The post OpenID4VC einfach erklärt appeared first on j&s-soft.
]]>Was ist OpenID4VC?
OpenID4VC ist eine Erweiterung des bekannten OpenID-Standards, die speziell für den sicheren Austausch von digitalen Nachweisen (Verifiable Credentials) entwickelt wurde. Der Standard sorgt dafür, dass digitale Credentials besonders im Kontext der EUDI Wallet vertrauenswürdig und europaweit nutzbar sind.
OpenID4VC beschreibt dabei das Zusammenspiel von drei zentralen Rollen im Credential-Ökosystem:
- Issuer: stellt digitale Nachweise aus (z. B. Arbeitgeber, Bürgeramt, Krankenversicherung)
- Holder: besitzt und verwaltet diese Nachweise in einer Wallet (z. B. Mitarbeitende, Bürger:in, Versicherungsnehmer:in)
- Verifier: prüft die Echtheit und Gültigkeit der Nachweise (z. B. HR-Abteilung, Polizei, Krankenhaus)
Warum OpenID4VC für Unternehmen und Behörden entscheidend ist
Unternehmen und öffentliche Verwaltungen stehen heute vor der Herausforderung, Nachweise effizient und sicher zu verifizieren. Bewerbungsunterlagen, Mitgliedschaften oder Berechtigungen müssen häufig noch manuell geprüft werden. Das ist zeitaufwendig, fehleranfällig und anfällig für Manipulation. Mit OpenID4VC entstehen neue digitale und sichere Prozesse, die in Sekunden statt Tagen Ergebnisse liefern und EU-weit standardkonform einsetzbar sind. Besonders wichtig ist dabei auch der Datenschutz. Denn Holder können nur die Informationen teilen, die tatsächlich notwendig sind, und behalten die Kontrolle über ihre Daten.
OpenID4VC versetzt Organisationen in die Lage, digitale Nachweise selbst auszustellen. Unternehmen können beispielsweise Arbeitszeugnisse, Zertifikate oder Mitgliedschaftsnachweise als digitale Credentials bereitstellen. Grundlage dafür ist eine vollständige Infrastruktur mit einer OpenID4VC-Implementierung, einem flexiblen Backend mit Vorlagen und kryptografischer Signatur, einem Widerrufsmechanismus für ungültige Nachweise sowie einer nahtlosen Integration in bestehende Systemlandschaften.
Durch den Standard zum Präsentieren der digitalen Nachweise, dem sog. OpenID4VP, wird auch die Prüfung dieser Nachweise standardisiert und automatisiert. Ob beim digitalen Onboarding, bei Qualifikationsprüfungen oder bei Berechtigungsnachweisen, die Verifikation kann flexibel per QR-Code oder Link erfolgen. Dabei werden Echtheit und Widerrufsstatus automatisch geprüft, während Nutzerinnen und Nutzer durch selektive Datenfreigabe nur die wirklich erforderlichen Informationen offenlegen können.
Branchen-Use-Cases: Wo OpenID4VC echten Mehrwert schafft
OpenID4VC ist nicht nur eine Sammlung technischer Standards, sondern entwickelt sich zunehmend zu einem zentralen Schlüssel für neue digitale Prozesse in Wirtschaft, Bildung und öffentlicher Verwaltung. Besonders im Kontext der EUDI Wallet entstehen konkrete Anwendungen, die den Alltag von Organisationen und Bürgerinnen und Bürgern deutlich vereinfachen:
- HR & HCM: Digitale Arbeitszeugnisse, Qualifikationsnachweise und Onboarding-Credentials direkt aus SAP SuccessFactors, oder SAP HCM oder jedem anderen ERP bzw. HR-System.
- Öffentliche Verwaltung: Bürgerdienste, digitale Genehmigungen und Nachweise wie Sozialpässe oder Berechtigungen für kommunale Leistungen
- Bildung: Digitale Zeugnisse, Zertifikate und Teilnahmebestätigungen für Schulen, Hochschulen und Weiterbildungsträger
- Healthcare: Patientenidentifikation, Versicherungsnachweise und sichere digitale Kommunikation zwischen Praxis und Patient
- Versicherungen: VVG-konforme digitale Kommunikation, Policen-Verwaltung, Schadensabwicklung und verifizierbare Versicherungsnachweise
Fazit: OpenID4VC als Basis für digitale Nachweise und Wallets in Europa.
OpenID4VC ist einer der zentralen Standards für die Zukunft digitaler Identitäten in Europa. Unternehmen und Behörden, die sich heute damit beschäftigen, schaffen die Grundlage für sichere, effiziente und nutzerfreundliche Prozesse. Mit unserem Wallet-Portfolio und tiefem Entwickler-Know-how unterstützt js-soft Organisationen dabei, OpenID4VC praxisnah umzusetzen, sei es für Issuer, Verifier oder strategische Partner auf dem Weg zur EUDI-Wallet-Readiness.
Mehr Informationen auf www.js-soft.com/wallets und unserem Flyer.
FAQs
Wofür wird OpenID4VC genutzt?
OpenID4VC wird genutzt, um digitale Credentials wie Arbeitszeugnisse, Sozialpässe, Zertifikate oder Versicherungsnachweise über Wallets bereitzustellen und automatisiert zu verifizieren.
Was sind Verifiable Credentials?
Verifiable Credentials sind digitale Nachweise, die kryptografisch signiert und dadurch fälschungssicher sowie weltweit überprüfbar sind.
Welche Rolle spielt die EU Digital Identity Wallet bei OpenID4VC?
Die EU Digital Identity Wallet nutzt Standards wie OpenID4VC, um Bürgerinnen und Bürgern digitale Identitäten und Nachweise interoperabel in ganz Europa verfügbar zu machen.
Was ist der Unterschied zwischen OpenID4VC-I und OpenID4VP?
OpenID4VC-I beschreibt den Standard zur Ausstellung digitaler Nachweise, während OpenID4VP den der Präsentation und Prüfung dieser Nachweise beschreibt.
The post OpenID4VC einfach erklärt appeared first on j&s-soft.
]]>The post Schemen & Regeln – die Grundlagen appeared first on j&s-soft.
]]>Was ist ein Schema?
Ein Schema ist die Ablaufsteuerung der wichtigsten ABAP-Programme sowohl in der Zeitauswertung als auch in der Abrechnung. Du kannst es dir vorstellen wie ein Kochrezept oder eben einen Ablaufplan. Es sagt SAP, in welcher Reihenfolge welche Berechnungsschritte ausgeführt werden sollen. Ohne Schema geschieht nichts.
In SAP HCM gibt es unterschiedliche Schemen:
- SAP Standard Zeitwirtschaftsschemen (z. B. TM00)
- SAP Standard Abrechnungsschemen
- oder kundeneigene Z-Schemen für die Zeitwirtschaft oder die Abrechnung
Das Schema ist dabei (im Gegensatz zu einer Regel) kein einzelner Rechenschritt, sondern die Orchestrierung aller Schritte.
Konkretes Beispiel: das Schema TM00
Schemen kann man sich in einem SAP-System über die Transaktion PE01 ansehen.
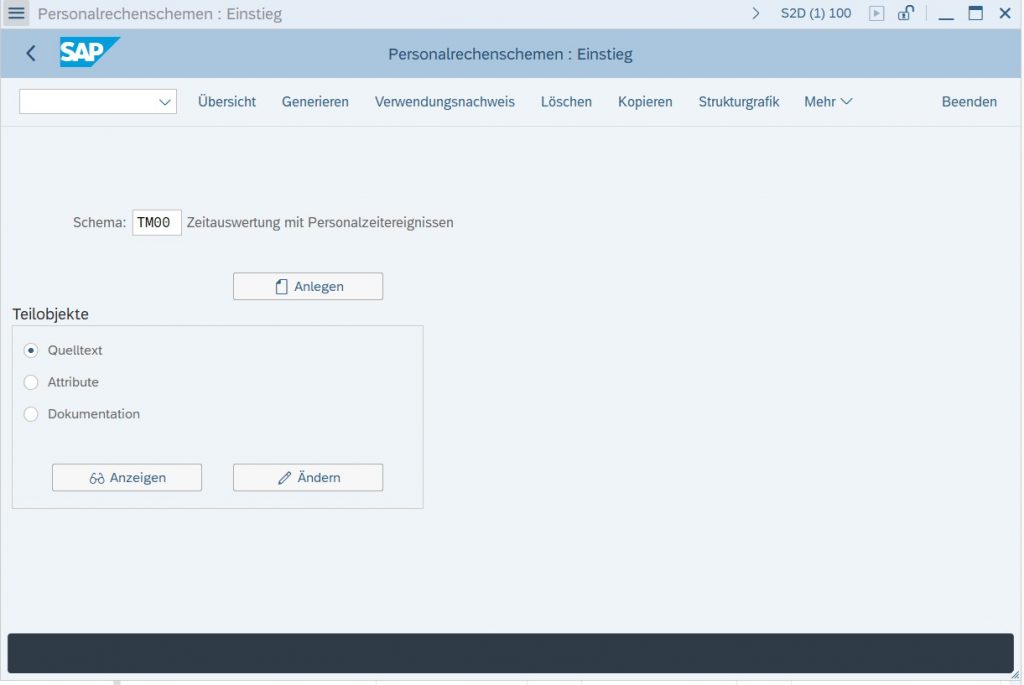
Nehmen wir als Beispiel das Schema TM00. Das ist ein Schema aus der Zeitwirtschaft, das den Ablauf der Zeitbewertung steuert. Bei der Darstellung eines Schemas gibt es mehrere Möglichkeiten. Man kann zwischen Tabellen- und Strukturdarstellung wechseln.
Tabellendarstellung

Darstellung Strukturgrafik

Es könnte sein, dass du – je nach SAP-Layout – die Buttons „Tabellendarstellung“ oder „Strukturgrafik“ auch so siehst:
Alternative Darstellung: Strukturgrafik

