2025年了谁还在用DVD文章首次出现在论野生技术&二次元。
]]>结果就是读出来全是错误。

播放出来大概是这样的:

然后我用mpv直接播放DVD里面的VRO文件,细心的我发现光驱刚开始转的时候画面是没有错误的,等光驱速度超级加倍之后就开始出现corrupt decoded frame。
脑子里出现了EAC三个大字。
于是我看了一眼盘上的标称速度。
草。这个DVD-RW的8cm盘最高读取速度只有2x,但是笨蛋光驱会用8x去读。然后我发现了这个宝贝:
 开心了再也没有数据错误了。
开心了再也没有数据错误了。
存档一下cdslow52en
2025年了谁还在用DVD文章首次出现在论野生技术&二次元。
]]>Windows 11 安装失败文章首次出现在论野生技术&二次元。
]]>
打开C:\$WINDOWS.~BT\Sources\Panther\setuperr.log,显示
指定的用户没有一个有效的配置文件:S-1-5-21-一串数字-1005
因为重试几次都是在接近100%时报错,因此和迁移用户数据阶段的可能性很大。
Windows开始引入安装助手不停机更新后,系统是用DISM部署到一个临时文件夹,然后迁移注册表和用户数据。
打开C:\$WINDOWS.~BT\Sources\Panther\setupact.log
2024-10-21 00:22:08, Warning MIG Duplicate profile detected for user S-1-5-21-一串数字-1005(C:\Users\defaultuser100000) vs. S-1-5-21-一串数字-1003(C:\Users\defaultuser100000).
因为我就一个账户,所以打开注册表HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\ProfileList,
删除1001以上的所有账户。
Google 说default10000是忘记密码的时候建的临时用户,然后我在注册表里看到最大的SID到了1008,所以我忘记了7次密码吗草
Windows 11 安装失败文章首次出现在论野生技术&二次元。
]]>Sunshine 的权限提升实现的坑文章首次出现在论野生技术&二次元。
]]>但是当前会话是RDP时,Windows会分配一个nobody用户,然后给WTSGetActiveConsoleSessionId里返回0。从而后面获取不到用户的token。
在这个贴子中,有人提到了遍历所有的会话,过滤掉不活动的和获取不到token的会话,从而一找到个实际登录的用户。
有了这个修复之后,只要使用物理显示器登录一次,或者用Sunshine 中的 Desktop 程序登录之后,实际串流即可找到正确的用户来提升权限。
我把它和打包出来的二进制放到了这里:
https://github.com/fffonion/Sunshine/releases/tag/0.21-fix
Sunshine 的权限提升实现的坑文章首次出现在论野生技术&二次元。
]]>Sunshine 云原神配置记录文章首次出现在论野生技术&二次元。
]]>下载Sunshine
下载地址 https://github.com/LizardByte/Sunshine/releases/tag/v0.21.0
如果你平时根本不开显示器而用远程桌面登录,需要这个fix https://github.com/fffonion/Sunshine/releases/tag/0.21-fix
如果使用portable版,需要运行 scripts/install-service.bat 安装服务,用来支持后面的权限提升操作。
安装Amyuni 虚拟显示驱动
下载地址 https://www.amyuni.com/forum/viewtopic.php?t=3030
因为显卡需要检测到连接的显示器才会输出视频信号,安装虚拟显示驱动即可不插显示器串流。
另外,也可以购买HDMI诱骗器。
配置远程桌面
非必需,用来手滑误操作时的救援。
注意,远程桌面也使用了虚拟显示器,并且在开启远程桌面时,会屏蔽其他所有的显示器。因此串流时应关闭远程桌面,另外也不能在远程桌面中直接启动 Sunshine,否则会检测不到正确的显示器。可以使用以下命令
timeout 10 && D:\Sunshine\sunshine.exe
在远程桌面中运行后,立即关闭远程桌面,即可在非远程桌面环境中启动 Sunshine。
查找虚拟显示器序号
在 Sunshine 目录中,运行 scripts\dxgi-info.exe 程序,寻找除了 \\.\DISPLAY1 以外的显示器。
配置 Sunshine
- 在 Applications 选项卡中,点击 + Add New
- 在 Command 中,填写下列命令打开触摸UI
"D:\Genshin Impact Game\YuanShen.exe" use_mobile_platform -is_cloud 1 -platform_type CLOUD_THIRD_PARTY_MOBILE -borderless -popupwindow
- 如果用来给 PC 客户端串流,填写
"D:\Genshin Impact Game\YuanShen.exe" -borderless -popupwindow
- 勾选 Run as administrator
- 点 Save 保存
自动适配分辨率
在新建的 Application 的 Do Command 中添加如下项
- 添加客户端的分辨率到虚拟显示器
cmd /C reg add "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\WUDF\Services\usbmmIdd\Parameters\Monitors" /v "2" /t REG_SZ /d %SUNSHINE_CLIENT_WIDTH%,%SUNSHINE_CLIENT_HEIGHT% /f
- 关闭虚拟显示器
cmd /C D:\usbmmidd_v2\deviceinstaller64.exe enableidd 0
- 打开虚拟显示器(使新分辨率可用)
