Contributed by: Annus Zulfiqar, University of Michigan
Challenge: Modern virtual switches cannot efficiently offload millions of dynamic wildcard rules to SmartNICs because hardware caches are too small, leading to high miss rates and costly software fallbacks.
Solution: Gigaflow introduces pipeline-aware sub-traversal caching with Longest Traversal Matching (LTM), decomposing vSwitch pipeline traversals into reusable segments that maximize SmartNIC table utilization and significantly improve cache efficiency.
Impact: This approach dramatically increases rule-space coverage and hit rates while reducing latency and software fallbacks, enabling scalable, line-rate packet processing for AI-scale and cloud workloads on P4-programmable SmartNICs.

The Challenge: Virtual Switches at Their Limits
Programmable networks have transformed how data centers and edge clouds enforce policies, connect end-host tenants (VMs and containers), and steer traffic throughout the network fabric. At the heart of this transformation are virtual switches (vSwitches), such as Open vSwitch (OVS), which provide flexible, programmable packet-processing pipelines configured using OpenFlow.
But vSwitches face a scaling wall. As line rates climb to 100–400 Gbps per link and workloads grow more dynamic (think AI training clusters or edge inference), CPUs struggle to keep up with the performance demands of modern end-host networking. To relieve the host CPUs from infrastructure responsibilities, operators are increasingly turning to SmartNICs. These NICs integrate P4-programmable table pipelines with on-chip memory, enabling traffic classification and steering at line rate.
However, existing SmartNIC caches are tiny—often accommodating just 10–50K wildcard entries—compared to the millions of rules needed to cover modern workloads. This creates high miss rates and forces much of the traffic back to software, eroding the benefits of hardware offload.
The Insight: Pipeline-Aware Locality in Virtual Switches
Traditional wildcard caches like Megaflow treat each packet’s complete journey through the vSwitch pipeline as a single traversal. The first packet in a flow is resolved through all pipeline tables; the result (a wildcard match plus an action) is cached, and later packets can skip the slow-path pipeline.
This works well in software—where single-table caches are key to performance—but wastes precious hardware cache space and underutilizes the multi-table architecture available in today’s SmartNICs. To fully utilize the underlying SmartNIC architecture, we look deeper into the structure of these vSwitch pipelines and note that many flows share common sub-traversals of the pipeline. For example, flows may take the same L2 and L3 lookups but diverge at ACL rules. Megaflow, on the other hand, caches each individual traversal as a separate entry, duplicating shared segments.

Figure 1: (a) A traversal is a complete sequence of table lookups through the vSwitch pipeline that generates a Megaflow rule. (b) A sub-traversal is a subset of these lookups within a traversal, capturing smaller, reusable segments shared across multiple flows.
Based on this observation, Gigaflow introduces a new form of caching using sub-traversals. Instead of caching entire traversals as separate cache entries in Megaflow, Gigaflow decomposes them into smaller, reusable segments or sub-traversals that capture a new form of locality, called pipeline-aware locality: overlapping sequences of lookups that occur across many flows.

Figure 2: Gigaflow—a new temporary memory storage method for virtual switches—helps direct heavy traffic in cloud data centers caused by AI and machine learning workloads. Rather than storing data packets as they arrive, Gigaflow instead breaks up packets into shared rule segments—processing steps multiple packets have in common. The system then identifies the order of rules, finds the most frequently used rules, and makes those easy to reach.
The Mechanism: Longest Traversal Matching (LTM)
Gigaflow maps sub-traversals onto the limited tables available inside SmartNIC pipelines (e.g., 4–8 stages). To ensure lookup correctness, it introduces Longest Traversal Matching (LTM), a new cache lookup scheme implemented in P4 on RMT-style architectures.
Partitioning for cache generation:
When generating cache entries from OVS traversals, Gigaflow automatically partitions traversals at disjoint header boundaries (e.g., between Ethernet, IP, and TCP fields). This maximizes the cross-product rule space coverage in Gigaflow tables by maximizing the sub-traversal sharing opportunity.
Cache lookup in Gigaflow:
- LTM prioritizes sub-traversals that span the most tables, ensuring the most specific path is taken—similar in spirit to Longest Prefix Match in IP routing.
- Each sub-traversal is tagged with a table ID, ensuring that packets progress through the correct sequence of cached segments, even when there are overlaps.
Implemented in P4, LTM tables are simple: each stage matches on a tag (table ID) and relevant packet headers, then updates the tag (next expected sub-traversal’s table ID), modifies the packet based on actions, and forwards to the following LTM table. This design makes Gigaflow naturally compatible with today’s P4-programmable SmartNICs and FPGAs.
Results: More Rule Space Coverage, Radically Fewer Misses
Our prototype integrates Gigaflow into OVS and offloads to a P4-programmable FPGA SmartNIC. Using real vSwitch pipelines (OVN, Antrea, OFDPA) and realistic workloads (Classbench, CAIDA), we find:
- Up to 51% higher hit rate (25% average) vs. Megaflow
- Up to 90% fewer misses, reducing costly software fallbacks
- Up to 450x more rule-space coverage with fewer entries
- Lower latency: up to 30% reduction in end-to-end packet processing delay
While sustaining line rate performance and utilizing just 38W of on-chip power on an Alveo U250 data center accelerator.
Why It Matters for P4
Gigaflow is fundamentally about using the pipeline structure itself as a source of locality to cache flows efficiently. This makes P4 central to Gigaflow’s design:
- P4 defines the pipeline: by exposing policies as ordered match-action tables, P4 programs provide the structure Gigaflow exploits.
