|--- JVM体系结构
|--- 运行时数据区域
|----------程序计数器
|----------虚拟机栈
|----------本地方法栈
|----------堆
|----------方法区
|----------运行时常量池
|----------直接内存
|--- 垃圾收集
|----------对象是否可以被回收
|--------------引用计数法
|--------------(GC Roots)可达性分析法
|--- 垃圾收集算法
|--------------标记-清除
|--------------复制
|-----------------[内存划分]eden+s+s+old[8:1:1]
|--------------标记-整理
|--------------分代收集
|--- 垃圾收集器
|--------------Serial收集器(单线程)
|--------------ParNew收集器(Serial收集器多线程版本)
|--------------Parallel Scavenge收集器(吞吐量优先收集器)
|--------------Serial Old收集器(Old:老年代版本)
|--------------Parallel Old收集器
|--------------CMS收集器(停顿时间优先收集器)
|--------------G1收集器(即兼顾吞吐量又兼顾了停顿时间)
|--- 内存分配与回收策略
|--------------Minor GC 与 Full GC
|--------------对象分配策略
|-----------------对象优先分配Eden
|-----------------大对象直接进入老年代
|-----------------存活时间长的对象进入老年代(存活时间判断)
|-----------------动态对象年龄判断
|-----------------空间分配担保
|--------------Minor GC触发条件
|-----------------Eden区域满 触发Minor GC
|--------------Full GC触发条件
|-----------------调用 System.gc()
|-----------------老年代空间不足
|-----------------空间分配担保失败
|-----------------JDK 1.7 及以前的永久代空间不足
|-----------------Concurrent Mode Failure
|--- 类加载机制
|--------------类加载过程
|--------------类初始化时机
|--------------类加载器分类
|-----------------虚拟机角度
|-----------------开发人员角度
|--------------双亲委派模型
|-----------------工作流程
|-----------------优点
|--- 基础知识
|--------------并发缺陷
|-----------------上下文切换[解决方案]
|--------------------无锁并发[concurrentHashMap中锁分段思想]
|--------------------CAS[乐观锁思想]
|--------------------使用最小线程
|--------------------协程[单线程中实现多任务调度,维持多任务切换]
|-----------------线程安全[引起原因]
|--------------------主内存和工作内存数据不一致
|--------------------重排序
|--- 线程基础
|-----------------如何创建线程
|--------------------继承Thread,重写run()
|--------------------实现runnable接口,重写run()
|--------------------实现callable接口,重写call()[异步]
|-----------------线程状态[6种]
|--------------------New
|--------------------Runnable
|--------------------Block
|--------------------Waiting
|--------------------Time-Waiting
|--------------------Terminated
|-----------------线程操作
|--------------------interrupted()[抛异常时 清除标记位]
|--------------------isInterrupted()[不清楚标记位]
|--------------------join()
|--------------------sleep()[与wait()区别]
|--------------------wait()[区别:本身、使用限制、锁是否释放、唤醒时机]
|--------------------yield()[与sleep()让出cpu资源时的区别]
|--- 并发理论
|-----------------JMM
|-----------------重排序
|--------------------as-if-serial关系
|--------------------happens-before关系
|--- 并发关键字
|-----------------synchronized
|--------------------底层实现原理[mintor监视器]
|--------------------happens-before关系
|--------------------JMM图示
|--------------------synchronied优化[缩短锁获取的时间]
|--------------------CAS原理、问题
|-----------------volatile
|--------------------底层实现原理[lock指令+缓存一致性]
|--------------------happens-before关系
|--------------------JMM图示
|-----------------原子性:synchronized[mintorEnter、mintorExit保证]
|-----------------可见性:synchronized、volatile
|-----------------有序性:synchronized、volatile[插入内存屏障禁止重排序]
|--- Lock体系
|-----------------AbstractQueuedSynchronizer(AQS)[同步组件底层]
|--------------------AQS工作流程[state状态+FIFO同步队列]、可重入概念
|-----------------ReentrantLock
|-----------------等待-唤醒机制[Lock+Condition、Synchroied+wait/notify、notifyAll]
|-----------------Lock VS Synchronied
|--- 并发容器
|-----------------ConcurrentHashMap[弱一致性迭代器]
|--------------------get()、put()、size()
|--------------------1.8版本与1.8之前版本的对比
|-----------------CopyOnWriteArrayList[add、迭代器的弱一致性]
|-----------------ThreadLocal
|--------------------ThreadLocalMap
|--------------------内存泄漏问题
|--- 线程池
|-----------------线程池实现原理、工作流程
|-----------------线程池构造核心参数[corePoolSize、maximumPoolSize、keepAliveTime、unit、workQueue、threadFactory、handler]
|-----------------线程池关闭[shutdownnow、shutdown]
|--- 并发工具类
|-----------------CountDownLatch
|-----------------CyclicBarrier
|-----------------Semaphore|--- TCP的三次握手与四次挥手
|-----------------为什么连接的时候是三次握手 二次为什么不行[服务端响应失效的SYN 会浪费资源]
|-----------------为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态
|-----------------如果已经建立了连接,但是客户端突然出现故障了怎么办[保活计数器]
|-----------------四次挥手断开连接过程
|-----------------Tcp VS Udp
|-----------------Tcp滑动窗口机制
|--- 计算机网络体系结构
|---Http和Https
|---Http状态码[1XX --> 5XX]
|---ARP协议原理
|---Cookie和Session
|---从输入网址到页面展现的整个流程|--- MySQL整体架构
|--- 索引
|-----------------什么是索引
|-----------------哪些字段可以成为索引
|-----------------索引的数据结构[二叉查找树、B树、B+树、Hash及BitMap]
|-----------------密集索引和稀疏索引
|-----------------如何定位并优化慢查询
|-----------------联合索引的最左匹配原则
|-----------------索引是否建立越多越好?