cmd /C D:\usbmmidd_v2\deviceinstaller64.exe enableidd 1
- 设置主显示器为虚拟显示器,注意修改 5 为上一步中找到的虚拟显示器序号
cmd /C D:\Games\Tools\MultiMonitorTool.exe /SetPrimary 5
另外,在Undo Command中填写
cmd /C D:\Games\Tools\MultiMonitorTool.exe /SetPrimary 1
用来恢复默认主显示器
- 设置虚拟显示器分辨率
cmd /C D:\Games\Tools\QRes.exe /X:%SUNSHINE_CLIENT_WIDTH% /Y:%SUNSHINE_CLIENT_HEIGHT%
- 设置O神的分辨率(宽度)
cmd /C reg add HKCU\Software\miHoYo\原神 /v "Screenmanager Resolution Width_h182942802" /t REG_DWORD /d %SUNSHINE_CLIENT_WIDTH% /f
- 设置原O的分辨率(高度)
cmd /C reg add HKCU\Software\miHoYo\原神 /v "Screenmanager Resolution Height_h2627697771" /t REG_DWORD /d %SUNSHINE_CLIENT_HEIGHT% /f
以上所有命令均需要勾选 Elevated 复选框。
如果在运行时遇到权限提升失败,检查服务是否已启用,并可以尝试重启 Sunshine。
安装 Moonlight 客户端
手机端使用 阿西西大佬 修改的多点触控版本 https://www.bilibili.com/video/BV1Si4y1Y7Jb/。
iOS可以使用 sideloadly 自签名安装。
PC端使用官方客户端即可。
进入后,在 Settings 中设置分辨率为当前设备的分辨率;手机端的Touch Mode 选择 Touchscreen。
配置 Wireguard 公网串流
在路由器端配置 Wireguard 隧道,或者在手机端配置 Wireguard 隧道,并设置路由规则。
登录Windows
使用Sunshine 的 Desktop 程序,或者在物理显示器上登录一次。注意远程桌面登录的没用。
效果
30M码率在 iPad Mini 6上流畅地公网串流,PC端开启1.5倍渲染高画质,比官方的云原神(10M码率)清晰不少,画质也提高了w
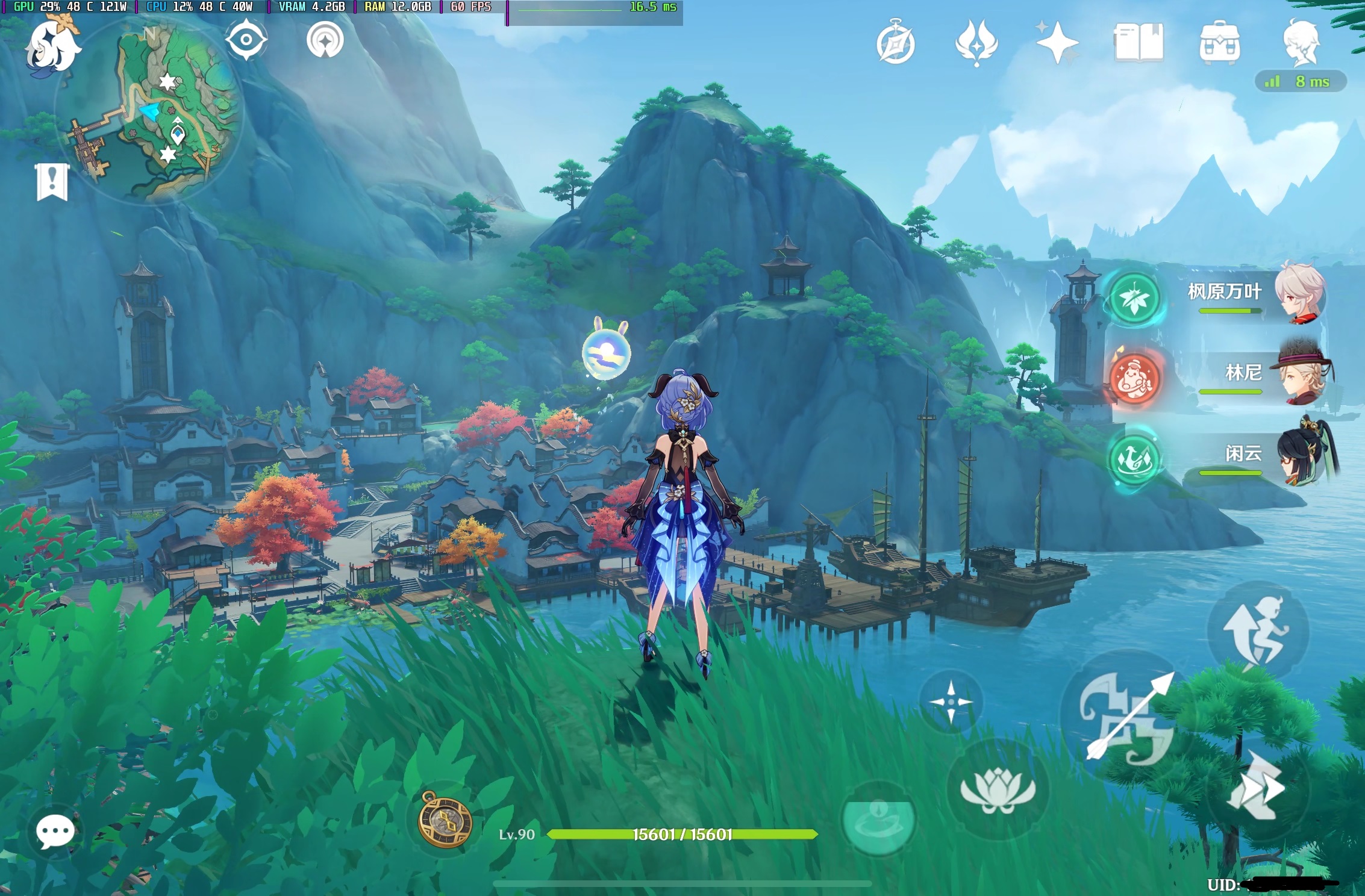
官方云原神:
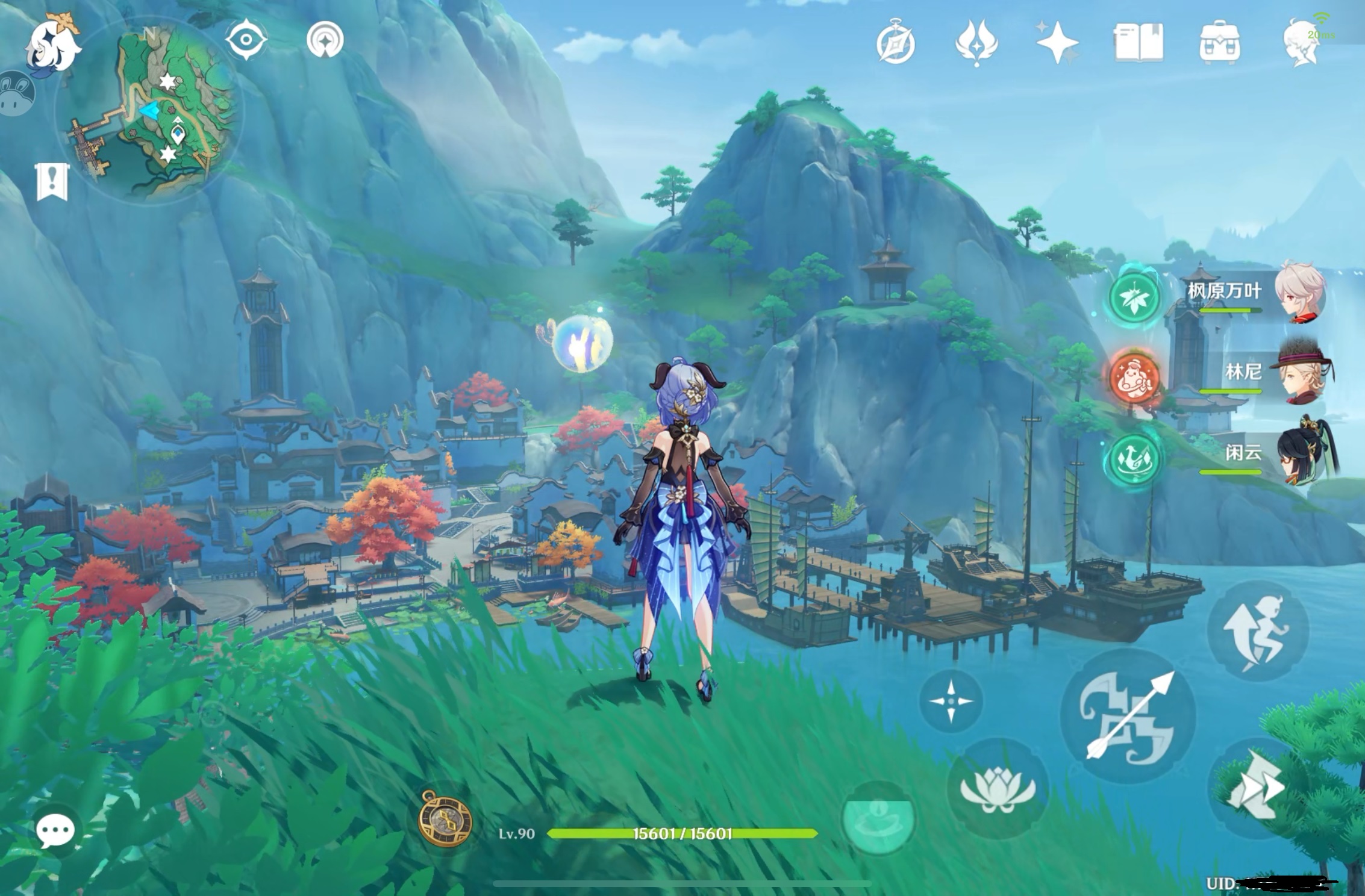
Sunshine 云原神配置记录文章首次出现在论野生技术&二次元。
]]>nginx配置HTTP/3的注意事项文章首次出现在论野生技术&二次元。
]]>打开reuseport
在多worker配置下需要打开HTTP/3端口的reuseport选项,否则会导致两个UDP包被不同的worker处理,从而客户端报ERR_DRAINING错误。
多个Host在同一个端口监听的话,只需在其中的任意一个listen directive中添加reuseport。
把$http_host替换成$host
由于HTTP/3不再发送 Host 头而改用 :authority 伪头来,$http_host 变量变为空值。因此$http_host和ngx.var.http_host都需要改为$host和ngx.var.host。
添加Alt-Svc头
浏览器不会默认通过 HTTP/3 连接,但在看到 Alt-Svc 头后才开始尝试使用 HTTP/3 协议。
另外,随着http3的加入,http2从listen directive中被弃用,改为单独的http2 on/off; directive。
我将以上更改写成一个自动化脚本,用来批量更新多个nginx conf文件。
nginx配置HTTP/3的注意事项文章首次出现在论野生技术&二次元。
]]>最新的固件是 YT3-X90F_USR_S200400_2108170402_WW17_BP_ROW,Android 6.0.1。
带ENG字样的是工程版,很卡,不建议用。
S1xxxx开头的是Android 5.1系统。
开发者模式勾选OEM解锁后,进fastboot线刷。
]]>Do not set HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\MiniNT when trying to enable ReFS文章首次出现在论野生技术&二次元。
]]>This is wrong. The MiniNT section is to indicate the system is a WinRE or WinPE system, thus certain USBccid devices’ driver won’t load. Including SmartCard reader, Windows Hello (mostly implemented as an internal USB camera).
很多教程提到在注册表里添加HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\MiniNT项,并添加名为AllowRefsFormatOverNonmirrorVolume的DWORD值。
其实这是错误的利用了WinRE启用了ReFS作为系统盘的功能。在正常的系统中出现MiniNT项会导致系统认为这是WinRE系统,从而不加载基于USB的驱动,包括智能卡读卡器和Windows Hello 驱动(很多 Windows Hello 摄像头是通过USB连接的)。
Do not set HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\MiniNT when trying to enable ReFS文章首次出现在论野生技术&二次元。
]]>需要将 Disk2-2 退役,在StoragePool1 中加入 Disk1-3,将 Disk1-2 加入StoragePool2。
按如下操作