Alternative Darstellung: Tabellendarstellung

Sehen wir uns das Schema TM00 genauer an. Das Schema TM00 ist eines der Standardschemen der Zeitwirtschaft und steuert die Zeitauswertung über den Report RPTIME00. Das heißt: Mithilfe eines Schemas kann man im SAP-System zentrale ABAP-Programme (wie z. B. die Zeitauswertung oder die Gehaltsabrechnung) steuern. Und genau deshalb sind Schemen und Regeln so mächtig – und jeder SAP-Berater, der vertiefende Kenntnisse hierzu hat, ist klar im Vorteil.
Das Schema TM00 dient zur Berechnung von Zeitsalden, Zeitlohnarten und Zeitkontingenten. Dabei verarbeitet es sowohl automatisch erfasste Zeitereignisse (z. B. Kommen-/Gehen-Buchungen) als auch manuell erfasste An- und Abwesenheiten. Die geleistete Arbeitszeit eines Mitarbeiters gilt als sogenannte Istzeit und wird vollständig mit Uhrzeit bzw. als ganztägige Arbeitszeit erfasst. Das Schema vergleicht die Istzeiten mit den Sollvorgaben aus dem Arbeitszeitplan (Arbeitsbeginn, -ende, Kernzeiten und Pausen) des Mitarbeiters. Zeiten außerhalb der Sollarbeitszeit gelten nicht automatisch als Arbeitszeit und müssen insbesondere bei Mehrarbeit gesondert genehmigt werden.
Doch genug der fachlichen Einordnung – zurück zur Darstellung eines Schemas im SAP-System.
Der wichtigste und daher voreingestellte Radiobutton ist immer der Quelltext, da du hier – je nach Darstellung als Tabelle oder Struktur – sehen kannst, was das Schema genau macht. Natürlich verstehst du noch nicht, was hier genau passiert, doch das decken wir in kommenden Blogartikeln noch ab. Neben dem
- • Radiobutton Quelltext
gibt es noch
- Attribute (Eigenschaften des Schemas)
- und Dokumentation
Wie arbeitet man mit den Regeln?
Im Kontext von Schemen kommt man an Regeln nicht vorbei. Eine Regel, auch PCR genannt (Personnel Calculation Rule = Personalrechenregel), lässt sich gut mit einem Vergleich erklären: Wenn das Schema das Kochrezept ist, dann ist die Regel die einzelne Kochanweisung. Ein Schema kann zum Beispiel sagen: „Jetzt Regel Z001 ausführen.“ Die Regel Z001 sagt dann: „Wenn Abwesenheit = Urlaub → Zeitart XY“. Die Regel ist also die Logik im Detail.
Regeln kann man über die Transaktion PE02 aufrufen oder im Schema durch Doppelklick auf eine Regel öffnen.
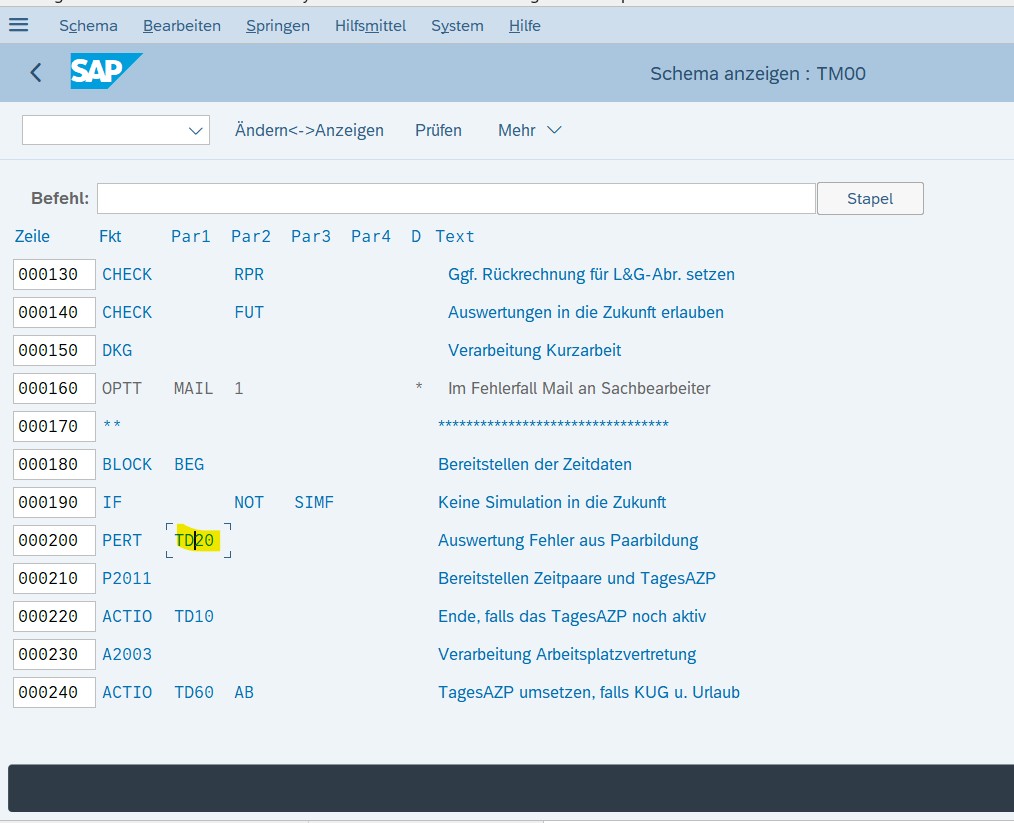
Keine Sorge: Du musst nicht alle Befehle sofort verstehen. Eine Regel erkennst du daran, dass sie vier Buchstaben hat und meist in der zweiten Spalte steht. Das reicht für den Einstieg. Regeln sehen anders aus als Schemen.
Wie bei Schemen gibt es zwei unterschiedliche Darstellungsweisen:
Tabellendarstellung
Strukturgrafik
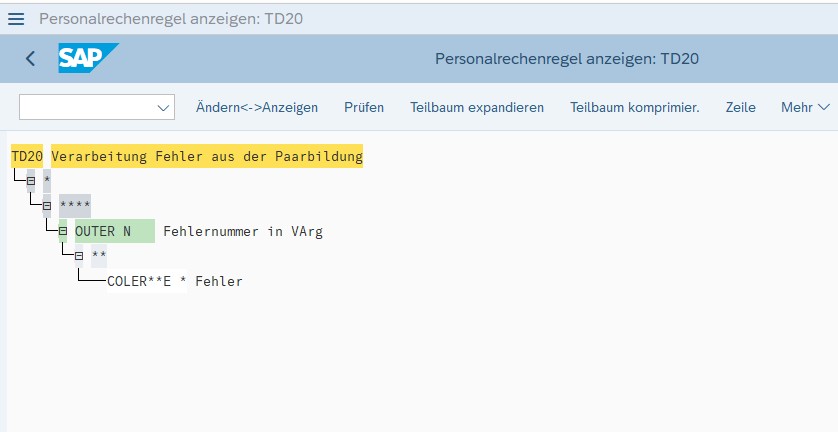
TIPP: Neben Regeln gibt es in Schemen auch Unterschemen. Probiere gern im Schema TM00 aus, welche Regeln oder Unterschemen du findest. Klicke dafür mal doppelt auf verschiedene Felder.
Wo liegt der Unterschied zwischen Schemen und Regeln?
Einfach erklärt ist der Unterschied zwischen Schema und Regel folgender: Ein Schema ist der Ablaufplan oder das Kochrezept und steuert die Reihenfolge. Eine Regel ist die einzelne Logik oder Kochanweisung und steuert das Verhalten. Das Schema beantwortet die Frage „Was passiert wann?“, die Regel beantwortet „Was passiert konkret?“.
SAP hat dieses Konzept entwickelt, um eine Berechnungslogik zu schaffen, die flexibel ist, ohne ABAP geändert werden kann, kundenspezifisch erweiterbar ist und international funktioniert. Deshalb entstand eine eigene „Mini-Sprache“: Schemen + Regeln = SAP-Regelwerk. Man programmiert nicht mit ABAP, sondern mit SAP-Logikbausteinen.
Schemen und Regeln findet man im System über die Transaktionen PE01 (Schemen anzeigen/bearbeiten) und PE02 (Regeln anzeigen/bearbeiten). Hier sieht man zum ersten Mal: SAP rechnet wie ein Programm. Zeile für Zeile. Schritt für Schritt.
Ohne Schema-Verständnis debuggt man blind, probiert herum, kopiert Customizing und hofft auf Glück. Mit Schema-Verständnis versteht man Berechnungsergebnisse, kann Fehler erklären, gezielt anpassen und verliert die Angst vor SAP-Logik. Schemen sind keine Magie. Sie sind nur strukturiert.
The post Schemen & Regeln – die Grundlagen appeared first on j&s-soft.
]]>The post SAP Integration Suite als Nachfolger von SAP PI/PO appeared first on j&s-soft.
]]>Das Ende von SAP PI/PO rückt näher: Nach dem 31. Dezember 2027 endet der reguläre Standardsupport für SAP Process Integration / Process Orchestration (PI/PO). Für viele Unternehmen ist das kein reines Infrastrukturthema – sondern eine strategische Entscheidung mit direktem Einfluss auf Stabilität, Security, Betriebskosten und die Zukunftsfähigkeit der Integrationslandschaft.
Gleichzeitig fehlt in vielen Organisationen das, was für eine Migration entscheidend ist: Zeit, Ressourcen, PI/PO- und Integration Suite-Expertise – und ein klarer Blick auf die Zielplattform.
Die gute Nachricht: Mit der SAP Integration Suite steht eine leistungsfähige, moderne iPaaS-Lösung (Integration Platform as a Service) bereit, die sich als Standard im SAP-Umfeld etabliert hat. Die Herausforderung liegt nicht in der Toolauswahl – sondern in einer strukturierten, realistischen Migration.
Das Wichtigste auf einen Blick
- Ende des PI/PO-Standardsupports: 31.12.2027
- Offizieller SAP-Nachfolger: SAP Integration Suite (SAP BTP)
- Zentrale Herausforderung: Migration ist nicht 1:1, sondern eine Modernisierung
- Empfehlung: Frühzeitig starten – besonders bei >50mehreren Schnittstellen oder hoher Kritikalität
- js-soft unterstützt: Analyse, Zielarchitektur, Migration, Qualitätssicherung, Enablement und Betriebskonzepte
Viele Integrationslandschaften sind historisch gewachsen: über Jahre entstanden Schnittstellen, Sonderlösungen, Workarounds, individuelle Mappings und schwer dokumentierte Prozessketten.
PI/PO hat diese Anforderungen lange zuverlässig abgedeckt – allerdings in einer Architektur, die heute nicht mehr dem entspricht, was moderne hybride Systemlandschaften benötigen.
Mit dem Wartungsende wird die Ablösung zum Pflichtprogramm.
Was ist die SAP Integration Suite?
Die SAP Integration Suite ist SAPs cloudbasierte Integrationsplattform auf der SAP Business Technology Platform (BTP). Sie unterstützt Integrationen zwischen SAP-Systemen und Non-SAP-Systemen als On Premise- oder Cloud-Anwendungen.
Die wichtigsten Unterschiede zwischen PI/PO und der SAP Integration Suite
Der wichtigste Unterschied ist nicht „on-premise vs. cloud“, sondern das Betriebs- und Architekturmodell.
SAP PI/PO
- klassisch On-Premise, stark systemzentriert
- Integrationen oft eng gekoppelt
- Betrieb stark abhängig von individuellen Konfigurationen
- Fokus auf klassische A2A-/B2B-Patterns
SAP Integration Suite
- Cloud-first, für hybride Landschaften entwickelt
- stärker API- und Event-orientiert
- klarer Fokus auf Standardisierung und Skalierbarkeit
- zentraler Baustein in SAPs BTP-Strategie
Das bedeutet: Die Migration ist keine reine technische Portierung, sondern eine Gelegenheit, Schnittstellen zu bereinigen, Prozesse zu vereinheitlichen und Architekturprinzipien zu modernisieren.
In der Praxis sind das schrittweise Programme, bei denen Schnittstellen priorisiert migriert werden. Ein typisches Beispiel ist ein Migrationsprojekt, in dem über 100 bestehende Schnittstellen schrittweise von PI/PO in die SAP Integration Suite überführt werden. Damit wird eine unterbrechungsfreie Kommunikation während der Übergangsphase gewährleistet.
Unser Angebot rund um SAP Integration Suite
js-soft unterstützt Unternehmen dabei, die SAP Integration Suite nicht nur einzuführen, sondern strategisch und sauber in die Integrationsarchitektur einzubetten. Kontaktieren Sie uns, wenn Sie Unterstützung brauchen.
Gerne direkt bei Estelle Hounsa unter der E-Mail: [email protected]
FAQs
Wann endet der Standardsupport für SAP PI/PO?
Am 31.12.2027.
Ist die SAP Integration Suite der offizielle Nachfolger?
Ja – sie ist SAPs strategische Plattform für Integrationsszenarien auf der BTP.
Kann man PI/PO-Schnittstellen 1:1 übernehmen?
Theoretisch ja, allerdings meist nicht sinnvoll. Die Gelegenheit zu einer Modernisierung und neue Architekturprinzipien sollte nicht verpasst werden.
Wie lange dauert ein Migrationsprojekt?
Das hängt stark von Anzahl und Komplexität der Schnittstellen ab. Typisch sind mehrere Monate bis über ein Jahr bei größeren Landschaften.
The post SAP Integration Suite als Nachfolger von SAP PI/PO appeared first on j&s-soft.
]]>The post LLMs, neuronale Netze, Chatbots und RAG – Eine nicht-technische Einführung appeared first on j&s-soft.
]]>Was funktioniert, was nicht?
Ziel ist daher eine nüchterne, aber verständliche Orientierung: Wir klären, was ein Large Language Model im Kern ist, warum moderne Chatbots so überzeugend wirken und weshalb ihr Wissen nicht beliebig aktuell, vollständig oder überprüfbar sein kann. Gerade diese Grenzen sind keine Randnotiz, sondern bestimmen, wann ein Chatbot ein hilfreiches Werkzeug ist und wann er eher zu Missverständnissen, Scheinpräzision oder unnötigen Risiken führt.
Im ersten Teil ordnen wir die Grundlagen ein:
- Was bedeutet Language Model, warum spielen neuronale Netze dabei eine zentrale Rolle, und weshalb ist das Large in LLM mehr als nur eine Größenangabe.
- Anschließend betrachten wir, wie LLMs trainiert werden und was es bedeutet, dass ihr Wissensstand nach dem Training im Wesentlichen feststeht.
- Darauf aufbauend beschreiben wir die typischen Probleme klassischer Chatbots: fehlendes Domänenwissen, mangelnde Aktualität, begrenzte Prüfbarkeit und die Möglichkeit überzeugender Fehlbehauptungen.
Im zweiten Teil führen wir Retrieval-Augmented Generation ein:
RAG ist keine neue Gattung neben dem Chatbot, sondern eine naheliegende Weiterentwicklung: Der Chatbot erhält die Fähigkeit, zur Laufzeit in einer Wissensbasis nachzuschlagen und Antworten an konkrete Fundstellen zu binden. Erst so werden Chatbots in vielen professionellen Anwendungsfällen zu verlässlichen KI-Werkzeugen.
Large Language Models und neuronale Netze
Das Herzstück moderner Chatbots wie OpenAI’s ChatGPT, Google Gemini oder Anthropic’s Claude ist ein Large Language Model (LLM), welches dediziert programmiert wurde, Ausgaben im Stile einer menschlichen Konversation zu erzeugen und Anfragen des Nutzer in menschlicher Sprache sinnvoll zu beantworten.
Language Model (dt. etwa Sprachmodell) ist ein längst etablierter Begriff aus der Domäne der Computerlinguistik, der Schnittmenge zwischen Sprachwissenschaft und Informatik. Er bezeichnet sinngemäß ein Computerprogramm, dass Text in menschlicher Sprache ausgeben kann und kann ohne Einschränkung der Gültigkeit des Begriffs als einfacher Textvervollständiger begriffen werden: Eine Eingabe des Nutzers wird vom Language Model Wort für Wort ergänzt, bis die Erzeugung durch eine Abbruchbedingung terminiert wird. Obgleich diese Formulierung auf den ersten Blick abstrakt erscheinen mag, deckt sie doch alle Anwendungen ab, deren Ein- und Ausgaben in menschlicher Sprache formuliert sind: Beispielsweise “vervollständigt” ein Übersetzungsprogramm einen deutschen Satz durch Ausgabe der Übersetzung in der Zielsprache und auch die Ausgabe eines Vierzeilers durch ChatGPT kann als Vervollständigung der Nutzeranfrage begriffen werden, ein Gedicht über Kaiserpinguine zu schreiben.
Wir betonen hier, dass diese Definition gänzlich ungeachtet der spezifischen Konzepte und Einzelheiten formuliert ist, die der Realisierung eines konkreten Language Models z.B. zur Übersetzung zugrunde liegen. Die Details der Antwort auf die Frage, wie genau man nun praktisch ein Language Model entwickeln würde, sind seit vielen Jahrzehnten Gegenstand aktiver Forschung. Einfache, rein frequentistische Ansätze, die lediglich die letzten Worte der Eingabe betrachten und diese gemäß der Wortverteilungen in einem Referenzkorpus vervollständigen, sind im Laufe der Zeit durch Architekturen auf Grundlage neuronaler Netze abgelöst worden, die sich empirisch als besonders geeignet herausgestellt haben, Ströme sequenzieller Daten wie z.B. der menschlichen Sprache abzubilden.
Neuronale Netze sind Computerprogramme, die lose an der Art der Signalverarbeitung des menschlichen Gehirns inspiriert sind und durch den Zusammenschluss vieler einfacher Bausteine zu komplexen und tiefen Netzwerken mathematisch nachweislich die Fähigkeit erlangen, beliebige Berechnungen durchführen zu können. Neuronale Netze finden daher neben der Sprachmodellierung auch in anderen Domänen wie bspw. der Bildverarbeitung zahlreiche Anwendung. Die Relevanz neuronaler Netze für die Zwecke dieses Artikels liegt allerdings nicht in dieser Eigenschaft der Universalität, sondern darin, dass in ihrem Kontext das “large” in “Large Language Model” zu interpretieren ist: es ist ein empirischer Befund, dass sich das Sprachverständnis eines neuronalen Language Models qualitativ verändert und verbessert, wenn die Anzahl der freien Parameter (der “Neuronen”) drastisch erhöht wird. Während kleine neuronale Language Models Probleme haben, einfache Anweisungen zu begreifen, können Modelle mit sehr vielen Parametern (large Language Models) problemlos Gedichte schreiben, Texte zusammenfassen, übersetzen und anhand von Beispielen neuen, ungesehen Aufgaben nachgehen. Diese beobachtete “Intelligenz” erscheint hier als emergentes Phänomen, das sich nur in der Makroebene eines komplexen Systems ausdrückt, wenn das Zusammenspiel hinreichend vieler kleiner und simpler Teile in ihrer Gesamtheit ein qualitativ mächtigeres Verhalten erzeugen kann.
