c post -o D:/post.json - 导出整个库
mongodump.exe --db riot,每个collection对应一个bson和metadata.json格式文件
角色 权限
- 角色控制 为某库添加可读可写的角色
use admin;
db.createUser(
{
user: "riot",
pwd: "riot",
roles: [ { role: "readWrite", db: "riot" } ]
}
)- 查看某角色的权限信息
 https://docs.mongodb.com/manual/reference/command/usersInfo/#examples
https://docs.mongodb.com/manual/reference/command/usersInfo/#examples - 检查某用户是否可以登录某数据库 ,先use进该库,然后
db.auth('user', 'pass')
工具
客户端工具我就推荐一个 Studio 3T 理由:
- 比官方自带的强大很多,有点类似 Navicat,导入导出,复制表,用户分配权限什么的都带
- 非商业用途免费使用
qsctl cp bak_mysql/intogolf001_2021_08_08_12_31_23.sql.gz qs://finley-soft/IntoGolf/bak_mysql/
参考
https://docsv3.qingcloud.com/storage/object-storage/manual/developer-tools/qsctl/
]]>问:我有一个需求,比如说有一个商品,用户下单后 (还未支付), 我先锁定改商品,10 分钟未支付就还原状态,但是用户在 9 分 59 秒的时候支付了,此时商品还原队列优先执行了,把商品设置为了正常状态并把订单设置为过期,然后支付回调检测到订单过期了,肯定不能正常下单了,这种业务逻辑改如何优化?
答:
- 订单过期 20 分钟,第三方订单过期 19 分钟,1 分钟时间差,避开就好~,其实也不用差 1 分钟这么久….😂
- 这个简单,像微信支付,在预支付订单接口可以传订单交易结束时间,这个时间设置为订单过期时间,超过时间无法支付
订单如何避免重复支付?
问:客户端 A 拉起微信支付,客户端 B 拉起支付宝支付,这个时候 张三同时进行输入支付密码支付,考虑 支付宝亦或是微信回调到服务端有可能失败。会多次回调服务端 或者说 回调处理完了订单 没有返回 微信或者支付 成功 或者说 正在处理中,在这样的一个场景下 应该如何避免这样的问题发生
答:
- 使用laravel的锁管理
- 支付回调发现已经支付了,做退款处理即可,你可以用锁或者其他限制在发起支付限制一下,但是无法完全限制,所以后备方案就是退款处理
- 购物车 -》订单 加一个锁 这个时间很短,比如说 10 秒没有完成,就解锁,退回购物车。 订单 -》支付 加一个锁,这个时间比较长,比如说 30 分钟。如果没有支付完成,解锁,同时将订单设为一取消状态。如果用户要重新支付,就要重新下单。
今天抽空总结一下,吸取一些优秀的地方。
首先打开composer.json看看项目中用到了哪些第三方类库
mews/captcha 很明显,生成验证码
mews/purifier 这个是html过滤,因为是bbs系统,过滤用户输入的内容
overtrue/pinyin 把汉字转换成拼音,主要是转换帖子标题,方便SEO
spatie/laravel-permission 这个类库很常见,权限控制,具体见文档
summerblue/administrator 快速的生成后台管理页面及功能
summerblue/laravel-active 提供了一些工具方法,比如判断是否是当前路由,当前控制器,是否包含了某查询参数等功能
viacreative/sudo-su 很有意思的类库,安装后,页面右下角有个用户列表,可以选择不同的用户身份登录系统,非常方便开发期调试使用
来看下目录结构,还是非常清晰的

再来看下路由
除去第三方带的的_debugbar, _ignition, Frozennode\Administrator, horizon
剩下的就是自己写的,topic,reply,user的增删改

挑一下比较重要的功能介绍下
- 添加文章
顺着路由走
routes/web.php 发现了
Route::resource('topics', 'TopicsController', ['only' => ['index', 'create', 'store', 'update', 'edit', 'destroy']]);
打开 TopicsController
public function store(TopicRequest $request, Topic $topic)
{
$topic->fill($request->all());
$topic->user_id = Auth::id();
$topic->save();
return redirect()->to($topic->link())->with('success', '成功创建话题!');
}很简单,重点是app/Observers/TopicObserver.php
class TopicObserver
{
public function saving(Topic $topic)
{
// XSS 过滤
$topic->body = clean($topic->body, 'user_topic_body');
// 生成话题摘录
$topic->excerpt = make_excerpt($topic->body);
}
public function saved(Topic $topic)
{
// 如 slug 字段无内容,即使用翻译器对 title 进行翻译
if ( ! $topic->slug) {
// 推送任务到队列
dispatch(new TranslateSlug($topic));
}
}
public function deleted(Topic $topic)
{
\DB::table('replies')->where('topic_id', $topic->id)->delete();
}
}这里用到了Model观察器,来监听保存事件
TIP
observers的使用场景: 当保存话题成功后,需要调用第三方服务,把话题标题从汉字转为拼音,同时要过滤内容,根据内容生成摘要,这些保存后的后续操作都可以放到观察者中。

根据官网介绍: Laravel 自带了 Ignition,这是一个由 Freek Van der Herten 与 Marcel Pociot 创建的关于异常详情页面的新的开源项目。相较之前的版本,Ignition 具有许多优势,比如改进的错误页面 Blade 文件与行号处理、对常见问题的运行时解决、代码编辑、异常共享以及改进的用户体验。
主要有以下特点: 1.可以与Telescope集成,如果你的项目同时也安装了Telescope,右上角的链接可以定位到Telescope的异常记录中

2.如果是某些拼写导致的错误,ignition会给出建议提醒,例如上面的 "Did you mean home.table?"
3.分享功能,如果你希望把该错误分享给项目其他组员,点击"Share",然后点击剪切板图标,会得到一个分享地址,类似 https://flareapp.io/share/17xDBK7b,可以把该地址分享给他人,默认该地址任何人都可以看到。 如果是私有项目,可以点击"Open share admin"这样可以随时删除该分享地址。

4.在Stack trace,也就是堆栈追踪页面,鼠标放到代码行中,后面会出现编辑图标,点击就可以用PHPStorm打开该文件,并定位到该行,其原理是 URL schema
应用内跳转
比如浏览器打开的地址是phpstorm://open?file=%2FUsers%2Fmafei%2Fsites%2Flara6-golf%2Fvendor%2Flaravel%2Fframework%2Fsrc%2FIlluminate%2FView%2FFileViewFinder.php&line=131
就会启动phpstorm,打开文件/Users/mafei/sites/lara6-golf/vendor/laravel/framework/src/Illuminate/View/FileViewFinder.php
并定位到131行
支持多媒体文件上传,下载,多个上传,图片压缩,转换处理(需安装依赖)
缺点:如果要结合Vue或React进行上传,需要使用的Pro版本,但是要额外收费
使用起来比较简单,以v7版本为例
- 运行下面的命令
composer require spatie/laravel-medialibrary
php artisan vendor:publish --provider="Spatie\MediaLibrary\MediaLibraryServiceProvider" --tag="migrations"
php artisan migrate主要是生成一个media表
- 建议添加一个filesystem配置项,与其他的区分开
config/filesystems.php
'media' => [
'driver' => 'local',
'root' => storage_path('app/public/media'),
'url' => env('APP_URL').'/storage/media',
'visibility' => 'public',
],-
运行
php artisan storage:link -
以Note模块为例,添加封面图功能
use Illuminate\Database\Eloquent\Model;
use Spatie\MediaLibrary\HasMedia\HasMedia;
use Spatie\MediaLibrary\HasMedia\HasMediaTrait;
class Note extends Model implements HasMedia
{
// 对应filesystem的配置项
const COVER_MEDIA_DISK = 'media';
// 图集名称
const COVER_MEDIA_COLLECTION_NAME = 'note.cover';
use HasMediaTrait;
/**
* 上传图片到media
* @param Request $request
* @throws \Spatie\MediaLibrary\Exceptions\FileCannotBeAdded\DiskDoesNotExist
* @throws \Spatie\MediaLibrary\Exceptions\FileCannotBeAdded\FileDoesNotExist
* @throws \Spatie\MediaLibrary\Exceptions\FileCannotBeAdded\FileIsTooBig
*/
public function updateCoverFromRequest(Request $request)
{
if ($request->hasFile('cover')) {
$this->addMedia($request->file('cover'))
->preservingOriginal()
->toMediaCollection(self::COVER_MEDIA_COLLECTION_NAME, self::COVER_MEDIA_DISK);
}
}
/**
* 获取图片
* @return string
*/
public function getCoverAttribute()
{
return $this->getFirstMediaUrl(self::COVER_MEDIA_COLLECTION_NAME);
}- 更新控制器
...
public function edit(Note $note)
{
return view('notes.edit', compact('note'));
}
public function store(Request $request)
{
$this->validate($request, [
'cover' => 'file',
'title' => 'required',
'body' => 'required'
]);
$note = Note::create([
'user_id' => $request->user()->id,
'title' => $request->title,
'slug' => Str::slug(($request->title) . Str::random(10)),
'body' => $request->body
]);
// 更新封面图
$note->updateCoverFromRequest($request);
return redirect('/');
}- 更新view
<img src="{{$note->cover}}" alt="">laravel-medialibrary的功能还是比较强大的,对接也比较方便,详细内容可以参照官方文档
参考
https://spatie.be/docs/laravel-medialibrary/v7/installation-setup
]]>const mix = require('laravel-mix');
/*
|--------------------------------------------------------------------------
| Mix Asset Management
|--------------------------------------------------------------------------
|
| Mix provides a clean, fluent API for defining some Webpack build steps
| for your Laravel application. By default, we are compiling the Sass
| file for the application as well as bundling up all the JS files.
|
*/
mix
.extract()
.scripts([
'resources/js/vendor/metisMenu.js',
'resources/js/vendor/jquery.mask.min.js',
'resources/js/vendor/bootstrap.bundle.js',
'resources/js/vendor/moment-2.24.0.js',
'resources/js/vendor/tempusdominus-bootstrap-4.js',
'resources/js/vendor/popper.min.js',
'resources/js/vendor/select2.min.js',
'resources/js/vendor/jquery.dataTables.min.js',
'resources/js/vendor/dataTables.bootstrap4.min.js',
], 'public/js/third-party.js')
.js('resources/js/app.js', 'public/js')
.styles([
'resources/css/metisMenu.css',
'resources/css/tempusdominus-bootstrap-4.css',
'resources/css/select2.min.css',
'resources/css/select2-bootstrap4.css',
'resources/css/dataTables.bootstrap4.min.css',
'resources/css/nprogress.css',
], 'public/css/vendor.css')
.sass('resources/sass/app.scss', 'public/css');
if (mix.inProduction()) {
mix.version();
} else {
if (process.env.MIX_PROXY_HOST) {
// mix.browserSync({
// proxy: process.env.MIX_PROXY_HOST
// });
}
}注意事项:
- extract()方法会提取所有import来自node_modules中的类库并合并到vendor.js中
- 当使用extract方法会自动生成一个manifest.js文件,这个文件是运行时代码,帮助缓存vendor.js
- 最终js目录会生成app.js、manifest.js、third-party.js和vendor.js,在blade中也要按上面的顺序加载
<script src="{{ mix('js/manifest.js') }}"></script>
<script src="{{ mix('js/vendor.js') }}"></script>
<script src="{{ mix('js/app.js') }}"></script>
<script src="{{ mix('js/third-party.js') }}"></script>这里结合Laravel聊聊实现过程,抛砖引玉,有更好的方案欢迎讨论
我们的需求:
- 根据不同域名访问不同数据库
- 泛域名解析
泛域名解析
这个其他文章里有介绍 我们先复杂问题简单化,假设只有两个客户A和B,登录域名已经配好 demo.test 和 lara6.test
大致思路
- 创建一个admin数据库,库中包含一个tenants表,用来保存租户的基本信息,如名称,数据库,域名
- 创建一个TenancyServiceProvider,每次请求中调用这个Provider,在里面实现根据当前访问域名动态切换数据库的方法
讨论:
https://learnku.com/laravel/t/44228
开源类库:
- https://github.com/spatie/laravel-multitenancy
- https://github.com/stancl/tenancy
- https://github.com/tenancy/tenancy
数据库切换: https://learnku.com/articles/28142
DB::unprepared("USE intogolf_demo;");
]]>snappy是一个对wkhtmltopdf封装的类库,使用非常简单。
而这里介绍的 laravel-snappy 则又是对snappy的封装,只不过方便集成到Laravel框架中。
在使用 laravel-snappy 之前我建议先浏览下 wkhtmltopdf官方文档 wkhtmltopdf下载后之后就是一个bin二进制文件,提供了非常多的参数。
这里介绍下怎么在Laravel6中使用laravel-snappy并生成pdf文件
- 首先下载安装wkhtmltopdf,以Ubuntu为例,来到https://wkhtmltopdf.org/downloads.html下载对应的版本
# 下载安装包
wget https://github.com/wkhtmltopdf/packaging/releases/download/0.12.6-1/wkhtmltox_0.12.6-1.
bionic_amd64.deb
# 安装
sudo dpkg -i wkhtmltox_0.12.6-1.bionic_amd64.deb
# 如果报错,如缺少依赖,可以执行下面这个
sudo apt-get -f install
# 检查是否安装成功
which wkhtmltopdf
# 输出
/usr/local/bin/wkhtmltopdf
which wkhtmltoimage
# 输出
/usr/local/bin/wkhtmltoimage-
按照 laravel-snappy 教程,添加Facade,生成config/snappy.php
-
新建
resources/views/pos/receipt-pdf.blade.php模板, 这里面有一些变量需要Controller传给视图,需要注意字体和图片的引用。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>RECEIPT</title>
<style type="text/css">
.container-fluid {
width: 100%;
padding-right: 15px;
padding-left: 15px;
margin-right: auto;
margin-left: auto;
}
@font-face {
font-family: 'Microsoft YaHei';
src: url('file://{{ public_path('fonts/msyh.ttc') }}') format('truetype');
font-weight: normal;
font-style: normal;
}
body {
font-family: 'Microsoft YaHei';
margin: 20px 40px;
color: #222222;
}
thead {
display: table-header-group;
}
tfoot {
display: table-row-group;
}
tr {
page-break-inside: avoid;
}
.mt-5 {
margin-top: 3rem;
}
.mb-5 {
margin-bottom: 3rem;
}
.font-bolder {
font-weight: bolder;
}
.text-center {
text-align: center;
}
.bottom-none {
border-bottom: none !important;
}
.float-left {
float: left !important;
}
.float-right {
float: right !important;
}
.text-gray {
color: #95aac9;
}
.text-danger {
color: #dc3545 !important;
}
.table-receipt td {
padding: 5px;
}
.table-items tr > td {
border-bottom: 1px solid #dee2e6;
padding: 15px;
}
.table-items tr > td:first-child {
padding-left: 0;
}
.table-items tr > td:last-child {
padding-right: 0;
}
tr.header {
color: #95aac9;
}
tr.header > td {
padding-top: 25px
}
</style>
</head>
<body>
<div class="container-fluid">
<div class="text-center">
<img height="auto" src="{{ public_path('images/logo-black.png') }}"/>
<h1>Receipt from {{data_get($companyInfo, 'comName')}}</h1>
<p class="text-gray" style="font-size: 18pt">Transaction ID: {{ $transactionID }}</p>
</div>
<table border="0" cellpadding="0" cellspacing="0" style="width: 100%" class="table-receipt">
<thead>
<tr class="header">
<td align="left">INVOICED FROM</td>
<td align="right">INVOICED TO</td>
</tr>
</thead>
<tbody>
<tr class="font-bolder">
<td>{{ data_get($companyInfo, 'comName')}}</td>
<td align="right">Guest</td>
</tr>
<tr>
<td>{{ data_get($companyInfo, 'comAddress1')}}</td>
<td align="right">--</td>
</tr>
<tr>
<td>{{ data_get($companyInfo, 'comAddress2')}}</td>
<td align="right">--</td>
</tr>
<tr class="header">
<td>INVOICE ID</td>
<td align="right">PAYMENT AT</td>
</tr>
<tr class="font-bolder">
<td>{{ $transactionID }}</td>
<td align="right">{{ date('m-d-Y') }} at {{ date('H:i:s') }}</td>
</tr>
<tr class="header">
<td>PAGE</td>
<td align="right">PAYMENT METHOD</td>
</tr>
<tr class="font-bolder">
<td>1 of 1</td>
<td align="right">{{ data_get($payMethod, 'label') }}</td>
</tr>
</tbody>
</table>
<hr class="mt-5" style="border: 1px solid #95aac9;opacity: 10%;">
<h3 class="text-gray text-center">THANK YOU FOR YOUR ORDER!</h3>
<h3 class="text-gray text-center">WE HOPE TO SEE YOU AGAIN SOON!</h3>
</div>
</body>
</html>- Controller中添加生成pdf方法 sendReceiptEmail是发送发票到客户邮箱中,需要先调用exportToPDF生成pdf格式的发票,然后作为邮箱附件发送出去。
public function exportToPDF($pdfData) {
$blade = 'pos.receipt-pdf';
$pdf = \App::make('snappy.pdf.wrapper');
// 传给pdf视图模板的变量,有可能是从数据库或session中获取,这里不展开
$body = \View::make($blade, $pdfData)->render();
$pdf->loadHTML($body)->setPaper('a4');
// 这里的参数其实是wkhtmltopdf的,文档里都可以查到,由于我们引用了本地图片和字体,需要开启本地访问文件权限
$pdf->setOption('enable-local-file-access', true);
$pdf->setOption('margin-top', '5mm');
$pdf->setOption('margin-bottom', '5mm');
$pdf->setOption('margin-left', '5mm');
$pdf->setOption('margin-right', '5mm');
return $pdf;
}
public function sendReceiptEmail(Request $request) {
// 保存pdf的临时路径
$pdfPath = storage_path('app/order-receipt/tmp/tmp.pdf');
if (file_exists($pdfPath)) {
\File::delete($pdfPath);
}
// 先获取pdf需要的数据
$pdfData = $this->processPdfData($request);
// 生成pdf
$pdf = $this->exportToPDF($pdfData);
// 保存成功,作为附件发送出去
if ($pdf->save($pdfPath)) {
Mail::to('[email protected]')
->send(new PosOrderReceipt());
}
}app/Mail/PosOrderReceipt.php
<?php
namespace App\Mail;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Mail\Mailable;
use Illuminate\Queue\SerializesModels;
class PosOrderReceipt extends Mailable
{
use Queueable, SerializesModels;
/**
* Create a new message instance.
*
* @return void
*/
public function __construct()
{
}
/**
* Build the message.
*
* @return $this
*/
public function build()
{
$location = storage_path('app/order-receipt/tmp/tmp.pdf');
return $this
->view('emails.pos.order-receipt', [
])
->attach($location, [
'as' => 'receipt.pdf',
'mime' => 'application/pdf']);
}
}注意事项
- 如果不开启
enable-local-file-access引用本地文件时会报类似Blocked access to file /DemoProjectPath/public/images/logo-black.png↵的错误 - 而且路径
storage_path('app/order-receipt/tmp/tmp.pdf')也需要有访问权限,可使用chmod 755解决
参考
]]>https://github.com/mewebstudio/captcha
图片处理 裁剪,加水印
http://image.intervention.io/ https://learnku.com/articles/14292/laravel-uses-interventionimage-to-process-pictures
媒体库
https://github.com/spatie/laravel-medialibrary
XSS 安全漏洞处理组件
https://packagist.org/packages/mews/purifier
有时候需要对用户自己输入的内容做限制或过滤 使用方法
- composer install mews/purifier
- config目录下新建 purifier.php 配置允许的html内容
<?php
return [
'encoding' => 'UTF-8',
'finalize' => true,
'cachePath' => storage_path('app/purifier'),
'cacheFileMode' => 0755,
'settings' => [
'user_topic_body' => [
'HTML.Doctype' => 'XHTML 1.0 Transitional',
'HTML.Allowed' => 'div,b,strong,i,em,a[href|title],ul,ol,ol[start],li,p[style],br,span[style],img[width|height|alt|src],*[style|class],pre,hr,code,h2,h3,h4,h5,h6,blockquote,del,table,thead,tbody,tr,th,td',
'CSS.AllowedProperties' => 'font,font-size,font-weight,font-style,margin,width,height,font-family,text-decoration,padding-left,color,background-color,text-align',
'AutoFormat.AutoParagraph' => true,
'AutoFormat.RemoveEmpty' => true,
],
],
];- 在需要过滤的地方
$topic->body = clean($topic->body);
Model
类库使用
开发搜集
]]>比如Cache::get('key');
Laravel 的入口文件是 public/index.php,此文件载入了 autoload.php, app.php 2个文件:
require __DIR__.'/../bootstrap/autoload.php';
$app = require_once __DIR__.'/../bootstrap/app.php';顾名思义 autoload.php 实现了自动加载,app.php 和容器相关。
初始化容器的过程这里不详细解说,不是本文重点。
初始化容器后,执行了以下代码:
// 得到 App\Http\Kernel 实例对象
$kernel = $app->make(Illuminate\Contracts\Http\Kernel::class);
// 执行对象handle 方法,此方法继承自 Illuminate\Foundation\Http\Kernel
$response = $kernel->handle(
$request = Illuminate\Http\Request::capture()
);让我们去看下 handle() 做了些什么:
public function handle($request)
{
//......省略......
$response = $this->sendRequestThroughRouter($request);
//......省略......
}sendRequestThroughRouter 方法:
protected function sendRequestThroughRouter($request)
{
//......省略......
// 启动一些启动器,诸如异常处理,配置,日志,Facade,运行环境监测等
$this->bootstrap();
//......省略......
}bootstrap 方法:
public function bootstrap()
{
if (! $this->app->hasBeenBootstrapped()) {
$this->app->bootstrapWith($this->bootstrappers());
}
}$this->bootstrappers() 中返回 $this->bootstrappers 保存的数据:
protected $bootstrappers = [
'Illuminate\Foundation\Bootstrap\DetectEnvironment',
'Illuminate\Foundation\Bootstrap\LoadConfiguration',
'Illuminate\Foundation\Bootstrap\ConfigureLogging',
'Illuminate\Foundation\Bootstrap\HandleExceptions',
// 可以看到
'Illuminate\Foundation\Bootstrap\RegisterFacades',
'Illuminate\Foundation\Bootstrap\RegisterProviders',
'Illuminate\Foundation\Bootstrap\BootProviders',
];RegisterFacades此类就是实现 Facade 的一部分,bootstrap 方法中 $this->app->bootstrapWith 会调用类的 bootstrap 方法:
class RegisterFacades
{
public function bootstrap(Application $app)
{
//......省略......
AliasLoader::getInstance($app->make('config')->get('app.aliases'))->register();
}
}$app->make('config')->get('app.aliases') 返回的是 config/app.php 配置文件中 'aliases' 键对应的值,
我们继续往下看 AliasLoader::getInstance 方法:
/**
* Get or create the singleton alias loader instance.
*
* @param array $aliases
* @return \Illuminate\Foundation\AliasLoader
*/
public static function getInstance(array $aliases = [])
{
if (is_null(static::$instance)) {
return static::$instance = new static($aliases);
}
$aliases = array_merge(static::$instance->getAliases(), $aliases);
static::$instance->setAliases($aliases);
return static::$instance;
}回头再看
AliasLoader::getInstance($app->make('config')->get('app.aliases'))->register();中调用了 AliasLoader->register 方法:
public function register()
{
if (!$this->registered) {
$this->prependToLoaderStack();
$this->registered = true;
}
}prependToLoaderStack 方法:
这里注册了当前对象中 load 方法为自动加载函数
protected function prependToLoaderStack()
{
spl_autoload_register([$this, 'load'], true, true);
}load 方法:
public function load($alias)
{
if (isset($this->aliases[$alias])) {
return class_alias($this->aliases[$alias], $alias);
}
}这里的 $this->aliases 即是 AliasLoader:getInstance 中实例化一个对象: new static($aliases) 时构造函数中设置的:
private function __construct($aliases)
{
$this->aliases = $aliases;这里 class_alias 是实现 Facade 的核心要点之一,该函数原型:
bool class_alias ( string $original, string $alias[, bool $autoload = TRUE ] )
第三个参数默认为 true,意味着如果原始类(string $original)没有加载,则自动加载。 更多该函数的解释请自行翻阅手册。
问题2 为什么可以像静态方法一样调用任何类的方法
打开vendor/laravel/framework/src/Illuminate/Support/Facades/Cache.php
class Cache extends Facade
{
/**
* Get the registered name of the component.
*
* @return string
*/
protected static function getFacadeAccessor()
{
return 'cache';
}
}看一下 父类 Illuminate\Support\Facades,发现父类中实现了魔术方法 __callStatic:
public static function __callStatic($method, $args)
{
$instance = static::getFacadeRoot();
if (! $instance) {
throw new RuntimeException('A facade root has not been set.');
}
return $instance->$method(...$args);
}谜底就是通过魔术方法去实现的。
自己实现
namespace Illuminate\Support\Facades {
class Facades {
public function __call($name, $params) {
return call_user_func_array([$this, $name], $params);
}
public static function __callStatic($name, $params) {
return call_user_func_array([new static(), $name], $params);
}
}
class Cache extends Facades {
protected function fn($a, $b) {
echo "function parameters: ${a} and ${b}<br>";
}
protected function static_fn($a, $b) {
echo "static function parameters: ${a} and ${b}<br>";
}
}
}
namespace {
class Autoload {
public $aliases;
public function __construct($aliases = []) {
$this->aliases = $aliases;
}
public function register() {
spl_autoload_register([$this, 'load'], true, true);
return $this;
}
public function load($alias) {
if (isset($this->aliases[$alias])) {
return class_alias($this->aliases[$alias], $alias);
}
}
}
$aliases = [
'Cache' => Illuminate\Support\Facades\Cache::class,
];
$autoloader = (new Autoload($aliases))->register();
Cache::fn(3,6);
Cache::static_fn(4,7);
}参考
]]>Illuminate\Support\Fluent 是个非常好用的类。
它封装了一些操作数组和对象
举例说明他能做的事情
<?php
// Create a new array containing sample data
$testArray = [
'first' => 'The first value',
'second' => 'The second value',
'third' => 'The third value'
];
// Create a new stdClass instance containing sample data
$testObject = new stdClass;
$testObject->first = 'The first value';
$testObject->second = 'The second value';
$testObject->third = 'The third value'
// 这样操作是没有问题的
// Retrieve the 'first' item
$value = $testArray['first'];
// Retrieve the 'first' property
$value = $testObject->first;
# 但是访问不存在的属性或key会报错
// Will raise an exception
$value = $testArray['does_not_exist'];
// Will raise an exception
$value = $testObject->doesNotExist;
# 传统做法,加if判断,是不是很麻烦,当然我们也可以用 Laravel 提供的 array_get, object_get, data_get
// Get a value from an array, or a default value
// if it does not exist.
if (array_key_exists('does_not_exist', $testArray))
{
$value = $testArray['does_not_exist'];
} else {
$value = 'Some default value';
}
// Get a value from an object, or a default value
// if it does not exist.
if (property_exists('doesNotExist', $testObject))
{
$objectValue = $testObject->doesNotExist;
} else {
$objectValue = 'Some default value';
}来看看使用Fluent后的做法,非常方便且优雅
<?php
// Some example data, which could be obtained from
// any number of sources.
$testArray = [
'first' => 'The first value',
'second' => 'The second value',
'third' => 'The third value'
];
// Create a new Fluent instance.
$fluent = new Fluent($testArray);
// Accessing a value like an array.
$value = $fluent['first'];
// Accessing a value like an object.
$secondValue = $fluent->first;
// 直接返回null,不会报错
$value = $fluent['does_not_exist'];
$secondValue = $fluent->doesNotExist;Fluent 还提供了几个方法,可以让你更加方便的操作数组和对象
<?php
// A test array for use with Fluent.
$testArray = [
'first' => 'The first value',
'second' => 'The second value',
'third' => 'The third value'
];
// A test object for use with Fluent.
$testObject = new stdClass;
$testObject->first = 'The first value';
$testObject->second = 'The second value';
$testObject->third = 'The third value';
$fluent = new Fluent($testArray);
# get($key, $default = null)
// The first value
$message = $fluent->get('first');
$fluent = new Fluent($testObject);
// The first value
$message = $fluent->get('first');
// Does not exist yet!
$message = $fluent->get('does_not_exist', function() {
return 'Does not exist yet!';
});
# Fluent与闭包
$testObject = new stdClass;
$testObject->method = function() {
return 'Hello, world!';
};
$fluent = new Fluent($testObject);
$message = $fluent->method;
// Or even this:
$message = $fluent->get('method');
// true
$isClosure = ($fluent->method instanceof Closure):
// Hello, world!
$message = value($fluent->method);
// Hello, world!
$message = value($fluent->get('method'));
# getAttributes()
$fluent = new Fluent($testObject);
// 返回数组
$attributes = $fluent->getAttributes();
$fluent = new Fluent($testObject);
// {"first":"The first value","second":"The second value","third":"The third value","method":{}}
$jsonValue = $fluent->toJson();参考
https://stillat.com/blog/2016/11/21/laravel-fluent-part-one-introduction
]]>计算机科学里的宏(Macro),是一种批量处理的称谓。 比如有些重复的动作,可以打包记录为一个宏,给宏名字,调用这个宏,就等于执行这一系列动作了。
下面看下Laravel中宏的源码实现
源码分析
<?php
trait Macroable
{
/**
* The registered string macros.
*
* @var array
*/
protected static $macros = [];
/**
* Register a custom macro.
*
* @param string $name
* @param object|callable $macro
* @return void
*/
public static function macro($name, $macro)
{
static::$macros[$name] = $macro;
}
/**
* Mix another object into the class.
*
* @param object $mixin
* @param bool $replace
* @return void
*
* @throws \ReflectionException
*/
public static function mixin($mixin, $replace = true)
{
// 通过反射获取该对象中所有公开和受保护的方法
$methods = (new ReflectionClass($mixin))->getMethods(
ReflectionMethod::IS_PUBLIC | ReflectionMethod::IS_PROTECTED
);
foreach ($methods as $method) {
if ($replace || ! static::hasMacro($method->name)) {
// 设置方法可访问,因为受保护的不能在外部调用
$method->setAccessible(true);
// 调用 macro 方法批量创建宏指令
static::macro($method->name, $method->invoke($mixin));
}
}
}
/**
* Checks if macro is registered.
*
* @param string $name
* @return bool
*/
public static function hasMacro($name)
{
return isset(static::$macros[$name]);
}
/**
* Dynamically handle calls to the class.
*
* @param string $method
* @param array $parameters
* @return mixed
*
* @throws \BadMethodCallException
*/
public static function __callStatic($method, $parameters)
{
if (! static::hasMacro($method)) {
throw new BadMethodCallException(sprintf(
'Method %s::%s does not exist.', static::class, $method
));
}
$macro = static::$macros[$method];
if ($macro instanceof Closure) {
return call_user_func_array( ($macro, null, static::class), $parameters);
}
return $macro(...$parameters);
}
/**
* Dynamically handle calls to the class.
*
* @param string $method
* @param array $parameters
* @return mixed
*
* @throws \BadMethodCallException
*/
public function __call($method, $parameters)
{
if (! static::hasMacro($method)) {
throw new BadMethodCallException(sprintf(
'Method %s::%s does not exist.', static::class, $method
));
}
$macro = static::$macros[$method];
if ($macro instanceof Closure) {
return call_user_func_array($macro->bindTo($this, static::class), $parameters);
}
return $macro(...$parameters);
}
}
class Father
{
public function say()
{
return function () {
echo 'say';
};
}
public function show()
{
return function () {
echo 'show';
};
}
protected function eat()
{
return function () {
echo 'eat';
};
}
protected function test()
{
echo 'eat';
}
}
class Child
{
use Macroable;
}
// 批量绑定宏指令
Child::mixin(new Father);
$child = new Child;
// 输出:say
$child->say();
// 输出:show
$child->show();
// 输出:eat
$child->eat();
// 因为 Macroable 加了 __callStatic 支持静态调用
$child::eat();
// 这样调用会报错,因为test返回的不是闭包
$child->test();Laravel中使用
在Laravel中,很多类都实现了Macroable,比如下列(in Laravel5.4)
Illuminate\Database\Query\Builder
Illuminate\Database\Eloquent\Builder
Illuminate\Database\Eloquent\Relations\Relation
Illuminate\Http\Request
Illuminate\Http\RedirectResponse
Illuminate\Http\UploadedFile
Illuminate\Routing\Router
Illuminate\Routing\ResponseFactory
Illuminate\Routing\UrlGenerator
Illuminate\Support\Arr
Illuminate\Support\Str
Illuminate\Support\Collection
Illuminate\Cache\Repository
Illuminate\Console\Scheduling\Event
Illuminate\Filesystem\Filesystem
Illuminate\Foundation\Testing\TestResponse
Illuminate\Translation\Translator
Illuminate\Validation\Rule我们就可以这么搞
use Illuminate\Support\Collection;
// 定义一个宏
Collection::macro('someMethod', function ($arg1 = 1, $arg2 = 1) {
// count 是 collection对象内置的方法
return $this->count() + $arg1 + $arg2;
});
// 调用宏
// 我们只是向类中添加了一个以前不存在的方法,而无需接触任何源文件。
$coll = new Collection([1, 2, 3]);
echo $coll->someMethod(1, 2);使用macro往一个类中添加新方法
$macroableClass = new class() {
use Macroable;
};
$macroableClass::macro('concatenate', function(... $strings) {
return implode('-', $strings);
};
$macroableClass->concatenate('one', 'two', 'three'); // returns 'one-two-three'使用mixin方法往一个类追加多个方法
$mixin = new class() {
public function mixinMethod()
{
return function() {
return 'mixinMethod';
};
}
public function anotherMixinMethod()
{
return function() {
return 'anotherMixinMethod';
};
}
};
$macroableClass->mixin($mixin);
$macroableClass->mixinMethod() // returns 'mixinMethod';
$macroableClass->anotherMixinMethod() // returns 'anotherMixinMethod';也就是说,我们可以通过宏扩展原有的功能,看这个例子,往Query Build中添加list方法
把宏定义添加到AppServiceProvider文件的boot方法中,这样可以在全局使用啦
Collection::macro('firstNth', function($take) {
// 加 static 确保返回 collection 类型
return new static(array_slice($this->item, 0, $take));
});参考
https://asklagbox.com/blog/laravel-macros
]]>interface Food {
public function weight();
}
class Apple implements Food {
public function __contructur($weight) {
return $this->weight = $weight;
}
public function weight() {
return $this->weight;
}
}
// 绑定容器
app()->bind('weight', function() {
return new Apple(100);
});
// 上面的等价写法
// 等价于 dd(app('weight'));
dd(resolve('weight'));参考
https://learnku.com/articles/2769/laravel-pipeline-realization-of-the-principle-of-single-component https://segmentfault.com/a/1190000022566835
]]><?php
class Builder
{
public $limit;
public function take($value)
{
return $this->limit($value);
}
public function limit($value)
{
$this->limit = $value;
return $this;
}
public function when($value, $callback, $default = null)
{
if ($value) {
return $callback($this, $value) ?: $this;
} elseif ($default) {
return $default($this, $value) ?: $this;
}
return $this;
}
public function tap($callback)
{
return $this->when(true, $callback);
}
}
$builder = new Builder();
$builder
->when(1, function($q) {
return $q->take(3);
})
->tap(function($q) {
return $q->take(4);
});
print_r($builder);打开根目录的public/index.php
// 定义常量,记录laravel框架启动时候的时间
define('LARAVEL_START', microtime(true));
// 加载composer包
require __DIR__.'/../vendor/autoload.php';
// 引导应用对象,返回真正的应用对象
// 这个比较重要,后续会更有详细的介绍
$app = require_once __DIR__.'/../bootstrap/app.php';
// 获取内核对象
$kernel = $app->make(Illuminate\Contracts\Http\Kernel::class);
// 处理请求,返回响应对象
$response = $kernel->handle(
$request = Illuminate\Http\Request::capture()
);
// 发送响应到浏览器
$response->send();
// 终止此次请求
$kernel->terminate($request, $response);打开根目录的boostrap/app.php
首先实例化了一个Application类,是本次的分析重点,我们进到源码里
$app = new Illuminate\Foundation\Application(
$_ENV['APP_BASE_PATH'] ?? dirname(__DIR__)
);路径是 src/Illuminate/Foundation/Application.php
这个文件比较大,1000多行,是作为应用最核心的类
<?php
namespace Illuminate\Foundation;
use Closure; // php 默认匿名函数类
use Illuminate\Container\Container; // laravel 容器类
use Illuminate\Contracts\Foundation\Application as ApplicationContract; // laravel 应用契约
use Illuminate\Contracts\Http\Kernel as HttpKernelContract; // laravel 内核类
use Illuminate\Events\EventServiceProvider; // laravel 事件服务提供者
use Illuminate\Filesystem\Filesystem; // laravel 文件系统类
use Illuminate\Foundation\Bootstrap\LoadEnvironmentVariables; // laravel 载入环境变量类
use Illuminate\Foundation\Events\LocaleUpdated;
use Illuminate\Http\Request; // laravel 请求对象类
use Illuminate\Log\LogServiceProvider; // laravel 日志服务提供者
use Illuminate\Routing\RoutingServiceProvider; // laravel 路由服务提供者
use Illuminate\Support\Arr; // laravel 数组操作类
use Illuminate\Support\Collection; // laravel 集合类
use Illuminate\Support\Env; // laravel 处理env文件类
use Illuminate\Support\ServiceProvider;
use Illuminate\Support\Str; // laravel 字符串操作类
use RuntimeException; // 运行异常类
use Symfony\Component\HttpFoundation\Request as SymfonyRequest; // Symfony 请求类
use Symfony\Component\HttpKernel\Exception\HttpException; //Symfony Http 异常类
use Symfony\Component\HttpKernel\Exception\NotFoundHttpException; // Symfony NotFound 异常类
use Symfony\Component\HttpKernel\HttpKernelInterface; // Symfony Http 内核接口
class Application extends Container implements ApplicationContract, HttpKernelInterface
{
/**
* The Laravel framework version.
*
* @var string
*/
const VERSION = '6.18.43';
/**
* The base path for the Laravel installation.
*
* @var string
*/
protected $basePath;
/**
* Indicates if the application has been bootstrapped before.
*
* @var bool
*/
protected $hasBeenBootstrapped = false;
/**
* Indicates if the application has "booted".
*
* @var bool
*/
protected $booted = false;
/**
* The array of booting callbacks.
*
* @var callable[]
*/
protected $bootingCallbacks = [];
/**
* The array of booted callbacks.
*
* @var callable[]
*/
protected $bootedCallbacks = [];
/**
* The array of terminating callbacks.
*
* @var callable[]
*/
protected $terminatingCallbacks = [];
/**
* All of the registered service providers.
*
* @var \Illuminate\Support\ServiceProvider[]
*/
protected $serviceProviders = [];
/**
* The names of the loaded service providers.
*
* @var array
*/
protected $loadedProviders = [];
/**
* The deferred services and their providers.
*
* @var array
*/
protected $deferredServices = [];
/**
* The custom application path defined by the developer.
*
* @var string
*/
protected $appPath;
/**
* The custom database path defined by the developer.
*
* @var string
*/
protected $databasePath;
/**
* The custom storage path defined by the developer.
*
* @var string
*/
protected $storagePath;
/**
* The custom environment path defined by the developer.
*
* @var string
*/
protected $environmentPath;
/**
* The environment file to load during bootstrapping.
*
* @var string
*/
protected $environmentFile = '.env';
/**
* Indicates if the application is running in the console.
*
* @var bool|null
*/
protected $isRunningInConsole;
/**
* The application namespace.
*
* @var string
*/
protected $namespace;
/**
* Create a new Illuminate application instance.
*
* @param string|null $basePath
* @return void
*/
public function __construct($basePath = null)
{
if ($basePath) {
$this->setBasePath($basePath);
}
$this->registerBaseBindings();
$this->registerBaseServiceProviders();
$this->registerCoreContainerAliases();
}
/**
* Get the version number of the application.
*
* @return string
*/
public function version()
{
return static::VERSION;
}
/**
* Register the basic bindings into the container.
*
* @return void
*/
protected function registerBaseBindings()
{
static::setInstance($this);
$this->instance('app', $this);
$this->instance(Container::class, $this);
$this->singleton(Mix::class);
$this->instance(PackageManifest::class, new PackageManifest(
new Filesystem, $this->basePath(), $this->getCachedPackagesPath()
));
}
/**
* Register all of the base service providers.
*
* @return void
*/
protected function registerBaseServiceProviders()
{
$this->register(new EventServiceProvider($this));
$this->register(new LogServiceProvider($this));
$this->register(new RoutingServiceProvider($this));
}
/**
* Run the given array of bootstrap classes.
*
* @param string[] $bootstrappers
* @return void
*/
public function bootstrapWith(array $bootstrappers)
{
$this->hasBeenBootstrapped = true;
foreach ($bootstrappers as $bootstrapper) {
$this['events']->dispatch('bootstrapping: '.$bootstrapper, [$this]);
$this->make($bootstrapper)->bootstrap($this);
$this['events']->dispatch('bootstrapped: '.$bootstrapper, [$this]);
}
}
/**
* Register a callback to run after loading the environment.
*
* @param \Closure $callback
* @return void
*/
public function afterLoadingEnvironment(Closure $callback)
{
return $this->afterBootstrapping(
LoadEnvironmentVariables::class, $callback
);
}
/**
* Register a callback to run before a bootstrapper.
*
* @param string $bootstrapper
* @param \Closure $callback
* @return void
*/
public function beforeBootstrapping($bootstrapper, Closure $callback)
{
$this['events']->listen('bootstrapping: '.$bootstrapper, $callback);
}
/**
* Register a callback to run after a bootstrapper.
*
* @param string $bootstrapper
* @param \Closure $callback
* @return void
*/
public function afterBootstrapping($bootstrapper, Closure $callback)
{
$this['events']->listen('bootstrapped: '.$bootstrapper, $callback);
}
/**
* Determine if the application has been bootstrapped before.
*
* @return bool
*/
public function hasBeenBootstrapped()
{
return $this->hasBeenBootstrapped;
}
/**
* Set the base path for the application.
*
* @param string $basePath
* @return $this
*/
public function setBasePath($basePath)
{
$this->basePath = rtrim($basePath, '\/');
$this->bindPathsInContainer();
return $this;
}
/**
* Bind all of the application paths in the container.
*
* @return void
*/
protected function bindPathsInContainer()
{
$this->instance('path', $this->path());
$this->instance('path.base', $this->basePath());
$this->instance('path.lang', $this->langPath());
$this->instance('path.config', $this->configPath());
$this->instance('path.public', $this->publicPath());
$this->instance('path.storage', $this->storagePath());
$this->instance('path.database', $this->databasePath());
$this->instance('path.resources', $this->resourcePath());
$this->instance('path.bootstrap', $this->bootstrapPath());
}
/**
* Get the path to the application "app" directory.
*
* @param string $path
* @return string
*/
public function path($path = '')
{
$appPath = $this->appPath ?: $this->basePath.DIRECTORY_SEPARATOR.'app';
return $appPath.($path ? DIRECTORY_SEPARATOR.$path : $path);
}
/**
* Set the application directory.
*
* @param string $path
* @return $this
*/
public function useAppPath($path)
{
$this->appPath = $path;
$this->instance('path', $path);
return $this;
}
/**
* Get the base path of the Laravel installation.
*
* @param string $path Optionally, a path to append to the base path
* @return string
*/
public function basePath($path = '')
{
return $this->basePath.($path ? DIRECTORY_SEPARATOR.$path : $path);
}
/**
* Get the path to the bootstrap directory.
*
* @param string $path Optionally, a path to append to the bootstrap path
* @return string
*/
public function bootstrapPath($path = '')
{
return $this->basePath.DIRECTORY_SEPARATOR.'bootstrap'.($path ? DIRECTORY_SEPARATOR.$path : $path);
}
/**
* Get the path to the application configuration files.
*
* @param string $path Optionally, a path to append to the config path
* @return string
*/
public function configPath($path = '')
{
return $this->basePath.DIRECTORY_SEPARATOR.'config'.($path ? DIRECTORY_SEPARATOR.$path : $path);
}
/**
* Get the path to the database directory.
*
* @param string $path Optionally, a path to append to the database path
* @return string
*/
public function databasePath($path = '')
{
return ($this->databasePath ?: $this->basePath.DIRECTORY_SEPARATOR.'database').($path ? DIRECTORY_SEPARATOR.$path : $path);
}
/**
* Set the database directory.
*
* @param string $path
* @return $this
*/
public function useDatabasePath($path)
{
$this->databasePath = $path;
$this->instance('path.database', $path);
return $this;
}
/**
* Get the path to the language files.
*
* @return string
*/
public function langPath()
{
return $this->resourcePath().DIRECTORY_SEPARATOR.'lang';
}
/**
* Get the path to the public / web directory.
*
* @return string
*/
public function publicPath()
{
return $this->basePath.DIRECTORY_SEPARATOR.'public';
}
/**
* Get the path to the storage directory.
*
* @return string
*/
public function storagePath()
{
return $this->storagePath ?: $this->basePath.DIRECTORY_SEPARATOR.'storage';
}
/**
* Set the storage directory.
*
* @param string $path
* @return $this
*/
public function useStoragePath($path)
{
$this->storagePath = $path;
$this->instance('path.storage', $path);
return $this;
}
/**
* Get the path to the resources directory.
*
* @param string $path
* @return string
*/
public function resourcePath($path = '')
{
return $this->basePath.DIRECTORY_SEPARATOR.'resources'.($path ? DIRECTORY_SEPARATOR.$path : $path);
}
/**
* Get the path to the environment file directory.
*
* @return string
*/
public function environmentPath()
{
return $this->environmentPath ?: $this->basePath;
}
/**
* Set the directory for the environment file.
*
* @param string $path
* @return $this
*/
public function useEnvironmentPath($path)
{
$this->environmentPath = $path;
return $this;
}
/**
* Set the environment file to be loaded during bootstrapping.
*
* @param string $file
* @return $this
*/
public function loadEnvironmentFrom($file)
{
$this->environmentFile = $file;
return $this;
}
/**
* Get the environment file the application is using.
*
* @return string
*/
public function environmentFile()
{
return $this->environmentFile ?: '.env';
}
/**
* Get the fully qualified path to the environment file.
*
* @return string
*/
public function environmentFilePath()
{
return $this->environmentPath().DIRECTORY_SEPARATOR.$this->environmentFile();
}
/**
* Get or check the current application environment.
*
* @param string|array $environments
* @return string|bool
*/
public function environment(...$environments)
{
if (count($environments) > 0) {
$patterns = is_array($environments[0]) ? $environments[0] : $environments;
return Str::is($patterns, $this['env']);
}
return $this['env'];
}
/**
* Determine if application is in local environment.
*
* @return bool
*/
public function isLocal()
{
return $this['env'] === 'local';
}
/**
* Determine if application is in production environment.
*
* @return bool
*/
public function isProduction()
{
return $this['env'] === 'production';
}
/**
* Detect the application's current environment.
*
* @param \Closure $callback
* @return string
*/
public function detectEnvironment(Closure $callback)
{
$args = $_SERVER['argv'] ?? null;
return $this['env'] = (new EnvironmentDetector)->detect($callback, $args);
}
/**
* Determine if the application is running in the console.
*
* @return bool
*/
public function runningInConsole()
{
if ($this->isRunningInConsole === null) {
$this->isRunningInConsole = Env::get('APP_RUNNING_IN_CONSOLE') ?? (\PHP_SAPI === 'cli' || \PHP_SAPI === 'phpdbg');
}
return $this->isRunningInConsole;
}
/**
* Determine if the application is running unit tests.
*
* @return bool
*/
public function runningUnitTests()
{
return $this['env'] === 'testing';
}
/**
* Register all of the configured providers.
*
* @return void
*/
public function registerConfiguredProviders()
{
$providers = Collection::make($this->config['app.providers'])
->partition(function ($provider) {
return strpos($provider, 'Illuminate\\') === 0;
});
$providers->splice(1, 0, [$this->make(PackageManifest::class)->providers()]);
(new ProviderRepository($this, new Filesystem, $this->getCachedServicesPath()))
->load($providers->collapse()->toArray());
}
/**
* Register a service provider with the application.
*
* @param \Illuminate\Support\ServiceProvider|string $provider
* @param bool $force
* @return \Illuminate\Support\ServiceProvider
*/
public function register($provider, $force = false)
{
if (($registered = $this->getProvider($provider)) && ! $force) {
return $registered;
}
// If the given "provider" is a string, we will resolve it, passing in the
// application instance automatically for the developer. This is simply
// a more convenient way of specifying your service provider classes.
if (is_string($provider)) {
$provider = $this->resolveProvider($provider);
}
$provider->register();
// If there are bindings / singletons set as properties on the provider we
// will spin through them and register them with the application, which
// serves as a convenience layer while registering a lot of bindings.
if (property_exists($provider, 'bindings')) {
foreach ($provider->bindings as $key => $value) {
$this->bind($key, $value);
}
}
if (property_exists($provider, 'singletons')) {
foreach ($provider->singletons as $key => $value) {
$this->singleton($key, $value);
}
}
$this->markAsRegistered($provider);
// If the application has already booted, we will call this boot method on
// the provider class so it has an opportunity to do its boot logic and
// will be ready for any usage by this developer's application logic.
if ($this->isBooted()) {
$this->bootProvider($provider);
}
return $provider;
}
/**
* Get the registered service provider instance if it exists.
*
* @param \Illuminate\Support\ServiceProvider|string $provider
* @return \Illuminate\Support\ServiceProvider|null
*/
public function getProvider($provider)
{
return array_values($this->getProviders($provider))[0] ?? null;
}
/**
* Get the registered service provider instances if any exist.
*
* @param \Illuminate\Support\ServiceProvider|string $provider
* @return array
*/
public function getProviders($provider)
{
$name = is_string($provider) ? $provider : get_class($provider);
return Arr::where($this->serviceProviders, function ($value) use ($name) {
return $value instanceof $name;
});
}
/**
* Resolve a service provider instance from the class name.
*
* @param string $provider
* @return \Illuminate\Support\ServiceProvider
*/
public function resolveProvider($provider)
{
return new $provider($this);
}
/**
* Mark the given provider as registered.
*
* @param \Illuminate\Support\ServiceProvider $provider
* @return void
*/
protected function markAsRegistered($provider)
{
$this->serviceProviders[] = $provider;
$this->loadedProviders[get_class($provider)] = true;
}
/**
* Load and boot all of the remaining deferred providers.
*
* @return void
*/
public function loadDeferredProviders()
{
// We will simply spin through each of the deferred providers and register each
// one and boot them if the application has booted. This should make each of
// the remaining services available to this application for immediate use.
foreach ($this->deferredServices as $service => $provider) {
$this->loadDeferredProvider($service);
}
$this->deferredServices = [];
}
/**
* Load the provider for a deferred service.
*
* @param string $service
* @return void
*/
public function loadDeferredProvider($service)
{
if (! $this->isDeferredService($service)) {
return;
}
$provider = $this->deferredServices[$service];
// If the service provider has not already been loaded and registered we can
// register it with the application and remove the service from this list
// of deferred services, since it will already be loaded on subsequent.
if (! isset($this->loadedProviders[$provider])) {
$this->registerDeferredProvider($provider, $service);
}
}
/**
* Register a deferred provider and service.
*
* @param string $provider
* @param string|null $service
* @return void
*/
public function registerDeferredProvider($provider, $service = null)
{
// Once the provider that provides the deferred service has been registered we
// will remove it from our local list of the deferred services with related
// providers so that this container does not try to resolve it out again.
if ($service) {
unset($this->deferredServices[$service]);
}
$this->register($instance = new $provider($this));
if (! $this->isBooted()) {
$this->booting(function () use ($instance) {
$this->bootProvider($instance);
});
}
}
/**
* Resolve the given type from the container.
*
* @param string $abstract
* @param array $parameters
* @return mixed
*/
public function make($abstract, array $parameters = [])
{
$this->loadDeferredProviderIfNeeded($abstract = $this->getAlias($abstract));
return parent::make($abstract, $parameters);
}
/**
* Resolve the given type from the container.
*
* @param string $abstract
* @param array $parameters
* @param bool $raiseEvents
* @return mixed
*/
protected function resolve($abstract, $parameters = [], $raiseEvents = true)
{
$this->loadDeferredProviderIfNeeded($abstract = $this->getAlias($abstract));
return parent::resolve($abstract, $parameters, $raiseEvents);
}
/**
* Load the deferred provider if the given type is a deferred service and the instance has not been loaded.
*
* @param string $abstract
* @return void
*/
protected function loadDeferredProviderIfNeeded($abstract)
{
if ($this->isDeferredService($abstract) && ! isset($this->instances[$abstract])) {
$this->loadDeferredProvider($abstract);
}
}
/**
* Determine if the given abstract type has been bound.
*
* @param string $abstract
* @return bool
*/
public function bound($abstract)
{
return $this->isDeferredService($abstract) || parent::bound($abstract);
}
/**
* Determine if the application has booted.
*
* @return bool
*/
public function isBooted()
{
return $this->booted;
}
/**
* Boot the application's service providers.
*
* @return void
*/
public function boot()
{
if ($this->isBooted()) {
return;
}
// Once the application has booted we will also fire some "booted" callbacks
// for any listeners that need to do work after this initial booting gets
// finished. This is useful when ordering the boot-up processes we run.
$this->fireAppCallbacks($this->bootingCallbacks);
array_walk($this->serviceProviders, function ($p) {
$this->bootProvider($p);
});
$this->booted = true;
$this->fireAppCallbacks($this->bootedCallbacks);
}
/**
* Boot the given service provider.
*
* @param \Illuminate\Support\ServiceProvider $provider
* @return mixed
*/
protected function bootProvider(ServiceProvider $provider)
{
if (method_exists($provider, 'boot')) {
return $this->call([$provider, 'boot']);
}
}
/**
* Register a new boot listener.
*
* @param callable $callback
* @return void
*/
public function booting($callback)
{
$this->bootingCallbacks[] = $callback;
}
/**
* Register a new "booted" listener.
*
* @param callable $callback
* @return void
*/
public function booted($callback)
{
$this->bootedCallbacks[] = $callback;
if ($this->isBooted()) {
$this->fireAppCallbacks([$callback]);
}
}
/**
* Call the booting callbacks for the application.
*
* @param callable[] $callbacks
* @return void
*/
protected function fireAppCallbacks(array $callbacks)
{
foreach ($callbacks as $callback) {
$callback($this);
}
}
/**
* {@inheritdoc}
*/
public function handle(SymfonyRequest $request, $type = self::MASTER_REQUEST, $catch = true)
{
return $this[HttpKernelContract::class]->handle(Request::createFromBase($request));
}
/**
* Determine if middleware has been disabled for the application.
*
* @return bool
*/
public function shouldSkipMiddleware()
{
return $this->bound('middleware.disable') &&
$this->make('middleware.disable') === true;
}
/**
* Get the path to the cached services.php file.
*
* @return string
*/
public function getCachedServicesPath()
{
return $this->normalizeCachePath('APP_SERVICES_CACHE', 'cache/services.php');
}
/**
* Get the path to the cached packages.php file.
*
* @return string
*/
public function getCachedPackagesPath()
{
return $this->normalizeCachePath('APP_PACKAGES_CACHE', 'cache/packages.php');
}
/**
* Determine if the application configuration is cached.
*
* @return bool
*/
public function configurationIsCached()
{
return file_exists($this->getCachedConfigPath());
}
/**
* Get the path to the configuration cache file.
*
* @return string
*/
public function getCachedConfigPath()
{
return $this->normalizeCachePath('APP_CONFIG_CACHE', 'cache/config.php');
}
/**
* Determine if the application routes are cached.
*
* @return bool
*/
public function routesAreCached()
{
return $this['files']->exists($this->getCachedRoutesPath());
}
/**
* Get the path to the routes cache file.
*
* @return string
*/
public function getCachedRoutesPath()
{
return $this->normalizeCachePath('APP_ROUTES_CACHE', 'cache/routes.php');
}
/**
* Determine if the application events are cached.
*
* @return bool
*/
public function eventsAreCached()
{
return $this['files']->exists($this->getCachedEventsPath());
}
/**
* Get the path to the events cache file.
*
* @return string
*/
public function getCachedEventsPath()
{
return $this->normalizeCachePath('APP_EVENTS_CACHE', 'cache/events.php');
}
/**
* Normalize a relative or absolute path to a cache file.
*
* @param string $key
* @param string $default
* @return string
*/
protected function normalizeCachePath($key, $default)
{
if (is_null($env = Env::get($key))) {
return $this->bootstrapPath($default);
}
return Str::startsWith($env, '/')
? $env
: $this->basePath($env);
}
/**
* Determine if the application is currently down for maintenance.
*
* @return bool
*/
public function isDownForMaintenance()
{
return file_exists($this->storagePath().'/framework/down');
}
/**
* Throw an HttpException with the given data.
*
* @param int $code
* @param string $message
* @param array $headers
* @return void
*
* @throws \Symfony\Component\HttpKernel\Exception\HttpException
* @throws \Symfony\Component\HttpKernel\Exception\NotFoundHttpException
*/
public function abort($code, $message = '', array $headers = [])
{
if ($code == 404) {
throw new NotFoundHttpException($message);
}
throw new HttpException($code, $message, null, $headers);
}
/**
* Register a terminating callback with the application.
*
* @param callable|string $callback
* @return $this
*/
public function terminating($callback)
{
$this->terminatingCallbacks[] = $callback;
return $this;
}
/**
* Terminate the application.
*
* @return void
*/
public function terminate()
{
foreach ($this->terminatingCallbacks as $terminating) {
$this->call($terminating);
}
}
/**
* Get the service providers that have been loaded.
*
* @return array
*/
public function getLoadedProviders()
{
return $this->loadedProviders;
}
/**
* Get the application's deferred services.
*
* @return array
*/
public function getDeferredServices()
{
return $this->deferredServices;
}
/**
* Set the application's deferred services.
*
* @param array $services
* @return void
*/
public function setDeferredServices(array $services)
{
$this->deferredServices = $services;
}
/**
* Add an array of services to the application's deferred services.
*
* @param array $services
* @return void
*/
public function addDeferredServices(array $services)
{
$this->deferredServices = array_merge($this->deferredServices, $services);
}
/**
* Determine if the given service is a deferred service.
*
* @param string $service
* @return bool
*/
public function isDeferredService($service)
{
return isset($this->deferredServices[$service]);
}
/**
* Configure the real-time facade namespace.
*
* @param string $namespace
* @return void
*/
public function provideFacades($namespace)
{
AliasLoader::setFacadeNamespace($namespace);
}
/**
* Get the current application locale.
*
* @return string
*/
public function getLocale()
{
return $this['config']->get('app.locale');
}
/**
* Set the current application locale.
*
* @param string $locale
* @return void
*/
public function setLocale($locale)
{
$this['config']->set('app.locale', $locale);
$this['translator']->setLocale($locale);
$this['events']->dispatch(new LocaleUpdated($locale));
}
/**
* Determine if application locale is the given locale.
*
* @param string $locale
* @return bool
*/
public function isLocale($locale)
{
return $this->getLocale() == $locale;
}
/**
* Register the core class aliases in the container.
*
* @return void
*/
public function registerCoreContainerAliases()
{
foreach ([
'app' => [self::class, \Illuminate\Contracts\Container\Container::class, \Illuminate\Contracts\Foundation\Application::class, \Psr\Container\ContainerInterface::class],
'auth' => [\Illuminate\Auth\AuthManager::class, \Illuminate\Contracts\Auth\Factory::class],
'auth.driver' => [\Illuminate\Contracts\Auth\Guard::class],
'blade.compiler' => [\Illuminate\View\Compilers\BladeCompiler::class],
'cache' => [\Illuminate\Cache\CacheManager::class, \Illuminate\Contracts\Cache\Factory::class],
'cache.store' => [\Illuminate\Cache\Repository::class, \Illuminate\Contracts\Cache\Repository::class, \Psr\SimpleCache\CacheInterface::class],
'cache.psr6' => [\Symfony\Component\Cache\Adapter\Psr16Adapter::class, \Symfony\Component\Cache\Adapter\AdapterInterface::class, \Psr\Cache\CacheItemPoolInterface::class],
'config' => [\Illuminate\Config\Repository::class, \Illuminate\Contracts\Config\Repository::class],
'cookie' => [\Illuminate\Cookie\CookieJar::class, \Illuminate\Contracts\Cookie\Factory::class, \Illuminate\Contracts\Cookie\QueueingFactory::class],
'encrypter' => [\Illuminate\Encryption\Encrypter::class, \Illuminate\Contracts\Encryption\Encrypter::class],
'db' => [\Illuminate\Database\DatabaseManager::class, \Illuminate\Database\ConnectionResolverInterface::class],
'db.connection' => [\Illuminate\Database\Connection::class, \Illuminate\Database\ConnectionInterface::class],
'events' => [\Illuminate\Events\Dispatcher::class, \Illuminate\Contracts\Events\Dispatcher::class],
'files' => [\Illuminate\Filesystem\Filesystem::class],
'filesystem' => [\Illuminate\Filesystem\FilesystemManager::class, \Illuminate\Contracts\Filesystem\Factory::class],
'filesystem.disk' => [\Illuminate\Contracts\Filesystem\Filesystem::class],
'filesystem.cloud' => [\Illuminate\Contracts\Filesystem\Cloud::class],
'hash' => [\Illuminate\Hashing\HashManager::class],
'hash.driver' => [\Illuminate\Contracts\Hashing\Hasher::class],
'translator' => [\Illuminate\Translation\Translator::class, \Illuminate\Contracts\Translation\Translator::class],
'log' => [\Illuminate\Log\LogManager::class, \Psr\Log\LoggerInterface::class],
'mailer' => [\Illuminate\Mail\Mailer::class, \Illuminate\Contracts\Mail\Mailer::class, \Illuminate\Contracts\Mail\MailQueue::class],
'auth.password' => [\Illuminate\Auth\Passwords\PasswordBrokerManager::class, \Illuminate\Contracts\Auth\PasswordBrokerFactory::class],
'auth.password.broker' => [\Illuminate\Auth\Passwords\PasswordBroker::class, \Illuminate\Contracts\Auth\PasswordBroker::class],
'queue' => [\Illuminate\Queue\QueueManager::class, \Illuminate\Contracts\Queue\Factory::class, \Illuminate\Contracts\Queue\Monitor::class],
'queue.connection' => [\Illuminate\Contracts\Queue\Queue::class],
'queue.failer' => [\Illuminate\Queue\Failed\FailedJobProviderInterface::class],
'redirect' => [\Illuminate\Routing\Redirector::class],
'redis' => [\Illuminate\Redis\RedisManager::class, \Illuminate\Contracts\Redis\Factory::class],
'redis.connection' => [\Illuminate\Redis\Connections\Connection::class, \Illuminate\Contracts\Redis\Connection::class],
'request' => [\Illuminate\Http\Request::class, \Symfony\Component\HttpFoundation\Request::class],
'router' => [\Illuminate\Routing\Router::class, \Illuminate\Contracts\Routing\Registrar::class, \Illuminate\Contracts\Routing\BindingRegistrar::class],
'session' => [\Illuminate\Session\SessionManager::class],
'session.store' => [\Illuminate\Session\Store::class, \Illuminate\Contracts\Session\Session::class],
'url' => [\Illuminate\Routing\UrlGenerator::class, \Illuminate\Contracts\Routing\UrlGenerator::class],
'validator' => [\Illuminate\Validation\Factory::class, \Illuminate\Contracts\Validation\Factory::class],
'view' => [\Illuminate\View\Factory::class, \Illuminate\Contracts\View\Factory::class],
] as $key => $aliases) {
foreach ($aliases as $alias) {
$this->alias($key, $alias);
}
}
}
/**
* Flush the container of all bindings and resolved instances.
*
* @return void
*/
public function flush()
{
parent::flush();
$this->buildStack = [];
$this->loadedProviders = [];
$this->bootedCallbacks = [];
$this->bootingCallbacks = [];
$this->deferredServices = [];
$this->reboundCallbacks = [];
$this->serviceProviders = [];
$this->resolvingCallbacks = [];
$this->terminatingCallbacks = [];
$this->afterResolvingCallbacks = [];
$this->globalResolvingCallbacks = [];
}
/**
* Get the application namespace.
*
* @return string
*
* @throws \RuntimeException
*/
public function getNamespace()
{
if (! is_null($this->namespace)) {
return $this->namespace;
}
$composer = json_decode(file_get_contents($this->basePath('composer.json')), true);
foreach ((array) data_get($composer, 'autoload.psr-4') as $namespace => $path) {
foreach ((array) $path as $pathChoice) {
if (realpath($this->path()) === realpath($this->basePath($pathChoice))) {
return $this->namespace = $namespace;
}
}
}
throw new RuntimeException('Unable to detect application namespace.');
}
}Closure::bind用法
下面循序渐进的的解释下:
跟JS一样,PHP中我们可以直接定义一个函数
$say = function(){
return '我是匿名函数'. "\n";
};
echo $say();闭包也可以当做参数传入到其他函数中
function test(Closure $callback){
return $callback();
}
echo test($say);在类中,我们无法直接访问一个私有属性
class Person {
private $name = 'finley';
private static $age = '18';
}
$p = new Person();
// 报错: Error: Cannot access private property Person::$name
$p->name;
// 报错: Error: Cannot access private property Person::$age
$p::$age;如果把private类型改为public才可以
TIP
在不改变访问类型的情况下可以通过Closure::bind访问类的私有属性!
// 首先定义一个匿名函数。注意里面的$this,这时还不知道他代表哪个对象
$getName = function() {
return $this->name;
};
// Closure::bind
// 第一个参数传匿名函数
// 第二参数传绑定到匿名函数的对象
// 第三个参数传绑定给闭包的类作用域(如果需要访问的属性,如name是公有的,可以不传第三个参数)
// Closure::bind 返回一个全新的匿名的函数
$t1 = Closure::bind($getName, new Person(), 'Person');
// Finley
echo $t1();
$getAge = function() {
return Person::$age;
};
// 对于静态属性,因为Person::$age属于正常使用,第二个参数可以写null,当然写new Person也不会报错
$t2 = Closure::bind($getAge, null, 'Person');
echo $t2();总结
总结: 1、一般匿名函数中有$this->name类似这样用 $this访问属性方式时,你在使用bind绑定时 ,第二个参数肯定要写,写出你绑定那个对象实例,第三个参数要不要呢,要看你访问的这个属性,在绑定对象中的权限属性,如果是private,protected 你要使用第三个参数 使其变为公有属性, 如果本来就是公有,你可以省略,也可以不省略 2、一般匿名函数中是 类名::静态属性 类似这样的访问方式(比如例子中A::$age),你在使用bind绑定时,第二个参数可以写null,也可以写出具体的对象实例,一般写null就行(写了具体对象实例多此一举),第三个参数写不写还是得看你访问的这个静态属性的权限是 private 还是 public,如果是私有private或受保护protected的,你就得第三个参数必须写,才能使其权限变为公有属性 正常访问,如果本来就是公有public可以不用写,可以省略
]]>Model
类库使用
开发搜集
]]>laravel/ui 是一个composer包,可以生成登录/注册代码的脚手架,使用方法叫文档
源码结构:

原理比较简单,提供一些命令
// 生成基本脚手架
php artisan ui bootstrap
php artisan ui vue
php artisan ui react
// 生成 登录/注册 脚手架...
php artisan ui bootstrap --auth
php artisan ui vue --auth
php artisan ui react --auth比如,执行php artisan ui vue会复制源码目录中的Presets/vue-stubs/相关文件到到项目目录的resources底下
源码分析 UiServiceProvider 这个文件没啥说的,明显注册服务
<?php
namespace Laravel\Ui;
use Illuminate\Contracts\Support\DeferrableProvider;
use Illuminate\Support\ServiceProvider;
class UiServiceProvider extends ServiceProvider implements DeferrableProvider
{
/**
* Register the package services.
*
* @return void
*/
public function register()
{
if ($this->app->runningInConsole()) {
$this->commands([
AuthCommand::class,
UiCommand::class,
]);
}
}
/**
* Get the services provided by the provider.
*
* @return array
*/
public function provides()
{
return [
AuthCommand::class,
UiCommand::class,
];
}
}UiCommand.php
核心文件,描述命令和发生的内容
<?php
namespace Laravel\Ui;
use Illuminate\Console\Command;
use InvalidArgumentException;
class UiCommand extends Command
{
/**
* The console command signature.
*
* @var string
*/
protected $signature = 'ui
{ type : The preset type (bootstrap, vue, react) }
{ --auth : Install authentication UI scaffolding }
{ --option=* : Pass an option to the preset command }';
/**
* The console command description.
*
* @var string
*/
protected $description = 'Swap the front-end scaffolding for the application';
/**
* Execute the console command.
*
* @return void
*
* @throws \InvalidArgumentException
*/
public function handle()
{
//
if (static::hasMacro($this->argument('type'))) {
return call_user_func(static::$macros[$this->argument('type')], $this);
}
if (! in_array($this->argument('type'), ['bootstrap', 'vue', 'react'])) {
throw new InvalidArgumentException('Invalid preset.');
}
// 这句很牛逼
// 如果type是vue,就执行 $this->vue()
// 如果type是react,就执行 $this->react()
$this->{$this->argument('type')}();
if ($this->option('auth')) {
$this->call('ui:auth');
}
}
/**
* Install the "bootstrap" preset.
*
* @return void
*/
protected function bootstrap()
{
Presets\Bootstrap::install();
$this->info('Bootstrap scaffolding installed successfully.');
$this->comment('Please run "npm install && npm run dev" to compile your fresh scaffolding.');
}
/**
* Install the "vue" preset.
*
* @return void
*/
protected function vue()
{
Presets\Bootstrap::install();
Presets\Vue::install();
$this->info('Vue scaffolding installed successfully.');
$this->comment('Please run "npm install && npm run dev" to compile your fresh scaffolding.');
}
/**
* Install the "react" preset.
*
* @return void
*/
protected function react()
{
Presets\Bootstrap::install();
Presets\React::install();
$this->info('React scaffolding installed successfully.');
$this->comment('Please run "npm install && npm run dev" to compile your fresh scaffolding.');
}
}Vue.php 这里学到一些如何用php解析package.json,操作文件或目录的命令
<?php
namespace Laravel\Ui\Presets;
use Illuminate\Filesystem\Filesystem;
use Illuminate\Support\Arr;
class Vue extends Preset
{
/**
* Install the preset.
*
* @return void
*/
public static function install()
{
// 先检查 resouces/js/components目录是否存在
static::ensureComponentDirectoryExists();
// 更新 package.json插入vue相关依赖
static::updatePackages();
// 拷贝 vue-stubs/webpack.mix.js 到 resouces/webpack.mix.js
static::updateWebpackConfiguration();
// 拷贝 vue-stubs/app.js 到 js/app.js
static::updateBootstrapping();
// 拷贝 Vue 相关组件文件到resouces目录
static::updateComponent();
// 删除 node_modules 目录和 yarn.lock 文件
static::removeNodeModules();
}
/**
* Update the given package array.
*
* @param array $packages
* @return array
*/
protected static function updatePackageArray(array $packages)
{
return [
'resolve-url-loader' => '^2.3.1',
'sass' => '^1.20.1',
'sass-loader' => '^8.0.0',
'vue' => '^2.5.17',
'vue-template-compiler' => '^2.6.10',
] + Arr::except($packages, [
'@babel/preset-react',
'react',
'react-dom',
]);
}
/**
* Update the Webpack configuration.
*
* @return void
*/
protected static function updateWebpackConfiguration()
{
copy(__DIR__.'/vue-stubs/webpack.mix.js', base_path('webpack.mix.js'));
}
/**
* Update the example component.
*
* @return void
*/
protected static function updateComponent()
{
(new Filesystem)->delete(
resource_path('js/components/Example.js')
);
copy(
__DIR__.'/vue-stubs/ExampleComponent.vue',
resource_path('js/components/ExampleComponent.vue')
);
}
/**
* Update the bootstrapping files.
*
* @return void
*/
protected static function updateBootstrapping()
{
copy(__DIR__.'/vue-stubs/app.js', resource_path('js/app.js'));
}
}操作vue和react的公共方法
updatePackages php操作编辑package.json
<?php
namespace Laravel\Ui\Presets;
use Illuminate\Filesystem\Filesystem;
class Preset
{
/**
* Ensure the component directories we need exist.
*
* @return void
*/
protected static function ensureComponentDirectoryExists()
{
$filesystem = new Filesystem;
if (! $filesystem->isDirectory($directory = resource_path('js/components'))) {
$filesystem->makeDirectory($directory, 0755, true);
}
}
/**
* Update the "package.json" file.
*
* @param bool $dev
* @return void
*/
protected static function updatePackages($dev = true)
{
if (! file_exists(base_path('package.json'))) {
return;
}
$configurationKey = $dev ? 'devDependencies' : 'dependencies';
$packages = json_decode(file_get_contents(base_path('package.json')), true);
$packages[$configurationKey] = static::updatePackageArray(
array_key_exists($configurationKey, $packages) ? $packages[$configurationKey] : [],
$configurationKey
);
ksort($packages[$configurationKey]);
file_put_contents(
base_path('package.json'),
json_encode($packages, JSON_UNESCAPED_SLASHES | JSON_PRETTY_PRINT).PHP_EOL
);
}
/**
* Remove the installed Node modules.
*
* @return void
*/
protected static function removeNodeModules()
{
tap(new Filesystem, function ($files) {
$files->deleteDirectory(base_path('node_modules'));
$files->delete(base_path('yarn.lock'));
});
}
}参考
https://learnku.com/articles/2769/laravel-pipeline-realization-of-the-principle-of-single-component https://segmentfault.com/a/1190000022566835
]]>- Laravel 6 (实际低版本也能用)
- PHP7.2 且开启redis扩展 (pecl install redis)
- Redis
WARNING
坑1 关于 php的redis扩展
Laravel6 默认是使用 phpredis 驱动
见config/database.php
默认是
'client' => env('REDIS_CLIENT', 'phpredis'),
实测可以安装predis扩展
composer require predis/predis
然后改为
'client' => env('REDIS_CLIENT', 'predis'),
安装 服务端
npm install -g laravel-echo-server
项目根目录,初始化服务端配置,会问一系列问题
laravel-echo-server init
// 是否在开发模式下运行此服务器(y/n) 输入y
? Do you want to run this server in development mode? (y/N)
// 设置服务器的端口 默认 6001 输入 6001就可以了 或者你想要的
? Which port would you like to serve from? (6001)
// 想用的数据库 选择 redis
? Which database would you like to use to store presence channel members? (Use arrow keys)
❯ redis
sqlite
// 这里输入 你的laravel 项目的访问域名
? Enter the host of your Laravel authentication server. (http://localhost)
// 选择 网络协议 http
? Will you be serving on http or https? (Use arrow keys)
❯ http
https
// 您想为HTTP API生成客户端ID/密钥吗 N
? Do you want to generate a client ID/Key for HTTP API? (y/N)
// 要设置对API的跨域访问吗?(y/n)N启动后端
laravel-echo-server start
开启 BroadcastServiceProvider
打开你的 config/app.php 文件并且取消 BroadcastServiceProvider 在这个 Providers 数组中的注释
打开 .env 修改
修改 BROADCAST_DRIVER 的值为你在 laravel-echo-server 初始化时定义的值(Redis 或者 Log)
同时修改 QUEUE_DRIVER 为你喜欢的任何队列驱动程序,在这个示例中你可以轻松的将其更改为 Redis 驱动程序,因为你在前面已经安装并且在运行了。
BROADCAST_DRIVER=redis
QUEUE_CONNECTION=redis创建一个ExampleEvent事件
php artisan make:event RssCreatedEvent
此命令会在 App/Events 目录下面会创建一个叫做 ExampleEvent.php 的事件类
- 我们在后端添加一个 RssCreatedEvent 事件并继承 ShouldBroadcast
- 包含一个名为rss的频道,频道发送的内容为当前时间
- 我们使用假数据,让它返回当前的时间,方便查看效果
<?php
namespace App\Events;
use Carbon\Carbon;
use Illuminate\Broadcasting\Channel;
use Illuminate\Broadcasting\InteractsWithSockets;
use Illuminate\Broadcasting\PresenceChannel;
use Illuminate\Broadcasting\PrivateChannel;
use Illuminate\Console\Scheduling\Schedule;
use Illuminate\Contracts\Broadcasting\ShouldBroadcast;
use Illuminate\Foundation\Events\Dispatchable;
use Illuminate\Queue\SerializesModels;
class RssCreatedEvent implements ShouldBroadcast
{
use Dispatchable, InteractsWithSockets, SerializesModels;
/**
* Create a new event instance.
*
* @return void
*/
public function __construct()
{
//
}
/**
* Get the channels the event should broadcast on.
*
* @return \Illuminate\Broadcasting\Channel|array
*/
public function broadcastOn()
{
// 14. 创建频道
return new Channel('rss');
// return new PrivateChannel('channel-name');
}
/**
* 指定广播数据。
*
* @return array
*/
public function broadcastWith()
{
// 返回当前时间
return ['name' => Carbon::now()->toDateTimeString()];
}
}接下来装客户端扩展
$ npm install --save socket.io-client
$ npm install --save laravel-echo客户端配置连服务端及监听频道
打开 resources/assets/js/bootstrap.js 文件
import Echo from 'laravel-echo'
window.io = require('socket.io-client');
window.Echo = new Echo({
broadcaster: 'socket.io',
host: window.location.hostname + ':6001'
});修改 resources/js/components/ExampleComponent.vue
<template>
<div class="container">
<div class="row justify-content-center">
<div class="col-md-8">
<div class="card">
<div class="card-header">Example Component</div>
<div class="card-body">
<ul>
<li v-for="name in names" :key="name">{{ name }}</li>
</ul>
</div>
</div>
</div>
</div>
</div>
</template>
<script>
export default {
data () {
return {
names: []
}
},
mounted() {
let that = this;
// 12. 创建 Echo 监听
Echo.channel('rss')
.listen('RssCreatedEvent', (e) => {
console.log(e);
that.names.push(e.name)
});
}
}
</script>ExampleComponent.vue
修改 resources/views/welcome.blade.php
<div class="content">
<div class="title m-b-md">
</div>
<example-component></example-component>
</div>为了模拟后端有数据,添加一个路由
打开 routes/web.php
Route::get('test-broadcast', function(){
broadcast(new \App\Events\RssCreatedEvent());
});测试
WARNING
坑2 使用广播必须开启队列