- P4 enables portability: LTM is expressed in portable P4 constructs—tags, priorities, ternary matches—making it implementable across FPGAs and ASIC SmartNICs.
- P4 empowers verification. By modeling sub-traversals in P4, we can reason about correctness and revalidation incrementally, rather than caching arbitrarily.
Gigaflow shows that domain-specific programmability via P4 is not just about expressiveness, but also about enabling new system architectures.
Building Gigaflow as an Open Source Codebase
As part of our commitment to the community, we are also building Gigaflow into a publicly available artifact through Google Summer of Code (GSoC), 2025. This summer, Advay Singh, a Senior from the University of Michigan, Ann Arbor, joined our team and implemented Gigaflow for the AMD/Xilinx Alveo U250 data center accelerator SmartNIC, integrating its low-level device APIs into Open vSwitch.
This effort was central to our roadmap for making Gigaflow broadly accessible—lowering the barrier for practitioners, researchers, and students to experiment with sub-traversal caching on real hardware—and we have actively showcased this progress through a P4 Dev Days talk and a live demo at the P4 Workshop, fostering broader engagement and adoption within the programmable networking community.
Learn More
- Research Article: [ASPLOS’25] Gigaflow – Pipeline-Aware Sub-Traversal Caching for Modern SmartNICs
- GitHub: Gigaflow prototype
- P4 Developer Day Recording: Gigaflow | Pipeline-Aware Sub-Traversal Caching for Modern SmartNICs

The P4 Language Consortium is back in Google Summer of Code (GSoC) 2026 for the third year in a row, and we’re looking for students who want to spend the summer coding with us.
GSoC is a Google-funded program that strengthens open source communities by welcoming new contributors. Selected students work closely with maintainers and experienced contributors to deliver impactful projects for the P4 ecosystem.
Project Ideas
This year, we proposed eight project ideas, grouped into three categories:
1. Core P4 Tooling
- Modernizing BMv2: BMv2 with Bazel and packet trace support: add Bazel as an additional build system, and add support for structured packet trace representation.
2. Exploratory P4 Tooling
- ns-3 / P4sim traffic management: redesign the switch model to make simulations more realistic by adding per-egress traffic management, queueing and scheduling, and more accurate delay modeling.
- Polyglot P4TC: P4TC brings the P4 programming model to Linux Traffic Control, but today it’s mostly driven via CLI and scripts. This project adds Python and Rust APIs so developers can manage pipelines, tables/actions, and runtime updates programmatically.
- PCIe TLP processing with P4 (FPGA): use P4 to parse/control PCIe Transaction Layer Packets on FPGAs, with a concrete DMA demo.
- 4MLIR exporter: implement idiomatic P4 from the P4MLIR representation, expand construct coverage, add tests, and integrate into existing workflows
3. P4 Research
- Extend Alkali with P4MLIR: build conversions between Alkali IR and P4MLIR to enable P4-based SmartNIC backends and reuse Alkali optimization flows.
- P4-SpecTec tutorials: write a hands-on tutorial, based on “nano-P4”, plus Docker images for easy onboarding and reproducible experimentation.
- Planter and P4Pi: integrate Planter into P4Pi, add p4c-dpdk target support, and ship end-to-end examples and teaching materials for ML-assisted dataplane workflows
Browse the full ideas list (with potential mentors) here and keep an eye on the page.
Next steps GSoC 2026
- February 19 – March 15: Community bonding & proposal shaping. If you want to apply, reach out early to a P4 community member listed as “Potential Mentor” and share a short draft: your goal, approach, and expected deliverables.
- March 16 – March 31 (18:00 UTC): Contributor application window. Submit your proposal through the official GSoC portal.
As global networks scale faster than ever, the need for agile, programmable infrastructure has never been in higher demand. Throughout this year, the P4 community continued to advance the state of open source data plane programmability, driving innovation and empowering a new generation of network capabilities. With global collaboration and contributions, and impactful events, P4 continues to be a driving force shaping the future networking landscape.
Below are highlights from an exciting and fast-paced year in the P4 community:
NEW MEMBERS
P4 was excited to welcome Cisco as a new Premier member in 2025. Oxide Computer Company and Xsight Labs also joined as General members, along with several universities and educational institutions as Associate members. View our members
NOTABLE NEWS
In January Intel announced the release of Tofino P4 software to open source, inviting broader participation and enabling new innovation by P4 developers.
P4 WORKING GROUP UPDATES
Regular meetings take place throughout the year to further the development and adoption of P4.
Language Design Working Group
The P4 Language Design Working Group had a productive year, with steady progress on both the language and its ecosystem. A major highlight this year has been the ongoing development of P4-Spectec by PLRG at KAIST, showcased in a P4 Developer Days talk. This work has helped uncover and resolve many ambiguities and bugs in both the P4 Specification and compiler.
Several “quality-of-life” features have been added to the language, such as Verilog-style +: slice operator with clear rules for indices and bounds, [op]= compound assignment operators for integral types,and support for arrays whose elements are not headers or header unions (e.g., bit, int, extern instances), with clearly defined semantics for out-of-bounds access.
After the introduction of For-loops into the language and specification in 2024, the WG is now evaluating whether loop boundedness should be defined in the spec itself or delegated to individual targets.
To better support the global community, meetings were restructured: two regular calls now run every other month, one Asia-friendly and one Europe-friendly.