$Disk1_2 = Get-PhysicalDisk -FriendlyName 'Disk1-2' $Disk1_3 = Get-PhysicalDisk -FriendlyName 'Disk1-3' Add-PhysicalDisk -PhysicalDisks $Disk1_3 -StoragePoolFriendlyName 'StoragePool1' # 如果虚拟磁盘创建时使用的物理磁盘均为自动分配 Set-PhysicalDisk -FriendlyName 'Disk1-3' -Usage AutoSelect # 如果虚拟磁盘创建时使用的物理磁盘均为手动分配 Add-PhysicalDisk -VirtualDiskFriendlyName 'VirtualDisk1' -PhysicalDisks $Disk1_3 # 将物理磁盘移出存储池的同时,会开始Mirror磁盘的重建 Remove-PhysicalDisk -PhysicalDisks $Disk1_2 -StoragePoolFriendlyName 'StoragePool1' # 查看重建进度 Get-StorageJob # 确认修复和重建成功 Repair-VirtualDisk -FriendlyName 'VirtualDisk1' Remove-PhysicalDisk -PhysicalDisks $Disk1_2 -StoragePoolFriendlyName 'StoragePool1' Reset-PhysicalDisk -FriendlyName 'Disk1-2' # 以下同StoragePool1的修复过程 Add-PhysicalDisk -PhysicalDisks $Disk1_2 -StoragePoolFriendlyName 'StoragePool2' # Set-PhysicalDisk -FriendlyName 'Disk1-2' -Usage AutoSelect Add-PhysicalDisk -VirtualDiskFriendlyName 'VirtualDisk2' -PhysicalDisks $Disk1_2 Remove-PhysicalDisk -PhysicalDisks $Disk2_2 -StoragePoolFriendlyName 'StoragePool2' Get-StorageJob Repair-VirtualDisk -FriendlyName 'VirtualDisk2'
]]>
DietPi 怎样关闭登陆后自动update文章首次出现在论野生技术&二次元。
]]>cat >> /etc/bashrc.d/00_disable_dietpi_login.sh << EOF export G_DIETPI_LOGIN=1
DietPi 怎样关闭登陆后自动update文章首次出现在论野生技术&二次元。
]]>Ubuntu 22.04 / OpenSSH 8.9 使用 gpg-agent 登录报错 agent refused operation 的解决方法文章首次出现在论野生技术&二次元。
]]>如果客户端和服务端都升级到了8.9或以上,则成功协商使用这一KEX算法,这时如果使用 gpg-agent 的 SSH 功能签名则会报 agent refused operation。
打印 gpg-agent 的日志可看到报错为 Provided object is too large。
解决方法是在客户端(~/.ssh/config)或服务端(/etc/ssh/sshd_config)中禁用这个算法
KexAlgorithms [email protected]
同理 diffie-hellman-group16-sha512 和 diffie-hellman-group18-sha512 也应该被禁用,但它们优先级本来就很低。
如果仍然有问题,把Kex Host Key Algorithm也改一下,如改成
HostKeyAlgorithms ssh-ed25519
Ubuntu 22.04 / OpenSSH 8.9 使用 gpg-agent 登录报错 agent refused operation 的解决方法文章首次出现在论野生技术&二次元。
]]>Go中JSON解码非UTF-8二进制值的问题文章首次出现在论野生技术&二次元。
]]>首先我们可以确定msgpack没有问题,因为输入给msgpack解码数据就与输入值不一致。
我们使用lua-cjson来编码一个JSON,因为结果不是printable的,所以在外面加一层base64.encode
print(ngx.encode_base64(require("cjson").encode({a = "\134123"})))结果是eyJhIjoihjEyMyJ9。
在Python里解码它:
json.loads(base64.b64decode('eyJhIjoihjEyMyJ9').decode('raw_unicode_escape'))结果是{‘a’: ‘\x86123’}。没有问题,和输入一致。
在Go里解码它:
type A struct {
Data string `json:"a"`
}
b64 := "eyJhIjoihjEyMyJ9"
jsonEncoded, _ := base64.StdEncoding.DecodeString(b64)
var aa A
err = json.Unmarshal(jsonEncoded, &aa)
fmt.Println([]byte(aa.Data))结果是[239 191 189 49 50 51],可以看到\x86被解码成了\239 \191 \189即\xefbfbd,表示无效的UTF8字符。
这是因为Go默认采用UTF-8解码,如果field被标记为string,则json.Unmarshal会使用utf8.DecodeRune来尝试解码输入https://github.com/golang/go/blob/master/src/encoding/json/decode.go#L1304。但在我们的场景中,\x86是一个单字节的非UTF-8字符,所以utf8.DecodeRune返回了utf8.RuneError并把它放到了结果里。