执行 php artisan queue:listen --tries=1
然后浏览器先打开你的后台地址 your-host
访问后
your-host/test-broadcast
浏览器network中可以看到有数据过来了

队列也能看到变化

laravel-echo-server

WARNING
坑3 注意 Channel 名称和 Event名称
Laravel 会自动给Channel加前缀,默认把这行掉
config/database.php
'prefix' => env('REDIS_PREFIX', Str::slug(env('APP_NAME', 'laravel'), '_').'_database_'),

正式环境
- 修改
laravel-echo-server.json关闭 devMode - 使用 pm2 管理 laravel-echo-server 创建 Socket.sh 内容
#!/usr/bin/env bash
laravel-echo-server startpm2 start socket.sh
关于数字含义
socket.io的frame里面,每个片段前面的数字代表什么意思?
这是 Engine .io协议,其中的数字是数据包编码:
<Packet type id> [<data>]
例:
2probe 这些是不同的数据包类型:
0 open
在打开新传输时从服务器发送(重新检查)
1 close
请求关闭此传输,但不关闭连接本身。
2 ping
由客户端发送。服务器应该用包含相同数据的乓包应答
示例1.客户端发送:2probe 2.服务器发送:3probe
3 pong
由服务器发送以响应ping数据包。
4 message
实际消息,客户端和服务器应该使用数据调用它们的回调。
实施例1
服务器发送:4HelloWorld客户端接收并调用回调socket.on('message',function(data){console.log(data);});
实施例2
客户端发送:4HelloWorld服务器接收并调用回调socket.on('message',function(data){console.log(data);});
5 upgrade
在engine.io切换传输之前,它测试,如果服务器和客户端可以通过这个传输进行通信。如果此测试成功,客户端发送升级数据包,请求服务器刷新其在旧传输上的缓存并切换到新传输。
6 noop
noop数据包。主要用于在接收到传入WebSocket连接时强制轮询周期。
参考
]]>-
Channel 提供设备间,应用间的实时通信,适用于实时图表、实时用户列表、实时地图、多人游戏和许多其他类型的UI更新。
-
Beams 跨平台的消息推送,iOS, Android and web
产品特点:SDK丰富,集成快速简单,debug调试也很人性。
我们这里指介绍Channel, 先按照官网教程来个纯JS和PHP的例子 后续会介绍结合一个全新的Laravel6.0项目如何快速引入push消息实时推送功能。
步骤
- 注册一个pusher账号
- 创建一个Channel APP
- 获取
app_id,key,secret和cluster - 客户端操作,新建一个html 代码如下,主要引入了pusher.js 初始化push配置
var pusher = new Pusher('APP_KEY', {
cluster: 'APP_CLUSTER'
});订阅频道, 频道名为'my-channel'
var channel = pusher.subscribe('my-channel');
监听频道发布消息事件,事件名叫做'my-event'
channel.bind('my-event', function(data) {
alert('An event was triggered with message: ' + data.message);
});WARNING
'my-channel'和'my-event'是在后台定义的
<!DOCTYPE html>
<head>
<title>Pusher Test</title>
</head>
<body>
<h1>Pusher Test</h1>
<p>
Publish an event to channel <code>my-channel</code>
with event name <code>my-event</code>; it will appear below:
</p>
<div id="app">
<ul>
<li v-for="message in messages">
{{message}}
</li>
</ul>
</div>
<script src="https://js.pusher.com/7.0/pusher.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script>
<script>
// Enable pusher logging - don't include this in production
Pusher.logToConsole = true;
var pusher = new Pusher('7b7a4b68e07138fc3b11', {
cluster: 'ap3'
});
var channel = pusher.subscribe('my-channel');
channel.bind('my-event', function(data) {
app.messages.push(JSON.stringify(data));
});
// Vue application
const app = new Vue({
el: '#app',
data: {
messages: [],
},
});
</script>
</body>- 服务端操作,需要安装服务端包
pusher-php-server
// First, run 'composer require pusher/pusher-php-server'
require __DIR__ . '/vendor/autoload.php';
$pusher = new Pusher\Pusher("APP_KEY", "APP_SECRET", "APP_ID", array('cluster' => 'APP_CLUSTER'));
$pusher->trigger('my-channel', 'my-event', array('message' => 'hello world'));- 正常下,每运行一次后台,前台就会多一条记录。
参考
]]>首先编辑.env,修改广播驱动为pusher
# BROADCAST_DRIVER=log
BROADCAST_DRIVER=pusher
PUSHER_APP_ID=1122467
PUSHER_APP_KEY=7b7a4b68e07138fc3b11
PUSHER_APP_SECRET=af7******aadbc26a4
PUSHER_APP_CLUSTER=ap3
MIX_PUSHER_APP_KEY="${PUSHER_APP_KEY}"
MIX_PUSHER_APP_CLUSTER="${PUSHER_APP_CLUSTER}"前端创建一个vue组件, Add按钮:往push服务端发送信息 同时,打开页面时监听广播并显示push服务端传回来的信息
resources/js/components/ExampleComponent.vue
<template>
<div class="container">
<div class="row justify-content-center">
<div class="col-md-8">
<div class="card">
<div class="card-header">Example Component</div>
<div class="card-body">
<button @click="add">Add</button>
<ul>
<li v-for="(item, index) in items" :key="index">{{ item.name }} -- {{ item.data }}</li>
</ul>
</div>
</div>
</div>
</div>
</div>
</template>
<script>
export default {
data() {
return {
items: []
}
},
methods: {
add() {
axios.post('/task/demo')
}
},
mounted() {
let that = this;
Echo.channel('task-event')
.listen('TaskEvent', (e) => {
console.log(e);
that.items.push(e)
});
}
}
</script>resources/js/app.js
Vue.component('example-component', require('./components/ExampleComponent.vue').default);
后端
php artisan make:event TaskEvent
打开 app/Events/TaskEvent.php 并编辑
<?php
namespace App\Events;
use Illuminate\Broadcasting\Channel;
use Illuminate\Broadcasting\InteractsWithSockets;
use Illuminate\Contracts\Broadcasting\ShouldBroadcast;
use Illuminate\Foundation\Events\Dispatchable;
use Illuminate\Queue\SerializesModels;
class TaskEvent implements ShouldBroadcast
{
use Dispatchable, InteractsWithSockets, SerializesModels;
public $task;
/**
* TaskEvent constructor.
* @param $task
*/
public function __construct($task)
{
//
$this->task = $task;
// 这行很重要,有时候我们一条广播信息,我们只希望通知给其他监听者,自己不用接收
// 比如我们添加一条记录,本身就可以push到当前列表,同时又要显示广播来的记录,就会重复显示
// $this->dontBroadcastToCurrentUser();
}
/**
* Get the channels the event should broadcast on.
*
* @return \Illuminate\Broadcasting\Channel|array
*/
public function broadcastOn()
{
return new Channel('task-event');
}
public function broadcastWith()
{
return $this->task;
}
}添加测试路由
routes/web.php
Route::get('/task', 'TaskController@index')->name('task');
Route::post('/task/demo', function () {
event(
(new App\Events\TaskEvent(['name' => 'foo', 'data' => rand(1000, 9999)]))
);
});这里省略了 TaskController 和 view 的代码
浏览器打开 http://laravel6.test/task

点add,打开pusher后台,会看到调试日志,非常方便

完整代码
https://github.com/mafeifan/chat-api-main/tree/echo-server
现实中,私有频道会更常见
- 服务端修改频道类型有私有
app/Events/TaskEvent.php
public function broadcastOn()
{
// return new Channel('task-event');
return new PrivateChannel('task-event');
}- 相应的客户端也要改
resources/js/components/ExampleComponent.vue
mounted() {
let that = this;
Echo.private('task-event')
.listen('TaskEvent', (e) => {
console.log(e);
that.items.push(e)
});
}刷新浏览器发现多出一个请求
http://demo.lara.test/broadcasting/auth 并且返回403 Forbidden
也就是说,客户端接收频道消息要授权
怎么判断授权是否成功?我们打开 routes/channels.php
Broadcast::channel('task-event', function ($user) {
// 在这里可以做复杂的权限判断
return $user->id;
});
/*
// 注意传参
Broadcast::channel('task-event/{id}', function ($user, $id) {
// 在这里可以做复杂的权限判断
return $user->id;
});
*/我们在使用路由的时候一个很常见的使用场景就是根据资源 ID 查询资源信息:
Route::get('note/{id}', function ($id) {
$task = \App\Models\Note::findOrFail($id);
});Laravel 提供了一个「路由模型绑定」功能来简化上述代码编写, 通过路由模型绑定,我们只需要定义一个特殊约定的参数名(比如 {note})来告知路由解析器需要从 Eloquent 记录中根据给定的资源 ID 去查询模型实例, 并将查询结果作为参数传入而不是资源 ID。
有两种方式来实现路由模型绑定:隐式绑定和显式绑定。
隐式绑定
使用路由模型绑定最简单的方式就是将路由参数命名为可以唯一标识对应资源模型的字符串(比如 $note 而非 $id), 然后在闭包函数或控制器方法中对该参数进行类型提示,此处参数名需要和路由中的参数名保持一致:
Route::get('note/{note}', function (\App\Models\Note $note) {
dd($note); // 打印 $note 明细
});这样就避免了我们传入 $id 后再进行查询,而是把这种模板式代码交由 Laravel 框架底层去实现。
由于路由参数({note})和方法参数($note)一样,并且我们约定了 $note 类型为 \App\Models\Note,
Laravel 就会判定这是一个路由模型绑定,每次访问这个路由时,应用会将传入参数值赋值给 {note},
然后默认以参数值作为资源 ID 在底层通过 Eloquent 查询获取对应模型实例,并将结果传递到闭包函数或控制器方法中。
路由模型绑定默认将传入 {note} 参数值作为模型主键 ID 进行 Eloquent 查询,你也可以自定义查询字段,这可以通过在模型类中重写 getRouteKeyName() 来实现
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class Note extends Model
{
public function getRouteKeyName() {
return 'slug'; // 以Note的slug字段作为路由模型绑定查询字段
}
}比如在note表中
| id | title | slug |
|---|---|---|
| 1 | hello world | hello-world |
note list页面中,我们可以直接这么写,其中生成的href地址会形如note/1,note/2,
@foreach($notes as $note)
<li class="list-group-item">
<a href="{{ url('note', [$note]) }}">
{{ $note->title }}
</a>
<span class="pull-right">{{ $note->updated_at->diffForHumans() }}</span>
</li>
@endforeach如果我们在getRouteKeyName方法中指定了新的字段名,比如slug
则生成的url就会变为note/hello-world这样对SEO很有帮助
显式绑定
显式绑定需要手动配置路由模型绑定,通常需要在 App\Providers\RouteServiceProvider 的 boot() 方法中新增如下这段配置代码:
public function boot()
{
// 显式路由模型绑定
Route::model('note_model', Note::class);
parent::boot();
}编写完这段代码后,以后每次访问包含 {task_model} 参数的路由时,路由解析器都会从请求 URL 中解析出模型 ID ,然后从对应模型类 Task 中获取相应的模型实例并传递给闭包函数或控制器方法:
Route::get('note/model/{note_model}', function (\App\Models\Note $note) {
dd($note);
});由于在正式开发中,出于性能的考虑通常会对模型数据进行缓存,此外在很多情况下,需要关联查询才能得到我们需要的结果,所以并不建议过多使用这种路由模型绑定。
参考
]]>
大致思路
服务器只返回某一html片段 客户端接收,利用JS的innerHTML替换为最新的HTML
关键代码
定义一个路由,每次请求随机查询5个用户,并且把用户信息放到view中,并返回这个view视图片段
web.php
Route::get('/partials/developers', function () {
$users = App\User::inRandomOrder()->limit(5)->get();
return view('_developers', ['users' => $users]);
});resource/view/_develop.blade.php
@foreach ($users as $user)
<li class="list-group-item">
<div class="row justify-content-between">
<div class="col-3 d-flex">
<a href="#" class="font-weight-bold ml-3"><h5>{{ $user->username }}</h5></a>
</div>
<div class="col-4">{{ $user->email }}</div>
<div class="col-2">
<button class="btn btn-light btn-block"><i class="fa fa-heart text-danger"></i> Sponsor</button>
</div>
</div>
</li>
@endforeachhome.blade.php
@extends('layouts.app')
@section('content')
......
<div class="card">
<div class="card-header d-flex justify-content-between align-items-center">
<span class="text-muted">Sponsored developers and organizations</span>
<button class="btn btn-outline-primary" onclick="fetchDevelopers()"><i class="fa fa-refresh"></i> Refresh</button>
</div>
<ul class="list-group list-group-flush" id="js-developers-partial-target">
<!-- -->
</ul>
</div>
<script>
function fetchDevelopers() {
fetch('/partials/developers')
.then(response => response.text())
.then(html => {
document.querySelector('#js-developers-partial-target').innerHTML = html
})
}
fetchDevelopers()
</script>
@endsection延伸
关于客户端替换功能,如果不想老是写script标签,重复的替换代码。 可以使用一个js包include-fragment-element
import '@github/include-fragment-element'
// 或者
<script src="proxy.php?url=https://unpkg.com/@github/include-fragment-element"></script>
<div class="tip">
<include-fragment src="proxy.php?url=/tips">
<p>Loading tip…</p>
</include-fragment>
</div>当页面加载时候,include-fragment会请求src中的地址,并且把结果解析为HTML,然后把整个include-fragment替换掉
参考
https://github.com/calebporzio/laracasts-server-fetched-partials
]]>- 单一职责原则
- 保持控制器的简洁
- 使用自定义Request类来进行验证
- 业务代码要放到服务层中
- DRY原则 不要重复自己
- 使用ORM而不是纯sql语句,使用集合而不是数组
- 集中处理数据
- 不要在模板中查询,尽量使用惰性加载
- 注释你的代码,但是更优雅的做法是使用描述性的语言来编写你的代码
- 不要把 JS 和 CSS 放到 Blade 模板中,也不要把任何 HTML 代码放到 PHP 代码里
- 在代码中使用配置、语言包和常量,而不是使用硬编码
- 使用社区认可的标准Laravel工具
- 遵循laravel命名约定
- 尽可能使用简短且可读性更好的语法
- 使用IOC容器来创建实例 而不是直接new一个实例
- 避免直接从 .env 文件里获取数据
- 使用标准格式来存储日期,用访问器和修改器来修改日期格式
- 其他的一些好建议
单一职责原则
一个类和一个方法应该只有一个责任。
例如:
public function getFullNameAttribute()
{
if (auth()->user() && auth()->user()->hasRole('client') && auth()->user()->isVerified()) {
return 'Mr. ' . $this->first_name . ' ' . $this->middle_name . ' ' . $this->last_name;
} else {
return $this->first_name[0] . '. ' . $this->last_name;
}
}更优的写法:
public function getFullNameAttribute()
{
return $this->isVerifiedClient() ? $this->getFullNameLong() : $this->getFullNameShort();
}
public function isVerifiedClient()
{
return auth()->user() && auth()->user()->hasRole('client') && auth()->user()->isVerified();
}
public function getFullNameLong()
{
return 'Mr. ' . $this->first_name . ' ' . $this->middle_name . ' ' . $this->last_name;
}
public function getFullNameShort()
{
return $this->first_name[0] . '. ' . $this->last_name;
}保持控制器的简洁
如果您使用的是查询生成器或原始SQL查询,请将所有与数据库相关的逻辑放入Eloquent模型或Repository类中。
例如:
public function index()
{
$clients = Client::verified()
->with(['orders' => function ($q) {
$q->where('created_at', '>', Carbon::today()->subWeek());
}])
->get();
return view('index', ['clients' => $clients]);
}更优的写法:
public function index()
{
return view('index', ['clients' => $this->client->getWithNewOrders()]);
}
class Client extends Model
{
public function getWithNewOrders()
{
return $this->verified()
->with(['orders' => function ($q) {
$q->where('created_at', '>', Carbon::today()->subWeek());
}])
->get();
}
}使用自定义Request类来进行验证
把验证规则放到 Request 类中.
例子:
public function store(Request $request)
{
$request->validate([
'title' => 'required|unique:posts|max:255',
'body' => 'required',
'publish_at' => 'nullable|date',
]);
....
}更优的写法:
public function store(PostRequest $request)
{
....
}
class PostRequest extends Request
{
public function rules()
{
return [
'title' => 'required|unique:posts|max:255',
'body' => 'required',
'publish_at' => 'nullable|date',
];
}
}业务代码要放到服务层中
控制器必须遵循单一职责原则,因此最好将业务代码从控制器移动到服务层中。
例子:
public function store(Request $request)
{
if ($request->hasFile('image')) {
$request->file('image')->move(public_path('images') . 'temp');
}
....
}更优的写法:
public function store(Request $request)
{
$this->articleService->handleUploadedImage($request->file('image'));
....
}
class ArticleService
{
public function handleUploadedImage($image)
{
if (!is_null($image)) {
$image->move(public_path('images') . 'temp');
}
}
}DRY原则 不要重复自己
尽可能重用代码,SRP可以帮助您避免重复造轮子。 此外尽量重复使用Blade模板,使用Eloquent的 scopes 方法来实现代码。
例子:
public function getActive()
{
return $this->where('verified', 1)->whereNotNull('deleted_at')->get();
}
public function getArticles()
{
return $this->whereHas('user', function ($q) {
$q->where('verified', 1)->whereNotNull('deleted_at');
})->get();
}更优的写法:
public function scopeActive($q)
{
return $q->where('verified', 1)->whereNotNull('deleted_at');
}
public function getActive()
{
return $this->active()->get();
}
public function getArticles()
{
return $this->whereHas('user', function ($q) {
$q->active();
})->get();
}使用ORM而不是纯sql语句,使用集合而不是数组
使用Eloquent可以帮您编写可读和可维护的代码。 此外Eloquent还有非常优雅的内置工具,如软删除,事件,范围等。
例子:
SELECT *
FROM `articles`
WHERE EXISTS (SELECT *
FROM `users`
WHERE `articles`.`user_id` = `users`.`id`
AND EXISTS (SELECT *
FROM `profiles`
WHERE `profiles`.`user_id` = `users`.`id`)
AND `users`.`deleted_at` IS NULL)
AND `verified` = '1'
AND `active` = '1'
ORDER BY `created_at` DESC更优的写法:
Article::has('user.profile')->verified()->latest()->get();集中处理数据
例子:
$article = new Article;
$article->title = $request->title;
$article->content = $request->content;
$article->verified = $request->verified;
// Add category to article
$article->category_id = $category->id;
$article->save();更优的写法:
$category->article()->create($request->validated());不要在模板中查询,尽量使用惰性加载
例子 (对于100个用户,将执行101次DB查询):
@foreach (User::all() as $user)
{{ $user->profile->name }}
@endforeach更优的写法 (对于100个用户,使用以下写法只需执行2次DB查询):
$users = User::with('profile')->get();
...
@foreach ($users as $user)
{{ $user->profile->name }}
@endforeach注释你的代码,但是更优雅的做法是使用描述性的语言来编写你的代码
例子:
if (count((array) $builder->getQuery()->joins) > 0)加上注释:
// 确定是否有任何连接
if (count((array) $builder->getQuery()->joins) > 0)更优的写法:
if ($this->hasJoins())不要把 JS 和 CSS 放到 Blade 模板中,也不要把任何 HTML 代码放到 PHP 代码里
例子:
let article = `{{ json_encode($article) }}`;更好的写法:
<input id="article" type="hidden" value='@json($article)'>
Or
<button class="js-fav-article" data-article='@json($article)'>{{ $article->name }}<button>在Javascript文件中加上:
let article = $('#article').val();当然最好的办法还是使用专业的PHP的JS包传输数据。
在代码中使用配置、语言包和常量,而不是使用硬编码
例子:
public function isNormal()
{
return $article->type === 'normal';
}
return back()->with('message', 'Your article has been added!');更优的写法:
public function isNormal()
{
return $article->type === Article::TYPE_NORMAL;
}
return back()->with('message', __('app.article_added'));使用社区认可的标准Laravel工具
强力推荐使用内置的Laravel功能和扩展包,而不是使用第三方的扩展包和工具。 如果你的项目被其他开发人员接手了,他们将不得不重新学习这些第三方工具的使用教程。 此外,当您使用第三方扩展包或工具时,你很难从Laravel社区获得什么帮助。 不要让你的客户为额外的问题付钱。
| 想要实现的功能 | 标准工具 | 第三方工具 |
|---|---|---|
| 权限 | Policies | Entrust, Sentinel 或者其他扩展包 |
| 资源编译工具 | Laravel Mix | Grunt, Gulp, 或者其他第三方包 |
| 开发环境 | Homestead | Docker |
| 部署 | Laravel Forge | Deployer 或者其他解决方案 |
| 自动化测试 | PHPUnit, Mockery | Phpspec |
| 页面预览测试 | Laravel Dusk | Codeception |
| DB操作 | Eloquent | SQL, Doctrine |
| 模板 | Blade | Twig |
| 数据操作 | Laravel集合 | 数组 |
| 表单验证 | Request classes | 他第三方包,甚至在控制器中做验证 |
| 权限 | Built-in | 他第三方包或者你自己解决 |
| API身份验证 | Laravel Passport, Laravel Sanctum | 第三方的JWT或者 OAuth 扩展包 |
| 创建 API | Built-in | Dingo API 或者类似的扩展包 |
| 创建数据库结构 | Migrations | 直接用 DB 语句创建 |
| 本土化 | Built-in | 第三方包 |
| 实时消息队列 | Laravel Echo, Pusher | 使用第三方包或者直接使用WebSockets |
| 创建测试数据 | Seeder classes, Model Factories, Faker | 手动创建测试数据 |
| 任务调度 | Laravel Task Scheduler | 脚本和第三方包 |
| 数据库 | MySQL, PostgreSQL, SQLite, SQL Server | MongoDB |
遵循laravel命名约定
来源 PSR standards.
另外,遵循Laravel社区认可的命名约定:
| 对象 | 规则 | 更优的写法 | 应避免的写法 |
|---|---|---|---|
| 控制器 | 单数 | ArticleController | |
| 路由 | 复数 | articles/1 | |
| 路由命名 | 带点符号的蛇形命名 | users.show_active | |
| 模型 | 单数 | User | |
| hasOne或belongsTo关系 | 单数 | articleComment | |
| 所有其他关系 | 复数 | articleComments | |
| 表单 | 复数 | article_comments | |
| 透视表 | 按字母顺序排列模型 | article_user | |
| 数据表字段 | 使用蛇形并且不要带表名 | meta_title | |
| 模型参数 | 蛇形命名 | $model->created_at | |
| 外键 | 带有_id后缀的单数模型名称 | article_id | |
| 主键 | - | id | |
| 迁移 | - | 2017_01_01_000000_create_articles_table | |
| 方法 | 驼峰命名 | getAll | |
| 资源控制器 | table | store | |
| 测试类 | 驼峰命名 | testGuestCannotSeeArticle | |
| 变量 | 驼峰命名 | $articlesWithAuthor | |
| 集合 | 描述性的, 复数的 | $activeUsers = User::active()->get() | |
| 对象 | 描述性的, 单数的 | $activeUser = User::active()->first() | |
| 配置和语言文件索引 | 蛇形命名 | articles_enabled | |
| 视图 | 短横线命名 | show-filtered.blade.php | |
| 配置 | 蛇形命名 | google_calendar.php | |
| 内容 (interface) | 形容词或名词 | Authenticatable | |
| Trait | 使用形容词 | Notifiable |
尽可能使用简短且可读性更好的语法
例子:
$request->session()->get('cart');
$request->input('name');更优的写法:
session('cart');
$request->name;更多示例:
| 常规写法 | 更优雅的写法 |
|---|---|
Session::get('cart') |
session('cart') |
$request->session()->get('cart') |
session('cart') |
Session::put('cart', $data) |
session(['cart' => $data]) |
$request->input('name'), Request::get('name') |
$request->name, request('name') |
return Redirect::back() |
return back() |
is_null($object->relation) ? null : $object->relation->id |
optional($object->relation)->id |
return view('index')->with('title', $title)->with('client', $client) |
return view('index', compact('title', 'client')) |
$request->has('value') ? $request->value : 'default'; |
$request->get('value', 'default') |
Carbon::now(), Carbon::today() |
now(), today() |
App::make('Class') |
app('Class') |
->where('column', '=', 1) |
->where('column', 1) |
->orderBy('created_at', 'desc') |
->latest() |
->orderBy('age', 'desc') |
->latest('age') |
->orderBy('created_at', 'asc') |
->oldest() |
->select('id', 'name')->get() |
->get(['id', 'name']) |
->first()->name |
->value('name') |
使用IOC容器来创建实例 而不是直接new一个实例
创建新的类会让类之间的更加耦合,使得测试越发复杂。请改用IoC容器或注入来实现。
例子:
$user = new User;
$user->create($request->validated());更优的写法:
public function __construct(User $user)
{
$this->user = $user;
}
....
$this->user->create($request->validated());避免直接从 .env 文件里获取数据
将数据传递给配置文件,然后使用config()帮助函数来调用数据
例子:
$apiKey = env('API_KEY');更优的写法:
// config/api.php
'key' => env('API_KEY'),
// Use the data
$apiKey = config('api.key');使用标准格式来存储日期,用访问器和修改器来修改日期格式
例子:
{{ Carbon::createFromFormat('Y-d-m H-i', $object->ordered_at)->toDateString() }}
{{ Carbon::createFromFormat('Y-d-m H-i', $object->ordered_at)->format('m-d') }}更优的写法:
// Model
protected $dates = ['ordered_at', 'created_at', 'updated_at'];
public function getSomeDateAttribute($date)
{
return $date->format('m-d');
}
// View
{{ $object->ordered_at->toDateString() }}
{{ $object->ordered_at->some_date }}其他的一些好建议
永远不要在路由文件中放任何的逻辑代码。
尽量不要在Blade模板中写原始 PHP 代码。
]]>集合(Collection)
Illuminate\Support\Collection类了提供一个便捷的操作数组的封装。
集合 Collection 类实现了部分 PHP 和 Laravel 的接口,例如:
ArrayAccess- 用于操作数组对象的接口。
IteratorAggregate- 用于创建外部迭代器的接口。
JsonSerializable
创建一个新的集合
一个集合可以使用collect()帮助函数基于一个数组被创建或者直接通过Illuminate\Support\Collection类实例化。
一个非常简单的使用collect()帮助函数的示例:
$newCollection = collect([1, 2, 3, 4, 5]); dd($newCollection);
Eloquent ORM 集合
Eloquent ORM 的调用会以集合的形式返回数据
/**
* 从用户表获取用户列表
*/
public function getUsers()
{
$users = User::all();
dd($users);
}该控制器方法会返回一个如下显示的所有用户的 Laravel 集合。
你可以通过箭头符号便捷的访问集合属性。至于实例,想要获取 $users 集合的第一个用户的名字,我们可以这样做。
/**
* 获取第一个用户的名字
*/
public function firstUser()
{
$user = User::first();
dd($user->name);
}实例1
有如下订单数组,要求按日期分组计算出总价
$orders = [
[
'id' => 1,
'price' => 9.8,
'qty' => 2,
'date' => '2018-10-10'
],
[
'id' => 2,
'price' => 3.8,
'qty' => 1,
'date' => '2018-10-10'
],
[
'id' => 3,
'price' => 5.0,
'qty' => 2,
'date' => '2018-10-11'
]
];期望结果:
["2018-10-10"]=> float(23.4) ["2018-10-11"]=> float(10)过程:
$result = collect($orders)->groupBy('date')->map(function ($item) {
return $item->sum(function ($item) {
return $item['price'] * $item['qty'];
}
);
}
);
dd($result->all());实例2
使用tap调试集合 有时候我们希望在某集合处理过程中查看结果,这时可以使用tap
$items = [
['name' => 'David Charleston', 'member' => 1, 'active' => 1],
['name' => 'Blain Charleston', 'member' => 0, 'active' => 0],
['name' => 'Megan Tarash', 'member' => 1, 'active' => 1],
['name' => 'Jonathan Phaedrus', 'member' => 1, 'active' => 1],
['name' => 'Paul Jackson', 'member' => 0, 'active' => 1]
];
return collect($items)
->where('active', 1)
->tap(function($collection){
// 输出 David Charleston, Megan Tarash, Jonathan Phaedrus, Paul Jackson
return var_dump($collection->pluck('name'));
})
->where('member', 1)
->tap(function($collection){
// 输出 David Charleston, Megan Tarash, Jonathan Phaedrus
return var_dump($collection->pluck('name'));
});Tap vs Pipe
Laravel 也提供了另一个类似 tap 的集合操作方法 -- pipe,两者在集合调用上很类似,却有一个主要的区别:
通过调用 tap 方法不会改变原集合的结果,而 pipe 方法会根据返回值修改元集合的结果。示例如下:
return collect($items)
->where('active', 1)
->pipe(function ($collection) {
return $collection->push(['name' => 'John Doe']);
});
// David Charleston, Megan Tarash, Jonathan Phaedrus, Paul Jackson, John Doe实例3
常用技巧 使用map添加新属性
$items = [
['name' => 'Finley Ma', 'age' => 18],
['name' => 'Jack Zhang', 'age' => 28],
];
$result = collect($items)
->map(function ($item, $key) {
// 根据name追加一个firstName属性
$item['firstName'] = explode(' ',$item['name'])[1];
return $item;
})
// 指定数组的key为age,value为firstName
->pluck('firstName', 'age')
->all();
// [['18' => 'Ma'], ['28' => 'Zhang']]
dd($result);参考
]]>30 分钟未付款取消订单
初始方案,使用计划任务
$unPaid = Order::where('created','<',time()-30*60) //创建时间在30分钟以前
->where('order_status',1) // 刚下单未支付
->get();
foreach ($unPaid as $order) {
$order->cancel(); // 执行取消动作
}频率是每分钟执行一次$schedule->command('order:cancel')->everyMinute();
弊端:
- 很多查询是白白执行,不是每分钟都有订单会被取消
- 锁表现象:如果数量很多,前一个任务还没执行完下一个任务又开始启动了,然后锁着表改不了数据。
使用Redis的监听事件方案
在订单确认成功之后,往 redis 里加入 key, 用 ORDER_CONFIRM:订单ID 这样的格式来,然后定义他 30 分钟后过期,我们监听这个键过期事件就好了。
流程:
brew info redis 查看redis配置文件,Linux一般在/etc/redis.conf
修改Redis的配置文件,加入notify-keyspace-events "Ex"
- E 表示 Keyevent事件
- x 过期事件
重启redis服务 brew services restart redis
打开两个终端,先在命令行里测试功能,一个命令行中
redis-cli
psubscribe __keyevent@0__:expired另一个,存key,并设置过期时间
redis-cli
setex name 10 finley过10s后会发现第一个终端有数据产生 大致是:
127.0.0.1:6379> psubscribe __keyevent@0__:expired
Reading messages... (press Ctrl-C to quit)
1) "pmessage"
2) "__keyevent@0__:expired"
3) "__keyevent@0__:expired"
4) "name"- 修改php代码
$redis = new \Redis();
$redis->connect('127.0.0.1', '6379');
$redis->setOption(\Redis::OPT_READ_TIMEOUT, -1);
$cache_db = config('database.redis.default.database');
$pattern = '__keyevent@' . $cache_db . '__:expired';
$redis->psubscribe([$pattern], function ($redisInstance, $pattern, $channel, $msg) {
print_r($redisInstance);
// __keyevent@0__:expired
// echo '[pattern]' . $pattern . '/n';
// __keyevent@0__:expired
// echo '[channel]' . $channel . '/n';
// demolara_database_ORDER_CONFIRM:1
// echo '[msg]' . $msg . '/n';
$id = Str::after($msg, ':');
if ($id) {
Order::find($id)->cancel();
}
});在控制器中,保存订单成功的后面,加上往redis存key的逻辑,为方便测试,先把时间设置短点
$data = Order::where('created_at', '<', Carbon::now()
->subMinutes(30))
->get();
foreach ($data as $order) {
\RedisManager::setEx('ORDER_CONFIRM:' . $order->id, 10, $order->id);
}存数据后同时打开redis客户端,这里推荐Another Redis DeskTop Manager
// 订阅接收端
\RedisManager::subscribe(['news'], function ($msg) {
echo $msg;
Log::warning($msg);
});
// 发送端
\RedisManager::publish('news', json_encode(['foo' => 'bar']));购物车处理
需要存储用户ID(uid),商品ID(gid)和商品数量(count) 存储格式: cartuid:gid:count 比如 cart:1:10:2 表示用户ID1添加了2件id为10的商品 用redis中的哈希比较方便
# 用户添加了两种商品,2个101,1个102
127.0.0.1:6379> hset cart:1 101 2 102 1
OK
127.0.0.1:6379> hkeys cart:1
1) "101"
2) "102"
127.0.0.1:6379> hget cart:1 101
1) "2"
127.0.0.1:6379>class Cart
{
private $prefix = 'cart:';
private $redis = null;
public function __construct()
{
$this->redis = new Redis();
$this->redis->connect('127.0.0.1',6379);
}
public function userId()
{
return 1;
}
public function addItem($goodId, $count)
{
$key = $this->prefix . $this->userId();
$oldCount = $this->getItem($goodId);
// 添加过该商品,累加个数
if ($oldCount) {
$newCount = $oldCount + $count;
$this->redis->hset($key, $goodId, $newCount);
// 首次添加商品,直接记录
} else {
$this->redis->hset($key, $goodId, $count);
}
}
public function getItem($goodId)
{
$key = $this->prefix . $this->userId();
return $this->redis->hget($key, $goodId);
}
}
$cart = new Cart();
$cart->addItem('103', 2);
$cart->addItem('103', 1);
$cart->addItem('105', 1);
$cart->addItem('106', 3);
$cart->addItem('106', -2);WARNING
根据Redis 4.0.0,HMSET被视为已弃用。请在新代码中使用HSET。
参考
]]>简单说先创建语言包文件
比如项目要支持英语和荷兰语,需要创建resources/lang/en/auth.php和resources/lang/nl/auth.php
<?php
return [
/*
|--------------------------------------------------------------------------
| Authentication Language Lines
|--------------------------------------------------------------------------
|
| The following language lines are used during authentication for various
| messages that we need to display to the user. You are free to modify
| these language lines according to your application's requirements.
|
*/
'User Name' => 'User Name',
'Password' => 'Password',
'Employee Login' => 'Employee Login',
'failed' => 'Please check your account information.',
'sub-domain' => 'Login failed, Sub-domain or Company not match.',
'throttle' => 'Too many login attempts. Please try again in :seconds seconds.',
];然后在php文件和模板文件就可以引用了
// PHP中
echo __('auth.Password');
trans('auth.Password');
// 模板中
{{ __('auth.Password') }}
@lang('auth.Password')为了让前端知道我们现在使用的哪种语言,我们将语言输出到JS中
打开resources/views/layouts/app.blade.php
添加,一定要保证在app.js上面,因为默认情况下,app.js里面包含了Vue
<script>
window.Laravel = {
csrfToken: '{{ csrf_token() }}',
Locale: '<?php echo \App::getLocale(); ?>',
Languages: <?php echo json_encode(['dashboard' => __('auth')], JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);?>
};
</script>
<script src="{{ mix('js/app.js') }}"></script>输出结果
<script>
window.Laravel = {
csrfToken: 'am9VXxfFaONZdOQHp4P7V1rP9tUdiK85j8KoJrB3',
Locale: 'en',
Languages: {
"dashboard": {
"User Name": "User Name",
"Password": "Password",
"Employee Login": "Employee Login",
"failed": "Please check your account information.",
"sub-domain": "Login failed, Sub-domain or Company not match.",
"throttle": "Too many login attempts. Please try again in :seconds seconds."
}
}
};
</script>然后打开app.js
const i18n = new VueI18n({
locale: window.Laravel.Locale || 'en',
// 需定义,详见 https://kazupon.github.io/vue-i18n/zh/started.html#html
messages,
});参考
]]>Controller中获取数据然后使用view方法将数据传送到视图中,比如下面
TopicsController.php
public function create(Topic $topic)
{
$categories = Category::all();
return view('topics.create_and_edit', compact('topic', 'categories'));
}这种思路是:路由->控制器->获取数据->渲染到视图
但是有时候有某一个视图片段需要在好几个页面中共同使用,有没有方法先指定视图中,然后告诉从哪加载数据呢?
使用视图合成器view composers可以轻松实现
需求
项目中的左侧菜单栏,是一个单独的组件view,位置在resources/views/includes/_sidebar.blade.php
其数据需要单独获取,不希望放到controller中。
注意,这里有一个menu表,用来存放具体的一二级菜单信息,因为系统需求是根据不同用户角色加载并显示不同的菜单列表,存到数据库而不是写死到代码中。 Menu模型中的getMenuItems方法用来根据角色查询菜单项
- 创建一个
App\Http\View\Composers\SidebarComposer类
<?php
namespace App\Http\View\Composers;
use App\Models\Employee;
use Illuminate\View\View;
class SidebarComposer
{
protected $menuList;
public function __construct(Menu $menu)
{
$this->menuList = $menu->getMenuItems();
}
public function compose(View $view)
{
$view->with('menuList', $this->menuList);
}
}- 修改
app/Providers/AppServiceProvider.phpboot方法内添加
view()->composer('includes._sidebar', 'App\Http\View\Composers\SidebarComposer');includes._sidebar可以放到layous/backend.blade.php等任何需要的地方
参考
https://learnku.com/docs/laravel/6.x/views/5141#view-composers
]]>比如Order订单表的发货状态发生了变化,当变为已付款要给相关角色发送邮件通知。
事件系统
本质上实现方式是观察者订阅者,和JS中的AddListener和类似
原生实现事件类
class Event
{
protected static $listens = array();
/**
* [listen 注册监听事件]
* @param [string] $event [事件名]
* @param [callback] $callback [事件内容]
* @param [bool] $once [是否是一次性事件,默认false]
*/
public static function listen($event, $callback, $once=false){
if(!is_callable($callback)) return false;
self::$listens[$event][] = array('callback'=>$callback, 'once'=>$once);
return true;
}
// 一次性事件
public static function one($event, $callback){
return self::listen($event, $callback, true);
}
public static function remove($event, $index=null){
if(is_null($index))
unset(self::$listens[$event]);
else
unset(self::$listens[$event][$index]);
}
public static function trigger(){
// 没有参数(传递事件) 退出
if(!func_num_args()) return;
// 事件名的数组
$args = func_get_args();
// 将函数名(callback)赋给 $event
$event = array_shift($args);
// 检测事件是否被注册过,没有则退出
if(!isset(self::$listens[$event])) return false;
foreach( self::$listens[$event] as $index=>$listen){
$callback = $listen['callback'];
$listen['once'] && self::remove($event, $index);
call_user_func_array($callback, $args);
}
}
}这个类包含了事件的注册,触发及移除方法。
下面添加一个事件,事件名叫walk,事件的动作就是输出 "I am walking...n" ,执行后。该事件会存储在 $listens 这个数组中。
Event::listen('walk', function($a='',$b=''){
echo "I am walking...n" .$a .$b;
});触发walk事件
Event::trigger('walk');
也可以传参数进去
Event::trigger('walk','~~~','!!!');
如果不移除该事件,触发一次就会执行一次。
而一次性事件执行过一次就会被销毁。再次调用没有任何反应。
Event::one('walkOnce', function(){
echo "run...once";
});
Event::trigger('walkOnce',true);
// 因为已经执行过了,再次调用返回了false
Event::trigger('walkOnce');下篇介绍Laravel中的事件系统
参考
]]>执行 php artisan event:generate 会生成事件相关类文件
路径 app/Events/Event.php
所有事件类放在app/Events目录下
所有监听器放在app/Listeners目录下
一个事件可以包含多个监听器
打开 app/Providers/EventServiceProvider.php
/**
* The event listener mappings for the application.
*
* @var array
*/
protected $listen = [
'App\Events\SomeEvent' => [
'App\Listeners\EventListener',
],
];项目中的运用
打开 app/Providers/EventServiceProvider.php
更新
protected $listen = [
'App\Events\SkuEvents\SkuCreated' => [
'App\Listeners\SkuListeners\RiotVerifySkuCreatedPusher',
],
]执行 php artisan event:generate 命令后就可以得到SkuCreated文件了
app/Events/SkuEvents/SkuCreated.php
<?php
namespace App\Events\SkuEvents;
use Illuminate\Broadcasting\InteractsWithSockets;
use Illuminate\Queue\SerializesModels;
use Riot\Sku\Models\Sku;
class SkuCreated
{
use InteractsWithSockets, SerializesModels;
public $sku = null;
/**
* Create a new event instance.
*
* SkuUpdated constructor.
* @param Sku $sku
* @param string $type
*/
public function __construct(Sku $sku, string $type = '')
{
$this->sku = $sku;
}
}我们在Controller中尝试触发事件, 即当往Sku表添加一条新记录时触发SkuCreated事件
Riot/Sku/Controllers/SkuController.php
public function store(CreateSkuRequest $request)
{
try {
$input = $request->all();
$sku = $this->repository->create($input);
// 事件触发
event(new SkuCreated($sku));
return $this->sendResponse($sku, 'Sku saved successfully.');
} catch (\Exception $e)
{
return $this->sendError($e->getMessage());
}
}Listener 具体逻辑 主要是同步SKU信息
<?php
namespace App\Listeners\SkuListeners;
use App\Events\SkuEvents\SkuCreated;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Contracts\Queue\ShouldQueue;
use App\Events\SkuEvents\SkuUpdated as SkuUpdatedEvent;
use Riot\Sku\Jobs\PushCreatedSkuInfo;
class RiotVerifySkuCreatedPusher
{
/**
* Create the event listener.
*
* @return void
*/
public function __construct()
{
//
}
/**
* Handle the event.
*
* @param SkuCreated $event
* @return void
*/
public function handle(SkuCreated $event)
{
$sku = $event->sku;
dd($sku);
}
}当然为了方便,可以在路由中测试
Route:get('/', function() {
$sku = \App\Sku::find(1);
event(new \App\Events\SkuEvents\SkuCreated($sku));
});参考
]]>系统的用户列表中添加一个绿点,表示他们是否在线。
方案
启动一个nodejs服务器追踪每个用户的socket连接,优点:准确,实时,缺点:麻烦
进一步方案
记录所有用户的上次的活动时间,只要超过一定当前时间,就判断为离线。
优点:实现简单,快速 缺点:可能需要为用户表添加字段,加重数据库负担
最终方案
我们不使用数据库,使用缓存。
为了保证在每个请求触发,需要创建一个middleware中间件
php artisan make:middleware LogLastUserActivity
内容如下:
// 判断是否是有效的登录用户
if(Auth::check()) {
// 缓存只存储5分钟
$expiresAt = Carbon::now()->addMinutes(5);
Cache::put('user-is-online-' . Auth::user()->id, true, $expiresAt);
}关于缓存
接下来,打开app/Http/Kernel.php,在protected $middlewareGroups的web中追加
\App\Http\Middleware\LogLastUserActivity::class,
最后,添加一个方法从缓存中读数据
在 app/User.php 我们添加下面的方法:
public function isOnline()
{
return Cache::has('user-is-online-' . $this->id);
}这样,在页面中调用方法
@if($user->isOnline())
user is online!!
@endif保存session到数据库
php artisan session:table
// 生成迁移文件
Schema::create('sessions', function ($table) {
$table->string('id')->unique();
$table->unsignedInteger('user_id')->nullable();
$table->string('ip_address', 45)->nullable();
$table->text('user_agent')->nullable();
$table->text('payload');
$table->integer('last_activity');
});php artisan migrate自定义字段
<?php
namespace App\Extension;
use Illuminate\Support\ServiceProvider;
class CustomSessionServiceProvider extends ServiceProvider
{
public function register()
{
$connection = $this->app['config']['session.connection'];
$table = $this->app['config']['session.table'];
$this->app['session']->extend('database', function ($app) use ($connection, $table) {
$lifetime = $this->app->config->get('session.lifetime');
return new \App\Extension\CustomDatabaseSessionHandler(
$this->app['db']->connection($connection),
$table,
$lifetime,
$this->app
);
});
}
}namespace App\Extension;
use Illuminate\Contracts\Auth\Guard;
use Illuminate\Session\DatabaseSessionHandler;
class CustomDatabaseSessionHandler extends DatabaseSessionHandler
{
public function write($sessionId, $data)
{
$type = Auth::currentType();
$user_id = (Auth::type($type)->check()) ? Auth::type($type)->id() : null;
if ($this->exists) {
$this->getQuery()->where('id', $sessionId)->update([
'payload' => base64_encode($data), 'last_activity' => time(), 'user_id' => $user_id, 'user_type' => $type,
]);
} else {
$this->getQuery()->insert([
'id' => $sessionId, 'payload' => base64_encode($data), 'last_activity' => time(), 'user_id' => $user_id, 'user_type' => $type,
]);
}
$this->exists = true;
}
}参考
https://learnku.com/docs/laravel/6.x/session/5143#configuration
https://stackoverflow.com/questions/24280781/creating-our-own-session-handler
https://laracasts.com/discuss/channels/laravel/how-to-store-users-id-in-session-table-laravel-5
]]>创建语种文件
config/app 中,应用默认语言是英文
/*
|--------------------------------------------------------------------------
| Application Locale Configuration
|--------------------------------------------------------------------------
|
| The application locale determines the default locale that will be used
| by the translation service provider. You are free to set this value
| to any of the locales which will be supported by the application.
|
*/
'locale' => 'en',resource/lang/ 是语言包目录,默认也只有英文 需要其他语种,可以到这个项目下载
假设我们这个项目需要实现荷兰语和英语
在resource/lang/下新建 nl 目录, 对应的文件也拷贝过来
最后为了灵活配置和扩展,新建config/locale.php
内容如下:
<?php
return [
/*
* Whether or not to show the language picker, or just default to the default
* locale specified in the app config file
*
* @var bool
*/
'status' => true,
/*
* Available languages
*
* Add your language code to this array.
* The code must have the same name as the language folder.
* Be sure to add the new language in an alphabetical order.
*
* The language picker will not be available if there is only one language option
* Commenting out languages will make them unavailable to the user
*
* @var array
*/
'languages' => [
/*
* Key is the Laravel locale code
* Index 0 of sub-array is the Carbon locale code
* Index 1 of sub-array is the PHP locale code for setlocale()
* Index 2 of sub-array is whether or not to use RTL (right-to-left) css for this language
*/
// 'ar' => ['ar', 'ar_AR', true],
// 'da' => ['da', 'da_DK', false],
// 'de' => ['de', 'de_DE', false],
// 'el' => ['el', 'el_GR', false],
'en' => ['en', 'en_US', false],
// 'es' => ['es', 'es_ES', false],
// 'fr' => ['fr', 'fr_FR', false],
// 'id' => ['id', 'id_ID', false],
// 'it' => ['it', 'it_IT', false],
'nl' => ['nl', 'nl_NL', false],
// 'pt_BR' => ['pt_BR', 'pt_BR', false],
// 'ru' => ['ru', 'ru-RU', false],
// 'sv' => ['sv', 'sv_SE', false],
// 'th' => ['th', 'th_TH', false],
],
];前端,创建dropdown menu
创建 resources/views/includes/lang.blade.php
<div class="dropdown-menu lang-menu">
@foreach (array_keys(config('locale.languages')) as $lang)
@if ($lang != App::getLocale())
<a class="dropdown-item" href="/lang/{{$lang}}">{{trans('menus.language-picker.langs.'.$lang)}}</a>
@endif
@endforeach
</div>从配置读所有语言,并只显示当前没有选中的语言,比如当前默认是en,配了两种语言en和nl。所以只显示nl
修改 resources/views/layouts/app.blade.php
<!-- Right Side Of Navbar -->
<ul class="navbar-nav ml-auto">
<li class="nav-item dropdown">
<a href="#" class="nav-link dropdown-toggle" data-toggle="dropdown" aria-expanded="false">
{{ trans('menus.language-picker.language') }}
<span class="caret"></span>
</a>
@include('includes.lang')
</li>
@yield('navigation')
</ul>关于 trans('menus.language-picker.language')
需要新建 resouces/lang/en/menus 是整个系统菜单区域的语言翻译文件
<?php
return [
/*
|--------------------------------------------------------------------------
| Menus Language Lines
|--------------------------------------------------------------------------
|
| The following language lines are used in menu items throughout the system.
| Regardless where it is placed, a menu item can be listed here so it is easily
| found in a intuitive way.
|
*/
'Home' => 'Home',
'language-picker' => [
'language' => 'Language',
/*
* Add the new language to this array.
* The key should have the same language code as the folder name.
* The string should be: 'Language-name-in-your-own-language (Language-name-in-English)'.
* Be sure to add the new language in alphabetical order.
*/
'langs' => [
'ar' => 'Arabic',
'da' => 'Danish',
'de' => 'German',
'el' => 'Greek',
'en' => 'English',
'es' => 'Spanish',
'fr' => 'French',
'id' => 'Indonesian',
'it' => 'Italian',
'nl' => 'Dutch',
'pt_BR' => 'Brazilian Portuguese',
'ru' => 'Russian',
'sv' => 'Swedish',
'th' => 'Thai',
],
],
];前端效果如下:

后端
切换时需要请求api,然后把新的语言存到session中,还需要创建一个中间件,请求过来时候,判断下从session中读语言
首先routes/web.php中添加一个路由
// Switch between the included languages
Route::get('lang/{lang}', 'LanguageController@swap');然后创建LanguageController.php
php artisan make:controller LanguageController
<?php
namespace App\Http\Controllers;
/**
* Class LanguageController.
*/
class LanguageController extends Controller
{
/**
* @param $lang
*
* @return \Illuminate\Http\RedirectResponse
*/
public function swap($lang)
{
\App::setLocale($lang);
session()->put('locale', $lang);
return redirect()->back();
}
}接着创建中间件
php artisan make:middle Localization
<?php
namespace App\Http\Middleware;
use Illuminate\Foundation\Http\Middleware\TrimStrings as Middleware;
class Localization extends Middleware
{
public function handle($request, \Closure $next)
{
if (session()->has('locale')) {
\App::setLocale(session()->get('locale'));
}
return $next($request);
}
}别忘了为了让中间件生效,需要在app/Http/Kernel.php中加入相应的配置
/**
* The application's route middleware groups.
*
* @var array
*/
protected $middlewareGroups = [
'web' => [
\App\Http\Middleware\EncryptCookies::class,
\Illuminate\Cookie\Middleware\AddQueuedCookiesToResponse::class,
\Illuminate\Session\Middleware\StartSession::class,
// \Illuminate\Session\Middleware\AuthenticateSession::class,
\Illuminate\View\Middleware\ShareErrorsFromSession::class,
\App\Http\Middleware\VerifyCsrfToken::class,
\Illuminate\Routing\Middleware\SubstituteBindings::class,
// 加到最下面
Localization::class,
],参考
https://www.larashout.com/how-to-create-multilingual-website-using-laravel-localization
]]>根据文档说明
Laravel 在处理邮件消息发送时触发两个事件。MessageSending 事件在消息发送前触发,MessageSent 事件则在消息发送后触发。
切记,这些事件是在邮件被 发送 时触发,而不是在队列化的时候。可以在 EventServiceProvider 中注册此事件的侦听器:
希望实现:每当邮件发送出去,就将一些基本信息(邮件发件人,收件人,邮件标题等)记录到相关的日志文件中,
- 打开
App\Providers\EventServiceProvider
修改
protected $listen = [
Registered::class => [
SendEmailVerificationNotification::class,
],
'Illuminate\Mail\Events\MessageSent' => [
'App\Listeners\EmailLogSentMessage',
],
];-
执行
php artisan make:listener EmailLogSentMessage -
打开新创建的
App\Listeners\EmailLogSentMessage -
修改handle方法
public function handle($event)
{
// 这里只打印了邮件头信息,邮件内容比较长,就不让输出了
\Log::channel('emailSend')->info($event->message->getHeaders());
}- 这里需要打开
config\logging, channels 下面添加一节 意思我希望输出日志,按天轮回,并且指定了输出日志的路径和文件名
'channels' => [
'stack' ...
'emailSend' => [
'driver' => 'daily',
'path' => storage_path('logs/emailSend.log'),
'level' => 'info',
'days' => 14,
],
...每次发送邮件把日志记录到数据库中
机制一样,根据MessageSending事件搞事情,直接安装这个laravel-email-database-log即可
]]>xdebug 3 和 2 的区别
详细见官方文档
个人简单翻译下
新概念
与Xdebug 2不同,在Xdebug 2中,每个功能都有一个启用设置,使用Xdebug 3,可以将Xdebug置于特定模式下,如debug或develop。
关于mode,YouTube 上有个非常好介绍,xdebug作者讲的。
推荐写成xdebug.mode=debug,develop
该配置与xdebug.start_with_request结合使用。
其背后的想法是Xdebug仅具有实际需要的功能的开销。例如,同时激活Profiling和Step Debugging功能是没有意义的。
除了使用xdebug.mode设置模式外,还可以使用XDEBUG_MODE环境变量来设置模式 。XDEBUG_MODE环境变量的值会覆盖通过xdebug.mode设置的值。
开启Step Debugging
之前是
xdebug.remote_enable=1
xdebug.default_enable=0
xdebug.profiler_enable=0
xdebug.auto_trace=0
xdebug.coverage_enable=0现在只需要修改php.ini为xdebug.mode=debug或者直接在命令行执行
export XDEBUG_MODE=debug
php script-name.php此外可以使用xdebug_info()方法查看Xdebug的配置信息,还会输出相关的调式连接的诊断信息和文件权限信息
Step Debugging
命令行激活
默认调试端口已从更改 9000 为 9003。
xdebug.client_port=9003
Instead of setting the XDEBUG_CONFIG environment variable to idekey=yourname, you must set XDEBUG_SESSION to yourname
不用再配置IDE Keyidekey=yourname,需要设置XDEBUG_SESSION,比如export XDEBUG_SESSION=xdebug_is_great
自动开启debugger
The xdebug.remote_autostart setting has been removed. Instead, set xdebug.start_with_request to yes.
xdebug.remote_autostart配置已被删除。而是将xdebug.start_with_request设置为yes。
请求时启动debugger
In Xdebug 3 calling xdebug_break() will only initiate a debugging session when xdebug.start_with_request is set to trigger.
在Xdebug 3中,仅当xdebug.start_with_request设置为trigger时,调用xdebug_break()才会启动调试session。
It will no longer trigger a debugging session when xdebug.start_upon_error=yes (the replacement for Xdebug 2's xdebug.remote_mode=jit).
当xdebug.start_upon_error = yes(xdebug2中对应的配置项是xdebug.remote_mode=jit)时,它将不再触发调试会话。
A debug session will be initiated upon a PHP Notice or Warning, or when a Throwable is thrown, when xdebug.start_upon_error is set to yes, regardless of what the value for xdebug.start_with_request is.
不管xdebug.start_with_request的值是什么,当xdebug.start_upon_error被设置为yes,当发生了PHP Notice或Warning时启动,或者有Throwable抛出。debugging session就会启动
修改了xdebug_break()函数行为
xdebug_break()
This function will no longer initiate a debugging session when xdebug.start_upon_error is set to yes (the replacement for Xdebug 2's xdebug.remote_mode=jit).
当xdebug.start_upon_error设置为yes(xdebug2中对应的配置项是xdebug.remote_mode=jit)时,此函数不在初始化debugging session
It will still initate a debugging request when xdebug.start_with_request is set to trigger.
重命名了很多函数名和常量名,这个不再翻译了
vscode中使用xdebug3调试
本机环境 MacOS
php7.3.28 with Xdebug v3.0.4
xdebug配置项:
zend_extension="xdebug.so"
xdebug.mode=debug,develop
xdebug.start_with_request = yes
xdebug.client_host = localhost
xdebug.client_port = 9003
xdebug.start_with_request = yes- vscode 安装PHP Debug扩展
- 打开vscode的setting页面, 确保勾选了Debug: Allow Breakpoints Everywhere

开启debug 选择php,选择创建 config


命令行调试
勾选绿色运行按钮,php文件中打个断点,新建terminal,命令行运行我们要调试的php文件
php xdebug-example.php, 由于我们这里以Laravel为例,可以是php artisan generate:slug

浏览器请求调试
非常简单,开启调试,浏览器打开php地址就可以了, 比如http://php.test/test/xdebug.php

有时候我们不需要修改ini文件,可以通过环境变量形式传入xdebug配置参数,如下:
php -dxdebug.mode=debug -dxdebug.client_host=127.0.0.1 -dxdebug.client_port=9003 -dxdebug.start_with_request=yes path/to/script.php
php -dxdebug.mode=debug -dxdebug.client_host=127.0.0.1 -dxdebug.client_port=9003 -dxdebug.start_with_request=yes artisan inspire参考
https://www.jetbrains.com/help/phpstorm/configuring-xdebug.html#configuring-xdebug-vagrant
https://www.youtube.com/watch?v=HF61HJHEYMk&ab_channel=DerickRethans
]]>假设 User 模型关联了 Phone 模型,要定义这样一个关联,需要在 User 模型中定义一个 phone 方法,该方法返回一个 hasOne 方法定义的关联
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
/**
* Get the phone record associated with the user.
*/
public function phone()
{
return $this->hasOne('App\Phone');
}
}hasOne 方法的第一个参数为要关联的模型,定义好之后,可以使用下列语法查询到关联属性了
$phone = User::find(1)->phone;
Eloquent 会假定关联的外键是基于模型名称的,因此 Phone 模型会自动使用 user_id 字段作为外键,可以使用第二个参数和第三个参数覆盖
return $this->hasOne('App\Phone', 'foreign_key');
return $this->hasOne('App\Phone', 'foreign_key', 'local_key');定义反向关系
定义上述的模型之后,就可以使用 User 模型获取 Phone 模型了,当然也可以通过 Phone 模型获取所属的 User 了,这就用到了 belongsTo 方法了
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Phone extends Model
{
/**
* Get the user that owns the phone.
*/
public function user()
{
return $this->belongsTo('App\User');
// return $this->belongsTo('App\User', 'foreign_key');
// return $this->belongsTo('App\User', 'foreign_key', 'other_key');
}
}One To Many
假设有一个帖子,它有很多关联的评论信息,这种情况下应该使用一对多的关联,使用 hasMany 方法
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Post extends Model
{
/**
* Get the comments for the blog post.
*/
public function comments()
{
return $this->hasMany('App\Comment');
}
}查询操作
$comments = App\Post::find(1)->comments;
foreach ($comments as $comment) {
$comment->content;
}定义反向关联
反向关联也是使用 belongsTo 方法,参考 One To One 部分。
$comment = App\Comment::find(1);
echo $comment->post->title;Many To Many
多对多关联因为多了一个中间表,实现起来比 hasOne 和 hasMany 复杂一些。
考虑这样一个场景,用户可以属于多个角色,一个角色也可以属于多个用户。 这就引入了三个表: users, roles, role_user。其中 role_user 表为关联表,包含两个字段 user_id 和 role_id。
多对多关联需要使用 belongsToMany 方法
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
/**
* The roles that belong to the user.
*/
public function roles()
{
// 指定关联表
// return $this->belongsToMany('App\Role', 'role_user');
// 指定关联表,关联字段
// return $this->belongsToMany('App\Role', 'role_user', 'user_id', 'role_id');
return $this->belongsToMany('App\Role');
}
}上述定义了一个用户属于多个角色,一旦该关系确立,就可以查询了
$user = App\User::find(1);
foreach ($user->roles as $role) {
//
}
$roles = App\User::find(1)->roles()->orderBy('name')->get();反向关联关系
反向关系与正向关系实现一样
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Role extends Model
{
/**
* The users that belong to the role.
*/
public function users()
{
return $this->belongsToMany('App\User');
}
}检索中间表的列值
对多对多关系来说,引入了一个中间表,因此需要有方法能够查询到中间表的列值,比如关系确立的时间等,使用 pivot 属性查询中间表
$user = App\User::find(1);
foreach ($user->roles as $role) {
echo $role->pivot->created_at;
}上述代码访问了中间表的 created_at 字段。
注意的是,默认情况下之后模型的键可以通过 pivot 对象进行访问,如果中间表包含了额外的属性,在指定关联关系的时候,需要使用 withPivot 方法明确的指定列名
return $this->belongsToMany('App\Role')->withPivot('column1', 'column2');
如果希望中间表自动维护 created_at 和 updated_at 字段的话,需要使用 withTimestamps()
return $this->belongsToMany('App\Role')->withTimestamps();
Has Many Through
这种关系比较强大,假设这样一个场景:Country 模型下包含了多个 User 模型,而每个 User 模型又包含了多个 Post 模型,也就是说一个国家有很多用户,而这些用户都有很多帖子,我们希望查询某个国家的所有帖子,怎么实现呢,这就用到了 Has Many Through 关系
countries
id - integer
name - string
users
id - integer
country_id - integer
name - string
posts
id - integer
user_id - integer
title - string可以看到,posts 表中并不直接包含 country_id,但是它通过 users 表与 countries 表建立了关系
使用 Has Many Through 关系
namespace App;
use Illuminate\Database\Eloquent\Model;
class Country extends Model
{
/**
* Get all of the posts for the country.
*/
public function posts()
{
// return $this->hasManyThrough('App\Post', 'App\User', 'country_id', 'user_id');
return $this->hasManyThrough('App\Post', 'App\User');
}
}方法 hasManyThrough 的第一个参数是我们希望访问的模型名称,第二个参数是中间模型名称。
HasManyThrough hasManyThrough(
string $related,
string $through,
string|null $firstKey = null,
string|null $secondKey = null,
string|null $localKey = null
)Polymorphic Relations (多态关联)
多态关联使得同一个模型使用一个关联就可以属于多个不同的模型,假设这样一个场景,我们有一个帖子表和一个评论表,用户既可以对帖子执行喜欢操作,也可以对评论执行喜欢操作,这样的情况下该怎么处理呢?
表结构如下
posts
id - integer
title - string
body - text
comments
id - integer
post_id - integer
body - text
likes
id - integer
likeable_id - integer
likeable_type - string可以看到,我们使用 likes 表中的 likeable_type 字段判断该记录喜欢的是帖子还是评论,表结构有了,接下来就该定义模型了
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Like extends Model
{
/**
* Get all of the owning likeable models.
*/
public function likeable()
{
return $this->morphTo();
}
}
class Post extends Model
{
/**
* Get all of the product's likes.
*/
public function likes()
{
return $this->morphMany('App\Like', 'likeable');
}
}
class Comment extends Model
{
/**
* Get all of the comment's likes.
*/
public function likes()
{
return $this->morphMany('App\Like', 'likeable');
}
}默认情况下,likeable_type 的类型是关联的模型的完整名称,比如这里就是 App\Post 和 App\Comment。
通常情况下我们可能会使用自定义的值标识关联的表名,因此,这就需要自定义这个值了,我们需要在项目的服务提供者对象的 boot 方法中注册关联关系,比如 AppServiceProvider 的 boot 方法中
use Illuminate\Database\Eloquent\Relations\Relation;
Relation::morphMap([
'posts' => App\Post::class,
'likes' => App\Like::class,
]);检索多态关系
// 访问一个帖子所有的喜欢
$post = App\Post::find(1);
foreach ($post->likes as $like) {
//
}
// 访问一个喜欢的帖子或者评论
$like = App\Like::find(1);
$likeable = $like->likeable;上面的例子中,返回的 likeable 会根据该记录的类型返回帖子或者评论。
多对多的多态关联
多对多的关联使用方法 morphToMany 和 morphedByMany,这里就不多废话了。
关联关系查询
在 Eloquent 中,所有的关系都是使用函数定义的,可以在不执行关联查询的情况下获取关联的实例。 假设我们有一个博客系统,User 模型关联了很多 Post 模型:
/**
* Get all of the posts for the user.
*/
public function posts()
{
return $this->hasMany('App\Post');
}你可以像下面这样查询关联并且添加额外的约束
$user = App\User::find(1);
$user->posts()->where('active', 1)->get();如果不需要对关联的属性添加约束,可以直接作为模型的属性访问,例如上面的例子,我们可以使用下面的方式访问 User 的 Post
$user = App\User::find(1);
foreach ($user->posts as $post) {
//
}动态的属性都是延迟加载的,它们只有在被访问的时候才会去查询数据库,与之对应的是预加载,预加载可以使用关联查询出所有数据,减少执行 sql 的数量。
查询关系存在性
使用 has 方法可以基于关系的存在性返回结果
// 检索至少有一个评论的所有帖子...
$posts = App\Post::has('comments')->get();
// Retrieve all posts that have three or more comments...
$posts = Post::has('comments', '>=', 3)->get();
// Retrieve all posts that have at least one comment with votes...
$posts = Post::has('comments.votes')->get();如果需要更加强大的功能,可以使用 whereHas 和 orWhereHas 方法,把 where 条件放到 has 语句中。
// 检索所有至少存在一个匹配foo%的评论的帖子
$posts = Post::whereHas('comments', function ($query) {
$query->where('content', 'like', 'foo%');
})->get();预加载
在访问 Eloquent 模型的时候,默认情况下所有的关联关系都是延迟加载的,在使用的时候才会开始加载,这就造成了需要执行大量的 sql 的问题,使用预加载功能可以使用关联查询出所有结果
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Book extends Model
{
/**
* Get the author that wrote the book.
*/
public function author()
{
return $this->belongsTo('App\Author');
}
}接下来我们检索所有的书和他们的作者
$books = App\Book::all();
foreach ($books as $book) {
echo $book->author->name;
}上面的查询将会执行一个查询查询出所有的书,然后在遍历的时候再执行 N 个查询查询出作者信息,显然这样做是非常低效的,幸好我们还有预加载功能,可以将这 N+1 个查询减少到 2 个查询,在查询的时候,可以使用 with 方法指定哪个关系需要预加载。
$books = App\Book::with('author')->get();
foreach ($books as $book) {
echo $book->author->name;
}对于该操作,会执行下列两个 sql
select * from books
select * from authors where id in (1, 2, 3, 4, 5, ...)预加载多个关系
$books = App\Book::with('author', 'publisher')->get();
嵌套的预加载
$books = App\Book::with('author.contacts')->get();
带约束的预加载
$users = App\User::with(['posts' => function ($query) {
$query->where('title', 'like', '%first%');
}])->get();
$users = App\User::with(['posts' => function ($query) {
$query->orderBy('created_at', 'desc');
}])->get();延迟预加载
有时候,在上级模型已经检索出来之后,可能会需要预加载关联数据,可以使用 load 方法
$books = App\Book::all();
if ($someCondition) {
$books->load('author', 'publisher');
}
$books->load(['author' => function ($query) {
$query->orderBy('published_date', 'asc');
}]);关联模型插入
save 方法 保存单个关联模型
$comment = new App\Comment(['message' => 'A new comment.']);
$post = App\Post::find(1);
$post->comments()->save($comment);保存多个关联模型
$post = App\Post::find(1);
$post->comments()->saveMany([
new App\Comment(['message' => 'A new comment.']),
new App\Comment(['message' => 'Another comment.']),
]);save 方法和多对多关联
多对多关联可以为 save 的第二个参数指定关联表中的属性
App\User::find(1)->roles()->save($role, ['expires' => $expires]);
上述代码会更新中间表的 expires 字段。
create 方法 使用 create 方法与 save 方法的不同在于它是使用数组的形式创建关联模型的
$post = App\Post::find(1);
$comment = $post->comments()->create([
'message' => 'A new comment.',
]);更新 "Belongs To" 关系
更新 belongsTo 关系的时候,可以使用 associate 方法,该方法会设置子模型的外键
$account = App\Account::find(10);
$user->account()->associate($account);
$user->save();要移除 belongsTo 关系的话,使用 dissociate 方法
$user->account()->dissociate();
$user->save();Many to Many 关系
中间表查询条件 当查询时需要对使用中间表作为查询条件时,可以使用 wherePivot, wherePivotIn,orWherePivot,orWherePivotIn 添加查询条件。
$enterprise->with(['favorites' => function($query) {
$query->wherePivot('enterprise_id', '=', 12)->select('id');
}]);Attaching / Detaching
$user = App\User::find(1);
// 为用户添加角色
$user->roles()->attach($roleId);
// 为用户添加角色,更新中间表的expires字段
$user->roles()->attach($roleId, ['expires' => $expires]);
// 移除用户的单个角色
$user->roles()->detach($roleId);
// 移除用户的所有角色
$user->roles()->detach();attach 和 detach 方法支持数组参数,同时添加和移除多个
$user = App\User::find(1);
$user->roles()->detach([1, 2, 3]);
$user->roles()->attach([1 => ['expires' => $expires], 2, 3]);更新中间表(关联表)字段 使用 updateExistingPivot 方法更新中间表
$user = App\User::find(1);
$user->roles()->updateExistingPivot($roleId, $attributes);同步中间表(同步关联关系) 使用 sync 方法,可以指定两个模型之间只存在指定的关联关系
$user->roles()->sync([1, 2, 3]);
$user->roles()->sync([1 => ['expires' => true], 2, 3]);上述两个方法都会让用户只存在 1,2,3 三个角色,如果用户之前存在其他角色,则会被删除。
更新父模型的时间戳 假设场景如下,我们为一个帖子增加了一个新的评论,我们希望这个时候帖子的更新时间会相应的改变,这种行为在 Eloquent 中是非常容易实现的。
在子模型中使用 $touches 属性实现该功能
<?php
namespace App;
use Illuminate\Database\Eloquent\Model;
class Comment extends Model
{
/**
* All of the relationships to be touched.
*
* @var array
*/
protected $touches = ['post'];
/**
* Get the post that the comment belongs to.
*/
public function post()
{
return $this->belongsTo('App\Post');
}
}现在,更新评论的时候,帖子的 updated_at 字段也会被更新
$comment = App\Comment::find(1);
$comment->text = 'Edit to this comment!';
$comment->save();参考
]]>1. Increments and Decrements
文章阅读量增加 1:
$article = Article::find($articleid);
$article->readcount++;
$article->save();你可以这样做:
$article = Article::find($article_id);
$article->increment('read_count');也可以这些做:
Article::find($article_id)->increment('read_count');
Article::find($article_id)->increment('read_count', 10); // +10
Product::find($produce_id)->decrement('stock'); // -12. XorY methods
Eloquent有很多功能,结合了两种方法,比如“请做X,否则做Y”。
-
findOrFail() :
$user = User::findOrFail($id);等价于:
$user = User::find($id); if (!$user) { abort (404); } -
firstOrCreate() :
$user = User::firstOrCreate(['email' => $email]);等价于:
$user = User::where('email', $email)->first(); if (!$user) { User::create(['email' => $email]); }
3. 模型 boot() 方法
在Eloquent模型中有一个名为boot()的方法,您可以在其中覆盖默认行为:
class User extends Model
{
public static function boot()
{
parent::boot();
static::updating(function ($model)
{
// do some logging
});
}
}可能最常见的例子之一是在创建模型对象时设置一些字段值。假设你想在那一刻生成UUID字段。
public static function boot()
{
parent::boot();
static::creating(function ($model)
{
$model->uuid = (string)Uuid::generate();
});
}4. Relationship with conditions and ordering
这是定义关系的典型方法:
public function users()
{
retrun $this->hasMany('App\User');
}但是你知道吗,此时我们已经可以添加where或orderBy了! 例如,如果您想要某种类型的用户(也是通过电子邮件订购)的特定关系,您可以这样做:
public function approvedUsers()
{
retrun $this->hasMany('App\User')->where('approved', 1)->orderBy('email');
}5. 模型属性:timestamps, appends等。
Eloquent模型有一些“参数”,以该类的属性形式出现。最受欢迎的可能是这些:

更多请查看默认abstract Model class的代码,并查看所有使用的特征。
6. find()
大家都知道**find()**方法可以这样用:
$user = User::find(1);其实**find()**还可以传递一个数组作为参数:
$users = User::find([1,2,3]);7. whereX
有一种优雅的方式可以解决这个问题:
$users = User::where('approved', 1)->get();等价于:
$users = User::whereApproved(1)->get();8. Order by relationship
一个更复杂的“技巧”。如果您有论坛主题但想通过最新帖子订购,该怎么办?顶部有最新更新主题的论坛中非常常见的要求,对吧?
首先,描述关于该主题的最新帖子的单独关系:
public function latestPost()
{
return $this->hasOne(\App\Post::class)->latest();
}然后,在我们的控制器中,我们可以这样做:
$users = Topic::with('latestPost')->get()->sortByDesc('latestPost.created_at');9. Eloquent::when() – no more if-else’s
我们中的许多人用 “if-else” 编写条件查询,如下所示:
if (request('filter_by') == 'likes') {
$query->where('likes', '>', request('likes_amount', 0));
}
if (request('filter_by') == 'date') {
$query->orderBy('created_at', request('ordering_rule', 'desc'));
}但有更好的方法 - 使用 when():
$query = Author::query();
$query->when(request('filter_by') == 'likes', function ($q) {
return $q->where('likes', '>', request('likes_amount', 0));
});
$query->when(request('filter_by') == 'date', function ($q) {
return $q->orderBy('created_at', request('ordering_rule', 'desc'));
});它可能不会感觉更短或更优雅,但最强大的是传递参数:
$query = User::query();
$query->when(request('role', false), function ($q) use ($role) {
return $q->where('role_id', $role);
});
$authors = $query->get();10. BelongsTo Default Models
假设你有Post属于Author,然后是Blade代码:
{{ $post->author->name }}但是如果作者被删除,或者由于某种原因没有设置呢?您将收到错误,例如“property of non-object”。 当然,您可以像这样阻止它:
{{ $post->author->name ?? '' }}但你可以在Eloquent关系层面上做到这一点:
public function author()
{
return $this->belongsTo('App\Author')->withDefault();
}在此示例中,如果没有作者附加到帖子,则 author()关系将返回空的 App \ Author 模型。 此外,我们可以将默认属性值分配给该默认模型。
public function author()
{
return $this->belongsTo('App\Author')->withDefault([
'name' => 'Guest Author'
]);
}11. 赋值函数排序
假设有这么一段代码:
public function getFullNameAttribute()
{
return $this->attributes['first_name'].' '.$this->attributes['last_name'];
}如果你想按照 full_name 进行排序,下面这句代码将不起作用:
$clients = Client::orderBy('full_name')->get(); // doesn't work解决办法很简单,我们只需要在获取集合之后利用 sortBy 对集合进行排序即可:
$clients = Client::get()->sortBy('full_name'); // works12. 全局范围内默认排序
如果你希望所有用户总是按照 name 字段排序,你可以在全局范围内做一个声明,让我们回到上面已经提到的boot()方法。
protected static function boot()
{
parent::boot();
// order by name ASC
static::addGlobalScope('order', function (Builder $builder) {
$builder->orderBy('name', 'asc);
});
}13. 原始查询方法
有时候我们需要在Eloquent查询语句中添加原始查询
// whereRaw
$orders = DB::table('orders')
->whereRaw('price > IF(state = "TX", ?, 100)', [200])
->get();
// havingRaw
Product::groupBy('category_id')->havingRaw('COUNT(*) > 1')->get();
// orderByRaw
User::where('created_at', '>', '2018-11-11')
->orderByRaw('(updated_at - created_at) desc')
->get();14. Replicate: 制作一行的副本
快速复制数据的最佳方法:
$task = Task::find(1);
$newTask = $task->replicate();
$newTask->save();复制并修改其中的一部分数据:
$article = Article::find(1)->replicate();
$article->title = 'Laravel 复制数据并修改标题';
$article->save();
dd(Article::all()->toArray());复制模型及关系:
$article = Article::with('tags')->find(1);
$clone = $article->replicate();
// 复制关系
$clone->push();
foreach($article->tags as $tag)
{
$clone->tags()->attach($tag);
}15. chunk() 方法批量处理大数据量
不完全与Eloquent相关,它更多关于Collection,但仍然很强大 - 处理更大的数据集,你可以将它们分成几块。 一般情况下数据量不太大的情况下会像下面这样遍历
$users = User::all();
foreach($users as $user) {
// ...
}数据太大就能显示 chunk() 的神威了
User::chunk(100, function ($users) {
foreach($users as $user) {
//...
}
});16. 命令行创建模型的同时,创建迁移文件和控制器
laravel创建模型的命令大家都很熟悉:
php artisan make:model Company不过你应该了解另外几个很常用的参数:
php artisan make:model Company -mphp artisan make:model Company -mcphp artisan make:model Company -mcrphp artisan make:model Company -mcrf-m 表示创建模型对应的迁移文件 -c 表示创建模型对应的控制器 -r 表示创建的控制器属于资源控制器 -f 表示创建模型对应的工厂文件
实际上上述几个情况,也可以通过 -a 来实现
php artisan make:model Company -a17. 保存数据的同时 覆盖 updated_at 的默认更新时间
其实 ->save() 方法是可以接受额外参数的,因此,我们可以告诉它“忽略”updated_at默认功能以填充当前时间戳。
$product = Product::find(1);
$product->updated_at = '2018-11-11 11:11:11';
$product->save(['timestamps' => false]);可以看到,我们用我们预先定义的版本覆盖默认的updated_at。
18. update() 方法的执行结果
你有没有想过这段代码究竟返回了什么?
$result = $product->whereNull('category_id')->update(['category_id' => 1]);更新是在数据库中执行的,但$ result会包含什么? 答案是受影响的行。因此,如果您需要检查受影响的行数,则无需再调用任何其他内容 - update()方法将为您返回此数字。
19. 将and 或者 or转换为Eloquent查询
在你的查询中肯定会遇到 and 或者 or 的情况,就像这样:
... where (gender = 'Male' and age > 18) or (gender = 'Female' and age >= 65)那么怎么转换成Eloquent查询呢?先来看一个错误的例子:
$q->where('gender', 'Male');
$q->where('age', '>', 18);
$q->orWhere('gender', 'Female');
$q->where('age', '>=', 65);正确的方法有点复杂,使用闭包函数作为子查询:
$q->where(function ($query) {
$query->where('gender', 'Male')->where('age', '>', 18);
})->orWhere(function ($query) {
$query->where('gender', 'Female')->orWhere('age', '>=', 65);
})20. orWhere() 有多个参数的情况
通常情况下遇到这种查询:
$q->where('a', 1);
$q->orWhere('b', 2);
$q->orWhere('c', 65);这种情况下可以传递一个数组作为 orWhere() 的参数:
$q->where('a', 1);
$q->orWhere(['b' => 2, 'c' => 65]);21. 重新加载新模型
使用 fresh() 从数据库加载一个全新的模型实例。
$user = App\User::first();
$user->name; // John
// 用户记录通过另一个线程更新了。 例如: 'name' 改成了 // Peter。
$updatedUser = $user->fresh();
$updatedUser->name; // Peter
$user->name; // John22. 重新加载现有模型
你可以使用 refresh() 从数据库中的新值来重新加载现有模型。
$user = App\User::first();
$user->name; // John
// 用户记录通过另一个线程更新了。 例如: 'name' 改成了 // Peter。
$user->refresh();
$user->name; // Peter23. 保存模型及其关系数据
$employee = Employee::first();
$employee->name = 'New Name';
$employee->address->city = 'New York';
$employee->push();save 只会保存 employee 表中的 name 字段,而不保存 address 表中的 city 字段。push 方法将保存两者。
参考
]]>在使用链式操作的时候,例如:
return $user->avatar->url;
如果 $user->avatar 为 null,就会引起 (E_ERROR) Trying to get property 'url' of non-object 错误。
这个是非常常见的错误,下面介绍几种解决的方法:
- 常规方法:使用 isset:
if(isset($user->avatar->url)) return $user->avatar->url; else return 'defaultUrl';
- PHP7 可以使用 ?? (NULL 合并操作符) :
return $user->avatar->url ?? 'not exist avatar'
- Laravel 5.5 及以上可以使用 optional 辅助函数:
optional 函数可以接受任何参数,并且允许你访问该对象的属性或者调用方法。如果给定的对象是 null , 那么属性和方法会简单地返回 null 而不是产生一个错误:
return optional($user->address)->street;
{!! old('name', optional($user)->name) !!}Laravel 5.7 中,optional 函数还可以接受 匿名函数 作为第二个参数:
/**
* 如果第一个参数不为 null, 则调用闭包
* 详见 https://laravel\com/docs/5.7/helpers#method-optional
*/
return optional(User::find($id), function ($user) {
return new DummyUser;
});- 使用 object_get 辅助函数
return object_get($user->avatar, 'url', 'default');
这个函数原意是用来已 . 语法来获取对象中的属性,例如:
return object_get($user, 'avatar.url', 'default');
if (! function_exists('data_get')) {
/**
* Get an item from an array or object using "dot" notation.
*
* @param mixed $target
* @param string|array $key
* @param mixed $default
* @return mixed
*/
function data_get($target, $key, $default = null)
{
if (is_null($key)) {
return $target;
}
$key = is_array($key) ? $key : explode('.', $key);
while (! is_null($segment = array_shift($key))) {
if ($segment === '*') {
if ($target instanceof Collection) {
$target = $target->all();
} elseif (! is_array($target)) {
return value($default);
}
$result = [];
foreach ($target as $item) {
$result[] = data_get($item, $key);
}
return in_array('*', $key) ? Arr::collapse($result) : $result;
}
if (Arr::accessible($target) && Arr::exists($target, $segment)) {
$target = $target[$segment];
} elseif (is_object($target) && isset($target->{$segment})) {
$target = $target->{$segment};
} else {
return value($default);
}
}
return $target;
}
}- 使用 data_get 辅助函数,这个函数可以非常方便的从数组或对象中取数据
return data_get($user, 'avatar.url', 'default'); 或
return data_get($user, ['avatar', 'url'], 'default');
if (! function_exists('data_get')) {
/**
* Get an item from an array or object using "dot" notation.
*
* @param mixed $target
* @param string|array|int $key
* @param mixed $default
* @return mixed
*/
function data_get($target, $key, $default = null)
{
if (is_null($key)) {
return $target;
}
$key = is_array($key) ? $key : explode('.', $key);
while (! is_null($segment = array_shift($key))) {
if ($segment === '*') {
if ($target instanceof Collection) {
$target = $target->all();
} elseif (! is_array($target)) {
return value($default);
}
$result = [];
foreach ($target as $item) {
$result[] = data_get($item, $key);
}
return in_array('*', $key) ? Arr::collapse($result) : $result;
}
if (Arr::accessible($target) && Arr::exists($target, $segment)) {
$target = $target[$segment];
} elseif (is_object($target) && isset($target->{$segment})) {
$target = $target->{$segment};
} else {
return value($default);
}
}
return $target;
}
}在创建模型对象时设置某些字段的值,大概是最受欢迎的例子之一了。 一起来看看在创建模型对象时,你想要生成 UUID 字段 该怎么做。
模型文件中
public static function boot()
{
parent::boot();
self::creating(function ($model) {
$model->uuid = (string)Uuid::generate();
});
static::updating(function($model)
{
// 写点日志啥的
// 覆盖一些属性,类似这样 $model->something = transform($something);
});
}php artisan make:observer UserObserver --model=User
1. 嵌套作用域查询
Laravel 支持将查用的查询封装为作用域
此技巧从larabbs源码中学到 功能需求:首页的列表排序功能,可按照发布时间和回复时间排序
Controller中
public function index(Request $request, Topic $topic, User $user)
{
// scopeWithOrder
$topics = $topic->withOrder($request->order)
->with('user', 'category') // 预加载防止 N+1 问题
->paginate(20);
return view('topics.index', compact('topics'));
}其中 withOrder 是 本地作用域
Model 中 scopeWithOrder 又包含了两个小作用域
public function scopeWithOrder($query, $order)
{
// 不同的排序,使用不同的数据读取逻辑
switch ($order) {
case 'recent':
$query->recent();
break;
default:
$query->recentReplied();
break;
}
}
public function scopeRecentReplied($query)
{
// 当话题有新回复时,我们将编写逻辑来更新话题模型的 reply_count 属性,
// 此时会自动触发框架对数据模型 updated_at 时间戳的更新
return $query->orderBy('updated_at', 'desc');
}
public function scopeRecent($query)
{
// 按照创建时间排序
return $query->orderBy('created_at', 'desc');
}2. 在 find 方法中指定属性
User::find(1, ['name', 'email']);
User::findOrFail(1, ['name', 'email']);3. Clone 一个 Model
$user = User::find(1);
$newUser = $user->replicate();
$newUser->save();4. 判断两个 Model 是否相同
$user = User::find(1);
$sameUser = User::find(1);
$diffUser = User::find(2);
$user->is($sameUser); // true
$user->is($diffUser); // false;5. 重新加载一个 Model
$user = User::find(1);
$user->name; // 'Peter'
// 如果 name 更新过,比如由 peter 更新为 John
$user->refresh();
$user->name; // John6. 加载新的 Model
$user = App\User::first();
$user->name; // John
//
$updatedUser = $user->fresh();
$updatedUser->name; // Peter
$user->name; // John7. 更新带关联的 Model
在更新关联的时候,使用 push 方法可以更新所有 Model
class User extends Model
{
public function phone()
{
return $this->hasOne('App\Phone');
}
}
$user = User::first();
$user->name = "Peter";
$user->phone->number = '1234567890';
$user->save(); // 只更新 User Model
$user->push(); // 更新 User 和 Phone Model8. 自定义软删除字段
Laravel 默认使用 deleted_at 作为软删除字段,我们通过以下方式将 deleted_at 改成 is_deleted
class User extends Model
{
use SoftDeletes;
* deleted_at 字段.
*
* @var string
*/
const DELETED_AT = 'is_deleted';
}或者使用访问器
class User extends Model
{
use SoftDeletes;
public function getDeletedAtColumn(){
return 'is_deleted';
}
}9. 查询 Model 更改的属性
$user = User::first();
$user->name; // John
$user->name = 'Peter';
$user->save();
dd($user->getChanges());
// 输出:
[
'name' => 'John',
'updated_at' => '...'
]10. 查询 Model 是否已更改
$user = User::first();
$user->name; // John
$user->isDirty(); // false
$user->name = 'Peter';
$user->isDirty(); // true
$user->getDirty(); // ['name' => 'Peter']
$user->save();
$user->isDirty(); // falsegetChanges() 与 getDirty() 的区别
getChanges() 方法用在 save() 方法之后输出结果集
getDirty() 方法用在 save() 方法之前输出结果集
11. 查询修改前的 Model 信息
$user = App\User::first();
$user->name; //John
$user->name = "Peter"; //Peter
$user->getOriginal('name'); //John
$user->getOriginal(); //Original $user record12. 使用 withDefault 保持返回格式统一
public function _city()
{
return $this->hasOne(City::class, 'id', 'city_id');
}比如 student 和 city 是一对一关系,如果一个 student 表中 city 字段为空,返回的结果可能是
{name: "jack", _city: null}
这样会造成的问题是前端如果使用了student._city.name会造成undefined等错误。
为了避免可以改为
public function _city()
{
return $this
->hasOne(City::class, 'id', 'city_id')
->withDefault([
'name' => '',
]);
}这样即使找不到也不会报错
返回的结果是:
{name: "jack", _city: {id: null, name: ""}}
13. 使用 wasRecentlyCreated 判断model刚刚是更新还是插入
$model = Message::updateOrCreate(
[
'msgNr' => $request->input('msgNr')
],
[
'msgTitle' => $request->input('msgTitle'),
'msgText' => $request->input('msgText'),
'msgTimeStamp' => date('Y-m-d H:i:s'),
]);
$result = Message::with('Employee:empNr,empName','MessageOpened:msoMsgNr,msoTimeStamp')
->whereRaw('now() between msgFrom and msgTo')
->orderBy('msgFrom')
->get();;
// 只有更新message记录了才发广播
if ($model->wasRecentlyCreated) {
broadcast(new \App\Events\MessageCreatedEvent($result));
}
return $this->sendOk($result);14. 使用 withCount 动态插入属性
Flight 和 FlightPlayers是一对多关系,需要获取某Flight下所有的players,并包含players的个数
Flight::withCount('flightPlayers')->where('fltNr', 9451973)->get()
// 传递到 withCount() 方法的每一个参数,最终都会在模型实例中创建一个参数名添加了 _count 后缀的属性。
// 返回的记录,flight_players_count动态创建的
/*
[{
"fltNr": 9451973,
"fltComNr": 9,
"fltRefType": null,
"fltRefNr": null,
"fltDate": 738084,
......
"flight_players_count": 2
}]
*/
// 获取属性
Flight::withCount('flightPlayers')->where('fltNr', 9451973)->first()->flight_players_count;
// 支持别名
Flight::withCount('flightPlayers as count')->where('fltNr', 9451973)->get();$fillable = [
'可批量填充的字段'
];
$guarded = [
'与上相反'
];
$hidden = [
'模型转换为数组时应当隐藏的字段'
];
$visable = [
'与上相反'
];
$appends = [
'模型转换为数组时应当追加的虚拟字段' // 例如访问器
];
$with = [
'应当预加载的关联关系',
];
$attributes = [
'字段名' => '字段默认值'
];
$casts = [
'字段名' => '自动类型转换的目标类型'
];
$dates = [
'应当被转换为日期时间的字段'
];
$touches = [
'模型更新时应当一并更新的关联关系'
];
// 以下为部分扩展包使用的属性
// https://github.com/dwightwatson/validating
$rules = [
'字段' => '模型自身验证规则'
];
// https://github.com/Askedio/laravel-soft-cascade
$softCascade = [
'软删除时一并删除的关联'
];
// https://github.com/spatie/eloquent-sortable
$sortable = [
'order_column_name' => 'order_column',
'sort_when_creating' => true,
];
// https://github.com/nicolaslopezj/searchable
$searchable = [
'columns' => [],
'joins' => [],
];Flight表关联了多张表,如果不指定字段,默认会返回所有,显得找起来很麻烦,尤其是表中很多字段的情况!
$result = Flight::query()
->where(['fltNr' => $id])->with([
'flightPlayers',
'flightPlayers.relation',
'flightPlayers.greenfee',
'flightPlayers.sales',
'flightPlayers.sales.item',
'flightPlayers.sales.salesTransaction',
])->first();输出结果
{
"fltNr": 9451976,
"fltComNr": 9,
"fltRefType": null,
"fltRefNr": null,
"fltDate": 738084,
"fltTime1Booked": 580,
"fltTimeFixedYN": null,
"fltTime1": 580,
"fltBreakTime": null,
"fltTime2": 720,
"fltCrlNr1": 44,
"fltCrlNr2": 0,
"fltAloneYN": null,
"fltHole": null,
"fltOrigin": null,
"fltSize": 3,
"fltCheckedIn": 0,
"fltTimestamp": "2020-08-20 15:51:37",
"fltCarNr": null,
"fltNotes": null,
"fltDownPaymentPerc": null,
"fltPaid": null,
"fltAgtNr": null,
"fltHotNr": null,
"fltOptionDate": null,
"fltCcard1": null,
"fltCcard2": null,
"fltCcardExpMonth": null,
"fltCcardExpYear": null,
"fltCcardCode": null,
"fltCcard3": null,
"fltCcard4": null,
"fltResNr": null,
"fltCost": null,
"fltStatus": null,
"fltHosNrLocked": 94,
"fltCheckResult": null,
"fltHosNr": 94,
"fltEmpNr": 24,
"flight_players": [{
"flpNr": 29803563,
"flpFltNr": 9451976,
"flpMatch": null,
"flpSide": 1,
"flpRelNr": 309,
"flpRelNrWildcard": null,
"flpName": "Slof",
"flpGrpNr1": null,
"flpGrpNr2": null,
"flpGrpNr3": null,
"flpExtra": null,
"flpPhone": "0172617000",
"flpEmail": "[email protected]",
"flpHandicap": 25.1,
"flpGrfNr": 7,
"flpGfcNr": null,
"flpItmNr": 212,
"flpPrice": 25,
"flpBilNr": null,
"flpGrfNrDiscount": null,
"flpGfcNrDiscount": null,
"flpItmNrDiscount": null,
"flpDiscount": null,
"flpSalNrDiscount": null,
"flpVoucher": null,
"flpScorecard": null,
"flpQualifying": null,
"flpCarNr": null,
"flpIntro": null,
"flpTeebox": null,
"flpCheckResult": null,
"flpRelNrMain": null,
"flpEmailMarkNY": 1,
"relation": {
"relNr": 309,
"relRelNrMain": null,
"relComNr": 9,
"relType": null,
"relName": "Slof",
"relGender": 1,
"relFirstName": "D",
"relPrefix": "",
"relRtlNr": 1,
"relAddress1": "Stik van Linschoten 22",
"relAddress2": "Stik van Linschoten 22",
"relCity": "Bergdorp",
"relPostalCode": "2411 PZ",
"relState": null,
"relCouNr": 1,
"relPhone": "0172617000",
"relPhoneMobile": "0172617000",
"relPhoneWork": "0172617000",
"relFax": null,
"relEmail": "[email protected]",
"relEmailVerifyCode": null,
"relEmailWork": null,
"relDateBirth": 717929,
"relCreatedDate": null,
"relHandicap": 25.1,
"relGolferId": null,
"relMemberCode": "142",
"relMemberType": "a",
"relExternalId": null,
"relDebtorId": null,
"relMaxCredit": null,
"relValue1": null,
"relValue2": null,
"relValue3": null,
"relGrfNr": null,
"relGrfNrDiscount": null,
"relRelNrCompany": null,
"relDftContactYN": null,
"relRelNrDebtor": null,
"relRelNrMail": null,
"relLngNr": null,
"relEmpNr": null,
"relRbrNr": null,
"relEndBlockDate": null,
"relGrpNr1": 136,
"relGrpNr2": 2580,
"relGrpNr3": 2581,
"relDontCheckYN": null,
"relPliNr": null,
"relSupplierYN": null,
"relImage": "https:\/\/s3-eu-west-1.amazonaws.com\/intogolf.nl\/new-avatar\/IoXwfFyPPg545W5LGDmhfy67ksQNCncor9e7e10C.jpeg",
"relNotes": null,
"relActualYN": 1,
"relHandicapYN": null,
"relCoursePermissionYN": null,
"relBankAccount": null,
"relChargeBankYN": null,
"relRttNr": null,
"relCallName": "Dirk",
"relVatId": null,
"relLastChanged": null,
"relIBAN": null,
"relBIC": null,
"relGolfPermitDate": null,
"relCoursePermDate": null,
"relRulesExam": null,
"relHomeclub": null,
"full_name": "D Slof",
"age": 55
},
"greenfee": {
"grfNr": 1,
"grfComNr": 9,
"grfOrdering": 10,
"grfName": "Standaard Greenfee",
"grfDateFrom": 737790,
"grfDateTo": 738155,
"grfIntroYN": 0,
"grfDiscountYN": 0,
"grfCardYN": 0,
"grfDiscountCardYN": 0,
"grfRounds": 0,
"grfRoundType": 1,
"grfCardPrice": 0,
"grfCardDuration": 12,
"grfCardDurationType": 0,
"grfActualYN": 0,
"grfWildcardYN": 0,
"grfFreePriceYN": 1,
"grfCardDiscount": 0,
"grfMlaNrCard": null,
"grfMaxPerPeriod": 0,
"grfMaxPeriod": 0
},
"sales": [],
"rateList": {
"1": {
"grfNr": 7,
"grfName": "Greenfeee",
"grfCard": 0,
"grfDiscountCard": 0,
"grfDiscount": 0,
"price": 0.02,
"itmNr": 212,
"gfcNr": null
}
},
"discountList": [{
"grfNr": 0,
"grfName": "...",
"grfCard": 0,
"grfDiscountCard": 0,
"grfDiscount": 1,
"price": 0,
"itmNr": 0
}],
"isSelected": false,
"flpFullName": "D Slof (Dirk)"
}]
}下面我们优化,只输出前台用到的字段
$result = Flight::query()
->select('fltNr', 'fltDate', 'fltTime1', 'fltTime2', 'fltCrlNr1', 'fltCrlNr2')
->with(['flightPlayers:flpNr,flpFltNr,flpBilNr,flpRelNr,flpGrfNr,flpScorecard',
'flightPlayers.greenfee:grfNr,grfName,grfCardPrice,grfRoundType,grfOrdering,grfDateFrom,grfDateTo',
'flightPlayers.relation:relNr,relName,relImage,relRtlNr,relMemberCode,relCity,relPhone,relGolferId,relAddress1,relDateBirth,relEmail,relHandicap,relFirstName,relCallName,relGender,relGrpNr1,relLastChanged',
'flightPlayers.sales:salNr,salTrnNr,salBilNr,salItmNr,salVat,salBilNr,salAmount,salTrnNr',
'flightPlayers.sales.item:itmNr,itmName,itmPrice,itmIsgNr,itmSellYN',
'flightPlayers.sales.salesTransaction:trnNr,trnTimestamp'
])
->where(['fltNr' => $id])
->first()需要注意,我们需要指定主键名称。 如 Flight 表和 flightPlayers 表是一对多关联,flpNr字段是flightPlayers表的主键,大概格式就是
->with[
'关联表1:关联表主键1,字段1,字段2'
'多级关联表1.多级关联表2:关联表主键2,字段1,字段2'
]$fillable = [
'可批量填充的字段'
];
$guarded = [
'与上相反'
];
$hidden = [
'模型转换为数组时应当隐藏的字段'
];
$visable = [
'与上相反'
];
$appends = [
'模型转换为数组时应当追加的虚拟字段' // 例如访问器
];
$with = [
'应当预加载的关联关系',
];
$attributes = [
'字段名' => '字段默认值'
];
$casts = [
'字段名' => '自动类型转换的目标类型'
];
$dates = [
'应当被转换为日期时间的字段'
];
$touches = [
'模型更新时应当一并更新的关联关系'
];
// 以下为部分扩展包使用的属性
// https://github.com/dwightwatson/validating
$rules = [
'字段' => '模型自身验证规则'
];
// https://github.com/Askedio/laravel-soft-cascade
$softCascade = [
'软删除时一并删除的关联'
];
// https://github.com/spatie/eloquent-sortable
$sortable = [
'order_column_name' => 'order_column',
'sort_when_creating' => true,
];
// https://github.com/nicolaslopezj/searchable
$searchable = [
'columns' => [],
'joins' => [],
];Model
开发搜集
]]>Mail::to('[email protected]')->send(new TestQueue());
TestQueue是邮件内容,用 php artisan make:mail TestQueue 生成
这时候可以改为队列执行。需要配置队列驱动
如果需要使用数据库驱动,要执行
php artisan queue:table
php artisan migrate如果是redis,安装redis即可
把邮件放到队列中非常简单 Mail::to('[email protected]')->queue(new TestQueue());
这里我们编辑.env将QUEUE_CONNECTION队列驱动从sync同步改为redis
为了监控队列的执行情况,比如成功几个,失败几个,情况如何,可以安装Horizon 队列管理工具
composer require laravel/horizon
php artisan horizon:install
php artisan queue:failed-table
php artisan migrate
# 运行 horizon
php artisan horizon
消息队列不知道大家看到这个词的时候,会不会觉得它是一个比较高端的技术,反正我是觉得它好像是挺牛逼的。
消息队列,一般我们会简称它为MQ(Message Queue),嗯,就是很直白的简写。
我们先不管消息(Message)这个词,来看看队列(Queue)。这一看,队列大家应该都熟悉吧。
队列是一种先进先出的数据结构。

那为什么还需要消息队列(MQ)这种中间件呢???其实这个问题,跟之前我学Redis的时候很像。Redis是一个以key-value形式存储的内存数据库,明明我们可以使用类似HashMap这种实现类就可以达到类似的效果了,那还为什么要Redis?《Redis合集》
- 到这里,大家可以先猜猜为什么要用消息队列(MQ)这种中间件,下面会继续补充。
消息队列可以简单理解为:把要传输的数据放在队列中。

科普: 把数据放到消息队列叫做生产者 从消息队列里边取数据叫做消费者
二、为什么要用消息队列?
2.1 解耦
为什么要用消息队列,也就是在问:用了消息队列有什么好处。我们看看以下的场景
现在我有一个系统A,系统A可以产生一个userId
然后,现在有系统B,C,D都需要这个userId去做相关的操作
系统A将userId写到消息队列中,系统C和系统D从消息队列中拿数据。这样有什么好处?
系统A只负责把数据写到队列中,谁想要或不想要这个数据(消息),系统A一点都不关心。
即便现在系统D不想要userId这个数据了,系统B又突然想要userId这个数据了,都跟系统A无关,系统A一点代码都不用改。 系统D拿userId不再经过系统A,而是从消息队列里边拿。系统D即便挂了或者请求超时,都跟系统A无关,只跟消息队列有关。
这样一来,系统A与系统B、C、D都解耦了。

2.2 异步
假设系统A运算出userId具体的值需要50ms,调用系统B的接口需要300ms,调用系统C的接口需要300ms,调用系统D的接口需要300ms。那么这次请求就需要50+300+300+300=950ms
并且我们得知,系统A做的是主要的业务,而系统B、C、D是非主要的业务。比如系统A处理的是订单下单,而系统B是订单下单成功了,那发送一条短信告诉具体的用户此订单已成功,而系统C和系统D也是处理一些小事而已。
那么此时,为了提高用户体验和吞吐量,其实可以异步地调用系统B、C、D的接口。所以,我们可以弄成是这样的:

2.3 削峰/限流
我们再来一个场景,现在我们每个月要搞一次大促,大促期间的并发可能会很高的,比如每秒3000个请求。假设我们现在有两台机器处理请求,并且每台机器只能每次处理1000个请求。

那多出来的1000个请求,可能就把我们整个系统给搞崩了...所以,有一种办法,我们可以写到消息队列中:

系统B和系统C根据自己的能够处理的请求数去消息队列中拿数据,这样即便有每秒有8000个请求,那只是把请求放在消息队列中,去拿消息队列的消息由系统自己去控制,这样就不会把整个系统给搞崩。
三、使用消息队列有什么问题?
经过我们上面的场景,我们已经可以发现,消息队列能做的事其实还是蛮多的。
- 无论是我们使用消息队列来做解耦、异步还是削峰,消息队列肯定不能是单机的。试着想一下,如果是单机的消息队列,万一这台机器挂了,那我们整个系统几乎就是不可用了。
- 我们将数据写到消息队列上,系统B和C还没来得及取消息队列的数据,就挂掉了。如果没有做任何的措施,我们的数据就丢了。 那存在哪呢?磁盘?数据库?Redis?分布式文件系统?
- 消费者怎么从消息队列里边得到数据?有两种办法: 生产者将数据放到消息队列中,消息队列有数据了,主动叫消费者去拿(俗称push) 消费者不断去轮训消息队列,看看有没有新的数据,如果有就消费(俗称pull)
- 其他除了这些,我们在使用的时候还得考虑各种的问题:消息重复消费了怎么办啊?我想保证消息是绝对有顺序的怎么做?
最后
本文主要讲解了什么是消息队列,消息队列可以为我们带来什么好处,以及一个消息队列可能会涉及到哪些问题。希望给大家带来一定的帮助。
参考资料:
- Kafka简明教程
- 消息队列使用的四种场景介绍,有图有解析,一看就懂
- 消息队列设计精要
- 消息队列的使用场景是怎样的
参考
]]># 列出标签
ansible-playbook --list-tags hello.yaml
ansible-playbook hello.yaml
ansible-playbook role_finley.yamlTo make vim use 2 spaces for a tab edit ~/.vimrc to contain:
set tabstop=2
set expandtab
set shiftwidth=2To enable bash completion:
echo 'source <(kubectl completion bash)' >>~/.bashrc
Question 1: Contexts
-
You have access to multiple clusters from your main terminal through kubectl contexts. Write all those context names into
/opt/course/1/contexts. -
Next write a command to display the current context into
/opt/course/1/context_default_kubectl.sh, the command should use kubectl. -
Finally write a second command doing the same thing into
/opt/course/1/context_default_no_kubectl.sh, but without the use of kubectl.
Solution:
k8s@terminal:~$ kubectl config get-contexts > /opt/course/1/contexts
k8s@terminal:~$ echo "kubectl config current-context"> /opt/course/1/context_default_kubectl.sh
k8s@terminal:~$ cat ~/.kube/config | grep current > /opt/course/1/context_default_kubectl.sh
Question 2: Schedule Pod on Master Node
Use context: kubectl config use-context k8s-c1-H
Create a single Pod of image httpd:2.4.41-alpine in Namespace default. The Pod should be named pod1 and the container should be named pod1-container. This Pod should only be scheduled on a master node, do not add new labels any nodes.
Shortly write the reason on why Pods are by default not scheduled on master nodes into /opt/course/2/master_schedule_reason
Solution:
k8s@terminal:~$ kubectl describe node cluster1-master1 | grep -i taint
Taints: node-role.kubernetes.io/master:NoSchedule
k8s@terminal:~$ kubectl get node cluster1-master1 --show-labelsk8s@terminal:~$ cat 2.yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: pod1
spec:
containers:
- image: httpd:2.4.41-alpine
name: pod1-container
command: ["sleep", "3600"]
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
nodeSelector:
node-role.kubernetes.io/master: ""Finally the short reason why Pods are not scheduled on master nodes by default:
# /opt/course/2/master_schedule_reason
master nodes usually have a taint definedQuestion 3: Scale down StatefulSet
Use context: kubectl config use-context k8s-c1-H
There are two Pods named o3db-* in Namespace project-c13.
C13 management asked you to scale the Pods down to one replica to save resources. Record the action.
k8s@terminal:~$ kubectl get statefulsets.apps -n project-c13
NAME READY AGE
o3db 2/2 139d
k8s@terminal:~$ kubectl scale statefulset --record --replicas=1 -n project-c13 o3db
statefulset.apps/o3db scaled
8s@terminal:~$ kubectl get statefulsets.apps -n project-c13
NAME READY AGE
o3db 1/1 139dQuestion 4: Pod Ready if Service is reachable
Use context: kubectl config use-context k8s-c1-H
Do the following in Namespace default. Create a single Pod named ready-if-service-ready of image nginx:1.16.1-alpine. Configure a LivenessProbe which simply runs true. Also configure a ReadinessProbe which does check if the url http://service-am-i-ready:80 is reachable, you can use wget -T2 -O- http://service-am-i-ready:80 for this. Start the Pod and confirm it isn't ready because of the ReadinessProbe.
Create a second Pod named am-i-ready of image nginx:1.16.1-alpine with label id: cross-server-ready. The already existing Service service-am-i-ready should now have that second Pod as endpoint.
Now the first Pod should be in ready state, confirm that.
Solution:
k8s@terminal:~$ cat pod4.yml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: ready-if-service-ready
name: ready-if-service-ready
spec:
containers:
- image: nginx:1.16.1-alpine
name: ready-if-service-ready
resources: {}
livenessProbe:
exec:
command:
- echo
- hi
readinessProbe:
exec:
command:
- wget
- -T2
- -O-
- http://service-am-i-ready:80
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}k8s@terminal:~$ cat pod42.yml
apiVersion: v1
kind: Pod
metadata:
name: am-i-ready
labels:
id: cross-server-ready
spec:
containers:
- image: nginx:1.16.1-alpine
name: amireadyQuestion 5: Kubectl sorting
Use context: kubectl config use-context k8s-c1-H
There are various Pods in all namespaces. Write a command into /opt/course/5/find_pods.sh which lists all Pods sorted by their AGE (metadata.creationTimestamp).
Write a second command into /opt/course/5/find_pods_uid.sh which lists all Pods sorted by field metadata.uid. Use kubectl sorting for both commands.
Solution:
k8s@terminal:~$ echo "kubectl get pods --all-namespaces --sort-by .metadata.creationTimestamp" > /opt/course/5/find_pods.shk8s@terminal:~$ kubectl get pods --all-namespaces --sort-by .metadata.uidQuestion 6: Storage, PV, PVC, Pod volume
Use context: kubectl config use-context k8s-c1-H
Create a new PersistentVolume named safari-pv. It should have a capacity of 2Gi, accessMode ReadWriteOnce, hostPath /Volumes/Data and no storageClassName defined.
Next create a new PersistentVolumeClaim in Namespace project-tiger named safari-pvc . It should request 2Gi storage, accessMode ReadWriteOnce and should not define a storageClassName. The PVC should bound to the PV correctly.
Finally create a new Deployment safari in Namespace project-tiger which mounts that volume at /tmp/safari-data. The Pods of that Deployment should be of image httpd:2.4.41-alpine.
Solution:
k8s@terminal:~$ cat pv6.yml
apiVersion: v1
kind: PersistentVolume
metadata:
name: safari-pv
labels:
type: local
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/Volumes/Data"
k8s@terminal:~$ cat pvc6.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: safari-pvc
namespace: project-tiger
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
k8s@terminal:~$ cat dep6.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: safari
namespace: project-tiger
spec:
replicas: 1
selector:
matchLabels:
app: task6
template:
metadata:
labels:
app: task6
spec:
volumes:
- name: myvol6
persistentVolumeClaim:
claimName: safari-pvc
containers:
- name: pod6-cont
image: httpd:2.4.41-alpine
volumeMounts:
- mountPath: "/tmp/safari-data"
name: myvol6Question 7: Node and Pod Resource Usage
Use context: kubectl config use-context k8s-c1-H
The metrics-server hasn't been installed yet in the cluster, but it's something that should be done soon. Your college would already like to know the kubectl commands to:
- show node resource usage
- show Pod and their containers resource usage
Please write the commands into /opt/course/7/node.sh and /opt/course/7/pod.sh.
Solution:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/troubleshooting-kubeadm/#%E6%97%A0%E6%B3%95%E5%9C%A8-kubeadm-%E9%9B%86%E7%BE%A4%E4%B8%AD%E5%AE%89%E5%85%A8%E5%9C%B0%E4%BD%BF%E7%94%A8-metrics-server
k8s@terminal:~$ kubectl top node
k8s@terminal:~$ kubectl top pod --containers=trueQuestion 8: Get Master Information
Use context: kubectl config use-context k8s-c1-H
Ssh into the master node with ssh cluster1-master1. Check how the master components kubelet, kube-apiserver, kube-scheduler, kube-controller-manager and etcd are started/installed on the master node. Also find out the name of the DNS application and how it's started/installed on the master node.
Write your findings into file /opt/course/8/master-components.txt. The file should be structured like:
# /opt/course/8/master-components.txt
kubelet: [TYPE]
kube-apiserver: [TYPE]
kube-scheduler: [TYPE]
kube-controller-manager: [TYPE]
etcd: [TYPE]
dns: [TYPE] [NAME]Choices of [TYPE] are: not-installed, process, static-pod, pod
Solution:
k8s@terminal:~$ ssh cluster1-master1
root@cluster1-master1:~# ps -ef | grep -i kubelet
root@cluster1-master1:/var/lib/kubelet# cat /var/lib/kubelet/config.yaml | grep -i static
staticPodPath: /etc/kubernetes/manifests
root@cluster1-master1:/var/lib/kubelet# ls /etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler-special.yaml kube-scheduler.yaml
root@cluster1-master1:~# kubectl get all -A | grep -i dns
kube-system pod/coredns-558bd4d5db-nvhgx 1/1 Running 0 139d
kube-system pod/coredns-558bd4d5db-tl6rl 1/1 Running 0 139d
kube-system service/kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 139d
kube-system deployment.apps/coredns 2/2 2 2 139d
kube-system replicaset.apps/coredns-558bd4d5db 2 2 2 139dkubelet: [PROCESS]
kube-apiserver: [Static POD]
kube-scheduler: [Static POD]
kube-controller-manager: [Static POD]
etcd: [Static POD]
dns: [POD] [COREDNS]Question 9: Kill Scheduler, Manual Scheduling
Task weight: 5%
Use context: kubectl config use-context k8s-c2-AC
Ssh into the master node with ssh cluster2-master1. Temporarily stop the kube-scheduler, this means in a way that you can start it again afterwards.
Create a single Pod named manual-schedule of image httpd:2.4-alpine, confirm its started but not scheduled on any node.
Now you're the scheduler and have all its power, manually schedule that Pod on node cluster2-master1. Make sure it's running.
Start the kube-scheduler again and confirm its running correctly by creating a second Pod named manual-schedule2 of image httpd:2.4-alpine and check if it's running on cluster2-worker1.
Solution:
root@cluster2-master1:~# kubectl get pods -n kube-system | grep sched
kube-scheduler-cluster2-master1 1/1 Running 0 139dTo kill the scheduler, move it from the manifests directory (as it's basically a static pod):
root@cluster2-master1:~# mv /etc/kubernetes/manifests/kube-scheduler.yaml /etc/kubernetes/And it shall be stopped:
root@cluster2-master1:~# kubectl get pods -n kube-system | grep schedNow create the Pod:
root@cluster2-master1:~# kubectl run manual-schedule --image=httpd:2.4-alpine
pod/manual-schedule created
root@cluster2-master1:~# kubectl get pods
NAME READY STATUS RESTARTS AGE
manual-schedule 0/1 Pending 0 5sroot@cluster2-master1:~# kubectl get pod manual-schedule -o yaml > 9.ymlroot@cluster2-master1:~# kubectl replace --force -f 9.yml
pod "manual-schedule" deleted
pod/manual-schedule replaced
root@cluster2-master1:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
manual-schedule 1/1 Running 0 52s 10.32.0.4 cluster2-master1 <none> <none>Start the scheduler again:
root@cluster2-master1:~# mv /etc/kubernetes/kube-scheduler.yaml /etc/kubernetes/manifests/
root@cluster2-master1:~# kubectl get pods -A | grep -i sched
default manual-schedule 1/1 Running 0 113s
kube-system kube-scheduler-cluster2-master1 0/1 Running 0 13s
root@cluster2-master1:~# kubectl run manual-schedule2 --image httpd:2.4-alpine
pod/manual-schedule2 created
root@cluster2-master1:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
manual-schedule 1/1 Running 0 4m16s 10.32.0.4 cluster2-master1 <none> <none>
manual-schedule2 1/1 Running 0 4s 10.44.0.2 cluster2-worker1 <none> <none>Question 10: RBAC ServiceAccount Role RoleBinding
Use context: kubectl config use-context k8s-c1-H
Create a new ServiceAccount processor in Namespace project-hamster. Create a Role and RoleBinding, both named processor as well. These should allow the new SA to only create Secrets and ConfigMaps in that Namespace.
Solution:
k8s@terminal:~$ kubectl create serviceaccount processor --namespace project-hamster
k8s@terminal:~$ cat role10.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: project-hamster
name: processor
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["secrets", "configmaps"]
verbs: ["create"]
k8s@terminal:~$ cat rolebind10.yml
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: processor
namespace: project-hamster
subjects:
- kind: ServiceAccount
name: processor # "name" is case sensitive
roleRef:
kind: Role #this must be Role or ClusterRole
name: processor # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.ioTo test it:
k8s@terminal:~$ kubectl -n project-hamster auth can-i create secret --as system:serviceaccount:project-hamster:processor
yes
k8s@terminal:~$ kubectl -n project-hamster auth can-i create configmaps --as system:serviceaccount:project-hamster:processor
yes
k8s@terminal:~$ kubectl -n project-hamster auth can-i create pod --as system:serviceaccount:project-hamster:processor
noQuestion 11: DaemonSet on all Nodes
Use context: kubectl config use-context k8s-c1-H
Use Namespace project-tiger for the following. Create a DaemonSet named ds-important with image httpd:2.4-alpine and labels id=ds-important and uuid=18426a0b-5f59-4e10-923f-c0e078e82462. The Pods it creates should request 10 millicore cpu and 10 megabytes memory. The Pods of that DaemonSet should run on all nodes.
Solution:
k8s@terminal:~$ cat q11.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ds-important
namespace: project-tiger
labels:
id: ds-important
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462
spec:
selector:
matchLabels:
id: ds-important
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462
template:
metadata:
labels:
id: ds-important
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462
spec:
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: ds-cont
image: httpd:2.4-alpine
resources:
limits:
memory: 10Mi
requests:
cpu: 10m
memory: 10MiQuestion 12: Deployment on all Nodes
Use context: kubectl config use-context k8s-c1-H
Use Namespace project-tiger for the following. Create a Deployment named deploy-important with label id=very-important (the pods should also have this label) and 3 replicas. It should contain two containers, the first named container1 with image nginx:1.17.6-alpine and the second one named container2 with image kubernetes/pause.
There should be only ever one Pod of that Deployment running on one worker node. We have two worker nodes: cluster1-worker1 and cluster1-worker2. Because the Deployment has three replicas the result should be that on both nodes one Pod is running. The third Pod won't be scheduled, unless a new worker node will be added.
In a way we kind of simulate the behaviour of a DaemonSet here, but using a Deployment and a fixed number of replicas.
Solution:
k8s@terminal:~$ cat q12.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-important
namespace: project-tiger
labels:
id: very-important
spec:
replicas: 3
selector:
matchLabels:
id: very-important
template:
metadata:
labels:
id: very-important
spec:
containers:
- image: nginx:1.17.6-alpine
name: container1
- image: kubernetes/pause
name: container2
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: id
operator: In
values:
- very-important
topologyKey: kubernetes.io/hostnamek8s@terminal:~$ kubectl get pods -n project-tiger -o wide -l id=very-important
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploy-important-658db6465d-84dp9 0/2 Pending 0 48s <none> <none> <none> <none>
deploy-important-658db6465d-9kn64 2/2 Running 0 48s 10.44.0.20 cluster1-worker1 <none> <none>
deploy-important-658db6465d-fgg59 2/2 Running 0 48s 10.47.0.26 cluster1-worker2 <none> <none>Question 13: Multi Containers and Pod shared Volume
Use context: kubectl config use-context k8s-c1-H
Create a Pod named multi-container-playground in Namespace default with three containers, named c1, c2 and c3. There should be a volume attached to that Pod and mounted into every container, but the volume shouldn't be persisted or shared with other Pods.
Container c1 should be of image nginx:1.17.6-alpine and have the name of the node where its Pod is running on value available as environment variable MY_NODE_NAME.
Container c2 should be of image busybox:1.31.1 and write the output of the date command every second in the shared volume into file date.log. You can use while true; do date >> /your/vol/path/date.log; sleep 1; done for this.
Container c3 should be of image busybox:1.31.1 and constantly write the content of file date.log from the shared volume to stdout. You can use tail -f /your/vol/path/date.log for this.
Check the logs of container c3 to confirm correct setup.
Solution:
k8s@terminal:~$ cat q13.yml
apiVersion: v1
kind: Pod
metadata:
name: multi-container-playground
spec:
containers:
- image: nginx:1.17.6-alpine
name: c1
env:
- name: MY_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- mountPath: /vol
name: vol
- image: busybox:1.31.1
name: c2
command: ["sh", "-c", "while true; do date >> /vol/date.log; sleep 1; done"]
volumeMounts:
- mountPath: /vol
name: vol
- image: busybox:1.31.1
name: c3
command: ["sh", "-c", "tail -f /vol/date.log"]
volumeMounts:
- mountPath: /vol
name: vol
volumes:
- name: vol
emptyDir: {}
restartPolicy: Alwaysk8s@terminal:~$ kubectl exec -it multi-container-playground -c c2 -- ps -ef
PID USER TIME COMMAND
1 root 0:00 sh -c while true; do date >> /vol/date.log; sleep 1; done
534 root 0:00 sleep 1
535 root 0:00 ps -efk8s@terminal:~$ kubectl exec -it multi-container-playground -c c2 -- head /vol/date.log
Tue Sep 21 18:13:53 UTC 2021
Tue Sep 21 18:13:54 UTC 2021
Tue Sep 21 18:13:55 UTC 2021
Tue Sep 21 18:13:56 UTC 2021
Tue Sep 21 18:13:57 UTC 2021
Tue Sep 21 18:13:58 UTC 2021
Tue Sep 21 18:13:59 UTC 2021
Tue Sep 21 18:14:00 UTC 2021
Tue Sep 21 18:14:01 UTC 2021
Tue Sep 21 18:14:02 UTC 2021k8s@terminal:~$ kubectl exec -it multi-container-playground -c c1 -- envQuestion 14: Find out Cluster Information
Use context: kubectl config use-context k8s-c1-H
You're ask to find out following information about the cluster k8s-c1-H:
How many master nodes are available? How many worker nodes are available? What is the Pod CIDR of cluster1-worker1? What is the Service CIDR? Which Networking (or CNI Plugin) is configured and where is its config file? Which suffix will static pods have that run on cluster1-worker1? Write your answers into file /opt/course/14/cluster-info, structured like this:
# /opt/course/14/cluster-info
1: [ANSWER]
2: [ANSWER]
3: [ANSWER]
4: [ANSWER]
5: [ANSWER]
6: [ANSWER]Solution:
Q1 & Q2.
k8s@terminal:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
cluster1-master1 Ready control-plane,master 140d v1.21.0
cluster1-worker1 Ready <none> 140d v1.21.0
cluster1-worker2 Ready <none> 140d v1.21.0Q3.
k8s@terminal:~$ kubectl describe node cluster1-worker1 | grep -i cidr
PodCIDR: 10.244.1.0/24
PodCIDRs: 10.244.1.0/24Q4.
root@cluster1-master1:~# cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep -i range
- --service-cluster-ip-range=10.96.0.0/12Q5.
root@cluster1-master1:~# ls -l /etc/cni/net.d/
total 4
-rw-r--r-- 1 root root 318 May 4 10:41 10-weave.conflistQ6.
The suffix is the node hostname with a leading hyphen. It used to be -static in earlier Kubernetes versions.# /opt/course/14/cluster-info
1: [One]
2: [Two]
3: [10.244.1.0/24]
4: [10.96.0.0/12]
5: [weave, /etc/cni/net.d/10-weave.conflist]
6: [-cluster1-worker1]Question 15: Cluster Event Logging
Use context: kubectl config use-context k8s-c2-AC
Write a command into /opt/course/15/cluster_events.sh which shows the latest events in the whole cluster, ordered by time. Use kubectl for it.
Now kill the kube-proxy Pod running on node cluster2-worker1 and write the events this caused into /opt/course/15/pod_kill.log.
Finally kill the main docker container of the kube-proxy Pod on node cluster2-worker1 and write the events into /opt/course/15/container_kill.log.
Do you notice differences in the events both actions caused?
Solution:
k8s@terminal:~$ cat /opt/course/15/cluster-events.sh
kubectl get events -A --sort-by=.metadata.creationTimestampk8s@terminal:~$ kubectl get pods -A -o wide | grep worker1
k8s@terminal:~$ kubectl delete pod -n kube-system kube-proxy-67qkp
pod "kube-proxy-67qkp" deleted
k8s@terminal:~$ kubectl get events -A --sort-by=.metadata.creationTimestamp > /opt/course/15/pod_kill.log
k8s@terminal:~$ cat /opt/course/15/pod_kill.log
NAMESPACE LAST SEEN TYPE REASON OBJECT MESSAGE
kube-system 2m43s Normal Killing pod/kube-proxy-67qkp Stopping container kube-proxy
kube-system 2m37s Normal SuccessfulCreate daemonset/kube-proxy Created pod: kube-proxy-f7nr8
kube-system 2m37s Normal Scheduled pod/kube-proxy-f7nr8 Successfully assigned kube-system/kube-proxy-f7nr8 to cluster2-worker1
kube-system 2m36s Normal Pulled pod/kube-proxy-f7nr8 Container image "k8s.gcr.io/kube-proxy:v1.21.0" already present on machine
kube-system 2m36s Normal Created pod/kube-proxy-f7nr8 Created container kube-proxy
kube-system 2m35s Normal Started pod/kube-proxy-f7nr8 Started container kube-proxy
default 2m35s Normal Starting node/cluster2-worker1 Starting kube-proxy.k8s@terminal:~$ ssh cluster2-worker1
root@cluster2-worker1:~# docker ps -a
root@cluster2-worker1:~# docker kill k8s_kube-proxy_kube-proxy-f7nr8_kube-system_4e715479-78b7-4616-a29d-5b3295ed5677_0Comparing the events we see that when we deleted the whole Pod there were more things to be done, hence more events. For example was the DaemonSet in the game to re-create the missing Pod. Where when we manually killed the main container of the Pod, the Pod would still exist but only its container needed to be re-created, hence less events.
Question 16: Namespaces and Api Resources
Use context: kubectl config use-context k8s-c1-H
Create a new Namespace called cka-master.
Write the names of all namespaced Kubernetes resources (like Pod, Secret, ConfigMap...) into /opt/course/16/resources.txt.
Find the project-* Namespace with the highest number of Roles defined in it and write its name and amount of Roles into /opt/course/16/crowded-namespace.txt.
Solution:
k8s@terminal:~$ kubectl create namespace cka-masterk8s@terminal:~$ kubectl api-resources --namespaced=true -o name > /opt/course/16/resources.txtk8s@terminal:~$ kubectl get roles -n project-c14 --no-headers | wc -l
300
#/opt/course/16/crowded-namespace.txt
project-c14 with 300 resourcesQuestion 17: Find Container of Pod and check logs
Use context: kubectl config use-context k8s-c1-H
In Namespace project-tiger create a Pod named tigers-reunite of image httpd:2.4.41-alpine with labels pod=container and container=pod. Find out on which node the Pod is scheduled. Ssh into that node and find the docker container(s) belonging to that Pod.
Write the docker IDs of the container(s) and the process/command these are running into /opt/course/17/pod-container.txt.
Finally write the logs of the main docker container (from the one you specified in your yaml) into /opt/course/17/pod-container.log using the docker command.
Solution:
k8s@terminal:~$ cat q17.yml
apiVersion: v1
kind: Pod
metadata:
name: tigers-reunite
namespace: project-tiger
labels:
pod: container
container: pod
spec:
containers:
- image: httpd:2.4.41-alpine
name: cont17
restartPolicy: Alwaysk8s@terminal:~$ kubectl get pod -n project-tiger -o wide
tigers-reunite 1/1 Running 0 42s 10.47.0.27 cluster1-worker2root@cluster1-worker2:~# docker ps -a | grep -i tigers-reunite
b724938c82f8 54b0995a6305 "httpd-foreground" 2 minutes ago Up 2 minutes k8s_cont17_tigers-reunite_project-tiger_9395b314-a5ca-4b9e-b8e2-957f664718c5_0
7c0595bee6a1 k8s.gcr.io/pause:3.4.1 "/pause" 2 minutes ago Up 2 minutes k8s_POD_tigers-reunite_project-tiger_9395b314-a5ca-4b9e-b8e2-957f664718c5_0
The Containers IDs:
b724938c82f8 && 7c0595bee6a1
The process/command:
httpd-foreground && /pauseroot@cluster1-worker2:~# docker logs b724938c82f8
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.47.0.27. Set the 'ServerName' directive globally to suppress this message
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.47.0.27. Set the 'ServerName' directive globally to suppress this message
[Tue Sep 21 23:06:46.830126 2021] [mpm_event:notice] [pid 1:tid 140028133616968] AH00489: Apache/2.4.41 (Unix) configured -- resuming normal operations
[Tue Sep 21 23:06:46.830181 2021] [core:notice] [pid 1:tid 140028133616968] AH00094: Command line: 'httpd -D FOREGROUND'Question 18: Fix Kubelet
Use context: kubectl config use-context k8s-c3-CCC
There seems to be an issue with the kubelet not running on cluster3-worker1. Fix it and confirm that cluster3 has node cluster3-worker1 available in Ready state afterwards. Schedule a Pod on cluster3-worker1.
Write the reason of the is issue into /opt/course/18/reason.txt.
Solution:
k8s@terminal:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready control-plane,master 141d v1.21.0
cluster3-worker1 NotReady <none> 141d v1.21.0root@cluster3-worker1:~# systemctl status kubelet
root@cluster3-worker1:~# journalctl -u kubeletEdit the file:
root@cluster3-worker1:~# vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
ExecStart=/usr/bin/kubeletThen restart:
root@cluster3-worker1:~# systemctl daemon-reload
root@cluster3-worker1:~# systemctl restart kubeletroot@cluster3-master1:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready control-plane,master 141d v1.21.0
cluster3-worker1 Ready <none> 141d v1.21.0Question 19: Create Secret and mount into Pod
Use context: kubectl config use-context k8s-c3-CCC
Do the following in a new Namespace secret. Create a Pod named secret-pod of image busybox:1.31.1 which should keep running for some time. It should be able to run on master nodes as well, create the proper toleration.
There is an existing Secret located at /opt/course/19/secret1.yaml, create it in the secret Namespace and mount it readonly into the Pod at /tmp/secret1.
Create a new Secret in Namespace secret called secret2 which should contain user=user1 and pass=1234. These entries should be available inside the Pod's container as environment variables APP_USER and APP_PASS.
Confirm everything is working.
Solution:
Edit the secret1:
k8s@terminal:~$ cat /opt/course/19/secret1.yaml
apiVersion: v1
data:
halt: IyEgL2Jpbi9zaAojIyMgQkVHSU4gSU5JVCBJTkZPCiMgUHJvdmlkZXM6ICAgICAgICAgIGhhbHQKIyBSZXF1aXJlZC1TdGFydDoKIyBSZXF1aXJlZC1TdG9wOgojIERlZmF1bHQtU3RhcnQ6CiMgRGVmYXVsdC1TdG9wOiAgICAgIDAKIyBTaG9ydC1EZXNjcmlwdGlvbjogRXhlY3V0ZSB0aGUgaGFsdCBjb21tYW5kLgojIERlc2NyaXB0aW9uOgojIyMgRU5EIElOSVQgSU5GTwoKTkVURE9XTj15ZXMKClBBVEg9L3NiaW46L3Vzci9zYmluOi9iaW46L3Vzci9iaW4KWyAtZiAvZXRjL2RlZmF1bHQvaGFsdCBdICYmIC4gL2V0Yy9kZWZhdWx0L2hhbHQKCi4gL2xpYi9sc2IvaW5pdC1mdW5jdGlvbnMKCmRvX3N0b3AgKCkgewoJaWYgWyAiJElOSVRfSEFMVCIgPSAiIiBdCgl0aGVuCgkJY2FzZSAiJEhBTFQiIGluCgkJICBbUHBdKikKCQkJSU5JVF9IQUxUPVBPV0VST0ZGCgkJCTs7CgkJICBbSGhdKikKCQkJSU5JVF9IQUxUPUhBTFQKCQkJOzsKCQkgICopCgkJCUlOSVRfSEFMVD1QT1dFUk9GRgoJCQk7OwoJCWVzYWMKCWZpCgoJIyBTZWUgaWYgd2UgbmVlZCB0byBjdXQgdGhlIHBvd2VyLgoJaWYgWyAiJElOSVRfSEFMVCIgPSAiUE9XRVJPRkYiIF0gJiYgWyAteCAvZXRjL2luaXQuZC91cHMtbW9uaXRvciBdCgl0aGVuCgkJL2V0Yy9pbml0LmQvdXBzLW1vbml0b3IgcG93ZXJvZmYKCWZpCgoJIyBEb24ndCBzaHV0IGRvd24gZHJpdmVzIGlmIHdlJ3JlIHVzaW5nIFJBSUQuCgloZGRvd249Ii1oIgoJaWYgZ3JlcCAtcXMgJ15tZC4qYWN0aXZlJyAvcHJvYy9tZHN0YXQKCXRoZW4KCQloZGRvd249IiIKCWZpCgoJIyBJZiBJTklUX0hBTFQ9SEFMVCBkb24ndCBwb3dlcm9mZi4KCXBvd2Vyb2ZmPSItcCIKCWlmIFsgIiRJTklUX0hBTFQiID0gIkhBTFQiIF0KCXRoZW4KCQlwb3dlcm9mZj0iIgoJZmkKCgkjIE1ha2UgaXQgcG9zc2libGUgdG8gbm90IHNodXQgZG93biBuZXR3b3JrIGludGVyZmFjZXMsCgkjIG5lZWRlZCB0byB1c2Ugd2FrZS1vbi1sYW4KCW5ldGRvd249Ii1pIgoJaWYgWyAiJE5FVERPV04iID0gIm5vIiBdOyB0aGVuCgkJbmV0ZG93bj0iIgoJZmkKCglsb2dfYWN0aW9uX21zZyAiV2lsbCBub3cgaGFsdCIKCWhhbHQgLWQgLWYgJG5ldGRvd24gJHBvd2Vyb2ZmICRoZGRvd24KfQoKY2FzZSAiJDEiIGluCiAgc3RhcnR8c3RhdHVzKQoJIyBOby1vcAoJOzsKICByZXN0YXJ0fHJlbG9hZHxmb3JjZS1yZWxvYWQpCgllY2hvICJFcnJvcjogYXJndW1lbnQgJyQxJyBub3Qgc3VwcG9ydGVkIiA+JjIKCWV4aXQgMwoJOzsKICBzdG9wKQoJZG9fc3RvcAoJOzsKICAqKQoJZWNobyAiVXNhZ2U6ICQwIHN0YXJ0fHN0b3AiID4mMgoJZXhpdCAzCgk7Owplc2FjCgo6Cg==
kind: Secret
metadata:
creationTimestamp: null
name: secret1
namespace: secretCreate the secret1:
k8s@terminal:~$ kubectl create -f /opt/course/19/secret1.yamlCreate the other secret:
k8s@terminal:~$ kubectl create secret generic secret2 --from-literal=user=user1 --from-literal=pass=1234 --namespace=secretCreate the POD:
k8s@terminal:~$ cat q19pod.yml
apiVersion: v1
kind: Pod
metadata:
name: secret-pod
namespace: secret
spec:
containers:
- image: busybox:1.31.1
name: cont19
command: ["sleep", "3600"]
volumeMounts:
- name: whatever
mountPath: "/tmp/secret1"
readOnly: true
env:
- name: APP_USER
valueFrom:
secretKeyRef:
name: secret2
key: user
- name: APP_PASS
valueFrom:
secretKeyRef:
name: secret2
key: pass
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
volumes:
- name: whatever
secret:
secretName: secret1Test it:
k8s@terminal:~$ kubectl exec -it secret-pod -n secret -- env | grep -i APP
APP_USER=user1
APP_PASS=1234
k8s@terminal:~$ kubectl exec -it secret-pod -n secret -- ls -l /tmp/secret1
total 0
lrwxrwxrwx 1 root root 11 Sep 22 18:01 halt -> ..data/haltQuestion 20: Update Kubernetes Version and join cluster
Use context: kubectl config use-context k8s-c3-CCC
Your coworker said node cluster3-worker2 is running an older Kubernetes version and is not even part of the cluster. Update kubectl and kubeadm to the exact version that's running on cluster3-master1. Then add this node to the cluster, you can use kubeadm for this.
Solution:
root@cluster3-master1:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready control-plane,master 141d v1.21.0
cluster3-worker1 Ready <none> 141d v1.21.0root@cluster3-master1:~# kubelet --version
Kubernetes v1.21.0
root@cluster3-master1:~# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.0", GitCommit:"cb303e613a121a29364f75cc67d3d580833a7479", GitTreeState:"clean", BuildDate:"2021-04-08T16:30:03Z", GoVersion:"go1.16.1", Compiler:"gc", Platform:"linux/amd64"}
root@cluster3-master1:~# kubectl version
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.0", GitCommit:"cb303e613a121a29364f75cc67d3d580833a7479", GitTreeState:"clean", BuildDate:"2021-04-08T16:31:21Z", GoVersion:"go1.16.1", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.0", GitCommit:"cb303e613a121a29364f75cc67d3d580833a7479", GitTreeState:"clean", BuildDate:"2021-04-08T16:25:06Z", GoVersion:"go1.16.1", Compiler:"gc", Platform:"linux/amd64"}root@cluster3-worker2:~# apt-get install -y kubeadm=1.21.0-00 kubectl=1.21.0-00root@cluster3-master1:~# kubeadm token create --print-join-command
kubeadm join 192.168.100.31:6443 --token tmy9px.gmzclyvt0j1ghi33 --discovery-token-ca-cert-hash sha256:11bf0d439e7dfce0ee98d34d7333fc8933cde32e27c67b63a14dbd7c052d149broot@cluster3-worker2:~# kubeadm join 192.168.100.31:6443 --token tmy9px.gmzclyvt0j1ghi33 --discovery-token-ca-cert-hash sha256:11bf0d439e7dfce0ee98d34d7333fc8933cde32e27c67b63a14dbd7c052d149b
[preflight] Running pre-flight checksroot@cluster3-master1:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready control-plane,master 141d v1.21.0
cluster3-worker1 Ready <none> 141d v1.21.0
cluster3-worker2 Ready <none> 2m25s v1.22.2************************* Done **************************
]]>CKA Simulator Kubernetes 1.22
Pre Setup
Once you've gained access to your terminal it might be wise to spend ~1 minute to setup your environment. You could set these:
alias k=kubectl # will already be pre-configured
export do="--dry-run=client -o yaml" # k get pod x $do
export now="--force --grace-period 0" # k delete pod x $nowVim To make vim use 2 spaces for a tab edit ~/.vimrc to contain:
set tabstop=2
set expandtab
set shiftwidth=2More setup suggestions are in the tips section.
Question 1 | Contexts
Task weight: 1%
You have access to multiple clusters from your main terminal through kubectl contexts. Write all those context names into /opt/course/1/contexts.
Next write a command to display the current context into /opt/course/1/context_default_kubectl.sh, the command should use kubectl.
Finally write a second command doing the same thing into /opt/course/1/context_default_no_kubectl.sh, but without the use of kubectl.
Answer: Maybe the fastest way is just to run:
k config get-contexts # copy manually
k config get-contexts -o name > /opt/course/1/contexts
# Or using jsonpath:
k config view -o yaml # overview
k config view -o jsonpath="{.contexts[*].name}"
k config view -o jsonpath="{.contexts[*].name}" | tr " " "\n" # new lines
k config view -o jsonpath="{.contexts[*].name}" | tr " " "\n" > /opt/course/1/contextsThe content should then look like:
# /opt/course/1/contexts
k8s-c1-H
k8s-c2-AC
k8s-c3-CCCNext create the first command:
# /opt/course/1/context_default_kubectl.sh
kubectl config current-context➜ sh /opt/course/1/context_default_kubectl.sh
k8s-c1-HAnd the second one:
# /opt/course/1/context_default_no_kubectl.sh
cat ~/.kube/config | grep current➜ sh /opt/course/1/context_default_no_kubectl.sh
current-context: k8s-c1-HIn the real exam you might need to filter and find information from bigger lists of resources, hence knowing a little jsonpath and simple bash filtering will be helpful.
The second command could also be improved to:
# /opt/course/1/context_default_no_kubectl.sh
cat ~/.kube/config | grep current | sed -e "s/current-context: //"Question 2 | Schedule Pod on Master Node
Task weight: 3%
Use context: kubectl config use-context k8s-c1-H
Create a single Pod of image httpd:2.4.41-alpine in Namespace default. The Pod should be named pod1 and the container should be named pod1-container.
This Pod should only be scheduled on a master node, do not add new labels any nodes.
Shortly write the reason on why Pods are by default not scheduled on master nodes into /opt/course/2/master_schedule_reason.
Answer: First we find the master node(s) and their taints:
k get node # find master node
k describe node cluster1-master1 | grep Taint # get master node taints
# -A 是显示匹配后和它后面的n行
# -B 是显示匹配行和它前面的n行。
# -C 是匹配行和它前后各n行。
k describe node cluster1-master1 | grep Labels -A 10 # get master node labels
k get node cluster1-master1 --show-labels # OR: get master node labelsNext we create the Pod template:
check the export on the very top of this document so we can use $do
k run pod1 --image=httpd:2.4.41-alpine $do > 2.yamlvim 2.yaml Perform the necessary changes manually. Use the Kubernetes docs and search for example for tolerations and nodeSelector to find examples:
# 2.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod1
name: pod1
spec:
containers:
- image: httpd:2.4.41-alpine
name: pod1-container # change
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
tolerations: # add
- effect: NoSchedule # add
key: node-role.kubernetes.io/master # add
nodeSelector: # add
node-role.kubernetes.io/master: "" # add
# kubernetes.io/hostname: "cluster1-master1"
status: {}Important here to add the toleration for running on master nodes, but also the nodeSelector to make sure it only runs on master nodes.
If we only specify a toleration the Pod can be scheduled on master or worker nodes.
Now we create it:
k -f 2.yaml create
Let's check if the pod is scheduled:
➜ k get pod pod1 -o wide
NAME READY STATUS RESTARTS ... NODE NOMINATED NODE
pod1 1/1 Running 0 ... cluster1-master1 <none>Finally the short reason why Pods are not scheduled on master nodes by default:
# /opt/course/2/master_schedule_reason
master nodes usually have a taint definedQuestion 3 | Scale down StatefulSet
Task weight: 1%
Use context: kubectl config use-context k8s-c1-H
There are two Pods named o3db-* in Namespace project-c13.
C13 management asked you to scale the Pods down to one replica to save resources. Record the action.
Answer: If we check the Pods we see two replicas:
➜ k -n project-c13 get pod | grep o3db
o3db-0 1/1 Running 0 52s
o3db-1 1/1 Running 0 42sFrom their name it looks like these are managed by a StatefulSet.
But if we're not sure we could also check for the most common resources which manage Pods:
➜ k -n project-c13 get deploy,ds,sts | grep o3db
statefulset.apps/o3db 2/2 2m56sConfirmed, we have to work with a StatefulSet. To find this out we could also look at the Pod labels:
➜ k -n project-c13 get pod --show-labels | grep o3db
o3db-0 1/1 Running 0 3m29s app=nginx,controller-revision-hash=o3db-5fbd4bb9cc,statefulset.kubernetes.io/pod-name=o3db-0
o3db-1 1/1 Running 0 3m19s app=nginx,controller-revision-hash=o3db-5fbd4bb9cc,statefulset.kubernetes.io/pod-name=o3db-1To fulfil the task we simply run:
➜ k -n project-c13 scale sts o3db --replicas 1 --record
statefulset.apps/o3db scaled
➜ k -n project-c13 get sts o3db
NAME READY AGE
o3db 1/1 4m39sThe --record created an annotation:
➜ k -n project-c13 describe sts o3db
Name: o3db
Namespace: project-c13
CreationTimestamp: Sun, 20 Sep 2020 14:47:57 +0000
Selector: app=nginx
Labels: <none>
Annotations: kubernetes.io/change-cause: kubectl scale sts o3db --namespace=project-c13 --replicas=1 --record=true
Replicas: 1 desired | 1 totalC13 Management is happy again.
Question 4 | Pod Ready if Service is reachable
Task weight: 4%
Use context: kubectl config use-context k8s-c1-H
Do the following in Namespace default. Create a single Pod named ready-if-service-ready of image nginx:1.16.1-alpine.
Configure a LivenessProbe which simply runs true.
Also configure a ReadinessProbe which does check if the url http://service-am-i-ready:80 is reachable, you can use wget -T2 -O- http://service-am-i-ready:80 for this.
Start the Pod and confirm it isn't ready because of the ReadinessProbe.
Create a second Pod named am-i-ready of image nginx:1.16.1-alpine with label id: cross-server-ready.
The already existing Service service-am-i-ready should now have that second Pod as endpoint.
Now the first Pod should be in ready state, confirm that.
Answer: It's a bit of an anti-pattern for one Pod to check another Pod for being ready using probes, hence the normally available readinessProbe.httpGet doesn't work for absolute remote urls.
Still the workaround requested in this task should show how probes and Pod<->Service communication works.
First we create the first Pod:
k run ready-if-service-ready --image=nginx:1.16.1-alpine $do > 4_pod1.yaml
vim 4_pod1.yamlNext perform the necessary additions manually:
# 4_pod1.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: ready-if-service-ready
name: ready-if-service-ready
spec:
containers:
- image: nginx:1.16.1-alpine
name: ready-if-service-ready
resources: {}
livenessProbe: # add from here
exec:
command:
- 'true'
readinessProbe:
exec:
command:
- sh
- -c
- 'wget -T2 -O- http://service-am-i-ready:80' # to here
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}Then create the Pod:
k -f 4_pod1.yaml create
And confirm its in a non-ready state:
➜ k get pod ready-if-service-ready
NAME READY STATUS RESTARTS AGE
ready-if-service-ready 0/1 Running 0 7sWe can also check the reason for this using describe:
➜ k describe pod ready-if-service-ready
...
Warning Unhealthy 18s kubelet, cluster1-worker1 Readiness probe failed: Connecting to service-am-i-ready:80 (10.109.194.234:80)
wget: download timed outNow we create the second Pod:
k run am-i-ready --image=nginx:1.16.1-alpine --labels="id=cross-server-ready"
# The already existing Service service-am-i-ready should now have an Endpoint:
k describe svc service-am-i-ready
k get ep # also possibleWhich will result in our first Pod being ready, just give it a minute for the Readiness probe to check again:
➜ k get pod ready-if-service-ready
NAME READY STATUS RESTARTS AGE
ready-if-service-ready 1/1 Running 0 53sLook at these Pods coworking together!
Question 5 | Kubectl sorting
Task weight: 1%
Use context: kubectl config use-context k8s-c1-H
There are various Pods in all namespaces. Write a command into /opt/course/5/find_pods.sh which lists all Pods sorted by their AGE (metadata.creationTimestamp).
Write a second command into /opt/course/5/find_pods_uid.sh which lists all Pods sorted by field metadata.uid. Use kubectl sorting for both commands.
Answer: A good resources here (and for many other things) is the kubectl-cheat-sheet. You can reach it fast when searching for "cheat sheet" in the Kubernetes docs.
# /opt/course/5/find_pods.sh
kubectl get pod -A --sort-by=.metadata.creationTimestampAnd to execute:
➜ sh /opt/course/5/find_pods.sh
NAMESPACE NAME ... AGE
kube-system kube-scheduler-cluster1-master1 ... 63m
kube-system etcd-cluster1-master1 ... 63m
kube-system kube-apiserver-cluster1-master1 ... 63m
kube-system kube-controller-manager-cluster1-master1 ... 63m
...For the second command:
# /opt/course/5/find_pods_uid.sh
kubectl get pod -A --sort-by=.metadata.uidAnd to execute:
➜ sh /opt/course/5/find_pods_uid.sh
NAMESPACE NAME ... AGE
kube-system coredns-5644d7b6d9-vwm7g ... 68m
project-c13 c13-3cc-runner-heavy-5486d76dd4-ddvlt ... 63m
project-hamster web-hamster-shop-849966f479-278vp ... 63m
project-c13 c13-3cc-web-646b6c8756-qsg4b ... 63mQuestion 6 | Storage, PV, PVC, Pod volume
Task weight: 8%
Use context: kubectl config use-context k8s-c1-H
Create a new PersistentVolume named safari-pv. It should have a capacity of 2Gi, accessMode ReadWriteOnce, hostPath /Volumes/Data and no storageClassName defined.
Next create a new PersistentVolumeClaim in Namespace project-tiger named safari-pvc . It should request 2Gi storage, accessMode ReadWriteOnce and should not define a storageClassName. The PVC should bound to the PV correctly.
Finally create a new Deployment safari in Namespace project-tiger which mounts that volume at /tmp/safari-data. The Pods of that Deployment should be of image httpd:2.4.41-alpine.
Answer
vim 6_pv.yaml
Find an example from https://kubernetes.io/docs and alter it:
# 6_pv.yaml
kind: PersistentVolume
apiVersion: v1
metadata:
name: safari-pv
spec:
capacity:
storage: 2Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/Volumes/Data"Then create it:
k -f 6_pv.yaml create
Next the PersistentVolumeClaim:
vim 6_pvc.yaml
Find an example from https://kubernetes.io/docs and alter it:
# 6_pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: safari-pvc
namespace: project-tiger
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gik -f 6_pvc.yaml create
And check that both have the status Bound:
➜ k -n project-tiger get pv,pvc
NAME CAPACITY ... STATUS CLAIM ...
persistentvolume/safari-pv 2Gi ... Bound project-tiger/safari-pvc ...
NAME STATUS VOLUME CAPACITY ...
persistentvolumeclaim/safari-pvc Bound safari-pv 2Gi ...
# Next we create a Deployment and mount that volume:
k -n project-tiger create deploy safari --image=httpd:2.4.41-alpine $do > 6_dep.yamlvim 6_dep.yaml Alter the yaml to mount the volume:
# 6_dep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: safari
name: safari
namespace: project-tiger
spec:
replicas: 1
selector:
matchLabels:
app: safari
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: safari
spec:
volumes: # add
- name: data # add
persistentVolumeClaim: # add
claimName: safari-pvc # add
containers:
- image: httpd:2.4.41-alpine
name: container
volumeMounts: # add
- name: data # add
mountPath: /tmp/safari-data # addk -f 6_dep.yaml create
We can confirm its mounting correctly:
➜ k -n project-tiger describe pod safari-5cbf46d6d-mjhsb | grep -A2 Mounts:
Mounts:
/tmp/safari-data from data (rw) # there it is
/var/run/secrets/kubernetes.io/serviceaccount from default-token-n2sjj (ro)Question 7 | Node and Pod Resource Usage
Task weight: 1%
Use context: kubectl config use-context k8s-c1-H
The metrics-server hasn't been installed yet in the cluster, but it's something that should be done soon. Your college would already like to know the kubectl commands to:
show node resource usage show Pod and their containers resource usage Please write the commands into /opt/course/7/node.sh and /opt/course/7/pod.sh.
Answer: The command we need to use here is top:
Display Resource (CPU/Memory/Storage) usage.
The top command allows you to see the resource consumption for nodes or pods.
This command requires Metrics Server to be correctly configured and working on the server.
Available Commands:
node Display Resource (CPU/Memory/Storage) usage of nodes
pod Display Resource (CPU/Memory/Storage) usage of podsWe see that the metrics server is not configured yet:
error: Metrics API not availableBut we trust the kubectl documentation and create the first file:
# /opt/course/7/node.sh
kubectl top nodeFor the second file we might need to check the docs again:
➜ k top pod -h
Display Resource (CPU/Memory/Storage) usage of pods.