In 2026, the focus will be on continuing to improve P4-Spectec and moving toward adopting it as the official representation of the P4 specification. There is also strong interest in exploring first-class, Rust-style macros for P4,although this initiative is still in an early phase of discussion.
API Working Group
In 2025, the P4 API working group put a strong focus on making the P4Runtime more powerful, flexible, and easier to use. A key accomplishment was the addition of P4Runtime support for more flexible and advanced group programming, as commonly required in ML networking scenarios. More specifically, groups can now support packet spraying, dynamic load balancing, and global load balancing, where egress ports (and, more generally, actions) can be selected randomly according to a specified distribution or chosen directly by the switch, rather than just deterministically based on a hash. In addition, specific group modes (action-selection mode and resource-allocation mode) can now be configured at the per-group level instead of only at the per-table level, providing finer-grained control. Several incremental fixes and clarifications to the specification were made along the way, tightening and correcting the P4Runtime specification. Furthermore, the P4Runtime Protobufs were made easier to consume in Rust, and the build system and supported OS versions were updated. Last but not least, P4Runtime v1.5.0 has been released and is available here.
Looking ahead to 2026, the group plans to replace the current ad hoc solutions with a standard approach that allows users to specify preferred string formats for common types such as IP addresses, MAC addresses, and ports. This would directly benefit tools like CLIs, GUIs, and debuggers. The group also aims to advance work on P4Runtime for high-performance use cases and on supporting composite values (such as structs and nested structs) as action parameters.
Education Working Group
The Education Working Group played an active role in organizing the P4 Workshop at the Open Compute Project (OCP) Global Summit, with Fernando Ramos serving as chair and contributing to the definition of the technical agenda. As no major networking-focused academic conferences were held in Europe this year, EuroP4 could not take place; nevertheless, the initiative will be put forward again for 2026.
In parallel, we are preparing a proposal for a SmartNIC tutorial and are currently searching for a suitable conference to which it can be submitted. The WG has also compiled a first list of academic courses in which P4 is currently being taught, which will soon be published among the education materials. The goal of this effort is not only to support academia in teaching P4, but also to significantly expand the reach of P4 in networking education by making it easier for academics to adopt it through hands-on exercises, teaching resources, and pedagogical material—thereby broadening its overall impact.
Finally, we have also been discussing the possibility of submitting a proposal for a Dagstuhl seminar on networking education, where P4 could play an important role.
NEW PROJECT: P4 MLIR
P4 MLIR is a new community-driven initiative and is part of a long-term vision aimed at providing a modern MLIR-based intermediate representation (IR) for P4 programs. The project aims to solve long-standing performance issues with the P4C IR while simultaneously enabling the use of MLIR-based approaches for more comprehensive P4 program analysis, optimization, and transformation. To date, the P4 high-level MLIR dialect has reached a level of completeness that allows it to fully represent the majority of non-trivial, real-world P4 applications. Development is currently focused on adding standard frontend/midend lowering and optimization passes, as well as providing proof-of-concept support for proprietary and open-source (BMV2, eBPF) targets. .. P4MLIR aims to improve the P4 compiler, p4c and is a tool that translates P4 programs into a language readable by a target.
The project does not have a dedicated P4 working group driving it currently and is being led by Anton Korobeynikov, Bili Dong, and Fabian Ruffy.
P4 COMMUNITY AWARDS
2025 SIGCOMM Networking Systems Award honored the Tofino programmable switch and the P4 language. Tofino made programmable data planes accessible to academia and industry, helping establish P4 as the de facto standard for programmable networks. Read More
The 2025 Distinguished P4 Contributor Award was awarded to Vladimir Gurevitch at the 2025 P4 Workshop in recognition for his ongoing outstanding service to the P4 community. He is a leading P4 educator, training 1,500+ people from 500+ organizations via Barefoot Academy, Intel Connectivity Academy, and P4ica. During his tenure at Intel, he ran the Connectivity Research Program, supporting Tofino projects across 300+ universities worldwide.
NEW P4 MEMBER TARGETS
We are pleased to share news and insights this year from P4 community members who have announced new hardware and software devices where P4 programming is leveraged, allowing developers to tailor the network behavior to applications needs with greater agility and control.
- AMD – Pollara
- Cisco – Unified Networking Architecture
- Intel – IPU/DPU
- “Within Intel, we have different NIC product lines for IPUs and FNICs, and also some specific Telco use cases. Convergence of HW and SW across these different vectors is highly important. Designing a HW packet processor that is agnostic to protocol nuances, and based on match-action capabilities instead, provides us the HW convergence, and leveraging P4 as the underlying SW abstraction helps us in keeping our SW investment effectively reused across product lines. As speeds and feeds for IPUs and FNICs keep increasing, to Terabit speeds and beyond, we feel this is the only scalable approach that can keep up with the challenges”. – Deb Chatterjee, Head of Network Acceleration and Tools, Intel
- Xsight Labs – X2 Series Ethernet Switch
- “P4 is Xsight’s language of choice for developing advanced network applications on the X2. With its programmable parser and match-action architecture, the X2 is well-suited for a language like P4. By writing their network programs in P4, an open and standardized language, customers can describe precisely how packets should be processed. These programs then compile down to X-ISA, Xsight’s open instruction set, giving our users exceptional transparency and control. Together, P4 and X-ISA deliver the best of both worlds: the high-level expressiveness of P4 for defining network behavior, and the low-level precision of X-ISA to optimize packet-processing at the instruction level. With this combination we give developers the tools to unlock the full potential of the X2 platform.” – Fabian Ruffy, Software Architect, XSight Labs
Additional P4 Targets
- iWave – SmartNIC
- Silicom – SmartNIC
- A presentation by Silicom about P4 on the ThunderFjord SmartNIC was also featured in a P4 Developer Days webinar earlier this year – view presentation.
