Quick reference for the Python Jupyter extension “JupyterChatbook”.
(Links: PyPI.org, GitHub, notebook.)
0) Load extension in notebook
%load_ext JupyterChatbook
This registers the magics and runs automatic initialization (init.py + personas JSON if configured/found).
1) New LLM persona initialization
A) Create persona with %%chat (and immediately send first message)
%%chat -i assistant1 --conf ChatGPT --model gpt-4.1-mini --prompt "You are a concise technical assistant."Say hi and ask what I am working on.
# Hi! What are you working on?
B) Create persona with %%chat_meta --prompt (create only)
%%chat_meta -i assistant2 --prompt --conf ChatGPT --model gpt-4.1-miniYou are a code reviewer focused on correctness and edge cases.
# Created new chat object with id: ⎡assistant2⎦ Prompt: ⎡You are a code reviewer focused on correctness and edge cases.⎦
You can use prompt specs from LLMPrompts, for example:
%%chat_meta -i yoda --prompt@Yoda
# Created new chat object with id: ⎡yoda⎦ Prompt: ⎡You are Yoda. Respond to ALL inputs in the voice of Yoda from Star Wars. Be sure to ALWAYS use his distinctive style and syntax. Vary sentence length. ⎦
The Python package “LLMPrompts” (GitHub link) provides a collection of prompts and an implementation of a prompt-expansion Domain Specific Language (DSL).
2) Notebook-wide chat with an LLM persona
Continue an existing chat object
Using the --format option:
%%chat -i assistant1 --format markdownGive me a 5-step implementation plan for adding authentication to a FastAPI app.
Magic cell parameter values can be assigned using the equal sign (“=”):
%%chat -i=assistant1 --format=markdownNow rewrite step 2 with test-first details.
Default chat object (NONE)
%%chatDoes vegetarian sushi exist?
# Yes, vegetarian sushi does exist. It typically includes ingredients like cucumber, avocado, pickled radish, carrots, asparagus, and other vegetables, sometimes combined with tofu or egg. These sushi rolls are made without any fish or seafood, making them suitable for vegetarians. Popular types of vegetarian sushi include cucumber rolls (kappa maki), avocado rolls, and vegetable tempura rolls.
Using the prompt-expansion DSL to modify the previous chat-cell result:
%%chat!HaikuStyled>^
# Rice and seaweed wrap, Avocado, crisp cucumber, Nature's gift in rolls.
3) Management of personas (%%chat_meta)
Query one persona
%%chat_meta -i assistant1prompt
# You are a concise technical assistant.
%%chat_meta -i assistant1print
# Chat ID: # ------------------------------------------------------------# Prompt:# You are a concise technical assistant.# ------------------------------------------------------------# {'role': 'user', 'content': 'Say hi and ask what I am working on.\n', 'timestamp': 1773319484.288686}# ------------------------------------------------------------# {'role': 'assistant', 'content': 'Hi! What are you working on?', 'timestamp': 1773319485.7126122}# ------------------------------------------------------------# {'role': 'user', 'content': 'Give me a 5-step implementation plan for adding authentication to a FastAPI app.\n', 'timestamp': 1773319485.780502}# ------------------------------------------------------------# {'role': 'assistant', 'content': "Here is a 5-step implementation plan for adding authentication to a FastAPI app:\n\n1. Choose Authentication Method: Decide on the type of authentication (e.g., OAuth2 with Password, JWT tokens, API keys).\n\n2. Install Dependencies: Install necessary packages such as `fastapi`, `uvicorn`, `python-jose` for JWT, and `passlib` for password hashing.\n\n3. Create User Models and Database: Define user models and set up a database to store user credentials securely.\n\n4. Implement Authentication Logic: Write functions for user registration, login, password hashing, token creation, and token verification.\n\n5. Protect Routes: Use FastAPI's dependency injection to secure endpoints, requiring valid authentication tokens for access.", 'timestamp': 1773319488.981312}# ------------------------------------------------------------# {'role': 'user', 'content': 'Now rewrite step 2 with test-first details.\n', 'timestamp': 1773319489.01122}# ------------------------------------------------------------# {'role': 'assistant', 'content': 'Step 2 (Test-First): Write tests that verify the presence and correct installation of required authentication packages (`fastapi`, `uvicorn`, `python-jose`, `passlib`). For example, create tests that attempt to import these packages and check their versions. Then, install the dependencies and run the tests to ensure the environment is correctly set up before proceeding.', 'timestamp': 1773319490.414032}
Query all personas