|--- 锁
|-----------------MyISAM与Innodb锁区别
|-----------------乐观锁[实现原理:数据库版本记录机制]和悲观锁
|-----------------并发--> 事务[ACID]
|-----------------简述隔离级别
|-----------------MVCC实现原理和三种锁算法[Record Lock、Gap Lock、Next-Key Lock]
|-----------------不可重复读、幻读解决方案
|---视图
|---DELETE、TRUNCATE和DROP区别|---Redis与Memcache区别
|---Redis为什么速度快
|---Redis基本数据结构[String、Hash、list、set、Zset]
|---海量key中查询固定前缀的key[keys --> scan]
|---Redis实现分布式锁[setNX --> expire --> 改进的set]
|---Redis异步队列的实现[list -->BLpop --> pub/sub模式 ]
|---Redis持久化[RDB --> AOF --> 混合式]
|---pipe优势
|---主从同步原理
|---Redis集群原理[一致性哈希算法]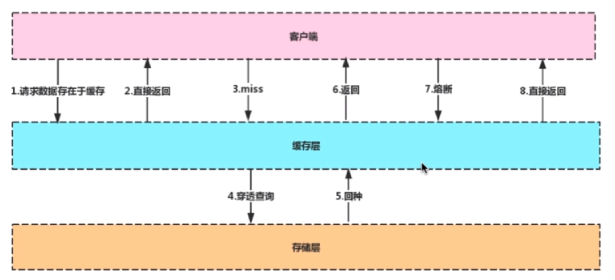
|---什么是全文检索[倒排索引]、与数据库检索额区别
|---ES核心概念[NRT、Cluster、Node、Document、Index、Type、Shard、replica]
|---ES与传统数据库对比
|---ES基础分布式架构[扩容方案、负载均衡、节点对等]
|---横向扩容,若超出极限,如何提升容错率[扩展 replica shard]
|---容错机制[三步]
|---分布式文档结构[document核心元数据:_index、_type、_id|doucument id生成方式|document删除内部细节(标记为DELETE,容量超出时 才后天删除)]
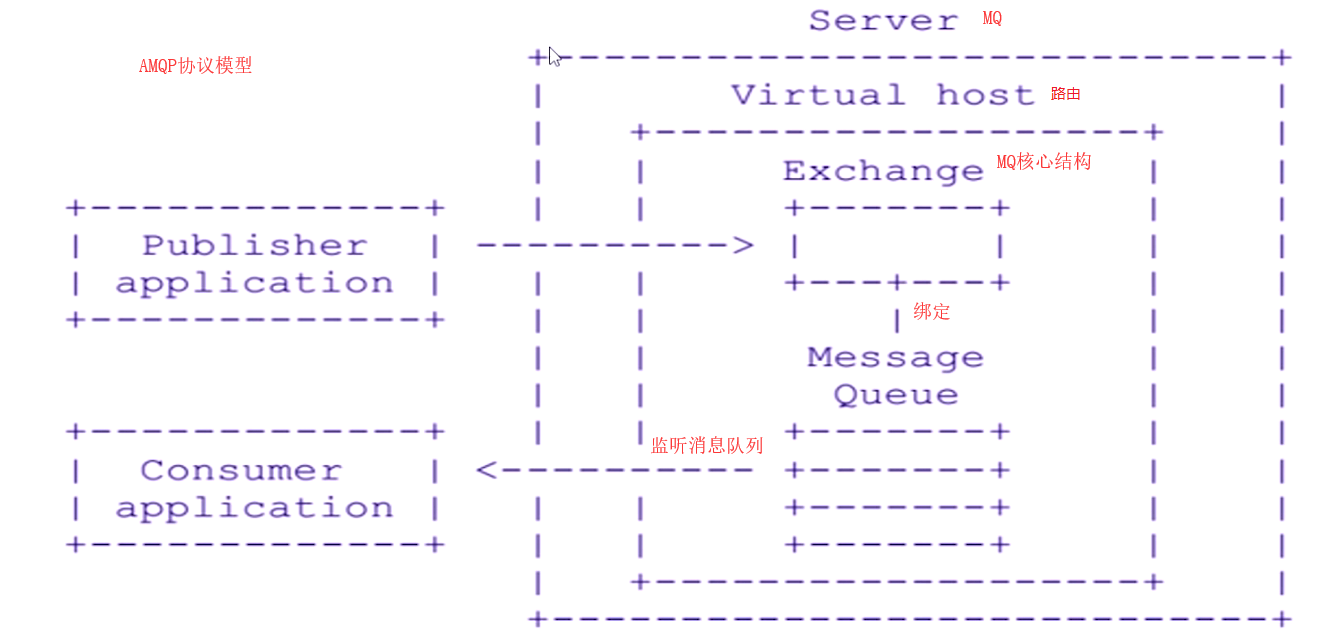
|--- 为什么要使用MQ[解耦、异步、削峰]
|--- ActiveMQ、RabbitMQ、RocketMQ、Kafka技术选型
|--- MQ一致性保障
|---linux架构
|---如何查找指定的文件[find]
|---如何检索文件[grep]
|---如何做日志内容统计[awk]
|---批量操作文本内容[sed]|---String.inner()、new String()、常量池存储确定的字面量
|---百亿url布隆过滤器去重