Zusammenfassend meint Large Language Model in der Alltagspraxis daher ein Language Model, das auf einer spezifischen Architektur neuronaler Netze basiert und hinreichend groß und mächtig ist, um intelligentes Verhalten produzieren zu können. Was als hinreichend intelligent bezeichnet wird hängt von der konkreten Anwendung ab. Die Erkennung von Spam ist eine qualitativ einfachere Aufgabe als die Übersetzung zwischen kulturfremden Sprachen und kann mit einem kleineren, weniger rechenintensiven oder kostspieligen LLM bewältigt werden. In diesem Sinne ist ein moderner Chatbot wie ChatGPT also eine bestimmte Art von LLM.
Training von LLMs
Im Gegensatz zu gewöhnlichen Computerprogrammen, die als explizite Folge menschlich formulierter Regeln (Algorithmen) vorliegen, bildet sich das gewünschte Verhalten eines LLMs erst im Zuge eines Trainingsprozesses aus. In diesem Prozess wird das Modell mit sehr großen Mengen menschlicher Sprache konfrontiert und lernt, welche Fortsetzungen einer gegebenen Eingabe in einem bestimmten Kontext als plausibel gelten. Es beantwortet Anfragen folglich nicht deshalb, weil irgendwo eine passende Fallunterscheidung (etwa ein if/else-Zweig) hinterlegt wäre, sondern weil es aus einer Vielzahl statistischer Muster ein generalisiertes Sprachverhalten herausgebildet hat.
Konzeptionell kann man sich dieses Training als eine extrem großskalige Übung im Textvervollständigen vorstellen: Dem Modell werden Textpassagen präsentiert, in denen ein Teil ausgespart ist, und es soll den fehlenden Anteil vorhersagen. Weicht seine Vorhersage von der Referenz ab, wird es intern geringfügig korrigiert wobei dieser Zyklus Milliarden Male wiederholt wird. Entscheidend ist hierbei nicht der einzelne Trainingssatz, sondern die schiere Menge und Heterogenität des Materials: Erst aus der Breite der Beispiele entsteht allmählich ein robustes, in vielen Situationen anwendbares Musterwissen, das sich in Grammatik, Stil, häufigen Sachverhalten, typischen Argumentationsformen und nicht zuletzt in einer gewissen Konversationskompetenz niederschlägt.
Damit dieser Prozess überhaupt zu den heute beobachtbaren Fähigkeiten führt, sind Datenmengen und Rechenaufwand erforderlich, die sich jenseits einer alltagstauglichen Intuition bewegen. Ein LLM besteht aus sehr vielen freien Parametern, die man sich als verstellbare Regler vorstellen kann, deren Einstellungen das Sprachverhalten determinieren. Training bedeutet dann, diese Regler so einzustellen, dass das Modell im Mittel “gute” Fortsetzungen produziert. Empirisch gilt dabei: Mehr Parameter und mehr (geeignete) Daten führen häufig zu deutlich besseren Ergebnissen – allerdings für den Preis stark wachsender Kosten und Komplexität.
Für das weitere Verständnis ist ein Punkt zentral: Nach Abschluss des Trainings ist ein LLM im Normalbetrieb zunächst statisch. Es verfügt nicht über eine eingebaute, fortlaufend aktualisierte Wissensdatenbank, sondern trägt sein Wissen implizit in seinen internen Parametern. Fragt man das Modell nach sehr aktuellen Ereignissen oder nach unternehmensinternen, domänenspezifischen Details, kann es diese Informationen nicht einfach nachträglich aufnehmen und dauerhaft verfügbar machen. Es kann zwar innerhalb einer konkreten Unterhaltung zusätzliche Informationen berücksichtigen, sofern man sie im Gesprächskontext zur Verfügung gestellt hat. Jedoch ist dies keine Form des Lernens, sondern lediglich eine temporäre Konditionierung der Ausgabe, die mit dem Löschen des Gesprächskontexts wieder verschwindet.
Aus dieser Eigenschaft folgen zwei Konsequenzen, die später den Übergang zu RAG motivieren: Erstens ist das Wissen eines Chatbots stets durch Umfang, Qualität und Aktualität seiner Trainingsdaten begrenzt (insbesondere bei Nischenthemen, proprietärem Unternehmenswissen oder neuen Entwicklungen). Zweitens sind Antworten ohne explizite Anbindung an externe Quellen nur schwer nachprüfbar: Das Modell produziert eine sprachlich plausible Antwort aus verinnerlichten Mustern, nicht aber eine belegte Aussage, die sich sauber auf ein konkretes Dokument zurückführen ließe.
Probleme eines Chatbots
Aus der beschriebenen Statik folgt, dass ein Chatbot im Alltag weniger einem allwissenden Assistenten gleicht als vielmehr einem sehr redegewandten Gesprächspartner mit eingefrorenem Wissensstand. Er kann Formulierungen glätten, Argumente strukturieren und Zusammenhänge plausibel darstellen – doch sobald es um konkrete, belastbare Informationen geht, treten einige systematische Grenzen zutage.
- Domänenspezifische Inhalte sind nur in dem Maße verfügbar, in dem sie im Training in ausreichender Breite und Qualität repräsentiert waren. Unternehmensinterne Prozesse, aktuelle Richtlinien, Produktstände, projektspezifische Details oder auch schlicht die jeweilige Fachsprache eines Teams liegen typischerweise nicht in öffentlichen Trainingsdaten vor. Was dem Modell an dieser Stelle fehlt, lässt sich im laufenden Betrieb nicht einfach ergänzen: Man kann es im Gespräch informieren, aber diese Information wird nicht dauerhaft Teil seines Wissens.
- Ähnliches gilt für Aktualität. Selbst wenn ein Modell im Training Vieles gelernt hat, bleibt dieses Wissen eine Momentaufnahme. Neue Gesetzeslagen, geänderte Normen, Produktreleases, Sicherheitsmeldungen oder nur der Stand eines laufenden Vorhabens können außerhalb dieser Momentaufnahme liegen. Das Modell kann dann zwar eine Antwort formulieren, besitzt jedoch kein zuverlässiges Mittel, den eigenen Wissensstand gegen die Gegenwart zu prüfen.
- Die Nachvollziehbarkeit der Antworten ist grundsätzlich eingeschränkt. Ein LLM generiert Text aus verinnerlichten Mustern; es liest beim Antworten nicht automatisch ein bestimmtes Dokument, aus dem sich eine Aussage sauber ableiten ließe. Damit fehlen im Standardfall Belege, die man wie Quellenangaben, Fundstellen oder Verweise auditieren könnte. In Kontexten, in denen Verantwortung, Compliance oder fachliche Sorgfalt zählen, ist das ein praktisches Problem: Nicht die Eloquenz der Antwort ist entscheidend, sondern ihre Überprüfbarkeit.
- Es kommt ein Phänomen hinzu, das in der Praxis besonders irritiert: Modelle können selbstbewusst falsche Aussagen erzeugen. Das ist weniger ein Zufallsfehler als eine Konsequenz ihres Ziels, sprachlich plausible Fortsetzungen zu produzieren. Wo die Faktenlage dünn ist, wird Plausibilität zum leitenden Prinzip – und das Ergebnis kann wie eine gut formulierte, aber unzutreffende Synthese wirken. Verstärkt wird dies durch die Interaktionslogik vieler Chatbots, die darauf ausgelegt sind, hilfreich zu sein und eine Frage nicht mit einem bloßen Nichtwissen enden zu lassen.
Diese vier Punkte – fehlende Domänentiefe, fehlende Aktualität, geringe Prüfbarkeit und das Risiko überzeugender Fehlbehauptungen – markieren die zentralen Grenzen klassischer Chatbots. Genau hier setzt Retrieval-Augmented Generation an: nicht indem es das LLM ersetzt, sondern indem es ihm zur Laufzeit die relevanten, aktuellen und überprüfbaren Informationen aus einer Wissensbasis bereitstellt.
RAG – Chatbots mit Suchmaschine
Retrieval-Augmented Generation, kurz RAG, ist der Versuch, die Stärken eines LLMs mit einer sehr pragmatischen Ergänzung zu verbinden: einer gezielten Suche nach passenden Informationen zur Laufzeit. Der Begriff ist sperrig und wirkt eher wie Terminologie aus einem Forschungsprototyp als etwas, das sich im Alltag gut einprägt. Inhaltlich ist die Idee jedoch erstaunlich einfach. Ein RAG-System ist im Kern ein Chatbot, der nicht nur aus dem Gedächtnisstand seines Modells antwortet, sondern vor der Beantwortung in einer angeschlossenen Wissensbasis nachschlägt.
Die Wissensbasis kann je nach Einsatzfall vieles sein: eine Sammlung interner Dokumente, ein Wiki, Handbücher, Richtlinien, Projektunterlagen, Tickets, Produktdokumentation oder auch eine angebundene Internetsuchmaschine wie Google. Entscheidend ist nicht die Quelle als solche, sondern der Mechanismus: Zu einer konkreten Frage werden zunächst die relevanten Textstellen gesucht, anschließend werden diese Fundstellen dem LLM als Kontext mitgegeben, und erst dann wird die Antwort formuliert.
In einer vereinfachten Sicht lässt sich ein RAG-Ablauf in drei Schritte fassen:
- Frage verstehen: Das System nimmt die Nutzerfrage entgegen und bereitet sie für die Suche auf.
- Wissen abrufen: Es sucht in der Wissensbasis nach den inhaltlich passendsten Abschnitten und wählt einige davon aus.
- Antwort generieren: Das LLM formuliert die Antwort auf Basis dieser Abschnitte, idealerweise mit Verweisen auf die verwendeten Quellen.
Damit adressiert RAG die zuvor beschriebenen Grenzen klassischer Chatbots sehr direkt:
Domänentiefe: Wenn unternehmensspezifisches Wissen nicht im Training enthalten ist, kann es dennoch genutzt werden, sofern es in der Wissensbasis vorliegt. Das Modell muss die Inhalte nicht dauerhaft in seine Parameter aufnehmen, sondern erhält sie genau dann, wenn sie benötigt werden.
Aktualität: Da die Informationen zur Laufzeit abgerufen werden, kann die Wissensbasis laufend aktualisiert werden, ohne dass das LLM neu trainiert werden muss. Neue Richtlinien, geänderte Prozessbeschreibungen oder der aktuelle Stand einer Dokumentation werden damit unmittelbar nutzbar.
Prüfbarkeit: RAG ermöglicht, die Antwort mit Fundstellen zu unterfüttern. In vielen Implementierungen werden die herangezogenen Dokumente oder konkrete Abschnitte als Quellen angezeigt, sodass Fachanwender die Aussage überprüfen und bei Bedarf vertiefen können. Das verändert die Rolle des Chatbots: von einem reinen Antwortgenerator hin zu einer navigierbaren Schnittstelle in eine Wissenslandschaft.
Fehlbehauptungen: Wenn das Modell seine Antwort an konkrete Textstellen anlehnen muss, sinkt erfahrungsgemäß die Neigung, Lücken mit plausibel klingenden, aber falschen Details zu füllen. Wichtig ist hierbei die Formulierung: RAG reduziert dieses Risiko, es eliminiert es nicht. Die Qualität hängt an der Güte der Wissensbasis und daran, ob die Suche tatsächlich die relevanten Passagen findet. Ein RAG-System ist daher dann am stärksten, wenn es nicht nur Antworten produziert, sondern auch sichtbar macht, worauf es sich stützt.
In der Praxis ist RAG damit weniger ein weiterer KI-Modetrend als eine natürliche Ausbaustufe von Chatbots: Man akzeptiert, dass ein LLM nicht automatisch über aktuelles, internes oder überprüfbares Wissen verfügt, und ergänzt es um einen Abrufmechanismus, der genau diese Eigenschaften zur Laufzeit bereitstellt.
Daher sollte RAG nicht als eigenständige Kategorie neben dem Chatbot betrachtet werden, sondern als dessen naheliegende Reifung. Das Interaktionsprinzip bleibt unverändert: Nutzer formulieren Fragen in natürlicher Sprache und erhalten eine Antwort im selben Medium. Der Unterschied liegt darin, dass der Chatbot seine Antwort nicht mehr ausschließlich aus seinem Modellwissen formt, sondern sich wie ein gewissenhafter Mitarbeiter vorab an den relevanten Unterlagen orientiert und Informationen einholt. RAG ist also eine konsequente Ergänzung von Chatbots, die diese in vielen professionellen Anwendungsfällen überhaupt erst verlässlich einsetzbar macht.
Abschließend noch ein praktischer Tipp: Wenn Sie RAG einmal ohne Setup im Alltag spüren möchten, probieren Sie Perplexity aus. Es handelt sich hierbei um ein KI-gestütztes Such- und Antwortsystem (RAG), das seine Quellen in der Regel direkt mit ausweist und damit sehr anschaulich zeigt, wie Antworten entstehen wenn ein Modell zur Laufzeit in externen Informationen nachschlägt
The post LLMs, neuronale Netze, Chatbots und RAG – Eine nicht-technische Einführung appeared first on j&s-soft.
]]>Am Beispiel einer Handschrifterkennung mit der MNIST-Datenbank wird ein einfaches, einschichtiges Netz mit Matrixmultiplikation, Sigmoid-Aktivierung und Gradiententraining vollständig in ABAP umgesetzt.
The post Neuronale Netze in ABAP, Beispiel: Handschrifterkennung (MNIST) appeared first on j&s-soft.
]]>Doch was ist mit Organisationen, die mit ihrem On-Premise-SAP-System zufrieden sind und trotzdem mit kleineren KI-Modellen experimentieren möchten? Kann man künstliche Intelligenz auch direkt in ABAP programmieren? Die Antwort lautet: Ja. Um diese Möglichkeit zu demonstrieren, habe ich das „Hello World!“ des Machine Learnings in ABAP umgesetzt: eine einfache Handschrifterkennung auf Basis der MNIST-Datenbank. Ich habe mich dabei an der Lösung aus dem LinkedIn Learning Kurs Neuronale Netze in C/C++ von Dr. Gerhard Stein orientiert.
Wie KI funktioniert
Künstliche Neuronale Netze
Auch wenn es den Anschein hat, als sei KI eine ganz neue Entwicklung, ist das zugrunde liegende Prinzip schon seit Jahrzehnten bekannt. Erste Versuche, diese Art von KI zu realisieren, gab es bereits Mitte des 20. Jahrhunderts.
Kernbestandteil von KI-Systemen sind künstlichen neuronalen Netze (KNN). Sie bestehen aus einer Vielzahl von Neuronen, deren Funktionsweise der einer biologischer Nervenzelle nachempfunden ist. Ein solches künstliches Neuron ist in Abbildung 1 dargestellt.