%%chat_meta --allkeys
# ['python', 'html', 'latex', 'ce', 'assistant1', 'assistant2', 'yoda', 'NONE']
%%chat_meta --allprint
# {'python': {'id': '', 'type': 'chat', 'prompt': "'You are Code Writer and as the coder that you are, you provide clear and concise code only, without explanation nor conversation. \\nYour job is to output code with no accompanying text.\\nDo not explain any code unless asked. Do not provide summaries unless asked.\\nYou are the best Python programmer in the world but do not converse.\\nYou know the Python documentation better than anyone but do not converse.\\nYou can provide clear examples and offer distinctive and unique instructions to the solutions you provide only if specifically requested.\\nOnly code in Python unless told otherwise.\\nUnless they ask, you will only give code.\\n'", 'messages': 0}, 'html': {'id': '', 'type': 'chat', 'prompt': "'You are Code Writer and as the coder that you are, you provide clear and concise code only, without explanation nor conversation. \\nYour job is to output code with no accompanying text.\\nDo not explain any code unless asked. Do not provide summaries unless asked.\\nYou are the best HTML programmer in the world but do not converse.\\nYou know the HTML documentation better than anyone but do not converse.\\nYou can provide clear examples and offer distinctive and unique instructions to the solutions you provide only if specifically requested.\\nOnly code in HTML unless told otherwise.\\nUnless they ask, you will only give code.\\n'", 'messages': 0}, 'latex': {'id': '', 'type': 'chat', 'prompt': "'You are Code Writer and as the coder that you are, you provide clear and concise code only, without explanation nor conversation. \\nYour job is to output code with no accompanying text.\\nDo not explain any code unless asked. Do not provide summaries unless asked.\\nYou are the best LaTeX programmer in the world but do not converse.\\nYou know the LaTeX documentation better than anyone but do not converse.\\nYou can provide clear examples and offer distinctive and unique instructions to the solutions you provide only if specifically requested.\\nOnly code in LaTeX unless told otherwise.\\nUnless they ask, you will only give code.\\n'", 'messages': 0}, 'ce': {'id': '', 'type': 'chat', 'prompt': "'Perform basic copy editing on the following text, correcting errors in grammar, spelling and punctuation; improvements to style and clarity may also be made, but do not make more significant changes to content or structure: \\n\\n'", 'messages': 0}, 'assistant1': {'id': '', 'type': 'chat', 'prompt': "'You are a concise technical assistant.'", 'messages': 6}, 'assistant2': {'id': '', 'type': 'chat', 'prompt': "'You are a code reviewer focused on correctness and edge cases.'", 'messages': 0}, 'yoda': {'id': '', 'type': 'chat', 'prompt': "'You are Yoda. \\nRespond to ALL inputs in the voice of Yoda from Star Wars. \\nBe sure to ALWAYS use his distinctive style and syntax. Vary sentence length.\\n'", 'messages': 0}, 'NONE': {'id': '', 'type': 'chat', 'prompt': "''", 'messages': 4}}
Delete one persona
%%chat_meta -i assistant1delete
# Dropped the chat object assistant1.
Clear message history of one persona (keep persona)
%%chat_meta -i assistant2clear
# Cleared 0 messages of chat object assistant2.
Delete all personas
%%chat_meta --alldelete
# Dropped all chat objects ['python', 'html', 'latex', 'ce', 'assistant2', 'yoda', 'NONE'].
%%chat_meta command aliases / synonyms:
deleteordropkeysornamesprintorsay
4) Regular chat cells vs direct LLM-provider cells
Regular chat cells (%%chat)
- Stateful across cells (conversation memory stored in chat objects).
- Persona-oriented via
--chat_id+ optional--prompt. - Backend chosen with
--conf(default:ChatGPT).
Direct provider cells (%%chatgpt, %%openai, %%gemini, %%ollama, %%dalle)
- Direct single-call access to provider APIs.
- Useful for explicit provider/model control.
- Do not use chat-object memory managed by
%%chat.
Examples:
%%chatgpt --model gpt-4.1-mini --format markdownWrite a regex for US ZIP+4.