2025 EVENT HIGHLIGHTS
2025 P4 Workshop
The P4 Workshop 2025 brought together researchers, industry leaders, and developers from across the programmable networking community to showcase the latest advances in P4 and its expanding role in modern systems. The event was held this year adjacent to the OCP Global Summit and attracted a record number of attendees. View all the presentations from P4 Workshop here.
P4 Developer Days
In 2025, P4 Developer Days webinars brought the community together for a series of virtual events showcasing projects and products built with P4. This webinar series is designed to foster knowledge sharing across the ecosystem and stimulate new ideas. Across 13+ sessions led by academics and industry experts, we highlighted new P4 targets, emerging applications, and active research. View all videos and slides from these insightful talks here.
Google Summer of Code
For the second consecutive year, the P4 Consortium was accepted into Google Summer of Code (GSoC), a global program funded by Google that enables students to contribute to open source projects guided by P4 community members. Four projects were selected from the many applicants. View the presentations by each of the contributors here.
LOOKING AHEAD TO 2026
As we look ahead to 2026, the P4 Governing Board is energized by the opportunities before us and grounded in our commitment to continuous improvement, innovation, and service to the P4 community. The coming year will be defined not only by strengthening our core programs and partnerships, but also by thoughtfully incorporating emerging technologies—particularly artificial intelligence. By embracing innovation while staying true to our values, we are positioning P4 for a forward-thinking, sustainable, and impactful 2026.
PARTICIPATE IN THE P4 COMMUNITY
- Technical Steering Team (TST) and Working Groups – learn more about how to join regular meetings and working group focuses here.
- Periodic Email Updates – If you have not already registered, please sign up to receive our periodic newsletter with news about members, projects and events within the P4 community.
- 2026 Events – view the full events calendar
- P4Developer Days – ongoing
- P4 GSoC – ongoing
- P4 Workshop – tentatively scheduled for October 2026
We are pleased to share the results of the recent 2026 P4 Technical Steering Team (TST) Elections. Bili Dong (Google), Shweta Shrivastava (Intel), and Steffen Smolka (Google) have been elected to two-year terms.
The P4 community maintained strong momentum in 2025, marked by significant advancements from working groups and increased engagement through the annual P4 Workshop, regular virtual events, blogs, and publications. We anticipate an even more exciting year ahead. You can get involved and follow all the P4 updates for 2026.
About the Newly-Elected P4 TST Members
Bili Dong
 Bili has participated in the P4 community since 2022 and been an active community member. Bili has 3.5 years of experience in industry working on programming networking offloads on programmable NICs (w/wo P4), and applying formal methods to automatically reason about packet forwarding behaviors of NICs and switches (w/wo P4).
Bili has participated in the P4 community since 2022 and been an active community member. Bili has 3.5 years of experience in industry working on programming networking offloads on programmable NICs (w/wo P4), and applying formal methods to automatically reason about packet forwarding behaviors of NICs and switches (w/wo P4).
Bili’s contributions to the P4 project include code contributions to P4C and BMv2; proposing and helping incubating the P4MLIR project; organization of P4’s participation in Google Summer of Code (GSoC) 2024 & 2025; and serving as mentors in several P4 GSoC projects.
In his role as a member of the P4 TST, Bili is seeking to evolve the open source P4 toolchain and the language itself if necessary to better support real-world programmable packet processor targets, both hardware and software. As part of that, Bili seeks to improve P4’s interoperability with other technologies, for example, allowing programming parts of the target in P4, while the rest in C++, as frictionless as possible. More experimentally, Bili also wishes to explore the ideas of P4 as intermediate representation (IR), and P4 as embedded domain specific language (eDSL).
Shweta Shrivastava
 Shweta has worked with P4 for the past four years and has led multiple Intel projects involving P4-based offload of networking capabilities, including ACLs, load balancing, routing, forwarding, and connection tracking, onto the Intel IPU’s Packet Processing Pipeline. She has been leading development of offload solutions for high-speed dataplanes such as SONiC DASH and next-generation firewall capabilities on Intel IPUs, with a strong focus on scale and performance. Shweta presented Intel’s SONiC-DASH design and performance results at the P4 Workshop 2024.
Shweta has worked with P4 for the past four years and has led multiple Intel projects involving P4-based offload of networking capabilities, including ACLs, load balancing, routing, forwarding, and connection tracking, onto the Intel IPU’s Packet Processing Pipeline. She has been leading development of offload solutions for high-speed dataplanes such as SONiC DASH and next-generation firewall capabilities on Intel IPUs, with a strong focus on scale and performance. Shweta presented Intel’s SONiC-DASH design and performance results at the P4 Workshop 2024.
In her role as a P4 TST member, Shweta seeks to drive broader P4 adoption by using learnings from her experience developing large-scale datapaths on Intel IPU to help bridge the gap between hardware IPU/SmartNIC implementations and portable P4 architectures. She also plans to focus on evolving these architectures to address advanced use cases, including multi-tenant deployments, AI/HPC networking, and next-generation telemetry.
Steffen Smolka
 Steffen has been involved with P4 since 2016, when he interned at Barefoot Networks. He currently serves as co-chair of the P4 API Working Group.