Ein Neuron hat mehrere Eingänge und immer genau einen Ausgang. Die Eingänge laufen im Neuron durch eine Übertragungsfunktion. Dafür wird jeder Eingangswert mit einem individuellen Gewicht multipliziert. Zusätzlich zu diesen Gewichten gibt es einen Bias, der die Flexibilität des Neurons erhöht und es zum Beispiel ermöglicht, auch bei Eingangswerten von null einen Aktivierungswert zu erzeugen. Anschließend werden alle gewichteten Eingabewerte zusammen mit dem Bias aufsummiert. Das Ergebnis dieser Übertragungsfunktion wird dann durch eine Aktivierungsfunktion ausgewertet, die beispielsweise einen Schwellwert definiert, ab dem der Ausgang „aktiv“ wird (also den Wert 1 annimmt).
Werden mehrere solcher Neuronen miteinander verbunden oder verkettet, entsteht so ein künstliches neuronales Netz.
Eine der zentralen Aufgaben bei der Umsetzung ist es, die Funktion eines Neurons mathematisch und programmatisch abzubilden. Hierfür eignet sich die Matrixmultiplikation hervorragend. Die Übertragungsfunktion des Neurons aus Abbildung 1, lässt sich in Matrizenschreibweise wie in Abbildung 2 darstellen:
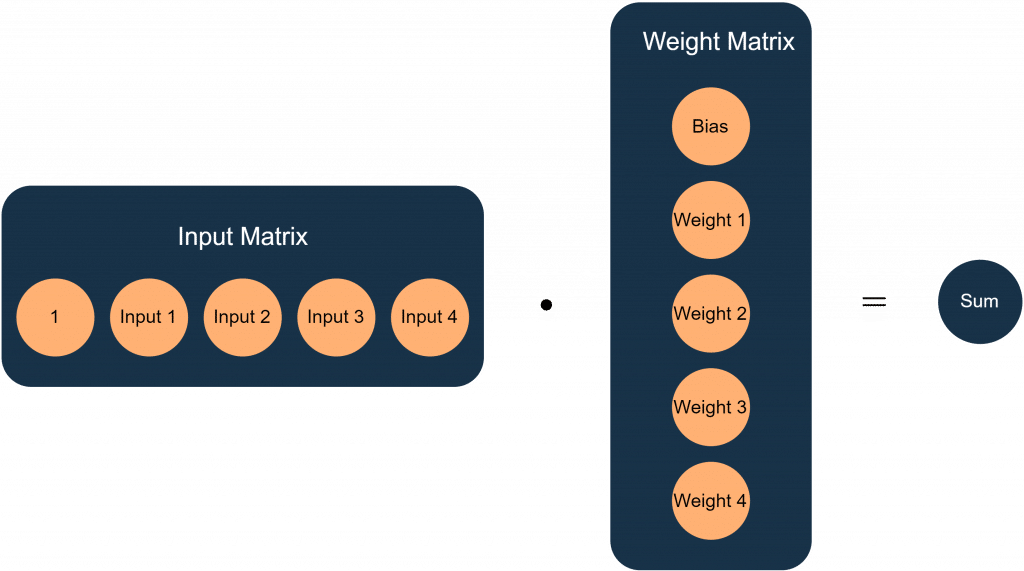
In diesem Fall bilden die Eingänge eine Zeilenmatrix, während die Gewichte eine Spaltenmatrix darstellen. Eine besondere Eigenschaft der Matrixmultiplikation ist, dass sich mit einer einzigen Operation mehrere Ergebnisse gleichzeitig berechnen lassen. Möchte man beispielsweise die Ausgabewerte eines Neurons für mehrere Eingangskombinationen bestimmen, fügt man einfach zusätzliche Zeilen zur Eingangsmatrix hinzu. Analog können mehrere Neuronen berechnet werden, indem man weitere Spalten an die Gewichtsmatrix anhängt. Aus einem einzelnen Ergebniswert entsteht so eine ganze Matrix von Ergebnissen.
Training
Das Ziel des Trainings besteht darin, die Gewichte des Netzes so anzupassen, dass die Ergebnisse möglichst genau den gewünschten Ausgaben entsprechen. Dafür gibt es verschiedene Ansätze. In diesem Beispiel verwenden wir Supervised Learning. Dafür haben wir eine große Liste mit Beispielen für Eingangswerte mit den dazugehörigen gewünschten Ergebnissen.
Im ersten Schritt werden die Gewichte der Neuronen zufällig (innerhalb bestimmter Grenzen) initialisiert. Anschließend wird überprüft, wie gut das Netz die gewünschten Ergebnisse reproduziert. Über eine Verlustfunktion lässt sich der Fehler bestimmen.
Im Trainingsprozess wird dieser Fehler schrittweise minimiert: Ein Gradientenverfahren vergleicht Soll- und Istwerte, und passt die Gewichte so an, dass der Fehler tendenziell kleiner wird. Danach wird das Netz erneut getestet. Dieser Zyklus wiederholt sich so lange, bis die Genauigkeit zufriedenstellend ist. Der Gradient ist die Ableitung der Verlustfunktion.
Da die Menge der Trainingsdaten häufig enorm ist, und die Gewichte nur langsam und vorsichtig angepasst werden, kann dieser Prozess sehr lange dauern. Am Ende des Trainings erhält man eine Menge von Gewichten, mit denen das Netz neue, bislang unbekannte Eingabedaten klassifizieren kann.
Handschrifterkennung mit MNIST-Datenbank
Die MNIST-Datenbank enthält zehntausende Bilder handgeschriebener Ziffern. Zu jedem Bild gibt es ein Label, das angibt, welche Ziffer tatsächlich dargestellt ist. MNIST ist ein Akronym und steht für „Modified National Institute of Standards and Technology“. Der Datensatz ist in 60.000 Trainingsbilder und 10.000 Testbilder unterteilt. Jedes Bild hat eine Auflösung von 28×28 Pixeln, also insgesamt 784 Pixelwerte. Einige Beispielbilder sind in Abbildung 3 zu sehen.

Implementierung des neuronalen Netzes
Um alle Ziffern (0–9) erkennen zu können, nutzen wir ein einschichtiges Netz mit Zehn Neuronen – eines für jede Ziffer. Wenn ein Neuron seine Ziffer erkennt, soll es eine 1 ausgeben, ansonsten eine 0.
Die Eingabedaten bestehen aus den Pixelwerten des Bildes (im Bereich 0–255). Diese Werte werden als Eingänge der Neuronen verwendet. Zusätzlich wird ein konstanter Eingangswert von 1 für den Bias ergänzt. Damit ergibt sich eine Gesamtzahl von 785 Eingängen (784 Pixel + 1 Bias). Ein schematischer Überblick ist in Abbildung 4 dargestellt.

Weitere Details
Der Vollständigkeit halber möchte ich an dieser Stelle noch einige technische Details nennen, die zwar für das Grundverständnis nicht zwingend notwendig sind, aber für das Training eine wichtige Rolle spielen: Als Aktivierungsfunktion wird die Sigmoid-Funktion genutzt. Diese bildet das Ergebnis der Übertragungsfunktion auf einen Bereich von 0 bis 1 ab, wobei eine Summe 0 der Übertragungsfunktion dem Ausgabewert 0,5 entspricht.
Für die Verlustfunktion und die Gradientenfunktion werden logarithmische Varianten verwendet, da diese gut mit der Sigmoid-Aktivierungsfunktion funktionieren.
Trainingsprozess
Beim Training werden allen zehn Neuronen wiederholt alle 60.000 Trainingsbilder „gezeigt“. Nach jeder Trainingsrunde (Iteration) werden die Gewichte mithilfe des Gradientenverfahrens angepasst. Um den Fortschritt zu überwachen, kann der Fehlerwert nach jeder Iteration über die Verlustfunktion ausgegeben werden.
Da wir für die Berechnungen Matrizen nutzen, lässt sich die Übertragungsfunktion aller Neuronen für alle Bilder in einer einzigen Matrixoperation auswerten. Im Anschluss wird die Aktivierungsfunktion auf jedes Element der Ergebnismatrix angewendet. In Abbildung 5 ist die Matrixmultiplikation eines Trainingsschrittes dargestellt.