那么到底是哪里出了问题呢?
首先,JSON的RFC指出,其中的字符串必须以UTF-8编码(https://datatracker.ietf.org/doc/html/rfc8259#section-8.1),但是同时也提到,除了几个特殊的字符外,其中的字符可以被escape也可以不escape(https://datatracker.ietf.org/doc/html/rfc8259#section-7)。所以lua-cjson的这种编码方式似乎也是合法的?
解决办法是写一个自己的Unmarshal方法。首先把结构体中的field标记为自定义类型:
type Payload struct {
A RawBytes `json:"a"`
}
type rawBytes []byte
func (r *rawBytes) UnmarshalJSON(b []byte) error {
unqoutedBytes, ok := unqouteBytes(b)
if !ok {
return fmt.Errorf("failed to uncode msgpacked data")
}
*r = unqoutedBytes
return nil
}然后我们魔改unquote方法,在原来的基础上加上对解码结果是否为utf8.RuneError的判断
// getu4 has been copied verbatim from
// https://github.com/golang/go/blob/2580d0e08d5e9f979b943758d3c49877fb2324cb/src/encoding/json/decode.go#L1167-L1188
func getu4(s []byte) rune {
if len(s) < 6 || s[0] != '\\' || s[1] != 'u' {
return -1
}
var r rune
for _, c := range s[2:6] {
switch {
case '0' <= c && c <= '9':
c = c - '0'
case 'a' <= c && c <= 'f':
c = c - 'a' + 10
case 'A' <= c && c <= 'F':
c = c - 'A' + 10
default:
return -1
}
r = r*16 + rune(c)
}
return r
}
// unqouteBytes converts a quoted literal []byte s.
// The rules are different than for Go, so cannot use strconv.Unqoute().
// This function is copied verbatim from
// https://github.com/golang/go/blob/2580d0e08d5e9f979b943758d3c49877fb2324cb/src/encoding/json/decode.go#L1198-L1310
// Please read the comment beginning with "PATCHED" below.
func unqouteBytes(s []byte) (t []byte, ok bool) {
if len(s) < 2 || s[0] != '"' || s[len(s)-1] != '"' {
return
}
s = s[1 : len(s)-1]
// Check for unusual characters. If there are none,
// then no unquoting is needed, so return a slice of the
// original bytes.
r := 0
for r < len(s) {
c := s[r]
if c == '\\' || c == '"' || c < ' ' {
break
}
if c < utf8.RuneSelf {
r++
continue
}
rr, size := utf8.DecodeRune(s[r:])
if rr == utf8.RuneError && size == 1 {
break
}
r += size
}
if r == len(s) {
return s, true
}
b := make([]byte, len(s)+2*utf8.UTFMax)
w := copy(b, s[0:r])
for r < len(s) {
// Out of room? Can only happen if s is full of
// malformed UTF-8 and we're replacing each
// byte with RuneError.
if w >= len(b)-2*utf8.UTFMax {
nb := make([]byte, (len(b)+utf8.UTFMax)*2)
copy(nb, b[0:w])
b = nb
}
switch c := s[r]; {
case c == '\\':
r++
if r >= len(s) {
return
}
switch s[r] {
default:
return
case '"', '\\', '/', '\'':
b[w] = s[r]
r++
w++
case 'b':
b[w] = '\b'
r++
w++
case 'f':
b[w] = '\f'
r++
w++
case 'n':
b[w] = '\n'
r++
w++
case 'r':
b[w] = '\r'
r++
w++
case 't':
b[w] = '\t'
r++
w++
case 'u':
r--
rr := getu4(s[r:])
if rr < 0 {
return
}
r += 6
if utf16.IsSurrogate(rr) {
rr1 := getu4(s[r:])
if dec := utf16.DecodeRune(rr, rr1); dec != unicode.ReplacementChar {
// A valid pair; consume.