Steffen has been involved with P4 since 2016, when he interned at Barefoot Networks. He currently serves as co-chair of the P4 API Working Group.
For the past 6 years, Steffen has been leveraging P4 at Google, where he founded and leads the Automated Reasoning and Contracts for Networking (ARCNET) team. ARCNET uses P4 as a specification language and builds and applies tools that perform automated switch validation against such a given P4 spec — an approach known as P4-Based Automated Reasoning (P4-BAR) [learn more].
As a P4 TST member and active user of P4, Steffen can offer both an industrial/practical perspective (as a Google engineer) as well as an academic/theoretical perspective (having done a PhD in programming languages).
Steffen’s goals for his term on the P4 TST are to promote more industry involvement in the community, and continue increasing awareness around and momentum behind the usage of P4 as a specification language, beyond Google.
A big thank you to Nate Foster and Hari Thantry for their service and contributions over the past two years!
Interested in getting involved? P4 TST meetings are held monthly on the first Friday. Check out the full calendar of TST meetings, Working Groups, and upcoming events.
The P4 Workshop 2025 brought together researchers, industry leaders, and developers from across the programmable-networking community to showcase the latest advances in P4 and its expanding role in modern systems. Chaired by Fernando Ramos (IST, University of Lisbon), with support from Andy Fingerhut (Cisco), Denise Barton (StratiView), Michelle Roth (Linux Foundation), and a distinguished Program Committee, the workshop highlighted how P4 is progressing beyond packet processing into broader systems domains. The event was hosted in conjunction with OCP Global Summit and included two keynotes and five live talks.
 In the first keynote, “High-Level and Target-Agnostic Transport Programs,” Mina Tahmasbi Arashloo (University of Waterloo) argued that while packet-processing languages have matured for L2/L3 tasks, the transport layer still lacks domain-specific abstractions. She proposed a new programming model that treats flows and events with target-agnostic primitives, enabling compiler-driven generation of efficient implementations across heterogeneous hardware — noting that P4’s design principles can inspire the next generation of transport-layer DSLs.
In the first keynote, “High-Level and Target-Agnostic Transport Programs,” Mina Tahmasbi Arashloo (University of Waterloo) argued that while packet-processing languages have matured for L2/L3 tasks, the transport layer still lacks domain-specific abstractions. She proposed a new programming model that treats flows and events with target-agnostic primitives, enabling compiler-driven generation of efficient implementations across heterogeneous hardware — noting that P4’s design principles can inspire the next generation of transport-layer DSLs.
 In the second keynote, “Using P4 NICs for Resilient Scale-out GPU Interconnect,” Krishna Doddapaneni (AMD Pensando) examined the increasingly demanding connectivity needs of large-scale AI systems. He showed how P4-programmable NICs with multi-plane architectures and advanced fault-handling mechanisms can support resilient, high-performance GPU-interconnect fabrics, transforming failure-prone, large-scale AI networks into robust and manageable systems.
In the second keynote, “Using P4 NICs for Resilient Scale-out GPU Interconnect,” Krishna Doddapaneni (AMD Pensando) examined the increasingly demanding connectivity needs of large-scale AI systems. He showed how P4-programmable NICs with multi-plane architectures and advanced fault-handling mechanisms can support resilient, high-performance GPU-interconnect fabrics, transforming failure-prone, large-scale AI networks into robust and manageable systems.
The five invited talks covered a broad spectrum of developments: “DVaaS Detective: The Case of the Failing Tests” addressed debugging and reliability for P4-based services; “Cisco Silicon One: Unifying Network Forwarding with P4 Programmability” presented how commercial ASICs can be programmed end-to-end with P4; “Unifying P4 with eBPF and DPDK via XDP2” introduced methods to harmonise heterogeneous dataplane ecosystems; “New Dawn of P4” reflected on P4’s emerging role in new systems domains; and “XASM: A Foundation to Program the X2 with P4” described a new programming foundation for next-generation XSight architectures.
 The workshop also featured a live demonstration at the P4 booth — “Gigaflow: Pipeline-Aware Caching in Virtual Switches with P4” by the University of Michigan, which showcased practical innovations in virtual switch performance.
The workshop also featured a live demonstration at the P4 booth — “Gigaflow: Pipeline-Aware Caching in Virtual Switches with P4” by the University of Michigan, which showcased practical innovations in virtual switch performance.
In addition, eight pre-recorded technical talks were released as part of the P4 Workshop and the videos and slides are now available online for the broader community.
 The programme included the 2025 Distinguished Contributor Award, presented to Vladimir Gurevich for his outstanding service to the P4 community.
The programme included the 2025 Distinguished Contributor Award, presented to Vladimir Gurevich for his outstanding service to the P4 community.
This year’s discussions revealed a clear overarching trend: P4 is moving upward in the stack, becoming an essential enabler for AI-centric, high-performance infrastructures and tighter hardware-software convergence across NICs, GPUs, and switches. The talks and demo highlighted P4’s growing role as a unifying abstraction layer connecting ecosystems such as eBPF, DPDK, and emerging toolchains — illustrating the vibrant collaboration space spanning academia, startups, and industry deployments.
Please check out the 2025 P4 Workshop web page to view all the exciting talks now on-demand.
]]>
Modern critical networks increasingly rely on high-performance validation and testing to ensure reliability, resilience, and predictable behavior under load. Traditional traffic generators either depend on software stacks that struggle at high speeds, or on proprietary appliances that are expensive and inflexible. P4TG was developed to bridge this gap.
