- Image Captioning is the task of describing the content of an image in words. This task lies at the intersection of computer vision and natural language processing. Most image captioning systems use an encoder-decoder framework, where an input image is encoded into an intermediate representation of the information in the image, and then decoded into a descriptive text sequence.
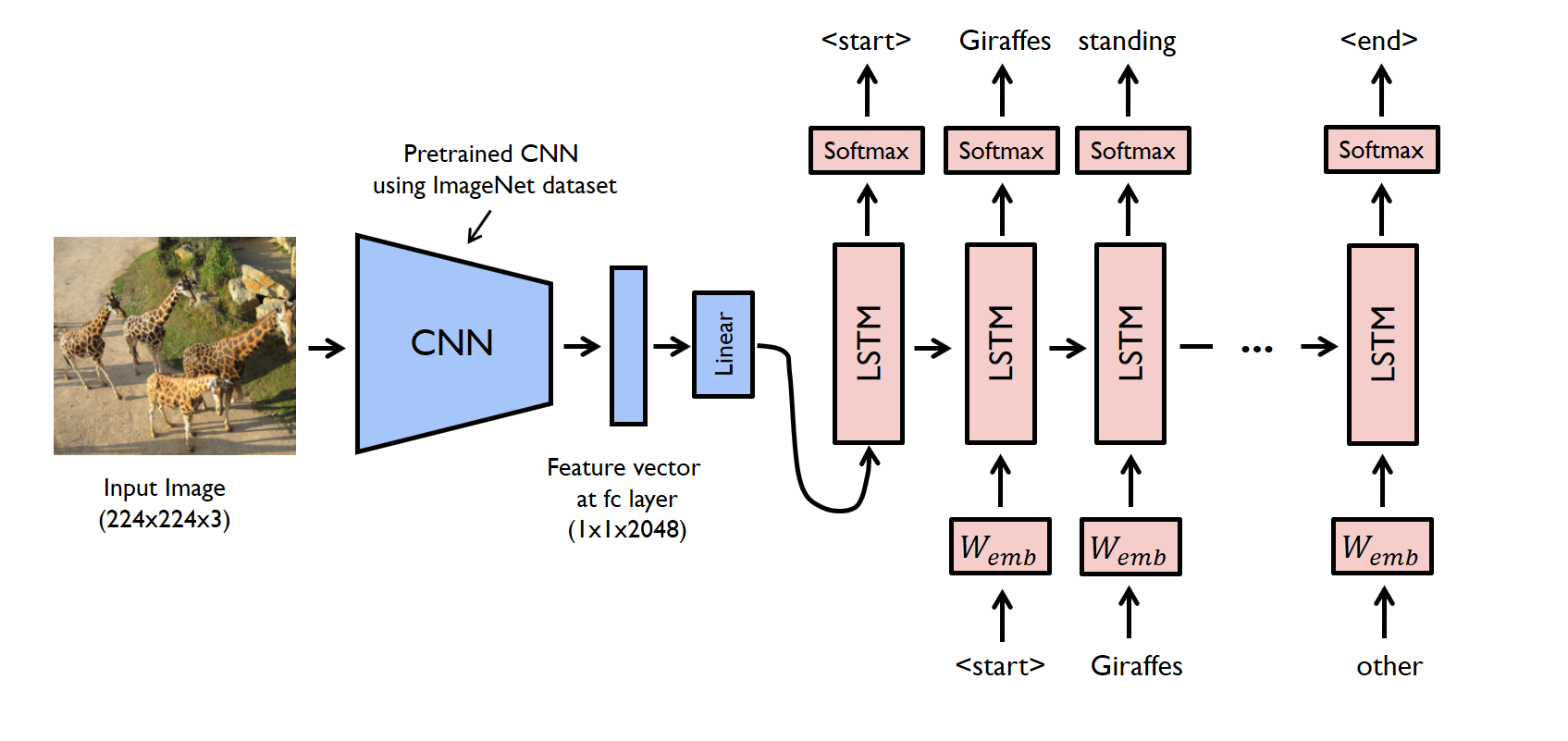
- Here a CNN+LSTM architecture based approach has been taken to generate captions corresponding to an input image

- To perform Image Captioning we will require two deep learning models combined into one for the training purpose
- CNNs extract the features from the image of some vector size aka the vector embeddings. The size of these embeddings depend on the type of pretrained network being used for the feature extraction
- LSTMs are used for the text generation process. The image embeddings are concatenated with the word embeddings and passed to the LSTM to generate the next word
Dataset used: Flickr8K (https://www.kaggle.com/datasets/adityajn105/flickr8k)
pip install numpy
pip install pandas
pip install matplotlib
pip install seaborn
pip install tensorflow
pip install textwrap
pip install tqdm