Wie man anhand der Größen der Matrizen erkennen kann, ist diese Berechnung sehr rechenintensiv und stellt die größte Herausforderung für die Performance des ABAP-Programms dar.
Implementierung in ABAP
Bisher wurde der Prozess allgemein beschrieben, jetzt muss er noch in ABAP umgesetzt werden. Für die Implementierung verwende ich drei Klassen, auf die ich im nächsten Kapitel weiter eingehe:
- Eine Klasse für die Matrizenrechnung,
- Eine Klasse für das Neuronale Netz,
- Eine Klasse für die Verarbeitung der MNIST-Daten.
Matrizenrechnung
Da ABAP keine native Unterstützung für Matrizenrechnung hat, muss diese Funktionalität in einer eigenen Klasse abgebildet werden. Die Matrixmultiplikation ist der ausschlaggebende Faktor für die Performance, also muss hier besonders viel Wert auf eine möglichst effektive Lösung gelegt werden.
Das naheliegendste Äquivalent zur Matrix in ABAP ist die interne Tabelle. Damit lässt sich eine Matrix zwar prinzipiell über zweidimensionale Indizes abbilden (x, y), allerdings ist die zugrunde liegende Datenstruktur dafür nicht optimal geeignet. Interne Tabellen sind in der Regel als verkettete Listen realisiert, und der Zugriff über Indizes ist vergleichsweise teuer.
Es gibt in ABAP leider keine Alternative dazu, aber man kann die Indexzugriffe reduzieren, indem man die Matrix „flachklopft“, also die Zeilen hintereinander in einer eindimensionalen Tabelle speichert. Eine Alternative zum Zugriff über Indizes ist das ‚loop at‘, allerdings konnte ich damit keine schnellere Umsetzung finden.
Für die Matrizenrechnung habe ich daher die Klasse Z_RW_CL_MATRIX angelegt. Diese hat zwei Attribute:
- die Dimensionen (x, y)
- Matrixdaten in einer internen Tabelle
Als Datentyp für die Werte verwende ich „f“, da dieser eine 64-bit Gleitkommazahl darstellt. Das ist ein gängiger Standard im KI-Bereich. Die Alternative “decfloat34“ wäre speicherintensiver und langsamer. Die statische Methode MATRIX_MULTIPLY nimmt zwei Objekte der Matrixklasse entgegen und gibt das Ergebnis als neues Matrixobjekt zurück. In Abbildung 6 wird der ABAP optimierte Code gezeigt.

Hier sind mehrere Optimierungsansätze umgesetzt:
- Speicherplatz für Produkt-Matrix wird vorab reserviert (Kein append im loop)
- Dereferenzierungen von Attributen werden Feldsymbolen zugewiesen
- Datendeklaration erfolgt außerhalb der Schleifen
- Matrixdaten sind in einer eindimensionalen internen Tabelle abgelegt
- Indizes werden akkumuliert anstatt über Koordinaten berechnet
- Die Summen werden über eine lokale Variable berechnet, um Tabellenzugriffe zu reduzieren
Zum Vergleich zeigt Abbildung 7 meinen ersten Entwurf zur Matrixmultiplikation. Dieser braucht etwa 2,6 mal so lange, wie die optimierte Version.

Wer meinen Blog zu Parallel Processing in ABAP gelesen hat, weiß, dass sich diese Aufgabe hervorragend parallelisieren lässt. Bei großen Matrizen skaliert die Performance nahezu linear mit der Anzahl der Worker Threads. Bei meinem Parallelisierungsansatz werden die Zeilen der Matrix A auf vier Worker-Threads verteilt, um die Berechnung weiter zu beschleunigen.
Das Neuronale Netz
Für die Implementierung der Operationen, die speziell Neuronale Netze betreffen, habe ich die Klasse Z_RW_CL_NET_SINGLE_LAYER angelegt. Es handelt sich dabei um eine abstrakte Klasse, da die Parameter der Neuronen, also Gewichte und Biases, in den Reports als Matrixobjekte gespeichert und dort verwaltet werden. Die Klasse implementiert folgende private Methoden:
- SIGMOID – berechnet Aktivierungsfunktion
- GET_LOSS – berechnet Verlustfunktion
- GET_GRADIENT – berechnet Gradientenfunktion
- FORWARD – berechnet aus den Eingabewerten die Ausgabematrix
Zusätzlich implementiert die Klasse das Interface Z_RW_IF_NEURAL_NET, das die zentrale Steuerung des neuronalen Netzes ermöglicht. Es definiert folgende Methoden:
- TRAIN – startet den Trainingsprozess
- CLASSIFY – klassifiziert Eingabedaten
- TEST – führt die Klassifizierung für das gesamte Testdatenset aus und ermittelt die Fehlerrate
Abbildung 8 zeigt den ABAP-Code für die Sigmoid-, Verlust- und Gradientenfunktionen.

