From finding to verified PR.
11 stages. Zero LLM-judges-LLM.
A bug report goes in. A verified pull request comes out. 11 stages in between, zero prompts. Backed by 66 MCP tools, 64 deterministic HOR rules, 5 science-backed git analytics, and 7 verification algorithms. Every claim traces to a paper.
> /plugin install ai-architect
Requires macOS 14+ with Apple Silicon (M1/M2/M3/M4)
What you get
$ /ai-architect:run-pipeline [00/10] Health Check ............... PASS 0m 08s [01/10] Discovery .................. PASS 1m 24s [02/10] Impact & Compound Score .... PASS 2m 12s [03/10] Integration Design ......... PASS 3m 05s [04/10] PRD Generation ............. PASS 14m 18s [04.5] Plan Interview (10-dim) ... PASS 2m 47s [05/10] Review (7 verifiers) ....... PASS 6m 33s [06/10] Implementation ............. PASS 22m 41s [07/10] Verification (64 HOR) ...... PASS 4m 16s [08/10] Benchmark .................. PASS 1m 22s [09/10] Deployment (544 tests) ..... PASS 2m 08s [10/10] Pull Request + Cortex ...... PASS 0m 52s Pipeline complete. PR #142 created. 12 files changed, 1,847 insertions(+), 203 deletions(-) Cortex: 4 memories stored for next session
What this pipeline does
It takes a finding and ships a verified pull request without asking you anything.
Give it a bug report, a feature request, a research paper, or any actionable input. The pipeline parses it, scores the impact with compound scoring (relevance × uniqueness × impact × confidence), designs the integration, generates a verified PRD, runs a 10-dimension Plan Interview gate, implements the code, runs 7 verification algorithms, executes the full test suite, benchmarks the result, and opens a pull request. One command: /ai-architect:run-pipeline.
It is not magic. The pipeline is 11 sequential stages (0-10), each with defined inputs, outputs, and failure modes. When a stage fails, it retries with the failure context — up to 3 times — before moving on. 64 deterministic HOR rules across 10 categories (structural, security, resilience, observability, etc.) enforce output quality. Zero LLM-judges-LLM: verification is algorithmic, not prompted.
Built on three MCP servers: ai-architect (49 orchestration tools), ai-codebase-intelligence (17 typed graph tools with tree-sitter parsing for 13 languages), and cortex (optional persistent memory). 544 tests passing. Every algorithm traces to a published paper.
It works with Python, TypeScript, Swift, Go, Rust, Java, Kotlin, C#, Ruby, PHP, C, C++, and JavaScript — through configuration, not code changes. Dogfoods itself: this pipeline shipped its own refactoring PRs.
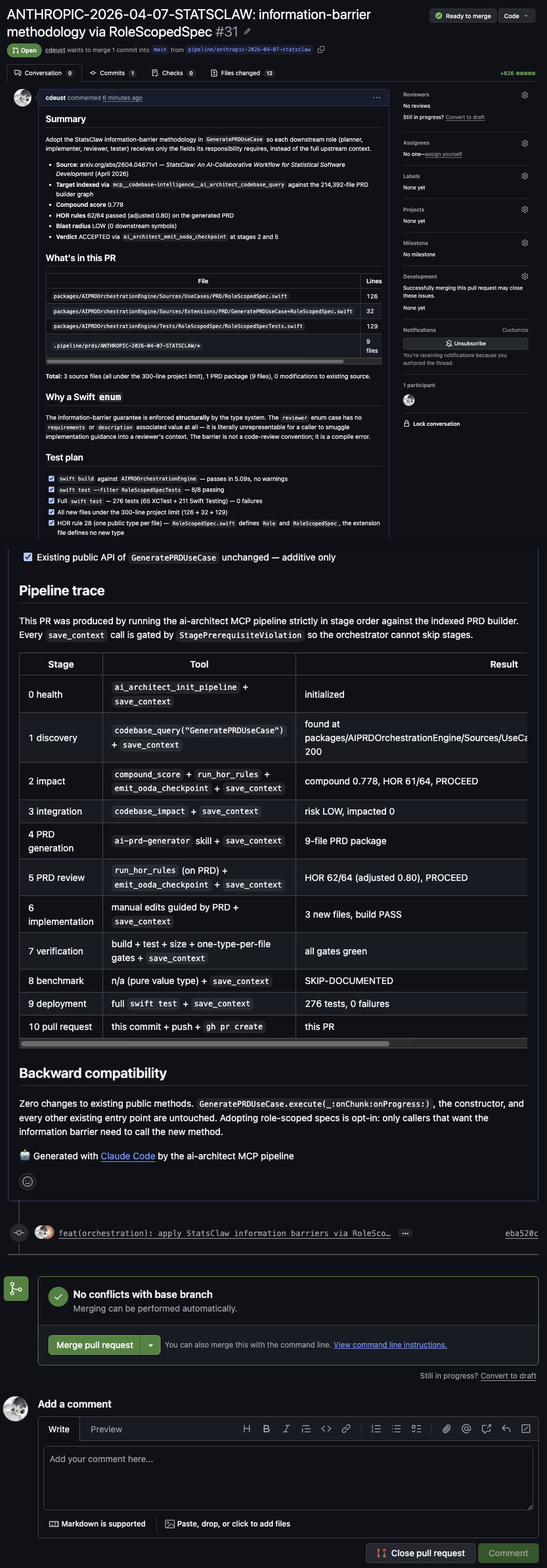
Real example — verified end-to-end