r += 6
w += utf8.EncodeRune(b[w:], dec)
break
}
// Invalid surrogate; fall back to replacement rune.
rr = unicode.ReplacementChar
}
w += utf8.EncodeRune(b[w:], rr)
}
// Quote, control characters are invalid.
case c == '"', c < ' ':
return
// ASCII
case c < utf8.RuneSelf:
b[w] = c
r++
w++
// Coerce to well-formed UTF-8.
default:
// PATCHED: on RuneError, copy verbatim
rr, size := utf8.DecodeRune(s[r:])
if rr != utf8.RuneError {
r += size
w += utf8.EncodeRune(b[w:], rr)
} else {
b[w] = s[r]
r++
w++
}
}
}
return b[0:w], true
}还需要注意的是,Go的json包默认对[]byte类型的field进行base64编解码:
b, _ := json.Marshal(map[string][]byte{
"x": []byte{147},
})
fmt.Println("> ", b, string(b))结果是> [123 34 120 34 58 34 107 119 61 61 34 125] {“x”:”kw==”};同理Unmarshal时也会需要输入为base64编码结果。
因此在上面这个解决方法中,我们用rawBytes这个新类型来alias到[]byte,而并不直接使用[]byte类型再在之后自己解码。
发了一个issue:https://github.com/golang/go/issues/51094。
另外的JSON库没有这个问题,测试了https://github.com/json-iterator/go 和 https://github.com/bytedance/sonic 。
Go中JSON解码非UTF-8二进制值的问题文章首次出现在论野生技术&二次元。
]]>开源了咸鱼捡的京付的三色墨水屏驱动文章首次出现在论野生技术&二次元。
]]> 35块一个,长这样
35块一个,长这样

经过一番Google找到了对应的原厂屏,是Gooddisplay的GDEH042Z96,屏幕芯片是SSD1619A,这个芯片初始化序列比幻塔的新手教程还长。
整理了一下官方例程之后,发了一个PR:https://github.com/ZinggJM/GxEPD2/pull/47;有一些点需要注意:
- 三色屏(实际上是双色)是两种液晶分开刷新的,先刷黑色,再刷红色。其中SSD1619A的红色输入值需要取反,否则屏幕整块都是红的。
- 这块屏只支持全刷,全刷一次要20秒,要把GxEPD2的默认等待BUSY pin的时间调长。
效果如下图所示,用的是我魔改的中文版天气:https://github.com/fffonion/ESP32-e-Paper-Weather-Display

开源了咸鱼捡的京付的三色墨水屏驱动文章首次出现在论野生技术&二次元。
]]>LuaJIT中ctypes和FFI的一点杂谈文章首次出现在论野生技术&二次元。
]]>因为听到了两声雷,所以要发两篇博客。
——鲁迅
这篇博客来聊聊LuaJIT FFI里面ctypes的实现。
FFI全称是Foreign Function Interface即异世界语言接口,LuaJIT中使用FFI可以调用其他语言编译的库。
一个示例如下:
local ffi = require("ffi")
local C = ffi.C
ffi.cdef [[
typedef unsigned int time_t;
typedef unsigned int suseconds_t;
typedef struct timeval {
time_t tv_sec;
suseconds_t tv_usec;
} timeval;
typedef struct timezone {
int tz_minuteswest;
int tz_dsttime;
} timezone;
int gettimeofday(struct timeval *tv, struct timezone *tz);
]]
local tv = ffi.new("timeval[1]")
local tz = ffi.new("timezone[1]")
C.gettimeofday(tv, tz)
print(tv[1].tv_sec)
print(tz[1].tz_dsttime)
print("tv_sec in timeval offset:", ffi.offsetof(tv[1], "tv_sec"))
print("tv_usec in timeval offset:", ffi.offsetof(tv[1], "tv_usec"))以上示例会输出
991970
0
tv_sec in timeval offset:0
tv_usec in timeval offset:4
有关FFI的具体语法不想写了,感兴趣的朋友可以看LuaJIT关于FFI的四篇文档。看完之后可以再看看同事的一个讲座。
在上面这个示例中,我们定义了time_t和suseconds_t作为int_t的别名,timeval和timezone两个结构体,和gettimeofday这个函数的签名。简单地说,FFI首先会在当前进程映像中找到gettimeofday的偏移,由于这个C函数在libc中实现,所以一定会在当前映像中找到。根据函数签名,将输入值按定义的数据类型长度压入栈中;然后,当取值时,FFI根据当前平台和架构计算结构体中每个成员的偏移量,然后直接取出内存中对应偏移下对应字长的数据。
虽然ffi.cdef定义时的语法和C一样,但是FFI并没有真正编译它,而只是将它们按规则转换成偏移量,并且记录下来。
不论是enum,typedef还是function,LuaJIT FFI都用一种ctypes来表示它。为了方便用户不用重新定义像uint32_t这样的类型,LuaJIT自带了95种初始的ctypes。在这里推荐一个工具parseback,可以方便查看各个已定义的ctypes的类型。这个工具依赖的是一个没有文档的方法ffi.typeinfo:
local pp = require("parseback.parseback")
for i=1,95 do
print(i, ":", pp.typeinfo(i).c)
end输出:
1:void
2:const void
3:bool
4:const char
5:char
6:unsigned char
7:short
8:unsigned short
9:int
10:unsigned int
11:long
12:unsigned long
13:float
14:double
15:complex float
16:complex double
17:void *
18:const void *
19:const char *
20:const char [0]
21:enum { }
22:typedef void * va_list;
23:typedef void * __builtin_va_list;
24:typedef void * __gnuc_va_list;
25:typedef long ptrdiff_t;
26:typedef unsigned long size_t;
27:typedef int wchar_t;
28:typedef char int8_t;
29:typedef short int16_t;
30:typedef int int32_t;
31:typedef long int64_t;
32:typedef unsigned char uint8_t;
33:typedef unsigned short uint16_t;
34:typedef unsigned int uint32_t;
35:typedef unsigned long uint64_t;
36:typedef long intptr_t;
37:typedef unsigned long uintptr_t;
38:typedef long ssize_t;
39:/* keyword void: 269 */
40:/* keyword _Bool: 270 */
41:/* keyword bool: 270 */
42:/* keyword char: 271 */
43:/* keyword int: 272 */
