Shell-History
Wer mit einer Shell unter Linux arbeitet, weiss schnell die History-Funktion zu schätzen. Statt Befehle immer wieder einzutippen, verwendet man die Pfeiltaste, um alte Befehle zurück zu holen oder man wiederholt Befehle aus der History mit «!<Befehlsnummer>». Auch die Kombination history | grep Suchstring kommt sicher vielen bekannt vor.
In diesem Blogbeitrag stelle ich eine bessere und mächtigere Variante vor, mit der Shell-History zu arbeiten, indem man das Werkzeug Atuin verwendet.
Was ist Atuin
Auf der Webseite mit der Dokumentation wird Atuin wie folgt beschrieben:
Atuin replaces your existing shell history with a SQLite database, and records additional context for your commands. With this context, Atuin gives you faster and better search of your shell history.
Additionally, Atuin (optionally) syncs your shell history between all of your machines. Fully end-to-end encrypted, of course.
Atuin ist ein Ersatz der Shell-History durch eine Datenbank, der nützliche Erweiterungen und, wenn das gewünscht wird, sogar die Synchronisation der Shell-History über mehrere Systeme hinweg bietet.
Atuin ist OpenSource-Software und wird nur durch Sponsoren unterstützt. Die Entwicklerinnen sind froh um Unterstützung.
Unterstützte Shells
Atuin unterstützt die folgenden Shell-Varianten:
- zsh
- bash
- fish
- nushell
- xonsh
Weiterentwicklung
Im Zusammenhang mit Atuin werden inzwischen auch Werkzeuge entwickelt, mit denen Shell-Konfigurationsfiles zwischen Rechnern synchronisiert werden können, um Umgebungsvariablen und Aliases konsistent auf verschiedenen Rechnern verwenden zu können. (Siehe: https://docs.atuin.sh/guide/dotfiles/)
Ein weiteres Werkzeug ist Atuin Desktop, das Dokumentation und ausführbare Programmsequenzen zusammenbringen will. (Siehe: https://github.com/atuinsh/desktop)
Installation
Für die Installation von Atuin gibt es ein Skript, das mit folgendem Befehl heruntergeladen und ausgeführt werden kann:
curl --proto '=https' --tlsv1.2 -LsSf https://setup.atuin.sh | sh
Das Kommando ergänzt z.B. die Konfigurationsdatei .bashrc für bash mit dem Befehl
eval "$(atuin init bash)"
zum Start des Initialisierungs-Skripts von Atuin beim Starten der bash-Shell. Die Pfadvariable sollte in .bashrc mit dem atuin-Befehl ergänzt werden:
PATH="$PATH:~/.atuin/bin"
Es wird empfohlen, für die bash-Shell auch ble.sh zu installieren.
ble.sh ist ein bash-Shell Zeileneditor, der Syntax-Highlighting (auch mit Farben), Kommandovervollständigung, einen vim-Editiermodus und weitere Features bietet. Atuin kann ihn für die Kommandovervollständigung und die farbige Darstellung von Befehlen brauchen. Der aktuelle Buildstand von ble.sh kann mit folgendem Befehl (alles auf einer Zeile) installiert werden:
curl -L https://github.com/akinomyoga/ble.sh/releases/download/nightly/ble-nightly.tar.xz | tar xJf -bash ble-nightly/ble.sh --install ~/.local/share
In .bashrc sollte ble.sh vor dem Start von Atuin mit folgender Zeile auch gleich gestartet werden:
source -- ~/.local/share/blesh/ble.sh
Bestehende Kommandhistorie
Atuin kann nach der Installation die bestehende Shell-Kommandhistorie importieren und dann wie jene neuer Kommandos verwenden. Der Import geschieht mit folgendem Kommando:
atuin import auto
Hier noch die Dokumentation des Import-Befehls:
$ atuin help import
Import shell history from file
Usage: atuin import <COMMAND>
Commands:
auto Import history for the current shell
zsh Import history from the zsh history file
zsh-hist-db Import history from the zsh history file
bash Import history from the bash history file
replxx Import history from the replxx history file
resh Import history from the resh history file
fish Import history from the fish history file
nu Import history from the nu history file
nu-hist-db Import history from the nu history file
xonsh Import history from xonsh json files
xonsh-sqlite Import history from xonsh sqlite db
help Print this message or the help of the given subcommand(s)Verwendung und gespeicherte Daten
Atuin kann via Konfigurationsdateien den eigenen Bedürfnissen angepasst werden. Die Angaben hier beziehen sich auf die Defaultkonfiguration nach der Installation von Atuin in der bash-Shell.
Während der Verwendung der Shell speichert Atuin in der Datenbank die folgenden Angaben, die dann in Atuin gebraucht werden können (siehe: https://docs.atuin.sh/guide/basic-usage/):
- verwendetes Kommando
- Verzeichnis, in dem das Kommando aufgerufen wurde
- Zeitpunkt des Kommandoaufrufs und die Ausführungszeit
- Returnwert des Kommandos
- Host- und Usernamen
- Shell-Session, in der das Kommando aufgerufen wurde
TUI, Terminal User Interface
Mit der Pfeiltaste gegen oben oder mit <ctrl><r> kann das User Interface gestartet werden. Hier ein Screenshot als Beispiel:

Zuoberst sieht man auch gleich die wichtigsten Shortcuts:
<esc>um Atuin zu verlassen<tab>um den Befehl auf die Kommandozeile zu holen, um ihn dort anzupassen<enter>um den Befehl direkt auszuführen
Mit der Pfeiltaste nach oben oder unten kann man durch die Befehle navigieren.
Mit <ctrl><R> kann man den Scope wechseln zwischen [GLOBAL] wie im Screenshot und [HOST], [SESSION] oder [DIRECTORY]. Es werden dann jeweils alle Befehle aus der History oder nur jene von demselben Host, jene aus der aktuellen Session oder jene, die im aktuellen Verzeichnis aufgerufen wurden, angezeigt.
<ctrl><o> öffnet den ‹Inspektor›. Mit dem Inspektor kann man die Angaben, die zum aktuellen Befehl gespeichert sind, anschauen und auch den entsprechenden Eintrag aus der Atuin-Datenbank löschen.
<Alt><#>, wobei # für die Nummer (1 bis 9) des Befehls in der Liste steht, ruft den Befehl mit dieser Nummer auf.
Wenn man einfach beginnt zu tippen, so wird in der History mit einer ‹fuzzy›-Suche nach dem eingetippten Text gesucht und es werden die gefundenen Befehle angezeigt.

Mit <ctrl><s> kann man zwischen den verschiedenen Suchmodi PREFIX, FULLTEXT und FUZZY wechseln. PREFIX würde im Beispiel kein Resultat liefern, FULLTEXT nur die untersten Befehle, bei denen der Suchtext rot umrandet ist und FUZZY hilft meist auch dann, wenn man den genauen Befehl nicht mehr weiss.
Shortcuts
Die Default-Shortcuts werden in der Dokumentation wie folgt beschrieben:
| Shortcut | Action |
| enter | Execute selected item |
| tab | Select item and edit |
| ctrl + r | Cycle through filter modes |
| ctrl + s | Cycle through search modes |
| alt + 1 to alt + 9 | Select item by the number located near it |
| ctrl + c / ctrl + d / ctrl + g / esc | Return original |
| ctrl + y | Copy selected item to clipboard |
ctrl +  / alt + b / alt + b | Move the cursor to the previous word |
ctrl +  / alt + f / alt + f | Move the cursor to the next word |
| ctrl + b / | Move the cursor to the left |
| ctrl + f / | Move the cursor to the right |
| ctrl + a / home | Move the cursor to the start of the line |
| ctrl + e / end | Move the cursor to the end of the line |
| ctrl + backspace / ctrl + alt + backspace | Remove the previous word / remove the word just before the cursor |
| ctrl + delete / ctrl + alt + delete | Remove the next word or the word just after the cursor |
| ctrl + w | Remove the word before the cursor even if it spans across the word boundaries |
| ctrl + u | Clear the current line |
ctrl + n / ctrl + j /  | Select the next item on the list |
ctrl + p / ctrl + k /  | Select the previous item on the list |
| ctrl + o | Open the inspector |
| page down | Scroll search results one page down |
| page up | Scroll search results one page up |
| (with no entry selected) | Return original or return query depending on settings |
| Select the next item on the list |
Suche
Atuin bietet viele Suchmöglichkeiten, um Befehle in der History zu finden. Ein kleines Beispiel ist die folgende Suche, die den ältesten sudo-Befehl aus der History anzeigt:
atuin search --limit 1 --reverse sudo
Die Suche in Atuin ist auf der Webseite wie folgt beschrieben:
Atuin search supports wildcards, with either the * or % character. By default, a prefix search is performed (ie, all queries are automatically appended with a wildcard).
| Arg | Description |
| –cwd/-c | The directory to list history for (default: all dirs) |
| –exclude-cwd | Do not include commands that ran in this directory (default: none) |
| –exit/-e | Filter by exit code (default: none) |
| –exclude-exit | Do not include commands that exited with this value (default: none) |
| –before | Only include commands ran before this time(default: none) |
| –after | Only include commands ran after this time(default: none) |
| –interactive/-i | Open the interactive search UI (default: false) |
| –human | Use human-readable formatting for the timestamp and duration (default: false) |
| –limit | Limit the number of results (default: none) |
| –offset | Offset from the start of the results (default: none) |
| –delete | Delete history matching this query |
| –delete-it-all | Delete all shell history |
| –reverse | Reverse order of search results, oldest first |
| –format/-f | Available variables: {command}, {directory}, {duration}, {user}, {host}, {time}, {exit} and {relativetime}. Example: —format “{time} – [{duration}] – {directory}$\t{command}“ |
| –inline-height | Set the maximum number of lines Atuin’s interface should take up |
| –help/-h | Print help |
Interessant ist die Möglichkeit, mit --exit oder --exclude-exit vergangene Kommandos mit einem bestimmten Exitcode oder beispielsweise jene, die nicht erfolgreich ausgeführt wurden
(--exclude-exit 0), zu suchen.
Statistik
Mit atuin stats bekommt man eine einfache Statistik zu den Befehlen in der History. Mit atuin history list werden die gespeicherten Befehle und Daten ausgegeben, wobei das Format der Ausgabe mit Parametern angepasst werden kann.
Update
Wenn Zugriff zum Internet besteht, so lässt sich ein Update ganz einfach mit folgendem Befehl durchführen:
atuin-update
Support
Für Fragen zu Atuin gibt es ein Forum: https://forum.atuin.sh/
Im Forum können auch Ideen für Weiterentwicklungen vorgeschlagen werden.
Synchronisation zwischen Rechnern
Es ist möglich, die History mit Atuin über Rechnergrenzen hinweg zu speichern und zu synchronisieren. Dazu braucht es für Atuin eine Datenbank auf einem Synchronisationsserver in der Cloud oder auf einem eigenen Rechner, die dann von verschiedenen Rechnern aus verwendet wird. Der Datentransport von und zur Datenbank wird dabei sicher verschlüsselt.
Auf die Details wird in diesem Blogbeitrag nicht eingegangen. Sie sind auf der Atuin-Webseite beschrieben: https://docs.atuin.sh/self-hosting/server-setup.
Fazit
Das OpenSource-Werkzeug Atuin bietet eine verbesserte und einfach zu bedienende Shell-History mit vielen Suchmöglichkeiten. Es ist schnell installiert und es kann bei Bedarf auch über Rechnergrenzen hinweg sicher verwendet werden. Ein rundum gelungenes kleines Werkzeug, das die Arbeit mit der Shell erleichtert.
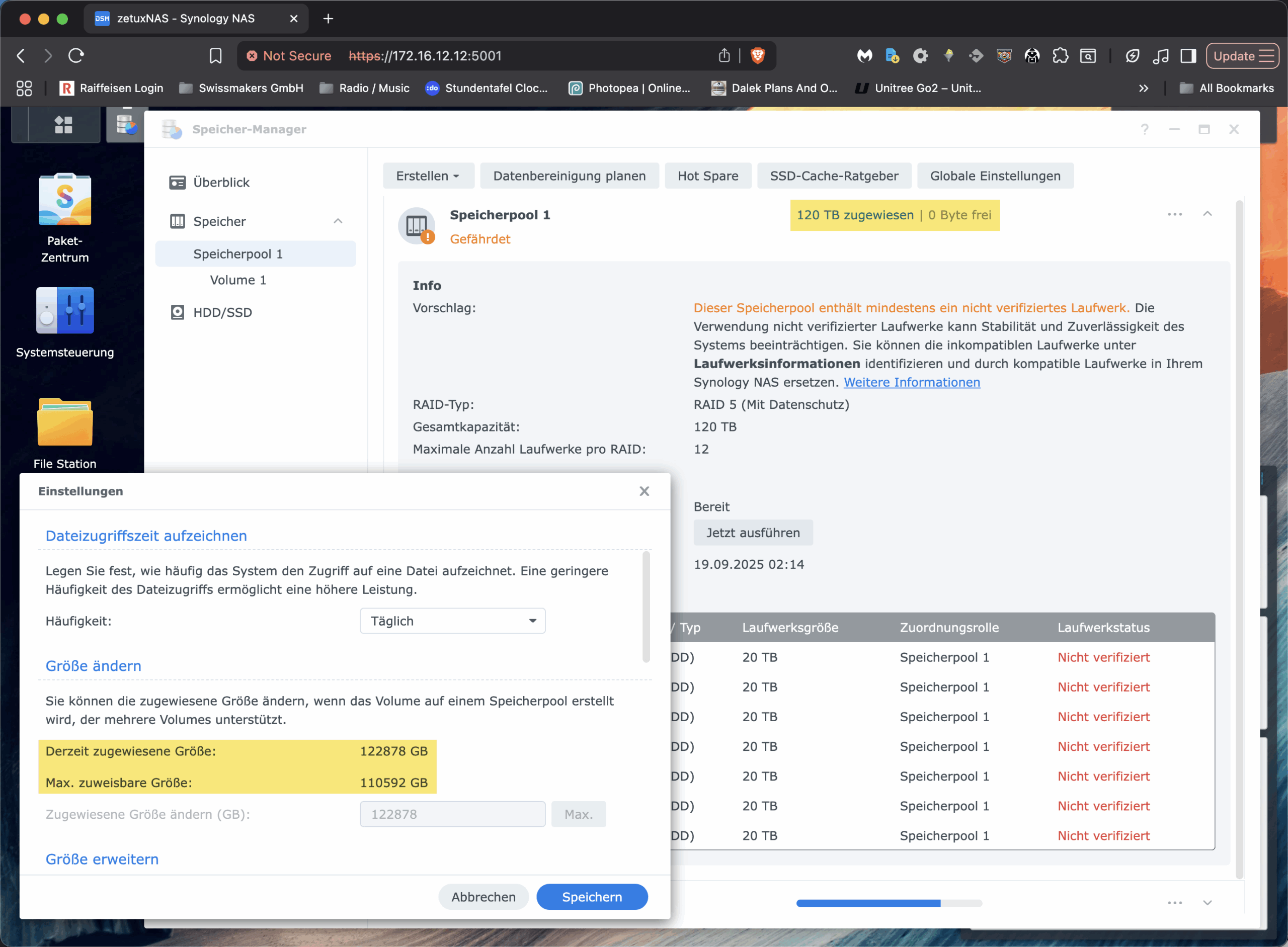
Vor dieser Frage stand ich kürzlich, als wir bei einer unserer Installationen von Swissmakers vor einem vertrauten, aber irritierenden Phänomen standen: Ein Synology-NAS mit sieben 22-TB-HDDs im RAID-5 zeigte im Speicherpool korrekt rund «120 TB» an (1), liess aber das vorhandene Volume partout nicht über ca. 108 TB vergrössern (2/3). Die Oberfläche bot keine Option, obwohl der Pool noch freie Kapazität hatte. Für alle, die ähnliches beobachten und in dem GUI gegen eine unsichtbare Decke laufen: Das ist kein technologisches Limit von Btrfs oder LVM und hat auch nichts mit der RAM-Bestückung zu tun. Es ist eine modellabhängige Software-Schranke in der DSM-Oberfläche. In diesem Beitrag zeige ich, warum das so ist und wie man das Synology Volume trotzdem sauber und online per CLI über diese Grenze hinaus erweitert.