MNIST-Datenverarbeitung
Die Bilddaten und Labels der MNIST-Datenbank liegen im CSV-Format vor und können daher problemlos in ABAP eingelesen werden. Jede Zeile der Datei entspricht einem Bild: Der erste Wert ist das Label (eine Ziffer von 0 bis 9), die restlichen 784 Werte sind die Pixelintensitäten (jeweils 0–255).
Für das Einlesen und Aufbereiten der Daten verwende ich die Klasse Z_RW_CL_MNIST. Sie enthält sechs Matrixattribute:
- M_DIGITS_TRAIN und M_DIGITS_TEST – Eingabedaten für Trainings- bzw. Testset
- M_LABELS_TRAIN und M_LABELS_TEST – die numerischen Labels aus der CSV-Datei (0–9)
- M_NEURON_LABELS_TRAIN und M_NEURON_LABELS_TEST – die in One-Hot-Encoding umgewandelten Label-Matrizen für das neuronale Netz (je Neuron eine 1 oder 0)
Der Konstruktor der Klasse kann so parametrisiert werden, dass er nur eines der beiden Datensets lädt. Zudem lässt sich die Datenmenge begrenzen, um die Rechenzeit während der Tests zu verkürzen – insbesondere, da das vollständige Set mit 60.000 Bildern sehr rechenintensiv wäre.
Da die Attribute public read-only deklariert sind, können sie direkt an die Klasse des neuronalen Netzes übergeben werden, etwa zur Durchführung des Trainings oder zur Evaluation auf dem Testdatensatz.
Auswertung der Lösung
Training
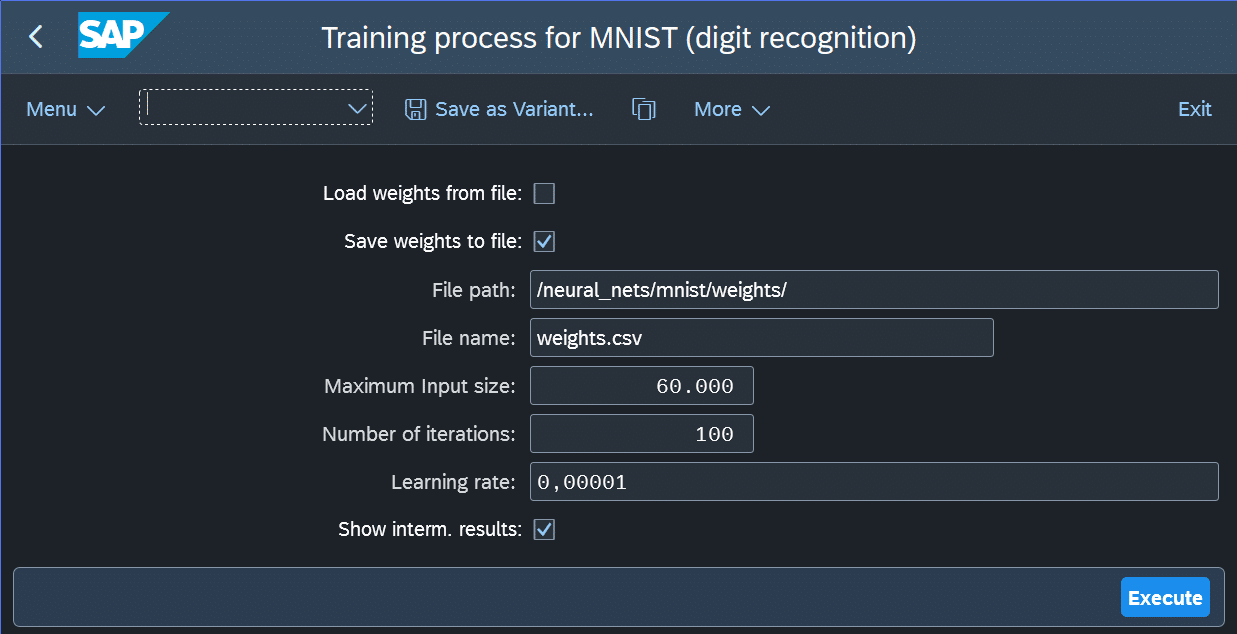
Das Training des neuronalen Netzes kann über einen eigenen Report gestartet werden. Dieser ist parametrierbar und ermöglicht es, die während des Trainings ermittelten Gewichte als CSV-Datei zu speichern und später wieder zu laden, um das Training fortzusetzen. Darüber hinaus können Parameter wie Lernrate und Anzahl der Trainingsschritte eingestellt werden.
Die Lernrate steuert, wie stark die Gewichte pro Iteration angepasst werden und beeinflusst damit, wie schnell (und stabil) das Optimum gefunden wird. Es lohnt sich, mit diesen Werten zu experimentieren, um ein Gefühl dafür zu bekommen, welchen Einfluss sie auf den Trainingsprozess haben. Abbildung 9 zeigt den Selektionsbildschirm des Reports.
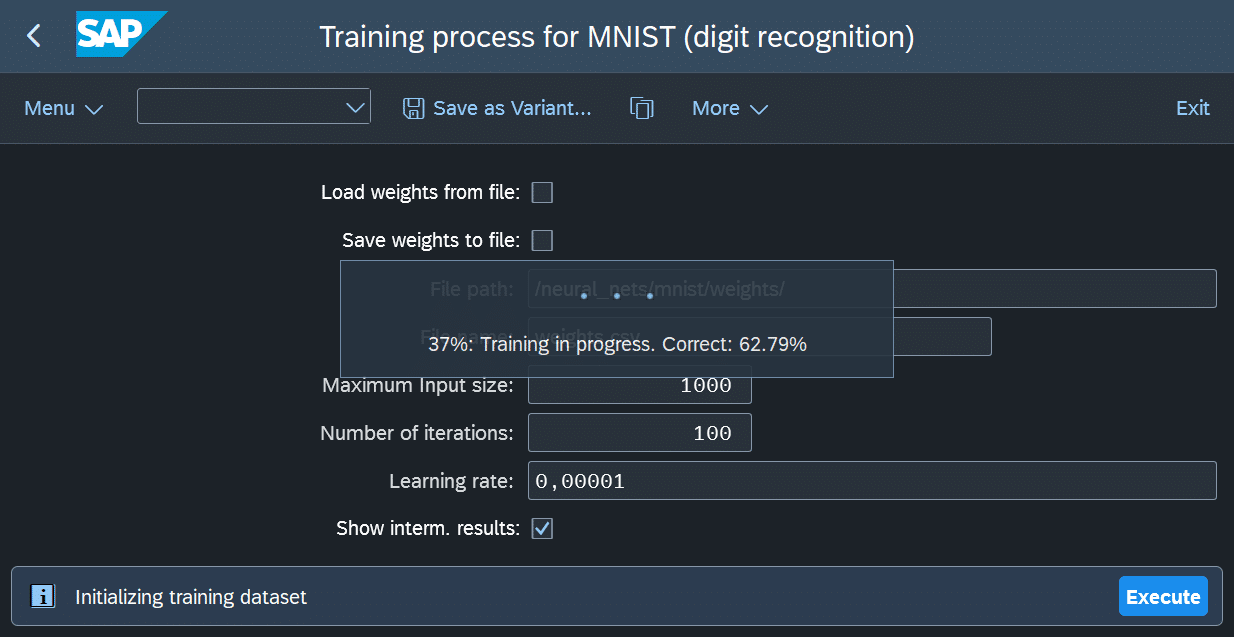
Nach der Parametrierung kann der Trainingsprozess gestartet werden. Dieser ist rechenintensiv und kann, je nach Anzahl der Iterationen, viel Zeit in Anspruch nehmen. Der Report zeigt während des Trainings regelmäßig Zwischenergebnisse an.
Dabei werden die aktuellen Gewichte mithilfe des Testdatensatzes überprüft, um die Klassifikationsgenauigkeit zu messen. In Abbildung 10 ist ein Beispiel für die Anzeige dieser Zwischenergebnisse zu sehen.
Für längere Trainingsläufe empfiehlt es sich, eine Variante des Reports anzulegen und den Prozess als Hintergrundjob auszuführen. Auf unserem System (eine virtuelle Maschine auf einem Intel-Xeon) dauert das Training mit allen 60.000 Bildern über 100 Iterationen etwa sechs Stunden, trotz Optimierungen und Parallelisierung.
Nach diesen 100 Iterationen erreicht das Netz eine Genauigkeit von rund 90 % auf den Trainingsdaten. Das ist ein realistischer Wert für ein einfaches, einschichtiges neuronales Netz und als Proof of Concept völlig ausreichend, auch wenn komplexere Netze deutlich bessere Resultate erzielen könnten.
Fairerweise muss man anmerken, dass ein neuronales Netz, das immer denselben Wert (z. B. „0“) ausgibt, bei einem gleichmäßig verteilten Datensatz ebenfalls etwa 90 % korrekte Ergebnisse liefern würde. Dieser Wert sollte daher mit Vorsicht interpretiert werden.
Um die Genauigkeit weiter zu steigern, habe ich das Training als periodischen Hintergrundprozess eingeplant, der jede Stunde fünf zusätzliche Iterationen durchführt. Nach etwa einer Woche konnte das Netz so eine Genauigkeit von rund 97 % erreichen, ohne das System dauerhaft auszulasten.
Klassifizierung
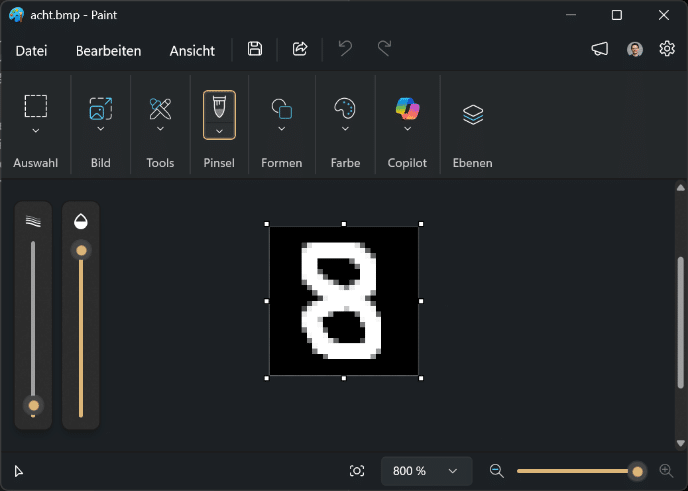
Nach dem Training kann das neuronale Netz zur Ziffernerkennung verwendet werden. Dafür habe ich einen separaten Report erstellt, über den man eine Bitmap-Datei mit den Maßen 28 × 28 Pixel hochladen kann. Ich habe die Testbilder in MS Paint erstellt, wie in Abbildung 11 zu sehen ist.
Der Klassifizierungsreport gibt anschließend die Ergebnisse der zehn Neuronen aus, also die berechneten Wahrscheinlichkeiten für jede Ziffer, sowie die Laufzeit der Klassifizierung. Abbildung 12 zeigt den Ergebnisbildschirm.
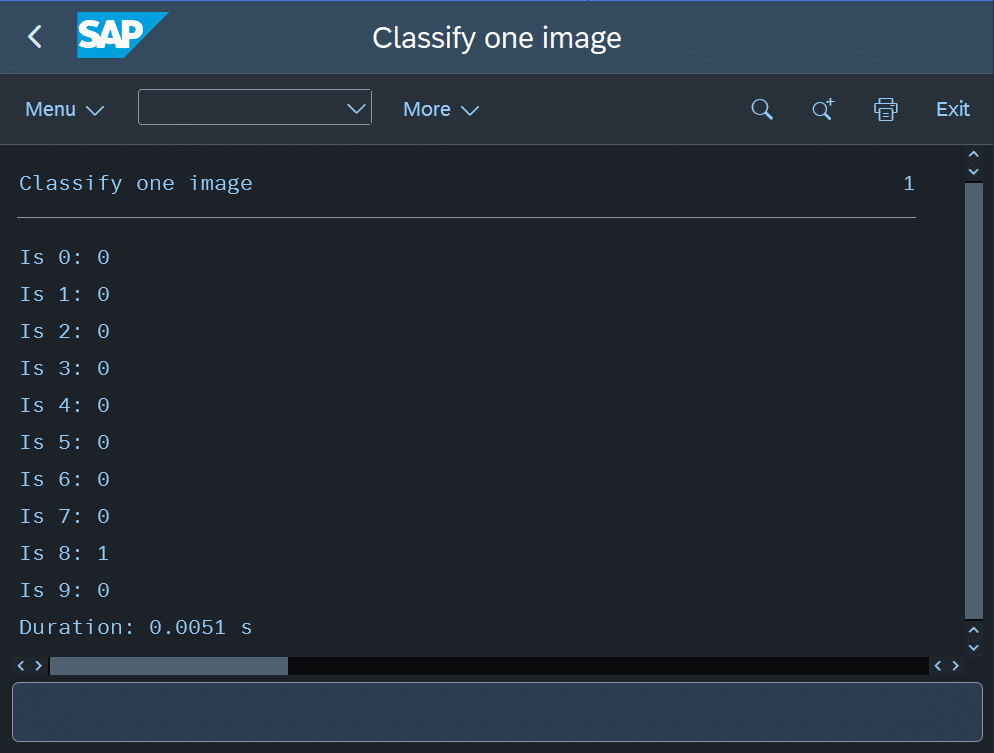
In diesem Test konnte das neuronale Netz die handgezeichnete „8“ korrekt klassifizieren. Ich habe bewusst diese Ziffer gewählt, da sie vom Netz am zuverlässigsten erkannt wird. Bei anderen Ziffern treten trotz einer Gesamtgenauigkeit von rund 97 % noch häufiger Verwechslungen oder uneindeutige Klassifizierungen mit mehreren falschen Positiven auf.
Vermutlich unterscheidet sich meine Handschrift zu stark von den Trainingsdaten, wahrscheinlicher ist jedoch, dass dieses einfache Netz zu wenig Kapazität hat, um zuverlässig zu generalisieren. Trotzdem betrachte ich das Ergebnis als Erfolg: Der Klassifizierungsprozess funktioniert mit den im Training ermittelten Gewichten vollständig in ABAP, und die Berechnungen laufen korrekt ab, auch wenn das Ergebnis nicht immer stimmt.
Wie der Screenshot zeigt, dauert eine Klassifizierung etwa 5 Millisekunden. Nach dem einmaligen Training ist der Betrieb des Netzes also äußerst schnell, da nur noch ein Durchlauf (Feedforward) erfolgt.
Insgesamt umfasst das Netz 7.850 Parameter (785 Eingänge × 10 Neuronen). Rein theoretisch hochgerechnet würde ein Netz mit einer Milliarde Parametern, also etwa der Größe eines kleinen Large Language Models (LLM), auf demselben System mehrere Minuten pro Durchlauf benötigen, vorausgesetzt, es gäbe genug Arbeitsspeicher. Das zeigt, warum ABAP trotz aller Optimierungen nicht für moderne KI-Anwendungen wie Bildverarbeitung oder LLMs geeignet ist. Selbst ein kleiner Einplatinenrechner wie der Raspberry Pi würde mithilfe eines Frameworks wie Ollama diese Berechnungen deutlich schneller ausführen.
Fazit
Es ist tatsächlich möglich, neuronale Netze in ABAP zu implementieren und auszuführen. Die Performance reicht zwar nicht für aktuelle Anwendungen wie komplexe Bilderkennung oder Large Language Models, aber als Proof of Concept zeigt dieses Projekt eindrucksvoll, wie flexibel ABAP sein kann.
Neben der reinen Implementierung spielen auch das Design des Netzes und die Parametrierung des Trainingsprozesses eine entscheidende Rolle. Wer eigene neuronale Netze in ABAP umsetzen möchte, sollte sich daher sowohl mit der Mathematik als auch mit den Performanceaspekten der Programmiersprache intensiv auseinandersetzen.
The post Neuronale Netze in ABAP, Beispiel: Handschrifterkennung (MNIST) appeared first on j&s-soft.
]]>The post So profitieren Makler und Pools in der Kundenkommunikation von Wallets appeared first on j&s-soft.
]]>Use Case 1: Wohngebäudeversicherung mit nur wenigen Klicks abschließen
Die Kundin oder der Kunde möchte z.B. eine Wohngebäudeversicherung abschließen. Statt alle Angaben erneut einzutippen oder Dokumente hochzuladen, nutzt sie die in der Wallet hinterlegten Daten z. B. zur Immobilie, zu ihrer Identität oder zu Vorschäden. Die Anfrage wird automatisch vorausgefüllt, kann mit einem Klick bestätigt und abgesendet werden.
Ergebnis: Deutlich weniger Abbrüche im Abschlussprozess, schnellere Policenerstellung und ein reibungsloses, modernes Kundenerlebnis.
Use Case 2: Policeversand digital statt kuvertieren, frankieren, archivieren
Ein neuer Vertrag ist abgeschlossen. Doch statt PDF im E-Mail-Anhang oder einem Brief per Post landet die Police direkt in der Wallet der Kundin. Auf Wunsch mit Empfangsbestätigung, strukturiertem Rückkanal und automatischer Ablage beim Kunden oder bei der Kundin.
Ergebnis: Keine Papierkosten, keine E-Mail-Flut und die Kundin hat alles direkt parat.
Use Case 3: Schadensmeldung direkt aus der Wallet
Die Kundin oder der Kunde meldet einen Schaden und kann direkt über die Wallet ein Foto hochladen, fehlende Informationen ergänzen oder den Status einsehen. Der gesamte Kommunikationsverlauf ist nachvollziehbar und datensicher dokumentiert.
Ergebnis: Schnellere Bearbeitung, weniger Rückfragen und höheres Vertrauen für Makler und Kundinnen und Kunden.
Weitere Vorteile für Makler, Pools & Versicherer:
- Direkte Kundenverbindung: Mit QR-Code statt Login
- Automatisierte Kommunikation: Zu Beginn der Kundenbeziehung bis Vertragsänderungen
- Weniger Nachfassen, mehr Struktur: Rückkanäle inklusive
- Höhere Sichtbarkeit beim Kunden: Wallet bleibt auf dem Smartphone präsent
- Skalierbar: Vom Einzelmakler bis zum Großpool
- Schnell ins Verwaltungssystem integrierbar: Einsatzbereit in kurzer Zeit
- Individueller Look: App im gewünschten Design
Und für Endkunden bzw. -kundinnen?
- Verträge & Nachweise: Gebündelt und sicher an einem Ort
- Keine E-Mails, kein Papier: Alles kommt zuverlässig an
- Einfach interagieren: Mit wenigen Klicks Schaden melden und Unterlagen hochladen
- Volle Kontrolle: Entscheidung
Sie wollen mehr erfahren?
Kontaktieren Sie mich (Michael Feygelman)
Rückblick:
Im ersten Blogbeitrag hier haben wir gezeigt, welche 7 Datenschutz-Fallen in der Kundenkommunikation lauern und wie Wallet-Technologien hier DSGVO-konform schützen.
Im zweiten Blogbeitrage haben wir hier neue Technologien vorgestellt, die in Zukunft wichtige Wettbewerbsvorteile darstellen.
The post So profitieren Makler und Pools in der Kundenkommunikation von Wallets appeared first on j&s-soft.
]]>The post Wie identifiziere ich passende Anwendungsfälle für KI appeared first on j&s-soft.
]]>- Sie kann standardisierte, wiederkehrende Tätigkeiten schneller und genauer ausführen.
- Sie kann große Datenmengen effizient analysieren.
- Sie kann Prognosen erstellen und Empfehlungen geben – diese sind allerdings kritisch zu betrachten. Denn die Qualität der KI-Ergebnisse hängt stark von der Qualität der zugrunde liegenden Daten und dem gewählten KI-Modell ab.
Mitarbeitende sind die wichtigsten Ideengeber
Auch wenn KI „Chefsache“ ist, werden die besten Anwendungsfälle meist direkt in den Abteilungen erkannt. Die Teams kennen die Arbeitsroutinen genau. Deshalb sollten immer mehrere Mitarbeitende aus unterschiedlichen Teams in das Projekt einbezogen werden. Nur dort sind die Vorgänge und Probleme im Detail bekannt – und die Akzeptanz bei der Umsetzung des Projekts ist im Anschluss deutlich größer.
Die strategischen Ziele des Unternehmens und die verfügbaren Ressourcen kennt natürlich nur das Management. Deshalb ist der Ansatz interessant, mit den Ideen der Mitarbeitenden zu beginnen. Im zweiten Schritt lässt sich klären, ob die Projekte im Sinne der Unternehmensentwicklung zu einer echten Verbesserung führen.
Ein guter Ansatz, um Einsatzmöglichkeiten zu identifizieren: Wo sind die Arbeitsabläufe, die unnötig viel Zeit und Ressourcen verbrauchen? Wo besteht eine hohe Fehlerquote, die durch eine KI-Prüfung minimiert werden könnte?
Typische Beispiele:
- Terminplanungen / Arbeitspläne
- Verarbeitung von Formularen
- Verarbeitung großer Datenmengen
Alle Ideen werden im Use-Case-Template gesammelt
Welche Ideen gibt es? Das Template deckt wichtige Fragen ab:
- Welches Problem soll gelöst werden?
- Welche Daten werden benötigt?
- Wie schnell kann die Lösung umgesetzt werden?
- Welche Technologie ist am besten geeignet?
Zusätzlich wird die passende Risikoklasse anhand des AI-Acts, der DSGVO und Informationssicherheit festgelegt.
Das Problem genau definieren
Bei KI gibt es zwei Möglichkeiten:
- Einen vorhandenen Prozess automatisieren – idealerweise ein Prozess, der auch für andere Abteilungen nützlich ist und somit eine hohe Skalierbarkeit aufweist.
- Umdenken: Prüfen, ob sich durch Automatisierungsmöglichkeiten der Prozess grundsätzlich verändern lässt. Dieses Potenzial findet sich oft in großen Unternehmen mit vielen Abteilungen. In der Regel sind solche neuen Prozesse dann interessant, wenn bisher jede Abteilung einen bestimmten Anteil an einem Prozess hatte – der nun zusammengelegt werden kann.
Wie wähle ich die richtigen Projekte aus?
Kriterien:
- Umsetzbarkeit: schnell umsetzbar
- Für mehrere Abteilungen nützlich (Skalierbarkeit)
Schritt eins ist der Prototyp/Minimal Viable Product (MVP)
Der einfachste und effizienteste Weg ist ein Prototyp. Ein MVP kann schnell angepasst werden, bevor eine große Lösung gebaut wird. Anpassungen und Inhalte lassen sich frühzeitig erkennen.
Ein MVP ist der ideale Ansatz, um zu testen, ob die Lösung die gewünschten Ergebnisse liefert und welche Anpassungen sinnvoll wären.
Die richtigen KPIs
Um das Projekt bereits in der Prototypenphase sicher bewerten zu können, müssen die passenden Key Performance Indicators (KPIs) für KI-Use-Cases festgelegt werden. Nur dann ist der Erfolg messbar und belegbar.
Beispiele:
- 60 % verringerte Fehlerquote in drei Monaten
- 20 % eingesparte Arbeitsstunden in sechs Monaten
- 15 % höherer Umsatz durch verbesserten Kundenservice
Welche Daten brauche ich? Welche Daten habe ich?
Die Prüfung und Beschaffung der Daten ist die Grundlage für den Erfolg vieler KI-Projekte.
Wenn für ein KI-Projekt eine Datenbasis nötig ist, die jedoch lückenhaft oder fehlerhaft ist, lohnt es sich, zunächst ein Datenvorprojekt zu initiieren.
Gute Nachricht: In der Prototyp-Phase kann häufig auch mit lückenhaften Daten gearbeitet werden, um erste Erkenntnisse zu gewinnen. Das Datenvorprojekt läuft dann parallel zur KI-Entwicklung.
Starten Sie mit einem Workshop
Lassen Sie sich von Fachleuten beraten, die Ihnen bei dem Weg zur richtigen Anwendung und einem Blick von außen auf Ihre Unternehmen zur Seite stehen. Je nachdem wie weit Sie in Ihrem Projekt sind, buchen Sie:
AI Start-Workshop: Analyse & Use-Case-Identifikation
Interaktiver dreitägiger Workshop, in dem wir gemeinsam Ihre geschäftlichen Herausforderungen herausarbeiten, priorisieren und passende KI-gestützte Automatisierungs- und Assistenzlösungen ableiten. Mehr
Prototyp-Workshop: Pilot Sprint AI-Agent
Entwicklung eines funktionsfähigen AI-gestützten Automatisierungsagenten in weniger als 10 Tagen – von Prozess- und Datenanalyse über Prototyping und Anwender-Tests bis zur Übergabe aller technischen Unterlagen, Quellcodes sowie eines Fahrplans mit Aufwandsschätzung und ROI-Bewertung für das Minimum Viable Product (MVP). Mehr
Chatbot-Workshop: Pilot Sprint RAG Assistant
Entwicklung eines funktionsfähigen Retrieval-Augmented Generation (RAG) Assistenten in weniger als 10 Tagen – von der Analyse der Dokumentenquellen über die Implementierung einer Prototyp-RAG-Pipeline bis hin zu Tests mit Fachanwendern und der Übergabe aller technischen Unterlagen inklusive Roll-out-Fahrplan. Mehr
Workshop Datenerkennung: Pilot Sprint Intelligente Informationsgewinnung
Erstellung eines Prototyps zur automatischen Extraktion strukturierter Daten aus unstrukturierten Dokumententypen in 5 Tagen – von der Quellanalyse über die Pipeline-Entwicklung bis hin zur Evaluation und Übergabe. Mehr
Melden Sie sich einfach bei uns, wir beraten Sie und finden das passende Workshopformat für Sie. Wenn Sie Fachleute in einem bereits laufenden Projekt brauchen, kann unser AI-Team sie ebenfalls unterstützen. Mehr über: [email protected] (Estelle Hounsa).
The post Wie identifiziere ich passende Anwendungsfälle für KI appeared first on j&s-soft.
]]>The post VERO: Forschungsprojekt zur Verifikation von Gesundheitsinformationen appeared first on j&s-soft.
]]>Fachlicher Fokus: Kinderkardiologie
Inhaltlich konzentriert sich VERO auf den Bereich der Kinderkardiologie. Dies ist einerseits durch die Beteiligung der Abteilung für Kinderkardiologie des Universitätsklinikums Bonn (UKB KK) begründet, die als hochspezialisierter wissenschaftlicher Partner valide Wissensquellen und klinische Expertise einbringt. Andererseits stellt die Medizin als Gesamtgebiet eine enorme Komplexität dar; die Fokussierung auf einen klar abgegrenzten Teilbereich ermöglicht es, eine realistische und produktive erste Ausbaustufe des Systems zu entwickeln, umzusetzen und unter realen Bedingungen zu evaluieren.
Zu den Projektpartnern zählen neben dem UKB KK die Abteilung für Medizindidaktik am Universitätsklinikum Bonn (UKB MD) für die didaktische Aufbereitung und Auswertung des Nutzerfeedbacks, die snoopmedia GmbH (Grafschaft) für Endnutzer-App und Projektkoordination sowie die Fördergemeinschaft Deutsche Kinderherzzentren e. V. („Kinderherzen“).
Zentrale Funktionen
Das System verfolgt zwei Kernfunktionen:
- Aussagenprüfung und Fragebeantwortung:
Nutzerinnen und Nutzer können Gesundheitsinformationen, die sie im Internet gefunden haben, auf faktische Korrektheit prüfen oder eigene Fragen stellen. Die Antworten des RAG-Systems basieren ausschließlich auf einer kuratierten, wissenschaftlich abgesicherten Wissensbasis und werden durch explizite Quellenangaben belegt. Ergänzend visualisiert ein Trust Score die Evidenzlage. Dieser dient nicht als medizinische Diagnose, sondern als kalibrierte Einschätzung, wie belastbar eine Aussage durch die referenzierten Belege gestützt wird. - Aufbau eines vertrauenswürdigen Informations- und Quellenkatalogs: Über die Zeit entsteht durch die Nutzung ein Katalog geprüfter Gesundheitsinformationen und -quellen. Die Anwendung kann Webseiten oder Textauszüge analysieren und deren Qualität nachvollziehbar bewerten. Die Ergebnisse fließen in eine browserbasierte Nutzeroberfläche ein, die künftig beim Surfen einen Trust Score für besuchte Seiten anzeigt.
Technische Bestandteile und Herausforderungen
Die technische Umsetzung beruht auf einer modularen RAG-Architektur mit klar getrennten Pipelines für Erfassung, Aufbereitung, Retrieval, Begründung und Antwortsynthese.
- Datenbasis: Dokumente aus klinischen Leitlinien, Patienteninformationen und wissenschaftlichen Publikationen werden eingepflegt, semantisch segmentiert, zweisprachig (Deutsch/Englisch) normalisiert und mit Metadaten wie Publikationsdatum und Herkunft versehen.
- Retrieval: Evaluierte Embedding- und Sprachmodelle ermöglichen ein stabiles Arbeiten mit medizinischer Fachsprache. Als mittelfristige Ausbaustufe sollen ergänzend Reranking-Verfahren, Ontologie-basierte Synonymerkennung (z. B. „Ventrikelseptumdefekt/VSD“) sowie eine strikte Zitationspflicht in der Antwortgenerierung zum Einsatz kommen.
- Verifikation: Zu verfizierende Aussagen werden in überprüfbare Teilbehauptungen zerlegt und gegen mehrere Quellen geprüft. Die aggregierte Evidenz fließt in einen Trust Score ein, der Faktoren wie Quellabdeckung, Konsistenz, Aktualität und Widerspruchserkennung berücksichtigt.
VERO ist ausdrücklich als Unterstützungs- und Aufklärungssystem konzipiert. Es ersetzt weder ärztliche Beratung noch trifft es klinische Entscheidungen. Stattdessen werden Quellen sichtbar gemacht, Aussagen überprüft und ein Werkzeug zur gezielteren Gesprächsvorbereitung mit den behandelnden Ärzt:innen bereitgestellt. Damit trägt das System dazu bei, Unsicherheiten zu reduzieren und die begrenzten Ressourcen in Praxen und Kliniken effizienter einzusetzen.
In dieser Blogserie möchten wir periodisch über den Projektfortschritt berichten und interessante technische Sachverhalte im Rahmen der Entwicklung des RAG-Systems darstellen. Stay tuned!
The post VERO: Forschungsprojekt zur Verifikation von Gesundheitsinformationen appeared first on j&s-soft.
]]>The post Payroll Control Center (PCC): 7 Tipps fürs Troubleshooting appeared first on j&s-soft.
]]>Doch auch die besten Systeme haben hin und wieder einen Schluckauf. Dieser Blog stellt Lösungen vor – ganz ohne Programmierkenntnisse. Ein Erste-Hilfe-Set für den Payroll-Alltag.
Tipp 1: Prozesschritte bleiben hängen

