Recommender systems are used for providing personalized recommendations based on the user profile and previous behaviour. Recommender systems such as Amazon, Netflix, and YouTube are widely used in the Internet Industry. Recommendation systems help the users to find and select items (e.g., books, movies, restaurants) from the wide collection available on the web or in other electronic information sources. Among a large set of items and a description of the user’s needs, they present to the user a small set of the items that are well suited to the description. This project focuses on Movie recommendation. Recommendation algorithms mainly follow following approaches:
-
Content-based filtering: They suggest similar items based on a particular item. This system uses item metadata, such as genre, director, description, actors, etc. for movies, to make these recommendations.
-
Collaborative filtering: user-to-user and item-to-item This system matches persons with similar interests and provides recommendations based on this matching. It does not require item metadata like its content-based counterparts, but requires usres and there respective ratings.
-
Demographic: They offer generalized recommendations to every user, based on movie popularity and/or genre. The System recommends the same movies to users with similar demographic features. The basic idea behind this system is that movies that are more popular and critically acclaimed will have a higher probability of being liked by the average audience.
-
Knowledge-based: It suggests products based on inferences about user’s needs and preferences, item selection and its basis for recommendation.
-
Hybrid: It is the one that combines multiple recommendation techniques together to produce the output. If one compares hybrid recommender systems with collaborative or content-based systems, the recommendation accuracy is usually higher in hybrid system.

Scrapping using beautiful soup from imdb website that shows list of films year wise, used Beautiful Soup library in python and passed the url of IMDB website that sorted movies based on of number of votes over years 1991-2022. Scrapping code
Collaborative-filerting datset
This engine computes similarity between movies based on certain metrics and suggests movies that are most similar to a particular movie that a user liked. The metrics used here are:
- Movie descriotion.
- Director name, Cast and Genre.
To calculate a similarity between two movies Cosine Similarity is used
Used the TF-IDF Vectorizer, so calculating the Dot Product will directly gives the Cosine Similarity Score. Therefore, sklearn's linear_kernel was used instead of cosine_similarities since it is much faster.
- It is not capable of capturing tastes and providing recommendations across genres.
- It doesn't capture the personal tastes and biases of a user.
- Anyone querying our engine for recommendations based on a movie will receive the same recommendations for that movie, regardless of who s/he is.
These limitations are overcame by
It is of 2 types:
-
User based filtering- This system recommends products to a user that similar users have liked. For measuring the similarity between two users we can either use pearson correlation or cosine similarity. One main issue is that users’ preference can change over time. It indicates that precomputing the matrix based on their neighboring users may lead to bad performance. To tackle this problem, we can apply item-based CF.
-
Item Based Collaborative Filtering- This recommends items based on their similarity with the items that the target user rated. Likewise, the similarity can be computed with Pearson Correlation or Cosine Similarity. The major difference is that, in this, we fill in the blank vertically, as oppose to the horizontal manner that user-based CF does.

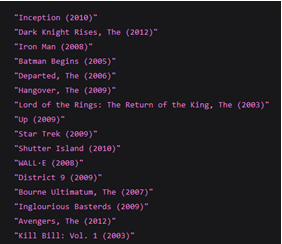
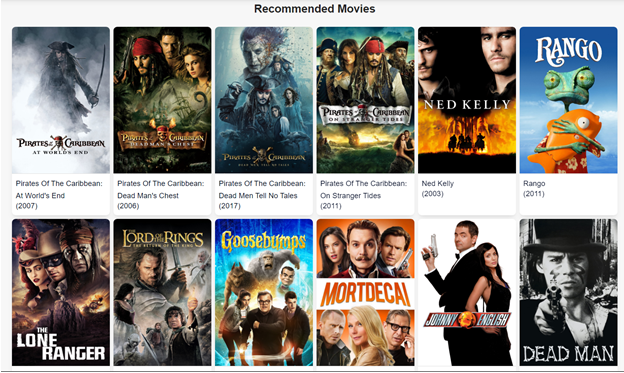
In content-based we see that for our system is able to identify it as a Batman film and subsequently recommend other Batman films as its top recommendations. Also this takes into considerations very important features such as cast, crew, director and genre, which determine the rating and the popularity of a movie.
In case of Collaborative Filtering recommendations are personalized to that user as someone who liked “The Dark Knight” probably likes it more because of Nolan and would love movies made by him. From these results its clear that for the same movie collaborative filtering gives much better recommendations than content-based filtering.
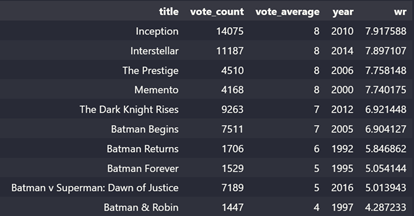
Another experiment was that it recommends movies regardless of ratings and popularity. As all movies recommended by content-based has a lot of similar characters as compared to The Dark Knight but all movies aren’t that great. Therefore, I added a mechanism to remove bad movies and return movies which are popular and have had a good critical response.
I took the top 25 movies based on similarity scores and calculate the vote of the 60th percentile movie. Then, using this as the value of m, I calculated the weighted rating of each movie using IMDB's formula.
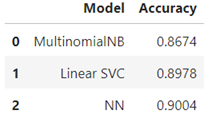
The model is trained on IMDB movie reviews dataset on kaggle. Used 3 approacehs Linear SVC , MultinomialDB and nueral network. NN model performed better.
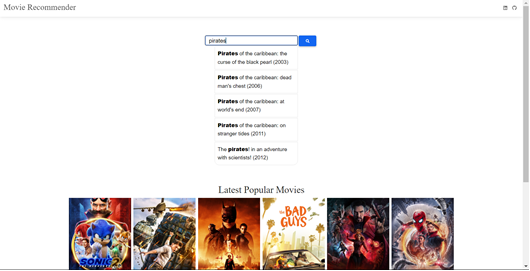
- Automatically add new released movies after week of there release in dataset.
- Create dataset for collborative filtering, i.e need user ratings and movie ratings for the movies for my dataset.
- Github user
- Kaggle
- Collaborative Filtering : medium article
- Reddy, S. R. S., et al. "Content-based movie recommendation system using genre correlation." Smart Intelligent Computing and Applications. Springer, Singapore, 2019. 391-397.
- Paknejad, Sepideh. "Sentiment classification on Amazon reviews using machine learning approaches." (2018).