Die Fakten
Beginnen wir mit den Zahlen. Festplattenhersteller rechnen dezimal: 1 TB sind 10¹² Byte. Betriebssysteme und auch das DSM rechnen binär: 1 TiB sind 2⁴⁰ Byte. Eine 22-TB-Platte entspricht also real etwa 20,0 TiB. Sieben dieser Laufwerke in RAID-5 ergeben brutto ungefähr 140 TiB; eine Platte fällt für Parität weg, netto bleiben rund 120 TiB im Pool. An dieser Stelle ist noch alles stimmig. Der Stolperstein entsteht später, auf der Ebene des Volumes.
Synology organisiert sein System so: Zuunterst läuft ein mdadm-RAID, darauf liegt ein LVM mit einer Volume Group (bei vielen Geräten „vg1“ genannt), und darauf wiederum das eigentliche Dateisystem, in unserem Fall Btrfs. DSM trennt bewusst zwischen Speicherpool und Volume. Der Pool repräsentiert die physische Kapazität des RAID-Sets; Volumes sind LVM-Logical-Volumes, denen man via GUI Kapazität aus dem Pool zuweist. Und genau hier besitzt DSM eine modellabhängige Obergrenze für die Grösse eines einzelnen Volumes, die bei zahlreichen Plus-Modellen und anderen Modellen bei 108 TiB liegt. Das ist keine technische Notwendigkeit von LVM oder Btrfs, sondern eine durch Synology bewusst platzierte Software-Schranke in der Oberfläche. Der Beleg dafür ist trivial: Der Pool zeigt freie Extents und LVM kann sie an das bestehende LV hängen; danach lässt sich das Btrfs online resizen, vollständig ohne Umformatieren, Downtime oder sonstige «magische» Schritte.
Btrfs selbst ist in dieser Konstellation nicht der limitierende Faktor. Das Dateisystem unterstützt Online-Resize, ist chunk-basiert aufgebaut und verwaltet Daten und Metadaten in getrennten Bereichen. Es skaliert auf Kapazitäten weit oberhalb dessen, was eine 7-Bay-Konfiguration überhaupt liefern kann. Auch die block-device-Geschichte ist mit LVM unkritisch: Solange die VG freie Extents hat, lässt sich das LV vergrössern. Weder die CPU-Architektur eines Plus-Modells noch die RAM-Ausstattung bestimmen hart die maximal adressierbare Grösse eines Btrfs-Volumes. Mehr RAM hilft Caches und damit der Performance, aber es ändert nichts an den Adressbreiten der beteiligten Schichten. Wer also in der DSM-Maske bei «Max. zuweisbare Grösse 110 592 GB» hängenbleibt, stösst auf eine UI-Einschränkung, nicht aber auf eine technisch bedingte Grenze.
Die Lösung dazu
Die Lösung liegt im Werkzeugkasten, den wir als Linux-Ingenieure ohnehin täglich benutzen: Wir erweitern das Logical Volume mit LVM und ziehen das Btrfs anschliessend nach. Dabei bleibt das System im Betrieb; Services, Freigaben und NFS/SMB-Clients arbeiten weiter. Der Ablauf ist bei jedem UNIX-basierten System, welches LVM einsetzt, gleich: zunächst den Ist-Zustand zweifelsfrei verifizieren, das LV vergrössern, und zum Schluss das Dateisystem auf 100% der Grösse des LVs resizen. Ich werden gleich die konkreten Kommandos alle niederschreiben, damit man die einzelnen Schritte direkt auch in die eigene Umgebung durchführen kann.
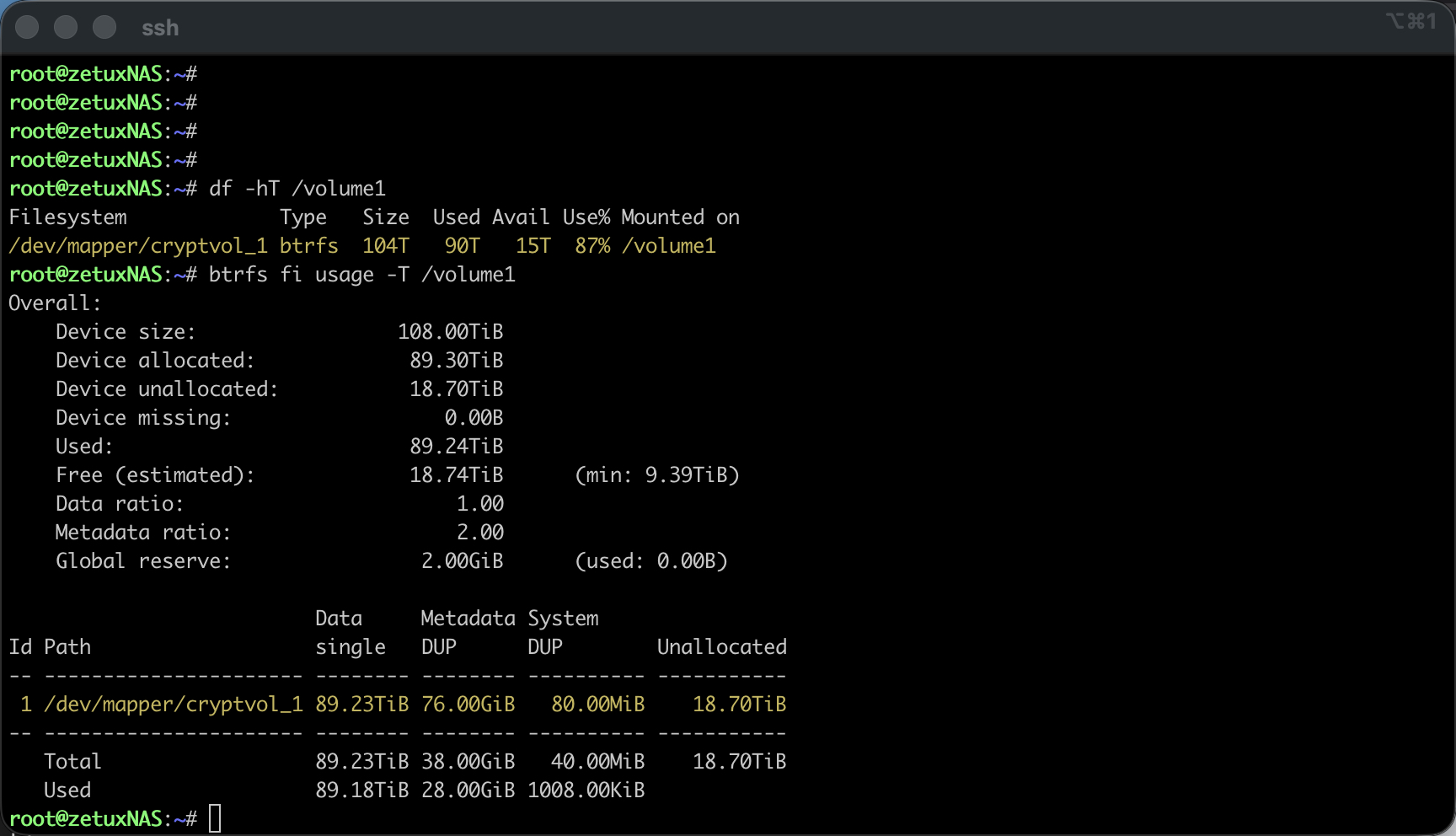
Zuerst wähle ich den sicheren Einstieg per SSH und eskaliere auf root (Wie das genau gemacht werden kann, wurde bereits hier beschrieben: Link). Danach prüfe ich die beteiligten Storage-Schichten.# df -hT /volume1 bestätigt das Dateisystem und den Mountpunkt, # mount | grep volume1 zeigt die tatsächliche Gerätedatei, die bei Synology in der Regel bei verschlüsselten Volumen über den Mapper als /dev/mapper/cryptvol_1 eingebunden ist. Mit # vgs -o vg_name,vg_size,vg_free,# lvs -o lv_name,vg_name,lv_size,lv_path und # pvs -o pv_name,vg_name,pv_size,pv_free verschaffe ich mir Klarheit, wie die Volume Group heisst, welche Logical Volumes existieren und wie viele freie Extents im Pool tatsächlich anliegen. An dieser Stelle sollte «VFree» eine Grössenordnung um die in der GUI angezeigten 12 TB, «12.00t» frei zeigen; entscheidend ist ausserdem der exakte lv_path, meist /dev/vg1/volume_1.

Ist die Ausgangslage eindeutig, kann das LV erweitert werden. Dazu genügt ein einzelner Aufruf, der alle freien Extents der VG an das Ziel-LV hängt. Mit einer Pfadangabe aus der lvs-Ausgabe sieht das so aus:
lvextend -l +100%FREE /dev/vg1/volume_1Die Option -l arbeitet mit Extents und ist in dieser Situation robuster als eine genaue Grössenangabe in Bytes; sie konsumiert in Kombination mit 100% exakt den freien Bereich der VG, unabhängig von Rundungen. Ein unmittelbar folgendes # lvs -o lv_name,lv_size,lv_path zeigt die neue LV-Grösse. Bis hierher hat sich am Dateisystem noch nichts geändert, wir haben lediglich die Blockdevice-Schicht erweitert.

Reboot (Empfohlen)
Ein Reboot ist nicht in allen Fällen nötig, jedoch falls das Volume1 zusätzlich verschlüsselt wurde, oder das Synology den Einbau eines Caches unterstützt, so muss noch vor dem btrfs resize das dm-crypt/LUKS-Device (cryptvol_1) als sowohl das darunter liegende cachedev_0 auf die neue LV-Grösse vergrössert werden. Eine kurze Kontrolle erfolgt anhand: # dmsetup ls --tree

Wird eines oder beide der genannten virtuellen Devices angezeigt, so empfielt sich ein reboot. Um cachedev_0 als sowohl cryptvol_1 alternativ online zu vergrössern kann folgendermassen vorgegangen werden: (Ohne Reboot – jedoch nicht ohne Risiko)
# Aktuelle Sektorgrösse von cachedev_0 abfragen:
dmsetup table --showkeys cachedev_0
# Neue Sektorgrösse vom LV holen:
SECTORS=$(blockdev --getsz /dev/vg1/volume_1)
# cachedev_0 suspenden, cachedev_0 Table mit neuer Länge reloaden und reaktivieren:
dmsetup suspend cachedev_0
dmsetup table --showkeys cachedev_0 \
| sed '/^Size Hist:/,$d' \
| awk -v S="$SECTORS" 'NR==1{$2=S} {print}' OFS=" " \
| dmsetup reload cachedev_0 --table -
dmsetup resume cachedev_0
# Falls vorhanden LUKS/dm-crypt auf neue Grösse von cachedev_0 resizen:
cryptsetup resize cryptvol_1
# Prüfen ob cachedev_0 (und cryptvol_1) erfolgreich resized wurden:
dmsetup table --showkeys cachedev_0
blockdev --getsize64 /dev/mapper/cryptvol_1Resize des Filesystems
Nach dem Reboot oder dem manuellen resize des cachedev_0 sowie anfälligem cryptvol_1, informiere ich jetzt das Btrfs über den zusätzlichen Platz. Das funktioniert online über den Mountpoint. Wer die maximale verfügbare Grösse auch im FS nutzen möchte, nimmt die bequeme Variante:
btrfs filesystem resize max /volume1Alternativ lässt sich eine konkrete Differenz angeben, zum Beispiel +12t. Nach wenigen Augenblicken bestätigt # df -h /volume1 die gewachsene Kapazität, und # btrfs fi usage -T /volume1 zeigt den neuen freien Bereich auf der Ebene der Btrfs-Chunks. Der gesamte Vorgang läuft ohne Unterbrechung der Freigaben.

Je nach Füllstand lohnt sich anschliessend ein leichter Balance-Lauf, der nur stark belegte Chunks anfasst, um die Verteilung zu glätten, ohne das System unnötig zu beschäftigen:
btrfs balance start -dusage=5 -musage=5 /volume1
btrfs balance status /volume1Der Balance-Schritt ist optional; er sorgt dafür, dass zukünftige Allokationen nicht an Altlasten scheitern, z.B. wenn Daten und Metadaten ungleichmässig verteilt sind. Er ist gerade bei sehr grossen Dateisystemen mit langer Historie nützlich, in frischen Setups jedoch oft nicht nötig.

Zurück in der DSM-Oberfläche wird das Volume anschliessend mit der neuen, vollen Grösse angezeigt. Der Dialog «Grösse ändern» wird weiterhin die bekannte Obergrenze als «Max. zuweisbare Grösse» nennen; dies gilt jedoch lediglich für den DSM-Disk-Assistent. Künftige Erweiterungen laufen auf demselben Weg wieder über LVM und btrfs filesystem resize. Wer die Operation kontrolliert begleiten möchte, überwacht parallel # dmesg -w und die Btrfs-Statistiken, während die Änderung greift.
Ein Wort zur Sicherheit gehört in diesen Kontext: Auch wenn der Weg technisch sauber ist, bleibt er von Synology in dieser Form «nicht unterstützt». Für produktive Volumes gilt wie immer, dass ein aktuelles, getestetes Backup Voraussetzung ist. Das Verfahren verändert keine Dateninhalte, aber es operiert an verschiedenen Speicher Schichten, die für alles darüber verantwortlich sind. Wer mehrere Volumes im selben Pool betreibt, vergewissert sich vor dem Extend, dass er das richtige LV erwischt; die eindeutige lv_path-Prüfung vor dem eigentlichen Befehl ist der entscheidende Schutz gegen Vertipper.
Fazit
Der scheinbare Widerspruch zwischen freiem Speicher im Pool und einer starren Grenze beim Volume ist kein Indiz für ein Limit von Btrfs, LVM oder der Hardware und schon gar nicht eine Frage der RAM-Ausstattung. Es ist eine Hersteller- und GUI-seitige Schranke im DSM, die den Disk-Assistent limitiert, nicht die darunter liegende Technologie. Wer das versteht, kann ein bestehendes Volume online und ohne Downtime vergrössern, indem er das Logical Volume per lvextend erweitert und das Btrfs per btrfs filesystem resize nachzieht. Danach steht die Kapazität dort zur Verfügung, wo sie hingehört: im Dateisystem, dort wo die Daten gespeichert werden. Für mich ist das der pragmatischste Weg, mit dem sich grosse Pools auf allen Synology Geräten sinnvoll nutzen lassen, ohne dabei auf die künstliche 108-TiB-Deckelung hereinzufallen.
]]>Für Swissmakers GmbH war klar: Eine dynamische Landingpage, die sich ohne manuellen Aufwand aktualisiert, ist essenziell für konsistente Dokumentation und effizientes Auffinden von Informationen.
Warum Wiki.js das nicht von Haus aus mitliefert
Die Wiki.js-Version 2 basiert intern auf einem Vue.js Single-Page-Application-Ansatz. Alle Seiteninhalte werden clientseitig nachgeladen; serverseitig generierte Platzhalter wie „[children]“ (bekannt aus anderen Markdown-Plugins) existieren nicht. Das Entwicklerteam von Wiki.js hat zwar für Version 3 ein modulares Blocks-System angekündigt, doch für v2-Instanzen bleibt nur der Weg über die öffentliche GraphQL-API oder ein Upgrade. Letzteres ist jedoch im produktiven Umfeld definitiv nicht empfohlen da die v3 seit nun fast zwei Jahren lediglich als Alpha Version verfügbar ist und bis heute als «unstable» gilt. Zudem sind die meisten Features noch gar nicht oder nicht richtig implementiert.
Unsere Lösung: Ein leichtgewichtiger GraphQL-Client im Frontend
Um das Feature umzusetzen, haben wir ein JavaScript-Snippet entwickelt, das wir in jeder gewünschten Landingpage oder übergeordnete «Tech-Page» einbinden können. Der Code wird dabei in die jeweilige Seite unter den «Page Properties» im Tab «Script» eingefügt:

Der Code folgt beim Aufruf der jeweiligen Seite dem folgendem Ablauf:
- holt einmalig alle Seiten aus der GraphQL-API (Standartlimit bis 1000 gesetzt),
- filtert ausschliesslich jene, deren Pfad unterhalb des automatisch erkannten Seitenpfads liegt (also unterhalb der aktuell geöffneten Seite),
- entfernt die Landingpage selbst aus der Ausgabe,
- rendert das Ergebnis als übersichtliche Link-Liste mit dem bereits eingebauten
links-list-Styling von Wiki.js.
In der wiki-Seite selbst wird dann der gerenderte HTML-content innerhalb des<div id="pageTree">Loading pages …</div> mit dem generierten Menu ersetzt.