P4TG is a hardware-accelerated traffic generator and analyzer implemented directly in the data plane of Intel® Tofino programmable switches. It combines the flexibility of P4 with
programmable switches. It combines the flexibility of P4 with the performance of switching ASICs to provide line-rate traffic generation and precise measurement capabilities at terabit speeds. Alongside the data-plane implementation, P4TG includes a Rust-based control plane, a REST API for automated testing workflows, and a web-based frontend for convenient configuration and live visualization, making it suitable for both hands-on lab work and fully scripted test pipelines. P4TG is already used across different industries by telecommunication providers, research labs, aerospace companies and IT companies.
the performance of switching ASICs to provide line-rate traffic generation and precise measurement capabilities at terabit speeds. Alongside the data-plane implementation, P4TG includes a Rust-based control plane, a REST API for automated testing workflows, and a web-based frontend for convenient configuration and live visualization, making it suitable for both hands-on lab work and fully scripted test pipelines. P4TG is already used across different industries by telecommunication providers, research labs, aerospace companies and IT companies.
Flexible Traffic Generation and Protocol Support
P4TG can generate traffic rates of up to 10×400 Gb/s or 40×25 Gb/s. Traffic patterns range from constant bit-rate to Poisson-distributed random traffic, with customizable headers and encapsulations. Packet contents can be adapted per port and per flow to emulate diverse traffic distributions. The platform currently supports:
- Ethernet, IPv4, IPv6 with address randomization
- VLAN, QinQ, MPLS (up to 15 labels)
- SRv6 (on Tofino 2, up to 3 SIDs), VXLAN, and combinations of encapsulations
This allows P4TG to emulate a wide range of realistic deployment scenarios from backbone routers to data center overlays, while maintaining full control over frame structure and traffic distribution.
Integrated Measurement in the Data Plane
Measurement logic is embedded directly into the data plane. P4TG measures traffic rates, round-trip times (RTT), packet loss, out-of-order packets, and frame statistics at high precision. Results are available via the REST API and visualized live in the frontend dashboard during testing.
 Figure 2: The P4TG dashboard with a measured RTT histogram.
Figure 2: The P4TG dashboard with a measured RTT histogram.
Roadmap and Timeline
P4TG was originally developed by Steffen Lindner at the University of Tübingen and is now being further evolved by Fabian Ihle and Etienne Zink. What began as a research prototype has grown into a mature, feature-rich platform with support for modern protocols, automation, and new hardware generations. The roadmap below shows how P4TG continues to advance with more features yet to come.
 Figure 3: History and roadmap of P4TG.
Figure 3: History and roadmap of P4TG.
BDBOS: Bringing P4TG Into a Critical Network Environment
A recent and meaningful adoption of P4TG comes from the German Federal Agency for Public Safety Digital Radio (BDBOS), which operates the communication network used by the government and its administration bodies, as well as emergency, security and rescue services at federal, state and municipal level to communicate securely and reliably at all times across Germany. Ensuring the reliability of this network is not just an operational challenge, it is part of national safety infrastructure.
In their laboratory environment, BDBOS now uses P4TG to simulate realistic high-load conditions. These tests help explore how the network behaves when large amounts of data move between data centers, when thousands of devices connect at once, or when demand spikes unexpectedly.
Because P4TG is cost-efficient, adaptable, and capable of very high bandwidth tests, it complements the commercial tools already in use. Instead of replacing existing systems, it expands the range of what can be tested, especially at the upper end of performance.
References
[1]: S. Lindner, Marco Häberle, and M. Menth: P4TG: 1 Tb/s Traffic Generation for Ethernet/IP Networks, in IEEE Access, vol. 11, p. 17525 – 17535, Feb. 2023, IEEE
[2]: F. Ihle, E. Zink, and M. Menth: Enhancements to P4TG: Histogram-Based RTT Monitoring in the Data Plane, in Proceedings of the 1st KuVS Workshop on Resilient Networks and Systems (ReNeSys) in conjunction with KuVS International Conference on Networked Systems (NetSys), Sept. 2025, Ilmenau, Germany
[3]: F. Ihle, E. Zink, S. Lindner, and M. Menth: Enhancements to P4TG: Protocols, Performance, and Automation, in KuVS Fachgespräch – Workshop on Network Softwarization (KuVS NetSoft), April 2025, Online
[4]: uni-tue-kn. GitHub: P4TG. https://github.com/uni-tue-kn/P4TG
[5]: LinkedIn Post by BDBOS: https://www.linkedin.com/posts/bdbos_bdbos-opensource-p4tg-activity-7385570407245922304-19Uk
]]>Using P4 for Static Analysis of Network Device Stacks
Programmability in computer networks is evolving. Merchant silicon and network programming languages like P4 give us remarkable flexibility, but this flexibility comes at a cost: the software stack running on network devices—responsible for packet forwarding and interpreting control plane instructions—has grown substantially more complex. This complexity can introduce faults, which can take down entire networks. Traditional network verification techniques can check network-wide properties like reachability or loop-freedom, but these tools often assume that individual devices execute forwarding entries correctly. This assumption is less tenable as device stacks become deeper and more intricate. There’s a clear need for network-device verification, focusing on the functional correctness of the software stack within a single device. Figure 1 illustrates this distinction.