44:/* keyword __int8: 272 */
45:/* keyword __int16: 272 */
46:/* keyword __int32: 272 */
47:/* keyword __int64: 272 */
48:/* keyword float: 273 */
49:/* keyword double: 273 */
50:/* keyword long: 274 */
51:/* keyword short: 276 */
52:/* keyword _Complex: 277 */
53:/* keyword complex: 277 */
54:/* keyword __complex: 277 */
55:/* keyword __complex__: 277 */
56:/* keyword signed: 278 */
57:/* keyword __signed: 278 */
58:/* keyword __signed__: 278 */
59:/* keyword unsigned: 279 */
60:/* keyword const: 280 */
61:/* keyword __const: 280 */
62:/* keyword __const__: 280 */
63:/* keyword volatile: 281 */
64:/* keyword __volatile: 281 */
65:/* keyword __volatile__: 281 */
66:/* keyword restrict: 282 */
67:/* keyword __restrict: 282 */
68:/* keyword __restrict__: 282 */
69:/* keyword inline: 283 */
70:/* keyword __inline: 283 */
71:/* keyword __inline__: 283 */
72:/* keyword typedef: 284 */
73:/* keyword extern: 285 */
74:/* keyword static: 286 */
75:/* keyword auto: 287 */
76:/* keyword register: 288 */
77:/* keyword __extension__: 289 */
78:/* keyword __attribute: 291 */
79:/* keyword __attribute__: 291 */
80:/* keyword asm: 290 */
81:/* keyword __asm: 290 */
82:/* keyword __asm__: 290 */
83:/* keyword __declspec: 292 */
84:/* keyword __cdecl: 293 */
85:/* keyword __thiscall: 293 */
86:/* keyword __fastcall: 293 */
87:/* keyword __stdcall: 293 */
88:/* keyword __ptr32: 294 */
89:/* keyword __ptr64: 294 */
90:/* keyword struct: 295 */
91:/* keyword union: 296 */
92:/* keyword enum: 297 */
93:/* keyword sizeof: 298 */
94:/* keyword __alignof: 299 */
95:/* keyword __alignof__: 299 */可以看到许多关键词也被加入了初始列表中,这是为了防止熊孩子乱用关键词做类型名称。
parseback工具还能生成一个dot图来描述ctype,我们来看看之前的gettimeofday是怎么表示的:
local i = 96
while true do
if not ffi.typeinfo(i) then
i = i-1
break
end
i = i + 1
end
print(pp.dot(i))因为OpenResty也定义了一堆FFI类型,所以我们用一个循环来寻找ctypes表里面的最后一个类型,然后用以下命令
resty test.lua | dot -Tpng > 1.png
得到这样的图:

这个图好像有点复杂,我们先看看其中id为460的timeval结构体。

首先它的类型是CT_STRUCT,代表它是一个结构体的开始。
它的size是8,FFI通过这个属性知道当ffi.new(“timeval”)被调用时,需要分配多少内存。
它的cid(child ID)是0,这里先跳过。
它有一个sid(sibling ID)属性,值为461,它代表单链表的下一个成员。timeval由两个成员构成,分别是tv_sec和tv_usec;两个成员都有指为10的cid,对CT_FIELD来说,cid代表这个成员的类型,在这里它们都是size为4的CT_NUM。LuaJIT不会在类型上区分int,uint,long,它们都是CT_NUM,区别在于size和unsigned标记。如id为10的类型就是一个unsigned int。tv_usec的offset是4,代表它在结构体里的偏移量;当取timeval的tv_usec成员时,FFI跳过4字节,取它的类型长度也就是4字节内存。
我们再回到前一张复杂的图。
gettimeofday是个CT_FUNC类型的ctype,也就是function;当一个ctype是CT_FUNC时,它的cid表示返回值的类型,这个例子里是9,也就是signed int。
对一个CT_FUNC来说,sid代表参数列表的类型。sid值是469,指向了名为tv的CT_FIELD,它代表一个成员名称;LuaJIT在存储函数类型时,其实和存储一个结构体是类似的。id为469的CT_FIELD的cid为468,表示它的类型是468;468是一个指针CT_PTR,指向id是460的timeval结构体CT_STRUCT。连起来就是说,它是一个*timeval。
理解了这个之后,我们来看下面的故事。LuaJIT FFI中,你可以把一个lua函数作为回调函数传回FFI中,例如:
local ffi = require("ffi")
ffi.cdef [[
typedef void (*callback)(int param);
int function invoke(callback cb, int a);
]]
ffi.C.invoke(function(param)
-- do something
end, 1)当然在C里,你也可以:
typedef void (callback)(int param);
int function invoke(callback *cb, int a);
void function myCallback(int a) {
}
invoke(myCallback, 1);这样在FFI里可以写成:
local ffi = require("ffi")
ffi.cdef [[
typedef void (callback2)(int param);
int function invoke(callback2 *cb, int a);
]]
local pp = ffi.cast("callback2*", function(param)
-- do something end
end)
ffi.C.invoke(pp, 1)
pp:free()看起来没问题对吧,但是我们如果我们多次循环ffi.cast:
while true do
local pok, pp = pcall(ffi.cast, "cb1*", function() end)
if not pok then
print(pp)
break
end
if pp then pp:free() end
end最终会报错”table overflow”,这个错误来自https://github.com/LuaJIT/LuaJIT/blob/1e66d0f9e6698fdee672c40a9a5b4159c9254091/src/lj_ctype.c#L158,因为某种原因存储ctypes的表被填满了。它的上限是65535。我们来看看它被什么填满了:

是一个匿名指针,指向一个匿名函数,它的返回值是void。毫无疑问我们的ffi.cast(“callback2*”, …)会在每次调用时创建两个新的ctype。
在LuaJIT的代码里,ffi.cdef,ffi.new,ffi.cast都会经过同一段C parser的代码段lj_cparse的cp_decl_intern函数里,因为除了在cdef中定义类型外,我们也可以在new和cast里定义匿名结构体,所以这些函数都能产生新的ctype。