Not a demo. An actual PR shipped through the pipeline: compound score 0.778, HOR 62/64, 276 tests 0 failures, ready to merge. Every stage traced with the exact tool and result.
Get Started in 2 Commands
Install, run. The pipeline handles the rest.
Install the plugin
> /plugin marketplace add cdeust/ai-architect-mcp
> /plugin install ai-architect
Start the pipeline
> /ai-architect:run-pipeline
The pipeline discovers findings, analyzes impact, generates a PRD, implements code, verifies the result, and delivers a pull request.
11 stages, zero LLM-judges-LLM
Each stage runs autonomously with defined inputs and outputs. When a stage fails, the pipeline retries with the failure context. Every verification is algorithmic — no LLM evaluates another LLM's output.
00 Stage 0 — Health Check
Validates all 49 orchestration tools and 17 codebase intelligence tools are reachable. Verifies MCP server connectivity, tree-sitter parsers, and Cortex availability (if configured). Fails fast if the environment is misconfigured.
01 Stage 1 — Discovery
Queries the codebase via the typed graph engine (tree-sitter for 13 languages). Runs churn analysis (Nagappan & Ball 2005) and cochange coupling detection (Gall 1998, Zimmermann 2005). Recalls prior findings from Cortex — agents don't start from zero.
02 Stage 2 — Impact & Compound Score
Computes compound score across four dimensions: relevance × uniqueness × impact × confidence. Adds ownership ratio (Bird et al. 2011) and bus factor risk (Avelino et al. 2016) to flag single-maintainer danger zones. Findings below threshold are filtered.
03 Stage 3 — Integration Design
Designs architectural modifications using cochange coupling (hidden dependencies), dead code detection (Grove 1997, Tip 1999, CHA-based reachability), and port design patterns. Enforces parameterization, centralization, composability, backward compatibility.
04 Stage 4 — PRD Generation
Delegates to the AI PRD Generator to produce a 9-file PRD package: overview, requirements, technical spec, user stories, acceptance criteria, roadmap, JIRA tickets, test cases, and verification report.
4.5 Stage 4.5 — Plan Interview Gate
10-dimension deterministic quality gate — zero LLM calls. Scores the PRD across completeness, testability, feasibility, clarity, consistency, non-goals, dependencies, risk awareness, acceptance criteria quality, and measurability. Must pass all 10 to proceed.
05 Stage 5 — Review (7 Verification Algorithms)
Runs 5 verification algorithms + 2 prompting algorithms in parallel: Chain of Verification, KS Adaptive Stability, Multi-Agent Debate, NLI Entailment, Zero-LLM Graph Verification, plus TRM Self-Refine and Metacognitive Monitor. Loops on score < 0.85.