...
Namespace in current context is ignored even if specified with --namespace.
--containers=false: If present, print usage of containers within a pod.
--no-headers=false: If present, print output without headers.
...With this we can finish this task:
# /opt/course/7/pod.sh
kubectl top pod --containers=trueQuestion 8 | Get Master Information
Task weight: 2%
Use context: kubectl config use-context k8s-c1-H
Ssh into the master node with ssh cluster1-master1. Check how the master components kubelet, kube-apiserver, kube-scheduler, kube-controller-manager and etcd are started/installed on the master node.
Also find out the name of the DNS application and how it's started/installed on the master node.
Write your findings into file /opt/course/8/master-components.txt. The file should be structured like:
# /opt/course/8/master-components.txt
kubelet: [TYPE]
kube-apiserver: [TYPE]
kube-scheduler: [TYPE]
kube-controller-manager: [TYPE]
etcd: [TYPE]
dns: [TYPE] [NAME]
Choices of [TYPE] are: not-installed, process, static-pod, podAnswer: We could start by finding processes of the requested components, especially the kubelet at first:
➜ ssh cluster1-master1
root@cluster1-master1:~# ps aux | grep kubelet # shows kubelet processWe can see which components are controlled via systemd looking at /etc/systemd/system directory:
➜ root@cluster1-master1:~# find /etc/systemd/system/ | grep kube
/etc/systemd/system/kubelet.service.d
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
/etc/systemd/system/multi-user.target.wants/kubelet.service
➜ root@cluster1-master1:~# find /etc/systemd/system/ | grep etcdThis shows kubelet is controlled via systemd, but no other service named kube nor etcd.
It seems that this cluster has been setup using kubeadm, so we check in the default manifests directory:
➜ root@cluster1-master1:~# find /etc/kubernetes/manifests/
/etc/kubernetes/manifests/
/etc/kubernetes/manifests/kube-controller-manager.yaml
/etc/kubernetes/manifests/etcd.yaml
/etc/kubernetes/manifests/kube-scheduler-special.yaml
/etc/kubernetes/manifests/kube-apiserver.yaml
/etc/kubernetes/manifests/kube-scheduler.yaml
cat kube-scheduler-special.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: kube-scheduler-special
labels:
component: kube-scheduler
tier: control-plane
namespace: kube-system
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --port=7776
- --secure-port=7777
- --kubeconfig=/etc/kubernetes/kube-scheduler.conf
- --leader-elect=false
- --scheduler-name=kube-scheduler-special
- --this-is-no-parameter=what-the-hell
image: k8s.gcr.io/kube-scheduler:v1.22.1
imagePullPolicy: IfNotPresent
name: kube-scheduler-special
resources:
requests:
cpu: 100m
volumeMounts:
- mountPath: /etc/kubernetes/scheduler.conf
name: kubeconfig
readOnly: true
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/scheduler.conf
type: FileOrCreate
name: kubeconfig
status: {}(The kubelet could also have a different manifests directory specified via parameter --pod-manifest-path in it's systemd startup config)
This means the main 4 master services are setup as static Pods. There also seems to be a second scheduler kube-scheduler-special existing.
Actually, let's check all Pods running on in the kube-system Namespace on the master node:
➜ root@cluster1-master1:~# kubectl -n kube-system get pod -o wide | grep master1
coredns-5644d7b6d9-c4f68 1/1 Running ... cluster1-master1
coredns-5644d7b6d9-t84sc 1/1 Running ... cluster1-master1
etcd-cluster1-master1 1/1 Running ... cluster1-master1
kube-apiserver-cluster1-master1 1/1 Running ... cluster1-master1
kube-controller-manager-cluster1-master1 1/1 Running ... cluster1-master1
kube-proxy-q955p 1/1 Running ... cluster1-master1
kube-scheduler-cluster1-master1 1/1 Running ... cluster1-master1
kube-scheduler-special-cluster1-master1 0/1 CrashLoopBackOff ... cluster1-master1
weave-net-mwj47 2/2 Running ... cluster1-master1There we see the 5 static pods, with -cluster1-master1 as suffix.
We also see that the dns application seems to be coredns, but how is it controlled?
➜ root@cluster1-master1$ kubectl -n kube-system get ds
NAME DESIRED CURRENT ... NODE SELECTOR AGE
kube-proxy 3 3 ... kubernetes.io/os=linux 155m
weave-net 3 3 ... <none> 155m
➜ root@cluster1-master1$ kubectl -n kube-system get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
coredns 2/2 2 2 155mSeems like coredns is controlled via a Deployment. We combine our findings in the requested file:
# /opt/course/8/master-components.txt
kubelet: process
kube-apiserver: static-pod
kube-scheduler: static-pod
kube-scheduler-special: static-pod (status CrashLoopBackOff)
kube-controller-manager: static-pod
etcd: static-pod
dns: pod corednsYou should be comfortable investigating a running cluster, know different methods on how a cluster and its services can be setup and be able to troubleshoot and find error sources.
Question 9 | Kill Scheduler, Manual Scheduling
Task weight: 5%
Use context: kubectl config use-context k8s-c2-AC
Ssh into the master node with ssh cluster2-master1. Temporarily stop the kube-scheduler, this means in a way that you can start it again afterwards.
Create a single Pod named manual-schedule of image httpd:2.4-alpine, confirm its created but not scheduled on any node.
Now you're the scheduler and have all its power, manually schedule that Pod on node cluster2-master1. Make sure it's running.
Start the kube-scheduler again and confirm its running correctly by creating a second Pod named manual-schedule2 of image httpd:2.4-alpine and check if it's running on cluster2-worker1.
Answer: Stop the Scheduler First we find the master node:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster2-master1 Ready master 26h v1.22.1
cluster2-worker1 Ready <none> 26h v1.22.1Then we connect and check if the scheduler is running:
➜ ssh cluster2-master1
➜ root@cluster2-master1:~# kubectl -n kube-system get pod | grep schedule
kube-scheduler-cluster2-master1 1/1 Running 0 6s
# Kill the Scheduler (temporarily):
➜ root@cluster2-master1:~# cd /etc/kubernetes/manifests/
➜ root@cluster2-master1:~# mv kube-scheduler.yaml ..
And it should be stopped:
➜ root@cluster2-master1:~# kubectl -n kube-system get pod | grep schedule
➜ root@cluster2-master1:~#Create a Pod
Now we create the Pod:
k run manual-schedule --image=httpd:2.4-alpine
And confirm it has no node assigned:
➜ k get pod manual-schedule -o wide
NAME READY STATUS ... NODE NOMINATED NODE
manual-schedule 0/1 Pending ... <none> <none>Manually schedule the Pod Let's play the scheduler now:
k get pod manual-schedule -o yaml > 9.yaml
# 9.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-09-04T15:51:02Z"
labels:
run: manual-schedule
managedFields:
...
manager: kubectl-run
operation: Update
time: "2020-09-04T15:51:02Z"
name: manual-schedule
namespace: default
resourceVersion: "3515"
selfLink: /api/v1/namespaces/default/pods/manual-schedule
uid: 8e9d2532-4779-4e63-b5af-feb82c74a935
spec:
nodeName: cluster2-master1 # add the master node name
containers:
- image: httpd:2.4-alpine
imagePullPolicy: IfNotPresent
name: manual-schedule
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: default-token-nxnc7
readOnly: true
dnsPolicy: ClusterFirst
...The only thing a scheduler does, is that it sets the nodeName for a Pod declaration.
How it finds the correct node to schedule on, that's a very much complicated matter and takes many variables into account.
As we cannot kubectl apply or kubectl edit , in this case we need to delete and create or replace:
k -f 9.yaml replace --force
# How does it look?
➜ k get pod manual-schedule -o wide
NAME READY STATUS ... NODE
manual-schedule 1/1 Running ... cluster2-master1It looks like our Pod is running on the master now as requested, although no tolerations were specified.
Only the scheduler takes trains/tolerations/affinity into account when finding the correct node name.
That's why its still possible to assign Pods manually directly to a master node and skip the scheduler.
Start the scheduler again
➜ ssh cluster2-master1
➜ root@cluster2-master1:~# cd /etc/kubernetes/manifests/
➜ root@cluster2-master1:~# mv ../kube-scheduler.yaml .
# Checks its running:
➜ root@cluster2-master1:~# kubectl -n kube-system get pod | grep schedule
kube-scheduler-cluster2-master1 1/1 Running 0 16s
Schedule a second test Pod:
k run manual-schedule2 --image=httpd:2.4-alpine
➜ k get pod -o wide | grep schedule
manual-schedule 1/1 Running ... cluster2-master1
manual-schedule2 1/1 Running ... cluster2-worker1Back to normal.
Question 10 | RBAC ServiceAccount Role RoleBinding
Task weight: 6%
Use context: kubectl config use-context k8s-c1-H
Create a new ServiceAccount processor in Namespace project-hamster. Create a Role and RoleBinding, both named processor as well. These should allow the new SA to only create Secrets and ConfigMaps in that Namespace.
Answer:
TL;DR
k create ns project-hamster k create serviceaccount processor -n project-hamster k create role processor --verb=create --resource=secrets,configmaps -n project-hamster k create rolebinding processor --role=processor --serviceaccount=project-hamster:processor
Let's talk a little about RBAC resources A ClusterRole|Role defines a set of permissions and where it is available, in the whole cluster or just a single Namespace.
A ClusterRoleBinding|RoleBinding connects a set of permissions with an account and defines where it is applied, in the whole cluster or just a single Namespace.
Because of this there are 4 different RBAC combinations and 3 valid ones:
- Role + RoleBinding (available in single Namespace, applied in single Namespace)
- ClusterRole + ClusterRoleBinding (available cluster-wide, applied cluster-wide)
- ClusterRole + RoleBinding (available cluster-wide, applied in single Namespace)
- Role + ClusterRoleBinding (NOT POSSIBLE: available in single Namespace, applied cluster-wide)
To the solution We first create the ServiceAccount:
➜ k -n project-hamster create sa processor
serviceaccount/processor createdThen for the Role:
k -n project-hamster create role -h # examplesSo we execute:
k -n project-hamster create role processor \
--verb=create \
--resource=secret \
--resource=configmapWhich will create a Role like:
# kubectl -n project-hamster create role accessor --verb=create --resource=secret --resource=configmap
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: processor
namespace: project-hamster
rules:
- apiGroups:
- ""
resources:
- secrets
- configmaps
verbs:
- createNow we bind the Role to the ServiceAccount:
k -n project-hamster create rolebinding -h # examplesSo we create it:
k -n project-hamster create rolebinding processor \
--role processor \
--serviceaccount project-hamster:processorThis will create a RoleBinding like:
# kubectl -n project-hamster create rolebinding processor --role processor --serviceaccount project-hamster:processor
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: processor
namespace: project-hamster
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: processor
subjects:
- kind: ServiceAccount
name: processor
namespace: project-hamsterTo test our RBAC setup we can use kubectl auth can-i:
k auth can-i -h # examplesLike this:
➜ k -n project-hamster auth can-i create secret \
--as system:serviceaccount:project-hamster:processor
yes
➜ k -n project-hamster auth can-i create configmap \
--as system:serviceaccount:project-hamster:processor
yes
➜ k -n project-hamster auth can-i create pod \
--as system:serviceaccount:project-hamster:processor
no
➜ k -n project-hamster auth can-i delete secret \
--as system:serviceaccount:project-hamster:processor
no
➜ k -n project-hamster auth can-i get configmap --as system:serviceaccount:project-hamster:processor
noDone.
Question 11 | DaemonSet on all Nodes
Task weight: 4%
Use context: kubectl config use-context k8s-c1-H
Use Namespace project-tiger for the following. Create a DaemonSet named ds-important with image httpd:2.4-alpine and labels id=ds-important and uuid=18426a0b-5f59-4e10-923f-c0e078e82462. The Pods it creates should request 10 millicore cpu and 10 mebibyte memory. The Pods of that DaemonSet should run on all nodes, master and worker.
Answer: As of now we aren't able to create a DaemonSet directly using kubectl, so we create a Deployment and just change it up:
k -n project-tiger create deployment --image=httpd:2.4-alpine ds-important $do > 11.yaml
vim 11.yaml(Sure you could also search for a DaemonSet example yaml in the Kubernetes docs and alter it.)
Then we adjust the yaml to:
# 11.yaml
apiVersion: apps/v1
kind: DaemonSet # change from Deployment to Daemonset
metadata:
creationTimestamp: null
labels: # add
id: ds-important # add
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462 # add
name: ds-important
namespace: project-tiger # important
spec:
#replicas: 1 # remove
selector:
matchLabels:
id: ds-important # add
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462 # add
#strategy: {} # remove
template:
metadata:
creationTimestamp: null
labels:
id: ds-important # add
uuid: 18426a0b-5f59-4e10-923f-c0e078e82462 # add
spec:
containers:
- image: httpd:2.4-alpine
name: ds-important
resources:
requests: # add
cpu: 10m # add
memory: 10Mi # add
tolerations: # add
- effect: NoSchedule # add
key: node-role.kubernetes.io/master # add
#status: {} # removeIt was requested that the DaemonSet runs on all nodes, so we need to specify the toleration for this.
Let's confirm:
k -f 11.yaml create
➜ k -n project-tiger get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
ds-important 3 3 3 3 3 <none> 8s
➜ k -n project-tiger get pod -l id=ds-important -o wide
NAME READY STATUS NODE
ds-important-6pvgm 1/1 Running ... cluster1-worker1
ds-important-lh5ts 1/1 Running ... cluster1-master1
ds-important-qhjcq 1/1 Running ... cluster1-worker2Question 12 | Deployment on all Nodes
Task weight: 6%
Use context: kubectl config use-context k8s-c1-H
Use Namespace project-tiger for the following. Create a Deployment named deploy-important with label id=very-important (the Pods should also have this label) and 3 replicas. It should contain two containers, the first named container1 with image nginx:1.17.6-alpine and the second one named container2 with image kubernetes/pause.
There should be only ever one Pod of that Deployment running on one worker node. We have two worker nodes: cluster1-worker1 and cluster1-worker2. Because the Deployment has three replicas the result should be that on both nodes one Pod is running. The third Pod won't be scheduled, unless a new worker node will be added.
In a way we kind of simulate the behaviour of a DaemonSet here, but using a Deployment and a fixed number of replicas.
Answer: The idea here is that we create a "Inter-pod anti-affinity" which allows us to say a Pod should only be scheduled on a node where another Pod of a specific label (here the same label) is not already running.
Let's begin by creating the Deployment template:
k -n project-tiger create deployment \
--image=nginx:1.17.6-alpine deploy-important $do > 12.yaml
vim 12.yamlThen change the yaml to:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
id: very-important # change
name: deploy-important
namespace: project-tiger # important
spec:
replicas: 3 # change
selector:
matchLabels:
id: very-important # change
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
id: very-important # change
spec:
containers:
- image: nginx:1.17.6-alpine
name: container1 # change
resources: {}
- image: kubernetes/pause # add
name: container2 # add
affinity: # add
podAntiAffinity: # add
requiredDuringSchedulingIgnoredDuringExecution: # add
- labelSelector: # add
matchExpressions: # add
- key: id # add
operator: In # add
values: # add
- very-important # add
topologyKey: kubernetes.io/hostname # add
status: {}Specify a topologyKey, which is a pre-populated Kubernetes label, you can find this by describing a node.
Let's run it:
k -f 12.yaml create
# Then we check the Deployment status where it shows 2/3 ready count:
➜ k -n project-tiger get deploy -l id=very-important
NAME READY UP-TO-DATE AVAILABLE AGE
deploy-important 2/3 3 2 2m35s
# And running the following we see one Pod on each worker node and one not scheduled.
➜ k -n project-tiger get pod -o wide -l id=very-important
NAME READY STATUS ... NODE
deploy-important-58db9db6fc-9ljpw 2/2 Running ... cluster1-worker1
deploy-important-58db9db6fc-lnxdb 0/2 Pending ... <none>
deploy-important-58db9db6fc-p2rz8 2/2 Running ... cluster1-worker2If we kubectl describe the Pod deploy-important-58db9db6fc-lnxdb it will show us the reason for not scheduling is our implemented pod affinity/anti-affinity ruling:
Warning FailedScheduling 63s (x3 over 65s) default-scheduler 0/3 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 2 node(s) didn't match pod affinity/anti-affinity, 2 node(s) didn't satisfy existing pods anti-affinity rules.
Question 13 | Multi Containers and Pod shared Volume
Task weight: 4%
Use context: kubectl config use-context k8s-c1-H
Create a Pod named multi-container-playground in Namespace default with three containers, named c1, c2 and c3. There should be a volume attached to that Pod and mounted into every container, but the volume shouldn't be persisted or shared with other Pods.
Container c1 should be of image nginx:1.17.6-alpine and have the name of the node where its Pod is running available as environment variable MY_NODE_NAME.
Container c2 should be of image busybox:1.31.1 and write the output of the date command every second in the shared volume into file date.log. You can use while true; do date >> /your/vol/path/date.log; sleep 1; done for this.
Container c3 should be of image busybox:1.31.1 and constantly send the content of file date.log from the shared volume to stdout. You can use tail -f /your/vol/path/date.log for this.
Check the logs of container c3 to confirm correct setup.
Answer: First we create the Pod template:
k run multi-container-playground --image=nginx:1.17.6-alpine $do > 13.yaml
vim 13.yamlAnd add the other containers and the commands they should execute:
# 13.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: multi-container-playground
name: multi-container-playground
spec:
containers:
- image: nginx:1.17.6-alpine
name: c1 # change
resources: {}
env: # add
- name: MY_NODE_NAME # add
valueFrom: # add
fieldRef: # add
fieldPath: spec.nodeName # add
volumeMounts: # add
- name: vol # add
mountPath: /vol # add
- image: busybox:1.31.1 # add
name: c2 # add
command: ["sh", "-c", "while true; do date >> /vol/date.log; sleep 1; done"] # add
volumeMounts: # add
- name: vol # add
mountPath: /vol # add
- image: busybox:1.31.1 # add
name: c3 # add
command: ["sh", "-c", "tail -f /vol/date.log"] # add
volumeMounts: # add
- name: vol # add
mountPath: /vol # add
dnsPolicy: ClusterFirst
restartPolicy: Always
volumes: # add
- name: vol # add
emptyDir: {} # add
status: {}k -f 13.yaml create
Oh boy, lot's of requested things. We check if everything is good with the Pod:
➜ k get pod multi-container-playground
NAME READY STATUS RESTARTS AGE
multi-container-playground 3/3 Running 0 95sGood, then we check if container c1 has the requested node name as env variable:
➜ k exec multi-container-playground -c c1 -- env | grep MY
MY_NODE_NAME=cluster1-worker2And finally we check the logging:
➜ k logs multi-container-playground -c c3
Sat Dec 7 16:05:10 UTC 2077
Sat Dec 7 16:05:11 UTC 2077
Sat Dec 7 16:05:12 UTC 2077
Sat Dec 7 16:05:13 UTC 2077
Sat Dec 7 16:05:14 UTC 2077
Sat Dec 7 16:05:15 UTC 2077
Sat Dec 7 16:05:16 UTC 2077Question 14 | Find out Cluster Information
Task weight: 2%
Use context: kubectl config use-context k8s-c1-H
You're ask to find out following information about the cluster k8s-c1-H:
How many master nodes are available? How many worker nodes are available? What is the Service CIDR? Which Networking (or CNI Plugin) is configured and where is its config file? Which suffix will static pods have that run on cluster1-worker1? Write your answers into file /opt/course/14/cluster-info, structured like this:
# /opt/course/14/cluster-info
1: [ANSWER]
2: [ANSWER]
3: [ANSWER]
4: [ANSWER]
5: [ANSWER]Answer: How many master and worker nodes are available?
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster1-master1 Ready master 27h v1.22.1
cluster1-worker1 Ready <none> 27h v1.22.1
cluster1-worker2 Ready <none> 27h v1.22.1We see one master and two workers.
What is the Service CIDR?
➜ ssh cluster1-master1
➜ root@cluster1-master1:~# cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep range
- --service-cluster-ip-range=10.96.0.0/12Which Networking (or CNI Plugin) is configured and where is its config file?
➜ root@cluster1-master1:~# find /etc/cni/net.d/
/etc/cni/net.d/
/etc/cni/net.d/10-weave.conflist
➜ root@cluster1-master1:~# cat /etc/cni/net.d/10-weave.conflist
{
"cniVersion": "0.3.0",
"name": "weave",
...By default the kubelet looks into /etc/cni/net.d to discover the CNI plugins. This will be the same on every master and worker nodes.
Which suffix will static pods have that run on cluster1-worker1? The suffix is the node hostname with a leading hyphen. It used to be -static in earlier Kubernetes versions.
Result The resulting /opt/course/14/cluster-info could look like:
# /opt/course/14/cluster-info
# How many master nodes are available?
1: 1
# How many worker nodes are available?
2: 2
# What is the Service CIDR?
3: 10.96.0.0/12
# Which Networking (or CNI Plugin) is configured and where is its config file?
4: Weave, /etc/cni/net.d/10-weave.conflist
# Which suffix will static pods have that run on cluster1-worker1?
5: -cluster1-worker1Question 15 | Cluster Event Logging
Task weight: 3%
Use context: kubectl config use-context k8s-c2-AC
Write a command into /opt/course/15/cluster_events.sh which shows the latest events in the whole cluster, ordered by time. Use kubectl for it.
Now kill the kube-proxy Pod running on node cluster2-worker1 and write the events this caused into /opt/course/15/pod_kill.log.
Finally kill the containerd container of the kube-proxy Pod on node cluster2-worker1 and write the events into /opt/course/15/container_kill.log.
Do you notice differences in the events both actions caused?
Answer:
# /opt/course/15/cluster_events.sh
kubectl get events -A --sort-by=.metadata.creationTimestampNow we kill the kube-proxy Pod:
k -n kube-system get pod -o wide | grep proxy # find pod running on cluster2-worker1
k -n kube-system delete pod kube-proxy-z64cgNow check the events:
sh /opt/course/15/cluster_events.sh
Write the events the killing caused into /opt/course/15/pod_kill.log:
# /opt/course/15/pod_kill.log
kube-system 9s Normal Killing pod/kube-proxy-jsv7t ...
kube-system 3s Normal SuccessfulCreate daemonset/kube-proxy ...
kube-system <unknown> Normal Scheduled pod/kube-proxy-m52sx ...
default 2s Normal Starting node/cluster2-worker1 ...
kube-system 2s Normal Created pod/kube-proxy-m52sx ...
kube-system 2s Normal Pulled pod/kube-proxy-m52sx ...
kube-system 2s Normal Started pod/kube-proxy-m52sx ...Finally we will try to provoke events by killing the container belonging to the container of the kube-proxy Pod:
➜ ssh cluster2-worker1
➜ root@cluster2-worker1:~# crictl ps | grep kube-proxy
1e020b43c4423 36c4ebbc9d979 About an hour ago Running kube-proxy ...
➜ root@cluster2-worker1:~# crictl rm 1e020b43c4423
1e020b43c4423
➜ root@cluster2-worker1:~# crictl ps | grep kube-proxy
0ae4245707910 36c4ebbc9d979 17 seconds ago Running kube-proxy ...We killed the main container (1e020b43c4423), but also noticed that a new container (0ae4245707910) was directly created. Thanks Kubernetes!
Now we see if this caused events again and we write those into the second file:
sh /opt/course/15/cluster_events.sh
# /opt/course/15/container_kill.log
kube-system 13s Normal Created pod/kube-proxy-m52sx ...
kube-system 13s Normal Pulled pod/kube-proxy-m52sx ...
kube-system 13s Normal Started pod/kube-proxy-m52sx ...Comparing the events we see that when we deleted the whole Pod there were more things to be done, hence more events.
For example was the DaemonSet in the game to re-create the missing Pod.
Where when we manually killed the main container of the Pod, the Pod would still exist but only its container needed to be re-created, hence less events.
Question 16 | Namespaces and Api Resources
Task weight: 2%
Use context: kubectl config use-context k8s-c1-H
Create a new Namespace called cka-master.
Write the names of all namespaced Kubernetes resources (like Pod, Secret, ConfigMap...) into /opt/course/16/resources.txt.
Find the project-* Namespace with the highest number of Roles defined in it and write its name and amount of Roles into /opt/course/16/crowded-namespace.txt.
Answer: Namespace and Namespaces Resources We create a new Namespace:
k create ns cka-master
Now we can get a list of all resources like:
k api-resources # shows all
k api-resources -h # help always good
k api-resources --namespaced -o name > /opt/course/16/resources.txtWhich results in the file:
# /opt/course/16/resources.txt
bindings
configmaps
endpoints
events
limitranges
persistentvolumeclaims
pods
podtemplates
replicationcontrollers
resourcequotas
secrets
serviceaccounts
services
controllerrevisions.apps
daemonsets.apps
deployments.apps
replicasets.apps
statefulsets.apps
localsubjectaccessreviews.authorization.k8s.io
horizontalpodautoscalers.autoscaling
cronjobs.batch
jobs.batch
leases.coordination.k8s.io
events.events.k8s.io
ingresses.extensions
ingresses.networking.k8s.io
networkpolicies.networking.k8s.io
poddisruptionbudgets.policy
rolebindings.rbac.authorization.k8s.io
roles.rbac.authorization.k8s.ioNamespace with most Roles
➜ k -n project-c13 get role --no-headers | wc -l
No resources found in project-c13 namespace.
0
➜ k -n project-c14 get role --no-headers | wc -l
300
➜ k -n project-hamster get role --no-headers | wc -l
No resources found in project-hamster namespace.
0
➜ k -n project-snake get role --no-headers | wc -l
No resources found in project-snake namespace.
0
➜ k -n project-tiger get role --no-headers | wc -l
No resources found in project-tiger namespace.
0Finally we write the name and amount into the file:
# /opt/course/16/crowded-namespace.txt
project-c14 with 300 resourcesQuestion 17 | Find Container of Pod and check info
Task weight: 3%
Use context: kubectl config use-context k8s-c1-H
In Namespace project-tiger create a Pod named tigers-reunite of image httpd:2.4.41-alpine with labels pod=container and container=pod. Find out on which node the Pod is scheduled. Ssh into that node and find the containerd container belonging to that Pod.
Using command crictl:
Write the ID of the container and the info.runtimeType into /opt/course/17/pod-container.txt Write the logs of the container into /opt/course/17/pod-container.log
Answer: First we create the Pod:
k -n project-tiger run tigers-reunite \
--image=httpd:2.4.41-alpine \
--labels "pod=container,container=pod"Next we find out the node it's scheduled on:
k -n project-tiger get pod -o wide
or fancy:
k -n project-tiger get pod tigers-reunite -o jsonpath="{.spec.nodeName}"
Then we ssh into that node and and check the container info:
➜ ssh cluster1-worker2
➜ root@cluster1-worker2:~# crictl ps | grep tigers-reunite
b01edbe6f89ed 54b0995a63052 5 seconds ago Running tigers-reunite ...
➜ root@cluster1-worker2:~# crictl inspect b01edbe6f89ed | grep runtimeType
"runtimeType": "io.containerd.runc.v2",Then we fill the requested file (on the main terminal):
# /opt/course/17/pod-container.txt
b01edbe6f89ed io.containerd.runc.v2Finally we write the container logs in the second file:
ssh cluster1-worker2 'crictl logs b01edbe6f89ed' &> /opt/course/17/pod-container.log
The &> in above's command redirects both the standard output and standard error.
You could also simply run crictl logs on the node and copy the content manually, if its not a lot. The file should look like:
# /opt/course/17/pod-container.log
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.44.0.37. Set the 'ServerName' directive globally to suppress this message
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 10.44.0.37. Set the 'ServerName' directive globally to suppress this message
[Mon Sep 13 13:32:18.555280 2021] [mpm_event:notice] [pid 1:tid 139929534545224] AH00489: Apache/2.4.41 (Unix) configured -- resuming normal operations
[Mon Sep 13 13:32:18.555610 2021] [core:notice] [pid 1:tid 139929534545224] AH00094: Command line: 'httpd -D FOREGROUND'Question 18 | Fix Kubelet
Task weight: 8%
Use context: kubectl config use-context k8s-c3-CCC
There seems to be an issue with the kubelet not running on cluster3-worker1. Fix it and confirm that cluster has node cluster3-worker1 available in Ready state afterwards. You should be able to schedule a Pod on cluster3-worker1 afterwards.
Write the reason of the issue into /opt/course/18/reason.txt.
Answer: The procedure on tasks like these should be to check if the kubelet is running, if not start it, then check its logs and correct errors if there are some.
Always helpful to check if other clusters already have some of the components defined and running, so you can copy and use existing config files. Though in this case it might not need to be necessary.
Check node status:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready master 27h v1.22.1
cluster3-worker1 NotReady <none> 26h v1.22.1First we check if the kubelet is running:
➜ ssh cluster3-worker1
➜ root@cluster3-worker1:~# ps aux | grep kubelet
root 29294 0.0 0.2 14856 1016 pts/0 S+ 11:30 0:00 grep --color=auto kubeletNope, so we check if its configured using systemd as service:
➜ root@cluster3-worker1:~# service kubelet status
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: inactive (dead) since Sun 2019-12-08 11:30:06 UTC; 50min 52s ago
...Yes, its configured as a service with config at /etc/systemd/system/kubelet.service.d/10-kubeadm.conf, but we see its inactive. Let's try to start it:
➜ root@cluster3-worker1:~# service kubelet start
➜ root@cluster3-worker1:~# service kubelet status
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: activating (auto-restart) (Result: exit-code) since Thu 2020-04-30 22:03:10 UTC; 3s ago
Docs: https://kubernetes.io/docs/home/
Process: 5989 ExecStart=/usr/local/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=203/EXEC)
Main PID: 5989 (code=exited, status=203/EXEC)
Apr 30 22:03:10 cluster3-worker1 systemd[5989]: kubelet.service: Failed at step EXEC spawning /usr/local/bin/kubelet: No such file or directory
Apr 30 22:03:10 cluster3-worker1 systemd[1]: kubelet.service: Main process exited, code=exited, status=203/EXEC
Apr 30 22:03:10 cluster3-worker1 systemd[1]: kubelet.service: Failed with result 'exit-code'.We see its trying to execute /usr/local/bin/kubelet with some parameters defined in its service config file. A good way to find errors and get more logs is to run the command manually (usually also with its parameters).
➜ root@cluster3-worker1:~# /usr/local/bin/kubelet
-bash: /usr/local/bin/kubelet: No such file or directory➜ root@cluster3-worker1:~# whereis kubelet kubelet: /usr/bin/kubelet
Another way would be to see the extended logging of a service like using journalctl -u kubelet.
Well, there we have it, wrong path specified. Correct the path in file /etc/systemd/system/kubelet.service.d/10-kubeadm.conf and run:
vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf # fix
systemctl daemon-reload && systemctl restart kubelet
systemctl status kubelet # should now show runningAlso the node should be available for the api server, give it a bit of time though:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready master 27h v1.22.1
cluster3-worker1 Ready <none> 27h v1.22.1Finally we write the reason into the file:
# /opt/course/18/reason.txt
wrong path to kubelet binary specified in service configQuestion 19 | Create Secret and mount into Pod
Task weight: 3%
Use context: kubectl config use-context k8s-c3-CCC
Do the following in a new Namespace secret. Create a Pod named secret-pod of image busybox:1.31.1 which should keep running for some time. It should be able to run on master nodes as well, create the proper toleration.
There is an existing Secret located at /opt/course/19/secret1.yaml, create it in the secret Namespace and mount it readonly into the Pod at /tmp/secret1.
Create a new Secret in Namespace secret called secret2 which should contain user=user1 and pass=1234. These entries should be available inside the Pod's container as environment variables APP_USER and APP_PASS.
Confirm everything is working.
Answer First we create the Namespace and the requested Secrets in it:
k create ns secret
cp /opt/course/19/secret1.yaml 19_secret1.yaml
vim 19_secret1.yamlWe need to adjust the Namespace for that Secret:
# 19_secret1.yaml
apiVersion: v1
data:
halt: IyEgL2Jpbi9zaAo...
kind: Secret
metadata:
creationTimestamp: null
name: secret1
namespace: secret # changek -f 19_secret1.yaml create
Next we create the second Secret:
k -n secret create secret generic secret2 --from-literal=user=user1 --from-literal=pass=1234
Now we create the Pod template:
k -n secret run secret-pod --image=busybox:1.31.1 $do -- sh -c "sleep 5d" > 19.yaml
vim 19.yaml
Then make the necessary changes:
# 19.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: secret-pod
name: secret-pod
namespace: secret # add
spec:
tolerations: # add
- effect: NoSchedule # add
key: node-role.kubernetes.io/master # add
containers:
- args:
- sh
- -c
- sleep 1d
image: busybox:1.31.1
name: secret-pod
resources: {}
env: # add
- name: APP_USER # add
valueFrom: # add
secretKeyRef: # add
name: secret2 # add
key: user # add
- name: APP_PASS # add
valueFrom: # add
secretKeyRef: # add
name: secret2 # add
key: pass # add
volumeMounts: # add
- name: secret1 # add
mountPath: /tmp/secret1 # add
readOnly: true # add
dnsPolicy: ClusterFirst
restartPolicy: Always
volumes: # add
- name: secret1 # add
secret: # add
secretName: secret1 # add
status: {}It might not be necessary in current K8s versions to specify the readOnly: true because it's the default setting anyways.
And execute:
k -f 19.yaml create
Finally we check if all is correct:
➜ k -n secret exec secret-pod -- env | grep APP
APP_PASS=1234
APP_USER=user1
➜ k -n secret exec secret-pod -- find /tmp/secret1
/tmp/secret1
/tmp/secret1/..data
/tmp/secret1/halt
/tmp/secret1/..2019_12_08_12_15_39.463036797
/tmp/secret1/..2019_12_08_12_15_39.463036797/halt
➜ k -n secret exec secret-pod -- cat /tmp/secret1/halt
#! /bin/sh
### BEGIN INIT INFO
# Provides: halt
# Required-Start:
# Required-Stop:
# Default-Start:
# Default-Stop: 0
# Short-Description: Execute the halt command.
# Description:
...All is good.
Question 20 | Update Kubernetes Version and join cluster
Task weight: 10%
Use context: kubectl config use-context k8s-c3-CCC
Your coworker said node cluster3-worker2 is running an older Kubernetes version and is not even part of the cluster. Update Kubernetes on that node to the exact version that's running on cluster3-master1. Then add this node to the cluster. Use kubeadm for this.
Answer: Upgrade Kubernetes to cluster3-master1 version Search in the docs for kubeadm upgrade: https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready control-plane,master 116m v1.22.1
cluster3-worker1 NotReady <none> 112m v1.22.1Master node seems to be running Kubernetes 1.22.1 and cluster3-worker2 is not yet part of the cluster.
➜ ssh cluster3-worker2
➜ root@cluster3-worker2:~# kubeadm version
ubeadm version: &version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.1", GitCommit:"632ed300f2c34f6d6d15ca4cef3d3c7073412212", GitTreeState:"clean", BuildDate:"2021-08-19T15:44:22Z", GoVersion:"go1.16.7", Compiler:"gc", Platform:"linux/amd64"}
➜ root@cluster3-worker2:~# kubectl version
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.4", GitCommit:"3cce4a82b44f032d0cd1a1790e6d2f5a55d20aae", GitTreeState:"clean", BuildDate:"2021-08-11T18:16:05Z", GoVersion:"go1.16.7", Compiler:"gc", Platform:"linux/amd64"}
The connection to the server localhost:8080 was refused - did you specify the right host or port?
➜ root@cluster3-worker2:~# kubelet --version
Kubernetes v1.21.4Here kubeadm is already installed in the wanted version, so we can run:
➜ root@cluster3-worker2:~# kubeadm upgrade node
couldn't create a Kubernetes client from file "/etc/kubernetes/kubelet.conf": failed to load admin kubeconfig: open /etc/kubernetes/kubelet.conf: no such file or directory
To see the stack trace of this error execute with --v=5 or higher
This is usually the proper command to upgrade a node. But this error means that this node was never even initialised, so nothing to update here. This will be done later using kubeadm join. For now we can continue with kubelet and kubectl:
➜ root@cluster3-worker2:~# apt-get update
...
➜ root@cluster3-worker2:~# apt-cache show kubectl | grep 1.22
Version: 1.22.1-00
Filename: pool/kubectl_1.22.1-00_amd64_2a00cd912bfa610fe4932bc0a557b2dd7b95b2c8bff9d001dc6b3d34323edf7d.deb
Version: 1.22.0-00
Filename: pool/kubectl_1.22.0-00_amd64_052395d9ddf0364665cf7533aa66f96b310ec8a2b796d21c42f386684ad1fc56.deb
Filename: pool/kubectl_1.17.1-00_amd64_0dc19318c9114db2931552bb8bf650a14227a9603cb73fe0917ac7868ec7fcf0.deb
SHA256: 0dc19318c9114db2931552bb8bf650a14227a9603cb73fe0917ac7868ec7fcf0
...
➜ root@cluster3-worker2:~# apt-get install kubectl=1.22.1-00 kubelet=1.22.1-00
Reading package lists... Done
Building dependency tree
Reading state information... Done
...
Preparing to unpack .../kubectl_1.22.1-00_amd64.deb ...
Unpacking kubectl (1.22.1-00) over (1.21.4-00) ...
Preparing to unpack .../kubelet_1.22.1-00_amd64.deb ...
Unpacking kubelet (1.22.1-00) over (1.21.4-00) ...
Setting up kubectl (1.22.1-00) ...
Setting up kubelet (1.22.1-00) ...
➜ root@cluster3-worker2:~# kubelet --version
Kubernetes v1.22.1
Now we're up to date with kubeadm, kubectl and kubelet. Restart the kubelet:
➜ root@cluster3-worker2:~# systemctl restart kubelet
➜ root@cluster3-worker2:~# service kubelet status
...$KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=255)
Main PID: 21457 (code=exited, status=255)
...
Apr 30 22:15:08 cluster3-worker2 systemd[1]: kubelet.service: Main process exited, code=exited, status=255/n/a
Apr 30 22:15:08 cluster3-worker2 systemd[1]: kubelet.service: Failed with result 'exit-code'.
We can ignore the errors and move into next step to generate the join command.Add cluster3-master2 to cluster First we log into the master1 and generate a new TLS bootstrap token, also printing out the join command:
➜ ssh cluster3-master1
➜ root@cluster3-master1:~# kubeadm token create --print-join-command
kubeadm join 192.168.100.31:6443 --token leqq1l.1hlg4rw8mu7brv73 --discovery-token-ca-cert-hash sha256:2e2c3407a256fc768f0d8e70974a8e24d7b9976149a79bd08858c4d7aa2ff79a
➜ root@cluster3-master1:~# kubeadm token list
TOKEN TTL EXPIRES ...
mnkpfu.d2lpu8zypbyumr3i 23h 2020-05-01T22:43:45Z ...
poa13f.hnrs6i6ifetwii75 <forever> <never> ...
We see the expiration of 23h for our token, we could adjust this by passing the ttl argument.Next we connect again to worker2 and simply execute the join command:
➜ ssh cluster3-worker2
➜ root@cluster3-worker2:~# kubeadm join 192.168.100.31:6443 --token leqq1l.1hlg4rw8mu7brv73 --discovery-token-ca-cert-hash sha256:2e2c3407a256fc768f0d8e70974a8e24d7b9976149a79bd08858c4d7aa2ff79a
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
➜ root@cluster3-worker2:~# service kubelet status
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; vendor preset: enabled)
Drop-In: /etc/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: active (running) since Wed 2021-09-15 17:12:32 UTC; 42s ago
Docs: https://kubernetes.io/docs/home/
Main PID: 24771 (kubelet)
Tasks: 13 (limit: 467)
Memory: 68.0M
CGroup: /system.slice/kubelet.service
└─24771 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kuber>
If you have troubles with kubeadm join you might need to run kubeadm reset.This looks great though for us. Finally we head back to the main terminal and check the node status:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready control-plane,master 24h v1.22.1
cluster3-worker1 Ready <none> 24h v1.22.1
cluster3-worker2 NotReady <none> 32s v1.22.1Give it a bit of time till the node is ready.
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster3-master1 Ready control-plane,master 24h v1.22.1
cluster3-worker1 Ready <none> 24h v1.22.1
cluster3-worker2 Ready <none> 107s v1.22.1We see cluster3-worker2 is now available and up to date.
Question 21 | Create a Static Pod and Service
Task weight: 2%
Use context: kubectl config use-context k8s-c3-CCC
Create a Static Pod named my-static-pod in Namespace default on cluster3-master1. It should be of image nginx:1.16-alpine and have resource requests for 10m CPU and 20Mi memory.
Then create a NodePort Service named static-pod-service which exposes that static Pod on port 80 and check if it has Endpoints and if its reachable through the cluster3-master1 internal IP address. You can connect to the internal node IPs from your main terminal.
Answer:
➜ ssh cluster3-master1
➜ root@cluster1-master1:~# cd /etc/kubernetes/manifests/
➜ root@cluster1-master1:~# kubectl run my-static-pod \
--image=nginx:1.16-alpine \
-o yaml --dry-run=client > my-static-pod.yamlThen edit the my-static-pod.yaml to add the requested resource requests:
# /etc/kubernetes/manifests/my-static-pod.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: my-static-pod
name: my-static-pod
spec:
containers:
- image: nginx:1.16-alpine
name: my-static-pod
resources:
requests:
cpu: 10m
memory: 20Mi
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}And make sure its running:
➜ k get pod -A | grep my-static
NAMESPACE NAME READY STATUS ... AGE
default my-static-pod-cluster3-master1 1/1 Running ... 22sNow we expose that static Pod:
k expose pod my-static-pod-cluster3-master1 \
--name static-pod-service \
--type=NodePort \
--port 80This would generate a Service like:
# kubectl expose pod my-static-pod-cluster3-master1 --name static-pod-service --type=NodePort --port 80
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
labels:
run: my-static-pod
name: static-pod-service
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
run: my-static-pod
type: NodePort
status:
loadBalancer: {}Then run and test:
➜ k get svc,ep -l run=my-static-pod
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/static-pod-service NodePort 10.99.168.252 <none> 80:30352/TCP 30s
NAME ENDPOINTS AGE
endpoints/static-pod-service 10.32.0.4:80 30sLooking good.
Question 22 | Check how long certificates are valid
Task weight: 2%
Use context: kubectl config use-context k8s-c2-AC
Check how long the kube-apiserver server certificate is valid on cluster2-master1. Do this with openssl or cfssl. Write the exipiration date into /opt/course/22/expiration.
Also run the correct kubeadm command to list the expiration dates and confirm both methods show the same date.
Write the correct kubeadm command that would renew the apiserver server certificate into /opt/course/22/kubeadm-renew-certs.sh.
Answer: First let's find that certificate:
➜ ssh cluster2-master1
➜ root@cluster2-master1:~# find /etc/kubernetes/pki | grep apiserver
/etc/kubernetes/pki/apiserver.crt
/etc/kubernetes/pki/apiserver-etcd-client.crt
/etc/kubernetes/pki/apiserver-etcd-client.key
/etc/kubernetes/pki/apiserver-kubelet-client.crt
/etc/kubernetes/pki/apiserver.key
/etc/kubernetes/pki/apiserver-kubelet-client.keyNext we use openssl to find out the expiration date:
➜ root@cluster2-master1:~# openssl x509 -noout -text -in /etc/kubernetes/pki/apiserver.crt | grep Validity -A2
Validity
Not Before: Jan 14 18:18:15 2021 GMT
Not After : Jan 14 18:49:40 2022 GMTThere we have it, so we write it in the required location on our main terminal:
# /opt/course/22/expiration
Jan 14 18:49:40 2022 GMTAnd we use the feature from kubeadm to get the expiration too:
➜ root@cluster2-master1:~# kubeadm certs check-expiration | grep apiserver
apiserver Jan 14, 2022 18:49 UTC 363d ca no