Sie führen einen Prozess aus – z.B. Simulation und Prüfung der Gehaltsabrechnung – aber das PCC bleibt bei einem Schritt „hängen“ also im Status „In Bearbeitung“. Unten rechts in der Aktionsleiste lässt sich der Schritt nicht durch „Starten/Wiederholen/Bestätigen“ ändern. Dadurch können auch nachfolgende Prozessschritte nicht ausgeführt werden und der gesamte Prozess kann nicht weiterbearbeitet werden.
Ohne in eine tiefere Analyse einzusteigen, bietet SAP hier ein sehr nützliches Tool an, um Schritte eines Prozesses zurückzusetzen.
Folgende Schritte können Sie ausführen:
- Sie loggen sich über den Browser oder den SAP Logon in das angebundene Backend ein (SAP ERP System).
- Sie bestimmen die Prozessinstanz-ID des Prozesses: das ist die ID eines Prozesses für einen bestimmten Zeitraum
- Über die Transaktion SE16 die Tabelle PYC_D_PYPT aufrufen.
- Die gewünschte Prozess-ID auswählen und kopieren.
- Über die Transaktion SE16 die Tabelle PYC_D_PYPI aufrufen.
- Die im vorherigen Schritt kopierte Prozess-ID in das Feld „Prozess-ID“ eingeben.
- Sie sehen nun eine Übersicht über die vorhandenen Prozessinstanz-Namen und -IDs. Suchen Sie die ID (Spalte PYPI-ID), die Ihrer Abrechnungsperiode entspricht.

3. Nun führen Sie die Transaktion SA38 aus und dann den Report PYC_SUPPORT_SKIP_PROCESS_STEP.
Dort geben Sie die Prozessinstanz-ID ein.

4. Fahren Sie nun mit der Bearbeitung des Prozesses im “Abrechnungs-Control-Center – Prozessmanagement” fort.
Tipp 2: Richtlinien oder prozesse sind durch einen user gesperrt
Manchmal kann man einen Prozess oder eine Richtlinie im Reiter „Prozesse verwalten“ oder „Richtlinien verwalten“ nicht bearbeiten, da dieser bereits durch einen anderen Benutzer bearbeitet wurde und die Bearbeitung nicht abgeschlossen wurde.

Wenn Sie versuchen, diesen Prozess oder diese Richtlinie zu bearbeiten, erhalten Sie die Fehlermeldung: „Fehler – Prozess in Bearbeitung durch …“.

In diesem Fall bietet SAP die Möglichkeit, über einen Admin Report im Backend die Sperre wieder zu entfernen.
Folgende Schritte sind dafür notwendig:
- Loggen Sie sich über den Browser oder den Sap Logon in das angebundene Backend ein (SAP ERP System).
- Sie führen den Report PYC_ADMIN_TRANSACTION aus:
- Sie geben den Transaktionscode: „SA38“ in die Kommandozeile ein.
- Sie geben den Reportnamen: „PYC_ADMIN_TRANSACTION“ ein und führen ihn aus
Im Menüeintrag Sperreinträge pflegen > Prozesskonfiguration wird der entsprechende Sperreintrag sichtbar.