06 Stage 6 — Implementation
Creates a feature branch. One worker per file, dependency-ordered — based on the cochange graph from Stage 1. Builds the project, runs tests after each file. Uses Adaptive Expansion (ToT/GoT) and Signal-Aware Thought Buffer for complex implementations.
07 Stage 7 — Verification (64 HOR Rules)
64 deterministic Hard Output Rules across 10 categories: structural, security, resilience, observability, testing, naming, complexity, dependencies, documentation, concurrency. Plus a build gate. No LLM involved — pure deterministic validation. Loops on failure.
08 Stage 8 — Benchmark
Runs performance gates extracted from prd-tests.md. Compares against baselines defined in the PRD. Blocks the pipeline if the PRD specified performance requirements and they fail.
09 Stage 9 — Deployment
Runs the full test suite. Zero failures required — 544/544 passing on the reference codebase. Validates migrations, configuration, and build artifacts in an isolated environment.
10 Stage 10 — Pull Request + Cortex
Pushes the branch, opens a PR with structured description (compound score, HOR rule results, verification scores, benchmark deltas, retry history). Saves lessons to Cortex — next session's pipeline starts smarter than this one.
Why this architecture matters
Stages, retries, and external validation.
Zero LLM-judges-LLM
Most AI coding pipelines use one LLM to evaluate another LLM's output — which just propagates biases. This pipeline verifies with deterministic algorithms: 64 HOR rules, tree-sitter parsers, graph-based reachability, NLI entailment checks, and KS statistical stability. Algorithms don't hallucinate.
Every claim traces to a paper
Churn (Nagappan & Ball 2005). Ownership (Bird et al. 2011). Bus factor (Avelino et al. 2016). Cochange coupling (Gall 1998, Zimmermann 2005). Dead code (Grove 1997, Tip 1999). No hand-wavy heuristics — every decision cites peer-reviewed research.
Cortex memory compounds
Every pipeline run recalls prior findings from Cortex before starting and saves lessons after finishing. Run 1: the pipeline explores. Run 10: it knows your codebase. Run 100: it anticipates. 544 tests passing on the reference codebase — and the pipeline shipped most of those tests itself.
| Capability | Most AI Agents | AI Architect Pipeline |
|---|---|---|
| Task Decomposition | Prompt → Output | 11 sequential stages, one worker per file, dependency-ordered |
| Codebase Understanding | Scan all files | Tree-sitter typed graph (13 languages), BM25 + RRF hybrid search |
| Verification | LLM judges LLM | 5 algorithms: CoV, KS Adaptive, Multi-Agent Debate, NLI, Zero-LLM Graph |
| Quality Gates | Prompt templates | 64 deterministic HOR rules across 10 categories |
| Git Analytics | None | 5 science-backed: churn, ownership, bus factor, cochange, dead code |
| Memory | Stateless | Cortex integration — recall before, remember after |
| Retry Logic | Fail or hang | Stage-level retry with failure context, max 3 attempts |
| PRD Integration | Generate + hope | Delegated to AI PRD Generator with 10-dim interview gate |
This is not CI/CD
CI/CD runs after code is written. This pipeline writes the code.
CI/CD triggers when a developer pushes code: build, test, deploy. It assumes a human wrote the code. This pipeline operates upstream — it takes a finding and produces the code, tests, and pull request that your CI/CD system then validates. It does not replace your build system. It feeds it.
| Aspect | Traditional CI/CD | AI Architect Pipeline |
|---|---|---|
| Trigger | Code push by developer | Finding: bug, feature, advisory |
| Input | Source code | Unstructured requirements |
| Output | Build artifact, deploy | Pull request with code, tests, docs |
| Code authorship | Human developer | Autonomous AI agent |
| Verification | Test suite only | Tests + semantic verification + benchmarks |
| Retry strategy | Re-run same build | Re-implement with failure context |
| Scope | Build → Deploy | Finding → Pull Request |
It generates the commits. Your CI/CD validates and deploys them.
Works with your stack
Adapts to your project through configuration, not code changes.
The pipeline reads your project's configuration files, test framework, build system, and directory structure. It runs your test suite natively and respects your linter settings. Django backend, React frontend, Go microservice, Rust CLI, Swift iOS app — same pipeline, different configuration.