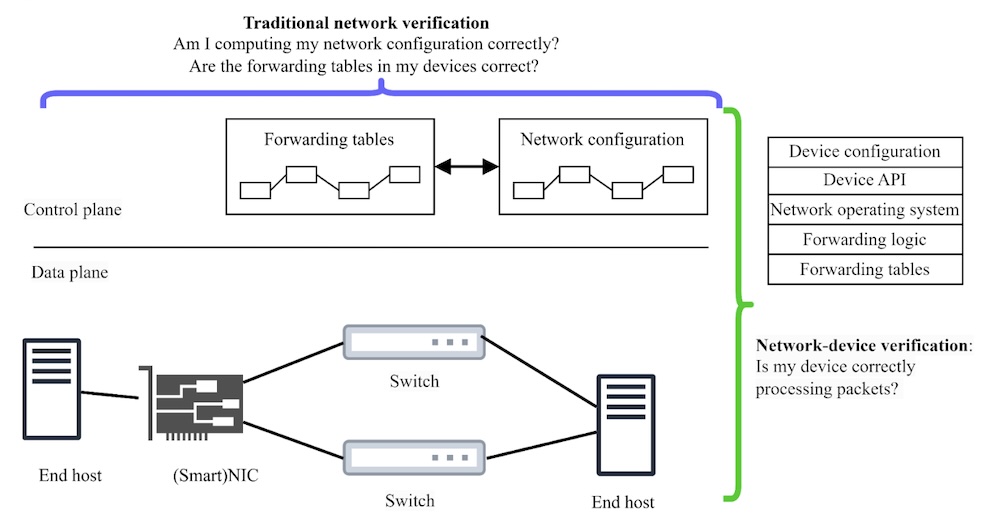
Figure 1: Traditional horizontal network verification vs vertical network-device verification.
General-purpose static analysis tools to check networking stacks exist, but they often struggle. Languages like C++ or Python, common in device stacks, make precise analysis difficult or computationally expensive because of the presence of pointers, aliasing, and complex control flow. General tools also lack awareness of the specific constraints and execution models inherent in packet processing hardware. Attempting to verify device stacks requires a different approach—one that captures the nuances of packet processing from the hardware pipeline up to the software abstract layers.
The P4 Advantage: A Foundation for Static Analysis
Our work explores using P4 itself as a foundation for building effective static analysis tools. P4 is not just a language for programming data planes; its design implicitly encodes a model of packet processing suitable for formal analysis. Several properties make P4 amenable to this approach:
- Restricted Semantics: P4 deliberately omits features common in general-purpose languages, such as general loops, aliasing, dynamic memory allocation, and complex pointer arithmetic. This restriction simplifies the development of precise semantic models.
- Explicit Execution Model: P4 programs typically target hardware pipelines with specific constraints (e.g., run-to-completion, fixed time budgets). The language structure reflects these constraints, providing a clearer model for analysis.
- Decidability: The finite-state nature of many P4 constructs can make challenging problems like program equivalence decidable, which in turn can enable better automated verification techniques compared to general-purpose languages.
Our Approach: An SMT-Based Execution Model
We use P4’s properties to develop an execution model for P4 based on Satisfiability Modulo Theories (SMT). We translate P4 language constructs and architecture behaviors into SMT formulas. This model is designed to be:
- Protocol-Independent: Like P4, we represent packet processing using primitives like arithmetic, table lookups, and state manipulation via registers, rather than being tied to specific network protocols.
- Device-Agnostic: We capture P4 semantics as defined in the official specification and include extension mechanisms to model specific device behaviors accurately.
- Precise: Our approach produces a test oracle. We do not require a second compiler or device model to perform our testing. We also do not require developer-written assertions to generate tests. Since the model is bit-level accurate we can also detect subtle bugs.
Applying the Model: Three Tools
We developed and applied this SMT-based model across three distinct projects, each addressing a different aspect of network device stack analysis:
- Gauntlet: Focuses on testing P4 compilers. It uses translation validation (comparing SMT models of code before and after compiler passes) and random P4 program generation to find compiler crashes and miscompilations. The paper is available here.
- P4Testgen: Acts as an extensible test oracle. It generates high-fidelity input packets, control-plane configurations, and expected output packets to test the entire device stack’s implementation of a P4 program by modeling detailed target-specific semantics. The paper is available here.
- Flay: Optimizes P4 programs using incremental specialization. It uses our SMT model, extended with control-plane semantics (based on P4Runtime), to simplify data-plane forwarding logic based on the current control-plane configuration, This tool recompiles only when necessary. The paper is available here.
Each tool builds on the previous one, progressively developing a more comprehensive execution model. Gauntlet models the P4 language core. P4Testgen adds device behavior and whole-program semantics. Flay incorporates the influence of the control plane. Figure 2 shows the expanding scope of the execution model across these tools.