%%gemini --model gemini-2.5-flash --format=markdownExplain async/await in Python using three point each with less than 10 words.
%%ollama --model gemma3:1b --format markdownGive me three Linux troubleshooting tips. VERY CONCISE.
%%dalle --model dall-e-3 --size landscapeA dark-mode screensaver digital painting of a lighthouse in stormy weather.

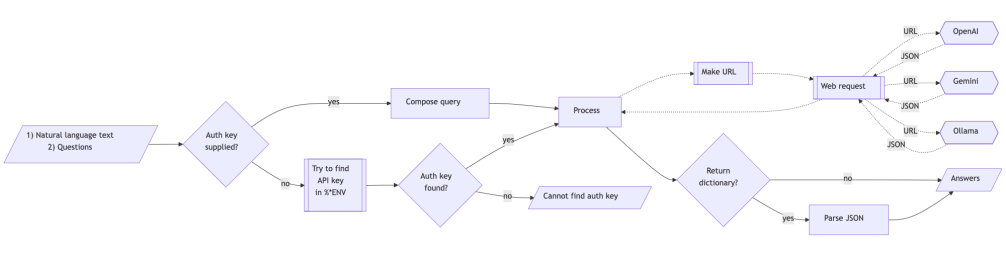
5) LLM provider access facilitation
API keys can be passed inline (--api_key) or through environment variables.
Notebook-session environment setup
%env OPENAI_API_KEY=YOUR_OPENAI_KEY%env GEMINI_API_KEY=YOUR_GEMINI_KEY%env OLLAMA_API_KEY=YOUR_OLLAMA_KEY
or:
import osos.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"os.environ["GEMINI_API_KEY"] = "YOUR_GEMINI_KEY"os.environ["OLLAMA_API_KEY"] = "YOUR_OLLAMA_KEY"
Ollama-specific defaults:
OLLAMA_HOST(default host fallback ishttp://localhost:11434)OLLAMA_MODEL(default model if--modelnot given)
The magic cells %%chat, %%chatgpt, and %%ollama take as argument --base_url. This allows to use LLMs that have ChatGPT compatible APIs. The argument --base_url is a synonym of --hostfor magic cell %%ollama.
6) Aliases
The Jupyter notebook framework allows to define magic cell aliases with %alias_magic. Here a new magic cells that “shortcuts” the access of a locally-run LLaMA (llamafile) model via %%chatgpt:
%alias_magic -c -p "--base_url=http://127.0.0.1:8080/v1 --max_tokens=8192 --format=markdown" llama chatgpt
# Created `%%llama` as an alias for `%%chatgpt --base_url=http://127.0.0.1:8080/v1 --max_tokens=8192 --format=markdown`.
Here is an invocation:
%%llamaHow many people live in Brazil?
Remark: The above results are computed with the llamafile (LLaMA model) “google_gemma-3-12b-it-Q4_K_M.llamafile”.
7) Notebook/chatbook session initialization with custom code + personas JSON
Initialization runs when the extension is loaded.
A) Custom Python init code
- Env var override:
PYTHON_CHATBOOK_INIT_FILE - If not set, first existing file is used in this order:
~/.config/python-chatbook/init.py~/.config/init.py
Use this for imports/helpers you always want in chatbook sessions.
B) Pre-load personas from JSON
- Env var override:
PYTHON_CHATBOOK_LLM_PERSONAS_CONF - If not set, first existing file is used in this order:
~/.config/python-chatbook/llm-personas.json~/.config/llm-personas.json
Supported JSON shapes:
Shape 1: object (keys become chat_id)
{ "writer": { "conf": "ChatGPT", "prompt": "@CodeWriterX|Python", "model": "gpt-4.1-mini", "max_tokens": 4096, "temperature": 0.4 }, "editor": "You are a strict copy editor."}
Shape 2: list of persona specs
[ { "chat_id": "python", "conf": "ChatGPT", "prompt": "@CodeWriterX|Python", "model": "gpt-4.1-mini", "max_tokens": 8192, "temperature": 0.4 }]
Recognized persona spec fields include:
chat_id(orid,name)promptconf(orconfiguration)model,max_tokens,temperature,base_urlapi_keyevaluator_args(object)
Verify pre-loaded personas:
%%chat_meta --allkeys