- Wechseln Sie in den Änderungsmodus, setzen Sie einen Haken bei dem entsprechenden Sperreintrag und betätigen Sie den Button „Assign User“
- Bestätigen Sie das Pop-Up „Information“
- Sie können der Prozessbearbeitung nun einen neuen Benutzer zuordnen, beispielsweise Ihren eigenen, wenn Sie den Prozess bearbeiten möchten
- Nun betätigen Sie den Button „Speichern“

Achtung: Falls Sie keinen Zugriff auf den Report PYC_ADMIN_TRANSACTION haben, besitzen Sie nicht die notwendigen Berechtigungen. Wenden Sie sich in diesem Fall an Ihren Administrator.
3. Nun können Sie in das Frontend wechseln und den Prozess oder die Richtlinie weiterbearbeiten.
Tipp 3: Es werden zu viele Abrechnungsperioden angezeigt oder fehlen
Sie möchten im PCC im Reiter „Prozesse verwalten“ einen neuen Prozess einrichten, beispielsweise einen neuen Prozess für die produktive Abrechnung. Bei der Auswahl im Abschnitt „Wiederholungen“ werden jedoch sehr viele Perioden angezeigt, die sehr weit in die Vergangenheit reichen. Um die aktuellen Perioden auswählen zu können, müssen Sie sehr lange nach unten scrollen. Oder die aktuellen Perioden fehlen ganz.

Lösung: Im Backend gibt es für die Steuerung der Abrechnungsperioden eine Tabelle, in dieser können Sie die Perioden entfernen oder hinzufügen. Führen Sie dafür die folgenden Schritte aus:
- Loggen Sie sich über den Browser oder den SAP Logon in das angebundene Backend ein (SAP ERP System).
- Geben Sie im Kommandofeld die Transaktion „SM30“ ein.
- Geben Sie die Tabellensicht „V_T549Q“ ein und klicken Sie auf den Button „Pflegen“. Geben Sie den Periodenparameter ein, z. B. „01 – monatlich“

4. Sie kommen zu einer Übersicht der Perioden, die bei der Erstellung eines Prozesses im PCC angezeigt werden. Prüfen Sie hier die gepflegten Perioden und löschen Sie ggf. nicht mehr benötigte Abrechnungsperioden.

Achtung: Falls Sie keinen Zugriff auf die Transaktion SM30 oder auf die Tabelle haben, besitzen Sie vermutlich nicht die notwendigen Berechtigungen. Wenden Sie sich in diesem Fall an Ihren Administrator.
Tipp 4: Fehler bei Ausführung des Schrittes “Personalabrechnungs-Testdaten anlegen”
Sie führen einen Prozess aus, bei dem in einem Schritt die Abrechnungssimulation ausgeführt wird. Dabei wird Ihnen folgender Fehler angezeigt: „Ungültige Kombination von Selektionsbildparametern oder inaktive BF für Test-PY“ (HRDCT_MSG014). Die Simulation der Abrechnung wird nicht durchgeführt.
Hintergrund dieses Fehlers: Die Simulation der Abrechnung wird von einem Report im Backend ausgeführt. Dabei wurde eine Report-Variante definiert, die nicht mit dem PCC kompatibel ist.
Sie können den Fehler beheben, indem Sie die Variante im Backend anpassen. Führen Sie dafür folgende Schritte aus:
- Loggen Sie sich über den Browser oder den SAP Logon in das angebundene Backend ein (SAP-ERP-System).
- Rufen Sie das Programm der Abrechnungssimulation auf, indem Sie im Kommandofeld die Transaktion PC00_M01_CALC_SIMU eingeben.

3. Rufen Sie die Variante auf, die vom PCC genutzt wird.
4. Entfernen Sie den Haken im Feld „Testlauf (kein Update)“ und speichern Sie die Variante.

Erläuterung: Für die Abrechnungssimulation im PCC wird im Backend der produktive Abrechnungstreiber genutzt. Das System erkennt im Frontend-System, dass es sich hierbei jedoch um eine Simulation handelt.
5. Damit die neu gespeicherte Variante in den Prozessschritt übernommen wird, muss jetzt noch einmal ein neuer Prozess angelegt werden. Gehen Sie dafür in das PCC (Frontend) und legen Sie im Reiter „Prozesse verwalten“ einen neuen Prozess an. Sie können sich dabei an dem alten Prozess orientieren.
6. Starten Sie den Prozess im Reiter „Meine Prozesse“ und führen Sie den Schritt der Abrechnungssimulation aus. Der Fehler taucht bei der Ausführung nicht mehr auf.
Tipp 5: PCC-Reiter werden nicht angezeigt
Sie rufen das Abrechnungskontrollzentrum (Payroll Control Center) in SAP SuccessFactors auf – jedoch können Sie nicht auf das gewünschte PCC zugreifen.
Die Ursache hierfür ist meistens, dass die entsprechenden Berechtigungen für das PCC nicht vergeben wurden. Führen Sie folgende Schritte durch, um den Fehler zu beheben:
- Führen Sie im SuccessFactors-Frontend das Programm „Gehaltsabrechnungssystemzuweisung“ aus und weisen Sie Ihrem User das Payroll-System zu. Bei mehreren Systemen können Sie einen „Standard“ auswählen. Das heißt, dieses System wird beim PCC-Aufruf als erstes angezeigt.

2. Sollte das PCC noch nicht angezeigt werden, müssen zusätzliche Berechtigungen unter „Berechtigungsrollen verwalten“ eingerichtet werden. Hierzu kontaktieren Sie bitte Ihren SuccessFactors-Administrator.
Tipp 6: Eine Validierungsregel oder eine Richtlinie wird nicht angezeigt
Sie versuchen, im PCC-Frontend im Reiter „Richtlinien verwalten“ eine Richtlinie neu anzulegen. Allerdings wird die gewünschte Validierungsregel nicht angezeigt. Oder Sie versuchen, im Reiter „Prozesse verwalten“ einen Prozess einzurichten, allerdings wird die gewünschte Richtlinie nicht im Auswahlmenü angezeigt.

Wenn Sie wissen, dass es eine Validierungsregel oder eine Richtlinie geben müsste, diese allerdings im Frontend nicht angezeigt wird, kann das auf eine Inkonsistenz zwischen Validierungsregel und Richtlinie oder zwischen Richtlinie und Prozesstyp hinweisen. Führen Sie folgende Schritte durch, um die Inkonsistenz zu beheben:
- Loggen Sie sich über den Browser oder den SAP Logon in das angebundene Backend ein (SAP-ERP-System).
- Rufen Sie mit der Transaktion „PYC_CONF_WB“ die Konfigurations-Workbench im Backend auf.
- Wählen Sie im Dropdown-Menü die „Validierungsregel“ aus.

Rufen Sie mit einem Doppelklick die Validierungsregel auf, die im Frontend angezeigt werden soll.
- Stellen Sie sicher, dass die Einstellungen im Reiter „Basisinformationen“ zur Richtlinie passen, z. B. dass die Einstellung im Feld „Land/Region“ auf „* – alle Regionen“ oder auf „01 – Deutschland“ steht.

- Speichern Sie die Änderungen.
- Sie können nun die Validierungsregel für das Erstellen der Richtlinie im Frontend auswählen.
- Gehen Sie analog zur Anpassung der Richtlinie vor, um diese für die Prozesserstellung auswählen zu können.
Tipp 7: Das PCC aufräumen
Im Laufe der Zeit kommt es vor, dass sich sehr viele abgeschlossene Prozesse im Reiter „Abgeschlossene Prozesse“ sammeln, dass Richtlinien obsolet werden oder dass vielleicht sogar bereits begonnene Prozesse vom Reiter „Aktive Prozesse“ wieder in den Reiter „Anstehende Prozesse“ zurückgeführt werden sollen.
Damit das PCC übersichtlich bleibt, ist es sinnvoll, von Zeit zu Zeit Aufräumarbeiten durchzuführen.
Abgeschlossene Prozesse löschen
- Loggen Sie sich über den Browser oder den SAP Logon in das angebundene Backend ein (SAP-ERP-System).
- Geben Sie im Kommandofeld die Transaktion SA38 ein und führen Sie das Programm PYC_SUPPORT_DEL_COMPLETED_PI aus.
- Wählen Sie eine Prozess-ID aus und das Enddatum der Prozessinstanzen.

4. Prüfen Sie die Prozesse und betätigen Sie den Button „Alle löschen“.

Richtlinien löschen
- Rufen Sie im PCC-Frontend den Reiter „Richtlinien verwalten“ auf.
- Klicken Sie den Button „Bearbeiten“.
- Sie können nun mit Klicken auf das „X“ eine Richtlinie löschen.

Aktive Prozesse in den Reiter „anstehende Prozesse“ zurücksetzen

- Loggen Sie sich über den Browser oder den SAP Logon in das angebundene Backend ein (SAP-ERP-System).
- Sie bestimmen die Prozessinstanz-ID des Prozesses: Das ist die ID eines Prozesses für einen bestimmten Zeitraum.
- Über die Transaktion SE16 die Tabelle PYC_D_PYPT aufrufen.
- Die gewünschte Prozess-ID auswählen und kopieren.
- Über die Transaktion SE16 die Tabelle PYC_D_PYPI aufrufen.
- Die im vorherigen Schritt kopierte Prozess-ID in das Feld „Prozess-ID“ eingeben.
- Sie sehen nun eine Übersicht über die vorhandenen Prozessinstanz-Namen und -IDs. Suchen Sie die ID (Spalte PYPI-ID), die Ihrer Abrechnungsperiode entspricht.
- Geben Sie im Kommandofeld die Transaktion SA38 ein und führen Sie das Programm PYC_RESET_PROC_INST aus.
- Geben Sie die Prozessinstanz-ID, die Sie im Schritt 2 bestimmt haben, ein und markieren Sie alle Haken – das Programm wird in der Simulation ausgeführt.

5. Das Protokoll zeigt Ihnen eine Übersicht der Schritte, die zurückgesetzt werden. Gehen Sie wieder zur Auswahl zurück und entfernen Sie den Haken bei „Simulation“, um die Änderungen auszuführen.

6. Aktualisieren Sie das PCC im Browser – der Prozess ist nun wieder im Reiter „Anstehende Prozesse“ zu finden und kann erneut gestartet werden.

Wir hoffen, dass Ihnen unsere Tipps den Umgang mit dem PCC erleichtern und Sie im Arbeitsalltag davon profitieren. Denken Sie daran: Ein PCC arbeitet immer nur so gut, wie es eingerichtet ist – und genau dabei unterstützen wir Sie gerne. Wenn Sie Fragen haben oder Unterstützung benötigen, sind wir jederzeit für Sie da!
The post Payroll Control Center (PCC): 7 Tipps fürs Troubleshooting appeared first on j&s-soft.
]]>The post Welche SAP-Version nutze ich? appeared first on j&s-soft.
]]>Ob SAP ECC, S/4HANA oder ein älteres Release: Die genaue SAP-Version finden Sie direkt im System. Öffnen Sie dazu im SAP-GUI die Transaktion System → Status und klicken Sie dort auf den Button „Komponenteninformationen“. In der Spalte „Komponente“ erkennen Sie z. B. Einträge wie SAP_BASIS, S4CORE oder SAP_APPL – die dazugehörige Versionsnummer finden Sie direkt daneben.
Welche SAP-Versionen gibt es?
Grundlegend gibt es seit 1972 folgende SAP-Versionen:
- 1972: SAP R/1
- 1979: SAP R/2
- 1992: SAP R/3 (Edition 1.0 – Edition 4.7)
- 2004: SAP ERP Central Component (ECC)
- 2005: SAP ERP 6.0
o 2006: SAP Enhancement Package 1 for SAP ERP 6.0
o 2007: SAP Enhancement Package 2 for SAP ERP 6.0
o SAP Enhancement Package 3 for SAP ERP 6.0
o SAP Enhancement Package 4 for SAP ERP 6.0
o 2010: SAP Enhancement Package 5 for SAP ERP 6.0
o 2012: SAP Enhancement Package 6 for SAP ERP 6.0
o 2013: SAP Enhancement Package 7 for SAP ERP 6.0
o 2016: SAP Enhancement Package 8 for SAP ERP 6.0 - 2015: SAP S/4 Business Suite for HANA (auch: SAP S/4HANA oder abgekürzt: SAP S4)
Quelle: SAP ERP

Abb. 1: SAP-Versionen
Welche ECC-Versionen gibt es?
SAP ECC (SAP ERP Central Component) ist der Vorgänger von SAP S/4HANA. ECC 6.0 EHP 618 ist das letzte ECC-Release. Die „1“ in der Versionsnummer zeigt an, dass das System HANA-enabled ist.

Abb. 2: ECC-Versionen
Wie erkenne ich meine ECC-Version?
Wie finden Sie diese Information in Ihrem SAP System?
SAP Easy Access > System > Status > SAP-Systemdaten > Lupe bei Produktversion > Installierte Produktversionen

Abb. 3: ECC-Version erkennen
HANA-DB-enabled System erkennen
Wie finden Sie diese Information in Ihrem SAP System?
SAP Easy Access > System > Status > SAP-Systemdaten > Lupe bei Produktversion > Installierte Softwarekomponentenversionen
Wenn das Release der SAP_APPL-Komponente in der Mitte eine 1 hat, dann ist das System HANA-DB-enabled.

Abb. 4: HANA-DB-enabled System erkennen
The post Welche SAP-Version nutze ich? appeared first on j&s-soft.
]]>