Die Page kann dabei beliebig gestaltet oder erweitert werden, wichtig ist nur, dass das erwähnte Div am gewünschten Ort innerhalb der Seite platziert wird, wo die dynamische Sub-Übersicht gewünscht ist.
JavaScript Code
Achtung: Für alle, die diese Seite auf Englisch lesen. Bitte kopiert den Code aus der deutschen Original-Seite. Unsere Deepl-Übersetzungsapp hat momentan einen Bug und löscht teils Code aus Codeblöcken oder Newlines heraus. Ein Bugreport ist erstellt. Besten Dank und Sorry für die Umstände.
<script>
(() => {
const debug = false; // auf true setzen, falls etwas nicht wie gewünscht funktioniert.
const MAX_ATTEMPTS = 30; // bis zu 30 × 200 ms auf #pageTree warten (timeout)
let attempts = 0;
const log = (...a) => debug && console.log(...a);
const warn = (...a) => debug && console.warn(...a);
const error = (...a) => debug && console.error(...a);
function init() {
const container = document.getElementById('pageTree');
if (!container) {
attempts++;
warn(`#pageTree not found, attempt ${attempts}`);
if (attempts < MAX_ATTEMPTS) return setTimeout(init, 200);
error('Gave up waiting for #pageTree');
return;
}
/** Pfad der aktuellen Seite ohne führenden Locale-Teil */
const selfPath = location.pathname
.replace(/^\/[^/]+\//, '') // z.B. /en/ entfernen
.replace(/^\/|\/$/g, ''); // führenden / und trailing / entfernen
/** Präfix, das alle childs gemeinsam haben (selfPath + "/") */
const childPrefix = selfPath.endsWith('/') ? selfPath : selfPath + '/';
log('[Wiki.js] selfPath:', selfPath);
log('[Wiki.js] childPrefix:', childPrefix);
const query = `
query {
pages {
list(limit: 1000, orderBy: PATH, orderByDirection: ASC) {
path
title
locale
}
}
}`;
fetch('/graphql', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query })
})
.then(r => r.json())
.then(({ data }) => {
if (!data?.pages?.list) {
container.textContent = 'API-Fehler: keine Seitendaten.';
error('pages.list fehlt im Response', data);
return;
}
const pages = data.pages.list
.filter(p => p.path.startsWith(childPrefix)) // nur echte Unterseiten
.filter(p => p.path !== selfPath); // Landingpage selbst soll raus
log('[Wiki.js] gefilterte Seiten:', pages);
if (!pages.length) {
container.textContent = 'Keine Unterseiten vorhanden.';
return;
}
const listHTML = pages.map(
p => `<li><a href="proxy.php?url=/${p.locale}/${p.path}">${p.title}</a></li>`
).join('');
container.innerHTML = `<ul class="links-list">${listHTML}</ul>`;
})
.catch(err => {
container.textContent = 'Fehler beim Laden der Seitenliste.';
error(err);
});
}
init();
})();
</script>Was passiert im Detail?
Nachfolgend haben wir für jene, die sich für JavaScript interessieren oder einfach genauer wissen möchten, was Zeile für Zeile genau passiert, das Ganze auf die einzelnen Zeilen aufgeschlüsselt. (Die Zeilennummern beziehen sich auf das komplette Snippet, inklusive <script>-Tag.)
| Zeile(n) | Code | Technische Erklärung |
|---|---|---|
| 1 | <script> | Öffnet einen HTML-Script-Block – der Browser interpretiert alles bis </script> als JavaScript. |
| 2 | (() => { | Start eines IIFE (Immediately Invoked Function Expression). Dadurch liegt der gesamte Code in einem eigenen Scope; globale Namenskollisionen werden vermieden. |
| 3 | const debug = true; | Schalter für ausführliche Konsolenausgabe. Bei false werden alle Log-Aufrufe unterdrückt. |
| 4 | const MAX_ATTEMPTS = 30; | Maximale Anzahl Wiederholungen beim Polling auf das DOM-Element. |
| 5 | let attempts = 0; | Zähler für die bereits erfolgten Polling-Versuche. |
| 7 – 9 | const log…warn…error… | Drei Arrow Functions, die jeweils nur dann auf console.* zugreifen, wenn debug aktiv ist. So spart man if-Blöcke in der Logik darunter. |
| 11 | function init() { | Hauptfunktion. Sie wird wiederholt aufgerufen, bis das Ziel-Element vorhanden ist. |
| 12 | const container = document.getElementById('pageTree'); | Sucht das DIV, in dem später die Linkliste gerendert wird. |
| 13 – 18 | if (!container) { … } | Polling-Logik: • Zähler erhöhen • Warnung loggen • Wenn attempts < MAX_ATTEMPTS, mit setTimeout(init, 200) nach 200 ms erneut prüfen.• Nach dem Limit Abbruch mit Fehlermeldung. |
| 22 – 24 | const selfPath = location.pathname.replace… | Ermittelt den Pfad der aktuellen Wiki-Seite, entfernt dabei: 1. die Sprachpräfix-Sektion (Regex ^\/[^\/]+\/)2. evtl. führenden bzw. abschliessenden Slash. |
| 27 | const childPrefix = selfPath.endsWith('/') ? selfPath : selfPath + '/'; | Stellt sicher, dass der Child-Präfix immer mit / endet. Beispiel: 07-internal-it/it-services/. |
| 29 – 30 | log('[Wiki.js] selfPath:' …) | Debug-Ausgabe des aktuellen Pfades und des sub-Präfixes. |
| 32 – 41 | const query = \…`;` | Template Literal mit GraphQL-Query. • pages.list liefert bis zu 1000 Seiten.• Sortiert nach Pfad, damit childs automatisch gruppiert sind. |
| 43 – 47 | fetch('/graphql', { … }) | Stellt einen HTTP-POST an den Wiki.js-GraphQL-Endpunkt. Header Content-Type: application/json ist Pflicht. |
| 48 | }).then(r => r.json()) | Erster Promise-Schritt: Die Antwort wird per Response.json() geparst. |
| 49 | .then(({ data }) => { | Zweiter Promise-Schritt: ES6-Destrukturierung, um data sofort herauszuziehen. |
| 50 – 54 | if (!data?.pages?.list) { … } | Prüfung auf Existenz der erwarteten Struktur unter Nutzung von Optional Chaining (?.). Bei Fehler: Meldung für den Benutzer und Logging. |
| 56 – 58 | const pages = data.pages.list.filter… | Zweistufiger Filter: 1. startsWith(childPrefix) → nur echte Unterseiten2. !== selfPath → eigene Seite ausschliessen. |
| 60 | log('[Wiki.js] gefilterte Seiten:', pages); | Debug-Ausgabe des Ergebnisses nach dem Filter. |
| 62 – 65 | if (!pages.length) { … } | Fehlermeldung, falls keine Unterseiten existieren (z. B. nach Migration). |
| 67 – 69 | const listHTML = pages.map(p => `<li>…`).join(''); | Baut für jede Unterseite ein <li><a …></a></li> und verbindet alles zu einem HTML-String. |
| 71 | container.innerHTML = \<ul class=»links-list»>${listHTML}</ul>`;` | Rendert die Linkliste. Die Klasse links-list sorgt für das card-artige Styling, das Wiki.js mitliefert. |
| 73 – 76 | .catch(err => { … }) | Fehlerbehandlung der Fetch-Kette. Zeigt nutzerfreundliche Meldung und loggt das Exception-Objekt. |
| 79 | init(); | Erster Aufruf der Init-Funktion – löst das Polling aus. |
| 80 | })(); | Schliesst das IIFE und ruft es sofort auf. |
| 81 | </script> | Ende des Script-Blocks. |
Kleiner Zusatz: Alphabetisches Sortieren nach «Page-Titel» anstatt Pfad
Im Standard GraphQL-Respond sind die jeweiligen Pages nach dem Pfad (PATH URL) sortiert. Diese kann sich aber vom eigentlichen Titel unterscheiden und so kann es auch Sinn machen, die Seiten nach ihrem Titel alphabetisch zu sortieren.
Dafür wird im JavaScript-Code noch vor dem Rendern der Liste const listHTML = pages.map (Zeile 67) das Array der Seiten mit der Funktion sort() und localeCompare() nachsortiert. Der benötigte Code sieht so aus:
pages.sort((a, b) => a.title.localeCompare(b.title));Die nötige Änderung, respektive Ergänzung im Code müsste also wie folgt aussehen:
pages.sort((a, b) => a.title.localeCompare(b.title));
const listHTML = pages.map(
p => `<li><a href="proxy.php?url=/${p.locale}/${p.path}">${p.title}</a></li>`
).join('');Praxiserfahrungen nach der Integration
Nach wenigen Minuten ist das Snippet in mehreren Bereichen aktiv. Seitdem
- erscheinen neue Dokumente sofort in der Übersicht,
- entfällt die manuelle Pflege der Landingpages / Subpages Übersicht,
- bleibt die Navigation auch bei tiefen Verschachtelungen konsistent.
Gleichzeitig ist das Skript so schlank, dass es künftige Migrationen bis v3 (sollte diese Version dann doch noch irgendwann erscheinen) nicht behindert. Bis dahin sichert es die Funktionsfähigkeit unseres Wikis mit minimalem Aufwand.
Der folgende Screenshot zeigt ein Beispiel, bei dem eine alphabetische Sortierung nach dem Page-Namen mehr Sinn machen würde.
Fazit
Ein fehlendes Kernfeature muss nicht zwangsläufig auf das nächste Major-Upgrade warten. Mit einem präzisen Blick in die GraphQL-API und wenigen Zeilen JavaScript konnten wir unsere Dokumentationsqualität deutlich erhöhen. Wer ebenfalls auf Wiki.js v2 setzt, kann das Snippet ohne weitere Abhängigkeiten übernehmen. Fragen oder Verbesserungsvorschläge bitte an [email protected], wir tauschen uns gerne aus. Für Unterstützung bei der Installation und Konfiguration von Wiki.js kontaktieren Sie uns ungeniert für ein Beratungsgespräch.
]]>Elastic bietet Beispieldaten, die unter ‹Integrations → Sample data → Other sample data sets› installiert werden können. Im folgenden Beispiel werden die Beispiele aus «Sample eCommerce orders» verwendet. Mit diesen Daten kann das Beispiel nachvollzogen werden.
Dashboard als Vorlage
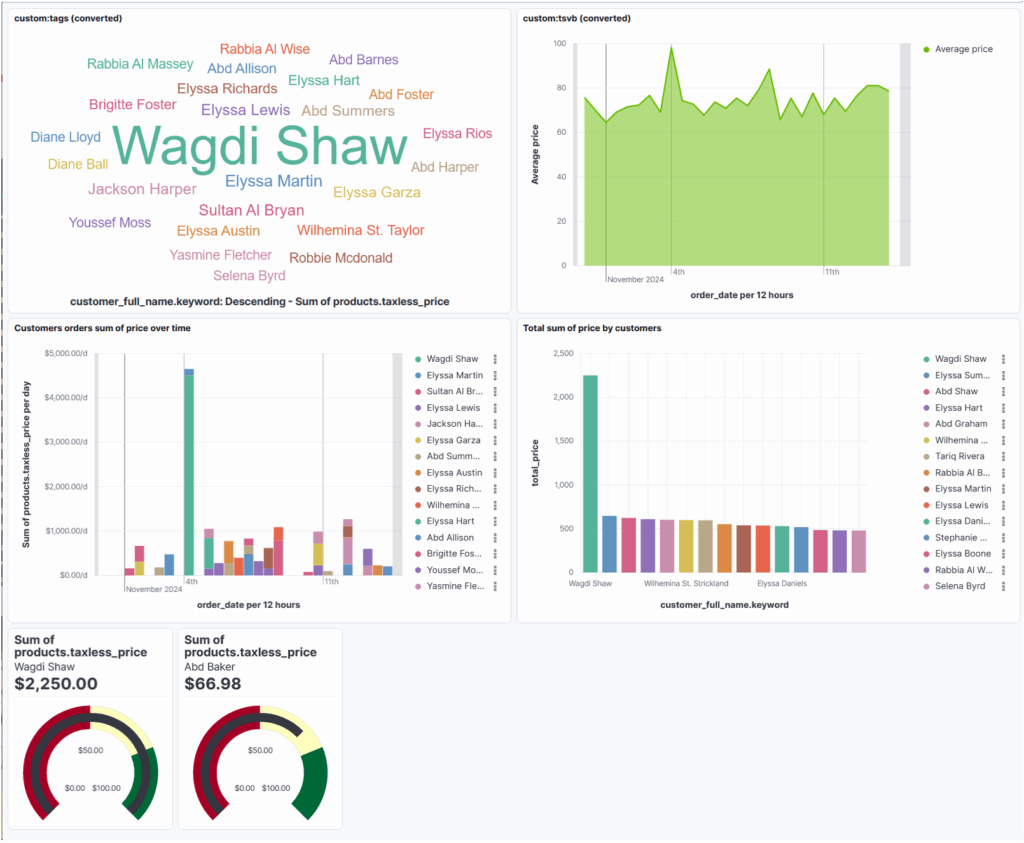
Daten aus dem eCommerce-Beispiel sind im Dashboard in einem Tag-cloud-, einem Liniengrafik-, zwei Balkendiagramm- und zwei Gauge-Panels (Pegeldiagramme) dargestellt worden. Die Gauge-Panels zeigen via Filter die Daten einzelner Kunden aus der eCommerce-Datei. Das Tag-cloud-Panel mit 25 Tags und das Panel mit der Liniengrafik sind als «Legacy → Aggregation based» Panels erstellt und dann in Kibana-Lens-Panels konvertiert worden, die anderen Panels sind direkt mit Kibana-Lens definiert worden. Das Dashboard sieht wie folgt aus:
Dieses Beispiel-Dashboard ist dann in die Datei blog_beispiel5.ndjson exportiert worden.
Inputdatei mit Variablen
In der Inputdatei blog_beispiel5_vars.json werden vorerst wieder einige Variablen definiert.
{
"tag_cloud": {
"title": "Kunden mit grösstem Umsatz",
"anzahl": 30
},
"area": {
"title": "Durchschnittlicher Preis der Bestellungen über die Zeit"
},
"bars_stacked": {
"title": "Totale Kosten der Bestellungen nach Kunde über die Zeit"
},
"bars": {
"title": "Totaler Umsatz pro Kunde"
},
"gauge": {
"hoehe": 10,
"breite": 8
},
"dashboard_title": "generiertes_dashboard_blog_beispiel5"
}Es wird wiederum ein Titel für das Dashboard definiert. Für die ersten 4 Grafiken werden nur andere Titel gesetzt und für die Tag-cloud die Anzahl Tags geändert und die Grösse der Gauge-Panel wird angegeben. Das sind alles nur triviale Anpassungen, die aber zeigen, wie ein solches Dashboard mit Variablen angepasst und neu generiert werden kann. Bei Bedarf lässt sich das dann weiter ausbauen.
Einfügen von jinja2 Elementen
Die Datei blog_beispiel5.j2 ist wiederum erst umgeformt worden, damit sie einfacher angepasst werden kann. Für das Tag-cloud-Panel wird der Titel und die Anzahl Tags wie folgt eingefügt:
"panelsJSON": "[{\"type\":\"lens\",
--------->\"gridData\":{\"x\":0,
--------->\"y\":0,
--------->\"w\":24,
--------->\"h\":15,
--------->\"i\":\"7338d1e1-501e-4084-8d8a-5b7593a87e66\"},
--------->\"panelIndex\":\"7338d1e1-501e-4084-8d8a-5b7593a87e66\",
--------->\"embeddableConfig\":{\"attributes\":{\"title\":\"{{ tag_cloud.title }}\",
--------->\"visualizationType\":\"lnsTagcloud\",
--------->\"type\":\"lens\",
--------->\"references\":[{\"type\":\"index-pattern\",
--------->\"id\":\"ff959d40-b880-11e8-a6d9-e546fe2bba5f\",
--------->\"name\":\"indexpattern-datasource-layer-83a576c3-0e7c-4f46-8284-f87ab836f522\"}],
--------->\"state\":{\"visualization\":{\"layerId\":\"83a576c3-0e7c-4f46-8284-f87ab836f522\",
--------->\"tagAccessor\":\"8ff218c8-cd38-42a9-90bf-06ba8c0543a1\",
--------->\"valueAccessor\":\"d0227fac-22a7-4277-aa2e-cabe22f58736\",
--------->\"maxFontSize\":72,
--------->\"minFontSize\":18,
--------->\"orientation\":\"single\",
--------->\"showLabel\":true,
--------->\"colorMapping\":{\"assignments\":[],
--------->\"specialAssignments\":[{\"rule\":{\"type\":\"other\"},
--------->\"color\":{\"type\":\"loop\"},
--------->\"touched\":false}],
--------->\"paletteId\":\"eui_amsterdam_color_blind\",
--------->\"colorMode\":{\"type\":\"categorical\"}},
--------->\"layerType\":\"data\",
--------->\"palette\":{\"name\":\"default\",
--------->\"type\":\"palette\"}},
--------->\"query\":{\"query\":\"\",
--------->\"language\":\"kuery\"},
--------->\"filters\":[],
--------->\"datasourceStates\":{\"formBased\":{\"layers\":{\"83a576c3-0e7c-4f46-8284-f87ab836f522\":{\"ignoreGlobalFilters\":false,
--------->\"columns\":{\"8ff218c8-cd38-42a9-90bf-06ba8c0543a1\":{\"label\":\"customer_full_name.keyword: Descending\",
--------->\"dataType\":\"string\",
--------->\"operationType\":\"terms\",
--------->\"scale\":\"ordinal\",
--------->\"sourceField\":\"customer_full_name.keyword\",
--------->\"isBucketed\":true,
--------->\"params\":{\"size\":{{ tag_cloud.anzahl }},
--------->\"orderBy\":{\"type\":\"column\",Die Id des Dashboards wird wiederum gelöscht, damit Kibana beim Import eine neue, eindeutige Dashboard-Id generiert.
"created_at": "2024-12-11T16:21:16.255Z",
"id": "24248d69-cca9-4e52-be60-bd2fa96d24ac",Das mit dem Template und der obigen Inputdatei generierte Dashboard sieht dann wie folgt aus, wobei das Tag-cloud-Panel nun 30 Tags darstellt und die Titel der Panels angepasst sind (im Screenshot rot umrahmt):

Inputdatei für eine flexible Anzahl Gauge-Panels
Um das Beispiel 5 etwas interessanter zu machen, wird die Inputdatei mit Variablen für mehrere Gauge-Panels ergänzt. Diese sollen wie im früheren Beispiel die Markdown-Panels in Reihen und Spalten angeordnet werden und sie sollen Angaben für verschiedene Kunden aus den eCommerce-Beispieldaten anzeigen.
"tag_cloud": {
"title": "Kunden mit grösstem Umsatz",
"anzahl": 30
},
"area": {
"title": "Durchschnittlicher Preis der Bestellungen über die Zeit"
},
"bars_stacked": {
"title": "Totale Kosten der Bestellungen nach Kunde über die Zeit"
},
"bars": {
"title": "Totaler Umsatz pro Kunde"
},
"gauge": {
"hoehe": 10,
"breite": 8,
"spalten": 6,
"anzahl": 20
},
"namen": [
"Wagdi Shaw",
"Elyssa Summers",
"Abd Shaw",
"Elyssa Hart",
"Abd Graham",
"Wilhemina St. Strickland",
"Tariq Rivera",
"Rabbia Al Baker",
"Elyssa Martin",
"Elyssa Lewis",
"Elyssa Daniels",
// etc. ...
"Elyssa Hale",
"Abd Burton",
"Sultan Al Marshall",
"Betty Morrison",
"Mary Hampton",
"Elyssa Rowe",
"Elyssa Austin"
],
"dashboard_title": "generiertes_dashboard_blog_beispiel5"
}Das Array mit den Namen von Kunden aus eCommerce kann für die Filter und Beschriftungen der Gauge-Panels verwendet werden.
Data-View-Ids
DataView-Ids werden in Kibana für Referenzen auf die Daten verwendet. In den ndjson-Dateien wird noch der frühere Name Indexpattern verwendet. Die DataView-Ids sind in der ndjson-Vorlage meist schon vorhanden und sie können einfach weiter verwendet werden. Ansonsten findet man die DataView-Ids unter «Stack Management→DataViews». Dort wählt man die DataView aus, klickt auf «Edit» und «Show advanced settings» und bekommt dann die DataView-Id angezeigt. Die Id ist zudem Teil der Url:

Referenzen und Panel-Ids
Anders als bei den Beispielen mit den Markdown-Panels werden in Beispiel 5 in Elastic gespeicherte Daten verwendet, auf die aus dem Dashboard zugegriffen wird. Dazu werden im Dashboard gegen Ende der ndjson-Datei Referenzen und Ids definiert und z.B. in den Gauge-Panels wird im Array «references» darauf referenziert.
Etwas Dokumentation dazu findet man unter den folgenden Links:
References
References (references) are regular saved object references forming a graph of saved objects which depend on each other. For the Lens case, these references can be annotation groups or data views (called type: «index-pattern» in code), referencing permanent data views which are used in the current Lens visualization. Often there is just a single data view in use, but it’s possible to use multiple data views for multiple layers in a Lens xy chart. The id of a reference needs to be the saved object id of the referenced data view (see the «Handling data views» section below). The name of the reference is comprised out of multiple parts used to map the data view to the correct layer : indexpattern-datasource-layer-<id of the layer>. Even if multiple layers are using the same data view, there has to be one reference per layer (all pointing to the same data view id). References array can be empty in case of adhoc dataviews (see section below).
references array
Objects with name, id, and type properties that describe the other saved objects that this object references. Use name in attributes to refer to the other saved object, but never the id, which can update automatically during migrations or import and export.
In der exportierten Dashboardvorlage sieht die Definition der Referenzen beispielsweise wie folgt aus:
"references": [
{
"id": "ff959d40-b880-11e8-a6d9-e546fe2bba5f",
"name": "7338d1e1-501e-4084-8d8a-5b7593a87e66:indexpattern-datasource-layer-83a576c3-0e7c-4f46-8284-f87ab836f522",
"type": "index-pattern"
},
//… …
{
"id": "ff959d40-b880-11e8-a6d9-e546fe2bba5f",
"name": "1400e794-2571-4b4a-b78b-2d5aab20263b:indexpattern-datasource-layer-38148eb9-48c3-40ac-8090-011abf2cdefe",
"type": "index-pattern"
},
{
"id": "ff959d40-b880-11e8-a6d9-e546fe2bba5f",
"name": "1400e794-2571-4b4a-b78b-2d5aab20263b:08984911-134f-4ff2-8c1d-bf86d034351c",
"type": "index-pattern"
}
],Die Einträge mit
"name": "1400e794-2571-4b4a-b78b-2d5aab20263bsind jene, die im einen Gauge-Panel referenziert werden. Dort kommt der «name» als «panelIndex» und als Komponente «i» in «gridData» vor. So kann man diese Einträge im Referenz-Array finden. Die übrigen Einträge dort gehören zu den anderen Panels. «id» ist überall die DataView-Id für die eCommerce-Beispieldaten, auf die von allen Panels aus referenziert wird.
Wenn im Dashboard mehrere Gauge-Panels definiert werden sollen, so müssen diese alle einen eindeutigen Panel-Index haben. Für das Format der Panel-Indices gelten offenbar keine grossen Vorgaben, so dass man ziemlich frei ist bei der Wahl eindeutiger Werte. Die Panel-Indices müssen bei den Gauge-Paneldefinitionen und übereinstimmend im Array mit den Referenzen definiert werden.
Einfügen von jinja2 Elementen
Die Definitionen der Gauge-Panels werden in einer Schleife generiert wie in beispiel4.j2 jene für die Markdown-Panels. Als Panelindex wird einfach «gauge_panel_nri» definiert, wobei «i» eine Laufnummer ist. So können die Indices einfach für die Panels und die Referenzen in zwei unabhängigen Schleifen generiert werden.
Die wichtigsten jinja2-Elemente bei der Definition der Gauge-Panels in blog_beisiel5.j2 sind dann:
--------->{% set global = namespace(row = 0) %}{% for i in range(0, gauge.anzahl) %}{\"type\":\"lens\",
--------->\"gridData\":{\"x\":{{ (i) % gauge.spalten * gauge.breite }},
--------->\"y\":{{ 30 + gauge.hoehe * global.row }}{% if (i + 1) % gauge.spalten == 0 %}{% set global.row = global.row + 1 %}{% endif %},
--------->\"w\":{{ gauge.breite }},
--------->\"h\":{{ gauge.hoehe }},
--------->\"i\":\"gauge_panel_nr{{ i }}\"},
--------->\"panelIndex\":\"gauge_panel_nr{{ i }}\",
--------->\"embeddableConfig\":{\"attributes\":{\"title\":\"Gauge visualization\",
--------->\"visualizationType\":\"lnsGauge\",
--------->\"type\":\"lens\",
--------->\"references\":[{\"type\":\"index-pattern\",
--------->\"id\":\"ff959d40-b880-11e8-a6d9-e546fe2bba5f\",
--------->\"name\":\"indexpattern-datasource-layer-38148eb9-48c3-40ac-8090-011abf2cdefe\"}],
--------->\"state\":{\"visualization\":{\"shape\":\"arc\",
--------->\"layerId\":\"38148eb9-48c3-40ac-8090-011abf2cdefe\",
--------->\"layerType\":\"data\",
--------->\"ticksPosition\":\"auto\",
--------->\"labelMajorMode\":\"auto\",
--------->\"metricAccessor\":\"e4f872bd-8510-456b-ac48-8da24c92b19d\",
--------->\"colorMode\":\"palette\",
--------->\"percentageMode\":false,
--------->\"palette\":{\"name\":\"custom\",
--------->\"params\":{\"maxSteps\":5,
--------->\"name\":\"custom\",
--------->\"progression\":\"fixed\",
--------->\"rangeMax\":100,
--------->\"rangeMin\":0,
--------->\"rangeType\":\"number\",
--------->\"reverse\":false,
--------->\"continuity\":\"none\",
--------->\"colorStops\":[{\"color\":\"#A50026\",
--------->\"stop\":0},
--------->{\"color\":\"#FEFEBD\",
--------->\"stop\":50},
--------->{\"color\":\"#006837\",
--------->\"stop\":75}],
--------->\"stops\":[{\"color\":\"#A50026\",
--------->\"stop\":50},
--------->{\"color\":\"#FEFEBD\",
--------->\"stop\":75},
--------->{\"color\":\"#006837\",
--------->\"stop\":100}],
--------->\"steps\":5},
--------->\"type\":\"palette\"},
--------->\"minAccessor\":\"4399d773-95c6-4ecb-bc1b-a26a9d9f0d09\",
--------->\"maxAccessor\":\"9a3f8db0-a822-4627-9906-8fab5bf235df\",
--------->\"labelMinor\":\"{{ namen[i] }}\"},
--------->\"query\":{\"query\":\"customer_full_name.keyword : \\\"{{ namen[i] }}\\\" \",
--------->\"language\":\"kuery\"},
--------->\"filters\":[{\"meta\":{\"alias\":null,
--------->\"disabled\":false,
--------->\"index\":\"5c0dea8b-d51a-4f34-8240-520a78d12164\",
--------->\"key\":\"products.taxless_price\",
--------->\"negate\":false,
--------->\"type\":\"exists\",
--------->\"value\":\"exists\"},
--------->\"query\":{\"exists\":{\"field\":\"products.taxless_price\"}},
//… ...
--------->\"enhancements\":{},
--------->\"hidePanelTitles\":true},
--------->\"title\":\"Gauge visualization\"}{% if loop.index != loop.length %},{% endif %}{% endfor %}]",Am Anfang und Ende stehen die Angaben für die Schleife, wobei am Ende wieder geprüft werden muss, ob ein Komma nötig ist oder ob das letzte Element des Arrays erreicht ist. Das uns die Berechnung der Position der Panels ist analog Beispiel 4 gemacht.
Weiter wird noch der Name aus dem Array mit den Kundennamen als Label definiert und in der Filterabfrage angegeben.
Wichtig sind die zwei Definitionen für die Panelindices.
--------->\"i\":\"gauge_panel_nr{{ i }}\"},
--------->\"panelIndex\":\"gauge_panel_nr{{ i }}\",Zudem müssen weiter unten die Referenzen für alle Gauge-Panels in einer Schleife generiert werden.
{
"id": "ff959d40-b880-11e8-a6d9-e546fe2bba5f",
"name": "51c3912f-6d82-4be5-82e4-31a6549d9df4:indexpattern-datasource-layer-446d03ef-469d-419a-90ab-40632cd777f5",
"type": "index-pattern"
},
{% for i in range(0, gauge.anzahl) %}{
"id": "ff959d40-b880-11e8-a6d9-e546fe2bba5f",
"name": "gauge_panel_nr{{ i }}:indexpattern-datasource-layer-38148eb9-48c3-40ac-8090-011abf2cdefe",
"type": "index-pattern"
},{% endfor %}
{
"id": "ff959d40-b880-11e8-a6d9-e546fe2bba5f",
"name": "gauge_panel_nr0:08984911-134f-4ff2-8c1d-bf86d034351c",
"type": "index-pattern"
}Der Befehl
jinjanate blog_beispiel5.j2 blog_beispiel5_vars.json -o generiertes_dashboard_blog_beispiel5.ndjsongeneriert nun folgendes Dashboard, in dem die Gauge-Panels wiederholt werden und regelmässig in 6 Spalten angeordnet sind:
Variante mit Gauge-Panels zu verschiedenen Metriken
Als weitere Variante von Beispiel 5 habe ich Gauge-Panels zu zwei Metriken generiert und die Grenzen für die Farben sowie die Maximalwerte in den Gauge-Panels über Variablen in der Inputdatei definiert. Wenn nur eine Metrik angegeben wird, kann damit auch das vorherige Dashboard generiert werden.
Inputdatei mit zwei Metriken für die Gauge-Panels
Der folgende Teil der Inputdatei ist angepasst worden, wobei für die Angaben jeweils Arrays verwendet worden sind.
"gauge": {
"hoehe": 10,
"breite": 8,
"spalten": 6,
"anzahl": 18,
"query_fields": [
"products.taxless_price",
"products.quantity"
],
"range_max" : [500, 12],
"color_start" : [[0, 100, 300],
[0,3,6]],
"color_stop" : [[100, 300, 500],
[3,6,12]]
},
"namen": [
"Wagdi Shaw",
"Elyssa Summers",Einfügen von jinja2 Elementen
Hier sind nun zwei verschachtelte Schleifen nötig, eine über die Metriken und innerhalb dieser Schleife jeweils eine über die Anzahl gewünschter Gauge-Panels.
Als Hilfestellung hier noch die wichtigen Teile der json-Datei vor der Umformatierung in blog_beispiel5.j2:
--------->{% set global = namespace(row = 0) %}{% for field in gauge.query_fields %}{% set outer_loop = loop %}{% for i in range(0, gauge.anzahl) %}{\"type\":\"lens\",
--------->\"gridData\":{\"x\":{{ (i + ( outer_loop.index0 * gauge.anzahl ) ) % gauge.spalten * gauge.breite }},
--------->\"y\":{{ 30 + gauge.hoehe * global.row }}{% if (i + 1 + ( outer_loop.index0 * gauge.anzahl ) ) % gauge.spalten == 0 %}{% set global.row = global.row + 1 %}{% endif %},
--------->\"w\":{{ gauge.breite }},
--------->\"h\":{{ gauge.hoehe }},
--------->\"i\":\"gauge_panel_nr{{ i + ( outer_loop.index0 * gauge.anzahl ) }}\"},
--------->\"panelIndex\":\"gauge_panel_nr{{ i + ( outer_loop.index0 * gauge.anzahl ) }}\",
--------->\"embeddableConfig\":{\"attributes\":{\"title\":\"Gauge visualization\",
//… …
--------->\"rangeMax\":{{ gauge.range_max[outer_loop.index0] }},
--------->\"rangeMin\":0,
--------->\"rangeType\":\"number\",
--------->\"reverse\":false,
--------->\"continuity\":\"none\",
--------->\"colorStops\":[{\"color\":\"#A50026\",
--------->\"stop\":{{ gauge.color_start[outer_loop.index0][0] }}},
--------->{\"color\":\"#FEFEBD\",
--------->\"stop\":{{ gauge.color_start[outer_loop.index0][1] }}},
--------->{\"color\":\"#006837\",
--------->\"stop\":{{ gauge.color_start[outer_loop.index0][2] }}}],
--------->\"stops\":[{\"color\":\"#A50026\",
--------->\"stop\":{{ gauge.color_stop[outer_loop.index0][0] }}},
--------->{\"color\":\"#FEFEBD\",
--------->\"stop\":{{ gauge.color_stop[outer_loop.index0][1] }}},
--------->{\"color\":\"#006837\",
--------->\"stop\":{{ gauge.color_stop[outer_loop.index0][2] }}}],
--------->\"steps\":5},
//… …
--------->\"9a3f8db0-a822-4627-9906-8fab5bf235df\":{\"label\":\"Static value: {{ gauge.range_max[outer_loop.index0] }}\",
--------->\"dataType\":\"number\",
--------->\"operationType\":\"static_value\",
--------->\"isStaticValue\":true,
--------->\"isBucketed\":false,
--------->\"scale\":\"ratio\",
--------->\"params\":{\"value\":\"{{ gauge.range_max[outer_loop.index0] }}\"},
//… …
--------->\"title\":\"Gauge visualization\"}{% if outer_loop.index != outer_loop.length or loop.index != loop.length %},{% endif %}{% endfor %}{% endfor %}]",Das generierte Dashboard mit den Gauge-Panels zu den zwei verschiedenen Metriken sieht dann wie folgt aus:

Weitere Ideen
Es geht in dieser Blogreihe darum, das Prinzip zur Generierung von Dashboards mit jinja2-Templates vorzustellen. Analog können viele weitere Ideen zur Automatisierung umgesetzt werden und zwar auch in anderen Bereichen.
Mit Shell-Skripts oder Skripts in anderen Skriptsprachen kann die Automatisierung erweitert werden. Beispielsweise können in einem Skript mehrere Dashboards generiert oder in einer Schleife können Dashboards für verschiedene Umgebungen oder Kunden generiert werden.
Es können auch mehrere Dashboards in eine einzelne ndjson-Datei geschrieben werden.
Der Import von Dashboards in Kibana per REST-Schnittstelle kann ebenfalls nach der Generierung von Dashboards in dasselbe Skript eingefügt werden. Die Dokumentation dazu findet man hier:
- https://www.elastic.co/docs/api/doc/kibana/operation/operation-importsavedobjectsdefault
- https://www.elastic.co/docs/api/doc/kibana/operation/operation-resolveimporterrors
Fazit
Mit den vorgestellten Ideen und Werkzeugen lassen sich Kibana-Dashboards flexibel generieren. Leider fehlt eine Referenzdokumentation für das Format der beim Export und Import von Dashboards und weiteren gespeicherten Objekten verwendeten ndjson-Dateien. So braucht es manchmal etwas Fantasie und Tests für die konkrete Umsetzung. Das Vorgehen lohnt sich aber schnell, wenn mehrere ähnliche Dashboards gebraucht werden.
Dasselbe Vorgehen zur Automatisierung kann nicht nur im Elastic Stack sondern mit vielen anderen Softwarepaketen verwendet werden.
Melden Sie sich ohne zu zögern für ein kostenloses Beratungsgespräch bei Swissmakers, um zu erfahren, wie wir Sie in den Bereichen Automatisierung und Elastic unterstützen können.
]]>Kinder und Jugendliche verdienen unseren umfassenden Schutz – besonders in Bildungseinrichtungen wie Schulen, Internaten, Kindergärten, Kitas oder Kompetenzzentren. Viele Einrichtungen sind bereits auf externe Gefahren vorbereitet und setzen Firewalls, Virenscanner oder Zugangsbeschränkungen ein. Trotzdem entsteht eine empfindliche Lücke, sobald potenzielle Bedrohungen innerhalb der Organisation auftauchen: Übergriffe durch Mitarbeitende, Radikalisierung, Cybermobbing oder das unerlaubte Konsumieren illegaler Inhalte bleiben oft lange unentdeckt.
Als Vater eines dreijährigen Sohnes kann ich mir nur schwer vorstellen, was es bedeutet, wenn das eigene Kind in eine solche Situation gerät. Die Dunkelziffer ist nach wie vor hoch, und viele Fälle bleiben unentdeckt. Aus der Überzeugung heraus, dass wir alle Verantwortung dafür tragen, unsere Kinder bestmöglich zu schützen, haben wir bei der Swissmakers GmbH entschieden, unsere technologische Expertise im Bereich Cybersicherheit und Elasticsearch zu nutzen und gezielt zum Kinderschutz einzusetzen. In diesem Blog-Beitrag möchten wir daher einen ersten Überblick geben, wie ein klassisches SIEM-System durch minimale Anpassungen im Schul- und Betreuungsumfeld, effizient zum Schutz von Kindern eingesetzt werden kann.

Was ist ein SIEM-System und warum ist es ideal für den Kinderschutz?
Ein SIEM-System (Security Information and Event Management System) sammelt und analysiert in Echtzeit die Protokolldaten sämtlicher Anwendungen und Endgeräte innerhalb einer Einrichtung. Im Gegensatz zu einer lückenlosen Überwachung aller Inhalte, verarbeitet ein SIEM in erster Linie Metadaten (z. B. Zeitpunkt einer Kommunikation, Abweichungen vom üblichen Nutzungsverhalten), um Anomalien frühzeitig zu erkennen. Lehrkräften und Sozialpädagogen bietet dies eine Möglichkeit, erste Warnsignale für problematisches Verhalten zu identifizieren, bevor Schlimmeres passiert – und zwar ohne die Privatsphäre von Kindern und Jugendlichen unnötig zu verletzen.
Gerade im pädagogischen Kontext sorgt das Thema „digitale Überwachung“ verständlicherweise für Skepsis. Ein modernes SIEM-Konzept kann Ängste vor totaler Kontrolle jedoch wirksam entkräften, weil es keine lückenlose Überprüfung sämtlicher Chats oder Dokumente vornimmt. Vielmehr beobachtet das System grundlegende Parameter (zum Beispiel die Häufigkeit, mit der Dateien ausgetauscht werden) und löst nur dann einen Alarm aus, wenn bestimmte, zuvor definierte Muster auftreten. So bleibt die persönliche Kommunikation weitgehend geschützt, während potenziell kritische Ereignisse rechtzeitig ans Licht kommen.
Wie ein SIEM konkret hilft: Praxisnahe Beispiele
Schulen, Internate und weitere Betreuungseinrichtungen bündeln eine Vielzahl an digitalen Aktivitäten: Chats, E-Mails, Online-Lernplattformen, Lern-Apps, Netzwerkspeicher und vieles mehr. Hinzu kommt, dass viele Kinder und Jugendliche bereits in sehr jungem Alter eigenständig im Internet surfen – teils auf privaten Geräten, teils auf Schul-Tablets oder Computern im Schulnetzwerk. Gerade in diesem komplexen Umfeld ist es entscheidend, Frühwarnsignale zu erkennen, bevor Missbrauch stattfindet.

Ein SIEM-System hilft dabei, diese Vorgänge frühzeitig zu registrieren. Anstatt erst nach schweren Vorfällen reagieren zu können, kann die Schulleitung oder ein eingestelltes Security-Team präventiv einschreiten und klärende Gespräche führen, sobald auffällige Anomalien im Verhalten auftauchen.
Vorteile und Herausforderungen
Warum viele Schulen noch hinterherhinken
Obwohl die IT-Ausstattung an Schulen stetig wächst, bleibt die Sicherheitsinfrastruktur häufig auf einem veralteten Stand. Firewalls und Virenscanner lassen sich relativ einfach einrichten, doch die Analyse interner Datenströme ist komplexer. Fehlendes Fachpersonal, unklare Zuständigkeiten und die Scheu vor vermeintlicher Überwachung führen dazu, dass ein grosser Teil der Problematiken unentdeckt bleibt. Genau hier setzen SIEM-Lösungen an: Sie werten Daten automatisch aus, schlagen zuverlässig Alarm und ermöglichen es, rechtzeitig einzugreifen. So wird aus Technik eine wertvolle Hilfe für mehr Sicherheit im pädagogischen Alltag. Mit anderen Worten: Wenn Gefahr nicht laut ruft, braucht es Systeme, die leise Signale erkennen.

Warum Swissmakers GmbH?
Die Swissmakers GmbH ist seit Jahren ein verlässlicher Schweizer Partner von Elasticsearch und verfügt über umfassende Erfahrung im Bereich Cybersicherheit und SIEM-Implementierungen. Unser oberstes Ziel bei diesem Projekt ist es, das Wohl der Kinder zu unterstützen und gleichzeitig die Privatsphäre von Schülern und Mitarbeitenden zu respektieren.
- Technische Fachkenntnisse: Wir verfügen über langjährige Erfahrung in der technischen Umsetzung von SIEM-Lösungen und IT-Sicherheitskonzepten – auch in sensiblen Einsatzbereichen.
- Individuelle Lösungen: Jede Institution ist einzigartig. Wir entwickeln passgenaue Konzepte, die Ihre bestehenden Abläufe nahtlos ergänzen.
- Datenschutzkompetenz: Durch unsere langjährige Erfahrung können wir die geltenden Vorgaben des DSG und des Kinderschutzes integrieren, um einen sicheren und gesetzeskonformen Betrieb zu gewährleisten.
- Ganzheitlicher Ansatz: Von der Konzeption über die Implementierung und Schulung bis zum Betrieb und fortlaufenden Audits – wir begleiten Sie durchgehend.
Fazit: Technologie zum Schutz unserer Kinder
Die Vorstellung, dass unsere Kinder Opfer von Übergriffen werden, ist für viele Eltern kaum erträglich. Dennoch ist es wichtig, dieser Realität ins Auge zu sehen und aktiv etwas dagegen zu unternehmen. Durch den gezielten Einsatz eines SIEM-Systems auf Basis von Elasticsearch lassen sich auffällige Muster, riskante Interaktionen und gefährliche Online-Aktivitäten frühzeitig erkennen – ohne dabei wahllos alle Daten offenzulegen oder die Privatsphäre der Schülerinnen und Schüler zu verletzen.
Kein technologisches Werkzeug kann 100-prozentigen Schutz garantieren oder den menschlichen Blick sowie das persönliche Gespräch vollständig ersetzen. Doch je besser wir unsere digitalen Hilfsmittel nutzen, desto eher können wir potenzielle Gefahren erkennen, bevor irreparabler Schaden entsteht.
Falls Sie mehr darüber erfahren möchten, wie eine solche SIEM-Lösung in Ihrer Einrichtung technisch und organisatorisch umgesetzt werden kann, stehen wir Ihnen gerne zur Verfügung. Unsere Expertinnen und Experten beraten Sie umfassend zu den Themen Datensicherheit, Datenschutz und Prozessintegration – damit wir gemeinsam einen wichtigen Schritt zum Schutz unserer Kinder gehen können.
In diesem ersten Beispiel geht es nur darum, das Vorgehen zu zeigen.
Dashboard als Vorlage
Als einfaches Beispiel, das keine Datenabfragen macht, kann ein Dashboard mit einem oder mehreren Makrdown-Panels verwendet werden. In der Praxis werden Dashboards, die nur Markdown-Panels enthalten, wohl nur selten gebraucht, aber das Vorgehen lässt sich daran gut zeigen und die Beispiele lassen sich einfach nachvollziehen. Hier der Screenshot der interaktiv erstellten Dashboardvorlage für das erste Beispiel:

Dieses Dashboard wird nun exportiert und als blog_beispiel1.ndjson gespeichert.
Inputdatei mit Variablen
Da sonst auch json-Dateien verwendet werden, bietet es sich an, die Variablen ebenfalls in einer neuen json-Datei blog_beispiel1_vars.json zu definieren. Es empfiehlt sich, auch den Titel resp. Namen des Dashboards – in diesem Beispiel steht «title»: «Blog_Beispiel1» in der ndjson-Datei – in der Inputdatei zu definieren und dabei einen neuen Namen zu wählen, damit man beim Import das ursprüngliche Dashboard nicht gleich überschreibt, falls keine neue Id generiert wird.
Hier ein Beispiel des Dateiinhaltes, in dem alle Texte des Markdown-Panels definiert sind:
{
"markdown": {
"title": "Markdown_Titel",
"textzeilen": ["Textzeile1", "Textzeile2"," "]
},
"dashboard_title": "generiertes_dashboard_blog_beispiel1"
}
"]
},
"dashboard_title": "generiertes_dashboard_blog_beispiel1"
}Umformen der ndjson-Datei mit dem Dashboard
Danach macht man am besten eine Kopie der Datei mit dem Dashboard, hier mit dem Namen blog_beispiel1.j2.
Die Zeile mit der Dashboarddefinition kopiert man nun in eine weitere, neue Datei blog_beispiel1.json, um sie besser editieren zu können. Diese neue Datei öffnet man in VSCode und formatiert sie mit <ctrl><alt><b> (vscode-json: Beautify). Zudem können an Kommata Zeilenumbrüche und die Zeichenfolge ——> angehängt werden, um eine bessere Übersicht zu bekommen. Die Zeilenumbrüche und die Zeichenfolge lassen sich später wieder einfach entfernen.
Der Teil der Datei mit der Definition des Markdown-Panels sieht dann etwa wie folgt aus:
...
"panelsJSON": "[{\"type\":\"visualization\",
------>\"gridData\":{\"x\":0,
------>\"y\":0,
------>\"w\":20,
------>\"h\":9,
------>\"i\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\"},
------>\"panelIndex\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\",
------>\"embeddableConfig\":{\"enhancements\":{\"dynamicActions\":{\"events\":[]}},
------>\"savedVis\":{\"id\":\"\",
------>\"title\":\"\",
------>\"description\":\"\",
------>\"type\":\"markdown\",
------>\"params\":{\"fontSize\":12,
------>\"openLinksInNewTab\":false,
------>\"markdown\":\"# Markdown_Titel\\n\\nTextzeile1\\n\\nTextzeile 2\\n\\n\"},
------>\"uiState\":{},
------>\"data\":{\"aggs\":[],
------>\"searchSource\":{\"query\":{\"query\":\"\",
------>\"language\":\"kuery\"},\"filter\":[]}}}}}]",
"timeRestore": false,
],
"timeRestore": false,
"title": "Blog_Beispiel1",
"version": 2
},
…Achtung, die Backslashes vor den Anführungs- und Schlusszeichen und vor Backslashes müssen nach dem Umformen der Datei noch vorhanden sein.
Einfügen von jinja2 Elementen
Jetzt können in der Datei blog_beispiel1.json Referenzen auf die Variablen aus der Inputdatei eingefügt werden. Die Dokumentation zu jinja2 ist wie schon zuvor angegeben auf folgender Webseite zu finden: https://jinja.palletsprojects.com/en/stable/templates/. Um den Wert eines Elementes der Inputdatei einzufügen, genügt es, den Namen der Variable in doppelten geschweiften Klammern anzugeben.
"markdown": "# Markdown_Titel\n\nTextzeile1\n\nTextzeile 2\n\n"muss dazu für die obige Inputdatei wie folgt angepasst werden:
"markdown": "# {{ markdown.title }}\n\n{{ markdown.textzeilen.0 }}\n\n{{ markdown.textzeilen.1 }}\n\n{{ markdown.textzeilen.2 }}"markdown.textzeilen ist als Array definiert und mit den Zahlen kann auf die einzelnen Arrayelemente zugegriffen werden. Die Zeile mit dem Dashboardnamen (gegen Ende der Datei vor der Versionsangabe) wird dann noch wie folgt definiert:
"title": "{{ dashboard_title }}",Dashboard-Id löschen
Jetzt muss man noch die Dashboard-Id in blog_beispiel1.json löschen, da man sonst möglicherweise einen Konflikt mit dem ursprünglichen Dashboard und dem mit neuem Namen generierten Dashboard bekommt. Die Id steht gegen Ende der Datei nach der Angabe created_at:
"created_at": "2024-11-26T16:56:50.240Z",
"id": "2d77705c-912a-4730-a565-242f6ae43475",Man kann einfach die Zeile mit der Id löschen.
Formatieren als ndjson-Template
Zuerst müssen die eingefügten Zeilenumbrüche und Zeichenfolgen mit einem entsprechenden Replace all im Editor wieder gelöscht werden.
Mit der Tastenkombination <ctrl><alt><u> (vscode-json: Uglify) kann jetzt das json in blog_beisiel1.json wieder auf eine einzelne Zeile geschrieben werden.
Mit dieser Zeile ersetzt man die ursprüngliche Zeile in blog_beisiel1.j2 und erhält so ein Template, um das Dashboard, das interaktiv erstellt wurde, neu zu generieren.
Dashboard generieren und importieren
Auf der Kommandozeile generiert man nun das neue Dashboard:
jinjanate blog_beispiel1.j2 blog_beispiel1_vars.json -o generiertes_dashboard_blog_beispiel1.ndjsonIn Elastic kann nun unter dem Menüpunkt «Management → Stack Management → Saved Objects» die neu generierte Dateien generiertes_dashboard_blog_beispiel1.ndjson importiert werden. Es sollte zum Import die Option «Create new objects with random Ids» ausgewählt werden. So erhält man am wenigsten Konflikte, bekommt aber allenfalls mehrere Objekte mit demselben Namen, bei denen man die alten Versionen löschen kann. Da muss man schauen, welche Variante am einfachsten ist und ob eventuell die Ids oben nicht gelöscht werden sollen.
Wenn man beim Import eine Meldung folgender Art bekommt « ‚generiertes_dashboard_blog_beispiel‘ conflicts with an existing object.», so hat man ein Problem mit Ids und dem neuen Dashboardnamen.
Das neu importierte Dashboard sieht dann genau so aus wie die Vorlage im Screenshot oben.
Mehrere Markdown Panels generieren
Ausgangspunkt ist dieselbe Vorlage wie in Beispiel 1.
Inputdatei mit Variablen
Die Inputdatei wird mit Angaben für mehrere Markdown-Panels erweitert. Neben dem Text für die Panels wird auch die Position und Grösse definiert. Hier die Beispieldatei blog_beispiel2_vars.json:
{
"markdown": [
{
"title": "Swissmakers",
"textzeilen": [
"Aus Freude an Technik",
"Engeneering / Security / Consulting",
"swissmakers.ch  "
],
"position": [4,0],
"groesse": [20,8]
},
{
"title": "Codeatelier",
"textzeilen": [
"Wir bauen deine digitale Zukunft",
"Webdesign
"
],
"position": [4,0],
"groesse": [20,8]
},
{
"title": "Codeatelier",
"textzeilen": [
"Wir bauen deine digitale Zukunft",
"Webdesign  SEO Webapps Webshops",
"codeatelier.ch "
],
"position": [9,9],
"groesse": [25,8]
},
{
"title": "Swissmakers",
"textzeilen": [
"Ihre ITC-Spezialistinnen und -Spezialisten",
"Engeneering, Linux und Netzsicherheit",
"swissmakers.ch
SEO Webapps Webshops",
"codeatelier.ch "
],
"position": [9,9],
"groesse": [25,8]
},
{
"title": "Swissmakers",
"textzeilen": [
"Ihre ITC-Spezialistinnen und -Spezialisten",
"Engeneering, Linux und Netzsicherheit",
"swissmakers.ch  "
],
"position": [0,18],
"groesse": [35,8]
}
],
"dashboard_title": "generiertes_dashboard_blog_beispiel2"
}
"
],
"position": [0,18],
"groesse": [35,8]
}
],
"dashboard_title": "generiertes_dashboard_blog_beispiel2"
}Umformen der ndjson-Datei mit dem Dashboard
Wie in Beispiel 1 sollte man die Datei blog_beispiel2.j2 umformen, damit sie einfacher zu ändern ist. Damit man mehrere Markdown-Panels erhält, kann man im jinja2-Template in panelsJSON die Angaben für die Panels wiederholen. Im mit eckigen Klammern begrenzten Teil nach panelsJSON wiederholt man den ganzen Teil von {\"type\":\"visualization\", bis zu \"filter\":[]}}}}} wobei zwischen diesen Definitionen der Panels jeweils ein Komma als Trennzeichen von Array-Elementen eingefügt werden muss. Am Ende des Arrays darf aber kein Komma mehr stehen. Das Ganze kann in einer ersten Variante direkt im Editor gemacht werden und sieht dann wie folgt aus:
"panelsJSON": "[{\"type\":\"visualization\",
------>\"gridData\":{\"x\":0,
------>\"y\":0,
------>\"w\":20,
------>\"h\":9,
------>\"i\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\"},
------>\"panelIndex\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\",
------>\"embeddableConfig\":{\"enhancements\":{\"dynamicActions\":{\"events\":[]}},
------>\"savedVis\":{\"id\":\"\",
------>\"title\":\"\",
------>\"description\":\"\",
------>\"type\":\"markdown\",
------>\"params\":{\"fontSize\":12,
------>\"openLinksInNewTab\":false,
------>\"markdown\":\"# Markdown_Titel\\n\\nTextzeile1\\n\\nTextzeile 2\\n\\n\"},
------>\"uiState\":{},
------>\"data\":{\"aggs\":[],
------>\"searchSource\":{\"query\":{\"query\":\"\",
------>\"language\":\"kuery\"},
------>\"filter\":[]}}}}},
------>{\"type\":\"visualization\",
------>\"gridData\":{\"x\":0,
------>\"y\":0,
------>\"w\":20,
------>\"h\":9,
------>\"i\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\"},
------>\"panelIndex\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\",
------>\"embeddableConfig\":{\"enhancements\":{\"dynamicActions\":{\"events\":[]}},
------>\"savedVis\":{\"id\":\"\",
------>\"title\":\"\",
------>\"description\":\"\",
------>\"type\":\"markdown\",
------>\"params\":{\"fontSize\":12,
------>\"openLinksInNewTab\":false,
------>\"markdown\":\"# Markdown_Titel\\n\\nTextzeile1\\n\\nTextzeile 2\\n\\n\"},
------>\"uiState\":{},
------>\"data\":{\"aggs\":[],
------>\"searchSource\":{\"query\":{\"query\":\"\",
------>\"language\":\"kuery\"},
------>\"filter\":[]}}}}},
------>{\"type\":\"visualization\",
------>\"gridData\":{\"x\":0,
… …
------>\"language\":\"kuery\"},
------>\"filter\":[]}}}}}]",
"timeRestore": false,
"title": "Blog_Beispiel2",
"version": 2
},
"coreMigrationVersion": "8.8.0",Löschen der Panel-Indices
Ein Panel bekommt in Kibana einen Index-Wert. Diese müssen (ausser dem ersten) gelöscht werden, resp. es darf nicht mehrmals derselbe Index vorkommen, sonst überschreiben sich die Panels. Folgende Zeilen in der Datei blog_beispiel2.j2 müssen also noch gelöscht werden:
-----→\"panelIndex\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\",Auch die Dashboard-Id sollte am besten wieder gelöscht werden.
Einfügen von jinja2 Elementen
Analog Beispiel 1 können nun die Variablen aus der Inputdatei eingefügt werden. Man hat dabei eine Array-Ebene mehr als im ersten Beispiel und neben den Texten sind auch noch die Positionen und die Grösse der Panels anzugeben. Auszugsweise sieht das dann so aus:
"panelsJSON": "[{\"type\":\"visualization\",
------>\"gridData\":{\"x\":{{ markdown.0.position.0 }},
------>\"y\":{{ markdown.0.position.1 }},
------>\"w\":{{ markdown.0.groesse.0 }},
------>\"h\":{{ markdown.0.groesse.1 }},
… …
------>\"markdown\":\"# {{ markdown.0.title }}\\n\\n{{ markdown.0.textzeilen.0 }}\\n\\n{{ markdown.0.textzeilen.1 }}\\n\\n{{ markdown.0.textzeilen.2 }}\"},
… …Für die weiteren zwei Panels heisst es dann {{ markdown.1. … }} und {{ markdown.2. … }}.
Auch der Name des Dashboards muss noch angepasst werden:
"title":"{{ dashboard_title }}"Weitere Schritte
Analog Beispiel 1 muss die Datei blog_beispiel2.j2 wieder als ndjson formatiert werden.
Dann kann das Dashboard generiert werden mit dem Befehl:
jinjanate blog_beispiel2.j2 blog_beispiel2_vars.json -o generiertes_dashboard_blog_beispiel2.ndjsonDas generierte Dashboard wird wiederum mit der Option «Create new objects with random Ids» importiert. Das Resultat sieht man im folgenden Screenshot:

Generieren von mehreren Panels in einer Schleife
Das Dashboard aus Beispiel 2 lässt sich auch etwas eleganter generieren. Anstelle der Aneinanderreihung der Markdown-Panels im jinja2-Template können die Panels in Beispiel 3 in einer Schleife generiert werden. Diese Lösung bietet mehr Flexibilität.
Als Inputdatei mit Variablen wird vorerst eine Kopie blog_beispiel3_vars.json der Inputdatei von Beispiel 2 gebraucht, in der nur der Name resp. Titel des Dashboards auf generiertes_dashboard_blog_beispiel3 angepasst worden ist.
blog_beispiel3.json ist wieder die umformatierte Datei mit dem ursprünglich interaktiv erstellten Dashboard, in die nun jinja2-Elemente eingefügt werden. Die Datei ist vorerst eine Kopie von blog_beispiel1.json, die nur die Definition eines Markdown-Panels enthält, nicht die Datei mit den drei Panels aus Beispiel 2. Hier nun der entsprechende Teil der Datei mit den neuen jinja2-Elementen:
"panelsJSON": "[{% for item in markdown %}{\"type\":\"visualization\",
------->\"gridData\":{\"x\":{{ markdown[loop.index0]['position'][0] }},
------->\"y\":{{ markdown[loop.index0]['position'][1] }},
------->\"w\":{{ markdown[loop.index0]['groesse'][0] }},
------->\"h\":{{ markdown[loop.index0]['groesse'][1] }},
------->\"i\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\"},
------->\"embeddableConfig\":{\"enhancements\":{\"dynamicActions\":{\"events\":[]}},
------->\"savedVis\":{\"id\":\"\",
------->\"title\":\"\",
------->\"description\":\"\",
------->\"type\":\"markdown\",
------->\"params\":{\"fontSize\":12,
------->\"openLinksInNewTab\":false,
------->\"markdown\":\"# {{ markdown[loop.index0]['title'] }}\\n\\n{{ markdown[loop.index0]['textzeilen'][0] }}\\n\\n{{ markdown[loop.index0]['textzeilen'][1] }}\\n\\n{{ markdown[loop.index0]['textzeilen'][2] }}\"},
------->\"uiState\":{},
------->\"data\":{\"aggs\":[],
------->\"searchSource\":{\"query\":{\"query\":\"\",
------->\"language\":\"kuery\"},
------->\"filter\":[]}}}}}{% if loop.index != loop.length %},{% endif %}
{% endfor %}]",
"timeRestore": false,
"title": "{{ dashboard_title }}",
"version": 2
},In jinja2 kann eine Schleife mit den folgenden Elementen definiert werden:
{% for item in markdown %}
{% endfor %}Für jedes Element im Array markdown in der Inputdatei wird dann der ganze Teil innerhalb der Schleife wiederholt. Damit erhält man die drei Paneldefinitionen im Output.
Wie beim Anpassen der Datei für Beispiel 2 muss man beachten, dass die Paneldefinitionen in einem json-Array stehen, zwischen dessen Elementen ein Komma stehen muss, aber am Ende des Arrays darf kein Komma mehr stehen. Dies kann mit einer Bedingung in jinja2 erreicht werden:
{% if loop.index != loop.length %},{% endif %}Wenn der Schleifenindex noch nicht gleich der Anzahl Schleifen ist, so wird das Komma zwischen der if-Bedingung und dem {% endif %} in den Output geschrieben, aber beim letzten Schleifendurchgang nicht mehr.
Für die Angabe der Arrayelemente aus der Inputdatei wird hier eine alternative Syntax verwendet, bei der die Array-Ebenen nicht durch Punkte getrennt sind wie es in Beispiel 1 und Beispiel 2 gebraucht wurde, sondern in eckigen Klammern angegeben werden. loop.index0 ist eine Variable, die innerhalb einer for-Schleife zur Verfügung steht und die angibt, in welchem Durchgang der Schleife man ist, wenn mit 0 zu zählen begonnen wird, um Unterschied zur oben verwendeten Variable loop.index, bei der mit 1 zu zählen begonnen wird. Die Namensteile ohne Anführungs- und Schlusszeichen sind jinja2-Variablen, deren Wert dort eingesetzt wird, jene in Anführungs- und Schlusszeichen sind die Namen aus dem json in der Inputdatei. Anführungs- und Schlusszeichen sind also wichtig und müssen korrekt gesetzt sein.
Wie in den anderen Beispielen muss nun die Datei umformatiert und als ganzes Template blog_beispiel3.j2 gespeichert werden.
Der Befehl
jinjanate blog_beispiel3.j2 blog_beispiel3_vars.json -o generiertes_dashboard_blog_beispiel3.ndjsongeneriert dann ein Dashboard, das genau so aussieht wie jenes in Beispiel 2.
Neue Inputdatei mit Variablen
Mit der Schleife im Template ist Beispiel 3 nun viel flexibler als Beispiel 2. Es genügt, die Inputdatei anzupassen, um unterschiedlich viele Markdown-Panels im Dashboard zu generieren. Es können natürlich auch verschiedene Inputdateien mit demselben Template verwendet werden, z.B. für verschiedene Stages (dev, preprod, prod) etc.
Hier eine neue Inputdatei:
{
"markdown": [
{
"title": "**Swissmakers**",
"textzeilen": [
"Aus Freude an Technik",
"Engeneering / Security / Consulting",
"swissmakers.ch "
],
"position": [0,0],
"groesse": [15,8]
},
{
"title": "**Swissmakers**",
"textzeilen": [
"Einfach Top!",
"swissmakers.ch 
 ",
""
],
"position": [18,0],
"groesse": [15,8]
},
{
"title": "**Codeatelier**",
"textzeilen": [
"Wir bauen deine digitale Zukunft",
"Webdesign SEO Webapps Webshops",
"codeatelier.ch "
],
"position": [9,9],
"groesse": [18,8]
},
{
"title": "**Swissmakers**",
"textzeilen": [
"Ihre ITC-Spezialistinnen und -Spezialisten",
"Engeneering, Linux und Netzsicherheit",
"swissmakers.ch "
],
"position": [0,18],
"groesse": [18,8]
},
{
"title": "**Swissmakers**",
"textzeilen": [
"Ihre ITC-Expertinnen und -Experten",
"für ihre Private Cloud basierend auf Nextcloud",
"swissmakers.ch "
],
"position": [18,18],
"groesse": [18,8]
}
],
"dashboard_title": "generiertes_dashboard_blog_beispiel3_b"
}
",
""
],
"position": [18,0],
"groesse": [15,8]
},
{
"title": "**Codeatelier**",
"textzeilen": [
"Wir bauen deine digitale Zukunft",
"Webdesign SEO Webapps Webshops",
"codeatelier.ch "
],
"position": [9,9],
"groesse": [18,8]
},
{
"title": "**Swissmakers**",
"textzeilen": [
"Ihre ITC-Spezialistinnen und -Spezialisten",
"Engeneering, Linux und Netzsicherheit",
"swissmakers.ch "
],
"position": [0,18],
"groesse": [18,8]
},
{
"title": "**Swissmakers**",
"textzeilen": [
"Ihre ITC-Expertinnen und -Experten",
"für ihre Private Cloud basierend auf Nextcloud",
"swissmakers.ch "
],
"position": [18,18],
"groesse": [18,8]
}
],
"dashboard_title": "generiertes_dashboard_blog_beispiel3_b"
}Ohne weitere Anpassungen wird daraus mit demselben Template das folgende Dashboard generiert:

Automatisches Anordnen von Panels
In Beispiel 4 geht es darum, ein paar weitere Möglichkeiten von jinja2-Templates zu zeigen und Panels im Dashboard automatisch in Zeilen und Spalten anzuordnen.
Es wird eine feste Anzahl von Markdown-Panels verwendet, die je nach der gewünschten Anzahl Panels im Dashboard wiederholt werden.
Inputdatei mit Variablen
Als Inputdatei mit Variablen wird eine Kopie der Inputdatei von Beispiel 3 verwendet. Grösse und Position der Markdown-Panels werden aber für alle Panels einheitlich gesetzt und ausserhalb des markdown-Arrays im json-File definiert. Dort wird auch die gewünschte Anzahl Markdown-Panels und die Anzahl Spalten für die Panels im Dashboard angegeben. Die Breite der Panels ist kleiner definiert als in den vorangehenden Beispielen, weil die Panels sonst in Kibana automatisch etwas anders angeordnet werden, da sie nicht wie eigentlich gewünscht Platz finden im Dashboard.
Die Inputdatei blog_beispiel4_vars.json sieht wie folgt aus:
{
"hoehe": 8,
"breite": 10,
"spalten": 4,
"anzahl": 20,
"markdown": [
{
"title": "**Swissmakers**",
"textzeilen": [
"Aus Freude an Technik",
"Engeneering / Security / Consulting",
"swissmakers.ch "
]
},
{
"title": "**Swissmakers**",
"textzeilen": [
"Einfach Top!",
"swissmakers.ch ",
""
]
},
{
"title": "**Codeatelier**",
"textzeilen": [
"Wir bauen deine digitale Zukunft",
"Webdesign SEO Webapps Webshops",
"codeatelier.ch "
]
},
{
"title": "**Swissmakers**",
"textzeilen": [
"Ihre ITC-Spezialistinnen und -Spezialisten",
"Engeneering, Linux und Netzsicherheit",
"swissmakers.ch "
]
},
{
"title": "**Swissmakers**",
"textzeilen": [
"Ihre ITC-Expertinnen und -Experten",
"für ihre Private Cloud basierend auf Nextcloud",
"swissmakers.ch "
]
}
],
"dashboard_title": "generiertes_dashboard_blog_beispiel4"
}Generieren und anordnen der Panels
blog_beispiel4.json ist wieder die umformatierte Datei mit dem ursprünglich interaktiv erstellten Dashboard.
Für das Beispiel 4 ist noch der Panel-Titel ausgeschaltet und die Schriftgrösse etwas verkleinert worden.
"optionsJSON": "{\"useMargins\":true,\"syncColors\":false,\"syncCursor\":true,\"syncTooltips\":false,\"hidePanelTitles\":true}",
------→\"params\":{\"fontSize\":10,In blog_beispiel4.json werden nun wiederum jinja2-Elemente eingefügt. Hier nun der entsprechende Teil der Datei mit den teilweise neuen jinja2-Elementen:
"panelsJSON": "{% set global = namespace(row = 0) %}[{% for i in range(0, anzahl - 1) %}{\"type\":\"visualization\",
------->\"gridData\":{\"x\":{{ (i) % spalten * breite }},
------->\"y\":{{ hoehe * global.row }}{% if (i + 1) % spalten == 0 %}{% set global.row = global.row + 1 %}{% endif %},
------->\"w\":{{ breite }},
------->\"h\":{{ hoehe }},
------->\"i\":\"09747f18-d4b6-4cb0-a25e-63abf3a9cce8\"},
------->\"embeddableConfig\":{\"enhancements\":{\"dynamicActions\":{\"events\":[]}},
------->\"savedVis\":{\"id\":\"\",
------->\"title\":\"\",
------->\"description\":\"\",
------->\"type\":\"markdown\",
------->\"params\":{\"fontSize\":10,
------->\"openLinksInNewTab\":false,
------->\"markdown\":\"# {{ markdown[i % markdown|length]['title'] }}\\n\\n{{ markdown[i % markdown|length]['textzeilen'][0] }}\\n\\n{{ markdown[i % markdown|length]['textzeilen'][1] }}\\n\\n{{ markdown[i % markdown|length]['textzeilen'][2] }}\"},
------->\"uiState\":{},
------->\"data\":{\"aggs\":[],
------->\"searchSource\":{\"query\":{\"query\":\"\",
------->\"language\":\"kuery\"},
------->\"filter\":[]}}}}}{% if loop.index != loop.length %},{% endif %}{% endfor %}]",Die insgesamt 20 Markdown-Panels «anzahl»: 20 sollen in Zeilen mit je 4 Panels «spalten»: 4 angeordnet werden. Dazu wird die Hilfsvariable row definiert, in der die Zeile für das Panel steht und mit der dann die y-Position berechnet wird. row wird mit dem Wert 0 initialisiert:
{% set global = namespace(row = 0) %}Die Schleife über die Panels wird etwas anders definiert als zuvor:
{% for i in range(0, anzahl) %}Man hat so die Schleifenvariable i, die von 0 bis anzahl -1, im Beispiel also von 0 bis 29, läuft. Die obere Grenze anzahl in der range-Funktion wird von der Funktion nicht zurück geliefert, man muss also anzahl und nicht anzahl – 1 als obere Grenze angeben. Am Ende der Schleife hat man wieder die Bedingung wegen den Kommata zwischen den Paneldefinitionen aber nicht am Ende das Arrays:
{% if loop.index != loop.length %},{% endif %}% ist in Jinja2 der Modulo-Operator, der den Rest einer ganzzahligen Division angibt. Damit lassen sich die jeweiligen x-Positionen der Panels berechnen:
{{ (i) % spalten * breite }}Beim Zugriff auf die Elemente des markdown-Arrays in der Inputdatei wird ebenfalls der Modulo-Operator zusammen mit der Laufvariable i verwendet, um nach dem letzten Array-Element wieder auf das erste zuzugreifen:
{{ markdown[i % markdown|length]['title'] }}Mit dem Filter length in markdown|length erhält man die Anzahl Elemente im Array markdown, die man hier braucht.
Wie in den anderen Beispielen muss nun die Datei umformatiert und als ganzes Template blog_beispiel4.j2 gespeichert werden.
Der Befehl
jinjanate blog_beispiel4.j2 blog_beispiel4_vars.json -o generiertes_dashboard_blog_beispiel4.ndjsongeneriert nun folgendes Dashboard, in dem die Markdown-Panels wiederholt werden und regelmässig in 4 Spalten angeordnet sind:

Dashboards mit Elastic-Daten
Sie kennen nun erste Beispiele. Erkunden Sie die Möglichkeit der Dashboard-Generierung mit Elastic-Beispieldaten in einigen Wochen in unserem nächsten Teil dieses Blogbeitrags.
Natürlich können Sie jederzeit auf Swissmakers zukommen für Unterstützung bei der Erstellung professioneller Kibana-Dashboards.
]]>What is OT and why is it important?
Operational technology (OT) refers to the hardware and software systems used to monitor, control, and automate industrial processes in sectors like energy, water supply, and transportation. Unlike traditional IT systems, which manage data and business applications, OT interacts directly with physical equipment such as power grids, water treatment plants, and industrial control systems.
In critical infrastructure, OT ensures that essential services remain operational. Systems like SCADA (supervisory sontrol and data acquisition), PLC (programmable logic controllers), and RTU (remote terminal units) are used to regulate energy distribution, monitor gas and water pipelines, and control public transportation networks. These systems must be highly reliable, as disruptions can have far-reaching consequences for public safety and economic stability.
With increasing digitalization and interconnectivity, OT systems are no longer isolated from external networks. Many now integrate with IT networks for remote monitoring, predictive maintenance, and automation. This convergence improves efficiency but also introduces new security challenges, as OT networks – traditionally designed for reliability over security – are now exposed to cyber threats that can cause physical disruptions.
Common OT communications protocols
In OT, communication protocols are designed to support real-time control, reliability, and efficiency in industrial and critical infrastructure environments. Unlike in IT, where the vast majority of communication occurs over common protocols such as TCP/IP, UDP/IP, OT networks rely on specialized protocols tailored for specific applications. These protocols are often optimized for low-latency control, deterministic behavior, and legacy hardware compatibility, but many were not designed with security in mind. Below is an overview of four key OT communication protocols widely used in energy infrastructure and industrial automation.
Modbus
Modbus is one of the oldest and most widely used industrial communication protocols. Developed in 1979 by Modicon (now Schneider Electric), it enables communication between programmable logic controllers (PLCs), sensors, and SCADA systems. Modbus exists in two main variants:
- Modbus RTU (uses serial communication)
- Modbus TCP (runs over Ethernet networks)
Application Areas:
- Industrial automation (factories, process control)
- Energy infrastructure (power plants, substations, grid monitoring)
- SCADA systems
M-Bus
M-Bus is a protocol specifically designed for remote reading of utility meters (electricity, water, gas, and heat). It allows utility companies to efficiently collect and manage consumption data from a large number of distributed meters.
Application Areas:
- Smart metering (gas, water, electricity, district heating)
- Utility infrastructure
- Building management systems
IEC 60870-5-104
IEC 60870-5-104 is a standardized SCADA protocol used for power grid control and monitoring, particularly in Europe. It is an IP-based version of IEC 60870-5-101 and allows remote telemetry and control of substations and distribution systems.
Application Areas:
- Power grid SCADA systems
- Transmission and distribution substations
- Energy dispatch centers
IEC 61850
IEC 61850 is a modern protocol for substation automation and smart grids. Unlike traditional protocols that rely on simple data polling, IEC 61850 introduces object-oriented communication and high-speed event-driven messaging (GOOSE and MMS). It is designed to support automation, predictive maintenance, and real-time grid stability.
Application Areas:
- Smart grids and modern substation automation
- High-voltage power transmission and distribution
- Renewable energy integration (solar, wind farms, battery storage systems)
OT security and common threats in OT networks
OT networks are essential for managing industrial processes in energy, utilities, and other critical infrastructure sectors. Unlike IT networks, which are built with security in mind, OT systems have traditionally prioritized reliability and availability over cybersecurity. Many of the protocols and devices in use today were developed decades ago, long before cyber threats became a concern. As a result, these systems often lack fundamental security measures, making them attractive targets for attackers.
One of the most significant vulnerabilities in OT networks is the lack of authentication and encryption. Many widely used industrial communication protocols, such as Modbus, M-Bus, and IEC 60870-5-104, were not designed to verify the identity of devices or users communicating within the network. This means that any system capable of sending properly formatted messages can potentially issue commands to industrial controllers, actuators, or meters. Even more concerning is that these protocols transmit data in plain text, without any encryption, making it easy for attackers to intercept and manipulate communications. For example, in a Man-in-the-Middle (MITM) attack, an attacker could intercept traffic between a control center and a substation, altering sensor data or injecting false commands. In a replay attack, an attacker could capture and resend a previously valid command, such as a shutdown signal, to disrupt operations. Because these protocols were designed with reliability rather than security in mind, such attacks can go undetected until serious consequences arise.
Beyond communication weaknesses, physical security risks present another major challenge in OT environments. While many assume that industrial control systems are protected by air gaps, meaning they are isolated from external networks, real-world incidents have repeatedly proven otherwise. Physical access points such as USB ports, maintenance laptops, and exposed network interfaces provide direct entry to critical systems. A well-known example is the Stuxnet attack, where malware was introduced into an air-gapped system via infected USB drives, allowing attackers to sabotage industrial centrifuges. Similarly, a malicious insider or an external attacker with brief physical access to a control panel or an industrial Ethernet switch could introduce rogue commands, install malware, or even shut down critical processes.
The combination of unsecured communication protocols and weak physical security controls makes OT networks highly susceptible to cyberattacks. Unlike IT breaches, where the primary concern is data theft, attacks on OT systems can lead to power outages, water supply disruptions, or even physical damage to industrial machinery. As the integration between OT and IT systems continues to grow, securing these environments becomes an urgent priority.
Monitoring Modbus: Detecting and mitigating rogue devices in power infrastructure
Let’s assume a local energy provider operates a power distribution network managed by a SCADA system that communicates with remote substations, circuit breakers, and monitoring devices over a Modbus TCP/IP network. What are the potential security risks and consequences if an attacker gains unauthorized access to the network and how could a SIEM system help detect and mitigate the threat?
Modbus: How it works, network topology, and security risks
Modbus has a master-slave architecture, where a central device (master) sends requests to one or more subordinate devices (slaves) and awaits responses. These requests can include reading sensor data, modifying device settings, or controlling actuators. The blog post on Realpars.com provides a comprehensive explanation of how Modbus works.
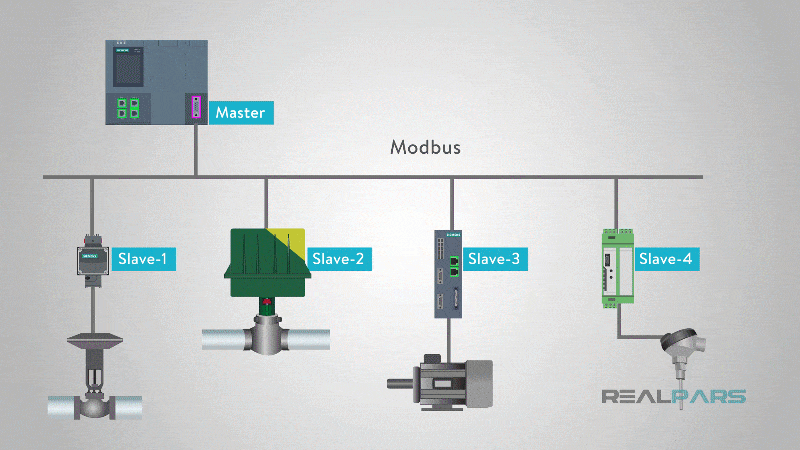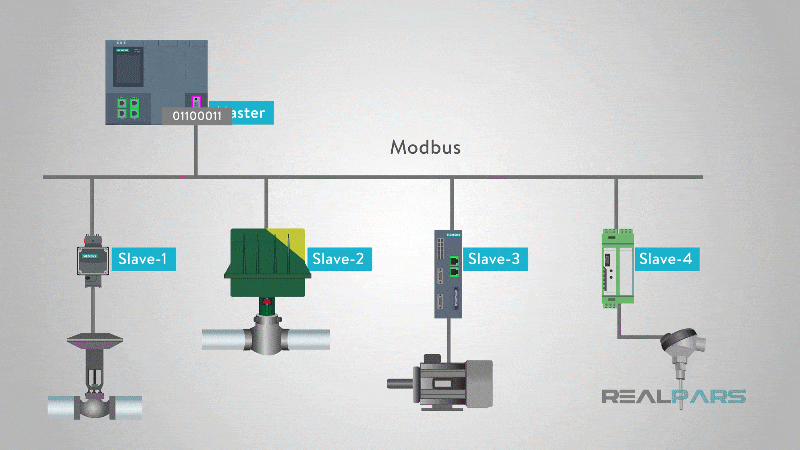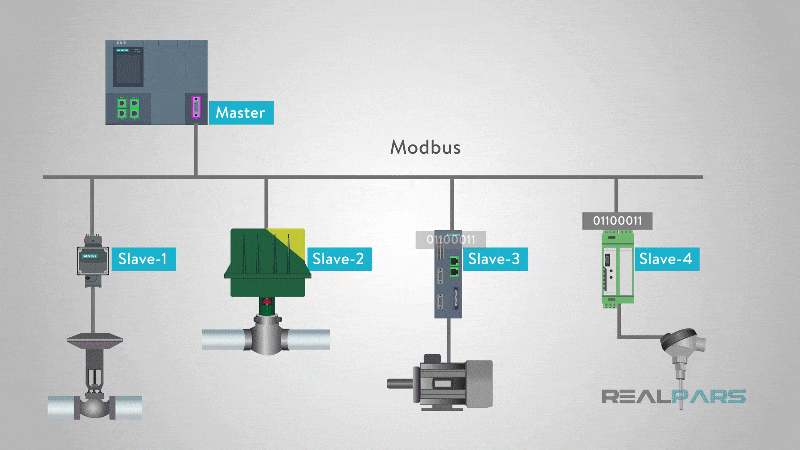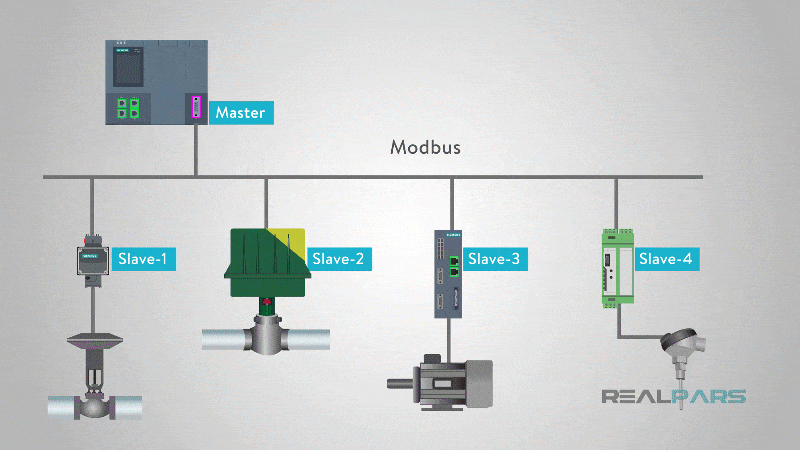
The protocol operates in two main variants:
- Modbus RTU (remote terminal unit): Uses serial communication (RS-232 or RS-485), often seen in legacy systems.
- Modbus TCP: Uses Ethernet networks, allowing for easier integration with modern OT and IT systems.