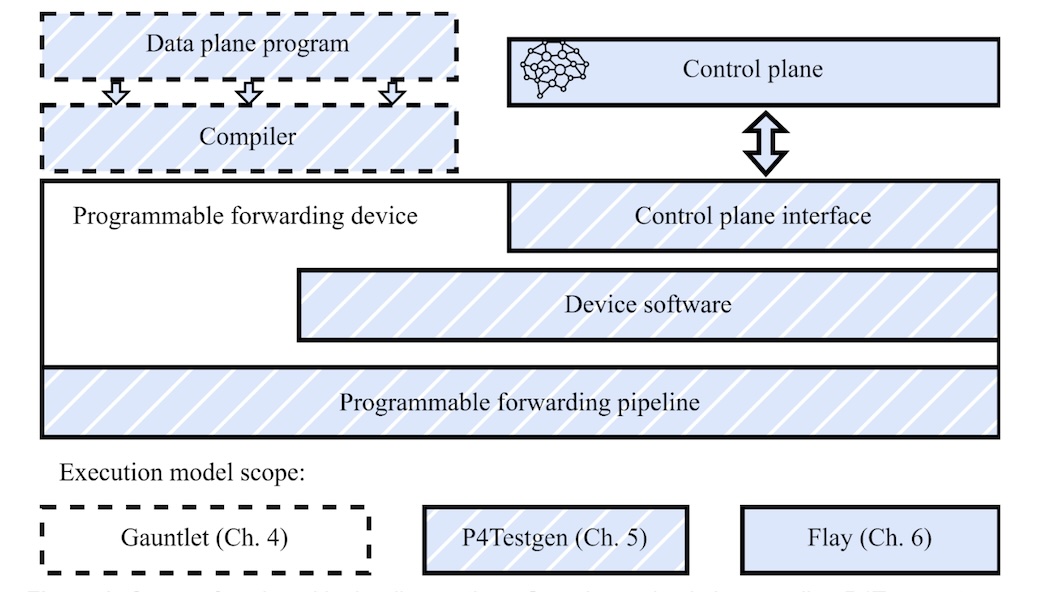
Figure 2: Scope of each tool in the dissertation – Gauntlet to check the compiler; P4Testgen to generate tests; Flay to optimize network programs.
Impact and Open Contributions
We used our P4-based static analysis approach with Gauntlet to identify approximately 100 unique, confirmed P4 compiler bugs (crashes and miscompilations). P4Testgen and Flay, using the extended model, uncovered around 30 additional confirmed bugs related to incorrect packet processing within device stacks (including compilers, control plane interactions, and target models). Flay also demonstrated significant resource savings (e.g., 20% stage reduction in a Tofino 2 program) through control-plane-aware specialization.
All tools developed from this research (Gauntlet’s components, P4Testgen, Flay’s prototype, and supporting tools like the control-plane fuzzer RTSmith) have been contributed back to the P4 community as open-source projects, primarily integrated within the P4C repository and related projects. This work heavily benefited from the openness of the P4 language, its specifications (like P4Runtime), and the surrounding tooling (P4C, BMv2). For us, the ecosystem was essential for developing, validating, and sharing these analysis techniques.
We believe this approach demonstrates the value of using domain-specific languages like P4 not just for programming, but also as a basis for rigorous analysis of the increasingly complex systems they run on.
If you are interested in learning more about these techniques and tools, the full dissertation is available here: https://cs.nyu.edu/media/publications/ruffy_fabian_dissertation.pdf If you have questions, reach out to Fabian at [email protected].
P.S.:
A German doctoral tradition is for the newly minted doctor to receive a PhD hat themed based on their focus area and hobbies after a successful defense. Here is Dr. Ruffy with his Doktorhut, appropriately themed around computer networking.

Google Summer of Code is a global, online program focused on bringing new contributors into open source software development. GSoC Contributors work with an open source organization such as P4, on a project under the guidance of community mentors.
This year, we had an overwhelming response, having received over 34 applications for 6 project proposals. Here are the projects that were accepted:
P4MLIR: MLIR-based high-level IR for P4 compilers
Contributor: Xiaomin Liu, New York University
Mentors: Anton Korobeynikov, Bili Dong, Fabian Ruffy
BMv2 with all possible output packets
Contributor: Xiyu Hao, New York University
Mentors: Matthew Lam, Jonathan DiLorenzo, Bili Dong, Antonin Bas
P4Simulator: Enabling P4 Simulations in ns-3
Contributor: Vineet Goel, Indian Institute of Technology Roorkee
Mentors: Mingyu Ma, Tommaso Pecorella, Davide Scano
Gigaflow: A Smart Cache for a SmartNIC
Contributor: Advay Singh, University of Michigan
Mentors: Annus Zulfiqar, Ali Imran, Davide Scano, Ben Pfaff, Muhammad Shahbaz
SpliDT: Scaling Stateful Decision Tree Algorithms in P4
Contributor – Sankalp Jha, Ajay Kumar Garg Engineering College,
Mentors: Murayyiam-Parvez, Annus Zulfiqar, Ali Imran, Davide Scano, Walter Willinger, Muhammad Shahbaz
Learn more about each of these exciting projects!
]]>
Since the introduction of Cisco’s Silicon One ASIC in 2019, Cisco has relied on P4 to enable their engineers to deliver a variety of features that meet the evolving needs of their customers. Eli Stein, Vice President of Engineering at Cisco shared, “Cisco incorporated P4 programmability into the Silicon One architecture from its inception, empowering our customers with unmatched network agility, customizable data-plane behavior, and the flexibility to optimize performance and drive innovation in response to evolving business needs.”
This is one example, stay tuned for more on how Cisco is leveraging P4 across the portfolio.
With Cisco’s new role as a premier member of the P4 Consortium, we are excited to see how their contributions will continue to shape the future of programmable networking.
]]>In the press release, Andy Fingerhut, Chair of the P4 Consortium Technical Steering Team was quoted, “The P4 Consortium is eager to collaborate and explore the advancements that the X-Switch architecture will drive in the ecosystem. By open-sourcing its ISA, Xsight Labs is empowering developers and the broader industry to push the boundaries of networking innovation, enabling the development of a P4 compiler, and fostering industry-wide collaboration on the transformative potential of the X-Switch architecture.”
]]>