在这个函数里,当一个符号被认定为function,它就会无条件地新建一个新的ctype。在我们的写法里,typedef void (callback2)(int param);定义了一个名为callback2的“函数类型”,然后在ffi.cast里,cparser解析了callback2,为它创建了一个新的CT_FUNC类型,然后解析了*,新建了一个指针指向新的CT_FUNC。
实际上,LuaJIT确实是可以通过一些额外的标志位来使ffi.cast不会创建新的函数类型的。CType这个类型可以增加一个新的成员,来记录自己的id,通过这种办法,当解析为CT_FUNC时,如果这个id已赋值,则可以直接使用已有的ctype。我尝试了一个简单的patch来验证我的想法,证明了它的可行性;但是没有跑完整的测试集。
我在issues里提问了这个问题,Mike Pall小哥热心地回复了我。当然作者选择目前这种做法确实是更简洁的;而且本身对“函数类型”的typedef,可以有不同角度的理解。所以以后记得写回调函数的时候,定义一个正常的“函数指针”就好了。
LuaJIT中ctypes和FFI的一点杂谈文章首次出现在论野生技术&二次元。
]]>自定义字体反爬虫方法的对抗文章首次出现在论野生技术&二次元。
]]>我说好啊好啊,这就来发博客。
我们先来看这段网页:

无限好文,尽在jjwxc
注意HTML中,许多字符的显示是方框。检查HTML源代码后发现,有些字符被替换成了这样的编码。

在第一张图中,可以发现当前的段落应用了名为jjwxcfont_00294的自定义字体。“气”字对应的UTF-8编码是6c14,GBK编码是c6f8,BIG5中是c9a,我觉得按照jj的技术水平,应该不会想到用别的编码集;所以e7ba应该不属于任何标准的编码集。而‌ 是防止粘连的特殊字符,因为使用非标准的编码,浏览器渲染时可能会把字符误当成粘连字符而和一个正常的字符重叠;在爬虫处理过程中直接去除即可。
解析字体
我们把这个自定义字体下载下来,然后用python的fonttools列举出其中所有的字符:
import re
import requests
import subprocess
from fontTools.ttLib import TTFont
ttf_path = "00294.ttf"
# xiazai
ttf_content = requests.get("http://static.jjwxc.net/tmp/fonts/jjwxcfont_00294.ttf")
with open(ttf_path, "wb") as f:
f.write(ttf_content.content)
# jiexi
ttf = TTFont(ttf_path, 0, allowVID=0, ignoreDecompileErrors=True, fontNumber=-1)
ttf_chars = set()
for x in ttf["cmap"].tables:
for y in x.cmap.items():
char_unicode = chr(y[0])
if char_unicode == "x":
continue
ttf_chars.add(char_unicode)注意有些TTF字体中包含一个编码的多个字形,所以我们用set()来去重;并且舍弃了”x”字符。
因为无法辨认自定义字体中的编码对应的真实汉字,我们使用ImageMagick工具包中的convert来渲染字体,并且每行20个字符来分段,防止出现超长的棍子图片:
PER_LINE = 20
txt_path = ttf_path + ".txt"
img_path = ttf_path + ".jpg"
chars = list(ttf_chars)
# fenduan xieru suoyou zifu
with open(txt_path, "w") as f:
f.write("\n".join(["".join(chars[i:i+PER_LINE]) for i in range(0, len(chars), PER_LINE)]))
# shengcheng tupian
subprocess.call(["convert", "-font", ttf_path, "-pointsize", "64", "-background", "rgba(255,255,255)",
"label:@%s" % txt_path, img_path])完成后得到如下图片:

我合理怀疑这就是微软雅黑
可以看到其中包含了200个常用字。通过翻阅章节可以发现自定义字体有复数多个,且其中每个字对应的内部编码均不相同,所以接下来我们需要一种自动化的方法来将自定义字体中的编码映射回原始文字。
识别字体
这里我们使用开源的tesseract工具来进行OCR识别。2021年了,tesseract都用上神经网络了,你还有理由不学点AI吗?

随便找的图,并不是恰饭
因为tesseract默认只能识别英语和数字,我们需要安装简体中文训练数据(chi_sim),可以从tessdata项目获得。安装完成后,验证训练数据能被加载:
$ tesseract --list-langs List of available languages (4): chi_sim eng osd snum
然后我们调用tesseract来识别字符:
tesseract_result = "00294"
subprocess.call(["tesseract", img_path, tesseract_result, "-l", "chi_sim", "--psm", "6"])
char_map = {}
with open(tesseract_result + ".txt") as f:
# remove single byte characters
ct = re.sub("[\x00-\x7F]+", "", f.read())
if len(chars) != len(ct):
raise Exception("%d chars but %d recognized" % (len(chars), len(ct)))
for i in range(len(chars)):
char_map["%x" % ord(chars[i])] = ct[i]
print(char_map)注意因为自动分段和分词的问题,tesseract会识别出奇怪的拉丁字符和数字,我们通过正则表达式把它们连同空白字符一起去除。
最后得到结果:
{'e2c7': '不', 'e8f0': '大', 'e7ba': '气', 'e803': '高', 'e0fe': '笑', 'e354': '行', 'eca5': '小', 'ece7': '代', 'ecdf': '者', 'e127': '重', 'eeb7': '中', 'e681': '要', 'e36e': '说', 'e306': '还', 'ef8c': '力', 'e809': '用', 'e9b9': '四', 'e737': '名', 'e589': '发', 'eb85': '种', 'ee46': '无', 'e3f5': '民', 'eec1': '事', 'e45a': '思', 'eaa5': '把', 'e851': '理', 'ef10': '法', 'e655': '关', 'e07f': '与', 'e21b': '到', 'ef9e': '三', 'efe8': '之', 'ed39': '由', 'e959': '起', 'e946': '声', 'e321': '问', 'e0b9': '得', 'e1c0': '回', 'e47b': '有', 'e800': '书', 'e9cb': '再', 'ebd8': '以', 'e45b': '也', 'e76e': '去', 'e05d': '对', 'e599': '性', 'ea48': '己', 'e966': '走', 'eefa': '子', 'e6aa': '两', 'e5b2': '分', 'eb7e': '老', 'eba0': '死', 'e370': '话', 'e6b1': '后', 'e793': '生', 'ecdc': '西', 'e8e4': '了', 'e435': '主', 'e523': '都', 'e8c4': '真', 'e9fb': '物', 'ea94': '个', 'e41c': '只', 'e84f': '会', 'e609': '正', 'e692': '别', 'e6b5': '少', 'e50e': '道', 'e0af': '文', 'e776': '而', 'e11c': '更', 'e85a': '于', 'e50d': '看', 'e799': '着', 'ee0c': '身', 'e3f1': '然', 'ef56': '这', 'e143': '二', 