In a typical Modbus network topology, a SCADA system or control server acts as the master, while multiple field devices—such as PLCs, sensors, meters, and RTUs—function as slaves. Communication is direct and unencrypted, meaning that any device on the network can send or modify data if it has access.
The threat: A malicious or infected Modbus device in the network
Let’s consider a scenario where an attacker introduces a rogue Modbus slave device into the network of our ficticious energy provider. This rogue device could be a compromised sensor, meter, or a PLC acting as a slave. Since Modbus does not include authentication or device verification, any device connected to the network can respond to Modbus requests if it knows the expected format.
How a Rogue Modbus Slave Can Exploit the Network
- Spoofing legitimate devices: The rogue slave could impersonate an existing, trusted device by using its address and responding to requests with falsified data. If the real device is still online, the attacker could race to respond first, feeding operators incorrect readings. Example: A rogue temperature sensor reports normal values, masking an actual overheating issue in a substation.
- Flooding the network with fake responses: A rogue slave could continuously respond to Modbus queries, overwhelming the master and making it difficult for legitimate devices to communicate. Example: A malicious device sends thousands of responses per second, causing latency and operational delays.
- Passive Data Exfiltration (eavesdropping on queries): Even if the rogue device does not actively send malicious responses, it could passively listen to Modbus requests, learning operational details about the grid. Example: The rogue slave logs all SCADA queries, capturing real-time energy distribution data for industrial espionage.
Because Modbus devices inherently trust all network participants, these attacks can go unnoticed unless proper monitoring mechanisms are in place.
How a SIEM can detect and react to a malicious Modbus device
A Security Information and Event Management (SIEM) system plays a crucial role in detecting and responding to threats in an OT network. Since Modbus lacks authentication and encryption, a SIEM can act as a second layer of defense, continuously monitoring network activity, tracking devices, and flagging abnormal behavior.
Monitoring and inventory of Modbus devices
One of the first security measures a SIEM can provide is building an inventory of legitimate devices in the Modbus network. This can be done in two ways:
- Passive Monitoring: The SIEM listens to normal Modbus traffic, logging which slave devices respond to requests from the master. If a new, unrecognized Modbus slave suddenly appears in the network, the SIEM can raise an alarm, as this could indicate an unauthorized device.
- Active Polling (Inventory Scans): The SIEM can periodically instruct the master to send queries to all possible slave addresses and track their responses. This ensures that only known devices are operating in the network and helps detect unauthorized Modbus slaves in real-time. Additionally, the SIEM can collect device-specific information, such as Modbus function codes supported, register values, and response patterns, helping to identify potential anomalies.
Automated Response & Mitigation
When the SIEM detects a rogue Modbus device, it can trigger various predetermined actions to contain the threat before it escalates:
- Isolation of the Rogue Device: If the SIEM detects a new or suspicious Modbus slave, it can instruct a managed switch to block the device’s MAC address or shut down the Ethernet port to prevent further communication.
- Blocking Unauthorized Modbus Commands: The SIEM can integrate with firewalls or intrusion prevention systems (IPS) to block specific Modbus function codes (e.g., unauthorized WRITE commands to critical registers).
- Real-Time Alerts to Security Teams: The SIEM sends high-priority alerts to the Security Operations Center (SOC), allowing security analysts to manually investigate and confirm the threat.
- Correlation with other security events: If a rogue Modbus device also tries to communicate with an external network, the SIEM can correlate this with firewall logs, identifying potential data exfiltration.
How to retrofit security in a brownfield OT environment
Securing an existing (brownfield) OT environment can be challenging. However, integrating a SIEM system into the OT network can provide real-time visibility, anomaly detection, and automated response without disrupting operations.
Steps to Improve Security in a brownfield OT network
- Deploy a SIEM System
- Ensure the SIEM Access to all OT network segments
- Create a device inventory: Leverage the SIEM to passively map out all existing OT devices and their communication patterns. Identify legacy or undocumented devices that could pose security risks.
- Monitor network traffic continuously: Establish a baseline of normal Modbus/OT traffic to detect deviations and anomalies. Track which devices communicate and how frequently to spot unexpected behaviors.
- Detect and alert on unauthorized devices or behavior: Raise real-time alerts if a new device appears or if an existing device starts acting abnormally. Flag unexpected function codes, unauthorized write attempts, or anomalous response behavior.
- Automate incident response: Integrate the SIEM with managed switches or firewalls to isolate compromised devices.
By following these steps, brownfield OT networks can achieve a higher level of security without requiring a complete infrastructure overhaul.
Conclusion
Implementing a SIEM system is crucial for securing OT networks in energy infrastructure, especially with the increasing cyber threats targeting Modbus-based systems. A SIEM enables real-time monitoring, anomaly detection, and automated threat response, helping energy providers identify rogue devices, prevent disruptions, and maintain operational integrity.
With extensive expertise in SIEM solutions for energy suppliers, Swissmakers offers tailored security monitoring based on Elasticsearch, providing automated analysis and proactive threat detection. Our SOC-lite service ensures continuous SIEM maintenance, alarm analysis, and incident response, allowing energy providers to focus on their core operations while we safeguard their critical infrastructure.
Motivation
Es ist einfach und praktisch, in Kibana interaktiv Dashboards zu gestalten. Oft möchte man aber verschiedene Varianten eines Dashboards haben, beispielsweise für unterschiedliche Umgebungen oder Kunden. Oder man möchte exakt dieselben Positionen oder dieselben Farben für Dashboard-Elemente verwenden. Dann wird es mühsam, alles interaktiv zu gestalten. Einfacher und effizienter ist es in solchen Fällen, wenn Dashboards mit Hilfe von Variablen automatisch generiert werden können.
Idee
Templates und ein einfacher Template-Prozessor (Template-Engine) können verwenden werden, um flexibel Kibana Dashboards zu generieren.
Diese Idee lässt sich für viele andere Automatisierungslösungen analog brauchen und ist keine spezielle Idee für Kibana Dashboards. Ursprünglich wurden Template-Prozessoren vor allem verwendet, um HTML-Seiten zu generieren.
Folgende Komponenten sind nötig:
- Inputdatei(en) mit Variablen
- Template als Textdatei
- Template-Prozessor
Der Template-Prozessor generiert aus dem Template zusammen mit den Inputdatei(en) Outputdatei(en) wie beispielsweise Konfigurationsdateien oder Dateien in einem der folgenden Formate: html, xml, json, ndjson oder was immer im gegebenen Kontext gebraucht wird.
Der Template-Prozessor muss mindestens einfache mathematische Operationen (Addition, Multiplikation, Modulo), Schleifen und Bedingungen ausführen können und nicht nur Texte ersetzen oder generieren. Siehe auch http://www.simple-is-better.org/template/index.html.
Gewählte Werkzeuge
Json-Dateien werden für die Inputdatei mit Variablen verwendet, aber es sind auch yaml-Dateien oder weitere Formate möglich.
Der Python-Template-Prozessor Jinja2 wird als Template-Prozessor verwendet. Python ist weit verbreitet und Jinja2 wird ebenfalls oft verwendet, beispielsweise in Ansible.
Jinja2 kann in Python-Skripts verwendet werden. Einfacher ist es für das Generieren von Dashboards aber, ein fertiges Kommandozeilenwerkzeug zu verwenden. Für komplexere Anwendungen kann dieses auch aus einem Shellskript aufgerufen werden. Hier wird jinjanator gebraucht, das aktiv weiterentwickelt wird. Eine Alternative wäre yasha, das gut funktioniert, aber etwas älter ist.
Es gibt noch viele weitere Alternativen für Template-Prozessoren, z.B. das Perl Template Toolkit. Dieses ist viel mächtiger als Python und jinja2, wird aber nicht mehr wirklich weiterentwickelt.
Für eine Liste von Template-Prozessoren siehe z.B.: https://en.wikipedia.org/wiki/Comparison_of_web_template_engines
Wenn Python installiert ist, werden Jinja2 und jinjanator mit pip installiert:
pip install Jinja2
pip install jinjanatorVisualStudioCode (VSCode) wird als Editor für die Inputdateien und Templates gebraucht. VSCode kann unter Windows, Linux und gut auch in Windows WSL2 gebraucht werden und es gibt für VSCode gute Unterstützung für Python und json-Dateien mit Extensions im VSCode-Marketplace.
Für das Erstellen der Templates empfehle ich, VSCode mit der Extension vscode-json zusammen mit der Python Extension von Microsoft zu verwenden.
Umsetzung für Kibana Dashboards
Voraussetzungen
Kibana Dashboards haben wie andere Kibana Saved-Objects eine Repräsentation als ndjson-Datei. Solche ndjson-Dateien können aus Kibana exportiert und in Kibana importiert werden.
Ndjson-Dateien sind Textdateien und lassen sich generieren, um flexibel Dashboards zu erstellen.
Ndjson-Dateien mit Dashboarddefinitionen
Ndjson steht für «Newline delimited json». Es ist ein Standard für Dateien, die pro Zeile ein json-Dokument enthalten. Das ist sehr praktisch, um in Kibana mehrere Objekte in eine einzelne Datei zu exportieren oder aus einer Datei zu importieren. Die Dateien haben aber sehr lange Zeilen und sie sind deshalb nicht gut geeignet, um interaktiv Änderungen an ihnen vorzunehmen.
Das ndjson-Format für Dashboards ist nicht dokumentiert ausser im Code von Kibana. Manchmal braucht es etwas Fantasie um das Format zu verstehen. Tests und einfache Beispiele können dabei helfen. Das Nachführen für neue Kibana-Versionen kann deshalb aufwändig sein und man hat keinen guten Überblick darüber, was wirklich alles möglich wäre beim Generieren von Dashboards aus Programmen heraus.
Ein paar Hinweise zum ndjson-Format für Dashboards können folgende Dateien im Code von Kibana liefern:
- kibana/packages/kbn-check-mappings-update-cli/current_fields.json
- kibana/api_docs/dashboard.devdocs.json
- kibana/src/plugins/dashboard/server/content_management/v3/transform_utils.ts
Dashboard als Vorlage
In Kibana wird zuerst interaktiv ein Dashboard erstellt, das dann als Grundlage für ein Template dient. In der Vorlage sollten Panels, die im generierten Dashboard mehrmals platziert werden sollen, bereits mehrfach vorkommen. Möglichst alle Elemente und Einstellungen, die gebraucht werden, sollten schon in der Vorlage vorkommen, damit deren Repräsentation im ndjson-File des Dashboards schon vorhanden ist.
Dashboard exportieren
In Elastic können unter dem Menüpunkt «Management → Stack Management → Saved Objects» Dashboards (und weitere gespeicherte Objekte) exportiert und als ndjson-Dateien gespeichert werden.
Es empfiehlt sich, sowohl das Dashboard, das als Vorlage dient, als auch die ndjson-Datei mit dem exportierten Dashboard zu sichern. Nach Kibana Updates kann dann das aktualisierte Dashboard neu exportiert und mit der alten, exportierten Version verglichen werden. Das hilft, um dann auch Templates für das Generieren von Dashboards an neue Kibana-Versionen anzupassen.
Inputdatei mit Variablen
Es muss eine json-Inputdatei mit allen Variablen, die im generierten Dashboard vorkommen sollen, geschrieben werden. Es empfiehlt sich auch, einen Titel (Namen) für das Dashboard in der Inputdatei zu definieren, damit man im Kibana-GUI die Dashboards unterscheiden kann. Das genaue Format der Inputdatei ist nicht so wichtig, es muss nur auf einfache Weise auf die Werte zugegriffen werden können.
Durch Anpassungen an den Inputdateien oder die Verwendung verschiedener Inputdateien können dann unterschiedliche Dashboards erzeugt werden.
Umformen der ndjson-Datei mit dem Dashboard
Ndjson-Dateien sind für interaktive Änderungen in VSCode nicht geeignet, da sie lange Zeilen aufweisen und nicht gut lesbar sind. Zudem sind es keine gültigen json-Dateien und viele json-Editoren und Erweiterungen haben Mühe, mit ihnen umzugehen.
Eine weitere Schwierigkeit ist es, dass die Angaben zu den Dashboard-Panels, die angepasst werden sollen, in Arrayelementen stehen, die eigentlich wieder json-Teile enthalten. Da sich aber in json so etwas nicht verschachtelt definieren lässt, braucht es dort vor Anführungs- und Schlusszeichen und vor weiteren Spezialzeichen wie den Backslashes als Escape-Zeichen einen vorangestellten Backslash. Hier muss man aufpassen, dass bei Umformatierungen diese Backslashes erhalten bleiben, sonst kann die am Ende generierte ndjson-Datei nicht mehr in Kibana importiert werden.
Am einfachsten ist es, wenn man die Dateien vor dem Editieren in VSCode formatiert und danach die Formatierung wieder rückgängig macht. Dazu dienen die folgenden Schritte:
- Kopieren der ndjson-Datei mit dem Dashboard in eine Datei mit der Extension .j2. So bleibt die ursprüngliche Datei erhalten. Das Ändern der Dateiextension ist nicht wirklich nötig, kennzeichnet aber die Datei als Datei mit jinja2-Elementen.
- Kopieren der Zeile mit der benötigten Dashboard-Definition und speichern dieser Zeile in einer eigenen, temporären Datei mit der Extension .json.
- Öffnen der json-Datei mit der Dashboarddefinition in VSCode.
- Umwandeln in eine besser lesbare, formatierte json-Datei mit <ctrl><alt><b> (vscode-json: Beautify).
- Bei Bedarf im Teil mit der Dashboard-Panel-Definition Zeilenumbrüche und weitere Zeichen einfügen, damit die Datei besser editiert werden kann. Das kann mit einem Replace der Kommata im Editor gemacht werden, bei dem ein Zeilenumbruch und eine Zeichenfolge, die sonst in der Datei nicht vorkommt, eingefügt wird.
- Editieren der Datei und jinja2-Elemente einfügen.
- Die allenfalls in Schritt 5 eingefügten Zeilenumbrüche und Zeichenfolgen wieder löschen.
- Sicherheitshalber Ids löschen, damit beim späteren Import neue Ids generiert werden und keine Konflikte entstehen. Insbesondere darf es nicht mehrere Dashboards mit derselben Id in einer Datei geben, sonst gibt es später einen Fehler beim Import.
- Formatierung der Datei wieder zurücksetzen mit <ctrl><alt><u> (vscode-json: Uglify).
- Die Zeile mit dem Dashboard-Template kopieren und in der in Schritt 1 erstellten j2-Datei die Dashboard-Definition damit ersetzen.
Template mit jinja2
Im Schritt 6 von oben wird interaktiv ein Template mit jinja2 Variablen und Ausdrücken erstellt. Die Variablen und Ausdrücke verwenden die Definitionen der Werte aus der Inputdatei. Die Dokumentation zu Jinja2 findet man hier: https://jinja.palletsprojects.com/en/stable/templates
Zur Dokumentation des Templates können jinja2-Kommentare der Form {# Kommentartext #} direkt in die Templatedatei eingefügt werden.
Template-Prozessor
Mit dem Template-Prozessor jinja2 kann nun aus der Inputdatei mit den Variablen und der jinja2-Templatedatei eine ndjson-Datei mit dem generierten Dashboard erzeugt werden. Dafür kann jinjanate auf der Kommandozeile gebraucht werden.
jinjanate template_datei.j2 inputdatei_vars.json -o generiertes_dashboard.ndjsonDashboard importieren
In Elastic können unter dem Menüpunkt «Management → Stack Management → Saved Objects» Dashboards (und weitere gespeicherte Objekte) interaktiv aus ndjson-Dateien importiert werden. Hier kann nun das generierte Dashboard in Kibana importiert werden.
Am besten wählt man dabei die Option «Create new objects with random Ids» aus, damit Konflikte mit Ids möglichst vermieden werden.
Beispiele gewünscht?
Gespannt auf die ersten Anwendungsbeispiele? Diese finden Sie in einigen Wochen in unserem nächsten Teil dieses Blogbeitrags.
Natürlich können Sie jederzeit auf Swissmakers zukommen für Unterstützung bei der Erstellung professioneller Kibana-Dashboards.
In der heutigen digitalen Welt ist die Sicherheit des Datenaustauschs im Internet von entscheidender Bedeutung. HTTPS (HyperText Transfer Protocol Secure) ist ein Protokoll, das die sichere Übertragung von Daten zwischen einem Webserver und einem Webbrowser gewährleistet. In diesem Blog-Beitrag werden wir uns eingehend mit dem HTTPS-Transportprotokoll beschäftigen, die Rolle von TLS 1.2 (Transport Layer Security) erläutern und detailliert auf die Funktionsweise von Verschlüsselung und CA-Validierung (Certificate Authority) eingehen. Am Ende des Artikels haben wir zum besseren Verständnis ein zusammenfassendes Beispiel einer HTTPS-Anfrage von einem Client an den Webserver www.swissmakers.ch erstellt. Dies soll die einzelnen Schritte noch einmal abschliessend und verständlich zusammenfassen.
HTTPS und TLS: Ein kurzer Überblick
HTTPS ist eine Erweiterung des HTTP-Protokolls und verwendet TLS, um eine sichere Kommunikation über ein Computernetzwerk zu gewährleisten. Während HTTP die Daten im Klartext überträgt, verschlüsselt HTTPS die Daten, um sie vor unbefugtem Zugriff zu schützen.
TLS ist das Protokoll, welches eine sichere Kommunikation über HTTPS ermöglicht. Es besteht aus zwei Hauptphasen: dem TLS-Handshake und der Datenübertragung (Record-Protocol).
Der TLS-Handshake dient dem Aufbau einer sicheren Verbindung zwischen dem Client (Webbrowser) und dem Server (Webserver), während die Datenübertragung die eigentliche Verschlüsselung der Daten mit den ausgehandelten Schlüsseln übernimmt.
Der TLS-Handshake im Detail
Der TLS-Handshake ist ein mehrstufiger Prozess, der vereinfacht folgende Schritte umfasst:
- Client Hello: Der Client sendet eine Nachricht an den Server mit den unterstützten TLS-Versionen, Verschlüsselungs-Suites und anderen Konfigurationsparametern, welche vom Client unterstützt werden.
- Server Hello: Der Server antwortet mit seinen unterstützten Versionen und wählt die sichersten verfügbaren Parameter für die Verbindung, einschliesslich der TLS-Version und Verschlüsselungs-Suite, welche von beiden Parteien unterstützt werden.
- Zertifikataustausch: Der Server sendet sein öffentliches digitales Zertifikat (welches unter anderem den öffentlichen Schlüssel enthält), das von einer vertrauenswürdigen Zertifizierungsstelle (CA) signiert wurde, an den Client.
- Schlüsselaustausch: Nach erfolgreicher Validierung durch die CA (clientseitig) tauschen Client und Server kryptographische Schlüssel (asymmetrisch verschlüsselt) aus, um später eine symmetrische Verschlüsselung zu ermöglichen. Dies kann durch verschiedene Verfahren geschehen, z.B. mit RSA oder alternativ auch Diffie-Hellman.
- Handshake-Abschluss: Beide Parteien bestätigen, dass der Handshake abgeschlossen ist.
Die sichere Verbindung wird durch die symmetrische Verschlüsselung etabliert.
Ver- und Entschlüsselung der Daten
Nach erfolgreichem TLS-Handshake beginnt die verschlüsselte Übertragung der Daten. Dabei kommen symmetrische Verschlüsselungsalgorithmen wie AES (Advanced Encryption Standard) zum Einsatz. Symmetrische Verschlüsselung bedeutet, dass derselbe Schlüssel sowohl zum Ver- als auch zum Entschlüsseln der Daten verwendet wird.
Symmetrische Verschlüsselung
- Serverseitige Verschlüsselung: Der Server verschlüsselt die Daten mit dem symmetrischen Schlüssel und sendet sie an den Client.
- Clientseitige Verschlüsselung: Der Client verschlüsselt seine Anfragen oder Antworten mit demselben symmetrischen Schlüssel und sendet sie an den Server.
Diese Methode stellt sicher, dass nur der jeweilige Client und Server die übertragenen Daten verschlüsseln, entschlüsseln und lesen können.
Asymmetrische Verschlüsselung und Schlüsselaustausch
Beim TLS-Handshake wird die asymmetrische Verschlüsselung verwendet, um symmetrische Schlüssel sicher auszutauschen. Dabei wird ein Schlüsselpaar verwendet, welches aus einem öffentlichen Schlüssel (Public Key) und einem privaten Schlüssel (Private Key) besteht:
- Öffentlicher Schlüssel: Wird vom Server an den Client gesendet und kann von jedem zur Verschlüsselung von Daten verwendet werden.
- Privater Schlüssel: Wird sicher auf dem Server aufbewahrt und zum Entschlüsseln der mit dem öffentlichen Schlüssel verschlüsselten Daten verwendet.
Der eigentliche Schlüsselaustausch kann durch verschiedene Methoden erfolgen, einschliesslich des RSA-Schlüsselaustauschs oder eines zusätzlichen Diffie-Hellman-Schlüssels, welcher auf dem Server konfiguriert werden kann. Diffie-Hellman ist ein Verfahren, bei dem zwei Parteien gemeinsam einen zusätzlichen geheimen Schlüssel erzeugen können, auch wenn die Kommunikation über eine unsichere Verbindung erfolgt. Dieses Verfahren kann in Kombination mit anderen Algorithmen verwendet werden, um beispielsweise die Sicherheit eines Reverse Proxies oder eines Webservers zu erhöhen.
Es ist wichtig zu betonen, dass TLS auch ohne die zusätzliche Implementierung von Diffie-Hellman funktioniert. Der RSA-Schlüsselaustausch, bei dem der symmetrische Schlüssel mit dem öffentlichen Schlüssel des Servers verschlüsselt und dann vom Server mit seinem privaten Schlüssel entschlüsselt wird, ist das Standardverfahren.
Die CA-Validierung
Die Validierung des öffentlichen Schlüssels (Public Key) über vertrauenswürdige öffentliche Zertifizierungsstellen (Public Trusted Root CAs) ist ein wichtiger Bestandteil des TLS-Handshakes für eine später als «sicher» geltende Verbindung. Die jeweilige CA prüft nämlich bereits beim Antrag zum Erstellen eines neuen öffentlichen Schlüssels (Einrichtung einer neuen HTTPS-verschlüsselten Webseite) die Identität des Serverbetreibers anhand der Domain und stellt nur dann ein digitales Zertifikat (welches die Authentizität der später erreichbaren https://-Seite bestätigt) aus, wenn alle Prüfungen erfolgreich durchlaufen wurden.
Somit kann (in den meisten Fällen) davon ausgegangen werden, dass nach erfolgreicher Prüfung des Server-Zertifikats, durch den Client, dieses gültig ist und keine Man-in-the-Middle-Angriffe erfolgen können.
Die Client-Zertifikatsprüfung: Der Client (Browser) prüft das Zertifikat während des TLS-Handshakes, indem er die Zertifikatskette gegen die Liste der vertrauenswürdigen Root-CAs validiert / Prüfsummen prüft. Wenn das Zertifikat als vertrauenswürdig eingestuft wird und die Zertifikatskette (Certificate-Chain) nicht gebrochen wurde, kann eine validierte und sichere Verbindung aufgebaut werden. In unserem Fall lautet die Root-CA «ISRG Root X1», von welcher eine Sub-CA namens «R3» erstellt wurde, welche wiederum unser Zertifikat für «swissmakers.ch» ausgestellt hat.