apiserver-etcd-client Jan 14, 2022 18:49 UTC 363d etcd-ca no
apiserver-kubelet-client Jan 14, 2022 18:49 UTC 363d ca noLooking good. And finally we write the command that would renew all certificates into the requested location:
# /opt/course/22/kubeadm-renew-certs.sh
kubeadm certs renew apiserverQuestion 23 | Kubelet client/server cert info
Task weight: 2%
Use context: kubectl config use-context k8s-c2-AC
Node cluster2-worker1 has been added to the cluster using kubeadm and TLS bootstrapping.
Find the "Issuer" and "Extended Key Usage" values of the cluster2-worker1:
- kubelet client certificate, the one used for outgoing connections to the kube-apiserver.
- kubelet server certificate, the one used for incoming connections from the kube-apiserver.
Write the information into file /opt/course/23/certificate-info.txt.
Compare the "Issuer" and "Extended Key Usage" fields of both certificates and make sense of these.
Answer: To find the correct kubelet certificate directory, we can look for the default value of the --cert-dir parameter for the kubelet.
For this search for "kubelet" in the Kubernetes docs which will lead to: https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet.
We can check if another certificate directory has been configured using ps aux or in /etc/systemd/system/kubelet.service.d/10-kubeadm.conf.
First we check the kubelet client certificate:
➜ ssh cluster2-worker1
➜ root@cluster2-worker1:~# openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet-client-current.pem | grep Issuer
Issuer: CN = kubernetes
➜ root@cluster2-worker1:~# openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet-client-current.pem | grep "Extended Key Usage" -A1
X509v3 Extended Key Usage:
TLS Web Client AuthenticationNext we check the kubelet server certificate:
➜ root@cluster2-worker1:~# openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet.crt | grep Issuer
Issuer: CN = cluster2-worker1-ca@1588186506
➜ root@cluster2-worker1:~# openssl x509 -noout -text -in /var/lib/kubelet/pki/kubelet.crt | grep "Extended Key Usage" -A1
X509v3 Extended Key Usage:
TLS Web Server AuthenticationWe see that the server certificate was generated on the worker node itself and the client certificate was issued by the Kubernetes api. The "Extended Key Usage" also shows if its for client or server authentication.
More about this: https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet-tls-bootstrapping
Question 24 | NetworkPolicy
Task weight: 9%
Use context: kubectl config use-context k8s-c1-H
There was a security incident where an intruder was able to access the whole cluster from a single hacked backend Pod.
To prevent this create a NetworkPolicy called np-backend in Namespace project-snake. It should allow the backend-* Pods only to:
- connect to db1-* Pods on port 1111
- connect to db2-* Pods on port 2222 Use the app label of Pods in your policy.
After implementation, connections from backend-* Pods to vault-* Pods on port 3333 should for example no longer work.
Answer: First we look at the existing Pods and their labels:
➜ k -n project-snake get pod
NAME READY STATUS RESTARTS AGE
backend-0 1/1 Running 0 8s
db1-0 1/1 Running 0 8s
db2-0 1/1 Running 0 10s
vault-0 1/1 Running 0 10s
➜ k -n project-snake get pod -L app
NAME READY STATUS RESTARTS AGE APP
backend-0 1/1 Running 0 3m15s backend
db1-0 1/1 Running 0 3m15s db1
db2-0 1/1 Running 0 3m17s db2
vault-0 1/1 Running 0 3m17s vaultWe test the current connection situation and see nothing is restricted:
➜ k -n project-snake get pod -o wide
NAME READY STATUS RESTARTS AGE IP ...
backend-0 1/1 Running 0 4m14s 10.44.0.24 ...
db1-0 1/1 Running 0 4m14s 10.44.0.25 ...
db2-0 1/1 Running 0 4m16s 10.44.0.23 ...
vault-0 1/1 Running 0 4m16s 10.44.0.22 ...
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.25:1111
database one
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.23:2222
database two
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.22:3333
vault secret storageNow we create the NP by copying and chaning an example from the k8s docs:
vim 24_np.yaml
# 24_np.yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: np-backend
namespace: project-snake
spec:
podSelector:
matchLabels:
app: backend
policyTypes:
- Egress # policy is only about Egress
egress:
- # first rule
to: # first condition "to"
- podSelector:
matchLabels:
app: db1
ports: # second condition "port"
- protocol: TCP
port: 1111
- # second rule
to: # first condition "to"
- podSelector:
matchLabels:
app: db2
ports: # second condition "port"
- protocol: TCP
port: 2222The NP above has two rules with two conditions each, it can be read as:
allow outgoing traffic if:
(destination pod has label app=db1 AND port is 1111)
OR
(destination pod has label app=db2 AND port is 2222)Wrong example Now let's shortly look at a wrong example:
# WRONG
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: np-backend
namespace: project-snake
spec:
podSelector:
matchLabels:
app: backend
policyTypes:
- Egress
egress:
- # first rule
to: # first condition "to"
- podSelector: # first "to" possibility
matchLabels:
app: db1
- podSelector: # second "to" possibility
matchLabels:
app: db2
ports: # second condition "ports"
- protocol: TCP # first "ports" possibility
port: 1111
- protocol: TCP # second "ports" possibility
port: 2222The NP above has one rule with two conditions and two condition-entries each, it can be read as:
allow outgoing traffic if:
(destination pod has label app=db1 OR destination pod has label app=db2)
AND
(destination port is 1111 OR destination port is 2222)Using this NP it would still be possible for backend-* Pods to connect to db2-* Pods on port 1111 for example which should be forbidden.
Create NetworkPolicy We create the correct NP:
k -f 24_np.yaml create
And test again:
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.25:1111
database one
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.23:2222
database two
➜ k -n project-snake exec backend-0 -- curl -s 10.44.0.22:3333
^CAlso helpful to use kubectl describe on the NP to see how k8s has interpreted the policy.
Great, looking more secure. Task done.
Question 25 | Etcd Snapshot Save and Restore
Task weight: 8%
Use context: kubectl config use-context k8s-c3-CCC
Make a backup of etcd running on cluster3-master1 and save it on the master node at /tmp/etcd-backup.db.
Then create a Pod of your kind in the cluster.
Finally restore the backup, confirm the cluster is still working and that the created Pod is no longer with us.
Answer: Etcd Backup First we log into the master and try to create a snapshop of etcd:
➜ ssh cluster3-master1
➜ root@cluster3-master1:~# ETCDCTL_API=3 etcdctl snapshot save /tmp/etcd-backup.db
Error: rpc error: code = Unavailable desc = transport is closingBut it fails because we need to authenticate ourselves. For the necessary information we can check the etc manifest:
➜ root@cluster3-master1:~# vim /etc/kubernetes/manifests/etcd.yamlWe only check the etcd.yaml for necessary information we don't change it.
# /etc/kubernetes/manifests/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.100.31:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt # use
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --initial-advertise-peer-urls=https://192.168.100.31:2380
- --initial-cluster=cluster3-master1=https://192.168.100.31:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key # use
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.100.31:2379 # use
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.100.31:2380
- --name=cluster3-master1
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt # use
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: k8s.gcr.io/etcd:3.3.15-0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
host: 127.0.0.1
path: /health
port: 2381
scheme: HTTP
initialDelaySeconds: 15
timeoutSeconds: 15
name: etcd
resources: {}
volumeMounts:
- mountPath: /var/lib/etcd
name: etcd-data
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd # important
type: DirectoryOrCreate
name: etcd-data
status: {}But we also know that the api-server is connecting to etcd, so we can check how its manifest is configured:
➜ root@cluster3-master1:~# cat /etc/kubernetes/manifests/kube-apiserver.yaml | grep etcd
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --etcd-servers=https://127.0.0.1:2379We use the authentication information and pass it to etcdctl:
➜ root@cluster3-master1:~# ETCDCTL_API=3 etcdctl snapshot save /tmp/etcd-backup.db \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.keySnapshot saved at /tmp/etcd-backup.db
NOTE: Dont use snapshot status because it can alter the snapshot file and render it invalid
Etcd restore
Now create a Pod in the cluster and wait for it to be running:
➜ root@cluster3-master1:~# kubectl run test --image=nginx
pod/test created
➜ root@cluster3-master1:~# kubectl get pod -l run=test -w
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 60sNOTE: If you didn't solve questions 18 or 20 and cluster3 doesn't have a ready worker node then the created pod might stay in a Pending state. This is still ok for this task.
Next we stop all controlplane components:
root@cluster3-master1:~# cd /etc/kubernetes/manifests/
root@cluster3-master1:/etc/kubernetes/manifests# mv * ..
root@cluster3-master1:/etc/kubernetes/manifests# watch crictl psNow we restore the snapshot into a specific directory:
➜ root@cluster3-master1:~# ETCDCTL_API=3 etcdctl snapshot restore /tmp/etcd-backup.db \
--data-dir /var/lib/etcd-backup \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.key
2020-09-04 16:50:19.650804 I | mvcc: restore compact to 9935
2020-09-04 16:50:19.659095 I | etcdserver/membership: added member 8e9e05c52164694d [http://localhost:2380] to cluster cdf818194e3a8c32We could specify another host to make the backup from by using etcdctl --endpoints http://IP, but here we just use the default value which is: http://127.0.0.1:2379,http://127.0.0.1:4001.
The restored files are located at the new folder /var/lib/etcd-backup, now we have to tell etcd to use that directory:
➜ root@cluster3-master1:~# vim /etc/kubernetes/etcd.yaml
# /etc/kubernetes/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
...
- mountPath: /etc/kubernetes/pki/etcd
name: etcd-certs
hostNetwork: true
priorityClassName: system-cluster-critical
volumes:
- hostPath:
path: /etc/kubernetes/pki/etcd
type: DirectoryOrCreate
name: etcd-certs
- hostPath:
path: /var/lib/etcd-backup # change
type: DirectoryOrCreate
name: etcd-data
status: {}Now we move all controlplane yaml again into the manifest directory. Give it some time (up to several minutes) for etcd to restart and for the api-server to be reachable again:
root@cluster3-master1:/etc/kubernetes/manifests# mv ../*.yaml .
root@cluster3-master1:/etc/kubernetes/manifests# watch crictl psThen we check again for the Pod:
➜ root@cluster3-master1:~# kubectl get pod -l run=test
No resources found in default namespace.Awesome, backup and restore worked as our pod is gone.
Extra Question 1 | Find Pods first to be terminated
Use context: kubectl config use-context k8s-c1-H
Check all available Pods in the Namespace project-c13 and find the names of those that would probably be terminated first if the nodes run out of resources (cpu or memory) to schedule all Pods. Write the Pod names into /opt/course/e1/pods-not-stable.txt.
Answer: When available cpu or memory resources on the nodes reach their limit, Kubernetes will look for Pods that are using more resources than they requested. These will be the first candidates for termination. If some Pods containers have no resource requests/limits set, then by default those are considered to use more than requested.
Kubernetes assigns Quality of Service classes to Pods based on the defined resources and limits, read more here: https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod
Hence we should look for Pods without resource requests defined, we can do this with a manual approach:
k -n project-c13 describe pod | less -p Requests # describe all pods and highlight Requests
Or we do:
k -n project-c13 describe pod | egrep "^(Name:| Requests:)" -A1
We see that the Pods of Deployment c13-3cc-runner-heavy don't have any resources requests specified. Hence our answer would be:
# /opt/course/e1/pods-not-stable.txt
c13-3cc-runner-heavy-65588d7d6-djtv9map
c13-3cc-runner-heavy-65588d7d6-v8kf5map
c13-3cc-runner-heavy-65588d7d6-wwpb4map
o3db-0
o3db-1 # maybe not existing if already removed via previous scenarioTo automate this process you could use jsonpath like this:
➜ k -n project-c13 get pod \
-o jsonpath="{range .items[*]} {.metadata.name}{.spec.containers[*].resources}{'\n'}"
c13-2x3-api-86784557bd-cgs8gmap[requests:map[cpu:50m memory:20Mi]]
c13-2x3-api-86784557bd-lnxvjmap[requests:map[cpu:50m memory:20Mi]]
c13-2x3-api-86784557bd-mnp77map[requests:map[cpu:50m memory:20Mi]]
c13-2x3-web-769c989898-6hbgtmap[requests:map[cpu:50m memory:10Mi]]
c13-2x3-web-769c989898-g57nqmap[requests:map[cpu:50m memory:10Mi]]
c13-2x3-web-769c989898-hfd5vmap[requests:map[cpu:50m memory:10Mi]]
c13-2x3-web-769c989898-jfx64map[requests:map[cpu:50m memory:10Mi]]
c13-2x3-web-769c989898-r89mgmap[requests:map[cpu:50m memory:10Mi]]
c13-2x3-web-769c989898-wtgxlmap[requests:map[cpu:50m memory:10Mi]]
c13-3cc-runner-98c8b5469-dzqhrmap[requests:map[cpu:30m memory:10Mi]]
c13-3cc-runner-98c8b5469-hbtdvmap[requests:map[cpu:30m memory:10Mi]]
c13-3cc-runner-98c8b5469-n9lswmap[requests:map[cpu:30m memory:10Mi]]
c13-3cc-runner-heavy-65588d7d6-djtv9map[]
c13-3cc-runner-heavy-65588d7d6-v8kf5map[]
c13-3cc-runner-heavy-65588d7d6-wwpb4map[]
c13-3cc-web-675456bcd-glpq6map[requests:map[cpu:50m memory:10Mi]]
c13-3cc-web-675456bcd-knlpxmap[requests:map[cpu:50m memory:10Mi]]
c13-3cc-web-675456bcd-nfhp9map[requests:map[cpu:50m memory:10Mi]]
c13-3cc-web-675456bcd-twn7mmap[requests:map[cpu:50m memory:10Mi]]
o3db-0{}
o3db-1{}This lists all Pod names and their requests/limits, hence we see the three Pods without those defined.
Or we look for the Quality of Service classes:
➜ k get pods -n project-c13 \
-o jsonpath="{range .items[*]}{.metadata.name} {.status.qosClass}{'\n'}"
c13-2x3-api-86784557bd-cgs8g Burstable
c13-2x3-api-86784557bd-lnxvj Burstable
c13-2x3-api-86784557bd-mnp77 Burstable
c13-2x3-web-769c989898-6hbgt Burstable
c13-2x3-web-769c989898-g57nq Burstable
c13-2x3-web-769c989898-hfd5v Burstable
c13-2x3-web-769c989898-jfx64 Burstable
c13-2x3-web-769c989898-r89mg Burstable
c13-2x3-web-769c989898-wtgxl Burstable
c13-3cc-runner-98c8b5469-dzqhr Burstable
c13-3cc-runner-98c8b5469-hbtdv Burstable
c13-3cc-runner-98c8b5469-n9lsw Burstable
c13-3cc-runner-heavy-65588d7d6-djtv9 BestEffort
c13-3cc-runner-heavy-65588d7d6-v8kf5 BestEffort
c13-3cc-runner-heavy-65588d7d6-wwpb4 BestEffort
c13-3cc-web-675456bcd-glpq6 Burstable
c13-3cc-web-675456bcd-knlpx Burstable
c13-3cc-web-675456bcd-nfhp9 Burstable
c13-3cc-web-675456bcd-twn7m Burstable
o3db-0 BestEffort
o3db-1 BestEffortHere we see three with BestEffort, which Pods get that don't have any memory or cpu limits or requests defined.
A good practice is to always set resource requests and limits.
If you don't know the values your containers should have you can find this out using metric tools like Prometheus.
You can also use kubectl top pod or even kubectl exec into the container and use top and similar tools.
Extra Question 2 | Curl Manually Contact API
Use context: kubectl config use-context k8s-c1-H
There is an existing ServiceAccount secret-reader in Namespace project-hamster. Create a Pod of image curlimages/curl:7.65.3 named tmp-api-contact which uses this ServiceAccount. Make sure the container keeps running.
Exec into the Pod and use curl to access the Kubernetes Api of that cluster manually, listing all available secrets. You can ignore insecure https connection. Write the command(s) for this into file /opt/course/e4/list-secrets.sh.
Answer: https://kubernetes.io/docs/tasks/run-application/access-api-from-pod
It's important to understand how the Kubernetes API works. For this it helps connecting to the api manually, for example using curl. You can find information fast by search in the Kubernetes docs for "curl api" for example.
First we create our Pod:
k run tmp-api-contact \
--image=curlimages/curl:7.65.3 $do \
--command > e2.yaml -- sh -c 'sleep 1d'
vim e2.yamlAdd the service account name and Namespace:
# e2.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: tmp-api-contact
name: tmp-api-contact
namespace: project-hamster # add
spec:
serviceAccountName: secret-reader # add
containers:
- command:
- sh
- -c
- sleep 1d
image: curlimages/curl:7.65.3
name: tmp-api-contact
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}Then run and exec into:
k -f 6.yaml create
k -n project-hamster exec tmp-api-contact -it -- shOnce on the container we can try to connect to the api using curl, the api is usually available via the Service named kubernetes in Namespace default (You should know how dns resolution works across Namespaces.). Else we can find the endpoint IP via environment variables running env.
So now we can do:
curl https://kubernetes.default
curl -k https://kubernetes.default # ignore insecure as allowed in ticket description
curl -k https://kubernetes.default/api/v1/secrets # should show Forbidden 403The last command shows 403 forbidden, this is because we are not passing any authorisation information with us. The Kubernetes Api Server thinks we are connecting as system:anonymous. We want to change this and connect using the Pods ServiceAccount named secret-reader.
We find the the token in the mounted folder at /var/run/secrets/kubernetes.io/serviceaccount, so we do:
➜ TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
➜ curl -k https://kubernetes.default/api/v1/secrets -H "Authorization: Bearer ${TOKEN}"
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0{
"kind": "SecretList",
"apiVersion": "v1",
"metadata": {
"selfLink": "/api/v1/secrets",
"resourceVersion": "10697"
},
"items": [
{
"metadata": {
"name": "default-token-5zjbd",
"namespace": "default",
"selfLink": "/api/v1/namespaces/default/secrets/default-token-5zjbd",
"uid": "315dbfd9-d235-482b-8bfc-c6167e7c1461",
"resourceVersion": "342",
...Now we're able to list all Secrets, registering as the ServiceAccount secret-reader under which our Pod is running.
To use encrypted https connection we can run:
CACERT=/var/run/secrets/kubernetes.io/serviceaccount/ca.crt
curl --cacert ${CACERT} https://kubernetes.default/api/v1/secrets -H "Authorization: Bearer ${TOKEN}"For troubleshooting we could also check if the ServiceAccount is actually able to list Secrets using:
➜ k auth can-i get secret --as system:serviceaccount:project-hamster:secret-reader
yesFinally write the commands into the requested location:
# /opt/course/e4/list-secrets.sh
TOKEN=$(cat /var/run/secrets/kubernetes.io/serviceaccount/token)
curl -k https://kubernetes.default/api/v1/secrets -H "Authorization: Bearer ${TOKEN}"CKA Simulator Preview Kubernetes 1.22
This is a preview of the full CKA Simulator course content.
The full course contains 25 scenarios from all the CKA areas. The course also provides a browser terminal which is a very close replica of the original one. This is great to get used and comfortable before the real exam. After the test session (120 minutes), or if you stop it early, you'll get access to all questions and their detailed solutions. You'll have 36 hours cluster access in total which means even after the session, once you have the solutions, you can still play around.
The following preview will give you an idea of what the full course will provide. These preview questions are in addition to the 25 of the full course. But the preview questions are part of the same CKA simulation environment which we setup for you, so with access to the full course you can solve these too.
The answers provided here assume that you did run the initial terminal setup suggestions as provided in the tips section, but especially:
alias k=kubectl
export do="-o yaml --dry-run=client"These questions can be solved in the test environment provided through the CKA Simulator
Preview Question 1
Use context: kubectl config use-context k8s-c2-AC
The cluster admin asked you to find out the following information about etcd running on cluster2-master1:
- Server private key location
- Server certificate expiration date
- Is client certificate authentication enabled Write these information into /opt/course/p1/etcd-info.txt
Finally you're asked to save an etcd snapshot at /etc/etcd-snapshot.db on cluster2-master1 and display its status.
Answer: Find out etcd information Let's check the nodes:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster2-master1 Ready master 89m v1.22.1
cluster2-worker1 Ready <none> 87m v1.22.1
➜ ssh cluster2-master1First we check how etcd is setup in this cluster:
➜ root@cluster2-master1:~# kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-k8f48 1/1 Running 0 26h
coredns-66bff467f8-rn8tr 1/1 Running 0 26h
etcd-cluster2-master1 1/1 Running 0 26h
kube-apiserver-cluster2-master1 1/1 Running 0 26h
kube-controller-manager-cluster2-master1 1/1 Running 0 26h
kube-proxy-qthfg 1/1 Running 0 25h
kube-proxy-z55lp 1/1 Running 0 26h
kube-scheduler-cluster2-master1 1/1 Running 1 26h
weave-net-cqdvt 2/2 Running 0 26h
weave-net-dxzgh 2/2 Running 1 25hWe see its running as a Pod, more specific a static Pod. So we check for the default kubelet directory for static manifests:
➜ root@cluster2-master1:~# find /etc/kubernetes/manifests/
/etc/kubernetes/manifests/
/etc/kubernetes/manifests/kube-controller-manager.yaml
/etc/kubernetes/manifests/kube-apiserver.yaml
/etc/kubernetes/manifests/etcd.yaml
/etc/kubernetes/manifests/kube-scheduler.yaml
➜ root@cluster2-master1:~# vim /etc/kubernetes/manifests/etcd.yamlSo we look at the yaml and the parameters with which etcd is started:
# /etc/kubernetes/manifests/etcd.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://192.168.102.11:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt # server certificate
- --client-cert-auth=true # enabled
- --data-dir=/var/lib/etcd
- --initial-advertise-peer-urls=https://192.168.102.11:2380
- --initial-cluster=cluster2-master1=https://192.168.102.11:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key # server private key
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.102.11:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://192.168.102.11:2380
- --name=cluster2-master1
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
...We see that client authentication is enabled and also the requested path to the server private key, now let's find out the expiration of the server certificate:
➜ root@cluster2-master1:~# openssl x509 -noout -text -in /etc/kubernetes/pki/etcd/server.crt | grep Validity -A2
Validity
Not Before: Sep 13 13:01:31 2021 GMT
Not After : Sep 13 13:01:31 2022 GMTThere we have it. Let's write the information into the requested file:
# /opt/course/p1/etcd-info.txt
Server private key location: /etc/kubernetes/pki/etcd/server.key
Server certificate expiration date: Sep 13 13:01:31 2022 GMT
Is client certificate authentication enabled: yesCreate etcd snapshot First we try:
ETCDCTL_API=3 etcdctl snapshot save /etc/etcd-snapshot.db
We get the endpoint also from the yaml. But we need to specify more parameters, all of which we can find the yaml declaration above:
ETCDCTL_API=3 etcdctl snapshot save /etc/etcd-snapshot.db \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.keyThis worked. Now we can output the status of the backup file:
➜ root@cluster2-master1:~# ETCDCTL_API=3 etcdctl snapshot status /etc/etcd-snapshot.db
4d4e953, 7213, 1291, 2.7 MBThe status shows:
- Hash: 4d4e953
- Revision: 7213
- Total Keys: 1291
- Total Size: 2.7 MB
Preview Question 2
Use context: kubectl config use-context k8s-c1-H
You're asked to confirm that kube-proxy is running correctly on all nodes. For this perform the following in Namespace project-hamster:
Create a new Pod named p2-pod with two containers, one of image nginx:1.21.3-alpine and one of image busybox:1.31. Make sure the busybox container keeps running for some time.
Create a new Service named p2-service which exposes that Pod internally in the cluster on port 3000->80.
Find the kube-proxy container on all nodes cluster1-master1, cluster1-worker1 and cluster1-worker2 and make sure that it's using iptables. Use command crictl for this.
Write the iptables rules of all nodes belonging the created Service p2-service into file /opt/course/p2/iptables.txt.
Finally delete the Service and confirm that the iptables rules are gone from all nodes.
Answer: Create the Pod First we create the Pod:
# check out export statement on top which allows us to use $do
k run p2-pod --image=nginx:1.21.3-alpine $do > p2.yaml
vim p2.yamlNext we add the requested second container:
# p2.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: p2-pod
name: p2-pod
namespace: project-hamster # add
spec:
containers:
- image: nginx:1.21.3-alpine
name: p2-pod
- image: busybox:1.31 # add
name: c2 # add
command: ["sh", "-c", "sleep 1d"] # add
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}And we create the Pod:
k -f p2.yaml create
Create the Service Next we create the Service:
k -n project-hamster expose pod p2-pod --name p2-service --port 3000 --target-port 80
This will create a yaml like:
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2020-04-30T20:58:14Z"
labels:
run: p2-pod
managedFields:
...
operation: Update
time: "2020-04-30T20:58:14Z"
name: p2-service
namespace: project-hamster
resourceVersion: "11071"
selfLink: /api/v1/namespaces/project-hamster/services/p2-service
uid: 2a1c0842-7fb6-4e94-8cdb-1602a3b1e7d2
spec:
clusterIP: 10.97.45.18
ports:
- port: 3000
protocol: TCP
targetPort: 80
selector:
run: p2-pod
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}We should confirm Pods and Services are connected, hence the Service should have Endpoints.
k -n project-hamster get pod,svc,ep
Confirm kube-proxy is running and is using iptables First we get nodes in the cluster:
➜ k get node
NAME STATUS ROLES AGE VERSION
cluster1-master1 Ready master 98m v1.22.1
cluster1-worker1 Ready <none> 96m v1.22.1
cluster1-worker2 Ready <none> 95m v1.22.1The idea here is to log into every node, find the kube-proxy container and check its logs:
➜ ssh cluster1-master1
➜ root@cluster1-master1$ crictl ps | grep kube-proxy
27b6a18c0f89c 36c4ebbc9d979 3 hours ago Running kube-proxy
➜ root@cluster1-master1~# crictl logs 27b6a18c0f89c
...
I0913 12:53:03.096620 1 server_others.go:212] Using iptables Proxier.
...This should be repeated on every node and result in the same output Using iptables Proxier.
Check kube-proxy is creating iptables rules
Now we check the iptables rules on every node first manually:
➜ ssh cluster1-master1 iptables-save | grep p2-service
-A KUBE-SEP-6U447UXLLQIKP7BB -s 10.44.0.20/32 -m comment --comment "project-hamster/p2-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-6U447UXLLQIKP7BB -p tcp -m comment --comment "project-hamster/p2-service:" -m tcp -j DNAT --to-destination 10.44.0.20:80
-A KUBE-SERVICES ! -s 10.244.0.0/16 -d 10.97.45.18/32 -p tcp -m comment --comment "project-hamster/p2-service: cluster IP" -m tcp --dport 3000 -j KUBE-MARK-MASQ
-A KUBE-SERVICES -d 10.97.45.18/32 -p tcp -m comment --comment "project-hamster/p2-service: cluster IP" -m tcp --dport 3000 -j KUBE-SVC-2A6FNMCK6FDH7PJH
-A KUBE-SVC-2A6FNMCK6FDH7PJH -m comment --comment "project-hamster/p2-service:" -j KUBE-SEP-6U447UXLLQIKP7BB
➜ ssh cluster1-worker1 iptables-save | grep p2-service
-A KUBE-SEP-6U447UXLLQIKP7BB -s 10.44.0.20/32 -m comment --comment "project-hamster/p2-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-6U447UXLLQIKP7BB -p tcp -m comment --comment "project-hamster/p2-service:" -m tcp -j DNAT --to-destination 10.44.0.20:80
-A KUBE-SERVICES ! -s 10.244.0.0/16 -d 10.97.45.18/32 -p tcp -m comment --comment "project-hamster/p2-service: cluster IP" -m tcp --dport 3000 -j KUBE-MARK-MASQ
-A KUBE-SERVICES -d 10.97.45.18/32 -p tcp -m comment --comment "project-hamster/p2-service: cluster IP" -m tcp --dport 3000 -j KUBE-SVC-2A6FNMCK6FDH7PJH
-A KUBE-SVC-2A6FNMCK6FDH7PJH -m comment --comment "project-hamster/p2-service:" -j KUBE-SEP-6U447UXLLQIKP7BB
➜ ssh cluster1-worker2 iptables-save | grep p2-service
-A KUBE-SEP-6U447UXLLQIKP7BB -s 10.44.0.20/32 -m comment --comment "project-hamster/p2-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-6U447UXLLQIKP7BB -p tcp -m comment --comment "project-hamster/p2-service:" -m tcp -j DNAT --to-destination 10.44.0.20:80
-A KUBE-SERVICES ! -s 10.244.0.0/16 -d 10.97.45.18/32 -p tcp -m comment --comment "project-hamster/p2-service: cluster IP" -m tcp --dport 3000 -j KUBE-MARK-MASQ
-A KUBE-SERVICES -d 10.97.45.18/32 -p tcp -m comment --comment "project-hamster/p2-service: cluster IP" -m tcp --dport 3000 -j KUBE-SVC-2A6FNMCK6FDH7PJH
-A KUBE-SVC-2A6FNMCK6FDH7PJH -m comment --comment "project-hamster/p2-service:" -j KUBE-SEP-6U447UXLLQIKP7BBGreat. Now let's write these logs into the requested file:
➜ ssh cluster1-master1 iptables-save | grep p2-service >> /opt/course/p2/iptables.txt
➜ ssh cluster1-worker1 iptables-save | grep p2-service >> /opt/course/p2/iptables.txt
➜ ssh cluster1-worker2 iptables-save | grep p2-service >> /opt/course/p2/iptables.txtDelete the Service and confirm iptables rules are gone Delete the Service:
k -n project-hamster delete svc p2-service
And confirm the iptables rules are gone:
➜ ssh cluster1-master1 iptables-save | grep p2-service
➜ ssh cluster1-worker1 iptables-save | grep p2-service
➜ ssh cluster1-worker2 iptables-save | grep p2-serviceDone.
Kubernetes Services are implemented using iptables rules (with default config) on all nodes. Every time a Service has been altered, created, deleted or Endpoints of a Service have changed, the kube-apiserver contacts every node's kube-proxy to update the iptables rules according to the current state.
Preview Question 3
Use context: kubectl config use-context k8s-c2-AC
Create a Pod named check-ip in Namespace default using image httpd:2.4.41-alpine. Expose it on port 80 as a ClusterIP Service named check-ip-service. Remember/output the IP of that Service.
Change the Service CIDR to 11.96.0.0/12 for the cluster.
Then create a second Service named check-ip-service2 pointing to the same Pod to check if your settings did take effect. Finally check if the IP of the first Service has changed.
Answer: Let's create the Pod and expose it:
k run check-ip --image=httpd:2.4.41-alpine
k expose pod check-ip --name check-ip-service --port 80And check the Pod and Service ips:
➜ k get svc,ep -l run=check-ip
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/check-ip-service ClusterIP 10.104.3.45 <none> 80/TCP 8s
NAME ENDPOINTS AGE
endpoints/check-ip-service 10.44.0.3:80 7sNow we change the Service CIDR on the kube-apiserver:
➜ ssh cluster2-master1
➜ root@cluster2-master1:~# vim /etc/kubernetes/manifests/kube-apiserver.yaml# /etc/kubernetes/manifests/kube-apiserver.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-apiserver
tier: control-plane
name: kube-apiserver
namespace: kube-system
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=192.168.100.21
...
- --service-account-key-file=/etc/kubernetes/pki/sa.pub
- --service-cluster-ip-range=11.96.0.0/12 # change
- --tls-cert-file=/etc/kubernetes/pki/apiserver.crt
- --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
...Give it a bit for the kube-apiserver and controller-manager to restart
Wait for the api to be up again:
➜ root@cluster2-master1:~# kubectl -n kube-system get pod | grep api
kube-apiserver-cluster2-master1 1/1 Running 0 49sNow we do the same for the controller manager:
➜ root@cluster2-master1:~# vim /etc/kubernetes/manifests/kube-controller-manager.yaml
# /etc/kubernetes/manifests/kube-controller-manager.yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
component: kube-controller-manager
tier: control-plane
name: kube-controller-manager
namespace: kube-system
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=127.0.0.1
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=10.244.0.0/16
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
- --node-cidr-mask-size=24
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --root-ca-file=/etc/kubernetes/pki/ca.crt
- --service-account-private-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=11.96.0.0/12 # change
- --use-service-account-credentials=trueGive it a bit for the controller-manager to restart.
We can check if it was restarted using crictl:
➜ root@cluster2-master1:~# crictl ps | grep scheduler
3d258934b9fd6 aca5ededae9c8 About a minute ago Running kube-scheduler ...Checking our existing Pod and Service again:
➜ k get pod,svc -l run=check-ip
NAME READY STATUS RESTARTS AGE
pod/check-ip 1/1 Running 0 21m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/check-ip-service ClusterIP 10.99.32.177 <none> 80/TCP 21mNothing changed so far. Now we create another Service like before:
k expose pod check-ip --name check-ip-service2 --port 80
And check again:
➜ k get svc,ep -l run=check-ip
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/check-ip-service ClusterIP 10.109.222.111 <none> 80/TCP 8m
service/check-ip-service2 ClusterIP 11.111.108.194 <none> 80/TCP 6m32s
NAME ENDPOINTS AGE
endpoints/check-ip-service 10.44.0.1:80 8m
endpoints/check-ip-service2 10.44.0.1:80 6m13sThere we go, the new Service got an ip of the new specified range assigned. We also see that both Services have our Pod as endpoint.
CKA Tips Kubernetes 1.22
In this section we'll provide some tips on how to handle the CKA exam and browser terminal.
Knowledge
Study all topics as proposed in the curriculum till you feel comfortable with all.
Resources
The majority of tasks in the CKA will also be around creating Kubernetes resources, like its tested in the CKAD. So we suggest to do:
- Maybe 2–3 times https://github.com/dgkanatsios/CKAD-exercises
- The CKAD series with scenarios on Medium
- The CKA series with scenarios on Medium
- Imagine and create your own scenarios to solve
- Know advanced scheduling: https://kubernetes.io/docs/concepts/scheduling/kube-scheduler
Components
- The other part is understanding Kubernetes components and being able to fix and investigate clusters. Understand this: https://kubernetes.io/docs/tasks/debug-application-cluster/debug-cluster
- When you have to fix a component (like kubelet) in one cluster, just check how its setup on another node in the same or even another cluster. You can copy config files over etc
- If you like you can look at Kubernetes The Hard Way once. But it's NOT necessary to do, the CKA is not that complex. But KTHW helps understanding the concepts
- You should install your own cluster using kubeadm (one master, one worker) in a VM or using a cloud provider and investigate the components
- Know how to use kubeadm to for example add nodes to a cluster
- Know how to create an Ingress resources
- Know how to snapshot/restore ETCD from another machine
General
Do 1 or 2 test session with this CKA Simulator. Understand the solutions and maybe try out other ways to achieve the same thing.
Setup your aliases, be fast and breath kubectl
CKA Preparation
Read the Curriculum
https://github.com/cncf/curriculum
Read the Handbook
https://docs.linuxfoundation.org/tc-docs/certification/lf-candidate-handbook
Read the important tips
https://docs.linuxfoundation.org/tc-docs/certification/tips-cka-and-ckad
Read the FAQ
https://docs.linuxfoundation.org/tc-docs/certification/faq-cka-ckad
Kubernetes documentation
Get familiar with the Kubernetes documentation and be able to use the search. You can have one browser tab open with one of the allowed links: https://kubernetes.io/docs https://github.com/kubernetes https://kubernetes.io/blog
NOTE: You can have the other tab open as a separate window, this is why a big screen is handy
Deprecated commands
Make sure to not depend on deprecated commands as they might stop working at any time. When you execute a deprecated kubectl command a message will be shown, so you know which ones to avoid.
With kubectl version 1.18+ things have changed. Like its no longer possible to use kubectl run to create Jobs, CronJobs or Deployments, only Pods still work. This makes things a bit more verbose when you for example need to create a Deployment with resource limits or multiple replicas.
What if we need to create a Deployment which has, for example, a resources section? We could use both kubectl run and kubectl create, then do some vim magic. Read more here.
The Test Environment / Browser Terminal
You'll be provided with a browser terminal which uses Ubuntu 20. The standard shells included with a minimal install of Ubuntu 20 will be available, including bash.
Laggin
There could be some lagging, definitely make sure you are using a good internet connection because your webcam and screen are uploading all the time.
Kubectl autocompletion and commands
Autocompletion is configured by default, as well as the k alias source and others:
kubectl with k alias and Bash autocompletion
yq and jqfor YAML/JSON processing
tmux for terminal multiplexing
curl and wget for testing web services
man and man pages for further documentation
Copy & Paste
There could be issues copying text (like pod names) from the left task information into the terminal. Some suggested to "hard" hit or long hold Cmd/Ctrl+C a few times to take action. Apart from that copy and paste should just work like in normal terminals.
Percentages and Score
There are 15-20 questions in the exam and 100% of total percentage to reach. Each questions shows the % it gives if you solve it. Your results will be automatically checked according to the handbook. If you don't agree with the results you can request a review by contacting the Linux Foundation support.
Notepad & Skipping Questions
You have access to a simple notepad in the browser which can be used for storing any kind of plain text. It makes sense to use this for saving skipped question numbers and their percentages. This way it's possible to move some questions to the end. It might make sense to skip 2% or 3% questions and go directly to higher ones.
Contexts
You'll receive access to various different clusters and resources in each. They provide you the exact command you need to run to connect to another cluster/context. But you should be comfortable working in different namespaces with kubectl.
Your Desktop
You are allowed to have multiple monitors connected and have to share every monitor with the proctor. Having one large screen definitely helps as you’re only allowed one application open (Chrome Browser) with two tabs, one terminal and one k8s docs.
NOTE: You can have the other tab open as a separate window, this is why a big screen is handy
The questions will be on the left (default maybe ~30% space), the terminal on the right. You can adjust the size of the split though to your needs in the real exam.
If you use a laptop you could work with lid closed, external mouse+keyboard+monitor attached. Make sure you also have a webcam+microphone working.
You could also have both monitors, laptop screen and external, active. You might be asked that your webcam points straight into your face. So using an external screen and your laptop webcam could not be accepted. Just keep that in mind.
You have to be able to move your webcam around in the beginning to show your whole room and desktop. Have a clean desk with only the necessary on it. You can have a glass/cup with water without anything printed on.
In the end you should feel very comfortable with your setup.
Browser Terminal Setup
It should be considered to spend ~1 minute in the beginning to setup your terminal. In the real exam the vast majority of questions will be done from the main terminal. For few you might need to ssh into another machine. Just be aware that configurations to your shell will not be transferred in this case.
Minimal Setup
Alias
The alias k for kubectl will be configured together with autocompletion. In case not you can configure it using this link.
Vim
Create the file ~/.vimrc with the following content:
set tabstop=2
set expandtab
set shiftwidth=2The expandtab make sure to use spaces for tabs. Memorize these and just type them down. You can't have any written notes with commands on your desktop etc.
Optional Setup
Fast dry-run output
export do="--dry-run=client -o yaml"
This way you can just run k run pod1 --image=nginx $do. Short for "dry output", but use whatever name you like.
Fast pod delete
export now="--force --grace-period 0"#
This way you can run k delete pod1 $now and don't have to wait for ~30 seconds termination time.
Persist bash settings
You can store aliases and other setup in ~/.bashrc if you're planning on using different shells or tmux.
Be fast
Use the history command to reuse already entered commands or use even faster history search through Ctrl r .
If a command takes some time to execute, like sometimes kubectl delete pod x. You can put a task in the background using Ctrl z and pull it back into foreground running command fg.
You can delete pods fast with:
k delete pod x --grace-period 0 --force
k delete pod x $now # if export from above is configuredVim
Be great with vim.
Toggle vim line numbers
When in vim you can press Esc and type :set number or :set nonumber followed by Enter to toggle line numbers. This can be useful when finding syntax errors based on line - but can be bad when wanting to mark© by mouse. You can also just jump to a line number with Esc :22 + Enter.
Copy&paste
Get used to copy/paste/cut with vim:
Mark lines: Esc+V (then arrow keys)
Copy marked lines: y
Cut marked lines: d
Past lines: p or PIndent multiple lines
In case not defined in .vimrc, to indent multiple lines press Esc and type :set shiftwidth=2.
First mark multiple lines using Shift v and the up/down keys. Then to indent the marked lines press > or <. You can then press . to repeat the action.
Split terminal screen
By default tmux is installed and can be used to split your one terminal into multiple. But just do this if you know your shit, because scrolling is different and copy&pasting might be weird.
https://www.hamvocke.com/blog/a-quick-and-easy-guide-to-tmux
]]> containers:
- image: ccr.ccs.tencentyun.com/shuhe/nginx:stable
imagePullPolicy: IfNotPresent
name: container-nginx
ports:
- containerPort: 80
name: tcp-80
protocol: TCP
resources: {}
volumeMounts:
- mountPath: /usr/share/nginx/html
name: workdir
initContainers:
- command:
- wget
- -O
- /work-dir/index.html
- https://kuboard.cn
image: busybox
imagePullPolicy: IfNotPresent
name: container-install
volumeMounts:
- mountPath: /work-dir
name: workdir containers:
- args:
- infinity
command:
- sleep
image: busybox
imagePullPolicy: IfNotPresent
name: busybox
volumeMounts:
- mountPath: /html
name: html
- image: ccr.ccs.tencentyun.com/shuhe/nginx:stable
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
name: tcp-80
protocol: TCP
volumeMounts:
- mountPath: /usr/share/nginx/html
name: html
restartPolicy: Always
volumes:
- emptyDir: {}
name: html- IPhone/IPad和Mac的版本必须Monterey或以上
- 同一局域网下

profile.blade.php<form method="POST" action="{{ route('admin.updateProfile') }}">
@method('PUT')
@csrf
@component('components.form.form-item-input', [
'fieldLabel' => 'admin.Name',
'fieldName' => 'name',
'fieldDefaultValue' => $user->name ?: '',
])@endcomponent
@component('components.form.form-item-input', [
'fieldLabel' => 'admin.Email',
'fieldName' => 'email',
'fieldDefaultValue' => $user->email ?: '',
])@endcomponent
@component('components.form.form-item-submit')@endcomponent
</form>@component相当于php的require_once功能,唯一不同的是你可以带入变量,而且可以复用一些html
@component("所引用的文件的相对路径。以views文件夹为起点", ["变量名字"=>"变量值"]) @endcomponent
控制器部分 更新逻辑写在了模型中,这样比较好
public function updateProfile(UpdateProfileRequest $request) {
request()->user()->updateProfile($request->only([
'email',
'name',
]));
return redirect(route('admin.profile'));
}