'e00f': '间', 'ee9d': '相', 'e9a6': '成', 'e438': '公', 'e2f2': '过', 'ea59': '向', 'e159': '样', 'e877': '又', 'eacc': '同', 'ece8': '意', 'ee49': '因', 'eefd': '听', 'ee8f': '论', 'eeaf': '见', 'e652': '十', 'eea4': '第', 'e5e2': '定', 'e4ba': '前', 'e070': '动', 'e52d': '神', 'eae9': '史', 'e64e': '却', 'e7df': '知', 'e430': '那', 'e87a': '门', 'e732': '眼', 'e183': '给', 'e772': '部', 'efbc': '上', 'e037': '它', 'edae': '才', 'e895': '体', 'e1b5': '点', 'e731': '学', 'e84a': '头', 'ec45': '口', 'ea25': '已', 'ee72': '在', 'efa8': '能', 'e6d2': '我', 'ed78': '义', 'eb7b': '是', 'ea6a': '国', 'eeb2': '感', 'e52b': '白', 'e68a': '可', 'e2d8': '就', 'e8b6': '家', 'eba9': '美', 'e974': '便', 'eec2': '日', 'e7f6': '社', 'e5cd': '年', 'ed1a': '长', 'efe7': '并', 'e525': '里', 'eb89': '太', 'ea6e': '她', 'e26b': '他', 'e2e3': '被', 'e663': '世', 'efa4': '使', 'e296': '化', 'e6de': '何', 'ee87': '好', 'eccd': '多', 'e4e2': '几', 'e156': '最', 'e727': '本', 'e3fb': '些', 'e498': '等', 'efd8': '没', 'efe3': '来', 'e997': '外', 'eb0c': '其', 'ea98': '下', 'e878': '什', 'e5d7': '地', 'e14b': '如', 'e7a7': '你', 'ec5d': '全', 'edd1': '天', 'e0c5': '出', 'e18f': '特', 'e866': '女', 'e01d': '们', 'e8ed': '想', 'ecab': '一', 'e45f': '打', 'e9dd': '此', 'ee50': '但', 'eb9d': '时', 'e0c6': '力', 'eb62': '先', 'eef4': '作', 'e1fc': '实', 'e58b': '儿', 'ef2f': '教', 'e094': '方', 'ec21': '情', 'e17b': '人', 'e134': '进', 'e51f': '当', 'e0b6': '和', 'e2be': '将', 'e7a2': '自', 'ea8c': '心', 'ec70': '明', 'ee0d': '手', 'e7e2': '很', 'e56e': '开', 'eea1': '的', 'e360': '面', 'e0cb': '现', 'e35a': '所', 'e2dd': '从', 'eaff': '经', 'eefc': '么', 'efe5': '写', 'eb04': '果', 'e99b': '新'}之前看到的e7ba确实被成功识别成了“气”。
提高效率和准确率
使用OCR当然是简单,但是一来速度慢(包好200个字符的单个字体需要5~10秒),二来由于没人知道神经网络里面具体发生了什么,在不同的字符排列顺序下,可能会出现误识别。通过比较OCR识别结果和字体中的Glyph(可以认为是字体中每个字的矢量表示)我们可以发现:
- 这个网站的所有字体中使用了相同的200个常用字
- 所有字体中代表相同字的Glyph路径完全相同
那么我们可以作出以下的优化:
- 在生成图片时,将字符按已知可正确识别的特定顺序排序(但实现起来还是比较冗杂)
- 比较所有的OCR结果,如果有多个字体的OCR结果相同,则认为是可信的
- 将可信结果中的某个字体的Glyph路径作为参考,与新字体的Glyph路径比较;如果相同则认为是同一个字
- 如果未来jj随机化Glyph中的坐标点,也可以分别计算每个点的距离,在一定范围内则认为近似相同
- 持续用OCR结果来验证路径比较结果
我把除了第一点的完整实现代码分享到了JJGet项目,链接中是一个服务端,将处理结果返回给JJGet。目前测试结果非常理想,感兴趣的朋友可以去康康。
自定义字体反爬虫方法的对抗文章首次出现在论野生技术&二次元。
]]>Hashicorp Nomad的坑文章首次出现在论野生技术&二次元。
]]>network allocation配额没有明确的提示
Nomad的文档以及各种Grafana dashboard都没有提到node上的network allocation其实是有上限的,虽然metrics里是有这一项的(nomad_client_allocated_network/nomad_client_unallocated_network)。具体如何计算尚不明确,可能需要看代码。我们的EC2上有看到500Mb和1000Mb的上限。
如果不指定,默认每个task占用100Mb的速度(见文档),这是一个硬上限,如果node完全被allocate的时候,超过这个限制的容器会被限速。个人觉得Nomad的这个设计是坑爹的,网速这类资源相比于CPU和内存是更加体现突发的特性的,如果只能设置硬性上限,利用率显然会非常低。这个是上个世纪的QoS了吧。
allocation启动时的template re-render
这是一个bug:https://github.com/hashicorp/nomad/issues/5459。如果用了集成的consul-template来做服务发现,某些情况下可能在allocation启动过程中触发re-render,从而nomad client向容器发送信号;但当容器还没起来的时候,nomad client会拒绝发送信号并且把这个容器干掉,并且不会尝试重新启动。
也不知道是哪个神仙想出来的这种奇葩设计。

system类型的task
如果一个task是system类型, 那它会在所有满足条件的node上运行。但是它默认的restart参数很容易会因为一些临时性的错误让整个task挂掉,我们重新设置了restart参数
restart {
attempts = 60 # attempts no more than interval / delay
mode = "delay"
delay = "5s"
interval = "5m"
}
容器里的单个端口无法映射成多个端口
docker里我们可以把容器里的一个端口映射成任意多个端口;但是nomad无法做到,看起来像是处理job definition时的一个bug(issue链接)。
下面的配置,只有8001端口会被映射;http1这个端口在port_map里被http2覆盖了。
job "test" {
group "test" {
task "test" {
driver = "docker"
config {
image = "nginx:latest"
port_map = {
http1 = 80
http2 = 80
}
}
resources {
network {
port "http1" {
static = 8000
}
port "http2" {
static = 8001
}
}
}
}
}
}下面的配置不会报错,但是仍然只有8001会被映射。
job "test" {
group "test" {
task "test" {
driver = "docker"
config {
image = "nginx:latest"
port_map = {
http1 = 80
}
}
resources {
network {
port "http1" {
static = 8000
static = 8001
}
}
}
}
}
}解决的办法是在容器内开多个端口,分别映射到不同的外部端口。
terraform provider无法检查nomad job的更改
远古bug: https://github.com/hashicorp/terraform-provider-nomad/issues/1
如果在terraform外部修改了nomad的job定义,在terraform provider里是无法检测到的。
不是很懂那我有它何用?
Hashicorp Nomad的坑文章首次出现在论野生技术&二次元。
]]>