Warum nicht jeder ein Zertifikat für eine beliebige Domain erhalten kann
Wie bereits kurz erwähnt, ist für die erfolgreiche Ausstellung eines neuen Zertifikats für eine «neu zu verschlüsselnde» Webseitenverbindung über HTTPS zunächst eine Überprüfung der Inhaberrechte erforderlich. Bei Let’s Encrypt können beispielsweise folgende Prüfungen durchgeführt werden:
- DNS-Validierung: Der Antragsteller muss einen spezifischen DNS-Eintrag erstellen, den die CA durch eine DNS-Abfrage auf der entsprechenden Domain vor der Ausstellung überprüfen kann.
- HTTP-Validierung: Der Antragsteller muss eine bestimmte Datei im Webserver-Root der Domain hinterlegen oder über ein Webserver-Modul eine ähnliche automatisierte Überprüfungsmethode ermöglichen, welche wiederum von der CA abgerufen und überprüft werden kann.
Nur der Inhaber der Domain kann die beiden notwendigen Einstellungen für diese Validierungsarten vornehmen und somit kann auch nur er ein neues Zertifikat beantragen und erhalten.
Die Erstellung eines neuen Zertifikats läuft grob in folgenden Schritten ab:
- Zertifikatsantrag: Der Serverbetreiber beantragt bei einer CA ein digitales Zertifikat. Beispielsweise kann Let’s Encrypt verwendet werden, um ein kostenloses Zertifikat zu erhalten. Der Zertifikatsantrag wird mit einem zuvor lokal erzeugten privaten Schlüssel signiert.
- Verifizierung: Die CA überprüft die Identität des Antragstellers und validiert, dass er die notwendigen Rechte als Inhaber der Domain besitzt, für welche das Zertifikat ausgestellt wird. Let’s Encrypt kann beispielsweise eine Domainvalidierung über DNS-Einträge durchführen, welche vom Serverbetreiber zu erstellen sind.
- Ausstellung des Zertifikats: Nach erfolgreicher Prüfung stellt die CA das digitale Zertifikat aus und signiert es mit dem privaten Schlüssel der CA.
Beispiel: HTTP-Anfrage an www.swissmakers.ch
Hier noch ein detailliertes Beispiel des Ablaufs, wenn ein PC über einen Webbrowser eine HTTP-Anfrage an www.swissmakers.ch stellt:
- DNS-Auflösung: Der Browser löst die Domain www.swissmakers.ch über DNS (Domain Name System) in eine IP-Adresse auf.
- Verbindungsaufbau: Der Browser initiiert eine TCP-Verbindung zur IP-Adresse des Servers.
- TLS-Handshake: Der Browser startet den TLS-Handshake, um eine sichere Verbindung aufzubauen:
- Der Browser sendet eine
Client HelloNachricht. - Der Server antwortet mit einer
Server HelloNachricht und sendet sein digitales Zertifikat. - Der Browser überprüft das Zertifikat anhand der Liste der vertrauenswürdigen CAs.
- Der Browser und der Server tauschen kryptographische Schlüssel aus.
- Beide Parteien bestätigen den Abschluss des Handshakes.
- Der Browser sendet eine
- Sichere Datenübertragung: Nach dem TLS-Handshake wird die eigentliche HTTP-Anfrage über die verschlüsselte Verbindung (HTTPS) gesendet:
- Der Browser sendet eine verschlüsselte GET-Anfrage an den Server «https://www.swissmakers.ch».
- Der Server verarbeitet die Anfrage und sendet die verschlüsselte Antwort zurück.
- Anzeige der Webseite: Der Browser entschlüsselt die Antwort und zeigt dem Benutzer die Webseite www.swissmakers.ch an:

Fazit
HTTPS und TLS spielen eine entscheidende Rolle bei der Sicherung der Kommunikation im Internet. Durch den Einsatz von Verschlüsselung und Zertifikatsvalidierung wird sichergestellt, dass die Daten zwischen dem Client und dem Server sicher übertragen werden. Das Verständnis der Funktionsweise von HTTPS und TLS ist unerlässlich, um eine sichere externe aber auch unternehmensinterne Kommunikation zwischen Applikationsservern und Clients gewährleisten zu können.
Für vertiefte weitere Informationen zu Algorithmen oder Protokollen empfehlen wir den Youtube-Kanal des renommierten Professors für Kryptographie Prof. Dr.-Ing. Christof Paar.
Wir hoffen, Ihnen mit diesem Blogbeitrag einen Überblick über das HTTPS-Transportprotokoll und die Rolle von TLS bei der sicheren Datenübertragung gegeben zu haben. Bleiben Sie sicher und achten Sie auch in Ihren internen Netzwerken auf verschlüsselte Verbindungen!
]]>Linux und Windows parallel verwenden
Viele Anwender möchten zwar mit Linux arbeiten, sind aber aus unterschiedlichen Gründen auch darauf angewiesen, auf einem Windowsrechner arbeiten zu können. Es gibt verschiedene Varianten, auf demselben Rechner Windows und Rocky Linux – oder eine andere Linuxdistribution – parallel zu verwenden.
Dualboot
Rocky Linux kann ab einem bootfähigen Datenträger (DVD, USB-Stick, Disk) mit einer Rocky Linux ISO-Datei in einer eigenen Diskpartition auf einem Rechner installiert werden, auf dem bereits Windows installiert ist.
Beim Neustart des Rechners kann dann jeweils gewählt werden, ob Rocky Linux oder Windows gestartet werden soll.
Vorteile
Nachteile
Virtuelle Maschine
Eine virtuelle Maschine mit Rocky Linux (bzw. einer anderen Linuxvariante) oder mit einer anderen Windowsversion bietet eine interessante Möglichkeit, auf einem Windowsrechner ein zweites oder sogar mehrere zusätzliche Betriebssysteme in virtuellen Maschinen zu verwenden.
VirtualBox ist wohl die bekannteste Variante, mit OpenSource-Software eine virtuelle Maschine unter Windows laufen zu lassen.
Eine andere Variante ist, Hyper-V von Microsoft zu verwenden. Hyper-V ist eine Manager für virtuelle Maschinen unter Windows. Hyper-V muss möglicherweise via «Einstellungen → System → optionale Features → mehr Windows Funktionen» resp. Via <Windows>+R ‹appwiz.cpl› Return und Auswahl ‹Windows Features aktivieren und deaktivieren› erst aktiviert werden. Danach muss der Rechner neu gestartet werden, damit Hyper-V verwendet werden kann.


Hyper-V ist eigentlich nur für Windows 10/11 pro verfügbar, kann offenbar aber auch für die Home-Versionen nachinstalliert werden. Hier die Anleitung dazu von Netzwelt.
Nach der Aktivierung von Hyper-V können mit dem Hyper-V-Manager virtuelle Maschinen mit Linux und anderen Systemen erstellt werden. Via ‹Schnellerstellung› (Quick Create) kann dann eine VM mit Ubuntu erstellt werden.

Für eine virtuelle Maschine mit Rocky Linux 9 kann die Minimal-ISO-Datei für Rocky Linux heruntergeladen und dann im Hyper-V-Manager für die Erstellung einer virtuellen Maschine importiert werden. Im Hyper-V-Manager muss dazu ‹Neu → Virtueller Computer› ausgewählt werden.
Auf YouTube findet man verschiedene Anleitungen zur Installation von Rocky Linux in Hyper-V unter Windows.
Vorteile
Nachteile
WSL (Windows-Subsystem für Linux)
Ich beziehe mich hier jeweils auf WSL 2 (aktuell WSL-Version 2.1.5.0). WSL 2 kann aus dem Microsoft Store installiert werden. Es setzt Windows 11 oder eine relativ neue Windows 10 Version voraus. Prüfe die Requirements für WSL 2 hier.
WSL 2
WSL 2 ist schneller als Version 1 und es bietet einige Möglichkeiten, die mit WSL 1 noch nicht verfügbar waren. Einen Vergleich inklusive der noch bestehenden Nachteile von WSL 2 im Vergleich zu WSL 1 findet man z.B. auf dieser Webseite von Microsoft.
WSL 2 verwendet einen normalen, vollständigen Linux Kernel in einer Hyper-V virtuellen Maschine und bietet damit volle Kompatibilität der Systemaufrufe zu einer normalen Linux-Installation. Eine Linux-Distribution läuft unter WSL 2 in einem isolierten Container in einer verwalteten virtuellen Maschine. WSL 2 unterstützt inzwischen auch systemd und ipv6.
WSL 2 verwendet einen für WSL optimierten Linux-Kernel, der hinsichtlich Grösse und Performance optimiert ist. Der Kernel wird mit den normalen Windows-Updates aktuell gehalten.
WSL 2 ist gut in Windows integriert. Copy/paste zwischen Windows und einer Linux-Distribution in WSL 2 ist unterstützt. Windows-Dateisysteme (Laufwerke) werden automatisch in Linux gemounted und können aus Linux verwendet werden. Das Laufwerk C: ist beispielsweise als /mnt/c verfügbar.
Linux-Anwendungen mit einer grafischen Oberfläche können in WSL 2 installiert werden. Danach können sie nicht nur in WSL, sondern auch via Windows-Start-Menü unter dem Namen der in WSL installierten Linux-Distribution gestartet werden.
Vorteile
Nachteile
Installation von Rocky Linux in WSL
Installation von Standard-Distributionen für WSL
Microsoft stellt ein paar Linux-Distributionen für WSL zur Verfügung, die einfach installiert werden können. Mit folgendem Befehl bekommt man die Liste der so verfügbaren Distributionen.
wsl --list --online
Nachstehend finden Sie eine Liste der gültigen Distributionen, die installiert werden können.
Führen Sie die Installation mithilfe des Befehls „wsl.exe --install <Distro>“ aus.
NAME FRIENDLY NAME
Ubuntu Ubuntu
Debian Debian GNU/Linux
kali-linux Kali Linux Rolling
Ubuntu-18.04 Ubuntu 18.04 LTS
Ubuntu-20.04 Ubuntu 20.04 LTS
Ubuntu-22.04 Ubuntu 22.04 LTS
Ubuntu-24.04 Ubuntu 24.04 LTS
OracleLinux_7_9 Oracle Linux 7.9
OracleLinux_8_7 Oracle Linux 8.7
OracleLinux_9_1 Oracle Linux 9.1
openSUSE-Leap-15.5 openSUSE Leap 15.5
SUSE-Linux-Enterprise-Server-15-SP4 SUSE Linux Enterprise Server 15 SP4
SUSE-Linux-Enterprise-15-SP5 SUSE Linux Enterprise 15 SP5Mit dem Befehl wsl --install wird Ubuntu in WLS installiert. Mit dem Parameter -d kann eine andere der oben aufgeführten Distributionen installiert werden, z.B. OpenSuse 15.5 mit dem Befehl wls --install -d openSUSE-Leap-15.5.
Installation von Rocky Linux
Es können problemlos auch andere als die von Microsoft zur Verfügung gestellten Distributionen, speziell auch Rocky Linux, in WSL installiert und verwendet werden.
Mit neuen WSL 2 Versionen ist es dabei nicht mehr nötig, bereits eine Linux-Distribution in WSL und Docker-Desktop installiert zu haben, wie es in den meisten Anleitungen noch aufgeführt ist.
Es sind nur folgende Schritte nötig:
- tar.xz- oder tar-File mit dem root-Filesystem der Linux-Distribution herunterladen
- Verzeichnis zur Speicherung der Linux-Dateien anlegen
- Tar-File in WSL importieren
- WSL mit der Distribution starten
- Linux-Update durchführen
- WSL neu starten
Danach kann weitere Software, die man verwenden will, installiert werden und Linux kann wie benötigt konfiguriert werden, z.B. können nun User eingerichtet werden.
Für RockyLinux sind zur Installation in WSL folgende Schritte und Befehle auszuführen:
- tar.xz-File hier herunterladen
- Verzeichnis anlegen, z.B.:
mkdir C:\data\tools\wsl\wslDistroStorage\rockylinux wsl --import rockylinux C:\data\tools\wsl\wslDistroStorage\rockyLinux Pfad_zur_heruntergeladenen_Datei\Rocky-9-Container-Base.latest.x86_64.tar.xz
Die Distribution kann dann mit folgendem Befehl (zusammen mit allenfalls bereits installierten Distributionen) angezeigt werden:wsl -l -v
NAME STATE VERSION
rockylinux Stopped 2wsl -d rockylinuxdnf update- In WSL:
exitoderlogout
In einem Windows Kommandofenster:wsl –shutdown
wsl -d rockylinux
Rocky Linux kann als Default-Distribution gesetzt werden mit dem Befehl, der in der PowerShell oder einem Kommandofenster eingegeben werden kann:
wsl --setdefault rockylinux
Verwendung von systemd
In neueren Versionen von WSL 2 kann in den installierten Linux-Distributionen systemd verwendet werden.
ACHTUNG, erst muss systemd installiert werden, falls er noch nicht installiert ist! Für Rocky Linux sieht man mit folgendem Befehl, ob der systemd bereits installiert ist.
sudo dnf info systemd
Wenn systemd noch nicht installiert ist, so muss er erst installiert werden mit dem Befehl
sudo dnf install systemd
Damit systemd nach dem nächsten Neustart des WSL verwendet wird, muss ein Eintrag in der Datei /etc/wsl.conf im Filesystem von Rocky Linux gemacht werden. Das kann als root-User mit folgendem Befehl erledigt werden:
tee -a /etc/wsl.conf > /dev/null <<EOT
[boot]
systemd=true
EOTDanach muss WSL neu gestartet werden. In WSL kann mit folgendem Befehl geprüft werden, ob systemd läuft:
sudo systemctl list-unit-files --type=service
Wenn die Konfiguration für systemd in /etc/wsl.conf gemacht wurde, systemd aber noch nicht installiert ist, so bekommt man folgende Fehlermeldung, wenn man versucht WSL neu zu starten:
wsl -d rockylinux
Schwerwiegender Fehler (resp. Catastrophic failure)
Error code: Wsl/Service/CreateInstance/E_UNEXPECTEDDieses Problem lässt sich dann fast nicht lösen. Es gibt die Möglichkeit, von einer anderen in WSL installierten Distribution aus das Filesystem der betroffenen Linux-Distribution zu mounten und den Eintrag für systemd in der Konfigurationsdatei wieder zu entfernen. Dies ist aber etwas umständlich zu machen und oft ist die einfachere Variante, die Distribution zu löschen und neu zu installieren.
Windows Terminal und WSL Terminal
Für die Arbeit auf der Kommandozeile in WSL verwendet man am besten WSL Terminal. Man findet WLS Terminal (wsltty) auf GitHub.

Wenn man WSL Terminal startet, so wird auch gleich WSL gestartet.
Alternativ kann man auch Windows Terminal verwenden, das vom Microsoft Store heruntergeladen werden kann.
Windows Terminal ist praktischer als cmd.exe. Man kann darin zum Beispiel mehrere Shells in verschiedenen Tabs öffnen.
Fazit

WSL in Version 2 ist leistungsfähig, schnell und gut in Windows integriert. Es unterstützt systemd und GUI-Anwendungen und stellt ein praktisch vollwertiges Linux zur Verfügung, das fast so schnell ist, wie ein direkt installiertes Linux.
Wenn man Windows und Linux zusammen braucht und wenn der direkte Zugriff auf die Hardware von Linux aus nicht wichtig ist, ist WSL eine gute Wahl. Mit WSL kann auch einfach auf Windows-Dateisysteme zugegriffen werden. Eine Linux-Distribution kann schnell und einfach in WSL installiert werden und es ist möglich, verschiedene Distributionen gleichzeitig zu installieren und zu verwenden. Das ist speziell für Tests mit unterschiedlichen Linux-Varianten sehr praktisch.
Das Engineering-Team von Swissmakers unterstützt Sie jederzeit gerne bei Fragen zu Rocky Linux. Erfahren Sie hier mehr zu Rocky Linux und unserem Service.